Solaris vs. Linux: Сравнительный анализ
by Dr Nikolai Bezroukov
Автор неравнодушен к Solaris
и не претендует на комплексный глобально-сравнительный анализ обеих архитектур со всеми вытекающими.
Солярис и линукс - 2 операционные системы,отвечающие стандартам POSIX.
Solaris официально POSIX-совместим, Linux также POSIX-совместим,
хотя официального сертификата никто вроде не видел.
Имея различную внутреннюю архитектуру,
каждая ось имеет свои сильные и слабые стороны.
Организация процесса разработки самих операционных систем накладывает отпечаток на них.
Хочется подчеркнуть особую роль совместимости в этом процессе.
Solaris может работать на 2-х архитектурах: UltraSparc и Intel
(Opteron особенно).
Linux остается в основном приверженцем X86.
Есть несколько попыток портировать Линукс на Alpha ,
на IBM Power architecture,
и вроде как ни одно из этих портирований не было коммерчески успешным.
Надо сказать,что базовый набор машинных инструкций для всех X86-64 CPUs включая Opteron
имеют старый
Intel x86
префикс.
Прямо скажем,это не очень дружественный с точки зрения компилятора набор инструкций.
Intel CPUs имеют little Endean байтовый порядок,
который характерен для устаревших микро-процессоров.
SPARC имеет Big Endean архитектуру , куда также входят IBM's System/3xx
и Power5.
Big Endean - это более естественный порядок байт ,
например с точки зрения анализа 16-ричных дампов,
или с точки зрения генерации IP-пакетов.
Например , строка "UNIX" будет выглядеть как "NUXI"
в машинном дампе в случае little Endean.
Big-endian-числа легче читать при дебаге.
IP-Protocol определяет стандартный "Big-Endian" сетевой порядок байт.
Этот порядок используется в заголовках пакетов.
Для Little Endean-архитектуры нужен дополнительный перевод.
Solaris - это тоже Unix (первый Solaris 4.x был клоном
Berkeley - Bill Joy ).
Linux не внес столько изменений ,
таких , как сан-овский
/proc VFS в 1985,
или RPC, NFS, and NIS/NIS+,
PAM).
Linux-ядро является монолитом с самого начала.
Этот фактор является одним из самых консервативных в его архитектуре.
Вопрос о POSIX-совместимости никогда не ставился в нем до конца.
Линуксу потребовалось 15 лет для того,чтобы наконец добраться до более-мене
жизнеспособного функционала.
После 15 лет он имеет все явные признаки раннего склероза:-)
Уровень совместимости между различными версиями ядра линукс ужасен.
Тем не менее линукс по-прежнему остается главной надеждой человечества :-)
Монолитные ядра являются более быстрыми.
Его структура более прозрачна и понятна.
Но это не значит,что она более масштабируемая.
Количество багов в последних версиях указывает на то,
что линуксовое ядро достигло критической массы,
и их отладка становится проблемой.
Недаром Andrew Morton предложил остановиться и заняться отлаживанием ядра :
[Barr2006,
Vaughan-Nichols2006]:
"'Похоже на то , что появление новых багов превышает процесс их выявления и отладки ..."
Это распространяется и на ISP, в который линукс делает большой вклад.
Например , Matt Heaton, президент Bluehost.com, писал:
blog:
У Redhat Enterprise 4 проблемы со стандартным линуксовым ядром.
Это затронуло около 40 серверов.
В конце концов мы взяли и собрали свое собственное ядро:-)
Линус в свое время определил,что микро-ядра - это полное дерьмо.
Он по-прежнему на этой позиции и начинает походить на Ивана Сусанина,
который заводит армию в тупик в связи с проблемами в очень больших монолитных ядрах :-)
Если рассматривать версию Linux kernel 1.0,то может быть,что он и прав.
Но ситуация немного отличается в случае SMP,
на которую наслаивается различные подсистемы и все более возрастающий размер ядра.
May 11, 2006, в статье "Debunking Linus's Latest" некто Dr. Jonathan Shapiro
из Systems Research Laboratory Dept. of Computer Science
Johns Hopkins University писал , что у ядра все проблемы
завязаны на его уровень развития.
Он говорит,что начиная с определенного уровня микро-ядерная архитектура может иметь преимущество над
монолитной:
[Shapiro2006]:
What modern microkernel advocates claim is that properly
component-structured systems are engineerable,
which is an entirely different issue. There are many
supporting examples for this assertion in hardware, in
software, in mechanics, in construction, in transportation,
and so forth. There are no supporting
examples suggesting that unstructured systems are
engineerable. In fact, the suggestion flies in the
face of the entire history of engineering experience going
back thousands of years. The triumph of 21st century
software, if there is one, will be learning how to structure
software in a way that lets us apply what we have learned
about the systems engineering (primarily in
the fields of aeronautics and telephony) during the 20th
century.
Linus argues that certain kinds of systemic performance
engineering are difficult to accomplish in
component-structured systems. At the level of drivers this
is true, and this has been an active topic of research in
the microkernel community in recent years. At the level of
applications, it is completely false. The success of things
like GNOME and KDE rely utterly on the use of IDL-defined
interfaces and separate component construction. Yes, these
components share an address space when they are run, but
this is an artifact of implementation. The important point
here is that these applications scale because they
are component structured.
Ultimately, Linus is missing the point. The
alternative to structured systems is unstructured
systems. The type of sharing that Linus advocates is
the central source of reliability, engineering, and
maintenance problems in software systems today. The
goal is not to do sharing efficiently. The goal is to
structure a system in such a way that sharing is minimized
and carefully controlled. Shared-memory concurrency
is extremely hard to manage. Consider that
thousands of bugs have been found in the Linux kernel
in this area alone. In fact, it is well known that this
approach cannot be engineered for robustness, and shared
memory concurrency is routinely excluded from robust system
designs for this reason.
Yes, there are areas where shared memory interfaces are
required for performance reasons. These are much fewer than
Linus supposes, but they are indeed hard to manage (see:
Vulnerabilities in Synchronous IPC Designs). The
reasons have to do with resource accountability, not with
system structure.
When you look at the evidence in the field, Linus's
statement ``the whole argument that microkernels are somehow
`more secure' or `more stable' is also total crap'' is
simply wrong. In fact, every example of stable or
secure systems in the field today is microkernel-based.
There are no demonstrated examples of highly secure or
highly robust unstructured (monolithic) systems in the
history of computing.
Архитектура линукса - один из юниксовых вариантов,причем не лучший.
Линукс - самая популярная свободная ось,
но архитектура ядра солярис более современна и работоспособна.
Развитие линуксового ядра пострадало из-за культа лидера,
которое стало более явным , чем в других проектах.
Взять к примеру развитие шедулера начиная с версии 1 до 2.6.
Коммерческая разработка Solaris имеет больше преимуществ
в силу более высокой дисциплины и лучшей архитектуры.
Команда пазработчиков линуксового ядра может поменять реализацию в любой момент,
в то время как в солярис процесс более надежен и стабилен.
Хотя эта критика может быть несправедлива.
Ядро линукса давно уже не развивается тем волонтерским способом,как это было во времена 1.0.
Разработка линуксового ядра теперь кооперативно структурирована коммерческим образом
(IBM,Intel) и очень хорошо оплачивается
(ну а Линус скорее всего самый высоко-оплачиваемый разработчик
юниксового ядра на планете :-)).
Эта тенденция к установлению "kernel oligarchy" стала особенно заметной после того,
как Linus ушел из Transmeta в Linux system laboratories IBM.
Исторически Solaris всегда был Net-ориентированным дистрибутивом Unix.
Отсюда идет концепция т.н. remote procedure call и NFS, здесь впервые появился
каталог /home
(который означает , что вы можете иметь доступ к одной и той же домашней директории
с разных машин).
Если судить о линуксовом ядре с точки зрения количества затраченных на него денег,
то вывод может быть не в его пользу.
Команда FreeBSD реализовала VM первой
(jails была добавлена во FreeBSD в 1999). Jails реализует
полную изоляцию для файловой системы, процессов, сети,
разделяемые права.
Linux же спустя аж 7 лет интегрировал XEN (который до сих пор находится в "progress").
Zones - новая реализация RBAC в 10-й солярис,
а также ZFS стали новыми достижениями
в области open source разработке юниксового ядра.
Смотрите [Bezroukov
1999a] и [Bezroukov 1999b]
Как BSD , так и Solaris - более сервер-ориентированные дистрибутивы:
их разработчиков мало волнуют десктопы.
Хотя в Sun используют Solaris на Acer laptops.
Для настоящих профессионалов юниксовый сервер - вполне приемлемый десктоп ;-).
Ядро Solaris много-поточное;
это сделано для поддержки нескольких процессоров.
Эта архитектура заимствована из традиционного юниксового ядра.
В Solaris, kernel threads
является обьектом для планировщика CPU.
Благодаря этому возможно выполнение множества потоков внутри единого виртуального пространства,
и переключение между этими потоками некритично в силу того,что не нужно делать
memory context switch.
As Max Bruning noted in his paper:
One of the big differences between
Solaris and the other two OSes is the capability to support multiple
"scheduling classes" on the system at the same time. All three OSes support
Posix SCHED_FIFO,
SCHED_RR, and
SCHED_OTHER
(or SCHED_NORMAL).
SCHED_FIFO
and SCHED_RR
typically result in "realtime" threads. (Note that Solaris and Linux support
kernel preemption in support of realtime threads.) Solaris has support
for a "fixed priority" class, a "system class" for system threads (such as
page-out threads), an "interactive" class used for threads running in a
windowing environment under control of the X server, and the Fair Share
Scheduler in support of resource management. See
priocntl(1) for
information about using the classes, as well as an overview of the features of
each class. See FSS(7)
for an overview specific to the Fair Share Scheduler. The scheduler on FreeBSD
is chosen at compile time, and on Linux the scheduler depends on the
version of Linux.
The ability to add new scheduling classes to
the system comes with a price. Everywhere in the kernel that a scheduling
decision can be made (except for the actual act of choosing the thread to run)
involves an indirect function call into scheduling class-specific code. For
instance, when a thread is going to sleep, it calls scheduling-class-dependent
code that does whatever is necessary for sleeping in the class. On Linux and
FreeBSD, the scheduling code simply does the needed action. There is no need
for an indirect call. The extra layer means there is slightly more overhead
for scheduling on Solaris (but more features).
Ядро Solaris собрано проприетарным компилером,который генерит оптимизированный код.
Sun Studio 11 complier бьет GCC на платформе SPARC .
Ядро,собранное с помощью GCC под SPARC , уступает нативному.
У меня нет данных о поведении Solaris compiler на платформе Intel.
Ядро Solaris стабильно, хорошо продумано , Solaris 8
и 9 на платформе UltraSparc стабильнее , чем Unix .
Все BSD-ядра также более стабильны , чем Linux.
Linux включает в себя такие критические компоненты , как scheduler, memory subsystem,
multithreading, а также
number and the rate
of publishing of new exploits ,
что может сделать проблему патчей для линуксовых серверов аналогичной виндовой.
Работа OS на платформе UltraSparc означает дополнительную защиту.
У меня сложилось субьективное представление,что сеть в линуксе в большинстве дистрибутивов менее стабильна.
Обычно линуксовый сервер требует ежемесячной или еженедельной перезагрузки.
Сетевой стек в линуксе менее стабилен и возможно менее быстр.
FireEngine Phase 1 , интегрированный в Solaris 10 , включает следующие улучшения в TCP/IP:
● Achieved 45% gain on web like workload on SPARC
● Achieved 43% gain on web like workload on x86
● Other gains (just due to FireEngine):
25% SSL
15% fileserving
40% throughput (ttcp)
● On v20z, Solaris is faster than RHEL 4.3 by 10-20% using Apache or Sun
One Webserver on a web based workload
Solaris 10 может обслуживать сеть 1Gb , загружая на 8% процессор 1x2.2Ghz Opteron ,
и сеть 10Gb , используя 2x2.2Ghz opteron CPUs с загрузкой менее чем на 50%.
Линуксовый сетевой стек обслуживает BSD sockets; для приложений , использующих
STREAMS, нужны дополнительные пакеты (например
www.gcom.com/home/linux/lis/).
Реализация таких сетевых протоколов,как Linux NFS и реализация automounter , такова ,
что линуксовые клиенты не могут использовать такие фичи , как Solaris automounter.
Реализация NSF по определению выше в Solaris.
Лишь в последней версии Red Hat появилась поддержка NFS v.4.
AIX кстатит поддерживает NFS 4 на том же уровне , что и сама Solaris.
Eric Kurzal по этому поводу заметил:
One new feature of Solaris 10 that has slipped
under the radar is NFSv4. I work on the client side for Solaris. You can find
the rfc here and
the community website here.
Original Design
Considerations. So what's the big deal of NFSv4 anyways?
NFSv4 makes security mandatory. NFS IS
SECURE!
Sun gave up control of NFS to the IETF.
A common ACL model (Unix and Windows working
together before Gates and Papadopulos made it
popular).
File level delegation to reduce network
latency and server workload for a class of applications.
COMPOUND procedure to allow for flexible
request construction and reduction of network latency and server workload.
Built in minor versioning to extend the
protocol through the auspices of the IETF protocol process.
Integrated locking (no need of a separate
protocol - NLM, and we work with Windows locking semantics).
One protocol and one port (2049) for all
functionality.
So who else is implementing NFSv4?
University of Michigan/CITI
has putback to Linux 2.6. Back in 1999/2000, this is where I spent my last
year in school working. Netapp has already
released
their implementation.
IBM too.
Have Windows in your environment?
Hummingbird can hook you up
today.
Rick at the
University of Guelph is implementing a server for
BSD.
I'll go into details for some of the features
of NFSv4 in future posts.
We hold regular interoperability-fests about
every 4 months via
Connectathon and (NFSv4
only) bake-a-thons (
last one).
Как Solaris , так и Linux поддерживают SMB (MS Windows).
Реализация NIS сделана лучше в Solaris ,включая аутентификацию с использованием
Pluggable Authentication Modules (PAM).
Sun работает над развитием сети в нескольких направлениях.
Во время презентации Sun в BayLISA в 2005 [Tripathi2005]
были показаны новые фичи:
Зафиксировано 25% прогресса для x86 и 20% для SPARC в части работы веба
с одновременным уменьшением interrupts, context switches, mutex
contentions.
Solaris поддерживает т.н. trunking - обьединение нескольких NICs в один скоростной линк.
Можно создать trunks из 1Gb NICs или 10GB NICs.
Каждый член trunk может контролировать процесс миграции пакетов.
Sun планирует достичь 30Gbps для trunk из 4-х 10Gb NICs в 2007.
Команда разработчиков Sun network представлена такими специалистами,как
Dr.
Radia Perlman. Они виртуализировали 1Gb и 10Gb NICs и
реализовали следующие фичи:
- Формирование приоритета в зависимости от других виртуальных стеков системы
- Возможность выбирать protocol layers, firewalls rules, encryption
rules для виртуального стека
Ими разработана т.н. "The Crossbow Architecture".
Ее фичи:
-
Use the NIC to separate out the incoming traffic and divide
NIC memory amongst the virtual stacks
-
Assign MSI interrupt per virtual stack
-
The FireEngine Squeue controls the rate of packet
arrival into the virtual stack by dynamically switching between interrupt &
polling
-
Incoming B/W is controlled by pulling only the allowed
number of packets per second
-
Virtual stack priority is controlled by the squeue
thread which does the Rx/Tx processing
Каждый контейнер в Solaris может иметь собственный виртуальный стек со своей routing table,
firewall, и администратор такого контейнера может настраивать его индивидуально.
Также реализован защитный механизм от DoS attacks.
Переключение между стеками реализовано на уровне аутентификации приложений.
Виртуальные стеки в Solaris изолированы друг от друга.
Both Solaris UFS and Linux
ext2f have a common ancestor:
BSD UFS filesystem[McKusick-Joy-Leffler-1984].
If we try to compare filesystems, the general impression is that
the current Solaris filesystem
(UFS) is more reliable then Linux ext2fs/ext3f, but feature-wise is more limited. Reisner filesystem is
definitely more modern filesystem then UFS, faster and less reliable. It is unclear
how it goes against ZFS in Solaris. One interesting for large enterprise
environment test of OS filesystem
layer is database performance. The recent test conducted by Sun [MySQL2006]
had show that optimized for Solaris MySQL beats MySQL on RED HAT ES by a
considerable margin, the margin which is difficult to explain by vendor bias:
...the open source MySQL database running online transaction
processing (OLTP) workload on 8-way Sun Fire V40z servers. The testing,
which measured the performance of both read/write and read-only operations,
showed that MySQL 5.0.18 running on the Solaris 10 Operating System (OS)
executed the same functions up to 64 percent faster in read/write mode and
up to 91 percent faster in read-only mode than when it ran on the Red Hat
Enterprise Linux 4 Advanced Server Edition OS.
Driven by two Sun Fire V40z servers, powered by
Dual-Core AMD Opteron(TM) Model 875 processors, the
benchmark testing generated data points at 11 different
load levels, starting with one concurrent user
connection (CUC) and gradually doubling that number, up
to a high of 1024 CUC.The primary difference between
the two servers was in the underlying operating system,
keeping the hardware configuration and database
properties the same. During the read/write test, both
systems reached their saturation point at eight CUC, at
which point the the server running the Solaris 10 OS was
30 percent faster. Additionally, the Sun Fire V40z
server running the Solaris 10 OS was running database
queries at a 64 percent better rate on average, when
compared to the server running Linux.
The Solaris advantage was magnified during the
read-only test, where performance exceeded the Linux
test case by 91 percent. Remarkably, in this experiment,
the peak performance under the Solaris 10 OS was
achieved with 16 CUC, while the less robust Red Hat
Linux tapered off at only eight CUC. Despite running at
twice the load during the peak phase, the Solaris
10-based server was performing 53 percent more
transactions per second than the Linux-based server.
Solaris UFS definitely has better security and
reliability records: it support ACLs for ten years (since version
2.5; released in 1995), while Linux only recently added limited and somewhat
inconsistent support (only in 2.6 kernel it was incorporated into kernel,
previous version can be supported with a patch only). In Linux it is still more a
vulnerability then a security feature due to behavior of GNU utilities (most of
them does not yet understand ACLs). Interoperability of Linux and Solaris
for ACLs is limited. NFS works correctly with ACLs only on Solaris.
Usage of GNU utilities like ls and
tar for files with ACLs on Solaris can lead
to strange results and wrong permissions displayed or set.
Solaris UFS filesystem does not implement some innovations introduced by
later versions of BSD filesystem like
immutable attribute for files while Linux ext2fs/ext3fs implements them
incorrectly. Immutable attribute was a really interesting innovation
originated in BSD camp. It eliminates "god-like" status of root: it is bound not
to UID, but depends purely on the run level and security level. As the name implies files with this attribute set can
only be read. What is important is that even root user on higher runlevels cannot write or delete them.
The system first needs to be switched to a single user mode to perform those
operations. This attribute is perfect for military-grade protection of
sensitive configuration files and executables: for most such servers patching can and
probably should be done in a single user mode. I am amazed that Solaris never
implemented this concept.
Servers with high requirement for uptime might represent a
problem but here one probably needs to use clusters, anyway.
Also immutable file or directory can 't be renamed, no further
link can be created to it and it cannot be removed. Note that this also prevents
changes to access time, so files with immutable attribute have "no access time"
attribute activated implicitly and as such can be accessed faster.
The second impresting additional attribute introduced by BSD can was
append-only files: a weaker version of immutable attribute with
similar semantic. Append-only files can be opened in write mode, but data is always appended at
the end of the file. Like immutable files, they cannot be deleted or renamed.
This is especially useful for log files which can only grow. For a directory,
this means that you can only add files to it, but you cannot rename or delete any
existing file. That means that for directories they
actually represent a useful variant of immutable attribute: you can only add files but
cannot tough any existing files.
In BSD the access to filesystem depends on additional global flag called a
securelevel. It is a one-way street: as soon as a securelevel set is cannot be decremented At higher
securelevels, not even root, can access the disk
directly, which is a classic method of bypassing all other protection mechanism
as long as one got root access. In some sense securelevels are similar to
runlevels.
Linux replicated BSD style attributes in
ext2f filesystem, but they are
implemented incorrectly as the key idea behind BSD solution (that idea that attributes are not
UID associated privileges, but the
run level
associated privileges) is missing. BTW that's really Windows-style behavior. Here is the list of
ext2fs attributes:
- A
(no
Access time):
if a file or directory has this attribute set, whenever it is accessed,
either for reading of for writing, its last access time will not be
updated. This can be useful, for example, on files or directories which
are very often accessed for reading, especially since this parameter is
the only one which changes on an inode when it's open read-only.
- a
(
append only):
if a file has this attribute set and is open for writing, the only
operation possible will be to append data to its previous contents. For a
directory, this means that you can only add files to it, but not rename or
delete any existing file. Only
root can set or
clear this attribute.
- d
(no
dump):
dump (8)
is the standard UNIX
utility for backups. It dumps any filesystem for which the dump counter is
1 in /etc/fstab
(see chapter
"Filesystems and Mount Points"). But if a file or directory has
this attribute set, unlike others, it will not be taken into account when
a dump is in progress. Note that for directories, this also includes all
subdirectories and files under it.
- i
(
immutable): a
file or directory with this attribute set simply can not be modified at
all: it can not be renamed, no further link can be created to it
[1] and it cannot be removed.
Only root
can set or clear this attribute. Note that this also prevents changes to
access time, therefore you do not need to set the
A
attribute when i
is set.
- s
(
secure deletion):
when such a file or directory with this attribute set is deleted, the
blocks it was occupying on disk are written back with zeroes.
- S
(
Synchronous mode):
when a file or directory has this attribute set, all modifications on it
are synchronous and written back to disk immediately.
There is a third-party patch for 2.6 kernel that makes the behavior identical to BSD
(see
Linux-Kernel
Archive [PATCH] BSD Secure Levels LSM (1-3)). See also
Improving the Unix API
Without tuning native Solaris filesystem behaves badly serving huge amount of
small files concentrated in few directories (the situation typical for corporate
mail servers running
Sendmail as well as some spamfilters). Here a B-tree based filesystem like Riesner might have an edge.
I suspect that Linux can be tuned to perform substantially better in this
environment but availability of NAS makes this point rather mute in the
enterprise environment.
Newer ZFS is still in too early stage for comparisons. Still one
thing, total complexity looks
promising:
A lot of comparisons have been done,
and will continue to be done, between ZFS and other filesystems.
People tend to focus on performance, features, and CLI tools as
they are easier to compare. I thought I'd take a moment to look
at differences in the code complexity between UFS and ZFS. It is
well known within the kernel group that UFS is about as brittle
as code can get. 20 years of ongoing development, with feature
after feature being bolted on tends to result in a rather
complicated system. Even the smallest changes can have wide
ranging effects, resulting in a huge amount of testing and
inevitable panics and escalations. And while SVM is considerably
newer, it is a huge beast with its own set of problems. Since
ZFS is both a volume manager and a filesystem, we can use
this script written by
Jeff to count the lines of source code in each component.
Not a true measure of complexity, but a reasonable approximation
to be sure. Running it on the latest version of the gate yields:-------------------------------------------------
UFS: kernel= 46806 user= 40147 total= 86953
SVM: kernel= 75917 user=161984 total=237901
TOTAL: kernel=122723 user=202131 total=324854
-------------------------------------------------
ZFS: kernel= 50239 user= 21073 total= 71312
-------------------------------------------------
The numbers are rather astounding. Having written most of the
ZFS CLI, I found the most horrifying number to be the 162,000
lines of userland code to support SVM. This is more than twice
the size of all the ZFS code (kernel and user) put together! And
in the end, ZFS is about 1/5th the size of UFS and SVM. I wonder
what those ZFS numbers will look like in 20 years...
ZFS has also some interesting ideas in
CLI interface design:
... One of the hardest parts of designing an effective CLI is to
make it simple enough for new users to understand, but powerful
enough so that veterans can tweak everything they need to. With
that in mind, we adopted a common design philosophy:
"Simple enough for 90% of the users to understand,
powerful enough for the other 10% to use
A good example of this philosophy is the 'zfs list' command.
I plan to delve into some of the history behind its development
at a later point, but you can quickly see the difference between
the two audiences. Most users will just use 'zfs list':
$ zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 55.5K 73.9G 9.5K /tank
tank/bar 8K 73.9G 8K /tank/bar
tank/foo 8K 73.9G 8K /tank/foo
But a closer look at the usage reveals a lot more power under
the hood:
list [-rH] [-o property[,property]...] [-t type[,type]...]
[filesystem|volume|snapshot] ...
In particular, you can ask questions like 'what is the amount
of space used by all snapshots under tank/home?' We made sure
that sufficient options existed so that power users could script
whatever custom tools they wanted.
Solution driven error messages
Having good error messages is a requirement for any
reasonably complicated system. The Solaris Fault Management
Architecture has proved that users understand and appreciate
error messages that tell you exactly what is wrong in plain
English, along with how it can be fixed.
A great example of this is through the 'zpool status' output.
Once again, I'll go into some more detail about the FMA
integration in a future post, but you can quickly see how basic
FMA integration really allows the user to get meaningful
diagnostics on their pool:
$ zpool status
pool: tank
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool online' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror ONLINE 0 0 0
c1d0s0 ONLINE 0 0 3
c0d0s0 ONLINE 0 0 0
Consistent command syntax
When it comes to command line syntax, everyone seems to have
a different idea of what makes the most sense. When we started
redesigning the CLI, we took a look at a bunch of other tools in
Solaris, focusing on some of the more recent ones which had
undergone a more rigorous design. In the end, our primary source
of inspiration were the SMF (Server Management Facility)
commands. To that end, every zfs(1M) and zpool(1M) command has
the following syntax:
<command> <verb> <options> <noun> ...
There are no "required options". We tried to avoid positional
parameters at all costs, but there are certain subcommands (zfs
get, zfs get, zfs clone, zpool replace, etc) that fundamentally
require multiple operands. In these cases, we try to direct the
user with informative error messages indicating that they may
have forgotten a parameter:
# zpool create c1d0 c0d0
cannot create 'c1d0': pool name is reserved
pool name may have been omitted
If you mistype something and find that the error message is
confusing, please let us know - we take error messages very
seriously. We've already had some feedback for certain commands
(such as 'zfs clone') that we're working on.
Modular interface design
On a source level, the initial code had some serious issues
around interface boundaries. The problem is that the user/kernel
interface is managed through ioctl(2) calls to /dev/zfs. While
this is a perfectly fine solution, we wound up with multiple
consumers all issuing these ioctl() calls directly, making it
very difficult to evolve this interface cleanly. Since we knew
that we were going to have multiple userland consumers (zpool
and zfs), it made much more sense to construct a library
(libzfs) which was responsible for managing this direct
interface, and have it present a unified object-based access
method for consumers. This allowed us to centralize logic in one
place, and the command themselves became little more than
glorified argument parsers around this library.
As much as I do not like Java is became a new Cobol and the most common
development language for enterprise developers.
Here Solaris has a definite edge over Linux in the quality of implementation:
Java is native for Solaris environment and the amount of attention to this
environment among developers is second only to Windows. Solaris has an
additional edge due to an excellent support of threads. Linux provides several
third party threads packages. Information on a variety of threads
implementations available for Linux can be found in the Linux Documentation
Project,
www.tldp.org/FAQ/Threads-FAQ/.
The most common package is the Linux threads package based on the 2.4
kernels, which is present in GNU libc version 2 and provided as part of all
current distributions. While similar to the POSIX threads implementation it has
a number of shortcomings. For more information see
http://pauillac.inria.fr/~xleroy/linuxthreads Detailed API comparisons can
be found at:
www.mvista.com/developer/shared/SolMig.pdf.
There is also a the newer Native POSIX Threads Library (NPTL). The Native
POSIX Threads Library (NPTL) implementation is much closer to the POSIX standard
and is based on the 2.6 kernel. This version is also included in GNU libc and
has been backported onto some distributions with RH kernel see
www.redhat.com/whitepapers/developer/POSIX_Linux_Threading.pdf
HP provides to customers Solaris threads-compatible threads library for
Linux,
see
www.opensource.hp.com/the_source/linux_papers/scl_solaris.htm . The project
homepage is located at
www.sourceforge.net/projects/sctl .
Solaris has the concept of processor sets as CPU sets. CPU sets let you
restrict which processors are utilized by various processes or process groups.
This is a very useful feature on systems where you can benefit from static
allocation of CPU resources and it can help to prevent certain types of denial
of service attacks.
Linux does not has this capability in standard kernels. but so third party tools
are available, see
www.bullopensource.org/cpuset/. HP provides its Process Resource
Manager (PRM) for their customers
www.hp.com/go/prm
It looks like on servers with 4 CPUs linux is still competitive. Sun Fire
V40z holds several world benchmarks with some paradoxically achieved under
Linux. It demonstrated SPECint_rate2000 score of 89.9:
SPEC CPU2000 is an industry-standard benchmark that measures CPU and
memory intensive computing tasks. It is made up of two benchmark suites
focused on integer and floating point performance of the processor, memory
and compiler on the tested system. The Sun Fire V40z server, equipped with
four AMD Opteron(TM) Model 856 processors and running SuSE Linux (SLES9),
achieved the record breaking SPECint_rate2000 score of 89.9.
Still
World Record 4-CPU floating point throughput
performance for x86 systems belongs to Solaris 10:
The combination of the Solaris 10 OS and Sun(TM) Studio 11 software
enabled the Sun Fire V40z server, equipped with four AMD Opteron Model 856
processors, to generate the SPECfp_rate2000 result of 106, effectively more
than doubling the score of 52.5 produced by the competing Dell PowerEdge
6850 server, equipped with four Intel Xeon processors.
The difference with linux is marginal, though (106 vs. 100.37):
Based on real world applications, the SPEC CPU2000 suite measures the
performance of the processor, memory and compiler on the tested system. The
Sun Fire V40z server, equipped with four AMD Opteron Model 856 processors
and running SuSE Linux (SLES9), beats other 4-CPU x86 Linux systems with
SPECfp_rate2000 result of 100.37.
Situation became more positive on servers with 8 CPUs, but the difference is
still marginal:
On the floating point throughput component of the compute-intensive SPEC
CPU2000 benchmark, the Sun Fire V40z server, equipped with the latest
multi-core AMD Opteron 880 processors, demonstrates linear scalability with
the processor frequency, when compared to the previously posted result. By
utilizing the latest Sun Studio 11 software running on the Solaris 10 OS,
Sun's server achieved the score of 153 and surpassed the previous HP record
of 144 by over 6%.
While it is difficult, or even impossible to discuss OS security
separate from hardening and qualification of personnel (see
Softpanorama law of hardening), still there are some architectural issues that
transcend hardening. One of such things is built-in stack overflow protection.
It is available in Solaris but not Linux and it makes the game completely
different. As Solaris X86 FAQ
states
(6.43) Is noexec_user_stack
supported in Solaris x86?
Yes, but only for AMD64 (Operon) on Solaris 10 or higher. For 32 bit x86,
you can set it but it won't do anything. On SPARC and AMD64, it prevents
execution of code that was placed on the stack. This is a popular technique
used to gain unauthorized root access to systems, locally or remotely, by
executing arbitrary code as root. This is possible with poorly-written
programs that have missing overflow checks. To enable stack protection, add
the following to /etc/system
set noexec_user_stack = 1
set noexec_user_stack_log = 1
and reboot with /usr/sbin/init 6
With Solaris 10 release it is clear that Solaris security
is superior and architecturally is reached more advanced stage, especially in
RBAC area and light-weight VM area (zones), than Linux security. I would
say that Solaris 10 RBAC implementation and zones make it the first XXI century
Unix. Red Hat implementation of SELinux in version 4 of Red Hat Enterprise makes
it more competitive with
Solaris then Suse, but still this is a less mature implementation and more
questionable architecture then Solaris RBAC (not every algorithm that NSA
produces reaches the quality of DES). RBAC was first distributed
with Solaris 8 that was released in 2000. Also SELinux looks overengeeneered and
completely administrator hostile: label-based security enforced by SELinux is a
huge overkill for non-military installations. That's why SUSE has an edge
over Red Hat in this area, but this edge was achieved by breaking compatibility
and adopting a different simpler approach.
To ensure working of complex applications is more difficult under SELinux then RBAC and that probably means that
in reality SELinux will be eventually switched off in many enterprise installations.
Due to availability of RBAC Solaris probably can
compete in security even with OpenBSD despite being substantially
larger, more complex OS as well as OS were security was not the primary
design goal. OpenBSD like Solaris 10 has a role-based system call
access manager. Like Solaris 10 RBAC, the OpenBSD systrace
policies define which users and programs can access which files and
devices in a manner completely independent of UNIX permissions. This
approach can help to diminishes risks associated with poorly written or
exploitable applications. While defining such policies is not a simple
task either in Solaris or OpenBSD, OpenBSD has an advantage because
systrace has been around for a long time and there are online
repositories with systrace sample policies (see for example
Project Hairy
Eyeball). Also, systrace includes a policy-generation tool
listing every system call available to the application for which the policy is
being generated. Although an experienced system administrator could probably
still tighten the security of the system by refining the default policy
generated by the tool, the defaults are often secure enough for most uses.
At the same time Red Hat Enterprise version 4 has better level
integration with firewall and better kerberization of major daemons. I do not
like the interface provides by new Solaris firewall (
IP filter ) as well as
semantic of operations. It might the best open source firewall but still I
would prefer something really well integrated into kernel not add-on package.
Red Hat interface is simpler and more corresponds to firewall 1 which is a
standard de-facto in this area. By default firewall is enabled and provides
substantial additional level of protection. Also by default neither telnet not
ftp are available, which is a good (although minor) thing. So in
applications area Red Hat looks slightly better then Solaris: it has better
integration of ssh, more secure default Apache installation and many other minor
but important things (for example root has its own separate directory /root). So
in applications area Red Hat generally wins over Solaris due to following
reasons:
-
Better documentation about securing applications (and better
course: 2006 version of RSH333 beats outdated Solaris SC-300 course)
-
Better more thoughtful defaults
-
Somewhat better kerberization of major daemons.
This better application security is very important because
people who install OSes in enterprise environment often do not understand the
details of applications, and applications "owners" are often completely clueless
about security.
Therefore we have slightly fuzzy situation here: on kernel and
filesystems level Solaris is definitly more secure than Red Hat 4
Enterprise 4, but on application level the situation can well be opposite
(unless you use zones to compensate for this in Solaris). Indirect evidence of
higher security of kernel and filesystem is higher grade of USA military
certification for Solaris. While this is largely a
bureaucratic procedure, Solaris is rated a level higher than Linux for graded
security. Two major security subsystems that Solaris kernel and filesystem
supports: ACLs and RBAC
- have weaker or "cut corners" type of implementation under Linux.
It's actually does not make sense to compare OSes without
hardening anymore, so availability and quality of hardening packages is another
important differentiator, especially for enterprise environment. Here Solaris
has slight edge as there is one enterprise-quality hardening package r
Solaris -- JASS and one easily modified package that can be adapted for 'ad hoc"
additional hardening (Titan) [Softpanorama2005a]. JASS
recently became Sun-supported package (configuration changes introduced by JASS are
supported by Sun's tech support).
JASS can also be used as a part of Jumpstart-powered installations.
Although JASS's scripts itself are very weak: primitively architectured and
written in not very suitable for the task language (Borne shell is used), the
resulting configurations are not bad.
There is also procedure for packages minimization for Solaris
that help to produce very tight, bastion host type
configurations.
While both Solaris on Sparc and Solaris on Opteron have
protection from buffer overflow, Solaris on Sparc is slightly more
secure. Also to write an exploit for UltraSparc you need to shell out
at least $500 to get an UltraSparc box (some ancient UltraSparc boxes
like Ultra 5 and Ultra 10 can be obtained for less on eBay, but this
might be pretty humiliating experience for exploit writer used to
disassembly and compilation speeds of dual CPU 3.x GHz Intel boxes ;-).
Attempts to write exploit "on a cheap" face the risk being caught
abusing your office or University lab server. So the main source
of Solaris exploits can be security companies selling some
vulnerabilities info and prototypes to IDS companies. But PR
return on such an investment is low, so Windows are their favorite
target with Linux as a close second and Solaris as distant, distant
third. In most cases they do not have specialists to cover more then
two OSes.
In any case the mere differences on hardware architecture
and the status of Intel as a dominating hardware architecture guarantees that the
potential number of people who can write a Solaris-specific exploit (or port an
exploit from Intel to UltraSparc) is several
orders of magnitude less than for Linux or Windows. In the latter case nothing
prevents you doing this in a privacy of your home using a regular PC. And no
amount of advocacy can change this simple fact.
I would like to stress it again, that UltraSparc provided a
usable defense for stack overflows, the
dominant exploit type for Linux. So to use linux advocates catch phase here Solaris rules and Linux sucks :-). To
slightly offset this advantage, it is fair to mention that Dtrace can probably be used
by exploit writers ;-)
Formally Solaris 10 is being evaluated for
RBACPP and CAPP. Solaris 10 trusted extension will include
LSPP. That means that Red Hat with its label based security does not
have advantage over Solaris even if we believe those largely bureaucratic
certification procedures (Sun's older Trusted
Solaris 8 complies with CAPP, RBACPP and LSPP at EAL 4+.)
Another topic are overflow exploits. Here we need to distinguish
what really works from what is theoretically possible. Solaris stack protection
really works. But most modern OSes now use additional technologies
to protect programs from primitive overflow exploits.
That actually means that exploits for which alerts are produced by usual
suspects like CERT may or may not be an actual
threat depending on the setting used. This is especially true for stack overflow exploits against which along
with hardware protection other methods exist and now can be activated (but
usually are not :-).
Although Solaris is not mentioned the following
blog entry gives a good overview of the additional options available
but provides incorrect comparison diagram.
Actually diagram looks more like a wishful
thinking then actual depiction of the state of the art. I am very skeptical that RHEL
ever can match OpenBSD in this area. Also it is new to me that RHEL 4 has
default hardware stack overflow protection enabled in non AS-level kernels. I think that this is a typo
and actual version should be 5 as
capabilities listed on the diagram below mostly belong to RHEL 5. Even in this
version most are still experimental (SELinux
restricts certain memory protection operation only if the appropriate Boolean
values enable these checks; those options are rarely used and if used might not
work in RHEL 4. For more information see [PDF]
Security Enhancements in Red Hat Enterprise Linux (beside SELinux), LWN Security-improving
technologies which could be deployed now ,
LWN Edgy and
Proactive Security and
danwalsh SELinux Reveals Bugs in other code.;
Both in Solaris and Linux workable stack protection requires
modern 64 CPUs like Opteron or Intel Duo.
Anyway here is diagram :
Note: OS X does have an NX stack now, but I dont
want to modify Gunnars chart. Note also:
this slide is currently sourced to Rich Johnson.
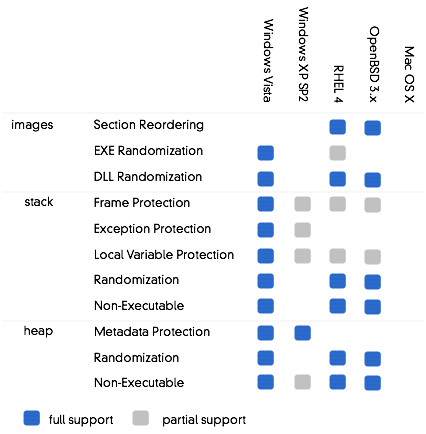
Section Reordering lines up executable image sections
so that a single data overflow cant take out, say, the
global offset table.
EXE randomization, a la PIE, randomizes the
layout of text sections in position-independent code.
DLL randomization makes the base addresses of
DLLs random so that shellcode wont know the address to jump
to to reach sensitive functions.
Frame Protection for the stack inserts
unpredictable cookie values and runtime checks to make sure
stack frames arent overwritten.
Exception Checks do the same thing for exception
handlers, which are function pointers stored in reliable
locations and a target for overflows.
Local Variable Protection creates checked guard
values next to overflowable stack buffers.
Stack Randomization makes stack address offsets
unpredictable.
Nonexecutable stacks use hardware page
protection to prevent code from running on the stack at all,
meaning shellcode needs to be stored somewhere else.
Heap Metadata Protection a la Win32 XORs key
fields in the allocator tracking structures so that they
dont have predictable valid values.
Randomization in the heap works like
randomization in the stack, and
The heap can also be made non-executable.
There are features that arent covered in Gunnars chart.
For instance, OpenBSD deserves ticks for Niels Provos
Systrace, which allows the OS to revoke capabilities from
programs entirely. Win32 uses cryptographic signatures for
code loaded in certain environments. Windows also supports
managed code. Even Cisco IOS had an elaborate periodic heap
sanity checker. MacOS X does not yet have any of these
features.
In general protection from buffer overflows is a complex topic and many theoretically attractive
methods are very difficult to implement in mainstream distribution like RHEL See
Comparative Study of Run-Time Defense Against Buffer Overflows. Also
to add insult to injury a lot of users switch SELinux off as the level of additional complexity it creates
is unacceptable to them.
Solaris RBAC
As for RBAC, Solaris 10 is probably the first Unix that implements
a usable, elegant
version of RBAC that might eventually seduce mainstream administrators. Before
that RBAC in Solaris can be implemented only under the gun.
Because of that the level of mainstream adoption of RBAC in Solaris 8 and 9 was essentially
limited to conversion of root to the role (that means that you cannot
directly to login to root; in order to get root privileges you need first to
login into your own account that has privileges of switching to root and only
then you can assume the root role. Even emulation of sudo capabilities did
not work well before Solaris 10 and many enterprises paradoxically installed
sudo on Solaris 8 and 9 servers.
While RBAC implementation alone puts Solaris 10 above Linux in security,
zones make linux just a backwater OS suitable only for non-security conscious
administrators (but we will discuss this issue separately). I would say that only Solaris 10 is up to the
task in helping to make sense out of such an
illusory and fuzzy goal as SOX conformance, this new Mecca of IT managers of
publicly traded large US companies (with newly minted ayatollahs from major
accounting companies dispersing their stupid or not so stupid fatwas with
interpretation of meaning of "compliance" with the holy book that in best
oriental religions tradition does not even explicitly mention IT :-)
Solaris also has pretty good support of PAM, but paradoxically
despite the fact that PAM originated in Solaris, Linux surpassed Solaris
in this area and the assortment and the level of integration into major
distributions of PAM modules is significantly higher for Red Hat and Suse. Both
has larger variety and sometimes higher quality of PAM modules
available. They can be converted into Solaris PAM modules without major
problems but you need to be a programmer (or hire one) to do that. For most
companies the fact that many Linux PAM modules licensed under GPL does not
matter as they do not plan to distribute the result of conversion outside the
company anyway. Still other things equal BSD licensed modules are a better
source of inspiration (see
Labyrinth of Software
Freedom (BSD vs. GPL and social aspects of free licensing debate for more details).
Zones
What is really important for enterprise
environment (and for enterprise security) is that version 10 has a light weight VM,
a derivative of BSD jails called
Solaris Zones.
While useful for many other purposes they completely and forever change Unix
security landscape. If Sun marketing is more inventive it should
adopt the initial internal name for zones and call them "Kevlar vests for
applications" :-)
Zone sometime called
containers because Sun marketing people cannot get their act together and have a
tendency to rename things until total user confusion (along with zones the
notable victim of their addiction to renaming is iPlanet aka SunOne or
whatever the name of this former Netscape Enterprise Web server is today; it seems they rename it each
quarter ;-)
Zones behaves
as an individual machine, with its own IP address. Paradoxically but in
The current SOX-crazy climate this is one of the most important things you can do to
insure isolation of applications on a given server instead of writing tons of
useless reports with mutipage spreadsheet in best Brezhnev socialism traditions. Sometimes you can also use
this for running several instances of the same application with different access
rights. For example, zones represent a very attractive solution for WEB hosting.
The
Register described this feature in the following way:
In many ways, the Solaris Zones -
known internally by the Kevlar code-name - will be a hardened version of the
Solaris Containers currently offered to users for keeping applications
isolated from each other. With the Zones, users can split up applications
into numerous different compartments all running on one OS image. The amount
of processor power, I/O bandwidth and memory for each Zone can be altered,
and each one can also be rebooted, said John Fowler, CTO of software at Sun.
"It's a pretty simple idea," Fowler said. "You want to keep the number of OS
images down to a reasonable level. With the Zones, you have a single layer of
hardware and a single operating system. You have applications that think they
are running on their own OS."
Sun customers currently rely on physical or hardware-based partitioning to
slice up their midrange and high end servers for different operating system
images. While this method of partitioning provides the most protection
between OSes, it does not let users create as many divisions as the logical
partitioning (LPAR) from IBM or HP.
Solaris Containers do help split up applications from each other and form
something resembling a logical partition, but they have not been proven to
isolate errors with the same success as a LPAR, say analysts. This could be
the same potential problem faced by Zones unless Sun can show the technology
works as billed.
"The big question with Kevlar is whether it will really isolate software
faults to nearly the same degree as LPARs," said,
Illuminata's Gordon Haff. "This is going to be a very tricky question to
get better than anecdotal evidence about even after the technology is
available."
Sun does get some benefit of the doubt when a new feature of Solaris is under
debate because the vendor tends not to muck around with its prized code base.
IBM and HP are beating the LPAR server consolidation drum quite hard, but Sun
is rejecting this path. It thinks adding more and more OS images is a waste
of users' time and money.
"I think there is a diminishing point of return if you want to run multiple
OS images on a single server," Fowler said.
Sun wants to avoid the road taken by HP and IBM, which puts one copy of the
OS in each LPAR. Tasks such as applying patches, software updates and adding
more disk space will take less time with just one image of the OS to worry
about, Fowler argued.
Documentation
The last, but not least important area is documentation.
Solaris has the best online documentation of all free OSes. Just compare Solaris
man pages with linux man pages to see the difference. While Solaris man pages
are far from being perfect they are current, workable documents. In many cases
linux man
pages provide just an illusion of information and in no way correspond to the version
of software installed.
In addition to man pages Solaris
has an extensive online documentation.
Sun's forte is actually in midsize documents called blueprints which are somewhat similar to long dead linux
How-to project. Each blueprint is devoted to one specific topic. More then a dozen out of
approximately hundred published blueprints are of extremely high technical quality
(the level equal of the best O'Reilly books) and
each of them addresses important areas of Solaris deployment saving many hours
for Solaris system administrators. In my opinion the level of
fragmentation of linux into semi-compatible distributions put brakes on any
meaningful work in this area.
As for amount of free "full-size" books Sun also looks
very good. It provides administrators with free electronic versions of all
major books for Solaris administration. Only IBM rivals Sun in the amount
and quality of electronic
books provided to administrators (IBM's world famous "Red Books" series).
|
| xlinuks | Очень напоминает Microsoft's "get the facts" страницу,
а также Sun-овскую где нагло пишут *Solaris the best OS in the world!" -
она *бест* но только под спарк и то только как сервер.
Тоже самое про Mac - *бест* но только под мас.
Читая эту статью слаживается впечатление что Solaris в 10 раз лучше чем Linux,
но используется (примерно) в 10 раз меньше (чем Linux),
не говоря о том что больше половины всех супер компьютеров работают также под Linux.
Если автор хочет казатся обьективным пусть обьяснит этот (парадоксальный) факт,
если он достаточно профессионален (в чем я не сомневаюсь)
думаю найдет хотябы 5 ключевых пунктов почему Linux намного чаще используется.
От себя добавлю, speaking out in ignorance might impress those who know less,
but it won't impress those who know the truth.
ps:
Пожалуйста, пусть этот коммент будет на этой странице.
2007-05-08 20:22:49 | | Яковлев Се� | Спасибо
Материал этой статьи достаточно тендециозен и случаен
И привел я его для того , чтобы показать :
мир состоит не только из сторонников open-source,
но и из его ярых противников
И мы должны раскрывать всю их подлую и коварную сущность :-)
2007-05-09 12:25:28 | | adr01t | Отдельные части материала смело фтопку просто потому, что это - дезинформация
(тыкать пальцем не буду - итак видно).
Не рассмотрено ни одной сильной черты ГНУтой ОС, т.е. обзор бесполезен.
Поменьше бы таких "обзоров"...
2007-06-13 13:50:59 | | Яковлев Се� | Я не стал бы вот так просто отмахиваться от солярки
Она уже внесла и будет вносить свой вклад в развитие ОС
Недавно Торвальдс сказал буквально следующее :
Если Sun действительно собирается выпустить OpenSolaris под GPLv3,
это может стать хорошей причиной для перехода Linux на новую лицензию
2007-06-13 16:05:49 | |
|
 LINUX
LINUX 
 OS
OS

