Perl 5
U N L E A S H E D
Kamran Husain , Robert F. Breedlove
Часть 1
Что такое Perl?
Содержание
Перл-интерпретируемый язык,оптимизированный для сканирования текстовых файлов,
выделения информации из них и их распечатки.
Он также хорош для многих системных задач.
Он легок в использовании,эффективен,элегантен,минимален.
Perl написал LarryWall (lwall@sems.com),
не без помощи конечно.
Юниксовые админы и разработчики подчас зависят от различных языков
для решения своих задач.
Например,для работы с файлами можно использовать шелл и утилиты
sh,grep,awk,sed. Админ конечно может использовать и си,
но это долго.
Было бы неплохо,если бы все вышеуказанные средства можно было обьединить с помощью
одного языка. Вот тут и приходит на помощь перл.
Perl обьединяет в себе преимущества C, sed,
awk,и sh.
Синтаксис Perl похож на си.
Перл может иметь дело не только с текстовыми,но и с бинарными данными.
It is helpful to your understanding of Perl to know a little bit
about why Perl was created and how it evolved.
Larry Wall developed Perl in 1986. He was a systems programmer
on a project that was developing multilevel, secure wide area
networks. Larry was in charge of an installation consisting of
three Vaxes and three Suns on the West Coast of the United States
connected over an encrypted serial line (1200 baud!) to a similar
configuration on the East Coast of the United States. Larry's
primary job was system support "guru." During this stint,
he developed several useful UNIX tools such as rn,
patch, and warp.
Perl was developed in response to a management requirement for
a configuration management and control system for all six Vaxes
and all six Suns. As with most management requests, Larry had
a month to develop this tool!
Larry considered the problem of a bicoastal configuration management
tool, without writing it from scratch. The tool would have to
be capable of viewing problem reports on both coasts with approvals
and control. His answer was B-news.
Larry installed B-news on three machines and added two control
commands. Configuration management was done using RCS, and approvals
and submissions were done using news and rn.
However, managers always need one thing more. Larry's manager
asked him to produce reports. B-news was maintained in separate
files on a master machine, with lots of cross references between
files. Larry's first thought was to use awk
to produce the reports. Unfortunately, awk
fell a bit short. It couldn't handle opening and closing multiple
files based on information in the files. Larry didn't want to
code a special purpose tool just for this job, so a new language
was born.
The language wasn't originally called Perl. Larry, his coworkers,
friends, and family considered just about every three- and four-letter
word in existence. One of the earliest names was "Gloria"
(his wife's name), but this was replaced due to the confusion
it caused in his household. The name became "Pearl,"
which was changed into the present day "Perl," partly
due to the existence of a graphics language called "pearl,"
but mostly because five letters was a bit much to type all the
time. You'll find a reference to the former five-letter version
in the entry for the acronym Practical Extraction and Report Language.
The early version of Perl lacked many of the features of today's
version. The language included the following :
- Pattern matching
- File handles
- Scalars
- Formats
- A crippled implementation of pattern matching
(from rn)
The manual page was only 15 pages long. But Perl was faster than
sed and awk
and began to be used on other aspects of the project.
Larry moved on to support research and development and took Perl
with him. Perl was becoming a good tool for system administration.
Larry borrowed Henry Spencer's regular expression package and
modified it for Perl. Then Larry added most of the goodies he
and other people wanted and released it on the Internet.
The current version (5+) of the language is a complete rewrite
from the previous versions. It provides the following additional
benefits:
| Usability enhancements | It is now possible to write much more readable Perl code. (How any C-like language can be called readable is still beyond me!)
|
| Simplified grammar | The new yacc grammar is one half the size of the old one. Many of the arbitrary grammar rules have been regularized. The number of reserved words has
been cut by two-thirds. Despite this, nearly all old Perl scripts will continue to work the same.
|
| Lexical scoping | Perl variables may now be declared within a lexical scope.
|
| Arbitrarily nested data structures | Any scalar value, including any array element, may now contain a reference to any other variable or subroutine.
|
| Modularity and reusability | The Perl library is now defined in terms of modules that can be shared easily among various packages.
|
| Object-oriented programming | A package can function as a class. Dynamic multiple inheritance and virtual methods are supported in a straightforward manner and with very little new syntax. File handles may now
be treated as objects.
|
| Embeddability and Extensibility | Perl may now be embedded easily in your C or C++ application and can either call or be called by your routines through a documented interface.
|
| POSIX compliant | A major new module is the POSIX module, which provides access to all available POSIX routines and definitions via object classes, where appropriate.
|
| Package constructors and destructors | The new BEGIN and END blocks provide a means to capture control as a package is being compiled and
after the program exits.
|
Multiple simultaneous
BM implementations
| A Perl program may now access DBM, NDBM, SDBM, GDBM, and Berkeley DB files from the same script, simultaneously.
|
| Subroutine definitions may be autoloaded |
The AUTOLOAD mechanism enables you to define any arbitrary semantics for undefined subroutine calls.
|
| Regular expression enhancements | You can now specify non-greedy quantifiers and performing grouping without creating a back reference.
You can write regular expressions with embedded white space and comments for readability. A consistent extensibility mechanism has been added that is upwardly compatible with all old, regular expressions.
|
Perl has many advantages as a general-purpose scripting language.
These benefits include its generous licensing (it's free), its
interpreted nature, the fact that Perl is available for most platforms,
and more. The following sections detail some of the benefits of
this excellent language.
First, Perl is generally available on most server platforms, including
the following:
- Most UNIX variants
- MS-DOS
- Windows NT
- Windows 95
- OS/2
- Macintosh
Perl also has the distinct advantage of being "low cost."
It is distributed free of charge or, at most, for a small copying
charge. Actually, Perl is distributed under the GNU "copyleft,"
which means that if you can execute Perl on your system, you should
have access to the source of Perl for no additional charge. (Actually,
a small copying charge might be imposed.) Perl may also be distributed
under the "artistic license," which some people find
less threatening than the copyleft.
Perl is readily available from many sources, including any comp.sources.unix
archive or CPAN site. If you don't have Perl on your server or
development machine, it is easy to obtain either as source code
or precompiled binaries for many platforms. For those not on the
Internet, Perl is available via anonymous Uucp from both uunet
and osu-cis. Perl is often
distributed with CD collections of utilities for UNIX platforms.
(See appendix B, "Perl Module Archives," for information
on Perl archives.)
Perl is interpreted. This can be either an advantage or disadvantage,
depending on your needs. For example, Perl has a short development
cycle compared to compiled languages, but it will never execute
as fast as a compiled language. I discuss the disadvantages in
the section called, "What Are the Negatives of Using Perl?,"
but there are some definite advantages.
One advantage of an interpreted language for tool or application
development is that you can perform incremental, iterative development
and testing without having to go through a create/compile/test/debug/fix
cycle. By eliminating the compile portion of the cycle, interpreted
languages can speed the development cycle drastically. It can
also be helpful if you are evolving your application by implementing
it with minimal capabilities and adding advanced capabilities
later.
Because it is interpreted and relatively C-like, you can also
use Perl as a prototyping language. This can be especially
useful with complex or technically difficult projects such as
network communication. You can use Perl's shortened development
cycle to evaluate your design and then, once it is proven, rewrite
the code in the language of your choice. By the way, C and C++
are good choices because Perl is a lot like C and supports much
the same functionality.
Perl is written to be practical. This means that it is
- Complete
- Easy to use
- Efficient
These design goals mean that Perl programs can generally accomplish
a goal that would otherwise take several other languages, require
complex programming, and take longer to process.
But for many of us, practicality goes beyond this. It means that
you can get things done in Perl. In fact, there are usually
several ways that Perl can accomplish the same task. It also means
that the programmer can concentrate on getting the task done rather
than dealing with the "beauty" of the language in which
he or she is working.
Complete
As mentioned before, Perl combines some of the best features of
several languages. Here's a list of these languages:
| grep/awk
| General pattern-matching languages for selecting elements from a file.
|
| C
| A general-purpose compiled programming language. (Perl is written in C.)
|
| sh
| A control language generally used for running programs and scripts written in other languages.
|
| sed
| A stream editor for processing text streams (STDIN/STDOUT).
|
These languages typically have been the tools used by UNIX administrators
to accomplish tasks. In fact, they are often touted as the reason
that UNIX is an excellent development platform. They are still
excellent tools for the purposes for which they were written.
However, if you have to deal with several languages, you also
have to deal with learning these languages. For instance,
a task to process a single text file might require the administrator
to write a shell script to run an awk
program to select lines that are subsequently processed by sed.
A single Perl script can often do the work of several other utilities:
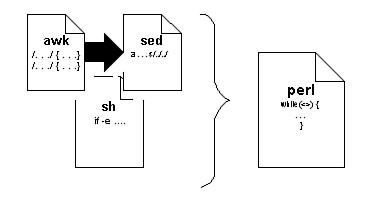
With Perl, the administrator or developer can accomplish his goals
in a single, easy-to-use language that performs the same tasks
as these languages.
With version 5.0 of Perl, the language also supports an object-oriented
approach to pro-gramming. This means that packages/modules can
be distributed as objects and used without knowledge of the underlying
code. These packages can also be extended as they can be in other
object-oriented languages. The key is that programmers only use
the object-oriented features of Perl if they need them for the
particular program they are writing.
Easy to Use
Above all, Perl is a language in which you can do things.
There are usually several ways to accomplish the same task. Although
some techniques are more efficient with system resources than
others, users can generally select the technique that is easier
for them to use (and maintain/enhance in the future) and go with
it.
The ease of use and completeness make Perl appropriate for quick-and-dirty,
one-time utilities as well as structured, complex applications.
Efficient
Perl is a straight-line language, which means that simple programs
do not have to deal with complex formatting or function/procedure
or object/method structures to accomplish their task. As a simple
example, let's pay homage to programming texts (including this
one) with the "Hello World!" program. Here it is in
C:
void main()
{
printf("Hello World!");
}
And here it is in Perl:
print 'Hello World!'
Get in, get out, and get the job done.
Perl is optimized for text processing and, therefore, is
very efficient at many tasks required of system administrators
and application developers. Many of the files used in UNIX systems
administration are plain text files. Selecting records, processing
the selected records, and reporting exceptions are the heart of
many tasks performed in UNIX administration.
In the current versions of Perl, the language also includes much
additional functionality, making it appropriate for tasks such
as processing socket calls, embedding in programs written in C,
and maintaining POSIX-compliant systems.
Perl can access C libraries to take advantage of much of the code
written for this popular language. Utilities included with Perl
distributions enable you to convert the headers for these C libraries
into their Perl equivalents.
Perl 5.0 can be integrated easily into C and C++ applications.
Perl can call or be called by routines written in C or C++. The
Perl interface is through a set of perl_call_*
functions. The call to C libraries is through the XS language
interface.
There are many specialized extensions to Perl, primarily for handling
specific databases such as Oracle, Ingres, Informix. These combine
the strengths of the Perl language with the access to the host
database.
At the time of this writing, ftp.demon.co.uk
(158.152.1.69) is the official
repository for database <foo>perls
(see the following list), which can be found in /pub/perl/db/perl4/.
It's mirrored at ftp.cis.ufl.edu
(198.17.47.33) in /pub/perl/scripts/db/.
| btreeperl
| NDBM extensions |
| ctreeperl
| C-Tree extensions |
| duaperl
| X.500 directory user agent |
| ingperl
| Ingres |
| isqlperl
| Informix |
| interperl
| Interbase |
| oraperl
| Oracle 6 and 7 |
| pgperl
| Postgres |
| sybperl
| Sybase 4 |
| uniperl
| UNIFY 5.0 |
See appendix B, "Perl Module Archives," for more information
on these repositories.
Perl has the capability to read/write TCP/IP sockets. This gives
it the capability to communicate with servers of all types that
rely on socket communication. It also enables you to write utility
and "robot" programs in the Perl language. For example,
Perl's socket capability can be used to write a robot program
to automate the checking of a World Wide Web (WWW) site to verify
the validity of links on your Web pages. This can be especially
useful in keeping a site up-to-date, given the volatility of the
Internet in its relative infancy.
Unlike many programming languages, Perl is designed to be practical
rather than beautiful. By this I mean that Perl was designed from
the start to be easy to use, efficient, and complete rather than
tiny, elegant, and minimal.
Programming in Perl is relatively easy, especially if you have
experience in C or another C-like language. Like many scripting
languages, Perl reads its programs from the first line to the
last line. It doesn't require complex structures to be able to
create a program. It does, however, support subroutines or functions
and, in version 5.0, can be object oriented.
The Perl interpreter has a built-in debugger that can help reduce
the time it takes to debug applications. The debugger is activated
through the use of the -d
switch on the command line. In addition, the -w
switch provides a complete set of warnings that can be invaluable
in debugging Perl scripts.
Because Perl is very popular as a scripting language, there is
a lot of help out there. Newsgroup discussions are a good place
to start when you require help on Perl programming. There are
newsgroups devoted entirely to Perl and newsgroups devoted to
Web page creation in which the majority of the discussion is about
Perl. Here are some of them:
| Newsgroup | Comment
|
| comp.lang.perl...
| This set of newsgroups covers information about Perl in general. Much of the discussion in the specific groups covers using Perl for utility purposes and also as a CGI scripting language.
|
| comp.lang.perl.announce
| Provides information about new modules for Perl programming.
|
| comp.lang.perl
| This is the main newsgroup about Perl. |
| comp.lang.perl.modules
| Provides discussions of Perl modules. |
| Comp.lang.perl.tk
| Provides discussions of Tk used with Perl.
|
There are, of course, Web pages related to Perl. Check the newsgroups
for announcements about these pages. Here are just a couple that
I have found as of this writing:
See appendix B for more complete information on Perl-related Web
pages.
Several lists of frequently asked questions (FAQ) are posted to
the Perl newsgroups. One of the best to start with is the Perl
Meta-FAQ, produced by Neil Bowers (neilb@khoros.unm.edu).
As you would expect, this is an FAQ about FAQs. It's available
at this writing from the following sources:
Again, because Perl is so popular as a utility language, there
are lots of examples of Perl modules out there. One of the best
sources is by file transfer protocol (FTP) from one of the Comprehensive
Perl Archive Network (CPAN) sites around the world (see appendix
B).
Perl has few negatives as a scripting language for system administration
tasks and as a language for module development. But there are
a few.
Perl is interpreted. Therefore, it will not be as fast as compiled
languages such as C or C++. Given the speed of modern CPUs, in
all but very large or time-critical applications, this will not
make a significant difference. And in fact, the interpreted nature
of the language can reduce development time significantly by eliminating
the time needed to compile and debug versions of the program (see
the previous section "The Benefits of Using Perl").
Perl isn't strictly in the public domain (see the license agreement
for details). But it's close enough. Many large companies have
policies against using public domain or copylefted software. In
many cases, this bias is more of a mind-set than a negative, but
it can be a detriment to using Perl (see the following section,
"Informal Support").
Because Perl is in the public domain, there is no corporation
that your company can apply leverage against to get something
done. But you do have access to the Perl source to make specific
needed changes to your environment, if required.
The support for Perl is on an informal basis through the volunteer
efforts of users worldwide. Does this mean it is bad? No, not
necessarily. In fact, the "support" given through the
Internet newsgroups is probably as good as any given by a major
corporation. But you can't depend on your question being
answered, at least in a timely manner. And you don't have a corporation
on which you can apply pressure to support your specific environment.
On the other hand, you do have access to the source code
for Perl and can look into problems yourself.
Perl isn't compiled (although there is an effort to make it so).
Thus, if you distribute your solutions, you distribute code.
This can be a deterrent to producing (at least your final application)
in Perl. (See the previous discussion of the benefits of Perl,
in the section "Interpreted Languages," as a prototyping
language.)
Perl, in its version 5+ incarnation, is undergoing some major
changes. Things might not work or might break later. This can
be a concern for the future of applications written for a specific
version and relying on a specific feature. On the positive side,
there are a lot of people testing each release through use. Many
of these bugs are quickly detected and ironed out.
Perl has somewhat of a reputation for being unreadable. This can
be a problem for system maintenance. However, Perl is probably
no more unreadable than any C-like language. (C itself, in my
opinion, is a very un-pretty-I won't say ugly-language; Perl suffers
from that heritage.)
Like with any other language, the maintainability of Perl relies
heavily on the willingness of the programmer to structure and
comment/document the code. Because many "quick-and-dirty"
utilities are written in Perl to get a specific job done and then
expanded to be more generally usable, much of the available source
code isn't all that pretty. (Sounds a little like the evolution
of Perl itself, doesn't it?)
The GNU license under which Perl is distributed is really quite
innocuous. But, it might be a problem depending upon the type
of application you are developing. If you intend to do any of
the following, Perl is probably not the best language to use:
- Sell the application as a packaged product
- Distribute an application that includes
trade secrets
- Keep your programming techniques secret
Perl is most commonly used to develop system administration tools.
But it has also gained enormous popularity on the Internet. Perl
can be, and is, used to develop many Internet applications and
their supporting utility applications. The following sections
describe some applications of Perl in systems administration and
on the Internet.
As mentioned before, Perl can perform the work of several other
tools, and usually in less time. It is particularly adept at processing
the text files typically used as configuration files.
Perl is one of the most popular languages for creating CGI applications.
There are literally thousands of examples of dynamic CGI programming
in Perl. Perl can be used to create dynamic Web pages that can
change depending on factors such as which visitor is viewing them.
One of the most common uses of Perl on the Internet is to process
form input. Perl is especially adept at this chore because most
of that input is textual-Perl's strength.
Another popular use of Perl is for the automated processing of
Internet e-mail. Perl scripts have been used to filter mail based
on address or content. Perl scripts have also been written to
automate mailing lists. One of the most popular of these programs
is Majordomo.
I personally have written a Perl script to automate my "What's
New?" Web page. This script processes mail messages and adds
them to my "What's New?" page. It also removes the entries
from the page after they have been there for a certain length
of time.
Perl can be used to automate the maintenance of Web sites. Because
Web pages are little more than text files in a specific format,
Perl is particularly adept at processing them. Perl's socket capability
can also be used to contact other sites and request information
using HTTP. There has even been a Web server written in Perl.
In order to check the links on a site, a Perl program must parse
the sites pages starting with the main page, extract the URLs,
and determine whether these URLs are still active.
There are several FTP clients written in Perl. Perl can be used
to automate file retrieval via FTP. Again, this combines the socket
capability of Perl with its text-processing capability.
Only you can answer that question. The next chapters will give
you a grounding in the Perl language that may help you decide
whether you wish to use Perl for Internet programming. If you
choose not to make it your main Web programming language, then
because of its versatility, ease of use, and popularity, you may
find that it becomes your utility language for the Web, if nothing
else.
Perl is a practical, easy-to-use, efficient programming language.
Add it to your toolbox and use it especially when you have tasks
that involve text processing.
Like any programming language, Perl is not the only language you
should have in your toolbox, but, when chosen for the appropriate
tasks, Perl can give you the ability to solve the problem quickly.
If you're looking for a language which is beautiful, elegant,
or minimal, Perl isn't for you. If, on the other hand, you're
looking for a tool to get things done, few languages can compare
with Perl.
A Brief Introduction to Perl
CONTENTS
This chapter offers a very brief introduction to Perl programming
and syntax. If this is the first time you are working with Perl,
do not despair at the barrage of information in this chapter.
As you progress through the book, any new or elaborate syntax
will be explained. This chapter is intended as an introduction
to Perl, not a complete tutorial-you'll learn more about the advanced
features of Perl in the subsequent chapters. If you are already
familiar with Perl, you might want to glance through this chapter
to get a quick overview of the syntax and reserved words.
| Note |
Please refer to the inside front cover for a quick reference of all the special variables in Perl.
|
Perl is a program just like any other program on your system,
only it's more powerful than most other programs! To run Perl,
you can simply type perl
at the prompt and then type your code. In almost all cases, you'll
want to keep your Perl code in files just like shell scripts.
A Perl program is referred to as a script.
Normally, the Perl program on your machine will be located in
the /usr/bin, /usr/bin/perl5,
or /usr/local/bin/perl5 directory.
Use a find command to see
whether you can locate Perl on your system. If you are certain
that you do not have Perl on your system, turn to Chapter 24,
"Building and Installing the Perl 5 Interpreter," for
information on how to install Perl on your machine. Perl scripts
are of the following form:
#!/usr/bin/perl
... insert code here ...
# comments are text after the # mark.
#
comments can begin anywhere on a line.
Here's a simple Perl script:
#/usr/bin/perl
print "\n Whoa! That was good!\n";
If the path to the Perl program on your system is different, you'll
have to use that pathname instead of /usr/bin/perl.
You also can specify programs on the command line with the -e
switch to Perl. For example, entering the following command at
the prompt will print Howdy!.
$ perl -e 'print "Howdy !\n";'
In all but the shortest of Perl programs, you'll use a file to
store your Perl code as a script. Using a script file offers you
the ease of not having to type all the commands interactively
and thus not being able to correct typing errors easily. Also,
a script file provides a written record of what commands to use
to accomplish a certain task.
To fire off a command on all lines in the input, use -n
option. Thus, the line
$perl -n 's/old/new/g' test.txt
runs the command to substitute all strings old
with new on each line from
the file test.txt. If you
use the -p option, it prints
each line as it is read in. The -v
option prints the version number of Perl you are running. This
book is written for Perl 5.002.
Now, let's begin the introduction to the Perl language.
Perl has three basic types of variables: scalars, arrays, and
associative arrays. A scalar variable is anything that
can hold one number (either as a floating point number or as an
integer) or a string. An array stores many scalars in a
sequence, where each scalar can be indexed using a number starting
with 0 on up. An associative array is like an array in
that it stores strings in sequence but uses another string as
an index to address individual items instead of a number. I cover
how to use these three types of variables in this chapter.
The syntax for a scalar variable is $variable_name.
A variable name is set up and addressed in the same way as Bourne
shell variables. To assign values to a scalar, you use statements
like these:
$name = "Kamran";
$number= 100;
$phone_Number = '555-1232';
A variable in Perl is evaluated at runtime to derive a value that
is one of the following: a string, a number, or a pointer to scalar.
(To see the use of pointers and references, refer to Chapter 3,
"References.")
To print out the value of a variable, you use a print
statement. Therefore, to print the value of $name,
you would make the following call:
print $name;
The value of $name is printed
to the screen. Perl scripts "expect" input from a standard
input (the keyboard) and to write to the standard output. Of course,
you can also use the print
statement to print the values of special variables that are built
into Perl.
Table 2.1 lists the special variables in Perl. The first column
contains the variable, and the second contains a verbose name
that you can use to make the code readable. The third column in
the table describes the contents of each variable.
You can use the verbose names (in column 2) by including the following
line in the beginning of your code:
use English;
This statement will let you use the English.pm
module in your code. (I cover the use of modules in Chapter 4,
"Introduction to Perl Modules.") Not all Perl variables
have an equivalent name in the English.pm
module. The entry "n/a" in the second column indicates
that there is not an English name for the variable.
Table 2.1. Special variables in Perl.
| Variable | English Name
| Description |
| $_ |
$ARG | The default input and output pattern searching space
|
| $1-$9 |
n/a | The subpattern from the last set of parentheses in a pattern match
|
| $&
| $MATch
| The last pattern matched (RO) |
| $` |
$PREMATch |
The string preceding a pattern match (RO) |
| $´
| $POSTMATch
| The string following a pattern match (RO) |
| $+ |
$LAST_PAREN_MATch
| The last bracket matched in a pattern (RO)
|
| $* |
$MULTILINE_MATchING
| Set to 1 to enable multi-line matching; set to 0 by default
|
| $. |
$INPUT_LINE_NUMBER
| The current input line number; reset on close() call only
|
| $/ |
$INPUT_RECORD_SEPARATOR
| The newline by default |
| $| |
$AUTO_FLUSH
| If set to 1, forces a flush on every write or print; 0 by default
|
| $, |
$OUTPUT_FIELD_SEPARATOR
| Specifies what is printed between fields |
| $\ |
$INPUT_RECORD_SEPARATOR
| The output record separator for the print operator
|
| $"
| $LIST_SEPARATOR
| The separator for elements within a list |
| $; |
$SUBSCRIPT_SEPARATOR
| The character for multidimensional array emulation
|
| $# |
$FORMAT |
Output format for printed numbers |
| $% |
$FORMAT_PAGE_NUMBER
| The current page number |
| $= |
$FORMAT_LINES_PER_PAGE
| The number of lines per page |
| $- |
$FORMAT_LINES_LEFT
| The number of lines still left to draw on the page
|
| $~ |
$FORMAT_NAME
| The name of the current format being used |
| $^ |
$FORMAT_TOP_NAME
| The name of the current top-of-page format
|
| $: |
$FORMAT_LINE_BREAK_chARACTERS
| The set of characters after which a string can be broken up to fill with continuation characters
|
| $^L |
$FORMAT_FORMFEED
| The default form feed operator |
| $^A |
$AccUMULATOR
| The current format line accumulator for format() lines
|
| $? |
$chILD_ERROR
| The status from the last tilde command |
| $! |
$ERRNO |
The last errno value
|
| $@ |
$EVAL_ERROR
| The Perl error message from the last eval statement
|
| $$ |
$PROCESS_ID
| The process number of this Perl script |
| $< |
$REAL_USER_ID
| The real UID of this process |
| $> |
$EFFECTIVE_USER_ID
| The effective UID of this process |
| $( |
$REAL_GROUP_ID
| The real group GID of this process |
| $) |
$EFFECTIVE_GROUP_ID
| The effective GID of this process |
| $0 |
$PROGRAM_NAME
| The name of the program in $ARGV[0]
|
| $[ |
n/a | Index of the first element in the array
|
| $] |
$PERL_VERSION
| The Perl version string |
| $^D |
$DEBUGGING
| The current value of the debugging flag |
| $^F |
$SYSTEM_FD_MAX
| The maximum file descriptors in the system (RO)
|
| $^I |
$INPLACE_EDIT
| The in-place edit extension |
| $^P |
$PERLDB |
The value of the internal debugger flag |
| $^T |
$BASETIME |
The time at which the debugged script started running
|
| $^W |
$WARNING |
The value of the -w switch
|
| $^X |
$EXECUTABLE_NAME
| The name of the program in $ARGV[0]
|
| $ARGV |
n/a | The name of the current file while reading from the <> in a while loop
|
| $VERSION
| n/a | The version number of the Perl interpreter
|
| %ENV |
n/a | The hash of the environment variables for the process
|
| %Inc |
n/a | The hash of filenames that have been included in the current file
|
| %SIG |
n/a | The hash of all signal handlers for the current process
|
| @ARGV |
n/a | The command-line arguments for the script
|
| @EXPORT
| n/a | The names of all exported functions in a module
|
| @F |
n/a | The command-line options used for the current program
|
| @Inc |
n/a | The pathnames of places to look in for all included files
|
| @ISA |
n/a | The names of all modules to search for when looking for a module
|
Don't worry if you do not recognize some of these strange characters.
I will be covering them all in the course of this book.
Now let's see how you can use these built-in variables as well
as your own variables in code.
Variables and assignment statements exist in code blocks. Each
code block is a section of code between two curly braces. Recognizing
code blocks matters when you are concerned about the scope of
influence of code on the value of a variable. (More on scope in
a moment.) Code blocks are simply assignment statements enclosed
between curly braces. Normally, you see code blocks in loop constructs
and conditionals. It's syntactically correct to use statements
like this in Perl programs:
{
print something;
print more of something;
more statements;
}
This coding style is rare and is usually done only if the programmer
explicitly wants to keep some special variables within the curly
braces. Usually, most of the application's code will be in one
type of block, either a subroutine, loop, or conditional, with
only the lines not in such blocks being those that are global
to the rest of the components of the program.
Here are some examples of code blocks available in Perl:
{
# a simple code block with statements in here.
}
while(condition) {
... execute code here while condition
is true;
}
until(condition) { # opposite of while statement.
... execute code here while condition
is false;
}
do {
... do this at least once ...
... stop if condition is false
...
} while(condition);
do {
... do this at least once ...
... stop if condition is true ...
} until(condition);
if (condition1) {
condition1_code true;
} else {
... no condition1 up to conditionN is
true;
}
if (condition1) {
... condition1_code true;
} elsif (condition2) {
condition1_code true;
....
} elsif (conditionN) {
conditionN_code true;
} else {
... no condition from 1 up to N is
true;
}
unless (condition1) { # opposite of "if" statement.
... do this if condition is false;
}
The condition in these blocks of code is anything from a Perl
variable to an expression that returns either a true
or false value. A true
value is a non-zero value or a non-empty string.
Code blocks can be declared within code blocks to create levels
of code blocks. Variables declared in one code block are usually
global to the rest of the program. To keep the scope of the variable
limited to the code block in which it is declared, use the my
$variableName syntax. If you declare with local
$variableName syntax, the $variableName
will be available to all lower levels but not outside the code
block.
Figure 2.1 illustrates how the scoping rules work in Perl. The
main block declares two variables, $x
and $y. There are two blocks
of code between curly braces, block A and block B. The variable
$x is not available to either
of these blocks, but $y will
be available.
Scoping rules in Perl:

Because block A is declared in the main block, the code in it
will be able to access $y
but not $x because $x
is declared as "my".
The variable $f will not
be available to other blocks of code even if they are declared
within block A. The variable $g
is not declared as "local"
or "my", so it's
not visible to the main module nor to block B.
The code in block B declares two variables, $k
and $m. The variable $k
can be assigned the value of $g,
provided that the code in block A is called before the code in
block B. If the code in block B is called before the code in block
A, the variable $g will not
be declared, and a value of 'undef'
will be assigned to $k. Also,
$m cannot use the value of
$f because $f
is declared in block A as a "my"
variable. The values of $y
and $g are available to code
in block B.
Finally, another code block (call it C) could be assigned in block
B. Block C is not shown in the figure. All variables in this new
block C that are declared as neither "my"
nor "local" would
be available to blocks A and B and the main program. Code in block
C would not be able to access variables $f,
$k, and $m
because they are declared as "my".
The variable $g would not
be available to code in block B or C because it is local to block
A.
Keep in mind that variables in code blocks are also declared at
the first time they are assigned a value. This creation includes
arrays and strings. Variables are then evaluated by the parser
when they appear in code, and even in strings. There are times
when you do not want the variable to be evaluated. This is the
time when you should be aware of quoting rules in Perl.
Three different types of quotes can be used in Perl. Double quotes
(") are used to enclose
strings. Any scalars in double-quoted strings are evaluated by
Perl. To force Perl not to evaluate anything in a quote, you'll
have to use single quotes (').
Anything that looks like code and is not quoted is interpreted
as code by the Perl interpreter, which attempts to evaluate the
code as an expression or a set of executable code statements.
Finally, to run some values in a shell program and get its return
value back, use the back quote (`)
symbol. See the Perl script in Listing 2.1 for an example.
Listing 2.1. Quoting in a Perl script.
1 #!/usr/bin/perl
2 $folks="100";
3 print "\$folks = $folks \n";
4 print '\$folks = $folks \n';
5 print "\n\n BEEP! \a \LSOME BLANK \ELINES HERE
\n\n";
6 $date = `date +%D`;
7 print "Today is [$date] \n";
8 chop $date;
9 print "Date after chopping off carriage return: [".$date."]\n";
The output from the code in Listing 2.1 is as follows:
$folks = 100
\$folks = $folks \n
BEEP! some blank LINES HERE
Today is [03/29/96
]
Date after chopping off carriage return: [03/29/96]
Let's go over the code shown in Listing 2.1. First of all, note
that the actual listing did not have line numbers. The line numbers
in this and subsequent scripts are used to identify specific lines
of code.
Line 1 is the mandatory first line of the Perl script. Change
the path shown in Listing 2.1 to where your Perl interpreter is
located if the script does not run. Be sure to make a similar
change to the rest of the source listings in this book.
Line 2 assigns a string value to the $folks
variable. Note that you did not have to declare the variable $folks
because it was created when used for the first time.
Line 3 prints the value of $folks
in between double quotes. The $
sign in $folks has to be
escaped with a backslash to prevent Perl from evaluating the value
of $folks instead of printing
the following line:
$folks = 100
In line 4, Perl does not evaluate anything between the single
quotes. Therefore, the entire contents of the line are left untouched
and printed here:
\$folks = $folks \n
Perl has several special characters to format text data for you.
Line 5 prints multiple blank lines with the \n
character and beeps at the terminal. Notice how the words SOME
BLANK are printed in lowercase letters. This is because
they are encased between the \L
and \E special characters,
which force all characters to be lowercase. Some of these special
characters are listed in Table 2.2.
Table 2.2. Special characters in Perl.
| Character | Meaning
|
| \\ |
Backslash. |
| \0ooo |
Octal number in ooo (for example, \0213).
|
| \a |
Beep. |
| \b |
Backspace. |
| \c |
Inserts the next character literally (for example, \$ puts $).
|
| \cC |
Inserts control character C.
|
| \l |
Next character is lowercase. |
| \L \E
| All characters between \L and \E are lowercase.
|
| \n |
New line (line feed). |
| \r |
Carriage return (MS-DOS). |
| \t |
Tab. |
| \u |
Next character is uppercase. |
| \U \E
| All characters between \U and \E are uppercase.
|
| \x## |
Hex number in ## (for example, \x1d).
|
In line 6, the script uses the back quotes (`)
to execute a command and return the results in the $date
variable. The string in between the two back quotes is what you
would type at the command line, with one exception: if you use
Perl variables in the command line for the back quotes, Perl evaluates
these variables before passing them off to the shell for execution.
For example, line 6 could be rewritten as this:
$parm = "+%D";
$date = `$date $parm`;
The returned value in $date
is printed out in line 7. Note that there is an extra carriage
return in the text for data. To remove it, use the chop
command as shown in line 8.
Then in line 9 the $date
output is shown to print correctly. Note how the period (.)
is used to concatenate three strings together for the output.
It's easy to construct strings in Perl with the period (.)
operator. Given two strings, $first
and $last, you can construct
the string $fullname like
this to get "Jim Smith":
$first = "Jim";
$last = "Smith";
$fullname = $first . " " . $last;
Numbers in Perl are stored as floating-point numbers; even variables
used as integers are really stored as floating point numbers.
There are a set of operations you can do with numbers. These operations
are listed in Table 2.3. The table also lists Boolean operators.
Table 2.3. Numeric operations with Perl.
| Operation | Description
|
| $r = $x + $y
| Adds $x to $y and assigns the result to $r
|
| $r = $x - $y
| Subtracts $y from $x and assigns the result to $r
|
| $r = $x * $y
| Multiplies $y and $x and assigns the result to $r
|
| $r = $x / $y
| Divides $x by $y and assigns the result to $r
|
| $r = $x % $y
| Modulo; divides $x by $y and assigns the remainder to $r
|
| $r = $x ** $y
| Raises $x to the power of $y and assigns the result to $r
|
| $r = $x << $n
| Shifts bits in $x left $n times and assigns to $r
|
| $r = $x >> $n
| Shifts bits in $x right $n times and assigns to $r
|
| $r = ++$x
| Increments $x and assigns $x to $r
|
| $r = $x++
| Assigns $x to $r and then increments $x
|
| $r += $x;
| Adds $x to $r and then assigns to $r
|
| $r = --$x
| Decrements $x and assigns $x to $r
|
| $r = $x--
| Assigns $x to $r and then decrements $x
|
| $r -= $x;
| Subtracts $x from $r and then assigns to $r
|
| $r /= $x;
| Divides $r by $x and then assigns to $r
|
| $r *= $x;
| Multiplies $r by $x and then assigns to $r
|
| $r = $x <=> $y
| $r is 1 if $x > $y; 0 if $x == $y; -1 if $x < $y
|
| $r = $x || $y
| $r is the logical OR of variables $x and $y
|
| $r = $x && $y
| $r is the logical AND of variables $x and $y
|
| $r = ! $x
| $r is the opposite Boolean value of $x
|
You can compare values of variables to check results of operations.
Table 2.4 lists the comparison operators for numbers and strings.
Table 2.4. Comparison operations with Perl.
| Operation | Description
|
| $x == $y
| True if $x is equal to $y
|
| $x != $y
| True if $x is not equal to $y
|
| $x < $y
| True if $x is less than $y
|
| $x <= $y
| True if $x is less than or equal to $y
|
| $x > $y
| True if $x is greater than $y
|
| $x >= $y
| True if $x is greater than or equal to $y
|
| $x eq $y
| True if string $x is equal to string $y
|
| $x ne $y
| True if string $x is not equal to string $y
|
| $x lt $y
| True if string $x is less than string $y
|
| $x le $y
| True if string $x is less than or equal to string $y
|
| $x gt $y
| True if string $x is greater than string $y
|
| $x ge $y
| True if string $x is greater than or equal to string $y
|
| $x x $y
| Repeats $x, $y times
|
| $x . $y
| Returns the concatenated value of $x and $y
|
| $x cmp $y
| Returns 1 if $x gt $y; 0 if $x eq $y; -1 if
$x lt $y
|
| $w ? $x : $y
| Returns $x if $w is true; $y if $w is false
|
Perl has arrays to let you group items using a single variable
name. Perl offers two types of arrays: those whose items are indexed
by number (arrays) and those whose items are indexed by a string
(associative arrays). An index into an array is referred to as
the subscript of the array.
| Tip |
An associative array is referred to as "hash" because of the way it's stored internally in Perl.
|
Arrays are referred to with the @
symbol. Individual items in an array are derived with a $
and the subscript. Therefore, the first item in an array @count
would be $count[0], the second
item would be $count[1],
and so on. See Listing 2.2 for usage of arrays.
Listing 2.2. Using arrays.
1 #!/usr/bin/perl
2 #
3 # An example to show how arrays work in Perl
4 #
5 @amounts = (10,24,39);
6 @parts = ('computer', 'rat', "kbd");
7
8 $a = 1; $b = 2; $c = '3';
9 @count = ($a, $b, $c);
10
11 @empty = ();
12
13 @spare = @parts;
14
15 print '@amounts = ';
16 print "@amounts \n";
17
18 print '@parts = ';
19 print "@parts \n";
20
21 print '@count = ';
22 print "@count \n";
23
24 print '@empty = ';
25 print "@empty \n";
26
27 print '@spare = ';
28 print "@spare \n";
29
30
31 #
32 # Accessing individual items in an array
33 #
34 print '$amounts[0] = ';
35 print "$amounts[0] \n";
36 print '$amounts[1] = ';
37 print "$amounts[1] \n";
38 print '$amounts[2] = ';
39 print "$amounts[2] \n";
40 print '$amounts[3] = ';
41 print "$amounts[3] \n";
42
43 print "Items in \@amounts = $#amounts \n";
44 $size = @amounts; print "Size of Amount = $size\n";
45 print "Item 0 in \@amounts = $amounts[$[]\n";
46
Here's the output from Listing 2.2:
@amounts = 10 24 39
@parts = computer rat kbd
@count = 1 2 3
@empty =
@spare = computer rat kbd
$amounts[0] = 10
$amounts[1] = 24
$amounts[2] = 39
$amounts[3] =
Items in @amounts = 2
Size of Amount = 3
Item 0 in @amounts = 10
In line 5, three integer values are assigned to the @amounts
array. In line 6, three strings are assigned to the @parts
array. In line 8, the script assigns both string and numeric values
to variables and then assigns the values of the variables to the
@count array. An empty array
is created in line 11. In line 12, the @spare
array is assigned the same values as those in @parts.
Lines 15 through 28 print out the first five lines of the output.
In lines 34 to 41, the script addresses individual items of the
@amounts array. Note that
$amounts[3] does not exist;
therefore, it is printed as an empty item.
The @#array syntax is used
in line 43 to print the last index in an array, so the script
prints 2. The size of the
amounts array is ($#amounts
+ 1). If an array is assigned to a scalar, as shown in line 44,
the size of the array is assigned to the scalar.
Line 45 shows the use of a special Perl variable, $[,
which is the base subscript (0)
of an array.
An associative array is really an array with two items per index.
The first item at each index is called a key and the other item
is called a value. You index into an associative array using keys
to get values. An associative array name is preceded with a percent
(%) sign and indexed items
are enclosed within curly braces ({}).
See Listing 2.3 for some sample uses of associative arrays.
Listing 2.3. Using associative arrays.
1 #!/usr/bin/perl
2 #
3 # Associative Arrays.
4 #
5
6 %subscripts = (
7 'bmp', 'Bitmap',
8 "cpp", "C++
Source",
9 "txt", 'Text
file' );
10
11 $bm = 'asc';
12 $subscripts{$bm} = 'Ascii File';
13
14 print "\n =========== Raw dump of hash =========
\n";
15 print %subscripts;
16
17 print "\n =========== using foreach =========
\n";
18 foreach $key (keys (%subscripts)) {
19 $value = $subscripts{$key};
20 print "Key = $key, Value = $value
\n";
21 }
22
23 print "\n === using foreach with sort ========= \n";
24 foreach $key (sort keys (%subscripts)) {
25 $value = $subscripts{$key};
26 print "Key = $key, Value = $value
\n";
27 }
28
29 print "\n =========== using each() =========
\n";
30 while (($key,$value) = each(%subscripts)) {
31 print "Key = $key, Value = $value
\n";
32 }
33
Here's the output from Listing 2.3:
=========== Raw dump of hash =========
txtText filecppC++ SourceascAscii FilebmpBitmap
=========== using foreach =========
Key = txt, Value = Text file
Key = cpp, Value = C++ Source
Key = asc, Value = Ascii File
Key = bmp, Value = Bitmap
=== using foreach with sort =========
Key = asc, Value = Ascii File
Key = bmp, Value = Bitmap
Key = cpp, Value = C++ Source
Key = txt, Value = Text file
=========== using each() =========
Key = txt, Value = Text file
Key = cpp, Value = C++ Source
Key = asc, Value = Ascii File
Key = bmp, Value = Bitmap
An associative array called %subscripts
is created in line 6 to line 9. Three items of (key,value)
pairs are added to %subscripts
as a list. At line 11, a new item is added to the %subscript
array by assigning $bm to
a key and then using $bm
as the index. We could have just as easily added the string 'Ascii
File' with this hard-coded statement:
$subscripts{'asc'} = 'Ascii File';
Items in an associative array are referred to as items stored
in a hash, because this is the way items are stored internally.
Look at the output from line 15, which dumps out the associative
array items.
In line 17, the script uses a foreach
statement to loop over the keys in the %subscripts
array. The keys() function
returns a list of keys for a given hash. The value of the item
at $subscripts{$key} is assigned
to $value at line 19. You
could combine lines 18 and 19 into one statement like this without
loss of meaning:
print "Key = $key, Value = $subscripts{$key}
\n";
Using the keys alone did not list the contents of the %subscripts
hash in the order we want. To sort the output, you should sort
the keys into the hash. This is shown in line 24. The sort()
function takes a list of items and returns a text-sorted version.
The foreach function takes
the output from the sort()
function applied to the value returned by the keys()
function. To sort in decreasing order, you can apply the reverse
function to the returned value of sort()
to get this line:
for $i (reverse sort (keys %@array))
{
It's more efficient to use the each()
function when working with associative arrays because only one
lookup is required per item to get both the key and its value.
See Line 30 where the ($key,$value)
pairs are assigned to the returned values by the each()
command. The variable $key
is assigned to the first item, and the variable $value
is assigned to the second item that is returned from the each()
function call.
The code in line 30 is important and deserves some explaining.
First of all, the while()
loop is used here. The format for a while
loop is defined as this:
while( conditionIsTrue) {
codeInLOOP
}
codeOutOfLOOP
If the condition in the while
loop is a nonzero number, a nonempty string, or a nonempty list,
the code in the area codeInLOOP
is executed. Otherwise, the next statement outside the loop (that
is, after the curly brace) is executed.
Second, look at how the list ($key,$value)
is mapped onto the list returned by the each()
function. The first item of the returned list is assigned to $key,
the next item to $value.
This is part of the array-slicing operations available in Perl.
When working with arrays in Perl, you are really working with
lists. You can add or remove items from the front or back of the
list. Items in the middle of the list can be indexed using subscripts
or keys. Sublists can be created by extracting items from lists,
and lists can be concatenated to create one or more new lists.
Let's view some examples of how they fit together. See Listing
2.4, which uses some of these concepts.
Listing 2.4. Array operations.
1 #!/usr/bin/perl
2 #
3 # Array operations
4 #
5
6 $a = 'RFI';
7 $b = 'UPS';
8 $c = 'SPIKE';
9
10 @words = ('DC','AC','EMI','SURGE');
11
12 $count = @words; # Get the count
13
14 #
15 # Using the for operator on a list
16 #
17 print "\n \@words = ";
18 for $i (@words) {
19 print "[$i] ";
20 }
21
22 print "\n";
23 #
24 # Using the for loop for indexing
25 #
26 for ($i=0;$i<$count;$i++) {
27 print "\n Words[$i] : $words[$i];";
28 }
29 #
30 # print 40 equal signs
31 #
32 print "\n";
33 print "=" x 40;
34 print "\n";
35 #
36 # Extracting items into scalars
37 #
38 ($x,$y) = @words;
39 print "x = $x, y = $y \n";
40 ($w,$x,$y,$z) = @words;
41 print "w = $x, x = $x, y = $y, z = $z\n";
42
43 ($anew[0], $anew[3], $anew[9], $anew[5]) = @words;
44
45 $temp = @anew;
46
47 #
48 # print 40 equal signs
49 #
50 print "=" x 40;
51 print "\n";
52
53 print "Number of elements in anew = ". $temp, "\n";
54 print "Last index in anew = ". $#anew, "\n";
55 print "The newly created Anew arrary is: ";
56 $j = 0;
57 for $i (@anew) {
58 print "\n \$anew[$j] = is $i ";
59 $j++;
60 }
61 print "\n";
62
63
Here's the output from Listing 2.4:
@words = [DC] [AC] [EMI] [SURGE]
Words[0] : DC;
Words[1] : AC;
Words[2] : EMI;
Words[3] : SURGE;
========================================
x = DC, y = AC
w = AC, x = AC, y = EMI z = SURGE
========================================
Number of elements in anew = 10
Last index in anew = 9
The newly created Anew arrary is:
$anew[0] = is DC
$anew[1] = is
$anew[2] = is
$anew[3] = is AC
$anew[4] = is
$anew[5] = is SURGE
$anew[6] = is
$anew[7] = is
$anew[8] = is
$anew[9] = is EMI
Lines 6, 7, and 8 assign values to scalars $a,
$b, and $c,
respectively. In line 10, four values are assigned to the @words
array. At line 12, you get a count of the number of elements in
the array.
The for() loop statement
is used to cycle through each element in the list. Perl takes
each item in the @words array,
assigns it to $i, and then
executes the statements in the block of code between the curly
braces. You could rewrite line 17 as the following and get the
same result:
for $i ('DC','AC','EMI','SURGE') {
In the example in Listing 2.4, the value of each item is printed
with square brackets around it. Line 22 simply prints a new line.
Now look at line 26, where the for
loop is defined. The syntax in the for
loop will be very familiar to C programmers:
for (startingCondition; endingCondition;
at_end_of_every_loop) {
execute_statements_in_this_block;
}
In line 26, $i is set to
zero when the for loop is
started. Before Perl executes the next statement within the block,
it checks to see whether $i
is less than $count. If $i
is less than $count, the
print statement is executed.
If $i is greater than or
equal to $count, the next
statement following the ending curly brace is executed. After
executing the last statement in a for
loop code block (see line 28), Perl increments the value of $i
with the statement for the end of loop: $i++.
So $i is incremented. Perl
goes back to the top of the loop to test for the ending condition
to see what to do next.
In lines 32 through 34, an output-delimiting line is printed with
40 equal signs. The x operator
in line 33 causes = to be repeated by the number following it.
Another way to print a somewhat fancier line would be to use the
following in lines 32 through 34:
32 print "[\n";
33 print "-=" x 20;
34 print "]\n";
Next, in line 38 the first two items in @words
are assigned to variables $x
and $y, respectively. The
rest of the items in @words
are not used. In line 40, four items from @words
are assigned to four variables. The mapping of items from @words
to variables is done on a one-to-one basis, based on the type
of parameter on the left side of the equal sign.
Had I used the following line in place of line 40, I would get
the value of $words[0] in
$x and the rest of @words
in @sublist:
($x,@sublist) = @words;
In line 43 a new array, @anew,
is created and assigned values from the @words
array, but not on a one-to-one basis. In fact, you'll see that
the @anew array is not even
the same size as @words.
Perl automatically resizes the @anew
array to be at least as large the largest index. In this case,
because $anew[9] is being
assigned a value, @anew will
be at least 10 items long to cover items from 0
to 9.
In lines 53 and 54, the script prints out the value of the number
of elements in the array and the highest valid index in the array.
Lines 57 through 60 print out the value of each item in the anew
area. Notice that items in the @anew
array are not assigned any values.
You can create other lists from lists, as well. See the example
in Listing 2.5.
Listing 2.5. Creating sublists.
1 #!/usr/bin/perl
2 #
3 # Array operations
4 #
5
6 $a = 'RFI';
7 $b = 'UPS';
8 $c = 'SPIKE';
9
10 @words = ('DC','AC','EMI','SURGE');
11
12 $count = @words; # Get the count
13 #
14 # Using the for operator on a list
15 #
16 print "\n \@words = ";
17 for $i (@words) {
18 print "[$i] ";
19 }
20
21 print "\n";
22 print "=" x 40;
23 print "\n";
24
25 #
26 # Concatenate lists together
27 #
28 @more = ($c,@words,$a,$b);
29 print "\n Putting a list together: ";
30 $j = 0;
31 for $i (@more) {
32 print "\n \$more[$j] = is $i ";
33 $j++;
34 }
35 print "\n";
36
37 @more = (@words,($a,$b,$c));
38 $j = 0;
39 for $i (@more) {
40 print "\n \$more[$j] = is $i ";
41 $j++;
42 }
43 print "\n";
44
45
46 $fourth = ($a x 4);
47 print " $fourth\n";
Here's the output from Listing 2.5:
@words = [DC] [AC] [EMI] [SURGE]
========================================
Putting a list together:
$more[0] = is SPIKE
$more[1] = is DC
$more[2] = is AC
$more[3] = is EMI
$more[4] = is SURGE
$more[5] = is RFI
$more[6] = is UPS
$more[0] = is DC
$more[1] = is AC
$more[2] = is EMI
$more[3] = is SURGE
$more[4] = is RFI
$more[5] = is UPS
$more[6] = is SPIKE
RFIRFIRFIRFI
In Listing 2.5, one list is created from another list. In Line
10, the script creates and fills the @words
array. In Lines 16 through 19, the script prints the array. Lines
21 through 23 are repeated again (which we will convert into a
subroutine soon).
At line 28, the @more array
is created by placing together the value of $c,
all the items in the entire @words
array, followed by the values $a
and $b. The size of the @more
array will therefore be 6.
The items in the @more array
are printed in lines 31 through 35.
The code at line 37 creates another @more
array with a different ordering. The previously created @more
array is freed back to the memory pool. The newly ordered @more
list is printed from lines 40 through 43.
The script then uses the x
operator in line 46 to create another item by concatenating four
copies of $a into the variable
$fourth.
I have covered how to add items to arrays but not how to remove
them. To remove an item from an array, use the delete
command on an array item. For example, to delete $more[2],
you would use the command:
delete $more[2];
If you are like me, you probably do want to type the same lines
of code again and again. For example, the code in lines 21 through
23 of Listing 2.5 could be made into a function that looks like
this:
sub printLine {
print "\n";
print "=" x 40;
print "\n";
}
Now when you want print the lines, call the subroutine with this
line of code:
&printLine;
I cover other aspects of subroutines in the section "Subroutines"
of this chapter, and a bit more in Chapter 3.
Now let's get back to some of the things you can do with arrays
using the functions supplied with Perl. See Listing 2.6 for a
script that uses the array functions I discuss here.
Listing 2.6. Using array functions.
1 #!/usr/bin/perl
2 #
3 # Functions for Arrays
4 #
5 sub printLine {
6 print "\n"; print "=" x 60; print
"\n";
7 }
8
9 $quote= 'Listen to me slowly';
10
11 #
12 # USING THE SPLIT function
13 #
14 @words = split(' ',$quote);
15
16 #
17 # Using the for operator on a list
18 #
19 &printLine;
20 print "The quote from Sam Goldwyn: $quote ";
21 &printLine;
22 print "The words \@words = ";
23 for $i (@words) {
24 print "[$i] ";
25 }
26
27 #
28 # chOP
29 #
30 &printLine;
31 chop(@words);
32 print "The chopped words \@words = ";
33 for $i (@words) {
34 print "[$i] ";
35 }
36 print "\n .. restore";
37 #
38 # Restore!
39 #
40 @words = split(' ',$quote);
41
42 #
43 # Using PUSH
44 #
45 @temp = push(@words,"please");
46 &printLine;
47 print "After pushing \@words = ";
48 for $i (@words) {
49 print "[$i] ";
50 }
51
52 #
53 # USING POP
54 #
55 $temp = pop(@words); # Take the 'please' off
56 $temp = pop(@words); # Take the 'slowly' off
57 &printLine;
58 print "Popping twice \@words = ";
59 for $i (@words) {
60 print "[$i] ";
61 }
62 #
63 # SHIFT from the front of the array.
64 #
65 $temp = shift @words;
66 &printLine;
67 print "Shift $temp off, \@words= ";
68 for $i (@words) {
69 print "[$i] ";
70 }
71 #
72 # Restore words
73 #
74 @words = ();
75 @words = split(' ',$quote);
76 &printLine;
77 print "Restore words";
78 #
79 # SPLICE FUncTION
80 #
81 @two = splice(@words,1,2);
82 print "\n Words after splice = ";
83 for $i (@words) {
84 print " [$i]";
85 }
86 print "\n Returned from splice = ";
87 for $i (@two) {
88 print " [$i]";
89 }
90 &printLine;
91
92 #
93 # Using the join function
94 #
95 $joined = join(":",@words,@two);
96 print "\n Returned from join = $joined ";
97 &printLine;
The split() function is used
in line 14 to split the items in the string $quote
into the @words array.
Next, the script uses chop()
on a list. This function removes a character from a string. When
applied to an array, chop()
removes a character from each item on the list. See lines 31 through
35.
You can add or delete items from an array using the pop(@Array)
or push(@Array) functions.
The pop() function removes
the last item from a list and returns it as a scalar. Look at
the push(ARRAY,LIST);
call to add items to a list. The push()
function takes an array as the first parameter and treats the
rest of the parameters as items to place at the end of the array.
At line 45, the push() function
pushes the word please into
the back of the @words array.
In lines 55 and 56, two words are popped off the @words
list. The size of the array @words
changes with each command.
Let's look at how the shift()
function is used in line 67. The shift(ARRAY)
function returns the first element of an array. The size of the
array is decreased by 1. You can use shift()
in one of three ways:
shift (@mine); # return first item of
@mine
shift @mine; # return first item of @mine
shift; # return first item in @ARGV
The special variable @ARGV
is the argument vector for your Perl program. The number of elements
in @ARGV is easily found
by assigning a scalar to $ARGC
that is equal to @#ARGV before
any operations are applied to @ARGV.
Then, after restoring @words
to its original value, the script uses the splice()
function to remove items from the @words
array. The splice() function
is a very important function and is really the key behind the
pop(), push(),
and shift() functions. Here's
the syntax for the splice()
function:
splice(@array,$offset,$length,$list)
The splice() function returns
the items removed in the form of a list. It replaces the $length
items in @array starting
from $offset with the contents
of $list. If you leave out
the $list parameter and just
use splice(@array,$offset,$length),
nothing is inserted in the original array. Any removed items are
returned from splice(). If
you leave out the $length
parameter to splice() and
use it as splice(@array,$offset),
the value of $length is used
to determine the number of the @array
to use starting from the offset.
Now that I have covered basic array and numeric operations, let's
cover some of the input/output operations where files are concerned.
A Perl program has three file handles when it starts up: STDIN
(for standard input), STDOUT
(for standard output), and STDERR
(for standard error message output). Note the use of capitals
and the lack of a dollar ($)
sign to signify that these are file handles. For a C/C++ programmer,
the three handles are akin to stdin,
stdout, and stderr.
To open a file for I/O you have to use the open
statement. Here's the syntax for the open
call:
open(HANDLE, $filename);
HANDLE is then used for all
the operations on a file. To close a file, you use the function
close HANDLE;.
For writing text to a file given a handle, you can use the print()
statement to write to the file:
print HANDLE $output;
The HANDLE defaults to STDIN
if no handle is specified. To read one line from the file given
a HANDLE, you use the <>
operators:
$line = <HANDLE>
In this code, $line will
be assigned all the input until a carriage return or eof.
When writing interactive scripts, you normally use the chop()
function to remove the end-of-line character. To read from the
standard input into a variable $response,
you use these statements in sequence:
$response = <STDIN>;
chop $response; # remove offensive carriage return.
You can perform binary read and write operations on a file using
the read() and write()
functions. Here's the syntax for each type of function:
read(HANDLE,$buffer,$length[,$offset]);
write(HANDLE,$buffer,$length[,$offset]);
The read function is used
to read from HANDLE into
$buffer, up to $length
bytes from the $offset in
bytes from the start of the file. The $offset
is optional, and read() defaults
reading to the current location in the file if $offset
is left out. The location in the file to read from is advanced
$length bytes. To check if
you have reached the end of the file, use the command:
eof(HANDLE);
A nonzero value returned signifies the end of the file; a zero
returned indicates that there is more to read in the file.
The write function is used
to write the contents of $buffer
to HANDLE. The number of
bytes to write is set in $length.
The location to write at
the handle is set in the variable $offset
as the number of bytes from the start of the file. The $offset
is optional, and write()
defaults writing to the current location in the file if $offset
is left out. The location in the file written to is advanced $length
bytes.
You can move to a position in the file using the seek()
function:
seek(HANDLE,$offset,$base)
The $offset is from the location
specified in $base. The seek
function behaves exactly like the C function call in that if $base
is 0, the $offset
is from the start of the file. If $base
is set to 1, the program
uses the current location of the file pointer. If $base
is $2, the program uses an
offset from the end of the file where the value of $offset
is negative.
There can be errors associated with opening files. It's a good
idea to see what the errors are before proceeding further in a
program. To print error messages before a script crashes, the
die function is used. A call
to open a file called test.data
would like this:
open(TESTFILE,"test.data")
|| die "\n $0 Cannot open $! \n";
This line literally reads Open test.data
for input or die if you cannot open it. The $0
is the Perl special variable for the process name, and the special
variable $! is set to a string
corresponding to the value of the system variable, errno.
The syntax in the string used for the filename also signifies
the type of operation you intend to perform with the file. Table
2.5 shows some of the ways you can open a file.
Table 2.5. File open types.
| File | Action
|
| test.data
| Opens test.data for reading. The file must exist.
|
| >test.data
| Opens test.data for writing. Creates the file if it does not exist and destroys any previous file called test.data.
|
| >>test.data
| Opens test.data for writing. Creates the file if it does not exist and appends to any existing file called test.data.
|
| +>test.data
| Opens test.data for reading and writing. Creates the file if it does not exist.
|
| | cmd |
Opens a pipe to write to. (Chapter 14, "Signals, Pipes, FIFOs, and Perl," covers pipes.)
|
| cm | |
Opens a pipe to read from. |
When working with multiple files, you can have more than one unique
handle to write to or read from. Use the select
HANDLE; call to set the default file handle to use
with print statements. For
example, suppose you have two file handles, LARRY
and CURLY; here's how to
switch between handles:
select LARRY;
print "Whatsssa matter?\n"; # write to LARRY
select CURLY;
print "Whoop, whoop, whoop!"; # write to CURLY
select LARRY;
print "I oughta.... "; # write to LARRY again
Of course, by explicitly stating the handle name you could get
the same result with these three lines of code:
print LARRY "Whatsssa matter?\n";
# write to LARRY
print CURLY "Whoop, whoop, whoop!"; # write to CURLY
print LARRY "I oughta.... "; # write to LARRY again
This is a very brief introduction to using file handles in Perl.
I cover the use of file handles throughout the rest of this book,
so don't worry if this pace of information is too quick. You'll
see plenty of examples throughout the book.
You can also check for the status of a file given a filename.
The available tests are listed in the source test file shown in
Listing 2.7.
Listing 2.7. Testing file parameters.
1 #!/usr/bin/perl
2
3 $name = "test.txt";
4 print "\nTesting flags for $name \n";
5 print "\n========== Effective User ID tests ";
6 print "\n is readable" if ( -r $name);
7 print "\n is writable" if ( -w $name);
8 print "\n is executable" if ( -x $name);
9 print "\n is owned " if ( -o $name);
10 print "\n========== Real User ID tests ";
11 print "\n is readable" if ( -R $name);
12 print "\n is writable" if ( -W $name);
13 print "\n is executable" if ( -X $name);
14 print "\n is owned by " if ( -O $name);
15
16 print "\n========== Reality Checks ";
17 print "\n exists " if ( -e $name);
18 print "\n has zero size " if ( -z $name);
19 print "\n has some bytes in it " if ( -s $name);
20
21 print "\n is a file " if (-f $name);
22 print "\n is a directory " if (-d $name);
23 print "\n is a link " if (-l $name);
24 print "\n is a socket " if (-S $name);
25 print "\n is a pipe " if (-p $name);
26
27 print "\n is a block device " if (-b $name);
28 print "\n is a character device " if (-c $name);
29
30 print "\n has setuid bit set " if (-u $name);
31 print "\n has sticky bit set " if (-k $name);
32 print "\n has gid bit set " if (-g $name);
33
34 print "\n is open to terminal " if (-t $name);
35 print "\n is a Binary file " if (-B $name);
36 print "\n is a Text file " if (-T $name);
37
38 printf "\n";
Perl has a very powerful regular expression parser as well as
a powerful string search-and-replace function. To search for a
substring, you use the following syntax (normally within an if
block):
if ($a =~ /"menu"/) {
print "\n Found menu in $a! \n";
}
The value in $a is the number
of matched strings. To search in a case-insensitive manner, use
an i at the end of the search
statement, like this:
if ($a =~ /"mEnU"/i) {
print "\n Found menu in $a! \n";
}
You can even search for items in an array. For example, if $a
was an array @a, the returned
value from the search operation is an array with all the matched
strings. If you do not specify the @a
=~ portion, Perl uses the $_
default name space to search on.
To search and replace strings, use the following syntax:
$expr =~ s/"old"/"new"/gie
The g, i,
and e are optional parameters.
If g is not specified, only
the first match to the old
string will be replaced with new.
The i flag specifies a case-insensitive
search, and e forces Perl
to use the new string as
a Perl expression. Therefore, in the following example, the value
of $a will be "HIGHWAY":
$a = "DRIVEWAY";
$a =~ s/"DRIVE"/"HIGH"/
print $a;
Perl has a grep() function
that is very similar the grep
function in UNIX. Perl's grep
function takes a regular expression and a list. The return value
from grep can be handled
one of two ways: if assigned to a scalar, it's the number of matches
found, or if assigned to a list, it's a sublist of all the items
found via grep.
Please check the man pages
for using grep. Some of the
main types of predefined patterns are shown in the following list:
| Code | Pattern
|
| * | Zero or more of the previous pattern
|
| + | One or more of the previous pattern
|
| . | Any character
|
| ? | Zero or one of the previous pattern
|
| \0 |
Null |
| \000 |
Octal |
| \cX |
ASCII control character |
| \d |
Digits [0-9] |
| \D |
Anything but digits |
| \f |
Formfeed |
| \n |
Newline |
| \r |
Carriage return |
| \s |
Space or tab or return or newline |
| \S |
Anything but \s
|
| \t |
Tab |
| \w |
[0-9a-zA-Z] |
| \W |
Anything but \w
|
| \X00 |
Hex |
Perl uses a special variable called $_.
This is the default variable to use in Perl if you do not explicitly
specify a variable name and Perl expects a variable. For example,
in the grep() function, if
you omit LIST, grep()
will use the string in the variable $_.
The $_ variable is Perl's
default string in which to search, assign input, or read for data
for a number.
Perl 5 supports subroutines and functions with the sub
command. You can use pointers to subroutines, too. Here's the
syntax for subroutines:
sub Name {
}
The ending curly brace does not require a semicolon to terminate
it. If you are using a reference to a subroutine, it can be declared
without a Name, as shown
here:
$ptr = sub {
};
Note the use of the semicolon to terminate the end of the subroutine.
To call this function, you use the following line:
&\$ptr(argument list);
Parameters to subroutines are passed in the @_
array. To get the individual items in the array, you can use $_[0],
$_[1], and so on. You can
define your own local variables with the local
keyword. Here's an example:
sub sample {
local ($a, $b, @c, $x) = @_
&lowerFunc();
}
In this subroutine, you'll find that $a
= $_[0], $b = $_[1],
and @c point to the rest
of the arguments as one list with $x
empty. Generally, an array is the last assignment in such an assignment
because it chews up all your parameters.
The local variables will
all be available for use in the lowerFunc()
function. To hide $a, $b,
@c, and $x
from lowerFunc, use the my
keyword like this:
my ($a, $b, @c, $x) = @_
Remember, $x is empty. Now,
the code in lowerFunc() is
not be able to access $a,
$b, @c,
or $x.
Parameters in Perl can be in form, from the looks of it. Since
Perl 5.002, you can define
prototypes for subroutine arguments with the following syntax:
sub Name (parameters)
{
}
If the parameters are not what the function expects, Perl bails
out with an error. The parameter format is as follows: $
for a scalar, @ for an array,
% for a hash, &
for a reference to a subroutine, and *
for anything. Therefore, if you want your function to accept only
three scalars, you would declare it as this:
sub func1($$$) {
my ($x,$y,$z) = @_;
code here
}
To pass the value of an array by reference (by pointer), you would
use a backslash (\). If you
pass two arrays without the backslash specifier, the contents
of the two arrays will be concatenated into one long array in
@_. The function prototype
to pass three arrays, a hash, and the rest in an array, would
look like this:
sub func2(\@\@\@\%@)
The returned value from a subroutine is always the value of the
last expression executed in the statement. The value can be a
scalar, array, hash, or reference to an array.
The Perl distribution comes with two programs: a2p
to convert awk programs to Perl, and s2p
to convert sed programs to Perl. It's often convenient to write
a sed script or an awk program to do a certain task. To see how
to do the same thing in Perl, run the a2p
or s2p program. For example,
to convert mine.awk to mine.pl,
you use the following command:
$ a2p mine.awk > mine.pl
This chapter has been a whirlwind introduction to Perl. I must
admit that this chapter does not cover every aspect of
Perl programming basics. As you progress through the book, you'll
learn more ways to do things than are described here. Even if
you are new to Perl, you should not have any problems understanding
how to use Perl because the programming paradigms in Perl are
not that different from any other programming language.
For more information, consult the following books:
- Teach Yourself Perl 5 in 21 Days, Dave Till, 0-672-30894-0,
Sams Publishing, 1995.
- Learning Perl, Randall Schwartz, 1-56592-042-2, O'Reilly
& Associates, 1993.
- Programming Perl, Larry Wall and Randall Schwartz,
0-937175-64-1, O'Reilly & Associates, 1990.
Chapter 3
References
CONTENTS
This chapter describes the use of Perl references and the concept
of pointers. It also shows you how to use references to create
fairly complex data structures and pass pointers, as well as how
to use pointers to subroutines and to pass parameters.
A reference is simply a pointer to something; it
is very similar to the concept of a pointer in C or PASCAL.
That something could be a Perl variable, array, hash, or
even a subroutine. A reference in your program is simply an address
to a value. How you use the value of that reference is really
up to you as the programmer and what the language lets you get
away with. In Perl, you can use the terms pointer and reference
interchangeably without any loss of meaning.
There are two types of references in Perl 5 with which you can
work: symbolic and hard.
A symbolic reference simply contains the name of a variable. Symbolic
references are useful for creating variable names and addressing
them at runtime. Basically, a symbolic reference is like the name
of a file or a soft link on a UNIX system. Hard references are
more like hard links in the file system; that is, a hard link
is merely another path to the same file. In Perl, a hard reference
is another name for a data item.
Hard references in Perl also keep track of the number of references
to items in an application. When the reference count becomes zero,
Perl automatically frees the item being referenced. If that item
happens to be a Perl object, the object is "destructed,"
that is, freed to the memory pool. Perl is object-oriented in
itself because everything in a Perl application is an object,
including the main package. When the main package terminates,
all other objects within the main object are also terminated.
Packages and modules in Perl further the ease of use of objects
in Perl. Perl modules are covered in Chapter 4,
"Introduction to Perl Modules."
When you use a symbolic reference that does not exist, Perl creates
the variable for you and uses it. For variables that already exist,
the value of the variable is substituted instead of the $variable
token. This substitution lets you construct variable
names from variable names.
Consider the following example:
$lang = "java";
$java = "coffee";
print "${lang}\n";
print "hot${lang}\n";
print "$$lang \n"
The third print line is important.
$$lang is first reduced to
$java, then the Perl interpreter
will recognize that $java
can also be reparsed, and the value of $java,
"coffee", is used.
Symbolic references are created via the ${}
construct, so ${lang} translates
to java, and hot${java}
translates to hotjava. If
you want to address a variable name hotjava,
you could use the statement: ${hot${lang}}.
This would be interpreted as, "take the value in $lang,
and append it to the word hot. Now take the constructed string
(hotjava) and use it as a
name because there is a ${}
around it."
In other words, the value of the scalar produced by $$lang
is taken to be the name of a new variable, and the variable at
$java is used. Here's the
output from this example:
java
hotjava
coffee
Thus, the difference between a hard reference ($lang)
and a symbolic reference ($$lang)
is how the variable name is derived. In a hard reference, you
are referring to a variable's value directly. With a symbolic
reference, you are using another level of indirection by constructing
or deriving a symbol name from an existing variable.
References are easy to use in Perl as long as they are used as
scalars. To use hard references as anything but scalars, you have
to explicitly dereference the variable and tell it how to be used.
A scalar value in this chapter refers to a variable, such
as $pointer, that contains
one data item. This item is a scalar and any scalar may hold a
hard reference. Arrays and hashes contain scalars; therefore,
they can hold many references. Thus, with judicious use of arrays
and hashes, you can easily build complex data structures of different
combinations of arrays of arrays, arrays of hashes, hashes of
functions, and so on.
There are several ways to construct references, and you can have
references to just about anything-arrays, scalar variables, subroutines,
file handles, and, yes (to the delight of C programmers), even
to other references.
To use the value of $pointer
as the pointer to an array, you reference the items in the array
as @$pointer. The notation
@$pointer roughly translates
to "take the value in $pointer,
and then use this value as the address to an array." Similarly,
you use %$pointer for hashes.
That is, "take the value of $pointer
and interpret is as an address to a hash."
Using the backslash operator is analogous to using the ampersand
(&) operator in C to
pass the address of an operator. This method is usually used to
create a second, new reference to the variable in question. Here's
how to create a reference to a scalar variable:
$variable = 22;
$pointer = \$variable;
$ice = "jello"
$iceptr = \$ice;
Now $pointer points to the
location containing the value of $variable.
The pointer $iceptr points
to jello. Even if the original
reference ($variable) goes
away, you can still access the value from the $pointer
reference. It's a hard reference at work here, so you have to
get rid of both $pointer
and $variable to free up
the space in which the value of jello
is allocated. Similarly, $variable
contains the number 22 and
because $pointer refers to
$variable, dereferencing
the $pointer with the statement
$$pointer returns a value
of 22. In a subroutine, both
$variable and $pointer
have to be declared as "local" or "my" variables.
If they are both not declared as such, at least one of these variables
will persist as a global variable long after the subroutine in
which they are declared returns. As long as either of these variables
exists, the space for storing the numbers will also exist.
The variable $pointer contains
the address of the $variable,
not the value itself. To get the value, you have to dereference
$pointer with two dollar
signs, $$. Listing
3.1 illustrates how this works.
Listing 3.1. References to scalars.
1 #!/usr/bin/perl
2
3 $value = 10;
4
5 $pointer = \$value;
6
7 printf "\n Pointer Address $pointer of $value
\n";
8
9 printf "\n What Pointer *($pointer) points to $$pointer\n";
$value in this script is
set to 10. $pointer
is set to point to the address of $value.
The two printf statements
show how the value of the variable is being referenced. If you
run this script, you'll see something very close to this output:
Pointer Address SCALAR(0x806c520) of
10
What Pointer *(SCALAR(0x806c520)) points to 10
The address shown in the output from your script definitely will
be different from the one shown here. However, you can see that
$pointer gave the address,
and $$pointer gave the value
of the scalar pointed to by $variable.
The word SCALAR followed
by a long hexadecimal number in the address value tells you that
the address points to a scalar variable. The number following
SCALAR is the address where
the information of the scalar variable is being kept.
This is perhaps the most important thing you must remember about
Perl: all Perl @ARRAYs and
%HASHes are always one-dimensional.
As such, the arrays and hashes hold only scalar values and do
not directly contain other arrays or complex data structures.
If it's a member of an array, it's either a data item or a reference
to a data item.
You can also use the backslash operator on arrays and hashes,
just as you would for scalar variables. For arrays, you use something
like the Perl script in Listing 3.2.
Listing 3.2. Using array references.
1 #!/usr/bin/perl
2 #
3 # Using Array references
4 #
5 $pointer = \@ARGV;
6 printf "\n Pointer Address of ARGV = $pointer\n";
7 $i = scalar(@$pointer);
8 printf "\n Number of arguments : $i \n";
9 $i = 0;
10 foreach (@$pointer) { # Access the entire array.
11 printf
"$i : $$pointer[$i++]; \n";
12 }
Let's examine the lines that pertain to references in this shell
script, which prints out the contents of the input argument array
@ARGV. Line 5 is where the
reference $pointer is set
to point to the array @ARGV.
Line 6 simply prints the address of ARGV
out for you. You probably will never have to use the address of
ARGV, but had you been using
another array, this would be a quick way to get to the address
of the first element of the array.
Now $pointer will return
the address of the first element of the array. This reference
to an array should sound familiar to C programmers, where a reference
to a one-dimensional array is really just a pointer to the first
element of the array.
In line 7, the function scalar()
(not to be confused with the type of variable scalar)
is called to get the count of the elements in an array. The parameter
passed in could be @ARGV,
but in the case of the reference in $pointer,
you have to specify the type of parameter expected by the
scalar() function. Are you confused yet? There is
a scalar() function; a scalar
variable holds one value; and a hard reference is a scalar
unless it's dereferenced to behave like a non-scalar.
| Note |
Remember that a reference to something will always be used as scalar. There is no implicit dereferencing in Perl. You specify how you want the scalar value of a reference to be used.
Once you have a scalar reference, you can dereference it to be used as a pointer to an array, hash, function, or whatever structure you want.
|
The type of $pointer in this
case is a pointer to the array whose number of elements you have
to return. The call is made to the function with @$pointer
as the passed parameter. $pointer
really gives the address of the first entry in the array, and
@ forces the passing of the
address of the first element for use as an array reference.
The same reference to the array in line 10 is the same as in line
7. In line 11 all the elements of the array are listed out using
the $$pointer[$i] item. How
would the Perl compiler interpret the same statement to dereference
$pointer to get an item in
an array? Well, $pointer
points to the first element in the array. Then you go to the ($i
- 1)th item in the array (via the use of
$pointer[$i++]) and also
increment the value of $i.
Finally, the value at $$pointer[$i]
is returned as a scalar. Because the autoincrement operator is
low on the priority list, $i
is incremented last of all.
The program is appropriately called testmeout.
Here is sample input and output for the code in Listing 3.2.
$ testmeout 1 2 3 4
Pointer Address
of ARGV = ARRAY(0x806c378)
Number of arguments
: 4
0 : 1;
1 : 2;
2 : 3;
3 : 4;
The number following ARRAY
in the pointer address of ARGV
in this example is the address of ARGV.
Not that that address does you any good, but just realize that
references to arrays and scalars are displayed with the type to
which they happen to be pointing.
The backslash operator can be used with associative arrays too.
The idea is the same: you are substituting the $pointer
for all references to the name of the associative array. You use
%$pointer instead of @$pointer
to refer to an array. By specifying the percent sign (%)
you are forcing Perl to use the value of $pointer
as a pointer to a hash.
For pointers to functions, the address is printed with the word
CODE. For a hash, it is printed
as HASH. Listing 3.3 provides
an example of using hashes.
Listing 3.3. Using references to associative arrays.
1 #!/usr/bin/perl
2
3 #
4 # Using References to Associative Arrays
5 #
6
7 %month = (
8
'01', 'Jan',
9
'02', 'Feb',
10
'03', 'Mar',
11
'04', 'Apr',
12
'05', 'May',
13
'06', 'Jun',
14
'07', 'Jul',
15
'08', 'Aug',
16
'09', 'Sep',
17
'10', 'Oct',
18
'11', 'Nov',
19
'12', 'Dec',
20
);
21
22 $pointer = \%month;
23
24 printf "\n Address of hash = $pointer\n ";
25
26 #
27 # The following lines would be used to print out the
28 # contents of the associative array if %month was used.
29 #
30 # foreach $i (sort keys %month) {
31 # printf "\n $i $$pointer{$i} ";
32 # }
33
34 #
35 # The reference to the associative array via $pointer
36 #
37 foreach $i (sort keys %$pointer) {
38 printf
"$i is $$pointer{$i} \n";
39 }
The associative array is referenced via the code in line 22 that
contains $pointer = \%month;.
This will create a hard reference, $pointer,
to the hash called %month.
Now you can also refer to the %month
associative array by using the value in the $pointer
variable. Using the %month
variable, you would refer to an element in the hash using the
syntax $month{$index}. In
order to use the $pointer
value, you would simply replace the month
with $pointer in the name
of the variable. This is very similar to the procedure used with
pointers to ordinary arrays. The elements of the %month
associative array are referenced with the $$pointer{$index}
construct. Of course, because the array is really a hash, the
$index is the key into the
hash and not a number.
Here is the output from running this test script.
$ mth
Address of hash
= HASH(0x806c52c)
01 is Jan
02 is Feb
03 is Mar
04 is Apr
05 is May
06 is Jun
07 is Jul
08 is Aug
09 is Sep
10 is Oct
11 is Nov
12 is Dec
Associative arrays do not have to be constructed using the comma
operator. You can use the =>
operator instead. In later Perl modules and sample code, you'll
see the use of the =>
operator, which is the same as the comma operator. Using the =>
operator makes the code a bit easier to read aloud. Examine the
output of Listing 3.3 with the print statements in the program
to see how the output was generated.
Now let's look at how pointers to arrays and hashes can be dereferenced
to get individual items. See the code in Listing 3.4 to see how
you can use the => operator.
Listing 3.4. Alternative use of the =>
operator.
1 #!/usr/bin/perl
2
3 #
4 # Using Array references
5 #
6
7 %weekday = (
8
'01' => 'Mon',
9
'02' => 'Tue',
10
'03' => 'Wed',
11
'04' => 'Thu',
12
'05' => 'Fri',
13
'06' => 'Sat',
14
'07' => 'Sun',
15
);
16
17 $pointer = \%weekday;
18
19 $i = '05';
20
21 printf "\n ================== start test =================
\n";
22 #
23 # These next two lines should show an output
24 #
25
printf '$$pointer{$i} is ';
26
printf "$$pointer{$i} \n";
27
printf '${$pointer}{$i} is ';
28
printf "${$pointer}{$i} \n";
29
30
printf '$pointer->{$i} is ';
31
printf "$pointer->{$i}\n";
32
33 #
34 # These next two lines should not show anything
35 #
36
printf '${$pointer{$i}} is ';
37
printf "${$pointer{$i}} \n";
38
printf '${$pointer->{$i}} is ';
39
printf "${$pointer->{$i}}";
40
41 printf "\n ================== end of test =================
\n";
Here is the output from the Perl script shown in listing 3.4.
================== start test =================
$$pointer{$i} is Fri
${$pointer}{$i} is Fri
$pointer->{$i} is Fri
${$pointer{$i}} is
${$pointer->{$i}} is
================== end of test =================
In this output, you can see that the first two lines gave you
the expected output. The first reference is used in the same way
as regular arrays. The second line uses ${pointer}
and indexes using {$i}, and
the leftmost $ dereferences
(gets) the value at the location reached after the indexing.
Then there are the two lines that did not work. In the third line
of the output, $pointer{$i}
tries to reference an array using the first element instead of
its address. The fourth line, ${$pointer->{$i}},
has an extra level of indirection leading to a scalar being used
as a pointer and therefore prints nothing.
The -> operator should
be very familiar to C++ or C programmers. Using a reference like
$variable->{$k} is synonymous
with the use of $$variable{$k}.
The -> simply means "use
the value of the left side of ->
as an address and dereference it as a pointer to an array."
So, in line 30, you use $pointer->
in place of $pointer to refer
to an array. The {$i} is
used to index into the array directly, because the $pointer->
is already defined as pointing to an array. In the case of $$pointer{$i},
two preceding dollar signs ($$)
are required: one to dereference the value in $pointer,
and the other to use the value at the i-th
index in the array as a scalar.
We will cover the use of the ->
operator in a moment when we use it to index into elements of
arrays. Let's first look at how we can use simple array concepts
to construct multidimensional arrays.
The way to create a reference to an array is with the statement
@array = list. You can create
a reference to a complex anonymous array by using square brackets.
Consider the following statement, which sets the parameters for
a three-dimensional drawing program:
$line = ['solid', 'black', ['1','2','3']
, ['4', '5', '6']];
This statement constructs an array of four elements. The array
is referred to by the scalar $line.
The first two elements are scalars indicating the type and color
of the line to draw. The next two elements of the array referred
to by $line are references
to anonymous arrays; they contain the starting and ending points
of the line.
To get to the elements of the inner array elements, you can use
the following multidimensional syntax:
$arrayReference->[$index] for a single
dimensional array, and
$arrayReference->[$index1][$index2] for a two dimensional array,
and
$arrayReference->[$index1][$index2][$index3] for a three dimensional
array.
Let's see how creating arrays within arrays works in practice.
Refer to Listing 3.5 to print out the information pointed to by
the $list reference.
Listing 3.5. Using multidimensional array references.
1 #!/usr/bin/perl
2
3 #
4 # Using Multidimensional Array references
5 #
6
7 $line = ['solid',
'black', ['1','2','3'] , ['4', '5', '6']];
8
9 print "\$line->[0]
= $line->[0] \n";
10 print "\$line->[1] = $line->[1] \n";
11 print "\$line->[2][0] = $line->[2][0] \n";
12 print "\$line->[2][1] = $line->[2][1] \n";
13 print "\$line->[2][2] = $line->[2][2] \n";
14 print "\$line->[3][0] = $line->[3][0] \n";
15 print "\$line->[3][1] = $line->[3][1] \n";
16 print "\$line->[3][2] = $line->[3][2] \n";
17
18 print "\n"; # The obligatory output beautifier.
Here is the output of the program that shows how to use two-dimensional
arrays.
$line->[0] = solid
$line->[1] = black
$line->[2][0] = 1
$line->[2][1] = 2
$line->[2][2] = 3
$line->[3][0] = 4
$line->[3][1] = 5
$line->[3][2] = 6
You can modify the script in Listing 3.5 to work with three-dimensional
(or even n-dimensional) arrays, as shown in Listing 3.6.
Listing 3.6. Extending to multiple dimensions.
1 #!/usr/bin/perl
2
3 #
4 # Using Multidimensional Array references again
5 #
6
7 $line = ['solid',
'black', ['1','2','3', ['4', '5', '6']]];
8
9 print "\$line->[0]
= $line->[0] \n";
10 print "\$line->[1] = $line->[1] \n";
11 print "\$line->[2][0] = $line->[2][0] \n";
12 print "\$line->[2][1] = $line->[2][1] \n";
13 print "\$line->[2][2] = $line->[2][2] \n";
14
15 print "\$line->[2][3][0] = $line->[2][3][0] \n";
16 print "\$line->[2][3][1] = $line->[2][3][1] \n";
17 print "\$line->[2][3][2] = $line->[2][3][2] \n";
18
19 print "\n";
In this example, the array is three deep; therefore, a reference
like $line->[2][3][0]
has to be used. For a C programmer, this is akin to the statement
Array_pointer[2][3][0], where
pointer is pointing to what's
declared as an array with three indexes.
In the previous examples, only hard-coded numbers were used as
the indexes. There is nothing preventing you from using variables
instead. As with array constructors, you can mix and match hashes
and arrays to create as complex a structure as you want.
Creating complex structures is the next step. Listing 3.7 illustrates
how these two types of arrays can be combined. It uses the point
numbers and coordinates to define a cube.
Listing 3.7. Using multidimensional arrays.
1 #!/usr/bin/perl
2
3 #
4 # Using Multidimensional Array and Hash references
5 #
6
7 %cube = (
8 '0',
['0', '0', '0'],
9 '1',
['0', '0', '1'],
10 '2',
['0', '1', '0'],
11 '3',
['0', '1', '1'],
12 '4',
['1', '0', '0'],
13 '5',
['1', '0', '1'],
14 '6',
['1', '1', '0'],
15 '7',
['1', '1', '1']
16 );
17
18 $pointer = \%cube;
19
20 print "\n Da Cube \n";
21 foreach $i (sort keys %$pointer) {
22 $list
= $$pointer{$i};
23 $x
= $list->[0];
24 $y
= $list->[1];
25 $z
= $list->[2];
26 printf
" Point $i = $x,$y,$z \n";
27
28 }
In this listing, %cube contains
point numbers and coordinates in a hash. Each coordinate itself
is an array of three numbers. The $list
variable is used to get a reference to each coordinate definition
with the following statement:
$list = $$pointer{$i};
After you get the list, you can reference off of it to get to
each element in the list with this statement:
$x = $list->[0];
$y = $list->[1];
Note that the same result of assigning values to $x,
$y, and $z
could be achieved by these two lines of code:
($x,$y,$z) = @$list;
$x = $list->[0];
This works because you are dereferencing what $list
points to and using it as an array, which in turn is assigned
to the list ($x,$y,$z). $x
is still assigned with the ->
operator.
When working with hashes or arrays, dereferencing by ->
is like a dollar-sign ($)
dereference. When accessing individual array elements, you are
often faced with writing statements like these two:
$$names[0] = "Kamran";
$names->[0] = "Kamran";
Both lines are equivalent. The substring "$names"
in the first line has been replaced with the
-> operator to create
the second line. The same procedure can be applied for hash operations:
$$lastnames{"Kamran"} = "Husain";
$lastnames->{"Kamran"} = "Husain";
Arrays in Perl can be created with a fixed size set to the value
of the highest index that is used. They do not have to remain
at this size, though, and can grow on demand. Referencing them
for the first time creates the array and space for the item that
is being indexed in the array. Referencing the array again at
different indexes creates those elements at the indexed references
if they do not already exist. Array references can be created
automatically when first referenced in the left side of an equation.
Using a reference such as $array[$i]
creates an array into which you can index with $i.
Such is the case with scalars and even multidimensional arrays.
Just as you can reference individual items such as arrays and
scalar variables, you can also point to subroutines. In C, this
would be akin to pointing to a function. To construct such a reference,
you use a statement like this:
$pointer_to_sub = sub { ... declaration
of sub ... } ;
Note the use of the semicolon at the end of the sub()
declaration. The subroutine pointed to by $pointer_to_sub
points to the same function reference even if the statement is
placed in a loop. This feature in Perl lets you declare several
anonymous sub() functions
in a loop without worrying about the fact that you are chewing
up memory by declaring the same function over and over as you
go about in a loop. As you come around the loop and reassign a
scalar to the sub, Perl simply
assigns to the same subroutine declared with the first use of
the sub() statement.
To call a referenced subroutine, use this syntax:
&$pointer_to_sub( parameters );
This code works because you are dereferencing the $pointer_to_sub
and using it with the ampersand (&)
as a pointer to a function. The parameters portion may or may
not be empty, depending on how your function is defined. The code
within a sub is simply a declaration created with this statement.
The code within the sub is not executed immediately; however,
it is compiled and set for each use. Consider the script shown
in Listing 3.8.
Listing 3.8. Using references to subroutines.
1 #!/usr/bin/perl
2
3 sub print_coor{
4
my ($x,$y,$z) = @_;
5
print "$x $y $z \n";
6
return $x;};
7
8 $k = 1;
9 $j = 2;
10 $m = 4;
11 $this = print_coor($k,$j,$m);
12
13 $that = print_coor(4,5,6);
When you execute this listing, you get the following output:
$ test
1 2 4
4 5 6
This output tells you that assignments of $x,
$y, and $z
were done when the first declaration of print_coor
was encountered as a call. Each reference to $this
and $that now points to a
completely different subroutine, the arguments to which were passed
at runtime.
Subroutines are not limited to returning only data types. They
can return references to other subroutines, too. The returned
subroutines run in the context of the calling routine but are
set up in the original routine that created them. This type of
behavior is caused by the way closure is handled in Perl. Closure
means that if you define a function in one context, it runs in
that particular context in which it was first defined. (A book
on object-oriented programming would provide more information
on closure.)
To see how closure works, look at Listing 3.9, which you can use
to set up different types of error messages. Such subroutines
are useful in creating templates of all error messages.
Listing 3.9. Using closure.
1 #!/usr/bin/perl
2
3 sub errorMsg {
4 my
$lvl = shift;
5
#
6
# define the subroutine to run when called.
7
#
8 return
sub {
9
10
my $msg = shift; # Define the error type now.
11
print "Err Level $lvl:$msg\n"; }; # print later.
12 }
13
14 $severe = errorMsg("Severe");
15 $fatal = errorMsg("Fatal");
16 $annoy = errorMsg("Annoying");
17
18 &$severe("Divide by zero");
19 &$fatal("Did you forget to use a semi-colon?");
20 &$annoy("Uninitialized variable in use");
The subroutine errorMsg declared
here uses a local variable called lvl.
After this declaration, errorMsg
uses $lvl in the subroutine
it returns back to the caller. Therefore, the value of $lvl
is set in the context when the subroutine errorMsg
is first called, even though the keyword my
is used. Therefore, the following three calls set up three different
$lvl variable values, each
in their own context:
$severe = errorMsg("Severe");
$fatal = errorMsg("Fatal");
$annoy = errorMsg("Annoying");
Now, when the reference to a subroutine is returned by the call
to the errorMsg function
in each of the lines above, the value of $lvl
within the errorMsg function
is retained for each context in which $lvl
was declared. Thus, the $msg
value from the referenced call is used, but the value of $lvl
is the value that was first set in the actual creation of the
function.
Sound confusing? It is. This is primarily the reason why you do
not see this type of code in most Perl programs.
Using arrays and pointers to subroutines, you can come up with
some nifty applications. Consider using an array of pointers to
subroutines to implement a state machine. Listing 3.10 provides
an example of a simple, asynchronous state machine.
Listing 3.10. A simple, asynchronous state machine.
1 #!/usr/bin/perl
2 # --------------------------------------------------------------
3 # Define each state
as subroutine. Then create a
4 # reference to each subroutine. We have four states here.
5 # --------------------------------------------------------------
6 $s0 = sub {
7 local
$a = $_[0];
8 print
"State 0 processing $a \n";
9 if
($a eq '0') { return(0); }
10 if
($a eq '1') { return(1); }
11 if
($a eq '2') { return(2); }
12 if
($a eq '3') { return(3); }
13 return
0;
14 };
15 # --------------------------------------------------------------
16 $s1 = sub {
17 local
$a = shift @_;
18 print
"State 1 processing $a \n";
19 if
($a eq '0') { return(0); }
20 if
($a eq '1') { return(1); }
21 if
($a eq '2') { return(2); }
22 if
($a eq '3') { return(3); }
23 return
1;
24 };
25 # --------------------------------------------------------------
26 $s2 = sub {
27 local
$a = $_[0];
28 print
"State 2 processing $a \n";
29 if
($a eq '0') { return(0); }
30 if
($a eq '1') { return(1); }
31 if
($a eq '2') { return(2); }
32 if
($a eq '3') { return(3); }
33 return
2;
34 };
35 # --------------------------------------------------------------
36 $s3 = sub {
37 my $a
= shift @_;
38 print
"State 3 processing $a \n";
39 if
($a eq '0') { return(0); }
40 if
($a eq '1') { return(1); }
41 if
($a eq '2') { return(2); }
42 if
($a eq '3') { return(3); }
43 return
3;
44 };
45 # --------------------------------------------------------------
46 # Create an array of pointers to subroutines. The index
47 # into this array is the current state.
48 # --------------------------------------------------------------
49 @stateTable = ($s0, $s1, $s2, $s3);
50 # --------------------------------------------------------------
51 # Initialize the state to 0.
52 # --------------------------------------------------------------
53 $this = 0;
54 # --------------------------------------------------------------
55 # Implement the state machine.
56 # set current state to 0
57 # forever
58 # get response
59 # set current
state to next state based on response.
60 # --------------------------------------------------------------
61 while (1)
62 {
63 print
"\n This state is : $this -> what next? ";
64 $reply
= <STDIN>;
65 chop($reply);
66 #
67 #
Stop the machine here
68 #
69 if
($reply eq 'q') { exit(0); }
70 print
" Reply = $reply \n";
71 #
72 #
Get the present state function.
73 #
74 $state
= $stateTable[$this];
75 #
76 #
Get the next state from this state.
77 #
78 $next
= &$state($reply);
79 printf
"Next state = $next from this state $this\n";
80 #
81 #
Now advance present state to next state
82 #
83 $this
= $next;
84 }
Let's see how each function implements the state transitions.
All input into each state consists of removing the initial state
as the first parameter into the subroutine. In Perl, the @_
variable is the array of input parameters into a subroutine
and is always defined in each subroutine. In line 37, the shift
command forces the first item from the list of input parameters
into $a. The value of $a
is then used as the current state of the program.
There are four states in this state machine: S0,
S1, S2,
and S3. Each state accepts
input in the form of a number. Each number is used to get the
next state to go to. Note how $a
is declared in each state function using the my
and local types. So if $a
has a value of 2 and receives
an input of 3, the current
state is 2, and the program
will do a state transition from 2
to 3. After the function
returns, the current state will be 3.
Lines 6 through 14 define a subroutine that defines the functionality
of a state. State S0 transitions
to states S1 on receiving
a 1, S2
on receiving a 2, and S3
on receiving a 3. All other
input will not cause a state transition. The other states, {S1,S2,S3},
behave in an analogous way.
The stateTable array is used
to store pointers to each of the functions of the state machine.
The four entries are set in line 49. The initial state is set
to 0.
Lines 61 through 84 implement the code for transitioning through
the state machine by accepting input from <STDIN>
and calling the present state function to handle the input. Line
74 is where you get the pointer to the function handling all input
for each state in the state machine, and line 78 is where the
state-handling function is called. The next state value returned
by the function is set to the present state ($this)
in line 83.
Having arrays is great for collecting relevant information. Now
you'll see how to work with multiple arrays via subroutines. Passing
one or more arrays into Perl subroutines is done by reference.
However, you have to keep in mind a few subtle things about using
the @_ symbol when processing
these arrays in the subroutine.
The @_ symbol is an array
of all the items in a subroutine. So, if you have a call to a
subroutine as follows:
$a = 2;
@b = ("x","y","z");
@c = ("cat","mouse","chase");
&simpleSub($a,@b,@c);
the @_ array within the subroutine
will be (2, "x",
"y", "z",
"cat", "mouse",
"chase"). That
is, the contents of all the elements will be glued together to
form one long array.
Obviously, this ability to glue together arrays will be a problem
to deal with if you want to do operations on two distinct arrays
sequentially. For example, if you have a list of names and a list
of phone numbers, you would want to take the first item from the
names array and the first item from the number array and print
an item. Then take the next name and the next number and print
a combination, and so on. If you pass in the contents of the arrays
to a function that simply uses @_,
the subroutine will see one long array, the first half of which
will be a list of strings (names) and the second half of which
will be a list of numbers.
The subroutine would have to split the @_
in half into two distinct arrays before it can start processing.
The problem gets more complicated if you were to pass three or
four arrays such as those containing items like address and ZIP
code. Now the subroutine will have to manipulate @_
even more to get the required number of arrays.
The simplest way to handle the passing of multiple arrays into
a subroutine is to use references to arrays in the argument list
to the subroutine. That is, you pass in a reference to each array
that the subroutine will be using. The references will be ordered
in the @_ array within the
subroutine. The code in the subroutine can dereference each item
in the @_ to the type of
array being referenced. This procedure is known as passing
by reference. The value of what is being referenced can be
changed by the subroutine. When an explicit value is sent to a
subroutine, (that is, you are passing by value), only the
copy of what is sent on the stack is changed, not the actual value.
In Perl, values are passed by reference unless you send in a constant
number. For example, from the following code:
sub doit {
$_[0] *= 3.141;
}
$\="\n";
$x = 3;
print $x;
doit ($x);
print $x;
# The following line will cause an error since you will attempt
to
# modify a read-only value:
# doit(3);
you will see the following values being printed:
3
9.423
The second number is the new value of $x
after the call to the doit
subroutine. Calling the doit
subroutine with a constant value such as shown in the commented
lines above will result in an exception with an error message
indicating that your program attempted to modify a read-only value.
The preceeding test confirms that Perl indeed passes values of
variables by reference and not by value.
| Note |
The value of the $\ system variable is the output separator. In the preceding example, it is set to a newline. By setting the value of $\ to \n,
the print statements did not have to prepend a \n to any string being printed. It's a matter of style, of course, and you do not have to use the $\ variable if you do not want to. The default value of this $\ variable is null. The $\ is useful in instances when you are writing special text records
with the print statement that have to have a special record separator such as END\n and RECORDEND\n\n.
|
Listing 3.11 provides a sample subroutine that expects a list
of names and a list of phone numbers.
Listing 3.11. Passing multiple arrays into a subroutine.
1 #!/usr/bin/perl
2
3 @names = (mickey,
goofy, daffy );
4 @phones = (5551234, 5554321, 666 );
5 $i = 0;
6 sub listem {
7
my (@a,@b) = @_;
8
foreach (@a) {
9
print "a[$i] = ". $a[$i] . " " . "\tb[$i]
= " . $b[$i] ."\n";
10 $i++;
11 }
12 }
13
14 &listem(@names, @phones);
Here's the output from this program:
a[0] = mickey
b[0] =
a[1] = goofy b[1] =
a[2] = daffy b[2] =
a[3] = 5551234 b[3]
=
a[4] = 5554321 b[4]
=
a[5] = 666 b[5] =
The @b array is empty, and
@a is just like the array
@b. This is because the @_
array is a solitary array of all parameters into a subroutine.
If you pass in 50 arrays, @_
is still going to be one array of all the elements of the 50 arrays
concatenated together.
In the subroutine in this example, the assignment
my (@a, @b) = @_
gets loosely interpreted by your Perl interpreter as "let's
see, @a is an array, so let's
assign one array from @_
to @a and then assign everything
else to @b." Never mind
the fact that @_ is itself
an array and will therefore get assigned to @a,
leaving nothing to assign to @b.
In order to get around this @_-interpretation
feature and to be able to pass arrays into subroutines, you would
have to pass arrays in by reference. This is done by modifying
the script to look like the one shown in Listing 3.12.
Listing 3.12. Passing multiple arrays by reference.
1 #!/usr/bin/perl
2
3 @names = (mickey,
goofy, daffy );
4 @phones = (5551234, 5554321, 666 );
5 $i = 0;
6 sub listem {
7
my ($a,$b) = @_;
8
foreach (@$a) {
9 print
"a[$i] = " . @$a[$i] . " " . "\tb[$i]
= " . @$b[$i] ."\n";
10
$i++;
11
}
12
}
13
14 &listem(\@names, \@phones);
Here are the major changes made to this script:
- The local variables for the sub listem
are now scalars, not array references. This way, $a
is the first item on the @_
list, and $b is the second
item.
- The local parameters ($a
and $b) are used as array
references with the statements @$a
and @$b, respectively.
- The call to the subroutine passes the
references to the arrays with the backslash, \@names
and \@phones, thus passing
only two items to the subroutine.
The output from this listing is what we expected:
a[0] = mickey b[0] = 5551234
a[1] = goofy b[1] = 5554321
a[2] = daffy b[2] = 666
Scalar variables, when used in a subroutine argument list, are
always passed by reference. You do not have a choice here. You
can modify the values of these variables if you really want to.
To access these variables, you can use the @_
array and index each individual element in it, using $_[$index],
where $index as an integer
goes from 0 on up.
Arrays and hashes are different beasts altogether. You can either
pass them as references once, or you can pass references to each
element in the array. For long arrays, the choice should be fairly
obvious, pass the reference to the array only. In either case,
you can use the reference(s) to modify what you want in the original
array.
Also, the @_ mechanism concatenates
all the input arrays to a subroutine into one long array. Sure,
this feature is nice if you do want to process the incoming arrays
as one long array. Normally, you want to keep the arrays separate
when processing them in a subroutine, and passing by reference
is the best way that you can do that.
There are times when you have to write the same output to different
output files. For instance, an application programmer might want
output to go to a screen in one instance, the printer in another,
and a file in yet another, or perhaps even all three at the same
time. Rather than make separate statements per handle, it would
be nice to write something like this:
spitOut(\*STDIN);
spitOut(\*LPHANDLE);
spitOut(\*LOGHANDLE);
Note how the file handle reference is sent with the \*FILEHANDLE
syntax. This is because you're referring to the symbol table in
the current package. In the subroutine handling the output to
the file handle, you have code that looks something like this:
sub spitOut {
my $fh = shift;
print $fh "Gee Wilbur, I like this
lettuce\n";
}
In UNIX (and other operating systems, too) the asterisk is a sort
of wildcard operator. In Perl you can refer to other variables,
arrays, subroutines, and so on by using the asterisk operator
like this:
*iceCream;
The asterisk used this way is also known as a typeglob.
The asterisk on the front can be thought of as a wildcard match
for all the mangled names used internally by Perl. When evaluated,
a typeglob of *name
produces a scalar value that represents the first object found
with that name.
A typeglob can be used the same way a reference can be used because
the dereference syntax always indicates the kind of reference
desired. Therefore, ${*iceCream}
and ${\$iceCream} both mean
the same scalar variable. Basically, *iceCream
refers to the entry in the internal _main
associative array of all symbol names for the _main
package. Thus, *kamran really
translates to $_main{'kamran'}
if you are in the _main package
context.
A package context implies the use of the associative array
of symbol names, called a symbol table, by Perl for resolving
variable names in a program. We will cover symbols and symbol
tables in Chapter 4. What is confusing
is that the terms module and package are used interchangeably
in all Perl documentation and these two terms mean the very
same thing. Basically, your Perl program runs in the _main
package (think "module") and uses other modules to switch
symbol tables. Code running in the context of a module has its
own symbol table that is different from the symbol table in the
main module.
The use of brackets around symbolic references makes it easier
to construct strings:
$road = ($w) ? "free":"high";
print "${road}way";
This line will print highway
or freeway, depending on
the value of $w. This type
of syntax will be very familiar to folks writing makefiles or
shell scripts. In fact, you can use this ${variable}
construct outside of double quotes, like the examples shown here:
print ${road};
print ${road} . "way";
print ${ road } . "way";
$if = "road";
print "\n ${if} way \n";
Note that you can use reserved words in the ${
} brackets, too. However, using reserved words for
anything other than their purpose is playing with fire. Be imaginative
and make up your own variables.
One last point. Symbolic references cannot be used on variables
declared with the my construct
because these variables are not kept in any symbol table. Variables
declared with the my construct
are valid only for the block in which they're created. Variables
declared with the local word
are visible to all ensuing lower code blocks because they are
in a symbol table.
The previous section brings up an interesting point about curly
braces for use other than as hashes. In Perl, curly braces are
normally reserved for delimiting blocks of code. Let's say you
are returning the passed list by sorting it in reverse order.
The passed list is in @_
of the called subroutine. Thus, these two statements are equivalent:
sub backward {
{
reverse sort @_ ; }
};
sub backward {
reverse
sort @_ ;
};
Curly braces, when preceded with the @
operator, allow you to set up small blocks of evaluated code.
The code in Listing 3.13 evaluates an array.
Listing 3.13. Evaluating references to arrays.
1 #!/usr/bin/perl
2 sub average {
3 ($a,$b,$c)
= @_;
4 $x
= $a + $b + $c;
5 $x2
= $a*$a + $b*$b + $c*$c;
6 return
($x/3, $x2/3 ); }
7 $x = 1;
8 $y = 34;
9 $x = 47;
10 print "The midpt is @{[&average($x,$y,$z)]} \n";
You should see the printout of 27
and 1121.6666. In line 10,
when @{} is seen in the double-quoted
string, the contents of @{}
are evaluated as a block of code. The block creates a reference
to an anonymous array containing the results of the call to the
subroutine average($x,$y,$z).
The array is constructed because of the []
brackets around the call. Thus, the []
construct returns a reference to an array, which in turn is converted
by @{} into a string and
inserted into the double-quoted string.
Perl does not directly support multidimensional associative arrays.
In most cases, you would not want to use multidimensional arrays,
though they are sometimes useful for tracking synonymous variable
names.
The syntax for using more than one index into an associative array
is not the same as that for multidimensional arrays that use a
numeric index. Therefore, you cannot use statements such as this:
$description{'pan'}{'handle'};
as you would with regular arrays. What you can use is the following:
$description{'pan' , 'handle'};
The latter statement lets you index into the %description
array using two strings, so you can index the array as
$description{'pan' , 'cake'};
$description{'pan' , 'der'};
$description{'pan' , 'da'};
Your first index here for a row would be pan
and each index into the row would be cake,
der, da,
and handle. It's a bit cumbersome
to use, but it will work.
You are not limited to using commas to separate indexes into an
associative array. By using the $;
system variable you can use more than one index into an associative
array and use a separator other than just a comma. The $;
system variable is a subscript separator for all items used to
index an associative array. The default value of $;
is the Ctrl-\ character, but you can set it to anything you want.
When more than one index is used to reference an associative array,
all items are concatenated together with the use of the $;
variable. That is, the statement
$description{"texas", "pan","handle"}
;
is interpreted as
$description{"texas" . $; .
"pan" . $; . "handle"} ;
By setting the value of $;
to "::", you can
use the index specifier. The following lines of code will illustrate
how to do this:
$; = "::";
$description{"pan", "cake"} = "edible";
$description{"pan::da"} = "cute";
The "::" is now
interchangeable with the comma separator. There is one catch to
using the "::"
as a separator: the "::"
is also used as an object::member
syntax as you will see in Chapter 5,
"Object-Oriented Programming in Perl." So a statement
like this with the $; set
to "::"
$description{"pan::handle",
"cake"}
will get translated to
$description{"pan::handle::cake"}
which is something you probably do not want! We will cover this
syntax and how to work with objects in Chapter 5,
so be patient.
To force only hard references in a program and protect yourself
from accidentally creating symbolic references, you can use a
module called strict, which
forces Perl to do strict type checking. To use this module, place
the following statement at the top of your Perl script:
use strict 'refs';
From this point, only hard references are allowed for the rest
of the script. You place this statement within curly braces, too,
where the type checking would be limited to only within the code
block for the curly braces.
To turn off the strict type checking at any time within a code
block, use this statement:
no strict 'refs';
Besides the obvious documents, such as the Perl man
pages, look at the Perl source code. The t/op
directory in the Perl source tree has some regression test routines
that should definitely get you thinking. There are lots of documents
and references at the Web sites www.perl.com/index.html,
mox.perl.com/index.html, and www.metronet.com/perlinfo/doc/manual/html/perl.html.
There are two types of references you can deal with in Perl 5:
hard or symbolic. Hard links work like the links in UNIX file
systems. You can have more than one hard link to the same item.
Perl keeps a reference count for you. This reference count is
incremented or decremented as references to the item are created
or destroyed. When the count goes to zero, the link and the object
it is pointing to are both destroyed. Symbolic links are created
via the ${} construct and
are useful in providing multiple stages of references to objects.
You can have references to scalars, arrays, hashes, subroutines,
and even other references. References themselves are scalars and
have to be dereferenced to the context before being used. Use
@$pointer for an array, %$pointer
for a hash, &$pointer
for a subroutine, and so on. Multidimensional arrays are possible
by using references in arrays and hashes. You can also have references
to other elements holding even more references to create very
complicated structures. There is a scalar()
function, a scalar variable
holds one value, and a hard reference is a scalar unless it's
dereferenced to behave like a non-scalar. Got that?
Parameters are passed into a subroutine through references. The
@_ array is really one long
array of all the passed parameters concatenated in one long array.
To send separate arrays, use the references to the individual
items.
The next chapter covers Perl objects and references to objects.
I deliberately did not cover Perl objects in this chapter because
they require some knowledge of objects, constructors, and packages.
| 
 LINUX
LINUX 
 Books
Books
