Ext2
Основные определения
Файловая система ext2 включает в себя следующие основные определения:
1. Блок - порция, на которую разбивается диск
2. Нода - структура, хранящая информацию о файле
3. Группа блоков - секция, на которую разбивается диск
4. Директория - структура для организации иерархической системы хранения файлов на диске
5. Нодовая битовая карта - таблица битов для хранения информации о свободных нодах
6. Блочная битовая карта - таблица битов для хранения информации о свободных блоках
7. Таблица нод - в ней хранятся все ноды данной группы блоков
8. Суперблок - структура, храящая основные параметры файловой системы
Ext2 включает в себя ACL - Access Control List, версионность и другие фичи.
Размер блока определяется при форматировании, от этого размера зависит напрямую производительность файловой системы,
максимальный размер файлов, максимальный размер самой файловой системы. Обычно размер блока кратен килобайту
и может быть равен 1, 2, 4, 8 и т.д. килобайтам.
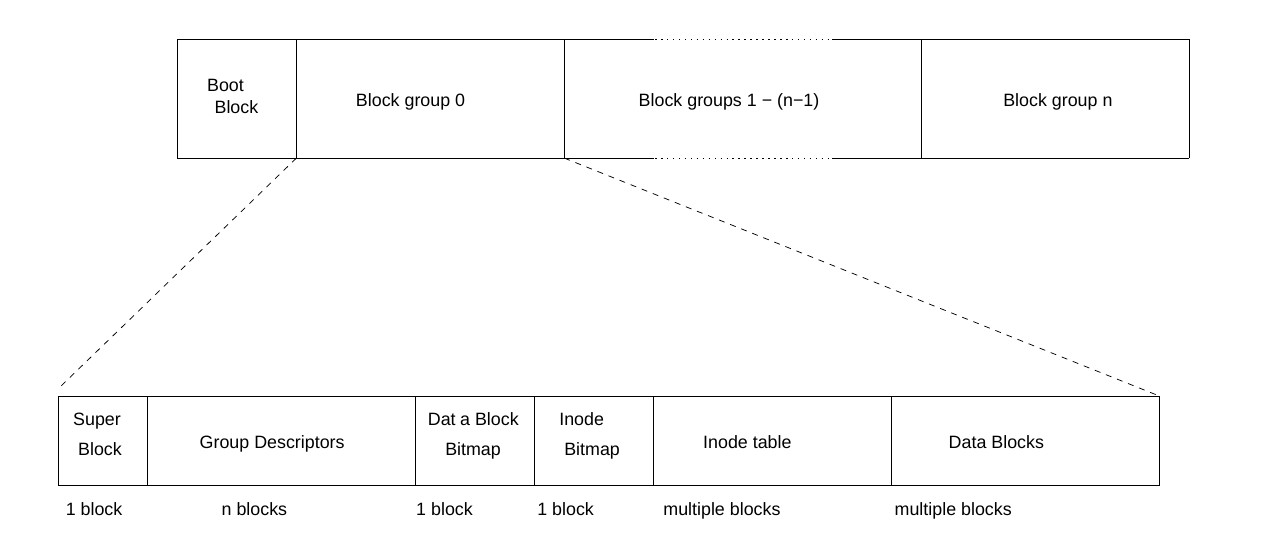
В линуксе Ext2 пришла на смену файловой системе minix. Принципиальным отличием ext2 явилось разбиение партиции на т.н. блоковые группы фиксированного
размера - с целью уменьшения фрагментации и времени чтения с диска. Каждая такая блоковая группа начинается с копии суперблока,
после которого идет таблица групповых дескрипторов или их адресов. Следующие 2 блока резервируются под битовые карты
нод и блоков. Далее несколько блоков выделены под таблицу нод, и остальные блоки в группе выделяются под данные.
Нода описывает все основные обьекты в файловой системе.
Нода имеет размер в 128 байт, в 4-килобайтном блоке умещается 32 таких ноды.
Ее структура содержит 2 вида информации - т.н. метаданные и указатели
на блоки самих данных. К метаданным относятся права, владеьцы, группы, флаги, размер, число блоков, время и т.д.
В ноде ext2 имеется 12 прямых указателей на 12 блоков данных. Есть также еще 3 не-прямых указателя на блоки данных:
не-прямой указатель на блоки данные, двойной не-прямой указатель, тройной не-прямой указатель.
С помощью двойных косвенных блоков может быть адресовано дисковое пространство в пределах двух гигабайт.
Все ноды хранятся в таблице нод, каждая группа блоков имеет одну такую таблицу. Эта таблица может занимать несколько блоков.
Хранение нод в памяти производится по мере их использования, после чего они сохраняются на диск и выгружаются из памяти.
Информация о занятых/свободных нодах и блоках хранится в битовых картах, или битмапах.
Размер битмапа ограничен одним блоком. Адреса битмапов хранятся в групповых дескрипторах.
Поскольку каждая блоковая группа имеет два собственных битмапа, хранить в памяти все битмапы для всех групп слишком накладно.
Поэтому в памяти хранится только два текущих битмапа, для выбора, какой битмап нужно хранить, используется алгоритм LRU.
Суперблок хранит информацию о конфигурации файловой системы. В нем есть такие поля:
общее число нод и блоков
число свободных нод и блоков
число нод и блоков в данной группе
время монтирования
версия
и т.д.
Первый суперблок хранится со смещением в килобайт от начала партиции.
Копия этого суперблока может храниться по-разному в зависимости от версии ext2, в первой версии копия хранилась в каждой блоковой группе.
Суперблок постоянно хранится в памяти, равно как и групповые дескрипторы.
Директория - это такой же обьект, что и файл, у нее есть нода. Для привязки файлов к конкретной директории ext2 использует
одно-связный список. Структура, хранящая директорию, включает в себя имя и номер ноды. При создании директории ей выделяется блок,
при добавлении файлов структура, хранящая имя файла, добавляется в этот же блок, при перепонении блока для новых файлов
для этой директории будет выделен новый блок.
Организация диска
Размер суперблока постоянен и не зависит от размера блока, хранится он со смещением в килобайт от начала партиции.
Сразу за суперблоком идет таблица групповых дескрипторов или адресов блоковых групп, на которые разбит диск.
В последних версиях ext2 копия суперблока хранится в группах с номерами 0, 1, 9, 25, 49.
Если размер блока равен 1 килобайту, суперблок расположен во втором блоке, во всех остальных случаях суперблок
находится в первом блоке. Суперблок имеет следующие поля:
s_inodes_count - 32-битное число, общее число нод, как занятых, так и свободных, во всей файловой системе
s_blocks_count - 32-битное число, общее число блоков, как занятых, так и свободных, во всей файловой системе
s_r_blocks_count - 32-битное число, общее число блоков, отведенное для супер-пользователя
s_free_blocks_count - 32-битное число, общее число свободных блоков во всей файловой системе
s_free_inodes_count - 32-битное число, общее число свободных нод во всей файловой системе
s_first_data_block - порядковый номер блока, в котором хранится суперблок - 0 либо 1 в зависимости от размера блока
s_log_block_size - размер блока
s_blocks_per_group - число блоков в группе
s_inodes_per_group - число нод в группе, оно не может быть больше, чем произведение размера блока в байтах на 8.
s_mtime - время монтирования
s_inode_size - 16-битовое число, размер ноды, в первой версии ext2 оно равно 128 байтам
s_prealloc_blocks - 8-битное число блоков, которое может быть выделено в момент создания файла
Таблица групповых дескрипторов хранит адреса всех блоковых групп, а также адреса битмапов, нодовой таблицы,
число свободных блоков и нод. Она располагается в блоке, следующим за суперблоком. Копии этой таблицы хранятся
по файловой системе так же, как и сам суперблок. Такая таблица создается для каждой блоковой группы.
Структура группового дескриптора имеет поля:
bg_block_bitmap - адрес первого блока блоковой битовой таблицы
bg_inode_bitmap - адрес первого блока нодовой битовой таблицы
bg_inode_table - адрес таблицы нод
bg_free_blocks_count - число свободных блоков группы
bg_free_inodes_count - число свободных нод группы
Нодовая таблица используется для хранения директорий, файлов, линков, храня их адреса, размер, тип, права доступа.
Имена в нодах не хранятся. Адрес таблицы нод хранится в параметре bg_inode_table группового дескриптора,
общее число нод - в параметре s_inodes_per_group. Нода имеет следующие поля:
i_mode - описывает тип обьекта, может быть сокетом, линком, регулярным файлом, директорией и т.д.
i_uid - владелец файла
i_size - размер файла в байтах
i_block - пятнадцать 32-битных чисел, указывающих на блоки, в которых хранятся данные, первые 12 - прямые указатели,
остальные - косвенные
Поскольку все ноды пронумерованы, номер ноды - это ее индекс в нодовой таблице. Размер нодовой таблице фиксирован
и определяется в момент форматирования.
Директории используются для иерархической организации хранения файлов. Каждый каталог может включать в себя
другие каталоги, регулярные файлы, специальные файлы.
Директории хранятся в той же группе блоков, что и сами данные.
Создание новой ext2 партиции
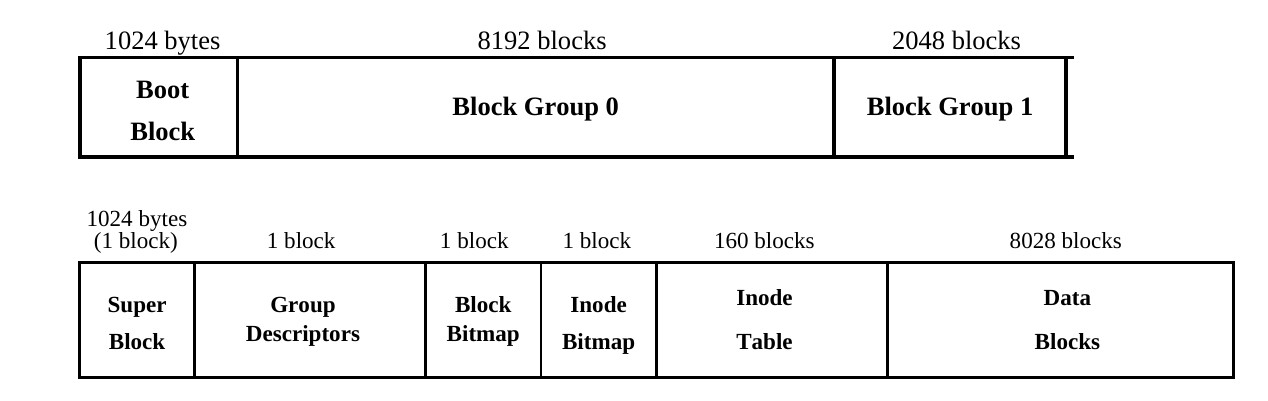
Рассмотрим создание партиции с размером блока в 1 килобайт и размером самой партиции в 10 мегабайт,
с использованием утилиты mke2fs:
dd if=/dev/zero of=/tmp/test-01.fs bs=1k count=10240
mke2fs -b 1024 -F -L ’test-01’ -v /tmp/test-01.fs
Подсчитаем максимальный размер блоковой группы - он равен 8 мегабайт:
8 ∗ block size → 8 ∗ 1024 = 8192
Таким образом, у нас получится 2 блоковых группы - :
Утилита mke2fs лежит в пакете e2fsprogs. Давайте посмотрим на код, в частности на функцию errcode_t ext2fs_initialize:
// выделяем память для базовой структуры
retval = ext2fs_get_mem(sizeof(struct struct_ext2_filsys),(void **) &fs);
// обнуляем эту память
memset(fs, 0, sizeof(struct struct_ext2_filsys));
// выделяем память для суперблока
retval = ext2fs_get_mem(SUPERBLOCK_SIZE, (void **) &super);
// создаем алиас для суперблока
fs->super = super;
// обнуляем суперблок
memset(super, 0, SUPERBLOCK_SIZE);
// начинаем инициализировать суперблок
super->s_magic = EXT2_SUPER_MAGIC;
super->s_state = EXT2_VALID_FS;
// устанавливае размер блока в 1024 байт
set_field(s_log_block_size, 0);
// для самой старой версии ext2 - первая нода будет лежать в блоке номер 11
set_field(s_first_ino, EXT2_GOOD_OLD_FIRST_INO);
// размер ноды - 128 байт
set_field(s_inode_size, EXT2_GOOD_OLD_INODE_SIZE);
// первая проверка случится через полгода
set_field(s_checkinterval, EXT2_DFL_CHECKINTERVAL);
// число используемых и зарезервированных блоков
super->s_blocks_count = param->s_blocks_count;
super->s_r_blocks_count = param->s_r_blocks_count;
// посчитаем число блоков для таблицы групповых дескрипторов
fs->desc_blocks = (fs->group_desc_count + EXT2_DESC_PER_BLOCK(super) - 1) / EXT2_DESC_PER_BLOCK(super);
// посчитаем число нод в группе
ipg = (super->s_inodes_count + fs->group_desc_count - 1) / fs->group_desc_count;
Мы проверяем, что число нод не превышает размер в битах битовой маски нод.
Мы проверяем, что в группе не может быть более 65536 нод, поскольку счетчик нод в групповом дескрипторе 16-битный.
Мы проверяем, что не превышаем общее число нод в файловой системе.
Мы проверяем, что число нод в группе кратно 8 - это для нормальной работы битмапа.
После этого мы инициализируем параметр inodes-per-group
// выделяем память для битмапов
retval = ext2fs_allocate_block_bitmap(fs, buf, &fs->block_map);
retval = ext2fs_allocate_inode_bitmap(fs, buf, &fs->inode_map);
// выделяем память для групповых дескрипторов
retval = ext2fs_get_mem((size_t) fs->desc_blocks * fs->blocksize, (void **) &fs->group_desc);
Структура групповых дескрипторов имеет следующий вид
struct ext2_group_desc
{
__u32 bg_block_bitmap; // адрес битмапа блоков
__u32 bg_inode_bitmap; // адрес битмапа нод
__u32 bg_inode_table; // адрес таблицы нод
__u16 bg_free_blocks_count; // число свободных блоков в группе
__u16 bg_free_inodes_count; // число свободных нод в группе
__u16 bg_used_dirs_count; // число каталогов в группе
...
};
Пишем на диск суперблок, битмапы, таблицу нод
ext2fs_mark_super_dirty(fs);
ext2fs_mark_bb_dirty(fs);
ext2fs_mark_ib_dirty(fs);
Затем обнуляем блоки с данными - и партиция готова.
Directory index
В ext2 директории хранятся в виде связного списка.
В девелоперской версии ядра 2.5 в ext2 появилась индексация директорий.
В основной ветке индексация вошла позже уже в следующей версии - ext3.
Разность в скорости работы ext2 без индексации и с индексацией директорий разительна: при увеличении каталога в первом случае
время поиска увеличивается по квадратичной зависимости, а во втором - по линейной.
В начале разработчики обсуждали реализацию индексации на основе бинарного поиска - btree, но эта идея была отвергнута
в силу того, что размер кода ее реализация оказался равен размеру кода самой ext2, и от этой идеи отказались.
Если код ext2 можно условно оценить в 5 тысяч строк, то реализация бинарного поиска может легко перекрыть
этот показатель раза в два. Вообще, ext2 отличает экстраординарная минималистичность основных решений.
Классический линейный поиск файла в ext2 каталоге на базе связных списков имеет квадратичную зависимость от числа файлов.
Другие файловые системы с бинарным поиском имеют зависимость, близкую к линейной.
Htree отличается от btree т.н. вырожденным (degenerate) древесным индексом, построенным на основе одного блока,
а также тем, что не нужно делать балансировку при добавлении узлов.
В ноде есть специальный флаг, проиндексирована директория или нет - это сделано для совместимости.
Рутовая нода является первым блоком в директории. У этого дерева есть листья, которые представляют из себя обычные блоки,
На листья может идти ссылка либо со стороны корня, либо со стороны промежуточных индексов.
Htree хеширует имена файлов для использования их в качестве ключей. Каждый такой ключ ссылается на диапазон файлов, которые
хранятся в одном листе. В Htree есть индексы первого уровня, каждый из которых может хранить несколько ключей,
а также хранит логические указатели на другие индексы. Все ключи внутри индекса расположены в порядке возрастания.
Ключ имеет размерность 32 бита.
Листья в htree в отличие от btree всегда находятся на одном уровне.
Также в htree один индекс на лист, в то время как в btree - один индекс на директорию.
Рутовый индекс также включает массив индексов. Указатели ссылаются на индексные блоки.
Каждый индекс имеет размер в 8 байт, что позволяет в случае с 4-килобайтным блоком ссылаться на 508 листов.
Каждый лист может хранить 200 записей, отсюда один индекс может управлять 75000 файлов.
Второй уровень в индексном дереве необходим для очень больших каталогов и может управлять 30 миллионами файлов.
Ниже приведен пример HTree дерева - видно, что в индексных блоках серого цвета хранятся индексы,
а в синих блоках данных хранятся собственно сами имена файлов:
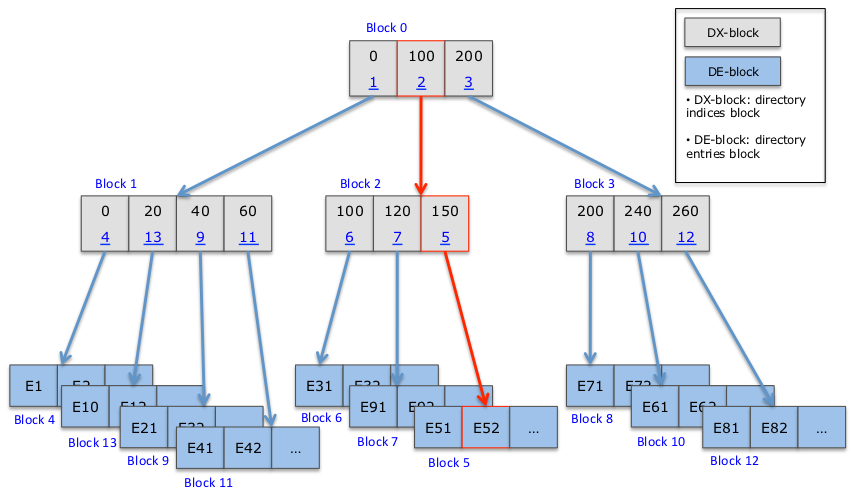
В нодах серого цвета - индексных нодах - хранятся 2 значения - хеш имени и индекс дочернего блока:
struct dx_entry
{
__le32 hash;
__le32 block;
};
В нодах синего цвета - листах - хранится одно значение - имя файла.
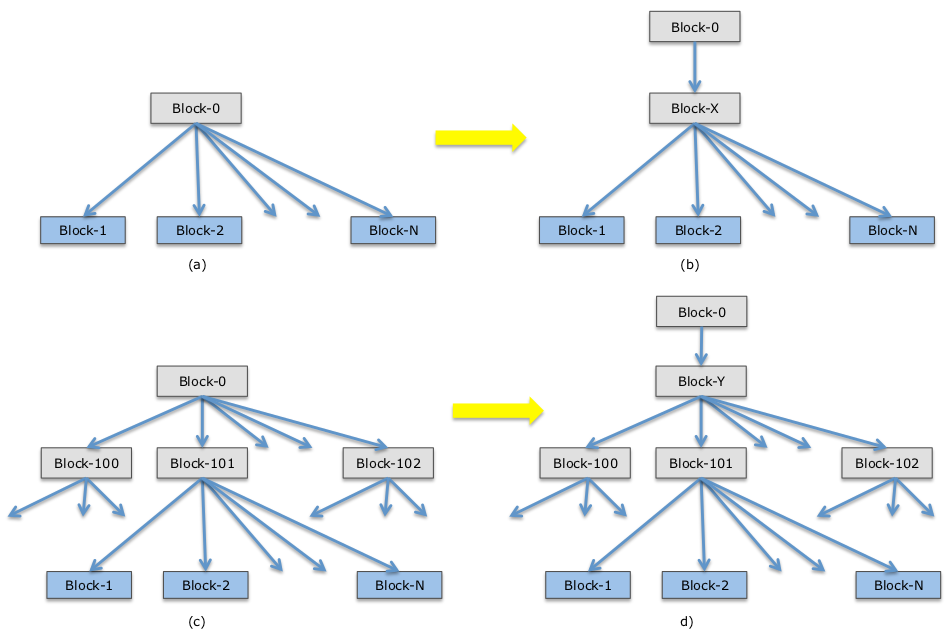
На следующем рисунке показано, как может расти Htree:
Индексные ноды в таком дереве заранее отсортированы, поэтому используется бинарный поиск.
Поскольку индексное дерево состоит из сравнительно небольшого числа блоков, они кешируются.
Алгоритм поиска выглядит следующим образом:
вычисляем хеш имени файла
читаем рутовую индексную ноду
используем алгоритм бинарного поиска для нахождения первого индекса или листа, который может включать искомый хеш
повторяем до тех пор, пока не достигнем нижнего уровня в дереве
читаем листовой блок и уже в нем ищем
если нашли, то возвращаем
в противном случае, если бит коллизии присутствует, ищем файл в следующем листовом блоке
При вставке нового файла листовая нода может разбиваться на две ноды в случае, если она переполнена.
| 
 LINUX
LINUX 
 Kernels
Kernels
