Монтирование каталогов внутри UML
Есть 2 варианта монтирования каталога в UML-hostfs и humfs.
hostfs-более старый и ограниченный метод,но и более удобен.
В обоих случаях это виртуальная файловая система,которая хранится внутри ядра.
Если посмотреть на /proc/filesystems,
то можно увидеть что-то типа:
host% cat /proc/filesystems
nodev sysfs
nodev rootfs
nodev bdev
nodev proc
nodev sockfs
nodev binfmt_misc
nodev debugfs
nodev usbfs
nodev pipefs
nodev futexfs
nodev tmpfs
nodev eventpollfs
nodev devpts
ext2
nodev ramfs
nodev hugetlbfs
iso9660
nodev mqueue
nodev selinuxfs
ext3
nodev rpc_pipefs
nodev autofs
Все,что относится к nodev-это виртуальная файловая система
и относится к ядру.
Переменные и структуры данных ядра становятся видимыми как файл.
Следующий рисунок показывает разницу между различными типами файловых систем.
hostfs и humfs входят в состав ядра.
Они концептуально более похожи на сеть типа NFS.
Данные,хранимые в них,прозрачны и доступны снаружи.
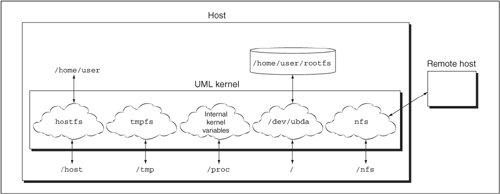
With a network filesystem, file accesses are translated into network requests to the server, which sends data and status back. With hostfs and humfs, file accesses are translated into file accesses on the host. You can think of this as a one-to-one translation of requestsa read, write, or mkdir within UML translates directly into a read, write, or mkdir to the host. This is actually not true in the most literal sense. An operation such as mkdir within one of these filesystems must create a directory on the host; therefore, it must translate into a mkdir there, but won't necessarily do so immediately. Because of caching with the filesystem, the operation may not happen until a long time later. Operations such as a read or write may not translate into a host read or write at all. They may, in fact translate into an mmap followed by directly reading or writing memory. And in any case, the lengths of the read and write operations will certainly change when they reach the host. Linux filesystem operations typically have page granularitythe minimum I/O size is a machine page, 4K on most extant systems. For example, a sequence of 1-byte reads will be converted into a single page-length read to the host followed by simply passing out bytes one at a time from the buffer into which that page was read.
So, while it is conceptually true that hostfs and humfs operations correspond one-to-one to host operations, the reality is somewhat different. This difference will become relevant later in this chapter when we look at simultaneous access to data from a UML and the host, or from two UMLs.
hostfs
hostfs is the older and simpler of the two ways to mount a host directory as a UML directory. It uses the most obvious mapping of UML file operations to host operations in order to provide access to the host files. This is complicated only by some technical aspects, such as making use of the UML page cache. This simplicity results in a number of limitations, which we will see shortly and which I will use to motivate humfs.
So, let's get a UML instance and make a hostfs mount inside it:
UML# mount none /mnt -t hostfs
Now we have a new filesystem mounted on /mnt:
UML# mount
/dev/ubd0 on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=4,mode=620)
shm on /dev/shm type tmpfs (rw)
none on /mnt type hostfs (rw)
Its contents show that it looks a lot like the host's root filesystem:
UML# ls /mnt
bin etc lib media opt sbin sys usr
boot home lib64 misc proc selinux tmp var
dev initrd lost+found mnt root srv tools
You can do the same ls on the host's / to verify this. Basically, we have mounted the host's root on the UML instance's /mnt, creating a completely normal Linux filesystem within the UML. For getting access to files on the host within UML, this is very convenient. You can do anything within this filesystem that you can do with a disk-based filesystem, with some restrictions that we will talk about later.
By default, when you make a hostfs mount, you get the host's root filesystem. This isn't always desirable, so there is an option to mount a different host directory:
UML# mkdir /mnt-home
UML# mount none /mnt-home/ -t hostfs -o /home
UML# ls /mnt-home/
jdike lost+found
The -o option specifies the host directory to mount. From that mount point, it is impossible to access any files outside that directory. In our case, the /mnt-home mount point gives us access to the host's /home, but, from there, we can't access anything outside of that. The obvious trick of using .. to try to access files outside of /home won't work because it's the UML that will interpret the .., not the host. Trying to "dotdot" your way out of this will get you to the UML instance's /, not the host's /.
Using -o is at the option of the user within the instance. Many times, the host administrator wants all hostfs mounts confined to a host subdirectory and makes it impossible to access the host's /. There is a command-line option to UML to allow this, hostfs=/path/to/UML/jail. With this enabled, hostfs mounts within the UML will be restricted to the specified host subdirectory. If the UML user does a mount specifying a mount path with -o, that path will be appended to the directory on the command line. So, -o can be used to mount subdirectories of whatever directory the UML's hostfs has been confined to, but can't be used to escape it.
Now, let's create a file within the host mount:
UML# touch /mnt/tmp/uml-file
UML# ls -l /mnt/tmp/uml-file
-rw-r--r-- 1 500 500 0 Jun 10 13:02 /mnt/tmp/uml-file
The ownerships on this new file are somewhat unexpected. We are root inside the UML, and thus expect that any new files we create will be owned by root. However, we are creating files on the host, and the host is responsible for the file, including its ownerships. The UML instance is owned by user ID (UID) 500, so from its point of view, a process owned by UID 500 created a file in /tmp. It's perfectly natural that it would end up being owned by that UID. The host doesn't know or care that the process contains another Linux kernel that would like that file to be owned by root.
This seems perfectly reasonable and innocent, but it has a number of consequences that make hostfs unusable for a number of purposes. To demonstrate this, let's become a different, unprivileged user inside UML and see how hostfs behaves:
UML# su user
UML% cd /mnt/tmp
UML% echo foo > x
UML% ls -l x
-rw-r--r-- 1 500 500 4 Jun 10 14:31 x
UML% echo bar >> x
sh: x: Permission denied
UML% rm x
rm: remove write-protected regular file `x'? y
rm: cannot remove `x': Operation not permitted
UML% chmod 777 x
chmod: changing permissions of `x': Operation not permitted
Here we see a number of unexpected permission problems arising from the ownership of the new file. We created a file in the host's /tmp and found that we couldn't subsequently append to it, remove it, or change its permissions.
It is created with the owner UID 500 on the host and is writable by that UID. However, I became user, with UID 1001, inside the UML instance, so my attempts to modify the file don't even make it past the UML's permission checking. When the file was created on the host, it was given its ownership and permissions by the host. hostfs shows those permissions, rather than the ones the UML instance provided, because they are more "real."
The ownership and permissions are interpreted locally by the UML when seeing whether a file operation should succeed. The fact that the file ownerships are set by the host to something different from what the UML expects can cause files to be unmodifiable by their owner within UML.
This isn't a problem for the root user within UML because the superuser doesn't undergo the same permission checks as a normal user, so the permission checks occur on the host.
However, this issue does make it impossible for multiple users within the UML to use hostfs. In fact, only root within the UML can realistically use it. The only way for a normal UML user to use hostfs is for its UID to match the host UID that the UML is running as. So, if user within UML had UID 500 (matching the UML instance's UID on the host), the previous example would have been more successful.
Let's look at another problem, in which root within the UML doesn't have permission to do some things that it should be able to do:
UML# mknod ubda b 0 98
mknod: `ubda': Operation not permitted
Here, creating a device node for ubda doesn't work, even for root. Again, the reason is that the operation is forwarded to the host, where it is attempted as the nonroot UML user, and fails because this operation requires root privileges. You will see similar problems with creating a couple of other types of files.
If you experiment long enough with hostfs, you will discover other problems, such as accessing UNIX sockets. If the hostfs mount contains sockets, they were created by processes on the host. When one is opened on the host, it can be used to communicate with the process that created it. However, they are visible within a hostfs mount, but a UML process opening one will fail to communicate with anything. The UML kernel, not the host kernel, will interpret the open request and attempt to find the process that created it. Within the UML kernel, this will fail because there is no such process.
Creating a directory on the host with a UML root filesystem in it, and booting from it, is also problematic. The filesystem, by and large, should be owned by root, and it won't be. All of the files are owned by whoever created them on the host. At this writing, there is a kludge in the hostfs code that changes (internally to the UML kernel) the ownerships of these files to root when the hostfs filesystem is the UML root filesystem. This makes booting from hostfs work, more or less, but all the problems described above are still there. Other kernel developers have objected to this ownership changing, and this kludge likely won't be available much longer. When this "feature" does disappear, booting from a hostfs root filesystem likely won't work anymore.
I've spent a good amount of time describing the deficiencies of hostfs, but I'd like to point out that, for a common use case, hostfs is exactly what you want. If you have a private UML instance, are logged in to it as root, and want access to your own files on the host, hostfs is perfect. The filesystem semantics will be exactly what you expect, and no prior host setup is needed. Just run the hostfs mount command, and you have all of your files available.
Most of the problems with hostfs that I've described stem from the fact that all hostfs file operations go through both the UML's and the host's permission checking. This is because both systems look at the same data, the file metadata on the host, in order to decide what's allowed and what's not.
UNIX domain sockets and named pipes are sort of a reflection of a process within the filesystemthere is supposed to be a process at the other end of it. When the filesystem (including the sockets) is exported to another system, whether a UML instance with a hostfs mount or another system with an NFS mount, the process isn't present on the other system. In this case, the file doesn't have the meaning it does on its home system.
humfs
We can fix these problems by making sure we see, inside UML, distinct file ownerships, permissions, and types from the host. To achieve this, UML can store these in a separate place, freeing itself from the host's permission checks. This is what humfs does. The actual file data is stored in exactly the same way that hostfs doesin a directory hierarchy on the host. However, permissions information is stored separately, by default, in a parallel directory hierarchy.
For example, here are the data and metadata for a file stored in this way:
host% ls -l data/usr/bin/ls
-rwxr-x--x 1 jdike jdike 201642 May 1 10:01 data/usr/bin/ls
host% ls -l file_metadata/usr/bin/ls
-rw-r--r-- 1 jdike jdike 8 Jun 10 18:04 file_metadata/usr/bin/ls
host% cat file_metadata/usr/bin/ls
493 0 0
The actual ls binary is stored in data/usr/bin/ls, while its ownership and permissions are stored in file_metadata/usr/bin/ls. Notice that the permissions on the binary are wide open for the file's owner. This, in effect, disables permission checking on the host, allowing UML's ideas about what's allowed and what's not to prevail.
Next, notice the contents of the metadata file. For a normal file, such as /usr/bin/ls, the permissions and ownerships are stored here. In the last line of the output, 493 is the decimal equivalent of 0755, and the zeros are UID root and group ID (GID) root.
We can see this by looking at this file inside UML:
UML# ls -l usr/bin/ls
-rwxr-xr-x 1 root root 201642 May 1 10:01 usr/bin/ls
The humfs filesystem has taken the file size and date from data/usr/bin/ls and merged the ownership and permission information from file_metadata/usr/bin/ls.
By storing this metadata as the contents of a file on the host, UML may modify it in any way it sees fit. We can go through the list of hostfs problems I described earlier and see why this approach fixes them all.
In the case of a new file having unexpected ownerships, we can see that this just doesn't happen in humfs. The data file's ownership will, in fact, be determined by the UID and GID of the UML process, but this doesn't matter since the ownerships you will see inside UML will be determined by the contents of the file_metadata file.
So, you will be able to create a file on a humfs mount and do anything with it, such as append to it, remove it, or change permissions.
Now, let's try to make a block device:
UML# mknod ubda b 98 0
UML# ls -l ubda
brw-r--r-- 2 root root 98, 0 Jun 10 18:46 ubda
This works, and it looks as we would expect. To see why, let's look at what occurred on the host:
host% ls -l data/tmp/ubda
-rwxrw-rw- 1 jdike jdike 0 Jun 10 18:46 data/tmp/ubda
host% ls -l file_metadata/tmp/ubda
-rw-r--r-- 1 jdike jdike 15 Jun 10 18:46 file_metadata/tmp/ubda
host% cat file_metadata/tmp/ubda
420 0 0 b 98 0
The file is empty, just a token to let the UML filesystem know a file is there. Almost all of the device's data is in the metadata file. The first three elements are the same permissions and ownership information that we saw earlier. The rest, which don't appear for normal files, describe the type of file, namely, a block device with major number 98 and minor number 0.
The host definitely won't recognize this as a block device, which is why this works. Creating a device requires root privileges, so hostfs can't create one unless the UML is run by root. Under humfs, creating a device is simply a matter of creating this new file with contents that describe the device.
It is apparent that the host socket and named pipe problem can't happen on this filesystem. Everything in this directory on the host is a normal file or directory. Host sockets and named pipes just don't exist. If a UML process makes a UNIX domain socket or a named pipe, that will cause the file's type to appear in the metadata file.
Along with these advantages, humfs has one disadvantage: It needs to be set up beforehand. You can't just take an arbitrary host subdirectory and mount it as a humfs filesystem. So, humfs is not really useful for quick access to your files on the host.
In order to set up humfs, you need to decide what's going to be in your humfs mount, create an empty directory, copy the files to the data subdirectory, and run a script that will create the metadata. As a quick example, here's how to create a humfs version of your host's /bin.
host% mkdir humfs-test
host% cd humfs-test
host# cp -a /bin data
host# perl ..humfsify.pl jdike jdike 100M
host% ls -al
total 24
drwxrw-rw- 5 jdike jdike 4096 Jun 10 19:40 .
drwxrw-r-- 16 jdike jdike 4096 Jun 10 19:40 ..
drwxrwxrwx 2 jdike jdike 4096 May 23 12:12 data
drwxr-xr-x 2 jdike jdike 4096 Jun 10 19:40 dir_metadata
drwxr-xr-x 2 jdike jdike 4096 Jun 10 19:40 file_metadata
-rw-r--r-- 1 jdike jdike 58 Jun 10 19:40 superblock
Two of the commands, the creation of the data subdirectory and the running of humfsify, have to be run as root. The copying of the directory needs to preserve file ownerships so that humfsify can record them in the metadata, and humfsify needs to change those ownerships so that you own all the files.
We now have two metadata directories, one for files and one for directories, and a superblock file. This file contains information about the filesystem as a whole, rather like the superblock on a disk-based filesystem:
host% cat superblock
version 2
metadata shadow_fs
used 6877184
total 104857600
This tells the UML filesystem:
What version of humfs it is dealing with What metadata format is being used How much disk space is used How much total disk space is available
The shadow_fs metadata format describes the parallel metadata directories. There are some other possibilities, which will be described later in this section. The total disk space amount is simply the number given to humfsify. This number is used by the filesystem within UML to enforce the limit on disk consumption. Quotas on the host can be used, but they are not necessary.
You may have noticed that it would be particularly easy to change the amount of disk space in this filesystem. Simply changing the total field by editing this file would seem to do the trick, and it does. At this writing, this ability is not implemented, but it is simple enough and easy enough to do that it will be implemented at some point.
Now, having created the humfs directory, we can mount it within the UML:
UML# mkdir /mnt-test
UML# mount none /mnt-test -t humfs -o \
path=/home/jdike/linux/humfs-test
UML# cd /mnt-test
If you do an ls at this point, you'll see your copy of the host's /bin. Note that the mount command is very similar to the hostfs mount command. It's a virtual filesystem, so we're telling it to mount none since there is no block device associated with it, and we specify the filesystem type and the host mount point. In the case of humfs, specifying the host mount point is mandatory because it must be prepared ahead of time. humfs is passed the root of the humfs tree, which is the directory in which the data and metadata directories were created.
You can now do all the things that didn't work under humfs and see that they do work here. humfs works as expected in all cases, with no interference from the host's permission checking. So, humfs is usable as a UML root filesystem, whereas hostfs can be used only with some trickery.
Now I'll cover some aspects of humfs that I didn't explain earlier. First, version 2 of humfs was created because version 1 had a bug, and fixing that bug led to the separate file_metadata and dir_metadata directories. As we've seen, the metadata files for files are straightforward. Directories have ownerships and permissions and need meta-data files, but they introduce problems in some corner cases.
The initial shadowfs design required a file called metadata in each directory in the metadata tree that would hold the ownerships and permissions for the parent directory. Of course, each file in the original directory would have a file in the metadata tree with the same name. But I missed this case: What metadata file should be used for a file called metadata? Both the file and the parent directory would want to use the same metadata file, metadata.
Another problem occurs with a subdirectory called metadata. In this case, the metadata file will want to be both a directory (because the metadata directory structure is identical to the data directory structure) and a file (because the parent directory will want to put its metadata there.
The solution I chose was to separate the file and directory metadata information from each other. With them in separate directory trees, the first collision I described doesn't exist. However, the second does. The solution to that is to allow the metadata directory to be created, and rename the parent directory's metadata file. It turns out that it can be renamed to anything that doesn't collide with a subdirectory. The reason is that in the dir_metadata tree, there will be only one normal file in each directory. If metadata is a directory, the humfs filesystem will need to scan the directory for a normal file, and that will be the metadata file for the parent directory.
The next question is this: Why do we specify the metadata format in the superblock file? When I first introduced humfs, with the version 1 shadow_fs format, there were a bunch of suggestions for alternate formats. They generally have advantages and disadvantages compared to the shadow_fs format, and I thought it would be interesting to support some of them and let system administrators choose among them.
These proposals came in two classesthose that preserved some sort of shadow metadata directory hierarchy, and those that put the metadata in some sort of database. An interesting example of the first class was to make all of the metadata files symbolic links, rather than normal files, and store the metadata in the link target. This would make them dangling links, as the targets would not exist, but it would allow somewhat more efficient reading of the metadata.
Reading a file requires three system calls: an open, a read, and a close. Reading the target of a symbolic link requires onea readlink. Against this slight performance gain, there would be some loss of manageability, as system administrators and their tools expect to read contents of files, not targets of symbolic links.
The second class of proposals, storing metadata in databases of various sorts, is also interesting. Depending on the database, it could allow for more efficient retrieval of metadata, which is nice. However, what makes it more interesting to me is that the database could be used on the host to do queries much more quickly than with a normal filesystem. The host administrator could ask questions about what files had been modified recently or what files are setuid root and could get answers very quickly, without having to search the entire filesystem.
Even more interesting would be the ability to import this capability into the UML, where the UML administrator, who probably cares about the answers more than the host administrator does, could ask these questions. I'm planning to allow this through yet another filesystem, which would make a database look like a filesystem. The UML admin would mount this filesystem inside the UML and query the database underneath it this like:
UML# cat /sqlfs/"select name from root_fs where setuid = 1"
/usr/bin/newgrp
/usr/bin/traceroute6
/usr/bin/chfn
/usr/bin/chsh
/usr/bin/gpasswd
/usr/bin/passwd
The "file" associated with a query would contain the results of that query. In the example above, we searched the database for all setuid files, and the results came back as the contents of a file.
With humfs, only the file metadata would be indexed in the data-base. It is possible to do the same thing with the contents of files. This would take a different framework than that which enables humfs but is still not difficult. It would be possible to load a UML filesystem into a database, be it SQL, Glimpse, or Google, and have that database imported into UML as a bootable filesystem. Queries to the database would be provided by a separate filesystem, as described earlier. In this way, UML users would have access to their files through any database the host administrator is willing to provide.
An alternate use of this is to load some portion of your data, such as your mail, into such a database-backed filesystem. These directories and files will remain accessible in the normal way, but the database interface to them will allow you to search the file contents more quickly than is possible with utilities such as find and grep. For example, loading your mail directory into a filesystem indexed by something like Glimpse would give you a very fast way to search your mail. It would still be a normal Linux filesystem, so mail clients and the like would still work on it, and the index would be kept up to date constantly since the filesystem sees all changes and feeds them into the index. This means that you could search for something soon after it is created (and find it) rather than waiting for the next indexing run, which would probably be in the wee hours, making the change visible in the index the following day.
Host Access to UML Filesystems
To round out this discussion of UML filesystem options, we need to take another look at the standard ubd block device. Both humfs and hostfs allow easy access on the host to the UML's file since both mount host directory hierarchies into UML. With hostfs, these files can be manipulated directly.
With humfs, some knowledge of the directory layout is necessary. Changing the contents of a file is done in the expected way, while changing metadatapermissions, ownerships, and file type in the case of devices, sockets, and named pipesrequires that the contents of the metadata file be changed, rather than simply using the usual tools such as chmod and chown. In the case of a database representation of the metadata, this would require a database update.
A ubd device allows even less convenient access to the UML's files, as a filesystem image is a rather opaque storage medium. However, loop-mounting the image on the host provides hostfs-like access to the files. This works as follows:
host# mount uml-root-fs host-mount-point -o loop
After this, the UML filesystem is available as a normal directory hierarchy under host-mount-point. However, the UML should not be running at this point, since there is no guarantee that the filesystem is consistent. There may be data cached inside the UML that hasn't been flushed out to the filesystem image and that is needed in order for the filesystem to be consistent. Second, any sort of mount requires root privileges. So, while a loopback-mount makes a ubd device look like a hostfs directory, it is necessary to be root on the host and, normally, for the UML to not be running. In the next section, we'll look at a way around this last restriction and describe a method for getting a consistent backup from a running UML instance.
This consistency problem is also present with hostfs and humfs. By default, they cache changes to their files inside the UML page cache, writing them out later. If you change a hostfs or humfs file, you probably won't see the change on the host immediately. When hostfs is used as a file transfer mechanism between the UML instance and the host, this can be a problem. It can be solved by mounting the filesystem synchronously, so that all changes are written immediately to the host. This is most easily done by adding sync to the options field in the UML /etc/fstab file:
none /host hostfs sync 0 0
If the filesystem is already mounted, it can be remounted to be synchronous without disturbing anything that might already be using it:
mount -o remount,sync /host
Doing this will decrease the performance of the filesystem, as the amount of I/O that it does will be greatly increased.
hostfs is more likely to be used as a file transfer mechanism between the UML instance and the host since the humfs directory structure doesn't lend itself as well to being used in this way. A host directory can also be shared with hostfs between multiple UML instances without problems because the filesystem consistency is maintained by the host. Delays in seeing file updates will happen with a hostfs mount shared by multiple UML instances just as they happen when the mount is shared by the host and UML instance. To avoid this, the hostfs directories have to be mounted synchronously by all of the UML instances.
The hostfs directory does not have to be mounted synchronously on the hostchanges made by the host are immediately visible.
Making Backups
The final point of comparison between ubd devices, hostfs, and humfs is how to back them up on the host. hostfs should normally be used only for access to host files that don't form a UML filesystem, so the question of specifically backing them up shouldn't arise. However, if a directory on the host is expected to be mounted as a hostfs mount, backing it up on the host can be done normally, using any backup utility desired. The consistency of the hierarchy is guaranteed by the host since it's a normal host filesystem. Any changes that are still cached inside the UML will obviously not be captured by a backup, but this won't affect the consistency of a backup.
humfs is a bit more difficult. Since file metadata is stored separately from the file, a straightforward backup on the host could possibly be inconsistent if the filesystem is active within the UML. For example, when a humfs file is deleted, both the data file and the meta-data file (in the case of the shadow_fs metadata format) must be deleted. If the backup is taken between these two deletions, it will be inconsistent, as it will show a partially deleted file. The obvious way around this problem is to ensure that the humfs filesystem isn't mounted at the time of the backup, either by shutting down the UML or by having it unmount the filesystem. This last option might be difficult if the humfs filesystem is the UML's root.
However, there is a neat trick to get around this problem: a facility within Linux called Magic SysRq. On a physical system, this involves using the SysRq key in combination with some other key in order to get the kernel to do one of a set of operations. This is normally used in emergencies, to exercise some degree of control over the machine when nothing else works. One of the functions provided by the facility is to flush all filesystem changes to stable storage. On a physical machine, this would normally be done prior to crashing it by turning off the power or hitting the reset button. Flushing out dirty data ensures that the filesystems will be in good shape when the system is rebooted.
In addition to this, UML's mconsole facility provides the ability to stop the virtual machine, so that it only listens to mconsole requests, and later continue it.
The trick involves these three operations:
host% uml_mconsole umid stop
OK
host% uml_mconsole umid sysrq s
OK
host% uml_mconsole umid go
OK
Here, we stop the UML, force it to sync all data to disk (sysrqs), and restart it.
When this is being done as part of a backup procedure, the actual backup would take place between the sysrq s command and continuing the UML.
Finally, backing up ubd filesystem images involves the same considerations as humfs filesystems. Without taking care, you may back up an inconsistent image, and booting a UML on it may not work. However, in lieu of shutting down the UML, the mconsole trick I just described for a humfs filesystem will work just as well for a ubd image. If the ubd filesystem uses a COW layer, this can be extremely fast. In this case, only the COW file needs to be copied, and if it is largely empty, and the backup tool is aware of sparse files, a multigigabyte COW file can be copied to a safe place in a few seconds.
Extending Filesystems
Sometimes you might set up a filesystem for a UML instance that sub-sequently turns out to be too small. For the different types of file-systems we have covered in this chapter, there are different options.
By default, the space available in a hostfs mount is the same as in the host filesystem in which the data resides. Increasing this requires either deleting files to increase the amount of free space or increasing the size of the filesystem somehow. If the filesystem resides on a logical volume, a free disk partition can be added to the corresponding volume group. Otherwise, you will need to move the hostfs data to a different partition or repartition the disk to increase the size of the existing partition.
Another option is to control the space consumption on hostfs mounts by using quotas on the host. By running different UML instances as different UIDs and assigning disk quotas to those UIDs, you can control the disk consumption independently of the space that's actually available on the host filesystem. In this case, increasing the space available to a UML instance on a hostfs mount is a matter of adjusting its disk quota on the host.
As we saw earlier, you can change the size of a humfs mount by changing the value on the total line in the superblock file.
The situation with a ubd block device is more complicated. Increasing the size of the host file is simple:
host% dd if=/dev/zero of=root_fs bs=1024 \
seek=$[ 2 * 1024 * 1024 ] count=1
This increases the size of the root_fs file to 2GB. A more complicated problem is making that extra space available within the UML filesystem. Some but not all filesystems support being resized without making a backup and recreating the filesystem from scratch. Fewer support being resized without unmounting the filesystem. One that does is ext2 (and ext3 since it has a nearly identical on-disk format). By default, ext2online resizes the filesystem to fill the disk that it resides on, which is what you almost always want:
UML# ext2online /dev/ubda
You can also specify the mount point rather than the block device, which may be more intuitive and less error prone:
With other filesystems, you may have to unmount the filesystem before resizing it to fill the device. If the filesystem in question is the UML instance's root filesystem, you will likely need to halt the instance and resize the filesystem on the host.
For filesystems that don't support resizing at all, you have to copy the data to someplace else and recreate the filesystem from scratch using mkfs. Then you can copy your data back into it. Again, if this is the root filesystem of the UML instance, you will need to shut it down and then recreate the filesystem on the host.
When to Use What
Now that you have learned about these three mechanisms for providing filesystem data to a UML, the question remains: Under what circumstances should you use each of them? The answer is fairly easy for hostfsnormally, it should be used only for access to host files that belong to the user owning the UML or to files that are available readonly. In the first case, the user should be logged in to the UML as root, and there should be no other UML users accessing the hostfs mount. In the second, the read-only restriction avoids all of the permission and ownership issues with hostfs.
humfs hierarchies and ubd images can be used to provide general-purpose filesystems, including root filesystems. humfs provides easier access to the UML files, although some care is needed when changing those files in order to ensure that the file metadata is updated properly.
There are also some potential efficiency advantages with both humfs and ubd devices. An issue with host memory consumption is that both the host and UML will generally cache file data separately. As a result, the host's memory will contain multiple copies of UML file data, one in the host's page cache and one for each UML that has read the data.
ubd devices can avoid this double caching by using O_DIRECT I/O on 2.6 hosts. O_DIRECT avoids the use of the host page cache, so the only copies of the data will be in the UMLs that have read it. In order to truly minimize host memory consumption, this should be used only for data that's private to the UML, such as a private filesystem image or a COW file. For a COW file, the memory savings obtained by avoiding the double caching are probably outweighed by the duplicate caching of the backing file data in the UMLs that are sharing it.
For shared data, humfs avoids the double caching by mapping the data from the host. The data is cached on the host, but mapping it provides the UML with the same page of memory that's in the host page cache. Taking advantage of this would require a form of COW for humfs, which currently doesn't exist. A file-level form of COW is possible and may exist by the time you read this. With this, a humfs equivalent of a backing file, in the form of a read-only host directory hierarchy, would be mapped into the UMLs that share it. They would all share the same memory, so there would be only one copy of it in the host's memory.
In short, both ubd devices and humfs directories have a place in a well-run UML installation. The use of one or the other should be driven by the importance of convenient host access to the UML filesystem, the ease and speed of making backups of the data, and avoidance of excessive host memory consumption.
Chapter 7. UML Networking in Depth
Manually Setting Up Networking
TUN/TAP with Routing
In earlier chapters we briefly looked at how to put a UML on the network. Now we will go into this area in some depth. The most involved part is setting up the host when the UML will be given access to the physical network. The host is responsible for transmitting packets between the network and the UML, so correct setup is essential for a working UML network.
There are two different methods for configuring the host to allow a UML access to the outside world: routing packets to and from the UML and bridging the host side of the virtual interface to the physical Ethernet device. First we will use the former method, which is more complicated. We will start with a completely unconfigured host, on which a UML will fail to get access to the network, and, step by step, we'll debug it until the UML is a fully functional network node. This will provide a good understanding of exactly what needs to be done to the host and will allow you to adapt it to your own needs. The step-by-step debugging will also show you how to debug connectivity problems that you encounter on your own.
Later in this chapter, we will cover the second method, bridging. It is simpler but has disadvantages and pitfalls of its own.
Configuring a TUN/TAP Device
We are going to use the same host mechanism, TUN/TAP, as before. Since we are doing this entirely by hand, we need to provide a TUN/TAP device for the UML to attach to. This is done with the tunctl utility:
host% tunctl
Failed to open '/dev/net/tun' : Permission denied
This is the first of many roadblocks we will encounter and overcome. In this case, we can't manipulate TUN/TAP devices as a normal user because the permissions on the control device are too restrictive:
host% ls -l /dev/net/tun
crw------- 1 root root 10, 200 Jul 30 07:36 /dev/net/tun
I am going to do something that's a bit risky from a security standpointchange the permissions to allow any user to create TUN/TAP devices:
host# chmod 666 /dev/net/tun
When the TUN/TAP control device is open like this, any user can create an interface and use it to inject arbitrary packets into the host networking system. This sounds nasty, but the actual practicality of an attack is doubtful. When you can construct packets and get the host to route them, you can do things like fake name server, DHCP, or Web responses to client requests. You could also take over an existing connection by faking packets from one of the parties. However, faking a server response requires knowing there was a request from a client and what its contents were. This is difficult because you have set yourself up to create packets, not receive them. Receiving packets still requires help from root.
Faking a server response without knowing whether there was an appropriate request requires guessing and spraying responses out to the network, hoping that some host has just sent a matching request and will be faked out by the response. If successful, such an attack could persuade a DHCP client to use a name server of your choice. With a maliciously configured name server, this would allow the attacker to see essentially all of the client's subsequent network traffic since nearly all transactions start with a name lookup.
Another possibility is to fake a name server response. If successful, this would allow the attacker to intercept the resulting connection, with the possibility of seeing sensitive data if the intercepted connection is to a bank Web site or something similar.
However, opening up /dev/net/tun as I have just done would require that such an attack be done blind, without being able to see any incoming packets. So, attacks on clients must be done randomly, which would require very high amounts of traffic for even a remote chance of success. Attacks on existing connections must similarly be done blind, with the added complication that the attack must correctly guess a random TCP sequence number.
So, normally, a successful attack would be remote. However, you should take this possibility seriously. The permissions on /dev/net/ tun are a layer of protection against this sort of attack, and removing it increases the possibility of being attacked using an unrelated vulnerability. For example, if there was an exploit that allowed an attacker to sniff the network, the arguments I just made about how unlikely a successful attack would be go right out the window. Attacks would no longer be blind, and the attacker could see DHCP and name requests and try to respond to them through a TUN/TAP device, with good chances of success. In this case, the /dev/net/tun permissions would have likely stopped the attacker.
So, before opening up /dev/net/tun, consider whether you have untrusted, and possibly malicious, users on the host and whether you think there is any possibility of holes that would allow outsiders to gain shell access to the host. If that is remotely possible, you may consider a better option, which is used by Debiancreate a uml-users group and make /dev/net/tun accessible only to members of that group. This reduces the number of accounts that could possibly be used to attack your network. It doesn't eliminate the risk, as one of those users could be malicious, or an outsider could gain access to one of those accounts.
However you have decided to set up /dev/net/tun, you should have read and write access to it, either as a normal user or as a member of a uml-users group. Once this is done, you can try the tunctl command again and it will succeed:
host% tunctl
Set 'tap0' persistent and owned by uid 500
This created a new TUN/TAP device and made it usable by the tunctl user.
For scripting purposes, a -b option makes tunctl output only the new device name:
This eliminates the need to parse the relatively verbose output from the first form of the command.
There are also -u and -t options, which allow you to specify, respectively, which user the new TUN/TAP device will belong to and which TUN/TAP device that will be:
host# tunctl -u jdike -t jeffs-uml
Set 'jeffs-uml' persistent and owned by uid 500
This demonstrates a highly useful feature: the ability to give arbitrary names to the devices. Suitably chosen, these can serve as partial documentation of your UML network setup. We will use this jeffs-uml device from now on.
For cleanliness, we should shut down all of the TUN/TAP devices created by our playing with tunctl with commands such as the following:
host% tunctl -d tap0
Set 'tap0' nonpersistent
ifconfig -a will show you all the network interfaces on the system, so you should probably shut down all of the TUN/TAP devices except for the last one you made and any others created for some other specific reason.
The first thing to do is to enable the device:
host# ifconfig jeffs-uml 192.168.0.254 up
host# ifconfig jeffs-uml
jeffs-uml Link encap:Ethernet HWaddr 2A:B1:37:41:72:D5
inet addr:192.168.0.254 Bcast:192.168.0.255 \
Mask:255.255.255.0
inet6 addr: fe80::28b1:37ff:fe41:72d5/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:5 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
As usual, choose an IP address that's suitable for your network. If IP addresses are scarce, you can reuse one that's already in use by the host, such as the one assigned to its eth0.
Basic Connectivity
Let's add a new interface to a UML instance. If you have an instance already running, you can plug a new network interface into it by using uml_mconsole:
uml_mconsole debian config eth0=tuntap,jeffs-uml
OK
If you are booting a new UML instance, you can do the same thing on the command line by adding eth0=tuntap,jeffs-uml.
This differs from the syntax we saw earlier. Before, we specified an IP address and no device name. Here, we specify the device name but not an IP address. When no device name is given, that signals the driver to invoke the uml_net helper to configure the host. When a name is given, the driver uses it and assumes that it has already been configured appropriately.
Now that the instance has an Ethernet device, we can configure it and bring it up:
UML# ifconfig eth0 192.168.0.253 up
Let's try pinging the host:
UML# ping 192.168.0.254
PING 192.168.0.254 (192.168.0.254): 56 data bytes
--- 192.168.0.254 ping statistics ---
28 packets transmitted, 0 packets received, 100% packet loss
Nothing but silence. The usual way to start debugging problems like this is to sniff the interface using tcpdump or a similar tool. With the ping running again, we see this:
host# tcpdump -i jeffs-uml -l -n
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on jeffs-uml, link-type EN10MB (Ethernet), capture \
size 96 bytes
18:12:34.115634 IP 192.168.0.253 > 192.168.0.254: icmp 64: echo \
request seq 0
18:12:35.132054 IP 192.168.0.253 > 192.168.0.254: icmp 64: echo \
request seq 256
Ping requests are coming out, but no replies are getting back to it. This is a routing problemwe have not yet set any routes to the TUN/TAP device, so the host doesn't know where to send the ping replies. This is easily fixed:
host# route add -host 192.168.0.253 dev jeffs-uml
Now, pinging from the UML instance works:
UML# ping 192.168.0.254
PING 192.168.0.254 (192.168.0.254): 56 data bytes
64 bytes from 192.168.0.254: icmp_seq=0 ttl=64 time=0.7 ms
64 bytes from 192.168.0.254: icmp_seq=1 ttl=64 time=0.1 ms
64 bytes from 192.168.0.254: icmp_seq=2 ttl=64 time=0.1 ms
--- 192.168.0.254 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.1/0.3/0.7 ms
It's always a good idea to check connectivity in both directions, in case there is a problem in one direction but not the other. So, check whether the host can ping the instance:
host% ping 192.168.0.253
PING 192.168.0.253 (192.168.0.253) 56(84) bytes of data.
64 bytes from 192.168.0.253: icmp_seq=0 ttl=64 time=0.169 ms
64 bytes from 192.168.0.253: icmp_seq=1 ttl=64 time=0.077 ms
--- 192.168.0.253 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.077/0.123/0.169/0.046 ms, pipe 2
So far, so good. The next step is to ping a host on the local network by its IP address:
UML# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3): 56 data bytes
--- 192.168.0.3 ping statistics ---
7 packets transmitted, 0 packets received, 100% packet loss
No joy. Using tcpdump to check what's happening shows this:
host# tcpdump -i jeffs-uml -l -n
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on jeffs-uml, link-type EN10MB (Ethernet), capture \
size 96 bytes
18:20:29.522769 arp who-has 192.168.0.3 tell 192.168.0.253
18:20:30.524576 arp who-has 192.168.0.3 tell 192.168.0.253
18:20:31.522430 arp who-has 192.168.0.3 tell 192.168.0.253
The UML instance is trying to figure out the Ethernet MAC address of the target. To this end, it's broadcasting an arp request on its eth0 interface and hoping for a response. It's not getting one because the target machine can't hear the request. arp requests, like other Ethernet broadcast protocols, are limited to the Ethernet segment on which they originate, and the UML eth0 to host TUN/TAP connection is effectively an isolated Ethernet strand with only two hosts on it. So, the arp requests never reach the physical Ethernet where the other machine could hear it and respond.
This can be fixed by using a mechanism known as proxy arp and enabling packet forwarding. First, turn on forwarding:
host# echo 1 > /proc/sys/net/ipv4/ip_forward
Then enable proxy arp on the host for the TUN/TAP device:
host# echo 1 > /proc/sys/net/ipv4/conf/jeffs-uml/proxy_arp
This will cause the host to arp to the UML instance on behalf of the rest of the network, making the host's arp database available to the instance. Retrying the ping and watching tcpdump shows this:
host# tcpdump -i jeffs-uml -l -n tcpdump: verbose output \
suppressed, use -v or -vv for full protocol decode
listening on jeffs-uml, link-type EN10MB (Ethernet), capture \
size 96 bytes
19:25:16.465574 arp who-has 192.168.0.3 tell 192.168.0.253
19:25:16.510440 arp reply 192.168.0.3 is-at ae:42:d1:20:37:e5
19:25:16.510648 IP 192.168.0.253 > 192.168.0.3: icmp 64: echo \
request seq 0
19:25:17.448664 IP 192.168.0.253 > 192.168.0.3: icmp 64: echo \
request seq 256
There is still no pinging, but the arp request did get a response. We can verify this by seeing what's in the UML arp cache.
UML# arp
Address HWtype HWaddress Flags Mask \
Iface
192.168.0.3 ether AE:42:D1:20:37:E5 C \
eth0
If you see nothing here, it's likely because too much time elapsed between running the ping and the arp, and the arp entry got flushed from the cache. In this case, rerun the ping, and run arp immediately afterward.
Since the instance is now getting arp service for the rest of the network, and ping requests are making it out through the TUN/TAP device, we need to follow those packets to see what's going wrong. On my host, the outside network device is etH1, so I'll watch that. On other machines, the outside network will likely be eth0. It's also a good idea to select only packets involving the UML, to eliminate the noise from other network activity:
host# tcpdump -i eth1 -l -n host 192.168.0.253
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on eth1, link-type EN10MB (Ethernet), capture size \
96 bytes
19:36:14.459076 IP 192.168.0.253 > 192.168.0.3: icmp 64: echo \
request seq 0
19:36:14.461960 arp who-has 192.168.0.253 tell 192.168.0.3
19:36:15.460608 arp who-has 192.168.0.253 tell 192.168.0.3
Here we see a ping request going out, which is fine. We also see an arp request from the other host for the MAC address of the UML instance. This is going unanswered, so this is the next problem.
We set up proxy arp in one direction, for the UML instance on behalf of the rest of the network. Now we need to set it up in the other direction, for the rest of the network on behalf of the instance, so that the host will respond to arp requests for the instance:
host# arp -Ds 192.168.0.253 eth1 pub
Retrying the ping gets some good results:
UML# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3): 56 data bytes
64 bytes from 192.168.0.3: icmp_seq=0 ttl=63 time=133.1 ms
64 bytes from 192.168.0.3: icmp_seq=1 ttl=63 time=4.0 ms
64 bytes from 192.168.0.3: icmp_seq=2 ttl=63 time=4.9 ms
--- 192.168.0.3 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 4.0/47.3/133.1 ms
To be thorough, let's make sure we have connectivity in the other direction and ping the UML instance from the other host:
192.168.0.3% ping 192.168.0.254
PING 192.168.0.254 (192.168.0.254) from 192.168.0.3 : 56(84) \
bytes of data.
64 bytes from 192.168.0.254: icmp_seq=1 ttl=64 time=6.48 ms
64 bytes from 192.168.0.254: icmp_seq=2 ttl=64 time=2.76 ms
64 bytes from 192.168.0.254: icmp_seq=3 ttl=64 time=2.75 ms
--- 192.168.0.254 ping statistics ---
3 packets transmitted, 3 received, 0% loss, time 2003ms
rtt min/avg/max/mdev = 2.758/4.000/6.483/1.756 ms
We now have basic network connectivity between the UML instance and the rest of the local network. Here's a summary of the steps we took.
Create the TUN/TAP device for the UML instance to use to communicate with the host. Enable packet forwarding on the host. Enable proxy arp in both directions between the UML instance and the rest of the network.
Thoughts on Security
At this point, the machinations of the uml_net helper should make sense. To recap, let's add another interface to the instance and let uml_net set it up for us:
host% uml_mconsole debian config eth1=tuntap,,,192.168.0.252
OK
Configuring the new device in the instance shows us this:
UML# ifconfig eth1 192.168.0.251 up
* modprobe tun
* ifconfig tap0 192.168.0.252 netmask 255.255.255.255 up
* bash -c echo 1 > /proc/sys/net/ipv4/ip_forward
* route add -host 192.168.0.251 dev tap0
* bash -c echo 1 > /proc/sys/net/ipv4/conf/tap0/proxy_arp
* arp -Ds 192.168.0.251 jeffs-uml pub
* arp -Ds 192.168.0.251 eth1 pub
Here we can see the helper doing just about everything we just finished doing by hand. The one thing that's missing is actually creating the TUN/TAP device. uml_net does that itself, without invoking an outside utility, so that doesn't show up in the list of commands it runs on our behalf.
Aside from knowing how to configure the host in order to support a networked UML instance, this is also important for understanding the security implications of what we have done and for customizing this setup for a particular environment.
What uml_net does is not secure against a nasty root user inside the instance. Consider what would happen if the UML user decided to configure the UML eth0 with the same IP address as your local name server. uml_net would set up proxy arp to direct name requests to the UML instance. The real name server would still be there getting requests, but some requests would be redirected to the UML instance. With a name server in the UML instance providing bogus responses, this could easily be a real security problem. For this reason, uml_net should not be used in a serious UML establishment. Its purpose is to make UML networking easy to set up for the casual UML user. For any more serious uses of UML, the host should be configured according to the local needs, security and otherwise.
What we just did by hand isn't that bad because we set the route to the instance and proxy arp according to the IP address we expected it to use. If root inside our UML instance decides to use a different IP address, such as that of our local name server, it will see no traffic. The host will only arp on behalf of the IP we expect it to use, and the route is only good for that IP. All other traffic will go elsewhere.
A nasty root user can still send out packets purporting to be from other hosts, but since it can't receive any responses to them, it would have to make blind attacks. As I discussed earlier, this is unlikely to enable any successful attacks on its own, but it does remove a layer of protection that might prove useful if another exploit on the host allows the attacker to see the local network traffic.
So, it is probably advisable to filter out any unexpected network traffic at the iptables level. First, let's see that the UML instance can send out packets that pretend to be from some other host. As usual for this discussion, these will be pings, but they could just as easily be any other protocol.
UML# ifconfig eth0 192.168.0.100 up
UML# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3): 56 data bytes
--- 192.168.0.3 ping statistics ---
4 packets transmitted, 0 packets received, 100% packet loss
Here I am pretending to be 192.168.0.100, which we will consider to be an important host on the local network. Watching the jeffs-uml device on the host shows this:
host# tcpdump -i jeffs-uml -l -n
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on jeffs-uml, link-type EN10MB (Ethernet), capture \
size 96 bytes
20:20:34.978090 arp who-has 192.168.0.3 tell 192.168.0.100
20:20:35.506878 arp reply 192.168.0.3 is-at ae:42:d1:20:37:e5
20:20:35.508062 IP 192.168.0.100 > 192.168.0.3: icmp 64: echo \
request seq 0
We can see those faked packets reaching the host. Looking at the host's interface to the rest of the network, we can see they are reaching the local network:
tcpdump -i eth1 -l -n
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on eth1, link-type EN10MB (Ethernet), capture size \
96 bytes
20:23:30.741482 IP 192.168.0.100 > 192.168.0.3: icmp 64: echo \
request seq 0
20:23:30.744305 arp who-has 192.168.0.100 tell 192.168.0.3
Notice that arp request. It will be answered correctly, so the ping responses will go to the actual host that legitimately owns 192.168.0.100, which is not expecting them. That host will discard them, so they will cause no harm except for some wasted network bandwidth and CPU cycles. However, it would be preferable for those packets not to reach the network or the host in the first place. This can be done as follows:
host# iptables -A FORWARD -i jeffs-uml -s \! 192.168.0.253 -j \
DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
iptables is apparently complaining about the dash in the interface name, but it does create the rule, as we can see here:
host# iptables -L
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DROP all -- !192.168.0.253 anywhere
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
So, we have just told iptables to discard any packet it sees that:
Is supposed to be forwarded Enters the host through the jeffs-uml interface Has a source address other than 192.168.0.253
After creating this firewall rule, you should be able to rerun the previous ping and tcpdump will show that those packets are not reaching the outside network.
At this point, we have a reasonably secure setup. As originally configured, the UML instance couldn't see any traffic not intended for it. With the new firewall rule, the rest of the network will see only traffic from the instance that originates from the IP address assigned to it. A possible enhancement to this is to log any attempts to use an unauthorized IP address so that the host administrator is aware of any such attempts and can take any necessary action.
You could also block any packets from coming in to the UML instance with an incorrect IP address. This shouldn't happen because the proxy arp we have set up shouldn't attract any packets for IP addresses that don't belong somehow to the host, and any such packets that do reach the host won't be routed to the UML instance. However, an explicit rule to prevent this might be a good addition to a layered security model. In the event of a malfunction or compromise of this configuration, such a rule could end up being the one thing standing in the way of a UML instance seeing traffic that it shouldn't. This rule would look like this:
host# iptables -A FORWARD -o jeffs-uml -d \! 192.168.0.253 -j \
DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
Access to the Outside Network
We still have a bit of work to do, as we have demonstrated access only to the local network, using IP addresses rather than more convenient host names. So, we need to provide the UML instance with a name service. For a single instance, the easiest thing to do is copy it from the host:
host# cat > /etc/resolv.conf
; generated by /sbin/dhclient-script
search user-mode-linux.org
nameserver 192.168.0.3
I cut the contents of the host's /etc/resolv.conf and pasted them into the UML. You should do the same on your own machine, as my resolv.conf will almost certainly not work for you.
We also need a default route, which hasn't been necessary for the limited testing we've done so far but is needed for almost anything else:
UML# route add default gw 192.168.0.254
I normally use the IP address of the host end of the TUN/TAP device as the default gateway.
If you still have the unauthorized IP address assigned to your instance's eth0, reassign the original address:
ifconfig eth0 192.168.0.253
Now we should have name service:
UML# host 192.168.0.3
Name: laptop.user-mode-linux.org
Address: 192.168.0.3
That's a local namelet's check for a remote one:
UML# host www.user-mode-linux.org
www.user-mode-linux.org A 66.59.111.166
Now let's try pinging it, to see if we have network access to the outside world:
UML# ping www.user-mode-linux.org
PING www.user-mode-linux.org (66.59.111.166): 56 data bytes
64 bytes from 66.59.111.166: icmp_seq=0 ttl=52 time=487.2 ms
64 bytes from 66.59.111.166: icmp_seq=1 ttl=52 time=37.8 ms
64 bytes from 66.59.111.166: icmp_seq=2 ttl=52 time=36.0 ms
64 bytes from 66.59.111.166: icmp_seq=3 ttl=52 time=73.0 ms
--- www.user-mode-linux.org ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 36.0/158.5/487.2 ms
Copying /etc/resolv.conf from the host and setting the default route by hand works but is not the right thing to do. The real way to do these is with DHCP. The reason this won't work here is the same reason that ARP didn't workthe UML is on a different Ethernet strand than the rest of the network, and DHCP, being an Ethernet broadcast protocol, doesn't cross Ethernet broadcast domain boundaries.
DHCP through a TUN/TAP Device
Some tools work around the DHCP problem by forwarding DHCP requests from one Ethernet domain to another and relaying whatever replies come back. One such tool is dhcp-fwd. It needs to be installed on the host and configured. It has a fairly scary-looking default config file. You need to specify the interface from which client requests will come and the interface from which server responses will come.
In the default config file, these are etH2 and eth1, respectively.
On my machine, the client interface is jeffs-uml and the server interface is eth1. So, a global replace of eth2 with jeffs-uml, and leaving eth1 alone, is sufficient to get a working dhcp-fwd.
Let's get a clean start by unplugging the UML eth0 and plugging it back in. First we need to bring the interface down:
Then, on the host, remove the device:
host% uml_mconsole debian remove eth0
OK
Now, let's plug it back in:
host% uml_mconsole debian config eth0=tuntap,,fe:fd:c0:a8:00:fd,\
192.168.0.254
OK
Notice that we have a new parameter to this command. We are specifying a hardware MAC address for the interface. We never did this before because the UML network driver automatically generates one when it is assigned an IP address for the first time. It is important that these be unique. Physical Ethernet cards have a unique MAC burned into their hardware or firmware. It's tougher for a virtual interface to get a unique identity. It's also important for its IP address to be unique, and I have taken advantage of this in order to generate a unique MAC address for a UML's Ethernet device.
When the administrator provides an IP address, which is very likely to be unique on the local network, to a UML Ethernet device, the driver uses that as part of the MAC address it assigns to the device. The first two bytes of the MAC will be 0xFE and 0xFD, which is a private Ethernet range. The next four bytes are the IP address. If the IP address is unique on the network, the MAC will be, too.
When configuring the interface with DHCP, the MAC is needed before the DHCP server can assign the IP. Thus, we need to assign the MAC on the command line or when plugging the device into a running UML instance.
There is another case where you may need to supply a MAC on the UML command line, which I will discuss in greater detail later in this chapter. That is when the distribution you are using brings the interface up before giving it an IP address. In this case, the driver can't supply the MAC after the fact, when the interface is already up, so it must be provided ahead of time, on the command line.
Now, assuming the dhcp-fwd service has been started on the host, dhclient will work inside UML:
UML# dhclient eth0
Internet Software Consortium DHCP Client 2.0pl5
Copyright 1995, 1996, 1997, 1998, 1999 The Internet Software \
Consortium.
All rights reserved.
Please contribute if you find this software useful.
For info, please visit http://www.isc.org/dhcp-contrib.html
Listening on LPF/eth0/fe:fd:c0:a8:00:fd
Sending on LPF/eth0/fe:fd:c0:a8:00:fd
Sending on Socket/fallback/fallback-net
DHCPREQUEST on eth0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.254
bound to 192.168.0.9 -- renewal in 21600 seconds.
Final Testing
At this point, we have full access to the outside network. There is still one thing that could go wrong. Ping packets are relatively small; in some situations small packets will be unmolested but large packets, contained in full-size Ethernet frames, will be lost. To check this, we can copy in a large file:
UML# wget http://www.kernel.org/pub/linux/kernel/v2.6/\
linux-2.6.12.3.tar.bz2
--01:35:56-- http://www.kernel.org/pub/linux/kernel/v2.6/\
linux-2.6.12.3.tar.bz2 => `linux-2.6.12.3.tar.bz2'
Resolving www.kernel.org... 204.152.191.37, 204.152.191.5
Connecting to www.kernel.org[204.152.191.37]:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 37,500,159 [application/x-bzip2]
100%[====================================>] 37,500,159 \
87.25K/s ETA 00:00
01:43:04 (85.92 KB/s) - `linux-2.6.12.3.tar.bz2' saved \
[37500159/37500159]
Copying in a full Linux kernel tarball is a pretty good test, and in this case, it's fine. If this does nothing for you, it's likely that there's a problem with large packets. If so, you need to lower the Maximal Transfer Unit (MTU) of the UML's eth0:
UML# ifconfig eth0 mtu 1400
You can determine the exact value by experiment. Lower it until large transfers start working.
The cases where I've seen this involved a PPPoE connection to the outside world. PPPoE usually means a DSL connection, and I've seen UML connectivity problems when the host was my DSL gateway. Lowering the MTU to 1400 made the network fully functional. In fact, the MTU for a PPPoE connection is 1492, so lowering it to 1400 was overkill.
Bridging
As mentioned at the start of this chapter, there are two ways to configure a host to give a UML access to the outside world. We just explored one of them. The alternative, bridging, doesn't require the host to route packets to and from the UML, and so doesn't require new routes to be created or proxy arp to be configured. With bridging, the TUN/TAP device used by the UML instance is combined with the host's physical Ethernet device into a sort of virtual switch. The bridge interface forwards Ethernet frames from one interface to another based on their destination MAC addresses. This effectively merges the broadcast domains associated with the bridged interfaces. Since this caused DHCP and arp to not work when we were doing IP forwarding, bridging provides a neat solution to these problems.
If you currently have an active UML network, you should shut it down before continuing:
Then, on the host, remove the device:
host% uml_mconsole debian remove eth0
OK
Bring down and remove the TUN/TAP interface, which will delete the route and one side of the proxy arp, and delete the other side of the proxy arp:
host# ifconfig jeffs-uml down
host% tunctl -d jeffs-uml
Set 'jeffs-uml' nonpersistent
host# arp -i jeffs-uml -d 192.168.0.253 pub
Now, with everything cleaned up, we can start from scratch:
host% tunctl -u jdike -t jeffs-uml
Let's start setting up bridging. The idea is that a new interface will provide the host with network access to the outside world. The two interfaces we are currently using, eth0 and jeffs-uml, will be added to this new interface. The bridge device will forward frames from one interface to the other as needed, so that both eth0 and jeffs-uml will see traffic that's intended for them (or that needs to be sent to the local network, in the case of eth0).
The first step is to create the device using the brctl utility, which is in the bridge-utilities package of your favorite distribution:
host# brctl addbr uml-bridge
In the spirit of giving interfaces meaningful names, I've called this one uml-bridge.
Now we want to add the two existing interfaces to it. For the physical interface, choose a wired Ethernetfor some reason, wireless interfaces don't seem to work in bridges. The virtual interface will be the jeffs-uml TUN/TAP interface.
We need to do some configuration to make it usable:
host# ifconfig jeffs-uml 0.0.0.0 up
These interfaces can't have their own IP addresses, so we have to clear the one on eth0. This is a step you want to think about carefully. If you are logged in to the host remotely, this will likely kill your session and any network access you have to it. If the host has two network interfaces, and you know that your session and all other network activity you care about is traveling over the other, then it should be safe to remove the IP address from this one:
host# ifconfig eth0 0.0.0.0
We can now add the two interfaces to the bridge:
host# brctl addif uml-bridge jeffs-uml
host# brctl addif uml-bridge eth0
And then we can look at our work:
host# brctl show
bridge name bridge id STP enabled \
interfaces
uml-bridge 8000.0012f04be1fa no \
eth0
\
jeffs-uml
At this point, the bridge configuration is done and we need to bring it up as a new network interface:
host# dhclient uml-bridge
Internet Systems Consortium DHCP Client V3.0.2
Copyright 2004 Internet Systems Consortium.
All rights reserved.
For info, please visit http://www.isc.org/products/DHCP
/sbin/dhclient-script: configuration for uml-bridge not found. \
Continuing with defaults.
Listening on LPF/uml-bridge/00:12:f0:4b:e1:fa
Sending on LPF/uml-bridge/00:12:f0:4b:e1:fa
Sending on Socket/fallback
DHCPDISCOVER on uml-bridge to 255.255.255.255 port 67 interval 4
DHCPOFFER from 192.168.0.10
DHCPREQUEST on uml-bridge to 255.255.255.255 port 67
DHCPACK from 192.168.0.10
/sbin/dhclient-script: configuration for uml-bridge not found. \
Continuing with defaults.
bound to 192.168.0.2 -- renewal in 20237 seconds.
The bridge is functioning, but for any local connectivity to the UML instance, we'll need to set a route to it:
host# route add -host 192.168.0.253 dev uml-bridge
Now we can plug the interface into the UML instance and configure it there:
host% uml_mconsole debian config eth0=tuntap,jeffs-uml,\
fe:fd:c0:a8:00:fd
OK
UML# ifconfig eth0 192.168.0.253 up
Note that we plugged the jeffs-uml TUN/TAP interface into the UML instance. The bridge is merely a container for the other two interfaces, which can actually send and receive frames.
Also note that we assigned the MAC address ourselves rather than letting the UML driver do it. A MAC is necessary in order to make a DHCP request for an IP address, while the driver requires the IP address before it can construct the MAC. In order to break this circular requirement, we need to assign the MAC that the interface will get.
Now we can see some benefit from the extra setup that the bridge requires. DHCP within the UML instance now works:
UML# dhclient eth0
Internet Systems Consortium DHCP Client V3.0.2-RedHat
Copyright 2004 Internet Systems Consortium.
All rights reserved.
For info, please visit http://www.isc.org/products/DHCP
Listening on LPF/eth0/fe:fd:c0:a8:00:fd
Sending on LPF/eth0/fe:fd:c0:a8:00:fd
Sending on Socket/fallback
DHCPDISCOVER on eth0 to 255.255.255.255 port 67 interval 5
DHCPOFFER from 192.168.0.10
DHCPREQUEST on eth0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.10
bound to 192.168.0.253 -- renewal in 16392 seconds.
This requires no messing around with arp or dhcp-fwd. Binding the TUN/TAP interface and the host's Ethernet interface makes each see broadcast frames from the other. So, DHCP and arp requests sent from the TUN/TAP device are also sent through the eth0 device. Similarly, arp requests from the local network are forwarded to the TUN/ TAP interface (and thus the UML instance's eth0 interface), which can respond on behalf of the UML instance.
The bridge also forwards nonbroadcast frames, based on their MAC addresses. So, DHCP and arp replies will be forwarded as necessary between the two interfaces and thus between the UML instance and the local network. This makes the DHCP forwarding and the proxy arp that we did earlier completely unnecessary.
The main downside to bridging is the need to remove the IP address from the physical Ethernet interface before adding it to the bridge. This is a rather pucker-inducing step when the host is accessible only remotely over that one interface. Many people will use IP forwarding and proxy arp instead of bridging rather than risk taking their remote server off the net. Others have written scripts that set up the bridge, taking the server's Ethernet interface offline and bringing the bridge interface online.
Bridging and Security
Bridging provides access to the outside network in a different way than we got with routing and proxy arp. However, the security concerns are the samewe need to prevent a malicious root user from making the UML instance pretend to be an important server. Before, we filtered traffic going through the TUN/TAP device with iptables. This was appropriate for a situation that involved IP-level routing and forwarding, but it won't work here because the forwarding is done at the Ethernet level.
There is an analogous framework for doing Ethernet filtering and an analogous tool for configuring it: ebtables, with the "eb" standing for "Ethernet Bridging."
First, in order to demonstrate that we can do nasty things to our network, let's change our Ethernet MAC to one we will presume belongs to our name server or DHCP server. Then let's verify that we still have network access:
UML# ifconfig eth0 hw ether fe:fd:ba:ad:ba:ad
# ping -c 2 192.168.0.10
PING 192.168.0.10 (192.168.0.10) 56(84) bytes of data.
64 bytes from 192.168.0.10: icmp_seq=0 ttl=64 time=3.75 ms
64 bytes from 192.168.0.10: icmp_seq=1 ttl=64 time=1.85 ms
--- 192.168.0.10 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1018ms
rtt min/avg/max/mdev = 1.850/2.803/3.756/0.953 ms, pipe 2
We do, so we need to fix things so that the UML instance has network access only with the MAC we assigned to it.
Precisely, we want any Ethernet frame leaving the jeffs-uml interface on its way to the bridge that doesn't have a source MAC of fe:fd:c0:a8:00:fd to be dropped. Similarly, we want any frame being forwarded from the bridge to the jeffs-uml interface without that destination MAC to be dropped.
The ebtables syntax is very similar to iptables, and the following commands do what we want:
host# ebtables -A INPUT --in-interface jeffs-uml \
--source \! FE:FD:C0:A8:00:FD -j DROP
host# ebtables -A OUTPUT --out-interface jeffs-uml \
--destination \! FE:FD:C0:A8:00:FD -j DROP
host# ebtables -A FORWARD --out-interface jeffs-uml \
--destination \! FE:FD:C0:A8:00:FD -j DROP
host# ebtables -A FORWARD --in-interface jeffs-uml \
--source \! FE:FD:C0:A8:00:FD -j DROP
There is a slight subtlety heremy first reading of the ebtables man page suggested that using the FORWARD chain would be sufficient since that covers frames being forwarded by the bridge from one interface to another. This works for external traffic but not for traffic to the host itself. These frames aren't forwarded, so we could spoof our identity to the host if the ebtables configuration used only the FORWARD chain. To close this hole, I also use the INPUT and OUTPUT chains to drop packets intended for the host as well as those that are forwarded.
At this point the ebtables configuration should look like this:
ebtables -L
Bridge table: filter
Bridge chain: INPUT, entries: 1, policy: ACCEPT
-s ! fe:fd:c0:a8:0:fd -i jeffs-uml -j DROP
Bridge chain: FORWARD, entries: 2, policy: ACCEPT
-d ! fe:fd:c0:a8:0:fd -o jeffs-uml -j DROP
-s ! fe:fd:c0:a8:0:fd -i jeffs-uml -j DROP
Bridge chain: OUTPUT, entries: 1, policy: ACCEPT
-d ! fe:fd:c0:a8:0:fd -o jeffs-uml -j DROP
We can check our work by trying to ping an outside host again:
host# ping -c 2 192.168.0.10
PING 192.168.0.10 (192.168.0.10) 56(84) bytes of data.
From 192.168.0.253 icmp_seq=0 Destination Host Unreachable
From 192.168.0.253 icmp_seq=1 Destination Host Unreachable
--- 192.168.0.10 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet \
loss, time 1018ms, pipe 3
We should also check that we haven't made things too secure by accidentally dropping all packets. Let's reset our MAC to the approved value and see that we have connectivity:
UML# ifconfig eth0 hw ether FE:FD:C0:A8:00:FD
UML# ping -c 2 192.168.0.10
PING 192.168.0.10 (192.168.0.10) 56(84) bytes of data.
64 bytes from 192.168.0.10: icmp_seq=0 ttl=64 time=40.4 ms
64 bytes from 192.168.0.10: icmp_seq=1 ttl=64 time=3.93 ms
--- 192.168.0.10 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1036ms
rtt min/avg/max/mdev = 3.931/22.190/40.449/18.259 ms, pipe 2
At this point, the UML instance can communicate with other hosts using only the MAC that we assigned to it. We should also be concerned with whether it can do harm by spoofing its IP.
UML# ifconfig eth0 192.168.0.100
UML# ifconfig eth0 hw ether FE:FD:C0:A8:00:FD
UML# ping -c 2 192.168.0.10
PING 192.168.0.10 (192.168.0.10) 56(84) bytes of data.
64 bytes from 192.168.0.10: icmp_seq=0 ttl=64 time=3.57 ms
64 bytes from 192.168.0.10: icmp_seq=1 ttl=64 time=1.73 ms
--- 192.168.0.10 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1017ms
rtt min/avg/max/mdev = 1.735/2.655/3.576/0.921 ms, pipe 2
It can, so we need to apply some IP filtering. Because the jeffsuml interface is part of a bridge, we need to use the physdev module of iptables:
host# iptables -A FORWARD -m physdev --physdev-in jeffs-uml \
-s \! 192.168.0.253 -j DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
host# iptables -A FORWARD -m physdev --physdev-out jeffs-uml \
-d \! 192.168.0.253 -j DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
host# iptables -A INPUT -m physdev --physdev-in jeffs-uml \
-s \! 192.168.0.253 -j DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
host# iptables -A OUTPUT -m physdev --physdev-out jeffs-uml \
-d \! 192.168.0.253 -j DROP
Warning: wierd character in interface `jeffs-uml' (No aliases, \
:, ! or *).
These take care of packets intended for both this host and other systems. Earlier, I didn't include a rule to prevent packets with incorrect destination IP addresses from reaching a UML instance because the proxy arp and routing provided pretty good protection against that. I'm including the equivalent rule here because we don't have the same protection the bridging exposes the UML instances much more to the local network.
The UML Networking Transports
Now that we've had an in-depth look at using TUN/TAP devices on the host to get a UML instance on the network, it's time to look at the other mechanisms that can be used. There are a total of six, probably two of which are by far the most commonly used. However, there are situations in which you would choose to use one of the other four, albeit very rare situations for some of them.
In order to classify them, we can first divide them between transports that can be used to connect a UML to the host and those that can be used only to connect UML instances to each other. In the first group are TUN/TAP, Ethertap, SLIP, and Slirp. In the second are the virtual switch and multicast. Blurring this distinction somewhat is that uml_switch has an option to attach itself to a host TUN/TAP device, thereby providing access to the host. The final transport, pcap, is fundamentally different from the others and doesn't really belong in either group. It does connect to the host, but it can only receive packets, not transmit them. pcap allows you to use a UML instance as a preconfigured packet sniffer.
Access to the Host Network
TUN/TAP and Ethertap
Among the transports that can provide access to the host network, TUN/TAP is very much the preferred option. Ethertap is an older interface that does the same thing, only worse. Ethertap was the standard for this on Linux version 2.2, and early in 2.4. At that point, TUN/TAP entered the Linux kernel in its current form. It supplanted Ethertap because it lacked various problems that made Ethertap hard to work with.
These problems are pretty well hidden by the uml_net helper and the UML Ethertap driver, but they do affect performance and possibly security. These effects are caused by the fact that there needs to be a root helper to create the Ethertap device and to handle every packet going through the device. It's impossible for the helper to open a file descriptor to the Ethertap interface and pass it to UML, as is the case with TUN/TAP. So, UML sends and receives packets over a pipe to the helper, which communicates with the interface. This extra step hurts latency and throughput compared to TUN/TAP. Having a root helper running continuously may also be a security issue, as it would be a continuous target for any attacks.
The one advantage that Ethertap has over TUN/TAP is that it's available on Linux kernels that predate early version 2.4. So, if you have a host running such a kernel, and it can't be updated, you have to use Ethertap for your UML networking.
SLIP
The SLIP transport exists because it was the first networking mechanism for UML. Ethertap was available on the first host on which I developed UML, but SLIP was the first mechanism I learned about. There is essentially no reason to use it now. The only one I can think of is that maybe some UML hosts don't have either TUN/TAP or Ethertap available, and this can't be changed. Then SLIP would be the mechanism of choice, even though it's a poor choice.
The following issues are among its disadvantages.
It can carry only IP traffic. Important non-IP protocols such as DHCP and ARP, and other lesser-known protocols from the likes of Apple and Novell, can't be carried over it. The encapsulation required by the SLIP protocol is a performance drag. It can't carry Ethernet frames, so it can't talk directly to an Ethernet network. All packets must be routed through the host, which will convert them into Ethernet frames.
Slirp
Slirp is interesting but little used. The Slirp networking emulator provides network access without needing any root privileges or help whatsoever. It is unique in this regard, as all of the other transports require some sort of root assistance.
However, it has a number of disadvantages.
It is slow. Slirp contains a network stack of its own that is used to parse the packets coming from the UML network stack. Slirp opens a normal socket connection to the target and sends the packet payload to it. When receiving packets, the process is reversed. The data coming from the remote side is assembled into a network packet that is immediately disassembled by the UML network stack. It can't receive connections on well-known ports. Since it receives connections by attaching to host ports, as an unprivileged process, it can only attach to ports greater than 1024. Since it doesn't act as a full network node, it can't have its own ports that the host can route packets to. The disadvantages of SLIP also apply, since Slirp provides an emulated SLIP connection.
Nevertheless, in some situations, Slirp is the only mechanism for providing a UML instance access to the outside network. I've seen cases where people are running UML instances on hosts on which they have no privileges. In one case, the "host" was a vserver instance on which the user had "root" privileges, but the vserver was so limited that Slirp was the only way to get the UML instance on the network. Cases like these are rare, but when they do happen, Slirp is invaluable, despite its limitations.
Isolated Networks
There are two purely virtual transports, which can connect a UML only to other UML instances: uml_switch and multicast.
uml_switch
uml_switch is a process that implements a virtual switch. UML instances connect to it and communicate with it over a UNIX domain socket on the host. It can act as a switch, which is its normal operation, or as a hub, which is sometimes useful when you want to sniff the traffic between two UML instances from a third. It also has the ability to connect to a preconfigured TUN/TAP device, allowing the UML instances attached to it to communicate with the host and outside network.
Multicast
Multicast is the second purely virtual network transport for UML. As its name suggests, it uses a multicast network on the host in order to transmit Ethernet frames from one UML instance to another. The UML instances all join the same multicast network, so that a packet sent from any instance is seen by all of the others. This is somewhat less efficient than the virtual switch because it behaves like a huball packets are received by all nodes attached to it. So, the UML instances will have to process and drop any packets that aren't intended for it, unnecessarily consuming host CPU time.
pcap
The last transport is unlike the others, in that it doesn't provide two-way network traffic. A UML interface based on pcap is read-onlyit receives packets but doesn't transmit them. This allows UML to act as a preconfigured network sniffer. A variety of network sniffing and traffic analysis tools are available, and they can be complicated to configure. This transport makes it possible to install a set of network analysis tools in a UML root filesystem, configure them, and distribute the filesystem.
Users can then boot UML on this filesystem and specify the pcap interface on the command line or with uml_mconsole. The traffic analysis will then work, with no further configuration needed.
As the name suggests, this transport is based on the pcap library, which underlies tcpdump and other tools. Use of this may require some familiarity with libpcap or tcpdump, especially if you want to filter packets before the tools inside UML see them. In this case, you will need to provide a filter expression to select the desired packets. Anyone who has done anything similar with tcpdump will know how to write an appropriate expression. For those who have not used tcpdump, the man page contains a good reference to the expression language.
How to Choose the Right Transport
Now that we've seen all of the UML network transports, we can make decisions about when to use each one. The advantages and disadvantages discussed earlier should make this pretty clear, but it's useful to summarize them.
If you need to give the UML instances access to the outside network, TUN/TAP is preferred. This has been standard in Linux kernels since early version 2.4, so virtually all Linux machines that might host UML instances should be sufficiently new to have TUN/TAP support. If you have one that is not, upgrading would probably be a better idea than falling back to Ethertap.
Once you've decided to use TUN/TAP, the next decision is whether to give each UML its own TUN/TAP device or to connect them with uml_switch and have it forward packets to the host through its own TUN/TAP interface. Using the switch instead of individual TUN/TAP devices has a number of trade-offs.
The switch is a single point of control, meaning that bandwidth tracking and management as well as filtering can be done at a single interface, and it is a single point of failure. The switch is more efficient than individual TUN/TAP devices for traffic between the UML instances because the packets experience only Ethernet routing by the switch rather than IP routing by the host. However, for external traffic, there's one more process handling the packets, so that will introduce more latency. The switch may be less of a security worry. If you are concerned about making /dev/net/tun world accessible (or even group accessible by a uml-users group), you may be happier having it owned by a user whose only purpose is to run uml_switch. In this way, faked packets can be injected into the host only by an attacker who has managed to penetrate that one account.
Against this, there is the UNIX socket that uml_switch uses to set up connections with UML instances. This needs to be writable by any users who are allowed to connect UML instances to the switch. A rogue process could possibly connect to it and inject packets to the switch, for forwarding to the UML instances or the outside network.
This would seem to be a wash, where we are replacing a security concern about /dev/net/tun with the same concern about the UNIX socket used by the switch. However, access to /dev/ net/tun allows the creation of new interfaces, which aren't subject to whatever filtering is applied to "authorized" TUN/TAP interfaces. Any packets injected through the UNIX socket that go to the outside network will need to pass through the filters on the TUN/TAP interface used by the switch. On balance, I would have to call this a slight security gain.
SLIP and Slirp are useful only in very limited circumstances. Again, I would recommend fixing the host so that TUN/TAP can be used before using either SLIP or Slirp. If you must get a UML with network access, and you have absolutely no way to get root assistance, you may need to use Slirp.
For an isolated network, the choice is between uml_switch and multicast. Multicast is trivial to set up, as we will see in the next section. However, the switch isn't that difficult either. If you want a quick-and-dirty isolated network, multicast is likely the better choice. However, multicast is less efficient because of the hub behavior I mentioned earlier.
Configuring the Transports
We need to take care of one loose end. The usage of the transports varies somewhat because of their differing configuration needs. In most cases, these differences are confined to the configuration string provided to UML on the command line or to uml_mconsole. In the case of uml_switch, we also need to look at the invocation of the switch.
Despite the differences, there are some commonalities. The parameters to the device are separated by commas. Many parameters are optional; to exclude one, just specify it as an empty string. Trailing commas can be omitted. For example, a TUN/TAP interface that the uml_net helper will set up can look like this:
eth0=tuntap,,fd:fe:1:2:3:4,192.168.0.1
Leaving out the Ethernet MAC would make it look like this:
eth0=tuntap,,,192.168.0.1
Omitted parameters will be provided with default values. In the case above, the omitted MAC will be initialized as described below. The omitted TUN/TAP interface name will be determined by the uml_net helper when it configures the interface.
The transports that create an Ethernet device inside UML can take an Ethernet MAC in the device specification. If not specified, it will be assigned a MAC when it is first assigned an IP address. The MAC will be derived from the IPthe first two bytes are 0xfd and 0xfe, and the last four are the IP address. This makes the MAC as unique as the IP address. Normally, the MAC can be left out. However, when you want the UML instance to be able to use DHCP, you must specify a MAC because the device will not operate without one and it must have a MAC in order for the DHCP server to provide an IP address. When it is acceptable for the UML interface to not work until it is assigned an IP address, you can let the driver assign the MAC.
However, if the interface is already up before it is assigned an IP address, the driver cannot change the MAC address on its own. Some distributions enable interfaces like this. In this case, the MAC will end up as fd:fe:00:00:00:00. If you are running several UML instances, it is likely that these MACs will conflict, causing mysterious network failures. The easiest way to fix this problem is to provide the MAC on the command line. You can also take the interface down and bring it back up by hand. When you bring it back up, you should specify the IP address on the ifconfig command line. This will ensure that the driver knows the IP address when the interface is enabled, so it can be assigned a reasonable MAC.
Whenever there is a network interface on the host that the transport communicates through, such as a TUN/TAP or Ethertap device, the IP address of that interface, the host-side IP, can be included. As we saw earlier in the chapter, when an IP address is specified in the device configuration, the driver will run the uml_net helper in order to set up the device on the host. When it is omitted, a preconfigured host device should be included in the configuration string.
As we have already seen, the configuration syntax for a device is identical whether it is being configured on the UML command line or being hot-plugged with an MConsole client.
TUN/TAP
The TUN/TAP configuration string comes in two forms, depending on whether you are assigning the UML interface a preconfigured host interface or whether you want the uml_net helper to create and configure the host interface.
In the first case, you specify
For example:
eth0=tuntap,my-uml-tap,fe:fd:1:2:3:4
or
In the second case, you specify
tuntap An empty parameter, in place of the host interface name Optionally, the MAC of the UML interface The IP address of the host interface to be configured
For example:
eth0=tuntap,,fe:fd:1:2:3:4,192.168.0.1
or
eth0=tuntap,,,192.168.0.1
The three commas mean that parameters two and three (the host interface name and Ethernet MAC) are empty and will be assigned values by the driver.
Ethertap
The Ethertap configuration string is nearly identical, except that the device type is ethertap and that you must specify a host interface name. When the host interface doesn't exist and you provide an IP address, uml_net will configure that device. This example tells the driver to use a preconfigured Ethertap interface:
This results in the uml_net helper creating and configuring a new Ethertap interface:
eth0=ethertap,tap0,,192.168.0.1
SLIP
The SLIP configuration is comparatively simpleonly the IP address of the host SLIP device needs to be specified. It must be there since uml_net will always run in order to configure the SLIP interface. There is no possibility of specifying a MAC since the UML interface will not be an Ethernet device. This means that DHCP and other Ethernet protocols, such as ARP, can't be used with SLIP.
Slirp
The Slirp configuration requires
If you decide to try this, you should probably first configure and run Slirp without UML. Once you can run it by hand, you can put the Slirp command line in the configuration string and it will work as it did before.
Adding the Slirp command line requires that it be transformed somewhat in order to not confuse the driver's parser. First, the command and its arguments should be separated by commas rather than spaces. Second, any spaces embedded in an argument should be changed to underscores. However, in the normal case Slirp takes no arguments, and only the path to the Slirp executable needs to be specified.
If some arguments need to be provided, Slirp will read options from your ~/.sliprc. Putting the requisite information there will simplify the UML command line. It is also possible to pass the name of a wrapper script that will invoke slirp with the correct arguments.
Multicast
Multicast is the simplest transport to configure, if you want the defaults:
The full configuration contains
mcast Optionally, the MAC of the UML interface Optionally, the address of the multicast network Optionally, the port to bind to in order to send and receive multi- cast packets Optionally, the time to live (TTL) for transmitted packets
Specifying the MAC is the same with mcast as with all the other transports.
The address determines which multicast group the UML instance will join. You can have multiple, simultaneous, mcast-based virtual networks by assigning the interfaces to different multicast groups. All IP addresses within the range 224.0.0.0 to 239.255.255.255 are multicast addresses. If a value isn't specified, 239.192.168.1 will be used.
The TTL determines how far the packets will propagate.
0: The packet will not leave the host. 1: The packet will not leave the local network and will not cross a router. Less than 32: The packet will not leave the local organization. Less than 64: The packet will not leave the region. Less than 128: The packet will not leave the continent. All other values: The packet is unrestricted.
Obviously, the terms "local organization," "region," and "continent" are not well defined in terms of networking hardware, even if they are well-defined geographically, which they often aren't. It is up to the router administrators to decide whether or not their equipment is on the border of one of these areas and configure it appropriately. Once configured, the routers will drop any multicast packets that have insufficient TTLs to cross the border.
The default TTL is 1, so the packet can leave the host but not the local Ethernet.
The port should be specified if there are multiple UML instances on different multicast networks on the host so that instances on different networks are attached to different ports. The default port is 1102.
However, not all hosts provide multicast support. The CONFIG_IP_MULTICAST and CONFIG_IP_MROUTE (under "IP: Multicast router" in the kernel configuration) must be enabled. Without these, you'd see:
mcast_open: IP_ADD_MEMBERSHIP failed, error = 19
There appears not to be a multicast-capable network \
interface on the host.
eth0 should be configured in order to use the multicast \
transport.
uml_switch
The daemon TRansport differs from all the others in requiring a process to be started before the network will work. The process is uml_switch, which implements a virtual switch, as its name suggests. The simplest invocation is this:
host% uml_switch
uml_switch attached to unix socket '/tmp/uml.ctl'
The corresponding UML device configuration would be:
The defaults of both uml_switch and the UML driver are such that they will interoperate with each other. So, if you want a single switch on the host, the configurations above will work.
If you want multiple switches on the host, then all but one of them, and the UML instances that will connect to them, need to be configured differently. The switch and the UML instances communicate with datagrams over UNIX domain sockets. The default socket is /tmp/ uml.ctl, as the message from the switch indicates.
A different socket can be specified with:
host% uml_switch -unix /tmp/uml-2.ctl
In order to attach to this switch, the same socket must be provided to the UML network driver:
eth0=daemon,,unix,/tmp/uml-2.ctl
unix specifies the type of socket to use, and the following argument specifies the socket address. At this writing, only UNIX domain sockets are supported, but this is intended to extend to allowing communication over IP sockets as well. In this case, the socket address would consist of an IP address or host name and a port number.
Some distributions (notably Debian) change the default location of the pipe used by uml_switch (to /var/run/uml-utilities/ uml_switch.ctl2 in Debian's case). If you use the defaults as described above and there is no connection between the UML instance and the uml_switch process, you need to figure out where the uml_switch socket is and configure the UML interface to use it.
As I mentioned earlier, uml_switch normally acts as a switch, so that it remembers what Ethernet MACs it has seen on what ports and transmits packets only to the port that the UML instance with the destination MAC is attached to. This saves the switch from having to forward all packets to all its instances, and it also saves the UML instances from having to receive and parse them and discard all packets not addressed to them.
uml_switch can be configured as a hub by using the -hub switch. In this case, all instances attached to it will see all packets on the network. This is sometimes useful when you want to sniff traffic between two UML instances from a third.
Normally, the switch provides an isolated virtual network, with no access to the host network. There is an option to have it connect to a preconfigured TUN/TAP device, in which case, that device will be another port on the switch, and packets will be forwarded to the host through it as appropriate. The command line would look like this:
uml_switch -tap switch-tap
switch-tap must be a TUN/TAP device that has already been created and configured as described in the TUN/TAP section earlier. Either bridging or routing, IP packet forwarding, and proxy arp should already be configured for this device.
The full UML device configuration contains
daemon Optionally, the MAC of the UML interface Optionally, the socket type, which currently must be unix Optionally, the socket that the switch has attached to
pcap
The oddball transport, pcap, has a configuration unlike any of the others. The configuration comprises
pcap The host interface to sniff A filter expression that determines which packets the UML inter- face will emit Up to two options from the set promisc, nopromisc, optimize, and nooptimize
The host interface may be the special string any. This will cause all host interfaces to be opened and sniffed.
The filter expression is a pcap filter program that specifies which packets should be selected.
The promisc flag determines whether libpcap will explicitly set the interface as promiscuous. The default is 1, so promisc has no effect, except for documentation. Even if nopromisc is specified, the pcap library may make the interface promiscuous for some other reason, such as being required to sniff the network.
The optimize and nooptimize flags control whether libpcap optimizes the filter expression.
Here is an example of configuring a pcap interface to emit only TCP packets to the UML interface:
This configures a second interface that would emit only non-TCP packets:
An Extended Example
Now that we've covered most of what there is to know about setting up UML networking, I am going to show off some of how it works. This extended example involves multiple UML instances. To simplify their launching, I will assign them unique filesystems by giving them different COW files with the same backing file and by giving each a different umid. So, the command line of the first one will have this:
ubda=cow1,../..debian30 umid=debian1
and the second will have this:
ubda=cow2,../..debian30 umid=debian2
You'll probably want to do something similar as you follow along. I will be hot-plugging all network interfaces, so those won't be on the command lines.
A Multicast Network
To start, I'll run two UML instances like this. We'll begin the networking with the simplest virtual networka default multicast network. So, let's plug a multicast device into both:
host% uml_mconsole debian1 config eth0=mcast
OK
host% uml_mconsole debian2 config eth0=mcast
OK
The kernel log of each instance shows something like this:
Configured mcast device: 239.192.168.1:1102-1
Netdevice 0 : mcast backend multicast address: \
239.192.168.1:1102, TTL:1
You can see this by running dmesg, and it may also appear on the main console, depending on the distribution you are running.
Now, let's bring up both UML instances. I'm using the 192.168.1.0/24 network to keep the virtual network separate from my physical network since I intend to hook this network up to the host later. So, the first one is 192.168.1.1:
UML1# ifconfig eth0 192.168.1.1 up
and the second is 192.168.1.2:
UML2# ifconfig eth0 192.168.1.2 up
Figure 7.1 shows what we have set up so fartwo UML instances on the 192.168.1.0 network connected by the host's multicast network.
Now, check connectivity in one direction:
UML1# ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2): 56 data bytes
64 bytes from 192.168.1.2: icmp_seq=0 ttl=64 time=0.4 ms
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.3 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.3 ms
--- 192.168.1.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.3/0.3/0.4 ms
Pinging in the other direction will show something similar.
A Second Multicast Network
Now, let's set up a second, partially overlapping multicast network. This will demonstrate the use of nondefault multicast parameters. It will also make us set up some routing in order to get the two UMLs that aren't on the same network to talk to each other.
This calls for launching a third UML instance, which will get a third COW file and umid, with this on its command line:
ubda=cow3,../..debian30 umid=debian3
Let's put the second and third instances on the new multicast network:
host% uml_mconsole debian2 config eth1=mcast,,239.192.168.2,1103
OK
host% uml_mconsole debian3 config eth0=mcast,,239.192.168.2,1103
OK
The second instance's etH1 and the third instance's eth0 are now on this new network, which is defined by being on the next multicast IP and the next port. Now, we configure them on a different subnet:
UML2# ifconfig eth1 192.168.2.2 up
and
UML3# ifconfig eth0 192.168.2.1 up
Figure 7.2 shows our network so far.
Testing connectivity here shows us what we expect:
UML3# ping 192.168.2.2
PING 192.168.2.2 (192.168.2.2): 56 data bytes
64 bytes from 192.168.2.2: icmp_seq=0 ttl=64 time=25.7 ms
64 bytes from 192.168.2.2: icmp_seq=1 ttl=64 time=0.4 ms
--- 192.168.2.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.4/13.0/25.7 ms
Now, let's ping the first UML from the third:
UML3# ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1): 56 data bytes
ping: sendto: Network is unreachable
ping: wrote 192.168.1.1 64 chars, ret=-1
ping: sendto: Network is unreachable
ping: wrote 192.168.1.1 64 chars, ret=-1
--- 192.168.1.1 ping statistics ---
2 packets transmitted, 0 packets received, 100% packet loss
The third UML has no idea how to reach that other network. So, we need to do some routing:
UML3# route add -net 192.168.1.0/24 gw 192.168.2.2
Retrying the ping gives us different behaviordead silence:
ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1): 56 data bytes
--- 192.168.1.1 ping statistics ---
4 packets transmitted, 0 packets received, 100% packet loss
Let's watch tcpdump on the second UML instance to learn what traffic it sees:
UML2# tcpdump -i eth1 -l -n
device eth1 entered promiscuous mode
tcpdump: listening on eth1
02:06:28.795435 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:06:29.820703 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:06:30.848753 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
This is fine; ping requests are reaching the gateway between the two networks. Next, the pings should be sent out through eth1 to the target UML instance:
# tcpdump -i eth0 -l -n
device eth0 entered promiscuous mode
tcpdump: listening on eth0
0 packets received by filter
0 packets dropped by kernel
device eth0 left promiscuous mode
They're not. This is a big clue to something we saw on the hostgenerally, Linux systems aren't set up as gateways and need to be told to forward packets when they can:
UML2# echo 1 > /proc/sys/net/ipv4/ip_forward
Let's look at the gateway instance's eth0 again while the ping is running:
UML2# tcpdump -i eth0 -l -n
device eth0 entered promiscuous mode
tcpdump: listening on eth0
02:09:45.388353 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:09:45.389009 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:09:46.415998 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:09:46.416025 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:09:47.432823 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:09:47.432854 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
6 packets received by filter
0 packets dropped by kernel
device eth0 left promiscuous mode
Now pings are going out the gateway's eth0. We should look at the target's eth0:
UML1# tcpdump -i eth0 -l -n
device eth0 entered promiscuous mode
tcpdump: listening on eth0
02:12:36.599365 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
02:12:37.631098 192.168.2.1 > 192.168.1.1: icmp: echo \
request (DF)
2 packets received by filter
0 packets dropped by kernel
device eth0 left promiscuous mode
Nothing but requests here. There should be replies, but there aren't. This is the same problem we saw on the pinging UMLit doesn't know how to reply to the other network. A new route will fix this:
UML1# route add -net 192.168.2.0/24 gw 192.168.1.2
If you left the ping running, you'll see it immediately start getting replies at this point.
Now, we have three UML instances on two virtual networks, with one UML acting as a gateway between the two and with routing set up so that all three instances can communicate with each other. I'm running ping only to test connectivity, but it is fun to ssh between them and to fetch Web pages from one to another.
Adding a uml_switch Network
Let's bring the virtual switch into the action, and with it, the host. First, we'll set up a TUN/TAP device for the switch to communicate with the host:
host% tunctl -t switch
Set 'switch' persistent and owned by uid 500
host# ifconfig switch 192.168.3.1 up
Now let's run the switch using a nondefault socket:
host% uml_switch -unix /tmp/switch.sock -tap switch
uml_switch attached to unix socket '/tmp/switch.sock' \
tap device 'switch'
New connection
Addr: 86:e5:03:6f:7e:49 New port 5
It fakes a new connection to itself when it attaches to the TUN/TAP device. You'll see the same sorts of messages when we plug interfaces into the UML instances. I'll attach UML1 and UML3 to the switch:
host% uml_mconsole debian1 config eth1=daemon,,unix,\
/tmp/switch.sock
OK
host% uml_mconsole debian3 config eth1=daemon,,unix,\
/tmp/switch.sock
OK
You'll see a message like this in each instance:
Netdevice 1 : daemon backend (uml_switch version 3) - \
unix:/tmp/switch.sock
Let's bring these up on the 192.168.3.0/24 network:
UML1# ifconfig eth1 192.168.3.2 up
UML3# ifconfig eth1 192.168.3.3 up
These are getting 192.168.3.2 and 192.168.3.3 because 192.168.3.1 was assigned to the TUN/TAP device.
Figure 7.3 shows our growing network.
As usual, let's check connectivity, this time through the switch:
UML3# ping 192.168.3.2
PING 192.168.3.1 (192.168.3.1): 56 data bytes
64 bytes from 192.168.3.1: icmp_seq=0 ttl=64 time=26.8 ms
64 bytes from 192.168.3.1: icmp_seq=1 ttl=64 time=0.2 ms
64 bytes from 192.168.3.1: icmp_seq=2 ttl=64 time=0.2 ms
64 bytes from 192.168.3.1: icmp_seq=3 ttl=64 time=0.2 ms
--- 192.168.3.1 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.2/6.8/26.8 ms
You'll get something similar if you ping in the other direction.
Some chatter from the switch occurs as you configure the devices and run ping:
New connection
New connection
Addr: fe:fd:c0:a8:03:02 New port 7
Addr: fe:fd:c0:a8:03:01 New port 6
Addr: d2:a1:c9:78:bd:d7 New port 5
The New connection message is printed whenever a new device is attached to the switch, whether it's a UML instance or a host TUN/ TAP interface. This is the equivalent of plugging something new into a physical switch. The New connection message is more or less equivalent to the link light on that port.
Messages such as Addr: fe:fd:c0:a8:03:02 New port 7 are printed whenever the switch sees a new Ethernet MAC on a port. The address is self-explanatory. The port is the file descriptor over which the switch is communicating with the other device. Physical switches have a fixed number of ports, but this virtual switch is limited only by the number of file descriptors it can have open.
These messages will be repeated periodically as the switch does garbage collection and throws out MACs that haven't been seen recently. When the connection later wakes up, as the UML refreshes its arp cache or something similar, the switch will remember the MAC again and print another message to that effect.
At this point, we should have access to the host from the first and third UML instances through the TUN/TAP device attached to the switch:
UML3# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
ping: sendto: Network is unreachable
ping: wrote 192.168.0.2 64 chars, ret=-1
--- 192.168.0.2 ping statistics ---
1 packets transmitted, 0 packets received, 100% packet loss
Well, not quite, but we've seen this message before, and we know what to do about it:
UML1# route add -net 192.168.0.0/24 gw 192.168.3.1
UML3# route add -net 192.168.0.0/24 gw 192.168.3.1
This is setting the gateway to the 192.168.3.0/24 network to be the switch TUN/TAP device. This ensures that packets to this network are addressed to the TUN/TAP device so that the switch routes them appropriately. Once they've reached the TUN/TAP device, they are on the host, and the host will deal with them as it sees fit.
At this point, the first and third UML instances have connectivity with the host:
UML3# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
64 bytes from 192.168.0.2: icmp_seq=0 ttl=64 time=26.4 ms
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.2 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.2 ms
--- 192.168.0.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.2/8.9/26.4 ms
The second UML instance has no access to the host because it is attached only to the two virtual networks. So, let's fix that by having it route packets through the third UML. We've done part of this already. We can finish it by enabling IP forwarding on the gateway and routing on the second UML:
UML3# echo 1 > /proc/sys/net/ipv4/ip_forward
UML2# route add -net 192.168.3.0/24 gw 192.168.2.1
UML2# route add -net 192.168.0.0/24 gw 192.168.2.1
Rather than adding two routes, it would also work to specify 192.168.2.1 as the default gateway for UML2.
The gateway is set to 192.168.2.1 since that's the IP address that the gateway UML has on the 192.168.2.0/24 network.
The ping doesn't work:
UML2# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
--- 192.168.0.2 ping statistics ---
115 packets transmitted, 0 packets received, 100% packet loss
Now we have to go through the usual tcpdump exercise. Running tcpdump on the gateway's eth0 tells us whether the requests are showing up:
UML3# tcpdump -i eth0 -l -n
device eth0 entered promiscuous mode
tcpdump: listening on eth0
16:37:19.634422 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:20.654462 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:21.683267 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
3 packets received by filter
0 packets dropped by kernel
They are, so let's make sure they are being forwarded to etH1 so they reach the switch:
UML3# tcpdump -i eth1 -l -n
device eth1 entered promiscuous mode
tcpdump: listening on eth1
16:37:24.738960 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:25.768702 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:26.697330 arp who-has 192.168.3.1 tell 192.168.3.3
16:37:26.697483 arp reply 192.168.3.1 is-at d2:a1:c9:78:bd:d7
16:37:26.787541 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:27.818978 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
16:37:28.839216 192.168.2.2 > 192.168.0.2: icmp: echo \
request (DF)
7 packets received by filter
0 packets dropped by kernel
device eth1 left promiscuous mode
So far, so good. The next interface the packets should reach is the switch TUN/TAP interface, so let's go to the host and tcpdump that:
host# tcpdump -i switch -l -n
tcpdump: verbose output suppressed, use -v or -vv for full \
protocol decode
listening on switch, link-type EN10MB (Ethernet), capture \
size 96 bytes
12:44:31.851022 arp who-has 192.168.3.1 tell 192.168.3.3
12:44:32.208988 arp reply 192.168.3.1 is-at d2:a1:c9:78:bd:d7
12:44:32.209001 IP 192.168.2.2 > 192.168.0.2: icmp 64: echo \
request seq 0
12:44:32.817880 IP 192.168.2.2 > 192.168.0.2: icmp 64: echo \
request seq 256
12:44:33.846666 IP 192.168.2.2 > 192.168.0.2: icmp 64: echo \
request seq 512
12:44:34.875457 IP 192.168.2.2 > 192.168.0.2: icmp 64: echo \
request seq 768
6 packets captured
6 packets received by filter
0 packets dropped by kernel
Here's the problemping requests are reaching the host, but no replies are being sent back. The reason is that the host doesn't have a route back to the 192.168.2.0/24 network:
host% route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric \
Ref Use Iface
192.168.3.0 0.0.0.0 255.255.255.0 U 0 \
0 0 switch
192.168.0.0 0.0.0.0 255.255.255.0 U 0 \
0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 0 \
0 0 eth1
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 \
0 0 eth1
We didn't need to add a route for 192.168.3.0/24 because we got one automatically when we assigned the 192.168.3.1 address to the switch TUN/TAP device. We need to manually add a route for the 192.168.2.0/24 network because that's hidden behind the switch, and the host can't see it directly.
So, let's add one and see if this changes anything:
host# route add -net 192.168.2.0/24 gw 192.168.3.3
UML2# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
64 bytes from 192.168.0.2: icmp_seq=0 ttl=63 time=0.5 ms
64 bytes from 192.168.0.2: icmp_seq=1 ttl=63 time=0.4 ms
--- 192.168.0.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.4/0.4/0.5 ms
For good measure, since this is the most complicated routing we have done so far, let's check pinging in the other direction:
ping 192.168.2.2
PING 192.168.2.2 (192.168.2.2) 56(84) bytes of data.
64 bytes from 192.168.2.2: icmp_seq=0 ttl=63 time=16.2 ms
64 bytes from 192.168.2.2: icmp_seq=1 ttl=63 time=0.369 ms
--- 192.168.2.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.369/8.295/16.221/7.926 ms, pipe 2
Summary of the Networking Example
We've grown a fairly complicated network during this example, so before shutting everything down, it's useful to recap what we've done.
We now have three UMLs and three two-node networks:
192.168.1.0/24 is a multicast network with UML1 and UML2. 192.168.2.0/24 is a second multicast network with UML2 and UML3. 192.168.3.0/24 is a uml_switch network connecting UML1 and UML3, with access to the host through a TUN/TAP device.
UML2 is acting as the gateway between the two multicast networks, 192.168.1.0/24 and 192.168.2.0/24.
UML3 is acting as the gateway between the 192.168.2.0/24 multicast network and the uml_switch network.
The gateway UMLs need to have IP forwarding enabled so they will forward packets that are not addressed to them.
The UMLs that are not directly attached to a network need a route to that network through the gateway UML. Finally, the host needs a route for any networks it is not directly attached to.
Chapter 8. Managing UML Instances from the Host
One of the major advantages of a virtual machine over a physical one is that it is far more manageable. It is possible to provide access to it when it has been mismanaged or misconfigured and to control it in ways that are otherwise impossible. We've seen some examples of this already, with hot-plugging of devices and querying their configurations with the uml_mconsole utility. This chapter covers the full suite of UML management tools.

The Management Console
The UML Management Console (MConsole) support comes in two distinct piecesa protocol and the clients that support the protocol. All we've seen so far is the default MConsole client, uml_mconsole. The protocol determines how uml_mconsole (and other clients) send requests to the MConsole driver in the UML kernel and get responses back.
We will talk more about the MConsole protocol later in this chapter. For now, it suffices to say that the protocol is dead simple, and it takes much less than a day of work to implement a basic client for it in any reasonable language such as C or a scripting language such as Perl.
MConsole clients can, and do, implement some functionality that has no counterpart in the MConsole protocol. These things are implemented locally, within the client, and will differ from client to client. The upcoming discussion refers to the uml_mconsole client. Later, we will talk about some other MConsole clients.
uml_mconsole can be used to perform a number of types of queries and control operations on a UML instance, such as:
Reporting the version of the UML kernel Hot-plugging, hot-unplugging and reporting the configuration of the virtual hardware Doing any operation supported by the SysRq facility Reporting the contents of any file in the UML instance's /proc
MConsole Queries
Version
The most basic query is the version command, which returns the version of the kernel that the UML instance is running. The syntax is simple:
host% uml_mconsole debian version
OK Linux usermode 2.6.13-rc5 #29 Fri Aug 5 19:12:02 EDT 2005 \
i686
This returns nearly the same output as uname -a would return inside the UML instance:
# uname -a
Linux usermode 2.6.13-rc5 #29 Fri Aug 5 19:12:02 EDT 2005 \
i686 GNU/Linux
The output is composed of the following pieces:
Linux the kernel name, from uname -s.
usermode the node name, from uname -n.
2.6.13-rc5 the kernel version, from uname -r.
#29 Fri Aug 5 19:12:02 EDT 2005 i686 the kernel build information, from uname -v. The fact that uname calls this the kernel version is misleading because it's not obvious how that would differ from the kernel release. It is made up of the build number since the last mrproper clean of the UML kernel tree. The first part, #29, indicates that this is the 29th build of this tree since it was last configured. The date and timestamp are when this UML kernel was built, and i686 is the architecture of the build host.
You don't generally care about the version that a particular UML is running since, if you are a careful UML administrator, you should know that already. The real value of this query is that it serves as a sort of ping to the UML to check that it is alive, at least enough to respond to interrupts.
Hardware Configuration
We've seen this use of uml_mconsole already, when figuring out which host devices our UML consoles and serial lines had been attached to and when hot-plugging block and network devices. Even in those examples, we've seen only some of the available functionality. All of the drivers that have MConsole support, which is all of the commonly used ones, support the following operations:
Hot-plugging Hot-unplugging Configuration request
The syntax for hot-plugging a device is:
config device=configuration
The syntax for hot-unplugging a device is:
The syntax for requesting the configuration of a device is:
Unplugging a device will fail if the device is busy in some way that makes it hard or impossible to remove.
Table 8.1 summarizes the device names, syntax of the configuration data, and busyness criteria.
Table 8.1. Device Hot-Plugging, Hot-Unplugging, and ConfigurationDevice Type | Device Name | Configuration Syntax | Busy When |
|---|
Console |
|
conn=fd:n
conn=xterm
conn=port:n
conn=tty: tty device
ssln=pts
ssln=pty: pty device
ssln=null
ssln=none
| A UML processss has the console open | Network interface |
|
ethn=tuntap, tap device
ethn=tuntap,, MAC, host IP
address
ethn=ethertap, tap device
ethn=ethertap, tap
device, MAC, host IP address
ethn=daemon, MAC, unix, control
socket
ethn=mcast, MAC, host multicast
IP, port, TTL
ethn=slip, host IP address
ethn=slirp, MAC, Slirp command
line
ethn=pcap, host interface ,
filter expression, flags
| The interface is up
| Block device |
| ubd<n><flags>=filename
ubd<n><flags>=COW file ,
backing file
| The device is open in any way, including being mounted | Memory |
| mem=+ memory increase
mem=- memory decrease
mem= memory
| Alwaysthe amount of memory size can be decreased but can't be removed totally |
Halting and Rebooting a UML Instance
A UML instance can be halted or rebooted from the host using the halt or reboot commands, respectively. The kernel will run its shutdown procedure, which involves flushing unwritten data out to stable storage, shutting down some subsystems, and freeing host resources. However, this is a forced shutdownthe distribution's shutdown procedure will not run. So, services that are running inside the UML will not be shut down cleanly, and this may cause some problems with them on the next reboot. For example, pid files won't be removed, and these may prevent the initialization scripts from starting services by faking them into believing they are already running.
For a mechanism to shut down the guest more cleanly, use the MConsole cad command.
The halt and reboot commands are useful when the UML instance's userspace isn't responding reasonably and can't shut itself down. If the kernel is still responding to interrupts, these commands can ensure a clean kernel shutdown with the filesystems unmounted and clean.
Invoking the Ctrl-Alt-Del Handler
The distribution's Ctrl-Alt-Del handler can be invoked using the cad command. Unlike the halt and reboot commands, cad can be used to cleanly shut down the guest, including running the distribution's full shutdown procedure. This will cause all the services to be cleanly turned off, so there will be no problems as a result on the next boot.
The exact action taken by the UML instance in response to this command depends on the distribution. The init process is in charge of handling this, as the kernel passes the event on to it. An entry in /etc/ inittab controls what init does. The most common action is to reboot, as shown in this entry:
# What to do when CTRL-ALT-DEL is pressed.
ca:12345:ctrlaltdel:/sbin/shutdown -t1 -a -r now
Before booting a UML instance on a filesystem image, it's best to decide on the preferred action for Ctrl-Alt-Del. If you want to halt the UML instance rather than reboot it, remove the -r from the inittab entry above.
Note that actually pressing the Ctrl, Alt, and Del keys on your keyboard into a UML session will not have the desired effect. If that has any effect at all, it will reboot the host since the keyboard belongs to it rather than the UML instance. Since UML doesn't have anything like a keyboard that can be made to treat a particular key combination specially, it uses this rather more abstract method in order to obtain the same results.
Invoking the SysRq Handler
The SysRq key is another way to get the kernel to perform some action on your behalf. Generally, this is intended to debug a sick system or to shut it down somewhat cleanly when nothing else will work. Like Ctrl Alt-Del, access to this is provided through the MConsole protocol, using the sysrq command to the uml_console client.
Use of this command requires that the UML kernel have CONFIG_MAGIC_SYSRQ enabled. Failure to do this will result in an error such as the following:
host% uml_mconsole debian sysrq p
ERR Sysrq not compiled in
The facility also must be turned on during boot. This is controlled by the /proc/sys/kernel/sysrq file (if it contains 1, SysRq is enabled; 0 means that it is disabled) and by the kernel.sysrq sysctl parameter. Some distributions disable SysRq by default during boot. For example, Fedora Core 4 disables it with these lines in /etc/sysctl.conf:
# Controls the System Request debugging functionality of the kernel
kernel.sysrq = 0
You would need to change that 0 to 1in order for the instance to support sysrq requests.
Any output from a sysrq command is returned to the MConsole client and sent to the UML kernel log and, depending on the distribution, the main console.
For example, invoking the sysrq m command, to dump the kernel's memory statistics, looks like this:
host% uml_mconsole debian sysrq m
OK SysRq : Show Memory
Mem-info:
DMA per-cpu:
cpu 0 hot: low 62, high 186, batch 31 used:174
cpu 0 cold: low 0, high 62, batch 31 used:19
Normal per-cpu: empty
HighMem per-cpu: empty
Free pages: 433128kB (0kB HighMem)
Active:1995 inactive:1157 dirty:2 writeback:0 unstable:0 \
free:108282 slab:917 mapped:1399 pagetables:510
DMA free:433128kB min:2724kB low:3404kB high:4084kB \
active:7980kB inactive:4628kB present:463768kB pages_scanned:0 \
all_unreclaimable? no
lowmem_reserve[]: 0 0 0
Normal free:0kB min:0kB low:0kB high:0kB active:0kB inactive:0kB \
present:0kB pages_scanned:0 all_unreclaimable? no
lowmem_reserve[]: 0 0 0
HighMem free:0kB min:128kB low:160kB high:192kB active:0kB \
inactive:0kB present:0kB pages_scanned:0 all_unreclaimable? no
lowmem_reserve[]: 0 0 0
DMA: 2*4kB 2*8kB 5*16kB 2*32kB 1*64kB 0*128kB 1*256kB 1*512kB \
0*1024kB 1*2048kB 105*4096kB = 433128kB
Normal: empty
HighMem: empty
Swap cache: add 0, delete 0, find 0/0, race 0+0
Free swap = 0kB
Total swap = 0kB
Free swap: 0kB
115942 pages of RAM
0 pages of HIGHMEM
3201 reserved pages
5206 pages shared
0 pages swap cached
The output will also appear in the kernel log. This and the output of many of the other commands are dumps of internal kernel state and aren't meant to be analyzed by normal users. This information is useful when a UML instance is in sufficiently bad shape as to require internal kernel information for a diagnosis.
Table 8.2 summarizes the sysrq commands and what they do.
Table 8.2. sysrq CommandsCommand | Function |
|---|
09 | Set the log level: 0 is the lowest, 9 is the highest. Any messages with a priority at least as high as this are logged. | b | RebootUML cleanup, but no kernel or userspace cleanup. | e | Terminate all tasks by sending a SIGTERM. | f | Simulate an out-of-memory condition, forcing a process to be killed to reclaim its memory. | i | Kill all tasks by sending a SIGKILL. | m | Show memory usage. | n | Make all real-time tasks become normal round-robin tasks. | p | Dump the registers and stack of the current task. | s | Sync dirty data to stable storage. | t | Show the state, stack trace, and registers for all tasks on the system. | u | Remount all filesystems read-only. |
Stopping and Restarting a UML Instance
MConsole provides the ability to stop and continue a UML instance. When it is stopped in this manner, it is doing nothing but interpreting MConsole commands. Nothing else is happening. Processes aren't running and nothing else in the kernel is running, including device interrupts.
This state will persist until the MConsole driver receives the command to continue.
The main use of this functionality is to perform an online backup by stopping the instance, having it write out all unwritten file data to disk, copying the now clean filesystem to someplace safe, and continuing the UML instance.
The full procedure looks like this:
host% uml_mconsole debian stop
OK
host% uml_mconsole debian sysrq s
OK SysRq : Emergency Sync
host% cp --sparse=always cow save-cow
host% uml_mconsole debian go
OK
The sysrq s command performs the synchronization of unwritten data to disk, resulting in this output to the kernel log:
SysRq : Emergency Sync
Emergency Sync complete
In this example, I just copied the UML instance's COW file to a file in the same directory. Obviously, a rather more organized backup system would be advisable on a serious UML host. Such a system would keep track of what UML instances had been backed up, when they were last backed up, and the location of the backups.
I used the --sparse=always switch to cp in order to preserve the sparseness of the COW file. This is important for speeding up the copy and for conserving disk space. Without it, all unoccupied blocks in the COW file will be filled with zeros on disk in the copy. This will result in those zero-filled blocks occupying host page cache for a while and will require that they all be written out to disk at some point. Keeping the copy sparse ensures that unoccupied blocks don't become instantiated, so they don't occupy memory before being written to disk, I/O bandwidth while being written, and disk space afterward.
The copy took just under three seconds on my laptop, making this a very quick way to get a backup of the UML instance's data, causing almost no downtime.
This works particularly well with COW files since backing up a full filesystem image would take noticeably longer and consume more bandwidth while writing the copy out to disk.
Logging to the UML Instance's Kernel Log
The log command enables arbitrary text to be inserted into the UML instance's kernel log. This was written in order to allow administrators of UML honeypots to overwrite the preexisting, UML-specific kernel log with a log that looks like it came from a physical machine. Since the purpose of a virtual honeypot is to pretend to be a physical machine, it is important that there be no easy ways for an intruder to discern that it is a virtual machine. Examining the kernel log is a fairly easy way to tell what sort of machine you're on because it contains a great deal of information about the hardware.
Since the kernel log has a fixed size, logging enough data will cause any previous data to be lost, and the kernel log will contain only what you logged with MConsole.
There are probably limited uses of this ability outside of honeypots, but it could be useful in a situation where events inside a UML instance need to be coordinated with events outside. If the kernel log of the UML instance is the official record of the procedure, the log MConsole command can be used to inject outside messages so that the kernel log contains all relevant information in chronological order.
The uml_mconsole client has a log -f <file> command that will log the contents of the given file to the UML instance's kernel log.
Examining the UML Instance's /proc
You can use the MConsole proc command to examine the contents of any file within the UML's /proc. This is useful for debugging a sick UML instance, as well as for gathering performance data from the host.
This output gets returned to the MConsole client, as seen here:
host% uml_mconsole debian proc meminfo
OK MemTotal: 450684 kB
MemFree: 434608 kB
Buffers: 724 kB
Cached: 8180 kB
SwapCached: 0 kB
Active: 7440 kB
Inactive: 3724 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 450684 kB
LowFree: 434608 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 0 kB
Writeback: 0 kB
Mapped: 5632 kB
Slab: 3648 kB
CommitLimit: 225340 kB
Committed_AS: 10820 kB
PageTables: 2016 kB
VmallocTotal: 2526192 kB
VmallocUsed: 24 kB
VmallocChunk: 2526168 kB
This sort of thing would be useful in monitoring the memory consumption of the UML instances running on a host. Its intended purpose is to allow a daemon on the host to monitor memory pressure inside the UML instances and on the host, and to use memory hot-plug to shift memory between instances in order to optimize use of the host's physical memory. At this writing, this is a work in progress, as support in the host kernel is needed in order to make this work. A prototype of the host functionality has recently been implemented. However, it is unclear whether this interface will survive or when this ability will appear in the mainline kernel.
Currently, this command can be used only for /proc files that you know exist. In other words, it doesn't work on directories, meaning you can't use it to discover what processes exist inside the UML and get their statistics.
Forcing a Thread into Context
The MConsole stack command is a bit of a misnomer. While it does do what it suggests, its real purpose is somewhat different. Sending this command to a UML instance will cause it to dump the stack of the given process:
host% uml_mconsole debian stack 1
OK EIP: 0073:[<400ecdb2>] CPU: 0 Not tainted ESP: 007b:bf903da0 \
EFLAGS: 00000246
Not tainted
EAX: ffffffda EBX: 0000000b ECX: bf903de0 EDX: 00000000
ESI: 00000000 EDI: bf903dd8 EBP: bf903dd8 DS: 007b ES: 007b
15b07a20: [<080721bd>] show__regs+0xd1/0xd8
15b07a40: [<0805997d>] _switch_to+0x6d/0x9c
15b07a80: [<081b3371>] schedule+0x2e5/0x574
15b07ae0: [<081b3d37>] schedule__timeout+0x4f/0xbc
15b07b20: [<080c1a85>] do__select+0x255/0x2e4
15b07ba0: [<080c1d75>] sys__select+0x231/0x43c
15b07c20: [<0805f591>] handle__syscall+0xa9/0xc8
15b07c80: [<0805e65a>] userspace+0x1ae/0x2bc
15b07ce0: [<0805f11e>] new__thread_handler+0xaa/0xbc
15b07d20: [<00dde420>] 0xdde420
The process ID I gave was one internal to UML, that of the init process. If you don't know what processes are running on the system, you can get a list of them with sysrq t:
host% uml_mconsole debian2 sysrq t
The output looks in part like this:
apache S 00000246 0 253 238 \
252 (NOTLB)
14f03b10 00000001 bfffe0cc 0013a517 00000246 14f03b10 \
000021a0 144d8000
14e75860 1448c740 144db98c 144db8d4 0805e941 00000001 \
12002000 00000000
00000033 00000025 bfffe0cc 0013a517 00000246 bfacf178 \
0000007b 0013a517 Call Trace:
144db990: [<0805f039>] switch__to_skas+0x39/0x74
144db9c0: [<08059955>] _switch_to+0x45/0x9c
144dba00: [<081b38a1>] schedule+0x2e5/0x574
144dba60: [<081b4289>] schedule__timeout+0x71/0xbc
144dba90: [<08187cf9>] inet__csk_wait_for_connect+0xc5/0x10c
144dbad0: [<08187de1>] inet__csk_accept+0xa1/0x150
144dbb00: [<081a529a>] inet__accept+0x26/0xa4
144dbb30: [<08165e10>] sys__accept+0x80/0x12c
144dbbf0: [<081667dd>] sys__socketcall+0xbd/0x1c4
144dbc30: [<0805f591>] handle__syscall+0xa9/0xc8
144dbc90: [<0805e65a>] userspace+0x1ae/0x2bc
144dbcf0: [<0805f1e0>] fork__handler+0x84/0x9c
144dbd20: [<00826420>] 0x826420
As with sysrq output, this will also be recorded in the kernel message log.
This tells us we have an apache process whose process ID is 253. This also dumps the stack of every process on the system in exactly the same format as with the stack command.
So why have the stack command when sysrq t gives us the same information and more? The reason is that the real intent of this command is to temporarily wake up a particular thread within the UML instance so it will hit a breakpoint, letting you examine the thread with the debugger.
To do this, you must have the UML instance running under gdb, either from the start or by attaching to the instance later. You put a breakpoint on the show_regs() call in _switch_to, which is currently in arch/um/kernel/process_kern.c:
do {
current->thread.saved_task = NULL ;
CHOOSE_MODE_PROC(switch_to_tt, switch_to_skas, prev, \
next);
if(current->thread.saved_task)
show_regs(&(current->thread.regs));
next= current->thread.saved_task;
prev= current;
} while(current->thread.saved_task);
This call is what actually dumps out the stack. But since you put a breakpoint there, gdb will stop before that actually happens. At this point, gdb is sitting at the breakpoint with the desired thread in context. You can now examine that thread in detail. Obviously this is not useful for the average UML user. However, it is immensely useful for someone doing kernel development with UML who is seeing processes hang. Most commonly, it's a deadlock of some sort, and figuring out exactly what threads are holding what locks, and why is essential to debugging it. Waking up a particular thread and making it hit a breakpoint is very helpful.
This sort of thing had been possible in tt mode for a long time, but not in skas mode until this functionality was implemented. In tt mode, every UML process or thread has a corresponding host process, and that process includes the UML kernel stack. This makes it possible to see the kernel stack for a process by attaching gdb to the proper host process.
In skas mode, this is not the case. The UML kernel runs entirely within a single process, using longjmp to switch between kernel stacks on context switches. gdb can't easily access the kernel stacks of processes that are not currently running. Temporarily waking up a thread of interest and making it hit a breakpoint is a simple way to fix this problem.
Sending an Interrupt to a UML Instance
The int command is implemented locally within uml_mconsole. It sends an interrupt signal (SIGINT) to the UML instance that uml_mconsole is communicating with. It operates by reading the instance's pid file and sending the signal to that process.
Normally, that instance will be running under gdb, in which case, the interrupt will cause the UML instance to stop running and return control to gdb. At that point, you can use gdb to examine the instance as you would any other process.
If the UML instance is not running under gdb, the signal will cause it to shut down.
Getting Help
Finally, there is a help command, which will display a synopsis of the available MConsole commands:
host% uml_mconsole debian help
OK Commands:
version Get kernel version
help Print this message
halt Halt UML
reboot Reboot UML
config <dev>=<config> - Add a new device to UML;
same syntax as command line
config <dev> - Query the configuration of a device
remove <dev> - Remove a device from UML
sysrq <letter> - Performs the SysRq action controlled by \
the letter
cad - invoke the Ctrl-Alt-Del handler
stop - pause the UML; it will do nothing until it receives \
a 'go'
go - continue the UML after a 'stop'
log <string> - make UML enter <string> into the kernel \
log
proc <file> - returns the contents of the UML's \
/proc/<file>
Additional local mconsole commands:
quit - Quit mconsole
switch <socket-name> - Switch control to the given \
machine
log -f <filename> - use contents of <filename> as \
UML log messages
mconsole-version - version of this mconsole program
The first section shows requests supported by the MConsole driver within the UML kernel. These are available to all clients, although perhaps in a different form. The second section lists the commands supported locally by this particular client, which may not be available in others.
There is no predetermined set of requests within the MConsole protocol. Requests are defined by the driver and can be added or removed without changing the protocol. This provides a degree of separation between the client and the UML kernelthe kernel can add more commands and existing clients will be able to use them.
This separation can be seen in the help message above. The first section was provided by the UML kernel and merely printed out by the uml_mconsole client. When a new request is added to the driver, it will be added to the kernel's help string, and it will automatically appear in the help text printed by the uml_mconsole client.
Running Commands within the UML Instance
An oft-requested MConsole feature is the ability to run an arbitrary command within a UML instance. I oppose this on the basis that there are perfectly good ways to run commands inside a UML instance, for example, by logging in and executing a command within a shell.
A design ethic in the Linux kernel community holds that only things that need to be done in the kernel should be done there. The existence of other ways to run commands within a UML is proof that this functionality doesn't need to be in the kernel. Thus, I have refused to implement this or to merge other people's implementations.
Nevertheless, a patch implementing this ability does exist, and it has a following in the UML community. With a suitably patched UML, it works like this:
host% uml_mconsole debian exec "ps uax > /tmp/x"
OK The command has been started successfully.
The command's output isn't returned back to the MConsole client because it would be complicated to start a process from a kernel thread, capture its output, and return it to the outside. Thus, if you want the output, you need to save it someplace, as I did above by redirecting the output to /tmp/x, and then retrieve it.
This is convenient, but I would claim that, with a little foresight on behalf of the host administrator, essentially the same thing can be done in other ways.
The most straightforward way to do this is simply to log in to the UML and run the commands you need. Some people make a couple of common objections to this method.
A login is hard because it's tough to parse the login and password prompts and respond to them robustly. A login modifies things such as network counters and wtmp and utmp enTRies, which some people would prefer to see unchanged. MConsole exec is harder for the UML user to disable, purposefully or not, than a login.
I have what I believe to be solid answers to these objections. First, with an ssh key in the appropriate place in the UML filesystem, parsing the login and password prompts is unnecessary because there aren't any.
Second, logging in over a UML console doesn't modify any network counters. Dedicating this console to the admin makes it possible to have a root shell permanently running on it, making even ssh unnecessary, and also not modifying the wtmp or utmp files because there's no login.
Third, I don't think any of the alternatives are any more robust against disabling or manipulation than MConsole exec. An ssh login can be disabled by the UML root user deleting the ssh key. The console with a permanent root shell can be disabled by editing the UML instance's /etc/inittab. But MConsole exec can be disabled by moving or replacing the commands that the host administrator will run.
The desire for something like MConsole exec is a legitimate one, and all of the current solutions have limitations. I believe that the longterm solution may be something like allowing a host process to migrate into the UML instance, allowing it to do its work inside that environment. In this case, the UML environment wouldn't be as opaque to the host as it is now. It would be possible to create a process on the host, guaranteeing that it is running the correct executable, and then move it into the UML instance. It would then see the UML filesystem, devices, processes, and so on and operate in that environment. However, it would retain ties to the host environment. For example, it would retain the file descriptors opened on the host before the migration, and it would be able to accept input and send output through them. Something like this, which can be seen as a limited form of clustering, seems to me to suffice and has none of the limitations of the other solutions.
The uml_mconsole Client
We've already seen a great deal of the uml_mconsole client, as it has been used to illustrate all of the MConsole discussion to date. However, there are some aspects we haven't seen yet.
We have seen the format of the output of a successful request, such as this:
host% uml_mconsole debian version
OK Linux usermode 2.6.13-rc5 #29 Fri Aug 5 19:12:02 EDT 2005 \
i686
It always starts with OK or ERR to simplify automating the determination of whether the request succeeded or failed. This is how a failure looks:
host% uml_mconsole debian remove ubda
ERR Device is currently open
Because the /dev/ubda device is currently mounted, the removal request fails and is reported with ERR followed by the human-readable error message.
An important part of uml_mconsole that we haven't seen is its internal command line. Every example I have used so far has had the command in the argument list. However, if you ran uml_mconsole with just one argument, a umid for a running UML instance, you would see something like this:
host% uml_mconsole debian
(debian)
At this point, you can run any MConsole command. The prompt tells you which UML instance your request will be sent to.
You can change which UML you are talking to by using the switch local command:
(debian) switch new-debian
Switched to 'new-debian'
(new-debian)
At this point, all requests will go to the new-debian UML instance.
Finally, there is a local command that will tell you what version of the client you are running:
(new-debian) mconsole-version
uml_mconsole client version 2
Whether you're using uml_mconsole in single-shot mode, with the command on the uml_mconsole command line, or you're using its internal command line, commands intended for the UML MConsole driver are generally passed through unchanged. A single-shot command is formed by concatenating the command-line argument vector into a single string with spaces between the arguments.
The one exception to this is for commands that take filenames as arguments. Currently, there is only one time this happenswhen indicating the files that a block device will be attached to. These may be specified as relative paths, which can cause problems when the UML instance and uml_mconsole process don't have the same working directory. A path relative to the uml_mconsole process working directory will not be successfully opened by the UML instance from its working directory. To avoid this problem, uml_mconsole makes such paths absolute before passing the request to the UML instance.
The MConsole Protocol
The MConsole protocol, between the MConsole client and the MConsole driver in the UML kernel, is the glue that makes the whole thing work. I'm going to describe the protocol in enough detail that someone, sufficiently motivated, could implement a client. This won't take too long since the protocol is extremely simple.
As with any client-server protocol, the client forms a request, sends it to the server, and at some later point gets a reply from the server.
The request structure contains
A magic number A version number The request The request length
In C, it looks like this:
#define MCONSOLE_MAGIC (0xcafebabe)
#define MCONSOLE_MAX_DATA (512)
#define MCONSOLE_VERSION 2
struct mconsole_request {
u32 magic;
u32 version;
u32 len;
char data[MCONSOLE_MAX_DATA];
};
The command goes into the data field as a string consisting of space-separated wordsexactly what the uml_mconsole client reads from its command line. The length of the command, the index of the NULL-terminator, is put in the len field.
In Perl, forming a request looks like this:
my $MCONSOLE_MAGIC = 0xcafebabe;
my $MCONSOLE_MAX_DATA = 512;
my $MCONSOLE_VERSION = 2;
my $msg = pack("LiiA*", $MCONSOLE_MAGIC, $MCONSOLE_VERSION, \
length($cmd),
$cmd);
Once the request is formed, it must be sent to the server in the UML MConsole driver over a UNIX domain socket created by the driver. On boot, UML creates a subdirectory for instance-specific data, such as this socket. The subdirectory has the same name as the UML instance's umid, and its parent directory is the umid directory, which defaults to ~/.uml. So, a UML instance with a umid of debian will have its MConsole socket created at ~/.uml/debian/mconsole. The umid directory can be changed with the umid= switch on the UML command line.
The request is sent as a datagram to the MConsole socket, where it is received by the driver and handled. The response will come back over the same socket in a form very similar to the request:
struct mconsole_reply {
u32 err;
u32 more;
u32 len;
char data[MCONSOLE_MAX_DATA];
};
err is the error indicatorif it is zero, the request succeeded and data contains the reply. If it is nonzero, there was some sort of error, and the data contains the error message.
more indicates that the reply is too large to fit into a single reply, so more reply packets are coming. The final reply packet will have a more field of zero.
As with the request, the len field contains the length of the data in this packet.
In Perl, the response looks like this:
($err, $more, $len, $data) = unpack("iiiA*", $data);
where $data is the packet read from the socket.
The use of a UNIX domain socket, as opposed to a normal IP socket, is intentional. An IP socket would allow an MConsole client to control a UML instance on a different host. However, allowing this would require some sort of authentication mechanism built into the protocol, as this would enable anyone on the network to connect to a UML instance and start controlling it.
The use of a UNIX domain socket adds two layers of protection. First, it is accessible only on the UML instance's host, so any users must be logged in to the host. Second, UNIX domain sockets are protected by the normal Linux file permission system, so that access to it can be controlled by setting the permissions appropriately.
Rather than invent another authentication and authorization mechanism, the use of UNIX domain sockets forces the use of existing mechanisms. If remote access to the UML instance is required, executing the uml_mconsole command over ssh will use ssh authentication. Similarly, the file permissions on the socket make up the MConsole authorization mechanism.
The MConsole Perl Library
As is evident from the Perl snippets just shown, uml_mconsole is not the only MConsole client in existence. There is a Perl client that is really a library, not a standalone utility. Part of the UML test suite, it is used to reconfigure UML instances according to the needs of the tests.
In contrast to the uml_mconsole client, this library has a method for every MConsole request, rather than simply passing commands through to the server unchanged.
Requests Handled in Process and Interrupt Contexts
There is a subtlety in how MConsole requests are handled inside the driver that can affect whether a sick UML will respond to them. Some requests must be handled in a process context, rather than in the MConsole interrupt handler. Any request that could potentially sleep must be handled in a process context. This includes config and remove, halt and reboot, and proc. These all call Linux kernel functions, which for one reason or another might sleep and thus can't be called from an interrupt handler.
These requests are queued by the interrupt handler, and a special worker thread takes care of them at some later time. If the UML is sufficiently sick that it can't switch to the worker thread, such as if it is stuck handling interrupts, or the worker thread can't run, then these requests will never run, and the MConsole client will never get a reply.
In this case, another mechanism is needed to bring down the UML instance in a semicontrolled manner. For this, see the final section of this chapter, on controlling UML instances With Signals from the host.
MConsole Notifications
So far, we have seen MConsole traffic initiated only by clients. However, sometimes the server in the UML kernel can initiate traffic. A notification mechanism in the MConsole protocol allows asynchronous events in the UML instance to cause a message to be sent to a client on the host. Messages can result from the following events.
The UML instance has booted far enough that it can handle MConsole requests. This is to prevent races where a UML instance is booted and an MConsole client tries to send requests to it before it has set up its MConsole socket. This notification is sent once the socket is initialized and includes the location of the socket. When this notification is received, the MConsole driver is running and can receive requests. The UML instance is panicking. The panic message is included in the notification. The UML instance has hung. This one is unusual in not being generated by the UML kernel itself. Since the UML is not responding to anything, it is likely unable to diagnose its own hang and send this notification. Rather, the message is generated by an external process on the host that is communicating with the UML harddog driver, which implements something like a hardware watchdog. If this process doesn't receive a message from the harddog driver every minute, and it has been told to generate a hang notification, it will construct the notification and send it. At that point, it is up to the client to decide what to do with the hung UML instance. A UML user has generated a notification. This is done by writing to the /proc/mconsole file in the UML instance. This file is created when the UML instance has been told on the command line to generate notifications.
The client that receives these notifications may be a different client than you would use to control the UML. In fact, the uml_mconsole client is incapable of receiving MConsole notifications. In order to generate notifications, a switch on the UML command line is needed to specify the UNIX socket to which the instance will send notifications. This argument on the command line specifies the file /tmp/notify, which must already exist, as the notification socket for this UML instance:
mconsole=notify:/tmp/notify
Using this small Perl script, we can see how notifications come back from the UML instance:
use UML::MConsole;
use Socket;
use strict;
my $sock = "/tmp/notify";
!defined(socket(SOCK, AF_UNIX, SOCK_DGRAM, 0)) and
die "socket failed : $!\n";
!defined(bind(\*SOCK, sockaddr_un($sock))) and
die "UML::new bind failed : $!\n";
while(1){
my ($type, $data) = UML::MConsole->read_notify(\*SOCK, undef);
print "Notification type = \"$type\", data = \"$data\"\n";
}
By first running this script and then starting the UML instance with the switch given above, we can see notifications being generated.
The first one is the socket notification telling us that the MConsole request socket is ready:
Notification type = "socket", data = \
"/home/jdike/.uml/debian/mconsole"
Once the instance has booted, we can log in and send messages to the host through the /proc/mconsole file:
UML# echo "here is a user notification" > /proc/mconsole
This results in the following output from the notification client:
Notification type = "user notification", \
data = "here is a user notification"
These notifications all have a role to play in an automated UML hosting environment. The socket notification tells when a UML instance is booted enough to be controllable with an MConsole client. When this message is received, the instance can be marked as being active and the control tools told of the location of the MConsole socket.
The panic and hang notifications are needed in order to know when the UML should be restarted, in the case of a panic, or forcibly killed and then restarted, in the case of a hang.
The user notifications have uses that are limited only by the imagination of the administrator. I implemented them for the benefit of workloads running inside a UML instance that need to send status messages to the host. In this scenario, whenever some milestone is reached or some significant event occurs, a user notification would be sent to the client on the host that is keeping track of the workload's progress.
You could also imagine having a tool such as a log watcher or intrusion detection system sending messages to the host through /proc/mconsole whenever an event of interest happens. A hosting provider could also use this ability to allow users to make requests from inside the UML instance.
Controlling a UML Instance with Signals
So far, I've described the civilized ways to control UML instances from the host. However, sometimes an instance isn't healthy enough to cooperate with these mechanisms. For these cases, some limited amount of control is available by sending the instance a signal.
To send a UML instance a signal, you first need to know which process ID to send it to. A UML instance is comprised of a number of threads, so the choice is not obvious. Also, when the host has a number of instances, there is a real chance of misreading the output of ps and hitting the wrong UML instance.
To solve this problem, a UML instance writes the process ID of its main thread into the pid file in its umid directory. This thread is the one responsible for handling the signals that can be used for this last ditch control. Given a umid, sending a signal to the corresponding instance is done like this:
kill -TERM `cat ~/.uml/debian/pid`
When this main thread receives SIGINT, SIGTERM, or SIGHUP, it will run the UML-specific parts of the shutdown process. This will have the same effect as the MConsole halt or sysrq b requests. No userspace or kernel cleanup will happen. Only the host resources that have been allocated by UML will be released. The UML instance's filesystems will be dirty and need either an fsck or a journal replay.
Chapter 9. Host Setup for a Small UML Server
After having talked about UML almost exclusively so far, we will now talk about the host. This chapter and the next will cover setting up and running a secure, well-performing UML server. First we will talk about running a small UML server, where the UML instances will be controlled by fairly trusted people, such as the host administrator or others with logins on the host. Thus, we won't need the same level of security as on a large UML server with unknown, untrusted people inside the UML instances. We will have a basic level of security, where nothing can break out of a UML instance onto the host. We won't be particularly paranoid about whether network traffic from the UMLs is originating from the expected IP addresses or whether there is too much of it. Similarly, we will talk about getting good performance from the UML instances, but we won't try to squeeze every bit of UML hosting capacity from the host.
All of these things, which a large UML hosting provider cares about more than a casual in-house UML user does, will be discussed in the next chapter. There, we will cover tougher security measures, such as how to protect the host even if a user does somehow manage to break out of a UML instance and how to ensure that UML instances are not spoofing IP addresses or sending out unreasonably large amounts of traffic. We will also discuss how to log resource usage, such as network traffic, in that chapter. But first, let's cover what more casual users want to know.
Host Kernel Version
Technically, UML will run on any x86 host kernel from a stable series (Linux kernel versions 2.2, 2.4, or 2.6) since 2.2.15. However, the 2.2 kernel is of historic interest onlyif you have such a machine that you are going run UML instances on, you should upgrade. The 2.4 and 2.6 kernels make good hosts, but 2.6 is preferred. UML will run on any x86_64 (Opteron/AMD64 or Intel EM64T) host, which is a newer architecture and has had the necessary basic support since the beginning. However, x86_64 hosts are stable only on hosts running 2.6.12 or later. On S/390, a fairly new 2.6 host kernel is required because of bugs that were found and fixed during the UML port to that architecture.
UML makes use of the AIO and O_DIRECT facilities in the 2.6 kernels for better performance and lower memory consumption. AIO is kernel-level asynchronous I/O, where a number of I/O requests can be issued at once, and the process that issued them can receive notifications asynchronously when they finish. The kernel issues the notifications when the data is available, and the order in which that happens may not be related to the order in which they are issued.
The alternative, which is necessary on earlier kernels, is to either make normal read and write system calls, which are synchronous, and make the process sleep until the operation finishes, or to dedicate a thread (or multiple threads) to I/O operations. Doing I/O synchronously allows only one operation to be pending at any given time. Doing I/O asynchronously by having a separate thread do synchronous I/O at least allows the process to do other work while the operation is pending. On the other hand, only one operation can be pending for each such I/O thread, and the process must context-switch back and forth from these threads and communicate with them as operations are issued and completed. Having one thread for each pending I/O operation is hugely wasteful.
glibc has AIO support in all kernels, even those without AIO support, and it implements this using threads, potentially one thread per outstanding I/O request. UML, on such hosts, emulates AIO in a similar way. It creates a single thread, allowing one I/O request to be pending at a time.
The AIO facility present in the 2.6 kernel series allows processes to do true AIO. UML uses this by having a separate thread handle all I/O requests, but now, this thread can have many operations pending at once. It issues operations to the host and waits for them to finish. As they finish, the thread interrupts the main UML kernel so that it can finish the operations and wake up anything that was waiting for them.
This allows better I/O performance because more parallel I/O is possible, which allows data to be available earlier than if only one I/O request can be pending.
O_DIRECT allows a process to ask that an I/O request be done directly to and from its own address space without being cached in the kernel, as shown in Figure 9.1. At first glance, the lack of caching would seem to hurt performance. If a page of data is read twice with O_DIRECT enabled, it will be read from disk twice, rather than the second request being satisfied from the kernel's page cache. Similarly, write requests will go straight to disk, and the request won't be considered finished until the data is on the disk.
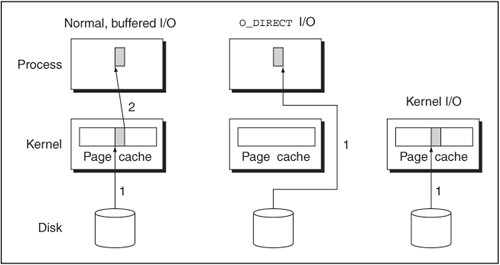
However, O_DIRECT is intended for specialized applications that implement their own caching and use AIO. For an application like this, using O_DIRECT can improve performance and lower its total memory requirements, including memory allocated on its behalf inside the kernel. UML is such an application, and use of O_DIRECT actually makes it behave more like a native kernel.
A native kernel must wait for the disk when it writes data, and there is no caching level below it (except perhaps for the on-disk cache), so if it reads data, it must again wait for the disk. This is exactly the behavior imposed on a process when it uses O_DIRECT I/O.
The elimination of the caching of data at the host kernel level means that the only copy of the data is inside the UML instance that read it. So, this eliminates one copy of the data, reducing the memory consumption of the host. Eliminating this copy also improves I/O latency, making the data available earlier than if it was read into the host's page cache and then copied (or mapped) into the UML instance's address space.
For these reasons, for x86 hosts, a 2.6 host kernel is preferable to 2.4. As I pointed out earlier, running UML on x86_64 or S/390 hosts requires a 2.6 host because of host bugs that were fixed fairly recently.
UML Execution Modes
Traditionally, UML has had two modes of operation, one for unmodified hosts and one for hosts that have been patched with what is known as the skas patch. The first mode is called tt mode, or "tracing thread" mode, after the single master thread that controls the operation of the rest of the UML instance. The second is called skas mode, or "separate kernel address space" mode. This requires a patch applied to the host kernel. UML running in this mode is more secure and performs better than in tt mode.
Recently, a third mode has been added that provides the same security as skas, plus some of the performance benefits, on unmodified hosts. The current skas host patch is the third version, so it's called skas3. This new mode is called skas0 since it requires no host changes. The intent is for this to completely replace tt mode since it is generally superior, but tt mode still has some advantages. Once this is no longer the case, the support for tt mode will be removed. Even so, I will describe tt mode here since it is not clear when support for it will be removed, and you may need an older release of UML that doesn't have skas0 support.
As the term skas suggests, the main difference between tt mode and the two skas modes is how UML lays out address spaces on the host. Figure 9.2 shows a process address space in each mode. In tt mode, the entire UML kernel resides within each of its process's address spaces. In contrast, in skas3 mode, the UML kernel resides entirely in a different host address space. skas0 mode is in between, as it requires that a small amount of UML kernel code and data be in its process address spaces.
The relationship between UML processes and the corresponding host processes for each mode follows from this. Figure 9.3 shows these relationships.
tt mode really only exists on x86 hosts. The x86_64 and S/390 ports were made after skas0 mode was implemented, and they both use that rather than tt mode. Because of this, in the following discussion about tt mode, I will talk exclusively about x86. Also, the discussion about address space sizes and constraints on UML physical memory sizes are confined to x86, since this issue affects only 32-bit hosts.
tt Mode
In tt mode, a single tracing thread controls the rest of the threads in the UML instance by deciding when to intercept their system calls and have them executed within UML. When a UML process is running, it intercepts its system calls, and when the UML kernel is running, it doesn't. This is the tracing that gives this thread its name.
The tracing thread has one host process per UML process under its control. This is necessary because UML needs a separate host address space for each UML process address space, and creating a host process is the only way to get a new host address space. This is wasteful since all of the other host kernel data associated with the process, such as the kernel stack and task structure, are unnecessary from the point of view of UML. On a uniprocessor UML instance, there can be only one of these host processes running at any given time, so all of the idle execution contexts represented by the other host processes are wasted. This problem is fixed in skas3 mode, as described in the next section.
The UML kernel is placed in the upper .5GB of each process address space. This is the source of the insecurity of tt modethe UML kernel, including its data, is present and writable in the address spaces of its processes. Thus, a process that knew enough about the internals of UML could change the appropriate data inside UML and escape onto the host by tricking the tracing thread into not intercepting its system calls.
It is possible to protect the kernel's memory from its processes by write-protecting it when exiting the kernel and write-enabling it when entering the kernel. This has been implemented but never used because it imposes a huge performance cost. This protection has other problems as well, including complicating the code and making Symmetric Multi-Processing (SMP) impossible. So, it has probably never been used except in testing.
The fact that UML occupies a portion of the process address space is also a problem. The loss to UML processes of the upper .5GB of address space is inconvenient to some processes, and confining UML to that small address space limits the size of its physical memory. Since normal physical memory must be mapped into the kernel address space, the maximum physical memory size of a UML is less than .5GB. In practice, the limit is around 480MB.
You can use Highmem support to get around this. Highmem support in Linux exists because of the need to support more than 4GB of physical memory in 32-bit x86 machines, which can access only 4GB of memory in a single 32-bit address space. In practice, since the x86 kernel has 1GB of address space (by default, it occupies the upper 1GB of its process's address spaces), it needs Highmem support to access more than 1GB of physical memory.
The memory pages above the lower 1GB can be easily used for process memory, but if the kernel is to use a Highmem page for its own memory, it must temporarily map it into its address space, manipulate the data in it, and then unmap it. This imposes a noticeable performance cost.
UML has a similar problem with Highmem memory, and, in tt mode, it starts at around .5GB of physical memory, rather than 1GB. To access memory outside this region, it must also map it into its address space, but this mapping is more expensive for UML than it is for the host. So, UML suffers a greater performance penalty with a large physical memory than the host does.
skas3 Mode
The problems with tt mode motivated the development of the skas3 host patch. These problems were driven by host limitations (or so we thought until someone figured out a way around them), so the skas3 patch added mechanisms to the host that allowed UML to avoid them.
skas3 gets its name from using the third version of the "separate kernel address space" host patch. As its rather unimaginative name suggests, the skas3 patch allows the UML kernel to be in a separate host address space from its processes. This protects it from nosy processes because those processes can't form a UML kernel address to write. The UML kernel is completely inaccessible to its processes.
skas3 also improved UML performance. Removing the UML kernel from its processes made new process creation faster, shrunk some pieces of data in the host kernel, and may speed context switching. In combination, these effects produced a very noticeable performance improvement over tt mode.
To allow the UML kernel to exist in a separate address space from its processes, a small number of new facilities were needed in the host:
Creation, manipulation, and destruction of host address spaces that are not associated with a process Extraction of page fault information, such as the faulting address, access type, and processor flags, after a process receives a SIGSEGV Manipulation of the Local Descriptor Table (LDT) entries of another process
The address space manipulation is enabled through a new file in /proc called /proc/mm. Opening it creates a new, empty host address space and returns a file descriptor that refers to that address space. When the file descriptor is closed, and there are no users of the address space, the address space is freed.
A number of operations were formerly impossible to perform on an outside address space. Changing mappings is the most obvious. To handle a page fault in tt mode, it is sufficient to call mmap since the kernel is inside the process address space. When the process is outside it, we need something else. We can have the address space file descriptor support these operations through writing specially formatted structures to it. Mapping, unmapping, and changing permissions on pages are done this way, as is changing LDT entries associated with the address space.
Now that we can create host address spaces without creating new host processes, the resource consumption associated with tt mode goes away. Instead of one host process per UML process, there is now one host process per virtual processor. The UML kernel is in one host process that does system call interception on another, which, on a uniprocessor UML, runs all UML processes. It does so by switching between address spaces as required, under the control of the UML kernel invoking another ptrace extension, PTRACE_SWITCH_MM. This extension makes the ptraced process switch from one host address space to another.
With the UML kernel in its own address space, it is no longer constrained to the 1GB of address space of tt mode. This enables it to have a much larger physical memory without needing to resort to Highmem. In principal, the entire 3GB address space on x86 is available for use as UML physical memory. In practice, the limit is some what lower, but, at around 2.5GB, still much greater than the 480MB limit imposed by tt mode.
In order to achieve this higher limit, the UML kernel must be configured with CONFIG_MODE_TT disabled. With both CONFIG_MODE_TT and CONFIG_MODE_SKAS enabled, the resulting UML kernel must be able to run in both modes, depending on its command line and the host capabilities it detects when it boots. A dual-mode UML instance will be compiled to load into the upper .5GB of its address space, as required for tt mode, and will be subject to the 480MB physical memory limit. Disabling CONFIG_MODE_TT causes the UML binary to be compiled so it loads lower in its address space, where more normal processes load. In this case, the physical memory limit increases to around 2.5GB.
This is fortunate since Highmem is slower in skas3 mode than in tt mode, unlike almost all other operations. This is because a skas3 mode UML instance needs to map Highmem pages into its address space much more frequently than a tt mode UML instance does. When a UML process makes a system call, it is often the case that one of the arguments is a pointer, and the data referenced by that pointer must be copied into the UML kernel address space. In tt mode, that data is normally available to simply copy since the UML kernel is in the UML process address space. In skas3 mode, that isn't the case. Now, the UML kernel must work out from the process pointer it was given where in its own physical memory that data lies. In the case of Highmem memory, that data is not in its physical memory, and the appropriate page must be mapped into its address space before it can access the data.
Finally, it is necessary to extract page fault information from another process. Page faults happen when a process tries to execute code or access data that either has not been read yet from disk or has been swapped out. Within UML, process page faults manifest themselves as SIGSEGV signals being delivered to the process. Again, in tt mode, this is easy because the UML kernel itself receives the SIGSEGV signal, and all the page fault information is on its stack when it enters the signal handler. In skas3 mode, this is not possible because the UML kernel never receives the SIGSEGV. Rather, the UML kernel receives a notification from the host that its process received a SIGSEGV, and it cancels the signal so that it is never actually delivered to the process. So, the skas3 patch adds a ptrace option, PTRACE_FAULTINFO, to read this information from another process.
Together, these host changes make up the skas3 patch. UML needed to be modified in order to use them, of course. Once this was done, and the security and performance benefits became apparent, skas3 became the standard for serious UML installations.
skas0 Mode
More recently, an Italian college student, Paolo Giarrusso, who had been doing good work on UML, thought that it might be possible to implement something like skas3 on hosts without the skas3 patch.
His basic idea was to insert just enough code into the address space of each UML process to perform the address space updates and information retrieval for which skas3 requires a host patch. As I implemented it over the following weekend, this inserted code takes the form of two pages mapped by the UML kernel at the top of each process address space. One of these pages is for a SIGSEGV signal frame and is mapped with write permission, and the other contains UML code and is mapped read-only.
The code page contains a function that invokes mmap, munmap, and mprotect as requested by the UML kernel. The page also contains the SIGSEGV signal handler. The function is invoked whenever address space changes are needed in a UML process and is the equivalent of requesting an address space change through a /proc/mm file descriptor. The signal handler implements the equivalent of PTRACE_FAULTINFO by receiving the SIGSEGV signal, reading all of the fault information from its stack, and putting it in a convenient form where the UML kernel can read it.
Without changes in the host kernel, we have no way to create new host address spaces without creating new host processes. So, skas0 mode resembles tt mode in having one host process for each UML process.
This is the only similarity between skas0 mode and tt mode. In skas0 mode, the UML kernel runs in a separate host process and has a separate host address space from its processes. All of the skas3 benefits to security and performance flow from this property. The fact that the UML kernel is controlling many more processes than in skas3 mode means that we have the same wasted kernel memory that tt mode has. This makes skas0 mode somewhat less efficient than skas3 mode but still a large improvement over tt mode.
To Patch or Not to Patch?
With respect to how you want to run UML, at this writing, the basic choice is between skas0 mode and skas3 mode. The decision is controlled by whether you are willing to patch the host kernel in order to get better performance than is possible by using skas0 mode.
We have a number of performance-improving patches in the works, some or all of which may be merged into the mainline kernel by the time this book reaches your bookshelf. You will be able to tell what, if any, patches are missing from your host kernel by looking at the early boot messages. Here is an example:
Checking that ptrace can change system call numbers...OK
Checking syscall emulation patch for ptrace...missing
Checking PROT_EXEC mmap in /tmp...OK
Checking if syscall restart handling in host can be \
skipped...OK
Checking for the skas3 patch in the host:
- /proc/mm...not found
- PTRACE_FAULTINFO...not found
- PTRACE_LDT...not found
UML running in SKAS0 mode
Adding 16801792 bytes to physical memory to account for \
exec-shield gap
The message about the syscall emulation patch is talking about a ptrace extension that cuts in half the number of ptrace calls needed to intercept and nullify a host system call. This is separate from the skas3 patch and is used in all UML execution modes. At this writing, this patch is in the mainline kernel, so a UML instance running on a host with 2.6.14 or later will benefit from this.
A few lines later, you can see the instance checking for the individual pieces of the skas3 patch /proc/mm, PTRACE_FAULTINFO, and PTRACE_LDT. Two of these, the two ptrace extensions, are likely to be merged into the mainline kernel separately, so there will likely be a set of host kernels for which UML finds some of these features but not all. In this case, it will use whatever host capabilities are present and use fallback code for those that are missing. /proc/mm will never be in the mainline kernel, so we are thinking about alternatives that will be acceptable to Linus.
For a smallish UML installation, a stock unmodified host kernel will likely provide good UML performance. So, in this case, it is probably not necessary to patch and rebuild a new kernel for the host.
Note that tt mode was not recommended in any situation. However, sometimes you may need to run an old version of UML in which skas0 is not available. In this case, it may be a good idea to patch the host with the skas3 patch. If UML running under tt mode is too slow or too resource intensive, or you need the security that comes with skas3 mode, then patching with the skas3 patch is the best course.
Vanderpool and Pacifica
Yet another option, which at this writing is not yet available but will be relatively soon, is to take advantage of the hardware virtualization support that Intel and AMD are incorporating into their upcoming processors. These extensions are called Vanderpool and Pacifica, respectively. UML is currently being modified in order to take advantage of this support.
Vanderpool and Pacifica are similar, and compatible, in roughly the same way that AMD's Opteron and Intel's EM64T architectures are similar. There are some differences in the instructions, but they are relatively minor, and software written for one will generally run unmodified on the other. UML is currently getting Vanderpool Technology support, with the work being done by a pair of Intel engineers in Russia, but the result will likely run, perhaps with some tweaks, on an AMD processor with Pacifica support.
This support will likely bring UML performance close to native performance. The hardware support is sufficient to eliminate some of the largest performance bottlenecks that UML faces on current hardware. The main bottleneck is the context switching that ptrace requires to intercept and nullify system calls on the host. The hardware virtualization support will enable this to be eliminated, allowing UML to receive process system calls directly, without having to go through the host kernel. A number of other things will be done more efficiently than is currently possible, such as modifying process address spaces and creating new tasks.
In order to use this hardware virtualization support, you will need a host new enough to have the support in its processor. You will also need a version of UML that has the required support. Given these two requirements are met, UML will likely perform noticeably better than it does without that support.
Managing Long-Lived UML Instances
It is common to want a UML instance to outlive the login session in which it is started. As with other processes, it is possible to background a UML instance and have it survive the end of the login session. The problem with this is the main console. It is natural to have it attached to the standard input and standard output of the UML instance's main process. But this means that the UML instance must be the foreground process. It can be backgrounded (with some difficulty because it sets the terminal raw, so Ctrl-Z and Ctrl-C don't send SIGTSTP and SIGINT, respectively, to the process), and once it is, and you log out, the main console is lost.
To avoid this, you can use a very handy tool called screen. Upon running it with no arguments, you get a new shell. At this point, you can run your UML instance as you normally do. When you decide to log out, you can detach the screen session, and it will, in effect, background the UML instance in a way that lets you reattach to it later.
Run screen -r and the session, with the UML instance and main console intact, will return. So, in the simplest case, here is the procedure for maintaining a long-lived UML instance.
Start the UML instance inside the resulting screen session. Detach the screen session with Ctrl-A Ctrl-D. Later, log back in and run screen -r. Detach, reattach, and repeat as often as necessary.
With a number of UML instances running on the host, the same procedure will work. The problem is knowing which screen session belongs to the UML instance you want to reattach to. The result of running screen -r may be something like this:
There are several suitable screens on:
28348.pts-1.tp-w (Detached)
28368.pts-1.tp-w (Detached)
28448.pts-1.tp-w (Detached)
28408.pts-1.tp-w (Detached)
28308.pts-1.tp-w (Detached)
28488.pts-1.tp-w (Detached)
28530.pts-1.tp-w (Detached)
28328.pts-1.tp-w (Detached)
28428.pts-1.tp-w (Detached)
28550.pts-1.tp-w (Detached)
28468.pts-1.tp-w (Detached)
28288.pts-1.tp-w (Detached)
28510.pts-1.tp-w (Detached)
28388.pts-1.tp-w (Detached)
Type "screen [-d] -r [pid.]tty.host" to resume one of them.
This is not helpful in figuring out which one you want to resume. To simplify this, screen has the ability to attach names to screen sessions. The -S switch will assign a meaningful name to the session and this name is what you will use to resume it. So, will start a screen session named joes-uml. You can assign a name to each session you start. Then when you want to resume a particular one, run screen -r and you'll see something like this:
There are several suitable screens on:
28868.work-uml (Detached)
28826.spare3-uml (Detached)
28910.simulator-uml (Detached)
28890.devel-uml (Detached)
28804.spare2-uml (Detached)
28784.spare1-uml (Detached)
28848.dmz-uml (Detached)
28764.janes-uml (Detached)
28742.named-uml (Detached)
28700.joes-uml (Detached)
Type "screen [-d] -r [pid.]tty.host" to resume one of them.
It is now easy to pick out the one you want:
With good enough names, it may not even be necessary to look at the list in order to remember which one you want.
Finally, you may wish to start a set of UML instances during the host boot sequence. There is no terminal for the new UML instances to use as their main consoles, unless, of course, you provide them one. screen is useful here as well. The -d -m switch will start the screen session detached. Now you're not available to start the UML instances by hand, so screen will need to do this automatically. This can be accomplished, along with the other tricks we've seen, with something like this:
host% screen -d -m -S boot-uml ./linux con0=fd:0,fd:1 \
con1=none con=pts ssl=pts umid=debian mem=450M \
ubda=../../debian30 devfs=nomount mconsole=notify:/tmp/notify
This starts the screen session detached, runs the UML command that follows the screen switches, and names the screen session boot-uml. screen -r shows it like this:
16799.boot-uml (Detached)
Now, once the host has booted, and the UML instances with it, you can log in to the host and attach to whatever UML instance you wish.
Networking
I've covered networking in sufficient detail earlier in the book that I don't need to belabor it here. However, I will repeat a few important points.
Given that you control the host, the only two networking mechanisms you should consider for allowing access to the host network are TUN/TAP and uml_switch. Both bridging TUN/TAP devices with the host Ethernet and routing to unbridged TUN/TAP devices are appropriate models. They have differing setup and security requirements, which should drive the decision between the two. Make use of the ability to give descriptive names to your TUN/ TAP devices to document your UML configuration.
UML Physical Memory
UML uses a temporary file as its physical memory. It does this rather than use anonymous memory since it needs file-backed memory so pages of memory can be mapped in multiple locations in multiple address spaces. This is impossible with anonymous memory. By default, UML creates the file in /tmp and removes it so it can't be accessed by any other process. If you look at the open file descriptors of a UML instance, you will see something like this:
lrwx------ 1 jdike jdike 64 Aug 14 13:15 3 -> \
/tmp/vm_file-lQkcul (deleted)
Because the file has been deleted and UML is holding a reference to it by keeping it open, the file is occupying space in /tmp but isn't visible to ls. If you ran df, you would see that some space has disappeared, but there are no visible files consuming that space.
Thus, the first requirement on the host with respect to UML physical memory is that the filesystem on which it will create its physical memory files must be large enough to hold all of those files. For example, if you decide not to change the default and to use /tmp, the filesystem on which /tmp lives must have enough free space to hold all of the physical memory files for all of the UML instances on the host. These files will be the same size as the physical memory assigned to the UML instances. So, to decide how big your /tmp needs to be, you must add the physical memory sizes of all UML instances that will put their physical memory files in /tmp.
The UML instances will not occupy all of this space immediately. Rather, it will be consumed as they allocate and use pages of their own physical memory. Thus, the space on the host used by a UML instance will grow asymptotically to its physical memory size.
For performance reasons, it is a very good idea to create the UML physical memory files on a tmpfs filesystem. UML instances that have their memory files on a disk-based filesystem are noticeably slower. The filesystem should be sized as described above. In /etc/fstab, the entry for a 512MB tmpfs mount on /tmp would look like this:
none /tmp tmpfs \
size=512M 0 0
The equivalent command for doing this mount is:
host# mount none /tmp -t tmpfs -o size=512M
This is sufficient for one or two reasonably-sized UML instances. For a larger number, a much larger size, obtained by adding the physical memory sizes, would be needed.
You may wish to give each UML instance a separate tmpfs mount or to group them into several mounts, providing a degree of isolation between the UMLs or the groups. This could be useful if one instance somehow outgrew its physical memory and started occupying more space than it should.
This shouldn't happen, and I know of no cases where it has, but it is a conceivable failure that would affect the stability of the other UML instances sharing a tmpfs filesystem. If the filesystem gets filled, the host will stop allocating memory for new pages of memory within it. Since this is caused by the UML instances changing hitherto unmodified memory, if the tmpfs filesystem is full, those memory references will start failing. The UML instances will start receiving SIGBUS signals and very likely crash when some of those references occur inside the UML kernel.
Creating multiple tmpfs filesystems, up to one per UML instance, reduces the vulnerability of a UML instance to another overallocating space. With one UML instance per filesystem, if a UML instance somehow exceeded its physical memory size, that instance would be the only one affected.
Finally, a point I mentioned earlier bears repeating here. Giving a UML instance so much physical memory that it needs to use some of it as Highmem will hurt its performance. If you need to have physical memory sizes greater than the 480MB limit of tt mode, you should disable CONFIG_MODE_TT.
Host Memory Consumption
Host memory is often the bottleneck constraining the number of UML instances that can be run while maintaining good performance. You can do two principle things to reduce the amount of host memory consumed by the UML instances. Both ideas involve cutting down on the caching of multiple copies of the same data.
Run 2.6 on the host. As described earlier, this will cause the UML instances to use the O_DIRECT capability introduced in 2.6. Data read by the UML instances will be read directly into their page caches and won't occupy memory in the host page cache. Use COW files wherever possible. This will cause data from the backing files to be shared between the UML instances using them. Instead of having one copy in the host page cache for each UML instance, there will be only one total. There will still be one copy in every UML instance sharing that page.
An enhancement that is not fully implemented at this writing is to have the humfs filesystem map, rather than copy, pages from its files into its page cache. This would reduce the number of copies of shared file pages from one per UML instance to one total since all the UML instances would be sharing the host's copy. This would require the UML host administrator to create humfs root filesystems and boot the UML instances on them.
The UML block driver can't use mmap because the filesystems using it would lose control over when their file data and metadata are written to disk. This control is essential in their guarantees of file consistency and recovery in the case of a crash. Control would be lost because modifications to mapped data can be written to disk at any time by the host. Preventing this problem was one of the motivations for writing humfs. With the filesystem doing the mapping itself, rather than the underlying block device, it retains that control.
umid Directories
By default, the unique machine id, or umid, directory for a UML instance is .uml/<umid> in the home directory of the user running the instance. This directory contains the mconsole socket and the pid file for the instance. If you decide to provide each instance with its own tmpfs mount, as described earlier, this would be a natural place to create it.
For management purposes, you may want to move the umid directories to a different location. For example, you might want to have each UML instance owned by a different user on the host but to have all of their umid directories in a single location. To do this, there is a UML switch that specifies the umid directory:
For instance, putting these switches on the command line for a UML would create its umid directory at /var/run/uml/debian:
umid=debian uml_dir=/var/run/uml
Overall Recommendations
This chapter boils down to a small number of recommendations for managing a modest UML server.
Use a recent 2.6 kernel on the host. This will have performance enhancements for UML on all architectures and necessary bug fixes on x86_64 and S/390. It will give you the AIO and O_DIRECT capabilities, which UML will take advantage of. Make sure CONFIG_MODE_TT is disabled. It is disabled in the default configuration of UML, so you likely won't have to do anything except verify this. Having CONFIG_MODE_TT disabled will give you more flexibility in the amount of physical memory you can provide to your UML instances. Consider applying the skas3 patch to the host. This will provide somewhat better performance than skas0. Mount a tmpfs filesystem on /tmp, or wherever you have the UML instances create their physical memory files, and make sure it is large enough to hold all of those files. screen is an essential tool for managing long-lived UML instances. Become familiar with it. Be careful about managing the host's physical memory. If the sum of the UML instances' physical memory sizes greatly exceeds the host's physical memory, performance will suffer as the host swaps out the UML instances. Look into techniques for reducing memory consumption such as COWing your ubd filesystem images or booting from humfs directories. It may simplify the management of your instances to centralize their umid directories.
Chapter 10. Large UML Server Management
In the previous chapter, we talked about setting up a smallish UML server where the UML users would be local users who have accounts on the host and where it is not a goal to run as many UML instances on the host as possible. Now, we will take a look at running a large server where the UML users are untrusted, we want the largest possible number of instances running with acceptable performance, and we are willing to tune the host in order to accomplish this.
Security is going to be a major theme. The presence of untrusted users who do not have accounts on the host and who should stay confined to their UML instances requires a layered approach to security. The first layer is UML itself. There are no known exploits to break out of a UML jail, but it is prudent to take that possibility into account and ensure that if such an exploit did exist, the host would not be harmed.
We are also going to be careful about network security, taking steps to minimize the possibility of someone using a UML instance to launch attacks or otherwise engage in hostile network behavior.
Security is also an issue when providing users access to their console devices. These are normally attached to devices on the host, making it necessary to have access to the host in order to get console access.
Instead, we will look at a way to provide this access by using a dedicated UML instance for it, avoiding the need to provide direct access to the host.
Finally, I will describe some enhancements on both the host and UML that will improve performance, resource consumption, and manageability of UML instances in the future.
Security
UML Configuration
When you are concerned about preventing people from breaking out of a UML instance, the first thing to look at is the configuration of UML itself. Like the host, UML has two protection levels, user mode and kernel mode. In user mode, system calls are intercepted by the UML kernel, nullified, and executed in the context of UML. This is the basis for UML jailing. The system calls and their arguments are interpreted within the context of UML.
For example, when a process executes a read from its file descriptor zero, the file that is written is taken from the first entry of the process's file table within the UML kernel rather than the first entry of the file table in the host kernel. That would be the standard input of UML itself rather than that of the UML process. Similarly, when a process opens a file, it is the filesystem code of the UML, rather than the host, that does the filename lookup. This ensures that a UML process has no access to files on the host. The same is true for all other resources, for the same reason.
When the UML kernel itself is running, system call tracing is disabled, and the kernel does have access to host resources. This is the critical difference between user mode and kernel mode in UML. Since the UML kernel can execute system calls on the host, all code in the UML kernel must remain trusted. If a user were able to insert arbitrary code into the kernel, that user could break out. It would simply be a matter of executing a shell on the host from within the UML kernel.
There is a well-known mechanism in Linux for doing exactly this: kernel modules. Of course, they are intended for something entirely differentdynamically extending the kernel's functionality by adding drivers, filesystems, network protocols, and the like. But extending the kernel's functionality, in the context of UML, can also be interpreted as allowing the UML user to execute arbitrary commands on the host.
Since we can't prevent this and also allow legitimate kernel modules to be installed, in a secure UML configuration, modules need to be disabled completely.
It turns out that modules aren't the only mechanism by which a user could inject code into the UML kernel. An entry in /dev, /dev/mem, provides access to the system's physical memory. Since the kernel and its data are in that memory, with the ability to write to this file, a nasty UML user could manually inject the equivalent of a module into the kernel and change data structures in order to activate it so that the kernel will execute the code.
This may sound hard to actually carry out successfully, but it is a skill that rootkit writers have perfected. In certain circles, it is very well known how to inject code into a Linux kernel and activate it, even in the absence of module support, and there are reliable tools for doing this automatically.
The obvious way to prevent someone from writing to a file is to set the permissions on the file in order to make that impossible. However, since the UML user could very likely be root, file permissions are useless. The root user is not in any way restricted by them.
Another mechanism is effective against the root user: capabilities. These are a set of permissions associated with a process rather than a file. They have two important properties.
They are inherited by a process from its parent. They can be dropped, and once dropped, can't be regained by the process or its children.
Together, these properties imply that if the kernel or init, which is ultimately the parent of every other process on the system, drop a capability, then that capability is gone forever for that system. No process can ever regain it.
It turns out that there is a capability that controls access to /dev/ mem, and that is CAP_SYS_RAW. If this is dropped by the kernel before running init, no process on the system, including any process run by the root user, will be able to modify the UML instance's physical memory through /dev/mem. Removing CAP_SYS_RAW from the initial set of capabilities (the bounding set) will irreversibly remove it from the entire system, and nothing will be able to write to kernel memory.
A second issue is access to host filesystems. If the UML kernel has CONFIG_EXTERNFS or CONFIG_HOSTFS enabled, a UML user will be able to mount directories on the host as filesystems within the UML instance. For a secure UML environment, this is usually undesirable. The easiest way to prevent this is to disable CONFIG_EXTERNFS and CONFIG_HOSTFS in the UML kernel.
If you do want to allow some access to host files, it can be done securely, but it requires some care because it opens up some more avenues of attacks. There are no known holes here, but allowing any extra access to the host from the UML instance will provide more possibilities for malicious users or software to attack the host.
First of all, it's a good idea to run the UML instance inside a jail (we talk about setting up a good jail later in this chapter) and, inside that, provide the directory that you wish to allow the instance to access. Second, you can use a UML switch to force all hostfs mounts to be within a specified host directory. For example, the following option will restrict all hostfs mounts to be within the directory /uml-jails/jeffs-uml:
hostfs=/uml-jails/jeffs-uml
This is done by prepending that directory name to every host directory the UML attempts to mount. So, if the UML user tries to mount the host's /home like this:
UML# mount none /mnt -t hostfs -o /home
the UML instance will really attempt to mount /uml-jails/jeffs-uml/home. If there really is a directory named /uml-jails/jeffs-uml/home, that mount will succeed, and if not, it will fail. But in no case will the UML instance attempt to mount the host's /home.
If you wish to provide each UML instance with some host directory that will be private to the instance, simply copying that directory into the instance's jail is the easiest way to make it available.
If you wish to provide the same host directory to a number of UML instances, you can make it available within each jail directory with a bind mount. Bind mounts are new with 2.6, so you'll need a 2.6 host in order to use them. This facility allows you to make an existing directory available from multiple places within the filesystem. For example, here is how to make /tmp available as ~/tmp:
host% mkdir ~/tmp
host# mount --bind /tmp ~/tmp
host% ls /tmp
gconfd-jdike orbit-jdike ssh-Xqcrac2878
keyring-4gMKe0 ssh-QWYGts4184 ssh-vlklKu4277
mapping-jdike ssh-VMnkLn4309 xses-jdike.oBNeep
host% ls ~/tmp
gconfd-jdike orbit-jdike ssh-Xqcrac2878
keyring-4gMKe0 ssh-QWYGts4184 ssh-vlklKu4277
mapping-jdike ssh-VMnkLn4309 xses-jdike.oBNeep
Now the same directory is available through the paths /tmp and ~/tmp. It's exactly the same directorycreating a new file through one path will result in it being visible through the other.
To use this technique to provide a common hostfs directory to a set of UML instances, you would do something like this for each instance:
host# mount --bind /umls/common-data /umls/uml1-jail/data
Following this with the hostfs jailing switch would add another layer of protection:
hostfs=/umls/uml1-jail/data
As I mentioned before, this does add another possible avenue of attacks on the host from the UML instances. However, the risk of a UML instance gaining access to information outside the directories explicitly provided to it is minimal when the instances are jailed and the hostfs mounts themselves are jailed.
Generally, such data would be read-only and would be provided to the UML instances as a reference, such as a package repository. This being the case, all files and subdirectories should be write-protected against the UML instances. You can accomplish this by having these files and subdirectories owned by a user that does not own any of the UML instances and having everything be read-only for the owner, group, and world.
In the spirit of having multiple layers of protection, an additional hostfs option, append, restricts the file modifications that can be performed through a hostfs mount.
When you add append to the hostfs switch as shown, the following restrictions come into force.
All file opens are done with O_APPEND. This means that all file writes will append to the file rather than overwriting data that's already there. Files can't be shrunk, as with TRuncate. Files can't be removed.
The purpose of the append switch is to prevent data from being destroyed through the hostfs mount. It does not prevent writing of new data, so if you want that restriction, you must still write-protect the hostfs directories and everything in them.
If you do wish to provide the UML instances with the ability to write to their hostfs mounts, you are providing a new avenue of attack to a malicious UML user. This potentially enables a denial-of-service attack on the host's disk space rather than its data. By filling the hostfs directories with data and filling up the filesystem on which it lives, an instance could make that host disk space unusable by the other UML instances. This possible problem can be handled with disk quotas on the host if each UML instance is owned by a different host user.
Even so, humfs is probably a better option in this case. When writing files on the host, the permission and ownership problems I mentioned earlier rear their heads. hostfs files will be owned by the host user that is running the UML instance, rather than the UML user that created them, leading to a situation where a UML user can create a file but subsequently can't modify it. humfs handles this correctly, and it has a built-in size limit that can be used to control the consumption of host disk space.
Jailing UML Instances
The centerpiece of any layered security design for a large UML server is the jail that the UML instances are confined to. Even though UML confines its users, it is prudent to assume that, at some point, someone will find a hole through which they can escape onto the host. No such holes are known, but it's impossible to prove that they don't exist and, if one did exist, that it couldn't be exploited.
This jail will make use of the Linux chroot system call, which confines a process to a specific directory. You can see the effect of using the chroot command, which is a wrapper around the system call, to confine a shell to /sbin.
host# chroot /sbin ./sash
Stand-alone shell (version 3.7)
> -pwd
/
> -ls
.
..
MAKEDEV
Notice how the current directory is /, but its contents are those of /sbin. chroot arranges that the directory specified as the jail becomes the new process's root directory. The process can do anything it normally has permissions to do within that directory tree but can't access anything outside it. This fact forced the choice of sash as the shell to run within the chroot. Most other shells are dynamically loaded, so they need libraries from /lib and /usr/lib in order to run. When jailed, they can no longer access those librarieseven if the libraries are within the jail, they will be in the wrong location for the dynamic loader to find, even when the dynamic loader itself can be found.
So, for demo purposes, the easiest way to show how chroot works is by running a statically linked shell within its own directory. More serious purposes require constructing a complete but minimal environment, which we will do now. This environment must contain everything that the jailed process will need, but nothing else.
We will construct a jail that is surprisingly empty. This provides as few tools as possible to an attacker who somehow manages to break out of a UML instance. He or she will want to continue the attack in order to subvert the host. In order to do this, the attacker will need to break out of the chroot environment. If there is a vulnerability (and I am aware of no current holes in chroot), the attacker will need tools in order to exploit it. Making the chroot environment as empty as it can be will go some way toward denying him or her these tools.
First we must decide what a UML instance needs in order to simply boot. Looking at the shared libraries that UML links against and a typical UML command line gives us a start:
host% ldd linux
linux-gate.so.1 => (0x003ca000)
libutil.so.1 => /lib/libutil.so.1 (0x00c87000)
libc.so.6 => /lib/libc.so.6 (0x0020a000)
/lib/ld-linux.so.2 (0x001ec000)
host% ./linux con0=fd:0,fd:1 con1=none con=pts ssl=pts \
umid=debian mem=450M ubda=../../debian30 devfs=nomount
With this UML binary, those libraries would need to be present within. /lib and within the jail in order to even launch it. After launching, the command line makes a number of other requirements in order for UML to boot:
The root filesystem, debian30, needs to be present in the jail, and not two directory levels higher, as I have it here. con=pts and ssl=pts require that ./dev/pts exist within the jail. The UML instance will try to create the umid directory for the pid file and mconsole socket in the user's home directory within the jail.
This would be far from being an empty directory, and it would contain files such as libraries and device nodes that an attacker might find useful. Fortunately, these requirements can be reduced in some fairly simple ways.
First, to eliminate the requirement for libraries, we can make the UML executable statically, rather than dynamically, linked. If CONFIG_MODE_TT is enabled, UML is linked statically. However, for a serious server, it is highly recommended that the UML instances use either skas0, if the server is running an unmodified kernel, or skas3, if the skas3 patch can be applied to the host kernel. With CONFIG_MODE_TT disabled, UML will link dynamically. However desirable this is in general, it complicates setting up a jail. So, a configuration option for UML, CONFIG_STATIC_LINK, forces the UML build to produce a statically linked executable, even when CONFIG_MODE_TT is disabled.
Enabling CONFIG_STATIC_LINK results in a larger UML binary, which is slightly less efficient for the host because the UML instances are no longer sharing library code that they would share if they were linked dynamically. This is unavoidableeven if you copied the necessary libraries into the jail, each UML instance would have its own copy of them, so there would still be no sharing. There is a clever way to have the libraries be present in each jail but still shared with each otheruse the mount --bind capability described earlier to mount the necessary libraries into the jails.
However, this is too cleverit opens up a possible security hole. If an attacker were somehow able to break out of a UML instance, gain access to the jail contents, and modify the libraries, those libraries would be modified for the entire system. So, if the attacker could add code to libc, at some point that code would be executed by a root-owned process, and the host would be subverted. So, for security reasons, we need no shared code between the UML instance and anything else on the system. Once we have made that decision, there is no further cost to statically linking the UML binary.
The next issue is the /dev/pts requirements imposed by the console and serial line arguments. These are easy to dispose of by changing those configurations to ones that require no files in the jail. We have a variety of possibilitiesnull, port, fd, and none all fill the bill. null and none effectively make the consoles and serial lines unusable. port and fd make them usable from the host outside the jail. For an fd configuration, you would have to open the necessary file descriptors and pass them to the UML instance on its command line.
Finally, there is the umid directory. We can't eliminate it without losing the ability to control the instance, but we can specify that it be put someplace other than the user's home directory within the jail. By creating a ./tmp directory within the jail and using the uml_dir switch to UML, we can arrange for the pid file and mconsole socket to be put there.
At this point, the jail contents look like this:
host% ls -Rl
.:
total 1033664
-rw-rw-r-- 1 jdike jdike 1074790400 Aug 18 17:46 debian30
-rwxrwxr-x 1 jdike jdike 20860108 Aug 18 17:39 linux
drwxrwxr-x 2 jdike jdike 4096 Aug 18 17:46 tmp
./tmp:
total 0
As a quick test of whether UML can boot in this environment and of its new command-line switches, we can do the following as root in the jail directory:
host# chroot. ./linux con0=fd:0,fd:1 con1=none con=port:9000 \
ssl=port:9000 umid=debian mem=450M ubda=debian30 \
devfs=nomount uml_dir=tmp
It does boot, printing out a couple messages we haven't seen before:
/proc/cpuinfo not available - skipping CPU capability checks
No pseudo-terminals available - skipping pty SIGIO check
Because /proc and /dev are not available inside the jail, UML couldn't perform some of its normal checks of the host's capabilities. These are harmless, as the /proc/cpuinfo checks come into play only on old processors, and the pseudo-terminal test is necessary only when attaching consoles to host pseudo-terminals, which we are not doing.
Running UML in this way is useful as a test, but we ran UML as root, which is very much not recommended. Running UML as a normal, nonprivileged user is one of the layers of protection the host has, and running UML as root throws that away. Root privileges are needed in order to enter the chroot environment, so we need a way to drop them before running UML.
It is tempting to try something like this:
host# chroot jail su 1000 ./linux ...
However, this won't work because the su binary must be present inside the jail, which is undesirable. So, we need something like the following small C program, which does the chroot, changes its uid to one we provide on the command line, and executes the remainder of its command line:
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int uid;
char *dir, **command, *end;
if(argc < 3){
fprintf(stderr, "Usage - do-chroot dir uid \
command-line...\n");
exit(1);
}
dir = argv[1];
uid = strtoul(argv[2], &end, 10);
if(*end != '\0'){
fprintf(stderr, "the uid \"%s\" isn't a number\n", \
argv[2]);
exit(1);
}
command = &argv[3];
if(chdir(dir) < 0){
perror("chroot");
exit(1);
}
if(chroot(".") < 0){
perror("chroot");
exit(1);
}
if(setuid(uid) < 0){
perror("setuid");
exit(1);
}
execv(command[0], command);
perror("execv");
exit(1);
}
This is run as follows:
host# do-chroot jail 1000 ./linux con0=fd:0,fd:1 con1=none \
con=port:9000 ssl=port:9000 umid=debian mem=450M \
ubda=debian30 devfs=nomount uml_dir=tmp
Since I am specifying a nonexistent uid, everything in the jail should be owned by that user in order to prevent permission problems:
host# chown -R 1000.1000 jail
Now UML runs as we would like. It is owned by a nonexistent user, so it has even fewer permissions on the host than something run by a normal user.
We saw the contents of the jail directory as we have it set up. With the UML instance running, there are a couple more things in it:
host% ls -Rl
.:
total 1033664
-rw-rw-r-- 1 1000 1000 1074790400 Aug 18 19:12 debian30
-rwxrwxr-x 1 1000 1000 20860108 Aug 18 17:39 linux
drwxrwxr-x 3 1000 1000 4096 Aug 18 19:12 tmp
./tmp:
total 4
drwxr-xr-x 2 1000 root 4096 Aug 18 19:12 debian
./tmp/debian:
total 4
srwxr-xr-x 1 1000 root 0 Aug 18 19:12 mconsole
-rw-r--r-- 1 1000 root 5 Aug 18 19:12 pid
We also have the mconsole socket and the pid file in the tmp directory.
This is reasonably minimal, but we can do better. Some files are opened and never closed. In these cases, we can remove the files after we know that the UML instance has opened them. The instance will be able to access the file through the open file descriptor and won't need the file to actually exist within its jail.
Chief among these are the UML binary and the filesystem. We can remove them after we are sure that UML is running and has opened its filesystem. It is tempting to remove them immediately after executing UML, but that is somewhat prone to failure because the removals might run before the UML instance has run or before it has opened its filesystem.
To avoid this, we can use the MConsole notify mechanism we saw in Chapter 8. We'll use a slightly modified version of the Perl script used in that chapter to read notifications from a UML instance:
use UML::MConsole;
use Socket;
use strict;
@ARGV < 2 and die "Usage : running.pl notify-socket uid";
my $sock = $ARGV[0];
my $uid = $ARGV[1];
!defined(socket(SOCK, AF_UNIX, SOCK_DGRAM, 0)) and
die "socket failed : $!\n";
!defined(bind(\*SOCK, sockaddr_un($sock))) and
die "UML::new - bind failed : $!\n";
chown $uid, $uid, $sock || die "chown failed - $!";
my ($type, $data) = UML::MConsole->read_notify(\*SOCK, undef);
$type ne "socket" and
die "Expected socket notification, got \"$sock\" " .
"notification with data \"$data\"";
exit 0;
Running this as root like this:
host# perl running.pl tmp/notify 1000
and adding the following:
mconsole=notify:tmp/notify
to the UML command line will cause the running.pl script to exit when the instance announces that it has booted sufficiently to respond to MConsole requests.
At this point, the UML instance is clearly running and has the root filesystem open, so the UML binary and the filesystem can be safely removed. Under tmp, there is the MConsole socket and pid file.
The pid file is for management convenience, so it can be read and removed. The MConsole socket can be moved outside the jail, where it's inaccessible to anyone who somehow manages to break out of the UML instance, but where an MConsole client can access it.
The only thing that can't be removed is the notify socket, which has to stay where it is so that the UML instance can send notifications to it. If that socket is removed, you lose an element of control since you can't find out if the instance has crashed. If this is OK, you can remove the socket, and the UML instance will run in a completely empty jail.
One thing we haven't done here is to provide the UML instance with a swap device. Like the root filesystem, the swap device file needs to be in the jail. If it's removed, it can possibly be lost by the UML instance. If swapoff is run inside the instance, the block driver will close the swap device file. When this happens, the instance will lose the only handle it had to the file. If swapon is subsequently run, the block driver will attempt to open the file, and fail, since you removed it. This is not a problem for the root filesystem since, once mounted, it is never unmounted until the instance is shut down.
One side effect of removing the UML binary is that reboot will stop working. Rebooting is implemented by exec-ing the binary to get a clean start for the new instance. If the binary has been removed, exec will fail. However, this is probably not a big problem since a reboot is no different from a shutdown followed by a restart.
You need to be careful with the root filesystem. If you simply copy it into the jail, boot the UML instance, and remove the filesystem file, the instance will have access to the filesystem as long as it keeps the file open. When it shuts down, it will close the file, and it will be removed, along with whatever changes were made to it. To prevent this, you should keep the filesystem out of the jail and make a hard link to it from inside the jail. Now there will remain one reference to the filethe original name for itand it will not be removed when the instance closes it.
Providing Console Access Securely
If you're running a large UML server where you need to be concerned about the behavior of outsiders, you're likely going to need a way to provide console access to the UML instances in a secure way. The obvious way to do this is to attach the UML consoles to some host device and provide some sort of login on the host, where the login shell is a script that connects the user to the appropriate UML console. That's relatively simple, but it does have the disadvantage of providing users with unjailed access to the host. This sort of script often turns out to have security holes in it. Some kind of command interpreter inside might, through a programming mistake, allow a user to execute some arbitrary command on the host.
There is a way to provide console access that doesn't require any new tools to be written and doesn't give the UML user any unjailed access to the host.
The idea is to run a separate UML instance that serves as a console server for the other UML instances on the host. The other instances have their consoles attached to terminals within this console server. Each UML administrator has a normal, unprivileged account on this UML and has access to his or her consoles through these pseudo-terminals, which have been appropriately protected so as to allow access only to the administrator for the instance to which they connect.
I described this mechanism in Chapter 4, as a virtual serial line running between two UML instances. This is merely an application of it, with a bit of extra infrastructure. I will go through the process of setting this up for one UML by hand. If you run a large UML host, this procedure will need to be automated and included in your UML provisioning process.
First, we need to boot two UML instances and establish a virtual serial line connection between them. We start by finding a console in the user's instance that is attached to a host pseudo-terminal. Since I do so with all spare consoles and serial lines, this is easy:
host% uml_mconsole jeff config con2
OK pts:/dev/pts/11
I attach the slave end of this pseudo-terminal to an unused console in the console server instance:
host% uml_mconsole console-server config con6=tty:/dev/pts/11
OK
Now I need to create a normal user account for myself in the console server:
console-server# adduser jeff
console-server# passwd jeff
Changing password for user jeff.
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
Since tty6 in the console server is attached to my instance, I need to own the device file:
# chown jeff.jeff /dev/tty6
This allows me to access my instance, and it prevents other unprivileged users from accessing it.
Everything is now set up, and I should be able to log in over the network to the console server as jeff and from there attach to my UML instance over this virtual serial line:
[jdike@tp]$ ssh jeff@console-server
jeff@console-server's password:
[jeff@console-server ~]$ screen /dev/tty6
In the screen session, I now have the login prompt from my own UML instance and can log in to it:
Debian GNU/Linux testing/unstable jeff tty2
jeff login: root
Password:
Last login: Fri Jan 20 22:26:53 2006 on tty2
jeff:~#
This is fairly simple, but it's a powerful mechanism that allows your users to log in to their UML instances on a "hardwired" console without needing accounts on the host. If I kill the network on my instance, I can log in over a console and fix it. Without a mechanism like this, I would have to appeal to the host administrator to log in to my UML instance and fix it for me. Using a UML instance as the console server increases the security of this arrangement by making it unnecessary to provide accounts on the host for the UML users.
skas3 versus skas0
The previous chapter contained a discussion of whether to leave the host unmodified and have the UML instances running in skas0 mode or to patch the host with the skas3 patch for better performance. Since we're now talking about a large UML server and we're trying to get every bit of UML hosting capacity from it, I recommend patching the host with the skas3 patch.
The reasons were mostly covered in the discussion in the last chapter. You'll get better performance with skas3 than skas0 for the following reasons.
skas3 creates one host process per UML processor while skas0 creates one per UML process. This consumes host kernel memory unnecessarily and slows down process creation. skas3 page faulting performance is better because it has a more efficient way to get page fault information from the host and to update the process address space in response to those page faults.
In addition to better performance, skas3 will have somewhat lower host resource consumption due to the smaller number of processes created on the host.
Future Enhancements
A number of host kernel enhancements for improving UML performance host resource consumption are in the works. Some are working and ready to be merged into the mainline kernel, and some are experimental and won't be in the mainline kernel for a while.
sysemu
Starting with the mature ones, the sysemu patch adds a ptrace option that allows host system calls to be intercepted and nullified with one call to ptrace, rather than two. Without this patch, in order to intercept system calls, a process must intercept them both at system call entry and exit. A tool like strace needs to make the two calls to ptrace on each system call because the tool needs to print the system call when it starts, and it needs to print the return value when it exits. For something like UML, which nullifies the system call and doesn't need to see both the system call entry and exit, this is one ptrace call and two context switches too many.
This patch noticeably speeds up UML system calls, as well as workloads that aren't really system call intensive. A getpid() loop is faster by about 40%. A kernel build, which is a somewhat more representative workload than a getpid() loop, is faster by around 3%.
This improvement is not related to the skas3 patch at all. It is purely to speed up system call nullification, which UML has to do no matter what mode it is running in.
The sysemu patch went into the mainline kernel in 2.6.14, so if your host is running 2.6.14 or later, you already have this enhancement.
PTRACE_FAULTINFO
PTRACE_FAULTINFO is another patch that has been around for a long time. It is part of the skas3 patch but will likely be split out since it's less objectionable than other parts of skas3, such as /proc/mm. PTRACE_FAULTINFO is used by UML in either skas mode in order to extract page fault information from a UML process. skas0 mode has a less efficient way to do this but will detect the presence of PTRACE_FAULTINFO and use it if present on the host.
MADV_TRUNCATE
This is a relatively new patch from Badari Pulavarty of IBM. It allows a process to throw out modified data from a tmpfs file it has mapped. Rather than being a performance improvement like the previous patches, MADV_TRUNCATE reduces the consumption of host memory by its UML instances.
The problem this solves is that memory-mapped files, such as those used by UML for its physical memory, preserve their contents. This is normally a good thing. If you put some data in a file and it later just disappeared, you would be rather upset. However, UML sometimes doesn't care if its data disappears. When a page of memory is freed within the UML kernel, the contents of that page doesn't matter anymore. So, it would be perfectly alright if the host were to free that page and use it for something else. When that page of UML physical memory was later allocated and reused, the host would have to provide a page of its own memory, but it would have an extra page of free memory in the meantime.
I made an earlier attempt at creating a solution, which involved a device driver, /dev/anon, rather than an madvise extension. The driver allowed a process to map memory from it. This memory had the property that, when it was unmapped, it would be freed. /dev/anon mostly worked, but it was never entirely debugged.
Both /dev/anon and MADV_TRUNCATE are trying to do the same thingpoke a hole in a file. A third proposed interface, a system call for doing this, may still come into existence at some point.
The main benefit of these solutions is that it provides a mechanism for implementing hot-plug memory. The basic idea of hot-plug memory on virtual machines is that the guest contains a driver that communicates with the host. When the host is short of memory and wants to take some away from a guest, it tells the driver to remove some of the guest's memory. The guest does this simply by allocating memory and freeing it on the host. If the guest doesn't have enough free memory, it will start swapping out data until it does.
When the host wants to give memory back to a guest, it simply tells the driver to free some of its allocated memory back to the UML kernel.
This gives us what we need to avoid the pathological interaction between the host and guest virtual memory systems I described in Chapter 2. To recap, suppose that both the host and the guest are short of memory and are about to start swapping memory. They will both look for pages of memory that haven't been recently used to swap out. They will both likely find some of the same pages. If the host manages to write one of these out before the guest does, it will be on disk, and its page of memory will be freed. When the guest decides to write it out to its swap, the host will have to read it back in from swap, and the guest will immediately write it out to its own swap device.
So, that page of memory has made three trips between memory and disk when only one was necessary. This increased the I/O load on the host when it was likely already under I/O pressure. Reading the page back in for the benefit of the guest caused the host to allocate memory to hold it, again when it was already under memory pressure.
To make matters even worse, to the host, that page of memory is now recently accessed. It won't be a candidate for swapping from the host, even though the guest has no need for the data.
Hot-pluggable memory allows us to avoid this by ensuring that either the host or the UML instances swap, but not both. If the UML instances are capable of swappingthat is, the host administrator gave them swap deviceswe should manage the host's memory to minimize its swapping. This can be done by using a daemon on the host that monitors the memory pressure in the UML instances and the host. When the host is under memory pressure and on the verge of swapping, the daemon can unplug some memory from an idle UML instance and release it to the host.
Hot-plug memory also allows the UML instances to make better use of the host's memory. By unplugging some memory from an idle UML instance and plugging the same amount into a busy one, it will effectively transfer the memory from one to the other. When some UML instances will typically be idle at any given time, this allows more of them to run on the host without consuming more host memory. When an idle UML instance wakes up and becomes busy again, it will receive some memory from an instance that is now idle.
Since the MADV_TRUNCATE patch is new, it is uncertain when it will be merged into the mainline kernel and what the interface to it will be when it is. Whatever the interface ends up being, UML will use it in its hot-plug memory code. If MADV_TRUNCATE is not available in a mainline kernel, it will be available as a separate patch.
The interface to plug and unplug UML physical memory likely will remain as it is, regardless of the host interface. This uses the MConsole protocol to treat physical memory as a device that can be reconfigured dynamically. Removing some memory is done like this:
host% uml_mconsole debian config mem=-64M
This removes 64MB of memory from the specified UML instance.
The relevant memory statistics inside the UML (freshly booted, with 192MB of memory) before the removal look like this:
UML# grep Mem /proc/meminfo
MemTotal: 191024 kB
MemFree: 117892 kB
Afterward, they look like this:
UML# grep Mem /proc/meminfo
MemTotal: 191024 kB
MemFree: 52172 kB
Just about what we would expect. The memory can be plugged back in the same way with:
host% uml_mconsole debian config mem=+64M
That brings us basically back to where we started:
UML# grep Mem /proc/meminfo
MemTotal: 191024 kB
MemFree: 117396 kB
The main limitation to this currently is that you can't plug arbitrary amounts of memory into a UML instance. It can't end up with more than it had when it was booted because a kernel data structure that is sized according to the physical memory size at boot can't be changed later. It is possible to work around this by assigning UML instances a very large physical memory at boot and immediately unplugging a lot of it.
This limitation may not exist for long. People who want Linux to run on very large systems are doing work that would make this data structure much more flexible, with the effect for UML that it could add memory beyond what it had been booted with.
Since this capability is brand new, the UML management implications of it aren't clear at this point. It is apparent that there will be a daemon on the host monitoring the memory usage of the host and the UML instances and shuffling memory around in order to optimize its use. What isn't clear is exactly what this daemon will measure and exactly how it will implement its decisions. It may occasionally plug and unplug large amounts of memory, or it may constantly make small adjustments.
Memory hot-plugging can also be used to implement policy. One UML instance may be considered more important than another (possibly because its owner paid the hosting company some extra money) and will have preferential access to the host's memory as a result. The daemon will be slower to pull memory from this instance and quicker to give it back.
All of this is in the future since this capability is so new. It will be used to implement both functionality and policy. I can't give recommendations as to how to use this capability because no one has any experience with it yet.
remap_file_pages
Ingo Molnar spent some time looking at UML performance and at ways to increase it. One of his observations was that the large number of virtual memory areas in the host kernel hurt UML performance. If you look in /proc/<pid>/maps for the host process corresponding to a UML process, you will see that it contains a very large number of entries. Each of these entries is a virtual memory area, and each is typically a page long. If you look at the corresponding maps for the same process inside the UML instance, you will see basically the same areas of virtual memory, except that they will be much fewer and much larger.
This page-by-page mapping of host memory creates data structures in the host kernel and slows down the process of searching, adding, and deleting these mappings. This, in turn, hurts UML performance.
Ingo's solution to this was to create a new system call, remap_file_pages, that allows pages within one of these virtual memory areas to be rearranged. Thus, whenever a page is mapped into a UML process address space, it is moved around beneath the virtual memory area rather than creating a new one. So, there will be only one such area on the host for a UML process rather than hundreds and sometimes thousands.
This patch has a noticeable impact on UML performance. It has been around for a while, and Paolo Giarrusso has recently resurrected it, making it work and splitting it into pieces for easier review by the kernel development team. It is a candidate for inclusion into Andrew Morton's kernel tree. It was sent once but dropped because of clashes with another patch. However, Andrew did encourage Paolo to keep it maintained and resubmit it again.
VCPU
VCPU is another of Ingo's patches. This deals with the inefficiency of the ptrace interface for intercepting system calls. The idea, which had come up several times before, is to have a single process with a "privileged" context and an "unprivileged" context. The process starts in the privileged context and eventually makes a system call that puts it in the unprivileged context. When it receives a signal or makes a system call, it returns through the original system call back to the privileged context. Then it decides what to do with the signal or system call.
In this case, the UML kernel would be the privileged context and its processes would be unprivileged contexts. The behavior of regaining control when another process makes a system call or receives a signal is exactly what ptrace is used for. In this case, the change of control would be a system call return rather than a context switch, reducing the overhead of doing system call and signal interception.
Final Points
Managing a large UML server requires attention to a number of areas that aren't of great concern with a smaller server. Security requires some care. In order to run a secure installation, I recommend the following guidelines.
The host should be running a fairly recent kernel. This will give you the performance enhancements that are trickling into the mainline kernel. Also consider applying some of the other patches I have mentioned. In particular, the file-punching patch, which is currently MADV_TRUNCATE, creates a number of new possibilities for UML management and hosting policy. Configure the UML instances carefully. Loadable module support should definitely be disabled, as should tt mode support. If access to host filesystems is provided, those filesystems should be bind-mounted into the UML jail. They should also be read-only if possible. Jail the UML instances tightly. The jail should be as minimal as you can make it, consistent with your other goals. I expect that the jailing will never be exercised since I know of no way for anyone to break out of a properly configured UML instance. However, a good jail will provide another level of security in the event of a configuration error or an exploitable escape from UML.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books
