|
В этом разделе будет описана стандартная библиотека I/O.
Она имеет спецификацию ISO C,
поскольку ее реализация есть не только в юниксе.
Дополнительные интерфейсы находятся в расширении ISO C,
которое называется Single UNIX Specification.
Библиотека I/O управляет такими вещами,
как выделение буфера и оптимизация.
Она написана Dennis Ritchie в 1975.
Потоки и файловые обьекты
In Chapter 3, all the I/O routines centered around file descriptors. When a file is opened, a file descriptor is returned, and that descriptor is then used for all subsequent I/O operations. With the standard I/O library, the discussion centers around streams. (Do not confuse the standard I/O term stream with the STREAMS I/O system that is part of System V and standardized in the XSI STREAMS option in the Single UNIX Specification.) When we open or create a file with the standard I/O library, we say that we have associated a stream with the file.
With the ASCII character set, a single character is represented by a single byte. With international character sets, a character can be represented by more than one byte. Standard I/O file streams can be used with single-byte and multibyte ("wide") character sets. A stream's orientation determines whether the characters that are read and written are single-byte or multibyte. Initially, when a stream is created, it has no orientation. If a multibyte I/O function (see <wchar.h>) is used on a stream without orientation, the stream's orientation is set to wide-oriented. If a byte I/O function is used on a stream without orientation, the stream's orientation is set to byte-oriented. Only two functions can change the orientation once set. The freopen function (discussed shortly) will clear a stream's orientation; the fwide function can be used to set a stream's orientation.
#include <stdio.h>
#include <wchar.h>
int fwide(FILE *fp, int mode);
| Returns: positive if stream is wide-oriented,
negative if stream is byte-oriented,
or 0 if stream has no orientation |
The fwide function performs different tasks, depending on the value of the mode argument.
If the mode argument is negative, fwide will try to make the specified stream byte-oriented. If the mode argument is positive, fwide will try to make the specified stream wide-oriented. If the mode argument is zero, fwide will not try to set the orientation, but will still return a value identifying the stream's orientation.
Note that fwide will not change the orientation of a stream that is already oriented. Also note that there is no error return. Consider what would happen if the stream is invalid. The only recourse we have is to clear errno before calling fwide and check the value of errno when we return. Throughout the rest of this book, we will deal only with byte-oriented streams.
When we open a stream, the standard I/O function fopen returns a pointer to a FILE object. This object is normally a structure that contains all the information required by the standard I/O library to manage the stream: the file descriptor used for actual I/O, a pointer to a buffer for the stream, the size of the buffer, a count of the number of characters currently in the buffer, an error flag, and the like.
Application software should never need to examine a FILE object. To reference the stream, we pass its FILE pointer as an argument to each standard I/O function. Throughout this text, we'll refer to a pointer to a FILE object, the type FILE * as a file pointer.
Throughout this chapter, we describe the standard I/O library in the context of a UNIX system. As we mentioned, this library has already been ported to a wide variety of other operating systems. But to provide some insight about how this library can be implemented, we will talk about its typical implementation on a UNIX system.
5.3. Standard Input, Standard Output, and Standard Error
Three streams are predefined and automatically available to a process: standard input, standard output, and standard error. These streams refer to the same files as the file descriptors STDIN_FILENO, STDOUT_FILENO, and STDERR_FILENO, which we mentioned in Section 3.2.
These three standard I/O streams are referenced through the predefined file pointers stdin, stdout, and stderr. The file pointers are defined in the <stdio.h> header.
5.4. Buffering
The goal of the buffering provided by the standard I/O library is to use the minimum number of read and write calls. (Recall Figure 3.5, where we showed the amount of CPU time required to perform I/O using various buffer sizes.) Also, it tries to do its buffering automatically for each I/O stream, obviating the need for the application to worry about it. Unfortunately, the single aspect of the standard I/O library that generates the most confusion is its buffering.
Three types of buffering are provided:
Fully buffered. In this case, actual I/O takes place when the standard I/O buffer is filled. Files residing on disk are normally fully buffered by the standard I/O library. The buffer used is usually obtained by one of the standard I/O functions calling malloc (Section 7.8) the first time I/O is performed on a stream. The term flush describes the writing of a standard I/O buffer. A buffer can be flushed automatically by the standard I/O routines, such as when a buffer fills, or we can call the function fflush to flush a stream. Unfortunately, in the UNIX environment, flush means two different things. In terms of the standard I/O library, it means writing out the contents of a buffer, which may be partially filled. In terms of the terminal driver, such as the tcflush function in Chapter 18, it means to discard the data that's already stored in a buffer. Line buffered. In this case, the standard I/O library performs I/O when a newline character is encountered on input or output. This allows us to output a single character at a time (with the standard I/O fputc function), knowing that actual I/O will take place only when we finish writing each line. Line buffering is typically used on a stream when it refers to a terminal: standard input and standard output, for example. Line buffering comes with two caveats. First, the size of the buffer that the standard I/O library is using to collect each line is fixed, so I/O might take place if we fill this buffer before writing a newline. Second, whenever input is requested through the standard I/O library from either (a) an unbuffered stream or (b) a line-buffered stream (that requires data to be requested from the kernel), all line-buffered output streams are flushed. The reason for the qualifier on (b) is that the requested data may already be in the buffer, which doesn't require data to be read from the kernel. Obviously, any input from an unbuffered stream, item (a), requires data to be obtained from the kernel. Unbuffered. The standard I/O library does not buffer the characters. If we write 15 characters with the standard I/O fputs function, for example, we expect these 15 characters to be output as soon as possible, probably with the write function from Section 3.8. The standard error stream, for example, is normally unbuffered. This is so that any error messages are displayed as quickly as possible, regardless of whether they contain a newline.
ISO C requires the following buffering characteristics.
Standard input and standard output are fully buffered, if and only if they do not refer to an interactive device. Standard error is never fully buffered.
This, however, doesn't tell us whether standard input and standard output can be unbuffered or line buffered if they refer to an interactive device and whether standard error should be unbuffered or line buffered. Most implementations default to the following types of buffering.
Standard error is always unbuffered. All other streams are line buffered if they refer to a terminal device; otherwise, they are fully buffered. The four platforms discussed in this book follow these conventions for standard I/O buffering: standard error is unbuffered, streams open to terminal devices are line buffered, and all other streams are fully buffered.
We explore standard I/O buffering in more detail in Section 5.12 and Figure 5.11.
If we don't like these defaults for any given stream, we can change the buffering by calling either of the following two functions.
#include <stdio.h>
void setbuf(FILE *restrict fp, char *restrict buf);
int setvbuf(FILE *restrict fp, char *restrict buf,
 int mode,
size_t size); int mode,
size_t size);
| Returns: 0 if OK, nonzero on error |
These functions must be called after the stream has been opened (obviously, since each requires a valid file pointer as its first argument) but before any other operation is performed on the stream.
With setbuf, we can turn buffering on or off. To enable buffering, buf must point to a buffer of length BUFSIZ, a constant defined in <stdio.h>. Normally, the stream is then fully buffered, but some systems may set line buffering if the stream is associated with a terminal device. To disable buffering, we set buf to NULL.
With setvbuf, we specify exactly which type of buffering we want. This is done with the mode argument:
_IOFBF | fully buffered | _IOLBF | line buffered | _IONBF | unbuffered |
If we specify an unbuffered stream, the buf and size arguments are ignored. If we specify fully buffered or line buffered, buf and size can optionally specify a buffer and its size. If the stream is buffered and buf is NULL, the standard I/O library will automatically allocate its own buffer of the appropriate size for the stream. By appropriate size, we mean the value specified by the constant BUFSIZ.
Some C library implementations use the value from the st_blksize member of the stat structure (see Section 4.2) to determine the optimal standard I/O buffer size. As we will see later in this chapter, the GNU C library uses this method.
Figure 5.1 summarizes the actions of these two functions and their various options.
Figure 5.1. Summary of the setbuf and setvbuf functionsFunction | mode | buf | Buffer and length | Type of buffering |
|---|
setbuf | | non-null | user buf of length BUFSIZ | fully buffered or line buffered | NULL | (no buffer) | unbuffered | setvbuf | _IOLBF | non-null | user buf of length size | fully buffered | NULL | system buffer of appropriate length | _IOFBF | non-null | user buf of length size | line buffered | NULL | system buffer of appropriate length | _IONBF | (ignored) | (no buffer) | unbuffered |
Be aware that if we allocate a standard I/O buffer as an automatic variable within a function, we have to close the stream before returning from the function. (We'll discuss this more in Section 7.8.) Also, some implementations use part of the buffer for internal bookkeeping, so the actual number of bytes of data that can be stored in the buffer is less than size. In general, we should let the system choose the buffer size and automatically allocate the buffer. When we do this, the standard I/O library automatically releases the buffer when we close the stream.
At any time, we can force a stream to be flushed.
#include <stdio.h>
int fflush(FILE *fp);
| Returns: 0 if OK, EOF on error |
This function causes any unwritten data for the stream to be passed to the kernel. As a special case, if fp is NULL, this function causes all output streams to be flushed.
5.5. Opening a Stream
The following three functions open a standard I/O stream.
#include <stdio.h>
FILE *fopen(const char *restrict pathname, const
char *restrict type);
FILE *freopen(const char *restrict pathname, const
char *restrict type,
FILE *restrict fp);
FILE *fdopen(int filedes, const char *type);
| All three return: file pointer if OK, NULL on error |
The differences in these three functions are as follows.
The fopen function opens a specified file. The freopen function opens a specified file on a specified stream, closing the stream first if it is already open. If the stream previously had an orientation, freopen clears it. This function is typically used to open a specified file as one of the predefined streams: standard input, standard output, or standard error. The fdopen function takes an existing file descriptor, which we could obtain from the open, dup, dup2, fcntl, pipe, socket, socketpair, or accept functions, and associates a standard I/O stream with the descriptor. This function is often used with descriptors that are returned by the functions that create pipes and network communication channels. Because these special types of files cannot be opened with the standard I/O fopen function, we have to call the device-specific function to obtain a file descriptor, and then associate this descriptor with a standard I/O stream using fdopen. Both fopen and freopen are part of ISO C; fdopen is part of POSIX.1, since ISO C doesn't deal with file descriptors.
ISO C specifies 15 values for the type argument, shown in Figure 5.2.
Figure 5.2. The type argument for opening a standard I/O streamtype | Description |
|---|
r or rb | open for reading | w or wb | truncate to 0 length or create for writing | a or ab | append; open for writing at end of file, or create for writing | r+ or r+b or rb+ | open for reading and writing | w+ or w+b or wb+ | truncate to 0 length or create for reading and writing | a+ or a+b or ab+ | open or create for reading and writing at end of file |
Using the character b as part of the type allows the standard I/O system to differentiate between a text file and a binary file. Since the UNIX kernel doesn't differentiate between these types of files, specifying the character b as part of the type has no effect.
With fdopen, the meanings of the type argument differ slightly. The descriptor has already been opened, so opening for write does not truncate the file. (If the descriptor was created by the open function, for example, and the file already existed, the O_TRUNC flag would control whether or not the file was truncated. The fdopen function cannot simply truncate any file it opens for writing.) Also, the standard I/O append mode cannot create the file (since the file has to exist if a descriptor refers to it).
When a file is opened with a type of append, each write will take place at the then current end of file. If multiple processes open the same file with the standard I/O append mode, the data from each process will be correctly written to the file.
Versions of fopen from Berkeley before 4.4BSD and the simple version shown on page 177 of Kernighan and Ritchie [1988] do not handle the append mode correctly. These versions do an lseek to the end of file when the stream is opened. To correctly support the append mode when multiple processes are involved, the file must be opened with the O_APPEND flag, which we discussed in Section 3.3. Doing an lseek before each write won't work either, as we discussed in Section 3.11.
When a file is opened for reading and writing (the plus sign in the type), the following restrictions apply.
Output cannot be directly followed by input without an intervening fflush, fseek, fsetpos,or rewind. Input cannot be directly followed by output without an intervening fseek, fsetpos,or rewind, or an input operation that encounters an end of file.
We can summarize the six ways to open a stream from Figure 5.2 in Figure 5.3.
Figure 5.3. Six ways to open a standard I/O streamRestriction | r | w | a | r+ | w+ | a+ |
|---|
file must already exist | • | | | • | | | previous contents of file discarded | | • | | | • | | stream can be read | • | | | • | • | • | stream can be written | | • | • | • | • | • | stream can be written only at end | | | • | | | • |
Note that if a new file is created by specifying a type of either w or a, we are not able to specify the file's access permission bits, as we were able to do with the open function and the creat function in Chapter 3.
By default, the stream that is opened is fully buffered, unless it refers to a terminal device, in which case it is line buffered. Once the stream is opened, but before we do any other operation on the stream, we can change the buffering if we want to, with the setbuf or setvbuf functions from the previous section.
An open stream is closed by calling fclose.
#include <stdio.h>
int fclose(FILE *fp);
| Returns: 0 if OK, EOF on error |
Any buffered output data is flushed before the file is closed. Any input data that may be buffered is discarded. If the standard I/O library had automatically allocated a buffer for the stream, that buffer is released.
When a process terminates normally, either by calling the exit function directly or by returning from the main function, all standard I/O streams with unwritten buffered data are flushed, and all open standard I/O streams are closed.
5.6. Reading and Writing a Stream
Once we open a stream, we can choose from among three types of unformatted I/O:
Character-at-a-time I/O. We can read or write one character at a time, with the standard I/O functions handling all the buffering, if the stream is buffered. Line-at-a-time I/O. If we want to read or write a line at a time, we use fgets and fputs. Each line is terminated with a newline character, and we have to specify the maximum line length that we can handle when we call fgets. We describe these two functions in Section 5.7. Direct I/O. This type of I/O is supported by the fread and fwrite functions. For each I/O operation, we read or write some number of objects, where each object is of a specified size. These two functions are often used for binary files where we read or write a structure with each operation. We describe these two functions in Section 5.9. The term direct I/O, from the ISO C standard, is known by many names: binary I/O, object-at-a-time I/O, record-oriented I/O, or structure-oriented I/O.
(We describe the formatted I/O functions, such as printf and scanf, in Section 5.11.)
Input Functions
Three functions allow us to read one character at a time.
#include <stdio.h>
int getc(FILE *fp);
int fgetc(FILE *fp);
int getchar(void);
| All three return: next character if OK, EOF on end of file or error |
The function getchar is defined to be equivalent to getc(stdin). The difference between the first two functions is that getc can be implemented as a macro, whereas fgetc cannot be implemented as a macro. This means three things.
The argument to getc should not be an expression with side effects. Since fgetc is guaranteed to be a function, we can take its address. This allows us to pass the address of fgetc as an argument to another function. Calls to fgetc probably take longer than calls to getc, as it usually takes more time to call a function.
These three functions return the next character as an unsigned char converted to an int. The reason for specifying unsigned is so that the high-order bit, if set, doesn't cause the return value to be negative. The reason for requiring an integer return value is so that all possible character values can be returned, along with an indication that either an error occurred or the end of file has been encountered. The constant EOF in <stdio.h> is required to be a negative value. Its value is often 1. This representation also means that we cannot store the return value from these three functions in a character variable and compare this value later against the constant EOF.
Note that these functions return the same value whether an error occurs or the end of file is reached. To distinguish between the two, we must call either ferror or feof.
#include <stdio.h>
int ferror(FILE *fp);
int feof(FILE *fp);
| Both return: nonzero (true) if condition is true, 0 (false) otherwise | void clearerr(FILE *fp); |
In most implementations, two flags are maintained for each stream in the FILE object:
An error flag An end-of-file flag
Both flags are cleared by calling clearerr.
After reading from a stream, we can push back characters by calling ungetc.
#include <stdio.h>
int ungetc(int c, FILE *fp);
| Returns: c if OK, EOF on error |
The characters that are pushed back are returned by subsequent reads on the stream in reverse order of their pushing. Be aware, however, that although ISO C allows an implementation to support any amount of pushback, an implementation is required to provide only a single character of pushback. We should not count on more than a single character.
The character that we push back does not have to be the same character that was read. We are not able to push back EOF. But when we've reached the end of file, we can push back a character. The next read will return that character, and the read after that will return EOF. This works because a successful call to ungetc clears the end-of-file indication for the stream.
Pushback is often used when we're reading an input stream and breaking the input into words or tokens of some form. Sometimes we need to peek at the next character to determine how to handle the current character. It's then easy to push back the character that we peeked at, for the next call to getc to return. If the standard I/O library didn't provide this pushback capability, we would have to store the character in a variable of our own, along with a flag telling us to use this character instead of calling getc the next time we need a character.
When we push characters back with ungetc, they don't get written back to the underlying file or device. They are kept incore in the standard I/O library's buffer for the stream.
Output Functions
We'll find an output function that corresponds to each of the input functions that we've already described.
#include <stdio.h>
int putc(int c, FILE *fp);
int fputc(int c, FILE *fp);
int putchar(int c);
| All three return: c if OK, EOF on error |
Like the input functions, putchar(c) is equivalent to putc(c, stdout), and putc can be implemented as a macro, whereas fputc cannot be implemented as a macro.
5.7. Line-at-a-Time I/O
Line-at-a-time input is provided by the following two functions.
#include <stdio.h>
char *fgets(char *restrict buf, int n, FILE
*restrict fp);
char *gets(char *buf);
| Both return: buf if OK, NULL on end of file or error |
Both specify the address of the buffer to read the line into. The gets function reads from standard input, whereas fgets reads from the specified stream.
With fgets, we have to specify the size of the buffer, n. This function reads up through and including the next newline, but no more than n1 characters, into the buffer. The buffer is terminated with a null byte. If the line, including the terminating newline, is longer than n1, only a partial line is returned, but the buffer is always null terminated. Another call to fgets will read what follows on the line.
The gets function should never be used. The problem is that it doesn't allow the caller to specify the buffer size. This allows the buffer to overflow, if the line is longer than the buffer, writing over whatever happens to follow the buffer in memory. For a description of how this flaw was used as part of the Internet worm of 1988, see the June 1989 issue (vol. 32, no. 6) of Communications of the ACM . An additional difference with gets is that it doesn't store the newline in the buffer, as does fgets.
This difference in newline handling between the two functions goes way back in the evolution of the UNIX System. Even the Version 7 manual (1979) states "gets deletes a newline, fgets keeps it, all in the name of backward compatibility."
Even though ISO C requires an implementation to provide gets, use fgets instead.
Line-at-a-time output is provided by fputs and puts.
#include <stdio.h>
int fputs(const char *restrict str, FILE *restrict
fp);
int puts(const char *str);
| Both return: non-negative value if OK, EOF on error |
The function fputs writes the null-terminated string to the specified stream. The null byte at the end is not written. Note that this need not be line-at-a-time output, since the string need not contain a newline as the last non-null character. Usually, this is the casethe last non-null character is a newlinebut it's not required.
The puts function writes the null-terminated string to the standard output, without writing the null byte. But puts then writes a newline character to the standard output.
The puts function is not unsafe, like its counterpart gets. Nevertheless, we'll avoid using it, to prevent having to remember whether it appends a newline. If we always use fgets and fputs, we know that we always have to deal with the newline character at the end of each line.
5.8. Standard I/O Efficiency
Using the functions from the previous section, we can get an idea of the efficiency of the standard I/O system. The program in Figure 5.4 is like the one in Figure 3.4: it simply copies standard input to standard output, using getc and putc. These two routines can be implemented as macros.
Figure 5.4. Copy standard input to standard output using getc and putc
#include "apue.h"
int
main(void)
{
int c;
while ((c = getc(stdin)) != EOF)
if (putc(c, stdout) == EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit(0);
}
We can make another version of this program that uses fgetc and fputc, which should be functions, not macros. (We don't show this trivial change to the source code.)
Finally, we have a version that reads and writes lines, shown in Figure 5.5.
Figure 5.5. Copy standard input to standard output using fgets and fputs
#include "apue.h"
int
main(void)
{
char buf[MAXLINE];
while (fgets(buf, MAXLINE, stdin) != NULL)
if (fputs(buf, stdout) == EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit(0);
}
Note that we do not close the standard I/O streams explicitly in Figure 5.4 or Figure 5.5. Instead, we know that the exit function will flush any unwritten data and then close all open streams. (We'll discuss this in Section 8.5.) It is interesting to compare the timing of these three programs with the timing data from Figure 3.5. We show this data when operating on the same file (98.5 MB with 3 million lines) in Figure 5.6.
Figure 5.6. Timing results using standard I/O routinesFunction | User CPU (seconds) | System CPU (seconds) | Clock time (seconds) | Bytes of program text |
|---|
best time from Figure 3.5 | 0.01 | 0.18 | 6.67 | | fgets, fputs | 2.59 | 0.19 | 7.15 | 139 | getc, putc | 10.84 | 0.27 | 12.07 | 120 | fgetc, fputc | 10.44 | 0.27 | 11.42 | 120 | single byte time from Figure 3.5 | 124.89 | 161.65 | 288.64 | |
For each of the three standard I/O versions, the user CPU time is larger than the best read version from Figure 3.5, because the character-at-a-time standard I/O versions have a loop that is executed 100 million times, and the loop in the line-at-a-time version is executed 3,144,984 times. In the read version, its loop is executed only 12,611 times (for a buffer size of 8,192). This difference in clock times is from the difference in user times and the difference in the times spent waiting for I/O to complete, as the system times are comparable.
The system CPU time is about the same as before, because roughly the same number of kernel requests are being made. Note that an advantage of using the standard I/O routines is that we don't have to worry about buffering or choosing the optimal I/O size. We do have to determine the maximum line size for the version that uses fgets, but that's easier than trying to choose the optimal I/O size.
The final column in Figure 5.6 is the number of bytes of text spacethe machine instructions generated by the C compilerfor each of the main functions. We can see that the version using getc and putc takes the same amount of space as the one using the fgetc and fputc functions. Usually, getc and putc are implemented as macros, but in the GNU C library implementation, the macro simply expands to a function call.
The version using line-at-a-time I/O is almost twice as fast as the version using character-at-a-time I/O. If the fgets and fputs functions are implemented using getc and putc (see Section 7.7 of Kernighan and Ritchie [1988], for example), then we would expect the timing to be similar to the getc version. Actually, we might expect the line-at-a-time version to take longer, since we would be adding the overhead of 200 million extra function calls to the existing 6 million ones. What is happening with this example is that the line-at-a-time functions are implemented using memccpy(3). Often, the memccpy function is implemented in assembler instead of C, for efficiency.
The last point of interest with these timing numbers is that the fgetc version is so much faster than the BUFFSIZE=1 version from Figure 3.5. Both involve the same number of function callsabout 200 millionyet the fgetc version is almost 12 times faster in user CPU time and slightly more than 25 times faster in clock time. The difference is that the version using read executes 200 million function calls, which in turn execute 200 million system calls. With the fgetc version, we still execute 200 million function calls, but this ends up being only 25,222 system calls. System calls are usually much more expensive than ordinary function calls.
As a disclaimer, you should be aware that these timing results are valid only on the single system they were run on. The results depend on many implementation features that aren't the same on every UNIX system. Nevertheless, having a set of numbers such as these, and explaining why the various versions differ, helps us understand the system better. From this section and Section 3.9, we've learned that the standard I/O library is not much slower than calling the read and write functions directly. The approximate cost that we've seen is about 0.11 seconds of CPU time to copy a megabyte of data using getc and putc. For most nontrivial applications, the largest amount of the user CPU time is taken by the application, not by the standard I/O routines.
5.9. Binary I/O
The functions from Section 5.6 operated with one character at a time, and the functions from Section 5.7 operated with one line at a time. If we're doing binary I/O, we often would like to read or write an entire structure at a time. To do this using getc or putc, we have to loop through the entire structure, one byte at a time, reading or writing each byte. We can't use the line-at-a-time functions, since fputs stops writing when it hits a null byte, and there might be null bytes within the structure. Similarly, fgets won't work right on input if any of the data bytes are nulls or newlines. Therefore, the following two functions are provided for binary I/O.
#include <stdio.h>
size_t fread(void *restrict ptr, size_t size,
size_t nobj,
FILE *restrict fp);
size_t fwrite(const void *restrict ptr, size_t
size, size_t nobj,
FILE *restrict fp);
| Both return: number of objects read or written |
These functions have two common uses:
Read or write a binary array. For example, to write elements 2 through 5 of a floating-point array, we could write
float data[10];
if (fwrite(&data[2], sizeof(float), 4, fp) != 4)
err_sys("fwrite error");
Here, we specify size as the size of each element of the array and nobj as the number of elements. Read or write a structure. For example, we could write
struct {
short count;
long total;
char name[NAMESIZE];
} item;
if (fwrite(&item, sizeof(item), 1, fp) != 1)
err_sys("fwrite error");
Here, we specify size as the size of structure and nobj as one (the number of objects to write).
The obvious generalization of these two cases is to read or write an array of structures. To do this, size would be the sizeof the structure, and nobj would be the number of elements in the array.
Both fread and fwrite return the number of objects read or written. For the read case, this number can be less than nobj if an error occurs or if the end of file is encountered. In this case ferror or feof must be called. For the write case, if the return value is less than the requested nobj, an error has occurred.
A fundamental problem with binary I/O is that it can be used to read only data that has been written on the same system. This was OK many years ago, when all the UNIX systems were PDP-11s, but the norm today is to have heterogeneous systems connected together with networks. It is common to want to write data on one system and process it on another. These two functions won't work, for two reasons.
The offset of a member within a structure can differ between compilers and systems, because of different alignment requirements. Indeed, some compilers have an option allowing structures to be packed tightly, to save space with a possible runtime performance penalty, or aligned accurately, to optimize runtime access of each member. This means that even on a single system, the binary layout of a structure can differ, depending on compiler options. The binary formats used to store multibyte integers and floating-point values differ among machine architectures.
We'll touch on some of these issues when we discuss sockets in Chapter 16. The real solution for exchanging binary data among different systems is to use a higher-level protocol. Refer to Section 8.2 of Rago [1993] or Section 5.18 of Stevens, Fenner, & Rudoff [2004] for a description of some techniques various network protocols use to exchange binary data.
We'll return to the fread function in Section 8.14 when we'll use it to read a binary structure, the UNIX process accounting records.
5.10. Positioning a Stream
There are three ways to position a standard I/O stream:
The two functions ftell and fseek. They have been around since Version 7, but they assume that a file's position can be stored in a long integer. The two functions ftello and fseeko. They were introduced in the Single UNIX Specification to allow for file offsets that might not fit in a long integer. They replace the long integer with the off_t data type. The two functions fgetpos and fsetpos. They were introduced by ISO C. They use an abstract data type, fpos_t, that records a file's position. This data type can be made as big as necessary to record a file's position.
Portable applications that need to move to non-UNIX systems should use fgetpos and fsetpos.
#include <stdio.h>
long ftell(FILE *fp);
| Returns: current file position indicator if OK, 1L on error |
int fseek(FILE *fp, long offset, int whence);
| Returns: 0 if OK, nonzero on error |
void rewind(FILE *fp);
|
For a binary file, a file's position indicator is measured in bytes from the beginning of the file. The value returned by ftell for a binary file is this byte position. To position a binary file using fseek, we must specify a byte offset and how that offset is interpreted. The values for whence are the same as for the lseek function from Section 3.6: SEEK_SET means from the beginning of the file, SEEK_CUR means from the current file position, and SEEK_END means from the end of file. ISO C doesn't require an implementation to support the SEEK_END specification for a binary file, as some systems require a binary file to be padded at the end with zeros to make the file size a multiple of some magic number. Under the UNIX System, however, SEEK_END is supported for binary files.
For text files, the file's current position may not be measurable as a simple byte offset. Again, this is mainly under non-UNIX systems that might store text files in a different format. To position a text file, whence has to be SEEK_SET, and only two values for offset are allowed: 0meaning rewind the file to its beginningor a value that was returned by ftell for that file. A stream can also be set to the beginning of the file with the rewind function.
The ftello function is the same as ftell, and the fseeko function is the same as fseek, except that the type of the offset is off_t instead of long.
#include <stdio.h>
off_t ftello(FILE *fp);
| Returns: current file position indicator if OK, (off_t)1 on error |
int fseeko(FILE *fp, off_t offset, int whence);
| Returns: 0 if OK, nonzero on error |
Recall the discussion of the off_t data type in Section 3.6. Implementations can define the off_t type to be larger than 32 bits.
As we mentioned, the fgetpos and fsetpos functions were introduced by the ISO C standard.
#include <stdio.h>
int fgetpos(FILE *restrict fp, fpos_t *restrict pos);
int fsetpos(FILE *fp, const fpos_t *pos);
| Both return: 0 if OK, nonzero on error |
The fgetpos function stores the current value of the file's position indicator in the object pointed to by pos. This value can be used in a later call to fsetpos to reposition the stream to that location.
5.11. Formatted I/O
Formatted Output
Formatted output is handled by the four printf functions.
#include <stdio.h>
int printf(const char *restrict format, ...);
int fprintf(FILE *restrict fp, const char
*restrict format, ...);
| Both return: number of characters output if OK, negative value if output error |
int sprintf(char *restrict buf, const char
*restrict format, ...);
int snprintf(char *restrict buf, size_t n,
const char *restrict format, ...);
| Both return: number of characters stored in array if OK, negative value if encoding error |
The printf function writes to the standard output, fprintf writes to the specified stream, and sprintf places the formatted characters in the array buf. The sprintf function automatically appends a null byte at the end of the array, but this null byte is not included in the return value.
Note that it's possible for sprintf to overflow the buffer pointed to by buf. It's the caller's responsibility to ensure that the buffer is large enough. Because this can lead to buffer-overflow problems, snprintf was introduced. With it, the size of the buffer is an explicit parameter; any characters that would have been written past the end of the buffer are discarded instead. The snprintf function returns the number of characters that would have been written to the buffer had it been big enough. As with sprintf, the return value doesn't include the terminating null byte. If snprintf returns a positive value less than the buffer size n, then the output was not truncated. If an encoding error occurs, snprintf returns a negative value.
The format specification controls how the remainder of the arguments will be encoded and ultimately displayed. Each argument is encoded according to a conversion specification that starts with a percent sign (%). Except for the conversion specifications, other characters in the format are copied unmodified. A conversion specification has four optional components, shown in square brackets below:
%[flags][fldwidth][precision][lenmodifier]convtype
The flags are summarized in Figure 5.7.
Figure 5.7. The flags component of a conversion specificationFlag | Description |
|---|
- | left-justify the output in the field | + | always display sign of a signed conversion | (space) | prefix by a space if no sign is generated | # | convert using alternate form (include 0x prefix for hex format, for example) | 0 | prefix with leading zeros instead of padding with spaces |
The fldwidth component specifies a minimum field width for the conversion. If the conversion results in fewer characters, it is padded with spaces. The field width is a non-negative decimal integer or an asterisk.
The precision component specifies the minimum number of digits to appear for integer conversions, the minimum number of digits to appear to the right of the decimal point for floating-point conversions, or the maximum number of bytes for string conversions. The precision is a period (.) followed by a optional non-negative decimal integer or an asterisk.
Both the field width and precision can be an asterisk. In this case, an integer argument specifies the value to be used. The argument appears directly before the argument to converted.
The lenmodifier component specifies the size of the argument. Possible values are summarized in Figure 5.8.
Figure 5.8. The length modifier component of a conversion specificationLength modifier | Description |
|---|
hh | signed or unsigned char
| h | signed or unsigned short
| l | signed or unsigned long or wide character | ll | signed or unsigned long long
| j | intmax_t or uintmax_t
| z | size_t
| t | ptrdiff_t | L | long double
|
The convtype component is not optional. It controls how the argument is interpreted. The various conversion types are summarized in Figure 5.9.
Figure 5.9. The conversion type component of a conversion specificationConversion type | Description |
|---|
d,i | signed decimal | o | unsigned octal | u | unsigned decimal | x,X | unsigned hexadecimal | f,F | double floating-point number | e,E | double floating-point number in exponential format | g,G | interpreted as f, F, e, or E, depending on value converted | a,A | double floating-point number in hexadecimal exponential format | c | character (with l length modifier, wide character) | s | string (with l length modifier, wide character string) | p | pointer to a void
| n | pointer to a signed integer into which is written the number of characters written so far | % | a % character | C | wide character (an XSI extension, equivalent to lc) | S | wide character string (an XSI extension, equivalent to ls) |
The following four variants of the printf family are similar to the previous four, but the variable argument list (...) is replaced with arg.
#include <stdarg.h>
#include <stdio.h>
int vprintf(const char *restrict format, va_list arg);
int vfprintf(FILE *restrict fp, const char
*restrict format,
va_list arg);
| Both return: number of characters output if OK, negative value if output error |
int vsprintf(char *restrict buf, const char
*restrict format,
va_list arg);
int vsnprintf(char *restrict buf, size_t n,
const char *restrict format, va_list
arg);
| Both return: number of characters stored in array if OK, negative value if encoding error |
We use the vsnprintf function in the error routines in Appendix B.
Refer to Section 7.3 of Kernighan and Ritchie [1988] for additional details on handling variable-length argument lists with ISO Standard C. Be aware that the variable-length argument list routines provided with ISO Cthe <stdarg.h> header and its associated routinesdiffer from the <varargs.h> routines that were provided with older UNIX systems.
Formatted Input
Formatted input is handled by the three scanf functions.
#include <stdio.h>
int scanf(const char *restrict format, ...);
int fscanf(FILE *restrict fp, const char *restrict
format, ...);
int sscanf(const char *restrict buf, const char
*restrict format,
...);
| All three return: number of input items assigned,
EOF if input error or end of file before any conversion |
The scanf family is used to parse an input string and convert character sequences into variables of specified types. The arguments following the format contain the addresses of the variables to initialize with the results of the conversions.
The format specification controls how the arguments are converted for assignment. The percent sign (%) indicates the start of a conversion specification. Except for the conversion specifications and white space, other characters in the format have to match the input. If a character doesn't match, processing stops, leaving the remainder of the input unread.
There are three optional components to a conversion specification, shown in square brackets below:
%[*][fldwidth][lenmodifier]convtype
The optional leading asterisk is used to suppress conversion. Input is converted as specified by the rest of the conversion specification, but the result is not stored in an argument.
The fldwidth component specifies the maximum field width in characters. The lenmodifier component specifies the size of the argument to be initialized with the result of the conversion. The same length modifiers supported by the printf family of functions are supported by the scanf family of functions (see Figure 5.8 for a list of the length modifiers).
The convtype field is similar to the conversion type field used by the printf family, but there are some differences. One difference is that results that are stored in unsigned types can optionally be signed on input. For example, 1 will scan as 4294967295 into an unsigned integer. Figure 5.10 summarizes the conversion types supported by the scanf family of functions.
Figure 5.10. The conversion type component of a conversion specificationConversion
type | Description |
|---|
d | signed decimal, base 10 | i | signed decimal, base determined by format of input | o | unsigned octal (input optionally signed) | u | unsigned decimal, base 10 (input optionally signed) | x | unsigned hexadecimal (input optionally signed) | a,A,e,E,f,F,g,G | floating-point number | c | character (with l length modifier, wide character) | s | string (with l length modifier, wide character string) | [ | matches a sequence of listed characters, ending with ]
| [^ | matches all characters except the ones listed, ending with ]
| p | pointer to a void
| n | pointer to a signed integer into which is written the number of characters read so far | % | a % character | C | wide character (an XSI extension, equivalent to lc) | S | wide character string (an XSI extension, equivalent to ls) |
As with the printf family, the scanf family also supports functions that use variable argument lists as specified by <stdarg.h>.
#include <stdarg.h>
#include <stdio.h>
int vscanf(const char *restrict format, va_list arg);
int vfscanf(FILE *restrict fp, const char
*restrict format,
va_list arg);
int vsscanf(const char *restrict buf, const char
*restrict format,
va_list arg);
| All three return: number of input items assigned,
EOF if input error or end of file before any conversion |
Refer to your UNIX system manual for additional details on the scanf family of functions.
5.12. Implementation Details
As we've mentioned, under the UNIX System, the standard I/O library ends up calling the I/O routines that we described in Chapter 3. Each standard I/O stream has an associated file descriptor, and we can obtain the descriptor for a stream by calling fileno.
Note that fileno is not part of the ISO C standard, but an extension supported by POSIX.1.
#include <stdio.h>
int fileno(FILE *fp);
| Returns: the file descriptor associated with the stream |
We need this function if we want to call the dup or fcntl functions, for example.
To look at the implementation of the standard I/O library on your system, start with the header <stdio.h>. This will show how the FILE object is defined, the definitions of the per-stream flags, and any standard I/O routines, such as getc, that are defined as macros. Section 8.5 of Kernighan and Ritchie [1988] has a sample implementation that shows the flavor of many implementations on UNIX systems. Chapter 12 of Plauger [1992] provides the complete source code for an implementation of the standard I/O library. The implementation of the GNU standard I/O library is also publicly available.
Example
The program in Figure 5.11 prints the buffering for the three standard streams and for a stream that is associated with a regular file.
Note that we perform I/O on each stream before printing its buffering status, since the first I/O operation usually causes the buffers to be allocated for a stream. The structure members _IO_file_flags, _IO_buf_base, and _IO_buf_end and the constants _IO_UNBUFFERED and _IO_LINE_BUFFERED are defined by the GNU standard I/O library used on Linux. Be aware that other UNIX systems may have different implementations of the standard I/O library.
If we run the program in Figure 5.11 twice, once with the three standard streams connected to the terminal and once with the three standard streams redirected to files, we get the following result:
$ ./a.out stdin, stdout, and stderr connected to terminal
enter any character
we type a newline
one line to standard error
stream = stdin, line buffered, buffer size = 1024
stream = stdout, line buffered, buffer size = 1024
stream = stderr, unbuffered, buffer size = 1
stream = /etc/motd, fully buffered, buffer size = 4096
$ ./a.out < /etc/termcap > std.out 2> std.err
run it again with all three streams redirected
$ cat std.err
one line to standard error
$ cat std.out
enter any character
stream = stdin, fully buffered, buffer size = 4096
stream = stdout, fully buffered, buffer size = 4096
stream = stderr, unbuffered, buffer size = 1
stream = /etc/motd, fully buffered, buffer size = 4096
We can see that the default for this system is to have standard input and standard output line buffered when they're connected to a terminal. The line buffer is 1,024 bytes. Note that this doesn't restrict us to 1,024-byte input and output lines; that's just the size of the buffer. Writing a 2,048-byte line to standard output will require two write system calls. When we redirect these two streams to regular files, they become fully buffered, with buffer sizes equal to the preferred I/O sizethe st_blksize value from the stat structurefor the file system. We also see that the standard error is always unbuffered, as it should be, and that a regular file defaults to fully buffered.
Figure 5.11. Print buffering for various standard I/O streams
#include "apue.h"
void pr_stdio(const char *, FILE *);
int
main(void)
{
FILE *fp;
fputs("enter any character\n", stdout);
if (getchar() == EOF)
err_sys("getchar error");
fputs("one line to standard error\n", stderr);
pr_stdio("stdin", stdin);
pr_stdio("stdout", stdout);
pr_stdio("stderr", stderr);
if ((fp = fopen("/etc/motd", "r")) == NULL)
err_sys("fopen error");
if (getc(fp) == EOF)
err_sys("getc error");
pr_stdio("/etc/motd", fp);
exit(0);
}
void
pr_stdio(const char *name, FILE *fp)
{
printf("stream = %s, ", name);
/*
* The following is nonportable.
*/
if (fp->_IO_file_flags & _IO_UNBUFFERED)
printf("unbuffered");
else if (fp->_IO_file_flags & _IO_LINE_BUF)
printf("line buffered");
else /* if neither of above */
printf("fully buffered");
printf(", buffer size = %d\n", fp->_IO_buf_end - fp->_IO_buf_base);
}
5.13. Temporary Files
The ISO C standard defines two functions that are provided by the standard I/O library to assist in creating temporary files.
#include <stdio.h>
char *tmpnam(char *ptr);
| Returns: pointer to unique pathname |
FILE *tmpfile(void);
| Returns: file pointer if OK, NULL on error |
The tmpnam function generates a string that is a valid pathname and that is not the same name as an existing file. This function generates a different pathname each time it is called, up to TMP_MAX times. TMP_MAX is defined in <stdio.h>.
Although ISO C defines TMP_MAX, the C standard requires only that its value be at least 25. The Single UNIX Specification, however, requires that XSI-conforming systems support a value of at least 10,000. Although this minimum value allows an implementation to use four digits (00009999), most implementations on UNIX systems use lowercase or uppercase characters.
If ptr is NULL, the generated pathname is stored in a static area, and a pointer to this area is returned as the value of the function. Subsequent calls to tmpnam can overwrite this static area. (This means that if we call this function more than once and we want to save the pathname, we have to save a copy of the pathname, not a copy of the pointer.) If ptr is not NULL, it is assumed that it points to an array of at least L_tmpnam characters. (The constant L_tmpnam is defined in <stdio.h>.) The generated pathname is stored in this array, and ptr is also returned as the value of the function.
The tmpfile function creates a temporary binary file (type wb+) that is automatically removed when it is closed or on program termination. Under the UNIX System, it makes no difference that this file is a binary file.
Example
The program in Figure 5.12 demonstrates these two functions.
If we execute the program in Figure 5.12, we get
$ ./a.out
/tmp/fileC1Icwc
/tmp/filemSkHSe
one line of output
Figure 5.12. Demonstrate tmpnam and tmpfile functions
#include "apue.h"
int
main(void)
{
char name[L_tmpnam], line[MAXLINE];
FILE *fp;
printf("%s\n", tmpnam(NULL)); /* first temp name */
tmpnam(name); /* second temp name */
printf("%s\n", name);
if ((fp = tmpfile()) == NULL) /* create temp file */
err_sys("tmpfile error");
fputs("one line of output\n", fp); /* write to temp file */
rewind(fp); /* then read it back */
if (fgets(line, sizeof(line), fp) == NULL)
err_sys("fgets error");
fputs(line, stdout); /* print the line we wrote */
exit(0);
}
The standard technique often used by the tmpfile function is to create a unique pathname by calling tmpnam, then create the file, and immediately unlink it. Recall from Section 4.15 that unlinking a file does not delete its contents until the file is closed. This way, when the file is closed, either explicitly or on program termination, the contents of the file are deleted.
The Single UNIX Specification defines two additional functions as XSI extensions for dealing with temporary files. The first of these is the tempnam function.
#include <stdio.h>
char *tempnam(const char *directory, const char
*prefix);
| Returns: pointer to unique pathname |
The tempnam function is a variation of tmpnam that allows the caller to specify both the directory and a prefix for the generated pathname. There are four possible choices for the directory, and the first one that is true is used.
If the environment variable TMPDIR is defined, it is used as the directory. (We describe environment variables in Section 7.9.) If directory is not NULL, it is used as the directory. The string P_tmpdir in <stdio.h> is used as the directory. A local directory, usually /tmp, is used as the directory.
If the prefix argument is not NULL, it should be a string of up to five bytes to be used as the first characters of the filename.
This function calls the malloc function to allocate dynamic storage for the constructed pathname. We can free this storage when we're done with the pathname. (We describe the malloc and free functions in Section 7.8.)
Example
The program in Figure 5.13 shows the use of tempnam.
Note that if either command-line argumentthe directory or the prefixbegins with a blank, we pass a null pointer to the function. We can now show the various ways to use it:
$ ./a.out /home/sar TEMP specify both directory and prefix
/home/sar/TEMPsf00zi
$ ./a.out " " PFX use default directory: P_tmpdir
/tmp/PFXfBw7Gi
$ TMPDIR=/var/tmp ./a.out /usr/tmp " " use environment variable; no prefix
/var/tmp/file8fVYNi environment variable overrides directory
$ TMPDIR=/no/such/dir ./a.out /home/sar/tmp QQQ
/home/sar/tmp/QQQ98s8Ui invalid environment directory is ignored
As the four steps that we listed earlier for specifying the directory name are tried in order, this function also checks whether the corresponding directory name makes sense. If the directory doesn't exist (the /no/such/dir example), that case is skipped, and the next choice for the directory name is tried. From this example, we can see that for this implementation, the P_tmpdir directory is /tmp. The technique that we used to set the environment variable, specifying TMPDIR= before the program name, is used by the Bourne shell, the Korn shell, and bash.
Figure 5.13. Demonstrate tempnam function
#include "apue.h"
int
main(int argc, char *argv[])
{
if (argc != 3)
err_quit("usage: a.out <directory> <prefix>");
printf("%s\n", tempnam(argv[1][0] != ' ' ? argv[1] : NULL,
argv[2][0] != ' ' ? argv[2] : NULL));
exit(0);
}
The second function that XSI defines is mkstemp. It is similar to tmpfile, but returns an open file descriptor for the temporary file instead of a file pointer.
#include <stdlib.h>
int mkstemp(char *template);
| Returns: file descriptor if OK, 1 on error |
The returned file descriptor is open for reading and writing. The name of the temporary file is selected using the template string. This string is a pathname whose last six characters are set to XXXXXX. The function replaces these with different characters to create a unique pathname. If mkstemp returns success, it modifies the template string to reflect the name of the temporary file.
Unlike tmpfile, the temporary file created by mkstemp is not removed automatically for us. If we want to remove it from the file system namespace, we need to unlink it ourselves.
There is a drawback to using tmpnam and tempnam: a window exists between the time that the unique pathname is returned and the time that an application creates a file with that name. During this timing window, another process can create a file of the same name. The tempfile and mkstemp functions should be used instead, as they don't suffer from this problem.
The mktemp function is similar to mkstemp, except that it creates a name suitable only for use as a temporary file. The mktemp function doesn't create a file, so it suffers from the same drawback as tmpnam and tempnam. The mktemp function is marked as a legacy interface in the Single UNIX Specification. Legacy interfaces might be withdrawn in future versions of the Single UNIX Specification, and so should be avoided.
5.14. Alternatives to Standard I/O
The standard I/O library is not perfect. Korn and Vo [1991] list numerous defects: some in the basic design, but most in the various implementations.
One inefficiency inherent in the standard I/O library is the amount of data copying that takes place. When we use the line-at-a-time functions, fgets and fputs, the data is usually copied twice: once between the kernel and the standard I/O buffer (when the corresponding read or write is issued) and again between the standard I/O buffer and our line buffer. The Fast I/O library [fio(3) in AT&T 1990a] gets around this by having the function that reads a line return a pointer to the line instead of copying the line into another buffer. Hume [1988] reports a threefold increase in the speed of a version of the grep(1) utility, simply by making this change.
Korn and Vo [1991] describe another replacement for the standard I/O library: sfio. This package is similar in speed to the fio library and normally faster than the standard I/O library. The sfio package also provides some new features that aren't in the others: I/O streams generalized to represent both files and regions of memory, processing modules that can be written and stacked on an I/O stream to change the operation of a stream, and better exception handling.
Krieger, Stumm, and Unrau [1992] describe another alternative that uses mapped filesthe mmap function that we describe in Section 14.9. This new package is called ASI, the Alloc Stream Interface. The programming interface resembles the UNIX System memory allocation functions (malloc, realloc, and free, described in Section 7.8). As with the sfio package, ASI attempts to minimize the amount of data copying by using pointers.
Several implementations of the standard I/O library are available in C libraries that were designed for systems with small memory footprints, such as embedded systems. These implementations emphasize modest memory requirements over portability, speed, or functionality. Two such implementations are the uClibc C library (see http://www.uclibc.org for more information) and the newlibc C library (http://sources.redhat.com/newlib).
5.15. Summary
The standard I/O library is used by most UNIX applications. We have looked at all the functions provided by this library, as well as at some implementation details and efficiency considerations. Be aware of the buffering that takes place with this library, as this is the area that generates the most problems and confusion.
6.1. Introduction
A UNIX system requires numerous data files for normal operation: the password file /etc/passwd and the group file /etc/group are two files that are frequently used by various programs. For example, the password file is used every time a user logs in to a UNIX system and every time someone executes an ls -l command.
Historically, these data files have been ASCII text files and were read with the standard I/O library. But for larger systems, a sequential scan through the password file becomes time consuming. We want to be able to store these data files in a format other than ASCII text, but still provide an interface for an application program that works with any file format. The portable interfaces to these data files are the subject of this chapter. We also cover the system identification functions and the time and date functions.
6.2. Password File
The UNIX System's password file, called the user database by POSIX.1, contains the fields shown in Figure 6.1. These fields are contained in a passwd structure that is defined in <pwd.h>.
Figure 6.1. Fields in /etc/passwd fileDescription | struct passwd member | POSIX.1 | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
user name | char *pw_name | • | • | • | • | • | encrypted password | char *pw_passwd | | • | • | • | • | numerical user ID | uid_t pw_uid | • | • | • | • | • | numerical group ID | gid_t pw_gid | • | • | • | • | • | comment field | char *pw_gecos | | • | • | • | • | initial working directory | char *pw_dir | • | • | • | • | • | initial shell (user program) | char *pw_shell | • | • | • | • | • | user access class | char *pw_class | | • | | • | | next time to change password | time_t pw_change | | • | | • | | account expiration time | time_t pw_expire | | • | | • | |
Note that POSIX.1 specifies only five of the ten fields in the passwd structure. Most platforms support at least seven of the fields. The BSD-derived platforms support all ten.
Historically, the password file has been stored in /etc/passwd and has been an ASCII file. Each line contains the fields described in Figure 6.1, separated by colons. For example, four lines from the /etc/passwd file on Linux could be
root:x:0:0:root:/root:/bin/bash
squid:x:23:23::/var/spool/squid:/dev/null
nobody:x:65534:65534:Nobody:/home:/bin/sh
sar:x:205:105:Stephen Rago:/home/sar:/bin/bash
Note the following points about these entries.
There is usually an entry with the user name root. This entry has a user ID of 0 (the superuser). The encrypted password field contains a single character as a placeholder where older versions of the UNIX System used to store the encrypted password. Because it is a security hole to store the encrypted password in a file that is readable by everyone, encrypted passwords are now kept elsewhere. We'll cover this issue in more detail in the next section when we discuss passwords. Some fields in a password file entry can be empty. If the encrypted password field is empty, it usually means that the user does not have a password. (This is not recommended.) The entry for squid has one blank field: the comment field. An empty comment field has no effect. The shell field contains the name of the executable program to be used as the login shell for the user. The default value for an empty shell field is usually /bin/sh. Note, however, that the entry for squid has /dev/null as the login shell. Obviously, this is a device and cannot be executed, so its use here is to prevent anyone from logging in to our system as user squid. Many services have separate user IDs for the daemon processes (Chapter 13) that help implement the service. The squid enTRy is for the processes implementing the squid proxy cache service.
There are several alternatives to using /dev/null to prevent a particular user from logging in to a system. It is common to see /bin/false used as the login shell. It simply exits with an unsuccessful (nonzero) status; the shell evaluates the exit status as false. It is also common to see /bin/true used to disable an account. All it does is exit with a successful (zero) status. Some systems provide the nologin command. It prints a customizable error message and exits with a nonzero exit status. The nobody user name can be used to allow people to log in to a system, but with a user ID (65534) and group ID (65534) that provide no privileges. The only files that this user ID and group ID can access are those that are readable or writable by the world. (This assumes that there are no files specifically owned by user ID 65534 or group ID 65534, which should be the case.) Some systems that provide the finger(1) command support additional information in the comment field. Each of these fields is separated by a comma: the user's name, office location, office phone number, and home phone number. Additionally, an ampersand in the comment field is replaced with the login name (capitalized) by some utilities. For example, we could have
sar:x:205:105:Steve Rago, SF 5-121, 555-1111, 555-2222:/home/sar:/bin/sh
Then we could use finger to print information about Steve Rago.
$ finger -p sar
Login: sar Name: Steve Rago
Directory: /home/sar Shell: /bin/sh
Office: SF 5-121, 555-1111 Home Phone: 555-2222
On since Mon Jan 19 03:57 (EST) on ttyv0 (messages off)
No Mail.
Even if your system doesn't support the finger command, these fields can still go into the comment field, since that field is simply a comment and not interpreted by system utilities.
Some systems provide the vipw command to allow administrators to edit the password file. The vipw command serializes changes to the password file and makes sure that any additional files are consistent with the changes made. It is also common for systems to provide similar functionality through graphical user interfaces.
POSIX.1 defines only two functions to fetch entries from the password file. These functions allow us to look up an entry given a user's login name or numerical user ID.
#include <pwd.h>
struct passwd *getpwuid(uid_t uid);
struct passwd *getpwnam(const char *name);
| Both return: pointer if OK, NULL on error |
The getpwuid function is used by the ls(1) program to map the numerical user ID contained in an i-node into a user's login name. The getpwnam function is used by the login(1) program when we enter our login name.
Both functions return a pointer to a passwd structure that the functions fill in. This structure is usually a static variable within the function, so its contents are overwritten each time we call either of these functions.
These two POSIX.1 functions are fine if we want to look up either a login name or a user ID, but some programs need to go through the entire password file. The following three functions can be used for this.
#include <pwd.h>
struct passwd *getpwent(void);
| Returns: pointer if OK, NULL on error or end of file |
void setpwent(void);
void endpwent(void);
|
These three functions are not part of the base POSIX.1 standard. They are defined as XSI extensions in the Single UNIX Specification. As such, all UNIX systems are expected to provide them.
We call getpwent to return the next entry in the password file. As with the two POSIX.1 functions, getpwent returns a pointer to a structure that it has filled in. This structure is normally overwritten each time we call this function. If this is the first call to this function, it opens whatever files it uses. There is no order implied when we use this function; the entries can be in any order, because some systems use a hashed version of the file /etc/passwd.
The function setpwent rewinds whatever files it uses, and endpwent closes these files. When using getpwent, we must always be sure to close these files by calling endpwent when we're through. Although getpwent is smart enough to know when it has to open its files (the first time we call it), it never knows when we're through.
Example
Figure 6.2 shows an implementation of the function getpwnam.
The call to setpwent at the beginning is self-defense: we ensure that the files are rewound, in case the caller has already opened them by calling getpwent. The call to endpwent when we're done is because neither getpwnam nor getpwuid should leave any of the files open.
Figure 6.2. The getpwnam function
#include <pwd.h>
#include <stddef.h>
#include <string.h>
struct passwd *
getpwnam(const char *name)
{
struct passwd *ptr;
setpwent();
while ((ptr = getpwent()) != NULL)
if (strcmp(name, ptr->pw_name) == 0)
break; /* found a match */
endpwent();
return(ptr); /*a ptr is NULL if no match found */
}
6.3. Shadow Passwords
The encrypted password is a copy of the user's password that has been put through a one-way encryption algorithm. Because this algorithm is one-way, we can't guess the original password from the encrypted version.
Historically, the algorithm that was used (see Morris and Thompson [1979]) always generated 13 printable characters from the 64-character set [a-zA-Z0-9./]. Some newer systems use an MD5 algorithm to encrypt passwords, generating 31 characters per encrypted password. (The more characters used to store the encrypted password, the more combinations there are, and the harder it will be to guess the password by trying all possible variations.) When we place a single character in the encrypted password field, we ensure that an encrypted password will never match this value.
Given an encrypted password, we can't apply an algorithm that inverts it and returns the plaintext password. (The plaintext password is what we enter at the Password: prompt.) But we could guess a password, run it through the one-way algorithm, and compare the result to the encrypted password. If user passwords were randomly chosen, this brute-force approach wouldn't be too successful. Users, however, tend to choose nonrandom passwords, such as spouse's name, street names, or pet names. A common experiment is for someone to obtain a copy of the password file and try guessing the passwords. (Chapter 4 of Garfinkel et al. [2003] contains additional details and history on passwords and the password encryption scheme used on UNIX systems.)
To make it more difficult to obtain the raw materials (the encrypted passwords), systems now store the encrypted password in another file, often called the shadow password file. Minimally, this file has to contain the user name and the encrypted password. Other information relating to the password is also stored here (Figure 6.3).
Figure 6.3. Fields in /etc/shadow fileDescription | struct spwd member |
|---|
user login name | char *sp_namp
| encrypted password | char *sp_pwdp
| days since Epoch of last password change | int sp_lstchg
| days until change allowed | int sp_min
| days before change required | int sp_max
| days warning for expiration | int sp_warn
| days before account inactive | int sp_inact
| days since Epoch when account expires | int sp_expire. | reserved | unsigned int sp_flag
|
The only two mandatory fields are the user's login name and encrypted password. The other fields control how often the password is to changeknown as "password aging"and how long an account is allowed to remain active.
The shadow password file should not be readable by the world. Only a few programs need to access encrypted passwordslogin(1) and passwd(1), for exampleand these programs are often set-user-ID root. With shadow passwords, the regular password file, /etc/passwd, can be left readable by the world.
On Linux 2.4.22 and Solaris 9, a separate set of functions is available to access the shadow password file, similar to the set of functions used to access the password file.
#include <shadow.h>
struct spwd *getspnam(const char *name);
struct spwd *getspent(void);
| Both return: pointer if OK, NULL on error |
void setspent(void);
void endspent(void);
|
On FreeBSD 5.2.1 and Mac OS X 10.3, there is no shadow password structure. The additional account information is stored in the password file (refer back to Figure 6.1).
6.4. Group File
The UNIX System's group file, called the group database by POSIX.1, contains the fields shown in Figure 6.4. These fields are contained in a group structure that is defined in <grp.h>.
Figure 6.4. Fields in /etc/group fileDescription | struct group member | POSIX.1 | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
group name | char *gr_name | • | • | • | • | • | encrypted password | char *gr_passwd | | • | • | • | • | numerical group ID | int gr_gid | • | • | • | • | • | array of pointers to individual user names | char **gr_mem | • | • | • | • | • |
The field gr_mem is an array of pointers to the user names that belong to this group. This array is terminated by a null pointer.
We can look up either a group name or a numerical group ID with the following two functions, which are defined by POSIX.1.
#include <grp.h>
struct group *getgrgid(gid_t gid);
struct group *getgrnam(const char *name);
| Both return: pointer if OK, NULL on error |
As with the password file functions, both of these functions normally return pointers to a static variable, which is overwritten on each call.
If we want to search the entire group file, we need some additional functions. The following three functions are like their counterparts for the password file.
#include <grp.h>
struct group *getgrent(void);
| Returns: pointer if OK, NULL on error or end of file |
void setgrent(void);
void endgrent(void);
|
These three functions are not part of the base POSIX.1 standard. They are defined as XSI extensions in the Single UNIX Specification. All UNIX Systems provide them.
The setgrent function opens the group file, if it's not already open, and rewinds it. The getgrent function reads the next entry from the group file, opening the file first, if it's not already open. The endgrent function closes the group file.
6.5. Supplementary Group IDs
The use of groups in the UNIX System has changed over time. With Version 7, each user belonged to a single group at any point in time. When we logged in, we were assigned the real group ID corresponding to the numerical group ID in our password file entry. We could change this at any point by executing newgrp(1). If the newgrp command succeeded (refer to the manual page for the permission rules), our real group ID was changed to the new group's ID, and this was used for all subsequent file access permission checks. We could always go back to our original group by executing newgrp without any arguments.
This form of group membership persisted until it was changed in 4.2BSD (circa 1983). With 4.2BSD, the concept of supplementary group IDs was introduced. Not only did we belong to the group corresponding to the group ID in our password file entry, but we also could belong to up to 16 additional groups. The file access permission checks were modified so that not only was the effective group ID compared to the file's group ID, but also all the supplementary group IDs were compared to the file's group ID.
Supplementary group IDs are a required feature of POSIX.1. (In older versions of POSIX.1, they were optional.) The constant NGROUPS_MAX (Figure 2.10) specifies the number of supplementary group IDs. A common value is 16 (Figure 2.14).
The advantage in using supplementary group IDs is that we no longer have to change groups explicitly. It is not uncommon to belong to multiple groups (i.e., participate in multiple projects) at the same time.
Three functions are provided to fetch and set the supplementary group IDs.
#include <unistd.h>
int getgroups(int gidsetsize, gid_t grouplist[]);
| Returns: number of supplementary group IDs if OK, 1 on error |
#include <grp.h> /* on Linux */
#include <unistd.h> /* on FreeBSD, Mac OS X, and
Solaris */
int setgroups(int ngroups, const gid_t grouplist[]);
#include <grp.h> /* on Linux and Solaris */
#include <unistd.h> /* on FreeBSD and Mac OS X */
int initgroups(const char *username, gid_t basegid);
| Both return: 0 if OK, 1 on error |
Of these three functions, only getgroups is specified by POSIX.1. Because setgroups and initgroups are privileged operations, they are not part of POSIX.1. All four platforms covered in this book, however, support all three functions.
On Mac OS X 10.3, basegid is declared to be of type int.
The getgroups function fills in the array grouplist with the supplementary group IDs. Up to gidsetsize elements are stored in the array. The number of supplementary group IDs stored in the array is returned by the function.
As a special case, if gidsetsize is 0, the function returns only the number of supplementary group IDs. The array grouplist is not modified. (This allows the caller to determine the size of the grouplist array to allocate.)
The setgroups function can be called by the superuser to set the supplementary group ID list for the calling process: grouplist contains the array of group IDs, and ngroups specifies the number of elements in the array. The value of ngroups cannot be larger than NGROUPS_MAX.
The only use of setgroups is usually from the initgroups function, which reads the entire group filewith the functions getgrent, setgrent, and endgrent, which we described earlierand determines the group membership for username. It then calls setgroups to initialize the supplementary group ID list for the user. One must be superuser to call initgroups, since it calls setgroups. In addition to finding all the groups that username is a member of in the group file, initgroups also includes basegid in the supplementary group ID list; basegid is the group ID from the password file for username.
The initgroups function is called by only a few programs: the login(1) program, for example, calls it when we log in.
6.6. Implementation Differences
We've already discussed the shadow password file supported by Linux and Solaris. FreeBSD and Mac OS X store encrypted passwords differently. Figure 6.5 summarizes how the four platforms covered in this book store user and group information.
Figure 6.5. Account implementation differencesInformation | FreeBSD
5.2.1 | Linux
2.4.22 | Mac OS X 10.3 | Solaris
9 |
|---|
Account information | /etc/passwd | /etc/passwd | netinfo | /etc/passwd
| Encrypted passwords | /etc/master.passwd | /etc/shadow | netinfo | /etc/shadow
| Hashed password files? | yes | no | no | no | Group information | /etc/group | /etc/group | netinfo | /etc/group
|
On FreeBSD, the shadow password file is /etc/master.passwd. Special commands are used to edit it, which in turn generate a copy of /etc/passwd from the shadow password file. In addition, hashed versions of the files are also generated: /etc/pwd.db is the hashed version of /etc/passwd, and /etc/spwd.db is the hashed version of /etc/master.passwd. These provide better performance for large installations.
On Mac OS X, however, /etc/passwd and /etc/master.passwd are used only in single-user mode (when the system is undergoing maintenance; single-user mode usually means that no system services are enabled). In multiuser modeduring normal operationthe netinfo directory service provides access to account information for users and groups.
Although Linux and Solaris support similar shadow password interfaces, there are some subtle differences. For example, the integer fields shown in Figure 6.3 are defined as type int on Solaris, but as long int on Linux. Another difference is the account-inactive field. Solaris defines it to be the number of days since the user last logged in to the system, whereas Linux defines it to be the number of days after which the maximum password age has been reached.
On many systems, the user and group databases are implemented using the Network Information Service (NIS). This allows administrators to edit a master copy of the databases and distribute them automatically to all servers in an organization. Client systems contact servers to look up information about users and groups. NIS+ and the Lightweight Directory Access Protocol (LDAP) provide similar functionality. Many systems control the method used to administer each type of information through the /etc/nsswitch.conf configuration file.
6.7. Other Data Files
We've discussed only two of the system's data files so far: the password file and the group file. Numerous other files are used by UNIX systems in normal day-to-day operation. For example, the BSD networking software has one data file for the services provided by the various network servers (/etc/services), one for the protocols (/etc/protocols), and one for the networks (/etc/networks). Fortunately, the interfaces to these various files are like the ones we've already described for the password and group files.
The general principle is that every data file has at least three functions:
A get function that reads the next record, opening the file if necessary. These functions normally return a pointer to a structure. A null pointer is returned when the end of file is reached. Most of the get functions return a pointer to a static structure, so we always have to copy it if we want to save it. A set function that opens the file, if not already open, and rewinds the file. This function is used when we know we want to start again at the beginning of the file. An end enTRy that closes the data file. As we mentioned earlier, we always have to call this when we're done, to close all the files.
Additionally, if the data file supports some form of keyed lookup, routines are provided to search for a record with a specific key. For example, two keyed lookup routines are provided for the password file: getpwnam looks for a record with a specific user name, and getpwuid looks for a record with a specific user ID.
Figure 6.6 shows some of these routines, which are common to UNIX systems. In this figure, we show the functions for the password files and group file, which we discussed earlier in this chapter, and some of the networking functions. There are get, set, and end functions for all the data files in this figure.
Figure 6.6. Similar routines for accessing system data filesDescription | Data file | Header | Structure | Additional keyed lookup functions |
|---|
passwords | /etc/passwd | <pwd.h> | passwd | getpwnam, getpwuid
| groups | /etc/group | <grp.h> | group | getgrnam, getgrgid
| shadow | /etc/shadow | <shadow.h> | spwd | getspnam
| hosts | /etc/hosts | <netdb.h> | hostent | gethostbyname, gethostbyaddr
| networks | /etc/networks | <netdb.h> | netent | getnetbyname, getnetbyaddr
| protocols | /etc/protocols | <netdb.h> | protoent | getprotobyname, getprotobynumber
| services | /etc/services | <netdb.h> | servent | getservbyname, getservbyport
|
Under Solaris, the last four data files in Figure 6.6 are symbolic links to files of the same name in the directory /etc/inet. Most UNIX System implementations have additional functions that are like these, but the additional functions tend to deal with system administration files and are specific to each implementation.
6.8. Login Accounting
Two data files that have been provided with most UNIX systems are the utmp file, which keeps track of all the users currently logged in, and the wtmp file, which keeps track of all logins and logouts. With Version 7, one type of record was written to both files, a binary record consisting of the following structure:
struct utmp {
char ut_line[8]; /* tty line: "ttyh0", "ttyd0", "ttyp0", ... */
char ut_name[8]; /* login name */
long ut_time; /* seconds since Epoch */
};
On login, one of these structures was filled in and written to the utmp file by the login program, and the same structure was appended to the wtmp file. On logout, the entry in the utmp file was erasedfilled with null bytesby the init process, and a new entry was appended to the wtmp file. This logout entry in the wtmp file had the ut_name field zeroed out. Special entries were appended to the wtmp file to indicate when the system was rebooted and right before and after the system's time and date was changed. The who(1) program read the utmp file and printed its contents in a readable form. Later versions of the UNIX System provided the last(1) command, which read through the wtmp file and printed selected entries.
Most versions of the UNIX System still provide the utmp and wtmp files, but as expected, the amount of information in these files has grown. The 20-byte structure that was written by Version 7 grew to 36 bytes with SVR2, and the extended utmp structure with SVR4 takes over 350 bytes!
The detailed format of these records in Solaris is given in the utmpx(4) manual page. With Solaris 9, both files are in the /var/adm directory. Solaris provides numerous functions described in getutx(3) to read and write these two files.
On FreeBSD 5.2.1, Linux 2.4.22, and Mac OS X 10.3, the utmp(5) manual page gives the format of their versions of these login records. The pathnames of these two files are /var/run/utmp and /var/log/wtmp.
6.9. System Identification
POSIX.1 defines the uname function to return information on the current host and operating system.
#include <sys/utsname.h>
int uname(struct utsname *name);
| Returns: non-negative value if OK, 1 on error |
We pass the address of a utsname structure, and the function fills it in. POSIX.1 defines only the minimum fields in the structure, which are all character arrays, and it's up to each implementation to set the size of each array. Some implementations provide additional fields in the structure.
struct utsname {
char sysname[]; /* name of the operating system */
char nodename[]; /* name of this node */
char release[]; /* current release of operating system */
char version[]; /* current version of this release */
char machine[]; /* name of hardware type */
};
Each string is null-terminated. The maximum name lengths supported by the four platforms discussed in this book are listed in Figure 6.7. The information in the utsname structure can usually be printed with the uname(1) command.
POSIX.1 warns that the nodename element may not be adequate to reference the host on a communications network. This function is from System V, and in older days, the nodename element was adequate for referencing the host on a UUCP network.
Realize also that the information in this structure does not give any information on the POSIX.1 level. This should be obtained using _POSIX_VERSION, as described in Section 2.6.
Finally, this function gives us a way only to fetch the information in the structure; there is nothing specified by POSIX.1 about initializing this information.
Historically, BSD-derived systems provide the gethostname function to return only the name of the host. This name is usually the name of the host on a TCP/IP network.
#include <unistd.h>
int gethostname(char *name, int namelen);
| Returns: 0 if OK, 1 on error |
The namelen argument specifies the size of the name buffer. If enough space is provided, the string returned through name is null terminated. If insufficient room is provided, however, it is unspecified whether the string is null terminated.
The gethostname function, now defined as part of POSIX.1, specifies that the maximum host name length is HOST_NAME_MAX. The maximum name lengths supported by the four implementations covered in this book are summarized in Figure 6.7.
Figure 6.7. System identification name limitsInterface | Maximum name length |
|---|
FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
uname | 256 | 65 | 256 | 257 | gethostname | 256 | 64 | 256 | 256 |
If the host is connected to a TCP/IP network, the host name is normally the fully qualified domain name of the host.
There is also a hostname(1) command that can fetch or set the host name. (The host name is set by the superuser using a similar function, sethostname.) The host name is normally set at bootstrap time from one of the start-up files invoked by /etc/rc or init.
6.10. Time and Date Routines
The basic time service provided by the UNIX kernel counts the number of seconds that have passed since the Epoch: 00:00:00 January 1, 1970, Coordinated Universal Time (UTC). In Section 1.10, we said that these seconds are represented in a time_t data type, and we call them calendar times. These calendar times represent both the time and the date. The UNIX System has always differed from other operating systems in (a) keeping time in UTC instead of the local time, (b) automatically handling conversions, such as daylight saving time, and (c) keeping the time and date as a single quantity.
The time function returns the current time and date.
#include <time.h>
time_t time(time_t *calptr);
| Returns: value of time if OK, 1 on error |
The time value is always returned as the value of the function. If the argument is non- null, the time value is also stored at the location pointed to by calptr.
We haven't said how the kernel's notion of the current time is initialized. Historically, on implementations derived from System V, the stime(2) function was called, whereas BSD-derived systems used settimeofday(2).
The Single UNIX Specification doesn't specify how a system sets its current time.
The gettimeofday function provides greater resolution (up to a microsecond) than the time function. This is important for some applications.
#include <sys/time.h>
int gettimeofday(struct timeval *restrict tp, void
*restrict tzp);
| Returns: 0 always |
This function is defined as an XSI extension in the Single UNIX Specification. The only legal value for tzp is NULL; other values result in unspecified behavior. Some platforms support the specification of a time zone through the use of tzp, but this is implementation-specific and not defined by the Single UNIX Specification.
The gettimeofday function stores the current time as measured from the Epoch in the memory pointed to by tp. This time is represented as a timeval structure, which stores seconds and microseconds:
struct timeval {
time_t tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
Once we have the integer value that counts the number of seconds since the Epoch, we normally call one of the other time functions to convert it to a human-readable time and date. Figure 6.8 shows the relationships between the various time functions.
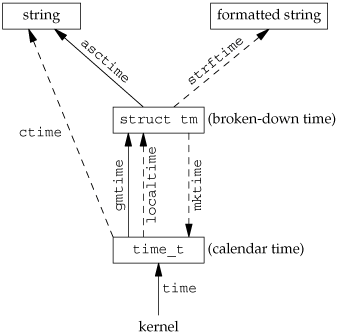
(The four functions in this figure that are shown with dashed lineslocaltime, mktime, ctime, and strftimeare all affected by the TZ environment variable, which we describe later in this section.)
The two functions localtime and gmtime convert a calendar time into what's called a broken-down time, a tm structure.
struct tm { /* a broken-down time */
int tm_sec; /* seconds after the minute: [0 - 60] */
int tm_min; /* minutes after the hour: [0 - 59] */
int tm_hour; /* hours after midnight: [0 - 23] */
int tm_mday; /* day of the month: [1 - 31] */
int tm_mon; /* months since January: [0 - 11] */
int tm_year; /* years since 1900 */
int tm_wday; /* days since Sunday: [0 - 6] */
int tm_yday; /* days since January 1: [0 - 365] */
int tm_isdst; /* daylight saving time flag: <0, 0, >0 */
};
The reason that the seconds can be greater than 59 is to allow for a leap second. Note that all the fields except the day of the month are 0-based. The daylight saving time flag is positive if daylight saving time is in effect, 0 if it's not in effect, and negative if the information isn't available.
In previous versions of the Single UNIX Specification, double leap seconds were allowed. Thus, the valid range of values for the tm_sec member was 061. The formal definition of UTC doesn't allow for double leap seconds, so the valid range for seconds is now defined to be 060.
#include <time.h>
struct tm *gmtime(const time_t *calptr);
struct tm *localtime(const time_t *calptr);
| Both return: pointer to broken-down time |
The difference between localtime and gmtime is that the first converts the calendar time to the local time, taking into account the local time zone and daylight saving time flag, whereas the latter converts the calendar time into a broken-down time expressed as UTC.
The function mktime takes a broken-down time, expressed as a local time, and converts it into a time_t value.
#include <time.h>
time_t mktime(struct tm *tmptr);
| Returns: calendar time if OK, 1 on error |
The asctime and ctime functions produce the familiar 26-byte string that is similar to the default output of the date(1) command:
Tue Feb 10 18:27:38 2004\n\0
#include <time.h>
char *asctime(const struct tm *tmptr);
char *ctime(const time_t *calptr);
| Both return: pointer to null-terminated string |
The argument to asctime is a pointer to a broken-down string, whereas the argument to ctime is a pointer to a calendar time.
The final time function, strftime, is the most complicated. It is a printf-like function for time values.
#include <time.h>
size_t strftime(char *restrict buf, size_t maxsize,
const char *restrict format,
const struct tm *restrict tmptr);
| Returns: number of characters stored in array if room, 0 otherwise |
The final argument is the time value to format, specified by a pointer to a broken-down time value. The formatted result is stored in the array buf whose size is maxsize characters. If the size of the result, including the terminating null, fits in the buffer, the function returns the number of characters stored in buf, excluding the terminating null. Otherwise, the function returns 0.
The format argument controls the formatting of the time value. Like the printf functions, conversion specifiers are given as a percent followed by a special character. All other characters in the format string are copied to the output. Two percents in a row generate a single percent in the output. Unlike the printf functions, each conversion specified generates a different fixed-size output stringthere are no field widths in the format string. Figure 6.9 describes the 37 ISO C conversion specifiers. The third column of this figure is from the output of strftime under Linux, corresponding to the time and date Tue Feb 10 18:27:38 EST 2004.
Figure 6.9. Conversion specifiers for strftimeFormat | Description | Example |
|---|
%a | abbreviated weekday name | Tue
| %A | full weekday name | Tuesday
| %b | abbreviated month name | Feb
| %B | full month name | February
| %c | date and time | Tue Feb 10 18:27:38 2004
| %C | year/100: [0099] | 20
| %d | day of the month: [0131] | 10
| %D | date [MM/DD/YY] | 02/10/04
| %e | day of month (single digit preceded by space) [131] | 10
| %F | ISO 8601 date format [YYYYMMDD] | 2004-02-10
| %g | last two digits of ISO 8601 week-based year [0099] | 04
| %G | ISO 8601 week-based year | 2004
| %h | same as %b | Feb
| %H | hour of the day (24-hour format): [0023] | 18
| %I | hour of the day (12-hour format): [0112] | 06
| %j | day of the year: [001366] | 041
| %m | month: [0112] | 02
| %M | minute: [0059] | 27
| %n | newline character | | %p | AM/PM | PM | %r | locale's time (12-hour format) | 06:27:38 PM
| %R | same as "%H:%M" | 18:27
| %S | second: [0060] | 38
| %t | horizontal tab character | | %T | same as "%H:%M:%S" | 18:27:38
| %u | ISO 8601 weekday [Monday=1, 17] | 2
| %U | Sunday week number: [0053] | 06
| %V | ISO 8601 week number: [0153] | 07
| %w | weekday: [0=Sunday, 06] | 2
| %W | Monday week number: [0053] | 06
| %x | date | 02/10/04
| %X | time | 18:27:38
| %y | last two digits of year: [0099] | 04
| %Y | year | 2004
| %z | offset from UTC in ISO 8601 format | -0500
| %Z | time zone name | EST
| %% | translates to a percent sign | %
|
The only specifiers that are not self-evident are %U, %V, and %W. The %U specifier represents the week number of the year, where the week containing the first Sunday is week 1. The %W specifier represents the week number of the year, where the week containing the first Monday is week 1. The %V specifier is different. If the week containing the first day in January has four or more days in the new year, then this is treated as week 1. Otherwise, it is treated as the last week of the previous year. In both cases, Monday is treated as the first day of the week.
As with printf, strftime supports modifiers for some of the conversion specifiers. The E and O modifiers can be used to generate an alternate format if supported by the locale.
Some systems support additional, nonstandard extensions to the format string for strftime.
We mentioned that the four functions in Figure 6.8 with dashed lines were affected by the TZ environment variable: localtime, mktime, ctime, and strftime. If defined, the value of this environment variable is used by these functions instead of the default time zone. If the variable is defined to be a null string, such as TZ=, then UTC is normally used. The value of this environment variable is often something like TZ=EST5EDT, but POSIX.1 allows a much more detailed specification. Refer to the Environment Variables chapter of the Single UNIX Specification [Open Group 2004] for all the details on the TZ variable.
All the time and date functions described in this section, except gettimeofday, are defined by the ISO C standard. POSIX.1, however, added the TZ environment variable. On FreeBSD 5.2.1, Linux 2.4.22, and Mac OS X 10.3, more information on the TZ variable can be found in the tzset(3) manual page. On Solaris 9, this information is in the environ(5) manual page.
6.11. Summary
The password file and the group file are used on all UNIX systems. We've looked at the various functions that read these files. We've also talked about shadow passwords, which can help system security. Supplementary group IDs provide a way to participate in multiple groups at the same time. We also looked at how similar functions are provided by most systems to access other system-related data files. We discussed the POSIX.1 functions that programs can use to identify the system on which they are running. We finished the chapter with a look at the time and date functions provided by ISO C and the Single UNIX Specification.
|

 LINUX
LINUX 
 Books
Books
