Глава 9. Межпроцессное взаимодействие по принципу System V
Каналы появились в Unix с первых дней создания этой системы и всегда служили превосходным средством обеспечения двухсторонней связи между двумя процессами на одном и том же компьютере. Позднее версия BSD (Berkeley Software Development) системы Unix подарила миру сокеты, которые позволяют обеспечить взаимодействие между двумя процессами на разных компьютерах (или на одном и том же компьютере).
В версии System V системы Unix были введены три механизма, которые теперь известны под общим названием System V IPC (средства межпроцессного взаимодействия по принципу System V). Как и каналы, все эти механизмы можно использовать только для взаимодействия между процессами на одном и том же компьютере. Однако в отличие и от каналов, и от сокетов средства IPC версии System V обеспечивают взаимодействие между многими процессами на одном и том же компьютере, а не только между двумя процессами. Кроме того, каналы (а не сокеты) имеют еще одно ограничение, связанное с тем, что два взаимодействующих процесса должны быть родственными. Они должны иметь общего предка — процесс, который устанавливает канал; обычно либо один процесс является родителем другого, либо оба процесса имеют общего родителя, который устанавливает канал для них обоих. Средства IPC System V, как и сокеты, обеспечивают взаимодействие между процессами, которые не имеют родственных связей, а соблюдают только соглашения о взаимодействии.
Тремя механизмами межпроцессного взаимодействия (IPC — interprocess communication), которые составляют средства System V IPC, являются очереди сообщений, семафоры и разделяемая память.
Очереди сообщений
Очереди сообщений версии System V — это метод, позволяющий процессам асинхронно посылать сообщения друг другу. В данном случае это означает, что не только отправитель после отправки сообщения не должен ждать, пока получатель проверит свою почту, и может перейти к выполнению другой работы, но и получатель не должен переходить в состояние ожидания, если нужные сообщения еще к нему не поступили. Шифрование и расшифровка сообщений входит в задачу процессов отправителя и получателя; реализация очереди сообщения не может им предоставить в этом особой помощи. Именно благодаря этому реализация общего механизма является такой несложной, однако эта простота достигается за счет некоторого дополнительного усложнения приложений.
Ниже описан простой сценарий использования очереди сообщений, который может быть осуществлен на компьютере с симметричной мультипроцессорной архитектурой. Единственный процесс планировщика, работающий на одном процессоре, посылает запросы на выполнение работы в определенную очередь сообщений. Запросы на выполнение работы могут принимать форму набора паролей для проверки в программе взлома, ряда пикселей для расчета в программе фрактального рисования, участка пространства для обновления в конкретной системе и т.п. Между тем, рабочие процессы, функционирующие на других процессорах, выбирают сообщения из очереди сообщений, когда у них не остается другой работы, и отправляют результирующие сообщения в другую очередь сообщений.
Эта архитектура является несложной для реализации и, при условии правильного подбора объемов работы, запрашиваемых каждым сообщением, может обеспечить весьма эффективное использование процессоров компьютера. (Заметим также, что планировщик вряд ли будет выполнять слишком большой объем работы, поэтому на процессоре планировщика оставшуюся часть времени может занять еще один рабочий процесс.) Таким образом, очереди сообщений можно использовать в качестве разновидности удаленного вызова процедур (RPC — remote procedure calling) низкого уровня.
Новые сообщения всегда добавляются к концу очереди, но они не всегда удаляются с ее начала; как будет показано далее в этой главе, они могут быть удалены из любого места очереди. Очередь сообщений, в определенном смысле, аналогична голосовой почте: новые сообщения всегда находятся в конце, а приемник сообщений может получать (и удалять) сообщения из середины списка.
Краткий обзор очереди сообщений
Очереди сообщений рассматриваются первыми, поскольку они имеют простейшую реализацию, но при этом демонстрируют некоторые архитектурные особенности, общие для всех трех механизмов System V IPC.
Процессы получают четыре системных вызова, относящихся к очереди сообщений:
- msgget. Неудачное имя (которое буквально означает «получить сообщение»); можно подумать, что это — команда на получение ждущего сообщения, но это не так. Вызывающая программа выдает ключ очереди сообщений, a msgget возвращает идентификатор либо существующей очереди с этим ключом, если таковая имеется, либо новую очередь сообщений с этим ключом, если таковой не было. Поэтому функция msgget позволяет получить не сообщение, а идентификатор, который однозначно обозначает очередь сообщений.
- msgsnd. Посылает сообщение в очередь сообщений.
- msgrcv. Принимает сообщение из очереди сообщений.
- msgctl. Выполняет ряд административных операций над очередью сообщений: выбирает информацию о ее пределах (например, о максимальном объеме содержательной части сообщений, которые могут находиться в этой очереди), удаляет очередь и т.д.
struct msg
15919: Объект struct msg представляет единственное сообщение, ожидающее в очереди. Он имеет следующие члены:
- msg_next. Указывает на следующее сообщение в очереди или содержит NULL, если это — последнее сообщение в очереди.
- msg_type. Определяемый пользователем код типа; его применение рассматривается далее в этой главе в описании процесса получения сообщений.
- msg_spot. Указывает на начало содержимого сообщения. Как будет показано ниже, пространство для сообщения всегда распределяется непосредственно над самим объектом struct msg, поэтому msg_spot всегда указывает на адрес, расположенный сразу после конца объекта struct msg.
- msg_stime. Содержит данные о времени отправки сообщения. Поскольку сообщения хранятся в порядке очереди (FIFO — first-in, first-out), сообщения в очереди характеризуются монотонно возрастающими значениями msg_stime.
- msg_ts. Содержит данные о размере сообщения («ts» — это сокращение от «text size», но сообщение не обязано быть текстом, предназначенным для восприятия человеком). Максимальный размер сообщения соответствует величине MSGMAX, которая установлена директивой #define равной 4056 байтам в строке 15902. Можно предположить, что эта величина принята равной 4 Кб (4096 байтам) минус размер объекта struct msg. Но размер этого объекта составляет только 20 байтов, поэтому назначение еще 20 байтов остается неизвестным.
struct msqid_ds
msgque
20129: Центральной структурой данных в реализации очереди сообщений является msgque — массив указателей на объекты struct msqid_ds. Существует всего MSGMNI таких указателей (эта величина установлена равной 128 с помощью директивы #define в строке 15900), что соответствует 128 очередям сообщений. Но почему бы просто не использовать массив объектов struct msqid_ds вместо массива указателей? Одной из причин этого является экономия места: вместо массива из 128 56-байтовых структур (7168 байтов или ровно 7 Кб) для msgque применяется массив из 128 4-байтовых указателей (512 байтов). В обычном случае, когда применяется ряд очередей сообщений, это позволяет сэкономить несколько килобайтов. В наихудшем случае, когда распределены все очереди сообщений, максимальный расход составляет 512 байтов. Единственным реальным недостатком является дополнительный уровень разадресации, что приводит к небольшому снижению быстродействия.
Зависимость между основными структурами данных очереди сообщений показана на рис. 9.1.
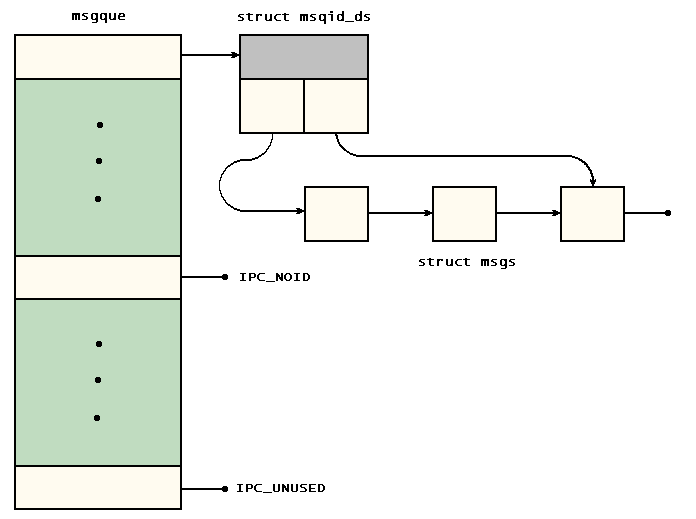
Рис. 9.1. Структуры данных очереди сообщений
msg_init
20137: Функция msg_init инициализирует переменные, используемые в этой реализации очереди сообщений. Основная часть ее работы является лишней, поскольку переменные уже были установлены в эти значения в их объявлениях непосредственно перед функцией.
20141: Однако цикл, который устанавливает входы msgque в значение IPC_UNUSED, необходим. Значение IPC_UNUSED, не рассматриваемое в этой книге, принято равным –1 (соответственно, приведенной к void*ndash;*); оно представляет неиспользуемую очередь сообщений. Еще одним специальным значением, которое может принять вход msgque, но только временно, на время создания очереди сообщений, является значение IPC_NOID (также не рассматриваемое в этой книге).
real_msgsnd
20149: Функция real_msgsnd реализует содержательную часть функции sys_msgsnd, системного вызова msgsnd. Это нарушение принятого в ядре соглашения об именовании «реализующих функций» системных вызовов с префиксом «do_».
Вызов функции real_msgsnd осуществляется из строки 20338, где она находится внутри пары функций lock_kernel/unlock_kernel. (Эти функции рассматриваются в главе 10 и в каждый данный момент заблокировать ядро может только один процессор, что имеет смысл для компьютеров с симметричной мультипроцессорной архитектурой.) Это элегантный способ обеспечения выполнения функции unlock_kernel; в противном случае, сложное управление последовательностью выполнения функции real_msgsnd было бы дополнительно усложнено, в связи с необходимостью всегда обеспечивать вызов функции unlock_kernel на пути выхода.
Как известно, в ядре такие проблемы в основном решаются с помощью переменных с кодом возврата и операторов goto. Принятый в sys_msgsnd способ проще, но он может не сработать в некоторых случаях. Например, рассмотрим, что произойдет, если функция должна будет получить несколько ресурсов и к некоторым из них она должна будет обратиться, только если все предшествующие ресурсы были успешно получены. Примитивное решение по принципу расширения функции sys_msgsnd потребовало бы создания множества функций, примерно так, как показано ниже:
void f1(void)
{
if (acquire_resource1()) {
f2();
release_resource1();
}
}
void f2(void)
{
if (acquire_resource2()) {]
f3();
release_resource2();
}
}
void f3(void)
{
if (acquire_resource3()) {
/* ... здесь выполняется настоящая работа ... */
release_resource3();
}
}
Эта конструкция быстро становится громоздкой и поэтому она в ядре не применяется.
20158: Начинает последовательность проверки допустимости. Вторая из трех проверок в этой строке не нужна, если учесть первую проверку: любой размер сообщения, который не пройдет вторую проверку, не сможет пройти также и первую. Однако в будущем положение может измениться, если предельное значение MSGMAX будет увеличено в достаточной степени. (В действительности, во время написания данной книги проводилась работа по полному устранению предела MSGMAX.)
20164: Идентификаторы очереди сообщений кодируют два фрагмента информации: индекс соответствующего элемента msgque находится в младших 7 битах, а порядковый номер, который вскоре будет описан, находится в 16 битах непосредственно над ними. В данный момент достаточно знать часть, содержащую индекс массива.
20166: Если по указанному индексу массива нет очереди сообщений или таковая была здесь создана, то в нее не должно быть поставлено ни одного сообщения.
20171: Хранимый порядковый номер в очереди сообщений должен соответствовать номеру, закодированному в параметре msqid. Идея состоит в том, что одно лишь обнаружение очереди сообщений по правильному индексу массива не означает, что это — та очередь сообщений, которая нужна вызывающей программе. С того момента, как вызывающая программа получила свою ссылку на эту очередь, очередь сообщений, находившаяся первоначально по этому индексу, могла быть удалена и на ее месте создана новая. 16-разрядный порядковый номер постоянно наращивается, поэтому новая очередь по тому же индексу будет иметь порядковый номер, отличный от первоначального. (Если только не случилось так, что в этот промежуток времени было создано еще 65535 новых очередей, что весьма маловероятно, или создано еще 131071 новых очередей, что еще более маловероятно, и т.д. Однако, как описано далее в этой главе, в действительности не так все просто.) Во всяком случае, если порядковые номера не совпадают, функция real_msgsnd возвращает ошибку EIDRM в качестве указания на то, что очередь сообщений, нужная для вызывающей программы, была удалена.
20174: Проверка того, что вызывающая программа имеет разрешение на запись в очередь сообщений. Аналогичная система рассматривается более подробно в главе 11; пока достаточно отметить, что применяется система, полностью аналогичная проверке прав доступа к файлам Unix.
20177: Проверка того, не будет ли превышен максимально допустимый размер очереди после записи поступившего сообщения в очередь. В следующей строке выполняются абсолютно такие же действия, очевидно, из-за недосмотра при редактировании кода, оставшегося после преобразования ядра серии 2.0. Между двумя проверками раньше находился код, который иногда позволял освободить немного места в очереди.
20180: В очереди нет свободного места. Если в структуре msgflg установлен бит IPC_NOWAIT, вызывающая программа не должна ждать, пока это случится, поэтому возвращается ошибка EAGAIN.
20182: Процесс должен быть переведен в состояние ожидания. Вначале функция real_msgsnd проверяет, существует ли сигнал, ожидающий этого процесса. Если это так, это рассматривается как прерывание процесса этим сигналом (после чего он может снова перейти в состояние ожидания, как будет вскоре показано).
20184: Если для процесса нет никакого сигнала, процесс переходит в состояние ожидания до тех пор, пока не будет активизирован в результате поступления сигнала или удаления сообщения из очереди. После активизации процесса он снова пытается выполнить запись в очередь.
20190: Распределение достаточного пространства как для заголовка очереди сообщений (объект struct msg), так и для тела сообщения; как было упомянуто ранее, тело сообщения будет записано непосредственно после заголовка сообщения. Значение msg_spot заголовка будет указывать на место сразу после заголовка, где должно находиться тело сообщения.
20196: Копирует тело сообщения из пространства пользователя.
20202: Повторная проверка исправности очереди сообщений. Вход msgque мог быть изменен другим процессом в то время, когда процесс находился в состоянии ожидания после выполнения строки 20184, поэтому msq нельзя считать действительным указателем до тех пор, пока не будет выполнена его проверка.
Несмотря на это, создается впечатление, что здесь возможна ошибка. А что, если очередь сообщений будет уничтожена и по тому же индексу массива будет развернута другая очередь сообщений, прежде чем текущий процесс достигает этой точки? Это не может произойти на однопроцессорном компьютере, поскольку функция freeque, которая уничтожает очереди сообщений (строка 20440), активизирует все процессы, ждущие в очереди, перед ее уничтожением и не перейдет эту точку, пока не закончит свою работу функция real_msgsnd (функция freeque рассматривается далее в этой главе).
Однако все же, кажется, что риск этого на компьютерах с симметричной мультипроцессорной архитектурой невелик.
Если бы это произошло, значение msgque[id] не равнялось бы IPC_UNUSED или IPC_NOID, но память, на которую указывает msq, была бы освобождена функцией freeque, поэтому в строке 20203 происходила бы разадресация недействительного указателя.
20209: Соответственно, заполняет заголовок сообщения, ставит его в очередь и обновляет собственную статистику очереди (в том числе, общий размер сообщений). Обратите внимание, что работа по заполнению заголовка сообщения откладывалась до последней возможности, чтобы она не была сделана впустую, если бы возникла ошибка с момента распределения до текущего момента.
20226: Активизирует все процессы, которые могут ожидать поступления сообщения в эту очередь, а затем возвращает 0 в случае успеха.
real_msgrcv
20230: Функция real_msgrcv, аналогично real_msgsnd, реализует системный вызов msgrcv. Параметр msgtyp несет большую смысловую нагрузку, как описано в развернутом комментарии, который начинается в строке 20248. Именно здесь применяется поле msg_type объекта struct msg: в этой функции оно сравнивается с параметром msgtyp.
Функция real_msgrcv аналогична функции real_msgsnd также тем, что ее вызов происходит внутри пары lock_kernel/unlock_kernel в строке 20349.
20239: Извлекает индекс msgque из msgid и проверяет, что по этому индексу находится допустимый вход.
20253: Входит в цикл, который повторяется до тех пор, пока процесс не получит сообщение или не откажется от этих попыток и выполнит возврат. Несмотря на такую прозрачную структуру, этот цикл всегда разрывается в середине и это всегда происходит в результате возвращения из функции. Поэтому вместо него можно было бы применить цикл while (1); он действовал бы точно так же, но только немного быстрее.
20254: Проверка того, что процесс предоставил правильный порядковый номер и что он имеет разрешение читать из этой очереди.
20262: Эта последовательность if/else позволяет выбрать сообщение из очереди. Первый случай проще всего: он просто захватывает первое сообщение в очереди, если оно имеется, устанавливая значение nmsg либо равным NULL, либо равным указателю на первый элемент очереди.
20266: Параметр msgtyp положителен и бит MSG_EXCEPT (строка 15862) в структуре msgflg установлен. Функция real_msgrcv проходит по очереди, отыскивая первый вход, тип которого не соответствует msgtyp.
20272: Параметр msgtyp положителен, но бит MSG_EXCEPT не установлен. Функция real_msgrcv проходит по очереди, отыскивая первый вход, тип которого соответствует заданному.
20279: Параметр msgtyp отрицателен. Функция real_msgrcv отыскивает сообщение с наименьшим значением члена msg_type, если это значение также меньше абсолютного значения msgtyp. Обратите внимание, что поскольку в строке 20281 в качестве сравнения используется <, а не <=, предпочтение отдается первому сообщению в очереди. Это не только удобно (такое строгое соблюдение принципов организации последовательной очереди, по-видимому, вполне оправдано), но также чуть более эффективно, поскольку при этом приходится выполнять меньше операций присваивания. Если бы в качестве сравнения применялось <=, то появление каждого подходящего значения влекло бы за собой присваивание.
20287: Если к этому моменту какое-либо сообщение удовлетворяет заданным критериям, nmsg указывает на него. В ином случае, nmsg содержит NULL.
20288: Даже если было найдено подходящее сообщение, оно не обязательно будет возвращено. Например, если буфер вызывающей программы не позволяет разместить в нем все тело сообщения, вызывающая программа обычно получает ошибку E2BIG. Однако ошибка не выдается, если установлен бит MSG_NOERROR (строка 15860) структуры msgflg. (Трудно представить себе причину, по которой нужно было бы устанавливать в приложении флажок MSG_NOERROR, и такие приложения еще не встречались автору на практике.)
20292: Если параметр msgsz указывает больше байтов, чем существует в теле сообщения, функция real_msgrcv уменьшает параметр msgsz до размера сообщения. После этого msgsz равен числу байтов, которое должно быть скопировано в буфер вызывающей программы.
Более распространенный способ записи этого иногда немного медленнее, но в среднем, вероятно, может оказаться быстрее:
if (msgsz > nmsg->msg_ts)
msgsz = nmsg->msg_ts;
20294: Удаляет выбранное сообщение из очереди. Очередь — это односвязный, а не двухсвязный список, поэтому, если удаляемое сообщение — не первое в очереди, функция real_msgrcv должна вначале пройти в цикле по очереди, чтобы найти предыдущий узел в очереди.
Нельзя обеспечить поиск предыдущего узла за постоянное время просто путем превращения очереди в двухсвязную.
Это изменение привело бы к потере места (для размещения дополнительных указателей), к потере времени (для обновления дополнительных указателей) и к потере простоты (из-за добавления кода, выполняющего эти действия). Тем не менее, эти потери не велики и двухсвязная организация очереди позволила бы существенно повысить скорость в том случае, когда удаляемое сообщение находится в середине очереди.
Однако на практике большинство приложений удаляют из очереди первое сообщение. В результате, дополнительное время, затраченное на управление указателями msg_prev (как их могли бы называть в двухсвязной очереди), обычно было бы явно потрачено напрасно. Оно окупалось бы только при удалении узла очереди из ее середины, но в приложениях это обычно не происходит.
Результатом явилось бы замедление в обычном случае ради ускорения в редком случае, а такое решение почти всегда является неудачным. Даже приложениям, в которых происходит удаление внутренних узлов очереди, не приходится ждать слишком долго, поскольку очереди сообщений обычно коротки и, как правило, не превышают нескольких десятков сообщений, и требуемое сообщение будет обнаружено в среднем примерно за половину итераций цикла. Следовательно, приложение может испытывать заметное замедление только в том случае, если очередь сообщений содержит сотни или тысячи сообщений, и приложение, как правило, удаляет внутренние узлы. Если учесть относительную маловероятность такого случая, разработчики ядра приняли наилучшее решение.
Кроме того, если приложение действительно характеризуется указанными особенностями и его разработчики крайне нуждаются в дополнительном повышении быстродействия, то для этого и предназначена система Linux. Разработчики приложения могут сами откорректировать исходный код ядра в соответствии со своими требованиями.
20305: Обеспечивает удаление единственного узла очереди.
20308: Обновляет статистику очереди сообщений.
20313: Активизирует все процессы, ожидающие записи к эту очередь сообщений, то есть все процессы, которые были переведены в состояние ожидания функцией real_msgsnd.
20314: Копирует сообщение в пространство пользователя и освобождает узел очереди (заголовок и тело).
20318: Выдает размер возвращаемого сообщения — это может быть важным для сообщений переменной длины, поскольку формат сообщения данного приложения может не предусматривать других способов определения конца сообщения.
20320: Ни одно сообщение не соответствовало критериям вызывающей программы. Дальнейшие действия зависят от вызывающей программы: если в вызывающей программе установлен бит IPC_NOWAIT структуры msgflg, то функция real_msgrcv может немедленно возвратить сообщение об отказе.
20323: В ином случае, вызывающая программа скорее перейдет в состояние ожидания, если нет доступных сообщений. Если появления ожидающего процесса ожидает какой-то сигнал, будет возвращена ошибка EINTR; иначе, вызывающая программа, вероятно, перейдет в состояние ожидания до тех пор, пока не поступит сигнал или пока какой-то другой процесс не начнет запись в очередь.
20329: Эта точка никогда не будет достигнута, но транслятор об этом не знает. Поэтому здесь находится фиктивный оператор return только для выполнения требований gcc.
sys_msgget
20412: Поскольку структура управления функции sys_msgget проще по сравнению с sys_msgsnd и sys_msgrcv, нет необходимости переводить весь код функции sys_msgget в отдельную вспомогательную функцию. Однако она имеет свои собственные вспомогательные функции, которые рассматриваются далее в этой главе.
20414: Выполняется ненужная инициализация в –EPERM переменной ret, которая отслеживает требуемое возвращаемое значение функции. Переменная ret получает значение на каждом пути через функцию, поэтому присваивание в этой строке является избыточным. Однако оптимизатор транслятора gcc достаточно интеллектуален для того, чтобы устранить это ненужное присваивание, поэтому вопрос о том, действительно ли эта инициализация не нужна, остается открытым.
20418: Специальный ключ IPC_PRIVATE (код его объявления здесь не приведен, но его значение равно 0) говорит о том, что вызывающая программа требует создать новую очередь, независимо от того, существуют ли другие очереди сообщений с таким же ключом. В этом случае просто сразу же создается очередь с использованием функции newque (строка 20370), которая будет описана ниже.
20420: Иначе, ключ однозначно идентифицирует очередь сообщений, с которой хочет работать вызывающая программа. Обычно разработчик выбирает ключ более или менее произвольно (или предоставляет способ выбрать ключ пользователю) и надеется на то, что он не будет конфликтовать с ключами других работающих приложений.
Это утверждение может показаться преувеличенным, но имена временных файлов создают во многом аналогичную проблему — вам просто остается надеяться, что в других приложениях не будет выбрана такая же схема именования. Однако на практике эта проблема возникает редко: тип key_t с помощью typedef просто установлен в int, поэтому существует более 4-х миллиардов возможных значений на 32-разрядном компьютере и свыше 9 квинтиллионов — на 64-разрядном компьютере. Такой огромный размер пространства ключей позволяет уменьшить вероятность случайного столкновения. К тому же, схема прав доступа способствует дополнительному уменьшению вероятности возникновения проблем, даже если возникает случайное совпадение ключей очереди сообщений или имен файлов.
Однако нельзя ли применить лучший подход? Стандартные библиотечные функции С, такие как tmpnam, значительно упрощают выработку имен временных файлов, гарантируя их уникальность во всей системе, но эквивалентного способа выработки ключей очереди сообщений с гарантией их уникальности не существует.
При более внимательном изучении здесь обнаруживаются две разные проблемы. Для приложения обычно не важно, каким будет имя его временного файла, при условии, что оно не конфликтует с именем существующего файла. Но приложение, как правило, должно знать заранее, каким будет ключ его очереди сообщений, чтобы другие приложения, которые хотят послать в нее сообщения, знали, в какую очередь их посылать. Если приложение выбирает ключ очереди сообщений динамически, оно должно иметь способ сообщить другим приложениям этот выбранный ключ. (Оно может с таким же успехом передавать вместо ключа параметр msqid.) А если рассматриваемые приложения уже имеют способ посылать друг другу сообщения наподобие этого, то для чего им тогда нужны очереди сообщений?
Следовательно, эта проблема, вероятно, не стоит выеденного яйца. Приложение, которое требует получения уникального ключа для очереди общего пользования, но не накладывает слишком жестких ограничений на то, каким будет этот ключ, может получить его, просто попытавшись применить ключ 1 (помните, что 0 — это ключ IPC_PRIVATE), а затем пробуя последовательные значения ключа одно за другим, пока не добьется успеха — это потребует немного больше работы, но в действительности вряд ли понадобится.
Во всяком случае, в этой строке для поиска существующей очереди сообщений с данным ключом используется функция findkey (строка 20354; она рассматривается ниже).
20421: Если ключ не используется, sys_msgget может создать очередь. Если бит IPC_CREAT не установлен, возвращается ошибка ENOENT; в ином случае, функция newque (строка 20370) создает очередь.
20425: Ключ используется. Если в вызывающей программе установлены оба бита, IPC_CREAT и IPC_EXCL, то ей в этом случае нужно было получить ошибку и она ее получает. (Это было специально сделано в виде полного аналога битов O_CREAT и O_EXCL функции open.)
Кстати, трудно сказать, выполнялась бы проверка if быстрее, если бы она была записана либо в этой, либо в следующей эквивалентной форме:
} else if (msgflg & (IPC_CREAT | IPC_EXCL) ==
(IPC_CREAT | IPC_EXCL)) {
В обоих вариантах выполняется проверка того, установлены ли оба бита, но по разным причинам можно предполагать, что один из них будет работать быстрее другого. Однако на практике gcc вырабатывает одинаковый код для обоих вариантов, по крайней мере, при компиляции с оптимизацией. (Если вам это интересно, то оптимизатор выбирает вариант с прямолинейной трансляцией варианта, предложенного автором, то есть преобразует вариант, применяемый в ядре, в код, где проверка обоих битов происходит одновременно.) Это весьма впечатляющая оптимизация, на которую трудно было рассчитывать.
20428: В ином случае, ключ находится в использовании и вызывающая программа соглашается использовать существующую очередь с этим ключом. (Это наиболее распространенный случай.) Если в указанном месте нет очереди сообщений (а это никогда не должно произойти, с учетом реализации функции findkey) или вызывающая программа не имеет права обращаться к этой очереди, возвращается ошибка.
20434: В возвращаемом значении закодированы порядковый номер и индекс msgque. Оно становится параметром msgid, который вызывающая программа передаст функциям sys_msgsnd, sys_msgrcv и sys_msgctl.
Эта схема кодирования имеет две важных особенности. Более очевидная особенность состоит в том, как обеспечивается раздельное хранение части с порядковым номером и части с индексом массива: поскольку id — это индекс массива в msgque, он может только принимать значения, достигающие (но не включающие) MSGMNI, число элементов в msgque. Поэтому после умножения порядкового номера на это значение младшие биты остаются свободными для хранения id — это своего рода система счисления по основанию MSGMNI.
Отметим также, что возвращаемое значение никогда не может быть отрицательным — это важно, поскольку эта реализация библиотеки С может предусматривать интерпретацию возвращаемого отрицательного значения как ошибки. Поскольку значение MSGMNI в настоящее время установлено равным 128, индекс массива занимает младшие 7 битов возвращаемого значения. Порядковые номера занимают 16 битов, поэтому в результате этого присваивания в 1 могут быть установлены только младшие 23 бита переменной ret, а все старшие биты равны 0. Поэтому, в частности, знаковый разряд равен 0, так что переменная ret может быть только положительной или равной 0.
20437: Итак, вычисления выполнены и теперь возвращается значение ret.
sys_msgctl
20468: Можно смело утверждать, что sys_msgctl — самая большая функция в реализации очереди сообщений. Это отчасти связано с тем, что она выполняет множество различных действий, аналогично ioctl, и реализует набор слабо связанных функциональных средств. (Кстати, не обвиняйте в этой неразберихе разработчиков Linux; они просто обеспечили совместимость с уродливым проектом System V.) Параметр msqid содержит имя очереди сообщений, а cmd сообщает, что должна сделать с этой очередью функция sys_msgctl. Как вскоре станет очевидно, параметр buf может потребоваться или не потребоваться, в зависимости от cmd, и его назначение меняется от случая к случаю, даже когда он используется.
20477: Отбрасывает явно недопустимые параметры. Выполнение этого перед вызовом lock_kernel позволяет избежать ненужной блокировки ядра в том, по общему признанию, редком случае, когда эти параметры являются недопустимыми. (Безусловно, приходится соответствующим образом корректировать последовательность выполнения, поскольку в этом случае нужно также обойти выполнение unlock_kernel.)
20481: В случаях применения IPC_INFO и MSG_INFO вызывающая программа хочет получить информацию о свойствах данной реализации очереди сообщений. Она может, например, использовать эту информацию для выбора размера сообщений — на компьютерах с большими максимальными размерами сообщений вызывающий процесс может устанавливать свой собственный предел объема информации, отправляемой в расчете на одно сообщение.
Все явные константы, которые определяют применяемые по умолчанию пределы данной реализации очереди сообщений, копируются через объект типа struct msginfo (строка 15888). Включается небольшая дополнительная информация, если в качестве cmd применялась MSG_INFO, а не IPC_INFO, как показано, начиная со строки 20495, но во всем остальном эти два случая идентичны.
Обратите внимание, что буфер вызывающей программы, buf, был объявлен как указатель на объект другого типа, struct msqid_ds. Это не имеет значения. Копирование выполняется с помощью функции copy_to_user (строка 13735), для которой типы параметров не имеют значения, но она активизирует ошибку, получив запрос на запись в недоступную память. Если вызывающая программа предоставит указатель на достаточно большое пространство, функция sys_msgctl скопирует туда затребованные данные; за определение правильного типа (или хотя бы размера) отвечает вызывающая программа.
20505: Если копирование было выполнено успешно, функция sys_msgctl возвращает один дополнительный фрагмент информации, max_msqid. Обратите внимание, что в этом случае был полностью проигнорирован параметр msqid. Это абсолютно оправдано, поскольку предусматривает возврат информации о данной реализации очереди сообщений в целом, а не о какой-либо очереди сообщений в частности. Однако мнения о том, нужно ли в этом случае отбрасывать отрицательное значение msqid, могут расходиться. По общему признанию, отбросив недопустимые значения msqid, даже если эти значения не будут использоваться, можно, безусловно, значительно упростить код.
20508: Команда MSG_STAT запрашивает статистическую информацию о данной очереди сообщений, хранимую в ядре: ее текущий и максимальный размер, идентификаторы процессов ее самых последних программ чтения и записи и т.д.
20512: Возвращает ошибку, если параметр msqid является недопустимым, в заданной позиции не существует очередь или вызывающая программа не имеет разрешения читать из очереди. Поэтому разрешение на чтение из очереди означает разрешение читать не только сообщения, поставленные в очередь, но и «метаданные» о самой очереди.
Кстати, отметим, что команда MSG_STAT предполагает, что msqid включает только индекс msgque и не содержит порядкового номера.
20521: Вызывающая программа прошла все проверки. Функция sys_msgctl копирует затребованную информацию во временную переменную, а затем копирует временную переменную обратно через буфер вызывающей программы.
20533: Возвращает «полный» идентификатор, в котором теперь закодирован порядковый номер (это выполняется в строке 20520).
20535: Осталось три случая: IPC_SET, IPC_STAT и IPC_RMID. В отличие от рассмотренных ранее случаев, которые были полностью отработаны внутри этого переключателя, последние три выполняются здесь только частично. Первый из них, IPC_SET, предусматривает просто проверку того, что буфер, предоставленный пользователем, не равен NULL, a затем копирует его в переменную tbuf для последующей обработки далее в этой функции. (Отметим, что присваивание значения переменной err в строке 20540 вслед за копированием является лишним: переменной err будет снова присвоено значение в строке 20550 перед ее использованием.)
20542: Во втором из оставшихся трех случаях, IPC_STAT, просто выполняется проверка допустимости: настоящая работа для этой команды предусмотрена далее в этой функции. Для последнего из этих трех случаев, IPC_RMID, в этом переключателе работы нет; вся его работа отложена в этой функции на дальнейшее.
20548: Этот код является общим для всех оставшихся случаев и теперь он должен выглядеть для вас знакомым: в нем происходит извлечение индекса массива из msqid, проверка того, что по указанному индексу существует действительная очередь сообщений и сверка порядкового номера.
20559: Выполнение оставшейся части команды IPC_STAT. Если пользователь имеет разрешение читать из очереди, функция sys_msgctl копирует статистическую информацию в буфер вызывающей программы. Если вам кажется, что это в значительной степени напоминает основную часть описанного раннее случая MSG_STAT, то вы правы. Единственным различием между этими двумя случаями является то, что MSG_STAT ожидает «неполный» msqid, как было показано выше, a IPC_STAT ожидает «полный» (то есть включающий порядковый номер).
20572: Копирует статистические данные в пространство пользователя. Эти три строки выполнялись бы чуть быстрее, если бы были перезаписаны следующим образом:
err = 0 ;
if (copy_to_user(buf, &tbuf, sizeof(*buf)))
err = -EFAULT;
В конце концов, запись в пространство пользователя, безусловно, чаще оканчивается успехом, чем неудачей. По той же причине, соответствующий код в случае MSG_STAT (начиная со строки 20530) работал бы быстрее, если его перезаписать следующим образом:
if (copy_to_user(buf, &tbuf, sizeof(*buf))) {
err = -EFAULT;
goto out;
}
err = id;
Или даже могли бы работать быстрее два следующих варианта, поскольку в них не выполняется ненужное присваивание:
if (copy_to_user (buf, &tbuf, sizeof(*buf)))
err = -EFAULT;
else
err = 0;
или
err = copy_to_user (buf, &buf, sizeof(*buf)) ? -EFAULT : 0 ;
Вопреки очевидному, проведенные автором проверки всех этих изменений показывают, что версия ядра работает быстрее. Причина этого заключается в том, как gcc вырабатывает объектный код: по-видимому, стоимость дополнительного присваивания в версии ядра не идет в сравнение со стоимостью дополнительного перехода в версии автора. (Дополнительный переход нельзя сразу обнаружить, рассматривая исходный код С: необходимо просматривать ассемблерный вывод gcc.) Напомним, что в предыдущих главах мы уже говорили о том, что переходы связаны со значительными потерями, поскольку они заставляют процессор терять преимущества некоторых внутренних алгоритмов параллельного выполнения. Разработчики процессора сделали очень многое по предотвращению влияния потерь, связанных с ветвлениями, но, очевидно, не смогли устранить все проблемы.
В конечном итоге, в процессе дальнейшего усовершенствования оптимизатора gcc разница между версией ядра и версией автора может стать более очевидной. Если две формы логически эквиваленты и одна из них быстрее, было бы замечательно, если бы gcc мог обнаруживать их эквивалентность и вырабатывать одинаковый код для них обоих. Однако эта проблема сложнее, чем может показаться. Для выработки самого быстрого кода gcc должен обладать способностью предвидеть, какое присваивание будет происходить с наибольшей вероятностью — другой случай предусматривает ветвление. (Однако в процессе работы над новейшими версиями gcc были заложены основы для таких усовершенствований.)
20576: В случае IPC_SET вызывающая программа стремится установить некоторые параметры очереди сообщений: ее максимальный размер, владельца и режим.
20578: Для того, чтобы иметь возможность манипулировать с параметрами очереди сообщений, вызывающая программа должна либо владеть этой очередью, либо иметь возможности CAP_SYS_ADMIN (строка 14092). Возможности описаны в главе 7.
20584: Повышение предела максимального числа байтов в очереди сообщений свыше обычного максимума во многом аналогично повышению максимальных значений любого другого ресурса свыше его жестко закодированного ограничения, поэтому для этого повышения требуется такая же возможность, CAP_SYS_RESOURCE (строка 14117). Ограничения ресурсов рассматриваются в главе 7.
20587: Вызывающей программе нужно позволить выполнить эту операцию, поэтому выбранные параметры установлены из буфера tbuf, предоставленного вызывающей программой.
20595: Команда IPC_RMID означает удаление указанной очереди: не только сообщений в ней, но и самой очереди. Если вызывающая программа владеет очередью или имеет возможность CAP_SYS_ADMIN, очередь освобождается с помощью вызова функции freeque (строка 20440).
20605: В конце концов, cmd не оказалась одной из распознанных команд, поэтому вызывающая программа получает ошибку EINVAL. В таком случае, можно было бы избежать работы, выполненной в строке 20548. Предположим, что мы попытались бы обнаружить неправильное значение cmd при самой первой возможности, удалив случай default из переключателя и добавив следующий код в первый переключатель функции в строке 20546:
case IPC_RMID:
break; /* Еще нечего делать. */
default:
err = -EINVAL;
goto out;
break; /* He достигнуто. */
Это привело бы к изменению поведения функции. Если бы вызывающая программа предоставила недопустимое значение и cmd, и msqid, она получила бы ошибку, отличную от той, которую получает сейчас: после этого изменения недопустимое значение cmd было бы обнаружено раньше недопустимого значения msqid. Однако документация к msgctl не обещает ни той, ни иной реакции, поэтому мы должны быть вправе внести это изменение. Результатом явилось бы незначительное ускорение случая с недопустимым значением cmd.
Однако, отметим, что это решение, к сожалению, требует введения пустого случая IPC_RMID в первом переключателе. Без этого функция неправильно отбросила бы IPC_RMID как неверное значение cmd. Эта дополнительная ветка case замедляет обработку, не намного, но замедляет, при нормальных условиях, в которых cmd имеет допустимое значение. К тому же, как вы знаете, ускорение выполнения редкого случая за счет обычного почти никогда не бывает хорошим решением. Поэтому лучше оставить все, как еcть.
findkey
20354: Функция findkey находит очередь сообщений с данным ключом от имени функции sys_msgget (вызов находится в строке 20420).
20359: Начинается цикл по всем слотам, которые могут заняты в msgque. Значение max_msqid позволяет отслеживать наивысший занятый элемент массива в msgque; оно используется здесь и сопровождается с помощью функций newque и freeque, которые вскоре будут рассмотрены. Без параметра max_msqid пришлось бы проходить в этом цикле по всем MSGMNI (128) элементам msgque, даже если, скажем, используются первые 5.
20360: Если текущий элемент массива имеет значение IPC_NOID, то здесь создается очередь сообщений. Очередь сообщений может иметь искомый ключ, поэтому функция findkey ожидает полного создания очереди. (Она может перейти в это состояние, когда вызов функции kmalloc в строке 20385 переводит процесс в состояние ожидания.)
20362: Если данный вход msgque не используется, ясно, что он не будет иметь соответствующего ключа.
20364: Если совпадающий ключ найден, будет возвращен соответствующий индекс массива.
20367: Если цикл был выполнен до конца и не найден соответствующий ключ, возвращается –1 в качестве сигнала об отказе.
newque
20370: Функция newque ищет неиспользуемый вход msgque и пытается создать здесь новую очередь сообщений.
20376: Проходит в цикле через msgque в поиске неиспользуемого входа. Если таковой будет найден, он будет отмечен значением IPC_NOID и управление перейдет на метку found в строке 20383.
20381: Если цикл завершится без обнаружения неиспользуемого входа, это значит, что массив msgque заполнен. Функция newque возвращает ошибку ENOSPC, которая указывает на то, что в таблице не осталось места.
20384: Распределяет объект struct msqid_ds, который будет представлять новую очередь.
20387: Если распределение окончится неудачей, этот вход msgque снова устанавливается в IPC_UNUSED.
20388: Активизируются все процессы findkey, которые были переведены в состояние ожидания после встречи IPC_NOID.
20391: Инициализация новой очереди.
20404: Если эта очередь была сформирована вслед за наивысшим ранее используемым слотом в msgque, функция newque соответствующим образом увеличивает параметр max_msqid.
20406: Устанавливает новую очередь в msgque.
20408: Активизация всех процессов findkey, которые могли ожидать окончания инициализации этой очереди.
20409: Возвращает порядковый номер и индекс массива msgque. (He мешало бы создать небольшой набор макрокоманд для выполнения этого кодирования и последующего декодирования.) Как ни странно, порядковый номер здесь не наращивается; это происходит в функции freeque, которая рассматривается ниже. Если подумать, это решение имеет смысл. Вам не нужен уникальный порядковый номер для каждой очереди — вам нужен только другой порядковый номер при каждом повторном использовании элемента msgque, чтобы данное сочетание индекса массива и порядкового номера больше не могло повториться. Индекс массива не может быть повторно использован до тех пор, пока очередь, установленная здесь, не будет освобождена, поэтому наращивание порядкового номера можно отложить до этого момента.
Просто для того, чтобы подчеркнуть правильность такого решения, отметим, что предусмотрена возможность применения одинакового порядкового номера двумя элементами msgque одновременно.
freeque
20440: Описание функции freeque, которая удаляет очередь и освобождает соответствующий вход msgque, позволяет подвести черту под обсуждением данной реализации очереди сообщений ядра.
20449: Если освобождаемый вход msgque представляет собой используемый вход с наибольшим индексом, функция freeque уменьшает значение max_msqid в наибольшей возможной степени. После этого цикла max_msqid снова представляет собой индекс максимального используемого входа msgque или 0, если все входы являются неиспользуемыми. Обратите внимание, что если max_msqid имеет значение 0, то массив msgque либо пуст, либо содержит только один вход.
20452: Элемент массива msgque отмечен как неиспользуемый, хотя объект struct msqid_ds еще не освобожден (функция freeque все еще содержит указатель на объект struct msqid_ds в переменной msq).
20454: Если какие-либо процессы ожидают чтения или записи в эту очередь, их нужно предупредить о том, что очередь вскоре исчезнет. В этом цикле все они активизируются. Все процессы, ожидающие отправки сообщения в очередь, обнаружат изменившийся порядковый номер в строке 20171; все процессы, ожидающие получения сообщения из очереди, обнаружат это же в строке 20254.
20458: Вызов функции schedule (строка 26686, описанной в главе 7) для предоставления активизированным процессам шанса на выполнение. Интересно, что активизированные процессы могут пока не получить процессорного времени, поскольку текущий процесс может иметь более низкое значение параметра goodness (более высокий приоритет). Однако, если это произойдет, то вновь активизированные процессы просто не будут удалены из соответствующих им очередей ожидания; функция freeque обнаружит это, продолжая проходить по циклу, и попытается снова активизировать процессы. В конечном итоге, процесс, выполняющий функцию freeque, исчерпает отведенное ему время и уступит место другим процессам. Тем не менее, с учетом всех обстоятельств, может быть лучше явно устанавливать флажок SCHED_YIELD текущего процесса (строка 16202) до того, как он вызовет schedule, чтобы предоставить другим процессам лучшие условия доступа к процессору.
20460: Нет ожидающих процессов чтения или записи, поэтому можно безопасно освободить очередь и все ее сообщения.
Семафоры
Семафор — это способ управления доступом к ресурсу. Обычно принято рассматривать семафор как сигнальный флажок (отсюда его название), но автор считает, что лучше его описывать как ключ. Это не целочисленные ключи, о которых мы говорили ранее, а, в этой аналогии, ключи от входной двери.
В простейшем случае семафор — это единственный ключ, который висит на гвозде рядом с запертой дверью. Чтобы пройти через дверь, нужно снять ключ с гвоздя; вы также обязаны снова повесить ключ на гвоздь, выйдя из комнаты. Если ключа не будет на месте, когда вы подойдете к двери, вам придется ждать до тех пор, пока тот, кто его взял, не повесит его на место, при условии, что вы твердо решили пройти через эту дверь. Иначе, вы можете сразу же уйти, если ключа нет на месте.
Это описание относится к ресурсу, которым может одновременно пользоваться только одна сущность; в том случае, когда имеется только один ключ, семафор называют двоичным. Семафоры для ресурсов, которые могут использоваться одновременно несколькими сущностями, называют счетными. Они действуют по такому же принципу, как описано выше, только на гвозде висят несколько ключей. Если ресурс может поддерживать четырех пользователей одновременно (или если доступно четыре эквивалентных ресурса, что по сути означает одно и то же), то имеется четыре ключа. Это естественное обобщение.
Процессы применяют семафоры для координации своей деятельности. Например, предположим, что вы написали программу и хотите исключить возможность выполнения более одного экземпляра программы на конкретном компьютере одновременно. Хорошим примером является программа воспроизведения звуковых файлов: вряд ли кому-то захочется воспроизводить несколько файлов одновременно, поскольку результатом будет неприятная какофония. В качестве другого примера можно привести сервер X Window. Иногда трудно предотвратить запуск более одного X-сервера на одном и том же компьютере одновременно, поэтому имеет смысл предусмотреть, чтобы X-сервер этого не допускал, по крайней мере, по умолчанию.
Семафоры предоставляют способ решения этой проблемы. Программа воспроизведения звука, или X-сервер, или любой другой процесс может определить семафор, проверять, находится ли он в использовании, и продолжать свою работу, если семафор свободен. Если семафор уже занят, это значит, что работает еще один экземпляр этой программы, и тогда программа должна ожидать освобождения семафора (что можно предусмотреть в программе воспроизведения звука), просто отказаться от дальнейших попыток и выйти (что можно предусмотреть в X-сервере), или продолжить работу и пока заниматься чем-то иным, время от времени повторяя попытку обратиться к семафору. Кстати, такой способ применения семафоров часто называют взаимоисключающим, по очевидным причинам; в исходном коде ядра можно встретить общепринятое сокращение соответствующего английского выражения mutual exclusion — mutex.
Для достижения такого же эффекта, как и при использовании двоичных семафоров, чаще применяются файлы блокировки, по крайней мере, при определенных обстоятельствах. Файлы блокировки несколько проще в использовании и некоторые реализации файлов блокировки могут применяться в сети, а семафоры — не могут. С другой стороны, файлы блокировки не применимы для более общего подхода, выходящего за пределы двоичного случая. Как бы то ни было, файлы блокировки не входят в тематику данной книги.
Программные реализации семафора и очереди сообщений настолько подобны, что нет нужды описывать функции sem_init (строка 20695), findkey (строка 20706), sys_semget (строка 20770), newary (строка 20722) и freeary (строка 20978), поскольку они почти полностью повторяют свои аналоги в реализации очереди сообщений.
struct sem
struct semid_ds
16927: Объект struct semid_ds представляет собой аналог объекта struct msqid_ds: он отслеживает всю информацию об отдельном семафоре и очереди операций, которые должны быть выполнены над ним. Ниже перечислены члены этого объекта, которые имеют интересные отличия от соответствующих членов объекта struct msqid_ds:
- sem_base. Указывает на массив объектов struct sem, иными словами, на массив семафоров. Так же как отдельный объект struct msqid_ds может содержать много сообщений, отдельный объект struct semid_ds может содержать несколько семафоров; все семафоры одного массива обычно называют набором семафоров. Однако, в отличие от очередей сообщений, число семафоров, отслеживаемых одним объектом struct semid_ds, не изменяется в течение срока его существования. Этот массив имеет постоянный размер. Максимальная длина этого массива — SEMMSL, и эта величина установлена равной 32 директивой #define в строке 16968. Фактическая длина массива регистрируется в члене sem_nsems объекта struct semid_ds.
- sem_pending. Отслеживает очередь групп операций с семафором, находящихся в состоянии ожидания. Как и следовало ожидать, операции с семафором выполняются немедленно, если это возможно, поэтому узлы добавляются к этой очереди, только если операция должна ждать. Это примерно равнозначно членам rwait и wwait объекта struct msqid_ds.
- sem_pending_last. Отслеживает хвост той же очереди. Обратите внимание, что он не указывает прямо на последний узел — он указывает на указатель на последний узел, что позволяет немного ускорить выполнение последующего кода (и немного усложнить понимание). (Кстати, автор не видит никакой причины, почему бы не применить эту же идею к очередям сообщений.)
- sem_undo. Очередь операций, которые должны быть выполнены во время выхода из различных процессов. Она будет описана далее в этой главе.
struct sem_queue
16989: Объект struct sem_queue представляет собой узел в очереди ожидающих операций в отдельном объекте struct semid_ds. Он имеет следующие члены:
- next и prev. Следующий и предыдущий узлы в очереди. Как и в случае с sem_pending_last, prev — это указатель на указатель на предыдущий узел. Далее в этой главе описано, почему prev никогда не принимает значение NULL; в вырожденном случае, когда очередь пуста, prev указывает на next.
- sleeper. Очередь ожидания, используемая в тех случаях, когда процесс должен ждать завершения операции с семафором. Очереди ожидания описаны в главе 2.
- undo. Массив операций, которые позволяют отменять операции, реализованные объектами sops; иными словами, это — противоположность sops.
- pid. Идентификатор процесса, который пытается выполнить операции, представленные в этом узле очереди.
- status. Регистрирует способ активизации ожидающего процесса.
- sma. Указывает обратно на объект struct semid_ds, в чьей очереди sem_pending находится данный объект struct sem_queue.
- sops. Указывает на массив из одной или нескольких операций, которые представляют данный узел очереди; он никогда не бывает равен NULL. Назначение работы, представленной этим узлом очереди, состоит в выполнении всех операций в массиве sops.
- nsops. Длина массива sops.
- alter. Указывает, будут ли эти операции воздействовать на любой из семафоров в наборе. Может показаться, что это значение всегда должно быть истинным, но нужно учитывать, что ожидание достижения семафором значения 0 (то есть ожидание его освобождения) не воздействует на сам семафор.
struct sembuf
16939: Объект struct sembuf представляет отдельную операцию, которая должна быть выполнена над семафором. Он имеет следующие члены:
- sem_num. Индекс массива семафоров, к которым относится эта операция в массиве sem_base объекта struct semid_ds. Поскольку объект struct sembuf составляет часть объекта struct sem_queue, и объект struct sem_queue содержит информацию о том, с каким объектом struct semid_ds он связан, никогда не возникает путаница в отношении того, для какого массива семафоров объекта struct semid_ds предназначена эта операция. В иных случаях, массив объектов struct sembuf спарен с индексом массива semary, который также подразумевает массив семафоров.
- sem_op. Операция над семафором, которая должна быть выполнена. Обычно она принимает значение –1, 0 или 1; –1 означает занятие семафора (снятие ключа с гвоздя), 1 означает освобождение семафора (возвращение ключа на гвоздь) и 0 означает ожидание возврата значения семафора к 0. Однако могут также применяться значения, отличные от этих, и они просто расшифровываются как занятие или освобождение большего числа значений семафора, то есть снятие или возврат большего числа ключей на гвоздь. (Слова «занять» и «освободить» могут выглядеть немного непривычными в этом контексте, но не беспокойтесь об этом; это общепринятая терминология для семафоров.)
- sem_flg. Один или несколько флажков (каждый из них представлен отдельным битом в этом коротком слове), которые могут изменить способ выполнения операции.
На рис. 9.2 показаны взаимосвязи между этими структурами данных.
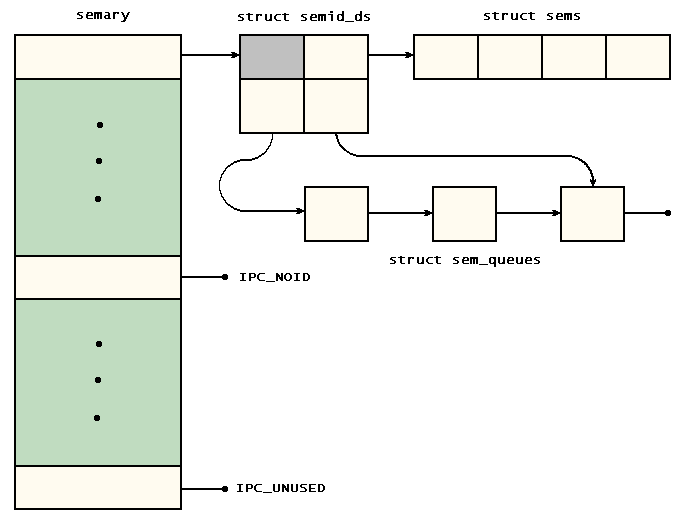
Рис. 9.2. Структуры данных для семафоров
struct sem_undo
17014: Объект struct sem_undo содержит достаточный объем информации для отмены отдельной операции над семафором. Если процесс выполняет операцию над семафором с установленным флажком SEM_UNDO, создается объект struct sem_undo, позволяющий отменить эту операцию. Все операции отмены, регламентируемые списком объектов struct sem_undo процесса, выполняются после выхода процесса. Читатели, знакомые с шаблонами проектирования, могут узнать в этом экземпляр шаблона Command.
Это средство позволяет процессу гарантировать автоматическую очистку ресурсов после себя, независимо от того, как произойдет его выход; таким образом, процесс не сможет случайно оставить другие процессы в состоянии бесконечного ожидания освобождения семафора, которое не сможет никогда произойти. (Может также возникнуть ситуация, что процесс приобретет семафор, а затем войдет в бесконечный цикл, но в задачу ядра не входит защита от такой ситуации; в этом случае реализовано намерение предоставить процессам возможность действовать правильно, а не вынуждать их действовать именно так.) Объект struct sem_undo имеет следующие члены:
- proc_next. Указывает на следующий объект struct sem_undo в списке объектов struct sem_undo владеющего ими процесса.
- id_next. Указывает на следующий объект struct sem_undo в списке объектов struct sem_undo, связанных с набором семафоров. Да, вы не ошиблись: один и тот же объект struct sem_undo находится в двух списках одновременно. Далее в этой главе показано, как они оба используются.
semid. Указывает вход semary, к которому принадлежит этот объект struct sem_undo.
- semadj. Массив корректировок, которые должны быть выполнены над каждым семафором в наборе семафоров, связанном с этим объектом struct sem_undo. Семафоры, о которых в этой структуре нет дополнительной информации, содержат в этом массиве 0 — корректировка не предусмотрена.
sys_semop
21244: Функция sys_semop реализует системный вызов semop. Функция sys_semop не имеет прямого эквивалента в программной реализации очереди сообщений, и является аналогом функции sys_msgsnd, sys_msgrcv, или их обеих, в зависимости от того, под каким углом она рассматривается. Как бы то ни было, ее назначение состоит в выполнении одной или нескольких операций над одним или несколькими семафорами. Она пытается выполнять все операции атомарно (то есть без прерывания). Если она не может выполнить их все, она не будет выполнять ни одной из них.
21254: Во многом аналогично функциям очереди сообщений, по-видимому, блокировка ядра выполняется немного раньше, чем в этом действительно возникает необходимость. Безусловно, блокировку можно было бы отложить примерно до строки 21265.
21255: Проверка допустимости параметров. Отметим, в частности, что значение nsops ограничено SEMOPM, максимальным числом операций над семафорами, которые можно попытаться выполнить за один раз. Это значение установлено равным 32 директивой #define в строке 16970.
21261: Копирует описание затребованных операций из пространства пользователя во временный буфер, sops.
21265: Проверка наличия входа в указанной позиции массива. Можно видеть, что эквивалентом массива msgque в программной реализации очереди сообщений является semary (строка 20688). Отметим также, что индекс массива и порядковый номер упакованы в параметре semid таким же способом, который применялся в программной реализации очереди сообщений. Здесь, безусловно, применяется немного другая константа, SEMMNI, значение которой установлено равным 128 (и случайно совпадает со значением MSGMNI) директивой #define в строке 16967.
21272: Начинается цикл по всем указанным операциям. В нем вначале выполняется проверка того, не находится ли номер семафора, заданный в этой операции, вне диапазона, и если это так, он отбрасывается. Любопытно, что при неудачном завершении здесь возвращается ошибка EFBIG (которая означает, что «файл слишком велик»), а не ошибка EINVAL («недопустимый параметр»). Однако это соответствует документации.
21275: Подсчет числа операций, для которых установлен флажок SEM_UNDO. Однако переменная undos просто применяется в качестве флажка: важно только знать, отличается ли она от 0, поэтому присвоение ей 1 (или любого другого ненулевого значения), если выполнено это условие, будет иметь одинаковый эффект. Тем не менее, версия ядра немного быстрее. А поскольку внешний цикл повторяется не более SEMOPM раз, значения undos не могут наращиваться так много раз, чтобы эта целочисленная переменная переполнилась и снова установилась в 0.
21277: Следующие несколько проверок обновляют два локальных флажка: decrease и alter. Они отслеживают, соответственно, будет ли какая-либо операция в наборе уменьшать значение семафора и будет ли какая-либо операция изменять значение семафора. Флажок alter вычисляется не полностью до выхода из цикла в строке 21282, поскольку внутри цикла он только следит за тем, увеличивает ли какая-либо операция значение семафора; затем это значение объединяется с информацией в флажке decrease для получения сведений о том, будут ли происходить какие-либо изменения.
Отметим, что в этом коде не предпринимается попытка обнаружить, не влекут ли за собой какие-либо сочетания операций их взаимной отмены, например, когда одна операция предусматривает уменьшение значения какого-то семафора на 1, а другая операция предусматривает увеличение его значения на 1. Поэтому, если бы встречались только такие операции, то значения флажков decrease и alter могли бы в определенном смысле вводить в заблуждение. В коде ядра можно предусмотреть попытку оптимизации этого алгоритма (и предусмотреть более сложные версии таких же действий), но это может не оправдать затраты времени и усилий. Приложение, которое настолько примитивно, что способно предусматривать выполнение таких взаимоисключающих операций, получает то, что заслуживает, и не следует наказывать более интеллектуальные приложения за его глупость.
21285: Проверка того, что процесс имеет разрешение на выполнение указанных операций с семафорами. Если переменная alter имеет истинное значение, то процесс изменяет семафоры и поэтому должен иметь разрешение на запись; в ином случае, он только ожидает, пока значения одного или нескольких семафоров не установятся в 0, поэтому он просто нуждается в разрешении на чтение.
21291: Набор операций включает некоторые операции отмены. Если текущий процесс уже имеет набор операций отмены, которые должны быть выполнены над данным набором семафоров во время выхода, то данные из нового набора операций отмены необходимо слить с этими данными. В цикле происходит поиск существующего набора операций отмены, и если он существует, в переменной un устанавливается указатель на этот набор, а если нет, в ней устанавливается значение NULL.
21295: Процесс еще не имеет набора операций отмены для данного набора семафоров, поэтому распределяется новый набор. В соответствии с принятой практикой, которую мы уже рассматривали на примере программной реализации очереди сообщений, пространство для корректировок отмены (массив semadj) распределяется непосредственно за самим объектом struct sem_undo в составе того же распределения памяти. После этого происходит заполнение объекта struct sem_undo.
21311: В рассматриваемом наборе операций нет операций отмены, поэтому переменная un просто устанавливается в NULL.
21313: Вызов функции try_atomic_semop (строка 20838, рассматривается ниже) для осуществления попытки выполнить все операции за один раз. Если существуют какие-либо операции, изменяющие состояние, переменная un отлична от NULL; в случае отказа, она будет использоваться для отмены любых частично выполненных операций перед возвратом из функции.
21315: Функция try_atomic_semop возвращает 0 в случае успеха и отрицательное значение — при возникновении ошибки. В любом из этих случаев управление переходит вперед на строку 21359.
21321: В ином случае, функция try_atomic_semop возвращает положительное значение. Оно указывает, что операции нельзя было выполнить прямо сейчас, но процесс собирается ждать, а затем предпринять еще оцну попытку. Для начала заполняется локальный объект struct sem_queue.
21328: Узлы, представляющие операции, которые изменят значения семафоров, размещены в конце очереди; все узлы, представляющие операции, которые ожидают достижения нуля значениями семафоров, размещаются в начале. Почему так происходит, мы покажем при описании функции update_queue (строка 20900) далее в этой главе.
Отметим, что это равносильно размещению локальной переменной в очереди ждущих операций, что очень необычно; такие структуры данных обычно имеют узлы, распределенные в куче. В данном случае это безопасно, поскольку узел будет удален из очереди перед возвратом из функции; переключение контекстов позаботится об остальном. Иным образом, вначале может потребоваться выйти из процесса и в этом случае очистку выполнит функция sem_exit (строка 21379).
21333: Начало цикла, который повторно пытается выполнить эти операции, и прекращает свою работу, только если были успешно выполнены все затребованные операции или если произошла ошибка.
21336: Переходит в состояние ожидания до тех пор, пока не возникнет прерывание от сигнала или пока появится какая-то причина для выполнения повторной попытки.
21342: Если процесс был активизирован функцией update_queue, поскольку у него теперь есть шанс добиться успеха, он повторяет операции.
21358: Удаляет этот процесс из очереди процессов, ждущих возможности изменить набор семафоров.
21360: Если этот набор операций изменил очередь, он мог создать условия, появления которых ждут какие-то другие процессы. Функция sys_semop вызывает update_queue, чтобы она нашла и активизировала такие процессы.
sys_semctl
21013: Функция sys_semctl, которая реализует системный вызов semctl, имеет много общего с функцией sys_msgctl. Поэтому здесь мы опишем только интересные различия, в частности, те команды sys_semctl, которые не имеют аналогов в sys_msgctl.
21093: Команды GETVAL, GETPID, GETNCNT, GETZCNT и SETVAL оперируют с отдельными семафорами, а не с наборами семафоров, поэтому в этих случаях нужно вначале проверить соответствие диапазону предоставленного параметра. Если semnum находится в диапазоне, переменная curr становится указателем на соответствующий семафор.
21115: Почти такой же набор команд — GETVAL, GETPID, GETNCNT и GETZCNT — предусматривает чтение или вычисление одного фрагмента информации о семафоре. Эта работа выполняется здесь. Обратите внимание, что верхние биты члена sempid обнуляются по маске в строке 21116; позже мы покажем, для чего это нужно.
21121: Команда GETALL представляет собой запрос на получение всех значений всех семафоров в этом наборе семафоров. Как и во многих других командах, вся работа по ее выполнению не сосредоточена в одном месте; вскоре мы опишем остальное.
21126: Команда SETVAL устанавливает семафор в заданное значение, безусловно, в заданных пределах. Опять-таки, в данный момент выполняется только часть работы, в основном, проверка диапазона.
21142: Команда SETALL — это обобщение SETVAL; она устанавливает значения всех семафоров в этом наборе. Как и в SETVAL, в данный момент выполняется только работа по настройке, например, проверка диапазона.
21173: Здесь начинается остальная часть программной реализации команды GETALL.
21175: Проверка того, что процесс имеет разрешение на чтение значений семафоров. Эта проверка разрешений дублирует выполняемую в строке 21112.
21177: Копирует значения семафоров в локальный массив sem_io, а затем копирует их оттуда в пространство пользователя.
21183: Остальная часть работы по выполнению команды SETVAL начинается здесь.
21187: Поскольку семафор принимает новое значение, все зарегистрированные корректировки отмены для семафора semnum являются недействительными. В этом цикле выполняется установка их в 0, чтобы они больше не имели силы.
21189: Устанавливает значение семафора в значение, предоставленное вызывающей программой, и вызывает функцию update_queue (строка 20900) для активизации всех процессов, которые ожидают возникших в результате этого условий.
21220: Основная часть программной реализации команды SETALL начинается здесь.
21224: Все значения семафоров установлены в значения, предоставленные вызывающей программой.
21226: Все корректировки отмены, относящиеся ко всем семафорам в наборе, установлены в нуль. Здесь не происходит ничего особенного, если семафор устанавливается в значение, которое он уже имел, и не должно происходить. Если вызывающая программа хочет установить в новое значение все семафоры, кроме одного, она не может имитировать это поведение, устанавливая данный семафор в то значение, которое он уже имел. Вместо этого, она должна использовать команду SETVAL для всех семафоров в наборе, кроме того, который не должен измениться.
sem_exit
21379: Функция sem_exit не имеет аналога в программной реализации очереди сообщений. Она выполняет все операции отмены, установленные процессом для автоматического выполнения во время его выхода. Поэтому она вызывается во время выхода процесса (в строке 23285).
21389: Если член semsleeping процесса отличен от NULL, то является истинным одно из двух следующих утверждений: либо процесс ожидал в одной из очередей sem_queue, либо он был только что удален из очереди, но значение semsleeping еще не было обновлено. В первом случае процесс удаляется из очереди, в которой он ожидал.
21395: Начинается проход по списку объектов struct sem_undo текущего процесса. Каждый из них будет обработан в свою очередь, а их освобождение происходит в части цикла, связанной с обновлением.
21397: Если семафоры, соответствующие этой структуре отмены, были освобождены, цикл просто продолжается. Поле semid объекта struct sem_undo может быть установлено в –1 функцией freeary, которая рассматривается далее в этой главе.
21399: Аналогичным образом, если соответствующий вход semque больше не действителен, цикл продолжается.
21406: Во многом аналогично удалению сообщения из середины очереди сообщений, этот цикл проходит по списку sma объектов struct sem_undo для поиска объекта, предшествующего тому, который должен быть удален. Когда он будет найден, функция sem_exit переходит вперед на метку found в строке 21413.
21411: Если структура отмены не была найдена в списке sma, что-то происходит не так. Функция sem_exit выводит предупреждающее сообщение и останавливает внешний цикл. Эта реакция кажется немного преувеличенной, поскольку могут еще оставаться другие структуры отмены, которые можно было бы обработать и освободить. Ведь, найдя одно гнилое яблоко, мы не выбрасываем весь ящик. Тем не менее, это «невозможный» случай, один из тех, которые (могут быть вызваны только логической ошибкой в ядре. Автор предполагает, что в основе этого поведения лежит принцип, что после обнаружения подобной ошибки нельзя доверять и оставшимся данным.
21414: В списке sma была найдена структура отмены и переменная unp указывает на указатель на ее предшественника. Переменная un удалена из очереди.
21417: Все корректировки семафоров в этой структуре отмены выполнены.
21427: Как всегда, происходит вызов функции update_queue на тот случай, если операции, выполненные этой функцией, создали условия для активизации какого-то ждущего процесса.
21429: Были обработаны все объекты struct sem_undo или в строке 21412 была обнаружена ошибка и выход из цикла произошел преждевременно. Так или иначе, очередь sem_undo текущего процесса устанавливается в NULL и функция выполняет возврат.
append_to_queue
20805: Добавление q к очереди sem_pending объекта sma. Это компактная реализация; она обычно выглядит примерно так:
q->prev = sma->last;
if (sma->sem_pending) /* He пуст? */
sma->sem_pending_last->next = q;
else
sma->sem_pending = q;
sma->sem_pending_last = q;
q->next = NULL;
Истинным преимуществом реализации, применяемой в ядре, является то, что в ней удалось избежать потенциально дорогостоящего ветвления. Эта более эффективная реализация отчасти стало возможной благодаря тому, что переменная sem_pending_last стала указателем на указатель на узел очереди, а не просто указателем на узел очереди.
prepend_to_queue
20812: Вставляет q перед очередью sem_pending объекта sma. Поскольку sem_pending это не указатель на указатель, эта реализация имеет, по существу, такую же форму, как и рассмотренная ранее наивная реализация.
remove_from_queue
20823: Последней примитивной операцией над очередями struct sem_queue является именно эта, в которой выполняется удаление узла из очереди.
20826: Частично удаляет q из очереди путем изменения указателя next предыдущего узла очереди.
20828: Обновляет также указатель prev следующего узла, если он есть, или sma->sem_pending_last, если это — последний узел в очереди. Обратите внимание, что нет явного кода для удаления единственного узла очереди; вам следует выделить время, чтобы разобраться в том, почему и этот случай работает, если вы еще этого не сделали.
20831: Устанавливает указатель prev удаленного узла в NULL, чтобы код в строках 21350 и 21390 позволял эффективно обнаружить, находится ли все еще в очереди этот узел.
try_atomic_semop
20838: В развернутом комментарии перед этой функцией упоминается, что она проверяет, может ли быть выполнен весь данный набор операций. В этом комментарии забыли отметить, что если все операции можно выполнить, обычно так и происходит.
20846: Начинается цикл по всем переданным операциям с проверкой каждой из них по очереди.
20850: Значение sem_op, равное 0, означает, что вызывающая программа должна ждать, пока значение curr->semval не достигнет 0. Следовательно, если значение curr->semval не равно 0, вызывающая программа должна заблокироваться, а это значит, что эти операции нельзя будет выполнить атомарно, или без прерываний (поскольку, пока этот процесс заблокирован, будет выполняться другая работа).
20853: Идентификатор процесса PID вызывающей программы временно записан в нижние 16 битов объекта curr->sempid; предыдущее значение идентификатор процесса перемещается на это время в верхние 16 битов.
20854: Выполняется корректировка curr->semval в соответствии с запросом, находящемся в sem_op, опять-таки, временно. Проверка sem_op на принадлежность к диапазону не выполняется ни здесь, ни в вызывающих эту операцию программах, но выполняется проверка принадлежности результата операции к диапазону в коде, расположенном непосредственно под этим. Это может иногда приводить к неожиданным последствиям при значениях sem_op, которые либо слишком велики, либо слишком малы, и поэтому вызывают переполнение semval с потерей первых значащих цифр.
20855: Если установлен флажок SEM_UNDO этой операции, указывающий, что операция должна быть автоматически отменена после выхода процесса, то обновляется соответствующая структура undo. Обратите внимание, что это подразумевает, что значение un отлично от NULL; за проверку того, что это действительно так, отвечает вызывающая программа.
20858: Проверка принадлежности к диапазону нового значения semval.
20864: Цикл полностью выполнен, поэтому все операции можно считать успешными. Если вызывающей программе нужно только проверить, будут ли операции успешными, но не нужно их сейчас выполнять, все операции будут немедленно отменены. В ином случае, операции уже выполнены и функция try_atomic_semop переходит к коду, который возвращает результат, свидетельствующий об успешном выполнении.
20874: Метка out_of_range достигается, если операция слишком увеличила бы значение semval. Код под этой меткой просто подготавливает к возврату ошибку ERANGE, а затем переходит вперед к коду отмены.
20878: Метка would_block достигается, если процессу пришлось бы ждать семафор либо потому, что ему пришлось бы ждать достижения семафором значения 0, либо потому, что операция не смогла приобрести семафор немедленно. Если вызывающая программа не намеревается ждать в этом случае, возвращается ошибка EAGAIN. В ином случае, функция возвращает 1 в качестве указания, что вызывающей программе нужно перейти в состояние ожидания.
20884: Код, расположенный за этой меткой undo, отменяет всю работу, которая была выполнена до сих пор, в цикле for, начинающемся в строке 20846.
20888: Очевидная часть этой строки говорит о том, что в ней восстанавливаются нижние 16 битов значения curr->sempid из значения, которое было временно отложено в строке 20853. Неочевидная часть состоит в том, что верхние 16 битов (здесь предполагается наличие 32-разрядной платформы) не обязательно заполняются нулями: в стандарте С преднамеренно оставлено на усмотрение компилятора право выбора — заполнять ли освободившиеся биты нулями или копией знакового бита. На практике компилятор применяет здесь самую быструю команду основополагающего компьютера и это иногда приводит к выбору одного из этих способов, а иногда — другого. (Именно поэтому в стандарте С не отдано предпочтение ни одному из них.) В результате, все верхние биты могут быть установлены в 0 или 1, и поэтому все биты, кроме нижних 16, заполняются по маске нулями в строке 21116.
update_queue
20900: Функция update_queue вызывается при изменении значения семафора. Она завершает все ждущие операции, которые могут теперь быть выполнены успешно (или окончиться неудачей), и удаляет процесс из очереди ожидания.
20907: Если флажок состояния этого узла был уже поднят в предыдущем вызове функции update_queue, процесс, связанный с этим узлом, еще не имел шанса удалить себя из этой очереди. Функция выполняет возврат, чтобы дать другому процессу шанс выполнить свои ожидающие операции и отключить себя от очереди.
20910: Проверка того, может ли теперь быть выполнен текущий набор ожидающих операций. В качестве последнего параметра передается q->alter, чтобы изменяющиеся операции были автоматически отменены в случае их успешного выполнения. Это связано с тем, что процесс сам будет предпринимать попытки выполнения операций, а они не должны быть выполнены дважды.
20914: В случае ошибки или успеха (а не необходимости продолжать ждать) этот узел удаляется из очереди и активизируется связанный с ним процесс. В ином случае, узел остается в очереди, чтобы стать объектом повторных попыток в какой-то момент в будущем.
20917: Если набор операций включает некоторые изменяющиеся операции, поднимается флажок q->status, чтобы процесс мог определить, что он активизирован в связи с тем, что он теперь может быть успешно выполнен; он попытается выполнить операции и удалить себя из очереди. Проверка флажка выполняется в строке 21342, как было описано выше.
20920: Функция сейчас выполняет возврат с тем, чтобы несколько изменяющихся процессов не пыталось одновременно провести свои изменения, которые могут оказаться несовместимыми. Помните, что неизменяющиеся операции хранятся в начале очереди, а изменяющиеся операции хранятся в конце. В результате, все неизменяющиеся процессы (которые не будут мешать друг другу) активизируются в первую очередь, а после этого активизируется, самое большее, один изменяющийся процесс.
20922: В ином случае, возникла ошибка. Код ошибки сохраняется в переменной q->status и этот узел очереди удаляется.
count_semncnt
20938: Функция count_semncnt вызывается из строки 21117 для реализации команды GETNCNT в функции sys_semctl. Ее задача состоит в подсчете числа задач, которые заблокированы и ждут приобретения семафора.
20949: Этот цикл выполняется для каждой ожидающей операции в каждой задаче, ожидающей в очереди ожидания объекта sma. Цикл наращивает значение semncnt каждый раз, когда находит подходящую операцию — ту, которая пытается занять указанный семафор и у которой не установлен флажок IPC_NOWAIT.
count_semzcnt
20957: Функция count_semzcnt вызывается из строки 21119 для реализации команды GETZCNT в функции sys_semctl. Она почти полностью аналогична функции count_semncnt, за исключением того, что она подсчитывает задачи, ожидающие достижения данным семафором значения 0 (то есть количество задач, ждущих, когда данный семафор станет доступным). Поэтому единственным отличием является строка 20970, где выполняется проверка равенства значения переменной нулю вместо проверки того, что это значение меньше нуля.
Разделяемая память
Термин «разделяемая память» точно соответствует своему названию: резервируется область памяти и к ней предоставляется доступ набору процессов. Поскольку это касается и вопросов взаимодействия, и вопросов управления памятью, в настоящем разделе упоминается материал, приведенный ранее в этой главе, а также материал главы 8.
Разделяемая память по своему быстродействию намного превосходит два других механизма взаимодействия между процессами, рассматриваемые в этой главе, и она проще в использовании: процесс после ее приобретения рассматривает ее просто как обычную память. Изменения, записанные в разделяемую память одним процессом, сразу же становятся очевидными для всех других процессов — они могут просто выполнить чтение через указатель, который указывает на пространство разделяемой памяти, а там, как по взмаху волшебной палочки, уже находится новое значение. Однако в разделяемой памяти типа System V нет встроенного способа обеспечения взаимного исключения: может оказаться, что один процесс пишет по данному адресу в области разделяемой памяти одновременно с тем, как другой процесс читает по тому же адресу, в результате чего программа чтения получает противоречивые данные. Эта проблема наиболее серьезна для компьютеров с симметричной мультипроцессорной архитектурой, но она может возникать и на однопроцессорных компьютерах: например, когда программа записи потеряет управление и перейдет в неактивное состояние в ходе записи какой-то крупной структуры в пространство разделяемой памяти, а программа чтения выполнит чтение из разделяемой памяти до того, как программа записи получит возможность закончить запись.
В результате, в процессах, использующих разделяемую память, нужно что-то предусмотреть для обеспечения тщательного отделения операций чтения от операций записи (и, если подумать, операций записи друг от друга). Исчерпывающее описание блокировок и связанных с ними понятий атомарных операций приведено в следующей главе. Но нам уже известен способ обеспечения взаимоисключающего доступа к области разделяемой памяти: применение семафоров. Идея состоит в приобретении семафора, доступе к области памяти, выполнении всех запланированных действий, а затем освобождении семафора после выполнения этой работы.
Разделяемая память может применяться в основном в таких же целях, как и очереди сообщений: процесс планировщика может записывать запрос на выполнение работы в одной части области разделяемой памяти, а рабочие процессы могут записывать результаты в другой части. Это значит, что общее пространство для запросов и результатов должно быть заранее разграничено приложением, но планирование и запись результатов выполняются быстрее по сравнению с очередями сообщений.
Область разделяемой памяти не обязана выглядеть для каждого процесса как имеющая один и том же адрес. Если и процесс А, и процесс В используют одну и ту же область разделяемой памяти, процесс А может обращаться к ней по одному адресу, а процесс В — по другому. Безусловно, каждая страница области разделяемой памяти будет отображена не более, чем на одну физическую страницу. Механизмы виртуальной памяти, описанные в предыдущей главе, просто применяют разные преобразования к логическим адресам каждого процесса.
В коде ядра области разделяемой памяти называются сегментами, то есть применяется та же терминология, которая иногда ошибочно применяется к областям VMA. Только для того, чтобы предотвратить какую-либо путаницу, отметим, что это — неформальное применение данного слова; оно не относится к сегментам, поддерживаемым на уровне аппаратного обеспечения (MMU), которые описаны в главе 8. Автор будет и далее использовать термин «область», чтобы избежать этой путаницы.
Программным код разделяемой памяти по своей конструкции и реализации имеет много общего с программным кодом очередей сообщений и семафоров. В результате, нет необходимости рассматривать входящие в его состав функции shm_init (строка 21482) и findkey (строка 21493). По тем же причинам, описание некоторых оставшихся функций и структур данных сокращено.
struct shmid_ds
17042: Немного нарушая сложившийся подход, разработчики ядра создали тип данных struct shmid_ds не в качестве структуры данных ядра для отслеживания областей разделяемой памяти. Вместо этого, struct shmid_ds содержит основную часть этой информации, все остальное размещается в объекте struct shmid_kernel, рассматриваемом ниже. Следующие члены объекта struct shmid_ds отличаются от соответствующих членов его аналогов:
- shm_segz. Размер данной области разделяемой памяти в байтах (а не страницах).
- shm_nattch. Число задач, «подключенных» к этой области, если пользоваться сложившейся терминологией, иными словами, число задач, использующих эту область разделяемой памяти. Этот член представляет собой счетчик ссылок.
- shm_unused, shm_unused2 и shm_unused3. Как и можно было предположить по их именам, эти члены больше не используются в данной реализации; по-видимому, их единственное назначение состоит в обеспечении неизменного размера данной структуры для обратной совместимости.
struct shmid_kernel
17056: Объект struct shmid_kernel существует как средство отделения «закрытой» информации, относящейся к разделяемой памяти, от «общедоступной» информации. Части объекта struct shmid_ds, к которым можно предоставить доступ пользовательским приложениям, остаются в объекте struct shmid_ds, a закрытая информация, связанная с ядром, размещается в объекте struct shmid_kernel. Пользовательские приложения должны иметь возможность передавать объект struct shmid_ds системному вызову shmctl, поэтому они должны иметь доступ к определению этого объекта, а закрытые подробности реализации, относящиеся к ядру, не должны быть выставлены на всеобщее обозрение в определении этого объекта. В ином случае, изменение реализации ядра может привести к нарушению работы приложения. Объект struct shmid_kernel имеет следующие члены:
- u. Объект struct shmid_ds, то есть общедоступная часть данных.
- shm_npages. Размер области разделяемой памяти в страницах. Это просто значение члена shm_segsz этого объекта, деленное на PAGE_SIZE (строка 10791).
- shm_pages. «Таблица страниц», которая отслеживает страницы, распределенные для этой области разделяемой памяти; здесь слова «таблица страниц» заключены в кавычки, поскольку это не настоящая таблица страниц, поддерживаемая на аппаратном уровне, как было описано в предыдущей главе. Однако она выполняет такую же работу.
- attaches. Связанный список областей VMA, которые отображают данную область разделяемой памяти от имени соответствующих им процессов. Области VMA описаны в главе 8.
newseg
21511: Данная функция является аналогом функций newque и newary. Она распределяет и инициализирует объект struct shmid_kernel, а затем устанавливает его в массив shm_segs.
21537: Распределение «таблицы страниц». Если бы эта программная реализация была построена по аналогии с другими механизмами межпроцессного взаимодействия, то эта память была бы распределена сразу после объекта struct shmid_kernel полностью в составе единственного большого распределения. Однако память для объекта struct shmid_kernel распределяется функцией kmalloc (в невыгружаемой памяти ядра), а «таблица страниц» распределяется функцией vmalloc (в выгружаемой памяти).
21546: Инициализация распределенного входа, начиная с обнуления таблицы страниц.
sys_shmget
21573: Это, безусловно, аналог функций sys_msgget и sys_semget. Единственным новым средством является применяемое в этой функции приобретение и освобождение семафора объекта struct mm_struct данного процесса. Это семафор ядра, который не следует путать с семафором типа System V; семафоры ядра рассматриваются в главе 10.
killseg
21610: Эта функция представляет собой аналог функций freeque и freeary. Ее программная реализация в основном аналогична этим функциям, но несколько ее средств заслуживают отдельного упоминания.
21616: Если программа killseg вызывается с индексом незанятого элемента shm_segs, она выводит предупреждающее сообщение и немедленно выполняет возврат. Ни в одном из ее аналогов нет подобного кода.
21629: Если член shm_pages данного входа имеет значение NULL, то где-то есть логическая ошибка. Это значит, что был не полностью построен объект struct shmid_kernel, или он был уничтожен, но не удален из массива, или возникло какое-то подобное «невероятное» состояние.
21635: Освобождение страниц, распределенных для данной таблицы страниц.
21638: Если в таблице страниц нет отображения для этой страницы, то для освобождения этого входа ничего не нужно делать.
21640: Если страница присутствует в физической памяти, она возвращается в пул доступных страниц и число резидентных страниц уменьшается.
21643: В ином случае, она находится в области подкачки, и освобождается и удаляется оттуда.
21648: Освобождение самой таблицы страниц.
sys_shmctl
21654: Функция sys_shmctl, безусловно, является аналогом функций sys_msgctl и sys_semctl и имеет с ними много общего. Здесь рассматриваются только две команды, относящиеся к управлению разделяемой памятью.
21733: Команда SHM_UNLOCK обратна SHM_LOCK, оператор case которой показан в строке 21742. Команда SHM_LOCK позволяет процессу с достаточными возможностями заблокировать целую область в физической памяти и предотвратить ее выгрузку на диск. Команда SHM_UNLOCK разблокирует заблокированную область, так что содержащиеся в ней страницы снова становятся доступными для свопинга. В обоих этих случаях выполняется не слишком много работы: в них только выполняется проверка того, что вызывающая программа имеет соответствующие возможности, а также того, что область, которая должна быть разблокирована, в настоящее время заблокирована (или наоборот), а затем установка или очистка соответствующего бита режима. Но это все, что должно быть сделано и результат появляется в функции shm_swap (строка 22172).
Обратите внимание, что существует отдельная возможность блокировки и разблокировки разделяемой памяти, CAP_IPC_LOCK (строка 14021).
insert_attach
21823: Эта короткая функция просто добавляет область VMA к списку областей VMA, подключенных к данному объекту struct shmid_kernel. Обратите внимание, что область VMA подключается с начала этого списка, поскольку порядок не играет роли и проще всего выполнить это действие именно так. В ином случае, пришлось бы отдельно отслеживать начало и конец списка attaches.
remove_attach
21833: Эта функция удаляет область VMA из списка, подключенного к данному объекту shmid_kernel. Интересной особенностью этой функции является то, что она не зависит от своего параметра shp: указатель на список attaches параметра shp был записан в первой области VMA в списке в строке 21829, а процедура обновления списка является одинаковой, независимо от того, является ли область VMA первой в списке (если это так, то обновляется также соответствующий список attaches).
sys_shmat
21898: Эта функция реализует системный вызов shmat, с помощью которого вызывающий процесс подключается к области разделяемой памяти.
21923: Дальнейшее нам уже немного знакомо: с учетом настройки функция sys_shmat начинает прорабатывать адрес, по которому эта область разделяемой памяти должна появиться в пространстве памяти вызывающего процесса. Вначале она проверяет адрес, переданный вызывающей программой. Если он равен NULL и флажок SHM_REMAP не установлен (см. строку 21959), запрос должен быть отвергнут, поскольку чтение или запись по адресу NULL являются недопустимыми.
21929: Вызывающая программа передала NULL в качестве целевого адреса, а это значит, что функция sys_shmat должна выбрать адрес в пространстве памяти процесса. Подходящий для этого адрес предоставляется функцией get_unmapped_area (строка 33432), которая была мельком упомянута в предыдущей главе. Если она возвращает 0 (значение, эквивалентное NULL во всех архитектурах, поддерживаемых этим ядром), это значит, что не удалось найти ни одной области подходящей величины.
21932: Если подходящий адрес еще не лежит точно на границе страницы, он округляется в большую сторону, к границе следующей страницы, расположенной в направлении старших адресов, а затем вместо него проверяется откорректированный адрес. Функция get_unmapped_area возвращает первый доступный адрес, равный данному или расположенный выше него, поэтому, если доступен адрес, округленный в большую сторону, он и будет использоваться.
Это позволяет понять, почему адрес округляется в большую, а не меньшую сторону (что было бы быстрее и проще): если бы функция sys_shmat округляла в меньшую сторону и адрес, округленный в меньшую сторону, был бы недоступен, то этот код вошел бы в бесконечный цикл. Следующий вызов функции get_unmapped_area приводил бы к просмотру в направлении старших адресов, начиная от адреса, округленного в меньшую сторону, и возвращал бы первоначальное неокругленное подходящее значение, которое было бы снова округлено в меньшую сторону, распознано как непригодное и снова передано функции get_unmapped_area.
Обратите внимание, что здесь для определения пригодности адреса используется значение SHMLBA (строка 11777), а не PAGE_SIZE (строка 10791). Однако можно видеть, что значение SHMLBA директивой #define установлено равным PAGE_SIZE, поэтому не имеет значение, какое из них здесь используется.
Но если значения SHMLBA и PAGE_SIZE одинаковы, то почему бы не убрать одно из них? Ответ состоит в том, что значение SHMLBA равно PAGE_SIZE на большинстве платформ, но не на всех. В архитектуре MIPS величина PAGE_SIZE равна 4 Кб и в системе Linux значение SHMLBA определено директивой #define равным огромному числу 0x40000 (256 Кб), причем в комментарии указано, что такое большое значение было выбрано в качестве соответствия интерфейсу ABI (Application Binary Interface) компании SGI для компьютеров на основе MIPS. Однако в описании интерфейса ABI версий 2 и 3 для MIPS явно сказано, что значение SHMLBA «может принимать разные значения в соответствующих реализациях», поэтому непонятно, почему разработчики ядра предположили, что от них потребуют придерживаться величины в 256 Кб. Возможно, это значение требовалось для самой первой версии ABI, но автор просмотрел все предыдущие версии ABI, вплоть до 1.2, и не нашел такого требования.
Кроме того, в системе SPARC-64 значение SHMLBA вдвое превышает PAGE_SIZE; к сожалению, в коде нет объяснения причин этого различия.
21936: Иначе, вызывающая программа передала предложенный адрес. Если это необходимо и допустимо, адрес округляется в меньшую сторону.
21945: Проверка того, что блок памяти размером len, начинающийся с выбранного адреса, поместится в допустимом пространстве памяти процесса. (Значение len вычисляется на несколько строк раньше, в строке 21943.) Эта проверка явно необходима, если вызывающая программа передает подходящий адрес и, на первый взгляд, она также, видимо, нужна, когда функция sys_shmat выбирает адрес с использованием функции get_unmapped_area. Функция get_unmapped_area выполняет аналогичную проверку, но переданный ей размер области, член shm_segsz объекта struct shmid_ds, не обязательно совпадает со значением len, поскольку len является кратным величине PAGE_SIZE, a shm_segsz может не быть таковым.
Однако, поскольку все адреса, используемые функцией get_unmapped_area, выровнены по границе страницы, на вычисления в этой функции не влияет то, является ли переданный ей размер области кратным размеру страницы.
21951: Как сказано в этом комментарии, в выбранной области нужно оставить немного места для стека процесса. Обязательным требованием является создание буферной зоны из четырех страниц: в этом числе нет ничего магического и его назначение состоит просто в том, чтобы оставить процессу немного места для стека. Напомним сказанное в предыдущей главе, что если задача исчерпывает объем своего стека, она должна быть уничтожена. С учетом всех соображений, вероятно, лучше допустить аварийное завершение одного системного вызова, чем грубое уничтожение целого процесса: процесс может корректно исправить последствия первой ситуации из указанных выше, но не последней из них.
21959: Здесь показано основное назначение флажка SHM_REMAP (строка 17075): если флажок SHM_REMAP установлен и область, указанная вызывающей программой, уже используется, ошибка не возникает, поскольку флажок SHM_REMAP для того и существует, чтобы дать возможность вызывающей программе отобразить область разделяемой памяти на память, которой она уже владеет, например, на глобальный буфер. Если этот флажок не установлен, то выбранный адрес не должен перекрывать какую-либо память, уже принадлежащую этому процессу.
21971: Если вызывающая программа не имеет разрешения на использование этой области памяти, данный системный вызов завершается неудачей. Если в качестве параметра передан флажок SHM_RDONLY (только чтение), вызывающая программа нуждается только в разрешении на чтение; в ином случае, вызывающая программа нуждается в разрешении и на чтение, и на запись.
21991: Заполнение новой области VMA. В частности, отметим, что ее член vm_ops инициализируется в значение указателя на shm_vm_ops (строка 21809), как описано в главе 8.
22004: Увеличение числа ссылок на эту область, чтобы она не была преждевременно уничтожена.
22005: Вызов функции shm_map (строка 21844) для отображения страниц разделяемой памяти на пространство памяти процесса. Если она терпит неудачу, то отменяет выполненные действия, уменьшая число ссылок, уничтожая область, если это была ее первая и единственная ссылка, и освобождая саму область VMA.
Обратите внимание, что область VMA не обязательно будет освобождена, даже если это последняя ссылка; эта область должна быть также отмечена флажком SHM_DEST (строка 17106). Флажок SHM_DEST может находиться среди флажков, установленных вызывающей программой; он может быть также установлен позже в ветви IPC_RMID функции sys_shmctl — см. строку 21780. Благодаря этому, область разделяемой памяти может пережить все подключенные к ней процессы. Это может оказаться полезным по тем же причинам, по которым иногда может быть полезен неуничтоженный файл контрольной точки, находящийся где-то на диске: может применяться продолжительный процесс, который работает несколько часов каждую ночь, оставляя свои результаты в области разделяемой памяти, которая продолжает существовать даже после того, как текущий фрагмент работы процесса был выполнен. На следующую ночь процесс может продолжить свою работу точно с того места, где он ее прекратил, просто подключившись к этой сохранившейся области разделяемой памяти. (Безусловно, поскольку области разделяемой памяти в отличие от файлов исчезают при выключении компьютера, этот подход не применим для работы, результаты которой нельзя терять.)
22014: Добавление shmd к списку областей VMA, подключенных к этой области, а затем обновление некоторой статистической информации, относящейся к области.
22019: Возвращение адреса, фактически выбранного для области разделяемой памяти в пространстве вызывающей программы, а затем успешный возврат.
shm_open
22028: Функцию shm_open можно считать облегченным вариантом функции sys_shmat (строка 21898). Она подключает переданную ей область VMA к области разделяемой памяти. Область VMA, переданная в качестве параметра, была скопирована из той, которая уже подключена к целевой области, поэтому сама область VMA уже заполнена правильно; работа функции shm_open в основном сводится только к выполнению подключения.
Как сказано в комментарии перед функцией shm_open, эта функция вызывается из функции do_fork (строка 23953), которая рассматривается в главе 7. Точнее, эта функция вызывается из строки 23692 в функции dup_mmap (строка 23654). Функция dup_mmap, в свою очередь, вызывается из строки 23801 функции copy_mm (строка 23774); a copy_mm вызывается из строки 24051, которая находится в функции do_fork.
22033: Извлечение индекса shm_segs из члена vm_pte данной области VMA, а затем проверка того, что здесь находится допустимый вход. Обратите внимание, что этот индекс не нужно проверять на соответствие диапазону, поскольку поразрядная операция AND, применяемая к величине SHM_ID_MASK (строка 11757),заставляет его находиться в диапазоне.
22040: Подключает область VMA к данной области и обновляет статистическую информацию данной области.
shm_close
22050: Функция shm_close, которая является противоположной функции shm_open, отключает область VMA от области разделяемой памяти, к которой она подключена. Хотя есть и другие места, где ядро вызывает операцию закрытия области VMA, по-видимому, строка 33821 является единственным таким местом, где это может окончиться вызовом функции shm_close. Это часть функции exit_mmap (строка 33802) и она обычно достигается функцией mmput (строка 23764), которая вызывается из функции __exit_mm (строка 23174), которая вызывается из функции do_exit (строка 23267), рассматриваемой в главе 7. Отметим, что есть и другие пути к функции shm_close, и один из них мы вскоре рассмотрим.
22056: Извлечение индекса shm_segs из члена vm_pte области VMA, а затем отключение области VMA от данной области. Этот индекс не нужно проверять на соответствие диапазону по тем же причинам, как и в функции shm_open. Отметим также, что функция shm_close не проверяет, находится ли допустимый вход shm_segs по указанному индексу. Для функции remove_attach это не имеет значение, поскольку, как было показано выше, она даже не зависит от своего параметра shp. Но в последней части функции shm_close предполагается, что остальная программная реализация разделяемой памяти разработана и применяется правильно, так что этот «невозможный» случай действительно не произойдет.
22058: Отключение области VMA от области разделяемой памяти, а затем обновление статистической информации этой области.
22061: Уменьшение числа ссылок области и, возможно, также ее освобождение.
sys_shmdt
22068: Функция sys_shmdt, которая является противоположной функции sys_shmat, отключает процесс от области разделяемой памяти.
22074: Начинает выполнение итераций по всем областям VMA, представляющим память процесса.
22076: Если область VMA представляет область разделяемой памяти (для определения этого предусмотрена элегантная проверка содержимого ее члена vm_ops) и область VMA начинается с целевого адреса, то нужно отменить отображение этой области VMA.
22079: Функция do_munmap (строка 33689) вызывает функцию unmap_fixup (строка 33578), которая (не сразу) вызывает функцию shm_close в строке 33592. Функции do_munmap и unmap_fixup описаны в главе 8.
Глава 10. Симметричная мультипроцессорная обработка
На протяжении всей этой книги автор не рассматривал код симметричной мультипроцессорной обработки, предпочитая сосредотачиваться на относительно простых случаях, в который используется только один процессор. Теперь настало время еще раз обратиться к материалу, который был изложен выше, рассматривая его под новым углом: что происходит, когда ядро должно поддерживать компьютер с несколькими процессорами?
Обычно применение нескольких процессоров для выполнения одной работы называется параллельной обработкой, которую можно рассматривать как целый спектр методов, начиная от распределенных вычислений на одном конце спектра и кончая симметричной мультипроцессорной обработкой на другом. Как правило, система становится более тесно связанной, то есть разделяющей больший объем ресурсов между процессорами, и более однородной по мере перемещения по этому спектру от распределенных вычислений к симметричной мультипроцессорной обработке. В типичной распределенной системе каждый процессор обычно имеет, по крайней мере, свой собственный кэш и свою собственную оперативную память. Часто каждый процессор имеет также свой собственный диск (диски) и может иметь свою собственную графическую подсистему, звуковую плату, монитор и так далее.
В предельном случае распределенные системы часто представляют собой лишь связку обычных компьютеров, возможно, с полностью различными архитектурами, взаимодействующих друг с другом по сети; при этом они даже не обязаны находиться в одной и той же локальной сети. К некоторым интересным распределенным системам, о которых часто приходится слышать, относятся Beowulf (общее название для довольно несложных, но чрезвычайно мощных распределенных систем Linux), SETI@home (в которой собраны миллионы компьютеров во всей Internet для помощи в поиске свидетельств внеземной жизни) и distributed.net (еще одна реализация аналогичной идеи, которая в основном сосредоточена на расшифровке двоичных программ, разработанных здесь, на Земле).
Симметричная мультипроцессорная обработка — это частный случай параллельной обработки, в котором все процессоры в системе являются идентичными. Симметричная мультипроцессорная обработка заслуживает такого названия только в том случае, если в один хомут запрягают, например, два процессора 80486 или два процессора Pentium (с одинаковой тактовой частотой), а не 80486 и Pentium или Pentium и PowerPC. В обычном толковании этого термина симметричная мультипроцессорная обработка также означает, что все процессоры находятся «под одной крышей», то есть установлены в одном и том же компьютере, и взаимодействуют друг с другом через аппаратные средства специального назначения.
Обычно система симметричной мультипроцессорной обработки ничем не отличается от простого однопроцессорного компьютера, не считая того, что в ней установлено два или несколько процессоров. Поэтому в системе симметричной мультипроцессорной обработки все, кроме процессоров, представлено в одном экземпляре: один графический адаптер, одна звуковая плата и так далее. Эти и аналогичные ресурсы, такие как оперативная память и диск, разделены между процессорами системы. (Однако в системах симметричной мультипроцессорной обработки все чаще применяется отдельный кэш для каждого процессора.)
Распределенные конфигурации требуют минимальной специализированной поддержки ядра или вообще ее не требуют; координация между узлами осуществляется с применением пользовательского программного обеспечения и таких сложившихся компонентов ядра, как сетевые подсистемы. Но симметричная мультипроцессорная обработка связана с созданием иной аппаратной конфигурации внутри компьютера и, как таковая, требует поддержки ядра специального назначения. Например, ядро должно обеспечить совместную работу процессоров во время доступа к их разделяемым ресурсам, а с этой проблемой не приходится сталкиваться в мире однопроцессорной обработки.
Системы симметричной мультипроцессорной обработки применяются все чаще, поскольку повышение производительности, которого можно достичь с помощью таких систем, обходится дешевле и является проще по сравнению с приобретением нескольких отдельных компьютеров и объединением их друг с другом, а также потому, что это намного быстрее по сравнению с ожиданием выпуска следующего поколения процессоров.
Асимметричные мультипроцессорные конфигурации не нашли столь широкого распространения, поскольку обычно аппаратная и программная поддержка, необходимая для симметричных конфигураций, намного проще. Однако часть кода ядра, зависящая от архитектуры, обычно не связана с решением вопросов о том, являются ли процессоры идентичными, иными словами, является ли конфигурация поистине симметричной, поэтому в этой части кода ядра не предусмотрены какие-то особые средства поддержки асимметричных конфигураций. Например, в асимметричной мультипроцессорной системе планировщик должен отдавать предпочтение выполнению процессов на более быстрых, а не на более медленных процессорах, но ядро Linux не делает таких различий.
Как говорится, «бесплатный сыр бывает только в мышеловке». В системах с симметричной мультипроцессорной обработкой за повышение производительности проходится платить повышенной сложностью ядра и увеличением административных издержек. Процессоры должны распределить работу так, чтобы не мешать друг другу, и при этом они не должны затрачивать на эту координацию так много времени, что дополнительная производительность процессора будет почти полностью израсходована.
Часть кода, относящаяся к симметричной мультипроцессорной обработке, транслируется с учетом возможности однопроцессорной обработки для того, чтобы однопроцессорные компьютеры не стали работать медленнее только потому, что в мире появились компьютеры с симметричной мультипроцессорной архитектурой. Такой подход отвечает двум принципам, которые проверены временем: «оптимизируй для самого распространенного случая» (однопроцессорные компьютеры встречаются намного чаще по сравнению с компьютерами с симметричной мультипроцессорной архитектурой) и «не плати за то, что не будешь использовать».
Понятия и примитивы параллельного программирования
Компьютер с симметричной мультипроцессорной архитектурой, в котором установлено два процессора, очевидно, простейшая из всех возможных параллельных конфигураций, но даже простейшая конфигурация открывает широкую область новых проблем; говорят, что иногда легче пасти стаю кошек, чем добиться гармоничной совместной работы двух одинаковых процессоров. К счастью, на эту тему существует широкий и хорошо изученный фонд научных исследований, проводимых, по меньшей мере, в течение последних 30 лет. (Это довольно продолжительное время, если учесть, что первые электронно-цифровые ЭВМ были созданы только около 50 лет тому назад.) Мы можем значительно упростить свою работу, если перед изучением того, как поддержка симметричной мультипроцессорной обработки влияет на код ядра, дадим обзор некоторых теоретических понятий, на которых основана эта поддержка.
Следует отметить, что не вся эта информация относится только к проблематике ядра симметричной мультипроцессорной системы. Некоторые вопросы, выдвинутые в теории параллельного программирования, актуальны и для ядра однопроцессорной системы, как с точки зрения поддержки прерываний, так и с точки зрения обеспечения взаимодействия между процессами. Поэтому это описание заслуживает вашего внимания, даже если вы не испытываете особого интереса к проблемам симметричной мультипроцессорной обработки.
Атомарные операции
В параллельной среде некоторые действия должны выполняться атомарно, то есть без какой-либо возможности прерывания. Эти операции должны быть неделимыми, какими в свое время считались атомы.
В качестве примера рассмотрим подсчет ссылок. Если вы хотите отказаться от своей доли в разделяемом ресурсе и узнать, владеет ли им кто-то еще, вы уменьшите счетчик этого разделяемого ресурса и проверите его на равенство нулю. Типичная последовательность действий может начинаться со следующего:
- Процессор загружает текущее значение счетчика (скажем, 2) в один из своих регистров.
- Процессор уменьшает это значение в своем регистре; теперь оно равно 1.
- Процессор записывает новое значение (1) обратно в память.
- Процессор решает, что поскольку значение равно 1, разделяемый объект используется каким-то другим процессом, поэтому не освобождает объект.
В однопроцессорных системах этот сценарий не вызывает особого беспокойства (за исключением некоторых случаев). Но в симметричных мультипроцессорных системах картина совершенно иная: а что будет, если окажется, что другой процессор выполняет ту же работу и в то же время? Наихудший случай выглядит примерно так:
- Процессор А загружает текущее число (2) в один из своих регистров.
- Процессор В загружает текущее число (2) в один из своих регистров.
- Процессор А уменьшает значение в своем регистре; теперь оно равно 1.
- Процессор В уменьшает значение в своем регистре; теперь оно равно 1.
- Процессор А записывает новое значение (1) обратно в память.
- Процессор В записывает новое значение (1) обратно в память.
- Процессор А решает, что поскольку значение равно 1, этот разделяемый объект используется каким-то другим процессом, поэтому не освобождает его.
- Процессор В решает, что поскольку значение равно 1, этот разделяемый объект использует какой-то другой процесс, поэтому не освобождает его.
Число ссылок в памяти теперь должно быть равно 0, но вместо этого, оно равно 1. Оба процесса удалили свои ссылки на разделяемый объект, но ни один из них его не освободил.
Это интересный отказ, поскольку каждый процессор выполнил именно то, что требовалось, и все равно возник неправильный результат. Проблема, безусловно, состоит в том, что процессоры не координировали свои действия, поэтому правая рука не знала, что делает левая.
А если мы попытаемся решить эту проблему в программном обеспечения? Рассмотрим все действия с точки зрения любого из процессоров, скажем, процессора А. Чтобы сообщить процессору В, что он должен оставить нетронутым число ссылок, поскольку вы хотите его уменьшить, вы должны как-то изменить некоторую информацию, доступную процессору В, то есть обновить данные в каком-то месте разделяемой памяти. Например, можно зарезервировать для этой цели какое-то место в разделяемой памяти и договориться, что в нем будет записана 1, если любой из процессоров собирается уменьшить число ссылок, и 0 — в ином случае. Это соглашение может выполняться примерно так:
- Процессор А загружает обусловленное значение из специального места в памяти в один из своих регистров.
- Процессор А проверяет это значение в своем регистре и обнаруживает, что оно равно 0. (Если нет, он осуществляет последующие попытки, повторяя их до тех пор, пока в регистре не появится 0.)
- Процессор А записывает 1 обратно в специальное место в памяти.
- Процессор А обращается к защищенному числу ссылок.
- Процессор А записывает 0 обратно в специальное место в памяти.
Да... Это выглядит неприятно знакомым. Ничто не может предотвратить такого развития событий:
- Процессор А загружает значение из специального места в памяти в один из своих регистров.
- Процессор В загружает значение из специального места в памяти в один из своих регистров.
- Процессор А проверяет значение в одном из своих регистров и обнаруживает, что оно равно 0.
- Процессор В проверяет значение в одном из своих регистров и обнаруживает, что оно равно 0.
- Процессор А записывает 1 обратно в специальное место в памяти.
- Процессор В записывает 1 обратно в специальное место в памяти.
- Процессор А обращается к защищенному числу ссылок.
- Процессор В обращается к защищенному числу ссылок.
- Процессор А записывает 0 обратно в специальное место в памяти.
- Процессор В записывает 0 обратно в специальное место в памяти.
Но, может, для защиты специального места в памяти, которое должно защищать первоначальное место в памяти, можно использовать еще одно специальное место в памяти...
Мы должны признать свое поражение. Такой подход позволяет только перевести проблему на другой уровень, но не решить ее. В конечном итоге, атомарность операций нельзя гарантировать только за счет одного программного обеспечения, без конкретной помощи со стороны аппаратных средств.
Па платформе х86 именно такую помощь предоставляет команда lock. (Точнее, lock — это скорее префикс, а не отдельная команда, но для наших целей эта разница не имеет значения.) Команда lock блокирует шину памяти (по меньшей мере, для указанного адреса назначения) на время выполнения следующей команды. Поскольку платформа х86 позволяет уменьшать значение прямо в памяти, без необходимости его явного предварительного чтения в регистр, мы имеем все необходимое для реализации атомарного уменьшения: нам достаточно заблокировать шину памяти, а затем немедленно выполнить команду decl с этим адресом в памяти.
Функция atomic_dec (строка 10241) выполняет именно это для платформы х86. Версия макрокоманды LOCK, которая определена директивой #define в строке 10192 для симметричной мультипроцессорной системы, развертывается в команду lock. (Версия для однопроцессорной системы, которая определена директивой #define двумя строками ниже, просто пуста, поскольку единственный процессор не нуждается в защите от других процессоров, и блокировка шины памяти будет напрасной тратой времени.) Теперь можно применять перед встроенным ассемблерным кодом макрокоманду LOCK и блокировать следующую команду для версий ядра симметричной мультипроцессорной системы. Если процессор В вызовет функцию atomic_dec в то время, как блокировка процессора А находится в действии, процессор В автоматически перейдет в состояние ожидания до тех пор, пока процессор А не удалит блокировку. Это успех!
Да, почти. Первоначальная проблема еще не совсем решена. Задача состояла не только в атомарном уменьшении числа ссылок, но также и в определении того, равно ли результирующее значение 0. Теперь мы может выполнять атомарное уменьшение, но что, если другой процессор успеет проскочить между этим уменьшением и проверкой результата?
К счастью, решение этой части проблемы не требует специализированной помощи процессора. Будучи заблокированной или нет, команда decl в архитектуре х86 всегда устанавливает флажок Zero процессора, если результат равен 0, и этот флажок является собственной принадлежностью процессора, поэтому никакой другой процессор не может повлиять на него между частью операций, связанной с уменьшением, и частью операций, связанной с проверкой. В соответствии с этим, в функции atomic_dec_and_test (строка 10249) выполняется блокированное уменьшение, как и раньше, а затем устанавливается значение локальной переменной с на основании значения флажка Zero процессора. Эта функция возвращает ненулевое (истинное) значение, если результат после уменьшения стал равен 0.
Функции atomic_dec, atomic_dec_and_test, а также другие функции, которые определены в том же файле, оперируют с объектами типа atomic_t (строка 10205). Объект atomic_t, как и макрокоманда LOCK, имеет разные определения для однопроцессорной системы и симметричной мультипроцессорной системы, и здесь разница состоит в том, что в случае симметричной мультипроцессорной системы введен спецификатор типа volatile, который указывает транслятору gcc, чтобы он не делал некоторых предположений относительно отмеченной переменной (например, не предполагал, что ее можно безопасно хранить в регистре).
Кстати, есть сведения, что все макрокоманды __atomic_fool_gcc, которые разбросаны по этому коду, больше не нужны; они применялись для обхода ошибки в выработке объектного кода в ранних версиях gcc.
Проверка и установка
Классическим параллельным примитивом является проверка и установка. Операция проверки и установки атомарно читает значение из какого-то места в памяти и записывает в него новое значение, возвращая старое. Как правило, в этом месте может находиться 0 или 1, и новым значением, которое записывает операция проверки и установки является 1, то есть «установка». Противоположностью операции проверки и установки является операция проверки и очистки, которая выполняет то же, за исключением того, что записывает 0 вместо 1. Некоторые варианты операции проверки и установки могут записывать либо 1, либо 0, поэтому две операции, проверка и установка или проверка и очистка, сводятся к одной операции только с разными операндами.
Примитив проверки и установки позволяет реализовать любые другие операции, предназначенные для параллельного выполнения. (И действительно, на некоторых процессорах в качестве параллельного примитива предусмотрена только проверка и установка.) Например, проверка и установка может применяться для защиты счетчика ссылок в предыдущем примере. Мы пытались применить аналогичный метод: прочитать значение из места в памяти, проверить, равняется ли оно 0 и если да, записать 1 и перейти на этап доступа к защищенному значению. Эта попытка оказалось неудачной не потому, что была логически не обоснована, а потому, что не было способа реализовать ее атомарно. При наличии атомарного примитива проверки и установки мы можем превратить decl в атомарную команду без применения команды lock.
Однако проверка и установка имеет свои недостатки:
- Это примитив низкого уровня. Если предусмотрен только он, на его основе придется реализовать все другие примитивы.
- Он приводит к ненужному расходу ресурсов. Что произойдет, если компьютер проверит значение и обнаружит, что оно уже равно 1? Значение в памяти не изменится, поскольку оно будет просто перекрыто тем же значением. Но тот факт, что оно уже было установлено, означает, что к защищенному объекту уже обращается какой-то другой процесс, поэтому выполнение пока нельзя продолжить. Требуется дополнительная логика (проверка и переход по циклу), которая бесполезно расходует время процессора и немного увеличивает объем программы (что, в свою очередь, приводит к потере места в кэше).
Команда lock процессора х86 позволяет упростить реализацию примитивов более высокого уровня, но в архитектуре х86 можно также применять атомарную проверку и установку. Самый прямолинейный способ состоит в применении команды lock в сочетании с btsl (bit-test-and-set — поразрядная проверка и установка). Такой подход применяется в блокировках в цикле, которые рассматриваются далее в этой главе.
Еще одним способом реализации проверки и установки в архитектуре х86 является применение предусмотренной в ней команды xchg (exchange — обмен), которая автоматически трактуется процессором х86, как если бы ей предшествовала команда lock, во всяком случае, когда один из ее операндов находится в памяти.
Команда xchg является более универсальной по сравнению с сочетанием lock/btsl, поскольку она позволяет обменивать одновременно 8, 16 или 32 бита, а не просто 1 бит.
Кроме одного применения в коде arch/i386/kernel/entry.S, в ядре команда xchg скрыта за макрокомандой xchg (строка 13052), которая, в свою очередь, реализована на основе функции __xchg (строка 13061). Это сделано для того, чтобы в коде ядра макрокоманду xchg можно было использовать в части кода, независимой от архитектуры; на каждой платформе предусмотрена собственная эквивалентная реализация этой макрокоманды.
Интересно, что макрокоманда xchg является основой еще одной макрокоманды, tas (test-and-set, проверка и установка, строка 13054). Однако эта макрокоманда в коде ядра нигде не используется.
В ядре макрокоманда xchg иногда применяется для выполнения простой проверки и установки (но не обязательно для повторного прохода по циклу до тех пор, пока блокировка не станет доступной, как в строке 22770), а также применяется для других целей (как в строке 27427).
Семафоры
В главе 9 были описаны основные понятия семафоров и показано их применение для межпроцессного взаимодействия. В ядре предусмотрены собственные реализации семафоров для его собственных целей, и эти конструкции обычно называют «семафорами ядра». (В настоящей главе под словом «семафор» без пояснительных слов следует понимать «семафор ядра».) Точно такое же основное определение семафора, которое было приведено в главе 9, применяется и к семафорам ядра: семафор должен допустить к ресурсу максимально возможное число пользователей (равное числу ключей, первоначально размещенных на гвозде перед входной дверью) и установить правило, что каждый претендент на ресурс должен взять ключ перед переходом к использованию ресурса.
Теперь вы, наверное, представляете себе, как можно построить семафоры с применением либо проверки и установки, для двоичных («одноключевых») семафоров, либо с применением такой функция, как atomic_dec_and_test, для счетных семафоров. Именно это и применяется в ядре: в нем семафоры представлены целыми числами, а функции down (строка 11644) и up (строка 11714), в числе прочих, служат для уменьшения и увеличения этого целого. Как будет вскоре показано, основополагающий код уменьшения и увеличения значений целочисленных переменных аналогичен тому, который применяется в atomic_dec_and_test и подобных функциях.
В качестве исторической справки отметим, что впервые понятие семафора формализовал голландский ученый Эдсгер Дийкстра (Edsger Dijkstra), поэтому фундаментальные операции над семафорами названы по-голландски — Proberen и Verhogen, которые обычно сокращенно обозначают Р и V. Эти слова переводятся как «проверка» (что означает проверку того, доступен ли ключ и взятие его, если да) и «приращение» (возвращение ключа снова на гвоздь). Эти первые буквы стали источником терминов «procure» (приобрести) и «vacate» (освободить), которые были введены в предыдущей главе. Однако в ядре Linux эта традиция нарушена и соответствующие операции получили названия down и up.
В ядре для представления семафоров используется очень простой тип: struct semaphore, который определен в строке 11609. Он имеет только три члена:
count. Отслеживает число все еще доступных ключей. Если он равен 0, ключ взят; если он отрицателен, ключ взят и его возврата ждут другие претенденты. Кстати, отметим, что число дополнительных претендентов равно абсолютному значению величины count, если она равна 0 или отрицательна.
Макрокоманда sema_init (строка 11637) позволяет инициализировать count с установкой в любое значение, поэтому семафоры ядра могут быть двоичными (если величина count инициализирована значением 1) или счетными (если предусмотрено какое-то другое положительное начальное значение). Весь код семафора ядра полностью поддерживает и двоичные, и счетные семафоры, и первый тип семафора является просто особым случаем последнего. Однако на практике величина count всегда инициализируется значением 1, поэтому семафоры ядра всегда являются двоичными. Тем не менее, ничто не препятствует применению разработчиками счетных семафоров в будущем.
Кстати, нет ничего магического в том, что в работе с семафором в качестве первоначального значения count используется положительное число и его уменьшение служит в качестве сигнала о том, что нужен семафор. Можно также использовать отрицательное (или нулевое) первоначальное значение count и предусмотреть увеличение или придерживаться какой-то иной схемы. Просто применение положительного числа принято для семафоров ядра, и оказалось, что оно прекрасно сочетается с абстрактной моделью ключей на гвозде. И действительно, как будет показано ниже, блокировка ядра организована полностью иным образом; в ней соответствующие переменные первоначально принимают отрицательное значение и увеличиваются, когда процессы хотят приобрести эти блокировки. - waking. Используется временно в течение и после операции up; эта величина устанавливается в 1, если up освобождает семафор, и в 0 — в ином случае.
- wait. Очередь процессов, которые должны были быть приостановлены в ожидании, пока этот семафор не станет снова доступным.
down
11644: Операция down уменьшает величину count семафора. Можно было надеяться, что ее реализация будет столь же элементарной, как и само это понятие, но увы, жизнь не настолько проста.
11648: Уменьшение величины count семафора, которое в симметричной мультипроцессорной системе происходит с учетом необходимости атомарного выполнения этой операции. В симметричной мультипроцессорной системе (и, безусловно, в однопроцессорной системе), по существу, выполняется то же, что и в функции atomic_dec_and_test, за исключением того, что доступ к целому числу осуществляется в объекте другого типа.
У читателя может возникнуть вопрос: может ли произойти антипереполнение величины count? He может: процесс после уменьшения величины count всегда переходит в состояние ожидания, поэтому каждый конкретный процесс может захватить одновременно только один семафор, и в запасе есть еще намного больше отрицательных значений величины типа int по сравнению с числом процессов.
11652: Если знаковый разряд установлен, семафор отрицателен. Это значит, что значение count было равным 0 или отрицательным непосредственно перед тем, как было уменьшено, поэтому процесс не сумел получить семафор и должен перейти в состояние ожидания до тех пор, пока семафор не станет доступным. Реализация этого потребовала применения в следующих нескольких строках многих хитростей. Команда js выполняет переход, если знаковый разряд установлен (то есть, если результат команды decl был отрицателен), и 2f обозначает цель перехода. Здесь 2f — не шестнадцатиричное значение, а специальный синтаксис ассемблера GNU: 2 означает переход к локальному символу «2», a f — поиск этого символа впереди. (2b означало бы поиск самого последнего локального символа «2» сзади.) Этот локальный символ находится в строке 11655.
11653: Ветвление не выполнено, поэтому процесс получил семафор. Это фактически конец функции down, несмотря на то, что он так не выглядит. Это вскоре станет ясно.
11654: Одной из самых сложных для понимания частей функции down является директива .section, находящаяся непосредственно перед адресатом перехода, которая указывает, что следующий код нужно собрать в отдельной секции ядра: в секции под названием .text.lock. Данная секция будет размещаться в памяти и рассматриваться как выполнимая программа. Это указано флажком ах — строкой, которая следует за именем секции; обратите внимание, что этот флажок ах не имеет ничего общего с регистром АХ процессора х86. В результате ассемблер перемещает команды в строках 11655 и 11656 из секции down, в которой они находятся, в другую секцию выполнимого кода ядра, поэтому объектный код, вырабатываемый на основе этих строк, не является физически смежным с кодом, вырабатываемом на основе предыдущих строк. Вот почему строка 11653 представляет собой конец функции down.
11655: Это адресат перехода, достигаемый, если нельзя было получить семафор. Команда pushl $1b (ее можно также записать и без знака $) не помещает в стек шестнадцатиричное значение 1b — это была бы команда pushl S0x1b. Вместо этого, данное значение 1b представляет собой тот же синтаксис ассемблера GNU, с которым мы ранее встретились в случае применения 2f: он указывает на адрес команды, в данном случае — на адрес первой локальной метки «1», которая встретится при поиске в обратном направлении. Таким образом, эта команда помещает в стек адрес строки 11653; данный адрес станет адресом возврата, чтобы после последующего перехода ход выполнения вернулся к концу функции down.
11656: Переход отсюда к функции __down_failed (не включена в эту книгу). Эта функция сохраняет несколько регистров в стеке и вызывает функцию __down (строка 26932), которая будет описана ниже, для выполнения работы по ожиданию семафора. После возврата из функции __down функция __down_failed возвращается к down, которая также выполняет возврат. Функция __down не выполняет возврат до тех пор, пока процесс не приобретет семафор; в результате, когда бы ни произошел возврат из функции down, процесс имеет семафор, независимо от того, получил ли он его немедленно или должен был ждать.
11657: Назначение директивы ассемблера .previous не описано в документации, но она должна означать возвращение к предыдущей секции и прекращение действия директивы .section в строке 11654.
down_interruptible
11664: Функция down_interruptible применяется, когда процесс желает приобрести семафор, но оставить за собой возможность прервать ожидание после поступления какого-либо сигнала. Реализация этой функции очень напоминает функцию down, но имеет два отличия, которые описаны в следующих двух абзацах.
11666: Первым отличием является то, что функция down_interruptible возвращает значение типа int для указания того, получила ли она семафор или была остановлена каким-то сигналом. Возвращаемое значение (которое представлено переменной result) равно 0 в первом случае и отрицательно — в последнем. Это частично выполняется в строке 11675, где переменная result обнуляется, если функция приобрела семафор без ожидания.
11679: Вторым отличием является то, что функция down_interruptible переходит на функцию __down_failed_interruptible (не включена в эту книгу), а не на функцию __down_failed. Следуя принципам, применяемым в функции __down_failed, __down_failed_interruptible просто корректирует несколько регистров и вызывает функцию __down_interruptible (строка 26942), которая будет описана ниже. Отметим, что адрес возврата, установленный для функции __down_failed_interruptible, строка 11676, следует за командой xorl, которая обнуляет переменную result в том случае, если семафор был приобретен сразу же. Возвращаемое значение функции __down_interruptible будет скопировано в переменную result.
down_trylock
11687: Функция down_trylock аналогична функции down_interruptible, за исключением того, что в ней предусмотрен вызов __down_failed_trylock (которая вызывает функцию __down_trylock, строка 26961, описанную ниже). Поэтому здесь нет необходимости рассматривать функцию down_trylock.
DOWN_VAR
26900: Это первая из трех макрокоманд, где размещен некоторый код, общий для функций __down и __down_interruptible. В ней просто объявлено несколько переменных.
DOWN_HEAD
26904: Эта макрокоманда просто переводит задачу tsk (которая была объявлена в макрокоманде DOWN_VAR) в состояние, указанное параметром task_state, а затем добавляет tsk к очереди заданий, ждущих семафора. И наконец, она начинает бесконечный цикл; размещенные в цикле функции __down и __down_interruptible прервут этот цикл, когда будут готовы выйти.
DOWN_TAIL
26926: Эта макрокоманда начинается со связанной с окончанием цикла по переводу задачи tsk снова в состояние task_state в ходе подготовки к повторной попытке захватить семафор.
26929: Произошел выход из этого цикла; задача tsk либо приобрела семафор, либо была прервана каким-то сигналом (только в функции __down_interruptible). Так или иначе, задача готова продолжить выполнение и больше не ждет семафора, поэтому она снова переводится в состояние TASK_RUNNING и извлекается из очереди ожидания семафора.
__down
26932: Функции __down и __down_interruptible организованы следующим образом:
- Объявление нужных локальных переменных с помощью макрокоманды DOWN_VAR, за которой могут следовать дополнительные объявления локальных переменных.
- Переход в бесконечный цикл с помощью макрокоманды DOWN_HEAD.
- Выполнение работы, специфической для этой функции, в теле цикла.
- Перепланирование.
- Завершение цикла с помощью макрокоманды DOWN_TAIL. Обратите внимание, что вызов функции schedule (строка 26686, рассматривается в главе 7) удалось переместить в макрокоманду DOWN_TAIL.
- Выполнение любой завершающей работы, специфической для этой функции.
Ниже рассмотрены только этапы, специфические для каждой функции (этапы 3 и 6).
26936: В теле цикла в функции __down происходит вызов функции waking_non_zero (не рассматривается), которая атомарно проверяет значение sem->waking для определения того, был ли процесс активизирован. Если да, она обнуляет значение waking и возвращает 1 (все это продолжает оставаться частью одной и той же атомарной операции); если нет, она возвращает 0. Поэтому возвращаемое ею значение указывает, захватил ли процесс семафор. Если он его захватил, происходит выход из цикла и функция выполняет возврат. В ином случае, процесс продолжает ждать. Кстати отметим, что функция __down пытается захватить семафор перед вызовом функции schedule. Почему бы не поступить иначе, если известно, что величина count семафора является отрицательной? Это не имело бы значения для любых итераций цикла, кроме первой, но удаление ненужной проверки может лишь немного ускорить первую итерацию. Если для этого есть какие-то конкретные причины, то вполне вероятно, что семафор мог бы быть освобожден (возможно, другим процессором) через несколько микросекунд после первой его проверки, и стоимость лишнего захвата флажка намного меньше стоимости дополнительного перепланирования. Поэтому функция __down могла бы также выполнить одну последнюю быструю проверку перед перепланированием.
__down_interruptible
26942: Функция __down_interruptible, по существу, аналогична функции __down, за исключением того, что она разрешает прерывания по сигналу.
26948: Следовательно, функция waking_non_zero_interruptible (не рассматривается) вызывается при захвате семафора. Она возвращает 0, если ей не удалось захватить семафор, возвращает 1, если она его получила, или –EINTR, если она была прервана каким-то сигналом. В первом случае цикл продолжается.
26958: В ином случае, функция __down_interruptible выходит, возвращая 0 (а не 1), если она получила семафор, или –EINTR, если была прервана.
__down_trylock
26961: Иногда, если семафор нельзя было получить немедленно, ядро просто должно продолжить работу. Следовательно, функция __down_trylock не остается в цикле. Она просто вызывает функцию waking_nonzero_trylock (не рассматривается), которая захватывает семафор и, если это не удается, наращивает величину count семафора (поскольку ядро больше не собирается ждать его освобождения) и выполняет возврат.
up
11714: Мы подробно рассмотрели, что происходит, когда ядро пытается приобрести семафор, а также что происходит, когда это не удается. Теперь настало время рассмотреть другую сторону этого уравнения: что происходит при освобождении семафора. Эта часть сравнительно проста.
11721: Атомарное увеличение значения count семафора.
11722: Если результат — меньше или равен 0, какой-то процесс ждет активизации. Функция up переходит вперед к строке 11725.
11724: В функции up применяется такой же прием, как и в функции down: все последующие действия выполняются в отдельной секции ядра, а не в самой функции up. Адрес конца функции up помещается в стек и функция up переходит к функции __up_wakeup (не рассматривается). Она выполняет такие же манипуляции с регистрами, как и в функции __down_failed, и вызывает функцию __up, которая рассматривается ниже.
__up
26877: Функция __up отвечает за активизацию всех процессов, ждущих данный семафор.
26879: Вызов функции wake_one_more (не рассматривается в этой книге), которая проверяет, не ждут ли какие-то процессы данный семафор и, если да, увеличивает значение члена waking, чтобы подать им сигнал, что они могут попытаться захватить семафор.
26880: Используется макрокоманда wake_up (строка 16612), которая просто вызывает функцию __wake_up (строка 26829) для активизации всех ждущих процессов.
__wake_up
26829: Как описано в главе 2, функция __wake_up активизирует все процессы в переданной ей очереди ожиданий, если они находятся в одном из состояний, предусмотренных параметром mode. При вызове из функции wake_up она активизирует все, что находится в состояниях TASK_UNINTERRUPTIBLE или TASK_INTERRUPTIBLE; при вызове из функции wake_up_interruptible (строка 16614), она активизирует только задачи, находящиеся в состоянии TASK_INTERRUPTIBLE.
26842: Процессы активизированы функцией wake_up_process (строка 26356), которая была кратко описана выше и будет рассмотрена более подробно далее в этой главе.
Сейчас для нас представляют интерес последовательности активизации всех процессов. Поскольку функция __wake_up активизирует все процессы, поставленные в очередь, а не только первый в очереди, все они конкурируют за семафор, поэтому в случае симметричной мультипроцессорной системы они могут претендовать на него буквально одновременно. Как правило, победителем будет тот, кто первым получил процессор. Это будет процесс с наилучшим значением адекватности (вспомните описание goodness, строка 26388, в главе 7). Это имеет смысл, поскольку процессы с более высоким значением goodness должны иметь приоритет при выполнении их работы. (Это может быть особенно важно для процессов в реальном масштабе времени.)
Недостатком этого подхода является риск перевода на голодный паек, который возникает, когда процесс постоянно лишается возможности получить ресурс, необходимый ему для продолжения работы. Здесь перевод на голодный паек может произойти, если два процесса, постоянно конкурирующие за один и тот же семафор, всегда находятся в таких условиях, когда первый процесс имеет более высокое значение goodness, чем второй. Второй процесс никогда не получит процессор. Этот сценарий не так уж маловероятен, как кажется: предположим, что один из них является процессом, работающим в реальном масштабе времени, а другой работает со значением nice (увеличение которого равносильно уменьшению приоритета), равным 20. Мы можем избежать риска перевода на голодный паек, всегда пробуждая только первый процесс в очереди, но это иногда было бы равносильно отказу в предоставлении процессора процессам, которые во всех иных отношениях в большей степени заслуживают его получения.
Этот вопрос до сих пор еще не рассматривался, но планировщик Linux может также полностью лишить процесс доступа к процессору при определенных обстоятельствах. Это не обязательно непредвиденное развитие событий, а лишь результат применения определенного проектного решения, и, по крайней мере, результат неуклонного применения конкретного принципа во всем коде ядра, что само по себе неплохо. Отметим также, что перевод на голодный паек может с таким же успехом возникать при использовании других описанных выше механизмов. Например, примитив проверки и установки так же может явиться потенциальной причиной перевода на голодный паек, как и семафор ядра.
Во всяком случае, на практике перевод на голодный паек возникает редко, поэтому представляет собой интересный теоретический случай.
Блокировка в цикле
Последним примитивом параллельного программирования, который важен для описания материала этой главы, является блокировка в цикле. Принцип блокировки в цикле состоит в применении жесткого цикла для повторного осуществления попытки захватить ресурс (блокировку), пока не будет достигнут успех. Это часто осуществляется с применением циклических конструкций, то есть многократного повторения операций типа проверки и установки, до тех пор, пока не будет получена блокировка.
Этот примитив во многом напоминает двоичный семафор, и действительно, таковым и является. Единственное принципиальное различие между блокировкой в цикле и двоичным семафором состоит в том, что ожидание семафора не всегда выполняется в цикле; можно попытаться захватить семафор и просто отказаться на время от этой попытки, если она сразу же не удалась. Как следствие, блокировку в цикле можно реализовать, вложив код семафора в цикл. Однако, поскольку блокировки в цикле представляют собой частный случай семафоров, они имеют более эффективную реализацию.
Переменная блокировки в цикле, в которой выполняется проверка и установка бита, всегда имеет тип spinlock_t (строка 12785). Применяется только самый младший бит объекта spinlock_t; он равен 0, если блокировка доступна, и 1, если она занята. Блокировка в цикле в ее объявлении инициализируется в значение SPIN_LOCK_UNLOCKED (строка 12789); иначе, ее можно инициализировать с помощью функции spin_lock_init (строка 12791). В обоих этих случаях член блокировки spinlock_t устанавливается в 0, то есть он разблокирован.
Обратите внимание, что в комментарии в строке 12795 вкратце упоминается и тут же отвергается стремление к справедливому подходу, который исключает возможность только что описанного перевода на голодный паек (считается, что переводить на голодный паек процессор или процесс — «несправедливо»).
Макрокоманды блокировки и разблокировки примитива блокировки в цикле построены на основе функций spin_lock_string и spin_unlock_string, поэтому в настоящем разделе подробно рассматриваются только эти функции. В других макрокомандах только добавляется блокировка и разблокировка прерываний, если они применяются.
spin_lock_string
12805: Эта макрокоманда имеет код, общий для всех макрокоманд блокировки примитива блокировки в цикле. Она также используется в предназначенных для архитектуры х86 версиях функций lock_kernel и unlock_kernel (которые не включены в эту книгу, хотя их универсальные версии — включены; см. строки 10174 и 10182).
12807: Попытка проверить и установить младший бит блокировки в цикле при заблокированной шине памяти, чтобы эта операция была атомарной по отношению к любым другим попыткам доступа к той же блокировке в цикле.
12808: При успешном завершении этой операции управление передается дальше; в ином случае, в макрокоманде spin_lock_string выполняется переход вперед к строке 12810 (команда btsl помещает старое значение бита во флажок Carry процессора, и поэтому здесь применяется команда jc). Это тот же прием, с которым мы уже встречались три раза: цель перехода находится в отдельной секции ядра.
12811: Команда стоит в жестком цикле, повторно проверяя младший бит блокировки в цикле. Обратите внимание, что команды btsl и testb интерпретируют свой первый операнд по-разному: для btsl это — битовая позиция, а для testb — битовая маска. Следовательно, в строке 12811 происходит проверка того же бита, который макрокоманда spin_lock_string пыталась (и не смогла) установить в строке 12807, даже несмотря на то, что в первом случае используется операнд $0, а во втором — операнд $1.
12813: Бит был очищен, поэтому макрокоманда spin_lock_string должна выполнить еще одну попытку его захватить. Она переходит назад к строке 12806. Этот код можно было бы упростить только до двух команд и префикса lock:
1: lock ; btsl $0, %0
jc 1b
Однако при использовании этой более простой версии производительность системы значительно снизится, поскольку блокировка шины памяти будет происходить при каждой итерации цикла. Версия, применяемая в ядре, длиннее, но она позволяет другим процессорам работать более эффективно, поскольку в ней предусмотрена блокировка шины памяти только в том случае, если есть основание надеяться, что можно будет захватить блокировку.
spin_unlock_string
Блокировка в цикле для чтения/записи
Частным случаем примитива блокировки в цикле является блокировка в цикле для чтения/записи. Основной принцип состоит в том, что в некоторых случаях необходимо обеспечить нескольким процессам доступ для чтения к одному и тому же объекту, но на то время, пока к объекту осуществляется доступ для записи, к нему не должны быть допущены другие процессы чтения или записи.
По такому же принципу, который применялся в блокировках в цикле на основе объекта типа spinlock_t, блокировки в цикле для чтения/записи представлены объектом типа rwlock_t (строка 12853), который может быть инициализирован в объявлении с помощью RW_LOCK_UNLOCKED (строка 12858). Макрокомандами самого низкого уровня, предназначенными для работы с rwlock_t, являются read_lock, read_unlock, write_lock и write_unlock; они рассматриваются в настоящем разделе. Все макрокоманды, которые будут описаны вслед за этими макрокомандами, и которые строятся на их основе, станут вполне понятными после изучения этих первых четырех макрокоманд.
В комментарии в строке 12860 указано, что член lock объекта rwlock_t имеет отрицательное значение, если какой-то процесс владеет блокировкой записи. Он равен 0, если нет ни процессов чтения, ни процессов записи, и положителен, если есть процессы чтения, но нет процессов записи; в этом случае значение lock показывает число процессов чтения.
read_lock
12867: Начинает работу с атомарного увеличения значения члена lock объекта rwlock_t. Это рискованная операция и она может быть отменена.
12868: Если значение после увеличения остается отрицательным, какой-то процесс держит эту блокировку записи или, по крайней мере, какой-то процесс пытается ее приобрести. Макрокоманда read_lock переходит вперед к строке 12870 (обратите внимание — в другую секцию ядра). В ином случае, не существует ни одного процесса записи (хотя могут быть или не быть другие процессы чтения — это просто не имеет значения), поэтому можно перейти к коду блокировки чтения.
12870: Имеется процесс записи. Макрокоманда read_lock отменяет результат увеличения в строке 12867.
12871: Циклическое повторение в ожидании, когда член lock объекта rwlock_t станет равным 0 или положительным.
12873: Переход назад к строке 12866 для повторной попытки.
read_unlock
write_lock
12883: Выдача сигнала о том, что какой-то процесс хочет приобрести блокировку записи: проверка и установка знакового бита блокировки для обеспечения отрицательного значения члена lock.
12884: Если знаковый бит уже установлен, какой-то еще процесс владеет блокировкой записи; макрокоманда write_lock переходит вперед к строке 12889 (которая, как и прежде, находится в другой секции ядра).
12885: Больше никто не пытался получать блокировку записи, но процессы чтения все еще могут существовать. Поскольку знаковый бит установлен, никакой иной процесс чтения не сможет приобрести эту блокировку чтения, но макрокоманда write_lock все еще обязана ждать, пока не исчезнут все прочие существующие процессы чтения. Она начинает работу с проверки того, установлен ли какой-либо из 31 бита в младших разрядах, что может служить свидетельством того, что значение lock перед этим было положительным. Если нет, то значение lock перед инверсией знакового бита было равно 0, а это значит, что нет процессов чтения, следовательно, данный процесс записи может безопасно продолжить свою работу, поэтому управление просто переходит дальше. Однако, если среди 31 бита в младших разрядах был установлен хоть один бит, это значит, что имеются процессы чтения, поэтому макрокоманда write_lock переходит к строке 12888, чтобы там ожидать завершения их работы.
12888: Данный процесс является единственным процессом записи, но есть еще процессы чтения. Макрокоманда write_lock на данный момент очищает знаковый бит (она снова захватит его позднее). Любопытно отметить, что эти манипуляции со знаковым битом не нарушают правильности операций процессов чтения с членом lock. Рассмотрим в качестве примера приведенную ниже последовательность событий:
- Два процесса чтения увеличивают значение lock; теперь шестнадцатиричное значение lock равно 0x00000002.
- Потенциальный процесс записи устанавливает знаковый бит; теперь lock имеет значение 0x80000002.
- Один из процессов чтения уходит; теперь lock имеет значение 0x80000001.
- Процесс записи обнаруживает, что не все оставшиеся биты равны 0; это значит, что есть еще процессы чтения. Таким образом, процесс записи все еще не может приобрести блокировку записи и поэтому очищает знаковый бит; теперь значение lock равно 0x00000001.
Таким образом, попытки чтения и записи могут чередоваться в любом порядке, не влияя на правильность результата.
12889: Циклическое выполнение в ожидании, пока значение счетчика не упадет до 0, то есть в ожидании, пока не уйдут все процессы чтения. В действительности, нулевое значение показывает, что не только ушли все процессы чтения, но и никто иной еще не приобрел блокировку записи.
12891: По-видимому, ушли все процессы чтения и записи; макрокоманда write_lock начинает все сначала и снова захватывает блокировку записи.
write_unlock
Усовершенствованные программируемые контроллеры прерываний и связь между процессорами
Спецификация мультипроцессорной обработки компании Intel основана на использовании усовершенствованных программируемых контроллеров прерываний (APIC — Advanced Programmable Interrupt Controller). Процессоры взаимодействуют друг с другом, посылая друг другу прерывания. Подключив к прерываниям запросы на выполнение действий, процессоры могут до определенной степени управлять работой друг друга. Каждый процессор имеет свой собственный APIC (называемый локальным контроллером APIC для данного процессора) и имеется также единственный контроллер APIC ввода/вывода, который обрабатывает прерывания, поступающие от устройств ввода/вывода. В обычной мультипроцессорной системе Intel контроллер APIC ввода/вывода занимает место микросхемы контроллера прерываний, которая мельком упоминалась в главе 6.
Ниже приведено несколько примеров функций, чтобы вы могли получить представление о том, как работают эти контроллеры.
smp_send_reschedule
5019: Эта однострочная функция, применение которой показано далее в этой главе, просто посылает прерывание на целевой процессор, идентификатор которого задан в качестве параметра. Она вызывает функцию send_IPI_single (строка 4937) с указанием идентификатора процессора и вектора RESCHEDULE_VECTOR. Вектор RESCHEDULE_VECTOR, наряду с другими векторами прерываний процессора, объявлен директивой #define в блоке, который начинается в строке 1723.
send_IPI_single
4937: Функция send_IPI_single посылает одно прерывание IPI (interprocessor interrupt — это принятое в компании Intel сокращение для межпроцессорного прерывания) на указанный процессор назначения. В этот момент ядро взаимодействует с локальным контроллером APIC процессора-отправителя на довольно низком уровне.
4949: Получение содержимого верхней половины регистра команды прерывания (ICR — Interrupt Command Register) — регистра, через который запрограммирован локальный контроллер APIC, но с полем назначения, установленным в dest. Несмотря на использование «2» в функции __prepare_ICR2 (строка 4885), в процессоре фактически имеется один ICR, а не два. Но это 64-разрядный регистр, который принято рассматривать в ядре как два 32-разрядных регистра, поэтому в коде ядра «ICR» означает младшие 32 бита регистра, a «ICR2» — старшие 32 бита. Поле регистра ICR с обозначением процессора назначения, которое нужно установить, находится в старших 32 битах, то есть в ICR2.
4950: Запись измененной информации обратно в ICR. В ICR теперь содержится информация о процессоре назначения.
4953: Вызов функции __prepare_ICR (строка 4874) для установки вектора прерываний, который нужно послать в процессор назначения. (Обратите внимание: ничто не препятствует тому, чтобы процессором назначения был текущий процессор, поскольку ICR вполне способен послать любое прерывание IPI в свой собственный процессор. Однако автор не может придумать ни одной причины, по какой это может потребоваться.)
4957: Отправляет прерывание, записывая новую конфигурацию ICR.
Как поддержка симметричной мультипроцессорной обработки влияет на архитектуру ядра
Теперь, после изучения примитивов, которые лежат в основе поддержки симметричной мультипроцессорной обработки, рассмотрим поддержку SMP в ядре. Оставшаяся часть главы посвящена анализу представительного набора кода симметричной мультипроцессорной обработки, распределенного по всему ядру.
Влияние SMP на планирование
Функция schedule (строка 26686) является функцией планировщика ядра и была рассмотрена очень подробно в главе 7. Версия schedule для симметричной мультипроцессорной системы имеет два основных отличия от версии для однопроцессорной системы:
- Блок кода, начинающийся со строки 26780 в самой функции schedule, который вычисляет некоторую информацию, необходимую в другом месте.
- Вызов функции __schedule_tail (строка 26638), который происходит и в симметричной мультипроцессорной системе, и в однопроцессорной системе, в последней не имеет силы, поскольку тело, функции __schedule_tail полностью содержит код симметричной мультипроцессорной обработки и поэтому, с точки зрения практики, относится к SMP.
schedule
26784: Получение текущего времени в виде числа циклов, которые истекли с момента включения компьютера. Это во многом аналогично проверке переменной jiffies, но со степенью детализации, измеряемой в циклах процессора, а не в импульсах сигнала времени таймера, очевидно, что это намного точнее.
26785: Вычисление величины промежутка времени, который истек с того момента, как функция schedule была запланирована на выполнение на этом процессоре, и регистрация текущего числа циклов на следующий раз, когда это снова произойдет. (Переменная schedule_data — это часть предназначенного для каждого процессора массива aligned_data, который определен в строке 26628.)
26790: Член avg_slice процесса (строка 16342) следит за тем, как долго процесс в среднем владел процессором в течение срока своего существования. Но это не простое среднее, а взвешенное среднее, в котором недавнее поведение процесса влияет на результаты намного сильнее, чем его поведение в отдаленном прошлом. (Поскольку настоящие компьютеры обладают конечной точностью, часть, относящаяся к «отдаленному прошлому», в конечном итоге приближается к нулю, когда прошлое становится достаточно отдаленным.) Этот член используется в функции reschedule_idle (строка 26221, которая рассматривается ниже) в качестве одного из оснований для принятия решения о том, направлять ли процесс на другой процессор. Поэтому он не нужен и не вычисляется для однопроцессорного случая.
26797: Регистрирует, какой процессор должен вступить в работу в следующую очередь (она выполняется на текущем процессоре), и поднимает его флажок has_cpu.
26803: При переключении контекста функция schedule регистрирует процесс, который теряет доступ к данному процессору; это нужно для работы функции __schedule_tail, которая рассматривается ниже.
__schedule_tail
26654: Если задача, которая только что потеряла доступ к процессору, изменила свое состояние (это описано в предыдущем комментарии), она отмечается для дальнейшего перепланирования.
26664: Поскольку ядро отключилось от этого процесса, он больше не имеет доступа к данному процессору и этот факт регистрируется.
reschedule_idle
26221: Функция reschedule_idle вызывается из функции wake_up_process, когда активизируемый процесс (идентификатор которого передается функции reschedule_idle в качестве параметра р) уже не находится в очереди выполнения. Функция пытается запланировать вновь активизированный процесс на другой процессор (холостой).
26225: Первая часть этой функции применяется и к симметричной мультипроцессорной системе, и к однопроцессорной системе. Она помогает высокоприоритетным процессам получить интервал времени процессора и, как правило, выполняет то же для процессов, переведенных на голодный паек. Если процесс является процессом в реальном масштабе времени или его динамический приоритет на определенную (произвольно выбранную) величину выше по сравнению с динамическим приоритетом процесса, который владеет процессором, этот процесс отмечается для перепланировки, чтобы он получил дополнительные шансы в конкуренции за процессор.
26263: Теперь мы переходим к части, касающейся симметричной мультипроцессорной системы, которая применяется только к процессам, не сумевшим пройти описанное выше испытание, однако это должно происходить довольно часто. Функция reschedule_idle должна определить, стоит ли попытаться выполнить этот процесс на другом процессоре.
Как уже упоминалось при описании функции schedule, член avg_slice процесса представляет собой взвешенную среднюю оценку потребления им процессорного времени, поэтому эта величина позволяет узнать, существует ли вероятность того, что определенный процесс будет непрерывно использовать процессор в течение относительно длительного времени, если он продолжит работу. Если нет, то этот процесс, вероятно, связан со вводом/выводом, во всяком случае он, по-видимому, не связан с интенсивным использованием процессора. Поскольку цель состоит в повышении общей пропускной способности за счет максимального распараллеливания, предоставление этому процессу, не связанному с использованием большого количества процессорного времени, другого процессора для его работы, вероятно, не имеет смысла.
26264: Во втором выражении этого условия if применяется макрокоманда related (расположенная сразу перед этой функцией в строке 26218), которая проверяет, владеют ли оба процесса или хотят ли владеть блокировкой ядра. Если да, то они, вероятно, не смогут выполняться одновременно, независимо от того, на какой процессор они запланированы, поэтому отправка данного процесса на другой процессор не повысит общую производительность параллельной обработки. Следовательно, если истинно это или предыдущее выражение, функция просто выполняет возврат, не рассматривая возможность перевода данного процесса на другой процессор.
26267: В остальных случаях вызывается функция reschedule_idle_slow (которая рассматривается ниже) для определения того, должен ли быть процесс уничтожен.
reschedule_idle_slow
26157: Функция reschedule_idle_slow, как сказано в этих комментариях, пытается найти холостой процессор для размещения на нем процесса с идентификатором р. Алгоритм основан на том наблюдении, что первые n входов массива заданий представляют собой холостые системные процессы, по одному на каждый из n процессоров компьютера. Холостые процессы работают тогда (и только тогда), когда ни один другой процесс на данном процессоре не хочет получить к нему доступ. Холостой процесс обычно переводит процессор в режим ожидания с малым потреблением энергии с помощью команды hlt, если это возможно. Следовательно, просмотр в цикле первых n процессов в массиве задач — это все, что требуется для поиска холостого процессора, если он существует. Функция reschedule_idle_slow просто опрашивает каждый холостой процесс, выполняется ли он в настоящее время; если да, то процессор, на котором он работает, должен быть холостым и поэтому должен быть хорошим кандидатом для размещения на нем процесса р.
Безусловно, всегда возможно, что выбранный процессор, который с виду является холостым, является таковым только временно и вскоре должен быть загружен сверх меры десятками высокоприоритетных процессов, нуждающихся в большом количестве процессорного времени, которые активизируются через несколько наносекунд. Поэтому такой алгоритм не является идеальным, но он вполне приемлем с точки зрения статистических данных о загрузке процессора, и помните, что такой алгоритм выбран также потому, что он полностью соответствует принятому в планировщике принципу «забегаловки» — не заглядывать слишком далеко вперед и стараться все выполнить побыстрее.
26180: Устанавливает локальные переменные. Здесь best_cpu представляет собой процессор, на котором сейчас работает процесс р; это — «наилучший» процессор, поскольку, если процесс р останется здесь, то не придется промывать кэш или нести другие издержки, a this_cpu обозначает процессор, на котором работает функция reschedule_idle_slow.
26182: Переменные idle и tsk проходят по массиву задач, a target_tsk представляет собой последний найденный работающий холостой процесс (или NULL, если такового нет).
26183: Переменная i инициализируется функцией smp_num_cpus (которая была вызвана за n итераций перед этим) и ведет обратный отсчет при каждой итерации.
26189: Если установлен флажок has_cpu этой холостой задачи, она активно работает на своем процессоре (мы будем называть его «целевым процессором»). Если нет, то целевой процессор занят какой-то другой задачей, поэтому он не является холостым и функция reschedule_idle_slow не будет пытаться запланировать процесс р на него. Здесь проявляется оборотная сторона проблемы, упомянутой перед этим: тот факт, что процессор сейчас не является холостым, не означает, что вскоре на нем не закончат свою работу все его процессы и не сделают его холостым. Но функция reschedule_idle_slow не имеет способа узнать об этом, поэтому она вполне может предполагать, что целевой процессор на какое-то время будет занят. Во всяком случае, вполне вероятно, что так оно и будет, и даже если случится иное, то достаточно скоро на этот процессор, который только что стал холостым, будут запланированы какие-то другие процессы.
26190: Однако, если целевой процессор является текущим процессором, он будет пропущен. Такое решение кажется неожиданным, но так или иначе это — «невероятный» случай: счетчик холостого процесса является отрицательным, поэтому проверка в строке 26226 должна была заранее предотвратить возможность достижения настоящей функцией данной точки.
26192: Был найден подходящий холостой процессор; связанный с ним холостой процесс сохраняется с использованием переменной target_tsk. Почему бы теперь просто не прервать цикл, коль скоро найден подходящий целевой процессор? Дело в том, что продолжение цикла может выявить, что процессор, на котором находится процесс р, также холост, и лучше оставить процесс на его текущем процессоре, чем послать на другой, если оба процессора являются холостыми.
26193: Здесь функция reschedule_idle_slow проверяет, является ли холостым процессор, на котором работает процесс р. Если только что найденный холостой процессор является именно тем процессором, на котором уже размещен процесс р, функция переходит вперед к метке send (строка 26203), чтобы запланировать процесс р на этот процессор.
26199: Функция рассмотрела возможность применения другого процессора; она выполняет обратный отсчет.
26204: Если в этом цикле обнаружены какие-либо холостые процессоры, холостая задача процессора отмечается для перепланирования и функция smp_send_reschedule (строка 5019) посылает на этот процессор прерывание IPI, чтобы он перепланировал свои процессы.
Можно видеть, что функция reschedule_idle_slow — это прекрасный пример работы по координации взаимодействия между процессорами, которая просто не нужна в однопроцессорной системе. В однопроцессорном компьютере задача определения процессора, который должен быть получен процессом, просто эквивалентна определению того, должен ли процесс получить единственный процессор системы или не должен получить ничего. Поэтому в компьютере с симметричной мультипроцессорной архитектурой нужно также приложить некоторые усилия для определения того, какой из процессоров системы в наибольшей степени подходит для данного процесса. Безусловно, полученное взамен невероятное повышение скорости вполне оправдывает это дополнительное усилие.
release
22951: Часть функции release, не связанная с симметричной мультипроцессорной системой, рассматривалась в главе 7, а здесь процесс-зомби отправляется в могилу и освобождается его объект struct task_struct.
22960: Проверка того, владеет ли процесс процессором. (Процессор, которым владеет этот процесс, мог еще не успеть очистить этот флажок; это вскоре будет сделано.) Если нет, функция release выходит из цикла и приступает, как обычно, к освобождению объекта struct task_struct.
22966: Иначе функция release ждет очистки флажка has_cpu процесса. Когда это произойдет, функция release снова повторит свою попытку. Это внешне странная ситуация (процесс уничтожен, но владеет процессором) встречается действительно редко, но не является невероятной. Процесс мог быть уничтожен на одном процессоре, который еще не нашел времени, чтобы очистить флажок has_cpu, a родитель данного процесса проверяет значение этого флажка с другого процессора.
smp_local_timer_interrupt
Эта функция является применяемым в симметричной мультипроцессорной системе аналогом функции update_process_times (строка 27382), применяемой только в однопроцессорных системах. Она выполняет все, что выполняет update_process_times (обновляет статистическую информацию процесса и ядра об использовании процессора), а также кое-что еще. Необычно то, что мультипроцессорная версия этих средств не была введена в однопроцессорную функцию, а была создана полностью отдельная функция такого же назначения. После изучения этой функции легко понять, почему было сделано именно так: она настолько отличается от однопроцессорной версии, что попытка объединить две версии для разных архитектур была бы бессмысленной. Функция smp_local_timer_interrupt может быть вызвана из двух мест:
- Из функции smp_apic_timer_interrupt (строка 5118), которая вырабатывает прерывание от таймера для симметричной мультипроцессорной системы. Ее настройка выполняется в строке 919 с использованием макрокоманды BUILD_SMP_TIMER_INTERRUPT, которая определена директивой #define в строке 1856.
- Из функции в строке 5776, которая представляет собой обычное однопроцессорное прерывание от таймера, do_timer_internipt. Это происходит только при эксплуатации симметричного мультипроцессорного ядра на однопроцессорном компьютере.
smp_local_timer_interrupt
5059: Счетчик prof_counter (строка 4610) следит за тем, как долго ядро должно ждать до обновления статистической информации процесса и ядра; если этот счетчик еще не достиг 0, управление фактически переходит к концу функции. Как описано в комментариях в этом коде, входы prof_counter начинают обратный отсчет с 1, если это значение не увеличено оператором root и, в связи с этим, эта работа по умолчанию выполняется при каждом импульсе сигнала таймера. Впоследствии, счетчик prof_counter[cpu] инициализируется из prof_multiplier[cpu].
Это, безусловно, оптимизация, поскольку выполнение всей работы внутри этого блока if при каждом импульсе сигнала времени привело бы к значительному замедлению, поэтому мы можем предпочесть пожертвовать некоторой точностью и выполнять эту работу с применением пакетной организации. Поскольку множитель профилирования является настраиваемым, можно выбрать желаемый коэффициент компромисса между быстродействием и точностью.
Однако автора в этом коде смущает одна тонкость: безусловно, после того, как счетчик prof_multiplier[cpu] будет исчерпан, статистические данные должны быть обновлены, как при истечении интервала, обозначенного величиной prof_multiplier[cpu], поскольку так и должно быть. (За исключением того случая, когда было просто изменено само значение prof_multiplier[cpu], но это мы пока не рассматриваем.) Вместо этого, код действует так, как если бы прошел интервал величиной только в один импульс таймера. Может быть, разработчики ядра намеревалась позднее где-то умножить число зарегистрированных импульсов таймера на величину prof_multiplier[cpu], но это в настоящее время не сделано.
5068: Если система во время активизации прерывания от таймера работала в режиме пользователя, то функция smp_local_timer_interrupt исходит из того, что весь этот импульс таймера был передан в режиме пользователя; в ином случае, она исходит из того, что весь импульс таймера был передан в режиме системы.
5073: Захватывает глобальную блокировку прерывания с помощью функции irq_enter (строка 1792). Это еще одна причина, по которой может потребоваться применение пакетной организации этой работы, поскольку вместо приобретения глобальной блокировки прерывания при каждом импульсе сигнала таймера, что может стать значительным источником конкуренции между процессорами, эта функция может захватывать его менее часто. Поэтому она действительно захватывает блокировку чаще, но в связи с этим, ей не приходится владеть этой блокировкой в течение более продолжительного времени при каждом ее захвате. Здесь опять возникает компромисс между повышением эффективности и потерей точности.
5074: Не заботится о ведении статистики для холостых процессов, поскольку это привело бы просто к бесполезному расходованию циклов процессора. Тем не менее, ядро отслеживает суммарное время простоя системы и любая более подробная статистическая информация об этом холостом процессе имела бы не очень большую ценность (например, мы знаем, что они всегда выполняются в режиме системы, поэтому нет необходимости явно вычислять интервалы времени их работы в системе).
5075: В этом функции update_process_times и smp_local_timer_interrupt имеют много общего: они обе вызывают функцию update_one_process для выполнения работы по обновлению статистической информации об использовании процессора отдельным процессом.
5077: Уменьшает значение счетчика процесса (его динамический приоритет), отмечая его для перепланирования, если он исчерпан.
5082: Обновление статистической информации ядра. Как и в функции update_process_times, время, израсходованное в режиме пользователя, будет отнесено либо к отсчету в ядре «времени пребывания в режиме с высоким значением nice» (с низким приоритетом), либо к отсчету обычного времени пользователя, в зависимости от того, находился ли приоритет данного процесса ниже DEF_PRIORITY.
5094: Повторная инициализация счетчика prof_counter процессора и освобождение глобальной блокировки прерывания. Безусловно, это должно выполняться именно в таком порядке, поскольку в другой последовательности выполнения перед повторной инициализацией значения prof_counter могло бы возникнуть еще одно прерывание от таймера.
lock_kernel и unlock_kernel
Эти функции имеют также версии, относящиеся к архитектуре х86; здесь рассматриваются только универсальные версии.
lock_kernel
10174: Эта довольно простая функция приобретает глобальную блокировку ядра; при этом, внутри любой пары lock_kernel/unlock_kernel должен находиться самое большее один процессор. В однопроцессорной системе это, безусловно, была бы пустая команда.
10176: Член lock_depth процесса первоначально был равен –1 (см. строку 24040). Когда это значение меньше 0 (если оно меньше 0, оно всегда равно –1), процесс не владеет блокировкой ядра; если оно больше или равно 0, он владеет блокировкой ядра. Поэтому единственный процесс может вызвать функцию lock_kernel, затем, не достигнув unlock_kernel, может вызвать другую функцию, которая также вызовет функцию lock_kernel. В этом случае процессу просто будет немедленно предоставлена блокировка ядра, а это именно то, что нам требуется. Поэтому, если после увеличения значения lock_depth процесса оно становится равным 0, процесс перед этим не владел блокировкой. Поэтому в данном случае функция приобретает блокировку в цикле, kernel_flag (строка 3587).
unlock_kernel
10182: Аналогичным образом, если уничтожение блокировки ядра приводит к уменьшению значения lock_depth ниже нуля, это значит, что процесс выходит из последней пары lock_kernel/unlock_kernel, в которой он находился. В этом случае должна быть разблокирована блокировка kernel_flag, чтобы ядро могли заблокировать другие процессы. Проверка знакового разряда результата (то есть применение «< 0», а не «== –1») заставляет транслятор gcc выработать немного более эффективный код и кроме этого, возможно, заставляет ядро корректно обрабатывать ситуацию при появлении несбалансированных пар lock_kernel/unlock_kernel (или не обрабатывать, в зависимости от принятого сценария).
softirq_trylock
Как было описано в главе 6, функция softirq_trylock применяется для обеспечения атомарной работы «нижних половин» обработчиков прерываний по отношению друг к другу, то есть для обеспечения того, чтобы в масштабах системы в любой конкретный момент времени выполнялось не более одной «нижней половины». В однопроцессорной системе это довольно просто: ядро должно только проверить и, возможно, также установить флажок. В симметричной мультипроцессорной системе это, естественно, гораздо сложнее.
softirq_trylock
12528: Проверка и установка бита 0 переменной global_bh_count. Хотя ее имя может вызывать другие ассоциации, переменная global_bh_count всегда равна либо 0, либо 1, поскольку может работать самое большее одна «нижняя половина». Во всяком случае, если переменная global_bh_count уже равна 1, это значит, что уже работает какая-то «нижняя половина», поэтому управление переходит к концу функции.
12529: Если также доступна блокировка global_bh_lock, то на этом процессоре могут выполняться «нижние половины». Это аналогично системе с двумя блокировками, которая используется в однопроцессорном случае.
12533: Функция softirq_trylock не смогла приобрести блокировку global_bh_lock, поэтому она отменяет свои действия.
cli и sti
Как было описано в главе 6, макрокоманды cli и sti применяются, соответственно, для запрещения и разрешения прерываний. В однопроцессорной системе каждая из них сводится к единственной команде cli или sti. Этого недостаточно для симметричной мультипроцессорной системы, в которой нужно не только запретить прерывания для данного локального процессора, но также временно исключить возможность обработки прерываний на всех других процессорах. Поэтому в симметричной мультипроцессорной системе макрокоманды cli и sti становятся вызовами функций __global_cli и __global_sti.
__global_cli
1220: Копирует регистр EFLAGS процессора в локальную переменную flags.
1221: Флажок Interrupts Enabled в архитектуре х86 — это девятый бит регистра EFLAGS, что позволяет понять определение EFLAG_IF_SHIFT в строке 1205. Эта переменная применяется для проверки того, были ли прерывания уже отменены, и в этом случае больше ничего не нужно делать для их отмены.
1223: Запрещает прерывания на этом процессоре.
1224: Если этот процессор еще не обрабатывает запрос на прерывание, функция __global_cli вызывает функцию get_irqlock (строка 1184) для приобретения глобальной блокировки прерываний. Если процессор уже обрабатывает какой-то запрос на прерывание, то он уже владеет глобальной блокировкой прерываний, как будет показано ниже.
Теперь прерывания на этом процессоре запрещены и этот процессор владеет глобальной блокировкой прерываний, поэтому работа выполнена.
__global_sti
1233: Если процессор еще не обрабатывает запрос на прерывание, функция __global_sti вызывает функцию release_irqlock (строка 10752) для уничтожения глобальной блокировки прерываний, которая была приобретена в функции __global_cli. Если процессор уже обрабатывает запрос на прерывание, то он уже владеет глобальной блокировкой прерываний и эта блокировка будет уничтожена в другом месте, как описано в следующем разделе.
1235: Снова разрешает прерывания на этом процессоре.
irq_enter и irq_exit
В главе 6 мельком упоминались однопроцессорные версии этих функций. Область кода, заключенная внутри пары irq_enter/irq_exit, является атомарной по отношению к любой другой подобной области; она также является атомарной по отношению к парам cli/sti.
irq_enter
1794: Вызов функции hardirq_enter (строка 10761) для атомарного увеличения как глобального счетчика прерываний, так и локального счетчика прерываний для этого процессора. Она регистрирует тот факт, что данный процессор обрабатывает запрос на прерывание.
1795: Выполняет проход по циклу до тех пор, пока этот процессор не получит глобальную блокировку прерываний. Именно поэтому автор ранее отметил, что этот процессор владеет глобальной блокировкой прерываний, если он уже обрабатывает запрос на прерывание, поскольку ко времени выхода из этой функции оба эти свойства будут предписаны. Задача отдельной трактовки этих свойств в коде ядра была бы тривиальной: в нем можно было бы просто непосредственно вызывать функцию hardirq_enter и при этом, не захватывать также глобальную блокировку прерываний. В нем это просто не применяется.
irq_exit
1802: Эта функция просто переходит к функции hardirq_exit (строка 10767), которая является обратной функции hardirq_enter. Кстати отметим, что и в функции irq_enter, и в функции irq_exit параметр irq игнорируется, по крайней мере, в архитектуре х86.
Глава 11. Настраиваемые параметры ядра
В соответствии с традицией, которая впервые возникла в версии BSD 4.4 системы Unix, в Linux предусмотрен системный вызов sysctl для динамической проверки и перенастройки некоторых средств системы без редактирования и перетрансляции исходного кода ядра и перезагрузки системы. Это значительный шаг вперед по сравнению с ранними версиями Unix, в которых настройка системы часто представляла собой нудную и утомительную работу. В Linux системные средства, которые могут быть проверены и перенастроены таким образом, сгруппированы по нескольким категориям: общие параметры ядра, параметры виртуальной памяти, сетевые параметры и так далее.
Те же средства доступны также через другой интерфейс — через файловую систему /proc. (Поскольку это на самом деле окно в систему, а не контейнер для настоящих файлов, /proc часто называют «псевдофайловой системой», но это — неуклюжий термин, и здесь эта разница не имеет никакого значения.) Категории настраиваемых параметров ядра соответствуют подкаталогам каталога /proc/sys, и каждый отдельный настраиваемый параметр ядра представлен файлом в одном из этих подкаталогов. Подкаталоги могут, в свою очередь, включать другие подкаталоги, которые содержат еще больше файлов, представляющих настраиваемые параметры ядра и, возможно, еще больше подкаталогов и так далее, хотя на практике уровень вложенности никогда не бывает слишком глубоким.
Каталог /proc/sys позволяет обойти обычный интерфейс sysctl, поскольку значение настраиваемого параметра ядра можно узнать, просто прочитав его из соответствующего файла, а его значение можно установить, просто выполнив запись в этот файл. К этим файлам применяются обычные права файловой системы Unix, поэтому их не может читать или писать первый попавшийся пользователь. Большинство этих файлов доступны для чтения любому пользователю, но для записи доступны только пользователю root, хотя есть и исключения; например, файлы в каталоге /proc/sys/vm (параметры виртуальной памяти) может читать и писать только пользователь root. Если бы не было каталога /proc/sys, проверка и настройка системы потребовала бы написания программы для вызова sysctl с необходимыми параметрами; это не сложная работа, но далеко не так удобна, как использование /proc/sys.
struct ctl_table
18274: Это центральная структура данных, используемая в коде, который описан в этой главе. Объекты struct ctl_table обычно объединяются в массивы и каждый такой массив соответствует входам в отдельном каталоге, находящемся где-то под каталогом /proc/sys. (По мнению автора, этот тип данных лучше было бы назвать struct ctl_table_entry.) Объект root_table (строка 30328) и массивы, которые следуют за ним, создают дерево массивов, в которых указатели child объекта struct ctl_table используются для соединения узлов дерева (указатели child рассматриваются в приведенном ниже списке). Отметим, что все эти массивы являются массивами объекта ctl_table, который просто служит объявлением typedef для объекта struct ctl_table; это установлено в строке 18184.
Связь в виде дерева массивов показана на рис. 11.1.
Рис. 11.1. Часть дерева объектов struct ctl_table
На этом рисунке показана небольшая часть дерева, состоящего из объекта root_table и таблиц, на которые он указывает.
Объект struct ctl_table имеет следующие члены:
ctl_name. Целое число, которое однозначно обозначает вход таблицы (тем не менее, оно однозначно обозначает вход только внутри массива, в котором он находится); эти числа в разных массивах могут повторяться. Любой элемент массива уже имеет такой уникальный номер (его индекс в массиве), но это число не может применяться для данной цели, поскольку разработчики ядра обязаны обеспечить совместимость с последующими выпусками ядра на уровне двоичного кода. Настраиваемый параметр ядра, связанный со входом массива, в одной версии ядра, может исчезнуть в будущей версии ядра, поэтому, если бы параметры обозначались их индексами массива, то повторное использование позиции устаревшего элемента массива могло бы нарушить работу программ, которые не были перетранслированы под новое ядро. Со временем, массивы стали бы забиты неиспользуемыми входами, которые просто занимали бы место ради обратной совместимости. Вместо этого, в данном подходе просто «неэкономно» используются целые числа, в которых никогда нет недостатка. (С другой стороны, поиск становится медленнее, поскольку при таком методе нельзя просто использовать индекс массива.)
Обратите внимание, что это очень напоминает ситуацию с системными вызовами: каждый системный вызов связан с уникальным номером, который обозначает его позицию в таблице системных вызовов. Но в этом случае применяется другое решение, вероятно потому, что быстродействие здесь не так важно. procname. Короткое, предназначенное для восприятия человеком имя файла для соответствующего входа под каталогом /proc/sys. data. Указатель на данные, связанные с этим входом таблицы. Он обычно указывает на данные типа int или char (и, безусловно, указатель на char — это строка). maxlen. Максимальное число байтов, которые могут быть считаны или записаны в член data. Например, если data указывает на один элемент типа int то maxlen должен быть равен sizeof(int). mode. Биты прав доступа к файлу в стиле Unix для файла (или каталога) /proc, соответствующего этому входу. Для описания этого члена нужно сделать краткий экскурс в мир файловых систем. Как и в других реализациях Unix, в Linux используется три набора по три бита в каждом для регистрации прав доступа к файлу (в листинге, который выдает команда ls -l, они обозначаются в виде трех групп, состоящих из символов r, w и х); см. рис. 11.2. Они занимают нижние 9 битов члена mode. В файловой системе оставшиеся биты параметра mode файла предназначены для других целей, например, для слежения за тем, является ли файл обычным файлом (если да, то устанавливается бит 16), каталогом (бит 15), выполнимой программой, для которой установлены права setuid или setgid (биты 12 и 11), и так далее. Однако для материала настоящей главы эти прочие биты не имеют значения.

Рис. 11.2. Биты режима доступа к файлу
В результате, в сочетании с членом mode можно часто видеть восьмеричные константы 004, 002 и 001, которые предназначены, соответственно, для проверки битов чтения (r), записи (w) и выполнения (х), возможно, после сдвига члена mode для получения требуемого набора из трех битов. В конечном итоге, этот сдвиг и проверка выполняются в функции test_perm, строка 30544.
Обратите внимание, что если вход таблицы имеет значение maxlen, равное 0, то он фактически не подлежит ни чтению, ни записи, независимо от значения его члена mode.
child. Указатель на дочернюю таблицу, если это — вход типа каталога. В этом случае с самим входом не связаны никакие данные, поэтому член data будет иметь значение NULL, a maxlen будет равен 0. proc_handler. Указатель на функцию, которая фактически читает или пишет член data; он используется при чтении или записи данных с применением файловой системы /proc. Таким образом, член data может указывать на данные любого типа, а корректную работу с ними обеспечивает функция proc_handler. В качестве proc_handler обычно применяются функции proc_dostring (строка 30820) или proc_dointvec (строка 30881); эти и другие часто используемые функции рассматриваются далее в настоящей главе. (Безусловно, может применяться любая функция с правильным прототипом.) Для входов типа каталога член proc_handler имеет значение NULL. strategy. Указатель на другую функцию, которая фактически выполняет чтение или запись в члене data; именно эта функция используется при чтении или записи с помощью системного вызова sysctl. Обычно это — функция sysctl_string (строка 31121), но может также применяться функция sysctl_intvec (строка 31163); обе эти функции рассматриваются далее в этой главе. По определенным причинам большинство настраиваемых параметров ядра подлежат изменению через интерфейс /proc, а не через системный вызов sysctl, поэтому этот указатель чаще имеет значение NULL, а не иное значение. de. Указатель на объект struct proc_dir_entry, используемый в коде файловой системы /proc для отслеживания файла или каталога в этой файловой системе. Если он отличен от NULL, то где-то под каталогом /proc зарегистрирован соответствующий объект struct ctl_table. extra1 и extra2. Указатели на любые дополнительные данные, необходимые при обработке этого элемента таблицы. Они в настоящее время используются только для указания минимальных и максимальных значений некоторых целочисленных параметров.
Поддержка /proc/sys
В эту книгу включен не весь код реализации интерфейса /proc/sys к настраиваемым параметрам ядра; в действительности, не включена основная часть этого кода, поскольку она главным образом относится к файловой системе /proc. К тому же, если вас не интересует, как работает остальная часть /proc, вы сможете легко разобраться в коде программы kernel/sysctl.c, которая работает с файловой системой /proc, для того, чтобы обеспечить доступ к настраиваемым параметрам ядра под каталогом /proc.
register_proc_table
30689: Функция register_proc_table регистрирует объект ctl_table под каталогом /proc/sys. Обратите внимание, что эта функция не требует, чтобы таблица, передаваемая в качестве параметра, была узлом корневого уровня (то есть объектом ctl_table без родителя) — эта таблица должна быть таковой, но за соблюдение данного требования отвечает вызывающая программа. Таблица устанавливается непосредственно под каталогом, обозначенным параметром root, который должен соответствовать каталогу /proc/sys или одному из подкаталогов под ним. (При первоначальном вызове root всегда указывает на proc_sys_root, но после рекурсивных вызовов его значение изменяется.)
30696: Начинается итерация по всем элементам массива table; итерация заканчивается, когда член ctl_name текущего элемента становится равным 0, что означает конец массива.
30698: Если поле procname объекта ctl_table имеет значение NULL, этот объект не должен быть видимым под каталогом /proc/sys, даже несмотря на то, что другие элементы того же массива могут быть видимыми. Такие элементы массива пропускаются.
30701: Если данный вход таблицы имеет отличное от NULL значение procname, а это означает, что он должен быть зарегистрирован под каталогом /proc/sys, он должен также иметь отличный от NULL член proc_handler (если это лист дерева или узел, подобный файлу) или член child (если это узел, подобный каталогу). Если в нем отсутствуют оба члена, выводится предупреждающее сообщение и цикл продолжается.
30711: Если вход таблицы имеет отличный от NULL член proc_handler, он отмечается как обычный файл.
30713: Иначе, как можно утверждать на основании строки 30701, он должен иметь отличный от NULL член child, поэтому данный вход будет рассматриваться как каталог. Обратите внимание: ничто не препятствует тому, чтобы оба члена объекта ctl_table, и proc_handler и child, были отличны от NULL, но в таком случае это соглашение должно соблюдаться во всем коде.
30715: Выполняет поиск указанного имени в существующем подкаталоге и оставляет de, указывающим на существующий вход, если он найден, или равным NULL, если он не найден. Трудно понять, почему аналогичная проверка не предусмотрена для файлов; в файловой системе /proc может быть какая-то тонкость, которую автор не смог понять, и ответ, безусловно, лежит здесь.
30723: Если указанный подкаталог не существует или параметр table соответствует файлу, а не каталогу, создается новый файл или каталог путем вызова функции create_proc_entry (не рассматривается).
30728: Если вход таблицы представляет собой лист-узел, функция register_proc_table сообщает коду файловой системы /proc, чтобы в нем использовались файловые операции, которые определены в функции proc_sys_inode_operations (строка 30295). В функции proc_sys_inode_operations определены только две операции — чтение и запись (нет ни поиска, ни отображения памяти, ни всего прочего). Эти операции выполняются с помощью функций proc_readsys и proc_writesys (строки 30802 и 30808), которые рассматриваются далее в этой главе.
30731: К этому моменту уже известно, что значение de не равно NULL; оно либо было уже отлично от NULL, либо было инициализировано в строке 30723.
30733: Если добавляемый вход относится к типу каталога, рекурсивно вызывается функция register_proc_table для добавления также всех дочерних записей данного входа. Это редкий случай использования рекурсии в ядре.
unregister_proc_table
30739: Функция unregister_proc_table удаляет связь между деревом массивов ctl_table и файловой системой /proc. Эти входы размещаются в объекте ctl_table и все входы во всех «подкаталогах» под ними исчезают из /proc/sys.
30743: Как и в строке 30696, здесь начинается итерация по переданному в качестве параметра массиву входов таблицы.
30744: Член de входов таблицы, не связанных ни с одним входом под каталогом /proc/sys, имеет значение NULL; эти входы, безусловно, можно пропустить.
30748: Если с точки зрения файловой системы /proc это — каталог, но вход этой таблицы представляет собой лист-узел (не каталог), эти две структуры противоречивы. Функция unregister_proc_table выводит предупреждающее сообщение и продолжает цикл, не пытаясь удалить этот вход.
30752: Каталоги освобождаются рекурсивно — еще один редкий случай использования рекурсии в ядре.
30756: После возврата из рекурсивного вызова функция unregister_proc_table проверяет, что все подкаталоги и файлы были рекурсивно удалены; если нет, то текущий элемент нельзя безопасно удалить и цикл продолжается.
30762: Вот почему некоторые подкаталоги (и файлы в них) могли не быть удалены: они в настоящее время могли находиться в использовании. Если данный элемент находится в использовании, цикл просто продолжается, поэтому этот элемент не будет удален.
30765: Узел удаляется из файловой системы с помощью функции proc_unregister (не рассматривается в этой книге) и освобождается память, распределенная для слежения за этим узлом.
do_rw_proc
30771: Функция do_rw_proc реализует содержательную часть функций proc_readsys (строка 30802) и proc_writesys (строка 30808), которые используются в коде файловой системы /proc для чтения и записи данных в объектах ctl_table.
30782: Проверка того, что с этим входом под каталогом /proc/sys связана какая-то таблица.
30785: Обратите внимание, что первая проверка в этой строке дублирует вторую проверку в строке 30782, поскольку объект table инициализирован из члена de->data.
30788: Проверка того, что вызывающий процесс имеет, соответственно, право на чтение или запись.
30795: Вызов функции proc_handler данного входа таблицы для фактического выполнения чтения или записи. (Отметим, что в строке 30785 было проверено, что член proc_handler отличен от NULL.) Как было упомянуто ранее, член proc_handler обычно имеет значение proc_dostring или proc_dointvec (строки 30820 и 30972), которые описаны в следующих нескольких разделах.
30799: Функция do_rw_proc возвращает число фактически считанных или записанных байтов. Обратите внимание, что локальная переменная res совсем не нужна; она может быть заменена параметром count.
proc_dostring
30820: Функция proc_dostring представляет собой функцию, которую вызывает код файловой системы /proc для чтения или записи параметра ядра, представляющего собой строку С.
Обратите внимание: флажок write означает, что вызывающая программа пишет в элемент таблицы, но эта процедура в основном сводится к чтению из входного буфера, следовательно, код записи занимает меньше места по сравнению с кодом чтения. Аналогичным образом, если флажок write не установлен, вызывающая программа читает из входа таблицы, что в основном требует записи в буфер, переданный в качестве параметра.
В строке 31085 есть также реализация этой функции в виде заглушки; эта заглушка используется, если файловая система /proc транслируется вне ядра. За описанием этой функции следует описание аналогичных заглушек для большинства других функций, которые будут описаны ниже.
30835: Символы считываются из входного буфера до тех пор, пока не будет найден заключительный символ NUL (0) или символ новой строки кода ASCII, или пока из входного буфера не будет считан максимально допустимый объем данных (который указан параметром lenp). (Чтобы избежать путаницы, напомним, что NULL — константа-указатель языка С, a NUL, с одним L, является обозначением в коде ASCII нулевого символа.)
30842: Если число байтов, считанных из буфера превышает объем, который может быть записан в данный вход таблицы, число байтов уменьшается. Вместо этого, вероятно, было бы эффективнее ограничить максимальную длину входных данных (lenp) перед циклом, поскольку чтение из буфера числа байтов, превышающего значение table->maxlen, в любом случае бессмысленно. В том виде, как есть, цикл может прочитать, скажем, 1024 байта, а затем уменьшить этот объем до 64, поскольку это все, что можно записать во вход таблицы.
30844: Строка считывается из входного буфера, а затем в ее конце записывается символ NUL.
30847: Ядро поддерживает переменную со значением «текущей позиции» для каждого файла, принадлежащего каждому процессу; это член f_pos объекта struct file. Он представляет собой значение, возвращаемое системным вызовом tell и устанавливаемое системным вызовом seek. Здесь текущая позиция в файле увеличивается на число записанных байтов.
proc_doutsstring
30871: Функция proc_doutsstring просто вызывает функцию proc_dostring после приобретения семафора uts_sem (строка 29975). Эта функция используется в нескольких входах объекта kern_table (строка 30341) для установки различных компонентов структуры system_utsname (строка 20094).
do_proc_dointvec
30881: Функция proc_dointvec (строка 30972) делегирует свою работу этой функции. Функция do_proc_dointvec читает или пишет массив данных типа int, на который указывает член data объекта table. Число переменных типа int, которые должны быть считаны или записаны, передается параметром lenp; обычно этот параметр равен 1, поэтому данная функция, как правило, используется для чтения или записи только единственной переменной типа int. Значения данных типа int заданы параметром buffer. Однако данные типа int не передаются в виде массива данных типа int во внутреннем представлении; вместо этого, они представлены в виде текста ASCII, который записывается пользователем в соответствующий файл /proc.
30898: Начинаются итерации по всем данным типа int для чтения или записи. Переменная left следит за оставшимся числом данных типа int, которые должны быть считаны или записаны вызывающей программой, а переменная vleft следит за числом допустимых элементов, оставшихся в объекте table->data. Цикл завершается, когда любое из этих значений достигает 0 или когда выход из него происходит в середине. Обратите внимание, что весь цикл можно было бы сделать чуть более эффективным, но также более сложным для сопровождения, если вывести из этого цикла оператор if в строке 30899, то есть вместо кода такой структуры:
for (; left && vleft--; i++, first=0) {
if (write) {
/* Код записи. */
} else {
/* Код чтения. */
}
}
применить код со следующей структурой:
if (write) {
for (; left && vleft--; i++, first=0) {
/* Код записи. */
}
} else {
for (; left && vleft--; i++, first=0) {
/* Код чтения. */
}
}
Таким образом, значение переменной write, которое не изменяется внутри цикла, можно было бы проверять только один раз, а не на каждой итерации цикла.
30900: Поиск вперед непробельного символа, то есть начала следующего числа на входе.
30913: Копирует фрагмент данных из пространства пользователя в локальный буфер buf, а затем записывает символ NUL в конце buf Теперь buf содержит весь оставшийся код ASCII со входа, или такую часть этого текста, которая в нем поместилась.
Такой подход выглядит не очень эффективным, поскольку он допускает чтение большего объема, чем это необходимо. Однако, поскольку размер буфера buf равен только 20 (TMPBUFLEN, строка 30885), в него нельзя считать намного больше, чем необходимо. Здесь идея, вероятно, состоит в том, что дешевле просто считать немного больше, чем проверять каждый байт и следить за тем, нужно ли закончить чтение.
Величина buf выбрана достаточно большой для того, чтобы в ней можно было разместить представление в коде ASCII любого 64-разрядного целого числа, поэтому данная функция может поддерживать не только 32-разрядные, но и 64-разрядные платформы. И действительно, буфер достаточно велик для того, чтобы в нем могло разместиться самое большое 64-разрядное положительное целое число, десятичное представление которого состоит из 19 цифр (завершающий байт NUL будет записан в 20-м байте). Но помните, что существуют целые числа со знаком, поэтому значение –9223372036854775808, наименьшее 64-разрядное целое число со знаком, также представляет собой допустимый ввод. Оно не может быть считано правильно. К счастью, исправление тривиально и очевидно.
Вскоре мы покажем, как будет действовать этот код при получении подобного ввода.
30919: Обработка ведущего знака минус (–), переход к символу за знаком минус и установка флажка, если знак минус был найден.
30923: Проверка того, что текст, который был считан из буфера (возможно, за ведущим знаком минус), по крайней мере, начинается с цифры, чтобы его можно было успешно преобразовать в целое число. Без этой проверки было бы невозможно узнать, вернул ли вызов функции simple_strtoul в строке 30925 значение 0 из-за того, что на входе был «0», или из-за того, что она совсем не смогла преобразовать входной текст.
30925: Преобразование текста в целое число и масштабирование результата с использованием параметра conv. Этот этап масштабирования применяется в таких функциях, как proc_dointvec_jiffies (строка 31077), которая преобразует свой вход из секунд в единицы измерения процессорного времени, просто путем умножения на константу HZ. Однако, как правило, коэффициент масштабирования равен 1, что равносильно отсутствию масштабирования.
30927: Если остается еще текст, который должен быть считан из буфера, и следующий символ, который должен быть считан, отличается от пробела, разделяющего параметры, это значит, что в буфер buf весь параметр не поместился. Такие входные данные являются недопустимыми, поэтому цикл преждевременно прекращается. (Одной из версий развития событий, при которой функция могла бы оказаться в этом состоянии, была бы передача в качестве параметра наименьшего 64-разрядного целого числа со знаком, как было описано выше.) Однако код ошибки не возвращается, поэтому вызывающая программа может ошибочно считать, что все было нормально. Однако это не совсем так: код ошибки будет возвращен в строке 31070, но только если недопустимый параметр был обнаружен при первой итерации цикла; если он будет обнаружен в последующей итерации цикла, ошибка не будет замечена.
30929: Параметр был прочитан успешно. Теперь учитывается ведущий знак минус, если он присутствовал на входе, корректируются другие локальные переменные для перехода к следующему параметру и параметр записывается во вход таблицы под указателем i.
30936: Вызывающая программа считывает значения из входа таблицы; это гораздо более простой случай, поскольку не требуется интерпретация текста ASCII. Вывод разграничен символами табуляции, поэтому после каждой итерации цикла, кроме первой, во временный буфер записывается символ табуляции (этот символ также не записывается после последнего параметра, а только между параметрами).
30938: Затем текущее значение целого числа делится на коэффициент conv и передается во временный буфер. Этот код страдает от той же проблемы, которая была описана выше: временный буфер, buf, может быть не достаточно велик для хранения всех целочисленных значений, которые могут быть в него выведены. В этом случае проблема усугубляется тем фактом, что в первой позиции буфера может находиться символ табуляции. При этом, полезный объем буфера buf становится на один символ меньше, что приводит к дальнейшему сужению диапазона входных данных, которые будут обработаны правильно.
Последствия появления слишком большого или слишком малого целого числа могут быть еще более неблагоприятными, чем в случае записи. В том случае код просто отбрасывает часть входных данных, которые он должен был принять, а в этом случае функция sprintf может выполнить запись за концом буфера buf.
Однако оказывается, что этот код, по-видимому, все равно работает правильно. В типичной реализации происходит примерно следующее: за концом буфера buf записываются, самое большее, два лишних байта (один, потому что может быть выполнена запись большего числа, чем ожидалось, и еще один — для символа табуляции). Указатель р обычно находится в стеке непосредственно после buf, поэтому запись с выходом за конец буфера buf перекрывает р. Но поскольку указатель р в дальнейшем больше не используется без предварительной повторной инициализации, нет никакого вреда в том, что его значение будет временно перезаписано.
Это любопытный выход из положения, но простое незначительное увеличение buf было бы гораздо лучшим решением, которое позволило бы обеспечить надежную работу этого кода на законных основаниях, а не по воле случая. Если этот код останется в том виде, как есть, то небольшое, вполне невинное изменение генератора объектного кода gcc может заставить проявиться эту скрытую ошибку.
30939: Копирует текстовое представление текущего значения int в буфер вывода или, по крайней мере, такую часть этого текстового представления, какая в ней поместится, и обновляет локальные переменные для перехода к следующему элементу массива данного входа таблицы.
30949: Завершает вывод символом новой строки, если вызывающая программа выполняла чтение. Условие if также выполняет проверку того, что цикл не закончился при его первой итерации и что есть место для записи символа новой строки. Обратите внимание, что буфер вывода не завершается байтом NUL кода ASCII (как можно было ожидать), поскольку этого не требуется: вызывающая программа может определить длину возвращенной строки из нового значения, записанного с помощью lenp.
30954: Пропуск всех пробельных символов, следующих за последним параметром, который был считан из входного буфера, если вызывающая программа писала значения во вход таблицы.
30967: Обновляет текущую позицию файла и значение lenp, а затем возвращает 0 в качестве обозначения успеха.
proc_dointvec_minmax
30978: Функция proc_dointvec_minmax почти аналогична do_proc_dointvec, за исключением того, что она дополнительно рассматривает члены extra1 и extra2 входа таблицы как массивы ограничений на те значения, которые могут быть записаны во вход таблицы. Значения в extra1 представляют собой минимумы, а значения в extra2 — максимумы. Еще одним отличием является то, что функция proc_dointvec_minmax не имеет параметра conv.
В связи с тем, что эти функции так похожи, в настоящем разделе будут рассмотрены только различия между ними.
31033: Вот самое значительное различие: при записи значения, выходящие за пределы диапазона, определенного величинами min и max (которые берутся в цикле из массивов extra1 и extra2), молча пропускаются. Очевидно, назначение этого кода состоит в обработке min и max наряду с val. После того, как значение будет считано со входа, оно должно быть проверено по отношению к следующему значению min и следующему значению max, а затем либо принято, либо пропущено. Однако это происходит не совсем так. Предположим, что текущее значение из буфера, которое было интерпретировано и записано в переменную val, меньше минимума; предположим также ради уточнения, что это третья итерация цикла, поэтому и min, и max указывают на третьи элементы соответствующих им массивов. Тогда значение val будет проверено по min и будет обнаружено, что оно выходит за пределы диапазона (слишком мало), поэтому цикл будет продолжен. Однако в качестве побочного эффекта этой проверки значение min будет обновлено, а значение max — нет. Теперь min указывает на четвертый элемент соответствующего ему массива, a max все еще указывает на третий элемент своего массива. Эти две величины не согласованы друг с другом и таковыми и останутся, поэтому следующее значение (и в действительности, все последующие значения), считанные из буфера, могут проверяться по неправильному пределу. Ниже описано простейшее исправление:
if (min && val < *min++) {
++max; /* Синхронизация значений max и min. */
continue;
}
if (max && val > *max++)
continue;
Однако, как вы узнаете далее из этой главы, оказывается, что эта ошибка никогда не проявит себя в текущем исходном коде Linux. (Другое дело — будущие выпуски, но это еще не написанный роман.)
Системный вызов sysctl
Еще одним интерфейсом к настраиваемым параметрам ядра является системный вызов sysctl, наряду со связанными с ним функциями. У автора создалось впечатление, что этот интерфейс попал в немилость. А как же иначе? В большинстве практических ситуаций sysctl (каким бы великолепным вначале он ни казался по сравнению со старым методом настройки ядра путем корректировки исходного кода) просто является более неуклюжим по сравнению с доступом к файлам через /proc. Чтение и запись через sysctl требует применения программы на С (или чего-то подобного), тогда как файловая система /proc легко доступна через команды командного интерпретатора (или, равным образом, через сценарии командного интерпретатора).
С другой стороны, если вы уже работаете в С, то вызов sysctl может оказаться гораздо более удобным по сравнением с открытием файла, чтением из него и/или записью в него, а затем закрытием файла, поэтому sysctl может найти применение в своем месте. Так или иначе, рассмотрим реализацию этого интерфейса.
do_sysctl
30471: Функция do_sysctl реализует значительную часть работы sys_sysctl (строка 30504), системного вызова sysctl. Обратите внимание, что sys_sysctl появляется также в строке 31275 и эта версия представляет собой просто функцию-заглушку, которая используется при трансляции системного вызова sysctl вне ядра. Старое значение параметра ядра возвращается через oldval, если параметр oldval не равен NULL, а его новое значение устанавливается из newval, если параметр newval не равен NULL. Параметры oldlenp и newlen указывают, соответственно, сколько байтов должно быть записано в oldval и считано из newval, если соответствующие указатели отличны от NULL; они игнорируются, если указатели равны NULL.
Обратите внимание на асимметрию: функция принимает указатель на старую длину, но не указатель на новую длину. Это связано с тем, что старая длина представляет собой одновременно входной и выходной параметр; его входное значение обозначает максимальное число байтов, которые могут быть возвращены через oldval, а его выходное значение обозначает число байтов, которые фактически были возвращены. В отличие от этого, новая длина — это только входной параметр.
30482: Устанавливает значение old_len из oldlenp, если вызывающая программа хочет получить старое значение параметра ядра.
30490: Начинает проход по циклическому списку деревьев таблицы. (См. описание функции register_sysctl_table далее в этой главе.)
30493: Использует функцию parse_table (строка 30560, рассматривается в следующем разделе) для поиска настраиваемого параметра ядра и для чтения и/или записи его значения.
30495: Если функция parse_table распределила память под какую-либо контекстную информацию, она освобождается. Трудно точно сказать, что подразумевается под этой контекстной информацией. Она не используется ни в каком коде, рассматриваемом в этой книге; в действительности, насколько может судить об этом автор, она в настоящее время не применяется ни в каком коде где-либо в ядре.
30497: Ошибка ENOTDIR просто означает, что указанный параметр ядра не был найден в этом дереве таблиц; он все еще может быть найден в другом дереве таблиц, где еще не выполнялся поиск. В ином случае, переменная error может содержать какой-то другой код ошибки или 0, в случае успеха; так или иначе, она должна быть (и будет) возвращена.
30499: Продвижение вперед итератора цикла с использованием макрокоманды DLIST_NEXT (не включена в эту книгу).
30501: Возвращает ошибку ENOTDIR, которая сообщает о том, что указанный параметр ядра не был найден ни в одной таблице.
parse_table
30560: Функция parse_table ищет вход в дереве таблиц по аналогии с тем, как происходит поиск в дереве каталогов полностью квалифицированного имени файла. Идея состоит в следующем: поиск происходит вдоль массива данных типа int (массива name) с просмотром каждого элемента типа int в массиве ctl_table. Если будет обнаружено совпадение, выполняется рекурсивный просмотр соответствующей дочерней таблицы (если совпадающий вход представляет собой вход типа каталога); или выполняется чтение и/или запись входа (если это вход типа файла).
30566: К некоторому удивлению, это начало цикла, который перебирает все элементы целочисленного массива name. Было бы более привычно, если бы все, начиная с этой строки и кончая строкой 30597, было заключено в цикл for, который мог бы начинаться примерно так:
for (; nlen; ++name, --nlen, table = table->child)
(Здесь также нужно было бы удалить строки 30567 и 30568 и заменить строки с 30587 по 30590 оператором break.) Возможно, фактически применяемая версия генерирует лучший объектный код.
30570: Начинается цикл по всем входам таблицы в поиске входа с текущим значением name; цикл заканчивается по окончании таблицы (когда значение table->ctl_name становится равным 0) или после того, как будет найден и обработан указанный вход таблицы.
30572: Считывает текущий вход массива name в переменную n, чтобы его можно было сверить со значением ctl_name в текущем входе таблицы. Поскольку значение name не меняется во внутреннем цикле, чтение этой переменной можно было бы вынести из цикла (то есть перенести в строку 30569) для небольшого ускорения.
30574: Проверяет, совпадает ли имя текущего элемента ctl_table с искомым именем или имеет специальное «подстановочное» значение CTL_ANY (строка 17761). Назначение второй части не ясно, поскольку CTL_ANY в настоящее время в коде ядра нигде не используется. Может быть применение этого значения запланировано на будущее; автор не думает, что оно осталось от прошлого, поскольку значение CTL_ANY не использовалось и в ядре 2.0, и весь интерфейс sysctl относится только к проекту разработок, который предшествовал версии 2.0.
30576: Если этот элемент таблицы имеет дочерний элемент, то он является «каталогом».
30577: В соответствии со стандартными правилами поведения Unix, выполняется проверка бита х (выполнимый) каталога для определения того, следует ли разрешить текущему процессу войти в него. Обратите внимание, что это происходит во многом аналогично тому, что принято в файловой системе, хотя этот интерфейс (/proc) не является интерфейсом файловой системы. Это сделано для того, чтобы оба интерфейса к настраиваемым параметрами ядра давали единообразные результаты, поскольку было бы очень удивительно, если бы один и тот же пользователь имел право изменять какой-то параметр ядра через один интерфейс, но не через другой.
30579: Если данный вход таблицы содержит strategy-функцию, может потребоваться отменить это решение, которое позволяет процессу войти в каталог. Выполняется обращение за консультацией к strategy-функции, и если она возвращает ненулевое значение, прерывается весь поиск.
30587: Выполнен вход в каталог. Это фактически приводит к продолжению внешнего цикла и к переходу в нем к следующему компоненту имени.
30592: Этот узел таблицы представляет собой лист-узел, а это значит, что найден параметр ядра. Обратите внимание, что функция не утруждает себя проверкой того, находится ли массив name в его последнем элементе (то есть того, равно ли теперь значение nlen единице), хотя можно утверждать, что иная ситуация представляла бы собой своего рода ошибку. Так или иначе, функция do_sysctl_strategy (строка 30603) получает поручение выполнить чтение и/или запись текущего элемента таблицы.
30598: Массив name не был пуст, но его элементы были исчерпаны до того, как был найден лист-узел. Функция parse_table возвращает ошибку ENOTDIR в качестве сигнала о неудаче при поиске указанного узла. Кстати, обратите внимание на лишнюю точку с запятой в предыдущей строке.
do_sysctl_strategy
30603: Функция do_sysctl_strategy выполняет чтение и/или запись данных в отдельном объекте ctl_table. Ее замысел состоит в использовании члена strategy данного элемента таблицы, если он присутствует, для выполнения чтения/записи. Если данный элемент таблицы не имеет свою собственную strategy-процедуру, вместо нее используется некоторый универсальный код чтения/записи. Как будет показано ниже, функция работает именно так, как задумано.
30610: Если значение oldval отлично от NULL, вызывающая программа пытается прочитать старое значение, поэтому в переменной ор устанавливается бит r. Аналогичным образом, если отлично от NULL значение newval, устанавливается бит w. Затем в строке 30614 выполняется проверка прав доступа и возвращается ошибка EPERM, если текущий процесс не имеет соответствующих прав.
30617: Если данный вход таблицы имеет свою собственную strategy-процедуру, эта процедура получает шанс выполнить запрос на чтение/запись. Если она возвращает отрицательное значение (ошибку), ошибка передается вызывающей программе. Если она возвращает положительное значение, вызывающей программе передается 0 (успех). Если strategy-процедура возвращает 0, это значит, что она отказалась сама выполнить запрос, и вместо нее будет использоваться правило поведения, принятое по умолчанию. (Вполне можно представить себе strategy-процедуру, которая всегда будет возвращать только 0, но все равно будет иметь право на существование, если ей будет поручена какая-то другая работа, например, сбор статистической информации о том, как часто происходил ее вызов.)
30630: Это начало универсального кода чтения. Обратите внимание, что возвращаемое значение функции get_user (строка 13254) не проверяется. (Аналогичная ошибка возникает в строках 9537 и 31186.)
30632: Проверка того, что будет возвращено не больше данных, чем указано в поле maxlen данного входа таблицы.
30634: Копирует затребованные данные из таблицы с помощью oldval и сохраняет фактически считанный объем данных с помощью oldlenp.
30642: Аналогично oldlenp, проверка того, что в данный вход таблицы не может быть записано больше данных, чем допускает его член maxlen. Обратите внимание, что может оказаться выполненным только частичное обновление члена table->data, если в ходе выполнения функции copy_from_user в строке 30644 будет обнаружена ошибка.
30648: Возвращает 0 в качестве обозначения успеха. Эта точка достигается в любом из следующих трех случаев:
- Вызывающая программа не пыталась ни читать, ни писать в этот вход таблицы.
- Вызывающая программа пыталась читать и/или писать в этот вход таблицы и все этапы на этом пути были успешными.
- Этот вход таблицы не имеет связанных с ним данных или он фактически предназначен только для чтения, поскольку его значение maxlen равно 0.
Первый из этих случаев в определенной степени удивителен, а последний удивляет еще больше. В первом случае удивительным является то, что вызов sysctl без запроса ни на чтение, ни на запись в указанный вход таблицы не имеет смысла, поэтому такой вызов можно на законных основаниях рассматривать как ошибку. Тем не менее, он в целом соответствует принципам реализации в ядре других системных вызовов, согласно которым запрос пустой команды не является ошибкой. Например, функция sys_brk (строка 33155), рассматриваемая в главе 8, не сообщает об ошибке, если новое значение brk, которое указано вызывающей программой, совпадает со старым значением.
Третий случай является более удивительным по сравнению с первым, поскольку он действительно может свидетельствовать об ошибке. Вызывающий код может, например, попытаться выполнить запись в параметр, для которого значение maxlen равно 0, и посчитать, что эта попытка удалась, поскольку системный вызов возвратил значение, свидетельствующее об успехе. Однако создается впечатление, что это в действительности не имеет значения, поскольку вход таблицы со значением maxlen равным 0, является бесполезным во всех отношениях; тем не менее, в коде есть вход таблицы со значением maxlen равным 0 — см. строку 30380. В конечном итоге, все это сводится к тому, что в действительности предусмотрено документацией к функции sysctl, но справочное руководство по этому поводу умалчивает. Однако, автор считает, что в этом случае функция do_sysctl_strategy должна возвращать ошибку EPERM.
register_sysctl_table
30651: Вставляет новое дерево объектов ctl_table, для которых указан корневой каталог, в циклически связанный список деревьев.
30655: Распределяет объект struct ctl_table_header для управления информацией о новом дереве.
30659: Вставляет новый заголовок (который отслеживает новое дерево массивов объектов ctl_table) в связанный список заголовков.
30666: Вызывает функцию register_proc_table (строка 30689, описана ранее в этой главе) для регистрации нового дерева таблиц под каталогом /proc/sys. Этот код транслируется вне ядра, если ядро транслируется без поддержки файловой системы /proc.
30668: Вновь распределенный заголовок возвращается вызывающей программе, с тем чтобы вызывающая программа могла в дальнейшем удалить дерево, передав этот заголовок функции unregister_sysctl_table (строка 30672).
unregister_sysctl_table
30672: Как было указано выше, эта простая функция только удаляет дерево объектов ctl_table из циклического списка таких деревьев ядра. Она также удаляет соответствующие данные из файловой системы /proc, если ядро транслировано с поддержкой /proc. Снова просмотрев строки 30490 и 30500, можно видеть, что объект root_table_header (строка 30256), или лист-узел, соответствующий объекту root_table, используется в качестве начального и конечного узла при проходе по циклическому списку деревьев. Теперь можно видеть, что в функции unregister_sysctl_table ничто не исключает возможности удаления объекта root_table_header из списка заголовков таблиц, просто этого никто не делает.
sysctl_string
31121: sysctl_string — это одна из strategy-процедур объекта ctl_table. Напомним, что strategy-процедуры при желании могут быть вызваны из строки 30618 (в функции do_sysctl_strategy) для замещения применяемого по умолчанию кода чтения/записи входа таблицы. (strategy-процедуры могут быть также вызваны из строки 30580, но данная процедура к ним не относится.)
31127: Если таблица не имеет связанных с ней данных или если длина доступной части равна 0, возвращается ошибка ENOTDIR. Это не совместимо с правилами поведения функции do_sysctl_strategy, которая в аналогичном случае возвращает успешный результат.
31138: Текущее значение строки копируется в пространство пользователя и результат оканчивается символом NUL (это значит, что может быть выведено число байтов, которое на единицу больше указанного параметром lenp; возможно, это — ошибка, в зависимости от того, что указано в документации). Поскольку текущее значение уже оканчивается символом NUL, эти четыре строки кода можно легко свести к двум:
if (copy_to_user(oldval, table->data, len + 1))
return -EFAULT;
Допустимость этого изменения частично зависит от трех свойств, которые учитываются в остальной части кода при записи в член table->data:
- В остальной части кода не происходит копирование в table->data больше символов, чем указано в table->maxlen. (При этом, также становится не нужной проверка в строке 31136. Даже если бы эта проверка была необходима, в ней нужно было проверять только соответствие оператору сравнения >, в не >=).
- Затем в конце table->data записывается символ NUL с перекрытием в случае необходимости последнего скопированного байта с тем, чтобы общая длина, включая символ NUL, не превышала величины table->maxlen.
- Величина table->maxlen никогда не изменяется.
Поскольку все эти три свойства соблюдаются, значение len всегда будет строго меньше значения table->maxlen в строке 31138, и завершающий символ NUL должен появляться в позиции или перед позицией table->data[len + 1].
31146: По аналогии с предыдущим случаем, новое значение копируется из пространства пользователя и результат оканчивается символом NUL. Однако в этом случае не стоит копировать байт NUL из пространства пользователя, поскольку будет менее эффективным копировать его из пространства пользователя, чем просто присвоить значение NUL соответствующему байту объекта . К тому же, это позволяет записывать символ NUL в конце table->data, даже если его не было на входе. Безусловно, строка, считанная из newval, уже могла оканчиваться символом NUL, и в этом случае присваивание в строке 31154 будет излишним. Это еще один пример того, что иногда быстрее просто выполнить работу, чем проверять, нужно ли ее выполнять.
31156: Возвращает 0 в качестве обозначения успеха. Вместо этого, возвращаемое значение должно быть положительным, чтобы результат интерпретировался в строка 30618 как успех. В ином случае, вызывающий код считает, что функция sysctl_string запрашивает выполнение обработки, применяемой по умолчанию, и снова переходит к выполнению ненужного копирования данных из пространства пользователя.
sysctl_intvec
31163: Функция sysctl_intvec это еще одна strategy-процедура, которая определена в программе kernel/sysctl.c. Если вызывающая программа выполняет запись в этот вход таблицы, эта функция проверяет, чтобы все записываемые данные типа int находились в пределах, указанных минимальным и максимальным значениями. (Кстати, функция sysctl_intvec в этом файле используется только один раз, в строке 30414; хотя она широко применяется в других местах в ядре, в коде, не включенном в эту книгу.)
31170: Если новый объем данных, подлежащий записи, не оканчивается на границе данных с размером int, он является недопустимым, поэтому попытка отвергается.
31173: Если вход таблицы не указывает набор максимальных или минимальных значений, входные значения никогда не могут выйти за пределы диапазона, поэтому для вызывающей программы вполне приемлем универсальный код записи (do_sysctl_strategy, строка 30603). Поэтому в данном случае функция sysctl_intvec возвращает 0.
31184: Начинается цикл, который проверяет, что все значения из входного массива лежат в соответствующем диапазоне.
31186: Этот код не проверяет возвращаемое значение функции get_user, поскольку в этом нет настоятельной необходимости. Если функция sysctl_intvec возвращает 0 (успех), не имея возможности прочесть входные данные из этого места в памяти, данную проблему обнаружит функция do_sysctl_strategy при попытке прочесть весь массив. Иначе, если из этого места в памяти не сможет прочесть функция get_user, в переменной value может оказаться мусор и ее значение может быть некорректно отброшено. В этом случае вызывающая программа получит ошибку EINVAL, а не ошибку EFAULT, которая является менее значимой ошибкой.
31187: Обратите внимание, что здесь не проявляется ошибка, которая нарушала работу аналогичного кода в строке 31033, где параллельная итерация по массивам минимальных и максимальных значений могла нарушить их синхронизацию.
Именно этот код препятствует проявлению ошибки в строке 31033. Когда это происходит, и sysctl_intvec и proc_dointvec_minmax всегда связаны с одними и теми же входами объекта ctl_table. Следовательно, любые значения, выходящие за пределы допустимого диапазона, будут перехвачены strategy-процедурой, sysctl_intvec, перед тем, как появится возможность вызвать процедуру обработки proc_dointvec_minmax.
Поэтому мы знаем, что с учетом текущих определений всех объектов ctl_table в ядре, функция proc_dointvec_minmax никогда не встретит значения, выходящего за пределы диапазона, а это единственный тип значения, который может активизировать эту ошибку.
Однако некоторые вызывающие программы могли бы зарегистрировать объект ctl_table, в котором используется функция proc_dointvec_minmax, но не strategy-процедура, поэтому все равно ошибка в функции proc_dointvec_minmax может когда-нибудь выйти наружу.
31193: Возвращает 0 в качестве обозначения успеха. Это не ошибка, как было в строке 31156, поскольку функция sysctl_intvec не пишет в table->data. Значения, считанные из пространства пользователя, просто попадают во временную переменную и проверяются на соответствие диапазону, а затем отбрасываются; одну единственную запись в table->data будет выполнять функция do_sysctl_strategy.
|

 LINUX
LINUX 
 Books
Books
