Шедулер
timeslice - время между двумя срабатываниями шедулера
run queue - очередь процессов.Она состоит из 2-х массивов :
Active - процессы , у которых еще не истекло timeslice.
Expired - процессы , у которых оно истекло.
В версии ядра 2.6 шедулер переписан заново и маркирован как шедулер O(1).
Шедулер - или планировщик - выполняет постоянную работу.
В 3-й главе показаны основы его работы.
В этом разделе будет показано , как задача выполняется в одно-процессорной системе.
Будет показано , как шедулер переключается между процессами - т.е. делает т.н. context switch.
Говоря конкретно , шедулер - это набор функций , который оперирует набором структур.
Реализация шедулера лежит в файлах
kernel/sched.c и include/linux/sched.h.
Термины task , process , и даже thread - это суть почти одно и то же , если смотреть комменты ядра.
Процесс - это набор контрольных структур.
Шедулер будет ссылаться на task_struct , являющейся основным идентификатором процесса.
В 3-й главе task_struct рассмотрен подробнее.
Переключение на другую задачу
После того как процесс проинициализирован и помещен в очередь , он должен выполняться.
Для этого есть 2 функции - schedule() и scheduler_tick().
scheduler_tick() - это системный таймер.
При срабатывании события таймера , процесс засыпает и управление передается ядру.
Когда это событие заканчивается , управление передается процессу обратно.
Для определения того ,какой именно процесс должен взять контроль ,
существует функция shedule().
Выполняемый процесс называется текущим процессом - current.
В некоторых ситуациях , управление другому процессу может быть и не отдано , и оно по прежнему
останется у этого же процесса. Это называется kernel preemption.
Figure 7.1
показано . как во времени происходит распределение между процессами.
Сначала выполняется процесс А.
Затем срабатывает таймер scheduler_tick() ,
управление передается ядру ,
вызывается schedule(),
выбирается процесс В и ядро передает ему управление. И т.д.
Следующий фрагмент кода ядра показывает , как происходит комбинация этих 2-х функций :
----------------------------------------------------------------------
kernel/sched.c
2184 asmlinkage void schedule(void)
2185 {
2186 long *switch_count;
2187 task_t *prev, *next;
2188 runqueue_t *rq;
2189 prio_array_t *array;
2190 struct list_head *queue;
2191 unsigned long long now;
2192 unsigned long run_time;
2193 int idx;
2194
2195 /*
2196 * Test if we are atomic. Since do_exit() needs to call into
2197 * schedule() atomically, we ignore that path for now.
2198 * Otherwise, whine if we are scheduling when we should not be.
2199 */
2200 if (likely(!(current->state & (TASK_DEAD | TASK_ZOMBIE)))) {
2201 if (unlikely(in_atomic())) {
2202 printk(KERN_ERR "bad: scheduling while atomic!\n ");
2203 dump_stack();
2204 }
2205 }
2206
2207 need_resched:
2208 preempt_disable();
2209 prev = current;
2210 rq = this_rq();
2211
2212 release_kernel_lock(prev);
2213 now = sched_clock();
2214 if (likely(now - prev->timestamp < NS_MAX_SLEEP_AVG))
2215 run_time = now - prev->timestamp;
2216 else
2217 run_time = NS_MAX_SLEEP_AVG;
2218
2219 /*
2220 * Tasks with interactive credits get charged less run_time
2221 * at high sleep_avg to delay them losing their interactive
2222 * status
2223 */
2224 if (HIGH_CREDIT(prev))
2225 run_time /= (CURRENT_BONUS(prev) ? : 1);
-----------------------------------------------------------------------
Строки 2213 - 2218
Мы вычисляем промежуток времени , в течение которого процесс будет выполняться.
Если процесс был активен более константы NS_MAX_SLEEP_AVG,
мы ограниичваем это время этой константой.
timeslice - это время , равное сумме 2-х промежутков : это время между 2-мя прерываниями шедулера
плюс время жизни процесса.
Если время жизни выходит за рамки timeslice , процесс становится неактивным.
timestamp - это максимум того времени , которое процесс может быть активен.
timestamp необходим для регулирования timeslice процесса.
Например , предположим , что процесс A имеет timeslice равный 50 clock cycles.
Пусть он активен всего 5 циклов.
С помощью timestamp процесс вычисляет , что у процесса А есть 45 циклов в запасе.
Строки 2224-2225
Интерактивные процессы - процессы , которые большую часть времени ожидают ввода.
Примером такого процесса является контроллер клавиатуры.
Такие процессы получают время жизни run_time путем деления на (sleep_avg/ max_sleep_avg * MAX_BONUS(10)):
----------------------------------------------------------------------
kernel/sched.c
2226
2227 spin_lock_irq(&rq->lock);
2228
2229 /*
2230 * if entering off of a kernel preemption go straight
2231 * to picking the next task.
2232 */
2233 switch_count = &prev->nivcsw;
2234 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
2235 switch_count = &prev->nvcsw;
2236 if (unlikely((prev->state & TASK_INTERRUPTIBLE) &&
2237 unlikely(signal_pending(prev))))
2238 prev->state = TASK_RUNNING;
2239 else
2240 deactivate_task(prev, rq);
2241 }
-----------------------------------------------------------------------
Строка 2227
Функция блокирует очередь , потому что мы собираемся ее модифицировать.
Строки 2233 - 2241
Если функция schedule() не получает kernel preemption,
текущий процесс продолжает выполняться .
kernel preemption - это когда процесс , выполняющий системный вызов , может быть прерван ,
а может и нет , в зависимости от настроек ядра.
В противном случае текущий процесс перестает быть таковым , и выбирается очередной процесс.
----------------------------------------------------------------------
kernel/sched.c
2243 cpu = smp_processor_id();
2244 if (unlikely(!rq->nr_running)) {
2245 idle_balance(cpu, rq);
2246 if (!rq->nr_running) {
2247 next = rq->idle;
2248 rq->expired_timestamp = 0;
2249 wake_sleeping_dependent(cpu, rq);
2250 goto switch_tasks;
2251 }
2252 }
2253
2254 array = rq->active;
2255 if (unlikely(!array->nr_active)) {
2256 /*
2257 * Switch the active and expired arrays.
2258 */
2259 rq->active = rq->expired;
2260 rq->expired = array;
2261 array = rq->active;
2262 rq->expired_timestamp = 0;
2263 rq->best_expired_prio = MAX_PRIO;
2264 }
-----------------------------------------------------------------------
Строка 2243
Вычисляется идентификатор CPU smp_processor_id().
Строки 2244 - 2252
Если в очереди нет процессов , текущим становится так называемый "нулевой" idle процесс,
и обнуляется timestamp.
Для много-процессорной системы нужно проверить все CPU.
Строки 2255 - 2264
Если очередь активных процессов пуста , мы переключаем указатель на очередь пассивных процессов.
----------------------------------------------------------------------
kernel/sched.c
2266 idx = sched_find_first_bit(array->bitmap);
2267 queue = array->queue + idx;
2268 next = list_entry(queue->next, task_t, run_list);
2269
2270 if (dependent_sleeper(cpu, rq, next)) {
2271 next = rq->idle;
2272 goto switch_tasks;
2273 }
2274
2275 if (!rt_task(next) && next->activated > 0) {
2276 unsigned long long delta = now - next->timestamp;
2277
2278 if (next->activated == 1)
2279 delta = delta * (ON_RUNQUEUE_WEIGHT * 128 / 100) / 128;
2280
2281 array = next->array;
2282 dequeue_task(next, array);
2283 recalc_task_prio(next, next->timestamp + delta);
2284 enqueue_task(next, array);
2285 }
2285 next->activated = 0;
-----------------------------------------------------------------------
Строки 2266 - 2268
С помощью sched_find_first_bit() находится процесс с наивысшим приоритетом ,
который станет текущим.
Строки 2270 - 2273
Еще одна дополнительная проверка процесса ,
после чего вызываем switch_tasks.
Предположим , что процесс А породил процесс В , который читает данные с устройства.
Секция кода dependent_sleeper() определит зависимость процесса А от процесса В
и переключит на последний.
Строки 2275 - 2285
Если процесс не является real-time task, он удаляется из очереди - queue.
Строка 2286
Атрибут активации процесса устанавливается в 0..
----------------------------------------------------------------------
kernel/sched.c
2287 switch_tasks:
2288 prefetch(next);
2289 clear_tsk_need_resched(prev);
2290 RCU_qsctr(task_cpu(prev))++;
2291
2292 prev->sleep_avg -= run_time;
2293 if ((long)prev->sleep_avg <= 0) {
2294 prev->sleep_avg = 0;
2295 if (!(HIGH_CREDIT(prev) || LOW_CREDIT(prev)))
2296 prev->interactive_credit--;
2297 }
2298 prev->timestamp = now;
2299
2300 if (likely(prev != next)) {
2301 next->timestamp = now;
2302 rq->nr_switches++;
2303 rq->curr = next;
2304 ++*switch_count;
2305
2306 prepare_arch_switch(rq, next);
2307 prev = context_switch(rq, prev, next);
2308 barrier();
2309
2310 finish_task_switch(prev);
2311 } else
2312 spin_unlock_irq(&rq->lock);
2313
2314 reacquire_kernel_lock(current);
2315 preempt_enable_no_resched();
2316 if (test_thread_flag(TIF_NEED_RESCHED))
2317 goto need_resched;
2318 }
-----------------------------------------------------------------------
Строка 2288
Попытка выделить память в кеше CPU для новой task structure (See include/linux/prefetch.h for more information.)
Строка 2290
Поскольку мы собираемся сделать context switch,
нам нужна информация о текущем состоянии CPU.
Актуально для мульти-процессорных систем.
Процесс называется read-copy. For more information, see http://lse.sourceforge.net/locking/rcupdate.html.
Строки 2292 - 2298
Проверяются и модифицируются атрибуты предыдущего процесса.
Timestamp становится равным текущему времени.
Строки 2300-2304
Меняем атрибуты выбранного процесса , увеличиваем счетчик очереди,
и наконец-то делаем выбранный процесс текущим.
Строки 2306 - 2308
Депаем context_switch().
Строки 2314 - 2318
Разблокировка ядра и возвращение наверх schedule().
После произведенного context_switch(), шедулинг продолжается.
scheduler_tick() может сделать маркировку для следующего процесса.
Context Switch
Called from schedule() in /kernel/sched.c, context_switch() does the machine-specific work of switching the memory environment and the processor state. In the abstract, context_switch swaps the current task with the next task. The function context_switch() begins executing the next task and returns a pointer to the task structure of the task that was running before the call:
----------------------------------------------------------------------
kernel/sched.c
1048 /*
1049 * context_switch - switch to the new MM and the new
1050 * thread's register state.
1051 */
1052 static inline
1053 task_t * context_switch(runqueue_t *rq, task_t *prev, task_t *next)
1054 {
1055 struct mm_struct *mm = next->mm;
1056 struct mm_struct *oldmm = prev->active_mm;
...
1063 switch_mm(oldmm, mm, next);
...
1072 switch_to(prev, next, prev);
1073
1074 return prev;
1075 }
-----------------------------------------------------------------------
Here, we describe the two jobs of context_switch: one to switch the virtual memory mapping and one to switch the task/thread structure. The first job, which the function switch_mm() carries out, uses many of the hardware-dependent memory management structures and registers:
----------------------------------------------------------------------
/include/asm-i386/mmu_context.h
026 static inline void switch_mm(struct mm_struct *prev,
027 struct mm_struct *next,
028 struct task_struct *tsk)
029 {
030 int cpu = smp_processor_id();
031
032 if (likely(prev != next)) {
033 /* stop flush ipis for the previous mm */
034 cpu_clear(cpu, prev->cpu_vm_mask);
035 #ifdef CONFIG_SMP
036 cpu_tlbstate[cpu].state = TLBSTATE_OK;
037 cpu_tlbstate[cpu].active_mm = next;
038 #endif
039 cpu_set(cpu, next->cpu_vm_mask);
040
041 /* Re-load page tables */
042 load_cr3(next->pgd);
043
044 /*
045 * load the LDT, if the LDT is different:
046 */
047 if (unlikely(prev->context.ldt != next->context.ldt))
048 load_LDT_nolock(&next->context, cpu);
049 }
050 #ifdef CONFIG_SMP
051 else {
-----------------------------------------------------------------------
Line 39
Bind the new task to the current processor.
Line 42
The code for switching the memory context utilizes the x86 hardware register cr3, which holds the base address of all paging operations for a given process. The new page global descriptor is loaded here from next->pgd.
Line 47
Most processes share the same LDT. If another LDT is required by this process, it is loaded here from the new next->context structure.
The other half of function context_switch() in /kernel/sched.c then calls the macro switch_to(), which calls the C function __switch_to(). The delineation of architecture independence to architecture dependence for both x86 and PPC is the switch_to() macro.
7.1.2.1. Following the x86 Trail of switch_to()
The x86 code is more compact than PPC. The following is the architecture-dependent code for __switch_to(). task_struct (not tHRead_struct) is passed to __switch_to(). The code discussed next is inline assembler code for calling the C function __switch_to() (line 23) with the proper task_struct structures as parameters.
The context_switch takes three task pointers: prev, next, and last. In addition, there is the current pointer.
Let us now explain, at a high level, what occurs when switch_to() is called and how the task pointers change after a call to switch_to().
Figure 7.2 shows three switch_to() calls using three processes: A, B, and C.
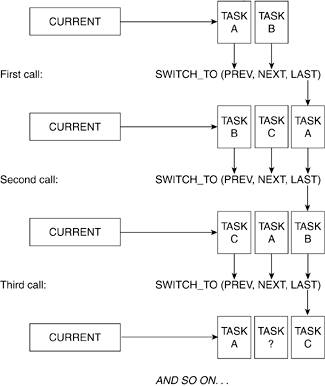
We want to switch A and B. Before, the first call we have
After the first call:
Current  B B Last A
Now, we want to switch B and C. Before the second call, we have
After the second call:
Current C Last B
Returning from the second call, current now points to task (C) and last points to (B).
The method continues with task (A) being swapped in once again, and so on.
The inline assembly of the switch_to() function is an excellent example of assembly magic in the kernel. It is also a good example of the gcc C extensions. See
Chapter 2, "Exploration Toolkit," for a tutorial featuring this function. Now, we carefully walk through this code block.
----------------------------------------------------------------------
/include/asm-i386/system.h
012 extern struct task_struct * FASTCALL(__switch_to(struct task_struct *prev, struct
 task_struct *next));
015 #define switch_to(prev,next,last) do { \
016 unsigned long esi,edi; \
017 asm volatile("pushfl\n\t" \
018 "pushl %%ebp\n\t" \
019 "movl %%esp,%0\n\t" /* save ESP */ \
020 "movl %5,%%esp\n\t" /* restore ESP */ \
021 "movl $1f,%1\n\t" /* save EIP */ \
022 "pushl %6\n\t" /* restore EIP */ \
023 "jmp __switch_to\n" \
023 "1:\t" \
024 "popl %%ebp\n\t" \
025 "popfl" \
026 :"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
027 "=a" (last),"=S" (esi),"=D" (edi) \
028 :"m" (next->thread.esp),"m" (next->thread.eip), \
029 "2" (prev), "d" (next)); \
030 } while (0)
----------------------------------------------------------------------- task_struct *next));
015 #define switch_to(prev,next,last) do { \
016 unsigned long esi,edi; \
017 asm volatile("pushfl\n\t" \
018 "pushl %%ebp\n\t" \
019 "movl %%esp,%0\n\t" /* save ESP */ \
020 "movl %5,%%esp\n\t" /* restore ESP */ \
021 "movl $1f,%1\n\t" /* save EIP */ \
022 "pushl %6\n\t" /* restore EIP */ \
023 "jmp __switch_to\n" \
023 "1:\t" \
024 "popl %%ebp\n\t" \
025 "popfl" \
026 :"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
027 "=a" (last),"=S" (esi),"=D" (edi) \
028 :"m" (next->thread.esp),"m" (next->thread.eip), \
029 "2" (prev), "d" (next)); \
030 } while (0)
-----------------------------------------------------------------------
Line 12
The FASTCALL macro resolves to __attribute__ regparm(3), which forces the parameters to be passed in registers rather than stack.
Lines 1516
The do {} while (0) construct allows (among other things) the macro to have local the variables esi and edi. Remember, these are just local variables with familiar names.
|
As we explore the kernel, whenever we need to retrieve or store information on the task (or process) which is currently running on a given processor, we use the global variable current to reference its task structure. For example, current->pid holds the process ID. Linux allows for a quick (and clever) method of referencing the current task structure.
Every process is assigned 8K of contiguous memory when it is created. (With Linux 2.6, there is a compile-time option to use 4K instead of 8K.) This 8K segment is occupied by the task structure and the kernel stack for the given process. Upon process creation, Linux puts the task structure at the low end of the 8K memory and the kernel stack pointer starts at the high end. The kernel stack pointer (especially for x86 and r1 for PPC) decrements as data is pushed onto the stack. Because this 8K memory region is page-aligned, its starting address (in hex notation) always ends in 0x000 (multiples of 4k bytes).
As you might have guessed, the clever method by which Linux references the current task structure is to AND the contents of the stack pointer with 0xffff_f000. Recent versions of the PPC Linux kernel have taken this one step further by dedicating General Purpose Register 2 to holding the current pointer. |
Lines 17 and 30
The construct asm volatile () encloses the inline assembly block and the volatile keyword assures that the compiler will not change (optimize) the routine in any way.
Lines 1718
Push the flags and ebp registers onto the stack. (Note: We are still using the stack associated with the prev task.)
Line 19
This line saves the current stack pointer esp to the prev task structure.
Line 20
Move the stack pointer from the next task structure to the current processor esp.
NOTE
By definition, we have just made a context switch.
We are now with a new kernel stack and thus, any reference to current is to the new (next) task structure.
Line 21
Save the return address for prev into its task structure. This is where the prev task resumes when it is restarted.
Line 22
Push the return address (from when we return from __switch_to()) onto the stack. This is the eip from next. The eip was saved into its task structure (on line 21) when it was stopped, or preempted the last time.
Line 23
Jump to the C function __switch_to() to update the following:
The next thread structure with the kernel stack pointer Thread local storage descriptor for this processor fs and gs for prev and next, if needed Debug registers, if needed I/O bitmaps, if needed
__switch_to() then returns the updated prev task structure.
Lines 2425
Pop the base pointer and flags registers from the new (next task) kernel stack.
Lines 2629
These are the output and input parameters to the inline assembly routine. See the "
Inline Assembly" section in
Chapter 2 for more information on the constraints put on these parameters.
Line 29
By way of assembler magic, prev is returned in eax, which is the third positional parameter. In other words, the input parameter prev is passed out of the switch_to() macro as the output parameter last.
Because switch_to() is a macro, it was executed inline with the code that called it in context_switch(). It does not return as functions normally do.
For the sake of clarity, remember that switch_to() passes back prev in the eax register, execution then continues in context_switch(), where the next instruction is return prev (line 1074 of kernel/sched.c). This allows context_switch() to pass back a pointer to the last task running.
7.1.2.2. Following the PPC context_switch()
The PPC code for context_switch() has slightly more work to do for the same results. Unlike the cr3 register in x86 architecture, the PPC uses hash functions to point to context environments. The following code for switch_mm() touches on these functions, but
Chapter 4, "Memory Management," offers a deeper discussion.
Here is the routine for switch_mm() which, in turn, calls the routine set_context().
----------------------------------------------------------------------
/include/asm-ppc/mmu_context.h
155 static inline void switch_mm(struct mm_struct *prev, struct
mm_struct *next,struct task_struct *tsk)
156 {
157 tsk->thread.pgdir = next->pgd;
158 get_mmu_context(next);
159 set_context(next->context, next->pgd);
160 }
-----------------------------------------------------------------------
Line 157
The page global directory (segment register) for the new thread is made to point to the next->pgd pointer.
Line 158
The context field of the mm_struct (next->context) passed into switch_mm() is updated to the value of the appropriate context. This information comes from a global reference to the variable context_map[], which contains a series of bitmap fields.
Line 159
This is the call to the assembly routine set_context. Below is the code and discussion of this routine. Upon execution of the blr instruction on line 1468, the code returns to the switch_mm routine.
----------------------------------------------------------------------
/arch/ppc/kernel/head.S
1437 _GLOBAL(set_context)
1438 mulli r3,r3,897 /* multiply context by skew factor */
1439 rlwinm r3,r3,4,8,27 /* VSID = (context & 0xfffff) << 4 */
1440 addis r3,r3,0x6000 /* Set Ks, Ku bits */
1441 li r0,NUM_USER_SEGMENTS
1442 mtctr r0
...
1457 3: isync
...
1461 mtsrin r3,r4
1462 addi r3,r3,0x111 /* next VSID */
1463 rlwinm r3,r3,0,8,3 /* clear out any overflow from VSID field */
1464 addis r4,r4,0x1000 /* address of next segment */
1465 bdnz 3b
1466 sync
1467 isync
1468 blr
------------------------------------------------------------------------
Lines 14371440
The context field of the mm_struct (next->context) passed into set_context() by way of r3, sets up the hash function for PPC segmentation.
Lines 14611465
The pgd field of the mm_struct (next->pgd) passed into set_context() by way of r4, points to the segment registers.
Segmentation is the basis of PPC memory management (refer to
Chapter 4). Upon returning from set_context(), the mm_struct next is initialized to the proper memory regions and is returned to switch_mm().
7.1.2.3. Following the PPC Trail of switch_to()
The result of the PPC implementation of switch_to() is necessarily identical to the x86 call; it takes in the current and next task pointers and returns a pointer to the previously running task:
----------------------------------------------------------------------
include/asm-ppc/system.h
88 extern struct task_struct *__switch_to(struct task_struct *,
89 struct task_struct *);
90 #define switch_to(prev, next, last)
((last) = __switch_to((prev), (next)))
91
92 struct thread_struct;
93 extern struct task_struct *_switch(struct thread_struct *prev,
94 struct thread_struct *next);
-----------------------------------------------------------------------
On line 88, __switch_to() takes its parameters as task_struct type and, at line 93, _switch() takes its parameters as tHRead_struct. This is because the thread entry within task_struct contains the architecture-dependent processor register information of interest for the given thread. Now, let us examine the implementation of __switch_to():
----------------------------------------------------------------------
/arch/ppc/kernel/process.c
200 struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *new)
201 {
202 struct thread_struct *new_thread, *old_thread;
203 unsigned long s;
204 struct task_struct *last;
205 local_irq_save(s);
...
247 new_thread = &new->thread;
248 old_thread = ¤t->thread;
249 last = _switch(old_thread, new_thread);
250 local_irq_restore(s);
251 return last;
252 }
-----------------------------------------------------------------------
Line 205
Disable interrupts before the context switch.
Lines 247248
Still running under the context of the old thread, pass the pointers to the thread structure to the _switch() function.
Line 249
_switch() is the assembly routine called to do the work of switching the two thread structures (see the following section).
Line 250
Enable interrupts after the context switch.
To better understand what needs to be swapped within a PPC thread, we need to examine the thread_struct passed in on line 249.
Recall from the exploration of the x86 context switch that the switch does not officially occur until we are pointing to a new kernel stack. This happens in _switch().
Tracing the PPC Code for _switch()
By convention, the parameters of a PPC C function (from left to right) are held in r3, r4, r5, …r12. Upon entry into switch(), r3 points to the thread_struct for the current task and r4 points to the thread_struct for the new task:
----------------------------------------------------------------------
/arch/ppc/kernel/entry.S
437 _GLOBAL(_switch)
438 stwu r1,-INT_FRAME_SIZE(r1)
439 mflr r0
440 stw r0,INT_FRAME_SIZE+4(r1)
441 /* r3-r12 are caller saved -- Cort */
442 SAVE_NVGPRS(r1)
443 stw r0,_NIP(r1) /* Return to switch caller */
444 mfmsr r11
...
458 1: stw r11,_MSR(r1)
459 mfcr r10
460 stw r10,_CCR(r1)
461 stw r1,KSP(r3) /* Set old stack pointer */
462
463 tophys(r0,r4)
464 CLR_TOP32(r0)
465 mtspr SPRG3,r0/* Update current THREAD phys addr */
466 lwz r1,KSP(r4) /* Load new stack pointer */
467 /* save the old current 'last' for return value */
468 mr r3,r2
469 addi r2,r4,-THREAD /* Update current */
...
478 lwz r0,_CCR(r1)
479 mtcrf 0xFF,r0
480 REST_NVGPRS(r1)
481
482 lwz r4,_NIP(r1) /* Return to _switch caller in new task */
483 mtlr r4
484 addi r1,r1,INT_FRAME_SIZE
485 blr
-----------------------------------------------------------------------
The byte-for-byte mechanics of swapping out the previous thread_struct for the new is left as an exercise for you. It is worth noting, however, the use of r1, r2, r3, SPRG3, and r4 in _switch() to see the basics of this operation.
Lines 438460
The environment is saved to the current stack with respect to the current stack pointer, r1.
Line 461
The entire environment is then saved into the current thread_struct pointer passed in by way of r3.
Lines 463465
SPRG3 is updated to point to the thread structure of the new task.
Line 466
KSP is the offset into the task structure (r4) of the new task's kernel stack pointer. The stack pointer r1 is now updated with this value. (This is the point of the PPC context switch.)
Line 468
The current pointer to the previous task is returned from _switch() in r3. This represents the last task.
Line 469
The current pointer (r2) is updated with the pointer to the new task structure (r4).
Lines 478486
Restore the rest of the environment from the new stack and return to the caller with the previous task structure in r3.
This concludes the explanation of context_switch(). At this point, the processor has swapped the two processes prev and next as called by context_switch in schedule().
----------------------------------------------------------------------
kernel/sched.c
1709 prev = context_switch(rq, prev, next);
-----------------------------------------------------------------------
prev now points to the process that we have just switched away from and next points to the current process.
Now that we've discussed how tasks are scheduled in the Linux kernel, we can examine how tasks are told to be scheduled. Namely, what causes schedule() to be called and one process to yield the CPU to another process?
7.1.3. Yielding the CPU
Processes can voluntarily yield the CPU by simply calling schedule(). This is most commonly used in kernel code and device drivers that want to sleep or wait for a signal to occur. Other tasks want to continually use the CPU and the system timer must tell them to yield. The Linux kernel periodically seizes the CPU, in so doing stopping the active process, and then does a number of timer-based tasks. One of these tasks, scheduler_tick(), is how the kernel forces a process to yield. If a process has been running for too long, the kernel does not return control to that process and instead chooses another one. We now examine how scheduler_tick()determines if the current process must yield the CPU:
----------------------------------------------------------------------
kernel/sched.c
1981 void scheduler_tick(int user_ticks, int sys_ticks)
1982 {
1983 int cpu = smp_processor_id();
1984 struct cpu_usage_stat *cpustat = &kstat_this_cpu.cpustat;
1985 runqueue_t *rq = this_rq();
1986 task_t *p = current;
1987
1988 rq->timestamp_last_tick = sched_clock();
1989
1990 if (rcu_pending(cpu))
1991 rcu_check_callbacks(cpu, user_ticks);
-----------------------------------------------------------------------
Lines 19811986
This code block initializes the data structures that the scheduler_tick() function needs. cpu, cpu_usage_stat, and rq are set to the processor ID, CPU stats and run queue of the current processor. p is a pointer to the current process executing on cpu.
Line 1988
The run queue's last tick is set to the current time in nanoseconds.
Lines 19901991
On an SMP system, we need to check if there are any outstanding read-copy updates to perform (RCU). If so, we perform them via rcu_check_callback().
----------------------------------------------------------------------
kernel/sched.c
1993 /* note: this timer irq context must be accounted for as well */
1994 if (hardirq_count() - HARDIRQ_OFFSET) {
1995 cpustat->irq += sys_ticks;
1996 sys_ticks = 0;
1997 } else if (softirq_count()) {
1998 cpustat->softirq += sys_ticks;
1999 sys_ticks = 0;
2000 }
2001
2002 if (p == rq->idle) {
2003 if (atomic_read(&rq->nr_iowait) > 0)
2004 cpustat->iowait += sys_ticks;
2005 else
2006 cpustat->idle += sys_ticks;
2007 if (wake_priority_sleeper(rq))
2008 goto out;
2009 rebalance_tick(cpu, rq, IDLE);
2010 return;
2011 }
2012 if (TASK_NICE(p) > 0)
2013 cpustat->nice += user_ticks;
2014 else
2015 cpustat->user += user_ticks;
2016 cpustat->system += sys_ticks;
-----------------------------------------------------------------------
Lines 19942000
cpustat keeps track of kernel statistics, and we update the hardware and software interrupt statistics by the number of system ticks that have occurred.
Lines 20022011
If there is no currently running process, we atomically check if any processes are waiting on I/O. If so, the CPU I/O wait statistic is incremented; otherwise, the CPU idle statistic is incremented. In a uniprocessor system, rebalance_tick() does nothing, but on a multiple processor system, rebalance_tick() attempts to load balance the current CPU because the CPU has nothing to do.
Lines 20122016
More CPU statistics are gathered in this code block. If the current process was niced, we increment the CPU nice counter; otherwise, the user tick counter is incremented. Finally, we increment the CPU's system tick counter.
----------------------------------------------------------------------
kernel/sched.c
2019 if (p->array != rq->active) {
2020 set_tsk_need_resched(p);
2021 goto out;
2022 }
2023 spin_lock(&rq->lock);
-----------------------------------------------------------------------
Lines 20192022
Here, we see why we store a pointer to a priority array within the task_struct of the process. The scheduler checks the current process to see if it is no longer active. If the process has expired, the scheduler sets the process' rescheduling flag and jumps to the end of the scheduler_tick() function. At that point (lines 20922093), the scheduler attempts to load balance the CPU because there is no active task yet. This case occurs when the scheduler grabbed CPU control before the current process was able to schedule itself or clean up from a successful run.
Line 2023
At this point, we know that the current process was running and not expired or nonexistent. The scheduler now wants to yield CPU control to another process; the first thing it must do is take the run queue lock.
----------------------------------------------------------------------
kernel/sched.c
2024 /*
2025 * The task was running during this tick - update the
2026 * time slice counter. Note: we do not update a thread's
2027 * priority until it either goes to sleep or uses up its
2028 * timeslice. This makes it possible for interactive tasks
2029 * to use up their timeslices at their highest priority levels.
2030 */
2031 if (unlikely(rt_task(p))) {
2032 /*
2033 * RR tasks need a special form of timeslice management.
2034 * FIFO tasks have no timeslices.
2035 */
2036 if ((p->policy == SCHED_RR) && !--p->time_slice) {
2037 p->time_slice = task_timeslice(p);
2038 p->first_time_slice = 0;
2039 set_tsk_need_resched(p);
2040
2041 /* put it at the end of the queue: */
2042 dequeue_task(p, rq->active);
2043 enqueue_task(p, rq->active);
2044 }
2045 goto out_unlock;
2046 }
-----------------------------------------------------------------------
Lines 20312046
The easiest case for the scheduler occurs when the current process is a real-time task. Real-time tasks always have a higher priority than any other tasks. If the task is a FIFO task and was running, it should continue its operation so we jump to the end of the function and release the run queue lock. If the current process is a round-robin real-time task, we decrement its timeslice. If the task has no more timeslice, it's time to schedule another round-robin real-time task. The current task has its new timeslice calculated by task_timeslice(). Then the task has its first time slice reset. The task is then marked as needing rescheduling and, finally, the task is put at the end of the round-robin real-time tasklist by removing it from the run queue's active array and adding it back in. The scheduler then jumps to the end of the function and releases the run queue lock.
----------------------------------------------------------------------
kernel/sched.c
2047 if (!--p->time_slice) {
2048 dequeue_task(p, rq->active);
2049 set_tsk_need_resched(p);
2050 p->prio = effective_prio(p);
2051 p->time_slice = task_timeslice(p);
2052 p->first_time_slice = 0;
2053
2054 if (!rq->expired_timestamp)
2055 rq->expired_timestamp = jiffies;
2056 if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) {
2057 enqueue_task(p, rq->expired);
2058 if (p->static_prio < rq->best_expired_prio)
2059 rq->best_expired_prio = p->static_prio;
2060 } else
2061 enqueue_task(p, rq->active);
2062 } else {
-----------------------------------------------------------------------
Lines 20472061
At this point, the scheduler knows that the current process is not a real-time process. It decrements the process' timeslice and, in this section, the process' timeslice has been exhausted and reached 0. The scheduler removes the task from the active array and sets the process' rescheduling flag. The priority of the task is recalculated and its timeslice is reset. Both of these operations take into account prior process activity. If the run queue's expired timestamp is 0, which usually occurs when there are no more processes on the run queue's active array, we set it to jiffies.
|
Jiffies is a 32-bit variable counting the number of ticks since the system has been booted. This is approximately 497 days before the number wraps around to 0 on a 100HZ system. The macro on line 20 is the suggested method of accessing this value as a u64. There are also macros to help detect wrapping in include/jiffies.h.
-----------------------------------------------------------------------
include/linux/jiffies.h
017 extern unsigned long volatile jiffies;
020 u64 get_jiffies_64(void);
-----------------------------------------------------------------------
|
We normally favor interactive tasks by replacing them on the active priority array of the run queue; this is the else clause on line 2060. However, we don't want to starve expired tasks. To determine if expired tasks have been waiting too long for CPU time, we use EXPIRED_STARVING() (see EXPIRED_STARVING on line 1968). The function returns true if the first expired task has been waiting an "unreasonable" amount of time or if the expired array contains a task that has a greater priority than the current process. The unreasonableness of waiting is load-dependent and the swapping of the active and expired arrays decrease with an increasing number of running tasks.
If the task is not interactive or expired tasks are starving, the scheduler takes the current process and enqueues it onto the run queue's expired priority array. If the current process' static priority is higher than the expired run queue's highest priority task, we update the run queue to reflect the fact that the expired array now has a higher priority than before. (Remember that high-priority tasks have low numbers in Linux, thus, the (<) in the code.)
----------------------------------------------------------------------
kernel/sched.c
2062 } else {
2063 /*
2064 * Prevent a too long timeslice allowing a task to monopolize
2065 * the CPU. We do this by splitting up the timeslice into
2066 * smaller pieces.
2067 *
2068 * Note: this does not mean the task's timeslices expire or
2069 * get lost in any way, they just might be preempted by
2070 * another task of equal priority. (one with higher
2071 * priority would have preempted this task already.) We
2072 * requeue this task to the end of the list on this priority
2073 * level, which is in essence a round-robin of tasks with
2074 * equal priority.
2075 *
2076 * This only applies to tasks in the interactive
2077 * delta range with at least TIMESLICE_GRANULARITY to requeue.
2078 */
2079 if (TASK_INTERACTIVE(p) && !((task_timeslice(p) -
2080 p->time_slice) % TIMESLICE_GRANULARITY(p)) &&
2081 (p->time_slice >= TIMESLICE_GRANULARITY(p)) &&
2082 (p->array == rq->active)) {
2083
2084 dequeue_task(p, rq->active);
2085 set_tsk_need_resched(p);
2086 p->prio = effective_prio(p);
2087 enqueue_task(p, rq->active);
2088 }
2089 }
2090 out_unlock:
2091 spin_unlock(&rq->lock);
2092 out:
2093 rebalance_tick(cpu, rq, NOT_IDLE);
2094 }
-----------------------------------------------------------------------
Lines 20792089
The final case before the scheduler is that the current process was running and still has timeslices left to run. The scheduler needs to ensure that a process with a large timeslice doesn't hog the CPU. If the task is interactive, has more timeslices than TIMESLICE_GRANULARITY, and was active, the scheduler removes it from the active queue. The task then has its reschedule flag set, its priority recalculated, and is placed back on the run queue's active array. This ensures that a process at a certain priority with a large timeslice doesn't starve another process of an equal priority.
Lines 20902094
The scheduler has finished rearranging the run queue and unlocks it; if executing on an SMP system, it attempts to load balance.
Combining how processes are marked to be rescheduled, via scheduler_tick() and how processes are scheduled, via schedule() illustrates how the scheduler operates in the 2.6 Linux kernel. We now delve into the details of what the scheduler means by "priority."
7.1.3.1. Dynamic Priority Calculation
In previous sections, we glossed over the specifics of how a task's dynamic priority is calculated. The priority of a task is based on its prior behavior, as well as its user-specified nice value. The function that determines a task's new dynamic priority is recalc_task_prio():
----------------------------------------------------------------------
kernel/sched.c
381 static void recalc_task_prio(task_t *p, unsigned long long now)
382 {
383 unsigned long long __sleep_time = now - p->timestamp;
384 unsigned long sleep_time;
385
386 if (__sleep_time > NS_MAX_SLEEP_AVG)
387 sleep_time = NS_MAX_SLEEP_AVG;
388 else
389 sleep_time = (unsigned long)__sleep_time;
390
391 if (likely(sleep_time > 0)) {
392 /*
393 * User tasks that sleep a long time are categorised as
394 * idle and will get just interactive status to stay active &
395 * prevent them suddenly becoming cpu hogs and starving
396 * other processes.
397 */
398 if (p->mm && p->activated != -1 &&
399 sleep_time > INTERACTIVE_SLEEP(p)) {
400 p->sleep_avg = JIFFIES_TO_NS(MAX_SLEEP_AVG -
401 AVG_TIMESLICE);
402 if (!HIGH_CREDIT(p))
403 p->interactive_credit++;
404 } else {
405 /*
406 * The lower the sleep avg a task has the more
407 * rapidly it will rise with sleep time.
408 */
409 sleep_time *= (MAX_BONUS - CURRENT_BONUS(p)) ? : 1;
410
411 /*
412 * Tasks with low interactive_credit are limited to
413 * one timeslice worth of sleep avg bonus.
414 */
415 if (LOW_CREDIT(p) &&
416 sleep_time > JIFFIES_TO_NS(task_timeslice(p)))
417 sleep_time = JIFFIES_TO_NS(task_timeslice(p));
418
419 /*
420 * Non high_credit tasks waking from uninterruptible
421 * sleep are limited in their sleep_avg rise as they
422 * are likely to be cpu hogs waiting on I/O
423 */
424 if (p->activated == -1 && !HIGH_CREDIT(p) && p->mm) {
425 if (p->sleep_avg >= INTERACTIVE_SLEEP(p))
426 sleep_time = 0;
427 else if (p->sleep_avg + sleep_time >=
428 INTERACTIVE_SLEEP(p)) {
429 p->sleep_avg = INTERACTIVE_SLEEP(p);
430 sleep_time = 0;
431 }
432 }
433
434 /*
435 * This code gives a bonus to interactive tasks.
436 *
437 * The boost works by updating the 'average sleep time'
438 * value here, based on ->timestamp. The more time a
439 * task spends sleeping, the higher the average gets -
440 * and the higher the priority boost gets as well.
441 */
442 p->sleep_avg += sleep_time;
443
444 if (p->sleep_avg > NS_MAX_SLEEP_AVG) {
445 p->sleep_avg = NS_MAX_SLEEP_AVG;
446 if (!HIGH_CREDIT(p))
447 p->interactive_credit++;
448 }
449 }
450 }
452
452 p->prio = effective_prio(p);
453 }
-----------------------------------------------------------------------
Lines 386389
Based on the time now, we calculate the length of time the process p has slept for and assign it to sleep_time with a maximum value of NS_MAX_SLEEP_AVG. (NS_MAX_SLEEP_AVG defaults to 10 milliseconds.)
Lines 391404
If process p has slept, we first check to see if it has slept enough to be classified as an interactive task. If it has, when sleep_time > INTERACTIVE_SLEEP(p), we adjust the process' sleep average to a set value and, if p isn't classified as interactive yet, we increment p's interactive_credit.
Lines 405410
A task with a low sleep average gets a higher sleep time.
Lines 411418
If the task is CPU intensive, and thus classified as non-interactive, we restrict the process to having, at most, one more timeslice worth of a sleep average bonus.
Lines 419432
Tasks that are not yet classified as interactive (not HIGH_CREDIT) that awake from uninterruptible sleep are restricted to having a sleep average of INTERACTIVE().
Lines 434450
We add our newly calculated sleep_time to the process' sleep average, ensuring it doesn't go over NS_MAX_SLEEP_AVG. If the processes are not considered interactive but have slept for the maximum time or longer, we increment its interactive credit.
Line 452
Finally, the priority is set using effective_prio(), which takes into account the newly calculated sleep_avg field of p. It does this by scaling the sleep average of 0 .. MAX_SLEEP_AVG into the range of -5 to +5. Thus, a process that has a static priority of 70 can have a dynamic priority between 65 and 85, depending on its prior behavior.
One final thing: A process that is not a real-time process has a range between 101 and 140. Processes that are operating at a very high priority, 105 or less, cannot cross the real-time boundary. Thus, a high priority, highly interactive process could never have a dynamic priority of lower than 101. (Real-time processes cover 0..100 in the default configuration.)
7.1.3.2. Deactivation
We already discussed how a task gets inserted into the scheduler by forking and how tasks move from the active to expired priority arrays within the CPU's run queue. But, how does a task ever get removed from a run queue?
A task can be removed from the run queue in two major ways:
The task is preempted by the kernel and its state is not running, and there is no signal pending for the task (see line 2240 in kernel/sched.c). On SMP machines, the task can be removed from a run queue and placed on another run queue (see line 3384 in kernel/sched.c).
The first case normally occurs when schedule() gets called after a process puts itself to sleep on a wait queue. The task marks itself as non-running (TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_STOPPED, and so on) and the kernel no longer considers it for CPU access by removing it from the run queue.
The case in which the process is moved to another run queue is dealt with in the SMP section of the Linux kernel, which we do not explore here.
We now trace how a process is removed from the run queue via deactivate_task():
----------------------------------------------------------------------
kernel/sched.c
507 static void deactivate_task(struct task_struct *p, runqueue_t *rq)
508 {
509 rq->nr_running--;
510 if (p->state == TASK_UNINTERRUPTIBLE)
511 rq->nr_uninterruptible++;
512 dequeue_task(p, p->array);
513 p->array = NULL;
514 }
-----------------------------------------------------------------------
Line 509
The scheduler first decrements its count of running processes because p is no longer running.
Lines 510511
If the task is uninterruptible, we increment the count of uninterruptible tasks on the run queue. The corresponding decrement operation occurs when an unin terruptible process wakes up (see kernel/sched.c line 824 in the function TRy_to_wake_up()).
Line 512513
Our run queue statistics are now updated so we actually remove the process from the run queue. The kernel uses the p->array field to test if a process is running and on a run queue. Because it no longer is either, we set it to NULL.
There is still some run queue management to be done; let's examine the specifics of dequeue_task():
----------------------------------------------------------------------
kernel/sched.c
303 static void dequeue_task(struct task_struct *p, prio_array_t *array)
304 {
305 array->nr_active--;
306 list_del(&p->run_list);
307 if (list_empty(array->queue + p->prio))
308 __clear_bit(p->prio, array->bitmap);
309 }
-----------------------------------------------------------------------
Line 305
We adjust the number of active tasks on the priority array that process p is oneither the expired or the active array.
Lines 306308
We remove the process from the list of processes in the priority array at p's priority. If the resulting list is empty, we need to clear the bit in the priority array's bitmap to show there are no longer any processes at priority p->prio().
list_del() does all the removal in one step because p->run_list is a list_head structure and thus has pointers to the previous and next entries in the list.
We have reached the point where the process is removed from the run queue and has thus been completely deactivated. If this process had a state of TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE, it could be awoken and placed back on a run queue. If the process had a state of TASK_STOPPED, TASK_ZOMBIE, or TASK_DEAD, it has all of its structures removed and discarded.
| 
 LINUX
LINUX 
 Books
Books
