Книга построена на основе анализа ядра 2.2
Код этого ядра лежит тут
Каждая строка кода имеет свой уникальный номер - всего этих номеров около 40000.
На эти номера идут ссылки на протяжении всей книги.
Глава 1. Введение в Linux
Возможно, детализированное представление о реальном функционировании большинства операционных систем (ОС) так и останется недостижимой мечтой многих программистов, поскольку исходные коды ОС зачастую являются тайной за семью печатями. Однако существуют и исключения из этого правила, к которым принадлежат ОС, разработанные либо для исследовательских целей, либо для учебных целей, либо для тех и других. Несмотря на то что исследование и обучение — цели достаточно важные и прекрасные, подобного рода системы демонстрируют скорее особенности процесса разработки реального программного обеспечения, нежели собственно операционных систем.
Лишь совсем немногие ОС доставляют удовольствие в исследовании, изучении и постижении их исходного кода, делая его доступным (причем совершенно бесплатно) любому желающему. Одна из таких ОС — Linux, которой, собственно, и посвящается эта книга.
Linux — бесплатная, с открытым исходным кодом (open source), стандартизированная, 32-разрядная (64-разрядная для 64-разрядных процессоров), Unix-образная операционная система. Linux обладает всем необходимым, чего можно ожидать от современной полноценной ОС:
- истинной приоритетной мультизадачностью, включая полную поддержку множества пользователей;
- механизмами защиты памяти;
- виртуальной памятью;
- возможностью выполнения как на традиционных однопроцессорных, так и на симметричных мультипроцессорных системах;
- выполнением POSIX-соглашения;
- наличием сетевой обработки;
- графическим пользовательским интерфейсом и рабочими столами;
- высоким быстродействием и устойчивостью.
Строго говоря, Linux не является целиком операционной системой. Во время установки того, что обычно называется Linux, на самом деле устанавливается изрядное количество инструментальных средств, которые в результате совместного функционирования и реализуют весь спектр задач ОС. Собственно Linux представляет собой ядро операционной системы, ее сердце, мозги и центральную нервную систему. (На систему целиком зачастую ссылаются как на GNU/Linux; это прояснится далее в главе.) Ядро эксклюзивно отвечает за выполнение наиболее низкоуровневых задач, которые делают возможным реализацию всего остального: манипуляций одновременно существующими процессами; управления памятью процессов с гарантией отсутствия коллизий; реализацию дисковых операций, запрошенных процессами и т.п.
В книге будет показано, как ядро Linux выполняет большинство из упомянутых критических задач.
Краткая история создания Linux и Unix
Что вы ожидаете найти в этой книге? Дабы прояснить этот вопрос, остановимся на миг и взглянем на историю возникновения Linux. Поскольку Linux основана на Unix, история начинается как раз с нее.
ОС Unix была разработана в 1969 г. Кеном Томпсоном (Ken Thompson) и Деннисом Ритчи (Dennis Ritchie) в Bell Laboratories, принадлежащей компании AT&T. Первоначально Unix была однопользовательской ОС, работающей на мини-ЭВМ PDP-7 и написанной на ассемблере. По прошествии короткого времени, когда Томпсон и Ритчи смогли убедить управляющих в необходимости приобретения более мощных PDP-11, Unix была переписана на специально придуманном для этой цели языке программирования С. Кроме того, эффективность новых на тот момент мини-ЭВМ обеспечила возможность создания и системы обработки текстов. И система стала таковой, но об этом немного позже. В первую очередь рассмотрим то, что касается непосредственно написания ОС.
В конце концов, инструментальные средства текстовой обработки были созданы, и Unix (вместе со всеми средствами, под ней работающими) стала широко применяться внутри компании AT&T. На конференции по ОС в 1973 г. Томпсон и Ритчи сделали доклад, посвященный системе, который вызвал повышенный интерес у всего академического сообщества. Компания AT&T не могла заняться компьютерным бизнесом по причине существования антимонопольного законодательства 1956 г., однако дала добро на распространение системы по номинальным ценам. И это было сделано в первую очередь для академических пользователей и, далее, для правительственных организаций и промышленных компаний.
Одним из счастливых обладателей Unix стал Калифорнийский Университет в Беркли (University of California at Berkeley), где силами группы по исследованиям компьютерных систем (Computer System Research Group, или CSRG) в ОС Unix были внесены существенные усовершенствования. Изменения привели к появленю новой модификации Unix, известной как Berkeley Software Development (BSD) Unix, которая стала одной из наиболее влиятельных модификаций, уступая, быть может, лишь разработкам собственно AT&T. В BSD были добавлены такие важные возможности, как сетевая обработка на базе протокола TCP/IP, улучшенная пользовательская файловая система (user file system, UFS), управление заданиями и усовершенствованный код управления памятью.
В течение ряда лет BSD лидировала в академической среде, в то время как версии, выпущенные компанией AT&T, кульминацией которых стала System V, доминировали в коммерческих организациях. Частично это объяснялось социологическими причинами: университетам нравилось неофициальное, причем зачастую более удачное BSD-семейство Unix, тогда как коммерческие организации предпочитали иметь дело с Unix от AT&T.
Будучи управляемой пользователями, равно как теми же пользователями и разработанной, BSD-разновидность Unix была и более новой, и более быстро разрабатываемой. В данной связи последняя официальная версия AT&T Unix, System V Release 4 (SVR4), воплотила в себе большинство положительных черт BSD. Частично по причине того, что в 1984 г. у AT&T появилась возможность заняться продажами Unix, работа над BSD постепенно увядала и сошла на нет в 1993 г., завершившись версией BSD 4.4. Однако работа над усовершенствованием BSD продолжается и поныне множеством разработчиков со всего мира. Существует, по крайней мере, четыре направления развития Unix, произрастающие непосредственно из BSD 4.4. И это уже не говоря о множестве коммерческих версий Unix, наподобие HP-UX от Hewlett-Packard, которая в подавляющем большинстве, если не полностью, основывается на BSD.
BSD и System V — не единственные вариации Unix. поскольку львиная часть кода Unix написана на C, код относительно просто переносить на другие машины и столь же просто переписать заново. Подобные преимущества делают Unix хорошим выбором для компаний, чей основной бизнес связан с продажами аппаратного обеспечения: Sun, SGI, Hewlett-Packard, IBM (неоднократно самостоятельно разрабатывавшая Unix), Digital Equipment Corporation, Amdahl и многие десятки других. Компания обычно создавала новое оборудование, после чего просто переносила на него Unix и в результате оборудование могло функционировать уже непосредственно после выпуска. По прошествии некоторого времени у каждого такого продавца появилась собственная разновидность Unix и контингент клиентов, «намертво» с нею связанный.
Результирующий беспорядок привел к тому, что возникла необходимость в проведении серьезной стандартизации, наиболее существенным достижением которой стало семейство стандартов POSIX, определяющее требования к интерфейсу и инструментальным средствам ОС. Код, написанный в POSIX-стандарте, теоретически переносим в любую ОС, соответствующую POSIX-стандарту, и жесткий пакет тестов POSIX дает предпосылки практического воплощения этой теории. В настоящее время соответствие POSIX-стандарту — одна из главных целей любой серьезной ОС.
Вернемся в начало 80-х. В 1984 г. талантливый хакер Ричард Столлмен (Richard Stallman) инициировал полностью независимый проект по созданию Unix-подобной ОС с ядром, средствами разработки и набором приложении для конечных пользователей. Дублируя название проекта GNU («GNU's Not Unix» — неплохая рекурсивная аббревиатура!), Столлмен ставил перед собой в равной степени как идеологические, так и технические цели. Он хотел получить, с одной стороны, высококачественную ОС, а с другой — такую, которая могла бы распространяться свободно. Когда Сталлмен говорил «свободно распространяемую», он имел в виду не только «распространяемую бесплатно», но, что более важно, «освобожденную» от каких бы то ни было лицензионных соглашений, ограничивающих свободу использования, копирования, исследования, повторного использования, изменения и перераспределения программного обеспечения. (Столлмен говорил: «Свобода слова — это не бесплатное пиво».) В конечном итоге Ричард Столлмен создал благотворительный фонд Free Software Foundation (FSF), цель которого заключалась в поиске источников финансирования разработки программного обеспечения GNU. (Помимо прочего, FSF имеет долевой процент в широком перечне интеллектуальной собственности.)
За свою 15-летнюю историю проект GNU породил и адаптировал поистине чудовищное количество программ, среди которых наиболее известные Linux-утилиты Emacs, gcc (компилятор GNU C) и bash (командная оболочка). В рамках проекта сейчас разрабатывается ядро GNU Hurd, последний основной компонент операционной системы GNU OS. (В настоящий момент Hurd уже функционирует, однако номер текущей версии — 0.3, так что несложно понять, как это еще далеко от замыслов разработчиков.)
Несмотря на популярность Linux, Hurd продолжает совершенствоваться по ряду причин. Во-первых, архитектура Hurd более точно воплощает идеи Столлмена о том, как должна работать ОС. Например, любой пользователь может изменять и заменять некоторые части Hurd во время его функционирования. (Изменения не отразятся на других пользователях, а лишь только на данном пользователе, к тому же если они не противоречат требованиям безопасности.) Другая причина связана с тем, что Hurd масштабируется в мультипроцессорных системах более осмысленно, нежели ядро Linux. Можно сказать, что Hurd разрабатывается просто потому, что есть заинтересованность в его разработке: программисты работают по желанию и бесплатно, и до тех пор пока хотя бы часть из них будет работать, Hurd будет развиваться.Если когда-либо все обещания будут выполнены, Hurd станет серьезным конкурентом Linux. Однако сегодня Linux — несомненно король свободно распространяемых ядер.
Приблизительно в середине процесса разработки GNU, в 1991 г., финскому студенту Линусу Торвальдсу (Linus Torvalds) потребовалось изучить новый центральный процессор Intel 80386. Он решил, что наилучшим путем реализации затеи будет написание собственного ядра ОС. Такое желание, плюс недостаточно эффективные доступные вариации Unix для компьютеров на базе Intel 80386, привели к необходимости разработки завершенного, полнофункционального, соответствующего POSIX-стандарту, Unix-подобного ядра, которое бы воплотило все лучшее из BSD и System V и оставило за бортом присущие им недостатки. Линус разработал ядро вплоть до версии 0.02 самостоятельно; с этого момента стало возможно запускать под его управлением gcc, bash и несколько других утилит, однако это все. Далее Линус начал искать поддержку в Internet.
За три года Unix версии Линуса — Linux — достиг версии 1.0. Объем исходного кода вырос более чем на порядок, в нем появилась начальная поддержка TCP/IP. (Этот код, связанный с сетевой обработкой уже переделывался, и, вероятнее всего, будет переделываться вновь.) В свое время Linux имел около 100000 пользователей.
Сегодня ядро Linux содержит свыше 1,5 миллионов строк кода, и сейчас число его пользователей далеко перевалило за 10 миллионов. (Более точно эту цифру сообщить трудно, поскольку Linux можно совершенно свободно получить или скопировать.) GNU/Linux, ядро Linux вместе с набором инструментальных средств, по оценкам, должно захватить около 50% рынка Unix. Многие компании, например Red Hat и Caldera, выпускают дистрибутивы Linux — пакеты, включающие ядро, множество утилит, приложений и программное обеспечение для установки ОС. GNU/Linux получила поддержку у таких компаний, как Sun, IBM и SGI, причем в планы последней входит поставка GNU/Linux вместе с новыми компьютерами на базе процессора Intel Merced вместо собственной разновидности UNIX — IRIX. Ядро Linux выбрано даже в качестве основы новой ОС, поставляемой компанией Amiga.
Соглашение GNU General Public License
Столь популярную и уважаемую операционную систему стоило бы изучить более подробно. Существенную помощь здесь оказывает тот факт, что исходный код Linux является свободно доступным согласно лицензии GNU General Public License (GPL), — достаточно необычной лицензии, не противоречащей философии Столлмена. Лицензия предоставляет право использовать, копировать, исследовать, повторно использовать и изменять код, равно как и повторно распространять программное обеспечение до тех пор, пока внесенные вами изменения остаются бесплатными. Таким образом, GPL гарантирует, что Linux (и множество другого программного обеспечения, попадающего под эту лицензию) будет свободным в распространении, использовании и модификации не только сегодня, но и всегда.
Следует отметить, что «свободный» в данном контексте вовсе не означает невозможность зарабатывать деньги на подобного рода программном обеспечении — доказательством тому может послужить процветающая компания Red Hat, занимающаяся выпуском одного из наиболее популярных дистрибутивов Linux. (Сейчас Red Hat стоит многие миллиарды долларов.) Просто лицензия не позволяет требовать какие-либо деньги за произведенные изменения.
Полный текст лицензии GNU General Public License можно найти в приложении В.
Процесс разработки Linux
ОС Linux доступна для любых исследований, поскольку она свободно распространяется. Она заслуживает того, чтобы ее изучать, просто потому, что она великолепна. Если бы это была слабая ОС, тогда ее бы не стоило использовать, равно как и изучать. Linux — высококачественная ОС, обеспечивающая решение широкого спектра задач.
Одна из причин, почему Linux достигла столь впечатляющих результатов, связана с тем, что ее разрабатывали многие величайшие умы. Линус Торвальдс, в прошлом студент, — гений, причем не только в программировании. Его организационные способности далеко выходят за рамки заурядных. На протяжении длительного времени ядро расширялось и совершенствовалось множеством лучших программистов со всего мира, причем их общение происходило, в основном, через Internet, а код разрабатывался в свое удовольствие. Это и понятно — они же строили операционную систему своей мечты!
Следующая причина несомненного успеха Linux уходит своими корнями в исключительно удачные концепции, положенные в основу ОС. Unix — простая и элегантная модель ОС. За плечами Unix более 20 лет «выдержки», а ведь Linux основывается на Unix, воспроизводя все его достоинства и по возможности избегая недостатков. Результат налицо — одна из наиболее быстрых, Unix-подобных, живучих, полнофункциональных и свободных от груза недостатков операционных систем.
Самое большое достоинство Linux — открытый процесс разработки. Поскольку исходный код ядра свободно доступен всем, любой может вносить изменения, которые станут доступными опять-таки всем. Если вы отыскали ошибку, лучше исправить ее самостоятельно, нежели просить кого-либо сделать это. Если вы размышляете о повышении производительности либо о добавлении новых возможностей, проще сделать это самостоятельно (скорее всего, это окажется более реально, чем терять время на объяснение кому-то своих проблем, а затем надеяться на то, что кто-то когда-нибудь сделает все необходимое). Когда обнаруживается «дыра» в системе безопасности, «залатывайте» ее самостоятельно и не ждите, пока этим займется поставщик ОС. Хорошо иметь исходный код — можно его досконально изучить, отыскать ошибки, медленно выполняющиеся части, просчеты в системе безопасности, исправить и подкорректировать их и тем самым застраховаться от неприятностей в дальнейшем.
Последние утверждения и советы могут вызвать некоторое замешательство у тех, кто не считает себя программистами. Послушайте, даже если вы не программист, все равно такая модель разработки Linux полезна, по крайней мере, по двум причинам:
- Извлекается польза (пусть и непрямая) от деятельности многих тысяч программистов, постоянно занимающихся усовершенствованиями ОС.
- Если необходимо внести какое-либо изменение, можно нанять для этой цели программиста. Любой программист, которому вы платите деньги и который работает только на вас, сделает все необходимое, причем с минимальными накладными расходами. Попытайтесь сделать подобное для закрытых ОС!
Свободную модель разработки, характерную для Linux, нарекли «базаром» в противоположность модели «собора», при которой исходные коды заперты в склепе, а очередные версии появляются тогда, когда это сочтет необходимым отдел маркетинга компании-разработчика. (Посмотрите статью Эрика С. Реймонда The Cathedral and the Bazaar по адресу http://www.tuxedo.org/~esr/writings/). Модель разработки, подобная «базару», продуцирует лучшее программное обеспечение, всячески поощряя экспериментирование, обратную связь на ранних этапах, и при этом вовлекает в процесс огромный творческий потенциал многих и многих программистов. (Кстати, Linux — далеко не первый проект, создаваемый по принципам «базара», хотя, несомненно, наиболее ощутимый.)
Дабы обеспечить предсказуемость и, самое главное, результативность подобного подхода, при проектировании Linux задействована так называемая система с двумя ветвями. Одна ветвь характеризуется устойчивостью, другая — напротив, постоянно находится в состоянии разработки (т.е. является неустойчивой). Все новые изменения, в особенности экспериментальные, сначала появляются во второй ветви. Если изменения связаны с исправлением ошибок, присутствующих в устойчивой ветви, они появляются в устойчивой ветви сразу же после того, как пройдут обкатку в ветви разработки. Как только количественные изменения в ветви разработки по мнению Линуса переходят в качественные, эта ветвь разработки становится новой устойчивой ветвью, после чего процесс продолжается.
Нумерация ветвей проводится согласно шаблону x.y.z. Для устойчивых ветвей y — четное число, для ветвей же разработки — нечетное и превышающее число соответствующей устойчивой ветви. На момент написания книги наиболее свежим устойчивым ядром было 2.2.12, а ядром разработки — 2.3.12. Исправленные в ветви 2.3 ошибки, скорее всего, будут распространены на ветвь 2.2, и как только ветвь 2.3 станет вполне зрелой, она преобразуется в ветвь 2.4.0. (Скорее всего, это время не за горами, поскольку разработчики ядра в настоящий момент пытаются внедрить более короткие циклы разработки.)
Последние версии ядра, равно как и сопутствующая информация, постоянно доступны на Web-сайте http://www.kernel.org.
Глава 2. Первое знакомство с кодом
Эта глава начинается с краткого обзора исходного кода ядра Linux —
рассматриваются некоторые его наиболее общие возможности, представляющие несомненный интерес.
Затем исследуется собственно код. Завершается глава набором полезных советов по поводу компиляции ядра,
которая потребуется для того, чтобы протестировать внесенные вами изменения.
Характерные особенности исходного кода ядра Linux
Ядро Linux написано на языке С и ассемблере. Был найден обычный компромисс между этими двумя языками: код на С более переносим и прост в поддержке, тогда как код на ассемблере обеспечивает большую скорость выполнения. В общем случае ассемблер в ядре используется только в тех местах, где наиболее критичным показателем является скорость, либо там, где требуется реализация кода, специфичного для конкретной платформы (например, кода непосредственного доступа к аппаратуре управления памятью).
Так сложилось, что части ядра компилируют в gcc (компилятор GNU C++), несмотря на то, что возможности объектов С++ не задействуются. Хотя объектно-ориентированный код С++ не характеризуется большой избыточностью, даже небольшая избыточность разработчиков ядра не устраивает.
Разработчики ядра ввели новый стиль программирования, представляющий Linux во всей своей красе. Ниже этот стиль обсуждается более подробно.
Использование свойств, специфических для gcc
Ядро Linux создавалось таким образом, чтобы легко компилироваться компилятором GNU C, т.е. gcc.
Ядро может быть откомпилировано далеко не в каждом компиляторе С, поскольку нередко в коде задействуются возможности, специфические для gcc. Большинство таких возможностей подробно описываются по ходу изложения материала. В части кода используются языковые расширения gcc, например, применение ключевого слова inline в С (не С++) для определения inline-функции, т.е. функции, чей код будет подставляться при каждом ее вызове, тем самым экономя затраты на обычный вызов функции.
Выражаясь более общими понятиями, код написан практически в сверхточном стиле, поскольку в зависимости от источника gcc продуцирует код различной эффективности. Теоретически компилятор может определять два различных пути достижения одних и тех же целей и оптимизировать код в обоих случаях к одним и тем же результатам, так что нет особой разницы в том, как пишется код. На практике оказывается, что некоторые способы написания кода приводят к более высокопроизводительным результатам. Разработчикам ядра известны подобного рода пути, поэтому написанный ими код как раз и отражает их знания.
Например, давайте обсудим частоту использования goto в ядре — во имя скорости ядро частенько прибегает к этому обычно нежелательному оператору. В почти 40000 строк кода goto встречается более 500 раз, т.е. один goto на приблизительно 80 строк кода. Если не принимать во внимание ассемблерный код, получается один goto на около 72 строк. Справедливости ради следует отметить, что такая частота использования goto связана, прежде всего, со спецификой выбранного кода — в основной части ядра, рассматриваемой в книге, наиболее важным требованием является скорость. Частота использования goto для ядра в целом составляет один goto на 260 строк, что представляет собой довольно большое значение.
Практика написания кода под конкретный компилятор достаточно резко противоречит идеологии разработки не только большинства прикладных приложений, но также и ядра. Разработчики прибегают к языку С по причине сохранения переносимости результирующего кода, даже если это код ОС. Преимущества здесь очевидны: взять хотя бы возможность перейти на другой, более мощный компилятор, как только он становится доступным.
Тесная привязка ядра к особенностям gcc существенно усложняет перенос кода ядра в другие компиляторы. Недавно Линус изложил свою позицию по этому поводу в конференции, посвященной ядру: «Помните: компилятор — это ИНСТРУМЕНТ». Такое утверждение прекрасно характеризует философию, лежащую в основе привязки к специфике gcc, — компилятор необходим только для завершения работы. Если критерии работы не могут быть реализованы в рамках существующих стандартов, следует отказываться от стандартов, но не от критериев работы.
В большинстве случаев подобная точка зрения неприемлима. Часто лучше пожертвовать некоторыми функциональными возможностями, скоростью или чем-то еще во имя соблюдения существующих языковых стандартов.
Однако в данном случае Линус прав. Ядро Linux — специальный случай, при котором скорость выполнения результирующего кода играет гораздо большую роль, нежели переносимость исходного кода в другие компиляторы. Если бы цель заключалась в создании переносимого, а не быстродействующего, ядра, либо ядра, которое каждый смог бы компилировать в любом компиляторе, решение оказалось бы другим. Но не эти цели заложены в Linux. На практике gcc генерирует код, который выполняется практически на каждом процессоре, поэтому базирование на gcc — не столь уж большой барьер для переносимости.
Дополнительное обсуждение целей проектирования ядра можно найти в главе 3.
Идиомы кода ядра
Код ядра демонстрирует ряд выдающихся идиом, часть из которых обсуждаются в этом разделе. Во время чтения кода ядра важно не столько понимание собственно идиом, а только тот факт, что они существуют и непротиворечиво применяются. Во время написания кода для ядра необходимо знать, какие идиомы используются ядром, и применять их в собственном коде.
Я дал идиомам имена, поэтому мне теперь проще о них говорить. Однако имена эти мои, и даны они только в интересах обсуждения. На практике мало кто явно ссылается на идиомы. Они — суть способ, в соответствии с которым ядро выполняет свою работу.
Одна общая идиома — это та, которую я называю идиома накопления ресурсов (resource acquisition idiom). В соответствии с этой идиомой, некоторая функция должна получать последовательность ресурсов — память, блокировки и т.д. Функция перейдет к получению следующего ресурса только после того, как будет успешно получен текущий ресурс. В конечном итоге, функция должна освободить все накопленные ресурсы и не предпринимать попытки освобождать те, при получении которых возникшли ошибки.
Идиома накопления ресурсов была показана в композиции с идиомой переменной ошибки (error variable idiom), которая предполагает использование временной переменной для записи возвращаемого из функции значения. Разумеется, множество функций делают это — тем-то и известна идиома переменной ошибки, когда некая переменная ошибки приеняется для того, чтобы справиться с управлением потоком, усложненным ради достижения высокой скорости. Значение переменной ошибки — либо 0 (успешное выполнение), либо отрицательная величина (ошибка). Рассмотренные две идиомы переходят из рук в руки, естественно приводя к коду, шаблон которого показан ниже:
int f(void)
{
int err;
resource * r1, * r2;
err = -ERR1; /* Предположить ошибку */
r1 = acquire_resource1();
if (!r1) /* Ресурс не получен */
goto out; /* Вернуть -ERR1 */
/* Получили ресурс r1; запрашиваем r2 */
err = -ERR2; /* Предположить ошибку */
if (!r2) /* Ресурс не получен */
goto out1; /* Вернуть -ERR2 */
/* Получили ресурсы r1 и r2 */
err = 0; /* Ошибок нет */
/* . . . Используем r1 и r2 . . . */
out2:
release_resource(r2);
out1:
release_resource(r1);
out:
return err;
}
Следует заметить, что уже само по себе существование переменной err указывает на присутствие идиомы переменной ошибки. Аналогично, имена меток out, out1, out2 непосредственно связаны с идиомой накопления ресурсов.
Всякий раз, когда достигается метка out2, r1 и r2 уже получены и должны быть освобождены. Всякий раз когда достигается метка out1 (либо строка за строкой, либо через goto), r2 — недоступен (возможно, r2 освобожден), но r1 — занят и должен быть освобожден. Аналогично, при достижении метки out, r1 и r2 освобождены, а err содержит код ошибки либо успешного завершения.
В рассмотренном примере не все присваивания err являются необходимыми. Реальный код следует приведенному шаблону, однако с некоторыми изменениями. Как показывают исследования, многие строки кода возвращают одно и то же значение ошибки, поэтому гораздо проще установить это значение один раз. В показанном выше примере преследовались чисто иллюстративные цели, реальный же пример кода подобного рода можно найти в функции sys_shmctl (строка 21654) в главе 9.
Сокращенное применение #if и #ifdef
Ядро Linux перенесено на множество платформ, и проблемы переносимости решались по мере их возникновения. Большинство кода для поддержки различных платформ завершается множеством препроцессорных заморочек, наподобие показанных ниже:
#if defined(SOLARIS)
/* делать что-либо способом, принятым в Solaris ... */
#elif defined(HPUX)
/* делать что-либо способом, принятым в HP-UX ... */
#elif defined (LINUX)
/* делать что-либо общепринятым и правильным способом ... */
#else
#error Неподдерживаемая платформа.
#endif
Несмотря на то что пример связан с обеспечением переносимости кода в различных ОС, а задача Linux заключается в обеспечении переносимости кода в различных процессорах, принципы реализации совершенно аналогичны. Задействование препроцессора для такой задачи — ошибочное решение. Весь этот хаос лишь усложняет чтение и понимание кода. Что еще хуже, добавление поддержки новой платформы заставляет возвращаться к каждому блоку этого хлама (попробуйте еще отыскать их все!) и добавлению кусочков кода там и сям.
С другой стороны, Linux обычно абстрагируется от платформ через простые вызовы функций (или макросов). Переносимость ядра достигается за счет реализации функций (или макросов) в соответствии с требованиями той или иной платформы. Подобный подход не только существенно упрощает чтение кода, но также позволяет не забывать учитывать все необходимое при переносе на новую платформу — в противном случае будет генерироваться ошибка, связанная с неразрешимой ссылкой на функцию. В некоторых случаях для поддержки различных архитектур все еще используется препроцессор, однако это скорее исключение из правил.
Нельзя не заметить четко прослеживающуюся аналогию между рассматриваемым решением и методологией использования объектов (или структур, заполненных указателями на функции, в С), которая применяется вместо множества операторов switch, реализующих различные варианты обработки. На определенном уровне проблемы и их решения весьма схожи.
Проблемы переносимости не ограничиваются платформами и центральными процессорами — в действие вступают также и компиляторы. Это еще одно место, позволяющее понять, почему предполагается, что Linux должен компилироваться в gcc. Нет необходимости предусматривать в коде блоки #if (либо #ifdef), обеспечивающие выбор того или иного компилятора, поскольку Linux предполагает существование только одного компилятора в мире. Основное использование #ifdef в коде ядра связано с поддержкой конструкций, которые могут не компилироваться. К таким конструкциям относится, например, код, тестирующий, определен ли макрос SMP, указывающий на необходимость поддержки многопроцессорных SMP-машин.
Пример кода
В предыдущем разделе приводились только рассуждения. Лучший способ оценить специфику кода Linux — это взглянуть на него. Сейчас не особенно важно понимать все тонкости показанного здесь кода, поскольку это не цель данного раздела. Цель же заключается в демонстрации того, что можно ожидать от кода в дальнейшем. Ниже рассматриваются несколько наиболее широко используемых фрагментов кода ядра.
printk(см. kernel/printk.c)
Printk (строка 25836) представляет собой внутреннюю функцию поддержки журнала сообщений ядра. При генерации какого-либо сообщения, например, когда ядро обнаруживает несовместимость в своих структурах данных, функция printk вызывается для отображения соответствующей информации на системной консоли. Обращения к printk попадают под одну из следующих категорий:
- Аварийные ситуации. Например, в функции panic (строка 25563) printk вызывается множество раз. Функция panic вызывается, когда ядро определяет неразрешимую внутреннюю ошибку; в такой ситуации лучшее решение — перегрузить систему. Обращения к printk уведомляют пользователя о том, что система завершает работу.
- Отладка. Блок #ifdef, начинающийся в строке 3816, использует printk для вывода в версии SMP информации о конфигурации каждого процессора, если код компилировался с флагом SMP_DEBUG.
- Общая информация. Например, во время загрузки ядро должно определить быстродействие системы, чтобы обеспечить корректное время ожидания для драйверов устройств. Эти расчеты обеспечивает функция calibrate_delay (строка 19654), в которой вызов printk (строка 19661) выводит сообщение о начале расчетов, а другой вызов printk (строка 19693) отображает результаты. Функция calibrate_delay подробно рассматривается в главе 4.
Просмотрев упомянутые выше строки кода, несложно убедиться, что аргументы printk подобны аргументам printf: строка формата, за которой следует 0 или более аргументов. Строка формата может начинаться с последовательности символов в форме «<N>», где N — цифра, от 0 до 7 включительно. Цифра определяет уровень регистрации сообщения; сообщение будет выводиться только если этот уровень меньше текущего уровня, определенного для консоли (console_loglevel, строка 25650). Уровень для консоли можно снижать, тем самым отфильтровывая менее важные сообщения. Если в строке формата не задается ни одного уровня регистрации, сообщение будет выводиться всегда. (В настоящий момент уровень регистрации не должен обязательно присутствовать в строке формата — он отыскивается в форматированном тексте.)
Блок конструкций #define, начинающийся в строке 14946, присваивает имена специальным последовательностям, что упрощает использование printk. Так уж вышло, что уровни с 0 по 4 относятся к тем, которые я называю «аварийными ситуациями», уровни 5 и 6 — к «общей информации», а 7 — к «отладке».
Обратим свой взгляд на код.
printk
25836: Аргумент fmt — это строка формата наподобие используемой в функции printf. Если имеются какие-либо затруднения в работе с частью "...", стоит обратиться к любой книге по программированию на языке С. Кроме того, неплохую справку можно получить в руководстве по GNU/Linux на странице stdarg (просто наберите man stdarg).
Выражаясь кратко, часть "..." уведомляет компилятор, что за fmt может следовать любое количество параметров любых типов. Поскольку на этапе компиляции эти параметры не имеют ни имен ни типов, необходимо манипулировать тройкой макросов va_start, va_arg и va_end и типом va_list.
25842: msg_level записывает уровень регистрации текущего сообщения. Может вызвать удивление, что msg_level имеет тип static — зачем при следующем вызове printk помнить текущий уровень регистрации? Ответ заключается в следующем: текущее сообщение завершается только после вывода символа новой строки (\n) либо после получения новой последовательности, определяющей уровень регистрации. Такой подход позволяет выводить длинное сообщение по частям, при этом последний вызов printk должен включать в себя символ новой строки.
25845: В версии SMP ядро может пытаться выводить на консоль буквально одновременно из различных центральных процессоров (ЦП). (Хоть это и неочевидно, но нечто подобное может возникать и в однопроцессорной версии. Оставим это до обсуждения прерываний.) Если не предпринять меры по координации, в результате получится жуткая путаница — хаотично перемешанные куски различных сообщений.
Для обеспечения защиты доступа к консоли в ядре используется механизм взаимной блокировки (см. главу 10).
Не стоит удивляться, что flags передается в spin_lock_irqsave без предварительной инициализации: spin_lock_irqsave (различные его версии реализованы в строках 12614, 12637, 12716 и 12837) — это макрос, а не функция. Этот макрос записывает в flags, но не читает из него. Информация, сохраненная в flags читается spin_unlock_irqrestore в строке 25895 (см. строки 12616, 12639, 12728 и 12841).
25846: Инициализация переменной args, которая представляет часть "..." параметров printk.
25848: Вызывает собственную реализацию ядра функции vsprintf (с опущенными пробелами). Это действует подобно обычному vsprintf, записывая форматированный текст в buf (строка 25634) и возвращая количество записанных символов (исключая завершающий строку нулевой символ). Далее будет показано, почему пропускаются первых три символа в buf.
Заметьте, что ничего не препятствует переполнению буфера (см. комментарий в строке 25847). В данном случае предполагается, что 1024-символьного буфера должно оказаться достаточно. Было бы гораздо лучше, если бы ядро использовало здесь функцию vsnprintf, которая имеет дополнительный параметр, определяющий количество записываемых символов.
25849: Определение элемента в buf, который использовался последним, и завершение прохода по параметру "..." путем вызова va_end.
25851: Начинает итерацию по форматированному сообщению. Существует внутренний цикл, обеспечивающий дополнительную обработку (это можно заметить сейчас). Упомянутый цикл вызывается при каждом прогоне внешнего цикла, соответствующего началу каждой отображаемой строки. Поскольку обычно printk вызывается только для печати одной строки, цикл выполняется один раз на вызов.
25853: Если уровень регистрации сообщения еще не известен, printk проверяет, соответствует ли начало строки последовательности, определяющей уровень регистрации.
25860: Если нет, первых три символа buf будут использоваться. (Для итераций, следующих после первой, это перезаписывает часть текста сообщения; тем не менее, все правильно, поскольку перезаписываемый текст относится к предыдущей строке, которая уже отображена и больше не нужна.) Последовательность, определяющая уровень регистрации, вставляется в buf.
25866: К этому моменту фиксируются следующие свойства: p указывает на последовательность, определяющую уровень регистрации (за которой следует текст сообщения), а msg — на текст сообщения (обратите внимание на установку msg в строках 25852 и 25865). Поскольку p известен как указатель на начало последовательности, определяющей уровень регистрации (возможно, построенной самой функцией), уровень регистрации может быть получен из p и сохранен в msg_level.
25868: Очистка флага line_feed, т.е. пока не встретилось ни одного символа новой строки.
25869: Внутренний цикл, упоминаемый ранее; он выполняется вплоть до конца строки (т.е. до получения символа новой строки) либо до конца буфера.
25870: В дополнение к выводу сообщений на консоль, printk запоминает последние выведенные LOG_BUF_LEN символов. (LOG_BUF_LEN равно 16К — см. строку 25632.) Если ядро вызывает printk перед открытием консоли, очевидно, что сообщение не может быть напечатано на консоли, однако оно сохраняется (во всяком случае, максимум возможного) в log_buf (строка 25656). Как только консоль откроется, данные из log_buf немедленно переносятся в нее (см. строку 25988).
Массив log_buf реализован в виде циклического буфера, в котором переменные log_start и log_size (строки 25657 и 25646) хранят, соответственно, начало буфера и его длину. Поразрядное AND в данной строке обеспечивает быстрое взятие по модулю (%); корректность выполнения операции зависит от того, является ли LOG_BUF_LEN степенью двойки.
25872: Поддержка переменных, отслеживающих циклический журнал регистрации. Очевидно, что размер журнала (log_size) может увеличиваться, только если он не превышает LOG_BUF_LEN. В противном случае log_size не изменяет своего значения, а вставка дополнительных символов приводит к увеличению log_start.
25878: Отметьте, что logged_chars (строка 25658), т.е. общее количество символов, записанное printk с момента перезагрузки компьютера, обновляется в каждой итерации цикла, а не один раз после завершения цикла. То же самое справедливо и для log_start и log_size. Это выглядит как возможность оптимизации, однако оставим обсуждение до того момента, когда рассмотрение функции будет завершено.
25879: Сообщения разбиты на строки, разделенные символами новой строки. Как только встречается один из символов новой строки, текущая строка выводится, а внутренний цикл завершается раньше.
25884: Не принимая во внимание более раннее завершение внутреннего цикла, символы от msg до p предназначены для вывода на консоль. (Я буду ссылаться на эту последовательность символов как на строку, однако не забывайте, что строка может и не завершаться символом новой строки, поскольку последний может и не присутствовать в buf.) Строка будет выведена, если ее уровень регистрации меньше уровня, определенного для системной консоли, а также при условии, что имеются доступные консоли. (Не следует забывать, что printk может вызываться и до открытия консолей.)
Если в анализируемом фрагменте сообщения не найдено ни одной последовательности, определяющей уровень регистрации, и msg_level не установлен во время предыдущего вызова printk, для данной строки msg_level будет равным -1. Поскольку console_loglevel всегда равен по меньшей мере 1 (если только администратор не счел необходимым изменить это), такого рода строки будут выводиться на консоль всегда.
25886: Эта строка будет напечатана. printk пройдется по списку драйверов открытых консолей, уведомляя каждый из них о необходимости вывода строки. (Ввиду того, что рассмотрение драйверов устройств выходит за рамки этой книги, код драйвера консоли здесь не приводится.)
25888: Здесь сообщение записывается без последовательности, определяющей уровень регистрации, — в качестве начала текста сообщения используется msg, а не p. Однако последовательность, определяющая уровень регистрации, записывается в буфер log_buf. Последнее разрешает выполнение кода, читающего log_buf с целью получения уровня регистрации сообщения (см. строку 25998) без искажений в отображении последовательностей.
25892: Если внутренний цикл наталкивается на символ новой строки, оставшиеся символы buf (если таковые имеются) перемещаются в начало нового сообщения, поэтому msg_level сбрасывается. В противном случае внешний цикл продолжается до тех пор, пока не будет исчерпан buf.
25895: Освобождение блокировки консоли, обеспеченной в строке 25845.
25896: Активизация всех процессов, которые ожидают освобождения консоли для записи в нее сообщений. Следует отметить, что подобное имеет место даже в случае, когда текст на консоль еще не выводился. Это вполне нормально, поскольку ожидающим процессам необходимо прочитать log_buf, который может содержать текст, подлежащий передаче на консоль. Ожидание доступа к log_buf для процессов реализовано в строке 25748. Использованный здесь механизм ожидания и очередизации описывается в следующем разделе.
25897: Возвращает количество символов, записанных в журнал.
Цикл for, определенный в строке 25869, мог работать быстрее, если бы не объем работы, выполняемый над каждым символом. Небольшое ускорение можно получить за счет лишь однократного обновления logged_chars после завершения цикла. Однако мы должны попытаться достигнуть большего. Размер сообщения известен заранее, поэтому log_size и log_start не должны увеличиваться до конца цикла. Вот как простенько можно ускорить цикл:
do {
static int wrapped = 0;
const int x = wrapped
? log_start
: log_size;
const int lim = LOG_BUF_LEN - x;
int n = buf_end - p;
if (n >= lim)
n = lim;
memcpy (log_buf+x, p, n);
p += n;
if (log_size < LOG_BUF_LEN)
log_size += n;
else {
wrapped = 1;
log_start += n;
log_start &= LOG_BUF_LEN - 1;
}
} while (p < buf_end);
Не следует забывать, что цикл, как правило, выполняется один раз; большее количество выполнений цикла имеет место тогда, когда запись по достижении конца log_buf переходит на начало. Следовательно, log_size и log_buf обновляются только один раз (или два, если случается переход на начало).
Ускорение достигнуто, но мы не будем поступать таким образом по двум причинам. Во-первых, ядро имеет собственную версию memcpy, и мы должны быть четко уверены, что вызов memcpy никогда не приведет к возврату в printk. (Некоторые версии ядра определяют собственные более быстрые версии memcpy, поэтому они должны быть согласны с последним утверждением.) Если memcpy обращается к printk для выдачи уведомления об ошибке, есть риск попасть в бесконечный цикл.
Однако не это самая большая проблема. Самое печальное, что версия цикла, реализованная в ядре, отслеживает также символы новой строки, так что применение memcpy для копирования всего сообщения в log_buf оказывается некорректным — при появлении символа новой строки, он попросту «перепрыгивается».
Можно попытаться убить двух зайцев одним выстрелом. Приведенная ниже замена оказывается несколько медленнее рассмотренной ранее, однако она не противоречит семантике существующей версии ядра:
/* В разделе объявлений */
int n;
char * start;
static char * log = log_buf;
/* . . . */
for (start = p; p < buf_end; p++) {
*log++ = *p;
if (log >= (log_buf + LOG_BUF_LEN))
log = log_buf; /* Wrap. */
if (*p == '\n') {
line_feed = 1;
break;
}
}
/* p - start представляет количество копируемых символов */
n = p - start;
logged_chars += n;
/*
* Задание для читателя:
* Воспользуйтесь n для обновления log_size и log_start
* (Это не так просто, как может показаться на первый взгляд)
*/
(Следует отметить, что оптимизатор gcc достаточно интеллектуален, чтобы определить, что выражение log_buf + LOG_BUF_LEN внутри цикла не изменяется, поэтому никакого выигрыша от выноса этого выражения за пределы цикла не будет.)
К сожалению, предложенное решение оказывается ненамного более быстродействующим, нежели реализованное в ядре, к тому же оно сложнее в понимании. Можно реализовать собственный подход, если того требуют принятые компромиссы. Какой бы ни был избран путь, полезное зерно всегда присутствует. Общий вывод таков: чем бы ни увенчались попытки усовершенствования кода ядра, успехом или неудачей, польза от исследования ядра неоценима.
Очереди ожидания
В предыдущем разделе кратко упоминалось о том, что процессы (т.е. выполняющиеся программы) могут быть переведены в состояние ожидания определенного события («спящее» состояние) и выведены из этого состояния после прихода события. Реализованная в ядре технология заключается в связывании с каждым событием очереди ожидания (wait queue). Процесс, который должен получить событие, переводится в режим ожидания и помещается в очередь. После прихода события ядро сканирует очередь и активизирует ожидающие задания. Проблема удаления из очереди находится полностью в компетенции заданий.
Очереди ожидания — на удивление мощный механизм, используемый повсеместно во всем ядре. К тому же реализация этого механизма требует не столь уж много кода.
struct wait_queue
18662: Эта простая структура данных хранит узел очереди ожидания. Она имеет всего лишь два члена:
- task — указатель на struct task_struct, представляющую процесс. struct task_struct начинается в строке 16325 и подробно рассматривается в главе 7.
- next — указатель на следующий узел в очереди. Таким образом, очередь ожидания представляет собой односвязный список.
Как правило, очередь ожидания представляется указателем на первый элемент (т.е. голову списка). Посмотрите на log_wait (строка 25647), где очередь ожидания используется в printk.
wait_event
16840: При помощи этого макроса код ядра переводит текущий выполняемый процесс в режим ожидания в очереди wq до тех пор, пока не будет удовлетворено заданное условие condition (которое может быть произвольным выражением).
16842: Если условие истино, процесс не должен ожидать.
16844: В противном случае процесс будет находиться в состоянии ожидания до тех пор, пока условие не станет истинным. Это завершается обращением к __wait_event (строка 16824). Поскольку __wait_event отделено от wait_event, фрагменты кода ядра, которым известно, что условие ожидания ложно, могут вызывать __wait_event напрямую, а не через макрос. В данном случае макрос выполняет избыточную проверку. Если условие истино, wait_event пропускает код, помещающий процесс в очередь ожидания.
Код wait_event заключен в несколько необычную конструкцию:
do {
/* . . . */
} while (0)
Этот небольшой трюк не настолько хорошо известен, как он того заслуживает. Идея состоит в том, чтобы заставить помещенный внутрь конструкции код действовать подобно одному оператору. Рассмотрим следующий макрос, который вызывает free, если p является ненулевым указателем:
#define FREE1(p) if (p) free(p)
Все хорошо до тех пор, пока FREE1 не будет задействован в ситуации наподобие:
if (expression)
FREE1(p);
else
printf ("expression ложно.\n");
После разворачивания макроса FREE1 конструкция else ассоциируется не с тем if (т.е. с if относящимся к FREE1).
Я наблюдал, как некоторые программисты так решали подобную проблему:
#define FREE2(p) if (p) { free(p); }
#define FREE3(p) { if (p) { free(p); } }
Ни одно из вышеприведенных решений нельзя считать удовлетворительным — точка с запятой, которую программист естественно ставит после вызова макроса, портит разворачиваемый текст. Возьмите, к примеру, FREE2. После разворачивания макроса и добавления отступов для лучшего чтения компилятор получит такой текст:
if (expression)
if (p) { free(p); }
;
else
printf("expression ложно.\n");
Результат — синтаксическая ошибка, поскольку else не связан ни с одним if. Аналогичная проблема имеет место и с FREE3. После некоторых размышлений становится ясно, что абсолютно неважно, есть ли if внутри тела макроса. Ту же проблему можно получить и в результате заключения тела макроса в скобки, причем неважно, что находится внутри макроса.
Вот почему применяется трюк с do/while(0). Посмотрите на макрос FREE4, свободный от описанных выше проблем:
#define FREE4(p) \
do { \
if (p) \
free(p); \
} while (0)
После помещения макроса в тот же самый код и его разворачивания получается:
if (expression)
do {
if (p)
free(p);
} while (0); /* ";" после макроса. */
else
printf("expression ложно.\n");
Разумеется, такой код работает корректно. Компилятор выполнит оптимизацию и минимизирует накладные расходы для этого поддельного цикла, поэтому никаких потерь в скорости не будет, а макрос будет работать именно так, как необходимо.
Перед завершением обсуждения данной проблемы нельзя не заметить, что даже несмотря на приемлимость последнего решения, написание функций гораздо лучше написания макросов. Если накладные расходы на вызов функции непозволительны (что имеет место для ядра, но в гораздо меньшей степени для других задач), воспользуйтесь inline-функциями. (Последнее доступно только в компиляторе С++, gcc или в компиляторах, поддерживающих последний стандарт ISO C, где добавлены inline-функции.)
__wait_event
16824: __wait_event переводит процесс в режим ожидания в очереди wq до тех пор, пока condition не станет истинным.
16829: Локальная переменная __wait связывается с очередью через вызов add_wait_queue (строка 16791). Следует отметить, что __wait хранится на стеке, а не в куче ядра — это один из типичных трюков, примененных в ядре. __wait удаляется из очереди ожидания перед завершением макроса, так что указатель на __wait в очереди оказывается всегда допустимым.
16830: Циклическая передача управления другим процессам до тех пор, пока не будет удовлетворено условие (см. ниже).
16831: Процесс переводится в состояние TASK_UNINTERRUPTIBLE (строка 16190), которое означает, что процесс находится в режиме ожидания и не должен из него выходить даже по сигналу. Сигналы описываются в главе 6, а состояния процессов — в главе 7.
16832: Если условие удовлетворяется, цикл может быть завершен.
Заметьте, что если условие истинно при первом проходе цикла, присваивание в предыдущей строке оказывается излишним, поскольку установка состояния процесса выполняется еще раз после завершения цикла. Однако, __wait_event исходит из предположения, что к моменту начала выполнения макроса условие еще не удовлетворено. Нет ничего вредного в некоторой задержке установки переменной состояния процесса. В очень редких случаях может оказаться так, что условие было ложным в начале выполнения __wait_event и истинным в момент достижения строки 16832. Такое изменение приведет к проблеме лишь в случае, если condition оценивается в фрагменте кода, где важную роль играет то, в какое состояние переходит процесс. Ничего подобного в коде ядра я не встречал.
16834: Вызов schedule (строка 26686, см. главу 7) для переключения ЦП на другой процесс. Возврат из вызова schedule не будет осуществлен до тех пор, пока процесс не получит ЦП вновь — это произойдет только после активизации процесса из очереди ожидания.
16836: Цикл завершен, так что условие удовлетворено. Процесс переводится в состояние TASK_RUNNING (строка 16188) и он готов продолжать свое выполнение.
16837: Процесс удаляется из очереди ожидания путем вызова remove_wait_queue (строка 16814).
wait_event_interruptible и __wait_event_interruptible (соответственно, строки 16868 и 16847) похожи на wait_event и __wait_event за тем лишь исключением, что они разрешают прерывание ожидающего процесса по сигналу. (Описание сигналов находится в главе 6.)
Кроме того, wait_event_interruptible заключено в скобки:
({
/* . . . */
})
Подобно трюку с do/while(0), показанное выше заставляет заключенный внутри код действовать как один модуль. Здесь заключенный внутри код — это одиночное выражение, а не оператор, т.е. он оценивается как одно значение, которое может участвовать в больших выражениях. Причина применения трюка связана со своеобразной магией непереносимости в gcc, когда последнее вычисленное в таком блоке выражение делается значением целого блока. В случае использования wait_event_interruptible в выражении, тело макроса выполняется и значением макроса будет значение __ret (см. строку 16873). С подобной концепцией хорошо знакомы программирующие на Lisp, однако она может показаться обескураживающей для тех, кто имел дело только с С и ему подобными процедурными языками.
__wake_up
26829: Это функция, активизирующая процессы, которые находятся в очереди ожидания. Она вызывается в wake_up и wake_up_interruptable (соответственно, строки 16612 и 16614). Эти макросы воспринимают параметр mode; процессы будут активизироваться только в случае, если они находятся в состояниях, определяемых mode.
26833: Как будет более подробно поясняться в главе 10, блокировки используются для защиты доступа к ресурсам; они особенно важны в версии SMP, когда один ЦП изменяет данные, которые в это же время читает другой ЦП, или, скажем, оба ЦП пытаются одновременно модифицировать одни и те же данные. В нашем случае совершенно очевидным ресурсом, который необходимо защитить, будет очередь ожидания. Что самое интересное, так это то, что все очереди ожидания защищаются одной и той же блокировкой. Поступать таким образом оказывается гораздо проще, нежели определять собственную блокировку для каждой очереди, однако в версии SMP может случиться так, что система будет ожидать блокировки в момент, когда это совершенно противопоказано.
26838: Проход по непустой очереди и вызов wake_up_process (строка 26356) для каждого ожидающего процесса с подходящим состоянием. Как утверждалось ранее, в этом месте процессы (узлы очереди) из очереди не удаляются, в основном, потому, что конкретный процесс может требовать оставаться в очереди, несмотря на активизацию процессов (это видно в __wait_event).
Модули ядра
Ядро не требует загрузки в память целиком. Конечно, определенная часть ядра должна присутствовать в памяти постоянно, например, все время резидентным должен быть код планировщика процессов. Однако другие фрагменты ядра, скажем, драйверы устройств, должны загружаться лишь тогда, когда в них возникает необходимость.
Например, код взаимодействия с устройством чтения CD-ROM должен присутствовать в памяти только в течение собственно взаимодействия с CD-ROM. Поэтому ядро можно сконфигурировать таким образом, что упомянутый код будет загружаться непосредственно перед началом обращения к CD-ROM. Как только взаимодействие завершено, ядро «забывает» о коде, т.е. код, который больше не используется, может быть удален из памяти. Разделы ядра, которые можно загружать и удалять во время выполнения, носят название модулей ядра (kernel modules).
Одно из достоинств модулей ядра заключается в упрощении процесса разработки самого ядра. Вообразите себе следующую ситуацию: вы приобрели совершенно новое устройство чтения CD-ROM со специальным высокоскоростным режимом доступа, который не поддерживается существующим драйвером. Разумеется, очень хочется вкусить все преимущества высокоскоростного режима в своей системе. Если компилировать новый драйвер устройства как модуль ядра, это даст массу преимуществ: после компиляции драйвер можно загрузить в ядро, протестировать, выгрузить, внести изменения, вновь загрузить, протестировать и т.д. В том же случае, когда драйвер погружается непосредственно в ядро, после каждой модификации драйвера придется перекомпилировать ядро целиком и каждый раз перегружать систему. Ну о-о-очень медленно!
Соблюдайте осторожность при работе с модулями ядра. Нельзя удалять из памяти модуль взаимодействия с диском, на котором расположены другие модули ядра, поскольку ядро будет обращаться к этому диску в поисках как раз модуля взаимодействия с диском (новость не особенно хороша). Это еще одна причина принятия решения, как должен компилироваться раздел ядра — как модуль либо как часть ядра, постоянно находящаяся в памяти. Поскольку вам известно как должна устанавливаться система, вам и карты в руки. (Если вы — сторонник наиболее безопасного подхода, компилируйте все в ядро.)
С использованием модулей связаны небольшие накладные расходы в смысле скорости, потому как код необходимого модуля должен быть предварительно считан с диска. Однако общая производительность системы, как правило, увеличивается за счет освобождения дополнительного объема ОЗУ под нужды прикладных приложений. Если ОЗУ резервируется под ядро, увеличивается свопинг прикладных приложений, что приводит к резкому снижению производительности. (Свопинг, или подкачка, рассматривается в главе 8.)
За модули ядра приходится платить также и сложностью. Это связано с тем, что добавление и удаление фрагментов ядра во время выполнения требует дополнительного кода. Однако сложностью можно управлять, как будет показано ниже. Дальнейшее снижение сложности достигается за счет делегирования части необходимой работы некоторой внешней программе. (Если быть более точным, это скорее перераспределяет сложность, нежели уменьшает.) Вот вам изящное дополнение к философии модулей ядра: даже поддержка модулей ядра является частично внешней и загружается только по мере необходимости.
Для этих целей используется программа, именуемая modprobe. Рассмотрение кода modprobe выходит за рамки данной книги, однако его можно найти во всех дистрибутивах Linux. Остаток раздела посвящен исследованиям кода ядра, который взаимодействует с modprobe для загрузки модулей.
request_module
24432: Как гласит комментарий, предшествующий этой строке, request_module представляет собой функцию, которая вызывается всегда, когда возникает необходимость загрузить модуль ядра. Как и со всем остальным, что делает ядро, этот запрос выполняется от имени текущего выполняемого процесса. С точки зрения процесса запрос всегда неявный — во время выполнения ядром других запросов вскрывается потребность в загрузке некоторого модуля. Подобный пример можно наблюдать в строке 10070, которая относится к коду, обсуждаемому в главе 7.
24446: Выполнение функции exec_modprobe (строка 24384) в виде отдельного процесса в рамках ядра. Это нельзя сделать в виде простого вызова функции, поскольку exec_modprobe будет приводить к обращению к exec для программы. Следовательно, простой вызов exec_modprobe никогда не приведет к возврату. Вызов весьма похож на использование fork для подготовки exec, поэтому о kernel_thread можно думать как об облегченной версии fork для ядра, хотя kernel_thread имеет одно существенное отличие от fork, которое заключается в том, что процесс начинает выполнение с поименованной функции, а не с точки вызова. Как и в fork, возвращаемым значением kernel_thread является идентификатор (ID) нового процесса.
24448: Опять таки, как и в fork, отрицательное значение возвращаемое kernel_thread означает ошибку.
24455: Как гласит комментарий к функции, для текущего процесса временно блокируется большинство сигналов.
24462: Ожидание завершения exec_modprobe, которое покажет, как загрузился требуемый модуль — успешно или с ошибкой.
24465: Завершение, восстановление сигналов и печать сообщения об ошибке, если exec_modprobe возвратила код ошибки.
exec_modprobe
24384: exec_modprobe запускает программу, которая присоединяет модуль к ядру. Имя модуля определяется как void *, а не char *, поскольку порождаемые kernel_thread функции требуют одного параметра void *.
24386: Установка списка параметров и среды для modprobe. modprobe_path (строка 24363), который определяет расположение программы modprobe, изменяется через возможность sysctl ядра, описываемую в главе 11 (см. строку 30388). Это означает, что администратор может динамически задавать программу, которая будет выполняться вместо /sbin/modprobe, например, если modprobe находится в другом каталоге.
24400: Избавление от задержанных сигналов и их дескрипторов, что связано с вопросами безопасности (как описано в коде). Наиболее важной частью здесь является обращение к flush_signal_handlers (строка 28041), которая заменяет все определенные пользователем дескрипторы сигналов на дескрипторы, определенные в ядре по умолчанию. На любые сигналы, которые могут поступить после этого момента, будет обеспечиваться стандартная реакция, которая заключается либо в игнорировании сигнала, либо в уничтожении процесса; в данном случае минимизируется риск нарушения системы безопасности. Ввиду того, что эта функция разветвляется из процесса, который ее активизирует (как описывалось ранее), не будет никакой разницы, если в этом месте оригинальный процесс изменит свои установленные дескрипторы сигналов.
24405: Закрытие всех файлов, которые могли быть открыты вызываемым процессом. Самое важное — это то, что программа modprobe не будет наследовать у вызываемого процесса ни стандартного ввода, ни стандартного вывода, ни стандартного потока ошибок, что потенциально может оказаться прорехой в системе защиты. (Проблема может быть решена в программе, которая придет на замену modprobe.)
24413: Программа modprobe запускается как привелигированный процесс, со всеми вытекающими из этого последствиями. Следует отметить, что этот привелигированный процесс, как и во множестве других мест в ядре, получает идентификатор пользователя всегда равный 0. Пользовательские идентификаторы, а также разрешительная система рассматриваются в главе 7.
24421: Попытка запуска программы modprobe. В случае неудачного завершения этой попытки ядро выдает сообщение об ошибке (при помощи printk) и возвращает код ошибки. Это одно из тех мест, где может возникнуть переполнение буфера printk — поскольку длина module_name не задается, все, что можно сказать, глядя на вызов, так это то, что длина может составлять миллионы символов. Дабы иметь уверенность в невозможности переполнения буфера, стоит пройтись по всем вызовам printk (в данном случае по вызовам request_module) и убедиться, что все они работают с достаточно короткими именами модулей, т.е. проблем с printk возникать не должно.
24427: Если execve выполняется удачно, возврата из нее не происходит, а это значит, что данная точка не достигается. Однако, компилятору это неизвестно, потому присутствующий оператор return служит только для gcc.
Более глубокое исследование системы модулей ядра выходит далеко за пределы этой главы и частично рассматривается в главах 4 и 5. Дополнительно исследуются два файла — include/linux/module.h (начинается со строки 15529) и kernel/module.c (начинается со строки 24476). В частности обратите внимание на struct module (строка 15581), а также на функции sys_create_module (строка 24586), sys_init_module (строка 24637), sys_delete_module (строка 24860) и sys_query_module (строка 25148). Эти функции реализуют системные вызовы, которые использует modprobe, плюс связанные программы insmod, lsmod и rmmod для установки, поиска и удаления модулей.
Может вызвать удивление тот факт, что ядро активизирует программу, которая просто делает вызовы того же ядра. Однако при этом выполняется дополнительная работа. С одной стороны, программа modprobe выполняет поиск на диске необходимых файлов модуля, которые должны быть загружены. Кроме того, и это более важно, привелигированный пользователь (root) получает больший контроль над системой модулей ядра, поскольку такой пользователь может запускать modprobe и связанные с нею программы. Следовательно, привелигированный пользователь имеет возможность вручную загружать, запрашивать и удалять модули, либо это может делать само ядро в автоматическом режиме.
Конфигурирование и компиляция ядра
Исходный код ядра Linux можно изучать и без того, чтобы непосредственно работать с ним, однако большую пользу можно извлечь, лишь предпринимая попытки вносить какие-то изменения, дополнения и т.п. Для этого потребуется научиться полностью пересобирать ядро. Ниже будет показано, как это делать, а также как распространить внесенные вами изменения всем, кто может ими заинтересоваться.
Конфигурирование ядра
Первый шаг при компиляции ядра связан с его конфигурированием. Именно здесь добавляются или убираются некоторые функциональные возможности ядра. Кроме того, на этом этапе можно изменять поведение определенных частей ядра, например, заставить ядро использовать другой канал DMA для звуковой карты. Если ядро уже сконфигурировано, данный шаг можно пропустить.
Для конфигурирования ядра необходимо быть привелигированным пользователем (root). Перейдите в каталог с исходным кодом ядра:
cd /usr/src/linux
Введите одну из следующих команд:
make config
make menuconfig
make xconfig
Приведенные выше команды позволяют конфигурировать ядро тремя различными способами:
make config — простейший и наименее приятный из упомянутых трех методов. Однако данный метод работает при любых условиях. Метод просто запрашивает вас обо всех функциональных возможностях ядра, которые необходимо подключить. На большинство вопросов необходимо отвечать y (компилировать данную возможность непосредственно в ядро), m (компилировать в виде модуля) или n (вообще отключить данную возможность). Хорошенько обдумайте каждый ответ, поскольку возможности отката назад не предусмотрено. В случае ошибочного ответа придется нажать Ctrl+C и начать все с начала. Для получения справочной информации можно нажимать символ вопросительного знака (?). На рис. 2.1 показан этот метод в действии.
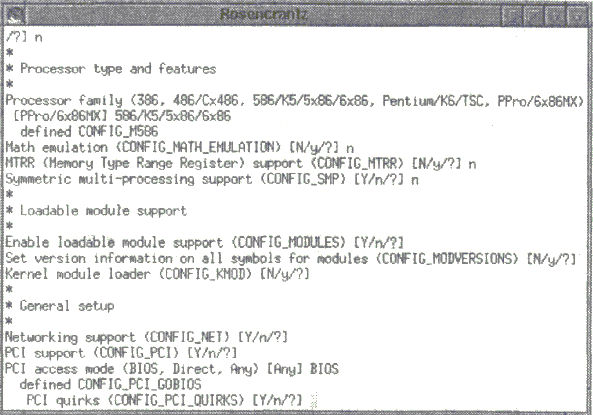
Рис. 2.1. make config в действии
К счастью, данный метод все же обладает некоторой долей интеллекта, например, в случае отказа от поддержки SCSI другие вопросы, связанные со SCSI, задаваться не будут. Нажатие просто на Enter приводит к выбору ответа по умолчанию. Следует заметить, что предпочтение обычно отдается одному из двух оставшихся методов. make menuconfig — механизм конфигурирования, реализованный в виде терминальной программы. Выбор осуществляется при помощи клавиш управления курсором (см. рис. 2.2). Для использования этого метода потребуется библиотека ncurses.
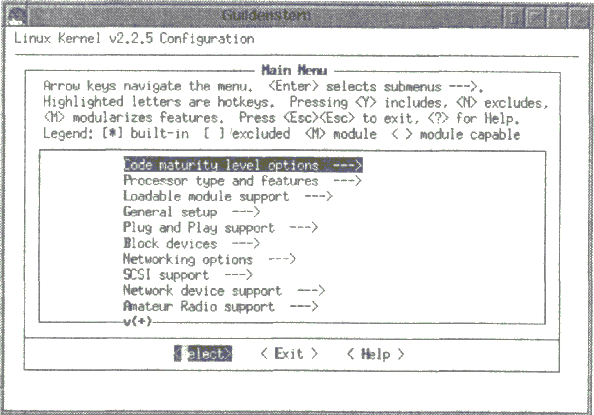
Рис. 2.2. make menuconfig в действии
make xconfig — наиболее предпочтительный метод. Функционирует только если выполняется под управлением сервера X и если вы готовы запускать X-приложения как привелигированный пользователь. (Да здравствует паранойя!) Кроме того, потребуется командный процессор Tcl. Взамен получается удобный эквивалент menuconfig, но с X-интерфейсом. На рис. 2.3 показан метод в действии.
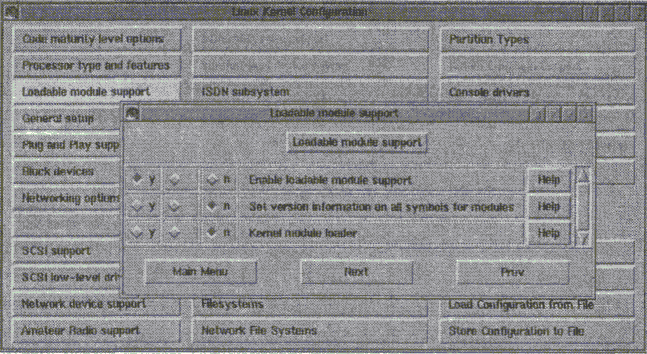
Рис. 2.3. make xconfig в действии
Как уже упоминалось, все три метода приводят к одному и тому же эффекту: они записывают файл .config, который используется при сборке ядра. Отличия состоят только в удобстве выбора тех или иных параметров.
Сборка ядра
Сборка ядра требует меньшей работы, нежели его конфигурирование. Существует несколько методов сборки и выбор конкретного из них зависит от того, каким образом требуется устанавливать систему. Ниже приводятся рекомендованные шаги. Перейдите в каталог с исходным кодом ядра, если это еще не было сделано:
cd /usr/src/linux
Выступая в качестве привелигированного пользователя, выполните сборку ядра, введя команду приведенную ниже.
make dep clean zlilo boot modules modules_install
После завершения make для активизации новой версии ядра потребуется перегрузить систему.
Резервное копирование
Не следует забывать о создании резервных копий ядра перед каждой его модификацией. Один из способов связан с настройкой Linux Loader (LILO), который позволит выбрать образ ядра для загрузки.
Проявив определенное терпение, вместо выходной цели zlilo можно указать zdisk, в результате чего загружаемый образ ядра запишется на дискету. Затем записанную экспериментальную версию ядра можно загрузить с дискеты.
Однако не следует забывать, что на дискету не будут записываться модули ядра — они сохраняются на жестком диске. Следовательно, использование в качестве цели zdisk не спасет, если потеряются модули ядра. В действительности этот недостаток присущ обеим методам. Несмотря на существование ряда более элегантных решений, простейший способ избежать упомянутой проблемы заключается в построении монолитного ядра без каких бы то ни было модулей.
Поскольку вносимые изменения могут привести к разрушению системы (порче данных на диске и т.п.), перед тестированием нового ядра неплохо было бы создать резервную копию системных данных. Если вы — потенциальный взломщик ядра, ближайшим удачным приобретением должен стать стример с изрядным набором лент.
Распространение изменений
Рассмотрим правила хорошего тона во время распространения внесенных изменений:
- Проверьте, не решена ли аналогичная проблема в последней версии ядра.
- Соблюдайте стиль кодирования ядра Linux. Если коротко, следует использовать 8-символьные отступы и скобки в стиле Кернигана и Ритчи (K&R), когда открывающая скобка должна находиться в той же строке, что и оператор if, else, for, while, switch и do. В каталоге с исходным кодом ядра имеется файл Documentation/CodingStyle, который подробно описывает необходимые шаги; здесь упоминаются лишь наиболее важные из них.
- Распространяйте не связанные друг с другом изменения независимо. В этом случае у пользователей появится возможность выбора.
- Предоставьте пользователям возможность узнать, что они могут ожидать от ваших изменений. Точно также необходимо продемонстрировать и уровень доверия к изменениям. Может, вы потратили на свой код несколько минут и даже не успели его как следует протестировать? А может быть, ваш код устойчиво работает и приносит несомненную пользу на протяжении длительного времени?
Как только появляется уверенность в необходимости распространения изменений, первым шагом будет подготовка файла с описанием ваших изменений. Такой файл генерируется автоматически при помощи программы diff. На выходе получается то, на что ссылаются как на diffs или, более распространенно, на patch (патч).
Процедура предельно проста. Пусть, например, оригинальная версия исходного кода находится в каталоге linux-2.2.5, а измененный код — в каталоге linux-my. Тогда потребуется ввести следующие команды (ln следует запускать только, если ссылка еще не существует):
ln -s linux-my linux
make -C linux-2.2.5 distclean
make -C linux distclean
diff -urN linux-2.2.5 linux >my.patch
Результирующий файл my.patch содержит все, что необходимо для пользователя, который пожелает применить патч. (Предупреждение. Все отличия между двумя версиями исходного кода будут отражаться в патч-файле. diff не показывает, каким образом внесенные изменения связаны друг с другом, поэтому применять изменения можно только все вместе.) Если размер результирующего патча оказывается небольшим, его можно отправить в конференцию, посвященную ядру. Если же размер патча значителен, сделайте его доступным через FTP, либо отправьте в конференцию соответствующую ссылку.
Файл с часто задаваемыми вопросами (FAQ) по использованию конференции, связанной с ядром, находится по адресу http://www.ececs.uc.edu/~rreilova/linux/lkml-faq.html.
Кстати, если есть желание постоянно быть в курсе всего, что связано с текущей разработкой ядра, настоятельно рекомендую периодически посещать исключительно полезный сайт http://www.kt.opensrc.org.
Глава 3. Обзор архитектуры ядра
В главе предлагается высокоуровневое исследование архитектуры ядра. В начале упоминаются цели, используемые при проектировании, рассматривается архитектура ядра, а в заключение приводится структура каталога с исходным кодом ядра.
Цели проектирования
Ядро демонстрирует множество целей проектирования, тесно переплетенных друг с другом: ясность, совместимость, переносимость, живучесть, безопасность и быстродействие. Иногда эти цели дополняют друг друга, а иногда и конфликтуют. Однако, до тех пор, пока это возможно, они применяются совместно, поэтому все характерные особенности проектирования и реализации ядра можно свести к упомянутым целям. В оставшейся части раздела рассматривается каждая из перечисленных выше целей вместе с исследованием соответствующих компромиссов между ними.
Ясность
Цель ядра должна быть настолько ясной, насколько это возможно в рамках существующих ограничений, накладываемых максимально достижимыми быстродействием и живучестью. Это резко контрастирует с большинством процессов проектирования современных приложений, цель которых связана с достижением максимальных показателей быстродействия и живучести за счет ясности. Таким образом, в ядре отношение важности быстродействия и ясности инвертировано.
До известной степени ясность дополняет живучесть: реализация, которая более просто и ясно понимается, может быть более просто доведена до корректного функционирования; та же реализация более просто отлаживается, если она работает некорректно. Поэтому упомянутые две цели конфликтуют достаточно редко. Часто конфликтуют как раз ясность и быстродействие. Трудно оптимизируемый алгоритм, который зачастую требует для своего совершенствования определенных знаний технологии генерации кода, заложенной в компиляторе, очень редко удается ясно и понятно реализовать. Если в ядре начинают конфликтовать ясность и быстродействие, предпочтение всегда отдается именно быстродействию. Тем не менее, разработчики все же не забывают о ясности, выполняя немалую работу по нахождению таких способов реализации, которые обеспечивают максимально возможное быстродействие и в то же время остаются ясными и простыми в понимании.
Совместимость
Как утверждалось в главе 1, ядро Linux написано с целью формирования функционально-полной совместимой с Unix ОС. Во время разработки наметилась также цель соответствия POSIX-стандарту. На самом деле нет существенной разницы между совместимостью с Unix (по крайней, мере для новейших версий Unix) и соответствием POSIX-стандарту.
Ядро предлагает другую разновидность совместимости. Система, основанная на Linux, обеспечивает дополнительную поддержку выполнения файлов классов Java (.class-файлов), как если бы это были обычные исполняемые модули. (Действительно, Linux стал первой операционной системой, предлагающей подобную поддержку.) Несмотря на то что собственно интерпретация исполняемых модулей Java находится в компетенции отдельного процесса — виртуальной машины Java (Java Virtual Machine), не входящей в состав ядра, — в ядре реализован механизм, который делает такую поддержку прозрачной для пользователей. Аналогичным способом можно подключить поддержку и других исполняемых форматов, возлагая выполнение определенного объема работы на собственно ядро (альтернатива ситуации с Java, когда большая часть работы реализуется внешним процессом). Дополнительные рассуждения, относящиеся к этой теме, можно найти в главе 7.
Уходя немного в сторону, следует отметить, что система GNU/Linux в целом поддерживает исполняемые модули DOS через эмулятор DOSEMU, а некоторые исполняемые модули Windows — через проект WINE. Аналогичным способом совместимые с Windows файлы и службы печати поддерживаются в SAMBA. Однако все это не имеет отношения к тематике ядра, потому в книге не рассматривается.
Еще один аспект совместимости связан со взаимодействием со внешними («чужеродными») файловыми системами. В Linux реализована поддержка достаточно большого спектра файловых систем: ext2 (встроенная, или «родная», файловая система), ISO-9660 (используемая CD-ROM), MS-DOS, Network File System (NFS) и т.д. Если вы столкнулись с диском в формате другой ОС или с файловым сервером, Linux с большой вероятностью сможет прочитать их.
Следующий аспект совместимости — это сетевая обработка, приобретающая все большую и большую важность в наши дни, когда Internet внедряется во все аспекты повседневной жизни. Будучи разновидностью Unix, Linux обладает естественной поддержкой TCP/IP практически с первых дней его разработки. Кроме того, в ядре присутствует: код для протокола AppleTalk, который позволяет компьютеру с установленным Linux взаимодействовать с сетью компьютеров Масintosh; семейство протоколов Novell, в числе которых Internetwork Packet Exchange (IPX), Sequenced Packet Exchange (SPX) и NetWare Core Protocol (NCP); новая версия протокола IP, имеющая название IPv6, и великое множество других, менее известных протоколов.
Последний аспект имеет отношение к совместимости с аппаратными средствами. Кажется, почти для всех загадочных видеокарт, «полуподпольных» сетевых адаптеров, нестандартных устройств чтения CD-ROM и запатентованных накопителей на магнитной ленте где-то, в каком-то месте, но все-таки можно отыскать Linux-драйвер. (Исключением из этого правила могут быть только устройства, преднамеренно спроектированные под совершенно конкретную ОС.) Поддержка аппаратных средств, заложенная в ядро, становится только лучше по мере того, как все большее число производителей понимают выгоду открытого исходного кода и создают соответствующие Linux-драйвера для своей продукции.
Все упомянутые аспекты совместимости достигаются за счет реализации одной промежуточной цели — модульности. Везде, где только возможно, ядро определяет для своих подсистем абстрактные интерфейсы, которые могут быть реализованы любыми способами. Например, поддержка новой файловой системы в ядре сводится к написанию новой реализации интерфейса виртуальной файловой системы (Virtual File System, VFS). Еще один пример связан с абстрактной поддержкой ядром двоичных обработчиков, обеспечивающих распознавание новых исполняемых форматов, к которым принадлежат и Java-классы (см. главу 7). Добавление распознания нового формата исполняемого файла — суть реализация интерфейса двоичного обработчика для этого формата.
Переносимость
Цель проектирования, в определенной степени имеющая отношение к совместимости с аппаратными средствами, — это переносимость, т.е. возможность выполнения Linux на различных аппаратных платформах. Первоначально Linux разрабатывался для семейства процессоров Intel х86, в стандартной версии для IBM PC-совместимых компьютеров. Никаких мыслей по поводу переносимости тогда не возникало. Однако с тех пор все изменилось. В настоящий момент официальные версии Linux выпускаются систем на базе процессоров Alpha, ARM, Motorola 680x0, MIPS, PowerPC, SPARC и SPARC-64. Именно поэтому Linux можно запускать на компьютерах Amiga, старых и новых моделях Масintosh, рабочих станциях от Sun и SGI, компьютерах NeXT и на множестве других моделей. Все перечисленные модификации создаются на основе дистрибутива стандартного ядра. Кроме того, выполняются работы по переносу Linux на дополнительные платформы — от старых моделей DEC VAX до новейших карманных компьютеров серии Palm от 3Com (например, Palm III). Успешно завершенные разработки, как правило, позже становятся официальными, так что некоторые из них попадают в главную ветвь разработки.
Поддержка широкого спектра платформ становится возможной частично благодаря четкому разделению исходного кода ядра на архитектурно-зависимые и архитектурно-независимые части. Ниже этот вопрос рассматривается более подробно.
Живучесть и безопасность
Linux намеренно сделан живучим и защищенным. Он никогда не будет иметь свои собственные ошибки, кроме того, он должен защищать процессы (и пользователей) друг от друга, равно как защищать себя в целом от других систем. Последнее утверждение относится в большей степени к области приложений с доверительными отношениями, однако ядро должно обеспечивать, по крайней мере, набор примитивов, на которых основывается безопасность. В общем случае, живучести и безопасности отдают большее предпочтение, чем чему бы то ни было, включая и быстродействию. (Что хорошего в том, что система сбойнет быстро?)
Живучесть и безопасность Linux гарантирует один наиболее важный фактор — открытый процесс разработки системы, который можно рассматривать как массивный просмотр «на равных». Каждая строка кода, каждое изменение за считанные минуты исследуется огромным числом разработчиков по всему миру. Часть из них специализируется на выявлении затаившихся ошибок, и в их же собственных интересах отловить все ошибки, поскольку они желают видеть свои Linux-системы как живучими, так и устойчивыми. Ошибки, не выявленные таким входным тестированием, могут быть локализованы и исправлены теми, кто их найдет, после чего исправления присоединяются к главной ветви проектирования и становятся доступны всем. Большинство нарушений безопасности исправляются в течение считанных дней, а то и часов.
Может быть, Linux и не самая безопасная из всех доступных ОС (многие считают таковой OpenBSD, одна из вариаций Unix, где во главу угла поставлена как раз безопасность), однако Linux — серьезный претендент на это. Что касается живучести, то Linux здесь — несомненный лидер.
Быстродействие
В основном, цель говорит сама за себя. Быстродействие является почти наиболее важным критерием, хотя и уступает живучести, безопасности, а иногда и совместимости. Кроме того, быстродействие — один из самых осязаемых критериев кода. Код ядра Linux основательно оптимизирован, причем один из наиболее часто используемых элементов — планировщик — оптимизирован в максимальной степени. Едва ли не каждый фрагмент кода выглядит загадочно, и это связано с тем, что его старались сделать максимально быстродействующим (хотя это не всегда очевидно). Иногда встречается и более прямолинейная реализация, которая также отличается высокой скоростью выполнения, хотя для подсчета подобного рода фрагментов хватило бы пальцев на одной руке.
В некоторых случаях в книге для определенных фрагментов кода, заведомо искаженных во имя быстродействия, рекомендуются более читабельные альтернативы.
Первый взгляд на архитектуру ядра
На рис. 3.1 показано стандартное представление Unix-подобной ОС, со всеми низкоуровневыми деталями, какие только могут понадобиться для платформенно-независимой ОС. Стоит подчеркнуть две характерные особенности ядра:
- Ядро отделяет прикладные приложения от аппаратных средств.
- Часть ядра учитывает специфику архитектуры и аппаратуры, другая же часть ядра является переносимой.
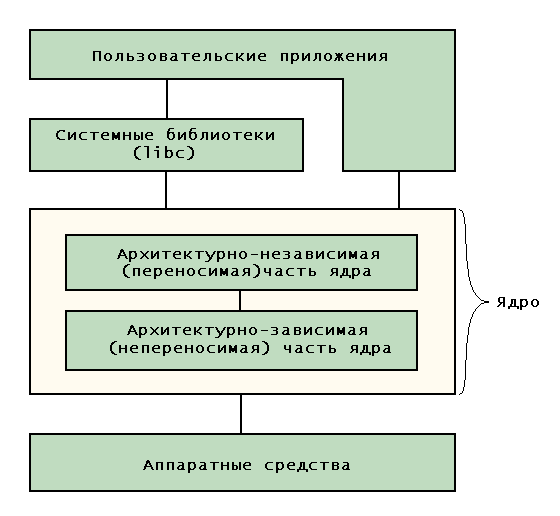
Рис. 3.1. Первый взгляд на архитектуру ядра
Первая особенность обсуждалась в предыдущих главах, поэтому повторять ее нет необходимости. Сейчас более интересной является вторая особенность, связанная с зависимым и независимым от архитектуры кодом. Ядро достигает переносимости, частично за счет применения по отношению к себе тех же самых трюков, что и по отношению к пользовательским приложениям. Это означает, что подобно тому как ядро отделяет пользовательские приложения от аппаратных средств, определенная часть ядра обеспечивает отделение оставшейся части ядра от той же аппаратуры. Благодаря такому разделению, и приложения, и часть ядра, становятся переносимыми.
Хотя это и не всегда очевидно в коде, независимая от архитектуры часть кода в общем случае определяет (или предполагает) интерфейс для низкоуровневой, зависящей от архитектуры части. Например, архитектурно-зависимые части кода управления памятью предполагают, что за счет включения определенного файла заголовков они, помимо прочего, получат подходящее определение макроса PAGE_SIZE (см. строку 10791), задающего размеры кусков, на которые аппаратура управления памятью будет разбивать пространство адресов (см. главу 8). Независимый от архитектуры код совершенно не заботится о точном определении макроса, оставляя это в ведении архитектурно-зависимого кода. (Кстати, это более изящно и понятно, чем присутствие блоков #ifdef/#endif везде, где должен реализовываться код под конкретную платформу.)
Таким образом, перенос ядра на новую платформу сводится к идентификации возможностей, наподобие рассмотренных выше, и реализации их, как того требует новая платформа.
Кстати, переносимость пользовательских приложений получает дальнейшую поддержку посредством слоя между приложениями и ядром — стандартной библиотекой С (libc). Приложения никогда не взаимодействуют с ядром напрямую, а только через libc. Единственная причина, по которой на рис. 3.1 показано непосредственное взаимодействие приложений с ядром, связано с тем, что это возможно. Реально приложения этого не делают. Все, что они могут делать за счет прямого обращения к ядру, они делают через libc, причем более просто.
Способ взаимодействия с ядром через libc является независимым от архитектуры, причем libc предохраняет пользовательский код от излишней детализации. Самое интересное, что большая часть libc также не использует упомянутую детализацию. Значительная часть libc, наподобие функций atoi и rand, вообще не взаимодействует с ядром. Оставшаяся часть libc, т.е. такие функции, как printf, выполняет существенный объем работы до и/или после взаимодействия с ядром. (printf сначала должна выполнить интерпретацию строки формата, выделить параметры, выяснить, как требуется их печатать, и вывести их во временный внутренний буфер. Только затем, для печати этого буфера, производится вызов системной функции write.) Еще одни фрагменты libc отделяются от системных вызовов весьма тонкими слоями, в связи с чем обращение к одной из таких функций транслируется непосредственно в вызов ядра, которое и выполняет большинство требуемой работы. На самом низком уровне практически вся libc направляется к ядру через своего рода «канал» с использованием механизма, описанного в главе 5.
По причине существования вышеупомянутого механизма, все пользовательские приложения, и даже большая часть библиотеки С, взаимодействуют с ядром способом, не зависящим от архитектуры.
Более пристальный взгляд на архитектуру ядра
Рис. 3.2 демонстрирует еще один концептуальный взгляд на ядро. Во главу угла здесь ставится не деление на зависящую и не зависящую от архитектуры части, но другие, более информативные вещи. В прямоугольнике «Ядро» показаны части ядра, которые рассматриваются в книге, вместе с номерами глав, где их можно найти. Поддержка симметричных мультипроцессорных систем (SMP) в книге рассматривается, однако на рисунке не присутствует частично потому, что большинство кода поддержки SMP распространяется вне ядра. Точно также поддержка инициализации ядра в книге рассматривается, а на рисунке не показана просто потому, что не представляет особого интереса с точки зрения проектирования.
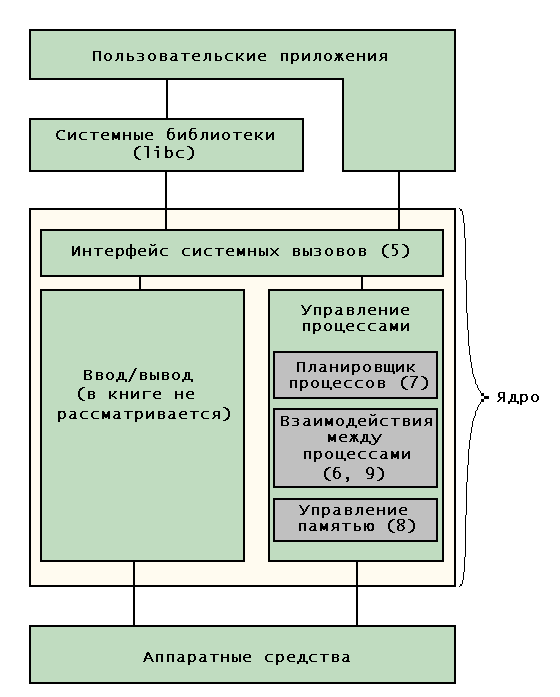
Рис. 3.2. Подробное представление архитектуры ядра
Взаимодействие процесса с ядром обычно выполняется так:
- Пользовательское приложение инициирует системный вызов, как привило, через libc.
- Этот вызов отлавливается функцией ядра system_call (строка 171, глава 5), которая пересылает запрос другой функции, отвечающей за его выполнение.
- Функция, отвечающая за выполнение запроса, затем взаимодействует с соответствующими внутренними модулями кода, которые, в свою очередь, взаимодействуют с другими модулями кода и/или требуемой аппаратурой.
- Результаты возвращаются обратно по тому же пути.
Однако, не все взаимодействия с ядром инициируются процессами. Иногда ядро самостоятельно принимает решение взаимодействовать с процессом, например, когда необходимо приостановить выполнение одного процесса для того, чтобы предоставить шанс запуститься другому процессу, либо когда требуется доставить сигнал процессу, либо когда требует уничтожить процесс по причине использования им всего позволенного времени ЦП. Взаимодействия подобного рода на рисунке не показаны, поскольку в общем случае они сводятся к модификации ядром своих внутренних структур данных (исключением из этого правила будет лишь доставка сигнала процессу).
Так что же, ядро многослойное, модульное, или какое?
Все методы минимизации сложности основываются на одном принципе: разделяй и властвуй. Таким образом, все они являются вариациями на тему разбиения большой и сложной в решении проблемы (или системы) на некоторое количество менее сложных подпроблем (или подсистем) до тех пор, пока результаты разбиения не станут столь просты, что их можно будет решить.
Рассмотрим три классических метода построения больших систем, принятые в компьютерной инженерии:
Слои (уровни). Декомпозиция решения на такие части, каждая из которых решает более низкий уровень проблемы, служит основой для более высокого уровня и способна работать на более высоком уровне абстракции. Наиболее известными и удачными примерами многослойного (многоуровневого) проектирования программного обеспечения следует считать OSI и стек протоколов TCP/IP. Подход с разбиением на слои к проектированию ОС может включать уровень, напрямую взаимодействующий с аппаратными средствами, и уровень абстракции аппаратных средств; в результате более высокие уровни могут взаимодействовать с дисковыми устройствами, сетевыми картами и т.п. без необходимости учета деталей функционирования каждого устройства.
Одна из характеристик, связанных с многослойным проектированием, заключается в том, что в процессе проектирования строится словарь со все увеличивающейся степенью детализации по мере поднятия на более высокие слои. Еще одна характеристика состоит в том, что можно прозрачно передать информацию с одного слоя на слои, находящиеся выше или ниже. В лучшем случае перенос многослойной ОС на другую платформу потребует переписывания только одного самого нижнего слоя. Чистая многослойная реализация может оказаться медленной, поскольку верхние слои должны выполнять свою работу непрямо, но через последовательность слоев, находящихся ниже, т.е. слой N взаимодействует со слоем N–1, который, в свою очередь, взаимодействует со слоем N–2, и т.д. до тех пор, пока не выполнится реальная работа на слое 0. Естественно, что результаты должны подняться по слоям до того слоя, на котором они необходимы. Следовательно, многие системы такого рода имеют возможности непосредственного взаимодействия между несмежными слоями, что увеличивает их быстродействие, но усложняет передачу информации, поскольку теперь от одного слоя, на который передается информация, могут зависеть несколько слоев, расположенных выше. Модули. Модуль скрывает некоторую хорошо определенную порцию функциональности за абстрактным интерфейсом. Одно из основных предназначений модулей — отделять интерфейс от реализации, что дает возможность изменять реализацию одного модуля без влияния на остальные модули, которые с ним взаимодействуют через его интерфейс. Контекст модуля отражает концептуальные границы определенного аспекта области решений. Чистой модульная ОС может иметь модуль для дисковой подсистемы, модуль для подсистемы управления памятью и т.д. Основное отличие чистой модульной от чистой многослойной системы заключается в том, что отдельный модуль может свободно использоваться любым другим модулем — здесь не существует понятия модуля, находящегося «выше» или «ниже». (В этом смысле модули являются обобщением слоев — слой подобен модулю, который может использоваться, как максимум, одним модулем, находящимся непосредственно над ним.) Объекты. Объекты отличаются от модулей, поскольку, во-первых, заключают в себе другой способ мышления и могут иметь независимое поведение. Однако для наших целей достаточно представлять объект как нечто, ненамного большее, чем структурированный способ использования модуля. Компоненты, очередное усовершенствование идеи объектов, ничего выдающегося в проектирование ОС пока еще не внесли. С нашей точки зрения они не настолько сильно отличаются от модулей, чтобы выносить их в отдельную категорию.
Рис. 3.1 демонстрирует ядро с точки зрения многослойного подхода, где заметны слой, зависящий от архитектуры, и над ним — слой, от архитектуры не зависящий. (Строго говоря, должен существовать еще один архитектурно-зависимый слой на верхушке, поскольку интерфейс системных вызовов находится между приложениями и ядром, а он-то как раз зависит от архитектуры.) В свою очередь, на рис. 3.2 продемонстрирован модульный подход к ядру.
Если рассуждать с точки зрения правильности, то оба представления совершенно правильны. Либо же оба неверны. Я мог бы целыми днями рисовать рисунки, пытаясь убедить кого-то, что ядро следует тем, а не иным правилам; это было бы возможно потому, что в ядре заложено множество идей. Истина, однако, состоит в том, что ядро Linux ни строго многослойное, ни строго модульное, однако строго прагматично. (Действительно, если и существует одно слово, которым можно охарактеризовать всю систему Linux от проектирования до реализации, то это слово «прагматизм».) Возможно, наиболее безопасной точкой зрения будет считать реализацию ядра модульной, хотя иногда модули преднамеренно пересекают границы модулей во имя достижения большего быстродействия.
Таким образом, процесс проектирования Linux отражает и теорию, и прагматизм. Linux вовсе не игнорирует методологии проектирования; в философии, положенной в основу проектирования Linux, методологии проектирования подобны компиляторам — инструментам для выполнения определенной работы. Выбор того или иного принципа проектирования (например, объектов) и всеобъемлющее, без каких бы то ни было исключений, его применение может послужить хорошим способом проверки границ применимости принципа или источником для построения обучающей системы для конкретной методологии. Однако это ошибочный путь построения ядра, которое бы удовлетворяло целям проектирования Linux, к тому же цели проектирования Linux не содержат в себе ничего «чистого». На пути достижения этих целей разработчики Linux, как правило, нарушаю принципы проектирования.
Действительно, что правильно для Linux, то правильно и для многих успешно завершенных систем. Большинство широко используемых, не «игрушечных» систем по сути своей прагматичны. Некоторые разработчики пытаются отыскать некую волшебную палочку, принципы проектирования или методологию, которые служили бы лекарством от всех бед. И вдруг они оказываются между молотом и наковальней. Успешно завершенные проекты, среди которых и ядро Linux, в общем случае зиждятся на применении множества методологий для различных частей системы или на различных уровнях описания. Результат может не быть чистым и понятным, однако полученный гибрид оказывается устойчивей и качественней эквивалентов, создаваемых в рамках чистых методологий.
Ядро Linux — в основном монолитное
Ядро операционной системы может быть либо микроядром, либо монолитным ядром (на последнее часто ссылаются как на макроядро). В сокращенном виде эти термины определяются следующим образом:
Микроядро. В микроядре большая часть функциональности ядра реализована в виде отдельных процессов, которые выполняются в привилегированном режиме и взаимодействуют друг с другом посредством сообщений. Как правило, проект предполагает наличие одного процесса для одного концептуального модуля; поэтому в случае, например, если проект имеет модуль системных вызовов, это значит, что имеется соответствующий процесс, который воспринимает запросы на системные вызовы и взаимодействует с другими процессами (модулями), выполняющими собственно реализацию системных вызовов.
При таком подходе микроядро представляет собой нечто большее, нежели концентратор сообщений: когда модуль системных вызовов желает отправить сообщение модулю файловой системы, это сообщение передается через микроядро. При этом достигается высокая степень изоляции модулей друг от друга. (Правда, иногда модули передают сообщения друг другу напрямую.) В некоторых проектах в микроядро погружается дополнительная функциональность, такая как ввод/вывод. Однако, базовая идея состоит в том, чтобы сохранять микроядро настолько малым, насколько возможно, поэтому перенос ядра в целом на другую платформу сводится к переносу только микроядра — другие модули зависят только друг от друга и от микроядра, но не от аппаратных средств.
Одно из преимуществ микроядра связано с простотой замены, скажем, модуля файловой системы на более эффективную его версию, причем замена эта никак не скажется на функционировании остальной части системы. Возможно даже разработать новые системные модули (или модифицировать существующие) и добавлять их «на лету», во время выполнения системы. Другое преимущество заключается в более эффективном использовании памяти за счет того, что модули, в которых нет необходимости, попросту не загружаются. Монолитные ядра. Монолитное ядро — это один большой процесс. Внутренне он может разделяться на модули (или слои, или как-то еще), однако на этапе выполнения это один большой двоичный образ. Вместо отправки сообщений внутренние модули взаимодействуют друг с другом за счет обычных вызовов функций.
Сторонники монолитного ядра ссылаются на его большую эффективность по сравнению с микроядром, поскольку у последнего имеют место накладные расходы, связанные с передачей сообщений. Сторонники микроядра утверждают, что высокая гибкость и возможность сопровождения, присущие микроядру, экономят время выполнения соответствующих работ, поэтому в целом эффективность обоих видов ядер оказывается практически одинаковой.
Не хочу во все это встревать, замечу только, что сей спор сильно напоминает несколько забытую дискуссию сторонников и противников процессоров с сокращенным (RISC) и полным (CISC) набором команд. В современных процессорах тесно переплетаются обе технологии, точно так же как в ядре Linux воплощены обе идеи — монолитного и микроядра. В основном ядро Linux — монолитное, однако оно не является чистым монолитным ядром. Система модулей ядра, рассмотренная в предыдущей главе, — это способ получения некоторых преимуществ подхода с микроядром. (Кстати, на мой взгляд, интересная ситуация возникла бы, если реализовать систему модулей ядра Linux в виде микроядра, которое просто не передает сообщений. Конечно, я с этим не могу согласиться, но мысль интересная...)
Почему Linux в основном монолитный? Одна из причин чисто историческая: по мнению Линуса, ядро Linux окажется гораздо проще установить и запустить, если оно будет монолитным. При таком решении не потребуется изобретать архитектуру с передачей сообщений, разрабатывать способы загрузки модулей и т.п. (Система модулей ядра появилась только несколько лет спустя.)
Другая причина связана с огромным запасом времени на разработку. Проект Linux не ограничивал разработчиков ни во времени, ни необходимостью выпуска демонстрационных версий для маркетинговых целей. Единственным ограничением является лишь сложность внесения изменений в ядро. Монолитный проект ядра достаточно модульный внутри, поэтому внесение изменений и дополнений не вызывает особых трудностей. Основной вывод отсюда — нет никакой необходимости переписывать ядро Linux в микроядро ради небольшого, к тому же непроверенного увеличения степени сопровождения. (Линус, в частности, неоднократно повторял, что за выгоды нельзя платить быстродействием.) В дальнейших главах мы еще вернемся к эффекту неограниченного времени разработки применительно к более конкретным ситуациям.
Если бы Linux имел вид микроядра, его было гораздо проще переносить на другие платформы. Действительно некоторые примеры микроядер, такие как Mach, наглядно демонстрируют все достоинства переносимости, присущие такому подходу. Однако, перенос Linux на другие платформы — процесс не тривиальный, но и не устрашающе сложный: типовая процедура переноса на совершенно новую платформу требует приблизительно 30000 – 60000 строк кода плюс еще 20000 строк кода для реализации драйверов. В среднем получается около 50000 строк кода. Это вполне реальная работа для одного программиста (по крайней мере, для небольшой команды программистов) в течение одного года. Может это и больше, нежели хотелось бы делать для переноса, однако сторонники Linux утверждают, что полученные в результате переноса версии гораздо эффективнее используют аппаратные средства по сравнению с микроядром. В конечном итоге, дополнительные затраты на перенос с лихвой окупаются за счет увеличения общей эффективности системы.
Выбор проектирования Linux в виде монолитного ядра не связан с сиюминутным решением, но продиктован обычной мудростью, которая прогнозирует хорошую перспективу архитектурам на основе микроядер, однако в будущем. Однако в настоящее время монолитное ядро очень хорошо зарекомендовало себя в лице Linux — относительная сложность переноса на другие платформы никак не обескураживает сообщество разработчиков, которые уже успешно перенесли ядро на множество реальных платформ, в числе которых и карманные компьютеры Palm. С ростом достоинств Linux будут появляться все новые и новые версии для различных платформ.
Отношения между проектированием и реализацией
Оставшиеся разделы главы посвящены рассмотрению полезных взаимосвязей между проектированием и реализацией ядра. Наиболее важным в этом плане следует считать структуру каталогов исходного кода ядра. Глава завершается краткой оценкой относительных размеров кода в частях, зависящих и не зависящих от архитектуры.
Структура каталогов исходного кода ядра
Исходный код ядра обычно устанавливается в каталог /usr/src/linux. В рамках этого каталога существует множество подкаталогов, в каждом из которых находится исходный код, реализующий то или иное подмножество функциональных возможностей ядра (или, более грубо, каждый подкаталог содержит высокоуровневый модуль кода).
Documentation
В этом подкаталоге находится не код, а множество полезной документации. Однако, ее трудно назвать полноценной. Некоторые части ядра, например, файловые системы, описаны достаточно хорошо и полно, тогда как другие, скажем, планировщих процессов, вообще не задокументированы. Все же несомненную пользу документация приносит.
arch
Подкаталоги, расположенные ниже подкаталога arch, содержат код, специфический для конкретной архитектуры. Каждый подкаталог, ориентированный на некоторую архитектуру, в свою очередь, содержит, по крайней мере, еще три подкаталога: kernel, в котором находится реализация для данной архитектуры таких базовых функций ядра, как обработка сигналов и поддержка SMP; lib, в котором расположена ориентированная на конкретную архитектуру реализация общеиспользуемых функций наподобие strlen и memcpy; и mm, содержащий процедуры манипуляции с памятью, реализованные для данной архитектуры.
В дополнение к упомянутым подкаталогам, многие архитектуры имеют еще и подкаталог boot, в котором находится часть или весь код для загрузки ядра на данной платформе. В противном случае такой код следует искать в подкаталоге kernel.
Наконец, большинство каталогов для конкретных платформ содержат дополнительные подкаталоги с реализацией дополнительной функциональности. Например, каталог i386 включает в себя подкаталог math-emu, в котором находится код эмуляции математического сопроцессора (FPU) на компьютерах, где он отсутствует. Другой пример, каталог m68k имеет подкаталоги для каждого компьютера на базе процессора 680x0.
В рамках каталога arch находятся такие подкаталоги:
arch/alpha/ — ядро Linux для рабочих станций на базе процессора DEC Alpha. arch/arm/ — ядро Linux для процессоров линии ARM, используемых в компьютерах типа Corel's NetWinder и Acorn RiscPC. arch/i386/ — наиболее близкая для Linux, «естественная», или «базовая», платформа на основе архитектуры Intel 80386, в числе которой и процессоры 80486, Pentium и т.п. Она же актуальна и для клонов компаний AMD, Cyrix и IDT.
В книге на эту архитектуру ссылаются как на х86. Более ранние процессоры компании Intel, такие как 80286, не обладают минимально необходимыми возможностями для запуска на них Linux, поэтому официальной поддержки Linux для них не существует. (Следует, однако, заметить, что версия Linux для таких процессоров от независимых разработчиков все же доступна. Она отличается ограниченной функциональностью.) Когда в книге упоминается платформа х86, имеется в виду компьютеры на базе процессоров 80386 и более новых. arch/m68k/ — версия Linux для серии процессоров Motorola 680x0. Поддерживаются компьютеры на базе процессоров от 68020 (укомплектованном устройством управления памятью 68851) до 68060. Серия процессоров 680x0 используется известными компаниями: Amiga Commodore (сейчас Gateway), Apple Macintosh, Atari ST и пр. Многие из устаревших моделей превратились в заслуживающие внимания рабочие станции с Linux. Кроме того, в стадии разработки находятся версии Linux для рабочих станций NeXT и Sun 3. arch/mips/ — версия Linux для процессоров линии MIPS. Наиболее известными компьютерами, которые используют процессоры этой серии, являются рабочие станции Silicon Graphics (SGI). arch/ppc/ — версия Linux для процессоров серии Motorola/IBM PowerPC, куда относятся компьютеры Macintosh и Amiga на базе PowerPC, BeBox, IBM RS/6000 и др. arch/sparc/ — версия Linux для 32-разрядных процессоров SPARC (компьютеры от Sun SPARC 1 до SPARC 20). arch/sparc64/ — версия Linux для 64-разрядных процессоров SPARC. Сюда относятся такие компьютеры от компании Sun, как Ultra 1, Ultra 2 и так далее, вплоть до новейшего Enterprise 10000. В настоящий момент версии Linux для 32- и 64-разрядных процессоров SPARC находятся в состоянии объединения.
Книга специализируется на исследованиях только исходного кода для процессоров х86.
drivers
В этом каталоге находится достаточно большой объем кода — практически половина всего ядра. Каталог содержит программные драйверы для видеокарт, сетевых плат, SCSI-адаптеров, накопителей на магнитных лентах, устройств PCI и другой периферии.
Некоторые подкаталоги, расположенные в каталоге drivers, содержат платформенно-зависимую реализацию, например, в подкаталоге zorro находится код взаимодействия с шиной Zorro. Эта шина используется только в компьютерах Amiga. Другие подкаталоги, скажем, pci, содержат частично независимый от платформы код.
fs
В этом каталоге находятся подкаталоги с реализациями всех файловых систем, поддерживаемых Linux. Файловая система — это код, который является посредником между устройствами хранения и процессами, требующими доступа к этим устройствам.
Файловая система может представлять локальное, физически присоединенное устройство хранения наподобие жесткого диска или CD-ROM; в этих случаях применяются файловые системы ext2 и isofs. С другой стороны, файловая система может представлять устройство хранения, доступ к которому совершается через сеть; это обеспечивает файловая система NFS.
Кроме того, существуют псевдофайловые системы, например, proc, которые представляют определенную информацию (в случае proc — внутренние переменные и структуры данных ядра) в виде файлов; каких-либо устройств хранения не имеется, однако для процессов все выглядит так, как-будто они присутствуют. (Иногда NFS неправильно называют псевдофайловой системой.)
include
В этом каталоге находится большинство включаемых (.h) файлов в дереве исходных кодов Linux. Файлы сгруппированы по каталогам следующим образом:
include/asm-*/ — каждый из множества таких подкаталогов соответствует своему подкаталогу в arch, т.е. include/asm-alpha, include/asm-arm, include/asm-i386 и т.д. Файлы в каждом таком подкаталоге содержат макросы препроцессора и короткие inline-функции для поддержки конкретной архитектуры. Большинство inline-функции, частично или целиком, реализованы на ассемблере.
Во время компиляции ядра символическая ссылка include/asm заменяется на каталог для соответствующей архитектуры. В результате независящий от архитектуры исходный код ядра может делать нечто, подобное следующему:
#include <asm/some-file>
Эта строка приводит к включению файла для соответствующей архитектуры. include/linux/ — в этом каталоге находятся файлы заголовков, которые определяют константы и структуры данных, необходимые для ядра и пользовательских приложений, требующих различные службы ядра. В основном все они не зависят от платформы. Этот каталог целиком копируется (или, чаще всего, присоединяется) в /usr/include/linux, так что пользовательские приложения могут включать соответствующие файлы заголовков и иметь уверенность, что файлы заголовков те же самые, что используются ядром. Пример можно найти в главе 9.
Части упомянутых файлов, необходимые только для ядра, помещаются в оболочку вида:
/* ... Прототипы для пользовательских приложений и ядра ... */
#ifdef __KERNEL__
/* ... Прототипы только для ядра ... */
#endif /* __KERNEL__ */
include/net/ — каталог содержит файлы заголовков для подсистемы сетевой обработки. include/scsi/ — каталог содержит файлы заголовков для SCSI-констроллеров и устройств. include/video/ — каталог содержит файлы заголовков для видеокарт и буферов кадров.
init
Наиболее важным в каталоге является файл main.с, который содержит львиную часть кода, необходимого для управления процессом инициализации ядра. Детальное рассмотрение кода приводится в главе 4.
ipc
Файлы из этого каталога реализуют межпроцессные взаимодействия (IPC) System V. Детальное рассмотрение кода приводится в главе 9.
kernel
Каталог содержит наиболее внутреннее ядро Linux — платформенно-независимую базовую функциональность. Сюда входят такие части, как планировщик процессов (kernel/sched.c) и код создания/уничтожения процессов (см. главу 7). Не хочу создавать впечатление, что все необходимое находится именно в этом каталоге, — остальные критически важные части кода располагаются в других каталогах. Однако, как не крути, наиболее важный код находится здесь.
lib
Каталог lib содержит две порции кода. Функции из lib/inflate.с занимаются распаковкой сжатого ядра во время загрузки системы (см. главу 4). Остальные файлы в каталоге реализуют полезное подмножество стандартной библиотеки С. Основной акцент ставится на функции работы со строками и памятью (strlen, memcpy и т.п.), а также на sprintf, atoi и им подобные.
Все файлы в каталоге написаны на С, а это значит, что их можно без каких-либо изменений использовать при переносе ядра на новые платформы. Однако, как упоминалось ранее, иногда при переносе разрабатывают собственные, более быстрые версии этих функций, используя для этого ассемблер.
mm
Здесь находится независящий от архитектуры код управления памятью. Как уже говорилось, специфические для каждой архитектуры процедуры управления памятью, которые реализуют низкоуровневые примитивы для соответствующей платформы, расположены в каталоге arch/platform/mm. Большая часть платформенно-независимого и специфического для х86 кода управления памятью обсуждается в главе 8.
net
Каталог содержит код, реализующий поддержку сетевых протоколов, доступных в Linux, среди которых AppleTalk, TCP/IP, IPX и т.д.
scripts
Этот каталог не содержит кода ядра, но содержит скрипты (сценарии), используемые для конфигурирования ядра. Взаимодействие с ними начинается тогда, когда вы запускаете команды наподобие make menuconfig или make xconfig.
Зависящий и независящий от архитектуры код
Сейчас мы находимся в том месте, где появляется возможность оценить относительные размеры зависящей и независящей от архитектуры частей кода. Ядро 2.2.5 занимает 1725645 строк кода. Из них 392844 строк находятся в каталогах, соответствующих архитектурно-зависимой части, т.е. arch/* и include/asm-*. Я подсчитал, что приблизительно 64000 строк кода уходит на реализацию драйверов для одной архитектуры. В итоге получается, что архитектурно-зависимая часть занимает приблизительно 26% от всего объема кода.
Однако, для одной архитектуры зависящая от нее доля кода оказывается небольшой. Если объем кода, необходимого для поддержки одной архитектуры, составляет около 50000 строк, в то время как объем архитектурно-независимого кода — 1250000 строк, доля архитектурно-зависимого кода не превышает 4%. Разумеется, не весь архитектурно-независимый код используется отдельной версией ядра, поэтому актуальная доля архитектурно-зависимого кода существенно зависит от того, как ядро сконфигурировано. Тем не менее, все же очевидно, что подавляющее большинство кода является архитектурно-независимым.
Глава 4. Инициализация системы
Когда возникает необходимость запустить программу, ее имя вводится в командном процессоре, либо, в случае использования графической среды наподобие GNOME или КDЕ, выполняется щелчок по значку, представляющему программу. Затем ядро загружает программу и запускает ее. Однако, какая-то программа должна вначале загрузить и запустить ядро. Как правило, такой программой является загрузчик ядра, такой как LOADLIN или LILO. Кроме того, кто-то должен загрузить и запустить сам загрузчик ядра — назовем его «загрузчик загрузчика ядра», — а затем для «загрузчика загрузчика ядра» понадобится «загрузчик загрузчика загрузчика ядра» и так далее до бесконечности...
В конце концов, что-то должно завершить эту бесконечную регрессию, и это что-то есть аппаратное обеспечение. Таким образом, на самом низком уровне первый шаг процесса загрузки системы требует помощи от аппаратуры. Как правило, эта аппаратура запускает коротенькую встроенную программу — именно программу, однако ту, которая прошита в постоянном запоминающем устройстве (ПЗУ) и находится по известным адресам, потому-то ей и не нужен загрузчик. Затем маленькая программа запускает что-то более сложное, которое в свою очередь, запускает еще более сложное и емкое, и так до тех пор, пока не будет загружено собственно ядро. Система попросту раскручивает себя, используя собственные «начальные загрузчики», которые являются метафорами термина «загрузка». Детали загрузки существенно зависят от архитектуры системы, однако лежащие в основе принципы везде одни и те же.
Как только описанные выше процессы завершаются и ядро загружается полностью, ядро приступает к инициализации себя и остальной части системы.
В главе объясняется собственно процесс загрузки типового персонального компьютера (ПК) на базе процессора х86, а также рассматриваются вещи, имеющие отношение к загрузке ядра.
Загрузка ПК
В разделе описывается процесс загрузки ПК на базе х86. Цель раздела заключается не в том, чтобы сделать из вас эксперта в области загрузки ПК, но в том, чтобы дать необходимые знания о процессе загрузки в определенной архитектуре применительно к инициализации ядра.
В начале каждый процессор должен себя проинициализировать, после чего запустить программу самотестирования. Ситуация в мультипроцессорных системах оказывается более сложной, однако не намного. В системе с двумя процессорами Pentium один из процессоров всегда ведущий, а второй — ведомый. Ведущий процессор отвечает за всю работу, связанную с загрузкой, а ведомый процессор активизируется позже по запросу от ядра. В мультипроцессорной системе на базе Pentium Pro для выяснения того, какой из процессоров будет заниматься загрузкой системы, все процессоры должны «соперничать за флаг» в соответствии с алгоритмом, разработанным компанией Intel. Победивший загружает систему, а ядро позже активизирует остальные процессоры. Таким образом, за оставшиеся шаги процедуры загрузки будет отвечать только один процессор. Поэтому, с целью упрощения, можно предположить, что в системе установлен только один процессор. Позже в главе будет показано, как ядро активизирует оставшиеся процессоры в системе.
Далее центральный процессор (ЦП) считывает и выполняет команду, находящуюся по адресу 0xfffffff0. Поскольку в большинстве ПК не установлено 4 Гб ОЗУ, как правило этот адрес не попадает на ОЗУ. Аппаратура управления памятью просто ретранслирует его. В тех же компьютерах, где присутствуют все 4 Гб ОЗУ, небольшой объем ОЗУ в верхних адресах не используется, поскольку резервируется BIOS (BIOS резервирует всего 64 Кб — ничтожная потеря памяти для компьютеров, у которых ее целых 4 Гб).
По упомянутому адресу находится оператор перехода на начало базовой системы ввода/вывода (Basic Input/Output System, или BIOS). BIOS встроена в материнскую плату и управляет следующими этапами загрузки. Следует отметить, что ЦП абсолютно не беспокоится о существовании BIOS, что позволяет использовать процессоры Intel в архитектурах, отличных от стандартных ПК, например, во встроенных системах управления. (Фактически, оператор перехода является частью BIOS, но это не самая удачная его характеристика.)
BIOS начинает с выбора устройства для загрузки в соответствие со встроенными правилами. Часто эти правила можно изменять, нажимая во время загрузки определенную клавишу (например, Delete) и получая меню со множеством опций. При стандартном процессе BIOS сначала пытается выполнить загрузку с флоппи-диска и, в случае неудачи, — с первого жесткого диска. Если и здесь загрузка невозможна, может предприниматься попытка загрузки с CD-ROM. В большинстве случаев загрузочным устройством будет жесткий диск.
BIOS читает из дискового загрузочного устройства первый сектор (первых 512 байт), который носит название главной загрузочной записи (Master Boot Record, или MBR). Следующие события зависят от того, как Linux установлен в системе. С целью упрощения предположим, что загрузчиком ядра является LILO. В большинстве случаев BIOS проверяет некоторые магические числа в MBR и затем отыскивает информацию о расположении загрузочного сектора. Далее BIOS загружает этот сектор, содержащий начало LILO, в память и переходит на его начало.
Именно сейчас произошел переход из области аппаратуры и встроенного программного обеспечения в область «истинного» программного обеспечения, от осязаемого к неосязаемому, от частей, которые можно, скажем, пнуть ногой, к частям, для которых это будет затруднительно.
Итак, загружается LILO. Он загружает остаток самого себя и отыскивает на диске данные о своей конфигурации, которые сообщают ему, помимо прочего, где находится ядро и какие параметры необходимо передать ядру во время загрузки. Затем LILO загружает ядро и передает ему управление.
Обычно ядро хранится в виде сжатых файлов, каждый из которых в своем начале содержит несколько команд для распаковки оставшейся части (т.е. каждый такой файл представляет собой самораспаковывающийся исполняемый модуль). Таким образом, следующий шаг состоит в распаковке ядра своими силами и передаче управления на начало распакованного образа. Загрузка ядра завершена.
Ниже приводится краткое резюме рассмотренных выше действий.
- ЦП инициализируется и выполняет одиночный оператор по фиксированному адресу.
- Этот оператор обеспечивает передачу управления BIOS.
- BIOS находит загрузочное устройство и считывает его MBR, который хранит расположение LILO.
- BIOS загружает LILO и передает ему управление.
- LILO загружает сжатое ядро.
- Сжатое ядро распаковывает само себя и передает управление на распакованный образ.
Как и можно было ожидать, за каждым шагом процесса загрузки стоит большая порция кода.
В соответствие с приведенными в начале главы рассуждениями, ЦП рассматривается как «загрузчик загрузчика загрузчика загрузчика ядра» (т.е. ЦП загружает BIOS, BIOS загружает LILO, LILO загружает сжатое ядро, а последнее загружает уже распакованное ядро). Однако, для краткости будем говорить просто «загрузчик«.
Инициализация ядра Linux
После того как ядро загружается в память (и по необходимости распаковывается), а ряд критичных аппаратных средств (например, устройство управления памятью) проходят низкоуровневую инициализацию, ядро обращается к start_kernel (строка 19802). Эта функция выполняет оставшуюся инициализацию системы. Перейдем к исследованию собственно start_kernel.
start_kernel
19802: Дескриптор __init заставляет компилятор gcc помещать эту функцию в специальный раздел ядра. После завершения собственной инициализации ядро может попытаться освободить этот специальный раздел. Подобного рода разделов существует два: .text.init и .data.init. Первый из них предназначен для кода, а второй — для данных. (Термин «text» относится к таким «чистым» разделам исполняемого модуля, как код и строковые литералы, которые могут совместно использоваться множеством процессов.) Кроме того, можно заметить и дескриптор __initfunc, который, как и __init, отмечает код инициализации, и __initdata, отмечающий данные инициализации.
19807: Как упоминалось ранее, даже в мультипроцессорной системе загрузку выполняет один ЦП. В терминологии Intel его называют процессором начальной загрузки (bootstrap processor, или BSP), на который во многих местах кода ядра ссылаются как на ВР. Следовательно, BSP достигает этой точки кода первым, пропускает следующий if и обнуляет флаг boot_cpu, так что когда другие ЦП попадут в эту точку, они зайдут внутрь if. Пока другие ЦП активизируются и добираются до этой точки, BSP находится в цикле ожидания (описанном ниже в главе), а initialize_secondary (строка 4355) следит за тем, когда другие ЦП присоединятся к BSP. Таким образом, другие ЦП не выполняют остаток start_kernel, что само по себе приятно, поскольку позволяет избежать повторной инициализации большого числа аппаратных средств и т.п.
Подобного рода странные телодвижения необходимы только для процессоров х86: для других платформ достаточно вызова smp_init, который выполнит остаток инициализации для систем SMP. Соответственно, другие платформы работают с пустыми определениями initialize_secondary.
19816: Выводит сообщение заголовка ядра (строка 20099), которое предоставляет различную информацию о том, как компилировалось ядро — на каком компьютере, когда, версия используемого компилятора и т.п. Если что-то сбоит, информация о происхождении ядра может сослужить хорошую службу в плане поиска причин сбоев.
19817: Инициализация некоторых компонентов ядра: памяти, аппаратных прерываний, планировщика и т.д. В частности, функция setup_arch (строка 19765) выполняет аппаратно-зависимую установку, после чего возвращает значения в command_line (параметры, передаваемые ядру), а также memory_start и memory_end (диапазон физических адресов, доступных ядру). Некоторые из следующих функций резервируют память небольшого объема: они получают memory_start и memory_end и после получения требуемого возвращают новое значение memory_start.
19823: Выполняет разбор параметров, передаваемых ядру. Функция parse_options (строка 19707), которая обсуждается ниже, также устанавливает начальные значения argv и envp.
19833: Ядро может профилировать себя во время выполнения, периодически выясняя, какие операторы выполняются, и обновляя полученными результатами таблицу. Это завершается обращением к x86_do_profile (строка 1896) во время прерывания по таймеру, как описано в главе 6. Таблица разделяет ядро на области одинаковых размеров (см. рис. 4.1) и просто отслеживает, сколько раз выполнялся оператор во время прерывания в данной области. Такое профилирование является, как и было задумано, грубым (отслеживание производится не по функциям или строкам кода, а по приближенным адресам), тем не менее, оно отличается низкими накладными расходами, высокой скоростью, небольшими размерами, и определенно помогает идентифицировать узкие места.
Рис. 4.1. Буфер профилирования
Кроме того, путем изменения значения prof_shift (строка 26142) можно настраивать количество адресов для каждого элемента таблицы (и, соответственно, точность «попадания»). profile_setup (строка 19076) позволяет устанавливать значение prof_shift во время загрузки, что гораздо предпочтительнее перекомпиляции всего ядра лишь только для изменения этого значения.
Данный блок if устанавливает отдельную область памяти для таблицы профилирования и обнуляет все ее элементы. Следует отметить, что если prof_shift равно 0 (значение по умолчанию), профилирование не выполняется и память под таблицу не выделяется.
19846: Разрешение аппаратных прерываний путем вызова sti (строка 13104 для однопроцессорных компьютеров; более подробно эта тема рассматривается в главе 6). Необходимо, чтобы прерывания по таймеру были активны, поэтому следующее обращение к calibrate_delay (строка 19654) вычислит BogoMIPS для данного компьютера (см. следующий раздел). Поскольку значение BogoMIPS требуется для некоторых драйверов устройств, ядро должно определить эту величину перед инициализацией большинства оборудования, файловой системы и т.д.
19876: Тестирует ЦП на предмет наличия определенных ошибок, например, ошибка Pentium F00F (см. главу 8), и сохраняет информацию о найденных ошибках для остальных частей ядра, обеспечивая им возможность обходить ошибки. (Ради экономии бумаги код функции check_bugs не приводится.)
19882: Вызов функции smp_init (строка 19787), которая, в свою очередь, обращается к другим функциям, активизирующим дополнительные ЦП в мультипроцессорной системе: для случая платформы х86 функция smp_boot_cpus (строка 4614) инициализирует определенные структуры данных ядра, которые отслеживают дополнительные ЦП и переводят их в режим ожидания; дальнейшее обращение к smp_commence (строка 4195) разрешает функционирование этих ЦП.
19883: Инициирует выполнение функции init как поток ядра. Дополнительную информацию по этому поводу можно найти далее в главе.
19885: Взводит флаг need_resched ожидающего процесса по причинам, на данный момент пока не вполне очевидным. Все станет ясно по прочтении глав 5, 6 и 7. До возникновения следующего прерывания по таймеру (см. главу 6) функция system_call (строка 171, обсуждаемая в главе 5) убеждается, что флаг need_resched ожидающего процесса взведен и вызывает schedule (строка 26686, обсуждаемая в главе 7) для того, чтобы переключить ЦП на другой процесс.
19886: Завершив инициализацию ядра (во всяком случае, передав ответственность за это функции init), все что осталось — это войти в цикл ожидания и отбирать у ЦП неиспользуемые циклы. Поэтому в данной строке производится обращение к cpu_idle (строка 2014), представляющей собой цикл ожидания. Из кода cpu_idle видно, что возврата из функции никогда не происходит. Однако, любая реальная задача эту функцию вытесняет.
Несложно заметить, что cpu_idle периодически выполняет системный вызов idle (системные вызовы рассматриваются в следующей главе), который проходит через sys_idle (строка 2064) для организации реального цикла ожидания — это видно из строки 2014 для однопроцессорной и строки 2044 для симметричной мультипроцессорной версии. Здесь производится вызов оператора hlt (останов), переводящего ЦП в «спящее» состояние, характеризующееся снижением энергопотребления. Такой режим означает, что ЦП не выполняет никакой реальной работы.
BogoMIPS
Значение BogoMIPS вычисляется ядром и выводится во время инициализации системы. Оно определяет сколько раз за секунду ЦП может выполнять короткий цикл временной задержки. В рамках ядра значение BogoMIPS используется, в основном, драйверами устройств, которые должны обеспечивать временные задержки для ожидания освобождения устройств — например, ожидание в течение нескольких микросекунд готовности информации.
Ограниченное применение числа BogoMIPS связано, прежде всего, с отсутствием документации на него. Следует отметить, что BogoMIPS реализует одну из наидревнейших, присущих человечеству потребностей — сведение до одного числа всей информации, характеризующей производительность компьютера. Часть «Bogo» в слове «BogoMIPS» произрастает из «bogus» («поддельный»), что определенно свидетельствует о желании отбить охоту его использовать; что же касаемо неаккуратности, безалаберности, непригодности, лживости, полной неспособности сравнивать производительность различных систем, то по этим «приятным» показателям значение BogoMIPS оставляет далеко позади другие системы оценки производительности. Вместе с тем, BogoMIPS не в меру обаятельно, потому-то оно здесь и рассматривается. (Часть «MIPS» в слове «BogoMIPS» означает «миллионов операций в секунду» (Millions of Instructions Per Second), что является общей единицей при оценке производительности ЦП.)
calibrate_delay
19654: calibrate_delay — это функция ядра, которая вычисляет значение BogoMIPS.
19662: Как первое приближение, calibrate_delay вычисляет количество циклов __delay (строка 6866), выполняемых в течение одного тика таймера, т.е. за одну сотую долю секунды.
19664: Вычисление количества циклов, приходящихся на один тик таймера, требует начать подсчет как можно более близко к началу тика. Глобальная переменная jiffies (строка 16588) хранит количество тиков таймера с момента начала подсчета ядром (более подробно об этом рассказывается в главе 6). jiffies обновляется асинхронно в прерывании, т.е. сто раз в секунду. При этом ядро приостанавливает все активные процессы, обновляет эту переменную, после чего возобновляет свою работу с того места, где она была приостановлена. Если этого не сделать, цикл в следующей строке никогда не завершится. Поскольку jiffies объявлена как volatile и ее значение будет изменяться по причинам, невидимым для компилятора, gcc может оптимизировать цикл таким образом, что он никогда не завершится, gcc пока еще не настоль интеллектуален, однако его создатели предпринимают попытки сделать его таковым.
19669: Как раз можно начинать отработку нового тика таймера, который только что совершился. Следующий шаг заключается в организации задержки размером loops_per_sec проходов цикла таймера и выяснении, прошел ли полный тик таймера. Если это так, цикл завершается, в противном случае цикл стартует заново с удвоенным значением loops_per_sec. Именно такая форма цикла связана частично с тем, что существующие компьютеры не могут выполнять цикл задержки где-то около 232 раз в секунду (для 64-разрядных компьютеров — менее 264 раз в секунду).
19677: Теперь ядру известно, что loops_per_sec проходов цикла задержки на данном компьютере выполняется дольше одной сотой доли секунды, поэтому оценка уточняется. Производится двоичный поиск истинного значения loops_per_sec, вначале исходя из предположения, что истинное значение находится в пределах между текущей оценкой и ее половиной — истинное значение не может превышать текущую оценку, однако может быть (вероятнее всего, это так) меньше ее.
19681: Тем же способом, что и ранее, calibrate_delay просматривает, не является ли уменьшенное значение loops_per_sec все еще настоль большим, чтобы отнимать полный тик таймера. Если это так, то правильное значение лежит где-то очень близко к текущей оценке (немного меньше ее). Цикл продолжается с меньшим значением. В противном случае цикл продолжается с большим значением.
19691: Ядро имеет очень хороший механизм оценки количества проходов цикла задержки на один полный тик таймера. Это число умножается на количество тиков в секунду, в результате чего получается количество проходов цикла задержки за секунду. Поскольку оценка есть оценка, а умножение ее дополнительно загрубляет, полученное число неточно вплоть до наносекунд. Однако для целей ядра этого оказывается вполне достаточно.
19693: Ядро выводит подсчитанное число, дабы привести пользователя в трепет. Бросается в глаза явное отсутствие спецификатора формата %f — везде, где это возможно, ядро старается избегать использования операций с плавающей запятой. Выводимые магические числа базируются на 500000, что произрастает из 1 миллиона (операций в секунду), деленного на 2 (количество операций в теле цикла задержки — decl и переход).
Разбор передаваемых ядру параметров
Функция parse_options выполняет разбор параметров, передаваемых во время выполнения загрузчиком ядра, воздействуя на некоторые из них самостоятельно, а другие передавая в процесс init. Параметры могут храниться в конфигурационном файле либо вводиться пользователем во время загрузки ядра.
parse_options
19707: Параметры собираются в одну длинную командную строку, указатель на начало которой передается ядру. Загрузчик ядра сохраняет эту строку по известному адресу.
19718: Выбор следующего параметра с сохранением его для следующей итерации цикла. Следует отметить, что параметры должны отделяться друг от друга пробелами. Любой найденный разделительный пробел в следующей строке кода заменяется нулевым байтом, что позволяет рассматривать строку как нормальную строку в стиле С, которая хранит один параметр. Если не найдено ни одного пробела, это значит, что достигнут последний параметр в line и цикл завершается на следующей итерации.
Обратите внимание, что код не обеспечивает пропуск множества пробелов. Пусть line хранит следующее значение (содержащее 2 пробела):
rw debug
В результате распознавания выделяются три параметра: "rw", "" (пустая строка) и "debug". Поскольку пустая строка не является допустимым параметром ядра, она передается в init (как вскоре будет показано) — совершенно не то, что хотел пользователь! Следовательно, за удаление лишних пробелов отвечает загрузчик ядра. LILO делает это с завидной элегантностью.
19721: Попытка интерпретации параметра. Первых два параметра, ro и rw, уведомляют ядро о необходимости смонтировать корневую файловую систему, где находится каталог /, в режимах, соответственно, только для чтения и для чтения/записи.
19729: Третий параметр, debug, увеличивает объем отладочной информации, выводимой по вызову do_syslog (строка 25724).
19733: Первые несколько параметров представляют собой стандартные флаги и не имеют аргументов. Кроме них, ядро распознает параметры, задаваемые в виде параметр=значенне. Например, строка init=/some/other/program задает команду, которая будет выполняться загрузчиком ядра вместо init. Код отбрасывает часть init=, а оставшуюся часть сохраняет в execute_command для дальнейшего использования в init (строка 20044). В отличие от обработки остальных параметров, обработка данного параметра не может делаться полностью в функции checksetup (строка 19612), поскольку выполняется модификация ее локальных переменных. Ниже будет показано, по какой причине три рассмотренных выше параметра обрабатываются здесь, а не в checksetup.
19745: Изрядная часть параметров ядра распознается в функции checksetup. В случае удачной обработки параметра эта функция возвращает истину и цикл продолжается.
19750: В противном случае line не содержит допустимый параметр ядра. В такой ситуации содержимое line трактуется как параметр или переменная окружения для процесса init. Переменная окружения должна задаваться в виде переменная=значение. До тех пор пока имеется свободное место в массивах argv_init и envp_init (соответственно, строки 19057 и 19059), параметры и переменные окружения будут в них сохраняться для дальнейшей передачи в функцию init.
Комментарий в строке 19736 сообщает, что строка auto не является префиксом для какого-либо параметра, поэтому в большинстве случаев будет нормальным ее присутствие в массиве argv_init, так как auto — допустимый параметр для init. Однако, когда встречается параметр init=, он используется для запуска вместо init командного процессора и auto может его обескуражить. В этой связи parse_options игнорирует аргумент init.
Любопытно, что цикл завершается когда заполняется один из двух массивов argv_init и envp_init, поскольку заполнение argv_init не означает, что в line больше не осталось переменных окружения, предназначенных для init. Кроме того, там еще могут оставаться и необработанные параметры ядра. Это выглядит еще более странно, если учесть, что MAX_INIT_ARGS (строка 19029) и MAX_INIT_ENVS (строка 19030) определены со значениями 8 — очень маленький предел, который быстро подходит к концу. Если изменить операторы break в строках 19752 и 19756 на continue, цикл будет продолжать распознавать параметры без записи их в конец массивов argv_init и envp_init. Это может оказаться весьма полезным в случае, если command_line содержит опции ядра, не предназначенные для init.
19760: Обработаны все параметры ядра. Последний шаг заключается в добавлении символа NULL в конец массивов argv_init и envp_init, чтобы init имела возможность вовремя остановиться.
checksetup
19612: Функция checksetup обеспечивает обработку большинства параметров ядра. Различают три категории параметров: использующие нормальные параметры ядра, разбираемые в части после знака =; разбираемые в части после знака = самостоятельно; разбираемые в части до и после знака =. На первую категорию ссылаются как на «обработанные» параметры, тогда как на вторую — как на «сырые». К последней категории относится только параметр IDE, имеющий отношение к драйверу IDE; этот случай проверяется первым в строке 19619.
19625: Далее checksetup сканирует массив raw_params (строка 19552) на предмет того, должен ли данный параметр оставаться необработанным. Элементы raw_params имеют тип struct kernel_param (строка 19223), ассоциирующий префикс параметра с функцией, которая вызывается, если такой параметр будет найден. Если атрибут str в каком-то элементе массива предваряется содержимым line, производится вызов соответствующей функции с передачей ей оставшейся части line и checksetup вернет ненулевое значение, которое говорит о том, что данный параметр обработан. Массив raw_params завершается двумя элементами NULL, поэтому цикл завершается также при встрече атрибута str, равного NULL. В таком случае цикл очевидно переходит в конец массива raw_params, не отыскав ни одного совпадения. Естественно, проверка атрибута setup_func функционирует в равной степени хорошо. Рассмотренный цикл иллюстрирует одно утверждение: в отличие от большей части ядра, инициализация не должна выполняться настолько быстро, насколько это возможно. Если даже ядро потратит на инициализацию на несколько микросекунд больше, чем планировалось, нет никаких оснований искать потери — пока еще никаких пользовательских приложений не запускалось, посему и терять-то нечего. В результате код выглядит необычно непроизводительным и требующим очевидной оптимизации. Например, длины строк в массиве raw_params можно было бы сохранить в том же массиве, а не вычислять их каждый раз (см. строку 19626). Для достижения еще больших результатов можно было отсортировать элементы массива raw_params в алфавитном порядке и предоставить возможность checksetup выполнять более быстрый двоичный поиск.
Нет ни малейших препятствий внести подобного рода усовершенствования в raw_params, однако, вряд ли игра будет стоить свеч, поскольку двоичный поиск дает существенную экономию только на больших массивах (точное значение признака «большой» зависит от конкретных обстоятельств). Коллега raw_params, массив cooked_params (строка 19228), определенно обладает большими возможностями для оптимизации, однако с ним связана одна проблема: сортировка по алфавиту может оказаться затруднительной, поскольку потребует разделения некоторых блоков #ifdef (см. строки с 19268 по 19272). Кроме того, из-за того, что алгоритм должен выполнять поиск по префиксам, он может оказаться чувствительным к порядку следования элементов. Все же упомянутые задачи не являются главенствующими и потенциальное возрастание производительности не стоит затраченного на это труда (в конце концов, дерево префиксов можно построить и статически). В данном случае предпочтение было отдано простоте.
Тем не менее, в аналогичном массиве root_dev_names (см. строку 19085), который отображает префиксы имен аппаратных устройств на их идентификаторы, разработчики несколько повысили производительность, поместив более часто используемые элементы (диски IDE и SCSI) перед менее часто используемыми (IDE-устройства чтения CD-ROM с интерфейсом подключения к порту принтера). Ничего подобного в случае raw_params и cooked_params не замечено.
Еще одно замечание. Уже сейчас можно предположить, почему параметры ro, rw и debug проверяются в parse_options, а не здесь — в parse_options выполняется полное сравнение, в то время как в checksetup проверяются только префиксы. В частности, параметр ro оказывается префиксом root= (строка 19553), а все должно работать корректно даже в случае присутствия в строке параметров и ro, и root=. Конечно, аргумент выглядит довольно-таки слабо. Посмотрите на параметр noinitrd (строка 19251). Он анализируется в cooked_params и, стало быть, подпадает под сравнение лишь префиксов; связанная с ним функция (no_initrd, строка 19902) игнорирует любые передаваемые ей параметры, т.е. ro, rw и debug, которые могут попасть в cooked_params.
19632: Этот цикл выполняет те же самые действия над массивом cooked_params, что и предыдущий цикл делал по отношению к raw_params. Единственное отличие между упомянутыми циклами (помимо массивов, конечно) состоит в том, что данный цикл имеет дело с частью line после знака =, вызывая get_options (строка 19062) перед обращением к функции установки. Функция get_options заполняет массив ints максимум десятью отрицательными числами. ints[0] хранит количество используемых элементов массива, т.е. сколько раз int get_options сохранялось в ints. Заполненный массив затем передается в функцию установки, которая соответствующим образом его интерпретирует.
19640: Возвращается 0, означающий, что параметр ядра в line не распознался.
profile_setup
19076: profile_setup является хорошим примером функции установки, вызываемой checksetup — она короткая, выполняет определенные действия над аргументом ints и у вас уже должно быть определенное понятие по поводу того, что она делает. Как упоминалось ранее, пользователь может устанавливать prof_shift во время загрузки. Сейчас рассмотрим, как это делается. profile_setup вызывается, если во время загрузки ядра указывается параметр profile=. Связь строки префикса и собственно функции выполняется в строке 19235. Следует заметить, что это находится в cooked_params, поэтому profile_setup получает обработанные параметры.
19079: Использует в качестве нового значения prof_shift первое число (если таковое присутствует), находящееся после profile=. Другие аргументы, которые могут указываться в параметре, полностью игнорируются.
19081: Если параметр profile= поступает без значений, prof_shift получает значение по умолчанию, равное 2. Такое значение по умолчанию может несколько обескуражить, поскольку, как уже должно быть известно, оно означает использование четверти доступной ядру памяти для профилирования — огромные накладные расходы. С другой стороны, такой объем позволит с высокой точностью определить узкие места, за исключением, быть может, нескольких операторов. В конечном счете, картина не столь страшна: ввиду того, что профилируется только код ядра, накладные расходы составят 25% от размера кода, а не от всей памяти ядра.
Init
Init представляет собой специальный процесс с несколькими характерными особенностями. Это первый пользовательский процесс, запускаемый ядром, и он отвечает за запуск всех остальных процессов, которые, собственно, и позволяют извлекать определенную пользу из системы. Работа управляется файлом /etc/inittab и предполагает установку процессов, связанных с регистрацией пользователей, инициализацию сетевых служб наподобие FTP и HTTP и многое другое. Без такого рода процессов на компьютере мало что удастся сделать.
Важная сторона, характерная для данного проекта, заключается в том, что init является предком любого процесса в системе, Init порождает процесс регистрации, который, в свою очередь, порождает процесс входа, а тот — командный процессор, в рамках которого пользователь порождает любой требуемый процесс. Помимо прочего, это позволяет получить уверенность в том, что все элементы в таблице процессов ядра в конце концов заполнятся. Выполнение определенной обработки после завершения процесса находится в ведении родителя процесса; если родитель процесса уже завершился, обработкой занимается родитель родителя и т.д. В таком случае, за выполнение обработки после завершения процессов несет ответственность init, который никогда не завершается.
Рассмотрим напоследок собственно init.
init
20044: Аргумент unused так называется в связи с необычным способом вызова данной функции. Функция init — не путать с процессом init — начинается как поток ядра, процесс, который выполняется как часть ядра. (Такая трактовка потока ядра может отличаться от таковой, принятой в многопотоковом программировании, — в этом смысле функция init не является потоком ядра.) Функция init похожа на усеченную main для нового процесса, и аргумент unused (указатель) является единственной заслуживающей внимания информацией, передаваемой в процесс — намного меньше, чем передается в обычный процесс через аргументы argc, argv и envp. Функция init не нуждается в дополнительной информации, поэтому и аргумент назван unused (т.е. неиспользованный).
Вот краткое резюме. Функция init является частью ядра, она выполняется в рамках ядра как независимая его часть; со всех точек зрения функция init — это часть кода ядра. Ни одна из перечисленных характеристик не относится к процессу init. В определенном смысле процесс init — специальный выделенный процесс, который не является частью собственно ядра. Код этого процесса находится в отдельном исполняемом образе, хранящемся на диске подобно любой другой программе. Несколько путает тот факт, что функция init, которая позже запускает процесс init, сама по себе запускается в виде процесса.
Поскольку идентификатор процесса (PID) со значением 0 уже зарезервирован для процесса idle (ожидание), функция init (и, следовательно, процесс init) получает PID, равный 1. (Идентификаторы процессов обсуждаются в главе 7.) Ядро во многих местах предполагает, что процесс с PID 1 — это idle, поэтому изменение PID для idle приводит к существенным накладным расходам.
20046: Обращение к lock_kernel (строка 17492 для однопроцессорной версии и 10174 — для мультипроцессорной) для выполнения нескольких нижеследующих строк без возможного влияния других частей ядра. Ядро будет разблокировано в строке 20053.
20047: Вызов do_basic_setup (строка 19916) с целью инициализации шин и порождения некоторых необходимых потоков ядра, а также выполнения других мелких действий.
20052: В настоящий момент ядро полностью инициализировано, поэтому free_initmem (строка 7620) избавляется от функций в разделе .text.init и данных в разделе .data.init ядра. Все функции, помеченные в начале как __initfunc, и все данные, помеченные как __initdata, в дальнейшем более не доступны, а занимаемая ими память освобождается и становится доступной для других целей.
20055: По возможности открывается консольное устройство, на которое процесс init будет выводить сообщения и с него считывать пользовательский ввод. Процесс init использует консоль исключительно для выдачи сообщений об ошибках, однако если вместо init запускается другой командный процессор, ему может потребоваться консоль для чтения данных, введенных пользователем. Если открытие консоли по open проходит успешно, /dev/console становится стандартным вводом (файловый дескриптор 0) для init.
20059: Вызов dup (создание копии) дважды для файлового дескриптора /dev/console, что дает возможность init использовать консоль дополнительно для стандартного вывода и стандартного вывода ошибок (файловые дескрипторы 1 и 2). Предполагая, что open в строке 20055 завершается успешно, в распоряжении init появляется первых три файловых дескриптора (стандартный ввод, стандартный вывод и стандартный вывод ошибок), связанные с системной консолью.
20067: Если в командной строке для ядра явно указывается путь к init (или другой аналогичной программе), init предпринимает попытку ее запуска.
Поскольку в случае успешного запуска целевой программы из execve возврата не происходит, управление на каждый последующий оператор будет передаваться, только если предыдущий оператор потерпит неудачу. В этой последовательности строк предпринимаются попытки нахождения init в различных местах, так сказать, с увеличением степени безрассудства: в первую очередь, в /sbin/init, стандартном месте расположения; затем еще в двух местах, где имеет смысл ожидать присутствие init — /etc/init и /bin/ink.
20072: Исчерпаны все места, где может находиться init. Если все докатилось до этой строки, значит, init понятия не имеет, где еще искать своего тезку. Скорее всего, что-то нехорошее случилось с компьютером. Предпринимается попытка создать взамен init интерактивный командный процессор /bin/sh. Самое лучшее, на что надеется init, пребывая в этой точке, — так это то, что привилегированный пользователь устранит неисправность и выполнит перезагрузку. (Будьте уверены, привилегированный пользователь надеется на то же самое.)
20073: init не смог создать даже командный процессор — определенно, что-то не так! Раз так, это неплохой повод запаниковать, т.е. обратиться к panic (строка 25563). Предпринимается попытка синхронизации дисков для приведения в согласованное состояние всех данных, после чего вся обработка останавливается. Компьютер может также перезагрузиться по истечении времени тайм-аута, определенного в параметрах ядра.
|

 LINUX
LINUX 
 Books
Books
