Глава 5. Указатели и массивы
Указатель - это переменная, содержащая адрес переменной. Указатели широко
применяются в Си - отчасти потому, что в некоторых случаях без них просто не
обойтись, а отчасти потому, что программы с ними обычно короче и эффективнее.
Указатели и массивы тесно связаны друг с другом: в данной главе мы рассмотрим
эту зависимость и покажем, как ею пользоваться.
Наряду с goto указатели когда-то были объявлены лучшим средством для
написания малопонятных программ. Так оно и есть, если ими пользоваться
бездумно. Ведь очень легко получить указатель, указывающий на что-нибудь
совсем нежелательное. При соблюдении же определенной дисциплины с помощью
указателей можно достичь ясности и простоты. Мы попытаемся убедить вас в
этом.
Изменения, внесенные стандартом ANSI, связаны в основном с формулированием
точных правил, как работать с указателями. Стандарт узаконил накопленный
положительный опыт программистов и удачные нововведения разработчиков
компиляторов. Кроме того, взамен char* в качестве типа обобщенного указателя
предлагается тип void* (указатель на void).
Начнем с того, что рассмотрим упрощенную схему организации памяти. Память
типичной машины подставляет собой массив последовательно пронумерованных или
проадресованных ячеек, с которыми можно работать по отдельности или связными
кусками. Применительно к любой машине верны следующие утверждения: один байт
может хранить значение типа char, двухбайтовые ячейки могут рассматриваться
как целое типа short, а четырехбайтовые - как целые типа long. Указатель -
это группа ячеек (как правило, две или четыре), в которых может храниться
адрес. Так, если c имеет тип char, а p - указатель на c, то ситуация выглядит
следующим образом:
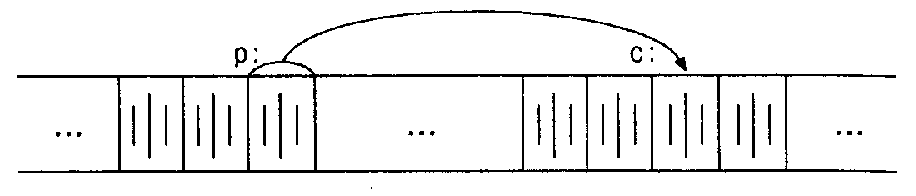
Унарный оператор & выдает адрес объекта, так что инструкция
p = &c;
присваивает переменной p адрес ячейки c (говорят, что p указывает на c).
Оператор & применяется только к объектам, расположенным в памяти: к
переменным и элементам массивов. Его операндом не может быть ни выражение, ни
константа, ни регистровая переменная.
Унарный оператор * есть оператор косвенного доступа. Примененный к указателю
он выдает объект, на который данный указатель указывает. Предположим, что x и
y имеют тип int, а ip – укаэатель на int. Следующие несколько строк придуманы
специально для того, чтобы показать, каким образом объявляются указатели и
как используются операторы & и *.
int х = 1, у = 2, z[10];
int *ip; /* ip - указатель на int */
ip = &x; /* теперь ip указывает на x */
y = *ip; /* y теперь равен 1 */
*ip = 0; /* x теперь равен 0 */
ip = &z[0]; /* ip теперь указывает на z[0] */
Объявления x, y и z нам уже знакомы. Объявление указателя ip
int *ip;
мы стремились сделать мнемоничным - оно гласит: "выражение *ip имеет тип
int". Синтаксис объявления переменной "подстраивается" под синтаксис
выражений, в которых эта переменная может встретиться. Указанный принцип
применим и в объявлениях функций. Например, запись
double *dp, atof (char *);
означает, что выражения *dp и atof(s) имеют тип double, а аргумент функции
atof есть указатель на char.
Вы, наверное, заметили, что указателю разрешено указывать только на объекты
определенного типа. (Существует одно исключение: "указатель на void" может
указывать на объекты любого типа, но к такому указателю нельзя применять
оператор косвенного доступа. Мы вернемся к этому в параграфе 5.11.)
Если ip указывает на x целочисленного типа, то *ip можно использовать в любом
месте, где допустимо применение x; например,
*ip = *ip + 10;
увеличивает *ip на 10.
Унарные операторы * и & имеют более высокий приоритет, чем арифметические
операторы, так что присваивание
y = *ip + 1;
берет то, на что указывает ip, и добавляет к нему 1, а результат присваивает
переменной y. Аналогично
*ip += 1;
увеличивает на единицу то, на что указывает ip; те же действия выполняют
++*ip;
и
(*iр)++;
В последней записи скобки необходимы, поскольку если их не будет, увеличится
значение самого указателя, а не то, на что он указывает. Это обусловлено тем,
что унарные операторы * и ++ имеют одинаковый приоритет и порядок выполнения
- справа налево.
И наконец, так как указатели сами являются переменными, в тексте они могут
встречаться и без оператора косвенного доступа. Например, если iq есть другой
указатель на int, то
iq = ip;
копирует содержимое ip в iq, чтобы ip и iq указывали на один и тот же объект.
Поскольку в Си функции в качестве своих аргументов получают значения
параметров, нет прямой возможности, находясь в вызванной функции, изменить
переменную вызывающей функции. В программе сортировки нам понадобилась
функция swap, меняющая местами два неупорядоченных элемента. Однако
недостаточно написать
swap(a, b);
где функция swap определена следующим образом:
void swap(int х, int у) /* НЕВЕРНО */
{
int temp;
temp = х;
x = y;
у = temp;
}
Поскольку swap получает лишь копии переменных a и b, она не может повлиять на
переменные a и b той программы, которая к ней обратилась. Чтобы получить
желаемый эффект, вызывающей программе надо передать указатели на те значения,
которые должны быть изменены:
swap(&a, &b);
Так как оператор & получает адрес переменной, &a есть указатель на a. В самой
же функции swap параметры должны быть объявлены как указатели, при этом
доступ к значениям параметров будет осуществляться косвенно.
void swap(int *px, int *py) /* перестановка *px и *py */
{
int temp;
temp = *рх;
*рх = *py;
*ру = temp;
}
Графически это выглядит следующим образом: в вызывающей программе:
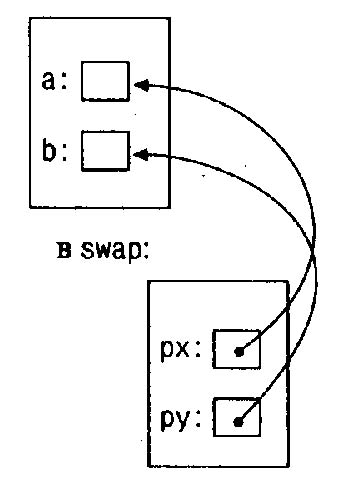
Аргументы-указатели позволяют функции осуществлять доступ к объектам
вызвавшей ее программы и дают возможность изменить эти объекты. Рассмотрим,
например, функцию getint, которая осуществляет ввод в свободном формате
одного целого числа и его перевод из текстового представления в значение типа
int. Функция getint должна возвращать значение полученного числа или
сигнализировать значением EOF о конце файла, если входной поток исчерпан. Эти
значения должны возвращаться по разным каналам, так как нельзя рассчитывать
на то, что полученное в результате перевода число никогда не совпадет с EOF.
Одно из решений состоит в том, чтобы getint выдавала характеристику состояния
файла (исчерпан или не исчерпан) в качестве результата, а значение самого
числа помещала согласно указателю, переданному ей в виде аргумента. Похожая
схема действует и в программе scanf, которую мы рассмотрим в параграфе 7.4.
Показанный ниже цикл заполняет некоторый массив целыми числами, полученными с
помощью getint.
int n, array[SIZE], getint (int *);
for (n = 0; n < SIZE && getint (&array[n]) != EOF; n++)
;
Результат каждого очередного обращения к getint посылается в array[n], и n
увеличивается на единицу. Заметим, и это существенно, что функции getint
передается адрес элемента array[n]. Если этого не сделать, у getint не будет
способа вернуть в вызывающую программу переведенное целое число.
В предлагаемом нами варианте функция getint возвращает EOF по концу файла;
нуль, если следующие вводимые символы не представляют собою числа; и
положительное значение, если введенные символы представляют собой число.
#include <ctype.h>
int getch (void);
void ungetch (int);
/* getint: читает следующее целое из ввода в *pn */
int getint(int *pn)
{
int c, sign;
while (isspace(c = getch()))
; /* пропуск символов-разделителей */
if(!isdigit(c) && c != EOF && c != '+' && c != '-') {
ungetch (c); /* не число */
return 0;
}
sign =(c =='-') ? -1 : 1;
if (с == '+' || с == '-')
с = getch();
for (*pn = 0; isdigit(c); c = getch())
*pn = 10 * *pn + (c -'0');
*pn *= sign;
if (c!= EOF)
ungetch(c);
return c;
}
Везде в getint под *pn подразумевается обычная переменная типа int. Функция
ungetch вместе с getch (параграф 4.3) включена в программу, чтобы обеспечить
возможность отослать назад лишний прочитанный символ.
Упражнение 5.1. Функция getint написана так, что знаки - или +, за которыми
не следует цифра, она понимает как "правильное" представление нуля.
Скорректируйте программу таким образом, чтобы в подобных случаях она
возвращала прочитанный знак назад во ввод.
Упражнение 5.2. Напишите функцию getfloat - аналог getint для чисел с плавающей
точкой. Какой тип будет иметь результирующее значение, задаваемое функцией
getfloat?
В Си существует связь между указателями и массивами, и связь эта настолько
тесная, что эти средства лучше рассматривать вместе. Любой доступ к элементу
массива, осуществляемый операцией индексирования, может быть выполнен с
помощью указателя. Вариант с указателями в общем случае работает быстрее, но
разобраться в нем, особенно непосвященному, довольно трудно.
Объявление
int a[10];
Определяет массив a размера 10, т. е. блок из 10 последовательных объектов
с именами a[0], a[1], ..., a[9].

Запись a[i] отсылает нас к i-му элементу массива. Если pa есть указатель на
int, т. е. объявлен как
int *pa;
то в результате присваивания
pa = &a[0];
pa будет указывать на нулевой элемент a, иначе говоря, pa будет содержать
адрес элемента a[0].
Теперь присваивание
x = *pa;
будет копировать содержимое a[0] в x.
Если pa указывает на некоторый элемент массива, то pa+1 по определению
указывает на следующий элемент, pa+i - на i-й элемент после pa, a pa-i - на
i-й элемент перед pa. Таким образом, если pa указывает на a[0], то
*(pa+1)
есть содержимое a[1], a+i - адрес a[i], a *(pa+i) - содержимое a[i].
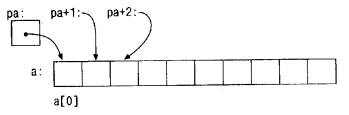
Сделанные замечания верны безотносительно к типу и размеру элементов массива
a. Смысл слов "добавить 1 к указателю", как и смысл любой арифметики с
указателями, состоит в том, чтобы pa+1 указывал на следующий объект, a pa+i -
на i-й после pa.
Между индексированием и арифметикой с указателями существует очень тесная
связь. По определению значение переменной или выражения типа массив есть
адрес нулевого элемента массива. После присваивания
pa = &a[0];
ра и a имеют одно и то же значение. Поскольку имя массива является синонимом
расположения его начального элемента, присваивание pa=&a[0] можно также
записать в следующем виде:
pa = a;
Еще более удивительно (по крайней мере на первый взгляд) то, что a[i] можно
записать как *(a+i). Вычисляя a[i], Си сразу преобразует его в *(a+i);
указанные две формы записи эквивалентны. Из этого следует, что полученные в
результате применения оператора & записи &a[i] и a+i также будут
эквивалентными, т. е. и в том и в другом случае это адрес i-го элемента
после a. С другой стороны, если pa - указатель, то его можно использовать с
индексом, т. е. запись pa[i] эквивалентна записи *(pa+i). Короче говоря,
элемент массива можно изображать как в виде указателя со смещением, так и в
виде имени массива с индексом.
Между именем массива и указателем, выступающим в роли имени массива,
существует одно различие. Указатель - это переменная, поэтому можно написать
pa=a или pa++. Но имя массива не является переменной, и записи вроде a=pa или
a++ не допускаются.
Если имя массива передается функции, то последняя получает в качестве
аргумента адрес его начального элемента. Внутри вызываемой функции этот
аргумент является локальной переменной, содержащей адрес. Мы можем
воспользоваться отмеченным фактом и написать еще одну версию функции strlen,
вычисляющей длину строки.
/* strlen: возвращает длину строки */
int strlen(char *s)
{
int n;
for (n = 0; *s != '\0'; s++)
n++;
return n;
}
Так как переменная s - указатель, к ней применима операция ++; s++ не
оказывает никакого влияния на строку символов функции, которая обратилась к
strlen. Просто увеличивается на 1 некоторая копия указателя, находящаяся в
личном пользовании функции strlen. Это значит, что все вызовы, такие как:
strlen("3дравствуй, мир"); /* строковая константа */
strlen(array); /* char array[100]; */
strlen(ptr); /* char *ptr; */
правомерны.
Формальные параметры
char s[];
и
char *s;
в определении функции эквивалентны. Мы отдаем предпочтение последнему
варианту, поскольку он более явно сообщает, что s есть указатель. Если
функции в качестве аргумента передается имя массива, то она может
рассматривать его так, как ей удобно - либо как имя массива, либо как
указатель, и поступать с ним соответственно. Она может даже использовать оба
вида записи, если это покажется уместным и понятным.
Функции можно передать часть массива, для этого аргумент должен указывать на
начало подмассива. Например, если a - массив, то в записях
f(&a[2])
или
f(a+2)
функции f передается адрес подмассива, начинающегося с элемента a[2]. Внутри
функции f описание параметров может выглядеть как
f(int arr[]) {...}
или
f(int *arr) {...}
Следовательно, для f тот факт, что параметр указывает на часть массива, а не
на весь массив, не имеет значения.
Если есть уверенность, что элементы массива существуют, то возможно
индексирование и в "обратную" сторону по отношению к нулевому элементу;
выражения p[-1], p[-2] и т.д. не противоречат синтаксису языка и обращаются к
элементам, стоящим непосредственно перед p[0]. Разумеется, нельзя "выходить"
за границы массива и тем самым обращаться к несуществующим объектам.
Если p есть указатель на некоторый элемент массива, то p++ увеличивает p так,
чтобы он указывал на следующий элемент, а p+=i увеличивает его, чтобы он
указывал на i-й элемент после того, на который указывал ранее. Эти и подобные
конструкции - самые простые примеры арифметики над указателями, называемой
также адресной арифметикой.
Си последователен и единообразен в своем подходе к адресной арифметике.
Это соединение в одном языке указателей, массивов и адресной арифметики -
одна из сильных его сторон. Проиллюстрируем сказанное построением простого
распределителя памяти, состоящего из двух программ. Первая, alloc(n),
возвращает указатель p на n последовательно расположенных ячеек типа char;
программой, обращающейся к alloc, эти ячейки могут быть использованы для
запоминания символов. Вторая, afree(p), освобождает память для, возможно,
повторной ее утилизации. Простота алгоритма обусловлена предположением, что
обращения к afree делаются в обратном порядке по отношению к соответствующим
обращениям к alloc. Таким образом, память, с которой работают alloc и afree,
является стеком (списком, в основе которого лежит принцип "последним вошел,
первым ушел"). В стандартной библиотеке имеются функции malloc и free,
которые делают то же самое, только без упомянутых ограничений: в параграфе
8.7 мы покажем, как они выглядят.
Функцию alloc легче всего реализовать, если условиться, что она будет
выдавать куски некоторого большого массива типа char, который мы назовем
allocbuf. Этот массив отдадим в личное пользование функциям alloc и afree.
Так как они имеют дело с указателями, а не с индексами массива, то другим
программам знать его имя не нужно. Кроме того, этот массив можно определить в
том же исходном файле, что и alloc и afree, объявив его static, благодаря
чему он станет невидимым вне этого файла. На практике такой массив может и
вовсе не иметь имени, поскольку его можно запросить с помощью malloc у
операционной системы и получить указатель на некоторый безымянный блок
памяти.
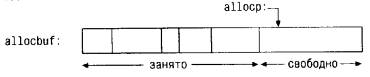
Естественно, нам нужно знать, сколько элементов массива allocbuf уже занято.
Мы введем указатель allocp, который будет указывать на первый свободный
элемент. Если запрашивается память для n символов, то alloc возвращает
текущее значение allocp (т. е. адрес начала свободного блока) и затем
увеличивает его на n, чтобы указатель allocp указывал на следующую свободную
область. Если же пространства нет, то alloc выдает нуль. Функция afree(p)
просто устанавливает allocp в значение p, если оно не выходит за пределы
массива allocbuf.
Перед вызовом allос:
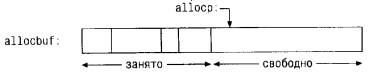
После вызова alloc:
#define ALLOCSIZE 10000 /* размер доступного пространства */
static char allocbuf[ALLOCSIZE]; /* память для alloc */
static char *allocp = allocbuf; /* указатель на своб. место */
char *alloc(int n) /* возвращает указатель на n символов */
{
if (allocbuf + ALLOCSIZE - allocp >= n) {
allocp += n; /* пространство есть */
return allocp – n; /* старое p */
} else /* пространства нет */
return 0;
}
void afree(char *p) /* освобождает память, на которую указывает p */
{
if (р >= allocbuf && p < allocbuf + ALLOCSIZE)
allocp = p;
}
В общем случае указатель, как и любую другую переменную, можно
инициализировать, но только такими осмысленными для него значениями, как нуль
или выражение, приводящее к адресу ранее определенных данных соответствующего
типа. Объявление
static char *allocp = allocbuf;
определяет allocp как указатель на char и инициализирует его адресом
массива allocbuf, поскольку перед началом работы программы массив allocbuf
пуст. Указанное объявление могло бы иметь и такой вид:
static char *allocp = &allocbuf[0];
поскольку имя массива и есть адрес его нулевого элемента. Проверка
if (allocbuf + ALLOCSIZE - allocp >= n) { /* годится */
контролирует, достаточно ли пространства, чтобы удовлетворить запрос на n
символов. Если памяти достаточно, то новое значение для allocp должно
указывать не далее чем на следующую позицию за последним элементом allocbuf.
При выполнении этого требования alloc выдает указатель на начало выделенного
блока символов (обратите внимание на объявление типа самой функции). Если
требование не выполняется, функция alloc должна выдать какой-то сигнал о том,
что памяти не хватает. Си гарантирует, что нуль никогда не будет правильным
адресом для данных, поэтому мы будем использовать его в качестве признака
аварийного события, в нашем случае нехватки памяти.
Указатели и целые не являются взаимозаменяемыми объектами. Константа нуль -
единственное исключение из этого правила: ее можно присвоить указателю, и
указатель можно сравнить с нулевой константой. Чтобы показать, что нуль - это
специальное значение для указателя, вместо цифры нуль, как правило,
записывают NULL - константу, определенную в файле <stdio.h> (I.B.: вообще-то эта константа
определена в <stddef.h> или <string.h>). С этого момента
и мы будем ею пользоваться. Проверки
if (allocbuf + ALLOCSIZE - allocp >= n) { /* годится */
и
if (p >= allocbuf && p < allocbuf + ALLOCSIZE)
демонстрируют несколько важных свойств арифметики с указателями. Во-
первых, при соблюдении некоторых правил указатели можно сравнивать.
Если p и q указывают на элементы одного массива, то к ним можно применять
операторы отношения ==, !=, <, >= и т. д. Например, отношение вида
p < q
истинно, если p указывает на более ранний элемент массива, чем q. Любой
указатель всегда можно сравнить на равенство и неравенство с нулем. А вот для
указателей, не указывающих на элементы одного массива, результат
арифметических операций или сравнений не определен. (Существует одно
исключение: в арифметике с указателями можно использовать адрес
несуществующего "следующего за массивом" элемента, т. е. адрес того
"элемента", который станет последним, если в массив добавить еще один
элемент.)
Во-вторых, как вы уже, наверное, заметили, указатели и целые можно складывать
и вычитать. Конструкция
p + n
означает адрес объекта, занимающего n-е место после объекта, на который
указывает p. Это справедливо безотносительно к типу объекта, на который
указывает p; n автоматически домножается на коэффициент, соответствующий
размеру объекта. Информация о размере неявно присутствует в объявлении p.
Если, к примеру, int занимает четыре байта, то коэффициент умножения будет
равен четырем.
Допускается также вычитание указателей. Например, если p и q указывают на
элементы одного массива и p<q, то q-p+1 есть число элементов от p до q
включительно. Этим фактом можно воспользоваться при написании еще одной
версии strlen:
/* strlen: возвращает длину строки s */
int strlen(char *s)
{
char *p = s;
while (*p != '\0')
p++;
return p - s;
}
В своем объявлении p инициализируется значением s, т. е. вначале p указывает
на первый символ строки. На каждом шаге цикла while проверяется очередной
символ; цикл продолжается до тех пор, пока не встретится '\0'. Каждое
продвижение указателя p на следующий символ выполняется инструкцией p++, и
разность p-s дает число пройденных символов, т. е. длину строки. (Число
символов в строке может быть слишком большим, чтобы хранить его в переменной
типа int. Тип ptrdiff_t, достаточный для хранения разности (со знаком)
двух указателей, определен в заголовочном файле <stddef.h>. Однако,
если быть очень осторожными, нам следовало бы для возвращаемого результата
использовать тип size_t, в этом случае наша программа соответствовала бы
стандартной библиотечной версии. Тип size_t есть тип беззнакового целого,
возвращаемого оператором sizeof.
Арифметика с указателями учитывает тип: если она имеет дело со значениями
float, занимающими больше памяти, чем char, и p - указатель на float, то p++
продвинет p на следующее значение float. Это значит, что другую версию alloc,
которая имеет дело с элементами типа float, а не char, можно получить простой
заменой в alloc и afree всех char на float. Все операции с указателями будут
автоматически откорректированы в соответствии с размером объектов, на которые
указывают указатели.
Можно производить следующие операции с указателями: присваивание значения
указателя другому указателю того же типа, сложение и вычитание указателя и
целого, вычитание и сравнение двух указателей, указывающих на элементы одного
и того же массива, а также присваивание указателю нуля и сравнение указателя
с нулем. Других операций с указателями производить не допускается. Нельзя
складывать два указателя, перемножать их, делить, сдвигать, выделять разряды;
указатель нельзя складывать со значением типа float или double; указателю
одного типа нельзя даже присвоить указатель другого типа, не выполнив
предварительно операции приведения (исключение составляют лишь указатели типа
void*).
Строковая константа, написанная в виде
"Я строка"
есть массив символов. Во внутреннем представлении этот массив заканчивается
нулевым символом '\0', по которому программа может найти конец строки. Число
занятых ячеек памяти на одну больше, чем количество символов, помещенных
между двойными кавычками.
Чаще всего строковые константы используются в качестве аргументов функций,
как, например, в
printf("здравствуй, мир\n");
Когда такая символьная строка появляется в программе, доступ к ней
осуществляется через символьный указатель; printf получает указатель на
начало массива символов. Точнее, доступ к строковой константе осуществляется
через указатель на ее первый элемент.
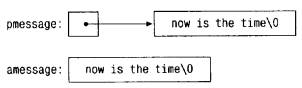
Строковые константы нужны не только в качестве аргументов функций. Если,
например, переменную pmessage объявить как
char *pmessage;
то присваивание
pmessage = "now is the time";
поместит в нее указатель на символьный массив, при этом сама строка не
копируется, копируется лишь указатель на нее. Операции для работы со строкой
как с единым целым в Си не предусмотрены.
Существует важное различие между следующими определениями:
char amessage[] = "now is the time"; /* массив */
char *pmessage = "now is the time"; /* указатель */
amessage - это массив, имеющий такой объем, что в нем как раз помещается
указанная последовательность символов и '\0'. Отдельные символы внутри
массива могут изменяться, но amessage всегда указывает на одно и то же место
памяти. В противоположность ему pmessage есть указатель, инициализированный
так, чтобы указывать на строковую константу. А значение указателя можно
изменить, и тогда последний будет указывать на что-либо другое. Кроме того,
результат будет неопределен, если вы попытаетесь изменить содержимое
константы.
Дополнительные моменты, связанные с указателями и массивами,
проиллюстрируем на несколько видоизмененных вариантах двух полезных программ,
взятых нами из стандартной библиотеки. Первая из них, функция strcpy (s, t),
копирует строку t в строку s. Хотелось бы написать прямо s = t, но такой
оператор копирует указатель, а не символы. Чтобы копировать символы, нам
нужно организовать цикл. Первый вариант strcpy, с использованием массива,
имеет следующий вид:
/* strcpy: копирует t в s; вариант с индексируемым массивом*/
void strcpy(char *s, char *t)
{
int i;
i = 0;
while ((s[i] = t[i]) != '\0')
i++;
}
Для сравнения приведем версию strcpy с указателями:
/* strcpy: копирует t в s: версия 1 (с указателями) */
void strcpy(char *s, char *t)
{
while ((*s = *t) != '\0') {
s++;
t++;
}
}
Поскольку передаются лишь копии значений аргументов, strcpy может свободно
пользоваться параметрами s и t как своими локальными переменными. Они должным
образом инициализированы указателями, которые продвигаются каждый раз на
следующий символ в каждом из массивов до тех пор, пока в копируемой строке t
не встретится '\0'.
На практике strcpy так не пишут. Опытный программист предпочтет более
короткую запись:
/* strcpy: копирует t в s; версия 2 (с указателями) */
void strcpy(char *s, char *t)
{
while ((*s++ = *t++) != '\0')
;
}
Приращение s и t здесь осуществляется в управляющей части цикла. Значением
*t++ является символ, на который указывает переменная t перед тем, как ее
значение будет увеличено; постфиксный оператор ++ не изменяет указатель t,
пока не будет взят символ, на который он указывает. То же в отношении s:
сначала символ запомнится в позиции, на которую указывает старое значение s,
и лишь после этого значение переменной s увеличится. Пересылаемый символ
является одновременно и значением, которое сравнивается с '\0'. В итоге
копируются все символы, включая и заключительный символ '\0'.
Заметив, что сравнение с '\0' здесь лишнее (поскольку в Си ненулевое значение
выражения в условии трактуется и как его истинность), мы можем сделать еще
одно и последнее сокращение текста программы:
/* strcpy: копирует t в s; версия 3 (с указателями) */
void strcpy(char *s, char *t)
{
while (*s++ = *t++)
;
}
Хотя на первый взгляд то, что мы получили, выглядит загадочно, все же такая
запись значительно удобнее, и следует освоить ее, поскольку в Си-программах
вы будете с ней часто встречаться.
Что касается функции strcpy из стандартной библиотеки <string.h> то она
возвращает в качестве своего результата еще и указатель на новую копию
строки.
Вторая программа, которую мы здесь рассмотрим, это strcmp(s,t). Она
сравнивает символы строк s и t и возвращает отрицательное, нулевое или
положительное значение, если строка s соответственно лексикографически
меньше, равна или больше, чем строка t. Результат получается вычитанием
первых несовпадающих символов из s и t.
/* strcmp: выдает < 0 при s < t, 0 при s == t, > 0 при s > t */
int strcmp(char *s, char *t)
{
int i;
for (i = 0; s[i]== t[i]; i++)
if (s[i] == '\0')
return 0;
return s[i] - t[i];
}
Та же программа с использованием указателей выглядит так:
/* strcmp: выдает < 0 при s < t, 0 при s == t, > 0 при s > t */
int strcmp(char *s, char *t)
{
for ( ; *s == *t; s++, t++)
if (*s == '\0')
return 0;
return *s - *t;
}
Поскольку операторы ++ и -- могут быть или префиксными, или постфиксными,
встречаются (хотя и не так часто) другие их сочетания с оператором *.
Например.
*--p;
уменьшит p прежде, чем по этому указателю будет получен символ. Например,
следующие два выражения:
*p++ = val; /* поместить val в стек */
val = *--p; /* взять из стека значение и поместить в val */
являются стандартными для посылки в стек и взятия из стека (см. параграф 4.3.).
Объявления функций, упомянутых в этом параграфе, а также ряда других
стандартных функций, работающих со строками, содержатся в заголовочном файле
<string.h>.
Упражнение 5.3. Используя указатели, напишите функцию strcat, которую мы
рассматривали в главе 2 (функция strcat(s,t) копирует строку t в конец строки
s).
Упражнение 5.4. Напишите функцию strend(s,t), которая выдает 1, если строка t
расположена в конце строки s, и нуль в противном случае.
Упражнение 5.5. Напишите варианты библиотечных функций strncpy, strncat и
strncmp, которые оперируют с первыми символами своих аргументов, число
которых не превышает n. Например, strncpy(t,s,n) копирует не более n символов
t в s. Полные описания этих функций содержатся в приложении B.
Упражнение 5.6. Отберите подходящие программы из предыдущих глав и упражнений
и перепишите их, используя вместо индексирования указатели. Подойдут, в
частности, программы getline (главы 1 и 4), atoi, itoa и их варианты (главы
2, 3 и 4), reverse (глава 3), а также strindex и getop (глава 4).
Как и любые другие переменные, указатели можно группировать в массивы. Для
иллюстрации этого напишем программу, сортирующую в алфавитном порядке
текстовые строки; это будет упрощенный вариант программы sort системы UNIX.
В главе 3 мы привели функцию сортировки по Шеллу, которая упорядочивает
массив целых, а в главе 4 улучшили ее, повысив быстродействие. Те же
алгоритмы используются и здесь, однако, теперь они будут обрабатывать
текстовые строки, которые могут иметь разную длину и сравнение или
перемещение которых невозможно выполнить за одну операцию. Нам необходимо
выбрать некоторое представление данных, которое бы позволило удобно и
эффективно работать с текстовыми строками произвольной длины.
Для этого воспользуемся массивом указателей на начала строк. Поскольку строки
в памяти расположены вплотную друг к другу, к каждой отдельной строке доступ
просто осуществлять через указатель на ее первый символ. Сами указатели можно
организовать в виде массива. Одна из возможностей сравнить две строки -
передать указатели на них функции strcmp. Чтобы поменять местами строки,
достаточно будет поменять местами в массиве их указатели (а не сами строки).
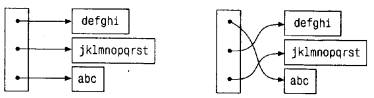
Здесь снимаются сразу две проблемы: одна - связанная со сложностью управления
памятью, а вторая - с большими накладными расходами при перестановках самих
строк. Процесс сортировки распадается на три этапа:
чтение всех строк из ввода
сортировка введенных строк
печать их по порядку
Как обычно, выделим функции, соответствующие естественному делению задачи, и
напишем главную программу main, управляющую этими функциями. Отложим на время
реализацию этапа сортировки и сосредоточимся на структуре данных и вводе-выводе.
Программа ввода должна прочитать и запомнить символы всех строк, а также
построить массив указателей на строки. Она, кроме того, должна подсчитать
число введенных строк - эта информация понадобится для сортировки и печати.
Так как функция ввода может работать только с конечным числом строк, то, если
их введено слишком много, она будет выдавать некоторое значение, которое
никогда не совпадет с количеством строк, например -1.
Программа вывода занимается только тем, что печатает строки, причем в том
порядке, в котором расположены указатели на них в массиве.
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /* максимальное число строк */
char *lineptr[MAXLINES]; /* указатели на строки */
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(char *lineptr[], int left, int right);
/* сортировка строк */
main()
{
int nlines; /* количество прочитанных строк */
if ((nlines = readlines(lineptr, MAXLINES)) >= 0) {
qsort(lineptr, 0, nlines-1);
writelines(lineptr, nlines);
return 0;
} else {
printf("ошибка: слишком много строк\n");
return 1;
}
}
#define MAXLEN 1000 /* максимальная длина строки */
int getline(char *, int);
char *alloc(int);
/* readlines: чтение строк */
int readlines(char *lineptr[], int maxlines)
{
int len, nlines;
char *p, line[MAXLEN];
nlines = 0;
while ((len = getline(line, MAXLEN)) > 0)
if (nlines >= maxlines || (p = alloc(len)) == NULL)
return -1;
else {
line[len-1] = '\0'; /* убираем символ \n */
strcpy(p, line);
lineptr[nlines++] = p;
}
return nlines;
}
/* writelines: печать строк */
void writelines(char *lineptr[], int nlines)
{
int i;
for (i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
}
Функция getline взята из параграфа 1.9. Основное новшество здесь - объявление
lineptr:
char *lineptr[MAXLINES];
в котором сообщается, что lineptr есть массив из MAXLINES элементов, каждый
из которых представляет собой указатель на char. Иначе говоря, lineptr[i] -
указатель на символ, а *lineptr[i] - символ, на который он указывает (первый
символ i-й строки текста).
Так как lineptr - имя массива, его можно трактовать как указатель, т. е. так
же, как мы это делали в предыдущих примерах, и writelines переписать
следующим образом:
/* writelines: печать строк */
void writelines(char *lineptr[], int nlines)
{
while (nlines-- > 0)
printf("%s\n", *lineptr++);
}
Вначале *lineptr указывает на первую строку: каждое приращение указателя
приводит к тому, что *lineptr указывает на следующую строку, и делается это
до тех пор, пока nlines не станет нулем.
Теперь, когда мы разобрались с вводом и выводом, можно приступить к
сортировке. Быструю сортировку, описанную в главе 4, надо несколько
модифицировать: нужно изменить объявления, а операцию сравнения заменить
обращением к strcmp. Алгоритм остался тем же, и это дает нам определенную
уверенность в его правильности.
/* qsort: сортирует v[left]...v[right] по возрастанию */
void qsort(char *v[], int left, int right)
{
int i, last;
void swap(char *v[], int i, int j);
if (left >= right) /* ничего не делается, если в массиве */
return; /* менее двух элементов */
swap(v, left, (left+right)/2);
last = left;
for(i = left+1; i <= right; i++)
if (strcmp(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1);
qsort(v, last+1, right);
}
Небольшие поправки требуются и в программе перестановки.
/* swap: поменять местами v[i] и v[j] */
void swap(char *v[], int i, int j)
{
char *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
Так как каждый элемент массива v (т. е. lineptr) является указателем на
символ, temp должен иметь тот же тип, что и v - тогда можно будет
осуществлять пересылки между temp и элементами v.
Упражнение 5.7. Напишите новую версию readlines, которая запоминала бы строки
в массиве, определенном в main, а не запрашивала память посредством программы
alloc. Насколько быстрее эта программа?
В Си имеется возможность задавать прямоугольные многомерные массивы, правда,
на практике по сравнению с массивами указателей они используются значительно
реже. В этом параграфе мы продемонстрируем некоторые их свойства.
Рассмотрим задачу перевода даты "день-месяц" в "день года" и обратно.
Например, 1 марта - это 60-й день невисокосного или 61-й день високосного
года. Определим две функции для этих преобразований: функция day_of_year
будет преобразовывать месяц и день в день года, a month_day - день года в
месяц и день. Поскольку последняя функция вычисляет два значения, аргументы
месяц и день будут указателями. Так вызов
month_day(1988, 60, &m, &d)
присваивает переменной m значение 2, а d - 29 (29 февраля).
Нашим функциям нужна одна и та же информация, а именно таблица, содержащая
числа дней каждого месяца. Так как для високосного и невисокосного годов эти
таблицы будут различаться, проще иметь две отдельные строки в двумерном
массиве, чем во время вычислений отслеживать особый случай с февралем. Массив
и функции, выполняющие преобразования, имеют следующий вид:
static char daytab[2][13] = {
{0, 31, 28, 31. 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}
}
/* day_of_year: определяет день года по месяцу и дню */
int day_of_year(int year, int month, int day)
{
int i, leap;
leap = year % 4 == 0 && year % 100 !=0 || year % 400 == 0;
for (i = 1; i < month; i++)
day += daytab[leap][i];
return day;
}
/* month_day: определяет месяц и день по дню года *•/
void month_day(int year, int yearday, int *pmonth, int *pday)
{
int i, leap;
leap = year % 4 == 0 && year % 100 != 0 || year % 400 == 0;
for (i = 1; yearday > daytab[leap][i]; i++)
yearday -= daytab[leap][i];
*pmonth = i;
*pday = yearday;
)
Напоминаем, что арифметическое значение логического выражения (например
выражения, с помощью которого вычислялось leap) равно либо нулю (ложь), либо
единице (истина), так что мы можем использовать его как индекс в массиве
daytab.
Массив daytab должен быть внешним по отношению к обеим функциям day_of_year и
month_day, так как он нужен и той и другой. Мы сделали его типа char, чтобы
проиллюстрировать законность применения типа char для малых целых без знака.
Массив daytab - это первый массив из числа двумерных, с которыми мы еще не
имели дела. Строго говоря, в Си двумерный массив рассматривается как
одномерный массив, каждый элемент которого - также массив. Поэтому
индексирование изображается так:
daytab[i][j] /* [строка] [столбец] */
а не так:
daytab[i,j] /* НЕВЕРНО */
Особенность двумерного массива в Си заключается лишь в форме записи, в
остальном его можно трактовать почти так же, как в других языках. Элементы
запоминаются строками, следовательно, при переборе их в том порядке, как они
расположены в памяти, чаще будет изменяться самый правый индекс.
Массив инициализируется списком начальных значений, заключенным в фигурные
скобки; каждая строка двумерного массива инициализируется соответствующим
подсписком. Нулевой столбец добавлен в начало daytab лишь для того, чтобы
индексы, которыми мы будем пользоваться, совпадали с естественными номерами
месяцев от 1 до 12. Экономить пару ячеек памяти здесь нет никакого смысла, а
программа, в которой уже не надо корректировать индекс, выглядит более ясной.
Если двумерный массив передается функции в качестве аргумента, то объявление
соответствующего ему параметра должно содержать количество столбцов;
количество строк в данном случае несущественно, поскольку, как и прежде,
функции будет передан указатель на массив строк, каждая из которых есть
массив из 13 значений типа int. B нашем частном случае мы имеем указатель на
объекты, являющиеся массивами из 13 значений типа int. Таким образом, если
массив daytab передается некоторой функции f, то эту функцию можно было бы
определить следующим образом:
f(int daytab[2][13]) {...}
Вместо этого можно записать
f(int daytab[][13]) {...}
поскольку число строк здесь не имеет значения, или
f(int (*daytab)[13]) {...}
Последняя запись объявляет, что параметр есть указатель на массив из 13
значений типа int. Скобки здесь необходимы, так как квадратные скобки []
имеют более высокий приоритет, чем *. Без скобок объявление
int *daytab[13]
определяет массив из 13 указателей на char. В более общем случае только
первое измерение (соответствующее первому индексу) можно не задавать, все
другие специфицировать необходимо. В параграфе 5.12 мы продолжим рассмотрение
сложных объявлений.
Упражнение 5.8. В функциях day_of_year и month_day нет никаких проверок
правильности вводимых дат. Устраните этот недостаток.
Напишем функцию month_name(n), которая возвращает указатель на строку
символов, содержащий название n-го месяца. Эта функция идеальна для
демонстрации использования статического массива. Функция month_name имеет в
своем личном распоряжении массив строк, на одну из которых она и возвращает
указатель. Ниже покажем, как инициализируется этот массив имен.
Синтаксис задания начальных значений аналогичен синтаксису предыдущих
инициализаций:
/* month_name: возвращает имя n-го месяца */
char *month_name(int n)
{
static char *name[] = {
"Неверный месяц",
"Январь","Февраль","Март","Апрель","Май","Июнь",
"Июль","Август","Сентябрь","Октябрь","Ноябрь","Декабрь"
};
return (n < 1 || n > 12) ? name[0] : name[n];
}
Объявление name массивом указателей на символы такое же, как и объявление
lineptr в программе сортировки. Инициализатором служит список строк, каждой
из которых соответствует определенное место в массиве. Символы i-й строки
где-то размещены, и указатель на них запоминается в name[i]. Так как размер
массива name не специфицирован, компилятор вычислит его по количеству
заданных начальных значений.
Начинающие программировать на Си иногда не понимают, в чем разница между
двумерным массивом и массивом указателей вроде name из приведенного примера.
Для двух следующих определений:
int a[10][20];
int *b[10];
записи a[3][4] и b[3][4] будут синтаксически правильным обращением к
некоторому значению типа int. Однако только a является истинно двумерным
массивом: для двухсот элементов типа int будет выделена память, а вычисление
смещения элемента a[строка][столбец] от начала массива будет вестись по
формуле 20 * строка + столбец, учитывающей его прямоугольную природу. Для b же
определено только 10 указателей, причем без инициализации. Инициализация
должна задаваться явно -либо статически, либо в программе. Предположим, что
каждый элемент b указывает на двадцатиэлементный массив, в результате где-то
будут выделены пространство, в котором разместятся 200 значений типа int, и
еще 10 ячеек для указателей. Важное преимущество массива указателей в том,
что строки такого массива могут иметь разные длины. Таким образом, каждый
элемент массива b не обязательно указывает на двадцатиэлементный вектор; один
может указывать на два элемента, другой - на пятьдесят, а некоторые и вовсе
могут ни на что не указывать.
Наши рассуждения здесь касались целых значений, однако чаще массивы
указателей используются для работы со строками символов, различающимися по
длине, как это было в функции month_name. Сравните определение массива
указателей и соответствующий ему рисунок:
char *name[] = {"Неправильный месяц", "Янв", "Февр", "Март"};
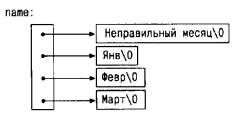
с объявлением и рисунком для двумерного массива:
char aname[][15] = {"Неправ. месяц", "Янв", "Февр", "Март"};

Упражнение 5.9. Перепишите программы day_of_year и month_day, используя
вместо индексов указатели.
В операционной среде, обеспечивающей поддержку Си, имеется возможность
передать аргументы или параметры запускаемой программе с помощью командной
строки. В момент вызова main получает два аргумента. В первом, обычно
называемом argc (сокращение от argument count), стоит количество аргументов,
задаваемых в командной строке. Второй, argv (от argument vector), является
указателем на массив символьных строк, содержащих сами аргументы. Для работы
с этими строками обычно используются указатели нескольких уровней.
Простейший пример - программа echo ("эхо"), которая печатает аргументы своей
командной строки в одной строчке, отделяя их друг от друга пробелами. Так,
команда
echo Здравствуй, мир!
Напечатает
Здравствуй, мир!
По соглашению argv[0] есть имя вызываемой программы, так что значение argc
никогда не бывает меньше 1. Если argc равен 1, то в командной строке после
имени программы никаких аргументов нет. В нашем примере argc равен 3, и
соответственно argv[0], argv[1] и argv[2] суть строки "echo", "Здравствуй," и
"мир!". Первый необязательный аргумент - это argv[1], последний - argv[argc-1].
Кроме того, стандарт требует, чтобы argv[argc] всегда был пустым
указателем.
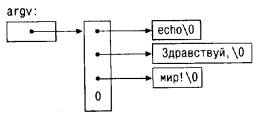
Первая версия программы echo трактует argv как массив символьных
указателей.
#include <stdio.h>
/* эхо аргументов командной строки: версия 1 */
main(int argc, char *argv[])
{
int i;
for (i = 1; i < argc; i++)
printf("%s%s", argv[i], (i < argc-1) ? " " : "");
printf("\n");
return 0;
}
Так как argv - это указатель на массив указателей, мы можем работать с ним
как с указателем, а не как с индексируемым массивом. Следующая программа
основана на приращении argv, он приращивается так, что его значение в каждый
отдельный момент указывает на очередной указатель на char; перебор указателей
заканчивается, когда исчерпан argc.
#include <stdio.h>
/* эхо аргументов командной строки; версия 2 */
main(int argc, char *argv[])
{
while (--argc > 0)
printf("%s%s", *++argv, (argc > 1) ? " " : "");
print f("\n");
return 0;
}
Аргумент argv - указатель на начало массива строк аргументов.
Использование в ++argv префиксного оператора ++ приведет к тому, что первым
будет напечатан argv[1],а не argv[0]. Каждое очередное приращение указателя
дает нам следующий аргумент, на который указывает *argv. В это же время
значение argc уменьшается на 1, и, когда оно станет нулем, все аргументы
будут напечатаны. Инструкцию printf можно было бы написать и так:
printf((argc > 1) ? "%s " : "%s", *++argv);
Как видим, формат в printf тоже может быть выражением.
В качестве второго примера возьмем программу поиска образца, рассмотренную в
параграфе 4.1, и несколько усовершенствуем ее. Если вы помните, образец для
поиска мы "вмонтировали" глубоко в программу, а это, очевидно, не лучшее
решение. Построим нашу программу по аналогии с grep из UNIXa, т. е. так,
чтобы образец для поиска задавался первым аргументом в командной строке.
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
/* find: печать строк с образцом, заданным 1-м аргументом */
main(int argc, char *argv[])
{
char line[MAXLINE];
int found == 0;
if (argc != 2)
printf("Используйте в find образец\n");
else
while (getline(line, MAXLINE) > 0)
if (strstr(line, argv[1]) >= NULL) {
printf ("%s", line);
found++;
}
return found;
}
Стандартная функция strstr(s,t) возвращает указатель на первую встретившуюся
строку t в строке s или NULL, если таковой в s не встретилось. Функция
объявлена в заголовочном файле <string.h>.
Эту модель можно развивать и дальше, чтобы проиллюстрировать другие
конструкции с указателями. Предположим, что мы вводим еще два необязательных
аргумента. Один из них предписывает печатать все строки, кроме тех, в которых
встречается образец; второй - перед каждой выводимой строкой печатать ее
порядковый номер.
По общему соглашению для Си-программ в системе UNIX знак минус перед
аргументом вводит необязательный признак или параметр. Так, если -x служит
признаком слова "кроме", которое изменяет задание на противоположное, а -n
указывает на потребность в нумерации строк, то команда
find -x -n образец
напечатает все строки, в которых не найден указанный образец, и, кроме того,
перед каждой строкой укажет ее номер.
Необязательные аргументы разрешается располагать в любом порядке, при этом
лучше, чтобы остальная часть программы не зависела от числа представленных
аргументов. Кроме того, пользователю было бы удобно, если бы он мог
комбинировать необязательные аргументы, например так:
find -nx образец
А теперь запишем нашу программу.
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
/* find: печать строк образцами из 1-го аргумента */
main(int argc, char *argv[])
{
char line[MAXLINE];
long lineno = 0;
int c, except = 0, number = 0, found = 0;
while (--argc > 0 && (*++argv)[0] == '-')
while (c = *++argv[0])
switch (c) {
case 'x':
except = 1;
break;
case 'n':
number = 1;
break;
default:
printf("find: неверный параметр %c\n", c);
argc = 0;
found = -1;
break;
}
if (argc != 1)
printf("Используйте: find -x -n образец\n");
else
while (getline(line, MAXLINE) > 0) {
lineno++;
if ((strstr(line, *argv) != NULL) != except) {
if (number)
printf("%ld:", lineno);
printf("%s", line);
found++;
}
}
return found;
}
Перед получением очередного аргумента argc уменьшается на 1, а argv
"перемещается" на следующий аргумент. После завершения цикла при отсутствии
ошибок argc содержит количество еще не обработанных аргументов, a argv
указывает на первый из них. Таким образом, argc должен быть равен 1, a *argv
указывать на образец. Заметим, что *++argv является указателем на аргумент-
строку, a (*++argv)[0] - его первым символом, на который можно сослаться и
другим способом:
**++argv;
Поскольку оператор индексирования [] имеет более высокий приоритет, чем * и
++, круглые скобки здесь обязательны, без них выражение трактовалось бы так
же, как *++(argv[0]). Именно такое выражение мы применим во внутреннем цикле,
где просматриваются символы конкретного аргумента. Во внутреннем цикле
выражение *++argv[0] приращивает указатель argv[0].
Потребность в более сложных выражениях для указателей возникает не так уж
часто. Но если такое случится, то разбивая процесс вычисления указателя на
два или три шага, вы облегчите восприятие этого выражения.
Упражнение 5.10. Напишите программу expr, интерпретирующую обратную польскую
запись выражения, задаваемого командной строкой, в которой каждый оператор и
операнд представлены отдельным аргументом. Например,
expr 2 3 4 + *
вычисляется так же, как выражение 2*(3+4).
Упражнение 5.11. Усовершенствуйте программы entab и detab (см. упражнения
1.20 и 1.21) таким образом, чтобы через аргументы можно было задавать список
"стопов" табуляции.
Упражнение 5.12. Расширьте возможности entab и detab таким образом, чтобы при
обращении вида
entab -m +n
"стопы" табуляции начинались с m-й позиции и выполнялись через каждые n
позиций. Разработайте удобный для пользователя вариант поведения программы по
умолчанию (когда нет никаких аргументов).
Упражнение 5.13. Напишите программу tail, печатающую n последних введенных
строк. По умолчанию значение n равно 10, но при желании n можно задать с
помощью аргумента. Обращение вида
tail -n
печатает n последних строк. Программа
должна вести себя осмысленно при любых входных данных и любом значении n.
Напишите программу так, чтобы наилучшим образом использовать память;
запоминание строк организуйте, как в программе сортировки, описанной в
параграфе 5.6, а не на основе двумерного массива с фиксированным размером
строки.
В Си сама функция не является переменной, но можно определить указатель на
функцию и работать с ним, как с обычной переменной: присваивать, размещать в
массиве, передавать в качестве параметра функции, возвращать как результат из
функции и т. д. Для иллюстрации этих возможностей воспользуемся программой
сортировки, которая уже встречалась в настоящей главе. Изменим ее так, чтобы
при задании необязательного аргумента -n вводимые строки упорядочивались по
их числовому значению, а не в лексикографическом порядке.
Сортировка, как правило, распадается на три части: на сравнение, определяющее
упорядоченность пары объектов; перестановку, меняющую местами пару объектов,
и сортирующий алгоритм, который осуществляет сравнения и перестановки до тех
пор, пока все объекты не будут упорядочены. Алгоритм сортировки не зависит от
операций сравнения и перестановки, так что передавая ему в качестве
параметров различные функции сравнения и перестановки, его можно настроить на
различные критерии сортировки.
Лексикографическое сравнение двух строк выполняется функцией strcmp (мы уже
использовали эту функцию в ранее рассмотренной программе сортировки); нам
также потребуется программа numcmp, сравнивающая две строки как числовые
значения и возвращающая результат сравнения в том же виде, в каком его выдает
strcmp. Эти функции объявляются перед main, а указатель на одну из них
передается функции qsort. Чтобы сосредоточиться на главном, мы упростили себе
задачу, отказавшись от анализа возможных ошибок при задании аргументов.
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /* максимальное число строк */
char *lineptr[MAXLINES]; /* указатели на строки текста */
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(void *lineptr[], int left, int right,
int (*comp)(void *, void *));
int numcmp(char *, char *);
/* сортировка строк */
main(int argc, char *argv[])
{
int nlines; /* количество прочитанных строк */
int numeric = 0; /* 1, если сорт. по числ. знач. */
if (argc > 1 && strcmp(argv[1], "-n") == 0)
numeric = 1;
if ((nlines = readlines(lineptr, MAXLINES)) >= 0) {
qsort((void **) lineptr, 0, nlines-1,
(int (*)(void*,void*))(numeric ? numcmp : strcmp));
writelines(lineptr, nlines);
return 0;
} else {
printf("Bведено слишком много строк\n");
return 1;
}
}
В обращениях к функциям qsort, strcmp и numcmp их имена трактуются как адреса
этих функций, поэтому оператор & перед ними не нужен, как он не был нужен и
перед именем массива.
Мы написали qsort так, чтобы она могла обрабатывать данные любого типа, а не
только строки символов. Как видно из прототипа, функция qsort в качестве
своих аргументов ожидает массив указателей, два целых значения и функцию с
двумя аргументами-указателями. В качестве аргументов-указателей заданы
указатели обобщенного типа void *. Любой указатель можно привести к типу
void * и обратно без потери информации, поэтому мы можем обратиться к qsort,
предварительно преобразовав аргументы в void *. Внутри функции сравнения ее
аргументы будут приведены к нужному ей типу. На самом деле эти преобразования
никакого влияния на представления аргументов не оказывают, они лишь
обеспечивают согласованность типов для компилятора.
/* qsort: сортирует v[left]...v[right] по возрастанию */
void qsort(void *v[], int left, int right,
int (*comp)(void *, void *))
{
int i, last;
void swap(void *v[], int, int);
if (left >= right) /* ничего не делается, если */
return; /* в массиве менее двух элементов */
swap(v, left, (left + right)/2);
last = left;
for (i = left+1; i <= right; i++)
if ((*comp)(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1, comp);
qsort(v, last+1, right, comp);
}
Повнимательней приглядимся к объявлениям. Четвертый параметр функции qsort:
int (*comp)(void *, void *)
сообщает, что comp - это указатель на функцию, которая имеет два аргумента-
указателя и выдает результат типа int. Использование comp в строке
if ((*comp)(v[i], v[left]) < 0)
согласуется с объявлением "comp - это указатель на функцию", и,
следовательно, *comp - это функция, а
(*comp)(v[i], v[left])
- обращение к ней. Скобки здесь нужны, чтобы обеспечить правильную трактовку
объявления; без них объявление
int *comp(void *, void *) /* НЕВЕРНО */
говорило бы, что comp - это функция, возвращающая указатель на int, а это
совсем не то, что требуется.
Мы уже рассматривали функцию strcmp, сравнивающую две строки. Ниже приведена
функция numcmp, которая сравнивает две строки, рассматривая их как числа;
предварительно они переводятся в числовые значения функцией atof.
#include <stdlib.h>
/* numcmp: сравнивает s1 и s2 как числа */
int numcmp(char *s1, char *s2)
{
double v1, v2;
v1 = atof(s1);
v2 = atof(s2);
if (v1 < v2)
return -1;
else if (v1 > v2)
return 1;
else
return 0;
}
Функция swap, меняющая местами два указателя, идентична той, что мы привели
ранее в этой главе за исключением того, что объявления указателей заменены на
void*.
void swap(void *v[], int i, int j)
{
void *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
Программу сортировки можно дополнить и множеством других возможностей;
реализовать некоторые из них предлагается в качестве упражнений.
Упражнение 5.14. Модифицируйте программу сортировки, чтобы она реагировала на
параметр -r, указывающий, что объекты нужно сортировать в обратном порядке,
т. е. в порядке убывания. Обеспечьте, чтобы -r работал и вместе с -n.
Упражнение 5.15. Введите в программу необязательный параметр -f, задание
которого делало бы неразличимыми символы нижнего и верхнего регистров
(например, a и A должны оказаться при сравнении равными).
Упражнение 5.16. Предусмотрите в программе необязательный параметр -d,
который заставит программу при сравнении учитывать только буквы, цифры и
пробелы. Организуйте программу таким образом, чтобы этот параметр мог
работать вместе с параметром -f.
Упражнение 5.17. Реализуйте в программе возможность работы с полями:
возможность сортировки по полям внутри строк. Для каждого поля предусмотрите
свой набор параметров. Предметный указатель этой книги (Имеется в виду оригинал книги на английским языке. – Примеч. пер.) упорядочивался с
параметрами: -df для терминов и -n для номеров страниц.
Иногда Си ругают за синтаксис объявлений, особенно тех, которые содержат в
себе указатели на функции. Таким синтаксис получился в результате нашей
попытки сделать похожими объявления объектов и их использование. В простых
случаях этот синтаксис хорош, однако в сложных ситуациях он вызывает
затруднения, поскольку объявления перенасыщены скобками и их невозможно
читать слева направо. Проблему иллюстрирует различие следующих двух
объявлений:
int *f(); /* f: функция, возвращающая ук-ль на int */
int (*pf)(); /* pf: ук-ль на ф-цию, возвращающую int */
Приоритет префиксного оператора * ниже, чем приоритет (), поэтому во
втором случае скобки необходимы.
Хотя на практике по-настоящему сложные объявления встречаются редко, все же
важно знать, как их понимать, а если потребуется, и как их конструировать.
Укажем хороший способ: объявления можно синтезировать, двигаясь небольшими
шагами с помощью typedef, этот способ рассмотрен в параграфе 6.7. В настоящем
параграфе на примере двух программ, осуществляющих преобразования правильных
Си-объявлений в соответствующие им словесные описания и обратно, мы
демонстрируем иной способ конструирования объявлений. Словесное описание
читается слева направо.
Первая программа, dcl, - более сложная. Она преобразует Си-объявления в
словесные описания так, как показано в следующих примерах:
char **argv
argv: указ. на указ. на char
int (*daytab)[13]
daytab: указ. на массив[13] из int
int (*daytab)[13]
daytab: массив[13] из указ. на int
void *comp()
comp: функц. возвр. указ. на void
void (*comp)()
comp: указ. на функц. возвр. void
char (*(*x())[])()
x: функц. возвр. указ. на массив[] из указ. на функц. возвр. char
char(*(*x[3])())[5]
x: массив[3] из указ. на функц. возвр. указ. на массив[5] из char
Функция dcl в своей работе использует грамматику, специфицирующую объявитель.
Эта грамматика строго изложена в параграфе 8.5 приложения A, а в упрощенном
виде записывается так:
объявитель: необязательные * собственно-объявитель
собственно-объявитель: имя
(объявитель)
собственно-объявитель()
собственно-объявитель [необязательный размер]
Говоря простым языком, объявитель есть собственно-объявитель, перед которым
может стоять * (т. е. одна или несколько звездочек), где собственно-
объявитель есть имя, или объявитель в скобках, или собственно-объявитель с
последующей парой скобок, или собственно-объявитель с последующей парой
квадратных скобок, внутри которых может быть помещен размер.
Эту грамматику можно использовать для грамматического разбора объявлений.
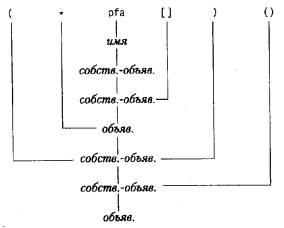
Рассмотрим, например, такой объявитель:
(*pfa[])()
Имя pfa будет классифицировано как имя и, следовательно, как собственно-
объявитель. Затем pfa[] будет распознано как собственно-объявитель, а
*pfa[] - как объявитель и, следовательно, (*pfa[]) есть собственно-объявитель.
Далее, (*pfa[])() есть собственно-объявитель и, таким образом, объявитель.
Этот грамматический разбор можно проиллюстрировать деревом разбора,
приведенным на следующей странице (где собственно-объявитель обозначен более
коротко, а именно собств.-объяв.).
Сердцевиной программы обработки объявителя является пара функций dcl и
dirdcl, осуществляющих грамматический разбор объявления согласно приведенной
грамматике. Поскольку грамматика определена рекурсивно, эти функции
обращаются друг к другу рекурсивно, по мере распознавания отдельных частей
объявления. Метод, примененный в обсуждаемой программе для грамматического
разбора, называется рекурсивным спуском.
/* dcl: разбор объявителя */
void dcl(void)
{
int ns;
for (ns = 0, gettoken() == '*';) /* подсчет звездочек */
ns++;
dirdcl();
while(ns-- > 0)
strcat(out, "указ. на”);
}
/* dirdcl: разбор собственно объявителя */
void dirdcl(void)
{
int type;
if (tokentype == '(') {
dcl();
if (tokentype != ')')
printf("oшибкa: пропущена )\n");
} else if (tokentype == NAME) /* имя переменной */
strcpy(name, token);
else
printf("ошибка: должно быть name или (dcl)\n");
while((type = gettoken()) == PARENS || type == BRACKETS)
if (type == PARENS)
strcat(out, "функц. возвр.");
else {
strcat(out, " массив");
strcat(out, token);
strcat(out, " из");
}
}
Приведенные программы служат только иллюстративным целям и не вполне надежны.
Что касается dcl, то ее возможности существенно ограничены. Она может
работать только с простыми типами вроде char и int и не справляется с типами
аргументов в функциях и с квалификаторами вроде const. Лишние пробелы для нее
опасны. Она не предпринимает никаких мер по выходу из ошибочной ситуации, и
поэтому неправильные описания также ей противопоказаны. Устранение этих
недостатков мы оставляем для упражнений. Ниже приведены глобальные переменные
и главная программа main.
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAXTOKEN 100
enum {NAME, PARENS, BRACKETS};
void dcl(void);
void dirdcl(void);
int gettoken(void);
int tokentype; /* тип последней лексемы */
char token[MAXTOKEN]; /* текст последней лексемы */
char name[MAXTOKEN]; /* имя */
char datatype[MAXTOKEN]; /* тип = char, int и т.д. */
char out[1000]; /* выдаваемый текст */
main() /* преобразование объявления в словесное описание */
{
while (gettoken() != EOF) { /* 1-я лексема в строке */
strcpy(datatype, token); /* это тип данных */
out[0] = '\0';
dcl(); /* разбор остальной части строки */
if (tokentype != '\n')
printf("синтаксическая ошибка\n");
printf("%s: %s %s\n", name, out, datatype);
}
return 0;
}
Функция gettoken пропускает пробелы и табуляции и затем получает следующую
лексему из ввода: "лексема" (token) - это имя, или пара круглых скобок, или
пара квадратных скобок (быть может, с помещенным в них числом), или любой
другой единичный символ.
int gettoken(void) /* возвращает следующую лексему */
{
int с, getch(void);
void ungetch(int);
char *p = token;
while ((c = getch()) == ' ' || с = '\t')
;
if (c == '(') {
if ((c = getch())== ')' {
strcpy(token, "()");
return tokentype = PARENS;
} else {
ungetch(c);
return tokentype = '(';
}
} else if (c == '['){
for (*p++ = c; (*p++ = getch()) != ']'; )
;
*p = '\0';
return tokentype = BRACKETS;
} else if (isalpha(c)) {
for (*p++ = c; isalnum(c = getch()); )
*p++ = c;
*p = '\0';
ungetch(c);
return tokentype = NAME;
} else
return tokentype = c;
}
Функции getch и ungetch были рассмотрены в главе 4.
Обратное преобразование реализуется легче, особенно если не придавать
значения тому, что будут генерироваться лишние скобки. Программа undcl
превращает фразу вроде "x есть функция, возвращающая указатель на массив
указателей на функции, возвращающие char", которую мы будем представлять в
виде
х () * [] * () char
в объявление
char (*(*х())[])()
Такой сокращенный входной синтаксис позволяет повторно пользоваться функцией
gettoken. Функция undcl использует те же самые внешние переменные, что и dcl.
/* undcl: преобразует словесное описание в объявление */
main()
{
int type;
char temp[MAXTOKEN];
while (gettoken() != EOF) {
strcpy(out, token);
while ((type = gettoken()) != '\n')
if (type == PARENS || type == BRACKETS)
strcat(out, token);
else if (type == '*' ) {
sprintf(temp, "(*%s)", out);
strcpy(out, temp);
} else if (type == NAME) {
sprintf(temp, "%s %s", token, out);
strcpy(out, temp);
} else
printf( "неверный элемент %s в фразе\n", token);
printf("%s\n", out);
}
return 0;
}
Упражнение 5.18. Видоизмените dcl таким образом, чтобы она обрабатывала
ошибки во входной информации.
Упражнение 5.19. Модифицируйте undcl так, чтобы она не генерировала лишних
скобок.
Упражнение 5.20. Расширьте возможности dcl, чтобы dcl обрабатывала объявления
с типами аргументов функции, квалификаторами вроде const и т. п.
Глава 6. Структуры
Структура - это одна или несколько переменных (возможно, различных типов),
которые для удобства работы с ними сгруппированы под одним именем. (В
некоторых языках, в частности в Паскале, структуры называются записями.)
Структуры помогают в организации сложных данных (особенно в больших
программах), поскольку позволяют группу связанных между собой переменных
трактовать не как множество отдельных элементов, а как единое целое.
Традиционный пример структуры - строка платежной ведомости. Она содержит
такие сведения о служащем, как его полное имя, адрес, номер карточки
социального страхования, зарплата и т. д. Некоторые из этих характеристик
сами могут быть структурами: например, полное имя состоит из нескольких
компонент (фамилии, имени и отчества); аналогично адрес, и даже зарплата.
Другой пример (более типичный для Си) - из области графики: точка есть пара
координат, прямоугольник есть пара точек и т. д.
Главные изменения, внесенные стандартом ANSI в отношении структур, - это
введение для них операции присваивания. Структуры могут копироваться, над
ними могут выполняться операции присваивания, их можно передавать функциям в
качестве аргументов, а функции могут возвращать их в качестве результатов. В
большинстве компиляторов уже давно реализованы эти возможности, но теперь они
точно оговорены стандартом. Для автоматических структур и массивов теперь
также допускается инициализация.
Сконструируем несколько графических структур. В качестве основного объекта
выступает точка с координатами x и y целого типа.
Указанные две компоненты можно поместить в структуру, объявленную, например,
следующим образом:
struct point {
int x;
int y;
};
Объявление структуры начинается с ключевого слова struct и содержит список
объявлений, заключенный в фигурные скобки. За словом struct может следовать
имя, называемое тегом структуры (от английского слова tag — ярлык, этикетка.
— Примеч. пер.), point в нашем случае. Тег дает название
структуре данного вида и далее может служить кратким обозначением той части
объявления, которая заключена в фигурные скобки.
Перечисленные в структуре переменные называются элементами (members -
В некоторых изданиях, в том числе во 2-м издании на русским языке этой
книги structure members переводится как члены структуры. - Примеч. ред). Имена
элементов и тегов без каких-либо коллизий могут совпадать с именами обычных
переменных (т. е. не элементов), так как они всегда различимы по контексту.
Более того, одни и те же имена элементов могут встречаться в разных
структурах, хотя, если следовать хорошему стилю программирования, лучше
одинаковые имена давать только близким по смыслу объектам.
Объявление структуры определяет тип. За правой фигурной скобкой, закрывающей
список элементов, могут следовать переменные точно так же, как они могут быть
указаны после названия любого базового типа. Таким образом, выражение
struct {...} x, y, z;
с точки зрения синтаксиса аналогично выражению
int х, у, z;
в том смысле, что и то и другое объявляет x, y и z переменными указанного
типа; и то и другое приведет к выделению памяти соответствующего размера.
Объявление структуры, не содержащей списка переменных, не резервирует памяти;
оно просто описывает шаблон, или образец структуры. Однако если структура
имеет тег, то этим тегом далее можно пользоваться при определении структурных
объектов. Например, с помощью заданного выше описания структуры point строка
struct point pt;
определяет структурную переменную pt типа struct point. Структурную
переменную при ее определении можно инициализировать, формируя список
инициализаторов ее элементов в виде константных выражений:
struct point maxpt = {320, 200};
Инициализировать автоматические структуры можно также присваиванием или
обращением к функции, возвращающей структуру соответствующего типа.
Доступ к отдельному элементу структуры осуществляется посредством конструкции
вида:
имя-структуры.элемент
Оператор доступа к элементу структуры . соединяет имя структуры и имя
элемента. Чтобы напечатать, например, координаты точки pt, годится следующее
обращение к printf:
printf("%d, %d", pt.x, pt.y);
Другой пример: чтобы вычислить расстояние от начала координат (0,0) до pt,
можно написать
double dist, sqrt(double);
dist = sqrt((double)pt.x * pt.x + (double)pt.y * pt.y);
Структуры могут быть вложены друг в друга. Одно из возможных представлений
прямоугольника - это пара точек на углах одной из его диагоналей:
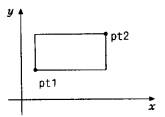
struct rect {
struct point pt1;
struct point pt2;
};
Структура rect содержит две структуры point. Если мы объявим screen как
struct rect screen;
то
screen.pt1.x
обращается к координате x точки pt1 из screen.
Единственно возможные операции над структурами - это их копирование,
присваивание, взятие адреса с помощью & и осуществление доступа к ее
элементам. Копирование и присваивание также включают в себя передачу функциям
аргументов и возврат ими значений. Структуры нельзя сравнивать.
Инициализировать структуру можно списком константных значений ее элементов;
автоматическую структуру также можно инициализировать присваиванием.
Чтобы лучше познакомиться со структурами, напишем несколько функций,
манипулирующих точками и прямоугольниками. Возникает вопрос: а как передавать
функциям названные объекты? Существует по крайней мере три подхода:
передавать компоненты по отдельности, передавать всю структуру целиком и
передавать указатель на структуру. Каждый подход имеет свои плюсы и минусы.
Первая функция, makepoint, получает два целых значения и возвращает структуру
point.
/* makepoint: формирует точку по компонентам x и y */
struct point makepoint(int х, int у)
{
struct point temp;
temp.x = х;
temp.у = у;
return temp;
}
Заметим: никакого конфликта между именем аргумента и именем элемента
структуры не возникает; более того, сходство подчеркивает родство
обозначаемых им объектов.
Теперь с помощью makepoint можно выполнять динамическую инициализацию любой
структуры или формировать структурные аргументы для той или иной функции:
struct rect screen;
struct point middle;
struct point makepoint(int, int);
screen.pt1 = makepoint(0, 0);
screen.pt2 = makepoint(XMAX, YMAX);
middle = makepoint((screen.pt1.x + screen.pt2.x)/2,
(screen.pt1.y + screen.pt2.y)/2);
Следующий шаг состоит в определении ряда функций, реализующих различные
операции над точками. В качестве примера рассмотрим следующую функцию:
/* addpoint: сложение двух точек */
struct point addpoint(struct point p1, struct point p2)
{
p1.x += p2.x;
p1.y += p2.y;
return p1;
}
Здесь оба аргумента и возвращаемое значение - структуры. Мы увеличиваем
компоненты прямо в р1 и не используем для этого временной переменной, чтобы
подчеркнуть, что структурные параметры передаются по значению так же, как и
любые другие.
В качестве другого примера приведем функцию ptinrect, которая проверяет:
находится ли точка внутри прямоугольника, относительно которого мы принимаем
соглашение, что в него входят его левая и нижняя стороны, но не входят
верхняя и правая.
/* ptinrect: возвращает 1, если p в r, и 0 в противном случае */
int ptinrect(struct point р, struct rect r)
{
return p.x >= r.pt1.x && p.x < r.pt2.x
&& p.y >= r.pt1.y && p.y < r.pt2.y;
}
Здесь предполагается, что прямоугольник представлен в стандартном виде, т.е.
координаты точки pt1 меньше соответствующих координат точки pt2. Следующая
функция гарантирует получение прямоугольника в каноническом виде.
#define min(a, b) ((a) < (b) ? (a) : (b))
#define max(a, b) ((a) > (b) ? (a) : (b))
/* canonrect: канонизация координат прямоугольника */
struct rect canonrect(struct rect r)
{
struct rect temp;
temp.pt1.x = min(r.pt1.x, r.pt2.x);
temp.ptl.y = min(r.pt1.y, r.pt2.у);
temp.pt2.x = max(r.pt1.x, r.pt2.x);
temp.pt2.y = max(r.pt1.y, r.pt2.y);
return temp;
}
Если функции передается большая структура, то, чем копировать ее целиком,
эффективнее передать указатель на нее. Указатели на структуры ничем не
отличаются от указателей на обычные переменные. Объявление
struct point *pp;
сообщает, что pp - это указатель на структуру типа struct point. Если pp
указывает на структуру point, то *pp - это сама структура, а (*pp).x и (*pp).y
- ее элементы. Используя указатель pp, мы могли бы написать
struct point origin, *pp;
pp = &origin;
printf("origin: (%d,%d)\n", (*pp).x, (*pp).y);
Скобки в (*pp).x необходимы, поскольку приоритет оператора . выше, чем
приоритет *. Выражение *pp.x будет проинтерпретировано как *(pp.x), что
неверно, поскольку pp.x не является указателем.
Указатели на структуры используются весьма часто, поэтому для доступа к ее
элементам была придумана еще одна, более короткая форма записи. Если p —
указатель на структуру, то
р->элемент-структуры
есть ее отдельный элемент. (Оператор -> состоит из знака -, за которым сразу
следует знак >.) Поэтому printf можно переписать в виде
printf("origin: (%d,%d)\n", pp->х, pp->y);
Операторы . и -> выполняются слева направо. Таким образом, при наличии
объявления
struct rect r, *rp = &r;
следующие четыре выражения будут эквивалентны:
r.pt1.x
rp->pt1.x
(r.pt1).x
(rp->pt1).x
Операторы доступа к элементам структуры . и -> вместе с операторами вызова
функции () и индексации массива [] занимают самое высокое положение в
иерархии приоритетов и выполняются раньше любых других операторов. Например,
если задано объявление
struct {
int len;
char *str;
} *p;
то
++p->len
увеличит на 1 значение элемента структуры len, а не указатель p, поскольку в
этом выражении как бы неявно присутствуют скобки: ++(p->len). Чтобы изменить
порядок выполнения операций, нужны явные скобки. Так, в (++р)->len, прежде
чем взять значение len, программа прирастит указатель p. В (р++)->len
указатель p увеличится после того, как будет взято значение len (в последнем
случае скобки не обязательны).
По тем же правилам *p->str обозначает содержимое объекта, на который
указывает str; *p->str++ прирастит указатель str после получения значения
объекта, на который он указывал (как и в выражении *s++), (*p->str)++
увеличит значение объекта, на который указывает str; *p++->str увеличит p
после получения того, на что указывает str.
Рассмотрим программу, определяющую число вхождений каждого ключевого слова в
текст Си-программы. Нам нужно уметь хранить ключевые слова в виде массива
строк и счетчики ключевых слов в виде массива целых. Один из возможных
вариантов - это иметь два параллельных массива:
char *keyword[NKEYS];
int keycount[NKEYS];
Однако именно тот факт, что они параллельны, подсказывает нам другую
организацию хранения - через массив структур. Каждое ключевое слово можно
описать парой характеристик
char *word;
int count;
Такие пары составляют массив. Объявление
struct key {
char *word;
int count;
} keytab[NKEYS];
объявляет структуру типа key и определяет массив keytab, каждый элемент
которого является структурой этого типа и которому где-то будет выделена
память. Это же можно записать и по-другому:
struct key {
char *word;
int count;
};
struct key keytab[NKEYS];
Так как keytab содержит постоянный набор имен, его легче всего сделать
внешним массивом и инициализировать один раз в момент определения.
Инициализация структур аналогична ранее демонстрировавшимся инициализациям -
за определением следует список инициализаторов, заключенный в фигурные
скобки:
struct key {
char *word;
int count;
} keytab[] = {
"auto", 0,
"break", 0,
"case", 0,
"char", 0,
"const", 0,
"continue", 0,
"default", 0,
/*...*/
"unsigned", 0,
"void", 0,
"volatile", 0,
"while", 0
};
Инициализаторы задаются парами, чтобы соответствовать конфигурации структуры.
Строго говоря, пару инициализаторов для каждой отдельной структуры следовало
бы заключить в фигурные скобки, как, например, в
{ "auto", 0 },
{ "break", 0 },
{ "case", 0 },
...
Однако когда инициализаторы - простые константы или строки символов и все они
имеются в наличии, во внутренних скобках нет необходимости. Число элементов
массива keytab будет вычислено по количеству инициализаторов, поскольку они
представлены полностью, а внутри квадратных скобок "[]" ничего не задано.
Программа подсчета ключевых слов начинается с определения keytab. Программа
main читает ввод, многократно обращаясь к функции getword и получая на каждом
ее вызове очередное слово. Каждое слово ищется в keytab. Для этого
используется функция бинарного поиска, которую мы написали в главе 3. Список
ключевых слов должен быть упорядочен в алфавитном порядке.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
int getword(char *, int);
int binsearch(char *, struct key *, int);
/* подсчет ключевых слов Си */
main()
{
int n;
char word[MAXWORD];
while(getword(word, MAXWORD) != EOF)
if (isalpha(word[0]))
if ((n = binsearch(word, keytab, NKEYS)) >= 0)
keytab[n].count++;
for (n = 0; n < NKEYS; n++)
if (keytab[n].count > 0)
printf("%4d %s\n", keytab[n].count, keytab[n].word);
return 0;
}
/* binsearch: найти слово в tab[0]...tab[n-1] */
int binsearch(char *word, struct key tab[], int n)
{
int cond;
int low, high, mid;
low = 0;
high = n-1;
while (low <= high) {
mid = (low + high)/2;
if ((cond = strcmp(word, tab[mid].word)) < 0)
high = mid - 1;
else if (cond > 0)
low = mid + 1;
else
return mid;
}
return -1;
}
Чуть позже мы рассмотрим функцию getword, а сейчас нам достаточно знать, что
при каждом ее вызове получается очередное слово, которое запоминается в
массиве, заданном первым аргументом.
NKEYS - количество ключевых слов в keytab. Хотя мы могли бы подсчитать число
таких слов вручную, гораздо легче и безопасней сделать это с помощью машины,
особенно если список ключевых слов может быть изменен. Одно из возможных
решений — поместить в конец списка инициализаторов пустой указатель (NULL) и
затем перебирать в цикле элементы keytab, пока не встретится концевой
элемент.
Но возможно и более простое решение. Поскольку размер массива полностью
определен во время компиляции и равен произведению количества элементов
массива на размер его отдельного элемента, число элементов массива можно
вычислить по формуле
размер keytab / размер struct key
В Си имеется унарный оператор sizeof, который работает во время компиляции.
Его можно применять для вычисления размера любого объекта. Выражения
sizeof объект
и
sizeof (имя типа)
выдают целые значения, равные размеру указанного объекта или типа в байтах.
(Строго говоря, sizeof выдает беззнаковое целое, тип которого size_t
определена заголовочном файле <stddef.h>.) Что касается объекта, то это может
быть переменная, массив или структура. В качестве имени типа может выступать
имя базового типа (int, double ...) или имя производного типа, например
структуры или указателя.
В нашем случае, чтобы вычислить количество ключевых слов, размер массива надо
поделить на размер одного элемента. Указанное вычисление используется в
инструкции #define для установки значения NKEYS:
#define NKEYS (sizeof keytab / sizeof(struct key))
Этот же результат можно получить другим способом - поделить размер массива на
размер какого-то его конкретного элемента:
#define NKEYS (sizeof keytab / sizeof keytab[0])
Преимущество такого рода записей в том, что их не надо коppектировать при
изменении типа.
Поскольку препроцессор не обращает внимания на имена типов, оператор sizeof
нельзя применять в #if. Но в #define выражение препроцессором не вычисляется,
так что предложенная нами запись допустима.
Теперь поговорим о функции getword. Мы написали getword в несколько более
общем виде, чем требуется для нашей программы, но она от этого не стала
заметно сложнее. Функция getword берет из входного потока следующее "слово".
Под словом понимается цепочка букв-цифр, начинающаяся с буквы, или отдельный
символ, отличный от символа-разделителя. В случае конца файла функция
возвращает EOF, в остальных случаях ее значением является код первого символа
слова или сам символ, если это не буква.
/* getword: принимает следующее слово или символ из ввода */
int getword (char *word, int lim)
{
int c, getch(void);
void ungetch(int);
char *w = word;
while (isspace(c = getch()))
;
if (c != EOF)
*w++ = c;
if (!isalpha(c)) {
*w = '\0';
return c;
}
for ( ; --lim > 0; w++)
if (!isalnum(*w = getch())) {
ungetch(*w);
break;
}
*w = '\0';
return word[0];
}
Функция getword обращается к getch и ungetch, которые мы написали в главе 4.
По завершении набора букв-цифр оказывается, что getword взяла лишний символ.
Обращение к ungetch позволяет вернуть его назад во входной поток. В getword
используются также isspace - для пропуска символов-разделителей, isalpha -
для идентификации букв и isalnum - для распознавания букв-цифр. Все они
описаны в стандартном заголовочном файле <ctype.h>.
Упражнение 6.1. Haшa вepcия getword не обрабатывает должным образом знак
подчеркивания, строковые константы, комментарии и управляющие строки
препроцессора. Напишите более совершенный вариант программы.
Для иллюстрации некоторых моментов, касающихся указателей на структуры и
массивов структур, перепишем программу подсчета ключевых слов, пользуясь для
получения элементов массива вместо индексов указателями.
Внешнее объявление массива keytab остается без изменения, a main и binsearch
нужно модифицировать.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
int getword(char *, int);
struct key *binsearch(char *, struct key *, int);
/* подсчет ключевых слов Си: версия с указателями */
main()
{
char word[MAXWORD];
struct key *p;
while (getword(word, MAXWORD) != EOF)
if (isalpha(word[0]))
if ((p = binsearch(word, keytab, NKEYS)) != NULL)
p->count++;
for (p = keytab; p < keytab + NKEYS; p++)
if (p->count > 0)
printf("%4d %s\n", p->count, p->word);
return 0;
}
/* binsearch: найти слово word в tab[0]...tab[n-1] */
struct key *binsearch(char *word, struct key *tab, int n)
{
int cond;
struct key *low = &tab[0];
struct key *high = &tab[n];
struct key *mid;
while (low < high) {
mid = low + (high - low) / 2;
if ((cond = strcmp(word, mid->word)) < 0)
high = mid;
else if (cond > 0)
low = mid + 1;
else
return mid;
}
return NULL;
}
Некоторые детали этой программы требуют пояснений. Во-первых, описание
функции binsearch должно отражать тот факт, что она возвращает указатель на
struct key, а не целое, это объявлено как в прототипе функции, так и в
функции binsearch. Если binsearch находит слово, то она выдает указатель на
него, в противном случае она возвращает NULL. Во-вторых, к элементам keytab
доступ в нашей программе осуществляется через указатели. Это потребовало
значительных изменений в binsearch. Инициализаторами для low и high теперь
служат указатели на начало и на место сразу после конца массива. Вычисление
положения среднего элемента с помощью формулы
mid = (low + high) / 2 /* НЕВЕРНО */
не годится, поскольку указатели нельзя складывать. Однако к ним можно
применить операцию вычитания, и так как high-low есть число элементов,
присваивание
mid = low + (high-low) / 2
превратит mid в указатель на элемент, лежащий посередине между low и high.
Самое важное при переходе на новый вариант программы - сделать так, чтобы не
генерировались неправильные указатели и не было попыток обратиться за пределы
массива. Проблема в том, что и &tab[-1], и &tab[n] находятся вне границ
массива. Первый адрес определенно неверен, нельзя также осуществить доступ и
по второму адресу. По правилам языка, однако, гарантируется, что адрес ячейки
памяти, следующей сразу за концом массива (т. е. &tab[n]), в арифметике с
указателями воспринимается правильно.
В главной программе main мы написали
for (р = keytab; р < keytab + NKEYS; р++)
Если p - это указатель на структуру, то при выполнении операций с р
учитывается размер структуры. Поэтому р++ увеличит р на такую величину, чтобы
выйти на следующий структурный элемент массива, а проверка условия вовремя
остановит цикл.
Не следует, однако, полагать, что размер структуры равен сумме размеров ее
элементов. Вследствие выравнивания объектов разной длины в структуре могут
появляться безымянные "дыры". Например, если переменная типа char занимает
один байт, а int - четыре байта, то для структуры
struct {
char с;
int i;
};
может потребоваться восемь байтов, а не пять. Оператор sizeof возвращает
правильное значение.
Наконец, несколько слов относительно формата программы. Если функция
возвращает значение сложного типа, как, например, в нашем случае она
возвращает указатель на структуру:
struct key *binsearch(char *word, struct key *tab, int n)
то "высмотреть" имя функции оказывается совсем не просто. В подобных случаях
иногда пишут так:
struct key *
binsearch(char *word, struct key *tab, int n)
Какой форме отдать предпочтение - дело вкуса. Выберите ту, которая больше
всего вам нравится, и придерживайтесь ее.
Предположим, что мы хотим решить более общую задачу - написать программу,
подсчитывающую частоту встречаемости для любых слов входного потока. Так как
список слов заранее не известен, мы не можем предварительно упорядочить его и
применить бинарный поиск. Было бы неразумно пользоваться и линейным поиском
каждого полученного слова, чтобы определять, встречалось оно ранее или нет -
в этом случае программа работала бы слишком медленно. (Более точная оценка:
время работы такой программы пропорционально квадрату количества слов.) Как
можно организовать данные, чтобы эффективно справиться со списком
произвольных слов?
Один из способов - постоянно поддерживать упорядоченность уже полученных
слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся
упорядоченность. Делать это передвижкой слов в линейном массиве не следует, -
хотя бы потому, что указанная процедура тоже слишком долгая. Вместо этого мы
воспользуемся структурой данных, называемой бинарным деревом.
В дереве на каждое отдельное слово предусмотрен "узел", который содержит:
- указатель на текст слова;
- счетчик числа встречаемости;
- указатель на левый сыновний узел;
- указатель на правый сыновний узел.
У каждого узла может быть один или два сына, или узел вообще может не иметь
сыновей.
Узлы в дереве располагаются так, что по отношению к любому узлу левое
поддерево содержит только те слова, которые лексикографически меньше, чем
слово данного узла, а правое - слова, которые больше него. Вот как выглядит
дерево, построенное для фразы "now is the time for all good men to come to
the aid of their party" ("настало время всем добрым людям помочь своей
партии"), по завершении процесса, в котором для каждого нового слова в него
добавлялся новый узел:
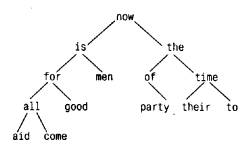
Чтобы определить, помещено ли уже в дерево вновь поступившее слово, начинают
с корня, сравнивая это слово со словом из корневого узла. Если они совпали,
то ответ на вопрос — положительный. Если новое слово меньше слова из дерева,
то поиск продолжается в левом поддереве, если больше, то — в правом. Если же
в выбранном направлении поддерева не оказалось, то этого слова в дереве нет,
а пустующая позиция, говорящая об отсутствии поддерева, как раз и есть то
место, куда нужно "подвесить" узел с новым словом. Описанный процесс по сути
рекурсивен, так как поиск в любом узле использует результат поиска в одном из
своих сыновних узлов. В соответствии с этим для добавления узла и печати
дерева здесь наиболее естественно применить рекурсивные функции.
Вернемся к описанию узла, которое удобно представить в виде структуры с
четырьмя компонентами:
struct tnode { /* узел дерева */
char *word; /* указатель на текст */
int count; /* число вхождений */
struct tnode *left; /* левый сын */
struct tnode *right; /* правый сын */
};
Приведенное рекурсивное определение узла может показаться рискованным, но оно
правильное. Структура не может включать саму себя, но ведь
struct tnode *left;
объявляет left как указатель на tnode, а не сам tnode.
Иногда возникает потребность во взаимоссылающихся структурах: двух
структурах, ссылающихся друг на друга. Прием, позволяющий справиться с этой
задачей, демонстрируется следующим фрагментом:
struct t {
...
struct s *p; /* р указывает на s */
};
struct s {
...
struct t *q; /* q указывает на t */
}
Вся программа удивительно мала - правда, она использует вспомогательные
программы вроде getword, уже написанные нами. Главная программа читает слова
с помощью getword и вставляет их в дерево посредством addtree.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
int getword(char *, int);
/* подсчет частоты встречаемости слов */
main()
{
struct tnode *root;
char word[MAXWORD];
root = NULL;
while (getword (word, MAXWORD) != EOF)
if (isalpha(word[0]))
root = addtree(root, word);
treeprint(root);
return 0;
}
Функция addtree рекурсивна. Первое слово функция main помещает на верхний
уровень дерева (корень дерева). Каждое вновь поступившее слово сравнивается
со словом узла и "погружается" или в левое, или в правое поддерево с помощью
рекурсивного обращения к addtree. Через некоторое время это слово обязательно
либо совпадет с каким-нибудь из имеющихся в дереве слов (в этом случае к
счетчику будет добавлена 1), либо программа встретит пустую позицию, что
послужит сигналом для создания нового узла и добавления его к дереву.
Создание нового узла сопровождается тем, что addtree возвращает на него
указатель, который вставляется в узел родителя.
struct tnode *talloc(void);
char *strdup(char *);
/* addtree: добавляет узел со словом w в р или ниже него */
struct tnode *addtree(struct tnode *p, char *w)
{
int cond;
if (р == NULL) { /* слово встречается впервые */
p = talloc(); /* создается новый узел */
p->word = strdup(w);
p->count = 1;
p->left = p->right = NULL;
} else if ((cond = strcmp(w, p->word)) == 0)
p->count++; /* это слово уже встречалось */
else if (cond < 0) /* меньше корня левого поддерева */
p->left = addtree(p->left, w);
else /* больше корня правого поддерева */
p->right = addtree(p->right, w);
return p;
}
Память для нового узла запрашивается с помощью программы talloc, которая
возвращает указатель на свободное пространство, достаточное для хранения
одного узла дерева, а копирование нового слова в отдельное место памяти
осуществляется с помощью strdup. (Мы рассмотрим эти программы чуть позже.) В
тот (и только в тот) момент, когда к дереву подвешивается новый узел,
происходит инициализация счетчика и обнуление указателей на сыновей. Мы
опустили (что неразумно) контроль ошибок, который должен выполняться при
получении значений от strdup и talloc.
Функция treeprint печатает дерево в лексикографическом порядке: для каждого
узла она печатает его левое поддерево (все слова, которые меньше слова
данного узла), затем само слово и, наконец, правое поддерево (слова, которые
больше слова данного узла).
/* treeprint: упорядоченная печать дерева р */
void treeprint(struct tnode *p)
{
if (p != NULL) {
treeprint (p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
Если вы не уверены, что досконально разобрались в том, как работает рекурсия,
"проиграйте" действия treeprint на дереве, приведенном выше. Практическое
замечание: если дерево "несбалансировано" (что бывает, когда слова поступают
не в случайном порядке), то время работы программы может сильно возрасти.
Худший вариант, когда слова уже упорядочены; в этом случае затраты на
вычисления будут такими же, как при линейном поиске. Существуют обобщения
бинарного дерева, которые не страдают этим недостатком, но здесь мы их не
описываем.
Прежде чем завершить обсуждение этого примера, сделаем краткое отступление от
темы и поговорим о механизме запроса памяти. Очевидно, хотелось бы иметь
всего лишь одну функцию, выделяющую память, даже если эта память
предназначается для разного рода объектов. Но если одна и та же функция
обеспечивает память, скажем) и для указателей на char, и для указателей на
struct tnode, то возникают два вопроса. Первый: как справиться с требованием
большинства машин, в которых объекты определенного типа должны быть выровнены
(например, int часто должны размещаться, начиная с четных адресов)? И второе:
как объявить функцию-распределитель памяти, которая вынуждена в качестве
результата возвращать указатели разных типов?
Вообще говоря, требования, касающиеся выравнивания, можно легко выполнить за
счет некоторого перерасхода памяти. Однако для этого возвращаемый указатель
должен быть таким, чтобы удовлетворялись любые ограничения, связанные с
выравниванием. Функция alloc, описанная в главе 5, не гарантирует нам любое
конкретное выравнивание, поэтому мы будем пользоваться стандартной
библиотечной функцией malloc, которая это делает. В главе 8 мы покажем один
из способов ее реализации.
Вопрос об объявлении типа таких функций, как malloc, является камнем
преткновения в любом языке с жесткой проверкой типов. В Си вопрос решается
естественным образом: malloc объявляется как функция, которая возвращает
указатель на void. Полученный указатель затем явно приводится к желаемому
типу (Замечание о приведении типа величины, возвращаемой функцией malloc,
нужно переписать. Пример коpректен и работает, но совет является спорным в
контексте стандартов ANSI/ISO 1988-1989 г. На самом деле это не обязательно
(при условии что приведение void* к ALMOSTANYTYPE* выполняется автоматически)
и возможно даже опасно, если malloc или ее заместитель не может быть объявлен
как функция, возвращающая void*. Явное приведение типа может скрыть случайную
ошибку. В другие времена (до появления стандарта ANSI) приведение считалось
обязательным, что также справедливо и для C++. — Примеч. авт.). Описания
malloc и связанных с ней функций находятся в стандартном заголовочном файле
<stdlib.h>. Таким образом, функцию talloc можно записать так:
#include <stdlib.h>
/* talloc: создает tnode */
struct tnode *talloc(void)
{
return (struct tnode *) malloc(sizeof(struct tnode));
}
Функция strdup просто копирует строку, указанную в аргументе, в место,
полученное с помощью malloc:
char *strdup(char *s) /* делает дубликат s */
{
char *p;
p = (char *) malloc(strlen(s)+1); /* +1 для '\0' */
if (p != NULL)
strcpy(p, s);
return p;
}
Функция malloc возвращает NULL, если свободного пространства нет; strdup
возвращает это же значение, оставляя заботу о выходе из ошибочной ситуации
вызывающей программе.
Память, полученную с помощью malloc, можно освободить для повторного
использования, обратившись к функции free (см. главы 7 и 8).
Упражнение 6.2. Напишите программу, которая читает текст Си-программы и
печатает в алфавитном порядке все группы имен переменных, в которых совпадают
первые 6 символов, но последующие в чем-то различаются. Не обрабатывайте
внутренности закавыченных строк и комментариев. Число 6 сделайте параметром,
задаваемым в командной строке.
Упражнение 6.3. Напишите программу печати таблицы "перекрестных ссылок",
которая будет печатать все слова документа и указывать для каждого из них
номера строк, где оно встретилось. Программа должна игнорировать "шумовые"
слова, такие как "и", "или" и пр.
Упражнение 6.4. Напишите программу, которая печатает весь набор различных
слов, образующих входной поток, в порядке возрастания частоты их
встречаемости. Перед каждым словом должно быть указано число вхождений.
В этом параграфе, чтобы проиллюстрировать новые аспекты применения
структур, мы напишем ядро пакета программ, осуществляющих вставку элементов в
таблицы и их поиск внутри таблиц. Этот пакет - типичный набор программ, с
помощью которых работают с таблицами имен в любом макропроцессоре или
компиляторе. Рассмотрим, например, инструкцию #define. Когда встречается
строка вида
#define IN 1
имя IN и замещающий его текст 1 должны запоминаться в таблице. Если затем имя
IN встретится в инструкции, например в
state = IN;
это должно быть заменено на 1.
Существуют две программы, манипулирующие с именами и замещающими их текстами.
Это install(s,t), которая записывает имя s и замещающий его текст t в
таблицу, где s и t - строки, и lookup(s), осуществляющая поиск s в таблице и
возвращающая указатель на место, где имя s было найдено, или NULL, если s в
таблице не оказалось.
Алгоритм основан на хэш-поиске: поступающее имя свертывается в
неотрицательное число (хэш-код), которое затем используется в качестве
индекса в массиве указателей. Каждый элемент этого массива является
указателем на начало связанного списка блоков, описывающих имена с данным
хэш-кодом. Если элемент массива равен NULL, это значит, что имен с
соответствующим хэш-кодом нет.
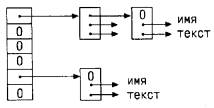
Блок в списке - это структура, содержащая указатели на имя, на замещающий
текст и на следующий блок в списке; значение NULL в указателе на следующий
блок означает конец списка.
struct nlist { /* элемент таблицы */
struct nlist *next; /* указатель на следующий элемент */
char *name; /* определенное имя */
char *defn; /* замещающий текст */
};
А вот как записывается определение массива указателей:
#define HASHSIZE 101
static struct nlist *hashtab[HASHSIZE]; /* таблица указателей */
Функция хэширования, используемая в lookup и install, суммирует коды символов
в строке и в качестве результата выдаст остаток от деления полученной суммы
на размер массива указателей. Это не самая лучшая функция хэширования, но
достаточно лаконичная и эффективная.
/* hash: получает хэш-код для строки s */
unsigned hash(char *s)
{
unsigned hashval;
for (hashval = 0; *s != '\0'; s++)
hashval = *s + 31 * hashval;
return hashval % HASHSIZE;
}
Беззнаковая арифметика гарантирует, что хэш-код будет неотрицательным.
Хэширование порождает стартовый индекс для массива hashtab; если
соответствующая строка в таблице есть, она может быть обнаружена только в
списке блоков, на начало которого указывает элемент массива hashtab с этим
индексом. Поиск осуществляется с помощью lookup. Если lookup находит элемент
с заданной строкой, то возвращает указатель на нее, если не находит, то
возвращает NULL.
/* lookup: ищет s */
struct nlist *lookup(char *s)
{
struct nlist *np;
for (np = hashtab[hash(s)]; np != NULL; np = np->next)
if (strcmp(s, np->name) == 0)
return np; /* нашли */
return NULL; /* не нашли */
}
В for-цикле функции lookup для просмотра списка используется стандартная
конструкция
for (ptr = head; ptr != NULL; ptr = ptr->next)
...
Функция install обращается к lookup, чтобы определить, имеется ли уже
вставляемое имя. Если это так, то старое определение будет заменено новым. В
противном случае будет образован новый элемент. Если запрос памяти для нового
элемента не может быть удовлетворен, функция install выдает NULL.
struct nlist *lookup(char *);
char *strdup(char *);
/* install: заносит имя и текст (name, defn) в таблицу */
struct nlist *install(char *name, char *defn)
{
struct nlist *np;
unsigned hashval;
if ((np = lookup(name)) == NULL) { /* не найден */
np = (struct nlist *) malloc(sizeof(*np));
if (np == NULL || (np->name = strdup(name)) == NULL)
return NULL;
hashval = hash(name);
np->next = hashtab[hashval];
hashtab[hashval] = np;
} else /* уже имеется */
free((void *) np->defn); /* освобождаем прежний defn */
if ((np->defn = strdup(defn)) == NULL)
return NULL;
return np;
}
Упражнение 6.5. Напишите функцию undef, удаляющую имя и определение из
таблицы, организация которой поддерживается функциями lookup и install.
Упражнение 6.6. Реализуйте простую версию #define-npoцeccopa (без
аргументов), которая использовала бы программы этого параграфа и годилась бы
для Си-программ. Вам могут помочь программы getch и ungetch.
Язык Си предоставляет средство, называемое typedef, которое позволяет давать
типам данных новые имена. Например, объявление
typedef int Length;
делает имя Length синонимом int. С этого момента тип Length можно применять в
объявлениях, в операторе приведения и т. д. точно так же, как тип int:
Length len, maxlen;
Length *lengths[];
Аналогично объявление
typedef char *String;
делает String синонимом char *, т. e. указателем на char, и правомерным
будет, например, следующее его использование:
String р, lineptr[MAXLINES], alloc(int);
int strcmp(String, String);
p = (String) malloc(100);
Заметим, что объявляемый в typedef тип стоит на месте имени переменной в
обычном объявлении, а не сразу за словом typedef. С точки зрения синтаксиса
слово typedef напоминает класс памяти - extern, static и т. д. Имена типов
записаны с заглавных букв для того, чтобы они выделялись.
Для демонстрации более сложных примеров применения typedef воспользуемся этим
средством при задании узлов деревьев, с которыми мы уже встречались в данной
главе.
typedef struct tnode *Treeptr;
typedef struct tnode { /* узел дерева: */
char *word; /* указатель на текст */
int count; /* число вхождений */
Treeptr left; /* левый сын */
Treeptr right; /* правый сын */
} Treenode;
В результате создаются два новых названия типов: Treenode (структура) и
Treeptr (указатель на структуру). Теперь программу talloc можно записать в
следующем виде:
Treeptr talloc(void)
{
return (Treeptr) malloc(sizeof(Treenode));
}
Следует подчеркнуть, что объявление typedef не создает объявления нового
типа, оно лишь сообщает новое имя уже существующему типу. Никакого нового
смысла эти новые имена не несут, они объявляют переменные в точности с теми
же свойствами, как если бы те были объявлены напрямую без переименования
типа. Фактически typedef аналогичен #define с тем лишь отличием, что при
интерпретации компилятором он может справиться с такой текстовой
подстановкой, которая не может быть обработана препроцессором. Например
typedef int (*PFI)(char *, char *);
создает тип PFI - "указатель на функцию (двух аргументов типа char *),
возвращающую int", который, например, в программе сортировки, описанной в
главе 5, можно использовать в таком контексте:
PFI strcmp, numcmp;
Помимо просто эстетических соображений, для применения typedef существуют две
важные причины. Первая - параметризация программы, связанная с проблемой
переносимости. Если с помощью typedef объявить типы данных, которые,
возможно, являются машинно-зависимыми, то при переносе программы на другую
машину потребуется внести изменения только в определения typedef. Одна из
распространенных ситуаций - использование typedef-имен для варьирования целыми
величинами. Для каждой конкретной машины это предполагает соответствующие
установки short, int или long, которые делаются аналогично установкам
стандартных типов, например size_t и ptrdiff_t.
Вторая причина, побуждающая к применению typedef,- желание сделать более
ясным текст программы. Тип, названный Тreeptr (от английских слов tree -
дерево и pointer - указатель), более понятен, чем тот же тип, записанный как
указатель на некоторую сложную структуру.
Объединение - это переменная, которая может содержать (в разные моменты
времени) объекты различных типов и размеров. Все требования относительно
размеров и выравнивания выполняет компилятор. Объединения позволяют хранить
разнородные данные в одной и той же области памяти без включения в программу
машинно-зависимой информации. Эти средства аналогичны вариантным записям в
Паскале.
Примером использования объединений мог бы послужить сам компилятор,
заведующий таблицей символов, если предположить, что константа может иметь
тип int, float или являться указателем на символ и иметь тип char *. Значение
каждой конкретной константы должно храниться в переменной соответствующего
этой константе типа. Работать с таблицей символов всегда удобнее, если
значения занимают одинаковую по объёму память и запоминаются в одном и том же
месте независимо от своего типа. Цель введения в программу объединения -
иметь переменную, которая бы на законных основаниях хранила в себе значения
нескольких типов. Синтаксис объединений аналогичен синтаксису структур.
Приведем пример объединения.
union u_tag {
int ival;
float fval;
char *sval;
} u;
Переменная u будет достаточно большой, чтобы в ней поместилась любая
переменная из указанных трех типов: точный ее размер зависит от реализации.
Значение одного из этих трех типов может быть присвоено переменной u и далее
использовано в выражениях, если это правомерно, т. е. если тип взятого ею
значения совпадает с типом последнего присвоенного ей значения. Выполнение
этого требования в каждый текущий момент - целиком на совести программиста. В
том случае, если нечто запомнено как значение одного типа, а извлекается как
значение другого типа, результат зависит от реализации. Синтаксис доступа к
элементам объединения следующий:
имя-объединения.элемент
или
указатель-на-объединение->элемент
т. е. в точности такой, как в структурах. Если для хранения типа текущего
значения u использовать, скажем, переменную utype, то можно написать такой
фрагмент программы:
if (utype == INT)
printf("%d\n", u.ival);
else if (utype === FLOAT)
printf("%f\n", u.fval);
else if (utype == STRING)
printf("%s\n", u.sval);
else
printf ("неверный тип %d в utype\n", utype);
Объединения могут входить в структуры и массивы, и наоборот. Запись доступа к
элементу объединения, находящегося в структуре (как и структуры, находящейся
в объединении), такая же, как и для вложенных структур. Например, в массиве
структур
struct {
char *name;
int flags;
int utype;
union {
int ival;
float fval;
char *sval;
} u;
} symtab[NSYM];
к ival обращаются следующим образом:
symtab[i].u.ival
а к первому символу строки sval можно обратиться любым из следующих двух
способов:
*symtab[i].u.sval
symtab[i].u.sval[0]
Фактически объединение - это структура, все элементы которой имеют нулевое
смещение относительно ее базового адреса и размер которой позволяет
поместиться в ней самому большому ее элементу, а выравнивание этой структуры
удовлетворяет всем типам объединения. Операции, применимые к структурам,
годятся и для объединений, т. е. законны присваивание объединения и
копирование его как единого целого, взятие адреса от объединения и доступ к
отдельным его элементам.
Инициализировать объединение можно только значением, имеющим тип его первого
элемента; таким образом, упомянутую выше переменную u можно инициализировать
лишь значением типа int.
В главе 8 (на примере программы, заведующей выделением памяти) мы покажем,
как, применяя объединение, можно добиться, чтобы расположение переменной было
выровнено по соответствующей границе в памяти.
При дефиците памяти может возникнуть необходимость запаковать несколько
объектов в одно слово машины. Одна из обычных ситуаций, встречающаяся в
задачах обработки таблиц символов для компиляторов, - это объединение групп
однобитовых флажков. Форматы некоторых данных могут от нас вообще не зависеть
и диктоваться, например, интерфейсами с аппаратурой внешних устройств: здесь
также возникает потребность адресоваться к частям слова.
Вообразим себе фрагмент компилятора, который заведует таблицей символов.
Каждый идентификатор программы имеет некоторую связанную с ним информацию:
например, представляет ли он собой ключевое слово и, если это переменная, к
какому классу принадлежит: внешняя и/или статическая и т. д. Самый компактный
способ кодирования такой информации - расположить однобитовые флажки в одном
слове типа char или int.
Один из распространенных приемов работы с битами основан на определении
набора "масок", соответствующих позициям этих битов, как, например, в
#define KEYWORD 01 /* ключевое слово */
#define EXTERNAL 02 /* внешний */
#define STATIC 04 /* статический */
или в
enum { KEYWORD = 01, EXTERNAL = 02, STATIC = 04 };
Числа должны быть степенями двойки. Тогда доступ к битам становится делом
"побитовых операций", описанных в главе 2 (сдвиг, маскирование, взятие
дополнения). Некоторые виды записи выражений встречаются довольно часто. Так,
flags |= EXTERNAL | STATIC;
устанавливает 1 в соответствующих битах переменной flags,
flags &= ~(EXTERNAL | STATIC);
обнуляет их, a
if ((flags & (EXTERNAL | STATIC)) == 0) ...
оценивает условие как истинное, если оба бита нулевые.
Хотя научиться писать такого рода выражения не составляет труда, вместо
побитовых логических операций можно пользоваться предоставляемым Си другим
способом прямого определения и доступа к полям внутри слова. Битовое поле
(или для краткости просто поле) - это некоторое множество битов, лежащих
рядом внутри одной, зависящей от реализации единицы памяти, которую мы будем
называть "словом". Синтаксис определения полей и доступа к ним базируется на
синтаксисе структур. Например, строки #define, фигурировавшие выше при
задании таблицы символов, можно заменить на определение трех полей:
struct {
unsigned int is_keyword : 1;
unsigned int is_extern : 1;
unsigned int is_static : 1;
} flags;
Эта запись определяет переменную flags, которая содержит три однобитовых
поля. Число, следующее за двоеточием, задает ширину поля. Поля объявлены как
unsigned int, чтобы они воспринимались как беззнаковые величины.
На отдельные поля ссылаются так же, как и на элементы обычных структур:
flags.is_keyword, flags.is_extern и т.д. Поля "ведут себя" как малые целые и
могут участвовать в арифметических выражениях точно так же, как и другие
целые. Таким образом, предыдущие примеры можно написать более естественно:
flags.is_extern = flags.is_static = 1;
устанавливает 1 в соответствующие биты;
flags.is_extern = flags.is_static = 0;
их обнуляет, а
if (flags.is_extern == 0 && flags.is_ststic == 0)
...
проверяет их.
Почти все технические детали, касающиеся полей, в частности, возможность поля
перейти границу слова, зависят от реализации. Поля могут не иметь имени; с
помощью безымянного поля (задаваемого только двоеточием и шириной)
организуется пропуск нужного количества разрядов. Особая ширина, равная нулю,
используется, когда требуется выйти на границу следующего слова.
На одних машинах поля размещаются слева направо, на других - справа налево.
Это значит, что при всей полезности работы с ними, если формат данных, с
которыми мы имеем дело, дан нам свыше, то необходимо самым тщательным образом
исследовать порядок расположения полей; программы, зависящие от такого рода
вещей, не переносимы. Поля можно определять только с типом int, а для того
чтобы обеспечить переносимость, надо явно указывать signed или unsigned. Они
не могут быть массивами и не имеют адресов, и, следовательно, оператор & к
ним не применим.
Глава 7. Ввод и вывод
Возможности для ввода и вывода не являются частью самого языка Си, поэтому мы
подробно и не рассматривали их до сих пор. Между тем реальные программы
взаимодействуют со своим окружением гораздо более сложным способом, чем те,
которые были затронуты ранее. В этой главе мы опишем стандартную библиотеку,
содержащую набор функций, обеспечивающих ввод-вывод, работу со строками,
управление памятью, стандартные математические функции и разного рода
сервисные Си-программы. Но особое внимание уделим вводу-выводу.
Библиотечные функции ввода-вывода точно определяются стандартом ANSI, так что
они совместимы на любых системах, где поддерживается Си. Программы, которые в
своем взаимодействии с системным окружением не выходят за рамки возможностей
стандартной библиотеки, можно без изменений переносить с одной машины на
другую.
Свойства библиотечных функций специфицированы в более чем дюжине заголовочных
файлов; вам уже встречались некоторые из них, в том числе <stdio.h>,
<string.h> и <ctype.h>. Мы не рассматриваем здесь всю библиотеку,
так как нас больше интересует написание Си-программ, чем использование
библиотечных функций. Стандартная библиотека подробно описана в приложении B.
Как уже говорилось в главе 1, библиотечные функции реализуют простую модель
текстового ввода-вывода. Текстовый поток состоит из последовательности строк;
каждая строка заканчивается символом новой строки. Если система в чем-то не
следует принятой модели, библиотека сделает так, чтобы казалось, что эта
модель удовлетворяется полностью. Например, пара символов - возврат-каретки и
перевод-строки - при вводе могла бы быть преобразована в один символ новой
строки, а при выводе выполнялось бы обратное преобразование.
Простейший механизм ввода - это чтение одного символа из стандартного ввода
(обычно с клавиатуры) функцией getchar:
int getchar(void)
В качестве результата каждого своего вызова функция getchar возвращает
следующий символ ввода или, если обнаружен конец файла, EOF. Именованная
константа EOF (аббревиатура от end of file - конец файла) определена в
<stdio.h>. Обычно значение EOF равно -1, но, чтобы не зависеть от конкретного
значения этой константы, обращаться к ней следует по имени (EOF).
Во многих системах клавиатуру можно заменить файлом, перенаправив ввод с
помощью значка <. Так, если программа prog использует getchar, то командная
строка
prog < infile
предпишет программе prog читать символы из infile, а не с клавиатуры.
Переключение ввода делается так, что сама программа prog не замечает подмены;
в частности строка "< infile" не будет включена в аргументы командной строки
argv. Переключение ввода будет также незаметным, если ввод исходит от другой
программы и передается конвейерным образом. В некоторых системах командная
строка
otherprog | prog
приведет к тому, что запустится две программы, otherprog и prog, и
стандартный выход otherprog поступит на стандартный вход prog. Функция
int putchar(int)
используется для вывода: putchar(c) отправляет символ c в стандартный вывод,
под которым по умолчанию подразумевается экран. Функция putchar в качестве
результата возвращает посланный символ или, в случае ошибки, EOF. То же и в
отношении вывода: с помощью записи вида > имя-файла вывод можно перенаправить
в файл. Например, если prog использует для вывода функцию putchar, то
prog > outfile
будет направлять стандартный вывод не на экран, а в outfile. А командная
строка
prog | anotherprog
соединит стандартный вывод программы prog со стандартным вводом программы
anotherprog.
Вывод, осуществляемый функцией printf, также отправляется в стандартный
выходной поток. Вызовы putchar и printf могут как угодно чередоваться, при
этом вывод будет формироваться в той последовательности, в которой
происходили вызовы этих функций.
Любой исходный Си-файл, использующий хотя бы одну функцию библиотеки
ввода-вывода, должен содержать в себе строку
#include <stdio.h>
причем она должна быть расположена до первого обращения к вводу-выводу. Если
имя заголовочного файла заключено в угловые скобки < и >, это значит, что
поиск заголовочного файла ведется в стандартном месте (например в системе
UNIX это обычно директорий /usr/include).
Многие программы читают только из одного входного потока и пишут только в
один выходной поток. Для организации ввода-вывода таким программам вполне
хватит функций getchar, putchar и printf, а для начального обучения уж точно
достаточно ознакомления с этими функциями. В частности, перечисленных функций
достаточно, когда требуется вывод одной программы соединить с вводом
следующей. В качестве примера рассмотрим программу lower, переводящую свой
ввод на нижний регистр:
#include <stdio.h>
#include <ctype.h>
main() /* lower: переводит ввод на нижний регистр */
{
int с;
while ((с = getchar()) != EOF)
putchar(tolower(c));
return 0;
}
Функция tolower определена в <ctype.h>. Она переводит буквы верхнего регистра
в буквы нижнего регистра, а остальные символы возвращает без изменений. Как
мы уже упоминали, "функции" вроде getchar и putchar из библиотеки <stdio.h> и
функция tolower из библиотеки <ctype.h> часто реализуются в виде макросов,
чтобы исключить накладные расходы от вызова функции на каждый отдельный
символ. В параграфе 8.5 мы покажем, как это делается. Независимо от того, как
на той или иной машине реализованы функции библиотеки <ctype.h>, использующие
их программы могут ничего не знать о кодировке символов.
Упражнение 7.1. Напишите программу, осуществляющую перевод ввода с верхнего
регистра на нижний или с нижнего на верхний в зависимости от имени, по
которому она вызывается и текст которого находится в arg[0].
Функция printf переводит внутренние значения в текст.
int printf(char *format, arg1, arg2, ...)
В предыдущих главах мы использовали printf неформально. Здесь мы покажем
наиболее типичные случаи применения этой функции: полное ее описание дано в
приложении B.
Функция printf преобразует, форматирует и печатает свои аргументы в
стандартном выводе под управлением формата. Возвращает она количество
напечатанных символов.
Форматная строка содержит два вида объектов: обычные символы, которые
напрямую копируются в выходной поток, и спецификации преобразования, каждая
из которых вызывает преобразование и печать очередного аргумента printf.
Любая спецификация преобразования начинается знаком % и заканчивается
символом-спецификатором. Между % и символом-спецификатором могут быть
расположены (в указанном ниже порядке) следующие элементы:
Знак минус, предписывающий выравнивать преобразованный аргумент по левому краю поля.
Число, специфицирующее минимальную ширину поля. Преобразованный аргумент
будет занимать поле по крайней мере указанной ширины. При необходимости
лишние позиции слева (или справа при левостороннем расположении) будут
заполнены пробелами.
Точка, отделяющая ширину поля от величины, устанавливающей точность.
Число (точность), специфицирующее максимальное количество печатаемых
символов в строке, или количество цифр после десятичной точки - для чисел с
плавающей запятой, или минимальное количество цифр - для целого.
Буква h, если печатаемое целое должно рассматриваться как short, или l
(латинская буква ell), если целое должно рассматриваться как long.
Символы-спецификаторы перечислены в таблице 7.1. Если за % не помещен символ-
спецификатор, поведение функции printf будет не определено. Ширину и точность
можно специфицировать с помощью *; значение ширины (или точности) в этом
случае берется из следующего аргумента (который должен быть типа int).
Например, чтобы напечатать не более max символов из строки s, годится
следующая запись:
printf("%.*s", max, s);
Таблица 7.1 Основные преобразования printf
| Символ |
Тип аргумента; вид печати |
d, i |
int; десятичное целое |
| o |
unsigned int; беззнаковое восьмеричное (octal) целое (без нуля слева) |
| x, X |
unsigned int; беззнаковое шестнадцатеричное целое (без 0x или 0X
слева), для 10...15 используются abcdef или ABCDEF |
| u |
unsigned int; беззнаковое десятичное целое |
| c |
int; одиночный символ |
| s |
char *; печатает символы, расположенные до знака \0, или в количестве, заданном точностью |
| f |
double; [-]m.dddddd, где количество цифр d задается точностью (по умолчанию равно 6) |
| e, E |
double; [-]m.dddddde±xx или [-]m.ddddddE±xx, где количество цифр d
задается точностью (по умолчанию равно 6) |
| g, G |
double; использует %e или %E, если порядок меньше, чем -4, или больше или равен точности; в противном случае использует %f.
Завершающие нули и завершающая десятичная точка не печатаются |
| p |
void *; указатель (представление зависит от реализации) |
| % |
Аргумент не преобразуется; печатается знак % |
Большая часть форматных преобразований была продемонстрирована в
предыдущих главах. Исключение составляет задание точности для строк. Далее
приводится перечень спецификаций и показывается их влияние на печать строки
"hello, world", состоящей из 12 символов. Поле специально обрамлено
двоеточиями, чтобы была видна его протяженность.
:%s: :hello, world:
:%10s :hello, world:
:%.10s: :hello, wor:
:%-10s: :hello, world:
:%.15s: :hello, world:
:%-15s: :hello, world :
:%15.10s: : hello, wor:
:%-15.10s: :hello, wor :
Предостережение: функция printf использует свой первый аргумент, чтобы
определить, сколько еще ожидается аргументов и какого они будут типа. Вы не
получите правильного результата, если аргументов будет не хватать или они
будут принадлежать не тому типу. Вы должны также понимать разницу в следующих
двух обращениях:
printf(s); /* НЕВЕРНО, если в s есть % */
printf("%s", s); /* ВЕРНО всегда */
Функция sprintf выполняет те же преобразования, что и printf, но вывод
запоминает в строке
int sprintf(char *string, char *format, arg1, arg2, ...)
Эта функция форматирует arg1, arg2 и т. д. в соответствии с информацией,
заданной аргументом format, как мы описывали ранее, но результат помещает не
в стандартный вывод, а в string. Заметим, что строка string должна быть
достаточно большой, чтобы в ней поместился результат.
Упражнение 7.2. Напишите программу, которая будет печатать разумным способом
любой ввод. Как минимум она должна уметь печатать неграфические символы в
восьмеричном или шестнадцатеричном виде (в форме, принятой на вашей машине),
обрывая длинные текстовые строки.
Этот параграф содержит реализацию минимальной версии printf. Приводится она
для того, чтобы показать, как надо писать функции со списками аргументов
переменной длины, причем такие, которые были бы переносимы. Поскольку нас
главным образом интересует обработка аргументов, функцию minprintf напишем
таким образом, что она в основном будет работать с задающей формат строкой и
аргументами; что же касается форматных преобразований, то они будут
осуществляться с помощью стандартного printf.
Объявление стандартной функции printf выглядит так:
int printf(char *fmt, ...)
Многоточие в объявлении означает, что число и типы аргументов могут
изменяться. Знак многоточие может стоять только в конце списка аргументов.
Наша функция minprintf объявляется как
void minprintf(char *fmt, ...)
поскольку она не будет выдавать число символов, как это делает printf.
Вся сложность в том, каким образом minprintf будет продвигаться вдоль списка
аргументов, - ведь у этого списка нет даже имени. Стандартный заголовочный
файл <stdarg.h> содержит набор макроопределений, которые устанавливают, как
шагать по списку аргументов. Наполнение этого заголовочного файла может
изменяться от машины к машине, но представленный им интерфейс везде одинаков.
Тип va_list служит для описания переменной, которая будет по очереди
указывать на каждый из аргументов; в minprintf эта переменная имеет имя ap
(от "argument pointer" - указатель на аргумент). Макрос va_start
инициализирует переменную ap) чтобы она указывала на первый безымянный
аргумент. К va_start нужно обратиться до первого использования ap. Среди
аргументов по крайней мере один должен быть именованным: от последнего
именованного аргумента этот макрос "отталкивается" при начальной установке.
Макрос va_arg на каждом своем вызове выдает очередной аргумент, а ap
передвигает на следующий: но имени типа он определяет тип возвращаемого
значения и размер шага для выхода на следующий аргумент. Наконец, макрос
va_end делает очистку всего, что необходимо. К va_end следует обратиться
перед самым выходом из функции.
Перечисленные средства образуют основу нашей упрощенной версии prinf.
#include <stdarg.h>
/* minprintf: минимальный printf с переменным числом аргументов */
void minprintf(char *fmt, ...)
{
va_list ap; /* указывает на очередной безымянный аргумент */
char *p, *sval;
int ival;
double dval;
va_start(ap, fmt); /* устанавливает ap на 1-й безымянный аргумент */
for (p=fmt; *p; p++) {
if (*p !='%') {
putchar(*p);
continue;
}
switch (*++p) {
case 'd':
ival = va_arg(ap, int);
printf ("%d", ival);
break;
case 'f':
dval = va_arg(ap, double);
printf("%f", dval);
break;
case 's':
for (sval = va_arg(ap, char *); *sval; sval++)
putchar(*sval);
break;
default:
putchar(*p);
break;
}
}
va_end(ap); /* очистка, когда все сделано */
}
Упражнение 7.3. Дополните minprintf другими возможностями printf.
Функция scanf, обеспечивающая ввод, является аналогом printf; она выполняет
многие из упоминавшихся преобразований, но в противоположном направлении. Ее
объявление имеет следующий вид:
int scanf(char *format, ...)
Функция scanf читает символы из стандартного входного потока, интерпретирует
их согласно спецификациям строки format и рассылает результаты в свои
остальные аргументы. Аргумент format мы опишем позже; другие аргументы,
каждый из которых должен быть указателем, определяют, где будут запоминаться
должным образом преобразованные данные. Как и для printf, в этом параграфе
дается сводка наиболее полезных, но отнюдь не всех возможностей данной
функции.
Функция scanf прекращает работу, когда оказывается, что исчерпался формат или
вводимая величина не соответствует управляющей спецификации. В качестве
результата scanf возвращает количество успешно введенных элементов данных. По
исчерпании файла она выдает EOF. Существенно то, что значение EOF не равно
нулю, поскольку нуль scanf выдает, когда вводимый символ не соответствует
первой спецификации форматной строки. Каждое очередное обращение к scanf
продолжает ввод символа, следующего сразу за последним обработанным.
Существует также функция sscanf, которая читает из строки (а не из
стандартного ввода).
int sscanf(char *string, char *format, arg1, arg2, ...)
Функция sscanf просматривает строку string согласно формату format и
рассылает полученные значения в arg1, arg2 и т. д. Последние должны быть
указателями.
Формат обычно содержит спецификации, которые используются для управления
преобразованиями ввода. В него могут входить следующие элементы:
Пробелы или табуляции, которые игнорируются.
Обычные символы (исключая %), которые, как ожидается, совпадут с очередными
символами, отличными от символов-разделителей входного потока.
Спецификации преобразования, каждая из которых начинается со знака % и
завершается символом-спецификатором типа преобразования. В промежутке между
этими двумя символами в любой спецификации могут располагаться, причем в том
порядке, как они здесь указаны: знак * (признак подавления присваивания);
число, определяющее ширину поля; буква h, l или L, указывающая на размер
получаемого значения; и символ преобразования (o, d, x).
Спецификация преобразования управляет преобразованием следующего вводимого
поля. Обычно результат помещается в переменную, на которую указывает
соответствующий аргумент. Однако если в спецификации преобразования
присутствует *, то поле ввода пропускается и никакое присваивание не
выполняется. Поле ввода определяется как строка без символов-разделителей;
оно простирается до следующего символа-разделителя или же ограничено шириной
поля, если она задана. Поскольку символ новой строки относится к символам-
разделителям, то sscanf при чтении будет переходить с одной строки на другую.
(Символами-разделителями являются символы пробела, табуляции, новой строки,
возврата каретки, вертикальной табуляции и перевода страницы.)
Символ-спецификатор указывает, каким образом следует интерпретировать
очередное поле ввода. Соответствующий аргумент должен быть указателем, как
того требует механизм передачи параметров по значению, принятый в Си.
Символы-спецификаторы приведены в таблице 7.2.
Перед символами-спецификаторами d, l, o, u и x может стоять буква h,
указывающая на то, что соответствующий аргумент должен иметь тип short * (а
не int *),или l (латинская ell), указывающая на тип long *. Аналогично, перед
символами-спецификаторами e, f и g может стоять буква l, указывающая, что тип
аргумента - double * (а не float *).
Таблица 7.2 Основные преобразования scanf
| Символ |
Вводимые данные; тип аргумента |
| d |
десятичное целое: int * |
| i |
целое: int *. Целое может быть восьмеричным (с 0 слева) или шестнадцатеричным (с 0x или 0X слева) |
| o |
восьмеричное целое (с нулем слева или без него); int * |
| u |
беззнаковое десятичное целое; unsigned int * |
| x |
шестнадцатеричное целое (с 0x или 0X слева или без них); int * |
| c |
символы; char *. Следующие символы ввода (по умолчанию один)
размещаются в указанном месте. Обычный пропуск символов-
разделителей подавляется; чтобы прочесть очередной символ,
отличный от символа-разделителя, используйте %1s |
| s |
Строка символов(без обрамляющих кавычек); char *, указывающая на
массив символов, достаточный для строки и завершающего символа '\0', который будет добавлен |
| e, f, g |
число с плавающей точкой, возможно, со знаком; обязательно
присутствие либо десятичной точки, либо экспоненциальной части, а
возможно, и обеих вместе; float * |
| % |
сам знак %, никакое присваивание не выполняется |
Чтобы построить первый пример, обратимся к программе калькулятора из главы 4,
в которой организуем ввод с помощью функции scanf:
#include <stdio.h>
main() /* программа-калькулятор */
{
double sum, v;
sum = 0;
while (scanf ("%lf", &v) == 1)
printf("\t%.2f\n", sum += v);
return 0;
}
Предположим, что нам нужно прочитать строки ввода, содержащие данные вида
25 дек 1988
Обращение к scanf выглядит следующим образом:
int day, year; /* день, год */
char monthname[20]; /* название месяца */
scanf ("%d %s %d", &day, monthname, &year);
Знак & перед monthname не нужен, так как имя массива есть указатель.
В строке формата могут присутствовать символы, не участвующие ни в одной из
спецификаций; это значит, что эти символы должны появиться на вводе. Так, мы
могли бы читать даты вида mm/dd/yy с помощью следующего обращения к scanf:
int day, month, year; /* день, месяц, год */
scanf("%d/%d/%d", &day, &month, &year);
В своем формате функция scanf игнорирует пробелы и табуляции. Кроме того, при
поиске следующей порции ввода она пропускает во входном потоке все символы-
разделители (пробелы, табуляции, новые строки и т.д.). Воспринимать входной
поток, не имеющий фиксированного формата, часто оказывается удобнее, если
вводить всю строку целиком и для каждого отдельного случая подбирать
подходящий вариант sscanf. Предположим, например, что нам нужно читать строки
с датами, записанными в любой из приведенных выше форм. Тогда мы могли бы
написать:
while (getline(line, sizeof(line)) > 0) {
if (sscanf(line, "%d %s %d", &day, monthname, &year) == 3)
printf("вepно: %s\r", line); /* в виде 25 дек 1968 */
else if (sscanf(line, "%d/%d/%d", &month, &day, &year) == 3)
printf("вepно: %s\n", line); /* в виде mm/dd/yy */
else
printf("неверно: %s\n", line); /* неверная форма даты */
}
Обращения к scanf могут перемежаться с вызовами других функций ввода. Любая
функция ввода, вызванная после scanf, продолжит чтение с первого еще
непрочитанного символа.
В завершение еще раз напомним, что аргументы функций scanf и sscanf должны
быть указателями.
Одна из самых распространенных ошибок состоит в том, что вместо того,
чтобы написать
scanf ("%d", &n);
пишут
scanf("%d", n);
Компилятор о подобной ошибке ничего не сообщает.
Упражнение 7.4. Напишите свою версию scanf по аналогии с minprintf из
предыдущего параграфа.
Упражнение 7.5. Перепишите основанную на постфиксной записи программу
калькулятора из главы 4 таким образом, чтобы для ввода и преобразования чисел
она использовала scanf и/или sscanf.
Во всех предыдущих примерах мы имели дело со стандартным вводом и стандартным
выводом, которые для программы автоматически предопределены операционной
системой конкретной машины.
Следующий шаг - научиться писать программы, которые имели бы доступ к файлам,
заранее не подсоединенным к программам. Одна из программ, в которой возникает
такая необходимость, - это программа cat, объединяющая несколько именованных
файлов и направляющая результат в стандартный вывод. Функция cat часто
применяется для выдачи файлов на экран, а также как универсальный "коллектор"
файловой информации для тех программ, которые не имеют возможности обратиться
к файлу по имени. Например, команда
cat x.c y.c
направит в стандартный вывод содержимое файлов x.c и y.c (и ничего более).
Возникает вопрос: что надо сделать, чтобы именованные файлы можно было
читать; иначе говоря, как связать внешние имена, придуманные пользователем, с
инструкциями чтения данных?
На этот счет имеются простые правила. Для того чтобы можно было читать из
файла или писать в файл, он должен быть предварительно открыт с помощью
библиотечной функции fopen. Функция fopen получает внешнее имя типа x.c или
y.c, после чего осуществляет некоторые организационные действия и
"переговоры" с операционной системой (технические детали которых здесь не
рассматриваются) и возвращает указатель, используемый в дальнейшем для
доступа к файлу.
Этот указатель, называемый указателем файла, ссылается на структуру,
содержащую информацию о файле (адрес буфера, положение текущего символа в
буфере, открыт файл на чтение или на запись, были ли ошибки при работе с
файлом и не встретился ли конец файла). Пользователю не нужно знать
подробности, поскольку определения, полученные из <stdio.h>, включают
описание такой структуры, называемой FILE.
Единственное, что требуется для определения указателя файла, - это задать
описания такого, например, вида:
FILE *fp;
FILE *fopen(char *name, char *mode);
Это говорит, что fp есть указатель на FILE, a fopen возвращает указатель на
FILE. Заметим, что FILE — это имя типа) наподобие int, а не тег структуры. Оно
определено с помощью typedef. (Детали того, как можно реализовать fopen в
системе UNIX, приводятся в параграфе 8.5.)
Обращение к fopen в программе может выглядеть следующим образом:
fp = fopen(name, mode);
Первый аргумент - строка, содержащая имя файла. Второй аргумент несет
информацию о режиме. Это тоже строка: в ней указывается, каким образом
пользователь намерен применять файл. Возможны следующие режимы: чтение (read
- "r"), запись (write - "w") и добавление (append - "a"), т. е. запись
информации в конец уже существующего файла. В некоторых системах различаются
текстовые и бинарные файлы; в случае последних в строку режима необходимо
добавить букву "b" (binary - бинарный).
Тот факт, что некий файл, которого раньше не было, открывается на запись или
добавление, означает, что он создается (если такая процедура физически
возможна). Открытие уже существующего файла на запись приводит к выбрасыванию
его старого содержимого, в то время как при открытии файла на добавление его
старое содержимое сохраняется. Попытка читать несуществующий файл является
ошибкой. Могут иметь место и другие ошибки; например, ошибкой считается
попытка чтения файла, который по статусу запрещено читать. При наличии любой
ошибки fopen возвращает NULL. (Возможна более точная идентификация ошибки;
детальная информация по этому поводу приводится в конце параграфа 1
приложения B.)
Следующее, что нам необходимо знать, - это как читать из файла или писать в
файл, коль скоро он открыт. Существует несколько способов сделать это, из
которых самый простой состоит в том, чтобы воспользоваться функциями getc и
putc. Функция getc возвращает следующий символ из файла; ей необходимо
сообщить указатель файла, чтобы она знала откуда брать символ.
int getc(FILE *fp);
Функция getc возвращает следующий символ из потока, на который указывает *fp;
в случае исчерпания файла или ошибки она возвращает EOF.
Функция putc пишет символ c в файл fp
int putc(int с, FILE *fp);
и возвращает записанный символ или EOF в случае ошибки. Аналогично getchar и
putchar, реализация getc и putc может быть выполнена в виде макросов, а не
функций.
При запуске Си-программы операционная система всегда открывает три файла и
обеспечивает три файловые ссылки на них. Этими файлами являются: стандартный
ввод, стандартный вывод и стандартный файл ошибок; соответствующие им
указатели называются stdin, stdout и stderr; они описаны в <stdio.h>. Обычно
stdin соотнесен с клавиатурой, а stdout и stderr - с экраном. Однако stdin и
stdout можно связать с файлами или, используя конвейерный механизм, соединить
напрямую с другими программами, как это описывалось в параграфе 7.1.
С помощью getc, putc, stdin и stdout функции getchar и putchar теперь можно
определить следующим образом:
#define getchar() getc(stdin)
#define putchar(c) putc((c), stdout)
Форматный ввод-вывод файлов можно построить на функциях fscanf и fprintf.
Они идентичны scanf и printf с той лишь разницей, что первым их аргументом
является указатель на файл, для которого осуществляется ввод-вывод, формат же
указывается вторым аргументом.
int fscanf(FILE *fp, char *format, ...)
int fprintf(FILE *fp, char *format, ...)
Вот теперь мы располагаем теми сведениями, которые достаточны для
написания программы cat, предназначенной для конкатенации (последовательного
соединения) файлов. Предлагаемая версия функции cat, как оказалось, удобна
для многих программ. Если в командной строке присутствуют аргументы, они
рассматриваются как имена последовательно обрабатываемых файлов. Если
аргументов нет, то обработке подвергается стандартный ввод.
#include <stdio.h>
/* cat: конкатенация файлов, версия 1 */
main(int argc, char *argv[])
{
FILE *fp;
void filecopy(FILE *, FILE *);
if (argc == 1) /* нет аргументов; копируется стандартный ввод */
filecopy(stdin, stdout);
else
while (--argc > 0)
if ((fp = fopen(*++argv, "r")) == NULL) {
printf("cat: не могу открыть файл %s\n", *argv);
return 1;
} else {
filecopy(fp, stdout);
fclose(fp);
}
return 0;
}
/* filecopy: копирует файл ifp в файл ofp */
void filecopy(FILE *ifp, FILE *ofp)
{
int c;
while ((c = getc(ifp)) != EOF)
putc(c, ofp);
}
Файловые указатели stdin и stdout представляют собой объекты типа FILE*.
Это константы, а не переменные, следовательно, им нельзя ничего присваивать.
Функция
int fclose(FILE *fp)
- обратная по отношению к fopen; она разрывает связь между файловым
указателем и внешним именем (которая раньше была установлена с помощью
fopen), освобождая тем самым этот указатель для других файлов. Так как в
большинстве операционных систем количество одновременно открытых одной
программой файлов ограничено, то файловые указатели, если они больше не
нужны, лучше освобождать, как это и делается в программе cat. Есть еще одна
причина применить fclose к файлу вывода, - это необходимость "опорожнить"
буфер, в котором putc накопила предназначенные для вывода данные. При
нормальном завершении работы программы для каждого открытого файла fclose
вызывается автоматически. (Вы можете закрыть stdin и stdout, если они вам не
нужны. Воспользовавшись библиотечной функцией freopen, их можно
восстановить.)
Обработку ошибок в cat нельзя признать идеальной. Беда в том, что если файл
по какой-либо причине недоступен, сообщение об этом мы получим по окончании
конкатенируемого вывода. Это нас устроило бы, если бы вывод отправлялся
только на экран, a не в файл или по конвейеру другой программе.
Чтобы лучше справиться с этой проблемой, программе помимо стандартного вывода
stdout придается еще один выходной поток, называемый stderr. Вывод в stderr
обычно отправляется на экран, даже если вывод stdout перенаправлен в другое
место. Перепишем cat так, чтобы сообщения об ошибках отправлялись в stderr.
#include <stdio.h>
/* cat: конкатенация файлов, версия 2 */
main(int argc, char *argv[])
{
FILE *fp;
void filecopy(FILE *, FILE *);
char *prog = argv[0]; /* имя программы */
if (argc == 1) /* нет аргументов, копируется станд. ввод */
filecopy(stdin, stdout);
else
while (--argc > 0)
if ((fp = fopen(*++argv, "r")) == NULL) {
fprintf(stderr, "%s: не могу открыть файл %s\n", prog, *argv);
exit(1);
} else {
filecopy(fp, stdout);
fclose(fp);
}
if (ferror(stdout)) {
fprintf(stderr, "%s: ошибка записи в stdout\n", prog);
exit(2);
}
exit(0);
}
Программа сигнализирует об ошибках двумя способами. Первый - сообщение об
ошибке с помощью fprintf посылается в stderr с тем, чтобы оно попало на
экран, а не оказалось на конвейере или в другом файле вывода. Имя программы,
хранящееся в argv[0], мы включили в сообщение, чтобы в случаях, когда данная
программа работает совместно с другими, был ясен источник ошибки.
Второй способ указать на ошибку - обратиться к библиотечной функции exit,
завершающей работу программы. Аргумент функции exit доступен некоторому
процессу, вызвавшему данный процесс. А следовательно, успешное или ошибочное
завершение программы можно проконтролировать с помощью некоей программы,
которая рассматривает эту программу в качестве подчиненного процесса. По
общей договоренности возврат нуля сигнализирует о том, что работа прошла
нормально, в то время как ненулевые значения обычно говорят об ошибках. Чтобы
опорожнить буфера, накопившие информацию для всех открытых файлов вывода,
функция exit вызывает fclose.
Инструкция return exp главной программы main эквивалентна обращению к функции
exit(exp). Последний вариант (с помощью exit) имеет то преимущество, что он
пригоден для выхода и из других функций, и, кроме того, слово exit легко
обнаружить с помощью программы контекстного поиска, похожей на ту, которую мы
рассматривали в главе 5. Функция ferror выдает ненулевое значение, если в
файле fp была обнаружена ошибка.
int ferror(FILE *fp)
Хотя при выводе редко возникают ошибки, все же они встречаются (например,
оказался переполненным диск); поэтому в программах широкого пользования они
должны тщательно контролироваться.
Функция feof(FILE *fp) aнaлoгичнa функции ferror; oнa вoзвpaщaeт нeнулевое
значение, если встретился конец указанного в аргументе файла.
int feof(FILE *fp);
В наших небольших иллюстративных программах мы не заботились о выдаче статуса
выхода, т. е. выдаче некоторого числа, характеризующего состояние программы в
момент завершения: работа закончилась нормально или прервана из-за ошибки?
Если работа прервана в результате ошибки, то какой? Любая серьезная программа
должна выдавать статус выхода.
В стандартной библиотеке имеется программа ввода fgets, аналогичная программе
getline, которой мы пользовались в предыдущих главах.
char *fgets(char *line, int maxline, FILE *fp)
Функция fgets читает следующую строку ввода (включая и символ новой строки)
из файла fp в массив символов line, причем она может прочитать не более
MAXLINE-1 символов. Переписанная строка дополняется символом '\0'. Обычно
fgets возвращает line, а по исчерпании файла или в случае ошибки - NULL.
(Наша getline возвращала длину строки, которой мы потом пользовались, и нуль
в случае конца файла.)
Функция вывода fputs пишет строку (которая может и не заканчиваться символом
новой строки) в файл.
int fputs(char *line, FILE *fp)
Эта функция возвращает EOF, если возникла ошибка, и неотрицательное
значение в противном случае.
Библиотечные функции gets и puts подобны функциям fgets и fputs. Отличаются
они тем, что оперируют только стандартными файлами stdin и stdout, и кроме
того, gets выбрасывает последний символ '\n', a puts его добавляет.
Чтобы показать, что ничего особенного в функциях вроде fgets и fputs нет, мы
приводим их здесь в том виде, в каком они существуют в стандартной библиотеке
на нашей системе.
/* fgets: получает не более n символов из iop */
char *fgets(char *s, int n, FILE *iop)
{
register int c;
register char *cs;
cs = s;
while (--n > 0 && (с = getc(iop)) != EOF)
if ((*cs++ = c) == '\n')
break;
*cs= '\0';
return (c == EOF && cs == s) ? NULL : s;
}
/* fputs: посылает строку s в файл iop */
int fputs(char *s, FILE *iop)
{
int c;
while (c = *s++)
putc(c, iop);
return ferror(iop) ? EOF : 0;
}
Стандарт определяет, что функция ferror возвращает в случае ошибки ненулевое
значение; fputs в случае ошибки возвращает EOF, в противном случае -
неотрицательное значение.
С помощью fgets легко реализовать нашу функцию getline:
/* getline: читает строку, возвращает ее длину */
int getline(char *line, int max)
{
if (fgets(line, max, stdin) == NULL)
return 0;
else
return strlen(line);
}
Упражнение 7.6. Напишите программу, сравнивающую два файла и печатающую
первую строку, в которой они различаются.
Упражнение 7.7. Модифицируйте программу поиска по образцу из главы 5 таким
образом, чтобы она брала текст из множества именованных файлов, а если имен
файлов в аргументах нет, то из стандартного ввода. Будет ли печататься имя
файла, в котором найдена подходящая строка?
Упражнение 7.8. Напишите программу, печатающую несколько файлов. Каждый файл
должен начинаться с новой страницы, предваряться заголовком и иметь свою
нумерацию страниц.
В стандартной библиотеке представлен широкий спектр различных функций.
Настоящий параграф содержит краткий обзор наиболее полезных из них. Более
подробно эти и другие функции описаны в приложении B.
Мы уже упоминали функции strlen, strcpy, strcat и strcmp, описание которых
даны в <string.h>. Далее, до конца пункта, предполагается, что s и t имеют
тип char *, c и n - тип int.
| strcat(s,t) | - приписывает t в конец s. |
| strncat(s,t,n) | - приписывает n символов из t в конец s. |
| strcmp(s,t) | - возвращает отрицательное число, нуль или положительное число
для s < t, s == t или s > t, соответственно. |
| strncmp(s,t,n) | - делает то же, что и strcmp, но количество сравниваемых
символов не может превышать n |
| strcpy(s,t) | - копирует t в s. |
| strncpy(s,t,n) | - копирует не более n символов из t в s. |
| strlen(s) | - возвращает длину s. |
| strchr(s,c) | - возвращает указатель на первое появление символа c в s или,
если c нет в s, NULL. |
| strrchr(s,c) | - возвращает указатель на последнее появление символа c в s или,
если c нет в s, NULL. |
Несколько функций из библиотеки <ctype.h> выполняют проверки и преобразование
символов. Далее, до конца пункта, переменная c - это переменная типа int,
которая может быть представлена значением unsigned, char или EOF. Все эти
функции возвращают значения типа int.
| isalpha(c) | - не нуль, если c - буква; 0 в противном случае. |
| isupper(c) | - не нуль, если c - буква верхнего регистра; 0 в противном случае. |
| islower(c) | - не нуль, если c - буква нижнего регистра; 0 в противном случае. |
| isdigit(c) | - не нуль, если c - цифра; 0 в противном случае. |
| isalnum(c) | - не нуль, если или isalpha(c), или isdigit(c) истинны; 0 в противном случае. |
| isspace(c) | - не нуль, если c - символ пробела, табуляции, новой строки, возврата каретки, перевода страницы, вертикальной табуляции. |
| toupper(c) | - возвращает c, приведенную к верхнему регистру. |
| tolower(c) | - возвращает c, приведенную к нижнему регистру. |
В стандартной библиотеке содержится более ограниченная версия функции ungetch
по сравнению с той, которую мы написали в главе 4. Называется она ungetc. Эта
функция, имеющая прототип
int ungetc(int с, FILE *fp)
отправляет символ c назад в файл fp и возвращает c, а в случае ошибки EOF.
Для каждого файла гарантирован возврат не более одного символа. Функцию
ungetc можно использовать совместно с любой из функций ввода вроде scanf,
getc, getchar и т. д.
Функция system(char *s) выполняет команду системы, содержащуюся в строке s, и
затем возвращается к выполнению текущей программы.
Содержимое s, строго говоря, зависит от конкретной операционной системы.
Рассмотрим простой пример: в системе UNIX инструкция
system("date");
вызовет программу date, которая направит дату и время в стандартный вывод.
Функция возвращает зависящий от системы статус выполненной команды. В системе
UNIX возвращаемый статус - это значение, переданное функцией exit.
Функции malloc и calloc динамически запрашивают блоки свободной памяти.
Функция malloc
void *malloc(size_t n)
возвращает указатель на n байт неинициализированной памяти или NULL, если
запрос удовлетворить нельзя. Функция calloc
void *calloc(size_t n, size_t size)
возвращает указатель на область, достаточную для хранения массива из n
объектов указанного размера (size), или NULL, если запрос не удается
удовлетворить. Выделенная память обнуляется.
Указатель, возвращаемый функциями malloc и calloc, будет выдан с учетом
выравнивания, выполненного согласно указанному типу объекта. Тем не менее к
нему должна быть применена операция приведения к соответствующему типу (Как уже отмечалось (см. примеч. в параграфе 6.5), замечания о приведении типов
значений, возвращаемых функциями malloc или calloc, — неверно. — Примеч. авт.), как
это сделано в следующем фрагменте программы:
int *ip;
ip = (int *) calloc(n, sizeof(int));
Функция free(p) освобождает область памяти, на которую указывает p, -
указатель, первоначально полученный с помощью malloc или calloc. Никаких
ограничений на порядок, в котором будет освобождаться память, нет, но
считается ужасной ошибкой освобождение тех областей, которые не были получены
с помощью calloc или malloc.
Нельзя также использовать те области памяти, которые уже освобождены.
Следующий пример демонстрирует типичную ошибку в цикле, освобождающем
элементы списка.
for (p = head; p != NULL; p = p->next) /* НЕВЕРНО */
free(p);
Правильным будет, если вы до освобождения сохраните то, что вам
потребуется, как в следующем цикле:
for (p = head; p != NULL; p = q) {
q = p->next;
free(p);
}
В параграфе 8.7 мы рассмотрим реализацию программы управления памятью вроде
malloc, позволяющую освобождать выделенные блоки памяти в любой
последовательности.
В <math.h> описано более двадцати математических функций. Здесь же
приведены наиболее употребительные. Каждая из них имеет один или два
аргумента типа double и возвращает результат также типа double.
| sin(x) | - синус x, x в радианах |
| cos(x) | - косинус x, x в радианах |
| atan2(y,x) | - арктангенс y/x, y и x в радианах |
| exp(x) | - экспоненциальная функция e в степени x |
| log(x) | - натуральный (по основанию e) логарифм x (x>0) |
| log10(x) | - обычный (по основанию 10) логарифм x (x>0) |
| pow(x,y) | - x в степени y |
| sqrt(x) | - корень квадратный x (x > 0) |
| fabs(x) | - абсолютное значение x |
Функция rand() вычисляет последовательность псевдослучайных целых в диапазоне
от нуля до значения, заданного именованной константой RAND_MAX, которая
определена в <stdlib.h>. Привести случайные числа к значениям с плавающей
точкой, большим или равным 0 и меньшим 1, можно по формуле
#define frand() ((double) rand() / (RAND_MAX+1.0))
(Если в вашей библиотеке уже есть функция для получения случайных чисел с
плавающей точкой, вполне возможно, что ее статистические характеристики лучше
указанной.)
Функция srand(unsigned) устанавливает семя для rand. Реализации rand и
srand, предлагаемые стандартом и, следовательно, переносимые на различные
машины, рассмотрены в параграфе 2.7.
Упражнение 7.9. Реализуя функции вроде isupper, можно экономить либо память,
либо время. Напишите оба варианта функции.
Глава 8. Интерфейс с системой UNIX
Свои услуги операционная система UNIX предлагает в виде набора системных
вызовов, которые фактически являются ее внутренними функциями и к которым
можно обращаться из программ пользователя. В настоящей главе описано, как в
Си-программах можно применять некоторые наиболее важные вызовы. Если вы
работаете в системе UNIX, то эти сведения будут вам полезны непосредственно и
позволят повысить эффективность работы или получить доступ к тем
возможностям, которых нет в библиотеке. Даже если вы используете Си в другой
операционной системе, изучение рассмотренных здесь примеров все равно
приблизит вас к пониманию программирования на Си; аналогичные программы
(отличающиеся лишь деталями) вы встретите практически в любой операционной
системе. Так как библиотека Си-программ, утвержденная в качестве стандарта
ANSI, в основном отражает возможности системы UNIX, предлагаемые программы
помогут вам лучше понять и библиотеку.
Глава состоит из трех основных частей, описывающих: ввод-вывод, файловую
систему и организацию управления памятью. В первых двух частях предполагается
некоторое знакомство читателя с внешними характеристиками системы UNIX.
В главе 7 мы рассматривали единый для всех операционных систем интерфейс
ввода-вывода. В любой конкретной системе программы стандартной библиотеки
пишутся с использованием средств именно этой конкретной системы. В следующих
нескольких параграфах мы опишем вызовы системы UNIX по вводу-выводу и
покажем, как с их помощью можно реализовать некоторые разделы стандартной
библиотеки.
8.1 Дескрипторы файлов
В системе UNIX любые операции ввода-вывода выполняются посредством чтения и
записи файлов, поскольку все внешние устройства, включая клавиатуру и экран,
рассматриваются как объекты файловой системы. Это значит, что все связи между
программой и внешними устройствами осуществляются в рамках единого
однородного интерфейса.
В самом общем случае, прежде чем читать или писать, вы должны
проинформировать систему о действиях, которые вы намереваетесь выполнять в
отношении файла; эта процедура называется открытием файла. Если вы
собираетесь писать в файл, то, возможно, его потребуется создать заново или
очистить от хранимой информации. Система проверяет ваши права на эти действия
(файл существует? вы имеете к нему доступ?) и, если все в порядке, возвращает
программе небольшое неотрицательное целое, называемое дескриптором файла.
Всякий раз, когда осуществляется ввод-вывод, идентификация файла выполняется
по его дескриптору, а не по имени. (Дескриптор файла аналогичен файловому
указателю, используемому в стандартной библиотеке, или хэндлу (handle) в MS-
DOS.) Вся информация об открытом файле хранится и обрабатывается операционной
системой; программа пользователя обращается к файлу только через его
дескриптор.
Ввод с клавиатуры и вывод на экран применяются настолько часто, что для
удобства работы с ними предусмотрены специальные соглашения. При запуске
программы командный интерпретатор (shell) открывает три файла с дескрипторами
0, 1 и 2, которые называются соответственно стандартным вводом, стандартным
выводом и стандартным файлом ошибок. Если программа читает из файла 0, а
пишет в файлы 1 и 2 (здесь цифры - дескрипторы файлов), то она может
осуществлять ввод и вывод, не заботясь об их открытии.
Пользователь программы имеет возможность перенаправить ввод-вывод в файл или
из файла с помощью значков < и >, как, например, в
prog < infile > outfile
В этом случае командный интерпретатор заменит стандартные установки
дескрипторов 0 и 1 на именованные файлы. Обычно дескриптор файла 2 остается
подсоединенным к экрану, чтобы на него шли сообщения об ошибках. Сказанное
верно и для ввода-вывода, связанного в конвейер. Во всех случаях замену файла
осуществляет командный интерпретатор, а не программа. Программа, если она
ссылается на файл 0 (в случае ввода) и файлы 1 и 2 (в случае вывода), не
знает, ни откуда приходит ее ввод, ни куда отправляется ее вывод.
8.2 Нижний уровень ввода-вывода (read и write)
Ввод-вывод основан на системных вызовах read и write, к которым Си-программа
обращается с помощью функций с именами read и write.
Для обеих первым аргументом является дескриптор файла. Во втором аргументе
указывается массив символов вашей программы, куда посылаются или откуда
берутся данные. Третий аргумент - это количество пересылаемых байтов.
int n_read = read(int fd, char *buf, int n);
int n_written = write(int fd, char *buf, int n);
Обе функции возвращают число переданных байтов. При чтении количество
прочитанных байтов может оказаться меньше числа, указанного в третьем
аргументе. Нуль означает конец файла, а -1 сигнализирует о какой-то ошибке.
При записи функция возвращает количество записанных байтов, и если это число
не совпадает с требуемым, следует считать, что запись не произошла.
За один вызов можно прочитать или записать любое число байтов. Обычно это
число равно или 1, что означает посимвольную передачу "без буферизации", или
чему-нибудь вроде 1024 или 4096, соответствующих размеру физического блока
внешнего устройства. Эффективнее обмениваться большим числом байтов,
поскольку при этом требуется меньше системных вызовов. Используя полученные
сведения, мы можем написать простую программу, копирующую свой ввод на свой
вывод и эквивалентную программе копирования файла, описанной в главе 1. С
помощью этой программы можно копировать откуда угодно и куда угодно,
поскольку всегда существует возможность перенаправить ввод-вывод на любой
файл или устройство.
#include "syscalls.h"
main() /* копирование ввода на вывод */
{
char buf[BUFSIZ];
int n;
while ((n = read(0, buf, BUFSIZ)) > 0)
write(i, buf, n);
return 0;
}
Прототипы функций, обеспечивающие системные вызовы, мы собрали в файле
syscalls.h, что позволяет нам включать его в программы этой главы. Однако имя
данного файла не зафиксировано стандартом.
Параметр BUFSIZ также определен в <syscalls.h>: в каждой конкретной системе
он имеет свое значение. Если размер файла не кратен BUFSIZ, то какая-то
операция чтения вернет значение меньшее, чем BUFSIZ, а следующее обращение к
read даст в качестве результата нуль.
Полезно рассмотреть, как используются read и write при написании программ
более высокого уровня — таких как getchar, putchar и т. д. Вот, к примеру,
версия программы getchar, которая осуществляет небуферизованный ввод, читая
по одному символу из стандартного входного потока.
#include "syscalls.h"
/* getchar: небуферизованный ввод одного символа */
int getchar(void)
{
char с;
return (read(0, &c, 1) == 1) ? (unsigned char) с : EOF;
}
Переменная c должна быть типа char, поскольку read требует указателя на char.
Приведение c к unsigned char перед тем, как вернуть ее в качестве результата,
исключает какие-либо проблемы, связанные с распространением знака.
Вторая версия getchar осуществляет ввод большими кусками, но при каждом
обращении выдает только один символ.
#include "syscalls.h"
/* getchar: простая версия с буферизацией */
int getchar(void)
{
static char buf[BUFSIZ];
static char *bufp = buf;
static int n = 0;
if (n == 0) { /* буфер пуст */
n = read(0, buf, sizeof buf);
bufp = buf;
}
return (--n >= 0) ? (unsigned char) *bufp++ : EOF;
}
Если приведенные здесь версии функции getchar компилируются с включением
заголовочного файла <stdio.h> и в этом заголовочном файле getchar
определена как макрос, то нужно задать строку #undef с именем getchar.
8.3 Системные вызовы open, creat, close, unlink
В отличие от стандартных файлов ввода, вывода и ошибок, которые открыты по
умолчанию, остальные файлы нужно открывать явно. Для этого есть два системных
вызова: open и creat.
Функция open почти совпадает с fopen, рассмотренной в главе 7. Разница между
ними в том, что первая возвращает не файловый указатель, а дескриптор файла
типа int. При любой ошибке open возвращает -1.
include <fcntl.h>
int fd;
int open(char *name, int flags, int perms);
fd = open(name, flags, perms);
Как и в fopen, аргумент name - это строка, содержащая имя файла. Второй
аргумент, flags, имеет тип int и специфицирует, каким образом должен быть
открыт файл. Его основными значениями являются:
O_RDONLY - открыть только на чтение;
O_WRONLY - открыть только на запись;
O_RDWR - открыть и на чтение, и на запись.
В System V UNIX эти константы определены в <fcntl.h>, а в версиях
Berkley (BSD) - в <sys/file.h>.
Чтобы открыть существующий файл на чтение, можно написать
fd = open(name, 0_RDONLY, 0);
Далее везде, где мы пользуемся функцией open, ее аргумент perms равен
нулю.
Попытка открыть несуществующий файл является ошибкой. Создание нового файла
или перезапись старого обеспечивается системным вызовом creat. Например
int creat(char *name, int perms);
fd = creat(name, perms);
Функция creat возвращает дескриптор файла, если файл создан, и -1, если по
каким-либо причинам файл создать не удалось. Если файл уже существует, creat
"обрежет" его до нулевой длины, что равносильно выбрасыванию предыдущего
содержимого данного файла; создание уже существующего файла не является
ошибкой.
Если строится действительно новый файл, то creat его создаст с правами
доступа, специфицированными в аргументе perms. В системе UNIX с каждым файлом
ассоциированы девять битов, содержащие информацию о правах пользоваться этим
файлом для чтения, записи и исполнения лицам трех категорий: собственнику
файла, определенной им группе лиц и всем остальным. Таким образом, права
доступа удобно специфицировать с помощью трех восьмеричных цифр. Например,
0755 специфицирует чтение, запись и право исполнения собственнику файла, а
также чтение и право исполнения группе и всем остальным.
Для иллюстрации приведем упрощенную версию программы cp системы UNIX, которая
копирует один файл в другой. В нашей версии копируется только один файл, не
позволяется во втором аргументе указывать директорий (каталог), и права
доступа не копируются, а задаются константой.
#include <stdio.h>
#include <fcntl.h>
#include "syscalls.h"
#define PERMS 0666 /* RW для собственника, группы и остальных */
void error(char *, ...);
/* cp: копирование f1 в f2 */
main(int argc, char *argv[])
{
int f1, f2, n;
char buf[BUFSIZ];
if (argc ! = 3)
error("Обращение: cp откуда куда");
if ((f1 = open(argv[1], O_RDONLY, 0)) == -1)
error("cp: не могу открыть файл %s", argv[1]);
if ((f2 = creat(argv[2], PERMS)) == -1)
error("cp: не могу создать файл %s, режим %03o",
argv[2], PERMS);
while ((n = read(f1, buf, BUFSIZ)) > 0)
if (write(f2, buf, n) != n)
error ("cp: ошибка при записи в файл %s", argv[2]);
return 0;
}
Данная программа создаст файл вывода с фиксированными правами доступа,
определяемыми кодом 0666. С помощью системного вызова stat, который будет
описан в параграфе 8.6, мы можем определить режим использования существующего
файла и задать тот же режим для копии.
Заметим, что функция error, вызываемая с различным числом аргументов, во
многом похожа на printf. Реализация error иллюстрирует, как пользоваться
другими программами семейства printf. Библиотечная функция vprintf аналогична
printf, с той лишь оговоркой, что переменная часть списка аргументов заменена
в ней одним аргументом, который инициализируется макросом va_start. Подобным
же образом соотносятся функции vfprinf с fprintf и vsprintf с sprintf.
#include <stdio.h>
#include <stdarg.h>
/* error: печатает сообщение об ошибке и умирает */
void error(char *fmt, ...)
{
va_list args;
va_start(args, fmt);
fprintf(stderr, "ошибка: ");
vfprintf(stderr, fmt, args);
fprintf(stderr, "\n");
va_end(args);
exit(1);
}
На количество одновременно открытых в программе файлов имеется ограничение
(обычно их число колеблется около 20). Поэтому любая программа, которая
намеревается работать с большим количеством файлов, должна быть готова
повторно использовать их дескрипторы. Функция close(int fd) разрывает связь
между файловым дескриптором и открытым файлом и освобождает дескриптор для
его применения с другим файлом. Она аналогична библиотечной функции fclose с
тем лишь различием, что никакой очистки буфера не делает. Завершение
программы с помощью exit или return в главной программе закрывает все
открытые файлы.
Функция unlink(char *name) удаляет имя файла из файловой системы. Она
соответствует функции remove стандартной библиотеки.
Упражнение 8.1. Перепишите программу cat из главы 7, используя функции read,
write, open и close. Замените ими соответствующие функции стандартной
библиотеки. Поэкспериментируйте, чтобы сравнить быстродействие двух версий.
8.4 Произвольный доступ (lseek)
Ввод-вывод обычно бывает последовательным, т. е. каждая новая операция
чтения-записи имеет дело с позицией файла, следующей за той, что была в
предыдущей операции (чтения-записи). При желании, однако, файл можно читать
или производить запись в него в произвольном порядке. Системный вызов lseek
предоставляет способ передвигаться по файлу, не читая и не записывая данные.
Так, функция
long lseek(int fd, long offset, int origin);
в файле с дескриптором fd устанавливает текущую позицию, смещая ее на
величину offset относительно места, задаваемого значением origin. Значения
параметра origin 0, 1 или 2 означают, что на величину offset отступают
соответственно от начала, от текущей позиции или от конца файла. Например,
если требуется добавить что-либо в файл (когда в командном интерпретаторе
shell системы UNIX ввод перенаправлен оператором >> в файл или когда в fopen
задан аргумент "a"), то прежде чем что-либо записывать, необходимо найти
конец файла с помощью вызова функции
lseek(fd, 0L, 2);
Чтобы вернуться назад, в начало файла, надо выполнить
lseek(fd, 0L, 0);
Следует обратить внимание на аргумент 0L: вместо 0L можно было бы написать
(long)0 или, если функция lseek должным образом объявлена, просто 0.
Благодаря lseek с файлами можно работать так, как будто это большие массивы,
правда, с замедленным доступом. Например, следующая функция читает любое
число байтов из любого места файла. Она возвращает число прочитанных байтов
или -1 в случае ошибки.
#include "syscalls.h"
/* get: читает n байт из позиции pos */
int get(int fd, long pos, char *buf, int n)
{
if (lseek(fd, pos, 0) >= 0) /* установка позиции */
return read(fd, buf, n);
else
return -1;
}
Возвращаемое функцией lseek значение имеет тип long и является новой позицией
в файле или, в случае ошибки, равно -1. Функция fseek из стандартной
библиотеки аналогична lseek: от последней она отличается тем, что в случае
ошибки возвращает некоторое ненулевое значение, а ее первый аргумент имеет
тип FILE*.
8.5 Пример. Реализация функций fopen и getc
Теперь на примере функций fopen и getc из стандартной библиотеки покажем, как
описанные выше части согласуются друг с другом.
Напомним, что файлы в стандартной библиотеке описываются файловыми
указателями, а не дескрипторами. Указатель файла - это указатель на
структуру, содержащую информацию о файле: указатель на буфер, позволяющий
читать файл большими кусками: число незанятых байтов буфера; указатель на
следующую позицию в буфере; дескриптор файла; флажки, описывающие режим
(чтение/запись), ошибочные состояния и т. д.
Структура данных, описывающая файл, содержится в <stdio.h>, который
необходимо включать (с помощью #include) в любой исходный файл, если в том
осуществляется стандартный ввод-вывод. Этот же заголовочный файл включен и в
исходные тексты библиотеки ввода-вывода.
В следующем фрагменте, типичном для файла <stdio.h>, имена,
используемые только в библиотечных функциях, начинаются с подчеркивания. Это
сделано для того, чтобы они случайно не совпали с именами, фигурирующими в
программе пользователя. Такое соглашение соблюдается во всех программах
стандартной библиотеки.
#define NULL 0
#define EOF (-1)
#define BUFSIZ 1024
#define OPEN_MAX 20 /* max число одновременно открытых файлов */
typedef struct _iobuf {
int cnt; /* количество оставшихся символов */
char *ptr; /* позиция следующего символа */
char *base; /* адрес буфера */
int flag; /* режим доступа */
int fd; /* дескриптор файла */
} FILE;
extern FILE _iob[OPEN_MAX];
#define stdin (&iob[0])
#define stdout (&_iob[1])
#define stderr (&_iob[2])
enum _flags {
_READ = 01, /* файл открыт на чтение */
_WRITE = 02, /* файл открыт на запись */
_UNBUF = 04, /* файл не буферизируется */
_EOF = 010, /* в данном файле встретился EOF */
_ERR = 020 /* в данном файле встретилась ошибка */
};
int _fillbuf(FILE *);
int _flushbuf(int, FILE *);
#define feof(p) (((p)->flag & _EOF) !- 0)
#define ferror(p) (((p)->flag & _ERR) != 0)
#define fileno(p) ((p)->fd)
#define getc(p) (--(p)->cnt >= 0 \
? (unsigned char) *(p)->ptr++ : _fillbuf(p))
#define putc(x,p) (--(p)->cnt >= 0 \
? *(p)->ptr++ = (x) : _flushbuf((x),p))
#define getchar() getc(stdin)
#define putchar(x) putc((x), stdout)
Макрос getc обычно уменьшает счетчик числа символов, находящихся в буфере, и
возвращает символ, после чего приращивает указатель на единицу. (Напомним,
что длинные #define с помощью обратной наклонной черты можно продолжить на
следующих строках.) Когда значение счетчика становится отрицательным, getc
вызывает _fillbuf, чтобы снова заполнить буфер, инициализировать содержимое
структуры и выдать символ. Типы возвращаемых символов приводятся к unsigned;
это гарантирует, что все они будут положительными.
Хотя в деталях ввод-вывод здесь не рассматривается, мы все же привели полное
определение putc. Сделано это, чтобы показать, что она действует во многом
так же, как и getc, вызывая функцию _flushbuf, когда буфер полон. В тексте
имеются макросы, позволяющие получать доступ к флажкам ошибки и конца файла,
а также к его дескриптору.
Теперь можно написать функцию fopen. Большая часть инструкций fopen относится
к открытию файла, к соответствующему его позиционированию и к установке
флажковых битов, предназначенных для индикации текущего состояния. Сама fopen
не отводит места для буфера; это делает _fillbuf при первом чтении файла.
#include <fcntl.h>
#include "syscalls.h"
#define PERMS 0666 /* RW для собственника, группы и проч. */
/* fopen: открывает файл, возвращает файловый указатель */
FILE *fopen(char *name, char *mode)
{
int fd;
FILE *fp;
if (*mode != 'r' && *mode != 'w' && *mode != 'a'
return NULL;
for (fp = _iob; fp < _iob + OPEN_MAX; fp++)
if ((fp->flag & (_READ | _WRITE)) == 0)
break; /* найдена свободная позиция */
if (fp >= _iob + OPEN_MAX) /* нет свободной позиция */
return NULL;
if (*mode == 'w')
fd = creat(name, PERMS);
else if (*mode == 'a') {
if ((fd = open(name, O_WRONLY, 0)) == -1)
fd = creat(name, PERMS);
lseek(fd, 0L, 2);
} else
fd = open(name, O_RDONLY, 0);
if (fd ==-1) /* невозможен доступ по имени name */
return NULL;
fp->fd = fd;
fp->cnt = 0;
fp->base = NULL;
fp->flag = (*mode == 'r') ? _READ : _WRITE;
return fp;
}
Приведенная здесь версия fopen реализует не все режимы доступа, оговоренные
стандартом; но, мы думаем, их реализация в полном объеме не намного увеличит
длину программы. Наша fopen не распознает буквы b, сигнализирующей о бинарном
вводе-выводе (поскольку в системах UNIX это не имеет смысла), и знака +,
указывающего на возможность одновременно читать и писать.
Для любого файла в момент первого обращения к нему с помощью макровызова
getc счетчик cnt равен нулю. Следствием этого будет вызов _fillbuf. Коли
выяснится, что файл на чтение не открыт, то функция _fillbuf немедленно
возвратит EOF. В противном случае она попытается запросить память для буфера
(если чтение должно быть с буферизацией).
После получения области памяти для буфера _fillbuf обращается к read, чтобы
его наполнить, устанавливает счетчик и указатели и возвращает первый символ
из буфера. В следующих обращениях _fillbuf обнаружит, что память для буфера
уже выделена.
#include "syscalls.h"
/* _fillbuf: запрос памяти и заполнение буфера */
int _fillbuf(FILE *fp)
{
int bufsize;
if ((fp->flag & ( _READ | _EOF | _ERR )) != _READ)
return EOF;
bufsize = (fp->flag & _UNBUF) ? 1 : BUFSIZ;
if (fp->base == NULL) /* буфера еще нет */
if ((fp->base = (char *) malloc(bufsize)) == NULL)
return EOF; /* нельзя получить буфер */
fp->ptr = fp->base;
fp->cnt = read(fp->fd, fp->ptr, bufsize);
if (--fp->cnt < 0) {
if (fp->cnt == -1)
fp->flag |= _EOF;
else
fp->flag |= _ERR;
fp->cnt = 0;
return EOF;
}
return (unsigned char) *fp->ptr++;
}
Единственное, что осталось невыясненным, - это каким образом организовать
начало счета. Массив _iob следует определить и инициализировать так, чтобы
перед тем как программа начнет работать, в нем уже была информация о файлах
stdin, stdout и stderr.
FILE _iob[OPEN_MAX] = { /* stdin, stdout, stderr: */
{0, (char *) 0, (char *) 0, _READ, 0 },
{0, (char *) 0, (char *) 0, _WRITE, 1 },
{0, (char *) 0, (char *) 0, _WRITE | _UNBUF, 2 }
};
Инициализация flag как части структуры показывает, что stdin открыт на
чтение, stdout - на запись, а stderr - на запись без буферизации.
Упражнение 8.2. Перепишите функции fopen и _fillbuf, работая с флажками как с
полями, а не с помощью явных побитовых операций. Сравните размеры и скорости
двух вариантов программ.
Упражнение 8.3. Разработайте и напишите функции _flushbuf, fflush и fclose.
Упражнение 8.4. Функция стандартной библиотеки
int fseek(FILE *fp, long offset, int origin)
идентична функции lseek с теми, однако, отличиями, что fp - это файловый
указатель, а не дескриптор, и возвращает она значение int, означающее
состояние файла, а не позицию в нем. Напишите свою версию fseek. Обеспечьте,
чтобы работа вашей fseek по буферизации была согласована с буферизацией,
используемой другими функциями библиотеки.
8.6 Пример. Печать каталогов
При разного рода взаимодействиях с файловой системой иногда требуется
получить только информацию о файле, а не его содержимое. Такая потребность
возникает, например, в программе печати каталога файлов, работающей
аналогично команде ls системы UNIX. Она печатает имена файлов каталога и по
желанию пользователя другую дополнительную информацию (размеры, права доступа
и т. д.). Аналогичной командой в MS-DOS является dir.
Так как в системе UNIX каталог - это тоже файл, функции ls, чтобы добраться
до имен файлов, нужно только его прочитать. Но чтобы получить другую
информацию о файле (например узнать его размер), необходимо выполнить
системный вызов. В других системах (в MS-DOS, например) системным вызовом
приходится пользоваться даже для получения доступа к именам файлов. Наша цель
- обеспечить доступ к информации по возможности системно-независимым способом
несмотря на то, что реализация может быть существенно системно-зависима.
Проиллюстрируем сказанное написанием программы fsize. Функция fsize - частный
случай программы ls: она печатает размеры всех файлов, перечисленных в
командной строке. Если какой-либо из файлов сам является каталогом, то, чтобы
получить информацию о нем, fsize обращается сама к себе. Если аргументов в
командной строке нет, то обрабатывается текущий каталог.
Для начала вспомним структуру файловой системы в UNIXe. Каталог - это файл,
содержащий список имен файлов и некоторую информацию о том, где они
расположены. "Место расположения" - это индекс, обеспечивающий доступ в
другую таблицу, называемую "списком узлов inode". Для каждого файла имеется
свой inode, где собрана вся информация о файле, за исключением его имени.
Каждый элемент каталога состоит из двух частей: из имени файла и номера узла
inode.
К сожалению, формат и точное содержимое каталога не одинаковы в разных
версиях системы. Поэтому, чтобы переносимую компоненту отделить от
непереносимой, разобьем нашу задачу на две. Внешний уровень определяет
структуру, названную Dirent, и три подпрограммы opendir, readdir и closedir:
в результате обеспечивается системно-независимый доступ к имени и номеру узла
inode каждого элемента каталога. Мы будем писать программу fsize, рассчитывая
на такой интерфейс, а затем покажем, как реализовать указанные функции для
систем, использующих ту же структуру каталога, что и Version 7 и System V
UNIX. Другие варианты оставим для упражнений.
Структура Dirent содержит номер узла inode и имя. Максимальная длина имени
файла равна NAME_MAX - это значение системно-зависимо. Функция opendir
возвращает указатель на структуру, названную DIR (по аналогии с FILE),
которая используется функциями readdir и closedir. Эта информация
сосредоточена в заголовочном файле dirent.h.
#define NAME_MAX 14 /* максимальная длина имени файла */
/* системно-зависимая величина */
typedef struct { /* универс. структура элемента каталога: */
long ino; /* номер inode */
char name[NAME_MAX+1]; /* имя + завершающий '\0' */
} Dirent;
typedef struct { /* минимальный DIR: без буферизации и т.д. */
int fd; /* файловый дескриптор каталога */
Dirent d; /* элемент каталога */
} DIR;
DIR *opendir(char *dirname);
Dirent *readdir(DIR *dfd);
void closedir(DIR *dfd);
Системный вызов stat получает имя файла и возвращает полную о нем информацию,
содержащуюся в узле inode, или -1 в случае ошибки. Так,
char *name;
struct stat stbuf;
int stat(char *, struct stat *);
stat(name, &stbuf);
заполняет структуру stbuf информацией из узла inode о файле с именем name.
Структура, описывающая возвращаемое функцией stat значение находится в
<sys/stat.h> и выглядит примерно так:
struct stat /* информация из inode, возвращаемая stat */
{
dev_t st_dev; /* устройство */
ino_t st_ino; /* номер inode */
short st_mode; /* режимные биты */
short st_nlink; /* число связей с файлом */
short st_uid; /* имя пользователя-собственника */
short st_gid; /* имя группы собственника */
dev_t st_rdev; /* для специальных файлов */
off_t st_size; /* размер файла в символах */
time_t st_atime; /* время последнего использования */
time_t st_mtime; /* время последней модификации */
time_t st_ctime; /* время последнего изменения inode */
};
Большинство этих значений объясняется в комментариях. Типы, подобные dev_t и
ino_t, определены в файле <sys/types.h>, который тоже нужно включить
посредством #include.
Элемент st_mode содержит набор флажков, составляющих дополнительную
информацию о файле. Определения флажков также содержатся в <sys/stat.h>
нам потребуется только та его часть, которая имеет дело с типом файла
#define S_IFMT 0160000 /* тип файла */
#define S_IFDIR 0040000 /* каталог */
#define S_IFCHR 0020000 /* символьно-ориентированный */
#define S_IFBLK 0060000 /* блочно-ориентированный */
#define S_IFREG 0100000 /* обычный */
Теперь мы готовы приступить к написанию программы fsize. Если режимные биты
(st_mode), полученные от stat, указывают, что файл не является каталогом, то
можно взять его размер (st_size) и напечатать. Однако если файл - каталог, то
мы должны обработать все его файлы, каждый из которых в свою очередь может
быть каталогом. Обработка каталога - процесс рекурсивный.
Программа main просматривает параметры командной строки, передавая каждый
аргумент функции fsize.
#include <stdio.h>
#include <string.h>
#include "syscalls.h"
#include <fcntl.h> /* флажки чтения и записи */
#include <sys/types.h> /* определения типов */
#include <sys/stat.h> /* структура, возвращаемая stat */
#include "dirent.h"
void fsize(char *);
/* печатает размер файлов */
main(int argc, char **argv)
{
if (argc == 1)/* по умолчанию берется текущий каталог */
fsize(".");
else
while (--argc > 0)
fsize(*++argv);
return 0;
}
Функция fsize печатает размер файла. Однако, если файл - каталог, она сначала
вызывает dirwalk, чтобы обработать все его файлы. Обратите внимание на то,
как используются имена флажков S_IFMT и S_IFDIR из <sys/stat.h> при
проверке, является ли файл каталогом. Здесь нужны скобки, поскольку приоритет
оператора & ниже приоритета оператора ==.
int stat(char *, struct stat *);
void dirwalk(char *, void (*fcn)(char *));
/* fsize: печатает размер файла "name" */
void fsize(char *name)
{
struct stat stbuf;
if (stat(name, &stbuf) == -1) {
fprintf(stderr, "fsize: нет доступа к %s\n", name);
return;
}
if ((stbuf.st_mode & S_IFMT) == S_IFDIR)
dirwalk(name, fsize);
printf("%8ld%s\n", stbuf.st_size, name);
}
Функция dirwalk - это универсальная программа, применяющая некоторую функцию
к каждому файлу каталога. Она открывает каталог, с помощью цикла перебирает
содержащиеся в нем файлы, применяя к каждому из них указанную функцию, затем
закрывает каталог и осуществляет возврат. Так как fsize вызывает dirwalk на
каждом каталоге, в этих двух функциях заложена косвенная рекурсия.
#define MAX_PATH 1024
/* dirwalk: применяет fcn ко всем файлам из dir */
void dirwalk(char *dir, void (*fcn)(char *))
{
char name[MAX_PATH];
Dirent *dp;
DIR *dfd;
if ((dfd = opendir(dir)) == NULL) {
fprintf(stderr, "dirwalk: не могу открыть %s\n", dir);
return;
}
while ((dp = readdir(dfd)) != NULL) {
if (strcmp(dp->name, ".") == 0
|| strcmp(dp->name, "..") == 0)
continue; /* пропустить себя и родителя */
if (strlen(dir)+strlen(dp->name) + 2 > sizeof(name))
fprintf(stderr, "dirwalk: слишком длинное имя %s/%s\n",
dir, dp->name);
else {
sprintf(name, "%s/%s", dir, dp->name);
(*fcn) (name);
}
}
closedir(dfd);
}
Каждый вызов readdir возвращает указатель на информацию о следующем файле или
NULL, если все файлы обработаны. Любой каталог всегда хранит в себе
информацию о себе самом в файле под именем "." и о своем родителе в файле под
именем "..": их нужно пропустить, иначе программа зациклится. Обратите
внимание: код программы этого уровня не зависит от того, как форматированы
каталоги. Следующий шаг — представить минимальные версии opendir, readdir и
closedir для некоторой конкретной системы. Здесь приведены программы для
систем Version 7 и System V UNIX. Они используют информацию о каталоге,
хранящуюся в заголовочном файле <sys/dir.h>, который выглядит следующим
образом:
#ifndef DIRSIZ
#define DIRSIZ 14
#endif
struct direct /* элемент каталога */
{
ino_t d_ino; /* номер inode */
char d_name[DIRSIZ]; /* длинное имя не имеет '\0' */
};
Некоторые версии системы допускают более длинные имена и имеют более сложную
структуру каталога.
Тип ino_t задан с помощью typedef и описывает индекс списка узлов node. В
системе, которой пользуемся мы, этот тип есть unsigned short, но в других
системах он может быть иным, поэтому его лучше определять через typedef.
Полный набор "системных" типов находится в <sys/types.h>.
Функция opendir открывает каталог, проверяет, является ли он действительно
каталогом (в данном случае это делается с помощью системного вызова fstat,
который аналогичен stat, но применяется к дескриптору файла), запрашивает
пространство для структуры каталога и записывает информацию.
int fstat(int fd, struct stat *);
/* opendir: открывает каталог для вызовов readdir */
DIR *opendir(char *dirname)
{
int fd;
struct stat stbuf;
DIR *dp;
if ((fd = open(dirname. O_RDONLY, 0)) == -1
|| fstat(fd, &stbuf) == -1
|| (stbuf.st_mode & S_IFMT) != S_IFDIR
|| (dp = (DIR *) malloc(sizeof(DIR))) == NULL)
return NULL;
dp->fd = fd;
return dp;
}
Функция closedir закрывает каталог и освобождает пространство.
/* closedir: закрывает каталог, открытый opendir */
void closedir(DIR *dp)
{
if (dp) {
close(dp->fd);
free(dp);
}
}
Наконец, readdir с помощью read читает каждый элемент каталога. Если некий
элемент каталога в данный момент не используется (соответствующий ему файл
был удален), то номер узла inode у него равен нулю, и данная позиция
пропускается. В противном случае номер inode и имя размещаются в статической
(static) структуре, и указатель на нее выдается в качестве результата. При
каждом следующем обращении новая информация занимает место предыдущей.
#include <sys/dir.h> /* место расположения структуры каталога */
/* readdir: последовательно читает элементы каталога */
Dirent *readdir(DIR *dp)
{
struct direct dirbuf; /* структура каталога на данной системе */
static Dirent d; /* возвращает унифицированную структуру */
while (read(dp->fd, (char *) &dirbuf, sizeof (dirbuf))
== sizeof(dirbuf)) {
if (dirbuf.d_ino == 0) /* пустой элемент, не используется */
continue;
d.ino = dirbuf.d_ino;
strncpy(d.name, dirbuf.d_name, DIRSIZ);
d.name[DIRSIZ] = '\0'; /* завершающий символ '\0' */
return &d;
}
return NULL;
}
Хотя программа fsize - довольно специализированная, она иллюстрирует два
важных факта. Первый: многие программы не являются "системными"; они просто
используют информацию, которую хранит операционная система. Для таких
программ существенно то, что представление информации сосредоточено
исключительно в стандартных заголовочных файлах. Программы включают эти
файлы, а не держат объявления в себе. Второе наблюдение заключается в том,
что при старании системно-зависимым объектам можно создать интерфейсы,
которые сами не будут системно-зависимыми. Хорошие тому примеры ~ функции
стандартной библиотеки.
Упражнение 8.5. Модифицируйте fsize таким образом, чтобы можно было печатать
остальную информацию, содержащуюся в узле inode.
8.7 Пример. Распределитель памяти
В главе 5 был описан простой распределитель памяти, основанный на принципе
стека. Версия, которую мы напишем здесь, не имеет ограничений: вызовы malloc
и free могут выполняться в любом порядке: malloc делает запрос в операционную
систему на выделение памяти тогда, когда она требуется. Эти программы
иллюстрируют приемы, позволяющие получать машинно-зависимый код сравнительно
машинно-независимым способом, и, кроме того, они могут служить примером
применения таких средств языка, как структуры, объединения и typedef.
Никакого ранее скомпилированного массива фиксированного размера, из которого
выделяются куски памяти, не будет. Функция malloc запрашивает память у
операционной системы по мере надобности. Поскольку и другие действия
программы могут вызывать запросы памяти, которые удовлетворяются независимо
от этого распределителя памяти, пространство, которым заведует malloc,
необязательно представляет собой связный кусок памяти. Поэтому свободная
память хранится в виде списка блоков. Каждый блок содержит размер, указатель
на следующий блок и само пространство. Блоки в списке хранятся в порядке
возрастания адресов памяти, при этом последний блок (с самым большим адресом)
указывает на первый.
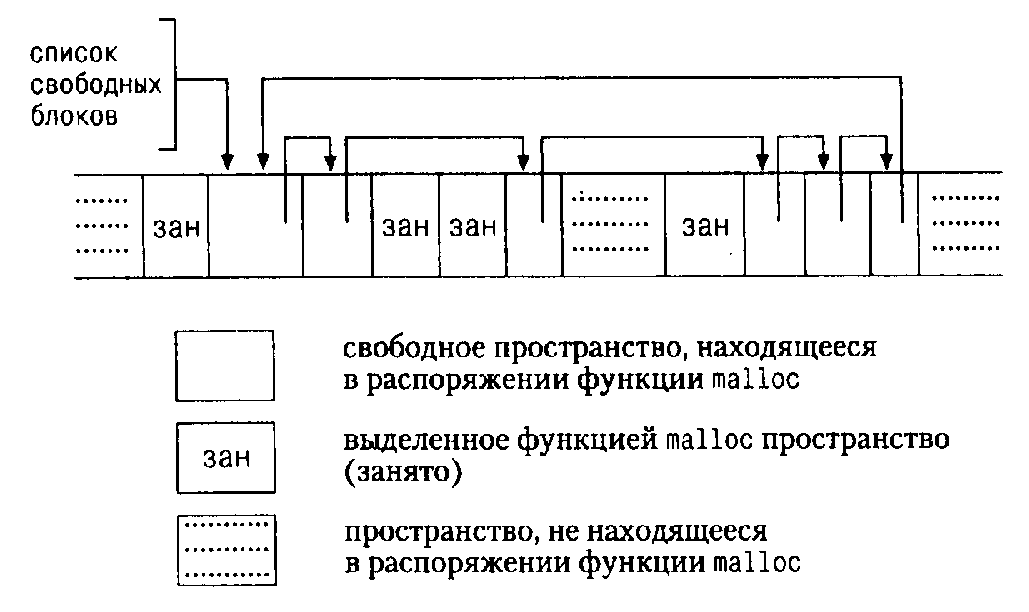
При возникновении запроса на память просматривается список свободных блоков,
пока не обнаружится достаточно большой блок. Такой алгоритм называется
"поиском первого подходящего" в отличие от алгоритма "поиска наилучшего
подходящего", который ищет наименьший блок из числа удовлетворяющих запросу.
Если размер блока в точности соответствует требованиям, то такой блок
исключается из списка и отдается в пользование. Если размер блока больше, чем
требуется, от него отрезается нужная часть - она отдается пользователю, а
ненужная оставляется в списке свободных блоков. Если блока достаточного
размера не оказалось, то у операционной системы запрашивается еще один
большой кусок памяти, который присоединяется к списку свободных блоков.
Процедура освобождения сопряжена с прохождением по списку свободных блоков,
поскольку нужно найти подходящее место для освобождаемого блока. Если
подлежащий освобождению блок примыкает с какой-то стороны к одному из
свободных блоков, то он объединяется с ним в один блок большего размера,
чтобы по возможности уменьшить раздробленность (фрагментацию) памяти.
Выполнение проверки, примыкают ли блоки друг к другу, не составляет труда,
поскольку список свободных блоков всегда упорядочен по возрастанию адресов.
Существует проблема, о которой мы уже упоминали в главе 5, состоящая в том,
что память, выдаваемая функцией malloc, должна быть соответствующим образом
выровнена с учетом объектов, которые будут в ней храниться. Хотя машины и
отличаются друг от друга, но для каждой из них существует тип, предъявляющий
самые большие требования на выравнивание, и, если по некоему адресу
допускается размещение объекта этого типа, то по нему можно разместить и
объекты всех других типов. На некоторых машинах таким самым "требовательным"
типом является double, на других это может быть int или long.
Свободный блок содержит указатель на следующий блок в списке, свой размер и
собственно свободное пространство. Указатель и размер представляют собой
управляющую информацию и образуют так называемый "заголовок". Чтобы упростить
выравнивание, все блоки создаются кратными размеру заголовка, а заголовок
соответствующим образом выравнивается. Этого можно достичь, сконструировав
объединение, которое будет содержать соответствующую заголовку структуру и
самый требовательный в отношении выравнивания тип. Для конкретности мы
выбрали тип long.
typedef long Align; /* для выравнивания по границе long */
union header { /* заголовок блока: */
struct {
union header *ptr; /* след. блок в списке свободных */
unsigned size; /* размер этого блока */
} s;
Align x; /* принудительное выравнивание блока */
};
typedef union header Header;
Поле Align нигде не используется: оно необходимо только для того, чтобы
каждый заголовок был выровнен по самому "худшему" варианту границы.
Затребованное число символов округляется в malloc до целого числа единиц
памяти размером в заголовок (именно это число и записывается в поле size
(размер) в заголовке); кроме того, в блок входит еще одна единица памяти -
сам заголовок. Указатель, возвращаемый функцией malloc, указывает на
свободное пространство, а не на заголовок. Со свободным пространством
пользователь может делать что угодно, но, если он будет писать что-либо за
его пределами, то, вероятно, список разрушится.
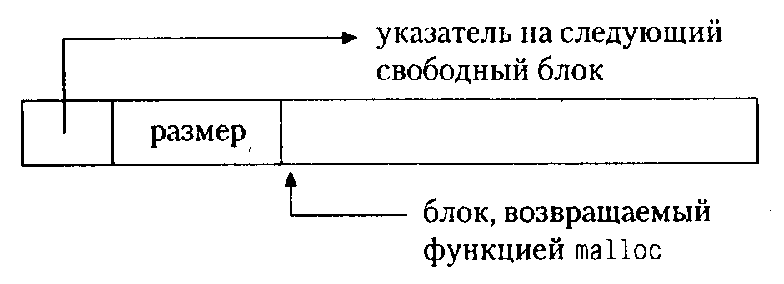
Поскольку память, управляемая функцией malloc, не обладает связностью,
размеры блоков нельзя вычислить по указателям, и поэтому без поля, хранящего
размер, нам не обойтись.
Для организации начала работы используется переменная base. Если freep есть
NULL (как это бывает при первом обращении к malloc), создается "вырожденный"
список свободного пространства; он содержит один блок нулевого размера с
указателем на самого себя. Поиск свободного блока подходящего размера
начинается с этого указателя (freep), т. е. с последнего найденного блока;
такая стратегия помогает поддерживать список однородным. Если найденный блок
окажется слишком большим, пользователю будет отдана его хвостовая часть; при
этом потребуется только уточнить его размер в заголовке найденного свободного
блока. В любом случае возвращаемый пользователю указатель является адресом
свободного пространства, размещающегося в блоке непосредственно за
заголовком.
static Header base; /* пустой список для нач. запуска */
static Header *freep = NULL; /* начало в списке своб. блоков */
/* malloc: универсальный распределитель памяти */
void *malloc(unsigned nbytes)
{
Header *p, *prevp;
Header *morecore(unsigned);
unsigned nunits;
nunits = (nbytes + sizeof(Header) - 1 ) / sizeof (Header) + 1;
if ((prevp = freep) == NULL) { /* списка своб. памяти еще нет */
base.s.ptr = freep = prevp = &base;
base.s.size = 0;
}
for (p = prevp->s.ptr; ; prevp = p, p = p->s.ptr) {
if (p->s.size >= nunits) { /* достаточно большой */
if (p->s.size == nunits) /* точно нужного размера */
prevp->s.ptr = p->s.ptr;
else { /* отрезаем хвостовую часть */
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void *)(p+1);
}
if (p == freep) /* прошли полный цикл по списку */
if ((p = morecore(nunits)) == NULL)
return NULL; /* больше памяти нет */
}
}
Функция morecore получает память от операционной системы. Детали того, как
это делается, могут не совпадать в различных системах. Так как запрос памяти
у системы - сравнительно дорогая операция, мы бы не хотели для этого каждый
раз обращаться к malloc. Поэтому используется функция morecore, которая
запрашивает не менее NALLOC единиц памяти; этот больший кусок памяти будет
"нарезаться" потом по мере надобности. После установки в поле размера
соответствующего значения функция morecore вызывает функцию free и тем самым
включает полученный кусок в список свободных областей памяти.
#define NALLOC 1024 /* миним. число единиц памяти для запроса */
/* morecore: запрашивает у системы дополнительную память */
static Header * morecore(unsigned nu)
{
char *cp, *sbrk(int);
Header *up;
if (nu < NALLOC)
nu = NALLOC;
cp = sbrk(nu * sizeof(Header));
if (cp == (char *) –1) /* больше памяти нет. */
return NULL;
up = (Header *) cp;
up->s.size = nu;
free((void *)(up+1));
return freep;
}
Системный вызов sbrk(n) в UNIXе возвращает указатель на n байт памяти или -1,
если требуемого пространства не оказалось, хотя было бы лучше, если бы в
последнем случае он возвращал NULL. Константу -1 необходимо привести к типу
char *, чтобы ее можно было сравнить с возвращаемым значением. Это еще один
пример того, как операция приведения типа делает функцию относительно
независимой от конкретного представления указателей на различных машинах.
Есть, однако, одна "некорректность", состоящая а том, что сравниваются
указатели на различные блоки, выдаваемые функцией sbrk. Такое сравнение не
гарантировано стандартом, который позволяет сравнивать указатели лишь в
пределах одного и того же массива. Таким образом, эта версия malloc верна
только на тех машинах, в которых допускается сравнение любых указателей.
В заключение рассмотрим функцию free. Она просматривает список свободной
памяти, начиная с freep, чтобы подыскать место для вставляемого блока.
Искомое место может оказаться или между блоками, или в начале списка, или в
его конце. В любом случае, если подлежащий освобождению блок примыкает к
соседнему блоку, он объединяется с ним в один блок. О чем еще осталось
позаботиться, - так это о том, чтобы указатели указывали в нужные места и
размеры блоков были правильными.
/* free: включает блок в список свободной памяти */
void free(void *ар)
{
Header *bp, *p;
bp = (Header *)ap –1; /* указатель на заголовок блока */
for (p = freep; !(bp > p && bp < p->s.ptr); p = p->s.ptr)
if (p >- p->s.ptr && (bp > p || bp < p->s.ptr))
break; /* освобождаем блок в начале или в конце */
if (bp + bp->s.size == p->s.ptr) { /* слить с верхним */
bp->s.size += p->s.ptr->s.size; /* соседом */
bp->s.ptr = p->s.ptr->s.ptr;
} else
bp->s.ptr = p->s.ptr;
if (p + p->s.size == bp) { /* слить с нижним соседом */
p->s.size += bp->s.size;
p->s.ptr = bp->s.ptr;
} else
p->s.ptr = bp;
freep = p;
}
Хотя выделение памяти по своей сути - машинно-зависимая проблема, с ней можно
справиться, что и иллюстрирует приведенная программа, в которой машинная
зависимость упрятана в очень маленькой ее части. Что касается проблемы
выравнивания, то мы разрешили ее с помощью typedef и union (предполагается,
что sbrk дает подходящий в смысле выравнивания указатель). Операции
приведения типов позволяют нам сделать явными преобразования типов и даже
справиться с плохо спроектированным интерфейсом системы. Несмотря на то, что
наши рассуждения касались распределения памяти, этот общий подход применим и
в других ситуациях.
Упражнение 8.6. Стандартная функция calloc(n, size) возвращает указатель на n
элементов памяти размера size, заполненных нулями. Напишите свой вариант
calloc, пользуясь функцией malloc или модифицируя последнюю.
Упражнение 8.7. Функция malloc допускает любой размер, никак не проверяя его
на правдоподобие: free предполагает, что размер освобождаемого блока -
правильный. Усовершенствуйте эти программы таким образом, чтобы они более
тщательно контролировали ошибки.
Упражнение 8.8. Напишите программу bfree(p, n), освобождающую произвольный
блок p, состоящий из n символов, путем включения его в список свободной
памяти, поддерживаемый функциями malloc и free. C помощью bfree пользователь
должен иметь возможность в любое время добавить в список свободной памяти
статический или внешний массив.
| 
 LINUX
LINUX 
 Books
Books
