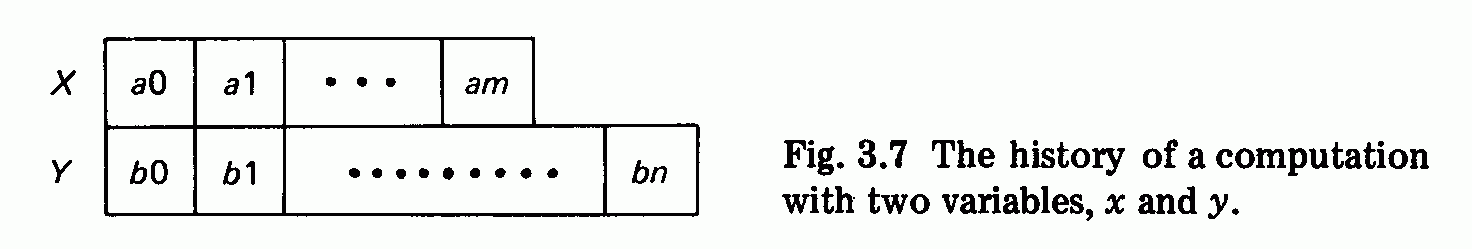Принципы операционной системы
BRINCH HANSEN , 1973
Вступление
Главная цель этой книги - дать представление об операционной системе как программе,
которая позволяет эффективно использовать компьютер и определяет правила поведения ее пользователей.
Тема этой книги - операционная система , которая радикально ничем не отличается от других больших программ.
Проблемы при ее разработке такие же , как и в остальных случаях при разработке таких больших программ,
как например компиляторы.
Историческое значение операционных систем в том , что они привели к открытию новых принципов совместного
использования ресурсов , мультипрограммирования , конструирования программ.
Задача операционной системы - распределение ресурсов между пользователями.
Для решения этой задачи разработчик должен ввести ограничения.
Один процессор может выполнять несколько различных вычислений,
создавая иллюзию , что они происходят одновременно.
Ось постоянно сталкивается с непредсказуемыми ситуациями,большим количеством различных запросов,
и она обязана распределять ресурсы между ними таким образом ,
чтобы каждый запрос получал адекватный по времени ответ.
Некоторые компоненты компьютера могут работать одновременно.
Проблемы , возникающие при программировании таких параллельных процессов,
заключаются в том , что очень сложно выявить ошибки при их тестировании.
Желательно выявлять такие ошибки еще на этапе компиляции.
В этой книге используется паскаль при обьяснении основных концепций и алгоритмов.
Книга состоит из 8 глав:
Часть 1 - обзорная. Обясняются цели и принципы операционных систем,
исторический взгляд на их разработку.
Показаны их технологические ограничения и возможности.
Часть 2 - показывает роль абстрактно-структурированного подхода при возникающих
вычислительных проблемах.Даются примеры последовательных программ
и иерархических програмных конструкций.
Часть 3 - о параллельных процессах,методах синхронизации,
семафорах,очередях,дидлоках.
Глава 4 - о планировщике процессов и real-time характеристиках.
Глава 5 - управление памятью .
Глава 6 - рассматривается теория планирования процессов на одно-процессорных системах.
Глава 7 - защита и распределение ресурсов системы.
Рассматривается взаимодействие таких систем,как управление процессами,
памятью,input/output, preemptive scheduling.
Глава 8 - конкретный пример системы на основе RC 4000.
Часть 1 - Обзор операционных систем
This chapter describes the purpose and technological background of
operating systems. It stresses the similarities of all operating systems and
points out the advantages of special-purpose over general-purpose systems.
1,1. THE PURPOSE OF AN OPERATING SYSTEM
1.1.1. Resource Sharing
An operating system is a set of manual and automatic procedures that
enable a group of people to share a computer installation efficiently.
The key word in this definition is sharing: it means that people will
compete for the use of physical resources such as processor time, storage
space, and peripheral devices; but it also means that people can cooperate
by exchanging programs and data on the same installation. The sharing of a
computer installation is an economic necessity, and the purpose of an
operating system is to make the sharing tolerable.
An operating system must have a policy for choosing the order in which
competing users are served and for resolving conflicts of simultaneous
requests for the same resources; it must also have means of enforcing this
policy in spite of the presence of erroneous or malicious user programs.
Present computer installations can execute several user programs
simultaneously and allow users to retain data on backing storage for weeks
or months. The simultaneous presence of data and programs belonging to
different users requires that an operating system protect users against each
other.
Since users must pay for the cost of computing, an operating system
must also perform accounting of the usage of resources.
In early computer installations, operators carried out most of these
functions. The purpose of present operating systems is to carry out these
tasks automatically by means of the computer itself. But when all
these aspects of sharing are automated, it becomes quite difficult for the
installation management to find out what the computer is actually doing
and to modify the rules of sharing to improve performance. A good
operating system will assist management in this evaluation by collecting
measurements on the utilization of the equipment.
Most components of present computer installations are sequential in
nature: they can only execute operations or transfer data items one at a
time. But it is possible to have activities going on simultaneously in several
of these components. This influences the design of operating systems so
much that our subject can best be described as the management of shared
multiprogramming systems.
1.1.2. Virtual Machines
An operating system defines several languages in which the rules of
resource sharing and the requests for service can be described. One of these
languages is the job control language, which enables users to identify
themselves and describe the requirements of computational jobs: the types
and amounts of resources needed, and the names of programs and data files
used.
Another language is the virtual machine language: the set of machine
operations available to a user during program execution. To maintain
control of a computer installation and isolate users from each other, an
operating system must prevent user programs from executing certain
operations; otherwise, these programs could destroy procedures or data
inside the operating system or start input/output on peripheral devices
assigned to other users. So the set of machine operations available to users
is normally a subset of the original machine language.
But users must have some means of doing input/output. The operating
system enables them to do so by calling certain standard procedures that
handle the peripherals in a well-defined manner. To the user programs,
these standard procedures appear to be extensions of the machine language
available to them. The user has the illusion of working on a machine that
can execute programs written in this language. Because this machine is
partly simulated by program, it is called a virtual machine. So an operating
system makes a virtual machine available to each user and prevents these
machines from interfering destructively with each other. The simultaneous
presence of several users makes the virtual machines much slower than the
physical machine.
An operating system can make the programming language of the virtual
machine more attractive than that of the original machine. This can be
done by relieving the user of the burden of technological details such as the
physical identity of peripheral devices and minor differences in their
operation. This enables the user to concentrate on logical concepts such as
the names of data files and the transfer of data records to and from these
files. The virtual machine can also be made more attractive by error
correction techniques; these make the virtual machine appear more reliable
than the real one (for example, by automatic repetition of unsuccessful
input/output operations). In this way an operating system may succeed in
making a virtue out of a necessity.
Yet another language is the one used inside the operating system itself
to define the policy of sharing, the rules of protection, and so on. A certain
amount of bitter experience with present operating systems has clearly
shown that an operating system may turn out to be inefficient, unreliable,
or built on wrong assumptions just like any other large program. Operating
systems should be designed so that they are simple to understand, and easy
to use and modify. Even if an operating system works correctly, there is
still a need for experimenting with its policy towards users and for adapting
it to the requirements of a particular environment, so it is important not
only to give users an attractive programming language, but also to design
good programming tools to be used inside the operating system itself. But
since the operating system is imposed on everyone, it is extremely
important that the language used to implement it reflect the underlying
machine features in an efficient manner.
1.1.3. Operating Systems and User Programs
Operating systems are large programs developed and used by a changing
group of people. They are often modified considerably during their
lifetimes. Operating systems must necessarily impose certain restrictions on
all users. But this should not lead us to regard them as being radically
different from other programs--they are just complicated applications of
general programming techniques.
During the construction of operating systems over the past decade, new
methods of multiprogramming and resource sharing were discovered. We
now realize that these methods are equally useful in other programming
applications. Any large programming effort will be heavily influenced by
the characteristics and amounts of physical resources available, by the
possibility of executing smaller tasks simultaneously, and by the need for
sharing a set of data among such tasks.
It may be useful to distinguish between operating systems and user
computations because the former can enforce certain rules of behavior on
the latter. But it is important to understand that each level of programming
solves some aspect of resource allocation.
Let me give a few examples of the influence of resource sharing on the
design of standard programs and user programs.
Store allocation. One of the main reasons for dividing a compiler into
smaller parts (called passes) is to allocate storage efficiently. During a
compilation, the passes can be loaded one at a time from drum or disk into
a small internal store where they are executed.
Job scheduling. A data processing application for an industrial plant can
involve quite complicated rules for the sequence in Which smaller tasks are
scheduled for execution. There may be a daily job which records details of
production; weekly and monthly jobs which compute wages; a yearly job
associated with the fiscal year; and several other jobs. Such long-term
scheduling of related jobs which share large data files is quite difficult to
control automatically. In contrast, most operating systems only worry
about the scheduling of independent jobs over time spans of a few minutes
or hours.
Multiprogramming. To control an industrial process, engineers must be
able to write programs that can carry out many tasks simultaneously, for
example, measure process variables continuously, report alarms to
operators, accumulate measurements of production, and print reports to
management.
Program protection. The ability to protect smaller components of a
large program against each other is essential in real-time applications (such
as banking and ticket reservation) where the service of reliable program
components must be continued while new components are being tested.
So the problems of resource sharing solved by operating systems repeat
themselves in user programs; or, to put it differently, every large
application of a computer includes a local operating system that
coordinates resource sharing among smaller tasks of that application. What
is normally called "the operating system" is just the one that coordinates
the sharing of an entire installation among users.
When you realize that resource sharing is not a unique characteristic of
operating systems, you may wonder whether the simulation of virtual
machines makes operating systems different from other programs. But alas,
a closer inspection shows that all programs simulate virtual machines.
Computer programs are designed to solve a class of problems such as
the editing of all possible texts, the compilation of all possible Algol
programs, the sorting of arbitrary sets of data, the computation of payrolls
for a varying number of employees, and so on. The user specifies a
particular case of the class of problems by means of a set of data, called the
input, and the program delivers as its result another set of data, called the
output.
One way of looking at this flexibility is to say that the input is a
sequence of instructions written in a certain language, and the function of
the program is to follow these instructions.
From this point of view, an editing program can execute other
programs written in an editing language consisting of instructions such as
search, delete, and insert textstring. And an Algol compiler can execute
programs written in the Algol 60 language. The computer itself can be
viewed as a physical implementation of a program called the instruction
execution cycle. This program can carry out other programs written in a
so-called machine language.
If we adopt the view that a computer is a device able to follow and
carry out descriptions of processes written in a formal language, then we
realize that each of these descriptions (or programs) in turn makes the
original computer appear to be another computer which interprets a
different language. In other words, an editing program makes the computer
behave like an editing machine, and an Algol compiler turns it into an Algol
60 machine. Using slightly different words, we can say that a program
executed on a physical machine makes that machine behave like a virtual
machine which can interpret a different programming language. And this
language is certainly more attractive for its purpose than the original
machine language; otherwise, there would be no reason to write the
program in the first place!
From these considerations it is hard to avoid the conclusion that
operating systems must be regarded merely as large application programs.
Their purpose is to manage resource sharing, and they are based on general
programming methods. The proper aim of education is to identify these
methods. But before we do that, I will briefly describe the technological
development of operating systems. This will give you a more concrete idea
of what typical operating systems do and what they have in common.
1.2. TECHNOLOGICAL BACKGROUND
1.2.1. Computer and Job Profiles
We now go back to the middle of the 1950's to trace the influence of
the technological development of computers on the structure of operating
systems.
When many users share a computer installation, queues of computa6
tions submitted for execution are normally formed, and a decision has to
be made about the order in which they should be executed to obtain
acceptable overall service. This decision rule is called a scheduling
algorithm.
A computation requested by a user is called a job; it can involve the
execution of several programs in succession, such as editing followed by
compilation and execution of a program written in a high-level language. A
job can also require simultaneous execution of several programs cooperating
on the same task. One program may, for example, control the printing
of data, while another program computes more output.
In the following, I justify the need for automatic scheduling of jobs by
quite elementary considerations about a computer installation with the
following characteristics:
instruction execution time 2/~sec
internal store 32 K words
card reader 1,000 cards/min
line printer 1,000 cards/min
magnetic tape stations 80,000 char/sec
(1 ~ = 10-6, and 1 K = 1024).
We will consider an environment in which the main problem is to
schedule a large number of small jobs whose response times are as short as
possible. {The response time of a job is the interval between the request for
its execution and the return of its results.) This assumption is justified for
universities and engineering laboratories where program development is the
main activity.
A number of people have described the typical job profile for this type
of environment (Rosin, 1965; Walter, 1967). We will assume that the
average job consists of a compilation and execution of a program written in
a high-level language. The source text read from cards and listed on a
printer, is the major part of the input/output. More precisely, the average
job will be characterized by the following figures:
input time (300 cards) 0.3 min
output time (500 lines) 0.5 min
execution time 1 min
1.2.2. Batch-processing Systems
For the moment we will assume that magnetic tape is the only form of
backing store available. This has a profound influence on the possible forms
of scheduling. We also impose the technological restriction on the computer
that its mode of operation be strictly sequential. This means that: (1) it can
Sec. 1.2. TECHNOLOGICAL BACKGROUND 7
only execute one program at a time; and (2) after the start of an
input/output operation, program execution stops until the transfer of data
has been completed.
The simplest scheduling rule is the open shop where users each sign up
for a period of, say, 15 min and operate the machine themselves. For the
individual user this is an ideal form of service: it enables him to correct
minor programming errors on the spot and experiment with programs
during their execution. Unfortunately, such a system leads to prohibitive
costs of idle machinery: for an average job, the central processor will only
be working for one out of every 15 min; the rest of the time will be spent
waiting for the operator. The situation can be characterized by two simple
measures of average performance:
processor utilization = execution time/total time
throughput = number of jobs executed per time unit
For the open shop, processor utilization is only about 7 per cent with a
throughput of no more than 4 jobs per hour, each requiring only one
minute of execution time(!).
Idle processor time caused by manual intervention can be greatly
reduced by even the most primitive form of automatic scheduling. Figure
1.1 illustrates an installation in which users no longer can interact with
programs during execution. They submit their jobs to an operator who
stacks them in the card reader in their order of arrival. From the card
reader, jobs are input directly to the computer, listed on the printer, and
executed one by one. This scheduling is done by an operating system which
resides permanently in the internal store.
Under this form of scheduling an average job occupies the computer for
1.8 min (the sum of input/output and execution times). This means that
processor utilization has been improved to 55 percent with a corresponding
throughput of 33 jobs per hour.
But even this simple form of automatic scheduling creates new
problems: How do we protect the operating system against erroneous user
programs? How can we force user programs to return control to the
operating system when they are finished, or if they fail to terminate after a
period of time defined by the operating system? Early operating systems
offered no satisfactory solutions to these problems and were frequently
brought down by their jobs. We will ignore this problem at the moment and
return to it in the chapters on processor management and resource
protection.
This argument in favor of automatic scheduling has ignored the
processor time that is lost while the operator handles the peripheral
devices: inserting paper in the printer, mounting tapes for larger jobs, and
so forth. The argument has also ignored processor time that is wasted when
the operator makes a mistake. But these factors are ignored throughout the
chain of arguments and do not affect the trend towards better utilization of
the processor.
The main weakness is that the argument did not include an evaluation
of the amount of processor time used by the new component--the
operating system. The reason for this omission is that an operating system
carries out certain indispensable functions (input/output, scheduling, and
accounting) which previously had to be done elsewhere in the installation
by operators and users. The relevant factor here--the amount of processor
time lost by an inefficient implementation of the operating system--
unfortunately cannot be measured. But in any case, the figures given in the
following are not my estimates, but measurements of the actual
performance of some recent operating systems.
The bottleneck in the previous simple system is the slow input/output
devices; they keep the central processor waiting 45 per cent of the time
during an average job execution. So the next step is to use the fast tape
stations to implement a batch processing system as shown in Fig. 1.2. First,
a number of jobs are collected from users by an operator and copied from
cards to magnetic tape on a small, cheap computer. This tape is carried by
the operator to the main computer, which executes the batch of jobs one
by one, delivering their output to another tape. Finally, this output tape is
carried to the small computer and listed on the printer. Notice that
although jobs are executed in their order of arrival inside a batch, the
printed output of the first job is not available until the entire batch has
been executed.
During the execution of a batch on the main computer, the operator
uses the small computer to print the output of an earlier batch and input a
new batch on tape. In this way the main computer, as well as the card
reader and printer, is kept busy all the time. Input/output delays on the
main computer are negligible in this system, but another source of idle time
has appeared: the mounting and dismounting of tapes. This can only be
reduced by batching many jobs together on a single tape. But in doing so
we also increase the waiting time of users for the results of their jobs. This
dilemma between idle processor time and user response time can be
expressed by the following relation:
processor utilization = (batch execution time) / batch response time
where
batch response time = batch mounting time + batch execution time
This can also be rewritten as follows:
batch response time = batch mounting time / 1 - processor utilization
Since there is a limit to the amount of idle processor time management
is prepared to accept, the net result is that response time for users is still
determined by the manual speed of operators! In the installation
considered a batch cycle typically proceeds as follows:
Delivery time of 50 jobs 30 min
Conversion of cards to tape 15 min
Mounting of tapes 5 min
Batch execution 50 min
Conversion of tape to printer 25 min
Manual separation of output 15 min
Total batch cycle 140 min
With a tape mounting time of 5 min per batch, utilization of the main
processor is now as high as 50/55 = 90 per cent, and throughput has
reached 55 jobs per hour. But at the same time, the shortest response time
for any job is 140 min. And this is obtained only if the job joins a batch
immediately after submission.
We have also ignored the problem of the large jobs: When jobs requiring
hours for execution are included in a batch, the jobs following will
experience much longer response times. Most users are only interested in
fast response during working hours. So an obvious remedy is to let the
operators sort jobs manually and schedule the shorter ones during the
daytime and the longer ones at night.
If the operator divides the jobs into three groups, the users might
typically expect response times of the following order:
1-minjobs: 2-3 hours
5-min jobs: 8-10 hours
other jobs: 1-7 days
We have followed the rationale behind the classical batch-processing
system of the late 1950's (Bratman, 1959). The main concern has been to
reduce idle processor time, unfortunately with a resultant increase in user
response time.
In this type of system the most complicated aspects of sharing are still
handled by operators, for example, the scheduling of simultaneous
input/output and program execution on two computers, and the
assignment of priorities to user jobs. For this reason I have defined an
operating system as a set of manual and automatic procedures that enable a
group of people to share a computer installation efficiently (Section 1.1.1).
1.2.3. Spooling Systems
It is illuminating to review the technological restrictions that dictated
the previous development towards batch processing. The first one was the
strict sequential nature of the computer which made it necessary to prevent
conversational interaction with running programs; the second limitation
was the sequential nature of the backing store (magnetic tapes) which
forced us to schedule large batches of jobs strictly in the order in which
they were input to the system.
The sequential restrictions on scheduling were made much less severe
(but were by no means removed) by technological developments in the
early 1960's. The most important improvement was the design of
autonomous peripheral devices which can carry out input/output operations
independently while the central processor continues to execute
programs.
The problem of synchronizing the central processor and the peripheral
devices after the completion of input/output operations was solved by the
interrupt concept. An interrupt is a timing signal set by a peripheral device
in a register connected to a central processor. It is examined by the central
processor after the execution of each instruction. When an interrupt occurs,
the central processor suspends the execution of its current program and
starts another program--the operating system. When the operating system
has responded properly to the device signal, it can either resume the
execution of the interrupted program or start a more urgent program (for
example, the one that was waiting for the input/output).
This technique made concurrent operation of a central processor and its
peripheral devices possible. The programming technique used to control
concurrent operation is called multiprogramming.
It was soon realized that the same technique could be used to simulate
concurrent execution of several user programs on a single processor. Each
program is allowed to execute for a certain period of time, say of the order
of 0.1-1 sec. At the end of this interval a timing device interrupts the
program and starts the operating system. This in turn selects another
program, which now runs until a timing interrupt makes the system switch
to a third program, and so forth.
This form of scheduling, in which a single resource (the central
processor) is shared by several users, one at a time in rapid succession, is
called multiplexing. Further improvements are made possible by enabling a
program to ask the operating system to switch to other programs while it
waits for input/output.
The possibility of more than one program being in a state of execution
at one time has considerable influence on the organization of storage. It is
no longer possible to predict in which part of the internal store a program
will be placed for execution. So there is no fixed correspondence at
compile time between the names used in a program to refer to data and the
addresses of their store locations during execution. This problem of
program relocation was first solved by means of a loading program, which
examined user programs before execution and modified addresses used in
them to correspond to the store locations actually used.
Later, program relocation was included in the logic of the central
processor: a base register was used to modify instruction addresses
automatically during execution by the start address of the storage area
assigned to a user. Part of the protection problem was solved by extending
this scheme with a limit register defining the size of the address space
available to a user; any attempt to refer to data or programs outside this
space would be trapped by the central processor and cause the operating
system to be activated.
The protection offered by base and limit registers was, of course,
illusory as long as user programs could modify these registers. The
recognition of this flaw led to the design of central processors with two
states of execution: a privileged state, in which there are no restrictions on
the operations executed; and a user state, in which the execution of
operations controlling interruption, input/output, and store allocation is
forbidden and will be trapped if attempted. A transition to the privileged
state is caused by interrupts from peripherals and by protection violations
inside user programs. A transition to the user state is caused by execution
of a privileged operation.
It is now recognized that it is desirable to be able to distinguish in a
more flexible manner between many levels of protection (and not just
two). This early protection system is safe, but it assigns more responsibility
to the operating system than necessary. The operating system must, for
example, contain code which can start input/output on every type of
device because no other program is allowed to do that. But actually, all that
is needed in this case is a mechanism which ensures that a job only operate
devices assigned to it; whether a job handles its own devices correctly or
not is irrelevant to the operating system. So a centralized protection
scheme tends to increase the complexity of an operating system and make
it a bottleneck at run time. Nevertheless, this early protection scheme must
be recognized as an invaluable improvement: clearly, the more responsibility
management delegates to an operating system, the less they can tolerate
that it breaks down.
Another major innovation of this period was the construction of large
backing stores, disks and drums, which permit fast, direct access to data
and programs. This, in combination with multiprogramming, makes it
possible to build operating systems which handle a continuous stream of
input, computation, and output on a single computer. Figure 1.3 shows
the organization of such a spooling system. The central processor is
multiplexed between four programs: one controls input of cards to a queue
on the backing store; another selects user jobs from this input queue and
starts their execution one at a time; and a third one controls printing of
output from the backing store. These three programs form the operating
system. The fourth program held in the internal store is the current user
program which reads its data from the input queue and writes its results in
an output queue on the backing store.
The point of using the backing store as a buffer is that the input of a
job can be fed into the machine in advance of its execution; and its output
can be printed during the execution of later jobs. This eliminates the
manual overhead of tape mounting. At the same time, direct access to the
backing store makes it possible to schedule jobs in order of priority rather
than in order of arrival. The spooling technique was pioneered on the Atlas
computer at Manchester University (Kilburn, 1961).
A very successful operating system with input/output spooling,
called Exec H, was designed by Computer Sciences Corporation (Lynch,
1967 and 1971). It controlled a Univac 1107 computer with an instruction
execution time of 4 psec. The backing store consisted of two or more fast
drums, each capable of transferring 10,000 characters during a single
revolution of 33 msec. The system typically processed 800 jobs per day,
each job requiring an average of 1.2 min. It was operated by the users
themselves: To run a job, a user simply placed his cards in a reader and
pushed a button. As a rule, the system could serve the users faster than
they could load cards. So a user could immediately remove his cards from
the reader and proceed to a printer where his output would appear shortly.
Less than 5 per cent of the jobs required magnetic tapes. The users who
needed tapes had to mount them in advance of program execution.
Fast response to student jobs was achieved by using the scheduling
algorithm shortest job next. Priorities were based on estimates of execution
time supplied by users, but jobs that exceeded their estimated time limits
were terminated by force.
Response times were so short that the user could observe an error,
repunch a few cards, and resubmit his job immediately. System
performance was measured in terms of the circulation time of jobs. This
was defined as the sum of the response time of a job after its submission
and the time required by the user to interpret the results, correct the cards,
and resubmit the job; or, to put it more directly, the circulation time was
the interval between two successive arrivals of the same job for execution.
About a third of all jobs had a circulation time of less than 5 min, and
90 per cent of all jobs were recirculated ones that had already been run one
or more times the same day. This is a remarkable achievement compared to
the earlier batch-processing system in which small jobs took a few hours to
complete! At the same time, the processor utilization in the Exec H system
was as high as 90 per cent.
The Exec H system has demonstrated that many users do not need a
direct, conversational interaction with programs during execution. Users
will often be quite satisfied with a non-interactive system which offers
them informal access, fast response, and minimal cost.
Non-interactive scheduling of small jobs with fast response is
particularly valuable for program testing. Program tests are usually short in
duration: After a few seconds the output becomes meaningless due to a
programming error. The main thing for the programmer is to get the initial
output as soon as possible and to be able to run another test after
correcting the errors shown by the previous test.
There are, however, also cases in which the possibility of interacting
with running programs is highly desirable. In the following section, I
describe operating systems which permit this.
1.2.4. Interactive Systems
To make direct conversation with running programs tolerable to human
beings, the computer must respond to requests within a few seconds. As an
experiment, try to ask a friend a series of simple questions and tell him to
wait ten seconds before answering each of them; I am sure you will agree
that this form of communication is not well-suited to the human
temperament.
A computer can only respond to many users in a few seconds when the
processing time of each request is very small. So the use of multiprogramming
for conversation is basically a means of giving fast response to
trivial requests; for example, in the editing of programs, in ticket
reservation systems, in teaching programs, and so forth. These are all
situations in which the pace is limited by human thinking. They involve
very moderate amounts of input/output data which can be handled by
low-speed terminals such as typewriters or displays.
In interactive systems in which the processor time per request is only a
few hundred milliseconds, scheduling cannot be based on reliable user
estimates of service time. This uncertainty forces the scheduler to allocate
processor time in small slices. The simplest rule is round-robin scheduling:
each job in turn is given a fixed amount of processor time called a time
slice; if a job is not completed at the end of its time slice, it is interrupted
and returned to the end of a queue to walt for another time slice. New jobs
are placed at the end of the queue. This policy guarantees fast response to
user requests that can be processed within a single time slice.
Conversational access in this sense was first proposed by Strachey
(1959). The creative advantages of a closer interaction between man and
machine were pointed out a few years later by Licklider and Clark (1962).
The earliest operational systems were the CTSS system developed at
Massachusetts Institute of Technology and the SDC Q-32 system built by
the System Development Corporation. They are described in excellent
papers by Corbato (1962) and Schwartz {1964 and 1967).
Figure 1.4 illustrates the SDC Q-32 system in a simplified form, ignoring
certain details. An internal store of 65 K words is divided between a
resident operating system and a single active user job; the rest of the jobs
are kept on a drum with a capacity of 400 K words.
The average time slice is about 40 msec. At the end of this interval, the
active job is transferred to the drum and another job is loaded into the
internal store. This exchange of jobs between two levels of storage is called
swapping. It takes roughly another 40 msec. During the swapping, the
central processor is idle so it is never utilized more than 50 per cent of the
time.
During the daytime the system is normally accessed simultaneously by
about 25 user terminals. So a user can expect response to a simple request
(requiring a single time slice only) in 25*80 msec = 2 sec.
A small computer controls terminal input/output and ensures that users
can continue typing requests and receiving replies while their jobs are
waiting for more time. A disk of 4000 K words with an average access time
of 225 msec is used for semi-permanent storage of data files and programs.
The users communicate with the operating system in a simple job
control language with the following instructions:
LOGIN: The user identifies himself and begins using the system.
LOAD: The user requests the transfer of a program from disk to
drum.
START: The user starts the execution of a loaded program or
resumes the execution of a stopped program.
STOP: The user stops the execution of a program temporarily.
DIAL: The user communicates with other users or with system
operators.
LOGOUT: The user terminates his use of the system.
The system has been improved over the years: Processor utilization has
been increased from 50 to 80 per cent by the use of a more complicated
scheduling algorithm. Nevertheless, it is still true that this system and
similar ones are forced to spend processor time on unproductive transfers
of jobs between two levels of storage: Interactive systems achieve
guaranteed response to short requests at the price of decreased processor
utilization.
In the SDC Q-32 system with an average of 25 active users, each user is
slowed down by a factor of 50. Consequently, a one-minute job takes
about 50 min to complete compared to the few minutes required in the
Exec H system. So interactive scheduling only makes sense for trivial
requests; it is not a realistic method for computational jobs that run for
minutes and hours.
Later and more ambitious projects are the MULTICS system (Corbato,
1965) also developed at MIT, and the IBM system TSS-360 (Alexander,
1968). In these systems, the problem of store multiplexing among several
users is solved by a more refined method: Programs and data are transferred
between two levels of storage in smaller units, called pages, when they are
actually needed during the execution of jobs. The argument is that this is
less wasteful in terms of processor time than the crude method of swapping
entire programs. But experience has shown that this argument is not always
valid because the overhead of starting and completing transfers increases
when it is done in smaller portions. We will look at this problem in more
detail in the chapter on store management. The paging concept was
originally invented for the Atlas computer (Kilburn, 1962).
Another significant contribution of these systems is the use of large
disks for semi-permanent storage of data and programs. A major problem in
such a filing system is to ensure the integrity of data in spite of occasional
hardware failures and protect them against unauthorized usage. The
integrity problem can be solved by periodic copying of data from disk to
magnetic tape. These tapes enable an installation to restore data on the disk
after a hardware failure. This is a more complicated example of the design
goal mentioned in Section 1.1.2: An operating system should try to make
the virtual machine appear more reliable than the real one.
The protection problem can be solved by a password scheme which
enables users to identify themselves and by maintaining as part of the filing
system a directory describing the authority of users (Fraser, 1971).
Interactive systems can also be designed for real-time control of
industrial processes. The central problem in a real-time environment is that
the computer must be able to receive data as fast as they arrive; otherwise,
they will be lost. (In that sense, a conversational system also works under
real-time constraints: It must receive input as fast as users type it.)
Usually, a process control system consists of several programs which are
executed simultaneously. There may, for example, be a program which is
started every minute to measure various temperatures, pressures, and flows
and compare these against preset alarm limits. Each time an alarm
condition is detected, another program is started to report it to an
operator, and while this is being done, the scan for further alarms
continues. Still other programs may at the same time accumulate
measurements on the production and consumption of materials and energy.
And every few hours these data are probably printed by yet another
program as a report to plant management.
This concludes the overview of the technological background of shared
computer installations. I have tried through a series of simple arguments to
illustrate the influence of technological constraints on the service offered
by operating systems. Perhaps the most valid conclusion is this: In spite of
the ability of present computer installations to perform some operations
simultaneously, they remain basically sequential in nature; a central
processor can only execute one operation at a time, and a drum or disk can
only transfer one block of data at a time. There are computers and backing
stores which can car~ out more than one operation at a time, but never to
the extent where the realistic designer of operating systems can afford to
forget completely about sequential resource constraints.
1.3. THE SIMILARITIES OF OPERATING SYSTEMS
The previous discussion may have left the impression that there are
basic differences between batch processing, spooling, and interactive
systems. This is certainly true as long as we are interested mainly in the
relation between the user service and the underlying technology. But to
gain a deeper insight into the nature of operating systems, we must look for
their similarities before we stress their differences.
To mention one example: All shared computer installations must
handle concurrent activities at some level. Even if a system only schedules
one job at a time, users can still make their requests simultaneously. This is
a real-time situation in which data (requests) must be received when they
arrive. The problem can, of course, be solved by the users themselves (by
forming a waiting line) and by the operators (by writing down requests on
paper); but the observation is important since our goal is to handle the
problems of sharing automatically.
It is also instructive to compare the batch-processing and spooling
systems. Both achieve high efficiency by means of a small number of
concurrent activities: In the batch processing system, independent
processors work together; in the spooling system, a single processor
switches among independent programs. Furthermore, both systems use
backing storage (tape and drum) as a buffer to compensate for speed
variations of the producers and consumers of data.
As another example, consider real-time systems for process control and
conversational programming. In these systems, concurrently executed
programs must be able to exchange data to cooperate on common tasks.
But again, this problem exists in all shared computer installations: In a
spooling system, user computations exchange data with concurrent
input/output processes; and in a batch processing system, another set of
concurrent processes exchanges data by means of tapes mounted by
operators.
As you see, all operating systems face a common set of problems. To
recognize these, we must reject the established classification of operating
systems (into batch processing, spooling, and interactive systems) which
stresses the dissimilarities of various forms of technology and user service.
This does not mean that the problems of adjusting an operating system to
the constraints of a particular environment should be ignored. But the
designer will solve them much more easily when he fully understands the
principles common to all operating systems.
1.4. DESIGN OBJECTIVES
The key to success in programming is to have a realistic, clearly-defined
goal and use the simplest possible methods to achieve it. Several operating
systems have failed because their designers started with very vague or
overambitious goals. In the following discussion, I will describe two quite
opposite views on the overall objectives of operating systems.
1.4.1. Special-purpose Systems
The operating systems described so far have one thing in common:
Each of them tries to use the available resources in the most simple and
efficient manner to give a restricted, but useful form of computational
service.
The Exec H spooling system, for example, strikes a very careful balance
between the requirements of fast response and efficient utilization. The
overhead of processor and store multiplexing is kept low by executing jobs
one at a time. But with only one job running, processor time is lost when a
job waits for input/output. So to reduce input/output delays, data are
buffered on a fast drum. But since a drum has a small capacity, it becomes
essential to keep the volume of buffered data small. This again depends on
the achievement of short response time for the following reason: the faster
the jobs are completed, the less time they occupy space within the system.
The keys to the success of the Exec H are that the designers: (1) were
aware of the sequential nature of the processor and the drum, and
deliberately kept the degree of multiprogramming low; and (2) took
advantage of their knowledge of the expected workload--a large number of
small programs executed without conversational interaction. In short, the
Exec H is a simple, very efficient system that serves a special purpose.
The SDC Q-32 serves a different special purpose: conversational
programming. It sacrifices 20 per cent of its processor time to give response
within a few seconds to 25 simultaneous users; its operating system
occupies only 16 K words of the internal store. This too is a simple,
successful system.
The two systems do not compete with each other. Each gives the users
a special service in a very efficient manner. But the spooling system is
useless for conversation, and so is the interactive system for serious
computation.
On the other hand, neither system would be practical in an
environment where many large programs run for hours each and where
operators mount a thousand tapes daffy. This may be the situation in a
large atomic research center where physicists collect and process large
volumes of experimental data. An efficient solution to this problem
requires yet another operating system.
The design approach described here has been called design according to
performance specifications. Its success strongly suggests that efficient
sharing of a large installation requires a range of operating systems, each of
which provides a special service in the most efficient and simple manner.
Such an installation might, for example, use three different operating
systems to offer:
(1) conversational editing and preparation of jobs;
(2) non-interactive scheduling of small jobs with fast response; and
(3) non-interactive scheduling of large jobs.
These services can be offered on different computers or at different times
on the same computer. For the users, the main thing is that programs
written in high-level languages can be processed directly by all three
systems.
1.4.2. General-purpose Systems
An alternative method is to make a single operating system which offers
a variety of services on a whole range of computers. This approach has
often been taken by computer manufacturers.
The 0S/360 for the IBM 360 computer family was based on this
philosophy. Mealy (1966) described it as follows:
"Because the basic structure of 0S/360 is equally applicable to
batchedojob and real-time applications, it may be viewed as one of the first
instances of a second-generation operating system. The new objective of
such a system is to accommodate an environment of diverse applications
and operating modes. Although not to be discounted in importance, various
other objectives are not new--they have been recognized to some degree in
prior systems. Foremost among these secondary objectives are:
Increased throughput
[] Lowered response time
[] Increased programmer productivity
[] Adaptability (of programs to changing resources)
[] Expandability
"A second-generation operating system must be geared to change and
diversity. System/360 itself can exist in an almost unlimited variety of
machine configurations."
Notice that performance (throughput and response) is considered to be
of secondary importance to functional scope.
An operating system that tries to be all things to all men naturally
becomes very large. 0S/360 is more than an operating system--it is a library
of compilers, utility programs, and resource management programs. It
contains several million instructions. Nash gave the following figures for the
resource management components of 0S/360 in 1966:
Data management 58.6 K statements
Scheduler 45.0
Supervisor 26.0
Utilities 53.0
Linkage editor 12.3
Testran 20.4
System generator 4.4
219.7 K
(Nato report, 1968, page 67).
Because of its size, the 0S/360 is also quite unreliable. To cite Hopkins:
"We face a fantastic problem in big systems. For instance, in 0S/360 we
have about 1000 errors each release and this number seems to be
reasonably constant" (Nato report, 1969, page 20).
This is actually a very low percentage of errors considering the size of
the system.
This method has been called design according to functional specifications.
The results have been generally disappointing, and the reason is
simply this: Resource sharing is the main purpose of an operating system,
and resources are shared most efficiently when the designer takes full
advantage of his knowledge of the special characteristics of the resources
and the jobs using them. This advantage is immediately denied him by
requiring that an operating system must work in a much more general case.
This concludes the overview of operating systems. In the following
chapters, operating systems are studied at a detailed level in an attempt to
build a sound theoretical understanding of the general principles of
multiprogramming and resource sharing.
1.5. LITERATURE
This chapter owes much to a survey by Rosin (1969) of the
technological development of operating systems.
With the background presented, you will easily follow the arguments in
the excellent papers on the early operating systems mentioned: Atlas
(Kilburn, 1961; Morris, 1967), Exec II (Lynch, 1967 and 1971), CTSS
(Corbato, 1962), and SDC Q-32 (Schwartz, 1964 and 1967). I recommend
that you study these papers to become more familiar with the purpose of
operating systems before you proceed with the analysis of their
fundamentals. The Atlas, Exec H, and SDC systems are of special interest
because they were critically reevaluated after several years of actual use.
The paper by Fraser (1971) explains in some detail the practical
problems of maintaining the integrity of data in a disk filing system in spite
of occasional hardware malfunction and of protecting these data against
unauthorized usage.
CORBATO, F. J., MERWIN.DAGGETT, M., and DALEY, R. C., "An experimental
time-sharing system," Proc. AFIPS Fall Joint Computer Conf., pp. 335-44, May 1962.
FRASER, A. G., "The integrity of a disc based file system," International Seminar on
Operating System Techniques, Belfast, Northern Ireland, Aug.-Sept. 1971.
KILBURN, T., HOWARTH, D. J., PAYNE, R. B., and SUMNER, F. H., "The
Manchester University Atlas operating system. Part I: Internal organization,"
Computer Journal 4, 3, 222-25, Oct. 1961.
LYNCH, W. C. "Description of a high capacity fast turnaround university computing
center," Proc. ACM National Meeting, pp. 273-88, Aug. 1967.
LYNCH, W. C., "An operating system design for the computer utility environment,"
International Seminar on Operating System Techniques, Belfast, Northern Ireland,
Aug.-Sept. 1971.
MORRIS, D., SUMNER, F. H., and WYLD, M. T., "An appraisal of the Atlas
supervisor," Proc. ACM National Meeting, pp. 67.75, Aug. 1967.
ROSIN, R. F., "Supervisory and monitor systems," Computing Surveys 1, 1, pp. 15-32,
March 1969.
SCHWARTZ, J. L, COFFMAN, E. G., and WEISSMAN, C., "A general purpose
time.sharing system," Proc. AFIPS Spring Joint Computer Conf., pp. 397-411, April
1964.
SCHWARTZ, J. I. and WEISSMAN, C., "The SDC timesharing system revisited," Proc.
ACMNationalMeeting, pp. 263-71, Aug. 1967.
Глава 2 - SEQUENTIAL PROCESSES
This chapter describes the role of abstraction and structure in problem
solving, and the nature of computations. It also summarizes the structuring
principles of data and sequential programs and gives an example of
hierarchal program construction.
2.1. INTRODUCTION
The starting point of a theory of operating systems must be a sequential
process--a succession of events that occur one at a time. This is the way our
machines work; this is the way we think. Present computers are built from
a small number of large sequential components: store modules which can
access one word at a time, arithmetic units which can perform one addition
at a time, and peripherals which can transfer one data block at a time.
Programs for these computers are written by human beings who master
complexity by dividing their tasks into smaller parts which can be analyzed
and solved one at a time.
This chapter is a summary of the basic concepts of sequential
programming. I assume you already have an intuitive understanding of
many of the problems from your own programming experience. We shall
begin by discussing the role of abstraction and structure in problem solving.
2.2. ABSTRACTION AND STRUCTURE
Human beings can think precisely only of simple problems. In our
efforts to understand complicated problems, we must concentrate at any
moment on a small number of properties that we believe are essential for
our present purpose and ignore all other aspects. Our partial descriptions of
the world are called abstractions or models.
One form of abstraction is the use of names as abbreviations for more
detailed explanations. This is the whole purpose of terminology. It enables
us to say "operating system" instead of "a set of manual and automatic
procedures that enable a group of people to share a computer installation
efficiently."
In programming, we use names to refer to variables. This abstraction
permits us to ignore their actual values. Names are also used to refer to
programs and procedures. We can, for example, speak of "the editing
program." And if we understand what editing is, then we can ignore, for
the moment, how it is done in detail.
Once a problem is understood in terms of a limited number of aspects,
we proceed to analyze each aspect separately in more detail. It is often
necessary to repeat this process so that the original problem is viewed as a
hierarchy of abstractions which are related as components within
components at several levels of detail.
In the previous example, when we have defined what an editing
program must do, we can proceed to construct it. In doing so, we will
discover the need for more elementary editing procedures which can
"search," "delete," and "insert" a textstring. And within these procedures,
we will probably write other procedures operating on single characters. So
we end up with several levels of procedures, one within the other.
As long as our main interest is the properties of a component as a
whole, it is considered a primitive component, but, when we proceed to
observe smaller, related components inside a larger one, the latter is
regarded as a structured component or system. When we wish to make a
distinction between a given component and the rest of the world, we refer
to the latter as the environment of that component.
The environment makes certain assumptions about the properties of a
component and vice versa: The editing program assumes that its input
consists of a text and some editing commands, and the user expects the
program to perform editing as defined in the manual. These assumptions
are called the connections between the component and its environment.
The set of connections between components at a given level of detail
defines the structure of the system at that level. The connections between
the editing program and its users are defined in the program manual. Inside
the editing program, the connections between the components "search,"
"delete," and "insert" are defined by what these procedures assume about
the properties and location of a textstring and by what operations they
perform on it.
Abstraction and recognition of structure are used in all intellectual
disciplines to present knowledge in forms that are easily understood and
remembered. Our concern is the systematic use of abstraction in the design
of operating systems. We will try to identify problems which occur in all
shared computer installations and define a set of useful components and
rules for connecting them into systems.
In the design of large computer programs, the following difficulties
must be taken for granted: (1) improved understanding of the problems
will change our goals in time; (2) technological innovations will eventually
change our tools; and (3) our intellectual limitations will often cause us to
make errors in the construction of large systems. These difficulties imply
that large systems will be modified during their entire existence by
designers and users, and it is essential that we build such systems with this
in mind. If it is difficult to understand a large system, it is also difficult to
predict the consequences of modifying it. So reliability is intimately related
to the simplicity of structure at all levels.
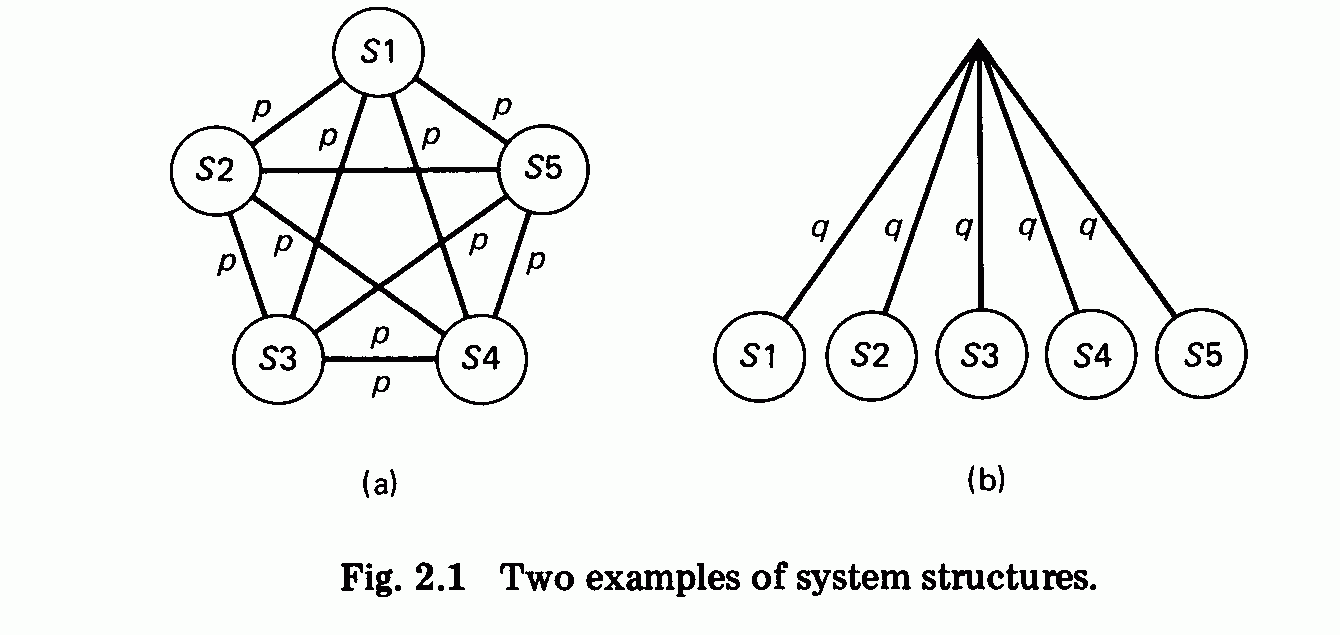
Figure 2.1(a) shows a complicated system S, consisting of n components
SI, $2 . . . . , Sn. In this system, each component depends directly on
the behavior of all other components. Suppose an average of p simple steps
of reasoning or testing are required to understand the relationship between
one component and another and to verify that they are properly
connected. Then the connection of a single component to its environment
can be verified in (n-1)p steps, and the complete system requires
n(n - 1)p steps.
This can be compared with the system shown in Fig. 2.1(b): There, the
connections between the n components are defined by a common set of
constraints chosen so that the number of steps q required to verify whether
a component satisfies them is independent of the number of components n.
The proof or test effort is now q steps per component and nq steps for the
whole system.
The argument is, of course, extreme, but it does drive home the
following point: If the intellectual effort required to understand and test a
system increases more than linearly with the size of the system, we shall
never be able to build reliable systems beyond a certain complexity. Our
only hope is to restrict ourselves to simple structures for which the effort
of verification is proportional to the number of components.
The importance of precise documentation of system structure can
hardly be overemphasized. Quite often, a group of designers intend to
adopt a simple structure, but they fail to state precisely what the
assumptions are at each level of programming, and instead rely on informal,
spoken agreements. Inevitably, the result is that each member of the group
adds complexity to the structure by making unnecessary or erroneous
assumptions about the behavior of components designed by his colleagues.
The importance of making assumptions explicit is especially felt when an
initial version of a system must be modified; perhaps by a different group
of people.
2.3. COMPUTATIONS
In Chapter 1 the word computation was used intuitively to refer to
program execution. In the following, this concept and its components data
and operations are defined explicitly.
2.3.1. Data and Operations
The exchange of facts or ideas among human beings by speech is based
on mutual agreement on the meaning of certain sounds and combinations
of sounds. Other conventions enable us to express the same ideas by means
of text and pictures, holes in punched cards, polarity of magnetized media,
and modulated electromagnetic waves. In short, we communicate by means
of physical phenomena chosen by us to represent certain aspects of our
world. These physical representations of our abstractions are called data,
and the meanings we assign to them are called their information.
Data are used to transmit information between human beings, to store
information for future use, and to derive new information by manipulating
the data according to certain rules. Our most important tool for the
manipulation of data is the digital computer.
A datum stored inside a computer can only assume a finite set of values
called its type. Primitive types are defined by enumeration of their values,
for example:
type boolean = (false, true)
or by definition of their range:
type integer = - 8388608..8388607
Structured types are defined in terms of primitive types, as is explained
later in this chapter.
The rules of data manipulation are called operations. An operation
maps a finite set of data, called its input, into a finite set of data, called its
output. Once initiated, an operation is executed to completion within a
finite time. These assumptions imply that the output of an operation is a
time-independent function of its input, or, to put it differently: An
operation always delivers the same output values when it is applied to a
given set of input values.
An operation can be defined by enumeration of its output values for all
possible combinations of its input values. This set of values must be finite
since an operation only involves a finite set of data with finite ranges. But
in practice, enumeration is only useful for extremely simple operations
such as the addition of two decimal digits. As soon as we extend this
method of definition to the addition of two decimal numbers of, say, 10
digits each, it requires enumeration of 10 2 0 triples (x, y, x + y)!
A more realistic method is to define an operation by a computational
rule involving a finite sequence of simpler operations. This is precisely the
way we define the addition of numbers. But like other abstractions,
computational rules are useful intellectual tools only as long as they remain
simple.
The most powerful method of defining an operation is by assertions
about the type of its variables and the relationships between their values
before and after the execution of the operation. These relationships are
expressed by statements of the following kind: If the assertion P is true
before initiation of the operation Q, then the assertion R will be true on its
completion. I will use the notation
"P" Q "R"
to define such relationships.
As an example, the effect of an operation sort which orders the n
elements of an integer array A in a non-decreasing sequence can be defined
as follows:
"A: array 1..n of integer"
sort(A);
"for all i, j: 1..n (i ~j implies A(i) ~ A(j))"
Formal assertions also have limitations: They tend to be as large as the
programs they refer to. This is evident from the simple examples that have
been published (Hoare, 1971a).
The whole purpose of abstraction is abbreviation. You can often help
the reader of your programs much more by a short, informal statement that
appeals to a common background of more rigorous definition. If your
reader knows what a Fibonacci number is, then why write
"F: array 0..n of integer & j: O. .n &
for all i: 0..j (F(i) = if i < 2 then i else F(i - 2) + F(i - 1))"
when the following will do
"F(0) to F(j) are the first j + 1 Fibonaeci numbers"
Definition by formal or informal assertion is an abstraction which
enables us to concentrate on what an operation does and ignore the details
of how it is carried out. The type concept is an abstraction which permits
us to ignore the actual values of variables and state that an operation has
the effect defined for all values of the given types.
2.3.2. Processes
Data and operations are the primitive components of computations.
More precisely, a computation is a finite set of operations applied to a
finite set of data in an attempt to solve a problem. If a computation solves
the given problem, it is also called an algorithm. But it is possible that a
computation is meaningless in the sense that it does not solve the problem
it was intended to solve.
The operations of a computation must be carried out in a certain order
of precedence to ensure that the results of some operations can be used by
others. The simplest possible precedence rule is the execution of operations
in strict sequential order, one at a time. This type of computation is called
a sequential process. It consists of a set of operations which are totally
ordered in time.
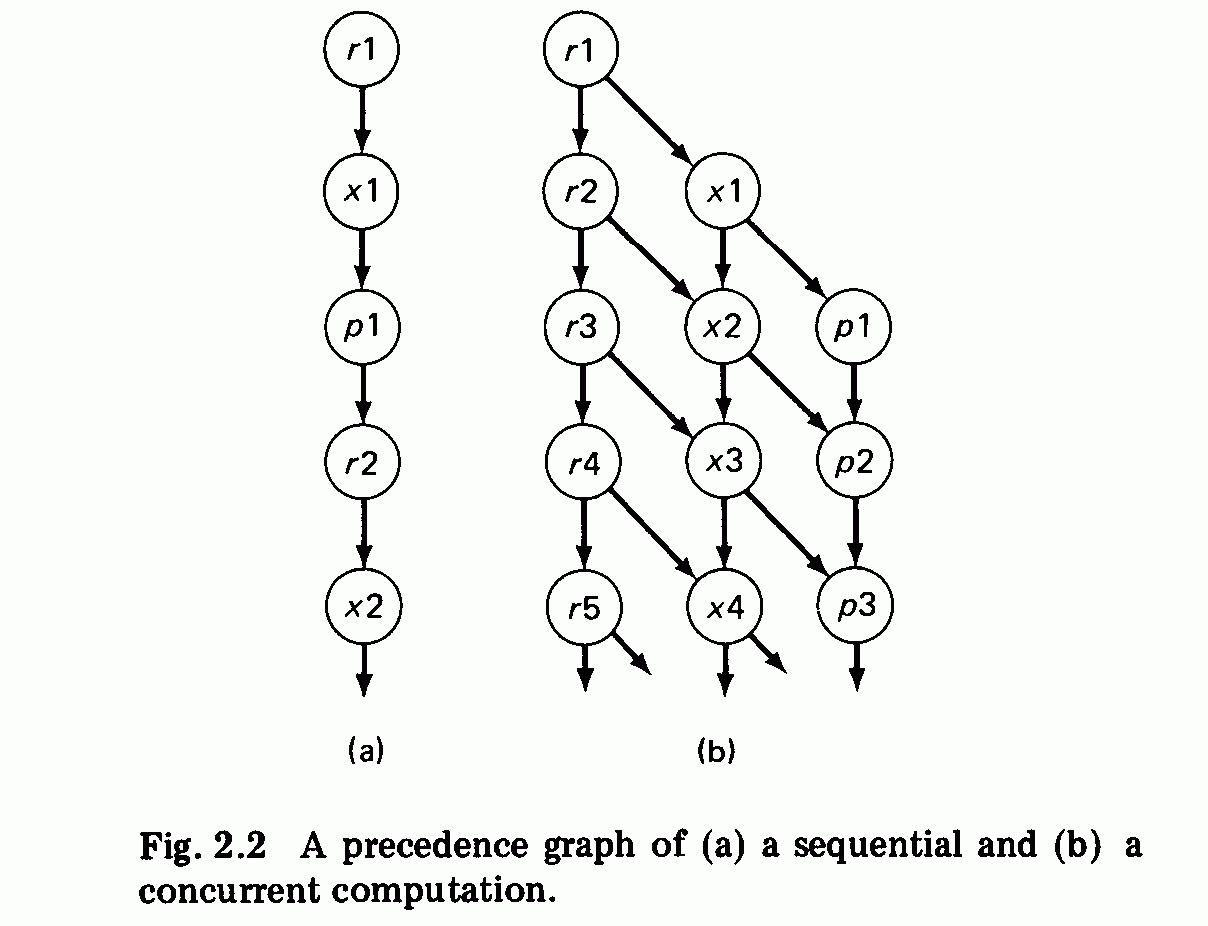
Figure 2.2(a) shows a precedence graph of the process performed by an
operating system that schedules user computations one at a time. Each
node represents an instance of one of the following operations: r (read user
request), x (execute user computation), and p (print user results). The
directed branches represent precedence of operations. In this case:
rl precedes xl,
xl precedes pl,
pl precedes r2,
r2 precedes x2,
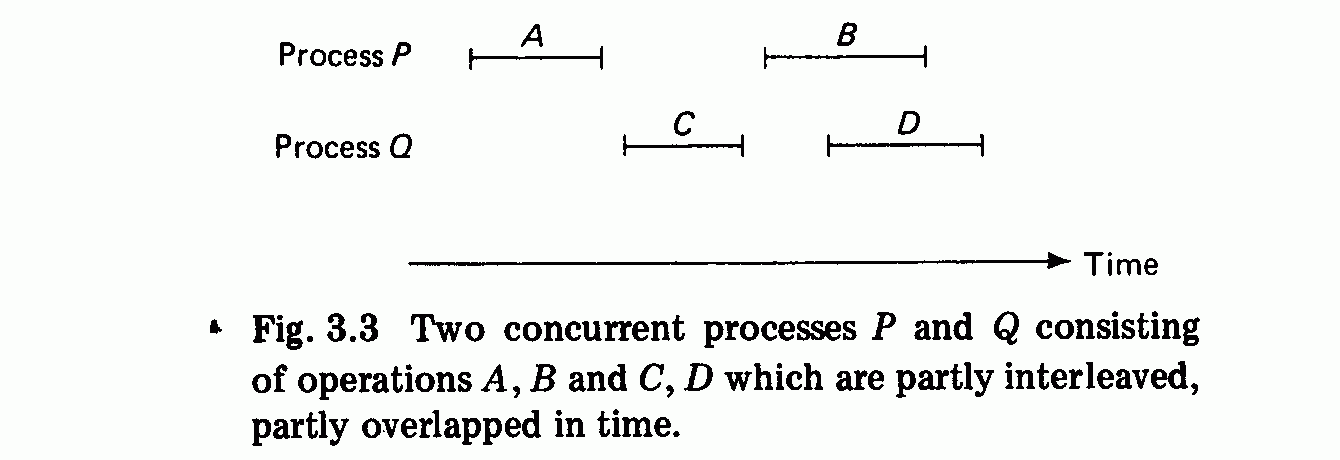
Most of our computational problems require only a partial ordering of
operations in time: Some operations must be carried out before others, but
some of them can also be carried out concurrently. This is illustrated in Fig.
2.2(b) by a precedence graph of a spooling system (see Chapter 1, Fig. 1.3).
Here the precedence rules are:
rl precedes xl and r2,
xl precedes pl and x2,
pl precedes p2,
r2 precedes x2 and r3,
Partial ordering makes concurrent execution of some operations
possible. In Fig. 2.2(b), the executions of the following operations may
overlap each other in time:
r2 and xl,
r3 and x2 and pl,
In order to understand concurrent computations, it is often helpful to
try to partition them into a number of sequential processes which can be
analyzed separately. This decomposition can usually be made in several
ways, depending on what your purpose is.
If you wish to design a spooling system, then you will probably
partition the computation in Fig. 2.2(b) into three sequential processes of a
cyclical nature each in control of a physical resource:
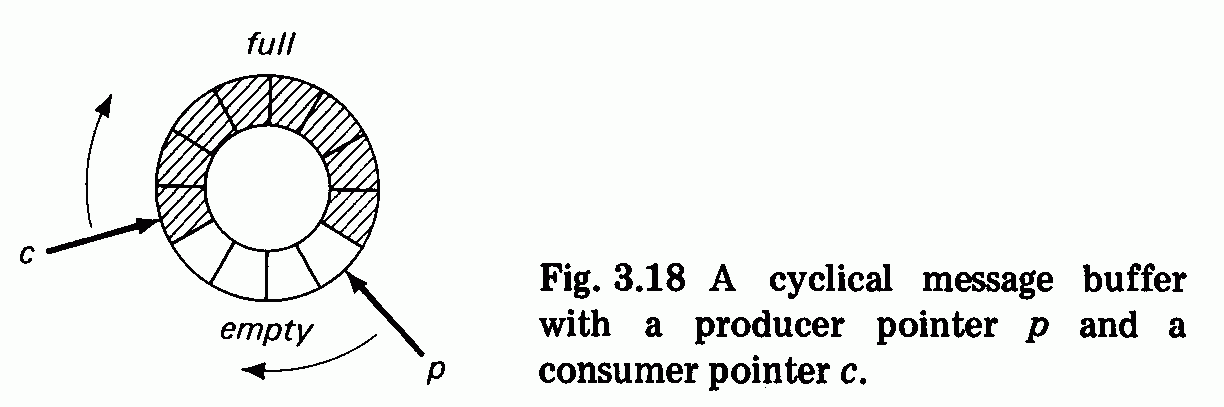
reader process: r l ; r 2 ; r 3 ; . . .
scheduler process: xl;x2;x3;. . .
printer process: pl;p2;p3;. . .
These processes can proceed simultaneously with independent speeds,
except during short intervals when they must exchange data: The scheduler
process must receive user requests from the reader process, and the printer
process must be informed by the scheduler process of where user results are
stored. Processes which cooperate in this manner are called loosely
connected processes.
On the other hand, if you are a user, it makes more sense to recognize
the following processes in Fig. 2.2(b):
job 1: r l ; x l ; p l ;
job 2: r2; x2; p2;
job 3: r3;x3;p3;
Both decompositions are useful for a particular purpose, but each of
them also obscures certain facts about the original computation. From the
first decomposition it is not evident that the reader, scheduler, and printer
processes execute a stream of jobs; the second decomposition hides the fact
that the jobs share the same reader, processor, and printer. A decomposition
of a computation into a set of processes is a partial description or an
abstraction of that computation. And how we choose our abstractions
depends on our present purpose.
The abstractions chosen above illustrate a general principle: In a
successful decomposition, the connections between components are much
weaker than the connections inside components. It is the loose connections
or infrequent interactions between the processes above which make it
possible for us to study them separately and consider their interactions
only at a few, well-defined points.
One of the recurrent themes of this book is process interaction. It is a
direct consequence of the sharing of a computer. Processes can interact for
various reasons: (1) because they exchange data, such as the reader,
scheduler, and printer processes; (2) because they share physical resources,
such as jobl, job2, job3, and so on; or (3) because interaction simplifies our
understanding and verification of the correctness of a computation--this is
a strong point in favor of sequential computations.
Concurrent computations permit better utilization of a computer
installation because timing constraints among physical components are
reduced to a minimum. But since the order of operations in time is not
completely specified, the output of a concurrent computation may be a
time-dependent function of its input unless special precautions are taken.
This makes it impossible to reproduce erroneous computations in order to
locate and correct observed errors. In contrast, the output of a sequential
process can always be reproduced when its input is known. This property
of sequential processes along with their extreme simplicity makes them
important components for the construction of concurrent computations.
The main obstacles to the utilization of concurrency in computer
installations are economy and human imagination. Sequential processes can
be carried out cheaply by repeated use of simple equipment; concurrent
computations require duplicated equipment.
Human beings find it very difficult to comprehend the combined effect
of activities which evolve simultaneously with independent speeds. Those
who have studied the history of nations in school, one by one--American
history, French history, and so on--recall how difficult it was to remember,
in connection with a crucial time of transition in one country, what
happened in other countries at the same time. The insight into our
historical background can be greatly improved by presenting history as a
sequence of stages and by discussing the situation in several countries at
each stage--but then the student finds it equally difficult to remember the
continuous history of a single nation !
It is hard to avoid the conclusion that we understand concurrent events
by looking at sequential subsets of them. This would mean that, even
though technological improvements may eventually make a high degree of
concurrency possible in our computations, we shall still attempt to
partition our problems conceptually into a moderate number of sequential
activities which can be programmed separately and then connected loosely
for concurrent execution.
In contrast, our understanding of a sequential process is independent of
its actual speed of execution. All that matters is that operations are carried
out one at a time with finite speed and that certain relations hold between
the data before and after each operation.
2.3.3. Computers and Programs
The idea of defining complicated computations rigorously implies the
use of a formal language to describe primitive data types and operations as
well as combinations of them. A formal description of a computation is
called a program, and the language in which it is expressed is called a
programming language.
Programs can be used to communicate algorithms among human beings,
but, in general, we write programs to solve problems on computers. We will
indeed define a computer installation as a physical system capable of
carrying out computations by interpreting programs.
Figure 2.3 shows a model of a computer installation. It consists of a
store and one or more processors. The store is a physical component in
which data and programs can be retained for future use. It is divided into a
finite set of primitive components called locations. Each location can store
any one of a finite set of data values.
A processor is a physical component which can carry out a sequential
process defined by a program. During its execution, a program is stored as a
sequence of data called instructions. An instruction consists of four
components defining an operation, its input and output, and a successor
instruction. Data used to identify store locations are called addresses.
The processors can work concurrently and share the common store.
Some of the processors are called terminals or peripheral devices; they are
dedicated to the transfer of data between the environment and the store.
Other processors are called central processors; they operate mainly on
stored data. For our purposes, the distinction between peripheral devices
and central processors is not fundamental; it merely reflects various degrees
of specialization.
The rest of this chapter is a discussion of the fundamental abstraction,
sequential processes. It summarizes methods of structuring data and
sequential programs, and serves as a presentation of the programming
language used throughout the text, a subset of the language Pascal, created
by Wirth. The algorithmic statements of Pascal are based on the principles
and notation of Algol 60. But the data structures of Pascal are much more
general than those of Algol 60.
Pascal permits hierarchal structuring of data and program, extensive
error checking at compile time, and production of efficient machine code
on present computers. It combines the clarity needed for teaching the
subject with the efficiency required for designing operating systems. If you
are familiar with Algol 60, you will find it quite natural to adopt Pascal as
your programming tool.
The following is a brief and very informal description of a subset of
Pascal with the emphasis on the language features that make it different
from Algol 60. Although my summary of Pascal is sufficient for
understanding the rest of the book, I recommend that you study the
official Pascal report, which is written in clear, informal prose (Wirth,
1971a).
I have taken a few minor liberties with the Pascal notation. They are
not mentioned explicitly because my subject is not rigorous language
definition, but operating system principles.
2.4. DATA STRUCTURES
2.4.1. Primitive Data Types
Constants are denoted by numbers or identifiers. A definition of the
form:
constal=cl, a2=c2, . . . , ak = ck;
introduces the identifiers al, a2 . . . . , ak as synonyms of the constants cl,
c2, . .. , ck, for example:
const e = 2.718281828;
Variables are introduced by declarations of the form:
vat vl, v2 . . . . , vk: ;
which associates the identifiers vl, v2 . . . . . , vk with a data type.
A data type is the set of values which can be assumed by a variable. A
type can be defined either directly in the declaration of a variable or
separately in a type definition which associates an identifier T with the
type:
type T = ;
vat vl, v2, . . . , vk: T;
A primitive type is a finite, ordered set of values. The primitive types:
boolean
integer
real
are predefined for a given computer.
Other primitive types can be defined by enumeration of a set of
successive values:
(al, a2, . . . ,ak)
denoted by identifiers al, a2, . . . , ak, for example:
type name of month =
(January, February, March, April, May, June, July,
August, September, October, November, December);
A primitive type can also be defined as a range within another primitive
type:
cmin. . emax
where cmin and cmax are constants denoting the minimum and maximum
values in the range, for example:
type number of day = 1..31;
vat payday: number of day;
war summer month: June..August;
The first example is a variable payday, which can assume the values 1 to 31
(a subrange of the standard type integer). The second example is a variable
summer month, which can assume the values June to August (a subrange of
the type name of month defined previously).
The set of values which can be assumed by a variable v of a primitive
type T can be generated by means of the standard functions:
rain(T) max(T) succ(v) pred(v)
in ascending order:
v:= rain(T);
while v -~ max(T) do v:= succ(v);
or in descending order:
v: = max(T);
while v ? min(T) do v: = pred(v);
2.4.2. Structured Data Types
Structured types are defined in terms of primitive types or in terms of
other structured types using the connection rules of arrays and records.
The type definition:
array D of R
defines a data structure consisting of a fixed number of components of
type R. Each component of an array variable v is selected by an index
expression E of type D:
v(E)
Examples:
type table = array 1..20 of integer;
vat A : table; i: 1. •20;
. . . A ( i ) . . .
vat length of month:
array name of month of number of day;
• . . length of month (February) . ..
The type definition:
record fl: T1; f2: T2;... ; fk: Tk end
defines a data structure consisting of a fixed number of components of
types T1, T 2 , . . . , Tk. The components are selected by identifiers f l ,
f2, . . . , fk. A component fj within a record variable v is denoted:
v.fi
Example:
type date = record
day: number of day;
month: number of month;
year: O. .2000;
end
vat birthday: date;
• . . birthday, month...
Good programmers do not confine themselves exclusively to the
structures defined by an available programming language. They invent
notations for abstractions that are ideally suited to their present purpose.
But they will choose abstractions which later can be represented efficiently
in terms of the standard features of their language.
I will occasionally do the same and postulate extensions to Pascal which
help me to stress essential concepts and, for the moment, ignore trivial
details.
As one example, I will assume that one can declare a variable s
consisting of a sequence of components of type T:
vat s: sequence of T
var s:sequence of T
Initially, the sequence is empty. The value of a variable t of type T can
be appended to or removed from the sequence s by means of the standard
procedures
put(t, s) get(t, s)
The components are removed in the order in which they are appended to
the sequence. In other words, a sequence is a first-in, first-out store.
The boolean function
empty(s)
defines whether or not the sequence s is empty.
The implementation of sequences by means of arrays will be explained
in Chapter 3. For a more detailed discussion of the representation of
various data structures see Knuth (1969).
2.5. PROGRAM STRUCTURES
2.5.1. Primitive Statements
Operations and combinations of them are described by statements. The
primitive statements are exit statements, assignment statements, and
procedure statements.
The exit statement
exit L
is a restricted form of a go to statement. It causes a jump to the end of a
compound statement labeled L:
labelLbegin . . . e x i t L ; . . , end
This use of jumps is an efficient way of leaving a compound statement
in the exceptional cases when a solution to a problem is found earlier than
expected, or when no solution exists. But in contrast to the unstructured
go to statement, the exit statement simplifies the verification of program
correctness.
Suppose an assertion P holds before a compound statement Q is
executed. There are now two cases to consider: Either Q is executed to
completion, in which case an assertion R is known to hold; or an exit is
made from Q when an exceptional case S holds. So the effect of statement
Q is the following:
"P" Q "R or S"
The assignment statement
V: = E
assigns the value of an expression E to a variable v. The expression must be
of the same type as v. Expressions consist of operators and functions
applied to constants, variables, and other expressions. The operators are:
arithmetic: + - * / mod
relational: = ~ < >
boolean: & or not
The function designator
F(al, a2, . . . . ak)
causes the evaluation of a function F with the actual parameters al,
a2, . . . , ak.
The procedure statement
P(al, a2, . . . ,ak)
causes the execution of a procedure P with the actual parameters al,
a2, . . . , ak.
The actual parameters of functions and procedures can be variables and
expressions. Expressions used as parameters are evaluated before a function
or procedure is executed.
Structured statements are formed by connecting primitive statements
or other structured statements according to the following rules:
(1) Concatenation of statements S1, $2, . . . , Sn into a compound
statement:
label L begin S1; $2; . . . ; Sn end
beginS1;S2; . . . ;Sn end
(See Fig. 2.4).
(2) Selection of one of a set of statements by means of a boolean
expression B:
ifB then S1 else $2
if B then S
or by means of an expression E of a primitive type T:
type T = (cl, c2 . . . . , cn);
. , •
case E of
cl: S1;c2: $2; . . . cn: Sn;
end
If E = c] then statement S] is executed (See Fig. 2.5).
Repetition of a statement S while a boolean expression B remains true
while B do S
or repetition of a sequence of statements S1, $2, . . . , Sn until a boolean
expression B becomes true:
repeat 81; $2; . . . ; Sn until B
(See Fig. 2.6).
Another possibility is to repeat a statement S with a succession of
primitive values assigned to a control variable v:
for v:= Emin to Emax do S
(4) Recursion of a procedure P which calls itself:
procedumP( . . . );
begin . . . P; . . . end
(See Fig. 2.7.)
Notice that the analytical effort required to understand the effect of
these structures is proportional to the number of component statements.
For example, in the analysis of an if statement, we must first prove that a
certain assertion R will be true after execution of statement S1, provided
assertions B and P hold before $1 is initiated, and similarly for $2:
"B & P"S1 "R" "not B & P"S2 "R"
From this we infer that
"P" ifB then S1 else $2 "R"
The repetition statements are understood by mathematical induction.
From
"B & P" S "P"
we infer that
"P" while B do S "not B & P"
The aim is to find an invariant P--an assertion which is true before the
iteration is started and remains true after each execution of the statment S.
For records, the following structured statement can be used:
with v do S
It enables the statement S to refer to the components of a record variable v
by their identifiers f l , f2, . . . , fk without qualifying them with the record
identifier v, for example:
with birthday do
begin day:= 19; month:= April; year:= 1938 end
Finally, we have the important abstraction of assigning a name to a
sequence of statements $1, $2, . . . , Sn by means of procedure and
function declarations of the form:
procedure P(pl; p2; . . . ; pk);
< local declarations >
beginS1;S2; . . . ;Snend
function F(pl;p2; . . . ;pk): ;
< local declarations >
begin S1; $2; . . . ; Sn end
where pl, p2, . . . . pk are declarations of formalparameters. The declaration
p] of a constant or variable parameter vj of type Tj has the form:
const vj: Tj var vj: Tj
The preceding specifier can be omitted for constant parameters.
A function F computes a value that must be of a primitive type. At
least one of its statements $1, $2, . . . , Sn must assign a result value to the
function identifier F
F:= E
where E is an expression of the result type.
The function statements must not assign values to actual parameters
and non-local variables. This rule simplifies program verification as will be
explained in Chapter 3.
The declarations of identifiers which are local to a procedure or
function are written before the begin symbol of the statement part. They
are written in the following order:
const
type
var
A program consists of a declaration part and a compound statement.
Finally, I should mention that comments are enclosed in quotes:
"This is a comment"
This concludes the presentation of the Pascal subset.
2.6. PROGRAM CONSTRUCTION
We design programs the same way we solve other complex problems: by
step-wise analysis and refinement. In this section, I give an example of
hierarchal program construction.
2.6.1. The Banker's Algorithm
The example chosen is a resource sharing problem first described and
solved by Dijkstra (1965). Although the problem involves concurrent
processes, it is used here as an example of sequential programming.
An operating system shares a set of resources among a number of
concurrent processes. The resources are equivalent in the sense that when a
process makes a request for one of them, it is irrelevant which one is
chosen. Examples of equivalent resources are peripheral devices of the same
type and store pages of equal size.
When a resource has been allocated to a process, it is occupied until the
process releases it again. When concurrent processes share resources in this
manner, there is a danger that they may end up in a deadlock, a state in
which two or more processes are waiting indefinitely for an event that will
never happen.
Suppose we have 5 units of a certain resource, and we are in a state
where 2 units are allocated to a process P and 1 unit to another process Q.
But both processes need two more units to run to completion. If we are
lucky, one of them, say Q, will acquire the last two units, run to
completion, and release all three of its units in time to satisfy further
requests from P. But it is also possible that P and Q both will acquire one of
the last two units and then (since there are no more) will decide to wait
until another unit becomes available. Now they are deadlocked: P cannot
continue until Q releases a unit; Q cannot continue until P releases a unit;
and each of them expects the other to resolve the conflict.
The deadlock could have been prevented by allocating all units needed
by P (or Q) at the same time rather than one by one. This policy would
have forced P and Q to run at different times, and as we have seen in
Chapter 1, this is often the most efficient way of using the resources. But
for the moment, we will try to solve the problem without this restriction.
Let me define the problem more precisely in Dijkstra's terminology: A
banker wishes to share a fixed capital of florins among a fixed number of
customers. Each customer specifies in advance his maximum need for
florins. The banker will accept a customer if his need does not exceed the
capital.
During a customer's transactions, he can only borrow or return florins
one by one. It may sometimes be necessary for a customer to wait before
he can borrow another florin, but the banker guarantees that the waiting
time will always be finite. The current loan of a customer can never exceed
his maximum need.
If the banker is able to satisfy the maximum need of a customer, then
the customer guarantees that he will complete his transactions and repay
his loan within a finite time.
The current situation is safe if it is possible for the banker to enable all
his present customers to complete their transactions within a finite time;
otherwise, it is unsafe.
We wish to find an algorithm which can determine whether the banker's
current situation is safe or unsafe. If the banker has such an algorithm, he
can use it in a safe situation to decide whether a customer who wants to
borrow another florin should be given one immediately or told to walt. The
banker makes this decision by pretending to grant the florin and then
observing whether this leads to a safe situation or not.
The situation of a customer is characterized by his current loan and his
further claim where
claim = need - loan
The situation of the banker is characterized by his original capital and
his current amount of cash where
cash = capital - sum of loans
The algorithm that determines whether the overall situation is safe or
not is quite simple. Let me illustrate it by an example: Fig. 2.8 shows a
situation in which three customers, P, Q, and R, share a capital of 10
florins. Their combined need is 20 florins. In the current situation, Fig.
2.8(a), customer Q has a loan of 2 florins and a claim of 1 florin; this is
denoted 2 (1). For P and R the loans and claims are 4 (4) and 2 (7)
respectively. So the available cash C at the moment is 10 - 4 - 2 - 2 = 2.
The algorithm examines the customers one by one, looking for one who
has a claim not exceeding the cash. In Fig. 2.8(a), customer Q has a claim
of 1. Since the cash is 2, customer Q will be able in this situation to
complete his transactions and return his current loan of 2 florins to the
banker.
After the departure of customer Q, the situation will be the one shown
in Fig. 2.8(b). The algorithm now scans the remaining customers and
compares their claims with the increased cash of 4 florins. It is now possible
to satisfy customer P completely.
This leads to the situation in Fig. 2.8(c) in which customer R can
complete his transactions. So finally, in Fig. 2.8(d) the banker has regained
his capital of 10 florins. Consequently, the original state Fig. 2.8(a) was
safe.
It is possible to go from the safe state in Fig. 2.8(a) to an unsafe
situation, such as the one in Fig. 2.9(a). Here, the banker has granted a
request from customer R for another florin. In this new situation, customer
Q can be satisfied. But this leads us to the situation in Fig. 2.9(b) in which
we are stuck: neither P nor R can complete their transactions.
If the banker's algorithm finds that a situation is unsafe, this does not
necessarily mean that a deadlock will occur--only that it might occur. But
if the situation is safe, it is always possible to prevent a deadlock. Notice
that the banker prevents deadlocks in the same way as we originally
proposed: by serving the customers one at a time; but the banker only does
so in situations where it is strictly necessary.
We will now program the banker's algorithm for the general case
considered by Habermann (1969), in which the banker's capital consists of
several currencies: florins, dollars, pounds, and so on.
2.6.2. A Hierarchal Solution
The first version of the banker's algorithm is trivial:
type S = ?
function safe(current state: S): boolean;
It consists of a boolean function safe with a parameter defining the current
state. The details of the function and the type of its parameter are as yet
unknown.
The first refinement (Algorithm 2.1) expresses in some detail what the
ALGORITHM 2. 1 The Banker's Algorithm
type S = ?
function safe(current state: S): boolean;
vat state: S;
begin
state:= current state;
complete transactions(state);
safe: = all transactions completed(state);
end
function safe does: It simulates the completion of customer transactions as
far as possible. If all transactions can be completed, the current state is safe.
In the second refinement (Algorithm 2.2), the state is decomposed
into: (1) an array defining the claim and loan of each customer and
whether or not that customer's transactions have been completed; and (2)
two components defining the capital and cash of the banker. The exact
representation of currencies (type C) is still undefined.
The procedure complete transactions is now defined in some detail. It
examines the transactions of one customer at a time: If they have not
already been completed and completion is possible, the procedure simulates
the return of the customer's loan to the banker. This continues until no
more transactions can be completed.
ALGORITHM 2.2 The Banker's Algorithm (cont.)
type S = record
transactions: array B of
record
claim, loan: C;
completed: boolean;
end
capital, cash: C;
end
B = 1..number of customers;
C=?
procedure complete transactions(vat state: S);
vat customer: B; progress: boolean;
begin
with state do
repeat
progress:= false;
for every customer do
with transactions(customer) do
ff not completed then
if completion possible(claim, cash) then
begin
return loan(loan, cash);
completed: = true;
progress:= true;
end
until not progress;
end
The statement
for every customer do...
is equivalent to
for customer:= rain(B) to max(B) do...
Algorithm 2.3 shows that the current state is safe if the banker
eventually can get his original capital back.
ALGORITHM 2.3 The Banker's AIgorithm (cont.)
function all transactions completed(state: S): boolean;
begin
with state do
all transactions completed := capital = cash;
end
In the third refinement (Algorithm 2.4), we define the representation
of a set of currencies as an array of integers and write the details of the
function completion possible, which shows that the transactions of a single
customer can be completed if his claim of each currency does not exceed
the available cash.
ALGORITHM 2.4 The Banker's Algorithm (cont.)
type C = array D of integer;
D = 1..number of currencies;
function completion possible(claim, cash: C): boolean;
vat currency: D;
label no
begin
for every currency do
if claim(currency) > cash(currency)then
begin
completion possible:= false;
exit no;
end
completion possible:= true;
end
Algorithm 2.5 shows the final details of the banker's algorithm.
ALGORITHM 2.5 The Banker's Algorithm (cont.)
procedure return loan(var loan, cash: C);
vat currency: D;
begin
for every currency do
cash (currency): = cash (currency) + loan (currency);
end
To be honest, I do not construct my first version of any program in the
orderly manner described here. Nor do mathematicians construct proofs in
the way in which they present them in textbooks. We must all experiment
with a problem by trial and error until we understand it intuitively and
have rejected one or more incorrect solutions. But it is important that the
final result be so well-structured that it can be described in a step-wise
hierarchal manner. This greatly simplifies the effort required for other
people to understand the solution.
2.6.3. Conclusion
I have constructed a non-trivial program (Algorithm 2.6) step by step in
a hierarchal manner. At each level of programming, the problem is
described in terms of a small number of variables and operations on these
variables.
ALGORITHM 2.6 The Complete Banker's AIgorithm
type S = record
transactions: array B of
record
claim, loan: C;
completed: boolean;
end
capital, cash: C;
end
B = 1..number of customers;
C = array D of integer;
D = 1..number of currencies;
function safe(current state: S): boolean;
vat state: S;
procedure complete transactions(vat state: S);
vat customer: B; progress: boolean;
Sec. 2.6. PROGRAM CONSTRUCTION
function completion possible(claim, cash: C): boolean;
var currency: D;
label no
begin
for every currency do
if claim(currency) > cash(currency)then
begin
completion possible:= false;
exit no;
end
completion possible := true;
end
procedure return loan(var loan, cash: C);
var currency: D;
begin
for every currency do
cash(currency):= cash(currency) + loan(currency);
end
begin
with state do
repeat
progress:= false;
for every customer do
with transactions(customer) do
if not completed then
if completion possible(claim, cash) then
begin
return loan(loan, cash);
completed: = true;
progress: = true;
end
until not progress;
end
function all transactions completed(state: S): boolean;
begin
with state do
all transactions completed:= capital = cash;
end
begin
state:= current state;
complete transactions( sta te ) ;
safe: = all transactions completed(state);
end
At the most abstract level, the program consists of a single variable,
current state, and a single operation, safe. If this operation had been
available as a machine instruction, our problem would have been solved.
Since this was not the case, we wrote another program (Algorithm 2.1),
which can solve the problem on a simpler machine using the operations
complete transactions and all transactions completed.
This program in turn was rewritten for a still simpler machine
(Algorithms 2.2 and 2.3). The refinement of previous solutions was
repeated until the level of detail required by the available machine was
reached.
So the design of a program involves the construction of a series of
programming layers, which gradually transform the data structures and
operations of an ideal, non-existing machine into those of an existing
machine. The non-existing machines, which are simulated by program, are
called virtual machines to distinguish them from the physical machine.
It was mentioned in Section 1.1.3 that every program simulates a
virtual machine that is more ideal than an existing machine for a particular
purpose: A machine that can execute the banker's algorithm is, of course,
ideally suited to the banker's purpose. We now see that the construction of
a large program involves the simulation of a hierarchy of virtual machines.
Figure 2.10 illustrates the virtual and physical machines on which the
banker's algorithm is executed.
At each level of programming, some operations are accepted as
primitives in the sense that it is known what they do as a whole, but the
details of how it is done are unknown and irrelevant at that level.
Consequently, it is only meaningful at each level to describe the effect of
the program at discrete points in time before and after the execution of
each primitive. At these points, the state of the sequential process is
defined by assertions about the relationships between its variables, for
exam ple:
"all transactions completed =- capital = cash"
Since each primitive operation causes a transition from one state to
another, a sequential process can also be defined as a succession of states in
time.
As we proceed from detailed to more abstract levels of programming,
some concepts become irrelevant and can be ignored. In Algorithm 2.2, we
must consider assertions about the local variable, progress, as representing
distinct states during the execution of the partial algorithm. But at the level
of programming where Algorithm 2.2 is accepted as a primitive, complete
transactions, the intermediate states necessary to implement it are completely
irrelevant.
So a state is a partial description of a computation just like the
concepts sequential process and operation. A precise definition of these
abstractions depends on the level of detail desired by the observer. A user
may recognize many intermediate states in his computation, but for the
operating system in control of its execution, the computation has only a
few relevant states, such as "waiting" or "running."
In order to test the correctness of a program, we must run it through all
its relevant states at least once by supplying it with appropriate input and
observing its output. I remarked in Section 2.3.1 that the definition of
operations by enumeration of all possible data values is impractical except
in extremely simple cases. The same argument leads to the conclusion that
exhaustive testing of operations for all possible input values is out of the
question.
If we were to test the addition of two decimal numbers of 10 digits
each exhaustively, it would require 1020 executions of a program loop of,
say 10/~sec, or, all in all, 3 * 107 years. The only way to reduce this time
is to use our knowledge of the internal structure of the adder. If we know
that it consists of 10 identical components, each capable of adding two
digits and a carry, we also know that it is sufficient to test each component
separately with 10 * 10 * 2 combinations of input digits. This insight
immediately reduces the number of test cases to 2000 and brings the total
test time down to only 20 msec.
Returning to the problem of testing the correctness of a program such
as the banker's algorithm, we must accept that such a test is impossible at a
level where it is only understood as a primitive: safe. We would have to
exhaust all combinations of various currencies and customers in every
possible state! But if we take advantage of the layered structure of our
programs (see Fig. 2.10), we can start at the machine level and demonstrate
once and for all that the machine instructions work correctly. This proof
can then be appealed to at higher programming levels independent of the
actual data values involved. At the next level of programming, it is proved
once and for all that the compiler transforms Pascal statements correctly
into machine instructions. And when we reach the levels at which the
banker's algorithm is programmed, it is again possible to test each level
separately, starting with Algorithm 2.5 and working towards Algorithm 2.1.
In this chapter, I have stressed the need for simplicity in programming.
I cannot accept the viewpoint that the construction of programs with a
pleasant structure is an academic exercise that is irrelevant or impractical to
use in real life. Simplicity of structure is not just an aesthetic pursuit--It is
the key to survival in programming! Large systems can only be fully
understood and tested if they can be studied in small, simple parts at many
levels of detail.
2.7. LITERATURE
This chapter has briefly summarized concepts which are recognized and
understood, at least intuitively, by most programmers.
The role of hierarchal structure in biological, physical, social, and
conceptual systems is discussed with deep insight by Simon (1962).
In the book by Minsky (1967) you will find an excellent and simple
presentation of the essential aspects of sequential machines and algorithms.
Homing and Randell (1972) have analyzed the concept "sequential
process" from a more formal point of view.
Hopefully, this book will make you appreciate the Pascal language. It is
defined concisely in the report by Wirth (1971a).
A subject which has only been very superficially mentioned here is
correctness proofs of algorithms. It was suggested independently by Naur
and Floyd and further developed by Hoare (1969).
The practice of designing programs as a sequence of clearly separated
layers is due to Dijkstra (1971a). He has successfully used it for the
construction of an entire operating system (1968). Eventually, this
constructive approach to programming may change the field from a
hazardous application of clever tricks into a mature engineering discipline.
DIJKSTRA, E. W., "The structure of THE multiprogramming system," Comm. ACM
11, 5, pp. 341-46, May 1968.
DIJKSTRA, E. W., A short introduction to the art of programming, Technological
University, Eindhoven, The Netherlands, Aug. 1971a.
HOARE, C. A. R., "An axiomatic basis for computer programming," Comm. ACM 12,
10, pp. 576-83, Oct. 1969.
HORNING, J. J. and RANDELL, B., "Process structuring," University of Newcastle
upon Tyne, England, 1972.
MINSKY, M. L., Computation: finite and infinite machines, Prentice-Hall Inc.,
Englewood Cliffs, New Jersey, 1967.
SIMON, H. A., "The architecture of complexity," Proc. American Philosophical Society
106, 6, pp. 468-82, 1962.
WIRTH, N., "The programming language Pascal," Acta Informatica 1, 1, pp. 35-63,
1971a.
Глава 3 CONCURRENT PROCESSES
This chapter is a study of concurrent processes. It emphasizes the role
of reproducible behavior in program verification and compares various
methods of process synchronization: critical regions, semaphores, message
buffers, and event queues. It concludes with an analysis of the prevention
of deadlocks by hierarchal ordering of process interactions.
3.1. CONCURRENCY
The process concept was introduced in the previous chapter (see
Section 2.3.2). In the following, I will summarize the basic properties of
sequential and concurrent processes, and introduce a language notation for
the latter.
3.1.1. Definition
A process is a sequence of operations carried out one at a time. The
precise definition of an operation depends on the level of detail at which
the process is described. For some purposes, you may regard a process as a
single operation A, as shown on top of Fig. 3.1. For other purposes, it may be
more convenient to look upon the same process as a sequence of simpler
operations B, C, D, and E. And when you examine it in still more detail,
previously recognized operations can be partitioned into still simpler ones:
F, G, H, and so on.
If you compare this picture with the hierarchy of machines on which
the banker's algorithm is executed (see Fig. 2.10), you will see that as we
proceed to more detailed levels of programming, a process is described in
terms of increasingly simpler operations which are carried out in increasingly
smaller grains of time.
At all levels of programming, we assume that when an operation is
initiated, it terminates within a finite time and delivers output which is a
time-independent function of its input (see Section 2.3.1).
If the variables of a process are inaccessible to other processes, it is easy
to show by induction that the final output of a sequence of operations will
be a time-independent function of the initial input. In this case, a process
can be regarded as a single operation, provided that it terminates.
But if one process can change the variables of another process, the
output of the latter may depend on the relative speed of the processes. In
this case, a process cannot be regarded as a single operation. I will describe
the problem of multiprogramming systems with time-dependent behavior
later and proceed here to describe the basic properties of concurrent
processes.
Processes are concurrent if their executions overlap in time. Figure 3.2
shows three concurrent processes, P, Q, and R.
Whether the individual operations of concurrent processes are
overlapped or interleaved in time, or both (as shown in Fig. 3.3), is
irrelevant. Whenever the first operation of one process is started before the
last operation of another process is completed, the two processes are
concurrent.
In an installation where several processors work simultaneously, the
machine instructions of concurrent processes can overlap in time. But if
one processor is multiplexed among concurrent processes, the machine
instructions of these processes can only be interleaved in time. The logical
problems turn out to be the same in both cases; they are caused by our
ignorance of the relative speeds of concurrent processes.
3.1.2. Concurrent Statements
The language notation
cobegin S1; $2; . . . ; Sn coend
indicates that the statements $1, $2, . . . , Sn can be executed
concurrently. It was first proposed by Dijkstra (1965).
To define the effect of a concurrent statement, we must take into
account the statements SO and Sn+l, which precede and follow it in a
given program:
This piece of program can be represented by the precedence graph shown in
Fig. 3.4. The desired effect is to execute SO first, and then execute S1,
$2 . . . . , Sn concurrently; when all the statements S1, $2, . . . , Sn have
been terminated, the following statement Sn +1 is executed.
Concurrent statements can be arbitrarily nested, for example:
cobegin
$1;
begin
$2;
cobegin $3; $4 coend
$5;
end
$6;
coend
This corresponds to the precedence graph shown in Fig. 3.5.
3.1.3. An Example: Copying
The use of the concurrent statement is illustrated by Algorithm 3.1,
which copies records from one sequence to another.
ALGORITHM 3.1 Copying of a Sequence of Records
procedure copy (vaz f, g: sequence of T);
vat s, t: T; completed: boolean;
begin
if not empty(f) then
begin
completed:= false;
get(s, f);
repeat
t:= s;
cobegin
put(t, g);
ff empty(f) then completed:= true
else get(s, f);
coend
until completed;
end
end
The variables used are two sequences, f and g, of records of type T; two
buffers, s and t, each holding one record; and a boolean, indicating whether
or not the copying has been completed.
The algorithm gets a record from the inPut sequence, copies it from one
buffer to another, puts it on the output sequence, and, at the same time,
gets the next record from the input sequence. The copying, output, and
input are repeated until the input sequence is empty.
Figure 3.6 shows a precedence graph of this computation using the
operations: g (get record), c {copy record), and p (put record).
3.2. FUNCTIONAL SYSTEMS
In the following, we consider more precisely what time-independent or
functional behavior means, and under what circumstances multiprogramming
systems have this property. As an introduction to this topic, we
will first examine our ability to verify the correctness of programs.
3.2.1. Program Verification
The ideal program is one which is known with absolute certainty to be
correct. It has been argued that this can be achieved by rigorous proofs
(Hoare, 1969 and 1971a). I believe that the use of proof techniques
contributes to the correctness of programs by forcing programmers to
express solutions to problems in two different ways: by an algorithm and
by a proof. But it must be remembered that a proof is merely another
formal statement of the same size as the program it refers to, and as such it
is also subject to human errors. This means that some other form of
program verification is still needed, at least for large programs.
The next best thing to absolute correctness is immediate detection of
errors when they occur. This can be done either at compile time or at run
time. In either case, we rely on a certain amount of redundancy in our
programs, which makes it possible to check automatically whether
operations are consistent with the types of their variables and whether they
preserve certain relations among those variables.
Error detection at compile time is possible only by restricting the
language constructions; error detection at run time is possible only by
executing redundant statements that check the effect of other statements.
In practice, both methods are used, but there are limits to how far one can
go in each direction: At some point, severe language restrictions and
excessive run-time checking will make the system useless for practical
purposes.
This leaves a class of errors that is caught neither at compile time nor at
run time. It seems fair to say that these errors can only be located and
corrected if programs have functional behavior which enables the designer
to reproduce errors under controlled circumstances.
One can subject a sequential program to a fairly systematic initial
testing by examining its internal structure and defining a sequence of input
data which will cause it to execute all statements at least once.
Dijkstra once remarked that "program testing can be used to show the
presence of errors, but never their absence" (Nato report, 1969). Even a
systematically tested program may contain some undetected errors after it
has been released for normal use. If it has been subject to intensive initial
testing, the remaining errors are usually quite subtle. Often, the designer
must repeat the erroneous computation many times and print successive
values of various internal variables to find out in which part of the program
the error was made.
So program testing is fundamentally based on the ability to reproduce
computations. The difficulty is that we must reproduce them under varying
external circumstances. In a multiprogramming system, several user
computations may be in progress simultaneously. These computations are
started at unpredictable times at the request of users. 8o, strictly speaking,
the environment of a program is unique during each execution. Even when
computations are scheduled one at a time, a programming error is frequently
observed by a user on one installation and corrected by a designer
on another installation with a different configuration.
This has the following consequences: (1) an operating system must
protect the data and physical resources of each computation against
unintended interference by other computations; and (2) the results of each
computation must be independent of the speed at which the computation
is carried out.
The protection problem is discussed in a later chapter. Here we are
concerned with the assumption of speed-independence. This assumption is
necessary because a computation has no influence on the rate at which it
proceeds. That rate depends on the presence of other computations and the
possibly dynamic policy of scheduling. It is also a highly desirable
assumption to make, considering our difficulty in understanding concurrent
processes in terms of their absolute speeds.
The next section illustrates the consequences of time-dependent
behavior of erroneous programs.
3.2.2. Time-dependent Errors
Consider again Algorithm 3.1, which copies records from a sequence f
to another sequence g. Initially, f contains a sequence of records 1, 2, . . . ,
m, while g is empty. We will denote this as follows:
f=(1,2, . . . ,m) g=(n)
When the copying has been completed, g contains all the records in
their original order while f is empty:
f = (D) g = (1, 2 . . . . , m)
The repetition statement in Algorithm 3.1 contains three component
statements, which will be called COPY, PUT, and GET:
COPY_= t:= s
PUT -~ put(t, g)
GET -= if empty(f) then completed:= true
else get (s, f)
They are used as follows:
repeat
COPY cobegin PUT; GET coend
until completed;
Now suppose the programmer expresses the repetition by mistake as
follows:
repeat
cobegin COPY; PUT; GET coend
until completed;
The copying, output, and input of a single record can now be executed
concurrently.
To simplify the argument, we will only consider cases in which the
statements COPY, PUT, and GET can be arbitrarily interleaved in time, but
we will ignore the possibility that they can overlap in time.
Suppose the first record is copied correctly from sequence f to g. The
computation will then be in the following state after the first execution of
the repetition statement:
s =2&f=(3, . . . ,m)&t =l&g=(1)
The following table shows the possible execution sequences of COPY,
PUT, and GET during the second execution of the repetition statement. It
also shows the resulting output sequence g after each execution sequence.
COPY; PUT; GET leads to g = (1, 2)
COPY; GET; PUT leads to g = (1, 2)
PUT; COPY; GET leads to g = (1, 1)
PUT; GET; COPY leads to g=(1,1)
GET; COPY; PUT leads to g = (1, 3)
GET; PUT; COPY leads to g = (1, 1)
One of these sequences is shown below in detail:
"s=2&f=(3, . . . ,m)&t=l&g =(1)''
GET;
"s =3&f=(4, . . . ,m)&t =l&g=(1)''
COPY;
"s= 3& f=(4 . . . . . m)& t= 3&g=(1) ''
PUT;
"s=3&f =(4, . . . ,m)&t =3&g = ( 1 , 3 ) ' '
The erroneous concurrent statement can be executed in six different
ways with three possible results: (1) if copying is completed before input
and output are initiated, the correct record will be output; (2) if output is
completed before copying is initiated, the previous record will again be
output; and (3) if input is completed before copying is initiated and this in
turn completed before output is initiated, the next record will instead be
output.
This is just for a single record of the output sequence. If we copy a
sequence of 10000 records, the program can give of the order of 3 l°°°°
different results! It is therefore extremely unlikely that the programmer
will ever observe the same result twice.
If we consider the general case in which concurrent operations overlap
in time, we are unable even to enumerate the possible results of a
programming error without knowing in detail how the machine reacts to
attempts to perform more than one operation simultaneously on the same
variable.
The actual sequence of operations in time will depend on the presence
of other (unrelated) computations and the scheduling policy used by the
operating system to share the available processors among them. The
programmer is, of course, unaware of the precise combination of external
events that caused his program to fail and is unable to repeat it under
controlled circumstances. When he repeats the program execution with the
same input, it will sometimes produce correct results, sometimes different
erroneous results.
The programmer's only hope of locating the error is to study the
program text. This can be very frustrating (if not impossible) if the text
consists of thousands of lines and one has no clues about where to look for
the error.
It can be argued that such errors are perfectly reproducible in the
sense that if we had observed and recorded the behavior of all
computations and physical resources continuously during the execution
of a given computation, it would also have been possible to reproduce
the complete behavior of the computer installation. But this is a purely
hypothetical possibility. Human beings are unable to design programs
which take into account all simultaneous events occurring in a large
computer installation. We must limit ourselves to programs which can be
verified independently of other programs. So, in practice, events causing
time-dependent results are not observed and recorded, and must therefore
be considered irreproducible.
Concurrent programming is far more hazardous than sequential
programming unless we ensure that the results of our computations are
reproducible in spite of errors. In the example studied here, this can
easily be checked at compile time, as I will describe in the next section.
- 3.2.3. Disjoint Processes
The two concurrent processes in Algorithm 3.1
cobegin
put(t, g);
if empty(f} then completed: = true
else get(s, f);
coend
are completely independent processes which operate on disjoint sets of
variables (t, g) and (s, f, completed).
Concurrent processes which operate on disjoint sets of variables are
called disjoint or non-interacting processes.
In the erroneous version of Algorithm 3.1
cobegin
t:=s;
put(t, g);
if empty(f) then completed:= true
else get(s,f);
coend
the processes are not disjoint: The output process refers to a variable t
changed by the copying process, and the copying process refers to a
variable s changed by the input process.
When a process refers to a variable changed by another process, it is
inevitable that the result of the former process will depend on the time at
which the latter process makes an assignment to this variable.
These time-dependent errors can be caught at compile time if the
following restriction on concurrent statements is made: The notation
cobeginS1;S2; . . . ;Sn coend
indicates that statements S1, $2, . . . , Sn define disjoint processes which
can be executed concurrently. This means that a variable vi changed by a
statement Si cannot be referenced by another statement Sj {where j ? i).
In other words, we insist that a variable subject to change by a process
must be strictly private to that process; but disjoint processes can refer
to common variables not changed by any of them.
To enable the compiler to check the disjointness of processes, the
language must have the following property: It must be possible to
determine the identity of a statement's constant and variable parameters by
inspecting the statement.
In Pascal this is certainly possible for assignment statements and
expressions involving variables of primitive types and record types only.
Components of arrays are selected by indices determined at run time
only. So, at compile time it is necessary to require that an entire array be
private to a single process within a concurrent statement.
Functions present no problems in Pascal since they cannot perform
assignment to non-local variables. But with procedures, it is necessary to
observe a certain discipline in the use of parameters.
The language notation must distinguish between constant and variable
parameters. Pascal already does this: A comparison of a procedure
statement
P(a, b)
with the corresponding procedure declaration
procedure P(const c: C; vat v: V)
immediately shows that the procedure statement will leave variable a
unchanged, but may change variable b.
To make a cleat distinction between constant and variable parameters,
we will not permit a variable to occur both as a constant and as a variable
parameter in the same procedure statement.
Without this rule one cannot make simple assertions about the effect of
procedures. Consider, for example, the following procedure:
procedure P(const c: integer; vat v: integer);
begin v := c + 1 end
If we call this procedure as follows:
P(a, b)
where a and b are integer variables, we can make the assertion that upon
return from the procedure, b = a + 1. But this assertion leads to a
contradiction in the following case:
P(a, a)
namely a = a + 1.
Another contradiction occurs if the same variable is used twice as a
variable parameter in a procedure statement. For example, if a program
contains the following procedure:
procedure P(var v, w: integer);
begin v: = 1; w: = 2 end
then the call
P(a, b)
leads to the result a = 1 & b = 2. But when the same assertion is used for
the call
P(a, a)
it leads to the contradiction a = 1 & a = 2.
These contradictions can be avoided by obeying the following rule: All
variables used as variable parameters in a procedure statement must be
distinct and cannot occur as constant parameters in the same statement.
A Pascal procedure can also have side effects: It can change non-local
variables directly, as is shown in the following example:
var v: T;
procedure P;
begin . . . v:= E . . . end
or call other procedures which have side effects. So, it is not possible to
identify the variables involved by simple inspection of a procedure
statement and the corresponding procedure declaration.
One possibility is to specify all global variables referred to within a
procedure P (and within other procedures called by P) explicitly in the
procedure declaration:
vat v: T;
procedure P;
global v;
begin . . . v:= E . . . end
A more radical solution is to forbid side effects and check that a
procedure only refers to non-local variables used as parameters.
A final difficulty is the exit statement. Consider the following program:
label L
begin . . . label M
begin . . .
cobegin
• . . exit L;
. . . exit M;
coend
end
end
Here we have two processes trying to exit different compound statements
labeled L and M at the same time. But this is meaningless: First, we have
defined that a concurrent statement is terminated only when all its
processes are terminated; so a single process cannot terminate it by an exit
statement; second, it is possible for the program to continue as a purely
sequential process after the concurrent statement (this is indeed the case in
the above example), so the desire to continue the process simultaneously at
two different points is a contradiction.
We will therefore also forbid jumps out of concurrent statements.
The rules presented here are due to Hoare (1971b). They enable a
compiler to identify the constant and variable parameters of every
statement by simple inspection and check the disjointness of concurrent
processes. This property also simplifies the analysis of programs by people
and should therefore be regarded as a helpful guideline for program
structuring--not as a severe language restriction.
When these rules are obeyed, the axiomatic properties of concurrent
statements become very simple. Suppose statements S1, $2, . . . , Sn
define disjoint processes, and each Si is an operation that makes a result Ri
true if a predicate Pi holds before its execution• In other words, it is known
that the individual statements have the following effects:
"PI" S1 "RI"
"P2" $2 "R2"
. . . . .
"Pn" Sn "R n"
(I assume that statements and assertions made about them only refer to
variables which are accessible to the statements according to the rule of
disjointness).
The concurrent statement
cobegin S1; $2; . . . ; Sn coend
can then be regarded as a single operation S with the following effect
"P" S "R"
where
P -= Pi & P2 & . . . & Pn
R=- RI&R2&...&Rn
As Hoare (1971b) puts it: "Each Si makes its contribution to the
common goal." The previous result can also be stated as follows:
Disjointness is a sufficient condition for time-independent behavior of
concurrent processes.
The usefulness of disjoint processes is of course, limited. In some cases,
concurrent processes must be able to access and change common variables.
I will introduce language constructs suitable for process interactions of this
kind later in this chapter.
In the following we will derive a sufficient condition for timeindependent
behavior of concurrent interacting processes. To do this, it is
first necessary to formulate the requirement of time-independence in a
slightly different way using the concept--the history of a computation.
3.2.4. The History Concept*
Consider a program which is connected to its environment by a single
input variable x and a single output variable y. During the execution of the
program, the input variable x assumes a sequence of values determined by
the environment:
x:= a0;x:= a l ; . . . ;x:= am;
and the output variable y assumes another sequence of values determined
by the program and its input:
y:= b0;y:= b l ; . . . ;y:= bn;
Together, the input sequence X = (a0, al, . . . , am) and the output
sequence Y = (bO, bl . . . . , bn) define the history of a computation. For
analytical purposes, the history can be represented by an array in which
each row defines the sequence of values assumed by a given variable, as
shown in Fig. 3.7.
A history is simply a listing of the sequences of input and output values
observed during a computation. It is a time-independent representation that
says nothing about the precise time at which these values were assigned to
the variables.
When a computation involves several variables, the history array
contains a row for each of them. We can divide the complete history into
the input history and the output history. Sometimes we will include the
history of internal variables in the output history.
A program is functional if the output history Y of its execution always
is a time-independent function f of its input history X:
Y = f(x)
A functional program produces identical output histories every time it is
executed with the same input history, independent of its speed of
execution.
As an example, let us again look at Algorithm 3.1 in which an input
sequence
f=(1,2, . . . ,m)
is copied to an (initially empty) output sequence g.
Figure 3.8 shows the sequence of assignments made initially during the
execution of this algorithm.
From these values (and the ones assigned during the rest of the
computation), we derive the history shown in Fig. 3.9.
The input history defines the sequence of assignments to the variable s;
the output history comprises the variables completed and t.
Notice that the rows in a history array are not necessarily of the same
completed
length because the number of assignments may be different for each
variable.
Notice also that the elements in a given column of a history array do
not necessarily define values assigned at the same time. A comparison of
Figs. 3.8 and 3.9 immediately shows that all values in the leftmost column
of the history array were assigned at different times. When a program
contains concurrent statements, the sequence in which assignments to
disjoint variables are made depends on the relative rates of the processes.
So, in general there are many different sequences in which a given
history can be produced in time. The functional requirement only says that
when the sequence of values is known for each input variable, it must be
possible to predict the sequence of values for each output variable,
independent of the rate at which they will be produced.
In some cases, we are still interested in observing actual rates of
progress. For this purpose, time is regarded as a discrete variable which is
increased by one each time an assignment to at least one of the variables
considered has been completed.
These instants of time are indicated explicitly in Fig. 3.8. In a history
array, an instant of time is defined by a line which crosses each row exactly
once. Such a time slice defines the extent of the history at a particular
instant.
Figure 3.10 shows the previous history with two successive time slices tl
and t2, which define the extent of the history after the first assignments to
the variables completed and s.
A history H1 is called an initial part of another history H2 if HI is
contained in H2. More precisely, H1 and H2 must have the same number of
rows, and each row in H1 must be equal to an initial part of the
corresponding row in H2; but some rows in HI may be shorter than the
corresponding rows in H2. This relationship is denoted
H1 ~ H2
During a computation, every time slice t defines an initial part H(t) of
the final history H.
We will use the history concept to prove an important theorem by Patil
(1970).
3.2.5. A Closure Property
Consider again a program which communicates with its environment by
means of a set of distinct input and output variables. We will observe the
execution of the program in two cases: In the first case, the environment
supplies an input history X, and the program responds by returning an
output history Y:
X~Y
In the second case, the observed input/output relationship is:
X~ -> Y~
So far, nothing has been said about whether the program is functional.
If we repeat the execution with the input history X' the program may
possibly produce a different output history, Y" ~ Y'.
But suppose we only consider programs which satisfy the following
requirement: If during its execution, a program is supplied with two
different input histories X and X', where X is contained in X', then the
same relationship will hold between the corresponding output histories Y
and Y':
X < X' implied Y < Y'
This is called the consistency requirement. It is a sufficient condition
for functional behavior. If a consistent program is executed twice with the
same input, it delivers the same output in both cases because
X = X' implies X ~ X' & X' ~ X
implies Y ~ Y' & Y' ~ Y
implies Y = Y'
Intuitively, the consistency requirement means that it is possible, at
every instant in time, to predict a portion Y of the final output from the
observed input X. If a program in execution is supplied with more input X'
X, the additional input cannot affect the output Y predicted earlier, but
can only extend it to Y' ~ Y.
X and X' refer to the input produced by the environment. This is not
necessarily the same as the input consumed by the program. The
environment may assign new values to input variables, due to erroneous
synchronization, before previous values have been consumed by the
program. In that case, it is impossible to predict the final output from the
observed input. So the program is not consistent.
The consistency requirement is also violated if concurrent processes can
enter a deadlock state in which they are unable to respond to further input
under circumstances which depend on their speed of execution (see Section
2.6.1).
We now introduce an additional requirement of consistent programs:
Since the output is a function of the input, a program in execution cannot
produce an output value until the corresponding input value is present. This
cause-and-effect relationship can be expressed as follows: Suppose we
observe an input history at successive instants in time
X(0),X(1), . . . ,X(t), . . . . X
where t indicates the earliest time at which an initial part X(t) of the input
is available. Let the final input and output histories be X and Y,
respectively. Now it is clear that an initial input history X(t) must be
contained in the final input history:
x(t) < x
Because the program is consistent, it is possible to predict part of the
output history from the initial input history X(t). But in a physical system
it takes a finite time to produce this output; so the earliest moment at
which some or all of this output can be available is the next instant of time
t + 1 where the output history is Y(t + 1). The output Y(t + 1), which is
predicted from an initial part of the input, must itself be an initial part of
the final output Y. So we have
Y(t + 1) ~< Y
If we combine these two physical conditions, we get the so-called
dependency requirement:
X(t) ~ X implies Y(t + 1) ~< Y
In the following, we will consider programs for which the consistency
and dependency requirements hold unconditionally. They are called
unconditionally functional programs. We will prove the important closure
property, which states that any interconnection of a finite number of
unconditionally functional programs is unconditionally functional as a
whole.
A system S consisting of a finite number of components S1, $2, . . . ,
Sn can always be partitioned successively into smaller systems consisting of
two components each:
S = (S1, $2')
$2' = ($2, $3')
• • •
Sn- l ' = ( Sn- l , Sn )
It is therefore sufficient to show that the interconnection of two
unconditionally functional programs, S1 and $2, also is an unconditionally
functional program S. The general theorem follows by induction.
The input and output histories of S are called X and Y, as shown in Fig.
3.11. X in turn consists of two separate input histories, X1 and X2 for S1
and $2, respectively. Similarly, Y consists of two separate output histories,
Y1 and Y2 for S1 and $2, respectively. The histories of internal output
produced by S1 for $2, and vice versa, are called J and K.
We will study the combined system S = (S1, $2) when it is supplied
with two different input histories X and X' where
X~< X'
and delivers the output histories J, K, Y and J', K', Y'.
Consider first subsystem S1 and observe its input history X, K and the
corresponding output history J as shown in Fig. 3.12. (The output history
Y1 is ignored for the moment.)
Suppose the following holds at time t:
X(t) ~ X' & K(t) < K'
This means that at time t during the first execution, the initial input history
to S1 is contained in its final input history of the second execution.
Now since S1 is unconditionally functional, it satisfies the dependency
requirement; so we have
X(t) ~ X' & K(t) ~ K' implies J(t + 1) ~ J'
By applying similar reasoning to subsystem $2, we find that
X(t) ~ X' & J(t) ~ J' implies K(t + 1) ~ K'
These results can be combined into the following:
X(t) ~ X' & J(t) ~ J' & K(t) < K'
implies J(t + 1) ~ J' & K(t + 1) ~ K'
We already assumed that X ~ X', so X(t) ~ X' holds at any instant of
time. Consequently, if the initial histories, J(t) and K(t), at time t are
contained in the final histories, J' and K', then this is also the case at time
t + 1. This is trivially true at time t = 0 where J(t) and K(t) are empty. So it
holds throughout the execution that
X ~ X' implies J < J' & K ~ K'
But since the subsystems satisfy the consistency requirement, this in turn
means that
X ~ X' implies Y ~ Y'
So the combined system S also satisfies the consistency requirement. And,
for physical reasons, it also satisfies the dependency requirement. (This can
be proved formally as well.)
The closure property enables a designer to verify that a large program is
functional by a step-wise analysis of smaller program components. The
functional behavior is ensured by local conditions (the consistency and
dependency requirements) which only constrain the relationship between a
program component and its immediate environment (represented by
input/output variables).
In actual systems, the consistency requirement seldom holds unconditionally.
The functional behavior may depend on certain additional
requirements; for example, that the input is of a certain type and is not
delivered more rapidly than the system is able to consume it. A system
which satisfies the consistency and dependency requirements, provided that
additional constraints hold, is called conditionally functional. For such
systems, the closure property holds when the additional constraints hold.
I will conclude the present discussion with some examples of useful
systems in which time-dependent behavior is inherent and desired.
3.2.6. Non-functional Systems
I have stressed the importance of designing multiprogramming systems
which are functional in behavior. But it must be admitted that some
computational tasks are inherently time-dependent.
Consider, for example, priority scheduling according to the rule
shortest job next. This involves decisions based on the particular set of
computations which users have requested at a given time. If a scheduling
decision is postponed a few seconds, the outcome may well be different
because new and more urgent requests can be made in the meantime by
users. So priority scheduling depends not only on the order in which users
input their requests, but also on their relative occurrence in time.
In the spooling system shown in Fig. 1.3 there is a time-dependent
relationship between the stream of jobs input and the stream of printed
output. But the spooling system has one important property which makes
the time-dependent behavior tolerable: It maintains a functional relationship
between the input and output of each job.
The user computations are disjoint; they could be carried out on
different machines. But, for economic reasons, they share the same
machine. And this can only be done efficiently by introducing a certain
amount of time-dependent behavior on a microscopic time scale. However,
on a macroscopic time scale, the operating system hides the timedependency
from the individual user and offers him a virtual machine with
perfectly reproducible behavior.
Figure 3.13 shows another example of the same principle: (a) shows
two disjoint processes consisting of the operations P, Q, R and S, Q, T; (b)
shows an equivalent system in which we have taken advantage of the
occurrence of a common operation Q in both processes. The processes now
share a single instance of operation Q, which can receive input from
operations P and S and deliver output to operations R and T.
The equivalence of the two systems in Fig. 3.13(a) and (b) is based on
the assumption that requests received by Q from P have no effect on the
response of Q to requests received from S, and vice versa, and that Q
responds to any request within a finite time.
An example of a set of common operations shared by all user
computations is a filing system, which permits users to create and
manipulate data and programs on backing storage and maintain them over a
certain period of time.
The system in Fig. 3.13(b) is non-functional if we observe the input and
output of the common operation Q because this is a time-dependent
merging of data values belonging to independent processes. But the system
is still functional if we only observe the relationship between the output
from P and the input to R (or that between the output from S and the
input to T).
So we come to the conclusion that functional behavior is an abstraction
just like the concepts operation, process, and state (see Section 2.6.3).
Whether or not a system is considered functional depends on the level of
description chosen by the observer.
• 3.3. MUTUAL EXCLUSION
Much has been said about the role of disjoint processes and functional
behavior in multiprogramming systems. We must now deal with interacting
processes--concurrent processes which have access to common variables.
Common variables are used to represent the state of physical resources
shared by competing processes. They are also used to communicate data
between cooperating processes. In general, we will say that all common
variables represent shared objects called resources. Interacting processes can
therefore also be defined as processes which share resources.
To share resources, concurrent processes must be synchronized.
Synchronization is a general term for any constraint on the ordering of
operations in time. We have already met synchronizing rules which specify
a precedence or priority of operations by constraints of the form
"operation A must be executed before operation B" and "an operation of
priority P must only be executed when all operations of higher priority
have been executed."
In this section, we will discuss process interactions in which the
constraint is of the form "operations A and B must never be executed at
the same time." This synchronizing rule specifies mutual exclusion of
operations in time.
3.3.1. Resource Sharing
We begin with an example in which two concurrent processes, P and Q,
share a single physical resource R. P and Q are cyclical processes which
every now and then wish to use R for a finite period of time, but they
cannot use it at the same time.
An example of a resource that can be accessed only by one process at a
time is a magnetic tape station. In this case, the requirement of mutual
exclusion is dictated by the physical characteristics of the resource: Since
we can only nhount one tape at a time on a magnetic tape station and access
its data strictly sequentially, it is impractical to let several processes use the
tape station at the same time. But, as we shall see, there is also a deeper
logical reason for the requirement of mutual exclusion of certain operations
in time.
We will follow a chain of arguments made by Dijkstra (1965) to
illuminate the nature of the mutual exclusion problem.
Let us first try the following approach: The resource R is represented
by a boolean, indicating whether it is free or occupied at the moment. Each
process goes through a cycle in which it first reserves the resource, then
uses it, and finally releases it again. Before reserving the resource, a process
waits in a loop until the resource is free. This leads to the following
program:
var free: boolean;
begin
free: = true;
cobegin
"P" repeat
repeat until free;
free: = false;
use resource;
free: = true;
P passive;
forever
"Q" repeat
repeat until free;
free:-- false;
use resource;
free:= true;
Q passive;
~orever~
coend
end
This program clearly violates the rules of concurrent statements laid
down in Section 3.2.3: Both processes change and refer to the variable free.
But let us ignore this for the moment.
Initially, free is true. It is therefore possible for P a~ld Q to refer to free
at the same time and find it true. Then, they will both in good faith assign
the value false to free and start using the resource. So this program does not
satisfy the condition that the resource can be used by at most one process
at a time.
Well, then we must try something else. In the next version, the boolean
free is replaced by another boolean, Pturn, which is true when it is P's turn
to use the resource and false when it is Q's turn:
vat Pturn : boolean;
begin
Pturn: = true;
cobegin
"P" repeat
repeat until Pturn;
use resource;
Pturn:= false;
P passive;
forever (cont.)
"Q" repeat
repeat until not Pturn;
use resource;
Pturn:= true;
Q passive;
forever
coend
end
There are only two cases to consider: either Pturn is true or it is false.
When Pturn is true, only process P can start using the resource and release it
again. And when Pturn is false, only process Q can start using the resource
and release it again. So mutual exclusion of P and Q is indeed achieved. But
the solution is far too restrictive: It forces the processes to share the
resource in a strictly alternating sequence:
P,Q,P,Q, . . .
If one of the processes, say P, is stopped in its passive state after having
released the resource, the other process Q will also be stopped when it has
released the resource (by means of the assignment Pturn:= true) and then
tries to reserve it again.
This is quite unacceptable in an installation where P and Q could be
two independent user computations. We must require that a solution to the
problem make no assumptions about the relative progress of the processes
when they are not using the resource.
Another highly undesirable effect of the previous solution is the waste
of processing time in unproductive waiting loops. This is called the busy
form of waiting.
Our third attempt uses two booleans to indicate whose turn it is:
vat Pturn, Qturn : boolean;
begin
Pturn : = false; Qturn : = false;
cobegin
"P" repeat
Pturn : = true;
repeat until not Qturn;
use resource;
Pturn := false;
P passive;
forever (cont.)
"Q" repeat
Qturn : = true;
repeat until not Pturn;
use resource;
Qturn := false;.
Q passive;
forever
coend
end
Assignment to variable Pturn is only made by process P. When P does
not use the resource, Pturn is false, so
not Pturn implies P passive
The two processes are completely symmetrical, so the assertion
not Pturn implies P passive
not Qturn implies Q passive
must be invariant.
Process P waits until Qturn is false before it uses the resource, so
P active implies not Q turn
implies Q passive
Similar reasoning about process Q leads to the conclusion that
P active implies Q passive
& Q active implies P passive
is invariant.
Mutual exclusion is therefore guaranteed, and it is not difficult to see
that stopping one process in its passive state does not influence the progress
of the other process. But it is a highly dangerous solution: The processes
can make the assignments
Pturn := true Qturn := true
' at the same time and then remain indefinitely in their waiting loops waiting
for one of the booleans to become false. In short, the solution can lead to a
deadlock.
We learn from our mistakes. The lesson of this one is that when
competing processes request the resource at the same time, the decision to
grant it to one of them must be made within a finite time.
It is possible to continue along these lines and find a correct solution.
This was first done by Dekker and described by Dijkstra (1965). Dijkstra
solved the general case, in which n processes share a single resource. The
solution turns out to be far too complicated and inefficient to be of
practical value.
I have described these preliminary, incorrect solutions to make you
appreciate the subtlety of the mutual exclusion problem and discover a set
of criteria that a realistic solution must satisfy. Let me repeat these criteria:
(1) The resource in question can be used by one process at a time at
most.
{2) When the resource is requested simultaneously by several processes,
it must be granted to one of them within a finite time.
(3) When a process acquires the resource, the process must release it
again within a finite time. Apart from this, no assumption is made about
the relative speeds of the processes; processes may even be stopped when
they are not using the resource.
(4) A process should not consume processing time when it is waiting to
acquire the resource. ~ ~P,~ ,~?K~
For the moment, we will leave the problem there and consider another
instance of it in which interacting processes are cooperating rather than
competing.
• 3.3.2. Data Sharing
The second example of process interaction is taken from an actual
system that supervises an industrial plant. Among other things, this
real-time system measures the consumption of energy and the production
of materials in the plant continuously and reports it to management every
few hours.
Consumption and production are measured in discrete units (kilowatthours
and product units) and recorded in pulse registers connected to a
computer. The computer is multiplexed among a number of concurrent
processes. A cyclical process P inputs and resets the pulse registers every
few seconds and adds their values (0 or 1) to a corresponding number of
integer variables. Another cyclical process Q outputs and resets the integer
counters every few hours. Operators can change the frequency of execution
of P and Q independently. The processes therefore do not know their
relative rates.
Let us assume that the periodic scheduling of processes and the input/
output are handled correctly by standard procedures. No generality is lost
by considering only one pulse counter v. As a first attempt, I suggest the
following solution:
var-v: integer;
begin
V: = 0;
cobegin
"P" repeat
delay(l);
v:= v + input;
forever
"Q" repeat
delay(18000);
output(v);
v:= 0;
forever
coend
end
This program too violates the rules of concurrent statements because
process Q refers to a variable v changed by process P. But again we will
ignore this violation for the moment since it expresses the desired
interaction between the processes.
The intention is that a value of v output at time t should define the
number of pulses accumulated over the past 18,000 seconds, or 5 hours,
prior to time t.
Now, in most computers, statements such as
v: = v + input output(v)
are executed as a sequence of instructions which use registers, say r and s,
to hold intermediate results:
r:= input; s: = v;
r: = r + v; output(s);
V: = r;
A concurrent statement can therefore be executed as a sequence of
instructions interleaved in time. The operating system will ensure that the
instructions of each process are executed in the right order, but apart from
this, the system may interleave them in many different ways. In the system
considered here, the operating system switches from one process to another
every 20 msec to maintain the illusion that they are executed simultaneously.
The actual interleaving of instructions in time is therefore a
time-dependent function of other concurrent processes not considered here.
One possibility is that the instructions of P and Q are interleaved as
follows:
"v = pulse count"
P: r: = 1;
Q: s: = v; output(s);
P: r:= r + v;v: = r;
Q: s: = 0; v: = 8;
"v = 0 & output = pulse count"
Another possibility is the following:
"v = pulse count"
P: r: = l;r: =r + v;
Q: s:= v; output(s);
Q: S: = 0; V: = S;
P: v:= r;
"v = pulse count + 1 & output = pulse count"
In the first case, the program measures an input pulse (r: = 1), but fails
to accumulate it (v = 0); in the second case, the program outputs the
current pulse count correctly, but proceeds to include it in the count over
the next five hours. The result should have been
"v = 1 & output = pulse count"
or
"v = 0 & output = pulse count + 1"
depending on when the last pulse was measured.
The penalty of breaking the laws of concurrent statements is
time-dependent erroneous behavior. The example shown here illustrates the
remark made in Section 3.1.1 about concurrent processes executed
simultaneously on several processors or on a single, multiplexed processor:
"The logical problems turn out to be the same in both cases; they are
caused by our ignorance of the relative speeds of concurrent processes."
It should be evident by now that our present programming tools are
hopelessly inadequate for controlling access to physical resources and data
shared by concurrent processes. A new tool is needed, and like our previous
tools it should be simple to understand, efficient to implement, and safe to
use.
• 3.3.3. Critical Regions
The erroneous behavior in the pulse counting program is caused by the
interleaving of concurrent statements in time. If we were sure that only one
process at a time could operate on the common variable v, the previous
solution would work.
So let us postulate a language construction which has precisely this
effect. I will use the notation
vat v: shared T
to declare a common variable v of type T.
Concurrent processes can only refer to and change common variables
within structured statements called critical regions. A critical region is
defined by the notation
region v do S
which associates a statement S with a common variable v. This notation
enables a compiler to check that common variables are used only inside
critical regions.
Critical regions referring to the same variable v exclude one another in
time. More precisely, we make the following assumptions about critical
regions on a variable v:
(1) When a process wishes to enter a critical region, it will be enabled
to do so within a finite time.
(2) At most, one process at a time can be inside a critical region.
(3) A process remains inside a critical region for a finite time only.
Criterion 3 says that all statements operating on a common variable
must terminate.
Criterion 2 expresses the requirement of mutual exclusion in time of
these statements.
Criteria 1 and 2 put the following constraints on the scheduling of
critical regions associated with a given variable: (a) when no processes are
inside critical regions, a process can enter a critical region immediately; (b)
when a process is inside a critical region, other processes trying to enter
critical regions will be delayed; and (c) when a process leaves a critical
region while other processes are trying to enter critical regions, one of the
processes will be enabled to proceed inside its region; (d) these decisions
must be made within finite periods of time.
Finally, (e) the priority rule used to select a delayed process must be
fair: It must not delay a process indefinitely in favor of more urgent
processes. An example of a fair scheduling policy is first-come, first-served,
which selects processes in their order of arrival; an unfair policy is
last-come, first-served, which favors the latest request.
Although we require that scheduling be fair, no assumptions are made
about the specific order in which processes are scheduled. This depends
entirely on the underlying implementation. As Dijkstra (1971b) puts it: "In
the long run a number of identical processes will proceed at the same
macroscopic speed. But we don't tell how long this run is." (See also
Dijkstra, 1972.)
Critical regions can be implemented in various ways. We are going to
consider some of them later.
• Critical regions referring to different variables can be executed
simultaneously, for example:
vat v: shared V; w: shared W;
cobegin
region v do P;
region w do Q;
coend
A process can also enter nested critical regions:
region v do
begin . . .
regionwdo . . . ;
. . .
end
In doing so, one must be aware of the danger of deadlock in such
constructions as:
cobegin
"P" region v do region w do . . . ;
"Q" region w do region v do . . . ;
coend
It is possible that process P enters its region v at the same time as
process Q enters its region w. When process P tries to enter its region w, it
will be delayed because Q is already inside its region w. And process Q will
be delayed trying to enter its region v because P is inside its region v. This is
a case in which correctness criterion 3 is violated: The processes do not
leave their critical regions after a finite time. A method of avoiding this
problem will be described later.
The concept critical region is due to Dijkstra (1965). The language
constructs which associate critical regions with a common variable are my
own (Brinch Hansen, 1972b). Similar constructs have been proposed
independently by Hoare (1971b).
With this new tool, common variables and critical regions, the solutions
to our previous problems become trivial. In the first problem, our only
concern was to guarantee mutual exclusion of operations on a physical
resource performed by concurrent processes. Algorithm 3.2 solves the
problem in the general case of n processes.
ALGORITHM 3.2 A Resource R Shared by n Concurrent Processes
vat R: shared boolean;
cobegin
"PI" repeat
region R do use resource;
P1 passive;
forever
• • • • •
"Pn" repeat
region R do use resource;
Pn passive;
forever
coend
The pulse counting problem is solved by Algorithm 3.3.
ALGORITHM 3.3 A Variable v Shared by Two Concurrent Processes
vat v: shared integer;
begin
v: = O;
cobegin
"P" repeat
delay(I);
region v do v:= v + input;
forever
"Q" repeat
delay(18000);
region v do begin
output(v);
V: = O;
end
forever
coend
end
3.3.4. Conclusion
Critical regions provide an elegant solution to the resource sharing
problem. But how fundamental is this concept? After all, we succeeded in
one instance in solving the problem without introducing critical regions in
our language. I am referring to the algorithm in Section 3.3.1, which
permits a resource to alternate between two processes: P, Q, P, Q, . . . .
This solution may not be ideal, but it does ensure mutual exclusion without
using critical regions--or does it?
In the analysis of its effect, I made the innocent statement: "There are
only two cases to consider: eitherPturn is true or it is false." These are the
only values that a boolean variable can assume from a formal point of view.
But suppose the computer installation consists of several processors
connected to a single store as shown in Fig. 2.3. Then, it is quite possible
that the operations of processes P and Q can overlap in time. We must now
carefully examine what happens in this physical system when P and Q try
to operate simultaneously on the variable Pturn.
Suppose process P initiates the assignment
Pturn := false
This storage operation takes a finite time. We know that Pturn is true
before the operation is started and that Pturn will be false when the
operation is completed. But there is a transitional period, called the
instruction execution time, during which the physical state of the storage
cell is unknown. It is changing in a time-dependent manner, determined by
the characteristics of the electronic circuits and the storage medium used.
If process Q is allowed to refer to the same storage location while the
assignment is in progress, the resulting value (or more precisely, the bit
combination used to represent the value) is unpredictable. In other words,
process Q is performing an undefined operation.
The hardware designer solves this problem by connecting the
concurrent processors to a sequential switching circuit called an arbiter.
The arbiter ensures that, at most, one processor at a time can access a given
storage location. It is a hardware implementation of critical regions.
So our reasoning on the effect of the algorithm in Section 3.3.1 was
based on the implicit assumption that load and store operations on a given
variable exclude each other in time. The same assumption underlies
Dekker's solution to the resource sharing problem.
The load and store operations are proper critical regions at the short
grains of time controlled by hardware. But at higher levels of programming,
we must guarantee mutual exclusion in larger grains of time for arbitrary
statements. The language construct
region v do S
is introduced for this purpose.
Mutual exclusion is indeed one of the most fundamental concepts of
programming. Whenever we make assertions about the effect of any
operation on a certain variable, for example:
"A: array 1..n of integer"
sort(A);
"for all i,1: 1.. n (i ~ jimpliesA(i) ~ A(j))"
it is tacitly understood that this is the only operation performed at that
time on this variable. In the above example, it would indeed have been a
coincidence if the array A had been sorted if other processes were happily
modifying it simultaneously.
• In sequential computations, mutual exclusion is automatically achieved
because the operations are applied one at a time. But we must explicitly
indicate the need for mutual exclusion in concurrent computations.
It is impossible to make meaningful statements about the effect of
concurrent computations unless operations on common variables exclude
one another in time. So in the end, our understanding of concurrent
processes is based on our ability to execute their interactions strictly
sequentially. Only disjoint processes can proceed at the same time.
• But there is one important difference between sequential processes and
critical regions: The statements $1, $2, . . . , Sn of a sequential process are
totally ordered in time. We can therefore make assertions about its progress
from an initial predicate P towards a final result R :
"P" S1 "Ri" $2 "R2" . . . "Rn-l" Sn "R"
In contrast, nothing is specified about the ordering of critical regions in
time--they can be arbitrarily interleaved. The idea of progressing towards a
final result is therefore meaningless. All we can expect is that each critical
region leave certain relationships among the components of a shared
variable v unchanged. These relationships can be defined by an assertion I
about v which must be true after initialization of v and before and after
each subsequent critical region. Such an assertion is called an invariant.
When a process enters a critical region to execute a statement S, a
predicate P holds for the variables accessible to the process outside the
critical region, and an invariant I holds for the shared variable accessible
inside the critical region. After the completion of statement S, a result R
holds for the former variables and invariant I has been maintained.
So a critical region has the following axiomatic property:
,,p,,
region v do "P & I" S "R & I";
,,R,,
The interactions controlled by critical regions are rather indirect--each
process can ignore the existence and function of other processes as long as
they exclude each other in time and maintain invariants for common
variables.
We will now study more direct interactions between processes
cooperating on common tasks. Such processes are well aware of each
other's existence and purpose: Each of them depends directly on data
produced by other members of the community.
3.4.1. Process Communication
To cooperate on common tasks, processes must be able to exchange
data. Figure 3.14 shows the situation we will study. A process P produces
and sends a sequence of data to another process C, which receives and
consumes them. The data are transmitted between the processes in discrete
portions called messages. They are regarded as output by P and as input by
C.
Since either process can proceed at a rate independent of the other's, it
is possible that the sender may produce a message at a time when the
receiver is not yet ready to consume it (it may still be processing an earlier
message). To avoid delaying the sender in this situation, we introduce a
temporary storage area in which the sender can place one or more messages
until the receiver is ready to consume them. This storage area is called a
buffer and designated B; its function is to smooth speed variations between
the processes and occasionally permit the sender to be ahead of the
receiver.
The communication must be subject to two resource constraints: (1)
the sender cannot exceed the finite capacity of the buffer; and (2) the
receiver cannot consume messages faster than they are produced.
These constraints are satisfied by the following synchronizing rule: If
the sender tries to put a message in a full buffer, the sender will be delayed
until the receiver has taken another message from the buffer; if the receiver
tries to take a message from an empty buffer, the receiver will be delayed
until the sender has put another message into the buffer.
We also assume that all messages are intended to be received exactly as
they were sent--in the same order and with their original content. Messages
must not be lost, changed, or permuted within the buffer. These
requirements can be stated more precisely with the aid of Fig. 3.15.
The sequence S of messages sent by a producer P and the corresponding
sequence R of messages received by a consumer C are shown conceptually
as infinite arrays:
vat S, R: array 0..co of message
Two index variables s and r
vat s, r: 0..co
initialized to zero, define the number of messages sent and received at any
instant in time:
s > 0 implies S(1) to S(s) have been sent in that order
r > 0 implies R(1) to R(r) have been received in that order
Our requirements are the following:
(1) The number of messages received cannot exceed the number of
messages sent
0 < r < s
(2) The number of messages sent, but not yet received, cannot exceed
the buffer capacity max
O < s-r < max
(3) Messages must be received exactly as they are sent
for i: 1..r (R(i) = S(i))
So, all in all, we have the following communication invariant:
O < r < s < r+max&
for i: 1..r (R(i) = S(i))
I suggest the following notation for a language construct which satisfies
this requirement:
var B: buffer max of T
It declares a message buffer B, which can transmit messages of type T
between concurrent processes. The buffer capacity is defined by an integer
constant, max.
Messages are sent and received by means of the following standard
procedures:
send(M, B) receive(M, B)
where M is a variable of type T.
Since send and receive refer to a common variable B, we require that
these operations exclude each other in time. They are critical regions with
respect to the buffer used.
It is worth pointing out that with the synchronizing rules defined, a
sender and a receiver cannot be deadlocked with respect to a single message
buffer. A sender can only be delayed when a buffer is full
s = r + max
and a receiver can only be delayed when a buffer is empty
s=r
A situation in which they are both delayed with respect to the same buffer
is therefore impossible if the buffer has a non:zero capacity max > O.
It is also interesting to notice that a message buffer (if properly used) is
unconditionally functional in the sense defined in Section 3.2.5.
If we observe a message sequence X going into a buffer, we expect that
a message sequence Y = X will eventually come out of it. And if we observe
two input sequences, X and X', where the former is contained in the latter,
then we have trivially that
X < X' implies Y < Y'
So a message buffer satisfies the consistency requirement if all messages
sent are eventually received. And since send and receive cannot take place
at the same time, it takes a finite time for a message to pass through the
buffer. So the dependency requirement is also satisfied.
From the closure property we conclude that a set of unconditionally
functional processes connected only by message buffers is unconditionally
functional as a whole, provided there are only one sender and one receiver
for each buffer, and all messages sent are eventually received.
It is quite possible, with the synchronizing rules defined here, to
connect several senders and receivers to a single buffer, as shown in Fig.
3.16. But when this is done, the input to the buffer is a time-dependent
merging of messages from m different processes, and the output is a
time-dependent splitting of messages to n different receivers. In that case,
there is no functional relationship between the output of each producer
and the input of each consumer.
The communication primitives, send and receive, as proposed here will
transmit messages by value; that is, by copying them first from a sender
variable M into a buffer B, and then from B into a receiver variable M'. This
is only practical for small messages.
For larger messages, the data structures and primitives must be defined
such that messages are transmitted by reference, that is; by copying an
address from one process to another. But in order to satisfy the
communication invariant, such a language construct must ensure that at
most one process at a time can refer to a message variable.
In the following, I will consider the simplest possible form of process
communication--the exchange of timing signals.
3.4.2. Semaphores
In some cases, a process is only interested in receiving a timing signal
from another process when a certain event has occurred. But apart from
that, no other exchange of data is required.
An example is Algorithm 3.3 where each process wishes to be delayed
until a certain interval of time has elapsed.
This can be regarded as a special case of process communication in
which an empty message is sent each time a certain event occurs. Since the
messages are empty (and therefore indistinguishable), it is sufficient to
count them. The buffer is therefore reduced to a single, non-negative
integer, which defines the number of signals sent, but not yet received.
Such a synchronizing variable is called a semaphore. It was first
proposed and investigated by Scholten and Dijkstra. A semaphore variable v
will be declared as follows:
vat v: semaphore
The corresponding send and receive primitives will be called
signal(v) wait(v)
(Dijkstra originally called them V and P.)
Since a semaphore is a common variable for its senders and receivers,
we must require that signal and wait operations on the same semaphore
exclude each other in time. They are critical regions with respect to the
semaphore.
Following Habermann (1972), a semaphore v will be characterized by
two integer components:
s(v) the number of signals sent
r(v) the number of signals received
Initially, s(v) = r(v) = O.
The communication invariant defined in the previous section now
becomes:
0 < r(v) < s(v) < r(v) + max(integer)
It means that: (1) a process can only send or receive some or no signals;
(2) signals cannot be received faster than they are sent; and (3) a semaphore
can only count to the upper limit of integers set by a given machine.
It is useful to permit an initial assignment to a semaphore before
process communication begins. So we will introduce a third semaphore
component:
c(v) the number of initial signals
and permit an assignment:
V: = C
to be made outside concurrent statements. But within concurrent statements,
the orily operations permitted on a semaphore v are still signal and
wait.
The semaphore invariant now becomes
0 < r(v) < s(v) + c(v) ~ r(v) + max(integer)
In most computers, the range of integers is much larger than the
number of unconsumed signals that can occur in practice. For example, in a
computer with 24-bit words, max(integer) = 8388607. We will therefore
ignore this constraint in the following and assume that an implementation
treats semaphore overflow as a programming error.
The synchronizing rules of semaphores are the following:
(1) If the operation wait (v) is started at a time when r(v) < s(v) + c(v),
then r(v) is increased by one and the receiver continues; but if r(v) = s(v) +
c(v), then the receiver is delayed in a process queue associated with the
semaphore v.
(2) The operation signal (v) increases s(v) by one; if one or more
processes are waiting in the queue associated with the semaphore v, then
one of them is selected and enabled to continue, and r(v) is increased by
one. The scheduling of waiting processes must be fair (see Section 3.3.3).
A critical region
vat R : shared T;
region R do S;
can be implemented by associating a semaphore mutex, initialized to one,
with the shared variable R and then surrounding the statement S by a pair
of wait and signal operations as shown in Algorithm 3.4.
Sec. 3.4. PROCESS COOPERATION 95
ALGORITHM 3.4 Mutual Exclusion Implemented With Semaphores
vat R: record content: T; mutex: semaphore end
begin
with R do mutex := 1;
cobegin
with R do
begin wait( mutex ) ; $1; signal( mutex ) end
• • .
with R do
begin wait( mu tex ) ; Sn ; signal( mutex ) end
o o o
coend
end
To see that this implementation is correct, observe the following: Since
the processes always execute a wait operation before a signal operation on
mutex, we have
0 ~< s(mutex) ~< r(mutex)
When this is combined with the semaphore invariant, the result is
0 ~< s(mutex) ~ r(mutex) ~ s(mutex) + 1
From the structure of Algorithm 3.4, it is evident that the number of
processes n that are inside their critical regions at a given time are those
which have passed a wait operation at the beginning of these regions, but
have not as yet passed a corresponding signal operation at the end of the
regions. So
n(mutex) = r(mutex) - s(mutex)
This in turn means that
0 ~ n(mutex) ~ 1
In other words, one process at most can be inside its critical region at
any time. When no processes are inside their critical regions, we have
n(mutex) = 0
or
r(mutex) = s(mutex)
Since r(mutex) < s(mutex) + 1, in this situation another process can
complete a wait operation and enter its critical region immediately.
So the correctness criteria for critical regions are satisfied provided each
of the statements $1 to Sn terminates.
It is an amusing paradox of critical regions that, in order to implement
one, we must appeal to the existence of simpler critical regions (namely,
wait and signal). In the next chapter, which explains an implementation of
wait and signal, I shall appeal to the existence of a storage arbiter--a
hardware implementation of still simpler critical regions, and so on, ad
infinitum. The buck ends at the atomic level, where nuclear states are
known to be discrete and mutually exclusive.
At this stage, it is tempting to conclude that there is no need for
extending a programming language with a construct for critical regions and
common variables. The problem can evidently be solved by wait and signal
operations on semaphores.
This conclusion is indeed valid in a world where programs are known to
be correct with absolute certainty. But in practice it is untenable. The
purpose of the language construct
• var v: shared T;
region v do S;
is to enable a compiler to distinguish between disjoint and interacting
processes, and check that common variables are used only within critical
regions.
If we replace this structured notation with semaphores, this will have
grave consequences:
(1) Since a semaphore can be used to solve arbitrary synchronizing
problems, a compiler cannot conclude that a pair of wait and signal
operations on a given semaphore initialized to one delimits a critical region,
nor that a missing member of such a pair is an error. A compiler will also be
unaware of the correspondence between a semaphore and the common
variable it protects. In short, a compiler cannot give the programmer any
assistance whatsoever in establishing critical regions correctly.
(2) Since a compiler is unable to recognize critical regions, it cannot
make the distinction between critical regions and disjoint processes.
Consequently, it must permit the use of common variables everywhere. So
a compiler can no longer give the programmer any assistance in avoiding
time-dependent errors in supposedly disjoint processes.
The horrors that this leads to have already been demonstrated (see
Section 3.2.2).
As an example of the first problem, consider the programmer who by
mistake writes the following:
wait(mutex); signal(mutex);
S; S;
wait(mutex); wait(mutex);
In the left example, the program will be deadlocked at the end of the
"critical" region; in the right example, the program will sometimes permit 3
processes to be inside a "critical" region simultaneously.
The advantage of language constructs is that their correctness can be
ALGORITHM 3.5 Periodic Scheduling of Concurrent Processes
vat schedule: array 1..n of
record deadline, interval: integer end
start: array 1..n of semaphore;
timer: semaphore;
task: 1.. n; t: in teger;
begin
timer: = O; initialize(schedule, start);
cobegin
repeat "hardware timer"
t: = interval desired;
while t > Odot:=t-1;
signal(timer);
forever
repeat "scheduler"
wait(timer);
for every task do
with schedule(task) do
begin
deadline := deadline - 1;
if deadline ~ 0 then
begin
deadline: = interval;
signal(start(task));
end
end
forever
repeat "task i"
wait(start(i));
perform task;
forever
coend
end
established once and for all when the compiler is tested. The alternative is
to test each critical region separately in all user programs!
It is reasonable to use semaphores in a compiler to implement critical
regions. But at higher levels of programming, the main applicability of
semaphores is in situations in which processes exchange only timing signals.
This is the concept that semaphores represent in a direct, natural manner.
As an example, let us again consider the problem of scheduling a
number of processes periodically in a real-time system. In Algorithm 3.3,
the periodic scheduling was handled by a standard procedure that delays a
process until a certain interval of time has elapsed. We now want to show
how this delay can be implemented in terms of semaphores.
For each task process, we introduce a record defining the time interval
between two successive executions (called the interval), the time interval
until its next execution. (called the deadline), and a semaphore on which
the process can wait until its next execution starts.
The time schedule of all tasks is scanned by a central scheduling process
every second: In each cycle, the scheduler decreases all deadlines by one
and sends a start signal to the relevant tasks.
The scheduling process in turn receives a signal from a hardware timer
every second.
This scheme is shown in Algorithm 3.5.
3.4.3. Conditional Critical Regions
The synchronizing tools introduced so far:
critical regions
message buffers
semaphores
are simple and efficient tools for delaying a process until a special condition
holds:
mutual exclusion
message available (or buffer element available)
signal available
We will now study a more general synchronizing tool which enables a
process to wait until an arbitrary condition holds.
For this purpose I propose a synchronizing primitive await, which
delays a process until the components of a shared variable v satisfy a
condition B:
var v: shared T
region v do
begin . . . await B; . . . end
The await primitive must be textually enclosed by a critical region
associated with the variable v. If critical regions are nested, the
synchronizing condition B is associated with the innermost enclosing
region.
The shared variable v can be of an arbitrary type T. The synchronizing
condition B is an arbitrary boolean expression which can refer to
components of v.
The await primitive can for example be used to implement conditional
critical regions of the form proposed by Hoare (1971b):
"Consumer" "Producer"
region v do region v do $2
begin await B; $1 end
Two processes, called the consumer and the producer, cooperate on a
common task. The consumer wishes to enter a critical region and operate
on a shared variable v by a statement $1 when a certain relationship B holds
among the components of v. The producer enters a critical region
unconditionally and changes v by a statement $2 to make B hold.
I will use this example and Fig. 3.17 to explain the implementation of
critical regions and the await primitive. When a process such as the
consumer above wishes to enter a critical region, it enters a main queue, Or,
associated with the shared variable v. From this queue, the processes enter
their critical regions one at a time to ensure mutual exclusion of operations
on v.
After entering its critical region, the consumer inspects the shared
variable v to determine whether it satisfies the condition B: In that case,
the consumer completes its critical region by executing the statement S1;
otherwise, the process leaves its critical region temporarily and joins an
event queue, Qe, associated with the shared variable.
Other processes can now enter their critical regions through the main
queue, Qv. These processes may either complete their critical regions
unconditionally or decide to await the holding of an arbitrary condition on
variable v. If their conditions are not satisfied, they all enter the same event
queue, Qe.
When another process such as the previous producer changes the shared
variable v by a statement $2 inside a critical region, it is possible that one or
more of the conditions expected by processes in the event queue, Qe, will
be satisfied. Consequently, when a critical region has been successfully
completed, all processes in the event queue, Qe, are transferred to the main
queue, Qv, to permit them to reenter their critical regions and inspect the
shared variable v again.
It is possible that a consumer will be transferred in vain between the
main queue and the event queue several times before its condition B holds.
But this can only occur as frequently as producers change the shared
variable. This controlled amount of busy waiting is the price we pay for the
conceptual simplicity achieved by using arbitrary boolean expressions as
synchronizing conditions.
In the case of simple critical regions, we expect that all operations on a
shared variable maintain an invariant I (see Section 3.3.4). Within
conditional critical regions, we must also require that the desired invariant
is satisfied before an await statement is executed. When the waiting cycle of
a consumer terminates, the assertion B & I holds.
In the following, we will solve two synchronizing problems using first
critical regions and semaphores, and then conditional critical regions. This
will enable us to make a comparison of these synchronizing concepts.
• 3.4.4. An Example: Message Buffers
We will implement the message buffer defined in Section 3.4.1 and
shown in Fig. 3.18.
The buffer consists of a finite number of identical elements arranged in
a circle. The circle consists of a sequence of empty elements that can be
filled by a producer and a sequence of full elements that can be emptied by
a consumer. The producer and consumer refer to empty and full elements
by means of two pointers, p and c. During a computation, both pointers
move clockwise around the circle without overtaking each other.
The sequence of messages received
R(1),R(2), . . . ,R(r)
must be contained in the sequence of messages sent
S(1),S(2), . . . ,S(s)
Let the buffer and its pointers be declared as follows:
buffer: array 0..max-1 of T;
p, c: O. .max-l;
The desired effect is achieved if the following rules are observed:
(1) During a computation, pointers p and e must enumerate the same
sequence of buffer elements:
buffer(O): = S(1); R(1):= buffer(O);
buffer(l): = S(2); R(2):= b u f f e r ( l ) ;
• * • • •
buffer(p - 1 rood max): = S(s);R(r): = buffer(c - 1 rood max);
(2) The receiver must not empty an element until it has been sent:
O~< r< s
(3) The sender must not fill an element until it has been received:
0 ~< s - r < max
The solution that uses conditional critical regions is Algorithm 3.6.
Initially, pointers p and c are equal and they are moved by the same
function p + 1 rood max and c + 1 mod max. So, the pointers enumerate
the same sequence of buffer elements.
ALGORITHM 3.6 Process Communication With Conditional Critical Regions
type B = shared record
buffer: array 0..max-1 of T;
p, c: O. .max- l ;
full: O. .max;
end
" I n i t i a l l y p = c = full = 0"
procedure send(m: T; vat b: B);
region b do
begin
await full < max;
buffer(p): = m;
p:= (p + 1) mod max;
full: = full + 1;
end
procedure receive(vat m: T; b: B);
region b do
begin
await full > 0;
m: = buffer(c);
c: = ( c + 1) mod max;
full: = full - 1;
end
The variable full is initially zero. It is increased by one after each send
and decreased by one after each receive. So
full = s - r
Receiving is only done when full > 0 or s > r; sending is only done
when full < max or s - r < max. The solution is therefore correct.
Now, let us solve the same problem with simple critical regions and
semaphores: We will use the pointers p and c exactly as before--so
condition 1 is still satisfied.
The delay of the receiver will be controlled by a semaphore full in the
following way:
initially: full: = 0
before receive: w a i t ( f u l l )
after send: signal(full)
When the semaphore is used in this way, we evidently have
0 ~< r ~< number of waits(full) &
0 ~< number of signals(full) ~< s
The semaphore invariant defined in Section 3.4.2 ensures that, when
the initial number of full signals has been consumed by wait operations,
further wait operations cannot be completed faster than the corresponding
signal operations:
number of waits(full) ~< number of signals(full) + 0
Immediately before a wait operation is completed, the stronger condition
number of waits(full) < number of signals(full) + 0
holds.
From this we conclude that before a message is received, the condition
0~< r< s
holds.
We have chosen to represent the condition r < s by the semaphore full.
But since timing signals are merely indistinguishable boolean events, we
cannot use the same semaphore to represent the other condition, s - r
max, which controls sending.
So we must introduce another semaphore, empty, and use it as follows:
initially: empty := max
before send: wait(empty)
after receive: signal(empty)
By similar reasoning, we can show that before sending the following
holds:
0 ~< s ~< number of waits(empty) &
0 ~< numberofsignals(empty) ~< r &
number of waits(empty) < number of signals(empty) + max
or
0 < s < r + max
The complete solution is Algorithm 3.7.
ALGORITHM 3.7 Process Communication With Semaphores
type B = record
v: shared record
buffer: array O..max-1 of T;
p, c: O. .max- l ;
end
full, empty: semaphore;
end
"Initially p = c = full = 0 & empty = max"
procedure send(m: T; vat b: B);
begin
with b do
begin
wait(empty);
region v do
begin
buffer(p) := m;
p:= (p + 1) mod max;
end
signal(full);
end
end
procedure receive(vat m: T; b: B);
begin
with b do
begin
wait(full);
region v do
begin
m: = buffer(c);
c: = (c +1) rood max;
end
signal(empty);
end
end
This exercise has already given a good indication of the diffel'ence
between conditional critical regions and semaphores:
(1) A semaphore can only transmit indistinguishable timing signals; it
can therefore only be used to count the number of times a specific event
has occurred in one process without being detected by another process.
Consequently, it is necessary to associate a semaphore with each
synchronizing condition.
The first algorithm with conditional critical regions uses two synchronizing
conditions
full > 0 full< max
but only one variable full.
In the second algorithm, these conditions are represented by two
semaphore variables
full empty
(2) Notice also that within conditional critical regions, the program
text shows directly the condition under which a region is executed. But in
the second algorithm, the association between a semaphore and a
synchronizing condition exists only in the mind of the programmer. He
cannot deduct from the statement
wait(empty)
that full < max before sending without examining the rest of the program
and discovering that full < max when
signal(empty)
is executed after receiving! When semaphores are used to represent general
scheduling conditions, these conditions can only be deduced from the
program text in the most indirect manner.
One can also explain the difficulty with semaphores in the following
way: If a process decided to wait on a semaphore inside a critical region, it
would be impossible for another process to enter its critical region and
wake up the former process. This is the reason that the wait operations in
Algorithm 3.7 are executed outside the critical regions.
However, it is dangerous to separate a synchronizing condition from a
successive critical region. The danger is that another process may enter its
critical region first and make the condition false again. If we split critical
regions in this way, we must introduce additional variables to represent
intermediate states of the form "I expect condition B to hold when I
enter my critical region." So, while a single variable full is sufficient in
Algorithm 3.6, we need two variables, full and empty, in Algorithm 3.7.
The elegance of Algorithm 3.6 makes it tempting to suggest that the
language constructs for message buffers suggested in Section 3.4.1 can be
replaced by conditional critical regions and common variables. But I wish
to point out that the arguments made earlier in favor of the language
construct for simple critical regions can also be made for message buffers.
In Section 3.4.1, we found that a system consisting of processes
connected only by buffers can be made functional as a whole. But this is
only true if the send and receive operations are implemented correctly and
if they are the only operations on the buffers. A compiler is unable to
recognize the data structure B in Algorithm 3.6 as a message buffer and
check that it is used correctly. So when message buffers are used
frequently, it may well be worth including them as a primitive concept in a
programming language.
We now proceed to the next problem, which is due to Courtois,
Heymans, and Parnas (1971).
|

 LINUX
LINUX 
 Books
Books