Template Argument Deduction
Явное определение параметров шаблона при каждом вызове делает код громоздким.
Компилятор в состоянии сам определять необходимость декларирования параметров шаблона -
для этого существует template argument deduction.

|
Deduction Process
Этот процесс сравнивает аргументы вызова функции с аргументами функции-шаблона
и делает вывод о корректности параметров.
Рассмотрим пример:
template<typename T>
T const& max (T const& a, T const& b)
{
return a<b?b:a;
}
int g = max(1, 1.0);
Мы видим , что первый аргумент имеет тип int и второй - double,что неверно.
Пример:
template<typename T>
typename T::ElementT at (T const& a, int i)
{
return a[i];
}
void f (int* p)
{
int x = at(p, 7);
}
Тип T определен как int*.
Этот тип не соответствует возвращаемому типу T::ElementT.
Следующий код более правильный :
void f (int* p)
{
int x = at<int*>(p, 7);
}
Рассмотрим примеры с типами , которые могут быть даны как ссылочные :
template<typename T> void f(T); //PisT
template<typename T> void g(T&); // P is also T
double x[20];
int const seven = 7;
f(x); // nonreference parameter: T is double*
g(x); // reference parameter: T is double[20]
f(seven); // nonreference parameter: T is int
g(seven); // reference parameter: T is int const
f(7); // nonreference parameter: T is int
g(7); // reference parameter: T is int => ERROR: can't pass 7 to int&
Вызов f(x) соответствует типу double*.
Вызов f(seven) будет с типом int.
Вызов g(x) будет типом double[20].
Вызов g(seven) в качестве типа имеет int const.
Вызов g(7) имеет тип int , что является ошибкой.
|
11.2 Deduced Contexts
Parameterized types that are considerably more complex than T can be matched to a given argument
type. Here are a few examples that are still fairly basic:
template<typename T>
void f1(T*);
template<typename E, int N>
void f2(E(&)[N]);
template<typename T1, typename T2, typename T3>
void f3(T1 (T2::*)(T3*));
class S {
public:
void f(double*);
};
void g (int*** ppp)
{
bool b[42];
f1(ppp); // deduces T to be int**
f2(b); // deduces E to be bool and N to be 42
f3(&S::f); // deduces T1 = void, T2=S, and T3 = double
}
Complex type declarations are built from more elementary constructs (pointer, reference, array, and function declarators; pointer-to-member declarators; template-ids; and so forth), and the matching process proceeds from the top-level construct and recurses through the composing elements. It is fair to say that most type declaration constructs can be matched in this way, and these are called deduced contexts. However, a few constructs are not deduced contexts:
Qualified type names. A type name like Q<T>::X will never be used to deduce a template parameter T, for example. Nontype expressions that are not just a nontype parameter. A type name like S<I+1> will never be used to deduce I, for example. Neither will T be deduced by matching against a parameter of type int(&)[sizeof(S<T>)].
These limitations should come as no surprise because the deduction would, in general, not be unique (or even finite), although qualified type names are sometimes easily overlooked. A nondeduced context does not automatically imply that the program is in error or even that the parameter being analyzed cannot participate in type deduction. To illustrate this, consider the following, more intricate example:
// details/fppm.cpp
template <int N>
class X {
public:
typedef int I;
void f(int) {
}
};
template<int N>
void fppm(void (X<N>::*p)(X<N>::I));
int main()
{
fppm(&X<33>::f); // fine: N deduced to be 33
}
In the function template fppm(), the subconstruct X<N>::I is a nondeduced context. However, the member-class component X<N> of the pointer-to-member type is a deducible context, and when the parameter N, which is deduced from it, is plugged in the nondeduced context, a type compatible with that of the actual argument &X<33>::f is obtained. The deduction therefore succeeds on that argument-parameter pair.
Conversely, it is possible to deduce contradictions for a parameter type entirely built from deduced contexts. For example, assuming suitably declared class templates X and Y:
template<typename T>
void f(X<Y<T>, Y<T> >);
void g()
{
f(X<Y<int>, Y<int> >()); // OK
f(X<Y<int>, Y<char> >()); // ERROR: deduction fails
}
The problem with the second call to the function template f() is that the two arguments deduce different arguments for the parameter T, which is not valid. (In both cases, the function call argument is a temporary object obtained by calling the default constructor of the class template X.)
|
11.3 Special Deduction Situations
There are two situations in which the pair (A, P) used for deduction is not obtained from the arguments to a function call and the parameters of a function template. The first situation occurs when the address of a function template is taken. In this case, P is the parameterized type of the function template declarator, and A is the function type underlying the pointer that is initialized or assigned to. For example:
template<typename T>
void f(T, T);
void (*pf)(char, char) = &f;
In this example, P is void(T, T) and A is void(char, char). Deduction succeeds with T substituted with char, and pf is initialized to the address of the specialization f<char>.
The other special situation occurs with conversion operator templates. For example:
class S {
public:
template<typename T, int N> operator T[N]&();
};
In this case, the pair (P, A) is obtained as if it involved an argument of the type to which we are attempting to convert and a parameter type that is the return type of the conversion operator. The following code illustrates one variation:
void f(int (&)[20]);
void g(S s)
{
f(s);
}
Here we are attempting to convert S to int (&)[20]. Type A is therefore int[20] and type P is T[N]. The deduction succeeds with T substituted with int and N with 20.
|
11.4 Allowable Argument Conversions
Normally, template deduction attempts to find a substitution of the function template parameters that make the parameterized type P identical to type A. However, when this is not possible, the following differences are tolerable:
If the original parameter was declared with a reference declarator, the substituted P type may be more const/volatile-qualified than the A type. If the A type is a pointer or pointer-to-member type, it may be convertible to the substituted P type by a qualification conversion (in other words, a conversion that adds const and/or volatile qualifiers). Unless deduction occurs for a conversion operator template, the substituted P type may be a base class type of the A type, or a pointer to a base class type of the class type for which A is a pointer type. For example:
template<typename T>
class B<T> {
};
template<typename T>
class D : B<T> {
};
template<typename T> void f(B<T>*);
void g(D<long> dl)
{
f(&dl); // deduction succeeds with T substituted with long
}
The relaxed matching requirements are considered only if an exact match was not possible. Even so, deduction succeeds only if exactly one substitution was found to fit the A type to the substituted P type with these added conversions.
|
11.5 Class Template Parameters
Template argument deduction applies exclusively to function and member function templates. In particular, the arguments for a class template are not deduced from the arguments to a call of one of its constructors. For example:
template<typename T>
class S {
public:
S(T b) : a(b) {
}
private:
T a;
};
S x(12); // ERROR: the class template parameter T is not deduced
// from the constructor call argument 12
|
11.6 Default Call Arguments
Default function call arguments can be specified in function templates just as they are in ordinary functions:
template<typename T>
void init (T* loc, T const& val = T())
{
*loc = val;
}
In fact, as this example shows, the default function call argument can depend on a template parameter. Such a dependent default argument is instantiated only if no explicit argument is provideda principle that makes the following example valid:
class S {
public:
S(int, int);
};
S s(0, 0);
int main()
{
init(&s, S(7, 42)); // T() is invalid for T=S, but the default
// call argument T() needs no instantiation
// because an explicit argument is given
}
Even when a default call argument is not dependent, it cannot be used to deduce template arguments. This means that the following is invalid C++:
template<typename T>
void f (T x = 42)
{
}
int main()
{
f<int>(); // OK: T = int
f(); // ERROR: cannot deduce T from default call argument
}
|
11.7 The Barton-Nackman Trick
In 1994, John J. Barton and Lee R. Nackman presented a template technique that they called restricted template expansion. The technique was motivated in part by the fact thatat the time function templates could not be overloaded
and namespaces were not available in most compilers.
To illustrate this, suppose we have a class template Array for which we want to define the equality operator ==. One possibility is to declare the operator as a member of the class template, but this is not good practice because the first argument (binding to the this pointer) is subject to conversion rules that are different from the second argument. Because operator == is meant to be symmetrical with respect to its arguments, it is preferable to declare it as a namespace scope function. An outline of a natural approach to its implementation may look like the following:
template<typename T>
class Array {
public:
…
};
template<typename T>
bool operator == (Array<T> const& a, Array<T> const& b)
{
…
}
However, if function templates cannot be overloaded, this presents a problem: No other operator == template can be declared in that scope, and yet it is likely that such a template would be needed for other class templates. Barton and Nackman resolved this problem by defining the operator in the class as a normal friend function:
template<typename T>
class Array {
public:
…
friend bool operator == (Array<T> const& a,
Array<T> const& b) {
return ArraysAreEqual(a, b);
}
};
Suppose this version of Array is instantiated for type float. The friend operator function is then declared as a result of that instantiation, but note that this function itself is not an instantiation of a function template. It is a normal nontemplate function that gets injected in the global scope as a side effect of the instantiation process. Because it is a nontemplate function, it could be overloaded with other declarations of operator == even before overloading of function templates was added to the language. Barton and Nackman referred to this as restricted template expansion because it avoided the use of a template operator==(T, T) that applied to all types T (in other words, unrestricted expansion).
Because operator == (Array<T> const&, Array<T> const&) is defined inside a class definition, it is implicitly considered to be an inline function, and we therefore decided to delegate the implementation to a function template ArraysAreEqual, which doesn't need to be inline and is unlikely to conflict with another template of the same name.
The Barton-Nackman trick is no longer needed for its original purpose, but it is interesting to study it because it allows us to generate nontemplate functions along with class template instantiations. Because the functions are not generated from function templates, they do not require template argument deduction but are subject to normal overload resolution rules (see Appendix B). In theory, this could mean that additional implicit conversions may be considered when matching the friend function to a specific call site. However, this is of relatively little benefit because in standard C++ (unlike the language at the time Barton and Nackman came up with their idea), the injected friend function is not unconditionally visible in the surrounding scope: It is visible only through ADL. This means that the arguments of the function call must already have the class containing the friend function as an associated class. The friend function would not be found if the arguments were of an unrelated class type that could be converted to the class containing the friend. For example:
class S {
};
template<typename T>
class Wrapper {
private:
T object;
public:
Wrapper(T obj) : object(obj) { // implicit conversion from
// T to Wrapper<T>
}
friend void f(Wrapper<T> const& a) {
}
};
int main()
{
Ss;
Wrapper<S> w(s);
f(w); // OK: Wrapper<S> is a class associated with w
f(s); // ERROR: Wrapper<S> is not associated with s
}
In this example, the call f(w) is valid because the function f() is a friend declared in Wrapper<S> which is a class associated with the argument w.
However, in the call f(s) the friend declaration of function f(Wrapper<S> const&) is not visible because the class Wrapper<S> in which it is defined is not associated with the argument s of type S. Hence, even though there is a valid implicit conversion from type S to type Wrapper<S> (through the constructor of Wrapper<S>), this conversion is never considered because the candidate function f is not found in the first place.
In conclusion, there is little advantage to define a friend function in a class template over simply defining an ordinary function template.
|
11.8 Afternotes
Template argument deduction for function templates was part of the original C++ design. In fact, the alternative provided by explicit template arguments did not become part of C++ until many years later.
Friend name injection was considered harmful by many C++ language experts because it made the validity of programs more sensitive to the ordering of instantiations. Bill Gibbons (who at the time was working on the Taligent compiler) was among the most vocal supporters of addressing the problem, because eliminating instantiation order dependencies enabled new and interesting C++ development environments (on which Taligent was rumored to be working). However, the Barton-Nackman trick required a form of friend name injection, and it is this particular technique that caused it to remain in the language in its current (weakened) form.
Interestingly, many people have heard of the "Barton-Nackman trick," but few correctly associate it with the technique described earlier. As a result, you may find many other techniques involving friends and templates being referred to incorrectly as the "Barton-Nackman trick" (for example, see Section 16.5 on page 299).
|
Chapter 12. Specialization and Overloading
So far we have studied how C++ templates allow a generic definition to be expanded into a family of related classes or functions. Although this is a powerful mechanism, there are many situations in which the generic form of an operation is far from optimal for a specific substitution of template parameters.
C++ is somewhat unique among other popular programming languages with support for generic programming because it has a rich set of features that enable the transparent replacement of a generic definition by a more specialized facility. In this chapter we study the two C++ language mechanisms that allow pragmatic deviations from pure genericness: template specialization and overloading of function templates.
|
12.1 When "Generic Code" Doesn't Quite Cut It
Consider the following example:
template<typename T>
class Array {
private:
T* data;
…
public:
Array(Array<T> const&);
Array<T>& operator = (Array<T> const&);
void exchange_with (Array<T>* b) {
T* tmp = data;
data = b->data;
b->data = tmp;
}
T& operator[] (size_t k) {
return data[k];
}
…
};
template<typename T> inline
void exchange (T* a, T* b)
{
T tmp(*a);
*a = *b;
*b = tmp;
}
For simple types, the generic implementation of exchange() works well. However, for types with expensive copy operations, the generic implementation may be much more expensiveboth in terms of machine cycles and in terms of memory usagethan an implementation that is tailored to the particular, given structure. In our example, the generic implementation requires one call to the copy constructor of Array<T> and two calls to its copy-assignment operator. For large data structures these copies can often involve copying relatively large amounts of memory. However, the functionality of exchange() could presumably often be replaced just by swapping the internal data pointers, as is done in the member function exchange_with().
12.1.1 Transparent Customization
In our previous example, the member function exchange_with() provides an efficient alternative to the generic exchange() function, but the need to use a different function is inconvenient in several ways:
Users of the Array class have to remember an extra interface and must be careful to use it when possible. Generic algorithms can generally not discriminate between various possibilities. For example:
template<typename T>
void generic_algorithm(T* x, T* y)
{
…
exchange(x, y); // How do we select the right algorithm?
…
}
Because of these considerations, C++ templates provide ways to customize function templates and class templates transparently. For function templates, this is achieved through the overloading mech-anism. For example, we can write an overloaded set of quick_exchange() function templates as follows:
template<typename T> inline
void quick_exchange(T* a, T* b) // (1)
{
T tmp(*a);
*a = *b;
*b = tmp;
}
template<typename T> inline
void quick_exchange(Array<T>* a, Array<T>* b) // (2)
{
a->exchange_with(b);
}
void demo(Array<int>* p1, Array<int>* p2)
{
int x, y;
quick_exchange(&x, &y); // uses (1)
quick_exchange(p1, p2); // uses (2)
}
The first call to quick_exchange() has two arguments of type int* and therefore deduction succeeds only with the first template (declared at point (1)) when T is substituted by int. There is therefore no doubt regarding which function should be called. In contrast, the second call can be matched with either template: Viable functions for the call quick_exchange(p1, p2) are obtained both when substituting Array<int> for T in the first template and when substituting int in the second template. Furthermore, both substitutions result in functions with parameter types that exactly match the argument types of the second call. Ordinarily, this would lead us to conclude that the call is ambiguous, but (as we will discuss later) the C++ language considers the second template to be "more specialized" than the first. All other things being equal, overload resolution prefers the more specialized template and hence selects the template at point (2).
12.1.2 Semantic Transparency
The use of overloading as shown in the previous section is very useful in achieving transparent customization of the instantiation process, but it is important to realize that this "transparency" depends a great deal on the details of the implementation. To illustrate this, consider our quick_exchange() solution. Although both the generic algorithm and the one customized for Array<T> types end up swapping the values that are being pointed to, the side effects of the operations are very different.
This is dramatically illustrated by considering some code that compares the exchange of struct objects with the exchange of Array<T>s:
struct S {
int x;
} s1, s2;
void distinguish (Array<int> a1, Array<int> a2)
{
int* p = &a1[0];
int* q = &s1.x;
a1[0] = s1.x = 1;
a2[0] = s2.x = 2;
quick_exchange(&a1, &a2); // *p == 1 after this (still)
quick_exchange(&s1, &s2); // *q == 2 after this
}
This example shows that a pointer p into the first Array becomes a pointer into the second array after quick_exchange() is called. However, the pointer into the non-Array s1 remains pointing into s1 even after the exchange operation: Only the values that were pointed to were exchanged. The difference is significant enough that it may confuse clients of the template implementation. The prefix quick_ is helpful in attracting attention to the fact that a shortcut may be taken to realize the desired operation. However, the original generic exchange() template can still have a useful optimization for Array<T>s:
template<typename T>
void exchange(Array<T>* a, Array<T>* b)
{
T* p = &a[0];
T* q = &b[0];
for (size_t k = a->size(); --k != 0; ) {
exchange(p++, q++);
}
}
The advantage of this version over the generic code is that no (potentially) large temporary Array<T> is needed. The exchange() template is called recursively so that good performance is achieved even for types such as Array<Array<char> >. Note also that the more specialized version of the template is not declared inline because it does a considerable amount of work of its own, whereas the original generic implementation is inline because it performs only a few operations (each of which is potentially expensive).
|
12.2 Overloading Function Templates
In the previous section we saw that two function templates with the same name can coexist, even though they may be instantiated so that both have identical parameter types. Here is another simple example of this:
// details/funcoverload.hpp
template<typename T>
int f(T)
{
return 1;
}
template<typename T>
int f(T*)
{
return 2;
}
When T is substituted by int* in the first template, a function is obtained that has exactly the same parameter (and return) types as the one obtained by substituting int for T in the second template. Not only can these templates coexist, their respective instantiations can coexist even if they have identical parameter and return types.
The following demonstrates how two such generated functions can be called using explicit template argument syntax (assuming the previous template declarations):
// details/funcoverload.cpp
#include <iostream>
#include "funcoverload.hpp"
int main()
{
std::cout << f<int*>((int*)0) << std::endl;
std::cout << f<int>((int*)0) << std::endl;
}
This program has the following output:
1
2
To clarify this, let's analyze the call f<int*>((int*)0) in detail.
The syntax f<int*> indicates that we want to substitute the first template parameter of the template f with int* without relying on template argument deduction. In this case there is more than one template f, and therefore an overload set is created containing two functions generated from templates: f<int*>(int*) (generated from the first template) and f<int*>(int**) (generated from the second template). The argument to the call (int*)0 has type int*. This matches only the function generated from the first template, and hence that is the function that ends up being called.
A similar analysis can be written for the second call.
12.2.1 Signatures
Two functions can coexist in a program if they have distinct signatures. We define the signature of a function as the following information
:
The unqualified name of the function (or the name of the function template from which it was generated) The class or namespace scope of that name and, if the name has internal linkage, the translation unit in which the name is declared The const, volatile, or const volatile qualification of the function (if it is a member function with such a qualifier) The types of the function parameters (before template parameters are substituted if the function is generated from a function template) Its return type, if the function is generated from a function template The template parameters and the template arguments, if the function is generated from a function template
This means that the following templates and their instantiations could, in principle, coexist in the same program:
template<typename T1, typename T2>
void f1(T1, T2);
template<typename T1, typename T2>
void f1(T2, T1);
template<typename T>
long f2(T);
template<typename T>
char f2(T);
However, they cannot always be used when they're declared in the same scope because instantiating both creates an overload ambiguity. For example:
#include <iostream>
template<typename T1, typename T2>
void f1(T1, T2)
{
std::cout << "f1(T1, T2)\n";
}
template<typename T1, typename T2>
void f1(T2, T1)
{
std::cout << "f1(T2, T1)\n";
}
// fine so far
int main()
{
f1<char, char>('a', 'b'); // ERROR: ambiguous
}
Here, the function f1<T1 = char, T2 = char>(T1, T2) can coexist with the function f1<T1 = char, T2 = char>(T2, T1), but overload resolution will never prefer one over the other. If the templates appear in different translation units, then the two instantiations can actually exist in the same program (and, for example, a linker should not complain about duplicate definitions because the signatures of the instantiations are distinct):
// Translation unit 1:
#include <iostream>
template<typename T1, typename T2>
void f1(T1, T2)
{
std::cout << "f1(T1, T2)\n";
}
void g()
{
f1<char, char>('a', 'b');
}
// Translation unit 2:
#include <iostream>
template<typename T1, typename T2>
void f1(T2, T1)
{
std::cout << "f1(T2, T1)\n";
}
extern void g(); // defined in translation unit 1
int main()
{
f1<char, char>('a', 'b');
g();
}
This program is valid and produces the following output:
f1(T2, T1)
f1(T1, T2)
12.2.2 Partial Ordering of Overloaded Function Templates
Reconsider our earlier example:
#include <iostream>
template<typename T>
int f(T)
{
return 1;
}
template<typename T>
int f(T*)
{
return 2;
}
int main()
{
std::cout << f<int*>((int*)0) << std::endl;
std::cout << f<int>((int*)0) << std::endl;
}
We found that after substituting the given template argument lists (<int*> and <int>), overload resolution ended up selecting the right function to call. However, a function is selected even when explicit template arguments are not provided. In this case, template argument deduction comes into play. Let's slightly modify function main() in the previous example to discuss this mechanism:
#include <iostream>
template<typename T>
int f(T)
{
return 1;
}
template<typename T>
int f(T*)
{
return 2;
}
int main()
{
std::cout << f(0) << std::endl;
std::cout << f((int*)0) << std::endl;
}
Consider the first call (f(0)): The type of the argument is int, which matches the type of the parameter of the first template if we substitute T with int. However, the parameter type of the second template is always a pointer and, hence, after deduction, only an instance generated from the first template is a candidate for the call. In this case overload resolution is trivial.
The second call (f((int*)0)) is more interesting: Argument deduction succeeds for both templates, yielding the functions f<int*>(int*) and f<int>(int*). From a traditional overload resolution perspective, both are equally good functions to call with an int* argument, which would suggest that the call is ambiguous (see Appendix B). However, in this sort of case an additional overload resolution criterion comes into play: The function generated from the "more specialized" template is selected. Here (as we see shortly), the second template is considered "more specialized" and thus the output of our example is (again):
1
2
12.2.3 Formal Ordering Rules
In our last example it may seem very intuitive that the second template is "more special" than the first because the first can accommodate just about any argument type whereas the second allows only pointer types. However, other examples are not necessarily as intuitive. In what follows, we describe the exact procedure to determine whether one function template participating in an overload set is more specialized than the other. However, note that these are partial ordering rules: It is possible that given two templates neither can be considered more specialized than the other. If overload resolution must select between two such templates, no decision can be made, and the program contains an ambiguity error.
Let's assume we are comparing two identically named function templates ft1 and ft2 that seem viable for a given function call. Function call parameters that are covered by a default argument and ellipsis parameters that are not used are ignored in what follows. We then synthesize two artificial lists of argument types (or for conversion function templates, a return type) by substituting every template parameter as follows:
Replace each template type parameter with a unique "made up" type. Replace each template template parameter with a unique "made up" class template. Replace each nontype template parameter with a unique "made up" value of the appropriate type.
If template argument deduction of the second template against the first synthesized list of argument types succeeds with an exact match, but not vice versa, then the first template is said to be more specialized than the second. Conversely, if template argument deduction of the first template against the second synthesized list of argument types succeeds with an exact match, but not vice versa, then the second template is said to be more specialized than the first. Otherwise (either no deduction succeeds or both succeed), there is no ordering between the two templates.
Let's make this concrete by applying it to the two templates in our last example. From these two templates we synthesize two lists of argument types by replacing the template parameters as described earlier: (A1) and (A2*) (where A1 and A2 are unique made up types). Clearly, deduction of the first template against the second list of argument types succeeds by substituting A2* for T. However, there is no way to make T* of the second template match the nonpointer type A1 in the first list. Hence, we formally conclude that the second template is more specialized than the first.
Finally, consider a more intricate example involving multiple function parameters:
template<typename T>
void t(T*, T const* = 0, ...);
template<typename T>
void t(T const*, T*, T* = 0);
void example(int* p)
{
t(p, p);
}
First, because the actual call does not use the ellipsis parameter for the first template and the last parameter of the second template is covered by its default argument, these parameters are ignored in the partial ordering. Note that the default argument of the first template is not used; hence the corresponding parameter participates in the ordering.
The synthesized lists of argument types are (A1*, A1 const*) and (A2 const*, A2*). Template argument deduction of (A1*, A1 const*) versus the second template actually succeeds with the substitution of T with A1 const, but the resulting match is not exact because a qualification adjustment is needed to call t<A1 const>(A1 const*, A1 const*, A1 const* = 0) with arguments of types (A1*, A1 const*). Similarly, no exact match can be found by deducing template arguments for the first template from the argument type list (A2 const*, A2*). Therefore, there is no ordering relationship between the two templates, and the call is ambiguous.
The formal ordering rules generally result in the intuitive selection of function templates. Once in a while, however, an example comes up for which the rules do not select the intuitive choice. It is therefore possible that the rules will be revised to accommodate those examples in the future.
12.2.4 Templates and Nontemplates
Function templates can be overloaded with nontemplate functions. All else being equal, the nontemplate function is preferred in selecting the actual function being called. The following example illustrates this:
// details/nontmpl.cpp
#include <string>
#include <iostream>
template<typename T>
std::string f(T)
{
return "Template";
}
std::string f(int&)
{
return "Nontemplate";
}
int main()
{
int x = 7;
std::cout << f(x) << std::endl;
}
This should output:
Nontemplate
|
12.3 Explicit Specialization
The ability to overload function templates, combined with the partial ordering rules to select the "best" matching function template, allows us to add more specialized templates to a generic implementation to tune code transparently for greater efficiency. However, class templates cannot be overloaded. Instead, another mechanism was chosen to enable transparent customization of class templates: explicit specialization. The standard term explicit specialization refers to a language feature that we call full specialization instead. It provides an implementation for a template with template parameters that are fully substituted: No template parameters remain. Class templates and function templates can be fully specialized. So can members of class templates that may be defined outside the body of a class definition (i.e., member functions, nested classes, and static data members).
In a later section, we will describe partial specialization. This is similar to full specialization, but instead of fully substituting the template parameters, some parameterization is left in the alternative implementation of a template. Full specializations and partial specializations are both equally "explicit" in our source code, which is why we avoid the term explicit specialization in our discussion. Neither full nor partial specialization introduces a totally new template or template instance. Instead, these constructs provide alternative definitions for instances that are already implicitly declared in the generic (or unspecialized) template. This is a relatively important conceptual observation, and it is a key difference with overloaded templates.
12.3.1 Full Class Template Specialization
A full specialization is introduced with a sequence of three tokens: template, <, and >.
In addition, the class name declarator is followed by the template arguments for which the specialization is declared. The following example illustrates this:
template<typename T>
class S {
public:
void info() {
std::cout << "generic (S<T>::info())\n";
}
};
template<>
class S<void> {
public:
void msg() {
std::cout << "fully specialized (S<void>::msg())\n";
}
};
Note how the implementation of the full specialization does not need to be related in any way to the generic definition: This allows us to have member functions of different names (info versus msg). The connection is solely determined by the name of the class template.
The list of specified template arguments must correspond to the list of template parameters. For example, it is not valid to specify a nontype value for a template type parameter. However, template arguments for parameters with default template arguments are optional:
template<typename T>
class Types {
public:
typedef int I;
};
template<typename T, typename U = typename Types<T>::I>
class S; // (1)
template<>
class S<void> { // (2)
public:
void f();
};
template<> class S<char, char>; // (3)
template<> class S<char, 0>; // ERROR: 0 cannot substitute U
int main()
{
S<int>* pi; // OK: uses (1), no definition needed
S<int> e1; // ERROR: uses (1), but no definition available
S<void>* pv; // OK: uses (2)
S<void,int> sv; // OK: uses (2), definition available
S<void,char> e2; // ERROR: uses (1), but no definition available
S<char,char> e3; // ERROR: uses (3), but no definition available
}
template<>
class S<char, char> { // definition for (3)
};
As this example also shows, declarations of full specializations (and of templates) do not necessarily have to be definitions. However, when a full specialization is declared, the generic definition is never used for the given set of template arguments. Hence, if a definition is needed but none is provided, the program is in error. For class template specialization it is sometimes useful to "forward declare" types so that mutually dependent types can be constructed. A full specialization declaration is identical to a normal class declaration in this way (it is not a template declaration). The only differences are the syntax and the fact that the declaration must match a previous template declaration. Because it is not a template declaration, the members of a full class template specialization can be defined using the ordinary out-of-class member definition syntax (in other words, the template<> prefix cannot be specified):
template<typename T>
class S;
template<> class S<char**> {
public:
void print() const;
};
// the following definition cannot be preceded by template<>
void S<char**>::print()
{
std::cout << "pointer to pointer to char\n";
}
A more complex example may reinforce this notion:
template<typename T>
class Outside {
public:
template<typename U>
class Inside {
};
};
template<>
class Outside<void> {
// there is no special connection between the following nested class
// and the one defined in the generic template
template<typename U>
class Inside {
private:
static int count;
};
};
// the following definition cannot be preceded by template<>
template<typename U>
int Outside<void>::Inside<U>::count = 1;
A full specialization is a replacement for the instantiation of a certain generic template, and it is not valid to have both the explicit and the generated versions of a template present in the same program. An attempt to use both in the same file is usually caught by a compiler:
template <typename T>
class Invalid {
};
Invalid<double> x1; // causes the instantiation of Invalid<double>
template<>
class Invalid<double>; // ERROR: Invalid<double> already instantiated!
Unfortunately, if the uses occur in different translation units, the problem may not be caught so easily. The following invalid C++ example consists of two files and compiles and links on many implementations, but it is invalid and dangerous:
// Translation unit 1:
template<typename T>
class Danger {
public:
enum { max = 10; };
};
char buffer[Danger<void>::max]; // uses generic value
extern void clear(char const*);
int main()
{
clear(buffer);
}
// Translation unit 2:
template<typename T>
class Danger;
template<>
class Danger<void> {
public:
enum { max = 100; };
};
void clear(char const* buf)
{
// mismatch in array bound!
for(intk=0;k<Danger<void>::max; ++k) {
buf[k] = '\0';
}
}
This example is clearly contrived to keep it short, but it illustrates that care must be taken to ensure that the declaration of the specialization is visible to all the users of the generic template. In practical terms, this means that a declaration of the specialization should normally follow the declaration of the template in its header file. When the generic implementation comes from an external source (such that the corresponding header files should not be modified), this is not necessarily practical, but it may be worth creating a header including the generic template followed by declarations of the specializations to avoid these hard-to-find errors. We find that, in general, it is better to avoid specializing templates coming from an external source unless it is clearly marked as being designed for that purpose.
12.3.2 Full Function Template Specialization
The syntax and principles behind (explicit) full function template specialization are much the same as those for full class template specialization, but overloading and argument deduction come into play.
The full specialization declaration can omit explicit template arguments when the template being specialized can be determined via argument deduction (using as argument types the parameter types provided in the declaration) and partial ordering. For example:
template<typename T>
int f(T) // (1)
{
return 1;
}
template<typename T>
int f(T*) // (2)
{
return 2;
}
template<> int f(int) // OK: specialization of (1)
{
return 3;
}
template<> int f(int*) // OK: specialization of (2)
{
return 4;
}
A full function template specialization cannot include default argument values. However, any default arguments that were specified for the template being specialized remain applicable to the explicit specialization:
template<typename T>
int f(T, T x = 42)
{
return x;
}
template<> int f(int, int = 35) // ERROR!
{
return 0;
}
template<typename T>
int g(T, T x = 42)
{
return x;
}
template<> int g(int, int y)
{
return y/2;
}
int main()
{
std::cout << f(0) << std::endl; // should print 21
}
A full specialization is in many ways similar to a normal declaration (or rather, a normal redeclaration). In particular, it does not declare a template, and therefore only one definition of a noninline full function template specialization should appear in a program. However, we must still ensure that a declaration of the full specialization follows the template to prevent attempts at using the function generated from the template. The declarations for template g in the previous example would therefore typically be organized in two files. The interface file might look as follows:
#ifndef TEMPLATE_G_HPP
#define TEMPLATE_G_HPP
// template definition should appear in header file:
template<typename T>
int g(T, T x = 42)
{
return x;
}
// specialization declaration inhibits instantiations of the template;
// definition should not appear here to avoid multiple definition errors
template<> int g(int, int y);
#endif // TEMPLATE_G_HPP
The corresponding implementation file may read:
#include "template_g.hpp"
template<> int g(int, int y)
{
return y/2;
}
Alternatively, the specialization could be made inline, in which case its definition can be (and should be) placed in the header file.
12.3.3 Full Member Specialization
Not only member templates, but also ordinary static data members and member functions of class templates, can be fully specialized. The syntax requires template<> prefix for every enclosing class template. If a member template is being specialized, a template<> must also be added to denote it is being specialized. To illustrate the implications of this, let's assume the following declarations:
template<typename T>
class Outer { // (1)
public:
template<typename U>
class Inner { // (2)
private:
static int count; // (3)
};
static int code; // (4)
void print() const { // (5)
std::cout << "generic";
}
};
template<typename T>
int Outer<T>::code = 6; // (6)
template<typename T> template<typename U>
int Outer<T>::Inner<U>::count = 7; // (7)
template<>
class Outer<bool> { // (8)
public:
template<typename U>
class Inner { // (9)
private:
static int count; // (10)
};
void print() const { // (11)
}
};
The ordinary members code at point (4) and print() at point (5) of the generic Outer template (1) have a single enclosing class template and hence need one template<> prefix to specialize them fully for a specific set of template arguments:
template<>
int Outer<void>::code = 12;
template<>
void Outer<void>::print()
{
std::cout << "Outer<void>";
}
These definitions are used over the generic ones at points (4) and (5) for class Outer<void>, but other members of class Outer<void> are still generated from the template at point (1). Note that after these declarations it is no longer valid to provide an explicit specialization for Outer<void>.
Just as with full function template specializations, we need a way to declare the specialization of an ordinary member of a class template without specifying a definition (to prevent multiple definitions). Although nondefining out-of-class declarations are not allowed in C++ for member functions and static data members of ordinary classes, they are fine when specializing members of class templates. The previous definitions could be declared with
template<>
int Outer<void>::code;
template<>
void Outer<void>::print();
The attentive reader might point out that the nondefining declaration of the full specialization of Outer<void>::code has exactly the same syntax as that required to provide a definition to be initialized with a default constructor. This is indeed so, but such declarations are always interpreted as nondefining declarations.
Therefore, there is no way to provide a definition for the full specialization of a static data member with a type that can only be initialized using a default constructor!
class DefaultInitOnly {
public:
DefaultInitOnly() {
}
private:
DefaultInitOnly(DefaultInitOnly const&); // no copying possible
};
template<typename T>
class Statics {
private:
T sm;
};
// the following is a declaration;
// no syntax exists to provide a definition
template<>
DefaultInitOnly Statics<DefaultInitOnly>::sm;
The member template Outer<T>::Inner can also be specialized for a given template argument without affecting the other members of the specific instantiation of Outer<T>, for which we are specializing the member template. Again, because there is one enclosing template, we will need one template<> prefix. This results in code like the following:
template<>
template<typename X>
class Outer<wchar_t>::Inner {
public:
static long count; // member type changed
};
template<>
template<typename X>
long Outer<wchar_t>::Inner<X>::count;
The template Outer<T>::Inner can also be fully specialized, but only for a given instance of Outer<T>. We now need two template<> prefixes: one because of the enclosing class and one because we're fully specializing the (inner) template:
template<>
template<>
class Outer<char>::Inner<wchar_t> {
public:
enum { count = 1; };
};
// the following is not valid C++:
// template<> cannot follow a template parameter list
template<typename X>
template<> class Outer<X>::Inner<void>; // ERROR!
Contrast this with the specialization of the member template of Outer<bool>. Because the latter is already fully specialized, there is no enclosing template, and we need only one template<> prefix:
template<>
class Outer<bool>::Inner<wchar_t> {
public:
enum { count = 2; };
};
|
12.4 Partial Class Template Specialization
Full template specialization is often useful, but sometimes it is natural to want to specialize a class template for a family of template arguments rather than just one specific set of template arguments. For example, let's assume we have a class template implementing a linked list:
template<typename T>
class List { // (1)
public:
…
void append(T const&);
inline size_t length() const;
…
};
A large project making use of this template may instantiate its members for many types. For member functions that are not expanded inline (say, List<T>::append()), this may cause noticeable growth in the object code. However, we may know that from a low-level point of view, the code for List<int*>::append() and List<void*>::append() is the same. In other words, we'd like to specify that all Lists of pointers share an implementation. Although this cannot be expressed in C++, we can achieve something quite close by specifying that all Lists of pointers should be instantiated from a different template definition:
template<typename T>
class List<T*> { // (2)
private:
List<void*> impl;
…
public:
…
void append(T* p) {
impl.append(p);
}
size_t length() const {
return impl.length();
}
…
};
In this context, the original template at point (1) is called the primary template, and the latter definition is called a partial specialization (because the template arguments for which this template definition must be used have been only partially specified). The syntax that characterizes a partial specialization is the combination of a template parameter list declaration (template<...>) and a set of explicitly specified template arguments on the name of the class template (<T*> in our example).
Our code contains a problem because List<void*> recursively contains a member of that same List<void*> type. To break the cycle, we can precede the previous partial specialization with a full specialization:
template<>
class List<void*> { // (3)
…
void append (void* p);
inline size_t length() const;
…
};
This works because matching full specializations are preferred over partial specializations. As a result, all member functions of Lists of pointers are forwarded (through easily inlineable functions) to the implementation of List<void*>. This is an effective way to combat so-called code bloat (of which C++ templates are often accused).
There exists a number of limitations on the parameter and argument lists of partial specialization declarations. Some of them are as follows:
The arguments of the partial specialization must match in kind (type, nontype, or template) the corresponding parameters of the primary template. The parameter list of the partial specialization cannot have default arguments; the default arguments of the primary class template are used instead. The nontype arguments of the partial specialization should either be nondependent values or plain nontype template parameters. They cannot be more complex dependent expressions like 2*N (where N is a template parameter). The list of template arguments of the partial specialization should not be identical (ignoring renaming) to the list of parameters of the primary template.
An example illustrates these limitations:
template<typename T, int I = 3>
class S; // primary template
template<typename T>
class S<int, T>; // ERROR: parameter kind mismatch
template<typename T = int>
class S<T, 10>; // ERROR: no default arguments
template<int I>
class S<int, I*2>; // ERROR: no nontype expressions
template<typename U, int K>
class S<U, K>; // ERROR: no significant difference
// from primary template
Every partial specializationlike every full specializationis associated with the primary template. When a template is used, the primary template is always the one that is looked up, but then the arguments are also matched against those of the associated specializations to determine which template implementation is picked. If multiple matching specializations are found, the "most specialized" one (in the sense defined for overloaded function templates) is selected; if none can be called "most specialized," the program contains an ambiguity error.
Finally, we should point out that it is entirely possible for a class template partial specialization to have more parameters than the primary template. Consider our generic template List (declared at point (1)) again. We have already discussed how to optimize the list-of-pointers case, but we may want to do the same with certain pointer-to-member types. The following code achieves this for pointer-to-member-pointers:
template<typename C>
class List<void* C::*> { // (4)
public:
// partial specialization for any pointer-to-void* member
// every other pointer-to-member-pointer type will use this
typedef void* C::*ElementType;
…
void append(ElementType pm);
inline size_t length() const;
…
};
template<typename T, typename C>
class List<T* C::*> { // (5)
private:
List<void* C::*> impl;
…
public:
// partial specialization for any pointer-to-member-pointer type
// except pointer-to-void* member which is handled earlier;
// note that this partial specialization has two template parameters,
// whereas the primary template only has one parameter
typedef T* C::*ElementType;
…
void append(ElementType pm) {
impl.append((void* C::*)pm);
}
inline size_t length() const {
return impl.length();
}
…
};
In addition to our observation regarding the number of template parameters, note that the common implementation defined at (4) to which all others are forwarded (by the declaration at point (5)) is itself a partial specialization (for the simple pointer case it is a full specialization). However, it is clear that the specialization at point (4) is more specialized than that at point (5); thus no ambiguity should occur.
|
12.5 Afternotes
Full template specialization was part of the C++ template mechanism from the start. Function template overloading and class template partial specialization, on other hand, came much later. The HP aC++ compiler was the first to implement function template overloading, and EDG's C++ front end was the first to implement class template partial specialization. The partial ordering principles described in this chapter were originally invented by Steve Adamczyk and John Spicer (who are both of EDG).
The ability of template specializations to terminate an otherwise infinitely recursive template definition (such as the List<T*> example presented in Section 12.4 on page 200) was known for a long time. However, Erwin Unruh was perhaps the first to note that this could lead to the interesting notion of template metaprogramming: Using the template instantiation mechanism to perform nontrivial computations at compile time. We devote Chapter 17 to this topic.
You may legitimately wonder why only class templates can be partially specialized. The reasons are mostly historical. It is probably possible to define the same mechanism for function templates (see Chapter 13). In some ways the effect of overloading function templates is similar, but there are also some subtle differences. These differences are mostly related to the fact that only the primary template needs to be looked up when a use is encountered. The specializations are considered only afterward, to determine which implementation should be used. In contrast, all overloaded function templates must be brought into an overload set by looking them up, and they may come from different namespaces or classes. This increases the likelihood of unintentionally overloading a template name somewhat.
Conversely, it is also imaginable to allow a form of overloading of class templates. Here is an example:
// invalid overloading of class templates
template<typename T1, typename T2> class Pair;
template<int N1, int N2> class Pair;
However, there doesn't seem to be a pressing need for such a mechanism.
|
Chapter 13. Future Directions
C++ templates evolved considerably from their initial design in 1988 until the standardization of C++ in 1998 (the technical work was completed in November 1997). After that, the language definition was stable for several years, but during that time various new needs have arisen in the area of C++ templates. Some of these needs are simply a consequence of a desire for more consistency or orthogonality in the language. For example, why wouldn't default template arguments be allowed on function templates when they are allowed on class templates? Other extensions are prompted by increasingly sophisticated template programming idioms that often stretch the abilities of existing compilers.
In what follows we describe some extensions that have come up more than once among C++ language and compiler designers. Often such extensions were prompted by the designers of various advanced C++ libraries (including the C++ standard library). There is no guarantee that any of these will ever be part of standard C++. On the other hand, some of these are already provided as extensions by certain C++ implementations.
|
13.1 The Angle Bracket Hack
Among the most common surprises for beginning template programmers is the necessity to add some blank space between consecutive closing angle brackets. For example:
#include <list>
#include <vector>
typedef std::vector<std::list<int> > LineTable; // OK
typedef std::vector<std::list<int>> OtherTable; // SYNTAX ERROR
The second typedef declaration is an error because the two closing angle brackets with no intervening blank space constitute a "right shift" (>>) operator, which makes no sense at that location in the source.
Yet detecting such an error and silently treating the >> operator as two closing angle brackets (a feature sometimes referred to as the angle bracket hack) is relatively simple compared with many of the other capabilities of C++ source code parsers. Indeed, many compilers are already able to recognize such situations and will accept the code with a warning.
Hence, it is likely that a future version of C++ will require the declaration of OtherTable (in the previous example) to be valid. Nevertheless, we should note that there are some subtle corners to the angle bracket hack. Indeed, there are situations when the >> operator is a valid token within a template argument list. The following example illustrates this:
template<int N> class Buf;
template<typename T> void strange() {}
template<int N> void strange() {}
int main()
{
strange<Buf<16>>2> >(); // the >> token is not an error
}
A somewhat related issue deals with the accidental use of the digraph <:, which is equivalent to the bracket [ (see Section 9.3.1 on page 129). Consider the following code extract:
template<typename T> class List;
class Marker;
List<::Marker>* markers; // ERROR
The last line of this example is treated as List[:Marker>* markers;, which makes no sense at all. However, a compiler could conceivably take into account that a template such as List can never validly be followed by a left bracket and disable the recognition of the corresponding digraph in that context.
|
13.2 Relaxed typename Rules
Some programmers and language designers find the rules for the use of typename (see Section 5.1 on page 43 and Section 9.3.2 on page 130) too strict. For example, in the following code, the occurrence of typename in typename Array<T>::ElementT is mandatory, but the one in typename Array<int>::ElementT is prohibited (an error):
template <typename T>
class Array {
public:
typedef T ElementT;
…
};
template <typename T>
void clear (typename Array<T>::ElementT& p); // OK
template<>
void clear (typename Array<int>::ElementT& p); // ERROR
Examples such as this can be surprising, and because it is not difficult for a C++ compiler implementation simply to ignore the extra keyword, the language designers are considering allowing the typename keyword in front of any qualified typename that is not already elaborated with one of the keywords struct, class, union, or enum. Such a decision would probably also clarify when the .template, ->template, and ::template constructs (see Section 9.3.3 on page 132) are permissible.
Ignoring extraneous uses of typename and template is relatively straightforward from an implementer's point of view. Interestingly, there are also situations when the language currently requires these keywords but when an implementation could do without them. For example, in the previous function template clear(), a compiler can know that the name Array<T>::ElementT cannot be anything but a type name (no expressions are allowed at that point), and therefore the use of typename could be made optional in that situation. The C++ standardization committee is therefore also examining changes that would reduce the number of situations when typename and template are required.
|
13.3 Default Function Template Arguments
When templates were originally added to the C++ language, explicit function template arguments were not a valid construct. Function template arguments always had to be deducible from the call expression. As a result, there seemed to be no compelling reason to allow default function template arguments because the default would always be overridden by the deduced value.
Since then, however, it is possible to specify explicitly function template arguments that cannot be deduced. Hence, it would be entirely natural to specify default values for those nondeducible template arguments. Consider the following example:
template <typename T1, typename T2 = int>
T2 count (T1 const& x);
class MyInt {
…
};
void test (Container const& c)
{
int i = count(c);
MyInt = count<MyInt>(c);
assert(MyInt == i);
}
In this example, we have respected the constraint that if a template parameter has a default argument value, then each parameter after that must have a default template argument too. This constraint is needed for class templates; otherwise, there would be no way to specify trailing arguments in the general case. The following erroneous code illustrates this:
template <typename T1 = int, typename T2>
class Bad;
Bad<int>* b; // Is the given int a substitution for T1 or for T2?
For function templates, however, the trailing arguments may be deduced. Hence, there is no technical difficulty in rewriting our example as follows:
template <typename T1 = int, typename T2>
T1 count (T2 const& x);
void test (Container const& c)
{
int i = count(c);
MyInt = count<MyInt>(c);
assert(MyInt == i);
}
At the time of this writing the C++ standardization committee is considering extending function templates in this direction.
In hindsight, programmers have also noted uses that do not involve explicit template arguments. For example:
template <typename T = double>
void f(T const& = T());
int main()
{
f(1); // OK: deduce T = int
f<long>(2); // OK: T = long; no deduction
f<char>(); // OK: same as f<char>('\0');
f(); // Same as f<double>(0.0);
}
Here a default template argument enables a default call argument to apply without explicit template arguments.
|
13.4 String Literal and Floating-Point Template Arguments
Among the restrictions on nontype template arguments, perhaps the most surprising to beginning and advanced template writers alike is the inability to provide a string literal as a template argument.
The following example seems intuitive enough:
template <char const* msg>
class Diagnoser {
public:
void print();
};
int main()
{
Diagnoser<"Surprise!">().print();
}
However, there are some potential problems. In standard C++, two instances of Diagnoser are the same type if and only if they have the same arguments. In this case the argument is a pointer valuein other words, an address. However, two identical string literals appearing in different source locations are not required to have the same address. We could thus find ourselves in the awkward situation that Diagnoser<"X"> and Diagnoser<"X"> are in fact two different and incompatible types! (Note that the type of "X" is char const[2], but it decays to char const* when passed as a template argument.)
Because of these (and related) considerations, the C++ standard prohibits string literals as arguments to templates. However, some implementations do offer the facility as an extension. They enable this by using the actual string literal contents in the internal representation of the template instance. Although this is clearly feasible, some C++ language commentators feel that a nontype template parameter that can be substituted by a string literal value should be declared differently from one that can be substituted by an address. At the time of this writing, however, no such declaration syntax has received overwhelming support.
We should also note an additional technical wrinkle in this issue. Consider the following template declarations, and let's assume that the language has been extended to accept string literals as template arguments in this case:
template <char const* str>
class Bracket {
public:
static char const* address() const;
static char const* bytes() const;
};
template <char const* str>
char const* Bracket<T>::address() const
{
return str;
}
template <char const* str>
char const* Bracket<T>::bytes() const
{
return str;
}
In the previous code, the two member functions are identical except for their namesa situation that is not that uncommon. Imagine that an implementation would instantiate Bracket<"X"> using a process much like macro expansion: In this case, if the two member functions are instantiated in different translation units, they may return different values. Interestingly, a test of some C++ compilers that currently provide this extension reveals that they do suffer from this surprising behavior.
A related issue is the ability to provide floating-point literals (and simple constant floating-point expressions) as template arguments. For example:
template <double Ratio>
class Converter {
public:
static double convert (double val) const {
return val*Ratio;
}
};
typedef Converter<0.0254> InchToMeter;
This too is provided by some C++ implementations and presents no serious technical challenges (unlike the string literal arguments).
|
13.5 Relaxed Matching of Template Template Parameters
A template used to substitute a template template parameter must match that parameter's list of template parameters exactly. This can sometimes have surprising consequences, as shown in the following example:
#include <list>
// declares:
// namespace std {
// template <typename T,
// typename Allocator = allocator<T> >
// class list;
// }
template<typename T1,
typename T2,
template<typename> class Container>
// Container expects templates with only one parameter
class Relation {
public:
…
private:
Container<T1> dom1;
Container<T2> dom2;
};
int main()
{
Relation<int, double, std::list> rel;
// ERROR: std::list has more than one template parameter
…
}
This program is invalid because our template template parameter Container expects a template taking one parameter, whereas std::list has an allocator parameter in addition to its parameter that determines the element type.
However, because std::list has a default template argument for its allocator parameter, it would be possible to specify that Container matches std::list and that each instantiation of Container uses the default template argument of std::list (see Section 8.3.4 on page 112).
An argument in favor of the status quo (no match) is that the same rule applies to matching function types. However, in this case the default arguments cannot always be determined because the value of a function pointer usually isn't fixed until run time. In contrast, there are no "template pointers," and all the required information can be available at compile time.
Some C++ compilers already offer the relaxed matching rule as an extension. This issue is also related to the issue of typedef templates (discussed in the next section). Indeed, consider replacing the definition of main() in our previous example with:
template <typename T>
typedef list<T> MyList;
int main()
{
Relation<int, double, MyList> rel;
}
The typedef template introduces a new template that now exactly matches Container with respect to its parameter list. Whether this strengthens or weakens the case for a relaxed matching rule is, of course, arguable.
This issue has been brought up before the C++ standardization committee, which is currently not inclined to add the relaxed matching rule.
|
13.6 Typedef Templates
Class templates are often combined in relatively sophisticated ways to obtain other parameterized types. When such parameterized types appear repeatedly in source code, it is natural to want a shortcut for them, just as typedefs provide a shortcut for unparameterized types.
Therefore, C++ language designers are considering a construct that may look as follows:
template <typename T>
typedef vector<list<T> > Table;
After this declaration, Table would be a new template that can be instantiated to become a concrete type definition. Such a template is called a typedef template (as opposed to a class template or a function template). For example:
Table<int> t; // t has type vector<list<int> >
Currently, the lack of typedef templates is worked around by using member typedefs of class templates. For our example we might use:
template <typename T>
class Table {
public:
typedef vector<list<T> > Type;
};
Table<int>::Type t; // t has type vector<list<int> >
Because typedef templates are to be full-fledged templates, they could be specialized much like class templates:
// primary typedef template:
template<typename T> typedef T Opaque;
// partial specialization:
template<typename T> typedef void* Opaque<T*>;
// full specialization:
template<> typedef bool Opaque<void>;
Typedef templates are not entirely straightforward. For example, it is not clear how they would participate in the deduction process:
void candidate(long);
template<typename T> typedef T DT;
template<typename T> void candidate(DT<T>);
int main()
{
candidate(42); // which candidate() should be called?
}
It is not clear that deduction should succeed in this case. Certainly, deduction is not possible with arbitrary typedef patterns.
|
13.7 Partial Specialization of Function Templates
In Chapter 12 we discussed how class templates can be partially specialized, whereas function templates are simply overloaded. The two mechanisms are somewhat different.
Partial specialization doesn't introduce a completely new template: It is an extension of an existing template (the primary template). When a class template is looked up, only primary templates are considered at first. If, after the selection of a primary template, it turns out that there is a partial specialization of that template with a template argument pattern that matches that of the instantiation, its definition (in other words, its body) is instantiated instead of the definition of the primary template. (Full template specializations work exactly the same way.)
In contrast, overloaded function templates are separate templates that are completely independent of one another. When selecting which template to instantiate, all the overloaded templates are considered together, and overload resolution attempts to choose one as the best fit. At first this might seem like an adequate alternative, but in practice there are a number of limitations:
It is possible to specialize member templates of a class without changing the definition of that class. However, adding an overloaded member does require a change in the definition of a class. In many cases this is not an option because we may not own the rights to do so. Furthermore, the C++ standard does not currently allow us to add new templates to the std namespace, but it does allow us to specialize templates from that namespace. To overload function templates, their function parameters must differ in some material way. Consider a function template R convert(T const&) where R and T are template parameters. We may very well want to specialize this template for R = void, but this cannot be done using overloading. Code that is valid for a nonoverloaded function may no longer be valid when the function is overloaded. Specifically, given two function templates f(T) and g(T) (where T is a template parameter), the expression g(&f<int>) is valid only if f is not overloaded (otherwise, there is no way to decide which f is meant). Friend declarations refer to a specific function template or an instantiation of a specific function template. An overloaded version of a function template would not automatically have the privileges granted to the original template.
Together, this list forms a compelling argument in support of a partial specialization construct for function templates.
A natural syntax for partially specializing function templates is the generalization of the class template notation:
template <typename T>
T const& max (T const&, T const&); // primary template
template <typename T>
T* const& max <T*>(T* const&, T* const&); // partial specialization
Some language designers worry about the interaction of this partial specialization approach with function template overloading. For example:
template <typename T>
void add (T& x, int i); // a primary template
template <typename T1, typename T2>
void add (T1 a, T2 b); // another (overloaded) primary template
template <typename T>
void add<T*> (T*&, int); // which primary template does this specialize?
However, we expect such cases would be deemed errors without major impact on the utility of the feature.
At the time of this writing, this extension is under consideration by the C++ standardization committee.
|
13.8 The typeof Operator
When writing templates, it is often useful to be able to express the type of a template-dependent expression. Perhaps the poster child of this situation is the declaration of an arithmetic operator for a numeric array template in which the element types of the operands are mixed. The following example should make this clear:
template <typename T1, typename T2>
Array<???> operator+ (Array<T1> const& x, Array<T2> const& y);
Presumably, this operator is to produce an array of elements that are the result of adding corresponding elements in the arrays x and y. The type of a resulting element is thus the type of x[0]+y[0]. Unfortunately, C++ does not offer a reliable way to express this type in terms of T1 and T2.
Some compilers provide the typeof operator as an extension that addresses this issue. It is reminiscent of the sizeof operator in that it can take an expression and produce a compile-time entity from it, but in this case the compile-time entity can act as the name of a type. In our previous example this allows us to write:
template <typename T1, typename T2>
Array<typeof(T1()+T2())> operator+ (Array<T1> const& x,
Array<T2> const& y);
This is nice, but not ideal. Indeed, it assumes that the given types can be default-initialized. We can work around this assumption by introducing a helper template as follows:
template <typename T>
T makeT(); // no definition needed
template <typename T1, typename T2>
Array<typeof(makeT<T1>()+makeT<T2>())>
operator+ (Array<T1> const& x,
Array<T2> const& y);
We really would prefer to use x and y in the typeof argument, but we cannot do so because they have not been declared at the point of the typeof construct. A radical solution to this problem is to introduce an alternative function declaration syntax that places the return type after the parameter types:
// operator function template:
template <typename T1, typename T2>
operator+ (Array<T1> const& x, Array<T2> const& y)
-> Array<typeof(x+y)>;
// regular function template:
template <typename T1, typename T2>
function exp(Array<T1> const& x, Array<T2> const& y)
-> Array<typeof(exp(x, y))>
As the example illustrates, a new keyword (here, function) is necessary to enable the new syntax for nonoperator functions (for operator functions, the operator keyword is sufficient to guide the parsing process).
Note that typeof must be a compile-time operator. In particular, typeof will not take into account covariant return types, as the following example shows:
class Base {
public:
virtual Base clone();
};
class Derived : public Base {
public:
virtual Derived clone(); // covariant return type
};
void demo (Base* p, Base* q)
{
typeof(p->clone()) tmp = p->clone();
// tmp will always have type Base
…
}
Section 15.2.4 on page 271 shows how promotion traits are sometimes used to partially address the absence of a typeof operator.
|
13.9 Named Template Arguments
Section 16.1 on page 285 describes a technique that allows us to provide a nondefault template argument for a specific parameter without having to specify other template arguments for which a default value is available. Although it is an interesting technique, it is also clear that it results in a fair amount of work for a relatively simple effect. Hence, providing a language mechanism to name template arguments is a natural thought.
We should note at this point, that a similar extension (sometimes called keyword arguments) was proposed earlier in the C++ standardization process by Roland Hartinger (see Section 6.5.1 of [StroustrupDnE]). Although technically sound, the proposal was ultimately not accepted into the language for various reasons. At this point there is no reason to believe named template arguments will ever make it into the language.
However, for the sake of completeness, we mention one syntactic idea that has floated among certain designers:
template<typename T,
Move: typename M = defaultMove<T>,
Copy: typename C = defaultCopy<T>,
Swap: typename S = defaultSwap<T>,
Init: typename I = defaultInit<T>,
Kill: typename K = defaultKill<T> >
class Mutator {
…
};
void test(MatrixList ml)
{
mySort (ml, Mutator <Matrix, Swap: matrixSwap>);
}
Note how the argument name (preceding a colon) is distinct from the parameter name. This allows us to keep the practice of using short names for the parameters used in the implementation while having a self-documenting name for the argument names. Because this can be overly verbose for some programming styles, one can also imagine the ability to omit the argument name if it is identical to the parameter name:
template<typename T,
: typename Move = defaultMove<T>,
: typename Copy = defaultCopy<T>,
: typename Swap = defaultSwap<T>,
: typename Init = defaultInit<T>,
: typename Kill = defaultKill<T> >
class Mutator {
…
};
|
13.10 Static Properties
In Chapter 15 and Chapter 19 we discuss various ways to categorize types "at compile time." Such traits are useful in selecting specializations of templates based on the static properties of the type. (See, for example, our CSMtraits class in Section 15.3.2 on page 279, which attempts to select optimal or near-optimal policies to copy, swap, or move elements of the argument type.)
Some language designers have observed that if such "specialization selections" are commonplace, they shouldn't require elaborate user-defined code if all that is sought is a property that the implementation knows internally anyway. The language could instead provide a number of built-in type traits. The following could be a valid complete C++ program with such an extension:
#include <iostream>
int main()
{
std::cout << std::type<int>::is_bit_copyable << '\n';
std::cout << std::type<int>::is_union << '\n';
}
Although a separate syntax could be developed for such a construct, fitting it in a user-definable syntax may allow for a more smooth transition from the current language to a language that would include such facilities. However, some of the static properties that a C++ compiler can easily provide may not be obtainable using traditional traits techniques (for example, determining whether a type is a union), which is an argument in favor of making this a language element. Another argument is that it can significantly reduce the amount of memory and machine cycles required by a compiler to translate programs that rely on such properties.
|
13.11 Custom Instantiation Diagnostics
Many templates put some implicit requirements on their parameters. When the arguments of an instantiation of such a template do not fulfill the requirements, either a generic error is issued or the generated instantiation does not function correctly. In early C++ compilers, the generic errors produced during template instantiations were often exceedingly opaque (see page 75 for an example). In more recent compilers, the error messages are sufficiently clear for an experienced programmer to track down a problem quickly, but there is still a desire to improve the situation. Consider the following artificial example (meant to illustrate what happens in real template libraries):
template <typename T>
void clear (T const& p)
{
*p = 0; // assumes T is a pointerlike type
}
template <typename T>
void core (T const& p)
{
clear(p);
}
template <typename T>
void middle (typename T::Index p)
{
core(p);
}
template <typename T>
void shell (T const& env)
{
typename T::Index i;
middle<T>(i);
}
class Client {
public:
typedef int Index;
…
};
Client main_client;
int main()
{
shell(main_client);
}
This example illustrates the typical layering of software development: High-level function templates like shell() rely on components like middle(), which themselves make use of basic facilities like core(). When we instantiate shell(), all the layers below it also need to be instantiated. In this example, a problem is revealed in the deepest layer: core() is instantiated with type int (from the use of Client::Index in middle()) and attempts to dereference a value of that type, which is an error. A good generic diagnostic will include a trace of all the layers that led to the problems, but this amount of information may be unwieldy.
An alternative that has often been proposed is to insert a device in the highest level template to inhibit deeper instantiation if known requirements from lower levels are not satisfied. Various attempts have been made to implement such devices in terms of existing C++ constructs (for example, see [BCCL]), but they are not always effective. Hence, it is not surprising that language extensions have been proposed to address the issue. Such an extension could clearly build on top of the static properties facilities discussed earlier. For example, we can envision modifying the shell() template as follows:
template <typename T>
void shell (T const& env)
{
std::instantiation_error(
std::type<T>::has_member_type<"Index">,
"T must have an Index member type");
std::instantiation_error(
!std::type<typename T::Index>::dereferencable,
"T::Index must be a pointer-like type");
typename T::Index i;
middle(i);
}
The instantiation_error() pseudo-function would presumably cause the implementation to abort the instantiation (thereby avoiding the diagnostics triggered by the instantiation of middle()) and cause the compiler to issue the given message.
Although this is feasible, there are some drawbacks to this approach. For example, it can quickly become cumbersome to describe all the properties of a type in this manner. Some have proposed to allow "dummy code" constructs to serve as the condition to abort instantiation. Here is one of the many proposed forms (this one introduces no new keywords):
template <typename T>
void shell (T const& env)
{
template try {
typename T::Index p;
*p = 0;
} catch "T::Index must be a pointer-like type";
typename T::Index i;
middle(i);
}
The idea here is that the body of a template try clause is tentatively instantiated without actually generating object code, and, if an error occurs, the diagnostic that follows is issued. Unfortunately, such a mechanism is hard to implement because even though the generation of code could be inhib-ited, there are other side effects internal to a compiler that are hard to avoid. In other words, this relatively small feature would likely require a considerable reengineering of existing compilation technology.
Most such schemes also have other limitations. For example, many C++ compilers can report diagnostics in different languages (English, German, Japanese, and so forth), but providing various translations in the source code could prove excessive. Furthermore, if the instantiation process is truly aborted and the precondition was not precisely formulated, a programmer might be much worse off than with a generic (albeit unwieldy) diagnostic.
|
13.12 Overloaded Class Templates
It is entirely possible to imagine that class templates could be overloaded on their template parameters. For example, one can imagine the following:
template <typename T1>
class Tuple {
// singleton
…
};
template <typename T1, typename T2>
class Tuple {
// pair
…
};
template <typename T1, typename T2, typename T3>
class Tuple {
// three-element tuple
…
};
In the next section we discuss an application of such overloading.
The overloading isn't necessarily restricted to the number of template parameters (such overloading could be emulated using partial specialization as is done for FunctionPtr in Chapter 22). The kind of parameters can be varied too:
template <typename T1, typename T2>
class Pair {
// pair of fields
…
};
template <int I1, int I2>
class Pair {
// pair of constant integer values
…
};
Although this idea has been discussed informally by some language designers, it has not yet been formally presented to the C++ standardization committee.
|
13.13 List Parameters
A need that shows up sometimes is the ability to pass a list of types as a single template argument. Usually, this list is meant for one of two purposes: declaring a function with a parameterized number of parameters or defining a type structure with a parameterized list of members.
For example, we may want to define a template that computes the maximum of an arbitrary list of values. A potential declaration syntax uses the ellipsis token to denote that the last template parameter is meant to match an arbitrary number of arguments:
#include <iostream>
template <typename T, ... list>
T const& max (T const&, T const&, list const&);
int main()
{
std::cout << max(1, 2, 3, 4) << std::endl;
}
Various possibilities can be thought of to implement such a template. Here is one that doesn't require new keywords but adds a rule to function template overloading to prefer a function template without a list parameter:
template <typename T> inline
T const& max (T const& a, T const& b)
{
// our usual binary maximum:
return a<b?b:a;
}
template <typename T, ... list> inline
T const& max (T const& a, T const& b, list const& x)
{
return max (a, max(b,x));
}
Let's go through the steps that would make this work for the call max(1, 2, 3, 4). Because there are four arguments, the binary max() function doesn't match, but the second one does match with T = int and list = int, int. This causes us to call the binary function template max() with the first argument equal to 1 and the second argument equal to the evaluation of max(2, 3, 4). Again, the binary operation doesn't match, and we call the list parameter version with T = int and list = int. This time the subexpression max(b,x) expands to max(3,4), and the recursion ends by selecting the binary template.
This works fairly well thanks to the ability of overloading function templates. There is more to it than our discussion, of course. For example, we'd have to specify precisely what list const& means in this context.
Sometimes, it may be desirable to refer to particular elements or subsets of the list. For example, we could use the subscript brackets for this purpose. The following example shows how we could construct a metaprogram to count the elements in a list using this technique:
template <typename T>
class ListProps {
public:
enum { length = 1 };
};
template <... list>
class ListProps {
public:
enum { length = 1+ListProps<list[1 ...]>::length };
};
This demonstrates that list parameters may also be useful for class templates and could be combined with the class overloading concept discussed earlier to enhance various template metaprogramming techniques.
Alternatively, the list parameter could be used to declare a list of fields:
template <... list>
class Collection {
list;
};
A surprising number of fundamental utilities can be built on top of such a facility. For more ideas, we suggest reading Modern C++ Design (see [AlexandrescuDesign]), where the lack of this feature is replaced by extensive template- and macro-based metaprogramming.
|
13.14 Layout Control
A fairly common template programming challenge is to declare an array of bytes that will be sufficiently large (but not excessively so) to hold an object of an as yet unknown type Tin other words, a template parameter. One application of this is the so-called discriminated unions (also called variant types or tagged unions):
template <... list>
class D_Union {
public:
enum { n_bytes; };
char bytes[n_bytes]; // will eventually hold one of various types
// described by the template arguments
…
};
The constant n_bytes cannot always be set to sizeof(T) because T may have more strict alignment requirements than the bytes buffer. Various heuristics exist to take this alignment into account, but they are often complicated or make somewhat arbitrary assumptions.
For such an application, what is really desired is the ability to express the alignment requirement of a type as a constant expression and, conversely, the ability to impose an alignment on a type, a field, or a variable. Many C and C++ compilers already support an __alignof__ operator, which returns the alignment of a given type or expression. This is almost identical to the sizeof operator except that the alignment is returned instead of the size of the given type. Many compilers also provide #pragma directives or similar devices to set the alignment of an entity. A possible approach may be to introduce an alignof keyword that can be used both in expressions (to obtain the alignment) and in declarations (to set the alignment).
template <typename T>
class Alignment {
public:
enum { max = alignof(T) };
};
template <... list>
class Alignment {
public:
enum { max = alignof(list[0]) > Alignment<list[1 ...]>::max
? alignof(list[0])
: Alignment<list[1 ...]>::max; }
};
// a set of Size templates could similarly be designed
// to determine the largest size among a given list of types
template <... list>
class Variant {
public:
char buffer[Size<list>::max] alignof(Alignment<list>::max);
…
};
|
13.15 Initializer Deduction
It is often said that "programmers are lazy," and sometimes this refers to our desire to keep programmatic notation compact. Consider, in that respect, the following declaration:
std::map<std::string, std::list<int> >* dict
= new std::map<std::string, std::list<int> >;
This is verbose, and in practice we would (and most likely should) introduce a typedef synonym for the type. However, there is something redundant in this declaration: We specify the type of dict, but it is also implicit in the type of its initializer. Wouldn't it be considerably more elegant to be able to write an equivalent declaration with only one type specification? For example:
dcl dict = new std::map<std::string, std::list<int> >;
In this last declaration, the type of a variable is deduced from the type of the initializer. A keyword (dcl in the example, but var, let, and even auto have been proposed as alternatives) is needed to make the declaration distinguishable from an ordinary assignment.
So far, this isn't a template-only issue. In fact, it appears such a construct was accepted by a very early version of the Cfront compiler (in 1982, before templates came on the scene). However, it is the verbosity of many template-based types that increases the demand for this feature.
One could also imagine partial deduction in which only the arguments of a template must be deduced:
std::list<> index = create_index();
Another variant of this is to deduce the template arguments from the constructor arguments. For example:
template <typename T>
class Complex {
public:
Complex(T const& re, T const& im);
…
};
Complex<> z(1.0, 3.0); // deduces T = double
Precise specifications for this kind of deduction are made more complicated by the possibility of overloaded constructors, including constructor templates. Suppose, for example, that our Complex template contains a constructor template in addition to a normal copy constructor:
template <typename T>
class Complex {
public:
Complex(Complex<T> const&);
template <typename T2> Complex(Complex<T2> const&);
…
};
Complex<double> j(0.0, 1.0);
Complex<> z = j; // Which constructor was intended?
In the latter initialization, it is probable that the regular copy constructor was intended; hence z should have the same type as j. However, making it an implicit rule to ignore constructor templates may be overly bold.
|
13.16 Function Expressions
Chapter 22 illustrates that it is often convenient to pass small functions (or functors) as parameters to other functions. We also mention in Chapter 17 that expression template techniques can be used to build small functors concisely without the overhead of explicit declarations (see Section 18.3 on page 340).
For example, we may want to call a particular member function on each element of a standard vector to initialize it:
class BigValue {
public:
void init();
…
};
class Init {
public:
void operator() (BigValue& v) const {
v.init();
}
};
void compute (std::vector<BigValue>& vec)
{
std::for_each (vec.begin(), vec.end(),
Init());
…
}
The need to define a separate class Init for this purpose is unwieldy. Instead, we can imagine that we may write (unnamed) function bodies as part of an expression:
class BigValue {
public:
void init();
…
};
void compute (std::vector<BigValue>& vec)
{
std::for_each (vec.begin(), vec.end(),
$(BigValue&) { $1.init(); });
…
}
The idea here is that we can introduce a function expression with a special token $ followed by parameter types in parentheses and a brace-enclosed body. Within such a construct, we can refer to the parameters with the special notation $n, where n is a constant indicating the number of the parameter.
This form is closely related to so-called lambda expressions (or lambda functions) and closures in other programming languages. However, other solutions are possible. For example, a solution might use anonymous inner classes, as seen in Java:
class BigValue {
public:
void init();
…
};
void compute (std::vector<BigValue>& vec)
{
std::for_each (vec.begin(), vec.end(),
class {
public:
void operator() (BigValue& v) const {
v.init();
}
};
);
…
}
Although these sorts of constructs regularly come up among language designers, concrete proposals are rare. This is probably a consequence of the fact that designing such an extension is a considerable task that amounts to much more than our examples may suggest. Among the issues to be tackled are the specification of the return type and the rules that determine what entities are available within the body of a function expression. For example, can local variables in the surrounding function be accessed? Function expressions could also conceivably be templates in which the types of the parameters would be deduced from the use of the function expression. Such an approach may make the previous example even more concise (by allowing us to omit the parameter list altogether), but it brings with it new challenges for the template argument deduction system.
It is not at all clear that C++ will ever include a concept like function expressions. However, the Lambda Library of Jaakko Järvi and Gary Powell (see [LambdaLib]) goes a long way toward providing the desired functionality, albeit at a considerable price in compiler resources.
|
13.17 Afternotes
It seems perhaps premature to talk about extending the language when C++ compilers are only barely becoming mostly compliant to the 1998 standard (C++98). However, it is in part because this compliance is being achieved that we (the C++ programmers community) are gaining insight into the true limitations of C++ (and templates in particular).
To meet the new needs of C++ programmers, the C++ standards committee (often referred to as ISO WG21/ANSI J16, or just WG21/J16) started examining a road to a new standard: C++0x. After a preliminary presentation at its April 2001 meeting in Copenhagen, WG21/J16 started examining concrete library extension proposals.
Indeed, the intention is to attempt as much as possible to confine extensions to the C++ standard library. However, it is well understood that some of these extensions may require work in the core language. We expect that many of these required modifications will relate to C++ templates, just as the introduction of STL in the C++ standard library stimulated template technology in the 1990s.
Finally, C++0x is also expected to address some "embarrassments" in C++98. It is hoped that doing so will improve the accessibility of C++. Some of the extensions in that direction were discussed in this chapter.
|
Chapter 14. The Polymorphic Power of Templates
Polymorphism is the ability to associate different specific behaviors with a single generic notation.
Polymorphism is also a cornerstone of the object-oriented programming paradigm, which in C++ is supported mainly through class inheritance and virtual functions. Because these mechanism are (at least in part) handled at run time, we talk about dynamic polymorphism. This is usually what is thought of when talking about plain polymorphism in C++. However, templates also allow us to associate different specific behaviors with a single generic notation, but this association is generally handled at compile time, which we refer to as static polymorphism. In this chapter we review the two forms of polymorphism and discuss which form is appropriate in which situations.
|
14.1 Dynamic Polymorphism
Historically, C++ started with supporting polymorphism only through the use of inheritance combined with virtual functions.
The art of polymorphic design in this context consists of identifying a common set of capabilities among related object types and declaring them as virtual function interfaces in a common base class.
The poster child for this design approach is an application that manages geometric shapes and allows them to be rendered in some way (for example, on a screen). In such an application we might identify a so-called abstract base class (ABC) GeoObj, which declares the common operations and properties applicable to geometric objects. Each concrete class for specific geometric objects then derives from GeoObj (see Figure 14.1):
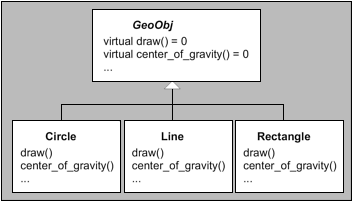
// poly/dynahier.hpp
#include "coord.hpp"
// common abstract base class GeoObj for geometric objects
class GeoObj {
public:
// draw geometric object:
virtual void draw() const = 0;
// return center of gravity of geometric object:
virtual Coord center_of_gravity() const = 0;
…
};
// concrete geometric object class Circle
// - derived from GeoObj
class Circle : public GeoObj {
public:
virtual void draw() const;
virtual Coord center_of_gravity() const;
…
};
// concrete geometric object class Line
// - derived from GeoObj
class Line : public GeoObj {
public:
virtual void draw() const;
virtual Coord center_of_gravity() const;
…
};
…
After creating concrete objects, client code can manipulate these objects through references or pointers to the base class, which enables the virtual function dispatch mechanism. Calling a virtual member function through a pointer or reference to a base class subobject results in an invocation of the appropriate member of the specific concrete object to which was referred.
In our example, the concrete code can be sketched as follows:
// poly/dynapoly.cpp
#include "dynahier.hpp"
#include <vector>
// draw any GeoObj
void myDraw (GeoObj const& obj)
{
obj.draw(); // call draw() according to type of object
}
// process distance of center of gravity between two GeoObjs
Coord distance (GeoObj const& x1, GeoObj const& x2)
{
Coord c = x1.center_of_gravity() - x2.center_of_gravity();
return c.abs(); // return coordinates as absolute values
}
// draw inhomogeneous collection of GeoObjs
void drawElems (std::vector<GeoObj*> const& elems)
{
for (unsigned i=0; i<elems.size(); ++i) {
elems[i]->draw(); // call draw() according to type of element
}
}
int main()
{
Line l;
Circle c, c1, c2;
myDraw(l); // myDraw(GeoObj&) => Line::draw()
myDraw(c); // myDraw(GeoObj&) => Circle::draw()
distance(c1,c2); // distance(GeoObj&,GeoObj&)
distance(l,c); // distance(GeoObj&,GeoObj&)
std::vector<GeoObj*> coll; // inhomogeneous collection
coll.push_back(&l); // insert line
coll.push_back(&c); // insert circle
drawElems(coll); // draw different kinds of GeoObjs
}
The key polymorphic interface elements are the functions draw() and center_of_gravity(). Both are virtual member functions. Our example demonstrates their use in the functions mydraw(), distance(),anddrawElems(). The latter functions are expressed using the common base type GeoObj. As a consequence it cannot be determined at compile time which version of draw() or center_of_gravity() has to be used. However, at run time, the complete dynamic type of the objects for which the virtual functions are invoked is accessed to dispatch the function calls. Hence, depending on the actual type of a geometric object, the appropriate operation is done: If mydraw() is called for a Line object, the expression obj.draw() calls Line::draw(), whereas for a Circle object the function Circle::draw() is called. Similarly, with distance() the member functions center_of_gravity() appropriate for the argument objects are called.
Perhaps the most compelling feature of this dynamic polymorphism is the ability to handle heterogeneous collections of objects. drawElems() illustrates this concept: The simple expression
elems[i]->draw()
results in invocations of different member functions, depending on the type of the element being iterated over.
|
14.2 Static Polymorphism
Templates can also be used to implement polymorphism. However, they don't rely on the factoring of common behavior in base classes. Instead, the commonality is implicit in that the different "shapes" of an application must support operations using common syntax (that is, the relevant functions must have the same names). Concrete classes are defined independently from each other (see Figure 14.2). The polymorphic power is then enabled when templates are instantiated with the concrete classes.
For example, the function myDraw() in the previous section
void myDraw (GeoObj const& obj) // GeoObj is abstract base class
{
obj.draw();
}
could conceivably be rewritten as follows:
template <typename GeoObj>
void myDraw (GeoObj const& obj) // GeoObj is template parameter
{
obj.draw();
}
Comparing the two implementations of myDraw(), we may conclude that the main difference is the specification of GeoObj as a template parameter instead of a common base class. There are, however, more fundamental differences under the hood. For example, using dynamic polymorphism we had only one myDraw() function at run time, whereas with the template we have distinct functions, such as myDraw<Line>() and myDraw<Circle>().
We may attempt to recode the complete example of the previous section using static polymorphism. First, instead of a hierarchy of geometric classes, we have several individual geometric classes:
// poly/statichier.hpp
#include "coord.hpp"
// concrete geometric object class Circle
// - not derived from any class
class Circle {
public:
void draw() const;
Coord center_of_gravity() const;
…
};
// concrete geometric object class Line
// - not derived from any class
class Line {
public:
void draw() const;
Coord center_of_gravity() const;
…
};
…
Now, the application of these classes looks as follows:
// poly/staticpoly.cpp
#include "statichier.hpp"
#include <vector>
// draw any GeoObj
template <typename GeoObj>
void myDraw (GeoObj const& obj)
{
obj.draw(); // call draw() according to type of object
}
// process distance of center of gravity between two GeoObjs
template <typename GeoObj1, typename GeoObj2>
Coord distance (GeoObj1 const& x1, GeoObj2 const& x2)
{
Coord c = x1.center_of_gravity() - x2.center_of_gravity();
return c.abs(); // return coordinates as absolute values
}
// draw homogeneous collection of GeoObjs
template <typename GeoObj>
void drawElems (std::vector<GeoObj> const& elems)
{
for (unsigned i=0; i<elems.size(); ++i) {
elems[i].draw(); // call draw() according to type of element
}
}
int main()
{
Line l;
Circle c, c1, c2;
myDraw(l); // myDraw<Line>(GeoObj&) => Line::draw()
myDraw(c); // myDraw<Circle>(GeoObj&) => Circle::draw()
distance(c1,c2); // distance<Circle,Circle>(GeoObj1&,GeoObj2&)
distance(l,c); // distance<Line,Circle>(GeoObj1&,GeoObj2&)
// std::vector<GeoObj*> coll; // ERROR: no inhomogeneous
// collection possible
std::vector<Line> coll; // OK: homogeneous collection possible
coll.push_back(l); // insert line
drawElems(coll); // draw all lines
}
As with myDraw(), GeoObj can no longer be used as a concrete parameter type for distance(). Instead, we provide for two template parameters GeoObj1 and GeoObj2. By using two different template parameters, different combinations of geometric object types can be accepted for the distance computation:
distance(l,c); // distance<Line,Circle>(GeoObj1&,GeoObj2&)
However, heterogeneous collections can no longer be handled transparently. This is where the static part of static polymorphism imposes its constraint: All types must be determined at compile time. Instead, we can easily introduce different collections for different geometric object types. There is no longer a requirement that the collection be limited to pointers, which can have significant advantages in terms of performance and type safety.
|
14.3 Dynamic versus Static Polymorphism
Let's categorize and compare both forms of polymorphisms.
Terminology
Dynamic and static polymorphism provide support for different C++ programming idioms
:
- Unbounded means that the interfaces of the types participating in the polymorphic behavior are not predetermined (other terms for this concept are noninvasive or nonintrusive). - Static means that the binding of the interfaces is done at compile time (statically).
So, strictly speaking, in C++ parlance, dynamic polymorphism and static polymorphism are shortcuts for bounded dynamic polymorphism and unbounded static polymorphism. In other languages other combinations exist (for example, Smalltalk provides unbounded dynamic polymorphism). However, in the context of C++, the more concise terms dynamic polymorphism and static polymorphism do not cause confusion.
Strengths and Weaknesses
Dynamic polymorphism in C++ exhibits the following strengths:
Heterogeneous collections are handled elegantly. The executable code size is potentially smaller (because only one polymorphic function is needed, whereas distinct template instances must be generated to handle different types). Code can be entirely compiled; hence no implementation source must be published (distributing template libraries usually requires distribution of the source code of the template implementations).
In contrast, the following can be said about static polymorphism in C++:
Collections of built-in types are easily implemented. More generally, the interface commonality need not be expressed through a common base class. Generated code is potentially faster (because no indirection through pointers is needed a priori and nonvirtual functions can be inlined much more often). Concrete types that provide only partial interfaces can still be used if only that part ends up being exercised by the application.
Static polymorphism is often regarded as more type safe than dynamic polymorphism because all the bindings are checked at compile time. For example, there is little danger of inserting an object of the wrong type in a container instantiated from a template. However, in a container expecting pointers to a common base class, there is a possibility that these pointers unintentionally end up pointing to complete objects of different types.
In practice, template instantiations can also cause some grief when different semantic assumptions hide behind identical-looking interfaces. For example, surprises can occur when a template that assumes an associative operator + is instantiated for a type that is not associative with respect to that operator. In practice, this kind of semantic mismatch occurs less often with inheritance-based hierarchies, presumably because the interface specification is more explicitly specified.
Combining Both Forms
Of course, you could combine both forms of inheritance. For example, you could derive different kinds of geometric objects from a common base class to be able to handle inhomogeneous collections of geometric objects. However, you can still use templates to write code for a certain kind of geometric object.
The combination of inheritance and templates is further described in Chapter 16. We will see (among other things) how the virtuality of a member function can be parameterized and how an additional amount of flexibility is afforded to static polymorphism using the inheritance-based curiously recurring template pattern (or CRTP).
|
14.4 New Forms of Design Patterns
The new form of static polymorphism leads to new ways of implementing design patterns. Take, for example, the bridge pattern, which plays a major role in C++ programs. One goal of using the bridge pattern is to switch between different implementations of an interface. According to [DesignPatternsGoV] this is usually done by using a pointer to refer to the actual implementation and delegating all calls to this class (see Figure 14.3).
However, if the type of the implementation is known at compile time, you could use the approach via templates instead (see Figure 14.4). This leads to more type safety, avoids pointers, and should be faster.
|
14.5 Generic Programming
Static polymorphism leads to the concept of generic programming. However, there is no one universally agreed-on definition of generic programming (just as there is no one agreed-on definition of object-oriented programming). According to [CzarneckiEiseneckerGenProg], definitions go from programming with generic parameters to finding the most abstract representation of efficient algorithms. The book summarizes:
Generic programming is a subdiscipline of computer science that deals with finding abstract representations of efficient algorithms, data structures, and other software concepts, and with their systematic organization…. Generic programming focuses on representing families of domain concepts. (pages 169 and 170)
In the context of C++, generic programming is sometimes defined as programming with templates (whereas object-oriented programming is thought of as programming with virtual functions). In this sense, just about any use of C++ templates could be thought of as an instance of generic programming. However, practitioners often think of generic programming as having an additional essential ingredient: Templates have to be designed in a framework for the purpose of enabling a multitude of useful combinations.
By far the most significant contribution in this area is the STL (the Standard Template Library, which later was adapted and incorporated into the C++ standard library). The STL is a framework that provides a number of useful operations, called algorithms, for a number of linear data structures for collections of objects, called containers. Both algorithms and containers are templates. However, the key is that the algorithms are not member functions of the containers. Instead, the algorithms are written in a generic way so that they can be used by any container (and linear collection of elements). To do this, the designers of STL identified an abstract concept of iterators that can be provided for any kind of linear collection. Essentially, the collection-specific aspects of container operations have been factored out into the iterators' functionality.
As a consequence, implementing an operation such as computing the maximum value in a sequence can be done without knowing the details of how values are stored in that sequence:
template <class Iterator>
Iterator max_element (Iterator beg, // refers to start of collection
Iterator end) // refers to end of collection
{
// use only certain Iterator's operations to traverse all elements
// of the collection to find the element with the maximum value
// and return its position as Iterator
…
}
Instead of providing all useful operations such as max_element() by every linear container, the container has to provide only an iterator type to traverse the sequence of values it contains and member functions to create such iterators:
namespace std {
template <class T, … >
class vector {
public:
typedef … const_iterator; // implementation-specific iterator
… // type for constant vectors
const_iterator begin() const; // iterator for start of collection
const_iterator end() const; // iterator for end of collection
…
};
template <class T, ... >
class list {
public:
typedef … const_iterator; // implementation-specific iterator
… // type for constant lists
const_iterator begin() const; // iterator for start of collection
const_iterator end() const; // iterator for end of collection
…
};
}
Now, you can find the maximum of any collection by calling the generic max_element() operation with the beginning and end of the collection as arguments (special handling of empty collections is omitted):
// poly/printmax.cpp
#include <vector>
#include <list>
#include <algorithm>
#include <iostream>
#include "MyClass.hpp"
template <typename T>
void print_max (T const& coll)
{
// declare local iterator of collection
typename T::const_iterator pos;
// compute position of maximum value
pos = std::max_element(coll.begin(),coll.end());
// print value of maximum element of coll (if any):
if (pos != coll.end()) {
std::cout << *pos << std::endl;
}
else {
std::cout << "empty" << std::endl;
}
}
int main()
{
std::vector<MyClass> c1;
std::list<MyClass> c2;
…
print_max (c1);
print_max (c2);
}
By parameterizing its operations in terms of these iterators, the STL avoids an explosion in the number of operation definitions. Instead of implementing each operation for every container, you implement the algorithm once so that it can be used for every container. The generic glue is the iterators that are provided by the containers and that are used by the algorithms. This works because iterators have a certain interface that is provided by the containers and used by the algorithms. This interface is usually called a concept, which denotes a set of constraints that a template has to fulfill to fit into this framework.
In principle, functionally such as an STL-like approach could be implemented with dynamic polymorphism. In practice, however, it would be of limited use because the iterator concept is too lightweight compared with the virtual function call mechanism. Adding an interface layer based on virtual functions would most likely slow down our operations by an order of magnitude (or more).
Generic programming is practical exactly because it relies on static polymorphism, which resolves interfaces at compile time. On the other hand, the requirement that the interfaces be resolved at compile time also calls for new design principles that are different in many ways from object-oriented design principles. Many of the most important of these generic design principles are described in the remainder of this book.
|
14.6 Afternotes
Container types were a primary motivation for the introduction of templates into the C++ programming language. Prior to templates, polymorphic hierarchies were a popular approach to containers. A popular example was the National Institutes of Health Class Library (NIHCL), which to a large extent translated the container class hierarchy of Smalltalk (see Figure 14.5).
Much like the C++ standard library, the NIHCL supported a rich variety of containers as well as iterators. However, the implementation followed the Smalltalk style of dynamic polymorphism: Iterators used the abstract base class Collection to operate on different types of collections:
Bag c1;
Set c2;
…
Iterator i1(s);
Iterator i2(b);
…
Unfortunately, the price of this approach was high both in terms of running time and memory usage. Running time was typically orders of magnitude worse than equivalent code using the C++ standard library because most operations ended up requiring a virtual call (whereas in the C++ standard library many operations are inlined, and no virtual functions are involved in iterator and container interfaces). Furthermore, because (unlike Smalltalk) the interfaces were bounded, built-in types had to be wrapped in larger polymorphic classes (such wrappers were provided by the NIHCL), which in turn could lead to dramatic increases in storage requirements.
Some sought solace in macros, but even in today's age of templates many projects still make suboptimal choices in their approach to polymorphism. Clearly there are many situations when dynamic polymorphism is the "right choice." Heterogeneous iterations are an example. However, in the same vein, many programming tasks are naturally and efficiently solved using templates, and homogeneous containers are an example of this.
Static polymorphism lends itself well to code very fundamental computing structures. In contrast, the need to choose a common base type implies that a dynamic polymorphic library will normally have to make domain-specific choices. It's no surprise then that the STL part of the C++ standard library never included polymorphic containers, but it contains a rich set of containers and iterators that use static polymorphism (as demonstrated in Section 14.5 on page 241).
Medium and large C++ programs typically need to handle both kinds of polymorphism discussed in this chapter. In some situations it may even be necessary to combine them very intimately. In many cases the optimal design choices are clear in light of our discussion, but spending some time thinking about long-term potential evolutions almost always pays off.
|
Chapter 15. Traits and Policy Classes
Templates enable us to parameterize classes and functions for various types. It could be tempting to introduce as many template parameters as possible to enable the customization of every aspect of a type or algorithm. In this way, our "templatized" components could be instantiated to meet the exact needs of client code. However, from a practical point of view it is rarely desirable to introduce dozens of template parameters for maximal parameterization. Having to specify all the corresponding arguments in the client code is overly tedious.
Fortunately, it turns out that most of the extra parameters we would introduce have reasonable default values. In some cases the extra parameters are entirely determined by a few main parameters, and we'll see that such extra parameters can be omitted altogether. Other parameters can be given default values that depend on the main parameters and will meet the needs of most situations, but the default values must occasionally be overridden (for special applications). Yet other parameters are unrelated to the main parameters: In a sense they are themselves main parameters, except for the fact that there exist default values that almost always fit the bill.
Policy classes and traits (or traits templates) are C++ programming devices that greatly facilitate the management of the sort of extra parameters that come up in the design of industrial-strength templates. In this chapter we show a number of situations in which they prove useful and demonstrate various techniques that will enable you to write robust and powerful devices of your own.
|
15.1 An Example: Accumulating a Sequence
Computing the sum of a sequence of values is a fairly common computational task. However, this seemingly simple problem provides us with an excellent example to introduce various levels at which policy classes and traits can help.
15.1.1 Fixed Traits
Let's first assume that the values of the sum we want to compute are stored in an array, and we are given a pointer to the first element to be accumulated and a pointer one past the last element to be accumulated. Because this book is about templates, we wish to write a template that will work for many types. The following may seem straightforward by now
:
// traits/accum1.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
template <typename T>
inline
T accum (T const* beg, T const* end)
{
T total = T(); // assume T() actually creates a zero value
while (beg != end) {
total += *beg;
++beg;
}
return total;
}
#endif // ACCUM_HPP
The only slightly subtle decision here is how to create a zero value of the correct type to start our summation. We use the expression T() here, which normally should work for built-in numeric types like int and float (see Section 5.5 on page 56).
To motivate our first traits template, consider the following code that makes use of our accum():
// traits/accum1.cpp
#include "accum1.hpp"
#include <iostream>
int main()
{
// create array of 5 integer values
int num[]={1,2,3,4,5};
// print average value
std::cout << "the average value of the integer values is "
<< accum(&num[0], &num[5]) / 5
<< '\n';
// create array of character values
char name[] = "templates";
int length = sizeof(name)-1;
// (try to) print average character value
std::cout << "the average value of the characters in \""
<< name << "\" is "
<< accum(&name[0], &name[length]) / length
<< '\n';
}
In the first half of the program we use accum() to sum five integer values:
int num[]={1,2,3,4,5};
…
accum(&num[0], &num[5])
The average integer value is then obtained by simply dividing the resulting sum by the number of values in the array.
The second half of the program attempts to do the same for all letters in the word template (provided the characters from a to z form a contiguous sequence in the actual character set, which is true for ASCII but not for EBCDIC
). The result should presumably lie between the value of a and the value of z. On most platforms today, these values are determined by the ASCII codes: a is encoded as 97 and z is encoded as 122. Hence, we may expect a result between 97 and 122. However, on our platform the output of the program is as follows:
the average value of the integer values is 3
the average value of the characters in "templates" is -5
The problem here is that our template was instantiated for the type char, which turns out to be too by introducing an additional template parameter AccT that describes the type used for the variable total (and hence the return type). However, this would put an extra burden on all users of our template: They would have to specify an extra type in every invocation of our template. In our example we may, therefore, need to write the following:
accum<int>(&name[0],&name[length])
This is not an excessive constraint, but it can be avoided.
An alternative approach to the extra parameter is to create an association between each type T for which accum() is called and the corresponding type that should be used to hold the accumulated value. This association could be considered characteristic of the type T, and therefore the type in which the sum is computed is sometimes called a trait of T. As is turns out, our association can be encoded as specializations of a template:
// traits/accumtraits2.hpp
template<typename T>
class AccumulationTraits;
template<>
class AccumulationTraits<char> {
public:
typedef int AccT;
};
template<>
class AccumulationTraits<short> {
public:
typedef int AccT;
};
template<>
class AccumulationTraits<int> {
public:
typedef long AccT;
};
template<>
class AccumulationTraits<unsigned int> {
public:
typedef unsigned long AccT;
};
template<>
class AccumulationTraits<float> {
public:
typedef double AccT;
};
The template AccumulationTraits is called a traits template because it holds a trait of its parameter type. (In general, there could be more than one trait and more than one parameter.) We chose not to provide a generic definition of this template because there isn't a great way to select a good accumulation type when we don't know what the type is. However, an argument could be made that T itself is often a good candidate for such a type (although clearly not in our earlier example).
With this in mind, we can rewrite our accum() template as follows:
// traits/accum2.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include "accumtraits2.hpp"
template <typename T>
inline
typename AccumulationTraits<T>::AccT accum (T const* beg,
T const* end)
{
// return type is traits of the element type
typedef typename AccumulationTraits<T>::AccT AccT;
AccT total = AccT(); // assume T() actually creates a zero value
while (beg != end) {
total += *beg;
++beg;
}
return total;
}
#endif // ACCUM_HPP
The output of our sample program then becomes what we expect:
the average value of the integer values is 3
the average value of the characters in "templates" is 108
Overall, the changes aren't very dramatic considering that we have added a very useful mechanism to customize our algorithm. Furthermore, if new types arise for use with accum(), an appropriate AccT can be associated with it simply by declaring an additional explicit specialization of the AccumulationTraits template. Note that this can be done for any type: fundamental types, types that are declared in other libraries, and so forth.
15.1.2 Value Traits
So far, we have seen that traits represent additional type information related to a given "main" type. In this section we show that this extra information need not be limited to types. Constants and other classes of values can be associated with a type as well.
Our original accum() template uses the default constructor of the return value to initialize the result variable with what is hoped to be a zero-like value:
AccT total = AccT(); // assume T() actually creates a zero value
…
return total;
Clearly, there is no guarantee that this produces a good value to start the accumulation loop. Type T may not even have a default constructor.
Again, traits can come to the rescue. For our example, we can add a new value trait to our AccumulationTraits:
// traits/accumtraits3.hpp
template<typename T>
class AccumulationTraits;
template<>
class AccumulationTraits<char> {
public:
typedef int AccT;
static AccT const zero = 0;
};
template<>
class AccumulationTraits<short> {
public:
typedef int AccT;
static AccT const zero = 0;
};
template<>
class AccumulationTraits<int> {
public:
typedef long AccT;
static AccT const zero = 0;
};
…
In this case, our new trait is a constant that can be evaluated at compile time. Thus, accum() becomes:
// traits/accum3.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include "accumtraits3.hpp"
template <typename T>
inline
typename AccumulationTraits<T>::AccT accum (T const* beg,
T const* end)
{
// return type is traits of the element type
typedef typename AccumulationTraits<T>::AccT AccT;
AccT total = AccumulationTraits<T>::zero;
while (beg != end) {
total += *beg;
++beg;
}
return total;
}
#endif // ACCUM_HPP
In this code, the initialization of the accumulation variable remains straightforward:
AccT total = AccumulationTraits<T>::zero;
A drawback of this formulation is that C++ allows us to initialize only a static constant data member inside its class if it has an integral or enumeration type. This excludes our own classes, of course, and floating-point types as well. The following specialization is, therefore, an error:
…
template<>
class AccumulationTraits<float> {
public:
typedef double AccT;
static double const zero = 0.0; // ERROR: not an integral type
};
The straightforward alternative is not to define the value trait in its class:
…
template<>
class AccumulationTraits<float> {
public:
typedef double AccT;
static double const zero;
};
The initializer then goes in a source file and looks something like the following:
…
double const AccumulationTraits<float>::zero = 0.0;
Although this works, it has the disadvantage of being more opaque to compilers. While processing client files, compilers are typically unaware of definitions in other files. In this case, for example, a compiler would not be able to take advantage of the fact that the value zero is really 0.0.
Consequently, we prefer to implement value traits, which are not guaranteed to have integral values as inline member functions.
For example, we could rewrite AccumulationTraits as follows:
// traits/accumtraits4.hpp
template<typename T>
class AccumulationTraits;
template<>
class AccumulationTraits<char> {
public:
typedef int AccT;
static AccT zero() {
return 0;
}
};
template<>
class AccumulationTraits<short> {
public:
typedef int AccT;
static AccT zero() {
return 0;
}
};
template<>
class AccumulationTraits<int> {
public:
typedef long AccT;
static AccT zero() {
return 0;
}
};
template<>
class AccumulationTraits<unsigned int> {
public:
typedef unsigned long AccT;
static AccT zero() {
return 0;
}
};
template<>
class AccumulationTraits<float> {
public:
typedef double AccT;
static AccT zero() {
return 0;
}
};
…
For the application code, the only difference is the use of function call syntax (instead of the slightly more concise access to a static data member):
AccT total = AccumulationTraits<T>::zero();
Clearly, traits can be more than just extra types. In our example, they can be a mechanism to provide all the necessary information that accum() needs about the element type for which it is called. This is the key of the traits concept: Traits provide an avenue to configure concrete elements (mostly types) for generic computations.
15.1.3 Parameterized Traits
The use of traits in accum() in the previous sections is called fixed, because once the decoupled trait is defined, it cannot be overridden in the algorithm. There may be cases when such overriding is desirable. For example, we may happen to know that a set of float values can safely be summed into a variable of the same type, and doing so may buy us some efficiency.
In principle, the solution consists of adding a template parameter but with a default value determined by our traits template. In this way, many users can omit the extra template argument, but those with more exceptional needs can override the preset accumulation type. The only bee in our bonnet for this particular case is that function templates cannot have default template arguments.
For now, let's circumvent the problem by formulating our algorithm as a class. This also illustrates the fact that traits can be used in class templates at least as easily as in function templates. The drawback in our application is that class templates cannot have their template arguments deduced. They must be provided explicitly. Hence, we need the form
Accum<char>::accum(&name[0], &name[length])
to use our revised accumulation template:
// traits/accum5.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include "accumtraits4.hpp"
template <typename T,
typename AT = AccumulationTraits<T> >
class Accum {
public:
static typename AT::AccT accum (T const* beg, T const* end) {
typename AT::AccT total = AT::zero();
while (beg != end) {
total += *beg;
++beg;
}
return total;
}
};
#endif // ACCUM_HPP
Presumably, most users of this template would never have to provide the second template argument explicitly because it can be configured to an appropriate default for every type used as a first argument.
As is often the case, we can introduce convenience functions to simplify the interface:
template <typename T>
inline
typename AccumulationTraits<T>::AccT accum (T const* beg,
T const* end)
{
return Accum<T>::accum(beg, end);
}
template <typename Traits, typename T>
inline
typename Traits::AccT accum (T const* beg, T const* end)
{
return Accum<T, Traits>::accum(beg, end);
}
15.1.4 Policies and Policy Classes
So far we have equated accumulation with summation. Clearly we can imagine other kinds of accumulations. For example, we could multiply the sequence of given values. Or, if the values were strings, we could concatenate them. Even finding the maximum value in a sequence could be formulated as an accumulation problem. In all these alternatives, the only accum() operation that needs to change is total += *start. This operation can be called a policy of our accumulation process. A policy class, then, is a class that provides an interface to apply one or more policies in an algorithm.
Here is an example of how we could introduce such an interface in our Accum class template:
// traits/accum6.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include "accumtraits4.hpp"
#include "sumpolicy1.hpp"
template <typename T,
typename Policy = SumPolicy,
typename Traits = AccumulationTraits<T> >
class Accum {
public:
typedef typename Traits::AccT AccT;
static AccT accum (T const* beg, T const* end) {
AccT total = Traits::zero();
while (beg != end) {
Policy::accumulate(total, *beg);
++beg;
}
return total;
}
};
#endif // ACCUM_HPP
With this a SumPolicy could be written as follows:
// traits/sumpolicy1.hpp
#ifndef SUMPOLICY_HPP
#define SUMPOLICY_HPP
class SumPolicy {
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const & value) {
total += value;
}
};
#endif // SUMPOLICY_HPP
In this example we chose to make our policy an ordinary class (that is, not a template) with a static member function template (which is implicitly inline). We discuss an alternative option later.
By specifying a different policy to accumulate values we can compute different things. Consider, for example, the following program, which intends to determine the product of some values:
// traits/accum7.cpp
#include "accum6.hpp"
#include <iostream>
class MultPolicy {
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const& value) {
total *= value;
}
};
int main()
{
// create array of 5 integer values
int num[]={1,2,3,4,5};
// print product of all values
std::cout << "the product of the integer values is "
<< Accum<int,MultPolicy>::accum(&num[0], &num[5])
<< '\n';
}
However, the output of this program isn't what we would like:
the product of the integer values is 0
The problem here is caused by our choice of initial value: Although 0 works well for summation, it does not work for multiplication (a zero initial value forces a zero result for accumulated multiplications). This illustrates that different traits and policies may interact, underscoring the importance of careful template design.
In this case we may recognize that the initialization of an accumulation loop is a part of the accumulation policy. This policy may or may not make use of the trait zero(). Other alternatives are not to be forgotten: Not everything must be solved with traits and policies. For example, the accumulate() function of the C++ standard library takes the initial value as a third (function call) argument.
15.1.5 Traits and Policies: What's the Difference?
A reasonable case can be made in support of the fact that policies are just a special case of traits. Conversely, it could be claimed that traits just encode a policy.
The New Shorter Oxford English Dictionary (see [NewShorterOED]) has this to say:
Based on this, we tend to limit the use of the term policy classes to classes that encode an action of some sort that is largely orthogonal with respect to any other template argument with which it is combined. This is in agreement with Andrei Alexandrescu's statement in his book Modern C++ Design (see page 8 of [AlexandrescuDesign])
:
Policies have much in common with traits but differ in that they put less emphasis on type and more on behavior.
Nathan Myers, who introduced the traits technique, proposed the following more open-ended definition (see [MyersTraits]):
Traits class:
A class used in place of template parameters. As a class, it aggregates useful types and constants; as a template, it provides an avenue for that "extra level of indirection" that solves all software problems.
In general, we therefore tend to use the following (slightly fuzzy) definitions:
To elaborate further on the possible distinctions between the two concepts, we list the following observations about traits:
Traits can be useful as fixed traits (that is, without being passed through template parameters). Traits parameters usually have very natural default values (which are rarely overridden, or simply cannot be overridden). Traits parameters tend to depend tightly on one or more main parameters. Traits mostly combine types and constants rather than member functions. Traits tend to be collected in traits templates.
For policy classes, we make the following observations:
Policy classes don't contribute much if they aren't passed as template parameters. Policy parameters need not have default values and are often specified explicitly (although many generic components are configured with commonly used default policies). Policy parameters are mostly orthogonal to other parameters of a template. Policy classes mostly combine member functions. Policies can be collected in plain classes or in class templates.
However, there is certainly an indistinct line between both terms. For example, the character traits of the C++ standard library also define functional behavior such as comparing, moving, and finding characters. And by replacing these traits you can define string classes that behave in a case-insensitive manner (see Section 11.2.14 in [JosuttisStdLib]) while keeping the same character type. Thus, although they are called traits, they have some properties associated with policies.
15.1.6 Member Templates versus Template Template Parameters
To implement an accumulation policy we chose to express SumPolicy and MultPolicy as ordinary classes with a member template. An alternative consists of designing the policy class interface using class templates, which are then used as template template arguments. For example, we could rewrite SumPolicy as a template:
// traits/sumpolicy2.hpp
#ifndef SUMPOLICY_HPP
#define SUMPOLICY_HPP
template <typename T1, typename T2>
class SumPolicy {
public:
static void accumulate (T1& total, T2 const & value) {
total += value;
}
};
#endif // SUMPOLICY_HPP
The interface of Accum can then be adapted to use a template template parameter:
// traits/accum8.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include "accumtraits4.hpp"
#include "sumpolicy2.hpp"
template <typename T,
template<typename,typename> class Policy = SumPolicy,
typename Traits = AccumulationTraits<T> >
class Accum {
public:
typedef typename Traits::AccT AccT;
static AccT accum (T const* beg, T const* end) {
AccT total = Traits::zero();
while (beg != end) {
Policy<AccT,T>::accumulate(total, *beg);
++beg;
}
return total;
}
};
#endif // ACCUM_HPP
The same transformation can be applied to the traits parameter. (Other variations on this theme are possible: For example, instead of explicitly passing the AccT type to the policy type, it may be advantageous to pass the accumulation trait and have the policy determine the type of its result from a traits parameter.)
The major advantage of accessing policy classes through template template parameters is that it makes it easier to have a policy class carry with it some state information (that is, static data members) with a type that depends on the template parameters. (In our first approach the static data members would have to be embedded in a member class template.)
However, a downside of the template template parameter approach is that policy classes must now be written as templates, with the exact set of template parameters defined by our interface. This, unfortunately, disallows any additional template parameters in our policies. For example, we may want to add a Boolean nontype template parameter to SumPolicy that selects whether summation should happen with the += operator or whether + only should be used. In the program using a member template we can simply rewrite SumPolicy as a template:
// traits/sumpolicy3.hpp
#ifndef SUMPOLICY_HPP
#define SUMPOLICY_HPP
template<bool use_compound_op = true>
class SumPolicy {
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const & value) {
total += value;
}
};
template<>
class SumPolicy<false> {
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const & value) {
total = total + value;
}
};
#endif // SUMPOLICY_HPP
With implementation of Accum using template template parameters such an adaptation is no longer possible.
15.1.7 Combining Multiple Policies and/or Traits
As our development has shown, traits and policies don't entirely do away with having multiple template parameters. However, they do reduce their number to something manageable. An interesting question, then, is how to order such multiple parameters.
A simple strategy is to order the parameters according to the increasing likelihood of their default value to be selected. Typically, this would mean that the traits parameters follow the policy parameters because the latter are more often overridden in client code. (The observant reader may have noticed this strategy in our development.)
If we are willing to add a significant amount of complexity to our code, an alternative exists that essentially allows us to specify the nondefault arguments in any order. Refer to Section 16.1 on page 285 for details. Chapter 13 also discusses potential future template features that could simplify the resolution of this aspect of template design.
15.1.8 Accumulation with General Iterators
Before we end this introduction to traits and policies, it is instructive to look at one version of accum() that adds the capability to handle generalized iterators (rather than just pointers), as expected from an industrial-strength generic component. Interestingly, this still allows us to call accum() with pointers because the C++ standard library provides so-called iterator traits. (Traits are everywhere!) Thus, we could have defined our initial version of accum() as follows (ignoring our later refinements):
// traits/accum0.hpp
#ifndef ACCUM_HPP
#define ACCUM_HPP
#include <iterator>
template <typename Iter>
inline
typename std::iterator_traits<Iter>::value_type
accum (Iter start, Iter end)
{
typedef typename std::iterator_traits<Iter>::value_type VT;
VT total = VT(); // assume T() actually creates a zero value
while (start != end) {
total += *start;
++start;
}
return total;
}
#endif // ACCUM_HPP
The iterator_traits structure encapsulates all the relevant properties of iterator. Because a partial specialization for pointers exists, these traits are conveniently used with any ordinary pointer types. Here is how a standard library implementation may implement this support:
namespace std {
template <typename T>
struct iterator_traits<T*> {
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef random_access_iterator_tag iterator_category;
typedef T* pointer;
typedef T& reference;
};
}
However, there is no type for the accumulation of values to which an iterator refers; hence we still need to design our own AccumulationTraits.
|
15.2 Type Functions
The initial traits example demonstrates that you can define behavior that depends on types. This is different from what you usually implement in programs. In C and C++, functions more exactly can be called value functions: They take some values as parameters and return another value as a result. Now, what we have with templates are type functions: a function that takes some type arguments and produces a type or constant as a result.
A very useful built-in type function is sizeof, which returns a constant describing the size (in bytes) of the given type argument. Class templates can also serve as type functions. The parameters of the type function are the template parameters, and the result is extracted as a member type or member constant. For example, the sizeof operator could be given the following interface:
// traits/sizeof.cpp
#include <stddef.h>
#include <iostream>
template <typename T>
class TypeSize {
public:
static size_t const value = sizeof(T);
};
int main()
{
std::cout << "TypeSize<int>::value = "
<< TypeSize<int>::value << std::endl;
}
In what follows we develop a few more general-purpose type functions that can be used as traits classes in this way.
15.2.1 Determining Element Types
For another example, assume that we have a number of container templates such as vector<T>, list<T>, and stack<T>. We want a type function that, given such a container type, produces the element type. This can be achieved using partial specialization:
// traits/elementtype.cpp
#include <vector>
#include <list>
#include <stack>
#include <iostream>
#include <typeinfo>
template <typename T>
class ElementT; // primary template
template <typename T>
class ElementT<std::vector<T> > { // partial specialization
public:
typedef T Type;
};
template <typename T>
class ElementT<std::list<T> > { // partial specialization
public:
typedef T Type;
};
template <typename T>
class ElementT<std::stack<T> > { // partial specialization
public:
typedef T Type;
};
template <typename T>
void print_element_type (T const & c)
{
std::cout << "Container of "
<< typeid(typename ElementT<T>::Type).name()
<< " elements.\n";
}
int main()
{
std::stack<bool> s;
print_element_type(s);
}
The use of partial specialization allows us to implement this without requiring the container types to know about the type function. In many cases, however, the type function is designed along with the applicable types and the implementation can be simplified. For example, if the container types define a member type value_type (as the standard containers do), we can write the following:
template <typename C>
class ElementT {
public:
typedef typename C::value_type Type;
};
This can be the default implementation, and it does not exclude specializations for container types that do not have an appropriate member type value_type defined. Nonetheless, it is usually advisable to provide type definitions for template type parameters so that they can be accessed more easily in generic code. The following sketches the idea:
template <typename T1, typename T2, ... >
class X {
public:
typedef T1 … ;
typedef T2 … ;
…
};
How is a type function useful? It allows us to parameterize a template in terms of a container type, without also requiring parameters for the element type and other characteristics. For example, instead of
template <typename T, typename C>
T sum_of_elements (C const& c);
which requires syntax like sum_of_elements<int>(list) to specify the element type explicitly, we can declare
template<typename C>
typename ElementT<C>::Type sum_of_elements (C const& c);
where the element type is determined from the type function.
Note that the traits can be implemented as an extension to the existing types. Thus, you can define these type functions even for fundamental types and types of closed libraries.
In this case, the type ElementT is called a traits class because it is used to access a trait of the given container type C (in general, more than one trait can be collected in such a class). Thus, traits classes are not limited to describing characteristics of container parameters but of any kind of "main parameters."
15.2.2 Determining Class Types
With the following type function we can determine whether a type is a class type:
// traits/isclasst.hpp
template<typename T>
class IsClassT {
private:
typedef char One;
typedef struct { char a[2]; } Two;
template<typename C> static One test(int C::*);
template<typename C> static Two test(…);
public:
enum { Yes = sizeof(IsClassT<T>::test<T>(0)) == 1 };
enum { No = !Yes };
};
This template uses the SFINAE (substitution-failure-is-not-an-error) principle of Section 8.3.1 on page 106. The key to exploit SFINAE is to find a type construct that is invalid for function types but not for other types, or vice versa. For class types we can rely on the observation that the pointer-to-member type construct int C::* is valid only if C is a class type.
The following program uses this type function to test whether certain types and objects are class types:
// traits/isclasst.cpp
#include <iostream>
#include "isclasst.hpp"
class MyClass {
};
struct MyStruct {
};
union MyUnion {
};
void myfunc()
{
}
enumE{e1}e;
// check by passing type as template argument
template <typename T>
void check()
{
if (IsClassT<T>::Yes) {
std::cout << " IsClassT " << std::endl;
}
else {
std::cout << " !IsClassT " << std::endl;
}
}
// check by passing type as function call argument
template <typename T>
void checkT (T)
{
check<T>();
}
int main()
{
std::cout << "int: ";
check<int>();
std::cout << "MyClass: ";
check<MyClass>();
std::cout << "MyStruct:";
MyStruct s;
checkT(s);
std::cout << "MyUnion: ";
check<MyUnion>();
std::cout << "enum: ";
checkT(e);
std::cout << "myfunc():";
checkT(myfunc);
}
The program has the following output:
int: !IsClassT
MyClass: IsClassT
MyStruct: IsClassT
MyUnion: IsClassT
enum: !IsClassT
myfunc(): !IsClassT
15.2.3 References and Qualifiers
Consider the following function template definition:
// traits/apply1.hpp
template <typename T>
void apply (T& arg, void (*func)(T))
{
func(arg);
}
Consider also the following code that attempts to use it:
// traits/apply1.cpp
#include <iostream>
#include "apply1.hpp"
void incr (int& a)
{
++a;
}
void print (int a)
{
std::cout << a << std::endl;
}
int main()
{
intx=7;
apply (x, print);
apply (x, incr);
}
The call
apply (x, print)
is fine. With T substituted by int, the parameter types of apply() are int& and void(*)(int), which corresponds to the types of the arguments. The call
apply (x, incr)
is less straightforward. Matching the second parameter requires T to be substituted with int&, and this implies that the first parameter type is int& &, which ordinarily is not a legal C++ type. Indeed, the original C++ standard ruled this an invalid substitution, but because of examples like this, a later technical corrigendum (a set of small corrections of the standard; see [Standard02]) made T& with T substituted by int& equivalent to int&.
For C++ compilers that do not implement the newer reference substitution rule, we can create a type function that applies the "reference operator" if and only if the given type is not already a reference. We can also provide the opposite operation: Strip the reference operator (if and only if the type is indeed a reference). And while we are at it, we can also add or strip const qualifiers.
All this is achieved using partial specialization of the following generic definition:
// traits/typeop1.hpp
template <typename T>
class TypeOp { // primary template
public:
typedef T ArgT;
typedef T BareT;
typedef T const ConstT;
typedef T & RefT;
typedef T & RefBareT;
typedef T const & RefConstT;
};
First, a partial specialization to catch const types:
// traits/typeop2.hpp
template <typename T>
class TypeOp <T const> { // partial specialization for const types
public:
typedef T const ArgT;
typedef T BareT;
typedef T const ConstT;
typedef T const & RefT;
typedef T & RefBareT;
typedef T const & RefConstT;
};
The partial specialization to catch reference types also catches reference-to-const types. Hence, it applies the TypeOp device recursively to obtain the bare type when necessary. In contrast, C++ allows us to apply the const qualifier to a template parameter that is substituted with a type that is already const. Hence, we need not worry about stripping the const qualifier when we are going to reapply it anyway:
// traits/typeop3.hpp
template <typename T>
class TypeOp <T&> { // partial specialization for references
public:
typedef T & ArgT;
typedef typename TypeOp<T>::BareT BareT;
typedef T const ConstT;
typedef T & RefT;
typedef typename TypeOp<T>::BareT & RefBareT;
typedef T const & RefConstT;
};
References to void types are not allowed. It is sometimes useful to treat such types as plain void however. The following specialization takes care of this:
// traits/typeop4.hpp
template<>
class TypeOp <void> { // full specialization for void
public:
typedef void ArgT;
typedef void BareT;
typedef void const ConstT;
typedef void RefT;
typedef void RefBareT;
typedef void RefConstT;
};
With this in place, we can rewrite the apply template as follows:
template <typename T>
void apply (typename TypeOp<T>::RefT arg, void (*func)(T))
{
func(arg);
}
and our example program will work as intended.
Remember that T can no longer be deduced from the first argument because it now appears in a name qualifier. So T is deduced from the second argument only, and T is used to create the type of the first parameter.
15.2.4 Promotion Traits
So far we have studied and developed type functions of a single type: Given one type, other related types or constants were defined. In general, however, we can develop type functions that depend on multiple arguments. One example that is very useful when writing operator templates are so-called promotion traits. To motivate the idea, let's write a function template that allows us to add two Array containers:
template<typename T>
Array<T> operator+ (Array<T> const&, Array<T> const&);
This would be nice, but because the language allows us to add a char value to an int value, we really would prefer to allow such mixed-type operations with arrays too. We are then faced with determining what the return type of the resulting template should be:
template<typename T1, typename T2>
Array<???> operator+ (Array<T1> const&, Array<T2> const&);
A promotion traits template allows us to fill in the question marks in the previous declaration as follows:
template<typename T1, typename T2>
Array<typename Promotion<T1, T2>::ResultT>
operator+ (Array<T1> const&, Array<T2> const&);
or, alternatively, as follows:
template<typename T1, typename T2>
typename Promotion<Array<T1>, Array<T2> >::ResultT
operator+ (Array<T1> const&, Array<T2> const&);
The idea is to provide a large number of specializations of the template Promotion to create a type function that matches our needs. Another application of promotion traits was motivated by the introduction of the max() template, when we want to specify that the maximum of two values of different type should have the "the more powerful type" (see Section 2.3 on page 13).
There is no really reliable generic definition for this template, so it may be best to leave the primary class template undefined:
template<typename T1, typename T2>
class Promotion;
Another option would be to assume that if one of the types is larger than the other, we should promote to that larger type. This can by done by a special template IfThenElse that takes a Boolean nontype template parameter to select one of two type parmeters:
// traits/ifthenelse.hpp
#ifndef IFTHENELSE_HPP
#define IFTHENELSE_HPP
// primary template: yield second or third argument depending on first argument
template<bool C, typename Ta, typename Tb>
class IfThenElse;
// partial specialization: true yields second argument
template<typename Ta, typename Tb>
class IfThenElse<true, Ta, Tb> {
public:
typedef Ta ResultT;
};
// partial specialization: false yields third argument
template<typename Ta, typename Tb>
class IfThenElse<false, Ta, Tb> {
public:
typedef Tb ResultT;
};
#endif // IFTHENELSE_HPP
With this in place, we can create a three-way selection between T1, T2, and void, depending on the sizes of the types that need promotion:
// traits/promote1.hpp
// primary template for type promotion
template<typename T1, typename T2>
class Promotion {
public:
typedef typename
IfThenElse<(sizeof(T1)>sizeof(T2)),
T1,
typename IfThenElse<(sizeof(T1)<sizeof(T2)),
T2,
void
>::ResultT
>::ResultT ResultT;
};
The size-based heuristic used in the primary template works sometimes, but it requires checking. If it selects the wrong type, an appropriate specialization must be written to override the selection. On the other hand, if the two types are identical, we can safely make it to be the promoted type. A partial specialization takes care of this:
// traits/promote2.hpp
// partial specialization for two identical types
template<typename T>
class Promotion<T,T> {
public:
typedef T ResultT;
};
Many specializations are needed to record the promotion of fundamental types. A macro can reduce the amount of source code somewhat:
// traits/promote3.hpp
#define MK_PROMOTION(T1,T2,Tr) \
template<> class Promotion<T1, T2> { \
public: \
typedef Tr ResultT; \
}; \
\
template<> class Promotion<T2, T1> { \
public: \
typedef Tr ResultT; \
};
The promotions are then added as follows:
// traits/promote4.hpp
MK_PROMOTION(bool, char, int)
MK_PROMOTION(bool, unsigned char, int)
MK_PROMOTION(bool, signed char, int)
…
This approach is relatively straightforward, but requires the several dozen possible combinations to be enumerated. Various alternative techniques exist. For example, the IsFundaT and IsEnumT templates could be adapted to define the promotion type for integral and floating-point types. Promotion would then need to be specialized only for the resulting fundamental types (and user-defined types, as shown in a moment).
Once Promotion is defined for fundamental types (and enumeration types if desired), other promotion rules can often be expressed through partial specialization. For our Array example:
// traits/promotearray.hpp
template<typename T1, typename T2>
class Promotion<Array<T1>, Array<T2> > {
public:
typedef Array<typename Promotion<T1,T2>::ResultT> ResultT;
};
template<typename T>
class Promotion<Array<T>, Array<T> > {
public:
typedef Array<typename Promotion<T,T>::ResultT> ResultT;
};
This last partial specialization deserves some special attention. At first it may seem that the earlier partial specialization for identical types (Promotion<T,T>) already takes care of this case. Unfortunately, the partial specialization Promotion<Array<T1>, Array<T2> > is neither more nor less specialized than the partial specialization Promotion<T,T> (see also Section 12.4 on page 200).
To avoid template selection ambiguity, the last partial specialization was added. It is more specialized than either of the previous two partial specializations.
More specializations and partial specializations of the Promotion template can be added as more types are added for which a concept promotion makes sense.
|
15.3 Policy Traits
So far, our examples of traits templates have been used to determine properties of template parameters: what sort of type they represent, to which type they should promote in mixed-type operations, and so forth. Such traits are called property traits.
In contrast, some traits define how some types should be treated. We call them policy traits. This is reminiscent of the previously discussed concept of policy classes (and we already pointed out that the distinction between traits and policies is not entirely clear), but policy traits tend to be more unique properties associated with a template parameter (whereas policy classes are usually independent of other template parameters).
Although property traits can often be implemented as type functions, policy traits usually encapsulate the policy in member functions. As a first illustration, let's look at a type function that defines a policy for passing read-only parameters.
15.3.1 Read-only Parameter Types
In C and C++, function call arguments are passed "by value" by default. This means that the values of the arguments computed by the caller are copied to locations controlled by the callee. Most programmers know that this can be costly for large structures and that for such structures it is appropriate to pass the arguments "by reference-to-const" (or "by pointer-to-const" in C). For smaller structures, the picture is not always clear, and the best mechanism from a performance point of view depends on the exact architecture for which the code is being written. This is not so critical in most cases, but sometimes even the small structures must be handled with care.
With templates, of course, things get a little more delicate: We don't know a priori how large the type substituted for the template parameter will be. Furthermore, the decision doesn't depend just on size: A small structure may come with an expensive copy constructor that would still justify passing read-only parameters "by reference-to-const."
As hinted at earlier, this problem is conveniently handled using a policy traits template that is a type function: The function maps an intended argument type T onto the optimal parameter type T or T const&. As a first approximation, the primary template can use "by value" passing for types no larger than two pointers and "by reference-to-const" for everything else:
template<typename T>
class RParam {
public:
typedef typename IfThenElse<sizeof(T)<=2*sizeof(void*),
T,
T const&>::ResultT Type;
};
On the other hand, container types for which sizeof returns a small value may involve expensive copy constructors. So we may need many specializations and partial specializations, such as the following:
template<typename T>
class RParam<Array<T> > {
public:
typedef Array<T> const& Type;
};
Because such types are common in C++, it may be safer to mark nonclass types "by value" in the primary template and then selectively add the class types when performance considerations dictate it (the primary template uses IsClassT<> from page 266 to identify class types):
// traits/rparam.hpp
#ifndef RPARAM_HPP
#define RPARAM_HPP
#include "ifthenelse.hpp"
#include "isclasst.hpp"
template<typename T>
class RParam {
public:
typedef typename IfThenElse<IsClassT<T>::No,
T,
T const&>::ResultT Type;
};
#endif // RPARAM_HPP
Either way, the policy can now be centralized in the traits template definition, and clients can exploit it to good effect. For example, let's suppose we have two classes, with one class specifying that calling by value is better for read-only arguments:
// traits/rparamcls.hpp
#include <iostream>
#include "rparam.hpp"
class MyClass1 {
public:
MyClass1 () {
}
MyClass1 (MyClass1 const&) {
std::cout << "MyClass1 copy constructor called\n";
}
};
class MyClass2 {
public:
MyClass2 () {
}
MyClass2 (MyClass2 const&) {
std::cout << "MyClass2 copy constructor called\n";
}
};
// pass MyClass2 objects with RParam<> by value
template<>
class RParam<MyClass2> {
public:
typedef MyClass2 Type;
};
Now, you can declare functions that use RParam<> for read-only arguments and call these functions:
// traits/rparam1.cpp
#include "rparam.hpp"
#include "rparamcls.hpp"
// function that allows parameter passing by value or by reference
template <typename T1, typename T2>
void foo (typename RParam<T1>::Type p1,
typename RParam<T2>::Type p2)
{
…
}
int main()
{
MyClass1 mc1;
MyClass2 mc2;
foo<MyClass1,MyClass2>(mc1,mc2);
}
There are unfortunately some significant downsides to using RParam. First, the function declaration is significantly more mess. Second, and perhaps more objectionable, is the fact that a function like foo() cannot be called with argument deduction because the template parameter appears only in the qualifiers of the function parameters. Call sites must therefore specify explicit template arguments.
An unwieldy workaround for this option is the use of an inline wrapper function template, but it assumes the inline function will be elided by the compiler. For example:
// traits/rparam2.cpp
#include "rparam.hpp"
#include "rparamcls.hpp"
// function that allows parameter passing by value or by reference
template <typename T1, typename T2>
void foo_core (typename RParam<T1>::Type p1,
typename RParam<T2>::Type p2)
{
…
}
// wrapper to avoid explicit template parameter passing
template <typename T1, typename T2>
inline
void foo (T1 const & p1, T2 const & p2)
{
foo_core<T1,T2>(p1,p2);
}
int main()
{
MyClass1 mc1;
MyClass2 mc2;
foo(mc1,mc2); // same as foo_core<MyClass1,MyClass2>(mc1,mc2)
}
15.3.2 Copying, Swapping, and Moving
To continue the theme of performance, we can introduce a policy traits template to select the best operation to copy, swap, or move elements of a certain type.
Presumably, copying is covered by the copy constructor and the copy-assignment operator. This is definitely true for a single element, but it is not impossible that copying a large number of items of a given type can be done significantly more efficiently than by repeatedly invoking the constructor or assignment operations of that type.
Similarly, certain types can be swapped or moved much more efficiently than a generic sequence of the classic form:
T tmp(a);
a = b;
b = tmp;
Container types typically fall in this category. In fact, it occasionally happens that copying is not allowed, whereas swapping or moving is fine. In the chapter on utilities, we develop a so-called smart pointer with this property (see Chapter 20).
Hence, it can be useful to centralize decisions in this area in a convenient traits template. For the generic definition, we will distinguish class types from nonclass types because we need not worry about user-defined copy constructors and copy assignments for the latter. This time we use inheritance to select between two traits implementations:
// traits/csmtraits.hpp
template <typename T>
class CSMtraits : public BitOrClassCSM<T, IsClassT<T>::No > {
};
The implementation is thus completely delegated to specializations of BitOrClassCSM<> ("CSM" stands for "copy, swap, move"). The second template parameter indicates whether bitwise copying can be used safely to implement the various operations. The generic definition conservatively assumes that class types can not be bitwised copied safely, but if a certain class type is known to be a plain old data type (or POD), the CSMtraits class is easily specialized for better performance:
template<>
class CSMtraits<MyPODType>
: public BitOrClassCSM<MyPODType, true> {
};
The BitOrClassCSM template consists, by default, of two partial specializations. The primary template and the safe partial specialization that doesn't copy bitwise is as follows:
// traits/csm1.hpp
#include <new>
#include <cassert>
#include <stddef.h>
#include "rparam.hpp"
// primary template
template<typename T, bool Bitwise>
class BitOrClassCSM;
// partial specialization for safe copying of objects
template<typename T>
class BitOrClassCSM<T, false> {
public:
static void copy (typename RParam<T>::ResultT src, T* dst) {
// copy one item onto another one
*dst = src;
}
static void copy_n (T const* src, T* dst, size_t n) {
// copy n items onto n other ones
for (size_tk=0;k<n; ++k) {
dst[k] = src[k];
}
}
static void copy_init (typename RParam<T>::ResultT src,
void* dst) {
// copy an item onto uninitialized storage
::new(dst) T(src);
}
static void copy_init_n (T const* src, void* dst, size_t n) {
// copy n items onto uninitialized storage
for (size_tk=0;k<n; ++k) {
::new((void*)((char*)dst+k)) T(src[k]);
}
}
static void swap (T* a, T* b) {
// swap two items
T tmp(a);
*a = *b;
*b = tmp;
}
static void swap_n (T* a, T* b, size_t n) {
// swap n items
for (size_tk=0;k<n; ++k) {
T tmp(a[k]);
a[k] = b[k];
b[k] = tmp;
}
}
static void move (T* src, T* dst) {
// move one item onto another
assert(src != dst);
*dst = *src;
src->~T();
}
static void move_n (T* src, T* dst, size_t n) {
// move n items onto n other ones
assert(src != dst);
for (size_tk=0;k<n; ++k) {
dst[k] = src[k];
src[k].~T();
}
}
static void move_init (T* src, void* dst) {
// move an item onto uninitialized storage
assert(src != dst);
::new(dst) T(*src);
src->~T();
}
static void move_init_n (T const* src, void* dst, size_t n) {
// move n items onto uninitialized storage
assert(src != dst);
for (size_tk=0;k<n; ++k) {
::new((void*)((char*)dst+k)) T(src[k]);
src[k].~T();
}
}
};
The term move here means that a value is transferred from one place to another, and hence the original value no longer exists (or, more precisely, the original location may have been destroyed). The copy operation, on the other hand, guarantees that both the source and destination locations have valid and identical values. This should not be confused with the distinction between memcpy() and memmove(), which is made in the standard C library: In that case, move implies that the source and destination areas may overlap, whereas for copy they do not. In our implementation of the CSM traits, we always assume that the sources and destinations do not overlap. In an industrial-strength library, a shift operation should probably be added to express the policy for shifting objects within a contiguous area of memory (the operation enabled by memmove()). We omit it for the sake of simplicity.
The member functions of our policy traits template are all static. This is almost always the case, because the member functions are meant to apply to objects of the parameter type rather than objects of the traits class type.
The other partial specialization implements the traits for bitwise types that can be copied:
// traits/csm2.hpp
#include <cstring>
#include <cassert>
#include <stddef.h>
#include "csm1.hpp"
// partial specialization for fast bitwise copying of objects
template <typename T>
class BitOrClassCSM<T,true> : public BitOrClassCSM<T,false> {
public:
static void copy_n (T const* src, T* dst, size_t n) {
// copy n items onto n other ones
std::memcpy((void*)dst, (void*)src, n);
}
static void copy_init_n (T const* src, void* dst, size_t n) {
// copy n items onto uninitialized storage
std::memcpy(dst, (void*)src, n);
}
static void move_n (T* src, T* dst, size_t n) {
// move n items onto n other ones
assert(src != dst);
std::memcpy((void*)dst, (void*)src, n);
}
static void move_init_n (T const* src, void* dst, size_t n) {
// move n items onto uninitialized storage
assert(src != dst);
std::memcpy(dst, (void*)src, n);
}
};
We used another level of inheritance to simplify the implementation of the traits for bitwise types that can be copied. This is certainly not the only possible implementation. In fact, for particular platforms it may be desirable to introduce some inline assembly (for example, to take advantage of hardware swap operations).
|
15.4 Afternotes
Nathan Myers was the first to formalize the idea of traits parameters. He originally presented them to the C++ standardization committee as a vehicle to define how character types should be treated in standard library components (for example, input and output streams). At that time he called them baggage templates and noted that they contained traits. However, some C++ committee members did not like the term baggage, and the name traits was promoted instead. The latter term has been widely used since then.
Client code usually does not deal with traits at all: The default traits classes satisfy the most common needs, and because they are default template arguments, they need not appear in the client source at all. This argues in favor of long descriptive names for the default traits templates. When client code does adapt the behavior of a template by providing a custom traits argument, it is good practice to typedef the resulting specializations to a name that is appropriate for the custom behavior. In this case the traits class can be given a long descriptive name without sacrificing too much source estate.
Our discussion has presented traits templates as being class templates exclusively. Strictly speaking, this does not need to be the case. If only a single policy trait needs to be provided, it could be passed as an ordinary function template. For example:
template <typename T, void (*Policy)(T const&, T const&)>
class X;
However, the original goal of traits was to reduce the baggage of secondary template arguments, which is not achieved if only a single trait is encapsulated in a template parameter. This justifies Myers's preference for the term baggage as a collection of traits. We revisit the problem of providing an ordering criterion in Chapter 22.
The standard library defines a class template std::char_traits, which is used as a policy traits parameter. To adapt algorithms easily to the kind of STL iterators for which they are used, a very simple std::iterator_traits property traits template is provided (and used in standard library interfaces). The template std::numeric_limits can also be useful as a property traits template, but it is not visibly used in the standard library proper. The class templates std::unary_function and std::binary_function fall in the same category and are very simple type functions: They only typedef their arguments to member names that make sense for functors (also known as function objects, see Chapter 22). Lastly, memory allocation for the standard container types is handled using a policy traits class. The template std::allocator is provided as the standard item for this purpose.
Policy classes have apparently been developed by many programmers and a few authors. Andrei Alexandrescu made the term policy classes popular, and his book Modern C++ Design covers them in more detail than our brief section (see [AlexandrescuDesign]).
|
|
|

 LINUX
LINUX