|
Здесь и далее обсуждаются некоторые особенности
операций чтения и записи при программировании TCP/IP. Представляет интерес не
конкретный API и детали системных вызовов, а семантические вопросы, связанные
с этими операциями.
Как сказано в совете 6, между операциями записи
и посылаемыми TCP сегментами нет взаимно-однозначного соответствия. Как именно
соотносятся обращения к операции записи с протоколом TCP, зависит от системы,
но все же спецификации протокола достаточно определенны и можно сделать некоторые
выводы при знакомстве с конкретной реализацией. Традиционная реализация подробно
описана в системе BSD. Она часто рассматривается как эталонная, и ее исходные
тексты доступны.
Примечание: Исходные тексты оригинальной
реализации для системы 4.4BSD-lite2 можно получить на CD-ROM у компании WalnutCreek
(http:// www.cdrom.com). Подробные пояснения к исходному тексту вы найдете в
книге [Wright and Stevens 1995].
Когда пользователь выполняет запись в TCP-соединение,
данные сначала копируются из буфера пользователя в память ядра. Дальнейшее зависит
от состояния соединения. TCP может «решить», что надо послать все данные, только
часть или ничего не посылать. О том, как принимается решение, будет сказано
ниже. Сначала рассмотрим операцию записи с точки зрения приложения.
Хочется думать, что если операция записи n байт
вернула значение n, то все эти n байт, действительно, переданы на другой конец
и, возможно, уже подтверждены. Увы, это не так. TCP посылает столько данных,
сколько возможно (или ничего), и немедленно возвращает значение n. Приложение
не определяет, какая часть данных послана и были ли они подтверждены.
В общем случае операция записи не блокирует процесс,
если только буфер передачи TCP не полон. Это означает, что после записи управление
почти всегда быстро возвращается программе. После получения управления нельзя
ничего гарантировать относительно местонахождения «записанных» данных. Как упоминается
в совете 9, это имеет значение для надежности передачи данных.
С точки зрения приложения данные записаны. Поэтому,
помня о гарантиях доставки, предлагаемых TCP, можно считать, что информация
дошла до другого конца. В действительности, некоторые (или все) эти данные в
момент возврата из операции записи могут все еще стоять в очереди на передачу.
И если хост или приложение на другом конце постигнет крах, то информация будет
потеряна.
Примечание: Если отправляющее приложение
завершает сеанс аварийно, то TCP все равно будет пытаться доставить данные.
Еще один важный момент, который нужно иметь в виду,
- это обработка ошибки записи. Если при записи на диск вызов write не вернул
код ошибки, то точно известно, что запись была успешной.
Примечание: Строго говоря, это неверно.
Обычно данные находятся в буфере в пространстве ядра до того момента, пока не
произойдет сброс буферов на диск. Поэтому если до этого момента система «упадет»,
то данные вполне могут быть потеряны. Но суть в том, что после возврата из write
уже не будет никаких сообщений об ошибках. Можно признать потерю не сброшенных
на диск данных неизбежной, но не более вероятной, чем отказ самого диска.
При работе с TCP получение кода ошибки от операции
записи - очень редкое явление. Поскольку операция записи возвращает управление
до фактической от правки данных, обычно ошибки выявляются при последующих операциях,
о чем говорилось в совете 9. Так как следующей операцией чаще всего бывает чтение,
предполагается, что ошибки записи обнаруживаются при чтении. Операция записи
возвращает лишь ошибки, очевидные в момент вызова, а именно:
- неверный дескриптор сокета;
- файловый дескриптор указывает не на сокет
(в случае вызова send и родственных функций);
- указанный при вызове сокет не существует
или не подсоединен;
- в качестве адреса буфера указан недопустимый
адрес.
Причина большинства этих проблем - ошибка в программе.
После завершения стадии разработки они почти не встречаются. Исключение составляет
код ошибки EPIPE (или сигнал SIGPIPE), который свидетельствует о сбросе соединения
хостом на другом конце. Условия, при которых такая ошибка возникает, обсуждались
в совете 9 при рассмотрении краха приложения-партнера.
Подводя итог этим рассуждениям, можно сказать,
что применительно к TCP соединениям операцию записи лучше представлять себе
как копирование в очередь для передачи, сопровождаемое извещением TCP о появлении
новых данных. Понятно, какую работу TCP произведет дальше, но эти действия будут
асинхронны по отношению к самой записи.
Как отмечалось выше, операция записи отвечает лишь
за копирование данных из буфера приложения в память ядра и уведомление TCP о
том, что появились данные для передачи. А теперь рассмотрим некоторые из критериев,
которыми руководствуется TCP, «принимая решение» о том, можно ли передать новые
данные незамедлительно и в каком количестве. Я не задаюсь целью полностью объяснить
логику отправки данных в TCP, а хочу лишь помочь вам составить представление
о факторах, влияющих на эту логику. Тогда вы сможете лучше понять принципы работы
своих программ.
Одна из основных целей стратегии отправки данных
в TCP - максимально эффективное использование имеющейся полосы пропускания.
TCP посылает данные блоками, размер которых равен MSS (maximum segment size
- максимальный размер сегмента).
Примечание: В процессе установления соединения
TCP на каждом конце может указать приемлемый для него MSS. TCP на другом конце
обязан удовлетворить это пожелание и не посылать сегменты большего размера.
MSS вычисляется на основе MTU (maximum transmission unit - максимальный размер
передаваемого блока),как описано в совете 7.
В то же время TCP не может переполнять буферы на
принимающем конце. Как вы видели в совете 1, это определяется окном передачи.
Если бы эти два условия были единственными, то
стратегия отправки была бы проста: немедленно послать все имеющиеся данные,
упаковав их в сегменты размером MSS, но не более чем разрешено окном передачи.
К сожалению, есть и другие факторы.
Прежде всего, очень важно не допускать перегрузки
сети. Если TCP неожиданно пошлет в сеть большое число сегментов, может исчерпаться
память маршрутизатора, что повлечет за собой отбрасывание датаграмм. А из-за
этого начнутся повторные передачи, что еще больше загрузит сеть. В худшем случае
сеть будет загружена настолько, что датаграммы вообще нельзя будет доставить.
Это называется затором (congestion collapse). Чтобы избежать перегрузки, TCP
не посылает по простаивающему соединению все сегменты сразу. Сначала он посылает
один сегмент и постепенно увеличивает число неподтвержденных сегментов в сети,
пока не будет достигнуто равновесие.
Примечание: Эту проблему можно наглядно
проиллюстрировать таким примером. Предположим, что в комнате, полной народу,
кто-то закричал: «Пожар!» Все одновременно бросаются к дверям, возникает давка,
и в результате никто не может выйти. Если же люди будут выходить по одному,
то пробки не возникнет, и все благополучно покинут помещение.
Для предотвращения перегрузки TCP применяет два
алгоритма, в которых используется еще одно окно, называемое окном перегрузки.
Максимальное число байтов, которое TCP может послать в любой момент, - это минимальная
из двух величин: размер окна передачи и размер окна перегрузки. Обратите внимание,
что эти окна отвечают за разные аспекты управления потоком. Окно передачи, декларируемое
TCP на другом конце, предохраняет от переполнения его буферов. Окно перегрузки,
отслеживаемое TCP на вашем конце, не дает превысить пропускную способность
сети. Ограничив объем передачи минимальным из этих двух окон, вы удовлетворяете
обоим требованиям управления потоком.
Первый алгоритм управления перегрузкой называется
«медленный старт». Он постепенно увеличивает частоту передачи сегментов в сеть
до пороговой величины.
Примечание: Слово «медленный» взято в кавычки,
поскольку на самом деле нарастание частоты экспоненциально. При медленном старте
окно перегрузки открывается на один сегмент при получении каждого АСК. Если
вы начали с одного сегмента, то последовательные размеры окна будут составлять
1,2, 4, 8 и т.д.
Когда размер окна перегрузки достигает порога,
который называется порогом медленного старта, этот алгоритм прекращает работу,
и в дело вступает алгоритм избежания перегрузки. Его работа предполагает, что
соединение достигло равновесного состояния, и сеть постоянно зондируется -
не увеличилась ли пропускная способность. На этой стадии окно перегрузки открывается
линейно — по одному сегменту за период кругового обращения.
В стратегии отправки TCP окно перегрузки в принципе
может запретить посылать данные, которые в его отсутствие можно было бы послать.
Если происходит перегрузка (о чем свидетельствует потерянный сегмент) или сеть
некоторое время простаивает, то окно перегрузки сужается, возможно, даже до
размера одного сегмента. В зависимости от того, сколько данных находится в
очереди, и сколько их пытается послать приложение, это может препятствовать
отправке всех данных.
Авторитетным источником информации об алгоритмах
избежания перегрузки является работа Jacobson 1988], в которой они впервые были
предложены. Джекобсон привел результаты нескольких экспериментов, демонстрирующие
заметное повышение производительности сети после внедрения управления перегрузкой.
В книге [Stevens-1994] содержится подробное объяснение этих алгоритмов и результаты
трассировки в локальной сети. В настоящее время эти алгоритмы следует включать
в любую реализацию, согласующуюся со стандартом (RFC 1122 [Braden 1989]).
Примечание: Несмотря на впечатляющие результаты,
реализация этих алгоритмов очень проста — всего две переменные состояния
и несколько строчек кода. Детали можно найти в книге [Wright and Stevens 1995].
Еще один фактор, влияющий на стратегию отправки
TCP, - алгоритм Нейгла. Этот алгоритм впервые предложен в RFC 896 [Nagle 1984].
Он требует, чтобы никогда не было более одного неподтвержденного маленького
сегмента, то есть сегмента размером менее MSS. Цель алгоритма Нейгла — не дать
TCP забить сеть последовательностью мелких сегментов. Вместо этого TCP сохраняет
в своих буферах небольшие блоки данных, пока не получит подтверждение на предыдущий
маленький сегмент, после чего посылает сразу все накопившиеся данные. В совете
24 вы увидите, что отключение алгоритма Нейгла может заметно сказаться на производительности
приложения.
Если приложение записывает данные небольшими порциями,
то эффект от алгоритма Нейгла очевиден. Предположим, что есть простаивающее
соединение, окна передачи и перегрузки достаточно велики, а выполняются подряд
две небольшие операции записи. Данные, записанные вначале, передаются немедленно,
поскольку окна это позволяют, а алгоритм Нейгла не препятствует, так как неподтвержденных
данных нет (соединение простаивало). Но, когда до TCP доходят данные, полученные
при второй операции, они не передаются, хотя в окнах передачи и перегрузки есть
место. Поскольку уже есть один неподтвержденный маленький сегмент, и алгоритм
Нейгла требует оставить данные в очереди, пока не придет АСК.
Обычно при реализации алгоритма Нейгла не посылают
маленький сегмент, если есть неподтвержденные данные. Такая процедура рекомендована
RFC 1122. Но реализация в BSD (и некоторые другие) несколько отходит от этого
правила и отправляет маленький сегмент, если это последний фрагмент большой
одновременно записанной части данных, а соединение простаивает. Например, MSS
для простаивающего соединения равен 1460 байт, а приложение записывает 1600
байт. При этом TCP пошлет (при условии, что это разрешено окнами передачи и
перегрузки) сначала сегмент размером 1460, а сразу вслед за ним, не дожидаясь
подтверждения, сегмент размером 140. При строгой интерпретации алгоритма Нейгла
следовало бы отложить отправку второго сегмента либо до подтверждения первого,
либо до того, как приложение запишет достаточно данных для формирования полного
сегмента.
Алгоритм Нейгла - это лишь один из двух алгоритмов,
позволяющих избежать синдрома безумного окна (SWS - silly window syndrome).
Смысл этой тактики в том, чтобы не допустить отправки небольших объемов данных.
Синдром SWS и его отрицательное влияние на производительность обсуждаются в
RFC 813 [Clark 1982]. Как вы видели, алгоритм Нейгла пытается избежать синдрома
SWS со стороны отправителя. Но требуются и усилия со стороны получателя, который
не должен декларировать слишком маленькие окна.
Напомним, что окно передачи дает оценку свободного
места в буферах хоста на другом конце соединения. Этот хост объявляет о том,
сколько в нем имеется места, включая в каждый посылаемый сегмент информацию
об обновлении окна. Чтобы избежать SWS, получатель не должен объявлять о небольших
изменениях.
Следует пояснить это на примере. Предположим, у
получателя есть 14600 свободных байт, a MSS составляет 1460 байт. Допустим
также, что приложением на Конце получателя читается за один раз всего по 100
байт. Отправив получателю 10 сегментов, окно передачи закроется. И вы будете
вынуждены приостановить отправку данных. Но вот приложение прочитало 100 байт,
в буфере приема 100 байт освободилось. Если бы получатель объявил об этих 100
байтах, то вы тут же послали бы ему маленький сегмент, поскольку TCP временно
отменяет алгоритм Нейгла, если из-за него длительное время невозможно отправить
маленький сегмент. Вы и дальше продолжали бы посылать стобайтные пакеты, так
как всякий раз, когда приложение на конце получателя читает очередные 100 байт,
получатель объявляет освобождении этих 100 байт, посылая информацию об обновлении
окна.
Алгоритм избежания синдрома SWS на получающем конце
не позволяет объявлять об обновлении окна, если объем буферной памяти значительно
не увеличился. В RFC 1122 «значительно» - это на размер полного сегмента или
более чем на половину максимального размера окна. В реализациях, производных
от BSD, требуется увеличение на два полных сегмента или на половину максимального
размера окна.
Может показаться, что избежание SWS со стороны
получателя излишне (поскольку отправителю не разрешено посылать маленькие сегменты),
но в действительности это защита от тех стеков TCP/IP, в которых алгоритм Нейгла
не реализован или отключен приложением (совет 24). RFC 1122 требует от реализаций
TCP, удовлетворяющих стандарту, осуществлять избежание SWS на обоих концах.
На основе этой информации теперь можно сформулировать
стратегию отправки, принятую в реализациях TCP, производных от BSD. В других
реализациях стратегия может быть несколько иной, но основные принципы сохраняются.
При каждом вызове процедуры вывода TCP вычисляет
объем данных, которые можно послать. Это минимальное значение количества данных
в буфере передачи, размера окон передачи и перегрузки и MSS. Данные отправляются
при выполнении хотя бы одного из следующих условий:
- можно послать полный сегмент размером MSS;
- соединение простаивает, и можно опустошить
буфер передачи;
- алгоритм Нейгла отключен, и можно опустошить
буфер передачи;
- есть срочные данные для отправки;
- есть маленький сегмент, но его отправка
уже задержана на достаточно дли тельное время;
Примечание: Если у TCP есть маленький сегмент,
который запрещено посылать, то он взводит таймер на то время, которое потребовалось
бы для ожидания АСК перед повторной передачей (но в пределах 5-60 с). Иными
словами, устанавливается тайм-аут ретрансмиссии (RТО). Если этот таймер, называемый
таймером терпения (persist timer), срабатывает, то TCP все-таки посылает сегмент
при условии, что это не противоречит ограничениям, которые накладывают окна
передачи и перегрузки. Даже если получатель объявляет окно размером нуль байт,
TCP все равно попытается послать один байт. Это делается для того, чтобы потерянное
обновление окна не привело к тупиковой ситуации.
- окно приема, объявленное хостом на другом
конце, открыто не менее чем наполовину;
- необходимо повторно передать сегмент;
- требуется послать АСК на принятые данные;
- нужно объявить об обновлении окна.
В этом разделе подробно рассмотрена операция записи.
С точки зрения приложения операцию записи проще всего представлять как копирование
из адресного пространства пользователя в буферы ядра и последующий возврат.
Срок передачи данных TCP и их объем зависят от состояния соединения, а приложение
не умеет подобной информации.
Проанализированы стратегия отправки, принятая в BSD TCP, а также влияние на
нее объема буферной памяти у получателя (представлен окном передачи), оценки
загрузки сети (представлена окном перегрузки), объема данных, готовых для передачи,
попытки избежать синдрома безумного окна и стратегии повторной передачи.
Как вы уже видели, в работе TCP-соединения есть
три фазы:
1. Установления соединения.
2. Передачи данных.
3. Разрыва соединения.
В этом разделе будет рассмотрен переход от фазы
передачи данных к фазе разрыва соединения. Точнее, как узнать, что хост на
другом конце завершил фазу передачи данных и готов к разрыву соединения, и
как он может сообщить об этом партнеру.
Вы увидите, что один хост может прекратить отправку
данных и сигнализировать партнеру об этом, не отказываясь, однако, от приема
данных. Это возможно, поскольку TCP-соединения полнодуплексные, потоки данных
в разных направлениях не зависят друг от друга.
Например, клиент может соединиться с сервером,
отправить серию запросов, а затем закрыть свою половину соединения, предоставив
тем самым серверу информацию, что больше запросов не будет. Серверу для ответа
клиенту, возможно, понадобится выполнить большой объем работы и даже связаться
с другими серверами, так что он продолжает посылать данные уже после того,
как клиент прекратил отправлять запросы. С другой стороны, сервер может послать
в ответ сколько угодно данных, так что клиент не определяет заранее, когда ответ
закончится. Поэтому сервер, вероятно, как и клиент, закроет свой конец соединения,
сигнализируя о конце передачи.
После того как ответ на последний запрос клиента
отправлен и сервер закрыл свой конец соединения, TCP завершает фазу разрыва.
Обратите внимание, что закрытие соединения рассматривается как естественный
способ известить партнера о прекращении передачи данных. По сути, посылается
признак конца файла EOF.
Как приложение закрывает свой конец соединения?
Оно не может просто завершить сеанс или закрыть сокет, поскольку у партнера
могут быть еще данные. " API сокетов есть интерфейс shutdown. Он используется
так же, как и вызов close, но при этом передается дополнительный параметр, означающий,
какую сторону соединения надо закрыть.
#include <sys/socket.h>
/* UNIX. */
#include <winsock2.h>
/* Windows. */
int shutdown( int s,
int how ); /* UNIX. */
int shutdown( SOCKET
s, int how ); /* Windows. */
Возвращаемое значение:
0- нормально, -1 (UNIX) или SOCKET_ERROR (Windows) - ошибка.
К сожалению, между реализациями shutdown в UNIX
и Windows есть различия в семантике и API. Традиционно в качестве значений
параметра how вызова shutdown использовались числа. И в стандарте POSIX, и в
спецификации Winsock им присвоены символические имена, только разные. В табл.
3.1 приведены значения, символические константы для них и семантика параметра
how.
Различия в символических именах можно легко компенсировать,
определив в заголовочном файле одни константы через другие или используя числовые
значения. А вот семантические отличия гораздо серьезнее. Посмотрим, для чего
предназначено каждое значение.
Таблица 3.1. Значения параметра how для вызова shutdown
|
Числовое
|
Значение how
|
Действие
|
|
POSIX
|
WINSOCK
|
|
0
|
SHUT_RD
|
SD_RECEIVE
|
Закрывается принимающая сторона соединения
|
|
1
|
SHUT_WR
|
SD_SEND
|
Закрывается передающая сторона соединения
|
|
2
|
SHUT_RDWR
|
SD_BOTH
|
Закрываются обе стороны
|
how = 0. Закрывается принимающая сторона соединения.
В обеих реализациях в сокете делается пометка, что он больше не может принимать
данные и должен вернуть EOF, если приложением делаются попытки еще что-то читать.
Но отношение к данным, уже находившимся в очереди приложения в момент выполнения
shutdown, а также к приему новых данных от хоста на другом конце различное.
В UNIX все ранее принятые, но еще не прочитанные данные уничтожаются, так что
приложение их уже не получит. Если поступают новые данные, то TCP их подтверждает
и тут же отбрасывает, поскольку приложение не хочет принимать новые данные.
Наоборот, в соответствии с Winsock соединение вообще разрывается, если в очереди
есть еще данные или поступают новые Поэтому некоторые авторы (например, [Quinn
and Shute 1996]) считают, что под Windows использование конструкции
shutdown (s, 0) ;
небезопасно.
how = 1. Закрывается отправляющая сторона соединения.
В сокете делается пометка, что данные посылаться больше не будут; все последующие
пытки выполнить для него операцию записи заканчиваются ошибкой. После того как
вся информация из буфера отправлена, TCP посылает сегмент FIN, сообщая партнеру,
что данных больше не будет. Это называется полузакрытием (half close). Такое
использование вызова shutdown наиболее типично, и его семантика в обеих реализациях
одинакова.
how = 2. Закрываются обе стороны соединения. Эффект
такой же, как при выполнении вызова shutdown дважды, один раз с how = 0, а другой
- с how = 1. Хотя, на первый взгляд, обращение
shutdown (s, 2);
эквивалентно вызову close или closesocket, в действительности
это не так. Обычно нет причин для вызова shutdown с параметром how = 2, но в
работе [Quinn and Shute 1996] сообщается, что в некоторых реализациях Winsock
вызов closesocket работает неправильно, если предварительно не было обращения
к shutdown с how = 2. В соответствии с Winsock вызов shutdown с how= 2 создает
ту же проблему, что и вызов с how = 0, - может быть разорвано соединение.
Между закрытием сокета и вызовом shutdown есть
существенные различия. Во-первых, shutdown не закрывает сокет по-настоящему,
даже если он вызван с параметром 2. Иными словами, ни сокет, ни ассоциированные
с ним ресурсы (за исключением буфера приема, если how= 0 или 2) не освобождаются.
Кроме того, воздействие shutdown распространяется на все процессы, в которых
этот сокет открыт. Так, например, вызов shutdown с параметром how = 1 делает
невозможной запись в этот сокет для всех его владельцев. При вызове же с lose
или closesocket все остальные процессы могут продолжать пользоваться сокетом.
Последний факт во многих случаях можно обратить
на пользу. Вызывая shutdown c how = 1, будьте уверены, что партнер получит EOF,
даже если этот сокет открыт и другими процессами. При вызове close или closesocket
это не гарантируется, поскольку TCP не пошлет FIN, пока счетчик ссылок на сокет
не станет равным нулю. А это произойдет только тогда, когда все процессы закроют
этот сокет.
Наконец, стоит упомянуть, что, хотя в этом разделе
говорится о TCP, вызов shutdown применим и к UDP. Поскольку нет соединения,
которое можно закрыть, польза обращения к shutdown с how = 1 или 2, остается
под вопросом, но задавать параметр how - 0 можно для предотвращения приема датаграмм
из конкретного UDP-порта.
Теперь, когда вы познакомились с вызовом shutdown,
посмотрите, как его можно использовать для аккуратного размыкания соединения.
Цель этой операции гарантировать, что обе стороны получат все предназначенные
им данные до того, соединение будет разорвано.
Примечание: Термин «аккуратное размыкание»
(orderly release) имеет некоторое отношение к команде t_sndrel из APIXTI (совет
5), которую также часто называют аккуратным размыканием в отличие от команды
грубого размыкания (abortive release) t_snddis. Но путать их не стоит. Команда
t_sndrel выполняет те же действия, что и shutdown. Обе команды используются
для аккуратного размыкания соединения.
Просто закрыть соединение в некоторых случаях недостаточно,
поскольку могут быть потеряны еще не принятые данные. Помните, что, когда приложение
закрывает соединение, недоставленные данные отбрасываются.
Чтобы поэкспериментировать с аккуратным размыканием,
запрограммируйте клиент, который посылает серверу данные, а затем читает и печатает
ответ сервера. Текст программы приведен в листинге 3.1. Клиент читает из стандартного
входа данные для отправки серверу. Как только f gets вернет NULL, индицирующий
конец файла, клиент начинает процедуру разрыва соединения. Параметр –с в командной
строке управляет этим процессом. Если -с не задан, то программа shutdownc вызывает
shutdown для закрытия передающего конца соединения. Если же параметр задан,
то shutdownc вызывает CLOSE, затем пять секунд «спит» и завершает сеанс.
Листинг 3.1. Клиент для экспериментов с аккуратным
размыканием
shutdownc.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 fd_set readmask;
6 fd_set allreads;
7 int re;
8 int len;
9 int c;
10 int closeit = FALSE;
11 int err = FALSE;
12 char lin[ 1024 ];
13 char lout[ 1024 ];
14 INIT();
15 opterr = FALSE;
16 while ( ( с = getopt( argc, argv, "c"
) ) != EOF )
17 {
18 switch( с )
19 {
20 case 'c' :
21 closeit = TRUE;
22 break;
23 case '?' :
24 err = TRUE;
25 }
26 }
27 if ( err || argc - optind != 2 )
28 error( 1, 0, "Порядок вызова: %s [-с]
хост порт\n",
29 program_name );
30 s = tcp_client( argv[ optind ], argv[ optind + 1 ] );
31 FD_ZERO( &allreads );
32 FD_SET( 0, &allreads ) ;
33 FD_SET( s, &allreads ) ;
34 for ( ; ; )
35 {
36 readmask = allreads;
37 re = select) s + 1, &readmask, NULL, NULL, NULL );
38 if ( re <= 0 )
39 error( 1, errno, "ошибка: select вернул (%d)", re );
40 if ( FD_ISSET( s, &readmask ) )
41 {
42 re = recv( s, lin, sizeof( lin ) - 1, 0 );
43 if ( re < 0 )
44 error( 1, errno, "ошибка вызова recv" );
45 if ( re == 0 )
46 error( 1, 0, "сервер отсоединился\п" ) ;
47 lin[ re ] = '\0';
48 if ( fputs( lin, stdout ) == EOF )
49 error( 1, errno, "ошибка вызова fputs" );
50 }
51 if ( FD_ISSET( 0, &readmask ) )
52 {
53 if ( fgets( lout, sizeof( lout ), stdin ) == NULL )
54 {
55 FD_CLR( 0, &allreads ) ;
56 if ( closeit )
57 {
58 CLOSE( s );
59 sleep( 5 ) ;
60 EXIT( 0 ) ;
61 }
62 else if ( shutdown( s, 1 ) )
63 error( 1, errno, "ошибка вызова shutdown" );
64 }
65 else
66 {
67 len = strlent lout );
68 re = send( s, lout, len, 0 );
69 if ( re < 0 )
70 error( 1, errno, "ошибка вызова send" );
71 }
72 }
73 }
74 }
Инициализация.
14-30 Выполняем обычную инициализацию клиента и
проверяем, есть ли в командной строке флаг -с.
Обработка данных.
40-50 Если в ТСР-сокете есть данные для чтения,
программа пытается прочитать, сколько можно, но не более, чем помещается в буфер.
При получении признака конца файла или ошибки завершаем сеанс, в противном случае
выводим все прочитанное на stdout.
Примечание: Обратите внимание на конструкцию
sizeof ( lin ) -1 в вызове recv на строке 42. Вопреки всем призывам избегать
переполнения буфера, высказанным в совете 11, в первоначальной версии этой программы
было написано sizeof ( lin ), что приведет к записи за границей буфера в операторе
lin[ re ] = '\0';
в строке 47.
53-64 Прочитав из стандартного входа EOF, вызываем
либо shutdown, либо CLOSE в зависимости от наличия флага -с.
65- 71 В противном случае передаем прочитанные данные
серверу.
Можно было бы вместе с этим клиентом использовать
стандартный системным сервис эхо-контроля, но, чтобы увидеть возможные ошибки
и ввести некоторую задержку, напишите собственную версию эхо-сервера. Ничего
особенного в программе tcpecho.с нет. Она только распознает дополнительный аргумент
в командной строке, при наличии которого программа «спит» указанное число секунд
между чтением и записью каждого блока данных (листинг 3.2).
Сначала запустим клиент shutdownc с флагом -с,
чтобы он закрывал сокет после считывания EOF из стандартного ввода. Поставим
в сервере tcpecho задержку на 4 с перед отправкой назад только прочитанных данных:
bsd: $ tcpecho 9000 4 &
[1] 3836
bsd: $ shutdownc –c localhost 9000
data1 Эти три строки были введены подряд максимально
быстро
data2
^D
tcpecho: ошибка вызова send: Broken pipe (32) Спустя
4 с после отправки “data1”.
Листинг3.2. Эхо-сервер на базе TCP
tcpecho.c
1 #include "etcp.h"
2 int main( int argc, char **argv)
3 {
4 SOCKET s;
5 SOCKET s1;
6 char buf[ 1024 ];
7 int re;
8 int nap = 0;
9 INIT();
10 if ( argc == 3 )
11 nap = atoi( argv[ 2 ] ) ;
12 s = tcp_server( NULL, argv[ 1 ] );
13 s1 = accept( s, NULL, NULL );
14 if ( !isvalidsock( s1 ) )
15 error( 1, errno, "ошибка вызова accept" );
16 signal( SIGPIPE, SIG_IGN ); /* Игнорировать сигнал SIGPIPE.*/
17 for ( ; ; )
18 {
19 re = recv( s1, buf, sizeof( buf ), 0 );
20 if ( re == 0 )
21 error( 1, 0, "клиент отсоединился\n" );
22 if ( re < 0 )
23 error( 1, errno, "ошибка вызова recv" );
24 if ( nap )
25 sleep( nap ) ;
26 re = send( s1, buf, re, 0 );
27 if ( re < 0 )
28 error( 1, errno, "ошибка вызова send" );
29 }
30 }
Затем нужно напечатать две строки datal и data2
и сразу вслед за ними нажать комбинацию клавиш Ctrl+D, чтобы послать программе
shutdownc конец файла и вынудить ее закрыть сокет. Заметьте, что сервер не вернул
ни одной строки. В напечатанном сообщении tcpecho об ошибке говорится, что
произошло. Когда сервер вернулся из вызова sleep и попытался отослать назад
строку datal, он получил RST, поскольку клиент уже закрыл соединение.
Примечание: Как объяснялось в совете 9,
ошибка возвращается при записи второй строки (data2). Заметьте, что это один
из немногих случаев, когда ошибку возвращает операция записи, а не чтения. Подробнее
об этом рассказано в совете 15.
В чем суть проблемы? Хотя клиент сообщил серверу
о том, что больше не будет посылать данные, но соединение разорвал до того,
как сервер успел завершить обработку, в результате информация была потеряна.
В левой половине рис. 3.2 показано, как происходил обмен сегментами.
Теперь повторим эксперимент, но на этот раз запустим
shutdownc без флага -с.
bsd: $ tcpecho 9000 4 &
[1] 3845
bsd: $ shutdownc localhost 9000
datal
data2
^D
datal Спустя 4 с после отправки "datal".
data2 Спустя 4 с после получения "datal".
tcpecho: клиент отсоединился
shutdownc: сервер отсоединился
На этот раз все сработало правильно. Прочитав из
стандартного входа признак конца файла, shutdownc вызывает shutdown, сообщая
серверу, что он больше не будет ничего посылать, но продолжает читать данные
из соединения. Когда сервер tcpecho обнаруживает EOF, посланный клиентом, он
закрывает соединение, в результате чего TCP посылает все оставшиеся в очереди
данные, а вместе с ними FIN. Клиент, получив EOF, определяет, что сервер отправил
все, что у него было, и завершает сеанс.
Заметьте, что у сервера нет информации, какую операцию
(shutdown или close) выполнит клиент, пока не попытается писать в сокет и не
получит код ошибки или EOF. Как видно из рис. 3.1, оба конца обмениваются теми
же сегментами, что и раньше, до того, как TCP клиента ответил на сегмент, содержащий
строку datal.
Стоит отметить еще один момент. В примерах вы несколько
раз видели, что, когда TCP получает от хоста на другом конце сегмент FIN, он
сообщает об этом приложению, возвращая нуль из операции чтения. Примеры приводятся
в строке 45 листинга 3.1 и в строке 20 листинга 3.2, где путем сравнения кода
возврата recv с нулем проверяется, получен ли EOF. Часто возникает путаница,
когда в ситуации, подобной той, что показана в листинге 3.1, используется системный
вызов select. Когда приложение на другом конце закрывает отправляющую сторону
соединения, вызывая close или shutdown либо просто завершая работу, select
возвращает управление, сообщая, что в сокете есть данные для чтения. Если приложение
при этом не проверяет EOF, то оно может попытаться обработать сегмент нулевой
длины или зациклиться, переключаясь между вызовами read и select.
В сетевых конференциях часто отмечают, что «select
свидетельствует о наличии информации для чтения, но в действительности ничего
не оказывается». В действительности хост на другом конце просто закрыл, как
минимум, отправляющую сторону соединения, и данные, о присутствии которых говорит
select, -это всего лишь признак конца файла.
Вы изучили системный вызов shutdown и сравнили
его с вызовом close. Также рассказывалось, что с помощью shutdown можно закрыть
только отправляющую, принимающую или обе стороны соединения; и счетчик ссылок
на сокет при этом изменяется иначе, чем при закрытии с помощью close.
Затем было показано, как использовать shutdown
для аккуратного размыкания соединения. Аккуратное размыкание - это последовательность
разрыва соединения, при которой данные не теряются.
В операционной системе UNIX и некоторых других
имеется сетевой суперсервер inetd, который позволяет почти без усилий сделать
приложение сетевым.
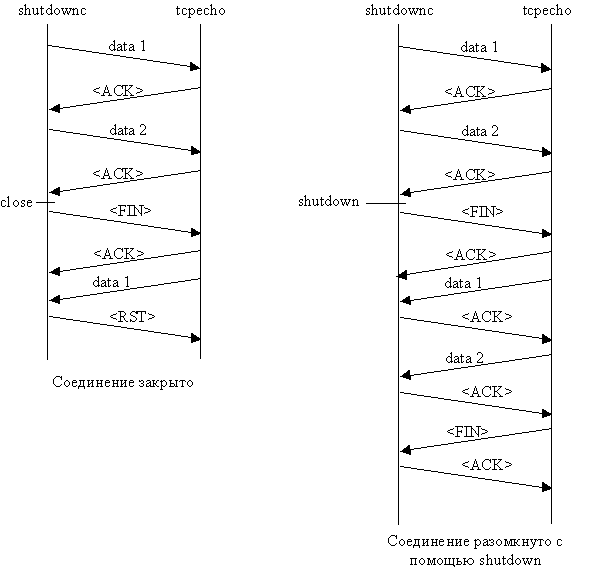
Рис. 3.1. Системные вызовы close и shutdown
Кроме того, если есть всего один процесс, который
прослушивает входящие соединения и входящие UDP-датаграммы, то можно сэкономить
системные ресурсы. Обычно inetd поддерживает, по меньшей мере, протоколы TCP
и UDP, а возможно, и некоторые другие. Здесь будут рассмотрены только два первых.
Поведение inetd существенно зависит от того, с каким протоколом - TCP или UDP
- он работает.
Для TCP-серверов inetd прослушивает хорошо известные
порты, ожидая запроса на соединение, затем принимает соединение, ассоциирует
с ним файловые Дескрипторы stdin, stdout и stderr, после чего запускает приложение.
Таким образом, сервер может работать с соединением через дескрипторы 0, 1 и
2. Если это допускается конфигурационным файлом inetd (/etc/ inetd.conf), то
inetd продолжает прослушивать тот же порт. Когда в этот порт поступает запрос
на новое соединение, запускается новый экземпляр сервера, даже если первый
еще не завершил сеанс. Это показано на рис. 3.2. Обратите внимание, что серверу
не нужно обслуживать нескольких клиентов. Он просто выполняет запросы одного
клиента, а потом завершается. Остальные клиенты обслуживаются дополнительными
экземплярами сервера.
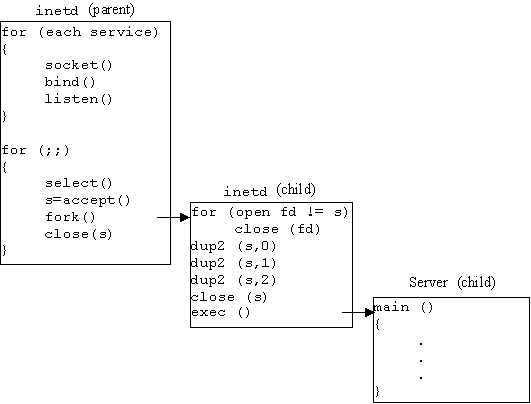
Рис. 3.2. Действия inetd при запуске
TCP-сервера
Применение inetd освобождает от необходимости самостоятельно
устанавливать TCP или UDP-соединение и позволяет писать сетевое приложение почти
так же, как обычный фильтр. Простой, хотя и не очень интересный пример приведен
в листинге 3.3.
Листинг 3.3. Программа rlnumd для подсчета строк
rlnumd.c
1 #include <stdio.h>
2 void main( void )
3 {
4 int cnt = 0;
5 char line[ 1024 ];
6 /*
7 *Мы должны явно установить режим построчной
буферизации,
8 *так как функции из библиотеки стандартного
ввода/вывод
9 *не считают сокет терминалом. */
10 setvbuf( stdout, NULL, _IOLBF, 0 );
11 while ( fgets ( line, sizeof( line ) , stdin
) != NULL )
12 printf( "%3i: %s", ++cnt, line
);
13 }
По поводу этой программы стоит сделать несколько
замечаний:
- в тексте программы не упоминается ни о
TCP, ни вообще о сети. Это не значит, что нельзя выполнять связанные с сокетами
вызовы (getpeername, [gs ] etsockopt и т.д.), просто в этом не всегда есть
необходимость. Нет никаких ограничений и на использование read и write. Кроме
того, можно пользоваться вызовами send, recv, sendto и recvfrom, как если
бы inetd не было.
- режим буферизации строк приходится устанавливать
самостоятельно, поскольку стандартная библиотека ввода/вывода автоматически
устанавливает подобный режим только в том случае, если считает, что вывод
производится на терминал. Это позволяет обеспечить быстрое время реакции для
интерактивных приложений;
- стандартная библиотека берет на себя разбиение
входного потока на строки. Об этом уже говорилось в совете 6;
- предполагаем, что не будет строк длиннее
1023 байт. Более длинные строки будут разбиты на несколько частей, и у каждой
будет свой номер;
Примечание: Этот факт, который указан в
книге [Oliver 2000], служит еще одним примером того, как можно легко допустить
ошибку переполнения буфера. Подробнее этот вопрос обсуждался в совете 11.
- хотя это приложение тривиально, но во многих
«настоящих» TCP-приложениях, например telnet, rlogin и ftp, используется такая
же техника.
Программа в листинге 3.3 может работать и как «нормальный»
фильтр, и как Удаленный сервис подсчета строк. Чтобы превратить ее в удаленный
сервис, нужно только выбрать номер порта, добавить в файл /etc/ services строку
с именем сервиса и номером порта и включить в файл /etc/inetd.conf строку, описывающую
этот сервис и путь к исполняемой программе. Например, если вы назовете сервис
rlnum, исполняемую программу для него –
rlnumd и назначите ему порт 8000, то надо будет
добавить в /etc/services строку
rlnum 8000/tcp # удаленный сервис подсчета строк,
а в /etc/inetd.conf - строку
rlnum stream tcp nowait jcs /usr/home/jcs/rlnumd
rlnumd.
Добавленная в /etc/services строка означает, что
сервис rlnum использует протокол TCP по порту 8000. Смысл же полей в строке,
добавленной в /etc/inetd.conf, таков:
- имя сервиса, как он назван в /etc/services.
Это имя хорошо известного порта, к которому подсоединяются клиенты данного
сервера. В вашем примере - rlnum;
- тип сокета, который нужен серверу. Для
TCP-серверов это stream, a для UDP-серверов - dgram. Поскольку здесь сервер
пользуется протоколом ТCP указан stream;
- протокол, применяемый с сервером, - tcp
или udp. В данном примере это tср;
- флаг wait/nowait. Для UDP-серверов его
значение всегда wait, а для ТСР-серверов - почти всегда nowait. Если задан
флаг nowait, то inetd сразу после запуска сервера возобновляет прослушивание
связанного с ним хорошо известного порта. Если же задан флаг wait, то inetd
не производит никакой работы с этим сокетом, пока сервер не завершится. А
затем он возобновляет прослушивание порта в ожидании запросов на новые соединения
(для stream-серверов) или новых датаграмм (для dgram-серверов). Если для stream-сервера
задан флаг wait, то inetd не вызывает accept для соединения, а передает сокет,
находящийся в режиме прослушивания, самому серверу, который должен принять
хотя бы одно соединение перед завершением. Как отмечено в сообщении [Kacker
1998], задание флага wait для TCP-приложения - это мощная, но редко используемая
возможность. Здесь приводится несколько применений флага wait для TCP-соединений:
-
в качестве механизма рестарта для ненадежных сетевых программ-демонов. Пока
демон работает корректно, он принимает соединения от клиентов, но если по какой-то
причине демон «падает», то при следующей попытке соединения inetd его рестартует;
-
как способ гарантировать одновременное подключение только одного клиента;
-
как способ управления многопоточным или многопроцессным приложением, зависящим
от нагрузки. В этом случае начальный процесс запускается inetd, а затем он
динамически балансирует нагрузку, создавая по мере необходимости дополнительные
процессы или потоки. При уменьшении нагрузки, потоки уничтожаются, а в случае
длительного простоя завершает работу и сам процесс, освобождая ресурсы и возвращая
прослушивающий сокет inetd.
В данном примере задан флаг nowait, как и обычно
для TCP-серверов.
·
имя пользователя, с правами которого будет запущен сервер. Это имя должно присутствовать
в файле /etc/passwd. Большинство стандартных серверов, прописанных в inetd.
conf, запускаются от имени root, но это совершенно необязательно. Здесь в качестве
имени пользователя выбрано jcs;
·
полный путь к файлу исполняемой программы. Поскольку rlnumd находится в каталоге
пользователя jcs, задан путь /usr/home/ jcs/rlnumd;
·
до пяти аргументов (начиная с argv [ 0 ]), которые будут переданы серверу. Поскольку
в этом примере у сервера нет аргументов, оставлен только argv [ 0 ]
Чтобы протестировать сервер, необходимо заставить
inetd перечитать свой конфигурационный файл (в большинстве реализаций для этого
нужно послать ему сигнал SIGHUP) и соединиться с помощью telnet:
bsd: $ telnet localhost rlnum
Trying 127.0.0.1. . .
Connected to localhost
Escape character is "^]".
hello
1: hello
world
2: world
^]
telnet> quit
Connection closed.
bsd: $
Поскольку в протоколе UDP соединения не устанавливаются
(совет 1), inetd нечего слушать. При этом inetd запрашивает операционную систему
(с помощью вызова select) о приходе новых датаграмм в порт UDP-сервера. Получив
извещение, inetd дублирует дескриптор сокета на stdin, stdout и stderr и запускает
UDP-сервер. В отличие от работы с TCP-серверами при наличии флага nowait, inetd
больше не предпринимает с этим портом никаких действий, пока сервер не завершит
сеанс. В этот момент он снова предлагает системе извещать его о новых датаграммах.
Прежде чем закончить работу, серверу нужно прочесть хотя бы одну датаграмму
из сокета, чтобы inetd не «увидел» то же самое сообщение, что и раньше. В противном
случае он опять запустит сервер, войдя в бесконечный цикл.
Пример простого UDP-сервера, запускаемого через
inetd, приведен в листинге 3.4. Этот сервер возвращает то, что получил, добавляя
идентификатор своего процесса.
Листинг 3.4. Простой сервер, реализующий протокол
запрос-ответ
udpecho1.с
1 ttinclude "etcp.h"
2 int main( int argc, char **argv
)
3 {
4 struct sockaddr_in peer;
5 int rc;
6 int len;
7 int pidsz;
8 char buf[ 120 ] ;
9 pidsz = sprintf( buf, "%d: ", getpid
() ) ;
10 len = sizeof( peer );
11 rc = recvfromt 0, buf + pidsz, sizeof( buf
) - pidsz, 0,
12 ( struct sockaddr * )&peer, &len);
13 if ( rc <= 0 )
14 exit ( 1 ) ;
15 sendto( 1, buf, re + pidsz, 0,
16 (struct sockaddr * )&peer, len);
17 exit( 0 );
18 }
updecho1
9 Получаем идентификатор процесса сервера (PID)
от операционной системы, преобразуем его в код ASCII и помещаем в начало буфера
ввода/вывода.
10-14 Читаем датаграмму от клиента и размещаем ее
в буфере после идентификатора процесса. 15-17 Возвращаем клиенту ответ и завершаем
сеанс.
Для экспериментов с этим сервером воспользуемся
простым клиентом, код которого приведен в листинге 3.5. Он читает запросы из
стандартного ввода, отсылает их серверу и печатает ответы на стандартном выводе.
Листинг 3.5. Простой UDP-клиент
udpclient.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
з {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rc = 0;
7 int len;
8 char buf[ 120 ];
9 INIT();
10 s = udp_client( argv[ 1 ], argvf 2 ], &peer
);
11 while ( fgets( buf, sizeof'( buf ), stdin
) != NULL )
12 {
13 rc = sendto( s, buf, strlenf buf ), 0,
14 (struct sockaddr * )&peer, sizeof(
peer ) );
15 if ( rc < 0 )
16 error( 1, errno, "ошибка вызова sendto"
);
17 len = sizeof( peer );
18 rc = recvfrom( s, buf, sizeof( buf ) -
1, 0,
19 (struct sockaddr * )&peer, &len
);
20 if ( rc < 0 )
21 error( 1, errno, "ошибка вызова recvfrom"
);
22 buff [rc ] = '\0';
23 fputsf (buf, stdout);
24 }
25 EXIT( 0 ) ;
26 }
10 Вызываем функцию udp_client, чтобы она поместила
в структуру peer адрес сервера и получила UDP-сокет.
11-16 Читаем строку из стандартного ввода и посылаем
ее в виде UDP-датаграммы хосту и в порт, указанные в командной строке.
17-21 Вызываем recvfrom для чтения ответа сервера
и в случае ошибки завершаем сеанс.
22-23 Добавляем в конец ответа двоичный нуль и
записываем строку на стандартный вывод.
В отношении программы udpclient можно сделать два
замечания:
- в реализации клиента предполагается, что
он всегда получит ответ от сервера. Как было сказано в совете 1, нет гарантии,
что посланная сервером датаграмма будет доставлена. Поскольку udpclient -
это интерактивная программа, ее всегда можно прервать и запустить заново,
если она «зависнет» в вызове recvfrom. Но если бы клиент не был интерактивным,
нужно было бы взвести таймер, чтобы предотвратить потери датаграмм;
Примечание: В сервере udpechol об этом не
нужно беспокоиться, так как точно известно, что датаграмма уже пришла (иначе
inetd не запустил бы сервер). Однако уже в следующем примере (листинг 3.6) приходится
думать о потере датаграмм, так что таймер ассоциирован с recvfrom.
- при работе с сервером udpechol не нужно
получать адрес и порт отправителя, так как они уже известны. Поэтому строки
18 и 19 можно было бы заменить на:
rc = recvfrom( s, buf, sizeof( buf ) - 1, 0, NULL,
NULL );
Но, как показано в следующем примере, иногда клиенту
необходимо иметь информацию, с какого адреса сервер послал ответ, поэтому приведенные
здесь UDP-клиенты всегда извлекают адрес.
Для тестирования сервера добавьте в файл /etc/inetd.conf
на машине bsd строку
udpecho dgram udp wait jcs /usr/home/jcs/udpechod
udpechod,
а в файл /etc/services – строку
udpecho 8001/udp
Затем переименуйте udpechol в udpechod и заставьте
программу inetd перечитать свой конфигурационный файл. При запуске клиента udpclient
на машине sparc получается:
sparc: $ udpclient bed udpeoho
one
28685: one
two
28686: two
three
28687: three
^C
spare: $
Этот результат демонстрирует важную особенность
UDP-серверов: они обычно ведут диалог с клиентом. Иными словами, сервер получает
один запрос и посылает один ответ. Для UDP-серверов, запускаемых через inetd,
типичными будут следующие действия: получить запрос, отправить ответ, выйти.
Выходить нужно как можно скорее, поскольку inetd не будет ждать других запросов,
направленных в порт этого сервера, пока тот не завершит сеанс.
Из предыдущей распечатки видно, что, хотя складывается
впечатление, будто udpclient ведет с udpechol диалог, в действительности каждый
раз вызывается новый экземпляр сервера. Конечно, это неэффективно, но важнее
то, что сервер не запоминает информации о состоянии диалога. Для udpechol это
несущественно так как каждое сообщение - это, по сути, отдельная транзакция.
Но так бывает не всегда. Один из способов решения этой проблемы таков: сервер
принимает сообщение от клиента (чтобы избежать бесконечного цикла), затем соединяется
с ним, получая тем самым новый (эфемерный) порт, создает новый процесс и завершает
работу. Диалог с клиентом продолжает созданный вновь процесс.
Примечание: Есть и другие возможности. Например,
сервер мог бы обслуживать нескольких клиентов. Принимая датаграммы от нескольких
клиентов, сервер амортизирует накладные расходы на свой запуск и не завершает
сеанс, пока не обнаружит, что долго простаивает без дела. Преимущество этого
метода в некотором упрощении клиентов за счет усложнения сервера.
Чтобы понять, как это работает, внесите в код udpechol
изменения, представленные в листинге 3.6.
Листинг 3.6. Вторая версия udpechod
udpecho2.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 int s;
6 int rc;
7 int len;
8 int pidsz;
9 char buf[ 120 ] ;
10 pidsz = sprintf( buf, "%d: ", getpid()
);
11 len = sizeof( peer );
12 rc = recvfrom( 0, buf + pidsz, sizeof( buf
) - pidsz,
13 0, ( struct sockaddr * )&peer, &len
);
14 if ( rc < 0 )
15 exit ( 1 );
16 s = socket( AF_INET, SOCK_DGRAM, 0 );
17 if ( s < 0 )
18 exit( 1 ) ;
19 if ( connect( s, ( struct sockaddr * )&peer,
len ) < 0)
20 exit (1);
21 if ( fork() != 0 ) /* Ошибка или родительский
процесс? */
22 exit( 0 ) ;
23 /* Порожденный процесс. */
24 while ( strncmp( buf + pidsz, "done",
4 ) != 0 )
25 {
26 if ( write( s, buf, re + pidsz ) < 0
)
27 break;
28 pidsz = sprintf( buf, "%d: ",
getpid() );
29 alarm( 30 );
30 rc = read( s, buf + pidsz, sizeof(
buf ) - pidsz );
31 alarm( 0 );
32 if ( re < 0)
33 break;
34 }
35 exit( 0 );
36 }
udpecho2
10-15 Получаем идентификатор процесса, записываем
его в начало буфера и читаем первое сообщение так же, как в udpechol.
16-20 Получаем новый сокет и подсоединяем его к
клиенту, пользуясь адресом в структуре peer, которая была заполнена при вызове
recvfrom.
21-22 Родительский процесс разветвляется и завершается.
В этот момент inetd может возобновить прослушивание хорошо известного порта
сервера в ожидании новых сообщений. Важно отметить, что потомок использует номер
порта new, привязанный к сокету s в результате вызова connect.
24-35 Затем посылаем клиенту полученное от него
сообщение, только с добавленным в начало идентификатором процесса. Продолжаем
читать сообщения от клиента, добавлять к ним идентификатор процесса-потомка
и отправлять их назад, пока не получим сообщение, начинающееся со строки done.
В этот момент сервер завершает работу. Вызовы alarm, окружающие операцию чтения
на строке 30, - это защита от клиента, который закончил сеанс, не послав done.
В противном случае сервер мог бы «зависнуть» навсегда. Поскольку установлен
обработчик сигнала SIGALRM, UNIX завершает программу при срабатывании таймера.
Переименовав новую версию исполняемой программы
в udpechod и запустив ее. вы получили следующие результаты:
sparc: $ udpclient bad udpecho
one
28743: one
two
28744: two
three
28744: three
done
^C
sparc: $
На этот раз, как видите, в первом сообщении пришел
идентификатор родительского процесса (сервера, запущенного inetd), а в остальных
- один и тот же идентификатор (потомка). Теперь вы понимаете, почему udpclient
всякий раз извлекает адрес сервера: ему нужно знать новый номер порта (а возможно,
и новый IP-адрес если сервер работает на машине с несколькими сетевыми интерфейсами),
в который посылать следующее сообщение. Разумеется, это необходимо делать только
для первого вызова recvfrom, но для упрощения здесь не выделяется особый случай.
В этом разделе показано, как заставить приложение
работать в сети, приложив совсем немного усилий. Демон inetd берет на себя ожидание
соединений или датаграмм, дублирует дескриптор сокета на stdin, stdout и stderr
и запускает приложение. После этого приложение может просто читать из stdin
или писать в stdout либо stderr, не имея информации о том, что оно работает
в сети. Рассмотрен пример простого фильтра, в котором вообще нет кода, имеющего
отношение к сети. Но этот фильтр тем не менее прекрасно работает в качестве
сетевого сервиса, если запустить его через inetd.
Здесь также приведен пример UDP-сервера, который способен вести продолжительный
диалог с клиентами. Для этого серверу пришлось получить новый сокет и номер
порта, а затем создать новый процесс и выйти.
Проектировщик сетевого сервера сталкивается с проблемой
выбора номера для хорошо известного порта. Агентство по выделению имен и уникальных
параметров протоколов Internet (Internet Assigned Numbers Authority - IANА)
подразделяет все номера портов на три группы: «официальные» (хорошо известные),
зарегистрированные и динамические, или частные.
Примечание: Термин «хорошо известный порт» используется
в общем смысле — как номер порта доступа к серверу. Строго говоря, хорошо известные
порты контролируются агентством IANA.
Хорошо известные - это номера портов в диапазоне
от 0 до 1023. Они контролируются агентством IANA. Зарегистрированные номера
портов находятся в диапазоне от 1024 до 49151. IANA не контролирует их, но регистрирует
и публикует в качестве услуги сетевому сообществу. Динамические или частные
порты имею номера от 49152 до 65535. Предполагается, что эти порты будут использоваться
как эфемерные, но многие системы не следуют этому соглашению. Так, системы,
производные от BSD, традиционно выбирают номера эфемерных портов из диапазона
от 1024-5000. Полный список всех присвоенных IANA и зарегистрированных номеров
портов можно найти на сайте http://www.isi.edu/in-notes/iana/ assignment/port-numbers/.
Проектировщик сервера может получить от IANA зарегистрированный
номер порта.
Примечание: Чтобы подать заявку на получение хорошо
известного или зарегистрированного номера порта, зайдите на Web-страницуhttp://www.isi.edu/cgi-bin/iana/port-numbers.pl.
Это, конечно, не помешает другим использовать тот
же номер, и рано или поздно два сервера, работающие с одним и тем же номером
порта, окажутся на одной машине. Обычно эту проблему решают, выделяя некоторый
номер порта по умолчанию, но позволяя задать другой в командной строке.
Другое более гибкое решение, но применяемое реже,
состоит в том, чтобы использовать возможность inetd (совет 17), которая называется
мультиплексором портов TCP (TCP Port Service Multiplexor - TCPMUX). Сервис TCPMUX
описан в RFC 1078 [Letter 1988]. Мультиплексор прослушивает порт 1 в ожидании
TCP-соединений. Клиент соединяется с TCPMUX и посылает ему строку с именем
сервиса, который он хочет запустить. Строка должна завершаться символами возврата
каретки и перевода строки (<CR><LF>). Сервер или, возможно, TCPMUX
посылает клиенту один символ: + (подтверждение) или - (отказ), за которым следует
необязательное пояснительное сообщение, завершаемое последовательностью <CR><LF>.
Имена сервисов (без учета регистра) также хранятся в файле inetd. conf, но начинаются
со строки tcpmux/, чтобы отличить их от обычных сервисов. Если имя сервиса начинаются
со знака +, то подтверждение посылает TCPMUX, а не сервер. Это позволяет таким
серверам, как rlnumd (листинг 3.3), которые проектировались без учета TCPMUX,
все же воспользоваться предоставляемым им сервисом.
Например, если вы захотите запустить сервис подсчета
строк из совета 17 в качестве TCPMUX-сервера, то надо добавить в файл inetd.
conf строку
tcpmux/+rlnumd stream tcp nowait jcs /usr/jome/jcs/rlnumd
rlnumd
Для тестирования заставьте inetd перечитать свой
конфигурационный файл, а затем подсоединитесь к нему с помощью telnet, указав
имя сервиса TCPMUX:
bsd: $ telnet localhost tcpmux
Trying 127.0.0.1 ...
Connected to localhost
Escape character is "^]".
rlnumd
+Go
hello
1: hello
world
2: world А]
telnet> quit
Connection closed
bsd: $
К сожалению, сервис TCPMUX поддерживается не всеми
операционными системами и даже не всеми UNIX-системами. Но, с другой стороны,
его реализация настолько проста, что возможно написать собственную версию. Поскольку
TCPMUX должен делать почти то же, что и inetd (за исключением мониторинга нескольких
шкетов), заодно будут проиллюстрированы те идеи, которые лежат в основе inetd.
Начнем с определения констант, глобальных переменных и функции main (листинг
3.7).
Листинг 3.7. tcpmux - константы, глобальные переменные
и main
tcpmux.с
1 #include"etcp.h"
2 #define MAXARGS 10 /*Максималиное число аргументов
сервера.*/
3 #define MAXLINE 256 /*Максимальная длина строки
в tcpmux.conf.*/
4 #define NSERVTAB 10 /*Число элементов в таблице
service_table.*/
5 #define CONFIG “tcpmux.conf”
6 typedef struct
7 {
8 int flag;
9 char *service;
10 char *path;
11 char *args[ MAXARGS + 1 ];
12 } servtab_t;
13 int ls; /* Прослушиваемый сокет. */
14 servtab_t service_table[ NSERVTAB + 1 ];
15 int main( int argc, char **argv )
16 {
17 struct sockaddr_in peer;
18 int s;
19 int peerlen;
20 /* Инициализировать и запустить сервер tcpmux.
*/
21 INIT ();
22 parsetab ();
23 switch ( argc }
24 {
25 case 1: /* Все по умолчанию. */
26 ls = tcp_server( NULL, "tcpmux"
);
27 break;
28 case 2 /* Задан интерфейс и номер порта.
*/
29 ls = tcp_server( argv[ 1 ], "tcpmux"
);
30 break;
31 case 3: /* Заданы все параметры. */
32 ls = tcp_server( argv[ 1 ], argv[ 2 ] );
33 break;
34 default:
35 error( 1, 0, "Вызов: %s [ интерфейс
[ порт ] ]\n",
36 program_name );
37 }
38 daemon( 0, 0 );
39 signal( SIGCHLD, reaper ) ;
40 /* Принять соединения с портом tcpmux. */
41 for ( ; ; )
42 {
43 peerlen = sizeof( peer );
44 s = accept( ls, (struct sockaddr * )&peer,
&peerlen ) ;
45 if ( s < 0 }
46 continue;
47 start_server( s );
48 CLOSE( s );
49 }
50 }
main
6-12 Структура servtab_t определяет тип элементов
в таблице service_table. Поле flag устанавливается в TRUE, если подтверждение
должен посылать tcpmux, а не сам сервер.
22 В начале вызываем функцию parsetab, которая читает
и разбирает файл tcpmux. conf и строит таблицу service_table. Текст процедуры
parsetab приведен в листинге 3.9.
23-37 Данная версия tcpmux позволяет пользователю
задать интерфейс или порт, который будет прослушиваться. Этот код инициализирует
сервер с учетом заданных параметров, а остальным присваивает значения по умолчанию.
38 Вызываем функцию daemon, чтобы перевести процесс
tcpmux в фоновый режим и разорвать его связь с терминалом.
39 Устанавливаем обработчик сигнала SIGCHLD. Это
не дает запускаемым серверам превратиться в «зомби» (и зря расходовать системные
ресурсы) при завершении.
Примечание: В некоторых системах функция signal
- это интерфейс к сигналам со старой «ненадежной» семантикой. В этом случае
надо пользоваться функцией sigaction, которая обеспечивает семантику надежных
сигналов. Обычно эту проблему решают путем создания собственной функции signal,
которая вызываетиз себя sigaction. Такая реализация приведена в приложении 1.
41-49 В этом цикле принимаются соединения с tcpmux
и вызывается функция start_server, которая создает новый процесс с помощью fork
и запускает запрошенный сервер с помощью ехес.
Теперь надо познакомимся с функцией start_server
(листинг 3.8). Именно здесь выполняются основные действия.
Листинг 3.8. Функция start_server
tcpmux.c
1 static void start_server( int s )
2 {
3 char line[ MAXLINE ];
4 servtab_t *stp;
5 int re;
6 static char errl[] = "-не могу прочесть
имя сервиса \r\n";
7 static char err2[ ] = "-неизвестный сервис\г\п";
8 static char еrrЗ[] = "-не могу запустить
сервис\г\п";
9 static char ok [ ] = "+OK\r\n";
10 rc = fork();
11 if(rc<0) /* Ошибка вызова fork. */
12 {
13 write( s, еrrЗ, sizeof( еrrЗ ) - 1 ) ;
14 return;'
15 }
16 if ( rc != 0 ) /* Родитель. */
17 return;
18 /* Процесс-потомок. */
19 CLOSE( ls ); /* Закрыть прослушивающий
сокет. */
20 alarm( 10 );
21 rc = readcrlf( s, line, sizeof( line ) );
22 alarm( 0 );
23 if ( rc <= 0 )
24 {
25 write( s, errl, sizeoff errl ) - 1 );
26 EXIT( 1 ) ;
27 }
28 for ( stp = service_table; stp->service;
stp+ + )
29 if ( strcasecmp( line, stp->service )
== 0 )
30 break;
31 if ( !stp->service )
32 {
33 write( s, err2, sizeof( err2 ) - 1 );
34 EXIT( 1 ) ;
35 }
36 if ( stp->flag )
37 if ( write( s, ok, sizeof( ok } - 1 ) <
0 )
38 EXIT( 1 );
39 dup2 ( s , 0 ) ;
40 dup2( s, 1 } ;
41 dup2( s, 2 ) ;
42 CLOSE( s ) ;
43 execv( stp->path, stp->args );
44 write( 1, еrrЗ, sizeof ( еrrЗ ) - 1 );
45 EXIT( 1 );
46 }
start_server
10-17 Сначала с помощью системного вызова fork создаем
новый процесс, идентичный своему родителю. Если fork завершился неудачно, то
посылаем клиенту сообщение об ошибке и возвращаемся (раз fork не отработал,
то процесса-потомка нет, и управление возвращается в функцию main родительского
процесса). Если fork завершился нормально, то это родительский процесс, и управление
возвращается.
19-27 В созданном процессе закрываем прослушивающий
сокет и из подсоединенного сокета читаем имя сервиса, которому нужно запустить
клиент. Окружаем операцию чтения вызовами alarm, чтобы завершить работу, если
клиент так и не пришлет имя сервиса. Если функция reader If возвращает ошибку,
посылаем клиенту сообщение и заканчиваем сеанс. Текст readcrlf приведен ниже
в листинге 3.10.
28-35 Ищем в таблице service_table имя запрошенного
сервиса. Если оно отсутствует, то посылаем клиенту сообщение об ошибке и завершаем
работу.
36-38 Если имя сервиса начинается со знака +, посылаем
клиенту подтверждение. В противном случае даем возможность сделать это серверу.
39-45 С помощью системного вызова dup дублируем
дескриптор сокета на stdin, stdout и stderr, после чего закрываем исходный сокет.
И, наконец, подменяем процесс процессом сервера с помощью вызова execv. После
этого запрошенный клиентом сервер - это процесс-потомок. Если execv возвращает
управление, то сообщаем клиенту, что не смогли запустить запрошенный сервер,
и завершаем сеанс.
В листинге 3.9 приведен текст подпрограммы parsetab.
Она выполняет простой, но несколько утомительный разбор файла tcpmux. conf.
Файл имеет следующий формат:
имя_сервиса путь аргументы ...
Листинг 3.9. Функция parsetab
tcpmux.с
1 static void parsetab( void )
2 {
3 FILE *fp;
4 servtab_t *stp = service_table;
5 char *cp;
6 int i;
7 int lineno;
8 char line[ MAXLINE ];
9 fp = fopen( CONFIG, "r" );
10 if ( fp == NULL )
11 error( 1, errno, "не могу открыть %s",
CONFIG );
12 lineno = 0;
13 while ( fgets( line, sizeof( line ), fp )
!= NULL )
14 {
15 lineno++;
16 if ( line[ strlen( line ) - 1 ] != '\n'
)
17 error( 1, 0, "строка %d слишком длинная\п",
lineno );
18 if ( stp >= service_table + NSERVTAB
)
19 error( 1, 0, "слишком много строк
в tcpmux.conf\n" );
20 cp = strchr( line, '#' );
21 if ( cp != NULL )
22 *cp = '\0';
23 cp = strtok( line, " \t\n" ) ;
24 if ( cp == NULL )
25 continue;
26 if ( *cp =='+')
28 stp->flag = TRUE;
29 cp++;
30 if ( *cp == '\0' || strchrf " \t\n",
*cp ) != NULL )
31 error( 1, 0, "строка %d: пробел после
‘+’'\n",
32 lineno );
34 stp->service = strdup( cp );
35 if ( stp->service == NULL )
36 error( 1, 0, "не хватило памяти\n"
);
37 cp = strtok( NULL, " \t\n" );
38 if ( cp == NULL)
39 error( 1, 0, "строка %d: не задан
путь (%s)\n",
40 lineno, stp->service );
41 stp->path = strdup( cp );
42 if ( stp->path == NULL )
43 error( 1, 0, "не хватило памяти\n"
);
44 for ( i = 0; i < MAXARGS; i++ )
45 {
46 cp = strtok( NULL, " \t\n" );
47 if ( cp == NULL )
48 break;
49 stp->args[ i ] = strdup( cp );
50 if ( stp->args[ i ] == NULL )
51 error( 1, 0, "не хватило памяти\n"
);
53 if ( i >= MAXARGS && strtok(
NULL, " \t\n" ) != NULL)
54 error( 1, 0, "строка %d: слишком
много аргументов (%s) \n,
55 lineno, stp->service );
56 stp->args[ i ] = NULL;
57 stp++;
58 }
59 stp->service = NULL;
60 fclose ( fp );
61 }
Показанная в листинге 3.10 функция readcrlf читает
из сокета по одному байту. Хотя это и неэффективно, но гарантирует, что будет
прочитана только первая строка данных, полученных от клиента. Все данные, кроме
первой строки, предназначены серверу. Если бы вы буферизовали ввод, а клиент
послал бы больше одной строки, то часть данных, адресованных серверу, считывал
бы tcpmux, и они были бы потеряны.
Обратите внимание, что readcrlf принимает также
и строку, завершающуюся только символом новой строки. Это находится в полном
соответствии с принципом устойчивости [Postel 1981a], который гласит: «Подходите
не слишком строго к тому, что принимаете, но очень строго - к тому, что посылаете».
В любом случае как <CR><LF>, так и одиночный <LF> отбрасываются.
Определение функции readcrlf такое же, как функций
read, readline, readn и readvrec:
#include "etcp.h"
int readcrlf( SOCKET
s, char *buf, size_t len );
Возвращаемое значение: число прочитанных байт или -1 в
случае ошибки.
Листинг 3.10. Функция readcrlf
readcrlf. с
1 int readcrlf( SOCKET s, char *buf, size_t
len )
2 {
3 char *bufx = buf;
4 int rc;
5 char с;
6 char lastc = 0;
7 while ( len > 0 )
8 {
9 if ( ( rc = recv( s, &c, 1, 0 ) ) !=1)
10 {
11 /*
12 *Если нас прервали, повторим,
13 *иначе вернем EOF или код ошибки.
14 */
15 if ( гс < 0 && errno = EINTR
)
16 continue;
17 return rc;
18 }
19 if ( с = '\n' )
20 {
21 if ( lastc == '\r' )
22 buf--;
23 *buf = '\0'; /* He включать <CR><LF>.
*/
24 return buf - bufx;
25 }
26 *buf++ = c;
27 lastc = c;
28 len--;
29 }
30 set_errno( EMSGSIZE );
31 return -1;
32 }
И наконец рассмотрим функцию reaper (листинг 3.11).
Когда сервер, запущенный с помощью tcpmux, завершает сеанс, UNIX посылает родителю
(то есть tcpmux) сигнал SIGCHLD. При этом вызывается обработчик сигнала reaper,
который, в свою очередь, вызывает waitpid для получения статуса любого из завершившихся
потомков. В системе UNIX это необходимо, поскольку процесс-потомок может возвращать
родителю свой статус завершения (например, аргумент функции exit).
Примечание: В некоторых вариантах UNIX потомок
возвращает и другую информацию. Так, в системах, производных от BSD, возвращается
сводная информация о количестве ресурсов, потребленных завершившимся процессом
и всеми его потомками. Во всех системах UNIX, no меньшей мере, возвращается
указание на то, как завершился процесс: из-за вызова exit (передается также
код возврата) или из-за прерывания сигналом (указывается номер сигнала).
Пока родительский процесс не заберет информацию
о завершении потомка с помощью вызова wait или waitpid, система UNIX должна
удерживать ту часть ресурсов, занятых процессом-потомком, в которой хранится
информация о состоянии. Потомки, которые уже завершились, но еще не передали
родителю информацию о состоянии, называются мертвыми (defunct) или «зомби».
Листинг 3.11. Функция reaper
tcpmux.c
1 void reaper( int sig )
2 {
3 int waitstatus;
4 while ( waitpid( -1, &waitstatus, WNOHANG
) > 0 ) {;}
5 }
Протестируйте tcpmux, создав файл tcpmux.conf из
одной строки:
+rlnum /usr/hone/jcs/rlnumd rlnumd
Затем запустите tcpmux на машине spare, которая
не поддерживает сервиса TCPMUX, и соединитесь с ним, запустив telnet на машине
bsd.
spare: # tcpmux
bsd: $ telnet spare tcpmux
Trying 127.0.0.1 ...
Connected to spare
Escape character is ‘^]’.
rlnumd
+OK
hello
1: hello
world
2: world
^]
telnet> quit
Connection closed
bsd: $
Сервис TCPMUX, имеющийся на очень многих системах,
помогает решить проблему выбора хорошо известного номера порта сервера. Здесь
реализована собственная версия демона tcpmux, так что если в какой-то системе
его нет, то им можно воспользоваться.
Во многих приложениях удобно разрешить нескольким
процессам или потокам читать из TCP-соединений и писать в них. Особенно распространена
эта практика в системе UNIX, где по традиции создается процесс-потомок, который,
например, пишет в TTY-соединение, тогда как родитель занимается чтением.
Типичная ситуация изображена на рис. 3.3, где показан
эмулятор терминала. Родительский процесс большую часть времени блокирован в
ожидании ввода из TTY-соединения. Когда на вход поступают данные, родитель читает
их и выводит на экран, возможно, изменяя на ходу формат. Процесс-потомок в основном
блокирован, ожидая ввода с клавиатуры. Когда пользователь вводит данные, потомок
выполняет необходимые преобразования и записывает данные в TTY-соединение.
Эта стратегия удобна, поскольку позволяет автоматически
мультиплексировать ввод с клавиатуры и из TTY-соединения и разнести логику преобразования
кодов клавиш и форматирования вывода на экран по разным модулям. За счет этого
программа получается концептуально проще, чем в случае нахождения кода
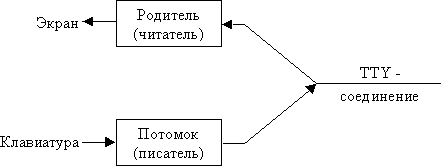
Рис. 3.3. Два процесса, обслуживающие TTY-соединение
в одном месте. В действительности, до появления
в операционной системе механизма select это был единственный способ обработки
поступления данных из нескольких источников.
Следует заметить, что ничего не изменится, если
на рис. 3.3 вместо TTY-coединения будет написано TCP-соединение. Поэтому та
же техника может применяться (и часто применяется) для работы с сетевыми соединениями.
Кроме того, использование потоков вместо процессов почти не сказывается на ситуации,
изображенной на рисунке, поэтому этот метод пригоден и для многопоточной среды.
Правда, есть одна трудность. Если речь идет о TTY-соединении,
то ошибки при операции записи возвращаются самим вызовом write, тогда как в
случае TCP ошибка, скорее всего, будет возвращена последующей операцией чтения
(совет 15). В много процессной архитектуре процессу-читателю трудно уведомить
процесс-писатель об ошибке. В частности, если приложение на другом конце завершается,
то об этом узнает читатель, который должен как-то известить писателя.
Немного изменим точку зрения и представим себе
приложение, которое принимает сообщения от внешней системы и посылает их назад
по TCP-соединению. Сообщения передаются и принимаются асинхронно, то есть не
для каждого входного сообщения генерируется ответ, и не каждое выходное сообщение
посылается в ответ на входное. Допустим также, что сообщения нужно переформатировать
на
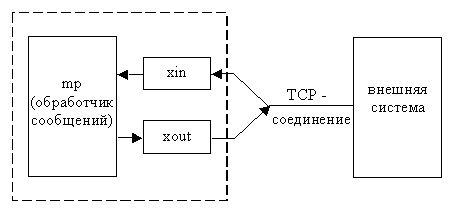
Рис. 3.4. Приложение, обменивающиеся сообщениями по TCP-соединению
входе или выходе из приложения. Тогда представленная
на рис. 3.4 архитектура многопроцессного приложения оказывается вполне разумной.
На этом рисунке процесс xin читает данные от внешней
системы, накапливает их в очереди сообщений, переформатирует и передает главному
процессу обработки сообщений. Аналогично процесс xout приводит выходное сообщение
к формату, требуемому внешней системой, и записывает данные в TCP-соединение.
Главный процесс mp обрабатывает отформатированные входные сообщения и генерирует
выходные сообщения. Оставляем неспецифицированным механизм межпроцессного взаимодействия
(IPC) между тремя процессами. Это может быть конвейер, разделяемая память, очереди
сообщений или еще что-то. Подробнее все возможности рассмотрены в книге [Stevens
1999]. В качестве реального примера такого рода приложения можно было бы привести
шлюз, через который передаются сообщения между системами. Причем одна из систем
работает по протоколу TCP, а другая - по какому-либо иному протоколу.
Если обобщить этот пример, учитывая дополнительные
внешние системы с иными требованиями к формату сообщений, то становится ясно,
насколько гибкие возможности предоставляет описанный метод. Для каждого внешнего
хоста имеется свой набор коммуникационных процессов, работающих только с его
сообщениями. Такая система концептуально проста, позволяет вносить изменения,
относящиеся к одному из внешних хостов, не затрагивая других, и легко конфигурируется
для заданного набора внешних хостов - достаточно лишь запустить свои коммуникационные
процессы для каждого хоста.
Однако при этом остается нерешенной вышеупомянутая
проблема: процесс-писатель не может получить сообщение об ошибке после операции
записи. А иногда у приложения должна быть точная информация о том, что внешняя
система действительно получила сообщение, и необходимо организовать протокол
подтверждений по типу того, что обсуждался в совете 9. Это означает, что нужно
либо создать отдельный коммуникационный канал между процессами xin и xout, либо
xin должен посылать информацию об успешном получении и об ошибках процессу mp,
который, в свою очередь, переправляет их процессу xout. To и другое усложняет
взаимодействие процессов.
Можно, конечно, отказаться от многопроцессной архитектуры
и оставить всего один процесс, добавив select для мультиплексирования сообщений.
Однако при этом приходится жертвовать гибкостью и концептуальной простотой.
Далее в этом разделе рассмотрим альтернативную
архитектуру, при которой сохраняется гибкость, свойственная схеме на рис. 3.4,
но каждый процесс самостоятельно следит за своим TCP-соединением.
Процессы xin и xout на рис. 3.4 делят между собой
единственное соединение с внешней системой, но возникают трудности при организации
разделения информации о состоянии этого соединения. Кроме того, с точки зрения
каждого из процессов xin и xout, это соединение симплексное, то есть данные
передаются по Нему только в одном направлении. Если бы это было не так, то xout
«похищал» бы входные данные у xin, a xin мог бы исказить данные, посылаемые
xout.
Решение состоит в том, чтобы завести два соединения
с внешней системой -по одному для xin и xout. Полученная после такого изменения
архитектура изображена на рис. 3.5.
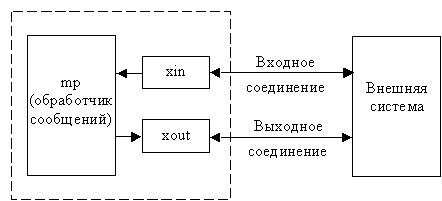
Рис.3.5. Приложение, обменивающееся сообщениями по двум TCP-соединениям
Если система не требует отправки подтверждений
на прикладном уровне, то при такой архитектуре выигрывает процесс xout, который
теперь имеет возможность самостоятельно узнавать об ошибках и признаке конца
файла, посланных партнером. С другой стороны, xout становится немного сложнее,
поскольку для получения уведомления об этих событиях он должен выполнять операцию
чтения. К счастью, это легко можно обойти с помощью вызова select.
Чтобы это проверить, запрограммируем простой процесс
xout, который читает данные из стандартного ввода и записывает их в TCP-соединение.
Программа, показанная в листинге 3.12, с помощью вызова select ожидает поступления
данных из соединения, хотя реально может прийти только EOF или извещение об
ошибке.
Листинг 3.12. Программа, готовая к чтению признака
конца файла или ошибки
xout1.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 fd_set allreads;
5 fd_set readmask;
6 SOCKET s;
7 int rc;
8 char buf [ 128 ] ;
9 INIT () ;
10 s = tcp_client( argv [ 1 ], argv[ 2 ]
);
11 FD_ZERO( kallreads );
12 FD_SET( s, &allreads );
13 FD_SET( 0, &allreads );
14 for ( ; ; )
15 {
16 readmask = allreads;
17 rc = select(s + 1, &readmask, NULL,
NULL, NULL );
18 if ( re <= 0)
19 error( 1, rc ? errno : 0, "select
вернул %d", rc );
20 if ( FD_ISSET( 0, &readmask ) }
21 {
22 rc = read( 0, buf, sizeof( buf ) - 1 );
23 if ( rc < 0 )
24 error( 1, errno, "ошибка вызова read"
};
25 if ( send( s, buf, rc, 0 ) < 0 )
26 error( 1, errno, "ошибка вызова send"
);
27 }
28 if ( FD_ISSET( s, &readmask ) )
29 {
30 rc = recv( s, buf, sizeof( buf ) - 1, 0
);
31 if ( rc == 0 )
32 error( 1, 0, "сервер отсоединился\n"
);
33 else if ( rc < 0 )
34 error( 1, errno, "ошибка вызова recv"
);
35 else
36 {
37 buf[ rc ] = '\0';
38 error( 1, 0, "неожиданный вход [%s]\n",
buf );
39 }
40 }
41 }
42 }
Инициализация
9-13 Выполняем обычную инициализацию, вызываем функцию
tcp_client для установки соединения и готовим select для извещения о наличии
входных данных в стандартном вводе или в только что установленном TCP-соединении.
Обработка событий stdin
20-27 Если данные пришли из стандартного ввода,
посылаем их удаленному хосту через TCP-соединение.
Обработка событий сокета
28-40 Если пришло извещение о наличии доступных
для чтения данных в сокете, то проверяем, это EOF или ошибка. Никаких данных
по этому соединению не должно быть получено, поэтому если пришло что-то иное,
то печатаем диагностическое сообщение и завершаем работу.
Продемонстрировать работу xout1 можно, воспользовавшись
программой keep (листинг 2.30) в качестве внешней системы и простым сценарием
на языке интерпретатора команд shell для обработки сообщений (mр на рис. 3.5).
Этот сценарий Каждую секунду выводит на stdout слово message и счетчик.
MSGNO=1
while true
do
echo message $MSGNO
sleep 1
MSGNO="expr $MSGNO + 1"
done
Обратите внимание, что в этом случае xoutl использует
конвейер в качестве механизма IPC. Поэтому в таком виде программа xoutl не переносится
на платформу Windows, поскольку вызов select работает под Windows только для
сокетов. Можно было бы реализовать взаимодействие между процессами с помощью
TCP или UDP, но тогда потребовался бы более сложный обработчик сообщений.
Для тестирования xoutl запустим сначала «внешнюю
систему» в одном окне, а обработчик сообщений и xoutl - в другом.
|
bsd: $ keep 9000
message 1
message 2
message 3
message 4
^C"Внешняя система"
завершила работу
bsd: $
|
bsd: $ mp I xoutl localhost 9000
xoutl: сервер отсоединился
Broken pipe
bsd: $
|
Сообщение Broken pipe напечатал сценарий mp. При
завершении программы xoutl конвейер между ней и сценарием закрывается. Когда
сценарий пытается записать в него следующую строку, происходит ошибка, и сценарий
завершается с сообщением Broken pipe.
Более интересна ситуация, когда между внешней системой
и приложением, обрабатывающим сообщения, необходим обмен подтверждениями. В
этом случае придется изменить и xin, и xout (предполагая, что подтверждения
нужны в обоих направлениях; если нужно только подтверждать внешней системе прием
сообщений, то изменения надо внести лишь в xin). Разработаем пример только процесса-писателя
(xout). Изменения в xin аналогичны.
Новый процесс-писатель обязан решать те же проблемы,
с которыми вы столкнулись при обсуждении пульсаций в совете 10. После отправки
сообщения удаленный хост должен прислать нам подтверждение до того, как сработает
таймер. Если истекает тайм-аут, необходима какая-то процедура восстановления
после ошибки. В примере работа просто завершается.
При разработке нового «писателя» xout2 вы не будете
принимать сообщений из стандартного ввода, пока не получите подтверждения от
внешней системы о том, что ей доставлено последнее ваше сообщение. Возможен
и более изощренный подход с использованием механизма тайм-аутов, описанного
в совете 20. Далее он будет рассмотрен, но для многих систем вполне достаточно
той простой схемы, которую будет применена. Текст xout2 приведен в листинге
3.13.
Листинг 3.13. Программа, обрабатывающая подтверждения
xout2.с
1 #include "etcp.h"
2 #define АСК 0х6 /*Символ подтверждения АСК.
*/
3 int main( int argc, char **argv)
4 {
5 fd_set allreads;
6 fd_set readmask;
7 fd_set sockonly;
8 struct timeval tv;
9 struct timeval *tvp = NULL;
10 SOCKET s;
11 int rc;
12 char buf[ 128 ];
13 const static struct timeval TO = {
2, 0 } ;
14 INIT();
15 s = tcp_client( argv[ 1 ], argv[ 2 ] );
16 FD_ZERO( &allreads );
17 FD_SET( s, &allreads ) ;
18 sockonly = allreads;
19 FD_SET( 0, &allreads );
20 readmask = allreads;
21 for ( ;; )
22 {
23 rc = select( s + 1, &readmask, NULL, NULL,
tvp );
24 if ( rc < 0 )
25 error( 1, errno, "ошибка вызова select"
);
26 if ( rc == 0 )
27 error( 1, 0, "тайм-аут при приеме сообщения\n"
);
28 if ( FD_ISSET( s, &readmask ) )
29 {
30 rc = recv( s, buf, sizeof( buf }, 0 );
31 if ( rc == 0 )
32 error( 1, 0, "сервер отсоединился\n"
);
33 else if ( rc < 0 )
34 error( 1, errno, "ошибка вызова
recv");
35 else if (rc != 1 || buf[ 0 ] != ACK)
36 error( 1, 0, "неожиданный вход [%c]\n",
buf[ 0 ] ) ;
37 tvp = NULL; /* Отключить таймер
*/
38 readmask = allreads; /* и продолжить чтение
из stdin. */
39 }
40 if ( FD_ISSET( 0, &readmask ) }
41 {
42 rc = read( 0, buf, sizeof( buf ) ) ;
43 if ( rc < 0 )
44 error( 1, errno, "ошибка вызова read"
);
45 if ( send( s, buf, rc, 0 ) < 0 )
46 error( 1, errno, "ошибка вызова send"
);
47 tv = T0; /* Переустановить таймер. */
48 tvp = &tv; /* Взвести таймер */
49 readmask = sockonly; /* и прекратить чтение
из stdin. */
50 }
51 }
52 }
Инициализация
14-15 Стандартная инициализация TCP-клиента.
16-20 Готовим две маски для select: одну для приема
событий из stdin и ТСР-сокета, другую для приема только событий из сокета. Вторая
маска sockonly применяется после отправки данных, чтобы не читать новые данные
из stdin, пока не придет подтверждение.
Обработка событий таймера
26-27 Если при вызове select произошел тайм-аут
(не получено вовремя подтверждение), то печатаем диагностическое сообщение и
завершаем сеанс,
Обработка событий сокета
28-39 Если пришло извещение о наличии доступных
для чтения данных в сокете, проверяем, это EOF или ошибка. Если да, то завершаем
работу так же, как в листинге 3.12. Если получены данные, убеждаемся, что это
всего один символ АСК. Тогда последнее сообщение подтверждено, поэтому сбрасываем
таймер, устанавливая переменную tvp в NULL, и разрешаем чтение из стандартного
ввода, устанавливая маску readmask так, чтобы проверялись и сокет, и stdin.
Обработка событий в stdin
40-66 Получив событие stdin, проверяем, не признак
ли это конца файла. Если чтение завершилось успешно, записываем данные в TCP-соединение.
47-50 Поскольку данные только что переданы внешней
системе, ожидается подтверждение. Взводим таймер, устанавливая поля структуры
tv и направляя на нее указатель tvp. В конце запрещаем события stdin,записывая
в переменную readmask маску sockonly.
Для тестирования программы xout2 следует добавить
две строки
if ( send( si, "\006", 1, 0 ) < 0
) /* \006 = АСК */
error( 1, errno, "ошибка вызова send");
перед записью на строке 24 в исходном тексте keep.
с (листинг 2.30). Если выполнить те же действия, как и для программы xoutl,
то получим тот же результат с тем отличием, что xout2 завершает сеанс, не получив
подтверждения от удаленного хоста
В этом разделе обсуждалась идея об использовании
двух соединений между приложениями. Это позволяет отслеживать состояние соединения
даже тогда, когда чтение и запись производятся в разных процессах.
В этом и следующем разделах будет рассказано об
использовании техники событийной управляемости в программировании TCP/IP. Будет
разработан универсальный механизм тайм-аутов, позволяющий указать программе,
что некоторое событие должно произойти до истечения определенного времени, и
асинхронно приступить к обработке этого события в указанное время. Здесь рассмотрим
реализацию механизма таймеров, а в совете 21 вернемся к архитектуре с двумя
соединениями и применим его на практике.
Разница между событийно-управляемым и обычным приложением
хорошо иллюстрируется двумя написанными ранее программами: hb_client2 (листинги
2.26 и 2.27) и tcprw (листинг 2.21). В tcprw поток управления последовательный:
сначала из стандартного ввода читается строка и передается удаленному хосту,
а затем от него принимается ответ и записывается на стандартный вывод. Обратите
внимание, что нет возможности ничего принять от удаленного хоста, пока ожидается
ввод из stdin. Как вы видели, в результате можно не знать, что партнер завершил
сеанс и послал ЕОЕ Ожидая также ответа от удаленного хоста, вы не можете читать
новые данные из stdin. Это значит, что приложение, с точки зрения пользователя,
слишком медленно реагирует. Кроме того, оно может «зависнуть», если удаленный
хост «падает» до того, как приложение ответило.
Сравните это поведение с работой клиента hb_client2,
который в любой момент способен принимать данные по любому соединению или завершиться
по тайм-ауту. Ни одно из этих событий не зависит от другого, именно поэтому
такая архитектура называется событийно-управляемой.
Заметим, что клиента hb_client2 можно легко обобщить
на большее число соединений или источников входной информации. Для этого существует
механизм select, который позволяет блокировать процесс в ожидании сразу нескольких
событий и возвращать ему управление, как только произойдет любое из них. В системе
UNIX этот механизм, а также родственный ему вызов poll, имеющийся в системах
на базе SysV, - это единственный эффективный способ обработки асинхронных событий
в немногопоточной среде.
Примечание: До недавнего времени считалось,
что из соображений переносимости следует использовать select, а не poll, так
как на платформе Windows, а равно в современных UNIX-системах поддерживается
именно select, тогда как poll встречается обычно в реализациях на базе SysV.
Однако некоторые большие серверные приложения (например, Web-серверы), поддерживающие
очень много одновременных соединений, применяют механизм poll, так как он лучше
масштабируется на большое число дескрипторов. Дело в том, что select ограничен
фиксированным числом дескрипторов. Обычно их не больше 1024, но бывает и меньше.
Так, в системе FreeBSD и производных от нее по умолчанию предел равен 256. Для
изменения значения по умолчанию нужно пересобирать ядро, что неудобно, хотя
и возможно. Но и пересборка ядра лишь увеличивает предел, а не снимает его.
Механизм же poll не имеет встроенных ограничений на число дескрипторов. Следует
также принимать во внимание эффективность. Типичная реализация select может
быть очень неэффективной при большом числе дескрипторов. Подробнее это рассматривается
в работе [Banga and Mogul 1998]. (В этой работе приводится еще один пример возникновения
трудностей при экстраполяции результатов, полученных в локальной сети, на глобальную.
Эта тема обсуждалась в совете 12.) Проблема большого числа дескрипторов стоит
особенно остро, когда ожидается немного событий на многих дескрипторах, то есть
первый аргумент - maxfd - велик, но с помощью FD_SET было зарегистрировано всего
несколько дескрипторов. Это связано с тем, что ядро должно проверить все возможные
дескрипторы (0,..., maxfd), чтобы понять, ожидаются ли приложением события хотя
бы на одном из них. В вызове poll используется массив дескрипторов, с помощью
которого ядру сообщается о том, в каких событиях заинтересовано приложение,
так что этой проблемы не возникает.
Итак, использование select или poll позволяет мультиплексировать
несколько событий ввода/вывода. Сложнее обстоит дело с несколькими таймерами,
поскольку в вызове можно указать лишь одно значение тайм-аута. Чтобы решить
эту проблему и создать тем самым более гибкое окружение для событийно-управляемых
программ, следует разработать вариант вызова select - tselect. Хотя функции
timeout и untimeout, связанные с tselect, построены по той же схеме, что и одноименные
подпрограммы ядра UNIX, они работают в адресном пространстве пользователя и
используют select для мультиплексирования ввода/вывода и получения таймера..
Таким образом, существуют три функции, ассоциированные
с tselect. Прежде всего это сама tselect, которая применяется аналогично select
для мультиплексирования ввода/вывода. Единственное отличие в том, что у tselect
нет параметра timeout (это пятый параметр select). События таймера задаются
с помощью вызова функции timeout, которая позволяет указать длительность таймера
и действие, которое следует предпринять при его срабатывании. Вызов untimeout
отменяет таймер до срабатывания.
Порядок вызова этих функций описан следующим образом:
#nclude "etcp.h"
int tselect ( int maxfd, fd_set *rdmask, fd_set *wrmask, fd_set
*exrnask );
Возвращаемое значение: число готовых событий, 0 - если
событий нет, -1 -.ошибка.
unsigned int timeout(
void (handler)(void * ), void *arg, int ms);
Возвращаемое значение:
идентификатор таймера для передачи untimeout
void untimeout( unsigned int timerid);
Когда срабатывает таймер, ассоциированный с вызовом
timeout, вызывается функция, заданная параметром handler, которой передается
аргумент, заданный параметром arg. Таким образом, чтобы организовать вызов функции
retransmit через полторы секунды с целым аргументом sock, нужно сначала написать
timeout( retransmit, ( void * ) sock, 1500 );
а затем вызывать tselect. Величина тайм-аута ms
задается в миллисекундах, но надо понимать, что разрешающая способность системных
часов может быть ниже. Для UNIX-систем типичное значение составляет 10 мс, поэтому
не следует ожидать от таймера более высокой точности.
Примеры использования tselect будут приведены далее,
а пока рассмотрим ее реализацию. В листинге 3.14 приведено определение структуры
tevent_t и объявления глобальных переменных.
Листинг 3.14. Глобальные данные для tselect
tselect.с
1 #include "etcp.h"
2 #define NTIMERS 25
3 typedef struct tevent_t tevent_t;
4 struct tevent_t
5 {
6 tevent_t *next;
7 struct timeval tv;
8 void ( *func )( void * );
9 void *arg;
10 unsigned int id;
11 };
12 static tevent_t *active = NULL; /* Активные
таймеры. */
13 static tevent_t *free_list = NULL; /* Неактивные
таймеры. */
Объявления
2 Константа NTIMERS определяет, сколько таймеров
выделять за один раз. Сначала таймеров нет вовсе, поэтому при первом обращении
к timeout будет выделено NTIMERS таймеров. Если все они задействованы и происходит
очередное обращение к timeout, то выделяется еще NTIMERS таймеров.
3-11 Каждый таймер представляет отдельную структуру
типа tevent_t. Структуры связаны в список полем next. В поле tv хранится время
срабатывания таймера. Поля func и arg предназначены для хранения указателя на
функцию обработки события таймера (которая вызывается при срабатывании) и ее
аргумента. Наконец, идентификатор активного таймера хранится в поле id.
12 Порядок расположения активных таймеров в списке
определяется моментом срабатывания. Глобальная переменная active указывает на
первый таймер в списке.
13 Неактивные таймеры находятся в списке свободных.
Когда функции timeout нужно получить новый таймер, она берет его из этого списка.
Глобальная переменная free_list указывает на начало списка свободных.
Далее изучим функцию timeout и подпрограммы выделения
таймеров (листинг 3.15).
Листинг 3.15. Функции timeout и allocateJimer
tselect.с
1 static tevent_t *allocate_timer( void )
2 {
3 tevent_t *tp;
4 if ( free_list = NULL ) /* нужен новый блок
таймеров? *./
5 {
6 free_list = malloc( NTIMERS * sizeof( tevent_t
));
7 if ( free_list = NULL )
8 error( 1, 0, "не удалось получить
таймеры\n" };
9 for ( tp = free_list;
10 tp < free_list + NTIMERS - 1; tp+ +
)
11 tp->next = tp + 1;
12 tp->next = NULL;
13 }
14 tp = free_list; /* Выделить первый. */
15 free_list = tp->next; /* Убрать его из
списка. */
16 return tp;
17 }
18 unsigned int timeout ( void ( *func ) ( void
* ), void *arg, int ms )
19 {
20 tevent_t *tp;
21 tevent_t *tcur;
22 tevent_t **tprev;
23 static unsigned int id = 1; /* Идентификатор
таймера. */
24 tp = allocate_timer();
25 tp->func = func;
26 tp->arg = arg;
27 if ( gettimeofday( &tp->tv, NULL
) < 0 )
28 error( 1, errno, "timeout: ошибка
вызова gettimeofday");
29 tp->tv.tv_usec + = ms * 1000;
30 if ( tp->tv.tv_usec > 1000000 )
31 {
32 tp->tv.tv_sec + = tp->tv.tv_usec
/ 1000000;
33 tp->tv.tv_usec %= 1000000;
34 }
35 for ( tprev = &active, tcur = active;
36 tcur && !timercmp( &tp->tv,
&tcur->tv, < ); /* XXX */
37 tprev = &tcur->next, tcur = tcur->next
)
38 { ; }
39 *tprev = tp;
40 tp->next = tcur;
41 tp->id = id++; /* Присвоить значение
идентификатору таймера. */
42 return tp->id;
43 }
allocate_timer
4-13 Функция allocate_timer вызывается из timeout
для получения свободного таймера. Если список свободных пуст, то из кучи выделяется
память для NTIMERS структур tevent_t, и эти структуры связываются в список.
14-16 Выбираем первый свободный таймер из списка
и возвращаем его вызывающей программе.
timeout
24-26 Получаем таймер и помещаем в поля func и arg
значения переданных нам параметров.
27-34 Вычисляем момент срабатывания таймера, прибавляя
значение параметра ms к текущему времени. Сохраняем результат в поле tv.
35-38 Ищем в списке активных место для вставки
нового таймера. Вставить таймер нужно так, чтобы моменты срабатывания всех предшествующих
таймеров были меньше либо равны, а моменты срабатывания всех последующих - больше
момента срабатывания нового. На рис. 3.6 показан
Рис. 3.6. Список активных таймеров
до и после поиска точки вставьки
процесс поиска и значения переменных tcur и tprev.
Вставляем новый таймер так, что его момент срабатывания tnew удовлетворяет условию
t0 < t1, < tnew < t2. Обведенный курсивом прямоугольник tnew показывает
позицию в списке, куда будет помещен новый таймер. Несколько странное использование
макроса timercmp в строке 36 связано с тем, что версия в файле winsock2.h некорректна
и не поддерживает оператора >=.
27-34 Вставляем новый таймер в нужное место, присваиваем
ему идентификатор и возвращаем этот идентификатор вызывающей программе. Возвращается
идентификатор, а не адрес структуры tevent_t, чтобы избежать «гонки» (race condition).
Когда таймер срабатывает, структура tevent_t возвращается в начало списка свободных.
При выделении нового таймера будет использована именно эта структура. Если приложение
теперь попытается отменить первый таймер, то при условии, что возвращается адрес
структуры, а не индекс, будет отменен второй таймер. Эту проблему решает возврат
идентификатора.
Идентификатор таймера, возвращенный в конце функции
из листинга 3.15, используется функцией untimeout (листинг 3.16).
Листинг 3.16. Функция untimeout
tselect.с
1 void untimeout( unsigned int id )
2 {
3 tevent_t **tprev;
4 tevent_t *tcur;
5 for ( tprev = &active, tcur = active;
6 tcur && id != tcur->id;
7 tprev = &tcur->next, tcur = tcur->next);
8 { ; }
9 if ( tcur == NULL )
10 {
11 error( 0, 0,
12 "при вызове untimeout указан несуществующий
таймер (%d) \n", id );
13 return;
14 }
15 *tprev = tcur->next;
16 tcur->next = free_list;
17 free_list = tcur;
18 }
Поиск таймера
5-8 Ищем в списке активных таймер с идентификатором
id. Этот цикл похож на тот, что используется в timeout (листинг 3.15).
9-14 Если в списке нет таймера, который пытаемся
отменить, то выводим диагностическое сообщение и выходим.
Отмена таймера
15-17 Для отмены таймера исключаем структуру tevent_t
из списка активных и возвращаем в список свободных.
Последняя из функций, работающих с таймерами, -
это tselect (листинг 3.17)
Листинг 3.17. Функция tselect
tselect.с
1 int tselect( int maxp1, fd_set *re, fd_set
*we, fd_set *ee )
2 {
3 fd_set rmask;
4 fd_set wmask;
5 fd_set emask;
6 struct timeval now;
7 struct timeval tv;
8 struct timeval *tvp;
9 tevent_t *tp;
10 int n;
11 if ( re )
12 rmask = *re;
13 if ( we )
14 wmask = *we;
15 if ( ее )
16 emask = *ee;
17 for ( ; ; )
18 {
19 if ( gettimeofday( know, NULL ) < 0 )
20 error( 1, errno, "tselect: ошибка
вызова gettimeofday" );
21 while ( active && !timercmp( know,
&active->tv, < ) )
22 {
23 active->func( active->arg );
24 tp = active;
25 active = active->next;
26 tp->next = free_list;
27 free_list = tp;
28 }
29 if ( active )
30 {
31 tv.tv_sec = active->tv.tv_sec - now.tv_sec;
32 tv.tv_usec = active->tv.tv_usec - now.tv_usec;
33 if ( tv.tv_usec < 0 )
34 {
35 tv.tv_usec += 1000000;
36 tv.tv_sec--;
37 }
38 tvp = &tv;
39 }
40 else if ( re == NULL && we == NULL
&& ее == NULL ) •
41 return 0;
42 else
43 tvp = NULL;
44 n = select ( maxpl, re, we, ее, tvp );
45 if ( n < 0 )
46 return -1;
47 if ( n > 0 )
48 return n;
49 if ( re )
50 *re = rmask;
51 if ( we )
52 *we = wmask;
53 if ( ее )
54 *ee = emask;
55 }
56 }
Сохранение масок событий
11-16 Поскольку при одном обращении к tselect может
несколько раз вызываться select, сохраняем маски событий, передаваемых select.
Диспетчеризация событий таймера
19-28 Хотя в первой структуре tevent_t, находящейся
в списке активных таймеров, время срабатывания меньше или равно текущему времени,
вызываем обработчик этого таймера, исключаем структуру из списка активных и
возвращаем в список свободных. Как и в листинге 3.15, странный вызов макроса
timercmp обусловлен некорректной его реализацией в некоторых системах.
Вычисление времени следующего события
29-39 Если список активных таймеров не пуст, вычисляем
разность между текущим моментом времени и временем срабатывания таймера в начале
списка. Это значение передаем системному вызову select.
40-41 Если больше таймеров нет и нет ожидаемых событий
ввода/вывода, то tselect возвращает управление. Обратите внимание, что возвращается
нуль, тем самым извещается об отсутствии ожидающих событий. Семантика кода
возврата отличается от семантики select.
42-43 Если нет событий таймера, но есть события
ввода/вывода, то устанавливаем tvp в NULL, чтобы select не вернулся из-за тайм-аута.
Вызов select
44-48 Вызываем select, чтобы он дождался события.
Если select завершается с ошибкой, то возвращаем код ошибки приложению. Если
select возвращает положительное значение (произошло одно или более событий ввода/вывода),
то возвращаем приложению число событий. Поскольку вызывали select, передавая
указатели на маски событий, подготовленные приложением, то биты событий в них
уже установлены-
49-54 Если select вернул нуль, то сработал один
или несколько таймеров. Поскольку в этом случае select обнулит все маски событий,
установленные приложением, восстановим их перед тем, как возвращаться к началу
цикла, где вызываются обработчики таймеров.
Для вставки и удаления таймеров из списка был использован
линейный поиск. При небольшом числе таймеров это не страшно, но при увеличении
их числа производительность программы снижается, так как для поиска требуется
О(n) операций, где n - число таймеров (для запуска обработчика события требуется
время порядка O(1)). Вместо линейного поиска можно воспользоваться пирамидой
[Sedgewick 1998] - для вставки, удаления и диспетчеризации требуется O(log n)
операций - или хэширующим кольцом таймеров (hashing timing wheel) [Varghese
and Lacuk 1997]; при этом эффективность может достигать О(1) для всех трех операций.
Заметим, что функция tselect не требует наличия
ожидающих событий ввода/вывода, поэтому ее вполне можно использовать только
как механизм организации тайм-аутов. В данном случае имеем следующие преимущества
по сравнению с системным вызовом sleep:
- в системе UNIX s leep позволяет задерживать
исполнение на интервал, кратный секунде, то есть разрешающая способность очень
мала. В Windows такого ограничения нет. Во многих реализациях UNIX есть иные
механизмы с более высокой степенью разрешения, однако они не очень распространены.
Хотелось бы иметь механизм таймеров с высокой степенью разрешения, работающий
на возможно большем числе платформ. Поэтому в UNIX принято использовать для
реализации высокоточных таймеров вызов select;
- применение sleep или «чистого» select для
организации нескольких таймеров затруднительно, поскольку требует введения
дополнительных структур данных. В функции tselect все это уже сделано.
К сожалению, в Windows функция tselect в качестве
таймера работает не совсем хорошо. В спецификации Winsock API [WinSock Group
1997] говорится, что использование selects качестве таймера «неудовлетворительно
и не имеет оправданий». Хотя на это можно возразить, что «неудовлетворительность»
-это когда системный вызов работает не так, как описано в опубликованной спецификации,
все же придется придерживаться этой рекомендации. Тем не менее можно использовать
функцию tselect и связанные с ней под Windows, только при этом следует указывать
также и события ввода/вывода.
В этом разделе обсуждены преимущества, которые
дает управляемость приложения событиями. Разработан также обобщенный механизм
работы с таймерами, не накладывающий ограничений на количество таймеров.
Здесь будет продолжено обсуждение, начатое в совете
20, а также проиллюстрировано использование функции tselect в приложениях и
рассмотрены некоторые другие аспекты событийно-управляемого программирования.
Вернемся к архитектуре с двумя соединениями из совета 19.
Взглянув на программу xout2 (листинг 3.13), вы
увидите, что она не управляется событиями. Отправив сообщение удаленному хосту,
вы не возвращаетесь к чтению новых данных из стандартного ввода, пока не придет
подтверждение Причина в том, что таймер может сбросить новое сообщение. Если
бы вы взвели таймер для следующего сообщения, не дождавшись подтверждения, то
никогда не узнали бы, подтверждено старое сообщение или нет.
Проблема, конечно, в том, что в программе xout2
только один таймер и поэтому она не может ждать более одного сообщения в каждый
момент. Воспользовавшись t select, вы сможете получить несколько таймеров из
одного, предоставляемого select.
Представьте, что внешняя система из совета 19 -
это шлюз, отправляющий сообщение третьей системе по ненадежному протоколу. Например,
он мог бы посылать датаграммы в радиорелейную сеть. Предположим, что сам шлюз
не дает информации о том, было ли сообщение успешно доставлено. Он просто переправляет
сообщение и возвращает подтверждение, полученное от третьей системы.
Чтобы в какой-то мере обеспечить надежность, новый
писатель xout3 повторно посылает сообщение (но только один раз), если в течение
определенного времени не получает подтверждения. Если и второе сообщение не
подтверждено, xout3 протоколирует этот факт и отбрасывает сообщение. Чтобы ассоциировать
подтверждение с сообщением, на которое оно поступило, xout 3 включает в каждое
сообщение некий признак. Конечный получатель сообщения возвращает этот признак
в составе подтверждения. Начнем с рассмотрения секции объявлений xout3 (листинг
3.18)
Листинг 3.18. Объявления для программы xout3
xout3.c
1 #define ACK 0x6 /* Символ подтверждения
АСК. */
2 #define MRSZ 128 /* Максимальное число неподтвержденных
сообщений.*/
3 #define T1 3000 /* Ждать 3 с до первого АСК
*/
4 #define T2 5000 /* и 5 с до второго АСК.
*/
5 #define ACKSZ ( sizeof ( u_int32_t ) + 1 )
6 typedef struct /* Пакет данных. */
7 {
8 u_int32_t len; /* Длина признака и данных.
*/
9 u_int32_t cookie; /* Признак сообщения. */
10 char buf[ 128 ]; /* Сообщение. */
11 } packet_t;
12 typedef struct /* Структура сообщения. */
13 {
14 packet_t pkt; /* Указатель на сохраненное
сообщение.*/
15 int id; /* Идентификатор таймера. */
16 } msgrec_t;
17 static msgrec_t mr[ MRSZ ];
18 static SOCKET s;
Объявления
5 Признак, включаемый в каждое сообщение, — это
32-разрядный порядковый номер сообщения. Подтверждение от удаленного хоста определяется
как ASCII-символ АСК, за которым следует признак подтверждаемого сообщения.
Поэтому константа ASCZ вычисляется как длина признака плюс 1.
6-11 Тип packet_t определяет структуру посылаемого
пакета. Поскольку сообщения могут быть переменной длины, в каждый пакет включена
длина сообщения. Удаленное приложение может использовать это поле для разбиения
потока данных на отдельные записи (об этом шла речь в совете 6). Поле len -
это общая длина самого сообщения и признака. Проблемы, связанные с упаковкой
структур, рассматриваются в замечаниях после листинга 2.15.
12-16 Структура msgrec_t содержит структуру packet_t,
посланную удаленному хосту. Пакет сохраняется на случай, если придется послать
его повторно. Поле id - это идентификатор таймера, выступающего в роли таймера
ретрансмиссии для этого сообщения.
17 С каждым неподтвержденным сообщением связана
структура msgrec_t. Все они хранятся в массиве mr.
Теперь обратимся к функции main программы xout3
(листинг 3.19).
Листинг 3.19. Функция main программы xout3
xout3.с
1 int main( int argc, char **argv )
2 {
3 fd_set allreads;
4 fd_set readmask;
5 msgrec_t *mp;
6 int rc;
7 int mid;
8 int cnt = 0;
9 u_int32_t msgid = 0;
10 char ack[ ACKSZ ];
11 INIT();
12 s = tcp_client( argv[ 1 ], argv[ 2 ] );
13 FD_ZERO( &allreads );
14 FD_SET( s, &allreads );
15 FD_SET( 0, &allreads );
16 for ( mp = mr; mp < mr + MRSZ; mp++ )
17 mp->pkt.len = -1;
18 for ( ; ; )
19 {
20 readmask = allreads;
21 rc-= tselectf s + 1, &readmask, NULL,
NULL );
22 if ( rc < 0 )
23 error( 1, errno, "ошибка вызова tselect"
);
24 if ( rc == 0 )
25 error( 1, 0, "tselect сказала, что
нет событий\n")
26 if ( FD_ISSET( s, &readmask ) )
27 {
28 rc = recv( s, ack + cnt, ACKSZ - cnt, 0
);
29 if ( rc == 0 )
30 error( 1, 0, "сервер отсоединился\n");
31 else if ( rc < 0 )
32 error( 1, errno, "ошибка вызова recv"
);
33 if ( ( cnt += rc ) < ACKSZ ) /* Целое
сообщение? */
34 continue; /* Нет, еще подождем. */
35 cnt =0; /* В следующий раз новое сообщение.
*/
36 if ( ack[ 0 ] != ACK)
37 {
38 error ( 0,0," предупреждение: неверное
подтверждение\n");
39 continue;
40 }
41 memcpy( &mid, ack + 1, sizeof( u_int32_t
) );
42 mp = findmsgrec( mid );
43 if ( mp != NULL)
44 {
45 untimeout( mp->id ); /* Отменить
таймер.*/
46 freemsgrecf mp ); /* Удалить сохраненное
сообщение. */
47 }
48 }
49 if ( FD_ISSET( 0, &readmask ) )
50 {
51 mp = getfreerec ();
52 rc = read( 0, mp->pkt.buf, sizeoft mp->pkt.buf
)
53 if ( rc < 0 )
54 error( 1, errno, "ошибка вызова read"
);
55 mp->pkt.buf[ rc ] = '\0';
56 mp->pkt.cookie = msgid++;
57 mp->pkt.len = htonl( sizeof( u_int32_t
) + rc );
58 if ( send( s, &mp->pkt,
59 2 * sizeof( u_int32_t ) + rc, 0 ) <
0 )
60 error( 1, errno, "ошибка вызова send"
);
61 mp->id = timeout( ( tofunc_t )lost_ACK,
mp, Tl );
62 }
63 }
64 }
Инициализация
11-15 Так же, как и в программе xout2, соединяемся
с удаленным хостои и инициализируем маски событий для tselect, устанавливая
в них биты для
дескрипторов stdin и сокета, который возвратилa tcp_client
16-17 Помечаем все структуры msgrec_t как свободные,
записывая в поле длины пакета
18-25 Вызываем tselect точно так же, как select,
только не передаем последний параметр (времени ожидания). Если tselect возвращает
ошибку или нуль, то выводим диагностическое сообщение и завершаем программу.
В отличие от select возврат нуля из tselect - свидетельство ошибки, так как
все тайм-ауты обрабатываются внутри.
Обработка входных данных из сокета
26-32 При получении события чтения из сокета ожидаем
подтверждение. В совете 6 говорилось о том, что нельзя применить recv в считывании
ASCZ байт, поскольку, возможно, пришли еще не все данные. Нельзя воспользоваться
и функцией типа readn, которая не возвращает управления до получения указанного
числа байт, так как это противоречило бы событийно-управляемой архитектуре приложения,
- ни одно событие не может быть обработано, пока readn не вернет управления.
Поэтому пытаемся прочесть столько данных, сколько необходимо для завершения
обработки текущего подтверждения. В переменной cnt хранится число ранее прочитанных
байт, поэтому ASCZ - cnt - это число недостающих байт.
33-35 Если общее число прочитанных байт меньше ASCZ,
то возвращаемся к началу цикла и назначаем tselect ожидание прихода следующей
партии данных или иного события. Если после только что сделанного вызова recv
подтверждение получено, то сбрасываем cnt в нуль в ожидании следующего подтверждения
(к этому моменту не было прочитано еще ни одного байта следующего подтверждения).
36-40 Далее, в соответствии с советом 11, выполняем
проверку правильности полученных данных. Если сообщение - некорректное подтверждение,
печатаем диагностическое сообщение и продолжаем работу. Возможно, здесь было
бы правильнее завершить программу, так как удаленный хост послал неожиданные
данные.
41-42 Наконец, извлекаем из подтверждения признак
сообщения, вызываем findmsgrec для получения указателя на структуру msgrec_t,
ассоциированную с сообщением, и используем ее для отмены таймера, после чего
освобождаем msgrec_t. Функции findmsgrec и freemsgrec приведены в листинге 3.20.
Обработка данных из стандартного ввода
51-57 Когда tselect сообщает о событии ввода из
stdin, получаем структуру msgrec_t и считываем сообщение в пакет данных. Присваиваем
сообщению порядковый номер, пользуясь счетчиком msgid, и сохраняем его в поле
cookie пакета. Обратите внимание, что вызывать htonl не нужно, так как удаленный
хост не анализирует признак, а возвращает его без изменения. Записываем в поля
пакета полную длину сообщения вместе с признаком. На этот раз вызываем htonl,
так как удаленный хост использует это поле для чтения оставшейся части сообщения
(совет 28).
55-61 Посылаем подготовленный пакет удаленному
хосту и взводим таймер ретрансмиссии, обращаясь к функции timeout.
Оставшиеся функции программы xout3 приведены в
листинге 3.20.
Листинг 3.20. Вспомогательные функции программы
xout3
xout3.c
1 msgrec_t *getfreerec( void )
2 {
3 msgrec_t *mp;
4 for ( mp = mr; mp < mr + MRSZ; mp++ )
5 if ( mp->pkt.len == -1 ) /* Запись свободна?
*/
6 return mp;
7 error(1,0, "getfreerec: исчерпан пул
записей сообщений\n" );
8 return NULL; /* "Во избежание предупреждений
компилятора.*/
9 }
10 msgrec_t *findmsgrec( u_int32_t mid )
11 {
12 msgrec_t *mp;
13 for ( mp = mr; mp < mr + MRSZ; mp++ )
14 if ( mp->pkt.len != -1 && mp->pkt.cookie
== mid )
15 return mp;
16 error (0, 0,"findmsgrec: нет сообщения,
соответствующего ACK %d\n", mid);
17 return NULL;
18 }
19 void freemsgrec( msgrec_t *mp )
20 {
21 if ( mp->pkt.len == -1 )
22 error(1,0, "freemsgrec: запись сообщения
уже освобождена\n" };
23 mp->pkt.len = -1;
24 }
25 gtatic void drop( msgrec_t *mp )
26 {
27 error( 0, 0, "Сообщение отбрасывается:
%s", mp->pkt.buf );
28 freemsgrec( mp );
29 }
30 static void lost_ACK( msgrec_t *mp )
31 {
32 error( 0, 0, "Повтор сообщения: %s",
mp->pkt.buf );
33 if ( send( s, &mp->pkt,
34 sizeof( u_int32_t ) + ntohl( mp->pkt.len
), 0 ) < 0 )
35 error ( 1, errno, "потерян АСК: ошибка
вызова send" );
36 mp->id = timeout) ( tofunc_t )drop, mp,
T2 );
37 }
getfreerec
1-9 Данная функция ищет свободную запись в таблице
mr. Просматриваем последовательно весь массив, пока не найдем пакет с длиной
-1. Это означает, что запись свободна. Если бы массив mr был больше, то можно
было бы завести список свободных, как было сделано для записей типа tevent_t
в листинге 3.15.
findmsgrec
10-18 Эта функция почти идентичная get f reerec,
только на этот раз ищем запись с заданным признаком сообщения.
freemsgrec
19-24 Убедившись, что данная запись занята, устанавливаем
длину пакета в -1, помечая тем самым, что теперь она свободна.
drop
25-29 Данная функция вызывается, если не пришло
подтверждение на второе посланное сообщение (см. lost_ACK). Пишем в протокол
диагностику и отбрасываем запись, вызывая freemsgrec.
lost_ACK
30-37 Эта функция вызывается, если не пришло подтверждение
на первое сообщение. Посылаем сообщение повторно и взводим новый таймер ре-трансмиссии,
указывая, что при его срабатывании надо вызвать функцию drop.
Для тестирования xout3 напишем серверное приложение,
которое случайным образом отбрасывает сообщения. Назовем этот сервер extsys
(сокращение от external system - внешняя система). Его текст приведен в листинге
3.21.
Листинг 3.21. Внешняя система
extsys.c
1 #include "etcp.h"
2 #define COOKIESZ 4 /* Так установлено клиентом.
*/
3 int main ( int argc, char **argv )
4 {
5 SOCKET s;
6 SOCKET s1;
7 int rc;
8 char buf[ 128 ] ;
9 INIT();
10 s = tcp_server( NULL, argv[ 1 ] );
11 s1 = accept( s, NULL, NULL );
12 if ( !isvalidsock) s1 ) )
13 error( 1, errno, "ошибка вызова accept"
);
!4 srand( 127 );
15 for ( ;; )
16 {
17 rc = readvrec( s1, buf, sizeof( buf ) );
18 if ( rc == 0 )
19 error( 1, 0, "клиент отсоединился\n"
);
20 if ( rc < 0 )
21 error( 1, errno, "ошибка вызова recv"
);
22 if ( rand() % 100 < 33 )
23 continue;
24 write! 1, buf + COOKIESZ, rc - COOKIESZ
);
25 memmove( buf + 1, buf, COOKIESZ );
26 buf[ 0 ] = ' \006';
27 if ( send( s1, buf, 1 + COOKIESZ, 0 ) <
0 )
28 error( 1, errno, "ошибка вызова send"
);
29 }
30 }
Инициализация
9-14 Выполняем обычную инициализацию сервера и
вызываем функцию srand для инициализации генератора случайных чисел.
Премечание: Функция rand из стандартной библиотеки
С работает быстрои проста в применении, но имеет ряд нежелательных свойств.
Хотя для демонстрации xout3 она вполне пригодна, но для серьезного моделирования
нужно было бы воспользоваться более развитым генератором случайных чисел [Knuth
1998].
17-21 Вызываем функцию readvrec для чтения записи
переменной длины, посланной xout3.
22-23 Случайным образом отбрасываем примерно треть
получаемых сообщений.
24-28 Если сообщение не отброшено, то выводим его
на stdout, сдвигаем в буфере признак на один символ вправо, добавляем в начало
символ АСК и возвращаем подтверждение клиенту.
Вы тестировали xout3, запустив extsys в одном окне
и воспользовавшись конвейером из совета 20 в другом (рис. 3.7).
Можно сделать следующие замечания по поводу работы
xout3:
- доставка сообщений по порядку не гарантирована.
На примере сообщении 17 и 20 на рис. 3.8 вы видите, что повторно посланное
сообщение нарушило порядок;
- можно было увеличить число повторных попыток,
добавив счетчик попыток в структуру msgrec_t и заставив функцию lost_ACK продолжать
попытки отправить сообщение до исчерпания счетчика;
- легко модифицировать xout3 так, чтобы она
работала по протоколу UDP а не TCP. Это стало бы первым шагом на пути предоставления
надежного UDP-сервиса (совет 8);
- если бы приложение работало с большим числом
сокетов (и использовало функцию tselect), то имело бы смысл вынести встроенный
код геаdn в отдельную функцию. Такая функция могла бы получать на входе структуру,
содержащую cnt, указатель на буфер ввода (или сам буфер) и адрес функции,
которую нужно вызвать после получения полного сообщения; р в качестве примера
xout3, пожалуй, выглядит чересчур искусственно, особенно в контексте совета
19, но так или иначе она иллюстрирует, как можно решить задачу, часто возникающую
на практике.
|
bsd $ mp I xout3 localhost 9000
xout3: Повтор сообщения: message 3
xout3: Повтор сообщения: message 4
xout3: Повтор сообщения: message 5
xoutS: Сообщение отбрасывается: message 4
xout3: Сообщение отбрасывается: message 5
xout3: Повтор сообщения: message 11
xout3: Повтор сообщения: message 14
xout3: Сообщение отбрасывается: message 11
xout3: Повтор сообщения: message 16
xout3: Повтор сообщения: message 17
xout3: Сообщение отбрасывается: message 14
xout3: Повтор сообщения: message 19
xout3: Повтор сообщения: message 20
xout3: Сообщение отбрасывается: message 16
xout3: Сервер отсоединился
Broken pipe
bsd $
|
bsd $ extsys 9000
message 1
message 2
message 3
message 6
message 7
message 8
message 9
message 10
message 12
message 13
message 15
message 18
message 17
message 21
message 20
message 23
^C сервер остановлен
bsd $
|
Рис. 3.7. Демонстрация xout 3
В этом и предыдущем разделах говорилось о событийно-управляемом
программировании и о том, как использовать вызов select для реагирования на
события по мере их поступления. В совете 20 разработана функция tselect, позволившая
получить несколько логических таймеров из одного физического. Эта Функция и
используемые с ней функции timeout и untimeout дают возможность задавать тайм-ауты
сразу для нескольких событий, инкапсулируя внутри себя все сопутствующие этому
детали.
Здесь была использована функция tselect, чтобы усовершенствовать
пример совета 19. Применение tselect позволило задавать отдельные таймеры ретрансмиссии
для каждого сообщения, посланного ненадежному удаленному хосту через сервер-шлюз
xout3.
В этом разделе рассказывается о том, что такое
состояние TIME-WAIT в протоколе TCP, для чего оно служит и почему не следует
пытаться обойти его.
Поскольку состояние TIME-WAIT запрятано глубоко
в недрах конечного автомата, управляющего работой TCP, многие программисты только
подозреваю о его существовании и смутно представляют себе назначение и важность
этого с стояния. Писать приложения TCP/IP можно, ничего не зная о состоянии
ТIME-WAIT, но необходимо разобраться в странном, на первый взгляд, поведении
приложения (совет 23). Это позволит избежать непредвиденных последствий.
Рассмотрим состояние TIME-WAIT и определим, каково
его место в работе TCP-соединения. Затем будет рассказано о назначении этого
состояния и его важности, а также, почему и каким образом некоторые программисты
пытаются обойти это состояние. В конце дано правильное решение этой задачи.
Состояние TIME-WAIT наступает в ходе разрыва соединения.
Помните (совет 7), что для разрыва TCP-соединения нужно обычно обменяться четырьмя
сегментами, как показано на рис. 3.8.
На рис. 3.8 показано соединение между двумя приложениями,
работающими на хостах 1 и 2. Приложение на хосте 1 закрывает свою сторону соединения,
при этом TCP посылает сегмент FIN хосту 2. Хост 2 подтверждает FIN сегментом
АСК и доставляет FIN приложению в виде признака конца файла EOF (предполагается,
что у приложения есть незавершенная операция чтения, - совет 16). Позже приложение
на хосте 2 закрывает свою сторону соединения, посылая FIN хосту 1, который отвечает
сегментом АСК.
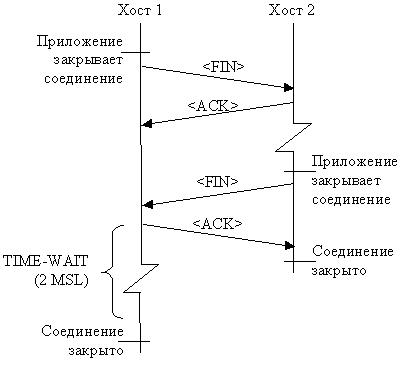
Рис. 3.8. Разрыв соединения
В этот момент хост 2 окончательно закрывает соединение
и освобождает ресурсы. С точки зрения хоста 2, соединения больше не существует.
Однако хост 1 закрывает соединение, а переходит в состояние TIME-WAIT и остается
в нем в течение двух максимальных продолжительностей существования сегмента
(2MSL maximum segment lifetime).
Примечание: Максимальное время существования
сегмента (MSL) - это максимальное время, в течение которого сегмент может оставаться
в сети, прежде чем будет уничтожен. В каждой IР-датаграммеесть поле TTL (time-to-live
- время жизни). Это поле уменьшается нa единицу каждым маршрутизатором, через
который проходит датаграмма. Когда TTL становится равным нулю, датаграмма уничтожается.
Хотя официально TTL измеряется в секундах, в действительности это поле почти
всегда интерпретируется маршрутизаторами как счетчик промежуточных узлов. В
RFC 1812 [Baker 1995] этот вопрос обсуждается подробнее.
Прождав время 2MSL, хост 1 также закрывает соединение
и освобождает ресурсы.
Относительно состояния TIME-WAIT следует помнить
следующее:
- обычно в состояние TIME-WAIT переходит
только одна сторона - та, что выполняет активное закрытие;
Примечание: Под активным закрытием понимается
отправка первого FIN. Считается, что вторая сторона при этом выполняет пассивное
закрытие. Возможно также одновременное закрытие, когда обе стороны закрывают
соединение примерно в одно время, поэтому посланные ими FIN одновременно находятся
в сети. В этом случае активное закрытие выполняют обе стороны, так что обе переходят
в состояние TIME- WAIT.
- в RFC 793 [Postel 1981b] MSL определено
равным 2 мин. При этом соединение должно оставаться в состоянии TIME-WAIT
в течение 4 мин. На практике это обычно не так. Например, в системах, производных
от BSD, MSL равно 30 с, так что состояние TIME-WAIT длится всего 1 мин. Можно
встретить и другие значения в диапазоне от 30 с до 2 мин;
- если в то время, когда соединение находится
в состоянии TIME-WAIT, прибывает новый сегмент, то таймер на 2MSL перезапускается.
Это будет рассматриваться ниже.
Состояние TIME-WAIT служит двум целям:
- не дать соединению пропасть при потере
последнего АСК, посланного активной стороной, в результате чего другая сторона
повторно посылает FIN;
- дать время исчезнуть «заблудившимся сегментам»,
принадлежащим этому соединению.
Рассмотрим каждую из этих причин. В момент, когда
сторона, выполняющая активное закрытие, готова подтвердить посланный другой
стороной FIN, все данные, отправленные другой стороной, уже получены. Однако
последний АСК может потеряться. Если это произойдет, то сторона, выполняющая
пассивное закрытие, обнаружит тайм-аут и пошлет свой FIN повторно (так как не
получила АСК на последний порядковый номер).
А теперь посмотрим, что случится, если активная
сторона не перейдет в состояние TIME-WAIT, а просто закроет соединение. Когда
прибывает повторно переданный FIN, у TCP уже нет информации о соединении, поэтому
он посылает в ответ RST (сброс), что для другой стороны служит признаком ошибки,
а не нормального закрытия соединения. Но, так как сторона, пославшая последний
АСК, все-таки перешла в состояние TIME-WAIT, информация о соединении еще хранится,
так что она может корректно ответить на повторно отправленный FIN.
Этим объясняется и то, почему 2МSL-таймер перезапускается,
если в состоянии TIME-WAIT приходит новый сегмент. Если последний АСК потерян,
и другая сторона повторно послала FIN, то сторона, находящаяся в состоянии TIME-WAIT,
еще раз подтвердит его и перезапустит таймер на случай, если и этот АСК будет
потерян.
Второе назначение состояния TIME-WAIT более важно.
Поскольку IР-дата-граммы могут теряться или задерживаться в глобальной сети,
TCP использует механизм подтверждений для своевременной повторной передачи неподтвержденных
сегментов (совет 1). Если датаграмма просто задержалась в пути, но не потеряна,
или потерян подтверждающий ее сегмент АСК, то после прибытия исходных данных
могут поступить также и повторно переданные. TCP в этом случае определяет, что
порядковые номера поступивших данных находятся вне текущего окна приема, и отбрасывает
их.
А что случится, если задержавшийся или повторно
переданный сегмент придет после закрытия соединения? Обычно это не проблема,
так как TCP просто отбросит данные и пошлет RST. Когда RST дойдет до хоста,
отправившего задержавшийся сегмент, то также будет отброшен, поскольку у этого
хоста больше нет информации о соединении. Однако если между этими двумя хостами
установлено новое соединение с такими же номерами портов, что и раньше, то заблудившийся
сегмент может быть принят как принадлежащий новому соединению. Если порядковые
номера данных в заблудившемся сегменте попадают в текущее окно приема нового
соединения, то данные будут приняты, следовательно, новое соединение - скомпрометировано.
Состояние TIME-WAIT предотвращает такую ситуацию,
гарантируя, что два прежних сокета (два IP-адреса и соответствующие им номера
портов) повторно не используются, пока все сегменты, оставшиеся от старого соединения,
не будут уничтожены. Таким образом, вы видите, что состояние TIME-WAIT играет
важную роль в обеспечении надежности протокола TCP. Без него TCP не мог бы гарантировать
доставку данных по порядку и без искажений (совет 9).
К сожалению, иногда можно досрочно выйти из состояния
TIM Е-WAIT. Это называется принудительной отменой (TIME-WAIT assassination)
и бывает случай но или намеренно.
Сначала посмотрим, как это может произойти случайно.
По стандарта RFC 793, если соединение находится в состоянии TIME-WAIT и приходит
RST то соединение должно быть немедленно закрыто. Предположим, что имеет единение
в состоянии TIME-WAIT и приходит старый сегмент-дубликат, который TCP не принимает
(например, потому, что порядковый номер оказался вне окна приема). TCP посылает
в ответ АСК, в котором указано, какой порядковый номер он ожидает (следующий
за номером сегмента FIN, посланного другой стороной). Но у хоста на другой стороне
уже нет информации о соединении, поэтому этот АСК он отвечает сегментом RST.
Когда этот RST приходит хосту, у которого соединение находится в состоянии TIME-WAIT,
тот немедленно закрывает соединение, - состояние TIME-WAIT принудительно отменено.
Эта ситуация описана в RFC 1337 [Braden 1992b],
где также рассматриваются трудности, сопряженные с принудительной отменой состояния
TIME-WAIT. Опасность состоит в возможности «воскрешения» старого соединения
(то есть появления соединения с теми же двумя сокетами), что может привести
к подтверждению старых данных, десинхронизации соединения с входом в бесконечный
цикл и к ошибочному завершению нового соединения.
Это легко предотвратить, изменив протокол TCP так,
чтобы в состоянии TIME-WAIT было разрешено игнорировать RST Хотя такое изменение,
рекомендованное в RFC 1337, официально не одобрено, тем не менее в некоторых
стеках оно реализовано.
Принудительно отменить состояние TIME-WAIT можно
и намеренно. С помощью опции сокета SO_LINGER программист требует немедленного
закрытия соединения даже в том случае, когда приложение выполняет «активное
закрытие. Этот сомнительный прием иногда рекомендуют применять, чтобы вывести
«упавший» сервер из состояния TIME-WAIT и запустить его заново. Подробнее об
этой проблеме и более правильном способе ее решения будет рассказано в совете
23. Корректно написанное приложение никогда не должно манипулировать состоянием
TIME-WAIT, поскольку это неотъемлемая часть механизма обеспечения надежности
TCP.
Обычно, когда приложение закрывает соединение,
вызов close или closesocket возвращается немедленно, даже если в буфере передачи
еще есть данные. Разумеется, TCP будет пытаться доставить эти данные, но приложение
не имеет информации, удалось ли это. Чтобы решить эту проблему, можно установить
опцию сокета SO_LINGER. Для этого следует заполнить структуру linger и вызывать
setsockopt с параметром SO_LINGER.
В большинстве UNIX-систем структура linger определена
в заголовочном файле /usr/include/sys/socket.h. В системе Windows она находится
в файле winsock2.h. В любом случае она выглядит так:
struct linger {
int l_onoff; /*Включить/выключить опцию.*/
int l_linger; /*Время задержки.*/
};
Если поле l_onoff равно нулю, то опция задержки
отключается, и выбирает поведение по умолчанию - вызов close или closesocket
возвращается немедленно, а ядро продолжает попытки доставить еще не переданные
данные. Если же l_onoff не равно нулю, то работа зависит от значения поля l_linger.
Если l_linger отлично от нуля, то считается, что это время, в течение которого
ядро должно подождать отправки и подтверждения оставшихся в буфере передает,
данных. При этом close или closesocket не возвращается, пока данные не будут
доставлены или не истечет указанное время.
Если к моменту завершения ожидания данные еще не
доставлены, то close или closesocket возвращает код EWOULDBLOCK, и недоставленные
данные могут быть потеряны. Если все данные уже доставлены, то оба вызова возвращают
нуль.
Примечание: К сожалению, семантика поля
l_linger зависит от реализации. В Windows и некоторых реализациях UNIX это число
секунд, на которое следует задержать закрытие сокета. В системах, производных
от BSD, это число тактов таймера (хотя в документации сказано, что это число
секунд).
Используя опцию SO_LINGER таким способом, вы гарантируете,
что данные будут доставлены уровню TCP на удаленном хосте. Но они не обязательно
будут прочитаны приложением. Более правильный способ добиться последнего - использовать
процедуру аккуратного размыкания, описанную в совете 16.
Если поле l_linger равно нулю, то соединение разрывается.
Это означает, что хосту на другом конце посылается RST, и соединение закрывается
немедленно, не переходя в состояние TIME-WAIT. Это преднамеренная принудительная
отмена состояния TIME-WAIT, о которой упоминалось выше. Как было сказано, это
опасный прием, который в обычном приложении применять не следует.
В этом разделе обсуждено состояние TIME-WAIT, которое
часто понимают неправильно. Это состояние - важная часть механизма обеспечения
надежности протокола TCP, и попытки обойти его неверны. Преждевременный выход
из состояния TIME-WAIT может быть обусловлен «естественным» стечением обстоятельств
в сети или программой, которая манипулирует опцией SO_LINGER.
В сетевых конференциях очень часто задают вопрос:
«Когда сервер «падает» или нормально завершает сеанс, я пытаюсь его перезапустить
и получаю ошибку «Address already in use». А через несколько минут сервер перезапускается
нормаль но. Как сделать так, чтобы сервер рестартовал немедленно?» Чтобы проиллюстрировать
эту проблему, напишем сервер эхо-контроля, который будет работа именно так (листинг
3.22).
Листинг 3.22. Некорректный сервер эхо-контроля
badserver.c
1 #include "etcp.h"
2 int main( int argc, char **argv)
3 {
4 struct sockaddr_in local;
5 SOCKET s;
6 SOCKET s1;
7 int rc;
8 char buf[ 1024 ];
9 INIT();
10 s = socket( PF_INET, SOCK_STREAM, 0 );
11 if ( !isvalidsock( s ) )
12 error( 1, errno, "He могу получить
сокет" ) ;
13 bzero( &local, sizeof( local ) );
14 local.sin_family = AF_INET;
15 local.sin_port = htons( 9000 );
16 local.sin_addr.s_addr = htonl( INADDR_ANY
);
17 if ( bind( s, ( struct sockaddr * )&local,
18 sizeof( local ) ) < 0 )
19 error( 1, errno, "He могу привязать
сокет" );
20 if ( listen) s, NLISTEN ) < 0 )
21 error( 1, errno, "ошибка вызова listen"
);
22 si = accept! s, NULL, NULL );
23 if ( !isvalidsock( s1 ) )
24 error( 1, errno, "ошибка вызова accept"
);
25 for ( ;; )
26 {
27 rc = recv( s1, buf, sizeof( buf ), 0 );
28 if ( rc < 0 )
29 error( 1, errno, "ошибка вызова recv"
);
30 if ( rc == 0 )
31 error( 1, 0, "Клиент отсоединился\n"
);
32 rc = send( s1, buf, rc, 0 );
33 if ( rc < 0 )
34 error( 1, errno, "ошибка вызова send"
);
35 }
36 }
На первый взгляд, сервер выглядит вполне нормально,
только номер порта «зашит» в код. Если запустить его в одном окне и соединиться
с ним с помощью программы telnet, запущенной в другом окне, то получится ожидаемый
результат. (На рис. 3.9 опущены сообщения telnet об установлении соединения.)
Проверив, что сервер работает, останавливаете клиента,
переходя в режим команд telnet и вводя команду завершения. Обратите внимание,
что если немедленно повторить весь эксперимент, то будет тот же результат. Таким
образом, adserver перезапускается без проблем.
А теперь проделайте все еще раз, но только остановите
сервер. При попытке перезапустить сервер вы получите сообщение «Address already
in use» (сообщение Разбито на две строчки). Разница в том, что во втором эксперименте
вы остановили сервер, а не клиент рис. 3.10.
|
bsd $ badserver
badserver: Клиент отсоединился
bsd $ : badserver
badserver : Клиент отсоединился
bsd $
|
bsd $ telnet localhost 9000
hello
hello
^]
telnet> quit Клиент завершил сеанс.
Connection closed.
Сервер перезапущен.
bsd $ telnet localhost 9000
world
world
^]
telnet> quit Клиент завершил сеанс.
Connection closed
bsd $
|
Рис. 3.9. Завершение работы клиента
|
bsd $ badeerver
^C Сервер остановлен
bsd $ badserver
badserver: He могу привязать сокет:
Address already in use (48)
bsd $
|
bsd $ telnet localhost 9000
hello again
hello again
Connection closed by
foreign host
bsd $
|
Рис. 3.10. Завершение работы сервера
Чтобы разобраться, что происходит, нужно помнить
о двух вещах:
- состоянии TIME-WAIT протокола TCP;
- TCP-соединение полностью определено четырьмя
факторами (локальный адрес, локальный порт, удаленный адрес, удаленный порт).
Как было сказано в совете 22, сторона соединения,
которая выполняет активное закрытие (посылает первый FIN), переходит в состояние
TIME-WAIT и остается в нем в течение 2MSL. Это первый ключ к пониманию того,
что вы наблюдали в двух предыдущих примерах: если активное закрытие выполняет
клиент, то можно перезапустить обе стороны соединения. Если же активное закрытие
выполняет сервер, то его рестартовать нельзя. TCP не позволяет это сделать,
так как предыдущее соединение все еще находится в состоянии TIME-WAIT.
Если бы сервер перезапустился и с ним соединился
клиент, то возникло новое соединение, возможно, даже с другим удаленным хостом.
Как было сказано, TCP-соединение полностью определяется локальными и удаленными
адресами и номерами портов, так что даже если с вами соединился клиент с того
же у ленного хоста, проблемы не возникнет при другом номере удаленного порта.
Примечание: Даже если клиент с того же удаленного
хоста воспользуется тем же номером порта, проблемы может и не возникнуть. Традиционно
реализация BSD разрешает такое соединение, если только порядковый номер посланного
клиентом сегмента SYN больше последнего порядкового номера, зарегистрированного
соединением, которое находится в состоянии TIME- WAIT.
Возникает вопрос: почему TCP возвращает ошибку,
когда делается попытка перезапустить сервер? Причина не в TCP, который требует
только уникальности указанных факторов, а в API сокетов, требующем двух вызовов
для полного определения этой четверки. В момент вызова bind еще неизвестно,
последует ли за ним connect, и, если последует, то будет ли в нем указано новое
соединение, или он попытается повторно использовать существующее. В книге [Torek
1994] автор - и не он один - предлагает заменить вызовы bind, connect и listen
одной функцией, реализующей функциональность всех трех. Это даст возможность
TCP выявить, действительно ли задается уже используемая четверка, не отвергая
попыток перезапустить закрывшийся сервер, который оставил соединение в состоянии
TIME-WAIT. К сожалению, элегантное решение Терека не было одобрено.
Но существует простое решение этой проблемы. Можно
разрешить TCP привязку к уже используемому порту, задав опцию сокета SO_REUSEADDR.
Чтобы проверить, как это работает, вставим между строками 7 и 8 файла badserver.
с строку
const int on = 1;
а между строками 12 и 13 - строки
if (setsockopt(s, SOL_SOCKET, SO_REUSEADDR, &on,
sizeoff on ) ) )
error( 1, errno, "ошибка вызова setsockopt");
Заметьте, что вызов setsockopt должен предшествовать
вызову bind. Если назвать исправленную программу goodserver и повторить эксперимент
(рис. 3.11), то получите такой результат:
|
bsd $ goodserver
^С Сервер остановлен.
bsd $
|
bsd $ telnet localhost 9000
hello once again
hello once again
Connection closed by foreign host
Сервер перезапущен.
bsd $ telnet localhoet 9000
hello one last time
hello one last time
|
Рис. 3.11. Завершение работы сервера,
в котором используется опция SO_REUSEADDR
Теперь вы смогли перезапустить сервер, не дожидаясь
выхода предыдущего соединения из состояния TIME-WAIT. Поэтому в сервере всегда
надо устанавливать опцию сокета SO_REUSEADDR. Обратите внимание, что в предлагаемом
каркасе в функции tcp_server это уже делается.
Некоторые, в том числе авторы книг, считают, что
задание опции SO_REUSEADDR опасно, так как позволяет TCP создать четверку, идентичную
уже используемой, и таким образом создать проблему. Это ошибка. Например, если
попытаться создать два идентичных прослушивающих сокета, то TCP отвергнет операцию
привязки даже если вы зададите опцию SO_REUSEADDR:
bsd $ goodserver &
[1] 1883
bsd $ goodserver
goodserver: He могу привязать сокет: Address already
in use (48)
bsd $
Аналогично если вы привяжете одни и те же локальный
адрес и порт к двум разным клиентам, задав SO_REUSEADDR, то bind для второго
клиента завершится успешно. Однако на попытку второго клиента связаться с тем
же удаленным хостом и портом, что и первый, TCP ответит отказом.
Помните, что нет причин, мешающих установке опции
SO_REUSEADDR в сервере. Это позволяет перезапустить сервер сразу после его завершения.
Если же этого не сделать, то сервер, выполнявший активное закрытие соединения,
не перезапустится.
Примечание: В книге [Stevens 1998] отмечено,
что с опцией SO_REUSEADDR связана небольшая проблема безопасности. Если сервер
привязывает универсальный адрес INADDR_ANY, как это обычно и делается, то другой
сервер может установить опцию SO_REUSEADDR и привязать тот же порт, но с конкретным
адресом, «похитив» тем самым соединение у первого сервера. Эта проблема действительно
существует, особенно для сетевой файловой системы (NFS) даже в среде UNIX, поскольку
NFS привязывает порт 2049 из открытого всем диапазона. Однако такая опасность
существует не из-за использования NFS опции SO_REUSEADDR, а потому что это может
сделать другой сервер. Иными словами, эта опасность имеет место независимо от
установки SO_REUSEADDR,так что это не причина для отказа от этой опции.
Следует отметить, что у опции SO_REUSEADDR есть
и другие применения. Предположим, например, что сервер работает на машине с
несколькими сетевыми интерфейсами и ему необходимо иметь информацию, какой интерфейс
клиент указал в качестве адреса назначения. При работе с протоколом TCP это
легко, так как серверу достаточно вызвать getsockname после установления соединения.
Но, если реализация TCP/IP не поддерживает опции сокета IP_RECVDSTADDR, то UDP-сервер
так поступить не может. Однако UDP-сервер может решить эту задачу, установив
опцию SO_REUSEADDR и привязав свой хорошо известный порт к конкретным, интересующим
его интерфейсам, а универсальный адрес INADDR_ANY - ко всем остальным интерфейсам.
Тогда сервер определит указанный клиентом адрес по сокету, в который поступила
датаграмма.
Аналогичная схема иногда используется TCP- и UDP-серверами,
которые хотят предоставлять разные варианты сервиса в зависимости от адреса,
указанного клиентом. Допустим, вы хотите использовать свою версию tcpmux (совет
18) Для предоставления одного набора сервисов, когда клиент соединяется с интерфейсов
По адресу 198.200.200.1, и другого - при соединении
клиента с иным интерфейсом. Для этого запускаете экземпляр tcpmux со специальными
сервисами на интерфейсе 198.200.200.1, а экземпляр со стандартными сервисами
- на всех остальных интерфейсах, указав универсальный адрес INADDR_ANY. Поскольку
tcpmux устанавливает опцию SO_REUSEADDR, TCP позволяет повторно привязать порт
1, хотя при второй привязке указан универсальный адрес.
И, наконец, SO_REUSEADDR используется в системах
с поддержкой группового вещания, чтобы дать возможность одновременно нескольким
приложениям прослушивать входящие датаграммы, вещаемые на группу. Подробнее
это рассматривается в книге [Stevens 1998].
В этом разделе рассмотрена опция сокета SO_REUSEADDR.
Ее установка позволяет перезапустить сервер, от предыдущего «воплощения» которого
еще осталось соединение в состоянии TIME-WAIT. Серверы должны всегда устанавливать
эту опцию, которая не влечет угрозу безопасности.
Для этой рекомендации есть несколько причин. Первая
очевидна и уже обсуждалась выше: каждое обращение к функциям записи (write,
send и т.д.) требует, по меньшей мере, двух контекстных переключений, а это
довольно дорогая операция. С другой стороны, многократные операции записи (если
не считать случаев типа записи по одному байту) не требуют заметных накладных
расходов в приложении. Таким образом, совет избегать лишних системных вызовов -
это, скорее, «правила хорошего тона», а не острая необходимость.
Есть, однако, и более серьезная причина избегать
многократной записи мелких блоков - эффект алгоритма Нейгла. Этот алгоритм
кратко рассмотрен в совете 15. Теперь изучим его взаимодействие с приложениями
более детально. Если не принимать в расчет алгоритм Нейгла, то это может привести
к неправильному решению задач, так или иначе связанных с ним, и существенному
снижению производительности некоторых приложений.
К сожалению, алгоритм Нейгла, равно как и состояние
TIME-WAIT, многие программисты понимают недостаточно хорошо. Далее будут рассмотрены
причины появления этого алгоритма, способы его отключения и предложены эффективные
решения, которые обеспечивают хорошую производительность приложению, оказывая
негативного влияния на сеть в целом.
Алгоритм был впервые предложен в 1984 году Джоном
Нейглом (RFC 896 [Nagle 1984]) для решения проблем производительности таких
программ, как telnet и ей подобных. Обычно эти программы посылают каждое нажатие
клавиши в отдельном сегменте, что приводит к засорению сети множеством крохотных
датаграмм (tinygrams). Если принять во внимание, что минимальный размер ТСР-сегмента
(без данных) равен 40 байт, то накладные расходы при посылке одного байта в
сегменте достигают 4000%. Но важнее то, что увеличивается число пакетов в сети.
А это приводит к перегрузке и необходимости повторной передачи, из-за чего перегрузка
еще более увеличивается. В неблагоприятном случае в сети находится несколько
копий каждого сегмента, и пропускная способность резко снижается по сравнению
с номинальной.
Соединение считается простаивающим, если в нем
нет неподтвержденных данных (то есть хост на другом конце подтвердил все отправленные
ему данные). В первоначальном виде алгоритм Нейгла должен был предотвращать
описанные выше проблемы. При этом новые данные от приложения не посылаются до
тех пор, пока соединение не перейдет в состояние простоя. В результате в соединении
не может находиться более одного небольшого неподтвержденного сегмента.
Процедура, описанная в RFC 1122 [Braden 1989] несколько
ослабляет это требование, разрешая посылать данные, если их хватает для заполнения
целого сегмента. Иными словами, если можно послать не менее MSS байт, то это
разрешено, даже если соединение не простаивает. Заметьте, что условие Нейгла
при этом по-прежнему выполняется: в соединении находится не более одного небольшого
неподтвержденного сегмента.
Многие реализации не следуют этому правилу буквально,
применяя алгоритм Нейгла не к сегментам, а к операциям записи. Чтобы понять,
в чем разница, предположим, что MSS составляет 1460 байт, приложение записывает
1600 байт, в окнах приема и передачи свободно, по меньшей мере, 2000 байт и
соединение простаивает. Если применить алгоритм Нейгла к сегментам, то следует
послать 1460 байт, а затем ждать подтверждения перед отправкой следующих 140
байт – алгоритм Нейгла применяется при посылке каждого сегмента. Если же использовать
алгоритм Нейгла к операциям записи, то следует послать 1460 байт, а вслед за
ними еще 140 байт - алгоритм применяется только тогда, когда приложение передаете
TCP новые данные для доставки.
Алгоритм Нейгла работает хорошо и не дает приложениям
забить сеть крохотными пакетами. В большинстве случае производительность не
хуже, чем в реализации TCP, в которой алгоритм Нейгла отсутствует.
Примечание: Представьте, например, приложение,
которое передает ТСP один байт каждые 200 мс. Если период кругового обращения
(RTT, для соединения равен одной секунде, то TCP без алгоритма Нейгла будет
посылать пять сегментов в секунду с накладными расходами 4000%. При наличии
этого алгоритма первый байт отсылается сразу, а следующие четыре байта, поступившие
от приложения, будут задержаны, пока не придет подтверждены на первый сегмент.
Тогда все четыре байта посылаются сразу. Таким образом, вместо пяти сегментов
послано только два, за счет чего накладные расходы уменьшились до 1600% при
сохранении той же скорости 5 байт/с.
К сожалению, алгоритм Нейгла может плохо взаимодействовать
с другой, добавленной позднее возможностью TCP - отложенным подтверждением.
Когда прибывает сегмент от удаленного хоста, TCP
задерживает отправку АСК в надежде, что приложение скоро ответит на только что
полученные данные. Поэтому АСК можно будет объединить с данными. Традиционно
в системах, производных от BSD, величина задержки составляет 200 мс.
Примечание: В RFC 1122 не говорится о сроке
задержки, требуется лишь, чтобы она была не больше 500 мс. Рекомендуется также
подтверждать, по крайней мере, каждый второй сегмент.
Отложенное подтверждение служит той же цели, что
и алгоритм Нейгла - уменьшить число повторно передаваемых сегментов.
Принцип совместной работы этих механизмов рассмотрим
на примере типичного сеанса «запрос/ответ». Как показано на рис. 3.12, клиент
посылает короткий запрос серверу, ждет ответа и посылает следующий запрос.
Заметьте, что алгоритм Нейгла не применяется, поскольку
клиент не посылает новый сегмент, не дождавшись ответа на предыдущий запрос,
вместе с которым приходит и АСК. На стороне сервера задержка подтверждения дает
серверу время ответить. Поэтому для каждой пары запрос/ответ нужно всего два
сегмента. Если через RTT обозначить период кругового обращения сегмента, а через
Тp - время, необходимое серверу для обработки запроса и отправки ответа (в миллисекундах),
то на каждую пару запрос/ответ уйдет RTT + Тp мс.
А теперь предположим, что клиент посылает свой
запрос в виде двух последовательных операций записи. Часто причина в том, что
запрос состоит из заголовка, за которым следуют данные. Например, клиент, который
посылает серверу запросы переменной длины, может сначала послать длину запроса,
а потом сам запрос.
Примечание: Пример такого типа изображен
на рис. 2.17, но там были приняты меры для отправки длины и данных в составе
одного сегмента.
На рис. 3.13. показан поток данных.
|
Рис. 3.12. Поток данных из одиночных
сегментов сеанса «запрос.ответ»
|
Рис. 3.13. Взаимодействие алгоритма
Нейгла и отложенного подтверждения
|
На этот раз алгоритмы взаимодействуют так, что число
сегментов, посланных на каждую пару запрос/ответ, удваивается, и это вносит
заметную задержку.
Данные из первой части запроса посылаются немедленно,
но алгоритм Нейгла не дает послать вторую часть. Когда серверное приложение
получает первую часть запроса, оно не может ответить, так как запрос целиком
еще не пришел. Это значит, что перед посылкой подтверждения на первую часть
должен истечь тайм-аут установленный таймером отложенного подтверждения. Таким
образом, алгоритмы Нейгла и отложенного подтверждения блокируют друг друга:
алгоритм Нейгла мешает отправке второй части запроса, пока не придет подтверждение
на первую а алгоритм отложенного подтверждения не дает послать АСК, пока не
сработает таймер, поскольку сервер ждет вторую часть. Теперь для каждой пары
запрос/ответ нужно четыре сегмента и 2 X RTT + Тp + 200 мс. В результате за
секунду можно обработать не более пяти пар запрос/ответ, даже если забыть о
времени обработки запроса сервером и о периоде кругового обращения.
Примечание: Для многих систем это изложение
чрезмерно упрощенное. Например, системы, производные от BSD, каждые 200 мс проверяют
все соединения, для которых подтверждение было отложено. При этом АСК посылается
независимо от того, сколько времен прошло в действительности. Это означает,
что реальная задержка может составлять от 0 до 200 мс, в среднем 100 мс. Однако
часто задержка достигает 200мс из-за «фазового эффекта состоящего в том, что
ожидание прерывается следующим тактом таймера через 200 мс. Первый же ответ
синхронизирует ответы с тактовым генератором. Хороший пример такого поведения
см. в работе [Minshall et al. 1999]. I
Последний пример показывает причину проблемы: клиент
выполняет последовательность операций «запись, запись, чтение». Любая такая
последовательность приводит к нежелательной интерференции между алгоритмом Нейгла
и алгоритмом отложенного подтверждения, поэтому ее следует избегать. Иными словами
приложение, записывающее небольшие блоки, будет страдать всякий раз, когда хост
на другом конце сразу не отвечает.
Представьте приложение, которое занимается сбором
данных и каждые 50 мс посылает серверу одно целое число. Если сервер не отвечает
на эти сообщения, а просто записывает данные в журнал для последующего анализа,
то будет наблюдаться такая же интерференция. Клиент, пославший одно целое, блокируется
алгоритмом Нейгла, а затем алгоритмом отложенного подтверждения, например на
200 мс, после чего посылает по четыре целых каждые 200 мс.
Поскольку сервер из последнего примера записывал
в журнал полученные данные, взаимодействие алгоритмов Нейгла и отложенного подтверждение
не принесло вреда и, по сути, уменьшило общее число пакетов в четыре раза. Допустим
что клиент посылает серверу серию результатов измерения температуры, и сервер
должен отреагировать в течение 100 мс, если показания выходят за пределы допустимого
диапазона. В этом случае задержка на 200 мс, вызванная интерференцией алгоритмов,
уже нетерпима, и ее надо устранить.
Хорошо, что RFC 1122 требует наличия метода, отключающего
алгоритм Нейгла. Пример с клиентом, следящим за температурой, - это один из
случаев, когда такое отключение необходимо. Менее драматичный, но более реалистичный
пример относится к системе X-Window, работающей на платформе UNIX. Поскольку
X использует протокол TCP для общения между дисплеем (сервером) и приложением
(клиентом), Х-сервер должен доставлять информацию о действиях пользователя
(перемещении курсора мыши) Х-клиенту без задержек, вносимых алгоритмом Нейгла.
В API сокетов можно отключить алгоритм Нейгла с
помощью установки опции сокета TCP_NODELAY.
const int on = 1
setsockopt( s, IPPROTO_TCP, TCP_NODELAY, &on,
sizeof( on ) );
Но возможность отключения алгоритма Нейгла вовсе
не означает, что это обязательно делать. Приложений, имеющих реальные основания
отключать алгоритм, значительно меньше, чем тех, которые это делают без причины.
Причина, по которой программисты с пугающей регулярностью сталкиваются с классической
проблемой интерференции между алгоритмами Нейгла и отложенного подтверждения,
в том, что делают много мелких операций записи вместо одной большой. Потом они
замечают, что производительность приложений намного хуже, чем ожидалось, и
спрашивают, что делать. И кто-нибудь обязательно ответит: «Это все алгоритм
Нейгла. Отключите его!». Нет нужды говорить, что после отключения этого алгоритма
проблема производительности действительно исчезает. Только за это приходится
расплачиваться увеличением числа крохотных пакетов в сети. Если так работают
многие приложения или, что еще хуже, алгоритм Нейгла отключен по умолчанию,
то возрастет нагрузка сети. В худшем случае это может привести к полному затору.
Как видите, существуют приложения, которые, действительно,
должны отключать алгоритм Нейгла, но в основном это делается из-за проблем с
производительностью, причина которых в отправке логически связанных данных серией
из Дельных операций записи. Есть много способов собрать данные, чтобы послать
вместе. Наконец всегда можно скопировать различные порции данных в один буфер,
которые потом и передать операции записи. Но, как объясняется в совете 26 к
такому методу следует прибегать в крайнем случае. Иногда можно организовать
хранение данных в одном месте, как и сделано в листинге 2.15. Чаще однако иные
находятся в нескольких несмежных буферах, а хотелось бы послать их одной операцией
записи.
Для этого и в UNIX, и в Winsock предусмотрен некоторый
способ. К сожалению, эти способы немного отличаются. В UNIX есть системный вызов
writev и парный ему вызов readv. При использовании writev вы задаете список
буферов, из которых должны собираться данные. Это решает исходную задачу: можно
размещать данные в нескольких буферах, а записывать их одной операцией, исключив
тем самым интерференцию между алгоритмами Нейгла и отложенного подтверждения.
#include <sys/uio.h>
ssize_t writev (int fd,
const struct iovec *iov, int cnt);
ssize_t readv(int fd,
const struct iovec *iov, int cnt);
Возвращаемое значение: число переданных байт или -1 в случае
ошибки.
Параметр iov- это указатель на массив структур
iovec, в которых хранятся указатели на буферы данных и размеры этих буферов:
struct iovec {
char *iov_base; /* Адрес начала буфера. */
size_t iov_len; /* Длина буфера. */
};
Примечание: Это определение взято из системы
FreeBSD. Теперь во многих системах адрес начала буфера определяется так:
void *iov_base; /* адрес начала буфера */
Третий параметр, cnt - это число структур iovec
в массиве (иными словами, количество буферов).
У вызовов writev и readv практически общий интерфейс.
Их можно использовать для любых файловых дескрипторов, а не только для сокетов.
Чтобы это понять, следует переписать клиент (листинг
3.23), работающий с записями переменной длины (листинг 2.15), с использованием
writev.
Листинг 3.23. Клиент, посылающий записи переменной
длины с помощью writev
vrcv.с
1 #include "etcp.h"
2 #include <sys/uio.h>
3 int main( int argc, char **argv)
4 {
5 SOCKET s;
6 int n;
7 char buf[128];
8 struct iovec iov[ 2 ];
9 INIT();
10 s = tcp_client( argv[ 1 ], argv[ 2 ] ) ;
11 iov[ 0 ].iov_base = ( char * )&n;
12 iov[ 0 ].iov_len = sizeof( n ) ;
13 iov[ 1 ].iov_base = buf;
14 while ( fgets( buf, sizeof( buf ), stdin )
!= NULL )
15 {
16 iov[ 1 ].iov_len = strlent buf );
17 n = htonl ( iov[ 1 ].iov_len ) ;
18 if ( writev( s, iov, 2 ) < 0 )
19 error( 1, errno, "ошибка вызова writev"
);
20 }
21 EXIT( 0 ) ;
22 }
Инициализация
9-13 Выполнив обычную инициализацию клиента, формируем
массив iov. Поскольку в прототипе writev имеется спецификатор const для структур,
на которые указывает параметр iov, то есть гарантия, что массив iov не будет
изменен внутри writev, так что большую часть параметров можно задавать вне цикла
while.
Цикл обработки событий
14-20 Вызываем fgets для чтения одной строки из
стандартного ввода, вычисляем ее длину и записываем в поле структуры из массива
iov. Кроме того, длина преобразуется в сетевой порядок байт и сохраняется в
переменной n.
Если запустить сервер vrs (совет 6) и вместе с
ним клиента vrcv, то получатся те же результаты, что и раньше.
В спецификации Winsock определен другой, хотя и
похожий интерфейс.
#include <winsock2.h>
int WSAAPI WSAsend (SOCKET
s, LPWSABUF, DWORD cnt, LPDWORD sent, DWORD flags, LPWSAOVERLAPPED ovl, LPWSAOVERLAPPED_COMPLETION_ROUTINE
func );
Возвращаемое значение:
0 в случае успеха, в противном случае SOCKET_ERROR.
Последние два аргумента используются при вводе/выводе
с перекрытием, и в данном случае не имеют значения, так что обоим присваивается
значение NULL. параметр buf указывает на массив структур типа WSABUF, играющих
ту же роль, Что структуры iovec в вызове writev.
typedef struct _WSABUF {
u_longlen; /* Длина буфера. */
char FAR * buf; /* Указатель на начало буфера.
*/
} WSABUF, FAR * LPWSABUF;
Параметр sent - это указатель на переменную типа
DWORD, в которой хранится число переданных байт при успешном завершении вызова.
Параметр flags аналогичен одноименному параметру в вызове send.
Версия клиента, посылающего сообщения переменной
длины, на платформе Windows выглядит так (листинг 3.24):
Листинг 3.24. Версия vrcv для Winsock
vrcvw.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int n;
6 char buf[ 128 ] ;
7 WSABUF wbuf[ 2 ];
8 DWORD sent;
9 INIT();
10 s = tcp_client( argv[ 1 ], argv[ 2 ] ) ;
11 wbuf[ 0 ].buf = ( char * )&n;
12 wbuf[ 0 ].len = sizeof( n );
13 wbuf[ 1 ].buf = buf;
14 while ( fgets( buf, sizeof( buf ), stdin )
!= NULL )
15 {
16 wbuff 1 ].len = strlen( buf );
17 n = htonl ( wbuff 1 ].len );
18 if ( WSASend( s, wbuf, 2, &sent, 0,
NULL, NULL ) < 0 )
19 error( 1, errno, "ошибка вызова WSASend"
);
20 }
21 EXIT( 0 );
22 }
Как видите, если не считать иного обращения к вызову
записи со сбором, то Winsock-версия идентична UNIX-версии.
В этом разделе разобран алгоритм Нейгла и его взаимодействие
с алгоритмом отложенного подтверждения. Приложения, записывающие в сеть несколько
маленьких блоков вместо одного большого, могут заметно снизить производительность.
Поскольку алгоритм Нейгла помогает предотвратить
действительно серьезную проблему - переполнение сети крохотными пакетами, не
следует отключать его для повышения производительности приложений, выполняющих
запись мелкими блоками. Вместо этого следует переписать приложение так, чтобы
все логические связанные данные выводились сразу. Здесь был рассмотрен удобный
способ решения этой задачи с помощью системного вызова writev в UNIX или WSASend
в Winsock.
В совете 7 отмечалось, что для установления TCP-соединения
стороны обычно должны обменяться тремя сегментами (это называется трехсторонним
квитированием). Как показано на рис. 3.14, эта процедура инициируется вызовом
connect со стороны клиента и завершается, когда сервер получает подтверждение
АСК на посланный им сегмент SYN.
Примечание: Возможны, конечно, и другие
варианты обмена сегментами. Например, одновременный connect, когда сегменты
SYN передаются навстречу друг другу. Но в большинстве случаев соединение устанавливается
именно так, как показано на рис. 3.14.
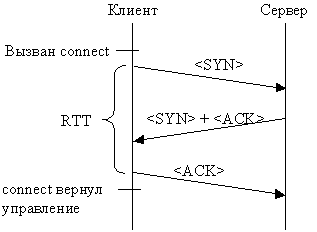
Рис. 3.14 Обычная процедура трехстороннего
квитирования
При использовании блокирующего сокета вызов connect
не возвращает управления, пока не придет подтверждение АСК на посланный клиентом
SYN. Поскольку для этого требуется, по меньшей мере, время RTT, а при перегрузке
сети или недоступности хоста на другом конце - даже больше, часто бывает полезно
прервать вызов connect. Обычно TCP делает это самостоятельно, но время ожидания
(как правило, 75 с) может быть слишком велико для приложения. В некоторых реализациях,
например в системе Solaris, есть опции сокета для управления величиной тайм-аута
connect, но, к сожалению, они имеются не во всех системах.
Есть два способа прерывания connect по тайм-ауту.
Самый простой - окружить этот вызов обращениями к alarm. Предположим, например,
что вы не хотите ждать завершения connect более пяти секунд. Тогда можно модифицировать
каркас tcpclient. skel (листинг 2.6), добавив простой обработчик сигнала и немного
видоизменив функцию main:
void alarm_hndlr (int sig)
{
return;
}
int main ( int argc, char **argv )
{
…
signal ( SIGALRM, alarm_hndlr );
alarm( 5 );
rc = connect(s, ( struct sockaddr * )&peer,
sizeof( peer ) )
alarm( 0 );
if ( rc < 0 )
{
if ( errno == EINTR )
error( 1, 0, "истек тайм-аут connect\n"
);
…
}
Назовем программу, созданную по этому каркасу,
connecto и попытаемся с помощью соединиться с очень загруженным Web-сервером
Yahoo. Получите ожидаемый результат:
bsd: $ connectto yahoo.com daytime
connectto: истек тайм-аут connect спустя 5 с
bsd: $
Хотя это и простое решение, с ним связано две потенциальных
проблемы. Сначала обсудим их, а потом рассмотрим другой метод - он сложнее,
но лишен этих недостатков.
Прежде всего в данном примере подразумевается,
что «тревожный» таймер, используемый в вызове alarm, нигде в программе не применяется,
и, значит, для сигнала SIGALRM не установлен другой обработчик. Если таймер
уже взведен где-то еще, то приведенный код его переустановит, поэтому старый
таймер не сработает. Правильнее было бы сохранить и затем восстановить время,
оставшееся до срабатывания текущего таймера (его возвращает вызов alarm), а
также сохранить и восстановить текущий обработчик сигнала SIGALRM (его адрес
возвращает вызов signal). Чтобы все было корректно, надо было также получить
время, проведенное в вызове connect, и вычесть его из времени, оставшегося до
срабатывания исходного таймера.
Далее, для упрощения вы завершаете клиент, если
connect не вернул управления вовремя. Вероятно, нужно было бы предпринять иные
действия. Однако надо иметь в виду, что перезапустить connect нельзя. Дело в
том, что в результате вызова connect сокет остался привязанным к ранее указанному
адресу, так что попытка повторного выполнения приведет к ошибке «Address already
in use». При желании повторить connect, возможно, немного подождав, придется
сначала закрыть, а затем заново открыть сокет, вызвав close (или closesocket)
и socket.
Еще одна потенциальная проблема в том, что некоторые
UNIX-системы могут автоматически возобновлять вызов connect после возврата из
обработчика сигнала. В таком случае connect не вернет управления, пока не истечет
тайм-аут TCP. Во всех современных вариантах системы UNIX поддерживается вызов
sigaction, который можно использовать вместо signal. В таком случае следует
указать, хотите ли вы рестартовать connect. Но в некоторых устаревших версиях
UNIX этот вызов не поддерживается, и тогда использование alarm для прерыва ния
connect по тайм-ауту затруднительно.
Если нужно вывести всего лишь диагностическое сообщение
и завершить сеанс, то это можно сделать в обработчике сигнала. Поскольку это
происходит до рес тарта connect, не имеет значения, поддерживает система вызов
sigaction или не. Однако если нужно предпринять какие-то другие действия, то,
вероятно, придется выйти из обработчика с помощью функции longjmp, а это неизбежно
приводит к возникновению гонки.
Примечание: Следует заметить, что гонка
возникает и в более простом случае, когда вы завершаете программу. Предположим,
что соединение успешно установлено, и connect вернул управление. Однако прежде
чем вы успели его отменить, таймер сработал, что привело к вызову обработчика
сигнала и, следовательно, к завершению программы.
alarm( 5 };
rc = connect( s, NULL, NULL );
/* здесь срабатывает таймер */
alarm ( 0 );
Вы завершаете программу, хотя соединение и удалось
установить. В первоначальном коде такая гонка не возникает, поскольку даже если
таймер сработает между возвратом из connect и вызовом alarm, обработчик сигнала
вернет управление, не предпринимая никаких действий.
Принимая это во внимание, многие эксперты считают,
что для прерывания вызова connect по тайм-ауту лучше использовать select.
Другой, более общий метод организации тайм-аута
connect состоит в том, чтобы сделать сокет неблокирующим, а затем ожидать с
помощью вызова select. При таком подходе удается избежать большинства трудностей,
возникающих при попытке воспользоваться alarm, но остаются проблемы переносимости
даже между разными UNIX-системами.
Сначала рассмотрим код установления соединения.
В каркасе tcpclient.skel Модифицируйте функцию main, как показано в листинге
3.25.
Листинг 3.25. Прерывание connect по тайм-ауту с
помощью select
connectto1.с
1 int main( int argc, char **argv )
2 {
3 fd_set rdevents;
4 fd_set wrevents;
5 fd_set exevents;
6 struct sockaddr_in peer;
7 struct timeval tv;
8 SOCKET s;
9 int flags;
10 int rc;
11 INIT();
12 set_address( argv[ 1 ], argv[ 2 ], &peer,
"tcp" );
13 S = socket( AF_INET, SOCK_STREAM, 0 );
14 if ( !isvalidsock( s ) )
15 error( 1, errno, "ошибка вызова socket");
16 if( ( flags = fcntl( s, F_GETFL, 0 ) ) <
0 )
17 error( 1, errno, "ошибка вызова fcntl
(F_GETFL)");
18 if ( fcntl( s, F_SETFL, flags | 0_NONBLOCK
) < 0 )
19 error( 1, errno, "ошибка вызова fcntl
(F_SETFL)");
20 if ( ( rc = connect ( s, ( struct sockaddr
* )&peer,
21 sizeoff peer ) ) ) && errno != EINPROGRESS
)
22 error( 1, errno, "ошибка вызова connect"
);
23 if ( rc == 0 ) /* Уже соединен? */
24 {
25 if ( fcntl( s, F_SETFL, flags ) < 0 )
26 error(1,errno,"ошибка вызова fcntl
(восстановление флагов)”);
27 client( s, &peer );
28 EXIT( 0 );
29 }
30 FD_ZERO( &rdevents );
31 FD_SET( s, krdevents );
32 wrevents = rdevents;
33 exevents = rdevents;
34 tv.tv_sec = 5;
35 tv.tv_usec =0;
36 rc = select( s + 1, &rdevents, &wrevents,
&exevents, &tv );
37 if ( rc < 0 )
38 error( 1, errno, "ошибка вызова select"
);
39 else if ( rc == 0 )
40 error( 1, 0, "истек тайм-аут connect\n"
);
41 else if ( isconnected( s, &rdevents, &wrevents,
kexevents ))
42 {
43 if (fcntl (s, F_SETFL, flags) < 0)
44 error(1,errno,"ошибка вызова fcntl(восстановление
флагов)");
45 client( s, &peer );
46 }
47 else
48 error( 1, errno, "ошибка вызова connect");
49 EXIT( 0 );
50 }
Инициализация
16-19 Получаем текущие флаги, установленные для
сокета, с помощью операции OR, добавляем к ним флаг O_NONBLOCK и устанавливаем
новые флаги.
Инициирование connect
20-29 Начинаем установление соединения с помощью
вызова connect. Поскольку сокет помечен как неблокирующий, connect немедленно
возвращает управление. Если соединение уже установлено (это возможно, если,
например, вы соединялись с той машиной, на которой запущена программа), то connect
вернет нуль, поэтому возвращаем сокет в режим блокирования и вызываем функцию
client. Обычно в момент Возврата из connect соединение еще не установлено, и
приходит код EINPROGRESS. Если возвращается другой код, то печатаем диагностическое
сообщение и завершаем программу.
Вызов select
30-36 Подготавливаем, как обычно, данные для select
и, в частности, устанавливаем тайм-аут на пять секунд. Также следует объявить
заинтересованность в событиях исключения. Зачем - станет ясно позже.
Обработка код возврата select
37-40 Если select возвращает код ошибки или признак
завершения по тайм-ауту, то выводим сообщение и заканчиваем работу. В случае
ответа можно было бы, конечно, сделать что-то другое.
41-46 Вызываем функцию isconnected, чтобы проверить,
удалось ли установить соединение. Если да, возвращаем сокет в режим блокирования
и вызываем функцию client. Текст функции isconnected приведен в листингах 3.26
и 3.27.
4 7-48 Если соединение не установлено, выводим сообщение
и завершаем сеанс.
К сожалению, в UNIX и в Windows применяются разные
методы уведомления об успешной попытке соединения. Поэтому проверка вынесена
в отдельную функцию. Сначала приводится UNIX-версия функции isconnected.
В UNIX, если соединение установлено, сокет доступен
для записи. Если же произошла ошибка, то сокет будет доступен одновременно для
записи и для чтения. Однако на это нельзя полагаться при проверке успешности
соединения, поскольку можно возвратиться из connect и получить первые данные
еще до обращения к select. В таком случае сокет будет доступен и для чтения,
и для записи -в точности, как при возникновении ошибки.
Листинг 3.26. UNIX-версия функции isconnected
connectto1 с
1 int isconnected( SOCKET s, fd_set *rd, fd_set
*wr, fd_set *ex )
2 {
3 int err;
4 int len = sizeoff err );
5 errno =0; /* Предполагаем, что ошибки нет.
*/
6 if ( !FD_ISSET( s, rd ) && !FD_ISSET(
s, wr ) )
7 return 0;
8 if (getsockopt( s, SOL_SOCKET, SO_ERROR, &err,
&len ) < 0)
9 return 0;
10 errno = err; /* Если мы не соединились. */
11 return err == 0;
12 }
5-7 Если сокет не доступен ни для чтения, ни для
записи, значит, соединение не установлено, и возвращается нуль. Значение errno
заранее установлено в нуль, чтобы вызывающая программа могла определить, что
сокет действительно, не готов (разбираемый случай) или имеет Metro ошибка.
8-11 Вызываем getsockopt для получения статуса сокета.
В некоторых версиях UNIX getsockopt возвращает в случае ошибки -1. В таком случае
записываем в errno код ошибки. В других версиях система просто возвращает статус,
оставляя его проверку пользователю. Идея кода, который корректно работает в
обоих случаях, позаимствована из книги [Stevens 1998].
Согласно спецификации Winsock, ошибки, которые
возвращает connect через неблокирующий сокет, индицируются путем возбуждения
события исключения в select. Следует заметить, что в UNIX событие исключения
всегда свидетельствует о поступлении срочных данных. Версия функции isconnected
для;Windows показана в листинге 3.27.
Листинг 3.27. Windows-версия функции isconnected
сonnectto1.с
1 int isconnected( SOCKET s, fd_set *rd, fd_set
*wr, fd_set *ex)
2 {
3 WSASetLastError ( 0 );
4 if ( !FD_ISSET( s, rd ) && !FD_ISSET(s,
wr ) )
5 return 0;
6 if ( FD_ISSET( s, ex ) )
7 return 0;
8 return 1;
9 }
3-5 Так же, как и в версии для UNIX, проверяем,
соединен ли сокет. Если нет, устанавливаем последнюю ошибку в нуль и возвращаем
нуль.
6-8 Если для сокета есть событие исключения, возвращается
нуль, в противном случае - единица.
Как видите, для переноса на разные платформы прерывать
вызов connect с помощью тайм-аута более сложно, чем обычно. Поэтому при выполнении
такого действия надо уделить особое внимание платформе.
Наконец, следует понимать, что сократить время ожидания
connect можно, а увеличить - нет. Все вышерассмотренные методы направлены
на то, чтобы прервать вызов connect раньше, чем это сделает TCP. He существует
переносимого механизма для изменения значения тайм-аута TCP на уровне одного
сокета.
Во многих сетевых приложениях, занимающихся, прежде
всего, переносом данных между машинами, большая часть времени процессора уходит
на копирование данных из одного буфера в другой. В этом разделе будет рассмотрено
несколько способов уменьшения объема копирования, что позволит «бесплатно» повысить
производительность приложения. Предложение избегать копирования больших объемов
данных в памяти оказывается не таким революционным, поскольку именно так всегда
и происходит. Массивы передаются не целиком, используются только указатели
на них.
Конечно, обычно данные между функциями, работающими
внутри одного процесса, не копируются. Но в многопроцессных приложениях часто
приходится передавать большие объемы данных от одного процесса другому с помощью
того или иного механизма межпроцессного взаимодействия. И даже в рамках одного
процесса часто доводится заниматься копированием, если сообщение состоит более
чем из двух частей, которые нужно объединить перед отправкой другому процессу
или другой машине. Типичный пример такого рода, обсуждавшийся в совете 24, -это
добавление заголовка в начало сообщения. Сначала копируется в буфер заголовок,
а вслед за ним - само сообщение.
Стремление избегать копирования данных внутри одного
процесса - признак хорошего стиля программирования. Если заранее известно, что
сообщению будет предшествовать заголовок, то надо оставить для него место в
буфере. Иными словами, если ожидается заголовок, описываемый структурой struct
hdr, то прочитать данные можно было бы так:
rc = read( fd, buf + sizeof( struct hdr ) ),
sizeoft ( buf ) - sizeof( struct hdr );
Пример применения такой техники содержится в листинге
3.6.
Еще один прием - определить пакет сообщения в виде
структуры, одним из элементов которой является заголовок. Тогда можно просто
прочитать заголовок в одном из полей:
struct {
struct hdr header; /* Структура определена в другом
месте.*/
char data[ DATASZ ];
} packet ;
rc = read( fd, packet, data. sizeof( packet data
) );
Пример использования этого способа был продемонстрирован
в листинге 2.15. Там же говорилось, что при определении такой структуры следует
проявлять осмотрительность.
Третий, очень гибкий, прием заключается в применении
операции записи со сбором - листинги 3.23 (UNIX) и 3.24 (Winsock). Он позволяет
объединять части сообщения с различными размерами.
Избежать копирования данных намного труднее, когда
есть несколько процессов. Эта проблема часто возникает в системе UNIX, где многопроцессные
приложения -распространенная парадигма (рис. 3.4). Обычно в этой ситуации
проблема даже острее, так как механизмы IPC, как правило, копируют данные отправляющего
процесса в пространство ядра, а затем из ядра в пространство принимающего процесса,
то есть копирование происходит дважды. Поэтому необходимо применять хотя бы
один из вышеупомянутых методов, чтобы избежать лишних операций копирования.
Обойтись почти без копирования, даже между разными
процессами, можно, воспользовавшись разделяемой памятью. Разделяемая память
- это область памяти, доступная сразу нескольким процессам. Каждый процесс отображает
блок виртуальной памяти на адрес в собственном адресном пространстве (в разных
процессах эти адреса могут быть различны), а затем обращается к нему, как к
собственной памяти.
Идея состоит в том, чтобы создать массив буферов
в разделяемой памяти, построить сообщение в одном из них, а затем передать индекс
буфера следующему процессу, применяя механизм IPC. При этом «перемещается» только
одно целое число, представляющее индекс буфера в массиве. Например, на рис.
3.15 в качестве механизма IPC используется TCP для передачи числа 3 от процесса
1 процессу 2. Когда процесс 2 получает это число, он определяет, что приготовлены
данные в буфере smbarray [ 3 ].
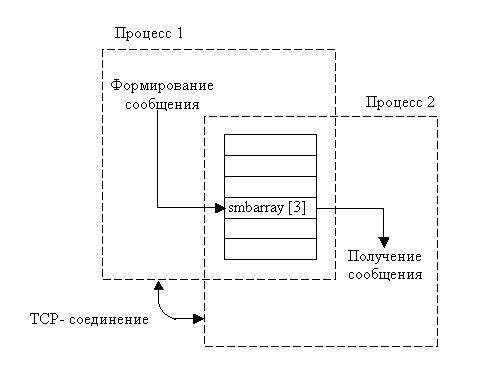
Рис. 3.15. Передача сообщений через
буфер в разделяемой памяти
На рис. 3.15 два пунктирных прямоугольника представляют
адресные пространства процессов 1 и 2, а их пересечение - общий сегмент разделяемой
памяти, который каждый из процессов отобразил на собственное адресное пространство.
Массив буферов находится в разделяемом сегменте и доступен обоим процессам.
Процесс 1 использует отдельный канал IPC (в данном случае - TCP) для информирования
процесса 2 о том, что для него готовы данные, а также место, где их искать.
Хотя здесь показано только два процесса, этот прием
прекрасно работает для любого их количества. Кроме того, процесс 2, в свою очередь,
может передать сообщение процессу 1, получив буфер в разделяемой памяти, построив
в нем сообщение и послав процессу 1 индекс буфера в массиве.
Единственное, что пока отсутствует, - это синхронизация
доступа к буферам, то есть предотвращение ситуации, когда два процесса одновременно
получат один и тот же буфер. Это легко делается с помощью мьютекса, что и будет
продемонстрировано ниже.
Описанную систему буферов в разделяемой памяти
легко реализовать. Основная сложность в том, как получить область разделяемой
памяти, отобразить ее на собственное адресное пространство и синхронизировать
доступ к буферам. Конечно, это зависит от конкретной системы, поэтому далее
будет приведена реализация как для UNIX, так и для Windows.
Но прежде чем перейти к системно-зависимым частям,
обратимся к API и его реализации. На пользовательском уровне система состоит
из пяти функций:
#include “etcp.h”
void init_smb( int init_freelist);
void *smballoc( void );
Возвращаемое значение: указатель на буфер в разделяемой памяти.
void smbfrее( void *smbptr );
void smbsend( SOCKET s, void * smbptr );
void *smbrecv( SOCKET s );
Возвращаемое значение: указатель на буфер в разделяемой памяти.
Перед тем как пользоваться системой, каждый процесс
должен вызвать функцию init_smb для получения и инициализации области разделяемой
памяти и синхронизирующего мьютекса. При этом только один процесс должен вызвать
init_smb с параметром init_f reelist, равным TRUE.
Для получения буфера в разделяемой памяти служит
функция smballoc, возвращающая указатель на только что выделенный буфер. Когда
буфер уже не нужен, процесс может вернуть его системе с помощью функции smb_frее.
Построив сообщение в буфере разделяемой памяти,
процесс может передать буфер другому процессу, вызвав smbsend. Как уже говорилось,
при этом передается только индекс буфера в массиве. Для получения буфера от
отправителя процесс-получатель вызывает функцию smbrecv, которая возвращает
указатель на буфер.
В данной системе для передачи индексов буферов
используется TCP в качестве механизма IPC, но это не единственное и даже не
оптимальное решение. Так Удобнее, поскольку этот механизм работает как под UNIX,
так и под Windows, к тому же можно воспользоваться уже имеющимися средствами,
а не изучать другие методы IPC. В системе UNIX можно было бы применить также
сокеты в адресом домене UNIX или именованные каналы. В Windows доступны SendMessage,
QueueUserAPC и именованные каналы.
Начнем рассмотрение реализации с функций smballoc
и smbfrее (листинг 3.28).
Листинг 3.28. Функции smballoc и smbfree
smb.c
1 #include "etcp.h"
2 #define FREE_LIST smbarray[ NSMB ].nexti
3 typedef union
4 {
5 int nexti;
6 char buf[ SMBUFSZ ];
7 }smb_t;
8 smb_t *smbarray;
9 void *smballoc( void )
10 {
11 smb_t *bp;
12 lock_buf();
13 if ( FREE_LIST < 0 )
14 error( 1, 0, "больше нет буферов в разделяемой
памяти\n" }
15 bр = smbarray + FREE_LIST;
16 FREE_LIST = bp->nexti;
17 unlock_buf ();
18 return bp;
19 }
20 void smbfree( void *b )
21 {
22 smb_t *bp;
23 bp = b;
24 lock_buf();
25 bp->nexti = FREE_LIST;
26 FREE_LIST = bp - smbarray;
27 unlock_buf();
28 }
Заголовок
2-8 Доступные буфера хранятся в списке свободных.
При этом в первых sizeof ( int ) байтах буфера хранится индекс
следующего свободного буфера. Такая организация памяти отражена в объединении
smb_t. В конце массива буферов есть одно целое число, которое содержит либо
индекс первого буфера в списке свободных, либо -1, если этот список пуст. Доступ
к этому числу вы получаете, адресуя его как smbarray [ NSMB ] . nexti. Для удобства
это выражение инкапсулировано в макрос FREE_LIST. На сам массив буферов указывает
переменная smbarray. Это, по сути, указатель на область разделяемой памяти,
которую каждый процесс отображает на свое адресное пространство. В массиве
использованы индексы, а не адреса элементов, так как в разных процессах эти
адреса могут быть различны.
smballoc
12 Вызываем функцию lock_buf, чтобы другой процесс
не мог обратиться к списку свободных. Реализация этой функции зависит от системы.
В UNIX будут использованы семафоры, а в Windows - мыотексы.
13-16 Получаем буфер из списка свободных. Если
больше буферов нет, то выводим диагностическое сообщение и завершаем сеанс.
Вместо этого можно было бы вернуть NULL.
17-18 Открываем доступ к списку свободных и возвращаем
указатель на буфер.
smbfree
23-27 После блокировки списка свободных, возвращаем
буфер, помещая его индекс в начало списка. Затем разблокируем список свободных
и возвращаем управление.
Далее рассмотрим функции smbsend и smbrecv (листинг
3.29). Они посылают и принимают целочисленный индекс буфера, которым обмениваются
процессы. Эти функции несложно адаптировать под иной механизм межпроцессного
взаимодействия.
Листинг 3.29. Функции smbsend и smbrecv
smb.c
1 void smbsend( SOCKET s, void *b )
2 {
3 int index;
4 index = ( smb_t * )b - smbarray;
5 if ( send( s, ( char * )&index, sizeoff
(index ), 0 ) < 0 )
6 error( 1, errno, "smbsend: ошибка вызова
send" );
7 }
8 void *smbrecv( SOCKET s )
9 {
10 int index;
11 int rc;
12 rc = readn( s, ( char * )&index, sizeoff
index ) );
13 if ( rc == 0 ) *,
14 error( 1, 0, "smbrecv: другой конец отсоединился\n"
};
15 else if ( rc != sizeof( index ) )
16 error( 1, errno, "smbrecv: ошибка вызова
readn" );
17 return smbarray + index;
18 }
smbsend
4-6 Вычисляем индекс буфера, на который указывает
Ь, и посылаем его другому процессу с помощью send.
smbrecv
12-16 Вызываем readn для чтения переданного индекса
буфера. В случае ошибки чтения или при получении неожиданного числа байт, выводим
сообщение и завершаем работу.
17 В противном случае преобразуем индекс буфера
в указатель на негеи возвращаем этот указатель вызывающей программе.
Для завершения реализации системы буферов в разделяемой
памяти нужны еще два компонента. Это способ выделения блока разделяемой памяти
и отображения его на адресное пространство процесса, а также механизм синхронизации
для предотвращения одновременного доступа к списку свободных. Для работы с разделяемой
памятью следует воспользоваться механизмом, разработанным в свое время для версии
SysV. Можно было бы вместо него применить отображенный на память файл, как в
Windows. Кроме того, есть еще разделяемая память в стандарте POSIX - для систем,
которые ее поддерживают.
Для работы с разделяемой памятью SysV понадобятся
только два системных вызова:
#include <sys/shm.h>
int shmget( key_t key,
size_t size, int flags );
Возвращаемое значение: идентификатор сегмента разделяемой
памяти в случае успеха, -1 - в случае ошибки.
void shmat( int segid,
const void *baseaddr, int flags );
Возвращаемое значение: базовый адрес сегмента в случае успеха, -1
- в случае ошибки.
Системный вызов shmget применяется для выделения
сегмента разделяемой памяти. Первый параметр, key, - это глобальный для всей
системы уникальный идентификатор, сегмента. Сегмент будет идентифицироваться
целым числом, представление которого в коде ASCII равно SMBM.
Примечание: Использование пространства имен,
отличного от файловой системы, считается одним из основных недостатков механизмов
IPC, появившихся еще в системе SysV. Для отображения имени файла на ключ IPС
можно применить функцию ft ok, но это отображение не будет уникальным. Кроме
того, как отмечается в книге [Stevens 1999], описанная в стандарте SVR4 функцияft
ok дает коллизию (то есть два имени файла отображаю на один и тот же ключ) с
вероятностью 75%.
Параметр size задает размер сегмента в байтах.
Во многих UNIX-систем его значение округляется до величины, кратной размеру
страницы. Параметру flags задает права доступа и другие атрибуты сегмента. Значения
SHM_R и SHM определяют соответственно права на чтение и на запись для владельца.
Права для группы и для всех получают путем сдвига этих значений вправо на три
(для группы) или шесть (для всех) бит. Иными словами, право на запись для группы
- это SHM_W » 3, а право на чтение для всех - SHM_R >> 6. Когда в параметр
flags с помощью побитовой операции OR включается флаг IPC_CREATE, создается
сегмент, если раньше его не было. При дополнительном включении флага IPC_EXCL
ghmget вернет код ошибки EEXIST, если сегмент уже существует.
Вызов shmget только создает сегмент в разделяемой
памяти. Для отображения его в адресное пространство процесса нужно вызвать shmat.
Параметр segid- это идентификатор сегмента, который вернул вызов shmget. При
желании можно указать адрес baseaddr, на который ядро должно отобразить сегмент,
но обычно этот параметр оставляют равным NULL, позволяя ядру самостоятельно
выбрать адрес. Параметр flags используется, если значение baseaddr не равно
NULL, - он управляет выравниваем заданного адреса на приемлемую для ядра границу.
Для построения механизма взаимного исключения следует
воспользоваться SysV-семафорами. Хотя они небезупречны (в частности, им присуща
та же проблема нового пространства имен, что и разделяемой памяти), SysV-семафоры
широко используются в современных UNIX-системах и, следовательно, обеспечивают
максимальную переносимость. Как и в случае разделяемой памяти, сначала надо
получить и инициализировать семафор, а потом уже его применять. В данной ситуации
понадобятся три относящихся к семафорам системных вызова.
Вызов semget аналогичен shmget: он получает у операционной
системы семафор и возвращает его идентификатор. Параметр key имеет тот же смысл,
что и для shmget - он именует семафор. В SysV-семафоры выделяются группами,
и параметр nsems означает, сколько семафоров должно быть в запрашиваемой группе.
Параметр flags такой же, как для shmget.
#include <sys/sem.h>
int semget( key_t key,
int nsems, int flags );
Возвращаемое значение:
идентификатор семафора в случае успеха, -1 - в случае ошибки.
int semctl( int semid,
int semnum, int cmd, ... );
Возвращаемое значение:
неотрицательное число в случае успеха, -1 - в случае ошибки.
int semop( int semid,
struct sembuf *oparray, size_t nops ); Возвращаемое значение: 0 в случае успеха,
-1 - в случае ошибки.
Здесь использована semctl для задания начального
значения семафора. Этот вызов служит также для установки и получения различных
управляющих параметров, связанных с семафором. Параметр semid - это идентификатор
семафора, ращенный вызовом semget. Параметр semnum означает конкретный семафор
из группы. Поскольку будет выделяться только один семафор, значение этого параметра
всегда равно нулю. Параметр cmd- это код выполняемой операции.
У вызова semget могут быть и дополнительные параметры,
о чем свидетельствует многоточие в прототипе.
Вызов semop используется для увеличения или уменьшения
значения семафора. Когда процесс пытается уменьшить семафор до отрицательного
значения, он переводится в состояние ожидания, пока другой процесс не увеличит
семафор до значения, большего или равного тому, на которое первый процесс пытался
его уменьшить. Поскольку надо использовать семафоры в качестве мьютексов, следует
уменьшать значение на единицу для блокировки списка свободных и увеличивать
на единицу - для разблокировки. Так как начальное значение семафора равно единице,
в результате процесс, пытающийся заблокировать уже блокированный список свободных,
будет приостановлен.
Параметр semid- это идентификатор семафора, возвращенный
semget. Параметр ораrrау указывает на массив структур sembuf, в котором заданы
операции над одним или несколькими семафорами из группы. Параметр nops задает
число элементов в массиве ораггау.
Показанная ниже структура sembuf содержит информацию
о том, к какому семафору применить операцию (sem_num), увеличить или уменьшить
значение семафора (sem_op), а также флаг для двух специальных действий (sem_f
lg):
struct sembuf {
u_short sem__num; /* Номер семафора. */
short sem_op; /* Операция над семафором. */
short sem_flg; /* Флаги операций. */
};
В поле sem_f lg могут быть подняты два бита флагов:
- IPC_NOWAIT - означает, что semop должна
вернуть код EAGAIN, а не приостанавливать процесс, если в результате операции
значение семафора окажется отрицательным;
- SEMJJNDO - означает, что semop должна отменить
действие всех операций над семафором, если процесс завершается, то есть мьютекс
будет освобожден.
Теперь рассмотрим UNIX-зависимую часть кода системы
буферов в разделяемой памяти (листинг 3.30).
Листинг 3.30. Функция init_smb для UNIX
smb.с
1 #include <sys/shm.h>
2 #include <sys/sem.h>
3 #define MUTEX_KEY Ox534d4253 /* SMBS */
4 #define SM_KEY Ox534d424d /* SMBM */
5 #define lock_buf() if ( semop( mutex, &lkbuf,
1 ) < 0 ) \
6 error( 1, errno, "ошибка вызова semop"
)
7 #define unlock_buf () if ( semop ( mutex,
unlkbuf, 1 )<0) \
8 error( 1, errno, "ошибка вызова semop"
)
9 int mutex;
10 struct sembuf lkbuf;
11 struct sembuf unlkbuf;
12 void init_smb( int init_freelist )
13 {
14 union semun arg;
15 int smid;
16 int i;
17 int rc;
18 Ikbuf.sem_op = -1;
19 Ikbuf.sem_flg = SEM_UNDO;
20 unlkbuf.sem_op = 1;
21 unlkbuf.sem_flg = SEM_UNDO;
22 mutex = semget( MUTEX_KEY, 1,
23 IPC_EXCL | IPC_CREAT | SEM_R | SEM_A );
24 if ( mutex >= 0 )
25 {
26 arg.val = 1;
27 rc = semctl ( mutex, 0, SETVAL, arg );
28 if ( rc < 0 )
29 error( 1, errno, "semctl failed"
);
30 }
31 else if ( errno == EEXIST )
32 {
33 mutex = semget( MUTEX_KEY, 1, SEM_R I SEM_A
);
34 if ( mutex < 0 )
35 error( 1, errno, "ошибка вызова semctl"
);
36 }
37 else
38 error( 1, errno, "ошибка вызова
semctl" );
39 smid = shmget( SM_KEY, NSMB * sizeof( smb_t
)+sizeof(int ),
40 SHM_R | SHM_W | IPC_CREAT );
41 if ( smid < 0 )
42 error( 1, errno, "ошибка вызова shmget"
);
43 smbarray = ( smb_t * )shmat( smid, NULL, 0
);
44 if ( smbarray == ( void * )-1 )
45 error( 1, errno, "ошибка вызова shmat"
);
46 if ( init_freelist )
47 {
48 for ( i = 0; i < NSMB - 1; i++ )
49 smbarray[ i ].nexti = i + 1;
50 smbarray[ NSMB - 1 ].nexti = -1;
51 FREE_LIST = 0;
52 }
53 }
Макросы и глобальные переменные
3-4 Определяем ключи сегмента разделяемой памяти
(SMBM) и семафЛpa (SMBS).
5-8 Определяем примитивы блокировки и разблокировки
в терминах операций над семафорами.
9-11 Объявляем переменные для семафоров, используемых
для реализащЯ мьютекса.
Получение и инициализация семафора
18-21 Инициализируем операции над семафорами, которыми
будем пользоваться для блокировки и разблокировки списка свободных.
22-38 Этот код создает и инициализирует семафор.
Вызываем semget с флагами IPC_EXCL и IPC_CREAT. В результате семафор будет создан,
если он еще не существует, и в этом случае semget вернет идентификатор семафора,
который инициализируем единицей (разблокированное состояние). Если же семафор
уже есть, то снова вызываем semget, уже не задавая флагов IPC_EXCL и IPC_CREAT,
для получения идентификатора этого семафора. Как отмечено в книге [Stevens 1999],
теоретически здесь возможна гонка, но не в данном случае, поскольку сервер вызывает
init_smb перед вызовом listen, а клиент не сможет обратиться к нему, пока вызов
connect не вернет управление.
Примечание: В книге [Stevens 1999] рассматриваются
условия, при которых возможна гонка, и показывается, как ее избежать.
Получение, отображение и инициализация буферов
в разделяемой памяти
39-45 Выделяем сегмент разделяемой памяти и отображаем
его на свое адресное пространство. Если сегмент уже существует, то shmget возвращает
его идентификатор.
46-53 Если init_smb была вызвана с параметром init_freelist,
равным TRUE, то помещаем все выделенные буферы в список свободных и возвращаем
управление.
Прежде чем демонстрировать систему в действии,
рассмотрим реализацию для Windows. Как было упомянуто выше, весь системно-зависимый
код сосредточен в функции init_smb. В Windows мьютекс создается очень просто
- дост точно вызвать функцию CreateMutex.
#include <windows.h>
HANDLE CreateMutex(
LPSECURITY_ATTRIBUTES Ipsa,
BOOL flnitialOwner,
LPTSTR IpszMutexName );
Возвращаемое значение: описание мьютекса в случае успеха, NULL -
в случае ошибки.
Параметр lpsa - это указатель на структуру с атрибутами
защиты. Здесь эта возможность не нужна, так что вместо этого аргумента передадим
NULL. Параметр flnitialOwner означает, будет ли создатель мьютекса его начальным
владельцем, то есть следует ли сразу заблокировать мьютекс. Параметр lpszMutexName
-эхо имя мьютекса, по которому к нему могут обратиться другие процессы. Если
мьютекс уже существует, то CreateMutex просто вернет его описание.
Блокировка и разблокировка мьютекса выполняются
соответственно с помощью функций WaitForSingleObject и ReleaseMutex.
#include <windows.h>
DWORD WaitForSingleObject(
HANDLE hObject, DWORD dwTimeout );
Возвращаемое значение:
WAIT_OBJECT_0 (0) в случае успеха, ненулевое значение - в случае ошибки.
BOOL ReleaseMutex(
HANDLE hMutex );
Возвращаемое значение:
TRUE в случае успеха, FALSE - в случает ошибки.
Параметр hObject функции WaitForSingleObject -
это описание ожидаемого объекта (в данном случае мьютекса). Если объект, заданный
с помощью hObject, не занят (signaled), то WaitForSingleObject занимает его
и возвращает управление. Если же объект занят (not signaled), то обратившийся
поток переводится в состояние ожидания до тех пор, пока объект не освободится.
После этого WaitForSingleObject переведет объект в занятое состояние и вернет
в работу «спящий» поток. Параметр dwTimeout задает время (в миллисекундах),
в течение которого потоком ожидается освобождение объекта. Если тайм-аут истечет
прежде, чем объект освободится, то WaitForSingleObject вернет код WAIT_TIMEOUT.
Таймер можно подавить, задав в качестве dwTimeout значение INFINITE.
Когда поток заканчивает работу с критической областью,
охраняемой мыотексом, он разблокирует его вызовом ReleaseMutex, передавая описание
мьютекса hMutex в качестве параметра.
В Windows вы получаете сегмент разделяемой памяти,
отображая файл на память каждого процесса, которому нужен доступ к разделяемой
памяти (в UNIX есть аналогичный системный вызов mmap). Для этого сначала создается
обычный файл с помощью функции CreateFile, затем - отображение файла посредством
вызова CreateFileMapping, а уже потом оно отображается на ваше адресное про-странство
вызовом MapViewOf File.
Параметр hFile в вызове CreateFileMapping - это
описание отображаемого файла. Параметр lpsa указывает на структуру с атрибутами
безопасности, которые в данном случае не нужны. Параметр fdwProtect определяет
права доступа к объекту в памяти. Он может принимать значения PAGE_READONLY,
PAGE_READWRITE или E_WRITECOPY. Последнее значение заставляет ядро сделать отдельную
копию данных, если процесс пытается записывать в страницу памяти. Здесь используется
PAGE_READWRITE, так как будет производится и чтение, и запись в разделяемую
память. Существуют также дополнительные флаги, объединяемые операцией побитового
OR, которые служат для управления кэшированием страниц памяти но они не понадобятся.
Параметры dwMaximumSizeHigh и dwMaximumSizeLowB совокупности дают 64-разрядный
размер объекта в памяти. Параметр lpszMapNaitie -это имя объекта. Под данным
именем объект известен другим процессам.
#include <windows,h>
HANDLE CreateFileMapping(
HANDLE hFile, LPSECURITY_ATTRIBUTES lpsa/ DWORD fdwProtect, DWORD dwMaximumSizeHigh,
DWORD dwMaximumSizeLow, LPSTR IpszMapName );
Возвращаемое значение:
описатель отображения файла в случае успеха, null -в случае ошибки.
LPVOID MapViewOfFile
( HANDLE hFileMapObject, DWORD dwDesiredAccess, DWORD dwFileOffsetHigh,
DWORD dwFileOffsetLow, DWORD dwBytesToMap );
Возвращаемое значение:
адрес, на который отображена память, в случае успеха, NULL - в случае ошибки.
После создания объект в памяти отображается на
адресное пространство каждого процесса с помощью функции MapViewOfFile. Параметр
hFi1eMapObj - это описание, возвращенное после вызова CreateFileMapping. Требуемый
уровень доступа следует задать с помощью dwDesiredAccess. Этот параметр может
принимать следующие значения: FILE_MAP_WRITE (доступ на чтение и запись), FILE_MAP_READ
(доступ только на чтение), FILE_MAP_ALL_ACCESS (то же, что FILE_MAP_WRITE) и
FILE_MAP_COPY. Если присвоено последнее значение, то при попытке записи создается
отдельная копия данных. Параметры dwFileOffsetHigh и dwFileOffsetLow задают
смещение от начала файла, с которого следует начинать отображение. Нужно отобразить
файл целиком, поэтому оба параметра будут равны 0. Размер отображаемой области
памяти задается с помощью параметра dwBytesToMap.
Подробнее использование мьютексов и отображение
памяти в Windows рассматриваются в книге [Richter 1997].
Теперь можно представить версию init_smb для Windows.
Как видно из листинга 3.31, она очень напоминает версию для UNIX.
Листинг 3.31. Функция init_smb для Windows
smb.c
1 #define FILENAME "./smbfile"
2 #define lock_buf () if ( WaitForSingleObject
( mutex, INFINITE
3 ! = WAIT_OBJECT_0 )
4 error ( 1, errno, "ошибка вызова lock_buf
" )
5 #define unlock_buf() if ( !ReleaseMutex(
mutex ) }
6 error( 1, errno, "ошибка вызова unlock_buf"
)
7 HANDLE mutex;
8 void init_smb( int init_freelist )
9 {
10 HANDLE hfile;
11 HANDLE hmap;
12 int i;
13 mutex = CreateMutex ( NULL, FALSE, "smbmutex"
);
14 if ( mutex == NULL )
15 error( 1, errno, "ошибка вызова CreateMutex"
);
16 hfile = CreateFile( FILENAME,
17 GENERIC_READ | GENERIC_WRITE,
18 FILE_SHARE_READ | FILE_SHARE_WRITE,
19 NULL, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL,
NULL };
20 if ( hfile == INVALID_HANDLE_VALUE )
21 error( 1, errno, "ошибка вызова CreateFile"
);
22 hmap = CreateFileMapping( hfile, NULL, PAGE_READWRITE,
23 0, NSMB * sizeof( smb_t ) + sizeof( int
), "smbarray" );
24 smbarray = MapViewOfFile( hmap, FILE_MAP_WRITE,
0, 0, 0 );
25 if ( smbarray == NULL )
26 error( 1, errno, "ошибка вызова MapViewOfFile"
);
27
28 if ( init_freelist )
29 {
30 for ( i = 0; i < NSMB
- 1; i++ )
31 smbarrayt i ].nexti = i + 1;
32 smbarray [ NSMB - 1 ].nexti = -1;
33 FREE_LIST = 0;
34 }
35 }
Для тестирования всей системы следует написать
небольшие программы клиентской (листинг 3.32) и серверной (листинг 3.33) частей.
Листинг 3.32. Клиент, использующий систему буферов
в разделяемой памяти
smbc.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 char *bp;
5 SOCKET s;
6 INIT();
7 s = tcp_client( argv[ 1 ], argv[
2 ] );
8 init_smb( FALSE );
9 bp = smballoc();
10 while ( fgets( bp, SMBUFSZ, stdin ) != NULL
)
11 {
12 smbsend( s, bp );
13 bp = smballocO;
14 }
15 EXIT( 0 ) ;
16 }
Листинг 3.33. Сервер, использующий систему буферов
в разделяемой памяти||
smbs.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 char *bp;
5 SOCKET s;
6 SOCKET s1;
7 INIT();
8 init_smb( TRUE );
9 s = tcp_server( NULL, argv[ 1 ]
);
10 s1 = accept( s, NULL, NULL );
11 if ( !isvalidsock( s1 ) )
12 error ( 1, errno, "ошибка вызова
accept" )
13 for ( ;; )
14 {
15 bp = smbrecv( s1 );
16 fputs( bp, stdout );
17 smbfree( bp );
18 }
19 EXIT( 0 );
20 }
Запустив эти программы, получите ожидаемый результат:
|
bsd: $ smbc localhost 9000
Hello
Wolds!
^C
bsd: $
|
bsd: $ smbs 9000
Hello
Wolds!
^C
bsd: $
|
Обратите внимание, что smbc читает каждую строку
из стандартного ввода прямо в буфер в разделяемой памяти, a smbs копирует каждую
строку из буфер3 сразу на стандартный вывод, поэтому не возникает лишнего копирования
данных.
В этом разделе описано, как избежать ненужного
копирования данных. Во многих сетевых приложениях на копирование данных из одного
буфера в другой тратится большая часть времени процессора.
Разработана схема взаимодействия между процессами,
в которой использую система буферов в разделяемой памяти. Это позволило передавать
единственнь экземпляр данных от одного процесса другому. Такая схема работает
и в UNIX и в Windows.
Хотя обычно используется только три поля из структуры
sockaddr_in: sin_family, sin_port и sin_addr, но, как правило, в ней есть и
другие поля. Например, во многих реализациях есть поле sin_len, содержащее длину
структуры. В частности, оно присутствует в системах, производных от версии 4.3BSD
Reno и более поздних. Напротив, в спецификации Winsock этого поля нет.
Если сравнить структуры sockaddr_in в системе FreeBSD
struct sockaddr_in {
u_char sin_len;
u_char sin_family;
u_char sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
и в Windows
struct sockaddr_in {
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
}
то видно, что в обеих структурах есть дополнительное
поле sin_zero. Хотя это поле и не используется (оно нужно для того, чтобы длина
структуры sockaddr_in была равна в точности 16 байт), но тем не менее должно
быть заполнено нулями.
Примечание: Причина в том, что в некоторых
реализациях во время привязки адреса к сокету производится двоичное сравнение
этой адресной структуры с адресами каждого интерфейса.Такой код будет работать
только в том случае, если поле sin_zero заполнено нулями.
Поскольку в любом случае необходимо обнулить поле
sin_zero, обычно перед использованием адресной структуры ее полностью обнуляют.
В этом случае заодно очищаются и все дополнительные поля, так что не будет проблем
из-за недокументированных полей. Посмотрите на листинг 2.3 - сначала в функции
set_address Делается вызов bzero для очистки структуры sockaddrjn.
В современных компьютерах целые числа хранятся
по-разному, в зависимости от архитектуры. Рассмотрим 32-разрядное число 305419896
(0x12345678). Четыре байта этого числа могут храниться двумя способами: сначала
два старших байта {такой порядок называется тупоконечным - big endian)
12 34 56 78
или сначала два младших байта (такой порядок называется
остроконечным - little endian)
78 56 34 12
Примечание: Термины «тупоконечный» и «остроконечный»
ввел Коэн [Cohen П1981], считавший, что споры о том, какой формат лучше, сродни
распрям лилипутов из романа Свифта «Путешествия Гулливера», которые вели бесконечные
войны, не сумев договориться, с какого конца следует разбивать яйцо — с тупого
или острого. Раньше были в ходу и другие форматы, но практически во все современных
машинах применяется либо тупоконечный, либо остроконечный порядок байтов.
Определить формат, применяемый в конкретной машине,
можно с помощью следующей текстовой программы, показывающей, как хранится число
0х12345б78 (листинг 3.34).
Листинг 3.34. Программа для определения порядка
байтов
endian.c
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include "etcp.h"
4 int main( void )
5 {
6 u_int32_t x = 0x12345678; /* 305419896 */
7 unsigned char *xp = ( char * )&x;
9 printf( "%0x %0x %0x %0x\n",
10 xp[ 0 ], xp[ 1 ], xp[ 2 ], xp[ 3 ] );
11 exit( 0 );
12 }
Если запустить эту программу на компьютере с процессором
Intel, то получится:
bsd: $ endian
78 56 34 12
bsd: $
Отсюда ясно видно, это - остроконечная архитектура.
Конкретный формат хранения иногда в шутку называют
полом байтов. Он важен, поскольку остроконечные и тупоконечные машины (а равно
те, что используют иной порядок) часто общаются друг с другом по протоколам
TCP/IP- Поскольку такая информация, как адреса отправления и назначения, номера
портов, длина датаграмм, размеры окон и т.д., представляется в виде целых чисел,
необходимо, чтобы обе стороны интерпретировали их одинаково.
Чтобы обеспечить взаимодействие компьютеров с разными
архитектурами» все целочисленные величины, относящиеся к протоколам, передаются
в сетевом порядке байтов, который по определению является тупоконечным. По большей
части, обо всем заботятся сами протоколы, но сетевые адреса, номера портов,
а иногда и другие данные, представленные в заголовках, вы задаете сами. И всякий
раз необходимо преобразовывать их в сетевой порядок.
Для этого служат две функции, занимающиеся преобразованием
из машинного порядка байт в сетевой и обратно. Представленные ниже объявления
этих функций заимствованы из стандарта POSIX. В некоторых версиях UNIX эти объявления
находятся не в файле netinet/in.h. Типы uint32_t и uint16_t приняты в POSIX
соответственно для без знаковых 32- и 16-разрядных целых. В некоторых реализациях
эти типы могут отсутствовать. Тем не менее функции htonl и ntohl всегда принимают
и возвращают беззнаковые 32-разрядные целые числа, будь то UNIX или Winsock.
Точно так же функции htons и ntohs всегда принимают и возвращают беззнаковые
16-разрядные целые.
Примечание: Буквы «l» и «s» в конце имен
функций означают long (длинное) и short (короткое). Это имело смысл, так как
первоначально данные функции появились в системе 4.2BSD, разработанной для 32-разрядной
машины, где длинное целое принимали равным 32 бит, а короткое - 16. С появлением
64-разрядных машин это уже не так важно, поэтому следует помнить, что 1-функции
работают с 32-разрядными числами, которые не обязательно представлены как long,
а s-функции - с 16разрядными числами, которые не обязательно представлены в
виде short. Удобно считать, что 1-функции предназначены для преобразования длинных
полей в заголовках протокола, а s-функции - коротких полей.
#include <netinet/in.h>
/* UNIX */
#include <winsock2
.h> /* Winsock */
uint32_t htonl( uint32_t
host32 );
uint16_t htons( uint16_t
host16 );
Обе функции возвращают
целое число в сетевом порядке.
uint32_t ntohl( uint32_t
network32 ) ;
uint16_t ntohs( uint16_t
network16 );
Обе функции возвращают
целое число в машинном порядке.
Функции htonl и htons преобразуют целое число из
машинного порядка байт в сетевой, тогда как функции ntohl и ntohs выполняют
обратное преобразование. Заметим, что на «тупоконечных» машинах эти функции
ничего не делают И обычно определяются в виде макросов:
#define htonl(x) (x)
На «остроконечных» машинах (и для иных архитектур)
реализация функций зависит от системы. Не надо задумываться, на какой машине
вы работаете, поскольку эти функции всегда делают то, что нужно.
Применение этих функций обязательно только для
полей, используемых протоколами. Пользовательские данные для протоколов IP,
UDP и TCP выглядят как множество неструктурированных байтов, так что неважно,
записаны целые числа в сетевом или машинном порядке. Тем не менее функции ntoh*
и hton* стоит применять при передаче любых данных, поскольку тем самым вы обеспечиваете
возможность совместной работы машин с разной архитектурой. Даже если сначала
предполагается, что приложение будет работать только на одной платформе обязательно
настанет день, когда его придется переносить на другую платформу. Тогда дополнительные
усилия окупятся с лихвой.
Примечание: В общем случае проблема преобразования
данных между машинами с разными архитектурами сложна. Многие программисты решают
ее, преобразуя все числа в код ASCII (или, возможно, в код EBCDIC для больших
машин фирмы IBM). Другой подход связан с использованием компоненты XDR (External
Data Representation -внешнее представление данных), входящей в состав подсистемы
вызова удаленных процедур (RFC - remote procedure call), разработанной фирмой
Sun. Компонента XDR определена в RFC 1832 [Srinivasan 1995] и представляет собой
набор правил для кодирования данных различных типов, а также язык, описывающий
способ кодирования. Хотя предполагалось, что XDR будет применяться как часть
RPC, можно пользоваться этим механизмом в ваших программах. В книге [Stevens
1999] обсуждается XDR и его применение без RPC.
И, наконец, следует помнить, что функции разрешения
имен, такие как gethostbyname и getservbyname (совет 29), возвращают значения,
представленные в сетевом порядке. Поэтому следующий неправильный код
struct servant *sp;
struct sockaddr_in *sap;
sp = getservbyname( name, protocol );
sap->sin_port = htons( sp->s_port );
приведет к ошибке, если исполняется не на «тупоконечной»
машине.
В этом разделе рассказывалось, что в TCP/IP применяется
стандартное представление в сетевом порядке байт для целых чисел, входящих в
заголовки прото колов. Здесь также приведены функции htonl, htons, ntohl и ntohs,
которь преобразуют целые из машинного порядка байт в сетевой и обратно. Кроме
того. было отмечено, что в общем случае для преобразования форматов данных между
машинами полезно средство XDR.
У программы есть только два способа получить IP-адрес
или номер порта:
- из аргументов в командной строке или, если
программа имеет графический интерфейс пользователя, с помощью диалогового
окна либо аналогичного механизма;
- с помощью функции разрешения имен, например
gethostbyname или getservbyname.
Примечание: Строго говоря, getservbyname
— это не функция разрешения имени (то есть она не входит в состав DNS-клиента,
который отображает имена на IP-адреса и наоборот). Но она рассмотре на вместе
с остальными, поскольку выполняет похожие действия.
Никогда не следует «зашивать» эти параметры в текст
программы или помещать их в собственный (не системный) конфигурационный файл.
И в UNIX, и в Windows есть стандартные способы получения этой информации, ими
и надо пользоваться.
Теперь IP-адреса все чаще выделяются динамически
с помощью протокола DHCP (dynamic host configuration protocol - протокол динамической
конфигурации хоста). И это убедительная причина избегать их задания непосредственно
в тексте программы. Некоторые считают, что из-за широкой распространенности
DHCP и сложности адресов в протоколе IPv6 вообще не нужно передавать приложению
числовые адреса, а следует ограничиться только символическими именами хостов,
которые приложение должно преобразовать в IP-адреса, обратившись к функции gethostbyname
или родственным ей. Даже если протокол DHCP не используется, управлять сетью
будет намного проще, если не «зашивать» эту информацию в код и не помещать ее
в нестандартные места. Например, если адрес сети изменяется, то все приложения
с «зашитыми» адресами просто перестанут работать.
Всегда возникает искушение встроить адрес или номер
порта непосредственно в текст программы, написанной «на скорую руку», и не возиться
с функциями типа getXbyY. К сожалению, такие программы начинают жить своей жизнью,
а иногда даже становятся коммерческими продуктами. Одно из преимуществ каркасов
и библиотечных функций на их основе (совет 4) состоит в том, что код уже написан,
так что нет необходимости «срезать углы».
Рассмотрим некоторые функции разрешения имен и
порядок их применения. Вы уже не раз встречались с функцией gethostbyname:
#include <netdb.h>
/* UNIX */
#include <winsock2.h>
/* Winsock */
struct hostent *gethostbyname(
const char *name );
Возвращаемое значение:
указатель на структуру hostent в случае успеха, h_errno и код ошибки в переменной
h_errno - в случае неудачи.
Функции gethostbyname передается имя хоста, а она
возвращает указателя на структуру ho в tent следующего вида:
struct hostent {
char *h_name; /* Официальное имя хоста.*/
char **h_aliases; /* Список синонимов.*/
int h_addrtype; /* Тип адреса хоста.*/
int h_length; /* Длина адреса.*/
char **h_addr_list; /* Список адресов, полученных
от DNS.*/
#define h_addr h_addr_list[0]; /* Первый адрес.*/
};
Поле h_name указывает на «официальное» имя хоста,
а поле h_aliases — на список синонимов имени. Поле h_addrtype содержит либо
AF_INET, либо AF_INET6 в зависимости от того, составлен ли адрес в соответствии
с протоколом IPv4 или IPv6. Аналогично поле h_length равно 4 или 16 в зависимости
от типа адреса. Все адреса типа h_addrtype возвращаются в списке, на который
указывает поле h_addr_list. Макрос h_addr выступает в роли синонима первого
(возможно, единственного) адреса в этом списке. Поскольку gethostbyname возвращает
список адресов, приложение может попробовать каждый из них, пока не установит
соединение с нужным хостом.
Работая с функцией gethostbyname нужно учитывать
следующие моменты:
- если хост поддерживает оба протокола IPv4
и IPv6, то возвращается только один тип адреса. В UNIX тип возвращаемого адреса
зависит от параметра RES_USE_INET6 системы разрешения имен, который можно
явно задать, обратившись к функции res_init или установив переменную среду,
а также с помощью опции в конфигурационном файле DNS. В соответствии с Win-sock,
всегда возвращается адрес IPv4;
- структура hostent находится в статической
памяти. Это означает, что функция gethostbyname не рентабельна;
- указатели, хранящиеся в статической структуре
hostent, направлены на другую статическую или динамически распределенную память,
поэтому при желании скопировать структуру необходимо выполнять глубокое копирование.
Это означает, что помимо памяти для самой структуры hostent необходимо выделить
память для каждой области, на которую указывают поля структуры, а затем скопировать
в нее данные;
- как говорилось в совете 28, адреса, хранящиеся
в списке, на который указывает поле h_addr_list, уже приведены к сетевому
порядку байтов, так что применять к ним функцию htonl не надо.
Вы можете также выполнить обратную операцию - отобразить
адреса хосто на их имена. Для этого служит функция gethostbyaddr.
#include <netdb.h>
/* UNIX. */
#include <winsock2.h>
/* Winsock. */
struct hostent *gethostbyaddr(const
char *addr, int len, int type);
Возвращаемое значение:
указатель на структуру hostent в случае успеха, NULL и код ошибки в переменной
h_errno - в случае неудачи.
Несмотря на то, что параметр addr имеет тип char*,
он указывает на структуру in_addr (или in6_addr в случае IPv6). Длина этой структуры
задается параметром len, а ее тип (AF_INET или AF_INET6) - параметром type.
Предыдущие замечания относительно функции gethostbyname касаются и gethostbyaddr.
Для хостов, поддерживающих протокол IPv6, функции
gethostbyname недостаточно, так как нельзя задать тип возвращаемого адреса.
Для поддержки IPv6 (и других адресных семейств) введена общая функция gethostbyname2,
допускающая получение адресов указанного типа.
#include <netdb.h>/*
UNIX */
struct hostent *gethostbyname2(const
char *name, int af );
Возвращаемое значение:
указатель на структуру hostent в случае успеха, NULL и код ошибки в переменной
h_errno - в случае неудачи.
Параметр af - это адресное семейство. Интерес представляют
только возможные значения AF_INET или AF_INET6. Спецификация Winsock не определяет
функцию gethostbyname2, а использует вместо нее функционально более богатый
(и сложный) интерфейс WSALookupServiceNext.
Примечание: Взаимодействие протоколов IPv4
и IPv6 - это в значительной мере вопрос обработки двух разных типов адресов.
И функция gethostbyname2 предлагает один из способов решения этой проблемы.
Эта тема подробно обсуждается в книге [Stevens 1998], где также приведена реализация
описанной в стандарте POSIX функции getaddrinfo. Эта функция дает удобный, не
зависящий от протокола способ работы с обоими типами адресов. Спомощъю getaddrinfo
можно написать приложение, которое будет одинаково работать и с IPv4, и с IPv6.
Раз системе (или службе DNS) разрешено преобразовывать
имена хостов в IP-адреса, почему бы ни сделать то же и для номеров портов? В
совете 18 рассматривался один способ решения этой задачи, теперь остановимся
на другом. Так же, как gethostbyname и gethostbyaddr выполняют преобразование
имени хоста в адрес и обратно, функции getservbyname и getservbyport преобразуют
символическое имя сервиса в номер порта и наоборот. Например, сервис времени
дня daytime прослушивает порт 13 в ожидании TCP-соединений или UDP-дата-грамм.
Можно обратиться к нему, например, с помощью программы telnet:
telnet bsd 13
Однако необходимо учитывать, что номер порта указанного
сервиса равен 13. К счастью, telnet понимает и символические имена портов:
telnet bsd daytime
Telnet выполняет отображение символических имен
на номера портов, вызывая функцию getservbyname; вы сделаете то же самое. В
листинге 2.3 выувидите, что в предложенном каркасе этот вызов уже есть. Функция
set_addres сначала оперирует параметром port как представленным в коде ASCII
целым числом, то есть пытается преобразовать его в двоичную форму. Если это
не получается, то вызывается функция getservbyname, которая ищет в базе данных
символическое имя порта и возвращает соответствующее ему числовое значение.
Прототип функции getservbyname похож на gethostbyname:
#include <netdb.h> /* UNIX */
#include <winsock2.h> /* Winsock */
struct servant *getservbyname(const
char *name, const char *proto );
Возвращаемое значение:
указатель на структуру servent в случае успеха, NULL - в случае неудачи.
Параметр name - это символическое имя сервиса,
например «daytime». Если параметр pro to не равен NULL, то возвращается сервис,
соответствующий заданным имени и типу протокола, в противном случае - первый
найденный сервис с именем name. Структура servent содержит информацию о найденном
сервисе:
struct servent {
char *s_name; /*Официальное имя сервиса. */
char **s_aliases; /*Список синонимов. */
int s_port; /*Номер порта. */
char *s_proto; /*Используемый протокол. */
};
Поля s_name и s_aliases содержат указатели на официальное
имя сервиса и его синонимы. Номер порта сервиса находится в поле s_port. Как
обычно, этот номер уже представлен в сетевом порядке байтов. Протокол (TCP или
UDP), иcпользуемый сервисом, описывается строкой в поле s_proto.
Вы можете также выполнить обратную операцию - найти
имя сервиса по номеру порта. Для этого служит функция getservbyport:
#include <netdb.h>
/* UNIX. */
#include <winsock2.h>
/* Winsock. */
struct servent *getservbyport(
int port, const char *proto);
Возвращаемое значение: указатель на структуру servent в случае успеха,
NULL - в случае неудачи
Передаваемый в параметре port номер порта должен
быть записан в сетевом порядке. Параметр pro to имеет тот же смысл, что и раньше.
С точки зрения программиста, данный каркас и библиотечные
функции решают задачи преобразования имен хостов и сервисов. Они сами вызывают
нужные функции, а как это делается, не должно вас волновать. Однако нужно знать,
как ввести в систему необходимую информацию.
Обычно это делается с помощью одного из трех способов:
- DNS;
- сетевой информационной системы (NIS) или
NIS+;
- файлов hosts и services.
DNS (Domain Name System - служба доменных имен)
- это распределенная база данных для преобразования имен хостов в адреса.
Примечание: DNS используется также для маршрутизации
электронной почты. Когда посылается письмо на адрес jsmithesomecompany. com,
с помощью DNS ищется обработчик (или обработчики) почтыдля компании somecompany.com.
Подробнее это объясняетсяв книге [Albitz and Lin 1998].
Ответственность за хранение данных распределяется
между зонами (грубо говоря, они соответствуют адресным доменам) и подзонами.
Например, bigcompany.com может представлять собой одну зону, разбитую на несколько
подзон, соответствующих отделам или региональным отделениям. В каждой зоне и
подзоне работает один или несколько DNS-серверов, на которых хранится вся информация
о хостах в этой зоне или подзоне. Другие DNS-серверы могут запросить информацию
у данных серверов для разрешения имен хостов, принадлежащих компании BigCompany.
Примечание: СистемаDNS -этохороший пример
UDP-приложения. Как правило, обмен с DNS-сервером происходит короткими транзакциями.
Клиент (обычно одна из функций разрешения имен) посылает UDP-датаграмму, содержащую
запрос к DNS-cepeepy.Если в течение некоторого времени ответ не получен, то
пробуется другой сервер, если таковой известен. В противном случае повторно
посылается запрос первому серверу, но с увеличенным тайм-аутом.
На сегодняшний день подавляющее большинство преобразований
между именами хостов и IP-адресами производится с помощью службы DNS. Даже
сети, не имеющие выхода вовне, часто пользуются DNS, так как это упрощает администрирование.
При добавлении в сеть нового хоста или изменении адреса существующего нужно
обновить только базу данных DNS, а не файлы hosts на каждой машине.
Система NIS и последовавшая за ней NIS+ предназначены
для ведения централизованной базы данных о различных аспектах системы. Помимо
имен хостов и IP-адресов, NIS может управлять именами сервисов, паролями, группами
и другими данными, которые следует распространять по всей сети. Стандартные
функции разрешения имен (о них говорилось выше) могут опрашивать и базы данных
NIS. В некоторых системах NIS-сервер при получении запроса на разрешение имени
хоста, о котором у него нет информации, автоматически посылает запрос DNS-серверу
В других системах этим занимается функция разрешения имен.
Преимущество системы NIS в том, что она централизует
хранение всех распространяемых по сети данных, упрощая тем самым администрирование
больших сетей. Некоторые эксперты не рекомендуют NIS, так как имеется потенциальная
угроза компрометации паролей. В системе NIS+ эта угроза снята, но все равно
многие опасаются пользоваться ей. NIS обсуждается в работе [Brown 1994].
Последнее и самое неудобное из стандартных мест
размещения информации об именах и IP-адресах хостов - это файл hosts, обычно
находящийся в каталоге /etc на каждой машине. В этом файле хранятся имена, синонимы
и IP-адреса хостов в сети. Стандартные функции разрешения имен просматривают
также и этот файл. Обычно при конфигурации системы можно указать, когда следует
просматривать файл hosts - до или после обращения к службе DNS.
Другой файл - обычно /etc/services - содержит информацию
о соответствии имен и портов сервисов. Если NIS не используется, то, как правило,
на каждой машине имеется собственная копия этого файла. Поскольку он изменяется
редко, с его администрированием не возникает таких проблем, как с файлом hosts.
В совете 17 было сказано о формате файла services.
Основной недостаток файла hosts - это очевидное
неудобство его сопровождения. Если в сети более десятка хостов, то проблема
быстро становится почти неразрешимой. В результате многие эксперты рекомендуют
полностью отказаться от такого метода. Например, в книге [Lehey 1996] советуется
следующее: «Есть только одна причина не пользоваться службой DNS - если ваш
компьютер не подсоединен к сети».
В этом разделе рекомендовано не «зашивать» адреса
и номера портов в программу. Также рассмотрено несколько стандартных схем получения
этой информации и обсуждены их достоинства и недостатки.
Здесь рассказывается об использовании вызова connect
применительно к протоколу UDP. Из совета 1 вам известно, что UDP - это протокол,
не требующий установления соединений. Он передает отдельные адресованные конкретному
получателю датаграммы, поэтому кажется, что слово «connect» (соединить) тут
неуместно. Следует, однако, напомнить, что в листинге 3.6 вы уже встречались
с примером, где вызов connect использовался в запускаемом через inetd UDP-сервере,
чтобы получить (эфемерный) порт для этого сервера. Только так inetd мог продолжать
прослушивать датаграммы, поступающие в исходный хорошо известный порт.
Прежде чем обсуждать, зачем нужен вызов connect
для UDP-сокета, вы должны четко представлять себе, что собственно означает «соединение»
в этом контексте. При использовании TCP вызов connect инициирует обмен информацией
о состоянии между сторонами с помощью процедуры трехстороннего квитирования
(рис. 3.14). Частью информации о состоянии является адрес и порт каждой стороны,
поэтому можно считать, что одна из функций вызова connect в протоколе TCP -
это привязка адреса и порта удаленного хоста к локальному сокету.
Хотя полезность вызова connect в протоколе UDP
может показаться сомнительной, но вы увидите, что, помимо некоторого повышения
производительности, он позволяет выполнить такие действия, которые без него
были бы невозможны. Рассмотрим причины использования соединенного сокета UDP
сначала с точки зрения отправителя, а потом - получателя.
Прежде всего, от подсоединенного UDP-сокета вы
получаете возможность ис-Щользования вызова send или write (в UNIX) вместо sendto.
Примечание: Для подсоединенного UDP-сокета
можно использовать и вызов sendto, но в качестве указателя на адрес получателя
надо задавать NULB, а в качестве его длины - нуль. Возможен, конечно, и вызов
sendmsg, но и в этом случае поле msg_name в структуре msghdr должно содержать
NULL, а поле msg_namel en - нуль.
Само по себе это, конечно, немного, но все же вызов
connect действительно дает заметный выигрыш в производительности.
В реализации BSD sendto - это частный случай connect.
Когда датаграмма посылается с помощью sendto, ядро временно соединяет сокет,
отправляет датаграмму, после чего отсоединяет сокет. Изучая систему 4.3BSD и
тесно связанную с ней SunOS 4.1.1, Партридж и Пинк [Partridge and Pink 1993]
заметили, что такой способ соединения и разъединения занимает почти треть времени,
уходящего на передачу датаграммы. Если не считать усовершенствования кода,
который служит для поиска, управляющего блока протокола (РСВ - protocol control
block) и ассоциирован с сокетом, исследованный этими авторами код почти без
изменений вошел в систему 4.4BSD и основанные на ней, например FreeBSD. В частности,
эти стеки по-прежнему выполняют временное соединение и разъединение. Таким образом,
если вы собираетесь посылать последовательность UDP-дата-грамм одному и тому
же серверу, то эффективность можно повысить, предварительно вызвав connect.
Этот выигрыш в производительности характерен только
для некоторых реализаций. А основная причина, по которой отправитель UDP-датаграмм
подсоединяет сокет, - это желание получать уведомления об асинхронных событиях.
Представим, что надо послать UDP-датаграмму, но никакой процесс на другой стороне
не прослушивает порт назначения. Протокол UDP на другом конце вернет ICMP-сообщение
о недоступности порта, информируя тем самым ваш стек TCP/IP, но если сокет не
подсоединен, то приложение не получит уведомления. Когда вы вызываете sendto,
в начало сообщения добавляется заголовок, после чего оно передается уровню IP,
где инкапсулируется в IP-датаграмму и помещается в выходную очередь интерфейса.
Как только датаграмма внесена в очередь (или отослана, если очередь пуста),
sendto возвращает управление приложению с кодом нормального завершения. Иногда
через некоторое время (отсюда и термин асинхронный) приходит ICMP-сообщение
от хоста на другом конце. Хотя в нем есть копия UDP-заголовка, у вашего стека
нет информации о том, какое приложение посылало датаграмму (вспомните совет
1, где говорилось, что из-за отсутствия установленного соединения система сразу
забывает об отправленных датаграммах). Если же сокет подсоединен, то этот факт
отмечается в управляющем блоке протокола, связанном с сокетом, и стек TCP/IP
может сопоставить полученную копию UDP-заголовка с тем, что хранится в РСВ,
чтобы определить, в какой сокет направить ICMP-сообщение.
Можно проиллюстрировать данную ситуацию с помощью
вашей программы udpclient (листинг 3.5) из совета 17 - следует отправить датаграмму
в порт, который не прослушивает ни один процесс:
bsd: $ udpclient bed 9000
Hello, World!
^C Клиент "зависает" и прерывается
вручную.
bsd: $
Теперь модифицируем клиент, добавив такие строки
if ( connect! s, ( struct sockaddr * )&peer,
sizeof( peer ) ) ) error( 1, errno, "ошибка вызова connect" );
сразу после вызова функции udp_client. Если назвать
эту программу udpcona и запустить ее, то вы получите следующее:
bsd: $ udpconnl bed 9000
Hello, World!
updconnl: ошибка вызова sendto: Socket is already
connected (56)
bsd: $
Ошибка произошла из-за того, что вы вызвали sendto
для подсоединенного сокета. При этом sendto потребовал от UDP временно подсоединить
сокет. Но UDP определил, что сокет уже подсоединен и вернул код ошибки EISCONN.
Чтобы исправить ошибку, нужно заменить обращение
к sendto на
rс = send( s, buf, strlen( buf ), 0 );
Назовем новую программу udpconn2. После ее запуска
получится такой результат:
bsd: $ udpconnl bed 9000
Hello, World!
updconn2: ошибка вызова recvfrom: Connection refused
(61)
bsd: $
На этот раз ошибку ECONNREFUSED вернул вызов recvfrom.
Эта ошибка - результат получения приложением ICMP-сообщения о недоступности
порта.
Обычно у получателя нет причин соединяться с отправителем
(если, конечно, ему самому не нужно стать отправителем). Однако иногда такая
ситуация может быть полезна. Вспомним аналогию с телефонным разговором и почтой
(совет 1) TCP-соединение похоже на частный телефонный разговор - в нем только
два участника. Поскольку в протоколе TCP устанавливается соединение, каждая
сторона знает о своем партнере и может быть уверена, что всякий полученный
байт действительно послал партнер.
С другой стороны, приложение, получающее UDP-датаграммы,
можно сравнить с почтовым ящиком. Как любой человек может отправить письмо по
данному адресу, так и любое приложение или хост может послать приложению-получателю
датаграмму, если известны адрес и номер порта.
Иногда нужно получать датаграммы только от одного
приложения. Получающее приложение добивается этого, соединившись со своим партнером.
Чтобы увидеть, как это работает, напишем UDP-сервер эхо-контроля, который соединяется
с первым клиентом, отправившим датаграмму (листинг 3.35).
Листинг 3.35. UDP-сервер эхо-контроля, выполняющий
соединение
udpconnserv.с
1 #include "etcp.h" :
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rс;
7 int len;
8 char buf[ 120 ];
9 INIT();
10 s = udp_server( NULL, argv[ 1 ] ) ;
11 len = sizeof( peer );
12 rс = recvfrom( s, buf, sizeoff buf ),
13 0, ( struct sockaddr * )&peer, &len
);
14 if ( rс < 0 )
15 error( 1, errno, "ошибка вызова recvfrom"
);
16 if ( connect( s, ( struct sockaddr * )&peer,
len ) )
17 error( 1, errno, "ошибка вызова connect"
);
18 while ( strncmp( buf, "done", 4
) != 0 )
19 {
20 if ( send( s, buf, rс, 0 ) < 0 )
21 error( 1, errno, "ошибка вызова send"
);
22 rc = recv( s, buf, sizeof( buf ), 0 );
23 if ( rс < 0 )
24 error( 1, errno, "ошибка вызова recv"
);
25 }
26 EXIT( 0 );
27 }
9-15 Выполняем стандартную инициализацию UDP и получаем
первую датаграмму, сохраняя при этом адрес и порт отправителя в переменной peer.
16-17 Соединяемся с отправителем.
18-25 В цикле отсылаем копии полученных датаграмм,
пока не придет датаграмма, содержащая единственное слово «done».
Для экспериментов с сервером udpconnserv можно
воспользоваться клиентом udpconn2. Сначала запускается сервер для прослушивания
порта 9000 в ожидании датаграмм:
udpconnserv 9000
а затем запускаются две копии udpconn2, каждая
в своем окне.
|
bsd: $ udpconn2 bsd 9000
one
one
three
three
done
^C
bsd: $
|
bsd: $ udpconn2 bsd 9000
two
udpconn2: ошибка вызова recvfroin:
Connection refused (61)
bsd: $
|
Когда в первом окне вы набираете one, сервер udpconnserv
возвращает копию датаграммы. Затем во втором окне вводите two, но recvf rom
возвращает код ошибки ECONNREFUSED. Это происходит потому, что UDP вернул ICMP-сообщение
о недоступности порта, так как ваш сервер уже соединился с первым экземпляром
udpconn2 и не принимает датаграммы с других адресов.
Примечание: Адреса отправителя у обоих экземпляров
udpconn2, конечно, одинаковы, но эфемерные порты, выбранные стеком TCP/IP, различны.
В первом окне вы набираете three, дабы убедиться, что udpconnserv все еще функционирует,
а затем — done, чтобы остановить сервер. В конце прерываем вручную первый экземпляр
udpconn2.
Как видите, udpconnserv не только отказывается
принимать датаграммы от другого отправителя, но также информирует приложение
об этом факте, посылая ICMP-сообщение. Разумеется, чтобы получить это сообщение,
клиент также должен подсоединиться к серверу. Если бы вы прогнали этот тест
с помощью первоначальной версии клиента udpclient вместо udpconn2, то второй
экземпляр клента просто «завис» после ввода слова «done».
В этом разделе рассмотрено использование вызова
connect в протоколе UDP. Хотя на первый взгляд может показаться, что для протокола
без установления соединения это не имеет смысла, но, как вы видели, такое действие,
во-первых, повышает производительность, а во-вторых, оно необходимо при желании
получать некоторые сообщения об ошибках при отправке UDP-датаграмм. Здесь также
описано, как использовать connect для приема датаграмм только от одного хоста.
До сих пор все примеры в этой книге были написаны
на языке С, но, конечно, это не единственно возможный выбор. Многие предпочитают
писать на C++, Java или даже Pascal. В этом разделе будет рассказано об использовании
языков сценарИ" ев для сетевого программирования и приведено несколько
примеров на языке Perl Вы уже встречались с несколькими примерами небольших
программ, написанных специально для тестирования более сложных приложений. Например,
в совете 30 использованы простые и похожие программы udpclient, udpconnl и udpconn2
для проверки поведения подсоединенного UDP-сокета. В таких случаях имеет смысл
воспользоваться каким-либо языком сценариев. Сценарии проще разрабатывать и
модифицировать хотя бы потому, что их не надо компилировать и компоновать со
специальной библиотекой, а также создавать файлы сборки проекта (Makefile) —
достаточно написать сценарий и сразу же запустить его.
В листинге 3.36 приведен текст минимального Perl-сценария,
реализующего функциональность программы udpclient.
Хотя я не собираюсь писать руководство по языку
Perl, но этот пример стоит изучить подробнее.
Примечание: Глава 6 стандартного учебника
по Perl [Wall et al. 1996] посвящена имеющимся в этом языке средствам межпроцессного
взаимодействия и сетевого программирования. Дополнительную информацию о языке
Perl можно найти на сайте http://www.perl.com.
Листинг 3.36. Версия программы udpclient на языке
Perl
pudpclient
1 #! /usr/bin/perl5
2 use Socket;
3 $host = shift || "localhost";
4 $port = shift || "echo";
5 $port = getservbyname( $port, "udp"
) if $port =~ /\D/;
6 $peer = sockaddr_in( $port, inet_aton( $host
) );
7 socket(S,PF_INET,SOCK_DGRAM,0)|| die "ошибка
вызова socket $!";
8 while ( $line = <STDIN> )
9 {
10 defined) send(S,$line,0,$peer))|| die "ошибка
вызова send $!";
11 defined) recv(S, $line, 120, 0))|| die "ошибка
вызова recv $!";
12 print $line;
13 }
Инициализация
2 В этой строке Perl делает доступными сценарию
определения некоторых констант (например, PF_INET).
Получение параметров командной строки
3-4 Из командной строки читаем имя хоста и номер
порта. Обратите внимание, что этот сценарий делает больше, чем программа на
языке С, так как по умолчанию он присваивает хосту имя localhost, а порту -echo,
если один или оба параметра не заданы явно.
Заполнение структуры sockaddr_in
и получение сокета
5-6 Этот код выполняет те же действия, что и функция
set_address в листинге 2.3 в совете 4. Обратите внимание на простоту кода. В
этих двух строчках IP-адрес хоста принимается как числовой и его имя символическое,
а равно числовое или символическое имя сервиса.
7 Получаем UDP-сокет.
Основной цикл
8-13 Так же, как в udpclient, читаем строки из
стандартного ввода, отправляем их удаленному хосту, читаем от него ответ и записываем
его на стандартный вывод.
Хотя знакомые сетевые функции иногда принимают
несколько иные аргументы и могут возвращать результат непривычным образом, но,
в общем, программа в листинге 3.36 кажется знакомой и понятной. Тот, кто знаком
с основами сетевого программирования и хотя бы чуть-чуть разбирается в Perl,
может добиться высокой производительности.
Для сравнения в листинге 3.37 представлен TCP-сервер
эхо-контроля. Вы можете соединиться с этим сервером с помощью программы telnet
или любого другого TCP-приложения, способного вести себя как клиент эхо-сервера.
Здесь также видна знакомая последовательность обращений
к API сокетов и, даже не зная языка Perl, можно проследить за ходом выполнения
программы. Следует отметить две особенности, присущие Perl:
· вызов
accept на строке 11 возвращает TRUE, если все хорошо, а новый со-кет возвращается
во втором параметре (S1). В результате естественно выглядит цикл for, в котором
принимаются соединения;
· поскольку
recv возвращает адрес отправителя (или специальное значение undef), а не число
прочитанных байт, получая длину строки $line (строка 16), следует явно проверять,
не пришел ли признак конца файла. Оператор last выполняет те же действия, что
break в языке С.
Листинг 3.37. Версия эхо-сервера на языке Perl
pechos
1 #! /usr/bin/perl5
2 use Socket;
3 $port = shift;
4 $port = getservbyname( $port, 'tcp' ) if $port
=~ /\D/;
5 die "Invalid port" unless $port;
6 socket( S, PF_INET, SOCK_STREAM, 0 ) || die
"socket: $!";
7 setsockopt( S,SOL_SOCKET, SO_REUSEADDR, pack(
'1' , 1 ) ) ||
8 die "setsockopt: $!";
9 bindf S, sockaddr_in( $port, INADDR_ANY )
) || die "bind: $!"
10 listen ( S, SOMAXCONN );
11 for( ; accept( SI, S ); close( SI ) )
12 {
13 while ( TRUE )
14 {
15 definedf recv( SI, $line, 120, 0 ) ) ||
die "recv: $!"
16 last if length( $line ) == 0;
17 definedt send( SI, $line, 0 ) ) II die "send:
$!";
18 }
19 }
Как видно из этих двух примеров, языки сценариев
вообще и Perl в частности -это отличный инструмент для написания небольших тестовых
программ, создания прототипов более крупных систем и утилит. Perl и другие языки
сценариев активно применяются при разработке Web-серверов и специализированных
Web-клиентов. Примеры рассматриваются в книгах [Castro 1998] и [Patchett and
Wright 1998].
Помимо простоты и скорости разработки прототипа,
есть и другие причины для использования языков сценариев. Одна из них - наличие
в таких языках специальных возможностей. Например, Perl обладает прекрасными
средствами для манипулирования данными и работы с регулярными выражениями. Поэтому
во многих случаях Perl оказывается удобнее таких традиционных языков, как С.
Предположим, что каждое утро вам надо проверять,
не появились ли в конференции comp.protocols.tcp-ip новые сообщения о протоколах
TCP и UDP. В листинге 3.38 приведен каркас Peri-сценария для автоматизации решения
этой задачи. В таком виде сценарий не очень полезен, так как он показывает все
сообщения от сервера новостей, даже старые; отбор сообщений осуществляется довольно
грубо. Можно было бы без труда модифицировать сценарий, ужесточив критерий отбора,
но лучше оставить его таким, как есть, чтобы не запутаться в деталях языка Perl.
Подробнее протокол передачи сетевых новостей (NNTP) рассматривается в RFC 977
[Каntor and Lapsley 1986].
Листинг 3.38. Peri-сценарий для формирования дайджеста
из сетевых конференций
tcpnews
1 #' /usr/bin/perl5
2 use Socket;
3 $host = inet_aton( 'nntp.ix.netcom.com') ||
die "хост: $!";
4 $port = getservbyname('nntp1, 'tcp')|| die
"некорректный порт";
5 socket( S, PF_INET, SOCK_STREAM, 0 ) || die
"socket: $!";
6 connect! S, sockaddr_in( $port, $host ) )
|| die "connect: $!";
7 select( S ) ;
8 $1 = 1;
9 select( STDOUT );
10 print S "group сотр.protocols.tcp-ip\r\n";
11 while ( $line = <S> )
12 {
13 last if $line =~ /^211/;
14 }
15 ($rc, $total, $start, $end ) = split( /\s/,
$line );
16 print S "xover $start-$end\nguit\r\n"
;
17 while ( $line = <S> )
18 {
19 ( $no, $sub, $auth, $date ) = split( /\t/,
$line );
20 print "$no, $sub, $date\n"
if $sub =~ /TCPIUDP/;
21 }
22 close( S );
Инициализация и соединение с сервером новостей
2-6 Это написанный на Perl аналог логики инициализации
стандартного TCP-клиента.
Установить режим небуферизованного ввода/вывода
7-9 В Perl функция print вызывает стандартную библиотеку
ввода/вывода, а та, как упоминалось в совете 17, буферизует вывод в сокет. Эти
три строки отключают буферизацию. Хотя по виду оператор select напоминает системный
вызов select, который рассматривался ранее, в действительности он просто указывает,
какой файловый дескриптор будет использоваться по умолчанию. Выбрав дескриптор,
вы можете отменить буферизацию вывода в сокет S, задав ненулевое значение специальной
переменной $ |, используемой в Perl.
Примечание: Строго говоря, это не совсем
так. Эти действия приводят к тому, что после каждого вызова wri te или print
для данного дескриптора автоматически выполняется функция fflush. Но результат
оказывается таким же, как если бы вывод в сокет был не буферизован.
В строке 9 stdout восстанавливается как дескриптор
по умолчанию.
Выбрать группу comp.protocols.
tcp-ip
10-14 Посылаем серверу новостей команду group, которая
означает, что текущей группой следует сделать comp. protocols. tcp-ip. Сервер
отвечает строкой вида
211 total_articles first_article# last_article#
group_namespace
В строке 13 вы ищете именно такой ответ, отбрасывая
все строки, которые начинаются не с кода ответа 211. Обратите внимание, что
оператор <. . . > сам разбивает на строки входной поток, поступающий от
TCP.
15-16 Обнаружив ответ на команду group, нужно послать
серверу строки
xover first_article#-last_article#
quit
Команда xover запрашивает сервер, заголовки всех
статей с номерами из заданного диапазона. Заголовок содержит список данных,
разделенных символами табуляции: номер статьи, тема, автор, дата и время, идентификатор
сообщения, идентификаторы сообщений для статей, на которую ссылается данная,
число баи тов и число строк. Команда quit приказывает серверу разорвать соединение,
та как запросов больше не будет.
Отбор заголовков статей
17-20 Читаем каждый заголовок, выделяем из него
интересующие нас поля и оставляем только те заголовки, для которых в теме присутствует
строка «TCP» или «UDP».
Запуск tcpnews дает следующий результат:
bsd: $ tcpnews
74179, Re: UDP multicast, Thu, 22 Jul 1999 21:06:47
GMT
74181, Re: UDP multicast, Thu, 22 Jul 1999 21:10:45
-0500
74187, Re: UDP multicast, Thu, 22 Jul 1999 23:23:00
+0200
74202, Re: NT 4.0 Server and TCP/IP, Fri, 23 Jul
1999 11:56:07 GMT
74227, New Seiko TCP/IP Chip, Thu, 22 Jul 1999 08:39:09
-0500
74267, WATTCP problems, Mon, 26 Jul 1999 13:18:14
-0500
74277, Re: New Seiko TCP/IP Chip, Thu, 26 Jul 1999
23:33:42 GMT
74305, TCP Petri Net model, Wed, 28 Jul 1999 02:27:20
+0200
bsd: $
Помимо языка Perl, есть и другие языки сценариев,
пригодные для сетевого программирования, например:
- TCL/Expect;
- Python;
- JavaScript;
- Visual Basic (для Windows).
Их можно использовать для автоматизации решения
простых сетевых задач, построения прототипов и быстрого создания удобных утилит
или тестовых примеров. Как вы видели, языки сценариев часто проще применять,
чем традиционные компилируемые языки программирования, поскольку интерпретатор
берет на себя многие технические детали (конечно, расплачиваясь эффективностью).
Усилия, потраченные на овладение хотя бы одним из таких языков, окупятся ростом
производительности труда.
В этом разделе говорилось об использовании языков
сценариев в сетевом программировании. Нередко их применение имеет смысл при
написании небольших утилит и тестовых программ.
Здесь приводятся некоторые эвристические правила
для задания размеров буферов приема и передачи в TCP. В совете 7 обсуждалось,
как задавать эти размеры с помощью функции setsockopt. Теперь вы узнаете, какие
значения следует устанавливать.
Необходимо сразу отметить, что выбор правильного
размера буфера зависит от приложения. Для интерактивных приложений типа telnet
желательно устанавливать небольшой буфер. Этому есть две причины:
- обычно клиент посылает небольшой блок данных
серверу и ждет ответа. Поэтому выделять большой буфер для таких соединений
- пустая трата системных ресурсов;
- при большом буфере реакция на действия
пользователя происходит не сразу. Например, если пользователь выводит на экран
большой файл и нажимает комбинацию клавиш прерывания (Ctrl+C), то вывод не
прекратится, пока в буферах есть данные. Если буфер велик, то до реального
прерывания просмотра может пройти заметное время.
Знать размер буфера необходимо для расчета максимальной
производительности. Например, это относится к приложениям, которые передают
большие объемы данных преимущественно в одном направлении. Далее будут рассматриваться
именно такие приложения.
Как правило, для получения максимальной пропускной
способности рекомендуется, чтобы размеры буферов приема и передачи были не меньше
произведения полосы пропускания на задержку. Как вы увидите, это правильный,
но не слишком полезный совет. Прежде чем объяснять причины, разберемся, что
представляет собой это произведение и почему размер буферов «правильный».
Вы уже несколько раз встречались с периодом кругового
обращения (RTT). Это время, которое требуется пакету на «путешествие» от одного
хоста на другой и обратно. Оно и представляет собой множитель «задержки», поскольку
определяет время между моментом отправки пакета и подтверждением его получателем.
Обычно RTT измеряется в миллисекундах.
Другой множитель в произведении - полоса пропускания
(bandwidth). Это количество данных, которое можно передать в единицу времени
по данному физическому носителю.
Примечание: Технически это не совсем корректно,
но этот термин уже давно используется.
Полоса пропускания измеряется в битах в секунду.
Например, для сети Ethernet полоса пропускания (чистая) равна 10 Мбит/с.
Произведение полосы пропускания на задержку BWD
вычисляется по формуле:
BWD = bandwidth X RTT.
Если RTT выражается в секундах, то единица измерения
BWD будет следующей:
бит
BWD = --------- X секунда = бит.
секунда
Если представить коммуникационный канал как «трубу»,
то произведение полосы пропускания на задержку - это объем трубы в битах (рис.
3.15), то есть количество данных, которые могут находиться в сети в любой момент
времени

Рис. 3.15. Труба емкостью BWD бит
А теперь представим, как выглядит эта труба в установившемся
режиме (после завершения алгоритма медленного старта) при массовой передаче
данных, занимающей всю доступную полосу пропускания. Отправитель слева на рис.
3.16 заполнил трубу TCP-сегментами и должен ждать, пока сегмент п покинет сеть.
Только после этого он сможет послать следующий сегмент. Поскольку в трубе находится
столько же сегментов АСК, сколько и сегментов данных, при получении подтверждения
на сегмент п - 8 отправитель может заключить, что сегмент п покинул сеть.
Это иллюстрирует феномен самосинхронизации (self-clocking
property) TCP-соединения в установившемся режиме [Jacobson 1988]. Полученный
сегмент АСК служит сигналом для отправки следующего сегмента данных.
Рис. 3.16. Сеть в установившемся режиме
Примечание: Этот механизм часто называют
АСК-таймером (АСК clock).
Если необходимо, чтобы механизм самосинхронизации работал
и поддерживал трубу постоянно заполненной, то окно передачи должно быть достаточно
велико для обеспечения 16 неподтвержденных сегментов (от п - 8 до п + 7). Это
означает, что буфер передачи на вашей стороне и буфер приема на стороне получателя
Должны иметь соответствующий размер для хранения 16 сегментов. В общем случае
необходимо, чтобы в буфере помещалось столько сегментов, сколько находится в
заполненной трубе. Значит, размер буфера должен быть не меньше произведения
полосы пропускания на задержку.
Выше было отмечено, что это правило не особенно
полезно. Причина в том, что обычно трудно узнать величину этого произведения.
Предположим, что вы пишете приложение типа FTP. Насколько велики должны быть
буферы приема и передачи? Во время написания программы неясно, какая сеть будет
использоваться, а поэтому Неизвестна и ее полоса пропускания. Но даже если это
можно узнать во время выполнения, опросив сетевой интерфейс, то остается еще
неизвестной величина задержки. ° Принципе, ее можно оценить с помощью какого-нибудь
механизма типа ping, но, скорее всего, задержка будет варьироваться в течение
существования соединения.
Примечание: Одно из возможных решений этой
проблемы предложено в п боте [Semke et al.]. Оно состоит в динамическом изменении
па. меров буферов. Авторы замечают, что размер окна перегризк можно рассматривать
как оценку произведения полосы пропиг кания на задержку. Подбирая размеры буферов
в соответствии с текущим размером окна перегрузки (конечно, применяя подходящее
демпфирование и ограничения, обеспечивающие справедливый режим для всех приложений),
они сумели получить очень высокую производительность на одновременно установленных
соединениях с разными величинами BWD. К сожалению, такоерешение требует изменения
в ядре операционной системы, так что прикладному программисту оно недоступно.
Как правило, размер буферов назначают по величине,
заданной по умолчанию или большей. Однако ни то, ни другое решение не оптимально.
В первом случае может резко снизиться пропускная способность, во втором, как
сказано в работе [Semke et al. 1998], - исчерпаны буферы, что приведет к сбою
операционной системы.
В отсутствии априорных знаний о среде, в которой
будет работать приложение, наверное, лучше всего использовать маленькие буферы
для интерактивных приложений и буферы размером 32-64 Кб - для приложений, выполняющих
массовую передачу данных. Однако не забывайте, что при работе в высокоскоростных
сетях следует задавать намного больший размер буфера, чтобы использовать всю
доступную полосу пропускания. В работе [Mahdavi 1997] приводятся некоторые рекомендации
по оптимизации настройки стеков TCP/IP.
Есть одно правило, которое легко применять на практике,
позволяющее повысить общую производительность во многих реализациях. В работе
[Comer and Lin 1995] описывается эксперимент, в ходе которого два хоста были
соединены сетью Ethernet в 10 Мбит и сетью ATM в 100 Мбит. Когда использовался
размер буфера 16 Кб, в одном и том же сеансе FTP была достигнута производительность
1,313 Мбит/с для Ethernet и только 0,322 Мбит/с для ATM.
В ходе дальнейших исследований авторы обнаружили,
что размер буфера, величина MTU (максимальный размер передаваемого блока), максимальный
размер сегмента TCP (MSS) и способ передачи данных уровню TCP от слоя сокетов
влияли на взаимодействие алгоритма Нейгла и алгоритма отложенного подтверждения
(совет 24).
Примечете: MTU (максимальный блок передачи)
- это максимальный размер фрейма, который может быть передан по физической сети.
Для Ethernet эта величина составляет 1500 байт. Для сети АТМ описанной в работе
[Comer and Lin 1995], - 9188 байт.
Хотя эти результаты были получены для локальной
сети ATM и конкретно реализации TCP (SunOS 4.1.1), они применимы и к другим
сетям и реализациям. Самые важные параметры: величина MTU и способ обмена между
сокетами TCP, который в большинстве реализаций, производных от TCP, один и тот
же.
Авторы нашли весьма элегантное решение проблемы.
Его привлекательность в том, что изменять надо только размер буфера передачи,
а размер буфера приема не играет роли. Описанное в работе [Comer and Lin 1995]
взаимодействие не имеет места, если размер буфера передачи, по крайней мере,
в три раза больше, чем MSS.
Примечание: Смысл этого решения в том, что
получателя вынуждают послать информацию об обновлении окна, а, значит, иАСК,
предотвращая тем самым откладывание подтверждения и нежелательную интерференцию
с алгоритмом Нейгла. Причины обновления информации о размере окна, различны
для случаев, когда буфер приема меньше или больше утроенного MSS, но в любом
случае обновление посылается.
Поэтому неинтерактивные приложения всегда должны
устанавливать буфер приема не менее чем 3 X MSS. Вспомните совет 7, где сказано,
что это следует делать до вызова listen или connect.
Производительность TCP в значительной степени зависит
от размеров буферов приема и передачи (совет 36). В этом разделе вы узнали,
что оптимальный размер буфера для эффективной передачи больших объемов данных
равен произведению полосы пропускания на задержку, но на практике это наблюдение
не особенно полезно.
Хотя правило произведения применять трудно, есть
другое, намного проще. Ему и рекомендуется всегда следовать: размер буфера передачи
должен быть, по крайней мере, в три раза больше, чем MSS.
| 
 LINUX
LINUX 
 Books
Books
