Управление памятью
Через управление памятью приложение получает доступ к доступной памяти
за счет манипуляций с железом и кодом.
Происходит выделение необходимой памяти , ее освобождение , управление.
Операционная система разбивает всю память на 2 части :
одна предназначена для нужд ядра , вторая - для динамических запросов.
Вторая часть необходима для вновь создаваемых процессов.
Нужно понимать , что управление памятью включает в себя несколько уровней.
В этой части мы рассмотрим , что такое система управление памятью
и что такое виртуальная память.
Будут рассмотрены структуры и алгоритмы , имеющие отношение к управлению памятью.
Мы рассмотрим , как происходит управление памятью, выделяемой процессу.
Мы узнаем , что такое page faults , и как они управляются в Power PC и x86.
Управление памятью выполняемого процесса - это один из базовых типов управления.
Для процесса необходимо загрузить в память все его данные ,
хранить актуальные адреса.Здесь ответственность ложится на прикладного программиста.
Операционная система должна грамотно распределять ресурсы между приложениями,
и ограничения на память не должны волновать прикладного программиста.
Виртуальная память применяется тогда , когда программе требуется памяти больше,
чем есть физически.
Это реализовано прозрачно , с использованием дискового пространства.
Figure 4.1
иллюстрирует связь между различными уровнями хранения данных.
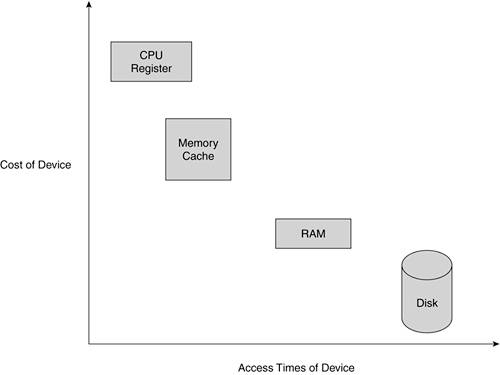
Для использования виртуальной памяти , данные программы разбиваются на части ,
которые могут быть перемещены с диска в память и обратно.
Испоьзуемые в данный момент части программы могут быть помещены в память.
Эти части программы , или куски виртуальной памяти , называются страницами.
Точно также и сама физическая память разбивается на такие страницы,
которые еще называются page frames.
При запросе страница загружается в память.
Если произведен запрос к странице , которой не существует , наступает page fault ,
которые отлавливаются ядром.
Ядро должно записать содержимое нужного page frame на диск .
Когда программа обращается к памяти , она использует для этого адреса.
Эти адреса называются виртуальными адресами и процесс выполняется в виртуальном адресном пространстве.
У каждого процесса свой диапазон виртуальных адресов.
Виртуальная память позволяет процессам использовать памяти больше ,чем ее есть физически.
Размер адресного пространства зависит от архитектуры.
Если процессор 32-битный , всего возможно 232 виртуальных адресов.
В нашем случае это 4 гигабайта памяти.
Если в системе физически 2 гига памяти,
пользовательская программа все равно должна иметь возможность получать доступ к 3 гигам памяти,
и один гиг остается для нужд ядра.
Процесс перемещения страницы с памяти на диск и обратно называется пэйджингом - paging.
Во время этого процесса происходит перевод виртуальных адресов в физические.
Страница - это базовый элемент памяти.
Переводом адресов занимается железяка по имени
Memory Management Unit (MMU),
а ядро инициализирует таблицу этих страниц.
|
Страницы
As the basic unit of memory managed by the memory manager, a page has a lot of state that it needs to be kept track of. For example, the kernel needs to know when pages become available for reallocation. To do this, the kernel uses page descriptors. Every physical page in memory is assigned a page descriptor.
This section describes various fields in the page descriptor and how the memory manager uses them. The page structure is defined in include/linux/mm.h.
-----------------------------------------------------------------------------
include/linux/mm.h
170 struct page {
171 unsigned long flags;
172
173 atomic_t count;
174 struct list_head list;
175 struct address_space *mapping;
176 unsigned long index;
177 struct list_head lru;
178
179 union {
180 struct pte_chain *chain;
181
182 pte_addr_t direct;
183 } pte;
184 unsigned long private;
185
...
196 #if defined(WANT_PAGE_VIRTUAL)
197 void *virtual;
198
199 #endif
200 };
-----------------------------------------------------------------------------
4.1.1. flags
Atomic flags describe the state of the page frame. Each flag is represented by one of the bits in the 32-bit value. Some helper functions allow us to manipulate and test particular flags. Also, some helper functions allow us to access the value of the bit corresponding to the particular flag. The flags themselves, as well as the helper functions, are defined in include/linux/page-flags.h.
Table 4.1 identifies and explains some of the flags that can be set in the flags field of the page structure.
Table 4.1. Flag Values for page->flagsFlag Name | Description |
|---|
PG_locked | This page is locked so it shouldn't be touched. This bit is used during disk I/O, being set before the I/O operation and reset upon completion. | PG_error | Indicates that an I/O error occurred on this page. | PG_referenced | Indicates that this page was accessed for a disk I/O operation. This is used to determine which active or inactive page list the page is on. | PG_uptodate | Indicates that the page's contents are valid, being set when a read completes upon that page. This is mutually exclusive to having PG_error set. | PG_dirty | Indicates a modified page. | PG_lru | The page is in one of the Least Recently Used lists used for page swapping. See the description of lru page struct field in this section for more information regarding LRU lists. | PG_active | Indicates that the page is in the active page list. | PG_slab | This page belongs to a slab created by the slab allocator, which is described in the "
Slab Allocator" section in this chapter. | PG_highmem | Indicates that this page is in the high memory zone (ZONE_HIGHMEM) and so it cannot be permanently mapped into the kernel virtual address space. The high memory zone pages are identified as such during kernel bootup in mem_init() (see
Chapter 8, "Booting the Kernel," for more detail). | PG_checked | Used by the ext2 filesystem. Killed in 2.5. | PG_arch_1 | Architecture-specific page state bit. | PG_reserved | Marks pages that cannot be swapped out, do not exist, or were allocated by the boot memory allocator. | PG_private | Indicates that the page is valid and is set if page->private contains a valid value. | PG_writeback | Indicates that the page is under writeback. | PG_mappedtodisk | This page has blocks currently allocated on a system disk. | PG_reclaim | Indicates that the page should be reclaimed. | PG_compound | Indicates that the page is part of a higher order compound page. |
4.1.1.1. count
The count field serves as the usage or reference counter for a page. A value of 0 indicates that the page frame is available for reuse. A positive value indicates the number of processes that can access the page data.
4.1.1.2. list
The list field is the structure that holds the next and prev pointers to the corresponding elements in a doubly linked list. The doubly linked list that this page is a member of is determined in part by the mapping it is associated with and the state of the page.
4.1.1.3. mapping
Each page can be associated with an address_space structure when it holds the data for a file memory mapping. The mapping field is a pointer to the address_space of which this page is a member. An address_space is a collection of pages that belongs to a memory object (for example, an inode). For more information on how address_space is used, go to
Chapter 7, "Scheduling and Kernel Synchronization," Section 7.14.
4.1.1.4. lru
The lru field holds the next and prev pointers to the corresponding elements in the Least Recently Used (LRU) lists. These lists are involved with page reclamation and consist of two lists: active_list, which contains pages that are in use, and incactive_list, which contains pages that can be reused.
4.1.1.5. virtual
virtual is a pointer to the page's corresponding virtual address. In a system with highmem, the memory mapping can occur dynamically, making it necessary to recalculate the virtual address when needed. In these cases, this value is set to NULL.
|
A compound page is a higher-order page. To enable compound page support in the kernel, "Huge TLB Page Support" must be enabled at compile time. A compound page is composed of more than one page, the first of which is called the "head" page and the remainder of which are called "tail" pages. All compound pages will have the PG_compound bit set in their respective page->flags, and the page->lru.next pointing to the head page. |
4.2. Memory Zones
Not all pages are created equal. Some computer architectures have constraints on what certain physical address ranges of memory can be used for. For example, in x86, some ISA buses are only able to address the first 16MB of RAM. Although PPC does not have this constraint, the memory zone concepts are ported to simplify the architecture-independent portion of the code. In the architecture-dependent portion of the PPC code, these zones are set to overlap. Another such constraint is seen in a system that has more RAM than it can address with its linear address space.
A memory zone is composed of page frames or physical pages, which means that a page frame is allocated from a particular memory zone. Three memory zones exist in Linux: ZONE_DMA (used for DMA page frames), ZONE_NORMAL (non-DMA pages with virtual mapping), and ZONE_HIGHMEM (pages whose addresses are not contained in the virtual address space).
4.2.1. Memory Zone Descriptor
As with all objects that the kernel manages, a memory zone has a structure called zone, which stores all its information. The zone struct is defined in include/linux/mmzone.h. We now closely look at some of the most commonly used fields:
-----------------------------------------------------------------------------
include/linux/mmzone.h
66 struct zone {
...
70 spinlock_t lock;
71 unsigned long free_pages;
72 unsigned long pages_min, pages_low, pages_high;
73
74 ZONE_PADDING(_pad1_)
75
76 spinlock_t lru_lock;
77 struct list_head active_list;
78 struct list_head inactive_list;
79 atomic_t refill_counter;
80 unsigned long nr_active;
81 unsigned long nr_inactive;
82 int all_unreclaimable; /* All pages pinned */
83 unsigned long pages_scanned; /* since last reclaim */
84
85 ZONE_PADDING(_pad2_)
...
103 int temp_priority;
104 int prev_priority;
...
109 struct free_area free_area[MAX_ORDER];
...
135 wait_queue_head_t * wait_table;
136 unsigned long wait_table_size;
137 unsigned long wait_table_bits;
138
139 ZONE_PADDING(_pad3_)
140
...
157 } ____cacheline_maxaligned_in_smp;
-----------------------------------------------------------------------------
4.2.1.1. lock
The zone descriptor must be locked when it is being manipulated to prevent read/write errors. The lock field holds the spinlock that protects the descriptor from this.
This is a lock for the descriptor itself and not for the memory range with which it is associated.
4.2.1.2. free_pages
The free_pages field holds the number of free pages that are left in the zone. This unsigned long is decremented every time a page is allocated from the particular zone and incremented every time a page is returned to the zone. The total amount of free RAM returned by a call to nr_free_pages() is calculated by adding this value from all three zones.
4.2.1.3. pages_min, pages_low, and pages_high
The pages_min, pages_low, and pages_high fields hold the zone watermark values. When the number of available pages reaches each of these watermarks, the kernel responds to the memory shortage in ways suited for each decrementally serious situation.
4.2.1.4. lru_lock
The lru_lock field holds the spinlock for the free page list.
4.2.1.5. active_list and inactive_list
active_list and inactive_list are involved in the page reclamation functionality. The first is a list of the active pages and the second is a list of pages that can be reclaimed.
4.2.1.6. all_unreclaimable
The all_unreclaimable field is set to 1 if all pages in the zone are pinned. They will only be reclaimed by kswapd, which is the pageout daemon.
4.2.1.7. pages_scanned, temp_priority, and prev_priority
The pages_scanned, temp_priority, and prev_priority fields are all involved with page reclamation functionality, which is outside the scope of this book.
4.2.1.8. free_area
The buddy system uses the free_area bitmap.
4.2.1.9. wait_table, wait_table_size, and wait_table_bits
The wait_table, wait_table_size, and wait_table_bits fields are associated with process wait queues on the zone's pages.
|
Cache aligning is done to improve performance on descriptor field accesses. Cache aligning improves performance by minimizing the number of instructions needed to copy a chunk of data. Take the case of having a 32-bit value not aligned on a word. The processor would need to make two "load word" instructions to get the data onto registers as opposed to just one. ZONE_PADDING shows how cache aligning is performed on a memory zone:
---------------------------------------------------------------------------
 include/linux/mmzone.h
#if defined(CONFIG_SMP)
struct zone_padding {
int x;
} ____cacheline_maxaligned_in_smp;
#define ZONE_PADDING(name) struct zone_padding name;
#else
#define ZONE_PADDING(name)
#endif
--------------------------------------------------------------------------- include/linux/mmzone.h
#if defined(CONFIG_SMP)
struct zone_padding {
int x;
} ____cacheline_maxaligned_in_smp;
#define ZONE_PADDING(name) struct zone_padding name;
#else
#define ZONE_PADDING(name)
#endif
---------------------------------------------------------------------------
If you want to know more about how cache aligning works in Linux, refer to include/linux/cache.h. |
4.2.2. Memory Zone Helper Functions
When actions are commonly applied to an object, or information is often requested of an object, usually, helper functions make coding easier. Here, we present a couple of helper functions that facilitate memory zone manipulation.
4.2.2.1. for_each_zone()
The for_each_zone() macro iterates over all zones:
-----------------------------------------------------------------------------
include/linux/mmzone.h
268 #define for_each_zone(zone) \
269 for (zone = pgdat_list->node_zones; zone; zone = next_zone(zone))
-----------------------------------------------------------------------------
4.2.2.2. is_highmem() and is_normal()
The is_highmem() and is_normal() functions check if zone struct is in the highmem or normal zones, respectively:
-----------------------------------------------------------------------------
include/linux/mmzone.h
315 static inline int is_highmem(struct zone *zone)
316 {
317 return (zone - zone->zone_pgdat->node_zones == ZONE_HIGHMEM);
318 }
319
320 static inline int is_normal(struct zone *zone)
321 {
322 return (zone - zone->zone_pgdat->node_zones == ZONE_NORMAL);
323 }
-----------------------------------------------------------------------------
4.3. Page Frames
A page frame is the unit of memory that holds a page. When a process requests memory, the kernel can request a page frame. In the same manner, when a page frame is no longer being used, the kernel releases it to make it available for another process. The following functions are called to perform those operations.
4.3.1. Functions for Requesting Page Frames
A few routines can be called to request a page frame. We can split up the functions into two groups depending on the type of their return value. One group returns a pointer to the page struct (return type is void *) that corresponds to the page frame that is allocated to the request. This includes alloc_pages() and alloc_page(). The second group of functions returns the 32-bit virtual address (return type is a long) of the first allocated page. These include __get_free_page() and __get_dma_pages(). Many of these routines are simply wrappers around a lower-level interface. Figures 4.2 and 4.3 show the calling graphs of these routines.

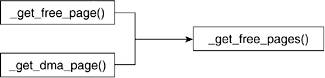
The following macros and functions refer to the number of pages being handled (requested or released) in powers of 2. Pages are requested or released in contiguous page frames in powers of 2. We can request 1, 2, 4, 8, 16, and so on groups of pages.
4.3.1.1. alloc_pages() and alloc_page()
alloc_page() requests a single page and thus has no order parameter. This function fills in a 0 value when calling alloc_pages_node(). Alternatively, alloc_pages() can request two order pages:
-----------------------------------------------------------------------------
include/linux/gfp.h
75 #define alloc_pages(gfp_mask, order) \
76 alloc_pages_node(numa_node_id(), gfp_mask, order)
77 #define alloc_page(gfp_mask) \
78 alloc_pages_node(numa_node_id(), gfp_mask, 0)
-----------------------------------------------------------------------------
As you can see from Figure 4.2, both macros then call __alloc_pages_node(), passing it the appropriate parameters. alloc_pages_node() is a wrapper function used for sanity checking of the order of requested page frames:
-----------------------------------------------------------------------------
include/linux/gfp.h
67 static inline struct page * alloc_pages_node(int nid, unsigned int gfp_mask, unsigned
int order)
68 {
69 if (unlikely(order >= MAX_ORDER))
70 return NULL;
71
72 return __alloc_pages(gfp_mask, order, NODE_DATA(nid)->node_zonelists + (gfp_mask &
GFP_ZONEMASK));
73 }
-----------------------------------------------------------------------------
As you can see, if the order of pages requested is greater than the allowed maximum order (MAX_ORDER), the request for page allocation does not go through. In alloc_page(), this value is always set to 0 and so the call always goes through. MAX_ORDER, which is defined in linux/mmzone.h, is set to 11. Thus, we can request up to 2,048 pages.
The __alloc_pages() function performs the meat of the page request. This function is defined in mm/page_alloc.c and requires knowledge of memory zones, which we discussed in the previous section.
4.3.1.2. __get_free_page() and __get_dma_pages()
The __get_free_page() macro is a convenience for when only one page is requested. Like alloc_page(), it passes a 0 as the order of pages requested to __get_free_pages(), which then performs the bulk of the request. Figure 4.3 illustrates the calling hierarchy of these functions.
-----------------------------------------------------------------------------
include/linux/gfp.h
83 #define __get_free_page(gfp_mask) \
84 __get_free_pages((gfp_mask),0)
-----------------------------------------------------------------------------
The __get_dma_pages() macro specifies that the pages requested be from ZONE_DMA by adding that flag onto the page flag mask. ZONE_DMA refers to a portion of memory that is reserved for DMA accesses:
-----------------------------------------------------------------------------
include/linux/gfp.h
86 #define __get_dma_pages(gfp_mask, order) \
87 __get_free_pages((gfp_mask) | GFP_DMA,(order))
-----------------------------------------------------------------------------
4.3.2. Functions for Releasing Page Frames
There are multiple routines for releasing page frames: two macros and the two functions for which they each serve as a wrapper. Figure 4.4 shows the calling hierarchy of the page release routines. We can again split up the functions into two groups. This time, the split is based on the type of parameters they take. The first group, which includes __free_page() and __free_pages(), takes a pointer to the page descriptor that refers to the page that is to be released. The second group, free_page() and free_pages(), takes the address of the first page to be released.
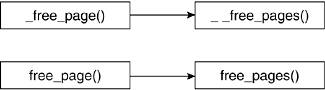
The __free_page() and free_page() macros release a single page. They pass a 0 as the order of pages to be released to the functions that perform the bulk of the work, __free_pages() and free_pages(), respectively:
-----------------------------------------------------------------------------
include/linux/gfp.h
94 #define __free_page(page) __free_pages((page), 0)
95 #define free_page(addr) free_pages((addr),0)
-----------------------------------------------------------------------------
free_pages() eventually calls __free_pages_bulk(), which is the freeing function for the Linux implementation of the buddy system. We explore the buddy system in more detail in the following section.
4.3.3. Buddy System
When page frames are allocated and deallocated, the system runs into a memory fragmentation problem called external fragmentation. This occurs when the available page frames are spread out throughout memory in such a way that large amounts of contiguous page frames are not available for allocation although the total number of available page frames is sufficient. That is, the available page frames are interrupted by one or more unavailable page frames, which breaks continuity. There are various approaches to reduce external fragmentation. Linux uses an implementation of a memory management algorithm called the buddy system.
Buddy systems maintain a list of available blocks of memory. Each list will point to blocks of memory of different sizes, but they are all sized in powers of two. The number of lists depends on the implementation. Page frames are allocated from the list of free blocks of the smallest possible size. This maintains larger contiguous block sizes available for the larger requests. When allocated blocks are returned, the buddy system searches the free lists for available blocks of memory that's the same size as the returned block. If any of these available blocks is contiguous to the returned block, they are merged into a block twice the size of each individual. These blocks (the returned block and the available block that is contiguous to it) are called buddies, hence the name "buddy system." This way, the kernel ensures that larger block sizes become available as soon as page frames are freed.
Now, look at the functions that implement the buddy system in Linux. The page frame allocation function is __alloc_pages() (mm/page_alloc.c). The page frame deallocation functions is __free_pages_bulk():
-----------------------------------------------------------------------------
mm/page_alloc.c
585 struct page * fastcall
586 __alloc_pages(unsigned int gfp_mask, unsigned int order,
587 struct zonelist *zonelist)
588 {
589 const int wait = gfp_mask & __GFP_WAIT;
590 unsigned long min;
591 struct zone **zones;
592 struct page *page;
593 struct reclaim_state reclaim_state;
594 struct task_struct *p = current;
595 int i;
596 int alloc_type;
597 int do_retry;
598
599 might_sleep_if(wait);
600
601 zones = zonelist->zones;
602 if (zones[0] == NULL) /* no zones in the zonelist */
603 return NULL;
604
605 alloc_type = zone_idx(zones[0]);
...
608 for (i = 0; zones[i] != NULL; i++) {
609 struct zone *z = zones[i];
610
611 min = (1<<order) + z->protection[alloc_type];
...
617 if (rt_task(p))
618 min -= z->pages_low >> 1;
619
620 if (z->free_pages >= min ||
621 (!wait && z->free_pages >= z->pages_high)) {
622 page = buffered_rmqueue(z, order, gfp_mask);
623 if (page) {
624 zone_statistics(zonelist, z);
625 goto got_pg;
626 }
627 }
628 }
629
630 /* we're somewhat low on memory, failed to find what we needed */
631 for (i = 0; zones[i] != NULL; i++)
632 wakeup_kswapd(zones[i]);
633
634 /* Go through the zonelist again, taking __GFP_HIGH into account */
635 for (i = 0; zones[i] != NULL; i++) {
636 struct zone *z = zones[i];
637
638 min = (1<<order) + z->protection[alloc_type];
639
640 if (gfp_mask & __GFP_HIGH)
641 min -= z->pages_low >> 2;
642 if (rt_task(p))
643 min -= z->pages_low >> 1;
644
645 if (z->free_pages >= min ||
646 (!wait && z->free_pages >= z->pages_high)) {
647 page = buffered_rmqueue(z, order, gfp_mask);
648 if (page) {
649 zone_statistics(zonelist, z);
650 goto got_pg;
651 }
652 }
653 }
...
720 nopage:
721 if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) {
722 printk(KERN_WARNING "%s: page allocation failure."
723 " order:%d, mode:0x%x\n",
724 p->comm, order, gfp_mask);
725 dump_stack();
726 }
727 return NULL;
728 got_pg:
729 kernel_map_pages(page, 1 << order, 1);
730 return page;
731 }
-----------------------------------------------------------------------------
The Linux buddy system is zoned, which means that lists of available page frames are maintained separate by zone. Hence, every search for available page frames has three possible zones from which to get the page frames.
Line 586
The gfp_mask integer value allows the caller of __alloc_pages() to specify both the manner in which to look for page frames (action modifiers). The possible values are defined in include/linux/gfp.h, and Table 4.2 lists them.
Table 4.2. Action Modifiers for gfp_maks in Page AllocationFlag | Description |
|---|
__GFP_WAIT | Allows the kernel to block the process waiting for page frames. For an example of its use, see line 537 of page_alloc.c. | __GFP_COLD | Requesting cache cold pages. | __GFP_HIGH | Page frame can be found at the emergency memory pool. | __GFP_IO | Can perform I/O transfers. | __GFP_FS | Allowed to call down on low-level FS operations. | __GFP_NOWARN | Upon failure of page-frame allocation, the allocation function sends a failure warning. If this modifier is selected, this warning is suppressed. For an example of its use, see lines 665666 of page_alloc.c. | __GFP_REPEAT | Retry the allocation. | __GFP_NORETRY | The request should not be retried because it might fail. | __GFP_DMA | The page frame is in ZONE_DMA. | __GFP_HIGHMEM | The page frame is in ZONE_HIGHMEM. |
Table 4.3 provides a pointer to the zonelists that correspond to the modifiers from gfp_mask.
Table 4.3. ZonelistFlag | Description |
|---|
GFP_USER | Indicates that memory should be allocated not in kernel RAM | GFP_KERNEL | Indicates that memory should be allocated from kernel RAM | GFP_ATOMIC | Used in interrupt handlers making the call to kmalloc because it assures that the memory allocation will not sleep | GFP_DMA | Indicates that memory should be allocated from ZONE_DMA |
Line 599
The function might_sleep_if() takes in the value of variable wait, which holds the logical bit AND of the gfp_mask and the value __GFP_WAIT. The value of wait is 0 if __GFP_WAIT was not set, and the value is 1 if it was. If Sleep-inside-spinlock checking is enabled (under the Kernel Hacking menu) during kernel configuration, this function allows the kernel to block the current process for a timeout value.
Lines 608628
In this block, we proceed to go through the list of zone descriptors once searching for a zone with enough free pages to satisfy the request. If the number of free pages satisfies the request, or if the process is allowed to wait and the number of free pages is higher than or equal to the upper threshold value for the zone, the function buffered_rmqueue() is called.
The function buffered_rmqueue() takes three arguments: the zone descriptor of the zone with the available page frames, the order of the number of page frames requested, and the temperature of the page frames requested.
Lines 631632
If we get to this block, we have not been able to allocate a page because we are low on available page frames. The intent here is to try and reclaim page frames to satisfy the request. The function wakeup_kswapd() performs this function and replenishes the zones with the appropriate page frames. It also appropriately updates the zone descriptors.
Lines 635653
After we attempt to replenish the page frames in the previous block, we go through the zonelist again to search for enough free page frames.
Lines 720727
This block is jumped to after the function determines that no page frames can be made available. If the modifier GFP_NOWARN is not selected, the function prints a warning of the page allocation failure, which indicates the name of the command that was called for the current process, the order of page frames requested, and the gfp_mask that was applied to this request. The function then returns NULL.
Lines 728730
This block is jumped to after the requested pages are found. The function returns the address of a page descriptor. If more than one page frames were requested, it returns the address of the page descriptor of the first page frame allocated.
When a memory block is returned, the buddy system makes sure to coalesce it into a larger memory block if a buddy of the same order is available. The function __free_pages_bulk() performs this function. We now look at how it works:
-----------------------------------------------------------------------------
mm/page_alloc.c
178 static inline void __free_pages_bulk (struct page *page, struct page *base,
179 struct zone *zone, struct free_area *area, unsigned long mask,
180 unsigned int order)
181 {
182 unsigned long page_idx, index;
183
184 if (order)
185 destroy_compound_page(page, order);
186 page_idx = page - base;
187 if (page_idx & ~mask)
188 BUG();
189 index = page_idx >> (1 + order);
190
191 zone->free_pages -= mask;
192 while (mask + (1 << (MAX_ORDER-1))) {
193 struct page *buddy1, *buddy2;
194
195 BUG_ON(area >= zone->free_area + MAX_ORDER);
196 if (!__test_and_change_bit(index, area->map))
...
206 buddy1 = base + (page_idx ^ -mask);
207 buddy2 = base + page_idx;
208 BUG_ON(bad_range(zone, buddy1));
209 BUG_ON(bad_range(zone, buddy2));
210 list_del(&buddy1->lru);
211 mask <<= 1;
212 area++;
213 index >>= 1;
214 page_idx &= mask;
215 }
216 list_add(&(base + page_idx)->lru, &area->free_list);
217 }
-----------------------------------------------------------------------------
Lines 184215
The __free_pages_bulk() function iterates over the size of the blocks corresponding to each of the free block lists. (MAX_ORDER is the order of the largest block size.) For each order and until it reaches the maximum order or finds the smallest possible buddy, it calls __test_and_change_bit(). This function tests to see whether the buddy page to our returned block is allocated. If so, we break out of the loop. If not, it sees if it can find a higher order buddy with which to merge our freed block of page frames.
Line 216
The free block is inserted into the proper list of free page frames.
|
4.4. Slab Allocator
We discussed that pages are the basic unit of memory for the memory manager. However, processes generally request memory on the order of bytes, not on the order of pages. To support the allocation of smaller memory requests made through calls to functions like kmalloc(), the kernel implements the slab allocator, which is a layer of the memory manager that acts on acquired pages.
The slab allocator seeks to reduce the cost incurred by allocating, initializing, destroying, and freeing memory areas by maintaining a ready cache of commonly used memory areas. This cache maintains the memory areas allocated, initialized, and ready to deploy. When the requesting process no longer needs the memory areas, they are simply returned to the cache.
In practice, the slab allocator is made up of many caches, each of which stores memory areas of different sizes. Caches can be specialized or general purpose. Specialized caches store memory areas that hold specific objects, such as descriptors. For example, process descriptors, the task_structs, are stored in a cache that the slab allocator maintains. The size of the memory areas held by this cache are sizeof(task_struct). In the same manner, inode and dentry data structures are also maintained in caches. General caches are made of memory areas of predetermined sizes. These sizes include memory areas of 32, 64, 128, 256, 512, 1,024, 2,048, 4,096, 8,192, 16,384, 32,768, 65,536, and 131,072 bytes.
If we run the command cat /proc/slabinfo, the existing slab allocator caches are listed. Looking at the first column of the output, we can see the names of data structures and a group of entries following the format size-*. The first set corresponds to specialized object caches; the latter set corresponds to caches that hold general-purpose objects of the specified size.
You might also notice that the general-purpose caches have two entries per size, one of which ends with (DMA). This exists because memory areas from either DMA or normal zones can be requested. The slab allocator maintains caches of both types of memory to facilitate these requests. Figure 4.5 shows the output of /proc/slabinfo, which shows the caches of both types of memory.
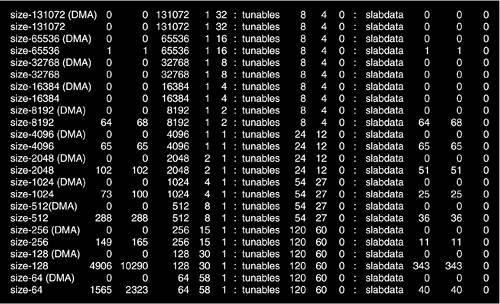
A cache is further subdivided into containers called slabs. Each slab is made up of one or more contiguous page frames from which the smaller memory areas are allocated. That is why we say that the slabs contain the objects. The objects themselves are address intervals of a predetermined size within a page frame that belongs to a particular slab. Figure 4.6 shows the slab allocator anatomy.
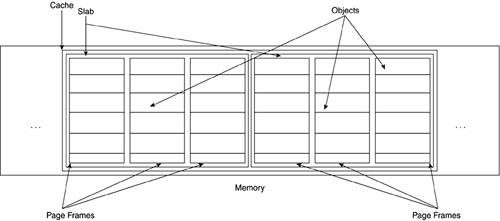
The slab allocator uses three main structures to maintain object information: the cache descriptor called kmem_cache, the general caches descriptor called cache_sizes, and the slab descriptor called slab. Figure 4.7 summarizes the relationships between all the descriptors.
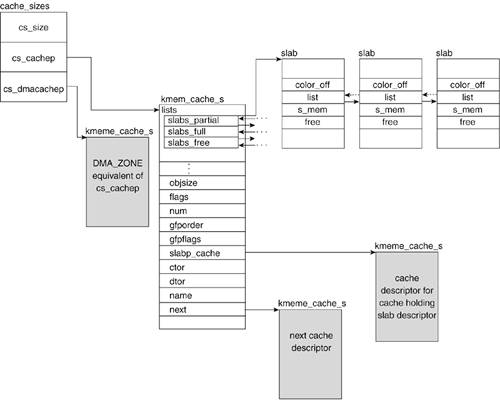
4.4.1. Cache Descriptor
Every cache has a cache descriptor of type kmem_cache_s, which holds its information. Most of these values are set or calculated at cache-creation time in kmem_cache_create() (mm/slab.c). We discuss this function in a later section. First, let's look at some of the fields in the cache descriptor and understand the information they hold.
-----------------------------------------------------------------------------
mm/slab.c
246 struct kmem_cache_s {
...
252 struct kmem_list3 lists;
...
254 unsigned int objsize;
255 unsigned int flags; /* constant flags */
256 unsigned int num; /* # of objs per slab */
...
263 unsigned int gfporder;
264
265 /* force GFP flags, e.g. GFP_DMA */
266 unsigned int gfpflags;
267
268 size_t color; /* cache coloring range */
269 unsigned int color_off; /* color offset */
270 unsigned int color_next; /* cache coloring */
271 kmem_cache_t *slabp_cache;
272 unsigned int dflags; /* dynamic flags */
273
273 /* constructor func */
274 void (*ctor)(void *, kmem_cache_t *, unsigned long);
275
276 /* de-constructor func */
277 void (*dtor)(void *, kmem_cache_t *, unsigned long);
278
279 /* 4) cache creation/removal */
280 const char *name;
281 struct list_head next;
282
...
301 };
-----------------------------------------------------------------------------
4.4.1.1. lists
The lists field is a structure that holds three lists heads, which each correspond to the three states that slabs can find themselves in: partial, full, and free. A cache can have one or more slabs in any of these states. It is by way of this data structure that the cache references the slabs. The lists themselves are doubly linked lists that are maintained by the slab descriptor field list. This is described in the "Slab Descriptor" section later in this chapter.
-----------------------------------------------------------------------------
mm/slab.c
217 struct kmem_list3 {
218 struct list_head slabs_partial;
219 struct list_head slabs_full;
220 struct list_head slabs_free;
...
223 unsigned long next_reap;
224 struct array_cache *shared;
225 };
-----------------------------------------------------------------------------
lists.slabs_partial
lists.slabs_partial is the head of the list of slabs that are only partially allocated with objects. That is, a slab in the partial state has some of its objects allocated and some free to be used.
lists.slabs_full
lists.slabs_full is the head of the list of slabs whose objects have all been allocated. These slabs contain no available objects.
lists.slabs_free
lists.slabs_free is the head of the list of slabs whose objects are all free to be allocated. Not a single one of its objects has been allocated.
Maintaining these lists reduces the time it takes to find a free object. When an object from the cache is requested, the kernel searches the partial slabs. If the partial slabs list is empty, it then looks at the free slabs. If the free slabs list is empty, a new slab is created.
lists.next_reap
Slabs have page frames allocated to them. If these pages are not in use, it is better to return them to the main memory pool. Toward this end, the caches are reaped. This field holds the time of the next cache reap. It is set in kmem_cache_create() (mm/slab.c) at cache-creation time and is updated in cache_reap() (mm/slab.c) every time it is called.
4.4.1.2. objsize
The objsize field holds the size (in bytes) of the objects in the cache. This is determined at cache-creation time based on requested size and cache alignment concerns.
4.4.1.3. flags
The flags field holds the flag mask that describes constant characteristics of the cache. Possible flags are defined in include/linux/slab.h and Table 4.4 describes them.
Table 4.4. Slab FlagsFlag Name | Description |
|---|
SLAB_POISON | Requests that a test pattern of a5a5a5a5 be written to the slab upon creation. This can then be used to verify memory that has been initialized. | SLAB_NO_REAP | When memory requests meet with insufficient memory conditions, the memory manager begins to reap memory areas that are not used. Setting this flag ensures that this cache won't be automatically reaped under these conditions. | SLAB_HWCACHE_ALIGN | Requests that objects be aligned to the processor's hardware cacheline to improve performance by cutting down memory cycles. | SLAB_CACHE_DMA | Indicates that DMA memory should used. When requesting new page frames, the GFP_DMA flag is passed to the buddy system. | SLAB_PANIC | Indicates that a panic should be called if kmem_cache_create() fails for any reason. |
4.4.1.4. num
The num field holds the number of objects per slab in this cache. This is determined upon cache creation (also in kmem_cache_create()) based on gfporder's value (see the next field), the size of the objects to be created, and the alignment they require.
4.4.1.5. gfporder
The gfporder is the order (base 2) of the number of contiguous page frames that are contained per slab in the cache. This value defaults to 0 and is set upon cache creation with the call to kmem_cache_create().
4.4.1.6. gfpflags
The gfpflags flags specify the type of page frames to be requested for the slabs in this cache. They are determined based on the flags requested of the memory area. For example, if the memory area is intended for DMA use, the gfpflags field is set to GFP_DMA, and this is passed on upon page frame request.
4.4.1.7. slabp_cache
Slab descriptors can be stored within the cache itself or external to it. If the slab descriptors for the slabs in this cache are stored externally to the cache, the slabp_cache field holds a pointer to the cache descriptor of the cache that stores objects of the type slab descriptor. See the "Slab Descriptor" section for more information on slab descriptor storage.
4.4.1.8. ctor
The ctor field holds a pointer to the constructor that is associated with the cache, if one exists.
4.4.1.9. dtor
Much like the ctor field, the dtor field holds a pointer to the destructor that is associated with the cache, if one exists.
Both the constructor and destructor are defined at cache-creation time and passed as parameters to kmem_cache_create().
4.4.1.10. name
The name field holds the human-readable string of the name that is displayed when /proc/slabinfo is opened. For example, the cache that holds file pointers has a value of filp in this field. This can be better understood by executing a call to cat /proc/slabinfo. The name field of a slab has to hold a unique value. Upon creation, the name requested for a slab is compared to the names of all other slabs in the list. No duplicates are allowed. The slab creation fails if another slab exists with the same name.
4.4.1.11. next
next is the pointer to the next cache descriptor in the singly linked list of cache descriptors.
4.4.2. General Purpose Cache Descriptor
As previously mentioned, the caches that hold the predetermined size objects for general use are always in pairs. One cache is for allocating the objects from DMA memory, and the other is for standard allocations from normal memory. If you recall the memory zones, you realize that the DMA cache is in ZONE_DMA and the standard cache is in ZONE_NORMAL. The struct cache_sizes is a useful way to store together all the information regarding general size caches.
-----------------------------------------------------------------------------
include/linux/slab.h
69 struct cache_sizes {
70 size_t cs_size;
71 kmem_cache_t *cs_cachep;
72 kmem_cache_t *cs_dmacachep;
73 };
-----------------------------------------------------------------------------
4.4.2.1. cs_size
The cs_size field holds the size of the memory objects contained in this cache.
4.4.2.2. cs_cachep
The cs_cachep field holds the pointer to the normal memory cache descriptor for objects to be allocated from ZONE_NORMAL.
4.4.2.3. cs_dmacachep
The cs_dmacachep field holds the pointer to the DMA memory cache descriptor for objects to be allocated from ZONE_DMA.
One question comes to mind, "Where are the cache descriptors stored?" The slab allocator has a cache that is reserved just for that purpose. The cache_cache cache holds objects of the type cache descriptors. This slab cache is initialized statically during system bootstrapping to ensure that cache descriptor storage is available.
4.4.3. Slab Descriptor
Each slab in a cache has a descriptor that holds information particular to that slab. We just mentioned that cache descriptors are stored in the specialized cache called cache_cache. Slab descriptors in turn can be stored in two places: They are stored within the slab itself (specifically, the first-page frame) or externally within the first "general purpose" cache with objects large enough to hold the slab descriptor. This is determined upon cache creation based on space left over from object alignment. This space is determined upon cache creation.
Let's look at some of the slab descriptor fields:
-----------------------------------------------------------------------------
mm/slab.c
173 struct slab {
174 struct list_head list;
175 unsigned long coloroff;
176 void *s_mem; /* including color offset */
177 unsigned int inuse; /* num of objs active in slab */
178 kmem_bufctl_t free;
179 };
-----------------------------------------------------------------------------
4.4.3.1. list
If you recall from the cache descriptor discussion, a slab can be in one of three states: free, partial, or full. The cache descriptor holds all slab descriptors in three listsone for each state. All slabs in a particular state are kept in a doubly linked list by means of the list field.
4.4.3.2. s_mem
The s_mem field holds the pointer to the first object in the slab.
4.4.3.3. inuse
The value inuse keeps track of the number of objects that are occupied in that slab. For full and partial slabs, this is a positive number; for free slabs, this is 0.
4.4.3.4. free
The free field holds an index value to the array whose entries represent the objects in the slab. In particular, the free field contains the index value of the entry representing the first available object in the slab. The kmem_bufctl_t data type links all the objects within a slab. The data type is simply an unsigned integer and is defined in include/asm/types.h. These data types make up an array that is always stored right after the slab descriptor, regardless of whether the slab descriptor is stored internally or externally to the slab. This becomes clear when we look at the inline function slab_bufctl(), which returns the array:
-----------------------------------------------------------------------------
mm/slab.c
1614 static inline kmem_bufctl_t *slab_bufctl(struct slab *slabp)
1615 {
1616 return (kmem_bufctl_t *)(slabp+1);
1617 }
-----------------------------------------------------------------------------
The function slab_bufctl() takes in a pointer to the slab descriptor and returns a pointer to the memory area immediately following the slab descriptor.
When the cache is initialized, the slab->free field is set to 0 (because all objects will be free so it should return the first one), and each entry in the kmem_bufctl_t array is set to the index value of the next member of the array. This means that the 0th element holds the value 1, the 1st element holds the value 2, and so on. The last element in the array holds the value BUFCTL_END, which indicates that this is the last element in the array.
Figure 4.8 shows how the slab descriptor, the bufctl array, and the slab objects are laid out when the slab descriptors are stored internally to the slab. Table 4.5 shows the possible values of certain slab descriptor fields when the slab is in each of the three possible states.

Table 4.5. Slab State and Descriptor Field Values| | Free | Partial | Full |
|---|
slab->inuse | 0 | X | N | slab->free | 0 | X | N | N = Number of objects in slab
X = Some variable positive number |
4.5. Slab Allocator's Lifecycle
Now, we explore the interaction of caches and the slab allocator throughout the lifecycle of the kernel. The kernel needs to make sure that certain structures are in place to support memory area requests on the part of processes and the creation of specialized caches on the part of dynamically loadable modules.
A few global structures play key roles for the slab allocator. Some of these were in passing previously in the chapter. Let's look at these global variables.
4.5.1. Global Variables of the Slab Allocator
There are a number of global variables that are associated with the slab allocator. These include
cache_cache.
The cache descriptor for the cache that is to contain all other cache descriptors. The human-readable name of this cache is kmem_cache. This cache descriptor is the only one that is statically allocated.
cache_chain.
The list element that serves as a pointer to the cache descriptor list.
cache_chain_sem.
The semaphore that controls access to cache_chain. Every time an element (new cache descriptor) is added to the chain, this semaphore needs to be acquired with a down() and released with an up().
malloc_sizes[].
The array that holds the cache descriptors for the DMA and non-DMA caches that correspond to a general cache.
Before the slab allocator is initialized, these structures are already in place. Let's look at their creation:
-----------------------------------------------------------------------------
mm/slab.c
486 static kmem_cache_t cache_cache = {
487 .lists = LIST3_INIT(cache_cache.lists),
488 .batchcount = 1,
489 .limit = BOOT_CPUCACHE_ENTRIES,
490 .objsize = sizeof(kmem_cache_t),
491 .flags = SLAB_NO_REAP,
492 .spinlock = SPIN_LOCK_UNLOCKED,
493 .color_off = L1_CACHE_BYTES,
494 .name = "kmem_cache",
495 };
496
497 /* Guard access to the cache-chain. */
498 static struct semaphore cache_chain_sem;
499
500 struct list_head cache_chain;
-----------------------------------------------------------------------------
The cache_cache cache descriptor has the SLAB_NO_REAP flag. Even if memory is low, this cache is retained throughout the life of the kernel. Note that the cache_chain semaphore is only defined, not initialized. The initialization occurs during system initialization in the call to kmem_cache_init(). We explore this function in detail here:
-----------------------------------------------------------------------------
mm/slab.c
462 struct cache_sizes malloc_sizes[] = {
463 #define CACHE(x) { .cs_size = (x) },
464 #include <linux/kmalloc_sizes.h>
465 { 0, }
466 #undef CACHE
467 };
-----------------------------------------------------------------------------
This piece of code initializes the malloc_sizes[] array and sets the cs_size field according to the values defined in include/linux/kmalloc_sizes.h. As mentioned, the cache sizes can span from 32 bytes to 131,072 bytes depending on the specific kernel configurations.
With these global variables in place, the kernel proceeds to initialize the slab allocator by calling kmem_cache_init() from init/main.c. This function takes care of initializing the cache chain, its semaphore, the general caches, the kmem_cache cachein essence, all the global variables that are used by the slab allocator for slab management. At this point, specialized caches can be created. The function used to create caches is kmem_cache_create().
4.5.2. Creating a Cache
The creation of a cache involves three steps:
1. | Allocation and initialization of the descriptor
| 2. | Calculation of the slab coloring and object size
| 3. | Addition of the cache to cache_chain list
|
General caches are set up during system initalization by kmem_cache_init() (mm/slab.c). Specialized caches are created by way of a call to kmem_cache_create().
We now look at each of these functions.
4.5.2.1. kmem_cache_init()
This is where the cache_chain and general caches are created. This function is called during the initialization process. Notice that the function has __init preceding the function name. As discussed in Chapter 2, "Exploration Toolkit," this indicates that the function is loaded into memory that gets wiped after the bootstrap and initialization process is over.
-----------------------------------------------------------------------------
mm/slab.c
659 void __init kmem_cache_init(void)
660 {
661 size_t left_over;
662 struct cache_sizes *sizes;
663 struct cache_names *names;
...
669 if (num_physpages > (32 << 20) >> PAGE_SHIFT)
670 slab_break_gfp_order = BREAK_GFP_ORDER_HI;
671
672
-----------------------------------------------------------------------
Lines 661663
The variable sizes and names are the head arrays for the kmalloc allocated arrays (the general caches with geometrically distributes sizes). At this point, these arrays are located in the __init data area. Be aware that kmalloc() does not exist at this point. kmalloc() uses the malloc_sizes array and that is precisely what we are setting up now. At this point, all we have is the statically allocated cache_cache descriptor.
Lines 669670
This code block determines how many pages a slab can use. The number of pages a slab can use is entirely determined by how much memory is available. In both x86 and PPC, the variable PAGE_SHIFT (include/asm/page.h) evaluates to 12. So, we are verifying if num_physpages holds a value greater than 8k. This would be the case if we have a machine with more than 32MB of memory. If this is the case, we fit BREAK_GFP_ORDER_HI pages per slab. Otherwise, one page is allocated per slab.
-----------------------------------------------------------------------------
mm/slab.c
690 init_MUTEX(&cache_chain_sem);
691 INIT_LIST_HEAD(&cache_chain);
692 list_add(&cache_cache.next, &cache_chain);
693 cache_cache.array[smp_processor_id()] = &initarray_cache.cache;
694
695 cache_estimate(0, cache_cache.objsize, 0,
696 &left_over, &cache_cache.num);
697 if (!cache_cache.num)
698 BUG();
699
...
-----------------------------------------------------------------------------
Line 690
This line initializes the cache_chain semaphore cache_chain_sem.
Line 691
Initialize the cache_chain list where all the cache descriptors are stored.
Line 692
Add the cache_cache descriptor to the cache_chain list.
Line 693
Create the per CPU caches. The details of this are beyond the scope of this book.
Lines 695698
This block is a sanity check verifying that at least one cache descriptor can be allocated in cache_cache. Also, it sets the cache_cache descriptor's num field and calculates how much space will be left over. This is used for slab coloring Slab coloring is a method by which the kernel reduces cache alignmentrelated performance hits.
-----------------------------------------------------------------------------
mm/slab.c
705 sizes = malloc_sizes;
706 names = cache_names;
707
708 while (sizes->cs_size) {
...
714 sizes->cs_cachep = kmem_cache_create(
715 names->name, sizes->cs_size,
716 0, SLAB_HWCACHE_ALIGN, NULL, NULL);
717 if (!sizes->cs_cachep)
718 BUG();
719
...
725
726 sizes->cs_dmacachep = kmem_cache_create(
727 names->name_dma, sizes->cs_size,
728 0, SLAB_CACHE_DMA|SLAB_HWCACHE_ALIGN, NULL, NULL);
729 if (!sizes->cs_dmacachep)
730 BUG();
731
732 sizes++;
733 names++;
734 }
-----------------------------------------------------------------------------
Line 708
This line verifies if we have reached the end of the sizes array. The sizes array's last element is always set to 0. Hence, this case is true until we hit the last cell of the array.
Lines 714718
Create the next kmalloc cache for normal allocation and verify that it is not empty. See the section, "kmem_cache_create()."
Lines 726730
This block creates the caches for DMA allocation.
Lines 732733
Go to the next element in the sizes and names arrays.
The remainder of the kmem_cache_init() function handles the replacement of the temporary bootstrapping data for kmalloc allocated data. We leave out the explanation of this because it is not directly pertinent to the actual initialization of the cache descriptors.
4.5.2.2. kmem_cache_create()
Times arise when the memory regions provided by the general caches are not sufficient. This function is called when a specialized cache needs to be created. The steps required to create a specialized cache are not unlike those required to create a general cache: create, allocate, and initialize the cache descriptor, align objects, align slab descriptors, and add the cache to the cache chain. This function does not have __init in front of the function name because persistent memory is available when it is called:
-----------------------------------------------------------------------------
mm/slab.c
1027 kmem_cache_t *
1028 kmem_cache_create (const char *name, size_t size, size_t offset,
1029 unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
1030 void (*dtor)(void*, kmem_cache_t *, unsigned long))
1031 {
1032 const char *func_nm = KERN_ERR "kmem_create: ";
1033 size_t left_over, align, slab_size;
1034 kmem_cache_t *cachep = NULL;
...
-----------------------------------------------------------------------------
Let's look at the function parameters of kmem_cache_create.
name
This is the name used to identify the cache. This gets stored in the name field of the cache descriptor and displayed in /proc/slabinfo.
size
This parameter specifies the size (in bytes) of the objects that are contained in this cache. This value is stored in the objsize field of the cache descriptor.
offset
This value determines where the objects are placed within a page.
flags
The flags parameter is related to the slab. Refer to Table 4.4 for a description of the cache descriptor flags field and possible values.
ctor and dtor
ctor and dtor are respectively the constructor and destructor that are called upon creation or destruction of objects in this memory region.
This function performs sizable debugging and sanity checks that we do not cover here. See the code for more details:
-----------------------------------------------------------------------------
mm/slab.c
1079 /* Get cache's description obj. */
1080 cachep = (kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
1081 if (!cachep)
1082 goto opps;
1083 memset(cachep, 0, sizeof(kmem_cache_t));
1084
...
1144 do {
1145 unsigned int break_flag = 0;
1146 cal_wastage:
1147 cache_estimate(cachep->gfporder, size, flags,
1148 &left_over, &cachep->num);
...
1174 } while (1);
1175
1176 if (!cachep->num) {
1177 printk("kmem_cache_create: couldn't create cache %s.\n", name);
1178 kmem_cache_free(&cache_cache, cachep);
1179 cachep = NULL;
1180 goto opps;
1181 }
-----------------------------------------------------------------------------
Lines 10791084
This is where the cache descriptor is allocated. Following this is the portion of the code that is involved with the alignment of objects in the slab. We leave this portion out of this discussion.
Lines 11441174
This is where the number of objects in cache is determined. The bulk of the work is done by cache_estimate(). Recall that the value is to be stored in the num field of the cache descriptor.
-----------------------------------------------------------------------------
mm/slab.c
...
1201 cachep->flags = flags;
1202 cachep->gfpflags = 0;
1203 if (flags & SLAB_CACHE_DMA)
1204 cachep->gfpflags |= GFP_DMA;
1205 spin_lock_init(&cachep->spinlock);
1206 cachep->objsize = size;
1207 /* NUMA */
1208 INIT_LIST_HEAD(&cachep->lists.slabs_full);
1209 INIT_LIST_HEAD(&cachep->lists.slabs_partial);
1210 INIT_LIST_HEAD(&cachep->lists.slabs_free);
1211
1212 if (flags & CFLGS_OFF_SLAB)
1213 cachep->slabp_cache = kmem_find_general_cachep(slab_size,0);
1214 cachep->ctor = ctor;
1215 cachep->dtor = dtor;
1216 cachep->name = name;
1217
...
1242
1243 cachep->lists.next_reap = jiffies + REAPTIMEOUT_LIST3 +
1244 ((unsigned long)cachep)%REAPTIMEOUT_LIST3;
1245
1246 /* Need the semaphore to access the chain. */
1247 down(&cache_chain_sem);
1248 {
1249 struct list_head *p;
1250 mm_segment_t old_fs;
1251
1252 old_fs = get_fs();
1253 set_fs(KERNEL_DS);
1254 list_for_each(p, &cache_chain) {
1255 kmem_cache_t *pc = list_entry(p, kmem_cache_t, next);
1256 char tmp;
...
1265 if (!strcmp(pc->name,name)) {
1266 printk("kmem_cache_create: duplicate cache %s\n",name);
1267 up(&cache_chain_sem);
1268 BUG();
1269 }
1270 }
1271 set_fs(old_fs);
1272 }
1273
1274 /* cache setup completed, link it into the list */
1275 list_add(&cachep->next, &cache_chain);
1276 up(&cache_chain_sem);
1277 opps:
1278 return cachep;
1279 }
-----------------------------------------------------------------------------
Just prior to this, the slab is aligned to the hardware cache and colored. The fields color and color_off of the slab descriptor are filled out.
Lines 12001217
This code block initializes the cache descriptor fields much like we saw in kmem_cache_init().
Lines 12431244
The time for the next cache reap is set.
Lines 12471276
The cache descriptor is initialized and all the information regarding the cache has been calculated and stored. Now, we can add the new cache descriptor to the cache_chain list.
4.5.3. Slab Creation and cache_grow()
When a cache is created, it starts empty of slabs. In fact, slabs are not allocated until a request for an object demonstrates a need for a new slab. This happens when the cache descriptor's lists.slabs_partial and lists.slabs_free fields are empty. At this point, we won't relate how the request for memory translates into the request for an object within a particular cache. For now, we take for granted that this translation has occurred and concentrate on the technical implementation within the slab allocator.
A slab is created within a cache by cache_grow(). When we create a slab, we not only allocate and initialize its descriptor; we also allocate the actual memory. To this end, we need to interface with the buddy system to request the pages. This is done by kmem_getpages() (mm/slab.c).
4.5.3.1. cache_grow()
The cache_grow() function grows the number of slabs within a cache by 1. It is called only when no free objects are available in the cache. This occurs when lists.slabs_partial and lists.slabs_free are empty:
-----------------------------------------------------------------------------
mm/slab.c
1546 static int cache_grow (kmem_cache_t * cachep, int flags)
1547 {
...
-----------------------------------------------------------------------------
The parameters passed to the function are
-----------------------------------------------------------------------------
mm/slab.c
1572 check_irq_off();
1573 spin_lock(&cachep->spinlock);
...
1581
1582 spin_unlock(&cachep->spinlock);
1583
1584 if (local_flags & __GFP_WAIT)
1585 local_irq_enable();
-----------------------------------------------------------------------------
Lines 15721573
Prepare for manipulating the cache descriptor's fields by disabling interrupts and locking the descriptor.
Lines 15821585
Unlock the cache descriptor and reenable the interrupts.
-----------------------------------------------------------------------------
mm/slab.c
...
1597 if (!(objp = kmem_getpages(cachep, flags)))
1598 goto failed;
1599
1600 /* Get slab management. */
1601 if (!(slabp = alloc_slabmgmt(cachep, objp, offset, local_flags)))
1602 goto opps1;
...
1605 i = 1 << cachep->gfporder;
1606 page = virt_to_page(objp);
1607 do {
1608 SET_PAGE_CACHE(page, cachep);
1609 SET_PAGE_SLAB(page, slabp);
1610 SetPageSlab(page);
1611 inc_page_state(nr_slab);
1612 page++;
1613 } while (--i) ;
1614
1615 cache_init_objs(cachep, slabp, ctor_flags);
-----------------------------------------------------------------------------
Lines 15971598
Interface with the buddy system to acquire page(s) for the slab.
Lines 16011602
Place the slab descriptor where it needs to go. Recall that slab descriptors can be stored within the slab itself or within the first general purpose cache.
Lines 16051613
The pages need to be associated with the cache and slab descriptors.
Line 1615
Initialize all the objects in the slab.
-----------------------------------------------------------------------------
mm/slab.c
1616 if (local_flags & __GFP_WAIT)
1617 local_irq_disable();
1618 check_irq_off();
1619 spin_lock(&cachep->spinlock);
1620
1621 /* Make slab active. */
1622 list_add_tail(&slabp->list, &(list3_data(cachep)->slabs_free));
1623 STATS_INC_GROWN(cachep);
1624 list3_data(cachep)->free_objects += cachep->num;
1625 spin_unlock(&cachep->spinlock);
1626 return 1;
1627 opps1:
1628 kmem_freepages(cachep, objp);
1629 failed:
1630 if (local_flags & __GFP_WAIT)
1631 local_irq_disable();
1632 return 0;
1633 }
-----------------------------------------------------------------------------
Lines 16161619
Because we are about to access and change descriptor fields, we need to disable interrupts and lock the data.
Lines 16221624
Add the new slab descriptor to the lists.slabs_free field of the cache descriptor. Update the statistics that keep track of these sizes.
Lines 16251626
Unlock the spinlock and return because all succeeded.
Lines 16271628
This gets called if something goes wrong with the page request. Basically, we are freeing the pages.
Lines 16291632
Disable the interrupt disable, which now lets interrupts come through.
4.5.4. Slab Destruction: Returning Memory and kmem_cache_destroy()
Both caches and slabs can be destroyed. Caches can be shrunk or destroyed to return memory to the free memory pool. The kernel calls these functions when memory is low. In either case, slabs are being destroyed and the pages corresponding to them are being returned for the buddy system to recycle. kmem_cache_destroy() gets rid of a cache. We explore this function in depth. Caches can be reaped and shrunk by kmem_cache_reap() (mm/slab.c) and kmem_cache_shrink(), respectively (mm/slab.c). The function to interface with the buddy system is kmem_freepages() (mm/slab.c).
4.5.4.1. kmem_cache_destroy()
There are a few instances when a cache would need to be removed. Dynamically loadable modules (assuming no persistent memory across loading and unloading) that create caches must destroy them upon unloading to free up the memory and to ensure that the cache won't be duplicated the next time the module is loaded. Thus, the specialized caches are generally destroyed in this manner.
The steps to destroy a cache are the reverse of the steps to create one. Alignment issues are not a concern upon destruction of a cache, only the deletion of descriptors and freeing of memory. The steps to destroy a cache can be summarized as
1. | Remove the cache from the cache chain.
| 2. | Delete the slab descriptors.
| 3. | Delete the cache descriptor.
|
-----------------------------------------------------------------------------
mm/slab.c
1421 int kmem_cache_destroy (kmem_cache_t * cachep)
1422 {
1423 int i;
1424
1425 if (!cachep || in_interrupt())
1426 BUG();
1427
1428 /* Find the cache in the chain of caches. */
1429 down(&cache_chain_sem);
1430 /*
1431 * the chain is never empty, cache_cache is never destroyed
1432 */
1433 list_del(&cachep->next);
1434 up(&cache_chain_sem);
1435
1436 if (__cache_shrink(cachep)) {
1437 slab_error(cachep, "Can't free all objects");
1438 down(&cache_chain_sem);
1439 list_add(&cachep->next,&cache_chain);
1440 up(&cache_chain_sem);
1441 return 1;
1442 }
1443
...
1450 kmem_cache_free(&cache_cache, cachep);
1451
1452 return 0;
1453 }
-----------------------------------------------------------------------------
The function parameter cache is a pointer to the cache descriptor of the cache that is to be destroyed.
Lines 14251426
This sanity check consists of ensuring that an interrupt is not in play and that the cache descriptor is not NULL.
Lines 14291434
Acquire the cache_chain semaphore, delete the cache from the cache chain, and release the cache chain semaphore.
Lines 14361442
This is where the bulk of the work related to freeing the unused slabs takes place. If the __cache_shrink() function returns true, that indicates that there are still slabs in the cache and, therefore, it cannot be destroyed. Thus, we reverse the previous step and reenter the cache descriptor into the cache_chain, again by first reacquiring the cache_chain semaphore, and releasing it once we finish.
Line 1450
We finish by releasing the cache descriptor.
4.6. Memory Request Path
Until now, we have approached the description of the slab allocator as though it were independent of any actual memory request. With the exception of the cache initialization functions, we have not tied together how all these functions come to be called. Now, we look at the flow of control associated with memory requests. When the kernel must obtain memory in byte-sized groupings, it uses the kmalloc() function, which eventually makes the call to kmem_getpages as follows:
kmalloc()->__cache_alloc()->kmem_cache_grow()->kmem_getpages()
4.6.1. kmalloc()
The kmalloc() function allocates memory objects in the kernel:
-----------------------------------------------------------------------------
mm/slab.c
2098 void * __kmalloc (size_t size, int flags)
2099 {
2100 struct cache_sizes *csizep = malloc_sizes;
2101
2102 for (; csizep->cs_size; csizep++) {
2103 if (size > csizep->cs_size)
2104 continue;
...
2112 return __cache_alloc(flags & GFP_DMA ?
2113 csizep->cs_dmacachep : csizep->cs_cachep, flags);
2114 }
2115 return NULL;
2116 }
-----------------------------------------------------------------------------
4.6.1.1. size
This is the number of bytes requested.
4.6.1.2. flags
Indicates the type of memory requested. These flags are passed on to the buddy system without affecting the behavior of kmalloc().Table 4.6 shows the flags, and they are covered in detail in the "Buddy System" section.
Table 4.6. vm_area_struct->vm_flags ValuesFlag | Description |
|---|
VM_READ | Pages in this region can be read. | VM_WRITE | Pages in this region can be written. | VM_EXEC | Pages in this region can be executed. | VM_SHARED | Pages in this region are shared with another process. | VM_GROWSDOWN | The linear addresses are added onto the low side. | VM_GROWSUP | The linear addresses are added onto the high side. | VM_DENYWRITE | These pages cannot be written. | VM_EXECUTABLE | Pages in this region consist of executable code. | VM_LOCKED | Pages are locked. | VM_DONTCOPY | These pages cannot be cloned. | VM_DNTEXPAND | Do not expand this virtual memory area. |
Lines 21022104
Find the first cache with objects greater than the size requested.
Lines 21122113
Allocate an object from the memory zone specified by the flags parameter.
4.6.2. kmem_cache_alloc()
This is a wrapper function around __cache_alloc(). It does not perform any additional functionality because its parameters are passed as is:
-----------------------------------------------------------------------------
mm/slab.c
2070 void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
2071 {
2072 return __cache_alloc(cachep, flags);
2073 }
-----------------------------------------------------------------------------
4.6.2.1. cachep
The cachep parameter is the cache descriptor of the cache from which we want to allocate objects.
4.6.2.2. flags
The type of memory requested. This is passed directly as indicated to kmalloc().
To free byte-sized memory allocated with kmalloc(), the kernel provides the kfree() interface, which takes as a parameter the pointer to the memory returned by kmalloc(). Figure 4.9 illustrates the flow from kfree to kmem_freepages.

4.7. Linux Process Memory Structures
Until now, we covered how the kernel manages its own memory. We now turn our attention to user space programs and how the kernel manages program memory. The wonder of virtual memory allows a user space process to effectively operate as though it has access to all memory. In reality, the kernel manages what gets loaded, how it gets loaded, and when that happens. All that we have discussed until now in this chapter relates to how the kernel manages memory and is completely transparent to a user space program.
Upon creation, a user space process is assigned a virtual address space. As previously mentioned, a process' virtual address space is a range of unsegmented linear addresses that the process can use. The size of the range is defined by the size of the register in the system's architecture. Most systems have a 32-bit address space. A G5, for example, has processes with a 64-bit address space.
Upon creation, the address range the process is presented with can grow or shrink through the addition or removal of linear address intervals, respectively. The address interval (a range of addresses) represents yet another unit of memory called a memory region or a memory area. It is useful to split the process address range into areas of different types. These different types have different protection schemes or characteristics. The process-memory protection schemes are associated with process context. For example, certain parts of a program's code are marked read-only (text) while others are writable (variables) or executable (instructions). Also, a particular process might access only certain memory areas that belong to it.
Within the kernel, a process address space, as well as all the information related to it, is kept in an mm_struct descriptor. You might recall from Chapter 3, "Processes: The Principal Model of Execution," that this structure is referenced in the task_struct for the process. A memory area is represented by the vm_area_struct descriptor. Each memory area descriptor describes the contiguous address interval it represents. Throughout this section, we refer to the descriptor for an address interval as a memory area descriptor or as vma_area_struct.We now look at mm_struct and vm_area_struct. Figure 4.10 illustrates the relationship between these data structures.
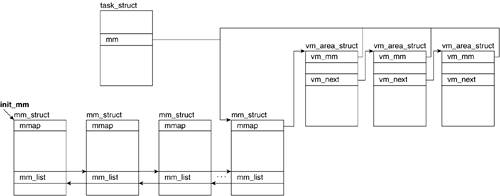
4.7.1. mm_struct
Every task has an mm_struct (include/linux/sched.h) structure that the kernel uses to represent its memory address range. All mm_struct descriptors are stored in a doubly linked list. The head of the list is the mm_struct that corresponds to process 0, which is the idle process. This descriptor is accessed by way of the global variable init_mm:
-----------------------------------------------------------------------------
include/linux/sched.h
185 struct mm_struct {
186 struct vm_area_struct * mmap;
187 struct rb_root mm_rb;
188 struct vm_area_struct * mmap_cache;
189 unsigned long free_area_cache;
190 pgd_t * pgd;
191 atomic_t mm_users;
192 atomic_t mm_count;
193 int map_count;
194 struct rw_semaphore mmap_sem;
195 spinlock_t page_table_lock
196
197 struct list_head mmlist;
...
202 unsigned long start_code, end_code, start_data, end_data;
203 unsigned long start_brk, brk, start_stack;
204 unsigned long arg_start, arg_end, env_start, env_end;
205 unsigned long rss, total_vm, locked_vm;
206 unsigned long def_flags;
207 cpumask_t cpu_vm_mask;
208 unsigned long swap_address;
...
228 };
-----------------------------------------------------------------------------
4.7.1.1. mmap
The memory area descriptors (which are defined in the next section) that have been assigned to a process are linked in a list. This list is accessed by means of the mmap field in the mm_struct. The list is traversed by way of the vm_next field of each vma_area_struct.
4.7.1.2. mm_rb
The simply linked list provides an easy way of traversing all the memory area descriptors that correspond to a particular process. However, if the kernel searches for a particular memory area descriptor, a simply linked list does not yield good search times. The memory area structures that correspond to a process address range are also stored in a red-black tree that is accessed through the mm_rb field. This yields faster search times when the kernel needs to access a particular memory area descriptor.
4.7.1.3. mmap_cache
mmap_cache is a pointer to the last memory area referenced by the process. The principle of locality states that when a memory address is referenced, memory areas that are close by tend to get referenced soon after. Hence, it is likely that the address being currently checked belongs to the same memory area as the last address checked. The hit rate of verifying whether the current address is in the last accessed memory area is approximately 35 percent.
4.7.1.4. pgd
The pgd field is a pointer to the page global directory that holds the entry for this memory area. In the mm_struct for the idle process (process 0), this field points to the swapper_pg_dir. See Section 4.9 for more information on what this field points to.
4.7.1.5. mm_users
The mm_users field holds the number of processes that access this memory area. Lightweight processes or threads share the same address intervals and memory areas. Thus, the mm_struct for threads generally have an mm_users field with a value greater than 1. This field is manipulated by way of the atomic functions: atomic_set(), atomic_dec_and_lock(), atomic_read(), and atomic_inc().
4.7.1.6. mm_count
mm_count is the usage count for the mm_struct. When determining if the structure can be deallocated, a check is made against this field. If it holds the value of 0, no processes are using it; therefore, it can be deallocated.
4.7.1.7. map_count
The map_count field holds the number of memory areas, or vma_area_struct descriptors, in the process address space. Every time a new memory area is added to the process address space, this field is incremented alongside with the vma_area_struct's insertion into the mmap list and mm_rb tree.
4.7.1.8. mm_list
The mm_list field of type list_head holds the address of adjacent mm_structs in the memory descriptor list. As previously mentioned, the head of the list is pointed to by the global variable init_mm, which is the memory descriptor for process 0. When this list is manipulated, mmlist_lock protects it from concurrent accesses.
The next 11 fields we describe deal with the various types of memory areas a process needs allocated to it. Rather than digress into an explanation that distracts from the description of the process memoryrelated structures, we now give a cursory description.
4.7.1.9. start_code and end_code
The start_code and end_code fields hold the starting and ending addresses for the code section of the processes' memory region (that is, the executable's text segment).
4.7.1.10. start_data and end_data
The start_data and end_data fields contain the starting and ending addresses for the initialized data (that found in the .data portion of the executable file).
4.7.1.11. start_brk and brk
The start_brk and brk fields hold the starting and ending addresses of the process heap.
4.7.1.12. start_stack
start_stack is the starting address of the process stack.
4.7.1.13. arg_start and arg_end
The arg_start and arg_end fields hold the starting and ending addresses of the arguments passed to the process.
4.7.1.14. env_start and env_end
The env_start and env_end fields hold the starting and ending addresses of the environment section.
This concludes the mm_struct fields that we focus on in this chapter. We now look at some of the fields for the memory area descriptor, vm_area_struct.
4.7.2. vm_area_struct
The vm_area_struct structure defines a virtual memory region. A process has various memory regions, but every memory region has exactly one vm_area_struct to represent it:
-----------------------------------------------------------------------------
include/linux/mm.h
51 struct vm_area_struct {
52 struct mm_struct * vm_mm;
53 unsigned long vm_start;
54 unsigned long vm_end;
...
57 struct vm_area_struct *vm_next;
...
60 unsigned long vm_flags;
61
62 struct rb_node vm_rb;
...
72 struct vm_operations_struct * vm_ops;
...
};
-----------------------------------------------------------------------------
4.7.2.1. vm_mm
All memory regions belong to an address space that is associated with a process and represented by an mm_struct. The structure vm_mm points to a structure of type mm_struct that describes the address space to which this memory area belongs to.
4.7.2.2. vm_start and vm_end
A memory region is associated with an address interval. In the vm_area_struct, this interval is defined by keeping track of the starting and ending addresses. For performance reasons, the beginning address of the memory region must be a multiple of the page frame size. The kernel ensures that page frames are filled with data from a particular memory region by also demanding that the size of memory region be in multiples of the page frame size.
4.7.2.3. vm_next
The field vm_next points to the next vm_area_struct in the linked list that comprises all the regions within a process address space. The head of this list is referenced by way of the mmap field in the mm_struct for the address space.
4.7.2.4. vm_flags
Within this interval, a memory region also has associated characteristics that describe it. These are stored in the vm_flags field and apply to the pages within the memory region. Table 4.6 describes the possible flags.
4.7.2.5. vm_rb
vm_rb holds the red-black tree node that corresponds to this memory area.
4.7.2.6. vm_ops
vm_ops consists of a structure of function pointers that handle the particular vm_area_struct. These functions include opening the memory area, closing, and unmapping it. Also, it holds a function pointer to the function called when a no-page exception occurs.
4.8. Process Image Layout and Linear Address Space
When a user space program is loaded into memory, it has its linear address space partitioned into various memory areas or segments. These segments are determined by functional differences in relation to the execution of the process. The functionally separated segments are mapped within the process address space. Six main segments are related to process execution:
Text.
This segment, also known as the code segment, holds the executable instructions of a program. As such, it has execute and read attributes. In the case that multiple processes can be loaded from a single program, it would be wasteful to load the same instructions twice. Linux allows for multiple processes to share this text segment in memory. The start_code and end_code fields of the mm_struct hold the addresses for the beginning and end of the text segment.
Data.
This section holds all initialized data. Initialized data includes statically allocated and global data that are initialized. The following code snippet shows an example of initialized data:
---------------------------------------------------------------------------
example1.c
int gvar = 10;
int main(){
...
}
-----------------------------------------------------------------------------
gvar.
A global variable that is initialized and stored in the data segment. This section has read/write attributes but cannot be shared among processes running the same program. The start_data and end_data fields of the mm_struct hold the addresses for the beginning and end of the data segment.
BSS.
This section holds uninitialized data. This data consists of global variables that the system initializes with 0s upon program execution. Another name for this section is the zero-initialized data section. The following code snippet shows an example of non-initialized data:
---------------------------------------------------------------------------
example2.c
int gvar1[10];
long gvar2;
int main() {
...
}
-----------------------------------------------------------------------------
Objects in this segment have only name and size attributes.
Heap.
This is used to grow the linear address space of a process. When a program uses malloc() to obtain dynamic memory, this memory is placed in the heap. The start_brk and brk fields of the mm_struct hold the addresses for the beginning and end of the heap. When malloc() is called to obtain dynamic memory, a call to the system call sys_brk() moves the brk pointer to its new location, thus growing the heap.
Stack.
This contains all the local variables that get allocated. When a function is called, the local variables for that function are pushed onto the stack. As soon as a function ends, the variables associated with the function are popped from the stack. Other information, including return addresses and parameters, is also stored in the stack. The field start_stack of the mm_struct marks the starting address of the process stack.
Although six main areas are related to process execution, they only map to three memory areas in the address space. These memory areas are called text, data, and stack. The data segment includes the executable's initialized data segment, the bss, and the heap. The text segment includes the executable's text segment.Figure 4.11 shows what the linear address space looks like and how the mm_struct keeps track of these segments.
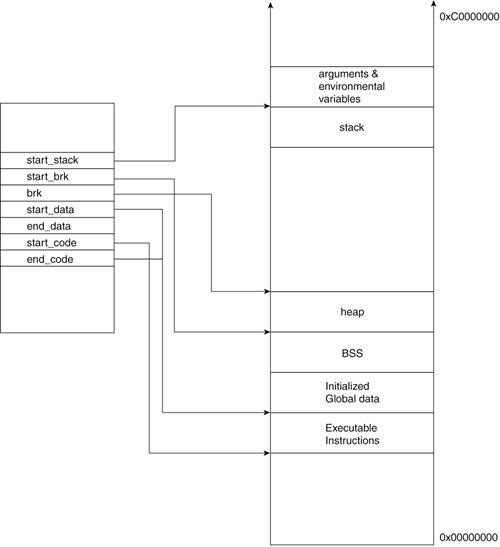
The various memory areas are mapped in the /proc filesystem. The memory map of a process may be accessed through the output of /proc/<pid>/maps. We now look at an example program and see the list of memory areas in the process' address space. The code in example3.c shows the program being mapped.
-----------------------------------------------------------------------------
example3.c
#include <stdio.h>
int main(){
while(1);
return(0);
}
-----------------------------------------------------------------------------
The output of /proc/<pid>/maps for our example yields what's shown in Figure 4.12.
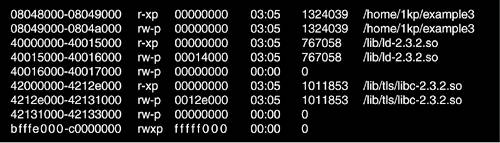
The left-most column shows the range of the memory segment. That is, the starting and ending addresses for a particular segment. The next column shows the access permissions for that segment. These flags are similar to the access permissions on files: r stands for readable, w stands for writeable, and x stands for executable. The last flag can be either a p, which indicates a private segment, or s, which indicates a shared segment. (A private segment is not necessarily unshareable.) The p indicates only that it is currently not being shared. The next column holds the offset for the segment. The fourth column from the left holds two numbers separated by a colon. These represent the major and minor numbers of the filesystem the file associated with that segment is found in. (Some segments do not have a file associated with them and, hence, just fill in this value with 00:00.) The fifth column holds the inode of the file and the sixth and right-most column holds the filename. For segments with no filename, this column is empty and the inode column holds a 0.
In our example, the first row holds a description of the text segment of our sample program. This can be seen on account of the permission flags set to executable. The next row describes our sample program's data segment. Notice that its permissions indicate that it is writeable.
Our program is dynamically linked, which means that functions it uses belonging to a library are loaded at runtime. These functions need to be mapped to the process' address space so that it can access them. The next six rows deal with dynamically linked libraries. The next three rows describe the ld library's text, data, and bss. These three rows are followed by descriptions of libc's test, data, and bss segments in that order.
The final row, whose permissions indicated that it is readable, writeable, and executable, represents the process stack and extends up to 0xC0000000. 0xC000000 is the highest memory address accessible for user space processes.
4.9. Page Tables
Program memory is comfortably managed with virtual addresses. The problem with this is that when an instruction is issued to the processor, it cannot do anything with a virtual address. The processor operates on physical addresses. The association between the virtual address and the corresponding physical address is kept by the kernel (with help from the hardware) in page tables.
Page tables keep track of memory in page frame units. They are stored in RAM throughout the kernel's lifespan. Linux has what is called a three-level paging scheme. Three-level paging is sufficient to ensure that 64-bit architectures have enough space to maintain mappings of all their virtual-to-physical associations. As the name implies, three-level paging has three types of paging tables: The top level directory is called the Page Global Directory (PGD) and is represented by a pgd_t datatype; the second page is called the Page Middle Directory (PMD) and is represented by a pmd_t datatype; the final page is called a Page Table (PTE) and is represented by a pte_t datatype. Figure 4.13 illustrates the page tables.
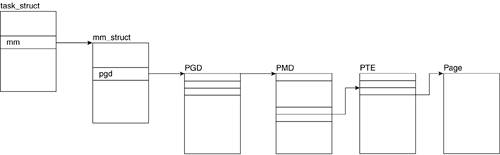
The PGD holds entries that refer to PMDs. The PMD holds entries that refer to PTEs, and the PTE holds entries that refer to specific pages. Each process has its own set of page tables. The mm_struct->pgd field points to the PGD for the process. The 32- or 64-bit virtual addresses are split up into variously sized (depending on the architecture) offset fields. Each field corresponds to an offset within the PGD, PMD, PTE, and the page itself.
|
4.10. Page Fault
Throughout the lifespan of a process, it is possible that it might attempt to access an address that belongs to its address space but is not loaded in RAM. It might alternatively access a page that is in RAM, but attempt action upon it that would violate the page's permission settings (for example, writing in a read-only area). When this happens, the system generates a page fault. The page fault is an exception handler that manages errors in a program's page access. Pages are fetched from storage when the hardware raises this page fault exception that the kernel traps. The kernel then allocates the missing page.
Each architecture has an architecture-dependent function that handles page faults. Both x86 and PPC call the function do_page_fault(). The x86 page fault handler do_page_fault(*regs, error_code) is located in /arch/i386/mm/fault.c. The PowerPC page fault handler do_page_fault(*regs, address, error_code) is located in /arch/ppc/mm/fault.c. The similarities are close enough that a discussion of do_page_fault() for the x86 covers the functionality of the PowerPC version.
The major difference in how the two architectures handle the page fault is in how the fault information is gathered and stored before do_page_fault() is called. We first explain the specifics of the x86 page fault handling and proceed to explain the do_page_fault() function. We follow this explanation by highlighting the differences seen in PowerPC.
4.10.1. x86 Page Fault Exception
The x86 page fault handler do_page_fault() is called as the result of a hardware interrupt 14. This interrupt occurs when the processor identifies the following conditions to be true:
Paging is enabled, and the present bit is clear in the page-directory or page-table entry needed for this address. Paging is enabled, and the current privilege level is less than that needed to access the requested page.
Upon raising this interrupt, the processor saves two valuable pieces of information:
The nature of the error in the lower 4 bits of a word pushed on the stack. (Bit 3 is not used by do_page_fault().) See Table 4.7 to see what each bit value corresponds to. Table 4.7. Page Fault error_code| | Bit 2 | Bit 1 | Bit 0 |
|---|
Value = 0 | Kernel | Read | Page not present | Value = 1 | User | Write | Protection fault |
The 32-bit linear address that caused the exception in cr2.
The regs parameter of do_page_fault() is a struct that contains the system registers, and the error_code parameter uses a 3-bit field to describe the source of the fault.
4.10.2. Page Fault Handler
For both architectures, the do_page_fault() function uses the just-given information and takes one of several actions. These code segments follow a fairly complicated series of checks to end up with one of the following:
The offending address being found by handle_mm_fault() The famous oops dump (no_context:) bad_page_fault() for PowerPC A segmentation fault (bad_area:) bad_page_fault() for PowerPC An error returned to the caller (fixup)
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
212 asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)
213 {
214 struct task_struct *tsk;
215 struct mm_struct *mm;
216 struct vm_area_struct * vma;
217 unsigned long address;
218 unsigned long page;
219 int write;
220 siginfo_t info;
221
222 /* get the address */
223 __asm__("movl %%cr2,%0":"=r" (address));
...
232 tsk = current;
233
234 info.si_code = SEGV_MAPERR;
-----------------------------------------------------------------------------
Line 223
The address at which the page fault occurred is stored in the cr2 control register. The linear address is read and the local variable address is set to hold the value.
Line 232
The task_struct pointer tsk is set to point at the task_struct current.
Now, we are ready to find out more about where the address that generated the page fault comes from. Figure 4.14 illustrates the flow of the following lines of code:
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
246 if (unlikely(address >= TASK_SIZE)) {
247 if (!(error_code & 5))
248 goto vmalloc_fault;
...
253 goto bad_area_nosemaphore;
254 }
...
257 mm = tsk->mm
...
-----------------------------------------------------------------------------

Lines 246248
This code checks if the address at which the page fault occurred was in kernel module space (that is, in a noncontiguous memory area). Noncontiguous memory area addresses have their linear address >= TASK_SIZE. If it was, it checks if bits 0 and 2 of the error_code are clear. Recall from Table 4.7 that this indicates that the error is caused by trying to access a kernel page that is not present. If so, this indicates that the page fault occurred in kernel mode and the code at label vmalloc_fault: is called.
Line 253
If we get here, it means that although the access occurred in a noncontiguous memory area, it occurred in user mode, hit a protection fault, or both. In this case, we jump to the label bad_area_semaphore:.
Line 257
This sets the local variable mm to point to the current task's memory descriptor. If the current task is a kernel thread, this value is NULL. This becomes significant in the next code lines.
At this point, we have determined that the page fault did not occur in a noncontiguous memory area. Again, Figure 4.15 illustrates the flow of the following lines of code:
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
...
262 if (in_atomic() || !mm)
263 goto bad_area_nosemaphore;
264
265 down_read(&mm->mmap_sem);
266
267 vma = find_vma(mm, address);
268 if (!vma)
269 goto bad_area;
270 if (vma->vm_start <= address)
271 goto good_area;
272 if (!(vma->vm_flags & VM_GROWSDOWN))
273 goto bad_area;
274 if (error_code & 4) {
...
281 if (address + 32 < regs->esp)
282 goto bad_area;
283 }
284 if (expand_stack(vma, address))
285 goto bad_area;
...
-----------------------------------------------------------------------------
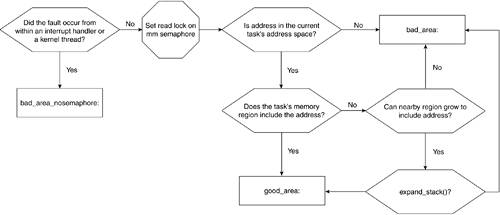
Lines 262263
In this code block, we check to see if the fault occurred while executing within an interrupt handler or in kernel space. If it did, we jump to label bad_area_ semaphore:.
Line 265
At this point, we are about to search through the memory areas of the current process, so we set a read lock on the memory descriptor's semaphore.
Lines 267269
Given that, at this point, we know the address that generated the page fault is not in a kernel thread or in an interrupt handler, we search the address space of the process to see if the address is in one of its memory areas. If it is not there, jump to label bad_area:.
Lines 270271
If we found a valid region within the process address space, we jump to label good_area:.
Lines 272273
If we found a region that is not valid, we check if the nearest region can grow to fit the page. If not, we jump to the label bad_area:.
Lines 274284
Otherwise, the offending address might be the result of a stack operation. If expanding the stack does not help, jump to the label bad_area:.
Now, we proceed to explain what each of the label jump points do. We begin with the label vmalloc_fault, which is illustrated in Figure 4.16:
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
473 vmalloc_fault:
{
int index = pgd_index(address);
pgd_t *pgd, *pgd_k;
pmd_t *pmd, *pmd_k;
pte_t *pte_k;
asm("movl %%cr3,%0":"=r" (pgd));
pgd = index + (pgd_t *)__va(pgd);
pgd_k = init_mm.pgd + index;
491 if (!pgd_present(*pgd_k))
goto no_context;
pmd = pmd_offset(pgd, address);
pmd_k = pmd_offset(pgd_k, address);
if (!pmd_present(*pmd_k))
goto no_context;
set_pmd(pmd, *pmd_k);
pte_k = pte_offset_kernel(pmd_k, address);
506 if (!pte_present(*pte_k))
507 goto no_context;
508 return;
509 }
-----------------------------------------------------------------------------
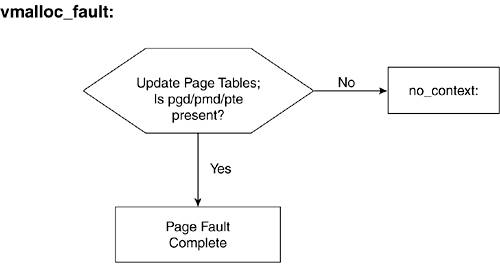
Lines 473509
The current process Page Global Directory is referenced (by way of cr3) and saved in the variable pgd and the kernel Page Global Directory is referenced by pgd_k (likewise for the pmd and the pte variables). If the offending address is not valid in the kernel paging system, the code jumps to the no_context: label. Otherwise, the current process uses the kernel pgd.
Now, we look at the label good_area:. At this point, we know that the memory area holding the offending address exists within the address space of the process. Now, we need to ensure that the access permissions were correct. Figure 4.17 shows the flow diagram:
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
290 good_area:
291 info.si_code = SEGV_ACCERR;
292 write = 0;
293 switch (error_code & 3) {
294 default: /* 3: write, present */
...
/* fall through */
300 case 2: /* write, not present */
301 if (!(vma->vm_flags & VM_WRITE))
302 goto bad_area;
303 write++;
304 break;
305 case 1: /* read, present */
306 goto bad_area;
307 case 0: /* read, not present */
308 if (!(vma->vm_flags & (VM_READ | VM_EXEC)))
309 goto bad_area;
310 }
-----------------------------------------------------------------------------
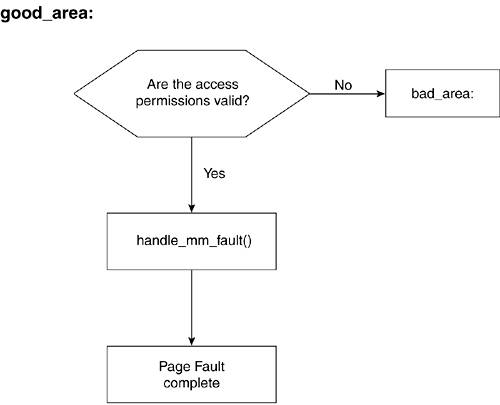
Lines 294304
If the page fault was caused by a memory access that was a write (recall that if this is the case, our left-most bit in the error code is set to 1), we check if our memory area is writeable. If it is not, we have a mismatch of permissions and we jump to the label bad_area:. If it was writeable, we fall through the case statement and eventually proceed to handle_mm_fault() with the local variable write set to 1.
Lines 305309
If the page fault was caused by a read or execute access and the page is present, we jump to the label bad_area: because this constitutes a clear permissions violation. If the page is not present, we check to see if the memory area has read or execute permissions. If it does not, we jump to the label bad_area: because even if we were to fetch the page, the permissions would not allow the operation. If it does, we fall out of the case statement and eventually proceed to handle_mm_fault() with the local variable write set to 0.
The following label marks the code we fall through to when the permissions checks comes out OK. It is appropriately labeled survive:.
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
survive:
318 switch (handle_mm_fault(mm, vma, address, write)) {
case VM_FAULT_MINOR:
tsk->min_flt++;
break;
case VM_FAULT_MAJOR:
tsk->maj_flt++;
break;
case VM_FAULT_SIGBUS:
goto do_sigbus;
case VM_FAULT_OOM:
goto out_of_memory;
329 default:
BUG();
}
-----------------------------------------------------------------------------
Lines 318329
The function handle_mm_fault() is called with the current memory descriptor (mm), the descriptor to the offending address' area, the offending address, and whether the access was a read/execute or write. The switch statement catches us if we fail at handling the fault, which ensures we exit gracefully.
The following code snippet describes the flow of the label bad_area and bad_area_no_semaphore. When we jump to this point, we know that either
The address generating the page fault is not in the process address space because we've searched its memory areas and did not find one that matched. The address generating the page fault is not in the process address space and the region that would contain it cannot grow to hold it. The address generating the page fault is in the process address space but the permissions of the memory area did not match the action we wanted to perform.
Now, we need to determine if the access is from within kernel mode. The following code and Figure 4.18 illustrates the flow of these labels:
-----------------------------------------------------------------------------
arch/i386/mm.fault.c
348 bad_area:
349 up_read(&mm->mmap_sem);
350
351 bad_area_nosemaphore:
352 /* User mode accesses just cause a SIGSEGV */
353 if (error_code & 4) {
354 if (is_prefetch(regs, address))
355 return;
356
357 tsk->thread.cr2 = address;
358 tsk->thread.error_code = error_code;
359 tsk->thread.trap_no = 14;
360 info.si_signo = SIGSEGV;
361 info.si_errno = 0;
362 /* info.si_code has been set above */
363 info.si_addr = (void *)address;
364 force_sig_info(SIGSEGV, &info, tsk);
365 return;
366 }
-----------------------------------------------------------------------------
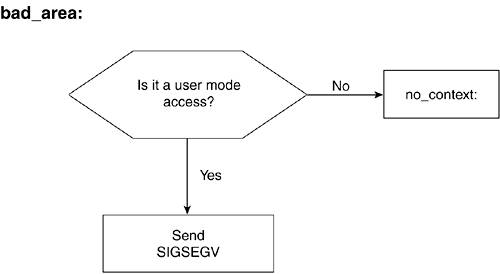
Line 348
The function up_read() releases the read lock on the semaphore of the process' memory descriptor. Notice that we have only jumped to the label bad_area after we place read lock on the memory descriptor's semaphore to look through its memory areas to see if our address was within the process address space. Otherwise, we have jumped to the label bad_area_nosemaphore. The only difference between the two is the lifting of the read lock on the semaphore.
Lines 351353
Because the address is not in the address space, we now check to see if the error was generated in user mode. If you recall from Table 4.7, an error code value of 4 indicates that the error occurred in user mode.
Lines 354366
We have determined that the error occurred in user mode, so we send a SIGSEGV signal (trap 14).
The following code snippet describes the flow of the label no_context. When we jump to this point, we know that either
Figure 4.19 illustrates the flow diagram of the label no_context:
-----------------------------------------------------------------------------
arch/i386/mm/fault.c
388 no_context:
390 if (fixup_exception(regs))
return;
432 die("Oops", regs, error_code);
bust_spinlocks(0);
do_exit(SIGKILL);
-----------------------------------------------------------------------------
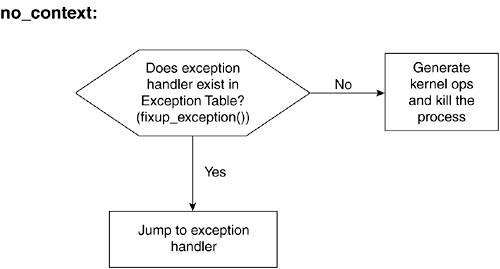
Line 390
The function fixup_exception() uses the eip passed in to search an exception table for the offending instruction. If the instruction is in the table, it must have already been compiled with "hidden" fault handling code built in. The page fault handler, do_page__fault(), uses the fault handling code as a return address and jumps to it. The code can then flag an error.
Line 432
If there is not an entry in the exception table for the offending instruction, the code that jumped to label no_context ends up with the oops screen dump.
4.10.3. PowerPC Page Fault Exception
The PowerPC page fault handler do_page_fault() is called as a result of an instruction or data store exception. Because of the subtle differences between the various versions of the PowerPC processors, the error codes are in a slightly different format, but yield similar information. The bits of interest are whether the offending operation was a read or write, and if it was a protection fault. The PowerPC page fault handler do_page_fault() does not initiate the oops error.
In PowerPC, the label no_context code is combined with the label bad_area code and placed in a function called bad_page_fault(), which ends by producing a segmentation fault. This function also has the fixup function that traverses the exception_table.
Project: Process Memory Map
We now look at what memory looks like for our own program. This project consists of an exploration of a user space program that illustrates where things are placed in memory. For this project, we create a simple shared library and a user space program that uses its function. From the program, we print the location of some of the variables and compare it against the process memory mappings to determine where the variables and functions are being stored.
The first step is to create the shared library. The shared library can have a single function, which we will call from our main program. We want to print the address of a local variable from within this function. Your shared library should look like this:
-----------------------------------------------------------------------------
lkpsinglefoo.c
mylibfoo()
{
int libvar;
printf("variable libvar \t location: 0x%x\n", &libvar);
}
-----------------------------------------------------------------------------
Compile and link singlefoo.c into a shared library:
#lkp>gcc c lkpsinglefoo.c
#lkp>gcc lkpsinglefoo.o o liblkpsinglefoo.so shared lc
The shared and lc flags are linker options. The shared option requests that a shared object that can be linked with other objects be produced. The lc flag indicates that the C library be searched when linking.
These commands generate a file called liblkpsinglefoo.so. To use it, you need to copy it to /lib.
The following is the main application we will call that links in your library:
-----------------------------------------------------------------------------
lkpmem.c
#include <fcntl.h>
int globalvar1;
int globalvar2 = 3;
void mylocalfoo()
{
int functionvar;
printf("variable functionvar \t location: 0x%x\n", &functionvar);
}
int main()
{
void *localvar1 = (void *)malloc(2048)
printf("variable globalvar1 \t location: 0x%x\n", &globalvar1);
printf("variable globalvar2 \t location: 0x%x\n", &globalvar2);
printf("variable localvar1 \t location: 0x%x\n", &localvar1);
mylibfoo();
mylocalfoo();
while(1);
return(0);
}
-----------------------------------------------------------------------------
Compile lkpmem.c as follows:
#lkp>gcc o lkpmem lkpmem.c llkplibsinglefoo
When you execute lkpmem, you get the print statements that indicate the memory locations of the various variables. The function blocks on the while(1); statement and does not return. This allows you to get the process PID and search the memory maps. To do so, use the following commands:
#lkp>./lkpmem
#lkp> ps aux | grep lkpmem
#lkp> cat /proc/<pid>/maps
Indicate the memory segment in which each variable is located.
|
|
|
|
|
|
|
|
|
| |

 LINUX
LINUX 
 Books
Books
