1.10. Time Values
Historically, UNIX systems have maintained two different time values:
Calendar time. This value counts the number of seconds since the Epoch: 00:00:00 January 1, 1970, Coordinated Universal Time (UTC). (Older manuals refer to UTC as Greenwich Mean Time.) These time values are used to record the time when a file was last modified, for example. The primitive system data type time_t holds these time values. Process time. This is also called CPU time and measures the central processor resources used by a process. Process time is measured in clock ticks, which have historically been 50, 60, or 100 ticks per second. The primitive system data type clock_t holds these time values. (We'll show how to obtain the number of clock ticks per second with the sysconf function in Section 2.5.4.)
When we measure the execution time of a process, as in Section 3.9, we'll see that the UNIX System maintains three values for a process:
Clock time User CPU time System CPU time
The clock time, sometimes called wall clock time, is the amount of time the process takes to run, and its value depends on the number of other processes being run on the system. Whenever we report the clock time, the measurements are made with no other activities on the system.
The user CPU time is the CPU time attributed to user instructions. The system CPU time is the CPU time attributed to the kernel when it executes on behalf of the process. For example, whenever a process executes a system service, such as read or write, the time spent within the kernel performing that system service is charged to the process. The sum of user CPU time and system CPU time is often called the CPU time.
It is easy to measure the clock time, user time, and system time of any process: simply execute the time(1) command, with the argument to the time command being the command we want to measure. For example:
$ cd /usr/include
$ time -p grep _POSIX_SOURCE */*.h > /dev/null
real 0m0.81s
user 0m0.11s
sys 0m0.07s
The output format from the time command depends on the shell being used, because some shells don't run /usr/bin/time, but instead have a separate built-in function to measure the time it takes commands to run.
In Section 8.16, we'll see how to obtain these three times from a running process. The general topic of times and dates is covered in Section 6.10.
1.11. System Calls and Library Functions
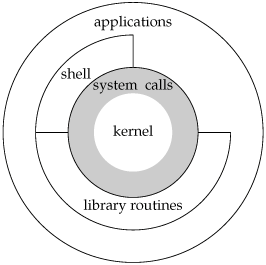
All operating systems provide service points through which programs request services from the kernel. All implementations of the UNIX System provide a well-defined, limited number of entry points directly into the kernel called system calls (recall Figure 1.1). Version 7 of the Research UNIX System provided about 50 system calls, 4.4BSD provided about 110, and SVR4 had around 120. Linux has anywhere between 240 and 260 system calls, depending on the version. FreeBSD has around 320.
The system call interface has always been documented in Section 2 of the UNIX Programmer's Manual. Its definition is in the C language, regardless of the actual implementation technique used on any given system to invoke a system call. This differs from many older operating systems, which traditionally defined the kernel entry points in the assembler language of the machine.
The technique used on UNIX systems is for each system call to have a function of the same name in the standard C library. The user process calls this function, using the standard C calling sequence. This function then invokes the appropriate kernel service, using whatever technique is required on the system. For example, the function may put one or more of the C arguments into general registers and then execute some machine instruction that generates a software interrupt in the kernel. For our purposes, we can consider the system calls as being C functions.
Section 3 of the UNIX Programmer's Manual defines the general-purpose functions available to programmers. These functions aren't entry points into the kernel, although they may invoke one or more of the kernel's system calls. For example, the printf function may use the write system call to output a string, but the strcpy (copy a string) and atoi (convert ASCII to integer) functions don't involve the kernel at all.
From an implementor's point of view, the distinction between a system call and a library function is fundamental. But from a user's perspective, the difference is not as critical. From our perspective in this text, both system calls and library functions appear as normal C functions. Both exist to provide services for application programs. We should realize, however, that we can replace the library functions, if desired, whereas the system calls usually cannot be replaced.
Consider the memory allocation function malloc as an example. There are many ways to do memory allocation and its associated garbage collection (best fit, first fit, and so on). No single technique is optimal for all programs. The UNIX system call that handles memory allocation, sbrk(2), is not a general-purpose memory manager. It increases or decreases the address space of the process by a specified number of bytes. How that space is managed is up to the process. The memory allocation function, malloc(3), implements one particular type of allocation. If we don't like its operation, we can define our own malloc function, which will probably use the sbrk system call. In fact, numerous software packages implement their own memory allocation algorithms with the sbrk system call. Figure 1.11 shows the relationship between the application, the malloc function, and the sbrk system call.
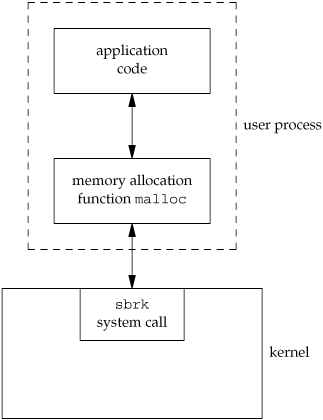
Here we have a clean separation of duties: the system call in the kernel allocates an additional chunk of space on behalf of the process. The malloc library function manages this space from user level.
Another example to illustrate the difference between a system call and a library function is the interface the UNIX System provides to determine the current time and date. Some operating systems provide one system call to return the time and another to return the date. Any special handling, such as the switch to or from daylight saving time, is handled by the kernel or requires human intervention. The UNIX System, on the other hand, provides a single system call that returns the number of seconds since the Epoch: midnight, January 1, 1970, Coordinated Universal Time. Any interpretation of this value, such as converting it to a human-readable time and date using the local time zone, is left to the user process. The standard C library provides routines to handle most cases. These library routines handle such details as the various algorithms for daylight saving time.
An application can call either a system call or a library routine. Also realize that many library routines invoke a system call. This is shown in Figure 1.12.
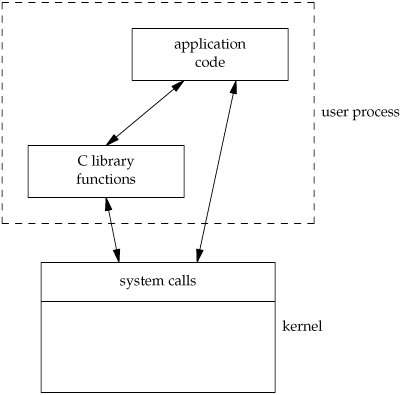
Another difference between system calls and library functions is that system calls usually provide a minimal interface, whereas library functions often provide more elaborate functionality. We've seen this already in the difference between the sbrk system call and the malloc library function. We'll see this difference later, when we compare the unbuffered I/O functions (Chapter 3) and the standard I/O functions (Chapter 5).
The process control system calls (fork, exec, and wait) are usually invoked by the user's application code directly. (Recall the bare-bones shell in Figure 1.7.) But some library routines exist to simplify certain common cases: the system and popen library routines, for example. In Section 8.13, we'll show an implementation of the system function that invokes the basic process control system calls. We'll enhance this example in Section 10.18 to handle signals correctly.
To define the interface to the UNIX System that most programmers use, we have to describe both the system calls and some of the library functions. If we described only the sbrk system call, for example, we would skip the more programmer-friendly malloc library function that many applications use. In this text, we'll use the term function to refer to both system calls and library functions, except when the distinction is necessary.
1.12. Summary
This chapter has been a short tour of the UNIX System. We've described some of the fundamental terms that we'll encounter over and over again. We've seen numerous small examples of UNIX programs to give us a feel for what the remainder of the text talks about.
The next chapter is about standardization of the UNIX System and the effect of work in this area on current systems. Standards, particularly the ISO C standard and the POSIX.1 standard, will affect the rest of the text.
2.1. Introduction
Much work has gone into standardizing the UNIX programming environment and the C programming language. Although applications have always been quite portable across different versions of the UNIX operating system, the proliferation of versions and differences during the 1980s led many large users, such as the U.S. government, to call for standardization.
In this chapter we first look at the various standardization efforts that have been under way over the past two decades. We then discuss the effects of these UNIX programming standards on the operating system implementations that are described in this book. An important part of all the standardization efforts is the specification of various limits that each implementation must define, so we look at these limits and the various ways to determine their values.
2.2. UNIX Standardization
2.2.1. ISO C
In late 1989, ANSI Standard X3.1591989 for the C programming language was approved. This standard has also been adopted as international standard ISO/IEC 9899:1990. ANSI is the American National Standards Institute, the U.S. member in the International Organization for Standardization (ISO). IEC stands for the International Electrotechnical Commission.
The C standard is now maintained and developed by the ISO/IEC international standardization working group for the C programming language, known as ISO/IEC JTC1/SC22/WG14, or WG14 for short. The intent of the ISO C standard is to provide portability of conforming C programs to a wide variety of operating systems, not only the UNIX System. This standard defines not only the syntax and semantics of the programming language but also a standard library [Chapter 7 of ISO 1999; Plauger 1992; Appendix B of Kernighan and Ritchie 1988]. This library is important because all contemporary UNIX systems, such as the ones described in this book, provide the library routines that are specified in the C standard.
In 1999, the ISO C standard was updated and approved as ISO/IEC 9899:1999, largely to improve support for applications that perform numerical processing. The changes don't affect the POSIX standards described in this book, except for the addition of the restrict keyword to some of the function prototypes. This keyword is used to tell the compiler which pointer references can be optimized, by indicating that the object to which the pointer refers is accessed in the function only via that pointer.
As with most standards, there is a delay between the standard's approval and the modification of software to conform to it. As each vendor's compilation systems evolve, they add more support for the latest version of the ISO C standard.
A summary of the current level of conformance of gcc to the 1999 version of the ISO C standard is available at http://www.gnu.org/software/gcc/c99status.html.
The ISO C library can be divided into 24 areas, based on the headers defined by the standard. Figure 2.1 lists the headers defined by the C standard. The POSIX.1 standard includes these headers, as well as others. We also list which of these headers are supported by the four implementations (FreeBSD 5.2.1, Linux 2.4.22, Mac OS X 10.3, and Solaris 9) that are described later in this chapter.
Figure 2.1. Headers defined by the ISO C standardHeader | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 | Description |
|---|
<assert.h> | • | • | • | • | verify program assertion | <complex.h> | • | • | • | | complex arithmetic support | <ctype.h> | • | • | • | • | character types | <errno.h> | • | • | • | • | error codes (Section 1.7) | <fenv.h> | | • | • | | floating-point environment | <float.h> | • | • | • | • | floating-point constants | <inttypes.h> | • | • | • | • | integer type format conversion | <iso646.h> | • | • | • | • | alternate relational operator macros | <limits.h> | • | • | • | • | implementation constants (Section 2.5) | <locale.h> | • | • | • | • | locale categories | <math.h> | • | • | • | • | mathematical constants | <setjmp.h> | • | • | • | • | nonlocal goto (Section 7.10) | <signal.h> | • | • | • | • | signals (Chapter 10) | <stdarg.h> | • | • | • | • | variable argument lists | <stdbool.h> | • | • | • | • | boolean type and values | <stddef.h> | • | • | • | • | standard definitions | <stdint.h> | • | • | • | | integer types | <stdio.h> | • | • | • | • | standard I/O library (Chapter 5) | <stdlib.h> | • | • | • | • | utility functions | <string.h> | • | • | • | • | string operations | <tgmath.h> | | • | | | type-generic math macros | <time.h> | • | • | • | • | time and date (Section 6.10) | <wchar.h> | • | • | • | • | extended multibyte and wide character support | <wctype.h> | • | • | • | • | wide character classification and mapping support |
The ISO C headers depend on which version of the C compiler is used with the operating system. When considering Figure 2.1, note that FreeBSD 5.2.1 ships with version 3.3.3 of gcc, Solaris 9 ships with both version 2.95.3 and version 3.2 of gcc, Mandrake 9.2 (Linux 2.4.22) ships with version 3.3.1 of gcc, and Mac OS X 10.3 ships with version 3.3 of gcc. Mac OS X also includes older versions of gcc.
2.2.2. IEEE POSIX
POSIX is a family of standards developed by the IEEE (Institute of Electrical and Electronics Engineers). POSIX stands for Portable Operating System Interface. It originally referred only to the IEEE Standard 1003.11988the operating system interfacebut was later extended to include many of the standards and draft standards with the 1003 designation, including the shell and utilities (1003.2).
Of specific interest to this book is the 1003.1 operating system interface standard, whose goal is to promote the portability of applications among various UNIX System environments. This standard defines the services that must be provided by an operating system if it is to be "POSIX compliant," and has been adopted by most computer vendors. Although the 1003.1 standard is based on the UNIX operating system, the standard is not restricted to UNIX and UNIX-like systems. Indeed, some vendors supplying proprietary operating systems claim that these systems have been made POSIX compliant, while still leaving all their proprietary features in place.
Because the 1003.1 standard specifies an interface and not an implementation, no distinction is made between system calls and library functions. All the routines in the standard are called functions.
Standards are continually evolving, and the 1003.1 standard is no exception. The 1988 version of this standard, IEEE Standard 1003.11988, was modified and submitted to the International Organization for Standardization. No new interfaces or features were added, but the text was revised. The resulting document was published as IEEE Std 1003.11990 [IEEE 1990]. This is also the international standard ISO/IEC 99451:1990. This standard is commonly referred to as POSIX.1, which we'll use in this text.
The IEEE 1003.1 working group continued to make changes to the standard. In 1993, a revised version of the IEEE 1003.1 standard was published. It included 1003.1-1990 standard and the 1003.1b-1993 real-time extensions standard. In 1996, the standard was again updated as international standard ISO/IEC 99451:1996. It included interfaces for multithreaded programming, called pthreads for POSIX threads. More real-time interfaces were added in 1999 with the publication of IEEE Standard 1003.1d-1999. A year later, IEEE Standard 1003.1j-2000 was published, including even more real-time interfaces, and IEEE Standard 1003.1q-2000 was published, adding event-tracing extensions to the standard.
The 2001 version of 1003.1 departed from the prior versions in that it combined several 1003.1 amendments, the 1003.2 standard, and portions of the Single UNIX Specification (SUS), Version 2 (more on this later). The resulting standard, IEEE Standard 1003.1-2001, includes the following other standards:
ISO/IEC 9945-1 (IEEE Standard 1003.1-1996), which includes IEEE Standard 1003.1-1990 IEEE Standard 1003.1b-1993 (real-time extensions) IEEE Standard 1003.1c-1995 (pthreads) IEEE Standard 1003.1i-1995 (real-time technical corrigenda)
IEEE P1003.1a draft standard (system interface revision) IEEE Standard 1003.1d-1999 (advanced real-time extensions) IEEE Standard 1003.1j-2000 (more advanced real-time extensions) IEEE Standard 1003.1q-2000 (tracing) IEEE Standard 1003.2d-1994 (batch extensions) IEEE P1003.2b draft standard (additional utilities) Parts of IEEE Standard 1003.1g-2000 (protocol-independent interfaces) ISO/IEC 9945-2 (IEEE Standard 1003.2-1993) The Base Specifications of the Single UNIX Specification, version 2, which include System Interface Definitions, Issue 5 Commands and Utilities, Issue 5 System Interfaces and Headers, Issue 5
Open Group Technical Standard, Networking Services, Issue 5.2 ISO/IEC 9899:1999, Programming Languages - C
Figure 2.2, Figure 2.3, and Figure 2.4 summarize the required and optional headers as specified by POSIX.1. Because POSIX.1 includes the ISO C standard library functions, it also requires the headers listed in Figure 2.1. All four figures summarize which headers are included in the implementations discussed in this book.
Figure 2.2. Required headers defined by the POSIX standardHeader | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 | Description |
|---|
<dirent.h> | • | • | • | • | directory entries (Section 4.21) | <fcntl.h> | • | • | • | • | file control (Section 3.14) | <fnmatch.h> | • | • | • | • | filename-matching types | <glob.h> | • | • | • | • | pathname pattern-matching types | <grp.h> | • | • | • | • | group file (Section 6.4) | <netdb.h> | • | • | • | • | network database operations | <pwd.h> | • | • | • | • | password file (Section 6.2) | <regex.h> | • | • | • | • | regular expressions | <tar.h> | • | • | • | • | tar archive values | <termios.h> | • | • | • | • | terminal I/O (Chapter 18) | <unistd.h> | • | • | • | • | symbolic constants | <utime.h> | • | • | • | • | file times (Section 4.19) | <wordexp.h> | • | • | | • | word-expansion types | <arpa/inet.h> | • | • | • | • | Internet definitions (Chapter 16) | <net/if.h> | • | • | • | • | socket local interfaces (Chapter 16) | <netinet/in.h> | • | • | • | • | Internet address family (Section 16.3) | <netinet/tcp.h> | • | • | • | • | Transmission Control Protocol definitions | <sys/mman.h> | • | • | • | • | memory management declarations | <sys/select.h> | • | • | • | • | select function (Section 14.5.1) | <sys/socket.h> | • | • | • | • | sockets interface (Chapter 16) | <sys/stat.h> | • | • | • | • | file status (Chapter 4) | <sys/times.h> | • | • | • | • | process times (Section 8.16) | <sys/types.h> | • | • | • | • | primitive system data types (Section 2.8) | <sys/un.h> | • | • | • | • | UNIX domain socket definitions (Section 17.3) | <sys/utsname.h> | • | • | • | • | system name (Section 6.9) | <sys/wait.h> | • | • | • | • | process control (Section 8.6) |
Figure 2.3. XSI extension headers defined by the POSIX standardHeader | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 | Description |
|---|
<cpio.h> | • | • | | • | cpio archive values | <dlfcn.h> | • | • | • | • | dynamic linking | <fmtmsg.h> | • | • | | • | message display structures | <ftw.h> | | • | | • | file tree walking (Section 4.21) | <iconv.h> | | • | • | • | codeset conversion utility | <langinfo.h> | • | • | • | • | language information constants | <libgen.h> | • | • | • | • | definitions for pattern-matching function | <monetary.h> | • | • | • | • | monetary types | <ndbm.h> | • | | • | • | database operations | <nl_types.h> | • | • | • | • | message catalogs | <poll.h> | • | • | • | • | poll function (Section 14.5.2) | <search.h> | • | • | • | • | search tables | <strings.h> | • | • | • | • | string operations | <syslog.h> | • | • | • | • | system error logging (Section 13.4) | <ucontext.h> | • | • | • | • | user context | <ulimit.h> | • | • | • | • | user limits | <utmpx.h> | | • | | • | user accounting database | <sys/ipc.h> | • | • | • | • | IPC (Section 15.6) | <sys/msg.h> | • | • | | • | message queues (Section 15.7) | <sys/resource.h> | • | • | • | • | resource operations (Section 7.11) | <sys/sem.h> | • | • | • | • | semaphores (Section 15.8) | <sys/shm.h> | • | • | • | • | shared memory (Section 15.9) | <sys/statvfs.h> | • | • | | • | file system information | <sys/time.h> | • | • | • | • | time types | <sys/timeb.h> | • | • | • | • | additional date and time definitions | <sys/uio.h> | • | • | • | • | vector I/O operations (Section 14.7) |
Figure 2.4. Optional headers defined by the POSIX standardHeader | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 | Description |
|---|
<aio.h> | • | • | • | • | asynchronous I/O | <mqueue.h> | • | | | • | message queues | <pthread.h> | • | • | • | • | threads (Chapters 11 and 12) | <sched.h> | • | • | • | • | execution scheduling | <semaphore.h> | • | • | • | • | semaphores | <spawn.h> | | • | | | real-time spawn interface | <stropts.h> | | • | | • | XSI STREAMS interface (Section 14.4) | <trace.h> | | | | | event tracing |
In this text we describe the 2001 version of POSIX.1, which includes the functions specified in the ISO C standard. Its interfaces are divided into required ones and optional ones. The optional interfaces are further divided into 50 sections, based on functionality. The sections containing nonobsolete programming interfaces are summarized in Figure 2.5 with their respective option codes. Option codes are two- to three-character abbreviations that help identify the interfaces that belong to each functional area. The option codes highlight text on manual pages where interfaces depend on the support of a particular option. Many of the options deal with real-time extensions.
Figure 2.5. POSIX.1 optional interface groups and codesCode | SUS mandatory | Symbolic constant | Description |
|---|
ADV | | _POSIX_ADVISORY_INFO | advisory information (real-time) | AIO | | _POSIX_ASYNCHRONOUS_IO | asynchronous input and output (real-time) | BAR | | _POSIX_BARRIERS | barriers (real-time) | CPT | | _POSIX_CPUTIME | process CPU time clocks (real-time) | CS | | _POSIX_CLOCK_SELECTION | clock selection (real-time) | CX | • | | extension to ISO C standard | FSC | • | _POSIX_FSYNC | file synchronization | IP6 | | _POSIX_IPV6 | IPv6 interfaces | MF | • | _POSIX_MAPPED_FILES | memory-mapped files | ML | | _POSIX_MEMLOCK | process memory locking (real-time) | MLR | | _POSIX_MEMLOCK_RANGE | memory range locking (real-time) | MON | | _POSIX_MONOTONIC_CLOCK | monotonic clock (real-time) | MPR | • | _POSIX_MEMORY_PROTECTION | memory protection | MSG | | _POSIX_MESSAGE_PASSING | message passing (real-time) | MX | | | IEC 60559 floating-point option | PIO | | _POSIX_PRIORITIZED_IO | prioritized input and output | PS | | _POSIX_PRIORITIZED_SCHEDULING | process scheduling (real-time) | RS | | _POSIX_RAW_SOCKETS | raw sockets | RTS | | _POSIX_REALTIME_SIGNALS | real-time signals extension | SEM | | _POSIX_SEMAPHORES | semaphores (real-time) | SHM | | _POSIX_SHARED_MEMORY_OBJECTS | shared memory objects (real-time) | SIO | | _POSIX_SYNCHRONIZED_IO | synchronized input and output (real-time) | SPI | | _POSIX_SPIN_LOCKS | spin locks (real-time) | SPN | | _POSIX_SPAWN | spawn (real-time) | SS | | _POSIX_SPORADIC_SERVER | process sporadic server (real-time) | TCT | | _POSIX_THREAD_CPUTIME | thread CPU time clocks (real-time) | TEF | | _POSIX_TRACE_EVENT_FILTER | trace event filter | THR | • | _POSIX_THREADS | threads | TMO | | _POSIX_TIMEOUTS | timeouts (real-time) | TMR | | _POSIX_TIMERS | timers (real-time) | TPI | | _POSIX_THREAD_PRIO_INHERIT | thread priority inheritance (real-time) | TPP | | _POSIX_THREAD_PRIO_PROTECT | thread priority protection (real-time) | TPS | | _POSIX_THREAD_PRIORITY_SCHEDULING | thread execution scheduling (real-time) | TRC | | _POSIX_TRACE | trace | TRI | | _POSIX_TRACE_INHERIT | trace inherit | TRL | | _POSIX_TRACE_LOG | trace log | TSA | • | _POSIX_THREAD_ATTR_STACKADDR | thread stack address attribute | TSF | • | _POSIX_THREAD_SAFE_FUNCTIONS | thread-safe functions | TSH | • | _POSIX_THREAD_PROCESS_SHARED | thread process-shared synchronization | TSP | | _POSIX_THREAD_SPORADIC_SERVER | thread sporadic server (real-time) | TSS | • | _POSIX_THREAD_ATTR_STACKSIZE | thread stack address size | TYM | | _POSIX_TYPED_MEMORY_OBJECTS | typed memory objects (real-time) | XSI | • | _XOPEN_UNIX | X/Open extended interfaces | XSR | | _XOPEN_STREAMS | XSI STREAMS |
POSIX.1 does not include the notion of a superuser. Instead, certain operations require "appropriate privileges," although POSIX.1 leaves the definition of this term up to the implementation. UNIX systems that conform to the Department of Defense security guidelines have many levels of security. In this text, however, we use the traditional terminology and refer to operations that require superuser privilege.
After almost twenty years of work, the standards are mature and stable. The POSIX.1 standard is maintained by an open working group known as the Austin Group (http://www.opengroup.org/austin). To ensure that they are still relevant, the standards need to be either updated or reaffirmed every so often.
2.2.3. The Single UNIX Specification
The Single UNIX Specification, a superset of the POSIX.1 standard, specifies additional interfaces that extend the functionality provided by the basic POSIX.1 specification. The complete set of system interfaces is called the X/Open System Interface (XSI). The _XOPEN_UNIX symbolic constant identifies interfaces that are part of the XSI extensions to the base POSIX.1 interfaces.
The XSI also defines which optional portions of POSIX.1 must be supported for an implementation to be deemed XSI conforming. These include file synchronization, memory-mapped files, memory protection, and thread interfaces, and are marked in Figure 2.5 as "SUS mandatory." Only XSI-conforming implementations can be called UNIX systems.
The Open Group owns the UNIX trademark and uses the Single UNIX Specification to define the interfaces an implementation must support to call itself a UNIX system. Implementations must file conformance statements, pass test suites that verify conformance, and license the right to use the UNIX trademark.
Some of the additional interfaces defined in the XSI are required, whereas others are optional. The interfaces are divided into option groups based on common functionality, as follows:
Encryption: denoted by the _XOPEN_CRYPT symbolic constant Real-time: denoted by the _XOPEN_REALTIME symbolic constant Advanced real-time Real-time threads: denoted by the _XOPEN_REALTIME_THREADS symbolic constant Advanced real-time threads Tracing XSI STREAMS: denoted by the _XOPEN_STREAMS symbolic constant Legacy: denoted by the _XOPEN_LEGACY symbolic constant
The Single UNIX Specification (SUS) is a publication of The Open Group, which was formed in 1996 as a merger of X/Open and the Open Software Foundation (OSF), both industry consortia. X/Open used to publish the X/Open Portability Guide, which adopted specific standards and filled in the gaps where functionality was missing. The goal of these guides was to improve application portability past what was possible by merely conforming to published standards.
The first version of the Single UNIX Specification was published by X/Open in 1994. It was also known as "Spec 1170," because it contained roughly 1,170 interfaces. It grew out of the Common Open Software Environment (COSE) initiative, whose goal was to further improve application portability across all implementations of the UNIX operating system. The COSE groupSun, IBM, HP, Novell/USL, and OSFwent further than endorsing standards. In addition, they investigated interfaces used by common commercial applications. The resulting 1,170 interfaces were selected from these applications, and also included the X/Open Common Application Environment (CAE), Issue 4 (known as "XPG4" as a historical reference to its predecessor, the X/Open Portability Guide), the System V Interface Definition (SVID), Edition 3, Level 1 interfaces, and the OSF Application Environment Specification (AES) Full Use interfaces.
The second version of the Single UNIX Specification was published by The Open Group in 1997. The new version added support for threads, real-time interfaces, 64-bit processing, large files, and enhanced multibyte character processing.
The third version of the Single UNIX Specification (SUSv3, for short) was published by The Open Group in 2001. The Base Specifications of SUSv3 are the same as the IEEE Standard 1003.1-2001 and are divided into four sections: Base Definitions, System Interfaces, Shell and Utilities, and Rationale. SUSv3 also includes X/Open Curses Issue 4, Version 2, but this specification is not part of POSIX.1.
In 2002, ISO approved this version as International Standard ISO/IEC 9945:2002. The Open Group updated the 1003.1 standard again in 2003 to include technical corrections, and ISO approved this as International Standard ISO/IEC 9945:2003. In April 2004, The Open Group published the Single UNIX Specification, Version 3, 2004 Edition. It included more technical corrections edited in with the main text of the standard.
2.2.4. FIPS
FIPS stands for Federal Information Processing Standard. It was published by the U.S. government, which used it for the procurement of computer systems. FIPS 1511 (April 1989) was based on the IEEE Std. 1003.11988 and a draft of the ANSI C standard. This was followed by FIPS 1512 (May 1993), which was based on the IEEE Standard 1003.11990. FIPS 1512 required some features that POSIX.1 listed as optional. All these options have been included as mandatory in POSIX.1-2001.
The effect of the POSIX.1 FIPS was to require any vendor that wished to sell POSIX.1-compliant computer systems to the U.S. government to support some of the optional features of POSIX.1. The POSIX.1 FIPS has since been withdrawn, so we won't consider it further in this text.
2.3. UNIX System Implementations
The previous section described ISO C, IEEE POSIX, and the Single UNIX Specification; three standards created by independent organizations. Standards, however, are interface specifications. How do these standards relate to the real world? These standards are taken by vendors and turned into actual implementations. In this book, we are interested in both these standards and their implementation.
Section 1.1 of McKusick et al. [1996] gives a detailed history (and a nice picture) of the UNIX System family tree. Everything starts from the Sixth Edition (1976) and Seventh Edition (1979) of the UNIX Time-Sharing System on the PDP-11 (usually called Version 6 and Version 7). These were the first releases widely distributed outside of Bell Laboratories. Three branches of the tree evolved.
One at AT&T that led to System III and System V, the so-called commercial versions of the UNIX System. One at the University of California at Berkeley that led to the 4.xBSD implementations. The research version of the UNIX System, developed at the Computing Science Research Center of AT&T Bell Laboratories, that led to the UNIX Time-Sharing System 8th Edition, 9th Edition, and ended with the 10th Edition in 1990.
2.3.1. UNIX System V Release 4
UNIX System V Release 4 (SVR4) was a product of AT&T's UNIX System Laboratories (USL, formerly AT&T's UNIX Software Operation). SVR4 merged functionality from AT&T UNIX System V Release 3.2 (SVR3.2), the SunOS operating system from Sun Microsystems, the 4.3BSD release from the University of California, and the Xenix system from Microsoft into one coherent operating system. (Xenix was originally developed from Version 7, with many features later taken from System V.) The SVR4 source code was released in late 1989, with the first end-user copies becoming available during 1990. SVR4 conformed to both the POSIX 1003.1 standard and the X/Open Portability Guide, Issue 3 (XPG3).
AT&T also published the System V Interface Definition (SVID) [AT&T 1989]. Issue 3 of the SVID specified the functionality that an operating system must offer to qualify as a conforming implementation of UNIX System V Release 4. As with POSIX.1, the SVID specified an interface, not an implementation. No distinction was made in the SVID between system calls and library functions. The reference manual for an actual implementation of SVR4 must be consulted to see this distinction [AT&T 1990e].
2.3.2. 4.4BSD
The Berkeley Software Distribution (BSD) releases were produced and distributed by the Computer Systems Research Group (CSRG) at the University of California at Berkeley; 4.2BSD was released in 1983 and 4.3BSD in 1986. Both of these releases ran on the VAX minicomputer. The next release, 4.3BSD Tahoe in 1988, also ran on a particular minicomputer called the Tahoe. (The book by Leffler et al. [1989] describes the 4.3BSD Tahoe release.) This was followed in 1990 with the 4.3BSD Reno release; 4.3BSD Reno supported many of the POSIX.1 features.
The original BSD systems contained proprietary AT&T source code and were covered by AT&T licenses. To obtain the source code to the BSD system you had to have a UNIX source license from AT&T. This changed as more and more of the AT&T source code was replaced over the years with non-AT&T source code and as many of the new features added to the Berkeley system were derived from non-AT&T sources.
In 1989, Berkeley identified much of the non-AT&T source code in the 4.3BSD Tahoe release and made it publicly available as the BSD Networking Software, Release 1.0. This was followed in 1991 with Release 2.0 of the BSD Networking Software, which was derived from the 4.3BSD Reno release. The intent was that most, if not all, of the 4.4BSD system would be free of any AT&T license restrictions, thus making the source code available to all.
4.4BSD-Lite was intended to be the final release from the CSRG. Its introduction was delayed, however, because of legal battles with USL. Once the legal differences were resolved, 4.4BSD-Lite was released in 1994, fully unencumbered, so no UNIX source license was needed to receive it. The CSRG followed this with a bug-fix release in 1995. This release, 4.4BSD-Lite, release 2, was the final version of BSD from the CSRG. (This version of BSD is described in the book by McKusick et al. [1996].)
The UNIX system development done at Berkeley started with PDP-11s, then moved to the VAX minicomputer, and then to other so-called workstations. During the early 1990s, support was provided to Berkeley for the popular 80386-based personal computers, leading to what is called 386BSD. This was done by Bill Jolitz and was documented in a series of monthly articles in Dr. Dobb's Journal throughout 1991. Much of this code appears in the BSD Networking Software, Release 2.0.
2.3.3. FreeBSD
FreeBSD is based on the 4.4BSD-Lite operating system. The FreeBSD project was formed to carry on the BSD line after the Computing Science Research Group at the University of California at Berkeley decided to end its work on the BSD versions of the UNIX operating system, and the 386BSD project seemed to be neglected for too long.
All software produced by the FreeBSD project is freely available in both binary and source forms. The FreeBSD 5.2.1 operating system was one of the four used to test the examples in this book.
Several other BSD-based free operating systems are available. The NetBSD project (http://www.netbsd.org) is similar to the FreeBSD project, with an emphasis on portability between hardware platforms. The OpenBSD project (http://www.openbsd.org) is similar to FreeBSD but with an emphasis on security.
2.3.4. Linux
Linux is an operating system that provides a rich UNIX programming environment, and is freely available under the GNU Public License. The popularity of Linux is somewhat of a phenomenon in the computer industry. Linux is distinguished by often being the first operating system to support new hardware.
Linux was created in 1991 by Linus Torvalds as a replacement for MINIX. A grass-roots effort then sprang up, whereby many developers across the world volunteered their time to use and enhance it.
The Mandrake 9.2 distribution of Linux was one of the operating systems used to test the examples in this book. That distribution uses the 2.4.22 version of the Linux operating system kernel.
2.3.5. Mac OS X
Mac OS X is based on entirely different technology than prior versions. The core operating system is called "Darwin," and is based on a combination of the Mach kernel (Accetta et al. [1986]) and the FreeBSD operating system. Darwin is managed as an open source project, similar to FreeBSD and Linux.
Mac OS X version 10.3 (Darwin 7.4.0) was used as one of the operating systems to test the examples in this book.
2.3.6. Solaris
Solaris is the version of the UNIX System developed by Sun Microsystems. It is based on System V Release 4, with more than ten years of enhancements from the engineers at Sun Microsystems. It is the only commercially successful SVR4 descendant, and is formally certified to be a UNIX system. (For more information on UNIX certification, see http://www.opengroup.org/certification/idx/unix.html.)
The Solaris 9 UNIX system was one of the operating systems used to test the examples in this book.
2.3.7. Other UNIX Systems
Other versions of the UNIX system that have been certified in the past include
AIX, IBM's version of the UNIX System HP-UX, Hewlett-Packard's version of the UNIX System IRIX, the UNIX System version shipped by Silicon Graphics UnixWare, the UNIX System descended from SVR4 and currently sold by SCO
2.4. Relationship of Standards and Implementations
The standards that we've mentioned define a subset of any actual system. The focus of this book is on four real systems: FreeBSD 5.2.1, Linux 2.4.22, Mac OS X 10.3, and Solaris 9. Although only Solaris can call itself a UNIX system, all four provide a UNIX programming environment. Because all four are POSIX compliant to varying degrees, we will also concentrate on the features that are required by the POSIX.1 standard, noting any differences between POSIX and the actual implementations of these four systems. Those features and routines that are specific to only a particular implementation are clearly marked. As SUSv3 is a superset of POSIX.1, we'll also note any features that are part of SUSv3 but not part of POSIX.1.
Be aware that the implementations provide backward compatibility for features in earlier releases, such as SVR3.2 and 4.3BSD. For example, Solaris supports both the POSIX.1 specification for nonblocking I/O (O_NONBLOCK) and the traditional System V method (O_NDELAY). In this text, we'll use only the POSIX.1 feature, although we'll mention the nonstandard feature that it replaces. Similarly, both SVR3.2 and 4.3BSD provided reliable signals in a way that differs from the POSIX.1 standard. In Chapter 10 we describe only the POSIX.1 signal mechanism.
2.5. Limits
The implementations define many magic numbers and constants. Many of these have been hard coded into programs or were determined using ad hoc techniques. With the various standardization efforts that we've described, more portable methods are now provided to determine these magic numbers and implementation-defined limits, greatly aiding the portability of our software.
Two types of limits are needed:
Compile-time limits (e.g., what's the largest value of a short integer?) Runtime limits (e.g., how many characters in a filename?)
Compile-time limits can be defined in headers that any program can include at compile time. But runtime limits require the process to call a function to obtain the value of the limit.
Additionally, some limits can be fixed on a given implementationand could therefore be defined statically in a headeryet vary on another implementation and would require a runtime function call. An example of this type of limit is the maximum number of characters in a filename. Before SVR4, System V historically allowed only 14 characters in a filename, whereas BSD-derived systems increased this number to 255. Most UNIX System implementations these days support multiple file system types, and each type has its own limit. This is the case of a runtime limit that depends on where in the file system the file in question is located. A filename in the root file system, for example, could have a 14-character limit, whereas a filename in another file system could have a 255-character limit.
To solve these problems, three types of limits are provided:
Compile-time limits (headers) Runtime limits that are not associated with a file or directory (the sysconf function) Runtime limits that are associated with a file or a directory (the pathconf and fpathconf functions)
To further confuse things, if a particular runtime limit does not vary on a given system, it can be defined statically in a header. If it is not defined in a header, however, the application must call one of the three conf functions (which we describe shortly) to determine its value at runtime.
2.5.1. ISO C Limits
All the limits defined by ISO C are compile-time limits. Figure 2.6 shows the limits from the C standard that are defined in the file <limits.h>. These constants are always defined in the header and don't change in a given system. The third column shows the minimum acceptable values from the ISO C standard. This allows for a system with 16-bit integers using one's-complement arithmetic. The fourth column shows the values from a Linux system with 32-bit integers using two's-complement arithmetic. Note that none of the unsigned data types has a minimum value, as this value must be 0 for an unsigned data type. On a 64-bit system, the values for long integer maximums match the maximum values for long long integers.
Figure 2.6. Sizes of integral values from <limits.h>Name | Description | Minimum acceptable value | Typical value |
|---|
CHAR_BIT | bits in a char | 8 | 8 | CHAR_MAX | max value of char | (see later) | 127 | CHAR_MIN | min value of char | (see later) | 128 | SCHAR_MAX | max value of signed char | 127 | 127 | SCHAR_MIN | min value of signed char | 127 | 128 | UCHAR_MAX | max value of unsigned char | 255 | 255 | INT_MAX | max value of int | 32,767 | 2,147,483,647 | INT_MIN | min value of int | 32,767 | 2,147,483,648 | UINT_MAX | max value of unsigned int | 65,535 | 4,294,967,295 | SHRT_MIN | min value of short | 32,767 | 32,768 | SHRT_MAX | max value of short | 32,767 | 32,767 | USHRT_MAX | max value of unsigned short | 65,535 | 65,535 | LONG_MAX | max value of long | 2,147,483,647 | 2,147,483,647 | LONG_MIN | min value of long | 2,147,483,647 | 2,147,483,648 | ULONG_MAX | max value of unsigned long | 4,294,967,295 | 4,294,967,295 | LLONG_MAX | max value of long long | 9,223,372,036,854,775,807 | 9,223,372,036,854,775,807 | LLONG_MIN | min value of long long | 9,223,372,036,854,775,807 | 9,223,372,036,854,775,808 | ULLONG_MAX | max value of unsigned long long | 18,446,744,073,709,551,615 | 18,446,744,073,709,551,615 | MB_LEN_MAX | max number of bytes in a multibyte character constant | 1 | 16 |
One difference that we will encounter is whether a system provides signed or unsigned character values. From the fourth column in Figure 2.6, we see that this particular system uses signed characters. We see that CHAR_MIN equals SCHAR_MIN and that CHAR_MAX equals SCHAR_MAX. If the system uses unsigned characters, we would have CHAR_MIN equal to 0 and CHAR_MAX equal to UCHAR_MAX.
The floating-point data types in the header <float.h> have a similar set of definitions. Anyone doing serious floating-point work should examine this file.
Another ISO C constant that we'll encounter is FOPEN_MAX, the minimum number of standard I/O streams that the implementation guarantees can be open at once. This value is in the <stdio.h> header, and its minimum value is 8. The POSIX.1 value STREAM_MAX, if defined, must have the same value as FOPEN_MAX.
ISO C also defines the constant TMP_MAX in <stdio.h>. It is the maximum number of unique filenames generated by the tmpnam function. We'll have more to say about this constant in Section 5.13.
In Figure 2.7, we show the values of FOPEN_MAX and TMP_MAX on the four platforms we discuss in this book.
Figure 2.7. ISO limits on various platformsLimit | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
FOPEN_MAX | 20 | 16 | 20 | 20 | TMP_MAX | 308,915,776 | 238,328 | 308,915,776 | 17,576 |
ISO C also defines the constant FILENAME_MAX, but we avoid using it, because some operating system implementations historically have defined it to be too small to be of use.
2.5.2. POSIX Limits
POSIX.1 defines numerous constants that deal with implementation limits of the operating system. Unfortunately, this is one of the more confusing aspects of POSIX.1. Although POSIX.1 defines numerous limits and constants, we'll only concern ourselves with the ones that affect the base POSIX.1 interfaces. These limits and constants are divided into the following five categories:
Invariant minimum values: the 19 constants in Figure 2.8 Invariant value: SSIZE_MAX Runtime increasable values: CHARCLASS_NAME_MAX, COLL_WEIGHTS_MAX, LINE_MAX, NGROUPS_MAX, and RE_DUP_MAX Runtime invariant values, possibly indeterminate: ARG_MAX, CHILD_MAX, HOST_NAME_MAX, LOGIN_NAME_MAX, OPEN_MAX, PAGESIZE, RE_DUP_MAX, STREAM_MAX, SYMLOOP_MAX, TTY_NAME_MAX, and TZNAME_MAX Pathname variable values, possibly indeterminate: FILESIZEBITS, LINK_MAX, MAX_CANON, MAX_INPUT, NAME_MAX, PATH_MAX, PIPE_BUF, and SYMLINK_MAX
Figure 2.8. POSIX.1 invariant minimum values from <limits.h>Name | Description: minimum acceptable value for | Value |
|---|
_POSIX_ARG_MAX | length of arguments to exec functions | 4,096 | _POSIX_CHILD_MAX | number of child processes per real user ID | 25 | _POSIX_HOST_NAME_MAX | maximum length of a host name as returned by gethostname | 255 | _POSIX_LINK_MAX | number of links to a file | 8 | _POSIX_LOGIN_NAME_MAX | maximum length of a login name | 9 | _POSIX_MAX_CANON | number of bytes on a terminal's canonical input queue | 255 | _POSIX_MAX_INPUT | space available on a terminal's input queue | 255 | _POSIX_NAME_MAX | number of bytes in a filename, not including the terminating null | 14 | _POSIX_NGROUPS_MAX | number of simultaneous supplementary group IDs per process | 8 | _POSIX_OPEN_MAX | number of open files per process | 20 | _POSIX_PATH_MAX | number of bytes in a pathname, including the terminating null | 256 | _POSIX_PIPE_BUF | number of bytes that can be written atomically to a pipe | 512 | _POSIX_RE_DUP_MAX | number of repeated occurrences of a basic regular expression permitted by the regexec and regcomp functions when using the interval notation \{m,n\} | 255 | _POSIX_SSIZE_MAX | value that can be stored in ssize_t object | 32,767 | _POSIX_STREAM_MAX | number of standard I/O streams a process can have open at once | 8 | _POSIX_SYMLINK_MAX | number of bytes in a symbolic link | 255 | _POSIX_SYMLOOP_MAX | number of symbolic links that can be traversed during pathname resolution | 8 | _POSIX_TTY_NAME_MAX | length of a terminal device name, including the terminating null | 9 | _POSIX_TZNAME_MAX | number of bytes for the name of a time zone | 6 |
Of these 44 limits and constants, some may be defined in <limits.h>, and others may or may not be defined, depending on certain conditions. We describe the limits and constants that may or may not be defined in Section 2.5.4, when we describe the sysconf, pathconf, and fpathconf functions. The 19 invariant minimum values are shown in Figure 2.8.
These values are invariant; they do not change from one system to another. They specify the most restrictive values for these features. A conforming POSIX.1 implementation must provide values that are at least this large. This is why they are called minimums, although their names all contain MAX. Also, to ensure portability, a strictly-conforming application must not require a larger value. We describe what each of these constants refers to as we proceed through the text.
A strictly-conforming POSIX application is different from an application that is merely POSIX conforming. A POSIX-conforming application uses only interfaces defined in IEEE Standard 1003.1-2001. A strictly-conforming application is a POSIX-conforming application that does not rely on any undefined behavior, does not use any obsolescent interfaces, and does not require values of constants larger than the minimums shown in Figure 2.8.
Unfortunately, some of these invariant minimum values are too small to be of practical use. For example, most UNIX systems today provide far more than 20 open files per process. Also, the minimum limit of 255 for _POSIX_PATH_MAX is too small. Pathnames can exceed this limit. This means that we can't use the two constants _POSIX_OPEN_MAX and _POSIX_PATH_MAX as array sizes at compile time.
Each of the 19 invariant minimum values in Figure 2.8 has an associated implementation value whose name is formed by removing the _POSIX_ prefix from the name in Figure 2.8. The names without the leading _POSIX_ were intended to be the actual values that a given implementation supports. (These 19 implementation values are items 25 from our list earlier in this section: the invariant value, the runtime increasable value, the runtime invariant values, and the pathname variable values.) The problem is that not all of the 19 implementation values are guaranteed to be defined in the <limits.h> header.
For example, a particular value may not be included in the header if its actual value for a given process depends on the amount of memory on the system. If the values are not defined in the header, we can't use them as array bounds at compile time. So, POSIX.1 decided to provide three runtime functions for us to callsysconf, pathconf, and fpathconfto determine the actual implementation value at runtime. There is still a problem, however, because some of the values are defined by POSIX.1 as being possibly "indeterminate" (logically infinite). This means that the value has no practical upper bound. On Linux, for example, the number of iovec structures you can use with readv or writev is limited only by the amount of memory on the system. Thus, IOV_MAX is considered indeterminate on Linux. We'll return to this problem of indeterminate runtime limits in Section 2.5.5.
2.5.3. XSI Limits
The XSI also defines constants that deal with implementation limits. They include:
Invariant minimum values: the ten constants in Figure 2.9 Numerical limits: LONG_BIT and WORD_BIT Runtime invariant values, possibly indeterminate: ATEXIT_MAX, IOV_MAX, and PAGE_SIZE
Figure 2.9. XSI invariant minimum values from <limits.h>Name | Description | Minimum acceptable value | Typical value |
|---|
NL_ARGMAX | maximum value of digit in calls to printf and scanf | 9 | 9 | NL_LANGMAX | maximum number of bytes in LANG environment variable | 14 | 14 | NL_MSGMAX | maximum message number | 32,767 | 32,767 | NL_NMAX | maximum number of bytes in N-to-1 mapping characters | (none specified) | 1 | NL_SETMAX | maximum set number | 255 | 255 | NL_TEXTMAX | maximum number of bytes in a message string | _POSIX2_LINE_MAX | 2,048 | NZERO | default process priority | 20 | 20 | _XOPEN_IOV_MAX | maximum number of iovec structures that can be used with readv or writev | 16 | 16 | _XOPEN_NAME_MAX | number of bytes in a filename | 255 | 255 | _XOPEN_PATH_MAX | number of bytes in a pathname | 1,024 | 1,024 |
The invariant minimum values are listed in Figure 2.9. Many of these values deal with message catalogs. The last two illustrate the situation in which the POSIX.1 minimums were too smallpresumably to allow for embedded POSIX.1 implementationsso the Single UNIX Specification added symbols with larger minimum values for XSI-conforming systems.
2.5.4. sysconf, pathconf, and fpathconf Functions
We've listed various minimum values that an implementation must support, but how do we find out the limits that a particular system actually supports? As we mentioned earlier, some of these limits might be available at compile time; others must be determined at runtime. We've also mentioned that some don't change in a given system, whereas others can change because they are associated with a file or directory. The runtime limits are obtained by calling one of the following three functions.
#include <unistd.h>
long sysconf(int name);
long pathconf(const char *pathname, int name);
long fpathconf(int filedes, int name);
| All three return: corresponding value if OK, 1 on error (see later) |
The difference between the last two functions is that one takes a pathname as its argument and the other takes a file descriptor argument.
Figure 2.10 lists the name arguments that sysconf uses to identify system limits. Constants beginning with _SC_ are used as arguments to sysconf to identify the runtime limit. Figure 2.11 lists the name arguments that are used by pathconf and fpathconf to identify system limits. Constants beginning with _PC_ are used as arguments to pathconf and fpathconf to identify the runtime limit.
Figure 2.10. Limits and name arguments to sysconfName of limit | Description | name argument |
|---|
ARG_MAX | maximum length, in bytes, of arguments to the exec functions | _SC_ARG_MAX
| ATEXIT_MAX | maximum number of functions that can be registered with the atexit function | _SC_ATEXIT_MAX
| CHILD_MAX | maximum number of processes per real user ID | _SC_CHILD_MAX
| clock ticks/second | number of clock ticks per second | _SC_CLK_TCK
| COLL_WEIGHTS_MAX | maximum number of weights that can be assigned to an entry of the LC_COLLATE order keyword in the locale definition file | _SC_COLL_WEIGHTS_MAX
| HOST_NAME_MAX | maximum length of a host name as returned by gethostname | _SC_HOST_NAME_MAX
| IOV_MAX | maximum number of iovec structures that can be used with readv or writev | _SC_IOV_MAX
| LINE_MAX | maximum length of a utility's input line | _SC_LINE_MAX
| LOGIN_NAME_MAX | maximum length of a login name | _SC_LOGIN_NAME_MAX
| NGROUPS_MAX | maximum number of simultaneous supplementary process group IDs per process | _SC_NGROUPS_MAX
| OPEN_MAX | maximum number of open files per process | _SC_OPEN_MAX
| PAGESIZE | system memory page size, in bytes | _SC_PAGESIZE
| PAGE_SIZE | system memory page size, in bytes | _SC_PAGE_SIZE
| RE_DUP_MAX | number of repeated occurrences of a basic regular expression permitted by the regexec and regcomp functions when using the interval notation \{m,n\} | _SC_RE_DUP_MAX
| STREAM_MAX | maximum number of standard I/O streams per process at any given time; if defined, it must have the same value as FOPEN_MAX | _SC_STREAM_MAX
| SYMLOOP_MAX | number of symbolic links that can be traversed during pathname resolution | _SC_SYMLOOP_MAX
| TTY_NAME_MAX | length of a terminal device name, including the terminating null | _SC_TTY_NAME_MAX
| TZNAME_MAX | maximum number of bytes for the name of a time zone | _SC_TZNAME_MAX
|
Figure 2.11. Limits and name arguments to pathconf and fpathconfName of limit | Description | name argument |
|---|
FILESIZEBITS | minimum number of bits needed to represent, as a signed integer value, the maximum size of a regular file allowed in the specified directory | _PC_FILESIZEBITS
| LINK_MAX | maximum value of a file's link count | _PC_LINK_MAX
| MAX_CANON | maximum number of bytes on a terminal's canonical input queue | _PC_MAX_CANON
| MAX_INPUT | number of bytes for which space is available on terminal's input queue | _PC_MAX_INPUT
| NAME_MAX | maximum number of bytes in a filename (does not include a null at end) | _PC_NAME_MAX | PATH_MAX | maximum number of bytes in a relative pathname, including the terminating null | _PC_PATH_MAX
| PIPE_BUF | maximum number of bytes that can be written atomically to a pipe | _PC_PIPE_BUF
| SYMLINK_MAX | number of bytes in a symbolic link | _PC_SYMLINK_MAX
|
We need to look in more detail at the different return values from these three functions.
All three functions return 1 and set errno to EINVAL if the name isn't one of the appropriate constants. The third column in Figures 2.10 and 2.11 lists the limit constants we'll deal with throughout the rest of this book. Some names can return either the value of the variable (a return value  0) or an indication that the value is indeterminate. An indeterminate value is indicated by returning 1 and not changing the value of errno. 0) or an indication that the value is indeterminate. An indeterminate value is indicated by returning 1 and not changing the value of errno. The value returned for _SC_CLK_TCK is the number of clock ticks per second, for use with the return values from the times function (Section 8.16).
There are some restrictions for the pathname argument to pathconf and the filedes argument to fpathconf. If any of these restrictions isn't met, the results are undefined.
The referenced file for _PC_MAX_CANON and _PC_MAX_INPUT must be a terminal file. The referenced file for _PC_LINK_MAX can be either a file or a directory. If the referenced file is a directory, the return value applies to the directory itself, not to the filename entries within the directory. The referenced file for _PC_FILESIZEBITS and _PC_NAME_MAX must be a directory. The return value applies to filenames within the directory. The referenced file for _PC_PATH_MAX must be a directory. The value returned is the maximum length of a relative pathname when the specified directory is the working directory. (Unfortunately, this isn't the real maximum length of an absolute pathname, which is what we want to know. We'll return to this problem in Section 2.5.5.) The referenced file for _PC_PIPE_BUF must be a pipe, FIFO, or directory. In the first two cases (pipe or FIFO) the return value is the limit for the referenced pipe or FIFO. For the other case (a directory) the return value is the limit for any FIFO created in that directory. The referenced file for _PC_SYMLINK_MAX must be a directory. The value returned is the maximum length of the string that a symbolic link in that directory can contain.
Example
The awk(1) program shown in Figure 2.12 builds a C program that prints the value of each pathconf and sysconf symbol.
The awk program reads two input filespathconf.sym and sysconf.symthat contain lists of the limit name and symbol, separated by tabs. All symbols are not defined on every platform, so the awk program surrounds each call to pathconf and sysconf with the necessary #ifdef statements.
For example, the awk program transforms a line in the input file that looks like
NAME_MAX _PC_NAME_MAX
into the following C code:
#ifdef NAME_MAX
printf("NAME_MAX is defined to be %d\n", NAME_MAX+0);
#else
printf("no symbol for NAME_MAX\n");
#endif
#ifdef _PC_NAME_MAX
pr_pathconf("NAME_MAX =", argv[1], _PC_NAME_MAX);
#else
printf("no symbol for _PC_NAME_MAX\n");
#endif
The program in Figure 2.13, generated by the awk program, prints all these limits, handling the case in which a limit is not defined.
Figure 2.14 summarizes results from Figure 2.13 for the four systems we discuss in this book. The entry "no symbol" means that the system doesn't provide a corresponding _SC or _PC symbol to query the value of the constant. Thus, the limit is undefined in this case. In contrast, the entry "unsupported" means that the symbol is defined by the system but unrecognized by the sysconf or pathconf functions. The entry "no limit" means that the system defines no limit for the constant, but this doesn't mean that the limit is infinite.
We'll see in Section 4.14 that UFS is the SVR4 implementation of the Berkeley fast file system. PCFS is the MS-DOS FAT file system implementation for Solaris.
Figure 2.12. Build C program to print all supported configuration limits
BEGIN {
printf("#include \"apue.h\"\n")
printf("#include <errno.h>\n")
printf("#include <limits.h>\n")
printf("\n")
printf("static void pr_sysconf(char *, int);\n")
printf("static void pr_pathconf(char *, char *, int);\n")
printf("\n")
printf("int\n")
printf("main(int argc, char *argv[])\n")
printf("{\n")
printf("\tif (argc != 2)\n")
printf("\t\terr_quit(\"usage: a.out <dirname>\");\n\n")
FS="\t+"
while (getline <"sysconf.sym" > 0) {
printf("#ifdef %s\n", $1)
printf("\tprintf(\"%s defined to be %%d\\n\", %s+0);\n", $1, $1)
printf("#else\n")
printf("\tprintf(\"no symbol for %s\\n\");\n", $1)
printf("#endif\n")
printf("#ifdef %s\n", $2)
printf("\tpr_sysconf(\"%s =\", %s);\n", $1, $2)
printf("#else\n")
printf("\tprintf(\"no symbol for %s\\n\");\n", $2)
printf("#endif\n")
}
close("sysconf.sym")
while (getline <"pathconf.sym" > 0) {
printf("#ifdef %s\n", $1)
printf("\tprintf(\"%s defined to be %%d\\n\", %s+0);\n", $1, $1)
printf("#else\n")
printf("\tprintf(\"no symbol for %s\\n\");\n", $1)
printf("#endif\n")
printf("#ifdef %s\n", $2)
printf("\tpr_pathconf(\"%s =\", argv[1], %s);\n", $1, $2)
printf("#else\n")
printf("\tprintf(\"no symbol for %s\\n\");\n", $2)
printf("#endif\n")
}
close("pathconf.sym")
exit
}
END {
printf("\texit(0);\n")
printf("}\n\n")
printf("static void\n")
printf("pr_sysconf(char *mesg, int name)\n")
printf("{\n")
printf("\tlong val;\n\n")
printf("\tfputs(mesg, stdout);\n")
printf("\terrno = 0;\n")
printf("\tif ((val = sysconf(name)) < 0) {\n")
printf("\t\tif (errno != 0) {\n")
printf("\t\t\tif (errno == EINVAL)\n")
printf("\t\t\t\tfputs(\" (not supported)\\n\", stdout);\n")
printf("\t\t\telse\n")
printf("\t\t\t\terr_sys(\"sysconf error\");\n")
printf("\t\t} else {\n")
printf("\t\t\tfputs(\" (no limit)\\n\", stdout);\n")
printf("\t\t}\n")
printf("\t} else {\n")
printf("\t\tprintf(\" %%ld\\n\", val);\n")
printf("\t}\n")
printf("}\n\n")
printf("static void\n")
printf("pr_pathconf(char *mesg, char *path, int name)\n")
printf("{\n")
printf("\tlong val;\n")
printf("\n")
printf("\tfputs(mesg, stdout);\n")
printf("\terrno = 0;\n")
printf("\tif ((val = pathconf(path, name)) < 0) {\n")
printf("\t\tif (errno != 0) {\n")
printf("\t\t\tif (errno == EINVAL)\n")
printf("\t\t\t\tfputs(\" (not supported)\\n\", stdout);\n")
printf("\t\t\telse\n")
printf("\t\t\t\terr_sys(\"pathconf error, path = %%s\", path);\n")
printf("\t\t} else {\n")
printf("\t\t\tfputs(\" (no limit)\\n\", stdout);\n")
printf("\t\t}\n")
printf("\t} else {\n")
printf("\t\tprintf(\" %%ld\\n\", val);\n")
printf("\t}\n")
printf("}\n")
}
Figure 2.13. Print all possible sysconf and pathconf values
#include "apue.h"
#include <errno.h>
#include <limits.h>
static void pr_sysconf(char *, int);
static void pr_pathconf(char *, char *, int);
int
main(int argc, char *argv[])
{
if (argc != 2)
err_quit("usage: a.out <dirname>");
#ifdef ARG_MAX
printf("ARG_MAX defined to be %d\n", ARG_MAX+0);
#else
printf("no symbol for ARG_MAX\n");
#endif
#ifdef _SC_ARG_MAX
pr_sysconf("ARG_MAX =", _SC_ARG_MAX);
#else
printf("no symbol for _SC_ARG_MAX\n");
#endif
/* similar processing for all the rest of the sysconf symbols... */
#ifdef MAX_CANON
printf("MAX_CANON defined to be %d\n", MAX_CANON+0);
#else
printf("no symbol for MAX_CANON\n");
#endif
#ifdef _PC_MAX_CANON
pr_pathconf("MAX_CANON =", argv[1], _PC_MAX_CANON);
#else
printf("no symbol for _PC_MAX_CANON\n");
#endif
/* similar processing for all the rest of the pathconf symbols... */
exit(0);
}
static void
pr_sysconf(char *mesg, int name)
{
long val;
fputs(mesg, stdout);
errno = 0;
if ((val = sysconf(name)) < 0) {
if (errno != 0) {
if (errno == EINVAL)
fputs(" (not supported)\n", stdout);
else
err_sys("sysconf error");
} else {
fputs(" (no limit)\n", stdout);
}
} else {
printf(" %ld\n", val);
}
}
static void
pr_pathconf(char *mesg, char *path, int name)
{
long val;
fputs(mesg, stdout);
errno = 0;
if ((val = pathconf(path, name)) < 0) {
if (errno != 0) {
if (errno == EINVAL)
fputs(" (not supported)\n", stdout);
else
err_sys("pathconf error, path = %s", path);
} else {
fputs(" (no limit)\n", stdout);
}
} else {
printf(" %ld\n", val);
}
}
Figure 2.14. Examples of configuration limitsLimit | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
UFS file system | PCFS file system |
|---|
ARG_MAX | 65,536 | 131,072 | 262,144 | 1,048,320 | 1,048,320 | ATEXIT_MAX | 32 | 2,147,483,647 | no symbol | no limit | no limit | CHARCLASS_NAME_MAX | no symbol | 2,048 | no symbol | 14 | 14 | CHILD_MAX | 867 | 999 | 100 | 7,877 | 7,877 | clock ticks/second | 128 | 100 | 100 | 100 | 100 | COLL_WEIGHTS_MAX | 0 | 255 | 2 | 10 | 10 | FILESIZEBITS | unsupported | 64 | no symbol | 41 | unsupported | HOST_NAME_MAX | 255 | unsupported | no symbol | no symbol | no symbol | IOV_MAX | 1,024 | no limit | no symbol | 16 | 16 | LINE_MAX | 2,048 | 2,048 | 2,048 | 2,048 | 2,048 | LINK_MAX | 32,767 | 32,000 | 32,767 | 32,767 | 1 | LOGIN_NAME_MAX | 17 | 256 | no symbol | 9 | 9 | MAX_CANON | 255 | 255 | 255 | 256 | 256 | MAX_INPUT | 255 | 255 | 255 | 512 | 512 | NAME_MAX | 255 | 255 | 765 | 255 | 8 | NGROUPS_MAX | 16 | 32 | 16 | 16 | 16 | OPEN_MAX | 1,735 | 1,024 | 256 | 256 | 256 | PAGESIZE | 4,096 | 4,096 | 4,096 | 8,192 | 8,192 | PAGE_SIZE | 4,096 | 4,096 | no symbol | 8,192 | 8,192 | PATH_MAX | 1,024 | 4,096 | 1,024 | 1,024 | 1,024 | PIPE_BUF | 512 | 4,096 | 512 | 5,120 | 5,120 | RE_DUP_MAX | 255 | 32,767 | 255 | 255 | 255 | STREAM_MAX | 1,735 | 16 | 20 | 256 | 256 | SYMLINK_MAX | unsupported | no limit | no symbol | no symbol | no symbol | SYMLOOP_MAX | 32 | no limit | no symbol | no symbol | no symbol | TTY_NAME_MAX | 255 | 32 | no symbol | 128 | 128 | TZNAME_MAX | 255 | 6 | 255 | no limit | no limit |
2.5.5. Indeterminate Runtime Limits
We mentioned that some of the limits can be indeterminate. The problem we encounter is that if these limits aren't defined in the <limits.h> header, we can't use them at compile time. But they might not be defined at runtime if their value is indeterminate! Let's look at two specific cases: allocating storage for a pathname and determining the number of file descriptors.
Pathnames
Many programs need to allocate storage for a pathname. Typically, the storage has been allocated at compile time, and various magic numbersfew of which are the correct valuehave been used by different programs as the array size: 256, 512, 1024, or the standard I/O constant BUFSIZ. The 4.3BSD constant MAXPATHLEN in the header <sys/param.h> is the correct value, but many 4.3BSD applications didn't use it.
POSIX.1 tries to help with the PATH_MAX value, but if this value is indeterminate, we're still out of luck. Figure 2.15 shows a function that we'll use throughout this text to allocate storage dynamically for a pathname.
Figure 2.15. Dynamically allocate space for a pathname
#include "apue.h"
#include <errno.h>
#include <limits.h>
#ifdef PATH_MAX
static int pathmax = PATH_MAX;
#else
static int pathmax = 0;
#endif
#define SUSV3 200112L
static long posix_version = 0;
/* If PATH_MAX is indeterminate, no guarantee this is adequate */
#define PATH_MAX_GUESS 1024
char *
path_alloc(int *sizep) /* also return allocated size, if nonnull */
{
char *ptr;
int size;
if (posix_version == 0)
posix_version = sysconf(_SC_VERSION);
if (pathmax == 0) { /* first time through */
errno = 0;
if ((pathmax = pathconf("/", _PC_PATH_MAX)) < 0) {
if (errno == 0)
pathmax = PATH_MAX_GUESS; /* it's indeterminate */
else
err_sys("pathconf error for _PC_PATH_MAX");
} else {
pathmax++; /* add one since it's relative to root */
}
}
if (posix_version < SUSV3)
size = pathmax + 1;
else
size = pathmax;
if ((ptr = malloc(size)) == NULL)
err_sys("malloc error for pathname");
if (sizep != NULL)
*sizep = size;
return(ptr);
}
If the constant PATH_MAX is defined in <limits.h>, then we're all set. If it's not, we need to call pathconf. The value returned by pathconf is the maximum size of a relative pathname when the first argument is the working directory, so we specify the root as the first argument and add 1 to the result. If pathconf indicates that PATH_MAX is indeterminate, we have to punt and just guess a value.
Standards prior to SUSv3 were unclear as to whether or not PATH_MAX included a null byte at the end of the pathname. If the operating system implementation conforms to one of these prior versions, we need to add 1 to the amount of memory we allocate for a pathname, just to be on the safe side.
The correct way to handle the case of an indeterminate result depends on how the allocated space is being used. If we were allocating space for a call to getcwd, for exampleto return the absolute pathname of the current working directory; see Section 4.22and if the allocated space is too small, an error is returned and errno is set to ERANGE. We could then increase the allocated space by calling realloc (see Section 7.8 and Exercise 4.16) and try again. We could keep doing this until the call to getcwd succeeded.
Maximum Number of Open Files
A common sequence of code in a daemon processa process that runs in the background, not connected to a terminalis one that closes all open files. Some programs have the following code sequence, assuming the constant NOFILE was defined in the <sys/param.h> header:
#include <sys/param.h>
for (i = 0; i < NOFILE; i++)
close(i);
Other programs use the constant _NFILE that some versions of <stdio.h> provide as the upper limit. Some hard code the upper limit as 20.
We would hope to use the POSIX.1 value OPEN_MAX to determine this value portably, but if the value is indeterminate, we still have a problem. If we wrote the following and if OPEN_MAX was indeterminate, the loop would never execute, since sysconf would return -1:
#include <unistd.h>
for (i = 0; i < sysconf(_SC_OPEN_MAX); i++)
close(i);
Our best option in this case is just to close all descriptors up to some arbitrary limit, say 256. As with our pathname example, this is not guaranteed to work for all cases, but it's the best we can do. We show this technique in Figure 2.16.
Figure 2.16. Determine the number of file descriptors
#include "apue.h"
#include <errno.h>
#include <limits.h>
#ifdef OPEN_MAX
static long openmax = OPEN_MAX;
#else
static long openmax = 0;
#endif
/*
* If OPEN_MAX is indeterminate, we're not
* guaranteed that this is adequate.
*/
#define OPEN_MAX_GUESS 256
long
open_max(void)
{
if (openmax == 0) { /* first time through */
errno = 0;
if ((openmax = sysconf(_SC_OPEN_MAX)) < 0) {
if (errno == 0)
openmax = OPEN_MAX_GUESS; /* it's indeterminate */
else
err_sys("sysconf error for _SC_OPEN_MAX");
}
}
return(openmax);
}
We might be tempted to call close until we get an error return, but the error return from close (EBADF) doesn't distinguish between an invalid descriptor and a descriptor that wasn't open. If we tried this technique and descriptor 9 was not open but descriptor 10 was, we would stop on 9 and never close 10. The dup function (Section 3.12) does return a specific error when OPEN_MAX is exceeded, but duplicating a descriptor a couple of hundred times is an extreme way to determine this value.
Some implementations will return LONG_MAX for limits values that are effectively unlimited. Such is the case with the Linux limit for ATEXIT_MAX (see Figure 2.14). This isn't a good idea, because it can cause programs to behave badly.
For example, we can use the ulimit command built into the Bourne-again shell to change the maximum number of files our processes can have open at one time. This generally requires special (superuser) privileges if the limit is to be effectively unlimited. But once set to infinite, sysconf will report LONG_MAX as the limit for OPEN_MAX. A program that relies on this value as the upper bound of file descriptors to close as shown in Figure 2.16 will waste a lot of time trying to close 2,147,483,647 file descriptors, most of which aren't even in use.
Systems that support the XSI extensions in the Single UNIX Specification will provide the getrlimit(2) function (Section 7.11). It can be used to return the maximum number of descriptors that a process can have open. With it, we can detect that there is no configured upper bound to the number of open files our processes can open, so we can avoid this problem.
The OPEN_MAX value is called runtime invariant by POSIX, meaning that its value should not change during the lifetime of a process. But on systems that support the XSI extensions, we can call the setrlimit(2) function (Section 7.11) to change this value for a running process. (This value can also be changed from the C shell with the limit command, and from the Bourne, Bourne-again, and Korn shells with the ulimit command.) If our system supports this functionality, we could change the function in Figure 2.16 to call sysconf every time it is called, not only the first time.
2.6. Options
We saw the list of POSIX.1 options in Figure 2.5 and discussed XSI option groups in Section 2.2.3. If we are to write portable applications that depend on any of these optionally-supported features, we need a portable way to determine whether an implementation supports a given option.
Just as with limits (Section 2.5), the Single UNIX Specification defines three ways to do this.
Compile-time options are defined in <unistd.h>. Runtime options that are not associated with a file or a directory are identified with the sysconf function. Runtime options that are associated with a file or a directory are discovered by calling either the pathconf or the fpathconf function.
The options include the symbols listed in the third column of Figure 2.5, as well as the symbols listed in Figures 2.17 and 2.18. If the symbolic constant is not defined, we must use sysconf, pathconf, or fpathconf to determine whether the option is supported. In this case, the name argument to the function is formed by replacing the _POSIX at the beginning of the symbol with _SC or _PC. For constants that begin with _XOPEN, the name argument is formed by prepending the string with _SC or _PC. For example, if the constant _POSIX_THREADS is undefined, we can call sysconf with the name argument set to _SC_THREADS to determine whether the platform supports the POSIX threads option. If the constant _XOPEN_UNIX is undefined, we can call sysconf with the name argument set to _SC_XOPEN_UNIX to determine whether the platform supports the XSI extensions.
Figure 2.17. Options and name arguments to sysconfName of option | Description | name argument |
|---|
_POSIX_JOB_CONTROL | indicates whether the implementation supports job control | _SC_JOB_CONTROL
| _POSIX_READER_WRITER_LOCKS | indicates whether the implementation supports readerwriter locks | _SC_READER_WRITER_LOCKS
| _POSIX_SAVED_IDS | indicates whether the implementation supports the saved set-user-ID and the saved set-group-ID | _SC_SAVED_IDS
| _POSIX_SHELL | indicates whether the implementation supports the POSIX shell | _SC_SHELL
| _POSIX_VERSION | indicates the POSIX.1 version | _SC_VERSION
| _XOPEN_CRYPT | indicates whether the implementation supports the XSI encryption option group | _SC_XOPEN_CRYPT
| _XOPEN_LEGACY | indicates whether the implementation supports the XSI legacy option group | _SC_XOPEN_LEGACY
| _XOPEN_REALTIME | indicates whether the implementation supports the XSI real-time option group | _SC_XOPEN_REALTIME
| _XOPEN_REALTIME_THREADS | indicates whether the implementation supports the XSI real-time threads option group | _SC_XOPEN_REALTIME_THREADS
| _XOPEN_VERSION | indicates the XSI version | _SC_XOPEN_VERSION
|
Figure 2.18. Options and name arguments to pathconf and fpathconfName of option | Description | name argument |
|---|
_POSIX_CHOWN_RESTRICTED | indicates whether use of chown is restricted | _PC_CHOWN_RESTRICTED
| _POSIX_NO_TRUNC | indicates whether pathnames longer than NAME_MAX generate an error | _PC_NO_TRUNC
| _POSIX_VDISABLE | if defined, terminal special characters can be disabled with this value | _PC_VDISABLE
| _POSIX_ASYNC_IO | indicates whether asynchronous I/O can be used with the associated file | _PC_ASYNC_IO
| _POSIX_PRIO_IO | indicates whether prioritized I/O can be used with the associated file | _PC_PRIO_IO
| _POSIX_SYNC_IO | indicates whether synchronized I/O can be used with the associated file | _PC_SYNC_IO
|
If the symbolic constant is defined by the platform, we have three possibilities.
If the symbolic constant is defined to have the value 1, then the corresponding option is unsupported by the platform. If the symbolic constant is defined to be greater than zero, then the corresponding option is supported. If the symbolic constant is defined to be equal to zero, then we must call sysconf, pathconf, or fpathconf to determine whether the option is supported.
Figure 2.17 summarizes the options and their symbolic constants that can be used with sysconf, in addition to those listed in Figure 2.5.
The symbolic constants used with pathconf and fpathconf are summarized in Figure 2.18. As with the system limits, there are several points to note regarding how options are treated by sysconf, pathconf, and fpathconf.
The value returned for _SC_VERSION indicates the four-digit year and two-digit month of the standard. This value can be 198808L, 199009L, 199506L, or some other value for a later version of the standard. The value associated with Version 3 of the Single UNIX Specification is 200112L. The value returned for _SC_XOPEN_VERSION indicates the version of the XSI that the system complies with. The value associated with Version 3 of the Single UNIX Specification is 600. The values _SC_JOB_CONTROL, _SC_SAVED_IDS, and _PC_VDISABLE no longer represent optional features. As of Version 3 of the Single UNIX Specification, these features are now required, although these symbols are retained for backward compatibility. _PC_CHOWN_RESTRICTED and _PC_NO_TRUNC return 1 without changing errno if the feature is not supported for the specified pathname or filedes. The referenced file for _PC_CHOWN_RESTRICTED must be either a file or a directory. If it is a directory, the return value indicates whether this option applies to files within that directory. The referenced file for _PC_NO_TRUNC must be a directory. The return value applies to filenames within the directory. The referenced file for _PC_VDISABLE must be a terminal file.
In Figure 2.19 we show several configuration options and their corresponding values on the four sample systems we discuss in this text. Note that several of the systems haven't yet caught up to the latest version of the Single UNIX Specification. For example, Mac OS X 10.3 supports POSIX threads but defines _POSIX_THREADS as
#define _POSIX_THREADS
without specifying a value. To conform to Version 3 of the Single UNIX Specification, the symbol, if defined, should be set to -1, 0, or 200112.
Figure 2.19. Examples of configuration optionsLimit | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
UFS file system | PCFS file system |
|---|
_POSIX_CHOWN_RESTRICTED | 1 | 1 | 1 | 1 | 1 | _POSIX_JOB_CONTROL | 1 | 1 | 1 | 1 | 1 | _POSIX_NO_TRUNC | 1 | 1 | 1 | 1 | unsupported | _POSIX_SAVED_IDS | unsupported | 1 | unsupported | 1 | 1 | _POSIX_THREADS | 200112 | 200112 | defined | 1 | 1 | _POSIX_VDISABLE | 255 | 0 | 255 | 0 | 0 | _POSIX_VERSION | 200112 | 200112 | 198808 | 199506 | 199506 | _XOPEN_UNIX | unsupported | 1 | undefined | 1 | 1 | _XOPEN_VERSION | unsupported | 500 | undefined | 3 | 3 |
An entry is marked as "undefined" if the feature is not defined, i.e., the system doesn't define the symbolic constant or its corresponding _PC or _SC name. In contrast, the "defined" entry means that the symbolic constant is defined, but no value is specified, as in the preceding _POSIX_THREADS example. An entry is "unsupported" if the system defines the symbolic constant, but it has a value of -1, or it has a value of 0 but the corresponding sysconf or pathconf call returned -1.
Note that pathconf returns a value of 1 for _PC_NO_TRUNC when used with a file from a PCFS file system on Solaris. The PCFS file system supports the DOS format (for floppy disks), and DOS filenames are silently truncated to the 8.3 format limit that the DOS file system requires.
2.7. Feature Test Macros
The headers define numerous POSIX.1 and XSI symbols, as we've described. But most implementations can add their own definitions to these headers, in addition to the POSIX.1 and XSI definitions. If we want to compile a program so that it depends only on the POSIX definitions and doesn't use any implementation-defined limits, we need to define the constant _POSIX_C_SOURCE. All the POSIX.1 headers use this constant to exclude any implementation-defined definitions when _POSIX_C_SOURCE is defined.
Previous versions of the POSIX.1 standard defined the _POSIX_SOURCE constant. This has been superseded by the _POSIX_C_SOURCE constant in the 2001 version of POSIX.1.
The constants _POSIX_C_SOURCE and _XOPEN_SOURCE are called feature test macros. All feature test macros begin with an underscore. When used, they are typically defined in the cc command, as in
cc -D_POSIX_C_SOURCE=200112 file.c
This causes the feature test macro to be defined before any header files are included by the C program. If we want to use only the POSIX.1 definitions, we can also set the first line of a source file to
#define _POSIX_C_SOURCE 200112
To make the functionality of Version 3 of the Single UNIX Specification available to applications, we need to define the constant _XOPEN_SOURCE to be 600. This has the same effect as defining _POSIX_C_SOURCE to be 200112L as far as POSIX.1 functionality is concerned.
The Single UNIX Specification defines the c99 utility as the interface to the C compilation environment. With it we can compile a file as follows:
c99 -D_XOPEN_SOURCE=600 file.c -o file
To enable the 1999 ISO C extensions in the gcc C compiler, we use the -std=c99 option, as in
gcc -D_XOPEN_SOURCE=600 -std=c99 file.c -o file
Another feature test macro is _ _STDC_ _, which is automatically defined by the C compiler if the compiler conforms to the ISO C standard. This allows us to write C programs that compile under both ISO C compilers and non-ISO C compilers. For example, to take advantage of the ISO C prototype feature, if supported, a header could contain
#ifdef _ _STDC_ _
void *myfunc(const char *, int);
#else
void *myfunc();
#endif
Although most C compilers these days support the ISO C standard, this use of the _ _STDC_ _ feature test macro can still be found in many header files.
2.8. Primitive System Data Types
Historically, certain C data types have been associated with certain UNIX system variables. For example, the major and minor device numbers have historically been stored in a 16-bit short integer, with 8 bits for the major device number and 8 bits for the minor device number. But many larger systems need more than 256 values for these device numbers, so a different technique is needed. (Indeed, Solaris uses 32 bits for the device number: 14 bits for the major and 18 bits for the minor.)
The header <sys/types.h> defines some implementation-dependent data types, called the primitive system data types. More of these data types are defined in other headers also. These data types are defined in the headers with the C typedef facility. Most end in _t. Figure 2.20 lists many of the primitive system data types that we'll encounter in this text.
Figure 2.20. Some common primitive system data typesType | Description |
|---|
caddr_t | core address (Section 14.9) | clock_t | counter of clock ticks (process time) (Section 1.10) | comp_t | compressed clock ticks (Section 8.14) | dev_t | device numbers (major and minor) (Section 4.23) | fd_set | file descriptor sets (Section 14.5.1) | fpos_t | file position (Section 5.10) | gid_t | numeric group IDs | ino_t | i-node numbers (Section 4.14) | mode_t | file type, file creation mode (Section 4.5) | nlink_t | link counts for directory entries (Section 4.14) | off_t | file sizes and offsets (signed) (lseek, Section 3.6) | pid_t | process IDs and process group IDs (signed) (Sections 8.2 and 9.4) | ptrdiff_t | result of subtracting two pointers (signed) | rlim_t | resource limits (Section 7.11) | sig_atomic_t | data type that can be accessed atomically (Section 10.15) | sigset_t | signal set (Section 10.11) | size_t | sizes of objects (such as strings) (unsigned) (Section 3.7) | ssize_t | functions that return a count of bytes (signed) (read, write, Section 3.7) | time_t | counter of seconds of calendar time (Section 1.10) | uid_t | numeric user IDs | wchar_t | can represent all distinct character codes |
By defining these data types this way, we do not build into our programs implementation details that can change from one system to another. We describe what each of these data types is used for when we encounter them later in the text.
2.9. Conflicts Between Standards
All in all, these various standards fit together nicely. Our main concern is any differences between the ISO C standard and POSIX.1, since SUSv3 is a superset of POSIX.1. There are some differences.
ISO C defines the function clock to return the amount of CPU time used by a process. The value returned is a clock_t value. To convert this value to seconds, we divide it by CLOCKS_PER_SEC, which is defined in the <time.h> header. POSIX.1 defines the function times that returns both the CPU time (for the caller and all its terminated children) and the clock time. All these time values are clock_t values. The sysconf function is used to obtain the number of clock ticks per second for use with the return values from the times function. What we have is the same term, clock ticks per second, defined differently by ISO C and POSIX.1. Both standards also use the same data type (clock_t) to hold these different values. The difference can be seen in Solaris, where clock returns microseconds (hence CLOCKS_PER_SEC is 1 million), whereas sysyconf returns the value 100 for clock ticks per second.
Another area of potential conflict is when the ISO C standard specifies a function, but doesn't specify it as strongly as POSIX.1 does. This is the case for functions that require a different implementation in a POSIX environment (with multiple processes) than in an ISO C environment (where very little can be assumed about the host operating system). Nevertheless, many POSIX-compliant systems implement the ISO C function, for compatibility. The signal function is an example. If we unknowingly use the signal function provided by Solaris (hoping to write portable code that can be run in ISO C environments and under older UNIX systems), it'll provide semantics different from the POSIX.1 sigaction function. We'll have more to say about the signal function in Chapter 10.
2.10. Summary
Much has happened over the past two decades with the standardization of the UNIX programming environment. We've described the dominant standardsISO C, POSIX, and the Single UNIX Specificationand their effect on the four implementations that we'll examine in this text: FreeBSD, Linux, Mac OS X, and Solaris. These standards try to define certain parameters that can change with each implementation, but we've seen that these limits are imperfect. We'll encounter many of these limits and magic constants as we proceed through the text.
The bibliography specifies how one can obtain copies of the standards that we've discussed.
|

 LINUX
LINUX 
 Books
Books