Я написал цикл статей для сайта IBM, в которых рассмотрел реализацию базовых структур данных
на примере связных списков, как одной из наиболее важных и фундаментальных структур.
Вторая половина цикла посвящена не менее значимой структуре данных — деревьям.
Особенности реализации структур данных в различных языках
Введение
В представленном цикле статей рассматриваются реализации базовых структур данных, созданные с использованием двух разных языков программирования - классического Си и более современного Python. Язык Си относится к компилируемым языкам программирования со строгой типизацией, в то время как Python представляет собой динамически интерпретируемый язык. Поэтому будет интересно сравнить, как одна и та же функциональность может быть реализована в разных языках, и определить сильные и слабые стороны каждого подхода.
В первой статье, открывающей серию, будут разбираться следующие вопросы:
Под структурой данных понимается способ хранения и организации данных для их дальнейшего эффективного использования. Образно выражаясь, сколько существует приложений, столько же существует и различных способов организации данных, порой весьма специфических. Например, B-tree широко используются в базах данных, а компиляторы широко используют хеш-таблицы.
При организации данных наряду со структурами большую роль играют алгоритмы для обработки этих данных. Однако в зависимости от платформы и используемого языка зачастую случается так, что именно структуры данных выходят на первый план, отодвигая алгоритмы на второй план.
Структуры данных имеют первостепенное значение, так как память компьютера может хранить и извлекать данные на основе их адресов. Эти адреса могут вычисляться статически (для массивов) или динамически (для связных списков).
Различные языки программирования сильно различаются в плане встроенной реализации базовых структур данных. Так, в языке Pascal есть встроенная поддержка многомерных массивов, а в Lisp имеется встроенная реализация связных списков. В средах Perl и Python реализованы хеш-таблицы. Но самое главное, что в различных языках используются различные реализации ссылок, записей и других объектов.
Запись (record или struct) - одна из самых «низкоуровневых» структур данных, состоит из нескольких значений или полей, которые последовательно располагаются в памяти. Все поля могут иметь различный размер, и программист может определить произвольную структуру с произвольным количеством полей. При этом для каждого поля в этой структуре необходимо задать 2 атрибута:
определенный тип;
идентификатор.
Также структура может включать в себя поля, на самом деле являющиеся функциями. Такие поля в языке Си имеют тип void *. Благодаря подобным полям можно реализовать объектно-ориентированное программирование. В общем случае, структура - это упорядоченный список элементов или объектов.
Cobol был первым языком, в котором реализовали тип record. Этот язык позволял создавать структуры с набором полей, имеющим символьный или численный тип произвольного размера и точности. Позднее такие же структуры появились в Fortran, Algol, Lisp и Pascal, а еще позже структуры были добавлены в Си, Ada, Modula.
С записями/структурами можно выполнять следующие операции:
объявить новый тип записи;
создать переменную, имеющую тип записи;
присвоить значение какому-то полю внутри записи;
выбрать поле из записи по его имени;
сравнить 2 записи;
вычислить хеш для записи.
Между двумя структурами одного типа можно выполнить операцию присваивания. При этом различные языки по-разному могут трактовать строгую типизацию: например, в некоторых языках значение поля типа short integer может быть присвоено полю типа long integer.
Как уже было сказано, поля структуры располагаются в памяти последовательно, в соответствии с их порядком записи. Некоторые компиляторы могут делать неявное выравнивание полей в памяти. Также языки могут реализовывать структуру как массив указателей на поля структуры.
Структуры в языке Си
В языке Си структура - это тип, представляющий из себя набор именованных объектов различного типа, как показано в листинге 1.
typedef struct {
int a;
int b;
int c;
} rec;
// создание объекта типа структуры
rec r1 = {1,2,3};
// создание второго объекта этого же типа
rec r2;
// выполнение присваивания между объектами
r2 = r1;
Указатели в языке Си
Для работы со структурами могут использоваться указатели. Указатель - это переменная, применяющаяся для использования структуры по ее адресу. Преимущество указателя в том, что его можно передать в качестве параметра в другую функцию, внутри которой можно будет использовать эту структуру. Указатель можно переназначить на другой указатель с помощью оператора «звездочка» (*), а помощью другого оператора -> можно обращаться к полям структуры, как показано ниже:
struct rec *r3 = &r1;
r3->c=3;
Указатели отличаются от обычных переменных тем, что при создании указателя создается ссылка на объект, в то время как в обычной переменной хранится адрес объекта. При использовании указателей необходимо учитывать следующие правила:
Указатель может указывать как на конкретный объект, так и ни на что не указывать. В последнем случае имеется в виду, что указатель установлен в NULL.
Указатель может быть разыменован. Это значит, что указатель не связан жестко с конкретным объектом, и в любой момент можно заменить объект, на который он указывает.
Указатель может быть плохим, когда после создания он не был инициализирован, то есть привязан к объекту. В языке Java при создании указателя он по умолчанию всегда устанавливается в NULL.
Указатель может быть назначен. Например, если есть два указателя - a и b, то между ними возможна операция назначения:
a = b
После этого оба указателя указывают на одну и ту же область памяти. Такая память называется общей (shared).
В языке Си указатели могут использоваться для передачи параметров в функцию по ссылке, при этом значение переданного параметра будет изменяться, как показано в листинге 4.
void alter(int *n) {
*n = 120;
}
void not_alter(int n) {
n = 10;
}
int x = 24;
alter(&x);
not_alter(x);
После вызова функции alter() значение переменной x изменится и станет равно 120, а вызов функции not_alter() никак не скажется на значении переменной x. Следует отметить, что работать с указателями нужно аккуратно и следовать перечисленным выше правилам, иначе возникновение проблем неизбежно.
Если в качестве параметра использовать не обычную переменную, а указатель, тогда в языке Си используется термин «двойной указатель». Например, в листинге 5 определяется элемент связного списка и указатель на первый элемент списка:
struct element
{
struct element * next;
int value;
};
struct element *head = NULL;
Если потребуется передать указатель head в функцию в качестве параметра по ссылке, то необходимо будет использовать двойной указатель:
void insert(struct element **head, int item) { }
Для добавления элемента в пустой список используется вызов:
insert(&head, item);
После этого указатель head будет указывать на первый элемент только что созданного связного списка.
Структуры данных в Python
В языке Python нет стандартного объекта struct, как в языке Си. Но этот объект можно легко реализовать с помощью классов. В листинге 6 представлен вариант преобразования структуры Си в класс Python.
struct Employee {
char * name;
int salary;
}
//объявление класса
class Employee(object):
def __init__(self, name=None, salary=2000):
self.name = name
self.salary = salary
//создание объекта
john = Employee('John Johnson', 3000)
В листинге 7 показано объявления класса, реализующего элемент в связном списке.
class Element:
def __init__(self, value = None, next = None):
self.value = value
self.next = next
По синтаксису это очень похоже на вариант, используемый в языке Си. Однако для параметров конструктора не требуется указывать тип, что значительно облегчает типизацию и решает связанные с этим проблемы.
Ссылки в Python
В Python нет указателей в том смысле, в каком они используются в языке Си. Зато все переменные одновременно являются и ссылками. Эта особенность Python избавляет от необходимости создавать дополнительные объекты типа указателей. При создании переменной в Python автоматически создается и ссылка на этот объект.
Ниже приведен фрагмент кода на языке Си:
int foo = 3;
int &bar = foo;
В нем создаются два объекта - переменная foo и ссылка bar. Оба объекта указывают на один и тот же адрес. Если изменить значение foo, то и значение bar автоматически изменится, и наоборот. Также ссылка bar не может быть переназначена на другой объект, так как ссылки в Си являются неизменяемыми (immutable).
В Python ссылка может быть переназначена, поскольку она одновременно является и переменной. В следующем примере создаются два списка:
>>> a1 = [1, 2, 3]
>>> a2 = [11, 22, 33]
Затем создается новая ссылка на первый список и в этот список добавляется элемент:
>>> b = a1
>>> a1.append(4)
Ссылка b по-прежнему ведет на первый список с уже измененными значениями:
>>> b
[1, 2, 3, 4]
Также можно переназначить ссылку на другой объект:
>>> b = a2
>>> b
[11, 22, 33]
Python также отличается от Си тем, что все параметры, передаваемые в функцию, по умолчанию имеют ссылочный тип. Но если говорить точнее, то почти все, так как в Python есть несколько стандартных типов, на которые это правило не распространяется: например immutable типы: целые и вещественные типы и строки. В листинге 8 в функцию в качестве параметра передается список:
def append(lst):
lst.append(4)
a = [1, 2, 3]
append(a)
print a
После вызова функции список, переданный в качестве параметра, изменится, так как по умолчанию в Python аргументы функции имеют ссылочный тип.
Python относится к динамическим языкам с поздним связыванием (late-binding), так как переменные не имеют типовой привязки к объектам. Поэтому преобразование типов в Python выполняется на лету. Сначала необходимо создать список и ссылку на него, как показано ниже:
>>> a = [1,2]
>>> b = a
Можно проверить, была ли создана новая копия объекта или просто ссылка:
>>>print id(a)
>>>print id(b)
134806220
134806220
Одинаковые значения говорят, что обе переменные - это ссылки, указывающие на один и тот же объект. Теперь можно создать второй объект целочисленного типа на основе уже существующей ссылки и проверить, что получилось:
Разные значения говорят о том, что каждая ссылка указывает на разный объект, причем тип переменной a был неявно изменен.
Списки в языке Python
В общепринятом смысле, список - это структура, состоящая из последовательности элементов, с которой можно выполнять следующие операции:
получить доступ к элементу по индексу;
вставить элемент в произвольную позицию списка;
удалить произвольный элемент;
объединить 2 списка в один;
сделать копию списка;
сортировать список;
найти элемент в списке и т.д.
Для операций вставки и удаления существуют специфические ситуации, связанные с обработкой элементов на первой и последней позициях в списке.
Стек (stack) - список, в котором операции вставки и удаления всегда выполняются над последним элементом. Стек еще называют LIFO-списком: last-in-first-out (последним пришел – первым ушел). В стеке есть верхняя позиция - top, куда всегда добавляется новый элемент, и нижняя позиция - bottom, которая извлекается из стека в последнюю очередь. Очередь (queue) - список, в котором операции вставки и удаления выполняются на разных концах списка. Очереди еще называют FIFO-списками: first-in-first-out (первым пришел – первым ушел).
В языке Python присутствует встроенный тип данных – «список», который можно определить с помощью квадратных скобок:
>>> list = []
Это динамическая структура, способная изменять свой размер в любой момент во время выполнения программы. В языке Си нет аналогичного встроенного типа в силу его низкоуровневости.
//добавление элементов в конец списка
>>> list.append(1)
>>> list.append(2)
//вставка элемента в начало списка
>>> list.insert(0,4)
//удаление элемента со значением 2
>>> list.remove(2)
//поиск позиции элемента в списке
>>> list.index(3)
//сортировка списка
>>> list.sort()
>>> list.reverse()
//реализация стека на основе стандартного списка и методов append() и top()
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack.pop()
>>> stack.pop()
//реализация очереди на основе встроенного класса
from collections import deque
>>> queue = deque([1,2,3,4,5])
>>> queue.append(6)
>>> queue.append(7)
>>> queue.popleft()
Организация списков на основе ссылок
В дальнейшем будут рассматриваться связные списки и деревья, построение которых немыслимо без ссылок. Под ссылкой понимается переменная, хранящая адрес объекта. На рисунке 1 показан список, построенный на основе ссылок.
Элемент FIRST - это переменная-ссылка, указывающая на первый элемент в списке. Такая организация списков, в отличие от традиционных массивов и стандартных списков, имеет следующие особенности, в которых есть как преимущества, так и недостатки.
Преимущества:
Удаление элементов в таком списке более эффективно, нежели удаление элементов из стандартного списка Python, который рассматривался в предыдущем разделе. Так как этот элемент удаляется из середины стандартного списка, то время, необходимое на эту операцию, будет зависеть от нескольких факторов: размера списка, положения удаляемого элемента относительно конца. Чем больше размер списка, тем медленнее будет происходить данная операция. В данном случае со ссылочной организацией списка удаление будет происходить одинаково быстро, независимо от размера списка и относительного положения элемента, так как потребуется всего лишь перевести ссылку в предыдущем элементе на следующий за удаляемым элемент.
То же самое можно сказать и про вставку элементов - она выполняется так же эффективно, как и удаление.
Объединение или разбиение 2-х списков будет выполняться быстрее, нежели в стандартном варианте.
Преимуществом связных списков является и то, что элемент такого списка может иметь произвольную структуру, и включать не одну, а сразу несколько ссылок, что является отличительной особенностью деревьев.
Недостатки:
Требуется выделять дополнительную память на ссылки, которые сами по себе не несут никакой полезной информации.
Доступ к произвольному элементу для стандартного массива в Си и для стандартного списка в Python есть величина постоянная и не зависящая от величины массива. В случае со ссылочными списками время доступа будет зависеть от величины списка, так как потребуется выполнить итерацию по всему списку.
Как видно из представленной информации, оба языка дают возможность создавать новые структуры данных с произвольным набором полей. Ссылочная архитектура переменных в Python позволяет легко переносить на этот язык код, написанный на языке Си. В Python также имеются дополнительные встроенные классы для организации списков. Создание списков на ссылочной основе позволяет преодолеть ограничения встроенных классов и создавать новые структуры данных, отвечающие требованиям приложения.
Часть 2
Связные списки
Массивы и связные списки
Связные списки используются, когда требуется структура данных, размер которой заранее неизвестен. В такие списки можно добавлять и удалять элементы уже после создания самого списка. Однако такой список требует дополнительных усилий для поддержания целостности при динамических операциях, так как при удалении элемента из списка обрывается связь между элементами, находящимися до и после него, и эти элементы необходимо снова связать между собой.
Списки широко используются в реальных проектах - операционных системах, базах данных, но для работы с ними требуется знать, как устроена арифметика указателей. В листинге 1 представлен массив из 100 элементов и инициализируются его первые 3 значения.
int my_array[100];
my_array[0]=1;
my_array[1]=20;
my_array[2]=100;
Физически все 100 элементов располагаются в памяти последовательно, и индекс элемента - это смещение в блоке памяти от его начала, поэтому извлечение элемента по индексу выполняется крайне быстро. Это и есть адресная арифметика, но так как память для стандартного массива выделяется на этапе компиляции, то и модифицировать его впоследствии уже нельзя.
Для выделения памяти для связного списка используется иной механизм, когда память выделяется динамически, во время работы программы. Данный тип памяти называется «куча» (heap) и добавляемые элементы физически могут располагаться в такой куче без всякого упорядочивания.
Создание связного списка на языке Си
Элемент (узел) - это область памяти, в которой хранится ячейка связного списка. Узел односвязного списка состоит из 2-х полей: в первом хранятся данные (это поле также называется ключом), а во втором - указатель на следующий узел. Существует специальный указатель head, указывающий на первый узел списка. Указатель head – это отдельная переменная, не принадлежащая списку. Последний узел в списке указывает на NULL, и для него тоже создается специальная переменная - указатель tail. Если первый элемент указывает на NULL, то это будет пустой список. В листинге 2 приведена структура для определения элемента списка:
Указатель next имеет тот же тип, что и сам элемент, и указывает на следующий элемент списка. В листинге 3 приведен пример создания списка из трех элементов.
// объявить три указателя на элементы списка
// указатель head ведет на первый элемент списка
struct node* head = NULL;
struct node* second = NULL;
struct node* third = NULL;
// выделить память под элементы
// метод sizeof вычисляет размер элемента
// метод malloc выделяет требуемое количество памяти
// установить указатели на выделенные фрагменты памяти
head = malloc(sizeof(struct node));
second = malloc(sizeof(struct node));
third = malloc(sizeof(struct node));
// инициализировать элементы списка и связать их между собой
head->data = 1;
head->next = second;
second->data = 2;
second->next = third;
third->data = 3;
third->next = NULL;
Создание связного списка в Python
В Python существует стандартная реализация списка, но ее не рекомендуется использовать из-за проблем с производительностью при выполнении динамических операций, о чем говорилось в прошлой статье. В листинге 4 представлен класс Node для определения элемента списка.
class Node:
def __init__(self, value = None, next = None):
self.value = value
self.next = next
Для определения связного списка потребуется еще один класс – LinkedList, в конструкторе которого будут определяться первый и последний элементы списка и его длина. Также в классе будут использоваться встроенный метод str для распечатки содержимого списка и метод clear для очистки списка.
import copy
import random
class LinkedList:
def __init__(self):
self.first = None
self.last = None
self.length = 0
def __str__(self):
if self.first != None:
current = self.first
out = 'LinkedList [\n' +str(current.value) +'\n'
while current.next != None:
current = current.next
out += str(current.value) + '\n'
return out + ']'
return 'LinkedList []'
def clear(self):
self.__init__()
//создание связного списка из 3-х элементов
L = LinkedList()
L.add(1)
L.add(2)
L.add(3)
Определение длины списка
Чтобы определить размер связного списка, необходимо пройти по списку и посчитать количество узлов. В листинге 6 приведена функция для подсчета числа узлов.
int Length(struct node* head)
{
struct node* current = head;
int count = 0;
while (current != NULL)
{
count++;
current = current->next;
}
return count;
}
В этой функции создается дополнительный указатель current, с помощью которого выполняется ИТЕРАЦИЯ связного списка:
current = current->next;
При этой операции со списком ничего не происходит, но указателю НАЗНАЧАЕТСЯ новое значение. Если вызвать эту функцию для пустого списка, у которого вершина равна NULL, то функция вернет ноль. Для определения длины списка в Python используется функция Len (см. листинг 7), которая вначале проверяет, не является ли список пустым, а затем выполняет итерацию по элементам списка.
void Push(struct node** headRef, int data)
{
struct node* newNode = malloc(sizeof(struct node));
newNode->data = data;
newNode->next = *headRef;
*headRef = newNode;
}
// пример использования этой функции
struct node* head = NULL; // создание первого элемента
Push(&head, 1);
Push(&head, 2);
Push(&head, 3);
Символ & - это указание компилятору, что параметр передается по ссылке, т.е. все изменения, которые будут сделаны с этим параметром внутри функции, останутся актуальными для переданного объекта и после выхода из функции. При передаче параметров по ссылке нужно следовать трем правилам:
в определении функции для указателей нужно использовать двойной указатель **;
при вызове функции перед ссылочным параметром нужно поставить &;
в самой функции к ссылочному параметру обращаться через указатель *.
В Python-реализации учитываются два варианта: в первом случае список пуст, а во втором создается новый узел, в конструктор которого в качестве второго параметра передается головной элемент списка.
Добавление элементов в конец списка
В листинге 10 представлен пример добавления элементов в конец списка.
struct node* AppendNode(struct node** headRef, int num)
{
struct node* current = *headRef;
struct node* newNode;
newNode = malloc(sizeof(struct node));
newNode->data = num;
newNode->next = NULL;
// если список пуст
if (current == NULL) {
*headRef = newNode;
}
else {
// иначе
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
В представленном коде выполняется итерация по списку для поиска последнего элемента, а затем его указатель next устанавливается на добавляемый элемент.
def add(self, x):
if self.first == None:
self.first = Node(x, None)
self.last = self.first
elif self.last == self.first:
self.last = Node(x, None)
self.first.next = self.last
else:
current = Node(x, None)
self.last.next = current
self.last = current
Вставка элемента на определенную позицию в списке
Для вставки элемента в список необходимо передать указатель на головной элемент, индекс позиции, куда будет вставлен элемент, и, собственно, сам элемент. Если индекс равен нулю, то вызывается функция Push, в противном случае выполняется итерация, а затем снова происходит вызов Push.
void InsertNth(struct node** headRef, int index, int data)
{
if (index == 0) Push(headRef, data);
else
{
struct node* current = *headRef;
int i;
for (i=0; i<index-1; i++)
{
current = current->next;
}
Push(&(current->next), data);
}
}
В Python необходимо сначала проверить, что список не пуст, а затем, что вставка не происходит на нулевую позицию. Если оба условия не выполняются, то происходит итерация по списку до нужной позиции и добавление элемента:
def InsertNth(self,i,x):
if (self.first == None):
self.first = Node(x,self.first)
self.last = self.first.next
return
if i == 0:
self.first = Node(x,self.first)
return
curr=self.first
count = 0
while curr != None:
if count == i-1:
curr.next = Node(x,curr.next)
if curr.next.next == None:
self.last = curr.next
break
curr = curr.next
Удаление головного элемента
Функция Pop удаляет из списка головной узел, вместе с функцией Push она реализует функциональность стека, отцепляя головной элемент от списка и освобождая память. Функция принимает на вход двойной указатель на головной элемент, а возвращает значение удаленного элемента.
Для реализации на Python потребуется создать временную локальную переменную для хранения головного элемента. Если список не пустой, то головным узлом становится элемент, следующий за узлом, сохраненным во временной переменной.
int Del(struct node ** head,int index)
{
int data = (*head)->data;
if(index==0) Pop(head);
else
{
int i;
struct node * current = *head;
for(i=0;i<index-1;i++)
current=current->next;
Pop(&(current->next));
}
return data;
};
В реализации для Python потребуется проверить список на пустоту и объявить две локальных переменных: первая будет хранить текущий элемент, а вторая - предыдущий. Потом выполняется итерация по списку для поиска удаляемого элемента и проверка того, не является ли он последним в списке. Если удаляемый элемент является последним, то предыдущий узел становится последним, в противном случае предыдущий узел связывается со следующим узлом вместо текущего.
def Del(self,i):
if (self.first == None):
return
old = curr = self.first
count = 0
if i == 0:
self.first = self.first.next
return
while curr != None:
if count == i:
if curr.next == self.last:
self.last = curr
break
else:
old.next = curr.next
break
old = curr
curr = curr.next
count += 1
Вставка элемента в отсортированный список
В листинге 18 представлена функция для вставки элемента в отсортированный список. Как обычно, сначала выполняется проверка, что список не пустой, а затем итерация в поисках ближайшего элемента, значение которого меньше, чем у добавляемого.
В реализации на языке Python выполняется проверка списка на пустоту, а затем выполняется итерация с помощью двух временных переменных, как и в листинге 18.
def SortedInsert(self,x):
if (self.first == None):
self.first = Node(x,self.last)
return
if self.first.value > x:
self.first = Node(x,self.first)
return
old = curr = self.first
while curr != None:
if curr.value > x:
curr = Node(x,curr)
old.next = curr
return
old = curr
curr = curr.next
curr = Node(x,None)
old.next = curr
Удаление повторяющихся значений
Данная функция должна применяться к уже отсортированному списку. В качестве параметра в неё передается головной узел списка, и если в ходе итерации текущий элемент оказывается равным следующему за ним, то текущий элемент удаляется.
void RemoveDuplicates(struct node* head)
{
struct node* current = head;
if (current == NULL) return;
while(current->next!=NULL)
{
if (current->data == current->next->data)
{
struct node* nextNext = current->next->next;
free(current->next);
current->next = nextNext;
}
else
{
current = current->next;
}
}
}
В версии на языке Python добавляется флаг, отмечающий наличие повторяющегося элемента. Этот флаг устанавливается при удалении повторяющегося элемента, и итерация прекращается, в противном случае итерация продолжается.
def RemoveDuplicates(self):
if (self.first == None):
return
old = curr = self.first
while curr != None:
_del = 0
if curr.next != None:
if curr.value == curr.next.value:
curr.next = curr.next.next
_del = 1
if _del == 0:
curr = curr.next
Копирование списков
В листинге 22 показана функция для копирования списков. В ней используется три указателя: на первый элемент оригинального списка и на первый и последний элементы скопированного списка.
В Python для копирования списков можно использовать стандартный модуль copy, как показано ниже.
import copy
L2 = copy.deepcopy(L) // создание копии списка L
Тестирование производительности
Следующий тест показывает основное преимущество компилируемых языков перед интерпретаторами - преимущество в скорости.
В следующем тесте создается одно-связный список длиной в 2000 нод, при этом ключ в ноде может иметь
значение от 0 до 100. Ноды вставляются в отсортированном порядке. Т.е. например начало списка может быть таким:
0 1 1 2 2 2 2 3 4 5 7 9 10 10 10 .....
Выяснилась следующая вещь: реализация одного и того же алгоритма вставки случайных нод в связный список
в отсортированном порядке ведет себя по-разному в зависимости от языка, а также от величины списка.
Различия начинают сильно проявляться начиная с длины списка от нескольких тысяч, причем не в пользу питона.
Итерация в питоне начинает тормозить на моей машине начиная где-то с 2-х тысяч. Профайл теста показывает,
что основная потеря процессорного времени уходит именно на итерацию.
Тестовый код:
import profile
import random
import time
class Node:
def __init__(self, value = None, next = None):
self.value = value
self.next = next
class LinkedList:
def __init__(self):
self.first = None
self.last = None
self.old = None
self.curr = None
self.ins = 0
def __str__(self):
if self.first != None:
current = self.first
out = 'LinkedList = ' +str(current.value) +' '
while current.next != None:
current = current.next
out += str(current.value) + ' '
return out + ''
return ''
def main():
t1 = time.time()
L = LinkedList()
for i in range ( 0, 2000 ) :
_r = int ( random.uniform ( 0, 100 ) )
if L.first == None:
L.first = Node(i,None)
elif L.first.value > _r:
L.first = Node(_r,L.first)
else:
L.old = L.curr = L.first
L.ins=0
while L.curr != None:
if L.curr.value > _r:
L.curr = Node(_r,L.curr)
L.old.next = L.curr
L.ins = 1
break
L.old = L.curr
L.curr = L.curr.next
if L.ins == 0:
L.curr = Node(_r,None)
L.old.next = L.curr
print L
t2 = time.time()
print "\t%.1f" % ((t2 - t1))
profile.run('main()')
Си-шный вариант теста:
#include < stdio.h>
#include < stdlib.h>
#include < time.h>
struct node
{
int data;
struct node * next;
};
void SortedInsert(struct node** headRef, struct node* newNode)
{
if (*headRef == NULL || (*headRef)->data >= newNode->data)
{
newNode->next = *headRef;
*headRef = newNode;
}
else
{
struct node* current = *headRef;
while (current->next!=NULL && current->next->data < newNode->data)
{
current = current->next;
}
newNode->next = current->next;
current->next = newNode;
}
}
int main()
{
time_t start,end;
volatile long unsigned t;
start = time(NULL);
struct node * List = NULL;
struct node * new;
int i = 0 ;
srand((unsigned int)time(NULL));
for (i = 0; i< 2000 ; i++)
{
new = malloc(sizeof(struct node));
new->data = rand() % 100 + 1;
SortedInsert(&List,new);
}
end = time(NULL);
printf("Loop %f seconds.\n", difftime(end, start));
return 0;
}
Си-шная версия работает практически мгновенно, хотя и ее можно заставить тормозить, но это начинается с гораздо
более высокого числового порога. Питоновскую же версию не спасают попытки сделать оптимизацию кода,
например за счет сокращения вызовов функции SortedInsert. При динамическом создании обьектов в питоне
начиная с определенного момента начинаются проблемы с их итерацией.
В ходе тестирования было выяснено, что реализация одного и того же алгоритма для вставки элементов в отсортированный
связный список ведет себя по-разному в зависимости от языка и размера списка.
Производительность Python-реализации начинает снижаться, когда в списке накапливается более 2-х тысяч элементов.
Анализ результатов теста показывает, что основные потери процессорного времени происходят во время итерации.
Исходный код тестов на языках Си и Python можно найти в архиве performance_benchmark.zip, прикрепленном к статье. Реализация на языке Си работает гораздо быстрее, и ее производительность начинает снижаться, когда размер списка становится значительно больше 2-х тысяч элементов. Версию на языке Python не спасает даже оптимизация кода за счет сокращения вызовов функции SortedInser, так как из-за динамического создания объектов в Python, начиная с определенного момента, возникают проблемы при итерации.
Cвязные списки предоставляют богатый набор функций для добавления и удаления элементов, сортировки, копирования и других операций. Поэтому связные списки являются «краеугольным камнем» и первой ступенью для изучения других структур данных связного типа.
Часть 3
Классификация связных списков
История связных списков
Основной принцип связных списков крайне прост: эта структура данных состоит из последовательности записей, в которой каждая запись хранит помимо самих данных еще и ссылку на следующую запись в этой последовательности. На рисунке 1 изображен связный список из трех записей, каждая запись которого состоит из поля данных - целого числа и ссылки на следующую запись.
У последней записи на рисунке отсутствует ссылка, но она есть и указывает на NULL. На основе списков можно реализовать структуры данных, такие как стеки, очереди и ассоциативные массивы.
Ранее уже упоминалось, что в массиве все элементы расположены в памяти по порядку, а в списке они в памяти никак не упорядочены. Более того, элемент может быть добавлен в любую позицию в списке. Однако сама операция по вставке элемента в список требует дополнительных ресурсов, так как нужно последовательно просканировать список для поиска нужной позиции.
В классическом языке Си есть только массив, но отсутствует встроенная реализация связного списка. Однако в других языках, например, в Lisp, существует встроенная реализация данной структуры. Официальная «дата рождения» связных списков - 1955 год, когда они появились на стыке логической теории машин и алгоритмов для решения шахматных задач. Тогда же связные списки начали использоваться для решения проблем трансляции натуральных языков в лингвистических задачах. В 1958 году появился язык Lisp, и связный список стал одной из базовых структур этого языка.
Связные списки стали применяться и при разработке операционных систем, например, для реализации файловых систем. Так, для операционной системы TSS/360 компания IBM разработала двойные связные списки и утилиту на их основе для исправления ошибок в файловой системе. Если при сканировании каталога обнаруживался поврежденный элемент, то происходил откат с заменой поврежденного элемента на его предыдущую версию.
Основные правила реализации связных списков
Список состоит из элементов, называемых узлами (node). Первый узел списка называется «головным» (head), а последний - «хвостовым» (tail). На рисунке 2 изображен двойной связный список.
Каждый элемент состоит из 3-х полей, два из которых являются указателями на предыдущий или следующий узел. Элемент может указывать и более чем на два узла, и в этом случае список называется многосвязным.
Помимо упоминавшихся ранее стандартных массивов существуют еще динамические массивы. Размер обычного массива является фиксированной величиной, а в динамический массив можно добавлять или удалять из него элементы. Если элемент добавляется в середину динамического массива, то происходит перераспределение элементов, находящихся справа от него, так как все элементы массива должны быть расположены в памяти строго по порядку. Поэтому вставка элемента в динамический массив требует дополнительных ресурсов, если элемент добавляется не в конец массива. Преимущество связного списка в том, что не требуется перестраивать последовательность узлов, независимо от того, в какую позицию списка вставляется новый элемент. Недостаток связных списков – это последовательный доступ (sequential access) к элементам, тогда как для массивов время доступа постоянно и не зависит от размера - random access. Если приложению требуется быстрый поиск элемента по индексу, то в данном случае списки не
подходят, и лучше воспользоваться массивами.
Еще один негативный момент при использовании связных списков связан с нерациональным использованием памяти. Если в узле хранится небольшая порция данных, например, булевское значение, то список становится неэффективными из-за того, что объем памяти, выделяемой под хранение связей, превышает объем памяти, выделяемой под хранение «полезной нагрузки». Для решения этой проблемы существуют развернутые связные списки - unrolled linked list, каждый элемент которого включает целый массив данных. Пример такого списка приведен в листинге 1.
record node
{
node next;
int numElements;
array elements;
}
Связный список - это рекурсивная структура, так как узел всегда содержит указатель на следующий узел. Это позволяет использовать простой рекурсивный алгоритм для таких операций, как объединение двух списков или изменение порядка элементов на обратный. У односвязных списков есть важное преимущество: если к вершине такого списка добавляется новый элемент, то старый список будет по прежнему доступен по ссылке на только что добавленный узел. Этот прием называется persistent data structure (постоянное хранение данных). У двусвязных списков есть свои преимущества, так как они позволяют выполнять итерацию в обоих направлениях, в отличие от односвязных списков.
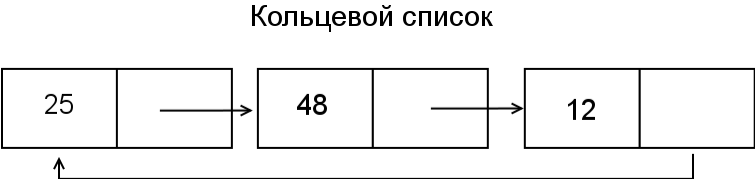
Если последний элемент будет указывать на первый элемент списка, то такая структура называется циклическим замкнутым (или кольцевым (circular)) списком. Кольцевые списки можно использовать для списка процессов, в которых применяется «карусельный» (round-robin) алгоритм. Для такого списка достаточно иметь один указатель, который одновременно указывает и на конец, и на начало очереди. Кольцевой список можно разбить на два кольцевых списка или, наоборот, объединить.
Техническая задача разбивается на ряд подзадач, при этом выполнение одних подзадач должно предшествовать выполнению других подзадач. Топологическая сортировка означает выполнение подзадач в таком порядке, чтобы перед началом выполнения каждой подзадачи все необходимые для этого подзадачи были уже выполнены.
В программе некоторые процедуры могут вызывать другие процедуры. Топологическая сортировка предполагает расположение описаний процедур в таком порядке, чтобы вызываемые процедуры описывались раньше тех, которые их вызывают.
Под топологической сортировкой понимается сортировка элементов, для которых определен частичный порядок, т.е. упорядочивание задано не для всех, а только для некоторых пар элементов.
Предполагается, что существует множество из 3-х элементов a, b и c, которое удовлетворяет трем правилам:
транзитивность: если a < b и b < c , то a < c;
асимметричность: если a < b , то не b < a;
антирефлексивность: невозможность a < a.
Цель топологической сортировки - преобразование частичного порядка в линейный. Графически процесс топологической сортировки показан на рисунках 4 и 5.
Топологическая сортировка начинается с того, что во множестве выбирается элемент, которому не предшествует никакой другой. Этот элемент помещается в начало списка и исключается из множества. В оставшемся множестве опять выбирается такой же по свойству элемент, и все повторяется до тех пор, пока множество не станет пустым. Для подобного алгоритма потребуются две структуры, первая будет называться лидером (leader), а вторая - ведомой (trailer).
Элемент исходного множества, содержащийся в нем только один раз, является лидером, а остальные — ведомыми. Первоначально исходное множество задается в виде списка пар, как показано в листинге 3.
На первом шаге эти пары читаются и создается список лидеров. Затем для каждого лидера формируется свой список ведомых. На платформе Unix есть специальная консольная утилита tsort, которая получает на вход список пар и выдает конечный линейный список.
Иосиф Флавий - это исторический деятель, живший в первом веке нашей эры, с которым была связана одна драматическая история.
Однажды он и еще 40 солдат оказались запертыми в пещере. Они решили не сдаваться римлянам, убив себя самих.
Они встали в круг, 40 человек. Выбрали первого, который убил себя тут же на месте.
Затем отсчитали по кругу, по часовой стрелке, троих, и тот, на кого упал счет, также убил себя.
И так далее по кругу, отсчитывая троих. В конце концов в круге осталось всего 2 человека,
одним из которых и был Flavius Josephus. Они и вышли к римлянам живыми вдвоем.
Об этой истории можно прочесть по
ссылке,
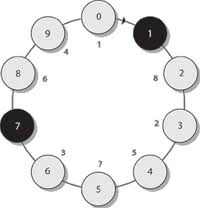
но в рамках статьи больший интерес представляет математическая задача, связанная с этой историей. В этой задаче предлагается вычислить, какой элемент останется последним в списке, если из списка последовательно будет удаляться каждый третий элемент, как показано на рисунке 6.
На рисунке 6, если начать отсчет с нулевого индекса, продвигаться по часовой стрелке и уничтожать каждый третий элемент, то останутся только элементы с индексами 1 и 7. Для моделирования этой ситуации можно взять кольцевой связный список или обычный массив. В связном списке удалить элемент гораздо проще, чем найти последний узел, который останется после удаления всех узлов, не удаляя физически элементов из списка.
В представленном алгоритме для решения задачи Иосифа Флавия для поиска последнего «оставшегося в живых» элемента используется двусвязный круговой список. В процессе поиска происходит динамическое удаление элементов из списка и перестройка связей для поддержки целостности списка. Оба варианта решения задачи на языках Си и Python находятся в файлах last_man_standing_task.c и last_man_standing_task.py, упакованных в архив sources.zip, прикрепленный к статье. Реализация алгоритма на языке Python получилась в два раза компактнее, чем на языке Си.
Использование связных списков в ядре Linux
В ядре Linux применяется особая реализация связных списков, в которой используются специальные алгоритмы для добавления/удаления элементов в список. В листинге 5 показан элемент связного списка, включающий структуру list_head.
struct mystruct
{
int data ;
struct list_head mylist ;
} ;
Если структуру list_head добавить к любой другой структуре, то эта структура станет частью связного списка. В листинге 6 создаются два элемента связного списка и инициализируются двумя различными способами.
Метод LIST_HEAD_INIT, используемый в первом варианте, - это следующий макрос:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
В ядре Linux макросы используются вместо обычных функций, так как макросы позволяют сгенерировать более эффективный код, что положительно сказывается на производительности. Во втором варианте используется inline-функция, приведенная в листинге 7.
Как видно из определения, создаваемый список является двусвязным, так как в нем содержатся указатели на следующий и предыдущий элементы. Использование inline-функции вместо обычной также окажет положительное влияние на производительность. Когда компилятор будет генерировать исполняемый код этой функции, то он поместит его в объектном файле непосредственно в то место, где была вызвана эта функция. Благодаря этому не потребуется тратить ресурсы на вызов функции.
Для создания самого списка, также будет использоваться макрос - LIST_HEAD:
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
А для добавления элементов будет использоваться inline-функция list_add, которая служит «оболочкой» для вызова еще одной функции __list_add.
В результате получится связный список, состоящий из 2-х элементов, и указатель на первый элемент в переменной mylinkedlist. Для просмотра содержимого списка или выполнения итерации также используются макросы с целью получения быстрого и эффективного исполняемого кода.
struct list_head* position ;
list_for_each ( position , & mylinkedlist )
{
printk ("surfing the linked list next = %p and prev = %p\n" ,
position->next,
position->prev );
}
Исходный код в листинге 11 суммирует всю информацию, представленную в этой статье. В нем демонстрируется реализация связного списка с помощью макроса define_list, принимающего на вход два параметра - имя списка и тип элемента. Также в листинге 11 объявлены уже знакомые и новые inline-функции, обеспечивающие функциональность связного списка. В методе main объявленные методы и структуры используются для создания связного списка из пяти элементов и последующей итерации по нему.
Ниже предлагается алгоритм решения проблемы иосифа, где будет использован циркулярный список,
при этом будет найдена последняя оставшаяся в живых нода. Используется дву-связный
циркулярный список. В процессе поиска происходит динамическое удаление нод из списка и необходимая
перестройка связей для поддержки целосности списка.
#include < stdio.h>
#include < stdlib.h>
#include < time.h>
#include < sys/time.h>
class Person
{
public:
Person(int count) : _next(NULL), _prev(NULL) { _count = count; }
int shout(int shout, int nth)
{
if (shout < nth) return (shout + 1);
_prev->_next = _next;
_next->_prev = _prev;
return 1;
}
int count() { return _count; }
Person* next() { return _next; }
void next(Person* person) { this->_next = person ; }
Person* prev() { return _prev; }
void prev(Person* person) { this->_prev = person; }
private:
int _count;
Person* _next;
Person* _prev;
};
class Chain
{
public:
Chain(int size) : _first(NULL)
{
Person* current = NULL;
Person* last = NULL;
for(int i = 0 ; i < size ; i++)
{
current = new Person(i);
if (_first == NULL) _first = current;
if (last != NULL)
{
last->next(current);
current->prev(last);
}
last = current;
}
_first->prev(last);
last->next(_first);
}
Person* kill(int nth)
{
Person* current = _first;
int shout = 1;
while(current->next() != current)
{
Person* tmp = current;
shout = current->shout(shout,nth);
current = current->next();
if (shout == 1)
{
printf("kill %d\n",tmp->count());
delete tmp;
}
}
_first = current;
return current;
}
Person* first() { return _first; }
private:
Person* _first;
};
int main(int argc, char** argv)
{
Chain* chain;
chain = new Chain(10);
printf("result: %d\n",chain->kill(3)->count());
delete chain;
return 0;
}
Аналогичная реализация на питоне:
class Person(object):
def __init__(self,count):
self.count = count;
self.prev = None
self.next = None
def shout(self,shout,deadif):
if (shout < deadif): return (shout + 1)
self.prev.next = self.next
self.next.prev = self.prev
return 1
class Chain(object):
def __init__(self,size):
self.first = None
last = None
for i in range(size):
current = Person(i)
if self.first == None : self.first = current
if last != None :
last.next = current
current.prev = last
last = current
self.first.prev = last
last.next = self.first
def kill(self,nth):
current = self.first
shout = 1
while current.next != current:
shout = current.shout(shout,nth)
if shout ==1:
print current.count
current = current.next
self.first = current
return current.count
import time
chain = Chain(40)
print chain.kill(3)
В данной статье рассматривались связные списки, которые относятся к наиболее важным структурам данных, использующихся в современном программировании. В статье рассматривались как теоретические аспекты со связными списками (задача Иосифа Флавия), так и практическая реализация связных списков в ядре ОС Linux. Для теоретической задачи была разработана реализация на двух различных языках программирования: Си и Python. Однако практическая задача была решена с помощью языка Си, так как в нем имеются такие возможности, как inline-функции и макросы, благодаря использованию которых можно значительно увеличить скорость работы приложения.
Часть 4
Связные списки и сортировка
Типы сортировок
Сортировка – это процесс перестановки объектов конечного множества в определенном порядке, предназначенный для облегчения последующего поиска элементов в уже отсортированном множестве. Для сортировки можно использовать огромное множество алгоритмов, поэтому часто требуется выполнить сравнительный анализ нескольких алгоритмов, чтобы определить оптимальный выбор для конкретной задачи.
Методы сортировки обычно разделяются на две категории: сортировка массивов и сортировка файлов, также называемые внутренней и внешней сортировкой, так как массивы располагаются во внутренней памяти, а файлы во внешней. Важнейшее требование к алгоритмам для сортировки массивов и связных списков - экономное расходование памяти, поэтому использование дополнительных массивов для сортировки считается дурным тоном.
Основным критерием для классификации алгоритмов сортировки является их быстродействие. При сортировке выполняются два типа операций - сравнение ключей и перестановка элементов (в случае со связными списками - переназначение указателей). Если в массиве n элементов, то алгоритм считается хорошим, если число перестановок равно произведению числа элементов массива n на логарифм этого числа log(n). Например, стандартная пузырьковая сортировка требует числа перестановок, равного квадрату от n.
Методы сортировки можно разбить на три основных класса:
сортировка включениями;
сортировка выбором;
сортировка обменом.
Принцип, лежащий в основе первого класса, заключается в том, что массив разбивается на две половины - итоговую и входную. Берется элемент из входной половины и вставляется в итоговую в порядке сортировки. Число перестановок элементов в общем случае равно квадрату от n.
В случае сортировки выбором алгоритм таков: берется минимальный элемент массива и ставится в начало массива, и т.д. Число перестановок элементов в общем случае меньше, чем в первом случае, и будет равно произведению числа элементов массива на логарифм от этого числа. Быстрая сортировка относится ко второму классу.
Пузырьковая сортировка
Первым будет рассматриваться алгоритм пузырьковой сортировки, который требует порядка n*n перестановок, поэтому является не самым удачным выбором. В функции llist_bubble_sort, приведенной в листинге 1, выполняется вложенная итерация по списку, с помощью которой реализуется алгоритм пузырьковой сортировки для языка Си.
import random
lista = []
for i in range ( 0, 10 ) :
lista.append ( int ( random.uniform ( 0, 10 ) ) )
print lista
def bubble_sort ( lista ) :
swap_test = False
for i in range ( 0, len ( lista ) - 1 ):
for j in range ( 0, len ( lista ) - i - 1 ):
if lista[j] > lista[j + 1] :
lista[j], lista[j + 1] = lista[j + 1], lista[j]
swap_test = True
if swap_test == False:
break
bubble_sort ( lista )
print lista
В листинге 3 приведен исходный код пузырьковой сортировки для Python, но уже на основе связных списков.
import random
class Node:
def __init__(self, value = None, next = None):
self.value = value
self.next = next
def __str__(self):
return 'Node ['+str(self.value)+']'
class LinkedList:
def __init__(self):
self.first = None
self.last = None
self.length = 0
def add(self, x):
if self.first == None:
self.first = Node(x, None)
self.last = self.first
elif self.last == self.first:
self.last = Node(x, None)
self.first.next = self.last
else:
current = Node(x, None)
self.last.next = current
self.last = current
def __str__(self):
if self.first != None:
current = self.first
out = 'LinkedList [ ' +str(current.value) +' '
while current.next != None:
current = current.next
out += str(current.value) + ' '
return out + ']\n'
return 'LinkedList []'
def BubbleSort(self):
a = Node(0,None)
b = Node(0,None)
c = Node(0,None)
e = Node(0,None)
tmp = Node(0,None)
while(e != self.first.next) :
c = a = self.first
b = a.next
while a != e:
if a and b:
if a.value > b.value:
if a == self.first:
tmp = b.next
b.next = a
a.next = tmp
self.first = b
c = b
else:
tmp = b.next
b.next = a
a.next = tmp
c.next = b
c = b
else:
c = a
a = a.next
b = a.next
if b == e:
e = a
else:
e = a
L = LinkedList()
for i in range ( 0, 10 ) :
L.add ( int ( random.uniform ( 0, 10 ) ) )
print L
L.BubbleSort()
print L
Как можно увидеть, код в листинге 3 очень похож на код на языке Си, приведенный в листинге 1, поскольку в Python работа со ссылками на объекты реализована практически так же, как и в языке Си.
Быстрая сортировка
В данном разделе будет рассмотрен алгоритм быстрой (quicksort) сортировки двусвязного списка, на основе рекурсивной функции QuickSortList, представленной в листинге 4. Данная функция работает следующим образом:
выполняется итерация по списку;
в ходе итерации определяется максимальное значение, которое записывается в конец массива;
выполняется следующая итерация, но без только что найденного максимума и т.д.
struct node
{
int number;
struct node *next;
};
struct node *addnode(int number, struct node *next)
{
struct node *tnode;
tnode = (struct node*)malloc(sizeof(*tnode));
if(tnode != NULL)
{
tnode->number = number;
tnode->next = next;
}
return tnode;
}
int Length(struct node* head)
{
int count = 0;
struct node* current = head;
while (current != NULL)
{
count++;
current = current->next;
}
return(count);
}
void FrontBackSplit(struct node* source,
struct node** frontRef,
struct node** backRef)
{
int len = Length(source);
int i;
struct node* current = source;
if (len < 2)
{
*frontRef = source;
*backRef = NULL;
}
else
{
int hopCount = (len-1)/2;
for (i = 0; i<hopCount; i++)
{
current = current->next;
}
// исходный список разбивается на два подсписка
*frontRef = source;
*backRef = current->next;
current->next = NULL;
}
}
struct node* SortedMerge(struct node* a, struct node* b)
{
struct node* result = NULL;
if (a==NULL) return(b);
else if (b==NULL) return(a);
if (a->number <= b->number)
{
result = a;
result->next = SortedMerge(a->next, b);
}
else
{
result = b;
result->next = SortedMerge(a, b->next);
}
return(result);
}
void MergeSort(struct node** headRef)
{
struct node* head = *headRef;
struct node* a;
struct node* b;
// вырожденный случай – длина списка равно 0 или 1
if ((head == NULL) || (head->next == NULL))
{
return;
}
FrontBackSplit(head, &a, &b);
MergeSort(&a); // рекурсивная сортировка подсписков
MergeSort(&b);
*headRef = SortedMerge(a, b);
}
Сравнение различных алгоритмов
После изучения различных алгоритмов сортировки можно выполнить их сравнительное тестирование. В качестве исходной позиции будет использоваться односвязный список длиной в 50000 элементов, при этом ключ в элементе может иметь значение от 0 до 100. Элементы вставляются в произвольном порядке, и исходный список может иметь следующий вид:
0 10 10 2 9 7 2 3 4 5 2 2 10 1 1 .....
А после сортировки список должен иметь следующий вид:
0 1 1 2 2 2 2 3 4 5 7 9 10 10 10 .....
В ходе теста будут фиксироваться три временных отметки: запуск программы, начало и конец сортировки. Наибольший интерес будет представлять время, непосредственно затраченное на сортировку. В листинге 6 приведен исходный код функции main для оценки производительности пузырьковой сортировки.
int main ()
{
time_t start,time2,end;
volatile long unsigned t;
start = time(NULL);
for(int i = 0; i < 50000; i++)
{
AddListItem((rand() % 100));
}
time2 = time(NULL);
printf("на подготовку потребовалось %f секунд.\n", difftime(time2, start));
QuickSortList(g_pFirstItem, g_pLastItem);
end = time(NULL);
printf("на сортировку потребовалось %f секунд.\n", difftime(end, time2));
return 0;
}
В случае с сортировкой слиянием главная проблема связана с увеличением стека при рекурсии, так как при увеличении длины списка свыше 50000 элементов могут возникнуть ошибки. Функция main для сортировки слиянием показана в листинге 8.
int main(void)
{
time_t start,time2,end;
volatile long unsigned t;
start = time(NULL);
struct node *head;
int i;
head = NULL;
for( i = 0; i < 100; i++)
{
head = addnode((rand() % 100), head);
}
time2 = time(NULL);
printf("на подготовку потребовалось %f секунд.\n", difftime(time2, start));
MergeSort(&head) ;
end = time(NULL);
printf("на сортировку потребовалось %f секунд.\n", difftime(end, time2));
return 0;
}
Стоит учесть, что этот тест не претендует на звание «абсолютной истины», так как речь идет о конкретной реализации, применяемой на конкретной системе. Наихудший результат, как и ожидалось, показала пузырьковая сортировка, которой на то, чтобы упорядочить связный список из 50000 элементов, потребовалось более 30 секунд. Быстрая сортировка справилась с этой же задачей за 10 секунд. А самой производительной оказалась сортировка слиянием, выполнив задачу еще быстрее, чем быстрая сортировка. Также тест выявил следующие закономерности.
Наибольшее число перестановок требуется пузырьковой сортировке, затем идет быстрая сортировка, и меньше всего перестановок требуется для сортировки слиянием.
При увеличении длины списка отношение числа перестановок в пузырьковой сортировке к числу перестановок в быстрой сортировке растет не в пользу первой, то есть при увеличении размера списка производительность пузырьковой сортировки начинает снижаться.
Сортировка слиянием имеет самые лучшие показатели по числу перестановок. Аналогичное соотношение числа перестановок для быстрой сортировки и сортировки слиянием при увеличении длины списка изменяется в пользу быстрой сортировки: чем больше список, тем меньше это соотношение, хотя и остается больше единицы.
Как было показано в данной статье, при использовании различных алгоритмов для сортировки связных списков можно добиться очень высокой производительности, невзирая на большой размер списка. Однако конечный результат зависит от целого комплекса факторов: эффективного использования памяти, глубины рекурсии, производительности целевой системы и т.д.
Часть 5
Деревья
Начиная с этой статьи мы переходим от связных списков к изучению деревьев. Это не случайно, так оба эти типа структур данных построены на основе рекурсии. Фактически, связные списки являются подвидом деревьев, называемым вырожденным деревом. В данной статье будут рассмотрены общие принципы построения деревьев и различные варианты обхода узлов дерева.
Первое появление концепции дерева в математике зафиксировано в середине 19-го века, а затем деревья стали использоваться в самых разных областях, например, в теории электрических цепей или химической изометрии. Использование древовидных структур в информационных технологиях началось с приложений для манипулирования алгебраическими формулами в 60-ых годах прошлого века, примерно тогда же появились традиционные алгоритмы для обхода деревьев.
В общем смысле, дерево - это иерархическая структура, хранящая коллекцию объектов. Деревья широко применяются в компьютерных технологиях, и самым близким примером является файловая система, представляющая собой иерархическую структуру из файлов и каталогов. Дерево (англ. tree) — это непустая коллекция вершин и ребер, удовлетворяющих определенным требованиям. Вершина (англ. vertex) — это объект, называемый также узлом (англ. node) по аналогии со списками, который может иметь имя и содержать другую информацию. Ключевое свойство дерева — между любыми двумя узлами существует только один путь, соединяющий их. Если между какой-либо парой узлов существует более одного пути или если между какой-либо парой узлов путь отсутствует, то подобная структура называется графом, а не деревом. Несвязанный набор деревьев называется лесом (англ. forest).
Для определения узлов существуют следующие сложившиеся термины:
root - узел, расположенный в корне дерева;
siblings - узлы, имеющие одного и того же родителя;
ancestor или parent – родительский узел;
descendant – дочерний узел;
size – размер узла, равный количеству дочерних узлов плюс один.
В рамках данной статьи будут обсуждаться деревья с произвольным количеством дочерних узлов. Упорядоченное (англ. ordered) дерево — это дерево с определенным корневым узлом, в котором также определен порядок следования дочерних узлов для каждого узла.
Деревья можно разделить на следующие категории:
деревья без корня;
деревья с корнем;
упорядоченные деревья;
м-арные и бинарные деревья.
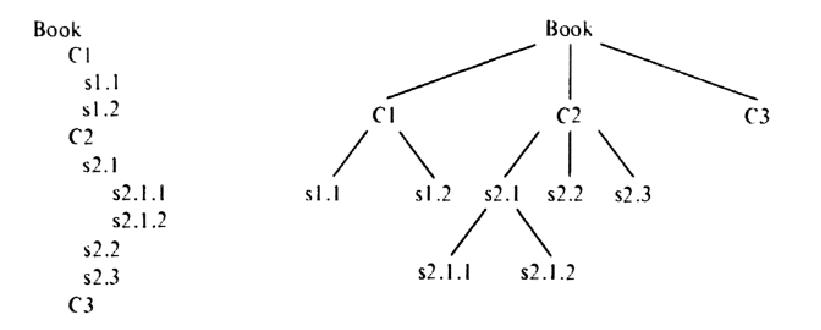
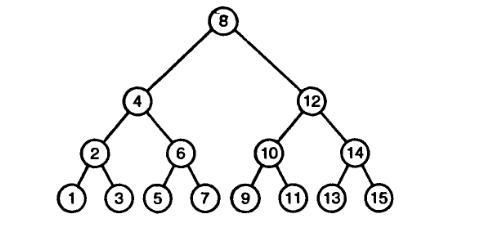
На рисунке 1 показано, как оглавление книги можно представить в виде дерева. В показанном примере корневой узел имеет три поддерева – три главы, каждая из которых в свою очередь имеет свои подразделы.
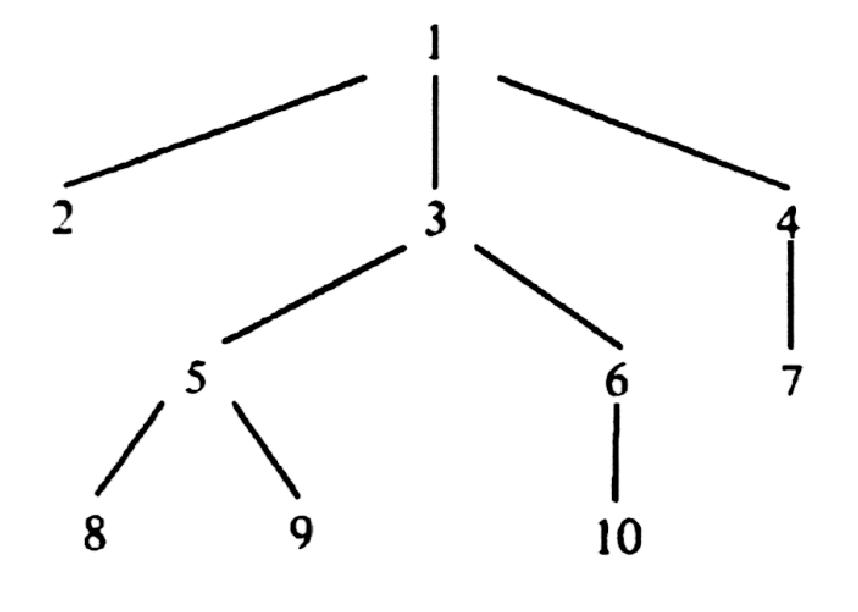
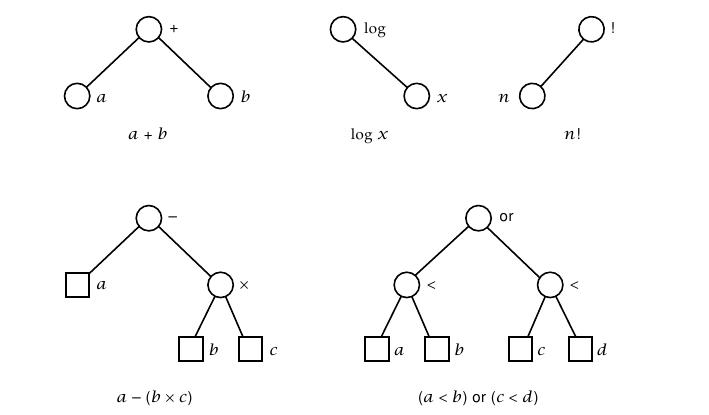
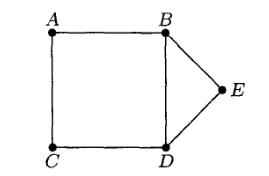
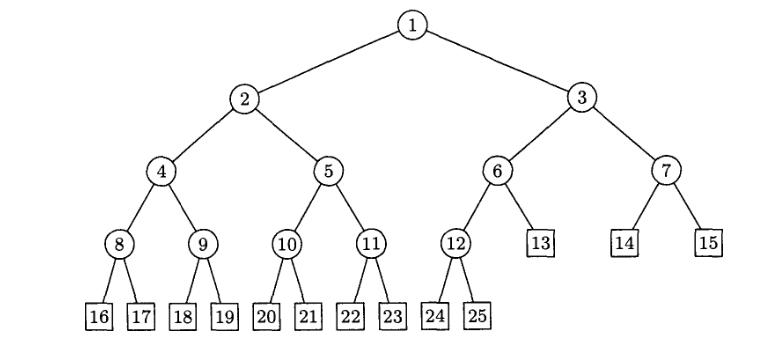
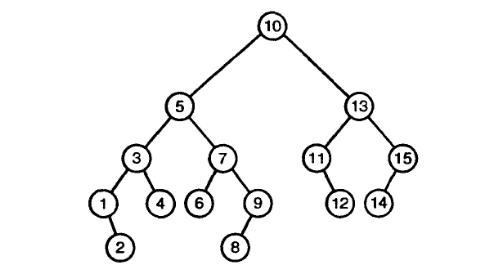
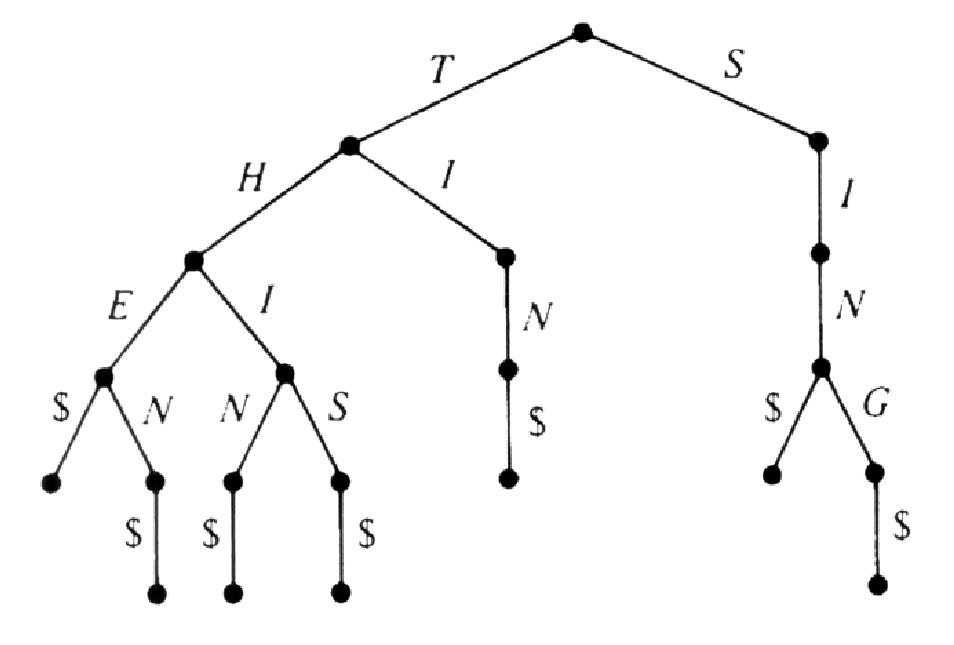
Путь (англ. path) - это последовательность узлов, которые нужно пройти, чтобы из корневого узла попасть в какой-либо дочерний узел. Длина пути равна числу узлов минус один. Высота (англ. height) - это путь от корня до наиболее удаленного узла. Например, на рисунке 1 высота поддерева часть № 1 равна единице, часть № 2 - двум, а высота поддерева часть № 3 равна нулю, так как оно не имеет дочерних узлов. Дочерние узлы обычно принять считать слева направо, но это можно делать в различном порядке. На рисунке 2 приведен пример дерева и результат использования трех различных подходов для обхода узлов.
preorder – сверху-вниз-слева-направо: F, B, A, D, C, E, G, I, H;
inorder – слева-вверх-вниз-вправо: A, B, C, D, E, F, G, H, I;
postorder – обратное движение от детей к родителям: A, C, E, D, B, H, I, G, F.
Если сравнить древовидные структуры со связными списками, то станет понятно, что наибольшую сложность при работе с деревьями представляют динамические операции, такие как вставка и удаление узлов. Например, при удалении узла из бинарного дерева необходимо решить проблему наличия двух дочерних и одного родительского узла.
Рекурсивная реализация алгоритмов для обхода дерева
В листинге 1 приведен псевдокод для трех описанных ранее алгоритмов обхода дерева, основанный на использовании рекурсии. В рамках рассматриваемой реализации было внесено ограничение, что у любого узла не может быть более трех дочерних узлов.
preorder(node)
print node.value
if node.left ≠ null then preorder(node.left)
if node.middle ≠ null then preorder(node.middle)
if node.right ≠ null then preorder(node.right)
inorder(node)
if node.left ≠ null then inorder(node.left)
print node.value
if node.middle ≠ null then inorder(node.middle)
if node.right ≠ null then inorder(node.right)
postorder(node)
if node.left ≠ null then postorder(node.left)
if node.middle ≠ null then postorder(node.middle)
if node.right ≠ null then postorder(node.right)
print node.value
В листинге 2 приведен пример обхода 3-нарного дерева (где каждый узел может иметь не более трех дочерних элементов) с помощью различных алгоритмов, реализованных на языке Си. Дерево из 10 узлов будет сформировано в методе main, а затем к нему будут применены три варианта обхода, которые будут приведены в отдельном листинге.
#include <stdio.h>
#include<stdlib.h>
//структура для описания узла дерева
struct tree
{
int data;
struct tree *lchild, *mchild, *rchild;
};
struct tree *my_insert(struct tree *p,int n, int dir);
void inorder(struct tree *p);
void preorder(struct tree *p);
void postorder(struct tree *p);
int main()
{
int x,y,i;
struct tree *root;
struct tree *node_2, *node_3, *node_5;
struct tree *node_8, *node_9, *node_6,*node_10,*node_4, *node_7 ;
//создание дерева
root = NULL;
root = my_insert(root,1,0);
node_2 = my_insert(root,2,0);
node_3 = my_insert(root,3,1);
node_4 = my_insert(root,4,2);
node_5 = my_insert(node_3,5,0);
node_8 = my_insert(node_5,8,0);
node_9 = my_insert(node_5,9,2);
node_6 = my_insert(node_3,6,2);
node_10 = my_insert(node_6,10,1);
node_7 = my_insert(node_4,7,1);
//выполнение обхода дерева различными способами
preorder(root);
printf("\n");
inorder(root);
printf("\n");
postorder(root);
return 0;
}
В листинге 3 приведен исходный код функции для вставки узлов в дерево. Данная функция принимает на вход три параметра: указатель на вставляемый узел, значение вставляемого узла и направление вставки — влево, в середину или вправо.
В листинге 5 приведена реализация алгоритмов обхода дерева на языке Python. В нем объявляются два класса — один для узлов и другой для самого дерева. В конструкторе класса Tree для наглядности объявляются ссылки на узлы.
//класс, представляющий узел
class node:
def __init__(self, data = None, lchild = None, mchild = None, rchild = None):
self.data = data
self.lchild = lchild
self.mchild = mchild
self.rchild = rchild
def __str__(self):
return 'Node ['+str(self.value)+']'
//класс, представляющий дерево
class Tree:
def __init__(self):
self.root = None
self.node_2 = None
self.node_3 = None
self.node_4 = None
self.node_5 = None
self.node_6 = None
self.node_7 = None
self.node_8 = None
self.node_9 = None
self.node_10 = None
//функция для добавления элементов в дерево
def my_insert(self, root_node, data, dir):
temp = node(0,None,None,None)
temp.data = data
if root_node == None:
return temp
else:
if dir == 0:
root_node.lchild = temp
return temp
elif dir == 1:
root_node.mchild = temp
return temp
else:
root_node.rchild = temp
return temp
//рекурсивные функции для обхода дерева
def inorder(self,noda):
if noda!=None:
self.inorder(noda.lchild);
print("%d " % noda.data)
self.inorder(noda.mchild)
self.inorder(noda.rchild)
def preorder(self,noda):
if noda!=None:
print (" %d " % noda.data)
self.preorder(noda.lchild);
self.preorder(noda.mchild)
self.preorder(noda.rchild)
def postorder(self,noda):
if noda!=None:
self.postorder(noda.lchild);
self.postorder(noda.mchild)
self.postorder(noda.rchild)
print (" %d " % noda.data)
//создание дерева
t = Tree()
t.root = t.my_insert(t.root,1,0)
t.node_2 = t.my_insert(t.root,2,0);
t.node_3 = t.my_insert(t.root,3,1);
t.node_4 = t.my_insert(t.root,4,2);
t.node_5 = t.my_insert(t.node_3,5,0);
t.node_8 = t.my_insert(t.node_5,8,0);
t.node_9 = t.my_insert(t.node_5,9,2);
t.node_6 = t.my_insert(t.node_3,6,2);
t.node_10 = t.my_insert(t.node_6,10,1);
t.node_7 = t.my_insert(t.node_4,7,1);
//обход дерева
t.preorder(t.root);
t.inorder(t.root);
t.postorder(t.root);
Нерекурсивная реализация обхода дерева
Дерево можно обойти, и не используя рекурсию, причем это можно сделать любым из трех способов: inorder, preorder и postorder. Для этого можно использовать стандартный стек, работающий по принципу LIFO (последним пришел, первым ушел), в который будут записываться узлы по мере их прохождения. В качестве примера также будет использоваться три-нарное дерево.
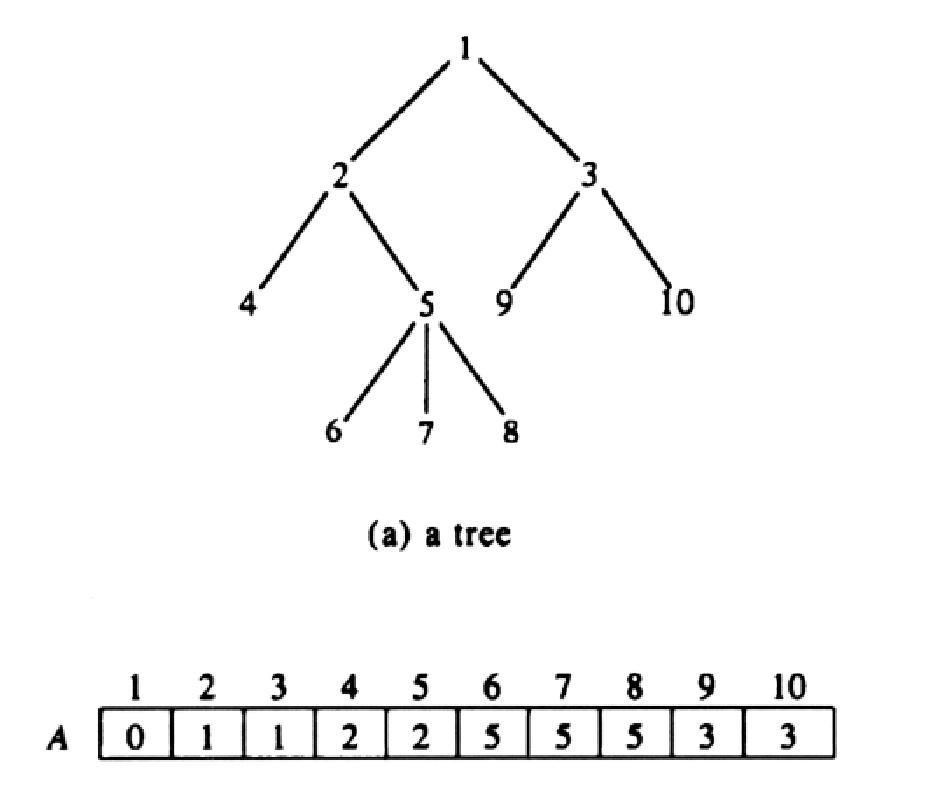
Одной из форм представления дерева является обычный массив. Пусть T - дерево, узлы в котором пронумерованы от 1 до n. Простейшей формой представления дерева T может быть линейный массив A, в котором каждый элемент массива A[i] представляет собой указатель на узел или его родителя.
Если i и j - два узла, и узел j является родителем для узла i, то
A[i] = j
Для идентификации корневого узла, указатель на его родителя можно сделать нулевым, как показано ниже:
A[i] = 0
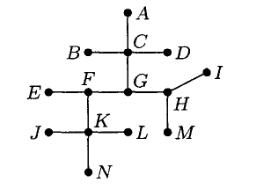
Каждый узел может иметь только одного родителя. Одновременно с массивом A можно завести массив L, в котором будут храниться метки для узлов. На рисунке 3 дерево представлено в виде массива родителей для каждого узла. Однако при использовании такого представления остается неясным, в каком порядке идут дочерние узлы.
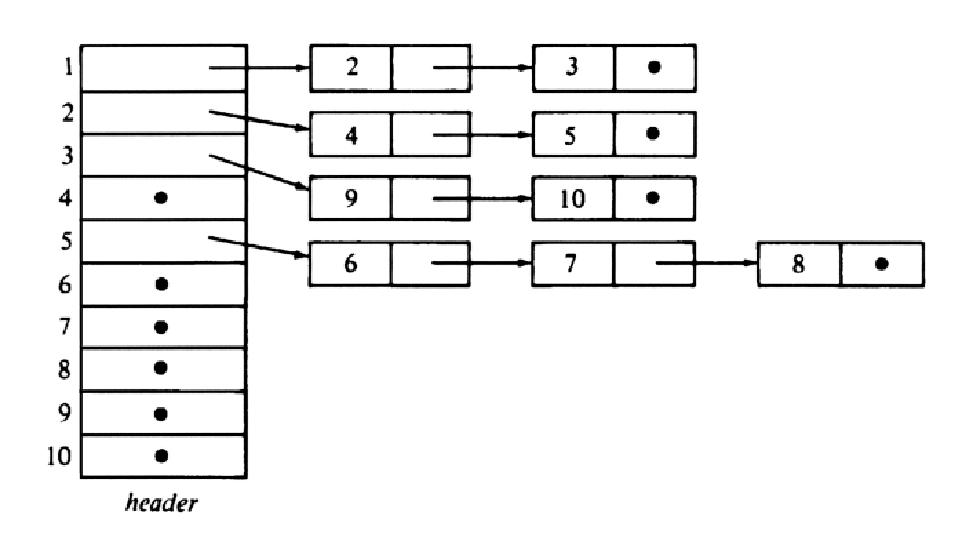
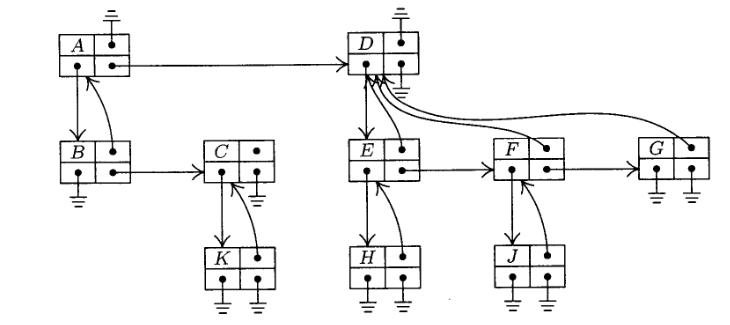
Еще один возможный вариант представления деревьев – это использование связного списка, содержащего все узлы дерева, при этом дочерние узлы хранятся вместе с родительским, как показано на рисунке 4.
На этом рисунке показан общий массив узлов, пронумерованный от 1 до 10. У отдельных узлов из этого списка есть дочерние узлы, которые в общем списке помечены точками. Но так как массив имеет фиксированный размер, то в такое дерево нельзя вставить новый узел.
Виды деревьев
А: Expression tree - это разновидность бинарных деревьев, полученные в результате арифметических
или логических выражений, при этом операнды размещаются в листьях.
Примеры представлены на следующем рисунке:
С помощью бинарных деревьев могут быть представлены достаточно сложные формулы - как например
для квадратичной формулы :
A triply linked tree: оно отличается от обычных деревьев тем, что кроме ссылок на левое и правое под-дерево, оно имеет ссылку
на родителя:
Кольцевая структура представлена на следующем рисунке.
Граф:
Free tree - дерево, не имеющее корня:
Теория деревьев является одной из самых востребованных и популярных научных дисциплин в области информационных технологий. Древовидные структуры подходят для решения большого круга задач в самых различных отраслях знания. В компьютерных технологиях деревья являются ключевым компонентом для создания алгоритмов хранения, поиска и обработки информации. Любой программист должен уметь работать с подобными структурами данных, тем более, что как было показано в этой статье, для этого используются стандартные и хорошо зарекомендовавшие себя алгоритмы.
Часть 6
Двоичные деревья
Бинарные (двоичные) деревья являются одним из самых востребованных вариантов данной структуры данных, так как широко используются в поисковых алгоритмах и для решения других вычислительных задач. В данной статье будут рассмотрены основные характеристики бинарных деревьев и различные операции, выполняющиеся над ними.
Как обычно, кроме теоретических аспектов: классификации бинарных деревьев и стандартных приемов для манипулирования ими, в статье будут примеры практической реализации алгоритмов для работы с бинарными деревьями на языках Си и Python.
Перед тем, как перейти к обсуждению различных типов бинарных деревьев, стоит остановиться на общей классификации поисковых алгоритмов.
В случае с линейным поиском искомый элемент сравнивается с каждым элементом списка в ходе последовательной итерации. Скорость такого поиска зависит от размера списка: чем больше список, тем ниже скорость, т.е. скорость обратно пропорциональна размеру списка. Увеличить скорость такого поиска можно, если предварительно отсортировать список. В этом случае уже не потребуется продолжать поиск, когда искомый элемент еще не будет найден, а элементы в списке уже станут больше искомого.
Для отсортированного списка существует и более эффективный алгоритм. В начале поиска необходимо сравнить искомое число с элементом, который находится ПОСЕРЕДИНЕ уже отсортированного списка. Если серединный элемент оказывается больше искомого числа, значит искомый элемент находится в левой половине. В противном случае - справа. Затем выполняется сравнение с числом, которое находится посередине нужной половины. И так далее до тех пор, пока не будет найдено искомое число. Данный тип поиска называется двоичным, и он, очевидно, быстрее линейного. Необходимое количество делений списка, состоящего из n элементов пополам, называется логарифмом от n по основанию 2. Двоичный поиск является алгоритмом порядка O(log) по основанию 2.
Однако традиционные связные списки не очень подходят для двоичного поиска, и здесь на помощь приходит двоичное дерево, пример которого изображен на рисунке 1.
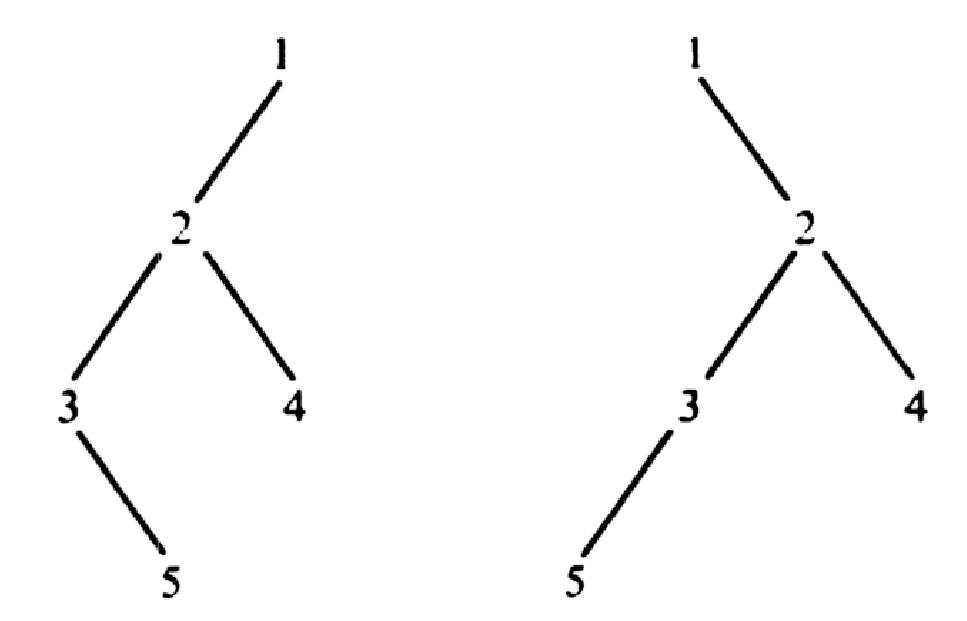
В общем случае каждый узел в дереве может иметь неограниченное количество дочерних узлов. Отличие бинарного дерева от остальных типов деревьев в том, что каждый узел в нем может иметь не более двух дочерних узлов. Обычное двоичное дерево — это структура, состоящая из узлов, каждый из которых содержит некоторое значение, а также указатели на левое и правое поддеревья. Один или оба указателя на эти поддеревья могут иметь значение NULL. Двоичные деревья, как и связные списки, являются рекурсивными структурами.
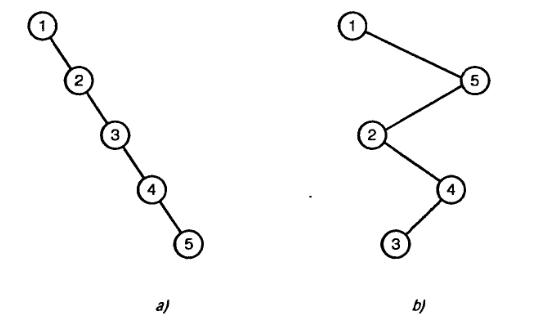
На рисунке 2 показаны бинарные деревья, которые имеют одинаковый набор узлов, но различный порядок их следования. В последнем случае дерево вырождается в связный список.
Существуют следующие разновидности бинарных деревьев:
полное бинарное дерево - каждый узел, за исключением листьев, имеет по 2 дочерних узла;
идеальное бинарное дерево - это полное бинарное дерево, в котором все листья находятся на одной высоте;
сбалансированное бинарное дерево - это бинарное дерево, в котором высота 2-х поддеревьев для каждого узла отличается не более чем на 1. Глубина такого дерева вычисляется как двоичный логарифм log(n), где n - общее число узлов;
вырожденное дерево - дерево, в котором каждый узел имеет всего один дочерний узел, фактически это связный список;
бинарное поисковое дерево (BST) - бинарное дерево, в котором для каждого узла выполняется условие: все узлы в левом поддереве меньше, и все узлы в правом поддереве больше данного узла.
Вычисление путей
Путь (англ. path) - это расстояние от корня дерева до какого либо узла. В расширенном бинарном дереве каждый путь оканчивается листом. Если число листьев обозначить как S, а число остальных узлов обозначить как N, то справедлива формула:
S = N +1
т.е. для расширенного дерева число листьев на единицу больше числа НЕлистьев (узлов, имеющих дочерние узлы).
Если путь от корневого узла до листа обозначить как внешний путь, а путь от корневого узла до НЕлиста обозначить как внутренний путь, тогда сумма всех внешних путей для дерева, изображенного на рисунке 3 равна:
сконструировать бинарное дерево таким образом, чтобы сумма путей была минимальной, так как это сокращает время вычислений для различных алгоритмов.
сконструировать полное расширенное бинарное дерево таким образом, чтобы сумма произведений путей от корневого узла до листьев на значение листового узла была минимальной.
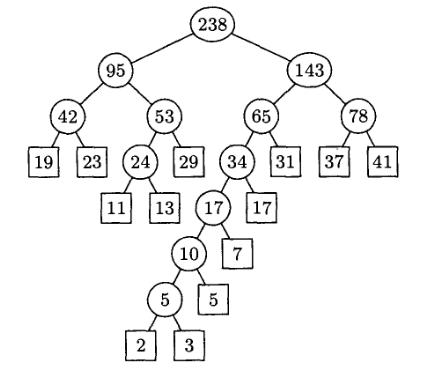
Давид Хаффман (David Huffman) предложил алгоритм для решения этой проблемы, в котором на каждом шаге выбираются и складываются два наименьших листа, как показано в листинге 1, что приводит к дереву, изображенному на рисунке 4.
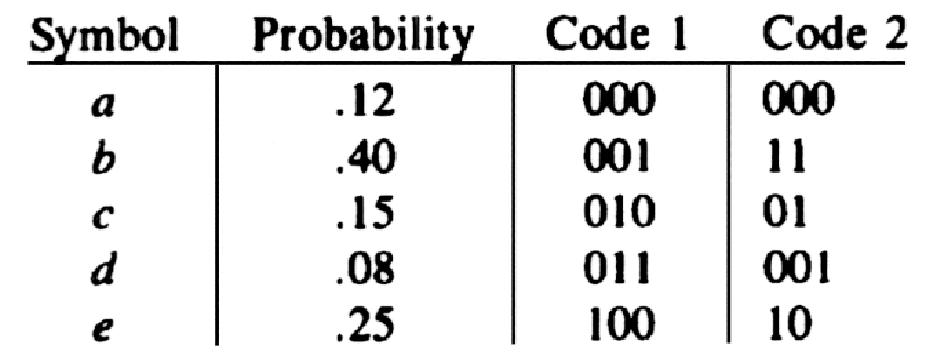
Коды Хаффмана - это алгоритм, используемый для сжатия данных. Пусть имеется некое исходное текстовое сообщение, состоящее из 5 символов: a, b, c, d, e, и каждый символ имеет свою собственную частоту:
a встречается 12 раз;
b - 4 раза;
c - 15 раз;
d - 8 раз;
e - 25 раз.
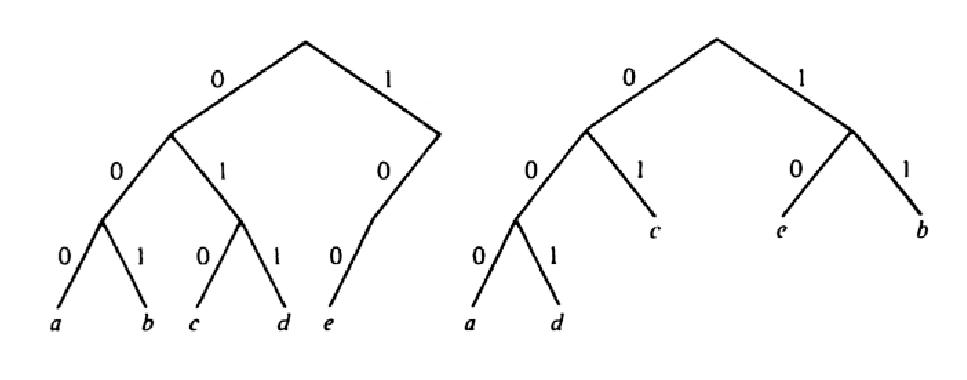
Нужно закодировать это сообщение с помощью 0 и 1 таким образом, чтобы размер результирующей строки оказался минимальным. В таблице приведен пример кодирования символов для данного сообщения:
Если зашифровать сообщение bcd с помощью кода №1, то получится - 001010011. С помощью кода №2 можно делать то же самое, но получившая строка будет короче - 1101001.
Теперь можно сформулировать саму проблему: необходимо подобрать такой алгоритм шифрования, при котором длина зашифрованной строки будет минимальной.
В первом варианте на каждый символ отводилось по 3 символа, а во втором варианте - уже 2.2, но можно сделать еще короче и получить коэффициент, равный 2.15. Это делается с помощью алгоритма Хаффмана, в котором берутся 2 символа, имеющие наименьшую частоту, и объединяются, как два дочерних узла.
Алгоритм для строки, состоящей из 5 символов, реализуется следующим образом. На первом шаге объединяются два символа - a и d, как имеющие наименьшую частоту. На втором в качестве родителя добавляется символ c. На третьем шаге добавляется символ e, и в конце - символ b. В результате получается следующий код:
b – 0;
e – 10;
c – 110;
a – 1111;
d – 1110.
Следующий код реализует поиск минимальных кодов для строки, показанной на рисунке:
#include < stdio.h>
#include < stdlib.h>
#include < string.h>
#define BYTES 256
struct huffcode
{
int nbits;
int code;
};
typedef struct huffcode huffcode_t;
struct huffheap {
int *h;
int n, s, cs;
long *f;
};
typedef struct huffheap heap_t;
/* heap handling funcs */
static heap_t *_heap_create(int s, long *f)
{
heap_t *h;
h = malloc(sizeof(heap_t));
h->h = malloc(sizeof(int)*s);
h->s = h->cs = s;
h->n = 0;
h->f = f;
return h;
}
static void _heap_destroy(heap_t *heap)
{
free(heap->h);
free(heap);
}
#define swap_(I,J) do { int t_; t_ = a[(I)]; \
a[(I)] = a[(J)]; a[(J)] = t_; } while(0)
static void _heap_sort(heap_t *heap)
{
int i=1, j=2; /* gnome sort */
int *a = heap->h;
while(i < heap->n) { /* smaller values are kept at the end */
if ( heap->f[a[i-1]] >= heap->f[a[i]] ) {
i = j; j++;
} else {
swap_(i-1, i);
i--;
i = (i==0) ? j++ : i;
}
}
}
#undef swap_
static void _heap_add(heap_t *heap, int c)
{
if ( (heap->n + 1) > heap->s ) {
heap->h = realloc(heap->h, heap->s + heap->cs);
heap->s += heap->cs;
}
heap->h[heap->n] = c;
heap->n++;
_heap_sort(heap);
}
static int _heap_remove(heap_t *heap)
{
if ( heap->n > 0 ) {
heap->n--;
return heap->h[heap->n];
}
return -1;
}
/* huffmann code generator */
huffcode_t **create_huffman_codes(long *freqs)
{
huffcode_t **codes;
heap_t *heap;
long efreqs[BYTES*2];
int preds[BYTES*2];
int i, extf=BYTES;
int r1, r2;
memcpy(efreqs, freqs, sizeof(long)*BYTES);
memset(&efreqs[BYTES], 0, sizeof(long)*BYTES);
heap = _heap_create(BYTES*2, efreqs);
if ( heap == NULL ) return NULL;
for(i=0; i < BYTES; i++) if ( efreqs[i] > 0 ) _heap_add(heap, i);
while( heap->n > 1 )
{
r1 = _heap_remove(heap);
r2 = _heap_remove(heap);
efreqs[extf] = efreqs[r1] + efreqs[r2];
_heap_add(heap, extf);
preds[r1] = extf;
preds[r2] = -extf;
extf++;
}
r1 = _heap_remove(heap);
preds[r1] = r1;
_heap_destroy(heap);
codes = malloc(sizeof(huffcode_t *)*BYTES);
int bc, bn, ix;
for(i=0; i < BYTES; i++) {
bc=0; bn=0;
if ( efreqs[i] == 0 ) { codes[i] = NULL; continue; }
ix = i;
while( abs(preds[ix]) != ix ) {
bc |= ((preds[ix] >= 0) ? 1 : 0 ) << bn;
ix = abs(preds[ix]);
bn++;
}
codes[i] = malloc(sizeof(huffcode_t));
codes[i]->nbits = bn;
codes[i]->code = bc;
}
return codes;
}
void free_huffman_codes(huffcode_t **c)
{
int i;
for(i=0; i < BYTES; i++) if (c[i] != NULL) free(c[i]);
free(c);
}
#define MAXBITSPERCODE 100
void inttobits(int c, int n, char *s)
{
s[n] = 0;
while(n > 0) {
s[n-1] = (c%2) + '0';
c >>= 1; n--;
}
}
const char *test = "abcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeaaaaccccccceeeeeeeeeeeeeeeeebbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb";
int main()
{
huffcode_t **r;
int i;
char strbit[MAXBITSPERCODE];
const char *p;
long freqs[BYTES];
memset(freqs, 0, sizeof freqs);
p = test;
while(*p != '\0') freqs[*p++]++;
r = create_huffman_codes(freqs);
for(i=0; i < BYTES; i++) {
if ( r[i] != NULL ) {
inttobits(r[i]->code, r[i]->nbits, strbit);
printf("%c (%d) %s\n", i, r[i]->code, strbit);
}
}
free_huffman_codes(r);
return 0;
}
Высота бинарного дерева
Для определения высоты дерева потребуется пройти от корня сначала по левому поддереву, потом по правому, сравнить две этих высоты и выбрать максимальное значение. И не забыть к получившемуся значению прибавить единицу (корневой элемент). В листинге 2 приведена рекурсивная функция для выполнения этой задачи.
int height(struct node *p)
{
struct node *temp=p;
int h1=0,h2=0;
if(p==NULL)return(0);
if(p->left){h1=height(p->left);}
if(p->right){h2=height(p->right);}
return(max(h1,h2)+1);
}
«Зеркальное» отражение бинарного дерева
Когда два дерева являются зеркальным отражением друг друга, то говорится, что они симметричны. Для получения «зеркальной» копии дерева используется алгоритм, приведенный в листинге 3. Сначала выполняется проверка на наличие у корня дерева дочерних узлов, и если эти узлы есть, то они меняются местами. Потом эти же действия рекурсивно повторяются для левого и правого дочерних узлов. Если существует только один дочерний узел, тогда можно переходить на один уровень ниже по дереву и продолжать.
int lookup(struct node* node, int target)
{
if (node == NULL)
{
return(0);
}
else
{
if (target == node->data) return(1);
else
{
if (target < node->data) return(lookup(node->left, target));
else return(lookup(node->right, target));
}
}
}
Ширина бинарного дерева
Под шириной дерева понимается максимальное количество узлов, которые расположены на одной высоте. Чтобы определить ширину дерева, достаточно просто добавить счетчик в уже рассмотренный алгоритм для определения высоты дерева.
К статье присоединен файл sources.zip, в котором находятся два файла исходного кода: tree_operations.c и tree_operations.py. В первом файле содержится полноценная программа на языке Си, использующая функции, разработанные в этой статье, для выполнения операций над бинарным деревом. Во втором файле приведен сценарий на языке Python, в котором реализованы сходные алгоритмы для работы с бинарными деревьями. Реализация на Python ближе по стилю к объектно-ориентированному программированию, так как в ней используются классы для объявления самого дерева и входящих в него узлов.
В данной статье была выполнена классификация бинарных деревьев и рассмотрены алгоритмы для выполнения важнейших операций: определение высоты и ширины дерева, отражение дерева и поиск в нем определенного элемента. Также был рассмотрен алгоритм Хаффмана, который может использоваться для построения расширенных деревьев и, как следствие, для кодирования информации.
Часть 7
Бинарные поисковые деревья (BST)
Эта статья посвящена одной из разновидностей двоичных деревьев: бинарным поисковым деревьям. Как обычно будут рассмотрены теоретические алгоритмы для выполнения различных операций: вставка и удаление узла, поиск максимума/минимума и практические реализации данных алгоритмов на языках Си и Python.
Бинарные поисковые деревья (англ. binary search tree или сокращенно BST) - это разновидность двоичного дерева, обладающая следующими отличительными свойствами:
для каждого узла X (если X не равен NULL) все узлы в его левом поддереве содержат значения, которые ВСЕГДА меньше значения узла X.
все узлы в правом поддереве узла Х содержат значения, которые соответственно ВСЕГДА больше значения узла X.
каждый узел в таком дереве является родителем для своих поддеревьев.
Преимущество двоичного поискового дерева в том, что все значения располагаются в нем в отсортированном порядке. В общем случае узлы необязательно должны подвергаться сортировке перед вставкой в бинарное поисковое дерево. Узлы могут вставляться в такое дерево в произвольном порядке, а сама сортировка может происходить в процессе вставки.
Результат вставки узлов в бинарное поисковое дерево может оказаться непредсказуемым. Если вставлять в такое дерево узлы, которые уже были предварительно отсортированы, то это приведет к вырождению дерева. На рисунке 1 показаны две одинаковые по содержанию реализации поискового дерева, но с различными корневыми узлами.
struct node
{
int data;
struct node * left;
struct node * right;
};
struct tree
{
struct node * root; // указатель на корень дерева
int count; // количество узлов в дереве
};
Структура, использующаяся для описания узла дерева, полностью совпадает со структурой, использующейся для описания связного списка. Используя эти две структуры можно подготовить функцию на языке Си для создания дерева (см. листинг 2).
struct tree * tree_create(void)
{
struct tree * new_tree = malloc(sizeof * new_tree);
if (new_tree == NULL) return NULL;
new_tree->root = NULL;
new_tree->count = 0;
return new_tree;
}
Вставка узла в бинарное поисковое дерево
Перед вставкой нового элемента в бинарное дерево обязательно нужно проверить, нет ли в нем уже такого элемента. Для этого необходимо начать обход дерева с корневого узла и проверить, не превосходит ли значение корневого узла добавляемого значения. Если корневой узел больше добавляемого элемента, то необходимо переместиться в левое дочернее дерево. В противном случае - в правое. Функция поиска определенного узла в дереве, приведенная в листинге 3, вернет 1 в случае, если искомое значение будет найдено, или 0, если указанное значение в дереве отсутствует.
int bin_search(const struct tree * search_tree, int item)
{
const struct node * search_node;
search_node = search_tree->root;
for(;;)
{
if (search_node == NULL) return 0;
else if (item == search_node->data) return 1;
else if (item > search_node->data) search_node = search_node->right;
else search_node = search_node->left;
}
}
После выполнения данной проверки можно переходить к добавлению узла в бинарное дерево. Функция вставки аналогична функции поиска: необходимо пройти по дереву и вставить узел в нужное место. Для этого следует выбрать левое или правое поддерево корневого узла, а затем рекурсивно перемещаться по выбранному поддереву до тех пор, пока не будет найдена позиция для вставки узла, как показано в листинге 4.
Элемент, добавленный первым, автоматически становится корнем дерева. Функция может вернуть одно из 3-х значений: 0 (при вставке произошла ошибка), 1 (узел успешно вставлен), 2 (такой элемент уже есть в дереве).
Удаление узла из бинарного поискового дерева
Функция удаления узла из бинарного дерева также будет возвращать 0, если возникла ошибка, или 1 в случае удачного удаления элемента. В данной функции используется уже знакомый алгоритм поиска, который будет искать элемент, помеченный для удаления. После того, как этот элемент будет обнаружен, возможны 3 варианта действий, которые представлены на рисунке 2.
В первом случае (вариант a) узел z имеет только левый дочерний узел, и при удалении он и будет заменен им. Во втором варианте (рисунок b) узел z заменяется узлом y.
В третьем варианте (рисунок с) корневой узел z заменяется узлом x, что приводит к дополнительным перестроениям в правом поддереве. Узел x становится преемником узла z, так как в левом поддереве узла z все узлы меньше 5, и преемника нужно искать в правом поддереве узла z.
Для прохода по дереву можно использовать рекурсию, так как любое двоичное дерево - это рекурсивная структура. Функции, приведенные в листинге 6, могут распечатать дерево, начиная с любого узла: сначала печатается левое поддерево, потом правое.
//функция для распечатки фрагмента дерева - с любого узла
static void walk(const struct node * search_node)
{
if(node == NDLL) return;
walk(node->left);
printf("%d ", search_node->data);
walk(node->right);
}
//функция для распечатки дерева целиком - с корня
void walk2(const struct tree * my_tree)
{
walk(my_tree->root);
}
Для прохода по дереву можно обойтись и одной функцией, если ввести массив указателей на узлы, который будет заполняться во время прохода. В функции будет выполняться вложенный цикл для прохода дерева от текущего узла влево до конца. А дополнительный массив поможет обойти все дерево за один проход, так как в нем будет храниться указатель на текущий корневой узел.
В листинге 8 присутствует намеренное упрощение, так как в нем используется упрощенный статический вариант стека, хотя в реальной ситуации память под стек обязательно должна выделяться динамически.
Удаление дерева
В этом разделе приведены функции для полного удаления дерева, начиная с листьев и заканчивая корневым узлом.
//функция для удаления отдельного узла дерева и его потомков
static void destroy(struct node * search_node)
{
if(search_node == NOLL) return;
destroy(search_node->left);
destroy(search_node->right);
free(search_node);
}
//функция для полного удаления дерева
void destroy(struct tree * search_tree)
{
destroy(search_tree->root);
free(search_tree);
}
Нахождение минимума и максимума в бинарном поисковом дереве
В листинге 10 приведены две функции для поиска в дереве узлов с минимальным и максимальным значением. Минимальное значение нужно искать в левом поддереве корневого элемента, а максимальное - в правом.
int isBST(struct node* node)
{
return(isBSTUtil(node, INT_MIN, INT_MAX));
}
int isBSTUtil(struct node* node, int min, int max)
{
if (node==NULL) return(true);
if (node->data<min || node->data>max) return(false);
return (
isBSTUtil(node->left, min, node->data) &&
isBSTUtil(node->right, node->data+1, max)
);
}
Практическая реализация алгоритмов
Реализация на си
Мы сначала добавляем в бинарное дерево 10 элементов, при этом естественно соблюдаются все его атрибуты -
т.е. для добавляемого элемента в дереве ищется его место по бинарному алгоритму.
Потом мы проходим дерево и распечатываем его, потом удаляем элемент,
потом снова распечатываем дерево, потом удаляем все дерево.
Весь работающий код целиком для двоичного поискового лерева:
class node:
def __init__(self, data = None, left = None, right = None):
self.data = data
self.left = left
self.right = right
def __str__(self):
return 'Node ['+str(self.data)+']'
class Tree:
def __init__(self):
self.root = None
self.count = 0
def insert(self,data):
if self.root == None:
self.root = node(data,None,None)
return
root = self.root
while (root != None):
if (data < root.data):
if root.left == None:
root.left = node(data, None, None)
return
else:
root = root.left
else:
if root.right == None:
root.right = node(data, None,None)
return
else:
root = root.right
def traverse(self,node):
if node == None:
return
print node.data
if node.left:
self.traverse(node.left)
if node.right:
self.traverse(node.right)
t = Tree()
res = t.insert( 100)
res = t.insert( 10)
res = t.insert( 4)
res = t.insert( 13)
res = t.insert( 27)
res = t.insert( 3)
res = t.insert( 31)
res = t.insert( 7)
res = t.insert( 12)
res = t.insert( 8)
t.traverse(t.root)
Программа на языке Си обладает большей функциональностью, нежели версия на Python. В Си-программе сначала создается бинарное поисковое действие из 10 узлов, затем содержимое дерева распечатывается, и из него удаляется один узел. После этого выполняется еще одна распечатка, чтобы проверить, как прошло удаление, и дерево удаляется уже полностью с освобождением памяти. В Python-программе выполняется только создание и распечатка бинарного поискового дерева из 10 узлов. Остальные алгоритмы остались нереализованными, но их можно разработать самостоятельно, используя версии на языке Си в качестве образца.
В данной статье были рассмотрены основные алгоритмы, использующиеся для работы с одной из самых популярных структур данных – бинарным поисковым деревом.
Кроме теоретических описаний в статье были представлены и практические реализации данных алгоритмов на языке программирования Си.
Следующий листинг показывает реализацию bst-деревьев на языке python.
Программа выполняет стандартные операции с bst-деревом: вставляет и удаляет ноды, проверяет валидность всего дерева.
По сценарию программа генерит bst-дерево, состоящее из 50 узлов, выводит его на экран, затем удаляет рутовую ноду
и снова выводит получившееся bst-дерево на экран:
import random
class BSTnode(object):
def __init__(self, parent, t):
self.key = t
self.parent = parent
self.left = None
self.right = None
self.size = 1
def update_stats(self):
self.size = (0 if self.left is None else self.left.size) + (0 if self.right is None else self.right.size)
def insert(self, t, NodeType):
self.size += 1
if t < self.key:
if self.left is None:
self.left = NodeType(self, t)
return self.left
else:
return self.left.insert(t, NodeType)
else:
if self.right is None:
self.right = NodeType(self, t)
return self.right
else:
return self.right.insert(t, NodeType)
def find(self, t):
if t == self.key:
return self
elif t < self.key:
if self.left is None:
return None
else:
return self.left.find(t)
else:
if self.right is None:
return None
else:
return self.right.find(t)
def minimum(self):
current = self
while current.left is not None:
current = current.left
return current
def successor(self):
if self.right is not None:
return self.right.minimum()
current = self
while current.parent is not None and current.parent.right is current:
current = current.parent
return current.parent
def delete(self):
if self.left is None or self.right is None:
if self is self.parent.left:
self.parent.left = self.left or self.right
if self.parent.left is not None:
self.parent.left.parent = self.parent
else:
self.parent.right = self.left or self.right
if self.parent.right is not None:
self.parent.right.parent = self.parent
current = self.parent
while current.key is not None:
current.update_stats()
current = current.parent
return self
else:
s = self.successor()
self.key, s.key = s.key, self.key
return s.delete()
def __repr__(self):
return ' '
class BST(object):
def __init__(self, NodeType=BSTnode):
self.root = None
self.NodeType = NodeType
self.psroot = self.NodeType(None, None)
def reroot(self):
self.root = self.psroot.left
def insert(self, t):
if self.root is None:
self.psroot.left = self.NodeType(self.psroot, t)
self.reroot()
return self.root
else:
return self.root.insert(t, self.NodeType)
def find(self, t):
if self.root is None:
return None
else:
return self.root.find(t)
def delete(self, t):
deleted = self.root.delete()
return
node = self.find(t)
if node:
#deleted = self.root.delete()
deleted = node.delete()
self.reroot()
return deleted
return None
def __str__(self):
if self.root is None: return ''
def recurse(node):
if node is None: return [], 0, 0
label = str(node.key)
left_lines, left_pos, left_width = recurse(node.left)
right_lines, right_pos, right_width = recurse(node.right)
middle = max(right_pos + left_width - left_pos + 1, len(label), 2)
pos = left_pos + middle // 2
width = left_pos + middle + right_width - right_pos
while len(left_lines) < len(right_lines):
left_lines.append(' ' * left_width)
while len(right_lines) < len(left_lines):
right_lines.append(' ' * right_width)
if (middle - len(label)) % 2 == 1 and node.parent is not None and \
node is node.parent.left and len(label) < middle:
label += '.'
label = label.center(middle, '.')
if label[0] == '.': label = ' ' + label[1:]
if label[-1] == '.': label = label[:-1] + ' '
lines = [' ' * left_pos + label + ' ' * (right_width - right_pos),
' ' * left_pos + '/' + ' ' * (middle-2) +
'\\' + ' ' * (right_width - right_pos)] + \
[left_line + ' ' * (width - left_width - right_width) +
right_line
for left_line, right_line in zip(left_lines, right_lines)]
return lines, pos, width
return '\n'.join(recurse(self.root) [0])
def validate_(self, min, max):
return self.validate(self.root, min, max)
def validate(self, root, min, max):
if (root == None):
return True
if (root.key <= min or root.key >= max):
return False
return self.validate(root.left, min, root.key) and self.validate(root.right, root.key, max);
tree = BST()
l = []
for i in range(1,50):
ii = random.randint(1, 50)
if ii in l:
pass
else:
l.append(ii)
for ll in l:
tree.insert(ll)
print tree
tree.delete(0)
print tree
f = open('bst','w')
f.write(str(tree))
f.close
print tree.validate_( 0, 10000000000)
Часть 8
Сбалансированные двоичные деревья (AVL-деревья)
В этой главе будет рассматриваться другая разновидность бинарных поисковых деревьев - AVL-деревья или сбалансированные двоичные деревья с минимальным временем поиска по дереву. Это свойство AVL-деревьев обеспечивается их сбалансированностью, которая одновременно усложняет алгоритмы для вставки узлов в дерево и их последующего удаления. В рамках статьи будут рассмотрены характеристики AVL-деревьев и алгоритмы для работы с ними, реализованные на языке Си.
Прежде чем переходить к обсуждению сбалансированных деревьев, необходимо вернуться к значению термина «высота дерева». Высота дерева – это число узлов от вершины до самого нижнего узла, т.е. максимальное количество узлов, по которому можно пройти, начав с корня дерева и перемещаясь в одном направлении.
Очевидно, что время поиска по двоичному дереву зависит от высоты дерева, и чем выше дерево - тем больше времени требуется на поиск определенного узла в дереве. Например, если высота дерева равна 5, то в наихудшем случае придется выполнить 5 сравнений.
Как было показано в прошлых статьях, из одного и того же набора узлов можно сконструировать различные варианты двоичных деревьев. В простейшем случае дерево можно построить так, что его высота будет равна числу элементов, и дерево выродится в односвязный список. В реальной жизни добавление и удаление элементов в дерево может происходить в произвольном порядке, что приводит к созданию различных деревьев, как показано на рисунке 1.
Чтобы создать сбалансированное двоичное дерево, необходимо изменить структуру узла, добавив в него дополнительный указатель на родительский узел, как показано в листинге 1.
static struct node * successor(struct node * x)
{
struct node * y;
if(x->right != NULL)
{
у = x->right;
while(y->left != NULL)
у = y->left;
}
else
{
у = x->parent;
while(y != NULL && x == y->right)
{
x = y ;
y = y->parent;
}
}
return y;
}
Если у узла имеется правый дочерний узел, то его наследником будет минимальное значение в правом поддереве (см. рисунок 2 – наследником узла 8 будет узел 9, как минимальный в правом поддереве узла 8). Если же правый потомок отсутствует, тогда в поисках наследника необходимо перемещаться вверх и вправо (см. рисунок 2 – наследником узла 11 будет узел 12).
Указатель на родительский узел - это не единственный способ облегчить проход по дереву. Так, в дереве возможна ситуация, когда узел не имеет дочерних узлов. Это можно использовать для хранения указателей на другие части дерева, например, на предшественника и наследника данного узла. Для этого в узел потребуется добавить два битовых поля, как показано в листинге 3.
Для данной реализации дерева есть специальное название - дерево с полными ссылками. Также существуют деревья с правыми ссылками, где вместо двух битовых полей используется одно. Дерево с правыми ссылками более эффективно при поиске, так как на его прохождение требуется меньше времени.
Для получения сбалансированного двоичного дерева придется потратить определенные усилия. Так, если в дерево вставлять уже отсортированный массив, то оно может выродиться в список. Поэтому после каждой вставки необходимо проводить балансировку дерева.
А в общем случае после любой модификации дерева требуется выполнять балансировку дерева, чтобы минимизировать его высоту, так как меньше всего времени требуется на поиск по двоичному дереву с минимальной высотой. Балансировка влияет и на процессы вставки/удаления узлов, которые также будут проходить быстрее из-за более эффективного поиска. На данный момент не существует общепринятых стандартов для балансировки дерева, так что в этой области допускается определенная свобода при реализации новых или выборе из уже существующих алгоритмов балансировки.
AVL-деревья
Одним из известных типов сбалансированных двоичных деревьев является AVL-дерево, у которого коэффициент сбалансированности находится в пределах от -1 до +1. Полностью сбалансированное двоичное дерево с n узлами имеет высоту равную log(n+1) по основанию 2, округленную до ближайшего целого числа. В листинге 5 приведен исходный код структуры, описывающей узел AVL-дерева.
AVL - аббревиатура, созданная из первых букв фамилий советских математиков: Г.М. Адельсона-Вельского и Е.М. Ландиса, придумавших данную структуру данных. Для определения AVL-дерева используется коэффициент сбалансированности - разница между высотой правого и левого поддеревьев.
struct avl_node
{
struct avl_node * link[2];
int data;
short bal;
};
В нем сразу видно отличие от классической реализации – указатели на поддеревья будут храниться в специальном массиве, а не в двух отдельных переменных. Переменная bal определяет значение коэффициента сбалансированности, и поэтому может принимать только значения из списка: -1, 0, +1.
Добавление узла в AVL-дерево
Процесс вставки узла в AVL-дерево отличается от добавления узла в обычное бинарное дерево. Так, для вставки нового узла в AVL-дерево, необходимо:
найти место, где должен будет находиться новый узел;
добавить узел в дерево на найденную позицию;
пересчитать коэффициенты сбалансированности для узлов, находящихся выше добавленного узла;
если дерево стало несбалансированным, то выполнить балансировку.
В листинге 6 приведен исходный код функции для вставки узла в AVL-дерево.
int avl_insert(struct avl_tree * tree, int item)
{
struct avl_node ** v, *w, *x, *y, *z;
/* если в дереве еще нет узлов */
v = &tree->root;
x = z = tree->root;
if(x == NULL)
{
tree->root = new_node(tree,item);
return tree->root != NULL;
}
/* фрагмент №1 */
/* поиск подходящей позиции и последующая вставка элемента */
for(;;)
{
int dir;
/* такой элемент уже есть в дереве – функцию можно завершить */
if(item == z->data) return 2;
dir = (item > z->data) ;
y = z->link[dir];
if(y == NULL)
{
y = z->link[dir] = new_node(tree,item);
if(y == NULL) return 0;
break;
}
if(y->bal != 0)
{
v = &z->link[dir];
x = y;
}
z = y;
}
/* фрагмент №2 */
/* пересчет коэффициентов сбалансированности для узлов, затронутых вставкой */
w = z = x->link[item > x->data];
while(z != y)
if(item < z->data)
{
z->bal = -1;
z = z->link[0];
}
else
{
z->bal = +1;
z = z->link[1];
}
/* фрагмент № 3 */
/* балансировка при добавлении нового узла в левое поддерево */
if(item < x->data)
{
if (x->bal != -1)
x->bal --;
else if(w->bal == -1)
{
*v=w;
x->link[0] = w->link[1];
w->link[1] = x;
x->bal = w->bal = 0;
}
else
{
*v = z = w->link[1];
w->link[1] = z->link[0];
z->link[0] = w;
x->link[0] = z->link[1];
z->link[1] = x;
if(z->bal == -1)
{
x->bal = 1;
w->bal = 0;
}
else if(z->bal == 0)
x->bal = w->bal = 0;
else
{
x->bal = 0;
w->bal = -1;
}
z->bal=0;
}
}
/* фрагмент № 4 */
/* балансировка при добавлении нового узла в правое поддерево */
else
{
if( x->bal != +1)
x->bal++;
else if(w->bal == +1)
{
*v = w;
x->link[1] = w->link[0];
w->link[0] = x;
x->bal = w->bal = 0;
}
else
{
*v = z = w->link[0];
w->link[0] = z->link[1];
z->link[1] = w;
x->link[1] = z->link[0];
z->link[0] = x;
if(z->bal == +1)
{
x->bal = -1;
w->bal = 0;
}
else if(z->bal == 0)
x->bal = w->bal = 0;
else
{
x->bal = 0;
w->bal = 1;
}
z->bal = 0;
}
}
return 1;
}
Так как функция avl_insert получилась довольно объемной, стоит рассмотреть ее в подробностях. В фрагменте №1 листинга 6 производится поиск позиции и вставка узла в AVL-дерево. В этом фрагменте используется временная переменная z для отслеживания текущего узла. Если значение добавляемого узла равно значению, содержащемуся в узле z, то функция завершается, так как бинарное дерево не может содержать узлы с дублирующимися значениями.
Затем в переменную y записывается указатель на следующий узел, находящийся в нужном поддереве (левом - если добавляемое значение меньше значения, содержащегося в текущем узле, или правом – если оно больше). Если y оказывается равным NULL, значит, у текущего узла отсутствует нужное поддерево и именно сюда и нужно вставлять добавляемое значение в виде нового узла. Для создания нового узла используется функция new_node приведенная в листинге 7.
Переменные x и v во фрагменте №1 используются для отслеживания последнего пройденного узла с ненулевым коэффициентом сбалансированности. Так как если коэффициент сбалансированности равен 0, то при вставке нового узла он изменится на +1 или -1, и в этом случае балансировка не потребуется. Если же коэффициент изначально не равен 0, то после вставки узла дерево придется балансировать.
Когда вставка нового узла y приводит к изменению коэффициентов для узлов, расположенных выше него, то требуется обновить коэффициенты для узлов, находящихся между узлами x и y. Эти действия выполняются во фрагменте №2 листинга 7.
Фрагмент № 3 листинга 6 соответствует ситуации, когда узел y находится в левом поддереве узла x. В этом случае, когда коэффициент сбалансированности для x изначально был равен -1, а после добавления узла стал равным -2, требуется выполнить балансировку. На рисунке 3 представлены два варианта выполнения балансировки.
В верхней половине рисунка 3 выполняется правая ротация узлов w и x, при этом узел w перемещается на место узла x. Узел x становится правым дочерним узлом для узла w, и в результате высота остается такой же, как и до вставки. В нижней половине рисунка 3 показана двойная ротация - сначала левая ротация узлов w и y, затем правая для узлов y и x.
Фрагмент №4 листинга описывает ситуацию с балансировкой, когда узел y находится в правом поддереве узла x.
Удаление узла из AVL-дерева
Удаление узла из AVL-дерева сложнее аналогичной операции для простого двоичного дерева и включает в себя следующие этапы:
поиск узла, который требуется удалить; в процессе поиска запоминаются пройденные узлы для выполнения последующей балансировки;
удаление искомого узла и обновление списка пройденных узлов;
выполнение балансировки и перерасчет коэффициентов сбалансированности.
В начале этой функции идет поиск узла, который необходимо удалить. Каждый пройденный узел z сравнивается с целевым значением item. Пройденные узлы помещаются в массив ap, а направления, по которым осуществляется движение, сохраняются в массив ad.
После этого происходит удаление узла из дерева, при этом возможны те же три варианта развития событий, как и при удалении узла из обычного двоичного дерева. Однако для AVL-дерева необходимо дополнительно отслеживать список узлов, расположенных выше удаляемого узла. После удаления выполняется балансировка, как и в случае с добавлением узла в дерево, но не по левому/правому поддеревьям, а по расположенным сверху элементам.
Несмотря на преимущества, предоставляемые AVL-деревьями при выполнении поиска по дереву, их использование затрудняется необходимостью балансировки после выполнения операций добавления / удаления узлов. Алгоритм балансировки представляет основную проблему, так как его неудачная реализация может негативно влиять на производительность программы, использующей данный тип дерева.
В статье были рассмотрены как теоретические аспекты работы с AVL-деревьями, так и основные алгоритмы для работы с ними, представленные в виде функций на языке Си. Изучив представленную реализацию и теоретические аспекты балансировки дерева, пользователь сможет сам разработать алгоритм балансировки AVL-дерева на Python.
Источник: Richard Heathfield . C Unleashed.
Часть 9
Красно-черные деревья
В данной статье рассматривается разновидность бинарных поисковых деревьев - красно-черные деревья, которые также относятся к сбалансированным деревьям. Такие деревья используются для решения самых разных задач, например, в одной из реализаций планировщика ядра ОС Linux (completely fair scheduler) или для создания ассоциативных массивов. В статье, как обычно, будут разбираться особенности реализации красно-черных деревьев и алгоритмов для работы с ними.
Красно-черное дерево (англ. red-black tree) - это еще одна форма сбалансированного бинарного поискового дерева. Впервые оно было представлено в 1972 году как еще одна разновидность сбалансированного бинарного дерева. Время поиска, вставки или удаления узла для красно-черного дерева является логарифмической функцией от числа узлов.
Данный тип деревьев отличается от других реализаций следующими свойствами:
каждый узел ассоциируется с определенным цветом - красным или черным;
корневой узел может быть любого цвета;
красные узлы могут иметь только черные дочерние узлы;
все пути от узла до любого листа, расположенного ниже в дереве, содержат одно и то же количество черных узлов.
Высота красно-черного дерева, состоящего из N узлов, лежит в диапазоне от двоичного логарифма log(N+1) до 2 * log(N+1).
В листинге 1 приведены структуры на языке Си, описывающие узлы красно-черного и AVL-деревьев.
/* структура, описывающая узел красно-черного дерева */
struct rb_node
{
int red;
int data;
struct rb_node *link[2];
};
/* структура, описывающая узел AVL-дерева */
struct avl_node
{
struct avl_node * link[2];
int data;
short bal;
};
Как можно заметить, структура узла AVL-дерева очень похожа на структуру, использующуюся для хранения информации об узле красно-черного дерева. Только коэффициент сбалансированности bal в красно-черном дереве заменен на переменную red, определяющую цвет узла (красный или черный). Но функции вставки/удаления узлов для красно-черного дерева значительно отличаются от аналогичных операций для AVL-дерева и должны быть рассмотрены отдельно.
Также для работы с красно-черным деревом потребуется вспомогательная структура из листинга 2.
struct rb_tree
{
struct rb_node *root; // указатель на корневой узел
int count; // количество узлов в дереве
};
Вставка узла в красно-черное дерево
При вставке нового узла в цветное дерево (другое название красно-черного дерева) для него изначально устанавливается красный цвет. Затем для добавляемого элемента выполняется поиск родительского узла и проверка его цвета. Если цвет родителя - черный, то основной критерий цветного дерева сохраняется. Если же родитель - красного цвета, то выполняется итеративная (нерекурсивная) балансировка дерева. В худшем случае время вставки может достичь значения логарифма от числа узлов в красном дереве.
Для упрощения алгоритма предполагается, что листья (узлы, не имеющие потомков) имеют черный цвет. В листинге 3 приведен исходный код функции для определения цвета узла.
Для ротации узлов в дереве будут использоваться функции, представленные в листинге 4. Первая функция меняет местами два узла, вторая функция выполняет два таких обмена:
При вставке узла в цветное дерево не требуется прибегать к рекурсии, так как это можно сделать за один проход. В общем случае при вставке нового узла возможны три варианта.
происходит изменение цвета;
требуется сделать один поворот;
требуется сделать двойной поворот.
Для этого в памяти кроме текущего узла нужно хранить еще три уровня дерева: «родителя», «деда» и «прадеда» текущего узла.
На рисунке 1 в первом варианте у добавляемого узла (q) проверяются дочерние узлы. Если дочерние узлы - красного цвета, а добавляемый узел – черного, то выполняется смена цветов. Необходимо также проверить на совпадение цвета 2 узла (второй и третий варианты) - добавляемый узел (q) и его родителя (p). Если они оба красного цвета, то выполняется одиночная либо двойная ротация.
int rb_insert ( struct rb_tree *tree, int data )
{
/* если добавляемый элемент оказывается первым – то ничего делать не нужно*/
if ( tree->root == NULL ) {
tree->root = make_node ( data );
if ( tree->root == NULL )
return 0;
}
else {
struct rb_node head = {0}; /* временный корень дерева*/
struct rb_node *g, *t; /* дедушка и родитель */
struct rb_node *p, *q; /* родитель и итератор */
int dir = 0, last;
/* вспомогательные переменные */
t = &head;
g = p = NULL;
q = t->link[1] = tree->root;
/* основной цикл прохода по дереву */
for ( ; ; )
{
if ( q == NULL ) {
/* вставка ноды */
p->link[dir] = q = make_node ( data );
tree->count ++ ;
if ( q == NULL )
return 0;
}
else if ( is_red ( q->link[0] ) && is_red ( q->link[1] ) )
{
/* смена цвета */
q->red = 1;
q->link[0]->red = 0;
q->link[1]->red = 0;
}
/* совпадение 2-х красных цветов */
if ( is_red ( q ) && is_red ( p ) )
{
int dir2 = t->link[1] == g;
if ( q == p->link[last] )
t->link[dir2] = rb_single ( g, !last );
else
t->link[dir2] = rb_double ( g, !last );
}
/* такой узел в дереве уже есть - выход из функции*/
if ( q->data == data )
{
break;
}
last = dir;
dir = q->data < data;
if ( g != NULL )
t = g;
g = p, p = q;
q = q->link[dir];
}
/* обновить указатель на корень дерева*/
tree->root = head.link[1];
}
/* сделать корень дерева черным */
tree->root->red = 0;
return 1;
}
Удаление узла из красно-черного дерева
При удалении узла из цветного дерева цвет родительского узла не изменяется. Удаление красного узла не влечет никаких последствий, коллизию может вызвать только удаление узла черного цвета. Поэтому при удалении черного узла для обеспечения целостности дерева необходимо использовать различные операции: простую смену цвета (если это возможно) или одну или несколько ротаций. На рисунке 2 представлены 4 ситуации, возможных при удалении черного узла.
Если при удалении черного узла, его «брат» (узел, находящийся на том же уровне, что и удаляемый) и все их четыре потомка имеют черный цвет (это вариант I на рисунке 2), то выполняется изменение цвета. Если «брат» удаляемого узла окрашен в красный цвет, то производится ротация, изображенная на варианте II. Если удаляемый узел и его «брат» черного цвета, а правый потомок «брата» - красного, то выполняется двойная ротация, изображенная на варианте 4. Если левый потомок «брата» красного, то выполняется одиночная ротация, как в пятом варианте.
int br_remove ( struct rb_tree *tree, int data )
{
if ( tree->root != NULL )
{
struct rb_node head = {0}; /* временный указатель на корень дерева */
struct rb_node *q, *p, *g; /* вспомогательные переменные */
struct rb_node *f = NULL; /* узел, подлежащий удалению */
int dir = 1;
/* инициализация вспомогательных переменных */
q = &head;
g = p = NULL;
q->link[1] = tree->root;
/* поиск и удаление */
while ( q->link[dir] != NULL ) {
int last = dir;
/* сохранение иерархии узлов во временные переменные */
g = p, p = q;
q = q->link[dir];
dir = q->data < data;
/* сохранение найденного узла */
if ( q->data == data )
f = q;
if ( !is_red ( q ) && !is_red ( q->link[dir] ) ) {
if ( is_red ( q->link[!dir] ) )
p = p->link[last] = rb_single ( q, dir );
else if ( !is_red ( q->link[!dir] ) ) {
struct rb_node *s = p->link[!last];
if ( s != NULL ) {
if ( !is_red ( s->link[!last] ) && !is_red ( s->link[last] ) ) {
/* смена цвета узлов */
p->red = 0;
s->red = 1;
q->red = 1;
}
else {
int dir2 = g->link[1] == p;
if ( is_red ( s->link[last] ) )
g->link[dir2] = rb_double ( p, last );
else if ( is_red ( s->link[!last] ) )
g->link[dir2] = rb_single ( p, last );
/* корректировка цвета узлов */
q->red = g->link[dir2]->red = 1;
g->link[dir2]->link[0]->red = 0;
g->link[dir2]->link[1]->red = 0;
}
}
}
}
}
/* удаление найденного узла */
if ( f != NULL ) {
f->data = q->data;
p->link[p->link[1] == q] =
q->link[q->link[0] == NULL];
free ( q );
}
/* обновление указателя на корень дерева */
tree->root = head.link[1];
if ( tree->root != NULL )
tree->root->red = 0;
}
return 1;
}
Сравнение AVL и красно-черных деревьев
У AVL и цветных деревьев есть как общие черты, так и отличия. Например, совпадает время, требующееся для вставки удаления/узлов в оба типа деревьев, которое в общем случае равно двоичному логарифму от общего числа узлов в дереве.
Для модификации обоих типов деревьев требуется выполнение дополнительных ротаций. Но вставка в AVL-дерево требует не более одной ротации, а удаление узла уже может потребовать большого количества ротаций, в общем случае, двоичный логарифм от числа узлов в дереве. Модификация красно-черных деревьев выполняется легче, так как вставка требует не более 2-х ротаций, а удаление - не более трех.
Также в случае, когда общее число узлов дерева] одинаково, максимальная высота AVL- дерева всегда будет меньше, чем максимальная высота красно-черного дерева. Высота красно-черного дерева может превышать высоту AVL-дерева в 1.38 раз, поэтому для выполнения поиска по красно-черному дереву требуется больше времени.
AVL-дерево должно хранить высоту в каждом узле, в то время как в узле красно-черного дерева хранится только дополнительный бит, определяющий цвет узла. Поэтому для хранения красно-черного дерева требуется меньше памяти, чем для AVL-дерева такого же размера.
Сравнение производительности AVL и красно-черных деревьев
В этом разделе сравнивается производительность вставки узлов в AVL-дерево и красно-черное дерево. Как уже было сказано, оба этих типа относятся к самобалансирующимся бинарным поисковым деревьям. Поэтому, если при вставке нарушается критерий сбалансированности (высота дерева становится неоптимальной, т.е. превышает минимально возможное значение), то выполняется автоматическая корректировка дерева.
В ходе сравнительного тестирования в дерево добавляются узлы, сгенерированные случайным образом, до тех пор, пока количество узлов в дереве не станет равно пяти миллионам. Такое большое значение было выбрано специально, чтобы наглядно выявить разницу в скорости работы двух типов деревьев, но для более слабых или наоборот более мощных процессоров можно использовать другие значения.
Реализация красно-черного дерева на языке Си была представлена в этой статье, а реализацию AVL-дерева можно взять из предыдущей статьи. В листинге 8 представлена программа для проверки производительности AVL-дерева, а в листинге 9 – эта же программа, но уже для красно-черного дерева.
Реализация на си:
struct rb_node
{
int red;
int data;
struct rb_node *link[2];
};
struct rb_tree
{
struct rb_node *root;
int count;
};
...
struct rb_tree * tree_create()
{
struct rb_tree * new_tree = malloc(sizeof * new_tree);
if (new_tree == NULL) return NULL;
new_tree->root = NULL;
new_tree->count = 0;
return new_tree;
}
int height(struct rb_node* node)
{
if (node==NULL)
return 0;
else
{
int left = height(node->link[0]);
int right = height(node->link[1]);
if (left > right)
return(left+1);
else return(right+1);
}
}
int main()
{
struct rb_tree * my_tree = tree_create();
int rnd = (rand() % count);
int res = rb_insert ( my_tree, rnd );
}
int main()
{
int count = 10000000;
int res = 0;
int i = 0 ;
int rnd = 0;
struct rb_tree * my_tree = tree_create();
time_t start,time2;
volatile long unsigned t;
start = time(NULL);
srand (time (NULL));
for( i = 0; i < count; i++)
{
rnd = (rand() % count);
res = rb_insert ( my_tree, rnd );
if(my_tree->count==5000000) break;
}
time2 = time(NULL);
printf("\n затрачено %f секунд.\n", difftime(time2, start));
printf("\n высота=%d количество узлов=%d\n",height(my_tree->root),my_tree->count);
return 0 ;
}
В ходе тестирования были получены следующие результаты: одному и тому же компьютеру потребовалось 16 секунд на вставку 5 миллионов узлов в AVL-дерево и 20 секунд на вставку такого же количества узлов в красно-черное дерево. При этом высота AVL-дерева оказалась равной 27, а цветного дерева - 28.
Таким образом, теория была подтверждена практикой: высота AVL-дерева оказалась чуть меньше высоты красно-черного дерева, что положительно сказалось на скорости вставки узлов в AVL-дерево. Используя представленные материалы, предлагается выполнить «обратное» тестирование на скорость удаления узлов из дерева, чтобы проверить утверждение, что удаление из AVL-дерева требует больше времени, нежели удаление из цветного дерева.
Часть 10
B-деревья и TRIE-деревья
TRIE-деревья
В современных текстовых редакторах (неважно online или offline) обязательно присутствует функция проверки орфографии вводимого текста на основе встроенного словаря. Эта функция должна извлечь из текста все слова и проверить их написание на соответствие со словарем. Для построения подобных словарей используется древовидная структура данных, которая называется TRIE-дерево (или дерево префиксов). Предположим, имеется следующий фрагмент текста:
THE THEN THIN THIS TIN SIN SING.
Требуется составить дерево из слов, входящих в это предложение, однако в этих словах присутствует много повторяющихся символов. TRIE-дерево предназначено для решения подобной задачи, как показано на рисунке 1.
Символ $ в терминальных узлах дерева - это endmarker, который позволит продолжить составление дерева со всеми возможными сочетаниями символов. Представленное дерево построено на основе английского алфавита, поэтому каждый узел может иметь не более 27 потомков - 26 букв и endmarker. На практике у большинства узлов будет меньше 27 потомков.
У TRIE-дерева есть свои преимущества и недостатки, так, оно требует больше памяти, чем двоичные деревья. В бинарном дереве у каждого узла может быть не более двух потомков, а в TRIE-дереве вообще нет ограничений на количество потомков, так что все упирается только в доступную память и количество символов в используемом алфавите.
В листинге 1 представлен один из возможных вариантов определения базовой структуры TRIE-дерева.
В TRIE-дереве листья обозначаются как TRIE_LEAF, а поддеревья обозначаются как TRIE_SUBTRIE. Поэтому можно определить два типа узлов, как показано в листингах 2 и 3.
//константы для управления скоростью поиска и использования памяти
#define LOG_TRIE_BRAHCH_FACTOR 4
#define TRIE_BRANCH_FACTOR (1<<L0G_TRIE_BRANCH_FACT0R)
struct trie_subtrie
{
enum trie_node_type type;
struct trie_leaf * exact_match;
//количество ключей, для которых узел является префиксом
int count;
trie_pointer next_level[TRIE_BRANCH_FACTOR];
};
Как было показано в предыдущих статьях, если бинарное поисковое дерево сбалансировано, то его высота имеет логарифмическую зависимость от числа узлов. Поэтому, чем больше высота дерева, тем больше времени требуется на поиск в нем, так как для поиска нужного значения нужно пройти по большему количеству узлов.
Для решения этой проблемы предлагается древовидная структура, в которой высота получившегося дерева специально понижена. В B-дереве каждый узел может иметь более двух дочерних узлов, так что это дерево уже нельзя назвать бинарным деревом.
Характеристики B-дерева:
m - порядок (максимальное количество дочерних узлов);
каждый узел, кроме корневого, должен иметь как минимум m/2 дочерних узлов;
корневой узел имеет как минимум 2 дочерних узла;
все листья находятся на одном уровне;
узел, имеющий k потомков, может иметь k-1 ключей.
Что касается ограничения на величину m, то оно зависит от характеристик жесткого диска, в частности от размера его блока.
Каждый узел в B-tree имеет упорядоченный набор ключей и набор указателей на своих потомков. Например, если у узла n0 имеются три потомка - n1, n2, n3, то ключами узла n0 должны быть два разделителя - a1 и a2, при этом - все ключи поддерева n1 должны быть меньше a1, все ключи поддерева n2 должны быть меньше a2, и т.д.
B-tree - это сбалансированное дерево, поэтому у каждого узла есть две константы:
U - максимально возможное число дочерних узлов;
L - минимально возможное число дочерних узлов.
Когда происходит вставка или удаление узла, эти константы рекурсивно проверяются по всему дереву сверху вниз. Если в каком-то узле возникает отклонение от значений L и U, то узлы будут объединяться или разделяться для восстановления баланса.
B-деревья широко применяются в базах данных и файловых системах. Также встречаются различные варианты B-деревьев, например, 2-3-дерево, где каждый узел может иметь не более трех потомков.
На рисунке 2 показан пример B-дерева. Когда количество ключей в узле превышает определенный порог, то этот узел разделяется на два узла, между которыми ключи делятся поровну. Каждый ключ в узле является корнем для поддерева, в котором хранятся ключи, находящиеся в диапазоне между соответствующими ключами корневого узла.
Так как B-дерево относится к сбалансированным, то путь от корня до любого листа требует одинакового количества шагов. Существует связь между максимальным количеством ключей в узле и максимальным количеством его потомков. Если число ключей обозначить как 2d, то число узлов обычно будет на единицу больше - 2d + 1. Также существует зависимость между высотой дерева h и количеством ключей n.
В данном типе дерева все листья должны располагаться на одном уровне дерева, поэтому такие деревья растут в сторону увеличения числа дочерних узлов, а не в высоту. Производительность поиска по B-дереву зависит от величины блока и скорости доступа к жесткому диску. Поэтому для повышения эффективности поиска важно уменьшить количество узлов за счет высокой ветвистости листьев.
Существуют два типа B-деревьев: B+ и B*. На рисунке 3 представлено B+-дерево. В данной реализации все данные хранятся в отдельном слое дерева - в листьях, при этом они отсортированы. Этот слой может быть организован в связный список, что является основным отличием от обычного B-дерева.
B*-дерево используется в файловых системах HFS и Reiser4 и отличается B+-деревьев тем, что когда узел полностью заполнен данными, то он не разбивается на 2 узла. Вместо этого ищется место в уже существующем соседнем узле, и только после того, как оба узла будут заполнены, они разделяются на три узла.
Операции с B-деревом
Для поиска или вставки узла в такое дерево требуется всего один проход. Поиск в B-дереве отличается от поиска в обычном бинарном дереве тем, что в последнем случае он основан на выборе между правым и левым узлом. В случае с B-деревом - это линейный поиск между соседними ключами.
При вставке ключа нужно учесть несколько вариантов: ключ может добавляться как в узел, так и в лист. В первом случае если происходит переполнение узла, то он делится пополам. На рисунке 4 показано, как может происходить формирование B-дерева в случае, когда в него последовательно вставляются натуральные числа от 1 до 7. В этом примере каждый узел может содержать не более двух ключей.
При удалении ключа происходит аналогичный процесс - объединение или разбиение узлов, который может затронуть все дерево от текущего узла до корня. Удаление также можно реализовать за один проход, но необходимо учесть два варианта развития событий:
ключ является разделителем;
при удалении ключа число ключей может стать меньше необходимого минимума.
Заключение
На этом цикл, посвященный различным структурам данных, закончен. В нем были рассмотрены базовые формы организации данных применительно к двум популярным языкам программирования: Си и Python.
Особое внимание было уделено связным спискам, как одной из наиболее важных и фундаментальных структур. Так было выполнено сравнение эффективности различных алгоритмов для работы со связными списками.
Вторая половина цикла была посвящена не менее значимой структуре данных — деревьям. Благодаря востребованности деревьев для файловых систем и баз данных, в данной области постоянно проводятся различные исследования и предлагаются новые подходы или оптимизированные версии уже существующих алгоритмов.
Оставьте свой комментарий !
Автор
Комментарий к данной статье
Анна
Подскажите,пожалуйста,подробнее вставку элемента в произвольное место связного списка,а в частности пошагово про struct node** 2013-01-21 05:32:48
Нонна
Замечательный цикл статей! Доступно изложены принципы работы с различными структурами данных.
Все проиллюстрировано примерами. Особая благодарность за pyton!
Спасибо за Вашу работу, которая облегчает жизнь нам, начинающим осваивать структуры данных. 2017-02-17 09:03:28
Феликс
Программа для работы с бинарным деревом на экране
https:soft.softodrom.ruapTrees-Portable-p19987 2019-11-30 17:59:45

 LINUX
LINUX 
 Languages
Languages