Adaptation of the system V/386 Filesystem for Linux
Paul b.Monday
Документ написан в далеком 1993 году
В документе описывается базовые понятия юниксовой VFS - виртуальной файловой системы и ее реализация в Линукс.
Любая ось предоставляет обычно несколько вариантов для выбора файловой системы.
В линуксе файловая система имеет набор высокоуровневых и низкоуровневых функций.
Каждая файловая система имеет похожий набор функций .
Добавление новой файловой системы в линуксе упрощено.
Мы рассмотрим , как это реализовано с помощью VFS.
Рассмотрим , как организован диск.
1. Сектор 1 : bootblock.
2. Сектор 2 : superblock.
3. Сектора с 3 по х: Испорченые блоки - bad blocks
4. Сектора с x+1 по y : ноды
5. Сектора с y+1 по z : блоки данных
Суперблок - сектор размером в 512 байт.
Его содержание динамически меняется.
Его структура :
offset 0(isize) : число блоков в списке нод
offset 2(fsize) : число блоков
offset 6(nfree) : число свободных адресов в кеше
offset 8(free) : кеш свободных блоков
offset 208(ninode) : число нод в кеше
offset 210(inode) : нодовый кеш
offset 410 : блокировочный бит (для манипуляций с блоковым кешем)
offset 411 : блокировочный бит (для манипуляций с нодовым кешем)
offset 412 : флаг модификации
offset 413 : флаг на чтение
offset 414(time) : время последней модификации супер-блока
offset 418 : информация о монтировании
offset 426 : общее число свободных блоков
offset 430 : общее число свободных нод
offset 432 : имя файловой системы
offset 438 : имя файловой системы
offset 444 : размер файловой системы
offset 492 : state
offset 496 : magic number
offset 500 : тип файловой системы
Некоторые поля не используются.
Каждое выделение нового блока или новой ноды не приводит к изменению числа
свободных блоков или числа свободных нод на диске ,
эти изменения кешируются в памяти. Изменения на диск пишутся либо при операциях монтирования,
либо при переполнении самого кеша.
При создании файловой системы, свободные блоки организуются в связанную структуру.
В блоковом кеше хранится 50 адресов.
Алгоритм выделения блоков следующий :
if tfree=0 then return false
if nfree=0 and tfree=1 then
address = free[0]
чтение блока по адресу address
перевод массива free[0-49] в массив block[0-49]
else
address = free[nfree]
nfree = nfree - 1
return address
Алгоритм освобождения блоков :
if nfree = 50 then
читаем блок по адресу address
пишем 50 адресов из free в block
nfree=1
free[0] = address
else
free[nfree] = address
nfree = nfree + 1
tfree = tfree + 1
return
Здесь возникает проблема со скоростью доступа к диску.
Периодически происходит доступ на запись к суперблоку между выделением блоков.
Другой сценарий : перезагружать кеш для каждого выделение блоков ,
что не является красивым и правильным решением.
Список свободных нод очень похож на список свободных блоков.
Ноды сами по себе отличаются от блоков данных.
Свободные ноды не связаны между собой так , как блоки данных.
Когда приходит время перезагрузки нодового кеша ,
он заполняется 100 свободныит нодами.
В ноде есть поле nlink=0 , что говорит о том , что нода готова к использованию и свободна.
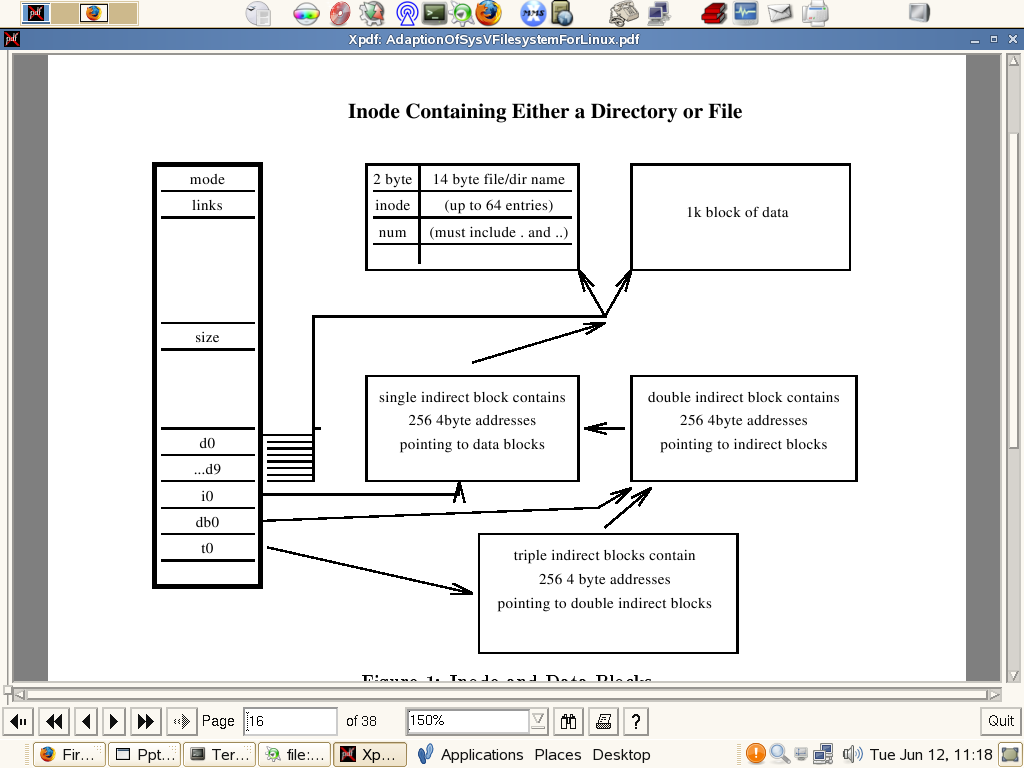
Ключ в понимании файловой системы лежит в понимании внутренней структуры ноды.
Многие поля нодовой структуры VFS аналогичны линуксовой ноде.
Юниксовая файловая система имеет несколько уровней абстрации для того ,
чтобы оперировать различными типами файловых систем.
Например , если поле ноды имеет значение 0x4000 , это означает каталог ,
и это справедливо для любой юниксовой файловой системы.
Рассмотрим подробнее линуксовую ноду :
offset 0(mode): режим и тип файла (*)
offset 2(nlink): число линков на файл (*)
offset 4(uid): File owner's userid (*)
offset 6(gid): File's group id (*)
offset 8(size): Size, in bytes, of the file (*)
offset 12(addr): Disk block addresses
offset 51(gen): File's generation number (*)
offset 52(atime): Last time file accessed (*)
offset 56(mtime): Last time fle modified (*)
offset 60(ctime): File creation time (*)
Адрес файла хранится в 3-байтовом формате , что позволяет иметь размер файла до 34646 КБ.
Этот формат может иметь и другой вариант - 4-х байтовый , в этом случае нода будет указывать
на дисковое пространство размером в 16777216 КБ.
Следующий рисунок показывает , как организована адресация блоков внутри ноды.
Direct-блоки контролируются байтами с 0 по 26-й в поле addr.
Показано , как различные уровни адресации связаны с блоками.
Каждый indirect-блок дает дополнительно по 32 блока для файла.
Double-блоки расширяют размер файла на 1024 блока и triple indirect блоки
дают дополнительно по 32768 блоков.
Адреса хранятся как long integers в inderect-блоках.
Блоки каталогов - directory blocks - похожи во многих файловых юниксовых системах.
Эти блоки заполнены номером ноды и именем файла.
Запись ссылается на ноду , которая может включать любой тип файла - каталог , данные , симлинк и т.д.
Имя файла может состоять из 14 символов.
На предыдущей картинке видно , как directory block работает с нодой.
Отличие директории от файла - в том , что хранится в поле mode.
Linux
Исходники VFS лежат в каталоге /fs.
Для каждого типа файловой системы тут есть свой подкаталог, например , fs/ext2/
В следующей таблице представлен список некоторых исходников этого каталога.
Средний столбик - system - означает следующее :
EXE - используется для загрузки исполняемых файлов ,
DEV - поддерживает драйвер ,
BUF - кеш буфера ,
VFS - базовй код для всех файловых систем.
| Filename | system | Purpose |
|---|
| binfmt_aout.c | EXE | Recognize and execute old-style a.out executables. |
| binfmt_elf.c | EXE | Recognize and execute new ELF executables |
| binfmt_java.c | EXE | Recognize and execute Java apps and applets |
| binfmt_script.c | EXE | Recognize and execute #!-style scripts |
| block_dev.c | DEV | Generic read(), write(), and fsync() functions for block devices. |
| buffer.c | BUF | The buffer cache, which caches blocks read from block devices. |
| dcache.c | VFS | The directory cache, which caches directory name lookups. |
| devices.c | DEV | Generic device support functions, such as registries. |
| dquot.c | VFS | Generic disk quota support. |
| exec.c | VFSg | Generic executable support. Calls functions in the binfmt_* files. |
| fcntl.c | VFSg | fcntl() handling. |
| fifo.c | VFSg | fifo handling. |
| file_table.c | VFSg | Dynamically-extensible list of open files on the system. |
| filesystems.c | VFS | All compiled-in filesystems are initialized from here by calling init_name_fs(). |
| inode.c | VFSg | Dynamically-extensible list of open inodes on the system. |
| ioctl.c | VFS | First-stage handling for ioctl's; passes handling to the filesystem or device driver if necessary. |
| locks.c | VFSg | Support for fcntl() locking, flock() locking, and manadatory locking. |
| namei.c | VFS | Fills in the inode, given a pathname. Implements several name-related system calls. |
| noquot.c | VFS | No quotas: optimization to avoid #ifdef's in dquot.c |
| open.c | VFS | Lots of system calls including (surprise) open(), close(), and vhangup(). |
| pipe.c | VFSg | Pipes. |
| read_write.c | VFS | read(), write(), readv(), writev(), lseek(). |
| readdir.c | VFS | Several different interfaces for reading directories. |
| select.c | VFS | The guts of the select() system call |
| stat.c | VFS | stat() and readlink() support. |
| super.c | VFS | Superblock support, filesystem registry, mount()/umount(). |
Загрузка файловой системы происходит следующим образом :
в каждом под-каталоге для каждой файловой системы есть шаблон вызова типа init_name_fs(),
например для ext2 :
int init_ext2_fs(void)
{
return register_filesystem(&ext2_fs_type);
}
Зарегистрировать файловую систему можно так :
static struct file_system_type ext2_fs_type =
{
ext2_read_super, "ext2", 1, NULL
};
Можно зарегистрировать более чем одну файловую систему :
static struct file_system_type sysv_fs_type[3] = {
{sysv_read_super, "xenix", 1, NULL},
{sysv_read_super, "sysv", 1, NULL},
{sysv_read_super, "coherent", 1, NULL}
};
int init_sysv_fs(void)
{
int i;
int ouch;
for (i = 0; i < 3; i++) {
if ((ouch = register_filesystem(&sysv_fs_type[i])) != 0)
return ouch;
}
return ouch;
}
Связь между файловой системой и ядром осуществляется через device.
Когда монтируется драйер , включающий в себя например ext2 , вызывается ext2_read_super().
Если супер-блок прочитан , происходит инициализации структуры super_block ,
в которую добавляется указатель на новую структуру super_operations,
уже в которой находятся указатели на функции.
Суперблок - это блок , в котором находится стартовая точка файловой системы.
В структуре super_operations находятся указатели на функции ,
которые манипулируют нодами , самим суперблоком .
Вариант того , как может выглядеть super_operations :
struct super_operations {
void (*read_inode) (struct inode *);
int (*notify_change) (struct inode *, struct iattr *);
void (*write_inode) (struct inode *);
void (*put_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
void (*statfs) (struct super_block *, struct statfs *, int);
int (*remount_fs) (struct super_block *, int *, char *);
};
А вот как может выглядеть инстанс этой структуры для ext2 :
static struct super_operations ext2_sops = {
ext2_read_inode,
NULL,
ext2_write_inode,
ext2_put_inode,
ext2_put_super,
ext2_write_super,
ext2_statfs,
ext2_remount
};
Обратите внимание , что некоторые поля структуры могут быть NULL.
Для линукса это в порядке вещей :-)
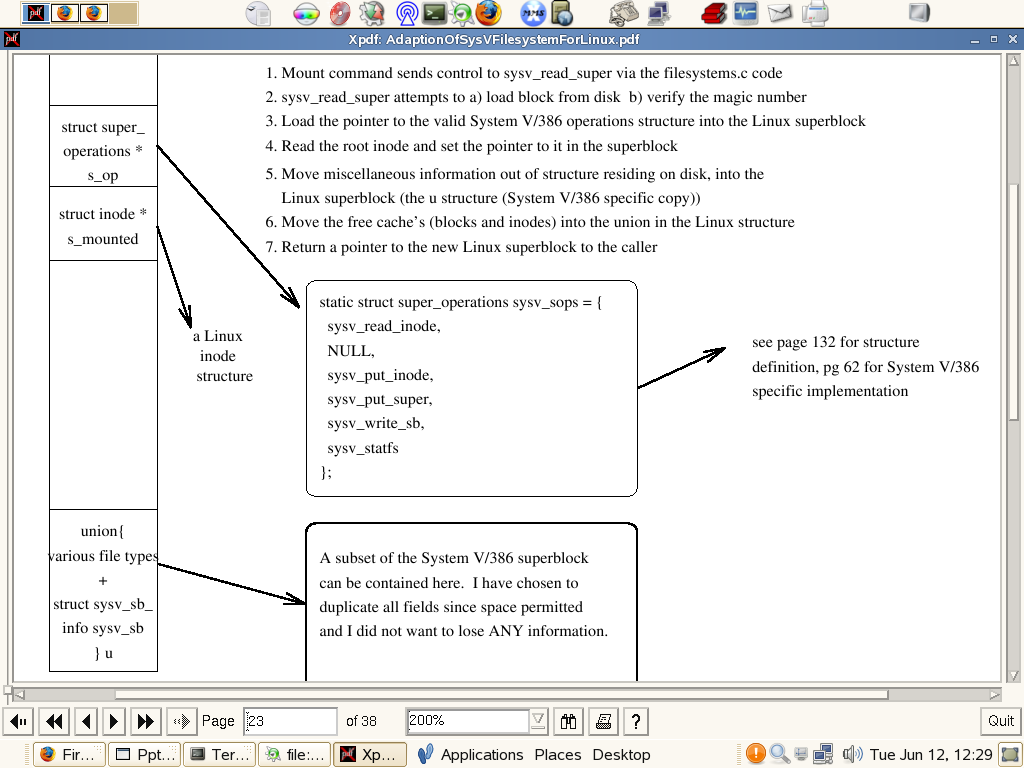
Функция , которая инит суперблок в Линуксе , называется sysv_read_super.
Каждая файловая система имеет соответствующую функцию.
Эта функция сканирует суперблок и грузит его в память.
Наиболее важные поля линуксового супер-блока :
1. offset 0(dev): точка отсчета супер-блока
2. offset 2(blocksize): Blocksize of blocks on device
3. offset 6(lock): бит блокировке , когда суперблок используется
4. offset 7(rdonly): бит - только на чтение
5. offset 8(dirt): бит устанавливается в1 при изменении супер-блока
6. offset 9(superop): указатель на структуру ,указывающую на типы операций с файловой системой
7. offset 13(ags): флаги fs , устанавливаемые при монтировании
8. offset 17(magic): Magic number for flesystem
9. offset 23(time): время монтирования
10. offset 27(covered): Pointer to inode of flesystem which was written over
11. offset 31(mounted): Pointer to root directory inode
12. offset 35(wait): Pointer to wait queue for superblock operations
13. offset 39(u): указатель на супер-блоки других примонтированных ФС
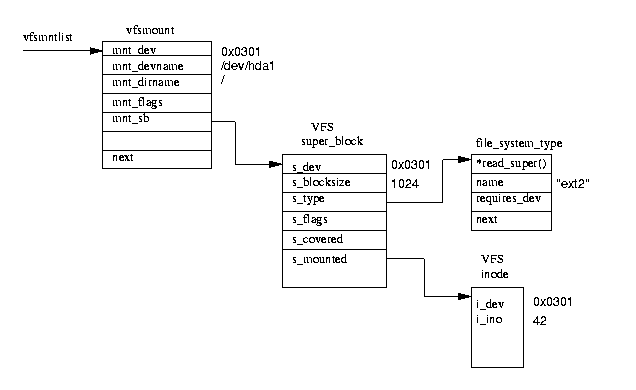
Заметим , что линуксовый супер-блок является одновременно контейнером для других суперблоков.
Структуры данных различных ФС в суперблоке заполняются в момент инициализации этих файловых систем.
После загрузки супер-блока мы имеем указатель на него в процедуре read_super.
При этом суперблок сразу блокируется.При этом :
1. read_super напрямую читает диск , сканирует 0-й блок и грузит его в память
2. Инится указатель на суперблок (смещение 512)
3. Проверка magic number
4. Читается корневая нода с диска и сохраняется в суперблоке в памяти.
5. В суперблок пишутся ряд параметров - время и т.д.
После возвращения из read_super суперблок хранит в себе размер блока , magic number ,
и указатели на функции файловой системы,рутовую ноду ,
При монтировании файловой системы , вызывается функция ext2_read_super() , которая читает супер-блок.
Структура super_block заполняется указателями на функции , специфичные для ext2.
В каком месте происходит монтирование файловой системы ?
Взгляните на fs/super.c , функцию do_umount() , в которой в свою очередь вызывается read_super(),
которая в свою очередь вызывает ext2_read_super(),которая возвращает супер-блок.
После монтирования мы имеем возможность получить доступ к файлу.
Для этого сначала нужно найти нужную ноду , а потом получить доступ к ней.
При поиске VFS оперирует путем , включающим слеши.
Это может быть как файл , так и директория.
В случае успеха , вернется inode number - уникальный номер ноды .
Следующий рисунок показывает структуру ноды ext2:
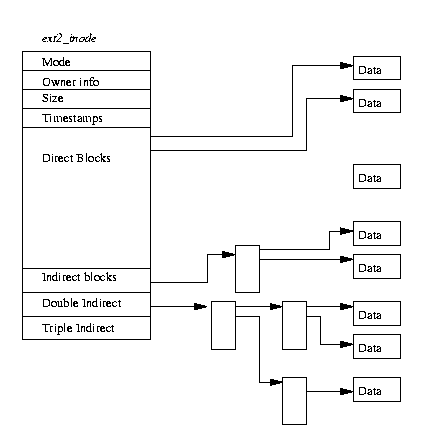 |
Далее вызывается namei() для трансформации номера в реальный путь.
Далее с помощью iget() можно получить содержимое самой этой ноды.
Функция iput() может модифицировать ноду.
Она хранит reference count , который говорит о том , занята нода или нет.
В супер-блоке есть указатель s_mounted на особую ноду , которая указывает на рутовый каталог файловой системы.
Все остальные ноды ищутся и пляшут именно от нее.
Каждая нода , являясь сама структурой , включает вложенную структуру inode_operations,
которая заполнена указателями на функции.Например , функция lookup() ищет другую ноду.
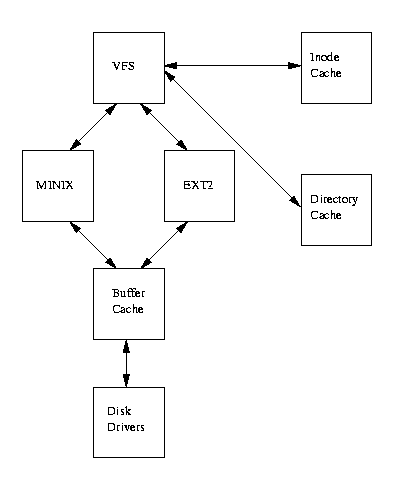
Линуксовые файловые системы имеют модульную структуру.
Линукс поддерживает фат,миникс,несколько типов ext и много чего еще.
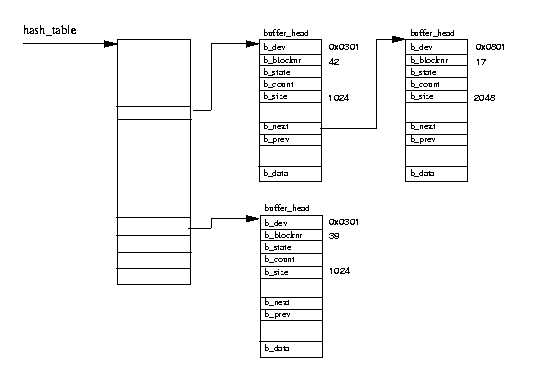
После монтирования файловая система работает с помощью буферов данных.
Линуксовая VFS - это гибрид традиционной юниксовой VFS , основанный на буферизации.
Следующий рисунок показывает , что происходит при чтении супер-блока.
Периодически возникает необходимость сохранения супер-блока на диск.
Это делает процедура sysv_write_sb.При этом :
1. Читаем 0-й блок суперблока в памяти
2. Находим смещение 512
3. Копируем время в буфер
4. Изменяем поля , отвечающие за кеш - free,inode,nfree,ninode
5. Делаем апдэйт для total free inodes , total free blocks
6. Маркируем буффер как dirty
7. Пишем буфер на диск
8. Отменяем атрибут dirty
Для добавления новой файловой системы в ядре при конфигурировании нужно модифицировать как минимум следующее :
1. Файл fs/filesystems.c - структура file_systems хранится в хидере fs.h.
Когда запускается read_super , в нее передается список монтируемых систем
2. include/linux/fs.h - во все структуры должны быть добавлены указатели на структуры добавляемой файловой системы
3. fs/Makefile
VFS :
 |
Монтирование файловой системы :
 |
Buffer cache :
 |
Файловые системы в Линукс :
 |
Базовые файловые структуры данных в Линукс :
 |
Устройство ноды :
 |
Устройство ноды :
 |
Состояния ноды :
 |
Яковлев С :
Ниже я взял базовые структуры из своего текущего ядра 2.6.16.
include/linux/fs.h
struct inode {
struct hlist_node i_hash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
umode_t i_mode;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
unsigned int i_blkbits;
unsigned long i_blksize;
unsigned long i_version;
unsigned long i_blocks;
unsigned short i_bytes;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
struct mutex i_mutex;
struct rw_semaphore i_alloc_sem;
struct inode_operations *i_op;
struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
/* These three should probably be a union */
struct list_head i_devices;
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
int i_cindex;
__u32 i_generation;
#ifdef CONFIG_DNOTIFY
unsigned long i_dnotify_mask; /* Directory notify events */
struct dnotify_struct *i_dnotify; /* for directory notifications */
#endif
#ifdef CONFIG_INOTIFY
struct list_head inotify_watches; /* watches on this inode */
struct semaphore inotify_sem; /* protects the watches list */
#endif
unsigned long i_state;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned int i_flags;
atomic_t i_writecount;
void *i_security;
union {
void *generic_ip;
} u;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
};
struct file {
/*
* fu_list becomes invalid after file_free is called and queued via
* fu_rcuhead for RCU freeing
*/
union {
struct list_head fu_list;
struct rcu_head fu_rcuhead;
} f_u;
struct dentry *f_dentry;
struct vfsmount *f_vfsmnt;
struct file_operations *f_op;
atomic_t f_count;
unsigned int f_flags;
mode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
unsigned int f_uid, f_gid;
struct file_ra_state f_ra;
unsigned long f_version;
void *f_security;
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
spinlock_t f_ep_lock;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
};
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned long s_blocksize;
unsigned char s_blocksize_bits;
unsigned char s_dirt;
unsigned long long s_maxbytes; /* Max file size */
struct file_system_type *s_type;
struct super_operations *s_op;
struct dquot_operations *dq_op;
struct quotactl_ops *s_qcop;
struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
struct mutex s_lock;
int s_count;
int s_syncing;
int s_need_sync_fs;
atomic_t s_active;
void *s_security;
struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct list_head s_dirty; /* dirty inodes */
struct list_head s_io; /* parked for writeback */
struct hlist_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_files;
struct block_device *s_bdev;
struct list_head s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
unsigned int s_prunes; /* protected by dcache_lock */
wait_queue_head_t s_wait_prunes;
int s_frozen;
wait_queue_head_t s_wait_unfrozen;
char s_id[32]; /* Informational name */
void *s_fs_info; /* Filesystem private info */
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct semaphore s_vfs_rename_sem; /* Kludge */
/* Granuality of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
};
struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*get_sb) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
};
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_write) (struct kiocb *, const char __user *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*sendfile) (struct file *, loff_t *, size_t, read_actor_t, void *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*dir_notify)(struct file *filp, unsigned long arg);
int (*flock) (struct file *, int, struct file_lock *);
#define HAVE_FOP_OPEN_EXEC
int (*open_exec) (struct inode *);
};
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *,int);
void * (*follow_link) (struct dentry *, struct nameidata *);
void (*put_link) (struct dentry *, struct nameidata *, void *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int, struct nameidata *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
};
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*read_inode) (struct inode *);
void (*dirty_inode) (struct inode *);
int (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
};
Файл fs / filesystems.c ;
/**
* register_filesystem - register a new filesystem
* @fs: the file system structure
*
* Adds the file system passed to the list of file systems the kernel
* is aware of for mount and other syscalls. Returns 0 on success,
* or a negative errno code on an error.
*
* The &struct file_system_type that is passed is linked into the kernel
* structures and must not be freed until the file system has been
* unregistered.
*/
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
if (!fs)
return -EINVAL;
if (fs->next)
return -EBUSY;
INIT_LIST_HEAD(&fs->fs_supers);
write_lock(&file_systems_lock);
p = find_filesystem(fs->name);
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
int get_filesystem_list(char * buf)
{
int len = 0;
struct file_system_type * tmp;
read_lock(&file_systems_lock);
tmp = file_systems;
while (tmp && len < PAGE_SIZE - 80) {
len += sprintf(buf+len, "%s\t%s\n",
(tmp->fs_flags & FS_REQUIRES_DEV) ? "" : "nodev",
tmp->name);
tmp = tmp->next;
}
read_unlock(&file_systems_lock);
return len;
}
|

 LINUX
LINUX 
 Kernels
Kernels