Системное Unix™ программирование: коммуникации , треды
Процессы в UNIX
A process is the basic active entity in most operating-system models. This chapter covers the UNIX process model, including process creation, process destruction and daemon processes. The chapter uses process fans and process chains to illustrate concepts of parentage, inheritance and other process relationships. The chapter also looks at the implications of critical sections in concurrent processes.
Learn how to create processes Experiment with fork and exec Explore the implications of process inheritance Use wait for process cleanup Understand the UNIX process model
|
|
Идентификация процесса
UNIX identifies processes by a unique integral value called the process ID. Each process also has a parent process ID, which is initially the process ID of the process that created it. If this parent process terminates, the process is adopted by a system process so that the parent process ID always identifies a valid process.
The getpid and getppid functions return the process ID and the parent process ID, respectively. The pid_t is an unsigned integer type that represents a process ID.
SYNOPSIS
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void) ;
POSIX
Neither the getpid nor the getppid functions can return an error.
Example 3.1 outputPID.c
The following program outputs its process ID and its parent process ID. Notice that the return values are cast to long for printing since there is no guarantee that a pid_t will fit in an int.
#include <stdio.h>
#include <unistd.h>
int main (void) {
printf("I am process %ld\n", (long)getpid());
printf("My parent is %ld\n", (long)getppid());
return 0;
}
System administrators assign a unique integral user ID and an integral group ID to each user when creating the user's account. The system uses the user and group IDs to retrieve from the system database the privileges allowed for that user. The most privileged user, superuser or root, has a user ID of 0. The root user is usually the system administrator.
A UNIX process has several user and group IDs that convey privileges to the process. These include the real user ID, the real group ID, the effective user ID and the effective group ID. Usually, the real and effective IDs are the same, but under some circumstances the process can change them. The process uses the effective IDs for determining access permissions for files. For example, a program that runs with root privileges may want to create a file on behalf of an ordinary user. By setting the process's effective user ID to be that of this user, the process can create the files "as if" the user created them. For the most part, we assume that the real and effective user and group IDs are the same.
The following functions return group and user IDs for a process. The gid_t and uid_t are integral types representing group and user IDs, respectively. The getgid and getuid functions return the real IDs, and getegid and geteuid return the effective IDs.
SYNOPSIS
#include <unistd.h>
gid_t getegid(void);
uid_t geteuid(void);
git_t getgid(void);
uid_t getuid(void);
POSIX
None of these functions can return an error.
Example 3.2 outputIDs.c
The following program prints out various user and group IDs for a process.
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("My real user ID is %5ld\n", (long)getuid());
printf("My effective user ID is %5ld\n", (long)geteuid());
printf("My real group ID is %5ld\n", (long)getgid());
printf("My effective group ID is %5ld\n", (long)getegid());
return 0;
}
|
Состояние процесса
The state of a process indicates its status at a particular time. Most operating systems allow some form of the states listed in Table 3.1. A state diagram is a graphical representation of the allowed states of a process and the allowed transitions between states. Figure 3.1 shows such a diagram. The nodes of the graph in the diagram represent the possible states, and the edges represent possible transitions. A directed arc from state A to state B means that a process can go directly from state A to state B. The labels on the arcs specify the conditions that cause the transitions between states to occur.
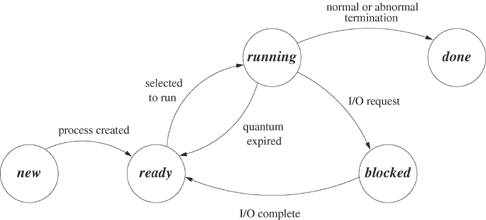
While a program is undergoing the transformation into an active process, it is said to be in the new state. When the transformation completes, the operating system puts the process in a queue of processes that are ready to run. The process is then in the ready or runnable state. Eventually the component of the operating system called the process scheduler selects a process to run. The process is in the running state when it is actually executing on the CPU.
Table 3.1. Common process states.|
new | being created | running | instructions are being executed | blocked | waiting for an event such as I/O | ready | waiting to be assigned to a processor | done | finished |
A process in the blocked state is waiting for an event and is not eligible to be picked for execution. A process can voluntarily move to the blocked state by executing a call such as sleep. More commonly, a process moves to the blocked state when it performs an I/O request. As explained in Section 1.2, input and output can be thousands of times slower than ordinary instructions. A process performs I/O by requesting the service through a library function that is sometimes called a system call. During the execution of a system call, the operating system regains control of the processor and can move the process to the blocked state until the operation completes.
A context switch is the act of removing one process from the running state and replacing it with another. The process context is the information that the operating systems needs about the process and its environment to restart it after a context switch. Clearly, the executable code, stack, registers and program counter are part of the context, as is the memory used for static and dynamic variables. To be able to transparently restart a process, the operating system also keeps track of the process state, the status of program I/O, user and process identification, privileges, scheduling parameters, accounting information and memory management information. If a process is waiting for an event or has caught a signal, that information is also part of the context. The context also contains information about other resources such as locks held by the process.
The ps utility displays information about processes. By default, ps displays information about processes associated with the user. The -a option displays information for processes associated with terminals. The -A option displays information for all processes. The -o option specifies the format of the output.
SYNOPSIS
ps [-aA] [-G grouplist] [-o format]...[-p proclist]
[-t termlist] [-U userlist]
POSIX Shells and Utilities
Example 3.3
The following is sample output from the ps -a command.
>% ps -a
PID TTY TIME CMD
20825 pts/11 0:00 pine
20205 pts/11 0:01 bash
20258 pts/16 0:01 telnet
20829 pts/2 0:00 ps
20728 pts/4 0:00 pine
19086 pts/12 0:00 vi
The POSIX:XSI Extension provides additional arguments for the ps command. Among the most useful are the full (-f) and the long (-l) options. Table 3.2 lists the fields that are printed for each option. An (all) in the option column means that the field appears in all forms of ps.
Example 3.4
The execution of the ps -la command on the same system as for Example 3.3 produced the following output.
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
8 S 4228 20825 20205 0 40 20 ? 859 ? pts/11 0:00 pine
8 S 4228 20205 19974 0 40 20 ? 321 ? pts/11 0:01 bash
8 S 2852 20258 20248 0 40 20 ? 328 ? pts/16 0:01 telnet
8 O 512 20838 18178 0 50 20 ? 134 pts/2 0:00 ps
8 S 3060 20728 20719 0 40 20 ? 845 ? pts/4 0:00 pine
8 S 1614 19086 18875 0 40 20 ? 236 ? pts/12 0:00 vi
Table 3.2. Fields reported for various options of the ps command in the POSIX:XSI Extension.|
F | -l | flags (octal and additive) associated with the process | S | -l | process state | UID | -f, -l | user ID of the process owner | PID | (all) | process ID | PPID | -f, -l | parent process ID | C | -f, -l | processor utilization used for scheduling | PRI | -l | process priority | NI | -l | nice value | ADDR | -l | process memory address | SZ | -l | size in blocks of the process image | WCHAN | -l | event on which the process is waiting | TTY | (all) | controlling terminal | TIME | (all) | cumulative execution time | CMD | (all) | command name (arguments with -f option) |
|
Создание UNIX-процесса и fork
A process can create a new process by calling fork. The calling process becomes the parent, and the created process is called the child. The fork function copies the parent's memory image so that the new process receives a copy of the address space of the parent. Both processes continue at the instruction after the fork statement (executing in their respective memory images).
SYNOPSIS
#include <unistd.h>
pid_t fork(void);
POSIX
Creation of two completely identical processes would not be very useful. The fork function return value is the critical characteristic that allows the parent and the child to distinguish themselves and to execute different code. The fork function returns 0 to the child and returns the child's process ID to the parent. When fork fails, it returns 1 and sets the errno. If the system does not have the necessary resources to create the child or if limits on the number of processes would be exceeded, fork sets errno to EAGAIN. In case of a failure, the fork does not create a child.
Example 3.5 simplefork.c
In the following program, both parent and child execute the x = 1 assignment statement after returning from fork.
#include <stdio.h>
#include <unistd.h>
int main(void) {
int x;
x = 0;
fork();
x = 1;
printf("I am process %ld and my x is %d\n", (long)getpid(), x);
return 0;
}
Before the fork of Example 3.5, one process executes with a single x variable. After the fork, two independent processes execute, each with its own copy of the x variable. Since the parent and child processes execute independently, they do not execute the code in lock step or modify the same memory locations. Each process prints a message with its respective process ID and x value.
The parent and child processes execute the same instructions because the code of Example 3.5 did not test the return value of fork. Example 3.6 demonstrates how to test the return value of fork.
Example 3.6 twoprocs.c
After fork in the following program, the parent and child output their respective process IDs.
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t childpid;
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) /* child code */
printf("I am child %ld\n", (long)getpid());
else /* parent code */
printf("I am parent %ld\n", (long)getpid());
return 0;
}
The original process in Example 3.6 has a nonzero value of the childpid variable, so it executes the second printf statement. The child process has a zero value of childpid and executes the first printf statement. The output from these processes can appear in either order, depending on whether the parent or the child executes first. If the program is run several times on the same system, the order of the output may or may not always be the same.
Exercise 3.7 badprocessID.c
What happens when the following program executes?
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t childpid;
pid_t mypid;
mypid = getpid();
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) /* child code */
printf("I am child %ld, ID = %ld\n", (long)getpid(), (long)mypid);
else /* parent code */
printf("I am parent %ld, ID = %ld\n", (long)getpid(), (long)mypid);
return 0;
}
Answer:
The parent sets the mypid value to its process ID before the fork. When fork executes, the child gets a copy of the process address space, including all variables. Since the child does not reset mypid, the value of mypid for the child does not agree with the value returned by getpid.
Program 3.1 creates a chain of n processes by calling fork in a loop. On each iteration of the loop, the parent process has a nonzero childpid and hence breaks out of the loop. The child process has a zero value of childpid and becomes a parent in the next loop iteration. In case of an error, fork returns 1 and the calling process breaks out of the loop. The exercises in Section 3.8 build on this program.
Figure 3.2 shows a graph representing the chain of processes generated for Program 3.1 when n is 4. Each circle represents a process labeled by its value of i when it leaves the loop. The edges represent the is-a-parent relationship. A B means process A is the parent of process B. B means process A is the parent of process B.

Program 3.1 simplechain.c
A program that creates a chain of n processes, where n is a command-line argument.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main (int argc, char *argv[]) {
pid_t childpid = 0;
int i, n;
if (argc != 2){ /* check for valid number of command-line arguments */
fprintf(stderr, "Usage: %s processes\n", argv[0]);
return 1;
}
n = atoi(argv[1]);
for (i = 1; i < n; i++)
if (childpid = fork())
break;
fprintf(stderr, "i:%d process ID:%ld parent ID:%ld child ID:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
return 0;
}
Exercise 3.8
Run Program 3.1 for large values of n. Will the messages always come out ordered by increasing i?
Answer:
The exact order in which the messages appear depends on the order in which the processes are selected by the process scheduler to run. If you run the program several times, you should notice some variation in the order.
Exercise 3.9
What happens if Program 3.1 writes the messages to stdout, using printf, instead of to stderr, using fprintf?
Answer:
By default, the system buffers output written to stdout, so a particular message may not appear immediately after the printf returns. Messages to stderr are not buffered, but instead written immediately. For this reason, you should always use stderr for your debugging messages.
Program 3.2 creates a fan of n processes by calling fork in a loop. On each iteration, the newly created process breaks from the loop while the original process continues. In contrast, the process that calls fork in Program 3.1 breaks from the loop while the newly created process continues for the next iteration.
Program 3.2 simplefan.c
A program that creates a fan of n processes where n is passed as a command-line argument.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main (int argc, char *argv[]) {
pid_t childpid = 0;
int i, n;
if (argc != 2){ /* check for valid number of command-line arguments */
fprintf(stderr, "Usage: %s processes\n", argv[0]);
return 1;
}
n = atoi(argv[1]);
for (i = 1; i < n; i++)
if ((childpid = fork()) <= 0)
break;
fprintf(stderr, "i:%d process ID:%ld parent ID:%ld child ID:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
return 0;
}
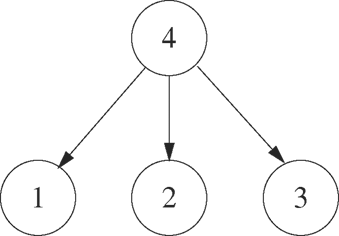
Figure 3.3 shows the process fan generated by Program 3.2 when n is 4. The processes are labeled by the value of i at the time they leave the loop. The original process creates n1 children. The exercises in Section 3.9 build on this example.
Exercise 3.10
Explain what happens when you replace the test
(childpid = fork()) <= 0
of Program 3.2 with
(childpid = fork()) == -1
Answer:
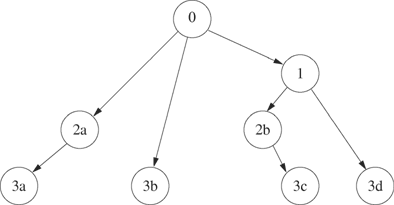
In this case, all the processes remain in the loop unless the fork fails. Each iteration of the loop doubles the number of processes, forming a tree configuration illustrated in Figure 3.4 when n is 4. The figure represents each process by a circle labeled with the i value at the time it was created. The original process has a 0 label. The lowercase letters distinguish processes that were created with the same value of i. Although this code appears to be similar to that of Program 3.1, it does not distinguish between parent and child after fork executes. Both the parent and child processes go on to create children on the next iteration of the loop, hence the population explosion.
Exercise 3.11
Run Program 3.1, Program 3.2, and a process tree program based on the modification suggested in Exercise 3.10. Carefully examine the output. Draw diagrams similar to those of Figure 3.2 through Figure 3.4, labeling the circles with the actual process IDs. Use  to designate the is-a-parent relationship. Do not use large values of the command-line argument unless you are on a dedicated system. How can you modify the programs so that you can use ps to see the processes that are created? to designate the is-a-parent relationship. Do not use large values of the command-line argument unless you are on a dedicated system. How can you modify the programs so that you can use ps to see the processes that are created?
Answer:
In their current form, the programs complete too quickly for you to view them with ps. Insert the sleep(30); statement immediately before return in order to have each process block for 30 seconds before exiting. In another command window, continually execute ps -l. Section 3.4 explains why some of the processes may report a parent ID of 1 when sleep is omitted.
The fork function creates a new process by making a copy of the parent's image in memory. The child inherits parent attributes such as environment and privileges. The child also inherits some of the parent's resources such as open files and devices.
Not every parent attribute or resource is inherited by the child. For instance, the child has a new process ID and of course a different parent ID. The child's times for CPU usage are reset to 0. The child does not get locks that the parent holds. If the parent has set an alarm, the child is not notified when the parent's alarm expires. The child starts with no pending signals, even if the parent had signals pending at the time of the fork.
Although a child inherits its parent's process priority and scheduling attributes, it competes for processor time with other processes as a separate entity. A user running on a crowded time-sharing system can obtain a greater share of the CPU time by creating more processes. A system manager on a crowded system might restrict process creation to prevent a user from creating processes to get a bigger share of the resources.
|
Функция wait
When a process creates a child, both parent and child proceed with execution from the point of the fork. The parent can execute wait or waitpid to block until the child finishes. The wait function causes the caller to suspend execution until a child's status becomes available or until the caller receives a signal. A process status most commonly becomes available after termination, but it can also be available after the process has been stopped. The waitpid function allows a parent to wait for a particular child. This function also allows a parent to check whether a child has terminated without blocking.
The waitpid function takes three parameters: a pid, a pointer to a location for returning the status and a flag specifying options. If pid is 1, waitpid waits for any child. If pid is greater than 0, waitpid waits for the specific child whose process ID is pid. Two other possibilities are allowed for the pid parameter. If pid is 0, waitpid waits for any child in the same process group as the caller. Finally, if pid is less than 1, waitpid waits for any child in the process group specified by the absolute value of pid. Process groups are discussed in Section 11.5.
The options parameter of waitpid is the bitwise inclusive OR of one or more flags. The WNOHANG option causes waitpid to return even if the status of a child is not immediately available. The WUNTRACED option causes waitpid to report the status of unreported child processes that have been stopped. Check the man page on waitpid for a complete specification of its parameters.
SYNOPSIS
#include <sys/wait.h>
pid_t wait(int *stat_loc);
pid_t waitpid(pid_t pid, int *stat_loc, int options);
POSIX
If wait or waitpid returns because the status of a child is reported, these functions return the process ID of that child. If an error occurs, these functions return 1 and set errno. If called with the WNOHANG option, waitpid returns 0 to report that there are possible unwaited-for children but that their status is not available. The following table lists the mandatory errors for wait and waitpid.
|
ECHILD | caller has no unwaited-for children (wait), or process or process group specified by pid does not exist (waitpid), or process group specified by pid does not have a member that is a child of caller (waitpid) | EINTR | function was interrupted by a signal | EINVAL | options parameter of waitpid was invalid |
Example 3.12
The following code segment waits for a child.
pid_t childpid;
childpid = wait(NULL);
if (childpid != -1)
printf("Waited for child with pid %ld\n", childpid);
The r_wait function shown in Program 3.3 restarts the wait function if it is interrupted by a signal. Program 3.3 is part of the restart library developed in this book and described in Appendix B. The restart library includes wrapper functions for many standard library functions that should be restarted if interrupted by a signal. Each function name starts with r_ followed by the name of the function. Include the restart.h header file when you use functions from the restart library in your programs.
Program 3.3 r_wait.c
A function that restarts wait if interrupted by a signal.
#include <errno.h>
#include <sys/wait.h>
pid_t r_wait(int *stat_loc) {
int retval;
while (((retval = wait(stat_loc)) == -1) && (errno == EINTR)) ;
return retval;
}
Example 3.13
The following code segment waits for all children that have finished but avoids blocking if there are no children whose status is available. It restarts waitpid if that function is interrupted by a signal or if it successfully waited for a child.
pid_t childpid;
while (childpid = waitpid(-1, NULL, WNOHANG))
if ((childpid == -1) && (errno != EINTR))
break;
Exercise 3.14
What happens when a process terminates, but its parent does not wait for it?
Answer:
It becomes a zombie in UNIX terminology. Zombies stay in the system until they are waited for. If a parent terminates without waiting for a child, the child becomes an orphan and is adopted by a special system process. Traditionally, this process is called init and has process ID equal to 1, but POSIX does not require this designation. The init process periodically waits for children, so eventually orphaned zombies are removed.
Example 3.15 fanwait.c
The following modification of the process fan of Program 3.2 causes the original process to print out its information after all children have exited.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include "restart.h"
int main(int argc, char *argv[]) {
pid_t childpid;
int i, n;
if (argc != 2) {
fprintf(stderr, "Usage: %s n\n", argv[0]);
return 1;
}
n = atoi(argv[1]);
for (i = 1; i < n; i++)
if ((childpid = fork()) <= 0)
break;
while(r_wait(NULL) > 0) ; /* wait for all of your children */
fprintf(stderr, "i:%d process ID:%ld parent ID:%ld child ID:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
return 0;
}
Exercise 3.16
What happens if you interchange the while loop and fprintf statements in Example 3.15?
Answer:
The original process still exits last, but it may output its ID information before some of its children output theirs.
Exercise 3.17
What happens if you replace the while loop of Example 3.15 with the statement wait(NULL);?
Answer:
The parent waits for at most one process. If a signal happens to come in before the first child completes, the parent won't actually wait for any children.
Exercise 3.18 parentwaitpid.c
Describe the possible forms of the output from the following program.
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main (void) {
pid_t childpid;
/* set up signal handlers here ... */
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0)
fprintf(stderr, "I am child %ld\n", (long)getpid());
else if (wait(NULL) != childpid)
fprintf(stderr, "A signal must have interrupted the wait!\n");
else
fprintf(stderr, "I am parent %ld with child %ld\n", (long)getpid(),
(long)childpid);
return 0;
}
Answer:
The output can have several forms, depending on exact timing and errors.
If fork fails (unlikely unless some other program has generated a runaway tree of processes and exceeded the system limit), the "Failed to fork" message appears. Otherwise, if there are no signals, something similar to the following appears.
I am child 3427
I am parent 3426 with child 3427
If the parent catches a signal after the child executes fprintf but before the child's return, the following appears.
I am child 3427
A signal must have interrupted the wait!
If the parent catches a signal after the child terminates and wait returns successfully, the following appears.
I am child 3427
I am parent 3426 with child 3427
If the parent catches a signal between the time that the child terminates and wait returns, either of the previous two results is possible, depending on when the signal is caught. If the parent catches a signal before the child executes fprintf and if the parent executes its fprintf first, the following appears.
A signal must have interrupted the wait!
I am child 3427
Finally, if the parent catches a signal before the child executes fprintf and the child executes its fprintf first, the following appears.
I am child 3427
A signal must have interrupted the wait!
Exercise 3.19
For the child of Exercise 3.18 to always print its message first, the parent must run wait repeatedly until the child exits before printing its own message. What is wrong with the following?
while(childpid != wait(&status)) ;
Answer:
The loop fixes the problem of interruption by signals, but wait can fail to return the childpid because it encounters a real error. You should always test errno as demonstrated in the r_wait of Program 3.3.
Exercise 3.20 fanwaitmsg.c
The following program creates a process fan. All the forked processes are children of the original process. How are the output messages ordered?
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main (int argc, char *argv[]) {
pid_t childpid = 0;
int i, n;
if (argc != 2){ /* check number of command-line arguments */
fprintf(stderr, "Usage: %s processes\n", argv[0]);
return 1;
}
n = atoi(argv[1]);
for (i = 1; i < n; i++)
if ((childpid = fork()) <= 0)
break;
for( ; ; ) {
childpid = wait(NULL);
if ((childpid == -1) && (errno != EINTR))
break;
}
fprintf(stderr, "I am process %ld, my parent is %ld\n",
(long)getpid(), (long)getppid());
return 0;
}
Answer:
Because none of the forked children are parents, their wait function returns 1 and sets errno to ECHILD. They are not blocked by the second for loop. Their identification messages may appear in any order. The message from the original process comes out at the very end after it has waited for all of its children.
Exercise 3.21 chainwaitmsg.c
The following program creates a process chain. Only one forked process is a child of the original process. How are the output messages ordered?
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main (int argc, char *argv[]) {
pid_t childpid;
int i, n;
pid_t waitreturn;
if (argc != 2){ /* check number of command-line arguments */
fprintf(stderr, "Usage: %s processes\n", argv[0]);
return 1;
}
n = atoi(argv[1]);
for (i = 1; i < n; i++)
if (childpid = fork())
break;
while(childpid != (waitreturn = wait(NULL)))
if ((waitreturn == -1) && (errno != EINTR))
break;
fprintf(stderr, "I am process %ld, my parent is %ld\n",
(long)getpid(), (long)getppid());
return 0;
}
Answer:
Each forked child waits for its own child to complete before outputting a message. The messages appear in reverse order of creation.
3.4.1 Status values
The stat_loc argument of wait or waitpid is a pointer to an integer variable. If it is not NULL, these functions store the return status of the child in this location. The child returns its status by calling exit, _exit, _Exit or return from main. A zero return value indicates EXIT_SUCCESS; any other value indicates EXIT_FAILURE. The parent can only access the 8 least significant bits of the child's return status.
POSIX specifies six macros for testing the child's return status. Each takes the status value returned by a child to wait or waitpid as a parameter.
SYNOPSIS
#include <sys/wait.h>
WIFEXITED(int stat_val)
WEXITSTATUS(int stat_val)
WIFSIGNALED(int stat_val)
WTERMSIG(int stat_val)
WIFSTOPPED(int stat_val)
WSTOPSIG(int stat_val)
POSIX
The six macros are designed to be used in pairs. The WIFEXITED evaluates to a nonzero value when the child terminates normally. If WIFEXITED evaluates to a nonzero value, then WEXITSTATUS evaluates to the low-order 8 bits returned by the child through _exit(), exit() or return from main.
The WIFSIGNALED evaluates to a nonzero value when the child terminates because of an uncaught signal (see Chapter 8). If WIFSIGNALED evaluates to a nonzero value, then WTERMSIG evaluates to the number of the signal that caused the termination.
The WIFSTOPPED evaluates to a nonzero value if a child is currently stopped. If WIFSTOPPED evaluates to a nonzero value, then WSTOPSIG evaluates to the number of the signal that caused the child process to stop.
Example 3.22 showreturnstatus.c
The following function determines the exit status of a child.
#include <errno.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "restart.h"
void show_return_status(void) {
pid_t childpid;
int status;
childpid = r_wait(&status);
if (childpid == -1)
perror("Failed to wait for child");
else if (WIFEXITED(status) && !WEXITSTATUS(status))
printf("Child %ld terminated normally\n", (long)childpid);
else if (WIFEXITED(status))
printf("Child %ld terminated with return status %d\n",
(long)childpid, WEXITSTATUS(status));
else if (WIFSIGNALED(status))
printf("Child %ld terminated due to uncaught signal %d\n",
(long)childpid, WTERMSIG(status));
else if (WIFSTOPPED(status))
printf("Child %ld stopped due to signal %d\n",
(long)childpid, WSTOPSIG(status));
}
3.5 The exec Function
The fork function creates a copy of the calling process, but many applications require the child process to execute code that is different from that of the parent. The exec family of functions provides a facility for overlaying the process image of the calling process with a new image. The traditional way to use the forkexec combination is for the child to execute (with an exec function) the new program while the parent continues to execute the original code.
SYNOPSIS
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg0, ... /*, char *(0) */);
int execle (const char *path, const char *arg0, ... /*, char *(0),
char *const envp[] */);
int execlp (const char *file, const char *arg0, ... /*, char *(0) */);
int execv(const char *path, char *const argv[]);
int execve (const char *path, char *const argv[], char *const envp[]);
int execvp (const char *file, char *const argv[]);
POSIX
All exec functions return 1 and set errno if unsuccessful. In fact, if any of these functions return at all, the call was unsuccessful. The following table lists the mandatory errors for the exec functions.
|
E2BIG | size of new process's argument list and environment list is greater than system-imposed limit of ARG_MAX bytes | EACCES | search permission on directory in path prefix of new process is denied, new process image file execution permission is denied, or new process image file is not a regular file and cannot be executed | EINVAL | new process image file has appropriate permission and is in a recognizable executable binary format, but system cannot execute files with this format | ELOOP | a loop exists in resolution of path or file argument | ENAMETOOLONG | the length of path or file exceeds PATH_MAX, or a pathname component is longer than NAME_MAX | ENOENT | component of path or file does not name an existing file, or path or file is an empty string | ENOEXEC | image file has appropriate access permission but has an unrecognized format (does not apply to execlp or execvp) | ENOTDIR | a component of the image file path prefix is not a directory |
The six variations of the exec function differ in the way command-line arguments and the environment are passed. They also differ in whether a full pathname must be given for the executable. The execl (execl, execlp and execle) functions pass the command-line arguments in an explicit list and are useful if you know the number of command-line arguments at compile time. The execv (execv, execvp and execve) functions pass the command-line arguments in an argument array such as one produced by the makeargv function of Section 2.6. The argi parameter represents a pointer to a string, and argv and envp represent NULL-terminated arrays of pointers to strings.
The path parameter to execl is the pathname of a process image file specified either as a fully qualified pathname or relative to the current directory. The individual command-line arguments are then listed, followed by a (char *)0 pointer (a NULL pointer).
Program 3.4 calls the ls shell command with a command-line argument of -l. The program assumes that ls is located in the /bin directory. The execl function uses its character-string parameters to construct an argv array for the command to be executed. Since argv[0] is the program name, it is the second argument of the execl. Notice that the first argument of execl, the pathname of the command, also includes the name of the executable.
Program 3.4 execls.c
A program that creates a child process to run ls -l.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(void) {
pid_t childpid;
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) { /* child code */
execl("/bin/ls", "ls", "-l", NULL);
perror("Child failed to exec ls");
return 1;
}
if (childpid != wait(NULL)) { /* parent code */
perror("Parent failed to wait due to signal or error");
return 1;
}
return 0;
}
An alternative form is execlp. If the first parameter (file) contains a slash, then execlp treats file as a pathname and behaves like execl. On the other hand, if file does not have a slash, execlp uses the PATH environment variable to search for the executable. Similarly, the shell tries to locate the executable file in one of the directories specified by the PATH variable when a user enters a command.
A third form, execle, takes an additional parameter representing the environment of the new process. For the other forms of execl, the new process inherits the environment of the calling process through the environ variable.
The execv functions use a different form of the command-line arguments. Use an execv function with an argument array constructed at run time. The execv function takes exactly two parameters, a pathname for the executable and an argument array. (The makeargv function of Program 2.2 is useful here.) The execve and execvp are variations on execv; they are similar in structure to execle and execlp, respectively.
Program 3.5 shows a simple program to execute one program from within another program. The program forks a child to execute the command. The child performs an execvp call to overwrite its process image with an image corresponding to the command. The parent, which retains the original process image, waits for the child, using the r_wait function of Program 3.3 from the restart library. The r_wait restarts its wait function if interrupted by a signal.
Example 3.23
The following command line to Program 3.5 causes execcmd to create a new process to execute the ls -l command.
execcmd ls -l
Program 3.5 avoids constructing the argv parameter to execvp by using a simple trick. The original argv array produced in Example 3.23 contains pointers to three tokens: myexec, ls and -l. The argument array for the execvp starts at &argv[1] and contains pointers to the two tokens ls and -l.
Exercise 3.24
How big is the argument array passed as the second argument to execvp when you execute execcmd of Program 3.5 with the following command line?
execcmd ls -l *.c
Answer:
The answer depends on the number of .c files in the current directory because the shell expands *.c before passing the command line to execcmd.
Program 3.6 creates an argument array from the first command-line argument and then calls execvp. Notice that execcmdargv calls the makeargv function only in the child process. Program 2.2 on page 37 shows an implementation of the makeargv function.
Program 3.5 execcmd.c
A program that creates a child process to execute a command. The command to be executed is passed on the command line.
#include <errno.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "restart.h"
int main(int argc, char *argv[]) {
pid_t childpid;
if (argc < 2){ /* check for valid number of command-line arguments */
fprintf (stderr, "Usage: %s command arg1 arg2 ...\n", argv[0]);
return 1;
}
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) { /* child code */
execvp(argv[1], &argv[1]);
perror("Child failed to execvp the command");
return 1;
}
if (childpid != r_wait(NULL)) { /* parent code */
perror("Parent failed to wait");
return 1;
}
return 0;
}
Exercise 3.25
How would you pass a string containing multiple tokens to execcmdargv of Program 3.6?
Answer:
Place the command string in double quotes so that the command line interpreter treats the string as a single token. For example, to execute ls -l, call execcmdargv with the following command line.
execcmdargv "ls -l"
Exercise 3.26
Program 3.6 only calls the makeargv function in the child process after the fork. What happens if you move the makeargv call before the fork?
Answer:
A parent call to makeargv before the fork allocates the argument array on the heap in the parent process. The fork function creates a copy of the parent's process image for the child. After fork executes, both parent and child have copies of the argument array. A single call to makeargv does not present a problem. However, when the parent represents a shell process, the allocation step might be repeated hundreds of times. Unless the parent explicitly frees the argument array, the program will have a memory leak.
Program 3.6 execcmdargv.c
A program that creates a child process to execute a command string passed as the first command-line argument.
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include "restart.h"
int makeargv(const char *s, const char *delimiters, char ***argvp);
int main(int argc, char *argv[]) {
pid_t childpid;
char delim[] = " \t";
char **myargv;
if (argc != 2) {
fprintf(stderr, "Usage: %s string\n", argv[0]);
return 1;
}
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) { /* child code */
if (makeargv(argv[1], delim, &myargv) == -1) {
perror("Child failed to construct argument array");
} else {
execvp(myargv[0], &myargv[0]);
perror("Child failed to exec command");
}
return 1;
}
if (childpid != r_wait(NULL)) { /* parent code */
perror("Parent failed to wait");
return 1;
}
return 0;
}
The exec function copies a new executable into the process image. The program text, variables, stack and heap are overwritten. The new process inherits the environment (meaning the list of environment variables and their associated values) unless the original process called execle or execve. Files that are open at the time of the exec call are usually still open afterward.
Table 3.3 summarizes the attributes that are inherited by processes after exec. The second column of the table gives library functions related to the items. The IDs associated with the process are intact after exec runs. If a process sets an alarm before calling exec, the alarm still generates a signal when it expires. Pending signals are also carried over on exec in contrast to fork. The process creates files with the same permissions as before exec ran, and accounting of CPU time continues without being reinitialized.
Table 3.3. Attributes that are preserved after calls to exec. The second column lists some library functions relevant to these attributes. A * indicates an attribute inherited in the POSIX:XSI Extension.|
process ID | getpid | parent process ID | getppid | process group ID | getpgid | session ID | getsid | real user ID | getuid | real group ID | getgid | supplementary group IDs | getgroups | time left on an alarm signal | alarm | current working directory | getcwd | root directory | | file mode creation mask | umask | file size limit* | ulimit | process signal mask | sigprocmask | pending signals | sigpending | time used so far | times | resource limits* | getrlimit, setrlimit | controlling terminal* | open, tcgetpgrp | interval timers* | ualarm | nice value* | nice | semadj values* | semop |
3.6 Background Processes and Daemons
The shell is a command interpreter that prompts for commands, reads the commands from standard input, forks children to execute the commands and waits for the children to finish. When standard input and output come from a terminal type of device, a user can terminate an executing command by entering the interrupt character. (The interrupt character is settable, but many systems assume a default value of Ctrl-C.)
Exercise 3.27
What happens when you execute the following commands?
cd /etc
ls -l
Now execute the ls -l command again, but enter a Ctrl-C as soon as the listing starts to display. Compare the results to the first case.
Answer:
In the first case, the prompt appears after the directory listing is complete because the shell waits for the child before continuing. In the second case, the Ctrl-C terminates the ls.
Most shells interpret a line ending with & as a command that should be executed by a background process. When a shell creates a background process, it does not wait for the process to complete before issuing a prompt and accepting additional commands. Furthermore, a Ctrl-C from the keyboard does not terminate a background process.
Exercise 3.28
Compare the results of Exercise 3.27 with the results of executing the following command.
ls -l &
Reenter the ls -l & command and try to terminate it by entering Ctrl-C.
Answer:
In the first case, the prompt appears before the listing completes. The Ctrl-C does not affect background processes, so the second case behaves in the same way as the first.
A daemon is a background process that normally runs indefinitely. The UNIX operating system relies on many daemon processes to perform routine (and not so routine) tasks. Under the Solaris operating environment, the pageout daemon handles paging for memory management. The in.rlogind handles remote login requests. Other daemons handle mail, file transfer, statistics and printer requests, to name a few.
The runback program in Program 3.7 executes its first command-line argument as a background process. The child calls setsid so that it does not get any signals because of a Ctrl-C from a controlling terminal. (See Section 11.5.) The runback parent does not wait for its child to complete.
Program 3.7 runback.c
The runback program creates a child process to execute a command string in the background.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include "restart.h"
int makeargv(const char *s, const char *delimiters, char ***argvp);
int main(int argc, char *argv[]) {
pid_t childpid;
char delim[] = " \t";
char **myargv;
if (argc != 2) {
fprintf(stderr, "Usage: %s string\n", argv[0]);
return 1;
}
childpid = fork();
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (childpid == 0) { /* child becomes a background process */
if (setsid() == -1)
perror("Child failed to become a session leader");
else if (makeargv(argv[1], delim, &myargv) == -1)
fprintf(stderr, "Child failed to construct argument array\n");
else {
execvp(myargv[0], &myargv[0]);
perror("Child failed to exec command");
}
return 1; /* child should never return */
}
return 0; /* parent exits */
}
Example 3.29
The following command is similar to entering ls -l & directly from the shell.
runback "ls -l"
3.7 Critical Sections
Imagine a scenario in which a computer system has a printer that can be directly accessed by all the processes in the system. Each time a process wants to print something, it writes to the printer device. How would the printed output look if several processes wrote to the printer simultaneously? The individual processes are allowed only a fixed quantum of processor time. If the quantum expires before a process completes writing, another process might send output to the printer. The resulting printout would have the output from the processes interspersedan undesirable feature.
The problem with the previous scenario is that the processes are "simultaneously" attempting to access a shared resourcea resource that should be used by only one process at a time. That is, the printer requires exclusive access by the processes in the system. The portion of code in which each process accesses such a shared resource is called a critical section. Programs with critical sections must be sure not to violate the mutual exclusion requirement.
One method of providing mutual exclusion uses a locking mechanism. Each process acquires a lock that excludes all other processes before entering its critical section. When the process finishes the critical section, it releases the lock. Unfortunately, this approach relies on the cooperation and correctness of all participants. If one process fails to acquire the lock before accessing the resource, the system fails.
A common approach is to encapsulate shared resources in a manner that ensures exclusive access. Printers are usually handled by having only one process (the printer daemon) with permissions to access the actual printer. Other processes print by sending a message to the printer daemon process along with the name of the file to be printed. The printer daemon puts the request in a queue and may even make a copy of the file to print in its own disk area. The printer daemon removes request messages from its queue one at a time and prints the file corresponding to the message. The requesting process returns immediately after writing the request or after the printer daemon acknowledges receipt, not when the printing actually completes.
Operating systems manage many shared resources besides the obvious devices, files and shared variables. Tables and other information within the operating system kernel code are shared among processes managing the system. A large operating system has many diverse parts with possibly overlapping critical sections. When one of these parts is modified, you must understand the entire operating system to reliably determine whether the modification adversely affects other parts. To reduce the complexity of internal interactions, some operating systems use an object-oriented design. Shared tables and other resources are encapsulated as objects with well-defined access functions. The only way to access such a table is through these functions, which have appropriate mutual exclusion built in. In a distributed system, the object interface uses messages. Changes to modules in a properly designed object-oriented system do not have the same impact as they do for uncontrolled access.
On the surface, the object-oriented approach appears to be similar to the daemons described in Section 3.6, but structurally these approaches can be very different. There is no requirement that daemons encapsulate resources. They can fight over shared data structures in an uncontrolled way. Good object-oriented design ensures that data structures are encapsulated and accessed only through carefully controlled interfaces. Daemons can be implemented with an object-oriented design, but they do not have to be.
|
3.8 Exercise: Process Chains
This section expands on the process chain of Program 3.1. The chain is a vehicle for experimenting with wait and with sharing of devices. All of the processes in the chain created by Program 3.1 share standard input, standard output and standard error. The fprintf to standard error is a critical section of the program. This exercise explores some implications of critical sections. Later chapters extend this exercise to critical sections involving other devices (Chapter 6) and a token-ring simulation (Chapter 7).
Program 3.1 creates a chain of processes. It takes a single command-line argument that specifies the number of processes to create. Before exiting, each process outputs its i value, its process ID, its parent process ID and the process ID of its child. The parent does not execute wait. If the parent exits before the child, the child becomes an orphan. In this case, the child process is adopted by a special system process (which traditionally is a process, init, with process ID of 1). As a result, some of the processes may indicate a parent process ID of 1.
Do not attempt this exercise on a machine with other users because it strains the resources of the machine.
3.9 Exercise: Process Fans
The exercises in this section expand on the fan structure of Program 3.2 through the development of a simple batch processing facility, called runsim. (Modifications in Section 14.6 lead to a license manager for an application program.) The runsim program takes exactly one command-line argument specifying the maximum number of simultaneous executions. Follow the outline below for implementing runsim. Write a test program called testsim to test the facility. Suggested library functions appear in parentheses.
Chapter 4. UNIX I/O
UNIX uses a uniform device interface, through file descriptors, that allows the same I/O calls to be used for terminals, disks, tapes, audio and even network communication. This chapter explores the five functions that form the basis for UNIX device-independent I/O. The chapter also examines I/O from multiple sources, blocking I/O with timeouts, inheritance of file descriptors and redirection. The code carefully handles errors and interruption by signals.
Learn the basics of device-independent I/O Experiment with read and write Explore ways to monitor multiple descriptors Use correct error handling Understand inheritance of file descriptors
|
|
4.1 Device Terminology
A peripheral device is piece of hardware accessed by a computer system. Common peripheral devices include disks, tapes, CD-ROMs, screens, keyboards, printers, mouse devices and network interfaces. User programs perform control and I/O to these devices through system calls to operating system modules called device drivers. A device driver hides the details of device operation and protects the device from unauthorized use. Devices of the same type may vary substantially in their operation, so to be usable, even a single-user machine needs device drivers. Some operating systems provide pseudodevice drivers to simulate devices such as terminals. Pseudoterminals, for example, simplify the handling of remote login to computer systems over a network or a modem line.
Some operating systems provide specific system calls for each type of supported device, requiring the systems programmer to learn a complex set of calls for device control. UNIX has greatly simplified the programmer device interface by providing uniform access to most devices through five functionsopen, close, read, write and ioctl. All devices are represented by files, called special files, that are located in the /dev directory. Thus, disk files and other devices are named and accessed in the same way. A regular file is just an ordinary data file on disk. A block special file represents a device with characteristics similar to a disk. The device driver transfers information from a block special device in blocks or chunks, and usually such devices support the capability of retrieving a block from anywhere on the device. A character special file represents a device with characteristics similar to a terminal. The device appears to represent a stream of bytes that must be accessed in sequential order.
4.2 Reading and Writing
UNIX provides sequential access to files and other devices through the read and write functions. The read function attempts to retrieve nbyte bytes from the file or device represented by fildes into the user variable buf. You must actually provide a buffer that is large enough to hold nbyte bytes of data. (A common mistake is to provide an uninitialized pointer, buf, rather than an actual buffer.)
SYNOPSIS
#include <unistd.h>
ssize_t read(int fildes, void *buf, size_t nbyte);
POSIX
If successful, read returns the number of bytes actually read. If unsuccessful, read returns 1 and sets errno. The following table lists the mandatory errors for read.
|
ECONNRESET | read attempted on a socket and connection was forcibly closed by its peer | EAGAIN | O_NONBLOCK is set for file descriptor and thread would be delayed | EBADF | fildes is not a valid file descriptor open for reading | EINTR | read was terminated due to receipt of a signal and no data was transferred | EIO | process is a member of a background process group attempting to read from its controlling terminal and either process is ignoring or blocking SIGTTIN or process group is orphaned | ENOTCONN | read attempted on socket that is not connected | EOVERFLOW | the file is a regular file, nbyte is greater than 0, and the starting position exceeds offset maximum | ETIMEDOUT | read attempted on socket and transmission timeout occurred | EWOULDBLOCK | file descriptor is for socket marked O_NONBLOCK and no data is waiting to be received (EAGAIN is alternative) |
A read operation for a regular file may return fewer bytes than requested if, for example, it reached end-of-file before completely satisfying the request. A read operation for a regular file returns 0 to indicate end-of-file. When special files corresponding to devices are read, the meaning of a read return value of 0 depends on the implementation and the particular device. A read operation for a pipe returns as soon as the pipe is not empty, so the number of bytes read can be less than the number of bytes requested. (Pipes are a type of communication buffer discussed in Chapter 6.) When reading from a terminal, read returns 0 when the user enters an end-of-file character. On many systems the default end-of-file character is Ctrl-D.
The ssize_t data type is a signed integer data type used for the number of bytes read, or 1 if an error occurs. On some systems, this type may be larger than an int. The size_t is an unsigned integer data type for the number of bytes to read.
Example 4.1
The following code segment reads at most 100 bytes into buf from standard input.
char buf[100];
ssize_t bytesread;
bytesread = read(STDIN_FILENO, buf, 100);
This code does no error checking.
The file descriptor, which represents a file or device that is open, can be thought of as an index into the process file descriptor table. The file descriptor table is in the process user area and provides access to the system information for the associated file or device.
When you execute a program from the shell, the program starts with three open streams associated with file descriptors STDIN_FILENO, STDOUT_FILENO and STDERR_FILENO. STDIN_FILENO and STDOUT_FILENO are standard input and standard output, respectively. By default, these two streams usually correspond to keyboard input and screen output. Programs should use STDERR_FILENO, the standard error device, for error messages and should never close it. In legacy code standard input, standard output and standard error are represented by 0, 1 and 2, respectively. However, you should always use their symbolic names rather than these numeric values. Section 4.6 explains how file descriptors work.
Exercise 4.2
What happens when the following code executes?
char *buf;
ssize_t bytesread;
bytesread = read(STDIN_FILENO, buf, 100);
Answer:
The code segment, which may compile without error, does not allocate space for buf. The result of read is unpredictable, but most probably it will generate a memory access violation. If buf is an automatic variable stored on the stack, it is not initialized to any particular value. Whatever that memory happens to hold is treated as the address of the buffer for reading.
The readline function of Program 4.1 reads bytes, one at a time, into a buffer of fixed size until a newline character ('\n') or an error occurs. The function handles end-of-file, limited buffer size and interruption by a signal. The readline function returns the number of bytes read or 1 if an error occurs. A return value of 0 indicates an end-of-file before any characters were read. A return value greater than 0 indicates the number of bytes read. In this case, the buffer contains a string ending in a newline character. A return value of 1 indicates that errno has been set and one of the following errors occurred.
An error occurred on read. At least one byte was read and an end-of-file occurred before a newline was read. nbytes-1 bytes were read and no newline was found.
Upon successful return of a value greater than 0, the buffer contains a string ending in a newline character. If readline reads from a file that does not end with a newline character, it treats the last line read as an error. The readline function is available in the restart library, of Appendix B.
Program 4.1 readline.c
The readline function returns the next line from a file.
#include <errno.h>
#include <unistd.h>
int readline(int fd, char *buf, int nbytes) {
int numread = 0;
int returnval;
while (numread < nbytes - 1) {
returnval = read(fd, buf + numread, 1);
if ((returnval == -1) && (errno == EINTR))
continue;
if ( (returnval == 0) && (numread == 0) )
return 0;
if (returnval == 0)
break;
if (returnval == -1)
return -1;
numread++;
if (buf[numread-1] == '\n') {
buf[numread] = '\0';
return numread;
}
}
errno = EINVAL;
return -1;
}
Example 4.3
The following code segment calls the readline function of Program 4.1 to read a line of at most 99 bytes from standard input.
int bytesread;
char mybuf[100];
bytesread = readline(STDIN_FILENO, mybuf, sizeof(mybuf));
Exercise 4.4
Under what circumstances does the readline function of Program 4.1 return a buffer with no newline character?
Answer:
This can only happen if the return value is 0 or 1. The return value of 0 indicates that nothing was read. The return of 1 indicates some type of error. In either case, the buffer may not contain a string.
The write function attempts to output nbyte bytes from the user buffer buf to the file represented by file descriptor fildes.
SYNOPSIS
#include <unistd.h>
ssize_t write(int fildes, const void *buf, size_t nbyte);
POSIX
If successful, write returns the number of bytes actually written. If unsuccessful, write returns 1 and sets errno. The following table lists the mandatory errors for write.
|
ECONNRESET | write attempted on a socket that is not connected | EAGAIN | O_NONBLOCK is set for file descriptor and thread would be delayed | EBADF | fildes is not a valid file descriptor open for writing | EFBIG | attempt to write a file that exceeds implementation-defined maximum; file is a regular file, nbyte is greater than 0, and starting position exceeds offset maximum | EINTR | write was terminated due to receipt of a signal and no data was transferred | EIO | process is a member of a background process group attempting to write to controlling terminal, TOSTOP is set, process is neither blocking nor ignoring SIGTTOU and process group is orphaned | ENOSPC | no free space remaining on device containing the file | EPIPE | attempt to write to a pipe or FIFO not open for reading or that has only one end open (thread may also get SIGPIPE), or write attempted on socket shut down for writing or not connected (if not connected, also generates SIGPIPE signal) | EWOULDBLOCK | file descriptor is for socket marked O_NONBLOCK and write would block (EAGAIN is alternative) |
Exercise 4.5
What can go wrong with the following code segment?
#define BLKSIZE 1024
char buf[BLKSIZE];
read(STDIN_FILENO, buf, BLKSIZE);
write(STDOUT_FILENO, buf, BLKSIZE);
Answer:
The write function assumes that the read has filled buf with BLKSIZE bytes. However, read may fail or may not read the full BLKSIZE bytes. In these two cases, write outputs garbage.
Exercise 4.6
What can go wrong with the following code segment to read from standard input and write to standard output?
#define BLKSIZE 1024
char buf[BLKSIZE];
ssize_t bytesread;
bytesread = read(STDIN_FILENO, buf, BLKSIZE);
if (bytesread > 0)
write(STDOUT_FILE, buf, bytesread);
Answer:
Although write uses bytesread rather than BLKSIZE, there is no guarantee that write actually outputs all of the bytes requested. Furthermore, either read or write can be interrupted by a signal. In this case, the interrupted call returns a 1 with errno set to EINTR.
Program 4.2 copies bytes from the file represented by fromfd to the file represented by tofd. The function restarts read and write if either is interrupted by a signal. Notice that the write statement specifies the buffer by a pointer, bp, rather than by a fixed address such as buf. If the previous write operation did not output all of buf, the next write operation must start from the end of the previous output. The copyfile function returns the number of bytes read and does not indicate whether or not an error occurred.
Example 4.7 simplecopy.c
The following program calls copyfile to copy a file from standard input to standard output.
#include <stdio.h>
#include <unistd.h>
int copyfile(int fromfd, int tofd);
int main (void) {
int numbytes;
numbytes = copyfile(STDIN_FILENO, STDOUT_FILENO);
fprintf(stderr, "Number of bytes copied: %d\n", numbytes);
return 0;
}
Exercise 4.8
What happens when you run the program of Example 4.7?
Answer:
Standard input is usually set to read one line at a time, so I/O is likely be entered and echoed on line boundaries. The I/O continues until you enter the end-of-file character (often Ctrl-D by default) at the start of a line or you interrupt the program by entering the interrupt character (often Ctrl-C by default). Use the stty -a command to find the current settings for these characters.
Program 4.2 copyfile1.c
The copyfile.c function copies a file from fromfd to tofd.
#include <errno.h>
#include <unistd.h>
#define BLKSIZE 1024
int copyfile(int fromfd, int tofd) {
char *bp;
char buf[BLKSIZE];
int bytesread, byteswritten;
int totalbytes = 0;
for ( ; ; ) {
while (((bytesread = read(fromfd, buf, BLKSIZE)) == -1) &&
(errno == EINTR)) ; /* handle interruption by signal */
if (bytesread <= 0) /* real error or end-of-file on fromfd */
break;
bp = buf;
while (bytesread > 0) {
while(((byteswritten = write(tofd, bp, bytesread)) == -1 ) &&
(errno == EINTR)) ; /* handle interruption by signal */
if (byteswritten <= 0) /* real error on tofd */
break;
totalbytes += byteswritten;
bytesread -= byteswritten;
bp += byteswritten;
}
if (byteswritten == -1) /* real error on tofd */
break;
}
return totalbytes;
}
Exercise 4.9
How would you use the program of Example 4.7 to copy the file myin.dat to myout.dat?
Answer:
Use redirection. If the executable of Example 4.7 is called simplecopy, the line would be as follows.
simplecopy < myin.dat > myout.dat
The problems of restarting read and write after signals and of writing the entire amount requested occur in nearly every program using read and write. Program 4.3 shows a separate r_read function that you can use instead of read when you want to restart after a signal. Similarly, Program 4.4 shows a separate r_write function that restarts after a signal and writes the full amount requested. For convenience, a number of functions, including r_read, r_write, copyfile and readline, have been collected in a library called restart.c. The prototypes for these functions are contained in restart.h, and we include this header file when necessary. Appendix B presents the complete restart library implementation.
Program 4.3 r_read.c
The r_read.c function is similar to read except that it restarts itself if interrupted by a signal.
#include <errno.h>
#include <unistd.h>
ssize_t r_read(int fd, void *buf, size_t size) {
ssize_t retval;
while (retval = read(fd, buf, size), retval == -1 && errno == EINTR) ;
return retval;
}
Program 4.4 r_write.c
The r_write.c function is similar to write except that it restarts itself if interrupted by a signal and writes the full amount requested.
#include <errno.h>
#include <unistd.h>
ssize_t r_write(int fd, void *buf, size_t size) {
char *bufp;
size_t bytestowrite;
ssize_t byteswritten;
size_t totalbytes;
for (bufp = buf, bytestowrite = size, totalbytes = 0;
bytestowrite > 0;
bufp += byteswritten, bytestowrite -= byteswritten) {
byteswritten = write(fd, bufp, bytestowrite);
if ((byteswritten) == -1 && (errno != EINTR))
return -1;
if (byteswritten == -1)
byteswritten = 0;
totalbytes += byteswritten;
}
return totalbytes;
}
The functions r_read and r_write can greatly simplify programs that need to read and write while handling signals.
Program 4.5 shows the readwrite function that reads bytes from one file descriptor and writes all of the bytes read to another one. It uses a buffer of size PIPE_BUF to transfer at most PIPE_BUF bytes. This size is useful for writing to pipes since a write to a pipe of PIPE_BUF bytes or less is atomic. Program 4.6 shows a version of copyfile that uses the readwrite function. Compare this with Program 4.2.
Program 4.5 readwrite.c
A program that reads from one file descriptor and writes all the bytes read to another file descriptor.
#include <limits.h>
#include "restart.h"
#define BLKSIZE PIPE_BUF
int readwrite(int fromfd, int tofd) {
char buf[BLKSIZE];
int bytesread;
if ((bytesread = r_read(fromfd, buf, BLKSIZE)) == -1)
return -1;
if (bytesread == 0)
return 0;
if (r_write(tofd, buf, bytesread) == -1)
return -1;
return bytesread;
}
Program 4.6 copyfile.c
A simplified implementation of copyfile that uses r_read and r_write.
#include <unistd.h>
#include "restart.h"
#define BLKSIZE 1024
int copyfile(int fromfd, int tofd) {
char buf[BLKSIZE];
int bytesread, byteswritten;
int totalbytes = 0;
for ( ; ; ) {
if ((bytesread = r_read(fromfd, buf, BLKSIZE)) <= 0)
break;
if ((byteswritten = r_write(tofd, buf, bytesread)) == -1)
break;
totalbytes += byteswritten;
}
return totalbytes;
}
The r_write function writes all the bytes requested and restarts the write if fewer bytes are written. The r_read only restarts if interrupted by a signal and often reads fewer bytes than requested. The readblock function is a version of read that continues reading until the requested number of bytes is read or an error occurs. Program 4.7 shows an implementation of readblock. The readblock function is part of the restart library. It is especially useful for reading structures.
Program 4.7 readblock.c
A function that reads a specific number of bytes.
#include <errno.h>
#include <unistd.h>
ssize_t readblock(int fd, void *buf, size_t size) {
char *bufp;
size_t bytestoread;
ssize_t bytesread;
size_t totalbytes;
for (bufp = buf, bytestoread = size, totalbytes = 0;
bytestoread > 0;
bufp += bytesread, bytestoread -= bytesread) {
bytesread = read(fd, bufp, bytestoread);
if ((bytesread == 0) && (totalbytes == 0))
return 0;
if (bytesread == 0) {
errno = EINVAL;
return -1;
}
if ((bytesread) == -1 && (errno != EINTR))
return -1;
if (bytesread == -1)
bytesread = 0;
totalbytes += bytesread;
}
return totalbytes;
}
There are only three possibilities for the return value of readblock. The readblock function returns 0 if an end-of-file occurs before any bytes are read. This happens if the first call to read returns 0. If readblock is successful, it returns size, signifying that the requested number of bytes was successfully read. Otherwise, readblock returns 1 and sets errno. If readblock reaches the end-of-file after some, but not all, of the needed bytes have been read, readblock returns 1 and sets errno to EINVAL.
Example 4.10
The following code segment can be used to read a pair of integers from an open file descriptor.
struct {
int x;
int y;
} point;
if (readblock(fd, &point, sizeof(point)) <= 0)
fprintf(stderr, "Cannot read a point.\n");
Program 4.8 combines readblock with r_write to read a fixed number of bytes from one open file descriptor and write them to another open file descriptor.
Program 4.8 readwriteblock.c
A program that copies a fixed number of bytes from one file descriptor to another.
#include "restart.h"
int readwriteblock(int fromfd, int tofd, char *buf, int size) {
int bytesread;
bytesread = readblock(fromfd, buf, size);
if (bytesread != size) /* can only be 0 or -1 */
return bytesread;
return r_write(tofd, buf, size);
}
|
4.3 Opening and Closing Files
The open function associates a file descriptor (the handle used in the program) with a file or physical device. The path parameter of open points to the pathname of the file or device, and the oflag parameter specifies status flags and access modes for the opened file. You must include a third parameter to specify access permissions if you are creating a file.
SYNOPSIS
#include <fcntl.h>
#include <sys/stat.h>
int open(const char *path, int oflag, ...);
POSIX
If successful, open returns a nonnegative integer representing the open file descriptor. If unsuccessful, open returns 1 and sets errno. The following table lists the mandatory errors for open.
|
EACCES | search permission on component of path prefix denied, or file exists and permissions specified by oflag denied, or file does not exist and write permission on parent directory denied, or O_TRUNC specified and write permission denied | EEXIST | O_CREAT and OEXCL are set and named file already exists | EINTR | signal was caught during open | EISDIR | named file is directory and oflag includes O_WRONLY or O_RDWR | ELOOP | a loop exists in resolution of path | EMFILE | OPEN_MAX file descriptors currently open in calling process | ENAMETOOLONG | the length of path exceeds PATH_MAX, or a pathname component is longer than NAME_MAX | ENFILE | maximum allowable number of files currently open in system | ENOENT | O_CREAT not set and name file does not exist, or O_CREAT is set and either path prefix does not exist or or path is an empty string | ENOSPC | directory or file system for new file cannot be expanded, the file does not exist and O_CREAT is specified | ENOTDIR | a component of the path prefix is not a directory | ENXIO | O_NONBLOCK is set, the named file is a FIFO, O_WRONLY is set, no process has file open for reading; file is a special file and device associated with file does not exist | EOVERFLOW | named file is a regular file and size cannot be represented by an object of type off_t | EROFS | the named file resides on a read-only file system and one of O_WRONLY, O_RDWR, O_CREAT (if the file does not exist), or O_TRUNC is set in oflag |
Construct the oflag argument by taking the bitwise OR (|) of the desired combination of the access mode and the additional flags. The POSIX values for the access mode flags are O_RDONLY, O_WRONLY and O_RDWR. You must specify exactly one of these designating read-only, write-only or read-write access, respectively.
The additional flags include O_APPEND, O_CREAT, O_EXCL, O_NOCTTY, O_NONBLOCK and O_TRUNC. The O_APPEND flag causes the file offset to be moved to the end of the file before a write, allowing you to add to an existing file. In contrast, O_TRUNC truncates the length of a regular file opened for writing to 0. The O_CREAT flag causes a file to be created if it doesn't already exist. If you include the O_CREAT flag, you must also pass a third argument to open to designate the permissions. If you want to avoid writing over an existing file, use the combination O_CREAT | O_EXCL. This combination returns an error if the file already exists. The O_NOCTTY flag prevents an opened device from becoming a controlling terminal. Controlling terminals are discussed in Section 11.5. The O_NONBLOCK flag controls whether the open returns immediately or blocks until the device is ready. Section 4.8 discusses how the O_NONBLOCK flag affects the behavior of read and write. Certain POSIX extensions specify additional flags. You can find the flags in fcntl.h.
Example 4.11
The following code segment opens the file /home/ann/my.dat for reading.
int myfd;
myfd = open("/home/ann/my.dat", O_RDONLY);
This code does no error checking.
Exercise 4.12
How can the call to open of Example 4.11 fail?
Answer:
The open function returns 1 if the file doesn't exist, the open call was interrupted by a signal or the process doesn't have the appropriate access permissions. If your code uses myfd for a subsequent read or write operation, the operation fails.
Example 4.13
The following code segment restarts open after a signal occurs.
int myfd;
while((myfd = open("/home/ann/my.dat", O_RDONLY)) == -1 &&
errno == EINTR) ;
if (myfd == -1) /* it was a real error, not a signal */
perror("Failed to open the file");
else /* continue on */
Exercise 4.14
How would you modify Example 4.13 to open /home/ann/my.dat for nonblocking read?
Answer:
You would OR the O_RDONLY and the O_NONBLOCK flags.
myfd = open("/home/ann/my.dat", O_RDONLY | O_NONBLOCK);
Each file has three classes associated with it: a user (or owner), a group and everybody else (others). The possible permissions or privileges are read(r), write(w) and execute(x). These privileges are specified separately for the user, the group and others. When you open a file with the O_CREAT flag, you must specify the permissions as the third argument to open in a mask of type mode_t.
Historically, the file permissions were laid out in a mask of bits with 1's in designated bit positions of the mask, signifying that a class had the corresponding privilege. Figure 4.1 shows an example of a typical layout of such a permission mask. Although numerically coded permission masks frequently appear in legacy code, you should avoid using numerical values in your programs.

POSIX defines symbolic names for masks corresponding to the permission bits so that you can specify file permissions independently of the implementation. These names are defined in sys/stat.h. Table 4.1 lists the symbolic names and their meanings. To form the permission mask, bitwise OR the symbols corresponding to the desired permissions.
Table 4.1. POSIX symbolic names for file permissions.|
S_IRUSR | read by owner | S_IWUSR | write by owner | S_IXUSR | execute by owner | S_IRWXU | read, write, execute by owner | S_IRGRP | read by group | S_IWGRP | write by group | S_IXGRP | execute by group | S_IRWXG | read, write, execute by group | S_IROTH | read by others | S_IWOTH | write by others | S_IXOTH | execute by others | S_IRWXO | read, write, execute by others | S_ISUID | set user ID on execution | S_ISGID | set group ID on execution |
Example 4.15
The following code segment creates a file, info.dat, in the current directory. If the info.dat file already exists, it is overwritten. The new file can be read or written by the user and only read by everyone else.
int fd;
mode_t fdmode = (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if ((fd = open("info.dat", O_RDWR | O_CREAT, fdmode)) == -1)
perror("Failed to open info.dat");
Program 4.9 copies a source file to a destination file. Both filenames are passed as command-line arguments. Because the open function for the destination file has O_CREAT | O_EXCL, the file copy fails if that file already exists.
Program 4.9 copyfilemain.c
A program to copy a file.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include "restart.h"
#define READ_FLAGS O_RDONLY
#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_EXCL)
#define WRITE_PERMS (S_IRUSR | S_IWUSR)
int main(int argc, char *argv[]) {
int bytes;
int fromfd, tofd;
if (argc != 3) {
fprintf(stderr, "Usage: %s from_file to_file\n", argv[0]);
return 1;
}
if ((fromfd = open(argv[1], READ_FLAGS)) == -1) {
perror("Failed to open input file");
return 1;
}
if ((tofd = open(argv[2], WRITE_FLAGS, WRITE_PERMS)) == -1) {
perror("Failed to create output file");
return 1;
}
bytes = copyfile(fromfd, tofd);
printf("%d bytes copied from %s to %s\n", bytes, argv[1], argv[2]);
return 0; /* the return closes the files */
}
Program 4.9 returns immediately after performing the copy and does not explicitly close the file. The return from main causes the necessary cleanup to release the resources associated with open files. In general, however, you should be careful to release open file descriptors by calling close.
The close function has a single parameter, fildes, representing the open file whose resources are to be released.
SYNOPSIS
#include <unistd.h>
int close(int fildes);
POSIX
If successful, close returns 0. If unsuccessful, close returns 1 and sets errno. The following table lists the mandatory errors for close.
|
EBADF | fildes is not a valid file descriptor | EINTR | the close function was interrupted by a signal |
Program 4.10 shows an r_close function that restarts itself after interruption by a signal. Its prototype is in the header file restart.h.
Program 4.10 r_close.c
The r_close.c function is similar to close except that it restarts itself if interrupted by a signal.
#include <errno.h>
#include <unistd.h>
int r_close(int fd) {
int retval;
while (retval = close(fd), retval == -1 && errno == EINTR) ;
return retval;
}
|
4.4 The select Function
The handling of I/O from multiple sources is an important problem that arises in many different forms. For example, a program may want to overlap terminal I/O with reading input from a disk or with printing. Another example occurs when a program expects input from two different sources, but it doesn't know which input will be available first. If the program tries to read from source A, and in fact, input was only available from source B, the program blocks. To solve this problem, we need to block until input from either source becomes available. Blocking until at least one member of a set of conditions becomes true is called OR synchronization. The condition for the case described is "input available" on a descriptor.
One method of monitoring multiple file descriptors is to use a separate process for each one. Program 4.11 takes two command-line arguments, the names of two files to monitor. The parent process opens both files before creating the child process. The parent monitors the first file descriptor, and the child monitors the second. Each process echoes the contents of its file to standard output. If two named pipes are monitored, output appears as input becomes available.
Program 4.11 monitorfork.c
A program that monitors two files by forking a child process.
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include "restart.h"
int main(int argc, char *argv[]) {
int bytesread;
int childpid;
int fd, fd1, fd2;
if (argc != 3) {
fprintf(stderr, "Usage: %s file1 file2\n", argv[0]);
return 1;
}
if ((fd1 = open(argv[1], O_RDONLY)) == -1) {
fprintf(stderr, "Failed to open file %s:%s\n", argv[1], strerror(errno));
return 1;
}
if ((fd2 = open(argv[2], O_RDONLY)) == -1) {
fprintf(stderr, "Failed to open file %s:%s\n", argv[2], strerror(errno));
return 1;
}
if ((childpid = fork()) == -1) {
perror("Failed to create child process");
return 1;
}
if (childpid > 0) /* parent code */
fd = fd1;
else
fd = fd2;
bytesread = copyfile(fd, STDOUT_FILENO);
fprintf(stderr, "Bytes read: %d\n", bytesread);
return 0;
}
While using separate processes to monitor two file descriptors can be useful, the two processes have separate address spaces and so it is difficult for them to interact.
Exercise 4.16
How would you modify Program 4.11 so that it prints the total number of bytes read from the two files?
Answer:
Set up some form of interprocess communication before creating the child. For example, the parent process could create a pipe and the child could send its byte count to the pipe when it has finished. After the parent has processed its file, the parent could wait for the child and read the byte count from the pipe.
The select call provides a method of monitoring file descriptors from a single process. It can monitor for three possible conditionsa read can be done without blocking, a write can be done without blocking, or a file descriptor has error conditions pending. Older versions of UNIX defined the select function in sys/time.h, but the POSIX standard now uses sys/select.h.
The nfds parameter of select gives the range of file descriptors to be monitored. The value of nfds must be at least one greater than the largest file descriptor to be checked. The readfds parameter specifies the set of descriptors to be monitored for reading. Similarly, writefds specifies the set of descriptors to be monitored for writing, and errorfds specifies the file descriptors to be monitored for error conditions. The descriptor sets are of type fd_set. Any of these parameters may be NULL, in which case select does not monitor the descriptor for the corresponding event. The last parameter is a timeout value that forces a return from select after a certain period of time has elapsed, even if no descriptors are ready. When timeout is NULL, select may block indefinitely.
SYNOPSIS
#include <sys/select.h>
int select(int nfds, fd_set *restrict readfds,
fd_set *restrict writefds, fd_set *restrict errorfds,
struct timeval *restrict timeout);
void FD_CLR(int fd, fd_set *fdset);
int FD_ISSET(int fd, fd_set *fdset);
void FD_SET(int fd, fd_set *fdset);
void FD_ZERO(fd_set *fdset);
POSIX
On successful return, select clears all the descriptors in each of readfds, writefds and errorfds except those descriptors that are ready. If successful, the select function returns the number of file descriptors that are ready. If unsuccessful, select returns 1 and sets errno. The following table lists the mandatory errors for select.
|
EBADF | one or more file descriptor sets specified an invalid file descriptor | EINTR | the select was interrupted by a signal before timeout or selected event occurred | EINVAL | an invalid timeout interval was specified, or nfds is less than 0 or greater than FD_SETSIZE |
Historically, systems implemented the descriptor set as an integer bit mask, but that implementation does not work for more than 32 file descriptors on most systems. The descriptor sets are now usually represented by bit fields in arrays of integers. Use the macros FD_SET, FD_CLR, FD_ISSET and FD_ZERO to manipulate the descriptor sets in an implementation-independent way as demonstrated in Program 4.12.
The FD_SET macro sets the bit in *fdset corresponding to the fd file descriptor, and the FD_CLR macro clears the corresponding bit. The FD_ZERO macro clears all the bits in *fdset. Use these three macros to set up descriptor masks before calling select. Use the FD_ISSET macro after select returns, to test whether the bit corresponding to the file descriptor fd is set in the mask.
Program 4.12 whichisready.c
A function that blocks until one of two file descriptors is ready.
#include <errno.h>
#include <string.h>
#include <sys/select.h>
int whichisready(int fd1, int fd2) {
int maxfd;
int nfds;
fd_set readset;
if ((fd1 < 0) || (fd1 >= FD_SETSIZE) ||
(fd2 < 0) || (fd2 >= FD_SETSIZE)) {
errno = EINVAL;
return -1;
}
maxfd = (fd1 > fd2) ? fd1 : fd2;
FD_ZERO(&readset);
FD_SET(fd1, &readset);
FD_SET(fd2, &readset);
nfds = select(maxfd+1, &readset, NULL, NULL, NULL);
if (nfds == -1)
return -1;
if (FD_ISSET(fd1, &readset))
return fd1;
if (FD_ISSET(fd2, &readset))
return fd2;
errno = EINVAL;
return -1;
}
The function whichisready blocks until at least one of the two file descriptors passed as parameters is ready for reading and returns that file descriptor. If both are ready, it returns the first file descriptor. If unsuccessful, whichisready returns 1 and sets errno.
Program 4.13 copy2files.c
A function that uses select to do two concurrent file copies.
#include <errno.h>
#include <stdio.h>
#include <string.h>
#include <sys/time.h>
#include "restart.h"
int copy2files(int fromfd1, int tofd1, int fromfd2, int tofd2) {
int bytesread;
int maxfd;
int num;
fd_set readset;
int totalbytes = 0;
if ((fromfd1 < 0) || (fromfd1 >= FD_SETSIZE) ||
(tofd1 < 0) || (tofd1 >= FD_SETSIZE) ||
(fromfd2 < 0) || (fromfd2 >= FD_SETSIZE) ||
(tofd2 < 0) || (tofd2 >= FD_SETSIZE))
return 0;
maxfd = fromfd1; /* find the biggest fd for select */
if (fromfd2 > maxfd)
maxfd = fromfd2;
for ( ; ; ) {
FD_ZERO(&readset);
FD_SET(fromfd1, &readset);
FD_SET(fromfd2, &readset);
if (((num = select(maxfd+1, &readset, NULL, NULL, NULL)) == -1) &&
(errno == EINTR))
continue;
if (num == -1)
return totalbytes;
if (FD_ISSET(fromfd1, &readset)) {
bytesread = readwrite(fromfd1, tofd1);
if (bytesread <= 0)
break;
totalbytes += bytesread;
}
if (FD_ISSET(fromfd2, &readset)) {
bytesread = readwrite(fromfd2, tofd2);
if (bytesread <= 0)
break;
totalbytes += bytesread;
}
}
return totalbytes;
}
The whichisready function of Program 4.12 is problematic because it always chooses fd1 if both fd1 and fd2 are ready. The copy2files function copies bytes from fromfd1 to tofd1 and from fromfd2 to tofd2 without making any assumptions about the order in which the bytes become available in the two directions. The function returns if either copy encounters an error or end-of-file.
The copy2files function of Program 4.13 can be generalized to monitor multiple file descriptors for input. Such a problem might be encountered by a command processor that was monitoring requests from different terminals. The program cannot predict which source will produce the next input, so it must use a method such as select. In addition, the set of monitored descriptors is dynamicthe program must remove a source from the monitoring set if an error condition arises on that source's descriptor.
The monitorselect function in Program 4.14 monitors an array of open file descriptors fd. When input is available on file descriptor fd[i], the program reads information from fd[i] and calls docommand. The monitorselect function has two parameters: an array of open file descriptors and the number of file descriptors in the array. The function restarts the select or read if either is interrupted by a signal. When read encounters other types of errors or an end-of-file, monitorselect closes the corresponding descriptor and removes it from the monitoring set. The monitorselect function returns when all descriptors have indicated an error or end-of-file.
The waitfdtimed function in Program 4.15 takes two parameters: a file descriptor and an ending time. It uses gettimeout to calculate the timeout interval from the end time and the current time obtained by a call to gettimeofday. (See Section 9.1.3.) If select returns prematurely because of a signal, waitfdtimed recalculates the timeout and calls select again. The standard does not say anything about the value of the timeout parameter or the fd_set parameters of select when it is interrupted by a signal, so we reset them inside the while loop.
You can use the select timeout feature to implement a timed read operation, as shown in Program 4.16. The readtimed function behaves like read except that it takes an additional parameter, seconds, specifying a timeout in seconds. The readtimed function returns 1 with errno set to ETIME if no input is available in the next seconds interval. If interrupted by a signal, readtimed restarts with the remaining time. Most of the complication comes from the need to restart select with the remaining time when select is interrupted by a signal. The select function does not provide a direct way of determining the time remaining in this case. The readtimed function in Program 4.16 sets the end time for the timeout by calling add2currenttime in Program 4.15. It uses this value when calling waitfdtimed from Program 4.15 to wait until the file descriptor can be read or the time given has occurred.
Program 4.14 monitorselect.c
A function to monitor file descriptors using select.
#include <errno.h>
#include <string.h>
#include <unistd.h>
#include <sys/select.h>
#include <sys/types.h>
#include "restart.h"
#define BUFSIZE 1024
void docommand(char *, int);
void monitorselect(int fd[], int numfds) {
char buf[BUFSIZE];
int bytesread;
int i;
int maxfd;
int numnow, numready;
fd_set readset;
maxfd = 0; /* set up the range of descriptors to monitor */
for (i = 0; i < numfds; i++) {
if ((fd[i] < 0) || (fd[i] >= FD_SETSIZE))
return;
if (fd[i] >= maxfd)
maxfd = fd[i] + 1;
}
numnow = numfds;
while (numnow > 0) { /* continue monitoring until all are done */
FD_ZERO(&readset); /* set up the file descriptor mask */
for (i = 0; i < numfds; i++)
if (fd[i] >= 0)
FD_SET(fd[i], &readset);
numready = select(maxfd, &readset, NULL, NULL, NULL); /* which ready? */
if ((numready == -1) && (errno == EINTR)) /* interrupted by signal */
continue;
else if (numready == -1) /* real select error */
break;
for (i = 0; (i < numfds) && (numready > 0); i++) { /* read and process */
if (fd[i] == -1) /* this descriptor is done */
continue;
if (FD_ISSET(fd[i], &readset)) { /* this descriptor is ready */
bytesread = r_read(fd[i], buf, BUFSIZE);
numready--;
if (bytesread > 0)
docommand(buf, bytesread);
else { /* error occurred on this descriptor, close it */
r_close(fd[i]);
fd[i] = -1;
numnow--;
}
}
}
}
for (i = 0; i < numfds; i++)
if (fd[i] >= 0)
r_close(fd[i]);
}
Program 4.15 waitfdtimed.c
A function that waits for a given time for input to be available from an open file descriptor.
#include <errno.h>
#include <string.h>
#include <sys/select.h>
#include <sys/time.h>
#include "restart.h"
#define MILLION 1000000L
#define D_MILLION 1000000.0
static int gettimeout(struct timeval end,
struct timeval *timeoutp) {
gettimeofday(timeoutp, NULL);
timeoutp->tv_sec = end.tv_sec - timeoutp->tv_sec;
timeoutp->tv_usec = end.tv_usec - timeoutp->tv_usec;
if (timeoutp->tv_usec >= MILLION) {
timeoutp->tv_sec++;
timeoutp->tv_usec -= MILLION;
}
if (timeoutp->tv_usec < 0) {
timeoutp->tv_sec--;
timeoutp->tv_usec += MILLION;
}
if ((timeoutp->tv_sec < 0) ||
((timeoutp->tv_sec == 0) && (timeoutp->tv_usec == 0))) {
errno = ETIME;
return -1;
}
return 0;
}
struct timeval add2currenttime(double seconds) {
struct timeval newtime;
gettimeofday(&newtime, NULL);
newtime.tv_sec += (int)seconds;
newtime.tv_usec += (int)((seconds - (int)seconds)*D_MILLION + 0.5);
if (newtime.tv_usec >= MILLION) {
newtime.tv_sec++;
newtime.tv_usec -= MILLION;
}
return newtime;
}
int waitfdtimed(int fd, struct timeval end) {
fd_set readset;
int retval;
struct timeval timeout;
if ((fd < 0) || (fd >= FD_SETSIZE)) {
errno = EINVAL;
return -1;
}
FD_ZERO(&readset);
FD_SET(fd, &readset);
if (gettimeout(end, &timeout) == -1)
return -1;
while (((retval = select(fd + 1, &readset, NULL, NULL, &timeout)) == -1)
&& (errno == EINTR)) {
if (gettimeout(end, &timeout) == -1)
return -1;
FD_ZERO(&readset);
FD_SET(fd, &readset);
}
if (retval == 0) {
errno = ETIME;
return -1;
}
if (retval == -1)
return -1;
return 0;
}
Program 4.16 readtimed.c
A function do a timed read from an open file descriptor.
#include <sys/time.h>
#include "restart.h"
ssize_t readtimed(int fd, void *buf, size_t nbyte, double seconds) {
struct timeval timedone;
timedone = add2currenttime(seconds);
if (waitfdtimed(fd, timedone) == -1)
return (ssize_t)(-1);
return r_read(fd, buf, nbyte);
}
Exercise 4.17
Why is it necessary to test whether newtime.tv_usec is greater than or equal to a million when it is set from the fractional part of seconds? What are the consequences of having that value equal to one million?
Answer:
Since the value is rounded to the nearest microsecond, a fraction such as 0.999999999 might round to one million when multiplied by MILLION. The action of functions that use struct timeval values are not specified when the tv_usec field is not strictly less than one million.
Exercise 4.18
One way to simplify Program 4.15 is to just restart the select with the same timeout whenever it is interrupted by a signal. What is wrong with this?
Answer:
If your program receives signals regularly and the time between signals is smaller than the timeout interval, waitfdtimed never times out.
The 2000 version of POSIX introduced a new version of select called pselect. The pselect function is identical to the select function, but it uses a more precise timeout structure, struct timespec, and allows for the blocking or unblocking of signals while it is waiting for I/O to be available. The struct timespec structure is discussed in Section 9.1.4. However, at the time of writing, (March 2003), none of the our test operating systems supported pselect.
|
4.5 The poll Function
The poll function is similar to select, but it organizes the information by file descriptor rather than by type of condition. That is, the possible events for one file descriptor are stored in a struct pollfd. In contrast, select organizes information by the type of event and has separate descriptor masks for read, write and error conditions. The poll function is part of the POSIX:XSI Extension and has its origins in UNIX System V.
The poll function takes three parameters: fds, nfds and timeout. The fds is an array of struct pollfd, representing the monitoring information for the file descriptors. The nfds parameter gives the number of descriptors to be monitored. The timeout value is the time in milliseconds that the poll should wait without receiving an event before returning. If the timeout value is 1, poll never times out. If integers are 32 bits, the maximum timeout period is about 30 minutes.
SYNOPSIS
#include <poll.h>
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
POSIX:XSI
The poll function returns 0 if it times out. If successful, poll returns the number of descriptors that have events. If unsuccessful, poll returns 1 and sets errno. The following table lists the mandatory errors for poll.
|
EAGAIN | allocation of internal data structures failed, but a subsequent request may succeed | EINTR | a signal was caught during poll | EINVAL | nfds is greater than OPEN_MAX |
The struct pollfd structure includes the following members.
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
The fd is the file descriptor number, and the events and revents are constructed by taking the logical OR of flags representing the various events listed in Table 4.2. Set events to contain the events to monitor; poll fills in the revents with the events that have occurred. The poll function sets the POLLHUP, POLLERR and POLLNVAL flags in revents to reflect the existence of the associated conditions. You do not need to set the corresponding bits in events for these. If fd is less than zero, the events field is ignored and revents is set to zero. The standard does not specify how end-of-file is to be handled. End-of-file can either be communicated by an revents flag of POLLHUP or a normal read of 0 bytes. It is possible for POLLHUP to be set even if POLLIN or POLLRDNORM indicates that there is still data to read. Therefore, normal reading should be handled before error checking.
Table 4.2. Values of the event flags for the poll function.|
POLLIN | read other than high priority data without blocking | POLLRDNORM | read normal data without blocking | POLLRDBAND | read priority data without blocking | POLLPRI | read high-priority data without blocking | POLLOUT | write normal data without blocking | POLLWRNORM | same as POLLOUT | POLLERR | error occurred on the descriptor | POLLHUP | device has been disconnected | POLLNVAL | file descriptor invalid |
Program 4.17 implements a function to process commands from multiple file descriptors by using the poll function. Compare the implementation with that of Program 4.14. The select call modifies the file descriptor sets that are passed to it, and the program must reset these descriptor sets each time it calls select. The poll function uses separate variables for input and return values, so it is not necessary to reset the list of monitored descriptors after each call to poll. The poll function has a number of advantages. The masks do not need to be reset after each call. Unlike select, the poll function treats errors as events that cause poll to return. The timeout parameter is easier to use, although its range is limited. Finally, poll does not need a max_fd argument.
Program 4.17 monitorpoll.c
A function to monitor an array of file descriptors by using poll.
#include <errno.h>
#include <poll.h>
#include <stdlib.h>
#include <stropts.h>
#include <unistd.h>
#include "restart.h"
#define BUFSIZE 1024
void docommand(char *, int);
void monitorpoll(int fd[], int numfds) {
char buf[BUFSIZE];
int bytesread;
int i;
int numnow = 0;
int numready;
struct pollfd *pollfd;
for (i=0; i< numfds; i++) /* initialize the polling structure */
if (fd[i] >= 0)
numnow++;
if ((pollfd = (void *)calloc(numfds, sizeof(struct pollfd))) == NULL)
return;
for (i = 0; i < numfds; i++) {
(pollfd + i)->fd = *(fd + i);
(pollfd + i)->events = POLLRDNORM;
}
while (numnow > 0) { /* Continue monitoring until descriptors done */
numready = poll(pollfd, numfds, -1);
if ((numready == -1) && (errno == EINTR))
continue; /* poll interrupted by a signal, try again */
else if (numready == -1) /* real poll error, can't continue */
break;
for (i = 0; i < numfds && numready > 0; i++) {
if ((pollfd + i)->revents) {
if ((pollfd + i)->revents & (POLLRDNORM | POLLIN) ) {
bytesread = r_read(fd[i], buf, BUFSIZE);
numready--;
if (bytesread > 0)
docommand(buf, bytesread);
else
bytesread = -1; /* end of file */
} else if ((pollfd + i)->revents & (POLLERR | POLLHUP))
bytesread = -1;
else /* descriptor not involved in this round */
bytesread = 0;
if (bytesread == -1) { /* error occurred, remove descriptor */
r_close(fd[i]);
(pollfd + i)->fd = -1;
numnow--;
}
}
}
}
for (i = 0; i < numfds; i++)
r_close(fd[i]);
free(pollfd);
}
4.6 File Representation
Files are designated within C programs either by file pointers or by file descriptors. The standard I/O library functions for ISO C (fopen, fscanf, fprintf, fread, fwrite, fclose and so on) use file pointers. The UNIX I/O functions (open, read, write, close and ioctl) use file descriptors. File pointers and file descriptors provide logical designations called handles for performing device-independent input and output. The symbolic names for the file pointers that represent standard input, standard output and standard error are stdin, stdout and stderr, respectively. These symbolic names are defined in stdio.h. The symbolic names for the file descriptors that represent standard input, standard output and standard error are STDIN_FILENO, STDOUT_FILENO and STDERR_FILENO, respectively. These symbolic names are defined in unistd.h.
Exercise 4.19
Explain the difference between a library function and a system call.
Answer:
The POSIX standard does not make a distinction between library functions and system calls. Traditionally, a library function is an ordinary function that is placed in a collection of functions called a library, usually because it is useful, widely used or part of a specification, such as C. A system call is a request to the operating system for service. It involves a trap to the operating system and often a context switch. System calls are associated with particular operating systems. Many library functions such as read and write are, in fact, jackets for system calls. That is, they reformat the arguments in the appropriate system-dependent form and then call the underlying system call to perform the actual operation.
Although the implementation details differ, versions of UNIX follow a similar implementation model for handling file descriptors and file pointers within a process. The remainder of this section provides a schematic model of how file descriptors (UNIX I/O) and file pointers (ISO C I/O) work. We use this model to explain redirection (Section 4.7) and inheritance (Section 4.6.3, Section 6.2 and Chapter 7).
4.6.1 File descriptors
The open function associates a file or physical device with the logical handle used in the program. The file or physical device is specified by a character string (e.g., /home/johns/my.dat or /dev/tty). The handle is an integer that can be thought of as an index into a file descriptor table that is specific to a process. It contains an entry for each open file in the process. The file descriptor table is part of the process user area, but the program cannot access it except through functions using the file descriptor.
Example 4.20
Figure 4.2 shows a schematic of the file descriptor table after a program executes the following.
myfd = open("/home/ann/my.dat", O_RDONLY);
The open function creates an entry in the file descriptor table that points to an entry in the system file table. The open function returns the value 3, specifying that the file descriptor entry is in position three of the process file descriptor table.
The system file table, which is shared by all the processes in the system, has an entry for each active open. Each system file table entry contains the file offset, an indication of the access mode (i.e., read, write or read-write) and a count of the number of file descriptor table entries pointing to it.
Several system file table entries may correspond to the same physical file. Each of these entries points to the same entry in the in-memory inode table. The in-memory inode table contains an entry for each active file in the system. When a program opens a particular physical file that is not currently open, the call creates an entry in this inode table for that file. Figure 4.2 shows that the file /home/ann/my.dat had been opened before the code of Example 4.20 because there are two entries in the system file table with pointers to the entry in the inode table. (The label B designates the earlier pointer in the figure.)
Exercise 4.21
What happens when the process whose file descriptor table is shown in Figure 4.2 executes the close(myfd) function?
Answer:
The operating system deletes the fourth entry in the file descriptor table and the corresponding entry in the system file table. (See Section 4.6.3 for a more complete discussion.) If the operating system also deleted the inode table entry, it would leave pointer B hanging in the system file table. Therefore, the inode table entry must have a count of the system file table entries that are pointing to it. When a process executes the close function, the operating system decrements the count in the inode entry. If the inode entry has a 0 count, the operating system deletes the inode entry from memory. (The operating system might not actually delete the entry right away on the chance that it will be accessed again in the immediate future.)
Exercise 4.22
The system file table entry contains an offset that gives the current position in the file. If two processes have each opened a file for reading, each process has its own offset into the file and reads the entire file independently of the other process. What happens if each process opens the same file for write? What would happen if the file offset were stored in the inode table instead of the system file table?
Answer:
The writes are independent of each other. Each user can write over what the other user has written because of the separate file offsets for each process. On the other hand, if the offsets were stored in the inode table rather than in the system file table, the writes from different active opens would be consecutive. Also, the processes that had opened a file for reading would only read parts of the file because the file offset they were using could be updated by other processes.
Exercise 4.23
Suppose a process opens a file for reading and then forks a child process. Both the parent and child can read from the file. How are reads by these two processes related? What about writes?
Answer:
The child receives a copy of the parent's file descriptor table at the time of the fork. The processes share a system file table entry and therefore also share the file offset. The two processes read different parts of the file. If no other processes have the file open, writes append to the end of the file and no data is lost on writes. Subsection 4.6.3 covers this situation in more detail.
4.6.2 File pointers and buffering
The ISO C standard I/O library uses file pointers rather than file descriptors as handles for I/O. A file pointer points to a data structure called a FILE structure in the user area of the process.
Example 4.24
The following code segment opens the file /home/ann/my.dat for output and then writes a string to the file.
FILE *myfp;
if ((myfp = fopen("/home/ann/my.dat", "w")) == NULL)
perror("Failed to open /home/ann/my.dat");
else
fprintf(myfp, "This is a test");
Figure 4.3 shows a schematic of the FILE structure allocated by the fopen call of Example 4.24. The FILE structure contains a buffer and a file descriptor value. The file descriptor value is the index of the entry in the file descriptor table that is actually used to output the file to disk. In some sense the file pointer is a handle to a handle.
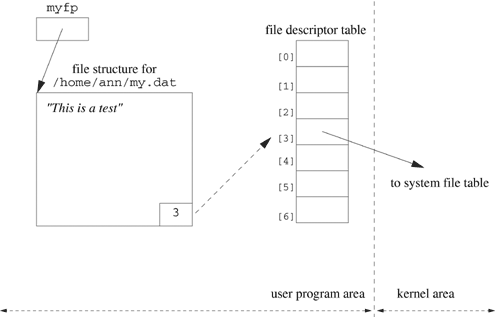
What happens when the program calls fprintf? The result depends on the type of file that was opened. Disk files are usually fully buffered, meaning that the fprintf does not actually write the This is a test message to disk, but instead writes the bytes to a buffer in the FILE structure. When the buffer fills, the I/O subsystem calls write with the file descriptor, as in the previous section. The delay between the time when a program executes fprintf and the time when the writing actually occurs may have interesting consequences, especially if the program crashes. Buffered data is sometimes lost on system crashes, so it is even possible for a program to appear to complete normally but its disk output could be incomplete.
How can a program avoid the effects of buffering? An fflush call forces whatever has been buffered in the FILE structure to be written out. A program can also call setvbuf to disable buffering.
Terminal I/O works a little differently. Files associated with terminals are line buffered rather than fully buffered (except for standard error, which by default, is not buffered). On output, line buffering means that the line is not written out until the buffer is full or until a newline symbol is encountered.
Exercise 4.25 bufferout.c
How does the output appear when the following program executes?
#include <stdio.h>
int main(void) {
fprintf(stdout, "a");
fprintf(stderr, "a has been written\n");
fprintf(stdout, "b");
fprintf(stderr, "b has been written\n");
fprintf(stdout, "\n");
return 0;
}
Answer:
The messages written to standard error appear before the 'a' and 'b' because standard output is line buffered, whereas standard error is not buffered.
Exercise 4.26 bufferinout.c
How does the output appear when the following program executes?
#include <stdio.h>
int main(void) {
int i;
fprintf(stdout, "a");
scanf("%d", &i);
fprintf(stderr, "a has been written\n");
fprintf(stdout, "b");
fprintf(stderr, "b has been written\n");
fprintf(stdout, "\n");
return 0;
}
Answer:
The scanf function flushes the buffer for stdout, so 'a' is displayed before the number is read in. After the number has been entered, 'b' still appears after the b has been written message.
The issue of buffering is more subtle than the previous discussion might lead you to believe. If a program that uses file pointers for a buffered device crashes, the last partial buffer created from the fprintf calls may never be written out. When the buffer is full, a write operation is performed. Completion of a write operation does not mean that the data actually made it to disk. In fact, the operating system copies the data to a system buffer cache. Periodically, the operating system writes these dirty blocks to disk. If the operating system crashes before it writes the block to disk, the program still loses the data. Presumably, a system crash is less likely to happen than an individual program crash.
4.6.3 Inheritance of file descriptors
When fork creates a child, the child inherits a copy of most of the parent's environment and context, including the signal state, the scheduling parameters and the file descriptor table. The implications of inheritance are not always obvious. Because children receive a copy of their parent's file descriptor table at the time of the fork, the parent and children share the same file offsets for files that were opened by the parent prior to the fork.
Example 4.27 openfork.c
In the following program, the child inherits the file descriptor for my.dat. Each process reads and outputs one character from the file.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
int main(void) {
char c = '!';
int myfd;
if ((myfd = open("my.dat", O_RDONLY)) == -1) {
perror("Failed to open file");
return 1;
}
if (fork() == -1) {
perror("Failed to fork");
return 1;
}
read(myfd, &c, 1);
printf("Process %ld got %c\n", (long)getpid(), c);
return 0;
}
Figure 4.4 shows the parent and child file descriptor tables for Example 4.27. The file descriptor table entries of the two processes point to the same entry in the system file table. The parent and child therefore share the file offset, which is stored in the system file table.

Exercise 4.28
Suppose the first few bytes in the file my.dat are abcdefg. What output would be generated by Example 4.27?
Answer:
Since the two processes share the file offset, the first one to read gets a and the second one to read gets b. Two lines are generated in the following form.
Process nnn got a
Process mmm got b
In theory, the lines could be output in either order but most likely would appear in the order shown.
Exercise 4.29
When a program closes a file, the entry in the file descriptor table is freed. What about the corresponding entry in the system file table?
Answer:
The system file table entry can only be freed if no more file descriptor table entries are pointing to it. For this reason, each system file table entry contains a count of the number of file descriptor table entries that are pointing to it. When a process closes a file, the operating system decrements the count and deletes the entry only when the count becomes 0.
Exercise 4.30
How does fork affect the system file table?
Answer:
The system file table is in system space and is not duplicated by fork. However, each entry in the system file table keeps a count of the number of file descriptor table entries pointing to it. These counts must be adjusted to reflect the new file descriptor table created for the child.
Example 4.31 forkopen.c
In the following program, the parent and child each open my.dat for reading, read one character, and output that character.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
int main(void) {
char c = '!';
int myfd;
if (fork() == -1) {
perror("Failed to fork");
return 1;
}
if ((myfd = open("my.dat", O_RDONLY)) == -1) {
perror("Failed to open file");
return 1;
}
read(myfd, &c, 1);
printf("Process %ld got %c\n", (long)getpid(), c);
return 0;
}
Figure 4.5 shows the file descriptor tables for Example 4.31. The file descriptor table entries corresponding to my.dat point to different system file table entries. Consequently, the parent and child do not share the file offset. The child does not inherit the file descriptor, because each process opens the file after the fork and each open creates a new entry in the system file table. The parent and child still share system file table entries for standard input, standard output and standard error.
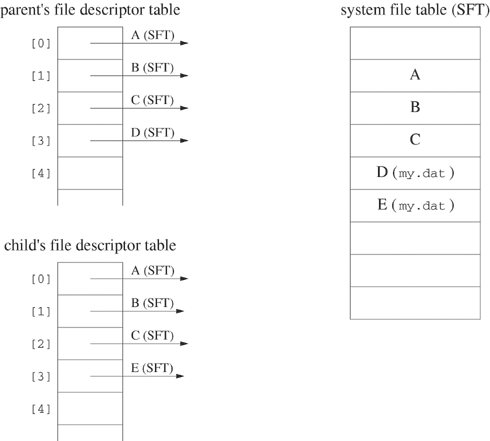
Exercise 4.32
Suppose the first few bytes in the file my.dat are abcdefg. What output would be generated by Example 4.31?
Answer:
Since the two processes use different file offsets, each process reads the first byte of the file. Two lines are generated in the following form.
Process nnn got a
Process mmm got a
Exercise 4.33 fileiofork.c
What output would be generated by the following program?
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("This is my output.");
fork();
return 0;
}
Answer:
Because of buffering, the output of printf is likely to be written to the buffer corresponding to stdout, but not to the actual output device. Since this buffer is part of the user space, it is duplicated by fork. When the parent and the child each terminate, the return from main causes the buffers to be flushed as part of the cleanup. The output appears as follows.
This is my output.This is my output.
Exercise 4.34 fileioforkline.c
What output would be generated by the following program?
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("This is my output.\n");
fork();
return 0;
}
Answer:
The buffering of standard output is usually line buffering. This means that the buffer is flushed when it contains a newline. Since in this case a newline is output, the buffer will probably be flushed before the fork and only one line of output will appear.
4.7 Filters and Redirection
UNIX provides a large number of utilities that are written as filters. A filter reads from standard input, performs a transformation, and outputs the result to standard output. Filters write their error messages to standard error. All of the parameters of a filter are communicated as command-line arguments. The input data should have no headers or trailers, and a filter should not require any interaction with the user.
Examples of useful UNIX filters include head, tail, more, sort, grep and awk. The cat command takes a list of filenames as command-line arguments, reads each of the files in succession, and echoes the contents of each file to standard output. However, if no input file is specified, cat takes its input from standard input and writes its results to standard output. In this case, cat behaves like a filter.
Recall that a file descriptor is an index into the file descriptor table of that process. Each entry in the file descriptor table points to an entry in the system file table, which is created when the file is opened. A program can modify the file descriptor table entry so that it points to a different entry in the system file table. This action is known as redirection. Most shells interpret the greater than character (>) on the command line as redirection of standard output and the less than character (<) as redirection of standard input. (Associate > with output by picturing it as an arrow pointing in the direction of the output file.)
Example 4.35
The cat command with no command-line arguments reads from standard input and echoes to standard output. The following command redirects standard output to my.file with >.
cat > my.file
The cat command of Example 4.35 gathers what is typed from the keyboard into the file my.file. Figure 4.6 depicts the file descriptor table for Example 4.35. Before redirection, entry [1] of the file descriptor table points to a system file table entry corresponding to the usual standard output device. After the redirection, entry [1] points to a system file table entry for my.file.
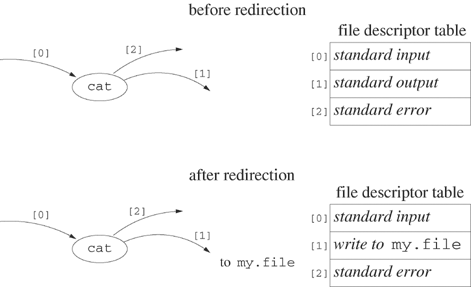
The redirection of standard output in cat > my.file occurs because the shell changes the standard output entry of the file descriptor table (a pointer to the system file table) to reference a system file table entry associated with my.file. To accomplish this redirection in a C program, first open my.file to establish an appropriate entry in the system file table. After the open operation, copy the pointer to my.file into the entry for standard output by executing the dup2 function. Then, call close to eliminate the extra file descriptor table entry for my.file.
The dup2 function takes two parameters, fildes and fildes2. It closes entry fildes2 of the file descriptor table if it was open and then copies the pointer of entry fildes into entry fildes2.
SYNOPSIS
#include <unistd.h>
int dup2(int fildes, int fildes2);
POSIX
On success, dup2 returns the file descriptor value that was duplicated. On failure, dup2 returns 1 and sets errno. The following table lists the mandatory errors for dup2.
|
EBADF | fildes is not a valid open file descriptor, or fildes2 is negative or greater than or equal to OPEN_MAX | EINTR | dup2 was interrupted by a signal |
Example 4.36
Program 4.18 redirects standard output to the file my.file and then appends a short message to that file.
Figure 4.7 shows the effect of the redirection on the file descriptor table of Program 4.18. The open function causes the operating system to create a new entry in the system file table and to set entry [3] of the file descriptor table to point to this entry. The dup2 function closes the descriptor corresponding to the second parameter (standard output) and then copies the entry corresponding to the first parameter (fd) into the entry corresponding to the second parameter (STDOUT_FILENO). From that point on in the program, a write to standard output goes to my.file.

Program 4.18 redirect.c
A program that redirects standard output to the file my.file.
#include <fcntl.h>
#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
#include "restart.h"
#define CREATE_FLAGS (O_WRONLY | O_CREAT | O_APPEND)
#define CREATE_MODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH)
int main(void) {
int fd;
fd = open("my.file", CREATE_FLAGS, CREATE_MODE);
if (fd == -1) {
perror("Failed to open my.file");
return 1;
}
if (dup2(fd, STDOUT_FILENO) == -1) {
perror("Failed to redirect standard output");
return 1;
}
if (r_close(fd) == -1) {
perror("Failed to close the file");
return 1;
}
if (write(STDOUT_FILENO, "OK", 2) == -1) {
perror("Failed in writing to file");
return 1;
}
return 0;
}
4.8 File Control
The fcntl function is a general-purpose function for retrieving and modifying the flags associated with an open file descriptor. The fildes argument of fcntl specifies the descriptor, and the cmd argument specifies the operation. The fcntl function may take additional parameters depending on the value of cmd.
SYNOPSIS
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
int fcntl(int fildes, int cmd, /* arg */ ...);
POSIX
The interpretation of the return value of fcntl depends on the value of the cmd parameter. However, if unsuccessful, fcntl returns 1 and sets errno. The following table lists the mandatory errors for fcntl.
|
EACCES | cmd is F_SETLK and locking not allowed | EBADF | fildes is not a valid open file descriptor or file is not opened properly for type of lock | EINTR | cmd is F_SETLKW and function interrupted by a signal | EINVAL | cmd is invalid, or cmd is F_DUPFD and arg is negative or greater than or equal to OPEN_MAX, or cmd is a locking function and arg is invalid, or fildes refers to a file that does not support locking | EMFILE | cmd is F_DUPFD and OPEN_MAX descriptors for process are open, or no file descriptors greater than or equal to arg are available | ENOLCK | cmd is F_SETLK or F_SETLKW and locks would exceed limit | EOVERFLOW | one of values to be returned cannot be represented correctly, or requested lock offset cannot be represented in off_t |
The fcntl function may only be interrupted by a signal when the cmd argument is F_SETLKW (block until the process acquires an exclusive lock). In this case, fcntl returns 1 and sets errno to EINTR. Table 4.3 lists the POSIX values of the cmd parameter for fcntl.
An important example of the use of file control is to change an open file descriptor to use nonblocking I/O. When a file descriptor has been set for nonblocking I/O, the read and write functions return 1 and set errno to EAGAIN to report that the process would be delayed if a blocking I/O operation were tried. Nonblocking I/O is useful for monitoring multiple file descriptors while doing other work. Section 4.4 and Section 4.5 discuss the select and poll functions that allow a process to block until any of a set of descriptors becomes available. However, both of these functions block while waiting for I/O, so no other work can be done during the wait.
Table 4.3. POSIX values for cmd as specified in fcntl.h.|
F_DUPFD | duplicate a file descriptor | F_GETFD | get file descriptor flags | F_SETFD | set file descriptor flags | F_GETFL | get file status flags and access modes | F_SETFL | set file status flags and access modes | F_GETOWN | if fildes is a socket, get process or group ID for out-of-band signals | F_SETOWN | if fildes is a socket, set process or group ID for out-of-band signals | F_GETLK | get first lock that blocks description specified by arg | F_SETLK | set or clear segment lock specified by arg | F_SETLKW | same as FSETLK except it blocks until request satisfied |
To perform nonblocking I/O, a program can call open with the O_NONBLOCK flag set. A program can also change an open descriptor to be nonblocking by setting the O_NONBLOCK flag, using fcntl. To set an open descriptor to perform nonblocking I/O, use the F_GETFL command with fcntl to retrieve the flags associated with the descriptor. Use inclusive bitwise OR of O_NONBLOCK with these flags to create a new flags value. Finally, set the descriptor flags to this new value, using the F_SETFL command of fcntl.
Example 4.37 setnonblock.c
The following function sets an already opened file descriptor fd for nonblocking I/O.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int setnonblock(int fd) {
int fdflags;
if ((fdflags = fcntl(fd, F_GETFL, 0)) == -1)
return -1;
fdflags |= O_NONBLOCK;
if (fcntl(fd, F_SETFL, fdflags) == -1)
return -1;
return 0;
}
If successful, setnonblock returns 0. Otherwise, setnonblock returns 1 and sets errno.
The setnonblock function of Example 4.37 reads the current value of the flags associated with fd, performs a bitwise OR with O_NONBLOCK, and installs the modified flags. After this function executes, a read from fd returns immediately if no input is available.
Example 4.38 setblock.c
The following function changes the I/O mode associated with file descriptor fd to blocking by clearing the O_NONBLOCK file flag. To clear the flag, use bitwise AND with the complement of the O_NONBLOCK flag.
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int setblock(int fd) {
int fdflags;
if ((fdflags = fcntl(fd, F_GETFL, 0)) == -1)
return -1;
fdflags &= ~O_NONBLOCK;
if (fcntl(fd, F_SETFL, fdflags) == -1)
return -1;
return 0;
}
If successful, setblock returns 0. If unsuccessful, setblock returns 1 and sets errno.
Example 4.39 process_or_do_work.c
The following function assumes that fd1 and fd2 are open for reading in nonblocking mode. If input is available from either one, the function calls docommand with the data read. Otherwise, the code calls dosomething. This implementation gives priority to fd1 and always handles input from this file descriptor before handling fd2.
#include <errno.h>
#include <unistd.h>
#include "restart.h"
void docommand(char *, int);
void dosomething(void);
void process_or_do_work(int fd1, int fd2) {
char buf[1024];
ssize_t bytesread;
for ( ; ; ) {
bytesread = r_read(fd1, buf, sizeof(buf));
if ((bytesread == -1) && (errno != EAGAIN))
return; /* a real error on fd1 */
else if (bytesread > 0) {
docommand(buf, bytesread);
continue;
}
bytesread = r_read(fd2, buf, sizeof(buf));
if ((bytesread == -1) && (errno != EAGAIN))
return; /* a real error on fd2 */
else if (bytesread > 0)
docommand(buf, bytesread);
else
dosomething(); /* input not available, do something else */
}
}
|
4.9 Exercise: Atomic Logging
Sometimes multiple processes need to output to the same log file. Problems can arise if one process loses the CPU while it is outputting to the log file and another process tries to write to the same file. The messages could get interleaved, making the log file unreadable. We use the term atomic logging to mean that multiple writes of one process to the same file are not mixed up with the writes of other processes writing to the same file.
This exercise describes a series of experiments to help you understand the issues involved when multiple processes try to write to the same file. We then introduce an atomic logging library and provide a series of examples of how to use the library. Appendix D.1 describes the actual implementation of this library, which is used in several places throughout the book as a tool for debugging programs.
The experiments in this section are based on Program 3.1, which creates a chain of processes. Program 4.19 modifies Program 3.1 so that the original process opens a file before creating the children. Each child writes a message to the file instead of to standard error. Each message is written in two pieces. Since the processes share an entry in the system file table, they share the file offset. Each time a process writes to the file, the file offset is updated.
Exercise 4.40
Run Program 4.19 several times and see if it generates output in the same order each time. Can you tell which parts of the output came from each process?
Answer:
On most systems, the output appears in the same order for most runs and each process generates a single line of output. However, this outcome is not guaranteed by the program. It is possible (but possibly unlikely) for one process to lose the CPU before both parts of its output are written to the file. In this, case the output is jumbled.
Program 4.19 chainopenfork.c
A program that opens a file before creating a chain of processes.
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/stat.h>
#define BUFSIZE 1024
#define CREATE_FLAGS (O_WRONLY | O_CREAT | O_TRUNC)
#define CREATE_PERMS (S_IRUSR | S_IWUSR| S_IRGRP | S_IROTH)
int main (int argc, char *argv[]) {
char buf[BUFSIZE];
pid_t childpid = 0;
int fd;
int i, n;
if (argc != 3){ /* check for valid number of command-line arguments */
fprintf (stderr, "Usage: %s processes filename\n", argv[0]);
return 1;
}
/* open the log file before the fork */
fd = open(argv[2], CREATE_FLAGS, CREATE_PERMS);
if (fd < 0) {
perror("Failed to open file");
return 1;
}
n = atoi(argv[1]); /* create a process chain */
for (i = 1; i < n; i++)
if (childpid = fork())
break;
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
/* write twice to the common log file */
sprintf(buf, "i:%d process:%ld ", i, (long)getpid());
write(fd, buf, strlen(buf));
sprintf(buf, "parent:%ld child:%ld\n", (long)getppid(), (long)childpid);
write(fd, buf, strlen(buf));
return 0;
}
Exercise 4.41
Put sleep(1); after the first write function in Program 4.19 and run it again. Now what happens?
Answer:
Most likely, each process outputs the values of the first two integers and then each process outputs the last two integers.
Exercise 4.42
Copy chainopenfork.c to a file called chainforkopen.c and move the code to open the file after the loop that forks the children. How does the behavior of chainforkopen.c differ from that of chainopenfork.c?
Answer:
Each process now has a different system file table entry, and so each process has a different file offset. Because of O_TRUNC, each open deletes what was previously written to the file. Each process starts writing from the beginning of the file, overwriting what the other processes have written. The last process to write has control of the final file contents.
Exercise 4.43
Run chainforkopen several times and see if it generates the same order of the output each time. Which process was executed last? Do you see anything unusual about the contents of the file?
Answer:
The process that outputs last may be different on different systems. If the last process writes fewer bytes than another process, the file contains additional bytes after the line written by the last process.
If independent processes open the same log file, the results might be similar to that of Exercise 4.43. The last process to output overwrites what was previously written. One way to try to solve this problem is to call lseek to move to the end of the file before writing.
Exercise 4.44
Copy chainforkopen.c to a file called chainforkopenseek.c. Add code before each write to perform lseek to the end of the file. Also, remove the O_TRUNC flag from CREATE_FLAGS. Run the program several times and observe the behavior. Use a different file name each time.
Answer:
The lseek operation works as long as the process does not lose the CPU between lseek and write. For fast machines, you may have to run the program many times to observe this behavior. You can increase the likelihood of creating mixed-up output, by putting sleep(1); between lseek and write.
If a file is opened with the O_APPEND flag, then it automatically does all writes to the end of the file.
Exercise 4.45
Copy chainforkopen.c to a file called chainforkappend.c. Modify the CREATE_FLAGS constant by replacing O_TRUNC with O_APPEND. Run the program several times, possibly inserting sleep(1) between the write calls. What happens?
Answer:
The O_APPEND flag solves the problem of processes overwriting the log entries of other processes, but it does not prevent the individual pieces written by one process from being mixed up with the pieces of another.
Exercise 4.46
Copy chainforkappend.c to a file called chainforkonewrite.c. Combine the pair of sprintf calls so that the program uses a single write call to output its information. How does the program behave?
Answer:
The output is no longer interleaved.
Exercise 4.47
Copy chainforkonewrite.c to a file called chainforkfprintf.c. Replace open with a corresponding fopen function. Replace the single write with fprintf. How does the program behave?
Answer:
The fprintf operation causes the output to be written to a buffer in the user area. Eventually, the I/O subsystem calls write to output the contents of the buffer. You have no control over when write is called except that you can force a write operation by calling fflush. Process output can be interleaved if the buffer fills in the middle of the fprintf operation. Adding sleep(1); shouldn't cause the problem to occur more or less often.
4.9.1 An atomic logging library
To make an atomic logger, we have to use a single write call to output information that we want to appear together in the log. The file must be opened with the O_APPEND flag. Here is the statement about the O_APPEND flag from the write man page that guarantees that the writing is atomic if we use the O_APPEND flag.
If the O_APPEND flag of the file status flags is set, the file offset will be set to the end of the file prior to each write and no intervening file modification operation will occur between changing the file offset and the write operation.
In the examples given here, it is simple to combine everything into a single call to write, but later we encounter situations in which it is more difficult. Appendix D.1 contains a complete implementation of a module that can be used with a program in which atomic logging is needed. A program using this module should include Program 4.20, which contains the prototypes for the publicly accessible functions. Note that the interface is simple and the implementation details are completely hidden from the user.
Program 4.20 atomic_logger.h
The include file for the atomic logging module.
int atomic_log_array(char *s, int len);
int atomic_log_clear();
int atomic_log_close();
int atomic_log_open(char *fn);
int atomic_log_printf(char *fmt, ...);
int atomic_log_send();
int atomic_log_string(char *s);
The atomic logger allows you to control how the output of programs that are running on the same machine is interspersed in a log file. To use the logger, first call atomic_log_open to create the log file. Call atomic_log_close when all logging is completed. The logger stores in a temporary buffer items written with atomic_log_array, atomic_log_string and atomic_log_printf. When the program calls atomic_log_send, the logger outputs the entire buffer, using a single write call, and frees the temporary buffers. The atomic_log_clear operation frees the temporary buffers without actually outputting to the log file. Each function in the atomic logging library returns 0 if successful. If unsuccessful, these functions return 1 and set errno.
The atomic logging facility provides three formats for writing to the log. Use atomic_log_array to write an array of a known number of bytes. Use atomic_log_string to log a string. Alternatively, you can use atomic_log_printf with a syntax similar to fprintf. Program 4.21 shows a version of the process chain that uses the first two forms for output to the atomic logger.
Exercise 4.48
How would you modify Program 4.21 to use atomic_log_printf?
Answer:
Eliminate the buf array and replace the four lines of code involving sprintf, atomic_log_array and atomic_log_string with the following.
atomic_log_printf("i:%d process:%ld ", i, (long)getpid());
atomic_log_printf("parent:%ld child ID:%ld\n",
(long)getppid(), (long)childpid);
Alternatively use the following single call.
atomic_log_printf("i:%d process:%ld parent:%ld child:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
Program 4.21 chainforkopenlog.c
A program that uses the atomic logging module of Appendix D.1.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "atomic_logger.h"
#define BUFSIZE 1024
int main (int argc, char *argv[]) {
char buf[BUFSIZE];
pid_t childpid = 0;
int i, n;
if (argc != 3){ /* check for valid number of command-line arguments */
fprintf (stderr, "Usage: %s processes filename\n", argv[0]);
return 1;
}
n = atoi(argv[1]); /* create a process chain */
for (i = 1; i < n; i++)
if (childpid = fork())
break;
if (childpid == -1) {
perror("Failed to fork");
return 1;
}
if (atomic_log_open(argv[2]) == -1) { /* open atomic log file */
fprintf(stderr, "Failed to open log file");
return 1;
}
/* log the output, using two different forms */
sprintf(buf, "i:%d process:%ld", i, (long)getpid());
atomic_log_array(buf, strlen(buf));
sprintf(buf, " parent:%ld child:%ld\n", (long)getppid(), (long)childpid);
atomic_log_string(buf);
if (atomic_log_send() == -1) {
fprintf(stderr, "Failed to send to log file");
return 1;
}
atomic_log_close();
return 0;
}
Exercise 4.49
Modify Program 4.19 to open an atomic log file after forking the children. (Do not remove the other open function call.) Repeat Exercises 4.40 through Exercise 4.47 after adding code to output the same information to the atomic logger as to the original file. Compare the output of the logger with the contents of the file.
Exercise 4.50
What happens if Program 4.19 opens the log file before forking the children?
Answer:
Logging should still be atomic. However, if the parent writes information to the log and doesn't clear it before the fork, the children have a copy of this information in their logging buffers.
Another logging interface that is useful for debugging concurrent programs is the remote logging facility described in detail in Appendix D.2. Instead of logging information being sent to a file, it is sent to another process that has its own environment for displaying and saving the logged information. The remote logging process has a graphical user interface that allows the user to display the log. The remote logger does not have a facility for gathering information from a process to be displayed in a single block in the log file, but it allows logging from processes on multiple machines.
|
4.10 Exercise: A cat Utility
The cat utility has the following POSIX specification[52].
NAME
cat - concatenate and print files
SYNOPSIS
cat [-u] [file ...]
DESCRIPTION
The cat utility shall read files in sequence and shall write
their contents to the standard output in the same sequence.
OPTIONS
The cat utility shall conform to the Base Definitions volume
of IEEE STd 1003.1-2001, Section 12.2, Utility Syntax Guidelines.
The following option shall be supported:
-u Write bytes from the input file to the standard output
without delay as each is read
OPERANDS
The following operand shall be supported:
file A pathname of an input file. If no file operands are
specified, the standard input shall be used. If a file
is '-', the cat utility shall read from the standard
input at that point in the sequence. The cat utility
shall not close and reopen standard input when it is
referenced in this way, but shall accept multiple
occurrences of '-' as a file operand.
STDIN
The standard input shall be used only if no file operands are
specified, or if a file operand is '-'. See the INPUT FILES
section.
INPUT FILES
The input files can be any file type.
ENVIRONMENT VARIABLES
(.... a long section omitted here ....)
ASYNCHRONOUS EVENTS
Default.
STDOUT
The standard output shall contain the sequence of bytes read from
the input files. Nothing else shall be written to the standard
output.
STDERR
The standard error shall be used only for diagnostic messages.
OUTPUT FILES
None.
EXTENDED DESCRIPTION
None.
EXIT STATUS
The following exit values shall be returned:
0: All input files were output successfully.
>0 An error occurred.
CONSEQUENCES OF ERRORS
Default.
The actual POSIX description continues with other sections, including APPLICATION USAGE, EXAMPLES and RATIONALE.
4.11 Additional Reading
Advanced Programming in the UNIX Environment by Stevens [112] has an extensive discussion of UNIX I/O from a programmer's viewpoint. Many books on Linux or UNIX programming also cover I/O. The USENIX Conference Proceedings are a good source of current information on tools and approaches evolving under UNIX.
|
|
|
|
|
|
|
|
|
|
|
| |

 LINUX
LINUX 
 Books
Books
