Глава 6. Течение времени в ядре Linux
About: "По мотивам перевода" Linux Device Driver 2-nd edition.
Перевод:
Князев Алексей knzsoft@mail.ru
ICQ 194144861
Дата последнего изменения: 02.12.2004
Авторскую страницу А.Князева можно найти тут :
http://lug.kmv.ru/wiki/index.php?page=knz_ldd2
Архивы в переводе А.Князева лежат тут:
http://lug.kmv.ru/wiki/files/ldd2_ch1.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch2.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch3tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch4.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch5.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch6.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch7.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch8.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch13.tar.bz2
Содержание
- Интервалы времени в ядре
- Процессоро-зависимые регистры
- Получение текущего времени
- Выполнение временной задержки
- Длительные временные задержки
- Короткие временные задержки
- Очереди задач
- Природа очереди задач
- Принципы работы очередей задач
- Предопределенные очереди задач (predefined task queue)
- Пояснение работы примера
- Очередь планировщика задач (scheduler queue)
- Очередь таймера (timer queue)
- Срочная очередь (immediate queue)
- Запуск собственной очереди
- Тасклеты (tasklets)
- Таймеры ядра
- Вопросы обратной совместимости
- Краткий справочник определений
Начав чтение этой главы мы уже знакомы с основами написания полнофункциональных модулей для управления символьными
устройствами. Фактически, мы ознакомились с построением скелета драйверов, и готовы к рассмотрению таких деталей,
как учет времени, управление памятью, доступ к физическим устройствам, и прочее. К счастью, ядро содержит элементы,
которые упрощают решение этих задач разработчикам драйверов. В следующих нескольких главах мы получим информацию о
доступных нам ресурсах ядра, и начнем это знакомство с ознакомления с таким важным ресурсом как время. Работа со
временем в ядре требует понимания следующих компонентов (в порядке роста сложности):
- Течение времени в ядре
- Получение текущего времени
- Выполнение времянной задержки
- Перепланировка асинхронных функций после истечения заданного интервала времени
Интервалы времени в ядре
Прерывания от таймера предствавляет собой механизм, используемый ядром для получения требуемых интервалов времени.
Прерывания представляют собой асинхронные события, которые обычно генерируются каким-либо внешним физическим
устройством. При этом, CPU прерывает исполнение своей текущей задачи, и начинает исполнять специальный код обработчика
прерывания (Interrupt Service Routine - ISR). Реализация прерываний и ISR будет рассмотрена нами в главе 9
"Interrupt Handling".
Прерывания таймера генерируются специальным системным электронным
компонентом (таймером) через равные заданные
промежутки времени. Значение интервала времени устанавливается ядром,
измеряется в Гц, является архитектурно-зависимым,
и определено в заголовочном файле <linux/param.h>
макроопределением HZ. Современный Linux, на большинстве платформ,
использует
прерывания с частотой 100 Гц. Некоторый платформы используют значение
1024 Гц, а эмуляция IA-64 использует прерывания
таймера с частотой 20 Гц. Независимо от того, какую аппаратную
платформу вы используете, разработчик драйвера, как
правило, не должен принимать во внимание специфическое значение HZ.
Каждый раз, когда возникает прерывание от таймера, инкрементируется значение переменной jiffies. jiffies
инициализируется нулем при загрузке системы, и, таким образом, показывает количество тиков таймера с момента включения
компьютера. Переменная определена в заголовочном файле ядра <linux/sched.h> как unsigned long volatile.
Переполнение переменной возможно после продолжительного интервала времени непрерывной работы (не менее 16 месяцев на
любой современной платформе). Требуется множество усилий разработчиков, чтобы быть уверенным в корректной работе ядра
при переполнении jiffies. К сожалению, разработчики драйверов, о переполнении jiffies, обычно, не беспокоятся.
Вы можете изменить значение интервала таймера изменением макроопределения HZ в заголовочном файле <linux/param.h>.
Некоторые разработчики используют Linux для жестких задач реального времени, и увеличивают значение HZ для уменьшения
времени отклика. Платой за это является увеличение общей доли времени, которое тратится на обработку прерывания таймера.
Доверяя разработчикам ядра, наверное лучшим значением для HZ будет значение принятое в каждом конкретном ядре по умолчанию.
Процессоро-зависимые регистры
Если вам необходимо измерить очень короткие интервалы времени, или требуется высокая точность измерения, то вы можете
использовать платформо-зависимые ресурсы, выбирая точность против против портируемости результирующего кода.
Большинство современных CPU содержат в себе высокоемкий счетчик, значение которого инкрементируется с каждым тактом
процессора. Такой счетчик может быть использован для точного измерения интервалов времени. Учитывая свойственную
большинству систем непредсказуемость времени исполнения инструкций (по причинам диспетчеризации, вероятностных
предсказаний переходов, и различных уровней кэша памяти), такой счетчик процессорных тиков представляет собой
единственно надежный способ выполнения задач точного измерения времени.
Детали реализации счетчика могут отличаться от платформы к платформе: регистр может быть доступен или не доступен на
чтение из пространства пользователя, он может быть доступен или не доступен для записи, и он может иметь емкость в 64
или 32 бита - в последнем случае вы должны будете обрабатывать его переполнения. Независимо от того, может ли этот
регистр быть обнулен или нет (в этом случае обнуляется банальным переполнением), мы можем оказаться крайне обескуражены
его сбросом. Но, так как вы всегда можете контролировать разность беззнаковых переменных, то вы можете контролировать и его
сброс/переполнение не приводя в замешательство счетчикозависимые участки кода драйвера.
Наиболее известным регистром счетчиком является регистр TSC (timestamp counter), представленный в семействе процессоров
x86 начиная с процессора Pentium. Это 64-битный регистр, который считает такты CPU. Он может быть прочитан как из
пространства ядра, так и из пространства пользователя. (Обратите внимание на этот важный факт!)
Включив заголовочный файл <asm/msr.h> (machine-specific registers), вы можете использовать следующие макросы:
rdtsc(low,high);
rdtscl(low);
С помощью первого макроса можно прочитать 64-битное значение счетчика в две 32-битовые переменные. Второй макрос читает
младшую половину регистра в 32-х битовую переменную, и является достаточным в большинстве случаев. Например, на 500 МГц
процессоре переполнение 32-х битового счетчика будет происходить каждые 8.5 секунд. Таким образом, вам не нужно полное
значение счетчика, если вы работаете с меньшими временными интервалами.
Следующие строки, например, измеряют время исполнения самого макроса:
unsigned long ini, end;
rdtscl(ini); rdtscl(end);
printk("time lapse: %li\n", end - ini);
Некоторые другие платформы предлагают похожую функциональность, и заголовки ядра предоставляют архитектурно-независимые функции,
которые вы можете использовать вместо rdtsc(). Функция называется get_cycles(), и была представлена во время разработки
ядра 2.1. Прототип функции выглядит следующим образом:
#include <linux/timex.h>
cycles_t get_cycles(void);
Эта функция определена для каждой платформы, и всегда возвращает ноль для тех платформ, которые не имеют регистра
счетчика тактов. Тип cycles_t беззнаковый тип, соответствующий по емкости регистрам общего назначения каждого
конкретного процессора. Такой выбор емкости означает, например, что на процессорах Pentium функция get_cycles()
возвратит только младшие 32 бит реального счетчика процессорных тиков. Это позволит избежать многорегистровых операций,
и не воспрепятствует цели наиболее частого использования счетчика - измерение коротких интервалов времени.
Несмотря на возможности архитектурно-независимой функции, мы бы хотели привести пример ассемблерного inline-кода. Для
этого, мы реализовали функцию rdtscl() для процессоров MIPS, которая будет также хорошо работать и на процессорах x86.
Мы строим наш пример на MIPS, потому что большинство MIPS процессоров могут представить 32-х битный счетчик как регистр
9 своего внутреннего "coprocessor 0". Для доступа к этому регистру из пространства ядра только на чтение, вы
можете определить следующее макро, которое выполняет ассемблерную инструкцию "move from coprocessor 0".
Завершающая инструкция "nop" требуется для предотвращения немедленного доступа к целевому регистру следующему
за инструкцией "mfc0". Такой вид внутренней блокировки типичен для прецессоров семейства RISC, и компилятор
может самостоятельно расставить необходимые задержки. Однако, в нашем случае, inline-ассемблер представляет из себя
черный ящик для компилятора, и никакая оптимизация и анализ этого кода не выполняются.
#define rdtscl(dest) \
__asm__ __volatile__("mfc0 %0,$9; nop" : "=r" (dest))
Используя это макро, мы сможем на процессоре MIPS выполнить представленный выше пример кода для процессоров x86 (Pentium
и выше).
Интересной особенностью inline-ассемблера для gcc является то, что распределение регистров общего назначения оставлено
за компилятором. Только что показанное макро использует %0 как место (placeholder) для "argument 0", который
впоследствии определится как "любой регистр (r) используемый для вывода (=)". Кроме того, в макро обозначено,
что этот регистр для вывода должен отобразиться в переменной dest языка Си. Синтаксис inline-ассемблера очень мощный, но
достаточно сложный, особенно для тех архитектур, которые имеют ограничения по использованию своих регистров (например,
семейство x86). Полный синтаксис описан в документации на gcc, обычно доступной в системе справочной службы info.
Короткий фрагмент Си-кода показанный в этом разделе был опробован на процессоре K7 семейства x86, и процессоре MIPS
VR4181 (используя только что показанное макро). На первом, был получен результат в 11 тактов, а на втором - 2 такта.
Такой результат был ожидаем, так как RISC процессоры, обычно, выполняют одну инструкцию за один такт процессора.
Получение текущего времени
Код ядра может всегда получить информацию о течении времени просматривая значение jiffies. Обычно, драйвер не
интересуется абсолютным значением времени, поэтому значение времени прошедшего с момента загрузки вполне удовлетворяет
требованиям драйвера. Текущее значение джиффисов (jiffies) можно использовать для вычисления интервалов времени между
событиями (например, для различения двойного и одинарного щелчков мыши). Таким образом, использование джиффисов всегда
вполне достаточно для измерения интервалов времени. Если же вам потребуется очень точное измерение коротких времянных
отрезков, то можно воспользоваться, по возможности, процессоро-зависимыми регистрами счетчиками тиков.
Маловероятно, что драйверу понадобится текущее значение времени суток, так как необходимость в таком времени испытывают
только программы пользователя, такие как cron и at. Если же значение времени суток все-таки понадобится драйверу, то это
будет некий особенный случай, и драйвер сможет получить полную информацию о времени из пользовательской программы.
Прямая работа со временем суток в драйвере может потребоваться для реализации некой политики управления драйвером,
которую мы рассмотрим более близко.
Если вашему драйверу действительно понадобится текущее время, то вы можете воспользоваться функцией do_gettimeofday().
Данная функция не сообщает вам текущий день недели, или что-нибудь в этом роде. Вместо этого она заполняет экземпляр
структуры timeval, переданный в функцию по указателю, с использованием значений секунд и микросекунд. Для пространства
пользователя существует аналогичный системный вызов gettimeofday(). Прототип для функции do_gettimeofday() выглядит
следующим образом:
#include <linux/time.h>
void do_gettimeofday(struct timeval *tv);
Функция do_gettimeofday() имеет "разрешение в пределах микросекунды" для многих архитектурах. Значение
точности колеблется от одной архитектуры к другой и может быть хуже на старых ядрах. Текущее значение времени, хоть и
меньшей точностью, может быть получена из переменной xtime (stuct timeval). Однако прямое использование этой переменной
может привести к ошибкам, так как вы не можете получить атомарный доступ к полям tv_sec и tv_usec структуры timeval, до
тех пор пока вы не запретите прерывания. В ядре 2.2 вы можете использовать быстрый, безопасный, но возможно с меньшей
точностью, способ получения времени, используюя функцию get_fast_time():
void get_fast_time(struct timeval *tv);
Вы можете познакомиться с кодом для чтения текущего времени изучив модуль jit ("Just In Time") из источников
представленных на FTP-сайте O'Reilly. jit создает файл, называемый /proc/currentime, который при чтении наполняется
следующим ASCII-контентом:
- Текущее время, возвращаемое функцией do_gettimeofday()
- Текущее время, полученное из переменной xtime
- Текущее значение переменной jiffies
Использование динамической файловой системы /proc позволяет уменьшить размер кода модуля для данного случая - нет смысла
создавать целое устройство для возвращения трех строк текста:
Вы можете использовать команду cat для чтения этого файла несколько раз, через время меньшее чем тик таймера. Таким
образом, вы сможете увидеть разницу между xtime и do_gettimeofday(), отражающую тот факт, что xtime обновляется с
меньшей частотой:
morgana% cd /proc; cat currentime currentime currentime
gettime: 846157215.937221
xtime: 846157215.931188
jiffies: 1308094
gettime: 846157215.939950
xtime: 846157215.931188
jiffies: 1308094
gettime: 846157215.942465
xtime: 846157215.941188
jiffies: 1308095
Выполнение времянной задержки
Часто, драйверам устройств необходимо выполнить времянную задержку в куске некоторого кода на некоторый период времени -
обычно это связано с долгой реакцией физических устройств при выполнении некоторой задачи. В этом разделе мы рассмотрим
различные технологии выполнения таких задержек. В зависимости от обстоятельств вы выберите ту или иную технику
выполнения задержки. В этом разделе мы рассмотрим достоинства и недостатки каждой из них.
При выборе подходящего способа реализации задержки необходимо сравнить время требуемой задержки и время тика системных
часов. Маленькие задержки должны быть реализованы с помощью программных циклов. Для реализации больших задержек можно
использовать системные часы.
Длительные временные задержки
Если вы хотите выполнить времянную задержку продолжительностью в множество системных тиков, или вам не требуется высокая
точность выполнения задержки (например, задержка в целое число секунд), то простейшей ее реализацией будет следующая
(известная как busy waiting):
unsigned long j = jiffies + jit_delay * HZ;
while (jiffies < j)
/* nothing */;
Разумеется, нужно избегать такого способа реализации задержки. Хотя, вы можете поэкспериментировать с этим кодом для
лучшего понимания работы другого кода.
Давайте рассмотрим, как этот код работает. Работа цикла гарантируется потому, что переменная jiffies объявлена в
заголовочном файле ядра как volatile, и поэтому ее значение будет перечитываться при каждом обращении к ней из Си-кода.
Верно также и то, что на время выполнения этого цикла процессор не сможет выполнить никакой полезной работы, т.к.
диспетчер задач не сможет прервать процесс, работающий в пространстве ядра. Еще хуже то, что если во время входа в цикл
будут запрещены прерывания, то значение jiffies не будут обновляться и условие цикла останется истинным навсегда.
Компьютер зависнет, и вам потребуется нажатие "красной кнопки" для возвращения его к жизни.
Реализацию этого кода вы можете посмотреть в модуле jit. Модуль задерживает чтение, созданных им файлов /proc/jit*, на
целую секунду, при каждом обращении к файлу. Если вы хотите протестировать "busy wait code" (код с полной
занятостью процессора при ожидании), то вы можете прочитать файл /proc/jitbusy, который реализует цикл с полной
загрузкой процессора на одну секунду при каждом обращении к методу read(). С помощью команды dd if=/proc/jitbusy bs=1 вы
реализуете односекундную задержку перед чтением каждого символа из файла /proc/jitbusy.
Как вы можете ожидать, чтение /proc/jifbusy, особенно предложенным только что способом, очень жестоко для системной
производительности, так как компьютер сможет выполнять другие процессы только одно мгновение в секунду.
Лучшим решением, которое позволило бы исполнение других процессов во время интервала задержки является следующее, хотя
оно и не может быть использовано в задачах жесткого реального времени или других критических во времени ситуациях.
while (jiffies < j)
schedule();
Переменная j в этом и следующих примерах имеет значение jiffies на момент окончания задержки, и вычисляется так, как это
показано в примере для "busy waiting" кода.
Этот код, который может быть протестирован чтением /proc/jitsched, еще не является оптимальным. Система может
планировать другие задачи; текущий процесс ничего не делает, но и не удерживает какую-либо заметную часть
процессорного времени. Недостатком такого решение является то, что процесс остается в очереди на выполнение на время
задержки, и все-таки расходует процессорное время впустую. Т.е. если этот процесс будет единственным в системе, то
получится буквально следующее: процесс вызовет планировщик задач, который вызовет этот процесс, который вызовет планировщик
задач, который выберет этот процесс, и т.д. Другими словами, загрузка компьютера (среднее число выполняющихся процессов)
будет по меньшей мере единица, и idle-задача (процесс номер 0, называемый swapper по историческим причинам) никогда не
будет запущен. И хотя это может показаться не важным, но запуск idle-задачи в то время, когда процессору нечего делать,
облегчает выполнение "отложенных" (workload) задач, уменьшает температуру процессора, увеличивая его время жизни, и
уменьшает разрядку батарей (для носимых компьютеров). Кроме того, поскольку процесс в действительности выполняется во
время задержки, то система учтет его как процесс, потребляющий все это время. Вы можете увидеть это на время запуска cat
/proc/jitsched.
При этом, если система имеет высокую загрузку, то драйвер может закончить ожидание заданного интервала значительно
позднее предполагаемого срока. Отдав управление диспетчеру, нет никакой гарантии, что другой процесс не займет
процессор на неопределенное время. Таким образом, если имеется какое либо важное ограничение на максимальное время
задержки, то вызов диспетчера в обозначенной выше манере, может оказаться не безопасным для работы драйвера.
Несмотря на свои недостатки, предыдущий цикл предоставляет простой, надежный, но некрасивый способ наблюдения за работой
драйвера. Если ошибка внутри вашего модуля приводит к зависанию системы, то добавление маленькой задержки после каждого
отладочного printk(), будет гарантией того, что каждое сообщение, которое вы выведите перед тем как процессор выполнит
ошибочный код достигнет системного лога прежде чем система повиснет. Без такой задержки, сообщения попадут в буфер
памяти, но система повиснет прежде, что klogd сможет выполнить свою работу.
Однако лучшим способом реализации задержки, является обращение к ядру с тем, чтобы оно сделало это для вас. Имеется два
способа установки таймаута, в зависимости от того, ожидает ли драйвер дополнительного события или нет.
Если ваш драйвер использует очередь ожидания для того, чтобы ждать некоторого события, но вы также хотите быть увереным,
что он продолжит работу через заданный интервал времени, то вы можете использовать версию функциии sleep() с таймаутом,
как показано в разделе "Уход в сон и пробуждение" главы 5 "Дополнительные операции в драйвере символьного
устройства".
sleep_on_timeout(wait_queue_head_t *q, unsigned long timeout);
interruptible_sleep_on_timeout(wait_queue_head_t *q,
unsigned long timeout);
Обе эти функции переведут процесс в спящее состояние по заданной очереди ожидания, но, что бы не случилось, вернут его к
жизни через заданный в джиффисах таймаут. Таким образом, они реализуют ограниченный во времени сон, который не будет
продолжаться вечно. Обратите внимание, что значение таймаута задается в джиффисах, а не в абсолютных временных единицах.
Такую реализацию задержки можно пронаблюдать в реализации /proc/jifqueue:
wait_queue_head_t wait;
init_waitqueue_head (&wait);
interruptible_sleep_on_timeout(&wait, jit_delay*HZ);
В обычном драйвере, выполнение может быть возобновлено одним из следующих способов: либо кто-то вызвал wake_up() над
данной очередью ожидания, либо вышел таймаут. В данном случае вызов wake_up() исключается, поэтому процесс будет
разбужен по истечении таймаута. Таким образом, это наиболее красивая реализация задержки, но если ваш драйвер не
интересуют никакие другие события, то задержка может быть реализована еще более простым способом, с использованием
функции schedule_timeout():
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout (jit_delay*HZ);
Такой код, переведет процесс в состояние сна, до тех пор, пока не выйдет заданное время. Аргумент для функции
schedule_timeout(), также, должен задаваться в джиффисах, а не в единицах абсолютного времени. Все эти
"сложности" позволят вам гарантировать, что исполнение процесса не задержится на неопределенное время после
истечения заданного времени задержки.
Короткие временные задержки
Иногда в драйвере требуется вычисление очень коротких интервалов времени, для синхронизации с работой физических
устройств. В этом случае, использование джиффисов не станет подходящим решением.
Для решения таких задач могут быть использования функции ядра udelay() и mdelay(). Литера "u" в названии
функции udelay() символизирует греческую букву "мю" и означает микро. Прототип функций выглядит следующим
образом:
#include <linux/delay.h>
void udelay(unsigned long usecs);
void mdelay(unsigned long msecs);
На большинстве поддерживаемых архитектур данные функции компилируются как inline. Первая функция использует программный
цикл задержки на заданное число микросекунд, а вторая - использует цикл вызова udelay(), обеспечивая тем самым удобство
программирования. Функция udelay() построена на использовании значения BogoMips: ее цикл основан на целом значении
loops_per_second, которое представляет собой значение BogoMips, вычисленное на этапе загрузки.
Функция udelay() может быть использована только для выполнения небольших временных задержек, потому что точность
переменной loops_per_second составляет только восемь бит, и, при вычислении больших интервалов времени, может накопиться
значительная ошибка. Несмотря на то, что максимально допустимая задержка, вычисляемая данной функцией, лежит в пределах
одной секунды, рекомендуемый максимум для udelay() составляет 1000 микросекунд (1 миллисекунду). Для вычисления больших
интервалов времени используйте функцию mdelay().
Важно понимать, что и udelay() и mdelay() представляют собой busy-waiting функции, т.е. функции занимающие процессор
целиком, и во время их вычислений не могут выполняться другие задачи. Поэтому, необходимо, по возможности, избегать их
использования, и искать другие решения. Особенно это касается использования функции mdelay().
В настоящий момент, реализация задержек более чем на несколько микросекунд и меньше одного тика таймера очень
неэффективна. Отчасти проблема кроется в том, что с одной стороны, задержка в одну сотую секунды начинает обладать достаточным
разрешением для человеческого восприятия, но, с другой стороны, задержка в одну микросекунду уже достаточно
продолжительна с точки зрения активности физических устройств.
Функция mdelay() не реализована в ядре 2.0, и предлагаемый нами заголовочный файл sysdep.h компенсирует этот недостаток.
Очереди задач
Многим драйверам интересна возможность планировки исполнения некоторых задач в некий последующий период времени без
обращения к прерываниям. Linux предлагает три различных интерфейса для этой цели: очереди задач, тасклеты (tasklets)
(ядро 2.3.43) и таймеры ядра. Очереди задач и тасклеты обеспечивают гибкий механизм планировки исполнения в некий
дальнейший интервал времени, с разным значением для слова "дальнейший". Они наиболее интересны при написании
обработчиков прерываний, и мы увидим их снова в разделе "Tasklets and Buttom-Half Processing" главы 9
"Interrupt Handling". Таймеры ядра используются для диспетчеризации выполнения задач в заданное время и мы
рассмотрим их в разделе "Таймеры ядра" позднее в этой главе.
Типичная ситуация, в которой вам может понадобиться использование очереди задач или тасклетов - это управление
физическими устройствами, которые не могут генерировать прерывания, но используют блокировку чтения. Вам потребуется
опрашивать готовность устройства, не обременяя, при этом, процессор ненужными операциями. Пробуждение читающего процесса
в заданные временные интервалы (например, используя current->timeout) не совсем удачная мысль, так как каждый опрос
будет требовать два переключения контекста (один для запуска опрашивающего кода в читающем процессе, и другой,
возвращающий читающему процессу результат опроса). Часто, подходящий механизм опроса может быть реализован только за
пределами контекста процесса.
Похожую проблему представляет своевременный обмен данными с каким либо простым устройством. Например, вам может
понадобиться периодическая передача воздействия шаговому двигателю, подключенному напрямую к параллельному порту -
управление таким двигателем строится на своевременной передаче управляющего воздействия. В этом случае, управляющий
процесс, просит драйвер о передаче движущего воздействия, но такая передача должна осуществляться шаг за шагом через
заданные интервалы времени.
Предпочтительным способом эффективного выполнения таких операций является регистрация задачи для последующего
исполнения. Ядро поддерживает очереди задач, в которых накапливаются задачи для диспетчеризации, в случае, если очередь
является активной (запущенной). Вы можете объявить свою собственную очередь и активизировать (to trigger) ее по желанию,
или можете регистрировать свои задачи в предопределенных очередях, которые будут обрабатываться (triggered) ядром
самостоятельно.
Сначала мы рассмотрим очереди задач, затем познакомимся с предопределенными очередями задач, которые предлагают неплохой
старт для некоторых интересных тестов (и могут повесить компьютер при неверном использовании). В завершении мы
познакомимся с тем как запускать свои собственные очереди задач. За тем мы рассмотрим новый интерфейс тасклетов, которые
заменяют очереди задач во многих ситуациях, начиная с версии ядра 2.4.
Природа очереди задач
Очереди задач представляют собой список задач, где каждая задача представляется указателем на функцию и ее аргументом.
Когда задача запускается она получает один аргумент void * и возвращает void. Аргумент указатель может быть использован
для передачи произвольной структуры данных в функцию, а может быть игнорирован. Сама очередь представляет список
структур (задач), которые принадлежат модулю ядра, в котором они описаны, и который ими управляет. Модуль полностью
ответственнен за распределение и уничтожение как динамических, так и статических структур, которые обычно используются
для этих целей.
Элемент очереди описывается следующей структурой, взятой непосредственно из <linux/tqueue.h>:
struct tq_struct {
struct tq_struct *next; /* linked list of active bh's */
/* связанный список активных "нижних половин" (bh - bottom half) */
int sync; /* must be initialized to zero */
/* должен быть инициализирован в ноль */
void (*routine)(void *); /* function to call */
/* вызываемая функция */
void *data; /* argument to function */
/* аргумент функции */
};
Акроним "bh" в первом комментарии означает "buttom half" (нижняя половина), т.е.
"отложенная часть обработчика прерываний" (half of an interrupt handler). Мы подробно рассмотрим эту
терминологию когда будем иметь дело с прерываниями в разделе "Tasklets and Buttom-Half Processing" главы 9
"Interrupt Handling". Пока лишь достаточно сказать, что button half (читается как "б'атон халф" это
механизм, обеспечиваемый драйвером устройства для обработки асинхронных задач, которые, обычно слишком времяемкие, чтобы
вычисляться целиком в обработчике прерываний. В этой главе мы не будем вдаваться в смысл этого понятия, будем лишь
ссылаться на него по необходимости.
Наиболее важными полями в только что показанной структуре данных являются поля routine и data. Чтобы поставить задачу в
очередь на дальнейшее исполнение вам необходимо будет заполнить оба эти поля перед тем, как установить структуру в
очередь. Поля sync и next должны быть обнулены. Флаг sync данной структуры используется ядром для предотвращения
очередизации одной и той же задачи более одного раза, потому что это может привести к повреждению указателя next. После
того, как задача была установлена в очередь, то предполагается, что структура принадлежит ядру и не должна
модифицироваться до теж пор, пока задача не запустится.
Другой структурой данных, которая используется в механизме очередей задач, является структура task_queue, которая в
настоящее время только является указателем на структуру tq_struct. Переопределение структуры на другой символ с помощью
typedef позволяет в будущем расширить структуру task_queue. Указатели task_queue должны быть проинициализированы в NULL
перед использованием.
В следующем списке мы привели операции, которые могут быть выполнены над очередями задач и структурой tq_struct.
- DECLARE_TASK_QUEUE(name);
-
Данное макро определяет очередь задач с данным именем, и инициализирует ее в пустое состояние.
- int queue_task(struct tq_struct *task, task_queue *list);
-
Как следует из имени, данная функция устанавливает задачу в очередь. Функция возвращает 0, если данная задача
уже представлена в этой очереди, иначе возвращается ненулевое значение.
- void run_task_queue(task_queue *list);
-
Данная функция используется для запуска обработки очереди накопленных задач. Вам не понадобится вызывать эту
функцию самостоятельно до тех пор, пока вы не объявите и не захотите использовать свою собственную очередь.
Перед тем как углубиться в детали использования очередей задач, нам необходимо задержаться на понимании того, как этот
механизм работает в ядре.
Принципы работы очередей задач
Как мы уже видели, очереди задач представляют собой связанные списки вызываемых функций. Когда функции run_task_queue()
требуется выполнить данную очередь, то вызывается на выполнение каждый элемент из списка. Когда вы пишите функции,
которые работают в очередях задач, вы должны понимать как и когда ядро вызывает run_task_queue(). Понимание этого
приведет к пониманию некоторых ограничений в использовании этого механизма. Вы не должны делать каких-либо предположений
относительно порядка, в котором выполняются задачи поставленные в очередь. Каждая из них дожна работать независимо от
других.
Возникает вопрос. Когда же запускается обработка очередей задач? Если вы используете одну из предопределенных очередей
задач, обсужденных в следующем разделе, то ответ будет следующим: "when kernel get around to it". Различные
очереди запускаются в разное время, но они всегда запускаются тогда, когда у ядра нет другой неотложной работы для
выполнения.
Наиболее важно то, что они почти наверняка не запустятся пока процесс, который положил задачу в очередь исполняется. Они
работают асинхронно. До данного момента, все что мы делали в наших примерах драйверов, запускалось в контексте процесса,
выполняющего системный вызов. Однако, когда выполняется очередь задач, то процесс может спать, выполняться на другом
процессоре, или, предположительно, пожет быть полностью завершен.
Такое асинхронное исполнение схоже с обработкой аппаратных прерываний, которые в деталях обсуждаются в главе 9
"Обработка прерываний". Фактом является то, что очереди задач часто запускаются как результат
"программных прерываний". Код запущенный в режиме прерываний (во время прерывания) должен следовать некоторым
ограничениям. Сейчас мы познакомимся с этими ограничениями, которые будут упомянуты в этой книге еще не раз.
Невыполнение этих условий является серьезной угрозой для стабильности системы.
Существует ряд действий требующих для исполнения контекста процесса. Когда код работает за пределами контекста процесса
(т.е. в режиме прерывания), вы должны соблюдать следующие правила:
- Нет доступа к пользовательскому пространству. Поскольку нет контекста процесса, то нет пути к пространству
пользователя, связанного с этим процессом.
- Текущий указатель не корректен в режиме прерывания, и не может быть использован.
- Нельзя выполнить планирование задач или уход в сон. Код режима прерывания не может вызвать функции schedule()
или sleep_on(). Также он не должен выполнять другие функции, которые могут уснуть. Например, вызов kmalloc(...,
GFP_KERNEL) - против правил. Семафоры также не могут быть использованы, так как они могут привести к погружению
в сон.
Код ядра может узнать, исполняется ли он в режиме прерывания через вызов функции in_interrupt(), которая не имеет
параметров и возвращает ненулевое значение если процессор работает во время (в режиме) прерывания.
Одной из возможностей текущей реализации очереди задач является то, что задача может повторно поставить себя в ту же
самую очередь, в которой она была исполнена. Например, задача которая была исполнена по тику таймера может
перепланировать сама себя, так, что она будет выполнена по следующему тику. Повторная установка себя в очередь
производится вызовом queue_task(). Перепланировка возможна, потому что голова очереди замещается указателем NULL
перед выполнением помещенных в очередь задач. В результате, новая очередь начинает формироваться сразу же после того,
как старая очередь начинает исполняться.
И хотя перепланировка одной и той же задачи снова и снова может показаться не совсем умной операцией, но иногда это
полезно. Например, представим себе драйвер, который управляет парой шаговых двигателей, выполняя один шаг за раз, за
каждый вызов благодаря перепланировке самого себя в очереди таймера до тех пор, пока цель не будет достигнута.
Другой пример - модуль jiq, которые выводит на печать информацию о функциях, которые планируют сами себя. Как
результат, несколько итераций на одной очереди таймера.
Предопределенные очереди задач (predefined task queue)
Простейшим способом выполнения отложенных вычислений является использование очередей, которые уже содержатся в ядре.
Существуют несколько таких очередей, но ваш драйвер может использовать только три из них, описанных в следующем списке.
Очереди объявлены в заголовочном файле <linux/tqueue.h>, который вы должны включить в вод вашего модудя.
- Очередь диспетчера (the scheduler queue)
-
Среди предопределенных очередей задач, очередь диспетчера является уникальной в том, что она выполняется в
контексте процесса, что подразумевает большую свободу действий, для выполняемых в ней задач. В Linux 2.4 эта
очередь не принадлежит "преданной" нити ядра, называемой keventd и доступ к ней производится
через функцию, называемую schedule_task(). В старых версиях ядра keventd не использовалась, и к очереди
(tq_scheduler) можно было обратиться напрямую.
- tq_timer
-
Эта очередь запускается тиком таймера. Так как тик (функция do_timer()) работает во время прерывания, то любая
задача в этой очереди, также работает во время (в режиме) прерывания.
- tq_immediate
-
Срочная очередь, запускаемая так скоро, как только это возможно, либо по возврату из системного вызова, либо во
время работы диспетчера - в зависимости от того, что раньше произойдет. Очередь выполняется во время прерывания.
Существуют, также, и другие предопределенные очереди задач, но они не представляют интерес для разработчиков драйверов.
Развитие во времени исполнения драйвера, использующего очередь задач представлено на рис. 6-1. Рисунок показывает драйвер,
который использует очередь tq_immediate из обработчика прерываний.
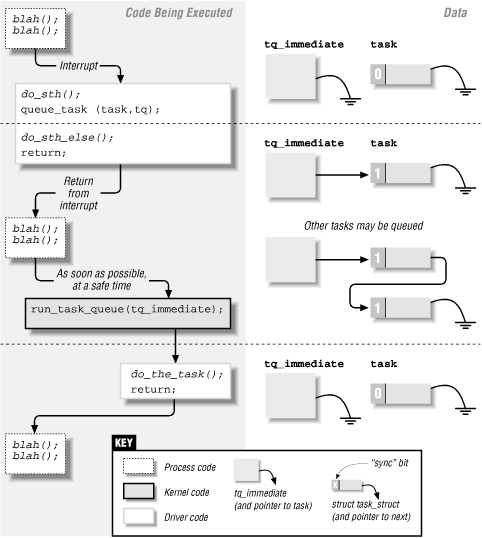
Рис. 6-1. Использование очереди задач
Пояснение работы примера
Примеры отложенного вычисления доступны в модуле jiq ("Just In Queue"), элементы кода которого уже были
приведены в данной главе. Этот модуль создает файлы в файловой системе /proc, которые могут быть прочитаны с
использованием dd или других инструментов. Работа модуля во многом похожа на jit.
Процесс, читающий файл jiq, переводится в состояние сна до тех пор, пока не будет заполнен буфер. Размер буфера /proc
равен размеру страницы памяти. Для платформы x86 размер страницы памяти равен 4 КБт. Сон обрабатывается простой очередью
ожидания, объявленной как
DECLARE_WAIT_QUEUE_HEAD (jiq_wait);
Буфер заполняется в процессе успешной обработки очереди задач. Обработка каждого элемента очереди добавляет в буфер
текстовую строку. Каждая строка содержит информацию о текущем времени в джиффисах, о текущем процессе, и о значении,
возвращаемом in_interrupt().
Код заполняющий буфер содержится в функции jiq_print_tq(), которая выполняется при обработке элемента очереди. Нет
смысла рассматривать код этой функции. Вместо этого рассмотрим инициализацию задачи, устанавливаемой в очередь:
struct tq_struct jiq_task; /* global: initialized to zero */
/* глобальный элемент: инициализирован нулем */
/* these lines are in jiq_init() */
/* строки из jiq_init() */
jiq_task.routine = jiq_print_tq;
jiq_task.data = (void *)&jiq_data;
Нет необходимости очистки полей sync и next в структуре jiq_task, потому что статические переменные инициализируются
нулем при компиляции.
Очередь планировщика задач (scheduler queue)
В некоторых случаях, очередь планировщика задач предпочтительнее в использовании. Так как задачи исполняемые из этой очереди
запускаются не в режиме прерываний, то они имеют сравнительную свободу в действиях. Так, например, они могут уйти в
спящее состояние. Многие части ядра используют эту очередь для выполнения широкого круга задач.
Что касается ядра 2.4.0-test11, действительная очередь задач, реализующая очередь планировщика спрятана от остальной части
ядра. Поэтому, вместо прямого использования queue_task(), код использующий эту очередь должен вызвать schedule_task() для
установки этой задачи в очередь:
int schedule_task(struct tq_struct *task);
где task, конечно, задача, которая должна быть спланирована. Возвращаемое значение напрямую передаются из
queue_task(): ненулевое значение говорит о том, что задача не была ранее представлена в очереди.
Опять же, что касается ядра 2.4.0-test11, то оно запускает специальный процесс, называемый keventd, исключительной
задачей которого является запуск задач из очереди планировщика. keventd обеспечивает предсказуемый контекст процесса для
задач, которые он запускает. Это отличается от предыдущих реализаций, в которых задачи запускаются под совершенно
случайным контекстом процесса.
Имеется пара "подводных камней" в такой реализации keventd, которые нужно иметь в виду. Во-первых, задачи из
такой очереди могут быть переведены в состояние сна, и некоторый код ядра получает преимущества от такой свободы.
Однако, хорошо написанный код должен позволять себе уход в сон только на очень короткий период времени, так как на время
сна keventd, другие задачи не смогут быть запущены из очереди диспетчера. Также, необходимо понимать, что ваша задача
разделяет очередь планировщика с другими задачами, которые тоже могут уйти в спящее состояние. В обычной ситуации, задачи
размещенные в очереди планировщика будут запущены очень быстро, возможно даже перед тем, как schedule_task() завершит
работу. Однако, если какая-нибудь другая задача находится в состоянии сна, то перед запуском вашей задачи может пройти
значительное время. Поэтому, задачи которые имеют узкие временные рамки запуска должны использовать другие очереди.
Файл /proc/jiqsched представляет собой пример использования очереди планировщика задач. Функция read() планирует элементы
очереди задач следующим способом:
int jiq_read_sched(char *buf, char **start, off_t offset,
int len, int *eof, void *data)
{
jiq_data.len = 0; /* nothing printed, yet */
jiq_data.buf = buf; /* print in this place */
jiq_data.jiffies = jiffies; /* initial time */
/* jiq_print will queue_task() again in jiq_data.queue */
jiq_data.queue = SCHEDULER_QUEUE;
schedule_task(&jiq_task); /* ready to run */
interruptible_sleep_on(&jiq_wait); /* sleep till completion */
*eof = 1;
return jiq_data.len;
}
Чтение файла /proc/jiqsched приводит к следующим строкам вывода:
time delta interrupt pid cpu command
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
601687 0 0 2 1 keventd
В приведенных выше строках, поле time содержит значение в джиффисах на момент запуска задачи, поле delta показывает
изменение в джиффисах с момента последнего запуска задачи, поле interrupt отображает результат функции in_interrupt(),
поле pid содержит идентификатор запущенного процесса, поле cpu показывает количество используемых CPU (на
однопроцессорных системах всегда равна 0) и поле command отображает команду, которая исполнялась при запуске текущей
задачи.
В приведенном примере мы видим, что задача всегда запускалась под процессом keventd. Кроме того, запуск производился
очень быстро - задача, которая перезакладывает сама себя в очередь диспетчера может быть запущена сотни и тысячи раз за
один тик таймера. Даже на сильнозагруженных системах, нерабочее состояние для очереди диспетчера очень непродолжительно.
Очередь таймера (timer queue)
Очередь таймера отличается от очереди диспетчера тем, что очередь tq_timer доступна напрямую. Кроме того, конечно,
задачи запущенные из очереди таймера запускаются в режиме прерывания. И в завершении, существует гарантия того, что
очередь будет обработана в следующий системный тик, что исключает провалы связанные с перегрузкой системы.
Приведем пример кода использующий очередь таймера для реализации /proc/jiqtimer. Обратите внимание, что для установки
задачи в очередь мы должны использовать queue_task().
int jiq_read_timer(char *buf, char **start, off_t offset,
int len, int *eof, void *data)
{
jiq_data.len = 0; /* nothing printed, yet */
jiq_data.buf = buf; /* print in this place */
jiq_data.jiffies = jiffies; /* initial time */
jiq_data.queue = &tq_timer; /* reregister yourself here */
queue_task(&jiq_task, &tq_timer); /* ready to run */
interruptible_sleep_on(&jiq_wait); /* sleep till completion */
*eof = 1;
return jiq_data.len;
}
Приведем пример файла /proc/jiqtimer, взятый с системы во время компиляции нового ядра (т.е. при хорошо загруженной
системе):
time delta interrupt pid cpu command
45084845 1 1 8783 0 cc1
45084846 1 1 8783 0 cc1
45084847 1 1 8783 0 cc1
45084848 1 1 8783 0 cc1
45084849 1 1 8784 0 as
45084850 1 1 8758 1 cc1
45084851 1 1 8789 0 cpp
45084852 1 1 8758 1 cc1
45084853 1 1 8758 1 cc1
45084854 1 1 8758 1 cc1
45084855 1 1 8758 1 cc1
Обратите внимание, что между запусками задачи проходит ровно один тик таймера, и что при запуске задачи работали
различные процессы.
Срочная очередь (immediate queue)
Последней предопределенной очередью, которая может быть использована кодом модуля, является срочная очередь. Эта очередь
запускается через механизм "нижних половинок", что требует дополнительного шага в использовании. "Нижние
половинки" запускаются только тогда, когда ядро считает их запуск необходимым. Это достигается пометкой
"marking" соответствующих нижних половинок. В случае использования tq_immediate, такая пометка осуществляется
вызовом mark_bh(IMMEDIATE_BH). Функцию mark_bh() следует запускать только после того, как задача будет установлена в
очередь, в противном случае, ядро может начать обработку очереди до того, как задача будет помещена в эту очередь.
Срочная очередь является наиболее быстрой очередью в системе - она исполняется как только возможно и запускается в
режиме прерывания. Очередь запускается на обработку либо планировщиком задач, либо сразу после того, как процесс завершит
системный вызов. Типичный отчет о работе срочной очереди может выглядеть следующим образом:
time delta interrupt pid cpu command
45129449 0 1 8883 0 head
45129453 4 1 0 0 swapper
45129453 0 1 601 0 X
45129453 0 1 601 0 X
45129453 0 1 601 0 X
45129453 0 1 601 0 X
45129454 1 1 0 0 swapper
45129454 0 1 601 0 X
45129454 0 1 601 0 X
45129454 0 1 601 0 X
45129454 0 1 601 0 X
45129454 0 1 601 0 X
45129454 0 1 601 0 X
45129454 0 1 601 0 X
Ясно, что срочная очередь не может быть использована для задержки выполнения задачи. Ее назначение выполнить задачу так
быстро, насколько это возможно и безопасно. Этот механизм предоставляет огромные возможности для обработчиков
прерываний, потому что предоставляет дополнительную точку входа в программный код обработчика за пределами
непосредственного обработчика прерываний. Например, механизм используемый для приема сетевых пакетов построен схожим
образом.
Обратите внимание, что вы не должны перерегистрировать вашу задачу в очереди (хотя мы и делаем это для jiqimmed в
пояснительных целях). Перерегистрация не имеет, для этого случая, никаких преимуществ, и может привести к зависанию
компьютера на некоторых сочетаниях платформа/ядро. Некоторые реализации используют перезапуск очереди до тех пор, пока
она не опустеет. Так, это имеет место для версии ядра 2.0 на платформе PC.
Запуск собственной очереди
Объявление новой очереди ядра не представляет собой сложной задачи. Драйвер может объявить одну или несколько
собственных очередей задач. Установка задач в собственные и предопределенные очереди одинакова.
Однако, в отличии от предопределенных очередей, пользовательская очередь не может быть запущена ядром автоматически.
Программист, создавший очередь, должен будет позаботиться и о ее запуске.
Следующее макро используется для объявление очереди. Данное макро расширяется в простое объявление переменной. Лучшим
местом его размещения является начало файла, до реализации любой из функций.
DECLARE_TASK_QUEUE(tq_custom);
Чтобы установить задачу в очередь можно воспользоваться следующей функцией:
queue_task(&custom_task, &tq_custom);
С помощью вызова следующей функции, вы сможете запустить очередь tq_custom на обработку, после ее упаковки необходимыми
задачами:
run_task_queue(&tq_custom);
Если вы ходите повозиться с пользовательскими очередями задач, то вам понадобиться функция зарегистрированная в одной из
предопределенных очередей, и используемая для запуска вашей очереди. И хотя такой косвенный способ запуска может
показаться нелепым, но это не так. Пользовательская очередь может оказаться полезной везде, где требуется накопление
задач для последующего одновременного запуска, даже если для этого запуска потребуется использование другой очереди.
Тасклеты (tasklets)
Практически перед выпуском ядра 2.4, разработчики добавили новый механизм для запуска отложенных задач ядра. Этот
механизм, называемый такслетами, представляет сейчас наиболее предпочтительный способ исполнения нижних половинок
(botton-half). Кроме того, в данный момент, нижние половинки, сами по себе, реализованы через такслеты.
Во многом, тасклеты похожи на очереди задач. Они предоставляют способ безопасного запуска отложенных задач, и всегда
исполняются в режиме прерывания. Как и очереди задач, такслеты могут быть запущены только единожды, даже при
многократной установке в планировщик, но тасклеты могут быть запущены параллельно с другими тасклетами на системах SMP.
Также, на системах SMP существует гарантия, что тасклеты будут запущены на том CPU, который впервые планировал их,
что обеспечивает лучшее использование кэша и более высокую производительность.
Каждый тасклет имеет связанную с ним функцию, которыя вызывается тогда, когда тасклет должен быть выполнен. Жизнь
некоторых разработчиков ядра была бы проще, если бы эта функция принимала бы свой единственный аргумент как экземпляр
типа unsigned long. С другой стороны, в некоторых случаях, предпочтительнее использовать в качестве аргумента указатель.
Как бы там не было, но проблемой это не является, так как преобразование аргумента long в тип указателя является
совершенно безопасным и может быть использовано на всех поддерживаемых платформах. Мы остановимся на этом вопросе в
главе 13 "mmap и DMA". Обсуждаемая тасклет-функция не возвращает значения (т.е. возвращает void).
Поддержка тасклетов предоставляется заголовочным файлом <linux/interrupt.h>. Тасклет может быть объявлен с помощью
одного из следующих макросов:
- DECLARE_TASKLET(name, function, data);
-
Объявляет тасклет с именем name. При исполнении тасклета вызывается функция function, в которую передается
значение data типа unsigned long.
- DECLARE_TASKLET_DISABLED(name, function, data);
-
Так же как и в предыдущем случае объявляет тасклет, но с начальным состоянием "disabled" (запрещено),
означающем, что он может учавствовать в планировке задач, но не может быть исполнен до тех пор, пока не будет разрешен в
последствии.
Пример драйвера jiq, при компиляции для ядра 2.4 реализует поддержку файла /proc/jiqtasklet, который работает также, как
и другие файлы, обрабатываемые драйвером jiq, но использует тасклеты. Мы не эмулируем тасклеты для старых версий ядра в
нашем заголовочном файле sysdep.h. Модуль объявляет свой тасклет следующим образом:
void jiq_print_tasklet (unsigned long);
DECLARE_TASKLET (jiq_tasklet, jiq_print_tasklet, (unsigned long)
&jiq_data);
Когда драйвер хочет диспетчеризовать тасклет для запуска, он вызывает функцию tasklet_schedule():
tasklet_schedule(&jiq_tasklet);
Если тасклет разрешен, то как только он диспетчеризуется, он будет запущен сразу же как только это будет возможно из
соображений безопасности. Тасклеты могут перепланировать сами себя много раз, также как и очереди задач. Тасклет
не должен беспокоиться о запуске своей копии на многопроцессорной системе, так как в ядре предприняты шаги к тому, чтобы
гарантировать запуск каждого из тасклетов только в одном месте. Также, необходимо понимать, что если ваш драйвер
реализует множество тасклетов, то он должен быть готов к тому, что более чем один из них может исполняться одновременно.
В этом случае, для защиты критических секций кода должен быть использован spinlock. Так как семафоры могут уйти в
состояние сна, то они не могут быть использованы в тасклетах, исполняемых в режиме прерывания.
Типичное содержимое файла /proc/jiqtasklet выглядит следующим образом:
time delta interrupt pid cpu command
45472377 0 1 8904 0 head
45472378 1 1 0 0 swapper
45472379 1 1 0 0 swapper
45472380 1 1 0 0 swapper
45472383 3 1 0 0 swapper
45472383 0 1 601 0 X
45472383 0 1 601 0 X
45472383 0 1 601 0 X
45472383 0 1 601 0 X
45472389 6 1 0 0 swapper
Заметьте, что тасклет всегда запускается на одном и том же CPU, даже если вывод файла производится на двупроцессорной
системе.
Подсистема тасклетов предлагает еще несколько функций для их углубленного использования:
- void tasklet_disable(struct tasklet_struct *t);
-
Функция запрещает данный тасклет. Тасклет может обрабатываться планировщиком по tasklet_schedule(), но его
исполнение будет отложено до тех пор, пока тасклет не будет разрешен.
- void tasklet_enable(struct tasklet_struct *t);
-
Разрешает тасклет, который был предварительно запрещен. При этом, если тасклет был уже спланирован, то он
будет скоро запущен, но не прямо из tasklet_enable().
- void tasklet_kill(struct tasklet_struct *t);
-
Эта функция может быть использована для тасклетов, которые перепланировали сами себя неконтролируемое число
раз. Функция tasklet_kill() удалит тасклеты из любой очереди, в которой он содержится. Для того, чтобы избежать
гонки (race condition) в запущенных, и планирующих себя тасклетах, эта функция ожидает
завершения работы тасклета, и только потом извлекает его из очереди. Таким образом, вы можете быть уверены, что
тасклеты не будут прерваны во время исполнения. Однако, если тасклет не является запущенным, и не
перепланирует сам себя, то функция tasklet_kill() может повиснуть. tasklet_kill() не может быть вызвана во
время прерывания.
Таймеры ядра
Последним ресурсом управления времени в ядре являются таймеры. Таймеры используются для планирования исполнения функции
(обработчика таймера) в заданное время. Таким образом, их работа отличается от работы очереди задач и тасклетов тем, что
вы можете определить время запуска обработчика таймера. С другой стороны, таймеры ядра похожи на очереди задач в том,
что функция зарегистрированная в таймере ядра выполняется только один раз.
Иногда возникает необходимость выполнения операций отсоединенных от какого-либо контекста процесса. Например, выключение
мотора флоппи-дисковода, или завершение других долгозавершаемых операций. В этом случае, задержка на ожидание окончания
завершения таких операций не должна сказываться на работе приложений. Использование, для этих целей, очереди задач было
было бы расточительно, потому что задача, запускаемая из очереди, должна перерегистрировать себя в очереди до тех пор,
пока операция не будет завершена.
Таймер много проще в использовании. Вы регистрируете свою функцию единожды, и ядро вызывает ее при истечении счета
таймера. Данная функциональность часто используется в самом ядре, но, иногда, требуется и в драйверах, как например, в
случае управления мотором флоппи-дисковода.
Таймеры ядра организуются в двунаправленный связанный список. Это означает, что вы можете создавать столько таймеров,
сколько захотите. Таймер характеризуется значением таймаута (в джиффисах), и функцией, вызываемой при истечении таймера.
Обработчик таймера принимает аргумент, который сохраняется в структуре данных, вместе с указателем на сам обработчик.
Структура таймера определена в заголовочном файле <linux/timer.h> и выглядит следующим образом:
struct timer_list {
struct timer_list *next; /* never touch this (это не трогать!)*/
struct timer_list *prev; /* never touch this (это тоже не трогать!)*/
unsigned long expires;/*the timeout, in jiffies (значение таймаута в джиффисах)*/
unsigned long data; /* argument to the handler (аргумент для обработчика)*/
void (*function)(unsigned long); /* handler of the timeout (обработчик)*/
volatile int running;
/* added in 2.4; don't touch (добавлен в ядре 2.4 - не трогать!)*/
};
Как уже говорилось, значение таймера задается в джиффисах. Таким образом, timer->function() будет запущена тогда,
когда значение джиффисов будет больше или равно заданному значению timer->expires. Таймаут задается в абсолютных
значениях джиффисов, обычно получаемых прибавлением желаемой задержки к текущему значению.
Как только структура timer_list инициализируется, add_timer() вставляет ее в сортированный список, который проверяется
около 100 раз в секунду. Даже такие системы как Alpha, которые работают с более высоким значением частоты системных
часов, не проверяют этот список чаще. Т.е. увеличение частоты системного таймера не увеличит частоту обработки этого
списка.
Для работы с таймером используются следующие функции:
- void init_timer(struct timer_list *timer);
-
Эта inline-функция используется для инициализации структуры таймера. В текущей реализации, она обнуляет
указатели prev и next (и флаг running на системах SMP). Для совместимости со следующими версиями ядра,
программистам крайне рекомендуется использовать эту функцию для инициализации таймера, и не использовать явную
инициализацию указателей этой структуры.
- void add_timer(struct timer_list *timer);
-
Данная функция вставляет таймер в глобальный список активных таймеров.
- int mod_timer(struct timer_list *timer, unsigned long expires);
-
Если вы захотите изменить время истечения таймера, то можно использовать функцию mod_timer(). После ее вызова,
для данного таймера будет использовано новое значение таймаута.
- int del_timer(struct timer_list *timer);
-
Если возникнет необходимость удалить таймер из списка до его истечения, то потребуется использование функции
del_timer. С другой стороны, при истечении таймера, он будет удален из списка автоматически.
- int del_timer_sync(struct timer_list *timer);
-
Работа этой функции схожа с работой del_timer(), но, по окончании своей работы, гарантирует, что функция таймера
не исполняется ни на одном из CPU. Функция del_timer_sync() используется для избежания гонок ("race
condition" - борьба за ресурсы) при запуске функции таймера в неожидаемое время. Это может быть
использовано во многих ситуациях. Код, вызывающий del_timer_sync(), должен быть убежден, что функция таймера не
использует add_timer() для повторной установки себя в список активных таймеров.
Пример использования таймера можно посмотреть в модуле jiq. Файл /proc/jitimer использует таймер для генерации двух
строк данных, используя ту же функцию печати как и в примере с использованием очереди задач. Первая строка данных
генерируется из системного вызова read(), вызываемого пользовательским процессом, использующим /proc/jitimer. Вторая
строка печатается из функции таймера по истечении одной секунды.
Код для /proc/jitimer выглядет следующим образом:
struct timer_list jiq_timer;
void jiq_timedout(unsigned long ptr)
{
jiq_print((void *)ptr); /* print a line (печатаем строку)*/
wake_up_interruptible(&jiq_wait); /* awaken the process (пробуждаем процесс) */
}
int jiq_read_run_timer(char *buf, char **start, off_t offset,
int len, int *eof, void *data)
{
jiq_data.len = 0;
/* prepare the argument for jiq_print() (готовим аргумент для jiq_print())*/
jiq_data.buf = buf;
jiq_data.jiffies = jiffies;
jiq_data.queue = NULL; /* don't requeue (а, это, в принципе, не требуется :) )*/
init_timer(&jiq_timer);
/* init the timer structure (инициализация структуры таймера)*/
jiq_timer.function = jiq_timedout;
jiq_timer.data = (unsigned long)&jiq_data;
jiq_timer.expires = jiffies + HZ; /* one second */
jiq_print(&jiq_data); /* print and go to sleep (печатаем и уходим в сон)*/
add_timer(&jiq_timer);
interruptible_sleep_on(&jiq_wait);
del_timer_sync(&jiq_timer);
/* in case a signal woke us up (при получении пробуждающего сигнала)*/
*eof = 1;
return jiq_data.len;
}
При чтении /proc/jitimer получаем следующий вывод:
time delta interrupt pid cpu command
45584582 0 0 8920 0 head
45584682 100 1 0 1 swapper
Из приведенного вывода видно, что функция таймера, печатающая последнюю строку, запущена вне контекста процесса - в
режиме прерывания.
При использовании таймера следует иметь ввиду, что таймер истекает в точно назначенное время, даже если процессор
выполняет, в этот момент, системный вызов. Раньше мы предполагали, что когда процесс выполняется в пространстве ядра, то
он не планируется вообще, т.е. не может быть прерван. Однако, таймеры являются специальным случаем, и выполняют все свои
задачи независимо от текущего процесса. Вы можете сравнить чтение /proc/jitbusy в фоновом режиме (background) и
/proc/jitimer в основном (foreground). И хотя система может оказаться жестко заблокированной системным вызовом
находящимся в ожидании, но и очередь таймера, и таймеры ядра будут продолжать обрабатываться.
Примечание переводчика: Не совсем понимаю термин "жесткой блокировки". Почему именно жесткой (solid).
Поэтому, смотрите сами: "... Although the system appears to be locked solid by the busy-waiting system call,
both the timer queue and the kernel timers continue running."
Таким образом, таймеры могут быть другим источником гонок (race conditions), даже на однопроцессорной системе. Любая
структура данных используемая функцией таймера должна быть защищена от конкурентного доступа, либо являясь
атомарным типом (обсуждаемым в главе 10 "Judicious Use of Data Types"), либо используя спинлоки.
Кроме того, следует быть осторожным, избегая гонок (race conditions) при удалении таймера. Представим ситуацию, в
которой функция таймера исполняется на одном процессоре, в то время как связанное с этой функцией событие возникает на
другом (закрытие файла или удаление модуля). В результате, функция таймера будет ожидать ситуацию, которая уже была
обработана, что может привести к краху системы. Для избежания такого типа гонок, ваш модуль должен использовать функцию
del_timer_sync(), вместо del_timer(). Если функция таймера, может перезапустить таймер (в общем случае), то вы, также,
должны иметь флаг "stop timer", который необходимо установить перед вызовом del_timer_sync(). Теперь, функция
таймера должна проверить значение флага и не перепланировать себя с помощью add_timer(), если флаг был установлен.
Другая ситуация, которая может привести к гонке (race conditions), возникает при модификации таймеров удалением через
del_timer(), при создании нового таймера с помощью add_timer(). В такой ситуации, лучшим решением является использование
mod_timer() для выполнения необходимых изменений.
Вопросы обратной совместимости
Подсистема очередей задач и управления таймерами ядра оставалась, по мере развития системы, относительно неизменной.
Однако, необходимо знать о тех немногих изменениях, которые, все же произошли.
Функции sleep_on_timeout(), interruptible_sleep_on_timeout() и schedule_timeout() были добавлены при разработке ядра
2.2. Во времена ядра 2.0, таймауты управлялись с помощью переменной (называемой timeout) из структуры task. В
результате, код, который теперь выглядит так:
interruptible_sleep_on_timeout(my_queue, timeout);
ранее выглядел следующим образом:
current->timeout = jiffies + timeout;
interruptible_sleep_on(my_queue);
Предлагаемый нами заголовочный файл sysdep.h определяет функцию schedule_timeout() для ядер, предшествующих ядру 2.4.
Используя его, вы можете использовать новый синтаксис под ядрами 2.0 и 2.2. Вот как выглядет наше определение этой
функции:
extern inline void schedule_timeout(int timeout)
{
current->timeout = jiffies + timeout;
current->state = TASK_INTERRUPTIBLE;
schedule();
current->timeout = 0;
}
В ядре 2.0 имелась пара дополнительных функций для укладки функций-обработчиков в очереди задач. Так, функция
queue_task_irq() могла бы быть вызвана вместо queue_task() в ситуациях, когда запрещены прерывания. Вызов этой функции
давал очень небольшой выигрыш производительности. Функция queue_task_irq_off() работает немного быстрее, но неправильно
функционирует лишь в случае, когда задача уже установлена в очередь или выполняется, и, таким образом, может быть
использована только в тех случаях, когда эти условия гарантированно не могут возникнуть. Ни одна из этих функций не
обеспечивала заметного выигрыша в производительности, и они были удалены начиная с ядра 2.1.30. Использование queue_task()
будет работать на всех версиях ядра. Еще стоит заметить, что функция queue_task() возвращала тип void в ядре 2.2 и в
предыдущих версиях.
До ядра 2.4, функция schedule_task() и процесс keventd не существовали. Вместо этого, предлагалась другая
предопределенная очередь задач - tq_scheduler. Задачи, помещенные в tq_scheduler, запускаются в функции schedule(), и,
таким образом, всегда выполняются в контексте процесса. Процесс, чей контекст будет использоваться для задач этой
очереди будет всегда различным. Это всегда будет тот процесс, который был спланирован на CPU в данный момент.
tq_scheduler имеет большую временную непредсказуемость в запуске задач, особенно для тех задач, которые перепланируют
сами себя. Предоставляемый нами заголовочный файл sysdep.h предлагает следующую реализацию schedule_task() для систем с
ядрами 2.0 и 2.2:
extern inline int schedule_task(struct tq_struct *task)
{
queue_task(task, &tq_scheduler);
return 1;
}
Как уже говорилось, при разработке серии ядра 2.3 был добавлен механизм тасклетов. Ранее, для выполнения "срочных
отложенных" задач был только механизм очередей задач. Подсистема нижних половинок в управлении устройствами имела
различные реализации в эволюции ядра, но большинство этих изменений скрыты за интерфейсом разработчика драйвера. Мы не
стали эмулировать тасклеты в нашем заголовочном файле sysdep.h, потому что они не являются остронеобходимым механизмом
управления драйверами. Поэтому, если вас интересует вопрос совместимости со старыми ядрами, то вам либо придется писать
свой эмулятор, либо использовать, вместо тасклетов, очереди задач.
В ядре 2.0 отсутствует функция in_interrupt(). Вместо этого, глобальная переменная intr_count хранит количество
запущенных обработчиков прерываний. Опрос intr_count семантически схож с вызовом in_interrupt(), поэтому совместимость
легко реализуется в заголовочном файле sysdep.h.
Функция del_timer_sync() не существовала до момента разработки ядра 2.4.0-test2. Кроме того, до версии ядра 2.0 не была
определена функция mod_timer(). Наш заголовочный файл sysdep.h восполняет обе эти бреши для модулей, стремящихся к
совместимости со старыми версиями ядра.
Краткий справочник определений
В этой главе было произведено ознакомление со следующими сиволами ядра:
- #include <linux/param.h>
- HZ
-
Символ HZ определяет количество системных тиков, генерируемых в секунду.
- #include <linux/sched.h>
- volatile unsigned long jiffies
-
Переменная jiffies инкрементируется при каждом системном тике. Таким образом, она инкрементируется HZ раз в
секунду.
- #include <asm/msr.h>
- rdtsc(low,high);
- rdtscl(low);
-
Читает процессорный timestamp-счетчик или его младшую половину. Этот заголовочный файл и макросы определены для
процессоров класса PC. На других платформах, для достижения подобного результата могут потребоваться ассемблерные
конструкции.
-
Примечания переводчика: Такой счетчик, для компьютеров класса PC, появился только начиная с процессоров
Pentium. Это восьмибайтовый счетчик, инкрементирующийся с каждым тактом процессора. Счетчик обнуляется при
запуске процессора. Для гигагерцового процессора счетчик переполняется примерно через три года непрерывной
работы.
- extern struct timeval xtime;
-
Текущее время, вычисленное на момент последнего тика таймера.
- #include <linux/time.h>
- void do_gettimeofday(struct timeval *tv);
- void get_fast_time(struct timeval *tv);
-
Функции возвращают текущее время. Первая из представленных функций имеет очень высокую точность. Вторая -
работает немного быстрее, но имеет худшее разрешение по точности.
- #include <linux/delay.h>
- void udelay(unsigned long usecs);
- void mdelay(unsigned long msecs);
-
Функции производят задержку на целое число микросекунд и миллисекунд соответственно. Первая из них может быть
использована для задержек на время не более одной миллисекунды. Вторая функция реализована на основе первой. Обе
эти функции должны использоваться с особой осторожностью, так как их реализация построена на обычной программной
петле, вычисляемой до истечения заданного времени (так называемая busy-loop реализация).
- int in_interrupt();
-
Функция возвращает не ноль, если процессор, в данный момент, исполняет код в режиме прерывания.
- #include <linux/tqueue.h>
- DECLARE_TASK_QUEUE(variablename);
-
Макро объявляет новую переменную (элемент очереди) и инициализирует ее.
- void queue_task(struct tq_struct *task, task_queue *list);
-
Функция регистрирует задачу для последующего выполнения.
- void run_task_queue(task_queue *list);
-
Данная функция занимается обработкой очереди задач.
- task_queue tq_immediate, tq_timer;
-
Предопределенные очереди задач. tq_immediate - обрабатывается так быстро, как только возможно. tq_timer -
обрабатывается при каждом тике таймера.
- int schedule_task(struct tq_struct *task);
-
Планирует задачу из очереди планировщика для выполнения.
- #include <linux/interrupt.h>
- DECLARE_TASKLET(name, function, data)
- DECLARE_TASKLET_DISABLED(name, function, data)
-
Объявляет структуру тасклета, с помощью которой будет вызвана заданная функция в которую будет передан параметр
unsigned long data. Вызов функции произойдет при исполнении тасклета. Второй макрос инициализирует тасклет в
запрещенное состояние. Это удержит тасклет от исполнения до тех пор, пока это не будет разрешено явно.
- void tasklet_schedule(struct tasklet_struct *tasklet);
-
Планирует данный тасклет для выполнения. Если тасклет разрешен, то он будет запущен на том же самом CPU, который
выполнял вызов tasklet_schedule().
- tasklet_enable(struct tasklet_struct *tasklet);
- tasklet_disable(struct tasklet_struct *tasklet);
-
Эти функции, соответственно, разрешают и запрещают заданный тасклет. Запрещенный тасклет учавствует в
планировании, но не может быть исполнен до тех пор, пока он не будет разрешен.
- void tasklet_kill(struct tasklet_struct *tasklet);
-
Используется при "бесконечной перепланировке" тасклета для завершения его исполнения. Эта функция
может быть блокирована, поэтому ее нельзя вызывать в режиме прерывания.
- #include <linux/timer.h>
- void init_timer(struct timer_list * timer);
-
Функция используется для инициализации нового таймера.
- void add_timer(struct timer_list * timer);
-
Эта функция вставляет таймер в глобальный список активных таймеров.
- int mod_timer(struct timer_list *timer, unsigned long expires);
-
Эта функция используется для изменения времени истечения таймера, который уже находится в глобальном списке
активных таймеров.
- int del_timer(struct timer_list * timer);
-
Функция del_timer() удаляет таймер из списка активных таймеров. Если таймер был действительно установлен в
очередь, то del_timer() возвратит 1, иначе - 0.
- int del_timer_sync(struct timer_list *timer);
-
Эта функция похожа на del_timer(), но гарантирует, что функция не исполняется в данный момент на другом CPU.
|

 LINUX
LINUX