Глава 2. Формирование и запуск модулей
About: "По мотивам перевода" Linux Device Driver 2-nd edition.
Перевод: Князев Алексей knzsoft@mail.ru
Дата последнего изменения: 03.08.2004
Авторскую страницу А.Князева можно найти тут :
http://lug.kmv.ru/wiki/index.php?page=knz_ldd2
Архивы в переводе А.Князева лежат тут:
http://lug.kmv.ru/wiki/files/ldd2_ch1.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch2.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch3tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch4.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch5.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch6.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch7.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch8.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch13.tar.bz2
Теперь начинаем программировать! В этой главе содержатся основные положения о модулях и о программировании в ядре.
Здесь мы соберем и запустим полноценный модуль, структура которого соответствует любому реальному модульному драйверу.
При этом, мы сконцентрируемся на главных позициях не учитывая специфику реальных устройств.
Все части ядра, такие как функции, переменные, заголовочные файлы и макросы, которые упоминаются здесь, будут
подробно описаны в конце главы.
Hello world!
В процессе ознакомления с оригинальным материалом написанным Alessndro
Rubini & Jonathan Corbet мне показался несколько неудачным пример,
приведенный в качестве Hello world! Поэтому, я хочу предоставить
читателю, на мой взгляд более удачный вариант первого модуля. Надеюсь,
что с его компиляцией и установкой под ядро версий 2.4.x не возникнет
никаких проблем. Предлагаемый модуль и способ его компиляции позволяют
использовать его в ядрах, как поддерживающих, так и не поддерживающих
контроль версий. Позднее вы ознакомитесь со всеми деталями и
терминологией, я сейчас открывайте vim и начинайте работать!
==================================================
//файл hello_knz.c
#include <linux/kernel.h>
#include <linux/module.h>
int init_module(void)
{
printk("<1>Hello, world\n");
return 0;
};
void cleanup_module(void)
{
printk("<1>Good bye cruel world\n");
}
MODULE_LICENSE(“GPL”);
==================================================
Для компиляции такого модуля можно использовать следующий Makefile.
Не забудьте поставить символ табуляции перед строкой, начинающейся с
$(CC) ... .
==================================================
FLAGS = -c -Wall -D__KERNEL__ -DMODULE
PARAM = -I/lib/modules/$(shell uname -r)/build/include
hello_knz.o: hello_knz.c
$(CC) $(FLAGS) $(PARAM) -o $@ $^
=================================================
Здесь используются две особенности, по сравнению с кодом
оригинального Hello world, предложенного Rubini & Corbet.
Во-первых, модуль будет иметь версию, совпадающую с версией ядра. Это
достигается значением переменной PARAM в сценарии компиляции.
Во-вторых, теперь модуль будет лицензирован в GPL (использование
макроса MODULE_LICENSE()). Если этого не сделать, то при установке
модуля в ядро вы можете увидеть, примерно, следующее предупреждение:
[root@knz hello_knz]# insmod hello_knz.o
Warning: loading hello_knz.o will taint the kernel: no license
See http://www.tux.org/lkml/#export-tainted for information about tainted modules
Module hello_knz loaded, with warnings
Поясним теперь опции компиляции модуля (макроопределения будут объяснены позже):
-с – при наличии данной опции, компилятор gcc остановит процесс
компиляции файла сразу после создания объектного файла, не делая
попытку создать исполняемый бинарник.
-Wall – максимальный уровень вывода предупреждений в процессе работы gcc.
-D - определения макросимволов. То же, что и директива #define в
компилируемом файле. Совершенно без разницы, каким способом определять,
используемые в данном модуле, макросимволы, с помощью #define в файле
исходнике или с помощью опции -D для компилятора.
-I – дополнительные пути поиска include-файлов. Обратите
внимание на использование подстановки “uname -r”, которая определит
точное название используемой в данный момент версии ядра.
В следующем разделе приведен другой пример модуля. Там же подробно объясняется способ его установки и выгрузки из ядра.
Оригинальный Hello world!
Теперь приведем оригинальный код простого модуля "Hello, World"
предлагаемого Rubini & Corbet. Этот код может быть скомпилирован
под ядрами версий с 2.0 по 2.4. Этот пример, как и все остальные,
представленные в книге, доступны на O'Reilly FTP сайте (см. Главу 1).
//файл hello.c
#define MODULE
#include <linux/module.h>
int init_module(void)
{
printk("<1>Hello, world\n");
return 0;
}
void cleanup_module(void)
{
printk("<1>Goodbye cruel world\n");
}
Функция printk() определена в Linux ядре и работает как стандартная библиотечная функция printf()
в языке Си . Ядру нужна своя собственная, желательно небольшая по
размерам, функция вывода, содержащаяся непосредственно в ядре, а не в
библиотеках пользовательского уровня. Модуль может вызвать функцию printk(), потому что после загрузки модуля с помощью команды insmod модуль связывается с ядром и имеет доступ к опубликованным (экспортированным) функциям и переменным ядра.
Строковый параметр “<1>”, передаваемый в функцию printk() - это
приоритет сообщения. В оригинальных английских источниках используется
термин loglevel, означающий уровень логирования сообщений. Здесь, мы
будем пользоваться термином приоритет, вместо оригинального “loglevel”.
В данном примере мы используем высокий приоритет для сообщения,
которому соответствует маленький номер. Высокий приоритет сообщения
задается умышленно, потому что сообщение с приоритетом принятым по
умолчанию может не вывестись в консоли, из которой модуль был
установлен. Направление вывода сообщений ядра с приоритетом по
умолчанию зависит от версии запущенного ядра, версии демона klogd, и вашей конфигурации. Более подробно, работу с функцией printk() мы объясним в Главе 4, "Техника отладки".
Вы можете протестировать модуль, с помощью команды insmod для установки модуля в ядро и команды rmmod
для удаления модуля из ядра. Ниже мы покажем как это можно сделать. При
этом точка входа init_module() исполняется при установке модуля в ядро,
а cleanup_module() при его извлечении из ядра. Помните, что только
привилегированный пользователь может загружать и выгружать модули.
Пример модуля, приведенный выше, может быть использован только с
ядром, которое было собрано с выключенным флагом “module version
support”. К сожалению, большинство дистрибутивов используют ядра с
контролем версий (это обсуждается в разделе "Контроль версии в модулях"
главы 11, "kmod and Advanced Modularization"). И хотя более старые
версии пакета modutils
позволяют загружать такие модули в ядра, собранные с контролем версий,
теперь это невозможно. Напомним, что пакет modutils содержит набор
программ, в который входят программы insmod и rmmod.
Задание: Определите номер версии и состав пакета modutils из вашего дистрибутива.
При попытке вставить такой модуль в ядро, поддерживающее контроль
версий, вы можете увидеть примерно следующее сообщение об ошибке:
[root@knz hello]# insmod hello.o
hello.o: kernel-module version mismatch
hello.o was compiled for kernel version 2.4.20
while this kernel is version 2.4.20-9asp.
В каталоге misc-modules примеров с ftp.oreilly.com вы
найдете оригинальный пример программы hello.c, которая содержит немного
больше строк, и может быть установлено в ядра как поддерживающие, так и
не поддерживающие контроль версий. Как бы то ни было, мы настоятельно
рекомендуем вам собрать собственное ядро без поддержки контроля версий.
При этом, рекомендуется взять оригинальные источники ядра на сайте www.kernel.org
Если вы новичок в сборке ядер, то попробуйте прочитать статью, которую
Alessandro Rubini (один из авторов оригинальной книги) разместил на http://www.linux.it/kerneldocs/kconf, и которая должна помочь вам в освоении этого процесса.
Выполните в текстовой консоли следующие команды для компиляции и тестирования приведенного выше оригинального примера модуля.
root# gcc -c hello.c
root# insmod ./hello.o
Hello, world
root# rmmod hello
Goodbye cruel world
root#
В зависимости от механизма, который использует ваша система для
передачи строк сообщения, направление вывода сообщений, посылаемых
функцией printk(),
может отличаться. В приведенном примере компиляции и тестирования
модуля, сообщения переданные из функции printk() оказались выведенными
в ту же консоль, откуда были даны команды на установку и запуск
модулей. Это пример был снят с текстовой консоли. Если же вы выполняете
команды insmod и rmmod из под программы xterm,
то, скорее всего, вы ничего не увидите на своем терминале. Вместо
этого, сообщение может оказаться в одном из системных логов, например в
/var/log/messages. Точное название файла зависит от
дистрибутива. Смотрите по времени изменения log-файлов. Механизм,
используемый для передачи сообщений из функции printk(), описан в
разделе "How Messages Get Logged" в главе 4 "Техника
отладки".
Для просмотра сообщений модуля в файле системных логов
/val/log/messages удобно пользоваться системной утилитой tail, которая,
по умолчанию, выводит последние 10 строчек переданного в нее файла.
Интересной опцией этой утилиты является опция -f которая запускает
утилиту в режиме слежения за последними строками файла, т.е. при
появлении в файле новых строк они будут автоматически выводиться. Чтобы
остановить выполнение команды в этом случае, необходимо нажать Ctrl+C.
Таким образом, для просмотра последних десяти строка файла системных
логов введите в командной строке следующее:
root# tail /var/log/messages
Как вы можете видеть, написание модуля не так сложно, как может
показаться. Самая трудная часть - это понять, как работает ваше
устройство и как увеличить быстродействие модуля. В продолжение этой
главы мы узнаем больше о написании простых модулей, а специфику
устройств оставим для следующих глав.
Различия между модулями ядра и приложениями
Прежде чем мы пойдем дальше, остановимся на различиях между модулем ядра и приложением.
Приложение имеет одну точку входа, которая начинает исполняется
сразу же после размещения запущенного приложения в оперативной памяти
компьютера. Эта точка входа описывается на языке Си как функция main().
Завершение функции main() означает завершение приложения. Модуль имеет
несколько точек входа, исполняемых при установке и удалении модуля из
ядра, а также при обработке поступающих, от пользователя, запросов.
Так, точка входа init_module() исполняется при загрузке модуля в ядро.
Функция cleanup_module() исполняется при выгрузке модуля. В дальнейшем
мы познакомимся с другими точками входа в модуль, которые исполняются
при выполнении различных запросов к модулю.
Возможность загрузки и выгрузки модулей – два кита механизма
модуляризации. Они могут быть оценены в разных ключах. Для разработчика
это означает, прежде всего, уменьшение времени разработки, т.к. вы
можете проводить тестирование функций драйвера без длительного процесса
перезагрузки.
Как программист вы знаете, что приложение может вызвать функцию,
которая не была объявлена в приложении. На стадиях статической или
динамической линковки определяются адреса таких функций из
соответствующих библиотек. Функция printf() одна из таких вызываемых функций, которая определена в библиотеке libc.
Модуль, с другой стороны, связан только с ядром и может вызывать только
те функции, которые экспортируются ядром. Код исполняемый в ядре не
может использовать внешние библиотеки. Так, например, функция printk(), которая использовалась в примере hello.c, представляет собой аналог известной функции printf(), доступной в приложениях пользовательского уровня. Функция printk()
размещена в ядре и должна иметь, по возможности, минимальный размер.
Поэтому, в отличии от printf(), она имеет очень ограниченную поддержку
типов данных, и, например, вообще не поддерживает чисел с плавающей
точкой.
Реализация ядер 2.0 и 2.2 не поддерживала спецификаторы типов L и Z.
Они были введены только в версии ядра 2.4.
На рис.2-1 изображена реализация механизма вызова функций,
являющихся точками входа в модуль. Также, на этом рисунке изображен
механизм взаимодействия установленного или устанавливаемого модуля с
ядром.
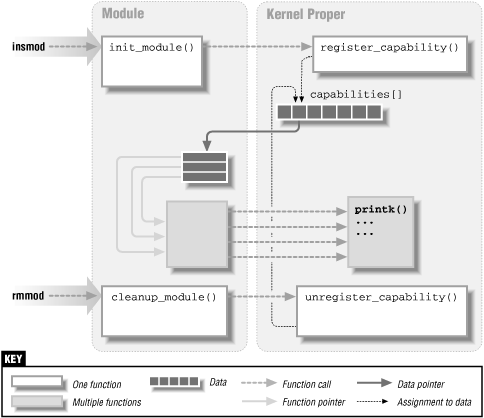
Рис. 2-1. Связь модуля с ядром
Одна из особенностей операционных систем Unix/Linux заключается в
отсутствии библиотек, которые могут быть слинкованы с модулями ядра.
Как вы уже знаете, модули, при их загрузке, линкуются в ядро, поэтому
все, внешние для вашего модуля, функции должны быть объявлены в
заголовочных файлах ядра и присутствовать в ядре. Исходники модулей никогда
не должны включать обычные заголовочные файлы из библиотек
пользовательского пространства. В модулях ядра вы можете использовать
только функции, которые действительно являются частью ядра.
Весь интерфейс ядра, описан в заголовочных файлах, находящихся в каталогах include/linux и include/asm внутри исходников ядра (обычно находящихся в /usr/src/linux-x.y.z (x.y.z - версия вашего ядра)). Более старые дистрибутивы (основанные на libc версии 5 или менее) использовали символические ссылки /usr/include/linux и /usr/include/asm
на соответствующие каталоги в исходниках ядра. Эти символические ссылки
дают возможность, при необходимости, использовать интерфейсы ядра в
пользовательских приложениях.
Несмотря на то, что интерфейс библиотек пользовательского
пространства теперь отделен от интерфейса ядра, иногда, в
пользовательских процессах возникает необходимость использования
интерфейсов ядра. Однако, многие ссылки в заголовочных файлах ядра
относятся только к самому ядру и не должны быть доступны приложениям
пользователя. Поэтому, эти объявления защищены #ifdef __KERNEL__ блоками. Вот почему ваш драйвер, как и другой код ядра, должен быть скомпилирован с объявленным макросимволом __KERNEL__.
Роль отдельных заголовочных файлов ядра будет обсуждаться в книге по мере необходимости.
Разработчики, работающие с любыми большими программными проектами (например, таким как ядро), должны учитывать и избегать "загрязнения пространства имен".
Эта проблема возникает при наличии большого количества функций и
глобальных переменных чьи имена не достаточно выразительны (различимы).
Программист, которому впоследствии приходится иметь дело с такими
приложениями, вынужден тратить гораздо больше времени на запоминание
"зарезервированных" имен и придумывание уникальных имен для новых
элементов. Коллизии имен (неоднозначности) могут создать широкий круг
проблем, начиная с ошибок при загрузке модуля, кончая нестабильным или
необъяснимым поведением программ, которое может проявиться у
пользователей, использующих ядро, собранное в другой конфигурации.
Разработчики не могут позволить себе таких ошибок при написании кода
ядра, потому что даже самый маленький модуль будет слинкован со всем
ядром. Лучшим решением для предотвращения коллизий имен является,
во-первых, объявление ваших объектов программы как static,
а, во-вторых, использование для именования глобальных объектов
уникальный, в пределах системы, префикс. Кроме того, как разработчик
модуля, вы можете управлять областями видимости объектов вашего кода,
как это описано позже в разделе "Таблица линковки ядра".
Большинство (но не все) версии команды insmod экспортируют все объекты модуля, которые не объявлены как static,
по умолчанию, т.е. если в модуле не определены специальные инструкции
на этот счет. Поэтому, вполне разумно объявлять объекты модуля, которые
вы не собираетесь экспортировать, как static.
Использование уникального префикса для локальных объектов внутри модуля
может быть хорошей практикой, так как это упрощает отладку. Во время
тестирования вашего драйвера, вам может понадобиться экспорт
дополнительных объектов в ядро. При использовании уникального префикса
для обозначения имен, вы не рискуете внести коллизии в пространство
имен ядра. Префиксы, используемые в ядре, по договоренности, используют
символы нижнего регистра, и мы будем придерживаться этого соглашения.
Еще одно существенное отличие между ядром и пользовательскими
процессами состоит в механизме обработки ошибок. Ядро контролирует
выполнение пользовательского процесса, поэтому ошибка в
пользовательском процессе приводит к возникновению безобидного для
системы сообщения: segmentation fault. При этом, всегда может быть
использован отладчик для отслеживания ошибки в исходном коде
пользовательского приложения. Ошибки возникающие в ядре фатальны – если
не для всей системы, то, по крайней мере, для текущего процесса. В
разделе “Отладка ошибок системы” главы 4 “Техника отладки” мы
рассмотрим способы отслеживания ошибок ядра.
Пользовательское пространство и пространство ядра
Модуль выполняется в так называемом пространстве ядра, тогда как приложения работают в пространстве пользовательского процесса. Эта концепция - основа теории операционных систем.
Одно из основных назначений операционной системы заключается в
предоставлении пользователю и пользовательским программам ресурсов
компьютера, большая часть которых представлена внешними устройствами.
Операционная система должна не только обеспечивать доступ к ресурсам,
но и контролировать их выделение и использование, предотвращая коллизии
и несанкционированный доступ. В дополнение к этому, операционная
система может создать независимые операции для программ и защититься от
неавторизированного доступа к ресурсам. Решение этой нетривиальной
задачи возможно только в том случае, если процессор обеспечивает защиту
системных программ от приложений пользователя.
Практически каждый современный процессор в состоянии обеспечить такое
разделение, за счет реализации различных уровней привилегий для
исполняемого кода (требуется не менее двух уровней). Например,
процессоры архитектуры I32 имеют четыре уровня привилегий от 0 до 3.
Причем, уровень 0 имеет наивысшие привилегии. Для таких процессоров
существует класс привилегированных инструкций, которые могут
исполняться только на привилегированных уровнях. Unix системы
используют два уровня привилегий процессора. Если процессор имеет более
двух уровней привилегий, то используются наинизший и наивысший. Ядро
Unix работает на наивысшем уровне привилегий, обеспечивая управление
оборудованием и процессами пользователя.
Когда мы говорим о пространстве ядра и пространстве пользовательского процесса имеются в виду не только разные уровни привилегий исполняемого кода, но и разные адресные пространства.
Unix передает исполнение из пространства пользовательского процесса
в пространство ядра в двух случаях. Во-первых, когда пользовательское
приложение выполняет обращение к ядру (системный вызов), и, во-вторых,
во время обслуживания аппаратных прерываний. Код ядра, исполняющийся при системном вызове работает в контексте процесса,
т.е. работая в интересах вызвавшего его процесса от имеет доступ к
данным адресного пространства процесса. С другой стороны, код
исполняемый при обслуживании аппаратного прерывания является
асинхронным, по отношению к процессу, и не относится к какому то
особенному процессу.
Назначение модулей заключается в расширении функциональности ядра.
Код модулей исполняется в пространстве ядра. Обычно, модуль
осуществляет обе задачи, отмеченные ранее: некоторые функции модуля
исполняются как часть системных вызовов, а некоторые ответственны за
управление прерываниями.
Распараллеливание в ядре
При программировании драйверов устройств, в отличии от
программирования приложений, особенно остро стоит вопрос о
распараллеливании исполняемого кода. Как правило, приложение
исполняется от начала до конца последовательно, не беспокоясь об
изменении своего окружения. Код ядра должен работать с учетом того, что
к нему одновременно может возникнуть несколько обращений.
Существует множество причин распараллеливания кода ядра. Обычно в
Linux запущено множество процессов, и некоторые из них могут попытаться
обратиться к коду вашего модуля одновременно. Многие устройства могут
вызвать аппаратные прерывания процессора. Обработчики прерываний
вызываются асинхронно и могут быть вызваны в тот момент, когда ваш
драйвер занимается исполнением другого запроса. Некоторые программные
абстракции (такие как таймеры ядра, объясняемые в главе 6 “Flow of
Time”) также запускаются асинхронно. Кроме того, Linux может быть
запущен на системе с симметричными мультипроцессорами (SMP), в
результате чего, код вашего драйвера может параллельно исполняться на
нескольких процессорах одновременно.
По этим причинам, код Linux ядра, включая коды драйверов, должен
быть реентерабельным, т.е. должен быть способен работать с более чем
одним контекстом данных одновременно. Структуры данных должны быть
разработаны с учетом параллельного исполнения нескольких потоков. В
свою очередь, код ядра, должен иметь способность обрабатывать несколько
параллельных потоков данных не повреждая их. Написание такого кода,
который может исполняться параллельно и избегать ситуаций, в которых
иная последовательность исполнения может привести к нежелательному
поведению системы, требует много времени, и, возможно, хитрости. Каждый
пример драйвера в этой книге написан с учетом возможного параллельного
исполнения. При необходимости, мы будем пояснять особенности техники
написания такого кода.
Наиболее общая ошибка, которую допускают программисты заключается в
их предположении, что параллельность не является проблемой, поскольку
некоторые сегменты кода не могут уйти в “спящее состояние”. И
действительно, ядро Linux является невыгружаемым, с важным исключением
относительно обработчиков прерываний, которые не могут получить
процессор во время исполнения важного кода ядра. В последнее время,
невыгружаемости было достаточно для предотвращения нежелательного
распараллеливания в большинстве случаев. На SMP системах, однако,
выгрузка кода не требуется по причине параллельного вычисления.
Если ваш код предполагает, что он не будет выгружен, то он не будет
правильно работать на SMP системах. Даже если вы не имеете такую
систему, ее может иметь кто-то другой, использующий ваш код. Также,
возможно, в будущем в ядре будет использоваться выгружаемость, поэтому,
даже однопроцессорные системы будут иметь дело с параллельностью
повсюду. Уже существуют варианты реализации таких ядер. Таким образом,
благоразумный программист будет писать код для ядра в предположении,
что он будет работать на системе с SMP.
Прим. переводчика: Простите, но последние два абзаца, мне не
понятны. Возможно, это результат неправильного перевода. Поэтому
привожу оригинальный текст.
A common
mistake made by driver programmers is to assume that concurrency is not
a problem as long as a particular segment of code
does not go to sleep (or "block"). It is true that the Linux kernel is
nonpreemptive; with the important exception of
servicing interrupts, it will not take the processor away from kernel
code that does not yield willingly. In past times, this nonpreemptive
behavior was enough to prevent unwanted concurrency most of the time.
On SMP systems, however, preemption is not required to cause
concurrent execution.
If your code assumes that it will not be preempted, it will not run
properly on SMP systems. Even if you do not have such a system,
others who run your code may have one. In the future, it is also
possible that the kernel will move to a preemptive mode of operation,
at which point even uniprocessor systems will have to deal with
concurrency everywhere (some variants of the kernel already implement
it).
Информация о текущем процессе
Хотя код модуля ядра не исполняется последовательно, как приложения,
но большинство обращений к ядру выполняются относительно, обратившегося
к нему, процесса. Код ядра может опознать вызвавший его процесс
обратившись к глобальному указателю который указывает на структуру struct task_struct, определенную, для ядер версии 2.4, в файле <asm/current.h>, включенном в <linux/sched.h>. Указатель current указывает на текущий исполняющийся пользовательский процесс. При исполнении таких системных вызовов как open() или close(),
обязательно существует процесс вызвавший их. Код ядра, при
необходимости, может вызвать специфическую информацию по вызвавшему его
процессу через указатель current. Примеры использования этого
указателя вы найдете в разделе “Управление доступом к файлу устройства”
в главе 5 “Enhanced Char Driver Operations”.
На сегодняшний день, указатель current не является более
глобальной переменной, как в ранних версиях ядра. Разработчики
оптимизировали доступ к структуре, описывающей текущий процесс
переносом ее в страницу стека. Вы можете посмотреть на детали
реализации current в файле <asm/current.h>. Код который
вы там увидите может показаться вам не простым. Имейте в виду, что
Linux это SMP-ориентированная система, и глобальная переменная просто
не будет работать, когда вы будете иметь дело с множеством CPU. Детали
реализации остаются скрытыми для других подсистем ядра, и драйвер
устройства может получить доступ к указателю current только через интерфейс <linux/sched.h>.
С точки зрения модуля, current похож на внешнюю ссылку printk(). Модуль может использовать current
везде, где потребуется. Например, следующий кусок кода печатает
идентификатор (process ID - PID) и имя команды вызвавшего модуль
процесса, получая их через соответствующие поля структуры struct task_struct:
printk("The process is \"%s\" (pid %i)\n",
current->comm, current->pid);
Поле current->comm представляет собой имя файла команды породившей текущий процесс.
Компиляция и загрузка модулей
Остаток этой главы посвящен написанию законченного, хотя и нетипичного,
модуля. Т.е. модуль не принадлежит ни к одному из классов, описанных в
разделе “Классы устройств и модулей” в главе 1 “Введение в драйвера
устройств”. Пример драйвера, показанного в этой главе будет носить
название skull (Simple Kernel Utility for Loading Localities). Вы
можете использовать модуль scull в качестве шаблона для написания
собственного локального кода.
Мы используем понятие “локального кода” (local) для подчеркивания
ваших персональных изменений кода, в старых добрых традициях Unix
(/usr/local).
Однако, перед тем как мы наполним содержанием функции init_module()
и cleanup_module(), мы напишем сценарий Makefile, который будем
использовать утилитой make для построения объектного кода модуля.
Перед тем, как препроцессор обработает включение любого
заголовочного файла, необходимо, чтобы директивой #define был определен
макросимвол __KERNEL__. Как упоминалось ранее, в интерфейсных файлах
ядра может быть определен специфичный для ядра контекст, видимый только
в случае если символ __KERNEL__ определен в стадии препроцессинга
заранее.
Другой важным символом, определяемым директивой #define, является
символ MODULE. От должен быть определен до включения интерфейса
<linux/module.h> (исключая те драйвера которые будут собраны
вместе с ядром). Драйвера, собираемые в ядро не будут описаны в данной
книге, поэтому символ MODULE будет присутствовать во всех наших
примерах.
Если вы собираете модуль для системы с SMP, вам, также, необходимо
определить макросимвол __SMP__ перед включением интерфейсов ядра. В
версии ядра 2.2 отдельным пунктом в конфигурацию ядра был внесен выбор
между однопроцессорной и многопроцессорной системой. Поэтому, включение
следующих строк самыми первыми строками вашего модуля приведет к
поддержке многопроцессорной системы.
#include <linux/config.h>
#ifdef CONFIG_SMP
# define __SMP__
#endif
Разработчики модуля, также должны определить флаг оптимизации -O для
компилятора, потому что многие функции объявлены как inline в
заголовочных файлах ядра. Компилятор gcc не выполняет расширение inline
для функций до тех пор пока не разрешена оптимизация. Разрешение
расширения подстановок inline с помощью опций -g и -O позволит вам, в
дальнейшем, отлаживать код использующий inline-функции в отладчике. Так
как ядро широко использует inline-функции, очень важно, чтобы они были
расширены правильно.
Заметьте, однако, что использование любой оптимизации выше уровня
-O2 рискованно, потому, что компилятор может расширить и те функции,
которые не описаны как inline. Это может привести к проблемам, т.к. код
некоторых функций ожидает найти стандартный стек своего вызова. Под
inline-расширением понимается вставка кода функции в точку ее вызова
вместо соответствующей инструкции вызова функции. Соответственно, при
этом, раз нет вызова функции, то нет и стека ее вызова.
Возможно, вам нужно будет проверить, что для компиляции модулей вы
используете тот же самый компилятор, который был использован для сборки
ядра, в которое данный модуль предполагается устанавливать. Подробности
смотрите в оригинальном документе из файла Documentation/Changes
расположенного в каталоге источников ядра. Разработки ядра и
компилятора, как правило, синхронизированы между группами
разработчиков. Возможны случаи, когда обновление одного из этих
элементов вскрывает ошибки в другом. Некоторые изготовители
дистрибутивов поставляют ультра-новые версии компилятора, которые не
соответствуют используемому ядру. В этом случае, они обычно
предоставляют отдельный пакет (часто называемый kgcc) с компилятором, специально предназначенным для
компиляции ядра.
Наконец, для того, чтобы предотвратить неприятные ошибки, мы предлагаем вам использовать опцию компиляции -Wall
(all warning – все предупреждения). Возможно, для удовлетворения всех
этих предупреждений, вам потребуется изменить ваш обычный стиль
программирования. При написании кода ядра предпочтительнее использовать
стиль кодирования предлагаемый Линусом Торвальдсом. Так, документ Documentation/CodingStyle, из каталога источников ядра, достаточно интересен и рекомендован всем тем, кто интересуется программированием уровня ядра.
Набор флагов компиляции модуля, с которыми мы познакомились недавно, рекомендуется размещать в переменной CFLAGS вашего Makefile. Для утилиты make это особая переменная, использование которой станет понятно из последующего описания.
Помимо флагов в переменной CFLAGS, в вашем Makefile может
понадобиться цель, объединяющая различные объектные файлы. Такая цель
необходима только в том случае, когда код модуля разделен на несколько
файлов источников, что, вообще, не является редкостью. Объектные файлы
объединяются командой ld -r, которая не является линковочной операцией в общепринятом смысле, не смотря на использование линковщика(ld). Результатом исполнения команды ld -r является другой объектный файл, объединяющий объектные коды входных файлов линковщика. Опция -r означает “relocatable – перемещаемость”,
т.е. выходной файл команды перемещаем в адресном пространстве, т.к. в
нем еще не проставлены абсолютные адреса вызова функций.
В следующем примере представлен минимальный Makefile необходимый для
компиляции модуля, состоящего их двух файлов источников. Если ваш
модуль состоит из одного файла источника, то из приведенного примера
необходимо убрать цель содержащую команду ld -r.
# Путь к вашему каталогу источников ядра можно изменить здесь,
# а можно передать его параметром при вызове “make”
KERNELDIR = /usr/src/linux
include $(KERNELDIR)/.config
CFLAGS = -D__KERNEL__ -DMODULE -I$(KERNELDIR)/include \
-O -Wall
ifdef CONFIG_SMP
CFLAGS += -D__SMP__ -DSMP
endif
all: skull.o
skull.o: skull_init.o skull_clean.o
$(LD) -r $^ -o $@
clean:
rm -f *.o *~ core
Если вы плохо знакомы с работой утилиты make, то вы, возможно,
удивитесь отсутствием правил компиляции *.c файлов в объектные *.o
файлы. Определение таких правил не является необходимыми, т.к. утилита
make, при необходимости, сама преобразовывает *.c файлы в *.o файлы
используя принятый по умолчанию компилятор или компилятор заданный
переменной $(CC). При этом содержимое переменной $(CFLAGS) используется для указания флагов компиляции.
Сpедующим шагом после построения модуля, является загрузка его в ядро.
Мы уже говорили, что для этого мы будем использовать утилиту insmod,
которая связывает все неопределенные символы (вызовы функций и пр.)
модуля с символьной таблицей запущенного ядра. Однако, в отличие от
линковщика (например такого как ld) она не изменяет дисковый файл
модуля, а загружает слинкованный с ядром объект модуля в оперативную
память. Утилита insmod может принимать некоторые опции командной
строки. Подробности можно посмотреть через man insmod.
Используя эти опции можно, например, назначить определенным целым и
строковым переменным вашего модуля заданные значения перед линковкой
модуля в ядро. Таким образом, если модуль правильно разработан, он
может быть сконфигурирован на этапе загрузки. Такой способ
конфигурирования модуля дает пользователю большую гибкость чем
конфигурирование на этапе компиляции. Конфигурирование на этапе
загрузки объясняется в разделе “Ручное и автоматическое
конфигурирование” позднее в этой главе.
Некоторым читателям будут интересны подробности работы утилиты
insmod. Реализация insmod основана не нескольких системных вызовах,
определенных в kernel/module.c. Функция sys_create_module()
распределяет в адресном пространстве ядра необходимое количество памяти
для загрузки модуля. Эта память распределяется с помощью функции
vmalloc() (см. раздел “vmalloc and Friends” в главе 7 “Getting Hold of
Memory”). Системный вызов get_kernel_sysms() возвращает символьную
таблицу ядра, которая будет использована для определения реальных
адресов объектов при линковке. Функция sys_init_module() копирует
объектный код модуля в адресное пространство ядра и вызывает
инициализационную функцию модуля.
Если вы посмотрите на источники кода ядра, то вы найдете там имена
системных вызовов, которые начинаются с префикса sys_. Этот префикс
используется только для системных вызовов. Никакие другие функции не
должны его использовать. Имейте это в виду при обработке источников
кода ядра утилитой поиска grep.
Зависимости версий
Если вы не знаете ничего больше того, что здесь было рассказано, то,
скорее всего, создаваемые вами модули должны будут перекомпилироваться
для каждой версии ядра, в которое они будут слинкованы. В каждом модуле
должен быть определен символ, называемый __module_kernel_version, значение которого
сравнивается с версией текущего ядра утилитой insmod. Этот символ расположен в секции .modinfo
файлов формата ELF (Executable and Linking Format). Более подробно это
объясняется в главе 11 “kmod and Advanced Modularization”. Пожалуйста
заметьте, что этот способ контроля версий применим только для версий
ядра 2.2 и 2.4. В ядре версии 2.0 это выполняется несколько иным
способом.
Компилятор определит этот символ везде, где будет включен заголовочный файл <linux/module.h>.
Поэтому, в приведенном ранее примере hello.c мы не описывали этот
символ. Это также означает, что если ваш модуль состоит из множества
файлов источников, вы должны включить файл <linux/module.h> в свой код только один раз. Исключением является случай использования определения __NO_VERSION__, с которым мы познакомимся позже.
Ниже приведено определение описываемого символа из файла module.h извлеченное из кода ядра 2.4.25.
static const char __module_kernel_versio/PRE__attribute__((section(".modinfo"))) =
"kernel_version=" UTS_RELEASE;
В случае отказа загрузки модуля по причине несоответствия версий, можно
попытаться загрузить этот модуль передав в строку параметров утилиты
insmod ключ -f
(force). Такой способ загрузки модуля не безопасен, и не всегда
успешен. Объяснить причины возможных неудач достаточно трудно.
Возможно, загрузка модуля не будет выполнена по причине неразрешимости
символов при линковке. В этом случае вы получите соответствующее
сообщение об ошибке. Причины неудачи могут скрываться и в изменении
работы или структуры ядра. В этом случае, загрузка модуля может
привести к серьезным ошибкам периода исполнения, а также к краху
системы (system panic). Последнее должно послужить хорошим стимулом для
использования системы контроля версий. Несоответствие версий может
управляться более элегантно при использовании контроля версий в ядре.
Об этом мы подробно поговорим в разделе “Version Control in Modules” в
главе 11 “kmod and Advanced Modularization”.
Если вы хотите скомпилировать ваш модуль для особой версии ядра, вы
должны включить заголовочные файл именно от этой версии ядра. В выше
описанном примере Makefile для определения каталога размещения этих
файлов использовалась переменная KERNELDIR.
Такая индивидуальная компиляция не является редкостью, при наличии
источников ядра. Также, нередкой является ситуация, наличия различных
версий ядра в дереве каталогов. Все приведенные в этой книге примеры
модулей используют переменную KERNELDIR для указания размещения
каталога источников той версии ядра, в которое предполагается
производить линковку собранного модуля. Для указания этого каталога
можно использовать системную переменную, или передавать его
расположение через параметры командной строки для утилиты make.
При загрузке модуля, утилита insmod использует свои собственные пути
поиска объектных файлов модуля, просматривая версии-зависимые каталоги
начиная от точки /lib/modules.
И хотя старые версии утилиты включали в пути поиска текущий каталог,
сейчас такое поведение считается недопустимым по причинам безопасности
(те же проблемы, что и с использованием системной переменной PATH). Таким образом, если вы хотите загрузить модуль из текущего каталога вы можете указать его в стиле ./module.o. Такое указание положения модуля сработает для любых версий утилиты insmod.
Иногда вы можете столкнуться с интерфейсами ядра, которые имеют
различия в версиях 2.0.x и 2.4.x. В этом случае, вам будет необходимо
прибегнуть к помощи макроса, определяющего текущую версию ядра. Данный
макрос расположен в заголовочном файле <linux/version.h>.
Мы укажем случаи различия интерфейсов при использовании таковых. Это
может быть сделано либо сразу по ходу описания, либо в конце раздела, в
специальной секции посвященной зависимости версий. Вынос подробностей в
отдельную секцию, в некоторых случаях, позволит не усложнять описание
по профилирующей для данной книги версии ядра 2.4.x.
В заголовочном файле linux/version.h определены следующие макросы, связанные с определением версии ядра.
- UTS_RELEASE
-
Макрос, расширяемый в строку, описывающую версию ядра текущего
дерева исходников. Например, макрос может расшириться в такую
строку: "2.3.48".
- LINUX_VERSION_CODE
-
Этот макрос расширяется в бинарное представление версии ядра, по
одному байту на каждую часть номера. Например, бинарное
представление для версии 2.3.48 будет 131888 (десятичное
представление для шестнадцатеричного 0x020330). Возможно, бинарное
представление покажется вам удобнее строкового. Заметьте, что такое
представление позволяет описать не более 256 вариантов в каждой
части номера.
- KERNEL_VERSION(major, minor, release)
-
Это макроопределение позволяет построить “kernel_version_code”
из индивидуальных элементов составляющих версию ядра. Например,
следующее макро KERNEL_VERSION(2, 3, 48)
расширится до 131888. Это макроопределение очень удобно при
сравнении текущей версии ядра с требуемым. Мы будем неоднократно
использовать это макроопределение в течении всей книги.
Приведем содержимое файла linux/version.h для ядра 2.4.25 (текст заголовочного файла приведен полностью).
#define UTS_RELEASE "2.4.25"
#define LINUX_VERSION_CODE 132121
#define KERNEL_VERSION(a,b,c) (((a) << 16) + ((b) << 8) + (c))
Заголовочный файл version.h включается в файл module.h, поэтому, как
правило, у вас не возникает необходимости включать version.h в код
вашего модуля явно. С другой стороны, вы можете предотвратить включение
заголовочного файла version.h в module.h объявлением макро __NO_VERSION__. Вы будете использовать __NO_VERSION__, например в случае, когда вам необходимо включить <linux/module.h> в несколько файлов источников, которые, впоследствии, будут слинкованы в один модуль. Объявление __NO_VERSION__ перед включением заголовочного файла module.h предотвращает
автоматическое описание строки __module_kernel_version или ее эквивалента в файлах источниках. Возможно, вам это понадобиться для удовлетворения жалобам линковщика при ld -r,
которому не понравится множественное описание символов в таблицах
линковки. Обычно, если код модуля разделен на несколько файлов
источников, включающих заголовочный файл <linux/module.h>, то объявление __NO_VERSION__ делается во всех этих файлах кроме одного. В конце книги приведен пример модуля, использующего __NO_VERSION__.
Большинство зависимостей связанных с версией ядра, может быть
обработано с помощью логики, построенной на директивах препроцессора, с
использованием макроопределений KERNEL_VERSION и LINUX_VERSION_CODE. Однако проверка зависимостей версий может сильно усложнить читаемость кода модуля за счет разношерстных директив #ifdef.
Поэтому, наверное лучшим решением является помещение проверки
зависимостей в отдельный заголовочный файл. Вот почему наш пример
включает заголовочный файл sysdep.h, используемый для размещения в нем всех макроопределений, связанных с проверками зависимостей версий.
Первая зависимость версий, которую мы хотим представить находится в объявлении цели "make install"
сценария компиляции нашего драйвера. Как вы могли ожидать,
инсталляционный каталог, который меняется согласно используемой версии
ядра, выбирается на основе просмотра файла version.h. Приведем фрагмент
кода из файла Rules.make, который используется всеми Makefile ядра.
VERSIONFILE = $(INCLUDEDIR)/linux/version.h
VREION = $(shell awk -F\" '/REL/ {print $$2}' $(VERSIONFILE))
INSTALLDIR = /lib/modules/$(VERSION)/misc
Обратите внимание, что для инсталляции всех наших драйверов мы
используем каталог misc (объявление INSTALLDIR в вышеприведенном
примере Makefile). Начиная с версии ядра 2.4 этот каталог является
рекомендованным для размещения пользовательских драйверов. Кроме того,
и старые и новые версии пакета modutils содержат каталог misc в своих
путях поиска.
Используя данное выше определение INSTALLDIR, цель install в Makefile может выглядеть следующим образом:
install:
install -d $(INSTALLDIR)
install -c $(OBJS) $(INSTALLDIR)
Зависимость от платформы
Каждая компьютерная платформа имеет свои особенности, которые должны
быть учтены разработчиками ядра для достижения наивысшей
производительности.
Разработчики ядра имеют гораздо больше свободы в выборе и принятии
решений неж/PCLASS="western"и разработчики приложений. Именно такая
свобода позволяет оптимизировать код, выжимая максимум из каждой
конкретной платформы.
Код модуля должен быть скомпилирован с использованием тех же самых
опций компилятора, которые были использованы при компиляции ядра. Это
относится и к использованию одинаковых схем использования регистров
процессора, и к выполнению одного и того же уровня оптимизации. Файл Rules.make,
расположенный в корне дерева источников ядра, включает
платформенно-зависимые определения, которые должны быть включены во все
Makefile компиляции. Все платформенно-зависимые сценарии компиляции
называются Makefile. platform и содержат значения переменных для утилиты make согласно текущей конфигурации ядра.
Другой интересной особенностью Makefile является поддержка
кросс-платформенной или просто кросс компиляции. Этот термин
используется при необходимости компиляции кода для другой платформы.
Например, используя платформу i86 вы собираетесь создать код для
платформы M68000. Если вы собираетесь использовать кросс компиляцию, то
вам потребуется заменить ваши инструменты компиляции (gcc, ld, и пр.) другим набором соответствующих инструментов
(например, m68k-linux-gcc, m68k-linux-ld).
Используемый префикс можно определить либо переменной $(CROSS_COMPILE)
Makefile, либо параметром командной строки для утилиты make, либо
переменной окружения системы.
Архитектура SPARC представляет собой особый случай, который должен
быть обработан соответствующим образом в Makefile. Пользовательские
программы запускаемые на SPARC64 (SPARC V9) платформе представляют
собой бинарники, как правило, предназначенные для платформы SPARC32
(SPARC V8). Поэтому, компилятор используемый по умолчанию на платформе
SPARC64 (gcc) генерирует объектный код для SPARC32. С другой стороны,
ядро предназначенное для работы на SPARC V9 должно содержать объектный
код для SPARC V9, поэтому, даже в этом случае, требуется кросс
компилятор. Все GNU/Linux дистрибутивы предназначенные для SPARC64
включают в себя соответствующий кросс компилятор, который необходимо
выбрать в Makefile сценарии компиляции ядра.
И хотя полный список зависимостей от версий и платформ немного более
сложен, чем описанный здесь, но этого вполне достаточно для выполнения
кросс компиляции. Для получения дополнительной информации вы можете
посмотреть Makefile сценарии компиляции и файлы источники ядра.
Особенности ядра 2.6
Время не стоит на месте. И сейчас мы являемся свидетелями появления
нового поколения ядра 2.6. К сожалению, в оригинале данной книги не
рассматривается новое ядро, поэтому переводчик возьмет на себя смелость
дополнить перевод новыми знаниями.
Вы можете пользоваться интегрированными средами разработки, такими
как TimeSys' TimeStorm, которые правильно сформируют скелет и сценарий
компиляции для вашего модуля в зависимости от требуемой версии ядра.
Если же вы собираетесь писать все это самостоятельно, то вам
понадобится некоторая дополнительная информация об основных отличиях,
привнесенных новым ядром.
Одна из особенностей ядра 2.6 заключается в необходимости
использования макросов module_init() и module_exit() для явной
регистрации имен функций инициализации и завершения.
Макроопределение MODULE_LISENCE(), введенное в ядре 2.4 по прежнему
необходимо, если вы не хотите наблюдать соответствующих предупреждений
при загрузке модуля. Вы можете выбрать следующие, обозначающие лицензии
строки, для передачи в макро: “GPL”, "GPL v2", "GPL and additional
rights", "Dual BSD/GPL" (выбор между BSD или GPL лицензиями), "Dual
MPL/GPL" (выбор между Mozilla или GPL лицензиями) и
"Proprietary".
Более существенным для нового ядра является новая схема компиляции
модулей, что влечет за собой не только изменения в коде самого модуля
но и в Makefile сценарии его компиляции.
Так, определение макросимвола MODULE теперь не требуется ни в коде
модуля ни в Makefile. При необходимости, новая схема компиляции сама
определит данный макросимвол. Также, вам не понадобится явное
определение макросимволов __KERNEL__, или более новых, таких как
KBUILD_BASENAME и KBUILD_MODNAME.
Также, вы не должны определять уровень оптимизации при компиляции
(-O2 или другие), т.к. ваш модуль будет скомпилирован со всем тем
набором флагов, в том числе и флаги оптимизации, с которыми
компилируются все другие модули вашего ядра – утилита make
автоматически использует весь необходимый набор флагов.
По этим причинам, Makefile для компиляции модуля для ядра 2.6 много
проще. Так для модуля hello.c Makefile будет выглядить следующим
образом:
obj-m := hello.o
Однако, для того, чтобы скомпилировать модуль, вам понадобится
доступ по записи к дереву источников ядра, где будут созданы временные
файлы и каталоги. Поэтому команда компиляции модуля к ядру 2.6,
задаваемая из текущего каталога, содержащего код источника модуля,
должна выглядеть следующим образом:
# make -C /usr/src/linux-2.6.1 SUBDIRS=`pwd` modules
Итак, имеем источник модуля hello-2.6.c, для компиляции в ядре 2.6:
//hello-2.6.c
#include <linux/module.h>
#include <linux/config.h>
#include <linux/init.h>
MODULE_LICENSE("GPL");
static int __init my_init(void)
{
printk("Hello world\n");
return 0;
};
static void __exit my_cleanup(void)
{
printk("Good bye\n");
};
module_init(my_init);
module_exit(my_cleanup);
Соответственно, имеем Makefile:
obj-m := hello-2.6.o
Вызываем утилиту make для обработки нашего Makefile со следующими параметрами:
# make -C/usr/src/linux-2.6.3 SUBDIRS=`pwd` modules
Нормальный процесс компиляции пройдет со следующим стандартным выводом:
make: Вход в каталог `/usr/src/linux-2.6.3'
*** Warning: Overriding SUBDIRS on the command line can cause
*** inconsistencies
make[1]: `arch/i386/kernel/asm-offsets.s' не требует обновления.
CHK include/asm-i386/asm_offsets.h
CC [M] /home/knz/j.kernel/3/hello-2.6.o
Building modules, stage 2.
/usr/src/linux-2.6.3/scripts/Makefile.modpost:17:
*** Uh-oh, you have stale module entries. You messed with SUBDIRS,
/usr/src/linux-2.6.3/scripts/Makefile.modpost:18:
do not complain if something goes wrong.
MODPOST
CC /home/knz/j.kernel/3/hello-2.6.mod.o
LD [M] /home/knz/j.kernel/3/hello-2.6.ko
make: Выход из каталог `/usr/src/linux-2.6.3'
Конечным результатом компиляции будет файл модуля hello-2.6.ko который можно устанавливать в ядро.
Обратите внимание, что в ядре 2.6 файлы модулей имеют суффикс .ko, а не .o как в ядре 2.4.
Таблица символов ядра
Мы уже говорили о том как утилита insmod использует таблицу
public-символов ядра при линковке модуля с ядром. Эта таблица содержит
адреса глобальных объектов ядра – функций и переменных – которые
требуются для реализации модульных вариантов драйвера. Таблица
public-символов ядра может быть прочитана в текстовой форме из файла
/proc/ksyms, при условии, что ваше ядро поддерживает файловую систему
/proc.
В ядре 2.6 файл /proc/ksyms переименован в /proc/modules.
При загрузке модуля, символы экспортируемые модулем становятся
частью таблицы символов ядра, и вы сможете просмотреть из в
/proc/ksyms.
Новые модули могут использовать символы экспортируемые вашим
модулем. Так, например, модуль msdos полагается на символы
экспортируемые модулем fat, а каждое устройство USB используемое в
режиме чтения использует символы модулей usbcore и input. Такая
взаимосвязь реализуемая последовательной загрузкой модулей называется
стеком модулей.
Стек модулей удобно использовать при создании сложных проектов
модулей. Такая абстракция удобна для разделения кода драйвера
устройства на аппаратно-зависимую и аппаратно-независимую части.
Например, набор драйверов video-for-linux состоит из основного модуля,
который экспортирует символы для низкоуровневого драйвера, учитывающего
специфику используемого оборудования. Согласно вашей конфигурации, вы
загружаете основной видео-модуль и модуль специфический для вашей
аппаратной части. Таким же образом реализуется поддержка параллельных
портов и широкого класса подключаемых устройств, таких как устройств
USB. Стек системы параллельного порта показан на рис. 2-2. Стрелками
показано взаимодействие между модулями и программным интерфейсом ядра.
Взаимодействие может осуществляться как на уровне функций, так и на
уровне структур данных, управляемых функциями.
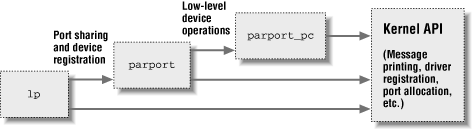
Рис 2-2. Стек модулей параллельного порта
При использовании стековых модулей удобно пользоваться утилитой
modprobe. Функциональность утилиты modprobe во многом похожа на утилиту
insmod, но при загрузке модуля проверяет его нижележащие зависимости,
и, при необходимости, подгружает необходимые модули до требуемого
заполнения стека модулей. Таким образом, одна команда modprobe может
приводить к нескольким вызовам команды insmod. Можно сказать, что
команда modprobe является интеллектуальной оболочкой над insmod. Вы
можете использовать modprobe вместо insmod везде, за исключением
случаев загрузки собственных модулей из текущего каталога, т.к.
modprobe просматривает только специальные каталоги размещения модулей,
и не сможет удовлетворить возможные зависимости.
Разделение модулей на части помогает уменьшить время разработки за
счет упрощения постановки задачи. Это похоже на разделение между
механизмом реализации и политикой управления, которое обсуждено в главе
1 “Введение в драйвера устройств”.
Обычно модуль реализует свою функциональность не нуждаясь в
экспортировании символов вообще. Экспортирование символов вам
понадобится в том случае, если другие модули смогут извлечь из этого
пользу. Вам может понадобится включение специальной директивы для
предотвращения экспортирования не static символов, т.к. в большинстве
реализаций утилиты modutils все они экспортируются по умолчанию.
Заголовочные файлы ядра Linux предлагают удобный способ для
управления видимостью ваших символов предотвращая, таким образом,
загрязнение пространства имен таблицы символов ядра. Механизм описанный
в этой главе работает в ядрах начиная с версии 2.1.18. Ядро 2.0 имело
совершенно другой механизм управления
видимости символов, который будет описан в конце главы.
Если ваш модуль не должен экспортировать символы вообще, вы можете
явно разместить следующий макровызов в файле источнике модуля:
EXPORT_NO_SYMBOLS;
Этот макровызов, определеный в файле linux/module.h расширяется в
директиву ассемблера и может быть указан в любой точке модуля. Однако,
при создании кода портируемого на разные ядра необходимо размещать этот
макровызов в инициализационной функции модуля (init_module), потому что
версия этого макроопределения определенная нами в нашем файле sysdep.h
для старых версий ядра будет работать только здесь.
С другой стороны, если вам необходимо экспортировать некую часть
символов из вашего модуля, то необходимо использовать макросимвол EXPORT_SYMTAB. Этот макросимвол должен быть определен перед включением заголовочного файла module.h. Общепринятой практикой является
определение этого макросимвола через флаг -D в Makefile.
Если макросимвол EXPORT_SYMTAB определен, то индивидуальные символы можно экспортировать с помощью пары макросов:
EXPORT_SYMBOL (name);
EXPORT_SYMBOL_NOVERS (name);
Любой из этих двух макросов сделает данный символ доступным за пределами модуля. Отличие заключаемся в том, что макрос EXPORT_SYMBOL_NOVERS
экспортирует символ без информации о версии (см. главу 11 “kmod and
Advanced Modularization”). Для получения более подробной информации
ознакомьтесь с заголовочным файлом <linux/module.h>, хотя
изложенного вполне достаточно для практического использования
макросов.
Инициализация и завершение модулей
Как уже упоминалось, функция init_module() регистрирует
функциональные компоненты модуля в ядре. После такой регистрации, для
использующего модуль приложения, будут доступны точки входа в модуль
через интерфейс, предоставляемый ядром.
Модули могут зарегистрировать множество различных компонентов в роли
которых, при регистрации, выступают имена функций модуля. В ядровую
функцию регистрации передается указатель на структуру данных,
содержащую указатели на функции реализующие предлагаемую
функциональность.
В главе 1 “Введение в драйвера устройств” была упомянута
классификация основных типов устройств. Вы можете зарегистрировать не
только упомянутые там типы устройств, но и любые другие, вплоть до
программных абстракций, таких как, например, файлы файловой системы
/proc и пр. Все, что может работать в ядре через программный интерфейс
драйвера может быть зарегистрировано как драйвер.
Если вы хотите узнать больше о типах регистрируемых драйверов на
примере вашего ядра, вы можете реализовать поиск подстроки
EXPORT_SYMBOL в источниках ядра и найти точки входа, предлагаемые
различными драйверами. Как правило функции регистрации используют в
своем имени префикс register_,
поэтому другой возможный путь их поиска – поиск подстроки register_ в файле /proc/ksyms с помощью утилиты grep. Как уже говорилось, в ядре 2.6.x файл /proc/ksyms заменен на /proc/modules.
Обработка ошибок в init_module
Если при инициализации модуля возникает какого-либо рода ошибка, то вы
должны отменить уже совершенную инициализацию перед остановом загрузки
модуля. Ошибка может возникнуть, например, из-за недостатка памяти в
системе при распределении структур данных. К сожалению, такое может
случиться, и хороший программный код должен уметь обрабатывать такие
ситуации.
Все, что было зарегистрировано или распределено до возникновения
ошибки в инициализационной функции init_module() необходимо отменить
или освободить самостоятельно, потому что ядро Linux не отслеживает
ошибки инициализации и не отменяет, уже выполненный кодом модуля, заем
и предоставление ресурсов. Если вы не откатили, или не смогли откатить
выполненную регистрацию, то ядро останется в нестабильном состоянии, и
при повторной загрузке модуля
вы не сможете повторить регистрацию уже зарегистрированных элементов, и
не сможете отменить ранее сделанную регистрацию, т.к. в новом
экземпляре функции init_module() вы не будете иметь правильного
значения адресов зарегистрированных функций. Для восстановления
прежнего состояния системы потребуется использование разных сложных
трюков, и чаще это делается простой перезагрузкой системы.
Реализация восстановления прежнего состояния системы при
возникновении ошибок инициализации модуля лучшим образом реализуется
использованием оператора goto. Обычно к этому оператору относятся
крайне отрицательно, и, даже, с ненавистью, но именно в этой ситуации
он оказывается очень полезным. Поэтому, в ядре, оператор goto часто
используется для обработки ошибок инициализации модуля.
Следующий простой код, на примере фиктивных функций регистрации и ее отмены, демонстрирует такой способ обработки ошибок.
int init_module(void)
{
int err;
/* registration takes a pointer and a name */
err = register_this(ptr1, "skull");
if (err) goto fail_this;
err = register_that(ptr2, "skull");
if (err) goto fail_that;
err = register_those(ptr3, "skull");
if (err) goto fail_those;
return 0; /* success */
fail_those: unregister_that(ptr2, "skull");
fail_that: unregister_this(ptr1, "skull");
fail_this: return err; /* propagate the error */
}
В этом примере производится попытка регистрации трех компонентов
модуля. Оператор goto используется при возникновении ошибки регистрации
и приводит к отмене регистрации зарегистрированных компонентов перед
остановом загрузки модуля.
Другим примером использования оператора goto не усложняющего чтение
кода является трюк с “запоминанием” успешно выполненных регистрационных
операций модуля и вызов cleanup_module() с передачей этой информации
при возникновении ошибки. Функция cleanup_module() предназначена для
отката выполненных инициализационных операций и автоматически
вызывается при выгрузке модуля. Значение которое возвращает функция
init_module() должна
представлять собой код ошибки инициализации модуля. В ядре Linux, код
ошибки представляет собой отрицательное число из множества определений
сделанных в заголовочном файле <linux/errno.h>.
Включите этот заголовочный файл в свой модуль для того, чтобы
использовать символическую мнемонику зарезервированных кодов ошибок,
таких как -ENODEV, -ENOMEM и т.п. Использование такой мнемоники
считается хорошим стилем программирования. Однако нужно заметить, что
некоторые версии утилит из пакета modutils неправильно обрабатывают
возвращаемые коды ошибок и выдают сообщение “Device busy”
в ответ на целую группу ошибок совершенно разного характера,
возвращаемых функцией init_modules(). В последних версиях пакета эта
досадная ошибка была исправлена.
Код функции cleanup_module() для приведенного выше случая может быть, например, таким:
void cleanup_module(void)
{
unregister_those(ptr3, "skull");
unregister_that(ptr2, "skull");
unregister_this(ptr1, "skull");
return;
}
Если ваш код инициализации и завершения более сложен, чем описанный
здесь, то использование оператора goto может привести к трудно
читаемому тексту программы, потому что код завершения должен быть
повторен в функции init_module() с использованием множества меток для
goto переходов. По этой причине используют более хитрый прием
использования вызова функции cleanup_module() в функции init_module() с
передачей информации об объеме успешной инициализации при возникновении
ошибки загрузки модуля.
Ниже приведен пример такого написания функций init_module() и
cleanup_module(). В этом примере используются глобально определенные
указатели, несущие информацию об объеме успешной инициализации.
struct something *item1;
struct somethingelse *item2;
int stuff_ok;
void cleanup_module(void)
{
if (item1)
release_thing(item1);
if (item2)
release_thing2(item2);
if (stuff_ok)
unregister_stuff();
return;
}
int init_module(void)
{
int err = -ENOMEM;
item1 = allocate_thing(arguments);
item2 = allocate_thing2(arguments2);
if (!item2 || !item2)
goto fail;
err = register_stuff(item1, item2);
if (!err)
stuff_ok = 1;
else
goto fail;
return 0; /* success */
fail:
cleanup_module();
return err;
}
В зависимости от сложности инициализационных операций вашего модуля
вы можете использовать один из приведенных здесь способов контроля
ошибок инициализации модуля.
Счетчик использования модуля
Система содержит счетчик использования каждого модуля для того,
чтобы определить возможность безопасной выгрузки модуля. Системе нужна
эта информация, потому что модуль не может быть выгружен, если он кем
нибудь или чем нибудь занят – вы не можете удалить драйвер файловой
системы, если эта файловая система примонтирована, или вы не можете
выгрузить модуль символьного устройства, если какой-нибудь процесс
использует это устройство. В противном случае,
это может привести к краху системы – segmentation fault или kernel
panic.
В современных ядрах, система может предоставить вам автоматический
счетчик использования модуля используя механизм, который мы рассмотрим
в следующей главе. Независимо от версии ядра вы можете использовать
ручное управление данным счетчиком. Так, код, который предполагается
использовать в старых версиях ядра должен использовать модель учета
используемости модуля построенную на следующих трех макросах:
- MOD_INC_USE_COUNT
- Увеличивает счетчик использования текущего модуля
- MOD_DEC_USE_COUNT
- Уменьшает счетчик использования текущего модуля
- MOD_IN_USE
-
- Возвращает истину если счетчик использования данного модуля равен нулю
Эти макросы определены в <linux/module.h>, и они
манипулируют специальной внутренней структурой данных прямой доступ к
которой нежелателен. Дело в том, что внутренняя структура и способ
управления этими данными могут меняться от версии к версии, в то время
как внешний интерфейс использования этих макросов остается неизменным.
Заметьте, что вам не требуется проверять MOD_IN_USE в коде
функции cleanup_module(), потому, что эта проверка выполняется
автоматически до вызова cleanup_module() в системном вызове
sys_delete_module(), который определен в kernel/module.c.
Корректное управление счетчиком использования модуля критично для
стабильности системы. Помните, что ядро может решить выгрузить
неиспользуемый модуль автоматически в любое время. Частая ошибка в
программировании модулей заключается в неправильном управлении этим
счетчиком. Например, в ответ на некий запрос, код модуля выполняет
некоторые действия и при завершении обработки увеличивает счетчик
использования модуля. Т.е. такой программист предполагает, что данный
счетчик предназначен для сбора статистики использования модуля, в то
время как, на самом деле, он является, фактически, счетчиком текущей
занятости модуля, т.е. ведет счет количества процессов использующих код
модуля в данный момент. Таким образом, при обработке запроса к модулю,
вы должны вызывать MOD_INC_USE_COUNT перед выполнением каких либо действий, и MOD_DEC_USE_COUNT после их выполнения.
Возможны ситуации, в которых, по понятным причинам, вы не сможете
выгрузить модуль если потеряете управление счетчиком его использования.
Такая ситуация часто встречается на этапе разработки модуля. Например,
процесс может прерваться при попытке разыменования NULL указателя, и вы
не сможете выгрузить такой модуль, пока не вернете счетчик его
использования к нулю. Одно из возможных решений такой проблемы на этапе
отладки модуля заключается в полном отказе от управления счетчиком
использования модуля путем переопределения MOD_INC_USE_COUNT и MOD_DEC_USE_COUNT
в пустой код. Другое решение заключается в создании ioctl() вызова
принудительно сбрасывающего счетчик использования модуля в ноль. Мы
рассмотрим это в разделе “Using the ioctl Argument” в главе 5 “Enhanced
Char Driver Operations”. Конечно, в готовом для использования драйвере
подобные обманные манипуляции со счетчиком должны быть исключены,
однако, на этапе отладки, они позволяют сэкономить время разработчика и
вполне допустимы.
Текущее значение системного счетчика использования каждого модуля вы
найдете в третьем поле каждой записи файла /proc/modules. Этот файл
содержит информацию о загруженных в данный момент модулях – по одной
строке на каждый модуль. Первое поле строки содержит название модуля,
второе поле – размер занимаемый модулем в памяти, и третье поле –
текущее значение счетчика использования. Эту информацию, в
отформатированном виде,
можно получить вызовом утилиты lsmod. Ниже приведен пример файла
/proc/modules:
parport_pc 7604 1 (autoclean)
lp 4800 0 (unused)
parport 8084 1 [parport_probe parport_pc lp]
lockd 33256 1 (autoclean)
sunrpc 56612 1 (autoclean) [lockd]
ds 6252 1
i82365 22304 1
pcmcia_core 41280 0 [ds i82365]
Здесь мы видим несколько модулей, загруженных в систему. В поле
флагов (последнее поле строки), в квадратных скобках отображен стек
зависимости модулей. Среди прочего можно заметить, что модули
параллельного порта взаимодействуют через стек модулей, как показано на
рис. 2-2. Флагом (autoclean) помечены модули управляемые kmod или
kerneld. Об этом будет рассказано в главе 11 “kmod and Advanced
Modularization”). Флаг (unused) означает, что модуль не используется в
данный момент. В ядре 2.0 поле размера отображала информацию не в
байтах, а в страницах, размер которой для большинства платформ
составляет 4кБт.
Выгрузка модуля
Дpя выгрузки модуля используйте утилиту rmmod. Выгрузка модуля более
простая задача нежели его загрузка, при которой выполняется его
динамическая линковка с ядром. При выгрузке модуля выполняется
системный вызов delete_module(), который либо выполняет вызов функции
cleanup_module() выгружаемого модуля в случае, если его счетчик
использования равен нулю, либо прекращает работу с ошибкой.
Как уже говорилось, в функции cleanup_module() выполняется откат
инициализационных операций выполненных при загрузке модуля функцией
cleanup_module(). Также, выполняется автоматическое удаление
экспортируемых символов модуля.
Явное определение функций завершения и инициализации
Как уже говорилось, при загрузке модуля ядро вызывает функцию
init_module(), а при выгрузке – cleanup_module(). Однако, в современных
версиях ядра эти функции часто имеют другие имена. Начиная с ядра
2.3.23 появилась возможность явного определения имени для функции
загрузки и выгрузки модуля. Сейчас, такое явное определения имен для
этих функций является рекомендумым стилем программирования.
Приведем пример. Если вы хотите объявить инициализационной функцией
вашего модуля функцию my_init(), а завершающей – функцию my_cleanup(),
вместо init_module() и cleanup_module() соответственно, то вам
необходимо будет добавить следующие два макроса с тексту модуля (обычно
их вставляют в конец
файла источника кода модуля):
module_init(my_init);
module_exit(my_cleanup);
Заметьте, что для использования этих макроопределений вы должны будете включить в ваш модуль заголовочный файл <linux/init.h>.
Удобство использования такого стиля заключается в том, что каждая
функция инициализации и завершения модулей в ядре может иметь свое
уникальное имя, что значительно помогает в отладке. Причем,
использование этих функций упрощают отладку независимо от того,
реализуете ли вы код вашего драйвера в виде модуля, или же собираетесь
встраивать его прямо в ядро. Конечно же, использование макроопределений
module_init и module_exit не требуется, если ваши функции инициализации
и завершения имеют зарезервированные имена, т.е. init_module() и
cleanup_module() соответствено.
Если вы познакомитесь с источниками ядра версий 2.2 или более
поздних, вы можете увидеть слегка отличную форму описания для функция
инициализации и завершения. Например:
static int __init my_init(void)
{
....
}
static void __exit my_cleanup(void)
{
....
}
Использование атрибута __init приведет к тому, что после
завершения инициализации, инициализационная функция будут выгружена из
памяти. Однако это работает только для встроенных в ядро драйверов, и
будет проигнорировано для модулей. Также, для драйверов встроенных в
ядро, атрибут __exit приведет к игнорированию целой функции, помеченной этим атрибутом. Для модулей этот флаг, также будет проигнорирован.
Использование атрибутов __init (и __initdata для описания данных) может уменьшить количество памяти используемой ядром. Пометка флагом __init
инициализационной функции модуля не принесет ни выгоды ни вреда.
Управление таким способом инициализации еще не реализовано для модулей,
хотя, возможно, это будет сделано в будущем.
Подведение итогов
Итак, в результате представленного материала мы можем представить следующий вариант “Hello world” модуля:
Код файла источника модуля
==============================================
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init my_init_module (void)
{
EXPORT_NO_SYMBOLS;
printk("<1>Hello world\n");
return 0;
};
static void __exit my_cleanup_module (void)
{
printk("<1>Good bye\n");
};
module_init(my_init_module);
module_exit(my_cleanup_module);
MODULE_LICENSE("GPL");
=============================================
Makefile для компиляции модуля
=============================================
CFLAGS = -Wall -D__KERNEL__ -DMODULE -I/lib/modules/$(shell uname -r)/build/include
hello.o:
=============================================
Обратите внимание, что при написании Makefile мы использовали
соглашение о способности утилиты GNU make самостоятельно определить
способ формирования объектного файла на основе переменной CFLAGS и
имеющегося в системе компилятора.
Использование ресурсов
Модуль не может выполнить свою задачу без использования системных
ресурсов, таких как память, порты ввода/вывода, память ввода/вывода,
линии прерывания, а также, каналы DMA.
Как программист, вы уже должны быть знакомы с управлением
динамической памятью. Управление динамической памятью в ядре не имеет
принципиальных отличий. Ваша программа может получить память используя
функцию kmalloc() и освободить ее, с помощью kfree().
Эти функции очень похожи на знакомые вам malloc() и free(), за тем
исключением, что в функцию kmalloc() передается дополнительный аргумент
– приоритет. Обычно приоритет принимает значения GFP_KERNEL или
GFP_USER. GFP представляет собой акроним от “get free page” - взять
свободную страницу. Управление динамической памятью в ядре подробно
излагается в главе 7 “Getting Hold of Memory”.
Начинающий разработчик драйверов может быть удивлен необходимостью
явного распределения портов ввода/вывода, памяти ввода/вывода и линий
прерываний. Только после этого, модуль ядра может получить простой
доступ к этим ресурсам. И хотя системная память может быть распределена
откуда угодно, память ввода/вывода, порты и линии прерывания играют
особую роль и распределяются иначе. Для примера, драйверу необходимо
распределить определенные порты, не
все, а те, которые ему нужны для управления устройством. Но драйвер не
может использовать эти ресурсы до тех пор, пока не убедится, что они не
используются кем-то еще.
Область
памяти принадлежащая периферийному устройству обычно называется памятью
ввода/вывода, для того чтобы отличать ее от системного ОЗУ (RAM),
называемую просто памятью.
Порты и память ввода/вывода
Работа обычного драйвера по большей части состоит из чтения и записи
портов и памяти ввода/вывода. Порты и память ввода/вывода объединены
общим названием – регион (или область) ввода/вывода.
К несчастью, не на каждой шинной архитектуре можно ясно определить
регион ввода/вывода принадлежащий каждому устройству, и возможно, что
драйверу придется предполагать размещение принадлежащего ему региона,
или, даже, пробовать операции чтения/записи возможных адресных
пространств. Эта проблема особенно
относится к шине ISA, которая еще до сих пор используется для установки
простых устройств в персональный компьютер и очень популярна в
индустриальном мире в реализации PC/104 (см. раздел “PC/104 и PC/104+”
главы 15 “Обзор периферийных шин”).
Какая бы не использовалась шина для подключения аппаратного
устройства, драйверу устройства должен быть гарантирован эксклюзивный
доступ к своему региону ввода/вывода для предотвращения коллизий между
драйверами. Если модуль, обращаясь к своему устройству произведет
запись в устройство ему не принадлежащее, то это может повлечь за собой
роковые последствия.
Разработчики Linux реализовали механизм запроса/высвобождения
регионов ввода/вывода главным образом для предотвращения коллизий между
различными устройствами. Этот механизм давно используется для портов
ввода/вывода и был недавно обобщен на механизм управления ресурсами
вообще. Заметьте, что этот механизм представляет программную абстракцию
и не распространяется на аппаратные возможности. Например,
неавторизованный доступ к портам ввода/вывода на уровне аппаратуры не
вызывает какую-либо ошибку аналогичную “segmentation fault”, так как
аппаратура не занимается выделением и авторизацией своих ресурсов.
Информация о зарегистрированных ресурсах доступна в текстовой форме
в файлах /proc/ioports и /proc/iomem. Эта информация представлена в
Linux начиная с ядра 2.3. Напомним, что данная книга посвящена
преимущественно ядру 2.4, и замечания о совместимости будут
представлены в конце главы.
Порты
Ниже представлено типичное содержимое файла /proc/ioports:
0000-001f : dma1
0020-003f : pic1
0040-005f : timer
0060-006f : keyboard
0080-008f : dma page reg
00a0-00bf : pic2
00c0-00df : dma2
00f0-00ff : fpu
0170-0177 : ide1
01f0-01f7 : ide0
02f8-02ff : serial(set)
0300-031f : NE2000
0376-0376 : ide1
03c0-03df : vga+
03f6-03f6 : ide0
03f8-03ff : serial(set)
1000-103f : Intel Corporation 82371AB PIIX4 ACPI
1000-1003 : acpi
1004-1005 : acpi
1008-100b : acpi
100c-100f : acpi
1100-110f : Intel Corporation 82371AB PIIX4 IDE
1300-131f : pcnet_cs
1400-141f : Intel Corporation 82371AB PIIX4 ACPI
1800-18ff : PCI CardBus #02
1c00-1cff : PCI CardBus #04
5800-581f : Intel Corporation 82371AB PIIX4 USB
d000-dfff : PCI Bus #01
d000-d0ff : ATI Technologies Inc 3D Rage LT Pro AGP-133
Каждая строка данного файла отображает в шестнадцатеричном виде
диапазон портов связанных с драйвером или владельцем устройства. В
ранних версиях ядра, файл имеет тот же самый формат, кроме того, что не
отображалась иерархия портов.
Файл может быть использован для избегания коллизий портов при
добавлении в систему нового устройства. Особенно это удобно при ручной
настройке устанавливаемого оборудования путем переключения перемычек
(jampers - джамперов). В этом случае пользователь может легко
посмотреть список используемых портов и выбрать свободный диапазон для
устанавливаемого устройства. И хотя большинство современных устройств
не используют перемычек ручной настройки вообще, тем не менее, они еще
используются при изготовлении мелкосерийных компонентов.
Что еще более важно, так это то, что с файлом /proc/ioports связана
структура данных, доступная программным путем. Поэтому, когда драйвер
устройства производит инициализацию он может узнать занятый диапазон
портов ввода/вывода. Значит, при необходимости просканировать порты в
поисках нового устройства, драйвер в состоянии избежать ситуации записи
в порты, занятые чужими устройствами.
Известно, что сканирование шины ISA является рискованной задачей.
Поэтому некоторые драйвера, распространяемые с официальным Linux ядром,
избегают такого сканирования при загрузке модуля. Тем самым, они
избегают риска повреждения запущенной системы за счет записи в порты,
используемые другим оборудованием. К счастью, современные архитектуры
шин невосприимчивы к этим проблемам.
Программный интерфейс используемый для доступа к регистрам ввода/вывода состоит из следующих трех функций:
int check_region(unsigned long start, unsigned long len);
struct resource *request_region(unsigned long start,
unsigned long len, char *name);
void release_region(unsigned long start, unsigned long len);
Функция check_region() может быть вызвана для проверки
занятости заданного диапазона портов. Она возвращает отрицательный код
ошибки (такой как -EBUSY или -EINVAL) при отрицательном ответе.
Функция request_region() выполняет распределение
заданного диапазона адресов возвращая, в случае успеха, ненулевой
указатель. Драйверу нет нужды сохранять или использовать возвращенный
указатель. Все, что необходимо сделать, это произвести его проверку на
NULL. Код который должен работать только с ядром 2.4 (или выше) вообще
не нуждается в вызове функции check_region(). Не подлежит сомнению
преимущество такого способа распределения, т.к.
неизвестно, что может произойти между вызовами функций check_region() и
request_region(). Если же вы хотите сохранить совместимость со старыми
версиями ядра, то вызов check_region() перед request_region()
необходим.
Функция release_region() должна быть вызвана при освобождении драйвером ранее используемых портов.
Действительное
значение указателя возвращаемого функцией request_region() используется
только подсистемой выделения ресурсов, работающей в ядре.
Эти три функции, в действительности, являются макросами определенными в <linux/ioport.h>.
Ниже приведен пример использования последовательности вызовов,
применяемой для регистрации портов. Пример взят из кода учебного
драйвера skull. (Здесь не показан код функции skull_probe_hw(), т.к.
она содержит аппаратно-зависимый код.)
#include <linux/ioport.h>
#include <linux/errno.h>
static int skull_detect(unsigned int port, unsigned int range)
{
int err;
if ((err = check_region(port,range)) < 0) return err; /* busy */
if (skull_probe_hw(port,range) != 0) return -ENODEV; /* not found */
request_region(port,range,"skull"); /* "Can't fail" */
return 0;
}
В данном примере сначала проверяется доступность требуемого диапазона
портов. Если порты не доступны, то и не возможен доступ к аппаратуре.
Действительное расположение портов устройства может быть уточнено при
сканировании. Функция request_region() не должен, в данном примере,
окончится неудачей. Ядро не может загрузить более одного модуля
одновременно, поэтому коллизий использования портов возникнуть не
должно.
Любые порты ввода/вывода распределенные драйвером должны быть
впоследствии освобождены. Наш драйвер skull делает это в функции
cleanup_module():
static void skull_release(unsigned int port, unsigned int range)
{
release_region(port,range);
}
Механизм запроса/высвобождения ресурсов похож на механизм
регистрации/дерегистрации модулей и отлично реализуется на основе
описанной выше схеме использования оператора goto.
Память
Информация о памяти ввода/вывода доступна через файл /proc/iomem.
Ниже приведен типичный пример такого файла для персонального
компьютера:
00000000-0009fbff : System RAM
0009fc00-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000f0000-000fffff : System ROM
00100000-03feffff : System RAM
00100000-0022c557 : Kernel code
0022c558-0024455f : Kernel data
20000000-2fffffff : Intel Corporation 440BX/ZX - 82443BX/ZX Host bridge
68000000-68000fff : Texas Instruments PCI1225
68001000-68001fff : Texas Instruments PCI1225 (#2)
e0000000-e3ffffff : PCI Bus #01
e4000000-e7ffffff : PCI Bus #01
e4000000-e4ffffff : ATI Technologies Inc 3D Rage LT Pro AGP-133
e6000000-e6000fff : ATI Technologies Inc 3D Rage LT Pro AGP-133
fffc0000-ffffffff : reserved
Значения диапазонов адресов показаны в шестнадцатеричной записи. Для каждого диапазона аресов показан его владелец.
Регистрация доступа к памяти ввода/вывода похожа на регистрацию
портов ввода/вывода и построена в ядре на том же самом механизме.
Для получения и высвобождения необходимого диапазона адресов памяти ввода/вывода, драйвер должен использовать следующие вызовы:
int check_mem_region(unsigned long start, unsigned long len);
int request_mem_region(unsigned long start, unsigned long len,
char *name);
int release_mem_region(unsigned long start, unsigned long len);
Обычно, драйверу известен диапазон адресов памяти ввода/вывода,
поэтому код распределения данного ресурса может быть уменьшен, по
сравнению с примером для распределения диапазона портов:
if (check_mem_region(mem_addr, mem_size)) { printk("drivername:
memory already in use\n"); return -EBUSY; }
request_mem_region(mem_addr, mem_size, "drivername");
Распределение ресурсов в Linux 2.4
Текущий механизм распределения ресурсов был введен в ядре Linux
2.3.11 и обеспечивает гибкий доступ управления системными ресурсами. В
этом разделе кратко описан данный механизм. Однако, функции базового
распределения ресурсов (такие как request_region() и др.) еще пока
реализованы в виде макросов и используются для обратной совместимости с
ранними версиями ядра. В большинстве случаев не нужно ничего знать о
реальном механизме распределения, но это может быть интересно при
создании более сложных драйверов.
Система управления ресурсами реализованная в Linux может управлять
произвольными ресурсами в единой иерархической манере. Глобальные
ресурсы системы (например, порты ввода/вывода) могут быть подразделены
на подмножества – например относящиеся к какому-либо слоту аппаратной
шины. Определенные драйверы, также, при желании, могут подразделять
захватываемые ресурсы на основе своей логической структуры.
Диапазон выделяемых ресурсов описывается через структуру struct
resource, которая объявлена в заголовочном файле
<linux/ioport.h>:
struct resource {
const char *name;
unsigned long start, end;
unsigned long flags;
struct resource *parent, *sibling, *child;
};
Глобальный (корневой) диапазон ресурсов создается во время загрузки.
Например, структура ресурсов, описывающая порты ввода/вывода создается
следующим образом:
struct resource ioport_resource =
{ "PCI IO", 0x0000, IO_SPACE_LIMIT, IORESOURCE_IO };
Здесь описан ресурс с именем PCI IO, который покрывает диапазон
адресов от нуля до IO_SPACE_LIMIT. Значение данной переменной зависит
от используемой платформы и может быть равен 0xFFFF (16-ти битовое
адресное пространство, для архитектур x86, IA-64, Alpha, M68k и MIPS),
0xFFFFFFFF (32-х битное пространство, для SPARC, PPC, SH) или
0xFFFFFFFFFFFFFFFF (64-х битное, SPARC64).
Поддиапазоны этого ресурса могут быть созданы с помощью вызова
allocate_resource(). Например, во время инициализации PCI шины, для
региона адресов этой шины, создается новый ресурс, назначаемый
физическому устройству. Когда код ядра управляющий шиной PCI
обрабатывает назначения портов и памяти, он создает новый ресурс только
для этих регионов и распределяет их с помощью вызовов ioport_resource()
или iomem_resource().
Драйвер может затем запросить подмножество некого ресурса (обычно
часть глобального ресурса) и пометить его как занятый. Захват ресурса
осуществляется вызовом request_region(), возвращающим либо указатель на
новую структуру struct resource, которая описывает запрашиваемый
ресурс, либо NULL в случае ошибки. Эта структура является частью
глобального дерева ресурсов. Как уже говорилось, после получения
ресурса, драйверу не понадобится значение этого указателя.
Интересующийся читатель может получить удовольствие от просмотра
деталей этой схемы управления ресурсами в файле kernel/resource.c,
расположенному в каталоге источников ядра. Однако, большинству
разработчиков будет достаточно уже изложенных знаний.
Слойный механизм распределения ресурсов приносит двойную выгоду. С
одной стороны, он дает наглядное представление о структурах данных
ядра. Еще раз обратимся к примеру файла /proc/ioports:
e800-e8ff : Adaptec AHA-2940U2/W / 7890
e800-e8be : aic7xxx
Диапазон e800-e8ff распределен для адаптера Adaptec, который
обозначил себя как драйвер на шине PCI. Большую часть этого диапазона
запросил драйвер aic7xxx.
Другим преимуществом такого управления ресурсами является разделение
адресного пространства на поддиапазоны, которые отражают реальную
взаимосвязь оборудования. Менеджер ресурсов не может выделить
пересекающиеся поддиапазоны адресов, что может предотвратить установку
неверно работающего драйвера.
Автоматическое и ручное конфигурирование
Некоторые параметры, необходимые драйверу, могут изменяться от
системы к системе. Например, драйвер должен знать о действительных
адресах ввода/вывода и диапазонах памяти. Для хорошо организованных
шинных интерфейсов это не является проблемой. Однако, иногда, вам
потребуется передавать параметры драйверу, чтобы помочь ему найти
собственное устройство, или разрешить/запретить некоторые его функции.
Эти параметры, влияющие на работу драйвера, зависят от устройства.
Например, это может быть номер версии установленного устройства.
Конечно, такая информация необходима драйверу для правильной работы с
устройством. Определение таких параметров (конфигурирование драйвера)
представляет собой достаточно
хитрую задачу, выполняемую при инициализации драйвера.
Обычно, имеются два способа для получения корректных значений
данного параметра – либо пользователь определяет их явно, либо драйвер
определяет их самостоятельно, на основе опроса оборудования. И хотя
автоопределение устройства несомненно является лучшим решением для
конфигурирования драйвера,
пользовательское конфигурирование гораздо легче в реализации.
Разработчик драйвера должен реализовывать автоконфигурирование драйвера
везде, где это возможно, но, одновременно с этим, он должен
предоставить пользователю механизм ручного конфигурирования. Конечно,
ручное конфигурирование должно иметь более высокий приоритет по
сравнению с автоконфигурированием. На начальных стадиях разработки,
обычно, реализовывают только ручную передачу параметров в драйвер.
Автоконфигурирование, по возможности, добавляют позже.
Многие драйвера, среди своих конфигурационных параметров, имеют
параметры управляющие операциями драйвера. Например, драйвера IDE
интерфейса (Integrated Device Electronics) позволяют пользователю
управлять операциями DMA. Таким образом, если ваш драйвер хорошо
выполняет автоопределение оборудования, возможно, вы захотите
предоставить пользователю возможность управления функциональностью
драйвера.
Значения параметров могут быть переданы в процессе загрузки модуля
командами insmod или modprobe. В последнее время стало возможным читать
значение параметров из конфигурационного файла (обычно
/etc/modules.conf). В качестве параметров можно передавать целые и
строковые значения. Таким образом, если вам необходимо предать целое
значение параметра skull_ival и строковое значение параметра
skull_sval, вы можете передать их во время загрузки модуля
дополнительными параметрами команды insmod:
insmod skull skull_ival=666 skull_sval="the beast"
Однако, прежде чем команда insmod может изменить значения параметров
модуля, модуль должен сделать эти параметры доступными. Параметры
объявляются с помощью макроопределения MODULE_PARM, которое определено
в заголовочном файле module.h. Макро MODULE_PARM принимает два
параметра: имя переменной и строку, определяющую ее тип. Данное
макроопределение должно быть размещено за пределами каких-либо функций
и обычно располагается в начале файла после определения переменных.
Так, два упомянутых выше параметра, могут быть объявлены следующим
образом:
int skull_ival=0;
char *skull_sval;
MODULE_PARM (skull_ival, "i");
MODULE_PARM (skull_sval, "s");
На данный момент поддерживаются пять типов параметров модуля:
- b – однобайтовая величина;
- h – (short) двухбайтовая величина;
- i – целое;
- l – длинное целое;
- s – строка (char *);
В случае строковых параметров, в модуле должен быть объявлен
указатель (char *). Команда insmod распределяет память для передаваемой
строки и инициализирует ее требуемым значением. С помощью макро
MODULE_PARM можно инициализировать массивы параметров. В этом случае,
целое число, предшествующее литере типа определяет длину массива. При
указании двух целых чисел разделенных знаком тире, они определяют
минимальное и максимальное количество передаваемых значений. Для более
подробного понимания работы данного макроопределения обратитесь к
заголовочному файлу <linux/module.h>.
Например, пусть массив параметров должен быть инициализирован не
менее чем двумя, и не менее чем четырьмя целыми значениями. Тогда он
может быть описан следующим образом:
int skull_array[4];
MODULE_PARM (skull_array, "2-4i");
Кроме этого, в инструментарии программиста имеется макроопределение
MODULE_PARM_DESC, которое позволяет помещать комментарии к передаваемым
параметрам модуля. Эти комментарии сохраняются в объектном файле модуля
и могут быть просмотрены с помощью, например, утилиты objdump, или с
помощью автоматизированных инструментов администрирования системы.
Приведем пример использования данного макроопределения:
int base_port = 0x300;
MODULE_PARM (base_port, "i");
MODULE_PARM_DESC (base_port, "The base I/O port (default 0x300)");
Желательно, чтобы все параметры модуля имели значения по умолчанию.
Изменение этих значений с помощью insmod должно требоваться только в
случае необходимости. Модуль может проверить явное задание параметров
проверив их текущие значения со значениями по умолчанию. Впоследствии
вы можете реализовать механизм автоконфигурирования на основе следующей
схемы. Если значения параметров имеют значения по умолчанию, то
выполняется автоконфигурирование. В противном случае - используются
текущие значения. Для того, чтобы данная схема работала, необходимо,
чтобы значения по умолчанию не соответствовали никакой из возможных
реальных конфигураций системы. Тогда можно будет предположить, что
такие значения не могут быть установлены пользователем в ручном
конфигурировании.
Следующий пример показывает как драйвер skull производит
автоопределение адресного пространства портов устройства. В приведенном
примере, в автоопределении используется просмотр множества устройств, в
то время как при ручном конфигурировании драйвер ограничивается одним
устройством. С функцией skull_detect вы уже встречались ранее в разделе
описания портов ввода/вывода. Реализация функции skull_init_board() не
показана, так как она
проводит аппаратно-зависимую инициализацию.
/*
* port ranges: the device can reside between
* 0x280 and 0x300, in steps of 0x10. It uses 0x10 ports.
*/
#define SKULL_PORT_FLOOR 0x280
#define SKULL_PORT_CEIL 0x300
#define SKULL_PORT_RANGE 0x010
/*
* the following function performs autodetection, unless a specific
* value was assigned by insmod to "skull_port_base"
*/
static int skull_port_base=0; /* 0 forces autodetection */
MODULE_PARM (skull_port_base, "i");
MODULE_PARM_DESC (skull_port_base, "Base I/O port for skull");
static int skull_find_hw(void) /* returns the # of devices */
{
/* base is either the load-time value or the first trial */
int base = skull_port_base ? skull_port_base
: SKULL_PORT_FLOOR;
int result = 0;
/* loop one time if value assigned; try them all if autodetecting */
do {
if (skull_detect(base, SKULL_PORT_RANGE) == 0) {
skull_init_board(base);
result++;
}
base += SKULL_PORT_RANGE; /* prepare for next trial */
}
while (skull_port_base == 0 && base < SKULL_PORT_CEIL);
return result;
}
Если конфигурационные переменные используются только внутри драйвера
(т.е. не опубликованы в символьной таблице ядра), то программист может
немного упростить жизнь пользователю не используя префиксы в имени
переменных (в нашем случае префикс skull_). Для пользователя эти
префиксы означают немного, а их отсутствие упрощает набор команды с
клавиатуры.
Для полноты описания мы приведем описание еще трех макроопределений,
позволяющих размещать некоторые комментарии в объектном файле.
- MODULE_AUTHOR (name)
-
-
Размещает строку с именем автора в объектном файле.
- MODULE_DESCRIPTION(desc)
-
Размещает строку с общим описанием к модулю в объектном файле.
- MODULE_SUPPORTED_DEVICE(dev)
-
Размещает строку, с описанием поддерживаемого модулем устройства. В
комментариях к источнику ядра говорится, что данный параметр может
быть использован со временем в механизме автоматической загрузке
модулей, но пока такое использование данной информации не
реализовано.
Что можно сделать с устройством в пользовательском процессе
Написание модуля может отнять много времени и нервов у Unix
программиста не знакомому с работой ядра. Написание пользовательской
программы, которая читает и пишет прямо в порты устройства гораздо
проще.
Имеется несколько аргументов в пользу программирования таких задач в
пользовательском пространстве. Преимущества такого способа построения
драйверов можно обобщить в следующих тезисах:
-
Вы можете линковаться ко всему богатству библиотек языка Си.
-
Отлаживать программу в пользовательском процессе намного проще и нагляднее.
-
Вы можете легко убить пользовательскую программу, в то время как зависший драйвер, работающий в ядре,
вешает систему целиком.
-
Память пользовательских программ, в отличии от памяти ядра, может быть выгружена на диск (swap). Нечасто
работающее устройство управляемое из ядра и захватившая большой объем памяти может
реально затормозить работу системы целиком.
-
Хорошо разработанная программа-драйвер пользовательского уровня может разделять устройство с другими
программами.
Примером драйвера пользовательского пространства является X сервер.
Он знает возможности оборудования своей аппаратной графической
подсистемы и предоставляет виртуальные графические ресурсы всем X
клиентам. Такое построение графической подсистемы проигрывает в
быстродействии, но сейчас намечается устойчивая тенденция реализации X
сервера на frame-buffer. В этом случае X сервер действует на основе
работающего в ядре драйвера, выполняющего все графические манипуляции.
Обычно, драйвера работающие в пользовательском пространстве
реализуются как серверный процесс. Клиентское приложение может
соединиться с сервером для управления устройством. Хорошо написанный
драйвер-сервер может обеспечить конкурентный доступ к устройству.
Отличным примером этого, также, является X сервер.
Другим примером драйвера работающего в пользовательском процессе
является сервер gpm, который разделяет устройство мыши между различными
клиентами. Благодаря ему, различные приложения могут использовать мышь
в разных виртуальных консолях.
Иногда, драйверы работающие в пользовательском процессе
предоставляют эксклюзивный доступ к устройству одной программе. Так,
например, работает библиотека libsvga. С помощью этой библиотеки,
пользовательская программа переключает TTY в графический режим и
единолично использует его для вывода графики. Таким образом, приложение
обеспечивает свои графические нужды не разделяя графический ресурс с
другими программами, что значительно улучшает производительность
графического вывода, и требует привилегированного пользователя.
Однако, такое построение драйверов имеет свои недостатки. Приведем список наиболее важных из них:
-
В пользовательском пространстве недоступно управление прерываниями.
Единственным способом обхода этого ограничения на платформе x86,
является использование системного вызова vm86(), платой за который
является понижение производительности. В этой книге мы не будем
обсуждать эту возможность как платформенно-специфичную.
-
Прямой доступ к памяти возможен только через механизм mmap (memory
mapping), доступный через интерфейс /dev/mem, и разрешенный только
привилегированному пользователю.
-
Доступ к портам ввода/вывода доступен только после получения разрешения через
системные функции ioperm() или iopl(). Кроме того, не все платформы
поддерживают такие системные вызовы, а доступ к портам через
/dev/port может оказаться слишком медленным. Кроме того, описанные
системные вызовы и файловый интерфейс доступа к портам доступны
только привилегированному пользователю.
-
Время отклика устройств не является оптимальным, так как, требуется
переключение контекста при передаче данных между клиентской
программой и обслуживающем ее драйвером. Дело в том, что вы все
равно, в большинстве случаев обращаетесь к драйверам, только не к
своим, а универсальным. Собственный драйвер позволит произвести
множество обращений к устройству за одно обращение к драйверу.
-
Хуже всего то, что драйвер работающий в пользовательском пространстве может
быть выгружен на диск, тогда время обращения к нему значительно
возрастет. В этом случае может помочь системный вызов mlock(), с
помощью которого вы можете заблокировать страницу памяти, но
пользовательская программа связана с большим количеством библиотек,
размещаемых в разных страницах памяти, а mlock() ограничен
привилегиями пользователя.
-
Большинство важных устройств не могут управляться драйверами работающими в
пространстве пользователя. Например, это относится к сетевым
интерфейсам и к блочным устройствам. Одной из проблем является
наличие критичных ко времени исполнения операций.
Как видно из этого, драйвера пользовательского пространства могут не
много. Тем не менее существуют интересные примеры таких приложений.
Например, поддержка SCSI сканеров (реализовано в пакете SANE) и
записывающих CD приводов (cdrecord и другие интрументы). В обоих
приведенных примерах, работа этих
пользовательских программ основана на “SCSI generic” драйвере ядра,
который экпортирует низкоуровневую функциональность SCSI в программы
пользовательского уровня.
Для того, чтобы написать драйвер работающий в пользовательском
пространстве достаточно некоторых знаний о работе управляемой
аппаратуры, и не нужны знания о работе ядра. В данной книге мы не будем
обсуждать драйвера работающие в пользовательском пространстве, а вместо
этого сосредоточимся на написании драйверов, работающих в ядре.
Есть еще один оправданный случай управления аппаратурой из
пользовательского пространства – это начальный этап разработки нового
устройства. Вы можете понять способ управления новым устройством без
риска повесить целую систему. После этого вы более безболезнено
переместите необходимую функциональность драйвера на уровень ядра.
Вопросы обратной совместимости
Ядро Linux находится в стадии постоянной доработки – многие вещи
изменяются и добавляются новые характеристики. В этой главе мы
обсуждали интерфейс ядра версии 2.4. Если вы хотите, чтобы ваш код
работал на более старых версиях ядра, вам необходимо учесть сделанные в
ядре изменения.
В этой книге это первый раздел посвященный обратной совместимости. В
конце каждой главы мы будем обсуждать изменения сделанные после версии
ядра 2.0. Также, мы будем обсуждать необходимые доработки кода модулей,
которые необходимо провести для совместимости со старыми версиями.
Прежде всего, для решения вопросов совместимости версий необходимо
воспользоваться макроопределением KERNEL_VERSION, которое появилось в
ядре 2.1.90. Для более создания более читабельного программного кода мы
создаем и используем заголовочный файл sysdep.h, в который переносим
решения этой проблемы.
Изменения в системе управления ресурсами
Новая система управления ресурсами принесла новые проблемы
совместимости для тех, кто хочет написать драйвер, который может
работать под более старыми, чем 2.4, версиями ядра. В этом разделе
обсуждается эта проблема, и предлагается метод ее решения с
использованием файла sysdep.h.
Наиболее существенное изменение принесенное новой схемой управления
ресурсами заключается в появлении группы функций для открытия доступа к
памяти ввода/вывода. Одна из таких функций request_mem_region(). Для
совместимости с более ранними версиями вы можете просто не вызывать эти
функции. При подключении к коду модуля, разработанного нами,
заголовочного файла sysdep.h решение данной задачи упрощается – в нем,
данные функции определены как макросы, возвращающие ноль для версий
ядра более ранних чем 2.4.
Другое отличие между 2.4 и более ранними версиями заключается в
изменениях существующих прототипов request_region() и соответственной
ему группе функций.
Ядра более ранние чем 2.4 объявляли request_region() и
release_region() как функции возвращающие void, что принуждало вас
использовать check_region() для проверки доступности запрашиваемых
адресов. В новой реализации, функции возвращают значение указателя,
анализируя которое можно судить об успешности операции. Действительное
значение этого указателя не используется в коде драйвера нигде, кроме
как его проверки на NULL при запросе региона адресов.
Если вы хотите сэкономить на нескольких строчках в исходном коде
вашего драйвера, и не собираетесь добиваться обратной совместимости, вы
можете использовать новую схему получения региона адресов и не вызывать
функцию check_region(). В действительности, современная реализация
check_region() построена на вызове request_region() с последующим
высвобождением запрошенного диапазона адресов в случае их успешного
предоставления. Перегрузка по коду, в этом случае незначительная, и не
принципиальна, так как ни одна из этих функций не вызывается в
критических ко времени исполнения кусках кода.
Если же вы предпочитаете совместимость, то вы можете использовать
представленный ранее пример кода захвата адресов и игнорировать
значения возвращаемые функциями request_region() и release_region(). В
любом случае, при использовании заголовочного файла sysdep.h, обе эти
функции объявляются макросами возвращающими ноль (успешное завершение).
Таким образом, вы можете добиться и обратной совместимости и
использовать проверку возвращаемых значений.
Последнее отличие в реализации механизма захвата диапазона адресов
между 2.4 и более ранними версиями, заключается в типе аргументов start
и len. Новые ядра используют тип unsigned long, в то время как старые
версии ядра использовали более короткие типы данных. Но эти изменения,
наверное, не несут проблем совместимости.
Компиляция для многопроцессорных систем
Версия ядра 2.0 не использует опцию конфигурации CONFIG_SMP для
построения SMP систем. Вместо этого, делается глобальное определение в
главном конфигурационном Makefile ядра. Заметьте, что модули,
скомпилированные для SMP системы не будут работать на однопроцессорном
ядре, и наоборот. Поэтому, данная поправка очень важна.
Простой код представленный в этой книге автоматически представляет
SMP в Makefile-ах. И этот код, показанный ранее, не нужно копировать в
каждый модуль. Однако мы не поддерживаем SMP в версии ядра 2.0. Это не
является проблемой, потому что поддержка многопроцессорности не лучшим
образом реализована в ядре
2.0, и для запуска SMP системы лучше использовать версии 2.2 или 2.4. В
данной книге затрагивается версия 2.0 только потому, что данная версия
еще используется для создания малых систем (особенно в своей не MMU
реализации), но в таких системах отсутствует многопроцессорность.
Экспортирование символов в Linux 2.0
В ядре 2.0 механизм экспорта символов был построен на функции
называемой register_symtab(). Модули ядра 2.0 должны были построить
таблицу, описывающую все символы, которые должны были быть
экспортируемы, и, затем, необходимо было вызвать функцию
register_symtab() из инициализационной функции модуля. При этом,
экспортировались в таблицу символов ядра только те символы, которые
были явно перечислены в таблице. В противном случае, если эта функция
не была вызвана, то экспортировались все глобальные символы модуля.
Если ваш модуль не нуждается в экспортировании никаких символов, и
вы не хотите объявлять глобальные переменные модуля как static (такие
переменные не экспортируются), то вам необходимо сделать следующий
вызов:
register_symtab(NULL);
Именно таким образом определяется макроопределение EXPORT_NO_SYMBOLS
для ядра 2.0 в заголовочном файле sysdep.h. Поэтому объявление
EXPORT_NO_SYMBOLS должно быть записано в функции init_module() для
достижения этого результата в любых версиях ядра.
Если вам необходимо экспортировать символы из модуля, то вам
необходимо создать соответствующую структуру, описывающую эти символы.
Заполнение такой структуры для ядра 2.0 задача не из легких, и
разработчики ядра предлагают специальные заголовочные файлы для
упрощения этой задачи. Следующий пример, демонстрирует описание такой
таблицы на основе использования соответствующих заголовочных файлов.
static struct symbol_table skull_syms = {
#include <linux/symtab_begin.h>
X(skull_fn1),
X(skull_fn2),
X(skull_variable),
#include <linux/symtab_end.h>
};
register_symtab(&skull_syms);
Написание портируемого кода, управляющего видимостью символов
требует серьезных усилий от разработчика драйвера. Это случай, когда не
достаточно определить несколько совместимых макросов. Вместо этого,
несмотря на простую концепцию, требуется описать множество условных
препроцессорных директив. Первым шагом является определение
используемой версии ядра, в зависимости от которой мы экспортируем
символы так или иначе. То, что мы сделали в sysdep.h - это определили
макро REGISTER_SYMTAB(), которое ничего не делает в версиях 2.2 и
старше, но расширяется в register_symtab() в версии 2.0. Также, если
должен быть использован старый код, определяется макро
__USE_OLD_SYMTAB__.
При использовании этого кода, экспортирование символов модуля
становится совместимым со старыми версиями ядра. Пример кода
представляет собой модуль, называемый misc_modules/export.c, который не
делает ничего, за исключением экспортирования одного символа. Этот
модуль, более детально обсуждаемый в разделе “Version Control in
Modules” главы 11 “kmod and Advanced Modularization”, включает
следующие строки для экспорта символов:
#ifdef __USE_OLD_SYMTAB__
static struct symbol_table export_syms = {
#include <linux/symtab_begin.h>
X(export_function),
#include <linux/symtab_end.h>
};
#else
EXPORT_SYMBOL(export_function);
#endif
int export_init(void)
{
REGISTER_SYMTAB(&export_syms);
return 0;
}
Если определен макросимвол __USE_OLD_SYMTAB__, то это означает, что
используется ядро 2.0, и соответствено описывается структура
symbol_table. В противном случае используется макро EXPORT_SYMBOL для
прямого экспорта символов, без предварительного создания структуры.
Затем, в init_module() вызывается REGISTER_SYMTAB, который расширяется
в ни во что везде, кроме ядра 2.0.
Параметры конфигурации модуля
Макро MODULE_PARM было введено в ядре версии 2.1.18. В ядре 2.0
параметры не описывались явно. Вместо этого, команда insmod имела
способность изменить значение любой переменной модуля. Такой режим
доступа пользователя к переменным модуля был неудобен, и даже опасен.
Кроме того, не осуществлялась проверка типов параметров.
Макроопределение MODULE_PARM делает механизм передачи параметров модулю
яснее и безопаснее, но приводит к несовместимости с ядром 2.0.
Для написания совместимого кода, можно провести простую
препроцессорную проверку текущей версии ядра для определения различных
MODULE_ - макросов расширяющихся в ни во что. В нашем примере, в
заголовочном файле sysdep.h эти макросы определяется при необходимости.
Краткий справочник определений
В этом разделе собраны краткие описания всех функций, переменных,
макросов и /proc-файлов, которые были затронуты в данной главе. Каждый
элемент напечатан после соответствующего заголовочного файла в котором
он определен. Такой раздел будет приведен в конце каждой главы.
- __KERNEL__
- MODULE
-
Препроцессорные символы, которые оба должны быть определены при компиляции драйвера в виде модуля ядра.
- __SMP__
-
Препроцессорный символ, который должен быть определен при компиляции модуля для многопроцессорной системы.
- int init_module(void);
- void cleanup_module(void);
-
Точки входа в модуль исполняемые при установке и выгрузке модуля из ядра. Должны
быть обязательно определены в объектном файле модуля.
- #include <linux/init.h>
- module_init(init_function);
- module_exit(cleanup_function);
-
Макроопределения обеспечивающие современный механизм для указания
инициализационной и завершающей функций модуля.
- #include <linux/module.h>
-
Заголовочный файл, который должен быть обязательно включен в код источника модуля.
- MOD_INC_USE_COUNT;
- MOD_DEC_USE_COUNT;
- MOD_IN_USE;
-
Макросы, обеспечивающие учет используемости (параллельной или
одновременной используемости) модуля.
- /proc/modules
-
Список загруженных на данный момент модулей. Каждая строка (элемент списка) содержит
имя модуля, используемый объем памяти и текущее значение счетчика
используемости модуля. Также, в строке могут быть определены флаги
с дополнительной информацией о текущем состоянии модуля.
- EXPORT_SYMTAB;
-
Макро препроцессора, требуемое для экспорта символов модуля
- EXPORT_NO_SYMBOLS;
-
Макро препроцессора, указывающее на то, что модуль не экспортирует символы в ядро.
- EXPORT_SYMBOL(symbol);
- EXPORT_SYMBOL_NOVERS(symbol);
-
Макросы, используемые для экспорта символов в ядро. Второй вариант
используется для подавления информации о версии ядра, для которой
был скомпилирован модуль.
- int register_symtab(struct symbol_table *);
-
Функция используемая для регистрации множества экспортируемых символов модуля.
Используется только в версии ядра 2.0.
- #include <linux/symtab_begin.h>
- X(symbol),
- #include <linux/symtab_end.h>
-
Заголовочные файлы и препроцессорное макро используемые для
объявления таблицы экспортируемых символов. Используется только в
ядре 2.0.
- MODULE_PARM(variable, type);
- MODULE_PARM_DESC(variable, description);
-
Макросы, которые делают переменную модуля доступными как параметр, которые
пользователь может использовать при загрузке модуля. Второй макрос
позволяет поместить строку комментариев к параметру в объектный код
модуля.
- MODULE_AUTHOR(author);
- MODULE_DESCRIPTION(description);
- MODULE_SUPPORTED_DEVICE(device);
-
Размещение дополнительных информационных строк в объектный файл
модуля.
- #include <linux/version.h>
-
Полезный заголовочный файл. Он включается в <linux/module.h> в случае,
если не определен макросимвол __NO_VERSION__ (см. далее).
- LINUX_VERSION_CODE
-
Целое (int) макроопределение. Используется
в условных макродирективах учета текущей версии.
- char kernel_version[] = UTS_RELEASE;
-
Переменная требуемая в каждом модуле. Заголовочный файл <linux/module.h> определяет ее в случае
если не определен макросимвол __NO_VERSION__ (см. далее).
- __NO_VERSION__
-
Символ препроцессора. Предотвращает описание kernel_version в <linux/module.h>
- #include <linux/sched.h>
-
Один из наиболее важных заголовочных файлов. Файл содержит определения большого
количества API функций ядра, используемых драйверами, включая
функции приостановки драйвера (sleeping) и описание переменной
счетчика используемости модуля.
- struct task_struct *current;
-
Указатель на структуру текущего процесса.
- current->pid
- current->comm
-
Идентификатор процесса и командное имя текущего процесса.
- #include <linux/kernel.h>
- int printk(const char * fmt, ...);
-
Аналог функции printf() для кода ядра.
- #include <linux/malloc.h>
- void *kmalloc(unsigned int size, int priority);
- void kfree(void *obj);
-
Аналоги функций malloc() и free() в пространстве ядра. Используют значение
GFP_KERNEL для указания приоритета.
- #include <linux/ioport.h>
- int check_region(unsigned long from, unsigned long extent);
- struct resource *request_region(unsigned long from, unsigned long extent, const char *name);
- void release_region(unsigned long from, unsigned long extent);
-
Функции, используемые для регистрации и освобождения портов
ввода/вывода.
- int check_mem_region (unsigned long start, unsigned long extent);
- struct resource *request_mem_region (unsigned long start, unsigned long extent, const char *name);
- void release_mem_region (unsigned long start, unsigned long extent);
-
Макросы, используемые для регистрации и освобождения диапазонов
памяти ввода/вывода.
- /proc/ksyms
-
Таблица символов ядра.
- /proc/ioports
-
Список портов ввода/вывода используемых инсталлированными драйверами.
- /proc/iomem
-
Список распределенных областей памяти ввода/вывода.
| 
 LINUX
LINUX