Как ядро обслуживает запросы
Эти запросы можно разбить на 2 группы- обычные и привилегированные.
Следующая политика выполняется при их обработке:
Если ядро ничем не занято,оно начнет обрабатывать первым привилегированный запрос
Если привилегированный запрос прийдет в тот момент,
когда ядро обслуживает обычный,ядро немедленно переключается на его обслуживание.
Если привилегированный запрос прийдет в тот момент,
когда ядро обрабатывает другой такой же,
ядро переключится на его обработку, а потом вернется к предыдущему.
Обычный запрос может быть проигнорирован в тот момент,
когда обрабатывается привилегированный,или поставлен в очередь.
Понятно,что ядро может находиться либо в состоянии Kernel Mode,
либо в User Mode.Во втором случае говорят , что ядро находится в состоянии idle.
К привилегированным запросам относятся прерывания,
к обычным - системные вызовы или исключения процессов в User Mode.
Для вызова системного вызова нужна инструкция int
$0x80 либо sysenter.
Эти инструкции форсируют переключение с User Mode в Kernel Mode.
Kernel Preemption
It is surprisingly hard to give a good definition of kernel preemption. As a first try, we could say that a kernel is preemptive if a process switch may occur while the replaced process is executing a kernel function, that is, while it runs in Kernel Mode. Unfortunately, in Linux (as well as in any other real operating system) things are much more complicated:
Both in preemptive and nonpreemptive kernels, a process running in Kernel Mode can voluntarily relinquish the CPU, for instance because it has to sleep waiting for some resource. We will call this kind of process switch a planned
process switch. However, a preemptive kernel
differs from a nonpreemptive kernel on the way a process running in Kernel Mode reacts to asynchronous events that could induce a process switchfor instance, an interrupt handler that awakes a higher priority process. We will call this kind of process switch a forced
process switch. All process switches are performed by the switch_to macro. In both preemptive and nonpreemptive kernels, a process switch occurs when a process has finished some thread of kernel activity and the scheduler is invoked. However, in nonpreemptive kernels, the current process cannot be replaced unless it is about to switch to User Mode (see the section "
Performing the Process Switch" in
Chapter 3).
Therefore, the main characteristic of a preemptive kernel is that a process running in Kernel Mode can be replaced by another process while in the middle of a kernel function.
Let's give a couple of examples to illustrate the difference between preemptive and nonpreemptive kernels.
While process A executes an exception handler (necessarily in Kernel Mode), a higher priority process B becomes runnable. This could happen, for instance, if an IRQ occurs and the corresponding handler awakens process B. If the kernel is preemptive, a forced process switch replaces process A with B. The exception handler is left unfinished and will be resumed only when the scheduler selects again process A for execution. Conversely, if the kernel is nonpreemptive, no process switch occurs until process A either finishes handling the exception handler or voluntarily relinquishes the CPU.
For another example, consider a process that executes an exception handler and whose time quantum expires (see the section "
The scheduler_tick( ) Function" in
Chapter 7). If the kernel is preemptive, the process may be replaced immediately; however, if the kernel is nonpreemptive, the process continues to run until it finishes handling the exception handler or voluntarily relinquishes the CPU.
The main motivation for making a kernel preemptive is to reduce the dispatch latency
of the User Mode processes, that is, the delay between the time they become runnable and the time they actually begin running. Processes performing timely scheduled tasks (such as external hardware controllers, environmental monitors, movie players, and so on) really benefit from kernel preemption, because it reduces the risk of being delayed by another process running in Kernel Mode.
Making the Linux 2.6 kernel preemptive did not require a drastic change in the kernel design with respect to the older nonpreemptive kernel versions. As described in the section "
Returning from Interrupts and Exceptions" in
Chapter 4, kernel preemption is disabled when the preempt_count field in the tHRead_info descriptor referenced by the current_thread_info( ) macro is greater than zero. The field encodes three different counters, as shown in
Table 4-10 in
Chapter 4, so it is greater than zero when any of the following cases occurs:
The kernel is executing an interrupt service routine. The deferrable functions are disabled (always true when the kernel is executing a softirq or tasklet). The kernel preemption has been explicitly disabled by setting the preemption counter to a positive value.
The above rules tell us that the kernel can be preempted only when it is executing an exception handler (in particular a system call) and the kernel preemption has not been explicitly disabled. Furthermore, as described in the section "
Returning from Interrupts and Exceptions" in
Chapter 4, the local CPU must have local interrupts enabled, otherwise kernel preemption is not performed.
A few simple macros listed in Table 5-1 deal with the preemption counter in the prempt_count field.
Table 5-1. Macros dealing with the preemption counter subfieldMacro | Description |
|---|
preempt_count( ) | Selects the preempt_count field in the tHRead_info descriptor | preempt_disable( ) | Increases by one the value of the preemption counter | preempt_enable_no_resched( ) | Decreases by one the value of the preemption counter | preempt_enable( ) | Decreases by one the value of the preemption counter, and invokes preempt_schedule( ) if the TIF_NEED_RESCHED flag in the thread_info descriptor is set | get_cpu( ) | Similar to preempt_disable( ), but also returns the number of the local CPU | put_cpu( ) | Same as preempt_enable( ) | put_cpu_no_resched( ) | Same as preempt_enable_no_resched( ) |
The preempt_enable( ) macro decreases the preemption counter, then checks whether the TIF_NEED_RESCHED flag is set (see
Table 4-15 in
Chapter 4). In this case, a process switch request is pending, so the macro invokes the preempt_schedule( ) function, which essentially executes the following code:
if (!current_thread_info->preempt_count && !irqs_disabled()) {
current_thread_info->preempt_count = PREEMPT_ACTIVE;
schedule();
current_thread_info->preempt_count = 0;
}
The function checks whether local interrupts are enabled and the preempt_count field of current is zero; if both conditions are true, it invokes schedule( ) to select another process to run. Therefore, kernel preemption may happen either when a kernel control path (usually, an interrupt handler) is terminated, or when an exception handler reenables kernel preemption by means of preempt_enable( ). As we'll see in the section "
Disabling and Enabling Deferrable Functions" later in this chapter, kernel preemption may also happen when deferrable functions are enabled.
We'll conclude this section by noticing that kernel preemption introduces a nonnegligible overhead. For that reason, Linux 2.6 features a kernel configuration option that allows users to enable or disable kernel preemption when compiling the kernel.
5.1.2. When Synchronization Is Necessary
Chapter 1 introduced the concepts of race condition and critical region for processes. The same definitions apply to kernel control paths
. In this chapter, a race condition can occur when the outcome of a computation depends on how two or more interleaved kernel control paths are nested. A critical region is a section of code that must be completely executed by the kernel control path that enters it before another kernel control path can enter it.
Interleaving kernel control paths complicates the life of kernel developers: they must apply special care in order to identify the critical regions
in exception handlers, interrupt handlers, deferrable functions, and kernel threads
. Once a critical region has been identified, it must be suitably protected to ensure that any time at most one kernel control path is inside that region.
Suppose, for instance, that two different interrupt handlers need to access the same data structure that contains several related member variables for instance, a buffer and an integer indicating its length. All statements affecting the data structure must be put into a single critical region. If the system includes a single CPU, the critical region can be implemented by disabling interrupts while accessing the shared data structure, because nesting of kernel control paths can only occur when interrupts are enabled.
On the other hand, if the same data structure is accessed only by the service routines of system calls, and if the system includes a single CPU, the critical region can be implemented quite simply by disabling kernel preemption while accessing the shared data structure.
As you would expect, things are more complicated in multiprocessor systems. Many CPUs may execute kernel code at the same time, so kernel developers cannot assume that a data structure can be safely accessed just because kernel preemption is disabled and the data structure is never addressed by an interrupt, exception, or softirq handler.
We'll see in the following sections that the kernel offers a wide range of different synchronization techniques. It is up to kernel designers to solve each synchronization problem by selecting the most efficient technique.
5.1.3. When Synchronization Is Not Necessary
Some design choices already discussed in the previous chapter simplify somewhat the synchronization of kernel control paths. Let us recall them briefly:
All interrupt handlers acknowledge the interrupt on the PIC and also disable the IRQ line. Further occurrences of the same interrupt cannot occur until the handler terminates. Interrupt handlers, softirqs, and tasklets are both nonpreemptable and non-blocking, so they cannot be suspended for a long time interval. In the worst case, their execution will be slightly delayed, because other interrupts occur during their execution (nested execution of kernel control paths). A kernel control path performing interrupt handling cannot be interrupted by a kernel control path executing a deferrable function or a system call service routine. Softirqs and tasklets cannot be interleaved on a given CPU. The same tasklet cannot be executed simultaneously on several CPUs.
Each of the above design choices can be viewed as a constraint that can be exploited to code some kernel functions more easily. Here are a few examples of possible simplifications:
Interrupt handlers and tasklets need not to be coded as reentrant functions. Per-CPU variables accessed by softirqs and tasklets only do not require synchronization. A data structure accessed by only one kind of tasklet does not require synchronization.
The rest of this chapter describes what to do when synchronization is necessary i.e., how to prevent data corruption due to unsafe accesses to shared data structures.
5.2. Synchronization Primitives
We now examine how kernel control paths can be interleaved while avoiding race conditions among shared data. Table 5-2 lists the synchronization techniques used by the Linux kernel. The "Scope" column indicates whether the synchronization technique applies to all CPUs in the system or to a single CPU. For instance, local interrupt disabling applies to just one CPU (other CPUs in the system are not affected); conversely, an atomic operation affects all CPUs in the system (atomic operations on several CPUs cannot interleave while accessing the same data structure).
Table 5-2. Various types of synchronization techniques used by the kernelTechnique | Description | Scope |
|---|
Per-CPU variables | Duplicate a data structure among the CPUs | All CPUs | Atomic operation | Atomic read-modify-write instruction to a counter | All CPUs | Memory barrier | Avoid instruction reordering | Local CPU or All CPUs | Spin lock | Lock with busy wait | All CPUs | Semaphore | Lock with blocking wait (sleep) | All CPUs | Seqlocks | Lock based on an access counter | All CPUs | Local interrupt disabling | Forbid interrupt handling on a single CPU | Local CPU | Local softirq disabling | Forbid deferrable function handling on a single CPU | Local CPU | Read-copy-update (RCU) | Lock-free access to shared data structures through pointers | All CPUs |
Let's now briefly discuss each synchronization technique. In the later section "Synchronizing Accesses to Kernel Data Structures," we show how these synchronization techniques can be combined to effectively protect kernel data structures.
5.2.1. Per-CPU Variables
The best synchronization technique consists in designing the kernel so as to avoid the need for synchronization in the first place. As we'll see, in fact, every explicit synchronization primitive has a significant performance cost.
The simplest and most efficient synchronization technique consists of declaring kernel variables as per-CPU variables
. Basically, a per-CPU variable is an array of data structures, one element per each CPU in the system.
A CPU should not access the elements of the array corresponding to the other CPUs; on the other hand, it can freely read and modify its own element without fear of race conditions, because it is the only CPU entitled to do so. This also means, however, that the per-CPU variables can be used only in particular casesbasically, when it makes sense to logically split the data across the CPUs of the system.
The elements of the per-CPU array are aligned in main memory so that each data structure falls on a different line of the hardware cache (see the section "Hardware Cache" in
Chapter 2). Therefore, concurrent accesses to the per-CPU array do not result in cache line snooping and invalidation, which are costly operations in terms of system performance.
While per-CPU variables provide protection against concurrent accesses from several CPUs, they do not provide protection against accesses from asynchronous functions (interrupt handlers and deferrable functions). In these cases, additional synchronization primitives are required.
Furthermore, per-CPU variables are prone to race conditions caused by kernel preemption
, both in uniprocessor and multiprocessor systems. As a general rule, a kernel control path should access a per-CPU variable with kernel preemption disabled. Just consider, for instance, what would happen if a kernel control path gets the address of its local copy of a per-CPU variable, and then it is preempted and moved to another CPU: the address still refers to the element of the previous CPU.
Table 5-3 lists the main functions and macros offered by the kernel to use per-CPU variables.
Table 5-3. Functions and macros for the per-CPU variablesMacro or function name | Description |
|---|
DEFINE_PER_CPU(type, name) | Statically allocates a per-CPU array called name of type data structures | per_cpu(name, cpu) | Selects the element for CPU cpu of the per-CPU array name | _ _get_cpu_var(name) | Selects the local CPU's element of the per-CPU array name | get_cpu_var(name) | Disables kernel preemption, then selects the local CPU's element of the per-CPU array name | put_cpu_var(name) | Enables kernel preemption (name is not used) | alloc_percpu(type) | Dynamically allocates a per-CPU array of type data structures and returns its address | free_percpu(pointer) | Releases a dynamically allocated per-CPU array at address pointer | per_cpu_ptr(pointer, cpu) | Returns the address of the element for CPU cpu of the per-CPU array at address pointer |
5.2.2. Atomic Operations
Several assembly language instructions are of type "read-modify-write" that is, they access a memory location twice, the first time to read the old value and the second time to write a new value.
Suppose that two kernel control paths running on two CPUs try to "read-modify-write" the same memory location at the same time by executing nonatomic operations. At first, both CPUs try to read the same location, but the memory arbiter (a hardware circuit that serializes accesses to the RAM chips) steps in to grant access to one of them and delay the other. However, when the first read operation has completed, the delayed CPU reads exactly the same (old) value from the memory location. Both CPUs then try to write the same (new) value to the memory location; again, the bus memory access is serialized by the memory arbiter, and eventually both write operations succeed. However, the global result is incorrect because both CPUs write the same (new) value. Thus, the two interleaving "read-modify-write" operations act as a single one.
The easiest way to prevent race conditions due to "read-modify-write" instructions is by ensuring that such operations are atomic at the chip level. Every such operation must be executed in a single instruction without being interrupted in the middle and avoiding accesses to the same memory location by other CPUs. These very small atomic operations can be found at the base of other, more flexible mechanisms to create critical regions.
Let's review 80x86 Instructions According To That classification:
Assembly language instructions that make zero or one aligned memory access are atomic. Read-modify-write assembly language instructions (such as inc or dec) that read data from memory, update it, and write the updated value back to memory are atomic if no other processor has taken the memory bus after the read and before the write. Memory bus stealing never happens in a uniprocessor system. Read-modify-write assembly language instructions whose opcode is prefixed by the lock byte (0xf0) are atomic even on a multiprocessor system. When the control unit detects the prefix, it "locks" the memory bus until the instruction is finished. Therefore, other processors cannot access the memory location while the locked instruction is being executed. Assembly language instructions whose opcode is prefixed by a rep byte (0xf2, 0xf3, which forces the control unit to repeat the same instruction several times) are not atomic. The control unit checks for pending interrupts before executing a new iteration.
When you write C code, you cannot guarantee that the compiler will use an atomic instruction for an operation like a=a+1 or even for a++. Thus, the Linux kernel provides a special atomic_t type (an atomically accessible counter) and some special functions and macros (see Table 5-4) that act on atomic_t variables and are implemented as single, atomic assembly language instructions. On multiprocessor systems, each such instruction is prefixed by a lock byte.
Table 5-4. Atomic operations in LinuxFunction | Description |
|---|
atomic_read(v) | Return *v | atomic_set(v,i) | Set *v to i | atomic_add(i,v) | Add i to *v | atomic_sub(i,v) | Subtract i from *v | atomic_sub_and_test(i, v) | Subtract i from *v and return 1 if the result is zero; 0 otherwise | atomic_inc(v) | Add 1 to *v | atomic_dec(v) | Subtract 1 from *v | atomic_dec_and_test(v) | Subtract 1 from *v and return 1 if the result is zero; 0 otherwise | atomic_inc_and_test(v) | Add 1 to *v and return 1 if the result is zero; 0 otherwise | atomic_add_negative(i, v) | Add i to *v and return 1 if the result is negative; 0 otherwise | atomic_inc_return(v) | Add 1 to *v and return the new value of *v | atomic_dec_return(v) | Subtract 1 from *v and return the new value of *v | atomic_add_return(i, v) | Add i to *v and return the new value of *v | atomic_sub_return(i, v) | Subtract i from *v and return the new value of *v |
Another class of atomic functions operate on bit masks (see Table 5-5).
Table 5-5. Atomic bit handling functions in LinuxFunction | Description |
|---|
test_bit(nr, addr) | Return the value of the nrth bit of *addr | set_bit(nr, addr) | Set the nrth bit of *addr | clear_bit(nr, addr) | Clear the nrth bit of *addr | change_bit(nr, addr) | Invert the nrth bit of *addr | test_and_set_bit(nr, addr) | Set the nrth bit of *addr and return its old value | test_and_clear_bit(nr, addr) | Clear the nrth bit of *addr and return its old value | test_and_change_bit(nr, addr) | Invert the nrth bit of *addr and return its old value | atomic_clear_mask(mask, addr) | Clear all bits of *addr specified by mask | atomic_set_mask(mask, addr) | Set all bits of *addr specified by mask |
5.2.3. Optimization and Memory Barriers
When using optimizing compilers, you should never take for granted that instructions will be performed in the exact order in which they appear in the source code. For example, a compiler might reorder the assembly language instructions in such a way to optimize how registers are used. Moreover, modern CPUs usually execute several instructions in parallel and might reorder memory accesses. These kinds of reordering can greatly speed up the program.
When dealing with synchronization, however, reordering instructions must be avoided. Things would quickly become hairy if an instruction placed after a synchronization primitive is executed before the synchronization primitive itself. Therefore, all synchronization primitives act as optimization and memory barriers
.
An optimization barrier primitive ensures that the assembly language instructions corresponding to C statements placed before the primitive are not mixed by the compiler with assembly language instructions corresponding to C statements placed after the primitive. In Linux the barrier( ) macro, which expands into asm volatile("":::"memory"), acts as an optimization barrier. The asm instruction tells the compiler to insert an assembly language fragment (empty, in this case). The volatile keyword forbids the compiler to reshuffle the asm instruction with the other instructions of the program. The memory keyword forces the compiler to assume that all memory locations in RAM have been changed by the assembly language instruction; therefore, the compiler cannot optimize the code by using the values of memory locations stored in CPU registers before the asm instruction. Notice that the optimization barrier does not ensure that the executions of the assembly language instructions are not mixed by the CPUthis is a job for a memory barrier.
A memory barrier primitive ensures that the operations placed before the primitive are finished before starting the operations placed after the primitive. Thus, a memory barrier is like a firewall that cannot be passed by an assembly language instruction.
In the 80x86 processors, the following kinds of assembly language instructions are said to be "serializing" because they act as memory barriers:
All instructions that operate on I/O ports All instructions prefixed by the lock byte (see the section "Atomic Operations") All instructions that write into control registers, system registers, or debug registers
(for instance, cli
and sti
, which change the status of the IF flag in the eflags
register) The lfence
, sfence
, and mfence
assembly language instructions, which have been introduced in the Pentium 4 microprocessor to efficiently implement read memory barriers, write memory barriers, and read-write memory barriers, respectively. A few special assembly language instructions; among them, the iret
instruction that terminates an interrupt or exception handler
Linux uses a few memory barrier primitives, which are shown in Table 5-6. These primitives act also as optimization barriers
, because we must make sure the compiler does not move the assembly language instructions around the barrier. "Read memory barriers" act only on instructions that read from memory, while "write memory barriers" act only on instructions that write to memory. Memory barriers can be useful in both multiprocessor and uniprocessor systems. The smp_xxx( ) primitives are used whenever the memory barrier should prevent race conditions that might occur only in multiprocessor systems; in uniprocessor systems, they do nothing. The other memory barriers are used to prevent race conditions occurring both in uniprocessor and multiprocessor systems.
Table 5-6. Memory barriers in LinuxMacro | Description |
|---|
mb( ) | Memory barrier for MP and UP | rmb( ) | Read memory barrier for MP and UP | wmb( ) | Write memory barrier for MP and UP | smp_mb( ) | Memory barrier for MP only | smp_rmb( ) | Read memory barrier for MP only | smp_wmb( ) | Write memory barrier for MP only |
The implementations of the memory barrier primitives depend on the architecture of the system. On an 80x86 microprocessor, the rmb( ) macro usually expands into asm volatile("lfence") if the CPU supports the lfence assembly language instruction, or into asm volatile("lock;addl $0,0(%%esp)":::"memory") otherwise. The asm statement inserts an assembly language fragment in the code generated by the compiler and acts as an optimization barrier. The lock; addl $0,0(%%esp) assembly language instruction adds zero to the memory location on top of the stack; the instruction is useless by itself, but the lock prefix makes the instruction a memory barrier for the CPU.
The wmb( ) macro is actually simpler because it expands into barrier( ). This is because existing Intel microprocessors never reorder write memory accesses, so there is no need to insert a serializing assembly language instruction in the code. The macro, however, forbids the compiler from shuffling the instructions.
Notice that in multiprocessor systems, all atomic operations described in the earlier section "Atomic Operations" act as memory barriers because they use the lock byte.
5.2.4. Spin Locks
A widely used synchronization technique is locking. When a kernel control path must access a shared data structure or enter a critical region, it needs to acquire a "lock" for it. A resource protected by a locking mechanism is quite similar to a resource confined in a room whose door is locked when someone is inside. If a kernel control path wishes to access the resource, it tries to "open the door" by acquiring the lock. It succeeds only if the resource is free. Then, as long as it wants to use the resource, the door remains locked. When the kernel control path releases the lock, the door is unlocked and another kernel control path may enter the room.
Figure 5-1 illustrates the use of locks. Five kernel control paths (P0, P1, P2, P3, and P4) are trying to access two critical regions (C1 and C2). Kernel control path P0 is inside C1, while P2 and P4 are waiting to enter it. At the same time, P1 is inside C2, while P3 is waiting to enter it. Notice that P0 and P1 could run concurrently. The lock for critical region C3 is open because no kernel control path needs to enter it.
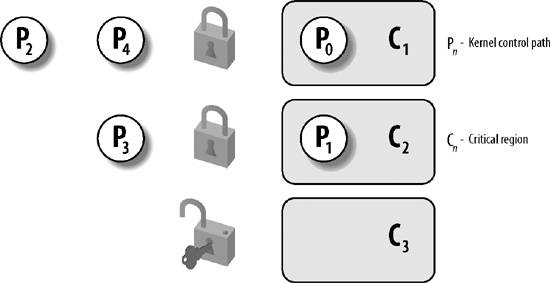
Spin locks are a special kind of lock designed to work in a multiprocessor environment. If the kernel control path finds the spin lock "open," it acquires the lock and continues its execution. Conversely, if the kernel control path finds the lock "closed" by a kernel control path running on another CPU, it "spins" around, repeatedly executing a tight instruction loop, until the lock is released.
The instruction loop of spin locks represents a "busy wait." The waiting kernel control path keeps running on the CPU, even if it has nothing to do besides waste time. Nevertheless, spin locks are usually convenient, because many kernel resources are locked for a fraction of a millisecond only; therefore, it would be far more time-consuming to release the CPU and reacquire it later.
As a general rule, kernel preemption is disabled in every critical region protected by spin locks. In the case of a uniprocessor system, the locks themselves are useless, and the spin lock primitives just disable or enable the kernel preemption. Please notice that kernel preemption is still enabled during the busy wait phase, thus a process waiting for a spin lock to be released could be replaced by a higher priority process.
In Linux, each spin lock is represented by a spinlock_t structure consisting of two fields:
slock Encodes the spin lock state: the value 1 corresponds to the unlocked state, while every negative value and 0 denote the locked state
break_lock Flag signaling that a process is busy waiting for the lock (present only if the kernel supports both SMP and kernel preemption)
Six macros shown in Table 5-7 are used to initialize, test, and set spin locks. All these macros are based on atomic operations; this ensures that the spin lock will be updated properly even when multiple processes running on different CPUs try to modify the lock at the same time.
Table 5-7. Spin lock macrosMacro | Description |
|---|
spin_lock_init( ) | Set the spin lock to 1 (unlocked) | spin_lock( ) | Cycle until spin lock becomes 1 (unlocked), then set it to 0 (locked) | spin_unlock( ) | Set the spin lock to 1 (unlocked) | spin_unlock_wait( ) | Wait until the spin lock becomes 1 (unlocked) | spin_is_locked( ) | Return 0 if the spin lock is set to 1 (unlocked); 1 otherwise | spin_trylock( ) | Set the spin lock to 0 (locked), and return 1 if the previous value of the lock was 1; 0 otherwise |
5.2.4.1. The spin_lock macro with kernel preemption
Let's discuss in detail the spin_lock macro, which is used to acquire a spin lock. The following description refers to a preemptive kernel for an SMP system. The macro takes the address slp of the spin lock as its parameter and executes the following actions:
Invokes preempt_disable( ) to disable kernel preemption. Invokes the _raw_spin_trylock( ) function, which does an atomic test-and-set operation on the spin lock's slock field; this function executes first some instructions equivalent to the following assembly language fragment:
movb $0, %al
xchgb %al, slp->slock
The xchg
assembly language instruction exchanges atomically the content of the 8-bit %al register (storing zero) with the content of the memory location pointed to by slp->slock. The function then returns the value 1 if the old value stored in the spin lock (in %al after the xchg instruction) was positive, the value 0 otherwise. If the old value of the spin lock was positive, the macro terminates: the kernel control path has acquired the spin lock. Otherwise, the kernel control path failed in acquiring the spin lock, thus the macro must cycle until the spin lock is released by a kernel control path running on some other CPU. Invokes preempt_enable( ) to undo the increase of the preemption counter done in step 1. If kernel preemption was enabled before executing the spin_lock macro, another process can now replace this process while it waits for the spin lock. If the break_lock field is equal to zero, sets it to one. By checking this field, the process owning the lock and running on another CPU can learn whether there are other processes waiting for the lock. If a process holds a spin lock for a long time, it may decide to release it prematurely to allow another process waiting for the same spin lock to progress. Executes the wait cycle:
while (spin_is_locked(slp) && slp->break_lock)
cpu_relax();
The cpu_relax( ) macro reduces to a pause
assembly language instruction. This instruction has been introduced in the Pentium 4 model to optimize the execution of spin lock loops. By introducing a short delay, it speeds up the execution of code following the lock and reduces power consumption. The pause instruction is backward compatible with earlier models of 80x86 microprocessors because it corresponds to the instruction rep;nop, that is, to a no-operation. Jumps back to step 1 to try once more to get the spin lock.
5.2.4.2. The spin_lock macro without kernel preemption
If the kernel preemption option has not been selected when the kernel was compiled, the spin_lock macro is quite different from the one described above. In this case, the macro yields a assembly language fragment that is essentially equivalent to the following tight busy wait:
1: lock; decb slp->slock
jns 3f
2: pause
cmpb $0,slp->slock
jle 2b
jmp 1b
3:
The decb assembly language instruction decreases the spin lock value; the instruction is atomic because it is prefixed by the lock byte. A test is then performed on the sign flag. If it is clear, it means that the spin lock was set to 1 (unlocked), so normal execution continues at label 3 (the f suffix denotes the fact that the label is a "forward" one; it appears in a later line of the program). Otherwise, the tight loop at label 2 (the b suffix denotes a "backward" label) is executed until the spin lock assumes a positive value. Then execution restarts from label 1, since it is unsafe to proceed without checking whether another processor has grabbed the lock.
5.2.4.3. The spin_unlock macro
The spin_unlock macro releases a previously acquired spin lock; it essentially executes the assembly language instruction:
movb $1, slp->slock
and then invokes preempt_enable( ) (if kernel preemption is not supported, preempt_enable( ) does nothing). Notice that the lock byte is not used because write-only accesses in memory are always atomically executed by the current 80x86 microprocessors.
5.2.5. Read/Write Spin Locks
Read/write spin locks have been introduced to increase the amount of concurrency inside the kernel. They allow several kernel control paths to simultaneously read the same data structure, as long as no kernel control path modifies it. If a kernel control path wishes to write to the structure, it must acquire the write version of the read/write lock, which grants exclusive access to the resource. Of course, allowing concurrent reads on data structures improves system performance.
Figure 5-2 illustrates two critical regions (C1 and C2) protected by read/write locks. Kernel control paths R0 and R1 are reading the data structures in C1 at the same time, while W0 is waiting to acquire the lock for writing. Kernel control path W1 is writing the data structures in C2, while both R2 and W2 are waiting to acquire the lock for reading and writing, respectively.
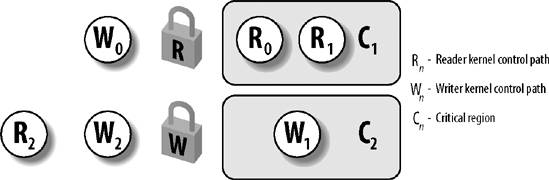
Each read/write spin lock is a rwlock_t structure; its lock field is a 32-bit field that encodes two distinct pieces of information:
A 24-bit counter denoting the number of kernel control paths currently reading the protected data structure. The two's complement value of this counter is stored in bits 023 of the field. An unlock flag that is set when no kernel control path is reading or writing, and clear otherwise. This unlock flag is stored in bit 24 of the field.
Notice that the lock field stores the number 0x01000000 if the spin lock is idle (unlock flag set and no readers), the number 0x00000000 if it has been acquired for writing (unlock flag clear and no readers), and any number in the sequence 0x00ffffff, 0x00fffffe, and so on, if it has been acquired for reading by one, two, or more processes (unlock flag clear and the two's complement on 24 bits of the number of readers). As the spinlock_t structure, the rwlock_t structure also includes a break_lock field.
The rwlock_init macro initializes the lock field of a read/write spin lock to 0x01000000 (unlocked) and the break_lock field to zero.
5.2.5.1. Getting and releasing a lock for reading
The read_lock macro, applied to the address rwlp of a read/write spin lock, is similar to the spin_lock macro described in the previous section. If the kernel preemption option has been selected when the kernel was compiled, the macro performs the very same actions as those of spin_lock( ), with just one exception: to effectively acquire the read/write spin lock in step 2, the macro executes the _raw_read_trylock( ) function:
int _raw_read_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
atomic_dec(count);
if (atomic_read(count) >= 0)
return 1;
atomic_inc(count);
return 0;
}
The lock fieldthe read/write lock counteris accessed by means of atomic operations. Notice, however, that the whole function does not act atomically on the counter: for instance, the counter might change after having tested its value with the if statement and before returning 1. Nevertheless, the function works properly: in fact, the function returns 1 only if the counter was not zero or negative before the decrement, because the counter is equal to 0x01000000 for no owner, 0x00ffffff for one reader, and 0x00000000 for one writer.
If the kernel preemption option has not been selected when the kernel was compiled, the read_lock macro yields the following assembly language code:
movl $rwlp->lock,%eax
lock; subl $1,(%eax)
jns 1f
call _ _read_lock_failed
1:
where _ _read_lock_failed( ) is the following assembly language function:
_ _read_lock_failed:
lock; incl (%eax)
1: pause
cmpl $1,(%eax)
js 1b
lock; decl (%eax)
js _ _read_lock_failed
ret
The read_lock macro atomically decreases the spin lock value by 1, thus increasing the number of readers. The spin lock is acquired if the decrement operation yields a nonnegative value; otherwise, the _ _read_lock_failed( ) function is invoked. The function atomically increases the lock field to undo the decrement operation performed by the read_lock macro, and then loops until the field becomes positive (greater than or equal to 1). Next, _ _read_lock_failed( ) tries to get the spin lock again (another kernel control path could acquire the spin lock for writing right after the cmpl instruction).
Releasing the read lock is quite simple, because the read_unlock macro must simply increase the counter in the lock field with the assembly language instruction:
lock; incl rwlp->lock
to decrease the number of readers, and then invoke preempt_enable( ) to reenable kernel preemption.
5.2.5.2. Getting and releasing a lock for writing
The write_lock macro is implemented in the same way as spin_lock( ) and read_lock( ). For instance, if kernel preemption is supported, the function disables kernel preemption and tries to grab the lock right away by invoking _raw_write_trylock( ). If this function returns 0, the lock was already taken, thus the macro reenables kernel preemption and starts a busy wait loop, as explained in the description of spin_lock( ) in the previous section.
The _raw_write_trylock( ) function is shown below:
int _raw_write_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
if (atomic_sub_and_test(0x01000000, count))
return 1;
atomic_add(0x01000000, count);
return 0;
}
The _raw_write_trylock( ) function subtracts 0x01000000 from the read/write spin lock value, thus clearing the unlock flag (bit 24). If the subtraction operation yields zero (no readers), the lock is acquired and the function returns 1; otherwise, the function atomically adds 0x01000000 to the spin lock value to undo the subtraction operation.
Once again, releasing the write lock is much simpler because the write_unlock macro must simply set the unlock flag in the lock field with the assembly language instruction:
lock; addl $0x01000000,rwlp
and then invoke preempt_enable().
5.2.6. Seqlocks
When using read/write spin locks, requests issued by kernel control paths to perform a read_lock or a write_lock operation have the same priority: readers must wait until the writer has finished and, similarly, a writer must wait until all readers have finished.
Seqlocks introduced in Linux 2.6 are similar to read/write spin locks, except that they give a much higher priority to writers: in fact a writer is allowed to proceed even when readers are active. The good part of this strategy is that a writer never waits (unless another writer is active); the bad part is that a reader may sometimes be forced to read the same data several times until it gets a valid copy.
Each seqlock is a seqlock_t structure consisting of two fields: a lock field of type spinlock_t and an integer sequence field. This second field plays the role of a sequence counter. Each reader must read this sequence counter twice, before and after reading the data, and check whether the two values coincide. In the opposite case, a new writer has become active and has increased the sequence counter, thus implicitly telling the reader that the data just read is not valid.
A seqlock_t variable is initialized to "unlocked" either by assigning to it the value SEQLOCK_UNLOCKED, or by executing the seqlock_init macro. Writers acquire and release a seqlock by invoking write_seqlock( ) and write_sequnlock( ). The first function acquires the spin lock in the seqlock_t data structure, then increases the sequence counter by one; the second function increases the sequence counter once more, then releases the spin lock. This ensures that when the writer is in the middle of writing, the counter is odd, and that when no writer is altering data, the counter is even. Readers implement a critical region as follows:
unsigned int seq;
do {
seq = read_seqbegin(&seqlock);
/* ... CRITICAL REGION ... */
} while (read_seqretry(&seqlock, seq));
read_seqbegin() returns the current sequence number of the seqlock; read_seqretry() returns 1 if either the value of the seq local variable is odd (a writer was updating the data structure when the read_seqbegin( ) function has been invoked), or if the value of seq does not match the current value of the seqlock's sequence counter (a writer started working while the reader was still executing the code in the critical region).
Notice that when a reader enters a critical region, it does not need to disable kernel preemption; on the other hand, the writer automatically disables kernel preemption when entering the critical region, because it acquires the spin lock.
Not every kind of data structure can be protected by a seqlock. As a general rule, the following conditions must hold:
The data structure to be protected does not include pointers that are modified by the writers and dereferenced by the readers (otherwise, a writer could change the pointer under the nose of the readers) The code in the critical regions of the readers does not have side effects (otherwise, multiple reads would have different effects from a single read)
Furthermore, the critical regions of the readers should be short and writers should seldom acquire the seqlock, otherwise repeated read accesses would cause a severe overhead. A typical usage of seqlocks in Linux 2.6 consists of protecting some data structures related to the system time handling (see
Chapter 6).
5.2.7. Read-Copy Update (RCU)
Read-copy update (RCU) is yet another synchronization technique designed to protect data structures that are mostly accessed for reading by several CPUs. RCU allows many readers and many writers to proceed concurrently (an improvement over seqlocks, which allow only one writer to proceed). Moreover, RCU is lock-free, that is, it uses no lock or counter shared by all CPUs; this is a great advantage over read/write spin locks and seqlocks, which have a high overhead due to cache line-snooping and invalidation.
How does RCU obtain the surprising result of synchronizing several CPUs without shared data structures? The key idea consists of limiting the scope of RCU as follows:
Only data structures that are dynamically allocated and referenced by means of pointers can be protected by RCU. No kernel control path can sleep inside a critical region protected by RCU.
When a kernel control path wants to read an RCU-protected data structure, it executes the rcu_read_lock( ) macro, which is equivalent to preempt_disable( ). Next, the reader dereferences the pointer to the data structure and starts reading it. As stated above, the reader cannot sleep until it finishes reading the data structure; the end of the critical region is marked by the rcu_read_unlock( ) macro, which is equivalent to preempt_enable( ).
Because the reader does very little to prevent race conditions, we could expect that the writer has to work a bit more. In fact, when a writer wants to update the data structure, it dereferences the pointer and makes a copy of the whole data structure. Next, the writer modifies the copy. Once finished, the writer changes the pointer to the data structure so as to make it point to the updated copy. Because changing the value of the pointer is an atomic operation, each reader or writer sees either the old copy or the new one: no corruption in the data structure may occur. However, a memory barrier is required to ensure that the updated pointer is seen by the other CPUs only after the data structure has been modified. Such a memory barrier is implicitly introduced if a spin lock is coupled with RCU to forbid the concurrent execution of writers.
The real problem with the RCU technique, however, is that the old copy of the data structure cannot be freed right away when the writer updates the pointer. In fact, the readers that were accessing the data structure when the writer started its update could still be reading the old copy. The old copy can be freed only after all (potential) readers on the CPUs have executed the rcu_read_unlock( ) macro. The kernel requires every potential reader to execute that macro before:
The CPU performs a process switch (see restriction 2 earlier). The CPU starts executing in User Mode. The CPU executes the idle loop (see the section "
Kernel Threads" in
Chapter 3).
In each of these cases, we say that the CPU has gone through a quiescent state.
The call_rcu( ) function is invoked by the writer to get rid of the old copy of the data structure. It receives as its parameters the address of an rcu_head descriptor (usually embedded inside the data structure to be freed) and the address of a callback function to be invoked when all CPUs have gone through a quiescent state. Once executed, the callback function usually frees the old copy of the data structure.
The call_rcu( ) function stores in the rcu_head descriptor the address of the callback and its parameter, then inserts the descriptor in a per-CPU list of callbacks. Periodically, once every tick (see the section "
Updating Local CPU Statistics" in
Chapter 6), the kernel checks whether the local CPU has gone through a quiescent state. When all CPUs have gone through a quiescent state, a local taskletwhose descriptor is stored in the rcu_tasklet per-CPU variableexecutes all callbacks in the list.
RCU is a new addition in Linux 2.6; it is used in the networking layer and in the Virtual Filesystem.
5.2.8. Semaphores
We have already introduced semaphores
in the section "
Synchronization and Critical Regions" in
Chapter 1. Essentially, they implement a locking primitive that allows waiters to sleep until the desired resource becomes free.
Actually, Linux offers two kinds of semaphores:
Kernel semaphores, which are used by kernel control paths System V IPC semaphores, which are used by User Mode processes
In this section, we focus on kernel semaphores, while IPC semaphores are described in
Chapter 19.
A kernel semaphore is similar to a spin lock, in that it doesn't allow a kernel control path to proceed unless the lock is open. However, whenever a kernel control path tries to acquire a busy resource protected by a kernel semaphore, the corresponding process is suspended. It becomes runnable again when the resource is released. Therefore, kernel semaphores can be acquired only by functions that are allowed to sleep; interrupt handlers and deferrable functions cannot use them.
A kernel semaphore is an object of type struct semaphore, containing the fields shown in the following list.
count Stores an atomic_t value. If it is greater than 0, the resource is free that is, it is currently available. If count is equal to 0, the semaphore is busy but no other process is waiting for the protected resource. Finally, if count is negative, the resource is unavailable and at least one process is waiting for it.
wait Stores the address of a wait queue list that includes all sleeping processes that are currently waiting for the resource. Of course, if count is greater than or equal to 0, the wait queue is empty.
sleepers Stores a flag that indicates whether some processes are sleeping on the semaphore. We'll see this field in operation soon.
The init_MUTEX( ) and init_MUTEX_LOCKED( ) functions may be used to initialize a semaphore for exclusive access: they set the count field to 1 (free resource with exclusive access) and 0 (busy resource with exclusive access currently granted to the process that initializes the semaphore), respectively. The DECLARE_MUTEX and DECLARE_MUTEX_LOCKED macros do the same, but they also statically allocate the struct semaphore variable. Note that a semaphore could also be initialized with an arbitrary positive value n for count. In this case, at most n processes are allowed to concurrently access the resource.
5.2.8.1. Getting and releasing semaphores
Let's start by discussing how to release a semaphore, which is much simpler than getting one. When a process wishes to release a kernel semaphore lock, it invokes the up( ) function. This function is essentially equivalent to the following assembly language fragment:
movl $sem->count,%ecx
lock; incl (%ecx)
jg 1f
lea %ecx,%eax
pushl %edx
pushl %ecx
call _ _up
popl %ecx
popl %edx
1:
where _ _up( ) is the following C function:
__attribute__((regparm(3))) void _ _up(struct semaphore *sem)
{
wake_up(&sem->wait);
}
The up( ) function increases the count field of the *sem semaphore, and then it checks whether its value is greater than 0. The increment of count and the setting of the flag tested by the following jump instruction must be atomically executed, or else another kernel control path could concurrently access the field value, with disastrous results. If count is greater than 0, there was no process sleeping in the wait queue, so nothing has to be done. Otherwise, the _ _up( ) function is invoked so that one sleeping process is woken up. Notice that _ _up( ) receives its parameter from the eax register (see the description of the _ _switch_to( ) function in the section "
Performing the Process Switch" in
Chapter 3).
Conversely, when a process wishes to acquire a kernel semaphore lock, it invokes the down( ) function. The implementation of down( ) is quite involved, but it is essentially equivalent to the following:
down:
movl $sem->count,%ecx
lock; decl (%ecx);
jns 1f
lea %ecx, %eax
pushl %edx
pushl %ecx
call _ _down
popl %ecx
popl %edx
1:
where _ _down( ) is the following C function:
__attribute__((regparm(3))) void _ _down(struct semaphore * sem)
{
DECLARE_WAITQUEUE(wait, current);
unsigned long flags;
current->state = TASK_UNINTERRUPTIBLE;
spin_lock_irqsave(&sem->wait.lock, flags);
add_wait_queue_exclusive_locked(&sem->wait, &wait);
sem->sleepers++;
for (;;) {
if (!atomic_add_negative(sem->sleepers-1, &sem->count)) {
sem->sleepers = 0;
break;
}
sem->sleepers = 1;
spin_unlock_irqrestore(&sem->wait.lock, flags);
schedule( );
spin_lock_irqsave(&sem->wait.lock, flags);
current->state = TASK_UNINTERRUPTIBLE;
}
remove_wait_queue_locked(&sem->wait, &wait);
wake_up_locked(&sem->wait);
spin_unlock_irqrestore(&sem->wait.lock, flags);
current->state = TASK_RUNNING;
}
The down( ) function decreases the count field of the *sem semaphore, and then checks whether its value is negative. Again, the decrement and the test must be atomically executed. If count is greater than or equal to 0, the current process acquires the resource and the execution continues normally. Otherwise, count is negative, and the current process must be suspended. The contents of some registers are saved on the stack, and then _ _down( ) is invoked.
Essentially, the _ _down( ) function changes the state of the current process from TASK_RUNNING to TASK_UNINTERRUPTIBLE, and it puts the process in the semaphore wait queue. Before accessing the fields of the semaphore structure, the function also gets the sem->wait.lock spin lock that protects the semaphore wait queue (see "
How Processes Are Organized" in
Chapter 3) and disables local interrupts. Usually, wait queue functions get and release the wait queue spin lock as necessary when inserting and deleting an element. The _ _down( ) function, however, uses the wait queue spin lock also to protect the other fields of the semaphore data structure, so that no process running on another CPU is able to read or modify them. To that end, _ _down( ) uses the "_locked" versions of the wait queue functions, which assume that the spin lock has been already acquired before their invocations.
The main task of the _ _down( ) function is to suspend the current process until the semaphore is released. However, the way in which this is done is quite involved. To easily understand the code, keep in mind that the sleepers field of the semaphore is usually set to 0 if no process is sleeping in the wait queue of the semaphore, and it is set to 1 otherwise. Let's try to explain the code by considering a few typical cases.
MUTEX semaphore open (count equal to 1, sleepers equal to 0) The down macro just sets the count field to 0 and jumps to the next instruction of the main program; therefore, the _ _down( ) function is not executed at all.
MUTEX semaphore closed, no sleeping processes (count equal to 0, sleepers equal to 0) The down macro decreases count and invokes the _ _down( ) function with the count field set to -1 and the sleepers field set to 0. In each iteration of the loop, the function checks whether the count field is negative. (Observe that the count field is not changed by atomic_add_negative( ) because sleepers is equal to 0 when the function is invoked.)
If the count field is negative, the function invokes schedule( ) to suspend the current process. The count field is still set to -1, and the sleepers field to 1. The process picks up its run subsequently inside this loop and issues the test again. If the count field is not negative, the function sets sleepers to 0 and exits from the loop. It tries to wake up another process in the semaphore wait queue (but in our scenario, the queue is now empty) and terminates holding the semaphore. On exit, both the count field and the sleepers field are set to 0, as required when the semaphore is closed but no process is waiting for it.
MUTEX semaphore closed, other sleeping processes (count equal to -1, sleepers equal to 1) The down macro decreases count and invokes the _ _down( ) function with count set to -2 and sleepers set to 1. The function temporarily sets sleepers to 2, and then undoes the decrement performed by the down macro by adding the value sleepers-1 to count. At the same time, the function checks whether count is still negative (the semaphore could have been released by the holding process right before _ _down( ) entered the critical region).
If the count field is negative, the function resets sleepers to 1 and invokes schedule( ) to suspend the current process. The count field is still set to -1, and the sleepers field to 1. If the count field is not negative, the function sets sleepers to 0, tries to wake up another process in the semaphore wait queue, and exits holding the semaphore. On exit, the count field is set to 0 and the sleepers field to 0. The values of both fields look wrong, because there are other sleeping processes. However, consider that another process in the wait queue has been woken up. This process does another iteration of the loop; the atomic_add_negative( ) function subtracts 1 from count, restoring it to -1; moreover, before returning to sleep, the woken-up process resets sleepers to 1.
So, the code properly works in all cases. Consider that the wake_up( ) function in _ _down( ) wakes up at most one process, because the sleeping processes in the wait queue are exclusive (see the section "
How Processes Are Organized" in
Chapter 3).
Only exception handlers
, and particularly system call service routines
, can use the down( ) function. Interrupt handlers or deferrable functions must not invoke down( ), because this function suspends the process when the semaphore is busy. For this reason, Linux provides the down_trylock( ) function, which may be safely used by one of the previously mentioned asynchronous functions. It is identical to down( ) except when the resource is busy. In this case, the function returns immediately instead of putting the process to sleep.
A slightly different function called down_interruptible( ) is also defined. It is widely used by device drivers, because it allows processes that receive a signal while being blocked on a semaphore to give up the "down" operation. If the sleeping process is woken up by a signal before getting the needed resource, the function increases the count field of the semaphore and returns the value -EINTR. On the other hand, if down_interruptible( ) runs to normal completion and gets the resource, it returns 0. The device driver may thus abort the I/O operation when the return value is -EINTR.
Finally, because processes usually find semaphores in an open state, the semaphore functions are optimized for this case. In particular, the up( ) function does not execute jump instructions if the semaphore wait queue is empty; similarly, the down( ) function does not execute jump instructions if the semaphore is open. Much of the complexity of the semaphore implementation is precisely due to the effort of avoiding costly instructions in the main branch of the execution flow.
5.2.9. Read/Write Semaphores
Read/write semaphores are similar to the read/write spin locks described earlier in the section "Read/Write Spin Locks," except that waiting processes are suspended instead of spinning until the semaphore becomes open again.
Many kernel control paths may concurrently acquire a read/write semaphore for reading; however, every writer kernel control path must have exclusive access to the protected resource. Therefore, the semaphore can be acquired for writing only if no other kernel control path is holding it for either read or write access. Read/write semaphores improve the amount of concurrency inside the kernel and improve overall system performance.
The kernel handles all processes waiting for a read/write semaphore in strict FIFO order. Each reader or writer that finds the semaphore closed is inserted in the last position of a semaphore's wait queue list. When the semaphore is released, the process in the first position of the wait queue list are checked. The first process is always awoken. If it is a writer, the other processes in the wait queue continue to sleep. If it is a reader, all readers at the start of the queue, up to the first writer, are also woken up and get the lock. However, readers that have been queued after a writer continue to sleep.
Each read/write semaphore is described by a rw_semaphore structure that includes the following fields:
count Stores two 16-bit counters. The counter in the most significant word encodes in two's complement form the sum of the number of nonwaiting writers (either 0 or 1) and the number of waiting kernel control paths. The counter in the less significant word encodes the total number of nonwaiting readers and writers.
wait_list Points to a list of waiting processes. Each element in this list is a rwsem_waiter structure, including a pointer to the descriptor of the sleeping process and a flag indicating whether the process wants the semaphore for reading or for writing.
wait_lock A spin lock used to protect the wait queue list and the rw_semaphore structure itself.
The init_rwsem( ) function initializes an rw_semaphore structure by setting the count field to 0, the wait_lock spin lock to unlocked, and wait_list to the empty list.
The down_read( ) and down_write( ) functions acquire the read/write semaphore for reading and writing, respectively. Similarly, the up_read( ) and up_write( ) functions release a read/write semaphore previously acquired for reading and for writing. The down_read_trylock( ) and down_write_trylock( ) functions are similar to down_read( ) and down_write( ), respectively, but they do not block the process if the semaphore is busy. Finally, the downgrade_write( ) function atomically transforms a write lock into a read lock. The implementation of these five functions is long, but easy to follow because it resembles the implementation of normal semaphores; therefore, we avoid describing them.
5.2.10. Completions
Linux 2.6 also makes use of another synchronization primitive similar to semaphores: completions
. They have been introduced to solve a subtle race condition that occurs in multiprocessor systems when process A allocates a temporary semaphore variable, initializes it as closed MUTEX, passes its address to process B, and then invokes down( ) on it. Process A plans to destroy the semaphore as soon as it awakens. Later on, process B running on a different CPU invokes up( ) on the semaphore. However, in the current implementation up( ) and down( ) can execute concurrently on the same semaphore. Thus, process A can be woken up and destroy the temporary semaphore while process B is still executing the up( ) function. As a result, up( ) might attempt to access a data structure that no longer exists.
Of course, it is possible to change the implementation of down( ) and up( ) to forbid concurrent executions on the same semaphore. However, this change would require additional instructions, which is a bad thing to do for functions that are so heavily used.
The completion is a synchronization primitive that is specifically designed to solve this problem. The completion data structure includes a wait queue head and a flag:
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
The function corresponding to up( ) is called complete( ). It receives as an argument the address of a completion data structure, invokes spin_lock_irqsave( ) on the spin lock of the completion's wait queue, increases the done field, wakes up the exclusive process sleeping in the wait wait queue, and finally invokes spin_unlock_irqrestore( ).
The function corresponding to down( ) is called wait_for_completion( ). It receives as an argument the address of a completion data structure and checks the value of the done flag. If it is greater than zero, wait_for_completion( ) terminates, because complete( ) has already been executed on another CPU. Otherwise, the function adds current to the tail of the wait queue as an exclusive process and puts current to sleep in the TASK_UNINTERRUPTIBLE state. Once woken up, the function removes current from the wait queue. Then, the function checks the value of the done flag: if it is equal to zero the function terminates, otherwise, the current process is suspended again. As in the case of the complete( ) function, wait_for_completion( ) makes use of the spin lock in the completion's wait queue.
The real difference between completions and semaphores is how the spin lock included in the wait queue is used. In completions, the spin lock is used to ensure that complete( ) and wait_for_completion( ) cannot execute concurrently. In semaphores, the spin lock is used to avoid letting concurrent down( )'s functions mess up the semaphore data structure.
5.2.11. Local Interrupt Disabling
Interrupt disabling
is one of the key mechanisms used to ensure that a sequence of kernel statements is treated as a critical section. It allows a kernel control path to continue executing even when hardware devices issue IRQ signals, thus providing an effective way to protect data structures that are also accessed by interrupt handlers. By itself, however, local interrupt disabling does not protect against concurrent accesses to data structures by interrupt handlers running on other CPUs, so in multiprocessor systems, local interrupt disabling is often coupled with spin locks (see the later section "
Synchronizing Accesses to Kernel Data Structures").
The local_irq_disable( ) macro, which makes use of the cli
assembly language instruction, disables interrupts on the local CPU. The local_irq_enable( ) macro, which makes use of the of the sti
assembly language instruction, enables them. As stated in the section "
IRQs and Interrupts" in
Chapter 4, the cli and sti assembly language instructions, respectively, clear and set the IF flag of the eflags
control register. The irqs_disabled( ) macro yields the value one if the IF flag of the eflags register is clear, the value one if the flag is set.
When the kernel enters a critical section, it disables interrupts by clearing the IF flag of the eflags register. But at the end of the critical section, often the kernel can't simply set the flag again. Interrupts can execute in nested fashion, so the kernel does not necessarily know what the IF flag was before the current control path executed. In these cases, the control path must save the old setting of the flag and restore that setting at the end.
Saving and restoring the eflags content is achieved by means of the local_irq_save and local_irq_restore macros, respectively. The local_irq_save macro copies the content of the eflags register into a local variable; the IF flag is then cleared by a cli assembly language instruction. At the end of the critical region, the macro local_irq_restore restores the original content of eflags; therefore, interrupts are enabled only if they were enabled before this control path issued the cli assembly language instruction.
5.2.12. Disabling and Enabling Deferrable Functions
In the section "
Softirqs" in
Chapter 4, we explained that deferrable functions can be executed at unpredictable times (essentially, on termination of hardware interrupt handlers). Therefore, data structures accessed by deferrable functions must be protected against race conditions.
A trivial way to forbid deferrable functions execution on a CPU is to disable interrupts on that CPU. Because no interrupt handler can be activated, softirq actions cannot be started asynchronously.
As we'll see in the next section, however, the kernel sometimes needs to disable deferrable functions without disabling
interrupts. Local deferrable functions can be enabled or disabled on the local CPU by acting on the softirq counter stored in the preempt_count field of the current's tHRead_info descriptor.
Recall that the do_softirq( ) function never executes the softirqs if the softirq counter is positive. Moreover, tasklets are implemented on top of softirqs, so setting this counter to a positive value disables the execution of all deferrable functions on a given CPU, not just softirqs.
The local_bh_disable macro adds one to the softirq counter of the local CPU, while the local_bh_enable( ) function subtracts one from it. The kernel can thus use several nested invocations of local_bh_disable; deferrable functions will be enabled again only by the local_bh_enable macro matching the first local_bh_disable invocation.
After having decreased the softirq counter, local_bh_enable( ) performs two important operations that help to ensure timely execution of long-waiting threads:
Checks the hardirq counter and the softirq counter in the preempt_count field of the local CPU; if both of them are zero and there are pending softirqs to be executed, invokes do_softirq( ) to activate them (see the section "
Softirqs" in
Chapter 4). Checks whether the TIF_NEED_RESCHED flag of the local CPU is set; if so, a process switch request is pending, thus invokes the preempt_schedule( ) function (see the section "
Kernel Preemption" earlier in this chapter).
|
5.3. Synchronizing Accesses to Kernel Data Structures
A shared data structure can be protected against race conditions by using some of the synchronization primitives shown in the previous section. Of course, system performance may vary considerably, depending on the kind of synchronization primitive selected. Usually, the following rule of thumb is adopted by kernel developers: always keep the concurrency level
as high as possible in the system.
In turn, the concurrency level in the system depends on two main factors:
To maximize I/O throughput, interrupts should be disabled for very short periods of time. As described in the section "
IRQs and Interrupts" in
Chapter 4, when interrupts are disabled, IRQs issued by I/O devices are temporarily ignored by the PIC, and no new activity can start on such devices.
To use CPUs efficiently, synchronization primitives based on spin locks should be avoided whenever possible. When a CPU is executing a tight instruction loop waiting for the spin lock to open, it is wasting precious machine cycles. Even worse, as we have already said, spin locks have negative effects on the overall performance of the system because of their impact on the hardware caches.
Let's illustrate a couple of cases in which synchronization can be achieved while still maintaining a high concurrency level:
A shared data structure consisting of a single integer value can be updated by declaring it as an atomic_t type and by using atomic operations. An atomic operation is faster than spin locks and interrupt disabling, and it slows down only kernel control paths that concurrently access the data structure. Inserting an element into a shared linked list is never atomic, because it consists of at least two pointer assignments. Nevertheless, the kernel can sometimes perform this insertion operation without using locks or disabling interrupts. As an example of why this works, we'll consider the case where a system call service routine (see "
System Call Handler and Service Routines" in
Chapter 10) inserts new elements in a singly linked list, while an interrupt handler or deferrable function asynchronously looks up the list. In the C language, insertion is implemented by means of the following pointer assignments:
new->next = list_element->next;
list_element->next = new;
In assembly language, insertion reduces to two consecutive atomic instructions. The first instruction sets up the next pointer of the new element, but it does not modify the list. Thus, if the interrupt handler sees the list between the execution of the first and second instructions, it sees the list without the new element. If the handler sees the list after the execution of the second instruction, it sees the list with the new element. The important point is that in either case, the list is consistent and in an uncorrupted state. However, this integrity is assured only if the interrupt handler does not modify the list. If it does, the next pointer that was just set within the new element might become invalid. However, developers must ensure that the order of the two assignment operations cannot be subverted by the compiler or the CPU's control unit; otherwise, if the system call service routine is interrupted by the interrupt handler between the two assignments, the handler finds a corrupted list. Therefore, a write memory barrier primitive is required:
new->next = list_element->next;
wmb( );
list_element->next = new;
5.3.1. Choosing Among Spin Locks, Semaphores, and Interrupt Disabling
Unfortunately, access patterns to most kernel data structures are a lot more complex than the simple examples just shown, and kernel developers are forced to use semaphores, spin locks, interrupts, and softirq disabling. Generally speaking, choosing the synchronization primitives depends on what kinds of kernel control paths access the data structure, as shown in Table 5-8. Remember that whenever a kernel control path acquires a spin lock (as well as a read/write lock, a seqlock, or a RCU "read lock"), disables the local interrupts, or disables the local softirqs, kernel preemption is automatically disabled.
Table 5-8. Protection required by data structures accessed by kernel control pathsKernel control paths accessing the data structure | UP protection | MP further protection |
|---|
Exceptions | Semaphore | None | Interrupts | Local interrupt disabling | Spin lock | Deferrable functions | None | None or spin lock (see Table 5-9) | Exceptions + Interrupts | Local interrupt disabling | Spin lock | Exceptions + Deferrable functions | Local softirq disabling | Spin lock | Interrupts + Deferrable functions | Local interrupt disabling | Spin lock | Exceptions + Interrupts + Deferrable functions | Local interrupt disabling | Spin lock |
5.3.1.1. Protecting a data structure accessed by exceptions
When a data structure is accessed only by exception handlers, race conditions are usually easy to understand and prevent. The most common exceptions that give rise to synchronization problems are the system call service routines (see the section "
System Call Handler and Service Routines" in
Chapter 10) in which the CPU operates in Kernel Mode to offer a service to a User Mode program. Thus, a data structure accessed only by an exception usually represents a resource that can be assigned to one or more processes.
Race conditions are avoided through semaphores, because these primitives allow the process to sleep until the resource becomes available. Notice that semaphores work equally well both in uniprocessor and multiprocessor systems.
Kernel preemption does not create problems either. If a process that owns a semaphore is preempted, a new process running on the same CPU could try to get the semaphore. When this occurs, the new process is put to sleep, and eventually the old process will release the semaphore. The only case in which kernel preemption must be explicitly disabled is when accessing per-CPU variables, as explained in the section "
Per-CPU Variables" earlier in this chapter.
5.3.1.2. Protecting a data structure accessed by interrupts
Suppose that a data structure is accessed by only the "top half" of an interrupt handler. We learned in the section "
Interrupt Handling" in
Chapter 4 that each interrupt handler is serialized with respect to itself that is, it cannot execute more than once concurrently. Thus, accessing the data structure does not require synchronization primitives.
Things are different, however, if the data structure is accessed by several interrupt handlers. A handler may interrupt another handler, and different interrupt handlers may run concurrently in multiprocessor systems. Without synchronization, the shared data structure might easily become corrupted.
In uniprocessor systems, race conditions must be avoided by disabling interrupts in all critical regions of the interrupt handler. Nothing less will do because no other synchronization primitives accomplish the job. A semaphore can block the process, so it cannot be used in an interrupt handler. A spin lock, on the other hand, can freeze the system: if the handler accessing the data structure is interrupted, it cannot release the lock; therefore, the new interrupt handler keeps waiting on the tight loop of the spin lock.
Multiprocessor systems, as usual, are even more demanding. Race conditions cannot be avoided by simply disabling local interrupts. In fact, even if interrupts are disabled on a CPU, interrupt handlers can still be executed on the other CPUs. The most convenient method to prevent the race conditions is to disable local interrupts (so that other interrupt handlers running on the same CPU won't interfere) and to acquire a spin lock or a read/write spin lock that protects the data structure. Notice that these additional spin locks cannot freeze the system because even if an interrupt handler finds the lock closed, eventually the interrupt handler on the other CPU that owns the lock will release it.
The Linux kernel uses several macros that couple the enabling and disabling of local interrupts with spin lock handling. Table 5-9 describes all of them. In uniprocessor systems, these macros just enable or disable local interrupts and kernel preemption.
Table 5-9. Interrupt-aware spin lock macrosMacro | Description |
|---|
spin_lock_irq(l) | local_irq_disable( ); spin_lock(l) | spin_unlock_irq(l) | spin_unlock(l); local_irq_enable() | spin_lock_bh(l) | local_bh_disable( ); spin_lock(l) | spin_unlock_bh(l) | spin_unlock(l); local_bh_enable() | spin_lock_irqsave(l,f) | local_irq_save(f); spin_lock(l) | spin_unlock_irqrestore(l,f) | spin_unlock(l); local_irq_restore(f) | read_lock_irq(l) | local_irq_disable( ); read_lock(l) | read_unlock_irq(l) | read_unlock(l); local_irq_enable( ) | read_lock_bh(l) | local_bh_disable( ); read_lock(l) | read_unlock_bh(l) | read_unlock(l); local_bh_enable( ) | write_lock_irq(l) | local_irq_disable( ); write_lock(l) | write_unlock_irq(l) | write_unlock(l); local_irq_enable( ) | write_lock_bh(l) | local_bh_disable( ); write_lock(l) | write_unlock_bh(l) | write_unlock(l); local_bh_enable( ) | read_lock_irqsave(l,f) | local_irq_save(f); read_lock(l) | read_unlock_irqrestore(l,f) | read_unlock(l); local_irq_restore(f) | write_lock_irqsave(l,f) | local_irq_save(f); write_lock(l) | write_unlock_irqrestore(l,f) | write_unlock(l); local_irq_restore(f) | read_seqbegin_irqsave(l,f) | local_irq_save(f); read_seqbegin(l) | read_seqretry_irqrestore(l,v,f) | read_seqretry(l,v); local_irq_restore(f) | write_seqlock_irqsave(l,f) | local_irq_save(f); write_seqlock(l) | write_sequnlock_irqrestore(l,f) | write_sequnlock(l); local_irq_restore(f) | write_seqlock_irq(l) | local_irq_disable( ); write_seqlock(l) | write_sequnlock_irq(l) | write_sequnlock(l); local_irq_enable( ) | write_seqlock_bh(l) | local_bh_disable( ); write_seqlock(l); | write_sequnlock_bh(l) | write_sequnlock(l); local_bh_enable( ) |
5.3.1.3. Protecting a data structure accessed by deferrable functions
What kind of protection is required for a data structure accessed only by deferrable functions? Well, it mostly depends on the kind of deferrable function. In the section "
Softirqs and Tasklets" in
Chapter 4, we explained that softirqs and tasklets essentially differ in their degree of concurrency.
First of all, no race condition may exist in uniprocessor systems. This is because execution of deferrable functions is always serialized on a CPU that is, a deferrable function cannot be interrupted by another deferrable function. Therefore, no synchronization primitive is ever required.
Conversely, in multiprocessor systems, race conditions do exist because several deferrable functions may run concurrently. Table 5-10 lists all possible cases.
Table 5-10. Protection required by data structures accessed by deferrable functions in SMPDeferrable functions accessing the data structure | Protection |
|---|
Softirqs | Spin lock | One tasklet | None | Many tasklets | Spin lock |
A data structure accessed by a softirq must always be protected, usually by means of a spin lock, because the same softirq may run concurrently on two or more CPUs. Conversely, a data structure accessed by just one kind of tasklet need not be protected, because tasklets of the same kind cannot run concurrently. However, if the data structure is accessed by several kinds of tasklets, then it must be protected.
5.3.1.4. Protecting a data structure accessed by exceptions and interrupts
Let's consider now a data structure that is accessed both by exceptions (for instance, system call service routines) and interrupt handlers.
On uniprocessor systems, race condition prevention is quite simple, because interrupt handlers are not reentrant and cannot be interrupted by exceptions. As long as the kernel accesses the data structure with local interrupts disabled, the kernel cannot be interrupted when accessing the data structure. However, if the data structure is accessed by just one kind of interrupt handler, the interrupt handler can freely access the data structure without disabling local interrupts.
On multiprocessor systems, we have to take care of concurrent executions of exceptions and interrupts on other CPUs. Local interrupt disabling must be coupled with a spin lock, which forces the concurrent kernel control paths to wait until the handler accessing the data structure finishes its work.
Sometimes it might be preferable to replace the spin lock with a semaphore. Because interrupt handlers cannot be suspended, they must acquire the semaphore using a tight loop and the down_trylock( ) function; for them, the semaphore acts essentially as a spin lock. System call service routines, on the other hand, may suspend the calling processes when the semaphore is busy. For most system calls, this is the expected behavior. In this case, semaphores are preferable to spin locks, because they lead to a higher degree of concurrency of the system.
5.3.1.5. Protecting a data structure accessed by exceptions and deferrable functions
A data structure accessed both by exception handlers and deferrable functions can be treated like a data structure accessed by exception and interrupt handlers. In fact, deferrable functions are essentially activated by interrupt occurrences, and no exception can be raised while a deferrable function is running. Coupling local interrupt disabling with a spin lock is therefore sufficient.
Actually, this is much more than sufficient: the exception handler can simply disable deferrable functions instead of local interrupts by using the local_bh_disable( ) macro (see the section "
Softirqs" in
Chapter 4). Disabling only the deferrable functions is preferable to disabling interrupts, because interrupts continue to be serviced by the CPU. Execution of deferrable functions on each CPU is serialized, so no race condition exists.
As usual, in multiprocessor systems, spin locks are required to ensure that the data structure is accessed at any time by just one kernel control.
5.3.1.6. Protecting a data structure accessed by interrupts and deferrable functions
This case is similar to that of a data structure accessed by interrupt and exception handlers. An interrupt might be raised while a deferrable function is running, but no deferrable function can stop an interrupt handler. Therefore, race conditions must be avoided by disabling local interrupts during the deferrable function. However, an interrupt handler can freely touch the data structure accessed by the deferrable function without disabling interrupts, provided that no other interrupt handler accesses that data structure.
Again, in multiprocessor systems, a spin lock is always required to forbid concurrent accesses to the data structure on several CPUs.
5.3.1.7. Protecting a data structure accessed by exceptions, interrupts, and deferrable functions
Similarly to previous cases, disabling local interrupts and acquiring a spin lock is almost always necessary to avoid race conditions. Notice that there is no need to explicitly disable deferrable functions, because they are essentially activated when terminating the execution of interrupt handlers; disabling local interrupts is therefore sufficient.
5.4. Examples of Race Condition Prevention
Kernel developers are expected to identify and solve the synchronization problems raised by interleaving kernel control paths. However, avoiding race conditions is a hard task because it requires a clear understanding of how the various components of the kernel interact. To give a feeling of what's really inside the kernel code, let's mention a few typical usages of the synchronization primitives defined in this chapter.
5.4.1. Reference Counters
Reference counters are widely used inside the kernel to avoid race conditions due to the concurrent allocation and releasing of a resource. A reference counter is just an atomic_t counter associated with a specific resource such as a memory page, a module, or a file. The counter is atomically increased when a kernel control path starts using the resource, and it is decreased when a kernel control path finishes using the resource. When the reference counter becomes zero, the resource is not being used, and it can be released if necessary.
5.4.2. The Big Kernel Lock
In earlier Linux kernel versions, a big kernel lock
(also known as global kernel lock, or BKL) was widely used. In Linux 2.0, this lock was a relatively crude spin lock, ensuring that only one processor at a time could run in Kernel Mode. The 2.2 and 2.4 kernels were considerably more flexible and no longer relied on a single spin lock; rather, a large number of kernel data structures were protected by many different spin locks. In Linux kernel version 2.6, the big kernel lock is used to protect old code (mostly functions related to the VFS and to several filesystems).
Starting from kernel version 2.6.11, the big kernel lock is implemented by a semaphore named kernel_sem (in earlier 2.6 versions, the big kernel lock was implemented by means of a spin lock). The big kernel lock is slightly more sophisticated than a simple semaphore, however.
Every process descriptor includes a lock_depth field, which allows the same process to acquire the big kernel lock several times. Therefore, two consecutive requests for it will not hang the processor (as for normal locks). If the process has not acquired the lock, the field has the value -1; otherwise, the field value plus 1 specifies how many times the lock has been taken. The lock_depth field is crucial for allowing interrupt handlers, exception handlers, and deferrable functions to take the big kernel lock: without it, every asynchronous function that tries to get the big kernel lock could generate a deadlock if the current process already owns the lock.
The lock_kernel( ) and unlock_kernel( ) functions are used to get and release the big kernel lock. The former function is equivalent to:
depth = current->lock_depth + 1;
if (depth == 0)
down(&kernel_sem);
current->lock_depth = depth;
while the latter is equivalent to:
if (--current->lock_depth < 0)
up(&kernel_sem);
Notice that the if statements of the lock_kernel( ) and unlock_kernel( ) functions need not be executed atomically because lock_depth is not a global variable each CPU addresses a field of its own current process descriptor. Local interrupts inside the if statements do not induce race conditions either. Even if the new kernel control path invokes lock_kernel( ), it must release the big kernel lock before terminating.
Surprisingly enough, a process holding the big kernel lock is allowed to invoke schedule( ), thus relinquishing the CPU. The schedule( ) function, however, checks the lock_depth field of the process being replaced and, if its value is zero or positive, automatically releases the kernel_sem semaphore (see the section "
The schedule( ) Function" in
Chapter 7). Thus, no process that explicitly invokes schedule( ) can keep the big kernel lock across the process switch. The schedule( ) function, however, will reacquire the big kernel lock for the process when it will be selected again for execution.
Things are different, however, if a process that holds the big kernel lock is preempted by another process. Up to kernel version 2.6.10 this case could not occur, because acquiring a spin lock automatically disables kernel preemption. The current implementation of the big kernel lock, however, is based on a semaphore, and acquiring it does not automatically disable kernel preemption. Actually, allowing kernel preemption inside critical regions protected by the big kernel lock has been the main reason for changing its implementation. This, in turn, has beneficial effects on the response time of the system.
When a process holding the big kernel lock is preempted, schedule( ) must not release the semaphore because the process executing the code in the critical region has not voluntarily triggered a process switch, thus if the big kernel lock would be released, another process might take it and corrupt the data structures accessed by the preempted process.
To avoid the preempted process losing the big kernel lock, the preempt_schedule_irq( ) function temporarily sets the lock_depth field of the process to -1 (see the section "
Returning from Interrupts and Exceptions" in
Chapter 4). Looking at the value of this field, schedule( ) assumes that the process being replaced does not hold the kernel_sem semaphore and thus does not release it. As a result, the kernel_sem semaphore continues to be owned by the preempted process. Once this process is selected again by the scheduler, the preempt_schedule_irq( ) function restores the original value of the lock_depth field and lets the process resume execution in the critical section protected by the big kernel lock.
5.4.3. Memory Descriptor Read/Write Semaphore
Each memory descriptor of type mm_struct includes its own semaphore in the mmap_sem field (see the section "
The Memory Descriptor" in
Chapter 9). The semaphore protects the descriptor against race conditions that could arise because a memory descriptor can be shared among several lightweight processes.
For instance, let's suppose that the kernel must create or extend a memory region for some process; to do this, it invokes the do_mmap( ) function, which allocates a new vm_area_struct data structure. In doing so, the current process could be suspended if no free memory is available, and another process sharing the same memory descriptor could run. Without the semaphore, every operation of the second process that requires access to the memory descriptor (for instance, a Page Fault
due to a Copy on Write) could lead to severe data corruption.
The semaphore is implemented as a read/write semaphore, because some kernel functions, such as the Page Fault exception handler (see the section "
Page Fault Exception Handler" in
Chapter 9), need only to scan the memory descriptors.
5.4.4. Slab Cache List Semaphore
The list of slab cache descriptors
(see the section "
Cache Descriptor" in
Chapter 8) is protected by the cache_chain_sem semaphore, which grants an exclusive right to access and modify the list.
A race condition is possible when kmem_cache_create( ) adds a new element in the list, while kmem_cache_shrink( ) and kmem_cache_reap( ) sequentially scan the list. However, these functions are never invoked while handling an interrupt, and they can never block while accessing the list. The semaphore plays an active role both in multiprocessor systems and in uniprocessor systems with kernel preemption supported.
5.4.5. Inode Semaphore
As we'll see in "
Inode Objects" in
Chapter 12, Linux stores the information on a disk file in a memory object called an inode. The corresponding data structure includes its own semaphore in the i_sem field.
A huge number of race conditions can occur during filesystem handling. Indeed, each file on disk is a resource held in common for all users, because all processes may (potentially) access the file content, change its name or location, destroy or duplicate it, and so on. For example, let's suppose that a process lists the files contained in some directory. Each disk operation is potentially blocking, and therefore even in uniprocessor systems, other processes could access the same directory and modify its content while the first process is in the middle of the listing operation. Or, again, two different processes could modify the same directory at the same time. All these race conditions are avoided by protecting the directory file with the inode semaphore.
Whenever a program uses two or more semaphores, the potential for deadlock is present, because two different paths could end up waiting for each other to release a semaphore. Generally speaking, Linux has few problems with deadlocks on semaphore requests, because each kernel control path usually needs to acquire just one semaphore at a time. However, in some cases, the kernel must get two or more locks. Inode semaphores are prone to this scenario; for instance, this occurs in the service routine in the rename( ) system call. In this case, two different inodes are involved in the operation, so both semaphores must be taken. To avoid such deadlocks, semaphore requests are performed in predefined address order.
|
Chapter 6. Timing Measurements
Countless computerized activities are driven by timing measurements
, often behind the user's back. For instance, if the screen is automatically switched off after you have stopped using the computer's console, it is due to a timer that allows the kernel to keep track of how much time has elapsed since you pushed a key or moved the mouse. If you receive a warning from the system asking you to remove a set of unused files, it is the outcome of a program that identifies all user files that have not been accessed for a long time. To do these things, programs must be able to retrieve a timestamp identifying its last access time from each file. Such a timestamp must be automatically written by the kernel. More significantly, timing drives process switches along with even more visible kernel activities such as checking for time-outs.
We can distinguish two main kinds of timing measurement that must be performed by the Linux kernel:
Keeping the current time and date so they can be returned to user programs through the time( ), ftime( ), and gettimeofday( ) APIs (see the section "
The time( ) and gettimeofday( ) System Calls" later in this chapter) and used by the kernel itself as timestamps for files and network packets Maintaining timers mechanisms that are able to notify the kernel (see the later section "
Software Timers and Delay Functions") or a user program (see the later sections "
The setitimer( ) and alarm( ) System Calls" and "System Calls for POSIX Timers") that a certain interval of time has elapsed
Timing measurements are performed by several hardware circuits based on fixed-frequency oscillators and counters. This chapter consists of four different parts. The first two sections describe the hardware devices that underly timing and give an overall picture of Linux timekeeping architecture. The following sections describe the main time-related duties of the kernel: implementing CPU time sharing, updating system time and resource usage statistics, and maintaining software timers. The last section discusses the system calls related to timing measurements and the corresponding service routines.
6.1. Clock and Timer Circuits
On the 80x86 architecture, the kernel must explicitly interact with several kinds of clocks
and timer circuits
. The clock circuits are used both to keep track of the current time of day and to make precise time measurements. The timer circuits are programmed by the kernel, so that they issue interrupts at a fixed, predefined frequency; such periodic interrupts are crucial for implementing the software timers used by the kernel and the user programs. We'll now briefly describe the clock and hardware circuits that can be found in IBM-compatible PCs.
6.1.1. Real Time Clock (RTC)
All PCs include a clock called Real Time Clock (RTC), which is independent of the CPU and all other chips.
The RTC continues to tick even when the PC is switched off, because it is energized by a small battery. The CMOS RAM and RTC are integrated in a single chip (the Motorola 146818 or an equivalent).
The RTC is capable of issuing periodic interrupts on IRQ 8 at frequencies ranging between 2 Hz and 8,192 Hz. It can also be programmed to activate the IRQ 8 line when the RTC reaches a specific value, thus working as an alarm clock.
Linux uses the RTC only to derive the time and date; however, it allows processes to program the RTC by acting on the /dev/rtc device file (see
Chapter 13). The kernel accesses the RTC through the 0x70 and 0x71 I/O ports. The system administrator can read and write the RTC by executing the clock Unix system program that acts directly on these two I/O ports.
6.1.2. Time Stamp Counter (TSC)
All 80x86 microprocessors include a CLK input pin, which receives the clock signal of an external oscillator. Starting with the Pentium, 80x86 microprocessors sport a counter that is increased at each clock signal. The counter is accessible through the 64-bit Time Stamp Counter(TSC) register, which can be read by means of the rdtsc
assembly language instruction. When using this register, the kernel has to take into consideration the frequency of the clock signal: if, for instance, the clock ticks at 1 GHz, the Time Stamp Counter is increased once every nanosecond.
Linux may take advantage of this register to get much more accurate time measurements than those delivered by the Programmable Interval Timer. To do this, Linux must determine the clock signal frequency while initializing the system. In fact, because this frequency is not declared when compiling the kernel, the same kernel image may run on CPUs whose clocks may tick at any frequency.
The task of figuring out the actual frequency of a CPU is accomplished during the system's boot. The calibrate_tsc( ) function computes the frequency by counting the number of clock signals that occur in a time interval of approximately 5 milliseconds. This time constant is produced by properly setting up one of the channels of the Programmable Interval Timer
(see the next section).
6.1.3. Programmable Interval Timer (PIT)
Besides the Real Time Clock and the Time Stamp Counter, IBM-compatible PCs include another type of time-measuring device called Programmable Interval Timer(PIT). The role of a PIT is similar to the alarm clock of a microwave oven: it makes the user aware that the cooking time interval has elapsed. Instead of ringing a bell, this device issues a special interrupt called timer interrupt, which notifies the kernel that one more time interval has elapsed. Another difference from the alarm clock is that the PIT goes on issuing interrupts forever at some fixed frequency established by the kernel. Each IBM-compatible PC includes at least one PIT, which is usually implemented by an 8254 CMOS chip using the 0x40-0x43 I/O ports.
As we'll see in detail in the next paragraphs, Linux programs the PIT of IBM-compatible PCs to issue timer interrupts
on the IRQ 0 at a (roughly) 1000-Hz frequency that is, once every 1 millisecond. This time interval is called a tick, and its length in nanoseconds is stored in the tick_nsec variable. On a PC, tick_nsec is initialized to 999,848 nanoseconds (yielding a clock signal frequency of about 1000.15 Hz), but its value may be automatically adjusted by the kernel if the computer is synchronized with an external clock (see the later section "
The adjtimex( ) System Call"). The ticks
beat time for all activities in the system; in some sense, they are like the ticks sounded by a metronome while a musician is rehearsing.
Generally speaking, shorter ticks result in higher resolution timers, which help with smoother multimedia playback and faster response time when performing synchronous I/O multiplexing (poll( )
and select( )
system calls). This is a trade-off however: shorter ticks require the CPU to spend a larger fraction of its time in Kernel Mode that is, a smaller fraction of time in User Mode. As a consequence, user programs run slower.
The frequency of timer interrupts depends on the hardware architecture. The slower machines have a tick of roughly 10 milliseconds (100 timer interrupts per second), while the faster ones have a tick of roughly 1 millisecond (1000 or 1024 timer interrupts per second).
A few macros in the Linux code yield some constants that determine the frequency of timer interrupts. These are discussed in the following list.
HZ yields the approximate number of timer interrupts per second that is, their frequency. This value is set to 1000 for IBM PCs. CLOCK_TICK_RATE yields the value 1,193,182, which is the 8254 chip's internal oscillator frequency. LATCH yields the ratio between CLOCK_TICK_RATE and HZ, rounded to the nearest integer. It is used to program the PIT.
The PIT is initialized by setup_pit_timer( ) as follows:
spin_lock_irqsave(&i8253_lock, flags);
outb_p(0x34,0x43);
udelay(10);
outb_p(LATCH & 0xff, 0x40);
udelay(10);
outb
(LATCH >> 8, 0x40);
spin_unlock_irqrestore(&i8253_lock, flags);
The outb( ) C function is equivalent to the outb assembly language instruction: it copies the first operand into the I/O port specified as the second operand. The outb_p( ) function is similar to outb( ), except that it introduces a pause by executing a no-op instruction to keep the hardware from getting confused. The udelay() macro introduces a further small delay (see the later section "
Delay Functions"). The first outb_ p( ) invocation is a command to the PIT to issue interrupts at a new rate. The next two outb_ p( ) and outb( ) invocations supply the new interrupt rate to the device. The 16-bit LATCH constant is sent to the 8-bit 0x40 I/O port of the device as two consecutive bytes. As a result, the PIT issues timer interrupts at a (roughly) 1000-Hz frequency (that is, once every 1 ms).
6.1.4. CPU Local Timer
The local APIC present in recent 80 x 86 microprocessors (see the section "
Interrupts and Exceptions" in
Chapter 4) provides yet another time-measuring device: the CPU local timer
.
The CPU local timer is a device similar to the Programmable Interval Timer just described that can issue one-shot or periodic interrupts. There are, however, a few differences:
The APIC's timer counter is 32 bits long, while the PIT's timer counter is 16 bits long; therefore, the local timer can be programmed to issue interrupts at very low frequencies (the counter stores the number of ticks that must elapse before the interrupt is issued). The local APIC timer sends an interrupt only to its processor, while the PIT raises a global interrupt, which may be handled by any CPU in the system. The APIC's timer is based on the bus clock signal (or the APIC bus signal, in older machines). It can be programmed in such a way to decrease the timer counter every 1, 2, 4, 8, 16, 32, 64, or 128 bus clock signals. Conversely, the PIT, which makes use of its own clock signals, can be programmed in a more flexible way.
6.1.5. High Precision Event Timer (HPET)
The High Precision Event Timer (HPET) is a new timer chip developed jointly by Intel and Microsoft. Although HPETs are not yet very common in end-user machines, Linux 2.6 already supports them, so we'll spend a few words describing their characteristics.
The HPET provides a number of hardware timers that can be exploited by the kernel. Basically, the chip includes up to eight 32-bit or 64-bit independent counters
. Each counter is driven by its own clock signal, whose frequency must be at least 10 MHz; therefore, the counter is increased at least once in 100 nanoseconds. Any counter is associated with at most 32 timers, each of which is composed by a comparator and a match register. The comparator is a circuit that checks the value in the counter against the value in the match register, and raises a hardware interrupt if a match is found. Some of the timers can be enabled to generate a periodic interrupt.
The HPET chip can be programmed through registers mapped into memory space (much like the I/O APIC). The BIOS establishes the mapping during the bootstrapping phase and reports to the operating system kernel its initial memory address. The HPET registers allow the kernel to read and write the values of the counters and of the match registers
, to program one-shot interrupts, and to enable or disable periodic interrupts on the timers that support them.
The next generation of motherboards will likely sport both the HPET and the 8254 PIT; in some future time, however, the HPET is expected to completely replace the PIT.
6.1.6. ACPI Power Management Timer
The ACPI Power Management Timer (or ACPI PMT) is yet another clock device included in almost all ACPI-based motherboards. Its clock signal has a fixed frequency of roughly 3.58 MHz. The device is actually a simple counter increased at each clock tick; to read the current value of the counter, the kernel accesses an I/O port whose address is determined by the BIOS during the initialization phase (see Appendix A).
The ACPI Power Management Timer is preferable to the TSC if the operating system or the BIOS may dynamically lower the frequency or voltage of the CPU to save battery power. When this happens, the frequency of the TSC changesthus causing time warps and others unpleasant effectswhile the frequency of the ACPI PMT does not. On the other hand, the high-frequency of the TSC counter is quite handy for measuring very small time intervals.
However, if an HPET device is present, it should always be preferred to the other circuits because of its richer architecture.
Table 6-2 later in this chapter illustrates how Linux takes advantage of the available timing circuits.
Now that we understand what the hardware timers are, we may discuss how the Linux kernel exploits them to conduct all activities of the system.
6.2. The Linux Timekeeping Architecture
Linux must carry on several time-related activities. For instance, the kernel periodically:
Updates the time elapsed since system startup. Updates the time and date. Determines, for every CPU, how long the current process has been running, and preempts it if it has exceeded the time allocated to it. The allocation of time slots (also called "quanta") is discussed in
Chapter 7. Updates resource usage statistics. Checks whether the interval of time associated with each software timer (see the later section "Software Timers and Delay Functions") has elapsed.
Linux's timekeeping architecture
is the set of kernel data structures and functions related to the flow of time. Actually, 80 x 86-based multiprocessor machines have a timekeeping architecture that is slightly different from the timekeeping architecture of uniprocessor machines:
In a uniprocessor system, all time-keeping activities are triggered by interrupts raised by the global timer (either the Programmable Interval Timer or the High Precision Event Timer). In a multiprocessor system, all general activities (such as handling of software timers) are triggered by the interrupts raised by the global timer, while CPU-specific activities (such as monitoring the execution time of the currently running process) are triggered by the interrupts raised by the local APIC timer.
Unfortunately, the distinction between the two cases is somewhat blurred. For instance, some early SMP systems based on Intel 80486 processors didn't have local APICs. Even nowadays, there are SMP motherboards so buggy that local timer interrupts are not usable at all. In these cases, the SMP kernel must resort to the UP timekeeping architecture. On the other hand, recent uniprocessor systems feature one local APIC, so the UP kernel often makes use of the SMP timekeeping architecture. However, to simplify our description, we won't discuss these hybrid cases and will stick to the two "pure" timekeeping architectures.
Linux's timekeeping architecture depends also on the availability of the Time Stamp Counter (TSC), of the ACPI Power Management Timer, and of the High Precision Event Timer (HPET). The kernel uses two basic timekeeping functions: one to keep the current time up-to-date and another to count the number of nanoseconds that have elapsed within the current second. There are different ways to get the last value. Some methods are more precise and are available if the CPU has a Time Stamp Counter or a HPET; a less-precise method is used in the opposite case (see the later section "The time( ) and gettimeofday( ) System Calls").
6.2.1. Data Structures of the Timekeeping Architecture
The timekeeping architecture of Linux 2.6 makes use of a large number of data structures. As usual, we will describe the most important variables by referring to the 80 x 86 architecture.
6.2.1.1. The timer object
In order to handle the possible timer sources in a uniform way, the kernel makes use of a "timer object," which is a descriptor of type timer_opts consisting of the timer name and of four standard methods shown in Table 6-1.
Table 6-1. The fields of the timer_opts data structureField name | Description |
|---|
name | A string identifying the timer source | mark_offset | Records the exact time of the last tick; it is invoked by the timer interrupt handler | get_offset | Returns the time elapsed since the last tick | monotonic_clock | Returns the number of nanoseconds since the kernel initialization | delay | Waits for a given number of "loops" (see the later section "Delay Functions") |
The most important methods of the timer object are mark_offset and get_offset. The mark_offset method is invoked by the timer interrupt handler, and records in a suitable data structure the exact time at which the tick occurred. Using the saved value, the get_offset method computes the time in microseconds elapsed since the last timer interrupt (tick). Thanks to these two methods, Linux timekeeping architecture achieves a sub-tick resolutionthat is, the kernel is able to determine the current time with a precision much higher than the tick duration. This operation is called time interpolation
.
The cur_timer variable stores the address of the timer object corresponding to the "best" timer source available in the system. Initially, cur_timer points to timer_none, which is the object corresponding to a dummy timer source used when the kernel is being initialized. During kernel initialization, the select_timer( ) function sets cur_timer to the address of the appropriate timer object. Table 6-2 shows the most common timer objects used in the 80x86 architecture, in order of preference. As you see, select_timer( ) selects the HPET, if available; otherwise, it selects the ACPI Power Management Timer
, if available, or the TSC. As the last resort, select_timer( ) selects the always-present PIT. The "Time interpolation" column lists the timer sources used by the mark_offset and get_offset methods of the timer object; the "Delay" column lists the timer sources used by the delay method.
Table 6-2. Typical timer objects of the 80x86 architecture, in order of preferenceTimer object name | Description | Time interpolation | Delay |
|---|
timer_hpet | High Precision Event Timer (HPET) | HPET | HPET | timer_pmtmr | ACPI Power Management Timer (ACPI PMT) | ACPI PMT | TSC | timer_tsc | Time Stamp Counter (TSC) | TSC | TSC | timer_pit | Programmable Interval Timer (PIT) | PIT | Tight loop | timer_none | Generic dummy timer source(used during kernel initialization) | (none) | Tight loop |
Notice that local APIC timers do not have a corresponding timer object. The reason is that local APIC timers are used only to generate periodic interrupts and are never used to achieve sub-tick resolution.
6.2.1.2. The jiffies variable
The jiffies variable is a counter that stores the number of elapsed ticks since the system was started. It is increased by one when a timer interrupt occursthat is, on every tick. In the 80 x 86 architecture, jiffies is a 32-bit variable, therefore it wraps around in approximately 50 daysa relatively short time interval for a Linux server. However, the kernel handles cleanly the overflow of jiffies thanks to the time_after, time_after_eq, time_before, and time_before_eq macros: they yield the correct value even if a wraparound occurred.
You might suppose that jiffies is initialized to zero at system startup. Actually, this is not the case: jiffies is initialized to 0xfffb6c20, which corresponds to the 32-bit signed value 300,000; therefore, the counter will overflow five minutes after the system boot. This is done on purpose, so that buggy kernel code that does not check for the overflow of jiffies shows up very soon in the developing phase and does not pass unnoticed in stable kernels.
In a few cases, however, the kernel needs the real number of system ticks elapsed since the system boot, regardless of the overflows of jiffies. Therefore, in the 80 x 86 architecture the jiffies variable is equated by the linker to the 32 less significant bits of a 64-bit counter called jiffies_64. With a tick of 1 millisecond, the jiffies_64 variable wraps around in several hundreds of millions of years, thus we can safely assume that it never overflows.
You might wonder why jiffies has not been directly declared as a 64-bit unsigned long long integer on the 80 x 86 architecture. The answer is that accesses to 64-bit variables in 32-bit architectures cannot be done atomically. Therefore, every read operation on the whole 64 bits requires some synchronization technique to ensure that the counter is not updated while the two 32-bit half-counters are read; as a consequence, every 64-bit read operation is significantly slower than a 32-bit read operation.
The get_jiffies_64( ) function reads the value of jiffies_64 and returns its value:
unsigned long long get_jiffies_64(void)
{
unsigned long seq;
unsigned long long ret;
do {
seq = read_seqbegin(&xtime_lock);
ret = jiffies_64;
} while (read_seqretry(&xime_lock, seq));
return ret;
}
The 64-bit read operation is protected by the xtime_lock seqlock (see the section "Seqlocks" in Chapter 5): the function keeps reading the jiffies_64 variable until it knows for sure that it has not been concurrently updated by another kernel control path.
Conversely, the critical region increasing the jiffies_64 variable must be protected by means of write_seqlock(&xtime_lock ) and write_sequnlock( &xtime_lock). Notice that the ++jiffies_64 instruction also increases the 32-bit jiffies variable, because the latter corresponds to the lower half of jiffies_64.
6.2.1.3. The xtime variable
The xtime variable stores the current time and date; it is a structure of type timespec having two fields:
tv_sec Stores the number of seconds that have elapsed since midnight of January 1, 1970 (UTC)
tv_nsec Stores the number of nanoseconds that have elapsed within the last second (its value ranges between 0 and 999,999,999)
The xtime variable is usually updated once in a tickthat is, roughly 1000 times per second. As we'll see in the later section "System Calls Related to Timing Measurements," user programs get the current time and date from the xtime variable. The kernel also often refers to it, for instance, when updating inode timestamps (see the section "File Descriptor and Inode" in Chapter 1).
The xtime_lock seqlock avoids the race conditions that could occur due to concurrent accesses to the xtime variable. Remember that xtime_lock also protects the jiffies_64 variable; in general, this seqlock is used to define several critical regions of the timekeeping architecture.
6.2.2. Timekeeping Architecture in Uniprocessor Systems
In a uniprocessor system, all time-related activities are triggered by the interrupts raised by the Programmable Interval Timer on IRQ line 0. As usual, in Linux, some of these activities are executed as soon as possible right after the interrupt is raised, while the remaining activities are carried on by deferrable functions (see the later section "Dynamic Timers").
6.2.2.1. Initialization phase
During kernel initialization, the time_init( ) function is invoked to set up the timekeeping architecture. It usually performs the following operations:
Initializes the xtime variable. The number of seconds elapsed since the midnight of January 1, 1970 is read from the Real Time Clock by means of the get_cmos_time( ) function. The tv_nsec field of xtime is set, so that the forthcoming overflow of the jiffies variable will coincide with an increment of the tv_sec fieldthat is, it will fall on a second boundary. Initializes the wall_to_monotonic variable. This variable is of the same type timespec as xtime, and it essentially stores the number of seconds and nanoseconds to be added to xtime in order to get a monotonic (ever increasing) flow of time. In fact, both leap seconds and synchronization with external clocks might suddenly change the tv_sec and tv_nsec fields of xtime so that they are no longer monotonically increased. As we'll see in the later section "System Calls for POSIX Timers," sometimes the kernel needs a truly monotonic time source. If the kernel supports HPET, it invokes the hpet_enable( ) function to determine whether the ACPI
firmware has probed the chip and mapped its registers in the memory address space. In the affirmative case, hpet_enable( ) programs the first timer of the HPET chip so that it raises the IRQ 0 interrupt 1000 times per second. Otherwise, if the HPET chip is not available, the kernel will use the PIT: the chip has already been programmed by the init_IRQ( ) function to raise 1000 timer interrupts per second, as described in the earlier section "Programmable Interval Timer (PIT)." Invokes select_timer( ) to select the best timer source available in the system, and sets the cur_timer variable to the address of the corresponding timer object. Invokes setup_irq( 0,&irq0) to set up the interrupt gate corresponding to IRQ0the line associated with the system timer interrupt source (PIT or HPET).The irq0 variable is statically defined as:
struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, 0,
"timer", NULL, NULL };
From now on, the timer_interrupt( ) function will be invoked once every tick with interrupts disabled, because the status field of IRQ 0's main descriptor has the SA_INTERRUPT flag set.
6.2.2.2. The timer interrupt handler
The timer_interrupt( ) function is the interrupt service routine (ISR) of the PIT or of the HPET; it performs the following steps:
Protects the time-related kernel variables by issuing a write_seqlock() on the xtime_lock seqlock (see the section "Seqlocks" in Chapter 5). Executes the mark_offset method of the cur_timer timer object. As explained in the earlier section "Data Structures of the Timekeeping Architecture," there are four possible cases: cur_timer points to the timer_hpet object: in this case, the HPET chip is the source of timer interrupts. The mark_offset method checks that no timer interrupt has been lost since the last tick; in this unlikely case, it updates jiffies_64 accordingly. Next, the method records the current value of the periodic HPET counter. cur_timer points to the timer_pmtmr object: in this case, the PIT chip is the source of timer interrupts, but the kernel uses the APIC Power Management Timer to measure time with a finer resolution. The mark_offset method checks that no timer interrupt has been lost since the last tick and updates jiffies_64 if necessary. Then, it records the current value of the APIC Power Management Timer counter. cur_timer points to the timer_tsc object: in this case, the PIT chip is the source of timer interrupts, but the kernel uses the Time Stamp Counter to measure time with a finer resolution. The mark_offset method performs the same operations as in the previous case: it checks that no timer interrupt has been lost since the last tick and updates jiffies_64 if necessary. Then, it records the current value of the TSC counter. cur_timer points to the timer_pit object: in this case, the PIT chip is the source of timer interrupts, and there is no other timer circuit. The mark_offset method does nothing.
Invokes the do_timer_interrupt( ) function, which in turn performs the following actions: Increases by one the value of jiffies_64. Notice that this can be done safely, because the kernel control path still holds the xtime_lock seqlock for writing. Invokes the update_times( ) function to update the system date and time and to compute the current system load; these activities are discussed later in the sections "Updating the Time and Date" and "Updating System Statistics." Invokes the update_process_times( ) function to perform several time-related accounting operations for the local CPU (see the section "Updating Local CPU Statistics" later in this chapter). If the system clock is synchronized with an external clock (an adjtimex( ) system call has been previously issued), invokes the set_rtc_mmss( ) function once every 660 seconds (every 11 minutes) to adjust the Real Time Clock. This feature helps systems on a network synchronize their clocks (see the later section "The adjtimex( ) System Call").
Releases the xtime_lock seqlock by invoking write_sequnlock().
6.2.3. Timekeeping Architecture in Multiprocessor Systems
Multiprocessor systems can rely on two different sources of timer interrupts: those raised by the Programmable Interval Timer or the High Precision Event Timer, and those raised by the CPU local timers.
In Linux 2.6, global timer interruptsraised by the PIT or the HPETsignal activities not related to a specific CPU, such as handling of software timers and keeping the system time up-to-date. Conversely, a CPU local timer interrupt signals timekeeping activities related to the local CPU, such as monitoring how long the current process has been running and updating the resource usage statistics.
6.2.3.1. Initialization phase
The global timer interrupt handler is initialized by the time_init( ) function, which has already been described in the earlier section "Timekeeping Architecture in Uniprocessor Systems."
The Linux kernel reserves the interrupt vector 239 (0xef) for local timer interrupts (see Table 4-2 in Chapter 4). During kernel initialization, the apic_intr_init( ) function sets up the IDT's interrupt gate corresponding to vector 239 with the address of the low-level interrupt handler apic_timer_interrupt( ). Moreover, each APIC has to be told how often to generate a local time interrupt. The calibrate_APIC_clock( ) function computes how many bus clock signals are received by the local APIC of the booting CPU during a tick (1 ms). This exact value is then used to program the local APICs in such a way to generate one local timer interrupt every tick. This is done by the setup_APIC_timer( ) function, which is executed once for every CPU in the system.
All local APIC timers are synchronized because they are based on the common bus clock signal. This means that the value computed by calibrate_APIC_clock( ) for the boot CPU is also good for the other CPUs in the system.
6.2.3.2. The global timer interrupt handler
The SMP version of the timer_interrupt() handler differs from the UP version in a few points:
The do_timer_interrupt( ) function, invoked by timer_interrupt( ), writes into a port of the I/O APIC chip to acknowledge the timer IRQ. The update_process_times( ) function is not invoked, because this function performs actions related to a specific CPU. The profile_tick( ) function is not invoked, because this function also performs actions related to a specific CPU.
6.2.3.3. The local timer interrupt handler
This handler performs the timekeeping activities related to a specific CPU in the system, namely profiling the kernel code and checking how long the current process has been running on a given CPU.
The apic_timer_interrupt( ) assembly language function is equivalent to the following code:
apic_timer_interrupt:
pushl $(239-256)
SAVE_ALL
movl %esp, %eax
call smp_apic_timer_interrupt
jmp ret_from_intr
As you can see, the low-level handler is very similar to the other low-level interrupt handlers already described in Chapter 4. The high-level interrupt handler called smp_apic_timer_interrupt( ) executes the following steps:
Gets the CPU logical number (say, n). Increases the apic_timer_irqs field of the nth entry of the irq_stat array (see the section "Checking the NMI Watchdogs" later in this chapter). Acknowledges the interrupt on the local APIC. Invokes the smp_local_timer_interrupt( ) function. Calls the irq_exit( ) function.
The smp_local_timer_interrupt( ) function executes the per-CPU timekeeping activities. Actually, it performs the following main steps:
Invokes the update_process_times( ) function to check how long the current process has been running and to update some local CPU statistics (see the section "Updating Local CPU Statistics" later in this chapter).
The system administrator can change the sample frequency of the kernel code profiler by writing into the /proc/profile file.To carry out the change, the kernel modifies the frequency at which local timer interrupts are generated. However, the smp_local_timer_interrupt( ) function keeps invoking the update_process_times( ) function exactly once every tick.
|
6.3. Updating the Time and Date
User programs get the current time and date from the xtime variable. The kernel must periodically update this variable, so that its value is always reasonably accurate.
The update_times( ) function, which is invoked by the global timer interrupt handler, updates the value of the xtime variable as follows:
void update_times(void)
{
unsigned long ticks;
ticks = jiffies - wall_jiffies;
if (ticks) {
wall_jiffies += ticks;
update_wall_time(ticks);
}
calc_load(ticks);
}
We recall from the previous description of the timer interrupt handler that when the code of this function is executed, the xtime_lock seqlock has already been acquired for writing.
The wall_jiffies variable stores the time of the last update of the xtime variable. Observe that the value of wall_jiffies can be smaller than jiffies-1, since a few timer interrupts can be lost, for instance when interrupts remain disabled for a long period of time; in other words, the kernel does not necessarily update the xtime variable at every tick. However, no tick is definitively lost, and in the long run, xtime stores the correct system time. The check for lost timer interrupts is done in the mark_offset method of cur_timer; see the earlier section "Timekeeping Architecture in Uniprocessor Systems."
The update_wall_time( ) function invokes the update_wall_time_one_tick( ) function ticks consecutive times; normally, each invocation adds 1,000,000 to the xtime.tv_nsec field. If the value of xtime.tv_nsec becomes greater than 999,999,999, the update_wall_time( ) function also updates the tv_sec field of xtime. If an adjtimex( ) system call has been issued, for reasons explained in the section "The adjtimex( ) System Call" later in this chapter, the function might tune the value 1,000,000 slightly so the clock speeds up or slows down a little.
The calc_load( ) function is described in the section "Keeping Track of System Load" later in this chapter.
6.4. Updating System Statistics
The kernel, among the other time-related duties, must periodically collect various data used for:
Checking the CPU resource limit of the running processes Updating statistics about the local CPU workload Computing the average system load Profiling the kernel code
6.4.1. Updating Local CPU Statistics
We have mentioned that the update_process_times( ) function is invokedeither by the global timer interrupt handler on uniprocessor systems or by the local timer interrupt handler in multiprocessor systemsto update some kernel statistics. This function performs the following steps:
Checks how long the current process has been running. Depending on whether the current process was running in User Mode or in Kernel Mode when the timer interrupt occurred, invokes either account_user_time( ) or account_system_time( ). Each of these functions performs essentially the following steps: Updates either the utime field (ticks spent in User Mode) or the stime field (ticks spent in Kernel Mode) of the current process descriptor. Two additional fields called cutime and cstime are provided in the process descriptor to count the number of CPU ticks spent by the process children in User Mode and Kernel Mode, respectively. For reasons of efficiency, these fields are not updated by update_process_times( ), but rather when the parent process queries the state of one of its children (see the section "Destroying Processes" in Chapter 3). Checks whether the total CPU time limit has been reached; if so, sends SIGXCPU and SIGKILL signals to current. The section "Process Resource Limits" in Chapter 3 describes how the limit is controlled by the signal->rlim[RLIMIT_CPU].rlim_cur field of each process descriptor. Updates some kernel statistics stored in the kstat per-CPU variable.
If some old version of an RCU-protected data structure has to be reclaimed, checks whether the local CPU has gone through a quiescent state and invokes tasklet_schedule( ) to activate the rcu_tasklet tasklet of the local CPU (see the section "Read-Copy Update (RCU)" in Chapter 5). Invokes the scheduler_tick( ) function, which decreases the time slice counter of the current process, and checks whether its quantum is exhausted. We'll discuss in depth these operations in the section "The scheduler_tick( ) Function" in Chapter 7.
6.4.2. Keeping Track of System Load
Every Unix kernel keeps track of how much CPU activity is being carried on by the system. These statistics are used by various administration utilities such as top. A user who enters the uptime command sees the statistics as the "load average" relative to the last minute, the last 5 minutes, and the last 15 minutes. On a uniprocessor system, a value of 0 means that there are no active processes (besides the swapper process 0) to run, while a value of 1 means that the CPU is 100 percent busy with a single process, and values greater than 1 mean that the CPU is shared among several active processes.
At every tick, update_times( ) invokes the calc_load( ) function, which counts the number of processes in the TASK_RUNNING or TASK_UNINTERRUPTIBLE state and uses this number to update the average system load.
6.4.3. Profiling the Kernel Code
Linux includes a minimalist code profiler called readprofile used by Linux developers to discover where the kernel spends its time in Kernel Mode. The profiler identifies the hot spots of the kernel the most frequently executed fragments of kernel code. Identifying the kernel hot spots is very important, because they may point out kernel functions that should be further optimized.
The profiler is based on a simple Monte Carlo algorithm: at every timer interrupt occurrence, the kernel determines whether the interrupt occurred in Kernel Mode; if so, the kernel fetches the value of the eip register before the interruption from the stack and uses it to discover what the kernel was doing before the interrupt. In the long run, the samples accumulate on the hot spots.
The profile_tick( ) function collects the data for the code profiler. It is invoked either by the do_timer_interrupt( ) function in uniprocessor systems (by the global timer interrupt handler) or by the smp_local_timer_interrupt( ) function in multiprocessor systems (by the local timer interrupt handler).
To enable the code profiler, the Linux kernel must be booted by passing as a parameter the string profile=N, where 2N denotes the size of the code fragments to be profiled. The collected data can be read from the /proc/profile file. The counters are reset by writing in the same file; in multiprocessor systems, writing into the file can also change the sample frequency (see the earlier section "Timekeeping Architecture in Multiprocessor Systems"). However, kernel developers do not usually access /proc/profile directly; instead, they use the readprofile system command.
The Linux 2.6 kernel includes yet another profiler called oprofile. Besides being more flexible and customizable than readprofile, oprofile can be used to discover hot spots in kernel code, User Mode applications, and system libraries. When oprofile is being used, profile_tick( ) invokes the timer_notify( ) function to collect the data used by this new profiler.
6.4.4. Checking the NMI Watchdogs
In multiprocessor systems, Linux offers yet another feature to kernel developers: a watchdog system
, which might be quite useful to detect kernel bugs that cause a system freeze. To activate such a watchdog, the kernel must be booted with the nmi_watchdog parameter.
The watchdog is based on a clever hardware feature of local and I/O APICs: they can generate periodic NMI interrupts
on every CPU. Because NMI interrupts are not masked by the cli
assembly language instruction, the watchdog can detect deadlocks even when interrupts are disabled.
As a consequence, once every tick, all CPUs, regardless of what they are doing, start executing the NMI interrupt handler; in turn, the handler invokes do_nmi( ). This function gets the logical number n of the CPU, and then checks the apic_timer_irqs field of the nth entry of irq_stat (see Table 4-8 in Chapter 4). If the CPU is working properly, the value must be different from the value read at the previous NMI interrupt. When the CPU is running properly, the nth entry of the apic_timer_irqs field is increased by the local timer interrupt handler (see the earlier section "The local timer interrupt handler"); if the counter is not increased, the local timer interrupt handler has not been executed in a whole tick. Not a good thing, you know.
When the NMI interrupt handler detects a CPU freeze, it rings all the bells: it logs scary messages in the system logfiles, dumps the contents of the CPU registers and of the kernel stack (kernel oops), and finally kills the current process. This gives kernel developers a chance to discover what's gone wrong.
|
6.5. Software Timers and Delay Functions
A timer is a software facility that allows functions to be invoked at some future moment, after a given time interval has elapsed; a time-out denotes a moment at which the time interval associated with a timer has elapsed.
Timers are widely used both by the kernel and by processes. Most device drivers use timers
to detect anomalous conditions floppy disk drivers, for instance, use timers to switch off the device motor after the floppy has not been accessed for a while, and parallel printer drivers use them to detect erroneous printer conditions.
Timers are also used quite often by programmers to force the execution of specific functions at some future time (see the later section "The setitimer( ) and alarm( ) System Calls").
Implementing a timer is relatively easy. Each timer contains a field that indicates how far in the future the timer should expire. This field is initially calculated by adding the right number of ticks to the current value of jiffies. The field does not change. Every time the kernel checks a timer, it compares the expiration field to the value of jiffies at the current moment, and the timer expires when jiffies is greater than or equal to the stored value.
Linux considers two types of timers called dynamic timers
and interval timers
. The first type is used by the kernel, while interval timers may be created by processes in User Mode.
One word of caution about Linux timers: since checking for timer functions is always done by deferrable functions that may be executed a long time after they have been activated, the kernel cannot ensure that timer functions will start right at their expiration times. It can only ensure that they are executed either at the proper time or after with a delay of up to a few hundreds of milliseconds. For this reason, timers are not appropriate for real-time applications in which expiration times must be strictly enforced.
Besides software timers
, the kernel also makes use of delay functions
, which execute a tight instruction loop until a given time interval elapses. We will discuss them in the later section "Delay Functions."
6.5.1. Dynamic Timers
Dynamic timers may be dynamically created and destroyed. No limit is placed on the number of currently active dynamic timers.
A dynamic timer is stored in the following timer_list structure:
struct timer_list {
struct list_head entry;
unsigned long expires;
spinlock_t lock;
unsigned long magic;
void (*function)(unsigned long);
unsigned long data;
tvec_base_t *base;
};
The function field contains the address of the function to be executed when the timer expires. The data field specifies a parameter to be passed to this timer function. Thanks to the data field, it is possible to define a single general-purpose function that handles the time-outs of several device drivers; the data field could store the device ID or other meaningful data that could be used by the function to differentiate the device.
The expires field specifies when the timer expires; the time is expressed as the number of ticks that have elapsed since the system started up. All timers that have an expires value smaller than or equal to the value of jiffies are considered to be expired or decayed.
The entry field is used to insert the software timer into one of the doubly linked circular lists that group together the timers according to the value of their expires field. The algorithm that uses these lists is described later in this chapter.
To create and activate a dynamic timer, the kernel must:
Create, if necessary, a new timer_list object for example, t. This can be done in several ways by: Defining a static global variable in the code. Defining a local variable inside a function; in this case, the object is stored on the Kernel Mode stack. Including the object in a dynamically allocated descriptor.
Initialize the object by invoking the init_timer(&t) function. This essentially sets the t.base pointer field to NULL and sets the t.lock spin lock to "open." Load the function field with the address of the function to be activated when the timer decays. If required, load the data field with a parameter value to be passed to the function. If the dynamic timer is not already inserted in a list, assign a proper value to the expires field and invoke the add_timer(&t) function to insert the t element in the proper list. Otherwise, if the dynamic timer is already inserted in a list, update the expires field by invoking the mod_timer( ) function, which also takes care of moving the object into the proper list (discussed next).
Once the timer has decayed, the kernel automatically removes the t element from its list. Sometimes, however, a process should explicitly remove a timer from its list using the del_timer( ), del_timer_sync( ), or del_singleshot_timer_sync( ) functions. Indeed, a sleeping process may be woken up before the time-out is over; in this case, the process may choose to destroy the timer. Invoking del_timer( ) on a timer already removed from a list does no harm, so removing the timer within the timer function is considered a good practice.
In Linux 2.6, a dynamic timer is bound to the CPU that activated itthat is, the timer function will always run on the same CPU that first executed the add_timer( ) or later the mod_timer( ) function. The del_timer( ) and companion functions, however, can deactivate every dynamic timer, even if it is not bound to the local CPU.
6.5.1.1. Dynamic timers and race conditions
Being asynchronously activated, dynamic timers are prone to race conditions. For instance, consider a dynamic timer whose function acts on a discardable resource (e.g., a kernel module or a file data structure). Releasing the resource without stopping the timer may lead to data corruption if the timer function got activated when the resource no longer exists. Thus, a rule of thumb is to stop the timer before releasing the resource:
...
del_timer(&t);
X_Release_Resources( );
...
In multiprocessor systems, however, this code is not safe because the timer function might already be running on another CPU when del_timer( ) is invoked. As a result, resources may be released while the timer function is still acting on them. To avoid this kind of race condition, the kernel offers the del_timer_sync( ) function. It removes the timer from the list, and then it checks whether the timer function is executed on another CPU; in such a case, del_timer_sync( ) waits until the timer function terminates.
The del_timer_sync( ) function is rather complex and slow, because it has to carefully take into consideration the case in which the timer function reactivates itself. If the kernel developer knows that the timer function never reactivates the timer, she can use the simpler and faster del_singleshot_timer_sync( ) function to deactivate a timer and wait until the timer function terminates.
Other types of race conditions exist, of course. For instance, the right way to modify the expires field of an already activated timer consists of using mod_timer( ), rather than deleting the timer and re-creating it thereafter. In the latter approach, two kernel control paths that want to modify the expires field of the same timer may mix each other up badly. The implementation of the timer functions is made SMP-safe by means of the lock spin lock included in every timer_list object: every time the kernel must access a dynamic timer, it disables the interrupts and acquires this spin lock.
6.5.1.2. Data structures for dynamic timers
Choosing the proper data structure to implement dynamic timers is not easy. Stringing together all timers in a single list would degrade system performance, because scanning a long list of timers at every tick is costly. On the other hand, maintaining a sorted list would not be much more efficient, because the insertion and deletion operations would also be costly.
The adopted solution is based on a clever data structure that partitions the expires values into blocks of ticks and allows dynamic timers to percolate efficiently from lists with larger expires values to lists with smaller ones. Moreover, in multiprocessor systems the set of active dynamic timers is split among the various CPUs.
The main data structure for dynamic timers is a per-CPU variable (see the section "Per-CPU Variables" in Chapter 5) named tvec_bases: it includes NR_CPUS elements, one for each CPU in the system. Each element is a tvec_base_t structure, which includes all data needed to handle the dynamic timers bound to the corresponding CPU:
typedef struct tvec_t_base_s {
spinlock_t lock;
unsigned long timer_jiffies;
struct timer_list *running_timer;
tvec_root_t tv1;
tvec_t tv2;
tvec_t tv3;
tvec_t tv4;
tvec_t tv5;
} tvec_base_t;
The tv1 field is a structure of type tvec_root_t, which includes a vec array of 256 list_head elements that is, lists of dynamic timers. It contains all dynamic timers, if any, that will decay within the next 255 ticks.
The tv2, tv3, and tv4 fields are structures of type tvec_t consisting of a vec array of 64 list_head elements. These lists contain all dynamic timers that will decay within the next 214-1, 220-1, and 226-1 ticks, respectively.
The tv5 field is identical to the previous ones, except that the last entry of the vec array is a list that includes dynamic timers with extremely large expires fields. It never needs to be replenished from another array. Figure 6-1 illustrates in a schematic way the five groups of lists.
The timer_jiffies field represents the earliest expiration time of the dynamic timers yet to be checked: if it coincides with the value of jiffies, no backlog of deferrable functions has accumulated; if it is smaller than jiffies, then lists of dynamic timers that refer to previous ticks must be dealt with. The field is set to jiffies at system startup and is increased only by the run_timer_softirq( ) function described in the next section. Notice that the timer_jiffies field might drop a long way behind jiffies when the deferrable functions that handle dynamic timers are not executed for a long timefor instance because these functions have been disabled or because a large number of interrupt handlers have been executed.
In multiprocessor systems, the running_timer field points to the timer_list structure of the dynamic timer that is currently handled by the local CPU.
6.5.1.3. Dynamic timer handling
Despite the clever data structures, handling software timers is a time-consuming activity that should not be performed by the timer interrupt handler. In Linux 2.6 this activity is carried on by a deferrable function, namely the TIMER_SOFTIRQ softirq.
The run_timer_softirq( ) function is the deferrable function associated with the TIMER_SOFTIRQ softirq. It essentially performs the following actions:
Stores in the base local variable the address of the tvec_base_t data structure associated with the local CPU. Acquires the base->lock spin lock and disables local interrupts. Starts a while loop, which ends when base->timer_jiffies becomes greater than the value of jiffies. In every single execution of the cycle, performs the following substeps: Computes the index of the list in base->tv1 that holds the next timers to be handled:
index = base->timer_jiffies & 255;
If index is zero, all lists in base->tv1 have been checked, so they are empty: the function therefore percolates the dynamic timers by invoking cascade( ):
if (!index &&
(!cascade(base, &base->tv2, (base->timer_jiffies>> 8)&63)) &&
(!cascade(base, &base->tv3, (base->timer_jiffies>>14)&63)) &&
(!cascade(base, &base->tv4, (base->timer_jiffies>>20)&63)))
cascade(base, &base->tv5, (base->timer_jiffies>>26)&63);
Consider the first invocation of the cascade( ) function: it receives as arguments the address in base, the address of base->tv2, and the index of the list in base->tv2 including the timers that will decay in the next 256 ticks. This index is determined by looking at the proper bits of the base->timer_jiffies value. cascade( ) moves all dynamic timers in the base->tv2 list into the proper lists of base->tv1; then, it returns a positive value, unless all base->tv2 lists are now empty. If so, cascade( ) is invoked once more to replenish base->tv2 with the timers included in a list of base->tv3, and so on. Increases by one base->timer_jiffies. For each dynamic timer in the base->tv1.vec[index] list, executes the corresponding timer function. In particular, for each timer_list element t in the list essentially performs the following steps: Removes t from the base->tv1's list. In multiprocessor systems, sets base->running_timer to &t. Releases the base->lock spin lock, and enables local interrupts. Executes the timer function t.function passing as argument t.data. Acquires the base->lock spin lock, and disables local interrupts. Continues with the next timer in the list, if any.
All timers in the list have been handled. Continues with the next iteration of the outermost while cycle.
The outermost while cycle is terminated, which means that all decayed timers have been handled. In multiprocessor systems, sets base->running_timer to NULL. Releases the base->lock spin lock and enables local interrupts.
Because the values of jiffies and timer_jiffies usually coincide, the outermost while cycle is often executed only once. In general, the outermost loop is executed jiffies - base->timer_jiffies + 1 consecutive times. Moreover, if a timer interrupt occurs while run_timer_softirq( ) is being executed, dynamic timers that decay at this tick occurrence are also considered, because the jiffies variable is asynchronously increased by the global timer interrupt handler (see the earlier section "The timer interrupt handler").
Notice that run_timer_softirq( ) disables interrupts and acquires the base->lock spin lock just before entering the outermost loop; interrupts are enabled and the spin lock is released right before invoking each dynamic timer function, until its termination. This ensures that the dynamic timer data structures are not corrupted by interleaved kernel control paths.
To sum up, this rather complex algorithm ensures excellent performance. To see why, assume for the sake of simplicity that the TIMER_SOFTIRQ softirq is executed right after the corresponding timer interrupt occurs. Then, in 255 timer interrupt occurrences out of 256 (in 99.6% of the cases), the run_timer_softirq( ) function just runs the functions of the decayed timers, if any. To replenish base->tv1.vec periodically, it is sufficient 63 times out of 64 to partition one list of base->tv2 into the 256 lists of base->tv1. The base->tv2.vec array, in turn, must be replenished in 0.006 percent of the cases (that is, once every 16.4 seconds). Similarly, base->tv3.vec is replenished every 17 minutes and 28 seconds, and base->tv4.vec is replenished every 18 hours and 38 minutes. base->tv5.vec doesn't need to be replenished.
6.5.2. An Application of Dynamic Timers: the nanosleep( ) System Call
To show how the outcomes of all the previous activities are actually used in the kernel, we'll show an example
of the creation and use of a process time-out.
Let's consider the service routine of the nanosleep() system call, that is, sys_nanosleep(), which receives as its parameter a pointer to a timespec structure and suspends the invoking process until the specified time interval elapses. The service routine first invokes copy_from_user() to copy the values contained in the User Mode timespec structure into the local variable t. Assuming that the timespec structure defines a non-null delay, the function then executes the following code:
current->state = TASK_INTERRUPTIBLE;
remaining = schedule_timeout(timespec_to_jiffies(&t)+1);
The timespec_to_jiffies( ) function converts in ticks the time interval stored in the timespec structure. To be on the safe side, sys_nanosleep( ) adds one tick to the value computed by timespec_to_jiffies( ).
The kernel implements process time-outs
by using dynamic timers. They appear in the schedule_timeout( ) function, which essentially executes the following statements:
struct timer_list timer;
unsigned long expire = timeout + jiffies;
init_timer(&timer);
timer.expires = expire;
timer.data = (unsigned long) current;
timer.function = process_timeout;
add_timer(&timer);
schedule( ); /* process suspended until timer expires */
del_singleshot_timer_sync(&timer);
timeout = expire - jiffies;
return (timeout < 0 ? 0 : timeout);
When schedule( ) is invoked, another process is selected for execution; when the former process resumes its execution, the function removes the dynamic timer. In the last statement, the function either returns 0, if the time-out is expired, or the number of ticks left to the time-out expiration if the process was awakened for some other reason.
When the time-out expires, the timer's function is executed:
void process_timeout(unsigned long __data)
{
wake_up_process((task_t *)__data);
}
The process_timeout( ) receives as its parameter the process descriptor pointer stored in the data field of the timer object. As a result, the suspended process is awakened.
Once awakened, the process continues the execution of the sys_nanosleep( ) system call. If the value returned by schedule_timeout( ) specifies that the process time-out is expired (value zero), the system call terminates. Otherwise, the system call is automatically restarted, as explained in the section "Reexecution of System Calls" in Chapter 11.
6.5.3. Delay Functions
Software timers are useless when the kernel must wait for a short time intervallet's say, less than a few milliseconds. For instance, often a device driver has to wait for a predefined number of microseconds until the hardware completes some operation. Because a dynamic timer has a significant setup overhead and a rather large minimum wait time (1 millisecond), the device driver cannot conveniently use it.
In these cases, the kernel makes use of the udelay( ) and ndelay( ) functions: the former receives as its parameter a time interval in microseconds and returns after the specified delay has elapsed; the latter is similar, but the argument specifies the delay in nanoseconds.
Essentially, the two functions are defined as follows:
void udelay(unsigned long usecs)
{
unsigned long loops;
loops = (usecs*HZ*current_cpu_data.loops_per_jiffy)/1000000;
cur_timer->delay(loops);
}
void ndelay(unsigned long nsecs)
{
unsigned long loops;
loops = (nsecs*HZ*current_cpu_data.loops_per_jiffy)/1000000000;
cur_timer->delay(loops);
}
Both functions rely on the delay method of the cur_timer timer object (see the earlier section "Data Structures of the Timekeeping Architecture"), which receives as its parameter a time interval in "loops." The exact duration of one "loop," however, depends on the timer object referred by cur_timer (see Table 6-2 earlier in this chapter):
If cur_timer points to the timer_hpet, timer_pmtmr, and timer_tsc objects, one "loop" corresponds to one CPU cyclethat is, the time interval between two consecutive CPU clock signals (see the earlier section "Time Stamp Counter (TSC)"). If cur_timer points to the timer_none or timer_pit objects, one "loop" corresponds to the time duration of a single iteration of a tight instruction loop.
During the initialization phase, after cur_timer has been set up by select_timer( ), the kernel executes the calibrate_delay( ) function, which determines how many "loops" fit in a tick. This value is then saved in the current_cpu_data.loops_per_jiffy variable, so that it can be used by udelay( ) and ndelay( ) to convert microseconds and nanoseconds, respectively, to "loops."
Of course, the cur_timer->delay( ) method makes use of the HPET or TSC hardware circuitry, if available, to get an accurate measurement of time. Otherwise, if no HPET or TSC is available, the method executes loops iterations of a tight instruction loop.
6.6. System Calls Related to Timing Measurements
Several system calls allow User Mode processes to read and modify the time and date and to create timers. Let's briefly review these and discuss how the kernel handles them.
6.6.1. The time( ) and gettimeofday( ) System Calls
Processes in User Mode can get the current time and date by means of several system calls:
time( ) Returns the number of elapsed seconds since midnight at the start of January 1, 1970 (UTC).
gettimeofday( ) Returns, in a data structure named timeval, the number of elapsed seconds since midnight of January 1, 1970 (UTC) and the number of elapsed microseconds in the last second (a second data structure named timezone is not currently used).
The time( ) system call is superseded by gettimeofday( ), but it is still included in Linux for backward compatibility. Another widely used function, ftime( ), which is no longer implemented as a system call, returns the number of elapsed seconds since midnight of January 1, 1970 (UTC) and the number of elapsed milliseconds in the last second.
The gettimeofday( ) system call is implemented by the sys_gettimeofday( ) function. To compute the current date and time of the day, this function invokes do_gettimeofday( ), which executes the following actions:
Acquires the xtime_lock seqlock for reading. Determines the number of microseconds elapsed since the last timer interrupt by invoking the get_offset method of the cur_timer timer object:
usec = cur_timer->getoffset( );
As explained in the earlier section "Data Structures of the Timekeeping Architecture," there are four possible cases: If cur_timer points to the timer_hpet object, the method compares the current value of the HPET counter with the value of the same counter saved in the last execution of the timer interrupt handler. If cur_timer points to the timer_pmtmr object, the method compares the current value of the ACPI PMT counter with the value of the same counter saved in the last execution of the timer interrupt handler. If cur_timer points to the timer_tsc object, the method compares the current value of the Time Stamp Counter with the value of the TSC saved in the last execution of the timer interrupt handler. If cur_timer points to the timer_pit object, the method reads the current value of the PIT counter to compute the number of microseconds elapsed since the last PIT's timer interrupt.
If some timer interrupt has been lost (see the section "Updating the Time and Date" earlier in this chapter), the function adds to usec the corresponding delay:
usec += (jiffies - wall_jiffies) * 1000;
Adds to usec the microseconds elapsed in the last second:
usec += (xtime.tv_nsec / 1000);
Copies the contents of xtime into the user-space buffer specified by the system call parameter tv, adding to the microseconds field the value of usec:
tv->tv_sec = xtime->tv_sec;
tv->tv_usec = xtime->tv_usec + usec;
Invokes read_seqretry( ) on the xtime_lock seqlock, and jumps back to step 1 if another kernel control path has concurrently acquired xtime_lock for writing. Checks for an overflow in the microseconds field, adjusting both that field and the second field if necessary:
while (tv->tv_usec >= 1000000) {
tv->tv_usec -= 1000000;
tv->tv_sec++;
}
Processes in User Mode with root privilege may modify the current date and time by using either the obsolete stime( ) or the settimeofday( ) system call. The sys_settimeofday( ) function invokes do_settimeofday( ), which executes operations complementary to those of do_gettimeofday( ).
Notice that both system calls modify the value of xtime while leaving the RTC registers unchanged. Therefore, the new time is lost when the system shuts down, unless the user executes the clock program to change the RTC value.
6.6.2. The adjtimex( ) System Call
Although clock drift ensures that all systems eventually move away from the correct time, changing the time abruptly is both an administrative nuisance and risky behavior. Imagine, for instance, programmers trying to build a large program and depending on file timestamps to make sure that out-of-date object files are recompiled. A large change in the system's time could confuse the make program and lead to an incorrect build. Keeping the clocks tuned is also important when implementing a distributed filesystem on a network of computers. In this case, it is wise to adjust the clocks of the interconnected PCs, so that the timestamp values associated with the inodes of the accessed files are coherent. Thus, systems are often configured to run a time synchronization protocol such as Network Time Protocol (NTP) on a regular basis to change the time gradually at each tick. This utility depends on the adjtimex( ) system call in Linux.
This system call is present in several Unix variants, although it should not be used in programs intended to be portable. It receives as its parameter a pointer to a timex structure, updates kernel parameters from the values in the timex fields, and returns the same structure with current kernel values. Such kernel values are used by update_wall_time_one_tick( ) to slightly adjust the number of microseconds added to xtime.tv_usec at each tick.
6.6.3. The setitimer( ) and alarm( ) System Calls
Linux allows User Mode processes to activate special timers called interval timers
. The timers cause Unix signals (see Chapter 11) to be sent periodically to the process. It is also possible to activate an interval timer so that it sends just one signal after a specified delay. Each interval timer is therefore characterized by:
The frequency at which the signals must be emitted, or a null value if just one signal has to be generated The time remaining until the next signal is to be generated
The earlier warning about accuracy applies to these timers. They are guaranteed to execute after the requested time has elapsed, but it is impossible to predict exactly when they will be delivered.
Interval timers are activated by means of the POSIX setitimer( ) system call. The first parameter specifies which of the following policies should be adopted:
ITIMER_REAL The actual elapsed time; the process receives SIGALRM signals.
ITIMER_VIRTUAL The time spent by the process in User Mode; the process receives SIGVTALRM signals.
ITIMER_PROF The time spent by the process both in User and in Kernel Mode; the process receives SIGPROF signals.
The interval timers can be either single-shot or periodic. The second parameter of setitimer( )
points to a structure of type itimerval that specifies the initial duration of the timer (in seconds and nanoseconds) and the duration to be used when the timer is automatically reactivated (or zero for single-shot timers).The third parameter of setitimer( ) is an optional pointer to an itimerval structure that is filled by the system call with the previous timer parameters.
To implement an interval timer for each of the preceding policies, the process descriptor includes three pairs of fields:
it_real_incr and it_real_value it_virt_incr and it_virt_value it_prof_incr and it_prof_value
The first field of each pair stores the interval in ticks between two signals; the other field stores the current value of the timer.
The ITIMER_REAL interval timer is implemented by using dynamic timers because the kernel must send signals to the process even when it is not running on the CPU. Therefore, each process descriptor includes a dynamic timer object called real_timer. The setitimer( ) system call initializes the real_timer fields and then invokes add_timer( ) to insert the dynamic timer in the proper list. When the timer expires, the kernel executes the it_real_fn( ) timer function. In turn, the it_real_fn( ) function sends a SIGALRM signal to the process; then, if it_real_incr is not null, it sets the expires field again, reactivating the timer.
The ITIMER_VIRTUAL and ITIMER_PROF interval timers do not require dynamic timers, because they can be updated while the process is running. The account_it_virt( ) and account_it_prof( ) functions are invoked by update_ process_times( ), which is called either by the PIT's timer interrupt handler (UP) or by the local timer interrupt handlers (SMP). Therefore, the two interval timers are updated once every tick, and if they are expired, the proper signal is sent to the current process.
The alarm( ) system call sends a SIGALRM signal to the calling process when a specified time interval has elapsed. It is very similar to setitimer( ) when invoked with the ITIMER_REAL parameter, because it uses the real_timer dynamic timer included in the process descriptor. Therefore, alarm( ) and setitimer( ) with parameter ITIMER_REAL cannot be used at the same time.
6.6.4. System Calls for POSIX Timers
The POSIX 1003.1b standard introduced a new type of software timers for User Mode programsin particular, for multithreaded and real-time applications. These timers are often referred to as POSIX timers
.
Every implementation of the POSIX timers must offer to the User Mode programs a few POSIX clocks
, that is, virtual time sources having predefined resolutions and properties. Whenever an application wants to make use of a POSIX timer, it creates a new timer resource specifying one of the existing POSIX clocks as the timing base. The system calls that allow users to handle POSIX clocks and timers are listed in Table 6-3.
Table 6-3. System calls for POSIX timers and clocksSystem call | Description |
|---|
clock_gettime() | Gets the current value of a POSIX clock | clock_settime( )
| Sets the current value of a POSIX clock | clock_getres( )
| Gets the resolution of a POSIX clock | timer_create( )
| Creates a new POSIX timer based on a specified POSIX clock | timer_gettime( )
| Gets the current value and increment of a POSIX timer | timer_settime( )
| Sets the current value and increment of a POSIX timer | timer_getoverrun( )
| Gets the number of overruns of a decayed POSIX timer | timer_delete( ) | Destroys a POSIX timer | clock_nanosleep() | Puts the process to sleep using a POSIX clock as time source |
The Linux 2.6 kernel offers two types of POSIX clocks:
CLOCK_REALTIME This virtual clock represents the real-time clock of the systemessentially the value of the xtime variable (see the earlier section "Updating the Time and Date"). The resolution returned by the clock_getres( ) system call is 999,848 nanoseconds, which corresponds to roughly 1000 updates of xtime in a second.
CLOCK_MONOTONIC This virtual clock represents the real-time clock of the system purged of every time warp due to the synchronization with an external time source. Essentially, this virtual clock is represented by the sum of the two variables xtime and wall_to_monotonic (see the earlier section "Timekeeping Architecture in Uniprocessor Systems"). The resolution of this POSIX clock, returned by clock_getres( ), is 999,848 nanoseconds.
The Linux kernel implements the POSIX timers by means of dynamic timers. Thus, they are similar to the traditional ITIMER_REAL interval timers we described in the previous section. POSIX timers, however, are much more flexible and reliable than traditional interval timers. A couple of significant differences between them are:
When a traditional interval timer decays, the kernel always sends a SIGALRM signal to the process that activated the timer. Instead, when a POSIX timer decays, the kernel can send every kind of signal, either to the whole multithreaded application or to a single specified thread. The kernel can also force the execution of a notifier function in a thread of the application, or it can even do nothing (it is up to a User Mode library to handle the event). If a traditional interval timer decays many times but the User Mode process cannot receive the SIGALRM signal (for instance because the signal is blocked or the process is not running), only the first signal is received: all other occurrences of SIGALRM are lost. The same holds for POSIX timers, but the process can invoke the timer_getoverrun( ) system call to get the number of times the timer decayed since the generation of the first signal.
Chapter 7. Process Scheduling
Like every time sharing
system, Linux achieves the magical effect of an apparent simultaneous execution of multiple processes by switching from one process to another in a very short time frame. Process switching itself was discussed in Chapter 3; this chapter deals with scheduling
, which is concerned with when to switch and which process to choose.
The chapter consists of three parts. The section "Scheduling Policy" introduces the choices made by Linux in the abstract to schedule processes. The section "The Scheduling Algorithm" discusses the data structures used to implement scheduling and the corresponding algorithm. Finally, the section "System Calls Related to Scheduling" describes the system calls that affect process scheduling.
To simplify the description, we refer as usual to the 80 x 86 architecture; in particular, we assume that the system uses the Uniform Memory Access model, and that the system tick is set to 1 ms.
7.1. Scheduling Policy
The scheduling algorithm of traditional Unix operating systems must fulfill several conflicting objectives: fast process response time, good throughput for background jobs, avoidance of process starvation, reconciliation of the needs of low- and high-priority processes, and so on. The set of rules used to determine when and how to select a new process to run is called scheduling policy
.
Linux scheduling is based on the time sharing technique: several processes run in "time multiplexing" because the CPU time is divided into slices, one for each runnable process. Of course, a single processor can run only one process at any given instant. If a currently running process is not terminated when its time slice or quantum expires, a process switch may take place. Time sharing relies on timer interrupts and is thus transparent to processes. No additional code needs to be inserted in the programs to ensure CPU time sharing.
The scheduling policy is also based on ranking processes according to their priority. Complicated algorithms are sometimes used to derive the current priority of a process, but the end result is the same: each process is associated with a value that tells the scheduler how appropriate it is to let the process run on a CPU.
In Linux, process priority is dynamic. The scheduler keeps track of what processes are doing and adjusts their priorities periodically; in this way, processes that have been denied the use of a CPU for a long time interval are boosted by dynamically increasing their priority. Correspondingly, processes running for a long time are penalized by decreasing their priority.
When speaking about scheduling, processes are traditionally classified as I/O-bound or CPU-bound. The former make heavy use of I/O devices and spend much time waiting for I/O operations to complete; the latter carry on number-crunching applications that require a lot of CPU time.
An alternative classification distinguishes three classes of processes:
Interactive processes These interact constantly with their users, and therefore spend a lot of time waiting for keypresses and mouse operations. When input is received, the process must be woken up quickly, or the user will find the system to be unresponsive. Typically, the average delay must fall between 50 and 150 milliseconds. The variance of such delay must also be bounded, or the user will find the system to be erratic. Typical interactive programs are command shells, text editors, and graphical applications.
Batch processes These do not need user interaction, and hence they often run in the background. Because such processes do not need to be very responsive, they are often penalized by the scheduler. Typical batch programs are programming language compilers, database search engines, and scientific computations.
Real-time processes These have very stringent scheduling requirements. Such processes should never be blocked by lower-priority processes and should have a short guaranteed response time with a minimum variance. Typical real-time programs are video and sound applications, robot controllers, and programs that collect data from physical sensors.
The two classifications we just offered are somewhat independent. For instance, a batch process can be either I/O-bound (e.g., a database server) or CPU-bound (e.g., an image-rendering program). While real-time programs are explicitly recognized as such by the scheduling algorithm in Linux, there is no easy way to distinguish between interactive and batch programs. The Linux 2.6 scheduler implements a sophisticated heuristic algorithm based on the past behavior of the processes to decide whether a given process should be considered as interactive or batch. Of course, the scheduler tends to favor interactive processes over batch ones.
Programmers may change the scheduling priorities by means of the system calls illustrated in Table 7-1. More details are given in the section "System Calls Related to Scheduling."
Table 7-1. System calls related to schedulingSystem call | Description |
|---|
nice( ) | Change the static priority of a conventional process | getpriority( ) | Get the maximum static priority of a group of conventional processes | setpriority( ) | Set the static priority of a group of conventional processes | sched_getscheduler( ) | Get the scheduling policy of a process | sched_setscheduler( ) | Set the scheduling policy and the real-time priority of a process | sched_getparam( ) | Get the real-time priority of a process | sched_setparam( ) | Set the real-time priority of a process | sched_yield( ) | Relinquish the processor voluntarily without blocking | sched_get_ priority_min( ) | Get the minimum real-time priority value for a policy | sched_get_ priority_max( ) | Get the maximum real-time priority value for a policy | sched_rr_get_interval( ) | Get the time quantum value for the Round Robin policy | sched_setaffinity( )
| Set the CPU affinity mask of a process | sched_getaffinity( )
| Get the CPU affinity mask of a process |
7.1.1. Process Preemption
As mentioned in the first chapter, Linux processes are preemptable. When a process enters the TASK_RUNNING state, the kernel checks whether its dynamic priority is greater than the priority of the currently running process. If it is, the execution of current is interrupted and the scheduler is invoked to select another process to run (usually the process that just became runnable). Of course, a process also may be preempted when its time quantum expires. When this occurs, the TIF_NEED_RESCHED flag in the thread_info structure of the current process is set, so the scheduler is invoked when the timer interrupt handler terminates.
For instance, let's consider a scenario in which only two programsa text editor and a compilerare being executed. The text editor is an interactive program, so it has a higher dynamic priority than the compiler. Nevertheless, it is often suspended, because the user alternates between pauses for think time and data entry; moreover, the average delay between two keypresses is relatively long. However, as soon as the user presses a key, an interrupt is raised and the kernel wakes up the text editor process. The kernel also determines that the dynamic priority of the editor is higher than the priority of current, the currently running process (the compiler), so it sets the TIF_NEED_RESCHED flag of this process, thus forcing the scheduler to be activated when the kernel finishes handling the interrupt. The scheduler selects the editor and performs a process switch; as a result, the execution of the editor is resumed very quickly and the character typed by the user is echoed to the screen. When the character has been processed, the text editor process suspends itself waiting for another keypress and the compiler process can resume its execution.
Be aware that a preempted process is not suspended, because it remains in the TASK_RUNNING state; it simply no longer uses the CPU. Moreover, remember that the Linux 2.6 kernel is preemptive, which means that a process can be preempted either when executing in Kernel or in User Mode; we discussed in depth this feature in the section "Kernel Preemption" in Chapter 5.
7.1.2. How Long Must a Quantum Last?
The quantum duration is critical for system performance: it should be neither too long nor too short.
If the average quantum duration is too short, the system overhead caused by process switches becomes excessively high. For instance, suppose that a process switch requires 5 milliseconds; if the quantum is also set to 5 milliseconds, then at least 50 percent of the CPU cycles will be dedicated to process switching.
If the average quantum duration is too long, processes no longer appear to be executed concurrently. For instance, let's suppose that the quantum is set to five seconds; each runnable process makes progress for about five seconds, but then it stops for a very long time (typically, five seconds times the number of runnable processes).
It is often believed that a long quantum duration degrades the response time of interactive applications. This is usually false. As described in the section "Process Preemption" earlier in this chapter, interactive processes have a relatively high priority, so they quickly preempt the batch processes, no matter how long the quantum duration is.
In some cases, however, a very long quantum duration degrades the responsiveness of the system. For instance, suppose two users concurrently enter two commands at the respective shell prompts; one command starts a CPU-bound process, while the other launches an interactive application. Both shells fork a new process and delegate the execution of the user's command to it; moreover, suppose such new processes have the same initial priority (Linux does not know in advance if a program to be executed is batch or interactive). Now if the scheduler selects the CPU-bound process to run first, the other process could wait for a whole time quantum before starting its execution. Therefore, if the quantum duration is long, the system could appear to be unresponsive to the user that launched the interactive application.
The choice of the average quantum duration is always a compromise. The rule of thumb adopted by Linux is choose a duration as long as possible, while keeping good system response time.
|
7.2. The Scheduling Algorithm
The scheduling algorithm
used in earlier versions of Linux was quite simple and straightforward: at every process switch the kernel scanned the list of runnable processes, computed their priorities, and selected the "best" process to run. The main drawback of that algorithm is that the time spent in choosing the best process depends on the number of runnable processes; therefore, the algorithm is too costlythat is, it spends too much timein high-end systems running thousands of processes.
The scheduling algorithm of Linux 2.6 is much more sophisticated. By design, it scales well with the number of runnable processes, because it selects the process to run in constant time, independently of the number of runnable processes. It also scales well with the number of processors because each CPU has its own queue of runnable processes. Furthermore, the new algorithm does a better job of distinguishing interactive processes and batch processes. As a consequence, users of heavily loaded systems feel that interactive applications are much more responsive in Linux 2.6 than in earlier versions.
The scheduler always succeeds in finding a process to be executed; in fact, there is always at least one runnable process: the swapper process, which has PID 0 and executes only when the CPU cannot execute other processes. As mentioned in Chapter 3, every CPU of a multiprocessor system has its own swapper process with PID equal to 0.
Every Linux process is always scheduled according to one of the following scheduling classes
:
SCHED_FIFO A First-In, First-Out real-time process. When the scheduler assigns the CPU to the process, it leaves the process descriptor in its current position in the runqueue list. If no other higher-priority real-time process is runnable, the process continues to use the CPU as long as it wishes, even if other real-time processes
that have the same priority are runnable.
SCHED_RR A Round Robin real-time process. When the scheduler assigns the CPU to the process, it puts the process descriptor at the end of the runqueue list. This policy ensures a fair assignment of CPU time to all SCHED_RR real-time processes that have the same priority.
SCHED_NORMAL A conventional, time-shared process.
The scheduling algorithm behaves quite differently depending on whether the process is conventional or real-time.
7.2.1. Scheduling of Conventional Processes
Every conventional process has its own static priority, which is a value used by the scheduler to rate the process with respect to the other conventional processes
in the system. The kernel represents the static priority of a conventional process with a number ranging from 100 (highest priority) to 139 (lowest priority); notice that static priority decreases as the values increase.
A new process always inherits the static priority of its parent. However, a user can change the static priority of the processes that he owns by passing some "nice values" to the nice( ) and setpriority( ) system calls (see the section "System Calls Related to Scheduling" later in this chapter).
7.2.1.1. Base time quantum
The static priority essentially determines the base time quantum
of a process, that is, the time quantum duration assigned to the process when it has exhausted its previous time quantum. Static priority and base time quantum are related by the following formula:
As you see, the higher the static priority (i.e., the lower its numerical value), the longer the base time quantum. As a consequence, higher priority processes usually get longer slices of CPU time with respect to lower priority processes. Table 7-2 shows the static priority, the base time quantum values, and the corresponding nice values for a conventional process having highest static priority, default static priority, and lowest static priority. (The table also lists the values of the interactive delta and of the sleep time threshold, which are explained later in this chapter.)
Table 7-2. Typical priority values for a conventional processDescription | Static priority | Nice value | Base time quantum | Interactivedelta | Sleep time threshold |
|---|
Highest static priority | 100 | -20 | 800 ms | -3 | 299 ms | High static priority | 110 | -10 | 600 ms | -1 | 499 ms | Default static priority | 120 | 0 | 100 ms | +2 | 799 ms | Low static priority | 130 | +10 | 50 ms | +4 | 999 ms | Lowest static priority | 139 | +19 | 5 ms | +6 | 1199 ms |
7.2.1.2. Dynamic priority and average sleep time
Besides a static priority, a conventional process also has a dynamic priority, which is a value ranging from 100 (highest priority) to 139 (lowest priority). The dynamic priority is the number actually looked up by the scheduler when selecting the new process to run. It is related to the static priority by the following empirical formula:
dynamic priority = max (100, min ( static priority - bonus
+ 5, 139)) (2)
The bonus is a value ranging from 0 to 10; a value less than 5 represents a penalty that lowers the dynamic priority, while a value greater than 5 is a premium that raises the dynamic priority. The value of the bonus, in turn, depends on the past history of the process; more precisely, it is related to the average sleep time
of the process.
Roughly, the average sleep time is the average number of nanoseconds that the process spent while sleeping. Be warned, however, that this is not an average operation on the elapsed time. For instance, sleeping in TASK_INTERRUPTIBLE state contributes to the average sleep time in a different way from sleeping in TASK_UNINTERRUPTIBLE state. Moreover, the average sleep time decreases while a process is running. Finally, the average sleep time can never become larger than 1 second.
The correspondence between average sleep times and bonus values is shown in Table 7-3. (The table lists also the corresponding granularity of the time slice, which will be discussed later.)
Table 7-3. Average sleep times, bonus values, and time slice granularityAverage sleep time | Bonus | Granularity |
|---|
Greater than or equal to 0 but smaller than 100 ms | 0 | 5120 | Greater than or equal to 100 ms but smaller than 200 ms | 1 | 2560 | Greater than or equal to 200 ms but smaller than 300 ms | 2 | 1280 | Greater than or equal to 300 ms but smaller than 400 ms | 3 | 640 | Greater than or equal to 400 ms but smaller than 500 ms | 4 | 320 | Greater than or equal to 500 ms but smaller than 600 ms | 5 | 160 | Greater than or equal to 600 ms but smaller than 700 ms | 6 | 80 | Greater than or equal to 700 ms but smaller than 800 ms | 7 | 40 | Greater than or equal to 800 ms but smaller than 900 ms | 8 | 20 | Greater than or equal to 900 ms but smaller than 1000 ms | 9 | 10 | 1 second | 10 | 10 |
The average sleep time is also used by the scheduler to determine whether a given process should be considered interactive or batch. More precisely, a process is considered "interactive" if it satisfies the following formula:
dynamic priority  3 x static priority / 4 + 28 (3) 3 x static priority / 4 + 28 (3)
which is equivalent to the following:
bonus - 5  static priority / 4 - 28 static priority / 4 - 28
The expression static priority / 4 - 28 is called the interactive delta
; some typical values of this term are listed in Table 7-2. It should be noted that it is far easier for high priority than for low priority processes to become interactive. For instance, a process having highest static priority (100) is considered interactive when its bonus value exceeds 2, that is, when its average sleep time exceeds 200 ms. Conversely, a process having lowest static priority (139) is never considered as interactive, because the bonus value is always smaller than the value 11 required to reach an interactive delta equal to 6. A process having default static priority (120) becomes interactive as soon as its average sleep time exceeds 700 ms.
7.2.1.3. Active and expired processes
Even if conventional processes having higher static priorities get larger slices of the CPU time, they should not completely lock out the processes having lower static priority. To avoid process starvation, when a process finishes its time quantum, it can be replaced by a lower priority process whose time quantum has not yet been exhausted. To implement this mechanism, the scheduler keeps two disjoint sets of runnable processes:
Active processes These runnable processes have not yet exhausted their time quantum and are thus allowed to run.
Expired processes These runnable processes have exhausted their time quantum and are thus forbidden to run until all active processes
expire.
However, the general schema is slightly more complicated than this, because the scheduler tries to boost the performance of interactive processes. An active batch process that finishes its time quantum always becomes expired. An active interactive process that finishes its time quantum usually remains active: the scheduler refills its time quantum and leaves it in the set of active processes. However, the scheduler moves an interactive process that finished its time quantum into the set of expired processes if the eldest expired process has already waited for a long time, or if an expired process has higher static priority (lower value) than the interactive process. As a consequence, the set of active processes will eventually become empty and the expired processes will have a chance to run.
7.2.2. Scheduling of Real-Time Processes
Every real-time process is associated with a real-time priority, which is a value ranging from 1 (highest priority) to 99 (lowest priority). The scheduler always favors a higher priority runnable process over a lower priority one; in other words, a real-time process inhibits the execution of every lower-priority process while it remains runnable. Contrary to conventional processes, real-time processes are always considered active (see the previous section). The user can change the real-time priority of a process by means of the sched_setparam( )
and sched_setscheduler( )
system calls (see the section "System Calls Related to Scheduling" later in this chapter).
If several real-time runnable processes have the same highest priority, the scheduler chooses the process that occurs first in the corresponding list of the local CPU's runqueue (see the section "The lists of TASK_RUNNING processes" in Chapter 3).
A real-time process is replaced by another process only when one of the following events occurs:
The process is preempted by another process having higher real-time priority. The process performs a blocking operation, and it is put to sleep (in state TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE). The process is stopped (in state TASK_STOPPED or TASK_TRACED), or it is killed (in state EXIT_ZOMBIE or EXIT_DEAD). The process voluntarily relinquishes the CPU by invoking the sched_yield( )
system call (see the section "System Calls Related to Scheduling" later in this chapter). The process is Round Robin real-time (SCHED_RR), and it has exhausted its time quantum.
The nice( )
and setpriority( )
system calls, when applied to a Round Robin real-time process, do not change the real-time priority but rather the duration of the base time quantum. In fact, the duration of the base time quantum of Round Robin real-time processes does not depend on the real-time priority, but rather on the static priority of the process, according to the formula (1) in the earlier section "Scheduling of Conventional Processes."
7.3. Data Structures Used by the Scheduler
Recall from the section "Identifying a Process" in Chapter 3 that the process list links all process descriptors, while the runqueue lists link the process descriptors of all runnable processesthat is, of those in a TASK_RUNNING stateexcept the swapper process (idle process).
7.3.1. The runqueue Data Structure
The runqueue data structure is the most important data structure of the Linux 2.6 scheduler. Each CPU in the system has its own runqueue; all runqueue structures are stored in the runqueues per-CPU variable (see the section "Per-CPU Variables" in Chapter 5). The this_rq( ) macro yields the address of the runqueue of the local CPU, while the cpu_rq(n) macro yields the address of the runqueue of the CPU having index n.
Table 7-4 lists the fields included in the runqueue data structure; we will discuss most of them in the following sections of the chapter.
Table 7-4. The fields of the runqueue structureType | Name | Description |
|---|
spinlock_t | lock | Spin lock protecting the lists of processes | unsigned long | nr_running | Number of runnable processes in the runqueue lists | unsigned long | cpu_load | CPU load factor based on the average number of processes in the runqueue | unsigned long | nr_switches | Number of process switches performed by the CPU | unsigned long | nr_uninterruptible | Number of processes that were previously in the runqueue lists and are now sleeping in TASK_UNINTERRUPTIBLE state (only the sum of these fields across all runqueues is meaningful) | unsigned long | expired_timestamp | Insertion time of the eldest process in the expired lists | unsigned long long | timestamp_last_tick | Timestamp value of the last timer interrupt | task_t * | curr | Process descriptor pointer of the currently running process (same as current for the local CPU) | task_t * | idle | Process descriptor pointer of the swapper process for this CPU | struct mm_struct * | prev_mm | Used during a process switch to store the address of the memory descriptor of the process being replaced | prio_array_t * | active | Pointer to the lists of active processes | prio_array_t * | expired | Pointer to the lists of expired processes | prio_array_t [2] | arrays | The two sets of active and expired processes | int | best_expired_prio | The best static priority (lowest value) among the expired processes | atomic_t | nr_iowait | Number of processes that were previously in the runqueue lists and are now waiting for a disk I/O operation to complete | struct sched_domain * | sd | Points to the base scheduling domain of this CPU (see the section "Scheduling Domains" later in this chapter) | int | active_balance | Flag set if some process shall be migrated from this runqueue to another (runqueue balancing) | int | push_cpu | Not used | task_t * | migration_thread | Process descriptor pointer of the migration
kernel thread | struct list_head | migration_queue | List of processes to be removed from the runqueue |
The most important fields of the runqueue data structure are those related to the lists of runnable processes. Every runnable process in the system belongs to one, and just one, runqueue. As long as a runnable process remains in the same runqueue, it can be executed only by the CPU owning that runqueue. However, as we'll see later, runnable processes may migrate from one runqueue to another.
The arrays field of the runqueue is an array consisting of two prio_array_t structures. Each data structure represents a set of runnable processes, and includes 140 doubly linked list heads (one list for each possible process priority), a priority bitmap, and a counter of the processes included in the set (see Table 3-2 in the section Chapter 3).
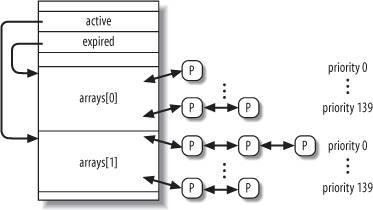
As shown in Figure 7-1, the active field of the runqueue structure points to one of the two prio_array_t data structures in arrays: the corresponding set of runnable processes includes the active processes. Conversely, the expired field points to the other prio_array_t data structure in arrays: the corresponding set of runnable processes includes the expired processes.
Periodically, the role of the two data structures in arrays changes: the active processes suddenly become the expired processes, and the expired processes become the active ones. To achieve this change, the scheduler simply exchanges the contents of the active and expired fields of the runqueue.
7.3.2. Process Descriptor
Each process descriptor includes several fields related to scheduling; they are listed in Table 7-5.
Table 7-5. Fields of the process descriptor related to the schedulerType | Name | Description |
|---|
unsigned long | thread_info->flags | Stores the TIF_NEED_RESCHED flag, which is set if the scheduler must be invoked (see the section "Returning from Interrupts and Exceptions" in Chapter 4) | unsigned int | thread_info->cpu | Logical number of the CPU owning the runqueue to which the runnable process belongs | unsigned long | state | The current state of the process (see the section "Process State" in Chapter 3) | int | prio | Dynamic priority of the process | int | static_prio | Static priority of the process | struct list_head | run_list | Pointers to the next and previous elements in the runqueue list to which the process belongs | prio_array_t * | array | Pointer to the runqueue's prio_array_t set that includes the process | unsigned long | sleep_avg | Average sleep time of the process | unsigned long long | timestamp | Time of last insertion of the process in the runqueue, or time of last process switch involving the process | unsigned long long | last_ran | Time of last process switch that replaced the process | int | activated | Condition code used when the process is awakened | unsigned long | policy | The scheduling class of the process (SCHED_NORMAL, SCHED_RR, or SCHED_FIFO) | cpumask_t | cpus_allowed | Bit mask of the CPUs that can execute the process | unsigned int | time_slice | Ticks left in the time quantum of the process | unsigned int | first_time_slice | Flag set to 1 if the process never exhausted its time quantum | unsigned long | rt_priority | Real-time priority of the process |
When a new process is created, sched_fork( ), invoked by copy_process( ), sets the time_slice field of both current (the parent) and p (the child) processes in the following way:
p->time_slice = (current->time_slice + 1) >> 1;
current->time_slice >>= 1;
In other words, the number of ticks left to the parent is split in two halves: one for the parent and one for the child. This is done to prevent users from getting an unlimited amount of CPU time by using the following method: the parent process creates a child process that runs the same code and then kills itself; by properly adjusting the creation rate, the child process would always get a fresh quantum before the quantum of its parent expires. This programming trick does not work because the kernel does not reward forks. Similarly, a user cannot hog an unfair share of the processor by starting several background processes in a shell or by opening a lot of windows on a graphical desktop. More generally speaking, a process cannot hog resources (unless it has privileges to give itself a real-time policy) by forking multiple descendents.
If the parent had just one tick left in its time slice, the splitting operation forces current->time_slice to 0, thus exhausting the quantum of the parent. In this case, copy_process( ) sets current->time_slice back to 1, then invokes scheduler_tick( ) to decrease the field (see the following section).
The copy_process( ) function also initializes a few other fields of the child's process descriptor related to scheduling:
p->first_time_slice = 1;
p->timestamp = sched_clock( );
The first_time_slice flag is set to 1, because the child has never exhausted its time quantum (if a process terminates or executes a new program during its first time slice, the parent process is rewarded with the remaining time slice of the child). The timestamp field is initialized with a timestamp value produced by sched_clock( ): essentially, this function returns the contents of the 64-bit TSC register (see the section "Time Stamp Counter (TSC)" in Chapter 6) converted to nanoseconds.
|
7.4. Functions Used by the Scheduler
The scheduler relies on several functions in order to do its work; the most important are:
scheduler_tick( ) Keeps the time_slice counter of current up-to-date
try_to_wake_up( ) Awakens a sleeping process
recalc_task_prio( ) Updates the dynamic priority of a process
schedule( ) Selects a new process to be executed
load_balance() Keeps the runqueues of a multiprocessor system balanced
7.4.1. The scheduler_tick( ) Function
We have already explained in the section "Updating Local CPU Statistics" in Chapter 6 how scheduler_tick( ) is invoked once every tick to perform some operations related to scheduling. It executes the following main steps:
Stores in the timestamp_last_tick field of the local runqueue the current value of the TSC converted to nanoseconds; this timestamp is obtained from the sched_clock( ) function (see the previous section). Checks whether the current process is the swapper process of the local CPU. If so, it performs the following substeps: If the local runqueue includes another runnable process besides swapper, it sets the TIF_NEED_RESCHED flag of the current process to force rescheduling. As we'll see in the section "The schedule( ) Function" later in this chapter, if the kernel supports the hyper-threading technology (see the section "Runqueue Balancing in Multiprocessor Systems" later in this chapter), a logical CPU might be idle even if there are runnable processes in its runqueue, as long as those processes have significantly lower priorities than the priority of a process already executing on another logical CPU associated with the same physical CPU. Jumps to step 7 (there is no need to update the time slice counter of the swapper process).
Checks whether current->array points to the active list of the local runqueue. If not, the process has expired its time quantum, but it has not yet been replaced: sets the TIF_NEED_RESCHED flag to force rescheduling, and jumps to step 7. Acquires the this_rq()->lock spin lock. Decreases the time slice counter of the current process, and checks whether the quantum is exhausted. The operations performed by the function are quite different according to the scheduling class of the process; we will discuss them in a moment. Releases the this_rq( )->lock spin lock. Invokes the rebalance_tick( ) function, which should ensure that the runqueues of the various CPUs contain approximately the same number of runnable processes. We will discuss runqueue balancing in the later section "Runqueue Balancing in Multiprocessor Systems."
7.4.1.1. Updating the time slice of a real-time process
If the current process is a FIFO real-time process, scheduler_tick( ) has nothing to do. In this case, in fact, current cannot be preempted by lower or equal priority processes, thus it does not make sense to keep its time slice counter up-to-date.
If current is a Round Robin real-time process, scheduler_tick( ) decreases its time slice counter and checks whether the quantum is exhausted:
if (current->policy == SCHED_RR && !--current->time_slice) {
current->time_slice = task_timeslice(current);
current->first_time_slice = 0;
set_tsk_need_resched(current);
list_del(¤t->run_list);
list_add_tail(¤t->run_list,
this_rq( )->active->queue+current->prio);
}
If the function determines that the time quantum is effectively exhausted, it performs a few operations aimed to ensure that current will be preempted, if necessary, as soon as possible.
The first operation consists of refilling the time slice counter of the process by invoking task_timeslice( ). This function considers the static priority of the process and returns the corresponding base time quantum, according to the formula (1) shown in the earlier section "Scheduling of Conventional Processes." Moreover, the first_time_slice field of current is cleared: this flag is set by copy_process( ) in the service routine of the fork( )
system call, and should be cleared as soon as the first time quantum of the process elapses.
Next, scheduler_tick( ) invokes the set_tsk_need_resched( ) function to set the TIF_NEED_RESCHED flag of the process. As described in the section "Returning from Interrupts and Exceptions" in Chapter 4, this flag forces the invocation of the schedule( ) function, so that current can be replaced by another real-time process having equal (or higher) priority, if any.
The last operation of scheduler_tick( ) consists of moving the process descriptor to the last position of the runqueue active list corresponding to the priority of current. Placing current in the last position ensures that it will not be selected again for execution until every real-time runnable process having the same priority as current will get a slice of the CPU time. This is the meaning of round-robin scheduling. The descriptor is moved by first invoking list_del( ) to remove the process from the runqueue active list, then by invoking list_add_tail( ) to insert back the process in the last position of the same list.
7.4.1.2. Updating the time slice of a conventional process
If the current process is a conventional process, the scheduler_tick( ) function performs the following operations:
Decreases the time slice counter (current->time_slice). Checks the time slice counter. If the time quantum is exhausted, the function performs the following operations: Invokes dequeue_task( ) to remove current from the this_rq( )->active set of runnable processes. Invokes set_tsk_need_resched( ) to set the TIF_NEED_RESCHED flag. Updates the dynamic priority of current:
current->prio = effective_prio(current);
The effective_prio( ) function reads the static_prio and sleep_avg fields of current, and computes the dynamic priority of the process according to the formula (2) shown in the earlier section "Scheduling of Conventional Processes." Refills the time quantum of the process:
current->time_slice = task_timeslice(current);
current->first_time_slice = 0;
If the expired_timestamp field of the local runqueue data structure is equal to zero (that is, the set of expired processes is empty), writes into the field the value of the current tick:
if (!this_rq( )->expired_timestamp)
this_rq( )->expired_timestamp = jiffies;
Inserts the current process either in the active set or in the expired set:
if (!TASK_INTERACTIVE(current) || EXPIRED_STARVING(this_rq( )) {
enqueue_task(current, this_rq( )->expired);
if (current->static_prio < this_rq( )->best_expired_prio)
this_rq( )->best_expired_prio = current->static_prio;
} else
enqueue_task(current, this_rq( )->active);
The TASK_INTERACTIVE macro yields the value one if the process is recognized as interactive using the formula (3) shown in the earlier section "Scheduling of Conventional Processes." The EXPIRED_STARVING macro checks whether the first expired process in the runqueue had to wait for more than 1000 ticks times the number of runnable processes in the runqueue plus one; if so, the macro yields the value one. The EXPIRED_STARVING macro also yields the value one if the static priority value of the current process is greater than the static priority value of an already expired process.
Otherwise, if the time quantum is not exhausted (current->time_slice is not zero), checks whether the remaining time slice of the current process is too long:
if (TASK_INTERACTIVE(p) && !((task_timeslice(p) -
p->time_slice) % TIMESLICE_GRANULARITY(p)) &&
(p->time_slice >= TIMESLICE_GRANULARITY(p)) &&
(p->array == rq->active)) {
list_del(¤t->run_list);
list_add_tail(¤t->run_list,
this_rq( )->active->queue+current->prio);
set_tsk_need_resched(p);
}
The TIMESLICE_GRANULARITY macro yields the product of the number of CPUs in the system and a constant proportional to the bonus of the current process (see Table 7-3 earlier in the chapter). Basically, the time quantum of interactive processes with high static priorities is split into several pieces of TIMESLICE_GRANULARITY size, so that they do not monopolize the CPU.
7.4.2. The try_to_wake_up( ) Function
The TRy_to_wake_up( ) function awakes a sleeping or stopped process by setting its state to TASK_RUNNING and inserting it into the runqueue of the local CPU. For instance, the function is invoked to wake up processes included in a wait queue (see the section "How Processes Are Organized" in Chapter 3) or to resume execution of processes waiting for a signal (see Chapter 11). The function receives as its parameters:
The descriptor pointer (p) of the process to be awakened A mask of the process states (state) that can be awakened A flag (sync) that forbids the awakened process to preempt the process currently running on the local CPU
The function performs the following operations:
Invokes the task_rq_lock( ) function to disable local interrupts and to acquire the lock of the runqueue rq owned by the CPU that was last executing the process (it could be different from the local CPU). The logical number of that CPU is stored in the p->thread_info->cpu field. Checks if the state of the process p->state belongs to the mask of states state passed as argument to the function; if this is not the case, it jumps to step 9 to terminate the function. If the p->array field is not NULL, the process already belongs to a runqueue; therefore, it jumps to step 8. In multiprocessor systems, it checks whether the process to be awakened should be migrated from the runqueue of the lastly executing CPU to the runqueue of another CPU. Essentially, the function selects a target runqueue according to some heuristic rules. For example: If some CPU in the system is idle, it selects its runqueue as the target. Preference is given to the previously executing CPU and to the local CPU, in this order. If the workload of the previously executing CPU is significantly lower than the workload of the local CPU, it selects the old runqueue as the target. If the process has been executed recently, it selects the old runqueue as the target (the hardware cache might still be filled with the data of the process). If moving the process to the local CPU reduces the unbalance between the CPUs, the target is the local runqueue (see the section "Runqueue Balancing in Multiprocessor Systems" later in this chapter).
After this step has been executed, the function has identified a target CPU that will execute the awakened process and, correspondingly, a target runqueue rq in which to insert the process.
If the process is in the TASK_UNINTERRUPTIBLE state, it decreases the nr_uninterruptible field of the target runqueue, and sets the p->activated field of the process descriptor to -1. See the later section "The recalc_task_prio( ) Function" for an explanation of the activated field. Invokes the activate_task( ) function, which in turn performs the following substeps: Invokes sched_clock( ) to get the current timestamp in nanoseconds. If the target CPU is not the local CPU, it compensates for the drift of the local timer interrupts by using the timestamps relative to the last occurrences of the timer interrupts on the local and target CPUs:
now = (sched_clock( ) - this_rq( )->timestamp_last_tick)
+ rq->timestamp_last_tick;
Invokes recalc_task_prio( ), passing to it the process descriptor pointer and the timestamp computed in the previous step. The recalc_task_prio( ) function is described in the next section. Sets the value of the p->activated field according to Table 7-6 later in this chapter. Sets the p->timestamp field with the timestamp computed in step 6a. Inserts the process descriptor in the active set:
enqueue_task(p, rq->active);
rq->nr_running++;
If either the target CPU is not the local CPU or if the sync flag is not set, it checks whether the new runnable process has a dynamic priority higher than that of the current process of the rq runqueue (p->prio < rq->curr->prio); if so, invokes resched_task( ) to preempt rq->curr. In uniprocessor systems the latter function just executes set_tsk_need_resched( ) to set the TIF_NEED_RESCHED flag of the rq->curr process. In multiprocessor systems resched_task( ) also checks whether the old value of whether TIF_NEED_RESCHED flag was zero, the target CPU is different from the local CPU, and whether the TIF_POLLING_NRFLAG flag of the rq->curr process is clear (the target CPU is not actively polling the status of the TIF_NEED_RESCHED flag of the process). If so, resched_task( ) invokes smp_send_reschedule( ) to raise an IPI and force rescheduling on the target CPU (see the section "Interprocessor Interrupt Handling" in Chapter 4). Sets the p->state field of the process to TASK_RUNNING. Invokes task_rq_unlock( ) to unlock the rq runqueue and reenable the local interrupts. Returns 1 (if the process has been successfully awakened) or 0 (if the process has not been awakened).
7.4.3. The recalc_task_prio( ) Function
The recalc_task_prio( ) function updates the average sleep time and the dynamic priority of a process. It receives as its parameters a process descriptor pointer p and a timestamp now computed by the sched_clock( ) function.
The function executes the following operations:
Stores in the sleep_time local variable the result of:
min (now - p->timestamp, 109 )
The p->timestamp field contains the timestamp of the process switch that put the process to sleep; therefore, sleep_time stores the number of nanoseconds that the process spent sleeping since its last execution (or the equivalent of 1 second, if the process slept more). If sleep_time is not greater than zero, it jumps to step 8 so as to skip updating the average sleep time of the process. Checks whether the process is not a kernel thread, whether it is awakening from the TASK_UNINTERRUPTIBLE state (p->activated field equal to -1; see step 5 in the previous section), and whether it has been continuously asleep beyond a given sleep time threshold. If these three conditions are fulfilled, the function sets the p->sleep_avg field to the equivalent of 900 ticks (an empirical value obtained by subtracting the duration of the base time quantum of a standard process from the maximum average sleep time). Then, it jumps to step 8. The sleep time threshold depends on the static priority of the process; some typical values are shown in Table 7-2. In short, the goal of this empirical rule is to ensure that processes that have been asleep for a long time in uninterruptible modeusually waiting for disk I/O operationsget a predefined sleep average value that is large enough to allow them to be quickly serviced, but it is also not so large to cause starvation for other processes. Executes the CURRENT_BONUS macro to compute the bonus
value of the previous average sleep time of the process (see Table 7-3). If (10 - bonus) is greater than zero, the function multiplies sleep_time by this value. Since sleep_time will be added to the average sleep time of the process (see step 6 below), the lower the current average sleep time is, the more rapidly it will rise. If the process is in TASK_UNINTERRUPTIBLE mode and it is not a kernel thread, it performs the following substeps: Checks whether the average sleep time p->sleep_avg is greater than or equal to its sleep time threshold (see Table 7-2 earlier in this chapter). If so, it resets the sleep_avg local variable to zerothus skipping the adjustment of the average sleep timeand jumps to step 6. If the sum sleep_avg + p->sleep_avg is greater than or equal to the sleep time threshold, it sets the p->sleep_avg field to the sleep time threshold, and sets sleep_avg to zero.
By somewhat limiting the increment of the average sleep time of the process, the function does not reward too much batch processes that sleep for a long time. Adds sleep_time to the average sleep time of the process (p->sleep_avg). Checks whether p->sleep_avg exceeds 1000 ticks (in nanoseconds); if so, the function cuts it down to 1000 ticks (in nanoseconds). Updates the dynamic priority of the process:
p->prio = effective_prio(p);
The effective_prio( ) function has already been discussed in the section "The scheduler_tick( ) Function" earlier in this chapter.
7.4.4. The schedule( ) Function
The schedule( ) function implements the scheduler. Its objective is to find a process in the runqueue list and then assign the CPU to it. It is invoked, directly or in a lazy (deferred) way, by several kernel routines.
7.4.4.1. Direct invocation
The scheduler is invoked directly when the current process must be blocked right away because the resource it needs is not available. In this case, the kernel routine that wants to block it proceeds as follows:
Inserts current in the proper wait queue. Changes the state of current either to TASK_INTERRUPTIBLE or to TASK_UNINTERRUPTIBLE. Checks whether the resource is available; if not, goes to step 2. Once the resource is available, removes current from the wait queue.
The kernel routine checks repeatedly whether the resource needed by the process is available; if not, it yields the CPU to some other process by invoking schedule( ). Later, when the scheduler once again grants the CPU to the process, the availability of the resource is rechecked. These steps are similar to those performed by wait_event( ) and similar functions described in the section "How Processes Are Organized" in Chapter 3.
The scheduler is also directly invoked by many device drivers that execute long iterative tasks. At each iteration cycle, the driver checks the value of the TIF_NEED_RESCHED flag and, if necessary, invokes schedule( ) to voluntarily relinquish the CPU.
7.4.4.2. Lazy invocation
The scheduler can also be invoked in a lazy way by setting the TIF_NEED_RESCHED flag of current to 1. Because a check on the value of this flag is always made before resuming the execution of a User Mode process (see the section "Returning from Interrupts and Exceptions" in Chapter 4), schedule( ) will definitely be invoked at some time in the near future.
Typical examples of lazy invocation
of the scheduler are:
When current has used up its quantum of CPU time; this is done by the scheduler_tick( ) function. When a process is woken up and its priority is higher than that of the current process; this task is performed by the try_to_wake_up( ) function. When a sched_setscheduler( ) system call is issued (see the section "System Calls Related to Scheduling" later in this chapter).
7.4.4.3. Actions performed by schedule( ) before a process switch
The goal of the schedule( ) function consists of replacing the currently executing process with another one. Thus, the key outcome of the function is to set a local variable called next, so that it points to the descriptor of the process selected to replace current. If no runnable process in the system has priority greater than the priority of current, at the end, next coincides with current and no process switch takes place.
The schedule( ) function starts by disabling kernel preemption and initializing a few local variables:
need_resched:
preempt_disable( );
prev = current;
rq = this_rq( );
As you see, the pointer returned by current is saved in prev, and the address of the runqueue data structure corresponding to the local CPU is saved in rq.
Next, schedule( ) makes sure that prev doesn't hold the big kernel lock
(see the section "The Big Kernel Lock" in Chapter 5):
if (prev->lock_depth >= 0)
up(&kernel_sem);
Notice that schedule( ) doesn't change the value of the lock_depth field; when prev resumes its execution, it reacquires the kernel_flag spin lock if the value of this field is not negative. Thus, the big kernel lock is automatically released and reacquired across a process switch.
The sched_clock( ) function is invoked to read the TSC and convert its value to nanoseconds; the timestamp obtained is saved in the now local variable. Then, schedule( ) computes the duration of the CPU time slice used by prev:
now = sched_clock( );
run_time = now - prev->timestamp;
if (run_time > 1000000000)
run_time = 1000000000;
The usual cut-off at 1 second (converted to nanoseconds) applies. The run_time value is used to charge the process for the CPU usage. However, a process having a high average sleep time is favored:
run_time /= (CURRENT_BONUS(prev) ? : 1);
Remember that CURRENT_BONUS returns a value between 0 and 10 that is proportional to the average sleep time of the process.
Before starting to look at the runnable processes, schedule( ) must disable the local interrupts and acquire the spin lock that protects the runqueue:
spin_lock_irq(&rq->lock);
As explained in the section "Process Termination" in Chapter 3, prev might be a process that is being terminated. To recognize this case, schedule( ) looks at the PF_DEAD flag:
if (prev->flags & PF_DEAD)
prev->state = EXIT_DEAD;
Next, schedule( ) examines the state of prev. If it is not runnable and it has not been preempted in Kernel Mode (see the section "Returning from Interrupts and Exceptions" in Chapter 4), then it should be removed from the runqueue. However, if it has nonblocked pending signals
and its state is TASK_INTERRUPTIBLE, the function sets the process state to TASK_RUNNING and leaves it into the runqueue. This action is not the same as assigning the processor to prev; it just gives prev a chance to be selected for execution:
if (prev->state != TASK_RUNNING &&
!(preempt_count() & PREEMPT_ACTIVE)) {
if (prev->state == TASK_INTERRUPTIBLE && signal_pending(prev))
prev->state = TASK_RUNNING;
else {
if (prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
deactivate_task(prev, rq);
}
}
The deactivate_task( ) function removes the process from the runqueue:
rq->nr_running--;
dequeue_task(p, p->array);
p->array = NULL;
Now, schedule( ) checks the number of runnable processes left in the runqueue. If there are some runnable processes, the function invokes the dependent_sleeper( ) function. In most cases, this function immediately returns zero. If, however, the kernel supports the hyper-threading technology (see the section "Runqueue Balancing in Multiprocessor Systems" later in this chapter), the function checks whether the process that is going to be selected for execution has significantly lower priority than a sibling process already running on a logical CPU of the same physical CPU; in this particular case, schedule( ) refuses to select the lower privilege process and executes the swapper process instead.
if (rq->nr_running) {
if (dependent_sleeper(smp_processor_id( ), rq)) {
next = rq->idle;
goto switch_tasks;
}
}
If no runnable process exists, the function invokes idle_balance( ) to move some runnable process from another runqueue to the local runqueue; idle_balance( ) is similar to load_balance( ), which is described in the later section "The load_balance( ) Function."
if (!rq->nr_running) {
idle_balance(smp_processor_id( ), rq);
if (!rq->nr_running) {
next = rq->idle;
rq->expired_timestamp = 0;
wake_sleeping_dependent(smp_processor_id( ), rq);
if (!rq->nr_running)
goto switch_tasks;
}
}
If idle_balance( ) fails in moving some process in the local runqueue, schedule( ) invokes wake_sleeping_dependent( ) to reschedule runnable processes in idle CPUs (that is, in every CPU that runs the swapper process). As explained earlier when discussing the dependent_sleeper( ) function, this unusual case might happen when the kernel supports the hyper-threading technology. However, in uniprocessor systems, or when all attempts to move a runnable process in the local runqueue have failed, the function picks the swapper process as next and continues with the next phase.
Let's suppose that the schedule( ) function has determined that the runqueue includes some runnable processes; now it has to check that at least one of these runnable processes is active. If not, the function exchanges the contents of the active and expired fields of the runqueue data structure; thus, all expired processes become active, while the empty set is ready to receive the processes that will expire in the future.
array = rq->active;
if (!array->nr_active) {
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = 140;
}
It is time to look up a runnable process in the active prio_array_t data structure (see the section "Identifying a Process" in Chapter 3). First of all, schedule( ) searches for the first nonzero bit in the bitmask of the active set. Remember that a bit in the bitmask is set when the corresponding priority list is not empty. Thus, the index of the first nonzero bit indicates the list containing the best process to run. Then, the first process descriptor in that list is retrieved:
idx = sched_find_first_bit(array->bitmap);
next = list_entry(array->queue[idx].next, task_t, run_list);
The sched_find_first_bit( ) function is based on the bsfl
assembly language instruction, which returns the bit index of the least significant bit set to one in a 32-bit word.
The next local variable now stores the descriptor pointer of the process that will replace prev. The schedule( ) function looks at the next->activated field. This field encodes the state of the process when it was awakened, as illustrated in Table 7-6.
Table 7-6. The meaning of the activated field in the process descriptorValue | Description |
|---|
0 | The process was in TASK_RUNNING state. | 1 | The process was in TASK_INTERRUPTIBLE or TASK_STOPPED state, and it is being awakened by a system call service routine or a kernel thread. | 2 | The process was in TASK_INTERRUPTIBLE or TASK_STOPPED state, and it is being awakened by an interrupt handler or a deferrable function. | -1 | The process was in TASK_UNINTERRUPTIBLE state and it is being awakened. |
If next is a conventional process and it is being awakened from the TASK_INTERRUPTIBLE or TASK_STOPPED state, the scheduler adds to the average sleep time of the process the nanoseconds elapsed since the process was inserted into the runqueue. In other words, the sleep time of the process is increased to cover also the time spent by the process in the runqueue waiting for the CPU:
if (next->prio >= 100 && next->activated > 0) {
unsigned long long delta = now - next->timestamp;
if (next->activated == 1)
delta = (delta * 38) / 128;
array = next->array;
dequeue_task(next, array);
recalc_task_prio(next, next->timestamp + delta);
enqueue_task(next, array);
}
next->activated = 0;
Observe that the scheduler makes a distinction between a process awakened by an interrupt handler or deferrable function, and a process awakened by a system call service routine or a kernel thread. In the former case, the scheduler adds the whole runqueue waiting time, while in the latter it adds just a fraction of that time. This is because interactive processes are more likely to be awakened by asynchronous events (think of the user pressing keys on the keyboard) rather than by synchronous ones.
7.4.4.4. Actions performed by schedule( ) to make the process switch
Now the schedule( ) function has determined the next process to run. In a moment, the kernel will access the tHRead_info data structure of next, whose address is stored close to the top of next's process descriptor:
switch_tasks:
prefetch(next);
The prefetch macro is a hint to the CPU control unit to bring the contents of the first fields of next's process descriptor in the hardware cache. It is here just to improve the performance of schedule( ), because the data are moved in parallel to the execution of the following instructions, which do not affect next.
Before replacing prev, the scheduler should do some administrative work:
clear_tsk_need_resched(prev);
rcu_qsctr_inc(prev->thread_info->cpu);
The clear_tsk_need_resched( ) function clears the TIF_NEED_RESCHED flag of prev, just in case schedule( ) has been invoked in the lazy way. Then, the function records that the CPU is going through a quiescent state (see the section "Read-Copy Update (RCU)" in Chapter 5).
The schedule( ) function must also decrease the average sleep time of prev, charging to it the slice of CPU time used by the process:
prev->sleep_avg -= run_time;
if ((long)prev->sleep_avg <= 0)
prev->sleep_avg = 0;
prev->timestamp = prev->last_ran = now;
The timestamps of the process are then updated.
It is quite possible that prev and next are the same process: this happens if no other higher or equal priority active process is present in the runqueue. In this case, the function skips the process switch:
if (prev == next) {
spin_unlock_irq(&rq->lock);
goto finish_schedule;
}
At this point, prev and next are different processes, and the process switch is for real:
next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
prev = context_switch(rq, prev, next);
The context_switch( ) function sets up the address space of next. As we'll see in "Memory Descriptor of Kernel Threads" in Chapter 9, the active_mm field of the process descriptor points to the memory descriptor that is used by the process, while the mm field points to the memory descriptor owned by the process. For normal processes, the two fields hold the same address; however, a kernel thread does not have its own address space and its mm field is always set to NULL. The context_switch( ) function ensures that if next is a kernel thread, it uses the address space used by prev:
if (!next->mm) {
next->active_mm = prev->active_mm;
atomic_inc(&prev->active_mm->mm_count);
enter_lazy_tlb(prev->active_mm, next);
}
Up to Linux version 2.2, kernel threads had their own address space. That design choice was suboptimal, because the Page Tables had to be changed whenever the scheduler selected a new process, even if it was a kernel thread. Because kernel threads run in Kernel Mode, they use only the fourth gigabyte of the linear address space, whose mapping is the same for all processes in the system. Even worse, writing into the cr3
register invalidates all TLB entries (see "Translation Lookaside Buffers (TLB)" in Chapter 2), which leads to a significant performance penalty. Linux is nowadays much more efficient because Page Tables aren't touched at all if next is a kernel thread. As further optimization, if next is a kernel thread, the schedule( ) function sets the process into lazy TLB mode (see the section "Translation Lookaside Buffers (TLB)" in Chapter 2).
Conversely, if next is a regular process, the context_switch( ) function replaces the address space of prev with the one of next:
if (next->mm)
switch_mm(prev->active_mm, next->mm, next);
If prev is a kernel thread or an exiting process, the context_switch( ) function saves the pointer to the memory descriptor used by prev in the runqueue's prev_mm field, then resets prev->active_mm:
if (!prev->mm) {
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
Now context_switch( ) can finally invoke switch_to( ) to perform the process switch between prev and next (see the section "Performing the Process Switch" in Chapter 3):
switch_to(prev, next, prev);
return prev;
7.4.4.5. Actions performed by schedule( ) after a process switch
The instructions of the context_switch( ) and schedule( ) functions following the switch_to macro invocation will not be performed right away by the next process, but at a later time by prev when the scheduler selects it again for execution. However, at that moment, the prev local variable does not point to our original process that was to be replaced when we started the description of schedule( ), but rather to the process that was replaced by our original prev when it was scheduled again. (If you are confused, go back and read the section "Performing the Process Switch" in Chapter 3.) The first instructions after a process switch are:
barrier( );
finish_task_switch(prev);
Right after the invocation of the context_switch( ) function in schedule( ), the barrier( ) macro yields an optimization barrier for the code (see the section "Optimization and Memory Barriers" in Chapter 5). Then, the finish_task_switch( ) function is executed:
mm = this_rq( )->prev_mm;
this_rq( )->prev_mm = NULL;
prev_task_flags = prev->flags;
spin_unlock_irq(&this_rq( )->lock);
if (mm)
mmdrop(mm);
if (prev_task_flags & PF_DEAD)
put_task_struct(prev);
If prev is a kernel thread, the prev_mm field of the runqueue stores the address of the memory descriptor that was lent to prev. As we'll see in Chapter 9, mmdrop( ) decreases the usage counter of the memory descriptor; if the counter reaches 0 (likely because prev is a zombie process), the function also frees the descriptor together with the associated Page Tables and virtual memory regions.
The finish_task_switch( ) function also releases the spin lock of the runqueue and enables the local interrupts. Then, it checks whether prev is a zombie task that is being removed from the system (see the section "Process Termination" in Chapter 3); if so, it invokes put_task_struct( ) to free the process descriptor reference counter and drop all remaining references to the process (see the section "Process Removal" in Chapter 3).
The very last instructions of the schedule( ) function are:
finish_schedule:
prev = current;
if (prev->lock_depth >= 0)
_ _reacquire_kernel_lock( );
preempt_enable_no_resched();
if (test_bit(TIF_NEED_RESCHED, ¤t_thread_info( )->flags)
goto need_resched;
return;
As you see, schedule( ) reacquires the big kernel lock
if necessary, reenables kernel preemption, and checks whether some other process has set the TIF_NEED_RESCHED flag of the current process. In this case, the whole schedule( ) function is reexecuted from the beginning; otherwise, the function terminates.
7.5. Runqueue Balancing in Multiprocessor Systems
We have seen in Chapter 4 that Linux sticks to the Symmetric Multiprocessing model (SMP
); this means, essentially, that the kernel should not have any bias toward one CPU with respect to the others. However, multiprocessor machines come in many different flavors, and the scheduler behaves differently depending on the hardware characteristics. In particular, we will consider the following three types of multiprocessor machines:
Classic multiprocessor architecture Until recently, this was the most common architecture for multiprocessor machines. These machines have a common set of RAM chips shared by all CPUs.
Hyper-threading A hyper-threaded chip is a microprocessor that executes several threads of execution at once; it includes several copies of the internal registers and quickly switches between them. This technology, which was invented by Intel, allows the processor to exploit the machine cycles to execute another thread while the current thread is stalled for a memory access. A hyper-threaded physical CPU is seen by Linux as several different logical CPUs.
NUMA CPUs and RAM chips are grouped in local "nodes" (usually a node includes one CPU and a few RAM chips). The memory arbiter (a special circuit that serializes the accesses to RAM performed by the CPUs in the system, see the section "Memory Addresses" in Chapter 2) is a bottleneck for the performance of the classic multiprocessor systems. In a NUMA architecture, when a CPU accesses a "local" RAM chip inside its own node, there is little or no contention, thus the access is usually fast; on the other hand, accessing a "remote" RAM chip outside of its node is much slower. We'll mention in the section "Non-Uniform Memory Access (NUMA)" in Chapter 8 how the Linux kernel memory allocator supports NUMA architectures.
These basic kinds of multiprocessor systems are often combined. For instance, a motherboard that includes two different hyper-threaded CPUs is seen by the kernel as four logical CPUs.
As we have seen in the previous section, the schedule( ) function picks the new process to run from the runqueue of the local CPU. Therefore, a given CPU can execute only the runnable processes that are contained in the corresponding runqueue. On the other hand, a runnable process is always stored in exactly one runqueue: no runnable process ever appears in two or more runqueues. Therefore, until a process remains runnable, it is usually bound to one CPU.
This design choice is usually beneficial for system performance, because the hardware cache of every CPU is likely to be filled with data owned by the runnable processes in the runqueue. In some cases, however, binding a runnable process to a given CPU might induce a severe performance penalty. For instance, consider a large number of batch processes that make heavy use of the CPU: if most of them end up in the same runqueue, one CPU in the system will be overloaded, while the others will be nearly idle.
Therefore, the kernel periodically checks whether the workloads of the runqueues are balanced and, if necessary, moves some process from one runqueue to another. However, to get the best performance from a multiprocessor system, the load balancing algorithm should take into consideration the topology of the CPUs in the system. Starting from kernel version 2.6.7, Linux sports a sophisticated runqueue balancing algorithm based on the notion of "scheduling domains." Thanks to the scheduling domains, the algorithm can be easily tuned for all kinds of existing multiprocessor architectures (and even for recent architectures such as those based on the "multi-core" microprocessors).
7.5.1. Scheduling Domains
Essentially, a scheduling domain is a set of CPUs whose workloads should be kept balanced by the kernel. Generally speaking, scheduling domains
are hierarchically organized: the top-most scheduling domain, which usually spans all CPUs in the system, includes children scheduling domains, each of which include a subset of the CPUs. Thanks to the hierarchy of scheduling domains, workload balancing can be done in a rather efficient way.
Every scheduling domain is partitioned, in turn, in one or more groups, each of which represents a subset of the CPUs of the scheduling domain. Workload balancing is always done between groups of a scheduling domain. In other words, a process is moved from one CPU to another only if the total workload of some group in some scheduling domain is significantly lower than the workload of another group in the same scheduling domain.
Figure 7-2 illustrates three examples of scheduling domain hierarchies, corresponding to the three main architectures of multiprocessor machines.
Figure 7-2 (a) represents a hierarchy composed by a single scheduling domain for a 2-CPU classic multiprocessor architecture. The scheduling domain includes only two groups, each of which includes one CPU.
Figure 7-2 (b) represents a two-level hierarchy for a 2-CPU multiprocessor box with hyper-threading technology. The top-level scheduling domain spans all four logical CPUs in the system, and it is composed by two groups. Each group of the top-level domain corresponds to a child scheduling domain and spans a physical CPU. The bottom-level scheduling domains (also called base scheduling domains
) include two groups, one for each logical CPU.
Finally, Figure 7-2 (c) represents a two-level hierarchy for an 8-CPU NUMA architecture with two nodes and four CPUs per node. The top-level domain is organized in two groups, each of which corresponds to a different node. Every base scheduling domain spans the CPUs inside a single node and has four groups, each of which spans a single CPU.
Every scheduling domain is represented by a sched_domain descriptor, while every group inside a scheduling domain is represented by a sched_group descriptor. Each sched_domain descriptor includes a field groups, which points to the first element in a list of group descriptors. Moreover, the parent field of the sched_domain structure points to the descriptor of the parent scheduling domain, if any.
The sched_domain descriptors of all physical CPUs in the system are stored in the per-CPU variable phys_domains. If the kernel does not support the hyper-threading technology, these domains are at the bottom level of the domain hierarchy, and the sd fields of the runqueue descriptors point to themthat is, they are the base scheduling domains. Conversely, if the kernel supports the hyper-threading technology, the bottom-level scheduling domains are stored in the per-CPU variable cpu_domains.
7.5.2. The rebalance_tick( ) Function
To keep the runqueues in the system balanced, the rebalance_tick( ) function is invoked by scheduler_tick( ) once every tick. It receives as its parameters the index this_cpu of the local CPU, the address this_rq of the local runqueue, and a flag, idle, which can assume the following values:
SCHED_IDLE The CPU is currently idle, that is, current is the swapper process.
NOT_IDLE The CPU is not currently idle, that is, current is not the swapper process.
The rebalance_tick( ) function determines first the number of processes in the runqueue and updates the runqueue's average workload; to do this, the function accesses the nr_running and cpu_load fields of the runqueue descriptor.
Then, rebalance_tick( ) starts a loop over all scheduling domains in the path from the base domain (referenced by the sd field of the local runqueue descriptor) to the top-level domain. In each iteration the function determines whether the time has come to invoke the load_balance( ) function, thus executing a rebalancing operation on the scheduling domain. The value of idle and some parameters stored in the sched_domain descriptor determine the frequency of the invocations of load_balance( ). If idle is equal to SCHED_IDLE, then the runqueue is empty, and rebalance_tick( ) invokes load_balance( ) quite often (roughly once every one or two ticks for scheduling domains corresponding to logical and physical CPUs). Conversely, if idle is equal to NOT_IDLE, rebalance_tick( ) invokes load_balance( ) sparingly (roughly once every 10 milliseconds for scheduling domains corresponding to logical CPUs, and once every 100 milliseconds for scheduling domains corresponding to physical CPUs).
7.5.3. The load_balance( ) Function
The load_balance( ) function checks whether a scheduling domain is significantly unbalanced; more precisely, it checks whether unbalancing can be reduced by moving some processes from the busiest group to the runqueue of the local CPU. If so, the function attempts this migration. It receives four parameters:
this_cpu The index of the local CPU
this_rq The address of the descriptor of the local runqueue
sd Points to the descriptor of the scheduling domain to be checked
idle Either SCHED_IDLE (local CPU is idle) or NOT_IDLE
The function performs the following operations:
Acquires the this_rq->lock spin lock. Invokes the find_busiest_group( ) function to analyze the workloads of the groups inside the scheduling domain. The function returns the address of the sched_group descriptor of the busiest group, provided that this group does not include the local CPU; in this case, the function also returns the number of processes to be moved into the local runqueue to restore balancing. On the other hand, if either the busiest group includes the local CPU or all groups are essentially balanced, the function returns NULL. This procedure is not trivial, because the function tries to filter the statistical fluctuations in the workloads. If find_busiest_group( ) did not find a group not including the local CPU that is significantly busier than the other groups in the scheduling domain, the function releases the this_rq->lock spin lock, tunes the parameters in the scheduling domain descriptor so as to delay the next invocation of load_balance( ) on the local CPU, and terminates. Invokes the find_busiest_queue( ) function to find the busiest CPUs in the group found in step 2. The function returns the descriptor address busiest of the corresponding runqueue. Acquires a second spin lock, namely the busiest->lock spin lock. To prevent deadlocks, this has to be done carefully: the this_rq->lock is first released, then the two locks are acquired by increasing CPU indices. Invokes the move_tasks( ) function to try moving some processes from the busiest runqueue to the local runqueue this_rq (see the next section). If the move_task( ) function failed in migrating some process to the local runqueue, the scheduling domain is still unbalanced. Sets to 1 the busiest->active_balance flag and wakes up the migration
kernel thread whose descriptor is stored in busiest->migration_thread. The migration kernel thread walks the chain of the scheduling domain, from the base domain of the busiest runqueue to the top domain, looking for an idle CPU. If an idle CPU is found, the kernel thread invokes move_tasks( ) to move one process into the idle runqueue. Releases the busiest->lock and this_rq->lock spin locks.
7.5.4. The move_tasks( ) Function
The move_tasks( ) function moves processes from a source runqueue to the local runqueue. It receives six parameters: this_rq and this_cpu (the local runqueue descriptor and the local CPU index), busiest (the source runqueue descriptor), max_nr_move (the maximum number of processes to be moved), sd (the address of the scheduling domain descriptor in which this balancing operation is carried on), and the idle flag (beside SCHED_IDLE and NOT_IDLE, this flag can also be set to NEWLY_IDLE when the function is indirectly invoked by idle_balance( ); see the section "The schedule( ) Function" earlier in this chapter).
The function first analyzes the expired processes of the busiest runqueue, starting from the higher priority ones. When all expired processes have been scanned, the function scans the active processes of the busiest runqueue. For each candidate process, the function invokes can_migrate_task( ), which returns 1 if all the following conditions hold:
The process is not being currently executed by the remote CPU. The local CPU is included in the cpus_allowed bitmask of the process descriptor. At least one of the following holds: The local CPU is idle. If the kernel supports the hyper-threading technology, all logical CPUs in the local physical chip must be idle. The kernel is having trouble in balancing the scheduling domain, because repeated attempts to move processes have failed. The process to be moved is not "cache hot" (it has not recently executed on the remote CPU, so one can assume that no data of the process is included in the hardware cache of the remote CPU).
If can_migrate_task( ) returns the value 1, move_tasks( ) invokes the pull_task( ) function to move the candidate process to the local runqueue. Essentially, pull_task( ) executes dequeue_task( ) to remove the process from the remote runqueue, then executes enqueue_task( ) to insert the process in the local runqueue, and finally, if the process just moved has higher dynamic priority than current, invokes resched_task( ) to preempt the current process of the local CPU.
7.6. System Calls Related to Scheduling
Several system calls have been introduced to allow processes to change their priorities and scheduling policies. As a general rule, users are always allowed to lower the priorities of their processes. However, if they want to modify the priorities of processes belonging to some other user or if they want to increase the priorities of their own processes, they must have superuser privileges.
7.6.1. The nice( ) System Call
The nice( ) system call allows processes to change their base priority. The integer value contained in the increment parameter is used to modify the nice field of the process descriptor. The nice Unix command, which allows users to run programs with modified scheduling priority, is based on this system call.
The sys_nice( ) service routine handles the nice( ) system call. Although the increment parameter may have any value, absolute values larger than 40 are trimmed down to 40. Traditionally, negative values correspond to requests for priority increments and require superuser privileges, while positive ones correspond to requests for priority decreases. In the case of a negative increment, the function invokes the capable( ) function to verify whether the process has a CAP_SYS_NICE capability. Moreover, the function invokes the security_task_setnice( ) security hook. We discuss that function in Chapter 20. If the user turns out to have the privilege required to change priorities, sys_nice( ) converts current->static_prio to the range of nice values, adds the value of increment, and invokes the set_user_nice( ) function. In turn, the latter function gets the local runqueue lock, updates the static priority of current, invokes the resched_task( ) function to allow other processes to preempt current, and release the runqueue lock.
The nice( ) system call is maintained for backward compatibility only; it has been replaced by the setpriority( )
system call described next.
7.6.2. The getpriority( ) and setpriority( ) System Calls
The nice( ) system call affects only the process that invokes it. Two other system calls, denoted as getpriority( ) and setpriority( ), act on the base priorities of all processes in a given group. getpriority( ) returns 20 minus the lowest nice field value among all processes in a given groupthat is, the highest priority among those processes; setpriority( ) sets the base priority of all processes in a given group to a given value.
The kernel implements these system calls by means of the sys_getpriority( ) and sys_setpriority( ) service routines. Both of them act essentially on the same group of parameters:
which The value that identifies the group of processes; it can assume one of the following:
PRIO_PROCESS Selects the processes according to their process ID (pid field of the process descriptor).
PRIO_PGRP Selects the processes according to their group ID (pgrp field of the process descriptor).
PRIO_USER Selects the processes according to their user ID (uid field of the process descriptor).
who The value of the pid, pgrp, or uid field (depending on the value of which) to be used for selecting the processes. If who is 0, its value is set to that of the corresponding field of the current process.
niceval The new base priority value (needed only by sys_setpriority( )). It should range between - 20 (highest priority) and + 19 (lowest priority).
As stated before, only processes with a CAP_SYS_NICE capability are allowed to increase their own base priority or to modify that of other processes.
As we will see in Chapter 10, system calls return a negative value only if some error occurred. For this reason, getpriority( ) does not return a normal nice value ranging between - 20 and + 19, but rather a nonnegative value ranging between 1 and 40.
7.6.3. The sched_getaffinity( ) and sched_setaffinity( ) System Calls
The sched_getaffinity( ) and sched_setaffinity( ) system calls respectively return and set up the CPU affinity mask of a processthe bit mask of the CPUs that are allowed to execute the process. This mask is stored in the cpus_allowed field of the process descriptor.
The sys_sched_getaffinity( ) system call service routine looks up the process descriptor by invoking find_task_by_pid( ), and then returns the value of the corresponding cpus_allowed field ANDed with the bitmap of the available CPUs.
The sys_sched_setaffinity( ) system call is a bit more complicated. Besides looking for the descriptor of the target process and updating the cpus_allowed field, this function has to check whether the process is included in a runqueue of a CPU that is no longer present in the new affinity mask. In the worst case, the process has to be moved from one runqueue to another one. To avoid problems due to deadlocks and race conditions, this job is done by the migration
kernel threads (there is one thread per CPU). Whenever a process has to be moved from a runqueue rq1 to another runqueue rq2, the system call awakes the migration thread of rq1 (rq1->migration_thread), which in turn removes the process from rq1 and inserts it into rq2.
7.6.4. System Calls Related to Real-Time Processes
We now introduce a group of system calls that allow processes to change their scheduling discipline and, in particular, to become real-time processes. As usual, a process must have a CAP_SYS_NICE capability to modify the values of the rt_priority and policy process descriptor fields of any process, including itself.
7.6.4.1. The sched_getscheduler( ) and sched_setscheduler( ) system calls
The sched_getscheduler( ) system call queries the scheduling policy currently applied to the process identified by the pid parameter. If pid equals 0, the policy of the calling process is retrieved. On success, the system call returns the policy for the process: SCHED_FIFO, SCHED_RR, or SCHED_NORMAL (the latter is also called SCHED_OTHER). The corresponding sys_sched_getscheduler( ) service routine invokes find_process_by_pid( ), which locates the process descriptor corresponding to the given pid and returns the value of its policy field.
The sched_setscheduler( ) system call sets both the scheduling policy and the associated parameters for the process identified by the parameter pid. If pid is equal to 0, the scheduler parameters of the calling process will be set.
The corresponding sys_sched_setscheduler( ) system call service routine simply invokes do_sched_setscheduler( ). The latter function checks whether the scheduling policy specified by the policy parameter and the new priority specified by the param->sched_priority parameter are valid. It also checks whether the process has CAP_SYS_NICE capability or whether its owner has superuser rights. If everything is OK, it removes the process from its runqueue (if it is runnable); updates the static, real-time, and dynamic priorities of the process; inserts the process back in the runqueue; and finally invokes, if necessary, the resched_task( ) function to preempt the current process of the runqueue.
7.6.4.2. The sched_ getparam( ) and sched_setparam( ) system calls
The sched_getparam( ) system call retrieves the scheduling parameters for the process identified by pid. If pid is 0, the parameters of the current process are retrieved. The corresponding sys_sched_getparam( ) service routine, as one would expect, finds the process descriptor pointer associated with pid, stores its rt_priority field in a local variable of type sched_param, and invokes copy_to_user( ) to copy it into the process address space at the address specified by the param parameter.
The sched_setparam( ) system call is similar to sched_setscheduler( ). The difference is that sched_setparam( ) does not let the caller set the policy field's value. The corresponding sys_sched_setparam( ) service routine invokes do_sched_setscheduler( ), with almost the same parameters as sys_sched_setscheduler( ).
7.6.4.3. The sched_ yield( ) system call
The sched_yield( ) system call allows a process to relinquish the CPU voluntarily without being suspended; the process remains in a TASK_RUNNING state, but the scheduler puts it either in the expired set of the runqueue (if the process is a conventional one), or at the end of the runqueue list (if the process is a real-time one). The schedule( ) function is then invoked. In this way, other processes that have the same dynamic priority have a chance to run. The call is used mainly by SCHED_FIFO real-time processes.
7.6.4.4. The sched_ get_priority_min( ) and sched_ get_priority_max( ) system calls
The sched_get_priority_min( ) and sched_get_priority_max( ) system calls return, respectively, the minimum and the maximum real-time static priority value that can be used with the scheduling policy identified by the policy parameter.
The sys_sched_get_priority_min( ) service routine returns 1 if current is a real-time process, 0 otherwise.
The sys_sched_get_priority_max( ) service routine returns 99 (the highest priority) if current is a real-time process, 0 otherwise.
7.6.4.5. The sched_rr_ get_interval( ) system call
The sched_rr_get_interval( ) system call writes into a structure stored in the User Mode address space the Round Robin time quantum for the real-time process identified by the pid parameter. If pid is zero, the system call writes the time quantum of the current process.
The corresponding sys_sched_rr_get_interval( ) service routine invokes, as usual, find_process_by_pid( ) to retrieve the process descriptor associated with pid. It then converts the base time quantum of the selected process into seconds and nanoseconds and copies the numbers into the User Mode structure. Conventionally, the time quantum of a FIFO real-time process is equal to zero.
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books

 ]
]