Small-Object Allocation
В этом разделе мы рассмотрим реализацию быстрого создания небольших обьектов.
Скорость создания таких обьектов сравнима с размещением обьектов в стеке.
Loki подчас использует очень маленькие обьекты размером в несколько байт.
Это используется в 5-й и 7-й главах.
В силу полиморфной природы,эти обьекты не могут быть сохранены в стеке и живут самостоятельной жизнью.
C++ использует операторы new и delete.
Дело в том,что для маленьких обьектов они ведут себя неподобающе.
Фактически,при таком выделении памяти может быть затрачено вдвое больше,чем нужно.
Оптимизация-корень всех зол,как сказал Кнут
("Early optimization is the root of all evils").
Падение производительности на порядок всего одной функции может стоить всему проекту жизни.
Преимущество быстрого создания маленьких обьектов может оказаться весьма существенным.
Во многих книгах по C++, таких как
Sutter (2000) и
Meyers (1998a),
подчеркивается важность написания собственных аллокаторов.
У второго можно найти кое-какие техническии детали реализации,
а первый ограничивается ссылкой на другие мануалы по С++.
|
Default Free Store Allocator
For occult reasons, the default allocator is notoriously slow. A possible reason is that it is usually implemented as a thin wrapper around the C heap allocator (malloc/realloc/ free). The C heap allocator is not focused on optimizing small chunk allocations. C programs usually make ordered, conservative use of dynamic memory. They don't naturally foster idioms and techniques that lead to numerous allocations and deallocations of small chunks of memory. Instead, C programs usually allocate medium-to large-sized objects (hundreds to thousands of bytes). Consequently, this is the behavior for which malloc/free is optimized.
In addition to being slow, the genericity of the default C++ allocator makes it very space inefficient for small objects. The default allocator manages a pool of memory, and such management often requires some extra memory. Usually, the bookkeeping memory amounts to a few extra bytes (4 to 32) for each block allocated with new. If you allocate 1024-byte blocks, the per-block space overhead is insignificant (0.4% to 3%). If you allocate 8-byte objects, the per-object overhead becomes 50% to 400%, a figure big enough to make you worry if you allocate many such small objects.
In C++, dynamic allocation is very important. Runtime polymorphism is most often associated with dynamic allocation. Strategies such as "the pimpl idiom" (Sutter 2000) prescribe replacing stack allocation with free store allocation.
Therefore, the poor performance of the default allocator makes it a bump on the road toward efficient C++ programs. Seasoned C++ programmers instinctively avoid constructs that foster using free store allocation because they know its costs from experience. Not only is the default allocator a concrete problem, but it also might become a psychological barrier.
|
4.2 The Workings of a Memory Allocator
Studying memory usage trends of programs is a very interesting activity, as proven by Knuth's seminal work (Knuth 1998). Knuth established many fundamental memory allocation strategies, and even more were invented later.
How does a memory allocator work? A memory allocator manages a pool of raw bytes and is able to allocate chunks of arbitrary size from that pool. The bookkeeping structure can be a simple control block having a structure like the following:
struct MemControlBlock
{
std::size_t size_;
bool available_;
};
The memory managed by a MemControlBlock object lies right after it and has size_ bytes. After the chunk of memory, there is another MemControlBlock, and so on.
When the program starts, there is only one MemControlBlock at the beginning of the pool, managing the entire memory as a big chunk. This is the root control block, which will never move from its original location. Figure 4.1 shows the memory layout for a 1MB memory pool at startup.
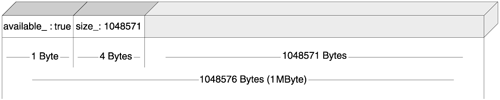
For each allocation request, a linear search of memory blocks finds a suitable block for the requested size. Its size must be equal to or larger than the size requested. It is amazing just how many strategies for fitting requests with available blocks exist, and how oddly they perform. You can go for first fit, best fit, worst fit, or even a random fit. Interestingly, worst fit is better than best fithow's that for an oxymoron?
Each deallocation incurs, again, a linear search for figuring out the memory block that precedes the block being deallocated, and an adjustment of its size.
As you can see, this strategy is not terribly time efficient. However, the overhead in size is quite smallonly one size_t plus a bool per memory block. In most concrete cases, you can even give up a bit in size_ and store available_ there, thus squeezing MemControl Block to the ultimate:
// Platform- and compiler-dependent code
struct MemControlBlock
{
std::size_t size_ : 31;
bool available_ : 1;
};
If you store pointers to the previous and next MemControlBlock in each MemControlBlock, you can achieve constant-time deallocation. This is because a block that's freed can access the adjacent blocks directly and adjust them accordingly. The necessary memory control block structure is
struct MemControlBlock
{
bool available_ ;
MemControlBlock* prev_;
MemControlBlock* next_;
};
Figure 4.2 shows the layout of a memory pool fostering such a doubly linked list of blocks. As you can see, the size_ member variable is not needed anymore because you can compute the size as this->next_ - this. Still, you have the overhead of two pointers and a bool for each allocated memory block. (Again, you can do some system-dependent tricks to pack that bool together with one of the pointers.)

Still, allocations take linear time. There are many neat techniques for mitigating that, each fostering a different set of trade-offs. Interestingly, there's no perfect memory allocation strategy; each of them has a memory use trend that makes it perform worse than others.
We don't need to optimize general allocators. Let's focus on specialized allocatorsallocators that deal best with small objects.
|
4.3 A Small-Object Allocator
The small-object allocator described in this chapter sports a four-layered structure, shown in Figure 4.3. The upper layers use functionality provided by the lower layers. At the bottom is a Chunk type. Each object of type Chunk contains and manages a chunk of memory consisting of an integral number of fixed-size blocks. Chunk contains logic that allows you to allocate and deallocate memory blocks. When there are no more blocks available in the chunk, the allocation function fails by returning zero.
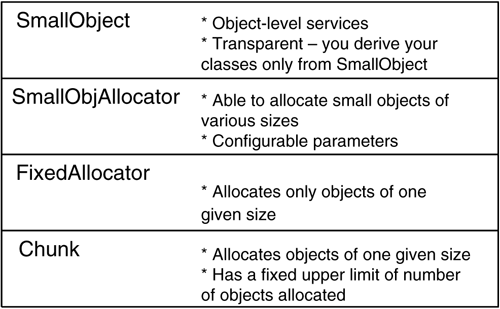
The next layer features the FixedAllocator class. A FixedAllocator object uses Chunk as a building block. FixedAllocator's primary purpose is to satisfy memory requests that go beyond a Chunk's capacity. FixedAllocator does this by aggregating an array of Chunks. Whenever a request for memory comes and all existing Chunks are occupied, FixedAllocator creates a new Chunk and appends it to the array. Then it satisfies the request by forwarding the request to that new Chunk.
SmallObjAllocator provides general allocation and deallocation functions. A SmallObjAllocator holds several FixedAllocator objects, each specialized for allocating objects of one size. Depending on the number of bytes requested, SmallObjAllocator dispatches memory allocation requests to one of its FixedAllocators or to the default ::operator new if the size requested is too large.
Finally, SmallObject wraps FixedAllocator to offer encapsulated allocation services for C++ classes. SmallObject overloads operator new and operator delete and passes them to a SmallObjAllocator object. This way, you make your objects benefit from specialized allocation by simply deriving them from SmallObject.
You can also use SmallObjAllocator and FixedAllocator directly. (Chunk is too primitive and unsafe, so it is defined in the private section of FixedAllocator.) Most of the time, however, client code will simply derive from the SmallObject base class to take advantage of efficient allocation. That's quite an easy-to-use interface.
|
4.4 Chunks
Each object of type Chunk contains and manages a chunk of memory containing a fixed amount of blocks. At construction time, you configure the block size and the number of blocks.
A Chunk contains logic that allows you to allocate and deallocate memory blocks from that chunk of memory. When there are no more blocks available in the chunk, the allocation function returns zero.
The definition of Chunk is as follows:
// Nothing is private Chunk is a Plain Old Data (POD) structure
// structure defined inside FixedAllocator
// and manipulated only by it
struct Chunk
{
void Init(std::size_t blockSize, unsigned char blocks);
void* Allocate(std::size_t blockSize);
void Deallocate(void* p, std::size_t blockSize);
unsigned char* pData_;
unsigned char
firstAvailableBlock_,
blocksAvailable_;
};
In addition to a pointer to the managed memory itself, a chunk stores the following integral values:
firstAvailableBlock_, which holds the index of the first block available in this chunk blocksAvailable_, the number of blocks available in this chunk
The interface of Chunk is very simple. Init initializes a Chunk object, and Release releases the allocated memory. The Allocate function allocates a block, and Deallocate deallocates a block. You have to pass a size to Allocate and Deallocate because Chunk does not hold it. This is because the block size is known at a superior level. Chunk would waste space and time if it redundantly kept a blockSize_ member. Don't forget we are at the very bottom hereeverything matters. Again for efficiency reasons, Chunk does not define constructors, destructors, or assignment operator. Defining proper copy semantics at this level hurts efficiency at upper levels, where we store Chunk objects in a vector.
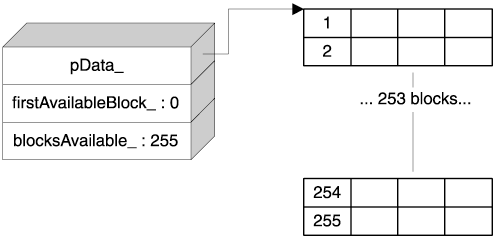
The Chunk structure reveals important trade-offs. Because blocksAvailable_ and firstAvailableBlock_ are of type unsigned char, it follows that you cannot have a chunk that contains more than 255 blocks (on a machine with 8-bit characters). As you will soon see, this decision is not bad at all and saves us a lot of headaches.
Now for the interesting part. A block can be either used or unused. We can store whatever we want in an unused block, so we take advantage of this. The first byte of an unused block holds the index of the next unused block. Because we hold the first available index in firstAvailableBlock_, we have a full-fledged singly linked list of unused blocks without using any extra memory.
At initialization, a chunk looks like Figure 4.4. The code that initializes a Chunk object looks like this:
void Chunk::Init(std::size_t blockSize, unsigned char blocks)
{
pData_ = new unsigned char[blockSize * blocks];
firstAvailableBlock_ = 0;
blocksAvailable_ = blocks;
unsigned char i = 0;
unsigned char* p = pData_;
for (; i != blocks; p += blockSize)
{
*p = ++i;
}
}
This singly linked list melted inside the data structure is an essential goodie. It offers a fast, efficient way of finding available blocks inside a chunkwithout any extra cost in size. Allocating and deallocating a block inside a Chunk takes constant time, which is exclusively thanks to the embedded singly linked list.
Now you see why the number of blocks is limited to a value that fits in an unsigned char. Suppose we used a larger type instead, such as unsigned short (which is 2 bytes on many machines). We would now have two problemsa little one and a big one.
We cannot allocate blocks smaller than sizeof(unsigned short), which is awkward because we're building a small-object allocator. This is the little problem. We run into alignment issues. Imagine you build an allocator for 5-byte blocks. In this case, casting a pointer that points to such a 5-byte block to unsigned int engenders undefined behavior. This is the big problem.
The solution is simple: We use unsigned char as the type of the "stealth index." A character type has size 1 by definition and does not have any alignment problem because even the pointer to the raw memory points to unsigned char.
This setting imposes a limitation on the maximum number of blocks in a chunk. We cannot have more than UCHAR_MAX blocks in a chunk (255 on most systems). This is acceptable even if the size of the block is really small, such as 1 to 4 bytes. For larger blocks, the limitation doesn't make a difference because we don't want to allocate chunks that are too big anyway.
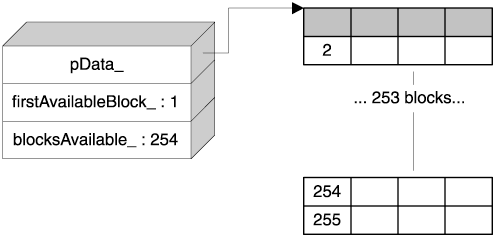
The allocation function fetches the block indexed by firstAvailableBlock_ and adjusts firstAvailableBlock_ to refer to the next available blocktypical list stuff.
void* Chunk::Allocate(std::size_t blockSize)
{
if (!blocksAvailable_) return 0;
unsigned char* pResult =
pData_ + (firstAvailableBlock_ * blockSize);
// Update firstAvailableBlock_ to point to the next block
firstAvailableBlock_ = *pResult;
blocksAvailable_;
return pResult;
}
The cost of Chunk::Allocate is one comparison, one indexed access, two dereference operations, an assignment, and a decrementquite a small cost. Most important, there are no searches. We're in pretty good shape so far. Figure 4.5 shows the layout of a Chunk object after the first allocation.
The deallocation function does exactly the opposite: It passes the block back to the free blocks list and increments blocksAvailable_. Don't forget that because Chunk is agnostic regarding the block size, you must pass the size as a parameter to Deallocate.
void Chunk::Deallocate(void* p, std::size_t blockSize)
{
assert(p >= pData_);
unsigned char* toRelease = static_cast<unsigned char*>(p);
// Alignment check
assert((toRelease - pData_) % blockSize == 0);
*toRelease = firstAvailableBlock_;
firstAvailableBlock_ = static_cast<unsigned char>(
(toRelease - pData_) / blockSize);
// Truncation check
assert(firstAvailableBlock_ ==
(toRelease - pData_) / blockSize);
++blocksAvailable_;
}
The deallocation function is lean, but it does a lot of assertions (which still don't catch all error conditions). Chunk respects the grand C and C++ tradition in memory allocation: Prepare for the worst if you pass the wrong pointer to Chunk::Deallocate.

|
4.5 The Fixed-Size Allocator
The next layer of our small-object allocator consists of FixedAllocator. FixedAllocator knows how to allocate and deallocate blocks of a fixed size but is not limited to a chunk's size. Its capacity is limited only by available memory.
To achieve this, FixedAllocator aggregates a vector of Chunk objects. Whenever an allocation request occurs, FixedAllocator looks for a Chunk that can accommodate the request. If all Chunks are filled up, FixedAllocator appends a new Chunk. Here is the relevant part of the definition of FixedAllocator:
class FixedAllocator
{
...
private:
std::size_t blockSize_;
unsigned char numBlocks_;
typedef std::vector<Chunk> Chunks;
Chunks chunks_;
Chunk* allocChunk_;
Chunk* deallocChunk_;
};
To achieve a speedy lookup, FixedAllocator does not iterate through chunks_ looking for a space for each allocation. Instead, it holds a pointer to the last chunk that was used for an allocation (allocChunk_). Whenever an allocation request comes, FixedAllocator::Allocate first checks allocChunk_ for available space. If allocChunk_ has a slot available, the allocation request is satisfiedprestousing allocChunk_. If not, a linear search occurs (and, possibly, a new Chunk is appended to the chunks_ vector). In any case, allocChunk_ is updated to point to that found or added chunk. This way we increase the likelihood of a fast allocation next time. Here's the code that implements this algorithm:
void* FixedAllocator::Allocate()
{
if (allocChunk_ == 0 ||
allocChunk_->blocksAvailable_ == 0)
{
// No available memory in this chunk
// Try to find one
Chunks::iterator i = chunks_.begin();
for (;; ++i)
{
if (i == chunks_.end())
{
// All filled up-add a new chunk
chunks_.reserve(chunks _.size()+1);
Chunk newChunk;
newChunk.Init(blockSize_, numBlocks_);
chunks_.push_back(newChunk);
allocChunk_ = &chunks_.back();
deallocChunk_ = &chunks_.back();
break;
}
if (i->blocksAvailable_ > 0)
{
// Found a chunk
allocChunk_ = &*i;
break;
}
}
}
assert(allocChunk_ != 0);
assert(allocChunk_->blocksAvailable_ > 0);
return allocChunk_->Allocate(blockSize_);
}
Using this strategy, FixedAllocator satisfies most of the allocations in constant time, with occasional slowdowns caused by finding and adding a new block. Some memory allocation trends make this scheme work inefficiently; however, they tend not to appear often in practice. Don't forget that every allocator has an Achilles' heel.
Memory deallocation is more problematic, because at deallocation time there's a piece of information missingall we have is a pointer to deallocate, and we don't know to what Chunk that pointer belongs. We can walk through chunks_ and check whether the given pointer falls in between pData_ and pData_ + blockSize_ * numBlocks_. If that's the case, then we pass the pointer to that Chunk's Deallocate member function. The problem is, this takes time. Although allocations are fast, deallocations take linear time. We need an additional device that speeds up deallocations.
We could use a supplemental cache memory for freed blocks. When user code frees a block using FixedAllocator::Deallocate(p), the FixedAllocator does not pass p back to the corresponding Chunk; instead, it adds p to an internal memorya cache that holds available blocks. When a new allocation request comes, FixedAllocator first looks up the cache. If the cache is not empty, FixedAllocator fetches the last available pointer from cache and returns it right away. This is a very fast operation. Only when the cache is depleted does FixedAllocator need to go the standard route by forwarding the allocation request to a Chunk. This is a promising strategy, but it works badly with certain allocation and deallocation trends that are common to small-object use.
There are four main trends in allocating small objects:
Bulk allocation.
Many small objects are allocated at the same time. For example, this is the case when you initialize a collection of pointers to small objects.
Deallocation in same order.
Many small objects are deallocated in the same order as they were allocated. This happens when most STL containers are destroyed.
Deallocation in reverse order.
Many small objects are deallocated in the reverse order of their allocation. This trend occurs naturally in C++ programs as you call functions that manipulate small objects. Function arguments and temporary stack variables follow this trend.
Butterfly allocation and deallocation.
Objects are created and destroyed without following a certain order. This happens as your program is running and has occasional need for small objects.
A caching strategy serves the butterfly trend very well because it can sustain quick allocations and deallocations if they arrive randomly. However, for bulk allocation and deallocation, caching is not of help. Worse, caching slows down deallocations because clearing the cache memory takes its own time.
A better strategy is to rely on the same concept as with allocation. The member variable FixedAllocator::deallocChunk_ points to the last Chunk object that was used for a deallocation. Whenever a deallocation occurs, deallocChunk_ is checked first. Then, if it's the wrong chunk, Deallocate performs a linear search, satisfies the request, and updates deallocChunk_.
Two important tweaks increase the speed of Deallocate for the allocation trends enumerated earlier. First, the Deallocate function searches the appropriate Chunk starting from deallocChunk_'s vicinity. That is, chunks_ is searched starting from deallocChunk_ and going up and down with two iterators. This greatly improves the speed of bulk deallocations in any order (normal or reversed). During a bulk allocation, Allocate adds chunks in order. During deallocation, either deallocChunk_ hits right away or the correct chunk is fetched in the next step.
The second tweak is the avoidance of borderline conditions. Say both allocChunk_ and deallocChunk_ point to the last Chunk in the vector, and there is no space left in the current set of chunks. Now imagine the following code is run:
for (...)
{
// Some smart pointers use the small-object
// allocator internally (see Chapter 7)
SmartPtr p;
... use p ....
}
Each pass through the loop creates and destroys a SmartPtr object. At creation time, because there's no more memory, FixedAllocator::Allocate creates a new Chunk and appends it to the chunks_ vector. At destruction time, FixedAllocator::Deallocate detects an empty block and frees it. This costly cycle gets repeated for each iteration of the for loop.
This inefficiency is unacceptable. Therefore, during deallocation, a chunk is freed only when there are two empty chunks. If there's only one empty chunk, it is efficiently swapped to the end of the chunks_ vector. Thus, we avoid costly vector<Chunk>::erase operations by always deleting the last element.
Of course, some situations defeat this simple heuristic. If you allocate a vector of SmartPtrs of appropriate size in a loop, you are back to the same problem. However, such situations tend to appear more rarely. Besides, as mentioned in the introduction of this chapter, any allocator may perform worse than others under specific circumstances.
The deallocation strategy chosen also fits the butterfly allocation trend acceptably. Even if not allocating data in an ordered manner, programs tend to foster a certain locality; that is, they access a small amount of data at a time. The allocChunk_ and deallocChunk_ pointers deal nicely with such memory use because they act as a cache for the latest allocations and deallocations.
In conclusion, we now have a FixedAllocator class that can satisfy fixed-memory allocation requests in an acceptably fast and memory-efficient manner. FixedAllocator is optimized for typical trends in small-object allocation.
|
4.6 The SmallObjAllocator Class
The third layer in our allocator architecture consists of SmallObjAllocator, a class capable of allocating objects of any size. SmallObjAllocator does so by aggregating several FixedAllocator objects. When SmallObjAllocator receives an allocation request, it either forwards it to the best matching FixedAllocator object or passes it to the default ::operator new.
The following is a synopsis of SmallObjAllocator. Explanations follow the code.
class SmallObjAllocator
{
public:
SmallObjAllocator(
std::size_t chunkSize,
std::size_t maxObjectSize);
void* Allocate(std::size_t numBytes);
void Deallocate(void* p, std::size_t size);
...
private:
std::vector<FixedAllocator> pool_;
...
};
The constructor takes two parameters that configure SmallObjAllocator. The chunkSize parameter is the default chunk size (the length in bytes of each Chunk object), and maxObjectSize is the maximum size of objects that must be considered to be "small." SmallObjAllocator forwards requests for blocks larger than maxObjectSize directly to ::operator new.
Oddly enough, Deallocate takes the size to deallocate as an argument. Deallocations are much faster this way. Otherwise, SmallObjAllocator::Deallocate would have to search through all FixedAllocators in pool_ to find the one to which the pointer belongs. This is too expensive, so SmallObjAllocator requires you to pass the size of the block to deallocate. As you'll see in the next section, this task is graciously handled by the compiler itself.
What's the mapping between the block size of FixedAllocator and pool_? In other words, given a size, what's the FixedAllocator that handles allocations and deallocations for blocks of that size?
A simple and efficient idea is to have pool_[i] handle objects of size i. You initialize pool_ to have a size of maxObjectSize, and then initialize each FixedAllocator accordingly. When an allocation request of size numBytes comes, SmallObjAllocator forwards it either to pool_[numBytes]a constant-time operationor to ::operator new.
However, this solution is not as clever as it seems. "Efficient" is not always "effective." The problem is, you might need allocators only for certain sizes, depending on your application. For instance, maybe you create only objects of size 4 and 64nothing else. In this case, you allocate 64 or more entries for pool_ although you use only 2.
Alignment and padding issues further contribute to wasting space in pool_. For instance, many compilers pad all user-defined types up to a multiple of a number (2, 4, or more). If the compiler pads all structures to a multiple of 4, for instance, you can count on using only 25% of pool_the rest is wasted.
A better approach is to sacrifice a bit of lookup speed for the sake of memory conservation. We store FixedAllocators only for sizes that are requested at least once. This way pool_ can accommodate various object sizes without growing too much. To improve lookup speed, pool_ is kept sorted by block size.
To improve lookup speed, we can rely on the same strategy as in FixedAllocator. SmallObjAllocator keeps a pointer to the last FixedAllocator used for allocation and a pointer to the last FixedDeallocator used for deallocation. The following is the complete set of member variables in SmallObjAllocator.
class SmallObjAllocator
{
...
private:
std::vector<FixedAllocator> pool_;
FixedAllocator* pLastAlloc_;
FixedAllocator* pLastDealloc_;
};
When an allocation request arrives, pLastAlloc_ is checked first. If it is not of the correct size, SmallObjAllocator::Allocate performs a binary search in pool_. Deal location requests are handled in a similar way. The only difference is that SmallObjAllocator::Allocate can end up inserting a new FixedAllocator object in pool_.
As discussed with FixedAllocator, this simple caching scheme favors bulk allocations and deallocations, which take place in constant time.
|
4.7 A Hat Trick
The last layer of our architecture consists of SmallObject, the base class that conveniently wraps the functionality provided by SmallObjAllocator.
SmallObject overloads operator new and operator delete. This way, whenever you create an object derived from SmallObject, the overloads enter into action and route the request to the fixed allocator object.
The definition of SmallObject is quite simple, if a bit intriguing.
class SmallObject
{
public:
static void* operator new(std::size_t size);
static void operator delete(void* p, std::size_t size);
virtual ~SmallObject() {}
};
SmallObject looks perfectly kosher, except for a little detail. Many C++ books, such as Sutter (2000), explain that if you want to overload the default operator delete in a class, operator delete must take a pointer to void as its only argument.
C++ offers a kind of a loophole that is of great interest to us. (Recall that we designed SmallObjAllocator to take the size of the block to be freed as an argument.) In standard C++ you can overload the default operator delete in two wayseither as
void operator delete(void* p);
or as
void operator delete(void* p, std::size_t size);
This issue is thoroughly explained in Sutter (2000), page 144.
If you use the first form, you choose to ignore the size of the memory block to deallocate. But we badly need that block size so that we can pass it to SmallObjAlloc. Therefore, SmallObject uses the second form of overloading operator delete.
How does the compiler provide the object size automagically? It seems as if the compiler is adding all by itself a per-object memory overhead that we have tried to avoid all through this chapter.
No, there is no overhead at all. Consider the following code:
class Base
{
int a_[100];
public:
virtual ~Base() {}
};
class Derived : public Base
{
int b_[200];
public:
virtual ~Derived() {}
};
...
Base* p = new Derived;
delete p;
Base and Derived have different sizes. To avoid the overhead of storing the size of the actual object to which p points, the compiler does a hat trick: It generates code that figures out the size on the fly. Four possible techniques of achieving that are listed here. (Wearing a compiler writer hat from time to time is funyou suddenly can do little miracles inaccessible to programmers.)
Pass a Boolean flag to the destructor meaning "Call/don't call operator delete after destroying the object." Base's destructor is virtual, so, in our example, delete p will reach the right object, Derived. At that time, the size of the object is known staticallyit's sizeof(Derived)and the compiler simply passes this constant to operator delete. Have the destructor return the size of the object. You can arrange (you're the compiler writer, remember?) that each destructor, after destroying the object, returns sizeof(Class). Again, this scheme works because the destructor of the base class is virtual. After invoking the destructor, the runtime calls operator delete, passing it the "result" of the destructor. Implement a hidden virtual member function that gets the size of an object, say _Size(). In this case, the runtime calls that function, stores the result, destroys the object, and invokes operator delete. This implementation might look inefficient, but its advantage is that the compiler can use _Size() for other purposes as well. Store the size directly somewhere in the virtual function table (vtable) of each class. This solution is both flexible and efficient, but less easy to implement.
(Compiler writer hat off.) As you see, the compiler makes quite an effort in passing the appropriate size to your operator delete. Why, then, ignore it and perform a costly search each time you deallocate an object?
It all dovetails so nicely. SmallObjAllocator needs the size of the block to de allocate. The compiler provides it, and SmallObject forwards it to FixedAllocator.
Most of the solutions listed assume you defined a virtual destructor for Base, which explains again why it is so important to make all of your polymorphic classes' destructors virtual. If you fail to do this, deleteing a pointer to a base class that actually points to an object of a derived class engenders undefined behavior. The allocator discussed herein will assert in debug mode and crash your program in NDEBUG mode. Anybody would agree that this behavior fits comfortably into the realm of "undefined."
To protect you from having to remember all this (and from wasting nights debugging if you don't), SmallObject defines a virtual destructor. Any class that you derive from SmallObject will inherit its virtual destructor. This brings us to the implementation of SmallObject.
We need a unique SmallObjAllocator object for the whole application. That SmallObjAllocator must be properly constructed and properly destroyed, which is a thorny issue on its own. Fortunately, Loki solves this problem thoroughly with its SingletonHolder template, described in Chapter 6. (Referring you to subsequent chapters is a pity, but it would be even more pitiful to waste this reuse opportunity.) For now, just think of SingletonHolder as a device that offers you advanced management of a unique instance of a class. If that class is X, you instantiate Singleton<X>. Then, to access the unique instance of that class, you call Singleton<X>::Instance(). The Singleton design pattern is described in Gamma et al. (1995).
Using SingletonHolder renders SmallObject's implementation extremely simple:
typedef Singleton<SmallObjAllocator> MyAlloc;
void* SmallObject::operator new(std::size_t size)
{
return MyAlloc::Instance().Allocate(size);
}
void SmallObject::operator delete(void* p, std::size_t size)
{
MyAlloc::Instance().Deallocate(p, size);
}
|
4.8 Simple, Complicated, Yet Simple in the End
The implementation of SmallObject turned out to be quite simple. However, it cannot remain that simple because of multithreading issues. The unique SmallObjAllocator is shared by all instances of SmallObject. If these instances belong to different threads, we end up sharing the SmallObjAllocator between multiple threads. As discussed in the appendix, in this case we must take special measures. It seems as if we must go back to all layers' implementations, figure out the critical operations, and add locking appropriately.
However, although it's true that multithreading complicates things a bit, it's not that complicated because Loki already defines high-level object synchronization mechanisms. Following the principle that the best step toward reuse is to use, let's include Loki's Threads.h and make the following changes to SmallObject (changes are shown in bold):
template <template <class T> class ThreadingModel>
class SmallObject : public ThreadingModel<SmallObject>
{
... as before ...
};
The definitions of operator new and operator delete also undergo a bit of surgery:
template <template <class T> class ThreadingModel>
void* SmallObject<ThreadingModel>::operator new(std::size_t size)
{
Lock lock;
return MyAlloc::Instance().Allocate(size);
}
template <template <class T> class ThreadingModel>
void SmallObject<ThreadingModel>::operator delete(void* p, std::size_t size)
{
Lock lock;
MyAlloc::Instance().Deallocate(p, size);
}
That's it! We don't have to modify any of the previous layerstheir functionality will be properly guarded by locking at the highest level.
Using the Singleton management and the multithreading features of Loki right inside Loki is witness to the power of reuse. Each of these two domainsglobal variables' lifetimes and multithreadinghas its own complications. Trying to handle them all in SmallObject starting from first principles would have been overwhelmingly difficultjust try to get peace of mind for implementing FixedAllocator's intricate caching while facing the spectrum of multiple threads spuriously initializing the same object. . .
|
4.9 Administrivia
This section discusses how to use the SmallObj.h file in your applications.
To use SmallObject, you must provide appropriate parameters to SmallObjAllocator's constructor: the chunk size and the maximum size of a small object. How is a small object defined? What is the size under which an object can be considered small?
To find an answer to this question, let's go back to the purpose of building a small-object allocator. We wanted to mitigate the inefficiencies in size and time introduced by the default allocator.
The size overhead imposed by the default allocator varies largely. After all, the default allocator can use similar strategies to the ones discussed in this chapter. For most generic allocators, however, you can expect a per-object overhead that varies between 4 and 32 bytes per object in typical desktop machines. For an allocator with 16 bytes of overhead per object, an object of 64 bytes wastes 25% of memory; thus, a 64-byte object should be considered small.
On the other hand, if SmallObjAllocator handles objects that are too large, you end up allocating much more memory than needed (don't forget that FixedAllocator tends to keep one chunk allocated even after you have freed all small objects).
Loki gives you a choice and tries to provide appropriate defaults. The SmallObj.h file uses three preprocessor symbols, described in Table 4.1. You should compile all the source files in a given project with the same preprocessor symbols defined (or don't define them at all and rely on the defaults). If you don't do this, nothing lethal happens; you just end up creating more FixedAllocators tuned to different sizes.
The defaults are targeted toward a desktop machine with a reasonable amount of physical memory. If you #define either MAX_SMALL_OBJECT_SIZE or DEFAULT_CHUNK_SIZE to be zero, then SmallObj.h uses conditional compilation to generate code that simply uses the default ::operator new and ::operator delete, without incurring any overhead at all. The interface of the objects defined remains the same, but their functions are inline stubs that forward to the default free store allocator.
The class template SmallObject used to have one parameter. To support different chunk sizes and object sizes, SmallObject gets two more template parameters. They default to DEFAULT_CHUNK_SIZE and MAX_SMALL_OBJECT_SIZE, respectively.
template
<
template <class T>
class ThreadingModel = DEFAULT_THREADING,
std::size_t chunkSize = DEFAULT_CHUNK_SIZE,
std::size_t maxSmallObjectSize = MAX_SMALL_OBJECT_SIZE
>
class SmallObject;
If you just say SmallObject<>, you get a class that can work with your default threading model, garnished with the default choices concerning memory management.
Table 4.1. Preprocessor Symbols Used by SmallObj.h
| DEFAULT_CHUNK_SIZE |
The default size (in bytes) of a memory chunk. |
4096 |
| MAX_SMALL_OBJECT_SIZE |
The maximum value that is handled by SmallObjAllocator. |
64 |
| DEFAULT_THREADING |
The default threading model used by the application. A multithreaded application should define this symbol to ClassLevelLockable. |
Inherited from Threads.h |
|
4.10 Summary
Some C++ idioms make heavy use of small objects allocated on the free store. This is because in C++, runtime polymorphism goes hand in hand with dynamic allocation and pointer/reference semantics. However, the default free store allocator (accessible through the global ::operator new and ::operator delete) is often optimized for allocating large objects, not small ones. This renders the default free store allocator unsuitable for allocating small objects because it is often slow and brings nonnegligible per-object memory overhead.
The solution is to rely on small-object allocatorsspecialized allocators that are tuned for dealing with small memory blocks (tens to hundreds of bytes). Small-object allocators use larger chunks of memory and organize them in ingenious ways to reduce space and time penalties. The C++ runtime support helps by providing the size of the block to be released. This information can be grabbed by simply using a less-known overloaded form of operator delete.
Is Loki's small-object allocator the fastest possible? Definitely not. Loki's allocator operates only within the confines of standard C++. As you saw throughout this chapter, issues such as alignment must be treated very conservatively, and being conservative spells being less than optimal. However, Loki is a reasonably fast, simple, and robust allocator that has the advantage of portability.
|
4.11 Small-Object Allocator Quick Facts
The allocator implemented by Loki has a four-layered architecture. The first layer consists of a private type Chunk, which deals with organizing memory chunks in equally sized blocks. The second layer is FixedAllocator, which uses a variable-length vector of chunks to satisfy memory allocation to the extent of the available memory in the system. In the third layer, SmallObjAllocator uses multiple FixedAllocator objects to provide allocations of any object size. Small objects are allocated using a FixedAllocator, and requests for large objects are forwarded to ::operator new. Finally, the fourth layer consists of SmallObject, a class template that wraps a SmallObjAllocator object. SmallObject class template synopsis:
template
<
template <class T>
class ThreadingModel = DEFAULT_THREADING,
std::size_t chunkSize = DEFAULT_CHUNK_SIZE,
std::size_t maxSmallObjectSize = MAX_SMALL_OBJECT_SIZE
>
class SmallObject
{
public:
static void* operator new(std::size_t size);
static void operator delete(void* p, std::size_t size);
virtual ~SmallObject() {}
};
You can benefit from a small-object allocator by deriving from an instantiation of SmallObject. You can instantiate the SmallObject class template with the default parameters (SmallObject<>) or tweak its threading model or its memory allocation parameters. If you create objects with new in multiple threads, you must use a multithreaded model as the ThreadingModel parameter. Refer to the appendix for information concerning ThreadingModel. The default value of DEFAULT_CHUNK_SIZE is 4096. The default value of MAX_SMALL_OBJECT_SIZE is 64. You can #define DEFAULT_CHUNK_SIZE or MAX_SMALL_OBJECT_SIZE, or both, to override the default values. After expansion, the macros must expand to constants of type (convertible to) std::size_t. If you #define either DEFAULT_CHUNK_SIZE or MAX_SMALL_OBJECT_SIZE to zero, then the SmallAlloc.h file uses conditional compilation to generate code that forwards directly to the free store allocator. The interface remains the same. This is useful if you need to compare how your program behaves with and without specialized memory allocation.
|
Chapter 5. Generalized Functors
This chapter describes generalized functors, a powerful abstraction that allows decoupled interobject communication. Generalized functors are especially useful in designs that need requests to be stored in objects. The design pattern that describes encapsulated requests, and that generalized functors follow, is Command (Gamma et al. 1995).
In brief, a generalized functor is any processing invocation that C++ allows, encapsulated as a typesafe first-class object. In a more detailed definition, a generalized functor
Encapsulates any processing invocation because it accepts pointers to simple functions, pointers to member functions, functors, and even other generalized functorstogether with some or all of their respective arguments. Is typesafe because it never matches the wrong argument types to the wrong functions. Is an object with value semantics because it fully supports copying, assignment, and pass by value. A generalized functor can be copied freely and does not expose virtual member functions.
Generalized functors allow you to store processing requests as values, pass them as parameters, and invoke them apart from the point of their creation. They are a much-modernized version of pointers to functions. The essential differences between pointers to functions and generalized functors are that the latter can store state and invoke member functions.
After reading this chapter, you will
Understand the Command design pattern and how generalized functors relate to it Know when the Command pattern and generalized functors are useful Grasp the mechanics of various functional entities in C++ and how to encapsulate them under a uniform interface Know how to store a processing request and some or all of its parameters in an object, pass it around, and invoke it freely Know how to chain multiple such delayed calls and have them performed in sequence Know how to use the powerful Functor class template that implements the described functionality
|
5.1 The Command Design Pattern
According to the Gang of Four (GoF) book (Gamma et al. 1995), the Command pattern's intent is to encapsulate a request in an object. A Command object is a piece of work that is stored away from its actual executor. The general structure of the Command pattern is presented in
Figure 5.1.
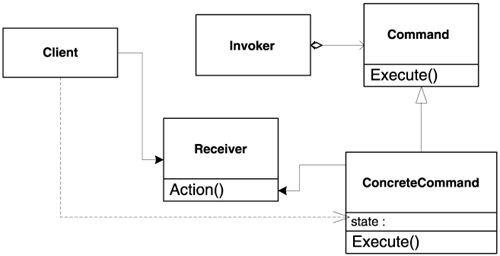
The pattern's main piece is the Command class itself. Its most important purpose is to reduce the dependency between two parts of a systemthe invoker and the receiver.
A typical sequence of actions is as follows:
The application (client) creates a ConcreteCommand object, passing it enough information to carry on a task. The dotted line in Figure 5.1 illustrates the fact that the Client influences ConcreteCommand's state. The application passes the Command interface of the ConcreteCommand object to the invoker. The invoker stores this interface. Later, the invoker decides it's time to execute the action and fires Command's Execute virtual member function. The virtual call mechanism dispatches the call to the Concrete-Command object, which takes care of the details. ConcreteCommand reaches the Receiver object (the one that is to do the job) and uses that object to perform the actual processing, such as calling its Action member function. Alternatively, the ConcreteCommand object might carry the processing all by itself. In this case, the receiver in Figure 5.1 disappears.
The invoker can invoke Execute at its leisure. Most important, at runtime you can plug various actions into the invoker by replacing the Command object that the invoker holds.
Two things are worth noting here. First, the invoker is not aware of how the work is done. This is not a new conceptto use a sorting algorithm, you don't need to know its implementation. But what's particular to Command is that the invoker doesn't even know what kind of processing the Command object is supposed to do. (By contrast, you certainly would expect the sorting algorithm to have a certain effect.) The invoker only calls for Execute for the Command interface it holds when certain circumstances occur. On the other side, the receiver itself is not necessarily aware that its Action member function was called by an invoker or otherwise.
The Command object thus ensures an important separation between the invoker and the receiver: They might be completely invisible to each other, yet communicate via Commands. Usually, an Application object decides the wiring between invokers and receivers. This means that you can use different invokers for a given set of receivers, and that you can plug different receivers into a given invokerall without their knowing anything about each other.
Second, let's look at the Command pattern from a timing perspective. In usual programming tasks, when you want to perform an action, you assemble an object, a member function of it, and the arguments to that member function into a call. For example:
window.Resize(0, 0, 200, 100); // Resize the window
The moment of initiating such a call is conceptually indistinguishable from the moment of gathering the elements of that call (the object, the procedure, and the arguments). In the Command pattern, however, the invoker has the elements of the call, yet postpones the call itself indefinitely. The Command pattern enables delayed calls as in the following example:
Command resizeCmd(
window, // Object
&Window::Resize, // Member function
0, 0, 200, 100); // Arguments
// Later on...
resizeCmd.Execute(); // Resize the window
(We will dwell on the slightly less-known C++ construct &Window::Resize a bit later.) In the Command pattern, the moment of gathering the environment necessary to perform a processing is different from the moment of performing the processing. Between the two moments, the program stores and passes around the processing request as an object. Had this timing-related desire not existed, there would have been no Command pattern. From this standpoint, the very existence of the Command object is a consequence of the timing issue: Because you need to perform processing later, there has to be an object that holds the request until then.
These points lead to two important aspects of the Command pattern:
The notion of environment is also important. The environment of a point of execution is the set of entities (variables and functions) that are visible from that point of execution. When the processing is actually started, the necessary environment must be available or else the processing cannot take place. A ConcreteCommand object might store part of its necessary environment as its own state and access part of it during Execute. The more environment a ConcreteCommand stores, the more independence it has.
From an implementation standpoint, two kinds of concrete Command classes can be identified. Some simply delegate the work to the receiver. All they do is call a member function for a Receiver object. We call them forwarding commands. Others do tasks that are more complex. They might call member functions of other objects, but they also embed logic that's beyond simple forwarding. Let's call them active commands.
Separating commands into active and forwarding is important for establishing the scope of a generic implementation. Active commands cannot be cannedthe code they contain is by definition application-specificbut we can develop helpers for forwarding commands. Because forwarding commands act much like pointers to functions and their C++ colleagues, functors, we call them generalized functors.
The aim of the rest of this chapter is to obtain a Functor class template that encapsulates any object, any member function of that object, and any set of arguments pertaining to that member function. Once executed, the Functor animates all these little things to obtain a function call.
A Functor object can be of tremendous help to a design that uses the Command pattern. In hand-coded implementations, the Command pattern doesn't scale well. You must write lots of small concrete Command classes (one for each action in the application: CmdAddUser, CmdDeleteUser, CmdModifyUser, and so on), each having a trivial Execute member function that just calls a specific member function of some object. A generic Functor class that can forward a call to any member function of any object would be of great help to such a design.
Some particular active commands are also worth implementing in Functor, such as the sequencing of multiple actions. Functor should be able to assemble multiple actions and execute them in order. The GoF book mentions such a useful object, Macro Command.
|
5.2 Command in the Real World
A popular example associated with the Command pattern is tied to windowing environments. Good object-oriented GUI frameworks have used one form or another of the Command pattern for years.
Windowing-system writers need a generic way to transmit user actions (such as mouse clicks and keystrokes) to the application. When the user clicks a button, selects a menu option, or the like, the windowing system must notify the underlying application logic. From the windowing system's standpoint, the Options command under the Tools menu does not hold any special meaning. If it did, the application would have been locked into a very rigid framework. An effective way to decouple the windowing system from the application is to use Command objects for passing user actions. Commands serve as generic vehicles that transport actions from the windows to the application logic.
In the windowing example, the invokers are user interface elements (such as buttons, checkboxes, menu items, and widgets), and the receiver is the object responsible for reacting to user interface commands (for example, a dialog or the application itself).
Command objects constitute the lingua franca that the user interface and the application use. As discussed in the previous section, Command offers double-ended flexibility. First, you can plug in new kinds of user interface elements without changing the application logic. Such a program is known as skinnable because you can add new "skins" without changing the design of the product itself. Skins do not encompass any architecturethey only provide slots for Commands and knowledge to fire them appropriately. Second, you can easily reuse the same user interface elements across different applications.
|
5.3 C++ Callable Entities
To put together a generic implementation for forwarding commands, let's try to get Command-specific notions closer to terms familiar to C++ programming.
A forwarding command is a callback on steroids, a generalized callback. A callback is a pointer to a function that can be passed around and called at any time, as illustrated in the following example.
void Foo();
void Bar();
int main()
{
// Define a pointer to a function that takes no
// parameters and returns void.
// Initialize that pointer with the address of Foo
void (*pF)() = &Foo;
Foo(); // Call Foo directly
Bar(); // Call Bar directly
(*pF)(); // Call Foo via pF
void (*pF2)() = pF; // Create a copy of pF
pF = &Bar; // Change pF to point to Bar
(*pF)(); // Now call Bar via pF
(*pF2)(); // Call Foo via pF2
}
There is an essential difference between calling Foo and calling (*pF). The difference is that in the latter case you can copy and change pointers to functions. You can take a pointer to a function, store it somewhere, and call it when the right time comeshence, the similarity with forwarding Commands, which are essentially a piece of work that is stored away from its actual executor and processed later.
In fact, callbacks are the C way of using the Command pattern in many windowing systems. X Windows, for instance, stores such a callback in each menu item and in each widget. The widget calls the callback when the user does something (like clicking on the widget). The widget does not know what the callback actually does.
In addition to simple callbacks, C++ defines many more entities that support the function-call operator. Let's enumerate all the things that support operator() in C++.
C-like functions C-like pointers to functions References to functions (which essentially act like const pointers to functions) Functors, that is, objects that define an operator() The result of applying operator.* or operator->* having a pointer to a member function in the right-hand side of the expression
You can add a pair of parentheses to the right of any of the enumerated items, put an appropriate list of arguments inside, and get some processing done. No other objects in C++ allow this except the ones just listed.
The objects that support operator() are known as callable entities. The goal of this chapter is to implement a set of forwarding commands that store and can forward a call to any callable entity. The Functor class template will encapsulate the forwarding commands and provide a uniform interface.
The implementation must handle the three essential cases: simple function calls, functor calls (including Functor calls; that is, you should be able to forward calls from one Functor to another), and member function calls. You might think to define an abstract base class and create a subclass for each case. All this sounds like straightforward C++. As you launch your favorite editor and start to type, however, an abundant crop of problems appears.
|
5.4 The Functor Class Template Skeleton
For Functor's implementation, we're certainly looking at the handle-body idiom (Coplien 1992). As Chapter 7 discusses in detail, in C++ a bald pointer to a polymorphic type does not strictly have first-class semantics because of the ownership issue. To lift the burden of lifetime management from Functor's clients, it's best to provide Functor with value semantics (well-defined copying and assignment). Functor does have a polymorphic implementation, but that's hidden inside it. We name the implementation base class FunctorImpl.
Let's now make an important observation. Command::Execute in the Command pattern should become a user-defined operator() in C++. There is a sound argument in favor of using operator() here: For C++ programmers, the function-call operator has the exact meaning of "execute," or "do your stuff." But there's a much more interesting argument for this: syntactic uniformity. A forwarding Functor not only delegates to a callable entity, but also is a callable entity itself. This renders a Functor able to hold other Functors. So from now on Functor constitutes part of the callable entities set; this will allow us to treat things in a more uniform manner in the future.
The problems start to crop up as soon as we try to define the Functor wrapper. The first shot might look like the following:
class Functor
{
public:
void operator()();
// other member functions
private:
// implementation goes here
};
The first issue is the return type of operator(). Should it be void? In certain cases, you would like to return something else, such as a bool or a std::string. There's no reason to disallow parameterized return values.
Templates are intended to solve this kind of problem, so, without further ado:
template <typename ResultType>
class Functor
{
public:
ResultType operator()();
// other member functions
private:
// implementation
};
This looks acceptable, although now we don't have one Functor; we have a family of Functors. This is quite sensible because Functors that return strings are functionally different from Functors that return integers.
Now for the second issue: Shouldn't Functor's operator() accept arguments too? You might want to pass to the Functor some information that was not available at Functor's construction time. For example, if mouse clicks on a window are passed via a Functor, the caller should pass position information (available exactly and only at call time) to the Functor object when calling its operator().
Moreover, in the generic world, parameters can be of any number, and each of them can have any type. There is no ground for limiting either the types that can be passed or their number.
The conclusion that stems from these facts is that each Functor is defined by its return type and its arguments' types. The language support needed here sounds a bit scary: variable template parameters combined with variable function-call parameters.
Unfortunately, such language support is very scarce. Variable template parameters simply don't exist. There are variable-argument functions in C++ (as there are in C), but although they do a decent job for C if you're really careful, they don't get along as well with C++. Variable arguments are supported via the dreaded ellipsis (à la printf or scanf). Calling printf or scanf without matching the format specification with the number and types of the arguments is a common and dangerous mistake illustrating the shortcomings of ellipsis functions. The variable-parameter mechanism is unsafe, is low level, and does not fit the C++ object model. To make a long story short, once you use ellipses, you're left in a world with no type safety, no object semantics (using full-fledged objects with ellipses engenders undefined behavior), and no support for reference types. Even the number of arguments is not accessible to the called function. Indeed, where there are ellipses, there's not much C++ left.
The alternative is to limit the number of arguments a Functor can take to an arbitrary (yet reasonably large) number. Choosing something in an arbitrary way is one of the most unpleasant tasks a programmer has to do. However, the choice can be made based on experimental grounds. Libraries (especially older ones) commonly use up to 12 parameters for their functions. Let's limit the number of arguments to 15. We cast this embarrassing arbitrary decision in stone and don't think about it again.
Even after making this decision, life is not a lot easier. C++ does not allow templates with the same name and different numbers of parameters. That is, the following code is invalid:
// Functor with no arguments
template <typename ResultType>
class Functor
{
...
};
// Functor with one argument
template <typename ResultType, typename Parm1>
class Functor
{
...
};
Naming the template classes Functor1, Functor2, and so on, would be a hassle.
Chapter 3 defines typelists, a general facility for dealing with collections of types. Functor's parameter types do form a collection of types, so typelists fit here nicely. The definition of Functor with typelists looks like this:
// Functor with any number and types of arguments
template <typename ResultType, class TList>
class Functor
{
...
};
A possible instantiation is as follows:
// Define a Functor that accepts an int and a double and
// returns a double
Functor<double, TYPELIST_2(int, double)> myFunctor;
An appealing advantage of this approach is that we can reuse all the goodies defined by the typelist facility instead of developing similar ones for Functor.
As you will soon see, typelists, although helpful, still require the Functor implementation to do painstaking repetition to encompass any number of arguments. From now on, let's focus on a maximum of 2 arguments. The included Functor.h file scales up to 15 arguments, as established.
The polymorphic class FunctorImpl, wrapped by Functor, has the same template parameters as Functor:
template <typename R, class TList>
class FunctorImpl;
FunctorImpl defines a polymorphic interface that abstracts a function call. For each number of parameters, we define a FunctorImpl explicit specialization (see Chapter 2). Each specialization defines a pure virtual operator() for the appropriate number and types of parameters, as shown in the following:
template <typename R>
class FunctorImpl<R, NullType>
{
public:
virtual R operator()() = 0;
virtual FunctorImpl* Clone() const = 0;
virtual ~FunctorImpl() {}
};
template <typename R, typename P1>
class FunctorImpl<R, TYPELIST_1(P1)>
{
public:
virtual R operator()(P1) = 0;
virtual FunctorImpl* Clone() const = 0;
virtual ~FunctorImpl() {}
};
template <typename R, typename P1, typename P2>
class FunctorImpl<R, TYPELIST_2(P1, P2)>
{
public:
virtual R operator()(P1, P2) = 0;
virtual FunctorImpl* Clone() const = 0;
virtual ~FunctorImpl() {}
};
The FunctorImpl classes are partial specializations of the primary FunctorImpl template. Chapter 2 describes the partial template specialization feature in detail. In our situation, partial template specialization allows us to define different versions of FunctorImpl, depending on the number of elements in the typelist.
In addition to operator(), FunctorImpl defines two scaffolding member functionsClone and a virtual destructor. The purpose of Clone is the creation of a polymorphic copy of the FunctorImpl object. (Refer to Chapter 8 for details on polymorphic cloning.) The virtual destructor allows us to destroy objects derived from FunctorImpl by invoking delete on a pointer to a FunctorImpl. Chapter 4 provides an extensive discussion of why this do-nothing destructor is vital.
Functor follows a classic handle-body implementation, as shown here.
template <typename R, class TList>
class Functor
{
public:
Functor();
Functor(const Functor&);
Functor& operator=(const Functor&);
explicit Functor(std::auto_ptr<Impl> spImpl);
...
private:
// Handy type definition for the body type
typedef FunctorImpl<R, TList> Impl;
std::auto_ptr<Impl> spImpl_;
};
Functor holds a smart pointer to FunctorImpl<R, TList>, which is its corresponding body type, as a private member. The smart pointer chosen is the standard std::auto_ptr.
The previous code also illustrates the presence of some Functor artifacts that prove its value semantics. These artifacts are the default constructor, the copy constructor, and the assignment operator. An explicit destructor is not needed, because auto_ptr cleans up resources automatically.
Functor also defines an "extension constructor" that accepts an auto_ptr to Functor Impl. The extension constructor allows you to define classes derived from FunctorImpl and to initialize Functor directly with pointers to those classes.
Why does the extension constructor take as its argument an auto_ptr and not a simple pointer? Constructing from auto_ptr is a clear statement to the outside world that Functor takes ownership of the FunctorImpl object. Users of Functor will actually have to type auto_ptr whenever they invoke this constructor; we assume that if they type auto_ptr, they know what auto_ptr is about.
|
5.5 Implementing the Forwarding Functor::operator()
Functor needs an operator() that forwards to FunctorImpl::operator(). We can use the same approach as with FunctorImpl itself: Provide a bunch of Functor partial specializations, one for each parameter count. However, this approach is not appropriate here. Functor defines a considerable amount of code, and it would be wasteful to duplicate it all only for the sake of operator().
But first, let's define the parameter types. Typelists are of great help here:
template <typename R, class TList>
class Functor
{
typedef TList ParmList;
typedef typename TypeAtNonStrict<TList, 0, EmptyType>::Result
Parm1;
typedef typename TypeAtNonStrict<TList, 1, EmptyType>::Result
Parm2;
... as above ...
};
TypeAtNonStrict is a template that accesses the type at a given position in a typelist. If no type is found, the result (i.e., the inner class TypeAtNonStrict<...>::Result) evaluates to the third template argument of TypeAtNonStrict. We chose EmptyType as that third argument. EmptyType is, as its name hints, a class that holds nothing between its brackets. (Refer to Chapter 3 for details on TypeAtNonStrict and to Chapter 2 for a description of EmptyType.) In conclusion, ParmN will be either the Nth type in the typelist, or EmptyType if the typelist has fewer than N elements.
To implement operator(), let's rely on an interesting trick. We define all versions of operator()for any number of parametersinside Functor's definition, as follows.
template <typename R, class TList>
class Functor
{
... as above ...
public:
R operator()()
{
return (*spImpl_)();
}
R operator()(Parm1 p1)
{
return (*spImpl_)(p1);
}
R operator()(Parm1 p1, Parm2 p2)
{
return (*spImpl_)(p1, p2);
}
};
Where's the trick? For a given Functor instantiation, only one operator() is correct. All others constitute compile-time errors. You would expect Functor not to compile at all. This is because each FunctorImpl specialization defines only one operator(), not a bunch of them as Functor does. The trick relies on the fact that C++ does not instantiate member functions for templates until they are actually used. Until you call the wrong operator(), the compiler doesn't complain. If you try to call an overload of operator() that doesn't make sense, the compiler tries to generate the body of operator() and discovers the mismatch. Here's an example.
// Define a Functor that accepts an int and a double and
// returns a double.
Functor<double, TYPELIST_2(int, double)> myFunctor;
// Invoke it.
// operator()(double, int) is generated.
double result = myFunctor(4, 5.6);
// Wrong invocation.
double result = myFunctor(); // error!
// operator()() is invalid because
// FunctorImpl<double, TYPELIST_2(int, double)>
// does not define one.
Because of this neat trick, we don't have to specialize Functor partially for zero, one, two, and so forth parametersspecializations that would have led to much code duplication. We just define all versions and let the compiler generate only the ones that are used.
Now that the necessary scaffolding is in place, we're ready to start defining concrete classes derived from FunctorImpl.
|
5.6 Handling Functors
Let's start with handling functors. Functors are loosely defined as instances of classes that define operator(), just as Functor itself does (that is, Functor is a functor). Consequently, Functor's constructor that accepts a functor object will be a template parameterized with the type of that functor.
template <typename R, class TList>
class Functor
{
... as above ...
public:
template <class Fun>
Functor(const Fun& fun);
};
To implement this constructor we need a simple class template FunctorHandler derived from FunctorImpl<R, TList>. That class stores an object of type Fun and forwards operator() to it. We resort to the same trick as in the previous section for implementing operator() properly.
To avoid defining too many template parameters for FunctorHandler, we make the Functor instantiation itself a template parameter. This single parameter collects all the others because it provides inner typedefs.
template <class ParentFunctor, typename Fun>
class FunctorHandler
: public FunctorImpl
<
typename ParentFunctor::ResultType,
typename ParentFunctor::ParmList
>
{
public:
typedef typename ParentFunctor::ResultType ResultType;
FunctorHandler(const Fun& fun) : fun_(fun) {}
FunctorHandler* Clone() const
{ return new FunctorHandler(*this); }
ResultType operator()()
{
return fun_();
}
ResultType operator()(typename ParentFunctor::Parm1 p1)
{
return fun_(p1);
}
ResultType operator()(typename ParentFunctor::Parm1 p1,
typename ParentFunctor::Parm2 p2)
{
return fun_(p1, p2);
}
private:
Fun fun_;
};
FunctorHandler looks much like Functor itself: It forwards requests to a stored member variable. The main difference is that the functor is stored by value, not by pointer. This is because, in general, functors are meant to be this waynonpolymorphic types with regular copy semantics.
Notice the use of the inner types ParentFunctor::ResultType, ParentFunctor::Parm1, and ParentFunctor::Parm2 where needed. FunctorHandler implements a simple constructor, the cloning function, and multiple operator() versions. The compiler picks up the appropriate one. If you use an illegal overload of operator(), a compile-time error occurs, as it should.
There is nothing special about FunctorHandler's implementation. This doesn't mean it didn't require a lot of thought. You will see in the next section just how much genericity this little class template brings us.
Given FunctorHandler's declaration, it's easy to write the templated constructor of Functor declared earlier in this section.
template <typename R, class TList>
template <typename Fun>
Functor<R, TList>::Functor(const Fun& fun)
: spImpl_(new FunctorHandler<Functor, Fun>(fun));
{
}
There's no copyediting error here. The two template parameter sets are necessary: The template <class R, class TList> stands for the class template Functor, and template <typename Fun> stands for the parameter that the constructor itself takes. In standardese, this type of code is known as an "out-of-class member template definition."
The body of the constructor initializes the spImpl_ member to point to a new object of type FunctorHandler, instantiated and initialized with the proper arguments.
There's something worth mentioning here, something that's germane to understanding the Functor implementation we're building. Note that upon entering this constructor of Functor, we have full type knowledge via the template parameter Fun. Upon exiting the constructor, the type information is lost as far as Functor is concerned, because all that Functor knows is spImpl_, which points to the base class FunctorImpl. This apparent loss of type information is interesting: The constructor knows the type and acts like a factory that transforms it in polymorphic behavior. The type information is preserved in the dynamic type of the pointer to FunctorImpl.
Although we haven't written much code (just a bunch of one-line functions), we're ready for a test drive. Here it is:
// Assume Functor.h includes the Functor implementation
#include "Functor.h"
#include <iostream>
// The using directive is acceptable for a small C++ program
using namespace std;
// Define a test functor
struct TestFunctor
{
void operator()(int i, double d)
{
cout << "TestFunctor::operator()(" << i
<< ", " << d << ") called.\n";
}
};
int main()
{
TestFunctor f;
Functor<void, TYPELIST_2(int, double)> cmd(f);
cmd(4, 4.5);
}
This little program will reliably print
TestFunctor::operator()(4, 4.5) called.
This means we've achieved our goal. We can now proceed to the next step.
|
5.7 Build One, Get One Free
Reading the previous section, you may have asked yourself, Why didn't we start with implementing support for pointers to regular functions, which seems to be the simplest case? Why did we jump directly to functors, templates, and so on? The answer is simple: By now, support for regular functions is already implemented. Let's modify the test program a bit:
#include "Functor.h"
#include <iostream>
using namespace std;
// Define a test function
void TestFunction(int i, double d)
{
cout << "TestFunction(" << i
<< ", " << d << ") called." << endl;
}
int main()
{
Functor<void, TYPELIST_2(int, double)> cmd(
TestFunction);
// will print: "TestFunction(4, 4.5) called."
cmd(4, 4.5);
}
The explanation for this nice surprise comes from the workings of template parameter deduction. When the compiler sees a Functor constructed from TestFunction, it has no choice but to try the templated constructor. The compiler will then instantiate the template constructor with the template argument void (&)(int, double), which is the type of TestFunction. The constructor instantiates FunctorHandler<Functor<...>, void (&)(int, double)>. Consequently, the type of fun_ in FunctorHandler is void (&)(int, double) as well. When you invoke FunctorHandler<...>::operator(), it forwards to fun_(), which is legal syntax for invoking a function through a pointer to function. Thus, FunctorHandler supports pointers to functions out of the box because of two things: the syntactic similarity between pointers to functions and functors and the type inference mechanism that C++ uses.
There is a problem, though. (It couldn't be perfect, could it?) If you overload Test-Functionor any function that you pass to Functor<...>you have to help a bit with some disambiguation. The reason is that if TestFunction is overloaded, the type of the symbol TestFunction is no longer defined. To illustrate this, let's add an overloaded version of TestFunction just before main:
// Declare an overloaded test function
// (no definition necessary)
void TestFunction(int);
Suddenly the compiler complains it cannot figure out which overload of TestFunction it should use. Because there are two functions called TestFunction, this name alone no longer suffices for identification.
In essence, in the presence of overloading, there are two ways to identify a specific function: by using initialization (or an assignment) and by using a cast. Let's illustrate both methods:
// as above, TestFunction is overloaded
int main()
{
// Typedef used for convenience
typedef void (*TpFun)(int, double);
// Method 1: use an initialization
TpFun pF = TestFunction;
Functor<void, TYPELIST_2(int, double)>
cmd1(4, 4.5);
// Method 2: use a cast
Functor<void, int, double> cmd2(
static_cast<TpFun>(TestFunction)); // Ok
cmd2(4, 4.5);
}
Both the initialization and the static cast let the compiler know that you're actually interested in the TestFunction that takes an int and a double and returns void.
|
5.8 Argument and Return Type Conversions
In an ideal world, we would like conversions to work for Functor just as they work for regular function calls. That is, we'd like to see this running:
#include <string>
#include <iostream>
#include "Functor.h"
using namespace std;
// Ignore arguments-not of interest
// in this example
const char* TestFunction(double, double)
{
static const char buffer[] = "Hello, world!";
// It's safe to return a pointer to a static buffer
return buffer;
}
int main()
{
Functor<string, TYPELIST_2(int, int)> cmd(TestFunction);
// Should print "world!"
cout << cmd(10, 10).substr(7);
}
Although the actual TestFunction has a slightly different signature (it takes two doubles and returns a const char *), it still should be bindable to a Functor<string, TYPELIST_2(int, int)>. We expect this to happen because int can be implicitly converted to double, and const char * is implicitly convertible to string. If Functor does not accept the same conversions that C++ accepts, Functor would be unnecessarily rigid.
To satisfy this new requirement, we don't have to write any new code. The previous example compiles and runs as expected with our current codebase. Why? The answer is found, again, in the way we defined FunctorHandler.
Let's see what happens with the code in the example after all the dust of template instantiation has settled. The function
string Functor<...>::operator()(int i, int j)
forwards to the virtual function
string FunctorHandler<...>::operator()(int i, int j)
whose implementation ultimately calls
return fun_(i, j);
where fun_ has type const char* (*)(double, double) and evaluates to TestFunction.
When the compiler encounters the call to fun_, it compiles it normally, just as if you had written it by hand. "Normally" here means that conversion rules apply as usual. The compiler then generates code to convert i and j to double, and the result to std::string.
The generality and flexibility of FunctorHandler illustrate the power of code generation. The syntactic replacement of template arguments for their respective parameters is typical of generic programming. Template processing predates compiling, allowing you to operate at source-code level. In object-oriented programming, in contrast, the power comes from late (after compilation) binding of names to values. Thus, object-oriented programming fosters reuse in the form of binary components, whereas generic programming fosters reuse at the source-code level. Because source code is inherently more information rich and higher level than binary code, generic programming allows richer constructs. This richness, however, comes at the expense of lowered runtime dynamism. You cannot do with STL what you can do with CORBA, and vice versa. The two techniques complement each other.
We are now able to handle functors of all kinds and regular functions using the same small codebase. As a bonus, we have implicit conversion for arguments and for the return value.
|
5.9 Handling Pointers to Member Functions
Although not very common in day-to-day programming activities, pointers to member functions can sometimes be of help. They act much like pointers to functions, but when you want to invoke them, you must pass an object (in addition to the arguments). The following example depicts the syntax and the semantics of pointers to member functions.
#include <iostream>
using namespace std;
class Parrot
{
public:
void Eat()
{
cout << "Tsk, knick, tsk...\n";
}
void Speak()
{
cout << "Oh Captain, my Captain!\n";
}
};
int main()
{
// Define a type: pointer to a member function of
// Parrot, taking no arguments and
// returning void.
typedef void (Parrot::* TpMemFun)();
// Create an object of that type
// and initialize it with the address of
// Parrot::Eat.
TpMemFun pActivity = &Parrot::eat;
// Create a Parrot...
Parrot geronimo;
// ...and a pointer to it
Parrot* pGeronimo = &geronimo;
// Invoke the member function stored in Activity
// via an object. Notice the use of operator.*
(geronimo.*pActivity)();
// Same, via pointer. Now we use operator->*
(pGeronimo->*pActivity)();
// Change the activity
pActivity = &Parrot::Speak;
// Wake up, Geronimo!
(geronimo.*pActivity)();
}
A closer look at pointers to member functions and their two related operators.* and ->*reveals strange features. There is no C++ type for the result of geronimo.*p-Activity and pGeronimo->*pActivity. Both are binary operations all right, and they return something to which you can apply the function-call operator immediately, but that "something" does not have a type. You cannot store the result of operator.* or operator->* in any way, although there is an entity that holds the fusion between your object and the pointer to a member function. This fusion seems to be very unstable. It appears from chaos just as you invoke operator.* or operator->*, exists just long enough to apply operator(), and then goes back to chaos. There's nothing else you can do with it.
In C++, where every object has a type, the result of operator->* or operator.* is a unique exception. It's even trickier than the ambiguity of pointers to functions introduced by overloading (discussed in the previous section). There we had too many types to choose from, but we could disambiguate the choice; here, we don't have any type to start with. For this reason, pointers to member functions and the two related operators are a curiously half-baked concept in C++. And by the way, you cannot have references to member functions (although you can have references to regular functions).
Some C++ compiler vendors define a new type and allow you to store the result of operator.* by using a syntax like this:
// __closure is a language extension
// defined by some vendors
void (__closure:: * geronimosWork)() =
geronimo.*pActivity;
// Invoke whatever Geronimo is doomed to do
geronimosWork();
There's nothing about Parrot in the type of geronimosWork. This means that later, you can bind geronimosWork to something that's not geronimo, and even to something that's not a Parrot. All you have to commit to is the return type and the arguments of the pointer to a member function. In fact, this language extension is a kind of Functor class, but restricted to objects and member functions only (it does not allow regular functions or functors).
Let's implement support for bound pointers to member functions in Functor. The experience with functors and functions suggests that it's good to keep things generic and not to jump too early into specificity. In the implementation of MemFunHandler, the object type (Parrot in the previous example) is a template parameter. Furthermore, let's make the pointer to a member function a template parameter as well. By doing this, we get automatic conversions for free, as happened with the implementation of FunctorHandler.
Here's the implementation of MemFunHandler. It incarnates the ideas just discussed, plus the ones already exploited in FunctorHandler.
template <class ParentFunctor, typename PointerToObj,
typename PointerToMemFn>
class MemFunHandler
: public FunctorImpl
<
typename ParentFunctor::ResultType,
typename ParentFunctor::ParmList
>
{
public:
typedef typename ParentFunctor::ResultType ResultType;
MemFunHandler(const PointerToObj& pObj, PointerToMemFn pMemFn)
: pObj_(pObj), pMemFn_(pMemFn) {}
MemFunHandler* Clone() const
{ return new MemFunHandler(*this); }
ResultType operator()()
{
return ((*pObj_).*pMemFn_)();
}
ResultType operator()(typename ParentFunctor::Parm1 p1)
{
return ((*pObj_).*pMemFn_)(p1);
}
ResultType operator()(typename ParentFunctor::Parm1 p1,
typename ParentFunctor::Parm2 p2)
{
return ((*pObj_).*pMemFn_)(p1, p2);
}
private:
PointerToObj pObj_;
PointerToMemFn pMemFn_;
};
Why is MemFunHandler parameterized with the type of the pointer (PointerToObj) and not with the type of the object itself? A more straightforward implementation would have looked like this:
template <class ParentFunctor, typename Obj,
typename PointerToMemFn>
class MemFunHandler
: public FunctorImpl
<
typename ParentFunctor::ResultType,
typename ParentFunctor::ParmList
>
{
private:
Obj* pObj_;
PointerToMemFn pMemFn_;
public:
MemFunHandler(Obj* pObj, PointerToMemFn pMemFn)
: pObj_(pObj), pMemFn_(pMemFn) {}
...
};
This code would have been easier to understand. However, the first implementation is more generic. The second implementation hardwires the pointer-to-object type in its implementation. It stores a bare, bald, unadorned pointer to Obj. Can this be a problem?
Yes it is, if you want to use smart pointers with MemFunHandler. Aha! The first implementation supports smart pointers; the second does not. The first implementation can store any type that acts as a pointer to an object; the second is hardwired to store and use only simple pointers. Moreover, the second version does not work for pointers to const. Such is the negative effect of hardwiring types.
Let's put in place a test run for the newly implemented feature. Parrot gets reused.
#include "Functor.h"
#include <iostream>
using namespace std;
class Parrot
{
public:
void Eat()
{
cout << "Tsk, knick, tsk...\n";
}
void Speak()
{
cout << "Oh Captain, my Captain!\n";
}
};
int main()
{
Parrot geronimo;
// Define two Functors
Functor<>
cmd1(&geronimo, &Parrot::Eat),
cmd2(&geronimo, &Parrot::Speak);
// Invoke each of them
cmd1();
cmd2();
}
Because MemFunHandler took the precaution of being as generic as possible, automatic conversions come for freejust as they did for FunctorHandler.
|
5.10 Binding
We could stop here. By now, we have everything in placeFunctor supports all the C++ callable entities defined in the beginning of the discussion, and in a nice manner. However, as Pygmalion might have remarked, sometimes the actual outcome of work is impossible to predict when you start doing it.
As soon as Functor is ready, new ideas come to mind. For instance, we'd like to be able to convert from a type of Functor to another. One such conversion is binding: Given a Functor that takes two integers, you want to bind one integer to some fixed value and let only the other one vary. Binding yields a Functor that takes only one integer, because the other one is fixed and therefore known, as illustrated in the following example.
void f()
{
// Define a Functor of two arguments
Functor<void, TYPELIST_2(int, int)> cmd1(something);
// Bind the first argument to 10
Functor<void, int> cmd2(BindFirst(cmd1, 10));
// Same as cmd1(10, 20)
cmd2(20);
// Further bind the first (and only) argument
// of cmd2 to 30
Functor<void> cmd3(BindFirst(cmd2, 30));
// Same as cmd1(10, 30)
cmd3();
}
Binding is a powerful feature. You can store not only callable entities but also part (or all) of their arguments. This greatly increases the expressive power of Functor because it allows packaging of functions and arguments without requiring glue code.
For instance, think of implementing redo support in a text editor. When the user types an "a," you execute the member function Document::InsertChar('a'). Then you append a canned Functor that contains the pointer to Document, the member function InsertChar, and the actual character. When the user selects Redo, all you have to do is fire that Functor and you're finished. Section 5.14 provides further discussion of undo and redo.
Binding is powerful from another, more profound, standpoint. Think of a Functor as a computation, and of its arguments as the environment necessary to perform that computation. So far, Functor delays the computation by storing pointers to functions and pointers to methods. However, Functor stores only the computation and nothing about the environment of that computation. Binding allows Functor to store part of the environment together with the computation and to reduce progressively the environment necessary at invocation time.
Before jumping into the implementation, let's recap the requirement. For an instantiation Functor<R, TList>, we want to bind the first argument (TList::Head) to a fixed value. Therefore, the return type is Functor<R, TList::Tail>.
This being said, implementing the BinderFirst class template is a breeze. We have to pay special attention only to the fact that there are two instantiations of Functor involved: the incoming Functor and the outgoing Functor. The incoming Functor type is passed as the ParentFunctor parameter. The outgoing Functor type is computed.
template <class Incoming>
class BinderFirst
: public FunctorImpl<typename Incoming::ResultType,
typename Incoming::Arguments::Tail>
{
typedef Functor<typename Incoming::ResultType,
Incoming::Arguments::Tail> Outgoing;
typedef typename Incoming::Parm1 Bound;
typedef typename Incoming::ResultType ResultType;
public:
BinderFirst(const Incoming& fun, Bound bound)
: fun_(fun), bound_(bound)
{
}
BinderFirst* Clone() const
{ return new BinderFirst(*this); }
ResultType operator()()
{
return fun_(bound_);
}
ResultType operator()(typename Outgoing::Parm1 p1)
{
return fun_(bound_, p1);
}
ResultType operator()(typename Outgoing::Parm1 p1,
typename Outgoing::Parm2 p2)
{
return fun_(bound_, p1, p2);
}
private:
Incoming fun_;
Bound bound_;
};
The class template BinderFirst works in conjunction with the template function BindFirst. The merit of BindFirst is that it automatically deduces its template parameters from the types of the actual arguments that you pass it.
// See Functor.h for the definition of BinderFirstTraits
template <class Fctor>
typename Private::BinderFirstTraits<Fctor>::BoundFunctorType
BindFirst(
const Fctor& fun,
typename Fctor::Parm1 bound)
{
typedef typename
private::BinderFirstTraits<Fctor>::BoundFunctorType
Outgoing;
return Outgoing(std::auto_ptr<typename Outgoing::Impl>(
new BinderFirst<Fctr>(fun, bound)));
}
Binding dovetails nicely with automatic conversion, conferring incredible flexibility on Functor. The following example combines binding with automatic conversions.
const char* Fun(int i, int j)
{
cout << Fun(" << i << ", " << j << ") called\n";
return "0";
}
int main()
{
Functor<const char*, TYPELIST_2(char, int)> f1(Fun);
Functor<std::string, TYPELIST_1(double)> f2(
BindFirst(f1, 10));
// Prints: Fun(10, 15) called
f2(15);
}
|
5.11 Chaining Requests
The GoF book (Gamma et al. 1995) gives an example of a MacroCommand class, a command that holds a linear collection (such as a list or a vector) of Commands. When a MacroCommand is executed, it executes in sequence each of the commands that it holds.
This feature can be very useful. For instance, let's refer to the undo/redo example again. One "do" operation might be accompanied by multiple "undo" operations. For example, inserting a character may automatically scroll the text window (some editors do this to ensure better text visibility). On undoing that operation, you'd like the window to "unscroll" back to where it was. (Most editors don't unscroll correctly. What a nuisance.) To unscroll, you need to store multiple Commands in a single Functor object and execute them as a single unit. The Document::InsertChar member function pushes a MacroCommand onto the undo stack. The MacroCommand would be composed of Document::Delete-Char and Window::Scroll. The latter member function would be bound to an argument that holds the old position. (Again, binding comes in very handy.)
Loki defines a class FunctorChain and the helper function Chain. Chain's declaration looks like this:
template <class Fun1, class Fun2>
Fun2 Chain(
const Fun1& fun1,
const Fun2& fun2);
FunctorChain's class implementation is trivialit stores the two functors, and FunctorChain::operator() calls them in sequence. You can chain multiple functors by issuing repeated calls to Chain.
Let's have Chain conclude the support for macro commands. One thing about "nice to have" features is that the list can go on forever. However, there's plenty of room to grow. Neither BindFirst nor Chain incurred any change to Functor, which is proof that you can build similar facilities on your own.
|
5.12 Real-World Issues I: The Cost of Forwarding Functions
The Functor class template is conceptually finished. Now we concentrate on optimizing it so that it works as efficiently as possible.
Let's focus on one of Functor's operator() overloads, which forwards the call to the smart pointer.
// inside Functor<R, TList>
R operator()(Parm1 p1, Parm2 p2)
{
return (*spImpl_)(p1, p2);
}
Each time you call operator(), an unnecessary copy is performed for each argument. If Parm1 and Parm2 are expensive to copy, you might have a performance problem.
Oddly enough, even if Functor's operator() is inline, the compiler is not allowed to optimize the extra copies away. Item 46 in Sutter (2000) describes this late language change, made just before standardization. What's called eliding of copy construction was banned for forwarding functions. The only situation in which a compiler can elide a copy constructor is for the returned value, which cannot be optimized by hand.
Are references an easy fix for our problem? Let's try this:
// inside Functor<R, TList>
R operator()(Parm1& p1, Parm2& p2)
{
return (*spImpl_)(p1, p2);
}
All looks fine, and it might actually work, until you try something like this:
void testFunction(std::string&, int);
Functor<void, TYPELIST_2(std::string&, int)> cmd(testFunction);
...
string s;
cmd(s, 5); //error!
The compiler will choke on the last line, uttering something like "References to references are not allowed." (Actually, the message may be slightly more cryptic.) The fact is, such an instantiation would render Parm1 as a reference to std::string, and consequently p1 would be a reference to a reference to std::string. References to references are illegal.
Fortunately, Chapter 2 provides a tool that addresses exactly this kind of problem. Chapter 2 features a class template TypeTraits<T> that defines a bunch of types related to the type T. Examples of such related types are the non-const type (if T is a const type), the pointed-to type (if T is a pointer), and many others. The type that can be safely and efficiently passed as a parameter to a function is ParameterType. The following table illustrates the link between the type you pass to TypeTraits and the inner type definition ParameterType. Consider U to be a plain type, such as a class or a primitive type.
| U |
U if U is primitive; otherwise, const U & |
| const U |
U if U is primitive; otherwise, const U & |
| U & |
U & |
| const U & |
const U & |
If you substitute the types in the right column for the arguments in the forwarding function, it will work correctly for any caseand without any copy overhead:
// Inside Functor<R, TList>
R operator()(
typename TypeTraits<Parm1>::ParameterType p1,
typename TypeTraits<Parm2>::ParameterType p2)
{
return (*spImpl_)(p1, p2);
}
What's even nicer is that references work great in conjunction with inline functions. The optimizer generates optimal code easier because all it has to do is short-circuit the references.
|
5.13 Real-World Issues II: Heap Allocation
Let's concentrate now on the cost of constructing and copying Functors. We have implemented correct copy semantics, but at a cost: heap allocation. Every Functor holds a (smart) pointer to an object allocated with new. When a Functor is copied, a deep copy is performed by using FunctorImpl::Clone.
This is especially bothersome when you think of the size of the objects we're using. Most of the time, Functor will be used with pointers to functions and with pairs of pointers to objects and pointers to member functions. On typical 32-bit systems, these objects occupy 4 and 20 bytes, respectively (4 for the pointer to an object and 16 for the pointer to a member function). When binding is used, the size of the concrete functor object increases roughly with the size of the bound argument (it may actually increase slightly more because of padding).
Chapter 4 introduces an efficient small-object allocator. FunctorImpl and its derivatives are perfect candidates for taking advantage of that custom allocator. Recall from Chapter 4 that one way to use the small-object allocator is to derive your class from the Small-Object class template.
Using SmallObject is very simple. We need, however, to add a template parameter to Functor and FunctorImpl that reflects the threading model used by the memory allocator. This is not troublesome, because most of the time you'll use the default argument. In the following code, changes are shown in bold:
template
<
class R,
class TL,
template <class T>
class ThreadingModel = DEFAULT_THREADING,
>
class FunctorImpl : public SmallObject<ThreadingModel>
{
public:
... as above ...
};
That's all it takes for FunctorImpl to take full advantage of the custom allocator.
Similarly, Functor itself adds a third template parameter:
template
<
class R,
class TL,
template <class T>
class ThreadingModel = DEFAULT_THREADING,
>
class Functor
{
...
private:
// Pass ThreadingModel to FunctorImpl
std::auto_ptr<FunctorImpl<R, TL, ThreadingModel> pImpl_;
};
Now if you want to use Functor with the default threading model, you don't have to specify its third template argument. Only if your application needs Functors that support two or more different threading models will you need to specify ThreadingModel explicitly.
|
5.14 Implementing Undo and Redo with Functor
The GoF book (Gamma et al. 1995) recommends that undo be implemented as an additional Unexecute member function of the Command class. The problem is, you cannot ex press Unexecute in a generic way because the relation between doing something and undoing something is unpredictable. The Unexecute solution is appealing when you have a concrete Command class for each operation in your application, but the Functor-based approach favors using a single class that can be bound to different objects and member function calls.
Al Stevens's article in Dr. Dobb's Journal (Stevens 1998) is of great help in studying generic implementations of undo and redo. He has built a generic undo/redo library that you certainly should check out before rolling your own, with Functor or not.
It's all about data structures. The basic idea in undo and redo is that you have to keep an undo stack and a redo stack. As the user "does" something, such as typing a character, you push a different Functor on the undo stack. This means the Document::InsertChar member function is responsible for pushing the action that appropriately undoes the insertion (such as Document::DeleteChar). This puts the burden on the member function that does the stuff and frees the Functor from knowing how to undo itself.
Optionally, you may want to push on the redo stack a Functor consisting of the Document and a pointer to the Document::InsertChar member function, all bound to the actual character type. Some editors allow "retyping": After you type something and select Redo, that block of typing is repeated. The binding we built for Functor greatly helps with storing a call to Document::InsertChar for a given character, all encapsulated in a single Functor. Also, not only should the last character typed be repeatedthat wouldn't be much of a featurebut the whole sequence of typing after the last nontyping action should be repeated. Chaining Functors enters into action here: As long as the user types, you append to the same Functor. This way you can treat later multiple keystrokes as a single action.
Document::InsertChar essentially pushes a Functor onto the undo stack. When the user selects Undo, that Functor will be executed and pushed onto the redo stack.
As you see, binding arguments and composition allows us to treat Functors in a very uniform way: No matter what kind of call there is, it's ultimately packed in a Functor. This considerably eases the task of implementing undo and redo.
|
5.15 Summary
Using good libraries in C++ is (or at least ought to be) a lot easier than writing them. On the other hand, writing libraries is a lot of fun. Looking back at all the implementation details, there are a few lessons to keep in mind when writing generic code:
When it comes to types, templatize and postpone. Be generic. FunctorHandler and MemFunHandler gain a lot from postponing type knowledge by using templates. Pointers to functions came for free. In comparison with what it offers, the codebase is remarkably small. All this comes from using templates and letting the compiler infer types as much as possible. Encourage first-class semantics. It would have been an incredible headache to operate only with FunctorImpl pointers. Imagine yourself implementing binding and chaining.
Clever techniques should be applied for the benefit of simplicity. After all this discussion on templates, inheritance, binding, and memory, we distill a simple, easy-to-use, well-articulated library.
In a nutshell, Functor is a delayed call to a function, a functor, or a member function. It stores the callee and exposes operator() for invoking it. Let's highlight some quick facts about it.
|
5.16 Functor Quick Facts
Functor is a template that allows the expression of calls with up to 15 arguments. The first parameter is the return type, and the second is a typelist containing the parameter types. The third template parameter establishes the threading model of the allocator used with Functor. Refer to Chapter 3 for details on typelists, the appendix for details on threading models, and Chapter 4 for details on small-object allocation. You initialize a Functor with a function, a functor, another Functor, or a pointer to an object and a pointer to a method, as exemplified in the following code:
void Function(int);
struct SomeFunctor
{
void operator()(int);
};
struct SomeClass
{
void MemberFunction(int);
};
void example()
{
// Initialize with a function
Functor<void, TYPELIST_1(int)> cmd1(Function);
// Initialize with a functor
SomeFunctor fn;
Functor<void, TYPELIST_1(int)> cmd2(fn);
// Initialize with a pointer to object
// and a pointer to member function
SomeClass myObject;
Functor<void, TYPELIST_1(int)> cmd3(&myObject,
&SomeClass::MemberFunction);
// Initialize a Functor with another
// (copying)
Functor<void, TYPELIST_1(int)> cmd4(cmd3);
}
You also can initialize Functor with a std::auto_ptr< FunctorImpl<R,TList> >. This enables user-defined extensions. Functor supports automatic conversions for arguments and return values. For instance, in the previous example, Function, SomeFunctor::operator(), and SomeClass:: MemberFunction might take a double, instead of an int, as an argument. Manual disambiguation is needed in the presence of overloading. Functor fully supports first-class semantics: copying, assigning to, and passing by value. Functor is not polymorphic and is not intended to be derived from. If you want to extend Functor, derive from FunctorImpl. Functor supports argument binding. A call to BindFirst binds the first argument to a fixed value. The result is a Functor parameterized with the rest of the arguments. Example:
void f()
{
// Define a Functor of three arguments
Functor<void, TYPELIST_3(int, int, double)> cmd1(
someEntity);
// Bind the first argument to 10
Functor<void, TYPELIST_2(int, double)> cmd2(
BindFirst(cmd1, 10));
// Same as cmd1(10, 20, 5.6)
cmd2(20, 5.6);
}
Multiple Functors can be chained in a single Functor object by using the Chain function.
void f()
{
Functor<> cmd1(something);
Functor<> cmd2(somethingElse);
// Chain cmd1 and cmd2
// as the container
Functor<> cmd3(Chain(cmd1, cmd2));
// Equivalent to cmd1(); cmd2();
cmd3();
}
The cost of using Functor is one indirection (call via pointer) for simple Functor objects. For each binding, there is an extra virtual call cost. For chaining, there is an extra virtual call cost. Parameters are not copied, except when conversion is necessary. FunctorImpl uses the small-object allocator defined in Chapter 4.
|
Chapter 6. Implementing Singletons
The Singleton design pattern (Gamma et al. 1995) is unique in that it's a strange combination: its description is simple, yet its implementation issues are complicated. This is proven by the abundance of Singleton discussions and implementations in books and magazine articles (e.g., Vlissides 1996, 1998). Singleton's description in the GoF book is as simple as it gets: "Ensure a class only has one instance, and provide a global point of access to it."
A singleton is an improved global variable. The improvement that Singleton brings is that you cannot create a secondary object of the singleton's type. Therefore, you should use Singleton when you model types that conceptually have a unique instance in the application, such as Keyboard, Display, PrintManager, and SystemClock. Being able to instantiate these types more than once is unnatural at best, and often dangerous.
Providing a global point of access has a subtle implicationfrom a client's standpoint, the Singleton object owns itself. There is no special client step for creating the singleton. Consequently, the Singleton object is responsible for creating and destroying itself. Managing a singleton's lifetime causes the most implementation headaches.
This chapter discusses the most important issues associated with designing and implementing various Singleton variants in C++:
The features that set apart a singleton from a simple global object The basic C++ idioms supporting singletons Better enforcement of a singleton's uniqueness Destroying the singleton and detecting postdestruction access Implementing solutions for advanced lifetime management of the Singleton object Multithreading issues
We will develop techniques that address each issue. In the end, we will use these techniques for implementing a generic SingletonHolder class template.
There is no "best" implementation of the Singleton design pattern. Various Singleton implementations, including nonportable ones, are most appropriate depending on the problem at hand. This chapter's approach is to develop a family of implementations on a generic skeleton, following a policy-based design (see Chapter 1). SingletonHolder also provides hooks for extensions and customizations.
By the end of this chapter, we will have developed a SingletonHolder class template that can generate many different types of singletons. SingletonHolder gives you fine-grained control over how the Singleton object is allocated, when it is destroyed, whether it is thread safe, and what happens if a client attempts to use it after it's been destroyed. The SingletonHolder class template provides Singleton-specific services and functionality over any user-defined type.
|
6.1 Static Data + Static Functions != Singleton
At first glance, it seems that the need for Singleton can be easily obviated by using static member functions and static member variables:
class Font { ... };
class PrinterPort { ... };
class PrintJob { ... };
class MyOnlyPrinter
{
public:
static void AddPrintJob(PrintJob& newJob)
{
if (printQueue_.empty() && printingPort_.available())
{
printingPort_.send(newJob.Data());
}
else
{
printQueue_.push(newJob);
}
}
private:
// All data is static
static std::queue<PrintJob> printQueue_;
static PrinterPort printingPort_;
static Font defaultFont_;
};
PrintJob somePrintJob("MyDocument.txt");
MyOnlyPrinter::AddPrintJob(somePrintJob);
However, this solution has a number of disadvantages in some situations. The main problem is that static functions cannot be virtual, which makes it difficult to change behavior without opening MyOnlyPrinter's code.
A subtler problem of this approach is that it makes initialization and cleanup difficult. There is no central point of initialization and cleanup for MyOnlyPrinter's data. Initialization and cleanup can be nontrivial tasksfor instance, defaultFont_ can depend on the speed of printingPort_.
Singleton implementations therefore concentrate on creating and managing a unique object while not allowing the creation of another one.
|
6.2 The Basic C++ Idioms Supporting Singletons
Most often, singletons are implemented in C++ by using some variation of the following idiom:
// Header file Singleton.h
class Singleton
{
public:
static Singleton* Instance() // Unique point of access
{
if (!pInstance_)
pInstance_ = new Singleton;
return pInstance_;
}
... operations ...
private:
Singleton(); // Prevent clients from creating a new Singleton
Singleton(const Singleton&); // Prevent clients from creating
// a copy of the Singleton
static Singleton* pInstance_; // The one and only instance
};
// Implementation file Singleton.cpp
Singleton* Singleton::pInstance_ = 0;
Because all the constructors are private, user code cannot create Singletons. However, Singleton's own member functionsand Instance in particularare allowed to create objects. Therefore, the uniqueness of the Singleton object is enforced at compile time. This is the essence of implementing the Singleton design pattern in C++.
If it's never used (no call to Instance occurs), the Singleton object is not created. The cost of this optimization is the (usually negligible) test incurred at the beginning of Instance. The advantage of the build-on-first-request solution becomes significant if Singleton is expensive to create and seldom used.
An ill-fated temptation is to simplify things by replacing the pointer pInstance_ in the previous example with a full Singleton object.
// Header file Singleton.h
class Singleton
{
public:
static Singleton* Instance() // Unique point of access
{
return &instance_;
}
int DoSomething();
private:
static Singleton instance_;
};
// Implementation file Singleton.cpp
Singleton Singleton::instance_;
This is not a good solution. Although instance_ is a static member of Singleton (just as pInstance_ was in the previous example), there is an important difference between the two versions. instance_ is initialized dynamically (by calling Singleton's constructor at runtime), whereas pInstance_ benefits from static initialization (it is a type without a constructor initialized with a compile-time constant).
The compiler performs static initialization before the very first assembly statement of the program gets executed. (Usually, static initializers are right in the file containing the executable program, so loading is initializing.) On the other hand, C++ does not define the order of initialization for dynamically initialized objects found in different translation units, which is a major source of trouble. (A translation unit is, roughly speaking, a com-pilable C++ source file.) Consider this code:
// SomeFile.cpp
#include "Singleton.h"
int global = Singleton::Instance()->DoSomething();
Depending on the order of initialization that the compiler chooses for instance_ and global, the call to Singleton::Instance may return an object that has not been constructed yet. This means that you cannot count on instance_ being initialized if other external objects are using it.
|
6.3 Enforcing the Singleton's Uniqueness
A few language-related techniques are of help in enforcing the singleton's uniqueness. We've already used a couple of them: The default constructor and the copy constructor are private. The latter measure disables code such as this:
Singleton sneaky(*Singleton::Instance()); // error!
// Cannot make 'sneaky' a copy of the (Singleton) object
// returned by Instance
If you don't define the copy constructor, the compiler does its best to be of help and defines a public one for you (Meyers 1998a). Declaring an explicit copy constructor disables automatic generation, and placing that constructor in the private section yields a compile-time error on sneaky's definition.
Another slight improvement is to have Instance return a reference instead of a pointer. The problem with having Instance return a pointer is that callers might be tempted to delete it. To minimize the chances of that happening, it's safer to return a reference:
// inside class Singleton
static Singleton& Instance();
Another member function silently generated by the compiler is the assignment operator. Uniqueness is not directly related to assignment, but one obvious consequence of uniqueness is that you cannot assign one object to another because there aren't two objects to start with. For a Singleton object, any assignment is a self-assignment, which doesn't make much sense anyway; thus, it is worthwhile to disable the assignment operator (by making it private and never implementing it).
The last coat of the armor is to make the destructor private. This measure prevents clients that hold a pointer to the Singleton object from deleting it accidentally.
After the enumerated measures are added, Singleton's interface looks like the following.
class Singleton
{
Singleton& Instance();
... operations ...
private:
Singleton();
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
~Singleton();
};
|
6.4 Destroying the Singleton
As discussed, Singleton is created on demand, when Instance is first called. The first call to Instance defines the construction moment but leaves the destruction problem open: When should the singleton destroy its instance? The GoF book doesn't discuss this issue, but, as John Vlissides's book Pattern Hatching (1998) witnesses, the problem is thorny.
Actually, if Singleton is not deleted, that's not a memory leak. Memory leaks appear when you allocate accumulating data and lose all references to it. This is not the case here: Nothing is accumulating, and we hold knowledge about the allocated memory until the end of the application. Furthermore, all modern operating systems take care of completely deallocating a process's memory upon termination. (For an interesting discussion on what is and is not a memory leak, refer to Item 10 in Effective C++ [Meyers 1998a].)
However, there is a leak, and a more insidious one: a resource leak. Singleton's constructor may acquire an unbound set of resources: network connections, handles to OS-wide mutexes and other interprocess communication means, references to out-of-process CORBA or COM objects, and so on.
The only correct way to avoid resource leaks is to delete the Singleton object during the application's shutdown. The issue is that we have to choose the moment carefully so that no one tries to access the singleton after its destruction.
The simplest solution for destroying the singleton is to rely on language mechanisms. For example, the following code shows a different approach to implementing a singleton. Instead of using dynamic allocation and a static pointer, the Instance function relies on a local static variable.
Singleton& Singleton::Instance()
{
static Singleton obj;
return obj;
}
This simple and elegant implementation was first published by Scott Meyers (Meyers 1996a, Item 26); therefore, we'll refer to it as the Meyers singleton.
The Meyers singleton relies on some compiler magic. A function-static object is initialized when the control flow is first passing its definition. Don't confuse static variables that are initialized at runtime with primitive static variables initialized with compile-time constants. For example:
int Fun()
{
static int x = 100;
return ++x;
}
In this case, x is initialized before any code in the program is executed, most likely at load time. For all that Fun can tell when first called, x has been 100 since time immemorial. In contrast, when the initializer is not a compile-time constant, or the static variable is an object with a constructor, the variable is initialized at runtime during the first pass through its definition.
In addition, the compiler generates code so that after initialization, the runtime support registers the variable for destruction. A pseudo-C++ representation of the generated code may look like the following code. (The variables starting with two underscores should be thought of as hidden, that is, variables generated and managed only by the compiler.)
Singleton& Singleton::Instance()
{
// Functions generated by the compiler
extern void __ConstructSingleton(void* memory);
extern void __DestroySingleton();
// Variables generated by the compiler
static bool __initialized = false;
// Buffer that holds the singleton
// (We assume it is properly aligned)
static char __buffer[sizeof(Singleton)];
if (!__initialized)
{
// First call, construct object
// Will invoke Singleton::Singleton
// In the __buffer memory
__ConstructSingleton(__buffer);
// register destruction
atexit(__DestroySingleton);
__initialized = true;
}
return *reinterpret_cast<Singleton *>(__buffer);
}
The core is the call to the atexit function. The atexit function, provided by the standard C library, allows you to register functions to be automatically called during a program's exit, in a last in, first out (LIFO) order. (By definition, destruction of objects in C++ is done in a LIFO manner: Objects created first are destroyed last. Of course, objects you manage yourself with new and delete don't obey this rule.) The signature of atexit is
// Takes a pointer to function
// Returns 0 if successful, or
// a nonzero value if an error occurs
int atexit(void (*pFun)());
The compiler generates the function __DestroySingletonwhose execution destroys the Singleton object seated in __buffer's memoryand passes the address of that function to atexit.
How does atexit work? Each call to atexit pushes its parameter on a private stack maintained by the C runtime library. During the application's exit sequence, the runtime support calls the functions registered with atexit.
We'll see in a short while that atexit has importantand sometimes unfortunatelinks with implementing the Singleton design pattern in C++. Like it or not, it's going to be with us until the end of this chapter. No matter what solution for destroying singletons we try, it has to play nice with atexit or else we break programmers' expectations.
The Meyers singleton provides the simplest means of destroying the singleton during an application's exit sequence. It works fine in most cases. We will study its problems and provide some improvements and alternate implementations for special cases.
|
6.5 The Dead Reference Problem
To make the discussion concrete, let's refer to an example that will be used throughout the rest of this chapter to validate various implementations. The example has the same traits as the Singleton pattern itself: It's easy to express and understand, but hard to implement.
Say we have an application that uses three singletons: Keyboard, Display, and Log. The first two model their physical counterparts. Log is intended for error reporting. Its incarnation can be a text file, a secondary console, or even a scrolling marquee on the LCD display of an embedded system.
We assume that Log's construction implies a certain amount of overhead, so it is best to instantiate it only if an error occurs. This way, in an error-free session, the program doesn't create Log at all.
The program reports to Log any error in instantiating Keyboard or Display. Log also collects errors in destroying Keyboard or Display.
Assuming we implement these three singletons as Meyers singletons, the program is incorrect. For example, assume that after Keyboard is constructed successfully, Display fails to initialize. Display's constructor creates Log, the error is logged, and it's likely the application is about to exit. At exit time, the language rule enters into action: The runtime support destroys local static objects in the reverse order of their creation. Therefore, Log is destroyed before Keyboard. If for some reason Keyboard fails to shut down and tries to report an error to Log, Log::Instance unwittingly returns a reference to the "shell" of a destroyed Log object. The program steps into the shady realm of undefined behavior. This is the dead-reference problem.
The order of construction and destruction of Keyboard, Log, and Display is not known beforehand. The need is to have Keyboard and Display follow the C++ rule (last created is first destroyed) but also to exempt Log from this rule. No matter when it was created, Log must be always destroyed after both Keyboard and Display so that it can collect errors from the destruction of either of these.
If an application uses multiple interacting singletons, we cannot provide an automated way to control their lifetime. A reasonable singleton should at least perform dead-reference detection. We can achieve this by tracking destruction with a static Boolean member variable destroyed_. Initially, destroyed_ is false. Singleton's destructor sets destroyed_ to true.
Before jumping to the implementation, it's time for an overhaul. In addition to creating and returning a reference to the Singleton object, Singleton::Instance now has an additional responsibilitydetecting the dead reference. Let's apply the design guideline that says, One function, one responsibility. We therefore define three distinct member functions: Create, which effectively creates the Singleton object; OnDeadReference, which performs error handling; and the well-known Instance, which gives access to the unique Singleton object. Of these, only Instance is public.
Let's implement a Singleton that performs dead-reference detection. First, we add a static bool member variable called destroyed_ to the Singleton class. Its role is to detect the dead reference. Then we change the destructor of Singleton to set pInstance_ to zero and destroyed_ to true. Here's the new class and the OnDeadReference function:
// Singleton.h
class Singleton
{
public:
Singleton& Instance()
{
if (!pInstance_)
{
// Check for dead reference
if (destroyed_)
{
OnDeadReference();
}
else
{
// First callinitialize
Create();
}
}
return pInstance_;
}
private:
// Create a new Singleton and store a
// pointer to it in pInstance_
static void Create();
{
// Task: initialize pInstance_
static Singleton theInstance;
pInstance_ = &theInstance;
}
// Gets called if dead reference detected
static void OnDeadReference()
{
throw std::runtime_error("Dead Reference Detected");
}
virtual ~Singleton()
{
pInstance_ = 0;
destroyed_ = true;
}
// Data
Singleton pInstance_;
bool destroyed_;
... disabled 'tors/operator= ...
};
// Singleton.cpp
Singleton* Singleton::pInstance_ = 0;
bool Singleton::destroyed_ = false;
It works! As soon as the application exits, Singleton's destructor gets called. The destructor sets pInstance_ to zero and destroyed_ to true. If some longer-living object tries to access the singleton afterward, the control flow reaches OnDeadReference, which throws an exception of type runtime_error. This solution is inexpensive, simple, and effective.
|
6.6 Addressing the Dead Reference Problem (I):
The Phoenix Singleton
If we apply the solution in the previous section to the KDL (Keyboard, Display, Log) problem, the result is unsatisfactory. If Display's destructor needs to report an error after Log has been destroyed, Log::Instance throws an exception. We got rid of undefined behavior; now we have to deal with unsatisfactory behavior.
We need Log to be available at any time, no matter when it was initially constructed. At an extreme, we'd even prefer to create Log again (although it's been destroyed) so that we can use it for error reporting at any time. This is the idea behind the Phoenix Singleton design pattern.
Just as the legendary Phoenix bird rises repeatedly from its own ashes, the Phoenix singleton is able to rise again after it has been destroyed. A single instance of the Singleton object at any given moment is still guaranteed (no two singletons ever exist simultaneously), yet the instance can be created again if the dead reference is detected. With the Phoenix Singleton pattern, we can solve the KDL problem easily: Keyboard and Display can remain "regular" singletons, while Log becomes a Phoenix singleton.
The implementation of the Phoenix Singleton with a static variable is simple. When we detect the dead reference, we create a new Singleton object in the shell of the old one. (C++ guarantees this is possible. Static objects' memory lasts for the duration of the program.) We also register this new object's destruction with atexit. We don't have to change Instance; the only change is in the OnDeadReference primitive.
class Singleton
{
... as before ...
void KillPhoenixSingleton(); // Added
};
void Singleton::OnDeadReference()
{
// Obtain the shell of the destroyed singleton
Create();
// Now pInstance_ points to the "ashes" of the singleton
// - the raw memory that the singleton was seated in.
// Create a new singleton at that address
new(pInstance_) Singleton;
// Queue this new object's destruction
atexit(KillPhoenixSingleton);
// Reset destroyed_ because we're back in business
destroyed_ = false;
}
void Singleton::KillPhoenixSingleton()
{
// Make all ashes again
// - call the destructor by hand.
// It will set pInstance_ to zero and destroyed_ to true
pInstance_->~Singleton();
}
The new operator that OnDeadReference uses is called the placement new operator. The placement new operator does not allocate memory; it only constructs a new object at the address passedin our case, pInstance_. For an interesting discussion about the placement new operator, you may want to consult Meyers (1998b).
The Singleton above added a new member function, KillPhoenixSingleton. Now that we use new to resurrect the Phoenix singleton, the compiler magic will no longer destroy it, as it does with static variables. We built it by hand, so we must destroy it by hand, which is what atexit(KillPhoenixSingleton) ensures.
Let's analyze the flow of events. During the application exit sequence, Singleton's destructor is called. The destructor resets the pointer to zero and sets destroyed_ to true. Now assume some global object tries to access Singleton again. Instance calls OnDeadReference. OnDeadReference reanimates Singleton and queues a call to KillPhoenixSingleton, and Instance successfully returns a reference to a valid Singleton object. From now on, the cycle may repeat.
The Phoenix Singleton class ensures that global objects and other singletons can get a valid instance of it, at any time. This is a strong enough guarantee to make the Phoenix singleton an appealing solution for robust, all-terrain objects, like the Log in our problem. If we make Log a Phoenix singleton, the program will work correctly, no matter what the sequence of failures is.
6.6.1 Problems with atexit
If you compared the code given in the previous section with Loki's actual code, you would notice a difference: The call to atexit is surrounded by an #ifdef preprocessor directive:
#ifdef ATEXIT_FIXED
// Queue this new object's destructor
atexit(KillPhoenixSingleton);
#endif
If you don't #define ATEXIT_FIXED, the newly created Phoenix singleton will not be destroyed, and it will leak, which is exactly what we are striving to avoid.
This measure has to do with an unfortunate omission in the C++ standard. The standard fails to describe what happens when you register functions with atexit during a call made as the effect of another atexit registration.
To illustrate this problem, let's write a short test program:
#include <cstdlib>
void Bar()
{
...
}
void Foo()
{
std::atexit(Bar);
}
int main()
{
std::atexit(Foo);
}
This little program registers Foo with atexit. Foo calls atexit(Bar), a case in which the behavior is not covered by the two standards. Because atexit and destruction of static variables go hand in hand, once the application exit sequence has started, we're left on shaky ground. Both the C and C++ standards are self-contradictory. They say that Bar will be called before Foo because Bar was registered last, but at the time it's registered, it's too late for Bar to be first because Foo is already being called.
Does this problem sound too academic? Let's put it another way: At the time of this writing, on three widely used compilers, the behavior ranges from incorrect (resource leaks) to application crashes.
Compilers will take some time to catch up with the solution to this problem. As of this moment, the macro is in there. On some compilers, if you create a Phoenix singleton the second time, it will eventually leak. Depending on what your compiler's documentation says, you may want to #define ATEXIT_FIXED prior to including the Singleton.h header file.
|
6.7 Addressing the Dead Reference Problem (II):
Singletons with Longevity
The Phoenix singleton is satisfactory in many contexts but has a couple of disadvantages. The Phoenix singleton breaks the normal lifetime cycle of a singleton, which may confuse some clients. If the singleton keeps state, that state is lost after a destruction-creation cycle. The implementer of a concrete singleton that uses the Phoenix strategy must pay extra attention to keeping state between the moment of destruction and the moment of reconstruction.
This is annoying especially because in situations such as the KDL example, you do know what the order should be: No matter what, if Log gets created, it must be destroyed after both Keyboard and Display. In other words, in this case we need Log to have a longer lifetime than Keyboard and Display. We need an easy way to control the lifetime of various singletons. If we can do that, we can solve the KDL problem by assigning Log a longer lifetime than both Display and Keyboard.
But wait, there's more: This problem applies not only to singletons but also to global objects in general. The concept emerging here is that of longevity control and is independent of the concept of a singleton: The greater longevity an object has, the later it will be destroyed. It doesn't matter whether the object is a singleton or some global dynamically allocated object. We need to write code like this:
// This is a Singleton class
class SomeSingleton { ... };
// This is a regular class
class SomeClass { ... };
SomeClass* pGlobalObject(new SomeClass);
int main()
{
SetLongevity(&SomeSingleton().Instance(), 5);
// Ensure pGlobalObject will be deleted
// after SomeSingleton's instance
SetLongevity(pGlobalObject, 6);
...
}
The function SetLongevity takes a reference to an object of any type and an integral value (the longevity).
// Takes a reference to an object allocated with new and
// the longevity of that object
template <typename T>
void SetLongevity(T* pDynObject, unsigned int longevity);
SetLongevity ensures that pDynObject will outlive all objects that have lesser longevity. When the application exits, all objects registered with SetLongevity are deleted in decreasing order of their longevity.
You cannot apply SetLongevity to objects whose lifetimes are controlled by the compiler, such as regular global objects, static objects, and automatic objects. The compiler already generates code for destroying them, and calling SetLongevity for those objects would destroy them twice. (That never helps.) SetLongevity is intended for objects allocated with new only. Moreover, by calling SetLongevity for an object, you commit to not calling delete for that object.
An alternative would be to create a dependency manager, an object that controls dependencies between other objects. DependencyManager would expose a generic function SetDependency as shown:
class DependencyManager
{
public:
template <typename T, typename U>
void SetDependency(T* dependent, U& target);
...
};
DependencyManager's destructor would destroy the objects in an ordered manner, destroying dependents before their targets.
The DependencyManager-based solution has a major drawbackboth objects must be in existence. This means that if you try to establish a dependency between Keyboard and Log, for example, you must create the Log objecteven if you are not going to need it at all.
In an attempt to avoid this problem, you might establish the Keyboard-Log dependency inside Log's constructor. This, however, tightens the coupling between Keyboard and Log to an unacceptable degree: Keyboard depends on Log's class definition (because Keyboard uses the Log), and Log depends on Keyboard's class definition (because Log sets the dependency). This is a circular dependency, and, as discussed in detail in Chapter 10, circular dependencies should be avoided.
Let's get back then to the longevity paradigm. Because SetLongevity has to play nice with atexit, we must carefully define the interaction between these two functions. For example, let's define the exact sequence of destructor calls for the following program.
class SomeClass { ... };
int main()
{
// Create an object and assign a longevity to it
SomeClass* pObj1 = new SomeClass;
SetLongevity(pObj1, 5);
// Create a static object whose lifetime
// follows C++ rules
static SomeClass obj2;
// Create another object and assign a greater
// longevity to it
SomeClass* pObj3 = new SomeClass;
SetLongevity(pObj3, 6);
// How will these objects be destroyed?
}
main defines a mixed bag of objects with longevity and objects that obey C++ rules. Defining a reasonable destruction order for these three objects is hard because, aside from using atexit, we don't have any means of manipulating the hidden stack maintained by the runtime support.
A careful constraints analysis leads to the following design decisions.
Each call to SetLongevity issues a call to atexit. Destruction of objects with lesser longevity takes place before destruction of objects with greater longevity. Destruction of objects with the same longevity follows the C++ rule: last built, first destroyed.
In the example program, the rules lead to the following guaranteed order of destruction: *pObj1, obj2, *pObj3. The first call to SetLongevity will issue a call to atexit for destroying *pObj3, and the second call will correspondingly issue a call to atexit for destroying *pObj1.
SetLongevity gives developers a great deal of power for managing objects' lifetimes, and it has well-defined and reasonable ways of interacting with the built-in C++ rules related to object lifetime. Note, however, that, like many other powerful tools, it can be dangerous. The rule of thumb in using it is as follows: Any object that uses an object with longevity must have a shorter longevity than the used object.
|
6.8 Implementing Singletons with Longevity
Once SetLongevity's specification is complete, the implementation is not that complicated. SetLongevity maintains a hidden priority queue, separate from the inaccessible atexit stack. In turn, SetLongevity calls atexit, always passing it the same pointer to a function. This function pops one element off the stack and deletes it. It's that simple.
The core is the priority queue data structure. The longevity value passed to SetLongevity establishes the priorities. For a given longevity, the queue behaves like a stack. Destruction of objects with the same longevity follows the last in, first out rule. In spite of its name, we cannot use the standard std::priority_queue class because it does not guarantee the ordering of the elements having the same priority.
The elements that the data structure holds are pointers to the type LifetimeTracker. Its interface consists of a virtual destructor and a comparison operator. Derived classes must override the destructor. (You will see in a minute what Compare is good for.)
namespace Private
{
class LifetimeTracker
{
public:
LifetimeTracker(unsigned int x) : longevity_(x) {}
virtual ~LifetimeTracker() = 0;
friend inline bool Compare(
unsigned int longevity,
const LifetimeTracker* p)
{ return p->longevity_ > longevity; }
private:
unsigned int longevity_;
};
// Definition required
inline LifetimeTracker::~LifetimeTracker() {}
}
The priority queue data structure is a simple dynamically allocated array of pointers to LifetimeTracker:
namespace Private
{
typedef LifetimeTracker** TrackerArray;
extern TrackerArray pTrackerArray;
extern unsigned int elements;
}
There is only one instance of the Tracker type. Consequently, pTrackerArray is exposed to all the Singleton problems just discussed. We are caught in an interesting chicken-and-egg problem: SetLongevity must be available at any time, yet it has to manage private storage. To deal with this problem, SetLongevity carefully manipulates pTrackerArray with the low-level functions in the std::malloc family (malloc, realloc, and free). This way, we transfer the chicken-and-egg problem to the C heap allocator, which fortunately is guaranteed to work correctly for the whole lifetime of the application. This being said, SetLongevity's implementation is simple: It creates a concrete tracker object, adds it to the stack, and registers a call to atexit.
The following code makes an important step toward generalization. It introduces a functor that takes care of destroying the tracked object. The rationale is that you don't always use delete to deallocate an object; it can be an object allocated on an alternate heap, and so on. By default, the destroyer is a pointer to a function that calls delete. The default function is called Delete and is templated with the type of the object to be deleted.
//Helper destroyer function
template <typename T>
struct Deleter
{
static void Delete(T* pObj)
{ delete pObj; }
};
// Concrete lifetime tracker for objects of type T
template <typename T, typename Destroyer>
class ConcreteLifetimeTracker : public LifetimeTracker
{
public:
ConcreteLifetimeTracker(T* p,
unsigned int longevity,
Destroyer d)
:LifetimeTracker(longevity),
,pTracked_(p)
,destroyer_(d)
{}
~ConcreteLifetimeTracker()
{
destroyer_(pTracked_);
}
private:
T* pTracked_;
Destroyer destroyer_;
};
void AtExitFn(); // Declaration needed below
}
template <typename T, typename Destroyer>
void SetLongevity(T* pDynObject, unsigned int longevity,
Destroyer d = Private::Deleter<T>::Delete)
{
TrackerArray pNewArray = static_cast<TrackerArray>(
std::realloc(pTrackerArray, sizeof(T) * (elements + 1)));
if (!pNewArray) throw std::bad_alloc();
pTrackerArray = pNewArray;
LifetimeTracker* p = new ConcreteLifetimeTracker<T, Destroyer>(
pDynObject, longevity, d);
TrackerArray pos = std::upper_bound(
pTrackerArray, pTrackerArray + elements, longevity, Compare);
std::copy_backward(pos, pTrackerArray + elements,
pTrackerArray + elements + 1);
*pos = p;
++elements;
std::atexit(AtExitFn);
}
It takes a while to get used to things like std::upper_bound and std::copy_backward, but indeed they make nontrivial code easy to write and read. The function above inserts a newly created pointer to ConcreteLifetimeTracker in the sorted array pointed to by pTrackerArray, keeps it ordered, and handles errors and exceptions.
Now the purpose of LifetimeTracker::Compare is clear. The array to which pTrackerQueue points is sorted by longevity. Objects with longer longevity are toward the beginning of the array. Objects of the same longevity appear in the order in which they were inserted. SetLongevity ensures all this.
The AtExitFn function pops the object with the smallest longevity (that is, the one at the end of the array) and deletes it. Deleting the pointer to LifetimeTracker invokes ConcreteLifetimeTracker's destructor, which in turn deletes the tracked object.
static void AtExitFn()
{
assert(elements > 0 && pTrackerArray != 0);
// Pick the element at the top of the stack
LifetimeTracker* pTop = pTrackerArray[elements - 1];
// Remove that object off the stack
// Don't check errors-realloc with less memory
// can't fail
pTrackerArray = static_cast<TrackerArray>(std::realloc(
pTrackerArray, sizeof(T) * --elements));
// Destroy the element
delete pTop;
}
Writing AtExitFn requires a bit of care. AtExitFn must pop the top element off the stack and delete it. In its destructor, the element deletes the managed object. The trick is, AtExitFn must pop the stack before deleting the top object because destroying some object may create another one, thus pushing another element onto the stack. Although this looks quite unlikely, it's exactly what happens when Keyboard's destructor tries to use the Log.
The code conveniently hides the data structures and AtExitFn in the Private namespace. The clients see only the tip of the icebergthe SetLongevity function.
Singletons with longevity can use SetLongevity in the following manner:
class Log
{
public:
static void Create()
{
// Create the instance
pInstance_ = new Log;
// This line added
SetLongevity(*this, longevity_);
}
// Rest of implementation omitted
// Log::Instance remains as defined earlier
private:
// Define a fixed value for the longevity
static const unsigned int longevity_ = 2;
static Log* pInstance_;
};
If you implement Keyboard and Display in a similar fashion, but define longevity_ to be 1, the Log will be guaranteed to be alive at the time when both Keyboard and Display are destroyed. This solves the KDL problemor does it? What if your application uses multiple threads?
|
6.9 Living in a Multithreaded World
Singleton has to deal with threads, too. Suppose we have an application that has just started, and two threads access the following Singleton:
Singleton& Singleton::Instance()
{
if (!pInstance_) // 1
{
pInstance_ = new Singleton; // 2
}
return *pInstance_; // 3
}
The first thread enters Instance and tests the if condition. Because it's the very first access, pInstance_ is null, and the thread reaches the line marked // 2 and is ready to invoke the new operator. It might just happen that the OS scheduler unwittingly interrupts the first thread at this point and passes control to the other thread.
The second thread enters the stage, invokes Singleton::Instance(), and finds a null pInstance_ as well because the first thread hasn't yet had a chance to modify it. So far, the first thread has managed only to test pInstance_. Now say the second thread manages to call the new operator, assigns pInstance_ in peace, and gets away with it.
Unfortunately, as the first thread becomes conscious again, it remembers it was just about to execute line 2, so it reassigns pInstance_ and gets away with it, too. When the dust settles, there are two Singleton objects instead of one, and one of them will leak for sure. Each thread holds a distinct instance of Singleton, and the application is surely slipping toward chaos. And that's only one possible situationwhat if multiple threads scramble to access the singleton? (Imagine yourself debugging this.)
Experienced multithreaded programmers will recognize a classic race condition here. It is to be expected that the Singleton design pattern meets threads. A singleton object is a shared global resource, and all shared global resources are always suspect for race conditions and threading issues.
6.9.1 The Double-Checked Locking Pattern
A thorough discussion of multithreaded singletons was first presented by Douglas Schmidt (1996). The same article describes a very nifty solution, called the Double-Checked Locking pattern, devised by Doug Schmidt and Tim Harrison.
The obvious solution works but is not appealing:
Singleton& Singleton::Instance()
{
// mutex_ is a mutex object
// Lock manages the mutex
Lock guard(mutex_);
if (!pInstance_)
{
pInstance_ = new Singleton;
}
return *pInstance_;
}
Class Lock is a classic mutex handler (refer to the appendix for details on mutexes). Lock's constructor locks the mutex, and its destructor unlocks the mutex. While mutex_ is locked, other threads that try to lock the same mutex are waiting.
We got rid of the race condition: While a thread assigns to pInstance_, all others stop in guard's constructor. When another thread locks the lock, it will find pInstance_ already initialized, and everything works smoothly.
However, a correct solution is not always an appealing one. The inconvenience is its lack of efficiency. Each call to Instance incurs locking and unlocking the synchronization object, although the race condition occurs only, so to say, once in a lifetime. These operations are usually very costly, much more costly than the simple if (!pInstance_) test. (On today's systems, the times taken by a test-and-branch and a critical-section lock differ typically by a couple of orders of magnitude.)
A would-be solution that attempts to avoid the overhead is presented in the following code:
Singleton& Singleton::Instance()
{
if (!pInstance_)
{
Lock guard(mutex_);
pInstance_ = new Singleton;
}
return *pInstance_;
}
Now the overhead is gone, but the race condition is back. The first thread passes the if test, but just when it is about to enter the synchronized portion of code, the OS scheduler interrupts it and passes control to the other thread. The second thread passes the if test itself (and to no one's surprise, finds a null pointer), enters the synchronized portion, and completes it. When the first thread is reactivated, it also enters the synchronized portion, but it's just too lateagain, two Singleton objects are constructed.
This seems like one of those brainteasers with no solution, but in fact there is a very simple and elegant one. It's called the Double-Checked Locking pattern.
The idea is simple: Check the condition, enter the synchronized code, and then check the condition again. By this time, rien ne va plusthe pointer is either initialized or null all right. The code that will help you to understand and savor the Double-Checked pattern follows. Indeed, there is beauty in computer engineering.
Singleton& Singleton::Instance()
{
if (!pInstance_) // 1
{ // 2
Guard myGuard(lock_); // 3
if (!pInstance_) // 4
{
pInstance_ = new Singleton;
}
}
return *pInstance_;
}
Assume the flow of execution of a thread enters the twilight zone (commented line 2). Here several threads may enter at once. However, in the synchronized section only one thread makes it at a time. On line 3, there's no twilight anymore. All is clear: The pointer has been either fully initialized or not at all. The first thread that enters initializes the variable, and all others fail the test on line 4 and do not create anything.
The first test is quick and coarse. If the Singleton object is available, you get it. If not, further investigation is necessary. The second test is slow and accurate: It tells whether Singleton was indeed initialized or the thread is responsible for initializing it. This is the Double-Checked Locking pattern. Now we have the best of both worlds: Most of the time the access to the singleton is as fast as it gets. During construction, however, no race conditions occur. Awesome. But . . .
Very experienced multithreaded programmers know that even the Double-Checked Locking pattern, although correct on paper, is not always correct in practice. In certain symmetric multiprocessor environments (the ones featuring the so-called relaxed memory model), the writes are committed to the main memory in bursts, rather than one by one. The bursts occur in increasing order of addresses, not in chronological order. Due to this rearranging of writes, the memory as seen by one processor at a time might look as if the operations are not performed in the correct order by another processor. Concretely, the assignment to pInstance_ performed by a processor might occur before the Singleton object has been fully initialized! Thus, sadly, the Double-Checked Locking pattern is known to be defective for such systems.
In conclusion, you should check your compiler documentation before implementing the Double-Checked Locking pattern. (This makes it the Triple-Checked Locking pattern.) Usually the platform offers alternative, nonportable concurrency-solving primitives, such as memory barriers, which ensure ordered access to memory. At least, put a volatile qualifier next to pInstance_. A reasonable compiler should generate correct, nonspeculative code around volatile objects.
|
6.10 Putting It All Together
This chapter has wandered around various possible implementations of Singleton, commenting on their relative strengths and weaknesses. The discussion doesn't lead to a unique implementation because the problem at hand is what dictates the best Singleton implementation.
The SingletonHolder class template defined by Loki is a Singleton container that assists you in using the Singleton design pattern. Following a policy-based design (see Chapter 1), SingletonHolder is a specialized container for a user-defined Singleton object. When using SingletonHolder, you pick the features needed, and maybe provide some code of your own. In extreme cases, you might still need to start all over againwhich is okay, as long as those are indeed extreme cases.
This chapter visited quite a few issues that are mostly independent of each other. How, then, can Singleton implement so many cases without utter code bloating? The key is to decompose Singleton carefully into policies, as discussed in Chapter 1. By decomposing SingletonHolder into several policies, we can implement all the cases discussed previously in a small number of lines of code. By using template instantiation, you select the features needed and don't pay anything for the unneeded ones. This is important: The implementation of Singleton put together here is not the do-it-all class. Only the features used are ultimately included in the generated code. Plus, the implementation leaves room for tweaks and extensions.
6.10.1 Decomposing SingletonHolder into Policies
Let's start by delimiting what policies we can distinguish for the implementations discussed. We identified creation issues, lifetime issues, and threading issues. These are the three most important aspects of Singleton development. The three corresponding polices therefore are as follows:
Creation.
You can create a singleton in various ways. Typically, the Creation policy invokes the new operator to create an object. Isolating creation as a policy is essential because it enables you to create polymorphic objects.
Lifetime.
We identified the following lifetime policies:
Following C++ ruleslast created, first destroyed Recurring (Phoenix singleton) User controlled (singleton with longevity) Infinite (the "leaking" singleton, an object that's never destroyed)
ThreadingModel.
Whether singleton is single threaded, is standard multithreaded (with a mutex and the Double-Checked Locking pattern), or uses a nonportable threading model.
All Singleton implementations must take the same precautions for enforcing uniqueness. These are not policies, because changing them would break the definition of Singleton.
6.10.2 Defining Requirements for SingletonHolder's Policies
Let's define the necessary requirements that SingletonHolder imposes on its policies.
The Creation policy must create and destroy objects, so it must expose two corresponding functions. Therefore, assuming Creator<T> is a class compliant with the Creation policy, Creator<T> must support the following calls:
T* pObj = Creator<T>::Create();
Creator<T>::Destroy(pObj);
Notice that Create and Destroy must be two static members of Creator. Singleton does not hold a Creator objectthis would perpetuate the Singleton lifetime issues.
The Lifetime policy essentially must schedule the destruction of the Singleton object created by the Creation policy. In essence, Lifetime policy's functionality boils down to its ability to destroy the Singleton object at a specific time during the lifetime of the application. In addition, Lifetime decides the action to be taken if the application violates the lifetime rules of the Singleton object. Hence:
If you need the singleton to be destroyed according to C++ rules, then Lifetime uses a mechanism similar to atexit. For the Phoenix singleton, Lifetime still uses an atexit-like mechanism but accepts the re-creation of the Singleton object. For a singleton with longevity, Lifetime issues a call to SetLongevity, described in Sections 6.7 and 6.8. For infinite lifetime, Lifetime does not take any action.
In conclusion, the Lifetime policy prescribes two functions: ScheduleDestruction, which takes care of setting the appropriate time for destruction, and OnDeadReference, which establishes the behavior in case of dead-reference detection.
If Lifetime<T> is a class that implements the Lifetime policy, the following expressions make sense:
void (*pDestructionFunction)();
...
Lifetime<T>::ScheduleDestruction(pDestructionFunction);
Lifetime<T>::OnDeadReference();
The ScheduleDestruction member function accepts a pointer to the actual function that performs the destruction. This way, we can compound the Lifetime policy with the Creation policy. Don't forget that Lifetime is not concerned with the destruction method, which is Creation's charter; the only preoccupation of Lifetime is timingthat is, when the destruction will occur.
OnDeadReference throws an exception in all cases except for the Phoenix singleton, a case in which it does nothing.
The ThreadingModel policy is the one described in the appendix. SingletonHolder does not support object-level locking, only class-level locking. This is because you have only one object anyway.
6.10.3 Assembling SingletonHolder
Now let's begin defining the SingletonHolder class template. As discussed in Chapter 1, each policy mandates one template parameter. In addition to it, we prepend a template parameter (T) that's the type for which we provide singleton behavior. The SingletonHolder class template is not itself a Singleton. SingletonHolder provides only singleton behavior and management over an existing class.
template
<
class T,
template <class> class CreationPolicy = CreateUsingNew,
template <class> class LifetimePolicy = DefaultLifetime,
template <class> class ThreadingModel = SingleThreaded
>
class SingletonHolder
{
public:
static T& Instance();
private:
// Helpers
static void DestroySingleton();
// Protection
SingletonHolder();
...
// Data
typedef ThreadingModel<T>::VolatileType InstanceType;
static InstanceType* pInstance_;
static bool destroyed_;
};
The type of the instance variable is not T* as you would expect. Instead, it's ThreadingModel<T>::VolatileType*. The ThreadingModel<T>::VolatileType type definition expands either to T or to volatile T, depending on the actual threading model. The volatile qualifier applied to a type tells the compiler that values of that type might be changed by multiple threads. Knowing this, the compiler avoids some optimizations (such as keeping values in its internal registers) that would make multithreaded code run erratically. A safe decision would be then to define pInstance_ to be type volatile T*: It works with multithreaded code (subject to your checking your compiler's documentation) and doesn't hurt in single-threaded code.
On the other hand, in a single-threaded model, you do want to take advantage of those optimizations, so T* would be the best type for pInstance_. That's why the actual type of pInstance_ is decided by the ThreadingModel policy. If ThreadingModel is a single-threaded policy, it simply defines VolatileType as follows:
template <class T> class SingleThreaded
{
...
public:
typedef T VolatileType;
};
A multithreaded policy would have a definition that qualifies T with volatile. See the appendix for more details on threading models.
Let's now define the Instance member function, which wires together the three policies.
template <...>
T& SingletonHolder<...>::Instance()
{
if (!pInstance_)
{
typename ThreadingModel<T>::Lock guard;
if (!pInstance_)
{
if (destroyed_)
{
LifetimePolicy<T>::OnDeadReference();
destroyed_ = false;
}
pInstance_ = CreationPolicy<T>::Create();
LifetimePolicy<T>::ScheduleCall(&DestroySingleton);
}
}
return *pInstance_;
}
Instance is the one and only public function exposed by SingletonHolder. Instance implements a shell over CreationPolicy, LifetimePolicy, and ThreadingModel. The ThreadingModel<T> policy class exposes an inner class Lock. For the lifetime of a Lock object, all other threads trying to create objects of type Lock will block. (Refer to the appendix.)
DestroySingleton simply destroys the Singleton object, cleans up the allocated memory, and sets destroyed_ to true. SingletonHolder never calls DestroySingleton; it only passes its address to LifetimePolicy<T>::ScheduleDestruction.
template <...>
void SingletonHolder<...>::DestroySingleton()
{
assert(!destroyed_);
CreationPolicy<T>::Destroy(pInstance_);
pInstance_ = 0;
destroyed_ = true;
}
SingletonHolder passes pInstance_ and the address of DestroySingleton to LifetimePolicy<T>. The intent is to give LifetimePolicy enough information to implement the known behaviors: C++ rules, recurring (Phoenix singleton), user controlled (singleton with longevity), and infinite. Here's how:
Per C++ rules.
LifetimePolicy<T>::ScheduleDestruction calls atexit, passing it the address of DestroySingleton. OnDeadReference throws a std::logic_error exception.
Recurring.
Same as above, except that OnDeadReference does not throw an exception. SingletonHolder's flow of execution continues and will re-create the object.
User controlled.
LifetimePolicy<T>::ScheduleDestruction calls SetLongevity(GetLongevity(pInstance)).
Infinite.
LifetimePolicy<T>::ScheduleDestruction has an empty implementation.
SingletonHolder handles the dead-reference problem as the responsibility of LifetimePolicy. It's very simple: If SingletonHolder::Instance detects a dead reference, it calls LifetimePolicy::OnDeadReference. If OnDeadReference returns, Instance continues with re-creating a new instance. In conclusion, OnDeadReference should throw an exception or terminate the program if you do not want Phoenix Singleton behavior. For a Phoenix singleton, OnDeadReference does nothing.
Well, that is the whole SingletonHolder implementation. Of course, now much work gets delegated to the three policies.
6.10.4 Stock Policy Implementations
Decomposition into policies is hard. After you do that, the policies are easy to implement. Let's collect the policy classes that implement the common types of singletons. Table 6.1 shows the predefined policy classes for SingletonHolder. The policy classes in bold are the default template parameters.
Table 6.1. Predefined Policies for SingletonHolder
| Creation |
CreateUsingNew |
Creates an object by using the new operator and the default constructor. |
| |
CreateUsingMalloc |
Creates an object by using std::malloc and its default constructor. |
| |
CreateStatic |
Creates an object in static memory. |
| Lifetime |
DefaultLifetime |
Manages the object's lifetime by obeying C++ rules. Uses atexit to get the job done. |
| |
PhoenixSingleton |
Same as DefaultLifetime but allows re-creation of the Singleton object. |
| |
SingletonWithLongevity |
Assigns longevity to the Singleton object. Assumes the existence of a namespace-level function GetLongevity that, called with pInstance_, returns the longevity of the Singleton object. |
| |
NoDestroy |
Does not destroy the Singleton object. |
| ThreadingModel |
SingleThreaded |
See the appendix for details about threading models. |
| |
ClassLevelLockable |
|
What remains is only to figure out how to use and extend this small yet mighty SingletonHolder template.
|
6.11 Working with SingletonHolder
The SingletonHolder class template does not provide application-specific functionality. It merely provides Singleton-specific services over another classT in the code in this chapter. We call T the client class.
The client class must take all the precautionary measures against unattended construction and destruction: The default constructor, the copy constructor, the assignment operator, the destructor, and the address-of operator should be made private.
If you take these protective measures, you also have to grant friendship to the Creator policy class that you use. These protective measures and the friend declaration are all the changes needed for a class to work with SingletonHolder. Note that these changes are optional and constitute a trade-off between the inconvenience of touching existing code and the risk of spurious instances.
The design decisions concerning a specific Singleton implementation usually are reflected in a type definition like the following one. Just as you would pass flags and options when calling some function, so you pass flags to the type definition selecting the desired behavior.
class A { ... };
typedef SingletonHolder<A, CreateUsingNew> SingleA;
// from here on you use SingleA::Instance()
Providing a singleton that returns an object of a derived class is as simple as changing the Creator policy class:
class A { ... };
class Derived : public A { ... };
template <class T> struct MyCreator : public CreateUsingNew<T>
{
static T* Create()
{
return new Derived;
}
};
typedef SingletonHolder<A, StaticAllocator, MyCreator> SingleA;
Similarly, you can provide parameters to the constructor or use a different allocation strategy. You can tweak Singleton along each policy. This way you can largely customize Singleton, while still benefiting from default behavior when you want to.
The SingletonWithLongevity policy class relies on you to define a namespace-level function GetLongevity. The definition would look something like this:
inline unsigned int GetLongevity(A*) { return 5; }
This is needed only if you use SingletonWithLongevity in the type definition of SingleA.
The intricate KDL problem has driven our tentative implementations. Here's the KDL problem solved by making use of the Singleton class template. Of course, these definitions go to their appropriate header files.
class KeyboardImpl { ... };
class DisplayImpl { ... };
class LogImpl { ... };
...
inline unsigned int GetLongevity(KeyboardImpl*) { return 1; }
inline unsigned int GetLongevity(DisplayImpl*) { return 1; }
// The log has greater longevity
inline unsigned int GetLongevity(LogImpl*) { return 2; }
typedef SingletonHolder<KeyboardImpl, SingletonWithLongevity> Keyboard;
typedef SingletonHolder<DisplayImpl, SingletonWithLongevity> Display;
typedef SingletonHolder<LogImpl, SingletonWithLongevity> Log;
It's a rather easy-to-grasp and self-documenting solution, given the complexity of the problem.
|
6.12 Summary
The introduction to this chapter describes the most popular C++ implementations of Singleton. It's relatively easy to protect Singleton against multiple instantiations because there is good language support in this area. The most complicated problem is managing a singleton's lifetime, especially its destruction.
Detecting postdestruction access is easy and inexpensive. This dead-reference detection ought to be part of any Singleton implementation.
We discussed four main variations on the theme: the compiler-controlled singleton, the Phoenix singleton, the singleton with longevity, and the "leaking" singleton. Each of these has different strengths and weaknesses.
There are serious threading issues surrounding the Singleton design pattern. The Double-Checked Locking pattern is of great help in implementing thread-safe singletons.
In the end, we collected and classified the variations, which helped us in defining policies and decomposing Singleton along these policies. We identified three policies with Singleton: Creation, Lifetime, and ThreadingModel. We harnessed the policies in a class template SingletonHolder with four template parameters (the client type plus one parameter for each policy) that cover all the combinations among these design choices.
|
6.13 SingletonHolder Class Template Quick Facts
SingletonHolder's declaration is as follows:
template <
class T,
template <class> class CreationPolicy = CreateUsingNew,
template <class> class LifetimePolicy = DefaultLifetime,
template <class> class ThreadingModel = SingleThreaded
>
class SingletonHolder;
You instantiate SingletonHolder by passing it your class as the first template parameter. You select design variations by combining the other four parameters. Example:
class MyClass { ... };
typedef Singleton<MyClass, CreateStatic>
MySingleClass;
You must define the default constructor, or you must use a creator other than the stock implementations of the Creator policy. The canned implementations of the three policies are described in Table 6.1. You can add your own policy classes as long as you respect the requirements.
|
|
|

 LINUX
LINUX 
 Books
Books
