11.1. Introduction
We discussed processes in earlier chapters. We learned about the environment of a UNIX process, the relationships between processes, and ways to control processes. We saw that a limited amount of sharing can occur between related processes.
In this chapter, we'll look inside a process further to see how we can use multiple threads of control (or simply threads) to perform multiple tasks within the environment of a single process. All threads within a single process have access to the same process components, such as file descriptors and memory.
Any time you try to share a single resource among multiple users, you have to deal with consistency. We'll conclude the chapter with a look at the synchronization mechanisms available to prevent multiple threads from viewing inconsistencies in their shared resources.
11.2. Thread Concepts
A typical UNIX process can be thought of as having a single thread of control: each process is doing only one thing at a time. With multiple threads of control, we can design our programs to do more than one thing at a time within a single process, with each thread handling a separate task. This approach can have several benefits.
We can simplify code that deals with asynchronous events by assigning a separate thread to handle each event type. Each thread can then handle its event using a synchronous programming model. A synchronous programming model is much simpler than an asynchronous one. Multiple processes have to use complex mechanisms provided by the operating system to share memory and file descriptors, as we will see in Chapters 15 and 17. Threads, on the other hand, automatically have access to the same memory address space and file descriptors. Some problems can be partitioned so that overall program throughput can be improved. A single process that has multiple tasks to perform implicitly serializes those tasks, because there is only one thread of control. With multiple threads of control, the processing of independent tasks can be interleaved by assigning a separate thread per task. Two tasks can be interleaved only if they don't depend on the processing performed by each other. Similarly, interactive programs can realize improved response time by using multiple threads to separate the portions of the program that deal with user input and output from the other parts of the program.
Some people associate multithreaded programming with multiprocessor systems. The benefits of a multithreaded programming model can be realized even if your program is running on a uniprocessor. A program can be simplified using threads regardless of the number of processors, because the number of processors doesn't affect the program structure. Furthermore, as long as your program has to block when serializing tasks, you can still see improvements in response time and throughput when running on a uniprocessor, because some threads might be able to run while others are blocked.
A thread consists of the information necessary to represent an execution context within a process. This includes a thread ID that identifies the thread within a process, a set of register values, a stack, a scheduling priority and policy, a signal mask, an errno variable (recall Section 1.7), and thread-specific data (Section 12.6). Everything within a process is sharable among the threads in a process, including the text of the executable program, the program's global and heap memory, the stacks, and the file descriptors.
The threads interface we're about to see is from POSIX.1-2001. The threads interface, also known as "pthreads" for "POSIX threads," is an optional feature in POSIX.1-2001. The feature test macro for POSIX threads is _POSIX_THREADS. Applications can either use this in an #ifdef test to determine at compile time whether threads are supported or call sysconf with the _SC_THREADS constant to determine at runtime whether threads are supported.
11.3. Thread Identification
Just as every process has a process ID, every thread has a thread ID. Unlike the process ID, which is unique in the system, the thread ID has significance only within the context of the process to which it belongs.
Recall that a process ID, represented by the pid_t data type, is a non-negative integer. A thread ID is represented by the pthread_t data type. Implementations are allowed to use a structure to represent the pthread_t data type, so portable implementations can't treat them as integers. Therefore, a function must be used to compare two thread IDs.
#include <pthread.h>
int pthread_equal(pthread_t tid1, pthread_t tid2);
| Returns: nonzero if equal, 0 otherwise |
Linux 2.4.22 uses an unsigned long integer for the pthread_t data type. Solaris 9 represents the pthread_t data type as an unsigned integer. FreeBSD 5.2.1 and Mac OS X 10.3 use a pointer to the pthread structure for the pthread_t data type.
A consequence of allowing the pthread_t data type to be a structure is that there is no portable way to print its value. Sometimes, it is useful to print thread IDs during program debugging, but there is usually no need to do so otherwise. At worst, this results in nonportable debug code, so it is not much of a limitation.
A thread can obtain its own thread ID by calling the pthread_self function.
#include <pthread.h>
pthread_t pthread_self(void);
| Returns: the thread ID of the calling thread |
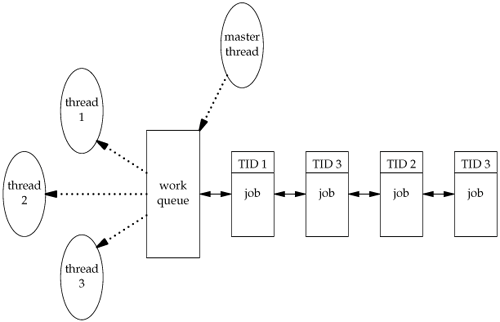
This function can be used with pthread_equal when a thread needs to identify data structures that are tagged with its thread ID. For example, a master thread might place work assignments on a queue and use the thread ID to control which jobs go to each worker thread. This is illustrated in Figure 11.1. A single master thread places new jobs on a work queue. A pool of three worker threads removes jobs from the queue. Instead of allowing each thread to process whichever job is at the head of the queue, the master thread controls job assignment by placing the ID of the thread that should process the job in each job structure. Each worker thread then removes only jobs that are tagged with its own thread ID.
11.4. Thread Creation
The traditional UNIX process model supports only one thread of control per process. Conceptually, this is the same as a threads-based model whereby each process is made up of only one thread. With pthreads, when a program runs, it also starts out as a single process with a single thread of control. As the program runs, its behavior should be indistinguishable from the traditional process, until it creates more threads of control. Additional threads can be created by calling the pthread_create function.
#include <pthread.h>
int pthread_create(pthread_t *restrict tidp,
const pthread_attr_t *restrict
 attr,
void *(*start_rtn)(void), void
*restrict arg); attr,
void *(*start_rtn)(void), void
*restrict arg);
| Returns: 0 if OK, error number on failure |
The memory location pointed to by tidp is set to the thread ID of the newly created thread when pthread_create returns successfully. The attr argument is used to customize various thread attributes. We'll cover thread attributes in Section 12.3, but for now, we'll set this to NULL to create a thread with the default attributes.
The newly created thread starts running at the address of the start_rtn function. This function takes a single argument, arg, which is a typeless pointer. If you need to pass more than one argument to the start_rtn function, then you need to store them in a structure and pass the address of the structure in arg.
When a thread is created, there is no guarantee which runs first: the newly created thread or the calling thread. The newly created thread has access to the process address space and inherits the calling thread's floating-point environment and signal mask; however, the set of pending signals for the thread is cleared.
Note that the pthread functions usually return an error code when they fail. They don't set errno like the other POSIX functions. The per thread copy of errno is provided only for compatibility with existing functions that use it. With threads, it is cleaner to return the error code from the function, thereby restricting the scope of the error to the function that caused it, instead of relying on some global state that is changed as a side effect of the function.
Example
Although there is no portable way to print the thread ID, we can write a small test program that does, to gain some insight into how threads work. The program in Figure 11.2 creates one thread and prints the process and thread IDs of the new thread and the initial thread.
This example has two oddities, necessary to handle races between the main thread and the new thread. (We'll learn better ways to deal with these later in this chapter.) The first is the need to sleep in the main thread. If it doesn't sleep, the main thread might exit, thereby terminating the entire process before the new thread gets a chance to run. This behavior is dependent on the operating system's threads implementation and scheduling algorithms.
The second oddity is that the new thread obtains its thread ID by calling pthread_self instead of reading it out of shared memory or receiving it as an argument to its thread-start routine. Recall that pthread_create will return the thread ID of the newly created thread through the first parameter (tidp). In our example, the main thread stores this in ntid, but the new thread can't safely use it. If the new thread runs before the main thread returns from calling pthread_create, then the new thread will see the uninitialized contents of ntid instead of the thread ID.
Running the program in Figure 11.2 on Solaris gives us
$ ./a.out
main thread: pid 7225 tid 1 (0x1)
new thread: pid 7225 tid 4 (0x4)
As we expect, both threads have the same process ID, but different thread IDs. Running the program in Figure 11.2 on FreeBSD gives us
$ ./a.out
main thread: pid 14954 tid 134529024 (0x804c000)
new thread: pid 14954 tid 134530048 (0x804c400)
As we expect, both threads have the same process ID. If we look at the thread IDs as decimal integers, the values look strange, but if we look at them in hexadecimal, they make more sense. As we noted earlier, FreeBSD uses a pointer to the thread data structure for its thread ID.
We would expect Mac OS X to be similar to FreeBSD; however, the thread ID for the main thread is from a different address range than the thread IDs for threads created with pthread_create:
$ ./a.out
main thread: pid 779 tid 2684396012 (0xa000a1ec)
new thread: pid 779 tid 25166336 (0x1800200)
Running the same program on Linux gives us slightly different results:
$ ./a.out
new thread: pid 6628 tid 1026 (0x402)
main thread: pid 6626 tid 1024 (0x400)
The Linux thread IDs look more reasonable, but the process IDs don't match. This is an artifact of the Linux threads implementation, where the clone system call is used to implement pthread_create. The clone system call creates a child process that can share a configurable amount of its parent's execution context, such as file descriptors and memory.
Note also that the output from the main thread appears before the output from the thread we create, except on Linux. This illustrates that we can't make any assumptions about how threads will be scheduled.
Figure 11.2. Printing thread IDs
#include "apue.h"
#include <pthread.h>
pthread_t ntid;
void
printids(const char *s)
{
pid_t pid;
pthread_t tid;
pid = getpid();
tid = pthread_self();
printf("%s pid %u tid %u (0x%x)\n", s, (unsigned int)pid,
(unsigned int)tid, (unsigned int)tid);
}
void *
thr_fn(void *arg)
{
printids("new thread: ");
return((void *)0);
}
int
main(void)
{
int err;
err = pthread_create(&ntid, NULL, thr_fn, NULL);
if (err != 0)
err_quit("can't create thread: %s\n", strerror(err));
printids("main thread:");
sleep(1);
exit(0);
}
11.5. Thread Termination
If any thread within a process calls exit, _Exit, or _exit, then the entire process terminates. Similarly, when the default action is to terminate the process, a signal sent to a thread will terminate the entire process (we'll talk more about the interactions between signals and threads in Section 12.8).
A single thread can exit in three ways, thereby stopping its flow of control, without terminating the entire process.
The thread can simply return from the start routine. The return value is the thread's exit code. The thread can be canceled by another thread in the same process. The thread can call pthread_exit.
#include <pthread.h>
void pthread_exit(void *rval_ptr);
|
The rval_ptr is a typeless pointer, similar to the single argument passed to the start routine. This pointer is available to other threads in the process by calling the pthread_join function.
#include <pthread.h>
int pthread_join(pthread_t thread, void **rval_ptr);
| Returns: 0 if OK, error number on failure |
The calling thread will block until the specified thread calls pthread_exit, returns from its start routine, or is canceled. If the thread simply returned from its start routine, rval_ptr will contain the return code. If the thread was canceled, the memory location specified by rval_ptr is set to PTHREAD_CANCELED.
By calling pthread_join, we automatically place a thread in the detached state (discussed shortly) so that its resources can be recovered. If the thread was already in the detached state, calling pthread_join fails, returning EINVAL.
If we're not interested in a thread's return value, we can set rval_ptr to NULL. In this case, calling pthread_join allows us to wait for the specified thread, but does not retrieve the thread's termination status.
Example
Figure 11.3 shows how to fetch the exit code from a thread that has terminated.
Running the program in Figure 11.3 gives us
$ ./a.out
thread 1 returning
thread 2 exiting
thread 1 exit code 1
thread 2 exit code 2
As we can see, when a thread exits by calling pthread_exit or by simply returning from the start routine, the exit status can be obtained by another thread by calling pthread_join.
Figure 11.3. Fetching the thread exit status
#include "apue.h"
#include <pthread.h>
void *
thr_fn1(void *arg)
{
printf("thread 1 returning\n");
return((void *)1);
}
void *
thr_fn2(void *arg)
{
printf("thread 2 exiting\n");
pthread_exit((void *)2);
}
int
main(void)
{
int err;
pthread_t tid1, tid2;
void *tret;
err = pthread_create(&tid1, NULL, thr_fn1, NULL);
if (err != 0)
err_quit("can't create thread 1: %s\n", strerror(err));
err = pthread_create(&tid2, NULL, thr_fn2, NULL);
if (err != 0)
err_quit("can't create thread 2: %s\n", strerror(err));
err = pthread_join(tid1, &tret);
if (err != 0)
err_quit("can't join with thread 1: %s\n", strerror(err));
printf("thread 1 exit code %d\n", (int)tret);
err = pthread_join(tid2, &tret);
if (err != 0)
err_quit("can't join with thread 2: %s\n", strerror(err));
printf("thread 2 exit code %d\n", (int)tret);
exit(0);
}
The typeless pointer passed to pthread_create and pthread_exit can be used to pass more than a single value. The pointer can be used to pass the address of a structure containing more complex information. Be careful that the memory used for the structure is still valid when the caller has completed. If the structure was allocated on the caller's stack, for example, the memory contents might have changed by the time the structure is used. For example, if a thread allocates a structure on its stack and passes a pointer to this structure to pthread_exit, then the stack might be destroyed and its memory reused for something else by the time the caller of pthread_join tries to use it.
Example
The program in Figure 11.4 shows the problem with using an automatic variable (allocated on the stack) as the argument to pthread_exit.
When we run this program on Linux, we get
$ ./a.out
thread 1:
structure at 0x409a2abc
foo.a = 1
foo.b = 2
foo.c = 3
foo.d = 4
parent starting second thread
thread 2: ID is 32770
parent:
structure at 0x409a2abc
foo.a = 0
foo.b = 32770
foo.c = 1075430560
foo.d = 1073937284
Of course, the results vary, depending on the memory architecture, the compiler, and the implementation of the threads library. The results on FreeBSD are similar:
$ ./a.out
thread 1:
structure at 0xbfafefc0
foo.a = 1
foo.b = 2
foo.c = 3
foo.d = 4
parent starting second thread
thread 2: ID is 134534144
parent:
structure at 0xbfafefc0
foo.a = 0
foo.b = 134534144
foo.c = 3
foo.d = 671642590
As we can see, the contents of the structure (allocated on the stack of thread tid1) have changed by the time the main thread can access the structure. Note how the stack of the second thread (tid2) has overwritten the first thread's stack. To solve this problem, we can either use a global structure or allocate the structure using malloc.
Figure 11.4. Incorrect use of pthread_exit argument
#include "apue.h"
#include <pthread.h>
struct foo {
int a, b, c, d;
};
void
printfoo(const char *s, const struct foo *fp)
{
printf(s);
printf(" structure at 0x%x\n", (unsigned)fp);
printf(" foo.a = %d\n", fp->a);
printf(" foo.b = %d\n", fp->b);
printf(" foo.c = %d\n", fp->c);
printf(" foo.d = %d\n", fp->d);
}
void *
thr_fn1(void *arg)
{
struct foo foo = {1, 2, 3, 4};
printfoo("thread 1:\n", &foo);
pthread_exit((void *)&foo);
}
void *
thr_fn2(void *arg)
{
printf("thread 2: ID is %d\n", pthread_self());
pthread_exit((void *)0);
}
int
main(void)
{
int err;
pthread_t tid1, tid2;
struct foo *fp;
err = pthread_create(&tid1, NULL, thr_fn1, NULL);
if (err != 0)
err_quit("can't create thread 1: %s\n", strerror(err));
err = pthread_join(tid1, (void *)&fp);
if (err != 0)
err_quit("can't join with thread 1: %s\n", strerror(err));
sleep(1);
printf("parent starting second thread\n");
err = pthread_create(&tid2, NULL, thr_fn2, NULL);
if (err != 0)
err_quit("can't create thread 2: %s\n", strerror(err));
sleep(1);
printfoo("parent:\n", fp);
exit(0);
}
One thread can request that another in the same process be canceled by calling the pthread_cancel function.
#include <pthread.h>
int pthread_cancel(pthread_t tid);
| Returns: 0 if OK, error number on failure |
In the default circumstances, pthread_cancel will cause the thread specified by tid to behave as if it had called pthread_exit with an argument of PTHREAD_CANCELED. However, a thread can elect to ignore or otherwise control how it is canceled. We will discuss this in detail in Section 12.7. Note that pthread_cancel doesn't wait for the thread to terminate. It merely makes the request.
A thread can arrange for functions to be called when it exits, similar to the way that the atexit function (Section 7.3) can be used by a process to arrange that functions can be called when the process exits. The functions are known as thread cleanup handlers. More than one cleanup handler can be established for a thread. The handlers are recorded in a stack, which means that they are executed in the reverse order from that with which they were registered.
#include <pthread.h>
void pthread_cleanup_push(void (*rtn)(void *),
void *arg);
void pthread_cleanup_pop(int execute);
|
The pthread_cleanup_push function schedules the cleanup function, rtn, to be called with the single argument, arg, when the thread performs one of the following actions:
Makes a call to pthread_exit Responds to a cancellation request Makes a call to pthread_cleanup_pop with a nonzero execute argument
If the execute argument is set to zero, the cleanup function is not called. In either case, pthread_cleanup_pop removes the cleanup handler established by the last call to pthread_cleanup_push.
A restriction with these functions is that, because they can be implemented as macros, they must be used in matched pairs within the same scope in a thread. The macro definition of pthread_cleanup_push can include a { character, in which case the matching } character is in the pthread_cleanup_pop definition.
Example
Figure 11.5 shows how to use thread cleanup handlers. Although the example is somewhat contrived, it illustrates the mechanics involved. Note that although we never intend to pass a nonzero argument to the thread start-up routines, we still need to match calls to pthread_cleanup_pop with the calls to pthread_cleanup_push; otherwise, the program might not compile.
Running the program in Figure 11.5 gives us
$ ./a.out
thread 1 start
thread 1 push complete
thread 2 start
thread 2 push complete
cleanup: thread 2 second handler
cleanup: thread 2 first handler
thread 1 exit code 1
thread 2 exit code 2
From the output, we can see that both threads start properly and exit, but that only the second thread's cleanup handlers are called. Thus, if the thread terminates by returning from its start routine, its cleanup handlers are not called. Also note that the cleanup handlers are called in the reverse order from which they were installed.
Figure 11.5. Thread cleanup handler
#include "apue.h"
#include <pthread.h>
void
cleanup(void *arg)
{
printf("cleanup: %s\n", (char *)arg);
}
void *
thr_fn1(void *arg)
{
printf("thread 1 start\n");
pthread_cleanup_push(cleanup, "thread 1 first handler");
pthread_cleanup_push(cleanup, "thread 1 second handler");
printf("thread 1 push complete\n");
if (arg)
return((void *)1);
pthread_cleanup_pop(0);
pthread_cleanup_pop(0);
return((void *)1);
}
void *
thr_fn2(void *arg)
{
printf("thread 2 start\n");
pthread_cleanup_push(cleanup, "thread 2 first handler");
pthread_cleanup_push(cleanup, "thread 2 second handler");
printf("thread 2 push complete\n");
if (arg)
pthread_exit((void *)2);
pthread_cleanup_pop(0);
pthread_cleanup_pop(0);
pthread_exit((void *)2);
}
int
main(void)
{
int err;
pthread_t tid1, tid2;
void *tret;
err = pthread_create(&tid1, NULL, thr_fn1, (void *)1);
if (err != 0)
err_quit("can't create thread 1: %s\n", strerror(err));
err = pthread_create(&tid2, NULL, thr_fn2, (void *)1);
if (err != 0)
err_quit("can't create thread 2: %s\n", strerror(err));
err = pthread_join(tid1, &tret);
if (err != 0)
err_quit("can't join with thread 1: %s\n", strerror(err));
printf("thread 1 exit code %d\n", (int)tret);
err = pthread_join(tid2, &tret);
if (err != 0)
err_quit("can't join with thread 2: %s\n", strerror(err));
printf("thread 2 exit code %d\n", (int)tret);
exit(0);
}
By now, you should begin to see similarities between the thread functions and the process functions. Figure 11.6 summarizes the similar functions.
Figure 11.6. Comparison of process and thread primitivesProcess primitive | Thread primitive | Description |
|---|
fork | pthread_create | create a new flow of control | exit | pthread_exit | exit from an existing flow of control | waitpid | pthread_join | get exit status from flow of control | atexit | pthread_cancel_push | register function to be called at exit from flow of control | getpid | pthread_self | get ID for flow of control | abort | pthread_cancel | request abnormal termination of flow of control |
By default, a thread's termination status is retained until pthread_join is called for that thread. A thread's underlying storage can be reclaimed immediately on termination if that thread has been detached. When a thread is detached, the pthread_join function can't be used to wait for its termination status. A call to pthread_join for a detached thread will fail, returning EINVAL. We can detach a thread by calling pthread_detach.
#include <pthread.h>
int pthread_detach(pthread_t tid);
| Returns: 0 if OK, error number on failure |
As we will see in the next chapter, we can create a thread that is already in the detached state by modifying the thread attributes we pass to pthread_create.
11.6. Thread Synchronization
When multiple threads of control share the same memory, we need to make sure that each thread sees a consistent view of its data. If each thread uses variables that other threads don't read or modify, no consistency problems exist. Similarly, if a variable is read-only, there is no consistency problem with more than one thread reading its value at the same time. However, when one thread can modify a variable that other threads can read or modify, we need to synchronize the threads to ensure that they don't use an invalid value when accessing the variable's memory contents.
When one thread modifies a variable, other threads can potentially see inconsistencies when reading the value of the variable. On processor architectures in which the modification takes more than one memory cycle, this can happen when the memory read is interleaved between the memory write cycles. Of course, this behavior is architecture dependent, but portable programs can't make any assumptions about what type of processor architecture is being used.
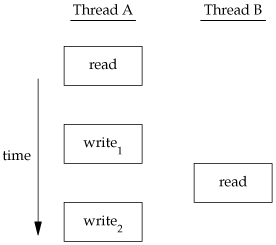
Figure 11.7 shows a hypothetical example of two threads reading and writing the same variable. In this example, thread A reads the variable and then writes a new value to it, but the write operation takes two memory cycles. If thread B reads the same variable between the two write cycles, it will see an inconsistent value.
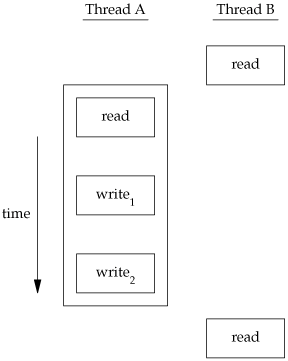
To solve this problem, the threads have to use a lock that will allow only one thread to access the variable at a time. Figure 11.8 shows this synchronization. If it wants to read the variable, thread B acquires a lock. Similarly, when thread A updates the variable, it acquires the same lock. Thus, thread B will be unable to read the variable until thread A releases the lock.
You also need to synchronize two or more threads that might try to modify the same variable at the same time. Consider the case in which you increment a variable (Figure 11.9). The increment operation is usually broken down into three steps.
Read the memory location into a register. Increment the value in the register. Write the new value back to the memory location.
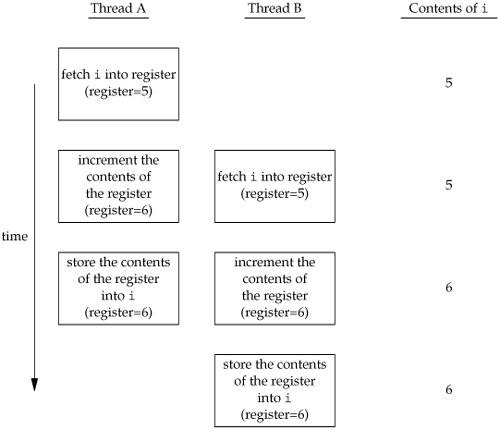
If two threads try to increment the same variable at almost the same time without synchronizing with each other, the results can be inconsistent. You end up with a value that is either one or two greater than before, depending on the value observed when the second thread starts its operation. If the second thread performs step 1 before the first thread performs step 3, the second thread will read the same initial value as the first thread, increment it, and write it back, with no net effect.
If the modification is atomic, then there isn't a race. In the previous example, if the increment takes only one memory cycle, then no race exists. If our data always appears to be sequentially consistent, then we need no additional synchronization. Our operations are sequentially consistent when multiple threads can't observe inconsistencies in our data. In modern computer systems, memory accesses take multiple bus cycles, and multiprocessors generally interleave bus cycles among multiple processors, so we aren't guaranteed that our data is sequentially consistent.
In a sequentially consistent environment, we can explain modifications to our data as a sequential step of operations taken by the running threads. We can say such things as "Thread A incremented the variable, then thread B incremented the variable, so its value is two greater than before" or "Thread B incremented the variable, then thread A incremented the variable, so its value is two greater than before." No possible ordering of the two threads can result in any other value of the variable.
Besides the computer architecture, races can arise from the ways in which our programs use variables, creating places where it is possible to view inconsistencies. For example, we might increment a variable and then make a decision based on its value. The combination of the increment step and the decision-making step aren't atomic, so this opens a window where inconsistencies can arise.
Mutexes
We can protect our data and ensure access by only one thread at a time by using the pthreads mutual-exclusion interfaces. A mutex is basically a lock that we set (lock) before accessing a shared resource and release (unlock) when we're done. While it is set, any other thread that tries to set it will block until we release it. If more than one thread is blocked when we unlock the mutex, then all threads blocked on the lock will be made runnable, and the first one to run will be able to set the lock. The others will see that the mutex is still locked and go back to waiting for it to become available again. In this way, only one thread will proceed at a time.
This mutual-exclusion mechanism works only if we design our threads to follow the same data-access rules. The operating system doesn't serialize access to data for us. If we allow one thread to access a shared resource without first acquiring a lock, then inconsistencies can occur even though the rest of our threads do acquire the lock before attempting to access the shared resource.
A mutex variable is represented by the pthread_mutex_t data type. Before we can use a mutex variable, we must first initialize it by either setting it to the constant PTHREAD_MUTEX_INITIALIZER (for statically-allocated mutexes only) or calling pthread_mutex_init. If we allocate the mutex dynamically (by calling malloc, for example), then we need to call pthread_mutex_destroy before freeing the memory.
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *restrict
mutex,
const pthread_mutexattr_t
*restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
| Both return: 0 if OK, error number on failure |
To initialize a mutex with the default attributes, we set attr to NULL. We will discuss nondefault mutex attributes in Section 12.4.
To lock a mutex, we call pthread_mutex_lock. If the mutex is already locked, the calling thread will block until the mutex is unlocked. To unlock a mutex, we call pthread_mutex_unlock.
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
| All return: 0 if OK, error number on failure |
If a thread can't afford to block, it can use pthread_mutex_trylock to lock the mutex conditionally. If the mutex is unlocked at the time pthread_mutex_trylock is called, then pthread_mutex_trylock will lock the mutex without blocking and return 0. Otherwise, pthread_mutex_trylock will fail, returning EBUSY without locking the mutex.
Example
Figure 11.10 illustrates a mutex used to protect a data structure. When more than one thread needs to access a dynamically-allocated object, we can embed a reference count in the object to ensure that we don't free its memory before all threads are done using it.
We lock the mutex before incrementing the reference count, decrementing the reference count, and checking whether the reference count reaches zero. No locking is necessary when we initialize the reference count to 1 in the foo_alloc function, because the allocating thread is the only reference to it so far. If we were to place the structure on a list at this point, it could be found by other threads, so we would need to lock it first.
Before using the object, threads are expected to add a reference count to it. When they are done, they must release the reference. When the last reference is released, the object's memory is freed.
Figure 11.10. Using a mutex to protect a data structure
#include <stdlib.h>
#include <pthread.h>
struct foo {
int f_count;
pthread_mutex_t f_lock;
/* ... more stuff here ... */
};
struct foo *
foo_alloc(void) /* allocate the object */
{
struct foo *fp;
if ((fp = malloc(sizeof(struct foo))) != NULL) {
fp->f_count = 1;
if (pthread_mutex_init(&fp->f_lock, NULL) != 0) {
free(fp);
return(NULL);
}
/* ... continue initialization ... */
}
return(fp);
}
void
foo_hold(struct foo *fp) /* add a reference to the object */
{
pthread_mutex_lock(&fp->f_lock);
fp->f_count++;
pthread_mutex_unlock(&fp->f_lock);
}
void
foo_rele(struct foo *fp) /* release a reference to the object */
{
pthread_mutex_lock(&fp->f_lock);
if (--fp->f_count == 0) { /* last reference */
pthread_mutex_unlock(&fp->f_lock);
pthread_mutex_destroy(&fp->f_lock);
free(fp);
} else {
pthread_mutex_unlock(&fp->f_lock);
}
}
Deadlock Avoidance
A thread will deadlock itself if it tries to lock the same mutex twice, but there are less obvious ways to create deadlocks with mutexes. For example, when we use more than one mutex in our programs, a deadlock can occur if we allow one thread to hold a mutex and block while trying to lock a second mutex at the same time that another thread holding the second mutex tries to lock the first mutex. Neither thread can proceed, because each needs a resource that is held by the other, so we have a deadlock.
Deadlocks can be avoided by carefully controlling the order in which mutexes are locked. For example, assume that you have two mutexes, A and B, that you need to lock at the same time. If all threads always lock mutex A before mutex B, no deadlock can occur from the use of the two mutexes (but you can still deadlock on other resources). Similarly, if all threads always lock mutex B before mutex A, no deadlock will occur. You'll have the potential for a deadlock only when one thread attempts to lock the mutexes in the opposite order from another thread.
Sometimes, an application's architecture makes it difficult to apply a lock ordering. If enough locks and data structures are involved that the functions you have available can't be molded to fit a simple hierarchy, then you'll have to try some other approach. In this case, you might be able to release your locks and try again at a later time. You can use the pthread_mutex_trylock interface to avoid deadlocking in this case. If you are already holding locks and pthread_mutex_trylock is successful, then you can proceed. If it can't acquire the lock, however, you can release the locks you already hold, clean up, and try again later.
Example
In this example, we update Figure 11.10 to show the use of two mutexes. We avoid deadlocks by ensuring that when we need to acquire two mutexes at the same time, we always lock them in the same order. The second mutex protects a hash list that we use to keep track of the foo data structures. Thus, the hashlock mutex protects both the fh hash table and the f_next hash link field in the foo structure. The f_lock mutex in the foo structure protects access to the remainder of the foo structure's fields.
Comparing Figure 11.11 with Figure 11.10, we see that our allocation function now locks the hash list lock, adds the new structure to a hash bucket, and before unlocking the hash list lock, locks the mutex in the new structure. Since the new structure is placed on a global list, other threads can find it, so we need to block them if they try to access the new structure, until we are done initializing it.
The foo_find function locks the hash list lock and searches for the requested structure. If it is found, we increase the reference count and return a pointer to the structure. Note that we honor the lock ordering by locking the hash list lock in foo_find before foo_hold locks the foo structure's f_lock mutex.
Now with two locks, the foo_rele function is more complicated. If this is the last reference, we need to unlock the structure mutex so that we can acquire the hash list lock, since we'll need to remove the structure from the hash list. Then we reacquire the structure mutex. Because we could have blocked since the last time we held the structure mutex, we need to recheck the condition to see whether we still need to free the structure. If another thread found the structure and added a reference to it while we blocked to honor the lock ordering, we simply need to decrement the reference count, unlock everything, and return.
This locking is complex, so we need to revisit our design. We can simplify things considerably by using the hash list lock to protect the structure reference count, too. The structure mutex can be used to protect everything else in the foo structure. Figure 11.12 reflects this change.
Note how much simpler the program in Figure 11.12 is compared to the program in Figure 11.11. The lock-ordering issues surrounding the hash list and the reference count go away when we use the same lock for both purposes. Multithreaded software design involves these types of tradeoffs. If your locking granularity is too coarse, you end up with too many threads blocking behind the same locks, with little improvement possible from concurrency. If your locking granularity is too fine, then you suffer bad performance from excess locking overhead, and you end up with complex code. As a programmer, you need to find the correct balance between code complexity and performance, and still satisfy your locking requirements.
Figure 11.11. Using two mutexes
#include <stdlib.h>
#include <pthread.h>
#define NHASH 29
#define HASH(fp) (((unsigned long)fp)%NHASH)
struct foo *fh[NHASH];
pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER;
struct foo {
int f_count;
pthread_mutex_t f_lock;
struct foo *f_next; /* protected by hashlock */
int f_id;
/* ... more stuff here ... */
};
struct foo *
foo_alloc(void) /* allocate the object */
{
struct foo *fp;
int idx;
if ((fp = malloc(sizeof(struct foo))) != NULL) {
fp->f_count = 1;
if (pthread_mutex_init(&fp->f_lock, NULL) != 0) {
free(fp);
return(NULL);
}
idx = HASH(fp);
pthread_mutex_lock(&hashlock);
fp->f_next = fh[idx];
fh[idx] = fp->f_next;
pthread_mutex_lock(&fp->f_lock);
pthread_mutex_unlock(&hashlock);
/* ... continue initialization ... */
pthread_mutex_unlock(&fp->f_lock);
}
return(fp);
}
void
foo_hold(struct foo *fp) /* add a reference to the object */
{
pthread_mutex_lock(&fp->f_lock);
fp->f_count++;
pthread_mutex_unlock(&fp->f_lock);
}
struct foo *
foo_find(int id) /* find an existing object */
{
struct foo *fp;
int idx;
idx = HASH(fp);
pthread_mutex_lock(&hashlock);
for (fp = fh[idx]; fp != NULL; fp = fp->f_next) {
if (fp->f_id == id) {
foo_hold(fp);
break;
}
}
pthread_mutex_unlock(&hashlock);
return(fp);
}
void
foo_rele(struct foo *fp) /* release a reference to the object */
{
struct foo *tfp;
int idx;
pthread_mutex_lock(&fp->f_lock);
if (fp->f_count == 1) { /* last reference */
pthread_mutex_unlock(&fp->f_lock);
pthread_mutex_lock(&hashlock);
pthread_mutex_lock(&fp->f_lock);
/* need to recheck the condition */
if (fp->f_count != 1) {
fp->f_count--;
pthread_mutex_unlock(&fp->f_lock);
pthread_mutex_unlock(&hashlock);
return;
}
/* remove from list */
idx = HASH(fp);
tfp = fh[idx];
if (tfp == fp) {
fh[idx] = fp->f_next;
} else {
while (tfp->f_next != fp)
tfp = tfp->f_next;
tfp->f_next = fp->f_next;
}
pthread_mutex_unlock(&hashlock);
pthread_mutex_unlock(&fp->f_lock);
pthread_mutex_destroy(&fp->f_lock);
free(fp);
} else {
fp->f_count--;
pthread_mutex_unlock(&fp->f_lock);
}
}
Figure 11.12. Simplified locking
#include <stdlib.h>
#include <pthread.h>
#define NHASH 29
#define HASH(fp) (((unsigned long)fp)%NHASH)
struct foo *fh[NHASH];
pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER;
struct foo {
int f_count; /* protected by hashlock */
pthread_mutex_t f_lock;
struct foo *f_next; /* protected by hashlock */
int f_id;
/* ... more stuff here ... */
};
struct foo *
foo_alloc(void) /* allocate the object */
{
struct foo *fp;
int idx;
if ((fp = malloc(sizeof(struct foo))) != NULL) {
fp->f_count = 1;
if (pthread_mutex_init(&fp->f_lock, NULL) != 0) {
free(fp);
return(NULL);
}
idx = HASH(fp);
pthread_mutex_lock(&hashlock);
fp->f_next = fh[idx];
fh[idx] = fp->f_next;
pthread_mutex_lock(&fp->f_lock);
pthread_mutex_unlock(&hashlock);
/* ... continue initialization ... */
}
return(fp);
}
void
foo_hold(struct foo *fp) /* add a reference to the object */
{
pthread_mutex_lock(&hashlock);
fp->f_count++;
pthread_mutex_unlock(&hashlock);
}
struct foo *
foo_find(int id) /* find a existing object */
{
struct foo *fp;
int idx;
idx = HASH(fp);
pthread_mutex_lock(&hashlock);
for (fp = fh[idx]; fp != NULL; fp = fp->f_next) {
if (fp->f_id == id) {
fp->f_count++;
break;
}
}
pthread_mutex_unlock(&hashlock);
return(fp);
}
void
foo_rele(struct foo *fp) /* release a reference to the object */
{
struct foo *tfp;
int idx;
pthread_mutex_lock(&hashlock);
if (--fp->f_count == 0) { /* last reference, remove from list */
idx = HASH(fp);
tfp = fh[idx];
if (tfp == fp) {
fh[idx] = fp->f_next;
} else {
while (tfp->f_next != fp)
tfp = tfp->f_next;
tfp->f_next = fp->f_next;
}
pthread_mutex_unlock(&hashlock);
pthread_mutex_destroy(&fp->f_lock);
free(fp);
} else {
pthread_mutex_unlock(&hashlock);
}
}
ReaderWriter Locks
Readerwriter locks are similar to mutexes, except that they allow for higher degrees of parallelism. With a mutex, the state is either locked or unlocked, and only one thread can lock it at a time. Three states are possible with a readerwriter lock: locked in read mode, locked in write mode, and unlocked. Only one thread at a time can hold a readerwriter lock in write mode, but multiple threads can hold a readerwriter lock in read mode at the same time.
When a readerwriter lock is write-locked, all threads attempting to lock it block until it is unlocked. When a readerwriter lock is read-locked, all threads attempting to lock it in read mode are given access, but any threads attempting to lock it in write mode block until all the threads have relinquished their read locks. Although implementations vary, readerwriter locks usually block additional readers if a lock is already held in read mode and a thread is blocked trying to acquire the lock in write mode. This prevents a constant stream of readers from starving waiting writers.
Readerwriter locks are well suited for situations in which data structures are read more often than they are modified. When a readerwriter lock is held in write mode, the data structure it protects can be modified safely, since only one thread at a time can hold the lock in write mode. When the readerwriter lock is held in read mode, the data structure it protects can be read by multiple threads, as long as the threads first acquire the lock in read mode.
Readerwriter locks are also called sharedexclusive locks. When a readerwriter lock is read-locked, it is said to be locked in shared mode. When it is write-locked, it is said to be locked in exclusive mode.
As with mutexes, readerwriter locks must be initialized before use and destroyed before freeing their underlying memory.
#include <pthread.h>
int pthread_rwlock_init(pthread_rwlock_t *restrict
rwlock,
const pthread_rwlockattr_t
*restrict attr);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
| Both return: 0 if OK, error number on failure |
A readerwriter lock is initialized by calling pthread_rwlock_init. We can pass a null pointer for attr if we want the readerwriter lock to have the default attributes. We discuss readerwriter lock attributes in Section 12.4.
Before freeing the memory backing a readerwriter lock, we need to call pthread_rwlock_destroy to clean it up. If pthread_rwlock_init allocated any resources for the readerwriter lock, pthread_rwlock_destroy frees those resources. If we free the memory backing a readerwriter lock without first calling pthread_rwlock_destroy, any resources assigned to the lock will be lost.
To lock a readerwriter lock in read mode, we call pthread_rwlock_rdlock. To write-lock a readerwriter lock, we call pthread_rwlock_wrlock. Regardless of how we lock a readerwriter lock, we can call pthread_rwlock_unlock to unlock it.
#include <pthread.h>
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
| All return: 0 if OK, error number on failure |
Implementations might place a limit on the number of times a readerwriter lock can be locked in shared mode, so we need to check the return value of pthread_rwlock_rdlock. Even though pthread_rwlock_wrlock and pthread_rwlock_unlock have error returns, we don't need to check them if we design our locking properly. The only error returns defined are when we use them improperly, such as with an uninitialized lock, or when we might deadlock by attempting to acquire a lock we already own.
The Single UNIX Specification also defines conditional versions of the readerwriter locking primitives.
#include <pthread.h>
int pthread_rwlock_tryrdlock(pthread_rwlock_t
*rwlock);
int pthread_rwlock_trywrlock(pthread_rwlock_t
*rwlock);
| Both return: 0 if OK, error number on failure |
When the lock can be acquired, these functions return 0. Otherwise, they return the error EBUSY. These functions can be used in situations in which conforming to a lock hierarchy isn't enough to avoid a deadlock, as we discussed previously.
Example
The program in Figure 11.13 illustrates the use of readerwriter locks. A queue of job requests is protected by a single readerwriter lock. This example shows a possible implementation of Figure 11.1, whereby multiple worker threads obtain jobs assigned to them by a single master thread.
In this example, we lock the queue's readerwriter lock in write mode whenever we need to add a job to the queue or remove a job from the queue. Whenever we search the queue, we grab the lock in read mode, allowing all the worker threads to search the queue concurrently. Using a readerwriter lock will improve performance in this case only if threads search the queue much more frequently than they add or remove jobs.
The worker threads take only those jobs that match their thread ID off the queue. Since the job structures are used only by one thread at a time, they don't need any extra locking.
Figure 11.13. Using readerwriter locks
#include <stdlib.h>
#include <pthread.h>
struct job {
struct job *j_next;
struct job *j_prev;
pthread_t j_id; /* tells which thread handles this job */
/* ... more stuff here ... */
};
struct queue {
struct job *q_head;
struct job *q_tail;
pthread_rwlock_t q_lock;
};
/*
* Initialize a queue.
*/
int
queue_init(struct queue *qp)
{
int err;
qp->q_head = NULL;
qp->q_tail = NULL;
err = pthread_rwlock_init(&qp->q_lock, NULL);
if (err != 0)
return(err);
/* ... continue initialization ... */
return(0);
}
/*
* Insert a job at the head of the queue.
*/
void
job_insert(struct queue *qp, struct job *jp)
{
pthread_rwlock_wrlock(&qp->q_lock);
jp->j_next = qp->q_head;
jp->j_prev = NULL;
if (qp->q_head != NULL)
qp->q_head->j_prev = jp;
else
qp->q_tail = jp; /* list was empty */
qp->q_head = jp;
pthread_rwlock_unlock(&qp->q_lock);
}
/*
* Append a job on the tail of the queue.
*/
void
job_append(struct queue *qp, struct job *jp)
{
pthread_rwlock_wrlock(&qp->q_lock);
jp->j_next = NULL;
jp->j_prev = qp->q_tail;
if (qp->q_tail != NULL)
qp->q_tail->j_next = jp;
else
qp->q_head = jp; /* list was empty */
qp->q_tail = jp;
pthread_rwlock_unlock(&qp->q_lock);
}
/*
* Remove the given job from a queue.
*/
void
job_remove(struct queue *qp, struct job *jp)
{
pthread_rwlock_wrlock(&qp->q_lock);
if (jp == qp->q_head) {
qp->q_head = jp->j_next;
if (qp->q_tail == jp)
qp->q_tail = NULL;
} else if (jp == qp->q_tail) {
qp->q_tail = jp->j_prev;
if (qp->q_head == jp)
qp->q_head = NULL;
} else {
jp->j_prev->j_next = jp->j_next;
jp->j_next->j_prev = jp->j_prev;
}
pthread_rwlock_unlock(&qp->q_lock);
}
/*
* Find a job for the given thread ID.
*/
struct job *
job_find(struct queue *qp, pthread_t id)
{
struct job *jp;
if (pthread_rwlock_rdlock(&qp->q_lock) != 0)
return(NULL);
for (jp = qp->q_head; jp != NULL; jp = jp->j_next)
if (pthread_equal(jp->j_id, id))
break;
pthread_rwlock_unlock(&qp->q_lock);
return(jp);
}
Condition Variables
Condition variables are another synchronization mechanism available to threads. Condition variables provide a place for threads to rendezvous. When used with mutexes, condition variables allow threads to wait in a race-free way for arbitrary conditions to occur.
The condition itself is protected by a mutex. A thread must first lock the mutex to change the condition state. Other threads will not notice the change until they acquire the mutex, because the mutex must be locked to be able to evaluate the condition.
Before a condition variable is used, it must first be initialized. A condition variable, represented by the pthread_cond_t data type, can be initialized in two ways. We can assign the constant PTHREAD_COND_INITIALIZER to a statically-allocated condition variable, but if the condition variable is allocated dynamically, we can use the pthread_cond_init function to initialize it.
We can use the pthread_mutex_destroy function to deinitialize a condition variable before freeing its underlying memory.
#include <pthread.h>
int pthread_cond_init(pthread_cond_t *restrict cond,
pthread_condattr_t *restrict
attr);
int pthread_cond_destroy(pthread_cond_t *cond);
| Both return: 0 if OK, error number on failure |
Unless you need to create a conditional variable with nondefault attributes, the attr argument to pthread_cond_init can be set to NULL. We will discuss condition variable attributes in Section 12.4.
We use pthread_cond_wait to wait for a condition to be true. A variant is provided to return an error code if the condition hasn't been satisfied in the specified amount of time.
The mutex passed to pthread_cond_wait protects the condition. The caller passes it locked to the function, which then atomically places the calling thread on the list of threads waiting for the condition and unlocks the mutex. This closes the window between the time that the condition is checked and the time that the thread goes to sleep waiting for the condition to change, so that the thread doesn't miss a change in the condition. When pthread_cond_wait returns, the mutex is again locked.
The pthread_cond_timedwait function works the same as the pthread_cond_wait function with the addition of the timeout. The timeout value specifies how long we will wait. It is specified by the timespec structure, where a time value is represented by a number of seconds and partial seconds. Partial seconds are specified in units of nanoseconds:
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
Using this structure, we need to specify how long we are willing to wait as an absolute time instead of a relative time. For example, if we are willing to wait 3 minutes, instead of translating 3 minutes into a timespec structure, we need to translate now + 3 minutes into a timespec structure.
We can use gettimeofday (Section 6.10) to get the current time expressed as a timeval structure and translate this into a timespec structure. To obtain the absolute time for the timeout value, we can use the following function:
void
maketimeout(struct timespec *tsp, long minutes)
{
struct timeval now;
/* get the current time */
gettimeofday(&now);
tsp->tv_sec = now.tv_sec;
tsp->tv_nsec = now.tv_usec * 1000; /* usec to nsec */
/* add the offset to get timeout value */
tsp->tv_sec += minutes * 60;
}
If the timeout expires without the condition occurring, pthread_cond_timedwait will reacquire the mutex and return the error ETIMEDOUT. When it returns from a successful call to pthread_cond_wait or pthread_cond_timedwait, a thread needs to reevaluate the condition, since another thread might have run and already changed the condition.
There are two functions to notify threads that a condition has been satisfied. The pthread_cond_signal function will wake up one thread waiting on a condition, whereas the pthread_cond_broadcast function will wake up all threads waiting on a condition.
The POSIX specification allows for implementations of pthread_cond_signal to wake up more than one thread, to make the implementation simpler.
#include <pthread.h>
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond);
| Both return: 0 if OK, error number on failure |
When we call pthread_cond_signal or pthread_cond_broadcast, we are said to be signaling the thread or condition. We have to be careful to signal the threads only after changing the state of the condition.
Example
Figure 11.14 shows an example of how to use condition variables and mutexes together to synchronize threads.
The condition is the state of the work queue. We protect the condition with a mutex and evaluate the condition in a while loop. When we put a message on the work queue, we need to hold the mutex, but we don't need to hold the mutex when we signal the waiting threads. As long as it is okay for a thread to pull the message off the queue before we call cond_signal, we can do this after releasing the mutex. Since we check the condition in a while loop, this doesn't present a problem: a thread will wake up, find that the queue is still empty, and go back to waiting again. If the code couldn't tolerate this race, we would need to hold the mutex when we signal the threads.
Figure 11.14. Using condition variables
#include <pthread.h>
struct msg {
struct msg *m_next;
/* ... more stuff here ... */
};
struct msg *workq;
pthread_cond_t qready = PTHREAD_COND_INITIALIZER;
pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;
void
process_msg(void)
{
struct msg *mp;
for (;;) {
pthread_mutex_lock(&qlock);
while (workq == NULL)
pthread_cond_wait(&qready, &qlock);
mp = workq;
workq = mp->m_next;
pthread_mutex_unlock(&qlock);
/* now process the message mp */
}
}
void
enqueue_msg(struct msg *mp)
{
pthread_mutex_lock(&qlock);
mp->m_next = workq;
workq = mp;
pthread_mutex_unlock(&qlock);
pthread_cond_signal(&qready);
}
12.1. Introduction
In Chapter 11, we learned the basics about threads and thread synchronization. In this chapter, we will learn the details of controlling thread behavior. We will look at thread attributes and synchronization primitive attributes, which we ignored in the previous chapter in favor of the default behaviors.
We will follow this with a look at how threads can keep data private from other threads in the same process. Then we will wrap up the chapter with a look at how some process-based system calls interact with threads.
12.2. Thread Limits
We discussed the sysconf function in Section 2.5.4. The Single UNIX Specification defines several limits associated with the operation of threads, which we didn't show in Figure 2.10. As with other system limits, the thread limits can be queried using sysconf. Figure 12.1 summarizes these limits.
Figure 12.1. Thread limits and name arguments to sysconfName of limit | Description | name argument |
|---|
PTHREAD_DESTRUCTOR_ITERATIONS | maximum number of times an implementation will try to destroy the thread-specific data when a thread exits (Section 12.6) | _SC_THREAD_DESTRUCTOR_ITERATIONS | PTHREAD_KEYS_MAX | maximum number of keys that can be created by a process (Section 12.6) | _SC_THREAD_KEYS_MAX
| PTHREAD_STACK_MIN | minimum number of bytes that can be used for a thread's stack (Section 12.3) | _SC_THREAD_STACK_MIN | PTHREAD_THREADS_MAX | maximum number of threads that can be created in a process (Section 12.3) | _SC_THREAD_THREADS_MAX |
As with the other limits reported by sysconf, use of these limits is intended to promote application portability among different operating system implementations. For example, if your application requires that you create four threads for every file you manage, you might have to limit the number of files you can manage concurrently if the system won't let you create enough threads.
Figure 12.2 shows the values of the thread limits for the four implementations described in this book. When the implementation doesn't define the corresponding sysconf symbol (starting with _SC_), "no symbol" is listed. If the implementation's limit is indeterminate, "no limit" is listed. This doesn't mean that the value is unlimited, however. An "unsupported" entry means that the implementation defines the corresponding sysconf limit symbol, but the sysconf function doesn't recognize it.
Note that although an implementation may not provide access to these limits, that doesn't mean that the limits don't exist. It just means that the implementation doesn't provide us with a way to get at them using sysconf.
Figure 12.2. Examples of thread configuration limitsLimit | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
PTHREAD_DESTRUCTOR_ITERATIONS | no symbol | unsupported | no symbol | no limit | PTHREAD_KEYS_MAX | no symbol | unsupported | no symbol | no limit | PTHREAD_STACK_MIN | no symbol | unsupported | no symbol | 4,096 | PTHREAD_THREADS_MAX | no symbol | unsupported | no symbol | no limit |
12.3. Thread Attributes
In all the examples in which we called pthread_create in Chapter 11, we passed in a null pointer instead of passing in a pointer to a pthread_attr_t structure. We can use the pthread_attr_t structure to modify the default attributes, and associate these attributes with threads that we create. We use the pthread_attr_init function to initialize the pthread_attr_t structure. After calling pthread_attr_init, the pthread_attr_t structure contains the default values for all the thread attributes supported by the implementation. To change individual attributes, we need to call other functions, as described later in this section.
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy(pthread_attr_t *attr);
| Both return: 0 if OK, error number on failure |
To deinitialize a pthread_attr_t structure, we call pthread_attr_destroy. If an implementation of pthread_attr_init allocated any dynamic memory for the attribute object, pthread_attr_destroy will free that memory. In addition, pthread_attr_destroy will initialize the attribute object with invalid values, so if it is used by mistake, pthread_create will return an error.
The pthread_attr_t structure is opaque to applications. This means that applications aren't supposed to know anything about its internal structure, thus promoting application portability. Following this model, POSIX.1 defines separate functions to query and set each attribute.
The thread attributes defined by POSIX.1 are summarized in Figure 12.3. POSIX.1 defines additional attributes in the real-time threads option, but we don't discuss those here. In Figure 12.3, we also show which platforms support each thread attribute. If the attribute is accessible through an obsolete interface, we show ob in the table entry.
Figure 12.3. POSIX.1 thread attributesName | Description | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
detachstate | detached thread attribute | • | • | • | • | guardsize | guard buffer size in bytes at end of thread stack | | • | • | • | stackaddr | lowest address of thread stack | ob | • | • | ob
| stacksize | size in bytes of thread stack | • | • | • | • |
In Section 11.5, we introduced the concept of detached threads. If we are no longer interested in an existing thread's termination status, we can use pthread_detach to allow the operating system to reclaim the thread's resources when the thread exits.
If we know that we don't need the thread's termination status at the time we create the thread, we can arrange for the thread to start out in the detached state by modifying the detachstate thread attribute in the pthread_attr_t structure. We can use the pthread_attr_setdetachstate function to set the detachstate thread attribute to one of two legal values: PTHREAD_CREATE_DETACHED to start the thread in the detached state or PTHREAD_CREATE_JOINABLE to start the thread normally, so its termination status can be retrieved by the application.
#include <pthread.h>
int pthread_attr_getdetachstate(const
pthread_attr_t *restrict attr,
int *detachstate);
int pthread_attr_setdetachstate(pthread_attr_t
*attr, int detachstate);
| Both return: 0 if OK, error number on failure |
We can call pthread_attr_getdetachstate to obtain the current detachstate attribute. The integer pointed to by the second argument is set to either PTHREAD_CREATE_DETACHED or PTHREAD_CREATE_JOINABLE, depending on the value of the attribute in the given pthread_attr_t structure.
Example
Figure 12.4 shows a function that can be used to create a thread in the detached state.
Note that we ignore the return value from the call to pthread_attr_destroy. In this case, we initialized the thread attributes properly, so pthread_attr_destroy shouldn't fail. Nonetheless, if it does fail, cleaning up would be difficult: we would have to destroy the thread we just created, which is possibly already running, asynchronous to the execution of this function. By ignoring the error return from pthread_attr_destroy, the worst that can happen is that we leak a small amount of memory if pthread_attr_init allocated any. But if pthread_attr_init succeeded in initializing the thread attributes and then pthread_attr_destroy failed to clean up, we have no recovery strategy anyway, because the attributes structure is opaque to the application. The only interface defined to clean up the structure is pthread_attr_destroy, and it just failed.
Figure 12.4. Creating a thread in the detached state
#include "apue.h"
#include <pthread.h>
int
makethread(void *(*fn)(void *), void *arg)
{
int err;
pthread_t tid;
pthread_attr_t attr;
err = pthread_attr_init(&attr);
if (err != 0)
return(err);
err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (err == 0)
err = pthread_create(&tid, &attr, fn, arg);
pthread_attr_destroy(&attr);
return(err);
}
Support for thread stack attributes is optional for a POSIX-conforming operating system, but is required if the system is to conform to the XSI. At compile time, you can check whether your system supports each thread stack attribute using the _POSIX_THREAD_ATTR_STACKADDR and _POSIX_THREAD_ATTR_STACKSIZE symbols. If one is defined, then the system supports the corresponding thread stack attribute. You can also check at runtime, by using the _SC_THREAD_ATTR_STACKADDR and _SC_THREAD_ATTR_STACKSIZE parameters to the sysconf function.
POSIX.1 defines several interfaces to manipulate thread stack attributes. Two older functions, pthread_attr_getstackaddr and pthread_attr_setstackaddr, are marked as obsolete in Version 3 of the Single UNIX Specification, although many pthreads implementations still provide them. The preferred way to query and modify a thread's stack attributes is to use the newer functions pthread_attr_getstack and pthread_attr_setstack. These functions clear up ambiguities present in the definition of the older interfaces.
#include <pthread.h>
int pthread_attr_getstack(const pthread_attr_t
*restrict attr,
void **restrict stackaddr,
size_t *restrict stacksize);
int pthread_attr_setstack(const pthread_attr_t *attr,
void *stackaddr, size_t
*stacksize);
| Both return: 0 if OK, error number on failure |
These two functions are used to manage both the stackaddr and the stacksize thread attributes.
With a process, the amount of virtual address space is fixed. Since there is only one stack, its size usually isn't a problem. With threads, however, the same amount of virtual address space must be shared by all the thread stacks. You might have to reduce your default thread stack size if your application uses so many threads that the cumulative size of their stacks exceeds the available virtual address space. On the other hand, if your threads call functions that allocate large automatic variables or call functions many stack frames deep, you might need more than the default stack size.
If you run out of virtual address space for thread stacks, you can use malloc or mmap (see Section 14.9) to allocate space for an alternate stack and use pthread_attr_setstack to change the stack location of threads you create. The address specified by the stackaddr parameter is the lowest addressable address in the range of memory to be used as the thread's stack, aligned at the proper boundary for the processor architecture.
The stackaddr thread attribute is defined as the lowest memory address for the stack. This is not necessarily the start of the stack, however. If stacks grow from higher address to lower addresses for a given processor architecture, the stackaddr thread attribute will be the end of the stack instead of the beginning.
The drawback with pthread_attr_getstackaddr and pthread_attr_setstackaddr is that the stackaddr parameter was underspecified. It could have been interpreted as the start of the stack or as the lowest memory address of the memory extent to use as the stack. On architectures in which the stacks grow down from higher memory addresses to lower addresses, if the stackaddr parameter is the lowest memory address of the stack, then you need to know the stack size to determine the start of the stack. The pthread_attr_getstack and pthread_attr_setstack functions correct these shortcomings.
An application can also get and set the stacksize thread attribute using the pthread_attr_getstacksize and pthread_attr_setstacksize functions.
#include <pthread.h>
int pthread_attr_getstacksize(const pthread_attr_t
*restrict attr,
size_t *restrict
stacksize);
int pthread_attr_setstacksize(pthread_attr_t *attr
, size_t stacksize);
| Both return: 0 if OK, error number on failure |
The pthread_attr_setstacksize function is useful when you want to change the default stack size but don't want to deal with allocating the thread stacks on your own.
The guardsize thread attribute controls the size of the memory extent after the end of the thread's stack to protect against stack overflow. By default, this is set to PAGESIZE bytes. We can set the guardsize thread attribute to 0 to disable this feature: no guard buffer will be provided in this case. Also, if we change the stackaddr thread attribute, the system assumes that we will be managing our own stacks and disables stack guard buffers, just as if we had set the guardsize thread attribute to 0.
#include <pthread.h>
int pthread_attr_getguardsize(const pthread_attr_t
*restrict attr,
size_t *restrict
guardsize);
int pthread_attr_setguardsize(pthread_attr_t *attr
, size_t guardsize);
| Both return: 0 if OK, error number on failure |
If the guardsize thread attribute is modified, the operating system might round it up to an integral multiple of the page size. If the thread's stack pointer overflows into the guard area, the application will receive an error, possibly with a signal.
The Single UNIX Specification defines several other optional thread attributes as part of the real-time threads option. We will not discuss them here.
More Thread Attributes
Threads have other attributes not represented by the pthread_attr_t structure:
The concurrency level controls the number of kernel threads or processes on top of which the user-level threads are mapped. If an implementation keeps a one-to-one mapping between kernel-level threads and user-level threads, then changing the concurrency level will have no effect, since it is possible for all user-level threads to be scheduled. If the implementation multiplexes user-level threads on top of kernel-level threads or processes, however, you might be able to improve performance by increasing the number of user-level threads that can run at a given time. The pthread_setconcurrency function can be used to provide a hint to the system of the desired level of concurrency.
#include <pthread.h>
int pthread_getconcurrency(void);
| Returns: current concurrency level |
int pthread_setconcurrency(int level);
| Returns: 0 if OK, error number on failure |
The pthread_getconcurrency function returns the current concurrency level. If the operating system is controlling the concurrency level (i.e., if no prior call to pthread_setconcurrency has been made), then pthread_getconcurrency will return 0.
The concurrency level specified by pthread_setconcurrency is only a hint to the system. There is no guarantee that the requested concurrency level will be honored. You can tell the system that you want it to decide for itself what concurrency level to use by passing a level of 0. Thus, an application can undo the effects of a prior call to pthread_setconcurrency with a nonzero value of level by calling it again with level set to 0.
12.4. Synchronization Attributes
Just as threads have attributes, so too do their synchronization objects. In this section, we discuss the attributes of mutexes, readerwriter locks, and condition variables.
Mutex Attributes
We use pthread_mutexattr_init to initialize a pthread_mutexattr_t structure and pthread_mutexattr_destroy to deinitialize one.
#include <pthread.h>
int pthread_mutexattr_init(pthread_mutexattr_t *attr);
int pthread_mutexattr_destroy(pthread_mutexattr_t
*attr);
| Both return: 0 if OK, error number on failure |
The pthread_mutexattr_init function will initialize the pthread_mutexattr_t structure with the default mutex attributes. Two attributes of interest are the process-shared attribute and the type attribute. Within POSIX.1, the process-shared attribute is optional; you can test whether a platform supports it by checking whether the _POSIX_THREAD_PROCESS_SHARED symbol is defined. You can also check at runtime by passing the _SC_THREAD_PROCESS_SHARED parameter to the sysconf function. Although this option is not required to be provided by POSIX-conforming operating systems, the Single UNIX Specification requires that XSI-conforming operating systems do support this option.
Within a process, multiple threads can access the same synchronization object. This is the default behavior, as we saw in Chapter 11. In this case, the process-shared mutex attribute is set to PTHREAD_PROCESS_PRIVATE.
As we shall see in Chapters 14 and 15, mechanisms exist that allow independent processes to map the same extent of memory into their independent address spaces. Access to shared data by multiple processes usually requires synchronization, just as does access to shared data by multiple threads. If the process-shared mutex attribute is set to PTHREAD_PROCESS_SHARED, a mutex allocated from a memory extent shared between multiple processes may be used for synchronization by those processes.
We can use the pthread_mutexattr_getpshared function to query a pthread_mutexattr_t structure for its process-shared attribute. We can change the process-shared attribute with the pthread_mutexattr_setpshared function.
#include <pthread.h>
int pthread_mutexattr_getpshared(const
pthread_mutexattr_t *
restrict attr,
int *restrict
pshared);
int pthread_mutexattr_setpshared
(pthread_mutexattr_t *attr,
int pshared);
| Both return: 0 if OK, error number on failure |
The process-shared mutex attribute allows the pthread library to provide more efficient mutex implementations when the attribute is set to PTHREAD_PROCESS_PRIVATE, which is the default case with multithreaded applications. Then the pthread library can restrict the more expensive implementation to the case in which mutexes are shared among processes.
The type mutex attribute controls the characteristics of the mutex. POSIX.1 defines four types. The PTHREAD_MUTEX_NORMAL type is a standard mutex that doesn't do any special error checking or deadlock detection. The PTHREAD_MUTEX_ERRORCHECK mutex type provides error checking.
The PTHREAD_MUTEX_RECURSIVE mutex type allows the same thread to lock it multiple times without first unlocking it. A recursive mutex maintains a lock count and isn't released until it is unlocked the same number of times it is locked. So if you lock a recursive mutex twice and then unlock it, the mutex remains locked until it is unlocked a second time.
Finally, the PTHREAD_MUTEX_DEFAULT type can be used to request default semantics. Implementations are free to map this to one of the other types. On Linux, for example, this type is mapped to the normal mutex type.
The behavior of the four types is shown in Figure 12.5. The "Unlock when not owned" column refers to one thread unlocking a mutex that was locked by a different thread. The "Unlock when unlocked" column refers to what happens when a thread unlocks a mutex that is already unlocked, which usually is a coding mistake.
Figure 12.5. Mutex type behaviorMutex type | Relock without unlock? | Unlock when not owned? | Unlock when unlocked? |
|---|
PTHREAD_MUTEX_NORMAL | deadlock | undefined | undefined | PTHREAD_MUTEX_ERRORCHECK | returns error | returns error | returns error | PTHREAD_MUTEX_RECURSIVE | allowed | returns error | returns error | PTHREAD_MUTEX_DEFAULT | undefined | undefined | undefined |
We can use pthread_mutexattr_gettype to get the mutex type attribute and pthread_mutexattr_settype to change the mutex type attribute.
#include <pthread.h>
int pthread_mutexattr_gettype(const
pthread_mutexattr_t *
restrict attr, int
*restrict type);
int pthread_mutexattr_settype(pthread_mutexattr_t
*attr, int type);
| Both return: 0 if OK, error number on failure |
Recall from Section 11.6 that a mutex is used to protect the condition that is associated with a condition variable. Before blocking the thread, the pthread_cond_wait and the pthread_cond_timedwait functions release the mutex associated with the condition. This allows other threads to acquire the mutex, change the condition, release the mutex, and signal the condition variable. Since the mutex must be held to change the condition, it is not a good idea to use a recursive mutex. If a recursive mutex is locked multiple times and used in a call to pthread_cond_wait, the condition can never be satisfied, because the unlock done by pthread_cond_wait doesn't release the mutex.
Recursive mutexes are useful when you need to adapt existing single-threaded interfaces to a multithreaded environment, but can't change the interfaces to your functions because of compatibility constraints. However, using recursive locks can be tricky, and they should be used only when no other solution is possible.
Example
Figure 12.6 illustrates a situation in which a recursive mutex might seem to solve a concurrency problem. Assume that func1 and func2 are existing functions in a library whose interfaces can't be changed, because applications exist that call them, and the applications can't be changed.
To keep the interfaces the same, we embed a mutex in the data structure whose address (x) is passed in as an argument. This is possible only if we have provided an allocator function for the structure, so the application doesn't know about its size (assuming we must increase its size when we add a mutex to it).
This is also possible if we originally defined the structure with enough padding to allow us now to replace some pad fields with a mutex. Unfortunately, most programmers are unskilled at predicting the future, so this is not a common practice.
If both func1 and func2 must manipulate the structure and it is possible to access it from more than one thread at a time, then func1 and func2 must lock the mutex before manipulating the data. If func1 must call func2, we will deadlock if the mutex type is not recursive. We could avoid using a recursive mutex if we could release the mutex before calling func2 and reacquire it after func2 returns, but this opens a window where another thread can possibly grab control of the mutex and change the data structure in the middle of func1. This may not be acceptable, depending on what protection the mutex is intended to provide.
Figure 12.7 shows an alternative to using a recursive mutex in this case. We can leave the interfaces to func1 and func2 unchanged and avoid a recursive mutex by providing a private version of func2, called func2_locked. To call func2_locked, we must hold the mutex embedded in the data structure whose address we pass as the argument. The body of func2_locked contains a copy of func2, and func2 now simply acquires the mutex, calls func2_locked, and then releases the mutex.
If we didn't have to leave the interfaces to the library functions unchanged, we could have added a second parameter to each function to indicate whether the structure is locked by the caller. It is usually better to leave the interfaces unchanged if we can, however, instead of polluting it with implementation artifacts.
The strategy of providing locked and unlocked versions of functions is usually applicable in simple situations. In more complex situations, such as when the library needs to call a function outside the library, which then might call back into the library, we need to rely on recursive locks.
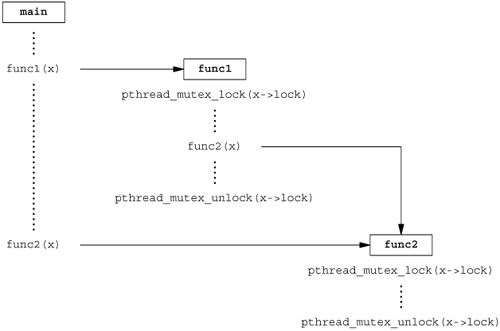
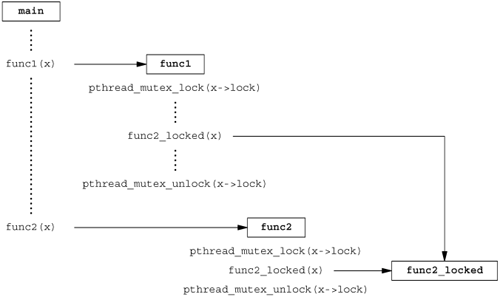
Example
The program in Figure 12.8 illustrates another situation in which a recursive mutex is necessary. Here, we have a "timeout" function that allows us to schedule another function to be run at some time in the future. Assuming that threads are an inexpensive resource, we can create a thread for each pending timeout. The thread waits until the time has been reached, and then it calls the function we've requested.
The problem arises when we can't create a thread or when the scheduled time to run the function has already passed. In these cases, we simply call the requested function now, from the current context. Since the function acquires the same lock that we currently hold, a deadlock will occur unless the lock is recursive.
We use the makethread function from Figure 12.4 to create a thread in the detached state. We want the function to run in the future, and we don't want to wait around for the thread to complete.
We could call sleep to wait for the timeout to expire, but that gives us only second granularity. If we want to wait for some time other than an integral number of seconds, we need to use nanosleep(2), which provides similar functionality.
Although nanosleep is required to be implemented only in the real-time extensions of the Single UNIX Specification, all the platforms discussed in this text support it.
The caller of timeout needs to hold a mutex to check the condition and to schedule the retry function as an atomic operation. The retry function will try to lock the same mutex. Unless the mutex is recursive, a deadlock will occur if the timeout function calls retry directly.
Figure 12.8. Using a recursive mutex
#include "apue.h"
#include <pthread.h>
#include <time.h>
#include <sys/time.h>
extern int makethread(void *(*)(void *), void *);
struct to_info {
void (*to_fn)(void *); /* function */
void *to_arg; /* argument */
struct timespec to_wait; /* time to wait */
};
#define SECTONSEC 1000000000 /* seconds to nanoseconds */
#define USECTONSEC 1000 /* microseconds to nanoseconds */
void *
timeout_helper(void *arg)
{
struct to_info *tip;
tip = (struct to_info *)arg;
nanosleep(&tip->to_wait, NULL);
(*tip->to_fn)(tip->to_arg);
return(0);
}
void
timeout(const struct timespec *when, void (*func)(void *), void *arg)
{
struct timespec now;
struct timeval tv;
struct to_info *tip;
int err;
gettimeofday(&tv, NULL);
now.tv_sec = tv.tv_sec;
now.tv_nsec = tv.tv_usec * USECTONSEC;
if ((when->tv_sec > now.tv_sec) ||
(when->tv_sec == now.tv_sec && when->tv_nsec > now.tv_nsec)) {
tip = malloc(sizeof(struct to_info));
if (tip != NULL) {
tip->to_fn = func;
tip->to_arg = arg;
tip->to_wait.tv_sec = when->tv_sec - now.tv_sec;
if (when->tv_nsec >= now.tv_nsec) {
tip->to_wait.tv_nsec = when->tv_nsec - now.tv_nsec;
} else {
tip->to_wait.tv_sec--;
tip->to_wait.tv_nsec = SECTONSEC - now.tv_nsec +
when->tv_nsec;
}
err = makethread(timeout_helper, (void *)tip);
if (err == 0)
return;
}
}
/*
* We get here if (a) when <= now, or (b) malloc fails, or
* (c) we can't make a thread, so we just call the function now.
*/
(*func)(arg);
}
pthread_mutexattr_t attr;
pthread_mutex_t mutex;
void
retry(void *arg)
{
pthread_mutex_lock(&mutex);
/* perform retry steps ... */
pthread_mutex_unlock(&mutex);
}
int
main(void)
{
int err, condition, arg;
struct timespec when;
if ((err = pthread_mutexattr_init(&attr)) != 0)
err_exit(err, "pthread_mutexattr_init failed");
if ((err = pthread_mutexattr_settype(&attr,
PTHREAD_MUTEX_RECURSIVE)) != 0)
err_exit(err, "can't set recursive type");
if ((err = pthread_mutex_init(&mutex, &attr)) != 0)
err_exit(err, "can't create recursive mutex");
/* ... */
pthread_mutex_lock(&mutex);
/* ... */
if (condition) {
/* calculate target time "when" */
timeout(&when, retry, (void *)arg);
}
/* ... */
pthread_mutex_unlock(&mutex);
/* ... */
exit(0);
}
ReaderWriter Lock Attributes
Readerwriter locks also have attributes, similar to mutexes. We use pthread_rwlockattr_init to initialize a pthread_rwlockattr_t structure and pthread_rwlockattr_destroy to deinitialize the structure.
#include <pthread.h>
int pthread_rwlockattr_init(pthread_rwlockattr_t
*attr);
int pthread_rwlockattr_destroy
(pthread_rwlockattr_t *attr);
| Both return: 0 if OK, error number on failure |
The only attribute supported for readerwriter locks is the process-shared attribute. It is identical to the mutex process-shared attribute. Just as with the mutex process-shared attributes, a pair of functions is provided to get and set the process-shared attributes of readerwriter locks.
#include <pthread.h>
int pthread_rwlockattr_getpshared(const
pthread_rwlockattr_t *
restrict attr,
int *restrict
pshared);
int pthread_rwlockattr_setpshared
(pthread_rwlockattr_t *attr,
int pshared);
| Both return: 0 if OK, error number on failure |
Although POSIX defines only one readerwriter lock attribute, implementations are free to define additional, nonstandard ones.
Condition Variable Attributes
Condition variables have attributes, too. There is a pair of functions for initializing and deinitializing them, similar to mutexes and readerwriter locks.
#include <pthread.h>
int pthread_condattr_init(pthread_condattr_t *attr);
int pthread_condattr_destroy(pthread_condattr_t
*attr);
| Both return: 0 if OK, error number on failure |
Just as with the other synchronization primitives, condition variables support the process-shared attribute.
#include <pthread.h>
int pthread_condattr_getpshared(const
pthread_condattr_t *
restrict attr,
int *restrict
pshared);
int pthread_condattr_setpshared(pthread_condattr_t
*attr,
int pshared);
| Both return: 0 if OK, error number on failure |
12.5. Reentrancy
We discussed reentrant functions and signal handlers in Section 10.6. Threads are similar to signal handlers when it comes to reentrancy. With both signal handlers and threads, multiple threads of control can potentially call the same function at the same time.
If a function can be safely called by multiple threads at the same time, we say that the function is thread-safe. All functions defined in the Single UNIX Specification are guaranteed to be thread-safe, except those listed in Figure 12.9. In addition, the ctermid and tmpnam functions are not guaranteed to be thread-safe if they are passed a null pointer. Similarly, there is no guarantee that wcrtomb and wcsrtombs are thread-safe when they are passed a null pointer for their mbstate_t argument.
Figure 12.9. Functions not guaranteed to be thread-safe by POSIX.1asctime | ecvt | gethostent | getutxline | putc_unlocked
| basename | encrypt | getlogin | gmtime | putchar_unlocked
| catgets | endgrent | getnetbyaddr | hcreate | putenv
| crypt | endpwent | getnetbyname | hdestroy | pututxline
| ctime | endutxent | getnetent | hsearch | rand
| dbm_clearerr | fcvt | getopt | inet_ntoa | readdir
| dbm_close | ftw | getprotobyname | l64a | setenv
| dbm_delete | gcvt | getprotobynumber | lgamma | setgrent
| dbm_error | getc_unlocked | getprotoent | lgammaf | setkey
| dbm_fetch | getchar_unlocked | getpwent | lgammal | setpwent
| dbm_firstkey | getdate | getpwnam | localeconv | setutxent
| dbm_nextkey | getenv | getpwuid | localtime | strerror | dbm_open | getgrent | getservbyname | lrand48 | strtok | dbm_store | getgrgid | getservbyport | mrand48 | ttyname | dirname | getgrnam | getservent | nftw | unsetenv | dlerror | gethostbyaddr | getutxent | nl_langinfo | wcstombs | drand48 | gethostbyname | getutxid | ptsname | wctomb |
Implementations that support thread-safe functions will define the _POSIX_THREAD_SAFE_FUNCTIONS symbol in <unistd.h>. Applications can also use the _SC_THREAD_SAFE_FUNCTIONS argument with sysconf to check for support of thread-safe functions at runtime. All XSI-conforming implementations are required to support thread-safe functions.
When it supports the thread-safe functions feature, an implementation provides alternate, thread-safe versions of some of the POSIX.1 functions that aren't thread-safe. Figure 12.10 lists the thread-safe versions of these functions. Many functions are not thread-safe, because they return data stored in a static memory buffer. They are made thread-safe by changing their interfaces to require that the caller provide its own buffer.
Figure 12.10. Alternate thread-safe functionsacstime_r | gmtime_r | ctime_r | localtime_r | getgrgid_r | rand_r | getgrnam_r | readdir_r | getlogin_r | strerror_r | getpwnam_r | strtok_r | getpwuid_r | ttyname_r
|
The functions listed in Figure 12.10 are named the same as their non-thread-safe relatives, but with an _r appended at the end of the name, signifying that these versions are reentrant.
If a function is reentrant with respect to multiple threads, we say that it is thread-safe. This doesn't tell us, however, whether the function is reentrant with respect to signal handlers. We say that a function that is safe to be reentered from an asynchronous signal handler is async-signal safe. We saw the async-signal safe functions in Figure 10.4 when we discussed reentrant functions in Section 10.6.
In addition to the functions listed in Figure 12.10, POSIX.1 provides a way to manage FILE objects in a thread-safe way. You can use flockfile and ftrylockfile to obtain a lock associated with a given FILE object. This lock is recursive: you can acquire it again, while you already hold it, without deadlocking. Although the exact implementation of the lock is unspecified, it is required that all standard I/O routines that manipulate FILE objects behave as if they call flockfile and funlockfile internally.
#include <stdio.h>
int ftrylockfile(FILE *fp);
| Returns: 0 if OK, nonzero if lock can't be acquired |
void flockfile(FILE *fp);
void funlockfile(FILE *fp);
|
Although the standard I/O routines might be implemented to be thread-safe from the perspective of their own internal data structures, it is still useful to expose the locking to applications. This allows applications to compose multiple calls to standard I/O functions into atomic sequences. Of course, when dealing with multiple FILE objects, you need to beware of potential deadlocks and to order your locks carefully.
If the standard I/O routines acquire their own locks, then we can run into serious performance degradation when doing character-at-a-time I/O. In this situation, we end up acquiring and releasing a lock for every character read or written. To avoid this overhead, unlocked versions of the character-based standard I/O routines are available.
#include <stdio.h>
int getchar_unlocked(void);
int getc_unlocked(FILE *fp);
| Both return: the next character if OK, EOF on end of file or error |
int putchar_unlocked(int c);
int putc_unlocked(int c, FILE *fp);
| Both return: c if OK, EOF on error |
These four functions should not be called unless surrounded by calls to flockfile (or ftrylockfile) and funlockfile. Otherwise, unpredictable results can occur (i.e., the types of problems that result from unsynchronized access to data by multiple threads of control).
Once you lock the FILE object, you can make multiple calls to these functions before releasing the lock. This amortizes the locking overhead across the amount of data read or written.
Example
Figure 12.11 shows a possible implementation of getenv (Section 7.9). This version is not reentrant. If two threads call it at the same time, they will see inconsistent results, because the string returned is stored in a single static buffer that is shared by all threads calling getenv.
We show a reentrant version of getenv in Figure 12.12. This version is called getenv_r. It uses the pthread_once function (described in Section 12.6) to ensure that the thread_init function is called only once per process.
To make getenv_r reentrant, we changed the interface so that the caller must provide its own buffer. Thus, each thread can use a different buffer to avoid interfering with the others. Note, however, that this is not enough to make getenv_r thread-safe. To make getenv_r thread-safe, we need to protect against changes to the environment while we are searching for the requested string. We can use a mutex to serialize access to the environment list by getenv_r and putenv.
We could have used a readerwriter lock to allow multiple concurrent calls to getenv_r, but the added concurrency probably wouldn't improve the performance of our program by very much, for two reasons. First, the environment list usually isn't very long, so we won't hold the mutex for too long while we scan the list. Second, calls to getenv and putenv are infrequent, so if we improve their performance, we won't affect the overall performance of the program very much.
If we make getenv_r thread-safe, that doesn't mean that it is reentrant with respect to signal handlers. If we use a nonrecursive mutex, we run the risk that a thread will deadlock itself if it calls getenv_r from a signal handler. If the signal handler interrupts the thread while it is executing getenv_r, we will already be holding env_mutex locked, so another attempt to lock it will block, causing the thread to deadlock. Thus, we must use a recursive mutex to prevent other threads from changing the data structures while we look at them, and also prevent deadlocks from signal handlers. The problem is that the pthread functions are not guaranteed to be async-signal safe, so we can't use them to make another function async-signal safe.
Figure 12.11. A nonreentrant version of getenv
#include <limits.h>
#include <string.h>
static char envbuf[ARG_MAX];
extern char **environ;
char *
getenv(const char *name)
{
int i, len;
len = strlen(name);
for (i = 0; environ[i] != NULL; i++) {
if ((strncmp(name, environ[i], len) == 0) &&
(environ[i][len] == '=')) {
strcpy(envbuf, &environ[i][len+1]);
return(envbuf);
}
}
return(NULL);
}
Figure 12.12. A reentrant (thread-safe) version of getenv
#include <string.h>
#include <errno.h>
#include <pthread.h>
#include <stdlib.h>
extern char **environ;
pthread_mutex_t env_mutex;
static pthread_once_t init_done = PTHREAD_ONCE_INIT;
static void
thread_init(void)
{
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&env_mutex, &attr);
pthread_mutexattr_destroy(&attr);
}
int
getenv_r(const char *name, char *buf, int buflen)
{
int i, len, olen;
pthread_once(&init_done, thread_init);
len = strlen(name);
pthread_mutex_lock(&env_mutex);
for (i = 0; environ[i] != NULL; i++) {
if ((strncmp(name, environ[i], len) == 0) &&
(environ[i][len] == '=')) {
olen = strlen(&environ[i][len+1]);
if (olen >= buflen) {
pthread_mutex_unlock(&env_mutex);
return(ENOSPC);
}
strcpy(buf, &environ[i][len+1]);
pthread_mutex_unlock(&env_mutex);
return(0);
}
}
pthread_mutex_unlock(&env_mutex);
return(ENOENT);
}
12.6. Thread-Specific Data
Thread-specific data, also known as thread-private data, is a mechanism for storing and finding data associated with a particular thread. The reason we call the data thread-specific, or thread-private, is that we'd like each thread to access its own separate copy of the data, without worrying about synchronizing access with other threads.
Many people went to a lot of trouble designing a threads model that promotes sharing process data and attributes. So why would anyone want to promote interfaces that prevent sharing in this model? There are two reasons.
First, sometimes we need to maintain data on a per thread basis. Since there is no guarantee that thread IDs are small, sequential integers, we can't simply allocate an array of per thread data and use the thread ID as the index. Even if we could depend on small, sequential thread IDs, we'd like a little extra protection so that one thread can't mess with another's data.
The second reason for thread-private data is to provide a mechanism for adapting process-based interfaces to a multithreaded environment. An obvious example of this is errno. Recall the discussion of errno in Section 1.7. Older interfaces (before the advent of threads) defined errno as an integer accessible globally within the context of a process. System calls and library routines set errno as a side effect of failing. To make it possible for threads to use these same system calls and library routines, errno is redefined as thread-private data. Thus, one thread making a call that sets errno doesn't affect the value of errno for the other threads in the process.
Recall that all threads in a process have access to the entire address space of the process. Other than using registers, there is no way for one thread to prevent another from accessing its data. This is true even for thread-specific data. Even though the underlying implementation doesn't prevent access, the functions provided to manage thread-specific data promote data separation among threads.
Before allocating thread-specific data, we need to create a key to associate with the data. The key will be used to gain access to the thread-specific data. We use pthread_key_create to create a key.
#include <pthread.h>
int pthread_key_create(pthread_key_t *keyp,
void (*destructor)(void *));
| Returns: 0 if OK, error number on failure |
The key created is stored in the memory location pointed to by keyp. The same key can be used by all threads in the process, but each thread will associate a different thread-specific data address with the key. When the key is created, the data address for each thread is set to a null value.
In addition to creating a key, pthread_key_create associates an optional destructor function with the key. When the thread exits, if the data address has been set to a non-null value, the destructor function is called with the data address as the only argument. If destructor is null, then no destructor function is associated with the key. When the thread exits normally, by calling pthread_exit or by returning, the destructor is called. But if the thread calls exit, _exit, _Exit, or abort, or otherwise exits abnormally, the destructor is not called.
Threads usually use malloc to allocate memory for their thread-specific data. The destructor function usually frees the memory that was allocated. If the thread exited without freeing the memory, then the memory would be lost: leaked by the process.
A thread can allocate multiple keys for thread-specific data. Each key can have a destructor associated with it. There can be a different destructor function for each key, or they can all use the same function. Each operating system implementation can place a limit on the number of keys a process can allocate (recall PTHREAD_KEYS_MAX from Figure 12.1).
When a thread exits, the destructors for its thread-specific data are called in an implementation-defined order. It is possible for the destructor function to call another function that might create new thread-specific data and associate it with the key. After all destructors are called, the system will check whether any non-null thread-specific values were associated with the keys and, if so, call the destructors again. This process will repeat until either all keys for the thread have null thread-specific data values or a maximum of PTHREAD_DESTRUCTOR_ITERATIONS (Figure 12.1) attempts have been made.
We can break the association of a key with the thread-specific data values for all threads by calling pthread_key_delete.
#include <pthread.h>
int pthread_key_delete(pthread_key_t *key);
| Returns: 0 if OK, error number on failure |
Note that calling pthread_key_delete will not invoke the destructor function associated with the key. To free any memory associated with the key's thread-specific data values, we need to take additional steps in the application.
We need to ensure that a key we allocate doesn't change because of a race during initialization. Code like the following can result in two threads both calling pthread_key_create:
void destructor(void *);
pthread_key_t key;
int init_done = 0;
int
threadfunc(void *arg)
{
if (!init_done) {
init_done = 1;
err = pthread_key_create(&key, destructor);
}
...
}
Depending on how the system schedules threads, some threads might see one key value, whereas other threads might see a different value. The way to solve this race is to use pthread_once.
#include <pthread.h>
pthread_once_t initflag = PTHREAD_ONCE_INIT;
int pthread_once(pthread_once_t *initflag, void
(*initfn)(void));
| Returns: 0 if OK, error number on failure |
The initflag must be a nonlocal variable (i.e., global or static) and initialized to PTHREAD_ONCE_INIT.
If each thread calls pthread_once, the system guarantees that the initialization routine, initfn, will be called only once, on the first call to pthread_once. The proper way to create a key without a race is as follows:
void destructor(void *);
pthread_key_t key;
pthread_once_t init_done = PTHREAD_ONCE_INIT;
void
thread_init(void)
{
err = pthread_key_create(&key, destructor);
}
int
threadfunc(void *arg)
{
pthread_once(&init_done, thread_init);
...
}
Once a key is created, we can associate thread-specific data with the key by calling pthread_setspecific. We can obtain the address of the thread-specific data with pthread_getspecific.
#include <pthread.h>
void *pthread_getspecific(pthread_key_t key);
| Returns: thread-specific data value or NULL if no value
has been associated with the key |
int pthread_setspecific(pthread_key_t key, const
void *value);
| Returns: 0 if OK, error number on failure |
If no thread-specific data has been associated with a key, pthread_getspecific will return a null pointer. We can use this to determine whether we need to call pthread_setspecific.
Example
In Figure 12.11, we showed a hypothetical implementation of getenv. We came up with a new interface to provide the same functionality, but in a thread-safe way (Figure 12.12). But what would happen if we couldn't modify our application programs to use the new interface? In that case, we could use thread-specific data to maintain a per thread copy of the data buffer used to hold the return string. This is shown in Figure 12.13.
We use pthread_once to ensure that only one key is created for the thread-specific data we will use. If pthread_getspecific returns a null pointer, we need to allocate the memory buffer and associate it with the key. Otherwise, we use the memory buffer returned by pthread_getspecific. For the destructor function, we use free to free the memory previously allocated by malloc. The destructor function will be called with the value of the thread-specific data only if the value is non-null.
Note that although this version of getenv is thread-safe, it is not async-signal safe. Even if we made the mutex recursive, we could not make it reentrant with respect to signal handlers, because it calls malloc, which itself is not async-signal safe.
Figure 12.13. A thread-safe, compatible version of getenv
#include <limits.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
static pthread_key_t key;
static pthread_once_t init_done = PTHREAD_ONCE_INIT;
pthread_mutex_t env_mutex = PTHREAD_MUTEX_INITIALIZER;
extern char **environ;
static void
thread_init(void)
{
pthread_key_create(&key, free);
}
char *
getenv(const char *name)
{
int i, len;
char *envbuf;
pthread_once(&init_done, thread_init);
pthread_mutex_lock(&env_mutex);
envbuf = (char *)pthread_getspecific(key);
if (envbuf == NULL) {
envbuf = malloc(ARG_MAX);
if (envbuf == NULL) {
pthread_mutex_unlock(&env_mutex);
return(NULL);
}
pthread_setspecific(key, envbuf);
}
len = strlen(name);
for (i = 0; environ[i] != NULL; i++) {
if ((strncmp(name, environ[i], len) == 0) &&
(environ[i][len] == '=')) {
strcpy(envbuf, &environ[i][len+1]);
pthread_mutex_unlock(&env_mutex);
return(envbuf);
}
}
pthread_mutex_unlock(&env_mutex);
return(NULL);
}
12.7. Cancel Options
Two thread attributes that are not included in the pthread_attr_t structure are the cancelability state and the cancelability type. These attributes affect the behavior of a thread in response to a call to pthread_cancel (Section 11.5).
The cancelability state attribute can be either PTHREAD_CANCEL_ENABLE or PTHREAD_CANCEL_DISABLE. A thread can change its cancelability state by calling pthread_setcancelstate.
#include <pthread.h>
int pthread_setcancelstate(int state, int *oldstate);
| Returns: 0 if OK, error number on failure |
In one atomic operation, pthread_setcancelstate sets the current cancelability state to state and stores the previous cancelability state in the memory location pointed to by oldstate.
Recall from Section 11.5 that a call to pthread_cancel doesn't wait for a thread to terminate. In the default case, a thread will continue to execute after a cancellation request is made, until the thread reaches a cancellation point. A cancellation point is a place where the thread checks to see whether it has been canceled, and then acts on the request. POSIX.1 guarantees that cancellation points will occur when a thread calls any of the functions listed in Figure 12.14.
Figure 12.14. Cancellation points defined by POSIX.1accept | mq_timedsend | putpmsg | sigsuspend
| aio_suspend | msgrcv | pwrite | sigtimedwait
| clock_nanosleep | msgsnd | read | sigwait
| close | msync | readv | sigwaitinfo
| connect | nanosleep | recv | sleep
| creat | open | recvfrom | system
| fcntl2 | pause | recvmsg | tcdrain
| fsync | poll | select | usleep
| getmsg | pread | sem_timedwait | wait
| getpmsg | pthread_cond_timedwait | sem_wait | waitid
| lockf | pthread_cond_wait | send | waitpid
| mq_receive | pthread_join | sendmsg | write
| mq_send | pthread_testcancel | sendto | writev
| mq_timedreceive | putmsg | sigpause | |
A thread starts with a default cancelability state of PTHREAD_CANCEL_ENABLE. When the state is set to PTHREAD_CANCEL_DISABLE, a call to pthread_cancel will not kill the thread. Instead, the cancellation request remains pending for the thread. When the state is enabled again, the thread will act on any pending cancellation requests at the next cancellation point.
In addition to the functions listed in Figure 12.14, POSIX.1 specifies the functions listed in Figure 12.15 as optional cancellation points.
Figure 12.15. Optional cancellation points defined by POSIX.1catclose | ftell | getwc | printf
| catgets | ftello | getwchar | putc
| catopen | ftw | getwd | putc_unlocked
| closedir | fwprintf | glob | putchar
| closelog | fwrite | iconv_close | putchar_unlocked
| ctermid | fwscanf | iconv_open | puts
| dbm_close | getc | ioctl | pututxline
| dbm_delete | getc_unlocked | lseek | putwc | dbm_fetch | getchar | mkstemp | putwchar | dbm_nextkey | getchar_unlocked | nftw | readdir | dbm_open | getcwd | opendir | readdir_r | dbm_store | getdate | openlog | remove | dlclose | getgrent | pclose | rename | dlopen | getgrgid | perror | rewind | endgrent | getgrgid_r | popen | rewinddir | endhostent | getgrnam | posix_fadvise | scanf | endnetent | getgrnam_r | posix_fallocate | seekdir | endprotoent | gethostbyaddr | posix_madvise | semop | endpwent | gethostbyname | posix_spawn | setgrent | endservent | gethostent | posix_spawnp | sethostent | endutxent | gethostname | posix_trace_clear | setnetent | fclose | getlogin | posix_trace_close | setprotoent | fcntl | getlogin_r | posix_trace_create | setpwent | fflush | getnetbyaddr | posix_trace_create_withlog | setservent | fgetc | getnetbyname | posix_trace_eventtypelist_getnext_id | setutxent | fgetpos | getnetent | posix_trace_eventtypelist_rewind | strerror | fgets | getprotobyname | posix_trace_flush | syslog | fgetwc | getprotobynumber | posix_trace_get_attr | tmpfile | fgetws | getprotoent | posix_trace_get_filter | tmpnam | fopen | getpwent | posix_trace_get_status | ttyname | fprintf | getpwnam | posix_trace_getnext_event | ttyname_r | fputc | getpwnam_r | posix_trace_open | ungetc | fputs | getpwuid | posix_trace_rewind | ungetwc | fputwc | getpwuid_r | posix_trace_set_filter | unlink | fputws | gets | posix_trace_shutdown | vfprintf | fread | getservbyname | posix_trace_timedgetnext_event | vfwprintf | freopen | getservbyport | posix_typed_mem_open | vprintf | fscanf | getservent | pthread_rwlock_rdlock | vwprintf | fseek | getutxent | pthread_rwlock_timedrdlock | wprintf | fseeko | getutxid | pthread_rwlock_timedwrlock | wscanf | fsetpos | getutxline | pthread_rwlock_wrlock | |
Note that several of the functions listed in Figure 12.15 are not discussed further in this text. Many are optional in the Single UNIX Specification.
If your application doesn't call one of the functions in Figure 12.14 or Figure 12.15 for a long period of time (if it is compute-bound, for example), then you can call pthread_testcancel to add your own cancellation points to the program.
#include <pthread.h>
void pthread_testcancel(void);
|
When you call pthread_testcancel, if a cancellation request is pending and if cancellation has not been disabled, the thread will be canceled. When cancellation is disabled, however, calls to pthread_testcancel have no effect.
The default cancellation type we have been describing is known as deferred cancellation. After a call to pthread_cancel, the actual cancellation doesn't occur until the thread hits a cancellation point. We can change the cancellation type by calling pthread_setcanceltype.
#include <pthread.h>
int pthread_setcanceltype(int type, int *oldtype);
| Returns: 0 if OK, error number on failure |
The type parameter can be either PTHREAD_CANCEL_DEFERRED or PTHREAD_CANCEL_ASYNCHRONOUS. The pthread_setcanceltype function sets the cancellation type to type and returns the previous type in the integer pointed to by oldtype.
Asynchronous cancellation differs from deferred cancellation in that the thread can be canceled at any time. The thread doesn't necessarily need to hit a cancellation point for it to be canceled.
12.8. Threads and Signals
Dealing with signals can be complicated even with a process-based paradigm. Introducing threads into the picture makes things even more complicated.
Each thread has its own signal mask, but the signal disposition is shared by all threads in the process. This means that individual threads can block signals, but when a thread modifies the action associated with a given signal, all threads share the action. Thus, if one thread chooses to ignore a given signal, another thread can undo that choice by restoring the default disposition or installing a signal handler for the signal.
Signals are delivered to a single thread in the process. If the signal is related to a hardware fault or expiring timer, the signal is sent to the thread whose action caused the event. Other signals, on the other hand, are delivered to an arbitrary thread.
In Section 10.12, we discussed how processes can use sigprocmask to block signals from delivery. The behavior of sigprocmask is undefined in a multithreaded process. Threads have to use pthread_sigmask instead.
#include <signal.h>
int pthread_sigmask(int how, const sigset_t
*restrict set,
sigset_t *restrict oset);
| Returns: 0 if OK, error number on failure |
The pthread_sigmask function is identical to sigprocmask, except that pthread_sigmask works with threads and returns an error code on failure instead of setting errno and returning -1.
A thread can wait for one or more signals to occur by calling sigwait.
#include <signal.h>
int sigwait(const sigset_t *restrict set, int
*restrict signop);
| Returns: 0 if OK, error number on failure |
The set argument specifies the set of signals for which the thread is waiting. On return, the integer to which signop points will contain the number of the signal that was delivered.
If one of the signals specified in the set is pending at the time sigwait is called, then sigwait will return without blocking. Before returning, sigwait removes the signal from the set of signals pending for the process. To avoid erroneous behavior, a thread must block the signals it is waiting for before calling sigwait. The sigwait function will atomically unblock the signals and wait until one is delivered. Before returning, sigwait will restore the thread's signal mask. If the signals are not blocked at the time that sigwait is called, then a timing window is opened up where one of the signals can be delivered to the thread before it completes its call to sigwait.
The advantage to using sigwait is that it can simplify signal handling by allowing us to treat asynchronously-generated signals in a synchronous manner. We can prevent the signals from interrupting the threads by adding them to each thread's signal mask. Then we can dedicate specific threads to handling the signals. These dedicated threads can make function calls without having to worry about which functions are safe to call from a signal handler, because they are being called from normal thread context, not from a traditional signal handler interrupting a normal thread's execution.
If multiple threads are blocked in calls to sigwait for the same signal, only one of the threads will return from sigwait when the signal is delivered. If a signal is being caught (the process has established a signal handler by using sigaction, for example) and a thread is waiting for the same signal in a call to sigwait, it is left up to the implementation to decide which way to deliver the signal. In this case, the implementation could either allow sigwait to return or invoke the signal handler, but not both.
To send a signal to a process, we call kill (Section 10.9). To send a signal to a thread, we call pthread_kill.
#include <signal.h>
int pthread_kill(pthread_t thread, int signo);
| Returns: 0 if OK, error number on failure |
We can pass a signo value of 0 to check for existence of the thread. If the default action for a signal is to terminate the process, then sending the signal to a thread will still kill the entire process.
Note that alarm timers are a process resource, and all threads share the same set of alarms. Thus, it is not possible for multiple threads in a process to use alarm timers without interfering (or cooperating) with one another (this is the subject of Exercise 12.6).
Example
Recall that in Figure 10.23, we waited for the signal handler to set a flag indicating that the main program should exit. The only threads of control that could run were the main thread and the signal handler, so blocking the signals was sufficient to avoid missing a change to the flag. With threads, we need to use a mutex to protect the flag, as we show in the program in Figure 12.16.
Instead of relying on a signal handler that interrupts the main thread of control, we dedicate a separate thread of control to handle the signals. We change the value of quitflag under the protection of a mutex so that the main thread of control can't miss the wake-up call made when we call pthread_cond_signal. We use the same mutex in the main thread of control to check the value of the flag, and atomically release the mutex and wait for the condition.
Note that we block SIGINT and SIGQUIT in the beginning of the main thread. When we create the thread to handle signals, the thread inherits the current signal mask. Since sigwait will unblock the signals, only one thread is available to receive signals. This enables us to code the main thread without having to worry about interrupts from these signals.
If we run this program, we get output similar to that from Figure 10.23:
$ ./a.out
^? type the interrupt character
interrupt
^? type the interrupt character again
interrupt
^? and again
interrupt
^\ $ now terminate with quit character
Figure 12.16. Synchronous signal handling
#include "apue.h"
#include <pthread.h>
int quitflag; /* set nonzero by thread */
sigset_t mask;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t wait = PTHREAD_COND_INITIALIZER;
void *
thr_fn(void *arg)
{
int err, signo;
for (;;) {
err = sigwait(&mask, &signo);
if (err != 0)
err_exit(err, "sigwait failed");
switch (signo) {
case SIGINT:
printf("\ninterrupt\n");
break;
case SIGQUIT:
pthread_mutex_lock(&lock);
quitflag = 1;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&wait);
return(0);
default:
printf("unexpected signal %d\n", signo);
exit(1);
}
}
}
int
main(void)
{
int err;
sigset_t oldmask;
pthread_t tid;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigaddset(&mask, SIGQUIT);
if ((err = pthread_sigmask(SIG_BLOCK, &mask, &oldmask)) != 0)
err_exit(err, "SIG_BLOCK error");
err = pthread_create(&tid, NULL, thr_fn, 0);
if (err != 0)
err_exit(err, "can't create thread");
pthread_mutex_lock(&lock);
while (quitflag == 0)
pthread_cond_wait(&wait, &lock);
pthread_mutex_unlock(&lock);
/* SIGQUIT has been caught and is now blocked; do whatever */
quitflag = 0;
/* reset signal mask which unblocks SIGQUIT */
if (sigprocmask(SIG_SETMASK, &oldmask, NULL) < 0)
err_sys("SIG_SETMASK error");
exit(0);
}
Linux implements threads as separate processes, sharing resources using clone(2). Because of this, the behavior of threads on Linux differs from that on other implementations when it comes to signals. In the POSIX.1 thread model, asynchronous signals are sent to a process, and then an individual thread within the process is selected to receive the signal, based on which threads are not currently blocking the signal. On Linux, an asynchronous signal is sent to a particular thread, and since each thread executes as a separate process, the system is unable to select a thread that isn't currently blocking the signal. The result is that the thread may not notice the signal. Thus, programs like the one in Figure 12.16 work when the signal is generated from the terminal driver, which signals the process group, but when you try to send a signal to the process using kill, it doesn't work as expected on Linux.
12.9. Threads and fork
When a thread calls fork, a copy of the entire process address space is made for the child. Recall the discussion of copy-on-write in Section 8.3. The child is an entirely different process from the parent, and as long as neither one makes changes to its memory contents, copies of the memory pages can be shared between parent and child.
By inheriting a copy of the address space, the child also inherits the state of every mutex, readerwriter lock, and condition variable from the parent process. If the parent consists of more than one thread, the child will need to clean up the lock state if it isn't going to call exec immediately after fork returns.
Inside the child process, only one thread exists. It is made from a copy of the thread that called fork in the parent. If the threads in the parent process hold any locks, the locks will also be held in the child process. The problem is that the child process doesn't contain copies of the threads holding the locks, so there is no way for the child to know which locks are held and need to be unlocked.
This problem can be avoided if the child calls one of the exec functions directly after returning from fork. In this case, the old address space is discarded, so the lock state doesn't matter. This is not always possible, however, so if the child needs to continue processing, we need to use a different strategy.
To clean up the lock state, we can establish fork handlers by calling the function pthread_atfork.
#include <pthread.h>
int pthread_atfork(void (*prepare)(void), void
(*parent)(void),
void (*child)(void));
| Returns: 0 if OK, error number on failure |
With pthread_atfork, we can install up to three functions to help clean up the locks. The prepare fork handler is called in the parent before fork creates the child process. This fork handler's job is to acquire all locks defined by the parent. The parent fork handler is called in the context of the parent after fork has created the child process, but before fork has returned. This fork handler's job is to unlock all the locks acquired by the prepare fork handler. The child fork handler is called in the context of the child process before returning from fork. Like the parent fork handler, the child fork handler too must release all the locks acquired by the prepare fork handler.
Note that the locks are not locked once and unlocked twice, as it may appear. When the child address space is created, it gets a copy of all locks that the parent defined. Because the prepare fork handler acquired all the locks, the memory in the parent and the memory in the child start out with identical contents. When the parent and the child unlock their "copy" of the locks, new memory is allocated for the child, and the memory contents from the parent are copied to the child's memory (copy-on-write), so we are left with a situation that looks as if the parent locked all its copies of the locks and the child locked all its copies of the locks. The parent and the child end up unlocking duplicate locks stored in different memory locations, as if the following sequence of events occurred.
The parent acquired all its locks. The child acquired all its locks. The parent released its locks. The child released its locks.
We can call pthread_atfork multiple times to install more than one set of fork handlers. If we don't have a need to use one of the handlers, we can pass a null pointer for the particular handler argument, and it will have no effect. When multiple fork handlers are used, the order in which the handlers are called differs. The parent and child fork handlers are called in the order in which they were registered, whereas the prepare fork handlers are called in the opposite order from which they were registered. This allows multiple modules to register their own fork handlers and still honor the locking hierarchy.
For example, assume that module A calls functions from module B and that each module has its own set of locks. If the locking hierarchy is A before B, module B must install its fork handlers before module A. When the parent calls fork, the following steps are taken, assuming that the child process runs before the parent.
The prepare fork handler from module A is called to acquire all module A's locks. The prepare fork handler from module B is called to acquire all module B's locks. A child process is created. The child fork handler from module B is called to release all module B's locks in the child process. The child fork handler from module A is called to release all module A's locks in the child process. The fork function returns to the child. The parent fork handler from module B is called to release all module B's locks in the parent process. The parent fork handler from module A is called to release all module A's locks in the parent process. The fork function returns to the parent.
If the fork handlers serve to clean up the lock state, what cleans up the state of condition variables? On some implementations, condition variables might not need any cleaning up. However, an implementation that uses a lock as part of the implementation of condition variables will require cleaning up. The problem is that no interface exists to allow us to do this. If the lock is embedded in the condition variable data structure, then we can't use condition variables after calling fork, because there is no portable way to clean up its state. On the other hand, if an implementation uses a global lock to protect all condition variable data structures in a process, then the implementation itself can clean up the lock in the fork library routine. Application programs shouldn't rely on implementation details like this, however.
Example
The program in Figure 12.17 illustrates the use of pthread_atfork and fork handlers.
We define two mutexes, lock1 and lock2. The prepare fork handler acquires them both, the child fork handler releases them in the context of the child process, and the parent fork handler releases them in the context of the parent process.
When we run this program, we get the following output:
$ ./a.out
thread started...
parent about to fork...
preparing locks...
child unlocking locks...
child returned from fork
parent unlocking locks...
parent returned from fork
As we can see, the prepare fork handler runs after fork is called, the child fork handler runs before fork returns in the child, and the parent fork handler runs before fork returns in the parent.
Figure 12.17. pthread_atfork example
#include "apue.h"
#include <pthread.h>
pthread_mutex_t lock1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t lock2 = PTHREAD_MUTEX_INITIALIZER;
void
prepare(void)
{
printf("preparing locks...\n");
pthread_mutex_lock(&lock1);
pthread_mutex_lock(&lock2);
}
void
parent(void)
{
printf("parent unlocking locks...\n");
pthread_mutex_unlock(&lock1);
pthread_mutex_unlock(&lock2);
}
void
child(void)
{
printf("child unlocking locks...\n");
pthread_mutex_unlock(&lock1);
pthread_mutex_unlock(&lock2);
}
void *
thr_fn(void *arg)
{
printf("thread started...\n");
pause();
return(0);
}
int
main(void)
{
int err;
pid_t pid;
pthread_t tid;
#if defined(BSD) || defined(MACOS)
printf("pthread_atfork is unsupported\n");
#else
if ((err = pthread_atfork(prepare, parent, child)) != 0)
err_exit(err, "can't install fork handlers");
err = pthread_create(&tid, NULL, thr_fn, 0);
if (err != 0)
err_exit(err, "can't create thread");
sleep(2);
printf("parent about to fork...\n");
if ((pid = fork()) < 0)
err_quit("fork failed");
else if (pid == 0) /* child */
printf("child returned from fork\n");
else /* parent */
printf("parent returned from fork\n");
#endif
exit(0);
}
13.1. Introduction
Daemons are processes that live for a long time. They are often started when the system is bootstrapped and terminate only when the system is shut down. Because they don't have a controlling terminal, we say that they run in the background. UNIX systems have numerous daemons that perform day-to-day activities.
In this chapter, we look at the process structure of daemons and how to write a daemon. Since a daemon does not have a controlling terminal, we need to see how a daemon can report error conditions when something goes wrong.
For a discussion of the historical background of the term daemon as it applies to computer systems, see Raymond [1996].
13.2. Daemon Characteristics
Let's look at some common system daemons and how they relate to the concepts of process groups, controlling terminals, and sessions that we described in Chapter 9. The ps(1) command prints the status of various processes in the system. There are a multitude of optionsconsult your system's manual for all the details. We'll execute
ps -axj
under BSD-based systems to see the information we need for this discussion. The -a option shows the status of processes owned by others, and -x shows processes that don't have a controlling terminal. The -j option displays the job-related information: the session ID, process group ID, controlling terminal, and terminal process group ID. Under System Vbased systems, a similar command is ps -efjc. (In an attempt to improve security, some UNIX systems don't allow us to use ps to look at any processes other than our own.) The output from ps looks like
PPID | PID | PGID | SID | TTY | TPGID | UID | COMMAND
| 0 | 1 | 0 | 0 | ? | -1 | 0 | init
| 1 | 2 | 1 | 1 | ? | -1 | 0 | [keventd]
| 1 | 3 | 1 | 1 | ? | -1 | 0 | [kapmd]
| 0 | 5 | 1 | 1 | ? | -1 | 0 | [kswapd]
| 0 | 6 | 1 | 1 | ? | -1 | 0 | [bdflush]
| 0 | 7 | 1 | 1 | ? | -1 | 0 | [kupdated]
| 1 | 1009 | 1009 | 1009 | ? | -1 | 32 | portmap
| 1 | 1048 | 1048 | 1048 | ? | -1 | 0 | syslogd -m 0 | 1 | 1335 | 1335 | 1335 | ? | -1 | 0 | xinetd -pidfile /var/run/xinetd.pid
| 1 | 1403 | 1 | 1 | ? | -1 | 0 | [nfsd]
| 1 | 1405 | 1 | 1 | ? | -1 | 0 | [lockd]
| 1405 | 1406 | 1 | 1 | ? | -1 | 0 | [rpciod]
| 1 | 1853 | 1853 | 1853 | ? | -1 | 0 | crond
| 1 | 2182 | 2182 | 2182 | ? | -1 | 0 | /usr/sbin/cupsd
|
We have removed a few columns that don't interest us, such as the accumulated CPU time. The column headings, in order, are the parent process ID, process ID, process group ID, session ID, terminal name, terminal process group ID (the foreground process group associated with the controlling terminal), user ID, and command string.
The system that this ps command was run on (Linux) supports the notion of a session ID, which we mentioned with the setsid function in Section 9.5. The session ID is simply the process ID of the session leader. A BSD-based system, however, will print the address of the session structure corresponding to the process group that the process belongs to (Section 9.11).
The system processes you see will depend on the operating system implementation. Anything with a parent process ID of 0 is usually a kernel process started as part of the system bootstrap procedure. (An exception to this is init, since it is a user-level command started by the kernel at boot time.) Kernel processes are special and generally exist for the entire lifetime of the system. They run with superuser privileges and have no controlling terminal and no command line.
Process 1 is usually init, as we described in Section 8.2. It is a system daemon responsible for, among other things, starting system services specific to various run levels. These services are usually implemented with the help of their own daemons.
On Linux, the kevenTD daemon provides process context for running scheduled functions in the kernel. The kapmd daemon provides support for the advanced power management features available with various computer systems. The kswapd daemon is also known as the pageout daemon. It supports the virtual memory subsystem by writing dirty pages to disk slowly over time, so the pages can be reclaimed.
The Linux kernel flushes cached data to disk using two additional daemons: bdflush and kupdated. The bdflush daemon flushes dirty buffers from the buffer cache back to disk when available memory reaches a low-water mark. The kupdated daemon flushes dirty pages back to disk at regular intervals to decrease data loss in the event of a system failure.
The portmapper daemon, portmap, provides the service of mapping RPC (Remote Procedure Call) program numbers to network port numbers. The syslogd daemon is available to any program to log system messages for an operator. The messages may be printed on a console device and also written to a file. (We describe the syslog facility in Section 13.4.)
We talked about the inetd daemon (xinetd) in Section 9.3. It listens on the system's network interfaces for incoming requests for various network servers. The nfsd, lockd, and rpciod daemons provide support for the Network File System (NFS).
The cron daemon (crond) executes commands at specified dates and times. Numerous system administration tasks are handled by having programs executed regularly by cron. The cupsd daemon is a print spooler; it handles print requests on the system.
Note that most of the daemons run with superuser privilege (a user ID of 0). None of the daemons has a controlling terminal: the terminal name is set to a question mark, and the terminal foreground process group is 1. The kernel daemons are started without a controlling terminal. The lack of a controlling terminal in the user-level daemons is probably the result of the daemons having called setsid. All the user-level daemons are process group leaders and session leaders and are the only processes in their process group and session. Finally, note that the parent of most of these daemons is the init process.
13.3. Coding Rules
Some basic rules to coding a daemon prevent unwanted interactions from happening. We state these rules and then show a function, daemonize, that implements them.
The first thing to do is call umask to set the file mode creation mask to 0. The file mode creation mask that's inherited could be set to deny certain permissions. If the daemon process is going to create files, it may want to set specific permissions. For example, if it specifically creates files with group-read and group-write enabled, a file mode creation mask that turns off either of these permissions would undo its efforts. Call fork and have the parent exit. This does several things. First, if the daemon was started as a simple shell command, having the parent terminate makes the shell think that the command is done. Second, the child inherits the process group ID of the parent but gets a new process ID, so we're guaranteed that the child is not a process group leader. This is a prerequisite for the call to setsid that is done next. Call setsid to create a new session. The three steps listed in Section 9.5 occur. The process (a) becomes a session leader of a new session, (b) becomes the process group leader of a new process group, and (c) has no controlling terminal.
Under System Vbased systems, some people recommend calling fork again at this point and having the parent terminate. The second child continues as the daemon. This guarantees that the daemon is not a session leader, which prevents it from acquiring a controlling terminal under the System V rules (Section 9.6). Alternatively, to avoid acquiring a controlling terminal, be sure to specify O_NOCTTY whenever opening a terminal device.
Change the current working directory to the root directory. The current working directory inherited from the parent could be on a mounted file system. Since daemons normally exist until the system is rebooted, if the daemon stays on a mounted file system, that file system cannot be unmounted. Alternatively, some daemons might change the current working directory to some specific location, where they will do all their work. For example, line printer spooling daemons often change to their spool directory. Unneeded file descriptors should be closed. This prevents the daemon from holding open any descriptors that it may have inherited from its parent (which could be a shell or some other process). We can use our open_max function (Figure 2.16) or the getrlimit function (Section 7.11) to determine the highest descriptor and close all descriptors up to that value. Some daemons open file descriptors 0, 1, and 2 to /dev/null so that any library routines that try to read from standard input or write to standard output or standard error will have no effect. Since the daemon is not associated with a terminal device, there is nowhere for output to be displayed; nor is there anywhere to receive input from an interactive user. Even if the daemon was started from an interactive session, the daemon runs in the background, and the login session can terminate without affecting the daemon. If other users log in on the same terminal device, we wouldn't want output from the daemon showing up on the terminal, and the users wouldn't expect their input to be read by the daemon.
Example
Figure 13.1 shows a function that can be called from a program that wants to initialize itself as a daemon.
If the daemonize function is called from a main program that then goes to sleep, we can check the status of the daemon with the ps command:
$ ./a.out
$ ps -axj
PPID PID PGID SID TTY TPGID UID COMMAND
1 3346 3345 3345 ? -1 501 ./a.out
$ ps -axj | grep 3345
1 3346 3345 3345 ? -1 501 ./a.out
We can also use ps to verify that no active process exists with ID 3345. This means that our daemon is in an orphaned process group (Section 9.10) and is not a session leader and thus has no chance of allocating a controlling terminal. This is a result of performing the second fork in the daemonize function. We can see that our daemon has been initialized correctly.
Figure 13.1. Initialize a daemon process
#include "apue.h"
#include <syslog.h>
#include <fcntl.h>
#include <sys/resource.h>
void
daemonize(const char *cmd)
{
int i, fd0, fd1, fd2;
pid_t pid;
struct rlimit rl;
struct sigaction sa;
/*
* Clear file creation mask.
*/
umask(0);
/*
* Get maximum number of file descriptors.
*/
if (getrlimit(RLIMIT_NOFILE, &rl) < 0)
err_quit("%s: can't get file limit", cmd);
/*
* Become a session leader to lose controlling TTY.
*/
if ((pid = fork()) < 0)
err_quit("%s: can't fork", cmd);
else if (pid != 0) /* parent */
exit(0);
setsid();
/*
* Ensure future opens won't allocate controlling TTYs.
*/
sa.sa_handler = SIG_IGN;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
if (sigaction(SIGHUP, &sa, NULL) < 0)
err_quit("%s: can't ignore SIGHUP");
if ((pid = fork()) < 0)
err_quit("%s: can't fork", cmd);
else if (pid != 0) /* parent */
exit(0);
/*
* Change the current working directory to the root so
* we won't prevent file systems from being unmounted.
*/
if (chdir("/") < 0)
err_quit("%s: can't change directory to /");
/*
* Close all open file descriptors.
*/
if (rl.rlim_max == RLIM_INFINITY)
rl.rlim_max = 1024;
for (i = 0; i < rl.rlim_max; i++)
close(i);
/*
* Attach file descriptors 0, 1, and 2 to /dev/null.
*/
fd0 = open("/dev/null", O_RDWR);
fd1 = dup(0);
fd2 = dup(0);
/*
* Initialize the log file.
*/
openlog(cmd, LOG_CONS, LOG_DAEMON);
if (fd0 != 0 || fd1 != 1 || fd2 != 2) {
syslog(LOG_ERR, "unexpected file descriptors %d %d %d",
fd0, fd1, fd2);
exit(1);
}
}
13.4. Error Logging
One problem a daemon has is how to handle error messages. It can't simply write to standard error, since it shouldn't have a controlling terminal. We don't want all the daemons writing to the console device, since on many workstations, the console device runs a windowing system. We also don't want each daemon writing its own error messages into a separate file. It would be a headache for anyone administering the system to keep up with which daemon writes to which log file and to check these files on a regular basis. A central daemon error-logging facility is required.
The BSD syslog facility was developed at Berkeley and used widely in 4.2BSD. Most systems derived from BSD support syslog.
Until SVR4, System V never had a central daemon logging facility.
The syslog function is included as an XSI extension in the Single UNIX Specification.
The BSD syslog facility has been widely used since 4.2BSD. Most daemons use this facility. Figure 13.2 illustrates its structure.
There are three ways to generate log messages:
Kernel routines can call the log function. These messages can be read by any user process that opens and reads the /dev/klog device. We won't describe this function any further, since we're not interested in writing kernel routines. Most user processes (daemons) call the syslog(3) function to generate log messages. We describe its calling sequence later. This causes the message to be sent to the UNIX domain datagram socket /dev/log. A user process on this host, or on some other host that is connected to this host by a TCP/IP network, can send log messages to UDP port 514. Note that the syslog function never generates these UDP datagrams: they require explicit network programming by the process generating the log message.
Refer to Stevens, Fenner, and Rudoff [2004] for details on UNIX domain sockets and UDP sockets.
Normally, the syslogd daemon reads all three forms of log messages. On start-up, this daemon reads a configuration file, usually /etc/syslog.conf, which determines where different classes of messages are to be sent. For example, urgent messages can be sent to the system administrator (if logged in) and printed on the console, whereas warnings may be logged to a file.
Our interface to this facility is through the syslog function.
#include <syslog.h>
void openlog(const char *ident, int option, int
facility);
void syslog(int priority, const char *format, ...);
void closelog(void);
int setlogmask(int maskpri);
| Returns: previous log priority mask value |
Calling openlog is optional. If it's not called, the first time syslog is called, openlog is called automatically. Calling closelog is also optionalit just closes the descriptor that was being used to communicate with the syslogd daemon.
Calling openlog lets us specify an ident that is added to each log message. This is normally the name of the program (cron, inetd, etc.). The option argument is a bitmask specifying various options. Figure 13.3 describes the available options, including a bullet in the XSI column if the option is included in the openlog definition in the Single UNIX Specification.
Figure 13.3. The option argument for openlogoption | XSI | Description |
|---|
LOG_CONS | • | If the log message can't be sent to syslogd via the UNIX domain datagram, the message is written to the console instead. | LOG_NDELAY | • | Open the UNIX domain datagram socket to the syslogd daemon immediately; don't wait until the first message is logged. Normally, the socket is not opened until the first message is logged. | LOG_NOWAIT | • | Do not wait for child processes that might have been created in the process of logging the message. This prevents conflicts with applications that catch SIGCHLD, since the application might have retrieved the child's status by the time that syslog calls wait. | LOG_ODELAY | • | Delay the open of the connection to the syslogd daemon until the first message is logged. | LOG_PERROR | | Write the log message to standard error in addition to sending it to syslogd. (Unavailable on Solaris.) | LOG_PID | • | Log the process ID with each message. This is intended for daemons that fork a child process to handle different requests (as compared to daemons, such as syslogd, that never call fork). |
The facility argument for openlog is taken from Figure 13.4. Note that the Single UNIX Specification defines only a subset of the facility codes typically available on a given platform. The reason for the facility argument is to let the configuration file specify that messages from different facilities are to be handled differently. If we don't call openlog, or if we call it with a facility of 0, we can still specify the facility as part of the priority argument to syslog.
Figure 13.4. The facility argument for openlogfacility | XSI | Description |
|---|
LOG_AUTH | | authorization programs: login, su, getty, ... | LOG_AUTHPRIV | | same as LOG_AUTH, but logged to file with restricted permissions | LOG_CRON | | cron and at | LOG_DAEMON | | system daemons: inetd, routed, ... | LOG_FTP | | the FTP daemon (ftpd) | LOG_KERN | | messages generated by the kernel | LOG_LOCAL0 | • | reserved for local use | LOG_LOCAL1 | • | reserved for local use | LOG_LOCAL2 | • | reserved for local use | LOG_LOCAL3 | • | reserved for local use | LOG_LOCAL4 | • | reserved for local use | LOG_LOCAL5 | • | reserved for local use | LOG_LOCAL6 | • | reserved for local use | LOG_LOCAL7 | • | reserved for local use | LOG_LPR | | line printer system: lpd, lpc, ... | LOG_MAIL | | the mail system | LOG_NEWS | | the Usenet network news system | LOG_SYSLOG | | the syslogd daemon itself | LOG_USER | • | messages from other user processes (default) | LOG_UUCP | | the UUCP system |
We call syslog to generate a log message. The priority argument is a combination of the facility shown in Figure 13.4 and a level, shown in Figure 13.5. These levels are ordered by priority, from highest to lowest.
Figure 13.5. The syslog levels (ordered)level | Description |
|---|
LOG_EMERG | emergency (system is unusable) (highest priority) | LOG_ALERT | condition that must be fixed immediately | LOG_CRIT | critical condition (e.g., hard device error) | LOG_ERR | error condition | LOG_WARNING | warning condition | LOG_NOTICE | normal, but significant condition | LOG_INFO | informational message | LOG_DEBUG | debug message (lowest priority) |
The format argument and any remaining arguments are passed to the vsprintf function for formatting. Any occurrence of the two characters %m in the format are first replaced with the error message string (strerror) corresponding to the value of errno.
The setlogmask function can be used to set the log priority mask for the process. This function returns the previous mask. When the log priority mask is set, messages are not logged unless their priority is set in the log priority mask. Note that attempts to set the log priority mask to 0 will have no effect.
The logger(1) program is also provided by many systems as a way to send log messages to the syslog facility. Some implementations allow optional arguments to this program, specifying the facility, level, and ident, although the Single UNIX Specification doesn't define any options. The logger command is intended for a shell script running noninteractively that needs to generate log messages.
Example
In a (hypothetical) line printer spooler daemon, you might encounter the sequence
openlog("lpd", LOG_PID, LOG_LPR);
syslog(LOG_ERR, "open error for %s: %m", filename);
The first call sets the ident string to the program name, specifies that the process ID should always be printed, and sets the default facility to the line printer system. The call to syslog specifies an error condition and a message string. If we had not called openlog, the second call could have been
syslog(LOG_ERR | LOG_LPR, "open error for %s: %m", filename);
Here, we specify the priority argument as a combination of a level and a facility.
In addition to syslog, many platforms provide a variant that handles variable argument lists.
#include <syslog.h>
#include <stdarg.h>
void vsyslog(int priority, const char *format,
va_list arg);
|
All four platforms described in this book provide vsyslog, but it is not included in the Single UNIX Specification.
Most syslogd implementations will queue messages for a short time. If a duplicate message arrives during this time, the syslog daemon will not write it to the log. Instead, the daemon will print out a message similar to "last message repeated N times."
13.5. Single-Instance Daemons
Some daemons are implemented so that only a single copy of the daemon should be running at a time for proper operation. The daemon might need exclusive access to a device, for example. In the case of the cron daemon, if multiple instances were running, each copy might try to start a single scheduled operation, resulting in duplicate operations and probably an error.
If the daemon needs to access a device, the device driver will sometimes prevent multiple opens of the corresponding device node in /dev. This restricts us to one copy of the daemon running at a time. If no such device is available, however, we need to do the work ourselves.
The file- and record-locking mechanism provides the basis for one way to ensure that only one copy of a daemon is running. (We discuss file and record locking in Section 14.3.) If each daemon creates a file and places a write lock on the entire file, only one such write lock will be allowed to be created. Successive attempts to create write locks will fail, serving as an indication to successive copies of the daemon that another instance is already running.
File and record locking provides a convenient mutual-exclusion mechanism. If the daemon obtains a write-lock on an entire file, the lock will be removed automatically if the daemon exits. This simplifies recovery, removing the need for us to clean up from the previous instance of the daemon.
Example
The function shown in Figure 13.6 illustrates the use of file and record locking to ensure that only one copy of a daemon is running.
Each copy of the daemon will try to create a file and write its process ID in it. This will allow administrators to identify the process easily. If the file is already locked, the lockfile function will fail with errno set to EACCES or EAGAIN, so we return 1, indicating that the daemon is already running. Otherwise, we truncate the file, write our process ID to it, and return 0.
We need to truncate the file, because the previous instance of the daemon might have had a process ID larger than ours, with a larger string length. For example, if the previous instance of the daemon was process ID 12345, and the new instance is process ID 9999, when we write the process ID to the file, we will be left with 99995 in the file. Truncating the file prevents data from the previous daemon appearing as if it applies to the current daemon.
Figure 13.6. Ensure that only one copy of a daemon is running
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <syslog.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <sys/stat.h>
#define LOCKFILE "/var/run/daemon.pid"
#define LOCKMODE (S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH)
extern int lockfile(int);
int
already_running(void)
{
int fd;
char buf[16];
fd = open(LOCKFILE, O_RDWR|O_CREAT, LOCKMODE);
if (fd < 0) {
syslog(LOG_ERR, "can't open %s: %s", LOCKFILE, strerror(errno));
exit(1);
}
if (lockfile(fd) < 0) {
if (errno == EACCES || errno == EAGAIN) {
close(fd);
return(1);
}
syslog(LOG_ERR, "can't lock %s: %s", LOCKFILE, strerror(errno));
exit(1);
}
ftruncate(fd, 0);
sprintf(buf, "%ld", (long)getpid());
write(fd, buf, strlen(buf)+1);
return(0);
}
13.6. Daemon Conventions
Several common conventions are followed by daemons in the UNIX System.
If the daemon uses a lock file, the file is usually stored in /var/run. Note, however, that the daemon might need superuser permissions to create a file here. The name of the file is usually name.pid, where name is the name of the daemon or the service. For example, the name of the cron daemon's lock file is /var/run/crond.pid. If the daemon supports configuration options, they are usually stored in /etc. The configuration file is named name.conf, where name is the name of the daemon or the name of the service. For example, the configuration for the syslogd daemon is /etc/syslog.conf. Daemons can be started from the command line, but they are usually started from one of the system initialization scripts (/etc/rc* or /etc/init.d/*). If the daemon should be restarted automatically when it exits, we can arrange for init to restart it if we include a respawn enTRy for it in /etc/inittab. If a daemon has a configuration file, the daemon reads it when it starts, but usually won't look at it again. If an administrator changes the configuration, the daemon would need to be stopped and restarted to account for the configuration changes. To avoid this, some daemons will catch SIGHUP and reread their configuration files when they receive the signal. Since they aren't associated with terminals and are either session leaders without controlling terminals or members of orphaned process groups, daemons have no reason to expect to receive SIGHUP. Thus, they can safely reuse it.
Example
The program shown in Figure 13.7 shows one way a daemon can reread its configuration file. The program uses sigwait and multiple threads, as discussed in Section 12.8.
We call daemonize from Figure 13.1 to initialize the daemon. When it returns, we call already_running from Figure 13.6 to ensure that only one copy of the daemon is running. At this point, SIGHUP is still ignored, so we need to reset the disposition to the default behavior; otherwise, the thread calling sigwait may never see the signal.
We block all signals, as is recommended for multithreaded programs, and create a thread to handle signals. The thread's only job is to wait for SIGHUP and SIGTERM. When it receives SIGHUP, the thread calls reread to reread its configuration file. When it receives SIGTERM, the thread logs a message and exits.
Recall from Figure 10.1 that the default action for SIGHUP and SIGTERM is to terminate the process. Because we block these signals, the daemon will not die when one of them is sent to the process. Instead, the thread calling sigwait will return with an indication that the signal has been received.
Figure 13.7. Daemon rereading configuration files
#include "apue.h"
#include <pthread.h>
#include <syslog.h>
sigset_t mask;
extern int already_running(void);
void
reread(void)
{
/* ... */
}
void *
thr_fn(void *arg)
{
int err, signo;
for (;;) {
err = sigwait(&mask, &signo);
if (err != 0) {
syslog(LOG_ERR, "sigwait failed");
exit(1);
}
switch (signo) {
case SIGHUP:
syslog(LOG_INFO, "Re-reading configuration file");
reread();
break;
case SIGTERM:
syslog(LOG_INFO, "got SIGTERM; exiting");
exit(0);
default:
syslog(LOG_INFO, "unexpected signal %d\n", signo);
}
}
return(0);
}
int
main(int argc, char *argv[])
{
int err;
pthread_t tid;
char *cmd;
struct sigaction sa;
if ((cmd = strrchr(argv[0], '/')) == NULL)
cmd = argv[0];
else
cmd++;
/*
* Become a daemon.
*/
daemonize(cmd);
/*
* Make sure only one copy of the daemon is running.
*/
if (already_running()) {
syslog(LOG_ERR, "daemon already running");
exit(1);
}
/*
* Restore SIGHUP default and block all signals.
*/
sa.sa_handler = SIG_DFL;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
if (sigaction(SIGHUP, &sa, NULL) < 0)
err_quit("%s: can't restore SIGHUP default");
sigfillset(&mask);
if ((err = pthread_sigmask(SIG_BLOCK, &mask, NULL)) != 0)
err_exit(err, "SIG_BLOCK error");
/*
* Create a thread to handle SIGHUP and SIGTERM.
*/
err = pthread_create(&tid, NULL, thr_fn, 0);
if (err != 0)
err_exit(err, "can't create thread");
/*
* Proceed with the rest of the daemon.
*/
/* ... */
exit(0);
}
Example
As noted in Section 12.8, Linux threads behave differently with respect to signals. Because of this, identifying the proper process to signal in Figure 13.7 will be difficult. In addition, we aren't guaranteed that the daemon will react as we expect, because of the implementation differences.
The program in Figure 13.8 shows how a daemon can catch SIGHUP and reread its configuration file without using multiple threads.
After initializing the daemon, we install signal handlers for SIGHUP and SIGTERM. We can either place the reread logic in the signal handler or just set a flag in the handler and have the main thread of the daemon do all the work instead.
Figure 13.8. Alternate implementation of daemon rereading configuration files
#include "apue.h"
#include <syslog.h>
#include <errno.h>
extern int lockfile(int);
extern int already_running(void);
void
reread(void)
{
/* ... */
}
void
sigterm(int signo)
{
syslog(LOG_INFO, "got SIGTERM; exiting");
exit(0);
}
void
sighup(int signo)
{
syslog(LOG_INFO, "Re-reading configuration file");
reread();
}
int
main(int argc, char *argv[])
{
char *cmd;
struct sigaction sa;
if ((cmd = strrchr(argv[0], '/')) == NULL)
cmd = argv[0];
else
cmd++;
/*
* Become a daemon.
*/
daemonize(cmd);
/*
* Make sure only one copy of the daemon is running.
*/
if (already_running()) {
syslog(LOG_ERR, "daemon already running");
exit(1);
}
/*
* Handle signals of interest.
*/
sa.sa_handler = sigterm;
sigemptyset(&sa.sa_mask);
sigaddset(&sa.sa_mask, SIGHUP);
sa.sa_flags = 0;
if (sigaction(SIGTERM, &sa, NULL) < 0) {
syslog(LOG_ERR, "can't catch SIGTERM: %s", strerror(errno));
exit(1);
}
sa.sa_handler = sighup;
sigemptyset(&sa.sa_mask);
sigaddset(&sa.sa_mask, SIGTERM);
sa.sa_flags = 0;
if (sigaction(SIGHUP, &sa, NULL) < 0) {
syslog(LOG_ERR, "can't catch SIGHUP: %s", strerror(errno));
exit(1);
}
/*
* Proceed with the rest of the daemon.
*/
/* ... */
exit(0);
}
13.7. ClientServer Model
A common use for a daemon process is as a server process. Indeed, in Figure 13.2, we can call the syslogd process a server that has messages sent to it by user processes (clients) using a UNIX domain datagram socket.
In general, a server is a process that waits for a client to contact it, requesting some type of service. In Figure 13.2, the service being provided by the syslogd server is the logging of an error message.
In Figure 13.2, the communication between the client and the server is one-way. The client sends its service request to the server; the server sends nothing back to the client. In the upcoming chapters, we'll see numerous examples of two-way communication between a client and a server. The client sends a request to the server, and the server sends a reply back to the client.
| 
 LINUX
LINUX 
 Books
Books
