Часть 2: Разработка клиента для простых сервисов
Перл позволяет писать сетевые приложения , которые могут многое делать -
от рассылки писем до доступа к веб-сервисам.
Клиентские модули могут состоять как из нескольких строк , так и из нескольких тысяч.
В этой части будут рассмотрены стандартные клиентские модули и показано ,
как их использовать для решения стандартных проблем.
В их основе лежит Berkeley socket API , которое мы рассмотрели в предыдущей части.
|
Раздел 6. FTP и Telnet
Two of the oldest Internet protocols are the
File Transfer Protocol, FTP, and Telnet, for remote login.
They illustrate the two extremes of network protocols: An FTP
session is a highly structured and predictable set of
transactions; a Telnet session is unpredictable and highly
interactive. Perl has modules that can tame them both.
|
Net::FTP
There's a directory on a remote FTP server
that changes every few weeks. You want to mirror a copy of the
directory on your local machine and update your copy every
time it changes. You can't use one of the many "mirror"
scripts to do this because the directory name contains a
timestamp, and you need to do a pattern match to identify the
right directory. Net::FTP to the rescue.
Net::FTP is part of the libnet utilities by
Graham Barr. In addition to Net::FTP, libnet includes
Net::SMTP, Net::NNTP, and Net::POP3 discussed in later
chapters. When you install the libnet modules, the install
script prompts you for various default configuration
parameters used by the Net::* modules. This includes such
things as an FTP firewall proxy and the default mail exchanger
for your domain. See the documentation for Net::Config (also
part of the libnet utilities) for information on how to
override the defaults later.
Net::FTP, like many of the client modules,
uses an object-oriented interface. When you first log in to an
FTP server, the module returns a Net::FTP object to you. You
then use this object to get directory listings from the
server, to transfer files, and to send other commands.
A Net::FTP Example
Figure
6.1 is a simple example that uses Net::FTP to connect to
ftp.perl.org and download the
file named RECENT from the
directory /pub/CPAN/. If the
program runs successfully, it creates a file named RECENT in the current directory. This
file contains the names of all files recently uploaded to
CPAN.
Lines 15: Initialize We load the
Net::FTP module and define constants for the host to connect
to and the file to download.
Line 6: Connect to remote host We
connect to the FTP host by invoking the Net::FTP
new() method with the name of the host to connect
to. If successful, new() returns a Net::FTP object
connected to the remote server. Otherwise, it returns
undef, and we die with an error message. In case of
failure, new() leaves a diagnostic error message in
$@.
Line 7: Log in to the server After
connecting to the server, we still need to log in by calling
the Net::FTP object's login() method with a
username and password. In this case, we are using anonymous
FTP, so we provide the username "anonymous" and let Net::FTP
fill in a reasonable default password. If login is
successful, login() returns a true value.
Otherwise, it returns false and we die, using the FTP
object's message() method to retrieve the text of
the server's last message.
Line 8: Change to remote directory
We invoke the FTP object's cwd() ("change working
directory") method to enter the desired directory. If this
call fails, we again die with the server's last message.
Line 9: Retrieve the file We call
the FTP object's get() method to retrieve the
desired file. If successful, Net::FTP copies the remote file
to a local one of the same name in the current directory.
Otherwise we die with an error message.
Lines 1011: Quit We call the FTP
object's quit() method to close the connection.
FTP and Command-Based
Protocols
FTP is an example of a common paradigm for
Internet services: the command-based protocol. The interaction
between client and server is constrained by a well-defined
protocol in which the client issues a single-line command and
the server returns a line-oriented response.
Each of the client commands is a short
case-insensitive word, possibly followed by one or more
arguments. The command is terminated by a CRLF pair. As we saw
in Chapter
5, when we used the gab2.pl
script to communicate with an FTP server, the client commands
in the FTP protocol include user and PASS, which
together are used to log into the server; HELP, to
get usage information; and QUIT, to quit the server.
Other commands are used to send and retrieve files, obtain
directory listings, and so forth. For example, when the client
wishes to log in under the user name "anonymous," it will send
this command to the server: USER anonymous
Each response from the server to the client
consists of one or more CRLF-delimited lines. The first line
always begin with a three-digit numeric result code indicating
the outcome of the command. This is usually followed by a
human-readable message. For example, a successful
USER command will result in the following server
response: 331 Guest login ok, send your complete e-mail address as password.
Sometimes a server response will stretch over
several lines. In this case, the numeric result code on the
first line will end in a "-", and the result code will be
repeated (without the dash) on the last line. The FTP
protocol's response to the HELP command illustrates this: HELP
214-The following commands are recognized (* =>'s unimplemented).
USER PORT STOR MSAM* RNTO NLST MKD CDUP
PASS PASV APPE MRSQ* ABOR SITE XMKD XCUP
ACCT* TYPE MLFL* MRCP* DELE SYST RMD STOU
SMNT* STRU MAIL* ALLO CWD STAT XRMD SIZE
REIN* MODE MSND* REST XCWD HELP PWD MDTM
QUIT RETR MSOM* RNFR LIST NOOP XPWD
214 Direct comments to ftp-bugs@wuarchive.wustl.edu
Commonly the client and server need to
exchange large amounts of non-command data. To do this, the
client sends a command to warn the server that the data is
coming, sends the data, and then terminates the information by
sending a lone dot (".") on a line by itself. We will see an
example of this in the next chapter when we examine the
interaction between an e-mail client and an SMTP server.
Server result codes are arbitrary but
generally follow a simple convention. Result codes between 100
and 199 are used for informational messages, while those in
the 200299 range are used to indicate successful completion
of a command. Codes in the 300399 range are used to indicate
that the client must provide more information, such as the
password that accompanies a username. Result codes of 400 or
greater indicate various errors: the 400499 codes are used
for client errors, such as an invalid command, while 500 and
greater are used for server-side errors, such as an out of
memory condition.
Because command-based servers are so common,
the libnet package comes with a generic building block module
called Net::Cmd. The module doesn't actually do anything by
itself, but adds functionality to descendents of the
IO::Socket module that allow them to easily communicate with
this type of network server. Net::FTP, Net::SMTP, Net::NNTP,
and Net::POP3 are all derived from Net::Cmd.
The two major methods provided by Net::Cmd
objects are command() and response():
|
$success =
$obj->command($command [,@args])
Send the command indicated by
$command to the server, optionally followed by
one or more arguments. command() automatically
inserts spaces between arguments and appends a CRLF to
the end of the command. If the command was delivered
successfully, the method returns true.
$status =
$obj->response
Fetches and parses the server's
response to the last command, returning the most
significant digit as the method result. For example, if
the server's result code is 331, response()
will return 3. It returns undef in case of
failure. |
Subclasses of Net::Cmd build more
sophisticated methods on top of the command() and
response(). For example, the Net::FTP
login() method calls command() twice: once
to issue the USER command and again to issue the
PASS command. You will not ordinarily call
command() and response(), yourself, but use
the more specialized (and convenient) methods provided by the
subclass. However, command() and response()
are available should you need access to functionality that
isn't provided by the module.
Several methods provided by Net::Cmd are
commonly used by end-user applications. These are
code(), message(), and ok():
|
$code =
$obj->code
Returns the three-digit numeric result
code from the last response.
$message =
$obj->message
Returns the text of the last message
from the server. This is particularly useful for
diagnosing errors.
$ok =
$obj->ok
The ok() method returns true
if the last server response indicated success, false
otherwise. It returns true if the result code is greater
than 0 but less than 400. |
The Net::FTP API
We'll now look at the Net::FTP API in greater
detail. Net::FTP is a descendent of both IO::Socket and
Net::Cmd. As a descendent of IO::Socket, it can be used as a
filehandle to communicate directly with the server. For
example, you canread and write to a Net::FTP object with
syswrite() and sysread(), although you would
probably not want to. As a descendent of Net::Cmd, Net::FTP
supports the code(), message(), and
ok() methods discussed in the previous section. The
FTP protocol's status codes are listed in RFC 959 (see Appendix
D).
To the generic methods inherited from its
ancestors, Net::FTP adds a large number of specialized methods
that support the special features of the FTP protocol. Only
the common methods are listed here. See the Net::FTP
documentation for the full API.
|
$ftp =
Net::FTP->new($host [,%options])
The new() method creates a
Net::FTP object. The mandatory first argument is the
domain name of the FTP server you wish to contact.
Additional optional arguments are a set of key/value
pairs that set options for the session, as shown in Table
6.1. For example, to connect to ftp.perl.org with hash marks
enabled and a timeout of 30 seconds, we could use this
statement: $ftp = Net::FTP('ftp.perl.org', Timeout=>30, Hash=>1);
|
Table 6.1.
Net::FTP->new() Options
| Firewall |
Name of the FTP proxy
to use when your machine is behind certain types of
firewalls |
| BlockSize |
Block size of
transfers (default 10240) |
| Port |
FTP port to connect to
(default 21) |
| Timeout |
Timeout value, in
seconds, for various operations (default 120
seconds) |
| Debug |
Debug level; set to
greater than zero for verbose debug messages |
| Passive |
Use FTP passive mode
for all file transfers; required by some firewalls |
| Hash |
Prints a hash mark to
STDERR for each 1024 bytes of data
transferred |
|
$success =
$ftp->login([$username [,$password
[,$account]]])
The login() method attempts to
log in to the server using the provided authentication
information. If no username is provided, then Net::FTP
assumes "anonymous". Ifno username or password is
provided, then Net::FTP looks up the authentication
information in the user's .netrc file. If this
is still not found, it generates a password of the form
"$user@", where $USER is your login
name.
The optional $account argument
is for use with some FTP servers that require an
additional authentication password to gain access to the
filesystem after logging into the server itself.
login() returns true if the login was
successful, and false otherwise.
See the Net::Netrc manual pages for
more information on the .netrc file.
$type =
$ftp->ascii
Puts the FTP object into ASCII mode.
The server automatically performs newline translation
during file transfers (ending lines with CRLF on Windows
machines, LF on UNIX machines, and CR on Macintoshes).
This is suitable for transferring text files.
The return value is the previous value
of the transfer type, such as "binary." Note: ASCII mode is the
default.
$type =
$ftp->binary
Puts the FTP object into binary mode.
The server will not perform translation. This is
suitable for transferring binary files such as
images.
$success =
$ftp->delete($file)
Deletes the file $file on the
server, provided you have sufficient privileges to do
this.
$success =
$ftp->cwd([$directory])
Attempts to change the current working
directory on the remote end to the specified path. If no
directory is provided, will attempt to change to the
root directory " / ". Relative directories are
understood, and you can provide a pathname of ".." to
move up one level.
$directory =
$ftp->pwd
Returns the full pathname of the
current working directory on the remote end.
$success =
$ftp->rmdir($directory)
Remove the specified directory,
provided you have sufficient privileges to do so.
$success =
$ftp->mkdir($directory [,$parents])
Creates a new directory at the
indicated path, provided you have sufficient privileges
to do so. If $parents is true, Net::FTP
attempts to create all missing intermediate directories
as well.
@items =
$ftp->ls([$directory])
Gets a short-format directory list of
all the files and subdirectories in the indicated
directory or, if not specified, in the current working
directory. In a scalar context, ls() returns a
reference to an array rather than the list itself.
By default, each member of the returned
list consists of just the bare file or directory name.
However, since the FTP daemon just passes the argument
to the ls command, you
are free to pass command-line arguments to ls. For example, this returns a
long listing: @items = $ftp->ls('-lF');
@items =
$ftp->dir([$directory])
Gets a long-format directory list of
all the files and subdirectories in the indicated
directory or, if not specified, in the current working
directory. In a scalar context, dir() returns a
reference to an array rather than the list itself.
In contrast to ls(), each
member of the returned list is a line of a directory
listing that provides the file modes, ownerships, and
sizes. It is equivalent to calling the ls command with the -lg options.
$success =
$ftp->get($remote [,$local [, $offset]])
The get() method retrieves the
file named $remote from the FTP server. You may
provide a full pathname or one relative to the current
working directory.
The $local argument specifies
the local pathname to store the retrieved file to. If
not provided, Net::FTP creates a file with the same name
as the remote file in the current directory. You may
also pass a filehandle in $local, in which case
the contents of the retrieved file are written to that
handle. This is handy for sending files to STDOUT: $ftp->get('RECENT',\*STDOUT)
The $offset argument can be
used to restart an interrupted transmission. It gives a
position in the file that the FTP server should seek
before transmitting. Here's an idiom for using it to
restart an interrupted transmission: my $offset = (stat($file))[7] || 0;
$ftp->get($file,$file,$offset);
The call to stat() fetches the
current size of the local file or, if none exists, 0.
This is then used as the offset to get().
$fh =
$ftp->retr($filename)
Like get(), the
retr() method can be used to retrieve a remote
file. However, rather than writing the file to a
filehandle or disk file, it returns a filehandle that
can be read from to retrieve the file directly. For
example, here is how to read the file named RECENT located on a remote FTP
server without creating a temporary local file: $fh = $ftp->retr('REMOTE') or die "can't get file ",$ftp->
message;
print while <$fh>;
$success =
$ftp->put($local [,$remote])
The put() method transfers a
file from the local host to the remote host. The naming
rules for $local and $remote are
identical to get(), including the ability to
use a filehandle for $local.
$fh =
$ftp->stor($filename)
$fh =
$ftp->appe($filename)
These two methods initiate file
uploads. The file will be stored on the remote server
under the name $filename. If the remote server
allows the transfer, the method returns a filehandle
that can be used to transmit the file contents. The
methods differ in how they handle the case of an
existing file with the specified name. The
stor(), method overwrites the existing file,
and appe() appends to it.
$modtime =
$ftp->mdtm($file)
The mdtm() method returns the
modification time of the specified file, expressed as
seconds since the epoch (the same format returned by the
stat() function). If the file does not exist or
is not a plain file, then this method returns
undef. Also be aware that some older FTP
servers (such as those from Sun) do not support
retrieval of modification times. For these servers
mdtm() will return undef.
$size =
$ftp->size($file)
Returns the size of the specified file
in bytes. If the file does not exist or is not a plain
file, then this method returns undef. Also be
aware that older FTP servers that do not support the
SIZE command also return
undef. |
A Directory Mirror Script
Using Net::FTP, we can write a simple FTP
mirroring script. It recursively compares a local directory
against a remote one and copies new or updated files to the
local machine, preserving the directory structure. The program
preserves file modes in the local copy (but not ownerships)
and also makes an attempt to preserve symbolic links.
The script, called ftp_mirror.pl, is listed in Figure
6.2. To mirror a file or directory from a remote server,
invoke the script with a command-line argument consisting of
the remote server's DNS name, a colon, and the path of the
file or directory to mirror. This example mirrors the file
RECENT, copying it to the local
directory only if it has changed since the last time the file
was mirrored:
%ftp_mirror.pl ftp.perl.org:/pub/CPAN/RECENT
The next example mirrors the entire contents
of the CPAN modules directory, recursively copying the remote
directory structure into the current local working directory
(don't try this verbatim unless you have a fast network
connection and a lot of free disk space): %ftp_mirror.pl ftp.perl.org:/pub/CPAN/
The script's command-line options include
--user and --pass, to provide a username and
password for non-anonymous FTP, --verbose for verbose status
reports, and --hash to print
out hash marks during file transfers.
Lines 15: Load modules We load the
Net::FTP module, as well as File::Path and Getopt::Long.
File::Path provides the mkpath() routine for
creating a subdirectory with all its intermediate parents.
Getopt::Long provides functions for managing command-line
arguments.
Lines 619: Process command-line
arguments We process the command-line arguments, using
them to set various global variables. The FTP host and the
directory or file to mirror are stored into the variables
$HOST and $PATH, respectively.
Lines 2023: Initialize the FTP
connection We call Net::FTP->new() to
connect to the desired host, and login() to log in.
If no username and password were provided as command-line
arguments, we attempt an anonymous login. Otherwise, we
attempt to use the authentication information to log in.
After successfully logging in, we set the
file transfer type to binary, which is necessary if we want
to mirror exactly the remote site, and we turn on hashing if
requested.
Lines 2426: Initiate mirroring If
all has gone well, we begin the mirroring process by calling
an internal subroutine do_mirror() with the
requested path. When do_mirror() is done, we close
the connection politely by calling the FTP object's
quit() method and exit.
Lines 2736: do_mirror()
subroutine The do_mirror() subroutine is the main
entry point for mirroring a file or directory. When first
called, we do not know whether the path requested by the
user is a file or directory, so the first thing we do is
invoke a utility subroutine to make that determination.
Given a path on a remote FTP server, find_type()
returns a single-character code indicating the type of
object the path points to, a "-" for an ordinary file, or a
"d" for a directory.
Having determined the type of the object,
we split the path into the directory part (the prefix) and
the last component of the path (the leaf; either the desired
file or directory). We invoke the FTP object's
cwd() method to change into the parent of the file
or directory to mirror.
If the find_type() subroutine
indicated that the path is a file, we invoke
get_file() to mirror the file. Otherwise, we invoke
get_dir().
Lines 3753: get_file() subroutine
This subroutine is responsible for fetching a file, but only
if it is newer than the local copy, if any. After fetching
the file, we try to change its mode to match the mode on the
remote site. The mode may be provided by the caller; if not,
we determine the mode from within the subroutine.
We begin by fetching the modification time
and the size of the remote file using the FTP object's
mdtm() and size() methods. Remember that
these methods might return undef if we are talking
to an older server that doesn't support these calls. If the
mode hasn't been provided by the caller, we invoke the FTP
object's dir() method to generate a directory
listing of the requested file, and pass the result to
parse_listing(), which splits the directory listing
line into a three-element list consisting of the file type,
name, and mode.
We now look for a file on the local machine
with the same relative path and stat() it,
capturing the local file's size and modification time
information. We then compare the size and modification time
of the remote file to the local copy. If the files are the
same size, and the remote file is as old or older than the
local one, then we don't need to freshen our copy.
Otherwise, we invoke the FTP object's get() method
to fetch the remote file. After the file transfer is
successfully completed, we change the file's mode to match
the remote version.
Lines 5473: get_dir() subroutine,
recursive directory mirroring The get_dir(),
subroutine is more complicated than get_file()
because it must call itself recursively in order to make
copies of directories nested within it. Like
get_file(), this subroutine is called with the path
of the directory and, optionally, the directory mode.
We begin by creating a local copy of the
directory in the current working directory if there isn't
one already, using mkpath() to create intermediate
directories if necessary. We then enter the newly created
directory with the chdir() Perl built-in, and
change the directory mode if requested.
We retrieve the current working directory
at the remote end by calling the FTP object's pwd()
method. This path gets stored into a local variable for
safekeeping. We now enter the remote copy of the mirror
directory using cwd().
We need to copy the contents of the
mirrored directory to the local server. We invoke the FTP
object's dir() method to generate a full directory
listing. We parse each line of the listing into its type,
pathname, and mode using the parse_listing()
subroutine. Plain files are passed to get_file(),
symbolic_links() to make_link(), and
subdirectories are passed recursively to
get_dir().
Having dealt with each member of the
directory listing, we put things back the way they were
before we entered the subroutine. We call the FTP object's
cwd(), routine to make the saved remote working
directory current, and chdir('..') to move up a
level in the local directory structure as well.
Lines 7484: find_type()
subroutine find_type() is a
not-entirely-satisfactory subroutine for guessing the type
of a file or directory given only its path. We would prefer
to use the FTP dir() method for this purpose, as in
the preceding get_dir() call, but this is
unreliable because of slight differences in the way that the
directory command works on different servers when you pass
it the path to a file versus the path to a directory.
Instead, we test whether the remote path is
a directory by trying to cwd() into it. If
cwd() fails, we assume that the path is a file.
Otherwise, we assume that the path is a directory. Note that
by this criterion, a symbolic link to a file is treated as a
file, and a symbolic link to a directory is treated as a
directory. This is the desired behavior.
Lines 8592: make_link()
subroutine The make_link() subroutine tries to
create a local symbolic link that mirrors a remote link. It
works by assuming that the entry in the remote directory
listing denotes the source and target of a symbolic link,
like this: README.html -> index.html
We split the entry into its two components
and pass them to the symlink(), built-in. Only
symbolic links that point to relative targets are created.
We don't attempt to link to absolute paths (such as "/CPAN")
because this will probably not be valid on the local
machine. Besides, it's a security issue.
Lines 93106: parse_listing()
subroutine The parse_listing() subroutine is
invoked by get_dir() to process one line of the
directory listing retrieved by Net::FTP->dir().
This subroutine is necessitated by the fact that the vanilla
FTP protocol doesn't provide any other way to determine the
type or mode of an element in a directory listing. The
subroutine parses the directory entry using a regular
expression that allows variants of common directory
listings. The file's type code is derived from the first
character of the symbolic mode field (e.g., the "d" in
drwxr-xr-x), and its mode from the remainder of the
field. The filename is whatever follows the date field.
The type, name, and mode are returned to
the caller, after first converting the symbolic file mode
into its numeric form.
Lines 107122: filemode()
subroutine This subroutine is responsible for converting a
symbolic file mode into its numeric equivalent. For example,
the symbolic mode rw-r--r-- becomes octal 0644. We
treat the setuid or setgid bits as if they were execute
bits. It would be a security risk to create a set-id file
locally.
When we run the mirror script in verbose mode
on CPAN, the beginning of the output looks like the
following: % ftp_mirror.pl --verbose ftp.perl.org:/pub/CPAN
Getting directory CPAN/
Symlinking CPAN.html -> authors/Jon_Orwant/CPAN.html
Symlinking ENDINGS -> .cpan/ENDINGS
Getting file MIRRORED.BY
Getting file MIRRORING.FROM
Getting file README
Symlinking README.html -> index.html
Symlinking RECENT -> indices/RECENT-print
Getting file RECENT.html
Getting file ROADMAP
Getting file ROADMAP.html
Getting file SITES
Getting file SITES.html
Getting directory authors/
Getting file 00.Directory.Is.Not.Maintained.Anymore
Getting file 00upload.howto
Getting file 00whois.html
Getting file 01mailrc.txt.gz
Symlinking Aaron_Sherman -> id/ASHER
Symlinking Abigail -> id/ABIGAIL
Symlinking Achim_Bohnet -> id/ACH
Symlinking Alan_Burlison -> id/ABURLISON
...
When we run it again a few minutes later, we
see messages indicating that most of the files are current and
don't need to be updated: % ftp_mirror.pl --verbose ftp.perl.org:/pub/CPAN
Getting directory CPAN/
Symlinking CPAN.html -> authors/Jon_Orwant/CPAN.html
Symlinking ENDINGS -> .cpan/ENDINGS
Getting file MIRRORED.BY: not newer than local copy.
Getting file MIRRORING.FROM: not newer than local copy.
Getting file README: not newer than local copy.
...
The major weak point of this script is the
parse_listing() routine. Because the FTP directory
listing format is not standardized, server implementations
vary slightly. During development, I tested this script on a
variety of UNIX FTP daemons as well as on the Microsoft IIS
FTP server. However, this script may well fail with other
servers. In addition, the regular expression used to parse
directory entries will probably fail on filenames that begin
with whitespace.
|
Net::Telnet
FTP is the quintessential line-oriented
server application. Every command issued by the client takes
the form of a single, easily parsed line, and each response
from the server to the client follows a predictable format.
Many of the server applications that we discuss in later
chapters, including POP, SMTP, and HTTP, are similarly simple.
This is because the applications were designed to interact
primarily with software, not with people.
Telnet is almost exactly the opposite. It was
designed to interact directly with people, not software. The
output from a Telnet session is completely unpredictable,
depending on the remote host's configuration, the shell the
user has installed, and the setup of the user's
environment.
Telnet does some things that make it easy for
human beings to use: It puts its output stream into a mode
that echoes back all commands that are sent to it, allowing
people to see what they type, and it puts its input stream
into a mode that allows it to read and respond to one
character at a time. This allows command-line editing and
full-screen text applications to work.
While these features make it easy for humans
to use Telnet-based applications, it makes scripting such
applications a challenge. Because the Telnet protocol is more
complex than sending commands and receiving responses, you
can't simply connect a socket to port 23 (Telnet's default) on
a remote machine and start exchanging messages. Before the
Telnet client and server can talk, they must engage in a
handshake procedure to negotiate communications session
parameters. Nor is it possible for a Perl script to open a
pipe to the Telnet client program because the Telnet, like
many interactive programs, expects to be opened on a terminal
device and tries to change the characteristics of the device
using various ioctl() calls.
Given these factors, it is best not to write
clients for interactive applications. Sometimes, though, it's
unavoidable. You may need to automate a legacy application
that is available only as an interactive terminal application.
Or you may need to remotely drive a system utility that is
only accessible in interactive form. A classic example of the
latter is the UNIX passwd
program for changing users' login passwords. Like Telnet,
passwd expects to talk directly
to a terminal device, and you must do special work to drive it
from a Perl script.
The Net::Telnet module provides access to
Telnet-based services. With its facilities, you can log into a
remote host via the Telnet protocol, run commands, and act on
the results using a straightforward pattern-matching idiom.
When combined with the IO::Pty module, you can also use
Net::Telnet to control local interactive programs.
Net::Telnet was written by Jay Rogers and is
available on CPAN. It is a pure Perl module, and will run
unmodified on Windows and Macintosh systems. Although it was
designed to interoperate with UNIX Telnet daemons, it is known
to work with the Windows NT Telnet daemon available on the
Windows NT Network Resource Kit CD and several of the freeware
daemons.
A Simple Net::Telnet Example
Figure
6.3 shows a simple script that uses Net::Telnet. It logs
into a host, runs the command ps
-ef to list all running processes, and then echoes the
information to standard output.
Lines 13: Load modules We load the
Net::Telnet module. Because it is entirely object-oriented,
there are no symbols to import.
Lines 46: Define constants We
hard-code constants for the host to connect to, and the user
and password to log in as (no, this isn't my real
password!). You'll need to change these as appropriate for
your system.
Line 7: Create a new Net::Telnet
object We call Net::Telnet->new() with the
name of the host. Net::Telnet attempts to connect to the
host, returning a new Net::Telnet object if successful or,
if a connection could not be established, undef.
Line 8: Log in to remote host We
call the Telnet object's login() method with the
username and password. login() will attempt to log
in to the remote system, and will return true if successful.
Lines 910: Run the "ps" command We
invoke the cmd() method with the command to run, in
this case ps -ef. If successful, this method
returns an array of lines containing the output of the
command (including the newlines). We print the result to
standard output.
When we run the remoteps.pl script, there is a brief
pause while the script logs into the remote host, and then the
output of the ps command
appears, as follows: % remoteps1.pl
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Jun26 ? 00:00:04 init
root 2 1 0 Jun26 ? 00:00:15 [kswapd]
root 3 1 0 Jun26 ? 00:00:00 [kflushd]
root 4 1 0 Jun26 ? 00:00:01 [kupdate]
root 34 1 0 Jun26 ? 00:00:01 /sbin/cardmgr
root 114 1 30 Jun26 ? 19:18:46 [kapmd]
root 117 1 0 Jun26 ? 00:00:00 [khubd]
bin 130 1 0 Jun26 ? 00:00:00 /usr/sbin/rpc.portmap
root 134 1 0 Jun26 ? 00:00:25 /usr/sbin/syslogd
...
Net::Telnet API
To accommodate the many differences between
Telnet implementations and shells among operating systems, the
Net::Telnet module has a large array of options. We only
consider the most frequently used of them here. See the
Net::Telnet documentation for the full details.
Net::Telnet methods generally have both a
named-argument form and a "shortcut" form that takes a single
argument only. For example, new() can be called
either this way: my $telnet = Net::Telnet->new('phage.cshl.org');
or like this: my $telnet = Net::Telnet->new(Host=>'phage.cshl.org', Timeout=>5);
We show both forms when appropriate.
The new() method is the constructor
for Net::Telnet objects:
|
$telnet =
Net::Telnet->new($host)
$telnet =
Net::Telnet->new(Option1=>$value1,Option2=>$value2
..)
The new() method creates a new
Net::Telnet object. It may be called with a single
argument containing the name of the host to connect to,
or with a series of option/ value pairs that provide
finer control over the object. new() recognizes
many options, the most common of which are shown in Table
6.2. |
Table 6.2.
Net::Telnet->new() Arguments
| Host |
Host to connect to |
"localhost" |
| Port |
Port to connect to |
23 |
| Timeout |
Timeout for pattern
matches, in seconds |
10 |
| Binmode |
Suppress CRLF
translation |
false |
| Cmd_remove_mode |
Remove echoed command
from input |
"auto" |
| Errmode |
Set the error mode |
"die" |
| Input_log |
Log file to write
input to |
none |
| Fhopen |
Filehandle to
communicate over |
none |
| Prompt |
Command-line prompt to
match |
"/[\$%#>]$/"
|
The Host and
Port options are the host and
port to connect to, and Timeout is the period in seconds
that Net::Telnet will wait for an expected pattern before
declaring a timeout.
Binmode
controls whether Net::Telnet will perform CRLF translation. By
default (Binmode=>0),
every newline sent from the script to the remote host is
translated into a CRLF pair, just as the Telnet client does
it. Likewise, every CRLF received from the remote host is
translated into a newline. With Binmode set to a true value,
this translation is suppressed and data is transmitted
verbatim.
Cmd_remove_mode controls the
removal of echoed commands. Most implementations of the Telnet
server echo back all user input. As a result, text you send to
the server reappears in the data read back from the remote
host. If CMD_REMOVE_MODE is set to true, the first line of all
data received from the server will be stripped. A false value
prevents stripping, and a value of "auto" allows Net::Telnet
to decide for itself whether to strip based on the "echo"
setting during the initial Telnet handshake.
Errmode
determines what happens when an error occurs, typically an
expected pattern not being seen before the timeout. The value
of Errmode can be one of the
strings "die" (the default) or "return". When set to "die",
Net::Telnet dies on anerror, aborting your program. A value of
"return" modifies this behavior, so that instead of dying the
failed method returns undef. You can then recover the
specific error message using errmsg(). In addition to
these two strings, Errmode
accepts either a code reference or an array reference. Both of
these forms are used to install custom handlers that are
invoked when an error occurs. The Net::Telnet documentation
provides further information.
The value for Input_log should be a filename or a
filehandle. All data received from the server is echoed to
this file or filehandle. Since the received data usually
contains the echoed command, this is a way to capture a
transcript of the Net::Telnet session and is invaluable for
debugging. If the argument is a previously opened filehandle,
then the log is written to that filehandle. Otherwise, the
argument is treated as the name of a file to open or
create.
The Fhopen
argument can be used to pass a previously opened filehandle to
Net::Telnet for it to use in communication. Net::Telnet will
use this filehandle instead oftrying to open its own
connection. We use this later to coerce Net::Telnet into
working across a Secure Shell link.
Prompt sets
the regular expression that Net::Telnet uses to identify the
shell command-line prompt. This is used by the
login() and cmd() methods to determine that
the command ran to completion. By default, Prompt is
set to a pattern that matches the default sh, csh, ksh, and
tcsh prompts.
Once a Net::Telnet object is opened you
control it with several object modules:
|
$result =
$telnet->login($username,$password)
$result =
$telnet->login(Name => $username,
Password
=> $password,
[Prompt =>
$prompt,]
[Timeout=>
$timeout])
The login() method attempts to
log into the remote host using the provided username and
password. In the named-parameter form of the method
call, you may override the values of Prompt and Timeout provided to
new().
If the Errmode is "die" and the
login method encounters an error, the call aborts your
script with an error message. Otherwise,
login() returns false.
$result =
$telnet->print(@values)
Print a value or list of values to the
remote host. A newline is automatically added for you
unless you explicitly disable this feature (see the
Net::Telnet documentation for details). The method
returns true if all of the data was successfully
written.
It is also possible to bypass
Net::Telnet's character translation routines and write
directly to the remote host by using the Net::Telnet
object as a filehandle: print $telnet "ls -lF\015\012";
$result =
$telnet->waitfor($pattern)
($before,$match) =
$telnet->waitfor($pattern)
($before,$match) =
$telnet->waitfor([Match=>$pattern,]
[String=>$string,]
[Timeout=>$timeout])
The waitfor() method is the
workhorse of Net::Telnet. It waits up to Timeout seconds for the
specified string or pattern to appear on the data stream
coming from the remote host. In a scalar context,
waitfor() returns a true value if the desired
pattern was seen. In a list context, the method returns
a two-element list consisting of the data seen before
the match and the matched string
itself. |
You can give waitfor() a regular
expression to pattern match or a simple string, in which case
Net::Telnet uses index() to scan for it in incoming
data. In the method's named-argument form, use the Match argument for a pattern match,
and String for a simple
string match. You can specify multiple alternative patterns or
strings to match simply by providing more than one Match and/or String arguments.
The strings used for MATCH must be correctly
delimited Perl pattern match operators. For example,
"/bash> $/" and "m(bash> $)" will both
work, but "bash> $" won't because of the absence
of pattern match delimiters.
In the single-argument form of
waitfor(), the argument is a pattern match. The Timeout argument may be used to
override the default timeout value.
This code fragment will issue an ls -lF command, wait for the command
line prompt to appear, and print out what came before the
prompt, which ought to be the output of the ls command: $telnet->print('ls -lF');
($before,$match) = $telnet->waitfor('/[$%#>] $/');
print $before;
To issue a command to the remote server and
wait for a response, you can use one of several versions of
cmd():
|
$result =
$telnet->cmd($command)
@lines =
$telnet->cmd($command)
@lines =
$telnet->cmd(String=>$command,
[Output=>$ref,]
[Prompt=>$pattern,]
[Timeout=>$timeout,]
[Cmd_remove_mode=>$mode]
The cmd() method is used to
send a command to the remote host and return its output,
if any. It is equivalent to a print() of the
command, followed by a waitfor() using the
default shell prompt
pattern. |
In a scalar context, cmd() returns
true if the command executed successfully, false if the method
timed out before the shell prompt was seen. In a list context,
this method returns all the lines received prior to matching
the prompt.
In the named-argument form of the call, the
Output argument designates
either a scalar reference or an array reference to receive the
lines that preceded the match. The Prompt, Timeout, and Cmd_remove_mode arguments allow you
to override the corresponding settings.
Note that a true result from cmd()
does not mean that the command
executed successfully. It only means that the command
completed in the time allotted for it.
To receive data from the server without
scanning for patterns, use get(), getline(),
or getlines():
|
$data =
$telnet->get([Timeout=>$timeout])
The get() method performs a
timed read on the Telnet session, returning any data
that is available. If no data is received within the
allotted time, the method dies if Errmode is set to "die" or
returns undef otherwise. The get()
method also returns undef on end-of-file
(indicating that the remote host has closed the Telnet
session). You can use eof() and
timed_out() to distinguish these two
possibilities.
$line =
$telnet->getline([Timeout=>$timeout])
The getline() method reads the
next line of text from the Telnet session. Like
get(), it returns undef on either a
timeout or an end-of-file. You may change the module's
notion of the input record separator using the
input_record_separator() method, described
below.
@lines =
$telnet->getlines([Timeout=>$timeout])
Return all available lines of text, or
an empty list on timeout or
end-of-file. |
Finally, several methods are useful for
debugging and for tweaking the communications session:
|
$msg =
$telnet->errmsg
This method returns the error message
associated with a failed method call. For example, after
a timeout on a waitfor(), errmsg()
returns "pattern match timed-out."
$line =
$telnet->lastline
This method returns the last line read
from the object. It's useful to examine this value after
the remote host has unexpectedly terminated the
connection because it might contain clues to the cause
of this event.
$value =
$telnet->input_record_separator([$newvalue])
$value =
$telnet->output_record_separator([$newvalue])
These two methods get and/or set the
input and output record separators. The input record
separator is used to split input into lines, and is used
by the getline(), getlines(), and
cmd() methods. The output record separator is
printed at the end of each line output by the
print() method. Both values default to
\n.
$value =
$telnet->prompt([$newvalue])
$value =
$telnet->timeout([$newvalue])
$value =
$telnet->binmode([$newvalue])
$value =
$telnet->errmode([$newvalue])
These methods get and/or set the
corresponding settings, and can be used to examine or
change the defaults after the Telnet object is
created.
$telnet->close
The close() method severs the
connection to the remote
host. |
A Remote Password-Changing
Program
As a practical example of Net::Telnet, we'll
develop a remote password-changing script named change_passwd.pl. This script will
contact each of the hosts named on the command line in turn
and change the user's login password. This might be useful for
someone who has accounts on several machines that don't share
the same authentication database. The script is used like
this: % change_passwd.pl --old=mothergOOse --new=bopEEp chiron masdorf sceptre
This command line requests the script to
change the current user's password on the three machines chiron, masdorf, and sceptre. The script reports success
or failure to change the password on each of the indicated
machines.
The script uses the UNIX passwd program to do its work. In
order to drive passwd, we need
to anticipate its various prompts and errors. Here's a sample
of a successful interaction: % passwd
Changing password for lstein
Old password: xyzzy
Enter the new password (minimum of 5, maximum of 8 characters)
Please use a combination of upper and lower case letters and numbers.
New password: plugn
Re-enter new password: plugn
Password changed.
At the three password: prompts I
typed my current and new passwords. However, the passwd program turns off terminal
echo so that the passwords don't actually display on the
screen.
A number of errors may occur during execution
of passwd. In order to be
robust, the password-changing script must detect them. One
error occurs when the original password is typed
incorrectly: % passwd
Changing password for lstein
Old password: xyzyy
Incorrect password for lstein.
The password for lstein is unchanged.
Another error occurs when the new password
doesn't satisfy the passwd
program's criteria for a secure, hard-to-guess password: % passwd
Changing password for lstein
Old password: xyzzy
Enter the new password (minimum of 5, maximum of 8 characters)
Please use a combination of upper and lower case letters and numbers.
New password: hi
Bad password: too short. Try again.
New password: aaaaaaaaaa
Bad password: a palindrome. Try again.
New password: 12345
Bad password: too simple. Try again.
This example shows several attempts to set
the password, each one rejected for a different reason. The
common part of the error message is "Bad password." We don't
have to worry about a third common error in running passwd, which is failing to retype
the password correctly at the confirmation prompt.
The change_passwd.pl script is listed in
Figure
6.4.
Lines 14: Load modules We load
Net::Telnet and the Getopt::Long module for command-line
option parsing.
Lines 512: Define constants We
create a DEBUG flag. If this is true, then we
instruct the Net::Telnet module to log all its input to a
file named passwd.log. This file contains password
information, so be sure to delete it promptly. The
USAGE constant contains the usage statement printed
when the user fails to provide the correct command-line
options.
Lines 1319: Parse command line
options We call GetOptions() to parse the
command-line options. We default to the current user's login
name if none is provided explicitly using the
LOGNAME environment variable. The old and new
password options are mandatory.
Line 20: Invoke change_passwd()
subroutine For each of the machines named on the command
line, we invoke an internal subroutine named
change_passwd(), passing it the name of the
machine, the user login name, and the old and new passwords.
Lines 2141: change_passwd()
subroutine Most of the work happens in change_
passwd(). We begin by opening up a new Net::Telnet
object on the indicated host, and then store the object in a
variable named $shell. If DEBUG is set, we
turn on logging to a hard-coded file. We also set
errmode() to "return" so that Net::Telnet calls
will return false rather than dying on an error.
We now call login() to attempt to
log in with the user's account name and password. If this
fails, we return with a warning constructed from the Telnet
object's errmsg() routine.
Otherwise we are at the login prompt of the
user's shell. We invoke the passwd command and wait for the
expected "Old password:" prompt. If the prompt appears within
the timeout limit, we send the old password to the server.
Otherwise, we return with an error message.
Two outcomes are possible at this point. The
passwd program may accept the
password and prompt us for the new password, or it may reject
the password for some reason. We wait for either of the
prompts to appear, and then examine the match string returned
by waitfor() to determine which of the two patterns
we matched. In the former case, we proceed to provide the new
password. In the latter, we return with an error message.
After the new desired password is printed
(line 33), there are again two possibilities: passwd may reject the proposed
password because it is too simple, or it may accept it and
prompt us to confirm the new password. We handle this in the
same way as before.
The last step is to print the new password
again, confirming the change. We do not expect any errors at
this point, but we do wait for the "Password changed"
confirmation before reporting success.
Because there is little standardization among
passwd programs, this script is
likely to work only with those variants of UNIX that use a
passwd program closely derived
from the BSD version. To handle other passwd variants, you will need to
modify the pattern matches appropriately by including other
Match patterns in the calls
to waitfor().
Running change_passwd.pl on a network of
Linux systems gives output like this: % change_passwd.pl --user=george --old=m00nd0g --new=swampH0und \
localhost pesto prego romano
Password changed for george on localhost.
Password changed for george on pesto.
Password changed for george on prego.
Password changed for george on romano.
While change_passwd.pl is running, the old
and new passwords are visible to anyone who runs a ps command to view the command lines
of running programs. If you wish to use this script in
production, you will probably want to modify it so as to
accept this sensitive information from standard input. Another
consideration is that the password information is passed in
the clear, and therefore vulnerable to network sniffers. The
SSH-enabled password-changing script in the next section
overcomes this difficulty.
Using Net::Telnet for Non-Telnet
Protocols
Net::Telnet can be used to automate
interactions with other network servers. Often it is as simple
as providing the appropriate Port argument to the new()
call. The Net::Telnet manual page provides an example of this
with the POP3 protocol, which we discuss in Chapter
8.
With help from the IO::Pty module,
Net::Telnet can be used to automate more complicated network
services or to script local interactive programs. Like the
standard Telnet client, the problem with local interactive
programs is that they expect access to a terminal device (a
TTY) in order to change screen characteristics, control the
cursor, and so forth. What the IO::Pty module does is to
create a "pseudoterminal device" for these programs to use.
The pseudoterminal is basically a bidirectional pipe. One end
of the pipe is attached to the interactive program; from the
program's point of view, it looks and acts like a TTY. The
other end of the pipe is attached to your script, and can be
used to send data to the program and read its output.
Because the use of pseudoterminals is a
powerful technique that is not well documented, we will show a
practical example. Many security-conscious sites have replaced
Telnet and FTP with the Secure Shell (SSH), a remote login
protocol that authenticates and encrypts login sessions using
a combination of public key and symmetric cryptography. The
change_passwd.pl script does
not work with sites that have disabled Telnet in favor of SSH,
and we would like to use the ssh client to establish the
connection to the remote host in order to run the passwd command.
The ssh client
emits a slightly different login prompt than Telnet. A typical session looks like
this: % ssh -l george prego
george@prego's password: *******
Last login: Mon Jul 3 08:20:28 2000 from localhost
Linux 2.4.01.
%
The ssh client
takes an optional -l
command-line switch to set the name of the user to log in as,
and the name of the remote host (we use the short name rather
than the fully qualified DNS name in this case). ssh prompts for the password on the
remote host, and then attempts to log in.
To work with ssh, we have to make two changes to
change_passwd.pl: (1) we open a
pseudoterminal on the ssh
client and pass the controlling filehandle to
Net::Telnet->new() as the Fhopen argument and (2) we replace
the call to login() with our own pattern matching
routine so as to handle ssh's
login prompt.
The IO::Pty module, available on CPAN, has a
simple API:
|
$pty =
IO::Pty->new
The new() method takes no
arguments and returns a new IO::Pty pseudoterminal
object. The returned object is a filehandle
corresponding to the controlling end of the pipe. Your
script will ordinarily use this filehandle to send
commands and read results from the program you're
driving.
$tty =
$pty->slave
Given a pseudoterminal created with a
call to IO::Pty->new(), the
slave(), method returns the TTY half of the
pipe. You will ordinarily pass this filehandle to the
program you want to control. |
Figure
6.5 shows the idiom for launching a program under the
control of a pseudoterminal. The do_cmd() subroutine
accepts the name of a local command to run and a list of
arguments to pass it. We begin by creating a pseudoterminal
filehandle with IO::Pty->new() (line 3). If
successful, we fork(), and the parent process returns
the pseudoterminal to the caller. The child process, however,
has a little more work to do. We first detach from the current
controlling TTY by calling POSIX::setsid() (see Chapter
10 for details). The next step is to recover the TTY half
of the pipe by calling the IO::Pty object's slave(),
method, and then close the pseudoterminal half (lines
78).
We now reopen STDIN,
STDOUT, and STDERR on the new TTY object
using fdopen(), and close the now-unneeded copy of
the filehandle (lines 912). We make STDOUT
unbuffered and invoke exec() to run the desired
command and arguments. When the command runs, its standard
input and output will be attached to thenew TTY, which in turn
will be attached to the pseudo-tty controlled by the parent
process.
With do_cmd() written, the other
changes to change_passwd.pl are relatively minor. Figure
6.6 shows the revised script written to use the ssh client, change_passwd_ssh.pl.
Lines 16: Load modules We load
IO::Pty and the setsid() routine from the POSIX
module.
Lines 723: Process command-line arguments
and call change_passwd() The only change here is a
new constant, PROMPT, that contains the pattern
match that we will expect from the user's shell command
prompt.
Lines 2427: Launch ssh subprocess
We invoke do_cmd() to run the ssh program using the requested
username and host. If do_cmd() is successful, it
returns a filehandle connected to the pseudoterminal driving
the ssh subprocess.
Lines 2831: Create and initialize Net::
Telnet object In the change_passwd() routine,
we create a new Net::Telnet object, but now instead of
allowing Net::Telnet to open a connection to the remote host
directly, we pass it the ssh
filehandle using the Fhopen
argument. After creating the Net::Telnet object, we
configure it by putting it into binary mode with
binmode(), setting the input log for debugging, and
setting the error mode to "return". The use of binary mode
is a small but important modification of the original
script. Since the SSH protocol terminates its lines with a
single LF character rather than CRLF pairs, the default
Net::Telnet CRLF translation is inappropriate.
Lines 3234: Log in Instead of
calling Net::Telnet's built-in login() method,
which expects Telnet-specific prompts, we roll our own by
waiting for the ssh
"password:" prompt and then providing the appropriate
response. We then wait for the user's command prompt. If,
for some reason, this fails, we return with an error
message.
Lines 3549: Change password The
remainder of the change_passwd() subroutine is
identical to the earlier version.
Lines 5065: do_cmd() subroutine
This is the same subroutine that we examined earlier.
The change_passwd_ssh.pl program now uses
the Secure Shell to establish connections to the indicated
machines and change the user's password. This is a big
advantage over the earlier version, which was prone to network
eavesdroppers who could intercept the new password as it
passed over the wire in unencrypted form. On multiuser systems
you will still probably want to modify the script to read the
passwords from standard input rather than from the command
line.
For completeness, Figure
6.7 lists a routine, prompt_for_passwd(i), that uses the
UNIX stty program to disable
command-line echo temporarily while the user is typing the
password. You can use it like this: $old = get_password('old password');
$new = get_password('new password');
A slightly more sophisticated version of this
subroutine, which takes advantage of the Term::ReadKey module,
if available, appears in Chapter
20.
The Expect Module
An alternative to Net::Telnet is the Expect
module, which provides similar services for talking to local
and remote processes that expect human interaction. Expect
implements a rich command language, which among other things
can pause the script and prompt the user for information, such
as passwords. Expect can be found on CPAN.
|
Chapter 7. SMTP: Sending Mail
E-mail is one of the oldest Internet
applications, and it should come as no surprise that many
client-side modules have been written to enable Perl to
interoperate with the mail system. Various modules allow you
to send and receive mail, manipulate various mailbox formats,
and work with MIME attachments.
|
Introduction to the Mail
Modules
If you examine the "Internet Mail and
Utilities" section of CPAN, you'll find a bewildering array of
similarly named modules. This is a quick guide to the major
components.
Net::SMTP This allows you to interact
directly with mail transport daemons in order to send Internet
mail via the Simple Mail Transport Protocol (SMTP). The module
also provides access to some of the other functions of these
daemons, such as expanding e-mail aliases.
MailTools This is a higher-level way
to create outgoing e-mail. It uses a variety of local mailer
packages to do the grunt work.
MIME-Tools This is a package of
modules for creating, decoding, and manipulating Multipurpose
Internet Mail Extensions (MIME), commonly known as
attachments.
Net::POP3 This is a client for the
Post Office Protocol version 3 (POP3). It provides a way to
retrieve a user's stored mail messages from a central
maildrop.
Net::IMAP This is a client module for
the Internet Message Access Protocol (IMAP), a sophisticated
protocol for storing and synchronizing e-mail messages between
mail drops and clients.
This chapter discusses tools involved in
creating outgoing mail, including Net::SMTP and MIME-Tools. Chapter
8 covers the Net::POP3 and Net::IMAP modules, both of
which are involved in processing incoming mail.
|
Net::SMTP
Net::SMTP operates at the lowest level of the
e-mail access modules. It interacts directly with the SMTP
daemons to transmit e-mail across the Internet. To use it
effectively, you must know a bit about the innards of SMTP.
The payoff for this added complexity is that Net::SMTP is
completely portable, and works as well from Macintoshes and
Windows machines as from UNIX systems.
The SMTP Protocol
When a client e-mail program wants to send
mail, it opens a network connection to a mail server somewhere
using the standard SMTP port, number 25. The client conducts a
brief conversation with the server, during which time it
establishes its identity, announces that it wishes to send
mail to a certain party, and transmits the e-mail message. The
server then takes care of seeing that the message gets where
it needs to go, whether by delivering it to a local user or by
transmitting the message to another server somewhere else in
the world.
The language spoken by SMTP servers is a
simple human-readable line-oriented protocol. Figure
7.1 shows the interaction needed to send a complete e-mail
manually using Telnet as the client (the client's input is in
bold).
After connecting to the SMTP port, the server
sends us a code "220" message containing a banner and
greeting. We issue a HELO command, identifying the
hostname of the client machine, and the server responds with a
"250" message, which essentially means "OK."
After this handshake, we are ready to send
some mail. We issue a MAIL command with the argument
<From: sender's address>, to designate the
sender. If the sender is OK, the server responds with another
"250" reply. We now issue a RCPT ("recipient")
command with the argument <To: recipient's
address> to indicate the recipient. The server again
acknowledges the command. Some SMTP servers have restrictions
on the senders and recipients they will service; for example,
they may refuse to relay e-mail to remote domains. Inthis
case, they respond with a variety of error codes in the 500 to
599 range. It is possible to issue multiple RCPT
commands for e-mail that has several recipients at the site(s)
served by the SMTP server.
Having established that the sender and
recipient(s) are OK, we send the DATA command. The
server responds with a message prompting us for the e-mail
message. The server will accept lines of input until it sees a
line containing just a ".".
Internet mail has a standard format
consisting of a set of header lines, ablank line, and the body
of the message. Even though we have already specified the
sender and recipient, we must do so again in order to create a
valid e-mailmessage. A minimal mail header has a From: field,
indicating the sender, a To: field, indicating the recipient,
and a Subject: field. Other standard fields, such as the date,
are filled in automatically by the mail daemon.
We add a blank line to separate the header
from the body, enter the e-mail message text, and terminate
the message with a dot. The server's code 250 acknowledgment
indicates that the message was queued successfully for
delivery.
We could now send additional messages by
issuing further MAIL commands, but instead we
disconnect politely by issuing the QUIT command. The
full specification of the SMTP protocol can be found in RFC
821. The standard format for Internet mail headers is
described in RFC 822.
The Net::SMTP API
Net::SMTP mirrors the SMTP protocol very
closely. Net::SMTP is part of the libnet utilities and is
available on CPAN. Like the other Net::* modules, it uses an
object-oriented interface in which you establish a connection
with a particular mailer daemon, yielding a Net::SMTP object.
You then call the SMTP object's methods to send commands to
the server. Like Net::FTP (but unlike Net::Telnet), Net::SMTP
inherits from Net::Cmd and IO::Socket::INET, allowing you to
use the Net::Cmd message() and code()
methods to retrieve the most recent message and numeric status
code from the server. All the low-level IO::Socket and
IO::Socket::INET methods are also inherited.
To create a new Net::SMTPobject, use the
new() constructor:
Table 7.1.
Net::SMTP->new() Arguments
| Hello |
The domain name to
use in the HELO command. |
Name of local
host |
| Timeout
|
Seconds to wait for
response from server. |
120 |
| Debug |
Turn on verbose
debugging information. |
undef
|
| Port |
Numeric or symbolic
name of port to connect to. |
25 |
|
$smtp =
Net::SMTP->new([$host] [,$opt1=>$val1,
$opt2=>$val2...])
The new() method establishes a
connection to an SMTP server and returns a new Net::SMTP
object. The first optional argument is the name of the
host to contact, and will default to the mail exchanger
configured into Net::Config when libnet was first
installed. The options are a series of named arguments.
In addition to the options recognized by the
IO::Socket::INET superclass, the arguments shown in Table
7.1 are possible. |
If the connection is refused (or times out),
new() returns false. Here's an example of contacting
the mail server for the cshl.org domain with a timeout of 60
seconds. $smtp = Net::SMTP->new('mail.cshl.org',Timeout=>60);
Once the object is created, you can send or
retrieve information to the server by calling object methods.
Some are quite simple:
|
$banner =
$smtp->banner()
$domain =
$smtp->domain()
Immediately after connecting to an SMTP
server, you can retrieve the banner and/or domain name
with which it identified by calling these two
methods. |
To send mail, you will first call the
mail() and recipient() methods to set up the
exchange:
|
$success =
$smtp->mail($address [,\%options])
The mail() method issues a
MAIL command to the server. The required first
argument is the address of the sender. The optional
second argument is a hash reference containing various
options to be passed to servers that support the
Extended Simple Mail Transport Protocol, or ESMTP. These
are rarely needed; see the Net::SMTP documentation for
details.
The address may be in any of the forms
accepted by e-mail clients, including doe@acme.org, <doe@acme.org>, John Doe <doe@acme.org>, and doe@acme.org (John Doe).
If successful, this method returns a
true value. Otherwise, it returns undef, and
the inherited message() method can be used to
return the text of the error message.
$success =
$smtp->recipient($address1,$address2,$address3,...)
@ok_addr =
$smtp->
recipient($addr1,$addr2,$addr3,...,{SkipBad=>1})
The recipient() method issues
an RCPT command to the server. The arguments
are a list of valid e-mail addresses to which the mail
is to be delivered. The list of addresses may be
followed by a hash reference containing various
options. |
The addresses passed to recipient()
must all be acceptable to the server, or the entire call will
return false. To modify this behavior, pass the option SkipBad in the options hash. The
module now ignores addresses rejected by the server, and
returns the list of accepted addresses as its result. For
example: @ok=$smtp->recipient('lstein@cshl.org','nobody@cshl.org',{SkipBad=>1})
Provided that the server has accepted the
sender and recipient, you may now commence sending the message
text using the data(), datasend(), and
dataend() methods.
|
$success =
$smtp->data([$text])
The data() method issues a
DATA command to the server. If called with a
scalar argument, it transmits the value of the argument
as the content (header and body) of the e-mail message.
If you wish to send the message one chunk at a time,
call data without an argument and make a series of calls
to the datasend() method. This method returns a
value indicating success or failure of the command.
$success =
$smtp->datasend(@data)
After calling data() without
an argument, you may call datasend() one or
more times to send lines of e-mail text to the server.
Lines starting with a dot are automatically escaped so
as not to terminate the transmission prematurely.
You may call datasend() with
an array reference, if you prefer. This method and
dataend() are both inherited from the Net::Cmd
base class.
$success =
$smtp->dataend
When your e-mail message is sent, you
should call dataend() to transmit the terminal
dot. If the message was accepted for delivery, the
return value is true. |
Two methods are useful for more complex
interactions with SMTPservers:
|
$smtp->reset
This sends an RSET command to
the server, aborting mail transmission operations in
progress. You might call this if one of the desired
recipients is rejected by the server; it resets the
server so you can try again.
$valid =
$smtp->verify($address)
@recipients =
$smtp->expand($address)
The expand() and
verify() methods can be used to check that a
recipient address is valid prior to trying to send mail.
verify() returns true if the specified address
is accepted.
expand() does something more
interesting. If the address is valid, it expands it into
one or more aliases, if any exist. This can be used to
identify forwarding addresses and mailing list
recipients. The method returns a list of aliases or, if
the specified address is invalid, an empty list. For
security reasons, many mail administrators disable this
feature, in which case, the method returns an empty
list. |
Finally, when you are done with the server,
you will call the quit() method:
|
$smtp->quit
This method politely breaks the
connection with the
server. |
Using Net::SMTP
With Net::SMTP we can write a one-shot
subroutine for sending e-mail. The mail() subroutine
takes two arguments: the text of an e-mail message to send
(required), and the name of the SMTP host to use (optional).
Call it like this: $msg =  'END';
From: John Doe <doe@acme.org>
To: L Stein <lstein@lsjs.org>
Cc: jac@acme.org, vvd@acme.org
Subject: hello there
This is just a simple e-mail message.
Nothing to get excited about.
Regards, JD
END
mail($msg,'presto.lsjs.org') or die "arggggh!"; 'END';
From: John Doe <doe@acme.org>
To: L Stein <lstein@lsjs.org>
Cc: jac@acme.org, vvd@acme.org
Subject: hello there
This is just a simple e-mail message.
Nothing to get excited about.
Regards, JD
END
mail($msg,'presto.lsjs.org') or die "arggggh!";
We create the text of the e-mail message
using the here-is () syntax and store it in the variable
$msg. The message must contain an e-mail header with
(at a minimum) the From: and To: fields. We pass the message
to the mail() subroutine, which extracts the sender
and recipient fields and invokes Net::SMTP to do the dirty
work. Figure
7.2 shows how mail() works.
Lines 19: Parse the mail message We
split the message into the header and the body by splitting
on the first blank line. Header fields frequently contain
continuation lines that begin with a blank, so we fold those
into a single line.
We parse the header into a hash using a
simple pattern match, and store the From: and To: fields in
local variables. The To: field can contain multiple
recipients, so we isolate the individual addressees by
splitting on the comma character (this will fail in the
unlikely case that any of the addresses contain commas). We
do likewise if the header contained a Cc: field.
Lines 1016: Send messages We create
a new Net::SMTP object and call its mail(), and
recipient() methods to initiate the message. The
call to recipient() uses the SkipBad option so that the method
will try to deliver the mail even if the server rejects some
of the recipients. We compare the number of recipients the
server accepted to the number we attempted, returning from
the subroutine if none were accepted, or just printing a
warning if only some were rejected.
We call data() to send the
complete e-mail message to the server, and quit()
to terminate the connection.
Although this subroutine does its job, it
lacks some features. For example, it doesn't handle the Bcc:
field, which causes mail to be delivered to a recipient
without that recipient appearing in the header. The MailTools
module, described next, corrects the deficiencies.
|
MailTools
The MailTools module, also written by Graham
Barr, is a high-level object-oriented interface to the
Internet e-mail system. MailTools, available on CPAN, provides
a flexible way to create and manipulate RFC 822-compliant
e-mail messages. Once the message is composed, you can send it
off using SMTP or use one of several UNIX command-line mailer
programs to do the dirty work. This might be necessary on a
local network that does not have direct access to an SMTP
server.
Using MailTools
A quick example of sending an e-mail from
within a script will give you the flavor of the MailTools
interface (Figure
7.3).

Lines 12: Load modules We bring in
the Mail::Internet module. It brings in other modules that
it needs, including Mail::Header, which knows how to format
RFC 822 headers, and Mail::Mailer, which knows how to send
mail by a variety of methods.
Lines 38: Create header We call
Mail::Header->new to create a new header object,
which we will use to build the RFC 822 header. After
creating the object, we call its add() method
several times to add the From:, To:, Cc:, and Subject:
lines. Notice that we can add the same header multiple
times, as we do with the Cc: line. Mail::Header will also
insert other required RFC 822 headers on its own.
Lines 913: Create body We create
the body text, which is just a block of text.
Lines 1416: Create the Mail::Internet
object We now create a new Mail::Internet object by
calling the package's new() method. The named
arguments include Header,
to which we pass the header object that we just created, and
Body, which receives the
body text. The Body
argument expects an array reference containing discrete
lines of body text, so we wrap $body into an
anonymous array reference. Modify, the third argument to
new(), flags Mail::Internet that it is OK to
reformat the header lines to meet restrictions on line
length that some SMTP mailers impose.
Line 17: Send mail We call the newly
created Mail::Internet object's send() method with
an argument indicating the sending method to use. The
"sendmail" argument indicates that Mail::Internet should try
to use the UNIX sendmail
program to deliver the mail.
Although at first glance Mail::Internet does
not hold much advantage over the Net::SMTP-based
mail() subroutine we wrote in the previous section,
the ability to examine and manipulate Mail::Header objects
gives MailTools its power. Mail::Header is also the base class
for MIME::Head, which manipulates MIME-compliant e-mail
headers that are too complex to be handled manually.
Mail::Header
E-mail headers are more complex than they
might seem at first. Some fields occur just once, others occur
multiple times, and some allow multiple values to be strung
together by commas or another delimiter. A field may occupy a
single line, or may be folded across multiple lines with
leading whitespace to indicate the presence of continuation
lines. The mail system also places an arbitrary limit on the
length of a header line. Because of these considerations, you
should be cautious of constructing e-mail headers by hand for
anything much more complicated than the simple examples shown
earlier.
The Mail::Header module simplifies the task
of constructing, examining, and modifying RFC 822 headers.
Once constructed, a Mail::Header object can be passed to
Internet::Mail for sending.
Mail::Header controls the syntax but not the
content of the header, which means that you can construct a
header with fields that are not recognized by the mail
subsystem. Depending on the mailer, a message with invalid
headers might make it through to its destination, or it might
get bounced. To avoid this, be careful to limit headers to the
fields listed in the SMTP and MIME RFCs (RFC 822 and RFC 2045,
respectively). Table
7.2 gives some of the common headers in e-mail
messages.
Fields that begin with X- are meant to be
used as extensions. You can safely build a header containing
any number of X- fields, and the fields will be passed through
unmodified by the mail system. For example: $header = Mail::Header->new(Modify=>1);
$header->add('X-Mailer' => "Fido's mailer v1.0");
$header->add('X-HiMom' => 'Hi mom!');
Mail::Header supports a large number of
methods. The following list gives the key methods. To create a
new object, call the Mail::Header new() method.
Table 7.2. Mail::Header
Fields
| Bcc |
Date |
Received |
Sender |
| Cc |
From |
References |
Subject |
| Comments |
Keywords |
Reply-To |
To |
| Content-Type |
Message-ID |
Resent-From |
X-* |
| Content-Transfer-Encoding |
MIME-Version |
Resent-To |
|
| Content-Disposition |
Organization |
Return-Path |
|
|
$head =
Mail::Header->new([$arg] [,@options])
The new() method is the
constructor for the Mail::Header class. Called with no
arguments, it creates a new Mail::Header object
containing an empty set of headers.
The first argument, if provided, is
used to initialize the object. Two types of arguments
are accepted. You may provide an open filehandle, in
which case the headers are read from the indicated file,
or you may provide an array reference, in which case the
headers are read from the array. In either case, each
line must be a correctly formatted e-mail header, such
as "Subject: this is a subject."
@options, if provided, is a
list of named arguments that control various header
options. The one used most frequently is Modify, which if set true
allows Mail::Header to reformat header lines to make
them fully RFC 822-compliant. For example: open HEADERS,"./mail.msg";
$head = Mail::Header(\*HEADERS, Modify=>1);
|
Once a Mail::Header object is created, you
may manipulate its contents in several ways:
|
$head->read(FILEHANDLE)
As an alternative way to populate a
header object, you can create an empty object by calling
new() with no arguments, and then read in the
headers from a filehandle using read().
$head->add($name,$value
[,$index])
$head->replace($name,$value
[,$index])
$head->delete($name
[,$index])
The add(), replace(),
and delete() methods allow you to modify the
Mail::Header object. Each takes the name of the field to
operate on, the value for the field, and optionally an
index that selects a member of a multivalued field.
The add() method appends a
field to the header. If $index is provided, it
inserts the field into the indicated position;
otherwise, it appends the field to the end of the
list.
The replace() method replaces
the named field with the indicated value. If the field
is multivalued, then $index is used to select
which value to replace; otherwise, the first field is
replaced.
Delete() removes the indicated
field. |
All three of these methods accept a shortcut
form that allows you to specify the field name and value in a
single line. This shortcut allows you to replace the Subject line like this: $head->replace('Subject: returned to sender')
rather than like this: $head->replace(Subject => 'returned to sender')
To retrieve information about a header
object, you use get() to get the value of a single
field, or tags() and commit() to get
information about all the available fields.
|
$line =
$head->get($name [,$index])
@lines =
$head->get($name)
The get() method retrieves the
named field. In a scalar context, it returns the text
form of the first indicated field; in a list context it
returns all such fields. You may provide an index in
order to select a single member of a multivalued
field.
A slightly annoying feature of
get() is that the retrieved field values
contain the terminating newlines. These must be removed
manually with chomp().
@fields =
$head->tags
Returns the list of field names (which
the Mail::Header documentation calls "tags").
$count =
$head->count($tag)
Returns the number of times the given
tag appears in the header. |
Finally, three methods are useful for
exporting the header in various forms:
|
$string =
$head->as_string
Returns the entire header as a string
in the form that will appear in the message.
$has =
$head->header_has ([\%headers])
The header_has () method
returns the headers as a hash reference. Each key is the
unique name of a field, and each value is an array
reference containing the header's contents. This form is
suitable for passing to
Mail::Mailer->open(), as described later in
this chapter.
You may also use this method to set the
header by passing it a hash reference of your own
devising. The composition of \%headers is
similar to header_has ()'s result, but the
hash values can be simple scalars if they are not
multivalued.
$head->print([FILEHANDLE])
Prints header to indicated filehandle
or, if not specified, to STDOUT. Equivalent
to: print FILEHANDLE $head->as_string
|
Mail::Internet
The Mail::Internet class is a high-level
interface to e-mail. It allows you to create messages,
manipulate them in various ways, and send them out. It was
designed to make it easy to write autoresponders and other
mail-processing utilities.
As usual, you create a new object using the
Mail::Internet new() method:
|
$mail =
Mail::Internet->new([$arg] [,@options])
The new() method constructs a
new Mail::Internet object. Called with no arguments, it
creates an empty object, which is ordinarily not
particularly useful. Otherwise, it initializes itself
from its arguments in much the same way as Mail::Header.
The first argument, if provided, may be either a
filehandle or an array reference. In the former case,
Mail::Internet tries to read the headers and body of the
message from the filehandle. If the first argument is an
array reference, then the new object initializes itself
from the lines of text contained in the array.
@options is a list of
named-argument pairs. Several arguments are recognized.
Header designates a
Mail::Header object to use with the e-mail message. If
present, this header is used, ignoring any header
information provided in $arg. Similarly, Body points to an array
reference containing the lines of the e-mail body. Any
body text provided by the $arg input is
ignored. |
Once the object is created, several methods
allow you to examine and modify its contents:
|
$arrayref =
$mail->body
The body() method returns the
body of the e-mail message as a reference to an array of
lines of text. You may manipulate these lines to modify
the body of the message.
$header =
$mail->head
The head() method returns the
message's Mail::Header object. Modifying this object
changes the message header.
$string =
$mail->as_string
$string =
$mail->as_mbox_string
The as_string() and
as_mbox_string() methods both return the
message (both header and body) as a single string. The
as_mbox_string() function returns the message
in a format suitable for appending to UNIX mbox-format mailbox files.
$mail->print([FILEHANDLE})
$mail->print_header([FILEHANDLE})
$mail->print_body([FILEHANDLE})
These three methods print all or part
of the message to the designated filehandle or, if not
otherwise specified,
STDOUT. |
Several utility methods perform common
transformations on the message's contents:
|
$mail->add_signature([$file])
$mail->remove_sig([$nlines])
These two methods manipulate the
signatures that are often appended to the e-mail
messages. The add_signature() function appends
the signature contained in $file to the bottom
of the e-mail message. If $file is not
provided, then the method looks for the file
$ENV{HOME}/.signature.
remove_sig() scans the last
$nlines of the message body looking for a line
consisting of the characters "--", which often sets the
body off from the signature. The line and everything
below it is removed. If not specified, $nlines
defaults to 10.
$reply =
$mail->reply
The reply() method creates a
new Mail::Internet object with the header initialized to
reply to the original message, and the body text
indented. This is suitable for autoreply
applications. |
Finally, the send() method sends the
message via the e-mail system:
|
$result =
$mail->send([$method] [,@args])
The send() method converts
message into a string and sends it using Mail::Mailer.
The $method and @args arguments select
and configure the mailing method. The next section
describes the available methodsmail, sendmail, smtp, and test.
If no method is specified,
send() chooses a default that should work on
your system. |
A Mail Autoreply Program
With Mail::Internet, we can easily write a
simple autoreply program for received e-mail (Figure
7.4). The autoreply.pl
script is similar to the venerable UNIX vacation program. When it receives
mail, it checks your home directory for the existence of a
file named .vacation. If the
file exists, the script replies to the sender using the
contents of the file. Otherwise, the program does nothing.

This autoreply script takes advantage of a
feature of the UNIX mail system that allows incoming e-mail to
be piped to a program. Provided that you're using such a
system, you may activate the script by creating a .forward file in your home directory
that contains lines like the following: lstein
| /usr/local/bin/autoreply.pl
Replace the first line with your login name,
and the second with the path to the autoreply script. This
tells the mail subsystem to place one copy of the incoming
mail in the user-specific inbox, and to send another copy to
the standard input of the autoreply.pl script.
Let's step through autoreply.pl.
Lines 13: Load modules We turn on
strict type checking and load the Mail::Internet module.
Lines 47: Define constants One
problem with working with programs run by the mailer daemon
is that the standard user environment isn't necessarily set
up. This means that $ENV{HOME} and other standard
environment variables may not exist. Our first action,
therefore, is to look up the user's home directory and login
name and store them in appropriate constants. Lines 4 and 5
use the getpwuid() function to retrieve this
information. We then use the HOME constant to find
the locations of the .vacation and
.signature files.
Lines 89: Create a Mail::Internet
object We check that the .vacation file is
present and, if it is not, exit. Otherwise, we create a new
Mail::Internet object initialized from the message sent us
on STDIN.
Lines 1019: Check that the message
should be replied to We shouldn't autoreply to certain
messages, such as those sent to us in the Cc: line, or those
distributed to a mailing list. Another type of message we
should be very careful not to reply to are bounced messages;
replying to those has the potential to set up a nasty
infinite loop. The next section of the code tries to catch
these situations.
We recover the header by calling the
Mail::Internet object's head() method, and perform
a series of pattern matches on its fields. First we check
that our username is mentioned on the To: line. If not, we
may be receiving this message as a Cc: or as a member of a
mailing list. We next check the Precedence: field. If it's
"bulk," then this message is probably part of a mass
mailing. If the Subject: line contains the strings "returned
mail" or "bounced mail", or if the sender is the mail system
itself (identified variously as "mailer daemon," "mail
subsystem," or "postmaster"), then we are likely dealing
with returned mail and we shouldn't reply or risk setting up
a loop. In each of these cases, we just exit normally.
Lines 2021: Generate reply To
create a new message initialized as a reply to the original,
we call the mail message object's reply() method.
Lines 2226: Prepend vacation message to
text The reply() method will have created body
text consisting of the original message quoted and indented.
We prepend the contents of the .vacation file to
this. We open the contents of .vacation, call the
mail message's body() method to return a reference
to the array of body lines, and then use unshift()
to insert the contents of .vacation in front of the
body. We could replace the body entirely, if we preferred.
Lines 2728: Add signature We call
the reply's add_signature() method to append the
contents of the user's signature file, if any, to the bottom
of the message body.
Lines 2930: Send message We call
the reply's send() method to send the message by
the most expedient means.
Here is an example of a reply issued by the
autoreply.pl script in response to the sample message
we composed with Net::SMTP in the previous section. The text
at the top came from ~/.vacation and the signature at
the bottom from ~/.signature. The remainder is quoted
from the original message. To: John Doe <doe@acme.org>
From: L Stein <lstein@lsjs.org>
Subject: Re: hello there
Date: Fri, 7 Jul 2000 08:12:17 -0400
Message-Id: <200007071212.IAA12128@pesto>
Hello,
I am on vacation from July 6-July 12, and will not be reading my
e-mail. I will respond to this message when I return.
Lincoln
John Doe <doe@acme.org> writes:
> This is just a simple e-mail message.
> Nothing to get excited about.
> Regards, JD
--
======================================================================
Lincoln D. Stein Cold Spring Harbor Laboratory
======================================================================
If you adapt this autoreply program to your
own use, you might want to check the size of the quoted body
and delete it if it is unusually large. Otherwise, you might
inadvertently echo back a large binary enclosure.
For complex e-mail-processing applications,
you should be sure to check out the procmail program, which uses a
special-purpose programming language to parse and manipulate
e-mail. A number of sophisticated applications have been
written on top of procmail,
including autoresponders, mailing list generators, and filters
for spam mail.
Mail::Mailer
The last component of MailTools that we
consider is Mail::Mailer, which is used internally by
Mail::Internet to deliver mail. Mail::Mailer provides yet
another interface for sending Internet mail. Although it
doesn't provide Mail::Internet's header- and body-handling
facilities, I find it simpler and more elegant to use in most
circumstances.
Unlike Net::SMTP and Mail::Internet, which
use object methods to compose and send mail, the Mail::Mailer
object acts like a filehandle. This short code fragment shows
the idiom: use Mail::Mailer;
my $mailer = Mail::Mailer->new;
$mailer->open( {To => 'lstein@lsjs.org',
From => 'joe@acme.org',
CC => ['jac@acme.org','vvd@acme.org'],
Subject => 'hello there'});
print $mailer "This is just a simple e-mail message.\n";
print $mailer "Nothing to get excited about.\n\n";
print $mailer "Regards, JD\n";
$mailer->close;
After creating the object with
new(), we initialize it by calling open()
with a hash reference containing the contents of the e-mailer
header. We then use the mailer object as a filehandle to print
several lines of the body text. Then we call the object's
close() method to finish processing the message and
send it out.
The complete list of Mail::Mailer methods is
relatively short.
|
$mailer =
Mail::Mailer->new([$method] [,@args])
The new() method creates a new
Mail::Mailer object. The optional $method
argument specifies how the mail will be sent out, and
@args passes additional arguments to the
mailer. Table
7.3 shows the currently recognized mail
methods. |
The contents of @args depends on the
method. In the "mail" and "sendmail" methods, whatever you
provide in @args is appended to the command line used
to invoke the mail and sendmail programs. For the "smtp"
method, you can pass the named argument Server to specify the SMTP server
to use. For example: $mailer = Mail::Mailer->new('smtp',Server => 'mail.lsjs.org')
Internally, Mail::Mailer opens up a pipe to
the indicated mailer program unless "smtp" is specified, in
which case it uses Net::SMTP to send the message. If no method
is explicitly provided, then Mail::Mailer scans the command
PATH looking for the appropriate executables and chooses the
first method it finds, beginning with "mail." The Mail::Mailer
documentation describes how you can alter this search order by
setting the PERL_MAILERS environment variable.
Table 7.3. Mail:Mailer Mailing
Methods
| mail |
Use the UNIX mail or
mailx programs. |
| sendmail |
Use the UNIX sendmail
program. |
| smtp |
Use Net::SMTP to send
the mail. |
| test |
A debug mode that
prints the contents of the message rather than mailing
it. |
Once created, you initialize the Mail::Mailer
object with a set of header fields:
|
$fh =
$mailer->open(\%headers)
The open() method begins a new
mail message with the specified headers. For the "mail",
"sendmail", and "test" mailing methods, this call forks
and execs the mailer program and then returns a pipe
opened on the mailer. For the "smtp" method,
open(), returns a tied filehandle that
intercepts calls to print() and passes them to
the datasend() method of Net::SMTP. The
returned filehandle is identical to the original
Mail::Mailer object, so you are free to use it as a
Boolean indicating success or failure of the
open() call. |
The argument to open() is a hash
reference whose keys are the fields of the mail header, and
whose values can be scalars containing the contents of the
corresponding field, or array references containing the values
for multivalued fields such as Cc: or To:. This format is
compatible with the header_has (), method of the
Mail::Header class. For example: $mailer->open({To => ['jdoe@acme.org','coyote@acme.org'],
From => 'lstein@cshl.org'}) or die "can't open: $!";
Once the object is initialized, you will
print the body of the message to it using it as a
filehandle: print $mailer "This is the first line of the mail message.\n";
When the body is done, you should call the
object's close() method:
|
$mailer->close
close() tidies up and sends
the message. You should not use the close()
Perl built-in for this purpose, because some of the
Mail::Mailer methods need to do postprocessing on the
message before sending it. |
|
MIME-Tools
Net::SMTP and MailTools provide the basic
functionality to create simple text-only e-mail messages. The
MIME-Tools package takes this a step further by allowing you
to compose multipart messages that contain text and nontext
attachments. You can also parse MIME-encoded messages to
extract the attachments, add or remove attachments, and resend
the modified messages.
A Brief Introduction to MIME
The Multipurpose Internet Mail Extensions, or
MIME, are described in detail in RFCs 1521, 2045, 2046, and
2049. Essentially, MIME adds three major extensions to
standard Internet mail:
-
Every message body
has a type. In the MIME world, the body of every
message has a type that describes its nature; this type is
given in the Content-Type: header field. MIME uses a type/subtype nomenclature in
which type indicates the
category of document, and subtype gives its specific
format. Table
7.4 lists some common types and subtypes. The major
media categories are "audio," "video," "text," and "image."
The "message" category is used for e-mail enclosures, such
as when you forward an e-mail onward to someone else, and
the "application" category is a hodgepodge of things that
could not be classified otherwise. We'll talk about
"multipart" momentarily.
-
Every message body
has an encoding. Internet e-mail was originally
designed to handle messages consisting entirely of 7-bit
ASCII text broken into relatively short lines; some parts of
the e-mail system are still limited to this type of message.
However, as the Internet became global, it became necessary
to accommodate non-English character sets that have 8- or
even 16-bit characters. Another problem was binary
attachments such as image files, which are not even
text-oriented.
To accommodate the full range of messages
that people want to send without rewriting the SMTP protocol
and all supporting software, MIME provides several standard
encoding algorithms that can encapsulate binary data in a
text form that conventional mailers can handle. Each header
has a Content-Transfer-Encoding: field that describes the
message body's encoding. Table
7.5 lists the five standard encodings.
If you are dealing with 8-bit data, only
the quoted-printable and base64 encodings are guaranteed to
make it through e-mail gateways.
-
Any message may
have multiple parts. The multipart/* MIME types designate
messages that have multiple parts. Each part has its own
content type andMIME headers. It's even possible for a part
to have its own subparts. The multipart/alternativec MIME type is
used when the various subparts correspond to the same
document repeated in different formats. For example, some
browser-based mailers send their messages in both text-only
and HTML form. multipart/mixed is used when the
parts are not directly related to each other, for example an
e-mail message and a JPEG enclosure.
Table 7.4. Common MIME
Types
| audio/* |
A sound |
| audio/basic |
Sun microsystem's
audio "au" format |
| audio/mpeg |
An MP3 file |
| audio/midi |
An MIDI file |
| audio/x-aiff |
AIFF sound
format |
| audio/x-wav |
Microsoft's "wav"
format |
| image/* |
An image |
| image/gif |
Compuserve GIF
format |
| image/jpeg |
JPEG format |
| image/png |
Portable network
graphics format |
| image/tiff |
TIFF format |
| message/* |
An e-mail
message |
| message/news |
Usenet news message
format |
| message/rfc822 |
Internet e-mail
message format |
| multipart/* |
A message containing
multiple parts |
| multipart/alternative |
The same information
in alternative forms |
| multipart/mixed |
Unrelated pieces of
information mixed together |
| text/* |
Human-readable
text |
| text/html |
Hypertext Markup
Language |
| text/plain |
Plain text |
| text/richtext |
Enriched text in RFC
1523 format |
| text/tab-separated-values |
Tables |
| video/* |
Moving video or
animation |
| video/mpeg |
MPEG movie
format |
| video/quicktime |
Quicktime movie
format |
| video/msvideo |
Microsoft "avi" movie
format |
| application/* |
None of the
above |
| application/msword |
Microsoft Word
Format |
| application/news-message-id |
News posting
format |
| application/octet-stream |
A raw binary
stream |
| application/postscript |
PostScript |
| application/rtf |
Microsoft rich text
format |
| application/wordperfect5.1 |
Word Perfect 5.1
format |
| application/gzip |
Gzip file compression
format |
| application/zip |
PKZip file compression
format |
Table 7.5. MIME
Encodings
| 7bi |
The body is not
actually encoded. This value simply asserts that text is
7-bit ASCII, with no line longer than 1,000
characters. |
| 8bit |
The body is not
actually encoded. This value asserts that the text may
contain 8-bit characters, but has no line longer than
1,000 characters. |
| binary |
The body is not
actually encoded. This value asserts that the text may
contain 8-bit characters and may have lines longer than
1,000 characters. |
| quoted-printable |
This encoding is used
for text-oriented messages that may contain 8-bit
characters (such as messages in non-English character
sets). All 8-bit characters are encoded into 7-bit
escape sequences, and long lines are folded at 72
characters. |
| base64 |
This encoding is used
for arbitrary binary data such as audio and images.
Every 8-bit character is encoded as a 7-bit string using
the uuencode algorithm. The resulting text is then
folded into 72-character
lines. |
Any part of a multipart MIME message may
contain a Content-Disposition: header, which is a hint to the
mail reader as to how to handle the part. Possible
dispositions include attachment, which tells the reader to
treat the part's body as an enclosure to be saved to disk, and
inline, which tells the reader
to try to display the part as a component of the document. For
example, a mail reader application may beable to display an
inline image in the same window as the textual part of the
message. The Content-Disposition: field can also suggest a
filename to store attachments under. Another field,
Content-Description:, provides an optional human-readable
description of the part.
Notice that an e-mail message with a JPEG
attachment is really a multipart MIME message containing two
parts, one for the text of the message and the other for the
JPEG image.
Without going into the format of a MIME
message in detail, Figure
7. 5 shows a sample multipart message to give you a feel
for the way they work. This message has four parts: a 7-bit
text message that appears at the top of the message, a
base64-encoded audio file that uses the Microsoft WAV format,
a base64-encoded JPEG file, and a final 7-bit part that
contains some parting words and the e-mail signature. (The
binary enclosures have been truncated to save space.)
Notice that each part of the message has its
own header and body, and that the parts are delimited by a
short unique boundary string beginning with a pair of hyphens.
The message as a whole has its own header, which is a superset
of the RFC 822 Internet mail header, and includes a
Content-Type: field of multipart/mixed.
This is pretty much all you need to know
about MIME. The MIME modules will do all the rest of the work
for you.
Organization of the MIME::*
Modules
MIME-Tools has four major parts.
- MIME::Entity
-
MIME::Entity is a MIME message. It contains
a MIME::Head (the message header) and a MIME::Body (the
message body). In multipart messages, the body may contain
other MIME::Entities, and any of these may contain their own
MIME::Entities, ad
infinitum.
Among other things, MIME::Entity has
methods for turning the message into a text string and for
mailing the message.
- MIME::Head
-
MIME::Head is the header part of a MIME
message. It has methods for getting and setting the various
fields.
- MIME::Body
-
MIME::Body represents the body part of a
message. Because MIME bodies can get quite large (e.g.,
audio files), MIME::Body has methods for storing data to
disk and reading and writing it in a filehandle-like
fashion.
- MIME::Parser
-
The MIME::Parser recursively parses a
MIME-encoded message from a file, a filehandle, or in-memory
data, and returns a MIME::Entity. You can then extract the
parts, or modify and remail the message.
Figure
7.6 is a short example of using MIME::Entity to build a
simple message that consists of a text greeting and an audio
enclosure.
Lines 13: Load modules We turn on
strict type checking and load the MIME::Entity module. It
brings in the other modules it needs, including MIME::Head
and MIME::Body.
Lines 48: Create top-level
MIME::Entity Using the
MIME::Entity->build(), method, we create a
"top-level" multipart MIME message that contains the two
subparts. The arguments to build() include the
From: and To: fields, the Subject: line, and a MIME Type of multipart/mixed. This returns a
MIME::Entity object.
Lines 918: Attach the text of the
message We create the text of the message and store it
in a scalar variable. Then, using the top-level MIME
entity's attach() method, we incorporate the text
data into the growing multipart message, specifying a MIME
Type of text/plain, an Encoding of 7bit, and the message text as the
Data.
Lines 1923: Attach the audio file
We again call attach(), but this time specify a
Type of audio/wav and an Encoding of base64. We don't want to read the
whole audio file into memory, so we use the Path argument to direct
MIME::Entity to the file where the audio data can be found.
The Description argument
adds a human-readable description of the attachment to the
outgoing message.
Lines 2425: Sign the message We
call the MIME entity object's sign() utility to
append our signature file to the text of the message.
Lines 2627: Send the message We
call the send() method to format and mail the
completed message using the smtp method.
That's all there is to it. In the next
sections we will look at the MIME modules more closely.
MIME::Entity
MIME::Entity is a subclass of Mail::Internet
and, like it, represents an entire e-mail message. However,
there are some important differences between Mail::Internet
and MIME::Entity. Whereas Mail::Internet contains just a
single header and body, the body of a MIME::Entity can be
composed of multiple parts, each of which may be composed of
subparts. Each part and subpart is itself a MIME::Entity (Figure
7.7). Because of these differences, MIME:: Entity adds
several methods for manipulating the message's body in an
object-oriented fashion.
This summary omits some obscure methods. See
the MIME::Entity POD documentation for the full details.
The main constructor for MIME::Entity is
build(): build() negotiates a large number
of constructors. These are the most common:
|
$entity =
MIME::Entity->build(arg1 => $val1, arg2 =>
$val2, ...)
The build() method is the main
constructor for MIME::Entity. It takes a series of named
arguments and returns an initialized MIME::Entity
object. The following arguments are the most
common. |
Field name. Any of the RFC 822 or
MIME-specific fields can be used as arguments, and the
provided value will be incorporated into the message header.
As in Mail::Header, you can use an array reference to pass a
multivalued field. You should probably confine yourself to
using RFC 822 fields, such as From: and To:, because any MIME
fields that you provide will override those generated by
MIME::Entity.
Data. For single-part entities only,
the data to use as the message body. This can be a scalar or
an array reference containing lines to be joined to form the
body.
Path. For single-part entities only,
the path to a file where the data for the body can be found.
This can be used to attach to the outgoing message a file that
is larger than you could store in main memory.
Boundary. The boundary string to place
between parts of a multipart message. MIME::Entity will choose
a good default for you; ordinarily you won't want to use this
argument.
Description. A human-readable
description of the body used as the value of the
Content-Description: field.
Disposition. This argument becomes the
value of the header's Content-Disposition: field. It may be
either attachment or inline, defaulting to inline if the argument is not
specified.
Encoding. The value of this argument
becomes the Content-Encoding: field. Youshould provide one of
7bit, 8bit, binary,
quoted-printable, or base64. Include this argument even if
you are sending a simple text message because, if you don't,
MIME::Entity defaults to binary. You may also provide a
special value of-SUGGEST to
have MIME::Entity make a guess based on a byte-by-byte
inspection of the entire body.
Filename. The recommended filename for
the mail reader to use when saving this entity to disk. If not
provided, the recommended filename will be derived from the
value of Path.
Type. The MIME type of the entity,
text/plain by default.
MIME::Entity makes no attempt to guess the MIME type from the
file name indicated by the Path argument or from the contents
of the Data argument.
Here's the idiom for creating a single-part
entity (which may later be attached to a multipart
entity): $part = MIME::Entity->build(To => 'jdoe@acme.org',
Type => 'image/jpeg',
Encoding => 'base64',
Path => '/tmp/pictures/oranges.jpg');
And here's the idiom for creating a multipart
entity, to which subparts will be added: $multipart = MIME::Entity->build(To => 'jdoe@acme.org',
Type => 'multipart/mixed');
Notice that single-part entities should have
a body specified using either the Data or the Path arguments. Multipart entities
should not.
Once the MIME::Entity is created, you will
attach new components to it using add-part() or
attach():
|
$part =
$entity->add_part($part [,$offset])
The add_part() method adds a
subpart to the multipart MIME::Entity contained in
$entity. The $part argument must be a
MIME::Entity object. Each multipart MIME::Entity object
maintains an array of its subparts, and by default, the
new part is appended to the end of the current array.
You can modify this by providing an offset argument. The
method returns the newly added part.
If you attempt to add a part to a
single-part entity, MIME::Entity automagically converts
the entity into type multipart/mixed, and reattaches
the original contents as a subpart. The entity you are
adding then becomes the second subpart on the list. This
feature allows you to begin to compose a single-part
message and later add attachments without having to
start anew.
$part =
$entity->attach(arg1 => $val1, arg2 => $val2,
...)
The attach() method is a
convenience function that first creates a new
MIME::Entity object using build(), and then
calls $entity->add_part() to insert the
newly created part into the message. The arguments are
identical to those of build(). If successful,
the method returns the new
MIME::Entity. |
Several methods provide access to the
contents of the entity:
|
$head =
$entity->head([$newhead])
The head() method returns the
MIME::Head object associated with the entity. You can
then call methods in the head object to examine and
change fields. The optional $newhead argument,
if provided, can be used to replace the header with a
different MIME::Body object.
$body =
$entity->bodyhandle([$newbody])
The bodyhandle() method gets
or sets the MIME::Body object associated with the
entity. You can then use this object to retrieve or
modify the unencoded contents of the body. The optional
$newbody argument can be used to replace the
body with a different MIME::Body object. Don't confuse
this method with body(), which returns an array
ref containing the text representation of the encoded
body.
If the entity is multipart, then there
will be no body, in which case bodyhandle(),
returns undef. Before trying to fetch the body,
you can use the is_multipart(), method to check
for this possibility.
$pseudohandle
= $entity->open($mode)
The open() method opens the
body of the entity for reading or writing, and returns a
MIME pseudohandle. As described later in the section on
the MIME::Body class, MIME pseudohandles have object
methods similar to those in the IO::Handle class (e.g.,
read(), getline(), and
print()), but they are not handles in the true
sense of the word. The pseudohandle can be used to
retrieve or change the contents of the entity's
body. $mode is one of "r" for reading, or "w" for writing.
@parts =
$entity->parts($index)
$parts =
$entity->parts($index)
@parst=
$entity->parts(\@parts)
The parts() method returns the
list of MIME::Entity parts in a multipart entity. If
called with no arguments, the method returns the entire
list of parts; if called with an integer index, it
returns the designated part. If passed the reference to
an array of parts, the method replaces the current parts
with the contents of the array. This allows you delete
parts or rearrange their order.
For example, this code fragment
reverses the order of the parts in the entity: $entity->parts([reverse $entity->parts])
If the entity is not multipart,
parts() returns an empty
list. |
A variety of methods return information about
the Entity:
|
$type =
$entity->mime_type
$type =
$entity->effective_type
The mime_type() and
effective_type() methods both return the MIME
type of the entity's body. Although the two methods
usually return the same value, there are some error
conditions in which MIME::Parser cannot decode the
entity and is therefore unable to return the body in its
native form. In this case, mime_type(), returns
the type that the body is supposed to be, and
effective_type() returns the type that actually
returns when you retrieve or save the body data (most
probably application/octet-stream). To
be safe, use effective_type() when retrieving
the body of an entity created by MIME::Parser. For
entities you created yourself with
MIME::Entity->build(), there's no
difference.
$boolean =
$entity->is_multipart
The is_multipart() method is a
convenience routine that returns true if the entity is
multipart, false if it contains a single part only.
$entity->sign(arg1 => $val1,
arg2=> $val2, ...)
The sign() method attaches a
signature to the message. If the message contains
multiple parts, MIME::Entity searches for the first text
entity and attaches the signature to that.
The method adds some improvements to
the version implemented in Mail::Internet, however you
must provide at least one set of named arguments.
Possibilities include:
File. This argument allows you
to use the signature text contained in a file. Its
value should be the path to a local file.
Signature. This argument uses
the indicated text as the signature. Its value can be
a scalar or a reference to an array of lines.
Force. Sign the entity even if
its content type isn't text/*. The value is treated
as a Boolean.
Remove. Call
remove_sig() to scan for an existing
signature and remove it before adding the new
signature. The value of this argument is passed to
remove_sig(). Provide 0 to disable signature
removal entirely.
For example, here's how to add a
signature using a scalar value: $entity->sign(Signature => "That's all folks!");
$entity->remove_sig([$nlines])
Remove_sig() scans the last
$nlines of the message body as it looks for a
line consisting of the characters "--". The line and
everything below it is removed. $nlines
defaults to 10.
$entity->dump_skeleton([FILEHANDLE])
Dump_skeleton() is a debugging
utility. It dumps a text representation of the structure
of the entity and its subparts to the indicated
filehandle, or, if no filehandle is provided, to
standard output. |
Finally, several methods are involved in
exporting the entity as text and mailing it:
|
$entity->print([FILEHANDLE])
$entity->print_header([FILEHANDLE])
$entity->print_body([FILEHANDLE])
These three methods, inherited from
Mail::Internet, print the encoded text representations
of the whole message, the header, or the body,
respectively. The parts of a multipart entity are also
printed. If no filehandle is provided, it prints to
STDOUT.
$arrayref =
$entity->header
The header() method, which is
inherited from Mail::Internet, returns the text
representation of the header as a reference to an array
of lines. Don't confuse this with the head()
method, which returns a MIME::Head object.
$arrayref =
$entity->body
This method, which is inherited from
Mail::Internet, returns the body of the message as a
reference to an array of lines. The lines are encoded in
a form suitable for passing to a mailer. Don't confuse
this method with bodyhandle() (discussed next),
which returns a MIME::Body object.
$string =
$entity->as_string $string
$string =
$entity->stringify_body
$string
$entity->stringify_header
The as_string() method
converts the message into a string, encoding any parts
that need to be. The stringify_body() and
stringify_header() methods respectively operate
on the body and header only.
$result =
$entity->send([$method])
The send() method, which is
inherited from Mail::Internet, sends off the message
using the selected method. I have noticed that some
versions of the UNIX mail
program have problems with MIME headers, and so it's
best to set $method explicitly to either
"sendmail" or "smtp".
$entity->purge
If you have received the MIME::Entity
object from MIME::Parser, it is likely that the body of
the entity or one of its subparts is stored in a
temporary file on disk. After you are finished using the
object, you should call purge() to remove these
temporary files, reclaiming the disk space. This does
not happen automatically
when the object is
destroyed. |
MIME::Head
The MIME::Head class contains information
about a MIME entity's header. It is returned by the
MIME::Entity head() method.
MIME::Head is a class of Mail::Header and
inherits most of its methods from there. It is a historical
oddity that one module is called "Head" and the other
"Header." MIME::Head adds a few utility methods to
Mail::Header, the most useful of which are read() and
from_file():
|
$head =
MIME::Head->read(FILEHANDLE)
In addition to creating a MIME::Head
object manually by calling add() for each
header field, you can create a fully initialized header
from an open filehandle by calling the read()
method. This supplements Mail::Header's read()
method, which allows you to read a file only into a
previously created object.
$head =
MIME::Head->from_file($file)
The from_file() constructor
creates a MIME::Head object from the indicated file by
opening it and passing the resulting filehandle to
read(). |
All other functions behave as they do in
Mail::Header. For example, here is one way to retrieve and
change the subject line in a MIME::Entity object: $old_subject = $entity->head->get('Subject');
$new_subject = "Re: $old_subject";
$entity->head->replace(Subject => $new_subject);
Like Mail::Header,
MIME::Head->get() also returns newlines at the
ends of removed field values.
MIME::Body
The MIME::Body class contains information on
the body part of a MIME::Entity. MIME::Body objects are
returned by the MIME::Entity bodyhandle() method, and
are created as needed by the MIME::Entity build() and
attach() methods. You will need to interact with
MIME::Body objects when parsing incoming MIME-encoded
messages.
Because MIME-encoded data can be quite large,
an important feature of MIME::Body is its ability to store the
data on disk or in memory ("in core" as the MIME-Tools
documentation calls it). The methods available in MIME::Body
allow you to control where the body data is stored, to read
and write it, and to create new MIME::Body objects.
MIME::Body has three subclasses, each
specialized for storing data in a different manner:
MIME::Body::File: This subclass
stores its body data in a disk file. This is suitable for
large binary objects that wouldn't easily fit into main
memory.
MIME::Body::Scalar: This subclass
stores its body data in a scalar variable in main memory.
It's suitable for small pieces of data such as the text part
of ane-mail message.
MIME::Body::InCore: This subclass
stores its body data in an array reference kept in main
memory. It's suitable for larger amounts of text on which
you will perform multiple reads or writes.
Normally MIME::Parser creates
MIME::Body::File objects to store body data on disk while it
is parsing.
|
$body =
MIME::Body::File->new($path)
To create a new MIME::Body object that
stores its data to a file, call the MIME::,
Body::File->new() method with the path to the
file. The file doesn't have to exist, but will be
created when you open the body for writing.
$body =
MIME::Body::Scalar->new(\$string)
The
MIME::Body::Scalar->new() method returns a
body object that stores its data in a scalar
reference.
$body =
MIME::Body::InCore->new($string)
$body =
MIME::Body::InCore->new(\$string)
$body =
MIME::Body::InCore->new(\@string)
The MIME::Body::InCore class has the
most flexible constructor. Internally it stores its data
in an array reference, but it can be initialized from a
scalar, a reference to a scalar, or a reference to an
array. |
Once you have a MIME::Body object, you can
access its contents by opening it with the open()
method.
|
$pseudohandle
= $body->open($mode)
This method takes a single argument
that indicates whether to open the body for reading
("r") or writing ("w"). The returned object is a
pseudohandle that implements the IO::Handle methods
read(), print(), and
getline(). However, it is not a true
filehandle, so be careful not to pass the returned
pseudohandle to any of the built-in procedures such as
<> or
read(). |
The following code fragment illustrates how
to read the contents of a large MIME::Body stored in a
MIME::Entity object and print it to STDOUT. The
contents recovered in this way are in their native form, free
of any MIME encoding: $body = $entity->body handle or die "no body";
$handle = $body->open("r");
print $data while $handle->read($data,1024);
For line-oriented data, we would have used
the getline() method instead.
Another code fragment illustrates how to
write a MIME::Body's contents using its print()
method. If the body is attached to a file, the data is written
there. Otherwise, it is written to an in-memory data
structure: $body = $entity->body handle or die "no body";
$handle = $body->open("w");
$handle->print($_) while <>;
MIME::Body provides a number of convenience
methods:
|
@lines =
$body->as_lines
$string =
$body->as_string
as_lines() and
as_string() are convenience functions that
return the entire contents of the body in a single
operation. as_lines() opens the body and calls
get_line() repeatedly, returning an array of
newline-terminated lines. as_string() reads the
entire body into a scalar. Because either method can
read a large amount of data into memory, you should
exercise some caution before calling them.
$path =
$body->path([$newpath])
If the body object is attached to a
file, as in MIME::Body::File, then path()
returns the path to the file or sets it if the optional
$newpath argument is provided. If the data is
kept in memory, then path() returns
undef.
$body->print([FILEHANDLE])
The print() method prints the
unencoded body to the indicated filehandle, or, if none
is provided, to the currently selected filehandle. Do
not confuse this with the print() method
provided by the pseudohandles returned by the
open() method, which is used to write data into
the body object.
$body->purge
Purge unlinks the file associated with
the body object, if any. It is not called automatically
when the object is
destroyed. |
MIME::Parser
The last major component of MIME-Tools is the
MIME::Parser class, which parses the text representation of a
MIME message into its various components. The class is simple
enough to use, but has a large number of options that control
various aspects of its operation. The short example in Figure
7.8 will give you the general idea.
Lines 13: Load modules We turn on
strict type checking and load the MIME::Parser module. It
brings in the other modules it needs, including
MIME::Entity.
Lines 45: Open a message We recover
the name of a file from the command line, which contains a
MIME-encoded message, and open it. This filehandle will be
passed to the parser later.
Lines 68: Create and configure the
parser We create a new parser object by calling
MIME::Parser->new(). We then call the newly
created object's output_dir(), method to set the
directory where the parser will write the body data of
extracted enclosures.
Lines 910: Parse the file We pass
the open filehandle to the parser's parse(),
method. The value returned from the method is a MIME::Entity
object corresponding to the top level of the message.
Lines 1114: Print information about the
top-level entity To demonstrate that we parsed the
message, we recover and print the From: and Subject: lines
of the header, calling the entity's head() method
to get the MIME::Head object each time. We also print the
MIME type of the whole message, and the number of subparts,
which we derive from the entity's parts() method.
Lines 1517: Print information about the
parts We loop through each part of the message. For
each, we call its mime_type() method to retrieve
the MIME type, and the path() method of the
corresponding MIME::Body to get the name of the file that
contains the data.
Line 18: Clean up When we are
finished, we call purge() to remove all the parsed
body data files.
When I ran the program on a MIME message
stored in the file mime.test,
this is was the result: % simple_parse.pl ~/mime.test
From = Lincoln Stein <lstein@cshl.org>
Subject = testing mime parser
MIME type = multipart/mixed
Parts = 5
text/plain /tmp/msg-1857-1.dat
audio/wav /tmp/assimilated.wav
image/jpeg /tmp/aw-2-19.jpg
audio/mpeg /tmp/NorthwestPassage.mp3
text/plain /tmp/msg-1857-2.dat
This multipart message contains five parts.
The first and last parts contain text data and correspond to
the salutation and the signature. The remaining parts are
enclosures, consisting of an audio/wav sound file, a JPEG
image, and a ripped MP3 track.
We will walk through a more complex example
of MIME::Parser in Chapter
8, where we deal with writing Post Office Protocol
clients. The example developed there will spawn external
viewers to view image and audio attachments.
Because MIME files can be quite large,
MIME::Parser's default is to store the parsed MIME::Body parts
as files using the MIME::Body::File class. You can control
where these files are stored using either the
output_dir() or the output_under() methods.
The output_dir() method tells MIME::Parser to store
the parts directly inside a designated directory.
output_under(), on the other hand, creates a two-tier
directory. For each parsed e-mail message, MIME::Parser
creates a subdirectory under the base directory specified by
output_under(), and then writes the MIME::Body::File
data there.
In either case, all the temporary files are
cleared when you call the top-level MIME::Entity's
purge() method. You can instead keep some or all of
the parts. To keep some parts, step through the message parts
and call purge() selectively on those that you don't
want to keep. You can either leave the other parts where they
are or move them to a different location for safekeeping. To
keep all parsed parts, don't call purge() at all.
Parsing is complex, and the parse()
method may die if it encounters any of a number of exceptions.
You can catch such exceptions and attempt to perform some
error recovery by wrapping the call to parse() in an
eval{} block: $entity = eval { $parser->parse(\*F) };
warn $@ if $@;
Here is a brief list of the major functions
in MIME::Parser, starting with the constructor.
|
$parser =
MIME::Parser->new
The new() method creates a new
parser object with default settings. It takes no
arguments.
$dir =
$parser->output_dir
$previous =
$parser->output_dir($newdir)
The output_dir() method gets
or sets the output directory for the parse. This is the
directory in which the various parts and enclosures of
the parsed message are (temporarily) stored.
If called with no arguments, it returns
the current value of the output directory. If called
with a directory path, it sets the output directory and
returns its previous value. The default setting is ".",
the current directory.
$dir =
$parser->output_under
$parser->output_under($basedir
[,DirName=>$dir [,Purge=>$purge]])
output_under() changes the
temporary file strategy to use a two-tier directory.
MIME::Parser creates a subdirectory inside the specified
base directory and then places the parsed
MIME::Body::File data in the newly created
subdirectory. |
In addition to $basedir,
output_under() accepts two optional named
arguments:
DirName. By default, the
subdirectory is named by concatenating the current time,
process ID, and a sequence number. If you would like a more
predictable directory name, you can use DirName to provide a subdirectory
name explicitly.
Purge. If you use the same
subdirectory name each time you run the program, you might
want to set Purge to a true
value, in which case output_under() will remove
anything in the subdirectory before beginning the parse.
Called with no arguments,
output_under() returns the current base directory
name. Here are two examples: # store enclosures in ~/mime_enclosures
$parser->output_under("$ENV{HOME}/mime_enclosures");
# store enclosures under /tmp in subdirectory "my_mime"
$parser->output_under("/tmp", DirName=>'my_mime', Purge=>1);
The main methods are parse(),
parse_data(), and parse_open():
|
$entity =
$parser->parse(\*FILEHANDLE)
The parse() method parses a
MIME message by reading its text from an open
filehandle. If successful, it returns a MIME::Entity
object. Otherwise, parse() can throw any number
of run-time exceptions. To catch those exceptions, wrap
parse() in an eval{} block as
described earlier.
$entity =
$parser->parse_data($data)
The parse_data() method parses
a MIME message that is contained in memory.
$data can be a scalar holding the text of the
message, a reference to a scalar, or a reference to an
array of scalars. The latter is intended to be used on
an array of the message's lines, but can be any array
which, when concatenated, yields the text of the
message. If successful, parse_data() returns a
MIME::Entity object. Otherwise, it generates a number of
run-time exceptions.
$entity =
$parser->parse_open($file)
The parse_open() method is a
convenience function. It opens the file provided, and
then passes the resulting filehandle to
parse(). It is equivalent to: open (F,$file);
$entity = $parser->parse(\*F);
|
Because parse_open() uses Perl's
open() function, you can play the usual tricks with
pipes. For example: $entity = $parser->parse_open("zcat ./mailbox.gz |");
This uncompresses the compressed mailbox
using the zcat program and
pipes the result to parse().
Several other methods control the way the
parse operates:
|
$flag =
$parser->output_to_core
$parser->output_to_core($flag)
The output_to_core() method
controls whether MIME::Parser creates files to hold the
decoded body data of MIME::Entity parts, or attempts to
keep the data in memory. If $flag is false (the
default), then the parts are parsed into disk files. If
$flag is true, then MIME::Parser stores the
body parts in main memory as MIME::Body::InCore
objects.
Since enclosures can be quite large,
you should be cautious about doing this. With no
arguments, this method returns the current setting of
the flag.
$flag =
$parser->ignore_errors
$parser->ignore_errors($flag)
The ignore_errors() method
controls whether MIME::Parser tolerates certain syntax
errors in the MIME message during parsing. If true (the
default), then errors generate warnings, but if not,
they cause a fatal exception during
parse().
$error =
$parser->last_error
$head =
$parser->last_head
These two methods are useful for
dealing with unparseable MIME messages.
last_error() returns the last error message
generated during the most recent parse. It is set when
an error was encountered, and either
ignore_errors() is true, or the call to
parse() was wrapped in an eval{}.
last_head() returns the
top-level MIME::Head object from the last stream we
attempted to parse. Even though the body of the message
wasn't successfully parsed, we can use the header
returned by this method to salvage some information,
such as the subject line and the name of the
sender. |
MIME Example: Mailing Recent CPAN
Entries
In this section, we develop an application
that combines the Net::FTP module from Chapter
19 with the Mail and MIME modules from this chapter. The
program will log into the CPAN FTP site at ftp.perl.org, read the RECENT file that contains a list of
modules and packages recently contributed to the site,
download them, and incorporate them as attachments into an
outgoing e-mail message. The idea is to run the script at
weekly intervals to get automatic notification of new CPAN
uploads.
Figure
7.9 shows the listing for the application, called mail_recent.pl.
Lines 14: Load modules We turn on
strict syntax checking and load the Net::FTP and
MIME::Entity modules.
Lines 59: Define constants We set
constants corresponding to the FTP site to connect to, the
CPAN directory, and the name of the RECENT file itself. We also declare
a constant with the e-mail address of the recipient of the
message (in this case, my local username), and a
DEBUG constant to turn on verbose progress
messages.
Lines 1011: Declare globals The
%RETRIEVE global contains the list of files to
retrieve from CPAN. $TMPDIR contains the path of a
directory in which to store the downloaded files temporarily
before mailing them. This is derived from the
TMPDIR environment variable, or, if not otherwise
specified, from /usr/tmp.
Windows and Macintosh users have to check and modify this
for their systems.
Lines 1215: Log into CPAN and fetch the
RECENT file We create a new
Net::FTP object and log into the CPAN mirror. If successful,
we change to the directory that contains the archive and
call the FTP object's retr() method to return a
filehandle from which we can read the RECENT file.
Lines 1723: Parse the RECENT file RECENT contains a list of all files
on the CPAN archive that are new or have changed recently,
but we don't want to download them all. The files we're
interested in have lines that look like this: modules/by-module/Apache/Apache-Filter-1.011.tar.gz
modules/by-module/Apache/Apache-iNcom-0.09.tar.gz
modules/by-module/Audio/Audio-Play-MPG123-0.04.tar.gz
modules/by-module/Bundle/Bundle-WWW-Search-ALL-1.09.tar.gz
We open the file for reading and scan
through it one line at a time, looking for lines that match
the appropriate pattern. We store the filename and its CPAN
path in %RETRIEVE.
After processing the filehandle, we close
it.
Lines 2432: Begin the mail message
We begin the outgoing mail message with ashort text message
that gives the number of enclosures. We create a new
MIME::Entity object by calling the build()
constructor with the introduction as its initial contents.
Notice that the arguments we pass to
build() create a single-part document of type text/plain. Later, when we add the
enclosures, we rely on MIME::Entity's ability to convert the
message into a multipart message when needed.
Lines 3344: Retrieve modules and attach
them to the mail We loop through the filenames stored in
%RETRIEVE. For each one, we call the FTP object's
get(), method to download the file to the temporary
directory. If successful, we use the Filename argument to attach the
file to the outgoing mail message by calling the top-level
entity's attach() method. Other attach()
arguments set the encoding to base64, and the MIME type to application/x-gzip. CPAN files are
gzipped by convention. We also add a short description to
the attachment; currently it is just a copy of the filename.
Line 45: Add signature to the outgoing
mail If there is a file named .signature in the current user's
home directory, we call the MIME entity's sign()
method to attach it to the end of the message.
Lines 4649: Send the mail We call
the entity's send() method to MIME-encode the
message and send it via the SMTP protocol. When this is
done, we call the entity's purge() method, deleting
the downloaded files in the temporary directory. This works
because the files became the basis for the MIME-entity
bodies via the MIME::Body::File subclass when they were
attached to the outgoing message, and purge()
recursively deletes these files.
Note that the send() method relies
on libnet being correctly configured to find a working SMTP
server. If this is not the case, check and fix the Libnet.cfg file.
Line 51: Close FTP connection Our
last step is to close the FTP connection by calling the FTP
object's quit() method.
Figure
7.10 shows a screenshot of Netscape Navigator displaying
the resulting MIME message. Clicking on one of the enclosures
will prompt you to save it to disk so that you can unpack and
build the module.
A deficiency in the program is that the CPAN
filenames can be cryptic, and it isn't always obvious what a
package does. A nice enhancement to this script would be to
unpack the package, scan through its contents looking for the
POD documentation, and extract the description line following
the NAME heading. This information could then be used as the
MIME::Entity Description: field rather than the filename
itself. A simpler alternative would be to enclose the .readme file that frequently (but not
always) accompanies a package's .tar.gz file.
|
Chapter 8. POP, IMAP, and NNTP
Processing Mail and
Netnews
In the last chapter we looked at client
modules for sending Internet mail. In the first part of this
chapter we'll look at modules for receiving mail and
processing messages with enclosures (including multimedia
enclosures). In the second part, we'll look at clients for the
closely related Netnews protocol.
|
The Post Office Protocol
POP3 and IMAP are the two protocols used most
to access Internet mail. Both were designed to allow a user to
access mail drops on remote machines, and provide methods to
list the contents of the user's mailbox, to download mail for
viewing, and to delete messages the user is no longer
interested in.
POP3 (Post Office Protocol version 3) is the
older and simpler of the two. Described in RFC 1725 and STD
53, it provides a straightforward interface for listing,
retrieving, and deleting mail held on a remote server. IMAP
(Internet Message Access Protocol), described in RFC 2060,
adds sophisticated facilities for managing sets of remote and
local mailboxes and synchronizing them when the user
connects.
We will consider fetching mail from a POP3
server in this section. There are at least two Perl modules on
CPAN for dealing with POP3 servers: Mail::POP3Client, written
by Sean Dowd, and Net::POP3, by Graham Barr. Both provide
essentially the same functionality but they use different
APIs. The most important feature difference between the two is
that Net::POP3 allows you to save the contents of a mail
message to a filehandle, while Mail::POP3Client reads the
entire mail message into memory. Because the ability to save
to a filehandle makes a big difference when dealing with large
e-mails (such as those containing MIME enclosures), I
recommend Net::POP3.
Net::POP3 inherits from Net::Cmd, making it
similar in style to Net::FTP and Net::SMTP. You begin by
creating a new Net::POP3 object connected to the mailbox host.
If this is successful, you log in using a username and
password, and then invoke various methods to list the contents
of the mailbox, retrieve individual messages, and possibly
delete the retrieved messages.
Summarizing a POP3 Mailbox
Figure
8.1 shows a small program that will access a user's
mailbox on a maildrop machine and print a brief summary of the
senders and subject lines of all new messages. The username
and mailhost are specified on the command line using the
format username@mailbox.host. The program prompts for
the password. Appendix A contains the listing for the PromptUtil.pm package.
Lines 16: Load modules We bring in
the Net::POP3 module to contact the remote POP server, and
Mail::Header to parse the retrieved mail headers. We also
bring in a new home-brewed utility module, PromptUtil, which
provides the get_passwd() function, along with a
few other user prompting functions.
Lines 68: Get username, host, and
password We get the username and host from the command
line, and prompt the user to enter his or her password using
the get_passwd() function. The latter turns off
terminal echo so that the password is not visible on the
screen.
Line 9: Connect to mailbox host We
call the Net::POP3 new() method to connect to the
indicated host, giving the server 30 seconds in which to
respond with the welcome banner. The new()
constructor returns a Net::POP3 object.
Lines 1013: Log in and count
messages We call the POP3 object's login()
method to log in with the user's name and password. If the
login is successful, it returns the total number of messages
in the user's mailbox; if there are no messages in the
mailbox, it returns 0E0 ("zero but true"). This
value has a property of 1 if treated in a logical text to
test whether login was successful, and is equal to 0 when
used to count the number of available messages.
Next we call the POP3 object's
last() method to return the number of the last
message the user read (0 if none read). We will use this to
list the unread messages. Because the message count
retrieved by new() can be 0E0, we add zero to it to
convert it into a more familiar number. We then print the
total number of old and new messages.
Lines 1421: Summarize messages Each
message is numbered from 1 to the total of messages in the
mailbox. For each one, we call the POP object's
top() method to retrieve the message header as a
reference to an array of lines, and pass this to
Mail::Header->new() for parsing. We call the
parsed header's get() method twice to retrieve the
Subject: and From: lines, and pass the sender's address to
the clean_from() utility subroutine to clean it up
a bit. We then print out the message number, sender's name,
and subject.
Line 22: Log out The POP object's
quit() method logs out cleanly.
Lines 2329: Clean up with the
clean_from() subroutine This subroutine cleans up
sender addresses a bit, by extracting the sender's name from
these three common address formats: "Lincoln Stein" <lstein@cshl.org>
Lincoln Stein <stein@cshl.org>
lstein@cshl.org (Lincoln Stein)
When we run this program, we get output like
this: % pop_stats.pl lstein@localhost
inbox has 6 messages (6 new)
1 Geoff Winisky Re: total newbie question
2 Robin Lofving Server updates
3 James W Goldblum Comments part 2
4 Jessica Raymond Statistics on Transaction Security
5 James W Goldbum feedback access from each page
6 The Western Web The Western Web Newsletter
Net::POP3 API
The Net::POP3 API is simple. You can log in,
log out, list messages, retrieve message headers, retrieve the
entire message, and delete messages.
|
$pop =
Net::POP3->new([$host] [,$opt1=>$val1,
$opt2=>$val2])
The new() method constructs a
new Net::POP3 object. The first, optional, argument is
the name or IP address of the mailbox host. This may be
followed by a series of option/value pairs. If the host
is not provided, it will be retrieved from the
Net::Config "POP3_hosts" value specified when the libnet
module was installed. The options are listed in Table
8.1.
The ResvPort option is used with
some POP3 servers that require clients to connect from
reserved ports.
If unsuccessful, new() returns
undef and $! is set to some error
code.
$messages =
$pop->login([$username [,$password]])
The login() method attempts to
log into the server using the provided username and
password. If one or both of the password and username
are not given, then login() looks in the user's
.netrc file for the
authentication information for the specified
host. |
If successful, login() returns the
total number of messages in the user's mailbox. If there are
no messages, login() returns the following point
number 0E0, which will be treated as true when used
in a logical context to test whether login was successful, but
evaluate to zero when treated in a numeric context to count
the number of available messages. If an error occurs,
login() returns undef and
$pop->message() contains an error message.
If the login fails, you may try again or try
to login using apop(). Some servers close the
connection after a number of unsuccessful login attempts. With
the exception of quit(), none of the other methods
will be accepted until the server accepts the login.
Some POP servers support the APOP
command.
$messages =
$pop->apop($username,$password)
|
APOP is similar to a standard
login, but instead of sending passwords across the
network in the clear, it uses a challenge/ response
system to authenticate the user without processing
cleartext passwords. Unlike login(), .netrc is not consulted if the
username and password are absent. The value returned
from apop() is the same as that from
login(). |
Table 8.1.
Net::POP3->new() Options
| Port |
Remote port to connect
to |
POP3(110) |
| ResvPort |
Local port to bind
to |
ephemeral port |
| Timeout |
Second to wait for a
response |
120 |
| Debug |
Turn on verbose
debugging |
undef
|
Many POP3 servers need special configuration
before the APOP command will authenticate correctly.
In particular, most UNIX servers need a password file distinct
from the system password file.
Once login is successful, you can use a
variety of methods to access the mailbox:
|
$last_msgnum
= $pop->last
POP messages are numbered from 1
through the total number of messages in the inbox. At
any time, the user may have read one or more messages
using the RETR command (see below), but not deleted them
from the inbox. Last() returns the highest
number from the set of retrieved messages, or 0 if no
messages have been retrieved. New messages begin at
$last_msgnum+1.
Many POP servers store the last-read
information between connections; however, a few discard
this information.
$arrayref =
$pop->get($msgnum [,FILEHANDLE])
Following a successful login, the
get() method retrieves the message indicated by
its message number, using the POP3 RETR
command. It can be called with a filehandle, in which
case the contents of the message (both header and body)
are written to the filehandle. Otherwise, the
get() method returns an array reference
containing the lines of the message.
$handle =
$pop->getfh($msgnum)
This is similar to get(), but
the return value is a tied filehandle. Reading from this
handle returns the contents of the message. When the
handle returns end-of-file, it should be closed and
discarded.
$flag =
$pop->delete($msgnum)
delete() marks the indicated
message for deletion. Marked messages are not removed
until the quit() method is called, and can be
unmarked by calling reset().
$arrayref =
$pop->top($msgnum[,$lines])
The top() method returns the
header of the indicated message as a reference to an
array of lines. This format is suitable for passing to
the Mail::Header->new() method. If the
optional $lines argument is provided, then the
indicated number of lines of the message body are
included.
$has =
$pop->list
$size =
$pop->list($msgnum)
The list() method returns
information on the size of mailbox messages. Called
without arguments, it returns a hash reference in which
the keys are message IDs, and the values are the sizes
of the messages, in bytes. Called with a message ID, the
method returns the size of the indicated message, or if
an invalid message number was provided, it returns
undef.
($msg_count,$size) =
$pop->popstat
pop_stat() returns a
two-element list that consists of the number of
undeleted messages in the mailbox and the size of the
mailbox in bytes.
$uidl =
$pop->uidl([$msgnum])
The uidl() method returns a
unique identifier for the given message number. Called
without an argument, it returns a hash reference in
which the keys are the message numbers for the entire
mailbox, and the values are their unique identifiers.
This method is intended to help clients track messages
across sessions, since the message numbers change as the
mailbox grows and shrinks. |
When you call the quit() method,
messages marked for deletion are removed unless you
reset() first.
|
$pop->reset
This method resets the mailbox,
unmarking the messages marked for deletion.
$pop->quit
The quit() method quits the
remote server and disconnects. Any messages marked for
deletion are removed from the
mailbox. |
Retrieving and Processing MIME
Messages via POP
To show Net::POP3 in a real-world
application, I developed a script called pop_fetch.pl that combines Net::POP3
and MIME::Parse. Figure
8.2 shows a session with this program. After I invoke it
with the mailbox name in user@host form, the program prompts
me for my login password. The program reports the number of
messages in my mailbox, and then displays the date, sender,
and subject line of the first, prompting me to read it or skip
to the next.
I choose to read the message, causing the
program to display the message header and the text part of the
body. It then reports that the message has two attachments
(technically, two non-text/plain MIME parts). For each one,
the program prompts me for the disposition of the attachment.
For the first attachment, of type image/jpeg, I choose to view the
attachment, causing my favorite image viewer (the XV
application, written by John Bradley) to pop up in a new
window and show the picture. After I quit the viewer, the
script prompts me again for the disposition. This time I
choose to save the image under its default name.
The next attachment is a Microsoft Word
document. No viewer is defined for this document type, so the
prompt only allows the attachment to be saved to disk.
After dealing with the last attachment, the
program prompts me to keep or delete the entire message from
the inbox, or to quit. I quit. The program then moves on to
the next unprocessed message.
The pop_fetch.pl Script
pop_fetch.pl
is broken into two parts. The main part, listed in Figure
8.3, handles the user interface. A smaller module named
PopParser.pm subclasses Net::POP3 in such a way that messages
retrieved from a POP3 mailbox are automatically parsed into
MIME::Entities.
We'll look at pop_fetch.pl first.
Lines 16: Activate taint checking and
load modules Since we will be launching external
applications (the viewers) based on information from
untrusted sources, we need to be careful to check for
tainted variables. The -T switch turns on taint checking.
(See Chapter
10 for more information.)
We load PopParser and PromptUtil, two
modules developed for this application.
Lines 711: Define viewers We define
constants for certain external viewers. For example, HTML
files are invoked with the command lynx %s, where %s is replaced by the name of the
HTML file to view. For variety, some of the viewers are
implemented as pipes. For example, the player for MP3 audio
files is invoked as mpg123-,
where the - symbol tells the
player to take its input from standard input.
At the end of the code walkthrough, we'll
discuss replacing this section of code with the standard
mailcap facility.
Lines 1213: Taint check precautions
As explained in more depth in Chapter
10, taint checking will not let us run with an untrusted
path or with several other environment variables set. We set
PATH to a known, trusted state, and delete four
other environment variables that affect the way that
commands are processed.
Lines 1420: Recover username and
mailbox host We process the command-line arguments to
recover the name of the user and the POP3 host.
The $entity global holds the most
recent parsed MIME::Entity object. We make it global so that
the script's END{} block can detect it and call its
purge(), method in case the user quits the program
prematurely. This will delete all temporary files from disk.
For similar reasons, we intercept the INT signal to
exit gracefully if the user hits the interrupt key.
Lines 2126: Log in to mailbox
server The PopParser.pm module defines a new subclass of
Net::POP3 that inherits all the behavior of the base class,
but returns parsed MIME::Entity objects from the
get() method rather than the raw text of the
message. We create a new PopParser object connected to the
mailbox host. If this is successful, we call
get_passwd() (imported from the PromptUtil module)
to get the user's login password.
Next, we authenticate ourselves to the
remote host. We don't know a priori whether the server
accepts APOP authentication or the less secure
cleartext authentication method, so we try them both. If the
apop() method fails, then we try login().
If that also fails, we die with an error message.
If login is successful, we print the number
of messages returned by the apop(), or
login() methods. We add 0 to the message count to
convert the 0E0 result code into a more user-friendly
integer.
Lines 2738: Enter the main
message-processing loop We now enter the main
message-processing loop. For each message, we fetch its
header by calling the PopParser object's top()
method (which is inherited without modification from
Net::POP3). The header text is then passed to our
print_header() method to display it as a one-line
message summary.
We ask the user if he or she wants to read
the message, and if so, we call the PopParser object's
get() method, which fetches the indicated message,
parses it, and returns a MIME::Entity object. This object is
passed to our display_entity(), subroutine in order
to display it and its subparts. When
display_entity() is finished, we delete the
entity's temporary files by calling its purge()
method.
The last step is to ask the user if he or
she wants to delete the message from the remote mailbox, and
if the answer is affirmative, we call the PopParser's
delete() method.
Lines 3945: print_header()
subroutine The print_header() subroutine takes an
array ref containing the header lines returned by
$POP->top() and turns it into a one-line summary
for display. Although we could have used the Mail::Header
module for this purpose, it turned out to be cleaner to
parse the header into a hash ourselves using the idiom of
the Mail::SMTP mail client of Figure
7.2.
The output line contains the date, sender,
and subject line, separated by tabs.
Lines 4660: display_entity()
subroutine This subroutine is responsible for displaying a
MIME::Entity object. It is called recursively to process
both the top-level object and each of its subparts (and
sub-subparts, if any).
We begin by retrieving the message's mail
header as a MIME::Head object. If the header contains a
From: field, then we can conclude that it is the top-level
entity. We print out the header so that the user can see the
sender's name and other fields.
Next we check whether the entity is
multipart, by calling its is_multipart(), method.
If this method returns true, then we call
handle_multipart() to prompt the user for each of
the parts. Otherwise, we invoke a subroutine called
display_part() to display the contents of the
entity.
Lines 6178: The
handle_multipart() subroutine The
handle_multipart(), subroutine loops through and
processes each part of a multipart MIME::Entity object. We
begin by calling the entity's parts() method to
fetch each of the subparts as a MIME::Entity object. We then
call Perl's grep() built-in twice to sort the parts
into those that we can display directly and those that are
to be treated as attachments that must be displayed using an
external application. Since we know how to display only
plain text, we sort on the MIME type text/plain.
For each of the text/plain parts, we call the
display_part() subroutine to print the message body
to the screen. If there are nontext attachments, we prompt
the user for permission to display them, and if so, invoke
display_entity(), recursively on each attachment.
This recursive invocation of display_entity(),
allows for attachments that are themselves multipart
messages, such as forwarded e-mails.
Lines 7999: The display_part()
subroutine The display_part() subroutine is invoked
to display a single-part MIME::Entity. Depending on the
user's wishes, its job is to display, save, or ignore the
part.
We begin by retrieving the part's header,
MIME type, description, and suggested filename for saving
(derived from the Content-Disposition: header, if present).
We also recover the part's MIME::Body object by calling its
bodyhandle() method. This object gives us access to
the body's unencoded content.
If the part's MIME type is text/plain, we do not need an
external viewer to display it. We simply call the body
object's print() method to print the contents to
standard output. Otherwise, we call get_viewer() to
return the name of an external viewer that can display this
MIME type. We print a summary that contains the part's MIME
type, description, and suggested filename, and then prompt
the user to view or save the part. Depending on the user's
response, we invoke save_body() to save the part's
content to disk, or display_body() to launch the
external viewer to display it. This continues in a loop
until the user chooses "n" to go to the next part.
If no viewer is defined for the part's MIME
type, the user's only option is to save the content to
disk.
Lines 100114: The save_body()
subroutine The save_body() subroutine accepts a
MIME::Body object and a default filename. It gives the user
the opportunity to change the filename, opens the file, and
writes the contents of the part to disk.
The most interesting feature of this
subroutine is the way that we treat the default filename for
the attachment. This filename is derived from the
Content-Disposition: header, and as such is untrusted data.
Someone who wanted to spoil our day could choose a malicious
pathname, such as one that would overwrite a treasured
configuration file. For this reason we forbid absolute
pathnames and those that contain the ".." relative path
component. We also forbid filenames that contain unusual
characters such as shell metacharacters. Having satisfied
these tests, we extract the filename using a pattern match,
thereby untainting it. Perl will now allow us to open the
file for writing. We do so and write the attachment's
contents to it by calling the MIME::Body object's
print() method.
Lines 116128: The display_body ()
subroutine The display_body() subroutine is called
to launch an external viewer to display an attachment. It is
passed a MIME::Body object, and a command to launch an
external viewer to display it.
To make this application a bit more
interesting, we allow for two types of viewers: those that
read the body data from a file on disk and those that read
from standard input. The former are distinguished from the
latter by containing the symbol %s, which will be replaced by the
filename before execution (this is a standard convention in
the UNIX mailcap file).
We begin by calling the MIME::Body object's
path() method to obtain the path to the temporary
file in which the object's data is stored. We then use this
in a pattern substitution to replace any occurrence of %s in the viewer command. If the
substitution is successful, it returns a true value, and we
call system() to invoke the command.
Otherwise, we assume that the viewer will
read the data from standard input. In this case, we use
open() to open a pipe to the viewer command, and
invoke the body object's print() method to print to
the pipe filehandle. Before doing this, however, we set the
PIPE handler to IGNORE to avoid the
program terminating unexpectedly because of a recalcitrant
viewer.
This subroutine works correctly both for
line-oriented applications, such as the Lynx HTML viewer,
and for windowing applications, such as XV.
Lines 129137: The get_viewer()
subroutine get_viewer() is an extremely simple
subroutine that uses a pattern match to examine the MIME
type of the attachment and selects a hard-coded viewer for
it.
Lines 138140: END{} block This
script's END{} block takes care of calling any
leftover MIME::Entity's purge() method. This
deletes temporary files that might be left around if the
user interrupted the script's execution unexpectedly.
The PopParser Module
The other main component of the pop_fetch.pl script is the PopParser
module, which subclasses Net::POP3 in a way that enables it to
parse MIME messages at the same time that it is fetching them.
Figure
8.4 shows the code for PopParser.pm.
Lines 16: Load modules We turn on
strict checking and load the Net::POP3 and MIME::Parser
modules. We use the global @ISA array to tell Perl
that PopParser is a subclass of Net::POP3.
Lines 715: Override the new()
method We override the Net::POP3 new() method in
order to create and initialize a MIME::Parser for later use.
We first invoke our parent's new() method to create
the basic object and connect to the remote host, create and
configure a MIME::Parser object, and store the parser for
later use by invoking our parser() accessor method.
Lines 1621: The parser() method
This method is an accessor for the MIME::Parser object
created during the call to new(). If we are called
with a parser object on our subroutine stack, we store it
among our instance variables. Otherwise, we return the
current parser object to the caller.
The way we stash the parser object among
our instance variables looks weird, but it is the
conventional way to store instance variables in filehandle
objects: ${*$self}{'pp_parser'} = shift
What this is doing is referencing a hash in
the symbol table that happens to have the same name as our
filehandle. We then index into that as if it were a
conventionally created hash. We need to store our instance
variables this way because Net::POP3 ultimately descends
from IO::Handle, which creates and manipulates blessed
filehandles, rather than more conventional blessed hash
references.
Lines 2230: Override the get()
method The last part of this module overrides the Net::POP3
get() method. We are called with the number of the
message to retrieve, which we pass to getfh() to
obtain a tied filehandle from which to read the desired
message. The returned filehandle is immediately passed to
our stored MIME::Parser object to parse the message and
return a MIME::Entity object.
The nice thing about the design of the
PopParser module is that message retrieval and message parsing
occur in tandem, rather than downloading the entire message
and parsing it in two steps. This saves considerable time for
long messages.
There are a number of useful enhancements one
could make to pop_fetch.pl. The
one with the greatest impact would be to expand the range and
flexibility of the viewers for nontext attachments. The best
way to do this would be to provide support for the system
/etc/mailcap and per-user .mailcap files, which on UNIX systems
map MIME types to external viewers. This would allow the user
to install and customize viewers without editing the code.
Support for the mailcap system can be found in the Mail::Cap
module, which is part of Graham Barr's MailTools package. To
use Mail::Cap in the pop_fetch.pl script, replace lines 7
through 11 of Figure
8.3 with these lines: use Mail::Cap;
my $mc = Mail::Cap-new;
This brings in the Mail::Cap module and
creates a new Mail::Cap object that we can use to fetch
information from the mailcap configuration files.
Replace line 90, which invokes the
get_viewer() subroutine, with the equivalent call
from Mail::Cap: my $viewer = $mc->viewCmd($type);
This takes a MIME type and returns the
command to invoke to view it if one is defined.
The last modification is to replace line 97,
which invokes the display_ body() subroutine to
invoke the viewer on the body of an attachment, with the
Mail::Cap equivalent: $mc->view($type,$body->path);
This call looks up the appropriate view
command for the specified MIME type, does any needed string
substitutions, and invokes the command using
system().
We no longer need the get_viewer()
and display_body() subroutines, because Mail::Cap
takes care of their functionality. You can delete them.
Other potential enhancements to this script
include:
-
the ability to reply to messages
-
the ability to list old and new messages
and jump directly to messages of interest
-
a full windowing display using the
text-mode Curses module or the graphical PerlTK package,
both available from CPAN
With a little work, you could turn this
script into a full-featured e-mail client!
|
The IMAP Protocol
The POP3 protocol was designed to handle the
case of a user who spends most of his or her time working on a
single machine. The mail client's job is to fetch the user's
unread mail from time to time from the remote mailbox server.
The user then reads the mail and possibly sorts it into
several local mail folders.
Keeping track of mail becomes more
complicated, however, when the user is moving around a lot:
working on a desktop in the office, a laptop while traveling,
and another desktop at home. In this case, the user wants to
see the same set of mail files no matter where he or she
happens to be working. The Internet Message Access Protocol
(IMAP) satisfies these needs by managing multiple remote mail
folders and transparently synchronizing them with local
copies, providing the user with a consistent view of stored
e-mail. IMAP clients also provide the user with the ability to
work off-line, and with sophisticated server-side message
search functions.
Unfortunately, the IMAP protocol is also
rather complex and it does certain things that the simple
request/response model of Net::POP3 can't easily handle. Among
other things, IMAP servers send unsolicited messages to the
client from time to time, for example to alert the client that
new mail has arrived. No fewer than three Perl modules on CPAN
deal with IMAP: Mail::IMAPClient, Net::IMAP, and
Net::IMAP::Simple.
Mail::IMAPClient, written by David Kernen,
provides the most functionality of the three, providing
methods for issuing all of the IMAP commands. However,
Mail::IMAPClient does not do such a good job at mapping the
IMAP server's responses onto easily handled Perl objects. To
use this module, you'll need RFC 2060 on hand and be prepared
to parse the server responses yourself.
Net::IMAP, written by Kevin Johnson, does a
better job at handling the server's responses, and provides a
nifty callback interface that allows you to intercept and
handle server events. Unfortunately, the module is in alpha
stage and the interfaces are changing. Also, at the time this
book was written, the module's documentation was
incomplete.
Currently, the most usable interface to IMAP
is Joao Fonseca's Net::IMAP::Simple, which provides access to
the subset of IMAP that is most like POP3. In fact,
Net::IMAP::Simple shares much of Net::POP3's method interface
and is, to a large extent, plug compatible.
Like Net::POP3, you work with
Net::IMAP::Simple by calling its new(), method to
connect to an IMAP server host, authenticate with
login(), list messages with list() and
top(), and retrieve messages with get().
Unlike Net::POP3, Net::IMAP::Simple has no apop()
method for authenticating without plaintext passwords. To make
up for this deficiency, it has the ability to work with
multiple remote mailboxes. Net::IMAP::Simple can list the
user's mailboxes, create and delete them, and copy messages
from one folder to another.
Summarizing an IMAP Mailbox
The pop_stats.pl program from Figure
8.1 summarizes the contents of a POP3 mailbox. We'll now
enhance this program to summarize an IMAP mailbox. As an added
feature, the new script, named imap_stats.pl, indicates whether a
message has been read. You call it like pop_stats.pl, but with an additional
optional command-line argument that indicates the name of the
mailbox to summarize: % pop_stats.pl lstein@localhoszt gd_bug_reports
lstein@localhost password:
gd has 6 messages (2 new)
1 Honza Pazdziora Re: ANNOUNCE: GD::Latin2 patch (fwd) read
2 Gurusamy Sarathy Re: patches for GD by Gurusamy Sarathy read
3 Honza Pazdziora Re: ANNOUNCE: GD::Latin2 patch (fwd) read
4 Erik Bertelsen GD-1.18, 2 minor typos read
5 Erik Bertelsen GD fails om some GIF's unread
6 Honza Pazdziora GDlib version 1.3 unread
Figure
8.5 lists imap_stats.pl.
Lines 15: Load modules We load
Net::IMAP::Simple, Mail::Header, and the Prompt Util module
used in earlier examples.
Lines 69: Process command-line
arguments We parse out the username and mailbox host
from the first command-line argument, and recover the
mailbox name from the second. If no mailbox name is
provided, we default to INBOX, which is the default mailbox
name on many UNIX systems. We then prompt for the user's
password.
Lines 1014: Connect to remote host
We call the Net::IMAP::Simple->new(), method to
connect to the designated host, and then call
login() to authenticate. If these steps are
successful, we call the object's select() method to
select the indicated mailbox. This call returns the total
number of messages in the mailbox, or if the mailbox is
empty or missing, undef. We fetch the number of the
last message read by calling last().
Lines 1524: List contents of the
mailbox We loop through each of the messages from first
to last. For each one, we fetch the header by calling
top(), parse it into a Mail::Header object, and
retrieve the Subject: and From: fields. We also call the
IMAP object's seen() method to determine whether
the message has been retrieved. We then print the message
number, sender, subject line, and read status.
Lines 2632: clean_from()
subroutine This is the same subroutine we saw in the earlier
version of this program. It cleans up the sender addresses.
The Net::IMAP::Simple API
Although Net::IMAP::Simple is very similar to
Net::POP3, there are some important differences. The most
dramatic difference is that Net::IMAP::Simple does not inherit
from Net::Cmd and, therefore, does not implement the
message() or code() methods. Furthermore,
Net::IMAP::Simple is not a subclass of IO::Socket and,
therefore, cannot be treated like a filehandle.
The new() and login()
methods are similar to Net::POP3:
|
$imap =
Net::IMAP::Simple->new($host [,$opt1=>$val1,
$opt2=>$val2])
The new() method constructs a
new Net::IMAP::Simple object. The first argument is the
name of the host, and is not optional (unlike the
Net::POP3 equivalent). This is followed by a series of
options that are passed directly to
IO::Socket::INET.
If unsuccessful, new() returns
undef and $! is set to some error
code. Otherwise, it returns a Net::IMAP::Simple object
connected to the server.
$messages =
$imap->login($username,$password)
The login() method attempts to
log into the server using the provided username and
password. The username and password are required, also a
departure from Net::POP3. If successful, the method
returns the number of messages in the user's default
mailbox, normally INBOX. Otherwise, login()
returns undef.
Note that login() does not return 0E0 for a
default mailbox that happens to be empty. The correct
test for a successful login is to test for a defined
return value. |
Several functions provide access to
mailboxes.
|
@mailboxes =
$imap->mailboxes
The mailboxes() method returns
a list of all the user's mailboxes.
$messages =
$imap->select($mailbox)
The select() method selects a
mailbox by name, making it current. If the mailbox
exists, select() returns the number of messages
it contains (0 for a mailbox that happens to be empty).
If the mailbox does not exist, the method returns
undef and the current mailbox is not
changed.
$success =
$imap->create_mailbox($mailbox)
$success =
$imap->delete_mailbox($mailbox)
$success =
$imap->rename_mailbox($old_name,$new_name)
The create_mailbox(),
delete_mailbox(), and rename_mailbox()
methods attempt to create, delete, and rename the named
mailbox, respectively. They return true if successful,
and false otherwise. |
Once you have selected a mailbox, you can
examine and retrieve its contents.
|
$last_msgnum
= $imap->last
The last() method returns the
highest number of the read messages in the current
mailbox, just as Net::POP3 does. You can also get this
information by calling the seen() method, as
described below.
$arrayref =
$imap->get($msgnum)
The get() method retrieves the
message indicated by the provided message number from
the current mailbox. The return value is a reference to
an array containing the message lines.
$handle =
$imap->getfh($msgnum)
This is similar to get() but
the return value is a filehandle that can be read from
in order to retrieve the indicated message. This method
differs from the similarly named Net::POP3 method by
returning a filehandle opened on a temporary file,
rather than a tied filehandle. This means that the
entire message is transferred from the remote server to
the local machine behind the scenes before you can begin
to ork with it.
$flag =
$imap->delete($msgnum)
The delete() method marks the
indicated message for deletion from the current mailbox.
Marked messages are not removed until the
quit() method is called. However, there is no
reset() call to undo a deletion.
$arrayref =
$imap->top($msgnum)
The top() method returns the
header of the indicated message as a reference to an
array of lines. This format is suitable for passing to
the Mail::Header->new() method. There is no
option for fetching a certain number of lines from the
body text.
$has =
$imap->list
$size =
$imap->list($msgnum)
The list() method returns
information on the size of mailbox messages. Called
without arguments, it returns a hash reference in which
the keys are message IDs, and the values are the sizes
of the messages, in bytes. Called with a message ID, the
method returns the size of the indicated message, or if
an invalid message number was provided, it returns
undef.
$flag =
$imap->seen($msgnum)
The seen() method returns true
if the indicated message has been read (by calling the
get() method), or false if it has not.
$success =
$imap->copy($msgnum,$mailbox_destination)
The copy() method attempts to
copy the indicated message from the current mailbox to
the indicated destination mailbox. If successful, the
method returns a true value and the indicated message is
appended to the end of its destination. You may wish to
call delete() to remove the message from its
original mailbox. |
When you are finished, the quit()
method will clean up:
|
$imap->quit()
quit() takes no arguments. It
deletes all marked messages and logs
off. |
|
Internet News Clients
The Netnews system dates back to 1979, when
researchers at Duke University and the University of North
Carolina designed a system to distribute discussion group
postings that would overcome the limitations of simple mailing
lists [Spencer & Lawrence, 1998]. This rapidly grew into
Usenet, a global Internet-based bulletin-board system
comprising thousands of named newsgroups.
Because of its sheer size (more than 34,000
newsgroups and daily news flow rates measured in the
gigabytes), Usenet has been diminishing in favor among
Internet users. However, there has been a resurgence of
interest recently in using Netnews for private discussion
servers, helpdesk applications, and other roles in corporate
intranets.
Netnews is organized in a two-level
hierarchy. At the upper level are the newsgroups. These have
long meaningful names like comp.graphics.rendering.raytracing.
Each newsgroup, in turn, contains zero or more articles. Users
post articles to their local Netnews server, and the Netnews
distribution software takes care of distributing the article
to other servers. Within a day or so, a copy of the article
appears on every Netnews server in the world. Articles live on
Netnews for some period before they are expired. Depending on
each server's storage capacity, a message may be held for a
few days or a few weeks before expiring it. A few large
Netnews servers, such as the one at http://www.deja.com/, hold news articles
indefinitely.
Newsgroups are organized using a hierarchical
namespace. For example, all newsgroups beginning with comp. are supposed to have something
to do with computers or computer science, and all those
beginning with soc.religion.
are supposed to concern religion in society. The creation and
destruction of newsgroups, by and large, is controlled by a
number of senior administrators. The exception is the alt hierarchy, in which newsgroups
can be created willy-nilly by anyone who desires to do so.
Some very interesting material resides in these groups.
Regardless of its position in the namespace
hierarchy, a newsgroup can be moderated or unmoderated.
Moderated groups are "closed." Only a small number of people
(typically a single moderator) have the right to post to the
newsgroup. When others attempt to post to the newsgroup, their
posting is automatically forwarded to the moderator via
e-mail. The moderator then posts the message at his or her
discretion. Anyone can post to unmoderated groups. The posted
article is visible immediately on the local server, and
diffuses quickly throughout the system.
Articles are structured like e-mails, and in
fact share the same RFC 822 specification. Figure
8.6 shows a news article recently posted to comp.lang.perl.modules. The article
consists of a message header and body. The header contains
several fields that you will recognize from the standard
e-mail, such as the Subject: and From: lines, and some fields
that are specific to news articles, such as Article:, Path:,
Message-ID:, Distribution:, and References:. Many of these
fields are added automatically by the Netnews server.
To construct a valid Netnews article, you
need only take a standard e-mail message and add a Newsgroups:
header containing a comma-delimited list of newsgroups to post
to. Another frequently used article header is Distribution:,
which limits the distribution of an article. Valid values for
Distribution: depend on the setup of your local Netnews
server, but they are typically organized geographically. For
example, the usa distribution
limits message propagation to the political boundaries of the
United States, and nj limits
distribution to New Jersey. The most common distribution is
world, which allows the article
to propagate globally.
Other article header fields have special
meaning to the Netnews system, and can be used to create
control messages that cancel articles, add or delete
newsgroups, and perform other special functions. See [Spencer
and Lawrence 1998] for information on constructing your own
control messages.
Netnews interoperates well with MIME. An
article can have any number of MIME-specific headers, parts,
and subparts, and MIME-savvy news readers are able to decode
and display the parts.
Articles can be identified in either of two
ways. Within a newsgroup, an article can be identified by its
message number within the group. For example, the article
shown in Figure
8.6 is message number 36,166 of the newsgroup comp.lang.perl.modules. Because
articles are constantly expiring and being replaced by new
ones, the number of the first message in a group is usually
not 1, but more often a high number. The message number for an
article is stable on any given news server. On two subsequent
days, you can retrieve the same article by entering a
particular newsgroup and retrieving the same message number.
However, message numbers are not stable across servers. An
article's number on one news server may be quite different on
another server.
The other way to identify articles is by the
message ID. The message ID of the sample article is <397a6e8d.524144494f47414741@radiogaga.harz.de>,
including the angle brackets at either side. Message IDs are
unique, global identifiers that remain the same from server to
server.
Net::NNTP
Historically, Netnews has been distributed in
a number of ways, but the dominant mode is now the Net News
Transfer Protocol, or NNTP, described in RFC 977. NNTP is used
both by Netnews servers to share articles among themselves and
by client applications to scan and retrieve articles of
interest. Graham Barr's Net::NNTP module, part of the libnet
utilities, provides access to NNTP servers.
Like other members of the libnet clan,
Net::NNTP descends from Net::Cmd and inherits that module's
methods. Its API is similar to Net::POP3 and
Net::IMAP::Simple. You connect to a remote Netnews server,
creating a new Net::NNTP object, and use this object to
communicate with the server. You can list and filter
newsgroups, make a particular newsgroup current, list
articles, download them, and post new articles.
newsgroup_stats.pl is a short script
that uses Net::NNTP to find all newsgroups that match a
pattern and count the number of articles in each. For example,
to find all the newsgroups that have something to do with
Perl, we could search for the pattern "*.perl*" (the
output has been edited slightly for space): % newsgroup_stats.pl '*.perl*'
alt.comp.perlcgi.freelance 454 articles
alt.flame.marshal.perlman 3 articles
alt.music.perl-jam 11 articles
alt.perl.sockets 45 articles
comp.lang.perl.announce 43 articles
comp.lang.perl.misc 18940 articles
comp.lang.perl.moderated 622 articles
comp.lang.perl.modules 2240 articles
comp.lang.perl.tk 779 articles
cz.comp.lang.perl 63 articles
de.comp.lang.perl.cgi 1989 articles
han.comp.lang.perl 174 articles
it.comp.lang.perl 715 articles
japan.comp.lang.perl 53 articles
Notice that the pattern match wasn't perfect,
and we matched alt.music.perl-jam as well as
newsgroups that have to do with the language. Figure
8.7 lists the code.
Lines 13: Load modules We turn on
strict checking and load the Net::NNTP module.
Line 4: Create new Net::NNTP object
We call Net::NNTP->new() to connect to a Netnews
host. If the host isn't specified explicitly, then Net::NNTP
chooses a suitable host from environment variables or the
default NNTP server specified when libnet was installed.
Lines 56: Print stats and quit For
each argument on the command line, we call the
print_stats() print_stats() subroutine to look up
the pattern and print out matching newsgroups. We then call
the NNTP object's quit() method.
Lines 717: print_stats()
subroutine In the print_stats() subroutine we
invoke the NNTP object's newsgroups() method to
find newsgroups that match a pattern. If successful,
newsgroups() returns a hash reference in which the
keys are newsgroup names and the values are brief
descriptions of the newsgroup.
If the value returned by
newsgroups() is undef or empty, we return.
Otherwise, we sort the groups alphabetically by name, and
loop through them. For each group, we call the NNTP object's
group() method to return a list containing
information about the number of articles in the group and
the message numbers of the first and last articles. We print
the newsgroup name and the number of articles it
contains.
The Net::NNTP API
The Net::NNTP API can be divided roughly into
those methods that deal with the server as a whole, those that
affect entire newsgroups, and those that concern individual
articles in a newsgroup.
Newsgroups can be referred to by name or, for
some methods, by a wildcard pattern match. The
pattern-matching system used by most NNTP servers is similar
to that used by the UNIX and DOS shells. "*" matches zero or
more of any characters, "?" matches exactly one character, and
a set of characters enclosed in square brackets, as in
"[abc]", matches any member of the set. Bracketed character
sets can also contain character ranges, as in "[09]" to match
the digits 0 through 9, and the "^" character may be used to
invert a setfor example, "[^AZ]" to match any character that
is not in the range A through
Z. Any other character matches itself exactly once. As in the
shell (and unlike Perl's regular expression operations), NNTP
patterns are automatically anchored to the beginning and end
of the target string.
Articles can be referred to by their number
in the current newsgroup, by their unique message IDs, or, for
some methods, by a range of numbers. In the latter case, the
range is specified by providing a reference to a two-element
array containing the first and last message numbers of the
range. Some methods allow you to search for particular
articles by looking for wildcard patterns in the header or
body of the message using the same syntax as newsgroup name
wildcards.
Other methods accept times and dates, as for
example, the newgroups() method that searches for
newsgroups created after a particular date. In all cases, the
time is expressed in its native Perl form as seconds since the
epoch, the same as that returned by the time()
built-in.
In addition to the basic NNTP functions, many
servers implement a number of extension commands. These
extensions make it easier to search a server for articles that
match certain criteria and to summarize quickly the contents
of a discussion group. Naturally, not all servers support all
extensions, and in such cases the corresponding method usually
returns undef In the discussion that follows, methods
that depend on NNTP extensions are marked.
We look first at methods that affect the
server itself.
|
$nntp =
Net::NNTP->new([$host],[$option1=>$val1,$option2=>$val2])
The new() method attempts to
connect to an NNTP server. The $host argument
is the DNS name or IP address of the server. If not
specified, Net::NNTP looks for the server name in the
NNTPSERVER and NEWSHOSTS environment
variables first, and then in the Net::Config nntp_hosts key. If none of
these variables is set, the Netnews host defaults to
news. |
In addition to the options accepted by
IO::Socket::INET, Net::NNTP recognizes the name/value pairs
shown in Table
8.2.
By default, when Net::NNTP connects to a
server, it announces that it is a news reader rather than a
news transport agent (a program chiefly responsible for bulk
transfer of messages). If you want to act like a news transfer
agent and really know what you're doing, provide
new() with the option Reader=>0.
|
$success =
$nntp->authinfo($user => $password)
Some NNTP servers require the user to
log in before accessing any information. The
authinfo() method takes a username and
password, and returns true if the credentials were
accepted.
$ok =
$nntp->postok()
postok() returns true if the
server allows posting of new articles. Even though the
server as a whole may allow posting, individual
moderated newsgroups may not.
$time =
$nntp->date()
The date() method returns the
time and date on the remote server, as the number of
seconds since the epoch. You can convert this into a
human-readable time-date string using the
localtime() or gmtime()
functions. |
Table 8.2.
Net::NNTP->new() Options
| Timeout |
Seconds to wait for
response from server |
120 |
| Debug |
Turn on verbose
debugging information |
undef |
| Port |
Numeric or symbolic
name of port to connect to |
119 |
| Reader |
Act like a news
reader |
1 |
|
$nntp->slave()
$nntp->reader()
[extension]
The slave() method puts the
NNTP server into a mode in which it expects to engage in
bulk transfer with the client. The reader()
method engages a mode more suitable for the interactive
transfer of individual articles. Unless explicitly
disabled, reader() is issued automatically by
the new() method.
$nntp->quit()
The quit() method cleans up
and severs the connection with the server. This is also
issued automatically when the NNTP object is
destroyed. |
Once created, you can query an NNTP object
for information about newsgroups. The following methods deal
with newsgroup-level functions.
|
$group_info =
$nntp->list()
The list() method returns
information about all active newsgroups. The return
value is a hash reference in which each key is the name
of a newsgroup, and each value is a reference to a
three-element array that contains group information. The
elements of the array are
[$first,$last,$postok], where $first
and $last are the message numbers of the first
and last articles in the group, and $postok is
"y" if the posting is allowed to the group or "m" if the
group is moderated.
$group =
$nntp->group([$group])
($articles,$first,$last,$name) =
$nntp->group([$group])
The group() method gets or
sets the current group. Called with a group name as its
argument, it sets the current group used by the various
article-retrieval methods.
Called without arguments, the method
returns information about the current group. In a scalar
context, the method returns the group name. In a list
context, the method returns a four-element list that
contains the number of articles in the group, the
message numbers of the first and last articles, and the
name of the group.
$group_info =
$nntp->newgroups($since [,$distributions])
The newgroups() method works
like list(), but returns only newsgroups that
have been created more recently than the date specified
in $since. The date must be expressed in
seconds since the epoch as returned by
time().
The $distributions argument,
if provided, limits the returned list to those
newsgroups that are restricted to the specified
distribution(s). You may provide a single distribution
name as a string, such as nj, or a reference to an array
of distributions, such as ['nj','ct','ny'] for
the New York tristate region.
$new_articles
= $nntp->newnews($since [,$groups
[,$distributions]])
The newnews() method returns a
list of articles that have been posted since the time
value indicated by $since. You may optionally
provide a group pattern or a reference to an array of
patterns in $groups, and a distribution pattern
or reference to an array of distribution patterns in
$distributions.
If successful, the method returns a
reference to an array that contains the message IDs of
all the matching articles. You may then use the
article() and/or articlefh() methods
described below to fetch the contents of the articles.
This method is chiefly of use for mirroring an entire
group or set of groups.
$group_info =
$nntp->active([$pattern]) [extension]
The active() method works like
list(), but limits retrieval to those newsgroup
that match the wildcard pattern $pattern. If no
pattern is specified, active() is functionally
equivalent to list().
This method and the ones that follow
all use common extensions to the NTTP protocol, and are
not guaranteed to work with all NNTP servers.
$group_descriptions =
$nntp->newsgroups([$pattern]) [extension]
$group_descriptions =
$nntp->xgtitle($pattern) [extension]
The newsgroups() method takes
a newsgroup wildcard pattern and returns a hash
reference in which the keys are group names and the
values are brief text descriptions of the group. Because
many Netnews sites have given up on keeping track of all
the newsgroups (which appear and disappear very
dynamically), descriptions are not guaranteed to be
available. In such cases, they appear as the string "No
description", as "?", or simply as an empty string.
xgtitle() is another extension
method that is functionally equivalent to
newsgroups(), with the exception that the group
pattern argument is required.
$group_times
= $nntp->active_times()[extension]
This method returns a reference to a
hash in which the keys are newsgroup names and the
values are a reference to a two-element list giving the
time the group was created and the ID of its creator.
The creator ID may be something useful, like an e-mail
address, but is more often something unhelpful, like
"newsmaster."
$distributions =
$nntp->distributions() [extension]
$subscriptions =
$nntp->subscriptions() [extension]
These two methods return information
about local server distribution and subscription lists.
Local distributions can be used to control the
propagation of messages in the local area network; for
example, a company that is running multiple NNTP servers
might define a distribution named engineering. Subscription lists
are used to recommend lists of suggested newsgroups to
new users of the system.
distributions() returns a hash
reference in which the keys are distribution names and
the values are human-readable descriptions of the
distributions. subscriptions() returns a hash
reference in which the keys are subscription list names
and the values are array references containing the
newsgroups that belong to the subscription
list. |
Once a group is selected using the
group() method, you can list and retrieve articles.
Net::NNTP gives you the option of retrieving a specific
article by specifying its ID or message number, or iteratively
fetching articles in sequence, starting at the current message
number and working upward.
|
$article_arrayref =
$nntp->article ([$message] [,FILEHANDLE])
The article() method retrieves
the indicated article. If $message is numeric,
it is interpreted as a message number in the current
newsgroup. Net::NNTP returns the contents of the
indicated message, and sets the current message pointer
to this article. An absent first argument or a value of
undef retrieves the current article.
If the first argument is not numeric,
Net::NNTP treats it as the article's unique message ID.
Net::NNTP retrieves the article, but does not change the
position of the current message pointer. In fact, when
referring to an article by its message ID, it is not
necessary for the indicated article to belong to the
current group
The optional filehandle argument can be
used to write the article to the specified destination.
Otherwise, the article's contents (header, blank
separating line, and body) are returned as a reference
to an array containing the lines of the
article. |
Should something go wrong, article()
returns undef and $nntp->message contains
an error message from the server. A common error is "no such
article number in this group", which can be issued even when
the message number is in range because of articles that expire
or are cancelled while the NNTP session is active.
Other article-retrieval methods are more
specialized.
|
$header_arrayref =
$nntp->head([$message] [,FILEHANDLE])
$body_arrayref =
$nntp->body([$message] [,FILEHANDLE])
The head() and body()
methods work like article() but retrieve only
the header or body of the article, respectively.
$fh =
$nntp->articlefh([$message])
$fh =
$nntp->headfh([$message])
$fh =
$nntp->bodyfh([$message])
These three methods act like
article(), head(), and
body(), but return a tied filehandle from which
the contents of the article can be retrieved. After
using the filehandle, you should close it. For example,
here is one way to read message 10000 of the current
newsgroup: $fh = $nntp->articlefh(10000) or die $nntp->message;
while (<$fh>) {
print;
}
$msgid =
$nntp->next()
$msgid =
$nntp->last()
$msgid =
$nntp->nntpstat($message)
The next(), last(),
and nntpstat() methods control the current
article pointer. next() advances the current
article pointer to the next article in the newsgroup,
and last() moves the pointer to the previous
entry. The nntpstat() method moves the current
article pointer to the position indicated by
$message, which should be a valid message
number. After setting the current article pointer, all
three methods return the message ID of the current
article. |
Net::NMTP allows you to post new articles
using the post(), postfh(), and
ihave() methods.
|
$success =
$nntp->post([$message])
The post() method posts an
article to Netnews. The posted article does not have to
be directed to the current newsgroup; in fact, the news
server ignores the current newsgroup when accepting an
article and looks only at the contents of its
Newsgroups: header. The article may be provided as an
array containing the lines of the article or as a
reference to such an array. Alternatively, you may call
post() with no arguments and use the
datasend() and dataend() methods
inherited from Net::Cmd to send the article one line at
a time.
If successful, post() returns
a true value. Otherwise, it returns undef and
$nntp->message contains an error message
from the server.
$fh =
$nntp->postfh()
The postfh() method provides
an alternative interface for posting an article. If the
server allows posting, this method returns a tied
filehandle to which you can print the contents of the
article. After finishing, be sure to close the
filehandle. The result code from close()
indicates whether the article was accepted by the
server.
$wants_it =
$nntp->ihave($messageID[,$message])
The ihave() method is chiefly
of use for clients that are acting as news relays. The
method asks the Netnews server whether it wishes to
accept the article whose ID is $messageID.
If the server indicates its assent, it
returns a true result. The article must then be
transferred to the server, either by providing the
article's contents in the $message argument or
by sending the article one line at a time using the
Net::Cmd datasend() and dataend()
methods. $message can be an array of article
lines or a reference to such an
array. |
Last, several methods allow you to search for
particular articles of interest.
|
$header_has =
$nntp->xhdr($header,$message_range)
[extension]
$header_has =
$nntp->xpat($header,$pattern,$message_range)
[extension]
$references =
$nntp->xrover($message_range) [extension]
The xhdr() method is an
extension function that allows you to retrieve the value
of a header field from multiple articles. The
$header article is the name of an article
header field, such as "Subject". $message_range
is either a single message number or a reference to a
two-element array containing the first and last messages
in the desired range. If successful, xhdr()
returns a hash reference in which the keys are the
message numbers (not IDs) and the values are the
requested header fields.
The header field is case-insensitive.
However, not all headers can be retrieved in this way
because NNTP servers typically index only that subset of
the headers used to generate overview listings (see the
next method).
The xpat() method is similar
to xhdr(), but it filters the articles returned
for those with $header fields that match the
wildcard pattern in $pattern. The
xrover() method returns the cross-reference
fields for articles in the specified range. It is
functionally identical to: $xref = $nntp->xhdr('References',[$start,$end]);
The result of this call is a hash
reference in which the keys are message numbers and the
values are the message IDs that the article refers to.
These are typically used to reconstruct discussion
threads.
$overview_has =
$nntp->xover($message_range) [extension]
$format_arrayref =
$nntp->overview_fmt() [extension]
The overview_fmt() and
xover() methods return newsgroup "overview"
information. The overview is a summary of selected
article header fields; it typically contains the
Subject: line, References:, article Date:, and article
length. It is used by newsreaders to index, sort, and
thread articles.
Pass the xover() method a
message range (a single message number or a reference to
an array containing the extremes of the range). If
successful, the method's return value is a hash
reference in which each key is a message number and each
value is a reference to an array of the overview
fields.
To discover what these fields are, call
the overview_fmt() method. It returns an array
reference containing field names in the order in which
they appear in the arrays returned by xover().
Each field is followed by a colon and, occasionally, by
a server-specific modifier. For example, my laboratory's
Netnews server returns the following overview
fields: ('Subject:','From:','Date:','Message- ID:','References:',
'Bytes:','Lines:','Xref:full')
|
If you would prefer the values of the
overview array to be a hash reference rather than an array
reference, you can use the small subroutine shown here to do
the transformation. The trick is to use the list of field
names returned by overview_fmt() to create a hash
slice to which we assign the article overview array: sub get_overview {
my ($nntp,$range) = @_;
my @fields = map {/(\w+):/&& $1} @{$nntp->overview_fmt};
my $over = $nntp->xover($range) || return;
foreach (keys %$over) {
my $h = {};
@{$h}{@fields}= @{$over->{$_}};
$over->{$_} = $h;
}
return $over;
}
Use the subroutine like this: $over = get_overview($nntp,[30000,31000]);
The returned value will have a structure like
this: {
30000 => {
'Bytes' => 2704
'Date' => 'Sat, 27 May 2000 19:35:10 GMT'
'From' => 'mr_lowell@my-deja.com'
'Lines' => 72
'Message-ID' => '<8gp81d$cuo$1@nnrp1.deja.com>'
'References' => ''
'Subject' => 'mod_perl make test'
'Xref' => 'Xref: rQdQ comp.lang.perl.modules:34162'
},
30001 => {
'Bytes' => 1117
'Date' => 'Sat, 27 May 2000 20:28:22 GMT'
'From' => 'Robert Gasiorowski <gasior@snet.net>'
'Lines' => 6
'Message-ID' => '<39303E6A.88397549@snet.net>'
'References' => ''
'Subject' => 'installing module as non-root'
'Xref' => 'Xref: rQdQ comp.lang.perl.modules:34163'
},
....
}
|
A News-to-Mail Gateway
The last code example of this chapter is a
custom news-to-mail gateway. It periodically scans Netnews for
articles of interest, bundles them into a MIME message, and
mails them via Internet mail. Each time the script is run it
keeps track of the messages it has previously sent and only
sends messages that haven't been seen before.
You control the script's scope by specifying
a list of newsgroups and, optionally, one or more patterns to
search for in the subject lines of the articles contained in
the newsgroups. If you don't specify any subject-line
patterns, the script fetches the entire contents of the listed
newsgroups.
The subject-line patterns take advantage of
Perl's pattern-matching engine, and can be any regular
expression. For performance reasons, however, we use the
built-in NNTP wildcard patterns for newsgroup names.
The following command searches the comp.lang.perl.* newsgroups for
articles that have the word "Socket" or "socket" in the
subject line. Matching articles will be mailed to the local
e-mail address lstein. Options
include -subject, to specify
the subject pattern match, -mail to set the mail recipient(s),
and -v to turn on verbose
progress messages. % scan_newsgroups.pl -v -mail lstein -subj '[sS]ocket' 'comp.lang.perl.*'
Searching comp.lang.perl.misc for matches
Fetching overview for comp.lang.perl.misc
found 39 matching articles
Searching comp.lang.perl.announce for matches
Fetching overview for comp.lang.perl.announce
found 0 matching articles
Searching comp.lang.perl.tk for matches
Fetching overview for comp.lang.perl.tk
found 1 matching articles
Searching comp.lang.perl.modules for matches
Fetching overview for comp.lang.perl.modules
found 4 matching articles
44 articles, 40 unseen
sending e-mail message to lstein
The received e-mail message contains a brief
prologue that describes the search and newsgroup patterns,
followed by the matching articles. Each article is attached as
an enclosure of MIME type message/rfc822. Depending on the
reader's mail-reading software, the enclosures are displayed
as either in-line components of the message or attachments.
The result is particularly nice in the Netscape mail reader
(Figure
8.8) because each article is displayed using fancy fonts
and hyperlinks.
Figure
8.9 lists the code for scan_newsgroups.pl.
Lines 17: Load modules We load the
Net::NNTP and MIME::Entity modules, as well as the
Getopt::Long module for argument processing. We need to keep
track of all the messages that we have found during previous
runs of the script, and the easiest way to do that is to
keep the message IDs in an indexed DBM database. However, we
don't know a priori what DBM library is available, so we
import the AnyDBM_File module, which chooses a library for
us. The code contained in the BEGIN{} block changes
the DBM library search order, as described in the
AnyDBM_File documentation.
We also load the Fcntl module in order to
have access to several constants needed to initialize the
DBM file.
Lines 922: Define constants We
choose a name for the DBM file, a file named .newscache in the user's home
directory, and create a usage message.
Lines 2325: Declare globals The
first line of globals correspond to command-line options.
The second line of globals are various data structures
manipulated by the script. The %Seen hash will be
tied to the DBM file. Its keys are the message IDs of
articles that we have previously retrieved.
%Articles contains information about the articles
recovered during the current search. Its keys are message
IDs, and its values are hash references of header fields
derived from the overview index. Last, @Fields
contains the list of header fields returned by the
xover() method.
Lines 2634: Process command-line
arguments We call GetOptions() to process the
command-line options, and then check consistency of the
arguments. If the e-mail recipient isn't explicitly given on
the command line, we default to the user's login name.
Lines 3536: Open connection to Netnews
server We open a connection to the Netnews server by
calling Net::NNTP->new(). If the server isn't
explicitly given on the command line, the $SERVER
option is undefined and Net::NNTP picks a suitable default.
Lines 3739: Open DBM file We tie
%Seen to the .newscache file using the
AnyDBM_File module. The options passed to tie()
cause the file to be opened read/write and to be created
with file mode 0640 (-rw-r-----), if it doesn't
already exist.
Lines 4041: Compile the pattern
match For efficiency's sake, we compile the pattern
matches into an anonymous subroutine. This subroutine takes
the text of a subject line and returns true if all the
patterns match, and false otherwise. The
match_code() subroutine takes the list of pattern
matches, compiles them, and returns an appropriate code
reference.
Lines 4243: Expand newsgroup
patterns We pass the list of newsgroups to a subroutine
named expand_newsgroups(). It calls the NNTP server
to expand the wildcards in the list of newsgroups and
returns the expanded list of newsgroup names.
Lines 4445: Search for matching
articles We loop through the expanded list of newsgroups
and call grep_group() for each one. The arguments
to grep_group() consist of the newsgroup name and a
code reference to filter them. Internally,
grep_group() accumulates the matched articles'
message IDs into the %Articles hash. We do it this
way because the same article may be cross-posted to several
related newsgroups; using the article IDs in a hash avoids
accumulating duplicates.
Lines 4648: Filter out articles already
seen We use Perl's grep() function to filter
out articles whose message IDs are already present in the
tied %Seen hash. New article IDs are added to the
hash so that on subsequent runs we will know that we've seen
them. The unseen article IDs are assigned to the
@to_fetch array.
If the user ran the script with the -all option, we short-circuit the
grep() operation so that all articles are
retrieved, including those we've seen before. This does not
affect the updating of the tied %Seen hash.
Lines 4952: Add articles to an outgoing
mail message and quit We pass the list of article IDs to
send_mail(), which retrieves their contents and
adds them to an outgoing mail message. We then call the NNTP
object's quit() method to disconnect from the
server, and exit ourselves.
Lines 5362: The match_code()
subroutine The match_code() subroutine takes a list
of zero or more patterns and constructs a code reference on
the fly. The subroutine is built up line-by-line in a scalar
variable called $code. The subroutine is designed
to return true only if all the patterns match the passed
subject line. If no patterns are specified, the subroutine
returns true by default. If the -insensitive option was passed to
the script, we do case-insensitive pattern matches with the
i flag. Otherwise, we do case-sensitive matches.
After constructing the subroutine code, we
eval() it and return the result to the caller. If
the eval() fails (presumably because of an error in
one or more of the regular expressions), we propagate the
error message and die.
Lines 6373: The
expand_newsgroups() subroutine The
expand_newsgroups(), subroutine takes a list of
newsgroup patterns and calls the NNTP object's
newsgroups() method on each of them in turn,
expanding them to a list of valid newsgroup names. If a
newsgroup contains no wildcards, we just pass it back
unchanged.
Lines 7485: The grep_group()
subroutine grep_group() scans the specified
newsgroup for articles whose subject lines match a set of
patterns. The patterns are provided in the form of a code
reference that returns true if the subject line matches.
We call the get_overview()
subroutine to return the server's overview index for the
newsgroup. get_overview() returns a hash reference
in which each key is a message number and each value is a
hash of indexed header fields. We step through each message,
recover its Subject: and Message-ID: fields, and pass the
subject field to the pattern-matching code reference. If the
code reference returns false, we go on to the next article.
Otherwise, we add the article's message ID and overview data
to the %Articles global.
When all articles have been examined, we
return to the caller the number of those that matched.
Lines 89102: The get_overview()
subroutine The get_overview() subroutine used here
is a slight improvement over the version shown earlier. We
start by calling the NNTP object's group() method,
recovering the newsgroup's first and last message numbers.
We then call the object's overview_fmt() method to
retrieve the names of the fields in the overview index.
Since this information isn't going to change during the
lifetime of the script, however, we cache it in the
@Fields global and call overview_fmt()
only if the global is empty. Before assigning to
@Fields, we clean up the field names by removing
the ":" and anything following it.
We recover the overview for the entire
newsgroup by calling the xover() method for the
range spanning the first and last article numbers. We now
loop through the keys of the returned overview hash,
replacing its array reference values, which lists fields by
position, with anonymous hashes that list fields by name. In
addition to recording the header fields that occur in the
article itself, we record a pseudofield named
Message-Number: that contains the group name and message
number in the form group.name:number. We use this
information during e-mail construction to create the default
name for the article enclosure.
Lines 103124: The send_mail()
subroutine send_mail() is called with an array of
article IDs to fetch, and is responsible for constructing a
multipart MIME message containing each article as an
attachment.
We create a short message prologue that
summarizes the program's run-time options and create a new
MIME::Entity by calling the build() method. The
message starts as a single-part message of type text/plain, but is automatically
promoted to a multipart message as soon as we start
attaching articles to it.
We then call attach_article() for
each article listed in $to_fetch. This array may be
empty, in which case we make no attachments. When all
articles have been attached, we call the MIME entity's
smtpsend() method to send out the mail using the
Mail::Mailer SMTP method, and clean up any temporary files
by calling the entity's purge() method.
Lines 125134: The
attach_article() subroutine For the indicated
message ID we fetch the entire article's contents as an
array of lines by calling the NNTP object's
article() method. We then attach the article to the
outgoing mail message, specifying a MIME type of message/rfc822, a description
corresponding to the article's subject line, and a suggested
filename derived from the article's newsgroup and message
number (taken from the global %Articles hash).
An interesting feature of this script is the
fact that because we are storing unique global message IDs in
the .newscache hashed database, we can switch to a
different NNTP server without worrying about retrieving
articles we have already seen.
|
Chapter 9. Web Clients
In the previous chapters we reviewed client
modules for sending and receiving Internet mail, transferring
files via FTP, and interacting with Netnews servers. In this
chapter we look at LWP, the Library for Web access in Perl.
LWP provides a unified API for interacting with Web, FTP, News
and Mail servers, as well as with more obscure services such
as Gopher.
With LWP you can (1) request a document from
a remote Web server using its URL; (2) POST data to a Web
server, emulating the submission of a fill-out form; (3)
mirror a document on a remote Web server in such a way that
the document is transferred only if it is more recent than the
local copy; (4) parse HTML documents to recover links and
other interesting features; (5) format HTML documents as text
and postscript; and (6) handle cookies, HTTP redirects, proxy
servers, and HTTP user authentication. Indeed, LWP implements
all the functionality one needs to write a Web browser in
Perl, and if you download and install the Perl-TK
distribution, you'll find it contains a fully functional
graphical Web browser written on top of LWP.
The base LWP distribution contains 35
modules, and another dozen modules are required for HTML
parsing and formatting. Because of its size and scope, we will
skim the surface of LWP. For an exhaustive treatment, see
LWP's POD documentation, or the excellent, but now somewhat
dated Web Client Programming with
Perl [Wong 1999].
|
Installing LWP
The first version of LWP appeared in 1995,
and was written by Martijn Koster and Gisle Aas. It has since
been maintained and extended by Gisle Aas, with help from many
contributors.
The basic LWP library, distributed via CPAN
in the file libwww-X.XX.tar.gz
(where X.XX is the most recent
version number), provides supports for the HTTP, FTP, Gopher,
SMTP, NNTP, and HTTPS (HTTP over Secure Sockets Layer)
protocols. However, before you can install it, you must
install a number of prerequisite modules:
|
URI |
URL parsing and manipulation |
|
Net::FTP |
to support ftp://URLs |
|
MIME::Base64 |
to support HTTP Basic
authentication |
|
Digest::MD5 |
to support HTTP Digest
authentication |
|
HTML::HeadParser |
for finding the <BASE> tag in
HTML headers |
You could download and install each of these
modules separately, but the easiest way is to install LWP and
all its prerequisites in batch mode using the standard CPAN
module. Here is how to do this from the command line: % perl -MCPAN -e 'install Bundle::LWP'
This loads the CPAN module and then calls the
install() function to download, build, and install
LWP and all the ancillary modules that it needs to run.
The HTML-parsing and HTML-formatting modules
were once bundled with LWP, but are now distributed as
separate packages named HTML-Parser and HTML-Formatter, respectively. They
each have a number of prerequisites, and again, the easiest
way to install them is via the CPAN module using this
command: % perl -CPAN -e 'install HTML::Parser' -e 'install HTML::Formatter'
If you want to install these libraries
manually, here is the list of the packages that you need to
download and install:
|
HTML-Parser |
HTML parsing |
|
HTML-Tree |
HTML syntax-tree generation |
|
Font-AFM |
Postscript font metrics |
|
HTML-Format |
HTML
formatting |
To use the HTTPS (secure HTTP) protocol, you
must install one of the Perl SSL modules, IO::Socket::SSL, as
well as OpenSSL, the open source SSL library that
IO::Socket::SSL depends on. OpenSSL is available from http://www.openssl.org/.
LWP is pure Perl. You don't need a C compiler
to install it. In addition to the module files, when you
install LWP you get four scripts, which serve as examples of
how to use the library, as well as useful utilities in their
own right. The scripts are:
-
lwp-request Fetch a URL and display
it.
-
lwp-download Download a document to
disk, suitable for files too large to hold in memory.
-
lwp-mirror Mirror a document on a
remote server, updating only the local copy if the remote
one is more recent.
-
lwp-rget Copy an entire document
hierarchy recursively.
|
LWP Basics
Figure
9.1 shows a script that downloads the URL given on the
command line. If successful, the document is printed to
standard output. Otherwise, the script dies with an
appropriate error message. For example, to download the HTML
source for Yahoo's weather page, located at http://www.yahoo.com/r/wt, you would call
the script like this:

% get_url.pl http://www.yahoo.com/r/wt > weather.html
The script can just as easily be used to
download a file from an FTP server like this: % get_url.pl ftp://www.cpan.org/CPAN/RECENT
The script will even fetch news articles,
provided you know the message ID: % get_url.pl news:3965e1e8.1936939@enews.newsguy.com
All this functionality is contained in a
script just 10 lines long.
Lines 13: Load modules We turn on
strict syntax checking and load the LWP module.
Line 4: Read URL We read the desired
URL from the command line.
Line 5: Create an LWP::UserAgent We
create a new LWP::UserAgent object by calling its
new() method. The user agent knows how to make
requests on remote servers and return their responses.
Line 6: Create a new HTTP::Request
We call HTTP::Request->new(), passing it a
request method of "GET" and the desired URL. This returns a
new HTTP::Request object.
Line 7: Make the request We pass the
newly created HTTP::Request to the user agent's
request() method. This issues a request on the
remote server, returning an HTTP::Response.
Lines 89: Print response We call
the response object's is_success() method to
determine whether the request was successful. If not, we die
with the server's error message, returned by the response
object's message() method. Otherwise, we retrieve
and print the response contents by calling the response
object's content() method.
Short as it is, this script illustrates the
major components of the LWP library. HTTP::Request contains
information about the outgoing request from the client to the
server. Requests can be simple objects containing little more
than a URL, as shown here, or can be complex objects
containing cookies, authentication information, and arguments
to be passed to server scripts.
HTTP::Response encapsulates the information
returned from the server to the client. Response objects
contain status information, plus the document contents
itself.
LWP::UserAgent intermediates between client
and server, transmitting HTTP::Requests to the remote server,
and translating the server's response into an HTTP::Response
to return to client code.
In addition to its object-oriented mode, LWP
offers a simplified procedural interface called LWP::Simple.
Figure
9.2 shows the same script rewritten using this module.
After loading the LWP::Simple module, we fetch the desired URL
from the command line and pass it to getprint(). This
function attempts to retrieve the indicated URL. If
successful, it prints its content to standard output.
Otherwise, it prints a message describing the error to
STDERR.

In fact, we could reduce Figure
9.1 even further to this one-line command: % perl -MLWP::Simple -e 'getprint shift' http://www.yahoo.com/r/wt
The procedural interface is suitable for
fetching and mirroring Web documents when you do not need
control over the outgoing request and you do not wish to
examine the response in detail. The object-oriented interface
is there when you need to customize the outgoing request by
providing authentication information and data to post to a
server script, or by changing other header information passed
to the server. The object-oriented interface also allows you
to interrogate the response to recover detailed information
about the remote server and the returned document.
HTTP::Request
The Web paradigm generalizes all
client/server interactions to a client request and a server
response. The client request consists of a Uniform Resource
Locator (URL) and a request method. The URL, which is known in
the LWP documentation by its more general name, URI (for
Uniform Resource Identifier), contains information on the
network protocol to use and the server to contact. Each
protocol uses different conventions in its URLs. The protocols
supported by LWP include:
HTTP The Hypertext Transfer Protocol,
the "native" Web protocol described in RFCs 1945 and 2616, and
the one used by all Web servers. HTTP URLs have this familiar
form: http://server.name:port/path/to/document
The http: at
the beginning identifies the protocol. This is followed by the
server DNS name, IP address, and, optionally, the port the
server is listening on. The remainder of the URL is the path
to the document.
FTP A document stored on an FTP
server. FTP URLs have this form: ftp://server.name:port/path/to/document
GOPHER A document stored on a server
running the now rarely used gopher protocol. Gopher URLs have
this form: gopher://server.name:port/path/to/document
SMTP LWP can send mail messages via
SMTP servers using mailto:
URLs. These have the form: mailto:user@some.host
where user@some.host is the recipient's
e-mail address. Notice that the location of the SMTP server
isn't part of the URL. LWP uses local configuration
information to identify the server.
NNTP LWP can retrieve a news posting
from an NNTP server given the ID of the message you wish to
retrieve. The URL format is: news:message-id
As in mail:
URLs, there is no way to specify the particular NNTP server. A
suitable server is identified automatically using Net::NNTP's
rules (see Chapter
8).
In addition to the URL, each request has a
method. The request method indicates the type of transaction
that is requested. A number of methods are defined, but the
most frequent ones are:
GET Fetch a copy of the document
indicated by the URL. This is the most common way of fetching
a Web page.
PUT Replace or create the document
indicated by the URL with the document contained in the
request. This is most commonly seen in the FTP protocol when
uploading a file, but is also used by some Web page editors.
POST Send some information to the
indicated URL. It was designed for posting e-mail messages and
news articles, but was long ago appropriated for use in
sending fill-out forms to CGI scripts and other server-side
programs.
DELETE Delete the document indicated
by the URL. This is used to delete files from FTP servers and
by some Web-based editing systems.
HEAD Return information about the
indicated document without changing or downloading it.
HTTP protocol requests can also contain other
information. Each request includes a header that contains a
set of RFC 822-like fields. Common fields include Accept:,
indicating the MIME type(s) the client is prepared to receive,
User-agent:, containing the name and version of the client
software, and Content-type:, which describes the MIME type of
the request content, if any. Other fields handle user
authentication for password-protected URLs.
For the PUT and POST methods, but not for
GET, HEAD, and DELETE, the request also contains content data.
For PUT, the content is the document to upload to the location
indicated by the URL. For POST, the content is some data to
send, such as the contents of a fill-out form to send to a CGI
script.
The LWP library uses a class named
HTTP::Request to represent all requests, even those that do
not use the HTTP protocol. You construct a request by calling
HTTP::Request->new() with the name of the desired
request method and the URL you wish to apply the request to.
For HTTP requests, you can then add or alter the outgoing
headers to do such things as add authentication information or
HTTP cookies. If the request method expects content data,
you'll normally add the data to the request object using its
content () method.
The API description that follows lists the
most frequently used HTTP:: Request methods. Some of them are
defined in HTTP::Request directly, and others are
inherited.
One begins by creating a new request object
with HTTP::Request->new().
|
$request =
HTTP::Request->new($method, $url [,$header
[,$content]])
The new() method constructs a
new HTTP::Request. It takes a minimum of two arguments.
$method is the name of the request method, such
as GET, and $url is the URL to act on. The URL
can be a simple string or a reference to a URI object
created using the URI module. We will not discuss the
URI module in detail here, but it provides functionality
for dissecting out the various parts of
URLs. |
new() also accepts optional header
and content arguments. $header should be a reference
to an HTTP::Headers object. However, we will not go over the
HTTP::Headers API because it's easier to allow HTTP::Request
to create a default headers object and then customize it after
the object is created. $content is a string
containing whatever content you wish to send to the
server.
Once the request object is created, the
header() method can be used to examine or change
header fields.
|
$request->header($field1 =>
$val1, $field2 => $val2 ...)
@values =
$request->header($field)
Call header() with one or more
field/value pairs to set the indicated fields, or with a
single field name to retrieve the current values. When
called with a field name, header() returns the
current value of the field. In a list context,
header() returns multivalued fields as a list;
in a scalar context, it returns the values separated by
commas. |
This example sets the Referer: field, which
indicates the URL of the document that referred to the one
currently being requested: $request->header(Referer => 'http://www.yahoo.com/whats_cool.html')
An HTTP header field can be multivalued. For
example, a client may have a Cookie: field for each cookie
assigned to it by the server. You can set multivalued field
values by using an array reference as the value, or by passing
a string in which values are separated by commas. This example
sets the Accept: field, which is a multivalued list of the
MIME types that the client is willing to accept: $request->header(Accept => ['text/html','text/plain','text/rtf'])
Alternatively, you can use the
push_header() method described later to set
multivalued fields.
|
$request->push_header($field
=> $value)
The push_header() method
appends the indicated value to the end of the field,
creating it if it does not already exist, and making it
multivalued otherwise. $value can be a scalar
or an array reference.
$request->remove_header(@fields)
The remove_header() method
deletes the indicated
fields. |
A variety of methods provide shortcuts for
dealing with header fields.
|
$request->scan(\&sub)
The scan() method iterates
over each of the HTTP headers in turn, invoking the code
reference provided in \&sub. The subroutine
you provide will be called with two arguments consisting
of the field name and its value. For multivalued fields,
the subroutine is invoked once for each value.
$request->date()
$request->expires()
$request->last_modified()
$request->if_modified_since()
$request->content_type()
$request->content_length()
$request->referer()
$request->user_agent()
These methods belong to a family of 19
convenience methods that allow you to get and set a
number of common unique-valued fields. Called without an
argument, they return the current value of the field.
Called with a single argument, they set it. The methods
that deal with dates use system time format, as returned
by time(). |
Three methods allow you to set and examine
one request's content.
|
$request->content([$content])
$request->content_ref
The content() method sets the
content of the outgoing request. If no argument is
provided, it returns the current content value, if any.
content_ref() returns a reference to the
content, and can be used to manipulate the content
directly.
When POSTing a fill-out form query to a
dynamic Web page, you use content() to set the
query string, and call content_type() to set
the MIME type to either application/x-www-form-urlencoded
or multipart/form-data.
It is also possible to generate content
dynamically by passing content() a reference to
a piece of code that returns the content. LWP invokes
the subroutine repeatedly until it returns an empty
string. This facility is useful for PUT requests to FTP
servers, and POST requests to mail and news servers.
However, it's inconvenient to use with HTTP servers
because the Content-Length: field must be filled out
before sending the request. If you know the length of
the dynamically generated content in advance, you can
set it using the content_length() method.
$request->add_content($data)
This method appends some data to the
end of the existing content, if any. It is useful when
reading content from a file. |
Finally, several methods allow you to change
the URL and method.
|
$request->uri([$uri])
This method gets or sets the outgoing
request's URI.
$request->method([$method])
This method() gets or sets the
outgoing request's method.
$string =
$request->as_string
The as_string() method returns
the outgoing request as a string, often used during
debugging. |
HTTP::Response
Once a request is issued, LWP returns the
server's response in the form of an HTTP::Response object.
HTTP::Response is used even for non-HTTP protocols, such as
FTP.
HTTP::Response objects contain status
information that reports the outcome of the request, and
header information that provides meta-information about the
transaction and the requested document. For GET and POST
requests, the HTTP::Response usually contains content
data.
The status information is available both as a
numeric status code and as a short human-readable message.
When using the HTTP protocol, there are more than a dozen
status codes, the most common of which are listed in Table
9.1. Although the text of the messages varies slightly
from server to server, the codes are standardized and fall
into three general categories:
-
Informational codes, in the range
100 through 199, are informational status codes issued
before the request is complete.
-
Success
codes, which occupy the 200 through 299 range, indicate
successful outcomes.
-
Redirection
status codes, in the 300 through 399 range, indicate that
the requested URL has moved elsewhere. These are commonly
encountered when a Web site has been reorganized and the
administrators have installed redirects to avoid breaking
incoming external links.
-
Errors in
the 400 through 499 range indicate various client-side
errors, and those 500 and up are server-side
errors.
When dealing with non-HTTP servers, LWP
synthesizes appropriate status codes. For example, when
requesting a file from an FTP server, LWP generates a 200
("OK") response if the file was downloaded, and 404 ("Not
Found") if the requested file does not exist.
The LWP library handles some status codes
automatically. For example, if a Web server returns a
redirection response indicating that the requested URL can be
found at a different location (codes 301 or 302), LWP
automatically generates a new request directed at the
indicated location. The response that you receive corresponds
to the new request, not the original. If the response requests
authorization (status code 401), and authorization information
is available, LWP reissues the request with the appropriate
authorization headers.
HTTP::Response headers describe the server,
the transaction, and the enclosed content. The most useful
headers include Content-type: and Content-length:, which
provide the MIME type and length of the returned document, if
any, Last-modified:, which indicates when the document was
last modified, and Date:, which tells you the server's idea of
the time (since client and server clocks are not necessarily
synchronized).
Table 9.1. Common HTTP Status Codes
and Messages
| 1XX codes: informational |
|
| 100 |
Continue |
Continue with
request. |
| 101 |
Switching
Protocols |
It is upgrading to
newer version of HTTP. |
| 2XX codes: success |
|
| 200 |
OK |
The URL was found. Its
contents follows. |
| 201 |
Created |
A URL was created in
response to a POST. |
| 202 |
Accepted |
The request was
accepted for processing at a later date. |
| 204 |
No Response
|
The request is
successful, but there's no content. |
| 3XX codes: redirection |
|
| 301 |
Moved |
The URL has
permanently moved to a new location. |
| 302 |
Found |
The URL can be
temporarily found at a new location. |
| 4XX codes: client errors |
|
| 400 |
Bad Request
|
There's a syntax error
in the request. |
| 401 |
Authorization
Required |
Password authorization
is required. |
| 403 |
Forbidden |
This URL is forbidden,
and authorization won't help. |
| 404 |
Not Found |
It isn't here. |
| 5XX codes: server errors |
|
| 500 |
Internal
Error |
The server encountered
an unexpected error. |
| 501 |
Not
Implemented |
Used for unimplemented
features. |
| 502 |
Overloaded
|
The server is
temporarily
overloaded. |
Like the request object, HTTP::Response
inherits from HTTP::Message, and delegates unknown method
calls to the HTTP::Headers object contained within it. To
access header fields, you can call header(),
content_type(), expires(), and all the other
header-manipulation methods described earlier.
Similarly, the response content can be
accessed using the content() and
content_ref() methods. Because some documents can be
quite large, LWP also provides methods for saving the content
directly to disk files and spooling them to subroutines in
pieces.
Although HTTP::Response has a constructor,
you will not usually construct it yourself, so it isn't listed
here. For brevity, a number of other infrequently used methods
are also omitted. See the HTTP::Response documentation for
full API.
|
$status_code
= $response->code
$status_message =
$response->message
The code() and
message() methods return information about the
outcome of the request. code() returns a
numeric status code, and message() returns its
human-readable equivalent. You can also provide these
methods with an argument in order to set the
corresponding field.
$text =
$response->status_line
The status_line() method
returns the status code followed by the message in the
same format returned by the Web server.
$boolean =
$response->is_success
$boolean =
$response->is_redirect
$boolean =
$response->is_info
$boolean =
$response->is_error
These four methods return true if the
response was successful, is a redirection, is
informational, or is an error, respectively.
$html =
$response->error_as_HTML
If is_error() returns true,
you can call error_as_HTML() to return a nicely
formatted HTML document describing the error.
$base =
$response->base
The base() method returns the
base URL for the response. This is the URL to use to
resolve relative links contained in the returned
document. The value returned by base() is
actually a URI object, and can be used to "absolutize"
relative URLs. See the URI module documentation for
details.
$request =
$response->request
The request() method returns a
copy of the HTTP::Request object that generated this
response. This may not be the same HTTP::Request that
you constructed. If the server generated a redirect or
authentication request, then the request returned by
this method is the object generated internally by
LWP.
$request =
$response->previous
previous() returns a copy of
the HTTP::Request object that preceded the current
object. This can be used to follow a chain of redirect
requests back to the original request. If there is no
previous request, this method returns
undef. |
Figure
9.3 shows a simple script named follow_chain.pl
that uses the previous() method to show all the
intermediate redirects between the requested URL and the
retrieved URL. It begins just like the get_url.pl script of Figure
9.1, but uses the HEAD method to retrieve information
about the URL without fetching its content. After retrieving
the HTTP::Response, we call previous() repeatedly to
retrieve all intermediate responses. Each response's URL and
status line is prepended to a growing list of URLs, forming a
response chain. At the end, we format the response chain a bit
and print it out.
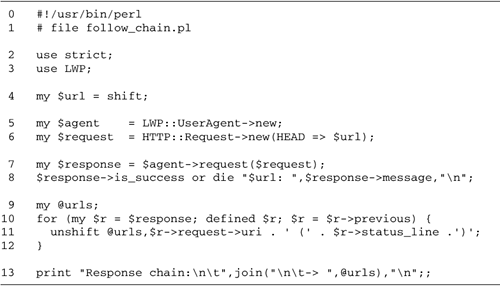
Here is the result of fetching a URL that has
been moved around a bit in successive reorganizations of my
laboratory's Web site: % follow_chain.pl http://stein.cshl.org/software/WWW
Response chain:
http://stein.cshl.org/software/WWW (302 Found)
-> http://stein.cshl.org/software/WWW/ (301 Moved Permanently)
-> http://stein.cshl.org/WWW/software/ (200 OK)
LWP::UserAgent
The LWP::UserAgent class is responsible for
submitting HTTP::Request objects to remote servers, and
encapsulating the response in a suitable HTTP::Response. It
is, in effect, a Web browser engine.
In addition to retrieving remote documents,
LWP::UserAgent knows how to mirror them so that the remote
document is transferred only if the local copy is not as
recent. It handles Web pages that require password
authentication, stores and returns HTTP cookies, and knows how
to negotiate HTTP proxy servers and redirect responses.
Unlike HTTP::Response and HTTP::Request,
LWP::UserAgent is frequently subclassed to customize the way
that it interacts with the remote server. We will see examples
of this in a later section.
|
$agent =
LWP::UserAgent->new
The new() method constructs a
new LWP::UserAgent object. It takes no arguments. You
can reuse one user agent multiple times to fetch
URLs.
$response =
$agent->request ($request, [$dest [,$size]])
The request() method issues
the provided HTTP::Request, returning an HTTP::
Response. A response is returned even on failed
requests. You should call the response's
is_success() or code() methods to
determine the exact outcome.
The optional $dest argument
controls where the response content goes. If it is
omitted, the content is placed in the response object,
where it can be recovered with the content()
and content_ref()
methods. |
If $dest is a scalar, it is treated
as a filename. The file is opened for writing, and the
retrieved document is stored to it. Because LWP prepends a
> symbol to the filename, you cannot use command
pipes or other tricks. Because the content is stored to the
file, the response object indicates successful completion of
the task, but content(), returns undef.
$dest can also be a reference to a
callback subroutine. In this case, the content data is passed
to the indicated subroutine at regular intervals, giving you a
chance to do something with the data, like pass it to an HTML
parser. The callback subroutine should look something like
this: sub handle_content {
my ($data,$response,$protocol) = @_;
...
}
The three arguments passed to the callback
are the current chunk of content data, the current
HTTP::Response object, and an LWP::Protocol object. The
response object is provided so that the subroutine can make
intelligent decisions about how to process the content, such
as piping data of type image/jpeg to an image viewer. The
LWP::Protocol object implements protocol-specific access
methods that are used by LWP internally. It is unlikely that
you will need it.
If you use a code reference for
$dest, you can exercise some control over the content
chunk size by providing a $size argument. For
example, if you pass 512 for $size, the callback will
be called repeatedly with 512-byte chunks of the content
data.
Two variants of request() are useful
in certain situations.
|
$response =
$agent->simple_request($request, [$dest
[,$size]])
simple_request() behaves like
request(), but does not automatically reissue
requests to handle redirects or authentication
requirements. Its arguments are identical to those of
request().
$response =
$agent->mirror($url,$file)
The mirror() method accepts a
URL (a URI object or a string) and the path to a file in
which to store the remote document. If the local file
doesn't already exist, then mirror() fetches
the remote document. Otherwise, mirror()
compares the modification dates of the remote and local
copies, and only fetches the document if the local copy
appears to be out of date. For HTTP URLs,
mirror() constructs an HTTP::Request object
that has the correct If-Modified-Since: header field to
perform a conditional fetch. For FTP URLs, LWP uses the
MDTM (modification time) command to fetch the
modification date of the remote
file. |
Two methods allow you to set time and space
limits on requests.
|
$timeout =
$agent->timeout([$timeout])
timeout() gets or sets the
timeout on requests, in seconds. The default is 180
seconds (3 minutes). If the timeout expires before the
request completes, the returned response has a status
code of 500, and a message indicating that the request
timed out.
$bytes =
$agent->max_size([$bytes])
The max_size() method gets or
sets a maximum size on the response content returned by
the remote server. If the content exceeds this size,
then the content is truncated and the response object
contains an X-Content-Range: header indicating the
portion of the document returned. Typically, this header
has the format bytes
start-end, where start and end are the start and endpoints
of the document portion.
By default, the size is undef,
meaning that the user agent will accept content of any
length. |
The agent() and form()
methods add information to the request.
|
$id =
$agent->agent([$id])
The agent() method gets or
sets the User-Agent: field that LWP will send to HTTP
servers. It has the form name/x.xx (comment), where
name is the client
software name, x.xx is
the version number, and (comment) is an optional
comment field. By default, LWP uses libwww-perl/x.xx, where x.xx is
the current module version number.
You may need to change the agent ID to
trigger browser-specific behavior in the remote server.
For example, this line of code changes the agent ID to
Mozilla/4.7, tricking the
server into thinking it is dealing with a Netscape
version 4.X series browser running on a Palm Pilot: $agent->agent('Mozilla/4.7 [en] (PalmOS)')
$address =
$agent->from([$address])
The from() method gets or sets
the e-mail address of the user responsible for the
actions of the user agent. It is incorporated into the
From: field used in mail and news postings, and will be
issued, along with other fields, to HTTP servers. You do
not need to provide this information when communicating
with HTTP servers, but it can be provided in Web
crawling robots as a courtesy to the remote
site. |
A number of methods control how the agent
interacts with proxies, which are commonly used when the
client is behind a firewall that doesn't allow direct Internet
access, or in situations where bandwidth is limited and the
organization wishes to cache frequently used URLs locally.
|
$proxy =
$agent->proxy($protocol => $proxyy)
The proxy() method sets or
gets the proxy servers used for requests. The first
argument, $protocol, is either a scalar
containing the name of a protocol to proxy, such as
"ftp", or an array reference that lists several
protocols to proxy, such as
['ftp','http','gopher']. The second argument,
$proxy, is the URL of the proxy server to use.
For example: $agent->proxy([qw(ftp http)] => 'http://proxy.cshl.org:8080')
You may call this method several times
if you need to use a different proxy server for each
protocol: $agent->proxy(ftp => 'http://proxy1.cshl.org:8080');
$agent->proxy(http => 'http://proxy2.cshl.org:9000');
As this example shows, HTTP servers are
commonly used to proxy FTP requests as well as HTTP
requests.
$agent->no_proxy(@domain_list)
Call the no_proxy() method to
deactivate proxying for one or more domains. You would
typically use this to turn off proxying for intranet
servers that you can reach directly. This code fragment
disables proxying for the "localhost" server and all
machines in the "cshl.org" domain: $agent->no_proxy('localhost','cshl.org')
Calling no_proxy() with an
empty argument list clears the list of proxyless
domains. It cannot be used to return the current
list.
$agent->env_proxy
env_proxy() is an alternative
way to set up proxies. Instead of taking proxy
information from its argument list, this method reads
proxy settings from *_proxy environment variables.
These are the same environment variables used by UNIX
and Windows versions of Netscape. For example, a C-shell
initialization script might set the FTP and HTTP proxies
this way: setenv ftp_proxy http://proxy1.cshl.org:8080
setenv http_proxy http://proxy2.cshl.org:9000
setenv no_proxy localhost,cshl.org
|
Lastly, the agent object offers several
methods for controlling authentication and cookies.
|
($name,$pass)
= $agent->get_basic_credentials($realm,$url
[,$proxy])
When a remote HTTP server requires
password authentication to access a URL, the user agent
invokes its get_basic_credentials() method to
return the appropriate username and password. The
arguments consist of the authentication "realm name",
the URL of the request, and an optional flag indicating
that the authentication was requested by an intermediate
proxy server rather than the destination Web server. The
realm name is a string that the server sends to identify
a group of documents that can be accessed using the same
username/password pair.
By default,
get_basic_credentials() returns the username
and password stored among the user agent's instance
variables by the credentials() method. However,
it is often more convenient to subclass LWP::UserAgent
and override get_basic_credentials() in order
to prompt the user to enter the required information.
We'll see an example of this later.
$agent->credentials($hostport,$realm,$name,$pass)
The credentials() method
stores a username and password for use by
get_basic_credentials(). The arguments are the
server hostname and port in the format hostname:port, authentication
realm, username, and password.
$jar =
$agent->cookie_jar([$cookie_jar])
By default, LWP::UserAgent ignores
cookies that are sent to it by remote Web servers. You
can make the agent fully cookie-compatible by giving it
an object of type HTTP::Cookies. The module will then
stash incoming cookies into this object, and later
search it for stored cookies to return to the remote
server. Called with an HTTP::Cookies argument,
cookie_jar() uses the indicated object to store
its cookies. Called without arguments,
cookie_jar() returns the current cookie
jar. |
We won't go through the complete
HTTP::Cookies API, which allows you to examine and manipulate
cookies, but here is the idiom to use if you wish to accept
cookies for the current session, but not save them between
sessions: $agent->cookie_jar(new HTTP::Cookies);
Here is the idiom to use if you wish to save
cookies automatically in a file named .lwp-cookies for use across multiple
sessions: my $file = "$ENV{HOME}/.lwp-cookies";
$agent->cookie_jar(HTTP::Cookies->new(file=>$file,autosave=>1));
Finally, here is how to tell LWP to use an
existing Netscape-format cookies file, assuming that it is
stored in your home directory in the file ~/.netscape/cookies (Windows and Mac
users must modify this accordingly): my $file = "$ENV{HOME}/.netscape/cookies";
$agent->cookie_jar(HTTP::Cookies::Netscape->new(file=>$file,
autosave=>1));
|
LWP Examples
Now that we've seen the LWP API, we'll look
at some practical examples that use it.
Fetching a List of RFCs
The Internet FAQ Consortium (http://www.faqs.org/) maintains a Web server
that archives a large number of useful Internet documents,
including Usenet FAQs and IETF RFCs. Our first example is a
small command-line tool to fetch a list of RFCs by their
numbers.
The RFC archive at http://www.faqs.org/ follows a predictable
pattern. To view RFC 1028, for example, we would fetch the URL
http://www.faqs.org/rfcs/rfc1028.html.
The returned HTML document is a minimally marked-up version of
the original text-only RFC. The FAQ Consortium adds an image
and a few links to the top and bottom. In addition, every
reference to another RFC becomes a link.
Figure
9.4 shows the get_rfc.pl script. It accepts one
or more RFC numbers on the command line, and prints their
contents to standard output. For example, to fetch RFCs 1945
and 2616, which describe HTTP versions 1.0 and 1.1,
respectively, invoke get_rfc.pl
like this:

% get_rfc.pl 1945 2616
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<HTML>
<HEAD>
<TITLE>rfc1945 - Hypertext Transfer Protocol -- HTTP/1.0</TITLE>
<LINK REV="made" ="mailto:rfc-admin@faqs.org";>
<META name="description" content="Hypertext Transfer Protocol -- HTTP/1.0">
<META name="authors" content="T. Berners-Lee, R. Fielding & H. Frystyk">
...
The retrieved files can be saved to disk or
viewed in a browser.
Lines 14: Load modules We turn on
strict syntax checking and load the LWP module. In addition,
we define a constant URL prefix to use for fetching the
desired RFC.
Line 5: Process command-line
arguments We check that at least one RFC number is given
on the command line, or die with a usage message.
Lines 68: Create user agent We
create a new LWP::UserAgent and change its default
User-Agent: field to get_rfc/1.0. We follow this with
the original default agent ID enclosed in parentheses.
Lines 918: Main loop For each RFC
listed on the command line, we construct the appropriate URL
and use it to create a new HTTP::Request GET request. We
pass the request to the user agent object's
request() method and examine the response. If the
response's is_success() method indicates success,
we print the retrieved content. Otherwise, we issue a
warning using the response's status message.
Mirroring a List of RFCs
The next example represents a slight
modification. Instead of fetching the requested RFCs and
sending them to standard output, we'll mirror local copies of
them as files stored in the current working directory. LWP
will perform the fetch conditionally so that the remote
document will be fetched only if it is more recent than the
local copy. In either case, the script reports the outcome of
each attempt, as shown in this example: % mirror_rfc.pl 2616 1945 11
RFC 2616: OK
RFC 1945: Not Modified
RFC 11: Not Found
We ask the script to retrieve RFCs 2616, 1945
and 11. The status reports indicate that RFC 2616 was
retrieved OK, RFC 1945 did not need to be retrieved because
the local copy is current, and that RFC 11 could not be
retrieved because no such file exists on the remote server
(there is, in fact, no RFC 11).
The code, shown in Figure
9.5, is only 15 lines long.
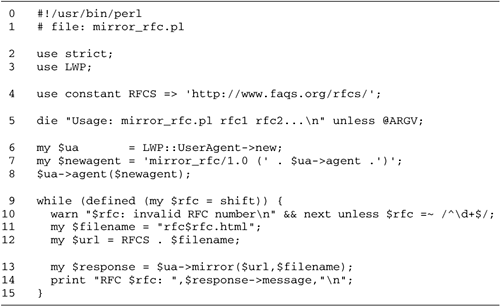
Lines 18: Load modules and create user
agent The setup of the LWP::UserAgent is identical to
the previous example, except that we modify the usage
message and the user agent ID appropriately.
Lines 915: Main loop We read RFC
numbers from the command line. For each RFC, we construct a
local filename of the form rfcXXXX.html, where XXXX is the number of the requested
document. We append this to the RFC server's base URL in
order to obtain the full remote URL.
In contrast with the previous example, we
don't need to create an HTTP::Request in order to do
mirroring. We simply pass the remote URL and local filename
to the agent's mirror() method, obtaining an
HTTP::Response in return. We then print the status message
returned by the response object's message()
method.
Simulating Fill-out Forms
The previous two examples fetched static
documents from remote Web servers. However, much of the
interesting content on the Web is generated by dynamic
server-side scripts such as search pages, on-line catalogs,
and news updates.
Server-side CGI scripts (as well as servlets
and other types of dynamic content) are usually driven by
fill-out HTML forms. Forms consist of a series of fields to
complete: typically a mixture of text fields, pop-up menus,
scrolling lists, and buttons. Each field has a name and a
value. When the form is submitted, usually by clicking on a
button, the names and current values of the form are bundled
into a special format and sent to the server script.
You can simulate the submission of a fill-out
form from within LWP provided that you know what arguments the
remote server is expecting and how it is expecting to receive
them. Sometimes the remote Web site documents how to call its
server-side scripts, but more often you have to reverse
engineer the script by looking at the fill-out form's source
code.
For example, the Internet FAQ Consortium
provides a search page at http://www.faqs.org/rfcs/ that includes,
among other things, a form for searching the RFC archive with
text search terms. By navigating to the page in a conventional
browser and selecting the "View Source" command, I obtained
the HTML source code for the page. Figure
9.6 shows an excerpt from this page, which contains the
definition for the search form (it's been edited slightly to
remove extraneous formatting tags).

In HTML, fill-out forms start with a
<FORM> tag and end with </FORM>.
Between the two tags are one or more <INPUT>
tags, which create simple fields like text entry fields and
buttons, <SELECT> tags, which define
multiple-choice fields like scrolling lists and pop-up menus,
and <TEXTAREA> tags, which create large text
entry fields with horizontal and vertical scrollbars.
Form elements have a NAME attribute,
which assigns a name to the field when it is sent to the Web
server, and optionally a VALUE attribute, which
assigns a default value to the field. <INPUT>
tags may also have a TYPE attribute that alters the
appearance of the field. For example, TYPE="text" creates a text field that
the user can type in, TYPE="checkbox"
creates an on/off checkbox, and TYPE="hidden" creates an element that
isn't visible in the rendered HTML, but nevertheless has its
name and value passed back to the server when the form is
submitted.
The <FORM> tag itself has two
required attributes. METHOD specifies how the
contents of the fill-out form are to be sent to the Web
server, and may be one of GET and POST. We'll talk about the
implications of the method later. ACTION specifies
the URL to which the form fields are to be sent. It may be a
full URL or an abbreviated form relative to the URL of the
HTML page that contains the form.
Occasionally, the ACTION attribute
may be missing entirely, in which case the form fields should
be submitted to the URL of the page in which the form is
located. Strictly speaking, this is not valid HTML, but it is
widely used.
In the example in Figure
9.6, the RFC search form consists of two elements. A text
field named "query" prompts the user for the text terms to
search for, and a menu named "archive" specifies which part of
the archive to search in. The various menu choices are
specified using a series of <OPTION> tags, and
include the values "rfcs", "rank", and "rfcindex". There is
also a submission button, created using an
<INPUT> tag with a TYPE attribute of
"submit". However, because it has no NAME attribute,
its contents are not included in the information to the
server. Figure
9.7 shows what this looks like when rendered by a
browser.
When the form is submitted, the browser
bundles the current contents of the form into a "query string"
using a MIME format known as application/x-www-form-urlencoded.
This format consists of a series of name= value pairs, where the names
and values are taken from the form elements and their current
values. Each pair is separated by an ampersand
(&) or semicolon (;). For example, if we
typed "MIME types" into the RFC search form's text field and
selected "Search RFC Index" from the pop-up menu, the query
string generated by the browser would be: query=MIME%20types&archive=rfcindex
Notice that the space in "MIME types" has
been turned into the string %20. This is a
hexadecimal escape for the space character (0x20 in ASCII). A
number of characters are illegal in query strings, and must be
escaped in this way. As we shall see, the URI::Escape module
makes it easy to create escaped query strings.
The way the browser sends the query string to
the Web server depends on whether the form submission method
is GET or POST. In the case of GET, a " ? " followed
by the query string is appended directly to the end of the URL
indicated by the <FORM> tag's ACTION
attribute. For example: http://www.faqs.org/cgi-bin/rfcsearch?query=MIME%20types&archive=rfcindex
In the case of a form that specifies the POST
method, the correct action is to POST a request to the URL
indicated by ACTION, and pass the query string as the
request content.
It is very important to send the query string
to the remote server in the way specified by the
<FORM> tag. Some server-side scripts are
sufficiently flexible to recognize and deal with both GET and
POST requests in a uniform way, but many do not.
In addition to query strings of type application/x-www-form-urlencoded,
some fill-out forms use a newer encoding system called multipart/form-data. We will talk
about dealing with such forms in the section File Uploads
Using multipart/form-data.
Our next sample script is named search_rfc.pl. It invokes the
server-side script located at http://www.faqs.org/cgi-bin/rfcsearch to
search the RFC index for documents having some relevance to
the search terms given on the command line. Here's how to
search for the term "MIME types": % search_rfc.pl MIME types
RFC 2503 MIME Types for Use with the ISO ILL Protocol
RFC 1927 Suggested Additional MIME Types for Associating Documents
search_rfc.pl works by simulating a
user submission of the fill-out form shown in Figures
9.6 and 9.7.
We generate a query string containing the query and archive fields, and POST it to the
server-side search script. We then extract the desired
information from the returned HTML document and print it
out.
To properly escape the query string, we use
the uri_escape() function, provided by the LWP module
named URI::Escape. uri_escape() replaces disallowed
characters in URLs with their hexadecimal escapes. Its
companion, uri_unescape(), reverses the process.
Figure
9.8 shows the code for the script.

Lines 14: Load modules We turn on
strict syntax checking and load the LWP and URI::Escape
modules. URI::Escape imports the uri_escape() and
uri_unescape() functions automatically.
Lines 57: Define constants We
define one constant for the URL of the remote search script,
and another for the page on which the fill-out form is
located. The latter is needed to properly fill out the
Referer: field of the request, for reasons that we will
explain momentarily.
Lines 810: Create user agent This
code is identical to the previous examples, except for the
user agent ID.
Lines 1112: Construct query string
We interpolate the command-line arguments into a string and
use it as the value of the fill-out form's query field. We are interested in
searching the archive's RFC index, so we use "rfcindex" as
the value of the archive
field. These are incorporated into a properly formatted
query string and escaped using uri_escape().
Lines 1315: Construct request We
create a new POST request on the remote search script, and
use the returned request object's content() method
to set the content to the query string. We also alter the
request object's Referer: header so that it contains the
fill-out form's URL. This is a precaution. For consistency,
some server-side scripts check the Referer: field to confirm
that the request came from a fill-out form located on their
own server, and refuse to service requests that do not
contain the proper value. Although the Internet FAQ
Consortium's search script does not seem to implement such
checks, we set the Referer: field here in case they decide
to do so in the future.
As an aside, the ease with which we are
able to defeat the Referer: check illustrates why this type
of check should never be relied on to protect server-side
Web scripts from misuse.
Lines 1617: Submit request We pass
the request to the LWP::UserAgent's request()
method, obtaining a response object. We check the response
status with is_success(), and die if the method
indicates a failure of some sort.
Lines 1821: Fetch and parse content
We retrieve the returned HTML document by calling the
response object's content() method and assign it to
a scalar variable. We now need to extract the RFC name and
title from the document's HTML. This is easy to do because
the document has the predictable structure shown in Figures
9.9 (screenshot) and 9.10
(HTML source). Each matching RFC is an item in an ordered
list (HTML tag <OL>) in which the RFC number
is contained within an <A> tag that links to
the text of the RFC, and the RFC title is contained between
a pair of <STRONG> tags.

We use a simple global regular expression
match to find and match all lines referring to RFCs, extract
the RFC name and title, and print the information to
standard output.
An enhancement to this script would be to
provide an option to fetch the text of each RFC returned by
the search. One way to do this would be to insert a call to
$ua->request() for each matched RFC. Another, and
more elegant, way would be to modify get_rfc.pl from
Figure
9.4 so as to accept its list of RFC numbers from standard
input. This would allow you to fetch the content of each RFC
returned by a search by combining the two commands in a
pipeline: % fetch_rfc.pl MIME type | get_rfc.pl
Because The Internet FAQ Consortium has not
published the interface to its search script, there is no
guarantee that they will not change either the form of the
query string or the format of the HTML document returned in
response to searches. If either of these things happen, search_rfc.pl will break. This is a
chronic problem for all such Web client scripts and a
compelling reason to check at each step of a complex script
that the remote Web server is returning the results you
expect.
This script contains a subtle bug in the way
it constructs its query strings. Can you find it? The bug is
revealed in the next section.
Using HTTP::Request::Common to Post
a Fill-out Form
Because submitting the field values from
fill-out forms is so common, LWP provides a class named
HTTP::Request::Common to make this convenient to do. When you
load HTTP::Request::Common, it imports four functions named
GET(), POST(), HEAD(), and
PUT(), which build various types of HTTP::Request
objects.
We will look at the POST() function,
which builds HTTP::Request objects suitable for simulating
fill-out form submissions. The other three are similar.
|
$request =
POST($url [,$form_ref] [,$header1=>$val1....])
The POST() function returns an
HTTP::Request object that uses the POST method.
$url is the requested URL, and may be a simple
string or a URI object. The optional $form_ref
argument is an array reference containing the names and
values of form fields to submit as content. If you wish
to add additional headers to the request, you can follow
this with a list of header/value
pairs. |
Using POST() here's how we could
construct a request to the Internet FAQ Consortium's RFC index
search engine: my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch',
[ query => 'MIME types',
archive => 'rfcindex' ]
);
And here's how to do the same thing but
setting the Referer: header at the same time: my $request =POST('http://www.faqs.org/cgi-bin/rfcsearch',
[ query => 'MIME types',
archive => 'rfcindex' ],
Referer => 'http://www.faqs.org/rfcs');
Notice that the field/value pairs of the
request content are contained in an array reference, but the
name/value pairs of the request headers are a simple list.
As an alternative, you may provide the form
data as the argument to a pseudoheader field named Content:.
This looks a bit cleaner when setting both request headers and
form content: my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch',
Content => [ query => 'MIME types',
archive => 'rfcindex' ],
Referer => 'http://www.faqs.org/rfcs');
POST() will take care of URI
escaping the form fields and constructing the appropriate
query string.
Using HTTP::Request::Common, we can rewrite
search_rfc.pl as shown in Figure
9.11. The new version is identical to the old except that
it uses POST() to construct the fill-out form
submission and to set the Referer: field of the outgoing
request (lines 1217). Compared to the original version of the
search_rfc.pl script, the new
script is easier to read. More significant, however, it is
less prone to bugs. The query-string generator from the
earlier versions contains a bug that causes it to generate
broken query strings when given a search term that contains
either of the characters "&" or "=". For example, given
the query string "mime&types", the original version
generates the string:

query=mime&types&archive=rfcindex
The manual fix would be to replace "
& " with " %26 " and " = " with
" %3D " in the search terms before
constructing the query string and passing it to
uri_escape(). However, the POST()-based
version handles this automatically, and generates the correct
content: query=mime%26types&archive=rfcindex
File Uploads Using multipart/form-data
In addition to form elements that allow users
to type in text data, HTML version 4 and higher provides an
<INPUT> element of type "file". When compatible
browsers render this tag, they generate a user interface
element that prompts the user for a file to upload. When the
form is submitted, the browser opens the file and sends it
contents, allowing whole files to be uploaded to a server-side
Web script.
However, this feature is not very compatible
with the application/x-www-form-urlencoded
encoding of query strings because of the size and complexity
of most uploaded files. Server scripts that support this
feature use a different type of query encoding scheme called
multipart/form-data. Forms that
support this encoding are enclosed in a <FORM>
tag with an ENCTYPE attribute that specifies this
scheme. For instance: <FORM METHOD=POST ACTION="/cgi-bin/upload" ENCTYPE="multipart/form-data">
The POST method is always used with this type
of encoding. multipart/form-data uses an encoding
scheme that is extremely similar to the one used for multipart
MIME enclosures. Each form element is given its own subpart
with a Content-Disposition: of "form-data", a name containing
the field name, and body data containing the value of the
field. For uploaded files, the body data is the content of the
file.
Although conceptually simple, it's tricky to
generate the multipart/form-data format correctly.
Fortunately, the POST() function provided by
HTTP::Request:: Common can also generate requests compatible
with multipart/form-data. The
key is to provide POST() with a Content_Type: header
argument of "form-data": my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch',
Content_Type => 'form-data',
Referer => 'http://www.faqs.org/rfcs',
Content => [ query => 'MIME types',
archive => 'rfcindex' ]
);
This generates a request to the RFC search
engine using the multipart/form-data encoding scheme.
But don't try it: the RFC FAQ site doesn't know how to handle
this scheme.
To tell LWP to upload a file, the value of
the corresponding form field must be an array reference
containing at least one element: $fieldname => [ $file, $filename, header1=>$value.... ]
The mandatory first element in the array,
$file, is the path to the file to upload. The
optional $filename argument is the suggested name to
use for the file, and is similar to the MIME::Entity Filename argument. This is followed
by any number of additional MIME headers. The one used most
frequently is Content_Type:, which gives the server script the
MIME type of the uploaded file.
To illustrate how this works, we'll write a
client for the CGI script located at http://stein.cshl.org/WWW/software/CGI/examples/file_upload.cgi.
This is a script that I wrote some years ago to illustrate how
CGI scripts accept and process uploaded files. The form that
drives the script (Figures
9.12 and 9.14)
contains a single file field named filename, and three checkboxes named
count with values named
"count lines", "count words", and "count
characters". There's also a hidden field named .cgifields with a value of
"count."
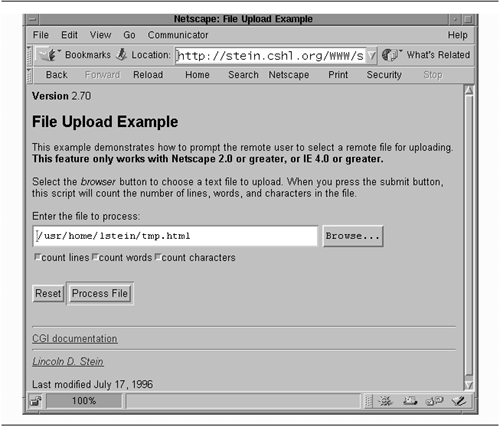
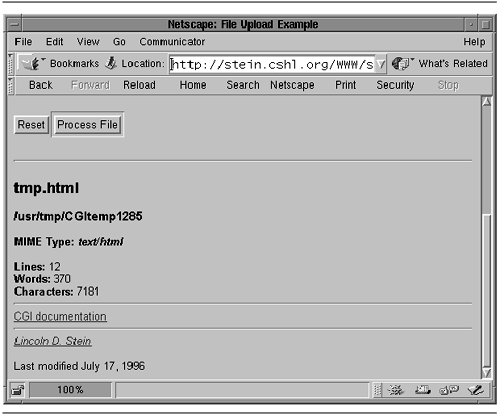
After form submission, the script reads the
uploaded file and counts its lines, words, and/or characters,
depending on which checkboxes are selected. It prints these
statistics, along with the name of the file and its MIME type,
if any (Figure
9.13).

We will now develop an LWP script to drive
this CGI script. remote_wc.pl
reads a file from the command line or standard input and
uploads it to file_upload.cgi.
It parses the HTML result and prints the word count returned
by the remote server: % remote_wc.pl ~/public_html/png.html
lines = 20; words = 47; characters = 362
This is a pretty difficult way to perform a
word count, but it does illustrate the technique! Figure
9.15 gives the code for remote_wc.pl.

Lines 14: Load modules We turn on
strict syntax checking and load the LWP and
HTTP::Request::Common modules.
Lines 57: Process arguments We
define a constant for the URL of the CGI script and recover
the name of the file to upload from the command line.
Lines 821: Create user agent and
request We create the LWP::UserAgent in the usual way.
We then create the request using the POST()
function, passing the URL of the CGI script as the first
argument, a Content_Type
argument of "form-data", and a Content argument containing the
various fields used by the upload form.
Notice that the count field appears three times in
the Content array, once for
each of the checkboxes in the form. The value of the filename field is an anonymous
array containing the file path provided on the command line.
We also provide values for the .cgifields hidden field and the
submit button, even though it
isn't clear that they are necessary (they aren't, but unless
you have the documentation for the remote server script, you
won't know this).
Lines 2223: Issue request We call
the user agent's request() method to issue the
POST, and get a response object in return. As in earlier
scripts, we check the is_success() method and die
if an error occurs.
Lines 2427: Extract results We call
the response's content() method to retrieve the
HTML document generated by the remote script, and perform a
pattern match on it to extract the values for the line,
word, and character counts (this regular expression was
generated after some experimentation with sample HTML
output). Before exiting, we print the extracted values to
standard output.
Fetching a Password-Protected
Page
Some Web pages are protected by username and
password using HTTP authentication. LWP can handle the
authentication protocol, but needs to know the username and
password.
There are two ways to provide LWP with this
information. One way is to store the username and password in
the user agent's instance variables using its
credentials() method. As described earlier,
credentials() stores the authentication information
in a hash table indexed by the Web server's hostname, port,
and realm. If you store a set of passwords before making the
first request, LWP::UserAgent consults this table to find a
username and password to use when accessing a protected page.
This is the default behavior of the
get_basic_credentials() method.
The other way is to ask the user for help at
runtime. You do this by subclassing LWP::UserAgent and
overriding the get_basic_credentials() method. When
invoked, the customized get_basic_credentials()
prompts the user to enter the required information.
The get_url2.pl script implements this
latter scheme. For unprotected pages, it acts just like the
original get_url.pl script (Figure
9.1). However, when fetching a protected page, it prompts
the user to enter his or her username and password. If the
name and password are accepted, the URL is copied to standard
output. Otherwise, the request fails with an "Authorization
Required" error (status code 401): % get_url2.pl http://stein.cshl.org/private/
Enter username and password for realm "example".
username: perl
password: programmer
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<html> <head>
<title>Password Protected Page</title>
<link rel="stylesheet" ="/stylesheets/default.css">
</head>
...
If you wish to try this script with the URL
given in the example, the username is "perl" and the password
is "programmer."
Figure
9.16 shows the code for get_url2.pl. Except for an odd little
idiom, it's straightforward. We are going to declare a
subclass of LWP::UserAgent, but we don't want to create a
whole module file just to override a single method. Instead,
we arrange for the script itself (package "main") to be a
subclass of LWP::UserAgent, and override the
get_basic_credentials() method directly in the main
script file. This is a common, and handy, trick.

Lines 16: Load modules We turn on
strict syntax checking and load LWP. We also load the
PromptUtil module (listed in Appendix A), which provides us
with the get_passwd() function for prompting the
user for a password without echoing it to the screen.
We set the @ISA array to make sure
that the current package is a subclass of
LWP::UserAgent.
Lines 712: Issue request, print
content The main section of the script is identical to
the original get_url.pl, with
one exception. Instead of calling LWP::User
Agent->new() to create a new user agent object, we
call _PACKAGE->new(). The Perl interpreter
automatically replaces the _PACKAGE_ token with the
name of the current package ("main" in this case), creating
the desired LWP::UserAgent subclass.
Lines 1320: Override
get_basic_credentials() method This section of the code
overrides get_basic_credentials() with a custom
subroutine. The subclass behaves exactly like LWP::UserAgent
until it needs to fetch authentication information, at which
point this subroutine is invoked.
We are called with three arguments,
consisting of the user agent object, the authentication
realm, and the URL that has been requested. We prompt the
user for a username, and then call get_passwd() to
prompt and fetch the user's password. These are returned to
the caller as a two-element list.
An interesting characteristic of this script
is that if the username and password aren't entered correctly
the first time, LWP invokes the
get_basic_credentials() once more and the user is
prompted to try again. If the credentials still aren't
accepted, the request fails with an "Authorization Required"
status. This nice "second try" feature appears to be built
into LWP.
Parsing HTML and XML
Much of the information on the Web is now
stored in the form of HTML documents. So far we have dealt
with HTML documents in an ad hoc manner by writing regular
expressions to parse out the particular information we want
from a Web page. However, LWP offers a more general solution
to this. The HTML::Parser class provides flexible parsing of
HTML documents, and HTML::Formatter can format HTML as text or
PostScript.
An added benefit of HTML::Parser is that at
the throw of a switch it can handle XML (eXtensible Markup
Language) as well. Because HTML was designed to display
human-readable documents, it doesn't lend itself easily to
automated machine processing. XML provides structured, easily
parsed documents that are more software-friendly than
traditional HTML. Over the next few years, HTML will gradually
be replaced by XHTML, a version of HTML that follows XML's
more exacting standards. HTML::Parser can handle HTML, XML,
and XHTML, and in fact can be used to parse much of the more
general SGML (Standard Generalized Markup Language) from which
both HTML and XML derive. The XML standard and a variety of
tutorials can be found at [http://www.w3.org/XML/].
In this section, we demonstrate how to use
HTML::Formatter to transform HTML into nicely formatted plain
text or postscript. Then we show some examples of using
HTML::Parser for the more general task of extracting
information from HTML files.
Formatting HTML
The HTML::Formatter module is the base class
for a family of HTML formatters. Only two members of the
family are currently implemented. HTML::FormatText takes an
HTML document and produces nicely formatted plain text, and
HTML::FormatPS creates postscript output. Neither subclass of
HTML::Formatter handles inline images, forms, or tables. In
some cases, this can be a big limitation.
There are two steps to formatting an HTML
file. The first step is to parse the HTML into a parse tree,
using a specialized subclass of HTML::Parser named
HTML::TreeBuilder. The second step is to pass this parse tree
to the desired subclass of HTML::Formatter to output the
formatted text.
Figure
9.17 shows a script named format_html.pl that uses these
modules to read an HTML file from the command line or standard
input and format it. If given the postscript option, the script
produces postscript output suitable for printing. Otherwise,
it produces plain text.

Lines 14: Load modules We turn on
strict syntax checking and load the Getopt::Long and
HTML:TreeBuilder modules. The former processes the
command-line arguments, if any. We don't load any
HTML::Formatter modules at this time because we don't know
yet whether to produce plain text or postscript.
Lines 57: Process command-line
options We call the GetOptions() function to
parse the command-line options. This sets the global
variable $PS to true if the postscript option is specified.
Lines 815: Create appropriate
formatter If the user requested postscript output, we
load the HTML::FormatPS module and invoke the class's
new() method to create a new formatter object.
Otherwise, we do the same thing with the HTML:: FormatText
class. When creating an HTML::FormatPS formatter, we pass
the new() method a PaperSize argument of "Letter" in
order to create output compatible with the common 81/2 x 11"
letter stock used in the United States.
Lines 1618: Parse HTML We create a
new HTML::TreeBuilder parser by calling the class's
new() method. We then read the input HTML one line
at a time using the <> operator and pass it to the
parser object. When we are done, we tell the parser so by
calling its eof() method.
This series of operations leaves the HTML
parse tree in the parser object itself, in a variable named
$tree.
Line 1920: Format and output the
tree We pass the parse tree to the formatter's
format() method, yielding a formatted string. We
print this, and then clean up the parse tree by calling is
delete() method.
The HTML::Formatter API
The API for HTML::Formatter and its
subclasses is extremely simple. You create a new formatter
with new() and perform the formatting with
format(). A handful of arguments recognized by
new() adjust the formatting style.
|
$formatter =
HTML::FormatText->new([leftmargin=>$left,rightmargin=>$right])
HTML::FormatText->new()
takes two optional arguments, leftmargin and rightmargin, which set the
left and right page margins, respectively. The margins
are measured in characters. If not specified, the left
and right margins default to 3 and 72, respectively. It
returns a formatter object ready for use in converting
HTML to text.
$formatter =
HTML::FormatPS->new([option1=>$val1,
option2=>$val2...])
Similarly,
HTML::FormatPS->new() creates a new
formatter object suitable for rendering HTML into
postscript. It accepts a larger list of argument/value
pairs, the most common of which are listed here:
-
PaperSize sets the page
height and width appropriately for printing.
Acceptable values are A3, A4,
A5, B4, B5, Letter, Legal, Executive, Tabloid,
Statement, Folio, 10x14, and Quarto. United States users
take note! The default PaperSize is the European
A4. You should change
this to Letter if you
wish to print on common 81/2 x 11" paper.
-
LeftMargin,
RightMargin, TopMargin, and BottomMargin control the
page margins. All are given in point units.
-
FontFamily sets the font
family to use in the output. Recognized values are
Courier, Helvetica, and
Times, the default.
-
FontScale allows you to
increase or decrease the font size by some factor. For
example, a value of 1.5 will scale the font size up by
50 percent. |
Once a formatter is created, you can use it
as many times as you like to format HTML::TreeBuilder
objects.
|
$text =
$formatter->format($tree)
Pass an HTML parse tree to the
format() method. The returned value is a scalar
variable, which you can then print, save to disk, or
send to a print spooler. |
The HTML::TreeBuilder API
The basic API for HTML::TreeBuilder is also
straightforward. You create a new HTML::TreeBuilder object by
calling the class's new() method, then parse a
document using parse() or parse_file(), and
when you're done, destroy the object using
delete().
|
$tree =
HTML::TreeBuilder->new
The new() method takes no
arguments. It returns a new, empty HTML::TreeBuilder
object.
$result =
$tree->parse_file($file)
The parse_file() method
accepts a filename or filehandle and parses its
contents, storing the parse tree directly in the
HTML::TreeBuilder object. If the parse was successful,
the result is a copy of the tree object; if something
went wrong (check $! for the error message),
the result is
undef. |
For example, we can parse an HTML file
directly like this: $tree->parse_file('rfc2010.html') or die "Couldn't parse: $!";
and parse from a filehandle like this: open (F,'rfc2010.html') or die "Couldn't open: $!";
$tree->parse_file(\*F);
|
$result =
$tree->parse($data)
With the parse() method, you
can parse an HTML file in chunks of arbitrary size.
$data is a scalar that contains the HTML text
to process. Typically you will call parse()
multiple times, each time with the next section of the
document to process. We will see later how to take
advantage of this feature to begin HTML parsing while
the file is downloading. If something goes wrong during
parsing, parse() returns undef. If
parse() is successful, it will return a copy of
the HTML::TreeBuilder object, undef
otherwise.
$tree->eof
Call this method when using
parse(). It tells HTML::TreeBuilder that no
more data is coming and allows it to finish the
parse. |
Figure
9.16 is a good example of using parse() and
eof() to parse the HTML file on standard input one
line at a time.
|
$tree->delete
When you are finished with an
HTML::TreeBuilder tree, call its delete()
method to clean up. Unlike other Perl objects, which are
automatically destroyed when they go out of scope, you
must be careful to call delete() explicitly
when working with HTML::TreeBuilder objects or risk
memory leaks. The HTML::Element POD documentation
explains why this is so. |
Many scripts combine HTML::TreeBuilder object
creation with file parsing using this idom: $tree = HTML::TreeBuilder->new->parse_file('rfc2010.html');
However, the HTML::TreeBuilder object created
this way will never be deleted, and will leak memory. If you
are parsing files in a loop, always create the
HTML::TreeBuilder object, call its parse_file()
method, and then call its delete() method.
The parse tree returned by HTML::TreeBuilder
is actually a very feature-rich object. You can recursively
descend through its nodes to extract information from the HTML
file, extract hypertext links, modify selected HTML elements,
and then convert the whole thing back into printable HTML.
However, the same functionality is also available in a more
flexible form in the HTML::Parser class, which we cover later
in this chapter. For details, see the HTML::TreeBuilder and
HTML::Element POD documentation.
Returning Formatted HTML from the
get_url.pl Script
We'll now rewrite get_url.pl a third time in order to
take advantage of the formatting features offered by
HTML::FormatText. When the new script, imaginatively
christened get_url3.pl, detects
an HTML document, it automatically converts it into formatted
text.
The interesting feature of this script is
that we combine LWP::UserAgent's request callback mechanism
with the HTML::TreeBuilder parse() method to begin
the parse as the HTML document is downloading. When we
parallelize downloading and parsing, the script executes
significantly faster. Figure
9.18 shows the code.

Lines 16: Load modules We bring in
LWP, PromptUtil, HTML::FormatText, and the HTML::TreeBuilder
modules.
Lines 711: Set up request We set up
the HTTP::Request as we did in earlier iterations of this
script. Again, when required, we prompt the user for
authentication information so the script is made a subclass
of LWP::UserAgent so that we can override the
get_basic_credentials() method.
Lines 1214: Send the request We
send the request using the agent's request(),
method. However, instead of allowing LWP to leave the
returned content in the HTTP::Response object for retrieval,
we give request() a second argument containing a
reference to the process_document() subroutine.
This subroutine is responsible for parsing incoming HTML
documents.
process_document() leaves the HTML
parse tree, if any, in the global variable
$html_tree, which we declare here. After the
request() is finished, we check the status of the
returned HTTP::Response object and die with an explanatory
error message if the request failed for some reason.
Lines 1520: Format and print the
HTML If the requested document is HTML, then
process_document() has parsed it and left the tree
in $html_tree. We check to see whether the tree is
nonempty. If so, we call its eof() method to tell
the parser to finish, and pass the tree to a newly created
HTML::FormatText object to create a formatted string that we
immediately print. We are now done with the parse tree, so
we call its delete() method.
As we shall see,
process_document() prints all non-HTML documents
immediately, so there's no need to take further action for
non-HTML documents.
Lines 2129: The process_document
() subroutine LWP::UserAgent invokes call-backs with
three arguments consisting of the downloaded data, the
current HTTP::Response object, and an LWP::Protocol object.
We call the response object's
content_type() method to get the MIME type of the
incoming document. If the type is text/html, then we pass the data to
the parse tree's parse() method. If necessary, we
create the HTML::TreeBuilder first, using the ||=
operator so that the call to
HTML::TreeBuilder->new() is executed only if the
$html_tree variable is undefined.
If the content type is something other than
text/html, then we
immediately print the data. This is a significant
improvement to earlier versions of get_url.pl because it means that
non-HTML data starts to appear on standard output as soon as
it arrives from the remote server.
Lines 3038: The
get_basic_credentials() subroutine This is the same
subroutine we looked at in get_url2.pl.
This script does not check for the case in
which the response does not provide a content type. Strictly
speaking it should do so, as the HTTP specification allows
(but strongly discourages) Web servers to omit this field. Run
the script with the -w switch to detect and report this case.
Useful enhancements to get_url3.pl might include using
HTML::FormatPS for printing support, or adapting the script to
use external viewers to display non-HTML MIME types the way we
did in the pop_fetch.pl script
of Chapter
8.
The HTML::Parser Module
HTML::Parser is a powerful but complex module
that allows you to parse HTML and XML documents. Part of the
complexity is inherent in the structure of HTML itself, and
part of it is due to the fact that there are two distinct APIs
for HTML::Parser, one used by version 2.2X of the module and
the other used in the current 3.X series.
HTML and XML are organized around a
hierarchical series of markup tags. Tags are enclosed by angle
brackets and have a name and a series of attributes. For
example, this tag <img src="/icons/arrow.gif" alt="arrow">
has the name img and the two attributes src and alt.
In HTML, tags can be paired or unpaired.
Paired tags enclose some content, which can be plain text or
can contain other tags. For example, this fragment of HTML <p>Oh dear, now the <strong>bird</strong> is gone!</p>
consists of a paragraph section, starting
with the <p> tag and ending with its mate, the
</p> tag. Between the two is a line of text, a
portion of which is itself enclosed in a pair of
<strong> tags (indicating strongly emphatic
text). HTML and XML both constrain which tags can occur within
others. For example, a <title> section, which
designates some text as the title of a document, can occur
only in the <head> section of an HTML document,
which in turn must occur in an <html> section.
See Figure
9.19 for a very minimal HTML document.

In addition to tags, an HTML document may
contain comments, which are ignored by rendering programs.
Comments begin with the characters <!-- and end
with --> as in: <!-- ignore this -->
HTML files may also contain markup
declarations, contained within the characters <!
and >. These provide meta-information to
validators and parsers. The only HTML declaration you are
likely to see is the <!DOCTYPE ...> declaration
at the top of the file that indicates the version of HTML the
document is (or claims to be) using. See the top of Figure
9.19 for an example.
Because the "<" and ">" symbols have
special significance, all occurrences of these characters in
proper HTML have to be escaped to the "character entities"
< and >, respectively. The
ampersand has to be escaped as well, to &. Many
other character entities are used to represent nonstandard
symbols such as the copyright sign or the German umlaut.
XML syntax is a stricter and regularized
version of HTMLs. Instead of allowing both paired and unpaired
tags, XML requires all tags to be paired. Tag and attribute
names are case sensitive (HTML's are not), and all attribute
values must be enclosed by double quotes. If an element is
empty, meaning that there is nothing between the start and end
tags, XML allows you to abbreviate this as an "empty element"
tag. This is a start tag that begins with <tagname
and ends with />. As an illustration of this,
consider these two XML fragments, both of which have exactly
the same meaning: <img src="/icons/arrow.gif" alt="arrow"></img>
<img src="/icons/arrow.gif" alt="arrow" />
Using HTML::Parser
HTML::Parser is event driven. It parses
through an HTML document, starting at the top and traversing
the tags and subtags in order until it reaches the end. To use
it, you install handlers for events that you are interested in
processing, such as encountering a start tag. Your handler
will be called each time the desired event occurs.
Before we get heavily into the HTML::Parser,
we'll look at a basic example. The print_links.pl script parses the HTML
document presented to it on the command line or standard
input, extracts all the links and images, and prints out their
URLs. In the following example, we use get_url2.pl to fetch the Google
search engine's home page and pipe its output to print_links.pl: % get_url2.pl http://www.google.com | print_links.pl
img: images/title_homepage2.gif
link: advanced_search.html
link: preferences.html
link: link_NPD.html
link: jobs.html
link: http://directory.google.com
link: adv/intro.html
link: websearch_programs.html
link: buttons.html
link: about.html
Figure
9.20 shows the code for print_links.pl.

Lines 13: Load modules After
turning on strict syntax checking, we load HTML:: Parser.
This is the only module we need.
Lines 45: Create and initialize the
parser object We create a new HTML::Parser object by
calling its new() method. For reasons explained in
the next section, we tell new() to use the version
3 API by passing it the api_version argument.
After creating the parser, we configure it
by calling its handler() method to install a
handler for start tag events. The start argument points to a
reference to our print_link() subroutine; this
subroutine is invoked every time the parser encounters a
start tag. The third argument to handler() tells
HTML:: Parser what arguments to pass to our handler when it
is called. We request that the parser pass
print_link() the name of the tag (tagname) and a hash reference
containing the tag's attributes (attr).
Lines 67: Parse standard input We
now call the parser's parse() method, passing it
lines read via the <> function. When we reach
the end of file, we call the parser's eof() method
to tell it to finish up. The parse() and
eof() methods behave identically to the
HTML::TreeBuilder methods we looked at earlier.
Lines 815: The print_link()
callback Most of the program logic occurs in
print_link(). This subroutine is called during the
parse every time the parser encounters a start tag. As we
specified when we installed the handler, the parser passes
the subroutine the name of the tag and a hash reference
containing the tag's attributes. Both the tag name and all
the attribute names are automatically transformed to
lowercase letters, making it easier to deal with the rampant
variations in case used in most HTML.
We are interested only in hypertext links,
the <a> tag, and inline images, the
<img> tag. If the tag name is "a", we print a
line labeled "link:" followed by the contents of the attribute. If, on the other
hand, the tag name is "img", we print "img:" followed by the
contents of the src attribute.
For any other tag, we do nothing.
The HTML::Parser API
HTML::Parser has two APIs. In the earlier
API, which was used through version 2 of the module, you
install handlers for various events by subclassing the module
and overriding methods named start(), end(),
and text(). In the current API, introduced in version
3.0 of the module, you call handler() to install
event callbacks as we did in Figure
9.20.
You may still see code that uses the older
API, and HTML::Parser goes to pains to maintain compatibility
with the older API. In this section, however, we highlight
only the most useful parts of the version 3 API. See the
HTML::Parser POD documentation for more information on how to
control the module's many options.
To create a new parser, call
HTML::Parser->new().
|
$parser =
HTML::Parser->new(@options)
The new() method creates a new
HTML::Parser. @options is a series of
option/value pairs that change various parser settings.
The most used option is api_version, which can be "2"
to create a version 2 parser, or "3" to create a version
3 parser. For backward compatibility, if you do not
specify any options new() creates a version 2
parser. |
Once the parser is created, you will call
handler() one or more times to install handlers.
|
$parser->handler($event =>
\&handler, $args)
The handler() method installs
a handler for a parse event. $event is the name
of the event, &handler contains a reference
to the callback subroutine to handle it, and
$args is a string telling HTML::Parser what
information about the event the subroutine wishes to
receive. |
The event name is one of start, end, text, comment, declaration,
process, or default. The
first three events are the most common. A start event is generated whenever the
parser encounters a start tag, such as
<strong>. An end
event is triggered when the parser encounters an end tag, such
as </strong>. text events are generated for the
text between tags. The comment
event is generated for HTML comments. declaration and process events apply primarily to XML
elements. Last, the default
event is a catchall for anything that is not explicitly
handled elsewhere.
$args is a string containing a
comma-delimited list of information that you want the parser
to pass to the handler. The information will be passed as
subroutine arguments in the exact order that they appear in
the $args list. There are many possible arguments.
Here are some of the most useful:
-
tagname the name of the tag
-
text the full text that triggered
the event, including the markup delimiters
-
dtext decoded text, with markup
removed and entities translated
-
attr a reference to a hash
containing the tag attributes and values
-
self a copy of the HTML::Parser
object itself
-
"string" the literal string (single
or double quotes required!)
For example, this call causes the
get_text() handler to be invoked every time the
parser processes some content text. The argument passed to the
handler will be a three-element list that contains the parser
object, the literal string "TEXT", and the decoded content
text: $parser->handler('text'=>\&get_text, "self,'TEXT',dtext");
-
tagname is
most useful in conjunction with start and end events. Tags are automatically
downcased, so that <UL>, <ul>,
and <Ul> are all given to the handler as
"ul". In the case of end tags, the "/" is suppressed, so
that an end handler receives
"ul" when a </ul> tag is encountered.
-
dtext is
used most often in conjunction with text events. It returns the nontag
content of the document, with all character entities
translated to their proper values.
-
The attr
hash reference is useful only with start events. If requested for
other events, the hash reference will be empty.
Passing handler() a second argument
of undef removes the handler for the specified event,
restoring the default behavior. An empty string causes the
event to be ignored entirely.
|
$parser->handler($event
=>\@array, $args)
Instead of having a subroutine invoked
every time the parser triggers an event, you can have
the parser fill an array with the information that would
have been passed to it, then examine the array at your
leisure after the parse is finished.
To do this, use an array reference as
the second argument to handler(). When the
parse is done, the array will contain one element for
each occurrence of the specified event, and each element
will be an anonymous array containing the information
specified by $args. |
Once initialized, you trigger the parse with
parse_file() or parse().
|
$result =
$parser->parse_file($file)
$result =
$parser->parse($data)
$parser->eof
The parse_file(), parse(), and
eof() methods work exactly as they do for
HTML::TreeBuilder. A handler that wishes to terminate
parsing early can call the parser object's
eof() method. |
Two methods are commonly used to tweak the
parser.
|
$bool =
$parser->unbroken_text([$bool])
When processing chunks of content text,
HTML::Parser ordinarily passes them to the text handler
one chunk at a time, breaking text at word boundaries.
If unbroken_text() is set to a true value, this
behavior changes so that all the text between two tags
is passed to the handler in a single operation. This can
make some pattern matches easier.
$bool =
$parser->xml_mode([$bool])
The xml_mode() method puts the
parser into a mode compatible with XML documents. This
has two major effects. First, it allows the empty
element construct, <tagname/>. When the
parser encounters a tag like this one, it generates two
events, a start event and
an end event.
Second, XML mode disables the automatic
conversion of tag and attribute names into lowercase.
This is because XML, unlike HTML, is case
sensitive. |
search_rfc.pl Using
HTML::Parser
We'll now rewrite search_rfc.pl (Figures
9.8 and 9.10) to use HTML::Parser. Instead of using an ad
hoc pattern match to find the RFC names in the search response
document, we'll install handlers to detect the appropriate
parts of the document, extract the needed information, and
print the results.
Recall that the matching RFCs are in an
ordered list (<OL>) section and have the
following format: <OL>
<LI><A ="ref1">rfc name 1</A> - <STRONG>description 1</STRONG>
<LI><A ="ref2">rfc name 2</A> - <STRONG>description 2</STRONG>
...
</OL>
We want the parser to extract and print the
text located within <A> and
<STRONG> elements, but only those located
within an <OL> section. The text from other
parts of the document, even those in other <A>
and <STRONG> elements, are to be ignored. The
strategy that we will adopt is to have the start handler detect when an
<OL> tag has been encountered, and to install a
text handler to intercept and
print the content of any subsequent <A> and
<STRONG> elements. An end handler will detect the
</OL> tag, and remove the text handler, so that other text is
not printed.
Figure
9.21 shows this new version, named search_rfc3.pl.

Lines 15: Load modules In addition
to the LWP and HTTP::Request::Common modules, we load
HTML::Parser.
Lines 618: Set up search We create
an LWP::UserAgent and a new HTTP::Request in the same way as
in the previous incarnation of this script.
Lines 1920: Create HTML::Parser We
create a new version 3 HTML::Parser object, and install a
handler for the start event.
The handler will be the start() subroutine, and it
will receive a copy of the parser object and the name of the
tag.
Lines 2122: Issue request and parse
We call the user agent's request() method to
process the request. As in the print_links.pl script (Figure
9.20), we use a code reference as the second argument to
request() so that we can begin processing incoming
data as soon as it arrives. In this case, the code reference
is an anonymous subroutine that invokes the parser's
parse() method.
After the request is finished, we call the
parser's eof() method to have it finish up.
Line 23: Warn of error conditions If
the response object's is_success() method returns
false, we die with an error message. Otherwise, we do
nothing: The parser callbacks are responsible for extracting
and printing the relevant information from the document.
Lines 2431: The start()
subroutine The start() subroutine is the callback
for the start event. It is
called whenever the parser encounters a start tag. We begin
by recovering the parser object and the tag name from the
stack. We need to remember the tag later when we are
processing text, so we stash it in the parser object under
the key last-tag. (The
HTML::Parser POD documentation informs us that the parser is
a blessed hash reference, and specifically invites us to
store information there in this manner.)
If the tag is anything other than "ol", we
do nothing and just return. Otherwise, we install two new
handlers. One is a handler for the text event. It will be passed the
parser object and the decoded text. The other is a handler
for the end event. Like
start(), it will be passed the parser object and
the name of the end tag.
Lines 3238: The end() subroutine
The end() subroutine is the handler for the end event. It begins by resetting
the last_tag key in the parser object. If the end
tag isn't equal to "ol", we just return, doing nothing.
Otherwise, we set both the text and the end handlers to undef,
disabling them.
Lines 3945: The extract()
subroutine extract() is the handler for the text event, and is the place where
the results from the search are extracted and printed. We
get a copy of the parser object and the decoded text on the
subroutine call stack. After stripping whitespace from the
text, we examine the value of the last_tag key stored in the parser
object. If the last tag is "a", then we are in the
<A> section that contains the name of the
RFC. We print the text, followed by a tab. If the last tag
is "strong", then we are in the section of the document that
contains the title of the RFC. We print that, followed by a
newline.
The new version of search_rfc.pl is more than twice as
long as the original, but it adds no new features, so what
good is it? In this case, a full-blown parse of the search
results document is overkill. However, there will be cases
when you need to parse a complex HTML document and regular
expressions will become too cumbersome to use. In these cases,
HTML::Parser is a life saver.
Extracting Images from a Remote
URL
To tie all the elements of this chapter
together, our last example is an application that mirrors all
the images in an HTML document at a specified URL. Given a
list of one or more URLs on the command line, mirror_images.pl retrieves each
document, parses it to find all inline images, and then
fetches the images to the current directory using the
mirror() method. To keep the mirrored images up to
date, this script can be run repeatedly.
As the script runs, it prints the local name
for the image. For example, here's what happened when I
pointed the script at http://www.yahoo.com/: % mirror_images.pl http://www.yahoo.com
m5v2.gif: OK
messengerpromo.gif: OK
sm.gif: OK
Running it again immediately gives three "Not
Modified" messages. Figure
9.22 gives the complete code listing for the script.

Lines 17: Load modules We turn on
strict syntax checking and load the LWP, PromptUtil,
HTTP::Cookies, HTML::Parser, and URI modules. The last
module is used for its ability to resolve relative URLs into
absolute URLs.
Lines 811: Create the user agent We
again use the trick of subclassing LWP::User Agent to
override the get_basic_credentials() method. The
agent is stored in a variable named $agent. Some of
the remote sites we contact might require HTTP cookies, so
we initialize an HTTP::Cookies object on a file in our home
directory and pass it to the agent's cookie_jar()
method. This allows the script to exchange cookies with the
remote sites automatically.
Lines 1215: Create the request and the
parser We enter a loop in which we shift URLs off the
command line and process them. For each URL, we create a new
GET request using HTTP::Request->new(), and an
HTML::Parser object to parse the document as it comes in.
We install the subroutine start()
as the parse handler for the start event. This handler will
receive a copy of the parser object, the name of the start
tag, and a hash reference containing the tag's attributes
and their values.
Lines 1624: Issue the request We
call the agent's request() method to issue the
request, returning a response object. As in the last
example, we provide request() with a code reference
as the second argument, causing the agent to pass the
incoming data to this subroutine as it arrives.
In this case, the code reference is an
anonymous subroutine. We first check that the MIME type of
the response is text/html. If
it isn't, we die with an error message. This doesn't cause
the script as a whole to die, but does abort processing of
the current URL and leaves the error message in a special
X-Died: field of the response header.
Otherwise, the incoming document is
parseable as an HTML file. Our handler is going to need two
pieces of extra information: the base URL of the current
response for use in resolving relative URLs, and the user
agent object so that we can issue requests for inline
images. We use the same technique as in Figure
9.21, and stash this information into the parser's hash
reference.
Lines 2527: Warn of error
conditions After the request has finished, we check the
response for the existence of the X-Died: header
and, if it exists, issue a warning. Likewise, we print the
response's status message if the is_success()
method returns false.
Lines 2837: The start() handler
The start() subroutine is invoked by the parser to
handle start tags. As called for by the argument list passed
to handler(), the subroutine receives a copy of the
parser object, the name of the current tag, and a hash
reference containing tag attributes.
We check whether we are processing an
<IMG> tag. If not, we return without taking
further action. We then check that the tag's src
attribute is defined, and if so, copy it to a local
variable.
The src attribute contains the URL
of the inline image, and may be an absolute URL like
http://www. yahoo.com/images/messengerpromo.gif, or
a relative one like images/messengerpromo.gif. To fetch
image source data, we must resolve relative URLs into
absolute URLs so that we can request them via the LWP user
agent. We must also construct a local filename for our copy
of the image.
Absolutizing relative URLs is an easy task
thanks to the URI module. The URI->new_abs()
method constructs a complete URL given a relative URL and a
base. We obtain the base URL of the document containing the
image by retrieving the "base" key from the parser hash
where we stashed it earlier. This is passed to
new_abs() along with the URL of the image (line
33), obtaining an absolute URL. If the URL was already
absolute, calling new_abs() doesn't hurt. The
method detects this fact and passes the URL through
unchanged.
Constructing the local filename is a matter
of extracting the filename part of the path (line 34), using
a pattern match to extract the rightmost component of the
image URL.
We now call the user agent's
mirror() method to copy the remote image to our
local filesystem and print the status message. Notice how we
obtain a copy of the user agent from the parser hash
reference. This avoids having to create a new user
agent.
Lines 3846: The
get_basic_credentials() method This is identical to
earlier versions.
There is a slight flaw in mirror_images.pl as it is now
written. All images are mirrored to the same directory, and no
attempt is made to detect image name clashes between sites, or
even within the same site when the image paths are flattened
(as might occur, for example, when mirroring remote images
named /images/whats_new.gif and
/news/hot_news/whats_new.gif).
To make the script fully general, you might
want to save each image in a separate subdirectory named after
the remote hostname and the path of the image within the site.
We can do this relatively painlessly by combining the URI
host() and path() methods with the
dirname() and mkpath() functions imported
from the File::Path and File::Basename modules. The relevant
section of start() would now look like this: ...
use File::Path 'mkpath';
use File::Basename 'dirname';
...
sub start {
...
my $remote_name = URI->new_abs($url,$parser->{base});
my $local_name = $remote_name->host . $remote_name->path;
mkpath(dirname($local_name),0,0711);
...
}
For the image URL http://www.yahoo.
com/images/whats_new.gif, this will mirror the file into
the subdirectory http://www.yahoo.com/images.
Summary
The LWP module allows you to write scripts
that act as World Wide Web clients. You can retrieve Web
pages, simulate the submission of fill-out forms, and easily
negotiate more obscure aspects of the HTTP protocol, such as
cookies and user authentication.
The HTML-Formatter and HTML-Parser modules
enhance LWP by giving you the ability to format and parse HTML
files. These modules allow you to transform HTML into text or
postscript for printing, and to extract interesting
information from HTML files without resorting to error-prone
regular expressions. As an added benefit, HTML::Parser can
parse XML.
There's more to LWP than can be covered in a
single book chapter. A good way to learn more about the
package is to examine the lwp-request, lwp-download, and lwp-rget scripts, and other examples
that come with the package.
|
|

 LINUX
LINUX 
 Books
Books
