Основные характеристики Ext2
Юникс использует несколько типов файловых систем.
Хотя все они имеют простой набор атрибутов для файлов,
реализация их все же различна.
Первая версия линукса была основана на файловой системе MINIX
.
Затем появилась расширенная файловая система (Ext FS).
2-я ее версия (Ext2) появилась в 1994;
она оказалась весьма эффективной.
Особенности Ext2:
При создании файловой системы Ext2,
админ может выбрать оптимальный размер блока - от 1 до 4 килобайт.
Если предполагается большое число мелких файлов,лучше выбрать блок в 1 килобайт,
в этом случае фрагментация будет меньше.
Для файловой системы с файлами большого размера предпочтителен бОльший размер блока
из-за меньшего оверхеда файловой системы и улучшения производительности диска.
При создании Ext2,
админ может выбрать максимальное количество нод для партиции ,
это опять же может уменьшить оверхед и будет эффективнее использовать дисковое пространство. -
Диск разбивается на группы блоков.
Каждая группа включает блоки данных и ноды,которые хранятся в смежных треках.
Благодаря этому файл целиком хранится в единой группе,
благодаря чему доступ к нему оптимален.
Файловая система резервирует место для регулярных файлов.
Когда такой файл увеличивается в размере,
место для этого уже есть,благодаря чему уменьшается фрагментация.
Поддерживаются линки на файлы.
Если его путь менее 60 символов,он хранится в ноде и для его трансляции
не нужно чтения дополнительного блока данных.
Тщательно продуманная реализация файловых апдэйтов.
При создании линка на файл,
счетчик линков в дисковой ноде увеличится на единицу,
и в указанной директории появится новое имя.
Если с нодой что-то произойдет,
удаление файла не приведет к катастрофическим последствиям.
Поддержка автоматической проверки файловой системы при загрузке.
Проверка выполняется программой e2fsck,
которая может быть выполнена после определенного числа монтирований файловой системы
или после определенного промежутка времени.
Поддержка т.н. immutable файлов
(они не могут быть модифицированы,удалены или переименованы) ,
а также т.н.
append-only файлов (
данные добавляются в конец).
Совместимость с Unix System V
Release 4 и BSD
в части групповых прав при создании файла.
В SVR4, новый созданный файл имеет user group ID процесса , его создавшего,
в BSD, новый файл наследует user group ID каталога.
Ext2 включает обе опции .
Ext2 - развивающаяся файловая система.
Одни фичи доступны в патчах,другие только планируются.
Наиболее важные из них:
Блочная фрагментация
Обычно выбирается большой размер блока ,
поскольку приложения имеют дело с файлами большого размера.
При этом маленькие файлы оказываются нерационально разбросаны по диску.
Эту проблему можно решить путем хранения таких файлов в различных фрагментах
одного и того же блока.
Прозрачное сжатие и криптование файлов
Позволят пользователям прозрачно хранить сжатые/криптованные версии файлов на диске.
Управление удалением Опция undelete
позволит пользователям восстанавливать содержимое удаленных файлов.
Журналирование
Журналирование позволит делать автоматическую проверку при крахе файловой системы.
Журналирование не было включено в Ext2,
оно появилось позже в Ext3.
Структура данных Ext2
Первый блок в любой Ext2 всегда зарезервирован для бут-сектора.
Остальная часть партиции разбита на группы блоков,
каждая из которых имеет вид как на рисунке
Figure 18-1.
Все группы имеют одинаковый размер и расположены последовательно,
для того чтобы ядро могло обращаться к ним просто по индексу.
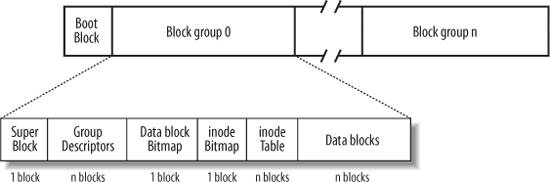
Групповая организация уменьшает файловую фрагментацию,
потому что файл сохраняется по возможности в одну группу.
Каждый блок в группе состоит из следующих частей:
Если блок не содержит информации,говорят,что он свободен.
Как мы видим из рисунка Figure 18-1,
суперблок и дескрипторы дублируются в каждом блоке.
Когда e2fsck выполняет проверку,
она ссылается на суперблок и на дескрипторы,которые хранятся в нулевом блоке,
и потом копирует их в остальные блоки.
Если по какой-то причине они окажутся в нулевом блоке испорченными,
утилита берет их из других блоков.
Число групп зависит от размера партиции и от размера самого блока.
Для этого используется block bitmap, который хранится в специальном блоке.
В каждой группе может быть 8xb блоков ,
где b = размер блока.
Число групп равно
s/(8xb),
где s - размер партиции в блоках.
Например рассмотрим партицию на 32 гига с 4-KB размером блока.
Т.о. в 4-байтным блоке находится битмап ,
который описывает 32-килобайтный блок, размером 128 MB. Нам нужно 256 групп.
Суперблок
Ext2 суперблок хранится в структуре ext2_super_block ,
поля которой перечислены в таблице Table 18-1.
Типы данных _ _u8, _ _u16, _ _u32
указывают на 8, 16, 32 бита,
типы данных _ _s8, _ _s16, _ _s32
для знаковых чисел 8, 16, 32.
Байт , 2 байта , 4 байта - типы данных _ _le16, _ _le32, _ _be16,
_ _be32 ;
порядок байт little-endian ordering
для 2-х и 4-байтных данных ,
остальные типы - порядок байт big-endian ordering
(старшие байты хранятся в старших адресах).
Table 18-1.
Поля суперблока Ext2 Type | Field | Description |
|---|
_ _le32 | s_inodes_count |
Общее число нод | _ _le32 | s_blocks_count |
Размер файловой системы в блоках | _ _le32 | s_r_blocks_count |
Число зарезервированных блоков | _ _le32 | s_free_blocks_count |
Число свободных блоков | _ _le32 | s_free_inodes_count |
Число свободных нод | _ _le32 | s_first_data_block |
Номер первого используемого блока (всегда 1) | _ _le32 | s_log_block_size |
Размер блока | _ _le32 | s_log_frag_size |
Размер фрагмента | _ _le32 | s_blocks_per_group | Number of blocks per group | _ _le32 | s_frags_per_group | Number of fragments per group | _ _le32 | s_inodes_per_group | Number of inodes per group | _ _le32 | s_mtime | Time of last mount operation | _ _le32 | s_wtime | Time of last write operation | _ _le16 | s_mnt_count | Mount operations counter | _ _le16 | s_max_mnt_count | Number of mount operations before check | _ _le16 | s_magic | Magic signature | _ _le16 | s_state | Status flag | _ _le16 | s_errors | Behavior when detecting errors | _ _le16 | s_minor_rev_level | Minor revision level | _ _le32 | s_lastcheck | Time of last check | _ _le32 | s_checkinterval | Time between checks | _ _le32 | s_creator_os | OS where filesystem was created | _ _le32 | s_rev_level | Revision level of the filesystem | _ _le16 | s_def_resuid | Default UID for reserved blocks | _ _le16 | s_def_resgid | Default user group ID for reserved blocks | _ _le32 | s_first_ino | Number of first nonreserved inode | _ _le16 | s_inode_size | Size of on-disk inode structure | _ _le16 | s_block_group_nr | Block group number of this superblock | _ _le32 | s_feature_compat | Compatible features bitmap | _ _le32 | s_feature_incompat | Incompatible features bitmap | _ _le32 | s_feature_ro_compat | Read-only compatible features bitmap | _ _u8 [16] | s_uuid | 128-bit filesystem identifier | char [16] | s_volume_name | Volume name | char [64] | s_last_mounted | Pathname of last mount point | _ _le32 | s_algorithm_usage_bitmap | Used for compression | _ _u8 | s_prealloc_blocks | Number of blocks to preallocate | _ _u8 | s_prealloc_dir_blocks | Number of blocks to preallocate for directories | _ _u16 | s_padding1 | Alignment to word | _ _u32 [204] | s_reserved | Nulls to pad out 1,024 bytes |
Поле s_inodes_count хранит число нод,
поле s_blocks_count хранит число блоков.
Поле s_log_block_size - размер блока :
0 - блок размером 1 байт,
1 - блок размером 2 байта , и т.д.
s_log_frag_size равно s_log_block_size,
поскольку фрагментация блока еще не реализована.
s_blocks_per_group, s_frags_per_group,
s_inodes_per_group хранят число блоков,фрагментов,нод в каждой группе блоков.
Несколько блоков зарезервировано за админом -
они позволяют ему работать даже в случае переполнения.
s_mnt_count, s_max_mnt_count, s_lastcheck,
s_checkinterval - это настроечные поля для автоматической проверки Ext2
при загрузке.
От них зависит запуск e2fsck
после определенного числа монтирований системы или определенного времени.
Поле s_state хранит 0 - если файловая система в процессе монтирования,
1 - если отмонтирована, 2 - если есть ошибки.
Групповые дескрипторы и битмап
Каждая группа блоков имеет свой дескриптор,
который описан структурой ext2_group_desc в Table 18-2.
Table 18-2. The fields of the Ext2 group descriptorType | Field | Description |
|---|
_ _le32 | bg_block_bitmap | Block number of block bitmap
| _ _le32 | bg_inode_bitmap | Block number of inode bitmap | _ _le32 | bg_inode_table | Block number of first inode table block | _ _le16 | bg_free_blocks_count | Number of free blocks in the group | _ _le16 | bg_free_inodes_count | Number of free inodes in the group | _ _le16 | bg_used_dirs_count | Number of directories in the group | _ _le16 | bg_pad | Alignment to word | _ _le32 [3] | bg_reserved | Nulls to pad out 24 bytes |
bg_free_blocks_count, bg_free_inodes_count, bg_used_dirs_count
используются при создании нод и блоков данных.
Они определяют блоки , в которых размещаются данные.
Битмап - это последовательность бит, 0 означает , что нода или блок данных свободен ,
1 - занят.
Поскольку блок кратен 1,2 или 4 байтам ,
один битмап может описывать состояние 8,192, 16,384, или 32,768 блоков.
Таблица нод
Таблица нод состоит из последовательности блоков,каждый из которых состоит
из определенного числа нод.
Номер первого блока в этой таблице хранится в поле
bg_inode_table группового дескриптора.
Все ноды имеют одинаковый размер: 128 байт.
В одно-байтовом блоке находится 8 нод, а в 4-байтном всего 32.
Для получения общего числа блоков в таблице,
нужно разделить общее число нод в группе - это поле в суперблоке , которое называется
s_inodes_per_group - на число нод в блоке.
Нода представлене структурой ext2_inode : Table 18-3.
Table 18-3. The fields of an Ext2 disk inodeType | Field | Description |
|---|
_ _le16 | i_mode | File type and access rights | _ _le16 | i_uid | Owner identifier | _ _le32 | i_size | File length in bytes | _ _le32 | i_atime | Time of last file access | _ _le32 | i_ctime | Time that inode last changed | _ _le32 | i_mtime | Time that file contents last changed | _ _le32 | i_dtime | Time of file deletion | _ _le16 | i_gid | User group identifier | _ _le16 | i_links_count | Hard links counter | _ _le32 | i_blocks | Number of data blocks of the file | _ _le32 | i_flags | File flags | union | osd1 | Specific operating system information | _ _le32 [EXT2_N_BLOCKS] | i_block | Pointers to data blocks | _ _le32 | i_generation | File version (used when the file is accessed by a network filesystem) | _ _le32 | i_file_acl | File access control list | _ _le32 | i_dir_acl | Directory access control list | _ _le32 | i_faddr | Fragment address | union | osd2 | Specific operating system information |
Многие поля похожи на соответствующие поля ноды в VFS.
Например, поле i_size хранит длину файла в байтах,
поле i_blocks хранит число блоков данных(по 512 байт),
которые выделены под файл.
Поля i_size и i_blocks
не связаны. Файл всегда состоит из целого числа блоков,
непустой файл состоит минимум мз одного блока,
и i_size может быть меньше чем 512 x i_blocks,
но может быть и больше чем 512 , умноженное на i_blocks.
Поле i_block - массив указателей EXT2_N_BLOCKS
(обычно 15) на блоки,используемые для данных,выделенных под файл.
32 бита , зарезервированные полем i_size ,
ограничивают размер файла в 4 GB.
Старший бит в поле i_size не используется,
поэтому максимальный размер ограничен 2 GB.
Ext2 разрешает большие файлы для 64-bit AMD , Opteron
или IBM's PowerPC
G5.
Поле i_dir_acl не используется,
оно представляет 32-битное расширение для i_size.
Размер файла хранится в ноде как 64-битное число.
64-версия работает как для 32-биной , так и для 64-битной архитектур.
В 32-битной версии , доступ к большим файлам невозможен до тех пор ,
пока не включен флаг O_LARGEFILE.
Одно из основных условий VFS - каждый файл должен иметь уникальный нодовый номер.
Для Ext2 , на диске не хранится маппинг между номером ноды и номером блока,
поскольку последний производен от номера блоковой группы и имеет позицию внутри таблицы нод.
Предположим , каждая группа блоков состоит из 4,096 нод ,
и нам нужно знать дисковый адрес ноды 13,021.
Нода принадлежит 3-й нодовой группе и ее дисковый адрес хранится
в 733-й строке нодовой таблицы.
Номер ноды используется Ext2 для быстрого получения нодового дескриптора.
Расширенные атрибуты ноды
Формат ноды Ext2 накладывает ограничения для разработчиков файловых систем.
Длина ноды должна быть кратна 2 для избежания фрагментации.
Почти все поля структуры ноды заняты.
Расширение ноды до 256 байт неоправданно , включая проблемы совместимости.
Для преодоления этих ограничений были введены т.н. расширенные атрибуты.
Они хранятся в блоке,размещенном за пределами нод.
Поле i_file_acl ноды указывает на блок ,
в котором находятся эти расширенные атрибуты.
Различные ноды могут указывать на один такой блок.
Каждый расширенный атрибут имеет имя и значение.
Они составляют массив переменной длины ,
определенный дескриптором ext2_xattr_entry .
Рисунок 18-2 показывает слой расширенных атрибутов внутри блока.
Каждый атрибут разбит на 2 части:
имя атрибута размещается в начале блока, а значение в конце.
Названия блоков упорядочены по имени,в то время как значения уже находятся
в соответствии со своими именами.
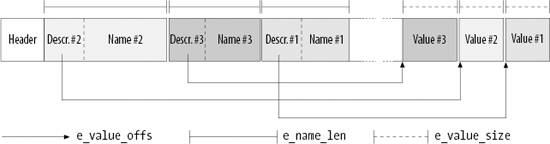
Есть множество системных вызовов для установки , получения , удаления расширенных атрибутов файла.
Системные вызовы setxattr( )
, lsetxattr( )
, fsetxattr( )
устанавливают атрибуиы.
Аналогично , системные вызовы
getxattr( )
, lgetxattr( )
, fgetxattr( )
возвращают значение расширенного атрибута.
Вызовы listxattr( ), llistxattr( )
, flistxattr( )
получают список атрибутов.
Вызовы removexattr( )
, lremovexattr( )
, fremovexattr( )
удаляют расширенный атрибут у файла .
Access Control Lists
Access control lists - механизм защиты файлов
в юниксовых системах.
Каждому файлу присваиваются привилегии группы , к которой принадлежит хозяин файла.
Linux 2.6 поддерживает ACLs с помощью расширенных атрибутов.
Собственно , расширенные атрибуты и были введены для поддержки ACL.
Функции chacl( )
, setfacl( )
, getfacl( )
, которые позволяют манипуляции с файловым ACL,
производны от системных вызовов setxattr( ) and getxattr( ).
К сожалению , расширение POSIX 1003.1 не принято в качестве стандарта .
И получается, что ACL поддерхиваются в большом количестве юниксовых систем ,
но реализация у них различная .
Как различные типы файлов используют дисковые блоки
Различные типы файлов Ext2
(regular files, pipes, etc.) используют блоки по-разному.
Некоторые из них вообще не нуждаются в блоках.
Типы файлов перечислены в таблице Table 18-4.
Table 18-4. Ext2 file typesFile_type | Description |
|---|
0 | Unknown | 1 | Regular file | 2 | Directory | 3 | Character device | 4 | Block device | 5 | Named pipe | 6 | Socket | 7 | Symbolic link |
Регулярный файл
Наиболее распространенный тип файлов.
Регулярный файл нуждается в блоках данных , если он включает какую-то информацию.
При создании такой файл пуст и блоки данных ему не нужны.
Если вы наберете команду >filename,
будет создан новый файл либо обнулен существующий.
Каталог
В Ext2 директории реализованы как файл, в котором блоки данных хранят имена файлов
с соответствующими нодовыми номерами.
Они включают структуру ext2_dir_entry_2.
Поля этой структуры показаны в таблице Table 18-5.
Структура имеет произвольную длину,
поскольку последнее поле name есть длина массива EXT2_NAME_LEN
(обычно 255). По соображениям эффективности эта длина кратна 4 ,
и при необходимости null-символы добавляются в конец файла.
Поле name_len хранит размер файла (Figure 18-3).
Table 18-5. The fields of an Ext2 directory entryType | Field | Description |
|---|
_ _le32 | inode | Inode number | _ _le16 | rec_len | Directory entry length | _ _u8 | name_len | Filename length | _ _u8 | file_type | File type | char [EXT2_NAME_LEN] | name | Filename |
Поле file_type хранит значение , которое определяет тип файла (Table 18-4).
Поле rec_len
есть указатель на следующий каталог , это смещение добавляется к стартовому адресу текущей директории
для получения следующего каталога.
Для удаления каталога поле inode
устанавливается в 0 и уменьшается значение поля rec_len
предыдущего . Обратите внимание на поле rec_len field of Figure 18-3 ;
oldfile было удалено , потому что поле rec_len usr
установлено в 12+16 (длина usr и oldfile ).
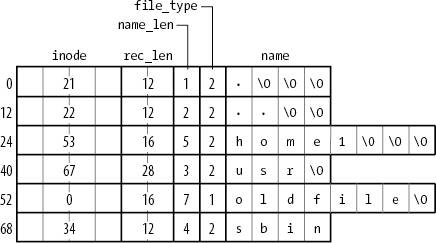
Симлинк
Если симлинк включает до 60 символов , он хранится в поле i_block
ноды, который включает массив из 15 4-байтовых чисел;
блоки данных здесь не требуются.
Если симлинк превышает 60 символов, блок данных нужен по-любому.
Файлы устройств , pipe, socket
Блоков данных здесь не требуется.
Вся информация хранится в ноде.
Ext2 Memory Data Structures
For the sake of efficiency, most information stored
in the disk data structures of an Ext2 partition are copied into RAM
when the filesystem is mounted, thus allowing the kernel to avoid many
subsequent disk read operations. To get an idea of how often some data
structures change, consider some fundamental operations:
When a new file is created, the values of the s_free_inodes_count field in the Ext2 superblock and of the bg_free_inodes_count field in the proper group descriptor must be decreased. If
the kernel appends some data to an existing file so that the number of
data blocks allocated for it increases, the values of the s_free_blocks_count field in the Ext2 superblock and of the bg_free_blocks_count field in the group descriptor must be modified. Even just rewriting a portion of an existing file involves an update of the s_wtime field of the Ext2 superblock.
Because all Ext2 disk data structures are stored in
blocks of the Ext2 partition, the kernel uses the page cache to keep
them up-to-date (see the section "Writing Dirty Pages to Disk" in Chapter 15).
Table 18-6
specifies, for each type of data related to Ext2 filesystems and files,
the data structure used on the disk to represent its data, the data
structure used by the kernel in memory, and a rule of thumb used to
determine how much caching is used. Data that is updated very
frequently is always cached; that is, the data is permanently stored in
memory and included in the page cache until the corresponding Ext2
partition is unmounted. The kernel gets this result by keeping the
page's usage counter greater than 0 at all times.
Table 18-6. VFS images of Ext2 data structuresType | Disk data structure | Memory data structure | Caching mode |
|---|
Superblock | ext2_super_block | ext2_sb_info | Always cached | Group descriptor | ext2_group_desc | ext2_group_desc | Always cached | Block bitmap | Bit array in block | Bit array in buffer | Dynamic | inode bitmap | Bit array in block | Bit array in buffer | Dynamic | inode | ext2_inode | ext2_inode_info | Dynamic | Data block | Array of bytes | VFS buffer | Dynamic | Free inode | ext2_inode | None | Never | Free block | Array of bytes | None | Never |
The never-cached data is not kept in any cache
because it does not represent meaningful information. Conversely, the
always-cached data is always present in RAM, thus it is never necessary
to read the data from disk (periodically, however, the data must be
written back to disk). In between these extremes lies the dynamic
mode. In this mode, the data is kept in a cache as long as the
associated object (inode, data block, or bitmap) is in use; when the
file is closed or the data block is deleted, the page frame reclaiming
algorithm may remove the associated data from the cache.
It is interesting to observe that inode and block
bitmaps are not kept permanently in memory; rather, they are read from
disk when needed. Actually, many disk reads are avoided thanks to the
page cache, which keeps in memory the most recently used disk blocks
(see the section "Storing Blocks in the Page Cache" in Chapter 15).
18.3.1. The Ext2 Superblock Object
As stated in the section "Superblock Objects" in Chapter 12, the s_fs_info
field of the VFS superblock points to a structure containing
filesystem-specific data. In the case of Ext2, this field points to a
structure of type ext2_sb_info, which includes the following information:
Most of the disk superblock fields An s_sbh pointer to the buffer head of the buffer containing the disk superblock An s_es pointer to the buffer containing the disk superblock The number of group descriptors, s_desc_ per_block, that can be packed in a block An s_group_desc pointer to an array of buffer heads of buffers containing the group descriptors (usually, a single entry is sufficient) Other data related to mount state, mount options, and so on
Figure 18-4 shows the links between the ext2_sb_info data structures and the buffers and buffer heads relative to the Ext2 superblock and to the group descriptors.
When the kernel mounts an Ext2 filesystem, it invokes the ext2_fill_super( ) function to allocate space for the data structures and to fill them with data read from disk (see the section "Mounting a Generic Filesystem" in Chapter 12). This is a simplified description of the function, which emphasizes the memory allocations for buffers and descriptors:
Allocates an ext2_sb_info descriptor and stores its address in the s_fs_info field of the superblock object passed as the parameter.
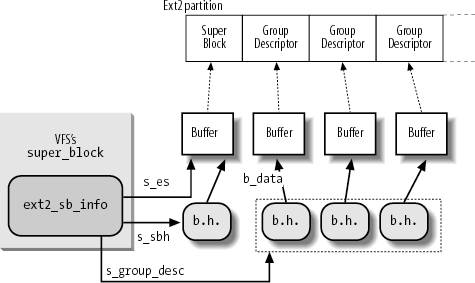 Invokes _ _bread( )
to allocate a buffer in a buffer page together with the corresponding
buffer head, and to read the superblock from disk into the buffer; as
discussed in the section "Searching Blocks in the Page Cache" in Chapter 15,
no allocation is performed if the block is already stored in a buffer
page in the page cache and it is up-to-date. Stores the buffer head
address in the s_sbh field of the Ext2 superblock object. Allocates an array of bytesone byte for each groupand stores its address in the s_debts field of the ext2_sb_info descriptor (see the section "Creating inodes" later in this chapter). Allocates an array of pointers to buffer heads, one for each group descriptor, and stores the address of the array in the s_group_desc field of the ext2_sb_info descriptor. Invokes repeatedly _ _bread( )
to allocate buffers and to read from disk the blocks containing the
Ext2 group descriptors; stores the addresses of the buffer heads in the
s_group_desc array allocated in the previous step. Allocates
an inode and a dentry object for the root directory, and sets up a few
fields of the superblock object so that it will be possible to read the
root inode from disk.
Clearly, all the data structures allocated by ext2_fill_super( )
are kept in memory after the function returns; they will be released
only when the Ext2 filesystem will be unmounted. When the kernel must
modify a field in the Ext2 superblock, it simply writes the new value
in the proper position of the corresponding buffer and then marks the
buffer as dirty.
18.3.2. The Ext2 inode Object
When opening a file, a pathname lookup is performed. For each component of the pathname that is not already in the dentry cache
, a new dentry object and a new inode object are created (see the section "Standard Pathname Lookup" in Chapter 12). When the VFS accesses an Ext2 disk inode, it creates a corresponding inode descriptor of type ext2_inode_info. This descriptor includes the following information:
The whole VFS inode object (see Table 12-3 in Chapter 12) stored in the field vfs_inode Most of the fields found in the disk's inode structure that are not kept in the VFS inode The i_block_group block group index at which the inode belongs (see the section "Ext2 Disk Data Structures" earlier in this chapter) The i_next_alloc_block and i_next_alloc_goal
fields, which store the logical block number and the physical block
number of the disk block that was most recently allocated to the file,
respectively The i_prealloc_block and i_prealloc_count fields, which are used for data block preallocation (see the section "Allocating a Data Block" later in this chapter) The xattr_sem field, a read/write semaphore that allows extended attributes to be read concurrently with the file data The i_acl and i_default_acl fields, which point to the ACLs of the file
When dealing with Ext2 files, the alloc_inode superblock method is implemented by means of the ext2_alloc_inode( ) function. It gets first an ext2_inode_info descriptor from the ext2_inode_cachep slab allocator cache, then it returns the address of the inode object embedded in the new ext2_inode_info descriptor.
Создание Ext2 Filesystem
There are generally two stages to creating
a filesystem on a disk. The first step is to format it so that the disk
driver can read and write blocks on it. Modern hard disks come
preformatted from the factory and need not be reformatted; floppy disks
may be formatted on Linux using a utility program such as superformat or fdformat.
The second step involves creating a filesystem, which means setting up
the structures described in detail earlier in this chapter.
Ext2 filesystems are created by the mke2fs utility program; it assumes the following default options, which may be modified by the user with flags on the command line:
Block size: 1,024 bytes (default value for a small filesystem) Fragment size: block size (block fragmentation is not implemented) Number of allocated inodes: 1 inode for each 8,192 bytes Percentage of reserved blocks: 5 percent
The program performs the following actions:
Initializes the superblock and the group descriptors. Optionally, checks whether the partition contains defective blocks; if so, it creates a list of defective blocks. For
each block group, reserves all the disk blocks needed to store the
superblock, the group descriptors, the inode table, and the two bitmaps. Initializes the inode bitmap and the data map bitmap of each block group to 0. Initializes the inode table of each block group. Creates the /root directory. Creates the lost+found directory, which is used by e2fsck to link the lost and found defective blocks. Updates the inode bitmap and the data block bitmap of the block group in which the two previous directories have been created. Groups the defective blocks (if any) in the lost+found directory.
Let's consider how an Ext2 1.44 MB floppy disk is initialized by mke2fs with the default options.
Once mounted, it appears to the VFS as a volume
consisting of 1,412 blocks; each one is 1,024 bytes in length. To
examine the disk's contents, we can execute the Unix command:
$ dd if=/dev/fd0 bs=1k count=1440 | od -tx1 -Ax > /tmp/dump_hex
to get a file containing the hexadecimal dump of the floppy disk contents in the /tmp directory.
By looking at that file, we can see that, due to the
limited capacity of the disk, a single group descriptor is sufficient.
We also notice that the number of reserved blocks is set to 72 (5
percent of 1,440) and, according to the default option, the inode table
must include 1 inode for each 8,192 bytes that is, 184 inodes stored in
23 blocks.
Table 18-7 summarizes how the Ext2 filesystem is created on a floppy disk when the default options are selected.
Table 18-7. Ext2 block allocation for a floppy diskBlock | Content |
|---|
0 | Boot block | 1 | Superblock | 2 | Block containing a single block group descriptor | 3 | Data block bitmap | 4 | inode bitmap | 5-27 | inode table: inodes up to 10: reserved (inode 2 is the root); inode 11: lost+found; inodes 12-184: free | 28 | Root directory (includes ., .., and lost+found) | 29 | lost+found directory (includes . and ..) | 30-40 | Reserved blocks preallocated for lost+found directory | 41-1439 | Free blocks |
Функции Ext2
Many of the VFS methods
described in Chapter 12
have a corresponding Ext2 implementation. Because it would take a whole
book to describe all of them, we limit ourselves to briefly reviewing
the methods implemented in Ext2. Once the disk and the memory data
structures are clearly understood, the reader should be able to follow
the code of the Ext2 functions that implement them.
18.5.1. Ext2 Superblock Operations
Many VFS superblock operations
have a specific implementation in Ext2, namely alloc_inode, destroy_inode, read_inode, write_inode, delete_inode, put_super, write_super, statfs, remount_fs, and clear_inode. The addresses of the superblock methods are stored in the ext2_sops array of pointers.
18.5.2. Ext2 inode Operations
Some of the VFS inode operations
have a specific implementation in Ext2, which depends on the type of the file to which the inode refers.
The inode operations for Ext2 regular files and Ext2 directories are shown in Table 18-8; the purpose of each method is described in the section "Inode Objects" in Chapter 12. The table does not show the methods that are undefined (a NULL
pointer) for both regular files and directories; recall that if a
method is undefined, the VFS either invokes a generic function or does
nothing at all. The addresses of the Ext2 methods for regular files and
directories are stored in the ext2_file_inode_operations and ext2_dir_inode_operations tables, respectively.
Table 18-8. Ext2 inode operations for regular files and directoriesVFS inode operation | Regular file | Directory |
|---|
create | NULL | ext2_create( ) | lookup | NULL | ext2_lookup( ) | link | NULL | ext2_link( ) | unlink | NULL | ext2_unlink( ) | symlink | NULL | ext2_symlink( ) | mkdir | NULL | ext2_mkdir( ) | rmdir | NULL | ext2_rmdir( ) | mknod | NULL | ext2_mknod( ) | rename | NULL | ext2_rename( ) | truncate | ext2_TRuncate( ) | NULL | permission | ext2_permission( ) | ext2_permission( ) | setattr | ext2_setattr( ) | ext2_setattr( ) | setxattr | generic_setxattr( ) | generic_setxattr( ) | getxattr | generic_getxattr( ) | generic_getxattr( ) | listxattr | ext2_listxattr( ) | ext2_listxattr( ) | removexattr | generic_removexattr( ) | generic_removexattr( ) |
The inode operations for Ext2 symbolic links are shown in Table 18-9
(undefined methods have been omitted). Actually, there are two types of
symbolic links: the fast symbolic links represent pathnames that can be
fully stored inside the inodes, while the regular symbolic links
represent longer pathnames. Accordingly, there are two sets of inode
operations, which are stored in the ext2_fast_symlink_inode_operations and ext2_symlink_inode_operations tables, respectively.
Table 18-9. Ext2 inode operations for fast and regular symbolic linksVFS inode operation | Fast symbolic link | Regular symbolic link |
|---|
readlink | generic_readlink( ) | generic_readlink( ) | follow_link | ext2_follow_link( ) | page_follow_link_light( ) | put_link | NULL | page_put_link( ) | setxattr | generic_setxattr( ) | generic_setxattr( ) | getxattr | generic_getxattr( ) | generic_getxattr( ) | listxattr | ext2_listxattr( ) | ext2_listxattr( ) | removexattr | generic_removexattr( ) | generic_removexattr( ) |
If the inode refers to a character device file, to a block device file, or to a named pipe (see "FIFOs" in Chapter 19), the inode operations do not depend on the filesystem. They are specified in the chrdev_inode_operations, blkdev_inode_operations, and fifo_inode_operations tables, respectively.
18.5.3. Ext2 File Operations
The file operations
specific to the Ext2 filesystem are listed in Table 18-10.
As you can see, several VFS methods are implemented by generic
functions that are common to many filesystems. The addresses of these
methods are stored in the ext2_file_operations table.
Table 18-10. Ext2 file operationsVFS file operation | Ext2 method |
|---|
llseek | generic_file_llseek( ) | read | generic_file_read( ) | write | generic_file_write( ) | aio_read | generic_file_aio_read( ) | aio_write | generic_file_aio_write( ) | ioctl | ext2_ioctl( ) | mmap | generic_file_mmap( ) | open | generic_file_open( ) | release | ext2_release_file( ) | fsync | ext2_sync_file( ) | readv | generic_file_readv( ) | writev | generic_file_writev( ) | sendfile | generic_file_sendfile( ) |
Notice that the Ext2's read and write methods are implemented by the generic_file_read( ) and generic_file_write( ) functions, respectively. These are described in the sections "Reading from a File" and "Writing to a File" in Chapter 16.
Управление дисковым пространством Ext2
The storage of a file on disk differs from the view
the programmer has of the file in two ways: blocks can be scattered
around the disk (although the filesystem tries hard to keep blocks
sequential to improve access time), and files may appear to a
programmer to be bigger than they really are because a program can
introduce holes into them (through the lseek( ) system call).
In this section, we explain how the Ext2 filesystem
manages the disk space how it allocates and deallocates inodes and data
blocks. Two main problems must be addressed:
Space management must make every effort to avoid file fragmentation
the physical storage of a file in several, small pieces located in
non-adjacent disk blocks. File fragmentation increases the average time
of sequential read operations on the files, because the disk heads must
be frequently repositioned during the read operation. This problem is similar to the external fragmentation of RAM discussed in the section "The Buddy System Algorithm" in Chapter 8. Space
management must be time-efficient; that is, the kernel should be able
to quickly derive from a file offset the corresponding logical block
number in the Ext2 partition. In doing so, the kernel should limit as
much as possible the number of accesses to addressing tables stored on
disk, because each such intermediate access considerably increases the
average file access time.
18.6.1. Creating inodes
The ext2_new_inode( ) function creates an Ext2 disk inode, returning the address of the corresponding inode object (or NULL,
in case of failure). The function carefully selects the block group
that contains the new inode; this is done to spread unrelated
directories among different groups and, at the same time, to put files
into the same group as their parent directories. To balance the number
of regular files and directories in a block group, Ext2 introduces a
"debt" parameter for every block group.
The function acts on two parameters: the address dir of the inode object that refers to the directory into which the new inode must be inserted and a mode that indicates the type of inode being created. The latter argument also includes the MS_SYNCHRONOUS mount flag (see the section "Mounting a Generic Filesystem" in Chapter 12) that requires the current process to be suspended until the inode is allocated. The function performs the following actions:
Invokes new_inode( ) to allocate a new VFS inode object; initializes its i_sb field to the superblock address stored in dir->i_sb, and adds it to the in-use inode list and to the superblock's list (see the section "Inode Objects" in Chapter 12). If the new inode is a directory, the function invokes find_group_orlov( ) to find a suitable block group for the directory. This function implements the following heuristics: Directories
having as parent the filesystem root should be spread among all block
groups. Thus, the function searches the block groups looking for a
group having a number of free inodes and a number of free blocks above
the average. If there is no such group, it jumps to step 2c. Nested
directoriesnot having the filesystem root as parentshould be put in the
group of the parent if it satisfies the following rules: The group does not contain too many directories The group has a sufficient number of free inodes left The group has a small "debt" (the debt of a block group is stored in the array of counters pointed to by the s_debts field of the ext2_sb_info descriptor; the debt is increased each time a new directory is added and decreased each time another type of file is added)
If
the parent's group does not satisfy these rules, it picks the first
group that satisfies them. If no such group exists, it jumps to step 2c. This
is the "fallback" rule, to be used if no good group has been found. The
function starts with the block group containing the parent directory
and selects the first block group that has more free inodes than the
average number of free inodes per block group.
If the new inode is not a directory, it invokes find_group_other( )
to allocate it in a block group having a free inode. This function
selects the group by starting from the one that contains the parent
directory and moving farther away from it; to be precise: Performs a quick logarithmic search starting from the block group that includes the parent directory dir. The algorithm searches log(n) block groups, where n
is the total number of block groups. The algorithm jumps further ahead
until it finds an available block group for example, if we call the
number of the starting block group i, the algorithm considers block groups i mod(n), i+1 mod(n), i+1+2 mod(n), i+1+2+4 mod(n), etc. If
the logarithmic search failed in finding a block group with a free
inode, the function performs an exhaustive linear search starting from
the block group that includes the parent directory dir.
Invokes read_inode_bitmap( )
to get the inode bitmap of the selected block group and searches for
the first null bit into it, thus obtaining the number of the first free
disk inode. Allocates
the disk inode: sets the corresponding bit in the inode bitmap and
marks the buffer containing the bitmap as dirty. Moreover, if the
filesystem has been mounted specifying the MS_SYNCHRONOUS flag (see the section "Mounting a Generic Filesystem" in Chapter 12), the function invokes sync_dirty_buffer( ) to start the I/O write operation and waits until the operation terminates. Decreases the bg_free_inodes_count field of the group descriptor. If the new inode is a directory, the function increases the bg_used_dirs_count field and marks the buffer containing the group descriptor as dirty. Increases or decreases the group's counter in the s_debts array of the superblock, according to whether the inode refers to a regular file or a directory. Decreases the s_freeinodes_counter field of the ext2_sb_info data structure; moreover, if the new inode is a directory, it increases the s_dirs_counter field in the ext2_sb_info data structure. Sets the s_dirt flag of the superblock to 1, and marks the buffer that contains it to as dirty. Sets the s_dirt field of the VFS's superblock object to 1. Initializes the fields of the inode object. In particular, it sets the inode number i_no and copies the value of xtime.tv_sec into i_atime, i_mtime, and i_ctime. Also loads the i_block_group field in the ext2_inode_info structure with the block group index. Refer to Table 18-3 for the meaning of these fields. Initializes the ACLs of the inode. Inserts the new inode object into the hash table inode_hashtable and invokes mark_inode_dirty( ) to move the inode object into the superblock's dirty inode list (see the section "Inode Objects" in Chapter 12). Invokes ext2_preread_inode( )
to read from disk the block containing the inode and to put the block
in the page cache. This type of read-ahead is done because it is likely
that a recently created inode will be written back soon. Returns the address of the new inode object.
18.6.2. Deleting inodes
The ext2_free_inode( ) function deletes a disk inode, which is identified by an inode object whose address inode
is passed as the parameter. The kernel should invoke the function after
a series of cleanup operations involving internal data structures and
the data in the file itself. It should come after the inode object has
been removed from the inode hash table, after the last hard link
referring to that inode has been deleted from the proper directory and
after the file is truncated to 0 length to reclaim all its data blocks
(see the section "Releasing a Data Block" later in this chapter). It performs the following actions:
Invokes clear_inode( ), which in turn executes the following operations: If the I_LOCK
flag of the inode is set, some of the inode's buffers are involved in
I/O data transfers; the function suspends the current process until
these I/O data transfers terminate. Invokes the clear_inode method of the superblock object, if defined; the Ext2 filesystem does not define it. If
the inode refers to a device file, it removes the inode object from the
device's list of inodes; this list is rooted either in the list field of the cdev character device descriptor (see the section "Character Device Drivers" in Chapter 13) or in the bd_inodes field of the block_device block device descriptor (see the section "Block Devices" in Chapter 14). Sets the state of the inode to I_CLEAR (the inode object contents are no longer meaningful).
Computes
the index of the block group containing the disk inode from the inode
number and the number of inodes in each block group. Invokes read_inode_bitmap( ) to get the inode bitmap. Increases the bg_free_inodes_count( ) field of the group descriptor. If the deleted inode is a directory, it decreases the bg_used_dirs_count field. Marks the buffer that contains the group descriptor as dirty. If the deleted inode is a directory, it decreases the s_dirs_counter field in the ext2_sb_info data structure, sets the s_dirt flag of the superblock to 1, and marks the buffer that contains it as dirty. Clears
the bit corresponding to the disk inode in the inode bitmap and marks
the buffer that contains the bitmap as dirty. Moreover, if the
filesystem has been mounted with the MS_SYNCHRONIZE flag, it invokes sync_dirty_buffer( ) to wait until the write operation on the bitmap's buffer terminates.
18.6.3. Data Blocks Addressing
Each nonempty regular file consists of a group of data blocks
. Such blocks may be referred to either by their relative position
inside the file their file block numberor by their position inside the
disk partitiontheir logical block number (see the section "Block Devices Handling" in Chapter 14).
Deriving the logical block number of the corresponding data block from an offset f inside a file is a two-step process:
Derive from the offset f the file block number the index of the block that contains the character at offset f. Translate the file block number to the corresponding logical block number.
Because Unix files do not include any control characters, it is quite easy to derive the file block number containing the f th character of a file: simply take the quotient of f and the filesystem's block size and round down to the nearest integer.
For instance, let's assume a block size of 4 KB. If f is smaller than 4,096, the character is contained in the first data block of the file, which has file block number 0. If f
is equal to or greater than 4,096 and less than 8,192, the character is
contained in the data block that has file block number 1, and so on.
This is fine as far as file block numbers
are concerned. However, translating a file block number into the
corresponding logical block number is not nearly as straightforward,
because the data blocks of an Ext2 file are not necessarily adjacent on
disk.
The Ext2 filesystem must therefore provide a method
to store the connection between each file block number and the
corresponding logical block number on disk. This mapping, which goes
back to early versions of Unix from AT&T, is implemented partly
inside the inode. It also involves some specialized blocks that contain
extra pointers, which are an inode extension used to handle large files.
The i_block field in the disk inode is an array of EXT2_N_BLOCKS components that contain logical block numbers. In the following discussion, we assume that EXT2_N_BLOCKS has the default value, namely 15. The array represents the initial part of a larger data structure, which is illustrated in Figure 18-5. As can be seen in the figure, the 15 components of the array are of 4 different types:
The first 12 components yield the logical
block numbers corresponding to the first 12 blocks of the fileto the
blocks that have file block numbers from 0 to 11. The component at index 12 contains the logical block number of a block, called indirect block, that represents a second-order array of logical block numbers. They correspond to the file block numbers ranging from 12 to b/4+11, where b
is the filesystem's block size (each logical block number is stored in
4 bytes, so we divide by 4 in the formula). Therefore, the kernel must
look in this component for a pointer to a block, and then look in that
block for another pointer to the ultimate block that contains the file
contents. The component at index 13
contains the logical block number of an indirect block containing a
second-order array of logical block numbers; in turn, the entries of
this second-order array point to third-order arrays, which store the
logical block numbers that correspond to the file block numbers ranging
from b/4+12 to (b/4)2+(b/4)+11. Finally,
the component at index 14 uses triple indirection: the fourth-order
arrays store the logical block numbers corresponding to the file block
numbers ranging from (b/4)2+(b/4)+12 to (b/4)3+(b/4)2+(b/4)+11.
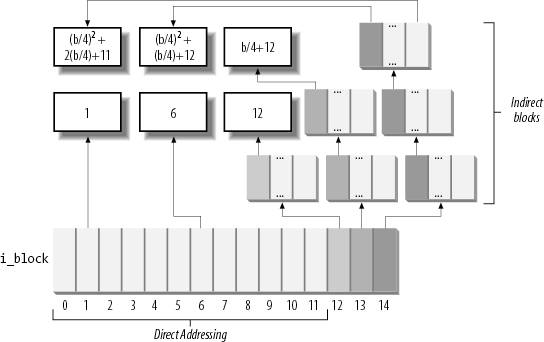
In Figure 18-5,
the number inside a block represents the corresponding file block
number. The arrows, which represent logical block numbers stored in
array components, show how the kernel finds its way through indirect
blocks to reach the block that contains the actual contents of the file.
Notice how this mechanism favors small files. If the
file does not require more than 12 data blocks, every data can be
retrieved in two disk accesses: one to read a component in the i_block
array of the disk inode and the other to read the requested data block.
For larger files, however, three or even four consecutive disk accesses
may be needed to access the required block. In practice, this is a
worst-case estimate, because dentry, inode, and page caches contribute
significantly to reduce the number of real disk accesses.
Notice also how the block size of the filesystem
affects the addressing mechanism, because a larger block size allows
the Ext2 to store more logical block numbers inside a single block. Table 18-11
shows the upper limit placed on a file's size for each block size and
each addressing mode. For instance, if the block size is 1,024 bytes
and the file contains up to 268 kilobytes of data, the first 12 KB of a
file can be accessed through direct mapping and the remaining 13-268 KB
can be addressed through simple indirection. Files larger than 2 GB
must be opened on 32-bit architectures by specifying the O_LARGEFILE opening flag.
Table 18-11. File-size upper limits for data block addressingBlock size | Direct | 1-Indirect | 2-Indirect | 3-Indirect |
|---|
1,024 | 12 KB | 268 KB | 64.26 MB | 16.06 GB | 2,048 | 24 KB | 1.02 MB | 513.02 MB | 256.5 GB | 4,096 | 48 KB | 4.04 MB | 4 GB | ~ 4 TB |
18.6.4. File Holes
A file hole is a
portion of a regular file that contains null characters and is not
stored in any data block on disk. Holes are a long-standing feature of
Unix files. For instance, the following Unix command creates a file in
which the first bytes are a hole:
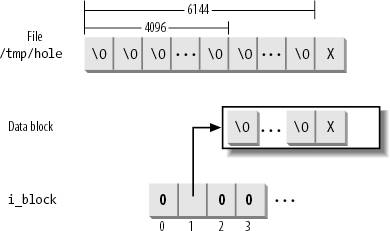
$ echo -n "X" | dd of=/tmp/hole bs=1024 seek=6
Now /tmp/hole has 6,145 characters (6,144 null characters plus an X character), yet the file occupies just one data block on disk.
File holes were introduced to avoid wasting disk
space. They are used extensively by database applications and, more
generally, by all applications that perform hashing on files.
The Ext2 implementation of file holes
is based on dynamic data block
allocation: a block is actually assigned to a file only when the
process needs to write data into it. The i_size field of each inode defines the size of the file as seen by the program, including the holes, while the i_blocks field stores the number of data blocks effectively assigned to the file (in units of 512 bytes).
In our earlier example of the dd command, suppose the /tmp/hole file was created on an Ext2 partition that has blocks of size 4,096. The i_size field of the corresponding disk inode stores the number 6,145, while the i_blocks field stores the number 8 (because each 4,096-byte block includes eight 512-byte blocks). The second element of the i_block
array (corresponding to the block having file block number 1) stores
the logical block number of the allocated block, while all other
elements in the array are null (see Figure 18-6).
18.6.5. Allocating a Data Block
When the kernel has to locate a block holding data for an Ext2 regular file, it invokes the ext2_get_block( )
function. If the block does not exist, the function automatically
allocates the block to the file. Remember that this function may be
invoked every time the kernel issues a read or write operation on an
Ext2 regular file (see the sections "Reading from a File" and "Writing to a File" in Chapter 16); clearly, this function is invoked only if the affected block is not included in the page cache.
The ext2_get_block( ) function handles the data structures already described in the section "Data Blocks Addressing," and when necessary, invokes the ext2_alloc_block( )
function to actually search for a free block in the Ext2 partition. If
necessary, the function also allocates the blocks used for indirect
addressing (see Figure 18-5).
To reduce file fragmentation, the Ext2 filesystem
tries to get a new block for a file near the last block already
allocated for the file. Failing that, the filesystem searches for a new
block in the block group that includes the file's inode. As a last
resort, the free block is taken from one of the other block groups.
The Ext2 filesystem uses preallocation of data
blocks. The file does not get only the requested block, but rather a
group of up to eight adjacent blocks. The i_prealloc_count field in the ext2_inode_info structure stores the number of data blocks preallocated to a file that are still unused, and the i_prealloc_block
field stores the logical block number of the next preallocated block to
be used. All preallocated blocks that remain unused are freed when the
file is closed, when it is truncated, or when a write operation is not
sequential with respect to the write operation that triggered the block
preallocation.
The ext2_alloc_block( ) function receives as its parameters a pointer to an inode object, a goal
, and the address of a variable that will store an error code. The goal
is a logical block number that represents the preferred position of the
new block. The ext2_get_block( ) function sets the goal parameter according to the following heuristic:
If
the block that is being allocated and the previously allocated block
have consecutive file block numbers, the goal is the logical block
number of the previous block plus 1; it makes sense that consecutive
blocks as seen by a program should be adjacent on disk. If
the first rule does not apply and at least one block has been
previously allocated to the file, the goal is one of these blocks'
logical block numbers. More precisely, it is the logical block number
of the already allocated block that precedes the block to be allocated
in the file. If
the preceding rules do not apply, the goal is the logical block number
of the first block (not necessarily free) in the block group that
contains the file's inode.
The ext2_alloc_block( ) function checks
whether the goal refers to one of the preallocated blocks of the file.
If so, it allocates the corresponding block and returns its logical
block number; otherwise, the function discards all remaining
preallocated blocks and invokes ext2_new_block( ).
This latter function searches for a free block inside the Ext2 partition with the following strategy:
If the preferred block passed to ext2_alloc_block( )the block that is the goalis free, the function allocates the block. If the goal is busy, the function checks whether one of the next blocks after the preferred block is free. If
no free block is found in the near vicinity of the preferred block, the
function considers all block groups, starting from the one including
the goal. For each block group, the function does the following: Looks for a group of at least eight adjacent free blocks. If no such group is found, looks for a single free block.
The search ends as soon as a free block is found. Before terminating, the ext2_new_block( ) function also tries to preallocate up to eight free blocks adjacent to the free block found and sets the i_prealloc_block and i_prealloc_count fields of the disk inode to the proper block location and number of blocks.
18.6.6. Releasing a Data Block
When a process deletes a file or truncates it to 0 length, all its data blocks must be reclaimed. This is done by ext2_truncate( ), which receives the address of the file's inode object as its parameter. The function essentially scans the disk inode's i_block
array to locate all data blocks and all blocks used for the indirect
addressing. These blocks are then released by repeatedly invoking ext2_free_blocks( ).
The ext2_free_blocks( ) function releases a group of one or more adjacent data blocks. Besides its use by ext2_truncate( ), the function is invoked mainly when discarding the preallocated blocks of a file (see the earlier section "Allocating a Data Block"). Its parameters are:
inode The address of the inode object that describes the file
block The logical block number of the first block to be released
count The number of adjacent blocks to be released
The function performs the following actions for each block to be released:
Gets the block bitmap of the block group that includes the block to be released Clears
the bit in the block bitmap that corresponds to the block to be
released and marks the buffer that contains the bitmap as dirty. Increases the bg_free_blocks_count field in the block group descriptor and marks the corresponding buffer as dirty. Increases the s_free_blocks_count field of the disk superblock, marks the corresponding buffer as dirty, and sets the s_dirt flag of the superblock object. If the filesystem has been mounted with the MS_SYNCHRONOUS flag set, it invokes sync_dirty_buffer( ) and waits until the write operation on the bitmap's buffer terminates.
Файловая система Ext3
In this section we'll briefly describe the enhanced filesystem that has evolved from Ext2, named Ext3. The new filesystem has been designed with two simple concepts in mind:
To be a journaling filesystem (see the next section) To be, as much as possible, compatible with the old Ext2 filesystem
Ext3 achieves both the goals very well. In
particular, it is largely based on Ext2, so its data structures on disk
are essentially identical to those of an Ext2 filesystem. As a matter
of fact, if an Ext3 filesystem has been cleanly unmounted, it can be
remounted as an Ext2 filesystem; conversely, creating a journal of an
Ext2 filesystem and remounting it as an Ext3 filesystem is a simple,
fast operation.
Thanks to the compatibility between Ext3 and Ext2,
most descriptions in the previous sections of this chapter apply to
Ext3 as well. Therefore, in this section, we focus on the new feature
offered by Ext3 "the journal."
18.7.1. Journaling Filesystems
As disks became larger, one design choice of
traditional Unix filesystems (such as Ext2) turns out to be
inappropriate. As we know from Chapter 14,
updates to filesystem blocks might be kept in dynamic memory for long
period of time before being flushed to disk. A dramatic event such as a
power-down failure or a system crash might thus leave the filesystem in
an inconsistent state. To overcome this problem, each traditional Unix
filesystem is checked before being mounted; if it has not been properly
unmounted, then a specific program executes an exhaustive,
time-consuming check and fixes all the filesystem's data structures on
disk.
For instance, the Ext2 filesystem status is stored in the s_mount_state field of the superblock on disk. The e2fsck utility program is invoked by the boot script to check the value stored in this field; if it is not equal to EXT2_VALID_FS, the filesystem was not properly unmounted, and therefore e2fsck starts checking all disk data structures of the filesystem.
Clearly, the time spent checking the consistency of
a filesystem depends mainly on the number of files and directories to
be examined; therefore, it also depends on the disk size. Nowadays,
with filesystems reaching hundreds of gigabytes, a single consistency
check may take hours. The involved downtime is unacceptable for every
production environment or high-availability server.
The goal of a journaling filesystem
is to avoid running time-consuming consistency checks on the whole
filesystem by looking instead in a special disk area that contains the
most recent disk write operations named journal. Remounting a journaling filesystem after a system failure is a matter of a few seconds.
18.7.2. The Ext3 Journaling Filesystem
The idea behind Ext3 journaling is to perform each
high-level change to the filesystem in two steps. First, a copy of the
blocks to be written is stored in the journal; then, when the I/O data
transfer to the journal is completed (in short, data is committed to the journal), the blocks are written in the filesystem. When the I/O data transfer to the filesystem terminates (data is committed to the filesystem), the copies of the blocks in the journal are discarded.
While recovering after a system failure, the e2fsck program distinguishes the following two cases:
The system failure occurred before a commit to the journal Either the copies of the blocks relative to the
high-level change are missing from the journal or they are incomplete;
in both cases, e2fsck ignores them.
The system failure occurred after a commit to the journal The copies of the blocks are valid, and e2fsck writes them into the filesystem.
In the first case, the high-level change to the
filesystem is lost, but the filesystem state is still consistent. In
the second case, e2fsck applies the whole high-level change, thus fixing every inconsistency due to unfinished I/O data transfers into the filesystem.
Don't expect too much from a journaling filesystem;
it ensures consistency only at the system call level. For instance, a
system failure that occurs while you are copying a large file by
issuing several write( )
system calls will interrupt the copy operation, thus the duplicated file will be shorter than the original one.
Furthermore, journaling filesystems do not usually
copy all blocks into the journal. In fact, each filesystem consists of
two kinds of blocks: those containing the so-called metadata
and those containing regular data. In
the case of Ext2 and Ext3, there are six kinds of metadata:
superblocks, group block descriptors, inodes, blocks used for indirect
addressing (indirection blocks), data bitmap blocks, and inode bitmap
blocks. Other filesystems may use different metadata.
Several journaling filesystems, such as SGI's XFS
and IBM's JFS
, limit themselves to logging the
operations affecting metadata. In fact, metadata's log records are
sufficient to restore the consistency of the on-disk filesystem data
structures. However, since operations on blocks of file data are not
logged, nothing prevents a system failure from corrupting the contents
of the files.
The Ext3 filesystem, however, can be configured to
log the operations affecting both the filesystem metadata and the data
blocks of the files. Because logging every kind of write operation
leads to a significant performance penalty, Ext3 lets the system
administrator decide what has to be logged; in particular, it offers
three different journaling modes
:
Journal All filesystem data and metadata changes are
logged into the journal. This mode minimizes the chance of losing the
updates made to each file, but it requires many additional disk
accesses. For example, when a new file is created, all its data blocks
must be duplicated as log records. This is the safest and slowest Ext3
journaling mode.
Ordered Only changes to filesystem metadata are logged
into the journal. However, the Ext3 filesystem groups metadata and
relative data blocks so that data blocks are written to disk before
the metadata. This way, the chance to have data corruption inside the
files is reduced; for instance, each write access that enlarges a file
is guaranteed to be fully protected by the journal. This is the default
Ext3 journaling mode.
Writeback Only changes to filesystem metadata are logged;
this is the method found on the other journaling filesystems and is the
fastest mode.
The journaling mode of the Ext3 filesystem is specified by an option of the mount system command. For instance, to mount an Ext3 filesystem stored in the /dev/sda2 partition on the /jdisk mount point with the "writeback" mode, the system administrator can type the command:
# mount -t ext3 -o data=writeback /dev/sda2 /jdisk
18.7.3. The Journaling Block Device Layer
The Ext3 journal is usually stored in a hidden file named .journal located in the root directory of the filesystem.
The Ext3 filesystem does not handle the journal on its own; rather, it uses a general kernel layer named Journaling Block Device, or JBD. Right now, only Ext3 uses the JBD layer, but other filesystems might use it in the future.
The JBD layer is a rather complex piece of software.
The Ext3 filesystem invokes the JBD routines to ensure that its
subsequent operations don't corrupt the disk data structures in case of
system failure. However, JBD typically uses the same disk to log the
changes performed by the Ext3 filesystem, and it is therefore
vulnerable to system failures as much as Ext3. In other words, JBD must
also protect itself from system failures that could corrupt the journal.
Therefore, the interaction between Ext3 and JBD is essentially based on three fundamental units:
Log record Describes a single update of a disk block of the journaling filesystem.
Atomic operation handle Includes log records
relative to a single high-level change of the filesystem; typically,
each system call modifying the filesystem gives rise to a single atomic
operation handle.
Transaction Includes several atomic operation handles whose log records are marked valid for e2fsck at the same time.
18.7.3.1. Log records
A log record is
essentially the description of a low-level operation that is going to
be issued by the filesystem. In some journaling filesystems, the log
record consists of exactly the span of bytes modified by the operation,
together with the starting position of the bytes inside the filesystem.
The JBD layer, however, uses log records consisting of the whole buffer
modified by the low-level operation. This approach may waste a lot of
journal space (for instance, when the low-level operation just changes
the value of a bit in a bitmap), but it is also much faster because the
JBD layer can work directly with buffers and their buffer heads.
Log records are thus represented inside the journal
as normal blocks of data (or metadata). Each such block, however, is
associated with a small tag of type journal_block_tag_t, which stores the logical block number of the block inside the filesystem and a few status flags.
Later, whenever a buffer is being considered by the
JBD, either because it belongs to a log record or because it is a data
block that should be flushed to disk before the corresponding metadata
block (in the "ordered" journaling mode), the kernel attaches a journal_head data structure to the buffer head. In this case, the b_private field of the buffer head stores the address of the journal_head data structure and the BH_JBD flag is set (see the section "Block Buffers and Buffer Heads" in Chapter 15).
18.7.3.2. Atomic operation handles
Every system call modifying the filesystem is
usually split into a series of low-level operations that manipulate
disk data structures.
For instance, suppose that Ext3 must satisfy a user
request to append a block of data to a regular file. The filesystem
layer must determine the last block of the file, locate a free block in
the filesystem, update the data block bitmap inside the proper block
group, store the logical number of the new block either in the file's
inode or in an indirect addressing block, write the contents of the new
block, and finally, update several fields of the inode. As you see, the
append operation translates into many lower-level operations on the
data and metadata blocks of the filesystem.
Now, just imagine what could happen if a system
failure occurred in the middle of an append operation, when some of the
lower-level manipulations have already been executed while others have
not. Of course, the scenario could be even worse, with high-level
operations affecting two or more files (for example, moving a file from
one directory to another).
To prevent data corruption, the Ext3 filesystem must ensure that each system call is handled in an atomic way. An atomic operation handle
is a set of low-level operations on the disk data structures that
correspond to a single high-level operation. When recovering from a
system failure, the filesystem ensures that either the whole high-level
operation is applied or none of its low-level operations is.
Each atomic operation handle is represented by a descriptor of type handle_t. To start an atomic operation, the Ext3 filesystem invokes the journal_start( )
JBD function, which allocates, if necessary, a new atomic operation
handle and inserts it into the current transactions (see the next
section). Because every low-level operation on the disk might suspend
the process, the address of the active handle is stored in the journal_info field of the process descriptor. To notify that an atomic operation is completed, the Ext3 filesystem invokes the journal_stop( ) function.
18.7.3.3. Transactions
For reasons of efficiency, the JBD layer manages the
journal by grouping the log records that belong to several atomic
operation handles into a single transaction. Furthermore, all log records relative to a handle must be included in the same transaction.
All log records of a transaction are stored in
consecutive blocks of the journal. The JBD layer handles each
transaction as a whole. For instance, it reclaims the blocks used by a
transaction only after all data included in its log records is
committed to the filesystem.
As soon as it is created, a transaction may accept
log records of new handles. The transaction stops accepting new handles
when either of the following occurs:
A fixed amount of time has elapsed, typically 5 seconds. There are no free blocks in the journal left for a new handle.
A transaction is represented by a descriptor of type TRansaction_t. The most important field is t_state, which describes the current status of the transaction.
Essentially, a transaction can be:
Complete All log records included in the transaction have
been physically written onto the journal. When recovering from a system
failure, e2fsck considers every complete transaction of the journal and writes the corresponding blocks into the filesystem. In this case, the t_state field stores the value T_FINISHED.
Incomplete At least one log record included in the
transaction has not yet been physically written to the journal, or new
log records are still being added to the transaction. In case of system
failure, the image of the transaction stored in the journal is likely
not up-to-date. Therefore, when recovering from a system failure, e2fsck does not trust the incomplete transactions
in the journal and skips them. In this case, the t_state field stores one of the following values:
T_RUNNING Still accepting new atomic operation handles.
T_LOCKED Not accepting new atomic operation handles, but some of them are still unfinished.
T_FLUSH All atomic operation handles have finished, but some log records are still being written to the journal.
T_COMMIT All log records of the atomic operation handles
have been written to disk, but the transaction has yet to be marked as
completed on the journal.
At any time the journal may include several transactions, but only one of them is in the T_RUNNING state it is the active transaction that is accepting the new atomic operation handle requests issued by the Ext3 filesystem.
Several transactions in the journal might be
incomplete, because the buffers containing the relative log records
have not yet been written to the journal.
If a transaction is complete, all its log records
have been written to the journal but some of the corresponding buffers
have yet to be written onto the filesystem. A complete transaction is
deleted from the journal when the JBD layer verifies that all buffers
described by the log records have been successfully written onto the
Ext3 filesystem.
18.7.4. How Journaling Works
Let's try to explain how journaling works with an
example: the Ext3 filesystem layer receives a request to write some
data blocks of a regular file.
As you might easily guess, we are not going to
describe in detail every single operation of the Ext3 filesystem layer
and of the JBD layer. There would be far too many issues to be covered!
However, we describe the essential actions:
The service routine of the write( )
system call triggers the write method of the file object associated with the Ext3 regular file. For Ext3, this method is implemented by the generic_file_write( ) function, already described in the section "Writing to a File" in Chapter 16. The generic_file_write( ) function invokes the prepare_write method of the address_space object several times, once for every page of data involved by the write operation. For Ext3, this method is implemented by the ext3_prepare_write( ) function. The ext3_prepare_write( ) function starts a new atomic operation by invoking the journal_start( )
JBD function. The handle is added to the active transaction. Actually,
the atomic operation handle is created only when executing the first
invocation of the journal_start( ) function. Following invocations verify that the journal_info field of the process descriptor is already set and use the referenced handle. The ext3_prepare_write( ) function invokes the block_prepare_write( ) function already described in Chapter 16, passing to it the address of the ext3_get_block( ) function. Remember that block_prepare_write( ) takes care of preparing the buffers and the buffer heads of the file's page. When the kernel must determine the logical number of a block of the Ext3 filesystem, it executes the ext3_get_block( ) function. This function is actually similar to ext2_get_block( ), which is described in the earlier section "Allocating a Data Block."
A crucial difference, however, is that the Ext3 filesystem invokes
functions of the JBD layer to ensure that the low-level operations are
logged: Before issuing a low-level write operation on a metadata
block of the filesystem, the function invokes journal_get_write_access( ).
Basically, this latter function adds the metadata buffer to a list of
the active transaction. However, it must also check whether the
metadata is included in an older incomplete transaction of the journal;
in this case, it duplicates the buffer to make sure that the older
transactions are committed with the old content. After updating the buffer containing the metadata block, the Ext3 filesystem invokes journal_dirty_metadata( ) to move the metadata buffer to the proper dirty list of the active transaction and to log the operation in the journal.
Notice
that metadata buffers handled by the JBD layer are not usually included
in the dirty lists of buffers of the inode, so they are not written to
disk by the normal disk cache flushing mechanisms described in Chapter 15. If the Ext3 filesystem has been mounted in "journal" mode, the ext3_prepare_write( ) function also invokes journal_get_write_access( ) on every buffer touched by the write operation. Control returns to the generic_file_write( ) function, which updates the page with the data stored in the User Mode address space and then invokes the commit_write method of the address_space object. For Ext3, the function that implements this method depends on how the Ext3 filesystem has been mounted: If the Ext3 filesystem has been mounted in "journal" mode, the commit_write method is implemented by the ext3_journalled_commit_write( ) function, which invokes journal_dirty_metadata( )
on every buffer of data (not metadata) in the page. This way, the
buffer is included in the proper dirty list of the active transaction
and not in the dirty list of the owner inode; moreover, the
corresponding log records are written to the journal. Finally, ext3_journalled_commit_write( ) invokes journal_stop( ) to notify the JBD layer that the atomic operation handle is closed. If the Ext3 filesystem has been mounted in "ordered" mode, the commit_write method is implemented by the ext3_ordered_commit_write( ) function, which invokes the journal_dirty_data( )
function on every buffer of data in the page to insert the buffer in a
proper list of the active transactions. The JBD layer ensures that all
buffers in this list are written to disk before the metadata buffers of
the transaction. No log record is written onto the journal. Next, ext3_ordered_commit_write( ) executes the normal generic_commit_write( ) function described in Chapter 15, which inserts the data buffers in the list of the dirty buffers of the owner inode. Finally, ext3_ordered_commit_write( ) invokes journal_stop( ) to notify the JBD layer that the atomic operation handle is closed. If the Ext3 filesystem has been mounted in "writeback" mode, the commit_write method is implemented by the ext3_writeback_commit_write( ) function, which executes the normal generic_commit_write( ) function described in Chapter 15, which inserts the data buffers in the list of the dirty buffers of the owner inode. Then, ext3_writeback_commit_write( ) invokes journal_stop( ) to notify the JBD layer that the atomic operation handle is closed.
The service routine of the write( )
system call terminates here. However, the JBD layer has not finished
its work. Eventually, our transaction becomes complete when all its log
records have been physically written to the journal. Then journal_commit_transaction( ) is executed. If the Ext3 filesystem has been mounted in "ordered" mode, the journal_commit_transaction( )
function activates the I/O data transfers for all data buffers included
in the list of the transaction and waits until all data transfers
terminate. The journal_commit_transaction( )
function activates the I/O data transfers for all metadata buffers
included in the transaction (and also for all data buffers, if Ext3 was
mounted in "journal" mode). Periodically,
the kernel activates a checkpoint activity for every complete
transaction in the journal. The checkpoint basically involves verifying
whether the I/O data transfers triggered by journal_commit_transaction( ) have successfully terminated. If so, the transaction can be deleted from the journal.
Of course, the log records in the journal never play
an active role until a system failure occurs. Only during system reboot
does the e2fsck utility program scan the journal stored in the
filesystem and reschedule all write operations described by the log
records of the complete transactions.
|
|

 LINUX
LINUX