Smart Pointers
На Smart pointers были потрачены реки чернил и горы кода.
Являясь одной из самых запутанных тем С++,они таят в себе много синтаксических и семантических проблем.
В этом разделе обсуждаются их аспекты- от самых простых до самых сложных,
ошибки в их реализации и разрешение проблем.
smart pointers-обьект,который похож на обычный указатель,
но реализован с помощью operator-> и унарного operator*.
Их часто используют для управления памятью и контролем за временем жизни
обьектов,построенных на указателях.
В этой главе также реализован класс-шаблон SmartPtr.
SmartPtr по сути есть smart pointer,
он достаточно надежен и легок в управлении.
После чтения этой главы,вы узнаете :
О преимуществах и недостатках smart pointers О стратегии управления обьектами О неявных преобразованиях О сравнительных тестах О том,что такое Multithreading
В этой главе реализован дженерик SmartPtr class template.
Представлено несколько вариантов реализации.
В конце сделана обобщенная реализация.
|
Smart Pointers 101
So what's a smart pointer? A smart pointer is a C++ class that mimics a regular pointer in syntax and some semantics, but it does more. Because smart pointers to different types of objects tend to have a lot of code in common, almost all good-quality smart pointers in existence are templated by the pointee type, as you can see in the following code:
template <class T>
class SmartPtr
{
public:
explicit SmartPtr(T* pointee) : pointee_(pointee);
SmartPtr& operator=(const SmartPtr& other);
~SmartPtr();
T& operator*() const
{
...
return *pointee_;
}
T* operator->() const
{
...
return pointee_;
}
private:
T* pointee_;
...
};
SmartPtr<T> aggregates a pointer to T in its member variable pointee_. That's what most smart pointers do. In some cases, a smart pointer might aggregate some handles to data and compute the pointer on the fly.
The two operators give SmartPtr pointer-like syntax and semantics. That is, you can write
class Widget
{
public:
void Fun();
};
SmartPtr<Widget> sp(new Widget);
sp->Fun();
(*sp).Fun();
Aside from the definition of sp, nothing reveals it as not being a pointer. This is the mantra of smart pointers: You can replace pointer definitions with smart pointer definitions without incurring major changes to your application's code. You thus get extra goodies with ease. Minimizing code changes is very appealing and vital for getting large applications to use smart pointers. As you will soon see, however, smart pointers are not a free lunch.

|
7.2 The Deal
But what's the deal with smart pointers? you might ask. What do you gain by replacing simple pointers with smart pointers? The explanation is simple. Smart pointers have value semantics, whereas some simple pointers do not.
An object with value semantics is an object that you can copy and assign to. Type int is the perfect example of a first-class object. You can create, copy, and change integer values freely. A pointer that you use to iterate in a buffer also has value semanticsyou initialize it to point to the beginning of the buffer, and you bump it until you reach the end. Along the way, you can copy its value to other variables to hold temporary results.
With pointers that hold values allocated with new, however, the story is very different. Once you have written
Widget* p = new Widget;
the variable p not only points to, but also owns, the memory allocated for the Widget object. This is because later you must issue delete p to ensure that the Widget object is destroyed and its memory is released. If in the line after the line just shown you write
p = 0; // assign something else to p
you lose ownership of the object previously pointed to by p, and you have no chance at all to get a grip on it again. You have a resource leak, and resource leaks never help.
Furthermore, when you copy p into another variable, the compiler does not automatically manage the ownership of the memory to which the pointer points. All you get is two raw pointers pointing to the same object, and you have to track them even more carefully because double deletions are even more catastrophic than no deletion. Consequently, pointers to allocated objects do not have value semanticsyou cannot copy and assign to them at will.
Smart pointers can be of great help in this area. Most smart pointers offer ownership management in addition to pointer-like behavior. Smart pointers can figure out how ownership evolves, and their destructors can release the memory according to a well-defined strategy. Many smart pointers hold enough information to take full initiative in releasing the pointed-to object.
Smart pointers may manage ownership in various ways, each appropriate to a category of problems. Some smart pointers transfer ownership automatically: After you copy a smart pointer to an object, the source smart pointer becomes null, and the destination points to (and holds ownership of) the object. This is the behavior implemented by the standard-provided std::auto_ptr. Other smart pointers implement reference counting: They track the total count of smart pointers that point to the same object, and when this count goes down to zero, they delete the pointed-to object. Finally, some others duplicate their pointed-to object whenever you copy them.
In short, in the smart pointers' world, ownership is an important topic. By providing ownership management, smart pointers are able to support integrity guarantees and full value semantics. Because ownership has much to do with constructing, copying, and destroying smart pointers, it's easy to figure out that these are the most vital functions of a smart pointer.
The following few sections discuss various aspects of smart pointer design and implementation. The goal is to render smart pointers as close to raw pointers as possible, but not closer. It's a contradictory goal: After all, if your smart pointers behave exactly like dumb pointers, they are dumb pointers.
In implementing compatibility between smart pointers and raw pointers, there is a thin line between nicely filling compatibility checklists and paving the way to chaos. You will find that adding seemingly worthwhile features might expose the clients to costly risks. Much of the craft of implementing good smart pointers consists of carefully balancing their set of features.
|
7.3 Storage of Smart Pointers
To start, let's ask a fundamental question about smart pointers. Is pointee_'s type necessarily T*? If not, what else could it be? In generic programming, you should always ask yourself questions like these. Each type that's hardcoded in a piece of generic code decreases the genericity of the code. Hardcoded types are to generic code what magic constants are to regular code.
In several situations, it is worthwhile to allow customizing the pointee type. One situation is when you deal with nonstandard pointer modifiers. In the 16-bit Intel 80x86 days, you could qualify pointers with modifiers like __near, __far, and __huge. Other segmented memory architectures use similar modifiers.
Another situation is when you want to layer smart pointers. What if you have a LegacySmartPtr<T> smart pointer implemented by someone else, and you want to enhance it? Would you derive from it? That's a risky decision. It's better to wrap the legacy smart pointer into a smart pointer of your own. This is possible because the inner smart pointer supports pointer syntax. From the outer smart pointer's viewpoint, the pointee type is not T* but LegacySmartPtr<T>.
There are interesting applications of smart pointer layering, mainly because of the mechanics of operator->. When you apply operator-> to a type that's not a built-in pointer, the compiler does an interesting thing. After looking up and applying the user-defined operator-> to that type, it applies operator-> again to the result. The compiler keeps doing this recursively until it reaches a pointer to a built-in type, and only then proceeds with member access. It follows that a smart pointer's operator-> does not have to return a pointer. It can return an object that in turn implements operator->, without changing the use syntax.
This leads to a very interesting idiom: pre-and postfunction calls (Stroustrup 2000). If you return an object of type PointerType by value from operator->, the sequence of execution is as follows:
Constructor of PointerType PointerType::operator-> called; likely returns a pointer to an object of type PointeeType Member access for PointeeTypelikely a function call Destructor of PointerType
In a nutshell, you have a nifty way of implementing locked function calls. This idiom has broad uses with multithreading and locked resource access. You can have PointerType's constructor lock the resource, and then you can access the resource; finally, Pointer Type's destructor unlocks the resource.
The generalization doesn't stop here. The syntax-oriented "pointer" part might sometimes pale in comparison with the powerful resource management techniques that are included in smart pointers. It follows that, in rare cases, smart pointers could drop the pointer syntax. An object that does not define operator-> and operator* violates the definition of a smart pointer, but there are objects that do deserve smart pointerlike treatment, although they are not, strictly speaking, smart pointers.
Look at real-world APIs and applications. Many operating systems foster handles as accessors to certain internal resources, such as windows, mutexes, or devices. Handles are intentionally obfuscated pointers; one of their purposes is to prevent their users from manipulating critical operating system resources directly. Most of the time, handles are integral values that are indices in a hidden table of pointers. The table provides the additional level of indirection that protects the inner system from the application programmers. Although they don't provide an operator->, handles resemble pointers in semantics and in the way they are managed.
For such a smart resource, it does not make sense to provide operator-> or operator*. However, you do take advantage of all the resource management techniques that are specific to smart pointers.
To generalize the type universe of smart pointers, we distinguish three potentially distinct types in a smart pointer:
The storage type.
This is the type of pointee_. By "default"in regular smart pointersit is a raw pointer.
The pointer type.
This is the type returned by operator->. It can be different from the storage type if you want to return a proxy object instead of just a pointer. (You will find an example of using proxy objects later in this chapter.)
The reference type.
This is the type returned by operator*.
It would be useful if SmartPtr supported this generalization in a flexible way. Thus, the three types mentioned here ought to be abstracted in a policy called Storage.
In conclusion, smart pointers can, and should, generalize their pointee type. To do this, SmartPtr abstracts three types in a Storage policy: the stored type, the pointer type, and the reference type. Not all types necessarily make sense for a given SmartPtr instantiation. Therefore, in rare cases (handles), a policy might disable access to operator-> or operator* or both.
|
7.4 Smart Pointer Member Functions
Many existing smart pointer implementations allow operations through member functions, such as Get for accessing the pointee object, Set for changing it, and Release for taking over ownership. This is the obvious and natural way of encapsulating SmartPtr's functionality.
However, experience has proven that member functions are not very suitable for smart pointers. The reason is that the interaction between member function calls for the smart pointer for the pointed-to object can be extremely confusing.
Suppose, for instance, that you have a Printer class with member functions such as Acquire and Release. With Acquire you take ownership of the printer so that no other application prints to it, and with Release you relinquish ownership. As you use a smart pointer to Printer, you may notice a strange syntactical closeness to things that are very far apart semantically.
SmartPtr<Printer> spRes = ...;
spRes->Acquire(); // acquire the printer
... print a document ...
spRes->Release(); // release the printer
spRes.Release(); // release the pointer to the printer
The user of SmartPtr now has access to two totally different worlds: the world of the pointed-to object members and the world of the smart pointer members. A matter of a dot or an arrow thinly separates the two worlds.
On the face of it, C++ does force you routinely to observe certain slight differences in syntax. A Pascal programmer learning C++ might even feel that the slight syntactic difference between & and && is an abomination. Yet C++ programmers don't even blink at it. They are trained by habit to distinguish such syntax matters easily.
However, smart pointer member functions defeat training by habit. Raw pointers don't have member functions, so C++ programmers' eyes are not habituated to detect and distinguish dot calls from arrow calls. The compiler does a good job at that: If you use a dot after a raw pointer, the compiler will yield an error. Therefore, it is easy to imagine, and experience proves, that even seasoned C++ programmers find it extremely disturbing that both sp.Release() and sp->Release() compile flag-free but do very different things. The cure is simple: A smart pointer should not use member functions. SmartPtr uses only nonmember functions. These functions become friends of the smart pointer class.
Overloaded functions can be just as confusing as member functions of smart pointers, but there is an important difference. C++ programmers already use overloaded functions. Overloading is an important part of the C++ language and is used routinely in library and application development. This means that C++ programmers do pay attention to differences in function call syntaxsuch as Release(*sp) versus Release(sp)in writing and reviewing code.
The only functions that necessarily remain members of SmartPtr are the constructors, the destructor, operator=, operator->, and unary operator*. All other operations of SmartPtr are provided through named nonmember functions.
For reasons of clarity, SmartPtr does not have any named member functions. The only functions that access the pointee object are GetImpl, GetImplRef, Reset, and Release, which are defined at the namespace level.
template <class T> T* GetImpl(SmartPtr<T>& sp);
template <class T> T*& GetImplRef(SmartPtr<T>& sp);
template <class T> void Reset(SmartPtr<T>& sp, T* source);
template <class T> void Release(SmartPtr<T>& sp, T*& destination);
GetImpl returns the pointer object stored by SmartPtr. GetImplRef returns a reference to the pointer object stored by SmartPtr. GetImplRef allows you to change the underlying pointer, so it requires extreme care in use. Reset resets the underlying pointer to another value, releasing the previous one. Release releases ownership of the smart pointer, giving its user the responsibility of managing the pointee object's lifetime.
The actual declarations of these four functions in Loki are slightly more elaborate. They don't assume that the type of the pointer object stored by SmartPtr is T*. As discussed in Section 7.3, the Storage policy defines the pointer type. Most of the time, it's a straight pointer, except in exotic implementations of Storage, when it might be a handle or an elaborate type.
|
7.5 Ownership-Handling Strategies
Ownership handling is often the most important raison d'âtre of smart pointers. Usually, from their clients' viewpoint, smart pointers own the objects to which they point. A smart pointer is a first-class value that takes care of deleting the pointed-to object under the covers. The client can intervene in the pointee object's lifetime by issuing calls to helper management functions.
For implementing self-ownership, smart pointers must carefully track the pointee object, especially during copying, assignment, and destruction. Such tracking brings some overhead in space, time, or both. An application should settle on the strategy that best fits the problem at hand and does not cost too much.
The following subsections discuss the most popular ownership management strategies and how SmartPtr implements them.
7.5.1 Deep Copy
The simplest strategy applicable is to copy the pointee object whenever you copy the smart pointer. If you ensure this, there is only one smart pointer for each pointee object. Therefore, the smart pointer's destructor can safely delete the pointee object. Figure 7.1 depicts the state of affairs if you use smart pointers with deep copy.
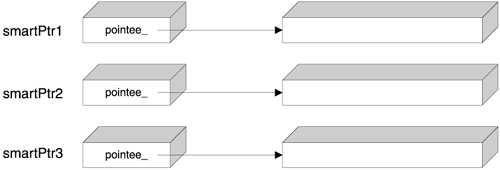
At first glance, the deep copy strategy sounds rather dull. It seems as if the smart pointer does not add any value over regular C++ value semantics. Why would you make the effort of using a smart pointer, when simple pass by value of the pointee object works just as well?
The answer is support for polymorphism. Smart pointers are vehicles for transporting polymorphic objects safely. You hold a smart pointer to a base class, which might actually point to a derived class. When you copy the smart pointer, you want to copy its polymorphic behavior, too. It's interesting that you don't exactly know what behavior and state you are dealing with, but you certainly need to duplicate that behavior and state.
Because deep copy most often deals with polymorphic objects, the following naive implementation of the copy constructor is wrong:
template <class T>
class SmartPtr
{
public:
SmartPtr(const SmartPtr& other)
: pointee_(new T(*other.pointee_))
{
}
...
};
Say you copy an object of type SmartPtr<Widget>. If other points to an instance of a class ExtendedWidget that derives from Widget, the copy constructor above copies only the Widget part of the ExtendedWidget object. This phenomenon is known as slicingonly the Widget "slice" of the object of the presumably larger type ExtendedWidget gets copied. Slicing is most often undesirable. It is a pity that C++ allows slicing so easilya simple call by value slices objects without any warning.
Chapter 8 discusses cloning in depth. As shown there, the classic way of obtaining a polymorphic clone for a hierarchy is to define a virtual Clone function and implement it as follows:
class AbstractBase
{
...
virtual Base* Clone() = 0;
};
class Concrete : public AbstractBase
{
...
virtual Base* Clone()
{
return new Concrete(*this);
}
};
The Clone implementation must follow the same pattern in all derived classes; in spite of its repetitive structure, there is no reasonable way to automate defining the Clone member function (beyond macros, that is).
A generic smart pointer cannot count on knowing the exact name of the cloning member functionmaybe it's clone, or maybe MakeCopy. Therefore, the most flexible approach is to parameterize SmartPtr with a policy that addresses cloning.
7.5.2 Copy on Write
Copy on write (COW, as it is fondly called by its fans) is an optimization technique that avoids unnecessary object copying. The idea that underlies COW is to clone the pointee object at the first attempt of modification; until then, several pointers can share the same object.
Smart pointers, however, are not the best place to implement COW, because smart pointers cannot differentiate between calls to const and non-const member functions of the pointee object. Here is an example:
template <class T>
class SmartPtr
{
public:
T* operator->() { return pointee_; }
...
};
class Foo
{
public:
void ConstFun() const;
void NonConstFun();
};
...
SmartPtr<Foo> sp;
sp->ConstFun(); // invokes operator->, then ConstFun
sp->NonConstFun(); // invokes operator->, then NonConstFun
The same operator-> gets invoked for both functions called; therefore, the smart pointer does not have any clue whether to make the COW or not. Function invocations for the pointee object happen somewhere beyond the reach of the smart pointer. (Section 7.11 explains how const interacts with smart pointers and the objects they point to.)
In conclusion, COW is effective mostly as an implementation optimization for full-featured classes. Smart pointers are at too low a level to implement COW semantics effectively. Of course, smart pointers can be good building blocks in implementing COW for a class.
The SmartPtr implementation in this chapter does not provide support for COW.
7.5.3 Reference Counting
Reference counting is the most popular ownership strategy used with smart pointers. Reference counting tracks the number of smart pointers that point to the same object. When that number goes to zero, the pointee object is deleted. This strategy works very well if you don't break certain rulesfor instance, you should not keep dumb pointers and smart pointers to the same object.
The actual counter must be shared among smart pointer objects, leading to the structure depicted in Figure 7.2. Each smart pointer holds a pointer to the reference counter (pRefCount_ in Figure 7.2) in addition to the pointer to the object itself. This usually doubles the size of the smart pointer, which may or may not be an acceptable amount of overhead, depending on your needs and constraints.
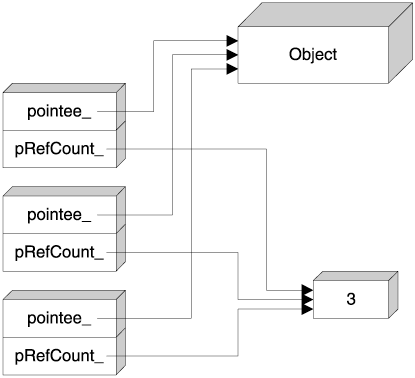
There is another, subtler overhead issue. Reference-counted smart pointers must store the reference counter on the free store. The problem is that in many implementations, the default C++ free store allocator is remarkably slow and wasteful of space when it comes to allocating small objects, as discussed in Chapter 4. (Obviously, the reference count, typically occupying 4 bytes, does qualify as a small object.) The overhead in speed stems from slow algorithms in finding available chunks of memory, and the overhead in size is incurred by the bookkeeping information that the allocator holds for each chunk.
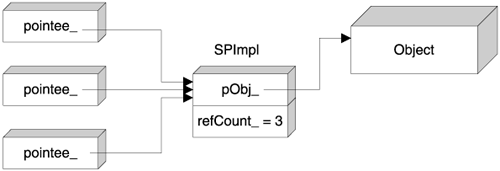
The relative size overhead can be partially mitigated by holding the pointer and the reference count together, as in Figure 7.3. The structure in Figure 7.3 reduces the size of the smart pointer to that of a pointer, but at the expense of access speed: The pointee object is an extra level of indirection away. This is a considerable drawback because you typically use a smart pointer several times, whereas you obviously construct and destroy it only once.
The most efficient solution is to hold the reference counter in the pointee object itself, as shown in Figure 7.4. This way SmartPtr is just the size of a pointer, and there is no extra overhead at all. This technique is known as intrusive reference counting, because the reference count is an "intruder" in the pointeeit semantically belongs to the smart pointer. The name also gives a hint about the Achilles' heel of the technique: You must design up front or modify the pointee class to support reference counting.
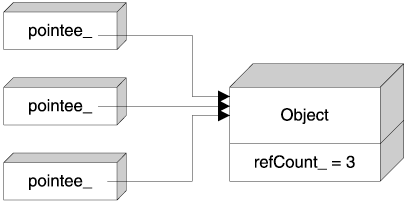
A generic smart pointer should use intrusive reference counting where available and implement a nonintrusive reference counting scheme as an acceptable alternative. For implementing nonintrusive reference counting, the small-object allocator presented in Chapter 4 can help a great deal. The SmartPtr implementation using nonintrusive reference counting leverages the small-object allocator, thus slashing the performance overhead caused by the reference counter.
7.5.4 Reference Linking
Reference linking relies on the observation that you don't really need the actual count of smart pointer objects pointing to one pointee object; you only need to detect when that count goes down to zero. This leads to the idea of keeping an "ownership list," as shown in Figure 7.5.
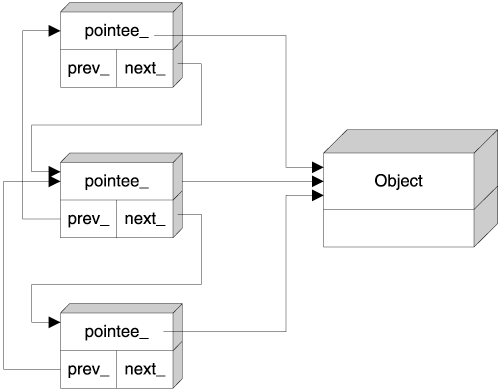
All SmartPtr objects that point to a given pointee form a doubly linked list. When you create a new SmartPtr from an existing SmartPtr, the new object is appended to the list; SmartPtr's destructor takes care of removing the destroyed object from the list. When the list becomes empty, the pointee object is deleted.
The doubly linked list structure fits reference tracking like a glove. You cannot use a singly linked list because removals from such a list take linear time. You cannot use a vector because the SmartPtr objects are not contiguous (and removals from vectors take linear time anyway). You need a structure sporting constant-time append, constant-time remove, and constant-time empty detection. This bill is fit precisely and exclusively by doubly linked lists.
In a reference-linking implementation, each SmartPtr object holds two extra pointersone to the next element and one to the previous element.
The advantage of reference linking over reference counting is that the former does not use extra free store, which makes it more reliable: Creating a reference-linked smart pointer cannot fail. The disadvantage is that reference linking needs more memory for its bookkeeping (three pointers versus only one pointer plus one integer). Also, reference counting should be a bit speedierwhen you copy smart pointers, only an indirection and an increment are needed. The list management is slightly more elaborate. In conclusion, you should use reference linking only when the free store is scarce. Otherwise, prefer reference counting.
To wrap up the discussion on reference count management strategies, let's note a significant disadvantage that they have. Reference managementbe it counting or linkingis a victim of the resource leak known as cyclic reference. Imagine an object A holds a smart pointer to an object B. Also, object B holds a smart pointer to A. These two objects form a cyclic reference; even though you don't use any of them anymore, they use each other. The reference management strategy cannot detect such cyclic references, and the two objects remain allocated forever. The cycles can span multiple objects, closing circles that often reveal unexpected dependencies that are very hard to debug.
In spite of this, reference management is a robust, speedy ownership-handling strategy. If used with precaution, reference management makes application development significantly easier.
7.5.5 Destructive Copy
Destructive copy does exactly what you think it does: During copying, it destroys the object being copied. In the case of smart pointers, destructive copy destroys the source smart pointer by taking its pointee object and passing it to the destination smart pointer. The std::auto_ptr class template features destructive copy.
In addition to being suggestive about the action taken, "destructive" also vividly describes the dangers associated with this strategy. Misusing destructive copy may have destructive effects on your program data, your program correctness, and your brain cells.
Smart pointers may use destructive copy to ensure that at any time there is only one smart pointer pointing to a given object. During the copying or assignment of one smart pointer to another, the "living" pointer is passed to the destination of the copy, and the source's pointee_ becomes zero. The following code illustrates a copy constructor and an assignment operator of a simple SmartPtr featuring destructive copy.
template <class T>
class SmartPtr
{
public:
SmartPtr(SmartPtr& src)
{
pointee_ = src.pointee_;
src.pointee_ = 0;
}
SmartPtr& operator=(SmartPtr& src)
{
if (this != &src)
{
delete pointee_;
pointee_ = src.pointee_;
src.pointee_ = 0;
}
return *this;
}
...
};
C++ etiquette calls for the right-hand side of the copy constructor and the assignment operator to be a reference to a const object. Classes that foster destructive copy break this convention for obvious reasons. Because etiquette exists for a reason, you should expect negative consequences if you break it. Indeed, here they are:
void Display(SmartPtr<Something> sp);
...
SmartPtr<Something> sp(new Something);
Display(sp); // sinks sp
Although Display means no harm to its argument (accepts it by value), it acts like a maelstrom of smart pointers: It sinks any smart pointer passed to it. After Display(sp) is called, sp holds the null pointer.
Because they do not support value semantics, smart pointers with destructive copy cannot be stored in containers and in general must be handled with almost as much care as raw pointers.
The ability to store smart pointers in a container is very important. Containers of raw pointers make manual ownership management tricky, so many containers of pointers can use smart pointers to good advantage. Smart pointers with destructive copy, however, do not mix with containers.
On the bright side, smart pointers with destructive copy have significant advantages:
They incur almost no overhead. They are good at enforcing ownership transfer semantics. In this case, you use the "maelstrom effect" described earlier to your advantage: You make it clear that your function takes over the passed-in pointer. They are good as return values from functions. If the smart pointer implementation uses a certain trick, you can return smart pointers with destructive copy from functions. This way, you can be sure that the pointee object gets destroyed if the caller doesn't use the return value.
They are excellent as stack variables in functions that have multiple return paths. You don't have to remember to delete the pointee object manuallythe smart pointer takes care of this for you.
The destructive copy strategy is used by the standard-provided std::auto_ptr. This brings destructive copy another important advantage:
For these reasons, the SmartPtr implementation should provide optional support for destructive copy semantics.
Smart pointers use various ownership semantics, each having its own trade-offs. The most important techniques are deep copy, reference counting, reference linking, and destructive copy. SmartPtr implements all these strategies through an Ownership policy, allowing its users to choose the one that best fits an application's needs. The default strategy is reference counting.
|
7.6 The Address-of Operator
In striving to make smart pointers as indistinguishable as possible from their native counterparts, designers stumbled upon an obscure operator that is on the list of overloadable operators: unary operator&, the address-of operator.
An implementer of smart pointers might choose to overload the address-of operator like this:
template <class T>
class SmartPtr
{
public:
T** operator&()
{
return &pointee_;
}
...
};
After all, if a smart pointer is to simulate a pointer, then its address must be substitutable for the address of a regular pointer. This overload makes code like the following possible:
void Fun(Widget** pWidget);
...
SmartPtr<Widget> spWidget(...);
Fun(&spWidget); // okay, invokes operator* and obtains a
// pointer to pointer to Widget
It seems very desirable to have such an accurate compatibility between smart pointers and dumb pointers, but overloading the unary operator& is one of those clever tricks that can do more harm than good. There are two reasons why overloading unary operator& is not a very good idea.
One reason is that exposing the address of the pointed-to object implies giving up any automatic ownership management. When a client freely accesses the address of the raw pointer, any helper structures that the smart pointer holds, such as reference counts, become invalid for all purposes. While the client deals directly with the address of the raw pointer, the smart pointer is completely unconscious.
The second reason, a more pragmatic one, is that overloading unary operator& makes the smart pointer unusable with STL containers. Actually, overloading unary operator& for a type pretty much makes generic programming impossible for that type, because the address of an object is too fundamental a property to play with naively. Most generic code assumes that applying & to an object of type T returns an object of type T*you see, address-of is a fundamental concept. If you defy this concept, generic code behaves strangely either at compile time orworseat runtime.
Thus, it is not recommended that unary operator& be overloaded for smart pointers or for any objects in general. SmartPtr does not overload unary operator&.
|
7.7 Implicit Conversion to Raw Pointer Types
Consider this code:
void Fun(Something* p);
...
SmartPtr<Something> sp(new Something);
Fun(sp); // OK or error?
Should this code compile or not? Following the "maximum compatibility" line of thought, the answer is yes.
Technically, it is very simple to render the previous code compilable by introducing a user-defined conversion:
template <class T>
class SmartPtr
{
public:
operator T*() // user-defined conversion to T*
{
return pointee_;
}
...
};
However, this is not the end of the story.
User-defined conversions in C++ have an interesting history. Back in the 1980s, when user-defined conversions were introduced, most programmers considered them a great invention. User-defined conversions promised a more unified type system, expressive semantics, and the ability to define new types that were indistinguishable from built-in ones. With time, however, user-defined conversions revealed themselves as awkward and potentially dangerous. They might become dangerous especially when they expose handles to internal data (Meyers 1998a, Item 29), which is precisely the case with the operator T* in the previous code. That's why you should think carefully before allowing automatic conversions for the smart pointers you design.
One potential danger comes inherently from giving the user unattended access to the raw pointer that the smart pointer wraps. Passing the raw pointer around defeats the inner workings of the smart pointer. Once unleashed from the confines of its wrapper, the raw pointer can easily become a threat to program sanity again, just as it was before smart pointers were introduced.
Another danger is that user-defined conversions pop up unexpectedly, even when you don't need them. Consider the following code:
SmartPtr<Something> sp;
...
// A gross semantic error
// However, it goes undetected at compile time
delete sp;
The compiler matches operator delete with the user-defined conversion to T*. At runtime, operator T* is called, and delete is applied to its result. This is certainly not what you want to do to a smart pointer, because it is supposed to manage ownership itself. An extra unwitting delete call throws out the window all the careful ownership management that the smart pointer performs under the covers.
There are quite a few ways to prevent the delete call from compiling. Some of them are very ingenious (Meyers 1996). One that's very effective and easy to implement is to make the call to delete intentionally ambiguous. You can achieve this by providing two automatic conversions to types that are susceptible to a call to delete. One type is T* itself, and the other can be void*.
template <class T>
class SmartPtr
{
public:
operator T*() // User-defined conversion to T*
{
return pointee_;
}
operator void*() // Added conversion to void*
{
return pointee_;
}
...
};
A call to delete against such a smart pointer object is ambiguous. The compiler cannot decide which conversion to apply, and the trick above exploits this indecision to good advantage.
Don't forget that disabling the delete operator was only a part of the issue. Whether to provide an automatic conversion to a raw pointer remains an important decision in implementing a smart pointer. It's too dangerous just to let it in, yet too convenient to rule it out. The final SmartPtr implementation will give you a choice about that.
However, forbidding implicit conversion does not necessarily eliminate all access to the raw pointer; it is often necessary to gain such access. Therefore, all smart pointers do provide explicit access to their wrapped pointer via a call to a function:
void Fun(Something* p);
...
SmartPtr<Something> sp;
Fun(GetImpl(sp)); // OK, explicit conversion always allowed
It's not a matter of whether you can get to the wrapped pointer; it's how easy it is. This may seem like a minor difference, but it's actually very important. An implicit conversion happens without the programmer or the maintainer noticing or even knowing it. An explicit conversionas is the call to GetImplpasses through the mind, the understanding, and the fingers of the programmer and remains written in the code for everybody to see it.
Implicit conversion from the smart pointer type to the raw pointer type is desirable, but sometimes dangerous. SmartPtr provides this implicit conversion as a choice. The default is on the safe sideno implicit conversions. Explicit access is always available through the GetImpl function.
|
7.8 Equality and Inequality
C++ teaches its users that any clever trick such as the one presented in the previous section (intentional ambiguity) establishes a new context, which in turn may have unexpected ripples.
Consider tests for equality and inequality of smart pointers. A smart pointer should support the same comparison syntax that raw pointers support. Programmers expect the following tests to compile and run as they do for a raw pointer.
SmartPtr<Something> sp1, sp2;
Something* p;
...
if (sp1) // Test 1: direct test for non-null pointer
...
if (!sp1) // Test 2: direct test for null pointer
...
if (sp1 == 0) // Test 3: explicit test for null pointer
...
if (sp1 == sp2) // Test 4: comparison of two smart pointers
...
if (sp1 == p) // Test 5: comparison with a raw pointer
...
There are more tests than depicted here if you consider symmetry and operator!=. If we solve the equality tests, we can easily define the corresponding symmetric and inequality tests.
There is an unfortunate interference between the solution to the previous issue (preventing delete from compiling) and a possible solution to this issue. With one user-defined conversion to the pointee type, most of the test expressions (except test 4) compile successfully and run as expected. The downside is that you can accidentally call the delete operator against the smart pointer. With two user-defined conversions (intentional ambiguity), you detect wrongful delete calls, but none of these tests compiles anymorethey have become ambiguous too.
An additional user-defined conversion to bool helps, but this, to nobody's surprise, introduces new trouble. Given this smart pointer:
template <class T>
class SmartPtr
{
public:
operator bool() const
{
return pointee_ != 0;
}
...
};
the four tests compile, but so do the following nonsensical operations:
SmartPtr<Apple> sp1;
SmartPtr<Orange> sp2; // Orange is unrelated to Apple
if (sp1 == sp2) // Converts both pointers to bool
// and compares results
...
if (sp1 != sp2) // Ditto
...
bool b = sp1; // The conversion allows this, too
if (sp1 * 5 == 200) // Ouch! SmartPtr behaves like an integral
// type!
...
As you can see, it's either not at all or too much: Once you add a user-defined conversion to bool, you allow SmartPtr to act as a bool in many more situations than you actually wanted. For all practical purposes, defining an operator bool for a smart pointer is not a smart solution.
A true, complete, rock-solid solution to this dilemma is to go all the way and overload each and every operator separately. This way any operation that makes sense for the bare pointer makes sense for the smart pointer, and nothing else. Here is the code that implements this idea.
template <class T>
class SmartPtr
{
public:
bool operator!() const // Enables "if (!sp) ..."
{
return pointee_ == 0;
}
inline friend bool operator==(const SmartPtr& lhs,
const T* rhs)
{
return lhs.pointee_ == rhs;
}
inline friend bool operator==(const T* lhs,
const SmartPtr& rhs)
{
return lhs == rhs.pointee_;
}
inline friend bool operator!=(const SmartPtr& lhs,
const T* rhs)
{
return lhs.pointee_ != rhs;
}
inline friend bool operator!=(const T* lhs,
const SmartPtr& rhs)
{
return lhs != rhs.pointee_;
}
...
};
Yes, it's a pain, but this approach solves the problems with almost all comparisons, including the tests against the literal zero. What the forwarding operators in this code do is to pass operators that client code applies to the smart pointer on to the raw pointer that the smart pointer wraps. No simulation can be more realistic than that.
We still haven't solved the problem completely. If you provide an automatic conversion to the pointee type, there still is the risk of ambiguities. Suppose you have a class Base and a class Derived that inherits Base. Then the following code makes practical sense yet is ill formed due to ambiguity.
SmartPtr<Base> sp;
Derived* p;
...
if (sp == p) {} // error! Ambiguity between:
// '(Base*)sp == (Base*)p'
// and 'operator==(sp, (Base*)p)'
Indeed, smart pointer development is not for the faint of heart.
We're not out of bullets, though. In addition to the definitions of operator== and operator!=, we can add templated versions of them, as you can see in the following code:
template <class T>
class SmartPtr
{
public:
... as above ...
template <class U>
inline friend bool operator==(const SmartPtr& lhs,
const U* rhs)
{
return lhs.pointee_ == rhs;
}
template <class U>
inline friend bool operator==(const U* lhs,
const SmartPtr& rhs)
{
return lhs == rhs.pointee_;
}
... similarly defined operator!= ...
};
The templated operators are "greedy" in the sense that they match comparisons with any pointer type whatsoever, thus consuming the ambiguity.
If that's the case, why should we keep the nontemplated operatorsthe ones that take the pointee type? They never get a chance to match, because the template matches any pointer type, including the pointee type itself.
The rule that "never" actually means "almost never" applies here, too. In the test if (sp == 0), the compiler tries the following matches.
The templated operators.
They don't match because zero is not a pointer type. A literal zero can be implicitly converted to a pointer type, but template matching does not include conversions.
The nontemplated operators.
After eliminating the templated operators, the compiler tries the nontemplated ones. One of these operators kicks in through an implicit conversion from the literal zero to the pointee type. Had the nontemplated operators not existed, the test would have been an error.
In conclusion, we need both the nontemplated and the templated comparison operators.
Let's see now what happens if we compare two SmartPtrs instantiated with different types.
SmartPtr<Apple> sp1;
SmartPtr<Orange> sp2;
if (sp1 == sp2)
...
The compiler chokes on the comparison because of an ambiguity: Each of the two SmartPtr instantiations defines an operator==, and the compiler does not know which one to choose. We can dodge this problem by defining an "ambiguity buster" as shown:
template <class T>
class SmartPtr
{
public:
// Ambiguity buster
template <class U>
bool operator==(const SmartPtr<U>& rhs) const
{
return pointee_ == rhs.pointee_;
}
// Similarly for operator!=
...
};
This newly added operator is a member that specializes exclusively in comparing SmartPtr<...> objects. The beauty of this ambiguity buster is that it makes smart pointer comparisons act like raw pointer comparisons. If you compare two smart pointers to Apple and Orange, the code will be essentially equivalent to comparing two raw pointers to Apple and Orange. If the comparison makes sense, then the code compiles; otherwise, it's a compile-time error.
SmartPtr<Apple> sp1;
SmartPtr<Orange> sp2;
if (sp1 == sp2) // Semantically equivalent to
// sp1.pointee_ == sp2.pointee_
...
There is one unsatisfied syntactic artifact left, namely, the direct test if (sp). Here life becomes really interesting. The if statement applies only to expressions of arithmetic and pointer type. Consequently, to allow if (sp) to compile, we must define an automatic conversion to either an arithmetic or a pointer type.
A conversion to arithmetic type is not recommended, as the earlier experience with operator bool witnesses. A pointer is not an arithmetic type, period. A conversion to a pointer type makes a lot more sense, and here the problem branches.
If you want to provide automatic conversions to the pointee type (see previous section), then you have two choices: Either you risk unattended calls to operator delete, or you forgo the if (sp) test. The tiebreaker is between the lack of convenience and a risky life. The winner is safety, so you cannot write if (sp). Instead, you can choose between if(sp != 0) and the more baroque if (!!sp). End of story.
If you don't want to provide automatic conversions to the pointee type, there is an interesting trick you can use to make if (sp) possible. Inside the SmartPtr class template, define an inner class Tester and define a conversion to Tester*, as shown in the following code:
template <class T>
class SmartPtr
{
class Tester
{
void operator delete(void*);
};
public:
operator Tester*() const
{
if (!pointee_) return 0;
static Tester test;
return &test;
}
...
};
Now if you write if (sp), operator Tester* enters into action. This operator returns a null value if and only if pointee_ is null. Tester itself disables operator delete, so if somebody calls delete sp, a compile-time error occurs. Interestingly, Tester's definition itself lies in the private part of SmartPtr, so the client code cannot do anything else with it.
SmartPtr addresses the issue of tests for equality and inequality as follows:
Define operator== and operator!= in two flavors (templated and nontemplated). Define operator!. If you allow automatic conversion to the pointee type, then define an additional conversion to void* to ambiguate a call to the delete operator intentionally; otherwise, define a private inner class Tester that declares a private operator delete, and define a conversion to Tester* for SmartPtr that returns a null pointer if and only if the pointee object is null.
|
7.9 Ordering Comparisons
The ordering comparison operators are operator<, operator<=, operator>, and operator>=. You can implement them all in terms of operator<.
Whether to allow ordering of smart pointers is an interesting question in and of itself and relates to the dual nature of pointers, which consistently confuses programmers. Pointers are two concepts in one: iterators and monikers. The iterative nature of pointers allows you to walk through an array of objects using a pointer. Pointer arithmetic, including comparisons, supports this iterative nature of pointers. At the same time, pointers are monikersinexpensive object representatives that can travel quickly and access the objects in a snap. The dereferencing operators * and -> support the moniker concept.
The two natures of pointers can be confusing at times, especially when you need only one of them. For operating with a vector, you might use both iteration and dereferencing, whereas for walking through a linked list or for manipulating individual objects, you use only dereferencing.
Ordering comparisons for pointers is defined only when the pointers belong to the same contiguous memory. In other words, you can use ordering comparisons only for pointers that point to elements in the same array.
Defining ordering comparisons for smart pointers boils down to this question: Do smart pointers to the objects in the same array make sense? On the face of it, the answer is no. Smart pointers' main feature is to manage object ownership, and objects with separate ownership do not usually belong to the same array. Therefore, it would be dangerous to allow users to make nonsensical comparisons.
If you really need ordering comparisons, you can always use explicit access to the raw pointer. The issue here is, again, to find the safest and most expressive behavior for most situations.
The previous section concludes that an implicit conversion to a raw pointer type is optional. If SmartPtr's client chooses to allow implicit conversion, the following code compiles:
SmartPtr<Something> sp1, sp2;
if (sp1 < sp2) // Converts sp1 and sp2 to raw pointer type,
// then performs the comparison
...
This means that if we want to disable ordering comparisons, we must be proactive, disabling them explicitly. A way of doing this is to declare them and never define them, which means that any use will trigger a link-time error.
template <class T>
class SmartPtr
{ ... };
template <class T, class U>
bool operator<(const SmartPtr<T>&, const U&); // Not defined
template <class T, class U>
bool operator<(const T&, const SmartPtr<U>&); // Not defined
However, it is wiser to define all other operators in terms of operator<, as opposed to leaving them undefined. This way, if SmartPtr's users think it's best to introduce smart pointer ordering, they need only define operator<.
// Ambiguity buster
template <class T, class U>
bool operator<(const SmartPtr<T>& lhs, const SmartPtr<U>& rhs)
{
return lhs < GetImpl(rhs);
}
// All other operators
template <class T, class U>
bool operator>(SmartPtr<T>& lhs, const U& rhs)
{
return rhs < lhs;
}
... similarly for the other operators ...
Note the presence, again, of an ambiguity buster. Now if some library user thinks that SmartPtr<Widget> should be ordered, the following code is the ticket:
inline bool operator<(const SmartPtr<Widget>& lhs,
const Widget* rhs)
{
return GetImpl(lhs) < rhs;
}
inline bool operator<(const Widget* lhs,
const SmartPtr<Widget>& rhs)
{
return lhs < GetImpl(rhs);
}
It's a pity that the user must define two operators instead of one, but it's so much better than defining eight.
This would conclude the issue of ordering, were it not for an interesting detail. Sometimes it is very useful to have an ordering of arbitrarily located objects, not just objects belonging to the same array. For example, you might need to store supplementary per-object information, and you need to access that information quickly. A map ordered by the address of objects is very effective for such a task.
Standard C++ helps in implementing such designs. Although pointer comparison for arbitrarily located objects is undefined, the standard guarantees that std::less yields meaningful results for any two pointers of the same type. Because the standard associative containers use std::less as the default ordering relationship, you can safely use maps that have pointers as keys.
SmartPtr should support this idiom, too; therefore, SmartPtr specializes std::less. The specialization simply forwards the call to std::less for regular pointers:
namespace std
{
template <class T>
struct less<SmartPtr<T> >
: public binary_function<SmartPtr<T>, SmartPtr<T>, bool>
{
bool operator()(const SmartPtr<T>& lhs,
const SmartPtr<T>& rhs) const
{
return less<T*>()(GetImpl(lhs), GetImpl(rhs));
}
};
}
In summary, SmartPtr does not define ordering operators by default. It declareswithout implementingtwo generic operator<s and implements all other ordering operators in terms of operator<. The user can define either specialized or generic versions of operator<.
SmartPtr specializes std::less to provide an ordering of arbitrary smart pointer objects.
|
7.10 Checking and Error Reporting
Applications need various degrees of safety from smart pointers. Some programs are computation-intensive and must be optimized for speed, whereas some others (actually, most) are input/output intensive, which allows better runtime checking without degrading performance.
Most often, right inside an application, you might need both models: low safety/high speed in some critical areas, and high safety/lower speed elsewhere.
We can divide checking issues with smart pointers into two categories: initialization checking and checking before dereference.
7.10.1 Initialization Checking
Should a smart pointer accept the null (zero) value?
It is easy to implement a guarantee that a smart pointer cannot be null, and it may be very useful in practice. It means that any smart pointer is always valid (unless you fiddle with the raw pointer by using GetImplRef). The implementation is easy with the help of a constructor that throws an exception if passed a null pointer.
template <class T>
class SmartPtr
{
public:
SmartPtr(T* p) : pointee_(p)
{
if (!p) throw NullPointerException();
}
...
};
On the other hand, the null value is a convenient "not a valid pointer" placeholder and can often be useful.
Whether to allow null values affects the default constructor, too. If the smart pointer doesn't allow null values, then how would the default constructor initialize the raw pointer? The default constructor could be lacking, but that would make smart pointers harder to deal with. For example, what should you do when you have a SmartPtr member variable but don't have an appropriate initializer for it at construction time? In conclusion, customizing initialization involves providing an appropriate default value.
7.10.2 Checking Before Dereference
Checking before dereference is important because dereferencing the null pointer engenders undefined behavior. For many applications, undefined behavior is not acceptable, so checking the pointer for validity before dereference is the way to go. Checks before de reference belong to SmartPtr's operator-> and unary operator*.
In contrast to the initialization check, the check before dereference can become a major performance bottleneck in your application, because typical applications use (dereference) smart pointers much more often than they create smart pointer objects. Therefore, you should keep a balance between safety and speed. A good rule of thumb is to start with rigorously checked pointers and remove checks from selected smart pointers as profiling demonstrates a need for it.
Can initialization checking and checking before dereference be conceptually separated? No, because there are links between them. If you enforce strict checking upon initialization, then checking before dereference becomes redundant because the pointer is always valid.
7.10.3 Error Reporting
The only sensible choice for reporting an error is to throw an exception.
You can do something in the sense of avoiding errors. For example, if a pointer is null upon dereference, you can initialize it on the fly. This is a valid and valuable strategy called lazy initializationyou construct the value only when you first need it.
If you want to check things only during debugging, you can use the standard assert or similar, more sophisticated macros. The compiler ignores the tests in release mode, so, assuming you remove all null pointer errors during debugging, you reap the advantages of both checking and speed.
SmartPtr migrates checking to a dedicated Checking policy. This policy implements checking functions (which can optionally provide lazy initialization) and the error reporting strategy.
|
7.11 Smart Pointers to const and const Smart Pointers
Raw pointers allow two kinds of constness: the constness of the pointed-to object and that of the pointer itself. The following is an illustration of these two attributes:
const Something* pc = new Something; // points to const object
pc->ConstMemberFunction(); // ok
pc->NonConstMemberFunction(); // error
delete pc; // ok (surprisingly)
Something* const cp = new Something; // const pointer
cp->NonConstMemberFunction(); // ok
cp = new Something; // error, can't assign to const pointer
const Something* const cpc = new Something; // const, points to const
cpc->ConstMemberFunction(); // ok
cpc->NonConstMemberFunction(); // error
cpc = new Something; // error, can't assign to const pointer
The corresponding uses of SmartPtr look like this:
// Smart pointer to const object
SmartPtr<const Something> spc(new Something);
// const smart pointer
const SmartPtr<Something> scp(new Something);
// const smart pointer to const object
const SmartPtr<const Something> scpc(new Something);
The SmartPtr class template can detect the constness of the pointed-to object either through partial specialization or by using the TypeTraits template defined in Chapter 2. The latter method is preferable because it does not incur source-code duplication as partial specialization does.
SmartPtr imitates the semantics of pointers to const objects, const pointers, and the combinations thereof.
|
7.12 Arrays
In most cases, instead of dealing with heap-allocated arrays and using new[] and delete[], you're better off with std::vector. The standard-provided std::vector class template provides everything that dynamically allocated arrays provide, plus much more. The extra overhead incurred is negligible in most cases.
However, "most cases" is not "always." There are many situations in which you don't need and don't want a full-fledged vector; a dynamically allocated array is exactly what you need. It is awkward in these cases to be unable to exploit smart pointer capabilities. There is a certain gap between the sophisticated std::vector and dynamically allocated arrays. Smart pointers could close that gap by providing array semantics if the user needs them.
From the viewpoint of a smart pointer to an array, the only important issue is to call delete[] pointee_ in its destructor instead of delete pointee_. This issue is already tackled by the Ownership policy.
A secondary issue is providing indexed access, by overloading operator[] for smart pointers. This is technically feasible; in fact, a preliminary version of SmartPtr did provide a separate policy for optional array semantics. However, only in very rare cases do smart pointers point to arrays. In those cases, there already is a way of providing indexed accessing if you use GetImpl:
SmartPtr<Widget> sp = ...;
// Access the sixth element pointed to by sp
Widget& obj = GetImpl(sp)[5];
It seems like a bad decision to strive to provide extra syntactic convenience at the expense of introducing a new policy.
SmartPtr supports customized destruction via the Ownership policy. You can therefore arrange array-specific destruction via delete[]. However, SmartPtr does not provide pointer arithmetic.
|
7.13 Smart Pointers and Multithreading
Most often, smart pointers help with sharing objects. Multithreading issues affect object sharing. Therefore, multithreading issues affect smart pointers.
The interaction between smart pointers and multithreading takes place at two levels. One is the pointee object level, and the other is the bookkeeping data level.
7.13.1 Multithreading at the Pointee Object Level
If multiple threads access the same object and if you access that object through a smart pointer, it can be desirable to lock the object during a function call made through operator->. This is possible by having the smart pointer return a proxy object instead of a raw pointer. The proxy object's constructor locks the pointee object, and its destructor unlocks it. The technique is illustrated in Stroustrup (2000). Some code that illustrates this approach is provided here.
First, let's consider a class Widget that has two locking primitives: Lock and Unlock. After a call to Lock, you can access the object safely. Any other threads calling Lock will block. When you call Unlock, you let other threads lock the object.
class Widget
{
...
void Lock();
void Unlock();
};
Next, we define a class template LockingProxy. Its role is to lock an object (using the Lock/Unlock convention) for the duration of LockingProxy's lifetime.
template <class T>
class LockingProxy
{
public:
LockingProxy(T* pObj) : pointee_ (pObj)
{ pointee_->Lock(); }
~LockingProxy()
{ pointee_->Unlock(); }
T* operator->() const
{ return pointee_; }
private:
LockingProxy& operator=(const LockingProxy&);
T* pointee_;
};
In addition to the constructor and destructor, LockingProxy defines an operator-> that returns a pointer to the pointee object.
Although LockingProxy looks somewhat like a smart pointer, there is one more layer to itthe SmartPtr class template itself.
template <class T>
class SmartPtr
{
...
LockingProxy<T> operator->() const
{ return LockingProxy<T>(pointee_); }
private:
T* pointee_;
};
Recall from Section 7.3, which explains the mechanics of operator->, that the compiler can apply operator-> multiple times to one -> expression, until it reaches a native pointer. Now imagine you issue the following call (assuming Widget defines a function DoSomething):
SmartPtr<Widget> sp = ...;
sp->DoSomething();
Here's the trick: SmartPtr's operator-> returns a temporary LockingProxy<T> object. The compiler keeps applying operator->. LockingProxy<T>'s operator-> returns a Widget*. The compiler uses this pointer to Widget to issue the call to DoSomething. During the call, the temporary object LockingProxy<T> is alive and locks the object, which means that the object is safely locked. As soon as the call to DoSomething returns, the temporary LockingProxy<T> object is destroyed, so the Widget object is unlocked.
Automatic locking is a good application of smart pointer layering. You can layer smart pointers this way by changing the Storage policy.
7.13.2 Multithreading at the Bookkeeping Data Level
Sometimes smart pointers manipulate data in addition to the pointee object. As you read in Section 7.5, reference-counted smart pointers share some datanamely the reference countunder the covers. If you copy a reference-counted smart pointer from one thread to another, you end up having two smart pointers pointing to the same reference counter. Of course, they also point to the same pointee object, but that's accessible to the user, who can lock it. In contrast, the reference count is not accessible to the user, so managing it is entirely the responsibility of the smart pointer.
Not only reference-counted pointers are exposed to multithreading-related dangers. Reference-tracked smart pointers (Section 7.5.4) internally hold pointers to each other, which are shared data as well. Reference linking leads to communities of smart pointers, not all of which necessarily belong to the same thread. Therefore, every time you copy, assign, and destroy a reference-tracked smart pointer, you must issue appropriate locking; otherwise, the doubly linked list might get corrupted.
In conclusion, multithreading issues ultimately affect smart pointers' implementation. Let's see how to address the multithreading issue in reference counting and reference linking.
7.13.2.1 Multithreaded Reference Counting
If you copy a smart pointer between threads, you end up incrementing the reference count from different threads at unpredictable times.
As the appendix explains, incrementing a value is not an atomic operation. For incrementing and decrementing integral values in a multithreaded environment, you must use the type ThreadingModel<T>::IntType and the AtomicIncrement and AtomicDecrement functions.
Here things become a bit tricky. Better said, they become tricky if you want to separate reference counting from threading.
Policy-based class design prescribes that you decompose a class into elementary behavioral elements and confine each of them to a separate template parameter. In an ideal world, SmartPtr would specify an Ownership policy and a ThreadingModel policy and would use them both for a correct implementation.
In the case of multithreaded reference counting, however, things are much too tied together. For example, the counter must be of type ThreadingModel<T>::IntType. Then, instead of using operator++ and operator, you must use AtomicIncrement and AtomicDecrement. Threading and reference counting melt together; it is unjustifiably hard to separate them.
The best thing to do is to incorporate multithreading in the Ownership policy. Then you can have two implementations: RefCounting and RefCountingMT.
7.13.2.2 Multithreaded Reference Linking
Consider the destructor of a reference-linked smart pointer. It likely looks like this:
template <class T>
class SmartPtr
{
public:
~SmartPtr()
{
if (prev_ == next_)
{
delete pointee_;
}
else
{
prev_->next_ = next_;
next_->prev_ = prev_;
}
}
...
private:
T* pointee_;
SmartPtr* prev_;
SmartPtr* next_;
};
The code in the destructor performs a classic doubly linked list deletion. To make implementation simpler and faster, the list is circularthe last node points to the first node. This way we don't have to test prev_ and next_ against zero for any smart pointer. A circular list with only one element has prev_ and next_ equal to this.
If multiple threads destroy smart pointers that are linked to each other, clearly the destructor must be atomic (uninterruptible by other threads). Otherwise, another thread can interrupt the destructor of a SmartPtr, for instance, between updating prev_->next_ and updating next_->prev_. That thread will then operate on a corrupt list.
Similar reasoning applies to SmartPtr's copy constructor and the assignment operator. These functions must be atomic because they manipulate the ownership list.
Interestingly enough, we cannot apply object-level locking semantics here. The appendix divides locking strategies into class-level and object-level strategies. A class-level locking operation locks all objects in a given class during that operation. An object-level locking operation locks only the object that's subject to that operation. The former technique leads to less memory being occupied (only one mutex per class) but is exposed to performance bottlenecks. The latter is heavier (one mutex per object) but might be speedier.
We cannot apply object-level locking to smart pointers because an operation manipulates up to three objects: the current object that's being added or removed, the previous object, and the next object in the ownership list.
If we want to introduce object-level locking, the starting observation is that there must be one mutex per pointee objectbecause there's one list per pointee object. We can dynamically allocate a mutex for each object, but this nullifies the main advantage of reference linking over reference counting. Reference linking was more appealing exactly because it didn't use the free store.
Alternatively, we can use an intrusive approach: The pointee object holds the mutex, and the smart pointer manipulates that mutex. But the existence of a sound, effective alternativereference-counted smart pointersremoves the incentive to provide this feature.
In summary, smart pointers that use reference counting or reference linking are affected by multithreading issues. Thread-safe reference counting needs integer atomic operations. Thread-safe reference linking needs mutexes. SmartPtr provides only thread-safe reference counting.
|
7.14 Putting It All Together
Not much to go! Here comes the fun part. So far we have treated each issue in isolation. It's now time to collect all the decisions into a unique SmartPtr implementation.
The strategy we'll use is the one described in Chapter 1: policy-based class design. Each design aspect that doesn't have a unique solution migrates to a policy. The SmartPtr class template accepts each policy as a separate template parameter. SmartPtr inherits all these template parameters, allowing the corresponding policies to store state.
Let's recap the previous sections by enumerating the variation points of SmartPtr. Each variation point translates into a policy.
Storage policy (Section 7.3).
By default, the stored type is T* (T is the first template parameter of SmartPtr), the pointer type is again T*, and the reference type is T&. The means of destroying the pointee object is the delete operator.
Ownership policy (Section 7.5).
Popular implementations are deep copy, reference counting, reference linking, and destructive copy. Note that Ownership is not concerned with the mechanics of destruction itself; this is Storage's task. Ownership controls the moment of destruction.
Conversion policy (Section 7.7).
Some applications need automatic conversion to the underlying raw pointer type; others do not.
Checking policy (Section 7.10).
This policy controls whether an initializer for SmartPtr is valid and whether a SmartPtr is valid for dereferencing.
Other issues are not worth dedicating separate policies to them or have an optimal solution:
The address-of operator (Section 7.6) is best not overloaded. Equality and inequality tests are handled with the tricks shown in Section 7.8. Ordering comparisons (Section 7.9) are left unimplemented; however, Loki specializes std::less for SmartPtr objects. The user may define an operator<, and Loki helps by defining all other ordering comparisons in terms of operator<. Loki defines const-correct implementations for the SmartPtr object, the pointee object, or both. There is no special support for arrays, but one of the canned Storage implementations can dispose of arrays by using operator delete[].
The presentation of the design issues surrounding smart pointers made these issues easier to understand and more manageable because each issue was discussed in isolation. It would be very helpful, then, if the implementation could decompose and treat issues in isolation instead of fighting with all the complexity at once.
Divide et Impera
this old principle coined by Julius Caesar can be of help even today with smart pointers. (I'd bet money he didn't predict that.) We break the problem into small component classes, called policies. Each policy class deals with exactly one issue. SmartPtr inherits all these classes, thus inheriting all their features. It's that simpleyet incredibly flexible, as you will soon see. Each policy is also a template parameter, which means you can mix and match existing stock policy classes or build your own.
The pointed-to type comes first, followed by each of the policies. Here is the resulting declaration of SmartPtr:
template
<
typename T,
template <class> class OwnershipPolicy = RefCounted,
class ConversionPolicy = DisallowConversion,
template <class> class CheckingPolicy = AssertCheck,
template <class> class StoragePolicy = DefaultSPStorage
>
class SmartPtr;
The order in which the policies appear in SmartPtr's declaration puts the ones that you customize most often at the top.
The following four subsections discuss the requirements of the four policies we have defined. A rule for all policies is that they must have value semantics; that is, they must define a proper copy constructor and assignment operator.
7.14.1 The Storage Policy
The Storage policy abstracts the structure of the smart pointer. It provides type definitions and stores the actual pointee_ object.
If StorageImpl is an implementation of the Storage policy and storageImpl is an object of type StorageImpl<T>, then the constructs in Table 7.1 apply.
Here is the default Storage policy implementation:
template <class T>
class DefaultSPStorage
{
protected:
typedef T* StoredType; //the type of the pointee_ object
typedef T* PointerType; //type returned by operator->
typedef T& ReferenceType; //type returned by operator*
public:
DefaultSPStorage() : pointee_(Default())
{}
DefaultSPStorage(const StoredType& p): pointee_(p) {}
PointerType operator->() const { return pointee_; }
ReferenceType operator*() const { return *pointee_; }
friend inline PointerType GetImpl(const DefaultSPStorage& sp)
{ return sp.pointee_; }
friend inline const StoredType& GetImplRef(
const DefaultSPStorage& sp)
{ return sp.pointee_; }
friend inline StoredType& GetImplRef(DefaultSPStorage& sp)
{ return sp.pointee_; }
protected:
void Destroy()
{ delete pointee_; }
static StoredType Default()
{ return 0; }
private:
StoredType pointee_;
};
In addition to DefaultSPStorage, Loki also defines the following:
ArrayStorage, which uses operator delete[] inside Release LockedStorage, which uses layering to provide a smart pointer that locks data while dereferenced (see Section 7.13.1) HeapStorage, which uses an explicit destructor call followed by std::free to release the data
Table 7.1. Storage Policy Constructs
| StorageImpl<T>::StoredType |
The type actually stored by the implementation. Default: T*. |
| StorageImpl<T>::PointerType |
The pointer type defined by the implementation.
This is the type returned by SmartPtr's operator->. Default: T*. Can be different from StorageImpl<T>::StoredType when you're using smart pointer layering (see Sections 7.3 and 7.13.1).
|
| StorageImpl<T>::ReferenceType |
The reference type. This is the type returned by SmartPtr's operator*. Default: T&. |
| GetImpl(storageImpl) |
Returns an object of type StorageImpl<T> ::StoredType. |
| GetImplRef(storageImpl) |
Returns an object of type StorageImpl<T> ::StoredType&, qualified with const if storageImpl is const. |
| storageImpl.operator->() |
Returns an object of type StorageImpl<T> ::PointerType. Used by SmartPtr's own operator->. |
| storageImpl.operator*() |
Returns an object of type StorageImpl<T> ::ReferenceType. Used by SmartPtr's own operator*. |
|
StorageImpl<T>::StoredType p;
p = storageImpl.Default();
|
Returns the default value (usually zero). |
| storageImpl.Destroy() |
Destroys the pointee object. |
7.14.2 The Ownership Policy
The Ownership policy must support intrusive as well as nonintrusive reference counting. Therefore, it uses explicit function calls rather than constructor/destructor techniques, as Koenig (1996) does. The reason is that you can call member functions at any time, whereas constructors and destructors are called automatically and only at specific times.
The Ownership policy implementation takes one template parameter, which is the corresponding pointer type. SmartPtr passes StoragePolicy<T>::PointerType to OwnershipPolicy. Note that OwnershipPolicy's template parameter is a pointer type, not an object type.
If OwnershipImpl is an implementation of Ownership and ownershipImpl is an object of type OwnershipImpl<P>, then the constructs in Table 7.2 apply.
Table 7.2. Ownership Policy Constructs
| P val1; P val2 = OwnershipImplImpl. Clone(val1); |
Clones an object. It can modify the source value if OwnershipImpl uses destructive copy. |
| const P val1; P val2 = ownershipImpl. Clone(val1); |
Clones an object. |
| P val;bool unique = ownershipImpl. Release(val); |
Releases ownership of an object. Returns true if the last reference to the object was released. |
| bool dc = OwnershipImpl<P>::destructiveCopy; |
States whether OwnershipImpl uses destructive copy. If that's the case, SmartPtr uses the Colvin/Gibbons trick (Meyers 1999) used in std::auto_ptr. |
An implementation of Ownership that supports reference counting is shown in the following:
template <class P>
class RefCounted
{
unsigned int* pCount_;
protected:
RefCounted() : pCount_(new unsigned int(1)) {}
P Clone(const P & val)
{
++*pCount_;
return val;
}
bool Release(const P&)
{
if (!--*pCount_)
{
delete pCount_;
return true;
}
return false;
}
enum { destructiveCopy = false }; // see below
{;
Implementing a policy for other schemes of reference counting is very easy. Let's write an Ownership policy implementation for COM objects. COM objects have two functions: AddRef and Release. Upon the last Release call, the object destroys itself. You need only direct Clone to AddRef and Release to COM's Release:
template <class P>
class COMRefCounted
{
public:
static P Clone(const P& val)
{
val->AddRef();
return val;
}
static bool Release(const P& val)
{
val->Release();
return false;
}
enum { destructiveCopy = false }; // see below
};
Loki defines the following Ownership implementations:
DeepCopy, described in Section 7.5.1. DeepCopy assumes that pointee class implements a member function Clone. RefCounted, described in Section 7.5.3 and in this section. RefCountedMT, a multithreaded version of RefCounted. COMRefCounted, a variant of intrusive reference counting described in this section. RefLinked, described in Section 7.5.4. DestructiveCopy, described in Section 7.5.5. NoCopy, which does not define Clone, thus disabling any form of copying.
7.14.3 The Conversion Policy
Conversion is a simple policy: It defines a Boolean compile-time constant that says whether or not SmartPtr allows implicit conversion to the underlying pointer type.
If ConversionImpl is an implementation of Conversion, then the construct in Table 7.3 applies.
The underlying pointer type of SmartPtr is dictated by its Storage policy and is StorageImpl<T>::PointerType.
As you would expect, Loki defines precisely two Conversion implementations:
AllowConversion DisallowConversion
Table 7.3. Conversion Policy Construct
| bool allowConv = ConversionImpl<P>::allow; |
If allow is true, SmartPtr allows implicit conversion to its underlying pointer type. |
Table 7.4. Checking Policy Constructs
| S value; checkingImpl.OnDefault(value); |
SmartPtr calls OnDefault in the default constructor call. If CheckingImpl does not define this function, it disables the default constructor at compile time. |
| S value; checkingImpl.OnInit(value); |
SmartPtr calls OnInit upon a constructor call. |
| S value; checkingImpl.OnDereference (value); |
SmartPtr calls OnDereference before returning from operator-> and operator*. |
| const S value;checkingImpl.OnDereference(value); |
SmartPtr calls OnDereference before returning from the const versions of operator-> and operator*. |
7.14.4 The Checking Policy
As discussed in Section 7.10, there are two main places to check a SmartPtr object for consistency: during initialization and before dereference. The checks themselves might use assert, exceptions, or lazy initialization or not do anything at all.
The Checking policy operates on the StoredType of the Storage policy, not on the PointerType. (See Section 7.14.1 for the definition of Storage.)
If S is the stored type as defined by the Storage policy implementation, and if CheckingImpl is an implementation of Checking, and if checkingImpl is an object of type CheckingImpl<S>, then the constructs in Table 7.4 apply.
Loki defines the following implementations of Checking:
AssertCheck, which uses assert for checking the value before dereferencing. AssertCheckStrict, which uses assert for checking the value upon initialization. RejectNullStatic, which does not define OnDefault. Consequently, any use of SmartPtr's default constructor yields a compile-time error. RejectNull, which throws an exception if you try to dereference a null pointer. RejectNullStrict, which does not accept null pointers as initializers (again, by throwing an exception). NoCheck, which handles errors in the grand C and C++ traditionthat is, it does no checking at all.
|
7.15 Summary
Congratulations! You have just read one of the longest, wildest chapters of this bookan effort that we hope has paid off. Now you know a lot of things about smart pointers and are equipped with a pretty comprehensive and configurable SmartPtr class template.
Smart pointers imitate built-in pointers in syntax and semantics. In addition, they perform a host of tasks that built-in pointers cannot. These tasks might include ownership management and checking against invalid values.
Smart pointer concepts go beyond actual pointer behavior; they can be generalized into smart resources, such as monikers (handles that don't have pointer syntax, yet resemble pointer behavior in the way they enable resource access).
Because they nicely automate things that are very hard to manage by hand, smart pointers are an essential ingredient of successful, robust applications. As small as they are, they can make the difference between a successful project and a failureor, more often, between a correct program and one that leaks resources like a sieve.
That's why a smart pointer implementer should invest as much attention and effort in this task as possible; the investment is likely to pay in the long term. Similarly, smart pointer users should understand the conventions that smart pointers establish and use them in accordance with those conventions.
The presented implementation of smart pointers focuses on decomposing the areas of functionality into independent policies that the main class template SmartPtr mixes and matches. This is possible because each policy implements a well-defined interface.
|
7.16 SmartPtr Quick Facts
SmartPtr declaration:
template
<
typename T,
template <class> class OwnershipPolicy = RefCounted,
class ConversionPolicy = DisallowConversion,
template <class> class CheckingPolicy = AssertCheck,
template <class> class StoragePolicy = DefaultSPStorage
>
class SmartPtr;
T is the type to which SmartPtr points. T can be a primitive type or a user-defined type. The void type is allowed. For the remaining class template parameters (OwnershipPolicy, ConversionPolicy, CheckingPolicy, and StoragePolicy), you can implement your own policies or choose from the defaults mentioned in Sections 7.14.1 through 7.14.4. OwnershipPolicy controls the ownership management strategy. You can select from the predefined classes DeepCopy, RefCounted, RefCountedMT, COMRefCounted, RefLinked, DestructiveCopy, and NoCopy, described in Section 7.14.2. ConversionPolicy controls whether implicit conversion to the pointee type is allowed. The default is to forbid implicit conversion. Either way, you can still access the pointee object by calling GetImpl. You can use the AllowConversion and DisallowConversion implementations (Section 7.14.3). CheckingPolicy defines the error checking strategy. The defaults provided are AssertCheck, AssertCheckStrict, RejectNullStatic, RejectNull, RejectNullStrict, and NoCheck (Section 7.14.4). StoragePolicy defines the details of how the pointee object is stored and accessed. The default is DefaultSPStorage, which, when instantiated with a type T, defines the reference type as T&, the stored type as T*, and the type returned from operator-> as T* again. Other storage types defined by Loki are ArrayStorage, LockedStorage, and HeapStorage (Section 7.14.1).
|
Chapter 8. Object Factories
Object-oriented programs use inheritance and virtual functions to achieve powerful abstractions and good modularity. By postponing until runtime the decision regarding which specific function will be called, polymorphism promotes binary code reuse and extensibility. The runtime system automatically dispatches virtual member functions to the appropriate derived object, allowing you to implement complex behavior in terms of polymorphic primitives.
You can find this kind of paragraph in any book teaching object-oriented techniques. The reason it is repeated here is to contrast the nice state of affairs in "steady mode" with the unpleasant "initialization mode" situation in which you must create objects in a polymorphic way.
In the steady state, you already hold pointers or references to polymorphic objects, and you can invoke member functions against them. Their dynamic type is well known (although the caller might not know it). However, there are cases when you need to have the same flexibility in creating objectssubject to the paradox of "virtual constructors." You need virtual constructors when the information about the object to be created is inherently dynamic and cannot be used directly with C++ constructs.
Most often, polymorphic objects are created on the free store by using the new operator:
class Base { ... };
class Derived : public Base { ... };
class AnotherDerived : public Base { ... };
...
// Create a Derived object and assign it to a pointer to Base
Base* pB = new Derived;
The issue here is the actual Derived type name appearing in the invocation of the new operator. In a way, Derived here is much like the magic numeric constants we are advised not to use. If you want to create an object of the type AnotherDerived, you have to go to the actual statement and replace Derived with AnotherDerived. You cannot make the new operator act more dynamically: You must pass it a type, and that type must be exactly known at compile time.
This marks a fundamental difference between creating objects and invoking virtual member functions in C++. Virtual member functions are fluid, dynamicyou can change their behavior without changing the call site. In contrast, each object creation is a stumbling block of statically bound, rigid code. One of the effects is that invoking virtual functions binds the caller to the interface only (the base class). Object orientation tries to break dependency on the actual concrete type. However, at least in C++, object creation binds the caller to the most derived, concrete class.
Actually, it makes a lot of conceptual sense that things are this way: Even in everyday life, creating something is very different from dealing with it. You are supposed, then, to know exactly what you want to do when you embark on the creation of an object. However, sometimes
You want to leave this exact knowledge up to another entity. For instance, instead of invoking new directly, you might call a virtual function Create of some higher-level object, thus allowing clients to change behavior through polymorphism. You do have the type knowledge, but not in a form that's expressible in C++. For instance, you might have a string containing "Derived", so you actually know you have to create an object of type Derived, but you cannot pass a string containing a type name to new instead of a type name.
These two issues are the fundamental problems addressed by object factories, which we'll discuss in detail in this chapter. The topics of this chapter include the following:
Examples of situations in which object factories are needed Why virtual constructors are inherently hard to implement in C++ How to create objects by substituting values for types An implementation of a generic object factory
By the end of this chapter, we'll put together a generic object factory. You can customize the generic factory to a large degreeby the type of product, the creation method, and the product identification method. You can combine the factory thus created with other components described in this book, such as Singleton (Chapter 6)for creating an application-wide object factoryand Functor (Chapter 5)for tweaking factory behavior. We'll also introduce a clone factory, which can duplicate objects of any type.
|
8.1 The Need for Object Factories
There are two basic cases in which object factories are needed. The first occurs when a library needs not only to manipulate user-defined objects, but also to create them. For example, imagine you develop a framework for multiwindow document editors. Because you want the framework to be easily extensible, you provide an abstract class Document from which users can derive classes such as TextDocument and HTMLDocument. Another framework component may be a DocumentManager class that keeps the list of all open documents.
A good rule to introduce is that each document that exists in the application should be known by the DocumentManager. Therefore, creating a new document is tightly coupled with adding it to DocumentManager's list of documents. When two operations are so coupled, it is best to put them in the same function and never perform them separately:
class DocumentManager
{
...
public:
Document* NewDocument();
private:
virtual Document* CreateDocument() = 0;
std::list<Document*> listOfDocs_;
};
Document* DocumentManager::NewDocument()
{
Document* pDoc = CreateDocument();
listOfDocs_.push_back(pDoc);
...
return pDoc;
}
The CreateDocument member function replaces a call to new. NewDocument cannot use the new operator because the concrete document to be created is not known by the time DocumentManager is written. In order to use the framework, programmers will derive from DocumentManager and override the virtual member function CreateDocument (which is likely to be pure). The GoF book (Gamma et al. 1995) calls CreateDocument a factory method.
Because the derived class knows exactly the type of document to be created, it can invoke the new operator directly. This way, you can remove the type knowledge from the framework and have the framework operate on the base class Document only. The override is very simple and consists essentially of a call to new; for example:
Document* GraphicDocumentManager::CreateDocument()
{
return new GraphicDocument;
}
Alternatively, an application built with this framework might support creation of multiple document types (for instance, bitmapped graphics and vectorized graphics). In that case, the overridden CreateDocument function might display a dialog to the user asking for the specific type of document to be created.
Thinking of opening a document previously saved on disk in the framework just outlined brings us to the secondand more complicatedcase in which an object factory may be needed. When you save an object to a file, you must save its actual type in the form of a string, an integral value, an identifier of some sort. Thus, although the type information exists, its form does not allow you to create C++ objects.
The general concept underlying this situation is the creation of objects whose type information is genuinely postponed to runtime: entered by the end user, read from a persistent storage or network connection, or the like. Here the binding of types to values is pushed even further than in the case of polymorphism: When using polymorphism, the entity manipulating an object does not know its exact type; however, the object itself is of a well-determined type. When reading objects from some storage, the type comes "alone" at runtime. You must transform type information into an object. Finally, you must read the object from the storage, which is easy once an empty object is created, by invoking a virtual function.
Creating objects from "pure" type information, and consequently adapting dynamic information to static C++ types, is an important issue in building object factories. Let's focus on it in the next section.
|
8.2 Object Factories in C++: Classes and Objects
To come up with a solution, we need a good grasp of the problem. This section tries to answer the following questions: Why are C++ constructors so rigid? Why don't we have flexible means to create objects in the language itself?
Interestingly, seeking an answer to this question takes us directly to fundamental decisions about C++'s type system. To find out why a statement such as
Base* pB = new Derived;
is so rigid, we must answer two related questions: What is a class, and what is an object? This is because the culprit in the given statement is Derived, which is a class name, and we'd like it to be a value, that is, an object.
In C++, classes and objects are different beasts. Classes are what the programmer creates, and objects are what the program creates. You cannot create a new class at runtime, and you cannot create an object at compile time. Classes don't have first-class status: You cannot copy a class, store it in a variable, or return it from a function.
In contrast, there are languages in which classes are objects. In those languages, some objects with certain properties are simply considered classes by convention. Consequently, in those languages, you can create new classes at runtime, copy a class, store it in a variable, and so on. If C++ were such a language, you could have written code like the following:
// Warning-this is NOT C++
// Assumes Class is a class that's also an object
Class Read(const char* fileName);
Document* DocumentManager::OpenDocument(const char* fileName)
{
Class theClass = Read(fileName);
Document* pDoc = new theClass;
...
}
That is, we could pass a variable of type Class to the new operator. In such a paradigm, passing a known class name to new is the same as using a hardcoded constant.
Such dynamic languages trade off some type safety and performance for the sake of flexibility, because static typing is an important source of optimization. C++ took the opposite approach, sticking to a static type system, yet trying to provide as much flexibility as possible in this framework.
The bottom line is that creating object factories is a complicated problem in C++. In C++ there is a fracture between types and values: A value has a type attribute, but a type cannot exist on its own. If you want to create an object in a totally dynamic way, you need a means to express and pass around a "pure" type and build a value from it on demand. Because you cannot do this, you somehow must represent types as objectsintegers, strings, and so on. Then, you must employ some trick to exchange the value for the right type, and finally to use that type to create an object. This object-type-object trade is fundamental for object factories in statically typed languages.
We will call the object that identifies a type a type identifier. (Don't confuse it with typeid.) The type identifier helps the factory in creating the appropriate type of object. As will be shown, sometimes you make the type identifierobject exchange without knowing exactly what you have or what you will get. It's like a fairy tale: You don't know exactly how the token works (and it's sometimes dangerous to try to figure it out), but you pass it to the wizard, who gives you a valuable object in exchange. The details of how the magic happens must be encapsulated in the wizard . . . the factory, that is.
We will explore a simple factory that solves a concrete problem, try various implementations of it, and then extract the generic part of it into a class template.
|
8.3 Implementing an Object Factory
Say you write a simple drawing application, allowing editing of simple vectorized drawings consisting of lines, circles, polygons, and so on. In a classic object-oriented manner, you define an abstract Shape class from which all your figures will derive:
class Shape
{
public:
virtual void Draw() const = 0;
virtual void Rotate(double angle) = 0;
virtual void Zoom(double zoomFactor) = 0;
...
};
You might then define a class Drawing that contains a complex drawing. A Drawing essentially holds a collection of pointers to Shapesuch as a list, a vector, or a hierarchical structureand provides operations to manipulate the drawing as a whole. Two typical operations you might want to do are saving a drawing as a file and loading a drawing from a previously saved file.
Saving shapes is easy: Just provide a pure virtual function such as Shape::Save(std:: ostream&). Then the Drawing::Save operation might look like this:
class Drawing
{
public:
void Save(std::ofstream& outFile);
void Load(std::ifstream& inFile);
...
};
void Drawing::Save(std::ofstream& outFile)
{
write drawing header
for (each element in the drawing)
{
(current element)->Save(outFile);
}
}
The Shape-Drawing example just described is often encountered in C++ books, including Bjarne Stroustrup's classic (Stroustrup 1997). However, most introductory C++ books stop when it comes to loading graphics from a file, exactly because the nice model of having separate drawing objects breaks. Explaining the gory details of reading objects makes for a big parenthesis, which understandably is often avoided. On the other hand, this is exactly what we want to implement, so we have to bite the bullet. A straightforward implementation is to require each Shape-derived object to save an integral identifier at the very beginning. Each object should have its own unique ID. Then reading the file would look like this:
// a unique ID for each drawing object type
namespace DrawingType
{
const int
LINE = 1,
POLYGON = 2,
CIRCLE = 3
};
void Drawing::Load(std::ifstream& inFile)
{
// error handling omitted for simplicity
while (inFile)
{
// read object type
int drawingType;
inFile >> drawingType;
// create a new empty object
Shape* pCurrentObject;
switch (drawingType)
{
using namespace DrawingType;
case LINE:
pCurrentObject = new Line;
break;
case POLYGON:
pCurrentObject = new Polygon;
break;
case CIRCLE:
pCurrentObject = new Circle;
break;
default:
handle errorunknown object type
}
// read the object's contents by invoking a virtual fn
pCurrentObject->Read(inFile);
add the object to the container
}
}
This is indeed an object factory. It reads a type identifier from the file, creates an object of the appropriate type based on that identifier, and invokes a virtual function that loads that object from the file. The only problem is that it breaks the most important rules of object orientation:
It performs a switch based on a type tag, with the associated drawbacks, which is exactly what object-oriented programs try to eliminate. It collects in a single source file knowledge about all Shape-derived classes in the program, which again you must strive to avoid. For one thing, the implementation file of Drawing::Save must include all headers of all possible shapes, which makes it a bottleneck of compile dependencies and maintenance. It is hard to extend. Imagine adding a new shape, such as Ellipse, to the system. In addition to creating the class itself, you must add a distinct integral constant to the namespace DrawingType, you must write that constant when saving an Ellipse object, and you must add a label to the switch statement in Drawing::Save. This is an awful lot more than what the architecture promisedtotal insulation between classesand all for the sake of a single function!
We'd like to create an object factory that does the job without having these disadvantages. One practical goal worth pursuing is to break the switch statement apartso that we can put the Line creation statement in the file implementation for Lineand do the same for Polygon and Circle.
A common way to keep together and manipulate pieces of code is to work with pointers to functions, as discussed at length in Chapter 5. The unit of customizable code here (each of the entries in the switch statement) can be abstracted in a function with the signature
Shape* CreateConcreteShape();
The factory keeps a collection of pointers to functions with this signature. In addition, there has to be a correspondence between the IDs and the pointer to the function that creates the appropriate object. Thus, what we need is an associative collectiona map. A map offers access to the appropriate function given the type identifier, which is precisely what the switch statement offers. In addition, the map offers the scalability that the switch statement, with its fixed compile-time structure, cannot provide. The map can grow at runtimeyou can add entries (tuples of IDs and pointers to functions) dynamically, which is exactly what we need. We can start with an empty map and have each Shape-derived object add an entry to it.
Why not use a vector? IDs are integral numbers, so we can keep a vector and have the ID be the index in the vector. This would be simpler and faster, but a map is better here. The map doesn't require its indices to be adjacent, plus it's more generalvectors work only with integral indices, whereas maps accept any ordered type as an index. This point will become important when we generalize our example.
We can start designing a ShapeFactory class, which has the responsibility of managing the creation of all Shape-derived objects. In implementing ShapeFactory, we will use the map implementation found in the standard library, std::map:
class ShapeFactory
{
public:
typedef Shape* (*CreateShapeCallback)();
private:
typedef std::map<int, CreateShapeCallback> CallbackMap;
public:
// Returns 'true' if registration was successful
bool RegisterShape(int ShapeId,
CreateShapeCallback CreateFn);
// Returns 'true' if the ShapeId was registered before
bool UnregisterShape(int ShapeId);
Shape* CreateShape(int ShapeId);
private:
CallbackMap callbacks_;
};
This is a basic design of a scalable factory. The factory is scalable because you don't have to modify its code each time you add a new Shape-derived class to the system. ShapeFactory divides responsibility: Each new shape has to register itself with the factory by calling RegisterShape and passing it its integral identifier and a pointer to a function that creates an object. Typically, the function has a single line and looks like this:
Shape* CreateLine()
{
return new Line;
}
The implementation of Line also must register this function with the ShapeFactory that the application uses, which is typically a globally accessible object. The registration is usually performed with startup code. The whole connection of Line with the Shape Factory is as follows:
// Implementation module for class Line
// Create an anonymous namespace
// to make the function invisible from other modules
namespace
{
Shape* CreateLine()
{
return new Line;
}
// The ID of class Line
const int LINE = 1;
// Assume TheShapeFactory is a singleton factory
// (see Chapter 6)
const bool registered =
TheShapeFactory::Instance().RegisterShape(
LINE, CreateLine);
}
Implementing the ShapeFactory is easy, given the amenities std::map has to offer. Basically, ShapeFactory member functions forward only to the callbacks_ member:
bool ShapeFactory::RegisterShape(int shapeId,
CreateShapeCallback createFn)
{
return callbacks_.insert(
CallbackMap::value_type(shapeId, createFn)).second;
}
bool ShapeFactory::UnregisterShape(int shapeId)
{
return callbacks_.erase(shapeId) == 1;
}
If you're not very familiar with the std::map class template, the previous code might need a bit of explanation:
std::map holds pairs of keys and data. In our case, keys are integral shape IDs, and the data consists of a pointer to function. The type of our pair is std::pair<const int, CreateShapeCallback>. You must pass an object of this type when you call insert. Because that's a lot to write, it's better to use the typedef found inside std::map, which provides a handy namevalue_typefor that pair type. Alternatively, you can use std::make_pair. The insert member function we called returns another pair, this time containing an iterator (which refers to the element just inserted) and a bool that is true if the value didn't exist before, and false otherwise. The.second field access after the call to insert selects this bool and returns it in a single stroke, without our having to create a named temporary. erase returns the number of elements erased.
The CreateShape member function simply fetches the appropriate pointer to a function for the ID passed in, and calls it. In the case of an error, it throws an exception. Here it is:
Shape* ShapeFactory::CreateShape(int shapeId)
{
CallbackMap::const_iterator i = callbacks_.find(shapeId);
if (i == callbacks_.end())
{
// not found
throw std::runtime_error("Unknown Shape ID");
}
// Invoke the creation function
return (i->second)();
}
Let's see what this simple class brought us. Instead of relying on the large, know-it-all switch statement, we obtained a dynamic scheme requiring each type of object to register itself with the factory. This moves the responsibility from a centralized place to each concrete class, where it belongs. Now whenever you define a new Shape-derived class, you can just add files instead of modifying files.
|
8.4 Type Identifiers
The only problem that remains is the management of type identifiers. Still, adding type identifiers requires a fair amount of discipline and centralized control. Whenever you add a new shape class, you must check all the existing type identifiers and add one that doesn't clash with them. If a clash exists, the second call to RegisterShape for the same ID fails, and you won't be able to create objects of that type.
We can solve this problem by choosing a more generous type than int for expressing the type identifier. Our design doesn't require integral types, only types that can be keys in a map, that is, types that support operator== and operator<. (That's why we can be happy we chose maps instead of vectors.) For example, we can store type identifiers as strings and establish the convention that each class is represented by its name: Line's identifier is "Line", Polygon's identifier is "Polygon", and so forth. This minimizes the chance of clashing names because class names are unique.
If you enjoy spending your weekends studying C++, maybe the previous paragraph rang a bell for you. Let's use type_info! The std::type_info class is part of the runtime type information (RTTI) provided by C++. You get a reference to a std:: type_info by invoking the typeid operator on a type or an expression. What seems nice is that std::type_info provides a name member function that returns a const char* pointing to a human-readable name of the type. For your compiler, you might have seen that typeid(Line).name() points to the string "class Line", which is exactly what we wanted.
The problem is, this does not apply to all C++ compiler implementations. The way type_info::name is defined makes it unsuitable for anything other than debugging purposes (such as printing it in a debug console). There is no guarantee that the string is the actual class name, and worse, there is no guarantee that the string is unique throughout the application. (Yes, you can have two classes that have the same name according to std::type_info::name.) And the shotgun argument is that there's no guarantee that the type name will be unique in time. There is no guarantee that typeid(Line).name() points to the same string when the application is run twice. Implementing persistence is an important application of factories, and std::type_info::name is not persistent. All this makes std::type_info deceptively close to being useful for our object factory, but it is not a real solution.
Back to the management of type identifiers. A decentralized solution for generating type identifiers is to use a unique value generatorfor instance, a random number or random string generator. You would use this generator each time you add a new class to the program, then hardcode that random value in the source file and never change it. This sounds like a brittle solution, but think of it this way: If you have a random string generator that has a 10-20 probability of repeating a value in a thousand years, you get a rate of error smaller than that of a program using a "perfect" factory.
The only conclusion that can be drawn here is that type identifier management is not the business of the object factory itself. Because C++ cannot guarantee a unique, persistent type ID, type ID management becomes an extra-linguistic issue that must be left to the programmers.
We have described all the elements in a typical object factory, and we have a prototype implementation. It's time now for the next stepthe step from concrete to abstract. Then, enriched with new insights, we'll go back to concrete.
|
8.5 Generalization
Let's enumerate the elements involved in our discussion of object factories. This gives us the intellectual workout necessary for putting together a generic object factory.
Concrete product.
A factory delivers some product in the form of an object.
Abstract product.
Products inherit a base type (in our example, Shape). A product is an object whose type belongs to a hierarchy. The base type of the hierarchy is the abstract product. The factory behaves polymorphically in the sense that it returns a pointer to the abstract product, without conveying knowledge of the concrete product type.
Product type identifier.
This is the object that identifies the type of the concrete product. As discussed, you have to have a type identifier to create a product because of the static C++ type system.
Product creator.
The function or functor is specialized for creating exactly one type of object. We modeled the product creator using a pointer to function.
The generic factory will orchestrate these elements to provide a well-defined interface, as well as defaults for the most used cases.
It seems that each of the notions just enumerated will transform into a template parameter of a Factory template class. There's only one exception: The concrete product doesn't have to be known to the factory. Had this been the case, we'd have different Factory types for each concrete product we're adding, and we are trying to keep Factory insulated from the concrete types. We want only different Factory types for different abstract products.
This being said, let's write down what we've grabbed so far:
template
<
class AbstractProduct,
typename IdentifierType,
typename ProductCreator
>
class Factory
{
public:
bool Register(const IdentifierType& id, ProductCreator creator)
{
return associations_.insert(
AssocMap::value_type(id, creator)).second;
}
bool Unregister(const IdentifierType& id)
{
return associations_.erase(id) == 1;
}
AbstractProduct* CreateObject(const IdentifierType& id)
{
typename AssocMap::const_iterator i =
associations_.find(id);
if (i != associations_.end())
{
return (i->second)();
}
handle error
}
private:
typedef std::map<IdentifierType, AbstractProduct>
AssocMap;
AssocMap associations_;
};
The only thing left out is error handling. If we didn't find a creator registered with the factory, should we throw an exception? Return a null pointer? Terminate the program? Dynamically load some library, register it on the fly, and retry the operation? The actual decision depends very much on the concrete situation; any of these actions makes sense in some cases.
Our generic factory should let the user customize it to do any of these actions and should provide a reasonable default behavior. Therefore, the error handling code should be pulled out of the CreateObject member function into a separate FactoryError policy (see Chapter 1). This policy defines only one function, OnUnknownType, and Factory gives that function a fair chance (and enough information) to make any sensible decision.
The policy defined by FactoryError is very simple. FactoryError prescribes a template of two parameters: IdentifierType and AbstractProduct. If FactoryErrorImpl is an implementation of FactoryError, then the following expression must apply:
FactoryErrorImpl<IdentifierType, AbstractProduct> factoryErrorImpl;
IdentifierType id;
AbstractProduct* pProduct = factoryErrorImpl.OnUnknownType(id);
Factory uses FactoryErrorImpl as a last-resort solution: If CreateObject cannot find the association in its internal map, it uses FactoryErrorImpl<IdentifierType, Abstract-Product>::OnUnknownType for fetching a pointer to the abstract product. If OnUnknownType throws an exception, the exception propagates out of Factory. Otherwise, CreateObject simply returns whatever OnUnknownType returned.
Let's code these additions and changes (shown in bold):
template
<
class AbstractProduct,
typename IdentifierType,
typename ProductCreator,
template<typename, class>
class FactoryErrorPolicy
>
class Factory
: public FactoryErrorPolicy<IdentifierType, AbstractProduct>
{
public:
AbstractProduct* CreateObject(const IdentifierType& id)
{
typename AssocMap::const_iterator i = associations_.find(id);
if (i != associations_.end())
{
return (i->second)();
}
return OnUnknownType(id);
}
private:
... rest of functions and data as above ...
};
The default implementation of FactoryError throws an exception. This exception's class is best made distinct from all other types so that client code can detect it separately and make appropriate decisions. Also, the class should inherit one of the standard exception classes so that the client can catch all kinds of errors with one catch block. DefaultFactoryError defines a nested exception class (called Exception) that inherits std::exception.
template <class IdentifierType, class ProductType>
class DefaultFactoryError
{
public:
class Exception : public std::exception
{
public:
Exception(const IdentifierType& unknownId)
: unknownId_(unknownId)
{
}
virtual const char* what()
{
return "Unknown object type passed to Factory.";
}
const IdentifierType GetId()
{
return unknownId_;
};
private:
IdentifierType unknownId_;
};
protected:
StaticProductType* OnUnknownType(const IdentifierType& id)
{
throw Exception(id);
}
};
Other, more advanced implementations of FactoryError can look up the type identifier and return a pointer to a valid object, return a null pointer (if the use of exceptions is undesirable), throw some exception object, or terminate the program. You can tweak the behavior by defining new FactoryError implementations and specifying them as the fourth argument of Factory.
|
8.6 Minutiae
Actually, Loki's Factory implementation does not use std::map. It uses a drop-in replacement for map, AssocVector, which is optimized for rare inserts and frequent lookups, the typical usage pattern of Factory. AssocVector is described in detail in Chapter 11.
In an initial draft of Factory, the map type was customizable by virtue of its being a template parameter. However, often AssocVector fits the bill exactly; in addition, using standard containers as template template parameters is not, well, standard. This is because implementers of standard containers are free to add more template arguments, as long as they provide defaults for them.
Let's focus now on the ProductCreator template parameter. Its main requirement is that it have functional behavior (accept operator() and take no arguments) and return a pointer convertible to AbstractProduct*. In the concrete implementation shown earlier, ProductCreator was a simple pointer to a function. This suffices if all we need is to create objects by invoking new, which is the most common case. Therefore, we choose
AbstractProduct* (*)()
as the default type for ProductCreator. The type looks a bit like a confusing emoticon because its name is missing. If you put a name after the asterisk within the parentheses,
AbstractProduct* (*PointerToFunction)()
the type reveals itself as a pointer to a function taking no parameters and returning a pointer to AbstractProduct. If this still looks unfamiliar to you, you may want to refer to Chapter 5, which includes a discussion on pointers to functions.
By the way, speaking of that chapter, there is a very interesting template parameter you can pass to Factory as ProductCreator, namely Functor<AbstractProduct*>. If you choose this, you gain great flexibility: You can create objects by invoking a simple function, a member function, or a functor, and bind appropriate parameters to any of them. The glue code is provided by Functor.
Our Factory class template declaration now looks like this:
template
<
class AbstractProduct,
class IdentifierType,
class ProductCreator = AbstractProduct* (*)(),
template<typename, class>
class FactoryErrorPolicy = DefaultFactoryError
>
class Factory;
Our Factory class template is now ready to be of use.
|
8.7 Clone Factories
Although genetic factories producing clones of the universal soldier are quite a scary prospect, cloning C++ objects is a harmless and useful activity most of the time. Here the goal is slightly different from what we have dealt with so far: We no longer have to create objects from scratch. We have a pointer to a polymorphic object, and we'd like to create an exact copy of it. Because we don't exactly know the type of the polymorphic object, we don't exactly know what new object to create, and this is the actual issue.
Because we do have an object at hand, we can apply classic polymorphism. Thus, the usual idiom used for object cloning is to declare a virtual Clone member function in the base class and to have each derived class override it. Here's an example using our geometric shapes hierarchy:
class Shape
{
public:
virtual Shape* Clone() const = 0;
...
};
class Line : public Shape
{
public:
virtual Line* Clone() const
{
return new Line(*this);
}
...
};
The reason that Line::Clone does not return a pointer to Shape is that we took advantage of a C++ feature called covariant return types. Because of covariant return types, you can return a pointer to a derived class instead of a pointer to the base class from an overridden virtual function. From now on, the idiom goes, you must implement a similar Clone function for each class you add to the hierarchy. The contents of the functions are the same: You create a Polygon, you return a new Polygon(*this), and so on.
This idiom works, but it has a couple of major drawbacks:
If the base class wasn't designed to be cloneable (didn't declare a virtual function equivalent to Clone) and is not modifiable, the idiom cannot be applied. This is the case when you write an application using a class library that requires you to derive from its base classes. Even if all the classes are changeable, the idiom requires a high degree of discipline. Forgetting to implement Clone in some derived classes will remain undetected by the compiler and may cause runtime behavior ranging from bizarre to pernicious.
The first point is obvious; let's discuss the second one. Imagine you derived a class DottedLine from Line and forgot to override DottedLine::Clone. Now say you have a pointer to a Shape that actually points to a DottedLine, and you invoke Clone on it:
Shape* pShape;
...
Shape* pDuplicateShape = pShape->Clone();
The Line::Clone function will be invoked, returning a Line. This is a very unfortunate situation because you assume pDuplicateShape to have the same dynamic type as pShape, when in fact it doesn't. This might lead to a lot of problems, from drawing unexpected types of lines to crashing the application.
There's no solid way to mitigate this second problem. You can't say in C++: "I define this function, and I require any direct or indirect class inheriting it to override it." You must shoulder the painful, repetitive task of overriding Clone in every shape class, and you're doomed if you don't.
If you agree to complicate the idiom a bit, you can get an acceptable runtime check. Make Clone a public nonvirtual function. From inside it call a private virtual function called, say, DoClone, and then enforce the equality of the dynamic types. The code is simpler than the explanation:
class Shape
{
...
public:
Shape* Clone() const//nonvirtual
{
// delegate to DoClone
Shape* pClone = DoClone();
// Check for type equivalence
// (could be a more sophisticated test than assert)
assert(typeid(*pClone) == typeid(*this));
return pClone;
}
private:
virtual Shape* DoClone() const = 0; // private
};
The only downside is that you can no longer use covariant return types.
Shape derivees would always override DoClone, leave it private so that clients cannot call it, and leave Clone alone. Clients use Clone only, which performs the runtime check. As you have certainly figured out, programming errors, such as overriding Clone or making DoClone public, can still sneak in.
Don't forget that, no matter what, if you cannot change all the classes in the hierarchy (the hierarchy is closed) and if it wasn't designed to be cloneable, you don't have any chance of implementing this idiom. This is quite a dismissive argument in many cases, so we should look for alternatives.
Here a special object factory may be of help. It leads to a solution that doesn't have the two problems mentioned earlier, at the cost of a slight performance hitinstead of a virtual call, there is a map lookup plus a call via a pointer to a function. Because the number of classes in an application is never really big (they are written by people, aren't they?), the map tends to be small, and the hit should not be significant.
It all starts from the idea that in a clone factory, the type identifier and the product have the same type. You receive as a type identifier the object to be duplicated and pass as output a new object that is a copy of the type identifier. To be more precise, they're not quite the same type: A cloning factory's IdentifierType is a pointer to AbstractProduct. The exact deal is that you pass a pointer to the clone factory, and you get back another pointer, which points to a cloned object.
But what's the key in the map? It can't be a pointer to AbstractProduct because you don't need as many entries as the objects we have. You need only one entry per type of object to be cloned, which brings us again to the std::type_info class. The type identifier passed when the factory is asked to create a new object is different from the type identifier that's stored in the association map, and that makes it impossible for us to reuse the code we've written so far. Another consequence is that the product creator now needs the pointer to the object to be cloned; in the factory we created earlier from scratch, no parameter was needed.
Let's recap. The clone factory gets a pointer to an AbstractProduct. It applies the typeid operator to the pointed-to object and obtains a reference to a std::type_info object. It then looks up that object in its private map. (The before member function of std::type_info introduces an ordering over the set of std::type_info objects, which makes it possible to use a map and perform fast searches.) If an entry is not found, an exception is thrown. If it is found, the product creator will be invoked, with the pointer to the AbstractProduct passed in by the user.
Because we already have the Factory class template handy, implementing the CloneFactory class template is a simple exercise. (You can find it in Loki.) There are a few differences and new elements:
CloneFactory uses TypeInfo instead of std::type_info. The class TypeInfo, discussed in Chapter 2, is a wrapper around a pointer to std::type_info, having the purpose of defining proper initialization, assignment, operator==, and operator<, which are all needed by the map. The first operator delegates to std::type_info::operator==; the second operator delegates to std::type_info::before. There is no longer an IdentifierType because the identifier type is implicit. The ProductCreator template parameter defaults to AbstractProduct* (*)(Abstract-Product*). The IdToProductMap is now AssocVector<TypeInfo, ProductCreator>.
The synopsis of CloneFactory is as follows:
template
<
class AbstractProduct,
class ProductCreator =
AbstractProduct* (*)(AbstractProduct*),
template<typename, class>
class FactoryErrorPolicy = DefaultFactoryError
>
class CloneFactory
{
public:
AbstractProduct* CreateObject(const AbstractProduct* model);
bool Register(const TypeInfo&,
ProductCreator creator);
bool Unregister(const TypeInfo&);
private:
typedef AssocVector<TypeInfo, ProductCreator>
IdToProductMap;
IdToProductMap associations_;
};
The CloneFactory class template is a complete solution for cloning objects belonging to closed class hierarchies (that is, class hierarchies that you cannot modify). Its simplicity and effectiveness stem from the conceptual clarifications made in the previous sections and from the runtime type information that C++ provides through typeid and std::type_info. Had RTTI not existed, clone factories would have been much more awkward to implementin fact, so awkward that putting them together wouldn't have made much sense in the first place.
|
8.8 Using Object Factories with Other Generic Components
Chapter 6 introduced the SingletonHolder class, which was designed to provide specific services to your classes. Because of the global nature of factories, it is natural to use Factory with SingletonHolder. They are very easy to combine by using typedef. For instance:
typedef SingletonHolder< Factory<Shape, std::string> > ShapeFactory;
Of course, you can add arguments to either SingletonHolder or Factory to choose different trade-offs and design decisions, but it's all in one place. From now on, you can isolate a bunch of important design choices in one place and use ShapeFactory throughout the code. Within the simple type definition just shown, you can select the way the factory works and the way the singleton works, thus exploiting all the combinations between the two. With a single line of declarative code, you direct the compiler to generate the right code for you and nothing more, just as at runtime you'd call a function with various parameters to perform some action in different ways. Because in our case it all happens at compile time, the emphasis is more on design decisions than on runtime behavior. Of course, runtime behavior is affected as well, but in a more global and subtle way. By writing "regular" code, you specify what's going to happen at runtime. When you write a type definition such as the one above, you specify what's going to happen during compile timein fact, you kind of call code-generation functions at compile time, passing arguments to them.
As alluded to in the beginning of this chapter, an interesting combination is to use Factory with Functor:
typedef SingletonHolder
<
Factory
<
Shape, std::string, Functor<Shape*>
>
>
ShapeFactory;
This gives you great flexibility in creating objects, by leveraging the power of Functor (for which implementation we took great pains in Chapter 5). You can now create Shapes in almost any way imaginable by registering various Functors with the Factory, and the whole thing is a Singleton.
|
8.9 Summary
Object factories are an important component of programs that use polymorphism. Object factories help in creating objects when their types are either not available or are available only in a form that's incompatible for use with language constructs.
Object factories are used mostly in object-oriented frameworks and libraries, as well as in various object persistence and streaming schemes. The latter case was analyzed in depth with a concrete example. The solution essentially distributes a switch of type across multiple implementation files, thus achieving low coupling. Although the factory remains a central authority that creates objects, it doesn't have to collect knowledge about all the static types in a hierarchy. Instead, it's the responsibility of each type to register itself with the factory. This marks a fundamental difference between the "wrong" and the "right" approach.
Type information cannot be easily transported at runtime in C++. This is a fundamental feature of the family of languages to which C++ belongs. Because of this, type identifiers that represent types have to be used instead. They are associated with creator objects that are callable entities, as described in Chapter 5 on generalized functors (pointers to functions or functors). A concrete object factory starting from these ideas was implemented and was then generalized into a class template.
Finally, we discussed clone factories (factories that can duplicate polymorphic objects).
|
8.10 Factory Class Template Quick Facts
Factory declaration:
template
<
class AbstractProduct,
class IdentifierType,
class ProductCreator = AbstractProduct* (*)(),
template<typename, class>
class FactoryErrorPolicy = DefaultFactoryError
>
class Factory;
AbstractProduct is the base class of the hierarchy for which you provide the object factory. IdentifierType is the type of the "cookie" that represents a type in the hierarchy. It has to be an ordered type (able to be stored in a std::map). Commonly used identifier types are strings and integral types. ProductCreator is the callable entity that creates objects. This type must support operator(), taking no parameters and returning a pointer to AbstractProduct. A ProductCreator object is always registered together with a type identifier. Factory implements the following primitives:
bool Register(const IdentifierType& id, ProductCreator creator);
Registers a creator with a type identifier. Returns true if the registration was successful; false otherwise (if there already was a creator registered with the same type identifier).
bool Unregister(const IdentifierType& id);
Unregisters the creator for the given type identifier. If the type identifier was previously registered, the function returns true.
AbstractProduct* CreateObject(const IdentifierType& id);
Looks up the type identifier in the internal map. If it is found, it invokes the corresponding creator for the type identifier and returns its result. If the type identifier is not found, the result of FactoryErrorPolicy<IdentifierType, AbstractProduct>:: OnUnknownType is returned. The default implementation of FactoryErrorPolicy throws an exception of its nested type Exception.
|
8.11 CloneFactory Class Template Quick Facts
CloneFactory declaration:
template
<
class AbstractProduct,
class ProductCreator =
AbstractProduct* (*)(const AbstractProduct*),
template<typename, class>
class FactoryErrorPolicy = DefaultFactoryError
>
class CloneFactory;
AbstractProduct is the base class of the hierarchy for which you want to provide the clone factory. ProductCreator has the role of duplicating the object received as a parameter and returning a pointer to the clone. CloneFactory implements the following primitives:
bool Register(const TypeInfo&, ProductCreator creator);
Registers a creator with an object of type TypeInfo (which accepts an implicit conversion constructor from std::type_info). Returns true if the registration was successful; false otherwise.
bool Unregister(const TypeInfo& typeInfo);
Unregisters the creator for the given type. If the type was previously registered, the function returns true.
AbstractProduct* CreateObject(const AbstractProduct* model);
Looks up the dynamic type of model in the internal map. If it is found, it invokes the corresponding creator for the type identifier and returns its result. If the type identifier is not found, the result of FactoryErrorPolicy<OrderedTypeInfo, AbstractProduct> ::OnUnknownType is returned.
|
Chapter 9. Abstract Factory
This chapter discusses a generic implementation of the Abstract Factory design pattern (Gamma et al. 1995). An abstract factory is an interface for creating a family of related or dependent polymorphic objects.
Abstract factories can be an important architectural component because they ensure that the right concrete objects are created throughout a system. You don't want a FunkyButton to appear on a ConventionalDialog; you can use the Abstract Factory design pattern to ensure that a FunkyButton can appear only on a FunkyDialog. You do this by controlling a small piece of code; the rest of the application works with the abstract types Dialog and Button.
After reading this chapter, you will
Understand the area of applicability of the Abstract Factory design pattern Know how to define and implement Abstract Factory components Know how to use the generic Abstract Factory facility provided by Loki and how to extend it to suit your needs
|
9.1 The Architectural Role of Abstract Factory
Let's say you are in the enviable position of designing a "find 'em and kill 'em" game, like Doom or Quake.
You want to entice regular taxpayers to enjoy your game, so you provide an Easy level. On the Easy level, the enemy soldiers are rather dull, the monsters move like molasses, and the super-monsters are quite friendly.
You also want to entice hardcore gamers to play your game, so you provide a Diehard level. On this level, enemy soldiers fire three times a second and are karate pros, monsters are cunning and deadly, and really bad super-monsters appear once in a while.
A possible modeling of this scary world would include defining a base class Enemy and deriving the refined interfaces Soldier, Monster, and SuperMonster from it. Then, you derive SillySoldier, SillyMonster, and SillySuperMonster from these interfaces for the Easy level. Finally, you implement BadSoldier, BadMonster, and BadSuperMonster for the Diehard level. The resulting inheritance hierarchy is shown in Figure 9.1.
It is worth noting that in your game, an instantiation of BadSoldier and an instantiation of SillyMonster never "live" at the same time. It wouldn't make sense; the player plays either the easy game with SillySoldiers, SillyMonsters, and SillySuperMonsters, or the tough game in the company of BadSoldiers, BadMonsters, and Bad SuperMonsters.
The two categories of types form two families; during the game, you always use objects in one of the two families, but you never combine them.
It would be nice if you could enforce this consistency. Otherwise, if you're not careful enough throughout the application, the beginner happily punching SillySoldiers could suddenly meet a BadMonster around the corner, get whacked, and exercise that money-back guarantee.
Because it's better to be careful once than a hundred times, you gather the creation functions for all the game objects into a single interface, as follows:
class AbstractEnemyFactory
{
public:
virtual Soldier* MakeSoldier() = 0;
virtual Monster* MakeMonster() = 0;
virtual SuperMonster* MakeSuperMonster() = 0;
};
Then, for each play level, you implement a concrete enemy factory that creates enemies as prescribed by the game strategy.
class EasyLevelEnemyFactory : public AbstractEnemyFactory
{
public:
Soldier* MakeSoldier()
{ return new SillySoldier; }
Monster* MakeMonster()
{ return new SillyMonster; }
SuperMonster* MakeSuperMonster()
{ return new SillySuperMonster; }
};
class DieHardLevelEnemyFactory : public AbstractEnemyFactory
{
public:
Soldier* MakeSoldier()
{ return new BadSoldier; }
Monster* MakeMonster()
{ return new BadMonster; }
SuperMonster* MakeSuperMonster()
{ return new BadSuperMonster; }
};
Finally, you initialize a pointer to AbstractEnemyFactory with the appropriate concrete class:
class GameApp
{
...
void SelectLevel()
{
if (user chooses the Easy level)
{
pFactory_ = new EasyLevelEnemyFactory;
}
else
{
pFactory_ = new DieHardLevelEnemyFactory;
}
}
private:
// Use pFactory_ to create enemies
AbstractEnemyFactory* pFactory_;
};
The advantage of this design is that it keeps all the details of creating and properly matching enemies inside the two implementations of AbstractEnemyFactory. Because the application uses pFactory_ as the only object creator, consistency is enforced by design. This is a typical usage of the Abstract Factory design pattern.
The Abstract Factory design pattern prescribes collecting creation functions for families of objects in a unique interface. Then you must provide an implementation of that interface for each family of objects you want to create.
The product types advertised by the abstract factory interface (Soldier, Monster, and SuperMonster) are called abstract products. The product types that the implementation actually creates (SillySoldier, BadSoldier, SillyMonster, and so on) are called concrete products. These terms should be familiar to you from Chapter 8.
The main disadvantage of Abstract Factory is that it is type intensive: The abstract factory base class (AbstractEnemyFactory in the example) must know about every abstract product that's to be created. In addition, at least in the implementation just provided, each concrete factory class depends on the concrete products it creates.
You can reduce dependencies by applying the techniques described in Chapter 8. There, you created a concrete object not by knowing its type but by knowing its type identifier (such as an int or a string). Such a dependency is much weaker.
However, the more you reduce dependencies, the more you also reduce type knowledge, and consequently the more you undermine the type safety of your design. This is yet another instance of the classic dilemma of better type safety versus lesser dependencies that often appears in C++.
As often happens, getting the right solution involves a trade-off between competing benefits. You should choose the setting that best suits your needs. As a rule of thumb, try to go with a static model when you can, and rely on a dynamic model when you must.
The generic implementation of Abstract Factory presented in the following sections sports an interesting feature that reduces static dependencies without compromising type safety.
|
9.2 A Generic Abstract Factory Interface
As hinted in Chapter 3, the Typelist facility makes implementing generic Abstract Factories a slam-dunk. This section describes how to define a generic AbstractFactory interface with the help of typelists.
The example shown in the previous section is a typical use of the Abstract Factory design pattern. To recap:
You define an abstract class (the abstract factory class) that has one pure virtual function for each product type. The virtual function corresponding to type T usually returns a T*, and its name is CreateT, MakeT, or something similar. You define one or more concrete factories that implement the interface defined by the abstract factory. You implement each member function by creating a new object of a derived type, usually by invoking the new operator.
All this seems simple enough, but as the number of products created by the abstract factory grows, the code becomes less and less maintainable. Furthermore, at any moment you might decide to plug in an implementation that uses a different allocation, or a prototype object.
A generic Abstract Factory would be of help here, but only if it's flexible enough to easily accommodate things such as custom allocators and passing arguments to constructors.
Recall the class template GenScatterHierarchy from Chapter 3. GenScatterHierarchy instantiates a basic templateprovided by the userwith each type in a typelist. By its structure, the resulting instantiation of GenScatterHierarchy inherits all the instantiations of the user-provided template. In other words, if you have a template Unit and a typelist TList, GenScatterHierarchy<TList, Unit> is a class that inherits Unit<T> for each type T in TList.
GenScatterHierarchy can be very useful for defining an abstract factory interfaceyou define an interface that can create objects of one type, and then you apply that interface to multiple types with GenScatterHierarchy.
The "unit" interface, which can create objects of a generic type T, is as follows.
template <class T>
class AbstractFactoryUnit
{
public:
virtual T* DoCreate(Type2Type<T>) = 0;
virtual ~AbstractFactoryUnit() {}
};
This little template looks perfectly koshervirtual destructor and allbut what's that Type2Type business? Recall from Chapter 2 that Type2Type is a simple template whose unique purpose is to disambiguate overloaded functions. Okay, but then where are those ambiguous functions? AbstractFactoryUnit defines only one DoCreate function. There will be several AbstractFactoryUnit instantiations in the same inheritance hierarchy, as you'll see in a moment. The Type2Type<T> helps in disambiguating the various DoCreate overloads generated.
The generic AbstractFactory interface uses GenScatterHierarchy in conjunction with AbstactFactoryUnit, as follows:
template
<
class TList,
template <class> class Unit = AbstractFactoryUnit
>
class AbstractFactory : public GenScatterHierarchy<TList, Unit>
{
public:
typedef TList ProductList;
template <class T> T* Create()
{
Unit <T>& unit = *this;
return unit.DoCreate(Type2Type<T>());
}
};
Aha, there's Type2Type in action to make it clear which DoCreate function is called by Create. Let's analyze what happens when you type the following:
// Application code
typedef AbstractFactory
<
TYPELIST_3(Soldier, Monster, SuperMonster)
>
AbstractEnemyFactory;
As Chapter 3 explains, the AbstractFactory template generates the hierarchy depicted in Figure 9.2. AbstractEnemyFactory inherits AbstractFactoryUnit<Soldier>, AbstractFactoryUnit<Monster>, and AbstractFactoryUnit<SuperMonster>. Each defines one pure virtual member function Create, so AbstractEnemyFactory has three Create overloads. In a nutshell, AbstractEnemyFactory is pretty much equivalent to the abstract class of the same name defined in the previous section.
The template member function Create of AbstractFactory is a dispatcher that routes the creation request to the appropriate base class:
AbstractEnemyFactory* p = ...;
Monster* pOgre = p->Create<Monster>();
One important advantage of the automatically generated version is that AbstractEnemyFactory is a highly granular interface. You can automatically convert a reference to an AbstractEnemyFactory to a reference to an AbstractFactory<Soldier>, AbstractFactory <Monster>, or AbstractFactory<SuperMonster>. This way, you can pass only small subunits of the factory to various parts of your application. For instance, a certain module (Surprises.cpp) needs only to create SuperMonsters. You can communicate to that module in terms of pointers or references to AbstractFactory<SuperMonster>, so that Surprises. cpp is not coupled with Soldier and Monster.
Using AbstractFactory's granularity, you can reduce the coupling that affects the Abstract Factory design pattern. You gain this decoupling without sacrificing the safety of your abstract factory interface because only the interface, not the implementation, is granular.
This brings us to the implementation of the interface. The second important advantage of the automatically generated AbstractEnemyFactory is that you can automate the implementation, too.
|
9.3 Implementing AbstractFactory
Now that we have defined the interface, we should look into ways to make implementation as easy as possible.
Given the use of typelists in defining the interface, a natural way of building a generic implementation of AbstractFactory would be to employ typelists of concrete products. In practical terms, building the Easy level concrete factory should be as simple as the following:
// Application code
typedef ConcreteFactory
<
// The abstract factory to implement
AbstractEnemyFactory,
// The policy for creating objects
// (for instance, use the new operator)
OpNewFactoryUnit,
// The concrete classes that this factory creates
TYPELIST_3(SillySoldier, SillyMonster, SillySuperMonster)
>
EasyLevelEnemyFactory;
The three arguments to the (now hypothetical) ConcreteFactory class template are enough information to implement a complete factory:
AbstractEnemyFactory provides the abstract factory interface to implement and, implicitly, the list of products. OpNewFactoryUnit is the policy that dictates how objects are actually created. (Chapter 1 discusses the policy class concept in detail.) The typelist provides the collection of concrete classes that the factory is supposed to create. Each concrete type in the typelist maps to the abstract type of the same index in AbstractFactory's typelist. For example, SillyMonster (index 1) is the concrete type for Monster (same index in the definition of AbstractEnemyFactory).
Now that we have established the synopsis of ConcreteFactory, let's figure out how we can implement it. Simple math leads us to the conclusion that there should be as many pure virtual function overrides as there are definitions. (Otherwise we wouldn't be able to instantiate ConcreteFactory, and by definition, ConcreteFactory must be ready to serve.) Consequently, ConcreteFactory should inherit OpNewFactoryUnit (which is responsible for implementing DoCreate) instantiated with every type in the typelist.
Here the GenLinearHierarchy class template, which complements GenScatterHierarchy (see Chapter 3), can be of great use because it takes care of all the details of generating the instantiations for us.
AbstractEnemyFactory must be the root of the hierarchy. All DoCreate implementations and ultimately EasyLevelEnemyFactory must derive from it. Each instantiation of OpNewFactoryUnit overrides one of the three DoCreate pure virtual functions defined by AbstractEnemyFactory.
Let's proceed by defining OpNewFactoryUnit. Obviously, OpNewFactoryUnit is a class template having the type to create as a template parameter. In addition, GenLinearHierarchy requires that OpNewFactoryUnit accept an additional template parameter and derive from it. (GenLinearHierarchy uses this second parameter to generate the string-shaped inheritance hierarchy shown in Figure 3.6.)
template <class ConcreteProduct, class Base>
class OpNewFactoryUnit : public Base
{
typedef typename Base::ProductList BaseProductList;
protected:
typedef typename BaseProductList::Tail ProductList;
public:
typedef typename BaseProductList::Head AbstractProduct;
ConcreteProduct* DoCreate(Type2Type<AbstractProduct>)
{
return new ConcreteProduct;
}
};
OpNewFactoryUnit must do only some type calculations for figuring out which abstract product to implement.
Each OpNewFactoryUnit instantiation is a component in a food chain. Each OpNewFactoryUnit instantiation "eats" the head of the product list by overriding the appropriate DoCreate function, and passes the beheaded ProductList down the class hierarchy. Thus, the topmost OpNewFactoryUnit instantiation (the one just below AbstractEnemyFactory) implements DoCreate(Type2Type<Soldier>), and the bottommost OpNewFactoryUnit instantiation implements DoCreate(Type2Type<SuperMonster>).
Let's recap how OpNewFactoryUnit honors its position in the food chain. First, OpNewFactoryUnit imports the ProductList type from its base class and renames it BaseProductList. (If you look at AbstractFactory's definition, you'll see that indeed it exports the ProductList type.) The abstract product that OpNewFactoryUnit implements is the head of BaseProductList, hence AbstractProduct's definition. Finally, OpNewFactoryUnit reexports BaseProductList::Tail as ProductList. This way the remaining list is passed down the inheritance hierarchy.
Notice that OpNewFactoryUnit::DoCreate does not return a pointer to AbstractProduct, as its pure counterpart does. Instead, OpNewFactoryUnit::DoCreate returns a pointer to a ConcreteProduct object. Does it still qualify as an implementation of the pure virtual function? The answer is yes, thanks to a C++ language feature called covariant return types. C++ allows you to override a function that returns a pointer to a base class with a function that returns a pointer to a derived class. It makes a lot of sense. With covariant return types, you either know the exact type of the concrete factory and you get maximum type information, or you know only the base type of the factory and you get lesser type information.
ConcreteFactory must generate a hierarchy using GenLinearHierarchy. Its implementation is straightforward:
template
<
class AbstractFact,
template <class, class> class Creator = OPNewFactoryUnit
class TList = typename AbstractFact::ProductList
>
class ConcreteFactory
: public GenLinearHierarchy<
typename TL::Reverse<TList>::Result, Creator, AbstractFact>
{
public:
typedef typename AbstractFact::ProductList ProductList;
typedef TList ConcreteProductList;
};
The class hierarchy that GenLinearHierarchy generates for ConcreteFactory is shown in Figure 9.3.
There is only one twist: ConcreteFactory must reverse the concrete product list when passing it to GenLinearHierarchy. Why? Well, we have to go back to Figure 3.6, which shows how GenLinearHierarchy generates a hierarchy. GenLinearHierarchy distributes types in the typelist to its Unit template argument from the bottom up; the first element in the typelist is passed to the Unit instantiation that's at the bottom of the class hierarchy. However, OpNewFactoryUnit implements the DoCreate overloads in a top-down fashion. In conclusion, ConcreteFactory reverses the typelist TList using the TL::Reverse compile-time algorithm (see Chapter 3) before passing it to GenLinearHierarchy.
If, at this point, you still find AbstractFactory and ConcreteFactory a bit confusing or too complicated, take heart. It is because the two class templates make nonchalant use of typelists. Typelists themselves are likely a new concept to you, and it will take some time to get used to them. If you think of typelists as a black-box concept"typelists are to types what regular lists are to values"the implementations in this chapter are very simple. And once you truly get used to typelists, the sky's the limit. Unconvinced? Read on.
|
9.4 A Prototype-Based Abstract Factory Implementation
The Prototype design pattern (Gamma et al. 1995) describes a method for creating objects starting from a prototype, an archetypal object. You obtain new objects by cloning the prototype. And the gist of it all is that the cloning function is virtual.
As Chapter 8 discusses in detail, the essential problem in creating polymorphic objects is the virtual constructor dilemma: Creation from scratch needs knowledge about the type of object being created, yet polymorphism fosters not knowing the exact type.
The Prototype pattern avoids the dilemma by using a prototype object. If you have one objecta prototypeyou can take advantage of virtual functions. The virtual constructor dilemma still applies to the prototype itself, but it's much more localized.
A prototype-based approach to building enemies for the game in our example would prescribe holding pointers to the base classes Soldier, Monster, and SuperMonster. Then we would write code like the following:
class GameApp
{
...
void SelectLevel()
{
if (user chooses Diehard level)
{
protoSoldier_.reset(new BadSoldier);
protoMonster_.reset(new BadMonster);
protoSuperMonster_.reset(new BadSuperMonster);
}
else
{
protoSoldier_.reset(new SillySoldier);
protoMonster_.reset(new SillyMonster);
protoSuperMonster_.reset(new SillySuperMonster);
}
}
Soldier* MakeSoldier()
{
// Each enemy class defines a Clone virtual function
// that returns a pointer to a new object
return pProtoSoldier_->Clone();
}
... MakeMonster and MakeSuperMonster similarly defined ...
private:
// Use these prototypes to create enemies
auto_ptr<Soldier> protoSoldier_;
auto_ptr<Monster> protoMonster_;
auto_ptr<SuperMonster> protoSuperMonster_;
};
Of course, real-world code would better separate the interface and the implementation. The basic idea is that GameApp holds pointers to base enemy classesthe prototypes. GameApp uses these prototypes to create enemy objects by calling the virtual function Clone on the prototypes.
A prototype-based Abstract Factory implementation would collect a pointer for each product type and use the Clone function to create new products.
In a ConcreteFactory that uses prototypes, there's no longer a need to provide the concrete types. In our example, building SillySoldiers or BadSoldiers is only a matter of providing the appropriate prototypes to the factory object. The prototype's static type is the base (Soldier) class. The factory does not have to know the concrete types of the objects; it just calls the Clone virtual member function for the appropriate prototype object. This reduces the concrete factory's dependency on the concrete types.
For the GenLinearHierarchy expansion mechanism to work correctly, however, there has to be a typelist. Recall ConcreteFactory's declaration:
template
<
class AbstractFact,
template <class, class> class Creator,
class TList
>
class ConcreteFactory;
TList is the concrete product list. In the EasyLevelEnemyFactory, TList was TYPELIST_3(SillySoldier, SillyMonster, SillySuperMonster). If we use the Prototype design pattern, TList becomes irrelevant. However, GenLinearHierarchy needs TList for generating one class for each product in the abstract product list. What to do?
In this case, a natural solution is to pass ConcreteFactory the abstract product list as the TList argument. Now GenLinearHierarchy generates the right number of classes, and there's no need to change ConcreteFactory's implementation.
ConcreteFactory's declaration now becomes
template
<
class AbstractFact,
template <class, class> class Creator,
class TList = typename AbstractFact::ProductList
>
class ConcreteFactory;
(Recall from AbstractFact's definition in Section 9.3 that it defines the inner type ProductList.)
Let's now implement PrototypeFactoryUnit, the unit template that holds the prototype and calls Clone. The implementation is straightforward and is actually simpler than OpNewFactoryUnit. This is because OpNewFactoryUnit had to maintain two typelists (the abstract products and the concrete products), whereas PrototypeFactoryUnit deals only with the abstract product list.
template <class ConcreteProduct, class Base>
class PrototypeFactoryUnit : public Base
{
typedef typename Base::ProductList BaseProductList;
protected;
typedef typename Base::ProductList TailProductList;
public;
typedef typename Base::ProductList::Head AbstractProduct;
PrototypeFactoryUnit(AbstractProduct* p = 0)
:pPrototype_(p)
{}
friend void DoGetPrototype(const PrototypeFactoryUnit& me,
AbstractProduct*& pPrototype)
{
pPrototype = me.pPrototype_;
}
friend void DoSetPrototype(PrototypeFactoryUnit& me,
AbstractProduct* pObj)
{
me.pPrototype_=pObj;
}
template <class U>
void GetPrototype(AbstractProduct*& p)
{
return DoGetPrototype(*this, p);
}
template <class U>
void SetPrototype(U* pObj)
{
DoSetPrototype(*this, pObj);
}
AbstractProduct* DoCreate(Type2Type<AbstractProduct>)
{
assert(pPrototype_);
return pPrototype_->Clone();
}
private:
AbstractProduct* pPrototype_;
};
The PrototypeFactoryUnit class template makes some assumptions that may or may not apply to your concrete situation. First, PrototypeFactoryUnit doesn't own its prototype; sometimes, you might want SetPrototype to delete the old prototype before reassigning it. Second, PrototypeFactoryUnit uses a Clone function that supposedly clones the product. In your application you might use a different name, either because you are constrained by another library or because you prefer another naming convention.
If you need to customize your prototype-based factory, you need only write a template similar to PrototypeFactoryUnit. You can inherit PrototypeFactoryUnit and override only the functions you want. For example, say you want to implement DoCreate so that it returns a null pointer if the prototype pointer is null.
template <class AbstractProduct, class Base>
class MyFactoryUnit
: public PrototypeFactoryUnit<AbstractProduct, Base>
{
public:
// Implement DoCreate so that it accepts a null prototype
// pointer
AbstractProduct* DoCreate(Type2Type<AbstractProduct>)
{
return pPrototype_ ? pPrototype_->Clone() : 0;
}
};
Let's get back to our game example. To define a concrete factory, all you have to write in the application code is the following:
// Application code
typedef ConcreteFactory
<
AbstractEnemyFactory,
PrototypeFactoryUnit
>
EnemyFactory;
To conclude, the AbstractFactory/ConcreteFactory duo offers you the following features:
You can easily define factories with the help of typelists. Because AbstractFactory inherits each of its units, the interface is very granular. You can pass individual "creator units" (pointers or references to AFUnit<T> sub objects) to different modules, thus reducing coupling. You can use ConcreteFactory to implement the AbstractFactory by providing a policy template that dictates the creation method. For statically bound creation policies (such as OpNewFactoryUnit, which uses the new operator), you need to pass the typelist of concrete products that the factory creates. A popular creation policy is to apply the Prototype design pattern; you can easily use Prototype with ConcreteFactory by using the canned PrototypeFactoryUnit class template.
Try to obtain all these benefits with a handcrafted implementation of the Abstract Factory design pattern.
|
9.5 Summary
The Abstract Factory design pattern fosters an interface for creating a family of related or dependent polymorphic objects. Using Abstract Factory, you can divide implementation classes into disjoint families.
It is possible to implement a generic abstract factory interface by using typelists and policy templates. The typelists provide the product list (both concrete and abstract) and the policy templates.
The AbstractFactory class template provides a skeleton for defining abstract factories and works in conjunction with the AFUnit class template. AbstractFactory requires a user-provided abstract product typelist. Internally, AbstractFactory uses GenScatterHierarchy (see Chapter 3) to generate a granular interface that inherits AFUnit<T> for each product T in the abstract product typelist. This structure gives you the opportunity to reduce coupling by passing only individual factory units to various parts of an application.
The ConcreteFactory template helps with implementing the AbstractFactory interface. ConcreteFactory uses a FactoryUnit policy for creating objects. Internally, Concrete Factory uses GenLinearHierarchy (see Chapter 3). Loki provides two predefined implementations of the FactoryUnit policy: OpNewFactoryUnit, which creates objects by calling the new operator, and PrototypeFactoryUnit, which creates objects by cloning a prototype.
|
9.6 AbstractFactory and ConcreteFactory Quick Facts
AbstractFactory synopsis:
template
<
class TList,
template <class> class Unit = AbstractFactoryUnit
>
class AbstractFactory;
where TList is the typelist of abstract products that the factory creates, and Unit is the template that defines the interface for each type in TList. For example,
typedef AbstractFactory<TYPELIST_3(Soldier, Monster, SuperMonster>
AbstractEnemyFactory;
defines an abstract factory capable of creating Soldiers, Monsters, and SuperMonsters.
AbstractFactoryUnit<T> defines an interface consisting of a pure virtual function with the signature T* DoCreate(Type2Type<T>). Usually you don't call DoCreate directly; instead, you use AbstractFactory::Create. AbstractFactory exposes a Create template function. You can instantiate Create with any of the types of the abstract products. For example:
AbstractEnemyFactory *pFactory = ...;
Soldier *pSoldier = pFactory->Create<Soldier>();
For implementing the interface that AbstractFactory defines, Loki provides the ConcreteFactory template. ConcreteFactory's synopsis is
template
<
class AbstractFact,
template <class, class> class FactoryUnit = OpNewFactoryUnit,
class TList = AbstractFact::ProductList
>
class ConcreteFactory;
where AbstractFact is the instantiation of AbstractFactory that is to be implemented, FactoryUnit is the implementation of the FactoryUnit creation policy, and TList is the typelist of concrete products.
The FactoryUnit policy implementation has access to both the abstract product and the concrete product that it must create. Loki defines two Creator policies: OpNewFactoryUnit (Section 9.3) and PrototypeFactoryUnit (Section 9.4). They can also serve as examples for implementing custom implementations of the FactoryUnit policy. OpNewFactoryUnit uses the new operator for creating objects. If you use OpNewFactoryUnit, you must provide a concrete product typelist as the third parameter to ConcreteFactory. For example:
typedef ConcreteFactory
<
AbstractEnemyFactory,
OpNewFactoryUnit,
TYPELIST_3(SillySoldier, SillyMonster, SillySuperMonster)
>
EasyLevelEnemyFactory;
PrototypeFactoryUnit stores pointers to abstract product types and creates new objects by calling the Clone member function of their respective prototypes. This implies that PrototypeFactoryUnit requires each abstract product T to define a virtual member function Clone that returns a T* and whose semantics is to duplicate the object. When using PrototypeFactoryUnit with ConcreteFactory, you don't provide the third template argument to ConcreteFactory. For example:
typedef ConcreteFactory
<
AbstractEnemyFactory,
PrototypeFactoryUnit,
>
EnemyFactory;
|
|
|

 LINUX
LINUX 
 Books
Books
