
Configuration
Before describing the various configuration interfaces, I should point out that it is highly recommended to run defconfig before doing anything else. I describe exactly why later in this section, but, for now, suffice it to say that doing so will give you a UML configuration that is much more likely to boot and run.
There are a variety of kernel configuration interfaces, ranging from the almost completely hands-off oldconfig to the graphical and fairly user-friendly xconfig. Here are the major choices.
Clicking repeatedly on an option causes it to cycle through its possible settings. Normally, these choices are Enable versus Disable or Enable versus Modular versus Disable. Enable means that the option is built into the final kernel binary, Disable means that it's simply turned off, and Modular means that the option is compiled into a kernel module that can be inserted into the kernel at some later point. Some options have numeric or string values. Double-clicking on these opens a little pane in which you can type a new value. The main menu for the UML configuration is shown in Figure 11.1.
menuconfig presents the same menu organization as text in your terminal window. Navigation is done by using the up and down arrow keys and by typing the highlighted letters as shortcuts. The Tab key cycles around the Select, Exit, and Help buttons at the bottom of the window. Choosing Select enters a submenuExit leaves it and returns to the parent menu. Help displays the help for the current option. Hitting the spacebar will cycle through the settings for the current option. Empty brackets next to an option mean that it is disabled. An asterisk in the brackets means that it is enabled, and an "M" means that it is a module. When you are done choosing options, you select the Exit button repeatedly until you exit the top-level menu and are asked whether to keep this configuration or discard it. Figure 11.2 shows menuconfig running in an xterm window displaying the main UML-specific configuration menu.
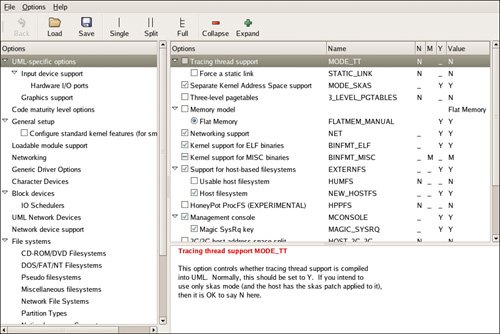
config is the simplest of the interactive configuration options. It asks you about every configuration option, one at a time. On a native x86 kernel, this is good for a soul-deadening afternoon. For UML, it's not nearly as bad, but this is still not the configuration method of choice. Some lesser-known configuration choices are useful in some situations. gconfig is a graphical configurator that's similar to xconfig. It's based on the GTK toolkit (which underlies the GNOME desktop environment) rather than the QT toolkit (which underlies the KDE desktop environment) as xconfig is. gconfig's behavior is nearly the same as xconfig's with the exception that checkboxes invite you to click on them, but they do nothing when you do. Instead, there are N, M, and Y columns on the right, as shown in Figure 11.3, which you can click in order to set options.
oldconfig is one of the mostly noninteractive configurators. It gives you a default configuration, with values taken from .config in the kernel tree if it's there, from the host's own configuration, or from the architecture's default configuration when all else fails. It does ask about options for which it does not have defaults. randconfig provides a random configuration. This is used to test the kernel build rather than to produce a useful kernel. defconfig provides a default configuration, using the defaults provided by the architecture. allmodconfig provides a configuration in which everything that can be configured as a module is. This is used either to get the smallest possible kernel binary for a given configuration or to test the kernel build procedure. allnoconfig provides a configuration with everything possible disabled. This is also used for kernel build testing rather than for producing useful kernels.
One important thing to remember throughout this process is that any time you run make in a UML pool, it is essential to put ARCH=um on the command line. This is because UML is a different architecture from the host, just like PowerPC (ppc) is a different architecture from PC (i386). UML's architecture name in the kernel pool is um. I dropped the l from uml because I considered it redundant in a Linux kernel pool.
Because the kernel build procedure will build a kernel for the machine on which it's running unless it's told otherwise, we need to tell it otherwise. This is the purpose of the ARCH=um switchit tells the kernel build procedure to build the um architecture, which is UML, rather than the host architecture, which is likely i386.
If you forget to add the ARCH=um switch at any point, as all of us do once in a while, the tree is likely to be polluted with host architecture data. I clean it up like this:
host% make mrproper
host% make mrproper ARCH=um
This does a full clean of both UML and the host architectures so that everything that was changed is cleaned up. Then, restart by redoing the configuration.
So, with that in mind, you can configure the UML kernel with something as simple as this:
host% make defconfig ARCH=um
This will give you the default configuration, which is recommended if this is the first time you are building UML. In this case, feel free to skip over to where we build UML. Otherwise, I'm going to talk about a number of UML-specific configuration options that are useful to know.
I recommend starting with defconfig before fine-tuning the UML configuration with another configurator. This is because, when starting with a clean tree, the other configurators look for a default configuration to start with. Unfortunately, they look in /boot and find the configuration for the host kernel, which is entirely unsuitable for UML. Using a configuration that started like this is likely to give you a UML that is missing many essential drivers and won't boot. Running defconfig as the first step, before anything else, will start you off with the default UML configuration. This configuration will boot, and the configuration you end up with after customizing it will likely boot as well. If it doesn't, you know what configuration changes you made and which are likely to have caused the problem.
Useful Configuration Options
Execution Mode-Specific Options
A number of configuration options are related to UML's execution mode. These are largely associated with tt mode, which may not exist by the time you read this. But it may still be present, and you may have to deal with a version of UML that has it.
MODE_TT and MODE_SKAS are the main options controlling UML's execution mode. They decide whether support for tt and skas modes, respectively, are compiled into the UML kernel. skas0 mode is part of MODE_SKAS. With MODE_TT disabled, tt mode is not available. Similarly, with MODE_SKAS disabled, skas3 and skas0 modes are not available. If you know you don't need one or the other, disabling an option will result in a somewhat smaller UML kernel. Having both enabled will produce a UML binary that tests the host's capabilities at runtime and chooses its execution mode accordingly. Given a UML with skas0 support, MODE_TT really isn't needed since skas0 will run on a standard, unmodified host. This used to be the rationale for tt mode, but skas0 mode makes it obsolete. At this point, the only reason for tt mode is to see if a UML problem is skas specific. In that case, you'd force UML to run in tt mode and see if the problem persists. Aside from this, MODE_TT can be safely disabled. STATIC_LINK forces the build to produce a statically linked binary. This is an option only when MODE_TT is disabled because a UML kernel with tt mode compiled in must be statically linked. With tt mode absent, the UML kernel is linked dynamically by default. However, as we saw in the last chapter, a statically linked binary is sometimes useful, as it simplifies setting up a chroot jail for UML. NEST_LEVEL makes it possible to run one UML inside another. This requires a configuration option because UML maps code and data into its own process address spaces in tt and skas0 modes. In tt mode, the entire UML kernel is present. In skas0 mode, there are just the two stub pages. When the UML process is another instance of UML, they will both want to load that data at the same location in the address space unless something is done to change that. NEST_LEVEL changes that. The default value is 0. By changing it to 1, you will build a UML that can run inside another UML instance. It will map its data lower in its process address spaces than the outer UML instance, so they won't conflict with each other. This is a total nonissue with skas3 mode since the UML kernel and its processes are in different address spaces. You can run a skas3 UML inside another UML without needing to specially configure either one. HOST_2G_2G is necessary for running a tt or skas0 UML on hosts that have the 2GB/2GB address space split. With this option enabled on the host, the kernel occupies the upper 2GB of the address space rather than the usual 1GB. This is uncommon but is sometimes done when the host kernel needs more address space for itself than the 1GB it gets by default. This allows the kernel to directly access more physical memory without resorting to Highmem. The downside of this is that processes get only the lower 2GB of address space, rather than the 3GB they get normally. Since UML puts some data into the top of its process address spaces in both tt and skas0 modes, it will try to access part of the kernel's address space, which is not allowed. The HOST_2G_2G option makes this data load into the top of a 2GB address space. CMDLINE_ON_HOST is an option that makes UML management on the host slightly easier. In tt mode, UML will make the process names on the host reflect the UML processes running in them, making it easy to see what's happening inside a UML from the host. This is accomplished through a somewhat nasty trick that ensures there is space on the initial UML stack to write this information so that it will be seen on the host. However, this trick, which involves UML changing its arguments and exec-ing itself, confuses some versions of gdb and makes it impossible to debug UML. Since this behavior is specific to tt mode, it is not needed when running in skas mode, even if tt mode support is present in the binary. This option controls whether the exec takes place. Disabling it will disable the nice process names on the host, but those are present only in tt mode anyway. PT_PROXY is a tt modespecific debugging option. Because of the way that UML uses ptrace in tt mode, it is difficult to use gdb to debug it. The tracing thread uses ptrace on all of the other threads, including when they are running in the kernel. gdb uses ptrace in order to control the process it has debugged, and two processes can't simultaneously use ptrace on a single process. In spite of this, it is possible to run gdb on a UML thread, in a clever but fairly nasty way. The UML tracing thread uses ptrace on gdb, intercepting its system calls. It emulates some of them in order to fake gdb into believing that it has successfully attached to a UML process and is controlling it. In reality, gdb isn't attached to or controlling anything. The UML tracing thread is actually controlling the UML thread, intercepting gdb operations and performing them itself. This behavior is enabled with the PT_PROXY operation. It gets its name from the ptrace operation proxying that the UML tracing thread does in order to enable running gdb on a tt mode UML. At runtime, this is invoked with the debug switch. This causes the tracing thread to start an xterm window with the captive gdb running inside it. Debugging a skas mode UML with gdb is much simpler. You can simply start UML under the control of gdb and debug it just as you would any other process. The KERNEL_HALF_GIGS option controls the amount of address space that a tt mode UML takes for its own use. This is similar to the host 2GB/2GB option mentioned earlier, and the motivation is the same. A larger kernel virtual address space allows it to directly access more physical memory without resorting to Highmem. The value for this option is an integer, which specifies how many half-gigabyte units of address space that UML will take for itself. The default value is 1increasing to 2 would cause UML to take the upper 1GB, rather than .5GB, for itself. In skas mode, with tt mode disabled, this is irrelevant. Since the kernel is in its own address space, it has a full process address space for its own use, and there's no reason to want to carve out a large chunk of its process address spaces.
Generic UML Options
A number of other configuration options don't depend on UML's execution mode. Some of these are shared with other Linux architectures but differ in interesting ways, while others are unique to UML.
The SMP and NR_CPUS options have the same meaning as with any other architectureSMP controls whether the UML kernel will be able to support multiple processors, and NR_CPUS controls the maximum number of processors the kernel can use. However, SMP on UML is different enough from SMP on physical hardware to warrant a discussion. Having an SMP virtual machine is completely independent from the host being SMP. An SMP UML instance has multiple virtual processors, which do not map directly to physical processors on the host. Instead, they map directly to processes on the host. If the UML instance has more virtual processors than the host has physical processors, the virtual processors will just be multiplexed on the physical ones by the host scheduler. Even if the host has the same or a greater number of processors than the UML instance, it is likely that the virtual processors will get timesliced on physical processors anyway, due to other demands on the host. An SMP UML instance can even be run on a uniprocessor host. This will lose the concurrency that's possible on an SMP host, but it does have its uses. Since having multiple virtual processors inside the UML instance translates into an equal number of potentially running processes on the host, a greater number of virtual processors provides a greater call on the host's CPU consumption. A four-CPU UML instance will be able to consume twice as much host CPU time as a two-CPU instance because it has twice as many processes on the host possibly running. Running an SMP instance on a host with a different number of processors is also useful for kernel debugging. The multiplexing of virtual processors onto physical ones can open up timing holes that wouldn't appear on a physical system. This can expose bugs that would be very hard or impossible to find on physical hardware. NR_CPUS limits the maximum number of processors that an SMP kernel will support. It does so by controlling the size of some internal data structures that have NR_CPUS elements. Making NR_CPUS unnecessarily large will waste some memory and maybe some CPU time by making the CPU caches less effective but is otherwise harmless. The HIGHMEM option also means the same thing as it does on the host. If you need more physical memory than can be directly mapped into the kernel's address space, what's left over must be Highmem. It can't be used for as many purposes as the directly mapped memory, and it must be mapped into the kernel's address space when needed and unmapped when it's not. Highmem is perfect for process memory on the host since that doesn't need to be mapped into the kernel's address space. This is true for tt mode UML instances, as well, since they follow the host's model of having the kernel occupy its process address spaces. However, for skas UML instances, which are in a different address space entirely, kernel access to process memory that has been mapped from the Highmem area is slow. It has to temporarily map the page of memory into its address space before it has access to it. This is one of the few examples of an operation that is faster in tt mode than in skas mode. The mapping operation is also slower for UML than for the host, making the performance cost of Highmem even greater. However, the need for Highmem is less because of the greater amount of physical memory that can be directly mapped into the skas kernel address space. The KERNEL_STACK_ORDER option is UML-specific and is somewhat specialized. It was introduced in order to facilitate running valgrind on UML. valgrind creates larger than normal signal frames, and since UML receives interrupts as signals, signal frames plus the normal call stack have to fit on a kernel stack. With valgrind, they often didn't, due to the increased signal frame size. This was later found to be useful in a few other cases. Some people doing kernel development in UML discovered that their code was overflowing kernel stacks. Increasing the KERNEL_STACK_ORDER parameter is useful in demonstrating that their system crashes are due to stack overflows and not something else, and to allow them to continue working without immediately needing to reduce their stack usage. By default, 3_LEVEL_PGTABLES is disabled on 32-bit architectures and enabled on 64-bit architectures. It is not available to be disabled in the 64-bit case, but it can be enabled for a 32-bit architecture. Doing this provides UML with the capability to access more than 4GB of memory, which is the two-level pagetable limit. This provides a way to experiment with very large physical memory UML instances on 32-bit hosts. However, the portion of this memory that can't be directly mapped will be Highmem, with the performance penalties that I have already mentioned. The UML_REAL_TIME_CLOCK option controls whether time intervals within UML are made to match real time as much as possible. This matters because the natural way for time to progress within a virtual machine is virtuallythat is, time progresses within the virtual machine only when it is actually running on the host. So, if you start a sleep for two seconds inside the UML instance and the host does other things for a few seconds before scheduling the instance, then five seconds or so will pass before the sleep ends. This is correct behavior in a sensethings running within the UML instance will perceive that time flows uniformly, that is, they will see that they can consistently do about the same amount of work in a unit of time. Without this, in the earlier example, a process would perceive the sleep ending immediately because it did no work between the start of the sleep and its end since the host had scheduled something else to run. In another sense, this is incorrect behavior. UML instances often have people interacting with them, and those people exist in real time. When someone asks for a five-second pause, it really should end in five real seconds, not five virtual ones. This behavior has actually broken tests. Some Perl regression tests run timers and fail if they take too long to expire. They measure the time difference by using gettimeofday, which is tied to the host's gettimeofday. When gettimeofday is real time and interval timers are virtual, there is bound to be a mismatch. So, the UML_REAL_TIME_CLOCK option was added to fix this problem. It is enabled by default since that is the behavior that almost everyone wants. However, in some cases it's not desired, so it is a configuration option, rather than hard coded. Intervals are measured by clock ticks, which on UML are timer interrupts from the host. The real-time behavior is implemented by looking at how many ticks should have happened between the last tick and the current one. Then the generic kernel's timer routine is called that many times. This makes the UML clock catch up with the real one, but it does so in spurts. Time stops for a while, and then it goes forward very quickly to catch up. When you are debugging UML, you may have it stopped at a gdb prompt for a long time. In this case, you don't want the UML instance to spend time in a loop calling the timer routine. For short periods of time, this isn't noticeable. However, if you leave the debugger for a number of hours before continuing it, there will be a noticeable pause while the virtual clock catches up with the real one. Another case is when you have a UML instance running on a laptop that is suspended overnight. When you wake it up, the UML instance will spend a good amount of time catching up with the many hours of real time it missed. In this case, the UML instance will appear to be hung until it catches up. If either of these situations happens enough to be annoying, and real-time timers aren't critical, you can disable this option.
Virtual Hardware Options
UML has a number of device drivers, each with its own configuration option. I'm going to mention a few of the less obvious ones here.
The MCONSOLE option enables the MConsole driver, which is required in order to control and configure the instance through an MConsole client. This is on by default and should remain enabled unless you have a good reason to not want it. The MAGIC_SYSRQ option is actually a generic kernel option but is related to MCONSOLE tHRough the MConsole sysrq command. Without MAGIC_SYSRQ enabled, the sysrq command won't work. The UML_RANDOM option enables a "hardware" random number generator for UML. Randomness is often a problem for a server that needs random numbers to seed ssh or https sessions. Desktop machines can rely on the user for randomness, such as the time between keystrokes or mouse movements. Physical servers rely on randomness, such as the time between I/O interrupts, from their drivers, which is sometimes insufficient. Virtual machines have an even harder time since they have fewer sources of randomness than physical machines. It is not uncommon for ssh or https key generation to hang for a while until the UML instance acquires enough randomness. The UML random number generator has access to all of the host's randomness from the host's /dev/random, rather than having to generate it all itself. If the host has problems providing enough random numbers, key generation and other randomness-consuming operations will still hang. But they won't hang for as long as they would without this driver. In order to use this effectively, you need to run the hwrng tools within the UML instance. This package reads randomness from /dev/hwrng, which is attached to this driver, and feeds it into /dev/random, from where the randomness is finally consumed. The MMAPPER option implements a virtual iomem driver. This allows a host file to be used as an I/O area that is mapped into the UML instance's physical memory. This specialized option is mostly used for writing emulated drivers and cluster interconnects. The WATCHDOG and UML_WATCHDOG options implement a "hardware" watchdog for UML. The "hardware" portion of it is a process running outside of UML. This process is started when the watchdog device is opened within the UML instance and communicates with the driver through a pipe. It expects to receive some data through that pipe at least every 60 seconds. This happens when the process inside the UML instance that opened the device writes to it. If the external watchdog process doesn't receive input within 60 seconds, it presumes that the UML instance is hung and takes measures to deal with it. If it was told on its command line that there is an MConsole notify socket, it will send a "hang" notification there. (We saw this in Chapter 8.) Otherwise, it will kill the UML instance itself by sending the main process a sufficiently severe signal to shut it down.
Networking
A number of networking options control how the UML instance can exchange packets with the host and with other UML instances. UML_NET enables UML networkingit must be enabled for any network drivers to be available at all. The rest each control a particular packet transport, and their names should be self-explanatory:
UML_NET_ETHERTAP UML_NET_TUNTAP UML_NET_SLIP UML_NET_DAEMON UML_NET_MCAST UML_NET_PCAP UML_NET_SLIRP
UML_NET and all of the transport options are enabled by default. Disabling ones that will not be needed will save a small amount of code.
Consoles
A similar set of console and serial line options control how they can be connected to devices on the host. Their names should also be self explanatory:
NULL_CHAN PORT_CHAN PTY_CHAN TTY_CHAN XTERM_CHAN
The file descriptor channel, which, by default, the main console uses to attach itself to stdin and stdout, is not configurable. It is always on because people were constantly disabling it and sending mail to the UML mailing lists wondering why UML wouldn't boot.
There is an option, SSL, to enable UML serial line support. Serial lines aren't much different from consoles, so having them doesn't do much more than add some variety to the device names through which you can attach to a UML instance.
Finally, the default settings for console zero, the rest of the consoles, and the serial lines are all configurable. These values are strings, and describe what host device the UML devices should be attached to. These, and their default values, are as follows:
CON_ZERO_CHAN0,fd:1 CON_CHANxterm SSL_CHANpty
Debugging
I talked about a number of debugging options in the context of tt mode already since they are specific to tt mode. A few others allow UML to be profiled by the gprof and gcov tools. These work only in skas mode since a tt mode UML instance breaks assumptions made by them.
The GPROF option enables gprof support in the UML build, and the GCOV option similarly enables gcov support. These change the compilation flags so as to tell the compiler to generate the code needed for the profiling. In the case of gprof, the generated code tracks procedure calls and keeps statistical information about where the UML instance is spending its time. The code generated for gcov tracks what blocks of code have been executed and how many times they were executed.
A UML profiling run is just like any other process. You start it, exercise it for a while, stop it, and generate the statistics you want. In the case of UML, the profiling starts when UML boots and ends when it shuts down. Running gprof or gcov after that is exactly like running it on any other application.
Compilation
Now that the UML has been configured, it is time to build it. On 2.6 hosts, we need to take care of one more detail. If the UML instance is to be built to use AIO support on the host, a header file, include/ linux/aio_abi.h in the UML tree, must be copied to /usr/ include/linux/aio_abi.h on the host.
With this taken care of, building UML is as simple as this:
If you have built Linux kernels before, you will see that the UML build is very similar to what you have seen before. When it finishes, you will get two identical files, called vmlinux and linux. In fact, they are hard links to the same file. Traditionally, the UML build produced a file called linux rather than the vmlinux or vmlinuz that the kernel build normally produces. I did this on purpose, believing that having the binary be named linux was more intuitive than vmlinux or vmlinuz.
This was true, and most people like the name, but some kernel hackers are very used to an output file named vmlinux. Also, the kernel build became stricter over time, and it became very hard to avoid having a final binary named vmlinux. So, I made the UML build produce the vmlinux file, and as a final step, link the name linux to that file. This way, everyone is happy.
Chapter 12. Specialized UML Configurations
So far we have seen UML instances with fairly normal virtual hardware configurationsthey are similar to common physical machines. Now we will look at using UML to emulate unusual configurations that can't even be approached with common hardware. This includes configurations with lots of devices, such as block devices and network interfaces, many CPUs, and very large physical memory, and more specialized configurations, such as clusters.
By virtualizing hardware, UML makes it easy to simulate these configurations. Virtual devices can be constructed as long as host and UML memory hold out and no built-in software limits are reached. There are no constraints such as those based on the number of slots on a bus or the number of buses on a system.
UML can also emulate hardware you might not even have one instance of. We'll see an example of this when we build a cluster, which will need a shared storage device. Physically, this is a disk that is some-how multiported, either because it is multiported itself or because it's on a shared bus. Either way, this is an expensive, noncommodity device. However, with UML, a shared device is simply a file on the host to which multiple UML instances have access.
Large Numbers of Devices
We'll start by configuring a UML instance with a large number of devices. The reasons for wanting to do this vary. For many people, there is value in looking at /proc/meminfo and seeing an absurdly large amount of memory, or running df and seeing more disk space than you could fit in a room full of disks.
More seriously, it allows you to explore the scalability limits of the Linux kernel and the applications running on it. This is useful when you are maintaining some software that may run into these limits, and your users may have hardware that may do so, but you don't. You can emulate the large configuration to see how your software reacts to it.
You may also be considering acquiring a very large machine but want to know whether it is fully usable by Linux and the applications you envision running on it. UML will let you explore the software limitations. Obviously, any hardware limitations, such as the number of bus slots and controllers and the like, can't be explored in this way.
Network Interfaces
Let's start by configuring a pair of UML instances with a large number of network interfaces. We will boot the two instances, debian1 and debian2, and hot-plug the interfaces into them. So, with the UML instances booted, you do this as follows:
host% for i in `seq 0 127`; do uml_mconsole debian1 \
config eth$i=mcast,,224.0.0.$i; done
host% for i in `seq 0 127`; do uml_mconsole debian2 \
config eth$i=mcast,,224.0.0.$i; done
These two lines of shell configure 128 network interfaces in each UML instance. You'll see a string of OK messages from each of these, plus a lot of console output in the UML instances if kernel output is logged there. Running dmesg in one of the instances will show you something like this:
Netdevice 124 : mcast backend multicast address: \
224.0.0.124:1102, TTL:1
Configured mcast device: 224.0.0.125:1102-1
Netdevice 125 : mcast backend multicast address: \
224.0.0.125:1102, TTL:1
Configured mcast device: 224.0.0.126:1102-1
Netdevice 126 : mcast backend multicast address: \
224.0.0.126:1102, TTL:1
Configured mcast device: 224.0.0.127:1102-1
Netdevice 127 : mcast backend multicast address: \
224.0.0.127:1102, TTL:1
Running ifconfig inside the UML instances will confirm that interfaces eth0 through etH127 now exist. If you're brave, run ifconfig -a. Otherwise, just do some spot-checking:
UML# ifconfig eth120
eth120 Link encap:Ethernet HWaddr 00:00:00:00:00:00
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 \
frame:0
TX packets:0 errors:0 dropped:0 overruns:0 \
carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interrupt:5
This indicates that we indeed have the network interfaces we asked for. I configured them to attach to multicast networks on the host, so they will be used purely to network between the two instances. They can't talk directly to the outside network unless you configure one of the instances with an interface attached to a TUN/TAP device and use it as a gate way. Each of an instance's interfaces is attached to a different host multicast address, which means they are on different networks. So, taken in pairs, the corresponding interfaces on the two instances are on the same network and can communicate with each other.
For example, the two eth0 interfaces are both attached to the host multicast IP address 224.0.0.0 and thus will see each other's packets. The two etH1 interfaces are on 224.0.0.1 and can see each other's packets, but they won't see any packets from the eth0 interfaces.
Next, we configure the interfaces inside the UML instances. I'm going to put each one on a different network in order to correspond to the connectivity imposed by the multicast configuration on the host. The eth0 interfaces will be on the 10.0.0.0/24 network, the etH1 interfaces will be on the 10.0.1.0/24 network, and so forth:
UML1# for i in `seq 0 127`; do ifconfig eth$i 10.0.$i.1/24 up; done
UML2# for i in `seq 0 127`; do ifconfig eth$i 10.0.$i.2/24 up; done
Now the interfaces in the first UML instance are running and have the .1 addresses in their networks, and the interfaces in the second instance have the .2 addresses. Again, some spot-checking will confirm this:
UML1# ifconfig eth75
eth75 Link encap:Ethernet HWaddr FE:FD:0A:00:4B:01
inet addr:10.0.75.1 Bcast:10.255.255.255 \
Mask:255.0.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 \
Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 \
frame:0
TX packets:0 errors:0 dropped:0 overruns:0 \
carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interrupt:5
UML2# ifconfig eth100
eth100 Link encap:Ethernet HWaddr FE:FD:0A:00:64:02
inet addr:10.0.100.2 Bcast:10.255.255.255 \
Mask:255.0.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 \
Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 \
frame:0
TX packets:0 errors:0 dropped:0 overruns:0 \
carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interrupt:5
Let's see if the interfaces work:
UML1# ping 10.0.50.2
PING 10.0.50.2 (10.0.50.2): 56 data bytes
64 bytes from 10.0.50.2: icmp_seq=0 ttl=64 time=56.3 ms
64 bytes from 10.0.50.2: icmp_seq=1 ttl=64 time=15.7 ms
64 bytes from 10.0.50.2: icmp_seq=2 ttl=64 time=16.6 ms
64 bytes from 10.0.50.2: icmp_seq=3 ttl=64 time=14.9 ms
64 bytes from 10.0.50.2: icmp_seq=4 ttl=64 time=16.4 ms
--- 10.0.50.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max = 14.9/23.9/56.3 ms
You can try some of the others by hand or check all of them with a bit of shell such as this:
UML1# for i in `seq 0 127`; do ping -c 1 10.0.$i.2 ; done
This exercise is fun and interesting, but what's the practical use? We have demonstrated that there appears to be no limit, aside from memory, on how many network interfaces Linux will support. To tell for sure, we would need to look at the kernel source. But if you are seriously asking this sort of question, you probably have some hardware limit in mind, and setting up some virtual machines is a quick way to tell whether the operating system or the networking tools have a lower limit.
By poking around a bit more, we can see that other parts of the system are being exercised. Taking a look at the routing table will show you one route for every device we configured. An excerpt looks like this:
UML1# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric \
Ref Use Iface
10.0.20.0 0.0.0.0 255.255.255.0 U 0 \
0 0 eth20
10.0.21.0 0.0.0.0 255.255.255.0 U 0 \
0 0 eth21
10.0.22.0 0.0.0.0 255.255.255.0 U 0 \
0 0 eth22
10.0.23.0 0.0.0.0 255.255.255.0 U 0 \
0 0 eth23
This would be interesting if you wanted a large number of networks, rather than simply a large number of interfaces.
Similarly, we are exercising the arp cache more than usual. Here is an excerpt:
UML# arp -an
? (10.0.126.2) at FE:FD:0A:00:7E:02 [ether] on eth126
? (10.0.64.2) at FE:FD:0A:00:40:02 [ether] on eth64
? (10.0.110.2) at FE:FD:0A:00:6E:02 [ether] on eth110
? (10.0.46.2) at FE:FD:0A:00:2E:02 [ether] on eth46
? (10.0.111.2) at FE:FD:0A:00:6F:02 [ether] on eth111
This all demonstrates that, if there are any hard limits in the Linux networking subsystem, they are reasonably high. A related but different question is whether there are any problems with performance scaling to this many interfaces and networks. If you are concerned about this, you probably have a particular application or workload in mind and would do well to run it inside a UML instance, varying the number of interfaces, networks, routes, or whatever its performance depends on.
For demonstration purposes, since I lack such a workload, I will use standard system tools to see how well performance scales as the number of interfaces increases.
Let's look at ping times as the number of interfaces increases. I'll shut down all of the Ethernet devices and bring up an increasing number on each test. The first two rounds look like this:
UML# export n=0 ; for i in `seq 0 $n`; \
do ifconfig eth$i 10.0.$i.1/24 up; done ; \
for i in `seq 0 $n`; do ping -c 2 10.0.$i.2 ; done ; \
for i in `seq 0 $n`; do ifconfig eth$i down ; done
PING 10.0.0.2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: icmp_seq=0 ttl=64 time=36.0 ms
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=4.9 ms
--- 10.0.0.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 4.9/20.4/36.0 ms
UML# export n=1 ; for i in `seq 0 $n`; \
do ifconfig eth$i 10.0.$i.1/24 up; done ; \
for i in `seq 0 $n`; do ping -c 2 10.0.$i.2 ; \
done ; for i in `seq 0 $n`; do ifconfig eth$i down ; done
PING 10.0.0.2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: icmp_seq=0 ttl=64 time=34.0 ms
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=4.9 ms
--- 10.0.0.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 4.9/19.4/34.0 ms
PING 10.0.1.2 (10.0.1.2): 56 data bytes
64 bytes from 10.0.1.2: icmp_seq=0 ttl=64 time=35.4 ms
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=5.0 ms
--- 10.0.1.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 5.0/20.2/35.4 ms
The two-interface ping times are essentially the same as the one-interface times. We are looking at how the times change, rather than their actual values compared to ping times on the host. A virtual machine will necessarily have different performance characteristics than a physical one, but they should scale similarly.
We see the first ping taking much longer than the second because of the arp request and response that have to occur before any ping requests can be sent out. The sending system needs to determine the Ethernet MAC address corresponding to the IP address you are pinging. This requires an arp request to be broadcast and a reply to come back from the target host before the actual ping request can be sent. The second ping time measures the actual time of a ping round trip.
I won't bore you with the full output of repeating this, doubling the number of interfaces at each step. However, this is typical of the times I got with 128 interfaces:
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 6.7/22.7/38.8 ms
PING 10.0.123.2 (10.0.123.2): 56 data bytes
64 bytes from 10.0.123.2: icmp_seq=0 ttl=64 time=39.1 ms
64 bytes from 10.0.123.2: icmp_seq=1 ttl=64 time=8.9 ms
--- 10.0.123.2 ping statistics ---
With 128 interfaces, both ping times are around 4 ms greater than with one. This suggests that the slowdown is in the IP routing code since this is exercised once for each packet. The arp requests don't go through the IP stack, so they wouldn't be affected by any slowdowns in the routing code.
The 4-ms slowdown is comparable to the fastest ping time, which was around 5 ms, suggesting that the routing overhead with 128 networks and 128 routes is comparable to the ping round trip time.
In real life, you're unlikely to be interested in how fast pings go when you have a lot of interfaces, routes, arp table entries, and so on. You're more likely to have a workload that needs to operate in an environment with these sorts of scalability requirements. In this case, instead of running pings with varying numbers of interfaces, you'd run your workload, changing the number of interfaces as needed, and make sure it behaves acceptably within the range you plan for your hardware.
Memory
Memory is another physical asset that a system may have a lot of. Even though it's far cheaper than it used to be, outfitting a machine with many gigabytes is still fairly pricy. You may still want to emulate a large-memory environment before splashing out on the actual physical article. Doing so may help you decide whether your workload will benefit from having lots of memory, and if so, how much memory you need. You can determine your memory sweet spot so you spend enough on memory but not too much.
You may have guessed by now that we are going to look at large-memory UML instances, and you'd be right. To start with, here is /proc/meminfo from a 64GB UML instance:
UML# more /proc/meminfo
MemTotal: 65074432 kB
MemFree: 65048744 kB
Buffers: 824 kB
Cached: 9272 kB
SwapCached: 0 kB
Active: 5252 kB
Inactive: 6016 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 65074432 kB
LowFree: 65048744 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 112 kB
Writeback: 0 kB
Mapped: 2772 kB
Slab: 4724 kB
CommitLimit: 32537216 kB
Committed_AS: 4064 kB
PageTables: 224 kB
VmallocTotal: 137370258416 kB
VmallocUsed: 0 kB
VmallocChunk: 137370258416 kB
This output is from an x86_64 UML on a 1GB host. Since x86_64 is a 64-bit architecture, there is plenty of address space for UML to map many gigabytes of physical memory. In contrast, x86, as a 32-bit architecture, doesn't have sufficient address space to cleanly handle large amounts of memory. On x86, UML must use the kernel's Highmem support in order to handle greater than about 3GB of physical memory. This works, but, as I discussed in Chapter 9, there's a large performance penalty to pay because of the requirement to map the high memory into low memory where the kernel can directly access it.
On an x86 UML instance, the meminfo output would have a large amount of Highmem in the HighTotal and HighFree fields. On 64-bit hosts, this is unnecessary, and all the memory appears as LowTotal and LowFree. The other unusual feature here is the even larger amount of vmalloc space, 137 terabytes. This is simply the address space that the UML instance doesn't have any other use for.
There has to be more merit to large-memory UML instances than impressive numbers in /proc/meminfo. That's enough for me, but other people seem to be more demanding. A more legitimate excuse for this sort of exercise is to see how the performance of a workload or application will change when given a large amount of memory.
In order to do this, we need to be able to judge the performance of a workload in a given amount of memory. On a physical machine, this would be a matter of running it and watching the clock on the nearest wall. Having larger amounts of memory improves performance by allowing more data to be stored in memory, rather than on disk. With insufficient memory, the system has to swap data to disk when it's unused and swap it back in when it is referenced again. Some intelligent applications, such as databases, do their own caching based on the amount of memory in the system. In this case, the trade-off is usually still against storing data in memory. For example, a database will read more index data from disk when it has enough memory, speeding lookups.
In the example above, the 64GB UML instance is running on a 1GB host. It's obviously not manufacturing 63GB of memory, so that extra memory is ultimately backed by disk. You can run applications that consume large amounts of memory, and the UML instance will not have to use its own swap. However, since this will exceed the amount of memory on the host, it will start swapping. This means you can't watch the clock in order to decide how your workload will perform with a lot of memory available.
Instead, you need to find a proxy for performance. A proxy is a measurement that can stand in for the thing you are really interested in when that thing can't be measured directly. I've been talking about disk I/O, either by the system swapping or by the application reading in data on its own. So, watching the UML instance's disk I/O is a good way to decide whether the workload's performance will improve. The greater the decrease in disk traffic, the greater the performance improvement you can expect.
As with increasing amounts of any resource, there will be a point of diminishing returns, where adding an increment of memory results in a smaller performance increase than the previous increment did. Graphing performance against memory will typically show a relatively narrow region where the performance levels off. It may still increase, but suddenly at a slower rate than before. This performance "knee" is usually what you aim at when you design a system. Sometimes the knee is too expensive or is unattainable, and you add as much memory as you can, accepting a performance point below the knee. In other cases, you need as much performance as you can get, and you accept the diminishing performance returns with much of the added memory.
As before, I'm going to use a little fake workload in order to demonstrate the techniques involved. I will create a database-like workload with a million small files. The file metadatathe file names, sizes, modification dates, and so onwill stand in for the database indexes, and their contents will stand in for the actual data. I need such a large number of files so that their metadata will occupy a respectable amount of memory. This will allow us to measure how changing the amount of system memory impacts performance when searching these files.
The following procedure creates the million files in three stages, increasing the number by a factor of 100 at each step:
First, copy 1024 characters from /etc/passwd into the file 0 and make 99 copies of it in the files 1 through 99. Next, create a subdirectory, move those files into it, and make 99 copies, creating 10,000 files. Repeat this, creating 99 more copies of the current directory, leaving us with a million files, containing 1024 characters apiece.
UML# mkdir test
UML# cd test
UML# dd if=/etc/passwd count=1024 bs=1 > 0
1024+0 records in
1024+0 records out
UML# for n in `seq 99` ; do cp 0 $n; done
UML# ls
1 14 19 23 28 32 37 41 46 50 55 6 \
64 69 73 78 82 87 91 96
10 15 2 24 29 33 38 42 47 51 56 60 \
65 7 74 79 83 88 92 97
11 16 20 25 3 34 39 43 48 52 57 61 \
66 70 75 8 84 89 93 98
12 17 21 26 30 35 4 44 49 53 58 62 \
67 71 76 80 85 9 94 99
13 18 22 27 31 36 40 45 5 54 59 63 \
68 72 77 81 86 90 95 0
UML# mkdir a
UML# mv * a
mv: cannot move `a' to a subdirectory of itself, `a/a'
UML# mv a 0
UML# for n in `seq 99` ; do cp -a 0 $n; done
UML# mkdir a
UML# mv * a
mv: cannot move `a' to a subdirectory of itself, `a/a'
UML# mv a 0
UML# for n in `seq 99` ; do cp -a 0 $n; done
Now let's reboot in order to get some clean memory consumption data. On reboot, log in, and look at /proc/diskstats in order to see how much data was read from disk during the boot:
UML# cat /proc/diskstats
98 0 ubda 375 221 18798 2860 55 111 1328 150 0 2740 3010
The sixth field (18798, in this case) is the number of sectors read from the disk so far. With 512-byte sectors, this means that the boot read around 9.6MB (9624576 bytes, to be exact).
Now, to see how much memory we need in order to search the metadata of the directory hierarchy, let's run a find over it:
UML# cd test
UML# find. > /dev/null
Let's look at diskstats again, using awk to pick out the correct field so as to avoid taxing our brains by having to count up to six:
UML# awk '{ print $6 }' /proc/diskstats
214294
UML# echo $[ (214214 - 18798) * 512 ]
100052992
This pulled in about 100MB of disk space. Any amount of memory much more than that will be plenty to hold all of the metadata we will need. To check this, we can run the find again and see that there isn't much disk input:
UML# awk '{ print $6 }' /proc/diskstats
215574
UML# find. > /dev/null
UML# awk '{ print $6 }' /proc/diskstats
215670
So, there wasn't much disk I/O, as expected.
To see how much total memory would be required to run this little workload, let's look at /proc/meminfo:
UML# grep Mem /proc/meminfo
MemTotal: 1014032 kB
MemFree: 870404 kB
A total of 143MB of memory has been consumed so far. Anything over that should be able to hold the full set of metadata. We can check this by rebooting with 160MB of physical memory:
UML# cd test
UML# awk '{ print $6 }' /proc/diskstats
18886
UML# find . > /dev/null
UML# awk '{ print $6 }' /proc/diskstats
215390
UML# find . > /dev/null
UML# awk '{ print $6 }' /proc/diskstats
215478
UML# grep Mem /proc/meminfo
MemTotal: 156276 kB
MemFree: 15684 kB
This turns out to be correct. We had essentially no disk reads on the second search and pretty close to no free memory afterward.
We can check this by booting with a lot less memory and seeing if there is a lot more disk activity on the second find. With an 80MB UML instance, there was about 90MB of disk activity between the two searches. This indicates that 80MB was not enough memory for optimal performance in this case, and a lot of data that was cached during the first search had to be discarded and read in again during the second. On a physical machine, this would result in a significant performance loss. On a virtual machine, it wouldn't necessarily, depending on how well the host is caching data. Even if the UML instance is swapping, the performance loss may not be nearly as great as on a physical machine. If the host is caching the data that the UML instance is swapping, then swapping the data back in to the UML instance involves no disk activity, in contrast to the case with a physical machine. In this case, swapping would result in a performance loss for the UML instance, but a lot less than you would expect for a physical system.
We measured the difference between an 80MB UML instance and a 160MB one, which are very far from the 64MB instance with which I started. These memory sizes are easily reached with physical systems today (it would be hard to buy a system with less than many times as much memory as this), and this difference could easily have been tested on a physical system.
To get back into the range of memory sizes that aren't so easily reached with a physical machine, we need to start searching the data. My million files, plus the rest of the files that were already present, occupy about 6.5GB.
With a 1GB UML instance, there are about 5.5GB of disk I/O on the first search and about the same on the second, indicating that this is not nearly enough memory and that there is less actual data being read from the disk than df would have us believe:
UML# awk '{ print $6 }' /proc/diskstats
18934
UML# find . -xdev -type f | xargs cat > /dev/null
UML# awk '{ print $6 }' /proc/diskstats
11033694
UML# find . -xdev -type f | xargs cat > /dev/null
UML# awk '{ print $6 }' /proc/diskstats
22050006
UML# echo $[ (11033694 - 18934) * 512 ]
5639557120
UML# echo $[ (22050006 - 11033694) * 512 ]
5640351744
With a 4GB UML instance, we might expect the situation to improve, but with still a noticeable amount of disk activity on the second search.
UML# awk '{ print $6 }' /proc/diskstats
89944
UML# find / -xdev -type f | xargs cat > /dev/null
UML# awk '{print $6}' /proc/diskstats
13187496
UML# echo $[ 13187496 * 512 ]
6751997952
UML# awk '{print $6}' /proc/diskstats
26229664
UML# echo $[ (26229664 - 13187496) * 512 ]
6677590016
Actually, there is no improvementthere was just as much input during the second search as during the first. In retrospect, this shouldn't be surprising. While a lot of the data could have been cached, it wasn't because the kernel had no way to know that it was going to be used again. So, the data was thrown out in order to make room for data that was read in later.
In situations like this, the performance knee is very sharpyou may see no improvement with increasing memory until the workload's entire data set can be held in memory. At that point, there will likely be a very large performance improvement. So, rather than the continuous performance curve you might expect, you would get something more like a sudden jump at the magic amount of memory that holds all of the data the workload will need.
We can check this by booting a UML instance with more than about 6.5GB of memory. Here are the results with a 7GB instance:
UML# awk '{print $6}' /proc/diskstats
19928
UML# find / -xdev -type f | xargs cat > /dev/null
UML# awk '{print $6}' /proc/diskstats
13055768
UML# echo $[ (13055768 - 19928) * 512 ]
6674350080
UML# find / -xdev -type f | xargs cat > /dev/null
UML# awk '{print $6}' /proc/diskstats
14125882
UML# echo $[ (14125882 - 13055768) * 512 ]
547898368
We had about a half gigabyte of data read in from disk on the second run, which I don't really understand. However, this is far less than we had with the smaller memory instances. On a physical system, this would have translated into much better performance. The UML instance didn't run any faster with more memory because real time is going to depend on real resources. The real resource in this case is physical memory on the host, which was the same for all of these tests. In fact, the larger memory instances performed noticeably worse than the smaller ones. The smallest instance could just about be held in the host's memory, so its disk I/O was just reading data on behalf of the UML instance. The larger instances couldn't be held in the host's memory, so there was that I/O, plus the host had to swap a large amount of the instance itself in and out.
This emphasizes the fact that, in measuring performance as you adjust the virtual hardware, you should not look at the clock on the wall. You should find some quantity within the UML instance that will correlate with performance of a physical system with that hardware running the same workload. Normally, this is disk I/O because that's generally the source for all the data that's going to fill your memory. However, if the data is coming from the network, and increasing memory would be expected to reduce network use, then you would look at packet counts rather than disk I/O.
If you were doing this for real in order to determine how much memory your workload needs for good performance, you wouldn't have created a million small files and run find over them. Instead, you'd copy your actual workload into a UML instance and boot it with varying amounts of memory. A good way to get an approximate number for the memory it needs is to boot with a truly large amount of memory, run the workload, and see how much data was read from disk. A UML instance with that amount of memory, plus whatever it needs during boot, will very likely not need to swap out any data or read anything twice.
However, this approximation may overstate the amount of memory you need for decent performancea good amount of it may be holding data that is not important for performance. So, it would also be a good idea, after checking this first amount of memory to see that it gives you good performance, to decrease the memory size until you see an increase in disk reads. At this point, the UML instance can't hold all of the data that is needed for good performance.
This, plus a bit more, is the amount of memory you should aim at with your physical system. There may be reasons it can't be reached, such as it being too expensive or the system not being able to hold that much. In this case, you need to accept lower than optimal performance, or take some more radical steps such as reworking the application to require less memory or spreading it across several machines, as with a cluster. You can use UML to test this, as well.
Clusters
Clusters are another area where we are going to see increasing amounts of interest and activity. At some point, you may have a situation where you need to know whether your workload would benefit in some way from running on a cluster.
I am going to set up a small UML cluster, using Oracle's ocfs2 to demonstrate it. The key part of this, which is not common as hardware, is a shared storage device. For UML, this is simply a file on the host that multiple UML instances can share. In hardware, this would require a shared bus of some sort, which you quite likely don't have and which would be expensive to buy, especially for testing. Since UML requires only a file on the host, using it for cluster experiments is much more convenient and less expensive.
Getting Started
First, since ocfs2 is somewhat experimental (it is in Andrew Morton's-mm TRee, not in Linus' mainline tree at this writing), you will likely need to reconfigure and rebuild your UML kernel. Second, procedures for configuring a cluster may change, so I recommend getting Oracle's current documentation. The user guide is available from http://oss.oracle.com/projects/ocfs2/.
The ocfs2 configuration script requires that everything related toocfs2 be built as modules, rather than just being compiled into the kernel. This means enabling ocfs2 (in the Filesystems menu) andconfigfs (which is the "Userspace-driven configuration filesystem" item in the Pseudo Filesystems submenu). These options both need to be set to "M."
After building the kernel and modules, you need to copy the modules into the UML filesystem you will be using. The easiest way to do this is to loopback-mount the filesystem on the host (at ./rootfs, in this example) and install the modules into it directly:
host% mkdir rootfs
host# mount root_fs.cluster rootfs -o loop
host# make modules_install INSTALL_MOD_PATH=`pwd`/rootfs
INSTALL fs/configfs/configfs.ko
INSTALL fs/isofs/isofs.ko
INSTALL fs/ocfs2/cluster/ocfs2_nodemanager.ko
INSTALL fs/ocfs2/dlm/ocfs2_dlm.ko
INSTALL fs/ocfs2/dlm/ocfs2_dlmfs.ko
INSTALL fs/ocfs2/ocfs2.ko
host# umount rootfs
You can also install the modules into an empty directory, create a tar file of it, copy that into the running UML instance over the network, and untar it, which is what I normally do, as complicated as it sounds.
Once you have the modules installed, it is time to set things up within the UML instance. Boot it on the filesystem you just installed the modules into, and log into it. We need to install the ocfs2 utilities, which I got from http://oss.oracle.com/projects/ocfs2-tools/. There's a Down-loads link from which the source code is available. You may wish to see if your UML root filesystem already has the utilities installed, in which case you can skip down to setting up the cluster configuration file.
My system doesn't have the utilities, so, after setting up the network, I grabbed the 1.1.2 version of the tools:
UML# wget http://oss.oracle.com/projects/ocfs2-tools/dist/\
files/source/v1.1/ocfs2-tools-1.1.2.tar.gz
UML# gunzip ocfs2-tools-1.1.2.tar.gz
UML# tar xf ocfs2-tools-1.1.2.tar
UML# cd ocfs2-tools-1.1.2
UML# ./configure
I'll spare you the configure output; I had to install a few packages, such as e2fsprogs-devel (for libcom_err.so ), readline-devel, and glibc2-devel. I didn't install the python development package, which is needed for the graphical ocfs2console. I'll be demonstrating everything on the command line, so we won't need that.
After configuring ocfs2, we do the usual make and install :
UML# make && make install
install will put things under /usr/local unless you configured it differently.
At this point, we can do some basic checking by looking at the cluster status and loading the necessary modules. The guide I'm reading refers to the control script as /etc/init.d/o2cb, which I don't have. Instead, I have ./vendor/common/o2cb.init in the source directory, which seems to behave as the fictional /etc/init.d/o2cb.
UML# ./vendor/common/o2cb.init status
Module "configfs": Not loaded
Filesystem "configfs": Not mounted
Module "ocfs2_nodemanager": Not loaded
Module "ocfs2_dlm": Not loaded
Module "ocfs2_dlmfs": Not loaded
Filesystem "ocfs2_dlmfs": Not mounted
Nothing is loaded or mounted. The script makes it easy to change this:
UML# ./vendor/common/o2cb.init load
Loading module "configfs": OK
Mounting configfs filesystem at /config: OK
Loading module "ocfs2_nodemanager": OK
Loading module "ocfs2_dlm": OK
Loading module "ocfs2_dlmfs": OCFS2 User DLM kernel \
interface loaded
OK
Mounting ocfs2_dlmfs filesystem at /dlm: OK
We can check that the status has now changed:
UML# ./vendor/common/o2cb.init status
Module "configfs": Loaded
Filesystem "configfs": Mounted
Module "ocfs2_nodemanager": Loaded
Module "ocfs2_dlm": Loaded
Module "ocfs2_dlmfs": Loaded
Filesystem "ocfs2_dlmfs": Mounted
Everything looks good. Now we need to set up the cluster configuration file. There is a template in documentation/samples/clus-ter.con, which I copied to /etc/ocfs2/cluster.conf after creating /etc/ocfs2 and which I modified slightly to look like this:
UML# cat /etc/ocfs2/cluster.conf
node:
ip_port = 7777
ip_address = 192.168.0.253
number = 0
name = node0
cluster = ocfs2
node:
ip_port = 7777
ip_address = 192.168.0.251
number = 1
name = node1
cluster = ocfs2
cluster:
node_count = 2
name = ocfs2
The one change I made was to alter the IP addresses to what I intend to use for the two UML instances that will form the cluster. You should use IP addresses that work on your network.
The last thing to do before shutting down this instance is to create the mount point where the cluster filesystem will be mounted:
Shut this instance down, and we will boot the cluster, after taking care of one last item on the hostcreating the device that the cluster nodes will share:
host% dd if=/dev/zero of=ocfs seek=$[ 100 * 1024 ] bs==1K count=1
Booting the Cluster
Now we boot two UML instances on COW files with the filesystem we just used as their backing file. So, rather than using ubda=rootfs as we had before, we will use ubda=cow.node0, rootfs and ubda=cow.node1,rootfs for the two instances, respectively. I am also giving them umid s of node0 and node1 in order to make them easy to reference with uml_mconsole later.
The reason for mostly configuring ocfs2, shutting the UML instance down, and then starting up the cluster nodes is that the filesystem changes we made, such as installing the ocfs2 tools and the configuration file, will now be visible in both instances. This saves us from having to do all of the previous work twice.
With the two instances running, we need to give them their separate identities. The cluster.conf file specifies the node names as node0 and node1. We now need to change the machine names of the two instances to match these. In Fedora Core 4, which I am using, the names are stored in /etc/sysconfig/network. The node part of the value of HOSTNAME needs to be changed in one instance to node0 and in the other to node1. The domain name can be left alone.
We need to set the host name by hand since we changed the configuration file too late:
and
Next, we need to bring up the network for both instances:
host% uml_mconsole node0 config eth0=tuntap,,,192.168.0.254
OK
host% uml_mconsole node1 config eth0=tuntap,,,192.168.0.252
OK
When configuring eth0 within the instances, it is important to assign IP addresses as specified in the cluster.conf file previously. In my example above, node0 has IP address 192.168.0.253 andnode1 has address 192.168.0.251 :
UML1# ifconfig eth0 192.168.0.253 up
and
UML2# ifconfig eth0 192.168.0.251 up
At this point, we need to set up a filesystem on the shared device, so it's time to plug it in:
host% uml_mconsole node0 config ubdbc=ocfs
and
host% uml_mconsole node1 config ubdbc=ocfs
The c following the device name is a flag telling the block driver that this device will be used as a clustered device, so it shouldn't lock the file on the host. You should see this message in the kernel log after plugging the device:
Not locking "/home/jdike/linux/2.6/ocfs" on the host
Before making a filesystem, it is necessary to bring the cluster up in both nodes:
UML# ./vendor/common/o2cb.init online ocfs2
Loading module "configfs": OK
Mounting configfs filesystem at /config: OK
Loading module "ocfs2_nodemanager": OK
Loading module "ocfs2_dlm": OK
Loading module "ocfs2_dlmfs": OCFS2 User DLM kernel interface loaded
OK
Mounting ocfs2_dlmfs filesystem at /dlm: OK
Starting cluster ocfs2: OK
Now, on one of the nodes, we run mkfs :
mkfs.ocfs2 -b 4K -C 32K -N 8 -L ocfs2-test /dev/ubdb
mkfs.ocfs2 1.1.2-ALPHA
Overwriting existing ocfs2 partition.
(1552,0):__dlm_print_nodes:380 Nodes in my domain \
("CB7FB73E8145436EB93D33B215BFE919"):
(1552,0):__dlm_print_nodes:384 node 0
Filesystem label=ocfs2-test
Block size=4096 (bits=12)
Cluster size=32768 (bits=15)
Volume size=104857600 (3200 clusters) (25600 blocks)
1 cluster groups (tail covers 3200 clusters, rest cover 3200 clusters)
Journal size=4194304
Initial number of node slots: 8
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing lost+found: done
mkfs.ocfs2 successful
This specifies a block size of 4096 bytes, a cluster size of 32768 bytes, a maximum cluster size of eight nodes, and a volume label of ocfs2-test.
At this point, we can mount the device in both nodes, and we have a working cluster:
UML1# mount /dev/ubdb /ocfs2 -t ocfs2
(1618,0):ocfs2_initialize_osb:1165 max_slots for this device: 8
(1618,0):ocfs2_fill_local_node_info:836 I am node 0
(1618,0):__dlm_print_nodes:380 Nodes in my domain \
("B01E29FE0F2F43059F1D0A189779E101"):
(1618,0):__dlm_print_nodes:384 node 0
(1618,0):ocfs2_find_slot:266 taking node slot 0
JBD: Ignoring recovery information on journal
ocfs2: Mounting device (98,16) on (node 0, slot 0)
UML2# mount /dev/ubdb /ocfs2 -t ocfs2
(1442,0):o2net_set_nn_state:417 connected to node node0 \
(num 0) at 192.168.0.253:7777
(1522,0):ocfs2_initialize_osb:1165 max_slots for this device: 8
(1522,0):ocfs2_fill_local_node_info:836 I am node 1
(1522,0):__dlm_print_nodes:380 Nodes in my domain \
("B01E29FE0F2F43059F1D0A189779E101"):
(1522,0):__dlm_print_nodes:384 node 0
(1522,0):__dlm_print_nodes:384 node 1
(1522,0):ocfs2_find_slot:266 taking node slot 1
JBD: Ignoring recovery information on journal
ocfs2: Mounting device (98,16) on (node 1, slot 1)
Now we start to see communication between the two nodes. This is visible in the output from the second mount and in the kernel log of node0 when node1 comes online.
To quickly demonstrate that we really do have a cluster, I will copy a file into the filesystem on node0 and see that it's visible on node1 :
UML1# cd /ocfs2
UML1# cp ~/ocfs2-tools-1.1.2.tar .
UML1# ls -al
total 2022
drwxr-xr-x 3 root root 4096 Oct 14 16:24 .
drwxr-xr-x 28 root root 4096 Oct 14 16:17 ..
drwxr-xr-x 2 root root 4096 Oct 14 16:15 lost+found
-rw-r--r-- 1 root root 2058240 Oct 14 16:24 \
ocfs2-tools-1.1.2.tar
On the second node, I'll unpack the tar file to see that it's really there.
UML2# cd /ocfs2
UML2# ls -al
total 2022
drwxr-xr-x 3 root root 4096 Oct 14 16:15 .
drwxr-xr-x 28 root root 4096 Oct 14 16:18 ..
drwxr-xr-x 2 root root 4096 Oct 14 16:15 lost+found
-rw-r--r-- 1 root root 2058240 Oct 14 16:24 \
ocfs2-tools-1.1.2.tar
UML2# tar xf ocfs2-tools-1.1.2.tar
UML2# ls ocfs2-tools-1.1.2
COPYING aclocal.m4 fsck.ocfs2 mount.ocfs2 \
rpmarch.guess
CREDITS config.guess glib-2.0.m4 mounted.ocfs2 \
runlog.m4
Config.make.in config.sub install-sh o2cb_ctl \
sizetest
MAINTAINERS configure libo2cb ocfs2_hb_ctl \
tunefs.ocfs2
Makefile configure.in libo2dlm ocfs2cdsl \
vendor
Postamble.make debian libocfs2 ocfs2console
Preamble.make debugfs.ocfs2 listuuid patches
README documentation mkfs.ocfs2 python.m4
README.O2CB extras mkinstalldirs pythondev.m4
This is the simplest possible use of a clustered filesystem. At this point, if you were evaluating a cluster as an environment for running an application, you would copy its data into the filesystem, run it on the cluster nodes, and see how it does.
Exercises
For some casual usage here, we could put our users' home directories in the ocfs2 filesystem and experiment with having the same file accessible from multiple nodes. This would be a somewhat advanced version of NFS home directories.
A more advanced project would be to boot the nodes into an ocfs2 root filesystem, making them as clustered as they can be, given only one filesystem. We would need to solve a couple of problems.
The cluster needs to be running before the root filesystem can be mounted. This would require an initramfs image containing the necessary modules, initialization script, and tools. A script within this image would need to bring up the network and run the ocfs2control script to bring up the cluster. The cluster nodes need some private data to give them their separate identities. Part of this is the network configuration and node names. Since the network needs to be operating before the root filesystem can be mounted, some of this information would be in the initramfs image. The rest of the node-private information would have to be provided in files on a private block device. These files would be bind-mounted from this device over a shared file within the cluster file system, like this:
UML# mount --bind /private/network /etc/sysconfig/network
Without having done this myself, I am no doubt missing some other issues. However, none of this seems insurmountable, and it would make a good project for someone wanting to become familiar with setting up and running a cluster.
Other Clusters
I've demonstrated UML's virtual clustering capabilities using Oracle'socfs2. This isn't the only clustering technology availableI chose it because it nicely demonstrates the use of a host file to replace an expensive piece of hardware, a shared disk. Other Linux cluster filesystems include Lustre from CFS, GFS from Red Hat, and, with a generous definition of clustering, NFS.
Further, filesystems aren't the only form of clustering technology that exists. Clustering technologies have a wide range, from simple failover, high-availability clusters to integrated single-system image clusters, where the entire cluster looks and acts like a single machine.
Most of these run with UML, either because they are architecture-independent and will run on any architecture that Linux supports, or because they are developed using UML and are thus guaranteed to run with UML. Many satisfy both conditions.
If you are looking into using clusters because you have a specific need or are just curious about them, UML is a good way to experiment. It provides a way to bring multiple nodes up without needing multiple physical machines. It also lets you avoid buying exotic hardware that the clustering technology may require, such as the shared storage required by ocfs2. UML makes it much more convenient and less expensive to bring in multiple clustering technologies and experiment with them in order to determine which one best meets your needs.
UML as a Decision-Making Tool for Hardware
In this chapter, I demonstrated the use of UML in simulating hardware that is difficult or expensive to acquire in order to make decisions about both software and hardware. By simulating a system with a great deal of devices of a particular sort, it is possible to probe the limits of the software you might run on such a machine. These limits could involve either the kernel or applications. By running the software stack on an appropriately configured UML instance, you can see whether it is going to have problems before you buy the hardware.
I demonstrated this with a UML instance with a very large number of Ethernet interfaces and some with varying amounts of memory, up to 64GB. The same could have been done with a number of other types of devices, such as CPUs and disks.
With memory, the objective was to analyze the memory requirements of a particular workload without actually having a physical system with the requisite memory in it. You must be careful about doing performance measurements in this case. Looking at wall-clock time is useless because real time will be controlled by the availability of real resources, such as physical memory in the host. A proxy for real time is needed, and when memory is concerned, disk I/O inside the virtual machine is usually a good choice.
The UML instance will act as though it has the memory that was configured on the command line, and the host will swap as necessary in order to maintain that illusion. Therefore, the virtual machine will explicitly swap only when that illusory physical memory is exhausted. A physical machine with that amount of memory will behave in the same way, so a lower amount of disk I/O in the virtual machine will translate into lower real time for the workload on a physical machine.
Finally, I demonstrated the configuration of a cluster of two UML instances. This substituted the use of a host file, rather than a shared disk device, as the cluster interconnect. The ability to substitute a free virtual resource for an expensive physical one is a good reason to prototype a cluster virtually before committing to a physical one. You can see whether your workload will run on a cluster, and if so, how well, with the earlier caveats about making performance measurements.
In a number of ways, a virtual machine is a useful tool for helping you make decisions about software intended to run on physical hardware and about the hardware itself. UML lets you simulate hardware that is expensive or inconvenient to acquire, so you can test-run the applications or workloads you intend to run on that hardware. By doing so, you can make more informed decisions about both the hardware and the software.
Chapter 13. The Future of UML
Currently, a UML instance is a standard virtual machine, hard to distinguish from a Linux instance provided by any of the other virtualization technologies available. UML will continue to be a standard virtual machine, with a number of performance improvements. Some of these have been discussed in earlier chapters, so I'm not going to cover them here. Rather, I will talk about how UML is also going to change out of recognition. Being a real port of the Linux kernel that runs as a completely normal process gives UML capabilities not possessed by any other virtualization technology that provides virtual machines that aren't standard Linux processes.
We discussed part of this topic in Chapter 6, when we talked about humfs and its ability to store file metadata in a database. The capabilities presented there are more general than we have talked about. humfs is based on a UML filesystem called externfs, which imports host data into a UML instance as a filesystem. By writing plugin modules for externfs, such as humfs, anything on the host that even remotely resembles a filesystem can be imported into a UML instance as a mountable filesystem.
Similarly, external resources that don't resemble filesystems but do resemble processes could be imported, in a sense, into a UML instance as a process. The UML process would be a representative of the outside resource, and its activity and statistics would be represented as the activity and statistics of the UML process. Operations performed on the UML process, such as sending it signals or changing its priority, would be reflected back out to the outside in whatever way makes sense.
An extension of this idea is to import the internal state of an application into UML as a filesystem. This involves embedding a UML instance into the application and modifying the application sufficiently to provide access to its data from the captive UML instance through a filesystem. Doing so requires linking UML into the application so that the UML instance and the application share an address space, making it easy for them to share data.
It may not be obvious why this is useful, but it has potential that may turn out to be revolutionary for two major reasons.
A small number of applications have some of the attributes of an operating system, and a larger number would benefit from gaining those attributes. As an operating system that is already in userspace, UML is available to provide those attributes very easily in comparison to implementing them from scratch. For example, there are a small number of clusterized applications, such as some databases. As Linux gains clustering capabilities, UML will acquire them, and those capabilities will become available to applications that embed a UML instance. A number of other capabilities exist, such as good SMP scaling, filesystems, and a full network stack. A UML instance embedded in an application with filesystem access to the application's internal data provides a standard development environment. This will make it easy to customize the application's behavior, add features to it, and make it interoperate with other applications that themselves contain embedded UML instances. All the application needs to do is embed the UML instance and provide it with access to whatever data it wishes to expose. At that point, the information is available through the standard Linux file interfaces and can be manipulated using standard Linux tools. Furthermore, applications within the embedded UML instance can use any development tools and environments available for Linux.
Some prominent individual applications would also benefit from embedding UML instances; I'll describe those later.
Another area of future work comes from UML being a virtualized Linux kernel, rather than a userspace Linux kernel. As a virtualized kernel, a UML instance (and all of the subsystems within it) operates as a guest, in the sense that it knows it's a guest and explicitly uses the resources provided by the host. This comes in handy because of the benefits of using pieces of UML, such as the scheduler, as guests on their own.
For example, I have prototyped a guest scheduler patch to the Linux kernel that runs the scheduler as a guest on the normal scheduler. The guest scheduler runs as a process on the host, and processes controlled by it compete for slices of the CPU time that the host scheduler provides to it. Thus, processes controlled by the guest scheduler are jailed with respect to their CPU consumption but unlimited in other respects.
Similarly, other subsystems pulled out of UML will jail processes in different ways. Combining these will allow the system administrator to confine processes and partition the system's resources in arbitrary ways.
The externfs Filesystem
humfs is a special case of a more general filesystem called externfs. The purpose of externfs is to allow any reasonable external data to be imported as a UML filesystem. externfs doesn't import anything by itselfit simply makes it easy to import external data by implementing an interface, defined by externfs, to the Linux filesystem layer. externfs provides the glue between that interface and the Linux kernel VFS interface, allowing the data to appear to be a Linux filesystem.
This will allow you to mount this data as a UML filesystem and use standard utilities and scripts to examine and manipulate it. The filesystem interface hides the specialized interface normally used to access the data. By providing a common way to access the information, data sources that are normally disjointed and isolated from each other can be made to interoperate. Data can be copied from one database to a completely different database merely by copying files.
The sqlfs example in Chapter 6 as a possible humfs metadata format demonstrates this by allowing you to examine and change a database using normal Linux utilities rather than a SQL monitor. Of course, the SQL interface is still there, but it has been hidden under the Linux filesystem interface by the UML filesystem that imported it.
Essentially any structured data anywhere can be represented somehow as files and directories, and a plugin for externfs that maps the structure onto files and directories will import that data as a UML filesystem.
This is a large universe of possibilities, but which of them will actually prove to be useful? Representing data this way would be useful for any database whose contents are not readily accessible as text. Having the database available as a set of directories and files allows you to use standard utilities such as find and grep on it. It would not be so useful for any database that already uses text, such as any of the ones in /etc (e.g., the password and group files). These can already be easily analyzed and searched with the standard text utilities.
A package database might be a good candidate for this sort of treatment. rpm and dpkg have their own syntaxes for querying their databases. However, having the host's package database, including installed and available packages and the information associated with them, as a set of text files would make it unnecessary to use those syntaxes. Instead, you would use ls, cat, and find to tell you what you need to know.
For example, in order to figure out which package owns a particular file, such as /etc/passwd, you would do something like this:
UML% find /host-packages -name passwd
/host-packages/installed/setup-2.5.46-1/files/etc/passwd
The output tells you that /etc/passwd is a part of the setup-2.5.46-1 package. Similarly, you could find the package's description like this:
UML% cat /host-packages/installed/setup-2.5.46-1/description
The setup package contains a set of important system
configuration and setup files, such as passwd, group, and
profile.
There's no reason that the package database filesystem would be limited to importing the host's package database. The package databases of other hosts on the network could also be imported into the UML using a network-aware version of this filesystem. Mounting another host's package database would involve communicating with a daemon on the remote side. So, via this daemon, you could have a set of filesystems such as /packages/my-host, /packages/bob-host, /packages/ jane-host, and /packages/web-server.
Having the package information for all the hosts on the network in one place would turn the UML into a sort of control center for the network in this regard. Then you could perform some useful operations.
Compare the configurations of different machines: UML% ls -1 /packages/my-host/installed > /tmp/x
UML% ls -1 /packages/bob-host/installed > /tmp/y
UML% diff /tmp/x /tmp/y Ensure that all machines on the network have the same versions of their packages installed by comparing the version files of the package subdirectories in the host package filesystems. Install and delete packages:
UML% rm -rf /packages/my-host/installed/bc-1.06-18
UML% mv firefox-1.0.4-5.i386.rpm /packages/my-host/installed
These two operations would translate into a package removal and a package installation on the host. In the installation example, the firefox RPM file would be copied out to the host and installed. Then a firefox subdirectory would appear in the /packages/ my-host/installed directory.
If you wanted to enforce a policy that all configuration changes to any machine on the network would have to be done from this UML control console, the daemon on each host would maintain a lock on the package database. This would prevent any changes from happening locally. Since these daemons would be controlled from the UML instance, configuration changes to any of the hosts could be done only from the UML instance through this filesystem.
If a number of machines needed to have the same configurations, you could also have them all mounted in the same place in the UML control console. Operations within this filesystem would be multiplexed to all of the hosts. So, installing a new package through this filesystem would result in the package being copied to all of the hosts and installed on all of them. Similarly, removing a package would result in it being removed from all the hosts.
You can consider using a UML as a similar control console for any other system administration database. Using it to manage the host's password or group files is probably not practical, as I mentioned earlier. However, it may be useful to manage the password or group files for a network, if you're not using an existing distributed mechanism, such as NIS, for them.
You could take this control console idea further and use an externfs plugin to front a number of databases on the network, not just one. For example, consider a large organization with several levels of management and an externfs-based filesystem that allows a mirror of this organization to be built in it. So, every manager would be represented by a directory that contains a directory for each person who reports directly to that manager. If some of these reporting people were also managers, there would be another level of directories further down. Hiring a new person would involve creating a directory underneath the hiring manager. The filesystem would see this directory creation and perform the necessary system administration tasks, such as:
Creating login and mail accounts Adding the new person to the appropriate groups and mailing lists Updating online organization charts and performing other organization-specific tasks
Similarly, removing a person's directory would result in the reversal of all of these tasks.
Performing these tasks would not need to be done by hand, nor would it require a specialized application to manage the whole process. It would be done by changing files and directories in this special filesystem and tying those changes to the necessary actions on the network. I'm not suggesting that someone would be literally running the mkdir and rmdir utilities in a shell whenever someone is hired or leaves, although that would work. There would likely be a graphical interface for doing this, and it would likely be customized for this task, to simplify the input of the required information. However, putting it in a filesystem makes this information available in a standardized way at a low enough level that any sort of application, from a shell script to a customized graphical interface, can be written to manipulate it.
If the filesystem contains sensitive data, such as pay rates or home addresses, Linux file permissions can help prevent unauthorized people from seeing that information. Each piece of data about an employee could potentially be in its own file, with user and group ownership and permissions that restrict access to people who are allowed to view the information.
This example seems to fit a filesystem particularly well. No doubt there are others. UML's externfs allows this sort of information to be plugged into a UML as a filesystem, where it can be viewed and manipulated by any tools that know how to deal with files and directories.
This scenario is not as far out in left field as it may appear. Practically every Linux system in the world is doing something similar by providing a unified interface to a number of disparate databases. A typical Linux system contains the following:
At least one, and often more, disk-based filesystems such as ext2, ext3, reiserfs, or xfs A number of virtual, kernel-based filesystems such as procfs, sysfs, and devpts Usually at least one CD or DVD filesystem Often some devices such as MP3 players or cameras that represent themselves as storage devices with FAT or HFS filesystems
You can think of all of these as being different kinds of databases to which the Linux VFS layer is providing a uniform interface. This lets you transparently move data between these different databases (as with ls -l /proc > /tmp/processes copying data from the kernel to /tmp ) and transparently search them. You don't need to be concerned about the underlying representation of the data, which differs greatly from filesystem to filesystem.
What I described above is close to the same thing, except that my example uses the Linux VFS interface to provide the same sort of access to a different class of databases: personnel databases, corporate phone books, and so on. In principle, these are no different from the on-disk databases your files are stored in. I'd like to see access to these be as transparent and unified as access to your disks, devices, and internal kernel information is now.
externfs provides the framework for making this access possible. Each different kind of database that needs to be imported into a UML instance would need an externfs plugin that knows how to access it. With that written, the database can be imported as a Linux filesystem. At that point, the files and directories can be rearranged as necessary with Linux bind mounts. In the example above, the overall directory hierarchy can be imported from the corporate personnel database. Information like phone numbers and office locations may be in another database. Those files can be bind-mounted into the employee hierarchy, so that when you look at the directory for an employee, all of that person's information is present there, even though it's coming from a number of different databases.
The infrastructure to provide a transparent, unified interface to these different databases already exists. The one thing lacking is the modules needed to turn them into filesystems.
Virtual Processes
Some things don't map well to files, directories, or filesystems, but you may wish to import them into Linux at a low level in order to manipulate them in a similar way. Many of these may resemble processes.
They start at a certain time and may stop at some point. They consume various sorts of resources while running. They may be in various states at different times, such as actively running, stopped, or waiting for an event.
It may make sense to represent such things as Linux processes, and it will be possible to create UML processes that represent the state of something external to the UML instance. This could be something very close to a process, such as a server on the host, or it could be something very unlike a process, such as a project.
This "virtual" process would appear in the UML instance's process list with all the attributes of a normal process, except that these would be fabricated from whatever it is representing. As with the filesystem example, actions performed on one of these processes would be reflected out to the real thing it represents. So, sending a signal to a virtual process that represents a service on some machine elsewhere on the network could shut down that service. Changing the virtual process's priority would have the analogous effect on the processes that belong to that service.
Representing a project as a "virtual" process is not as good a fit. It is hard to imagine that a high-level manager would sit in front of a process listing, look at processes representing projects within the company, and change their priorities or cancel them by clicking on a Linux process manager. Some things resemble processes, but their attributes don't map well onto Linux processes.
Representing network services as UML processes and managing them as such doesn't seem to me far fetched. Neither does representing hosts as a whole. Machines can respond to signals on their process representatives within the UML instance by shutting down or rebooting, and the status of a machine seems to map fairly well onto the status of a process.
Processes are more limited in this regard than filesystems are since they can't contain arbitrary data, such as names and file contents, and they have a limited number of attributes with fairly inflexible semantics. So, while I can imagine a synthetic filesystem being used to manage personnel in some sense, I don't think synthetic processes can be used in a similar way. Nevertheless, within those limits, I think there is potential for managing some process-like entities as synthetic UML processes and using that capability of UML to build a control console for those entities.
Captive UML
So far I've talked about using special filesystems to import the external state of outside entities into a UML instance where it can be manipulated through a filesystem. An extension of this is to import the internal state of an application into a UML instance to be manipulated in the same way.
This would be done by actually embedding the UML instance within the application. The application would link UML in as a library, and a UML instance would be booted when the application runs. The application would export to the UML instance whatever internal state it considers appropriate as a filesystem. Processes or users within that UML instance could then examine and manipulate that state through this filesystem, with side effects inside the application whenever anything is changed.
Secure mod_perl
Probably the best example of a real-world use for a captive UML that I know of is Apache's mod_perl. This loadable module for Apache contains a Perl interpreter and allows the use of Perl scripts running inside Apache to handle requests, generate HTML, and generally control the server. It is very powerful and flexible, but it can't be used securely in a shared Apache hosting environment, where a hosting company uses a single Apache server to serve the Web sites of a number of unrelated customers.
Since a Perl script runs in the context of the Apache server and can control it, one customer using mod_perl could take over the entire server, cause it to crash or exit, or misbehave in any number of other ways. The only way to generate HTML dynamically with a shared Apache is to use CGI, which is much slower than with mod_perl. CGI creates a new process for every HTML request, which can be a real performance drag on a busy server. This is especially the case when the Web site is generated with Perl, or something similar, because of the overhead of the Perl interpreter.
With some captive UML instances inside the Apache server, you could get most of the performance of standard mod_perl, plus a lot of its flexibility, and do so securely, so that no customer could interfere with other sites hosted on the same server or with the server itself. You would do this by having the customer's Perl scripts running inside the instances, isolating them from anything outside. Communication with the Apache server would occur through a special filesystem that would provide access to some of Apache's internal state.
The most important piece of state is the stream of requests flowing to a Web site. These would be available in this filesystem, and in a very stripped-down implementation, they would be the only thing available. So, with the special Apache filesystem mounted on /apache, there could be a file called /apache/request that the Perl script would read. Whenever a request arrived, it would appear as the contents of this file. The response would be generated and written back to that file, and the Apache server would forward it to the remote browser.
One advantage of this approach is immediately evident. Since the HTML generation is happening inside a full Linux host and communication with the host Apache server is through a set of files, the script can be written in any languagePerl, Python, Ruby, shell, or even compiled C, if maximum performance is desired. It could even be written in a language that didn't exist at the time this version of Apache was released. The new language environment would simply need to be installed in the captive UML instance.
Another advantage is that the Web site can be monitored in real time, in any manner desired, from inside the UML instance. This includes running an interactive debugger on the script that's generating the Web site, in order to trace problems that might occur only in a production deployment. Obviously, this should be done with caution, considering that debuggers generally slow down whatever they're debugging and can freeze everything while stopped at a breakpoint. However, for tracking down tricky problems, this is a capability that doesn't exist in mod_perl currently but comes for free with a captive UML instance.
So far, I've talked about using a single file, /apache/request, to receive HTTP requests and to return responses. This Apache filesystem can be much richer and can provide access to anything in the mod_perl API, which is safe within a shared server. For example, the API provides access to information about the connection over which a request came, such as what IP the remote host has and whether the connection supports keepalives. This information could be provided through other files in this filesystem.
The API also provides access to the Apache configuration tree, which is the in-memory representation of the httpd.conf file. Since this information is already a tree, it can be naturally represented as a directory hierarchy. Obviously, full access to this tree should not be provided to a customer in a shared server. However, the portions of the tree associated with a particular customer could be. This would allow customers to change the configuration of their own Web sites without affecting anyone else or the server as a whole.
For example, the owner of a VirtualHost could change its configuration or add new VirtualHosts for the same Web site. Not only would this be more convenient than asking the hosting company to change the configuration file, it also could be done on the fly. This would allow the site to be reconfigured as much and as often as desired without having to involve the hosting company.
It is common to have Apache running inside a UML instance. This scheme turns that inside-out, putting the UML instance inside Apache. Why do things this way instead of the standard Apache-inside-UML way? The reasons mirror the reasons that people use a shared Apache provider rather than colocating a physical machine and running a private Apache on it.
It's cheaper since it involves less hardware, and it doesn't require a separate IP address for every Web site. The captive UML instance has less running in it compared to running Apache inside UML. All Web sites on the server share the same Apache instance, and the only resources they don't share are those dedicated to generating the individual Web sites. Also, it's easier to administrate. The hosting company manages the Apache server and the server as a whole, and the customers are responsible only for their own Web sites.
Evolution
Putting a UML instance inside Apache is probably the most practical use of a captive UML instance, but my favorite example is Evolution. I use Evolution on a daily basis, and there are useful things that I could make it do if there were a UML instance inside it with access to its innards. For example, I have wanted an easy way to turn an e-mail message into a task by forwarding the e-mail to some special address. With a UML instance embedded inside Evolution, I would have the instance on the network with a mail server accepting e-mail. Then a procmail script, or something similar, would create the task via the filesystem through which the UML instance had access to Evolution's data.
So, given an e-mail whose title is "frobnitzis broken" and whose message is "The frobnitz utility crashes whenever I run it," the script would do something like this:
UML% cat > /evolution/tasks/"frobnitz is broken" << EOF
The frobnitz utility crashes whenever I run it
EOF
This would actually create this task inside Evolution, and it would immediately appear in the GUI. Here, I am imagining that the "Evolution filesystem" would be mounted on /evolution and would contain subdirectories such as tasks, calendar, and contacts that would let you examine and manipulate your tasks, appointments, and contacts, respectively. Within /evolution/tasks would be files whose names were the same as those assigned to the tasks through the Evolution GUI. Given this, it's not too much of a stretch to think that creating a new file in this directory would create a new task within Evolution, and the contents of the task would be the text added to the file.
In reality, an Evolution task is a good deal more complicated and contains more than a name and some text, so tasks would likely be represented by directories containing files for their attributes, rather than being simple files.
This example demonstrates that, with a relatively small interface to Evolution and the ability to run scripts that use that interface, you can easily make useful customizations. This example, using the tools found on any reasonable Linux system, would require a few lines of procmail script to provide Evolution with a fundamental new capabilityto receive e-mail and convert it into a new task.
The new script would also make Evolution network-aware in a sense that it wasn't before by having a virtual machine embedded within it that is a full network node.
I can imagine making it network-aware in other ways as well:
By having a bug-tracking system send it bug reports when they are assigned to you so they show up automatically in your task list, and by having it send a message back to the bug-tracking system to close a bug when you finish the task By allowing a task to be forwarded from one person to another with one embedded UML sending it to another, which recreates the task by creating the appropriate entries in the virtual Evolution filesystem
The fact that the captive UML instance could be a fully functional network node means that the containing application could be, too. The data exported through the filesystem interface could then be exported to the outside world in any way desired. Similarly, any data on the outside could be imported to the application through the filesystem interface. The application could export a Web interface, send and receive e-mail, and communicate with any other application through its captive UML instance.
Any application whose data needs to be moved to or from other applications could benefit from the same treatment. Our bug-tracking system could forward bugs to another bug tracker, receive bug reports as e-mail, or send statistics to an external database, even when the bug tracker couldn't do any of these itself. If it can export its data to the captive UML instance, scripts inside the instance can do all of these.
Given sufficient information exported to the captive UML instance, any application can be made to communicate with any other application. An organization could configure its applications to communicate with each other in suitable ways, without being constrained by the communication mechanisms built into the applications.
Application Administration
Some applications, such as databases and those that contain databases, require dedicated administration, and sometimes dedicated administrators. These applications try to be operating systems, in the sense that they duplicate and reimplement functionality that is already present in Linux. A captive UML within the application could provide these functions for free, allowing it to either throw out the duplicated functionality or avoid implementing it in the first place.
For example, databases and many Web sites require that users log in. They have different ways to store and manage account information. Almost everyone who uses Linux is familiar with adding users and changing passwords, but doing the same within a database requires learning some new techniques. However, with a captive UML instance handling this, the familiar commands and procedures suffice. The administrator can log in to the UML instance and add or modify accounts in the usual Linux way.
The captive UML instance can handle authentication and authorization. When a user logs in to such a Web site, the site passes the user ID and password to the UML instance to be checked against the password database.
If there are different levels of access, authorization is needed as well. After the captive UML instance validates the login, it can start a process owned by that user. This process can generate the HTML for requests from that user. With the site's data within this UML instance and suitably protected, authorization is provided automatically by the Linux file permission system. If a request is made for data that's inaccessible to the user, this process will fail to access it because it doesn't have suitable permissions.
The same is true with other tasks such as making backups. Databases have their own procedures for doing this, which differ greatly from the way it's done on Linux. With a captive UML instance having access to the application's data, the virtual filesystem that the instance sees can be backed up in the same way as any other Linux machines. The flip side of this is restoring a backup, which would also be done in the usual Linux way.
The added convenience of not having to learn new ways to perform old tasks is obvious. Moreover, there are security advantages. Doing familiar tasks in a familiar way reduces the likelihood of mistakes, for example, making it less likely that adding an account, and doing it wrong, will inadvertently open a security hole.
There is another security benefit, namely, that the application administrator logs in to the application's captive UML instance to perform administration tasks. This means that the administrator doesn't need a special account on the host, so there are fewer accounts, and thus fewer targets, on the host. When the administrator doesn't need root privileges on the host, there is one fewer person with root access, one fewer person who can accidentally do something disastrous to the host, and one fewer account that can be used to as a springboard to root privileges.
A Standard Application Programming Interface
Another side of a captive UML instance can be inferred from the discussion above, but I think it's worth talking about it specifically. A Linux environment, whether physical or virtual, normally comes with a large variety of programming tools. Add to this the ability of a captive UML instance to examine and manipulate the internal state of its application, and you have a standard programming environment that can be imported into any application.
The current state of application programmability and extensibility is that the application provides an API to its internals, and that API can be used by one of a small number of programming languages. To extend Emacs, you have to use Lisp. For GIMP, you have Scheme, TCL, and Perl. For Apache, there is Perl and Python. With a reasonable Linux environment, you get all of these and more. With an API based on the virtual filesystem I have described, application development and extension can be done with any set of tools that can manipulate files.
With an embedded UML instance providing the application's development environment, the developers don't need to spend time creating an API for every language they wish to support. They spend the time needed to embed a UML instance and export internal state through a UML virtual filesystem, and they are done. Their users get to choose what languages and tools they will use to write extensions.
Application-Level Clustering
A captive UML can also be used to provide application access to kernel functionality. Clustering is my favorite example. In Chapter 12 we saw two UML instances being turned into a little cluster, which is a simple example of process-level clustering. There is at least one real-world, commercial example of thisOracle clusters, where the database instances on multiple systems cooperate to run a single database.
There would be more examples like this if clustering were easier to do. Oracle did its own clustering from scratch, and any other product, commercial or open source, would have to do the same. With the clustering technologies that are currently in Linux and those that are on their way, UML can provide a much easier way to "clusterize" an application.
With UML, any clustering technology in the Linux kernel is automatically running in a process, assuming that it is not hardware-dependent. To clusterize an application, we need to integrate UML into the application in such a way that it can use that technology.
Integrating UML into the application is a matter of making UML available as a linkable library. At that point, the application can call into the UML library to get access to any functionality within it.
I am envisioning this as an enabling technology for much deeper Internet-wide collaborations than we've seen so far. At this point, most such collaborations have been Web-based. Why isn't that sufficient? Why do we need some new technology? The answer is the same as that for the question of why you don't do all of your work within a Web browser. You create a lotlikely allof your work with other applications because these other tools are specialized for the work you are doing, and your Web browser isn't. Your tools have interfaces that make it easy to do your work, and they understand your work in ways that enable them to help. Web browsers don't. Even when it is possible to do the same work in your Web browser, the Web interface is invariably slower, harder to use, and less functional than that for the specialized application.
Imagine taking one of these applications and making it possible for many people to work within it at the same time, working on the same data without conflicting with each other. Clusterizing the application would allow this.
To make our example a bit more concrete, let's take the ocfs2 UML cluster we saw in Chapter 12 and assume that an application wants to use it as the basis for making a cluster from multiple instances of itself. The ocfs2 cluster makes a shared disk accessible to multiple nodes in such a way that all the nodes see the same data at all times. The application shares some of its data between instances by storing it in an ocfs2 volume.
Let us say that this application is a document editor, and the value it gains from being clusterized is that many people can work on the same document at the same time without overwriting each other's work. In this case, the document is stored in the cluster filesystem, which is stored in a file on the host.
When an instance of this editor starts, the captive UML inside it boots enough that the kernel is initialized. It attaches itself to the ocfs2 shared disk and brings itself up as a cluster node. The editor knows how the document is stored within the shared disk and accesses it by directly calling into the Linux filesystem code rather than making system calls, such as open and read, as a normal process would.
With multiple instances of the editor attached to the same document, and the captive UML instances as nodes within the cluster, a user can make changes to the document at the same time as other users, without conflicting with them.
The data stored within the cluster filesystem needs to be the primary copy of the document, in the sense that changes are reflected more or less immediately in the filesystem. Otherwise, two users could change the same part of the document, and one would end up overwriting the other when the changes made it to the filesystem.
How quickly changes need to be reflected in the filesystem is affected to some extent by the organization of the document and the properties of the cluster being used. A cluster ensures that two nodes can't change the same data at the same time by locking the data so that only one node has access to it at any given time. If the locking is done on a per-file basis, and this editor stores its document in a single file, then the first user will have exclusive access to the entire document for the entire session. This is obviously not the desired effect.
Alternatively, the document could be broken into pieces, such as a directory hierarchy that reflects the organization of the document. The top-level directories could be volumes, with chapter subdirectories below that, sections below the chapters, and so on. The actual contents would reside within files at the lowest level. These would likely be at the level of paragraphs. A cluster that locks at the file level would let different people work on different paragraphs without conflict.
There are other advantages to doing this. It allows the Linux file permission system to be applied to the document with any desired granularity. When each contributor to the document is assigned a section to work on, this section would be contained inside some directory. The ownerships on these directories and files would be such that those people assigned to the section can edit it, and others can't, although they may have permission to read it. Groups can be set up so that some people, such as editors, can modify larger pieces of the document.
At first glance, it would appear that this could be implemented by running the application within a cluster, rather than having the cluster inside the application, as I am describing. However, for a number of reasons, that wouldn't work.
The mechanics of setting up the cluster require that it be inside the application. Consider the case where this idea is being used to support an Internet-wide collaboration. Running the application within a cluster requires the collaboration to have a cluster, and everyone contributing to it must boot their systems into this cluster. This immediately runs into a number of problems.
First, many people who would be involved in such an effort have no control over the systems they would be working from. They would have to persuade their system administrators to join this cluster. For many, such as those in a corporate environment, with systems installed with defined images, this would be impossible. However, when the application comes with its own clustering, this is much less of a problem. Installing a new application is much less problematic than having the system join a cluster.
Even if you can get your system to join this cluster, you need your system either to be a permanent member or to join when you run the application that needs it. These requirements pose logistical and security problems. To be a cluster node means sharing data with the other nodes, so having to do this whenever the system is booted is undesirable. To join the cluster only when the application is running requires the application to have root privileges or to be able to call on something with those privileges. This is also impossible for some types of clustering, which require that nodes boot into the cluster. Both of these options are risky from a security perspective. With the cluster inside the application, these problems disappear. The application boots into the cluster when it is started, and this requires no special privileges.
Second, there may be multiple clustered applications running on a given system. Having the system join a different cluster for each one may be impossible, as this would require that the system be a member of multiple clusters at the same time. For a cluster involving only a shared filesystem, this may be possible. But it also may not. If the different clusters require different versions of the same cluster, they may be incompatible with each other. There may be stupid problems like symbol conflicts with the two versions active on the host at the same time. For any more intrusive clustering, being a member of multiple clusters at once just won't work. The extreme case is a Single-System Image (SSI) cluster where the cluster acts as a single machine. It is absolutely impossible to boot into multiple instances of these clusters at once. However, with the cluster inside the application, this is not an issue. There can't be conflicts between different versions of the same clustering software between different clusters, or between different types of clusters, because each cluster is in its own application. They are completely separate from each other and can't conflict.
Consider the case where the large-scale collaboration decides to upgrade the cluster software it is using or decides to change the cluster software entirely. This change would require the administrators of all the involved systems to upgrade or change them. This logistical nightmare would knock most of the collaboration offline immediately and leave large parts of it offline for a substantial time. The effects of attempting this could even kill the collaboration. An upgrade would create two isolated groups, and the nonupgrading group could decide to stay that way, forking the collaboration. With the cluster as part of the application, rather than the other way around, an upgrade or change of cluster technologies would involve an upgrade of the application. This could also fail to go smoothly, but it is obviously less risky than upgrading the system as a whole.
Security also requires that the cluster be within the application. Any decent-size collaboration needs accountability for contributions and thus requires members to log in. This requires a unified user ID space across the entire cluster. For any cluster that spans organization boundaries, this is clearly impossible. No system administrator is going to give accounts to a number of outsiders for the benefit of a single application. It may also be mathematically impossible to assign user IDs such that they are the same across all of the systems in the cluster. With the application being its own cluster, this is obviously not a problem. With the captive UML instances being members of the cluster, they have their own separate, initially empty, user ID space. Assigning user IDs in this case is simple.
Now, consider the case where the application requires an SSI cluster. For it to require the system to be part of the cluster is impossible for logistical reasons, as I pointed out above. It's also impossible from a security standpoint. Every resource of every member of the cluster would be accessible to every other member. This is unthinkable for any but the smallest collaborations. This is not a problem if the cluster is inside the application. The application boots into the cluster, and all of its resources are available to the cluster. Since the application is devoted to contributing to this collaboration, it's expected that all of its information and resources are available to the other cluster nodes.
Earlier, I used the example of a UML cluster based on ocfs2 to show that process-level clustering using UML is possible and is the most practical way to clusterize an application. To implement the large-scale collaborations I have described, ocfs2 is inadequate for the underlying cluster technology for a number of reasons.
It requires a single disk shared among all of its nodes. For a UML cluster, this means a single file that's available to all nodes. This is impractical for any collaboration that extends much beyond a single host. It could work for a local network, sharing the file with something like NFS, but won't work beyond that. What is needed for a larger collaboration is a cluster technology that enables each node to have its own local storage, which it would share with the rest of the cluster as needed. ocfs2 clusters are static. The nodes and their IP addresses are defined in a cluster-wide configuration file. The shared filesystem has a maximum cluster size built into it. This can't work for a project that has contributors constantly coming and going. What is required is something that allows nodes to be added and removed dynamically and that does not impose a maximum size on the cluster. ocfs2 doesn't scale anywhere near enough to underlie a large collaboration. I am envisioning something with the scale of Wikipedia, with hundreds or thousands of contributors, requiring the clustering to scale to that number of nodes. ocfs2 is used for sharing a database, which is typically done with a number of systems in the two-digit range or less.
While ocfs2 doesn't have the ability to power such a project, I know of one clustering technology, GFS, that might. It stores data throughout the cluster. It claims to scale to tens of thousands of clients, a level that would support a Wikipedia-scale collaboration. It does seem to require good bandwidth (gigabit Ethernet or better) between nodes, which the Internet as a whole can't yet provide. Whether this is a problem probably depends on the quantity of data that needs to be exchanged between nodes, and that depends on the characteristics of the collaboration.
These projects probably will not be well served by existing technologies, at least at first. They will start with something that works well enough to get started and put pressure on the technology to develop in ways that serve them better. We will likely end up with clusters with different properties than we are familiar with now.
Virtualized Subsystems
I plan to take advantage of UML's virtualization in one more way: to use it to provide customizable levels of confinement for processes. For example, you may wish to control the CPU consumption of a set of processes without affecting their access to other machine resources. Or you may wish to make a container for some processes that restricts their memory usage and filesystem access but lets them consume as much CPU time as they like.
I'm going to use UML to implement such a flexible container system by breaking it into separate subsystems (e.g., the scheduler and the virtual memory system). When you break UML, which is a virtual kernel, into separate pieces, those pieces are virtual subsystems. They can run on or within their nonvirtual counterparts, and they require a nonvirtual counterpart to host them in order to function at all.
For example, my virtualized scheduler runs a guest scheduler inside a host process. The host process provides the context needed for the guest scheduler to function. The guest scheduler requires some CPU cycles to allocate among the processes in its care. These cycles come from its host process, which is competing with other processes for CPU cycles from the host scheduler.
Similarly, a guest virtual memory system would allocate memory to its processes from a pool of memory provided by the host virtual memory system.
You would construct a container by building a set of virtualized subsystems, such as the scheduler and virtual memory system, loading it into the host kernel, and then loading processes into it. Those processes, in the scheduler and virtual memory system case, would get their CPU cycles from the guest scheduler and their memory from the guest virtual memory system. In turn, these would have some allocation of cycles and memory from the host.
Let's take the guest scheduler as an example since it has been implemented. A new guest scheduler is created by a process opening a special file in /proc:
host% cat /proc/schedulers/guest_o1_scheduler &
Created sched_group 290 ('guest_o1_scheduler')
The contents of /proc/schedulers are the schedulers available for use. In this case, there is only one, guest_o1_scheduler. This creates a sched_group, which is the set of processes controlled by this scheduler. When the system boots, all processes are in sched_group 0, which is the host scheduler. sched_group 290 is the group controlled by the cat process we ran, which had process ID 290.
Once we have a guest scheduler, the next step is to give it some processes to control. This is done by literally moving processes from sched_group 0 to sched_group 290. Let's create three infinite shell loops and move two of them into the new scheduler:
host% bash -c 'while true; do true; done' &
[2] 292
host% bash -c 'while true; do true; done' &
[3] 293
host% bash -c 'while true; do true; done' &
[4] 294
host% mv /proc/sched-groups/0/293 /proc/sched-groups/290/
host% mv /proc/sched-groups/0/294 /proc/sched-groups/290/
Now process 290, which is the host representative of the guest scheduler, is competing with the other host processes, including the busy loop with process ID 292, for CPU time. Since those are the only two active processes on the host scheduler, they will each get half of the CPU. The guest scheduler, inside process 290, is going to take its half of the CPU and split it between the two processes under its control. Thus, processes 293 and 294 will each get half of that, or a quarter of the CPU each:
host% ps uax
...
root 292 49.1 0.7 2324 996 tty0 R 21:51 \
14:40 bash -c
root 293 24.7 0.7 2324 996 tty0 R 21:51 \
7:23 bash -c
root 294 24.7 0.7 2324 996 tty0 R 21:51 \
7:23 bash -c ...
The guest scheduler forms a CPU compartmentit gets a fixed amount of CPU time from the host and divides it among its processes. If it has many processes, it gets no more CPU time than if it had only a few. This is useful for enforcing equal access to the CPU for different users or workloads, regardless of how many processes they have running.
By loading each group of processes, whether a user, an application, a workload, or an arbitrary set of processes, into one of these compartments, you guarantee that the groups as a whole get treated equally by the scheduler.
I've described the guest schedulers as being loaded into the host kernel, but I can also see a role for userspace guest schedulers. Most obviously, by making the scheduler of a UML instance visible to the host as a guest scheduler, its processes become visible to the host in the same way as the host's own processes. Their names and resource usage become visible on the host. They also become controllable in the same waya signal can be sent to one from the host and the corresponding UML process will receive it.
Making a UML scheduler visible as a host guest scheduler requires an interface for a process to register itself as a guest scheduler. This interface would be the mechanism for telling the host about the guest's processes and their data. Once we have an interface like this, there's no reason that UML has to be the only user of it.
A number of other applications have internal process-like components and could use this interface. Anything with internal threads could make them visible on the host in the same way that UML processes would be. They would be controllable in the same way, and the attributes the host sees would be provided by the application.
A Web server could make requests or sessions visible as host processes. Similarly, a mail server could make incoming or outgoing e-mail messages look like processes. The ability to monitor and control these servers with this level of granularity would make them much more manageable.
The same ideas would apply to any other sort of compartment. A memory compartment would be assigned some amount of memory when created, just as a CPU compartment has a call on a certain amount of CPU time. Processes would be loaded into it and would then have their memory allocations satisfied from within that pool of memory.
If a compartment runs out of memory, it has to start swapping. It is required to operate on the fixed amount of memory it was provided and can't allocate more from the host when it runs short. It has to swap even if there is plenty of memory free on the rest of the system. In this way, the memory demands of the different groups of processes on the host are isolated from each other. One group can't adversely affect the performance of another by allocating all of the memory on the system.
Compartmentalization is an old subject, and there are many ways to do it, including some that are currently being implemented on Linux, principally, CKRM, or Class-based linux Kernel Resource Management. These projects add resource allocation and control infrastructures to the kernel and add interfaces that allow users to control the resulting compartments.
These approaches necessarily involve modifying the basic algorithms in the kernel, such as the scheduler and the virtual memory system. This adds some overhead to these algorithms even when compartments aren't being used, which is likely to be the common case. There is a bias in the Linux kernel development community against making common things more expensive in order to make uncommon things cheap. Compartmentalization performed in these ways conflicts with that ethos.
More importantly, these algorithms have been carefully tuned under a wide range of workloads. Any perturbations to them could throw off this tuning and require repeating all this work.
In contrast, the approach of gaining compartmentalization through virtualization requires no changes to these core algorithms. Instead of modifying an algorithm to accommodate compartments, a new copy of the same algorithm is used to implement them. Thus, there is no performance impact and no behavior perturbation when compartments are not being used.
The price of having two complete implementations of an algorithm instead of a single modified one is that compartments will tend to be more expensive. This is the trade-off against not affecting the performance and behavior when compartments are not being used.
Conclusion
UML differs from other virtualization technologies in implementing virtualization completely in userspace. This gives it capabilities that have not been realized yet, but I believe UML will ultimately be more widely used for purposes other than just as a virtual machine.
The fact that UML implements a virtual machine in a set of processes means that it can be repackaged as a library and linked into other applications, which gain an embedded virtual machine. This gives them a standard development and extension environment that is familiar to everyone who does Linux development. This may make those applications more useful than they would be otherwise. They gain the ability to communicate with each other in arbitrary ways, allowing them to adapt to the workflow rather than forcing the workflow to adapt to them.
For some specific applications, this may open up new markets. I described how shared Apache configurations could benefit from this.
They would gain the ability to securely host multiple dynamic Web sites using mod_perl, which currently requires a dedicated system for each site. This has obvious economic advantages, as a single system could replace the many systems currently hosting these sites. Other advantages flow from this approach, such as being freed from having to use a specific language for development and being able to interactively debug a Web site inside the live server.
The use of UML for compartmentalization demonstrates another aspect of userspace virtualization. While I demonstrated the guest scheduler being loaded into the kernel, it is not necessarily required to be there. It should be possible to have a guest scheduler running in a process, in userspace, doing all the things that the in-kernel guest scheduler does. The fact that the scheduler and the other subsystems can be virtualized at all is a result of the fact that they started from UML, in userspace. Since UML is already a virtualized Linux kernel, any pieces of it will be similarly virtualized.
Appendix A. UML Command-Line Options
There are a number of UML-specific command-line options. The largest group configures the hardware and devices that the virtual machine will have. The rest are used to specify how the instance will be managed from the host, to set debugging options, or to print information about the UML instance.
Device and Hardware Specifications
The following options set configurations for virtual devices and hardware.
dsp=dsp device and mixer=mixer device These two options specify the host audio interfaces for the use of the UML audio pass-through driver. The default values are /dev/sound/dsp and /dev/sound/mixer, respectively. If you wish to play sound from within your UML instance, and the host digital signal processor (dsp) or mixer devices are different from these, you'll need to use these switches. xterm=terminal emulator, title switch, exec switch This switch allows the use of terminal emulators besides xterm for UML consoles and serial lines. The arguments specify how to invoke the emulator with a given title and command running within it. The defaults, for xterm, are -T and -e, meaning that the title is specified with the -T switch and the command to run within the xterm follows the -e switch. The values for gnome-terminal are -t and -x, so xterm=gnome-terminal,-t,-x would make UML use gnome-terminal instead of xterm. initrd=initrd image This switch makes UML boot from an initial ramdisk (initrd) image. The image must be specified as a filename on the host. iomem=name, file This specifies the use of a host file as an I/O memory (iomem) region. name is the name of the driver that is going to own the region of memory. file is the name of the host file to be mapped into the UML instance's physical memory region. A demo iomem driver can be found in arch/um/drivers/ mmapper_kern.c in the UML source tree. mem=size Use this to specify the size of the UML instance's physical memory as a certain number of kilobytes, megabytes, or gigabytes via the K, M, or G suffixes, respectively. This has no relation to the amount of physical memory on the host. The UML instance's memory size can be either less or more than the host's memory size. If the UML memory size is more, and it is all used by the UML instance, the host will swap out the portion of the UML instance's memory that it thinks hasn't been used recently. root=root device This option specifies the device containing the root filesystem. By default, it is /dev/ubda. ncpus=n With CONFIG_SMP enabled, this switch specifies the number of virtual processors in the UML instance. If this is less than or equal to the number of processors on the host, the switch will enable that many threads to be running simultaneously, subject to scheduling decisions on the host. If there are more virtual processors than host processors, you can use this switch to determine the amount of host CPU power the UML instances can consume relative to each other. For example, a UML instance with four processors is entitled to twice as much host CPU time as an instance with two processors. ethn=interface configuration This configures the host side of a network interface, making the device available and able to receive and transmit packets. The interface configuration is summarized in Table 8.1 and described completely in Chapter 7. fake_ide This switch creates IDE entries in /proc that correspond to the ubd devices in the UML instance, which sometimes helps make distribution install procedures work inside UML. ubd<n><flags>=filename[:filename This configures a UML block device on the host. n specifies the device to be configured; either letters (a through z) or numbers can be used. Letters are preferred because they don't encourage the belief that the unit number on the command line is the same as the minor number within UML. ubda (and ubd0) has minor number 0 and ubdb (and ubd1) has minor number 16 since each device can have up to 16 partitions. flags can be one or more of the following. - - r The device is read-onlyread-write mounts will fail, as will any attempt to write anything to the device.
- - s All I/O to the host will be done synchronously (O_SYNC will be set).
- - d This device is to be considered as strictly data (i.e., even if it looks like a COW file, it is to be treated as a standalone device).
- - c This device will be shared writable between this UML instance and something else, normally another UML instance.
This would generally be done through a cluster filesystem. Either one or two filenames may be provided, separated by either a comma or a colon. If two filenames are specified, the first is a COW file and the second is its backing file. You can obtain the same effect by specifying the COW file by itself, as it contains the location of its backing file. Separating the two files by a colon allows shell filename completion to work on the second file. udb This option exists for the sole purpose of catching ubd to udb typos, which can be impossible to spot visually unless you are specifically looking for them. Adding this to the UML command line will simply cause a warning to be printed, alerting you to the typo.
Debugging Options
The debugging options come in two groupsthose that make kernel debugging possible in tt mode and those that disable use of host features in order to narrow down UML problems.
In the first group are two options for specifying that we want debugging and whether we want to use an already-running debugger.
debug In tt mode, this causes UML to bring up gdb in an xterm window in order to debug the UML kernel. gdb-pid=<pid> In tt mode, this switch specifies the process ID of an already-running debugger that the instance should attach to.
These may go away in the future if tt mode support is removed from UML.
The second group of options allows you to selectively disable the use of various host capabilities.
aio=2.4 This switch causes UML to avoid the use of the AIO support on the host if it's present and to fall back to its own I/O thread, which can keep one request in flight at a time. mode=tt This specifies that the UML instance should use tt mode rather than skas mode. mode=skas0 and skas0 Both of these switches avoid the use of the skas3 patch if it's present on the host, causing UML to use skas0 mode, unless mode=tt is also specified, in which case tt mode will be used. nosysemu This avoids the use of the sysemu patch if it's present on the host. noprocmm This avoids the use of /proc/mm if the skas3 patch is present on the host. noptracefaultinfo This avoids the use of PTRACE_FAULTINFO if the skas3 patch is present on the host.
Management Options
Several options control how you manage UML instances. The following control the location of the MConsole request and notification sockets and the pid file.
mconsole=notify: socket This specifies the UNIX domain socket that the mconsole driver will send notifications to. umid=name This assigns a name to the UML instance, making it more convenient to control with an MConsole client. uml_dir=directory This specifies the directory within which the UML instance will put the subdirectory containing its pid file and MConsole control socket. The name of this subdirectory is taken from the umid of the UML instance. These two control the behavior of the UML tty logging facility. tty_log_dir=directory With tty logging enabled, this specifies the directory within which logging data will be stored. tty_log_fd=descriptor This specifies that tty log data should be sent to an already-opened file descriptor rather than a file. For example, adding 10>tty_log tty_log_fd=10 to the UML command line will open file descriptor 10 onto the file tty_log and have all logging data be written to that descriptor.
Informational Options
Finally, three options cause UML to simply print some information and exit.
--showconfig This option prints the configuration file that the UML was built with and exits. --version This switch causes the UML instance to print its version and then exit. --help This option prints out all UML-specific command-line switches and their help strings, then exits.
humfsify
humfsify makes an existing directory structure mountable as a humfs filesystem. The directory hierarchy must have been copied to the data subdirectory of the current working directory with all file and directory ownerships and permissions preserved. The common usage of this would be to convert a ubd filesystem image into a humfs filesystem by loopback-mounting the image, copying it to ./data, and invoking humfsify.
humfsify has the following usage:
user is a user ID, which can be a username or numeric user ID. group is a group ID, which can be a group name or numeric group ID. size is the size of the humfs filesystem, specified as a number of bytes, with the K, M, and G suffixes meaning kilobytes, megabytes, and gigabytes, respectively.
All of the files and directories under data will be made readable and writeable by, and owned by, the specified user and group. The previous ownerships and permissions will be recorded under two new directories, file_metadata and dir_metadata. The file superblock will be created in the current directory. This contains information about the metadata format and the amount of space available and used within the mount.
uml_moo
uml_moo merges a COW file with its backing file. It can do an in-place merge, where the new blocks from the COW file are written directly into the backing file, or create a new file, leaving the existing backing file unchanged.
Create a new merged file like this:
uml_moo [-b backing file] COW-file new-backing-file
Here's the usage for doing an in-place merge:
uml_moo [-b backing file] -d COW-file
The -b switch is used when the COW file doesn't correctly specify the backing file. This can be required when the COW file was created in a chroot jail, in which case the path to the backing file stored in the COW file header will be relative to the jail.
uml_mconsole
uml_mconsole is the UML control utility. It allows a UML instance to be controlled from the host and allows information to be extracted from the UML instance. It is one client of several for the MConsole protocol, which communicates with a driver inside UML.
It can be run in either single-shot mode, where the request is specified on the command line, or in command-line mode, where the user interacts with the uml_mconsole command line to make multiple requests of a UML instance.
The single-shot usage is:
uml_mconsole umid request
umid is the name given to the UML instance. This is specified on the UML command line. If none is provided there, the instance will create a random umid, which will be visible in the boot log. request is what will be sent to the UML instance. This is described fully below.
A single-shot request will send the request to the UML instance, wait for a response, and then exit. The exit code will be zero if the request succeeded and nonzero otherwise.
The command-line usage is:
uml_mconsole will present a prompt consisting of the umid of the UML instance that requests will be sent to. In this mode, there are two commands available that are handled by uml_mconsole and are not sent to the UML instance.
A few commands are implemented within the uml_mconsole client and are available in both modes.
mconsole-version prints the version of the uml_mconsole client. This is different from the UML version that the version command returns. help prints all of the available commands and their usage. int sends an interrupt (SIGINT) to the UML instance. If it is running under gdb, this will break out to the gdb prompt. If it isn't, this will cause a shutdown of the UML instance. The commands sent to the UML instance are as follows. version returns the kernel version of the UML instance. halt performs a shutdown of the kernel. This will not perform a clean shutdown of the distribution. For this, see the cad command below. halt is useful when the UML instance can't run a full shutdown for some reason. reboot is similar to halt except that the UML instance reboots. config dev=config adds a new device to a UML instance. See Table 8.1 for a list of device and configuration syntax. config dev queries the configuration of a UML device. See Table 8.1 for a list of device syntax. remove dev removes a device from a UML instance. See Table 8.1 for a list of device syntax. sysrq letter performs the sysrq action specified by the given letter. This is the same as you would type on the keyboard to invoke the host's sysrq handler. These are summarized in Table 8.2. cad invokes the Ctrl-Alt-Del handler in the UML instance. The effect of this is controlled by the ca entry in the instance's /etc/ inittab. Usually this is to perform a shutdown. If a reboot is desired, /etc/inittab should be changed accordingly. stop pauses the UML instance until it receives a go command. In the meantime, it will do nothing but respond to MConsole commands. go continues the UML instance after a stop. log string makes the UML instance enter the string into its kernel log. log -f filename is a uml_mconsole extension to the log command. It sends the contents of filename to the UML instance to be written to the kernel log. proc file returns the contents of the UML instance's /proc/ file. This works only on normal files, so it can't be used to list the contents of a directory. stack pid returns the stack of the specified process ID within the UML instance. This is duplicated by one of the SysRq optionsthe real purpose of this command is to wake up the specified process and make it hit a breakpoint so that it can be examined with gdb.
tunctl
tunctl is used to create and delete TUN/TAP devices. The usage for creating a device is:
tunctl [-b] [-u owner] [-t device-name ] [-f tun-clone-device]
The -b switch causes tunctl to print just the new device name. This is useful in scripts, so that they don't have to parse the longer default output in order to find the device name. -u specifies the user that should own the new device. If unspecified, the owner will be the user running the command. This can be specified either as a username or a numeric user. You can specify a user other than yourself, but only that user or root will be able to open the device or delete it. -t specifies the name of the new device. This is useful for creating descriptive TUN/TAP device names. -f specifies the location of the TUN/TAP control device. The default is /dev/net/tun, but on some systems, it is /dev/misc/ net/tun.
The usage for deleting a TUN/TAP device is:
tunctl -d device-name [-f tun-clone-device]
More precisely, the -d switch makes the device nonpersistent, meaning that it will disappear when it is no longer opened by any process. The -f switch works as described above.
uml_switch
uml_switch is the UML virtual switch and has the following usage:
uml_switch [ -unix control-socket ] [ -hub ] [ -tap tap-device ]
The -unix switch specifies an alternate UNIX domain socket to be used for control messages. The default is /tmp/uml/ctl, but Debian changes this to /var/run/uml-utilities/uml_switch.ctl. -hub specifies hub rather than switch behavior. With this enabled, all frames will be forwarded to all ports, rather than the default behavior of forwarding frames to only one port when it is known that the destination MAC is associated with that port. -tap is used to connect the switch to a previously configured TUN/TAP device on the host. This gives a uml_switch-based network access to the host network.
Internal Utilities
A few of the UML utilities are used by UML itself and are not meant to be used on their own.
port-helper helps a UML instance use the host's telnetd server to accept telnet connections. This is used when attaching UML consoles and serial lines to host portals and xterms. uml_net is the setuid network setup helper. It is invoked by a UML instance whenever it needs to perform a network setup operation that it has no permissions for. This includes configuring network interfaces and establishing routes and proxy arp on the host. This is to ease the use of UML networking in casual use, where the root user inside the UML instance can be trusted. A secure UML configuration should not use uml_net and should instead use preconfigured TUN/TAP devices or uml_switch to communicate with the host. uml_watchdog is an external process used to track when a UML instance is running. It communicates with the UML harddog driver, expecting some communication at least once a minute. If that doesn't happen, uml_watchdog takes some action, either to kill the UML instance or to notify the administrator with an MConsole hang notification.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books
