Second Extended Filesystem
R?y Card, Laboratoire MASI--Institut Blaise Pascal,
E-Mail: card@masi.ibp.fr, and
Theodore Ts'o, Massachussets Institute of Technology,
E-Mail: tytso@mit.edu, and
Stephen Tweedie, University of Edinburgh,
E-Mail: sct@dcs.ed.ac.uk
Введение
Linux - юниксо-подобная система.
Он был реализован в самом начале как расширение Minix
[Tanenbaum 1987]
и его первая версия включала поддержку только Minix filesystem,
у которой есть серьезные ограничения:
размер всей файловой системы не может превышать 64 метров
и максимально возможная длина имени файла-14 символов.
Мы разработали и реализовали 2 новых файловых системы.
Они называются ``Extended File System'' (Ext fs) и
``Second Extended File System'' (Ext2 fs).
В этой статье мы опишем историю Linux filesystems
и кратко расскажем о 2-х фундаментальных концепциях.
Будет представлена Virtual File System
и детально код Second Extended File System.
История Linux filesystems
В самом начале линукс базировался на миниксе.
Торвальдс использовал миникс потому,что к тому моменту она была рапространенной
и достаточно устойчивой.
Но у файловой системы миникса есть серьезные ограничения,
поэтому люди сразу начали работать над реализацией новой файловой системы.
Вначале был разработан слой Virtual File System (VFS).
Он был создан Chris Provenzano, и затем переписан самим Торвальдсом.
После интеграции VFS в ядро ,
была реализована новая файловая система,названная ``Extended File System''.
Это произошло в April 1992 и добавлено в версию Linux 0.96c.
Были преодолены 2 больших ограничения Minix:
теперь файловая система могла содержать в себе 2 гига
и имя файла могло состоять из 255.
Но еще не было поддержки разделенного доступа,
модификации inode и data modification timestamps.
Эта файловая система была построена на связанных списках.
У нее был недостаток-по мере накопления она становилась сильно фрагментированная
и теряла в производительности.
В январе 1993 появились 2 новых файловых системы:
Xia filesystem и Second Extended File System.
Xia filesystem была прямой производной Minix filesystem.
Ext2fs была сделана уже на основе Extfs и значительно улучшена.
Xia fs вначале была более стабильной , нежели Ext2fs.
Но баги в Ext2fs вскоре починили,и на сегодняшний день
она является де-факто стандартом в области линуксовых файловых систем.
Таблица описывает особенности различных файловых систем:
| Minix FS | Ext FS | Ext2 FS | Xia FS |
|---|
| Max FS size | 64 MB | 2 GB | 4 TB | 2 GB |
|---|
| Max file size | 64 MB | 2 GB | 2 GB | 64 MB |
|---|
| Max file name | 16/30 c | 255 c | 255 c | 248 c |
|---|
| 3 times support | No | No | Yes | Yes |
|---|
| Extensible | No | No | Yes | No |
|---|
| Var. block size | No | No | Yes | No |
|---|
| Maintained | Yes | No | Yes | ? |
|---|
Базовые концепции файловых систем
Любая линуксовая фаловая система базируется на юниксовых концепциях
[Bach 1986],
и представляет из себя набор нод,каталогов и файлов.
Inodes
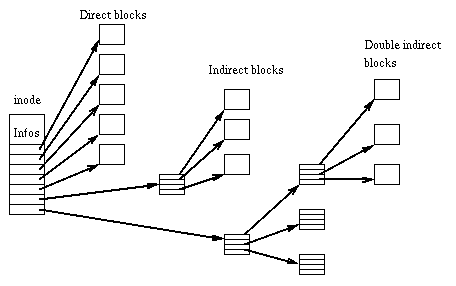
Каждый файл представлен структурой, которая называется inode.
Эта нода включает в себя описание файла: его тип,права доступа,владельца,
время модификаций,размер, указатель на блоки.
Адреса этих блоков хранятся в ноде.
Когда пользователь делает какую-то I/O операцию с файлом,
ядро берет адреса блоков,сверяет их со своей внутренней таблицей
и производит чтение или запись в эти блоки.
Структура ноды:
Каталоги
Каталоги структурированы в иерархическое дерево.
Любой каталог может включать как файлы,так и вложенные каталоги.
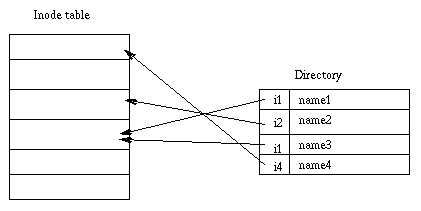
Каталог-это специальный тип файла.
Точнее,файл со вложенными элементами.
Каждый такой элемент включает номер ноды и имя файла.
Когда происходит поиск по пути,ядро сначала ищет номер ноды.
Потом эта нода загружается в память.
Каталог:
Links
В юниксовых файловых системах реализована концепция линка.
В ноде есть специальное поле,которое ассоциируется с файлом.
Создавая линк,мы создаем новый файловый обьект,
при удалении которого не будет удаляться файл,на который указывает этот линк.
Есть 2 типа линков: первый - hard link -
может указывать только на файл.
Второй тип - Symbolic links.
Он может быть создан на любой тип файла.
Файлы устройств
К девайсам возможен доступ через специальные файлы.
На самом деле эти файлы вообще не используют дисковое пространство.
Фактически они указывают на драйвер.
Существуют 2 типа таких файлов: символьные и блочные файлы.
Первый выполняет I/O операции в символьном режиме,
второй пишет данные в блочном режиме.
Файл ассоциируется с 2-мя числовыми идентификаторами: major number определяет тип устройства,
minor number определяет юнит.
Virtual File System
Принципы
Линуксовое ядро включает Virtual File System,которая используется для доступа к реальным файлам
и управляет системными файловыми вызовами.
Этот механизм используется для того,чтобы рядом сосуществовали различные файловые системы.
Когда процесс выполняет файловый системный вызов,
ядро вызывает функцию,входящую в VFS.
Она вызывает функцию уже внутри самой физической файловой системы:
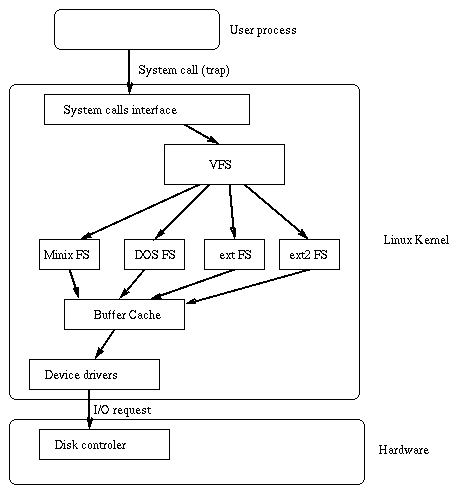
Структура VFS
VFS определяет набор функций,которые реализованы в любой файловой системе.
Есть 3 типа обьектов: файловые системы,ноды и открытые файлы.
VFS использует таблицу,встроенную в ядро.
Каждая строка в этой таблице описывает свой тип файловой системы,
она включает имя этой системы и указатель на функцию,которая монтирует эту систему.
Эта функция читает супер-блок на диске и возвращает дескриптор этой файловой системы.
VFS использует еще 2 дескриптора: inode descriptor и open file descriptor.
inode descriptor включает информацию об указателях на функции,
которые используются для любых файлов ( create, unlink).
file descriptors состоит из указателей на функции,
которые могут оперировать только с открытым файлом - read, write.
Second Extended File System
Second Extended File System является расширением для
первой Extended File System.
Нашей целью было создание мощной файловой системы,
которая использует юникс-семантику и предлагает продвинутые фичи.
В первую очередь мы хотели,чтобы Ext2fs была как можно более производительной.
Также мы хотели,чтобы это была надежная файловая система.
Также Ext2fs позволяет делать расширения без потери данных.
``Стандартные'' фичи Ext2fs
Ext2fs поддерживает стандартные типы файлов: регулярные файлы,каталоги,
файлы устройств и линки.
Ext2fs способна поддерживать файловую систему
на больших партициях.
Текущее ядро ограничивает размер файловой системы в 2 гига,
в то время как модернизация VFS уже привела к увеличению потолка до 4 террабайт.
Ext2fs обеспечивает длинные имена файлов.
Максимальная длина имени файла - 255 символов.
Это ограничение может быть при необходимости расширено до 1012.
Ext2fs резервирует несколько блоков для супер-пользователя
(root) - около 5%.
``Продвинутые'' Ext2fs фичи
Ext2fs поддерживает некоторые нестандартные для юникса расширения.
Файловые атрибуты,настраиваемые пользователем,
могут наследоваться в случае для вложенных файлов от каталога.
Для BSD файлы имеют тот же самый group id,что и родительская директория.
Для System V все сложнее: у каталога есть бит - setgid bit.
Новые файлы наследуют group id каталога,
а вот вложенные каталоги наследуют group id и setgid bit.
Ext2fs позволяет админу задавать размер логического блока при создании файловой системы.
Обычно он равен 1024, 2048 или 4096 байт.
Дальнейшее увеличение блока может привести к тормозам.
Большие блоки также неэффективно используют дисковое пространство.
В Ext2fs реализован быстрый симлинк.
Он не использует дата-блоков файловой системы.
Он хранится в ноде.Правда,размер дискового пространства в ноде ограничен,
и не каждый симлинк является быстрым.
Максимальный размер для файлового имени fast symbolic link - 60 символов.
Ext2fs с помощью специального поля в суперблоке хранит состояние файловой системы.
Когда система смонтирована как read/write,
ее статус = ``Not Clean''.
Для read-only =``Clean''.
При накоплении достаточного числа ошибок система маркируется как ``Erroneous''.
После чего система проводит проверку.
Ext2fs может форсировать проверку в тех случаях , когда пользователь ее отменяет.
В супер-блоке есть параметр - mount counter -
который увеличивается каждый раз, когда система монтируется на read/write.
Когда он достигает максимального значения,проверка форсируется.
Ext2fs предлагает некоторые утилиты.
tune2fs может быть использована для модификации параметров :
- error behavior. Когда файловая система маркируется как ``Erroneous'',
может быть одно из трех: нормальное продолжение,
remount файловой системы в режиме read-only ,
kernel panic и reboot для запуска checker.
- maximal mount count.
- maximal check interval.
- number of logical blocks reserved for the super user.
Тип файла Immutable files может быть только на чтение:
никто не может их изменять или удалять.
Это может быть использовано для конфигов.
Append-only files - в такой тип файлов данные всегда добавляются в конец.
Они не могут быть удалены или переименованы и хороши для лог-файлов.
Физическая структура
Физическая структура Ext2 унаследована из BSD filesystem [McKusick 1984].
Файловая система разбита на группы блоков,которые не привязаны к каким-то
дисковым блокам.
Физическая структура представлена в этой таблице:
Boot
Sector |
Block
Group 1 |
Block
Group 2 |
...
... |
Block
Group N |
Каждая группа содержит избыточную копию информации о файловой системе,
а также block bitmap, inode bitmap, часть inode table, и сами data blocks.
Структура группы представлена в таблице :
Super
Block |
FS
descriptors |
Block
Bitmap |
Inode
Bitmap |
Inode
Table |
Data
Blocks |
Использование block groups весьма надежно:
контроль расположен в самом блоке,
и легко восстановить блок.
Высокая производительность обеспечивается локальным расположением 2-х компонентов -
inode table и самих блоков данных.
В Ext2fs каталоги управляются с помощью связных списков переменной длины.
Структура включает в себя номер ноды, длину ноды,
имя файла и его длину.
Структура каталога:
| inode number | entry length |
name length | filename |
В качестве примера,в следующей таблице представлена структура
каталога,включающего 3 файла: file1,
long_file_name,f2:
Оптимизация производительности
Код в ядре по поддержке Ext2fs включает в себя многие оптимизационные моменты,
в том числе увеличение скорости I/O , чтения/записи файлов.
Ext2fs имеется buffer cache management при выполнении чтения:
при чтении какого-то блока ядро делает I/O запросы на несколько соседних блоков.
Таким образом блоки подгружаются в кеш.
Такое кеширование происходит во время последовательного чтения файлов,
а также каталогов (readdir(2) namei).
Ext2fs включает также несколько allocation-оптимизаций.
Ядро всегда выделяет data blocks для файла в той же самой группе блоков, что и его нода.
При записи данных в файл,Ext2fs выделяет 8 смежных блоков.
Данные файла при этом "стремятся" быть размещены последовательно,что уменьшает время доступа.
2 оптимизации:
- связнные файлы и группы блоков
- связные блоки и 8-битная кластеризация размещения блоков.
Библиотека Ext2fs
Библиотека libext2fs была разработана для пользовательских программ
с целью контроля над структурами Ext2 filesystem.
В нее входят утилиты для проверки и модификации данных самой Ext2.
Например,итератор ext2fs_block_interate()
может быть вызван для каждого блока в ноде.
Другой итератор может быть вызван для каждого файла в каталоге.
Ext2fs утилиты (mke2fs,
e2fsck, tune2fs, dumpe2fs,
debugfs) используют Ext2fs library.
Изменения в самой Ext2 filesystem сразу же находят отражение в Ext2fs library.
Ext2fs может быть собрана как shared library image.
Абстрактные интерфейсы Ext2fs library позволяют с легкостью
писать утилиты,которые имеют прямой доступ к Ext2fs filesystem.
Ext2fs library была использована в свое время при портировании 2-х утилит
4.4BSD - dump и restore backup.
Пришлось сделать всего несколько косметических изменений под линукс.
Ext2fs library обеспечивает доступ к нескольким классам операций.
Первый класс-операции,ориентированные на файловую систему.
Программа может открывать,закрывать,создавать новые файловые системы на диске.
Второй класс относится к каталогам.
С помощью Ext2fs library можно создавать,расширять и удалять каталоги.
Можно определить путь к ноде по ее номеру.
Третий класс относится к нодам.
Можно сканировать таблицу нод,читать и писать ноды,
сканировать блоки в нодах.
Можно выделять и освобождать блоки и ноды.
Ext2fs tools
Множество мощных средств было разработано под Ext2fs.
Эти утилиты используются для создания,модификации,корректировки Ext2 filesystems.
mke2fs используется для создания партиции на основе Ext2 filesystem.
tune2fs может быть использована для модификации параметров файловой системы.
Она может изменить error behavior, maximal mount count, maximal check interval,
число логических блоков,зарезервированных для супер-пользователя.
E2fsck предназначена для восстановления файловой системы после ее краха.
Оригинальная версия e2fsck была основана на программе Linus
Torvald's fsck для Minix filesystem.
Текущая версия e2fsck была полностью переписана,
используя Ext2fs library.
e2fsck работает максимально быстро.
Алгоритм построен на основе того, что не происходит повторных вызовов к диску.
Порядок проверки нод и каталогов отсортирован по номерам блоков.
Идеи были взяты из [Bina and Emrath 1989].
Во время первого прохода,
e2fsck делает проверку нод и не трогает файловую систему.
Проверяется валидность номеров блоков.
Если e2fsck обнаруживает общие блоки данных,
принадлежащие разным нодам,происходит клонирование таких блоков.
Первый проход долог, поскольку все ноды надо прочитать в память и проверить их там.
Критическая информация при этом кешируется в память.
Весь список блоков пишется на диск,который будет прочитан во время 2-го прохода.
Второй проход проверяет каталоги.
Каждый каталог может быть проверен индивидуально.
e2fsck сортирует блоки директорий по номерам и проверяет.
Каталог должен давать ссылки на реальные ноды, которые проверены до того.
Второй каталог кеширует информацию о всех родительских каталогах.
В конце 2 прохода все дисковые операции уже сделаны.
Информация,необходимая для проходов 3, 4 и 5 уже закеширована в памяти.
Эти проходы выполняются за 5-10% от общего времени работы утилиты.
В 3-м проходе проверяются каталоги .
E2fsck трейсит путь каждого каталога наверх до рута.
Проверяется валидность `..' для каждого каталога.
Все каталоги,которые не могут быть затрейсены на рут,
прилинковываются к /lost+found.
В 4-м проходе e2fsck проверяет reference counts для всех нод.
Все файлы,имеющие нулевые link count,попадут в
/lost+found.
5-й проход e2fsck проверяет валидность суммарной информации.
Сравниваются block и inode bitmaps,
и при необходимости происходит корректировка на диск.
Debugfs - утилита для проверки файловой системы.
У нее интерактивный интерфейс к Ext2fs library.
Performance Measurements
Description of the benchmarks
We have run benchmarks to measure filesystem performances.
Benchmarks have been made on a middle-end PC, based on a
i486DX2 processor, using 16 MB of memory and two 420 MB IDE
disks. The tests were run on Ext2 fs and Xia fs (Linux 1.1.62)
and on the BSD Fast filesystem in asynchronous and synchronous
mode (FreeBSD 2.0 Alpha--based on the 4.4BSD Lite
distribution).
We have run two different benchmarks. The Bonnie benchmark
tests I/O speed on a big file--the file size was set to 60 MB
during the tests. It writes data to the file using character
based I/O, rewrites the contents of the whole file, writes data
using block based I/O, reads the file using character I/O and
block I/O, and seeks into the file. The Andrew Benchmark was
developed at Carneggie Mellon University and has been used at
the University of Berkeley to benchmark BSD FFS and LFS. It
runs in five phases: it creates a directory hierarchy, makes a
copy of the data, recursively examine the status of every file,
examine every byte of every file, and compile several of the
files.
Results of the Bonnie benchmark
The results of the Bonnie benchmark are presented in this
table:
| Char Write
(KB/s) |
Block Write
(KB/s) |
Rewrite
(KB/s) |
Char Read
(KB/s) |
Block Read
(KB/s) |
|---|
| BSD Async | 710 | 684 | 401 | 721 | 888 |
| BSD Sync | 699 | 677 | 400 | 710 | 878 |
| Ext2 fs | 452 | 1237 | 536 | 397 | 1033 |
| Xia fs | 440 | 704 | 380 | 366 | 895 |
The results are very good in block oriented I/O: Ext2 fs
outperforms other filesystems. This is clearly a benefit of the
optimizations included in the allocation routines. Writes are
fast because data is written in cluster mode. Reads are fast
because contiguous blocks have been allocated to the file. Thus
there is no head seek between two reads and the readahead
optimizations can be fully used.
On the other hand, performance is better in the FreeBSD
operating system in character oriented I/O. This is probably
due to the fact that FreeBSD and Linux do not use the same
stdio routines in their respective C libraries. It seems that
FreeBSD has a more optimized character I/O library and its
performance is better.
Results of the Andrew benchmark
The results of the Andrew benchmark are presented in
this table:
|
P1 Create
(ms) |
P2 Copy
(ms) |
P3 Stat
(ms) |
P4 Grep
(ms) |
P5 Compile
(ms) |
| BSD Async | 2203 | 7391 | 6319 | 17466 | 75314 |
| BSD Sync | 2330 | 7732 | 6317 | 17499 | 75681 |
| Ext2 fs | 790 | 4791 | 7235 | 11685 | 63210 |
| Xia fs | 934 | 5402 | 8400 | 12912 | 66997 |
The results of the two first passes show that Linux benefits
from its asynchronous metadata I/O. In passes 1 and 2,
directories and files are created and BSD synchronously writes
inodes and directory entries. There is an anomaly, though: even
in asynchronous mode, the performance under BSD is poor. We
suspect that the asynchronous support under FreeBSD is not
fully implemented.
In pass 3, the Linux and BSD times are very similar. This is
a big progress against the same benchmark run six months ago.
While BSD used to outperform Linux by a factor of 3 in this
test, the addition of a file name cache in the VFS has fixed
this performance problem.
In passes 4 and 5, Linux is faster than FreeBSD mainly
because it uses an unified buffer cache management. The buffer
cache space can grow when needed and use more memory than the
one in FreeBSD, which uses a fixed size buffer cache.
Comparison of the Ext2fs and Xiafs results shows that the
optimizations included in Ext2fs are really useful: the
performance gain between Ext2fs and Xiafs is around 5-10%.
Conclusion
The Second Extended File System is probably the most widely
used filesystem in the Linux community. It provides standard
Unix file semantics and advanced features. Moreover, thanks to
the optimizations included in the kernel code, it is robust and
offers excellent performance.
Since Ext2fs has been designed with evolution in mind, it
contains hooks that can be used to add new features. Some
people are working on extensions to the current filesystem:
access control lists conforming to the Posix semantics
[IEEE 1992], undelete, and on-the-fly
file compression.
Ext2fs was first developed and integrated in the Linux
kernel and is now actively being ported to other operating
systems. An Ext2fs server running on top of the GNU Hurd has
been implemented. People are also working on an Ext2fs port in
the LITES server, running on top of the Mach microkernel
[Accetta et al. 1986], and
in the VSTa operating system. Last, but not least, Ext2fs is an
important part of the Masix operating system
[Card et al. 1993],
currently under development by one of the authors.
Acknowledgments
The Ext2fs kernel code and tools have been written mostly by
the authors of this paper. Some other people have also
contributed to the development of Ext2fs either by suggesting
new features or by sending patches. We want to thank these
contributors for their help.
References
[Accetta et al. 1986]
M. Accetta, R. Baron, W. Bolosky, D. Golub, R. Rashid, A. Tevanian, and
M. Young.
Mach: A New Kernel Foundation For UNIX Development.
In Proceedings of the USENIX 1986 Summer Conference, June 1986.
[Bach 1986]
M. Bach.
The Design of the UNIX Operating System.
Prentice Hall, 1986.
[Bina and Emrath 1989]
E. Bina and P. Emrath.
A Faster fsck for BSD Unix.
In Proceedings of the USENIX Winter Conference, January 1989.
[Card et al. 1993]
R. Card, E. Commelin, S. Dayras, and F. M?el.
The MASIX Multi-Server Operating System.
In OSF Workshop on Microkernel Technology for Distributed Systems,
June 1993.
[IEEE 1992]
SECURITY INTERFACE for the Portable Operating System Interface for
Computer Environments - Draft 13.
Institute of Electrical and Electronics Engineers, Inc, 1992.
[Kleiman 1986]
S. Kleiman.
Vnodes: An Architecture for Multiple File System Types
in Sun UNIX.
In Proceedings of the Summer USENIX Conference, pages 260--269,
June 1986.
[McKusick et al. 1984]
M. McKusick, W. Joy, S. Leffler, and R. Fabry.
A Fast File System for UNIX.
ACM Transactions on Computer Systems, 2(3):181--197, August
1984.
[Seltzer et al. 1993]
M. Seltzer, K. Bostic, M. McKusick, and C. Staelin.
An Implementation of a Log-Structured File System for
UNIX.
In Proceedings of the USENIX Winter Conference, January 1993.
[Tanenbaum 1987]
A. Tanenbaum.
Operating Systems: Design and Implementation.
Prentice Hall, 1987.
Thanks to Michael Johnson for HTMLizing it (originally for use in
the Kernel
Hacker's Guide).
|
| fatall | нифига не понятно, очень мало инфы, а английский в конце?...
2008-05-24 08:19:03 | | евген | Блин, а нельзя было без выкрутасов перевести? админ, фичы, тормоза, он, она..
2010-10-25 17:19:26 | | Anonimous | Что, промт сломался? Сроки поджимали? Нафига публиковать неполный перевод?
Превращаете инет в помойку.
2011-04-14 11:48:34 | | ыыы | Спасибо Серый :)
2013-11-26 21:36:31 | |
| 
 LINUX
LINUX 
 Kernels
Kernels
