mmap и DMA
About: "По мотивам перевода" Linux Device Driver 2-nd edition.
Перевод:
Князев Алексей knzsoft@mail.ru
ICQ 194144861
Дата последнего изменения: 02.12.2004
Авторскую страницу А.Князева можно найти тут :
http://lug.kmv.ru/wiki/index.php?page=knz_ldd2
Архивы в переводе А.Князева лежат тут:
http://lug.kmv.ru/wiki/files/ldd2_ch1.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch2.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch3tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch4.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch5.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch6.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch7.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch8.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch13.tar.bz2
Содержание
- Управление памятью в Linux
- Механизм mmap
- Интерфейс kiobuf
- Прямой доступ к памяти (DMA) и управление шиной
В этой главе мы окунемся в таинства управления памятью в Linux. Особое внимание будет уделено техникам, которые могут
быть использованы разработчиками драйверов. Материал этой главы достаточно сложен, и нужно сказать, что не каждому
разработчику драйверов подобные знания необходимы. Однако, многие задачи могут потребовать от вас глубокого понимания
подсистемы управления памятью. Кроме того, многим может показаться просто интересным узнать больше о работе этой важной
части ядра.
Материал этой главы разделен на три части. В первой рассказывается реализация системы mmap (memory map), которая
позволяет отображать память устройства прямо в адресное пространство пользовательского процесса. Далее мы рассмотрим
механизм kiobuf (kernel input/output buffer), который обеспечивает прямой доступ к памяти пользовательского процесса из
ядра. Система kiobuf может быть использована для реализации механизма "raw I/O" ("сырой" ввод/вывод
- сырой, значит без дополнительной обработки), требуемого некоторому классу устройств. И, наконец, в последней части мы расскажем о
механизме прямого доступа к памяти (DMA - Direct Memory Access), который обеспечивает внешним устройствам доступ к
системной памяти.
Конечно, все эти техники управления памятью требуют понимания того, как работает механизм управления памятью в Linux,
поэтому мы начнем с обсуждения этой подсистемы.
Управление памятью в Linux
В этом разделе, вместо описания общей теории управления памятью в операционных системах, приводятся главные особенности
реализации этой теории в Linux. И хотя для использования mmap вам не нужно быть гуру в области управления виртуальной
памятью в Linux, но базовые знания о том как это работает могут оказаться очень полезными. Конечно, для этого
потребуется честное ознакомление со всем множеством структур, используемых ядром для управления памятью. Однако, после
того как эта необходимая часть будет пройдена, мы сможем начать серьезную работу с этими структурами.
Типы адресов
Конечно, Linux представляет собой операционную систему работающую в абстракции виртуальной памяти, которая означает что
адреса, используемые программами пользователя не соответствуют напрямую адресам, которые используются аппаратной
платформой. Виртуальная память представляет собой некий слой коссвенной адресации, позволяющий множество интересных
вещей. Используя виртуальную память, программа может распределить во много раз больше памяти, чем это физически
доступно. Т.е. каждый процесс может иметь больше виртуального адресного пространства, чем физически доступно
операционной системе. Кроме того, использование виртуальной памяти позволяет различные трюки с адресными пространствами
процессов, включая отображение в память устройства.
Таким образом, мы говорим о виртуальных и физических адресах, и о множестве сопутствующих этим понятиям деталей. Система
Linux имеет дело с разными типами адресов, каждый из которых имеет свой смысл и назначение. К несчастью, по коду ядра не
всегда понятно какой тип адресации используется в каждой конкретной ситуации, поэтому программист должен быть
внимательным при изучении чужого кода.
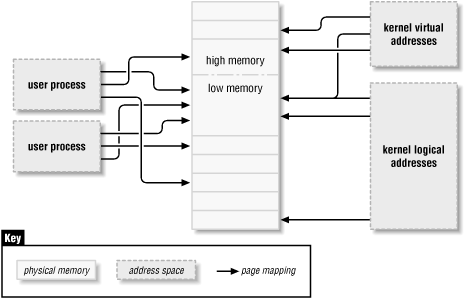
Рис. 13-1. Типы адресов используемые в Linux
Ниже представлен список типов адресов используемых в Linux. На рисунке 13-1 показано, как эти типы адресов относятся к
физической памяти.
- Виртуальные адреса пользовательских процессов (User virtual addresses)
-
Это обычные адреса используемые программами пользовательского процесса. Разрядность этих адресов 32 или 64 бита, в
зависимости от используемой аппаратной архитектуры. Каждый процесс имеет свое собственное виртуальное пространство.
- Физические адреса (Physical addresses)
-
Это адреса используемые процессором для доступа к системной памяти. Разрядность этих адресов 32 или 64 бита. В некоторых
случаях даже 32-х битные системы могут использовать 64-битную адресацию.
- Адреса шин (Bus addresses)
-
Адреса используемые между периферийными шинами и памятью. В некоторых случаях эти адреса могут совпадать с физическими
адресами используемыми процессором. Излишне говорить, что данных тип адресации сильно зависит от аппаратной архитектуры.
- Логические адреса пространства ядра (Kernel logical addresses)
-
Логические адреса являются обычными адресами, используемыми в ядре. Логические адреса отображают большую часть или всю
главную память (main memory), и часто выступают в качестве физических адресов. На большинстве архитектур логические
адреса, и связанные с ними физические адреса, отличаются только на постоянное смещение. Разрядность логического адреса
определяется разрядностью указателя принятой на данной аппаратной архитектуре. Таким образом, логические адреса не могут
адресовать всю физическую память доступную на хорошо оснащенной 32-х разрядной платформе (т.е. более 4-х гигабайт).
Логические адреса обычно хранят в переменных типа unsigned long или void*. Функция kmalloc() возвращает логический адрес
распределенной области памяти.
- Виртуальные адреса пространства ядра (Kernel virtual addresses)
-
Виртуальные адреса отличаются от логических адресов тем, что они могут не иметь прямого отображения в физические адреса.
При этом, все логические адреса являются виртуальными адресами пространства ядра (All logical addresses are kernel
virtual addresses). Память распределенная функцией vmalloc() имеет виртуальные адреса. Функция kmap() описанная позднее
в этой главе, также возвращает виртуальные адреса. Виртуальные адреса обычно сохраняются в переменных типа указателей.
Если у вас есть логический адрес, то макрос __pa(), определенный в <asm/page.h> может преобразовать его в физический
адрес. Физические адреса могут быть отображены обратно в логические с помощью макроса __va(). Понятно, что в этом случае
вы получите логические адреса только для нижних страниц памяти.
Различные функции ядра требуют различные типы адресов. Было бы прекрасно, если бы существовали различные типы данных,
определенные в языке Си, для явного обозначения различных типов адресов, но этого, к сожалению, нет. В этой главе мы
попробуем прояснить какой тип адресации где используется.
Верхняя (High) и нижняя (Low) память
Различие между логическими и виртуальными адресами в ядре хорошо заметны на 32-х разрядных системах, оснащенных большими
объемами доступной памяти. По определению, 32-х разрядная система может адресовать до 4ГБт памяти. Однако, Linux на 32-х
разрядной системе, до недавнего времени, мог адресоваться к существенно меньшему объему памяти. Сейчас Linux использует
виртуальное адресное пространство. Система не может управлять большим объемом памяти, чем это позволяет логическая
адресация, т.к. необходимо прямое отображение адресов ядра в память.
Последние разработки позволили преодолеть ограничения памяти, и 32-х битные системы теперь могут работать с объемами
памяти, которые превышают 4 ГБт (конечно в предположении, что такой объем памяти может адресовать процессор). Однако
остались ограничения на то, какой объем памяти может быть прямо отображен с помощью логических адресов. Только самая
нижняя часть памяти (до 1 или 2 ГБт, в зависимости от платформы и конфигурации ядра) имеет логическую адресацию. Память
выше этого предела логической (верхняя память - high memory) адресации не имеет. Верхняя память может потребовать
64-битной физической адресации, и ядро должно определить явный способ отображения виртуальных адресов для управления
ими. Многие функции ядра ограничены работой только с нижней памятью. Верхняя память, как правило, резервируется для
страниц процессов пользовательского пространства.
Прим. переводчика: Не могу сказать точно, но, вроде-бы, в ядре 2.6 предел нижней памяти может быть расширен до 4 ГБт.
Вообще, термин "верхняя память" ("high memory") является достаточно запутанным, потому что имеет другие значения в
мире ПК (персональных компьютеров). Поэтому, попробуем дать точные определения нижней и верхней памяти в контексте
данного материала:
- Нижняя память (Low memory)
-
Память для которой существует логическая адресация в пространстве ядра. На большинстве систем, с которыми вы
столкнетесь, вся память является нижней.
- Верхняя память (High memory)
-
Память для которой не существует логическая адресация. Присутствует на системах имеющих большие объемы памяти,
которые не могут быть адресованы через 32 бита.
На системах для i386 граница между нижней и верхней памятью обычно устанавливалась под 1 ГБт. Эта граница никак не
связана с 640-килобайтным лимитом существовавшем на оригинальных ПК. Лимит устанавливался ядром для разделения 32-х
битного адресного пространства между ядром и пространством пользователя.
В этой главе мы еще вернемся к разговору о границе между верхней и нижней памятью.
Отображение памяти и структура page
Исторически, ядро использовало логическую адресацию для отображения на реальные страницы памяти. Добавление поддержки
верхней памяти вскрыло очевидные проблемы такого подхода – логическим адресам не доступна верхняя память. Поэтому,
функции ядра, которые работают с памятью, все чаще, вместо логических адресов, используют указатель на структуру page.
Эта структура данных используется для хранения всего того, что необходимо знать ядру о физической памяти. На каждую
физическую страницу памяти в системе хранится одна структура page. Познакомимся с некоторыми полями этой структуры:
- atomic_t count;
-
Количество ссылок к данной странице. Когда количество ссылок падает до нуля, страница возвращается в список свободных
страниц.
- wait_queue_head_t wait;
-
Список процессов, ожидающих данную страницу. Процессы могут ждать страницу, если какая-либо функция адра заблокировала
ее по каким-либо причинам. Однако, драйвера обычно не сталкиваются с подобной проблемой.
- void *virtual;
-
Виртуальный адрес ядра для данной страницы. Может быть не отображен, тогда - NULL. Страницы нижней памяти всегда
отображены, в отличии от страниц верхней памяти.
- unsigned long flags;
-
Набор битовых флагов описывающих статус страницы. Среди них, например, флаг PG_locked, который показывает, что страница
заблокирована в памяти, и PG_reserved, который запрещает системе управления памятью использовать данную страницу вообще.
Прим. переводчика (по книге Алексея Лациса “Как построить и использовать суперкомпьютер”): Различают три класса
многопроцессорных систем по способу разделения памяти между процессами и процессорами. Это SMP (Symmetric Multi
Processing), MPP (Massive Parallel Processing) и промежуточный класс NUMA (Non-Uniform Memory Access). На системах SMP
между процессорами делятся вычисления, но не данные, которые принадлежат всем на равных. Это самый удобный для
программиста, но самый дорогой в аппаратной реализации способ организации параллельных вычислений - проблемы
одновременного доступа. Системы MPP состоят из отдельных вычислительных модулей, соединенных специальными каналами
связи. Такая архитектура позволяет бесконечное масштабирование. NUMA - это системы, в которых общая для многих
процессоров память присутствует (аппаратно или логически), но по своим архитектурным свойствам (быстродействию, прежде
всего) столь сильно отличается от локальной памяти процессора, что это необходимо явно учитывать при программировании. И
по цене и по стилю программирования эти системы ближе к SMP чем к MPP.
В структуре page содержится много другой информации, но это уже тонкости подсистемы управления памятью, которые не имеют
отношения к разработке драйверов.
Ядро может содержать один или более массивов, состоящий из элементов структуры page, которые покрывают всю физическую
память системы. Большинство систем имеет один массив, называемый mem_map. Однако, на некоторых системах ситуация более
сложная. Системы NUMA (non-uniform memory access) и похожие, имеют более одного такого массива, поэтому код, стремящийся
к портируемости, должен по возможности избегать прямого доступа к таким массивам. К счастью, обычно при работе с
указателями на структуру page не возникает потребности в уточнении того, к какому массиву данная структура относится.
Познакомимся с функциями и макросами, которые определены для преобразования между указателями на структуру page и
виртуальными адресами:
- struct page *virt_to_page(void *kaddr);
-
Этот макрос, определенный в <asm/page.h> берет логический адрес из пространства ядра и возвращает связанный с этим
адресом указатель на структуру page. Макрос работает только с логическими адресами, поэтому не будет работать с адресами
полученными от vmalloc() и адресами из верхней памяти.
- void *page_address(struct page *page);
-
Возвращает виртуальный адрес пространства ядра для этой страницы, если такой адрес существует. Для верхней памяти такой
адрес существует только в том случае, если страница отображена.
- #include <linux/highmem.h>
- void *kmap(struct page *page);
- void kunmap(struct page *page);
-
kmap() возвращает виртуальный адрес пространства ядра для любой страницы в системе. Для страниц из нижней памяти, просто
возвращается логический адрес страницы. Для страниц из верхней памяти, kmap() создает специальное отображение.
Отображение, создаваемое kmap() должно быть обязательно освобождено с помощью kunmap(). На общее количество отображений
существует ограничение, поэтому, лучше не удерживать отображение слишком долго. Вызовы kmap() аддитивны, т.е. вы можете
в разных функциях вызвать kmap() для одной и той же страницы. Имеете в виду, что kmap() может уснуть, если отображение
недоступно.
Позднее, мы увидим использование этих функций в примерах этой главы.
Таблицы страниц (Page Tables)
Когда программа просматривает виртуальные адреса, процессор должен конвертировать эти адреса в физические для того,
чтобы получить доступ к физической памяти. Этот шаг обычно выполняется разделением адреса на битовые поля. Каждое
битовое поле используется в качестве индекса в соответствующем массиве, которые называются таблицами страниц (page
table). Полученное из массива значение либо является индексом для следующей таблицы, либо физическим адресом, который
связан с исходным виртуальным.
Ядро Linux управляет тремя уровнями страничных таблиц, для отображения виртуальных адресов в физические.
Прим. переводчика: Тут что-то про редконаселенность множества уровней и про преимущества, которые это дает современным
системам. В общем я не понял. Читайте сами. "... The Linux kernel manages three levels of page tables in order to map
virtual addresses to physical addresses. The multiple levels allow the memory range to be sparsely populated; modern
systems will spread a process out across a large range of virtual memory. It makes sense to do things that way; it
allows for runtime flexibility in how things are laid out. ..."
Заметьте, что Linux использует трехуровневую систему даже на тех аппаратных платформах, которые поддерживают два уровня
страничных таблиц или, вообще, используют другой способ отображения виртуальных адресов в физические. Это позволяет
Linux использовать разные типы процессоров без загрязнения кода множеством директив условной компиляции #ifdef. Такой
тип кодирования не приводит к избыточным затратам при исполнении ядра на двухуровневых процессорах, потому что
компилятор оптимизирует не используемый слой.
Теперь, пришло время познакомиться со структурами данных, используемых для реализации страничной системы. На рисунке
13-2 показана реализация трехуровневой схемы, используемой в Linux.
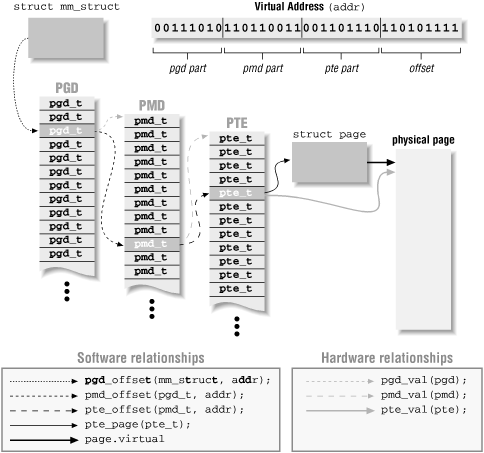
Рис. 13-2. Три уровня страничных таблиц в Linux
- Page Directory (PGD) - каталог страниц
-
Страничная таблица верхнего уровня. Представляет собой странично-выравненный (page-aligned) массив элементов pgd_t,
каждый из которых указывает на страничную таблицу второго уровня. Каждый процесс имеет свой собственный каталог страниц,
и один каталог страниц имеется у ядра.
- Page mid-level Directory (PMD) - каталог страниц среднего уровня
-
Таблица второго уровня. Представляет собой странично-выровненный массив элементов pmd_t. Двухуровневые процессоры
физически не имеют PMD. Поэтому, PMD на таких процессорах представляет собой массив одного элемента, значение которого
- сам PMD. Через некоторое время мы увидим как это описывается в языке Си и как компилятор оптимизирует этот уровень.
- Page Table - таблица страниц
-
Странично-выравненный массив элементов, каждый из которых называется Page Table Entry (Элемент Таблицы Страниц). Ядро
использует для этих элементов тип pte_t. В pte_t содержится физический адрес страницы данных.
Все эти типы данных определены в <asm/page.h>. Этот заголовочный файл должен быть в включен в каждый файл источник,
работающий со страницами.
Ядро не должно беспокоиться о том как происходит обработка страничных таблиц во время обычного исполнения программы, так
как такая обработка производится аппаратно. Однако в обязанности ядра входит подготовка таблиц для их аппаратной
обработки. Ядро должно выстраивать все таблицы и обрабатывать исключения "page fault", возникающие в случае, когда
требуемая процессору страница не отображена в физическую память. Драйвера устройств, также, должны строить таблицы и
обрабатывать исключения при реализации механизма mmap.
Интересно обратить внимание на то, как программная система управления памятью обрабатывает те же самые таблицы страниц,
которые использует процессор. Разница в обработке страничных таблиц на разных процессорах спрятана в самых нижних слоях
архитектурно-зависимого слоя. Поэтому, говоря о системе управления памятью в Linux мы всегда говорим о трехуровневых
страничных таблицах, независимо от того, поддержаны они в аппаратном слое или нет. Примером семейства процессоров не
поддерживающих страничные таблицы являются процессоры PowerPC. Разработчики PowerPC реализовали хэш-алгоритм
(ассоциативный алгоритм), который отображает виртуальные адреса в одноуровневую таблицу страниц. Когда производится
доступ к странице присутствующей в памяти, но ушедшей из кэша процессора, то процессору требуется произвести только одно
обращение к памяти, в противоположность двум или трем обращениям в реализации с многоуровневыми таблицами страниц.
Хэш-алгоритм, как и многоуровневые таблицы, делает возможним уменьшить использование памяти в отображении виртуальных
адресов в физические.
Независимо от механизма используемого процессором, программная реализация системы управления памятью в Linux построена
на трехуровневых таблицах страниц. Ниже описаны символы используемые для доступа к этим таблицам. Для использования этих
символов необходимо включить в код драйвера два заголовочных файла <asm/page.h> и <asm/pgtable.h>.
- PTRS_PER_PGD
- PTRS_PER_PMD
- PTRS_PER_PTE
-
Размер каждой из таблиц. Для двухуровневых процессоров величина PTRS_PER_PMD установлена в 1.
- unsigned pgd_val(pgd_t pgd)
- unsigned pmd_val(pmd_t pmd)
- unsigned pte_val(pte_t pte)
-
Эти три макроса используются для получения беззнакового значения из типизированных элементов данных. Действительный тип
возвращаемых данных зависит от аппаратной архитектуры и опций конфигурирования ядра. Это либо unsigned long для обычных
32-х разрядных процессоров, либо unsigned long long для 32-х разрядных процессоров поддерживающих верхнюю память, либо
unsigned int для процессоров SPARC64. Эти макросы помогают упростить код драйвера за счет точного определения типов
данных.
- pgd_t * pgd_offset(struct mm_struct * mm, unsigned long address)
- pmd_t * pmd_offset(pgd_t * dir, unsigned long address)
- pte_t * pte_offset(pmd_t * dir, unsigned long address)
-
Эти inline-функции используются для получения pgd, pmd и pte элементов связанных с данным адресом. Таблицы страниц
просматриваются начиная с указателя на структуру mm_struct. Указатель связанный с отображением памяти текущего процесса
хранится в current->mm, а указатель связанный с отображением памяти в ядре хранится в &init_mm. Для двухуровневых
процессоров pdm_offset(dir,add) определена как (pmd_t*)dir для оптимизации второго уровня. Функции которые просматривают
таблицы страниц всегда описаны как inline.
-
На 32-х разрядных процессорах SPARC данные функции являются не inline, а внешними функциями, которые не экспортируются в
код модуля. Таким образом, вы не сможете использовать эти функции в модулях, запущенных на процессорах SPARC, но обычно
это и не нужно.
- struct page *pte_page(pte_t pte)
-
Эта функция возвращает указатель на экземпляр структуры page из pte. Код, который работает с таблицами страниц, обычно
использует pte_page() вместо pte_val(), т.к. pte_page() работает с процессоронезависимым форматом элемента таблицы
страниц, и возвращает указатель на структуру page, что, обычно и требуется.
- pte_present(pte_t pte)
-
Данный макрос возвращает логическое значение, которое показывает, отображена ли текущая страница данных в памяти.
Наиболее часто используется некоторыми функциями, которые получают доступ к нижним битам pte - битам, которые
отбрасываются pte_page(). Конечно, страницы могут отсутствовать в памяти, если ядро сбросила их на диск в процессе
своппинга, или они еще ни разу не были загружены. Сами таблицы страниц всегда присутствуют в памяти в текущей реализации
Linux. Удержание страниц в памяти упрощает код ядра, потому что pgd_offset() и подобные функции всегда смогут вернуть
корректное значение. С другой стороны, даже процесс не использующий память (с нулевым "resident storage
size") постоянно держит свою таблицу страниц в физической памяти, уменьшая, тем самым, ее полезный объем.
Каждый процесс в системе имеет свою структуру mm_struct, которая содержит таблицы страниц процесса и множество других
вещей. Кроме всего прочего в ней содержится spinlock, называемый page_table_lock, который должен быть удержан при
модификации страничных таблиц.
Одного просмотра списка этих функций явно не достаточно, для того, чтобы стать экспертом в алгоритмах управления памяти,
используемых в Linux. Реальное управление памятью представляет собой очень сложную систему, которая имеет дело с не
менее сложными подсистемами, такими как подсистема управления кэшем. Тем не менее, приведенный список достаточен для
понимания того, как реализована система управления памятью. Все, что вам необходимо знать как разработчику драйверов -
это работу с таблицами страниц. Большую информацию вы можете получить изучая источники ядра в подкаталогах include/asm и
mm.
Виртуальные области памяти (Virtual Memory Areas)
Несмотря на то, что управление страницами работает на самом нижнем уровне системы управления памятью, для эффективного
управления компьютерными ресурсами необходимы знания и о более высоких механизмах управления. Вы уже знаете, что ядру
необходим высокоуровневый механизм для управления памятью процессов. Этот механизм реализуется в Linux созданием
областей виртуальной памяти, которые обычно называются областями VMA.
Областью называется однородный регион в виртуальной памяти процесса, имеющий непрерывный диапазон адресов с одинаковыми
флагами доступа. С некоторой степенью точности это соответствует понятию сегмента, хотя более удачным было бы
определение "бъект памяти со своим собственным набором свойств". Отображение памяти процесса состоит из следующих
элементов:
- Область с кодом исполняемой программы. Исторически, эта область называется text.
- По одной области на каждый блок данных, включая блоки обычных данных (BSS), стека и констант, значения которых
определены до начала выполнения кода программы.
(Термин BSS пришел из старой ассемблерной инструкции "Block started By Symbol". Сегмент BSS выполняемого файла не
хранится на диске, и ядро отображает его в нулевую страницу (zero page).)
- По одной области на каждое активное отображение памяти.
Области памяти процесса могут быть просмотрены из файла /proc/pid/maps (где pid - реальное числовое значение
идентификатора процесса). /proc/self - особый случай /proc/pid, потому что всегда относится к текущему процессу. В
качестве примера приведем пару отображений с короткими комментариями, добавленными после знака решетки (#):
morgana.root# cat /proc/1/maps # look at init
08048000-0804e000 r-xp 00000000 08:01 51297 /sbin/init # text
0804e000-08050000 rw-p 00005000 08:01 51297 /sbin/init # data
08050000-08054000 rwxp 00000000 00:00 0 # zero-mapped bss
40000000-40013000 r-xp 00000000 08:01 39003 /lib/ld-2.1.3.so # text
40013000-40014000 rw-p 00012000 08:01 39003 /lib/ld-2.1.3.so # data
40014000-40015000 rw-p 00000000 00:00 0 # bss for ld.so
4001b000-40108000 r-xp 00000000 08:01 39006 /lib/libc-2.1.3.so # text
40108000-4010c000 rw-p 000ec000 08:01 39006 /lib/libc-2.1.3.so # data
4010c000-40110000 rw-p 00000000 00:00 0 # bss for libc.so
bfffe000-c0000000 rwxp fffff000 00:00 0 # zero-mapped stack
morgana.root# rsh wolf head /proc/self/maps #### alpha-axp: static ecoff
000000011fffe000-0000000120000000 rwxp 0000000000000000 00:00 0 # stack
0000000120000000-0000000120014000 r-xp 0000000000000000 08:03 2844 # text
0000000140000000-0000000140002000 rwxp 0000000000014000 08:03 2844 # data
0000000140002000-0000000140008000 rwxp 0000000000000000 00:00 0 # bss
Поля каждой строки означают следующее:
start-end perm offset major:minor inode image.
Каждое поле в /proc/*/maps (исключая поле image) соответствует полю в структуре vm_area_struct, и описано ниже.
- start
- end
-
Начальный и конечный виртуальные адреса представленной области памяти.
- perm
-
Битовая маска, определяющая права на чтение, запись и выполнение для представленной области. Значение поля определяет
возможные операции, которые может выполнить процесс в данной области. Последним символом в этом поле является либо p
"private" (личный), либо s "shared" (разделяемый).
- offset
-
Смещение представленной области памяти в отображенном файле. Смещение равное нулю означает, что первая страница области
памяти соответствует первой странице файла.
- major
- minor
-
Старший и младший номера устройства, содержащего отображаемый файл. Не путайте эти номера с номерами отображения
устройств. В данном случае, старший и младший номера относятся к дисковому разделу содержащему специальный файл
устройства, который был открыт пользователем.
- inode
-
inode-номер отображенного файла.
- image
-
Имя файла (обычно исполняемый image) который был отображен.
Драйверу, который реализует метод mmap, необходимо заполнить структуру VMA в адресном пространстве процесса,
отображающего устройство. По этой причине разработчик драйвера должен иметь начальные знания о VMA.
Давайте рассмотрим наиболее важные поля структуры vm_area_struct (определенной в <linux/mm.h>). Эти поля могут быть
использованы разработчиком драйвера для реализации mmap. Заметьте, что ядро содержит списки и деревья VMA для
оптимизации просмотра области, и некоторые поля структуры vm_area_struct используются для их организации. Таким образом
VMA не могут создаваться драйвером, иначе эти внутренние деревья и списки будут разрушены. Основные поля VMA показаны
ниже (заметьте схожесть между этими полями и выводом /proc, который мы только что рассмотрели):
- unsigned long vm_start;
- unsigned long vm_end;
-
Виртуальный диапазон адресов, покрываемый данным VMA. Эти поля соответствуют первым двум полям показанным в
/proc/*/maps.
- struct file *vm_file;
-
Указатель на структуру file связанную с этой областью (если таковая имеется).
- unsigned long vm_pgoff;
-
Смещение области в файле, в страницах. Когда файл или устройство отображается, это поле определяет позицию первой
страницы файла, отображенной в этой области.
- unsigned long vm_flags;
-
Множество флагов, описывающих данную область. Наиболее интересными, для разработчика драйверов, являются флаги VM_IO и
VM_RESERVED. Флаг VM_IO помечает VMA как отображенную в памяти область ввода/вывода. Кроме всего прочего, области с
флагом VM_IO не включаются в core dump процесса. Флаг VM_RESERVED запрещает системе управления памятью сбрасывать данную
VMA на диск. Этот флаг должен быть установлен в большинстве случаев отображения.
- struct vm_operations_struct *vm_ops;
-
Набор функций, которое ядро может использовать для операций с этой областью памяти. Через нее, область памяти выступает
как "объект" ядра, как и структура file, которую мы используем по всему материалу данной книги для операций с
устройством.
- void *vm_private_data;
-
Поле, которое может быть использовано драйвером для сохранения собственной информации.
Как и структура vm_area_struct, структура vm_operations_struct определена в <linux/mm.h>. Структура vm_operations_struct
включает в себя операции, описанные ниже. Эти операции нужны для управления памятью процесса. Мы приведем их в порядке
описания. Позднее в этой главе, некоторые из этих функций будут реализованы, и описаны более подробно.
- void (*open)(struct vm_area_struct *vma);
-
Метод open() вызывается ядром для того, чтобы подсистема VMA инициализировала область, изменила счетчик использования
области и выполнила другие, необходимые драйверу инициализационные процедуры. Этот метод вызывается всякий раз, когда
создается новая ссылка на VMA (например, при выполнении fork() процесса). Исключение составляет случай создания VMA. В
этом случае вызывается метод mmap() драйвера.
- void (*close)(struct vm_area_struct *vma);
-
При уничтожении области ядро вызывает операцию close(). Обратите внимание, что счетчик использования VMA не
используется. Область открывается и закрывается как процесс, который ее использует.
- void (*unmap)(struct vm_area_struct *vma, unsigned long addr, size_t len);
-
Ядро вызывает этот метод для выполнения снятия отображения "unmap" для всей или части области. Если снимается
отображение со всей области, то ядро вызывает vm_ops->close() сразу после завершения vm_ops->unmap().
- void (*protect)(struct vm_area_struct *vma, unsigned long, size_t, unsigned int newprot);
-
Этот метод предназначен для изменения флагов защиты области памяти, но не используется в данный момент. Защита
реализуется на уровне страничных таблиц, и управляется ядром другим способом.
- int (*sync)(struct vm_area_struct *vma, unsigned long, size_t, unsigned int flags);
-
Этот метод вызывается системой msync для сохранения области памяти на сохраняемую среду. В случае успеха возвращается 0,
отрицательное число сигнализирует об ошибке сохранения.
- struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int write_access);
-
Когда процесс пытается получить доступ к странице принадлежащей корректной VMA, но которая не отображена в памяти, то
вызывается метод nopage(), если он определен, для текущей области. Этот метод возвращает указатель на структуру page,
после, возможно, чтения ее из вторичного носителя. Если метод nopage() не определен, то ядро связывает с этой областью
пустую страницу. Третий аргумент, write_access, считается как "no-share": ненулевое значение означает, что страница
должна принадлежать текущему процессу, а значение 0 означает возможность разделения страницы.
- struct page *(*wppage)(struct vm_area_struct *vma, unsigned long address, struct page *page);
-
Этот метод предназначен для обработки исключения "write-protected" страницы, но, в данный момент, не используется.
Ядро управляет попытками записи в защищенную страницу не вызывая area-specific callback. Исключение write-protect
используется для реализации copy-on-write. Личная (private) страница может быть разделена между процессами до тех пор,
пока ни один из процессов не пишет в нее. При записи страница клонируется, и каждый процесс пишет в свою собственную
копию страницы. Если же вся область помечена как read-only, то сигнал SIGSEGV посылается процессу, и copy-on-write не
выполняется.
- int (*swapout)(struct page *page, struct file *file);
-
Этот метод вызывается когда страница выбирается для выгрузки в своп. В случае ошибки, процессу, владеющему страницей,
посылается сигнал SIGBUS. Мало вероятно, что драйверу понадобится реализация этого метода - отображения устройства это
не то, что ядро может просто записать на диск.
На этом мы завершаем обзор структур данных, используемых Linux для управления памятью. С этим багажом мы приступим к
изучению реализации системного вызова mmap.
Механизм mmap
Отображение памяти (memory mapping) представляет собой одну из наиболее интересных характеристик современных Unix
систем. Настолько, насколько драйвер это позволит, отображение памяти может быть использовано для предоставления
программам пользователя прямого доступа к памяти устройства.
Показательным примером использования mmap может быть просмотр VMA для сервера X Window System:
cat /proc/731/maps
08048000-08327000 r-xp 00000000 08:01 55505 /usr/X11R6/bin/XF86_SVGA
08327000-08369000 rw-p 002de000 08:01 55505 /usr/X11R6/bin/XF86_SVGA
40015000-40019000 rw-s fe2fc000 08:01 10778 /dev/mem
40131000-40141000 rw-s 000a0000 08:01 10778 /dev/mem
40141000-40941000 rw-s f4000000 08:01 10778 /dev/mem
...
Прим. переводчика: Для вывода данного списка я пользуюсь следующим скриптом, исполняемым от суперпользователя:
#!/bin/bash
cat /proc/`ps ax | grep -v grep | grep "X "; | awk '{print($1)}' | sed 's/ //'`/maps
В обратных кавычках исполняется конвеерная команда, дающая своим результатом текущий pid для X-сервера. Пояснения,
наверное, требует только использование команды sed убирающей лишний пробел из идущего на ее вход потока. Не знаю как у
вас, но на моей Linux сборке, этот пробел имеет место быть. Пропустив вывод этого скрипта через еще одни фильтр "grep
mem" вы получите на стандартном выводе только области VMA, связанные с отображением устройства /dev/mem.
Если вы посмотрите на полный список VMA для X-сервера, то увидите, что он значительно длиннее приведенного в примере, но
большинство из его элементов нас, в данный момент, не интересуют. В списке мы можем видеть три различных отображения
/dev/mem, которые дают представление о том, как X-сервер работает с видеокартой. Первое отображение показывает 16КБт
регион, отображающее смещение fe2fc000. Этот адрес близок к наивысшему адресу доступному на 32-х разрядной системе. Это
область памяти PCI переферии (видеокарты) - область управления для этой карты. Второе отображение - смещение a0000,
представляет собой стандартное расположение видеобуфера в 640 килобайтной ISA hole. Последнее /dev/mem отображение и
есть сама видеопамять. Эти регионы, также, можно посмотреть из файла /proc/iomem:
000a0000-000bffff : Video RAM area
f4000000-f4ffffff : Matrox Graphics, Inc. MGA G200 AGP
fe2fc000-fe2fffff : Matrox Graphics, Inc. MGA G200 AGP
Отображение устройства означает связывание диапазона адресов пользовательского пространства с памятью устройства.
Всегда, когда программа читает или пишет в такой адресный диапазон, реализуется доступ к памяти устройства. Продолжая
пример по X-серверу, можно сказать, что используя mmap мы можем получить быстрый и легкий доступ к памяти видеокарты.
Таким образом, прямой доступ дает большие преимущества для критичных по производительности приложений.
Как вы можете подозревать, не каждое устройство предлагает mmap абстракцию. Это не имеет смысла, например, для
последовательных портов и других потоко-ориентированных устройств. Другим ограничением для mmap является то, что
отображение ведется дискретами, равными PAGE_SIZE. Ядро может распределять виртуальные адреса только на уровне
страничных таблиц. Поэтому, отображаемые области должны быть кратны PAGE_SIZE и должны начинаться в физической памяти
начиная с адреса кратного PAGE_SIZE. Вы уже знаете, что если запрашиваемый размер памяти не кратен размеру страницы, то
ядро реально распределяет несколько больший размер, кратный PAGE_SIZE.
Эти ограничения не являются существенными, так как программы, получающие доступ к устройству, в любом случае,
устройствозависимы. Если вы понимаете механизм отобращения областей памяти, то выравнивание по PAGE_SIZE не должно
являться проблемой. Большей проблемой является использование ISA устройств на некоторых не x86 платформах, потому что их
"аппаратный взгляд" на ISA устройство может отличаться. Например, некоторые компьютеры Alpha воспринимают ISA память
как множество 8-ми, 16-ти или 32-х битовых элементов не имеющих прямого отображения. В этом случае, вы не можете
использовать mmap вообще. Неспособность выполнять прямое отображение ISA адресов на Alpha адреса является следствием
несовместимости спецификаций передачи данных на этих двух системах. В то время, как Alpha процессоры могут выполнять
только 32-х и 64-х битный доступ к памяти, ISA может выполнять только 8-ми и 16-ти битную передачу данных, и не имеется
способа создания прозрачного отображения этих двух протоколов.
Преимущества от использования mmap очевидны. Например, мы уже рассмотрели X-сервер, который передает множество данных в
и из видеопамяти. Отображение графического дисплея в пространство пользователя существенно увеличивает пропускную
способность по сравнению с lseek/write реализацией. Другим типичным примером являются программы управляющие PCI
устройствами. Большинство таких устройств отображают свои регистры управления в память, и интересующееся ими приложение
может предпочесть прямой доступ к этим регистрам множеству системных вызовов ioctl().
Метод mmap() является частью структуры file_operations. Метод драйвера вызывается, когда приложение выполняет системный
вызов mmap(). Обрабатывая системный вызов, ядро выполняет множество дополнительной работы перед вызовом метода драйвера,
поэтому прототип метода существенно отличается от системного вызова. Это не похоже на такие вызовы как ioctl() или
poll(), где ядро не выполняет такую объемную работу перед вызовом соответствующих методов.
Системный вызов объявлен следующим образом (см. man-страницу mmap(2)):
mmap (caddr_t addr, size_t len, int prot, int flags, int fd, off_t offset)
С другой стороны, посмотрите на описание файловой операции:
int (*mmap) (struct file *filp, struct vm_area_struct *vma);
Аргумент filp в методе тот же, с которым мы познакомились в главе 3 "Драйверы символьных устройств". Аргумент vma
содержит информацию о диапазоне виртуальных адресов, которые используются для доступа к устройству. Таким образом,
большая часть работы выполняется ядром. В методе mmap() необходимо только построить соответствующие таблицы страниц для
диапазона адресов, и, если необходимо, заменить vma->vm_ops новым набором операций.
Существует два способа построения страничных таблиц: либо сделать все через вызов функции remap_page_range(), либо
обрабатывая одну страницу за раз через VMA-метод nopage(). Оба метода имеют свои преимущества. Мы начнем с варианта
"все за раз" который проще. Потом, мы познакомимся с более сложными решениями, которые могут потребоваться в реальных
системах.
Использование remap_page_range()
Работа по построению новых страничных таблиц для отображения диапазона физических адресов выполняется функцией
remap_page_range(), имеющей следующий прототип:
int remap_page_range(unsigned long virt_add, unsigned long phys_add,
unsigned long size, pgprot_t prot);
Значение возвращаемое функцией равно нулю, в случае успешного отображения, или представляет отрицательный код ошибки.
Опишем точное значение аргументов функции:
- virt_add
-
-
Виртуальный адрес пространства пользователя с которого должно начаться отображение. Функция построит таблицы страниц для
диапазона виртуальных адресов начиная с адреса virt_add, и кончая адресом virt_add+size.
- phys_add
-
Физический адрес, с которого начнется отображение виртуальных адресов. Функция покроет физические адреса начиная с
адреса phys_add, и кончая адресом phys_add+size.
- size
-
Размер отображаемой области в байтах.
- prot
-
Флаги защиты, запрашиваемые для нового VMA. Драйвер может и должен использовать значение полученное из
vma->vm_page_prot.
Аргументы передаваемые в remap_page_range() достаточно простые, и большинство из них предлагаются вам при вызове метода
mmap. Сложности есть в кэшировании. Обычно, ссылки на память устройства не кэшируются процессором. Даже если параметры
системного BIOS установлены правильно, возможно запрещение кэширования определенных VMA через поля защиты. К несчастью,
запрещение кэширования на этом уровне сильно зависит от архитектуры процессора. Любознательный читатель может
познакомиться с функцией pgprot_noncached() из drivers/char/mem.c на предмет ее использования. Мы же, более не будем
касаться этой темы.
Простой пример отображения памяти устройства
Если вашему драйверу требуется выполнить какое либо простое линейное отображение памяти устройства в адресное
пространство процесса, то сделать это можно с помощью функции remap_page_range(). Следующий пример демонстрирует
выполнение этой задачи в коде типичного модуля, названного simple (Simple Implementation Mapping Pages with Little
Enthusiasm):
#include <linux/mm.h>
int simple_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
if (offset >= __pa(high_memory) || (filp->f_flags & O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
if (remap_page_range(vma->vm_start, offset,
vma->vm_end-vma->vm_start, vma->vm_page_prot))
return -EAGAIN;
return 0;
}
Код /dev/mem проверяет, находится ли запрошенное смещение, сохраненное в vma->vm_pgoff, за пределами физической памяти.
Если это так, то VM_IO флаг выставляется для данной VMA, отмечая тем самым, что область принадлежит памяти ввода/вывода.
Кроме того, для предотвращения попыток системы выгрузить данную область в своп, всегда выставляется флаг VM_RESERVED.
Функция remap_page_range() только создает необходимые таблицы страниц.
Добавление VMA операций
Как мы видим, структура vm_area_struct содержит множество операций, которые могут быть применены к VMA. Теперь мы
рассмотрим простейшую реализацию этих операций. Позднее, мы познакомимся с более подробными примерами.
Рассмотрим реализацию операций open() и close() для нашего VMA. Эти операции будут вызываться всякий раз, когда процесс
открывает или закрывает VMA. Кроме того, метод open() будет вызываться при выполнении процессом функции fork(), по
которой будет создаваться новая ссылка на VMA. Методы open() и close() вызываются как дополнение к операциям выполняемым
ядром по обработке системного вызова. Это необходимо учитывать, чтобы не дублировать операции уже выполненные ядром.
Мы используем эти методы для инкрементирования счетчика использования модуля при открытии VMA, и его декрементирования
при закрытии. Для современных ядер, управление счетчиком использования не является обязательным - ядро не вызовет метод
драйвера release() пока VMA остается открытым. Однако, в ядре 2.0 не выполняется такого слежения, и портируемый код
должен поддерживать ручное управление счетчиком использования.
Продемонстрируем перекрытие умолчания для vma->vm_ops операциями, которые управляют счетчиком использования модуля.
Приводимый код достаточно простой и в полной реализации mmap для модуляризованного /dev/mem выглядит следующим образом:
void simple_vma_open(struct vm_area_struct *vma)
{ MOD_INC_USE_COUNT; }
void simple_vma_close(struct vm_area_struct *vma)
{ MOD_DEC_USE_COUNT; }
static struct vm_operations_struct simple_remap_vm_ops = {
open: simple_vma_open,
close: simple_vma_close,
};
int simple_remap_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long offset = VMA_OFFSET(vma);
if (offset >= __pa(high_memory) || (filp->f_flags & O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
if (remap_page_range(vma->vm_start, offset, vma->vm_end-vma->vm_start,
vma->vm_page_prot))
return -EAGAIN;
vma->vm_ops = &simple_remap_vm_ops;
simple_vma_open(vma);
return 0;
}
Этот код полагается на тот факт, что, для вновь созданной области, ядро инициализирует поле vm_ops в NULL перед вызовом
f_op->mmap(). Но, в общем случае, необходимо проверять текущее значение указателя, на случай, если в будущих версиях
ядра изменится инициализация vm_ops.
Макрос VMA_OFFSET используется в данном коде для устранения различий в структуре vma разных версий ядра. В ядре 2.4
смещение (offset) указано в страница, а в ядре 2.2 и более ранних - в байтах. В нашем заголовочном файле
<sysdep.h> мы описали это макроопределение для устранения этих отличий. Результат возвращаемый макросом определяет
смещение в байтах.
Отображение памяти с помощью функции nopage
Хотя использование remap_page_range() оправдано в большинстве случаев реализации механизма mmap в драйверах, иногда
возникает необходимость в более гибком управлении отображения. В этом случае, используется метод nopage().
Напомним, что метод nopage() имеет следующий прототип:
struct page (*nopage)(struct vm_area_struct *vma,
unsigned long address, int write_access);
Когда пользовательский процесс пытается получить доступ к странице в VMA, которая не представлена в памяти, то
вызывается, связанная с данной VMA, функция nopage(). Параметр address содержит выровненный к началу страницы
виртуальный адрес, который вызвал исключение. Функция nopage() должна разместить и вернуть указатель на структуру page,
ссылающейся к запрошенной пользователем странице. Кроме того, эта функция должна увеличить счетчик использования
страницы возвращенной через вызов макроса get_page():
get_page(struct page *pageptr);
Этот шаг необходим для поддержания корректного значения счетчика ссылок отображенных страниц. Ядро поддерживает этот
счетчик для каждой страницы. Когда счетчик становится равным нулю, ядро может переместить эту страницу в список
свободных. При снятии отображения с VMA, ядро декрементирует счетчик использования для каждой страницы в области. Если
ваш драйвер не инкрементирует счетчик при добавлении страницы в область, то счетчик использования может стать равным
нулю преждевременно и целостность системы может оказаться под сомнением.
Одной из ситуаций, в которой использование nopage() полезно, связано с системным вызовом mremap(), который используется
приложением для изменения граничных адресов отображенного региона. Если драйвер хочет обработать mremap(), то предыдущая
реализация не будет работать корректно, потому что не существует способа, с помощью которого драйвер бы знал, что
отображенный регион изменен.
Linux реализация системного вызова mremap() не уведомляет драйвер об изменениях в отобращенной области. На самом деле,
драйвер уведомляется, если размер области уменьшается через метод unmap(), но при увеличении размера области остается
для драйвера не замеченным.
Основная идея лежащая в такой концепции заключается в том, что драйвер (или файловая система отобращающая обычный файл в
память) должен знать о том, что с области памяти было снято отображение для того, чтобы драйвер смог выполнить
сопутствующие этому действия, например, сброс страниц на диск. Увеличение отображаемого региона, с другой стороны, не
существенна для драйвера, пока программа, вызывающая mremap(), не получила доступ к новым виртуальным адресам. В
реальности, вполне нормальна ситуация, когда отображенные регионы никогда не используются (например, неиспользуемые
куски программного кода). Поэтому, Linux ядро не уведомляет драйвер при увеличении отображаемого региона, потому что
метод nopage() проявляет заботу о страницах всякий раз, когда к ним производится доступ.
Другими словами, драйвер не уведомляется о росте отображаемого региона, потому что nopage() сделает это позже, не
расходуя память до того, как она в действительности понадобится. Такая оптимизация нацелена, главным образом, на обычные
файлы, отображение которых использует реальную память.
Таким образом, метод nopage() должен быть реализован, если вы хотите поддерживать системный вызов mremap(). Но если уж
вы реализовали nopage(), то вы можете использовать его более эффективно, с некоторыми ограничениями, описанными позднее.
Этот метод показан в следующем фрагменте кода. В этой реализации mmap(), метод драйвера только заменяет указатель
vma->vm_ops, а метод nopage() выполняет отображение одной страницы за раз, возвращая адрес структуры page. Так как здесь
мы только реализуем окно в физическую память, то сам шаг отображения простой - нам необходимо только распределить и
вернуть указатель на структуру page для требуемого адреса.
Реализация /dev/mem использующая nopage() выглядит следующим образом:
struct page *simple_vma_nopage(struct vm_area_struct *vma,
unsigned long address, int write_access)
{
struct page *pageptr;
unsigned long physaddr = address - vma->vm_start + VMA_OFFSET(vma);
pageptr = virt_to_page(__va(physaddr));
get_page(pageptr);
return pageptr;
}
int simple_nopage_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long offset = VMA_OFFSET(vma);
if (offset >= __pa(high_memory) || (filp->f_flags & O_SYNC))
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
vma->vm_ops = &simple_nopage_vm_ops;
simple_vma_open(vma);
return 0;
}
Так как здесь мы просто отображаем главную память, функция nopage() должна только найти соответствующую структуру page
для адреса, вызвавшего исключение, и увеличить счетчик ссылок. Такая задача выполняется следующей последовательностью
действий. Вычисляется желаемый физический адрес, потом, с помощью __va() преобразуем этот адрес в логический, и,
наконец, преобразуем логический адрес в структуру page с помощью virt_to_page(). В принципе возможно выполнить прямое
преобразование физического адреса в структуру page, но такой код будет сложно портировать на другие аппаратные
архитектуры. Однако, такой код может быть необходим, если вы захотите сделать отображение верхней памяти, которая, как
вы помните, не имеет логической адресации. Наш драйвер simple, будучи простым, не беспокоится об этом редком случае.
Если указатель на метод nopage() остается равным NULL (нет реализации метода), то код ядра, обрабатывая исключение page
faults, отображает нулевую страницу (zero page) на вызвавший исключение виртуальный адрес. Нулевая страница представляет
собой copy-on-write страницу, которая читается как ноль и которая используется, например, для отображения BSS сегмента.
Поэтому, если процесс расширяет отображенный регион вызовом mremap(), и драйвер не имеет реализации nopage(), ему
предоставляется нулевая страница, и segmentation fault не генерируется.
Метод nopage() обычно возвращает указатель на структуру page. Если, по некоторым причинам, страница не может быть
возвращена (например, рапрошенный адрес лежит за пределами области памяти устройства), то может быть возвращен сигнал
ошибки NOPAGE_SIGBUS. Функция nopage() может, в этом случае, возвратить NOPAGE_OOM, показывающее, что ошибка возникла по
причине ограничений ресурса.
Заметьте, что эта реализация будет работать для регионов памяти ISA, но не будет работать для PCI. Дело в том, что PCI
память отображается на самый верх системной памяти, для которой нет отображения в системной карте памяти. Так как нельзя
вернуть указатель на структуру page для этих адресов, то функция nopage() не может быть использована в такой ситуации.
Вместо этого, необходимо использовать remap_page_range().
Отображение специальных областей ввода/вывода
Все примеры, которые мы только что видели представляют собой реализацию /dev/mem. Они отображают физические адреса в
пространство пользователя. Типичному драйверу, однако, может потребоваться отображение только маленькой части адресов,
которые предоставляются их периферийным устройством. Для того, чтобы отобразить в пользовательское пространство целый
диапазон адресов, драйвер должен использовать значение смещения (offset). Следующие строки демонстрируют трюк
отображения области устройства размером simple_region_size байт, начиная с физического адреса simple_region_start
(который должен быть выровнен по странице).
unsigned long off = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physical = simple_region_start + off;
unsigned long vsize = vma->vm_end - vma->vm_start;
unsigned long psize = simple_region_size - off;
if (vsize > psize)
return -EINVAL; /* spans too high */
remap_page_range(vma->vm_start, physical, vsize, vma->vm_page_prot);
В добавлении к вычислению смещения, этот код выполняет проверку, оканчивающуюся ошибкой в случае, если программа
пытается отобразить больше памяти чем это доступно в регионе ввода/вывода целевого устройства. В этом коде, psize есть
размер физической области ввода/вывода, которая остаюется после того, как смещение было определено, а vsize -
запрашиваемый размер виртуальной памяти. Функция не выполняет отображение адресов, находящихся за пределами допустимого
диапазона памяти.
Заметьте, что пользовательский процесс всегда может использовать mremap() для расширения отображения, возможно, за
пределами физического пространства устройства. Если ваш драйвер не имеет реализации метода nopage(), то вы никогда не
получите уведомления о таком расширении и дополнительная область будет отображена в нулевую страницу. Как разработчик
драйвера, вы захотите контролировать такие ситуации. Так, отображение нулевой страницы в конец вашего региона не
является какой-то исключительно неприятной вещью, но мало вероятно, что какой-нибудь программист захочет, чтобы это
случилось.
Простейшим способом предотвращения расширения отображения является простой метод nopage(), который всегда возвращает
NOPAGE_SIGBUS процессу вызвавшему исключение page fault. Вот так выглядит подобная реализация:
struct page *simple_nopage(struct vm_area_struct *vma,
unsigned long address, int write_access);
{ return NOPAGE_SIGBUS; /* send a SIGBUS */}
Переотображение RAM
Конечно, в более тщательной реализации необходимо убедиться, что вызвавший исключение адрес находится в пределах области
устройства, и выполнять переотображение только в этом случае. Однако, следует напомнить, что nopage() не работает с
областями памяти PCI устройств, поэтому расширить PCI отображение невозможно. В Linux страница физических адресов
помечается как "reserved&gout; в карте памяти, что делает ее не доступной для системы управления памятью. Например, на
персональных компьютерах (PC) диапазон памяти между 640 КБт и 1 МБт помечены как "reserved", так, как будто бы это
были страницы памяти самого ядра.
Интересным ограничением для функции remap_page_range() является то, что она дает доступ только в зарезервированным
страницам и физическим адресам за вершиной физической памяти. Зарезервированные страницы блокируются в памяти и могут
быть безопасно отображены в пользовательское пространство. Такое ограничение представляет собой базовое требование для
стабильности системы.
Поэтому, remap_page_range() не позволит отобразить обычные адреса - которые вы получили через вызов get_free_page().
Вместо этого будут отображена нулевая страница. Тем не менее, функция делает все, что нужно большинству драйверов,
потому что она может переотобразить верхние PCI буфера и память ISA.
Ограничения remap_page_range() могут быть наблюдаемы с помощью программы mapper, которая находится в каталоге misc-progs
примеров с FTP-сайта O'Reilly. Программа mapper представляет собой простой инструмент, который используется для быстрого
тестирования системного вызова mmap(). Она отображает только на чтение часть файла согласно опциям командной строки и
выводит дамп отображенного региона на стандартный вывод. Приводимый пример показывает что /dev/mem не реализовала
отображение физической страницы расположенной по адресу 64 КБт - вместо этого мы видим страницу полную нулей (пример
был выполнен на персональном компьютере, но такой же результат будет на любой платформе):
morgana.root# ./mapper /dev/mem 0x10000 0x1000 | od -Ax -t x1
mapped "/dev/mem" from 65536 to 69632
000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
001000
Неспособность функции remap_page_range() работать с RAM говорит о том, что устройства подобные scullp не смогут легко
реализовать механизм mmap, потому что память устройства есть обычная память RAM, а не память ввода/вывода. В подобных
случаях необходимо использовать отображение с помощью nopage().
Переотображение RAM с помощью метода nopage()
Единственный способ отображения реальной RAM в пространство пользователя состоит в использовании vm_ops->nopage
обрабатывающей исключения page fault. Пример такой реализации можно увидеть в части модуля scullp, которая представлена
в главе 7 "Getting Hold of Memory".
Модуль scullp представляет собой странично ориентированное символьное устройство. По причине своей страничной
ориентированности он может реализовать mmap отображение своей памяти. Код реализующий отображение памяти использует
некоторые концепции, представленные ранее в разделе "Управление памятью в Linux".
Перед проверкой кода, давайте рассмотрим идеи, имеющие место в реализации механизма mmap в драйвере scullp.
-
Драйвер scullp не освобождает память устройства пока устройство отображено. Это скорее элемент политики нежели
необходимое требование, и это отличает его от поведения драйвера scull, который усекает до нуля свою память при открытии
на запись. Такое поведение драйвера scullp позволяет процессу перезаписывать область отображенную, в данный момент,
другим процессом, поэтому вы можете посмотреть, как взаимодействуют процессы и драйвер. Во избежании снятия отображения
с памяти устройства, драйвер должен удерживать счетчик активных отображений. Для этой цели используется поле vmas
структуры драйвера.
-
Отображение памяти выполняется только тогда, когда параметр order модуля scullp равен нулю. Этот параметр управляет
вызовом get_free_pages() (см. главу 7, разделы "Getting Hold of Memory" и "get_free_page and
Friends"). Этот выбор диктуется внутренней реализацией get_free_pages(). Для максимальной производительности распределения памяти, ядро Linux
содержит список свободных страниц для каждого варианта распределения, и только счетчик страниц первой страницы кластера
инкрементируется функцией get_free_pages() и декрементируется функцией free_pages(). Метод mmap() запрещается для
устройства scullp если порядок распределения (параметр order) больше нуля, потому что nopage() работает с одной
страницей, а не с кластерами страниц. (Вернитесь к разделу "A scull Using Whole Pages: scullp" главы 7, если вам
требуется освежить в памяти реализацию scullp и значение order порядка распределения.)
Последняя идея призвана упростить код драйвера. Возможна корректная реализация механизма mmap для многостраничного
распределения за счет управления счетчиком использования страниц, но это добавит сложности в понимании кода и не
принесет интересной информации.
Конечно, код отображающий RAM требует реализации методов open(), close() и nopage(), которые необходимы для реализации
доступа к отображаемой памяти и управления счетчиком использования страниц.
Эта реализация scullp_mmap() очень короткая, потому что предполагается, что функция nopage() выполнит всю остальную
работу:
int scullp_mmap(struct file *filp, struct vm_area_struct *vma)
{
struct inode *inode = INODE_FROM_F(filp);
/* refuse to map if order is not 0 */
if (scullp_devices[MINOR(inode->i_rdev)].order)
return -ENODEV;
/* don't do anything here: "nopage" will fill the holes */
vma->vm_ops = &scullp_vm_ops;
vma->vm_flags |= VM_RESERVED;
vma->vm_private_data = scullp_devices + MINOR(inode->i_rdev);
scullp_vma_open(vma);
return 0;
}
Первое условие позволяет избежать отображение памяти для тех устройств, для которых порядок распределения (параметр
order) не равен нулю. Операции модуля scullp сохраняются в поле vm_ops, и указатель на структуру устройства прячется в
поле vm_private_data. Наконец, метод vm_ops->open вызывается для изменения счетчика использования модуля и счетчика
активных отображений устройства.
Методы open() и close(), показанные ниже, просто выполняют слежение за этими счетчиками:
void scullp_vma_open(struct vm_area_struct *vma)
{
ScullP_Dev *dev = scullp_vma_to_dev(vma);
dev->vmas++;
MOD_INC_USE_COUNT;
}
void scullp_vma_close(struct vm_area_struct *vma)
{
ScullP_Dev *dev = scullp_vma_to_dev(vma);
dev->vmas--;
MOD_DEC_USE_COUNT;
}
Функция sculls_vma_to_dev() просто возвращает содержимое поля vm_private_date. Она необходима как отдельная функция,
потому что ядра до версии 2.4 не использовали это поле, получая данный указатель другим способом. Для подробностей
смотрите раздел "Вопросы обратной совместимости" в конце данной главы.
Большая часть работы выполняется методом nopage(). В реализации для scullp параметр address передаваемый в nopage()
используется для вычисления смещения в устройстве, которое потом используется для определения корректной страницы в
списке памяти scullp.
struct page *scullp_vma_nopage(struct vm_area_struct *vma,
unsigned long address, int write)
{
unsigned long offset;
ScullP_Dev *ptr, *dev = scullp_vma_to_dev(vma);
struct page *page = NOPAGE_SIGBUS;
void *pageptr = NULL; /* default to "missing" */
down(&dev->sem);
offset = (address - vma->vm_start) + VMA_OFFSET(vma);
if (offset >= dev->size) goto out; /* out of range */
/*
* Now retrieve the scullp device from the list, then the page.
* If the device has holes, the process receives a SIGBUS when
* accessing the hole.
*/
offset >>= PAGE_SHIFT; /* offset is a number of pages */
for (ptr = dev; ptr && offset >= dev->qset;) {
ptr = ptr->next;
offset -= dev->qset;
}
if (ptr && ptr->data) pageptr = ptr->data[offset];
if (!pageptr) goto out; /* hole or end-of-file */
page = virt_to_page(pageptr);
/* got it, now increment the count */
get_page(page);
out:
up(&dev->sem);
return page;
}
Модуль scullp использует память полученную с помощью функции get_free_pages(). Эта память адресуется с использованием
локальных адресов, поэтому, все что нужно сделать в методе scullp_nopage() для получения указателя на структуру page,
это вызвать virt_to_page().
Как мы можем видеть в приведенном ниже примере с использованием утилиты mapper, устройство scullp теперь работает как
ожидалось. В примере мы посылаем длинный список содержимого каталога /dev в устройство scullp. и, затем, используя
утилиту mapper, просматриваем часть листинга через механизм mmap.
morgana% ls -l /dev > /dev/scullp
morgana% ./mapper /dev/scullp 0 140
mapped "/dev/scullp" from 0 to 140
total 77
-rwxr-xr-x 1 root root 26689 Mar 2 2000 MAKEDEV
crw-rw-rw- 1 root root 14, 14 Aug 10 20:55 admmidi0
morgana% ./mapper /dev/scullp 8192 200
mapped "/dev/scullp" from 8192 to 8392
0
crw -- -- -- - 1 root root 113, 1 Mar 26 1999 cum1
crw -- -- -- - 1 root root 113, 2 Mar 26 1999 cum2
crw -- -- -- - 1 root root 113, 3 Mar 26 1999 cum3
Переотображение виртуальных адресов
Хотя необходимость в этом возникает достаточно редко, интересно посмотреть, как драйвер может отобразить свои
виртуальные адреса в пространство пользователя, используя механизм mmap. Напомним, что истинные виртуальные адреса, это
адреса возвращаемые функциями типа vmalloc() или kmap() - т.е. виртуальные адреса отображены в таблицах страниц ядра.
Код представленный в этом разделе взят из драйвера scullv. Этот драйвер работает схожим образом с драйвером scullp, но
для распределения памяти использует функцию vmalloc().
Большая часть реализации scullv похожа на только что описанную реализацию scullp, за исключением того, что не нужно
проверять значение параметра order, контролирующего распределение памяти. Основанием для этого является то, что
vmalloc() распределяет свои страницы по одной за раз, потому что одностраничное распределение со значительно большей
вероятностью приведет к успеху, чем многостраничное распределение. Поэтому проблема порядка распределения не имеет место
в пространстве vmalloc().
Большая часть работы vmalloc() состоит в построении страничных таблиц для доступа к распределенным страницам как к
непрерывному адресному пространству. Метод nopage(), наоборот, сканирует, созданную таким образом, структуру таблиц в
поисках нужной страницы, указатель на которую он должен возвратить.
Функция похожа на ту, что мы видели для scullp, за исключением конца. Приведем только часть функции nopage, которая
отличается от scullp:
pgd_t *pgd; pmd_t *pmd; pte_t *pte;
unsigned long lpage;
/*
* After scullv lookup, "page" is now the address of the page
* needed by the current process. Since it's a vmalloc address,
* first retrieve the unsigned long value to be looked up
* in page tables.
*/
lpage = VMALLOC_VMADDR(pageptr);
spin_lock(&init_mm.page_table_lock);
pgd = pgd_offset(&init_mm, lpage);
pmd = pmd_offset(pgd, lpage);
pte = pte_offset(pmd, lpage);
page = pte_page(*pte);
spin_unlock(&init_mm.page_table_lock);
/* got it, now increment the count */
get_page(page);
out:
up(&dev->sem);
return page;
Таблицы страниц просматриваются используя функции представленные в начале этой главы. Каталог страниц, используемый для
этой цели, хранится в структуре init_mm для пространства ядра. Заметьте, что scullv получает приоритет page_table_lock
при анализе страничных таблиц. Если эту блокировку не держать, то другой процессор может сделать изменения в страничное
таблице пока драйвер scullv находится в процессе просмотра, что может привести к ошибочным результатам.
Макрос VMALLOC_VMADDR(pageptr) возвращает корректное значение unsigned long, которое используется при просмотре
страничных таблиц vmalloc адреса. Простое приведение типа (cast) не будет работать на платформе x86 с ядром старше 2.1,
по причине некоторых сложностей в системе управления памятью. Система управления памятью была изменена в версии 2.1.1, и
VMALLOC_VMADDR теперь определяется как настоящая функция, как это всегда было для других платформ. Его использование
рекомендуется еще и потому, что приводит к портируемому коду.
На основе этого обсуждения вы можете захотеть отобразить адреса, полученные с помощью ioremap() в пользовательское
пространство. Такое отображение легко реализуемо, потому что вы можете использовать remap_page_range() прямо, без
реализации методов для виртуальных областей памяти. Другими словами, remap_page_range() уже готова для построения новых
страничных таблиц, которые отображают память ввода/вывода в пользовательское пространство. И не надо блокировать
страничные таблицы ядра, построенные vremap(), как мы это делали для драйвера scullv.
Интерфейс kiobuf
Начиная с версии ядра 2.3.12, Linux поддерживает абстракцию ввода/вывода называемую kiobuf (kernel I/O buffer).
Интерфейс kiobuf призван спрятать от драйверов устройств и других частей системы, использующих ввод/вывод, множество
непростых деталей реализации системы виртуальной памяти. Для kiobuf планируется много всяких характреристик, но его
первичным назначением является упрощение механизма отображения буферов пользовательского пространства в ядро.
Структура kiobuf
Любой код, который работает с механизмом kiobuf должен включать заголовочный файл . В этом файле
определена структура kiobuf, которая является сердцем интерфейса kiobuf. Эта структура описывает массив страниц, которые
составляют операции ввода/вывода. Рассмотрим поля этой структуры:
- int nr_pages;
-
Количество страниц в данном kiobuf
- int length;
-
Количество байт данных в буфере
- int offset;
-
Смещение первого используемого (valid) байта в буфере
- struct page **maplist;
-
Массив структур page, по одной на каждую страницу kiobuf
Ключом к интерфейсу kiobuf является массив maplist. Функции, которые обрабатывают страницы, сохраненные в kiobuf,
работают напрямую со структурами page - все переполнения системы управления виртуальной памятью не обрабатываются.
Такая реализация упрощает жизнь вообще, и позволяет драйверам функционировать независимо от сложностей системы
управления памятью.
Перед использованием, kiobuf должен быть проинициализирован. Инициализация отдельного kiobuf - редкий случай, но, если
это необходимо, эта инициализация может быть выполнена с помощью kiobuf_init():
void kiobuf_init(struct kiobuf *iobuf);
Обычно kiobuf-элементы связываются в группы как часть (kernel I/O)-вектора, обозначаемого kiovec. Этот вектор может
быть распределен и проинициализирован за один шаг, вызовом alloc_kiovec:
int alloc_kiovec(int nr, struct kiobuf **iovec);
Как обычно, возвращаемое значение равно нулю или коду ошибки. Когда ваш код заканчивает работу со структурой kiovec, ее
необходимо вернуть в систему:
void free_kiovec(int nr, struct kiobuf **);
Ядро предлагает пару функций для блокировки и снятия блокировки страниц, отображенных в kiovec:
int lock_kiovec(int nr, struct kiobuf *iovec[], int wait);
int unlock_kiovec(int nr, struct kiobuf *iovec[]);
Однако, блокировка kiovec обычно не является необходимой для большинства приложений, чьи kiobuf-элементы видны в
драйверах устройств.
Отображение буферов пользовательского пространства и сырой (raw) ввод/вывод
Системы Unix давно обеспечивают сырой "row" интерфейс для некоторого типа устройств - в особенности для блочных
устройств - который позволяет выполнять примой ввод/вывод из пользовательского пространства, предотвращая копирование
данных через ядро. В этом случае значительно повышается производительность, особенно, если переданные данные не
используются снова в ближайшем будущем. Например, в процессе backup читается большое количество данных только один раз.
Поэтому, запуск backup через сырой интерфейс позволяет избежать заполнения системных буферов кэша ненужными данными.
Ядро Linux традиционно не поддерживало сырой интерфейс по многим причинам. Однако, с ростом популярности системы, в нее
были портированы многие приложения, использующие сырой ввод/вывод, такие, например, как системы управления базами
данных. Поэтому, при разработке ядра 2.3 сырой ввод/вывод был добавлен в ядро Linux.
Нужно заметить, что вопреки некоторым заблуждениям, сырой ввод/вывод не всегда обеспечивает огромного повышения
производительности. Поэтому, реализовывать этот механизм только потому, что он есть, не имеет смысла. Накладные расходы
реализации сырой передачи данных могут оказаться значительными, и преимущества буферизации данных в ядре могут быть
потеряны. Например, необходимо заметить, что операции сырого ввода/вывода почти всегда должны быть синхронными - т.е.
системный вызов write() не завершится до тех пор, пока операция записи не будет завершена реальным устройством. На
сегодняшний день, в Linux отсутствует механизм, по которому пользовательская программа могла бы безопасно выполнять
сырой ввод/вывод над буфером пользовательского процесса.
В этом разделе мы добавим возможность сырого в наш блочный драйвер sbull. Если механизм kiobuf доступен, то sbull
регистрирует два устройства. В разделе "Loading Block Drivers" главы 12, мы подробно рассматривали sbull устройство,
но не касались второго, символьного, устройства, названного sbullr, и которое обеспечивает сырой доступ к устройству
RAM-диска. Таким образом, /dev/sbull0 и /dev/sbullr0 получают доступ к одной и той-же области памяти, но первое
обеспечивает традиционный, буферизованный режим доступа, а второе - сырой доступ через механизм kiobuf.
В системе Linux, драйверам блочных устройств не имеет смысла обеспечивать этот вид интерфейса. Raw-устройство в
/drivers/char/raw.c обеспечивает эту возможность элегантным и общим для всех блочных устройств способом. Поэтому,
блочным драйверам даже нет необходимости знать, как выполняется сырой ввод/вывод. Код, реализующий сырой ввод/вывод для
sbull, существенно упрощен в демонстрационных целях.
Сырой ввод/вывод в блочное устройство всегда должен быть выровнен по размеру сектора, и его длина должна быть кратна
размеру сектора. Некоторые устройства, такие как накопители на магнитных лентах, могут не иметь таких ограничений.
Поведение sbullr похоже на блочное устройство и вынуждено удовлетворять требованиям по выравниванию и длине. В sbullr
определены следующие символы:
# define SBULLR_SECTOR 512 /* insist on this */
# define SBULLR_SECTOR_MASK (SBULLR_SECTOR - 1)
# define SBULLR_SECTOR_SHIFT 9
Наше сырое устройство sbullr будет зарегистрировано только в том случае, если размер сектора жесткого диска будет равен
значению SBULLR_SECTOR. Вообще, не существует существенных причин по которым размер сектора больший сектора жесткого
диска не может быть поддержан, но это усложнит код драйвера.
Реализация sbullr добавляет к существующему коду для sbull совсем немного. Код для методов open() и close() вообще
используется без модификации. Однако, т.к. sbullr является символьным устройством, ему необходимы методы read() и
write(). Оба метода определяются для запуска простой функции передачи данных следующим образом:
ssize_t sbullr_read(struct file *filp, char *buf, size_t size,
loff_t *off)
{
Sbull_Dev *dev = sbull_devices +
MINOR(filp->f_dentry->d_inode->i_rdev);
return sbullr_transfer(dev, buf, size, off, READ);
}
ssize_t sbullr_write(struct file *filp, const char *buf, size_t size,
loff_t *off)
{
Sbull_Dev *dev = sbull_devices +
MINOR(filp->f_dentry->d_inode->i_rdev);
return sbullr_transfer(dev, (char *) buf, size, off, WRITE);
}
Функция sbullr_transfer() выполняет разного рода настроечные процедуры, передавая реальную передачу данных другой
функции. Код для sbullr_transfer() выглядит следующим образом:
static int sbullr_transfer (Sbull_Dev *dev, char *buf, size_t count,
loff_t *offset, int rw)
{
struct kiobuf *iobuf;
int result;
/* Only block alignment and size allowed */
if ((*offset & SBULLR_SECTOR_MASK) || (count & SBULLR_SECTOR_MASK))
return -EINVAL;
if ((unsigned long) buf & SBULLR_SECTOR_MASK)
return -EINVAL;
/* Allocate an I/O vector */
result = alloc_kiovec(1, &iobuf);
if (result)
return result;
/* Map the user I/O buffer and do the I/O. */
result = map_user_kiobuf(rw, iobuf, (unsigned long) buf, count);
if (result) {
free_kiovec(1, &iobuf);
return result;
}
spin_lock(&dev->lock);
result = sbullr_rw_iovec(dev, iobuf, rw,
*offset >> SBULLR_SECTOR_SHIFT,
count >> SBULLR_SECTOR_SHIFT);
spin_unlock(&dev->lock);
/* Clean up and return. */
unmap_kiobuf(iobuf);
free_kiovec(1, &iobuf);
if (result > 0)
*offset += result << SBULLR_SECTOR_SHIFT;
return result << SBULLR_SECTOR_SHIFT;
}
После выполнения пары разумных проверок, в вышеприведенном коде, с помощью функции alloc_kiovec() создается kiovec,
состоящий из одного kiobuf элемента. Затем, данный kiovec отображается в буфер пользовательского пространства с помощью
вызова map_user_kiobuf().
int map_user_kiobuf(int rw, struct kiobuf *iobuf,
unsigned long address, size_t len);
Результатом этого вызова, при удачном завершении, будет отображение буфера, заданного виртуальным адресом address
пользовательского процесса и длиной len в данный iobuf. Данная операция может уйти в сон, так как возможно, что часть
пользовательского буфера окажется не отображенным на физическую память.
С элемента kiobuf, который был отображен таким способом, отображение, в конечном счете должно быть снято, для
поддержания корректного значения счетчика ссылок. Снятие такого отображения выполняется передачей элемента kiobuf в
функцию unmap_kiobuf().
Только что, мы рассмотрели как подготавливается kiobuf для ввода/вывода, но не как, в действительности, выполняется этот
ввод/вывод. Последний шаг включает обработку каждой страницы kiobuf обеспечивая требуемую передачу. В sbullr эта задача
выполняется функцией sbullr_rw_iovec(). Данная функция обрабатывает отдельно каждую страницу, разбивая ее на куски
равные размеру сектора и передает их в фукнцию sbull_transfer() через структуру request.
static int sbullr_rw_iovec(Sbull_Dev *dev, struct kiobuf *iobuf, int rw,
int sector, int nsectors)
{
struct request fakereq;
struct page *page;
int offset = iobuf->offset, ndone = 0, pageno, result;
/* Perform I/O on each sector */
fakereq.sector = sector;
fakereq.current_nr_sectors = 1;
fakereq.cmd = rw;
for (pageno = 0; pageno < iobuf->nr_pages; pageno++) {
page = iobuf->maplist[pageno];
while (ndone < nsectors) {
/* Fake up a request structure for the operation */
fakereq.buffer = (void *) (kmap(page) + offset);
result = sbull_transfer(dev, &fakereq);
kunmap(page);
if (result == 0)
return ndone;
/* Move on to the next one */
ndone++;
fakereq.sector++;
offset += SBULLR_SECTOR;
if (offset >= PAGE_SIZE) {
offset = 0;
break;
}
}
}
return ndone;
}
Здесь, nr_pages, элемент структуры kiobuf, говорит нам как много страниц необходимо передать, а массив maplist дает нам
доступ к каждой странице. Передача производится в соответствующем цикле. Однако, обратите внимание, что для получения
адреса каждой страницы используется функция kmap(). Таким образом, функция будет работать даже если пользовательский
буфер находится в верхней памяти.
Грубая оценка, построенная на поверхностных тестах копирования данных в/из устройства sbullr, показывает что такая
передача данных производится за две трети времени передачи с использованием обычного блочного sbull устройства. Выигрыш
во времени объясняется избавлением от дополнительных операций над кэшем буфера. Заметьте, что если те же самые данные
обрабатываются несколько раз подряд, то преимущества исчезают - особенно для реального "железного" оборудования.
Таким образом, сырой ввод/вывод не всегда является лучшим решением, и только в некоторых случаях дают существенное
улучшение производительности.
Хотя механизм kiobuf остается спорным в сообществе разработчиков ядра, имеется интерес в его использовании в широком
контекстном диапазоне. Например, существует патч, который реализует Unix трубы (pipes - способ межпроцессного
взаимодействия) через механизм kiobuf - данные копируются из адресного диапазона одного процесса в адресный диапазон
другого процесса минуя буферизацию в ядре вообще. Также, существует патч, который упрощает использование kiobuf для
отображение виртуальной памяти ядра в адресное пространство процесса, не используя реализацию nopage(), показанную
ранее.
Прямой доступ к памяти (DMA) и управление шиной
Прямой доступ к памяти (DMA - Direct Memory Access) сложная тема завершающая наш обзор управления памятью. DMA - это
аппаратный механизм, который позволяет периферийным компонентам передавать свои данные непосредственно в/из главной
памяти компьютера без вовлечения в эту передачу процессора. Использование этого механизма может существенно увеличить
пропускную способность в/из устройства.
Для того, чтобы использовать DMA возможности оборудования, драйвер устройства должен правильно настроить DMA передачу и
синхронизироваться с аппаратурой. К несчастью, по причине своей аппаратной природы, DMA крайне системно-зависима. Каждая
система имеет свою собственную технику управления DMA передачей, и программный интерфейс различен для каждой из них. Не
ядро не может предложить универсальный интерфейс DMA, не драйвер не может слишком сильно абстрагироваться от лежащего
под ним оборудования. Однако, в последних ядрах производятся некоторые шаги в этом направлении.
Эта глава концентрируется главным образом на шине PCI, т.к. на данный момент это наиболее популярная периферийная шина.
Хотя многие из приводимых здесь концепций имеют более широкое применение. Также, мы коснемся работы DMA на некоторых
других шинах, таких как ISA и SBus.
Обзор механизмов передачи данных через DMA
Перед ознакомлением с деталями программирования, проведем обзор того, как осуществляется передача данный через DMA,
рассматривая, для упрощения, только передачу входного потока данных.
Передача данных может быть инициирована двумя способами: либо программа запрашивает данные (например, через функцию
read()), либо аппаратура вызывает асинхронную передачу данных в систему.
В первом случае выполняются следующие шаги:
- Когда процесс вызывает функцию read(), метод драйвера распределяет DMA буфер и настраивает аппаратуру
на передачу своих данных. Процесс, при этом, уходит в сон.
- Аппаратура пишет данные в DMA буфер и вызывает прерывание по завершении записи.
- Обработчик прерываний принимает входные данные, выполняет 'acknowledge' прерывания и пробуждает процесс,
которому теперь доступны переданные данные.
Второй случай имеет место, когда DMA используется асинхронно. Это случается, например, при использовании устройств
собирающих данные (data acquisition devices), которые вызывают цикл передачи данных даже тогда, когда их никто не
запрашивает. В этом случае, драйвер должен управлять буфером так, чтобы последующий вызов read() мог вернуть все
накопленные данные в пользовательское пространство. В этом случае, выполняются несколько иные шаги:
- Оборудование вызывает прерывание, извещающее, что пришли новые данные.
- Обработчик прерываний распределяет буфер и сообщает аппаратуре куда передавать его данные.
- Периферийное устройство пишет данные в буфер и вызывает другое прерывание по завершении записи.
- Обработчик прерывания диспетчеризует новые данные, будит все, интересующиеся этими данными процессы и выполняет
завершающие действия.
Примером такой асинхронной работы служат сетевые карты. Такие карты, как правило, работают с кольцевыми буферами (DMA
ring buffer) организованными в памяти, разделяемой с процессором. Каждый входящий пакет размещается в следующем
доступном буфере кольца, после чего вызывается прерывание. Затем, драйвер передает сетевые пакеты в ядро и размещает
новый DMA буфер в кольце.
В обоих случаях эффективность DMA зависит от работы механизма прерываний. Поэтому, несмотря на то, что существует
возможность реализации DMA для polling-драйвера (тип драйверов, занимающихся сбором информации), это не всегда имеет
смысл, потому что такой драйвер может свести к нулю преимущества предлагаемые DMA. Вместо потери времени на обслуживание
множества прерываний, иногда проще воспользоваться простым, управляемым через процессор вводом/выводом.
Другим, описываемым здесь элементом, является DMA буфер. Для использования механизма прямого доступа к памяти, драйвер
устройства должен иметь возможность распределить один или более специальных буферов, требуемых для DMA. Многие драйвера
распределяют свои буфера во время инициализации и используют их до завершения своей работы - поэтому, слово
"распределить" означает, в данном контексте, "удержать, распределенные ранее буфера".
Распределение DMA буферов
В этом разделе описывается распределение буферов DMA на низком уровне. Также, мы кратко ознакомимся с высокоуровневым
интерфейсом распределения, но было бы полезно понимать и внутреннюю организацию этого механизма.
Серьезной проблемой, связанной с распределением буферов DMA, является случай, когда распределяемая область занимает
более одной страницы. Необходимо выбрать подряд идущие страницы физической памяти, потому что устройства передают данные
используя либо ISA, либо PCI шины, обе из которых работают в контексте физических адресов. Интересно заметить, что
данное ограничение не применимо для шины SBus (см. раздел "SBus" главы 15 "Обзор периферийных шин"), которая
использует виртуальные адреса. Некоторые устройства также могут использовать виртуальные адреса на PCI шине, но
портируемый драйвер не должен полагаться на такой случай.
И хотя DMA буфера могут быть распределены как во время загрузки системы, так и во время ее работы, модули могут
распределять свои буфера только в период исполнения. В главе 7 "Работа с памятью" представлены эти техники: в разделе
"Boot-Time Allocation" говорится о распределении во время системной загрузки, а в разделах "Подробности о функции
kmalloc()" и "get_free_page and Friends" описано распределение памяти в процессе исполнения. Разработчики драйверов
должны использовать в распределении для DMA соответствующий ей тип памяти - не все зоны памяти подходят для механизма
DMA. В особенности, на большинстве систем, DMA не может работать с верхней памятью - периферийное оборудование просто
не может адресоваться к такой памяти.
Большая часть устройств на современных шинах может управлять 32-х битными адресами. Таким образом они будут прекрасно
работать с распределением из обычной памяти. Однако, некоторые PCI устройства не полностью реализуют стандарт PCI и не
могут работать с 32-х разрядными адресами. Кроме того, все ISA устройства ограничены 16-ти разрядной адресацией.
Для устройств с таким видом ограничения, память должна распределяться из зоны DMA, путем передачи флага GFP_DMA в
функции kmalloc() или get_free_page(). Если распределение производится с этим флагом, то для распределения используются
только 16-ти разрядные адреса.
Do-it-yourself allocation - "Самостоятельное" распределение памяти
Мы уже говорили, что get_free_page() (а, как следствие, и kmalloc()) не могут возвратить белее 128 КБт (т.е., обычно,
не более 32 страниц) непрерывного адресного пространства памяти. Более того, запрос может быть отклонен даже когда
распределяемый буфер меньше 128 КБт, потому что системная память становится, со временем, фрагментирована.
Слово, фрагментация, обычно применима к диску, для выражения того, что файлы сохраняются не последовательно на магнитном
носителе. Та же самая концепция применима и к памяти, когда виртуальное адресное пространство отображается на
непоследовательные физические страницы RAM, что усложняет получение непрерывных свободных страниц для DMA буфера.
Когда ядро не может возвратить запрошенный объем памяти, или когда требуется памяти более 128 КБт (требуемые, например,
для PCI frame grabbers), то альтернативой получения ошибки -ENOMEM является распределение памяти во время загрузки или
резервирование верхней физической памяти для вашего буфера. В разделе "Boot-Time Allocation" главы 7 "Работа с
памятью" мы описали распределение памяти во время загрузки, но этот механизм не доступен для модулей. Например, если у
вас имеется 32 МБт памяти, то параметр загрузки ядра mem=31M запретит ядру использование последнего мегабайта памяти.
Ваш модуль сможет, впоследствии, использовать следующий код для получения доступа к такой памяти:
dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
Вообще, существует другой способ распределения пространства для DMA. Необходимо выполнить агрессивный захват памяти до
тех пор пока вы не получите достаточное количество последовательно расположенных страниц для создания буфера. Мы крайне
не рекомендуем использовать эту технику распределения, если имеется какой-либо другой способ для достижения этой цели.
Агрессивное распределение памяти приведет к высокой машинной загрузке, и может привести к блокировке системы, если ваша
агрессивность плохо управляема. С другой стороны, иногда, не существует другого возможного способа получения требуемого
пространства памяти.
На практике, код вызывает kmalloc(GFP_ATOMIC) до тех пор пока не происходит отказ в запросе. После этого код ждет пока
ядро не освободит несколько страниц, и, затем, попытается выполнить распределение снова. Если вы будете наблюдать за
пулом распределения страниц, то, рано или поздно, вы увидите в нем появление вашего DMA-буфера последовательных страниц.
С этого момента, вы можете освободить любую страницу памяти, кроме выбранного буфера. Такой тип поведения достаточно
рискован, так как может привести к состоянию взаимной блокировки (deadlock). Мы предлагаем использование таймера ядра
для освобождения каждой из страниц, при условии, что распределение не завершилось до истечения таймера.
Прим. переводчика. Попробуйте перевести последний абзац самостоятельно: " ... In practice, the code invokes
kmalloc(GFP_ATOMIC) until the call fails; it then waits until the kernel frees some pages,
and then allocates everything once again. If you keep an eye on the pool of allocated pages, sooner or later you'll find
that your DMA buffer of consecutive pages has appeared; at this point you can release every page but the selected
buffer. This kind of behavior is rather risky, though, because it may lead to a deadlock. We suggest using a kernel
timer to release every page in case allocation doesn't succeed before a timeout expires. ..."
Здесь мы не будем приводить этот код. При желании, вы найдете его в misc-modules/allocator.c. Код хорошо
прокомментирован и разработан для использования другими модулями. В противоположность всем другим источникам,
сопровождающим эту книгу, код allocator.c находится под лицензией GPL. Причина, по которой мы решили разместить данный
код под GPL заключается в том, что он не является особенно изящным, умным и пр., и если кто-нибудь собирается
использовать его, то мы бы хотели, чтобы источник этого кода передавался бы вместе с модулем, которые его использует.
Адресация в шинах
Драйвер устройства, использующий DMA должен общаться с аппаратурой, подсоединенной к интерфейсной шине, использующей
физические адреса, в то время как программа использует виртуальные адреса.
На самом деле, ситуация крайне усложняется тем, что DMA-ориентированное оборудование использует шинные, а не физические,
адреса. И хотя, для персонального компьютера, адреса плат ISA и PCI являются обычными физическими адресами, для других
платформ это не так. Некоторые интерфейсные шины соединяются через электрические схемы мостов, которые отображают адреса
ввода/вывода в различные физические адреса. Некоторые системы даже имеют схемы страничного отображения, которые могут
предоставить периферийной шине последовательное отображение страниц, реально разбросанных в памяти.
На самом нижнем уровне, ядро Linux обеспечивает портируемое решение с помощью функций, определенных в <asm/io.h>:
unsigned long virt_to_bus(volatile void * address);
void * bus_to_virt(unsigned long address);
Функция преобразования virt_to_bus() должна быть использована при необходимости послать адресную информацию в
устройство, в то время как bus_to_virt() используется для приема адресной информации из подсоединенного к шине
оборудования.
DMA на шине PCI
Ядро 2.4 включает гибкий механизм поддерживающий PCI DMA, известный как bus mastering. Он обеспечивает распределение
буферов и может выполнить настройку подключенного к шине оборудования для многостраничной передачи данных, если
оборудование поддерживает такую передачу. Также, он позволяет использовать буфера, расположенные в не совместимых с DMA
зонами памяти, хотя это работает только на некоторых платформах и за счет использования дополнительных вычислительных
ресурсов (мы рассмотрим это позже).
Функции этого раздела используют структуру pci_dev. Детали настройки PCI устройств описаны в главе 15 "Overview of
Peripheral Busses". Однако заметьте, что описанные здесь процедуры могут использоваться и на ISA устройствах. В этом
случае, указатель на структуру pci_dev должен быть передан как NULL.
Драйвера, которые используют следующие функции должны включать заголовочный файл <linux/pci.h>.
Работа со сложным оборудованием
Первый вопрос, на который нужно найти ответ перед выполнением DMA это – может ли данное устройство обеспечить такую
операцию на данной вычислительной платформе. Многие PCI устройства не могут реализовать полное 32-х адресное
пространство, часто потому, что являются модификациями старого ISA оборудования. Ядро Linux пытается работать с такими
устройствами, но это не всегда возможно.
Функция pci_dma_supported() должна быть вызвана для любого устройства, которое имеет адресные ограничения:
int pci_dma_supported(struct pci_dev *pdev, dma_addr_t mask);
Параметр mask является простой битовой маской, описывающей, какие адресные биты устройство может успешно использовать.
Если возвращенное значение не равно нулю, то DMA возможен и ваш драйвер должен установить поле dma_mask в структуре PCI
устройства в значение mask. Для устройств, которые могут использовать только 16-ти битные адреса, вы можете попробовать
такой вариант использования:
if (pci_dma_supported (pdev, 0xffff))
pdev->dma_mask = 0xffff;
else {
card->use_dma = 0; /* We'll have to live without DMA */
printk (KERN_WARN, "mydev: DMA not supported\n");
}
Начиная с ядра 2.4.3 стала поддерживаться новая функция pci_set_dma_mask(), имеющая следующий прототип:
int pci_set_dma_mask(struct pci_dev *pdev, dma_addr_t mask);
Если DMA может быть поддержана с заданной маской, то эта функция возвращает 0, и устанавливает поле dma_mask. В
противном случае, возвращается ошибка -EIO.
Для устройств, которые могут использовать 32-х битную адресацию, в вызове pci_dma_supported() нет необходимости.
Отображение DMA
DMA отображение представляет собой комбинацию отображения DMA буфера и формирования такого адреса для этого буфера,
через который он может быть доступен с устройства. Во многих случаях, получение этого адреса выполняется через простой
вызов virt_to_bus(), однако некоторые устройства требуют, также, отображения своих управляющих регистров. Отображение
регистров является эквивалентом виртуальной памяти для устройств. На системах, где используются эти регистры,
периферийное оборудование имеет относительно небольшой специальный диапазон адресов в который оно может выполнять DMA.
Эти адреса отображаются через отображающие регистры в системную память. Эти регистры имеют некоторые приятные
характеристики, включающие способность выполнить отображение разбросанных в памяти страниц в непрерывное адресное
пространство устройства. Однако, не все архитектуры имеют отображающие регистры, в том числе, популярная платформа
персональных компьютеров не имеет отображающих регистров.
В некоторых случаях, установка полезных адресов для устройств, может потребовать организации bounce-буфера.
Bounce-буфера создаются, когда драйвер пытается выполнить DMA на адресе, который не доступен периферийному устройству -
например, адрес верхней памяти. Тогда, данные будут копироваться в/из bounce-буфера. Создание кода, корректно
работающего с bounce-буфером требует учета некоторых правил, с которыми мы кратко познакомимся.
Отображение DMA устанавливает новый тип dma_addr_t, для представления шинных адресов. Переменные типа dma_addr_t должны
прозрачно обрабатываться драйвером. Только допустимые операции должны передаваться в процедуры поддержки DMA и в само
устройство.
PCI код различает два типа DMA отображения в зависимости от того, как долго будут удержаны буферы DMA:
- Согласованные (consistent) DMA отображения
-
Такие отображения существуют в течении всего "времени жизни" драйвера. Согласованно отображенные
буферы должны быть одновременно доступны как CPU, так и периферии. Другие типы отображений, как мы увидим
позднее, могут быть доступны в только одному из устройств (CPU, переферия) в один момент времени. Кроме того,
по возможности, этот буфер не должен использовать кэширование, которое может привести к тому, что одно из этих
устройств не увидит изменения сделанные другим.
- Потоковое (streaming) DMA отображение
-
Такие отображения назначаются на одну операцию. В дальнейшем мы увидим, что некоторые архитектуры допускают
значительную оптимизацию при использовании потоковых отображений, но эти отображения также накладывают
определенное множество правил и ограничений. Разработчики ядра рекомендуют использовать потоковое отображение
вместо согласованного везде, где это возможно. Для этой рекомендации существуют две причины. Во-первых, для
каждого DMA-отображения, системы могут предоставлять отображение его регистров на шину. Согласованные отображения,
которые имеют долгое время жизни. могут монополизировать эти регистры на значительный период времени, даже если
ети регистры им не используются. Кроме того, на некотором оборудовании, потоковое отображение может быть
способами, недоступными для согласованных отображений.
Эти два типа отображения используются по разному. Рассмотрим реализации в подробностях.
Настройка согласованного отображения DMA
Драйвер можен настроить согласованное отображение через системный вызов pci_alloc_consistent():
void *pci_alloc_consistent(struct pci_dev *pdev, size_t size,
dma_addr_t *bus_addr);
Эта функция управляет как распределением, так и отображением буфера. Первые два аргумента задают описание PCI устройства
(через структуру pci_dev) и требуемый размер буфера. Функция возвращает результат DMA отображения в двух вариантах. Своим
телом функция возвращает виртуальный адрес буфера в адресном пространстве ядра. Кроме того, через аргумент bus_addr
возвращается адрес распределенного буфера на аппаратной шине. Распределение выполняется таким образом, что буфер располагается
в области доступной для DMA. Как правило, такая память распределяется с использованием системного вызова get_free_pages() c
указанием размера буфера в байтах, а не в показателе степени двух.
Большинство архитектур поддерживающих шину PCI выполняют распределение памяти для DMA буфера с использованием флага GFP_ATOMIC,
что предотвращает засыпание процессов, использующих этот буфер. Однако порт ARM является исключением из этого правила.
Когда распределенный буфер DMA больше не нужен, то его желательно вернуть в систему используя системный вызов pci_free_consistent().
Обычно это производится при выгрузке модуля из ядра.
void pci_free_consistent(struct pci_dev *pdev, size_t size,
void *cpu_addr, dma_handle_t bus_addr);
Заметьте, что эта функция требует как виртуальный адрес буфера из адресного пространства ядра, так и адрес буфера на шине
PCI.
Настройка потокового отображения DMA
Потоковое отображение имеет более сложный интерфейс чем согласованное отображение по нескольким причинам. Это отображение
работает в предположении, что буфер DMA уже был распределен драйвером. Таким образом, ему приходится работать с адресным
пространством, которое было выбрано без его участия. На некоторых архитектурах, потоковое отображение может работать с буферами
состоящими из множества, физически разбросанных в памяти страниц ("scatter-gather" буферы).
При настройке потокового отображения, вы должны указать ядру направление заполнения данных. Для этой цели определены следующие
флаги:
- PCI_DMA_TODEVICE
- PCI_DMA_FROMDEVICE
-
Назначение этих символов говорит само за себя. Если данные посылаются на устройство (возможно, системным вызовом write()),
то необходимо использовать флаг PCI_DMA_TODEVICE. При получении данных используется флаг PCI_DMA_FROMDEVICE.
- PCI_DMA_BIDIRECTIONAL
-
Данный флаг используется при настройке передачи данных в обоих направлениях.
- PCI_DMA_NONE
-
Этот флаг предлагается к использованию исключительно в целях отладки. Попытки использования буферов с этим флагом
направления может привести к ситуации "kernel panic".
По некоторым причинам, которые мы кратко опишем, задание правильного флага направления передачи имеет существенную важность
для потокового DMA отображения. Повсеместное использование универсального флага PCI_DMA_BIDIRECTIONAL возможно, но расплатой
за такой выбор может быть заметное снижение производительности на некоторых архитектурах.
Если вам необходим один буфер для передачи данных, то его отображение можно выполнить следующим системным вызовом:
dma_addr_t pci_map_single(struct pci_dev *pdev, void *buffer,
size_t size, int direction);
Данная функция возвращает значение отображенного адреса на аппаратной шине, которое вы можете передать в устройство, или
NULL, если отображение не удалось.
После завершения передачи данных, отображение может быть уничтожено системным вызовом pci_unmap_single():
void pci_unmap_single(struct pci_dev *pdev, dma_addr_t bus_addr,
size_t size, int direction);
Аргументы size и direction должны соответствовать значениям, которые были использованы при отображении буфера.
При использовании потокового DMA отображения следует иметь в виду несколько важных правил:
- Буфер должен использоваться только для передачи данных, что следует указать передачей соответствующего
флага при отображении.
- Как только буфер будет отображен, то он становится принадлежащим устройству, а не процессору. После снятия
отображения, содержимое буфера сохраняется. Безопасный доступ драйвера к содержимому буфера возможен только
после снятия отображения, вополняемого системным вызовом pci_unmap_single(). Здесь возможно исключение, которое
мы рассмотрим чуть позже. Кроме прочего, данное правило предполагает, что буфер, который будет записан в устройство,
не следует отображать до тех пор, пока в него не будут записаны все необходимые данные.
- Не следует снимать отображение буфера при активном сеансе DMA, иначе это приведет к нестабильности
системы.
Вас должен удивить тот факт, что драйвер не может работать с буфером пока буфер отображен. Существуют две причины определяющие
смысл данного правила.
Во-первых, когда буфер отображен для DMA, ядро должно быть уверено, что все данные буфера были перенесены в память. Может
случиться так, что некоторые данные могут остаться в кэше процессора, и должны быть явно сброшены (flushed) из кэша.
Таким образом, данные, которые процессор записал в буфер, могут быть увидены устройством только после выполнения сброса
процессорного кэша.
Во-вторых, попробуйте предположить, что случится если отображенный буфер находится в области памяти недоступной устройству.
В зависимости от архитектуры это приводит либо к неудачному завершению операции, либо к созданию дополнительного (bounce)
буферу. Такой буфер создается в области памяти, которая может быть доступна устройству. Если буфер отображается с
использованием флага PCI_DMA_TODEVICE, и возникает необходимость в создании дополнительного (bounce) буфера, то содержимое
исходного буфера копируется в дополнительный буфер во время его отображения. Ясно, что после такой операции, изменение
содержимого исходного буфера не будет видно устройством. Также, дополнительный буфер созданный по флагу PCI_DMA_FROMDEVICE
копируется в исходный буфер во время системного вызова pci_unmap_single(). Поэтому доступ к данным полученным от устройства
возможен только после снятия отображения.
Создание дополнительного (bounce) буфера является одной из причин, которая поясняет важность правильного задания флага
направления при отображении буфера. Задание универсального флага PCI_DMA_BIDIRECTIONAL приведет к копированию данных в и из
дополнительного буфера как при открытии, так и при снятии отображения, что приведет к дополнительным тратам процессорного
времени.
В некоторых случаях, драйверу требуется получить доступ к содержимому потокового DMA буфера без снятия отображения.
Использование следующего системного вызова делает это возможным:
void pci_sync_single(struct pci_dev *pdev, dma_handle_t bus_addr,
size_t size, int direction);
Эта функция должна быть вызвана до того, как процессор начнет обращение к буферу, отображенному с использованием флага
PCI_DMA_FROMDEVICE, и после того, как процессор обработает буфер отображенный флагом PCI_DMA_TODEVICE.
Кусочные отображения (scatter-gather mappings)
Кусочные отображения являются особым случаем потоковых отображений DMA. Предположим, что вы имеете несколько буферов,
которые необходимо передать в, или из, устройства. Такая задача может быть реализована различными путями, включая
использование системных вызовов readv() или writev(), кластерный дисковый запрос ввода/вывода, или список страниц в
отображенных буферах ввода/вывода ядра. Вы можете просто отобразить каждый буфер в отдельности и выполнить необходимую
операцию, но существуют более эффективные техники отображения целого списка сразу.
Одна из них состоит в том, что некоторые, особым образом сконструированные устройства, могут получить список указателей
на буферы и их длины для передачи данных за одну DMA операцию. Например, сетевая передача "zero-copy" может
быть реализована много проще, если иметь возможность организации передаваемых пакетов в специальный список. Вероятно,
в будущем, поддержка таких устройств в Linux будет еще более улучшена. Другая техника, состоящая в отображении отдельных
кусочных буферов в единую область, имеет преимущества на системах, которые позволяют отображать регистры на аппаратную
шину. В таких системах, физически разбросанные страницы могут быть представлены для устройства единой непрерывной областью.
Такая техника требует, чтобы элементы кусочного списка имели размер равный размеру страницы, за исключением первой и
последней области. При удовлетворении данного условия, вы сможете выполнить множество операция за одну операцию DMA, что,
соответственно, поднимет скорость передачи данных.
Если системе потребуется дополнительный (bounce) буфер, то кусочная природа буферов будет иметь значение только при
организации передачи данных из списка кусочных буферов в дополнительный буфер и обратно.
Таким образом, кусочные отображения заслуживают внимания в некоторых ситуациях. Первым шагом при отображении кусочных
буферов является создание и заполнение массива структур scatterlist, описывающих буферы для передачи. Эта структура
архитектурно-зависима и описана в заголовочном файле <linux/scatterlist.h>. Структура содержит, кроме прочего,
следующие, интересующие нас, два поля:
- char *address;
-
Адрес буфера, используемого в передаче (scatter/gather operation).
- unsigned int length;
-
-
Длина буфера
Для того, чтобы выполнить DMA операцию над кусочными буферами, ваш драйвер должен проинициализировать поля address и
length элемента структуры scatterlist для каждого передаваемого буфера. После этого, отображение выполняется с
использованием следующего системного вызова:
int pci_map_sg(struct pci_dev *pdev, struct scatterlist *list,
int nents, int direction);
Функция возвращает количество отображенных DMA буферов. Это значение может быть меньше, чем переданное в переменной
nents, число буферов подготовленных для отображения.
Ваш драйвер может теперь использовать для передачи данных все буфера, возвращенные системным вызовом pci_map_sg().
Аппаратный адрес на шине и длина каждого распределенного буфера будут сохранены в соответствующих элементах структуры
scatterlist, но их положение в структуре изменяется от одной архитектуры к другой. Для написания портируемого кода
предлагается использовать следующие два макроса для получения этих элементов структуры:
- _addr_t sg_dma_address(struct scatterlist *sg);
-
Возвращает адрес на аппаратной шине для отображенного буфера из элемента структуры scatterlist.
- unsigned int sg_dma_len(struct scatterlist *sg);
-
Возвращает длину этого буфера.
Обратите внимание, что адрес и длина буфера для передачи данных может отличаться от значений переданных в pci_map_sg().
Как только передача данных завершена, необходимо освободить кусочное отображение с помощью системного вызова pci_unmap_sg():
void pci_unmap_sg(struct pci_dev *pdev, struct scatterlist *list,
int nents, int direction);
Еще раз обратите внимание на то, что значение nents указывает на количество элементов, которые вы передали для
отображения, а не на то количество элементов, которые реально были отображены на аппаратную шину.
Кусочное отображение является вариантом потокового DMA отображения, поэтому к нему применимы правила потокового
отображения с небольшим изменением. Если вам необходимо получить доступ к отображенному списку кусочных буферов,
то, предварительно, необходимо синхронизировать буферы:
void pci_dma_sync_sg(struct pci_dev *pdev, struct scatterlist *sg,
int nents, int direction);
Поддержка PCI DMA на различных архитектурах
Как мы уже говорили в начале этого раздела, реализация DMA сильно зависит от аппаратной архитектуры. PCI DMA интерфейс,
о котором мы только что рассказали, абстрагируется от аппаратной реализации настолько, насколько это возможно. Здесь
мы обсудим аппаратно зависимые элементы DMA реализации.
- M68K
- S/390
- Super-H
-
На этих архитектурах не поддерживалась PCI шина до версии ядра 2.4.0.
- IA-32 (x86)
- MIPS
- PowerPC
- ARM
-
Данные платформы поддерживают PCI DMA интерфейс, но его реализация имеет множество недостатков. Не поддерживаются
отображающие регистры, не поддерживается кусочное отображение и не могут быть использованы
виртуальные адреса. Не поддерживается дополнительный (bounce) буфер, что означает невозможность использования
адресов верней памяти (high-memory). Функции отображения на архитектуре ARM могут уйти в сон, что не может
произойти на других платформах.
- IA-64
-
На архитектуре Itanium также отсутствуют отображающие регистры. 64-х битная архитектура может легко генерировать
адреса, которые не могут быть использованы на шине PCI. Однако, PCI интерфейс этой платформы реализует механизм
дополнительных (bounce) буферов, что позволяет (по-видимому) использовать любые адреса для DMA операций.
- Alpha
- MIPS64
- SPARC
-
На этих архитектурах поддерживается подсистема управления памятью ввода/вывода. Но до версии ядра 2.4.0, платформа
MIPS64 не использовала возможности данной подсистемы, и ее PCI DMA интерфейс выглядел схожим с платфомой IA-32.
Однако, на платформах Alpha и SPARC возможно полноценное кусочное отображение буферов.
Описанные различия в архитектурах не должны создавать проблемы для большинства разработчиков драйверов. Достаточно просто
знать и учитывать основные особенности поддерживаемых архитектур.
Простой пример использования PCI DMA
Реализация DMA операций на шине PCI сильно зависит от реализации поддерживаемого устройства. Таким образом, данный пример
не может быть применен к какому-либо реальному устройству, а представляет собой часть гипотетического устройства названного
как dad (DMA Acquisition Device - устройство сбора информации с использованием прямого доступа к памяти). Драйвер для этого
устройства может определить функцию передачи данных следующим образом:
int dad_transfer(struct dad_dev *dev, int write, void *buffer,
size_t count)
{
dma_addr_t bus_addr;
unsigned long flags;
/* Map the buffer for DMA */
dev->dma_dir = (write ? PCI_DMA_TODEVICE : PCI_DMA_FROMDEVICE);
dev->dma_size = count;
bus_addr = pci_map_single(dev->pci_dev, buffer, count,
dev->dma_dir);
dev->dma_addr = bus_addr;
/* Set up the device */
writeb(dev->registers.command, DAD_CMD_DISABLEDMA);
writeb(dev->registers.command, write ? DAD_CMD_WR : DAD_CMD_RD);
writel(dev->registers.addr, cpu_to_le32(bus_addr));
writel(dev->registers.len, cpu_to_le32(count));
/* Start the operation */
writeb(dev->registers.command, DAD_CMD_ENABLEDMA);
return 0;
}
Данная функция отображает буфер для передачи и запускает операцию передачи данных в устройство. Вторая половина этой работы
должна быть завершена в процедуре обработчике прерывания (ISR - Interrupt Service Routine), которая должна выглядеть примерно
следующим образом:
void dad_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
struct dad_dev *dev = (struct dad_dev *) dev_id;
/* Make sure it's really our device interrupting */
/* Unmap the DMA buffer */
pci_unmap_single(dev->pci_dev, dev->dma_addr, dev->dma_size,
dev->dma_dir);
/* Only now is it safe to access the buffer, copy to user, etc. */
...
}
Совершенно очевидно, что множество мелких деталей было опущено при написании данного примера, включая какие бы то ни
было шаги по предотвращению попыток запуска множества одновременных DMA операций.
Беглый взгляд на SBus
SPARC системы традиционно используют шину SBus (Sun-designed bus - шина, разработанная компанией Sun). Описание этой
шины выходит за рамки обзора данной книги, но, тем не менее, имеет смысл, кратко затронуть ее особенности. В заголовочном
файле <asm/sbus.h> содержится интерфейс для множества функций, используемых для операций отображения DMA на шину
SBus. Там, вы найдете, например, такие функции как sbus_alloc_consistent() и sbus_map_sg(). Другими словами SBus DMA API
очень схож с интерфейсом DMA для PCI. Конечно, для реальной работы с этой шиной требуется детальное изучение всех этих
функций, но следует отметить, что общая концепция работы с SBus очень схожа с той, что была обсуждена нами для шины PCI.
DMA для ISA устройств
Шина ISA предлагает два вида DMA передачи: native DMA и ISA bus master DMA. Native DMA использует стандартный схему
DMA контроллера, расположенную на материнской плате, для управления сигналами на шине ISA, в то время как ISA bus master
DMA полностью управляется устройством, подключенном к ISA шине. Последний тип DMA передачи используется достаточно
редко и не будет обсуждаться в данной книге, так как он сильно схож с реализацией DMA для устройств PCI, по крайней мере,
с точки зрения драйвера. В качестве примера использования ISA bus master можно привести драйвер для контроллера
SCSI 1542, код которого вы можете посмотреть в файле driver/scsi/aha1542.c источников ядра.
Обсуждение native DMA передачи, следует начать с трех основных элементов реализующих такую передачу на шине ISA:
- Контроллер 8237 DMA (DMAC - DMA controller)
-
Контроллер удерживает информацию о DMA передаче, такую как направление передачи данных, адрес буфера в памяти, и
размер передачи. Он также содержит счетчик, который следит за статусом выполняемой передачи данных. Когда
контроллер получает сигнал запроса DMA, он выполняет захват шины и управляет сигнальными линиями, которые
стробируют устройство для выполнения операций чтения или записи данных.
- Переферийное устройство
-
Устройство должно активизироваь сигнал запроса DMA, когда оно готово для передачи данных. Процесс передачи
управляется микросхемой DMAC. Контроллер стробирует устройство для осуществления процессов чтения и записи
данных на шину. Обычно, в конце передачи данных, устройство вызывает аппаратное прерывание.
- Драйвер устройства
-
Драйвер выполняет совсем немного работы. Он передает в DMAC направление передачи данных, адрес буфера на
аппаратной шине и размер передачи. Кроме этого он выполняет подготовку устройства к передаче данных и
реализует отклик на прерываение при завершении DMA передачи.
Оригинальный DMA контроллер используемый в PC, может управлять четырьмя "каналами", каждый из которых
связан со своим набором регистров DMA. Таким образом, четыре устройства могут сохранять свою DMA информацию в
контроллере одновременно. Более позние PC содержат эквивалент двух DMAC чипов: второй контроллер (master)
подключен к системному процессору, а первый (slave) подсоединен к каналу 0 второго контроллера. Сейчас эти чипы
являются частью чипсета, на котором строится материнская плата, но еще несколько лет назад это были два раздельных
чипа 8237. Оригинальная архитектура PC имела только один DMA контроллер. Второй был добавлен в архитектуру PC на
платформах i286. Однако второй контроллер был установлен как master, так как он управляет 16-битовой передачей,
в то время как первый контроллер управлял 8-ю битами передачи и был оставлен для обратной совместимости.
Каналы пронумерованы от 0 до 7. Канал номер 4 не доступен переферии ISA, потому что он используется для внутренних
целей каскадирования slave-контроллера к master-контроллеру. Доступные каналы имеют номера 0..3 на slave-контроллере
для 8-ми битовой передачи, и номера 5..7 на master-контроллере для 16-битовой передачи. Обратите внимание, что
4-ый канал общей нумерации соответствует 0-му каналу master-контроллера. Размер DMA-передачи сохраняется в контроллере
как 16-ти битовое число, и представляет собой число циклов шины необходимое для завершения передачи требуемого
количества данных. Таким образом, максимальный размер передачи для slave-контроллера равен 64КБт, и 128КБт для
master-контроллера.
Ядро операционной системы использует DMA-регистры и предлагает набор функций для конфигурирования каналов в DMA
контроллере.
Регистрация использования DMA
Использование DMA требует регистрации в соответствующей подсистеме ядра, похожей на ту, что мы использовали для
портов ввода/вывода и линий прерываний. После включения заголовочного файла <asm/dma.h> в код вашего драйвера
вам становятся доступны следующие функции, которые могут быть использованы для получения и освобождения владения
каналом DMA:
int request_dma(unsigned int channel, const char *name);
void free_dma(unsigned int channel);
Аргумент channel должен получить значение в интервале от 0 до 7. Если быть более точным, то это должно быть
положительное число меньшее чем MAX_DMA_CHANNELS. Для архитектуры PC, MAX_DMA_CHANNELS равно 8. Аргумент name
представляет собой строку, идентифицирующую устройство. Заданное имя устройства может быть прочитано в /proc/dma
и может быть прочитано программой пользовательского уровня.
Функция request_dma() возвращает 0 в случае успеха или коды -EINVAL, -EBUSY при возникновении ошибки. Ошибка -EINVAL
означает, что регистрируемый номер канала не существует в системе, а ошибка -EBUSY говорит о занятости канала.
Мы рекомендуем вам использовать ту же технику работы с каналами DMA, что и с портами ввода/вывода и линиями прерываний.
Канал следует открывать для передачи по необходимости а не при инициализации модуля. Также, следует освобождать канал
на время, когда он не нужен вашему драйверу, что позволит разделять каналы DMA между различными драйверами. Например,
ваша звуковая карта и ваш аналоговый интерфейс ввода/вывода могут разделять один и тот же DMA канал, если они не
используются в одно и то же время.
Мы также предполагаем, что вы будете запрашивать DMA канал после запроса линии прерывания, и освобождать DMA перед
освобождением линии прерывания. Это обычный порядок используемый при запросе двух ресурсов, который позволяет
избегать возможной ситуации взаимной блокировки (deadlock). Обратите внимание, что каждому устройству, использующему
DMA, также требуется линия прерывания. В противном случае, драйвер не сможет принять сигнал о завершении передачи.
Приведем типичный пример кода открытия процесса передачи данных. Код написан в контексте гипотетического модуля dad.
Устройство dad не поддерживает разделения линии прерывания.
int dad_open (struct inode *inode, struct file *filp)
{
struct dad_device *my_device;
/* ... */
if ( (error = request_irq(my_device.irq, dad_interrupt,
SA_INTERRUPT, "dad", NULL)) )
return error; /* or implement blocking open */
if ( (error = request_dma(my_device.dma, "dad")) ) {
free_irq(my_device.irq, NULL);
return error; /* or implement blocking open */
}
/* ... */
return 0;
}
Пример закрытия процесса передачи данных через DMA может выглядеть следующим образом:
void dad_close (struct inode *inode, struct file *filp)
{
struct dad_device *my_device;
/* ... */
free_dma(my_device.dma);
free_irq(my_device.irq, NULL);
/* ... */
}
При инсталлированной звуковой карте, файл /proc/dma может выглядеть следующим образом:
merlino% cat /proc/dma
1: Sound Blaster8
4: cascade
Интересно заметить, что используемый по умолчанию драйвер звуковой карты получает DMA канал при загрузке
системы и никогда не освобождает его. Элемент cascade отражает использование 4-го канала DMA для каскадирования
DMA контроллеров, как это было обсуждено выше.
Конфигурирование контроллера DMA
После регистрации, основная работа драйвера заключается в конфигурировании контроллера DMA для соответствующих операций.
Это не тривиальная задача, но, к счастью, ядро экспортирует все необходимые функции, требуемые типичному драйверу.
Необходимость в конфигурировании DMA контроллера возникает в драйвере при обращении к системным вызовам read(), write()
или при подготовке асинхронной передачи. Последняя задача выполняется либо во время открытия, либо во время отклика на
системный вызов ioctl(), в зависимости от драйвера и политики, которую он реализует. Приведенный здесь код обычно
вызывается методами read() или write().
В данном подразделе мы вкратце рассмотрим управление контроллером DMA, что поможет вам понять код приведенный чуть ниже.
Если вы хотите узнать об этом больше, то вам следует ознакомиться с содержимым заголовочного файла <asm/dma.h>.
Кроме того, желательно ознакомиться с соответствующими руководствами по архитектуре PC. Как правило, мы не имеем дело
с 8-ми битовой передачей в пользу 16-ти битовой. Если же вы имеете дело с написанием драйверов для ISA устройств, то
необходимо уточнить этот вопрос в техническом справочнике на устройство.
DMA контроллер является разделяемым ресурсом, и может возникнуть конфликт доступа, если несколько процессоров начнут
выполнение одной программы одновременно. По этой причине, контроллер должен быть защищен механизмом спинлока (spinlock),
через использование системного вызова dma_spin_lock(). Следует учесть, что драйвер не должен манипулировать флагом
блокировки напрямую. Для этих целей ядро предоставляет следующие две функции:
- unsigned long claim_dma_lock();
-
Получение спинлока DMA. Эта функция также блокирует прерывания для процессора, на котором она исполняется.
Таким образом, возращаемым значением является обычное значение "флагов", которое должно быть
использовано при разрешении прерываний.
- void release_dma_lock(unsigned long flags);
-
Возвращение спинлока DMA при сохранении статуса прерываний.
Спинлок должен быть удержан при использовании описанных ниже функций. Однако, его не следует удерживать непостредственно
во время операции ввода/вывода. Драйвер не должен уходить в сон при удерживании спинлока.
Информация, которая должна быть загружена в контроллер состоит из трех элементов: адрес буфера в оперативной памяти
компьютера, количество атомарных циклов передачи для заполнения буфера (в байтах и словах, в зависимости от 8-ми или
16-ти битовой передачи), и направление передачи.
В завершении, рассмотрим еще несколько функций, экспортируемых заголовочным файлом <asm/dma.h>:
- void set_dma_mode(unsigned int channel, char mode);
-
Установка направления передачи: чтение из устройства (DMA_MODE_READ) или запись в него (DMA_MODE_WRITE).
Также, возможна установка третьего режима, DMA_MODE_CASCADE, который используется для снятия управления
с шины. Каскадингом называется способ подключения первого DMA контроллера ко второму. Аналогичная абстракция
может быть применима и для устройства ISA-bus master. Здесь мы не будем обсуждать вопросы управления шиной.
- void set_dma_addr(unsigned int channel, unsigned int addr);
-
Назначение адреса буферу DMA. Функция сохраняет в контроллере 24 младших значащих бита, переданных в переменной
addr. Следует заметить, что аргумент addr должен являться адресом на аппаратной шине (см. описание шинной
адресации ранее в этой главе.
- void set_dma_count(unsigned int channel, unsigned int count);
-
Определяет количество байт для передачи. Для 16-битовой передачи, аргумент count также представляет количество
передаваемых байт. В последнем случае, значение count должно быть четным.
В добавлении к этим функциям, стоит обратить свое внимание не некоторые дополнительные функции, которые могут быть использованы
при работе с устройствами DMA:
- void disable_dma(unsigned int channel);
-
Канал DMA может быть запрещен из контроллера. Запрещение работы канала следует производить перед конфигурированием
контроллера, для предотвращения нежелательных операций. Контроллер программируется через 8-битовую передачу данных,
и, таким образом, ни одна из вышеописанных функций не может быть выполнена за одну DMA операцию.
- void enable_dma(unsigned int channel);
-
Данная функция сообщает контроллеру, что DMA канал содержит корректные данные.
- int get_dma_residue(unsigned int channel);
-
Драйверу может потребоваться информация о степени завершенности DMA операции. Эта функция возвращает число байт,
которые еще не были переданы. Если операция завершена (т.е. все данные переданы), то функция возвращает 0. Во время
работы контроллера результат функции непредсказуем. Непредсказуемость результата отражает тот факт, что остаток
представляет собой 16-битовое значение, которое извлекается за две 8-битовые входные операции.
- void clear_dma_ff(unsigned int channel)
-
Данная функция сбрасывает триггер DMA (flip-flop). Триггер используется для управления доступом к 16-битовым
регистрам. Доступ к регистрам осуществляется за две 8-битовые операции, и сброс триггера помечает операцию
с младшим значащим байтом. При установленном триггере выполняется операция со старшим байтом. Триггер автоматически
изменяет свое значение на противоположное при завершении очередной 8-битовой передаче. Программист должен сбрасывать
триггер перед обращением к регистрам DMA.
Используя эти функции, драйвер может реализовать следующий код подготовки к передаче данных через DMA:
int dad_dma_prepare(int channel, int mode, unsigned int buf,
unsigned int count)
{
unsigned long flags;
flags = claim_dma_lock();
disable_dma(channel);
clear_dma_ff(channel);
set_dma_mode(channel, mode);
set_dma_addr(channel, virt_to_bus(buf));
set_dma_count(channel, count);
enable_dma(channel);
release_dma_lock(flags);
return 0;
}
Проверка успешного завершения передачи DMA может выглядеть следующим образом:
int dad_dma_isdone(int channel)
{
int residue;
unsigned long flags = claim_dma_lock ();
residue = get_dma_residue(channel);
release_dma_lock(flags);
return (residue == 0);
}
Следует заметить, что общая задача конфигурирования включает в себя, также, и конфигурирование устройства.
Это специфическая для каждого устройства задача, которая, обычно, состоит из чтения и записи некоторых портов
ввода/вывода. Общая схема конфигурирования устройств не может быть представлена по причине значительных различий
в конфигурировании разного рода устройств. Например, некоторые устройства ожидают получение от драйвера информации
о размере буфера, а в некоторых случаях эту информацию должен получить драйвер, обратившись к специальному регистру
устройства. Информацию по конфигурированию устройства ищите в его техническом руководстве.
Вопросы обратной совместимости
Как и другие подсистемы ядра, механизмы отображения памяти и DMA претерпели с годами некоторые изменения. В этом разделе
мы ознакомимся с теми изменениями, которые необходимо иметь в виду разработчикам драйверов при написании портируемого
кода.
Изменения в подсистеме управления памятью
Основные изменения в механизме управления памятью были произведены в период разработки ветки ядра 2.3. В ядре 2.2
присутствовали значительные ограничения на объем используемой памяти, особенно, для 32-х разрядных процессоров. В ядре
2.4 эти ограничения были сняты. Теперь, ядро Linux может управлять всем объемом памяти, который в состоянии адресовать
процессор. Такое улучшение потребовало серьезной переработки ядра, но, к счастью, изменения в API оказались
незначительными.
Как мы видели, ядро 2.4 широко использует указатели на структуру page для обращения к необходимым страницам в памяти.
Эта структура была представлена в Linux в течении долгого времени, но, ранее, не использовалась для обращения к
непосредственно страницам. Вместо этого, ядро использовало логическую адресацию.
Таким образом, например, pte_page() возвращала значение unsigned long, вместо struct page *, а такого макро как
virt_to_page() не существовало вообще, и для получения элемента struct page вы должны были обращаться непостредственно к
таблицам отображения памяти. С помощью макро MAP_NR() можно было преобразовать логический адрес в индекс по mem_map, и,
таким образом, макро virt_to_page() могло быть определено следующим образом (как это и сделано в нашем заголовочном
файле sysdep.h):
#ifdef MAP_NR
#define virt_to_page(page) (mem_map + MAP_NR(page))
#endif
Макро MAP_NR() перестало поддерживаться в ядре Linux после появления virt_to_page(). Макро get_page() также не
существовало до версии ядра 2.4, и в нашем файле sysdep.h оно определено следующим образом:
#ifndef get_page
# define get_page(p) atomic_inc(&(p)->count)
#endif
Структура struct page также претерпела изменения со временем. В частности, поле virtual представлено только начиная с
ядра 2.4.
Функция page_table_lock() была введена в версии 2.3.10. Ранее, перед внесением изменений в таблицы страниц, код ядра
мог использовать только глобальную блокировку "big kernel lock", используя функции lock_kernel() и
unlock_kernel().
Рассмотрим изменения, которые были внесены в структуру vm_area_struct при разработке веток 2.1 и 2.3:
- Поле vm_pgoff называлось vm_offset в ядре 2.2 и ранее, и содержало смещение в байтах, а не в страницах.
- В ядре Linux 2.2 не существовало поля vm_private_data, и драйвера не имели возможность сохранять свою
собственную информацию в VMA. Справедливости ради надо сказать, что некоторые драйвера использовали для этого
поле vm_pte, но более безопасным способом является получение младшего номера устройства из vm_file и
использование этого номера для получения необходимой информации.
- Ядро 2.4 инициализирует указатель vm_file перед вызовом метода mmap(). В ядре 2.2, драйвера должны были
определять это значение самостоятельно, использую структуру, переданную в качестве аргумента.
- Указатель vm_file не существовал в ядре 2.0 вообще. Вместо этого, был определен указатель vm_inode, который
указывал на структуру inode. Это поле должно было назначаться драйвером. Кроме того, требовалось
инкрементирование inode-&qt;i_count в методе mmap.
- Флаг VM_RESERVED был добавлен в ядре 2.4.0-test10.
Также, изменениям подверглись различные методы vm_ops, сохраненные в VMA:
- Ядро 2.2 и более ранние версии имели метод advise(), который, в действительности, никогда не использовался
ядром. Также, имелся метод swapin(), который использовался для получения памяти из поддерживаемых устройств
хранения данных. И тот и другой методы, как правило, не представляют интереса для разработчиков драйверов.
- Методы nopage() и wppage() в ядре 2.2 возвращали unsigned long (т.е. логический адрес), а не struct page *,
как в современных ядрах.
- Коды возврата NOPAGE_SIGBUS и NOPAGE_OOM не существовали в ранних ядрах. Метод nopage() просто возвращает 0
для сообщения о проблеме и посылает шинный сигнал (bus signal) поврежденному процессу (affected process).
Поскольку метод nopage использовал для возврата тип unsigned long, значит он возвращал логический адрес страницы, а не
элемент из mem_map.
Конечно же, в старых ядрах не было поддержки верхней памяти (high-memory). Вся память имела логическую адресацию и не
существовало функций kmap() и kunmap().
В ядре 2.0, структура init_mm не экспортировалась модулям. Таким образом, модули, которые хотели получить доступ к
init_mm должны были анализировать таблицу задач для ее поиска (часть процесса init). При запуске на ядре 2.0, наш модуль
scullp находит init_mm с помощью следующего фрагмента кода:
static struct mm_struct *init_mm_ptr;
#define init_mm (*init_mm_ptr) /* to avoid ifdefs later */
/* для избежания ifdefs позднее */
static void retrieve_init_mm_ptr(void)
{
struct task_struct *p;
for (p = current ; (p = p->next_task) != current ; )
if (p->pid == 0)
break;
init_mm_ptr = p->mm;
}
Кроме того, для ядра 2.0 справедливо недостаточное различие между логической и физической адресацией. Не существовали
макросы __va() и __pa(). Тогда, в них просто не было необходимости.
Также, ядро 2.0 не имело поддержки счетчика использования модуля в представленной области отображения памяти. Драйвера,
которые реализовывали метод mmap() под ядро 2.0 должны были обеспечивать VMA операции open() и close() для
самостоятельного управления счетчиком использования модуля. Наши примеры модулей, демонстрирующих mmap() реализуют эти
операции.
И наконец, метод mmap() для версии ядра 2.0, как и большинство других методов, принимал аргумент struct inode, и его
прототип выглядел следующим образом:
int (*mmap)(struct inode *inode, struct file *filp,
struct vm_area_struct *vma);
Изменения в поддержке DMA
Как уже говорилос ранее, интерфейс для PCI DMA не существовал до версии ядра 2.3.41. До этого, управление DMA
производилось было более прямым - системно зависимым способом. Буфера отображались вызововм virt_to_bus() и не было
общего интерфейса для управления отображаемых на шину регистров.
Для тех, чья задача заключается в написании портируемого PCI драйвера, мы предлагаем рассмотреть наш заголовочный файл
sysdep.h на предмет примера реализации DMA-интерфейса ядра 2.4 для более старых ядер.
С другой стороны, интерфейс ISA не менялся со времен ядра 2.0. Архитектура ISA представляет собой пример старой
архитектруры, которая не испытывала каких-либо серьезных изменений для того, чтобы уделять ей большее внимание в
эволюции ядра. Единственным добавлением было появление DMA-спинлоков (spinlock) в ядре 2.2. До этой версии ядра, как бы
не было необходимости в защите от множественного параллельного доступа к контролеру DMA. В нашем заголовочном файле
sysdep.h можно посмотреть пример реализации этих функций, которые просто управляют запрещением и разрешением прерываний.
Краткий справочник определений
Приведем краткое определение символов, связанных с управлением памятью, с которыми мы познакомились в этой главе.
Приведенный список не включает символы объявленные в первом разделе главы, так как этот список достаточно большой и не
представляет большого интереса для разработчиков драйверов.
- #include <linux/mm.h>
-
В этом заголовочном файле определены прототипы всех функций и структур, имеющих отношение в подсистеме
управления памятью.
-
int remap_page_range(unsigned long virt_add, unsigned long phys_add, unsigned long size, pgprot_t prot);
-
Данная функция представляет собой сердце mmap. Она отображает size байтов физического адреса, начиная с адреса
phis_addr, в виртуальный адрес virt_add. В переменной prot определены биты защиты, связанные с виртуальным
пространством.
- struct page *virt_to_page(void *kaddr);
- void *page_address(struct page *page);
-
Эти макросы осуществляют преобразование между логическими адресами ядра и связанными с ними адресами
отображаемой памяти. Макрос page_address() работает только со страницами нижней (low-memory) и верхней
(high-memory), которые были явно отображены.
- void *__va(unsigned long physaddr);
- unsigned long __pa(void *kaddr);
-
Эти макросы осуществляют преобразование между логическими адресами ядра и физическими адресами.
- unsigned long kmap(struct page *page);
- void kunmap(struct page *page);
-
Функция kmap() возвращает адрес из виртуального пространства ядра, который отображается на данную страницу page,
создавая отображение при необходимости. Функция kunmap() удаляет это отображение для данной страницы page.
- #include <linux/iobuf.h>
- void kiobuf_init(struct kiobuf *iobuf);
- int alloc_kiovec(int number, struct kiobuf **iobuf);
- void free_kiovec(int number, struct kiobuf **iobuf);
-
Эти функции управляют распределением, инициализацией и освобождением буферов ввода/вывода ядра. Функция
kiobuf_init() инициализирует один kiobuf, и используется редко. Обычно, используется функция alloc_kiovec(),
которая распределяет и инициализирует вектор буферов kiobuf. Вектор буферов освобождается функцией
free_kiovec().
- int lock_kiovec(int nr, struct kiobuf *iovec[], int wait);
- int unlock_kiovec(int nr, struct kiobuf *iovec[]);
-
Эти функции устанавливают и снимают блокировку на вектор kiovec в памяти. Эти функции не являются необходимыми
при использовании буферов kiobuf в адресном пространстве пользователя.
- int map_user_kiobuf(int rw, struct kiobuf *iobuf, unsigned long address, size_t len);
- void unmap_kiobuf(struct kiobuf *iobuf);
-
Функция map_user_kiobuf() отображает буфер из адресного пространства пользователя в буфер ввода/вывода ядра.
Функция unmap_kiobuf() снимает это отображение.
- #include <asm/io.h>
- unsigned long virt_to_bus(volatile void * address);
- void * bus_to_virt(unsigned long address);
-
Данные функции выполняют преобразование между виртуальным адресом и адресом шины. Шинная адресация должна
использоваться для обращения к периферийным устройствам.
- #include <linux/pci.h>
-
В данном заголовочном файле определены следующие функции.
- int pci_dma_supported(struct pci_dev *pdev, dma_addr_t mask);
-
Данная функция определяет возможность поддержки DMA на системах, которые не могут адресоваться к полному 32-х
битовому диапазону адресов.
- void *pci_alloc_consistent(struct pci_dev *pdev, size_t size, dma_addr_t *bus_addr)
-
void pci_free_consistent(struct pci_dev *pdev, size_t size, void *cpuaddr, dma_handle_t bus_addr);
-
Эти функции распределяют и освобождают непрерывное отображение DMA, которое может останеться после работы
драйвера.
- PCI_DMA_TODEVICE
- PCI_DMA_FROMDEVICE
- PCI_DMA_BIDIRECTIONAL
- PCI_DMA_NONE
-
Эти символы используются для указания направления передачи данных (в/из буфера) функциям потокового
отображения (streaming mapping functions).
- dma_addr_t pci_map_single(struct pci_dev *pdev, void *buffer, size_t size, int direction);
- void pci_unmap_single(struct pci_dev *pdev, dma_addr_t bus_addr, size_t size, int direction);
-
Создание и уничтожение однопользовательского, потокового DMA отображения (single-use, streaming DMA mapping).
- void pci_sync_single(struct pci_dev *pdev, dma_handle_t bus_addr, size_t size, int direction)
-
Синхронизирует буфер, который имеет потоковое отображение. Эти функции должны использоваться, в случае, если
процессор должен получить доступ к буферу, в то время, когда потоковое отображение имеет место. Т.е. в то время,
пока устройство владеет буфером.
- struct scatterlist { /* ... */ };
- dma_addr_t sg_dma_address(struct scatterlist *sg);
- unsigned int sg_dma_len(struct scatterlist *sg);
-
Данная структура scatterlist описывает операции ввода/вывода, которые охватывают более одного буфера. Макросы
sg_dma_address() и sg_dma_len() могут быть использованы для извлечения шинных адресов и длин буферов для
передачи их в устройства, которые реализуют scatter-gather операции.
- pci_map_sg(struct pci_dev *pdev, struct scatterlist *list, int nents, int direction);
- pci_unmap_sg(struct pci_dev *pdev, struct scatterlist *list, int nents, int direction);
- pci_dma_sync_sg(struct pci_dev *pdev, struct scatterlist *sg, int nents, int direction)
-
pci_map_sg() отображает scatter-gather операции, а pci_unmap_sg() отменяет это отображение. Если доступ к буферу
необходим при активном отображении, то pci_dma_sync_sg() может быть использована для такой синхронизации.
- /proc/dma
-
Этот файл содержит текстовый "снимок" распределенных каналов контроллера DMA. DMA на шине PCI не
отображается, потому что каждый слот работает независимо, без необходимости распределения каналов в контроллере
DMA.
- #include <asm/dma.h>
-
В данном заголовочном файле содержатся определения всех функций и макросов, относящихся к операциям DMA. Он
должен быть включен, при использовании любого из следующих символов.
- int request_dma(unsigned int channel, const char *name);
- void free_dma(unsigned int channel);
-
Эти функции связаны с регистрацией каналов DMA. Регистрация должна быть выполнена перед использованием ISA DMA
каналов.
- unsigned long claim_dma_lock();
- void release_dma_lock(unsigned long flags);
-
Данные функции служат для захвата и освобождения спинлоков DMA, которые должны быть удержаны перед вызовом
других ISA DMA функций, описанных ниже в данном списке. Они также запрещают и, в последствии, разрешают
прерывания на локальном процессоре.
- void set_dma_mode(unsigned int channel, char mode);
- void set_dma_addr(unsigned int channel, unsigned int addr);
- void set_dma_count(unsigned int channel, unsigned int count);
-
Эти функции используются для передачи DMA информации в DMA контроллер. Аргумент addr представляет адрес на
шине.
- void disable_dma(unsigned int channel);
- void enable_dma(unsigned int channel);
-
Канал DMA должен быть запрещен во время конфигурирования. Эти функции изменяют статус канала DMA.
- int get_dma_residue(unsigned int channel);
-
Если вашему драйверу требуется информация о процессе передачи данных в сеансе DMA, то вы можете использовать эту
функцию, которая возвращает количество реально переданных данных. После успешного завершения цикла DMA, функция
возвращает 0. Если цикл передачи данных еще не начался, то значение функции непредсказуемо.
- void clear_dma_ff(unsigned int channel)
-
Режим DMA flip-flop используется контроллером для передачи 16-ти битовых значений за две 8-ми битовые операции.
Режим должен быть сброшен перед передачей каких-либо данных в контроллер.
|
| Leprekon | вау)) ничего не понял, для чего это?
2010-04-20 23:35:50 | |
|

 LINUX
LINUX 
 Books
Books
