Practical File System Design
Книга написана в 1999 году, автор - Dominic Giampaolo, разработчик файловой системы
для тогдашней операционной системы BeOS. Книга раскрывает строение файловых систем.
По ее прочтению вы поймете, как вообще работают файловые системы, и BFS в частности,
которая является 64-битной журналируемой файловой системой с расширенными файловыми атрибутами,
имеющей индексированный query-интерфейс в стиле баз данных.
Сам документ можно скачать тут
На этой странице выложен перевод первых 5 глав (всего 11).
Что такое файловая система ?
Компьютеры создают информацию, манипулируют ею, хранят ее, возвращают нам ее по первому требованию.
Файловая система управляет этой информацией на уровне жесткого диска.
Не существует готовых решений для написания "правильных" файловых систем.
Например, флеш-карта для игровых консолей имеет ограниченный функционал и не требует продвинутого
интерфейса с наличием атрибутов. А если взять какой-нибудь майнфреймовый сервер, то главным здесь
его способность поддерживать максимальное число транзакций в единицу времени.
Хранение, поиск, размещение и манипулирование информацией - это то, чем должна заниматься файловая система.
Основные термины файловой системы:
Диск - постоянное хранилище данных определенного размера. У каждого диска есть минимальнй размер сектора
или размер блока - минимальной порции информации, которая может быть прочитана за один раз.
Размер блока может быть 512 байт, килобайт и т.д.
Блок - минимальная порция данных, которая может быть записана на диск или файловую систему.
Размер блока файловой системы может совпадать с размером блока диска либо быть больше его в несколько раз.
Партиция - часть диска.
Том - обозначение партиции, диска, или нескольких дисков иил нескольких партиций.
Суперблок - область данных файловой системы, где хранится критическая и наиболее важная информация.
Здесь хранится размер файловой системы и т.д.
Метаданные - косвенная информация о данных, например, размер файла.
Журналирование - контроль метаданных файловой системы с учетов сбоев питания.
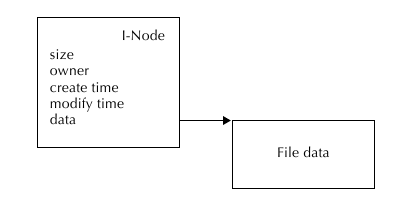
Нода (I-node) - место, где файловая система хранит метаданные о файле. Здесь также хранится информация
о том, как получить сами данные этого файла.
Расширение (extent) - непрерывная последовательность блоков, задается двумя параметрами - номером стартового блока
и количеством блоков в этой последовательности.
Атрибут - пара ключ-значение, значение может иметь произвольный тип.
Что такое файл ?
В любой файловой системе есть 2 фундаментальных концепции - файл и директория.
Прежде всего любая файловая система должна давать возможность хранить порцию данных и возвращать их
с помощью определенного имени, или файла. Файл - это место, где хранятся данные. Это может быть графическая
картинка, база данных, и т.д. Размер файла может варьироваться в широких пределах. Файловая система должна
уметь хранить достаточно большое количество файлов.
Файл обычно представляет из себя последовательность байт, а файловая система позволяет читать эти байты
в любой последовательности и в любом количестве. Другой формой организации данных является организация
файлов на базе записи (records), когда определяется размер и формат такой записи, после чего все данные
будут разбиваться на одинаковые порции в соответствии с их форматом при обращении к диску.
Имя файла должно составлять как минимум 32 символа - это минимальный порог вхождения для современных
файловых систем.
Имя файла относится к метаданным. Владелец файла, права доступа, дата создания, дата последней модификации,
размер - это тоже метаданные. Файловая система должна хранить не только сами данные, но и метаданные.
Метаданные хранятся обычно в одной ноде. Разные файловые системы могут хранить различные метаданные:
это может быть последнее время доступа, создатель файла, номер версии, ссылка на каталог и т.д.
Важнейшей частью информации, хранящейся в метаданных, является ссылка на сами данные. Нода хранит список
блоков, в которых хранятся данные файла. С точки зрения прикладного программиста файл есть последовательность
байт. Физически же данные могут быть расположены в виде блоков на диске совсем не последовательно.
Нода позволяет файловой системе с помощью специальной таблицы привязать произвольную байтовую позицию
внутри файла к физической позиции блока на диске. Нода содержит список блоков, входящих в файл.
Файловая система переводит логическую позицию в физическую координату, читает блок с диска, и возвращает
данные пользователю. "Правильная" файловая система располагает блоки данных одного файла последовательно,
это значительно ускоряет работу и повышает эффективность дисковых операций.
Пример ноды и данных, на которые она ссылается:
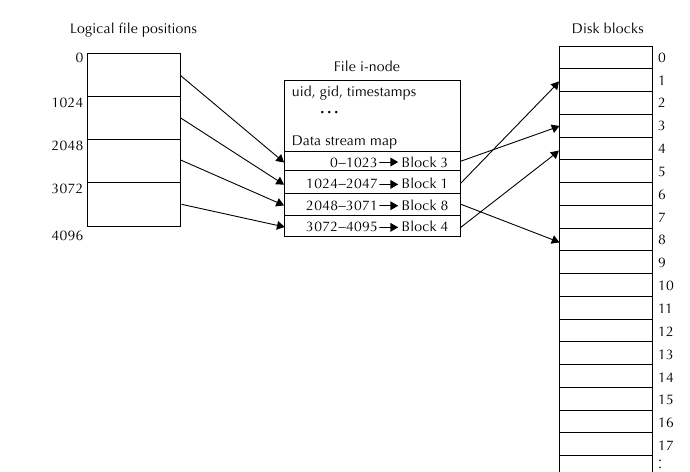
Пример распределения данных по блокам диска:
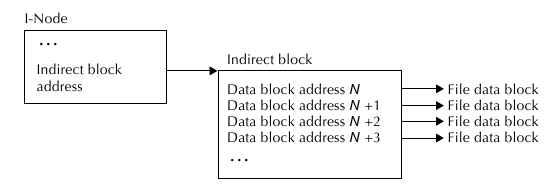
Непрямая адресация:
Следующий пример показывает таблицу соответствия файловых позиций и блоковых адресов:
Позиция файла Адрес дискового блока
0-1023 329922
1024-2047 493294
2048-3071 102349
3072-4095 374255
Нода может хранить информацию о данных файла несколькими способами. Самый простой вариант - хранить
весь список блоков данных. Например, если размер файла 4 килобайта, а размер блока 1 килобайт, то список
будет состоять из 4 блоков. Обычно большинство файлов имеют небольшой размер, и нода хранит список всех блоков
небольших файлов. Длина этого списка зависит от размера самой ноды, что в свою очередь зависит уже от
интерфейса самой файловой системы. Естественно, что для больших файлов нода не в состоянии хранить весь список
блоков данных. В этом случае на помощь приходят т.н. косвенные блоки (indirect blocks). Вместо списка
блоков данных нода хранит ссылки на такие косвенные блоки, которые уже в свою очередь хранят список блоков
данных самого файла. Косвенные блоки не хранят данных, они хранят ссылки на эти блоки данных. Нода может
хранить ссылку всего на один косвенный блок, который будет хранить ссылки на все блоки данных файла.
Число блоков, которые может хранить косвенный блок, равно отношению размера блока к размеру адреса блока.
В 32-битной файловой системе адрес блока равен 4 байтам, в 64-битной - 8 байтам. Если размер блока равен
одному килобайту, то для 32-битной системы косвенный блок может хранить 256 адреса блоков данных.
Но для очень больших файлов этого недостаточно. В таких случаях применяется технология двойных косвенных блоков
(double-indirect blocks). В них используются те же принципы, что и в предыдущем случае. Нода включает
в себя адреса двойных косвенных блоков, те в свою очередь состоят из адресов обычных косвенных блоков,
и дальше как обычно. Таким образом, в этом случае нода может ссылаться на :
256 * 256 = 65536 блоков , или 65 мегабайт блоков с размером одного блока = 1 килобайту.
Если размер блока равен 4 килобайтам, то в 32-битной файловой системе получается 4 гигабайта
(тысяча косвенных блоков по 4 килобайта каждый).
Псевдокод для связывания логической позиции внутри файла с индексом в таблице блоков представлен ниже.
В коде используются переменные dbl_indirect_index и indirect_index, которые позволяют вычислить адреса
простых косвенных и двойных косвенных блоков. Переменная block_offset позоляет установить на точное байтовое
смещение, соответсвующее файловой позиции. В этом примере у нас имеются 8 прямых блоков, размер блока в 1
килобайт, и 4-байтовый адрес. Из чего мы получаем, что косвенный блок может хранить: 1024/4= 256 адресов.
Файловая позиция в примере равна 786769. В этом случае нам прийдется использовать двойную косвенную адресацию.
В следующем примере:
blksize = размер блока
dsize = количество данных в прямых блоках
indsize = количество данных в косвенных блоках
if (filepos >= (dsize + indsize)) { /* двойные косвенные блоки */
filepos -= (dsize + indsize);
dbl_indirect_index = filepos / indsize;
if (filepos >= indsize) {
filepos -= (dbl_indirect_index * indsize);
indirect_index = filepos / blksize;
}
filepos -= (indirect_index * blksize); /* offset in data block */
block_offset = filepos;
}
blksize = 1024;
dsize = 8192;
indsize = 256 * 1024;
filepos = 786769;
if (filepos >= (dsize+indsize)) /* двойные косвенные блоки 786769 >= (8192+262144) */
{
filepos -= (dsize+indsize); /* 516433 */
dbl_indirect_index = filepos / indsize; /* 1 */
if (filepos >= indsize) /* косвенные блоки 516433 > 262144 */
{
filepos -= (dbl_indirect_index * indsize); /* 254289 */
indirect_index = filepos / blksize; /* 248 */
}
filepos -= (indirect_index * blksize); /* 337 */
block_offset = filepos; /* 337 */
}
Другой техникой для хранения информации о блоках данных являются расширенные списки (extent lists).
Вместо списка адресов блоков они хранят список диапазонов адресов блоков данных. Такой адрес состоит из
стартового адреса плюс длины диапазона. Такая техника позволяет хранить большее количество блоков.
Так, для 8-байтного адреса и 2-байтного поля, позволяет хранить таблицу в 65536 блоков.
Если размер блока равен 1 килобайту, файловая система может адресовать 2 в 58-й степени байт.
Недостатком расширенных списков является замедление скорости работы файловой системы в случае
ее дефрагментации, поскольку для больших файлов прийдется сканировать большое количество расширений.
Что такое каталог ?
Файловая система должна уметь работать не только с отдельными файлами, но и с группой файлов.
Для этого используется термин директория или папка для описания контейнера, который
организует и обьединяет группу файлов. Директория управляет списком файлов.
Директория включает список имен. С каждым именем ассоциируется указатель, указывающий
на содержимое файла. Файловая система хранит и имя файла, и номер его ноды. Имя является
ключем при поиске файла, номер ноды - это ссылка, дающая ей доступ к содержимому файла
и к его метаданным.
Существует несколько алгоритмов для хранения списка файлов в директории. Самый простой -
Простейший вариант - это линейный неотсортированный список. При большом количестве файлов
это становится неэффективно. Другой вариант - отсортированный массив структур, например
в форме бинарных деревьев, в которых ключи хранятся в отсортированном порядке, в этом
случае поиск эффективен. Могут использоваться другие варианты, например хешированные таблицы.
Основное требование к директориям - быстрый поиск и эффективная вставка/удаление файла.
На файловые имена существуют ограничения. Это относится к максимальной длине имени файла,
Минимальное ограничение - 32 символа, многие файловые системы имеют ограничение до 255 символов.
В разных операционных системах используются различные символы в качестве разделителей -
в юниксе это прямой слеш, в досе - обратный слеш, в маке - двоеточие. Кодировки, в которых
хранятся файловые имена, в разных операционных системах могут различаться: кодировка может
быть 2-байтовой юникодной, однобайтовой и т.д.
Файловая система должна давать возможность пользователям организовывать файлы в виде
иерархической структуры. Идея иерархии понятна большинству пользователей и легко
адаптируется в файловой системе. Директория может включать в себя ссылку, которая
указывает не на файл, а на другую директорию. Иерархия может быть произвольной. В теории
нет ограничений на уровень вложенности.
Базовые операции файловой системы.
Файловая система может выполнять с файлами и каталогами множество операций. Все файловые
системы должны обеспечивать базовый уровень обслуживания. Прежде всего должна быть
возможность создания пустой файловой системы для новой партиции. При этом учитывается
размер самой партиции для инициализации внутренних структур, от которых существенно
зависит ее производительность. Размер партиции используется для подсчета общего количества
блоков. На основе этого числа вычисляется размеры битмапов для занятых/используемых блоков,
число нод, размер журнала, если он присутствует. После размещения этих структур на диске
информация о их координатах на диске записывается в суперблок.
При инициализация должен быть создан корневой каталог, которые еще называется рутовым
каталогом. Адрес (или номер ноды) рутового каталога также сохраняется в суперблоке.
Инициализация файловой системы может быть сделана как от лица пользовательской программы,
так и являться ядром кода самой файловой системы. После чего партиция в качестве
пустого контейнера готова, после чего файловая система может быть смонтирована.
Во время монтирования происходит чтение суперблока, других системных метаданных.
В суперблоке может быть информация о том, что последний сеанс работы завершился корректно,
и проверка диска не требуется. Монтирование файловой системы с ошибками чревато полным
ее разрушением. Проверка и восстановление поломанной файловой системы - это комплексная
задача. Это может занять длительное время в зависимости от размера партиции.
Затем базовые структуры файловой системы загружаются в память, в ней создается копия
суперблока, который содержит ссылки на рутовый каталог и на битмапы занятых/свободных блоков.
Это необходимо для того, чтобы операционная система могла работать с содержимым диска.
Обратная операция - размонтирование - вызывает обратный сброс на диск всех базовых
структур, которые до этого находились в памяти и подвергались изменениям. В конце в
суперблоке делается отметка, что сеанс работы с файловой системой завершился корректно.
Следующей обязательной функцией файловой системы является создание файла. Для этого
необходимо знать директорию и имя файла. Файловая система создает ноду, после чего
в директорию добавляется ссылка на эту ноду. В качестве дополнительных аргументов
могут выступать файловые права, режимы и т.д. Вноде прописывается время создания,
размер файла, хозяин и т.д. При создании пустого файла место под его содержимое не выделяется,
оно будет выделено позже.
Создание каталога похоже на создание файла, при этом каталогу выделяется нода и в
родительской директории выделяется ссылка на нее. Сама директория должна включать ссылку
на родительский каталог в виде номера ноды, это упрощает иерархическую навигацию вверх-вниз.
Двойная точка .. указывает на родительский каталог, одинарная - на саму себя.
Открытие файла - наиболее часто используемая операция и состоит из 2-х частей.
В первой части берется имя файла и ищется его ссылка в его каталоге. Это может вызвать
сканирование большого числа вложенных каталогов. При этом сама внутрення структура директории,
ее нодовая организация в файловой системе может существенно влиять на производительность.
Вторая часть начинается после того, как получен номер ноды для файла, она может включать
проверку прав пользователя на этот файл. После этого файловая система создает в памяти
структуру для файла. В результате пользовательская программа получает т.н. хэндл - указатель-
на этот файл и может выполнять с ним операции ввода-вывода I/O . Операционная система
может выделить свою собственную структуру для работы с этим указателем в виде т.н.
файлового дескриптора.
При записи происходит сохранение данных в файл. Для этого нужна ссылка на открытый файл,
начальная позиция для записи, размер данных и сами данные в буфере. Если позиция выходит за
размер файла, границу файла нужно сначала увеличить, что приведет к выделению дополнительного
числа блоков и размещению списка этих выделенных блоков. При этом происходят изменения в
самой файловой ноде, в списке свободных/занятых блоков, даже суперблок может быть
модифицирован. После выделения блоков файловая система должна привязать файловую позицию
к адресу блока, с которого будет произведена запись данных.
Операция чтения файла позволяет программам получать доступ к содержимому файла.
В качестве аргумента здесь выступают указатель на файл, позиция, буфер и длина.
Чтение проще, чем запись, потому что не приводит к модификации файловой структуры.
Операция удаления файла в качестве аргумента принимает имя файла. Первая фаза этой
операции заключается в том, что файл маркируется как удаленный, это предотвратит его
открытие другими программами. Вторая фаза удаляет файл при условии, что ссылка на него
больше уже никем не используется. При этом файловая система возвращает блоки, занятые
удаленным файлом, в пул свободных блоков, и удаляет файловую ноду из списка. Система
должна дождаться, когда число ссылок на удаляемый файл станет равным нулю, и только тогда
удалять файл.
Переименование файла требует нескольких аргументов: директория источника, имя файла источника,
переименованная директория, переименованный файл. Необходимо, чтобы эти 2 каталога различались
друг от друга. После проверки происходит удаление файла источника и вставка переименованного файла.
Чтение метаданных позволяет получить информацию о файле. При этом копируются нужные
поля из соответствующей ноды. Примером чтения метаданных является системная функция stat().
Метаданные также можно модифицировать - это можно сделать с помощью системных вызовов
chown(), chmod(), utimes(), и т.д.
По аналогии с открытием файла - функцией open() - для открытия каталога есть функция
opendir(). Эта функция проверяет права программы на открытия каталога, и в положительном
случае далее вызывается функция readdir(). При этом создается экземпляр структуры state,
и при каждой итерации функция readdir() изменяет состояние этого экземпляра таким образом,
что при последующей итерации она получит следующий файл в открытой директории.
Расширенные файловые операции
Символические ссылки (Symbolic Links) - это просто ссылка на другой файл.
Она ассоциируется с именем файла. Если файл, на которыйона она на ссылается, будет переименован,
то ссылка уже будет указывать на несуществующий файл.
Жесткая ссылка - hard link - это другой тип ссылки, она ассоциируется с номером
ноды оригинального файла. Если файл и будет переименован или перемещен, ссылка по-прежнему
будет на него указывать.
Динамическая ссылка - dynamic link - аналогична символическим ссылкам, при этом она может
указывать на различные файлы, может выступать в качестве переменной окружения.
Операционные системы умеют буферизовывать содержимое файла в память. При этом изменения,
происходящие с копией файла в памяти, операционная система автоматически сбрасывает на диск.
В частности, подобным функционалом обладает функция mmap(), имеющая флаги, позволяющие
нескольким процессам получить одновременный доступ к файлу, хранящемуся в памяти.
Заботу о синхронизации берет на себя виртуальная память(virtual memory - VM).
Некоторые файловые системы поддерживают расширенные файловые атрибуты. Атрибут - это пара
имя - значение. В идеале файловая система должна давать возможность прикреплять к любому
файлу неограниченное количество расширенных атрибутов. Вопрос только в том, где и как они
должны храниться.
Атрибуты могут индексироваться для того, чтобы можно было к ним получать быстрый доступ.
Индексация атрибутов представляет из себя альтернативу файловой системы при навигации.
В файловых системах при возникновении ошибок есть различные варианты для восстановления
информации. Это могут быть специальные проверочные утилиты , запускаемые при старте и делающие
полную проверку диска в течение длительного времени.
Другой альтернативный вариант - журналируемые файловые системы.
Все изменения файла пишутся в транзакционный лог, что гарантирует атомарную целостность файла.
При ошибках происходит откат такого лога, который выполняется всего за несколько секунд.
Списки доступа - Access control lists (ACLs) - реализуют механизм доступа на основе прав.
Для файлов традиционно (POSIx) существуют 3 группы прав - для владельца файла, для группы,
к которой принадлежит владелец, и для всех остальных. ACL предписывает им всем различные
права.
Можно подвести итоги: Файловые системы позволяют хранить данные в иерархической структуре
и получать о них информацию. В основе файловых систем лежат 2 фундаментальных концепции -
файл и директория.
Обзор файловых систем
FFS
Berkeley Software Distribution Fast File System (BSD FFS, или просто FFS).
FFS является базисом для большинства современных файловых систем. Именно в ней впервые
появились такие категории, как суперблок, битовые карты для блоков и нод.
В основе самой FFS лежат первые юниксовые файловые системы. FFS стала использовать
размер блока, кратный 4 килобайтам.
В ней стала использоваться техника последовательного выделения дисковых блоков для одного
файла, что существенно увеличило скорость доступа.
Увеличение размера блока имеет свою обратную сторону - дефрагментация диска в случае,
когда размер файла меньше размера блока. FFS умеет фрагментировать сам блок, разбивая его
на фрагменты, для этого используется битовая карта, которая хранит фрагментацию внутри
самих блоков.
Простая диаграмма диска:
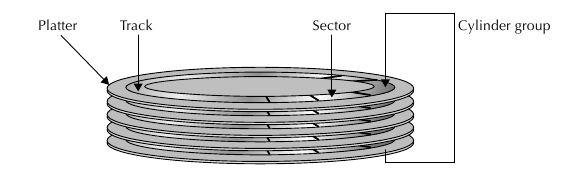
В FFS появилась концепция цилиндрических групп - cylinder groups - что позволило уменьшить
механический процесс перемещения дисковых головок при поиске. При этом учитывается физическая
организация заголовков, треков, цилиндров, секторов на самом диске. Цилиндрическая группа -
это набор всех блоков внутри физического трека на диске, которая представляет многослойную
структуру, при этом переключение между слоями, которые распологаются один под другим,
не вызывает пространственного перемещения головок диска. При этом создание новых директорий
происходит предпочтительно в новых цилиндрических группах.
В современных дисках функции по обслуживанию дисковых групп постепенно мигрируют с уровня
файловых систем на уровень драйверов самих дисков, т.е. еще на более низкий уровень,
чем файловые системы, т.е. вопрос с организацией цилиндрических групп внутри самих файловых
систем уже не так актуален.
В FFS был реализован новый механизм сохранения метаданных, который сделал файловые системы
более надежными в случае сбоев и последующих восстановлений данных. Например, при удалении файла
в каталоге происходит немедленный апдэйт самого каталога путем модификации его метаданных
минуя буферизацию. Платой за такую надежность является избыточная нагрузочная работа диска.
EXT2
EXT2 - классическая юниксовая реализация файловой системы. Здесь был реализован доступ
на уровне ACL. Она похожа на FFS, хотя не использует механизм цилиндрических групп,
целиком полагаясь в этом вопросе на драйвера самих дисков. Ext2 разбивает диск на блоковые
группы фиксированного размера, каждая из которых представляет из себя как бы файловую систему
в миниатюре. Каждая такая группа имеет свой суперблок, карту блоков, карту нод, таблицу нод.
Ext2 не дает гарантий в том, что любая операция ввода/вывода всегда будет гарантированно выполнена
до конца. В отличие от FFS, она в основном работает с закешированными файлами в памяти,
периодически сбрасывая их на диск. Производительность от этого естественно только выигрывает.
Фактически она ограничена только скоростью выполнения системного вызова memcpy().
Такая модель резко контрастирует с моделью FFS, которая заботливо синхронизирует все
изменения путем постоянного сброса их на диск.
В модели, с которой работает ext2, можно найти какие-то подводные камни, в частности
в варианте, когда с одними и теми же файлами работают одновременно сразу несколько
приложений, где последовательность и синхронность изменений становится проблематичной.
Ext2 не дает гарантий о точном порядке кеширования и сброса изменений на диск. На практике
такие ситуации встречаются крайне редко, и в целом ext2 по производительности значительно опережает
файловые системы, в основе которых лежит FFS.
Macintosh HFS
HFS появилась в 1984 году. Это была одна из первых файловых систем для поддержки
графического пользовательского интерфейса. Она непохожа на традиционную файловую систему.
В ней нет таблицы нод, в ней нет общепринятых каталогов, но в ней есть блоковые таблицы
для свободных и выделенных блоков.
HFS использует для хранения файловой структуры бинарные деревья. Две главные структуры -
это файл каталога (catalog file) и расширенный файл (extent overflow file). Первый может
быть четырех типов: записи каталогов (directore records), треды каталогов (directory thread),
записи файлов (file recoreds) и файловые треды (file thread). Файловый тред хранит имя файла
и каталог, в котором он лежит. Запись хранит метаданные: время последней модификации,
права доступа и т.д. Директория хранит все ссылки на свои файлы и подкаталоги в виде единой
структуры. Каждый файл имеет в своей структуре обязательный id-шник его каталога.
Недостатком каталогов HFS является то, что если в каталоге происходит добавление или
модификация отдельного файла, каталог полностью блокируется.
HFS налагает серьезные ограничения - каждый том может иметь не блое 65536 блоков.
Т.н. master directory block располагает всего двумя байтами для хранения числа блоков.
Это заставляет HFS использовать большие по размеру блоки. Например, нормальная практика
для HFS выделять на блок 32 килобайта. Это ограничение на 65536 блоков было снято в версии
HFS+ , которая вышла в 1998 году.
Irix XFS
Irix - это юниксовая операционная система компании SGI. В ней разработана файловая система XFS,
которая поддерживает журналирование и 64-битность. Они создавались с прицелом на очень
большой обьем хранилища, огромное количество файлов, это файловая система для "большого железа".
Традиционная классическая схема управления свободными дисковыми блоками реализуется
на основе битовой карты, где на 1 блок отводится 1 бит. Вместо этого в XFS используются
бинарные деревья. Она разбивает весь диск на т.н. выделенные группы - allocation groups.
В каждой такой группе есть два бинарных дерева, которые хранят информацию о свободных блоках.
В первом бинарном дереве блоки хранятся в порядке, отсортированном по их номерам.
Во втором дереве блоки хранятся в порядке, отсортированном по длине групп свободных блоков.
В такой схеме файловая система способна найти необходимое свободное место по его длине.
Это позволяет эффективно выделять дисковое пространство при создании файлов. Недостатком
такой схемы является дублирование информации плюс необходимость синхронизации между этими
двумя деревьями. XFS не делает предварительного выделения пространства для нод, как это делается
в классических юниксовых системах, вместо этого каждая выделенная группа выделяет внутри себя
блоки для нод лишь по мере необходимости. Каждая выделенная группа имеет специальное бинарное
дерево, в котором хранит расположение своих нод. Это снимает ограничение на общее количество
файлов в файловой системе. По сравнению с классическим вариантом такая организация нод имеет
недостаток: при табличной организации время доступа к ноде - величина постоянная, в то время
как при бинарной организации время доступа произвольно и зависит от размера бинарного дерева.
XFS использует расширенную битовую карту для выделенных блоков. Для ее управления также
используются бинарные деревья, в котором блоки одного файла хранятся в отсортированном виде.
Вообще бинарные деревья снимают многие ограниченя. Но за это естественно приходится
расплачиваться более сложной реализацией. XFS также использует бинарные деревья для
хранения директорий. В классическом варианте содержимое директорий хранится в линейном списке,
и в случае с ростом эти списки плохо масштабируются. Бинарное дерево, хранящее каталоги,
отсортировано по имени, и в случае с большим количеством файлов это эффективне, чем в
классическом варианте. XFS поддерживает многопоточное I/O. Это связано с многопроцессорной
архитектурой SGI-шного железа. В классической схеме, если к одному файлу происходит доступ
со стороны нескольких процессов на чтение/запись, то нода этого файла блокируется одним
текущим процессом. XFS снимает такие ограничения для схемы "один пишет / много читают",
буферизует файл и позволяет нескольким процессорам выполнять над ним операции.
Это существенно снижает нагрузку на дисковые контроллеры. В XFS также реализован режим
"много пишут" для одного файла также на основе кеширования.
В целом можно сказать, что XFS предлагает интересную и оригинальную трактовку реализации
файловой системы, которая отличается от классических схем.
NTFS
NTFS - 64-битная журналируемая файловая система с поддержкой атрибутов, компрессией файлов,
появилась в 1990 году. Главная структура - это мастер таблица - master file table (MFT).
MFT содержит список всех нод файловой системы. MFT сама по себе представляет файл и может
неограниченно расти. Каждая запись в такой таблице является ссылкой на файл. Размер записи
может быть 1, 2 или 4 килобайта. Нода включает всю информацию о файле в виде атрибутов.
Если размер ноды недостаточен для хранения новых атрибутов, в ноду добавляется ссылка на
другую дополнительную ноду в MFT, в которой они будут храниться. Данные самого файла и
данные атрибутов хранятся на диске в виде выделенных блоков.
Кроме MFT, имеются еще несколько базовых системных файлов: log file, volume file,
root directory, bitmap file, boot file и т.д.
Каталоги хранятся в бинарных деревьях и отсортированы по алфавиту. В них хранятся имена
файлов, номер файловой ноды, а также размер файла и время последней модификации.
NTFS - журналируемая файловая система, в ней используется опережающее логирование - write-ahead logging -
т.е. сначала изменения файла пишутся в лог, а уже потом в сам файл.
Вообще говоря, ни одна из рассмотренных файловых систем не является лучшей из всех.
Каждая из них имеет свои определенные преимущества в различных ситуациях.
Разработка файловой системы BFS.
Диск можно рассматривать как линейный список блоков, который имеет свой собственный -
железячный - размер блока - обычно это 512 байт. Размер блока в файловой системе тесно
связан с этим размером. Он должен быть кратен железячному размеру блока, т.е. он может
быть 512, 1024, 2048 и т.д байт. Как правило, размер блока файловой системе крате двум
блокам по 512, потому что это зависит от виртуальной файловой системы, которая накладывает
свои ограничения на размер и кратность своего буфера.
При выборе размера блока файловой системы размер самого диска не имеет существенного значения.
Существенное значение имеет другой фактор: если в файловой системе преобладают мелкие файлы,
размер блока должен быть меньше. Если преобладают файлы большого размера, размер блока должен
быть больше.
Для управления свободным пространством на диске есть 2 основных подхода. Наиболее простой
вариант - битовая карта. Второй более сложный варинт - бинарные деревья.
В первом случае каждый блок представлен в карте одним битом. Установка бита в единицу означает,
что этот блок уже выделен. Размер битовой карты в байтах вычисляется по формуле :
дисковое пространство в байтах делится на размер блока файловой системы в байтах, умноженный на 8.
Для жесткого диска в 1 гигабайт с размером блока в 1 килобайт размер карты = 128 килобайтам.
Основным недостатком этого метода является поиск достаточно большого числа свободных блоков.
Обычно карта хранится на диске в виде последовательности байтов, сразу после суперблока.
Место под нее обычно выделяется сразу при создании файловой системы.
Массив доступных блоков на диске мы разобьем на порции, которые назовем выделенными группами -
allocation groups. Рассмотрим пример с диском размером в 1 гигабайт и размером блока в 1 килобайт.
Мы уже посчитали, чтов этом случае размер битовой карты равен 128 килобайтам, т.е. на битовую
карту нам нужно выделить 128 блоков. Один такой блок может замапить 8192 блоков, т.е. минимальный
размер выделенный группы - 8192 блока по 1 килобайту, т.е 8 мегабайт. Максимальный размер выделенной
группы может быть 65536 блоков. На практике так оно и получается, что для 1-гигабайта
выбирается выделенная группа размером 8192 блоков.
Файловую ноду желательно помещать в ту же выделенную группу блоков, в которой находится
директория, которой принадлежит этот файл. Если в директории создается новая поддиректория,
ее желательно располагать в другой выделенной группе. То же самое относится к файловым данным.
Т.е. файловые метаданные и собственно самые данные можно разносить по разным выделенным
группам, хотя это зависит от свободного места на диске и обсуждаемо.
Битовые карты, хранящие информацию о свободных блоках, имеют индекс последнего выделенного
блока, этот индекс постоянно хранится в памяти для быстрого выеления блоков. Для каждой
выделенной группы также необходим флаг-индикатор на случай переполнения выделенной группы.
Организация блоков
Создадим базовую структуру для блоков, которую назовем block:
typedef struct block
{
int32 allocation_group;
uint16 start;
uint16 len;
} block;
Поле allocation_group указывает на выделенную группу, поле start указывает на первый блок
этой выделенной группы, поле len - это общее число блоков в выделенной группе.
Максимально возможное количество блоков - 2^48 , и учитывая размер блока в 1 килобайт,
максимально возможный размер диска - 2^58 байт. Что такое 2 в 58 степени ? Можно снять
видео длительностью в 200 лет с частотой 30 фреймов в секунду, так вот этого диска хватит
на то, чтобы сохранить видеоролик гигантского размера длительностью в 2 века.
Поле len - 16-битное, позволяет адресовать 65536 блоков, т.е. с помощью одной структуры
block мы можем управлять 64 мегабайтами дискового пространства.
Суперблок
В суперблоке нужно поместить различную информацию, описывающие как физические параметры
диска, так и дополнительную информацию о логировании и индексах, имя тома, байтовый порядок
файловой системы и т.д.
typedef struct super_block
{
char name[LENGTH];
int32 magic1;
int32 fs_byte_order;
uint32 block_size;
uint32 block_shift;
off_t num_blocks;
off_t used_blocks;
int32 inode_size;
int32 magic2;
int32 blocks_per_ag;
int32 ag_shift;
int32 num_ags;
int32 flags;
block log_blocks;
off_t log_start;
off_t log_end;
int32 magic3;
inode_addr root_dir;
inode_addr indices;
int32 pad[8];
} super_block;
Поле block_size хранит размер структуры. Поле block_shift используется для того, чтобы
из номера блока получить его байтовый адрес - оно хранит число бит, необходимых для сдвига
номера блока. Поле num_blocks хранит общее число блоков, поле used_blocks - число занятых
блоков. Тип off_t - это 64 бита. Поле inode_size - это размер одной ноды. В нашей системе
не будет заранее сформированной таблицы нод, каждую ноду мы будем создавать по мере
необходимости, и inode_size говорит нам, сколько блоков нужно для нее. Поле blocks_per_ag -
число блоков внутри выделенной группы. Поле ag_shift нужно для того, чтобы сконвертировать
адрес структуры block для каждой выделенной группы в байтовое смещение. Поле num_ags -
общее число выделенных групп.
Поле flags хранит состояние суперблока. Оно может иметь различное значение в зависимости
от того, в каком состоянии находится в данный момент система: например , момент полного
монтирования и момент записи изменений на диск - это 2 разных состояния.
Журнал - это место на диске, где хранятся изменения файловой системы, представляет из себя
последовательный массив дисковых блоков. Поля log_start и log_end указывают на стартовый
и конечный адреса лога. Поле root_dir - адрес рутовой ноды. Поле indices - область, в которой
хранятся индексы.
После монтирования системы суперблок грузится в память, для этого есть другая специальная
структура - fs_info.
Структура ноды.
При открытии файла используется его имя, представляющее строку символов. С этим именем
файла ассоциируется номер ноды, который фактически является ее же адресом на диске.
Нода регулирует доступ к содержимому файла. Нода хранит метаинформацию - размер файла,
владелец, Время создания и модификация файла и т.д. Нода указывает на адрес диска,
по которому лежит данные самого файла.
typedef struct inode
{
int32 magic1;
inode_addr inode_num;
int32 uid;
int32 gid;
int32 mode;
int32 flags;
bigtime_t create_time;
bigtime_t last_modified_time;
inode_addr parent;
inode_addr attributes;
uint32 type;
int32 inode_size;
binode_etc *etc;
data_stream data;
int32 pad[4];
int32 small_data[1];
} inode;
Внутри ноды хранится собственный номер inode_num в общем массиве блоков диска.
32-битные поля uid/gid - методы для манипулирования правовой информации.
Поле mode - это режимы доступа, т.е. чтение, запись или выполнение.
Поле flags описывает состояние ноды - занята/не занята, закеширована или нет,
журналируема или нет и т.д. Для упрощения мы будем журналировать только изменения
в директориях, изменения в файлах не журналируются. При удалении файла нода помечается
как удаленная. Временные поля структуры имеют 64-битный формат bigtime_t.
Первоначально используется стандартный формат time_t, который сдвигается на 16 бит
для получения уникального временного значения с целью последующего его индексирования.
Поле parent указывает на родительский каталог. Поле attributes - это адрес ноды, хранящей
файловые атрибуты в виде пар имя-значение. Поле type указывает на тип атрибута (число, строка и т.д.)
Нода и данные.
Целью ноды является привязывание файла к хранилищу данных.
Член нодовой структуры по имени data выполняет эту задачу. Тип данных data_stream
позволяет привязать байтовую позицию внутри файла к конкретному блоку на диске.
#define NUM_DIRECT_BLOCKS 12
typedef struct data_stream
{
block direct[NUM_DIRECT_BLOCKS];
off_t max_direct_range;
block indirect;
off_t max_indirect_range;
block double_indirect;
off_t max_double_indirect_range;
off_t size;
} data_stream;
Рассмотрим пример, в котором имеется файл размером 2048 байт. Если блок файловой
системы имеет размер 1024 байта, файлу потребуется 2 таких блока. Структура block может
ссылаться на 65536 блоков, идущих подряд, а нам нужно всего два.
Массив структур direct выделяет место для прямых блоков и может потенциально выделить
достаточно много места для одного файла,в лучшем случае до 768 мегабайт ( 12 block * 65536 ).
Очень большие файлы могут потребовать более чем 12 структур direct, для этого выделяются
косвенные блоки с помощью членов indirect и double_indirect. Первое поле indirect
указывает на массив адресов, которые в свою очередь указывают на реальные данные.
Поле double_indirect указывает на поле, которое является ссылкой на массив адресов,
указывающих на реальные данные.
Как подсчитать максимальный размер файла, который может быть в таком случае ? Проведем
расчеты для варианта, когда размер одного блока равен одному килобайту.
В зависимости от фрагментации диска один прямой block может мапить произвольной различное
количество данных. Блок, на который ссылается indirect, минимум всегда имеет размер
4 килобайта и может в свою очередь включать 512 блоков. Аналогично для поля double_indirect.
Использование непрямых блоков помогает победить фрагментацию.
Получаем в наихудшем варианте:
прямые блоки = 12 килобайт (12 блоков по 1 килобайту)
косвенные блоки = 512 килобайт (4 непрямых блока мапят 512 блоков по 1 килобайту)
двойные косвенные блоки = 1024 мегабайт ( 4 * 512 * 512 ).
Получаем максимальный размер файла в 1 гигабайт.
Получаем в наилучшем варианте:
прямые блоки = 768 мегабайт (12 блоков по 65536 килобайт)
косвенные блоки = 32,7 гигабайт (4 непрямых блока мапят 512 блоков по 65536 килобайт)
двойные косвенные блоки = 1024 мегабайт ( 4 * 512 * 512 ).
Получаем максимальный размер файла в 34 гигабайта. Понятно, что увеличение размера одного
блока, а также косвенная адресация приводит к увеличению этих цифр.
Связь прямой и косвенной адресации:
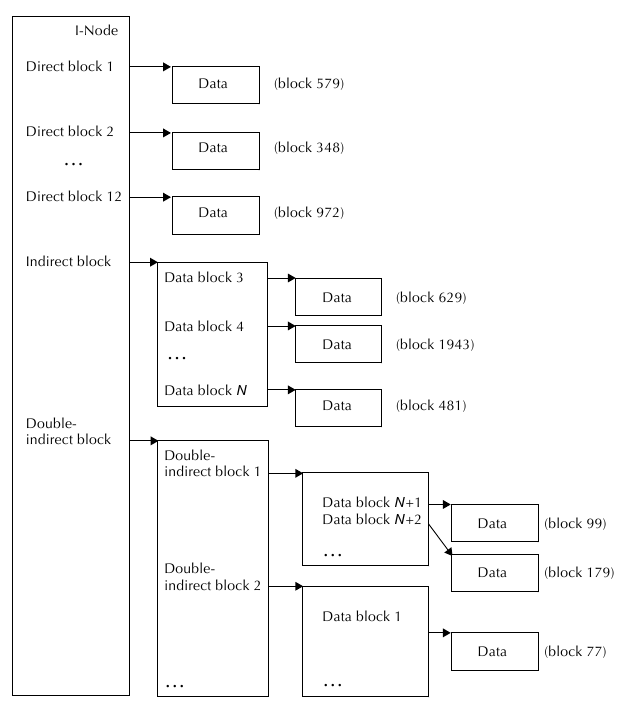
Теперь разберемся с вопросом, как логическая позиция внутри файла мапится на дисковый блок.
Рассмотрим пример с файлом и с его структурой data_stream, в который имеется массив
из 4-х "прямых" структур direct, каждая из которых в силу текущей фрагментации диска мапит
по 16 килобайт данных. Этот массив может выглядеть так:
direct[0] = { 12, 219, 16 }
direct[1] = { 15, 1854, 16 }
direct[2] = { 23, 962, 16 }
direct[3] = { 39, 57, 16 }
direct[4] = { 0, 0, 0 }
Допустим, нам нужно найти байт под номером 37934. В данном случае нам нужно просто
проитерировать все прямые блоки, пока мы не дойдем до нужного - псевдокод:
pos = 37934;
for (i=0, sum=0; i < NUM_DIRECT_BLOCKS; sum += direct[i].len * block_size, i++)
{
if (pos >= sum && pos < sum + (direct[i].len * block_size))
break;
}
В результате индекс i будет номером структуры direct, внутри которой будет лежать
данная позиция файла: i=2. Это будет блок с индексом = 2 - { 23, 962, 16 }, в которой
стартовый блок имеет номер 962, это 23-я выделенная группа размером в 16 килобайт.
Внутри этого блока позиция будет равна :
5166 = 37934 - 32768
В случае с косвенными блоками линейный поиск аналогичен , в случае
с двойными косвенными блоками необходимо выделять их в строго фиксированном размере,
для того, чтобы такой поиск работал эффективно.
Аттрибуты.
Атрибут - это пара: ключ - значение. Атрибуты позволяют хранить метаинформацию о файле.
Файл может иметь произвольное количество атрибутов. Значения атрибутов могут быть
целочисленными, плавающими, строковыми, это может быть произвольный набор данных.
Целочисленные атрибуты можно проиндексировать для ускорения доступа к ним.
Для хранения атрибутов мы будем использовать директорию - смотрите поле attributes в структуре
inode. Это не директория в обычном понимании, а список ключей, каждый из которых явдяется
указателем на соответствующее значение. Внутри самой ноды есть указатель small_data на блок,
в котором будут храниться основные атрибуты. small_data имеет следующцю структуру:
typedef struct small_data {
uint32 type;
uint16 name_size;
uint16 data_size;
char name[1];
} small_data;
Имя файла всегда находится внутри этой структуры.
Структура файла и его атрибутов:
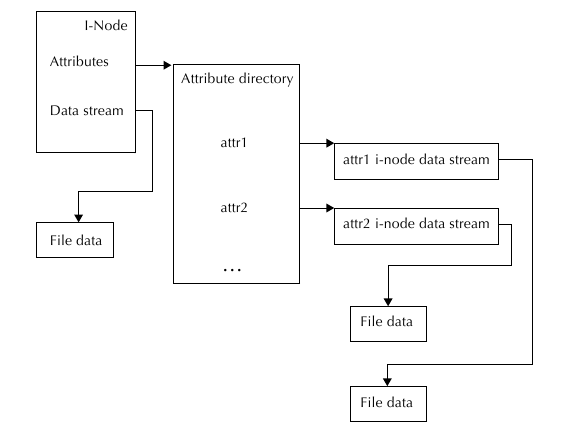
Директории.
Директории поддерживают иерархическую структуру файловой системы. Директория связывает
файловые имена с номерами нод. Нодовый номер, который хранится в директории, может ссылаться
на файл или на другую директорию. Суперблок включает в себя ноду рутовой директории.
Привязка номера ноды к файлу является основной функцией директории, и для этого существует
множество схем. Традиционная юниксовая система хранит линейный список пар "имя файла / номер ноды"
в данных самой директории. Это наиболее простой вариант, но не очень эффективный в случае
с большим количеством файлов. Другая схема - использование бинарных деревьев. В них пара
"ключ / значение" хранится в сбалансированном виде, имя является ключем, нода - значением.
Время поиска здесь имеет логарифмическую зависимость от числа файлов и в общем случае меньше,
чем в классическом варианте. Другим плюсом бинарных деревьев является возможность индексации.
Индексация.
Произвольный атрибут может быть добавлен к любому файлу и затем проиндексирован. Например,
почтовый демон для каждого емайл-сообщения может создать атрибуты from, to, subject,
на основе которых файловая система строит три индекса, каждый из которых содержит в себе
полные списки соответствующих атрибутов. Индексы можно делать также для имен файлов,
их размеров, времени последней модификации, что упрощает поиск нужных файлов по определенным
критериям. Для индексации можно использовать бинарные деревья. Индекс обязан уметь привязать
значение атрибута к номеру ноды. Если значение - строка, то индекс является директорией.
Файловая система хранит индексы как скрытые директории. Суперблок хранит в себе нодовый адрес
индексной директории.
Аттрибуты, индексация.
Индексирование атрибутов и быстрый поиск на основе этого приближает функционал файловой
системы к функционалу базы данных.
Атрибут - это пара "имя - значение", в качестве имени обычно выступает строка, в качестве
значения могут быть числа, строки или бинарные данные. Атрибут несет дополнительную информацию,
которая не хранится в самом файле. Это важно, потому что изменение атрибутов не изменяют
сам файл. В качестве атрибутов могут выступать:
графическая информация о положении иконки;
урл загруженного из веба документа;
тип файла;
последняя дата архивации;
ключевые слова в документе;
гамма-коррекция для картинки
и т.д.
Пользовательская программа может выполнять следующие операции с атрибутами:
записать атрибут;
прочитать атрибут;
открыть директорию атрибутов;
прочитать директорию атрибутов;
удалить атрибут;
переименовать атрибут.
Для доступа к файлу нужно открыть файл, дескриптор которого становится указателем к директории
атрибутов этого файла. На пользовательском уровне API может иметь следующий ыид:
ssize_t fs_read_attr(int fd, const char *attribute, uint32 type,off_t pos, void *buf, size_t count);
ssize_t fs_write_attr(int fd, const char *attribute, uint32 type,off_t pos, const void *buf, size_t count);
Первым аргументом идет файловый дескриптор, далее идут имя атрибута, тип атрибута. Это обычная
семантика для файловой операции.
Attribute Details
Атрибут - это символьное имя, его тип, а также порция данных. Тип может быть строковый, численный либо произвольный.
Тип используется при индексации. Для организации атрибутов полезно было бы использовать стандартную ноду.
Для хранения списка атрибутов одного файла также необходима структура типа директории, причем в файловой ноде
нужно сделать ссылку на эту директорию атрибутов. На рисунке 5.1 показана связь между этими структурами.
Размер нашей файловой ноды составляет 232 байта. Каждая такая нода будет занимать один блок, в котором
оставшееся место будет отведено под атрибуты. Нода будет выглядеть так, как на рисунке 5.2. Она разделена
на 2 части - основную и т.н. small_data.area для хранения атрибутов:
typedef struct small_data {
uint32 type;
uint16 name_size;
uint16 data_size;
char name[1];
} small_data;
Размер этой структуры оптимизирован для размещения в памяти , поскольку размер нашей ноды не может быть более 8 килобайт.
Данные самих атрибутов следуют сразу за этой структурой. Макрос, который указывает на эти данные, выглядит так:
#define SD_DATA(sd) \
(void *)((char *)sd + sizeof(*sd) + (sd->name_size-sizeof(sd->name)))
Процедуры, которые манипулируют этой структурой, используют нодовый указатель, который фактически является
также указателем на дисковый блок. К таким процедурам относятся например поиск атрибута по имени, создание
атрибута с именем,типом и данными, апдэйт атрибута. удаление атрибута и т.д.
Имея указатель на ноду, легко получить адрес первого атрибута, который располагается сразу за нодой, а также весь
массив таких атрибутов. Данную схему хранения атрибутов можно оптимизировать путем использования типа union
вместо поля name_size . Или имя атрибута name можно хранить в специальной таблице .
Псевдокод для записи атрибута может выглядеть так:
if length of data being written is small
find the attribute name in the small_data area
if found
delete it from small_data and from any indices
else
create the attribute name
write new data
if it fits in the small_data area
delete it from the attribute directory if present
else
create the attribute in the attribute directory
write the data to the attribute i-node
delete name from the small_data area if it exists
else
create the attribute in the attribute directory
write the data to the attribute i-node
delete name from the small_data area if it exists
Логика работы файловой системы с атрибутами следующая: сначала файловая система проверяет, есть ли данный
атрибут в small_data, если нет, то ищет его в директории атрибутов. Манипуляция атрибутом, который находится
в каталоге атрибутов, легче, поскольку для этого используются стандартные файловые операции.
Связь между нодой и атрибутами:
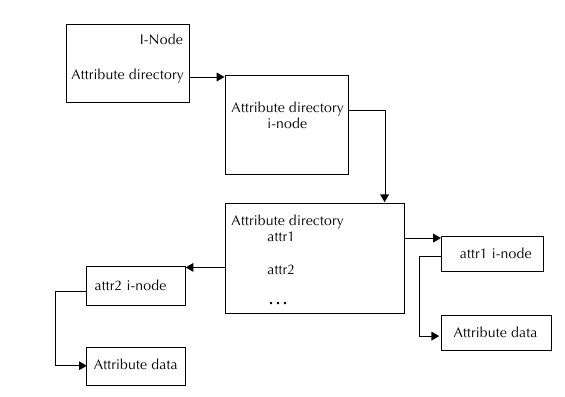
Нода BFS:
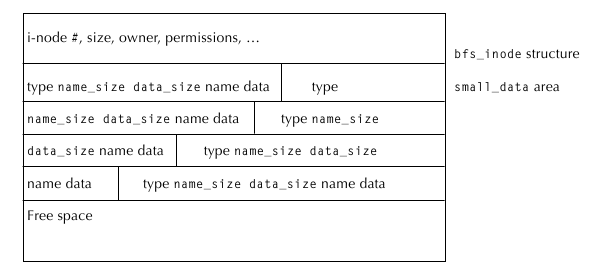
Индексация.
Индексация файловой системы необходима для быстрого поиска файлов. Индексация по имени, размеру, времени
модификации существенно ускоряет процесс поиска файла. Индекс - это список файлов а определенном порядке.
Если файловая система индексирует атрибуты, она становится похожей на традиционную базу данных.
Индексация - это механизм, который ускоряет поиск. Индекс - это структура, хранящая пару ключ/значение,
позволяющая быстро найти результат по ключу. В качестве значения как правило выступает конкретная нода.
Ключи в индексе лежат в определенном порядке. Файловая система может иметь большое количество разнообразных
индексов, и она должна уметь загружать их в память в произвольный момент одновременно. Индексы должны уметь
хранить дубликаты, в случае, когда 2 файла в разных каталогах имеют одно и то же имя.
Две наиболее популярных структуры данных, которые используются для индексации - это бинарные деревья
и хеш-таблицы. У обоих этих вариантов есть свои преимущества и недостатки.
Бинарное дерево - это древовидная структура организации нод. У него всегда имеется рутовая стартовая нода.
ЕЕ линки ссылаются на другие ноды, которые в свою очередь ссылаются также на другие ноды, и т.д., до тех пор,
пока не останется нода, которая ни на кого не ссылается (leaf node). В одной ноде может быть несколько пар ключ/значение.
На рисунке показан пример бинарного дерева. :
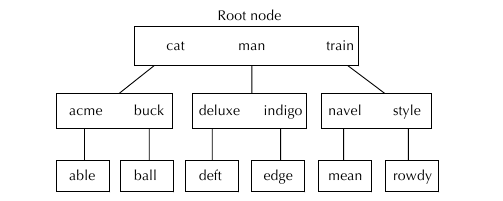
Бинарные деревья поддерживают относительное упорядочивание нод.
Обратите внимание, что в рутовой ноде имеется слово man, от него идет ссылка на слова , которые лежат строго
в алфавитносм диапазоне между рутовыми cat и man, то же самое можно заметить и для train - нода дает ссылки
на слова, которые старше, чем man. И это все работает аналогично вниз. Т.е. нода указывает на другие ноды,
которые меньше ее по значению - в этом особенность бинарного поиска.
Если например нам нужно найти слово deft, мы начинаем с рутовой ноды и видим, что первое слово cat меньше,
чем deft, поэтому мы переходим к следующему слову - man, видим, что оно больше, чем deft, и опускаемся на второй
уровень, рассматриваем пару deluxe - indigo , и т.д. В данном примере дерево хорошо сбалансировано, и время
поиск логарифмически пропорционально от числа нод, причем основанием логарифма является число ключей, приходящееся
на одну ноду. Под хорошей балансировкой бинарного дерева подразумевается то, что длина ветвей относительно одинакова.
Для поддержания балансировки при вставке ноды сначала находится нужная позиция, потом проверяется,
не произошло ли переполнение в узле, и в этом случае узел разбивается на 2 узла, между которыми происходит
перераспределение ключей, при этом должна быть модифицирована также и родительская нода.
При удалении ноды поддерживается аналогичная стратегия, здесь вместо разделения ноды может быть совершена
обратная операция - слияние 2-х нод.
Преимуществом бинарных деревьев является то, что они хорошо хранятся на диске. Каждая нода в дереве имеет
фиксированный размер, соответствующий размеру дискового блока. Бинарное дерево может быть сохранено в одном файле.
При добавлении ключа в дерево необходимо лишь сделать приращение в размере этого файла. Разбиение ноды -
достаточно эффективная операция, поскольку нода добавляется в конец файла, а данные остаются там же, только
переписываются нодовые указатели.
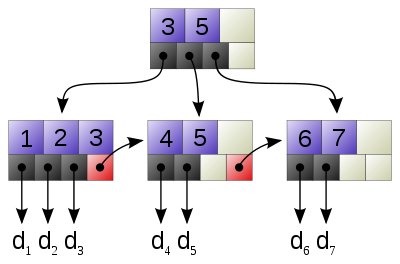
Имеется несколько вариантов бинарных деревьев. Простейший вариант - B*trees, где ставка делается на максимально
возможное размещение числа ключей в одной ноде. Другой вариант - B+trees, здесь в ноде хранятся только индексы,
а все пары ключ/значение хранятся в дочерних нодах, причем дочерние ноды прилинкованы друг к другу с помощью указателей.
B+tree :
Другая техника хранения данных на диске - хеширование. Каждый ключ трансформируется с помощью хеш-функции
в целочисленное значение, являющееся индексом в специальной таблице, в которой хранятся пары ключ/значение.
Скорость поиска любого ключа в такой таблице - величина постоянная и не зависящая от размера самой таблицы,
и это является безусловным преимуществом хеширования перед бинарными деревьями.
Недостатком является то, что ключи в такой таблице перемешаны беспорядочно. Другим недостатком является
дублирование ключей.Одним из вариантов хеширования является т.н. расширенное хеширование - extendible hashing -
при котором таблица разбивается на 2 части - таблицу указателей и таблицу данных. Когда таблица заполнена,
требуются затраты по времени на ее дальнейшее расширение.
|

 LINUX
LINUX 
 Kernels
Kernels
