typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags;
struct list_head lru;
struct page **pprev_hash;
struct buffer_head * buffers;
#if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
void *virtual;
#endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
} mem_map_t;
Вплоть до ядра 2.4.18, страница хранила ссылку на свою зону page->zone.
Теперь поле зоны удалено из структуры страницы и вместо нее имеется бит .
Инициализация зон :
zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES];
EXPORT_SYMBOL(zone_table);
MAX NR ZONES - максимальное число зон в ноде , т.е. = 3 .
Инициализация страниц происходит в free area init core()
zone_table[nid * MAX_NR_ZONES + j] = zone;
set_page_zone(page, nid * MAX_NR_ZONES + j);
nid - id-шник ноды , page - страница , j - индекс зоны .
Page Table Management
Linux layers the machine independent/dependent layer in an unusual manner
in comparison to other operating systems [#!cranor99!#]. Other operating
systems have objects which manage the underlying physical pages such as the
pmap object in BSD but Linux instead maintains the concept of
a three-level page table in the architecture independent code even if the
underlying architecture does not support it. While this is relatively easy
to understand, it also means that the distinction between different types
of pages is very blurry and page types are identified by their flags or what
lists they exist on rather than the objects they belong to.
Architectures that manage their MMU differently are expected to emulate the
three-level page tables. For example, on the x86 without PAE enabled, only
two page table levels are available. The Page Middle Directory (PMD)
is defined to be of size 1 and ``folds back'' directly onto the Page
Global Directory (PGD) which is optimised out at compile time. Unfortunately,
for architectures that do not manage their cache or Translation
Lookaside Buffer (TLB) automatically, hooks that are machine dependent have to
be explicitly left in the code for when the TLB and CPU caches need to be
altered and flushed even if they are null operations on some architectures
like the x86. Fortunately, the functions and how they have to be used are
very well documented in the cachetlb.txt file in the kernel
documentation tree [#!miller00!#].
This chapter will begin by describing how the page table is arranged and
what types are used to describe the three separate levels of the page table
followed by how a virtual address is broken up into its component parts for
navigating the table. Once covered, it will be discussed how the lowest
level entry, the Page Table Entry (PTE) and what bits are used
by the hardware. After that, the macros used for navigating a page table,
setting and checking attributes will be discussed before talking about how
the page table is populated and how pages are allocated and freed for the
use with page tables. Finally, it will be discussed how the page tables
are initialised during boot strapping.
Each process has its own Page Global Directory (PGD) which
is a physical page frame containing an array of pgd_t,
an architecture specific type defined in  asm/page.h
asm/page.h . The page
tables are loaded differently on each architecture. On the x86, the process
page table is loaded by copying the pointer to the PGD into the cr3
register which has the side effect of flushing the TLB. In fact this is how
the function __flush_tlb() is implemented in the architecture
dependent code.
. The page
tables are loaded differently on each architecture. On the x86, the process
page table is loaded by copying the pointer to the PGD into the cr3
register which has the side effect of flushing the TLB. In fact this is how
the function __flush_tlb() is implemented in the architecture
dependent code.
Each active entry in the PGD table points to a page frame containing an array
of Page Middle Directory (PMD) entries of type pmd_t
which in turn point to page frames containing Page Table Entries
(PTE) of type pte_t, which finally point to page frames
containing the actual user data. In the event the page has been swapped
out to backing storage, the swap entry is stored in the PTE and used by
do_swap_page() during page fault to find the swap entry
containing the page data.
Any given linear address may be broken up into parts to yield offsets within
these three page table levels and an offset within the actual page. To help
break up the linear address into its component parts, a number of macros are
provided in triplets for each page table level, namely a SHIFT,
a SIZE and a MASK macro. The SHIFT
macros specifies the length in bits that are mapped by each level of the
page tables as illustrated in Figure 4.1.
Figure 4.1:
Linear Address Bit Size
Macros
|
|
The MASK values can be ANDd with a linear address to mask out
all the upper bits and are frequently used to determine if a linear address
is aligned to a given level within the page table. The SIZE
macros reveal how many bytes are addressed by each entry at each level.
The relationship between the SIZE and MASK macros
is illustrated in Figure 4.2.
Figure 4.2:
Linear Address Size
and Mask Macros
|
|
For the calculation of each of the triplets, only SHIFT is
important as the other two are calculated based on it. For example, the
three macros for page level on the x86 are:
5 #define PAGE_SHIFT 12
6 #define PAGE_SIZE (1UL << PAGE_SHIFT)
7 #define PAGE_MASK (~(PAGE_SIZE-1))
PAGE_SHIFT is the length in bits of the offset part of
the linear address space which is 12 bits on the x86. The size of a page is
easily calculated as
 which is the equivalent of
the code above. Finally the mask is calculated as the negation of the bits
which make up the PAGE_SIZE - 1. If a page needs to be aligned
on a page boundary, PAGE_ALIGN() is used. This macro adds
PAGE_SIZE - 1 is added to the address before simply ANDing it
with the PAGE_MASK.
which is the equivalent of
the code above. Finally the mask is calculated as the negation of the bits
which make up the PAGE_SIZE - 1. If a page needs to be aligned
on a page boundary, PAGE_ALIGN() is used. This macro adds
PAGE_SIZE - 1 is added to the address before simply ANDing it
with the PAGE_MASK.
PMD_SHIFT is the number of bits in the linear address which
are mapped by the second level part of the table. The PMD_SIZE
and PMD_MASK are calculated in a similar way to the page
level macros.
PGDIR_SHIFT is the number of bits which are mapped by
the top, or first level, of the page table. The PGDIR_SIZE
and PGDIR_MASK are calculated in the same manner as above.
The last three macros of importance are the PTRS_PER_x
which determine the number of entries in each level of the page
table. PTRS_PER_PGD is the number of pointers in the PGD,
1024 on an x86 without PAE. PTRS_PER_PMD is for the PMD,
1 on the x86 without PAE and PTRS_PER_PTE is for the lowest
level, 1024 on the x86.
Описание Page Table Entry
As mentioned, each entry is described by the structures pte_t,
pmd_t and pgd_t for PTEs, PMDs and PGDs
respectively. Even though these are often just unsigned integers, they
are defined as structures for two reasons. The first is for type protection
so that they will not be used inappropriately. The second is for features
like PAE on the x86 where an additional 4 bits is used for addressing more
than 4GiB of memory. To store the protection bits, pgprot_t
is defined which holds the relevant flags and is usually stored in the lower
bits of a page table entry.
For type casting, 4 macros are provided in asm/page.h, which
takes the above types and returns the relevant part of the structures. They
are pte_val(), pmd_val(), pgd_val()
and pgprot_val(). To reverse the type casting, 4 more macros are
provided __pte(), __pmd(), __pgd()
and __pgprot().
Where exactly the protection bits are stored is architecture dependent.
For illustration purposes, we will examine the case of an x86 architecture
without PAE enabled but the same principles apply across architectures. On an
x86 with no PAE, the pte_t is simply a 32 bit integer within a
struct. Each pte_t points to an address of a page frame and all
the addresses pointed to are guaranteed to be page aligned. Therefore, there
are PAGE_SHIFT (12) bits in that 32 bit value that are free for
status bits of the page table entry. A number of the protection and status
bits are listed in Table 4.1 but what bits exist and what they mean varies between architectures.
Table 4.1:
Page Table Entry Protection and Status Bits
 |
These bits are self-explanatory except for the _PAGE_PROTNONE
which we will discuss further. On the x86 with Pentium III and higher,
this bit is called the Page Attribute Table (PAT)4.1and is used to indicate the size of the page the PTE is referencing. In a
PGD entry, this same bit is the PSE bit so obviously these bits are meant
to be used in conjunction.
As Linux does not use the PSE bit, the PAT bit is free in the PTE for other
purposes. There is a requirement for having a page resident in memory but
inaccessible to the userspace process such as when a region is protected with
mprotect() with the PROT_NONE flag. When the region
is to be protected, the _PAGE_PRESENT bit is cleared and the
_PAGE_PROTNONE bit is set. The macro pte_present()
checks if either of these bits are set and so the kernel itself knows the
PTE is present, just inaccessible to userspace which is a subtle,
but important point. As the hardware bit _PAGE_PRESENT is
clear, a page fault will occur if the page is accessed so Linux can enforce
the protection while still knowing the page is resident if it needs to swap
it out or the process exits.
Macros are defined in asm/pgtable.h which are important for the
navigation and examination of page table entries. To navigate the page
directories, three macros are provided which break up a linear address
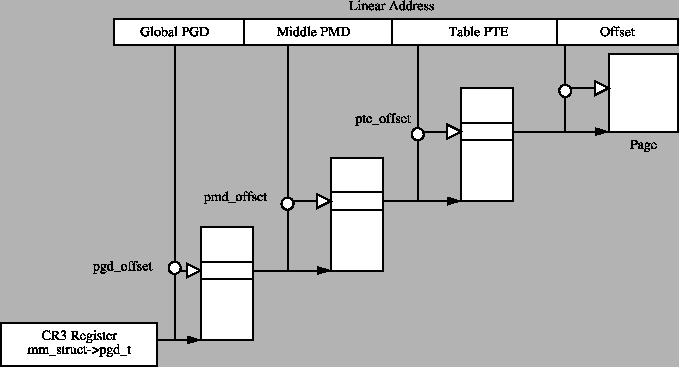
space into its component parts. pgd_offset() takes an address and
the mm_struct for the process and returns the PGD entry that
covers the requested address. pmd_offset() takes a PGD entry and
an address and returns the relevant PMD. pte_offset() takes a PMD
and returns the relevant PTE. The remainder of the linear address provided
is the offset within the page. The relationship between these fields is
illustrated in Figure 4.3
Figure 4.3:
Page Table Layout
|
|
The second round of macros determine if the page table entries are present or
may be used.
- pte_none(), pmd_none() and pgd_none()
return 1 if the corresponding entry does not exist;
- pte_present(), pmd_present() and
pgd_present() return 1 if the corresponding page table
entries have the PRESENT bit set;
- pte_clear(), pmd_clear() and pgd_clear()
will clear the corresponding page table entry;
- pmd_bad() and pgd_bad() are used to check entries
when passed as input parameters to functions that may change the
value of the entries. Whether it returns 1 varies between the few
architectures that define these macros but for those that actually
define it, making sure the page entry is marked as present and
accessed are the two most important checks.
There are many parts of the VM which are littered with page table walk code and
it is important to recognise it. A very simple example of a page table walk is
the function follow_page() in mm/memory.c. The following
is an excerpt from that function, the parts unrelated to the page table walk
are omitted:
407 pgd_t *pgd;
408 pmd_t *pmd;
409 pte_t *ptep, pte;
410
411 pgd = pgd_offset(mm, address);
412 if (pgd_none(*pgd) || pgd_bad(*pgd))
413 goto out;
414
415 pmd = pmd_offset(pgd, address);
416 if (pmd_none(*pmd) || pmd_bad(*pmd))
417 goto out;
418
419 ptep = pte_offset(pmd, address);
420 if (!ptep)
421 goto out;
422
423 pte = *ptep;
It simply uses the three offset macros to navigate the page tables and the
_none() and _bad() macros to make sure it is looking at
a valid page table.
The third set of macros examine and set the permissions of an entry.
The permissions determine what a userspace process can and cannot do with
a particular page. For example, the kernel page table entries are never
readable by a userspace process.
- The read permissions for an entry are tested with
pte_read(), set with pte_mkread() and
cleared with pte_rdprotect();
- The write permissions are tested with pte_write(),
set with pte_mkwrite() and cleared with
pte_wrprotect();
- The execute permissions are tested with pte_exec(),
set with pte_mkexec() and cleared with
pte_exprotect(). It is worth nothing that with the x86
architecture, there is no means of setting execute permissions on
pages so these three macros act the same way as the read macros;
- The permissions can be modified to a new value with
pte_modify() but its use is almost non-existent. It
is only used in the function change_pte_range() in
mm/mprotect.c.
The fourth set of macros examine and set the state of an entry. There
are only two bits that are important in Linux, the dirty bit and the
accessed bit. To check these bits, the macros pte_dirty()
and pte_young() macros are used. To set the bits, the macros
pte_mkdirty() and pte_mkyoung() are used. To
clear them, the macros pte_mkclean() and pte_old()
are available.
This set of functions and macros deal with the mapping of addresses and pages
to PTEs and the setting of the individual entries.
mk_pte() takes a struct page and protection bits
and combines them together to form the pte_t that needs to be
inserted into the page table. A similar macro mk_pte_phys()
exists which takes a physical page address as a parameter.
pte_page() returns the struct page which corresponds
to the PTE entry. pmd_page() returns the struct page
containing the set of PTEs.
set_pte() takes a pte_t such as that
returned by mk_pte() and places it within the process's page
tables. pte_clear() is the reverse operation. An additional
function is provided called ptep_get_and_clear() which clears an
entry from the process page table and returns the pte_t. This
is important when some modification needs to be made to either the PTE
protection or the struct page itself.
The last set of functions deal with the allocation and freeing of page tables.
Page tables, as stated, are physical pages containing an array of entries
and the allocation and freeing of physical pages is a relatively expensive
operation, both in terms of time and the fact that interrupts are disabled
during page allocation. The allocation and deletion of page tables, at any
of the three levels, is a very frequent operation so it is important the
operation is as quick as possible.
Hence the pages used for the page tables are cached in a number of different
lists called quicklists. Each architecture implements these
caches differently but the principles used are the same. For example, not
all architectures cache PGDs because the allocation and freeing of them
only happens during process creation and exit. As both of these are very
expensive operations, the allocation of another page is negligible.
PGDs, PMDs and PTEs have two sets of functions each for the allocation and
freeing of page tables. The allocation functions are pgd_alloc(),
pmd_alloc() and pte_alloc() respectively and the
free functions are, predictably enough, called pgd_free(),
pmd_free() and pte_free().
Broadly speaking, the three implement caching with the use of three
caches called pgd_quicklist, pmd_quicklist
and pte_quicklist. Architectures implement these three
lists in different ways but one method is through the use of a LIFO type
structure. Ordinarily, a page table entry contains pointers to other pages
containing page tables or data. While cached, the first element of the list
is used to point to the next free page table. During allocation, one page
is popped off the list and during free, one is placed as the new head of
the list. A count is kept of how many pages are used in the cache.
The quick allocation function from the pgd_quicklist
is not externally defined outside of the architecture although
get_pgd_fast() is a common choice for the function name. The
cached allocation function for PMDs and PTEs are publicly defined as
pmd_alloc_one_fast() and pte_alloc_one_fast().
If a page is not available from the cache, a page will be allocated using the
physical page allocator (see Chapter 7). The
functions for the three levels of page tables are get_pgd_slow(),
pmd_alloc_one() and pte_alloc_one().
Obviously a large number of pages may exist on these caches and so there
is a mechanism in place for pruning them. Each time the caches grow or
shrink, a counter is incremented or decremented and it has a high and low
watermark. check_pgt_cache() is called in two places to check
these watermarks. When the high watermark is reached, entries from the cache
will be freed until the cache size returns to the low watermark. The function
is called after clear_page_tables() when a large number of page
tables are potentially reached and is also called by the system idle task.
Kernel Page Tables
When the system first starts, paging is not enabled as page tables do not
magically initialise themselves. Each architecture implements this differently
so only the x86 case will be discussed. The page table initialisation is
divided into two phases. The bootstrap phase sets up page tables for just
8MiB so the paging unit can be enabled. The second phase initialises the
rest of the page tables. We discuss both of these phases below.
4.6.1 Bootstrapping
The assembler function startup_32() is responsible for
enabling the paging unit in arch/i386/kernel/head.S. While all
normal kernel code in vmlinuz is compiled with the base address
at PAGE_OFFSET + 1MiB, the kernel is actually loaded beginning
at the first megabyte (0x00100000) of memory4.2. The
bootstrap code in this file treats 1MiB as its base address by subtracting
__PAGE_OFFSET from any address until the paging unit is
enabled so before the paging unit is enabled, a page table mapping has to
be established which translates the 8MiB of physical memory at the beginning
of physical memory to the correct place after PAGE_OFFSET.
Initialisation begins with statically defining at compile time an
array called swapper_pg_dir which is placed using linker
directives at 0x00101000. It then establishes page table entries for 2 pages,
pg0 and pg1. As the Page Size Extension
(PSE) bit is set in the cr4 register, pages translated are 4MiB
pages, not 4KiB as is the normal case. The first pointers to pg0
and pg1 are placed to cover the region 1-9MiB and
the second pointers to pg0 and pg1 are placed at
PAGE_OFFSET+1MiB. This means that when paging is enabled, they
will map to the correct pages using either physical or virtual addressing.
Once this mapping has been established, the paging unit is turned on by setting
a bit in the cr0 register and a jump takes places immediately to
ensure the Instruction Pointer (EIP register) is correct.
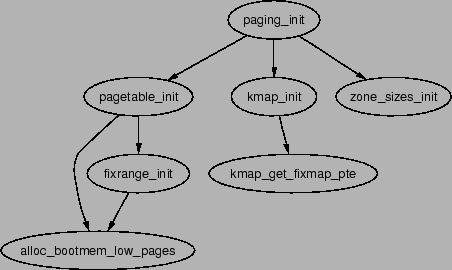
The function responsible for finalising the page tables is called
paging_init(). The call graph for this function on the x86
can be seen on Figure 4.4.
Figure 4.4:
Call Graph: paging_init()
|
|
For each pgd_t used by the kernel, the boot memory allocator
(see Chapter 6) is called to allocate a page
for the PMD. Similarly, a page will be allocated for each pmd_t
allocator. If the CPU has the PSE flag available, it will be set to enable
extended paging. This means that each page table entry in the kernel paging
tables will be 4MiB instead of 4KiB. If the CPU supports the PGE flag,
it also will be set so that the page table entry will be global. Lastly,
the page tables from PKMAP_BASE are set up with the function
fixrange_init(). Once the page table has been fully setup,
the statically defined page table at swapper_pg_dir is loaded
again into the cr3 register and the TLB is flushed.
Маппинг адресов в struct pages
There is a requirement for Linux to have a fast method of mapping virtual
addresses to physical addresses and for mapping struct pages
to their physical address. Linux achieves this by knowing where in both
virtual and physical memory the global mem_map array is as the
global array has pointers to all struct pages representing physical memory
in the system. All architectures achieve this with similar mechanisms but
for illustration purposes, we will only examine the x86 carefully. This
section will first discuss how physical addresses are mapped to kernel
virtual addresses and then what this means to the mem_map array.
4.7.1 Mapping Physical to Virtual Kernel Addresses
As we saw in Section 4.6, Linux sets up a
direct mapping from the physical address 0 to the virtual address
PAGE_OFFSET at 3GiB on the x86. This means that on the x86, any
virtual address can be translated to the physical address by simply
subtracting PAGE_OFFSET which is essentially what the function
virt_to_phys() with the macro __pa() does:
/* from <asm-i386/page.h> */
132 #define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
/* from <asm-i386/io.h> */
76 static inline unsigned long virt_to_phys(volatile void * address)
77 {
78 return __pa(address);
79 }
Obviously the reverse operation involves simply adding PAGE_OFFSET
which is carried out by the function phys_to_virt() with
the macro __va(). Next we see how this helps the mapping of
struct pages to physical addresses.
There is one exception where virt_to_phys() cannot be
used to convert virtual addresses to physical ones4.3. Specifically,
on the PPC and ARM architectures, virt_to_phys() cannot
be used to convert address that have been returned by the function
consistent_alloc(). consistent_alloc() is used on PPC
and ARM architectures to return memory from non-cached for use with DMA.
As we saw in Section 4.6.1, the kernel image is located at
the physical address 1MiB, which of course translates to the virtual address
PAGE_OFFSET + 0x00100000 and a virtual region totaling about 8MiB
is reserved for the image which is the region that can be addressed by two
PGDs. This would imply that the first available memory to use is located
at 0xC0800000 but that is not the case. Linux tries to reserve the first
16MiB of memory for ZONE_ DMA. This means the first virtual area used
for kernel allocations is 0xC1000000 which is where the global
mem_map is usually located. ZONE_ DMA will still get used,
but only when absolutely necessary.
Physical addresses are translated to struct pages by treating
them as an index into the mem_map array. Shifting a physical address
PAGE_SHIFT bits to the right will treat it as a PFN from physical
address 0 which is also an index within the mem_map array.
This is exactly what the macro virt_to_page() does which is
declared as follows in asm-i386/page.h:
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
virt_to_page() takes the virtual address kaddr, converts
it to the physical address with __pa(), converts it into an array
index by bit shifting it right PAGE_SHIFT bits and indexing
into the mem_map by simply adding them together. No macro is
available for converting struct pages to physical addresses
but at this stage, it should be obvious to see how it could be calculated.
4.7.3 Initialising mem_map
The mem_map area is created during system startup in one of two
fashions. On NUMA systems, the function free_area_init_node()
is called for each active node in the system and on UMA systems,
free_area_init() is used. Both use the core function
free_area_init_core() to perform the actual task of
allocating memory for the mem_map portions and initialising
the zones. Predictably, UMA calls the core function directly with
contig_page_data and the global mem_map as
parameters.
The core function free_area_init_core() allocates a local
lmem_map for the node being initialised. The memory for the array is
allocated from the boot memory allocator with alloc_bootmem_node()
(see Chapter 6). With UMA architectures,
this newly allocated memory becomes the global mem_map but it is
slightly different for NUMA.
NUMA architectures allocate the memory for lmem_map within
their own memory node. The global mem_map never gets explicitly
allocated but instead is set to PAGE_OFFSET where it is
treated as a virtual array. The address of the local map is stored in
pg_data_t node_mem_map which exists somewhere within
the virtual mem_map. For each zone that exists in the node, the
address within the virtual mem_map for the zone is stored in
zone_tzone_mem_map. All the rest of the code then
treats mem_map as a real array as only valid regions within it
will be used by nodes.
node_mem_map which exists somewhere within
the virtual mem_map. For each zone that exists in the node, the
address within the virtual mem_map for the zone is stored in
zone_tzone_mem_map. All the rest of the code then
treats mem_map as a real array as only valid regions within it
will be used by nodes.
Адресное пространство процесса
One of the principal advantages of virtual memory is that each process has
its own virtual address space, which is mapped to physical memory by the
operating system. In this chapter we will discuss the process address space
and how Linux manages it.
The kernel treats the userspace portion of the address space very differently
to the kernel portion. For example, allocations for the kernel are satisfied
immediately5.1 and are visible globally no matter what
process is on the CPU. With a process, space is simply reserved in the linear
address space by pointing a page table entry to a read-only globally visible
page filled with zeros. On writing, a page fault is triggered which results
in a new page being allocated, filled with zeros5.2, placed in the page table entry and marked writable.
The userspace portion is not trusted or presumed to be constant. After
each context switch, the userspace portion of the linear address space can
potentially change except when a lazy Translation Lookaside Buffer
(TLB) switch is used as discussed later in Section 5.3. As a result of this, the kernel must be prepared to catch
all exception and addressing errors raised from userspace. This is discussed
in Section 5.5.
This chapter begins with how the linear address space is broken up and what the
purpose of each section is. We then cover the structures maintained to describe
each process, how they are allocated, initialised and then destroyed. Next,
we will cover how individual regions within the process space are created
and all the various functions associated with them. That will bring us to
exception handling related to the process address space, page faulting and
the various cases that occur to satisfy a page fault. Finally, we will cover
how the kernel safely copies information to and from userspace.
Линейное адресное простанство
From a user perspective, the address space is a flat linear address space
but predictably, the kernel's perspective is very different. The linear
address space is split into two parts, the userspace part which potentially
changes with each full context switch and the kernel address space which
remains constant. The location of the split is determined by the value of
PAGE_OFFSET which is at 0xC0000000 on the x86. This
means that 3GiB is available for the process to use while the remaining 1GiB
is always mapped by the kernel.
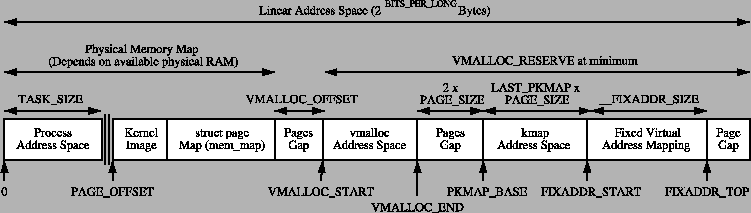
The linear virtual address space as the kernel sees it is illustrated in Figure
5.1. The area up to PAGE_OFFSET is
reserved for userspace and potentially changes with every context switch. In
x86, this is defined as 0xC0000000 or at the 3GiB mark leaving
the upper 1GiB of address space for the kernel.
Figure 5.1:
Kernel Address Space
|
|
8MiB (the amount of memory addressed by two PGDs5.3) is reserved at PAGE_OFFSET for loading the kernel
image to run. It is placed here during kernel page tables initialisation
as discussed in Section 4.6.1. Somewhere shortly after
the image5.4, the mem_map for UMA architectures, as discussed
in Chapter 3, is stored. With NUMA
architectures, portions of the virtual mem_map will be scattered
throughout this region and where they are actually located is architecture
dependent.
The region between PAGE_OFFSET and VMALLOC_START
- VMALLOC_OFFSET is the physical memory map and the size of the region
depends on the amount of available RAM. As we saw in Section 4.6, page table entries exist to map physical memory to the
virtual address range beginning at PAGE_OFFSET. Between the
physical memory map and the vmalloc address space, there is a gap of space
VMALLOC_OFFSET in size, which on the x86 is 8MiB, to guard
against out of bounds errors. For illustration, on a x86 with 32MiB of RAM,
VMALLOC_START will be located at PAGE_OFFSET +
0x02000000 + 0x00800000.
In low memory systems, the remaining amount of the virtual address space, minus
a 2 page gap, is used by vmalloc() for representing non-contiguous
memory allocations in a contiguous virtual address space. In high memory
systems, the vmalloc area extends as far as PKMAP_BASE
minus the two page gap and two extra regions are introduced. The first, which
begins at PKMAP_BASE, is an area reserved for the mapping of
high memory pages into low memory with kmap() as discussed in
Chapter 10. The second is for fixed
virtual address mappings which extend from FIXADDR_START
to FIXADDR_TOP. Fixed virtual addresses are needed
for subsystems that need to know the virtual address at compile
time such as the Advanced Programmable Interrupt Controller
(APIC)5.5. FIXADDR_TOP is statically defined to be
0xFFFFE000 on the x86 which is one page before the end of the
virtual address space. The size of the fixed mapping region is calculated
at compile time in __FIXADDR_SIZE and used to index
back from FIXADDR_TOP to give the start of the region
FIXADDR_START
The region required for vmalloc(), kmap() and the fixed
virtual address mapping is what limits the size of ZONE_ NORMAL. As
the running kernel needs these functions, a region of at least
VMALLOC_RESERVE will be reserved at the top of the address
space. VMALLOC_RESERVE is architecture specific but on the x86,
it is defined as 128MiB. This is why ZONE_ NORMAL is generally referred
to being only 896MiB in size; it is the 1GiB of the upper potion of the linear
address space minus the minimum 128MiB that is reserved for the vmalloc region.
The address space usable by the process is managed by a high level
mm_struct which is roughly analogous to the
vmspace struct in BSD [#!mckusick96!#].
Each address space consists of a number of page-aligned regions of memory
that are in use. They never overlap and represent a set of addresses
which contain pages that are related to each other in terms of protection
and purpose. These regions are represented by a struct
vm_area_struct and are roughly analogous to the
vm_map_entry struct in BSD. For clarity, a region may
represent the process heap for use with malloc(), a memory mapped
file such as a shared library or a block of anonymous memory allocated with
mmap(). The pages for this region may still have to be allocated,
be active and resident or have been paged out.
If a region is backed by a file, its
vm_file field will be set. By traversing
vm_filef_dentryd_inodei_mapping,
the associated address_space for the region may be
obtained. The address_space has all the filesystem specific
information required to perform page-based operations on disk.
A number of system calls are provided which affect the address space and
regions. These are listed in Table 5.1
Table 5.1:
System Calls Related to Memory Regions
 |
Дескриптор процесса
The process address space is described by the mm_struct
struct meaning that only one exists for each process and is shared
between threads. In fact, threads are identified in the task list by
finding all task_structs which have pointers to the same
mm_struct.
A unique mm_struct is not needed for kernel threads as they
will never page fault or access the userspace portion5.6. This results in the task_structmm
field for kernel threads always being NULL. For some tasks such as the boot
idle task, the mm_struct is never setup but for kernel threads,
a call to daemonize() will call exit_mm() to decrement
the usage counter.
As Translation Lookaside Buffer (TLB) flushes are extremely
expensive, especially with architectures such as the PPC, a technique called
lazy TLB is employed which avoids unnecessary TLB flushes by
processes which do not access the userspace page tables5.7. The call
to switch_mm(), which results in a TLB flush, is avoided by
``borrowing'' the mm_struct used by the previous task and
placing it in task_structactive_mm. This technique
has made large improvements to context switches times.
When entering lazy TLB, the function enter_lazy_tlb() is called
to ensure that a mm_struct is not shared between processors
in SMP machines, making it a NULL operation on UP machines. The second time
use of lazy TLB is during process exit when start_lazy_tlb()
is used briefly while the process is waiting to be reaped by the parent.
The struct has two reference counts called mm_users and
mm_count for two types of ``users''. mm_users
is a reference count of processes accessing the userspace portion of this
mm_struct, such as the page tables and file mappings. Threads
and the swap_out() code for instance will increment this count
making sure a mm_struct is not destroyed early. When it drops
to 0, exit_mmap() will delete all mappings and tear down the page
tables before decrementing the mm_count.
mm_count is a reference count of the ``anonymous users''
for the mm_struct initialised at 1 for the ``real'' user. An
anonymous user is one that does not necessarily care about the userspace
portion and is just borrowing the mm_struct. Example users
are kernel threads which use lazy TLB switching. When this count drops to 0,
the mm_struct can be safely destroyed. Both reference counts
exist because anonymous users need the mm_struct to exist even
if the userspace mappings get destroyed and there is no point delaying the
teardown of the page tables.
The mm_struct is defined in linux/sched.h
as follows:
210 struct mm_struct {
211 struct vm_area_struct * mmap;
212 rb_root_t mm_rb;
213 struct vm_area_struct * mmap_cache;
214 pgd_t * pgd;
215 atomic_t mm_users;
216 atomic_t mm_count;
217 int map_count;
218 struct rw_semaphore mmap_sem;
219 spinlock_t page_table_lock;
220
221 struct list_head mmlist;
222
226 unsigned long start_code, end_code, start_data, end_data;
227 unsigned long start_brk, brk, start_stack;
228 unsigned long arg_start, arg_end, env_start, env_end;
229 unsigned long rss, total_vm, locked_vm;
230 unsigned long def_flags;
231 unsigned long cpu_vm_mask;
232 unsigned long swap_address;
233
234 unsigned dumpable:1;
235
236 /* Architecture-specific MM context */
237 mm_context_t context;
238 };
The meaning of each of the field in this sizeable struct is as follows:
- mmap The head of a linked list of all VMA regions in the address space;
- mm_rb The VMAs are arranged in a linked list and in a red-black
tree for fast lookups. This is the root of the tree;
- mmap_cache The VMA found during the last call to find_vma()
is stored in this field on the assumption that the area will be used again
soon;
- pgd The Page Global Directory for this process;
- mm_users A reference count of users accessing the userspace portion
of the address space as explained at the beginning of the section;
- mm_count A reference count of the anonymous users for the
mm_struct starting at 1 for the ``real'' user as explained at
the beginning of this section;
- map_count Number of VMAs in use;
- mmap_sem This is a long lived lock which protects the VMA list
for readers and writers. As users of this lock require it for a long time
and may need to sleep, a spinlock is inappropriate. A reader of the list
takes this semaphore with down_read(). If they need to write,
it is taken with down_write() and the page_table_lock
spinlock is later acquired while the VMA linked lists are being updated;
- page_table_lock This protects most fields on the
mm_struct. As well as the page tables, it protects the RSS
(see below) count and the VMA from modification;
- mmlist All mm_structs are linked together via this field;
- start_code, end_code The start and end address of the code section;
- start_data, end_data The start and end address of the data section;
- start_brk, brk The start and end address of the heap;
- start_stack Predictably enough, the start of the stack region;
- arg_start, arg_end The start and end address of command line
arguments;
- env_start, env_end The start and end address of environment variables;
- rss Resident Set Size (RSS) is the number of resident
pages for this process;
- total_vm The total memory space occupied by all VMA regions in
the process;
- locked_vm The number of resident pages locked in memory;
- def_flags Only one possible value, VM_LOCKED. It is
used to determine if all future mappings are locked by default or not;
- cpu_vm_mask A bitmask representing all possible CPUs in an SMP
system. The mask is used by an InterProcessor Interrupt (IPI)
to determine if a processor should execute a particular function or not. This
is important during TLB flush for each CPU;
- swap_address Used by the pageout daemon to record the last address
that was swapped from when swapping out entire processes;
- dumpable Set by prctl(), this flag is important only when
tracing a process;
- context Architecture specific MMU context.
There are a small number of functions for dealing with
mm_structs. They are described in Table 5.2.
Table 5.2:
Functions related to memory region descriptors
 |
Two functions are provided to allocate a mm_struct. To be
slightly confusing, they are essentially the same but with small important
differences. allocate_mm() is just a preprocessor macro which
allocates a mm_struct from the slab allocator (see
Chapter 9). mm_alloc() allocates from
slab and then calls mm_init() to initialise it.
The first mm_struct in the system that is initialised is called
init_mm(). As all subsequent mm_struct's are copies,
the first one has to be statically initialised at compile time. This static
initialisation is performed by the macro INIT_MM().
242 #define INIT_MM(name) \
243 { \
244 mm_rb: RB_ROOT, \
245 pgd: swapper_pg_dir, \
246 mm_users: ATOMIC_INIT(2), \
247 mm_count: ATOMIC_INIT(1), \
248 mmap_sem: __RWSEM_INITIALIZER(name.mmap_sem), \
249 page_table_lock: SPIN_LOCK_UNLOCKED, \
250 mmlist: LIST_HEAD_INIT(name.mmlist), \
251 }
Once it is established, new mm_structs are created using their
parent mm_struct as a template. The function responsible for
the copy operation is copy_mm() and it uses init_mm()
to initialise process specific fields.
While a new user increments the usage count with
atomic_inc(&mm->mm_users), it is decremented with a call
to mmput(). If the mm_users count reaches zero, all
the mapped regions are destroyed with exit_mmap() and the page
tables destroyed as there are no longer any users of the userspace portions. The
mm_count count is decremented with mmdrop() as all the
users of the page tables and VMAs are counted as one mm_struct
user. When mm_count reaches zero, the mm_struct
will be destroyed.
The full address space of a process is rarely used, only sparse regions are.
Each region is represented by a vm_area_struct which
never overlap and represent a set of addresses with the same protection
and purpose. Examples of a region include a read-only shared library loaded
into the address space or the process heap. A full list of mapped regions a
process has may be viewed via the proc interface at /proc/PID/maps
where PID is the process ID of the process that is to be examined.
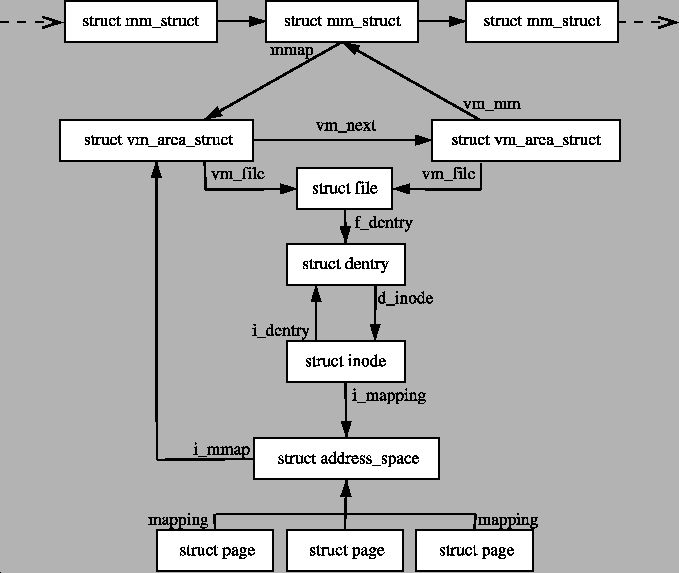
The region may have a number of different structures associated with it as
illustrated in Figure 5.2.
At the top, there is the vm_area_struct which on its own is
enough to represent anonymous memory.
If a file is memory mapped, the struct file is available through the
vm_file field which has a pointer to the struct
inode. The inode is used to get the struct address_space which
has all the private information about the file including a set of pointers
to filesystem functions which perform the filesystem specific operations
such as reading and writing pages to disk.
The struct vm_area_struct is declared as follows in
linux/mm.h:
44 struct vm_area_struct {
45 struct mm_struct * vm_mm;
46 unsigned long vm_start;
47 unsigned long vm_end;
49
50 /* linked list of VM areas per task, sorted by address */
51 struct vm_area_struct *vm_next;
52
53 pgprot_t vm_page_prot;
54 unsigned long vm_flags;
55
56 rb_node_t vm_rb;
57
63 struct vm_area_struct *vm_next_share;
64 struct vm_area_struct **vm_pprev_share;
65
66 /* Function pointers to deal with this struct. */
67 struct vm_operations_struct * vm_ops;
68
69 /* Information about our backing store: */
70 unsigned long vm_pgoff;
72 struct file * vm_file;
73 unsigned long vm_raend;
74 void * vm_private_data;
75 };
- vm_mm The mm_struct this VMA belongs to;
- vm_start The starting address of the region;
- vm_end The end address of the region;
- vm_next All the VMAs in an address space are linked together in an
address-ordered singly linked list via this field;
- vm_page_prot The protection flags that are set for each PTE in this
VMA. The different bits are described in Table 4.1;
- vm_flags A set of flags describing the protections and properties of
the VMA. They are all defined in linux/mm.h and are described
in Table 5.3
- vm_rb As well as being in a linked list, all the VMAs are stored on a
red-black tree for fast lookups. This is important for page fault
handling when finding the correct region quickly is important, especially
for a large number of mapped regions;
- vm_next_share Shared VMA regions based on file mappings (such as
shared libraries) linked together with this field;
- vm_pprev_share The complement of vm_next_share;
- vm_ops The vm_ops field contains functions pointers for
open(), close() and nopage(). These are needed
for syncing with information from the disk;
- vm_pgoff This is the page aligned offset within a file that is
memory mapped;
- vm_file The struct file pointer to the file being mapped;
- vm_raend This is the end address of a read-ahead window. When a fault
occurs, a number of additional pages after the desired page will be paged in.
This field determines how many additional pages are faulted in;
- vm_private_data Used by some device drivers to store private
information. Not of concern to the memory manager.
Figure 5.2:
Data Structures related to the Address
Space
|
|
Figure 5.3:
Memory Region Flags
 |
All the regions are linked together on a linked list ordered by address via
the vm_next field. When searching for a free area, it is a simple
matter of traversing the list but a frequent operation is to search for the
VMA for a particular address such as during page faulting for example. In this
case, the red-black tree is traversed as it has
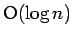 search time on average. The tree is ordered so that lower addresses than
the current node are on the left leaf and higher addresses are on the right.
search time on average. The tree is ordered so that lower addresses than
the current node are on the left leaf and higher addresses are on the right.
5.4.1 File/Device backed memory regions
In the event the region is backed by a file, the vm_file leads
to an associated address_space as shown in Figure 5.2. The struct contains information
of relevance to the filesystem such as the number of dirty pages which must
be flushed to disk. It is declared as follows in linux/fs.h:
401 struct address_space {
402 struct list_head clean_pages;
403 struct list_head dirty_pages;
404 struct list_head locked_pages;
405 unsigned long nrpages;
406 struct address_space_operations *a_ops;
407 struct inode *host;
408 struct vm_area_struct *i_mmap;
409 struct vm_area_struct *i_mmap_shared;
410 spinlock_t i_shared_lock;
411 int gfp_mask;
412 };
A brief description of each field is as follows:
- clean_pages A list of clean pages which do not have to be synchronised
with the disk;
- dirty_pages Pages that the process has touched and need to by sync-ed
with the backing storage;
- locked_pages The list of pages locked in memory;
- nrpages Number of resident pages in use by the address space;
- a_ops A struct of function pointers within the filesystem;
- host The host inode the file belongs to;
- i_mmap A pointer to the VMA the address space is part of;
- i_mmap_shared A pointer to the next VMA which shares this address
space;
- i_shared_lock A spinlock to protect this structure;
- gfp_mask The mask to use when calling __alloc_pages() for
new pages.
Periodically the memory manager will need to flush information to disk. The
memory manager doesn't know and doesn't care how information is written
to disk, so the a_ops struct is used to call the relevant
functions. It is defined as follows in linux/fs.h:
383 struct address_space_operations {
384 int (*writepage)(struct page *);
385 int (*readpage)(struct file *, struct page *);
386 int (*sync_page)(struct page *);
387 /*
388 * ext3 requires that a successful prepare_write()
* call be followed
389 * by a commit_write() call - they must be balanced
390 */
391 int (*prepare_write)(struct file *, struct page *,
unsigned, unsigned);
392 int (*commit_write)(struct file *, struct page *,
unsigned, unsigned);
393 /* Unfortunately this kludge is needed for FIBMAP.
* Don't use it */
394 int (*bmap)(struct address_space *, long);
395 int (*flushpage) (struct page *, unsigned long);
396 int (*releasepage) (struct page *, int);
397 #define KERNEL_HAS_O_DIRECT
398 int (*direct_IO)(int, struct inode *, struct kiobuf *,
unsigned long, int);
399 };
These fields are all function pointers which are described as follows;
- writepage Write a page to disk. The offset within the file to write
to is stored within the page struct. It is up to the filesystem specific
code to find the block. See buffer.c:block_write_full_page();
- readpage Read a page from disk. See
buffer.c:block_read_full_page();
- sync_page Sync a dirty page with disk. See
buffer.c:block_sync_page();
- prepare_write This is called before data is copied from userspace
into a page that will be written to disk. With a journaled filesystem,
this ensures the filesystem log is up to date. With normal filesystems,
it makes sure the needed buffer pages are allocated. See
buffer.c:block_prepare_write();
- commit_write After the data has been copied from userspace,
this function is called to commit the information to disk. See
buffer.c:block_commit_write();
- bmap Maps a block so that raw IO can be performed. Only of concern
to the filesystem specific code;
- flushpage This makes sure there is no IO pending on a page before
releasing it. See buffer.c:discard_bh_page();
- releasepage This tries to flush all the buffers associated with a
page before freeing the page itself. See try_to_free_buffers().
Table 5.3:
Memory Region VMA API
 |
The system call mmap() is provided for creating new
memory regions within a process. For the x86, the function calls
sys_mmap2() which calls do_mmap2() directly with
the same parameters. do_mmap2() is responsible for acquiring the
parameters needed by do_mmap_pgoff(), which is the principle
function for creating new areas for all architectures.
do_mmap2() first clears the MAP_DENYWRITE and
MAP_EXECUTABLE bits from the flags parameter as they
are ignored by Linux, which is confirmed by the mmap() manual page. If
a file is being mapped, do_mmap2() will look up the
struct file based on the file descriptor passed as a parameter and
acquire the mm_structmmap_sem semaphore before calling
do_mmap_pgoff().
do_mmap_pgoff() begins by performing some basic sanity checks. It
first checks that the appropriate filesystem or device functions are available
if a file or device is being mapped. It then ensures the size of the mapping
is page aligned and that it does not attempt to create a mapping in the
kernel portion of the address space. It then makes sure the size of the
mapping does not overflow the range of pgoff and finally that the
process does not have too many mapped regions already.
This rest of the function is large but broadly speaking it takes the
following steps:
- Sanity check the parameters;
- Find a free linear address space large enough for the memory mapping. If
a filesystem or device specific get_unmapped_area()
function is provided, it will be used otherwise
arch_get_unmapped_area() is called;
- Calculate the VM flags and check them against the file access
permissions;
- If an old area exists where the mapping is to take place, fix it up
so that it is suitable for the new mapping;
- Allocate a vm_area_struct from the slab allocator and
fill in its entries;
- Link in the new VMA;
- Call the filesystem or device specific mmap function;
- Update statistics and return.
A common operation is to find the VMA a particular address belongs to,
such as during operations like page faulting, and the function responsible
for this is find_vma(). The function find_vma() and
other API functions affecting memory regions are listed in Table 5.3.
It first checks the mmap_cache field which caches the result of
the last call to find_vma() as it is quite likely the same region
will be needed a few times in succession. If it is not the desired region,
the red-black tree stored in the mm_rb field is traversed. If
the desired address is not contained within any VMA, the function will return
the VMA closest to the requested address so it is important callers
double check to ensure the returned VMA contains the desired address.
A second function called find_vma_prev() is provided which is
functionally the same as find_vma() except that it also returns a
pointer to the VMA preceding the desired VMA5.8which is required as the list is a singly linked list. This is rarely used
but notably, it is used when two VMAs are being compared to determine if
they may be merged. It is also used when removing a memory region so that
the singly linked list may be updated.
The last function of note for searching VMAs is
find_vma_intersection() which is used to find a VMA which
overlaps a given address range. The most notable use of this is during a
call to do_brk() when a region is growing up. It is important to
ensure that the growing region will not overlap an old region.
When a new area is to be memory mapped, a free region has to be found that
is large enough to contain the new mapping. The function responsible for
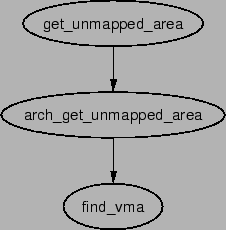
finding a free area is get_unmapped_area().
As the call graph in Figure 5.5 indicates, there is
little work involved with finding an unmapped area. The function is passed a
number of parameters. A struct file is passed representing the
file or device to be mapped as well as pgoff which is the offset
within the file that is been mapped. The requested address for
the mapping is passed as well as its length. The last parameter
is the protection flags for the area.
Figure 5.5:
Call Graph: get_unmapped_area()
|
|
If a device is being mapped, such as a video card, the associated
f_opget_unmapped_area() is used. This is
because devices or files may have additional requirements for mapping that
generic code can not be aware of, such as the address having to be aligned
to a particular virtual address.
If there are no special requirements, the architecture specific function
arch_get_unmapped_area() is called. Not all
architectures provide their own function. For those that don't, there is a
generic function provided in mm/mmap.c.
The principal function for inserting a new memory region is
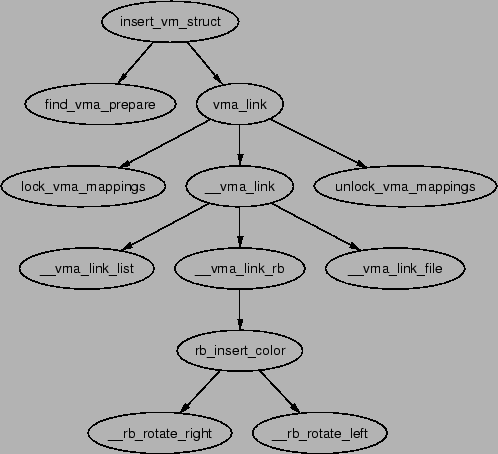
insert_vm_struct() whose call graph can be seen in Figure
5.6. It is a very simple function which first calls
find_vma_prepare() to find the appropriate VMAs the new region is
to be inserted between and the correct nodes within the red-black tree. It then
calls __vma_link() to do the work of linking in the new VMA.
Figure 5.6:
Call Graph: insert_vm_struct()
|
|
The function insert_vm_struct() is rarely used as it does not
increase the map_count field. Instead, the function commonly
used is __insert_vm_struct() which performs the same tasks
except that it increments map_count.
Two varieties of linking functions are provided, vma_link()
and __vma_link(). vma_link() is intended for use when
no locks are held. It will acquire all the necessary locks, including locking
the file if the VMA is a file mapping before calling __vma_link()
which places the VMA in the relevant lists.
It is important to note that many functions do not use the
insert_vm_struct() functions but instead prefer to
call find_vma_prepare() themselves followed by a later
vma_link() to avoid having to traverse the tree multiple times.
The linking in __vma_link() consists of three stages which are
contained in three separate functions. __vma_link_list() inserts
the VMA into the linear, singly linked list. If it is the first mapping in
the address space (i.e. prev is NULL), it will become the red-black tree
root node. The second stage is linking the node into the red-black tree
with __vma_link_rb(). The final stage is fixing up the file
share mapping with __vma_link_file() which basically inserts
the VMA into the linked list of VMAs via the vm_pprev_share()
and vm_next_share() fields.
Linux used to have a function called
merge_segments() [#!kernel-2-2!#] which was responsible for
merging adjacent regions of memory together if the file and permissions
matched. The objective was to remove the number of VMAs required, especially
as many operations resulted in a number of mappings being created such as
calls to sys_mprotect(). This was an expensive operation as it
could result in large portions of the mappings being traversed and was later
removed as applications, especially those with many mappings, spent a long
time in merge_segments().
The equivalent function which exists now is called vma_merge()
and it is only used in two places. The first user is sys_mmap()
which calls it if an anonymous region is being mapped, as anonymous regions
are frequently mergable. The second time is during do_brk() which is
expanding one region into a newly allocated one where the two regions should
be merged. Rather than merging two regions, the function vma_merge()
checks if an existing region may be expanded to satisfy the new allocation
negating the need to create a new region. A region may be expanded if there are
no file or device mappings and the permissions of the two areas are the same.
Regions are merged elsewhere, although no function is explicitly called to
perform the merging. The first is during a call to sys_mprotect()
during the fixup of areas where the two regions will be merged if the two
sets of permissions are the same after the permissions in the affected region
change. The second is during a call to move_vma() when it is
likely that similar regions will be located beside each other.
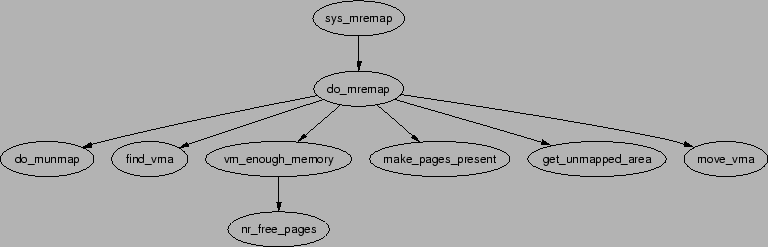
mremap() is a system call provided to grow or shrink an existing
memory mapping. This is implemented by the function sys_mremap()
which may move a memory region if it is growing or it would overlap another
region and MREMAP_FIXED is not specified in the flags. The
call graph is illustrated in Figure 5.7.
Figure 5.7:
Call Graph: sys_mremap()
|
|
If a region is to be moved, do_mremap() first calls
get_unmapped_area() to find a region large enough to contain the
new resized mapping and then calls move_vma() to move the old
VMA to the new location. See Figure 5.8 for the call graph
to move_vma().
Figure 5.8:
Call Graph: move_vma()
|
|
First move_vma() checks if the new location may be merged with the
VMAs adjacent to the new location. If they can not be merged, a new VMA is
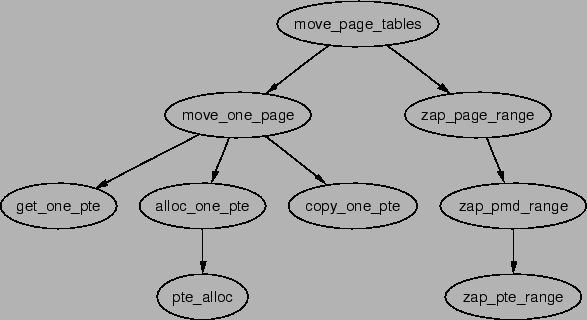
allocated literally one PTE at a time. Next move_page_tables()
is called(see Figure 5.9 for its call graph) which
copies all the page table entries from the old mapping to the new one. While
there may be better ways to move the page tables, this method makes error
recovery trivial as backtracking is relatively straight forward.
Figure 5.9:
Call Graph: move_page_tables()
|
|
The contents of the pages are not copied. Instead, zap_page_range()
is called to swap out or remove all the pages from the old mapping and the
normal page fault handling code will swap the pages back in from backing
storage or from files or will call the device specific do_nopage()
function.
Figure 5.10:
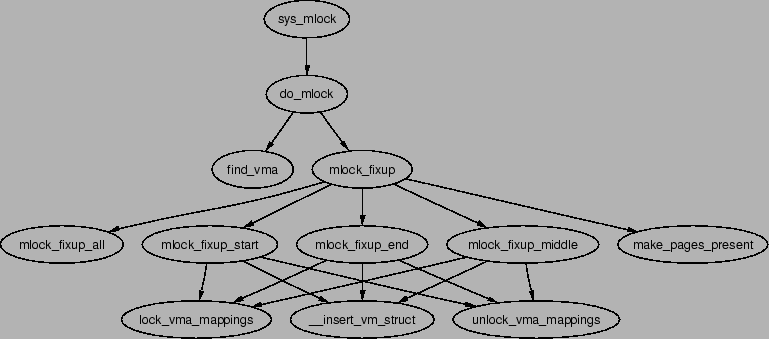
Call Graph: sys_mlock()
|
|
Linux can lock pages from an address range into memory via the system call
mlock() which is implemented by sys_mlock() whose call
graph is shown in Figure 5.10. At a high level, the function
is simple; it creates a VMA for the address range to be locked, sets the
VM_LOCKED flag on it and forces all the pages to be present with
make_pages_present(). A second system call mlockall()
which maps to sys_mlockall() is also provided which is a
simple extension to do the same work as sys_mlock() except for
every VMA on the calling process. Both functions rely on the core function
do_mlock() to perform the real work of finding the affected VMAs
and deciding what function is needed to fix up the regions as described later.
There are some limitations to what memory may be locked. The address range
must be page aligned as VMAs are page aligned. This is addressed by simply
rounding the range up to the nearest page aligned range. The second proviso
is that the process limit RLIMIT_MLOCK imposed by the system
administrator may not be exceeded. The last proviso is that each process may
only lock half of physical memory at a time. This is a bit non-functional as
there is nothing to stop a process forking a number of times and each child
locking a portion but as only root processes are allowed to lock pages, it does
not make much difference. It is safe to presume that a root process is trusted
and knows what it is doing. If it does not, the system administrator with the
resulting broken system probably deserves it and gets to keep both parts of it.
The system calls munlock() and munlockall() provide the
corollary for the locking functions and map to sys_munlock()
and sys_munlockall() respectively. The functions are much simpler
than the locking functions as they do not have to make numerous checks. They
both rely on the same do_mmap() function to fix up the regions.
When locking or unlocking, VMAs will be affected in one of four ways, each of
which must be fixed up by mlock_fixup(). The locking may affect
the whole VMA in which case mlock_fixup_all() is called. The
second condition, handled by mlock_fixup_start(), is where the
start of the region is locked, requiring that a new VMA be allocated to map the
new area. The third condition, handled by mlock_fixup_end(),
is predictably enough where the end of the region is locked. Finally,
mlock_fixup_middle() handles the case where the middle of a
region is mapped requiring two new VMAs to be allocated.
It is interesting to note that VMAs created as a result of locking are
never merged, even when unlocked. It is presumed that processes which lock
regions will need to lock the same regions over and over again and it is
not worth the processor power to constantly merge and split regions.
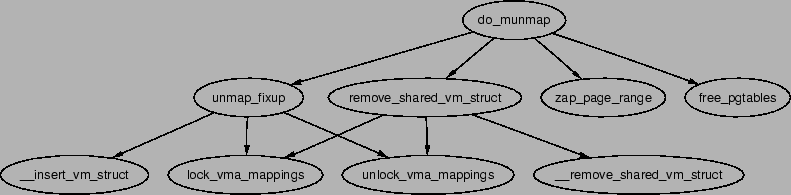
The function responsible for deleting memory regions or parts thereof is
do_munmap(). It is a relatively simple operation in comparison
to the other memory region related operations and is basically divided up
into three parts. The first is to fix up the red-black tree for the region
that is about to be unmapped. The second is to release the pages and PTEs
related to the region to be unmapped and the third is to fix up the regions
if a hole has been generated.
Figure 5.11:
Call Graph: do_munmap()
|
|
To ensure the red-black tree is ordered correctly, all VMAs to be affected by
the unmap are placed on a linked list called free and then deleted
from the red-black tree with rb_erase(). The regions if they still
exist will be added with their new addresses later during the fixup.
Next the linked list VMAs on free is walked through and checked
to ensure it is not a partial unmapping. Even if a region is just to be
partially unmapped, remove_shared_vm_struct() is still called
to remove the shared file mapping. Again, if this is a partial unmapping,
it will be recreated during fixup. zap_page_range() is called to
remove all the pages associated with the region about to be unmapped before
unmap_fixup() is called to handle partial unmappings.
Lastly free_pgtables() is called to try and free up all the
page table entries associated with the unmapped region. It is important
to note that the page table entry freeing is not exhaustive. It will only
unmap full PGD directories and their entries so for example, if only half a
PGD was used for the mapping, no page table entries will be freed. This is
because a finer grained freeing of page table entries would be too expensive
to free up data structures that are both small and likely to be used again.
During process exit, it is necessary to unmap all VMAs associated with a
mm_struct. The function responsible is exit_mmap(). It
is a very simply function which flushes the CPU cache before walking through
the linked list of VMAs, unmapping each of them in turn and freeing up
the associated pages before flushing the TLB and deleting the page table
entries. It is covered in detail in the Code Commentary.
5.7 Copying To/From Userspace
It is not safe to access memory in the process address space directly as
there is no way to quickly check if the page addressed is resident or not.
Linux relies on the MMU to raise exceptions when the address is invalid
and have the Page Fault Exception handler catch the exception and fix it
up. In the x86 case, assembler is provided by the __copy_user()
to trap exceptions where the address is totally useless. The location of the
fixup code is found when the function search_exception_table()
is called. Linux provides an ample API (mainly macros) for copying data to
and from the user address space safely as shown in Table 5.5.
Table 5.5:
Accessing Process Address Space API
 |
All the macros map on to assembler functions which all follow similar
patterns of implementation so for illustration purposes, we'll just trace
how copy_from_user() is implemented on the x86.
copy_from_user() calls either
__constant_copy_from_user() or
__generic_copy_from_user() depending on whether the size of
the copy is known at compile time or not. If the size is known at compile
time, there are different assembler optimisations to copy data in 1, 2 or
4 byte strides otherwise the distinction between the two copy functions is
not important.
The generic copy function eventually calls the function
__copy_user_zeroing() in asm-i386/uaccess.h
which has three important parts. The first part is the assembler for the
actual copying of size number of bytes from userspace. If any
page is not resident, a page fault will occur and if the address is valid,
it will get swapped in as normal. The second part is ``fixup'' code and the
third part is the __ex_table mapping the instructions from the
first part to the fixup code in the second part.
These pairings of execution points and fixup routines, as described
in Section 5.5, are copied to the kernel
exception handle table by the linker. If an invalid address is
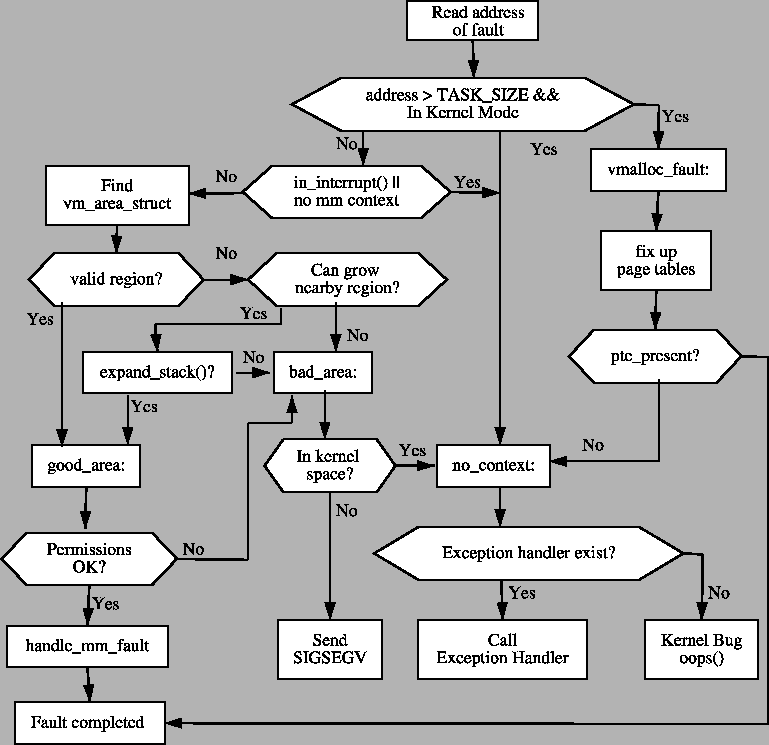
read, the function do_page_fault() will fall through, call
search_exception_table() and find the EIP where the faulty read
took place and jump to the fixup code which copies zeros into the remaining
kernel space, fixes up registers and returns. In this manner, the kernel
can safely access userspace with no expensive checks and letting the MMU
hardware handle the exceptions.
All the other functions that access userspace follow a similar pattern.
Figure 5.17:
do_page_fault Flow
Diagram
|
|
6. Boot Memory Allocator
It is impractical to statically initialise all the core kernel memory
structures at compile time as there are simply far too many permutations of
hardware configurations. Yet to set up even the basic structures requires
memory as even the physical page allocator, discussed in the next chapter,
needs to allocate memory to initialise itself. But how can the physical page
allocator allocate memory to initialise itself?
To address this, a specialised allocator called the Boot Memory
Allocator is used. It is based on the most basic of allocators, a First
Fit allocator which uses a bitmap to represent memory [#!tanenbaum01!#]
instead of linked lists of free blocks. If a bit is 1, the page is allocated
and 0 if unallocated. To satisfy allocations of sizes smaller than a page,
the allocator records the Page Frame Number (PFN) of the
last allocation and the offset the allocation ended at. Subsequent small
allocations are ``merged'' together and stored on the same page.
The reader may ask why this allocator is not used for the running system. One
compelling reason is that although the first fit allocator does not suffer badly
from fragmentation [#!johnstone98!#], memory frequently has to linearly
searched to satisfy an allocation. As this is examining bitmaps, it gets very
expensive, especially as the first fit algorithm tends to leave many small
free blocks at the beginning of physical memory which still get scanned for
large allocations, thus making the process very wasteful [#!wilson95!#].
Table 6.1:
Boot Memory Allocator API for UMA Architectures
 |
There are two very similar but distinct APIs for the allocator. One is for
UMA architectures, listed in Table 6.1 and the other is for NUMA, listed in Table 6.2. The principle difference is
that the NUMA API must be supplied with the node affected by the operation
but as the callers of these APIs exist in the architecture dependant layer,
it is not a significant problem.
This chapter will begin with a description of the structure the allocator
uses to describe the physical memory available for each node. We will then
illustrate how the limits of physical memory and the sizes of each zone are
discovered before talking about how the information is used to initialised
the boot memory allocator structures. The allocation and free routines will
then be discussed before finally talking about how the boot memory allocator
is retired.
Table 6.2:
Boot Memory Allocator API for NUMA Architectures
 |
A bootmem_data struct exists for each node of memory
in the system. It contains the information needed for the boot memory
allocator to allocate memory for a node such as the bitmap representing
allocated pages and where the memory is located. It is declared as follows
in linux/bootmem.h:
25 typedef struct bootmem_data {
26 unsigned long node_boot_start;
27 unsigned long node_low_pfn;
28 void *node_bootmem_map;
29 unsigned long last_offset;
30 unsigned long last_pos;
31 } bootmem_data_t;
The fields of this struct are as follows:
- node_boot_start This is the starting physical address of the
represented block;
- node_low_pfn This is the end physical address, in other words,
the end of the ZONE_ NORMAL this node represents;
- node_bootmem_map This is the location of the bitmap representing
allocated or free pages with each bit;
- last_offset This is the offset within the the page of the end of
the last allocation. If 0, the page used is full;
- last_pos This is the the PFN of the page used with the last allocation.
Using this with the last_offset field, a test can be made to
see if allocations can be merged with the page used for the last allocation
rather than using up a full new page.
Each architecture is required to supply a setup_arch() function
which, among other tasks, is responsible for acquiring the necessary parameters
to initialise the boot memory allocator.
Each architecture has its own function to get the necessary parameters. On
the x86, it is called setup_memory() but on other architectures
such as MIPS or Sparc, it is called bootmem_init() or the case
of the PPC, do_init_bootmem(). Regardless of the architecture,
the tasks are essentially the same. The parameters it needs to calculate are:
- min_low_pfn This is the lowest PFN that is available in the system;
- max_low_pfn This is the highest PFN that may be addressed by low
memory (ZONE_ NORMAL);
- highstart_pfn This is the PFN of the beginning of high memory
(ZONE_ HIGHMEM);
- highend_pfn This is the last PFN in high memory;
- max_pfn Finally, this is the last PFN available to the system.
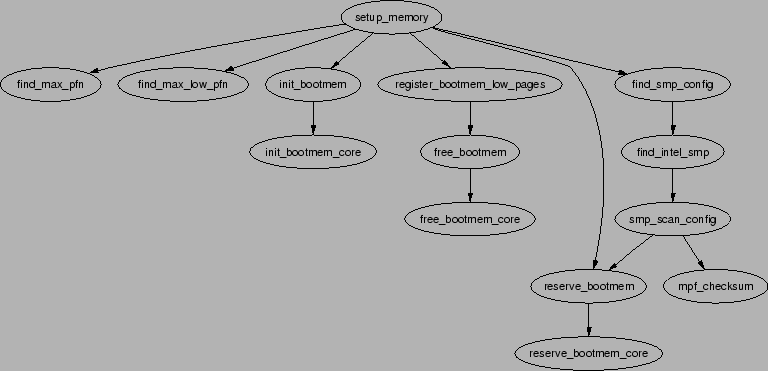
Figure 6.1:
Call Graph: setup_memory()
|
|
The PFN is an offset, counted in pages, within the physical memory map. The
first PFN usable by the system, min_low_pfn is located at the
beginning of the first page after _end which is the end of
the loaded kernel image. The value is stored as a file scope variable in
mm/bootmem.c for use with the boot memory allocator.
How the last page frame in the system, max_pfn,
is calculated is quite architecture specific. In the x86 case,
the function find_max_pfn() reads through the whole
e8206.1 map for the
highest page frame. The value is also stored as a file scope variable in
mm/bootmem.c.
The value of max_low_pfn is calculated on the x86
with find_max_low_pfn() and it marks the end of
ZONE_ NORMAL. This is the physical memory directly accessible by the
kernel and is related to the kernel/userspace split in the linear address
space marked by PAGE_OFFSET. The value, with the others,
is stored in mm/bootmem.c. Note that in low memory machines,
the max_pfn will be the same as the max_low_pfn.
With the three variables min_low_pfn, max_low_pfn
and max_pfn, it is straightforward to calculate the
start and end of high memory and place them as file scope variables
in arch/i386/init.c as highstart_pfn and
highend_pfn. The values are used later to initialise the high
memory pages for the physical page allocator as we will see in Section
6.5.
6.2.2 Initialising bootmem_data
Once the limits of usable physical memory are known, one of two boot memory
initialisation functions are selected and provided with the start and
end PFN for the node to be initialised. init_bootmem(), which
initialises contig_page_data, is used by UMA architectures,
while init_bootmem_node() is for NUMA to initialise a specified
node. Both function are trivial and rely on init_bootmem_core()
to do the real work.
The first task of the core function is to insert this
pgdat_data_t into the pgdat_list as at the end of
this function, the node is ready for use. It then records the starting and
end address for this node in its associated bootmem_data_t
and allocates the bitmap representing page allocations. The size in
bytes6.2 of the bitmap required is
straightforward:
The bitmap in stored at the physical address pointed to by
bootmem_data_tnode_boot_start
and the virtual address to the map is placed in
bootmem_data_tnode_bootmem_map. As there is no
architecture independent way to detect ``holes'' in memory, the entire bitmap
is initialised to 1, effectively marking all pages allocated. It is up to
the architecture dependent code to set the bits of usable pages to 0. In
the case of the x86, the function register_bootmem_low_pages()
reads through the e820 map and calls free_bootmem() for each
usable page to set the bit to 0 before using reserve_bootmem()
to reserve the pages needed by the actual bitmap.
The reserve_bootmem() function may be used to reserve
pages for use by the caller but is very cumbersome to use for
general allocations. There are four functions provided for easy
allocations on UMA architectures called alloc_bootmem(),
alloc_bootmem_low(), alloc_bootmem_pages() and
alloc_bootmem_low_pages() which are fully described in Table
6.1. All of these
macros call __alloc_bootmem() with different parameters. See
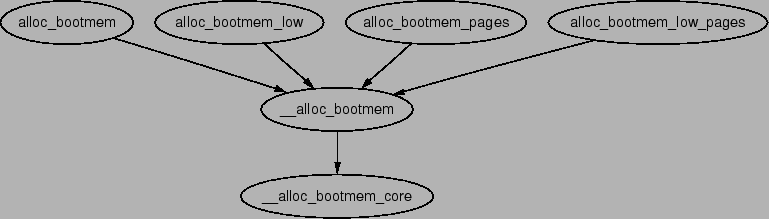
the call graph in Figure 6.2.
Figure 6.2:
Call Graph: __alloc_bootmem()
|
|
Similar functions exist for NUMA which take the node as an
additional parameter, as listed in Table 6.2. They are called
alloc_bootmem_node(), alloc_bootmem_pages_node()
and alloc_bootmem_low_pages_node(). All of these macros
call __alloc_bootmem_node() with different parameters.
The parameters to either __alloc_bootmem() and
__alloc_bootmem_node() are essentially the same. They are
- pgdat This is the node to allocate from. It is omitted in the UMA
case as it is assumed to be contig_page_data;
- size This is the size in bytes of the requested allocation;
- align This is the number of bytes that the request should be aligned
to. For small allocations, they are aligned to SMP_CACHE_BYTES,
which on the x86 will align to the L1 hardware cache;
- goal This is the preferred starting address to begin allocating
from. The ``low'' functions will start from physical address 0 where as the
others will begin from MAX_DMA_ADDRESS which is the maximum
address DMA transfers may be made from on this architecture.
The core function for all the allocation APIs is
__alloc_bootmem_core(). It is a large function but with
simple steps that can be broken down. The function linearly scans memory
starting from the goal address for a block of memory large enough
to satisfy the allocation. With the API, this address will either be 0 for
DMA-friendly allocations or MAX_DMA_ADDRESS otherwise.
The clever part, and the main bulk of the function, deals with deciding
if this new allocation can be merged with the previous one. It may be merged
if the following conditions hold:
- The page used for the previous allocation
(bootmem_datapos) is adjacent to the page found for this
allocation;
- The previous page has some free space in it
(bootmem_dataoffset != 0);
- The alignment is less than PAGE_SIZE.
Regardless of whether the allocations may be merged or not, the pos
and offset fields will be updated to show the last page used
for allocating and how much of the last page was used. If the last page was
fully used, the offset is 0.
6.5 Retiring the Boot Memory Allocator
Late in the bootstrapping process, the function start_kernel()
is called which knows it is safe to remove the boot allocator and all
its associated data structures. Each architecture is required to provide
a function mem_init() that is responsible for destroying the
boot memory allocator and its associated structures.
Figure 6.3:
Call Graph: mem_init()
|
|
The purpose of the function is quite simple. It is responsible for calculating
the dimensions of low and high memory and printing out an informational
message to the user as well as performing final initialisations of the hardware
if necessary. On the x86, the principal function of concern for the VM is the
free_pages_init().
This function first tells the boot memory allocator to retire itself
by calling free_all_bootmem() for UMA architectures or
free_all_bootmem_node() for NUMA. Both call the core function
free_all_bootmem_core() with different parameters. The core
function is simple in principle and performs the following tasks:
- For all unallocated pages known to the allocator for this node;
- Clear the PG_reserved flag in its struct page;
- Set the count to 1;
- Call __free_pages() so that the buddy allocator (discussed
next chapter) can build its free lists.
- Free all pages used for the bitmap and give them to the buddy allocator.
At this stage, the buddy allocator now has control of all the pages
in low memory which leaves only the high memory pages. The remainder
of the free_pages_init() function is responsible for
those. After free_all_bootmem() returns, it first counts
the number of reserved pages for accounting purposes and then calls
the function one_highpage_init() for every page between
highstart_pfn and highend_pfn.
This function simple clears the PG_reserved flag,
sets the PG_highmem flag, sets the count to 1 and calls
__free_pages() to release it to the buddy allocator in the same
manner free_all_bootmem_core() did.
At this point, the boot memory allocator is no longer required and the buddy
allocator is the main physical page allocator for the system. An interesting
feature to note is that not only is the data for the boot allocator removed
but also the code. All the init function declarations used for bootstrapping
the system are marked __init such as the following;
321 unsigned long __init free_all_bootmem (void)
All of these functions are placed together in the .init section by
the linker. On the x86, the function free_initmem() walks through
all pages from __init_begin to __init_end
and frees up the pages to the buddy allocator. With this method, Linux can
free up a considerable amount of memory6.3that is used by bootstrapping code that is no longer required.

 LINUX
LINUX 
 Kernels
Kernels

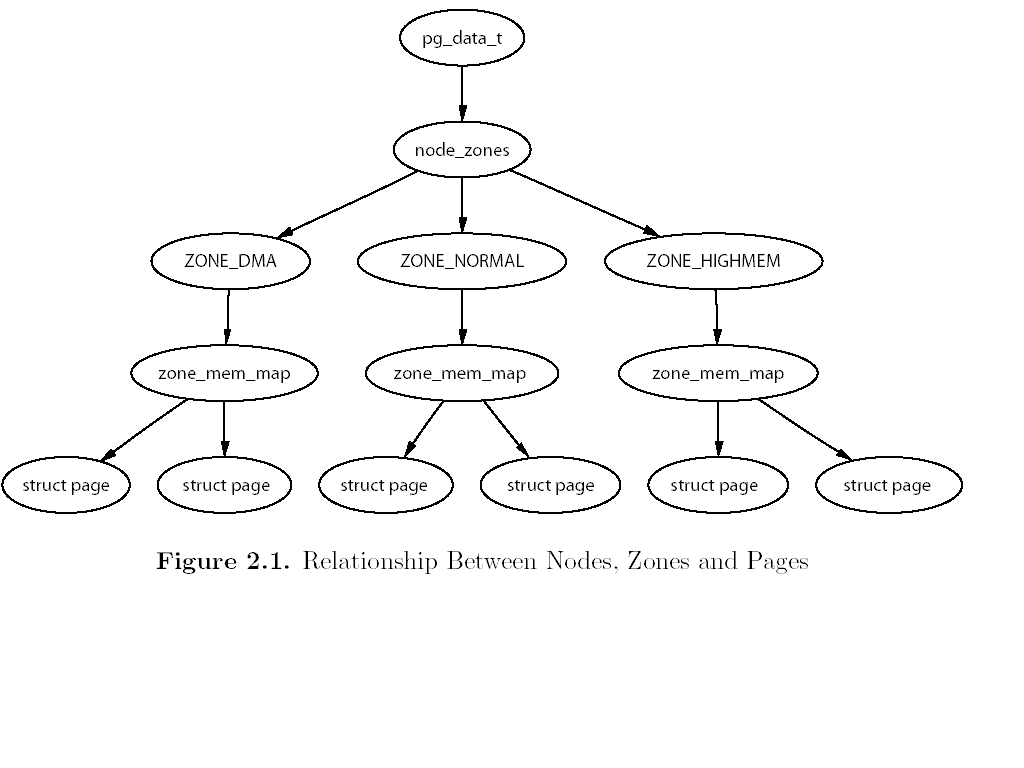
![\includegraphics[width=12cm]{graphs/address_size_macros.ps}](images/kernel/img12.png)
![\includegraphics[width=12cm]{graphs/address_size_macros_partII.ps}](images/kernel/img13.png)