18.2 Communication Channels
A communication channel is a logical pathway for information that is accessed by participants through communication endpoints. The characteristics of the channel constrain the types of interaction allowed between sender and receiver. Channels can be shared or private, one-way or two-way. Two-way channels can be symmetric or asymmetric. Channels are distinguished from the underlying physical conduit, which may support many types of channels.
In object-orient programming, clients communicate with an object by calling a method. In this context, client and server share an address space, and the communication channel is the activation record that is created on the process stack for the call. The request consists of the parameter values that are pushed on the stack as part of the call, and the optional reply is the method's return value. Thus, the activation record is a private, asymmetric two-way communication channel. The method call mechanism of the object-oriented programming language establishes the communication endpoints. The system infrastructure for managing the process stack furnishes the underlying conduit for communication.
Many system services in UNIX are provided by server processes running on the same machine as their clients. These processes can share memory or a file system, and clients make requests by writing to such a shared resource.
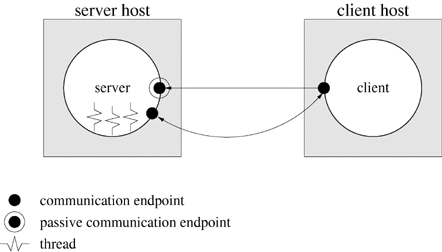
Programs 6.7 and 6.8 of Chapter 6 use a named pipe as a communication channel for client requests. The named pipe is used as a shared one-way communication channel that can handle requests from any number of clients. Named pipes have an associated pathname, and the system creates an entry in the file system directory corresponding to this pathname when mkfifo executes. The file system provides the underlying conduit. A process creates communication endpoints by calling open and accesses these endpoints through file descriptors. Figure 18.1 shows a schematic of the communication supported in this example.
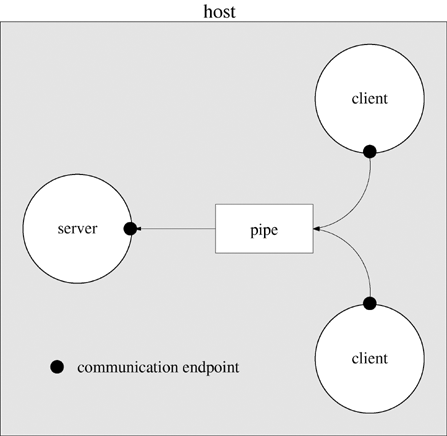
Named pipes can be used for short client requests, since a write of PIPE_BUF bytes or less is not interleaved with other writes to the same pipe. Unfortunately, named pipes present several difficulties when the requests are long or the server must respond. If the server simply opens another named pipe for responses, individual clients have no guarantee that they will read the response meant for them. If the server opens a unique pipe for each response, the clients and server must agree in advance on a naming convention. Furthermore, named pipes are persistent. They remain in existence unless their owners explicitly unlink them. A general mechanism for communication should release its resources when the interacting parties no longer exist.
Transmission Control Protocol (TCP) is a connection-oriented protocol that provides a reliable channel for communication, using a conduit that may be unreliable. Connection-oriented means that the initiator (the client) first establishes a connection with the destination (the server), after which both of them can send and receive information. TCP implements the connection through an exchange of messages, called a three-way handshake, between initiator and destination. TCP achieves reliability by using receiver acknowledgments and retransmissions. TCP also provides flow control so that senders don't overwhelm receivers with a flood of information. Fortunately, the operating system network subsystem implements TCP, so the details of the protocol exchanges are not visible at the process level. If the network fails, the process detects an error on the communication endpoint. The process should never receive incorrect or out-of-order information when using TCP.
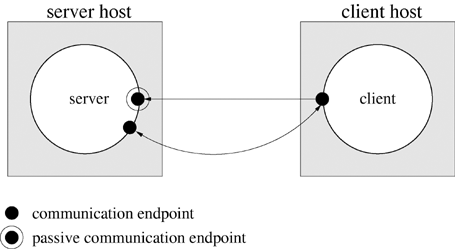
Figure 18.2 illustrates the setup for connection-oriented communication. The server monitors a passive communication endpoint whose address is known to clients. Unlike other endpoints, passive or listening endpoints have resources for queuing client connection requests and establishing client connections. The action of accepting a client request creates a new communication endpoint for private, two-way symmetric communication with that client. The client and server then communicate by using handles (file descriptors) and do not explicitly include addresses in their messages. When finished, the client and server close their file descriptors, and the system releases the resources associated with the connection. Connection-oriented protocols have an initial setup overhead, but they allow transparent management of errors when the underlying conduits are not error-free.
Exercise 18.1
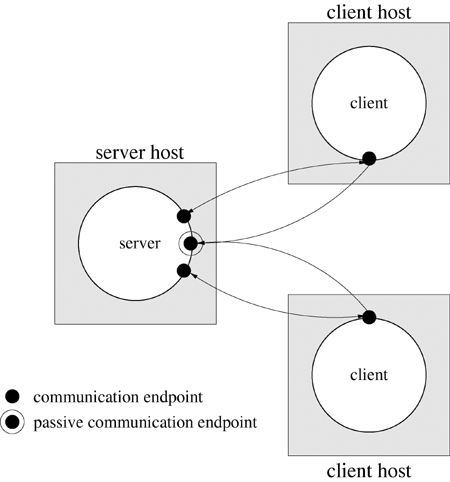
Figure 18.3 illustrates a situation in which two clients have established connections with a server. What strategies are available to the server for managing the resulting private communication channels (each with its own file descriptor)?
Answer:
The server cannot make any assumptions about the order in which information will arrive on the file descriptors associated with the clients' private communication channels. Therefore, a solution to alternately read from one descriptor and then the other is incorrect. Section 12.1 outlines the available approaches for monitoring multiple file descriptors. The server could use select or poll, but the server would not be able to accept any additional connection requests while blocking on these calls. Simple polling wastes CPU cycles. Asynchronous I/O is efficient, but complex to program. Alternatively, the server can fork a child process or create a separate thread to handle the client communication.
Both connectionless and connection-oriented protocols are considered to be low-level in the sense that the request for service involves visible communication. The programmer is explicitly aware of the server's location and must explicitly name the particular server to be accessed.
The naming of servers and services in a network environment is a difficult problem. An obvious method for designating a server is by its process ID and a host ID. However, the operating system assigns process IDs chronologically by process creation time, so the client cannot know in advance the process ID of a particular server process on a host.
The most commonly used method for specifying a service is by the address of the host machine (the IP address) and an integer called a port number. Under this scheme, a server monitors one or more communication channels associated with port numbers that have been designated in advance for a particular service. Web servers use port 80 by default, whereas ftp servers use port 21. The client explicitly specifies a host address and a port number for the communication. Section 18.8 discusses library calls for accessing IP addresses by using host names.
This chapter focuses on connection-oriented communication using TCP/IP and stream sockets with servers specified by host addresses and port numbers. More sophisticated methods of naming and locating services are available through object registries [44], directory services [129], discovery mechanisms [4] or middleware such as CORBA [104]. Implementations of these approaches are not universally available, nor are they particularly associated with UNIX.
18.3 Connection-Oriented Server Strategies
Once a server receives a request, it can use a number of different strategies for handling the request. The serial server depicted in Figure 18.2 completely handles one request before accepting additional requests.
Example 18.2
The following pseudocode illustrates the serial-server strategy.
for ( ; ; ) {
wait for a client request on the listening file descriptor
create a private two-way communication channel to the client
while (no error on the private communication channel)
read from the client
process the request
respond to the client
close the file descriptor for the private communication channel
}
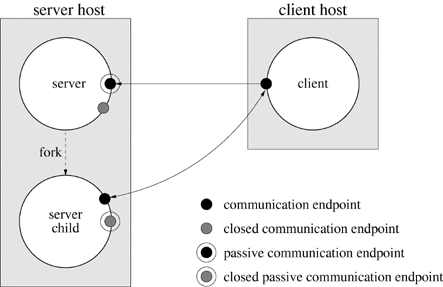
A busy server handling long-lived requests such as file transfers cannot use a serial-server strategy that processes only one request at a time. A parent server forks a child process to handle the actual service to the client, freeing the server to listen for additional requests. Figure 18.4 depicts the parent-server strategy. The strategy is ideal for services such as file transfers, which take a relatively long time and involve a lot of blocking.
Example 18.3
The following pseudocode illustrates the parent-server strategy.
for( ; ; ) {
wait for a client request on the listening file descriptor
create a private two-way communication channel to the client
fork a child to handle the client
close file descriptor for the private communication channel
clean up zombie children
}
The child process does the following.
close the listening file descriptor
handle the client
close the communication for the private channel
exit
Since the server's child handles the actual service in the parent-server strategy, the server can accept multiple client requests in rapid succession. The strategy is analogous to the old-fashioned switchboard at some hotels. A client calls the main number at the hotel (the connection request). The switchboard operator (server) answers the call, patches the connection to the appropriate room (the server child), steps out of the conversation, and resumes listening for additional calls.
Exercise 18.4
What happens in Example 18.3 if the parent does not close the file descriptor corresponding to the private communication channel?
Answer:
In this case, both the server parent and the server child have open file descriptors to the private communication channel. When the server child closes the communication channel, the client will not be able to detect end-of-file because a remote process (the server parent) still has it open. Also, if the server runs for a long time with many client requests, it will eventually run out of file descriptors.
Exercise 18.5
What is a zombie child? What happens in Example 18.3 if the server parent does not periodically wait for its zombie children?
Answer:
A zombie is a process that has completed execution but has not been waited for by its parent. Zombie processes do not release all their resources, so eventually the system may run out of some critical resource such as memory or process IDs.
The threaded server depicted in Figure 18.5 is a low-overhead alternative to the parent server. Instead of forking a child to handle the request, the server creates a thread in its own process space. Threaded servers can be very efficient, particularly for small or I/O intensive requests. A drawback of the threaded-server strategy is possible interference among multiple requests due to the shared address space. For computationally intensive services, the additional threads may reduce the efficiency of or block the main server thread. Per-process limits on the number of open file descriptors may also restrict the number of simultaneous client requests that can be handled by the server.
Example 18.6
The following pseudocode illustrates the threaded-server strategy.
for ( ; ; ) {
wait for a client request on the listening file descriptor
create a private two-way communication channel to the client
create a detached thread to handle the client
}
Exercise 18.7
What is the purpose of creating a detached (as opposed to attached) thread in Example 18.6?
Answer:
Detached threads release all their resources when they exit, hence the main thread doesn't have to wait for them. The waitpid function with the NOHANG option allows a process to wait for completed children without blocking. There is no similar option for the pthread_join function.
Exercise 18.8
What would happen if the main thread closed the communication file descriptor after creating the thread to handle the communication?
Answer:
The main thread and child threads execute in the same process environment and share the same file descriptors. If the main thread closes the communication file descriptor, the newly created thread cannot access it. Compare this situation to that encountered in the parent server of Example 18.3, in which the child process receives a copy of the file descriptor table and executes in a different address space.
Other strategies are possible. For example, the server could create a fixed number of child processes when it starts and each child could wait for a connection request. This approach allows a fixed number of simultaneous parallel connections and saves the overhead of creating a new process each time a connection request arrives. Similarly, another threading strategy has a main thread that creates a pool of worker threads that each wait for connection requests. Alternatively, the main thread can wait for connection requests and distribute communication file descriptors to free worker threads. Chapter 22 outlines a project to compare the performance of different server strategies.
|
18.4 Universal Internet Communication Interface (UICI)
The Universal Internet Communication Interface (UICI) library, summarized in Table 18.1, provides a simplified interface to connection-oriented communication in UNIX. UICI is not part of any UNIX standard. The interface was designed by the authors to abstract the essentials of network communication while hiding the details of the underlying network protocols. UICI has been placed in the public domain and is available on the book web site. Programs that use UICI should include the uici.h header file.
This section introduces the UICI library. The next two sections implement several client-server strategies in terms of UICI. Section 18.7 discusses the implementation of UICI using sockets, and Appendix C provides a complete UICI implementation.
When using sockets, a server creates a communication endpoint (a socket) and associates it with a well-known port (binds the socket to the port). Before waiting for client requests, the server sets the socket to be passive so that it can accept client requests (sets the socket to listen). Upon detection of a client connection request on this endpoint, the server generates a new communication endpoint for private two-way communication with the client. The client and server access their communication endpoints by using file descriptors to read and write. When finished, both parties close the file descriptors, releasing the resources associated with the communication channel.
Table 18.1. The UICI API. If unsuccessful, UICI functions return 1 and set errno.|
int u_open(u_port_t port)
| creates a TCP socket bound to port and sets the socket to be passive returns a file descriptor for the socket |
int u_accept(int fd,
char *hostn,
int hostnsize)
| waits for connection request on fd; on return, hostn has first hostname-1 characters of the client's host name returns a communication file descriptor |
int u_connect(u_port_t port,
char *hostn)
| initiates a connection to server on port port and host hostn. returns a communication file descriptor |
Figure 18.6 depicts a typical sequence of UICI calls used in client-server communication. The server creates a communication endpoint (u_open) and waits for a client to send a request (u_accept). The u_accept function returns a private communication file descriptor. The client creates a communication endpoint for communicating with the server (u_connect).
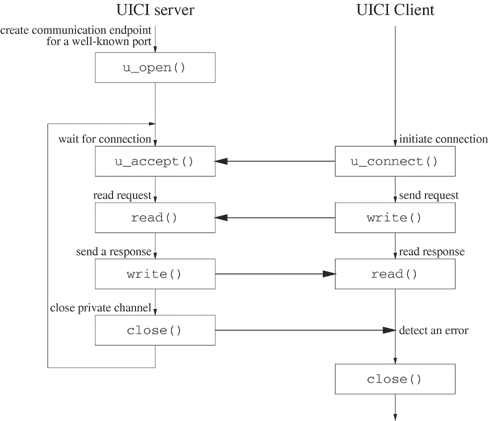
Once they have established a connection, a client and server can communicate over the network by using the ordinary read and write functions. Alternatively, they can use the more robust r_read and r_write from the restart library of Appendix B. Either side can terminate communication by calling close or r_close. After close, the remote end detects end-of-file when reading or an error when writing. The diagram in Figure 18.6 shows a single request followed by a response, but more complicated interactions might involve several exchanges followed by close.
In summary, UICI servers follow these steps.
Open a well-known listening port (u_open). The u_open functions returns a listening file descriptor.
Wait for a connection request on the listening file descriptor (u_accept). The u_accept function blocks until a client requests a connection and then returns a communication file descriptor to use as a handle for private, two-way client-server communication.
Communicate with the client by using the communication file descriptor (read and write).
Close the communication file descriptor (close).
UICI clients follow these steps.
Connect to a specified host and port (u_connect). The connection request returns the communication file descriptor used for two-way communication with the server.
Communicate with the server by using the communication file descriptor (read and write).
Close the communication file descriptor (close).
18.4.1 Handling errors
A major design issue for UICI was how to handle errors. UNIX library functions generally report errors by returning 1 and setting errno. To keep the UICI interface simple and familiar, UICI functions also return 1 and set errno. None of the UICI functions display error messages. Applications using UICI should test for errors and display error messages as appropriate. Since UICI functions always set errno when a UICI function returns an error, applications can use perror to display the error message. POSIX does not specify an error code corresponding to the inability to resolve a host name. The u_connect function returns 1 and sets errno to EINVAL, indicating an invalid parameter when it cannot resolve the host name.
18.4.2 Reading and writing
Once they have obtained an open file descriptor from u_connect or u_accept, UICI clients and servers can use the ordinary read and write functions to communicate. We use the functions from the restart library since they are more robust and simplify the code.
Recall that r_read and r_write both restart themselves after being interrupted by a signal. Like read, r_read returns the number of bytes read or 0 if it encounters end-of-file. If unsuccessful, r_read returns 1 and sets errno. If successful, r_write returns the number of bytes requested to write. The r_write function returns 1 and sets errno if an error occurred or if it could not write all the requested bytes without error. The r_write function restarts itself if not all the requested bytes have been written. This chapter also uses the copyfile function from the restart library, introduced in Program 4.6 on page 100 and copy2files introduced in Program 4.13 on page 111.
The restart library supports only blocking I/O. That is, r_read or r_write may cause the caller to block. An r_read call blocks until some information is available to be read. The meaning of blocking for r_write is less obvious. In the present context, blocking means that r_write returns when the output has been transferred to a buffer used by the transport mechanism. Returning does not imply that the message has actually been delivered to the destination. Writes may also block if message delivery problems arise in the lower protocol layers or if all the buffers for the network protocols are full. Fortunately, the issues of blocking and buffering are transparent for most applications.
18.5 UICI Implementations of Different Server Strategies
Program 18.1 shows a serial-server program that copies information from a client to standard output, using the UICI library. The server takes a single command-line argument specifying the number of the well-known port on which it listens. The server obtains a listening file descriptor for the port with u_open and then displays its process ID. It calls u_accept to block while waiting for a client request. The u_accept function returns a communication file descriptor for the client communication. The server displays the name of the client and uses copyfile of Program 4.6 on page 100 to perform the actual copying. Once it has finished the copying, the server closes the communication file descriptor, displays the number of bytes copied, and resumes listening.
Program 18.1 server.c
A serial server implemented using UICI.
#include <limits.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "restart.h"
#include "uici.h"
int main(int argc, char *argv[]) {
int bytescopied;
char client[MAX_CANON];
int communfd;
int listenfd;
u_port_t portnumber;
if (argc != 2) {
fprintf(stderr, "Usage: %s port\n", argv[0]);
return 1;
}
portnumber = (u_port_t) atoi(argv[1]);
if ((listenfd = u_open(portnumber)) == -1) {
perror("Failed to create listening endpoint");
return 1;
}
fprintf(stderr, "[%ld]:waiting for the first connection on port %d\n",
(long)getpid(), (int)portnumber);
for ( ; ; ) {
if ((communfd = u_accept(listenfd, client, MAX_CANON)) == -1) {
perror("Failed to accept connection");
continue;
}
fprintf(stderr, "[%ld]:connected to %s\n", (long)getpid(), client);
bytescopied = copyfile(communfd, STDOUT_FILENO);
fprintf(stderr, "[%ld]:received %d bytes\n", (long)getpid(), bytescopied);
if (r_close(communfd) == -1)
perror("Failed to close communfd\n");
}
}
Exercise 18.9
Under what circumstances does a client cause the server in Program 18.1 to terminate?
Answer:
The server executes the first return statement if it is not started with a single command-line argument. The u_open function creates a communication endpoint associated with a port number. The u_open function fails if the port is invalid, if the port is in use, or if system resources are not available to support the request. At this point, no clients are involved. Once the server has reached u_accept, it does not terminate unless it receives a signal. A client on a remote machine cannot cause the server to terminate. A failure of u_accept causes the server to loop and try again. Notice that I/O errors cause copyfile to return, but these errors do not cause server termination.
Program 18.2 implements the parent-server strategy. The parent accepts client connections and forks a child to call copyfile so that the parent can resume waiting for connections. Because the child receives a copy of the parent's environment at the time of the fork, it has access to the private communication channel represented by communfd.
Exercise 18.10
What happens if the client name does not fit in the buffer passed to u_accept?
Answer:
The implementation of u_accept does not permit the name to overflow the buffer. Instead, u_accept truncates the client name. (See Section 18.7.6.)
Exercise 18.11
What happens if after the connection is made, you enter text at standard input of the server?
Answer:
The server program never reads from standard input, and what you type at standard input is not sent to the remote machine.
Exercise 18.12
Program 18.2 uses r_close and r_waitpid from the restart library. How does this affect the behavior of the program?
Answer:
Functions in the restart library restart the corresponding function when the return value is 1 and errno is EINTR. This return condition occurs when the signal handler of a caught signal returns. Program 18.2 does not catch any signals, so using the restarted versions is not necessary. We use the functions from the restart library to make it easier to add signal handling capability to the programs.
Program 18.2 serverp.c
A server program that forks a child to handle communication.
#include <errno.h>
#include <limits.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "restart.h"
#include "uici.h"
int main(int argc, char *argv[]) {
int bytescopied;
pid_t child;
char client[MAX_CANON];
int communfd;
int listenfd;
u_port_t portnumber;
if (argc != 2) {
fprintf(stderr, "Usage: %s port\n", argv[0]);
return 1;
}
portnumber = (u_port_t) atoi(argv[1]);
if ((listenfd = u_open(portnumber)) == -1) {
perror("Failed to create listening endpoint");
return 1;
}
fprintf(stderr, "[%ld]: Waiting for connection on port %d\n",
(long)getpid(), (int)portnumber);
for ( ; ; ) {
if ((communfd = u_accept(listenfd, client, MAX_CANON)) == -1) {
perror("Failed to accept connection");
continue;
}
fprintf(stderr, "[%ld]:connected to %s\n", (long)getpid(), client);
if ((child = fork()) == -1) {
perror("Failed to fork a child");
continue;
}
if (child == 0) { /* child code */
if (r_close(listenfd) == -1) {
fprintf(stderr, "[%ld]:failed to close listenfd: %s\n",
(long)getpid(), strerror(errno));
return 1;
}
bytescopied = copyfile(communfd, STDOUT_FILENO);
fprintf(stderr, "[%ld]:received %d bytes\n",
(long)getpid(), bytescopied);
return 0;
}
if (r_close(communfd) == -1) /* parent code */
fprintf(stderr, "[%ld]:failed to close communfd: %s\n",
(long)getpid(), strerror(errno));
while (r_waitpid(-1, NULL, WNOHANG) > 0) ; /* clean up zombies */
}
}
18.6 UICI Clients
Program 18.3 shows the client side of the file copy. The client connects to the desired port on a specified host by calling u_connect. The u_connect function returns the communication file descriptor. The client reads the information from standard input and copies it to the server. The client exits when it receives end-of-file from standard input or if it encounters an error while writing to the server.
Program 18.3 client.c
A client that uses UICI for communication.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "restart.h"
#include "uici.h"
int main(int argc, char *argv[]) {
int bytescopied;
int communfd;
u_port_t portnumber;
if (argc != 3) {
fprintf(stderr, "Usage: %s host port\n", argv[0]);
return 1;
}
portnumber = (u_port_t)atoi(argv[2]);
if ((communfd = u_connect(portnumber, argv[1])) == -1) {
perror("Failed to make connection");
return 1;
}
fprintf(stderr, "[%ld]:connected %s\n", (long)getpid(), argv[1]);
bytescopied = copyfile(STDIN_FILENO, communfd);
fprintf(stderr, "[%ld]:sent %d bytes\n", (long)getpid(), bytescopied);
return 0;
}
Exercise 18.13
How would you use Programs 18.1 and 18.3 to transfer information from one machine to another?
Answer:
Compile the server of Program 18.1 as server. First, start the server listening on a port (say 8652) by executing the following command.
server 8652
Compile Program 18.3 as client. If the server is running on usp.cs.utsa.edu, start the client on another machine with the following command.
client usp.cs.utsa.edu 8652
Once the client and server have established a connection, enter text on the standard input of the client and observe the server output. Enter the end-of-file character (usually Ctrl-D). The client terminates, and both client and server print the number of bytes transferred. Be sure to replace usp.cs.utsa.edu with the host name of your server.
Exercise 18.14
How would you use Programs 18.1 and 18.3 to transfer the file t.in on one machine to the file t.out on another? Will t.out be identical to t.in? What happens to the messages displayed by the client and server?
Answer:
Use I/O redirection. Start the server of Program 18.1 on the destination machine (say, usp.cs.utsa.edu) by executing the following command.
server 8652 > t.out
Start the client of Program 18.3 on the source machine by executing the following command.
client usp.cs.utsa.edu 8652 < t.in
Be sure to substitute your server's host name for usp.cs.utsa.edu. The source and destination files should have identical content. Since the messages are sent to standard error, which is not redirected, these messages still appear in the usual place on the two machines.
The client and server programs presented so far support communication only from the client to the server. In many client-server applications, the client sends a request to the server and then waits for a response.
Exercise 18.15
How would you modify the server of Program 18.1 to produce a server called reflectserver that echoes its response back to the client, rather than to standard output?
Answer:
The only modification needed would be to replace the reference to STDOUT_FILENO with communfd.
Program 18.4 is a client program that can be used with the server of Exercise 18.15. The reflectclient.c sends a fixed-length message to a server and expects that message to be echoed back. Program 18.4 checks to see that it receives exactly the same message that it sends.
Program 18.4 reflectclient.c
A client that sends a fixed-length test message to a server and checks that the reply is identical to the message sent.
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "restart.h"
#include "uici.h"
#define BUFSIZE 1000
int main(int argc, char *argv[]) {
char bufrecv[BUFSIZE];
char bufsend[BUFSIZE];
int bytesrecvd;
int communfd;
int i;
u_port_t portnumber;
int totalrecvd;
if (argc != 3) {
fprintf(stderr, "Usage: %s host port\n", argv[0]);
return 1;
}
for (i = 0; i < BUFSIZE; i++) /* set up a test message */
bufsend[i] = (char)(i%26 + 'A');
portnumber = (u_port_t)atoi(argv[2]);
if ((communfd = u_connect(portnumber, argv[1])) == -1) {
perror("Failed to establish connection");
return 1;
}
if (r_write(communfd, bufsend, BUFSIZE) != BUFSIZE) {
perror("Failed to write test message");
return 1;
}
totalrecvd = 0;
while (totalrecvd < BUFSIZE) {
bytesrecvd = r_read(communfd, bufrecv + totalrecvd, BUFSIZE - totalrecvd);
if (bytesrecvd <= 0) {
perror("Failed to read response message");
return 1;
}
totalrecvd += bytesrecvd;
}
for (i = 0; i < BUFSIZE; i++)
if (bufsend[i] != bufrecv[i])
fprintf(stderr, "Byte %d read does not agree with byte written\n", i);
return 0;
}
Many client-server applications require symmetric bidirectional communication between client and server. The simplest way to incorporate bidirectionality is for the client and the server to each fork a child to handle the communication in the opposite direction.
Example 18.16
To make the client in Program 18.3 bidirectional, declare an integer variable, child, and replace the line
bytescopied = copyfile(STDIN_FILENO, communfd);
with the following code segment.
if ((child = fork()) == -1) {
perror("Failed to fork a child");
return 1;
}
if (child == 0) /* child code */
bytescopied = copyfile(STDIN_FILENO, communfd);
else /* parent code */
bytescopied = copyfile(communfd, STDOUT_FILENO);
Exercise 18.17
Suppose we try to make a bidirectional serial server from Program 18.1 by declaring an integer variable called child and replacing the following line with the replacement code of Example 18.16.
bytescopied = copyfile(communfd, STDOUT_FILENO);
What happens?
Answer:
This approach has several flaws. Both the parent and child return to the u_accept loop after completing the transfer. While copying still works correctly, the number of processes grows each time a connection is made. After the first connection completes, two server processes accept client connections. If two server connections are active, characters entered at standard input of the server go to one of the two connections. The code also causes the process to exit if fork fails. Normally, the server should not exit on account of a possibly temporary problem.
Example 18.18
To produce a bidirectional serial server, replace the copyfile line in Program 18.1 with the following code.
int child;
child = fork();
if ((child = fork()) == -1)
perror("Failed to fork second child");
else if (child == 0) { /* child code */
bytescopied = copyfile(STDIN_FILENO, communfd);
fprintf(stderr, "[%ld]:sent %d bytes\n", (long)getpid(), bytes_copied);
return 0;
}
bytescopied = copyfile(communfd, STDOUT_FILENO); /* parent code */
fprintf(stderr, "[%ld]:received %d bytes\n", (long)getpid(), bytescopied);
r_wait(NULL);
The child process exits after printing its message. The original process waits for the child to complete before continuing and does not accept a new connection until both ends of the transmission complete. If the fork fails, only the parent communicates.
Exercise 18.19
The modified server suggested in Example 18.18 prints out the number of bytes transferred in each direction. How would you modify the code to print a single number giving the total number of bytes transferred in both directions?
Answer:
This modification would not be simple because the values for transfer in each direction are stored in different processes. You can establish communication by inserting code to create a pipe before forking the child. After it completes, the child could write to the pipe the total number of bytes transferred to the parent.
Exercise 18.20
Suppose that the child of Example 18.18 returns the number of bytes transferred and the parent uses the return value from the status code to accumulate the total number of bytes transferred. Does this approach solve the problem posed in Exercise 18.19?
Answer:
No. Only 8 bits are typically available for the child's return value, which is not large enough to hold the number of bytes transferred.
Another way to do bidirectional transfer is to use select or poll as shown in Program 4.13 on page 111. The copy2files program copies bytes from fromfd1 to tofd1 and from fromfd2 to tofd2, respectively, without making any assumptions about the order in which the bytes become available in the two directions. You can use copy2files by replacing the copyfile line in both server and client with the following code.
bytescopied = copy2files(communfd, STDOUT_FILENO, STDIN_FILENO, communfd);
Program 18.5 shows the bidirectional client.
Exercise 18.21
How does using copy2files differ from forking a child to handle communication in the opposite direction?
Answer:
The copy2files function of Program 4.13 terminates both directions of communication if either receives an end-of-file from standard input or if there is an error in the network communication. The child method allows communication to continue in the other direction after one side is closed. You can modify copy2files to keep a flag for each file descriptor indicating whether the descriptor has encountered an error or end-of-file. Only active descriptors would be included in each iteration of select.
Program 18.5 client2.c
A bidirectional client.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "uici.h"
#include "restart.h"
int main(int argc, char *argv[]) {
int bytescopied;
int communfd;
u_port_t portnumber;
if (argc != 3) {
fprintf(stderr, "Usage: %s host port\n", argv[0]);
return 1;
}
portnumber = (u_port_t)atoi(argv[2]);
if ((communfd = u_connect(portnumber, argv[1])) == -1) {
perror("Failed to establish connection");
return 1;
}
fprintf(stderr, "[%ld]:connection made to %s\n", (long)getpid(), argv[1]);
bytescopied = copy2files(communfd, STDOUT_FILENO, STDIN_FILENO, communfd);
fprintf(stderr, "[%ld]:transferred %d bytes\n", (long)getpid(), bytescopied);
return 0;
}
18.7 Socket Implementation of UICI
The first socket interface originated with 4.1cBSD UNIX in the early 1980s. In 2001, POSIX incorporated 4.3BSD sockets and an alternative, XTI. XTI (X/Open Transport Interface) also provides a connection-oriented interface that uses TCP. XTI's lineage can be traced back to AT&T UNIX System V TLI (Transport Layer Interface). This book focuses on socket implementations. (See Stevens [115] for an in-depth discussion of XTI.)
This section introduces the main socket library functions and then implements the UICI functions in terms of sockets. Section 18.9 discusses a thread-safe version of UICI. Appendix C gives a complete unthreaded socket implementation of UICI as well as four alternative thread-safe versions. The implementations of this chapter use IPv4 (Internet Protocol version 4). The names of the libraries needed to compile the socket functions are not yet standard. Sun Solaris requires the library options -lsocket and -lnsl. Linux just needs -lnsl, and Mac OS X does not require that any extra libraries be specified. The man page for the socket functions should indicate the names of the required libraries on a particular system. If unsuccessful, the socket functions return 1 and set errno.
Table 18.2. Overview of UICI API implementation using sockets with TCP.|
u_open | socket
bind
listen | create communication endpoint
associate endpoint with specific port
make endpoint passive listener | u_accept | accept | accept connection request from client | u_connect | socket
connect | create communication endpoint
request connection from server |
Table 18.2 shows the socket functions used to implement each of the UICI functions. The server creates a handle (socket), associates it with a physical location on the network (bind), and sets up the queue size for pending requests (listen). The UICI u_open function, which encapsulates these three functions, returns a file descriptor corresponding to a passive or listening socket. The server then listens for client requests (accept).
The client also creates a handle (socket) and associates this handle with the network location of the server (connect). The UICI u_connect function encapsulates these two functions. The server and client handles, sometimes called communication or transmission endpoints, are file descriptors. Once the client and server have established a connection, they can communicate by ordinary read and write calls.
18.7.1 The socket function
The socket function creates a communication endpoint and returns a file descriptor. The domain parameter selects the protocol family to be used. We use AF_INET, indicating IPv4. A type value of SOCK_STREAM specifies sequenced, reliable, two-way, connection-oriented byte streams and is typically implemented with TCP. A type value of SOCK_DGRAM provides connectionless communication by using unreliable messages of a fixed length and is typically implemented with UDP. (See Chapter 20.) The protocol parameter specifies the protocol to be used for a particular communication type. In most implementations, each type parameter has only one protocol available (e.g., TCP for SOCK_STREAM and UDP for SOCK_DGRAM), so protocol is usually 0.
SYNOPSIS
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
POSIX
If successful, socket returns a nonnegative integer corresponding to a socket file descriptor. If unsuccessful, socket returns 1 and sets errno. The following table lists the mandatory errors for socket.
|
EAFNOSUPPORT | implementation does not support specified address family | EMFILE | no more file descriptors available for process | ENFILE | no more file descriptors available for system | EPROTONOSUPPORT | protocol not supported by address family or by implementation | EPROTOTYPE | socket type not supported by protocol |
Example 18.22
The following code segment sets up a socket communication endpoint for Internet communication, using a connection-oriented protocol.
int sock;
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1)
perror("Failed to create socket");
18.7.2 The bind function
The bind function associates the handle for a socket communication endpoint with a specific logical network connection. Internet domain protocols specify the logical connection by a port number. The first parameter to bind, socket, is the file descriptor returned by a previous call to the socket function. The *address structure contains a family name and protocol-specific information. The address_len parameter is the number of bytes in the *address structure.
SYNOPSIS
#include <sys/socket.h>
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
POSIX
If successful, bind returns 0. If unsuccessful, bind returns 1 and sets errno. The following table lists the mandatory errors for bind that are applicable to all address families.
|
EADDRINUSE | specified address is in use | EADDRNOTAVAIL | specified address not available from local machine | EAFNOSUPPORT | invalid address for address family of specified socket | EBADF | socket parameter is not a valid file descriptor | EINVAL | socket already bound to an address, protocol does not support binding to new address, or socket has been shut down | ENOTSOCK | socket parameter does not refer to a socket | EOPNOTSUPP | socket type does not support binding to address |
The Internet domain uses struct sockaddr_in for struct sockaddr. POSIX states that applications should cast struct sockaddr_in to struct sockaddr for use with socket functions. The struct sockaddr_in structure, which is defined in netinet/in.h, has at least the following members expressed in network byte order.
sa_family_t sin_family; /* AF_NET */
in_port_t sin_port; /* port number */
struct in_addr sin_addr; /* IP address */
For Internet communication, sin_family is AF_INET and sin_port is the port number. The struct in_addr structure has a member, called s_addr, of type in_addr_t that holds the numeric value of an Internet address. A server can set the sin_addr.s_addr field to INADDR_ANY, meaning that the socket should accept connection requests on any of the host's network interfaces. Clients set the sin_addr.s_addr field to the IP address of the server host.
Example 18.23
The following code segment associates the port 8652 with a socket corresponding to the open file descriptor sock.
struct sockaddr_in server;
int sock;
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons((short)8652);
if (bind(sock, (struct sockaddr *)&server, sizeof(server)) == -1)
perror("Failed to bind the socket to port");
Example 18.23 uses htonl and htons to reorder the bytes of INADDR_ANY and 8652 to be in network byte order. Big-endian computers store the most significant byte first; little-endian computers store the least significant byte first. Byte ordering of integers presents a problem when machines with different endian architectures communicate, since they may misinterpret protocol information such as port numbers. Unfortunately, both architectures are commonthe SPARC architecture (developed by Sun Microsystems) uses big-endian, whereas Intel architectures use little-endian. The Internet protocols specify that big-endian should be used for network byte order, and POSIX requires that certain socket address fields be given in network byte order. The htonl function reorders a long from the host's internal order to network byte order. Similarly, htons reorders a short to network byte order. The mirror functions ntohl and ntohs reorder integers from network byte order to host order.
18.7.3 The listen function
The socket function creates a communication endpoint, and bind associates this endpoint with a particular network address. At this point, a client can use the socket to connect to a server. To use the socket to accept incoming requests, an application must put the socket into the passive state by calling the listen function.
The listen function causes the underlying system network infrastructure to allocate queues to hold pending requests. When a client makes a connection request, the client and server network subsystems exchange messages (the TCP three-way handshake) to establish the connection. Since the server process may be busy, the host network subsystem queues the client connection requests until the server is ready to accept them. The client receives an ECONNREFUSED error if the server host refuses its connection request. The socket value is the descriptor returned by a previous call to socket, and the backlog parameter suggests a value for the maximum allowed number of pending client requests.
SYNOPSIS
#include <sys/socket.h>
int listen(int socket, int backlog);
POSIX
If successful, listen returns 0. If unsuccessful, listen returns 1 and sets errno. The following table lists the mandatory errors for listen.
|
EBADF | socket is not a valid file descriptor | EDESTADDRREQ | socket is not bound to a local address and protocol does not allow listening on an unbound socket | EINVAL | socket is already connected | ENOTSOCK | socket parameter does not refer to a socket | EOPNOTSUPP | socket protocol does not support listen |
Traditionally, the backlog parameter has been given as 5. However, studies have shown [115] that the backlog parameter should be larger. Some systems incorporate a fudge factor in allocating queue sizes so that the actual queue size is larger than backlog. Exercise 22.14 explores the effect of backlog size on server performance.
18.7.4 Implementation of u_open
The combination of socket, bind and listen establishes a handle for the server to monitor communication requests from a well-known port. Program 18.6 shows the implementation of u_open in terms of these socket functions.
Program 18.6 u_open.c
A socket implementation of the UICI u_open.
#include <errno.h>
#include <netdb.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/types.h>
#include "uici.h"
#define MAXBACKLOG 50
int u_ignore_sigpipe(void);
int u_open(u_port_t port) {
int error;
struct sockaddr_in server;
int sock;
int true = 1;
if ((u_ignore_sigpipe() == -1) ||
((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1))
return -1;
if (setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, (char *)&true,
sizeof(true)) == -1) {
error = errno;
while ((close(sock) == -1) && (errno == EINTR));
errno = error;
return -1;
}
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons((short)port);
if ((bind(sock, (struct sockaddr *)&server, sizeof(server)) == -1) ||
(listen(sock, MAXBACKLOG) == -1)) {
error = errno;
while ((close(sock) == -1) && (errno == EINTR));
errno = error;
return -1;
}
return sock;
}
If an attempt is made to write to a pipe or socket that no process has open for reading, write generates a SIGPIPE signal in addition to returning an error and setting errno to EPIPE. As with most signals, the default action of SIGPIPE terminates the process. Under no circumstances should the action of a client cause a server to terminate. Even if the server creates a child to handle the communication, the signal can prevent a graceful termination of the child when the remote host closes the connection. The socket implementation of UICI handles this problem by calling u_ignore_sigpipe to ignore the SIGPIPE signal if the default action of this signal is in effect.
The htonl and htons functions convert the address and port number fields to network byte order. The setsockopt call with SO_REUSEADDR permits the server to be restarted immediately, using the same port. This call should be made before bind.
If setsockopt, bind or listen produces an error, u_open saves the value of errno, closes the socket file descriptor, and restores the value of errno. Even if close changes errno, we still want to return with errno reporting the error that originally caused the return.
18.7.5 The accept function
After setting up a passive listening socket (socket, bind and listen), the server handles incoming client connections by calling accept. The parameters of accept are similar to those of bind. However, bind expects *address to be filled in before the call, so that it knows the port and interface on which the server will accept connection requests. In contrast, accept uses *address to return information about the client making the connection. In particular, the sin_addr member of the struct sockaddr_in structure contains a member, s_addr, that holds the Internet address of the client. The value of the *address_len parameter of accept specifies the size of the buffer pointed to by address. Before the call, fill this with the size of the *address structure. After the call, *address_len contains the number of bytes of the buffer actually filled in by the accept call.
SYNOPSIS
#include <sys/socket.h>
int accept(int socket, struct sockaddr *restrict address,
socklen_t *restrict address_len);
POSIX
If successful, accept returns the nonnegative file descriptor corresponding to the accepted socket. If unsuccessful, accept returns 1 and sets errno. The following table lists the mandatory errors for accept.
|
EAGAIN or EWOULDBLOCK | O_NONBLOCK is set for socket file descriptor and no connections are present to be accepted | EBADF | socket parameter is not a valid file descriptor | ECONNABORTED | connection has been aborted | EINTR accept | interrupted by a signal that was caught before a valid connection arrived | EINVAL | socket is not accepting connections | EMFILE | OPEN_MAX file descriptors are currently open in calling process | ENFILE | maximum number of file descriptors in system are already open | ENOTSOCK | socket does not refer to a socket | EOPNOTSUPP | socket type of specified socket does not support the accepting of connections |
Example 18.24
The following code segment illustrates how to restart accept if it is interrupted by a signal.
int len = sizeof(struct sockaddr);
int listenfd;
struct sockaddr_in netclient;
int retval;
while (((retval =
accept(listenfd, (struct sockaddr *)(&netclient), &len)) == -1) &&
(errno == EINTR))
;
if (retval == -1)
perror("Failed to accept connection");
18.7.6 Implementation of u_accept
The u_accept function waits for a connection request from a client and returns a file descriptor that can be used to communicate with that client. It also fills in the name of the client host in a user-supplied buffer. The socket accept function returns information about the client in a struct sockaddr_in structure. The client's address is contained in this structure. The socket library does not have a facility to convert this binary address to a host name. UICI calls the addr2name function to do this conversion. This function takes as parameters a struct in_addr from a struct sockaddr_in, a buffer and the size of the buffer. It fills this buffer with the name of the host corresponding to the address given. The implementation of this function is discussed in Section 18.8.
Program 18.7 implements the UICI u_accept function. The socket accept call waits for a connection request and returns a communication file descriptor. If accept is interrupted by a signal, it returns 1 with errno set to EINTR. The UICI u_accept function reinitiates accept in this case. If accept is successful and the caller has furnished a hostn buffer, then u_accept calls addr2name to convert the address returned by accept to an ASCII host name.
Program 18.7 u_accept.c
A socket implementation of the UICI u_accept function.
#include <errno.h>
#include <netdb.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <sys/types.h>
#include "uiciname.h"
int u_accept(int fd, char *hostn, int hostnsize) {
int len = sizeof(struct sockaddr);
struct sockaddr_in netclient;
int retval;
while (((retval =
accept(fd, (struct sockaddr *)(&netclient), &len)) == -1) &&
(errno == EINTR))
;
if ((retval == -1) || (hostn == NULL) || (hostnsize <= 0))
return retval;
addr2name(netclient.sin_addr, hostn, hostnsize);
return retval;
}
Exercise 18.25
Under what circumstances does u_accept return an error caused by client behavior?
Answer:
The conditions for u_accept to return an error are the same as for accept to return an error except for interruption by a signal. The u_accept function restarts accept when it is interrupted by a signal (e.g., errno is EINTR). The accept function may return an error for various system-dependent reasons related to insufficient resources. The accept function may also return an error if the client disconnects after the completion of the three-way handshake. A server that uses accept or u_accept should be careful not to simply exit on such an error. Even an error due to insufficient resources should not necessarily cause the server to exit, since the problem might be temporary.
18.7.7 The connect function
The client calls socket to set up a transmission endpoint and then uses connect to establish a link to the well-known port of the remote server. Fill the struct sockaddr structure as with bind.
SYNOPSIS
#include <sys/socket.h>
int connect(int socket, const struct sockaddr *address,
socklen_t address_len);
POSIX
If successful, connect returns 0. If unsuccessful, connect returns 1 and sets errno. The following table lists the mandatory errors for connect that are applicable to all address families.
|
EADDRNOTAVAIL | specified address is not available from local machine | EAFNOSUPPORT | specified address is not a valid address for address family of specified socket | EALREADY | connection request already in progress on socket | EBADF | socket parameter not a valid file descriptor | ECONNREFUSED | target was not listening for connections or refused connection | EINPROGRSS | O_NONBLOCK set for file descriptor of the socket and connection cannot be immediately established, so connection shall be established asynchronously | EINTR | attempt to establish connection was interrupted by delivery of a signal that was caught, so connection shall be established asynchronously | EISCONN | specified socket is connection mode and already connected | ENETUNREACH | no route to network is present | ENOTSOCK | socket parameter does not refer to a socket | EPROTOTYPE | specified address has different type than socket bound to specified peer address | ETIMEDOUT | attempt to connect timed out before connection made |
18.7.8 Implementation of u_connect
Program 18.8 shows u_connect, a function that initiates a connection request to a server. The u_connect function has two parameters, a port number (port) and a host name (hostn), which together specify the server to connect to.
Program 18.8 u_connect.c
A socket implementation of the UICI u_connect function.
#include <ctype.h>
#include <errno.h>
#include <netdb.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/select.h>
#include <sys/socket.h>
#include <sys/types.h>
#include "uiciname.h"
#include "uici.h"
int u_ignore_sigpipe(void);
int u_connect(u_port_t port, char *hostn) {
int error;
int retval;
struct sockaddr_in server;
int sock;
fd_set sockset;
if (name2addr(hostn,&(server.sin_addr.s_addr)) == -1) {
errno = EINVAL;
return -1;
}
server.sin_port = htons((short)port);
server.sin_family = AF_INET;
if ((u_ignore_sigpipe() == -1) ||
((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1))
return -1;
if (((retval =
connect(sock, (struct sockaddr *)&server, sizeof(server))) == -1) &&
((errno == EINTR) || (errno == EALREADY))) { /* asynchronous */
FD_ZERO(&sockset);
FD_SET(sock, &sockset);
while (((retval = select(sock+1, NULL, &sockset, NULL, NULL)) == -1)
&& (errno == EINTR)) {
FD_ZERO(&sockset);
FD_SET(sock, &sockset);
}
}
if (retval == -1) {
error = errno;
while ((close(sock) == -1) && (errno == EINTR));
errno = error;
return -1;
}
return sock;
}
The first step is to verify that hostn is a valid host name and to find the corresponding IP address using name2addr. The u_connect function stores this address in a struct sockaddr_in structure. The name2addr function, which takes a string and a pointer to in_addr_t as parameters, converts the host name stored in the string parameter into a binary address and stores this address in the location corresponding to its second parameter. Section 18.8 discusses the implementation of name2addr.
If the SIGPIPE signal has the default signal handler, u_ignore_sigpipe sets SIGPIPE to be ignored. (Otherwise, the client terminates when it tries to write after the remote end has been closed.) The u_connect function then creates a SOCK_STREAM socket. If any of these steps fails, u_connect returns an error.
The connect call can be interrupted by a signal. However, unlike other library functions that set errno to EINTR, connect should not be restarted, because the network subsystem has already initiated the TCP 3-way handshake. In this case, the connection request completes asynchronously to program execution. The application must call select or poll to detect that the descriptor is ready for writing. The UICI implementation of u_connect uses select and restarts it if interrupted by a signal.
Exercise 18.26
How would the behavior of u_connect change if
if ((u_ignore_sigpipe() != 0) ||
((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1))
return -1;
were replaced by the following?
if (((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1) ||
(u_ignore_sigpipe() != 0) )
return -1;
Answer:
If u_ignore_sigpipe() fails, u_connect returns with an open file descriptor in sock. Since the calling program does not have the value of sock, this file descriptor could not be closed.
Exercise 18.27
Does u_connect ever return an error if interrupted by a signal?
Answer:
To determine the overall behavior of u_connect, we must analyze the response of each call within u_connect to a signal. The u_ignore_sigpipe code of Appendix C only contains a sigaction call, which does not return an error when interrupted by a signal. The socket call does not return an EINTR error, implying that it either restarts itself or blocks signals. Also, name2addr does not return EINTR. An arriving signal is handled, ignored or blocked and the program continues (unless of course a handler terminates the program). The connect call can return if interrupted by a signal, but the implementation then calls select to wait for asynchronous completion. The u_connect function also restarts select if it is interrupted by a signal. Thus, u_connect should never return because of interruption by a signal.
18.8 Host Names and IP Addresses
Throughout this book we refer to hosts by name (e.g., usp.cs.utsa.edu) rather than by a numeric identifier. Host names must be mapped into numeric network addresses for most of the network library calls. As part of system setup, system administrators define the mechanism by which names are translated into network addresses. The mechanism might include local table lookup, followed by inquiry to domain name servers if necessary. The Domain Name Service (DNS) is the glue that integrates naming on the Internet [81, 82].
In general, a host machine can be specified either by its name or by its address. Host names in programs are usually represented by ASCII strings. IPv4 addresses are specified either in binary (in network byte order as in the s_addr field of struct in_addr) or in a human readable form, called the dotted-decimal notation or Internet address dot notation. The dotted form of an address is a string with the values of the four bytes in decimal, separated by decimal points. For example, 129.115.30.129 might be the address of the host with name usp.cs.utsa.edu. The binary form of an IPv4 address is 4 bytes long. Since 4-byte addresses do not provide enough room for future Internet expansion, a newer version of the protocol, IPv6, uses 16-byte addresses.
The inet_addr and inet_ntoa functions convert between dotted-decimal notation and the binary network byte order form used in the struct in_addr field of a struct sockaddr_in.
The inet_addr function converts a dotted-decimal notation address to binary in network byte order. The value can be stored directly in the sin_addr.s_addr field of a struct sockaddr_in.
SYNOPSIS
#include <arpa/inet.h>
in_addr_t inet_addr(const char *cp);
POSIX
If successful, inet_addr returns the Internet address. If unsuccessful, inet_addr returns (in_addr_t)1. No errors are defined for inet_addr.
The inet_ntoa function takes a struct in_addr structure containing a binary address in network byte order and returns the corresponding string in dotted-decimal notation. The binary address can come from the sin_addr field of a struct sockaddr_in structure. The returned string is statically allocated, so inet_ntoa may not be safe to use in threaded applications. Copy the returned string to a different location before calling inet_ntoa again. Check the man page for inet_ntoa on your system to see if it is thread-safe.
SYNOPSIS
#include <arpa/inet.h>
char *inet_ntoa(const struct in_addr in);
POSIX
The inet_ntoa function returns a pointer to the network address in Internet standard dot notation. No errors are defined for inet_ntoa.
The different data types used for the binary form of an address often cause confusion. The inet_ntoa function, takes a struct in_addr structure as a parameter; the inet_addr returns data of type in_addr_t, a field of a struct in_addr structure. POSIX states that a struct in_addr structure must contain a field called s_addr of type in_addr_t. It is implied that the binary address is stored in s_addr and that a struct in_addr structure may contain other fields, although none are specified. It seems that in most current implementations, the struct in_addr structure contains only the s_addr field, so pointers to sin_addr and sin_addr.s_addr are identical. To maintain future code portability, however, be sure to preserve the distinction between these two structures.
At least three collections of library functions convert between ASCII host names and binary addresses. None of these collections report errors in the way UNIX functions do by returning 1 and setting errno. Each collection has advantages and disadvantages, and at the current time none of them stands out as the best method.
UICI introduces the addr2name and name2addr functions to abstract the conversion between strings and binary addresses and allow for easy porting between implementations. The uiciname.h header file shown in Program C.3 contains the following prototypes for addr2name and name2addr.
int name2addr(const char *name, in_addr_t *addrp);
void addr2name(struct in_addr addr, char *name, int namelen);
Link uiciname.c with any program that uses UICI.
The name2addr function behaves like inet_addr except that its parameter can be either a host name or an address in dotted-decimal format. Instead of returning the address, name2addr stores the address in the location pointed to by addrp to allow the return value to report an error. If successful, name2addr returns 0. If unsuccessful, name2addr returns 1. An error occurs if the system cannot determine the address corresponding to the given name. The name2addr function does not set errno. We suggest that when name2addr is called by a function that must return with errno set, the value EINVAL be used to indicate failure.
The addr2name function takes a struct in_addr structure as its first parameter and writes the corresponding name to the supplied buffer, name. The namelen value specifies the size of the name buffer. If the host name does not fit in name, addr2name copies the first namelen - 1 characters of the host name followed by a string terminator. This function never produces an error. If the host name cannot be found, addr2name converts the host address to dotted-decimal notation.
We next discuss two possible strategies for implementing name2addr and addr2name. Section 18.9 discusses two additional implementations. Appendix C presents complete implementations using all four approaches. Setting the constant REENTRANCY in uiciname.c picks out a particular implementation. We first describe the default implementation that uses gethostbyname and gethostbyaddr.
A traditional way of converting a host name to a binary address is with the gethostbyname function. The gethostbyname function takes a host name string as a parameter and returns a pointer to a struct hostent structure containing information about the names and addresses of the corresponding host.
SYNOPSIS
#include <netdb.h>
struct hostent {
char *h_name; /* canonical name of host */
char **h_aliases; /* alias list */
int h_addrtype; /* host address type */
int h_length; /* length of address */
char **h_addr_list; /* list of addresses */
};
struct hostent *gethostbyname(const char *name);
POSIX:OB
If successful, gethostbyname returns a pointer to a struct hostent. If unsuccessful, gethostbyname returns a NULL pointer and sets h_errno. Macros are available to produce an error message from an h_errno value. The following table lists the mandatory errors for gethostbyname.
|
HOST_NOT_FOUND | no such host | NO_DATA | server recognized request and name but has no address | NO_RECOVERY | unexpected server failure that cannot be recovered | TRY_AGAIN | temporary or transient error |
The struct hostent structure includes two members of interest that are filled in by gethostbyname. The h_addr_list field is an array of pointers to network addresses used by this host. These addresses are in network byte order, so they can be used directly in the address structures required by the socket calls. Usually, we use only the first entry, h_addr_list[0]. The integer member h_length is filled with the number of bytes in the address. For IPv4, h_length should always be 4.
Example 18.28
The following code segment translates a host name into an IP address for the s_addr member of a struct sockaddr_in.
char *hostn = "usp.cs.utsa.edu";
struct hostent *hp;
struct sockaddr_in server;
if ((hp = gethostbyname(hostn)) == NULL)
fprintf(stderr, "Failed to resolve host name\n");
else
memcpy((char *)&server.sin_addr.s_addr, hp->h_addr_list[0], hp->h_length);
Often, a host has multiple names associated with it. For example, because usp.cs.utsa.edu is a web server for this book, the system also responds to the alias www.usp.cs.utsa.edu.
Exercise 18.29
Use the struct hostent structure returned in Example 18.28 to output a list of aliases for usp.cs.utsa.edu.
Answer:
char **q;
struct hostent *hp;
for (q = hp->h_aliases; *q != NULL; q++)
(void) printf("%s\n", *q);
Exercise 18.30
Use the struct hostent structure returned in Example 18.28 to find out how many IP addresses are associated with usp.cs.utsa.edu.
Answer:
int addresscount = 0;
struct hostent *hp;
char **q;
for (q = hp->h_addr_list; *q != NULL; q++)
addresscount++;
printf("Host %s has %d IP addresses\n", hp->h_name, addresscount);
Program 18.9 is one implementation of name2addr. The name2addr function first checks to see if name begins with a digit. If so, name2addr assumes that name is a dotted-decimal address and uses inet_addr to convert it to in_addr_t. Otherwise, name2addr uses gethostbyname.
Program 18.9 name2addr_gethostbyname.c
An implementation of name2addr using gethostbyname.
#include <ctype.h>
#include <netdb.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
int name2addr(char *name, in_addr_t *addrp) {
struct hostent *hp;
if (isdigit((int)(*name)))
*addrp = inet_addr(name);
else {
hp = gethostbyname(name);
if (hp == NULL)
return -1;
memcpy((char *)addrp, hp->h_addr_list[0], hp->h_length);
}
return 0;
}
The conversion from address to name can be done with gethostbyaddr. For IPv4, the type should be AF_INET and the len value should be 4 bytes. The addr parameter should point to a struct in_addr structure.
SYNOPSIS
#include <netdb.h>
struct hostent *gethostbyaddr(const void *addr,
socklen_t len, int type);
POSIX:OB
If successful, gethostbyaddr returns a pointer to a struct hostent structure. If unsuccessful, gethostbyaddr returns a NULL pointer and sets h_error. The mandatory errors for gethostbyaddr are the same as those for gethostbyname.
Example 18.31
The following code segment prints the host name from a previously set struct sockaddr_in structure.
struct hostent *hp;
struct sockaddr_in net;
int sock;
if (( hp = gethostbyaddr(&net.sin_addr, 4, AF_INET))
printf("Host name is %s\n", hp->h_name);
Program 18.10 is an implementation of the addr2name function that uses the gethostbyaddr function. If gethostbyaddr returns an error, then addr2name uses inet_ntoa to convert the address to dotted-decimal notation. The addr2name function copies at most namelen-1 bytes, allowing space for the string terminator.
Program 18.10 addr2name_gethostbyaddr.c
An implementation of addr2name using gethostbyaddr.
#include <ctype.h>
#include <netdb.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
void addr2name(struct in_addr addr, char *name, int namelen) {
struct hostent *hostptr;
hostptr = gethostbyaddr((char *)&addr, 4, AF_INET);
if (hostptr == NULL)
strncpy(name, inet_ntoa(addr), namelen-1);
else
strncpy(name, hostptr->h_name, namelen-1);
name[namelen-1] = 0;
}
When an error occurs, gethostbyname and gethostbyaddr return NULL and set h_errno to indicate an error. Thus, errno and perror cannot be used to display the correct error message. Also, gethostbyname and gethostbyaddr are not thread-safe because they use static data for storing the returned struct hostent. They should not be used in threaded programs without appropriate precautions being taken. (See Section 18.9.) A given implementation might use the same static data for both of these, so be careful to copy the result before it is modified.
A second method for converting between host names and addresses, getnameinfo and getaddrinfo, first entered an approved POSIX standard in 2001. These general functions, which can be used with both IPv4 and IPv6, are preferable to gethostbyname and gethostbyaddr because they do not use static data. Instead, getnameinfo stores the name in a user-supplied buffer, and getaddrinfo dynamically allocates a buffer to return with the address information. The user can free this buffer with freeaddrinfo. These functions are safe to use in a threaded environment. The only drawback in using these functions, other than the complication of the new structures used, is that they are not yet available on many systems.
SYNOPSIS
#include <sys/socket.h>
#include <netdb.h>
void freeaddrinfo(struct addrinfo *ai);
int getaddrinfo(const char *restrict nodename,
const char *restrict servname,
const struct addrinfo *restrict hints,
struct addrinfo **restrict res);
int getnameinfo(const struct sockaddr *restrict sa,
socklen_t salen, char *restrict node,
socklen_t nodelen, char *restrict service,
socklen_t servicelen, unsigned flags);
POSIX
If successful, getaddrinfo and getnameinfo return 0. If unsuccessful, these functions return an error code. The following table lists themandatory error codes for getaddrinfo and getnameinfo.
|
EAI_AGAIN | name cannot be resolved at this time | EAI_BADFLAGS | flags had an invalid value | EAI_FAIL | unrecoverable error | EAI_FAMILY | address family was not recognized or address length invalid for specified family | EAI_MEMORY | memory allocation failure | EAI_NONAME | name does not resolve for supplied parameters | EAI_SERVICE | service passed not recognized for socket (getaddrinfo) | EAI_SOCKTYPE | intended socket type not recognized (getaddrinfo) | EAI_SYSTEM | a system error occurred and error code can be found in errno | EAI_OVERFLOW | argument buffer overflow (getaddrinfo) |
The struct addrinfo structure contains at least the following members.
int ai_flags; /* input flags */
int ai_family; /* address family */
int ai_socktype; /* socket type */
int ai_protocol; /* protocol of socket */
socklen_t ai_addrlen; /* length of socket address */
struct sockaddr *ai_addr; /* socket address */
char *ai_canonname; /* canonical service name */
struct addrinfo *ai_next; /* pointer to next entry */
The user passes the name of the host in the nodename parameter of getaddrinfo. The servname parameter can contain a service name (in IPv6) or a port number. For our purposes, the nodename determines the address, and the servname parameter can be a NULL pointer. The hints parameter tells getaddrinfo what type of addresses the caller is interested in. For IPv4, we set ai_flags to 0. In this case, ai_family, ai_socktype and ai_protocol are the same as in socket. The ai_addrlen parameter can be set to 0, and the remaining pointers can be set to NULL. The getaddrinfo function, using the res parameter, returns a linked list of struct addrinfo nodes that it dynamically allocates to contain the address information. When finished using this linked list, call freeaddrinfo to free the nodes.
Program 18.11 shows an implementation of name2addr that uses getaddrinfo. After calling getaddrinfo, the function copies the address and frees the memory that was allocated.
Program 18.11 name2addr_getaddrinfo.c
An implementation of name2addr using getaddrinfo.
#include <ctype.h>
#include <netdb.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
int name2addr(char *name, in_addr_t *addrp) {
struct addrinfo hints;
struct addrinfo *res;
struct sockaddr_in *saddrp;
hints.ai_flags = 0;
hints.ai_family = PF_INET;
hints.ai_socktype = SOCK_STREAM;
hints.ai_protocol = 0;
hints.ai_addrlen = 0;
hints.ai_canonname = NULL;
hints.ai_addr = NULL;
hints.ai_next = NULL;
if (getaddrinfo(name,NULL,&hints,&res) != 0)
return -1;
saddrp = (struct sockaddr_in *)(res->ai_addr);
memcpy(addrp, &saddrp->sin_addr.s_addr, 4);
freeaddrinfo(res);
return 0;
}
To use getnameinfo to convert an address to a name, pass a pointer to a sockaddr_in structure in the first parameter and its length in the second parameter. Supply a buffer to hold the name of the host as the third parameter and the size of that buffer as the fourth parameter. Since we are not interested in the service name, the fifth parameter can be NULL and the sixth parameter can be 0. The last parameter is for flags, and it can be 0, causing the fully qualified domain name to be returned. The sin_family field of the sockaddr_in should be AF_INET, and the sin_addr field contains the addresses. If the name cannot be determined, the numeric form of the host name is returned, that is, the dotted-decimal form of the address.
Program 18.12 shows an implementation of addr2name. The addr2name function never returns an error. Instead, it calls inet_ntoa if getnameinfo produces an error.
Program 18.12 addr2name_getnameinfo.c
An implementation of addr2name using getnameinfo.
#include <ctype.h>
#include <netdb.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
void addr2name(struct in_addr addr, char *name, int namelen) {
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_port = 0;
saddr.sin_addr = addr;
if (getnameinfo((struct sockaddr *)&saddr, sizeof(saddr), name, namelen,
NULL, 0, 0) != 0) {
strncpy(name, inet_ntoa(addr), namelen-1);
name[namelen-1] = 0;
}
}
|
18.9 Thread-Safe UICI
The UNIX functions that use errno were originally unsafe for threads. When errno was an external integer shared by all threads, one thread could set errno and have another thread change it before the first thread used the value. Multithreaded systems solve this problem by using thread-specific data for errno, thus preserving the syntax for the standard UNIX library functions. This same problem exists with any function that returns values in variables with static storage class.
The TCP socket implementation of UICI in Section 18.7 is thread-safe provided that the underlying implementations of socket, bind, listen, accept, connect, read, write and close are thread-safe and that the name resolution is thread-safe. The POSIX standard states that all functions defined by POSIX and the C standard are thread-safe, except the ones shown in Table 12.2 on page 432. The list is short and mainly includes functions, such as strtok and ctime, that require the use of static data.
The gethostbyname, gethostbyaddr and inet_ntoa functions, which are used in some versions of UICI name resolution, appear on the POSIX list of functions that might not be thread-safe. Some implementations of inet_ntoa (such as that of Sun Solaris) are thread-safe because they use thread-specific data. These possibly unsafe functions are used only in name2addr and addr2name, so the issue of thread safety of UICI is reduced to whether these functions are thread-safe.
Since getnameinfo and getaddrinfo are thread-safe, then if inet_ntoa is threadsafe, the implementations of name2addr and addr2name that use these are also threadsafe. Unfortunately, as stated earlier, getnameinfo and getaddrinfo are not yet available on many systems.
On some systems, thread-safe versions of gethostbyname and gethostbyaddr, called gethostbyname_r and gethostbyaddr_r, are available.
SYNOPSIS
#include <netdb.h>
struct hostent *gethostbyname_r(const char *name,
struct hostent *result, char *buffer, int buflen,
int *h_errnop);
struct hostent *gethostbyaddr_r(const char *addr,
int length, int type, struct hostent *result,
char *buffer, int buflen, int *h_errnop);
These functions perform the same tasks as their unsafe counterparts but do not use static storage. The user supplies a pointer to a struct hostent in the result parameter. Pointers in this structure point into the user-supplied buffer, which has length buflen. The supplied buffer array must be large enough for the generated data. When the gethostbyname_r and gethostbyaddr_r functions return NULL, they supply an error code in the integer pointed to by *h_errnop. Program 18.13 shows a threadsafe implementation of addr2name, assuming that inet_ntoa is thread-safe. Section C.2.2 contains a complete implementation of UICI, using gethostbyname_r and gethostbyaddress_r.
Unfortunately, gethostbyname_r and gethostbyaddress_r were part of the X/OPEN standard, but when this standard was merged with POSIX, these functions were omitted. Another problem associated with Program 18.13 is that it does not specify how large the user-supplied buffer should be. Stevens [115] suggests 8192 for this value, since that is what is commonly used in the implementations of the traditional forms.
An alternative for enforcing thread safety is to protect the sections that use static storage with mutual exclusion. POSIX:THR mutex locks provide a simple method of doing this. Program 18.14 is an implementation of addr2name that uses mutex locks. Section C.2.3 contains a complete implementation of UICI using mutex locks. This implementation does not require inet_ntoa to be thread-safe, since its static storage is protected also.
Program 18.13 addr2name_gethostbyaddr_r.c
A version of addr2name using gethostbyaddr_r.
#include <ctype.h>
#include <netdb.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
#define GETHOST_BUFSIZE 8192
void addr2name(struct in_addr addr, char *name, int namelen) {
char buf[GETHOST_BUFSIZE];
int h_error;
struct hostent *hp;
struct hostent result;
hp = gethostbyaddr_r((char *)&addr, 4, AF_INET, &result, buf,
GETHOST_BUFSIZE, &h_error);
if (hp == NULL)
strncpy(name, inet_ntoa(addr), namelen-1);
else
strncpy(name, hp->h_name, namelen-1);
name[namelen-1] = 0;
}
Program 18.14 addr2name_mutex.c
A thread-safe version of addr2name using POSIX mutex locks.
#include <ctype.h>
#include <netdb.h>
#include <pthread.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void addr2name(struct in_addr addr, char *name, int namelen) {
struct hostent *hostptr;
pthread_mutex_lock(&mutex);
hostptr = gethostbyaddr((char *)&addr, 4, AF_INET);
if (hostptr == NULL)
strncpy(name, inet_ntoa(addr), namelen-1);
else
strncpy(name, hostptr->h_name, namelen-1);
pthread_mutex_unlock(&mutex);
name[namelen-1] = 0;
}
18.10 Exercise: Ping Server
The ping command can be used to elicit a response from a remote host. The default for some systems is to just display a message signifying that the host responded. On other systems the default is to indicate how long it took for a reply to be received.
Example 18.32
The following command queries the usp.cs.utsa.edu host.
ping usp.cs.utsa.edu
The command might output the following message to mean that the host usp.cs.utsa.edu is responding to network communication.
usp.cs.utsa.edu is alive
This section describes an exercise that uses UICI to implement myping, a slightly fancier version of the ping service. The myping function responds with a message such as the following.
usp.cs.utsa.edu: 5:45am up 12:11, 2 users, load average: 0.14, 0.08, 0.07
The myping program is a client-server application. A myping server running on the host listens at a well-known port for client requests. The server forks a child to respond to the request. The original server process continues listening. Assume that the myping well-known port number is defined by the constant MYPINGPORT.
Write the code for the myping client. The client takes the host name as a command-line argument, makes a connection to the port specified by MYPINGPORT, reads what comes in on the connection and echoes it to standard output until end-of-file, closes the connection, and exits. Assume that if the connection attempt to the host fails, the client sleeps for SLEEPTIME seconds and then retries. After the number of failed connection attempts exceeds RETRIES, the client outputs the message that the host is not available and exits. Test the program by using the bidirectional server discussed in Example 18.18.
Implement the myping server. The server listens for connections on MYPINGPORT. If a client makes a connection, the server forks a child to handle the request and the original process resumes listening at MYPINGPORT. The child closes the listening file descriptor, calls the process_ping function, closes the communication file descriptor, and exits.
Write a process_ping function with the following prototype.
int process_ping(int communfd);
For initial testing, process_ping can just output an error message to the communication file descriptor. For the final implementation, process_ping should construct a message consisting of the host name and the output of the uptime command. An example message is as follows.
usp.cs.utsa.edu: 5:45am up 13:11, 2 users, load average: 0.14, 0.08, 0.07
Use uname to get the host name.
SYNOPSIS
#include <sys/utsname.h>
int uname(struct utsname *name);
POSIX
If successful, uname returns a nonnegative value. If unsuccessful, uname returns 1 and sets errno. No mandatory errors are defined for uname.
The struct utsname structure, which is defined in sys/utsname.h, has at least the following members.
char sysname[]; /* name of this OS implementation */
char nodenamep[]; /* name of this node within communication network */
char release[]; /* current release level of this implementation */
char version[]; /* current version level of this release */
char machine[]; /* name of hardware type on which system is running */
18.11 Exercise: Transmission of Audio
This section extends the UICI server and client of Program 18.1 and Program 18.3 to send audio information from the client to the server. These programs can be used to implement a network intercom, network telephone service, or network radio broadcasts, as described in Chapter 21.
Start by incorporating audio into the UICI server and client as follows.
Run Programs 18.1 and 18.3 with redirected input and output to transfer files from client to server, and vice versa. Use diff to verify that each transfer completes correctly. Redirect the input to the client to come from the audio device (microphone) and redirect the output on the server to go to the audio device (speakers). You should be able to send audio across the network. (See Section 6.6 for information on how to do this.) Modify the bidirectional server and client to call the audio functions developed in Section 6.6 and Section 6.7 to transmit audio from the microphone of the client to the speaker of the server. Test your program for two-way communication.
The program sends even if no one is talking because once the program opens the audio device, the underlying device driver and interface card sample the audio input at a fixed rate until the program closes the file. The continuous sampling produces a prohibitive amount of data for transmission across the network. Use a filter to detect whether a packet contains voice, and throw away audio packets that contain no voice. A simple method of filtering is to convert the u-law (m-law) data to a linear scale and reject packets that fall below a threshold. Program 18.15 shows an implementation of this filter for Solaris. The hasvoice function returns 1 if the packet contains voice and 0 if it should be thrown away. Incorporate hasvoice or another filter so that the client does not transmit silence.
Program 18.15 hasvoice.c
A simple threshold function for filtering data with no voice.
#include <stdio.h>
#include <stdlib.h>
#include "/usr/demo/SOUND/include/multimedia/audio_encode.h"
#define THRESHOLD 20 /* amplitude of ambient room noise, linear PCM */
/* return 1 if anything in audiobuf is above THRESHOLD */
int hasvoice(char *audiobuf, int length) {
int i;
for (i = 0; i < length; i++)
if (abs(audio_u2c(audiobuf[i])) > THRESHOLD)
return 1;
return 0;
}
18.12 Additional Reading
Computer Networks, 4th ed. by Tanenbaum [123] is a standard reference on computer networks. The three-volume set TCP/IP Illustrated by Stevens and Wright [113, 134, 114] provides details of the TCP/IP protocol and its implementation. The two volumes of UNIX Network Programming by Stevens [115, 116] are the most comprehensive references on UNIX network programming. UNIX System V Network Programming by Rago [92] is an excellent reference book on network programming under System V. The standard for network services was incorporated into POSIX in 2001 [49].
Chapter 19. Project: WWW Redirection
The World Wide Web has a client-server architecture based on a resource identification scheme (URI), a communication protocol (HTTP) and a document format (HTML), which together allow easy access and exchange of information. The decentralized nature of the Web and its effectiveness in making information accessible have led to fundamental social and cultural change. Every product, from breakfast cereal to cars, has a presence on the Web. Businesses and other institutions have come to regard the Web as an interface, even the primary interface, with their customers. By providing ubiquitous access to information, the Web has reduced barriers erected by geographic and political borders in a profound way.
Learn the basic operation of the HTTP protocol Experiment with a ubiquitous distributed system Explore the operation of the World Wide Web Use client-server communication Understand the roles of tunnels, proxies and gateways
|
19.1 The World Wide Web
Electronic hypertext contains links to expanded or related information embedded at relevant points in a document. The links are analogous to footnotes in a traditional paper document, but the electronic nature of these documents allows easier physical access to the links. As early as 1945, Vannevar Bush proposed linked systems for documents on microfiche [18], but electronic hypertext systems did not take hold until the 1960s and 1970s.
In 1980, Tim Berners-Lee wrote a notebook program for CERN called ENQUIRE that had bidirectional links between nodes representing information. In 1989, he proposed a system for browsing the CERN Computer Center's documentation and help service. Tim Berners-Lee and Robert Cailliau developed a prototype GUI browser-editor for the system in 1990 and coined the name "World Wide Web." The initial system was released in 1991. At the beginning of 1993 there were 50 known web servers, a number that grew to 500 by the end of 1993 and to 650,000 by 1997. Today, web browsers have become an integral interface to information, and the Internet has millions of web servers.
The World Wide Web is a collection of clients and servers that have agreed to interact and exchange information in a certain format. The client (an application such as a browser) first establishes a connection with a server (an application that accepts connections and responds). Once it has established a connection, the client sends an initial request asking for service. The server responds with the requested information or an error.
As described so far, the World Wide Web is a simple client-server architecture, no different from many others. Its attractiveness lies in the simplicity of the rules for locating resources (URIs), communicating (HTTP) and presenting information (HTML). The next section describes URLs, the most common format for resource location on the Web. Section 19.3 gives an overview of HTTP, the web communication protocol. HTML, the actual format for web pages, is not within the scope of this book. Section 19.4 discusses tunnels, gateways and caching. The chapter project explores various aspects of tunnels, proxies and gateways. Sections 19.5 and 19.6 guide you through the implementation of a tunnel that might be used in a firewall. Section 19.7 describes a driver for testing the programs. Section 19.8 discusses the HTTP parsing needed for the proxy servers. Sections 19.9 and 19.10 describe a proxy server that monitors the traffic generated by the browsers that use it. Sections 19.12 and 19.13 explore the use of gateways for firewalls and load balancing, respectively.
|
19.2 Uniform Resource Locators (URLs)
A Uniform Resource Locator (URL) has the form scheme : location. The scheme refers to the method used to access the resource (e.g., HTTP), and the location specifies where the resource resides.
Example 19.1
The URL http://www.usp.cs.utsa.edu/usp/simple.html specifies that the resource is to be accessed with the HTTP protocol. This particular resource, usp/simple.html, is located on the server www.usp.cs.utsa.edu.
While http is not the only valid URL scheme, it is certainly the most common one. Other schemes include ftp for file transfer, mailto for mail through a browser or other web client, and telnet for remote shell services. The syntax for http URLs is as follows.
http_URL = "http:" "//" host [ ":" port ] [abs_path [ "?" query]]
The optional fields are enclosed in brackets. The host field should be the human-readable name of a host rather than a binary IP address (Section 18.8). The client (often a browser) determines the server location by obtaining the IP address of the specified host. If the URL does not specify a port, the client assumes port 80. The abs_path field refers to a path that is relative to the web root directory of the server. The optional query is not discussed here.
Example 19.2
The URL http://www.usp.cs.utsa.edu:8080/usp/simple.html specifies that the server for the resource is listening on port 8080 rather than default port 80. The URL's absolute path is /usp/simple.html.
When a user opens a URL through a browser, the browser parses the server's host name and makes a TCP connection to that host on the specified port. The browser then sends a request to the server for the resource, as designated by the URL's absolute path using the HTTP protocol described in the next section.
Example 19.3
Figure 19.1 shows the location of a typical web server root directory (web) in the host file system. Only the part of the file system below the web directory root is visible and accessible through the web server. If the host name is www.usp.cs.utsa.edu, the image title.gif has the URL http://www.usp.cs.utsa.edu/usp/images/title.gif.
The specification of a resource location with a URL ties it to a particular server. If the resource moves, web pages that refer to the resource are left with bad links. The Uniform Resource Name (URN) gives more permanence to resource names than does the URL alone. The owner of a resource registers its URN and the location of the resource with a service. If the resource moves, the owner just updates the entry with the registration service. URNs are not in wide use at this time. Both URLs and URNs are examples of Uniform Resource Identifiers (URIs). Uniform Resource Identifiers are formatted strings that identify a resource by name, location or other characteristics.
|
19.3 HTTP Primer
Clients and web servers have a specific set of rules, or protocol, for exchanging information called Hyper Text Transfer Protocol (HTTP). HTTP is a request-reply protocol that assumes that messages are delivered reliably. For this reason, HTTP communication usually uses TCP, and that is what we assume in this discussion. We also restrict our initial discussion to HTTP 1.0 [53].
Figure 19.2 presents a schematic of a simple HTTP transaction. The client sends a request (e.g., a message that starts with the word GET). The server parses the message and responds with the status and possibly a copy of the requested resource.
19.3.1 Client requests
HTTP client requests begin with an initial line that specifies the kind of request being made, the location of the resource and the version of HTTP being used. The initial line ends with a carriage return followed by a line feed. In the following, <CRLF> denotes a carriage return followed by a line feed, and <SP> represents a white space character. A white space character is either a blank or tab.
Example 19.4
The following HTTP 1.0 client request asks a server for the resource /usp/simple.html.
GET <SP> /usp/simple.html <SP> HTTP/1.0 <CRLF>
User-Agent:uiciclient <CRLF>
<CRLF>
The first or initial line of HTTP client requests has the following format.
Method <SP> Request-URI <SP> HTTP-Version <CRLF>
Method is usually GET, but other client methods include POST and HEAD.
The second line of the request in Example 19.4 is an example of a header line or header field. These lines convey additional information to the server about the request. Header lines are of the following form.
Field-Name:Field-Value <CRLF>
The last line of the request is empty. That is, the last header line just contains a carriage return and a line feed, telling the server that the request is complete. Notice that the HTTP request of Example 19.4 does not explicitly contain a server host name. The request of Example 19.4 might have been generated by a user opening the URL http://www.usp.cs.utsa.edu/usp/simple.html in a browser. The browser parses the URL into a server location www.usp.cs.utsa.edu and a location within that server /usp/simple.html. The browser then opens a TCP connection to port 80 of the server www.usp.cs.utsa.edu and sends the message of Example 19.4.
19.3.2 Server response
A web server responds to a client HTTP request by sending a status line, followed by any number of optional header lines, followed by an empty line containing just <CRLF>. The server then may send a resource. The status line has the following format.
HTTP-Version <SP> Status-Code <SP> Reason-Phrase <CRLF>
Table 19.1 summarizes the status codes, which are organized into groups by the first digit.
Table 19.1. Common status codes returned by HTTP servers.|
1xx | informational | reserved for future use | 2xx | success | successful request | 3xx | redirection | additional action must be taken (e.g., object has moved) | 4xx | client error | bad syntax or other request error | 5xx | server error | server failed to satisfy apparently valid request |
Example 19.5
When the request of Example 19.4 is sent to www.usp.cs.utsa.edu, the web server running on port 80 might respond with the following status line.
HTTP/1.0 <SP> 200 <SP> OK <CRLF>
After sending any additional header lines and an empty line to mark the end of the header, the server sends the contents of the requested file.
19.3.3 HTTP message exchange
HTTP presumes reliable transport of messages (in order, error-free), usually achieved by the use of TCP. Figure 19.3 shows the steps for the exchange between client and server, using a TCP connection. The server listens on a well-known port (e.g., 80) for a connection request. The client establishes a connection and sends a GET request. The server responds and closes the connection. HTTP 1.0 allows only a single request on a connection, so the client can detect the end of the sending of the resource by the remote closing of the connection. HTTP 1.1 allows the client to pipeline multiple requests on a single connection, requiring the server to send resource length information as part of the response.
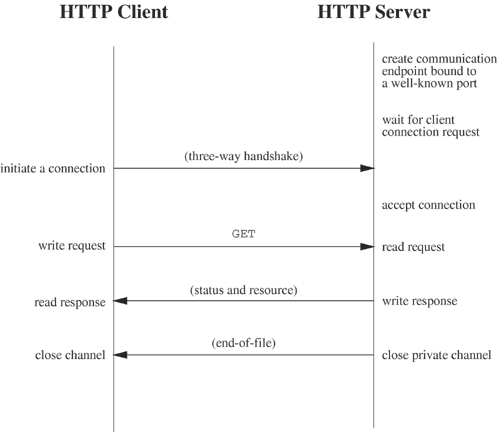
Exercise 19.6
How could you use Program 18.5 (client2) on page 629 to access the web server that is running on www.usp.cs.utsa.edu?
Answer:
Start client2 with the following command.
client2 www.usp.cs.utsa.edu 80
Type the HTTP request of Example 19.4 at the keyboard. The third line of the request is just an empty line. The host www.usp.cs.utsa.edu runs a web server that listens on port 80. The server interprets the message as an HTTP request and responds. The server then closes the connection.
Exercise 19.7
What message does client2 send to the host when you enter an empty line?
Answer:
The client2 program sends a single byte, the line feed character with ASCII code 10 (the newline character).
Exercise 19.8
Why does the web server still respond if you enter only a line feed and not a <CRLF> for the empty line?
Answer:
Although the HTTP specification [53] says that request lines should be terminated by <CRLF>, it also recommends that applications (clients and servers) be tolerant in parsing. Specifically, HTTP parsers should recognize a simple line feed as a line terminator and ignore the leading carriage return. It also recommends that parsers allow any number of space or tab characters between fields. Almost all web servers and browsers follow these guidelines.
Exercise 19.9
Run Program 18.5 in the same way as in Exercise 19.6, but enter the following.
GET <SP> /usp/badref.html <SP> HTTP/1.0 <CRLF>
<CRLF>
What happens?
Answer:
The server responds with the following initial line.
HTTP/1.1 <SP> 404 <SP> Not <SP> Found <CRLF>
The server response may contain additional header lines before the blank line marking the end of the header. After sending the header, the server closes the connection. Note that the server is using HTTP version 1.1, but it sends a response that can be understood by the client, which is using HTTP version 1.0.
Exercise 19.10
Run Program 18.5, using the following command to redirect the client's standard output to t.out.
client2 www.usp.cs.utsa.edu 80 > t.out
Enter the following at standard input of the client. What will t.out contain?
GET <SP> /usp/images/title.gif <SP> HTTP/1.0 <CRLF>
<CRLF>
Answer:
The t.out contains the server response, which consists of an ASCII header followed by a binary file representing an image. You can view the file by first removing the header and then opening the result in your browser. Use the UNIX more command to see how many header lines are there. If the file has 10 lines, use the following command to save the resources.
tail +11 t.out > t.gif
You can then use your web browser to display the result.
To summarize, an HTTP transaction consists of the following components.
An initial line (GET, HEAD or POST for clients and a status line for servers). Zero or more header lines (giving additional information). A blank line (contains only <CRLF>). An optional message body. For the server response, the message body is the requested item, which could be binary.
The initial and header lines are tokenized ASCII separated by linear white space (tabs and spaces).
|
19.4 Web Communication Patterns
According to HTTP terminology [133], a client is an application that establishes a connection, and a server is an application that accepts connections and responds. A user agent is a client that initiates a request for service. Your browser is both a client and a user agent according to this terminology.
The origin server is the server that has the resource. Figure 19.2 on page 661 shows communication between a client and an origin server. In the current incarnation of the World Wide Web, firewalls, proxy servers and content distribution networks have changed the topology of client-server interaction. Communication between the user agent and the origin server often takes place through one or more intermediaries. This section covers four fundamental building blocks of this more complex topology: tunnels, proxies, caches and gateways.
19.4.1 Tunnels
A tunnel is an intermediary that acts as a blind relay. Tunnels do not parse HTTP, but forward it to the server. Figure 19.4 shows communication between a user agent and an origin server with an intermediate tunnel.
The tunnel of Figure 19.4 accepts an HTTP connection from a client and establishes a connection to the server. In this scenario, the tunnel acts both as a client and as a server according to the HTTP definition, although it is neither a user agent nor an origin server. The tunnel forwards the information from the client to the server. When the server responds, the tunnel forwards the response to the client. The tunnel detects closing of connections by either the client or server and closes the other end. After closing both ends, the tunnel ceases to exist. The tunnel of Figure 19.4 always connects to the web server running on the host www.usp.cs.utsa.edu.
Sometimes a tunnel does not establish its own connections but is created by another entity such as a firewall or gateway after the connections are established. Figure 19.5 illustrates one such situation in which a client connects to www.usp.cs.utsa.edu, a host running outside of a firewall. The firewall software creates a tunnel for the connection to a machine usp.cs.utsa.edu that is behind the firewall. Clients behind the firewall connect directly to usp.cs.utsa.edu, but usp is not visible outside of the firewall. As far as the client is concerned, the content is on the machine www.usp.cs.utsa.edu. The client knows nothing of usp.cs.utsa.edu.
19.4.2 Proxies
A proxy is an intermediary between clients and servers that makes requests on behalf of its clients. Proxies are addressed by a special form of the GET request and must parse HTTP. Like tunnels, proxies act both as clients and servers. However, a proxy is generally long-lived and often acts as an intermediary for many clients. Figure 19.6 shows an example in which a browser has set its proxy to org.proxy.net. The HTTP client (e.g., a browser) makes a connection to the HTTP proxy (e.g., org.proxy.net) and writes its HTTP request. The HTTP proxy parses the request and makes a separate connection to the HTTP origin server (e.g., www.usp.cs.utsa.edu). When the origin server responds, the HTTP proxy copies the response on the channel connected to the HTTP client.
The GET request of Example 19.4 uses an absolute path to specify the resource location. Clients use an alternative form, the absolute URI, when directing requests to a proxy. The absolute URI contains the full HTTP address of the destination server. In Figure 19.6, the http://www.usp.cs.utsa.edu/usp/simple.html is an absolute URI; /usp/simple.html is an absolute path.
Example 19.11
This HTTP request contains an absolute URI rather than an absolute path.
GET <SP> http://www.usp.cs.utsa.edu/usp/simple.html <SP> HTTP/1.0 <CRLF>
User-Agent:uiciclient <CRLF>
<CRLF>
The proxy server parses the GET line and initiates an HTTP request to www.usp.cs.utsa.edu for the resource /usp/simple.html.
When directing a request through a proxy, user agents use the absolute URI form of the GET request and connect to the proxy rather than directly to the origin server. When a server receives a GET request containing an absolute URI, it knows that it should act as a proxy rather than as the origin server. The proxy reconstructs the GET line so that it contains an absolute path, such as the one shown in Example 19.4, and makes the connection to the origin server. Often, the proxy adds additional header lines to the request. The proxy itself can use another proxy, in which case it forwards the original GET to its designated proxy. Most browsers allow a user option of setting a proxy rather than connecting directly to the origin server. Once set up, the browser's operation with a proxy is transparent to the user, other than a performance improvement or degradation.
19.4.3 Caching and Transparency
A transparent proxy is one that does not modify requests or responses beyond what is needed for proxy identification and authentication. Nontransparent proxies may perform many other types of services on behalf of their clients (e.g., annotation, anonymity filtering, content filtering, censorship, media conversion). Proxies may keep statistics and other information about their clients. Search engines such as Google are proxies of a different sort, caching information about the content of pages along with the URLs. Users access the cached information by keywords or phrases. Clients that use proxies assume that the proxies are correct and trustworthy.
The most important service that proxies perform on behalf of clients is caching. A cache is a local store of response messages. Browsers usually cache recent response messages on disk. When a user opens a URL, the browser checks first to see if the resource can be found on disk and only initiates a network request if it didn't find the object locally.
Exercise 19.12
Examine the current settings and contents of the cache on your browser. Different browsers allow access to this information in different ways. The local cache and proxies are accessible under the Advanced option of the Preferences submenu on the Edit menu in Netscape 6. In Internet Explorer 6, you can access the information from the Internet Options submenu under the Tools menu. The cache is designated under Temporary Internet Files on the General menu. Proxies are designed under LAN Settings on the Connections submenu of Internet Options. Look at the files in the directory that holds your local browser cache. Your browser should offer an option for clearing the local cache. Use the option to clear your local cache, and examine the directory again. What is the effect? Why does the browser keep a local cache and how does the browser use this cache?
Answer:
Clearing the cache should remove the contents of the local cache directory. When the user opens a page in the browser, the browser first checks the local disk for the requested object. If the requested object is in the local cache, the browser can retrieve it locally and avoid a network transfer. Browsers use local caches to speed access and reduce network traffic.
A proxy cache stores resources that it fetches in order to more effectively service future requests for those resources. When the proxy cache receives a request for an object from a client, it first checks its local store of objects. If the object is found in the proxy's local cache (Figure 19.7), the proxy can retrieve the object locally rather than by transferring it from the origin server.
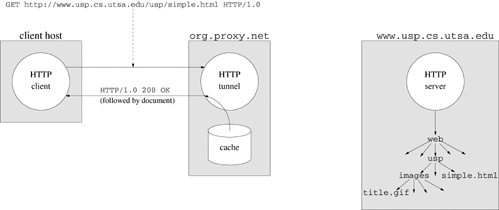
If the proxy cache does not find an object in its local store (Figure 19.8), it retrieves the object from the origin server and decides whether to save it locally. Some objects contain headers indicating they cannot be cached. The proxy may also decide not to cache an object for other reasons, for example, because the object is too large to cache or because the proxy does not want to remove other, frequently accessed, objects from its cache.
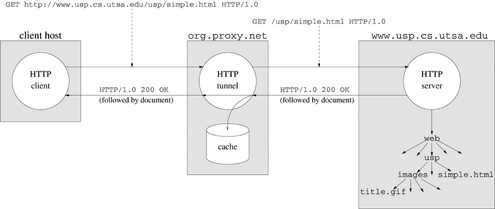
Often, proxy caches are installed at the gateways to local area networks. Clients on the local network direct all their requests through the proxy. The objects in the proxy cache's local store are responses to requests from many different users. If someone else has already requested the object and the proxy has cached the object, the response to the current request will be much faster.
You are probably wondering what happens if the object has changed since the cache stored the object. In this case, the proxy may return an object that is out-of-date, or stale, a situation that can be mitigated by expiration strategies. Origin servers often provide an expiration time as part of the response header. Proxy caches also use expiration policies to keep old objects from being cached indefinitely. Finally, the proxy (or any client) can execute a conditional GET by including an If-Modified-Since field as a header line. The server only returns objects that have changed since the specified modification date. Otherwise, the server returns a 304 Not Modified response, and the proxy can use the copy from its cache.
19.4.4 Gateways
While a proxy can be viewed as a client-side intermediary, a gateway is a server-side mechanism. A gateway receives requests as though it is an origin server. A gateway may be located at the boundary router for a local area network or outside a firewall protecting an intranet. Gateways provide a variety of services such as security, translation and load balancing. A gateway might be used as the common interface to a cluster of web servers for an organization or as a front-end portal to a web server that is behind a firewall.
Figure 19.9 shows an example of how a gateway might be configured to provide a common access point to resources inside and outside a firewall. The server www.usp.cs.utsa.edu acts as a gateway for usp.cs.utsa.edu, a server that is behind the firewall. If a GET request accesses a resource in the usp directory, the gateway creates a tunnel to usp.cs.utsa.edu. For other resources, the gateway creates a tunnel to the www.cs.utsa.edu server outside the firewall.
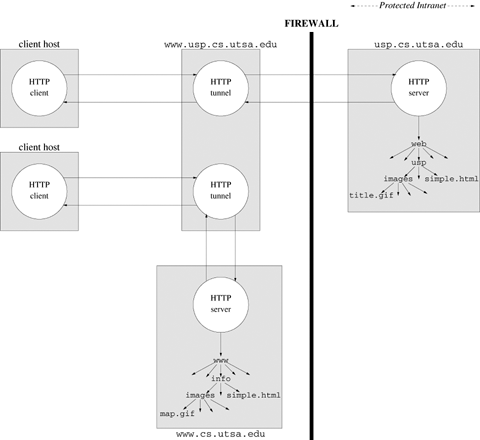
Exercise 19.13
How does a gateway differ from a tunnel?
Answer:
A tunnel is a conduit that passes information from one point to another without change. A gateway acts as a front end for a resource, perhaps a cluster of servers.
This chapter explores various aspects of tunnels, proxies and gateways. Sections 19.5 and 19.6 guide you through the implementation of a tunnel that might be used in a firewall. Section 19.7 describes a driver for testing the programs. Section 19.8 discusses the HTTP parsing needed for the proxy servers. Sections 19.9 and 19.10 describe a proxy server that monitors the traffic generated by the browsers that use it. Sections 19.12 and 19.13 explore the use of gateways for firewalls and load balancing, respectively.
|
19.5 Pass-through Monitoring of Single Connections
This section describes an implementation of a simple pass-through monitor, passmonitor, similar to the tunnel illustrated in Figure 19.4. The passmonitor program takes its listening port number, the destination web server host name and an optional destination web server port number as command-line arguments. If the last argument is omitted, passmonitor assumes that the destination web server uses port 80. The monitor listens at the specified port for TCP connection requests (using the UICI u_accept function). When it accepts a client connection, passmonitor initiates a TCP connection to the destination server (using u_connect) and calls the tunnel function described below. After control returns from tunnel, passmonitor resumes listening for another client connection request.
The tunnel function, which handles one session between a client and the origin server, has the following prototype.
int tunnel(int clientfd, int serverfd);
Here, clientfd is the open file descriptor returned after acceptance of the client's connection request. The serverfd parameter is an open file descriptor for a TCP connection between the monitor and the destination server. The tunnel function forwards all messages received from clientfd to serverfd, and vice versa. If either the client or the destination server closes a connection (clientfd or serverfd, respectively), tunnel closes its connections and returns the total number of bytes that were forwarded in both directions.
After control returns from tunnel, passmonitor writes status information to standard error, reporting the total number of bytes written for this communication and the time the communication took. The monitor then resumes listening for another client connection request.
To correctly implement passmonitor, you cannot assume that the client and the server strictly alternate responses. The passmonitor program reads from two sources (the client and the server) and must allow for the possibility that either could send next. Use select or poll as in Program 4.13 to monitor the two file descriptors. A simple implementation of tunnel is given in Example 19.14. Be sure to handle all errors returned by library functions. Under what circumstances should passmonitor exit? What other strategies should passmonitor use when errors occur?
Example 19.14
The tunnel function can easily be implemented in terms of the copy2files function of Program 4.13 on page 111.
int tunnel(int fd1, int fd2) {
int bytescopied;
bytescopied = copy2files(fd1, fd2, fd2, fd1);
close(fd1);
close(fd2);
return bytescopied;
}
Recall that copy2files returns if either side closes a file descriptor.
Exercise 19.15
Use Program 18.5 on page 629 to test passmonitor by having it connect to web servers through passmonitor. Why doesn't passmonitor have to parse the client's request before forwarding it to the destination server?
Answer:
The passmonitor program uses only the destination server that is passed to it on the command line.
Exercise 19.16
Suppose you start passmonitor on machine os1.cs.utsa.edu with the following command.
passmonitor 15000 www.usp.cs.utsa.edu
Start client2 on another machine with the following command.
client2 os1.cs.utsa.edu 15000
If you then enter the following request (on client2), the passmonitor sends the request to port 80 of www.usp.cs.utsa.edu.
GET <SP> /usp/simple.html <SP> HTTP/1.0 <CRLF>
User-Agent:uiciclient <CRLF>
<CRLF>
How does the reply differ from the one received by having client2 connect directly as in Example 19.4?
Answer:
The replies should be the same in the two cases if passmonitor is correct.
Exercise 19.17
Test passmonitor by using a web browser as the client. Start passmonitor as in Exercise 19.16. To access /usp/simple.html, open the URL as follows.
http://os1.cs.utsa.edu:15000/usp/simple.html
Notice that the browser treats the host on which passmonitor is running as the origin server with port number 15000. What happens when you don't specify a port number in the URL?
Answer:
The browser makes the connection to port 80 of the host running passmonitor.
Exercise 19.18
Suppose that you are using a browser and have started passmonitor as in Exercise 19.16. What series of connections are initiated when you open the URL as specified in Exercise 19.17?
Answer:
Your browser makes a connection to port 15000 on os1.cs.utsa.edu and sends a request similar to the one in Example 19.4 on page 660. The passmonitor program receives the request, establishes a connection to port 80 on www.usp.cs.utsa.edu, and forwards the browser's request. The passmonitor program returns www.usp.cs.utsa.edu's response to the browser and closes the connections.
|
19.6 Tunnel Server Implementation
A tunnel is a blind relay that ceases to exist when both ends of a connection are closed. The passmonitor program of Section 19.5 is technically not a tunnel because it resumes listening for another connection request after closing its connections to the client and the destination server. It acts as a server for the tunnel function. One limitation of passmonitor is that it handles only one communication at a time.
Modify the passmonitor program of Section 19.5 to fork a child to handle the communication. The child should call the tunnel function and print to standard output a message containing the total number of bytes written. Call the new program tunnelserver.
The parent, which you can base on Program 18.2 on page 623, should clean up zombies by calling waitpid with the WNOHANG option and resume listening for additional requests.
Exercise 19.19
How would you start tunnelserver on port 15002 to service the web server www.usp.cs.utsa.edu running on port 8080 instead of port 80?
Answer:
tunnelserver 15002 www.usp.cs.utsa.edu 8080
Exercise 19.20
Why can't the child process of tunnelserver return the total number of bytes processed to the parent process in its return value?
Answer:
Only 8 bits of the process return value can be stored in the status value from wait.
|
19.7 Server Driver for Testing
Modify Program 18.3 (client) on page 624 to create a test program for the tunnelserver program and call it servertester. The test program should take four command-line arguments: the tunnel server host name, the tunnel server port number, the number of children to fork and the number of requests each child should make. The parent process forks the specified number of children and then waits for them to exit. Wait for the children by calling wait(NULL) a number of times equal to the number of children created. (See, for example, Example 3.15 on page 73.) Each child executes the testhttp function described below and examines its return value. The testhttp function has the following prototype.
int testhttp(char *host, int port, int numTimes);
The testhttp function executes the following in a loop for numTimes times.
Make a connection to host on port (e.g., u_connect).
Write the REQUEST string to the connection. REQUEST is a string constant containing the three lines of a GET request similar to that of Example 19.4 on page 660. Use a REQUEST string appropriate for the host you plan to connect to.
Read from the connection until the remote end closes the connection or until an error occurs. Keep track of the total number of bytes read from this connection.
Close the connection.
Add the number of bytes to the overall total.
If successful, testhttp returns the total number of bytes read from the network. If unsuccessful, testhttp returns 1 and sets errno.
Begin by writing a simple version of servertester that calls testhttp with numTimes equal to 1 and saves and prints the number of bytes corresponding to one request.
After you have debugged the single request case, modify servertester to fork children after the first call to testhttp. Each child calls testhttp and displays an error message if the number of bytes returned is not numTimes times the number returned by the call made by the original parent process.
Add statements in the main program to read the time before the first fork and after the last child has been waited for. Output the difference in these times. Make sure there is no output to the screen between the two statements that read the time. Use conditional compilation to include or not include the print statements of tunnelserver. The tunnelserver program should not produce any output after its initial startup unless an error occurs.
Start testing servertester by directly accessing a web server. For example, access www.usp.cs.utsa.edu, using the following command to estimate how long it takes to directly access the web server.
servertester www.usp.cs.utsa.edu 80 10 20
Then, do some production runs of tunnelserver and compare the times. You can also run servertester on multiple machines to generate a heavier load.
Exercise 19.21
Suppose, as in Exercise 19.19, that tunnelserver was started on port 15002 of host os1.cs.utsa.edu to service the web server www.usp.cs.utsa.edu on port 8080. How would you start servertester to make 20 requests from each of 10 children?
Answer:
servertester os1.cs.utsa.edu 15002 10 20
Exercise 19.22
How do you expect the elapsed time for servertester to complete in Exercise 19.21 to compare with that of directly accessing the origin server?
Answer:
If both programs are run under the same conditions, Exercise 19.21 should take longer. The difference in time is an indication of the overhead incurred by going through the tunnel.
19.8 HTTP Header Parsing
In contrast to tunnels, proxies and gateways are party to the HTTP communication and must parse at least the initial line of the client request. This section discusses a parse function that parses the initial request line. The parse function has the following prototype.
int parse(char *inlin, char **commandp, char **serverp,
char **pathp, char **protocolp, char **portp);
The inlin parameter should contain the initial line represented as an array terminated by a line feed. Do not assume in your implementation of parse that inlin is a string, because it may not have a string terminator. The parse function parses inlin in place so that no additional memory needs to be allocated or freed.
The parse function returns 1 if the initial line contains exactly three tokens, or 0 otherwise. On a return of 1, parse sets the last five parameters to strings representing the command, server, path, protocol and port, respectively. These strings should not contain any blanks, tabs, carriage returns or line feeds.
The server and port pointers may be NULL. If an absolute path rather than an absolute URI is given, the server pointer is NULL. If the optional port number is not given, the port pointer is NULL. Allow any number of blanks or tabs at the start of inlin, between tokens, or after the last token. The inlin buffer may have an optional carriage return right before the line feed.
Example 19.23
Figure 19.10 shows the result of calling parse on a line containing an absolute path form of the URI. The line has two blanks after GET and two blanks after the path. The carriage return and line feed directly follow the protocol. The parse function sets the first blank after GET and the first blank after the path to the null character (i.e., '\0'). The parse function also replaces the carriage return by the null character. The NULL value of the *serverp parameter signifies that no host name was present in the initial inlin, and the NULL value of *portp signifies that no port number was specified.
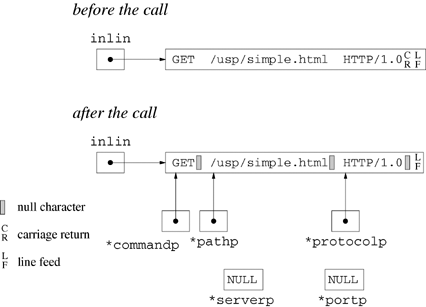
Example 19.24
Figure 19.11 shows the result of parse for a line that contains an absolute URI distinguished by the leading http:// after GET. Notice that parse moves the host name one character to the left so that it can insert a null character between the host name and the path. There is always room to do this, since the leading http:// is no longer needed.
Implement parse in stages. Start by skipping the leading blanks and tabs, and check that there are exactly three tokens before the first line feed. If inlin does not have exactly three tokens, return 0. Then break these tokens into three strings, setting the command, path and protocol pointers. Consider the second token to be an absolute URI if it starts with http:// and contains at least one additional / character. The server and port pointers should be set to NULL. After successful testing, handle the server pointer. When this is working, check for the port number.
You should write the code to break the input line into strings yourself. Do not use strtok, since it is not thread-safe. Be careful not to assume that the input line is terminated by a string terminator. Do not modify any memory before or after the input line. Test parse by writing a simple driver program. Remember not to assume that the first parameter to parse is a string.
|
19.9 Simple Proxy Server
This section describes a modification of the tunnelserver program of Section 19.6 so that it acts like a proxy rather than a tunnel. A proxy must parse the initial request line (unless the proxy happens to be using a proxy, too).
Example 19.25
When a proxy server receives the following GET line, it knows that it is to act as a proxy because the absolute URI form of the request is given.
GET http://www.usp.cs.utsa.edu/usp/simple.html HTTP/1.0
The proxy knows that the origin server is www.usp.cs.utsa.edu and replaces the initial line with the following initial line.
GET /usp/simple.html HTTP/1.0
The proxy then makes a connection to port 80 of www.usp.cs.utsa.edu.
Make a new directory with a copy of the files for tunnelserver of Section 19.6. Rename tunnelserver to proxyserver. The proxyserver program takes a single command-line argument, the port number at which it listens for requests. The proxyserver program does not need the destination web server as a command-line argument because it parses the initial HTTP request from the client, as in Example 19.25. Write a processproxy function that has the following prototype.
int processproxy(int clientfd);
The clientfd parameter is the file descriptor returned when the server accepts the client's connection request.
The processproxy function reads in the first line from clientfd and calls parse to parse the initial request. If parse is successful and the line contains an absolute URI (the server pointer is not NULL), processproxy establishes a connection to the destination server. Then processproxy writes to the destination server an initial line containing a command with an absolute path and calls the tunnel function to continue the communication. If the port parameter of parse is not NULL, use the indicated port. Otherwise use port 80.
If successful, processproxy returns the total number of bytes transferred, which is the return value from tunnel plus the length of the initial line read from the client and the corresponding line sent to the server. If unsuccessful, processproxy returns 1 and sets errno.
Assume a maximum line length of 4096 bytes for the initial command from the client so that you need not do dynamic memory allocation. This means that a longer request is considered invalid, but you must not let a long request overflow the buffer. To read the first line from the client, you must read one byte at a time until you get a newline.
If parse returns an error, processproxy should treat the connection request as an error. In this case, processproxy writes the following message on clientfd, closes the connection, and returns 1 with errno set.
HTTP/1.0 <SP> 400 <SP> Bad <SP> Request <CRLF>
<CRLF>
The proxyserver program listens for connection requests on the given port, and for each request it forks a child that calls processproxy and prints the number of bytes transferred.
Copy your servertester.c into proxytester.c and modify the request to contain an absolute URI instead of an absolute path. Use proxytester to test proxyserver.
Exercise 19.26
How would you test proxyserver through your browser?
Answer:
Set your browser to use proxyserver as its proxy. Suppose that proxyserver is running on machine os1.cs.utsa.edu using port 15000. Set your browser proxy to be os1.cs.utsa.edu on port number 15000. You should be able to use your browser with no noticeable difference.
19.10 Proxy Monitor
Make a copy of proxyserver from Section 19.9 and call it proxymonitor. Modify proxymonitor to take an optional command-line argument, pathname, giving the name of a log file. All header traffic and additional information should be dumped to this file in a useful format. Modify processproxy to take an additional parameter, the name of the log file. Do no logging if this additional parameter is NULL. Log the following information.
Client host name and destination host name Process ID of the process running processproxy Initial request line from the client to the proxy Initial request line sent by the proxy to the server All additional header lines from the client All additional header lines from the server The following byte counts Length of the initial request from the client Length of the initial request from the proxy Length of the additional header lines from the client Length of the additional header lines from the server Number of additional bytes sent by the server Number of additional bytes sent by the client Total number of bytes sent from the client to the proxy Total number of bytes sent from the proxy to the server Total number of bytes sent from the server to the proxy
All this information should be stored in a convenient readable format. All header lines should be labeled to indicate their source. Logging must be done atomically so that the log produced by one child running processproxy is not interleaved with another. You can do this by opening the log file with the O_APPEND flag and doing all logging with a single call to write. A simpler way would be to use the atomic logging facility described in Section 4.9. Section D.1 provides the complete code for this facility.
You will not be able to use tunnel for your implementation because sometimes proxymonitor reads lines and sometimes it reads binary content that is not line oriented. After sending the initial request to the host, as in the proxyserver, the client sends line-oriented data that the proxy logs until the client sends a blank line. The client may then send arbitrary data until the connection is closed. The proxymonitor needs to log only the number of bytes of this additional data. Similarly, the server sends line-oriented header information that proxymonitor logs until the server sends a blank line. The server may then send arbitrary data until the connection is closed, but the proxymonitor logs only the number of bytes the server sent for this portion.
Exercise 19.27
What is wrong with the following strategy for implementing proxymonitor?
Read the initial header line from the client and send the corresponding line to the server (as in the proxyserver). Read, log and send client header lines until encountering a blank line. Read, log and send server header lines until encountering a blank line. Handle binary data between the client and the server as in tunnel, keeping track of the number of bytes sent in each direction for logging.
Answer:
This should work for GET and HEAD, but it will fail for POST. For a POST command, the client sends its content before the server sends back a header, so the process blocks while waiting for the server header when in fact it should be reading the client content.
One method of implementing proxymonitor is to keep track of the states of the client and server. Each sends headers until a blank line and then sends content. Use select to determine which descriptor is ready and then process either a header line or content, depending on the state of the source. If proxymonitor encounters a blank header line, it changes the state of the respective client or server from header to content.
Exercise 19.28
What happens if several copies of proxymonitor run concurrently using the same log file?
Answer:
As long as the different copies run on different ports, there should not be a problem, provided that logging is atomic. In this case, you might also want to log the port number with each transaction.
Exercise 19.29
Why don't we log the total number of bytes sent from the proxy to the client?
Answer:
This should be the same as the total number of bytes sent from the server to the proxy.
Exercise 19.30
The last three numbers logged are the byte totals for a given transaction. How would you keep track of and log the total number of bytes for each of these items for all transactions processed by proxymonitor?
Answer:
This requires some work, since the different transactions are handled by different processes. One possibility is to convert the program to use threads rather than children. The total could then be kept in global variables and updated by each thread. The routines to update these totals would have to be protected by a synchronization construct such as a semaphore or a mutex lock.
To do this without using threads, proxymonitor could create an additional child process to keep track of the totals. This process could communicate with the children by running processproxy with two pipes, one to send the new values to this process and one to receive the new totals from this process. Create the two pipes and this child before doing any other processing. The server processes can store the integers in a structure and output them to the pipe in raw form with a single write operation. You need not worry about byte ordering, since the communication is on the same machine. You still need to worry about synchronization to guarantee that the totals received by the children include the values of the current transaction.
Exercise 19.31
Explain the last sentence of the answer to the previous exercise.
Answer:
Suppose we keep track of only one number. The child running processproxy sends the number corresponding to a transaction on one pipe and then reads the new total on the other pipe. Consider the case in which the proxy has just started up and so the current total is 1000. Child A is running a small transaction of 100 bytes, and child B is running a larger transaction of 100,000 bytes. Child A sends 100 on the first pipe and reads the new total on the second pipe. Child B sends 100,000 on the first pipe and reads the new total on the second pipe. If the sending and receiving for each process is not done atomically, The following ordering is possible.
Child A sends 100 on the first pipe. 1100 (the new total) is written to the second pipe. Child B sends 100,000 on the first pipe. 101,100 (the new total) is written to the second pipe. Child B reads 1100 from the second pipe. Child A reads 101,100 from the second pipe.
At this pipe, Child B will have completed a transaction of 100,000 bytes and report that the total so far (including this transaction) is 1100 bytes. To fix this problem, make the writing to the first pipe and the reading from the second pipe be atomic. You can do this by using a POSIX:XSI semaphore set shared by all the child processes.
19.11 Proxy Cache
Proxy caches save resources in local storage so that requests can be satisfied locally. The cache can be in memory or on disk.
Starting with the proxymonitor of Section 19.10, write a program called proxycache that stores all the resources from the remote hosts on disk. Each unique resource must be stored in a unique file. One way to do this is to use sequential file names like cache00001, cache00002, etc., and keep a list containing host name, resource name and filename. Most proxy implementations use some type of hashing or digest mechanism to efficiently represent and search the contents of the cache for a particular resource.
Start by just storing the resources without modifying the communication. If the same resource is requested again, update the stored value rather than create a new entry. Keep track of the number of hits on each resource.
The child processes must coordinate their access to the list of resources, and they must coordinate the generation of unique file names. Consider using threads, shared memory or message passing to implement the coordination.
Once you have the coordination working, implement the code to satisfy requests for cached items locally. Keep track of the total number of bytes transferred from client to proxy, proxy to server, server to proxy and proxy to client. Now the last two of these should be different. Remember that when you are testing with a browser, the browser also does caching, so some requests will not even go to the proxy server. Either turn off the browser's caching or force a remote access in the browser (usually by holding down the SHIFT key and pressing reload or refresh).
Real proxy caches need to contend with a number of issues.
Real caches are not infinite. Caches should not store items above a certain size. The optimal size may vary dynamically with cache content. The cache should have an expiration policy so that resources do not stay in the cache forever. The cache should respect directives from the server stating that certain items should not be cached. The cache should check whether an item has been modified before using a local copy.
How many of the above issues can you resolve in your implementation? What else could be added to this list?
|
19.12 Gateways as Portals
A gateway receives requests as though it were the origin server and acts as an intermediary for other servers. This section discusses a server program, gatewayportal, which implements a gateway as shown in Figure 19.9. In this configuration, gatewayportal directs certain requests to a web server that is inside a firewall and directs the remaining requests to a server outside the firewall. The gatewayportal program has three command-line arguments: the port number that it listens on, the default server host name and the default server port number. Start by copying proxyserver.c of Section 19.9 to gatewayportal.c. The gatewayportal program parses the initial line. If the line contains an absolute URI, gatewayportal returns an HTTP error response to the client. If the absolute path of the initial line is for a resource that starts with /usp, then gatewayportal creates a tunnel to www.usp.cs.utsa.edu. The gatewayportal program directs all other requests to the default server through another tunnel.
19.13 Gateway for Load Balancing
This section describes a gateway, called gatewaymonitor, used for load balancing. Start with tunnelserver of Section 19.6. The gatewaymonitor program takes two ports as command-line arguments: a listening port for client requests and a listening port for server registration requests. The gatewaymonitor program acts like tunnelserver of Section 19.6 except that instead of directing all requests to a particular server, it maintains a list of servers with identical resources and can direct the request to any of those servers. The gatewaymonitor program keeps track of how many requests it has directed to each of the servers. If a connection request to a particular server fails, gatewaymonitor outputs an error message to standard error, reporting which server failed and providing usage statistics for that server. The gatewaymonitor program removes the failed server from its list and sends the request to another server. If the server list is empty, gatewaymonitor sends an HTTP error message back to the client.
A server can add itself to gatewaymonitor's list of servers by making a connection request to the server listening port of gatewaymonitor. The server then registers itself by sending its host name and its request listening port number. The gatewaymonitor program monitors the client listening port as before but also monitors the server request listening port. (Use select here.) If a request comes in on the server listening port, gatewaymonitor accepts the connection, reads the port information from the server, adds the host and port number to the server list, and closes the connection. The server should send the port number as a string to avoid byte-ordering problems.
Write a server program called registerserver that registers a server with gatewaymonitor as described above. The registerserver takes three or four command-line arguments. The first two arguments are the host name and server registration port number of the gatewaymonitor. The third parameter is the port number that the registered server will listen on for client requests. The optional fourth command-line argument is the name of a host to register. When called with four command-line arguments, registerserver exits after registering the specified host. The four-argument version of registerserver can be used to register an existing web server. If only three command-line arguments are given, registerserver registers itself and waits for requests.
The registerserver should have a canned HTTP response (with a resource) to send in response to all requests. The host name and process ID should be embedded in the resource so that you can tell how the request to the gateway monitor was serviced. Test your program by using a browser with as many as five servers registering with the gateway. Kill various servers and make sure that gatewaymonitor responds correctly.
19.14 Postmortem
This section describes common pitfalls and mistakes that we have observed in student implementations of the servers described in this chapter.
19.14.1 Threading and timing errors
Most timing errors for this type of program result from an incorrect understanding of TCP. Do not assume that an entire request can be read in a single read, even if you provide a large enough buffer. TCP provides an abstraction of a stream of bytes without packet or message boundaries. You have no control over how much will be delivered in a single read operation because the amount depends on how the message was encapsulated into packets and how those packets were delivered through an unreliable channel. Unfortunately, a program that makes this assumption works most of the time when tested on a fast local area network.
Whether writing a tunnel, proxy or gateway, do not assume that a client first sends its entire request and then the server responds. A program that reads from the client until it detects the end of the HTTP request does not follow the specification. Your program should simultaneously monitor the incoming file descriptors for both the client and the origin server. (See Sections 12.1 and 12.2 for approaches to do this.)
According to the specification, passmonitor should measure the time it takes to process each client request. How you approach this depends, to some extent, on your method of handling multiple file descriptors. In any case, do not measure the start time before the accept call because doing so incorporates an indefinite client "think" time. Do not measure the end time right after the fork call if you are using multiple processes, right after pthread_create if you are using multiple threads, or right after select if you are monitoring multiple descriptors in a single thread of execution. Why not?
Be sure that the time values you measure are reasonable. Most time-related library functions return seconds and milliseconds, seconds and microseconds, or seconds and nanoseconds. A common mistake is to confuse the units of the second element. Another common mistake is to subtract the start and end times without allowing for wrap-around. If you come out with a time value in days or months, you know that you made a mistake.
Do not use sleep to "cover up" incorrectly synchronized code. These programs should not need sleep to work correctly, and the presence of a sleep call in the code is a tip-off that something is seriously wrong.
Logging of headers also presents a timing problem. If you write one header line at a time to the log file, it is possible that headers for responses and requests will be interleaved. Accumulate each header in a buffer and write it by using a single write function when your program detects that the header is complete.
Do not connect to the destination web server in the tunnel programs before accepting a client connection. If you type fast enough during testing, you might not detect a problem. However, most web servers disconnect after a fairly short time when no incoming request appears.
19.14.2 Uncaught errors and bad exits
If you did not seriously or correctly address how your servers react to errors and when they should exit, your running programs may represent a system threat, particularly if they run with heightened privileges.
A server usually should run until the system reboots, so think about exit strategies. Do not exit from any functions except the main function. In general, other functions should either handle the error or return an error code to the caller. Do not exit if the proxy fails to connect to the destination web serverthe problem may be temporary or may just be for that particular server. In general, a client should not be able to cause a server to exit. The server should exit only if there is an unrecoverable error due to lack of resources (memory, descriptors, etc.) that would jeopardize future correct execution. Remember the Mars Pathfinder (see page 483)! For these programs, a server should exit only when it fails to create a socket for listening to client requests. You should think about what actions to take in other situations.
Programs in C continue to execute even when a library function returns an error, possibly causing a fatal and virtually untrackable error later in the execution. To avoid this type of problem, check the return value for every library function that can return an error.
Releasing resources is always important. In servers, it is critical. Close all appropriate file descriptors when the client communication is finished. If a function allocates buffers, be sure to free them somewhere. Check to see that resources are freed on all paths through each function, paying particular attention to what happens when an error occurs.
Decide when a function should output an error message as well as return an error code. Use conditional compilation to leave informational messages in the source without having them appear in the released application. Remember that in the real world those messages have to go somewhereprobably to some unfortunate console log. Write messages to standard error, not to standard output. Usually, standard error is redirected to a console logwhere someone might actually read the message. Also, the system does not buffer standard error, so the message appears when the error occurs.
19.14.3 Writing style and presentation
Most significant projects have an accompanying report or auxiliary documentation. Here are some things to think about in producing such a report.
Clean up the spelling and grammar. No one is going to believe that the code is debugged if the report isn't. Using (and paying attention to) a grammar checker won't make you a great writer, but it will help you avoid truly awful writing. Be consistent in your style, typeface, numbering scheme and use of bullets. Not only does this attention to detail result in a more visually pleasing report, but it helps readers who may use style as a cue to meaning. Put some thought into the layout and organization of your report. Use section titles and subsection titles to make the organization of the report clear. Use paragraph divisions that are consistent with meaning. If your report contains single-spaced paragraphs that are a third of a page or longer, you probably need more paragraphs or more conciseness. Avoid excessive use of code in the report. Use outlines, pseudocode or block diagrams to convey implementation details. If readers want to see code, they can look at the programs.
Pay attention to the introduction. Be sure that it has enough information for readers to understand the project. However, irrelevant information is sometimes worse than no information at all.
Diagrams are useful and can greatly improve the clarity of the presentation, but a diagram that conveys the wrong idea is worse than no diagram. Ask yourself what information you are trying to convey by the diagram, and distinguish that information with carefully chosen and consistent symbols. For example, don't use the same style box to represent both a process and a port, or the same type of arrow to represent a connection request and a thread.
Use architectural diagrams to convey overall structure and differences in design. For example, if contrasting the implementations of the tunnel and the proxy, give separate architectural diagrams for each that are clearly distinct. Alternatively, you could give one diagram for both (not two copies of the same diagrams) and emphasize that the two implementations have the same communication structure but differ in other ways.
On your final pass, verify that the report agrees with the implementation. For example, you might describe a resource-naming scheme in the report and then modify it in the program during testing. It is easy to forget to change the documentation to reflect the modifications. Section 22.12 gives some additional discussion about technical reports.
19.14.4 Poor testing and presentation of results
Each of the tunnel and proxy programs should be tested in a controlled environment before being tested with browsers and web servers. Otherwise, you are contending with three linked systems, each with unknown behavior. This configuration is impossible to test in a meaningful way.
A good way to start is to test the tunnel programs with simple copying programs such as Programs 18.1 and 18.3 to be sure that tunnel correctly transfers all of the information. Be sure that ordinary and binary files are correctly transmitted for all versions. Testing that the program transmitted data is not the same as testing to see that it transmitted correctly. Use diff or other utilities to make sure that files were exactly transmitted.
Avoid random test syndrome by organizing the test cases before writing the programs. Think about what factors might affect program behaviordifferent types of web pages, different types of servers, different network connections, different times of day, etc., and clearly organize the tests.
State clearly in the report what tests were performed, what the results were, and what aspect of the program these tests were designed to exercise. The typical beginner's approach to test reporting is to write a short paragraph saying the program worked and then append a large log file of test results to the report. A better approach might be to organize the test results into a table with annotations of the outcomes and a column with page numbers in the output so that the reader can actually find the tests.
Always record and state the conditions under which tests or performance experiments were run (machines, times of day, etc.). These factors may not appear to be important at the time, but you usually can't go back later and reconstruct these details accurately. Include in your report an analysis of what you expected to happen and what actually did happen.
19.14.5 Programming errors and bad style
Well-written programs are always easier to debug and modify. If you try to produce clean code from the initial design, you will usually spend less time debugging.
Avoid large or inconsistent indentationit generally makes complicated code difficult to follow. Also avoid big loopsuse functions to reduce complexity. For example, parsing the GET line of an HTTP request should be done in a function and tested separately.
Don't reinvent the wheel. Use libraries if available. Consolidate common code. For example, in the proxy, call the same function for each direction once the GET line is parsed. Do not assume that a header or other data will never exceed some arbitrary, predetermined size. It is best to include code to resize arrays (by realloc) when necessary. Be careful of memory leaks. Alternatively, you could use a fixed-size buffer and report longer requests as invalid. Be sure your buffer size is large enough. In no circumstance should you write past the end of an array. However, be cognizant of when a badly behaved program (e.g., a client that tries to write an infinitely long HTTP request) might cause trouble and be prepared to take appropriate action.
Always free allocated resources such as buffers, but don't free them more than once because this can cause later allocations to fail. Good programming practice suggests setting the pointer argument of free to NULL after the call, since the free function ignores NULL pointers. Often, a function will correctly free a buffer or other resource when successful but will miss freeing it when certain error conditions occur.
Do not use numeric values for buffer sizes and other parameters within the program. Use predefined constants for default and initial values so that you know what they mean and only have to modify them in one place. Be careful about when to use a default value and when not to. Mistakes here can be difficult to detect during testing. For example, the absolute URL contains an optional port number. You should not assume port 80 if this optional number is present. Be sure that all command-line arguments meet their specifications.
Parsing the HTTP headers is quite difficult. If you implement robust parsing, you need to assume that lines can end in a carriage return followed by a line feed, by just a line feed, or by just a carriage return. The line feed is the same as the newline character. If you did this parsing inline in the main loop, you probably didn't test parsing very wellhow could you?
Headers in HTTP are in ASCII format, but resources may be in binary format. You will need to switch strategies in the middle of handling input.
19.15 Additional Reading
You can obtain more information about current developments on the World Wide Web by visiting the web site of the World Wide Web Consortium (W3C) [132], an organization that serves as a forum for development of new standards and protocols for the Web. The Internet Engineering Task Force (IETF) [55] is an open community of researchers, engineers and network operators concerned with the evolution and smooth operation of the Internet. Many important architectural developments and network designs appear in some form as IETF RFCs (Request for Comments). The specifications of HTTP/1.0 [53] and HTTP/1.1 [54] are of particular interest for this project. Both W3C and IETF maintain extensive web sites with much technical documentation. An excellent general reference on networking and the Internet can be found in Computer Networking: A Top-Down Approach Featuring the Internet by Kurose and Ross [68]. Web Protocols and Practice: HTTP/1.1, Networking Protocols, Caching, and Traffic Measurement [66] gives a more technical discussion of web performance and HTTP/1.1. "The state of the art in locally distributed web-server systems," by Cardellini et al. [21] reviews different architectures for web server clusters.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books
