История Apache
Я написал цикл статей для сайта IBM, в которых сделал исторический анализ
самого популярного open-source веб-сервера. Ссылки на cайт IBM:
Часть 1: У истоков Apache. Часть 1: CERN httpd
Часть 2: У истоков Apache. Часть 2: Библиотека libwww
Часть 3: У истоков Apache. Часть 3: История и обзор архитектуры
Часть 4: У истоков Apache. Часть 4: История и обзор архитектуры (часть 2)
Часть 5: Apache 1. Часть 5: Особенности архитектуры
Часть 6: Apache 1. Часть 6: Обзор API
Apache 2: Часть 7. Замечания по технике программирования
Apache 2: Часть 8. Apache Portable Runtime (APR)
У истоков APACHE лежит CERN httpd – веб-сервер, написанный на Cи в 1991 в ЦЕРН — Европейской организации по ядерным исследованиям, крупнейшей в мире лаборатории физики высоких энергий. Разработка программы осуществлялась на компьютере NeXT под управлением операционной системы NeXTSTEP, позже она была перенесена под unix.
Одним из авторов этого веб-сервера является Tim Berners-Lee, который еще в 1984 году начал работать во внутренней сети института и писать программы с использованием Remote Procedure Call (RPC), которые могли вызывать другие программы удаленно на другом компьютере. В 1988 у Тима созрела в голове модель гипертекстовой системы. К тому времени в институте работало 250 человек, и существующих майнфреймов уже не хватало для выполнения всех запросов. В 1990 году Тим привез из штатов компьютер NeXT и получил добро от начальства на разработку проекта под названием WorldWideWeb. Вскоре Тим уже имел прототип работающего браузера (см. рисунок).

К проекту подключился Nicola Pellow, который написал текстовой браузер, работающий практически на любой платформе. Был принят формат HTML, который пришел на смену уже существующему формату SGML. Для получения файлов в сети был придуман URL:
scheme : // host.domain:port / path / path # anchor
|
К тому времени уже давно существовала доменная система имен - Domain Name System (DNS). Клиент создавал соединение TCP-IP к хосту, используя доменное имя либо ip-адрес. В 1991 году новый веб-сервер работал на X-Workstation, Macintosh и PC. В 1992 году число веб-серверов достигло 50, часть их уже работала в США. В 1993 году сервер компилировался на платформах HP, SGI, Sun, DEC, NeXT, была добавлена авторизация, появилась утилита htadm для работы с файлом паролей, поддержка изображений. В 1994 году перенесен на Solaris, добавлена утилита cgiparse, реализован режим прокси.
Обычно CERN httpd работал на 80-м порту, но мог также выступать в качестве прокси для обслуживания внутренней сети, которая была прикрыта межсетевым файрволом. В последнем случае для повышения эффективности этот сервер имел возможность кэшировать документы.
Его достоинством является то, что для уже существующего межсетевого экрана не нужно модифицировать клиентов для таких протоколов, как ftp, gopher и т.д. - управлением такими клиентами справляется сам CERN. В случае прокси CERN выступает одновременно и как сервер, и как клиент: для внутренней сети он является сервером, для внешней - клиентом.
CERN httpd был разработан для обслуживания статических веб-страниц. Он получал из сети URL-запросы с помощью протокола HTTP/0.9 , переводил их в пути и возвращал контент запрашиваемых страниц. На раннем этапе CERN работал с внешними программами для обработки запросов. Была построена система обработки таких запросов, которая вызывала командную оболочку или внешний скрипт. Вывод скрипта перенаправлялся в браузер, в котором страница генерировалась на лету. Эта схема позволяла передавать скрипту список аргументов, создающих поисковую систему.
Сегодня мы рассмотрим:
- Конфигурация CERN httpd.
- Защита CERN httpd.
- CERN httpd в роли прокси-сервера.
- CERN httpd и CGI.
- CERN httpd и графический контент.
- Архитектура CERN httpd.
- Тест.
1. Конфигурация CERN httpd
Последняя финальная версия 3.0 была выпущена в 1996 году. Конфигурация CERN осуществлялась привычным образом: есть главный файл httpd.conf , в котором прописывался порт по умолчанию. Пример такого файла:
# домашний каталог
ServerRoot /usr/www
# полное доменное имя
HostName www.rummidge.ac.uk
# порт
Port 80
# авторизация: сервер запускается от рута, а потом переключается и
# работает от имени этого пользователя
UserId nobody
GroupId nogroup
# страница по умолчанию
Welcome home.html
# логирование
AccessLog /where/ever/httpd-log
ErrorLog /where/ever/httpd-errors
# домашний каталог ~/public_html
# В этом случае, если будет сделан запрос http://www.host.name/~ a_user/mydir/index.html,
# он будет транслирован в домашний каталог пользователя a_user:
# /home/a_user/public_html/mydir/index.html
UserDir public_html
# каталог для запуска cgi-скриптов
Exec /cgi-bin/* /your/script/directory/*
# правила трансляции
Pass /* /local/Web/*
|
2. Защита CERN httpd
В CERN существует несколько видов защиты, которые можно разделить на 3 основные группы:
- Ограничения по хостам.
- Ограничения по пользователям.
- Ограничения файловой системы на базе Access Control Lists.
Для ограничения по хостам в конфигурационном файле существует параметр Protect: в примере прописано разрешение для клиентских запросов, которые приходят с хостов, оканчивающихся на "ac.uk" или "ja.net". В этом случае клиент получает доступ к любым документам, урлы которые начинаются с /research-grants/ или /grant-awards/:
Protection UK_ACADEMIC
{
AuthType Basic
GetMask @*.ac.uk, @*.ja.net
}
Protect /research-grants/* UK_ACADEMIC
Protect /grant-awards/* UK_ACADEMIC
|
При этом нужно учитывать тот факт, что если в конфигурационном файле перед командой Protect стоит команда Pass на каталог /research-grants/, то разрешение будет получено в любом случае, независимо от того, есть Protect или нет.
Для ограничения доступа по пользователям есть параметр Protection:
Protection WEBWEAVERS
{
AuthType Basic
PasswordFile /WWW/Admin/passwd
GetMask handley, crowcroft
}
Protect /secret/* WEBWEAVERS
|
Определятся файл с зашифрованными паролями. Работа с файлом паролей выполняется с помощью команды htadm, которая идет в пакете исходников, которую можно применить так:
htadm -adduser /путь/к/файлу/паролей имя_пользователя
|
Пользователь должен будет набрать логин и пароль для дальнейшего доступа.
Пользователей можно разбить на группы с помощью специального файла group:
webweavers: handley, crowcroft
syspeople: jonathan, barry, ray, steve
trusted: authors, syspeople, anne
uclcs: @*.cs.ucl.ac.uk, @128.16.*, @193.63.58.*
verysecure: trusted@*.cs.ucl.ac.uk
|
Для них прописываются правила:
Protection VERYSECURE
{
AuthType Basic
PasswordFile /WWW/Admin/passwd
GroupFile /WWW/Admin/group
GetMask verysecure
}
Protect /secret/* VERYSECURE
|
При этом доступ к каталогу secret будет разрешен только группе trusted.
Доступ на уровне ACL полезен тогда, когда нужно разграничить доступ к отдельным файлам. Создается ACL-файл с именем www_ac:
ndex.html : GET : @*.cs.ucl.ac.uk
secret*.html: GET,POST : trusted@*.cs.ucl.ac.uk
*.html : GET : webweavers
|
В данном примере для пользователей группы webweavers снимаются вообще все ограничения в доступе.
3. CERN httpd в роли прокси-сервера
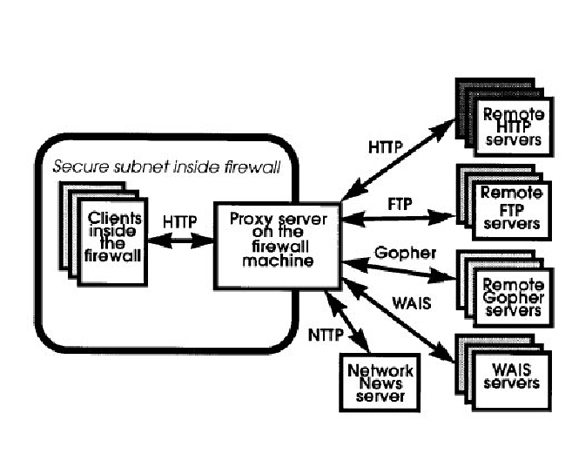
CERN может работать в качестве прокси. Эта схема состоит из 3 частей: внутренняя сеть, машина-файрвол и внешняя сеть. CERN устанавливается на файрволе и обслуживает запросы пользователей, которые находятся во внутренней сети и делают запросы во внешний мир. В этом случае конфигурация выглядит так:
Port 8080
Pass http:*
Pass ftp:*
Pass gopher:*
Pass wais:*
|
Защита в прокси реализована как по именам:
Protection protname {
Mask @(*.cern.ch, *.desy.de)
}
|
Так и на уровне IP:
Protection protname {
Mask @(128.141.*.*, 131.169.*.*)
}
|
Для сайтов, которые не находятся в домене UK, прописывается внешний прокси:
http_proxy http://www.hensa.ac.uk/
gopher_proxy http://www.hensa.ac.uk/
ftp_proxy http://www.hensa.ac.uk/
no_proxy uk
|
Настраивается суммарное место на диске - 300 метров, каталог для хранения кеша, перидичность очистки кеша:
Caching ON
NoCaching http://www.cs.ucl.ac.uk/*
CacheRoot /cs/research/mice/boom/scratch1/wwwcache
CacheSize 300 M
CacheLastModifiedFactor 0.2
GcDailyGc 2:00
|
4. CERN httpd и CGI
Начиная с версии 2.15, в CERN появился интерфейс работы с CGI скриптами. Адрес скрипта прописывался прямо в URL и отдавал контент веб-серверу. CGI настраивался в конфигурационном файле с помощью директивы Exec:
Exec /url-prefix/* /physical-path/*
|
Все скрипты лежали в домашней директории ServerRoot.
Такому скрипту можно было с сервера передавать параметры стандартным образом: через QUERY_STRING. Скрипт возвращал серверу результат, который начинался с Content-Type:
Content-Type: text/html
<HEAD>
<TITLE>Script test></TITLE>
</HEAD>
<BODY>
<H1>Привет !</H1>
....
</BODY>
|
Скрипт также мог вернуть какой-то статический документ с помощью Location:
Location: http://www.w3.org/pub/WWW/
|
В исходниках CERN можно найти утилиту cgiparse, которая обрабатывает методы GET и POST. В случае GET читается стандартный QUERY_STRING, в случае POST читается стандартный ввод. Можно написать сценарий на языке shell, который смоделирует работу cgiparse:
#!/bin/sh
eval `cgiparse -form`
$filename=$FORM_pubname
$doc_root="/cs/research/www/www/htdocs"
$fullfilename=$doc_root"/misc/uk/london/pubs/auto-"$filename".html"
#Write the entry to a file in HTML
echo "<TITLE>"$FORM_pubname"</TITLE>" > $fullfilename
echo "<H1>"$FORM_pubname"</H1><HR>" > $fullfilename
echo "<I>"$FORM_pubaddress"</I><P>" > $fullfilename
echo "<h2>Area:</h2> "$FORM_area"\n" > $fullfilename
echo -n "<h2>Description:</H2>" > $fullfilename
|
5. CERN httpd и графический контент
В CERN был реализован механизм просмотра "кликабельных" картинок внутри html-документа. При клике на нее контент возвращала специальная утилита htimage. Для этого нужно было создать специальный файл, в котором прописывались правила нахождения картинок. При этом внутри html-документа нужно было прописать:
<A HREF="/img/my_image.conf">
<IMG SRC="Image.gif" ISMAP>
</A>
|
В исходниках можно найти утилиту htimage, которая показывает картинку.
6. Архитектура CERN httpd
Исходники CERN версии 3.0 состоят из 2-х частей: библиотеки libwww и, собственно, самого демона httpd. Библиотека libwww была написана в 1992 году в рамках все того же CERN. Эта библиотека написана с прицелом на производительность, имеет модульную структуру и возможность для расширения. Она включает в себя эффективный код для работы с HTTP, URL, может быть использована для создания роботов на стороне клиента, браузеров и т. д. Обработка запросов происходит в асинхронном режиме.
Библиотека libwww имеет модульную архитектуру и состоит из 5 основных частей:
- Базовые модули: здесь происходит разделение кода для того, чтобы эта библиотека была платформенно-независимой. Она включает большое количество условных макросов, которые делают библиотеку переносимой.
- Ядро: оно невелико по размеру и включает в себя базовые функции для сетевого доступа, анализа сетевых объектов, управления действиями пользователя, выполняет ведение журнала событий. Ядро реализует стандартный интерфейс к пользовательским программам и управляет внешними запросами.
- Потоковые модули: данные, передаваемые от приложения в сеть и приходящие обратно, используют потоки. Поток представляет из себя объект в стиле ANSI C файлового потока. Как правило, поток получает входящие данные, обрабатывает их и формирует вывод.
Модули доступа: протокольно-специфичные модули - HTTP, FTP, Gopher, WAIS, NNTP, Telnet, rlogin, TN3270.
- Модули приложений: модули, специфичные для конкретного приложения.
Само приложение при работе с libwww использует напрямую последние 3 группы модулей.
Более подробно мы поговорим о libwww во втором документе нашего Apache-цикла.
CERN httpd на каждый запрос создает новый процесс (fork), который занимает минимальное количество памяти и несет в себе необходимую информацию для системных вызовов. CERN потребляет память в линейной зависимости пропорционально количеству запросов.
Механизм кеширования в том случае, когда CERN выступает в роли прокси, работает следующим образом: когда поступает запрос, CERN первым делом обращается напрямую к файловой системе и проверяет, находится ли в дисковом кеше запрашиваемый документ. Если его там нет, документ тут же сбрасывается на диск. При этом URL, которые отличаются только окончанием в ссылке, будут лежать в одном каталоге.
Главный управляющий файл демона - HTDaemon.c. Инициализация демона происходит следующим образом:
- HTDefaultConfig() ( HTConfig.c) - установка конфигурации по умолчанию.
- HTFileInit() ( HTSInit.c ) - инициализация таблицы суффиксов.
- Обработка аргументов командной строки.
- HTServerInit() ( HTConfig.c ) - инициализация таблицы ошибок и иконок.
- Вызов функции do_bind() - биндится порт и начинается его прослушивание - вызов стандартных библиотечных функций socket,bind,listen:
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if ((setsockopt(master_soc,SOL_SOCKET,SO_KEEPALIVE,...)
|
- Далее всю работу на себя берет базовый цикл server_loop() , в котором вызывается системный вызов select с таймаутом для регистрации запросов. При получении клиентского запроса порождается дочерний процесс с вызовом wait3 с параметром WNOHANG, создается новый сокет, который передается дочернему процессу.
- Дочерний процесс вызывает функцию HTHandle(), в которой генерируются структуры для хранения информации о запросе. Запрос разбирается и создается обьект HTRequest. Парсинг запроса осуществляется с помощью модуля HTFormat.c из библиотеки libwww.
- Вызывается HTHandle(), который создает выходящий поток, куда записывается результат запроса. Запись в поток выполняет модуль HTWriter.c библиотеки libwww.
- HTRetrieve() возвращает с диска запрашиваемый документ.
Этот алгоритм можно представить графически (см. рисунок):
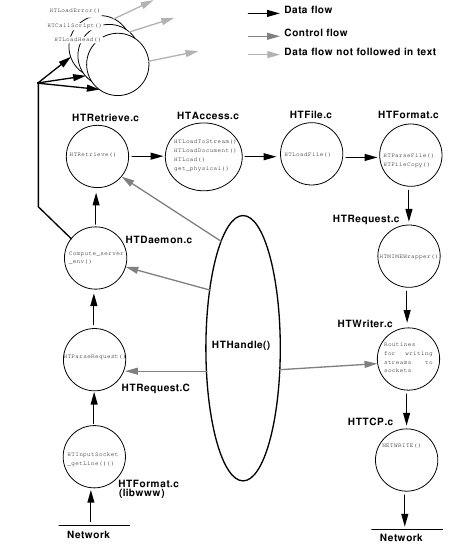
7. Тест
В тесте был использован Apache Bench (далее AB). Данная стандартная утилита входит во многие пакеты, в том числе и в стандартный дистрибутив Apache.
В качестве подопытных материалов были выбраны 3 дистрибутива:
- CERN httpd 2.3
- Apache 1.3.42
- Apache 2.2.15
Все дистрибутивы были собраны на ядре 2.6.34, и были проведены следующие тесты с использованием статичного html-документ размером в 250 килобайт. Следующая команда выполняет 1000 GET-запросов по локальному адресу с числом одновременно посылаемых сообщений, равным 100:
ab -n 1000 -c 100 http://127.0.0.1/test_doc.html
|
Вывод для CERN httpd:
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Benchmarking 127.0.0.1 (be patient)
Server Software: CERN/3.0A
Server Hostname: 127.0.0.1
Server Port: 80
Document Length: 252665 bytes
Concurrency Level: 100
Time taken for tests: 6.455 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 253127896 bytes
HTML transferred: 252943528 bytes
Requests per second: 154.92 [#/sec] (mean)
Time per request: 645.489 [ms] (mean)
Time per request: 6.455 [ms] (mean, across all concurrent requests)
Transfer rate: 38295.79 [Kbytes/sec] received
|
Собранный из исходников apache 1.3.42 с конфигурацией по умолчанию:
Concurrency Level: 100
Time taken for tests: 1.080 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 253626632 bytes
HTML transferred: 253374879 bytes
Requests per second: 926.25 [#/sec] (mean)
Time per request: 107.962 [ms] (mean)
Time per request: 1.080 [ms] (mean, across all concurrent requests)
Transfer rate: 229416.78 [Kbytes/sec] received
|
Собранный из исходников apache 2.2.15 с конфигурацией по умолчанию:
Concurrency Level: 100
Time taken for tests: 0.709 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 252921000 bytes
HTML transferred: 252665000 bytes
Requests per second: 1410.80 [#/sec] (mean)
Time per request: 70.882 [ms] (mean)
Time per request: 0.709 [ms] (mean, across all concurrent requests)
Transfer rate: 348457.80 [Kbytes/sec] received
|
Т.е. мы видим, что максимальную производительность в этом статическом тесте показывает второй Apache, и скорость выросла за 15 лет - с момента последнего релиза CERN httpd в 1996 г. - примерно на порядок. Производительность первого Apache меньше второго примерно в полтора раза.
Основы конфигурации, заложенные в этом проекте, получили свое дальнейшее развитие в последующих версиях Apache. Здесь были реализованы принципы авторизации и разграничения прав доступа, которые послужили основой для дальнейшего развития принципов защиты веб-серверов.
У истоков Apache. Часть 2: Библиотека libwww
Libwww - это открытая библиотека, включающая в себя API для работы с вебом.
Портирована под unix, windows, mac. На ее основе можно писать разнообразные клиентские приложения: браузеры, роботы и т. д. Библиотека включает в себя полный набор стандартов HTTP/1.1(кеширование, аутентификацию и т.д). На ее базе также написано различное программное обеспечение, в том числе CERN httpd, Cygwin, Lynx, Mosaic и другие.
1. Как инсталлировать libwww под unix
Исходники libwww можно найти по адресу: http://www.w3.org/Library/Distribution.html.
Процедура инсталляции стандартная:
./configure
make
make install
|
По умолчанию после инсталляции библиотека окажется в каталоге /usr/local/lib.
При конфигурации можно этот путь поменять на '--prefix=PATH'. По умолчанию динамическая и статическая линковки включены. Также в библиотеку включены опции:
--with-md5[=PATH] - поддержка HTTP digest authentication
--with-mysql[=PATH]
--with-regex[=PATH]
--with-ssl[=path]
--with-zlib[=PATH]
|
2. Архитектура libwww
Как уже было сказано в предыдущей статье, библиотека libwww имеет модульную архитектуру и состоит из 5 основных частей:
- Базовые модули: здесь реализована кросс-платформенная переносимость.
- Ядро: базовые функции.
- Потоковые модули: обработка потоков.
- Модули доступа: работа с интернет-протоколами.
- Модули приложений.
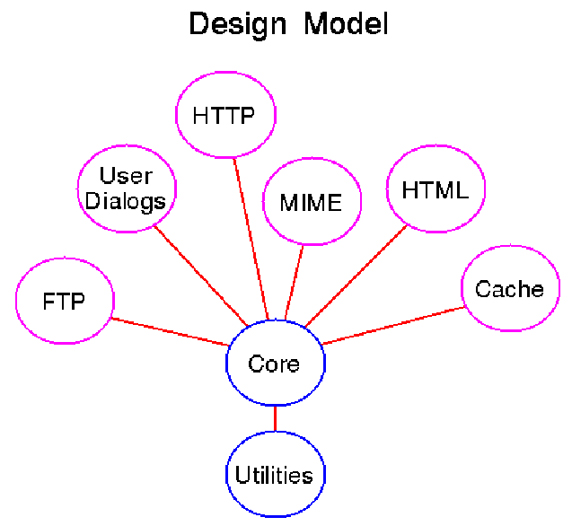
Ядро можно разделить на 3 слоя:
- Request обьект.
- Net обьект.
- Channel обьект.
Само приложение при работе с libwww использует напрямую последние 3 группы модулей.
В основе библиотеки лежит парадигма "запрос/ответ" (request/responce). Клиентское приложение делает запрос на сервер по определенному URL, который обрабатывается сервером, в файловой системе находится документ, соответствующий этому URL, и отдается клиенту. Библиотека рассчитана на одновременную обработку множества запросов от многих клиентов.
Поток (stream) - объект, который имеет дело с последовательностью символов, проходящих через стандартный вход/выход. Libwww использует потоки для транспортировки данных между 3 основными каналами: приложениями, сетью и файловой системой. Поток делает библиотеку событийной (event) в том смысле, что когда данные ложатся в поток, это фиксируется как событие под названием "поток готов". Есть один общий родитель, от которого унаследованы все остальные потоки - Generic Stream Class.
В нем есть набор методов, которые унаследуют все остальные потоки:
От этого родителя унаследован поток под названием Structured Stream Class, который переводит поток в набор тегов формата HTML 3.
Потоки в библиотеке libwww разделены на группы:
- Протокольные потоки.
- Конвертеры.
- Представления - запись данных в локальный файл.
- Потоки ввода/вывода - запись данных в сокет или в объект типа ANSI C FILE.
- Базовые потоки - реализуют технологию вложенных каскадных потоков.
Запрос, или request, - это операция, применимая к URL. Как клиентский, так и серверный объект Request происходят от одного класса. Пример запроса для клиента - это клиентский GET-запрос по определенному URL. Пример запроса для сервера - это загрузка локального файла по этому URL. Класс Request имеет большой набор методов – например, PUT, POST, DELETE и т.д. Время запроса ограничено временем его обслуживания. Libwww автоматически не удаляет объекты запросов, это делается на стороне приложения путем вызова callback-функций. Libwww может обрабатывать одновременно условно неограниченное число запросов.
Фильтр - объект, вызываемый непосредственно перед запросом. Например, аутентификационный фильтр проверяет, имеет ли клиент нужные права, после чего модифицирует информацию в хидере запроса либо отклоняет запрос.
Libwww использует модель не-блокирующих сокетов. Для управления событиями используется событийный класс Event. Его интерфейс включает регистрацию дескриптора сокета и текущее состояние операции. Когда менеджер событий получает информацию о том, что сокет прочитал порцию данных, он передает управление libwww. Libwww занимается созданием и удалением своих внутренних тредов, т.е. использует как бы многопоточную - Pseudo Threads - объектную модель. В основе этой модели лежат callback-функции.
В приложении должен быть как минимум один обработчик событий и один обработчик завершения. Библиотечная функция select() на самом деле блокирует клиентское приложение при отсутствии событий. Специальный Timeout Handler сделан для того, чтобы остановить эту ветку в приложении.
Библиотека хранит текущее состояние запроса. На следующей картинке описана реализация HTTP 1.0 модуля.
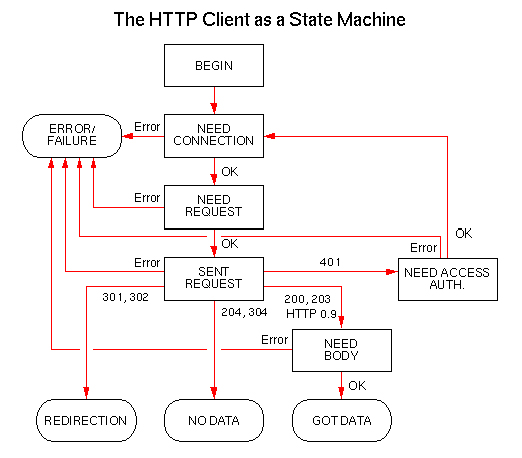
BEGIN State - начальное состояние модуля, когда ожидается запрос от клиента.
NEED_CONNECTION State - HTTP модуль готов установить коннект с удаленным хостом. Библиотека кеширует все произведенные коннекты и сортирует их в порядке времени, затраченном на само соединение. В последующем при повторном обращении с того же хоста из кеша выбираются соединения с наименьшим временем и инициализируются в первую очередь.
NEED_REQUEST State - после установки коннекта клиент посылает серверу объект HTTP Request, в который входит набор заголовков - HTTP Header, а также данные. Заголовок имеет формат:
<METHOD> <URI> <HTTP-VERSION> CRLF
|
SENT_REQUEST State - событие наступает, когда в ответ на запрос сервер вернет ответ, либо истечет тайм-аут, либо случится ошибка. Отличие протокола HTTP 0.9 от версии HTTP 1.0 в том, что 0.9 не включает HTTP заголовок в ответ.
NEED_ACCESS_AUTHORIZATION State - требуется идентификация пользователя по паролю.
REDIRECTION State - перенаправление на другой сервер.
NO_DATA State - данные отсутствуют.
NEED_BODY State - в ответе сервера присутствуют данные.
GOT_DATA State - данные получены, запрос можно закрывать.
ERROR или FAILURE State - в этом случае соединение закрывается.
3. Первое приложение
После того, как вы установили libwww, на ее основе можно строить веб-приложения. Библиотека разделена на несколько пакетов, интерфейс к которым описан в соответствующем заголовке www*.h.
Таблица пакетов и интерфейсов:
| Пакет | Библиотека | Заголовок |
|---|
| Basic Utility | libwwwutil.a | WWWUtil.h |
|---|
| Core | libwwwcore.a | WWWCore.h |
|---|
| Initialization | libwwwinit.a | WWWInit.h |
|---|
| Application | libwwwapp.a | WWWApp.h |
|---|
| Transport | libwwwtrans.a | WWWTrans.h |
|---|
| MIME | libwwwmime.a | WWWMIME.h |
|---|
| Protocol | libwwwfile.a
libwwwftp.a
libwwwhttp.a
| WWWFile.h
WWWFTP.h
WWWHTTP.h
|
|---|
| Caching | libwwwcache.a | WWWCache.h |
|---|
| Stream | libwwwstream.a | WWWStream.h |
|---|
| HTML / XML | libwwwhtml.a | WWWHTML.h |
|---|
| Database Access | libwwwsql.a | WWWSQL.h |
|---|
Для компиляции вашего приложения компилятору нужно передавать несколько параметров.
После инсталляции можно проверить эти опции из командной строки:
>> libwww-config --cflags - вывод флагов
>> libwww-config --libs - вывод флагов для линковки
|
Скомпилировать вашу программу можно прямо из командной строки.
Например, текст исходника libapp_1.c, в которой делается простая инициализация libwww:
#include "WWWLib.h"
int main()
{
HTLibInit("TestApp", "1.0");
HTLibTerminate();
return 0;
}
|
Компиляция этого примера из командной строки:
>> gcc -o app1 `libwww-config --cflags` libapp_1.c `libwww-config --libs`
|
4. Инициализация libwww
Следующий пример показывает, как зарегистрировать протокол и потоковый конвертер.
#include "WWWLib.h"
#include "WWWHTTP.h"
#include "WWWInit.h"
int main()
{
HTList * converters = HTList_new(); /* список конвертеров */
HTList * encodings = HTList_new(); /* список енкодеров */
HTEventInit(); /* инициализируем библиотечный event loop */
HTLibInit("TestApp", "1.0"); /* инициализация ядра libwww*/
HTSetTraceMessageMask("sop"); /* включаем трассировку */
HTTransportInit(); /* регистрируем транспортные протоколы*/
HTProtocolInit(); /* регистрируем протоколы */
HTNetInit(); /* регистрация фильтров BEFORE и AFTER*/
HTConverterInit(converters); /* регистрация конвертеров */
HTFormat_setConversion(converters);
HTTransferEncoderInit(encodings); /* регистрация енкодеров/декодеров */
HTFormat_setTransferCoding(encodings);
HTFileInit(); /* регистрируем файловую систему */
HTMIMEInit(); /* регистрация парсеров MIME-заголовков */
HTIconInit(NULL);
HTAlertInit();
HTLibTerminate(); /* закрываем библиотеку */
return 0;
}
|
5. Профайл
Ваше приложение может выполнять различные функции. В зависимости от функционала все приложения можно разделить на несколько основных категорий:
- Обычный клиент, выполняющий одновременно множество запросов с помощью не-блокирующих сокетов.
- HTML-клиент.
- Обычный клиент, но без кеширования.
- HTML-клиент без кеширования.
- Клиент на базе блокирующих сокетов.
- Робот.
Для инициализации типа клиента используется профайловый модуль - он же плагин, который инициализирует соответствующий тип такого клиента:
- extern void HTProfile_newClient ( const char * AppName, const char * AppVersion);
- extern void HTProfile_newHTMLClient (const char * AppName, const char * AppVersion);
- и т. д.
Удаляется профиль командой:
extern void HTProfile_delete (void);
|
6. Callback функции
Это еще один метод расширения функционала ядра. Такие функции, как правило, активируются в двух случаях:
- Перед запросом.
- После завершения запроса.
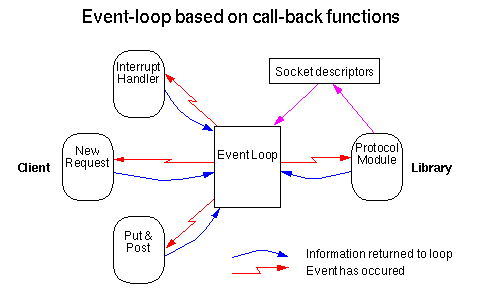
В библиотеке есть стандартный набор callback-функций для часто повторяющихся событий: проверка кеширования, прокси-запрос, логирование, проверка URL и т.д.
Callback функция может быть зарегистрирована как локально для одного запроса, так и глобально для всех.
7. Пример с загрузкой удаленного URL
В следующем примере мы рассмотрим, как загрузить удаленный документ. Собранный пример нужно запустить с двумя параметрами - удаленный URL и имя локального документа, куда он сохраняется:
loadtofile http://www.w3.org -o w3chome.html
|
Текст примера:
#include "WWWLib.h" /* Global Library Include file */
#include "WWWMIME.h" /* MIME parser/generator */
#include "WWWNews.h" /* News access module */
#include "WWWHTTP.h" /* HTTP access module */
#include "WWWFTP.h"
#include "WWWFile.h"
#include "WWWGophe.h"
#include "WWWInit.h"
#define APP_NAME "GETTOOL"
#define APP_VERSION "1.0"
#define DEFAULT_OUTPUT_FILE "get.out"
PRIVATE int printer (const char * fmt, va_list pArgs)
{
return (vfprintf(stdout, fmt, pArgs));
}
PRIVATE int tracer (const char * fmt, va_list pArgs)
{
return (vfprintf(stderr, fmt, pArgs));
}
/*
** Здесь завершается цикл - event loop - по загрузке урла.
*/
int terminate_handler (HTRequest * request, HTResponse * response, void *
param, int status)
{
HTRequest_delete(request); /* удаляем запрос */
HTProfile_delete(); /* удаляем профайл */
exit(status ? status : 0);
}
int main (int argc, char ** argv)
{
int arg = 0;
char * outputfile = NULL;
char * getme = NULL;
HTRequest * request = NULL;
HTProfile_newNoCacheClient(APP_NAME, APP_VERSION); /* Создание клиентского профайла */
HTPrint_setCallback(printer); /* вывод на экран */
HTTrace_setCallback(tracer);
HTNet_addAfter(terminate_handler, NULL, NULL, HT_ALL, HT_FILTER_LAST);
/* прерывающий фильтр для всего приложения */
HTHost_setEventTimeout(10000); /* тайм-аут для response */
/* Парсим командную строку */
for (arg=1; arg<argc; arg++) {
if (!strcmp(argv[arg], "-o")) {
outputfile = (arg+1 < argc && *argv[arg+1] != '-') ?
argv[++arg] : DEFAULT_OUTPUT_FILE;
} else {
getme = argv[arg];
}
}
if (!outputfile) outputfile = DEFAULT_OUTPUT_FILE;
if (getme && *getme) {
request = HTRequest_new();
/* Запускаем загрузку */
if (HTLoadToFile(getme, request, outputfile) != YES) {
HTPrint("Can't open output file\n");
HTProfile_delete();
return 0;
}
/* event loop... */
HTEventList_loop(request);
} else {
HTPrint("Type the URI of document you want to load and the name of the
local file.\n");
HTPrint("\t%s <address> -o <localfile>\n", argv[0]);
HTPrint("For example, %s http://www.w3.org -o w3chome.html\n", argv[0]);
/* Delete our profile if no load */
HTProfile_delete();
}
return 0;
}
|
8. Приложение-сервер
Библиотеку можно использовать для написания как клиентских, так и серверных приложений. Все протоколы регистрируются как на клиентской, так и на серверной стороне.
Все рассмотренные здесь примеры можно найти в самом дистрибутиве libwww в подкаталоге Library/Examples. Код данного примера лежит в исходнике под названием listen.c. Программа открывает слушающий raw-socket и в случае соединения посылает ответ:
/* регистрация TCP */
HTTransport_add("tcp", HT_TP_SINGLE, HTReader_new, HTWriter_new);
HTProtocol_add("noop", "tcp", ms->port, NO, NULL, HTLoadSocket);
ms->request = HTRequest_new(); /* инициализация обьекта Request */
HTRequest_setOutputFormat(ms->request, DEFAULT_FORMAT);
HTRequest_setOutputStream(ms->request, HTFWriter_new(ms->request, OUTPUT, YES));
/* запуск прослушивания */
HTPrint("Listening on port %d\n", ms->port);
if ((status = HTServeAbsolute("noop://localhost", ms->request)) == NO)
{
HTPrint("Can't listen on port %d\n", ms->port);
Cleanup(ms, -1);
}
/* event loop... */
if (status == YES) HTEventList_newLoop();
|
9. Альтернативы libwww
В библиотеке есть ряд недостатков, которые остались с момента прекращения поддержки.
Нет единого API, которое разбито на 2 уровня: средний и высокий. Вместо thread safe в библиотеке имеет место псевдопоточность. На данный момент есть несколько альтернатив, среди которых можно отметить:
- libcurl - является современным аналогом libwww, развивается и поддерживается сообществом. В сравнении с libwww библиотека libcurl работает быстрее, является thread-safe, поддерживает больше протоколов. В свою очередь libwww предлагает кеширование и парсинг HTML, чего нет в libcurl.
- Библиотека Netscape Network Library (netlib) является сердцевиной популярнейшего браузера, написана на С.
- Другим аналогом может выступать libghttp - GNOME http client, написан на С.
- http-tiny - компактная библиотека для работы из командной строки с http-запросами, умеет работать с прокси.
- wget - всем известное приложение, а не библиотека, его код может послужить основой для ваших собственных веб-приложений.
Библиотека libwww является ядром для CERN httpd, в ней сосредоточены наиболее важные API. Эта библиотека имеет модульную структуру, которая позже была скопирована в других веб-серверах, в частности, в Apache. Были рассмотрены возможности библиотеки в плане написания различных веб-приложений. На ее основе можно писать как клиентские, так и серверные приложения.
У истоков Apache. Часть 3: История и обзор архитектуры
1. История Apache
Apache ведет свою историю от веб-сервера NCSA httpd, написанного в свое время Rob McCool. NCSA в свою очередь был развитием CERN httpd. CERN имел более широкий функционал, в то время как NCSA был менее масштабен и более легок. NCSA появился после CERN в тот момент, когда возникла потребность в небольшом и быстром веб-сервере. Позднее к проекту подключились другие авторы, которые стали накладывать свои патчи.
В 1995 году Brian Behlendorf объединил эти патчи и создал список рассылки, на основе которого сформировалась группа разработчиков, выпустивших первую версию Apache.
Имя Apache — это сокращенное "a patchy server".
Первая версия имела номер 0.6.2. Один из участников — Robert Thau — разработал новую серверную архитектуру, которая появилась в версии 0.8.8. В декабре 1995 года вышел релиз Apache 1.0. Популярность к Apache пришла через год. В следующие годы группа разработчиков расширялась, и Apache был портирован на различные операционные системы.
В 1998 году появилась версия 1.3. В 1999 году была создана некоммерческая организация Apache Software Foundation.
В марте 2000 года состоялась первая конференция для разработчиков под названием ApacheCon. На ней была представлена версия Apache 2.0. В ней была переработана предыдущая серверная архитектура. Это дало широкие возможности для написания разнообразных модулей.
Не далее как 22 сентября 2010 года был зафиксирован 1-миллионный коммит.
Юбилейное изменение в репозитории было сделано Йоником Силеем (Yonik Seelay), разработчиком проекта Apache Lucene. Всего сейчас в сообществе Apache более 300 индивидуальных участников и 2300 коммитеров.
На сегодняшний день мирно сосуществуют 2 ветки Apache — 1.3 и 2.0. Обе версии на сегодняшний день поддерживаются. Они широко представлены и занимают половину серверного рынка в мире. Основной причиной успеха Apache является широкий спектр его функциональных возможностей. Apache может обслуживать одновременно большое количество клиентов. Он легко настраивается с помощью текстовых конфигурационных файлов и может быть на ходу переконфигурирован. Для разработки модулей имеется хорошо документированное API. Использование скриптовых языков позволяет использовать Apache в связке с базами данных и серверами приложений. Обе версии поддерживают протокол HTTP 1.1.
2. Модульная архитектура Apache
Ядро Apache включает в себя основные функциональные возможности, такие как обработка конфигурационных файлов, протокол HTTP и система загрузки модулей. Ядро (в отличие от модулей) полностью разрабатывается Apache Software Foundation, без участия сторонних программистов. Запускается Apache от рутового пользователя, а все последующие операции выполняет от лица непривилегированного пользователя.
Модули представляют из себя код, расширяющий функционал Apache. Модули могут быть статически слинкованы с ядром, либо загружаться динамически. В первом случае они собираются на этапе компиляции самого Apache. Во втором случае они загружаются при загрузке Apache, для этого есть дополнительный встроенный модуль mod_so.
Кроме того, имеется набор библиотек — Apache Portable Runtime (APR), который реализует кросс-платформенную поддержку системных функций.
Специальный модуль системного уровня — Multi-Processing Module (MPM) — дает возможность оптимизировать Apache в условиях конкретной операционной системы, предоставляя еще один вариант доступа к системным сервисам.
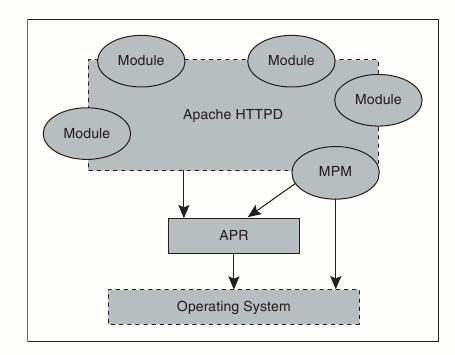
После стартовой начальной инициализации ядро передает управление модулю MPM, который поддерживает пул рабочих процессов/потоков, реализует интерфейс между сервером и данной операционной системой, оптимизируя работу сервера. MPM появился тогда, когда Apache был перенесен на Windows.
MPM имеет 2 основных режима работы:
- Prefork — это традиционный non-threaded вариант, присущий версии 1.3.
- Worker — многопоточный вариант, которому присущ меньший расход памяти.
Модуль взаимодействует с ядром с помощью простого интерфейса: в ядре регистрируется обработчик (handler), который потом может быть вызван. Также модуль может взаимодействовать с ядром с помощью специальных Apache API, которые позволяют модулям работать со структурами данных ядра.
Существует 4 основных типа обработчиков:
- Обработчики-переключатели.
- Конфигурационные обработчики.
- Фильтры.
- Функции-опции.
Обработчики-переключатели занимаются переключением обработчиков, выполняя роль событийного триггера. Такой обработчик имеет префикс ap_run_HOOKNAME. Они бывают двух типов:
- RUN_ALL/VOID — вызываются всегда, независимо от статуса выполняемой задачи;
- RUN_FIRST — вызываются до тех пор, пока задача не выполнена.
Модуль регистрирует в первую очередь обработчики этого типа. Вообще регистрация обработчиков отличается в первом и во втором Apache. В первом все обработчики регистрируются автоматически при старте. Во втором модуль регистрирует 4 обработчика-переключателя, остальные регистрируются потом с помощью функции ap_run_xxx.
Порядок, в котором вызываются переключатели, для первого Apache тот же, в котором они регистрируются. Во втором Apache механизм изменился: вызов ap_hook_xxx может изменить порядок регистрируемого переключателя. Каждый модуль может определить собственный набор конфигурационных директив. Конфигурационные обработчики выделяют память для чтения таких директив и определяют, что с ними делать.
Фильтры и функции-опции появились во втором Apache. Функции-опции похожи на обработчики.
3. Базовые концепции и структуры
В архитектуре Apache можно выделить следующие базовые объекты:
- Сервер.
- Коннект.
- Запрос.
- Процесс.
Каждый из этих объектов представлен соответствующей структурой в заголовочном файле httpd.h.
Помимо этих 4-х основных объектов в архитектуре Apache нужно отметить еще два объекта.
Первый объект — это пулы. Управлением ресурсов в Apache занимаются пулы — APR pools (apr_pool_t). Любой ресурс, выделяемый динамически, если он привязан к пулу, будет удален автоматически после использования. Пул привязывает ресурсы к жизненному циклу основных объектов, о которых мы сказали выше. Второй объект — это конфигурационный массив ap_conf_vector_t, причем каждому модулю в нем отводится свое место.
Массив хранит как глобальные конфигурационные данные, так и локальные.
В переводе на язык си основные четыре объекта представлены структурами:
request_rec
server_rec
conn_rec
process_rec
|
Более всего используются первые две. Каждый раз, когда на сервер приходит клиентский запрос, создается объект структуры request_rec, который передается в качестве параметра в любой обработчик, занятый обработкой запроса. Структура содержит не только стандартную информацию о HTTP-запросе, но и внутреннюю служебную информацию: пул запросов, массив глобальных и массив локальных конфигурационных записей, таблицы HTTP-заголовков, таблицу переменных окружения, указатели на сервер, коннект, фильтры, URL и его трансляцию, и т. д. Определение находится в httpd.h:
struct request_rec
{
apr_pool_t *pool;
conn_rec *connection;
server_rec *server;
request_rec *next;
request_rec *prev;
request_rec *main;
...
};
|
Структура server_rec представляет веб-сервер. Для каждого виртуального хоста имеется свой собственный экземпляр server_rec. Этот объект живет на протяжении всей жизни сервера. Ресурсы он берет из пула процессов. После структуры request_rec это вторая наиболее важная структура в Apache:
struct server_rec
{
process_rec *process;
server_rec *next;
const char *defn_name;
char *server_admin;
char *server_hostname;
apr_port_t port;
...
};
|
Структура conn_rec представляет TCP-коннект, создается при открытии коннекта и удаляется при его закрытии. Один коннект может породить несколько запросов. Запрос — это производный объект от коннекта:
struct conn_rec
{
apr_pool_t *pool;
server_rec *base_server;
void *vhost_lookup_data;
apr_sockaddr_t *local_addr;
apr_sockaddr_t *remote_addr;
...
};
|
Структура process_rec имеет более непосредственное отношение к операционной системе, нежели к архитектуре самого сервера. Пул процессов можно получить через нее посредством
server_rec -> process_rec -> pool.
|
Другие структуры Apache разнесены по разным хидерам, из которых можно выделить следующие группы:
- ap_ — хидеры с таким префиксом генерируют низко-уровневое API и напрямую, как правило, не используются.
- http_ — в этих хидерах находится API, представляющее наибольший интерес для разработчиков.
- util_ — эти хидеры аналогичны первой группе.
- mod_ — здесь находятся определения для модулей.
- apr_ — APR API.
Для разработчиков наибольший интерес представляют следующие заголовки:
http_config.h
http_connection.h
http_core.h
http_log.h
http_main.h
http_protocol.h
http_request.h
http_vhost.h
httpd.h
util_filter.h
ap_provider.h
mod_dbd.h
util_ldap.h
util_script.h
|
4. Обработка запросов
Большинство модулей Apache имеют непосредственное отношение к обработке клиентских запросов, участвуя в этом процессе в определенной последовательности. Такой подход позволяет каждому модулю сфокусироваться на узком аспекте обработки.
Веб-сервер возвращает клиенту ответ, формируемый генератором контента. Любой модуль может зарегистрировать свой генератор с помощью директив SetHandler или AddHandler в файле httpd.conf. Если такой регистрации нет, то генератор по умолчанию просто возвращает файл, получаемый напрямую из запроса. Модули, которые реализуют свои собственные генераторы, называются контент-генераторами. Такой генератор в принципе может управлять всеми функциями. Например, CGI программа, получившая запрос, генерирует ответ, полностью контролируя этот процесс.
Apache разбивает запрос на несколько фаз, например, проверяет авторизацию пользователя. Непосредственно самой генерации предшествуют несколько стадий, например:
- URL проверяется на предмет наличия для него предопределенного конфигурационного генератора контента.
- URL транслируется на файловую систему, результатом чего может быть статичный файл, CGI-скрипт.
- Может быть включен модуль mod_negotiation для определения версии ресурса.
- Может происходить проверка доступа.
- Модули mod_alias или mod_rewrite могут изменить текущий URL.
Запрос может быть обработан нестандартным образом в силу следующих причин:
- Может быть сгенерирован дополнительный вложенный запрос или выдан документ с ошибкой.
- Могут быть добавлены дополнительные фазы обработки запроса.
- Хук (hook) quick_handler может быть запущен модулем кеширования.
Для изменения процесса обработки запроса существует механизм хуков. К ним в первую очередь относятся:
- post_read_request — этот хук может быть запущен на ранней стадии обработки запроса.
- translate_name — трансляция URL.
- map_to_storage — читает опции конфигурации.
- header_parser — запускается в начале обработки для чтения заголовков.
- access_checker — этот хук может заменить стандартную логику проверки прав доступа.
- check_user_id — назначает аутентификацию.
- type_checker — назначает обработчик контента.
- fixups — применяется непосредственно перед генерацией контента для его окончательной корректировки, один из наиболее часто используемых хуков.
- handler — отсылает контент клиенту.
Модуль может использовать хуки в любой точке обработки запроса. В дополнение к этим стандартным хукам модуль может определить свои собственные хуки.
Главным отличием второго Apache является появление фильтров. Фильтры бывают входящими и выходящими. Когда стоит дилемма в выборе между хуком и фильтром, фильтр нужно реализовывать случае, если модуль обрабатывает входные и выходные данные и используется во многих приложениях.
Примеры модулей, реализованных как фильтры:
- mod_include — подключает скрипты.
- mod_ssl — реализует защищенный протокол.
- обработка картинок.
- mod_form, mod_upload — обработка форм и загрузок.
- mod_deflate — сжатие данных.
Обычно каждый модуль Apache декларирует набор данных и функций:
module AP_MODULE_DECLARE_DATA my_module =
{
STANDARD20_MODULE_STUFF, /* версионность */
my_dir_conf, /* локальная конфигурация */
my_dir_merge,
my_server_conf, /* генеральная конфигурация */
my_server_merge,
my_cmds, /* директивы конфигурации */
my_hooks /* обработчики, регистрируемые в ядре */
};
|
Функция для обработки запроса:
static void my_hooks(apr_pool_t *pool)
{
...
}
|
Хук для генератора контента:
ap_hook_handler(my_handler, NULL, NULL, APR_HOOK_MIDDLE);
|
Когда начнется генерация контента, будет вызван my_handler:
static int my_handler(request_rec *r)
{
...
}
|
5. Фильтры
В первом Apache обработчик контента работает по стандартной схеме. Вначале вызывается обработчик type_checker для определения типа контента, после чего ядро вызывает нужный обработчик для отсылки контента. Недостатком обработки контента в первом Apache является то, что если контент имеет комплексный тип и для его обработки требуется не один, а несколько обработчиков, то контент отсылается по очереди, и каждый последующий обработчик никак не может повлиять на то, что отсылается клиенту до него или после него.
Во втором Apache обработчик контента расширен путем добавления фильтров, которые могут манипулировать данными, посылаемыми клиенту. И несколько модулей могут параллельно обрабатывать один клиентский запрос. Фильтры могут быть назначены еще на этапе определения типа контента.
Фильтры бывают входящими (input filters) и исходящими (output filters).
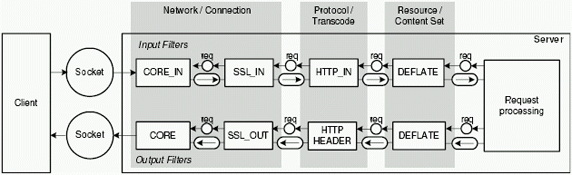
Обрабатываемые данные разбиваются на секции (brigade), которые в свою очередь разбиваются на сегменты (bucket). Один фильтр обрабатывает один сегмент, после чего передает его по цепочке на следующий фильтр.
Кроме деления на входящие и исходящие, фильтры можно разбить еще на три категории:
- Контент-фильтры.
- Протокольно-кодировочные фильтры.
- Сетевые фильтры.
6. Конфигурация Apache
Для конфигурации Apache есть 4 основных подхода:
- Компиляция / инсталляция: сборка из исходников позволяет выбрать необходимые модули, установить нужные флаги, пути и т. д.
- Параметры командной строки: позволяют конфигурировать Apache при запуске.
- Глобальные конфигурационные файлы: главный файл по умолчанию называется httpd.conf.
- Локальные конфигурационные файлы: использование .htaccess.
Конфигурационные директивы в файле httpd.conf можно разбить на 3 категории:
- Директивы, контролирующие общий процесс работы.
- Директивы виртуальных хостов.
- Настройки виртуальных хостов.
К директивам первой группы относятся <Directory>, <DirectoryMatch>, <Files>, <FilesMatch>, <Location>, <LocationMatch>.
Они применяются в привязке к конкретной файловой структуре либо к URL. В первом случае это <Directory>, во втором — <Location>. Apache может обслуживать одновременно несколько веб-сайтов с различными именами, реализуя виртуальный хостинг, что делается на основе директивы <VirtualHost>. Для того, чтобы изменения в главном конфиге вступили в силу, сервер должен быть перезапущен.
Локальная конфигурация реализована на основе .htaccess. Имя этого файла можно изменить в секции AccessFileName. Изменения в файле .htaccess вступают в силу немедленно, без перезапуска, его действие распространяется на каталог, в котором он лежит, со всеми вложенными подкаталогами. Избыточное использование .htaccess может повлиять на производительность сервера.
Содержимое основного конфига httpd.conf можно разделить на 5 секций:
- Глобальные директивы.
- <VirtualHost> — применимы к выиртуальным серверам.
- <Directory>, <DirectoryMatch> — применимы к каталогам.
- <Files>, <FilesMatch> — применимы к файлам.
- <Location>, <LocationMatch> — применимы к URL.
Директива может иметь несколько параметров, тип параметров может различаться.
Каждая директива обрабатывается определенным модулем.
Например, директива
LoadModule foo_module modules/mod_foo.so
|
будет обработана mod_so, в этой команде 2 аргумента — имя загружаемого модуля и имя файла.
Следующая директива будет обработана ядром:
DocumentRoot /usr/local/apache/htdocs
|
Следующая директива будет обработана модулем mod_env, будет установлена переменная окружения:
SetEnv hello ”Hello, World!”
|
Контейнер — специальная форма директивы с использованием скобок, которая имеет свой внутренний контекст. Например, контейнер <VirtualHost>:
<VirtualHost 10.31.2.139>
ServerName www.example.com
DocumentRoot /usr/www/example
ServerAdmin webmaster@example.com
CustomLog /var/log/www/example.log
</VirtualHost>
|
Содержимое локального файла .htaccess можно разделить также на 5 секций:
- AuthConfig — контроль авторизации.
- Limits — контроль доступа.
- Options — конкретные настройки каталогов.
- FileInfo — установка атрибутов для документов.
- Indexes — индексация каталогов.
7. Apache API
Apache API включает в себя все возможности веб-сервера. Модульная архитектура позволяет встраивать новые модули на основе этого функционала. Ядро дает любому модулю большой выбор в вызове функций. Эти функции могут быть вызваны со специальными структурами в качестве параметров и могут возвращать специальные структуры. Базовые структуры заранее определены.
Вторая версия Apache уже включает в себя весь существующий функционал первой версии Apache, плюс имеется новый функционал в форме Apache Portable Runtime (APR).
Ядро управляет распределением памяти и следит за ее освобождением после того, как модуль закончил свою работу. Вся память выделяется в ядре. Память организована в форме пула (pool), каждый пул привязан к определенной задаче и имеет свой жизненный цикл. Имеется 3 главных пула — серверный пул, пул коннектов, пул запросов. Любой модуль может создать свой пул произвольного формата. Модуль может попросить ядро в любой момент создать пул и в любой момент его удалить.
Apache также управляет выделением памяти под массивы и управляющую хеш-таблицу.
Функции, с которыми работают модули, имеют параметры и структуры предопределенного типа, тип этот модули менять не имеют права. Наиболее важные внутренние типы данных Apache:
- request_rec — одна из наиболее важных структур, включает информацию о запросе. В этой структуре находится ссылка на пул запросов, а также другая структура с различными форматами URL для их трансляции.
- server_rec – в основном содержатся конфигурационные данные, а также имя сервера, порт, таймаут и т.д.
- connection_rec — содержится информация о коннекте. На один коннект может приходиться несколько запросов. Время жизни коннекта может превышать время жизни запроса. Здесь также хранится информация о клиенте.
Функции дают возможность модулям манипулировать своими структурами данных. Системные вызовы находятся в компетенции ядра. Имеются функции для создания процессов, открытия коммуникационных каналов для внешних процессов, отсылки данных клиенту, прикладные функции типа работы со строками и т. д.
Все функции можно разбить по категориям:
- Управление памятью.
- Управления процессами.
- Управление массивами.
- Управление таблицами.
- Управление строками.
- Управление сетью.
- Динамическая линковка.
- Логирование.
- Управление мьютексами.
- Авторизация.
Во второй версии Apache появился Apache Portable Runtime — дополнительный API функционал. Он включает:
- File I/O + Pipes.
- Дополнительное обслуживание памяти.
- Mutex + Locks, Asynchronous Signals.
- Network I/O.
- Многозадачность, в том числе потоки (threads).
- Dynamic Linking (DSO).
- Time.
- Authentication.
APR — это по сути целый новый фреймворк для веб-сервера.
Apache обладает широким спектром возможностей, может обслуживать одновременно большое количество клиентов, легко настраивается с помощью текстовых конфигурационных файлов и может быть на ходу переконфигурирован. Для разработки модулей имеется хорошо документированное API. Использование скриптовых языков позволяет использовать Apache в связке с базами данных и серверами приложений.
У истоков Apache. Часть 4: История и обзор архитектуры (часть 2)
1. Исходные дистрибутивы
Дистрибутив исходных текстов первого Apache включает 780 файлов в 44 каталогах, 235 файлов состоят из кода на C. Следующий рисунок показывает структуру директорий этого дистрибутива. Каталог src включает исходники большинства модулей. Главные каталоги в этом дереве — main и modules.
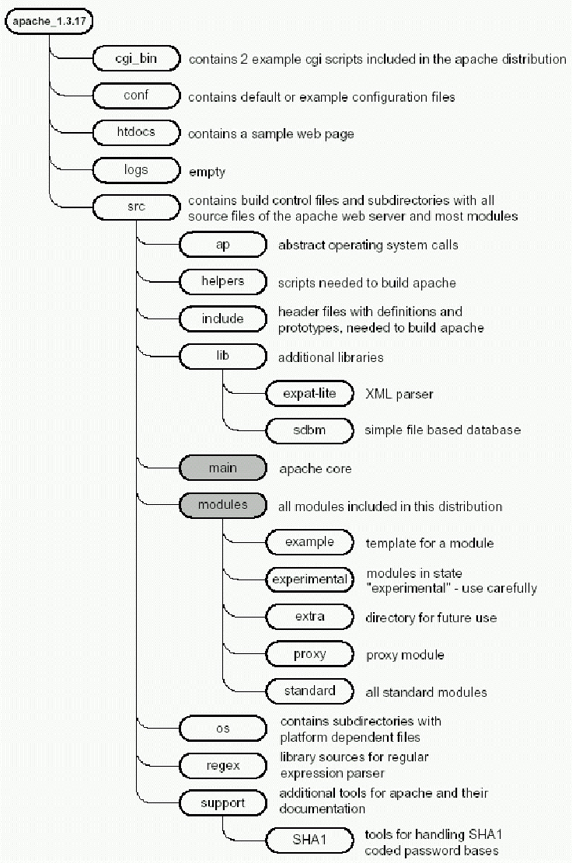
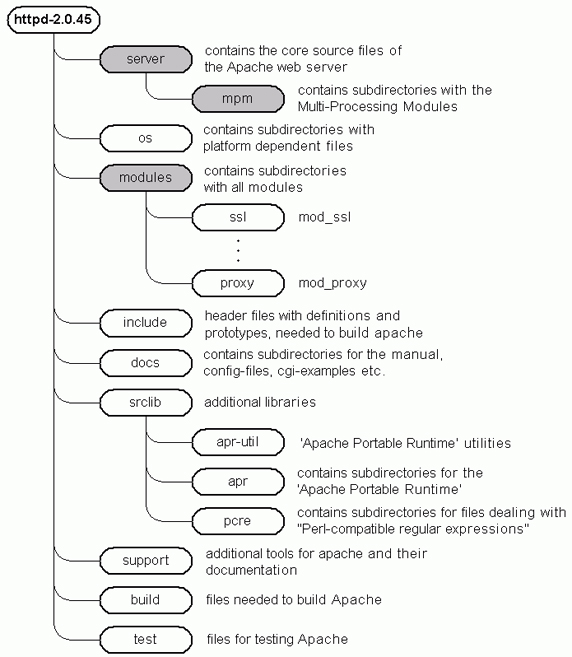
Следующий рисунок показывает структуру директорий второго Apache. Дерево исходников становится еще больше по сравнению с первым Apache. Это дерево включает 2165 файлов в 183 каталогах. 704 файла состоят из кода на C (280 000 строк). Ядро расположено в каталоге server, появился каталог mpm, модули по-прежнему расположены в каталоге modules.
<р4>2. Многозадачная архитектура
Многообразие операционных систем, на которых может быть установлен Apache, диктует свои условия, которые отличаются от системы к системе. Среда окружения, сценарий обработки, атомарность клиентского запроса, количество запросов, которые может одновременно обрабатывать сервер — все это имеет свою специфику применительно к конкретно взятой операционной системе, что накладывает свои требования и ограничения на саму архитектуру Apache.
Главный процесс веб-сервера, который ожидает входящие запросы, называется master server process. Когда приходит запрос от клиента, основной процесс устанавливает коннект и порождает (fork) т. н. child server process, после чего отдает управление процессом обработки этого запроса вновь созданному дочернему процессу.
Архитектура Apache основана на пуле задач. Во время старта порождается пул задач, каждому пришедшему клиентскому запросу присваивается задача из этого пула. Контролирует этот пул процесс master server. Это классический для unix-систем вариант preforking architecture. Причем пул может состоять не только из процессов, но и из потоков (thread). После установки коннекта запрос передается в пул, все права на коннект передаются дочернему процессу, который после завершения обработки запроса закрывает этот коннект. После этого дочерний процесс засыпает на время в очереди себе подобных, становится idle до тех пор, пока не получит новый запрос.
Пул задач создается при старте, и этот пул должен быть достаточно велик, хотя операционная система имеет ограничения. Модель, при которой каждой задаче в пуле поставлен отдельный процесс, достаточно стабильная, но при этом имеет ограничения в производительности.
На следующем рисунке показана Preforking-архитектура второго Apache, которая аналогична архитектуре первого Apache. Существенным отличием второй версии от первой является механизм управления дочерним процессом, а точнее его перезапуском — теперь это делается на основе пайпов (вместо сигнала в первой версии).
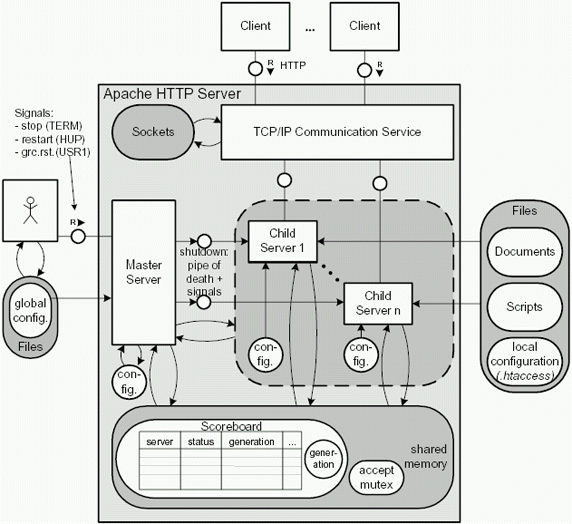
В этой архитектуре можно выделить несколько основных рабочих циклов:
- Начальная инициализация: происходит выделение ресурсов, читается конфигурация, запускается демон.
- Рестартовый цикл: перечитывается конфигурация, создается пул задач, передача управления master-server циклу.
- master-server цикл: контроль дочерних процессов.
- request-response цикл: ожидание места в очереди, получение коннекта, переход в рабочий статус и keep-alive цикл.
- keep-alive цикл: обработка запроса.
- Очистка и деактивация дочернего процесса.
3. Инициализация и рестарт
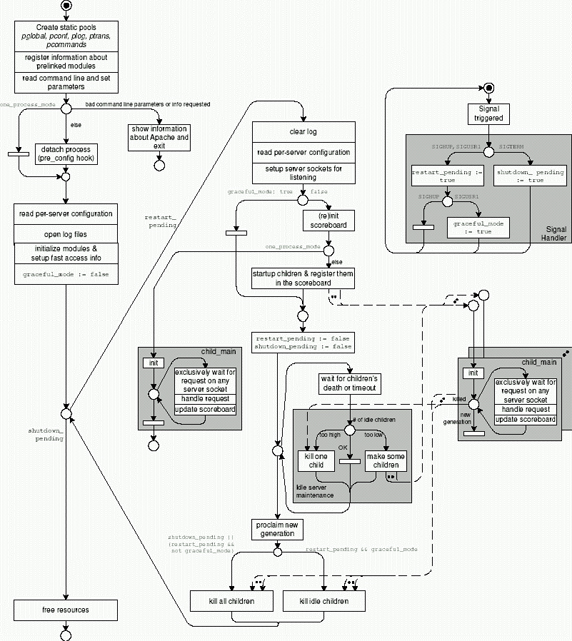
Второй Apache стартует в главной процедуре main(). После входа в Restart-цикл выполняется конфигурация MPM с помощью ap_mpm_run(). На следующем рисунке выполняется последовательность действий:
- Создание статических пулов.
- Регистрируется информация о модулях.
- Читаются командные параметры. Например, параметр -X блокирует создание дочерних процессов.
- Читается конфигурация, которой существует два вида — per-server и per-request, вторая лежит в .htaccess.
- detach process: после чтения конфигов и инициализации модулей сервер переходит в режим демона, при этом происходят стандартные вещи: создается копия главного серверного процесса, родитель при этом завершает работу, консоль отключается и т. д.
Каждый раз, когда администратор перезапускает Apache, запускается restart-цикл в функции main(). В первом Apache restart-цикл лежит в процедуре standalone_main(). Этот цикл состоит из следующих частей:
- Инициализация и подготовка ресурсов для создания дочерних процессов, чтение конфигурации.
- Генерация дочерних процессов.
- Переход в master server цикл, затем в Request-Response цикл.
Конфигурация читается главным процессом. Дочерние процессы получают свою конфигурацию от главного процесса. Дочерний процесс сам изменяет свой статус в scoreboard.
Последовательность действий в restart-цикле:
- Чтение конфигурации — в этот момент существует только один главный процесс.
- Инициализация сокетов для прослушивания. Apache может слушать несколько портов.
- Инициализируется scoreboard.
- one_process_mode — может быть использован для дебага.
- Создаются дочерние процессы с помощью процедуры startup_children(), которые регистрируются в scoreboard. Используется системный вызов fork(). Они получают ссылки от главного процесса на конфигурацию, сокеты, лог-файлы и т.д. В scoreboard для каждого дочернего процесса пишется его не привилегированный пользовательский id.
- Главный процесс попадает в matser server цикл.
- matser server цикл: регулируется общее число дочерних процессов путем добавления/удаления.
- Каждый раз при попадании в restart-цикл увеличивается счетчик под названием generation ID. Каждому дочернему процессу присваивается этот id. Если generation ID дочернего процесса в scoreboard не совпадает с текущим generation ID, этот дочерний процесс удаляется из scoreboard.
4. Сигналы
Контроль в Apache построен на сигналах. Сигнал представляет собой прерывание, которое может произойти в любой момент. При этом программа приостанавливается, начинается обработка сигналов, после чего программе возвращается управление. Администратор может послать сигнал kill из командной строки.
Apache реагирует на 3 сигнала:
- SIGTERM — остановка сервера (shutdown_pending).
- SIGHUP — перезапуск сервера (restart_pending и graceful_mode).
- SIGUSR1 — gracefull рестарт, при котором работающие дочерние процессы не убиваются.
Обработчик сигнала для главного процесса регистрируется в процедурах set_signals(), sig_term() и restart(). Если администратор останавливает или перезапускает сервер, главный процесс посылает соответствующий сигнал группе дочерних процессов и получает от них уведомления.
gracefull рестарт различается в первой и второй версиях Apache. В первом случае дочерним процессам отсылается сигнал SIGUSR1, во втором используются именованные каналы — Pipe of Death. В обоих вариантах при этом будут закрыты дочерние процессы, которые стоят в очереди в ожидании клиентских запросов, а те дочерние процессы, которые окажутся заняты в данный момент обработкой, будут продолжать работать.
5. Цикл Master server
На следующем рисунке показано, как главный процесс контролирует дочерние процессы и что происходит при перезапуске сервера.
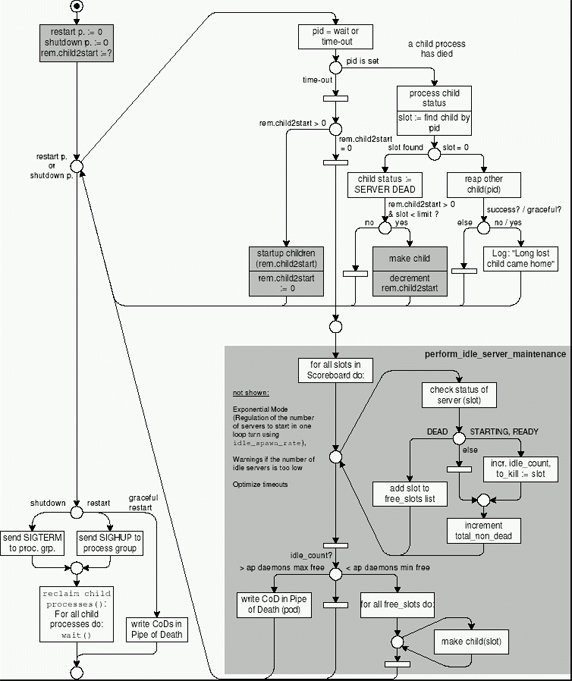
Restart-цикл находится в процедуре main(). Цикл Master server для Apache 2 находится в ap_mpm_run(), для первого — в процедуре standalone_main() (http_main.c). Верхняя часть картинки описывает graceful restart. В нижней части описано управление т. н. дочерними idle-процессами, которые ничем не заняты и стоят в ожидании. Их число хранится в переменной idle_count, ограничение задается в конфигурации переменными ap_daemons_max_free и ap_daemons_min_free. В случае превышения процесс уничтожается. Если их мало, idle-процесс создается.
Если администратор выполняет Graceful Restart, при этом происходят следующие события:
- Переменная remaining_children_to_start хранит число дочерних процессов, которые должны быть запущены после рестарта. Делая системный вызов wait(), главный процесс контролирует удаление idle-процессов. Он используется для остановки процессов, созданных с помощью fork(). Вызов wait() длится в течение фиксированного тайм-аута, после чего управление возвращается в matser server независимо от того, получено сообщение от дочернего процесса или нет.
- Если wait() возвращает pid, то:
- проверяется process_child_status;
- в scoreboard ищется дочерний процесс с помощью find_child_by_pid;
- статус найденного процесса устанавливается в SERVER DEAD;
- если remaining_children_to_start>0, генерируется новый дочерний процесс.
- Если после остановки дочерних процессов remaining_children_to_start !=0, в процедуре startup_children() создаются недостающие дочерние процессы.
В нижней части рисунка описано действие процедуры perform_idle_server_maintenance(), которая может быть вызвана во время работы master server цикла в произвольный момент, например, когда в этом цикле случается тайм-аут. Главный процесс подсчитывает число незанятых — idle — дочерних процессов, контролируя их число на основе трех параметров, полученных из конфигурации:
- ap_daemons_limit — максимальное число дочерних процессов. Scoreboard состоит из занятых дочерних процессов, свободных дочерних процессов и пустых слотов – slot. В сумме эти три величины должны быть равны ap_daemons_limit;
- ap_daemons_max_free — максимум свободных дочерних процессов. Если число таких процессов начнет превышать данный максимум, они начнут удаляться по одному за цикл;
- ap_daemons_min_free — минимум свободных дочерних процессов.
Дочерние процессы создаются с помощью процедуры make_child(). Master server цикл создает один дочерний процесс в первом цикле, во втором цикле создает два дочерних процесса, в третьем — три, и т. д. Это число создаваемых процессов в каждом цикле хранится в переменной idle_spawn_rate.
Пример: Допустим, переменная ap_daemons_min_free = 5. В какой-то момент выясняется, что остался один idle-процесс. Мастер сервер сразу же начинает их создавать и в первом цикле создает один дочерний процесс. В следующем цикле он создает еще два idle-процесса. После этого приходит запрос от клиента, после чего остается 3 idle-процесса. Главный процесс обнаруживает этот факт и в следующем цикле создает еще 4 idle-процесса. После чего выясняется, что число idle стало равно 7, и тогда переменная idle_spawn_rate опять становится равной 1.
6. Child server
Главный процесс создает дочерние на основе fork(). У каждого такого процесса своя собственная память, куда никто не имеет доступа. Поэтому конфигурация читается главным процессом, и потом под нее выделяется глобальная область памяти, которая доступна всем дочерним процессам. Поскольку каждый дочерний процесс представляет собой клон главного процесса, у них у всех есть общая память с единой конфигурацией.
Если администратор вносит изменения в конфигурацию, он перезапускает сервер, при этом все дочерние процессы должны быть убиты и воссозданы заново. Для корректной перезагрузки используется т. н. graceful рестарт, при котором дочерние процессы, занятые в этот момент обработкой клиентских запросов, продолжают работать.
Инициализация дочернего процесса происходит в процедуре child_main():
- Устанавливается доступ к ресурсам. Поскольку в момент создания дочерний процесс имеет те же привилегии, что и главный процесс, он получает доступ к ресурсам:
- локальная память — ap_make_sub_pool();
- scoreboard;
- accept mutex.
- Инициализация модулей — процедура ap_init_child_modules().
- Инициализируются таймауты. Таймаут необходим для того, чтобы дочерний процесс не блокировал главный процесс. Apache использует т.н. alarm — аналог сигнала. С помощью этого сигнала устанавливается таймаут, в течение которого главный процесс ждет отклика от дочернего процесса, по истечении которого происходит т.н. long jump обратно.
- Дочерний процесс имеет свой главный цикл, внутри которого происходит обнуление таймаутов, очистка пула запросов.
- Дочерний процесс выставляет для себя статус «готов» в соответствующем лоте scoreboard, и на этом инициализация заканчивается.
Apache использует accept mutex для распределения поступающих клиентских запросов между дочерними процессами. Этот мьютекс делает активным в текущий момент на прослушке коннектов только один дочерний процесс с помощью системного вызова accept() и представляет собой контроль доступа к TCP/IP. Для его инициализации сначала вызывается процедура accept_mutex_on() / accept_mutex_off(). После того, как дочерний процесс получает коннект, он начинает обрабатывать клиентский запрос, а на прослушуку становится другой дочерний процесс — в теории это называется Leader-Follower pattern. Кроссплатформенная обработка, зависящая от специфики конкретной операционной системы, реализована на основе MPM.
7. MPM
Во втором Apache появились новая отличительная архитектурная особенность — модули типа Multi Processing Modules (MPM). Структура такого модуля похожа на стандартную, в частности, он включает таблицу команд. MPM отвечает за запуск потоков или процессов — в зависимости от варианта. MPM также отвечает за прослушивание сокетов. Когда приходит несколько запросов, MPM распределяет их между потоками либо процессами. После чего в дело идут стандартные процедуры по обработке запросов.
Многопроцессная архитектура Apache позволяет реализовать быстрый отклик веб-сервера, эффективно используя для этого возможности операционной системы. В зависимости от конкретной операционной системы существует конкретный баланс между стабильностью и производительностью. Данная архитектура реализует стратегию создания и контроля большого числа одновременно выполняющихся задач и распределения клиентских запросов между ними.
Apache может более аккуратно и эффективно работать в самых разных операционных системах. В частности, версия Apache для Windows теперь работает намного более эффективно, благодаря тому, что МП-модуль mpm_winnt может использовать собственные сетевые функции Windows взамен сетевых функций уровня POSIX. Это касается и других операционных систем, для которых разработаны специальные МП-модули.
Сервер может быть настроен более оптимально для нужд конкретного сайта. Например, для сайтов, требующих значительной масштабируемости, может быть выбран многопоточный МП-модуль, такой как worker, а для сайтов, требующих большей стабильности или совместимости со старым ПО, может быть использован prefork. Кроме того, также предоставляются специальные возможности, такие как обслуживание различных хостов процессами с привилегиями различных пользователей (perchild).
МП-модуль должен быть выбран на этапе конфигурации, а затем скомпилирован вместе с сервером, чтобы стать его частью. Компиляторы способны оптимизировать многие функции при условии, что используются потоки, однако они должны знать еще на этапе компиляции, используются потоки или нет.
На уровне пользователя МП-модули почти не отличаются от всех остальных модулей Apache. Основное различие состоит в том, что с сервером может быть скомпилирован один и только один МП-модуль.
Чтобы подключить желаемый МП-модуль к Apache, используйте аргумент --with-mpm=MPM скрипта configure, где MPM — это название желаемого МП-модуля. После того, как сервер скомпилирован, всегда можно определить, какой МП-модуль был выбран, используя команду ./httpd -l, которая выведет список всех модулей, собранных вместе с сервером, в том числе и название МП-модуля. Если вы на этапе компиляции явно не указали другой МП-модуль, то по умолчанию в unix будет установлен prefork МП-модуль, в windows — mpm_winnt.
В зависимости от платформы, сервер может использовать либо процессы, либо потоки, либо и то, и другое. Процесс имеет больший ресурс и одновременно большее время переключения. У потоков меньший контекст, но многопоточная реализация таит в себе массу подводных камней.
Разные процессы могут общаться друг с другом с помощью глобальной памяти, сигналов или событий, семафоров, мьютексов, каналов, сокетов. MPM использует для этого пул задач — task pool. idle процессы спят до тех пор, пока не приходит новый клиентский запрос и из этой очереди не выдергивается один для обработки этого запроса.
Для этого, в зависимости от платформы, может быть использована условная переменная либо семафор.
Apache включает несколько вариантов многозадачности. Первый Apache имеет 2 варианта:
- Preforking Architecture для Unix.
- Job Queue Architecture для Windows.
Второй Apache включает 4 варианта MPM, при компиляции можно выбрать какой-то один конкретный вариант:
- Preforking / Netware — используется архитектура первого Apache.
- WinNT — виндовый вариант с использованием IOCP.
- Worker — новая комбинация из процессов и потоков.
- Leader / PerChild — линуксовый вариант, альтернатива для первого и третьего вариантов.
3-й вариант — Worker — использует комбинацию из процессов и потоков.
Процесс может включать несколько потоков (thread). Дочерний процесс теперь становится более сложно организован. Главный процесс создает один дочерний процесс. Этот дочерний процесс запускает стартовый поток. Этот стартовый поток запускает рабочие потоки и один слушающий поток. Общение между слушающим потоком и рабочими потоками сделано на основе двух очередей — job queue и idle queue. В зависимости от статуса поток может быть помещен в одну из этих очередей слушающим потоком. В этом варианте используется стабильность многопроцессной модели с производительностью многопоточной модели.
8. Обработка запроса
Рабочий цикл Request-Response является узловым во всем сервере. Каждый дочерний процесс имеет такой цикл, который заканчивается после завершения обработки клиентского запроса либо по просьбе главного процесса.
В зависимости от архитектуры право на обработку может получить свободный idle процесс либо тот, который находится в рабочей очереди. В первом случае он проснется по мьютексу, во втором его включит job queue. После того, как дочерний процесс получает запрос, он покидает пределы MPM, передав управление обработчикам (хукам — hook) pre_connection b process_connection. Модуль http_core.c регистрирует обработчик p_process_http_connection().
Клиент может использовать повторно существующий коннект для повторных запросов. Например, HTML документ с 5 картинками может быть получен в серии из 6 отдельных запросов в одном и том же коннекте. TCP коннект обычно закрывается по таймауту, равному 15 секундам. Модуль http_core.c регистрирует обработчик ap_process_http_connection() с keep-alive циклом внутри. Пул запросов очищается каждый раз после завершения keep-alive цикла. Дочерний процесс читает заголовок запроса с помощью процедуры ap_read_request() (protocol.c.) и результат чтения сохраняет в структуре request_rec. После того, как заголовок прочитан, статус дочернего процесса меняется на busy_write — т.е. пришло время отправлять ответ клиенту. Второй Apache отличается от первого тем, что ответ клиенту могут формировать различные модули, в то время как в первом этим занимается только один обработчик контента. Процедура p_process_request (http_request.c ) вызывает другую процедуру — process_request_internal (request.c), в которой происходит следующее:
- Модифицируется url процедурами ap_unescape_URL, ap_getparents.
- Читается конфигурация — location_walk().
- URL переводится в локальный url — ap_translate_name().
- Вызываются ap_directory_walk и ap_file_walk.
Могут выполниться 2 независимые проверки авторизации — одна на основе клиентского IP, вторая на основе проверки авторизации пользователя. В файлах конфигурации можно выставить контроль доступа по пользователям, группам, ip и т.д. При этом могут сработать следующие обработчики:
- access_checker — проверка IP.
- ap_check_user_id — проверка аутентификации.
- auth_checker — проверка авторизации.
- type_checker — получение MIME type запрашиваемого ресурса.
- fixups — любой модуль может писать в заголовок ответа клиенту.
- insert_filter — любой модуль может добавить фильтр.
- handler — формируется заголовок и тело ответа. Может быть подключен CGI-модуль для генерации контента. Результирующий ответ пропускается через фильтры.
- ap_finalize_request_protocol() — отсылается ответ клиенту в требуемой кодировке.
9. Конфигурационный процессор
Apache конфигурируется посредством командной строки, а также с помощью глобальных конфиг-файлов. Локальные конфиги (.htaccess) читаются и срабатывают при каждом конкретном запросе. Следующий рисунок показывает работу конфигурационного процессора. После того, как Apache запущен и конфигурационные файлы прочитаны, результат чтения сохраняется в специальном хранилище.
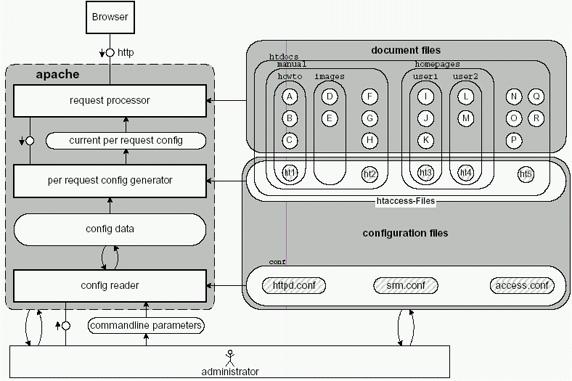
На каждый запрос дочерний процесс с помощью специального обработчика генерирует свою конфигурацию на основе глобальных данных, которая объединяется с возможными локальными конфигурационными данными.
На следующем рисунке показаны конфигурационные структуры данных в подробностях.
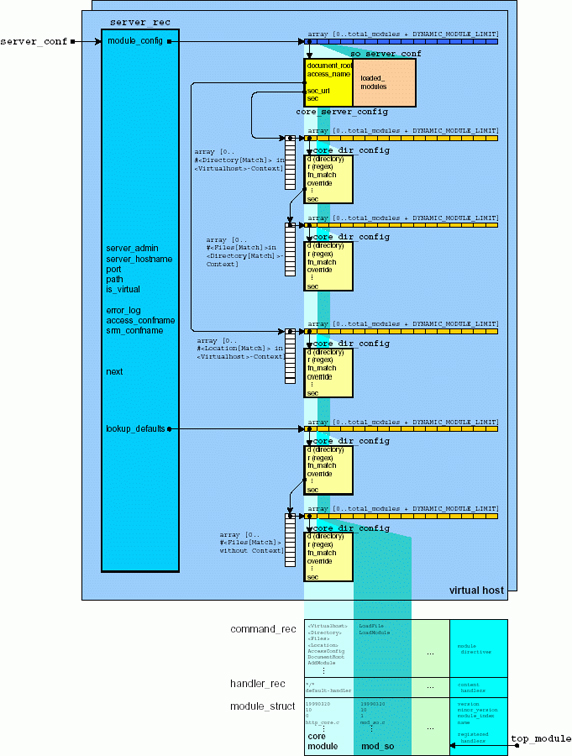
Каждый виртуальный хост имеет подобную структуру данных, представленную в списке server_recs, в которой есть 2 указателя — module_config и lookup_defaults — на структуры данных, которые определяются в соответствующих модулях. Указатель sec (секция) указывает на конкретную секцию конкретной виртуальной директории в конфиг-файле. Каждый модуль имеет возможность построить свою структуру данных для такой секции. lookup_defaults указывает на файловую структуру секции.
Процедура process_command_config читает командную строку, process_resource_config — глобальные конфигурационные данные. Эти данные обрабатываются внутри ap_srm_command_loop, здесь происходит управление прочитанных директив, которое выполняется модульными обработчиками. ap_read_config() вызывает процедуры process_command_config() и ap_process_resource_config(). Процедура process_command_config() обрабатывает командную строку. Процедура ap_process_resource_config() обрабатывает главные конфигурационные файлы.
Когда дочерний процесс начинает обрабатывать клиентский запрос, вызывается процедура process_request_internal(), в которой происходит трансляция URL, после чего вызывается процедура directory_walk(). Они проверяют уже созданные структуры данных на предмет нужного файла. Схема работы directory_walk показана на следующем рисунке:
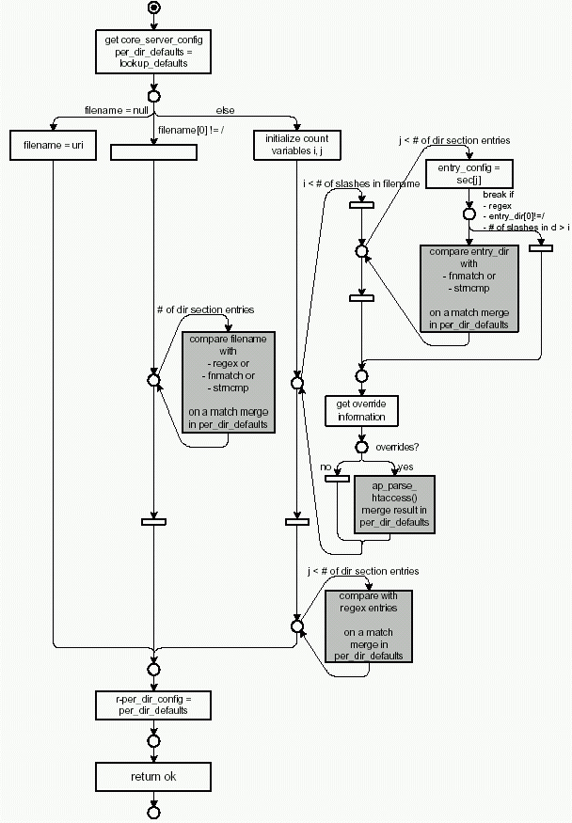
Вся иерархическая структура директории просматривается сверху вниз. Вначале создается объект структуры per_dir_defaults. На рисунке показан разбор URL, имя которого может включать несколько подкаталогов, разделенных слешами. URL берется из request_rec, парсится структура sec_url.
10. Управление памятью
Механизм управления памятью в Apache построен на пулах (pool). В пуле ведется учет всех выделенных ресурсов, пул может управлять памятью, сокетами, процессами.
Пул уменьшает вероятность возникновения ошибок на основе такого низкоуровневого языка, как С. Если в программе теряются ссылки на выделенные фрагменты памяти, впоследствии они не смогут быть использованы до тех пор, пока программа не будет перезапущена — это называется утечкой памяти — memory leak. Поскольку сервер работает на протяжении длительного времени, это может сказаться фатально на его работе.
Когда пул программно удаляется, автоматически очищаются все ресурсы, выделенные под него. Пулы также улучшают производительность.
Apache имеет несколько пулов на разные случаи жизни. Следующий рисунок показывает иерархию пулов.
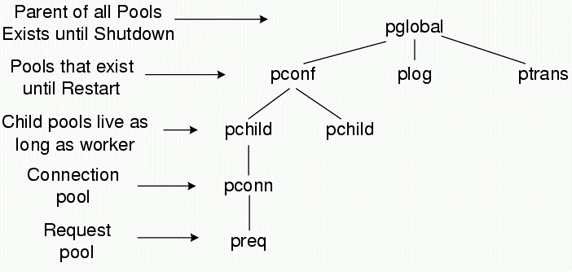
Пул pglobal существует на протяжении всей жизни сервера. Пул pchild имеет время жизни одного дочернего процесса. Пул pconn привязан к коннекту, пул preq привязан к запросу. Разработчик может создать свой собственный пул, используя ap_make_sub_pool, передавая ей в качестве аргумента родительский пул.
В программе его можно использовать аналогично другим пулам: привязать к какому-то родительскому пулу, и он автоматически будет удален в свое время вместе с родителем. Пул коннектов вложен в пул дочернего процесса, пул запросов вложен в пул коннектов.
Пул организован в форме связного списка. Память в нем выделяется с помощью предопределенных функций. При удалении пула вызываются функции очистки. Закрываются все дескрипторы файлов и сокетов. После этого удаляются все процессы. Затем освобождается память. Освобождение означает не физическое удаление, а удаление из пула занятой памяти и перемещение в список свободной памяти, который хранится в ядре.
Т. е. одна и та же физическая память не выделяется дважды, она перераспределяется.
Выделение памяти происходит блоками, блок привязывается к пулу.
Освобождаемые блоки добавляются в список свободных блоков.
Размер этого блока можно настроить в конфигурации.
Pool API позволяет выделять и освобождать ресурсы в произвольный момент. Для выделения памяти используются ap_palloc и ap_pcalloc, обеим функциям в качестве параметра нужно указывать пул и размер выделяемой памяти.
Функция ap_strdup выделяет память под строку. Функция ap_strcat выделяет память для нескольких строк.
11. Новые возможности в Apache 2.0
Во второй версии появилось много возможностей, которых не было в первой. Их можно разделить на 2 категории:
- Улучшения в ядре сервера.
- Улучшения в модулях сервера.
К первому типу можно отнести следующие улучшения:
- Многопоточность в Unix: на unix-платформах Apache. Apache теперь может выполняться в гибридном многопроцессово-многопоточном режиме.
- Новая система сборки: сборка была полностью изменена и теперь основывается на autoconf и libtool.
- Поддержка различных протоколов: теперь имеется специальная инфраструктура, способная обслуживать различные протоколы.
- Появились мультипроцессные модули (MPM), в которых теперь сконцентрирована основная часть кода, отвечающего за обработку запросов.
- Поддержка отличных от Unix платформ: это, прежде всего, касается Windows. Введение MPM + APR позволяет в Windows прозрачно вызывать нативные системные вызовы.
- Новый API: переписанный API улучшил организацию работы модулей.
- Использование фильтров: модули Apache теперь можно написать так, что они будут исполнять роль фильтров, обрабатывающих потоки данных, которые приходят или уходят из сервера. Это позволяет, к примеру, данным, являющимся результатом работы CGI-скрипта, быть обработанными SSI фильтром INCLUDES.
Ко второму типу можно отнести следующие улучшения:
- Добавлены новые модули: mod_ssl, mod_dav, mod_deflate, mod_auth_ldap, mod_charset_lite,mod_file_cache.
- Переписаны модули: mod_proxy, mod_negotiation, mod_autoindex, mod_include.
Многие конфигурационные директивы изменены, многие удалены.
Модули сторонних разработчиков, написанные для первой версии, во второй работать не будут.
Apache имеет многозадачную архитектуру, что достаточно стабильно, но имеет определенные ограничения. По умолчанию в Apache принята модель, в которой главный процесс создает дочерние на основе fork(). Для распределения запросов между дочерними процессами используются мьютексы. Multi Processing Modules (MPM), которые появились во втором Apache, позволяют эффективно использовать возможности конкретной операционной системы. Ключевым программным циклом является цикл обработки клиентского запроса. Управление памятью построено на основе пулов. Во второй версии Apache появились новые возможности, такие как фильтры, многопоточность и т. д.
Apache 1. Часть 5: Особенности архитектуры
Обычный сценарий, в который вовлечены, с одной стороны — пользователь с браузером, с другой — удаленный веб-сервер, состоит из следующих событий: пользователь нажимает в своем браузере на ссылку, посылает запрос на веб-сервер, который по нему извлекает определенный документ и возвращает содержимое этого документа удаленному клиенту.
1. Архитектура Apache 1.x
Клиентский запрос проходит в Apache несколько фаз:
- Запрашиваемый URL переводится в имя локального файла.
- Проверяется аутентификация пользователя.
- Проверяются права доступа.
- Определяется тип запрашиваемого документа: это может быть текст, картинка, звук, видео.
- Отсылается документ клиенту.
- Логирование.
Каждая фаза управляется собственным модулем Apache.
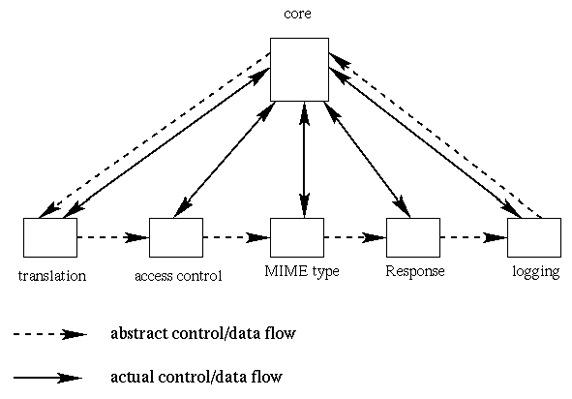
На каждый запрос ядро Apache создает объект структуры request_rec, которую затем передает по очереди соответствующему модулю и получает ее в модифицированном варианте.
На следующем рисунке архитектура Apache представлена более детально. Есть небольшие функциональные модули — ap, regex, которые используются как ядром, так и другими базовыми модулями. Отдельный модуль OS реализует кроссплатформенность Apache.
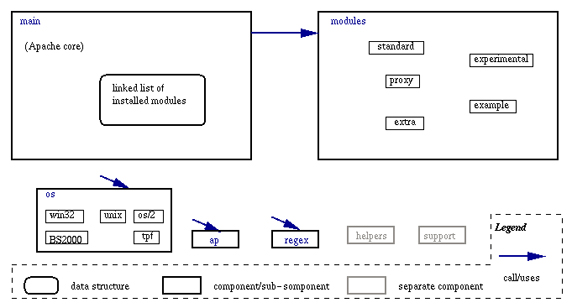
При ближайшем рассмотрении дерева исходников выясняется:
- Все заголовки сгруппированы в каталоге include.
- Ядро лежит в каталоге main (libmain.a).
- Базовые модули лежат в каталоге modules (libstandard.a).
- Реализация кроссплатформенности находится в каталоге os, который включает в себя соответствующие подкаталоги, в каждом из которых лежит свой соответствующий заголовок os.h. (libos.a).
- Отдельный библиотечный компонент для работы с регулярными выражениями лежит в каталоге regex (libregex.a).
- Отдельный компонент лежит в каталоге ap и включает набор различных функций (libap.a).
- Отдельный компонент лежит в каталоге support и включает в себя скрипты и код для вспомогательных утилит Apache, таких как ротация лог файлов, манипуляция с файлами паролей и т.д.
- Каталог helpers включает скрипты, используемые при компиляции самого Apache.
Практически все функции имеют префикс ap_, это было введено в версии 1.3 для избежания конфликта имен при переходе с версии 1.2.
2. Архитектура ядра Apache 1
Код ядра лежит в каталоге main. Ядро было разработано с учетом того, что любой, кто хочет расширять функционал Apache, по возможности не трогал код ядра, который уже включает все возможности для такого расширения. Единственный внутренний компонент ядра, который может подвергаться изменению — это реализация HTTP протокола.
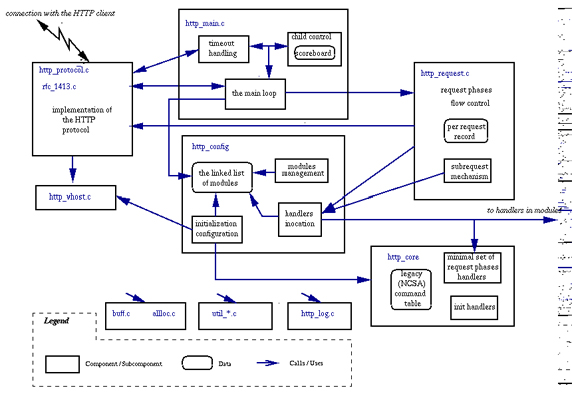
- http_main.c включает основной серверный цикл, управление таймаутами и дочерними процессами. В цикле устанавливается TCP/IP соединение, выделяется память под клиентский запрос, читается запрос и вызывается функция из http_request.c для управления этим запросом, после чего соединение закрывается и память освобождается.
- http_core.h описывает наиболее важные функции, обрабатывающие запрос.
- mod_core.c определяет структуру каждого модуля.
- http_core.c определяет таблицу стандартных конфигурационных команд, инициализацию самого ядра и управление фазами обработки запроса.
- http_request.c инициализирует модули и другие компоненты ядра. В нем реализовано чтение конфигурационных файлов и вызов соответствующих табличных конфигурационных команд. Хэндлеры всех модулей по обработке запроса находятся в связном списке, и из него происходит выбор нужного хэндлера для обработки соответствующей фазы запроса.
- http_protocol.c реализует HTTP протокол, управляет соединением с клиентом, закрывает коннект в случае ошибки. Для хранения информации о запросе есть текстовый заголовок и бинарный контент. Этот компонент ядра вызывается после установки коннекта, после его закрытия, а также в случае, когда документ готов для отправки клиенту.
- Файлы buff.c, alloc.c управляют ресурсами, буферизуют ввод/вывод. Пул ресурсов — это кусок памяти, необходимый для управления запросом, включает в себя файловые дескрипторы. Каждый запрос имеет свой собственный пул, который может быть освобожден после обработки запроса.
- http_log.c — управляет логированием, приоритетом сообщений, очередью сообщений.
- http_chost.c — один сервер может работать с нескольких адресов в соответствии с прописанными в конфиге правами для каждого из них.
3. Модули Apache
Модули реализуют функционал Apache. Модули могут напрямую общаться с ядром, но не могут напрямую общаться друг с другом. Каждый модуль фактически является набором обработчиков (хэндлеров) для различных фаз HTTP запроса. Следующий рисунок дает детальный обзор архитектуры модуля. Модуль — это коллекция функций-обработчиков, вызываемых ядром. Каждый модуль имеет собственную структуру под названием module, в которой хранятся указатели на обработчики, и объект такой структуры каждый модуль передает ядру.
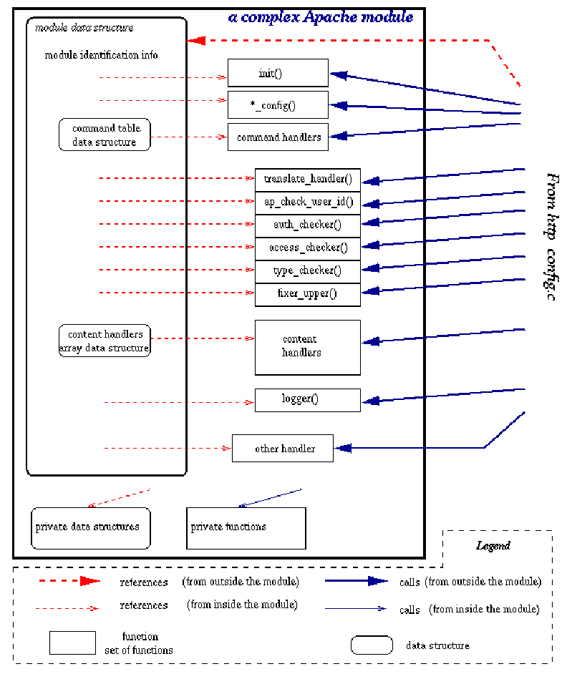
Каждый модуль должен быть проинициализирован ядром. По идее, любой модуль может использовать команды, которые пользователь прописывает в конфигурационном файле. Чтением файла занимается ядро, которое затем сопоставляет их с таблицей команд, полученных от модуля в структуре module. Каждая строка в этой таблице состоит из пары: тип контента — указатель на обработчик, где тип контента — это MIME type.
Обработчики, которые занимаются непосредственной отсылкой данных клиенту, называются content handlers или response handlers. Для каждого типа объекта имеется свой собственный обработчик.
В Apache все модули сгруппированы в каталоге modules. Стандартные модули сгруппированы в подкаталоге standard. реализация прокси лежит в каталоге proxy. Демонстрационный модуль, имеющий всего один обработчик, лежит в каталоге examples.
Все стандартные модули загружаются статично, хотя возможна динамическая загрузка: их можно слинковать с ядром и так, и так. При инсталляции Apache, когда вы запускаете конфигурацию, создается файл modules.c, в котором определяются 2 массива указателей на модульные структуры:
module *ap_prelinked_modules[] = {
&core_module,
&env_module,
&config_log_module,
&mime_module,
...
dule *ap_preloaded_modules[] = {
&core_module,
&env_module,
&config_log_module,
&mime_module,
&negotiation_module,
...
|
При этом все перечисленные модули можно разбить на следующие группы:
- Трансляция URL
- mod_userdir — перевод домашнего каталога в урл;
- mod_rewrite — переписывает урл на базе регулярных выражений.
- Аутентификация / авторизация
- mod_auth, mod_auth_anon,mod_auth_db, mod_auth_dbm — аутентификация пользователей на основе парольных файлов;
- mod_access — контроль доступа.
- MIME
- mod_mime — определение типа документа на основе файлового расширения;
- mod_mime_magic — определение типа документа по его заголовку;
- mod_negotiation.
- fix-ups
- mod_alias — алиасы;
- mod_env — переменные среды на основе конфигов;
- mod_speling — исправление ошибок в урлах;
- mod_expires, mod_headers.
- Отсылка данных клиенту
- mod_actions, mod_asis, mod_autoindex, mod_cgi, mod_dir, mod_imap, mod_include, mod_info, mod_negotiation, mod_status, mod_core.
- Логирование
- Proxy
- mod_proxy, proxy_cache, proxy_connect, proxy_ftp, proxy_http, proxy_util.
4. Параллелизм
При старте Apache создает (fork) по умолчанию 5 главных процессов, это минимальное возможное число процессов. Каждый процесс в свою очередь может поддерживать как минимум 50 потоков (thread — если многопоточность поддерживается операционной системой). На каждый клиентский запрос отводится один процесс. Существует специальная структура — scoreboard — которая хранит состояние всех процессов. Число одновременных возможных процессов по умолчанию — от 5 до 10. Максимальное число таких процессов — 256. Есть также специальная очередь для запросов на ожидание, которым пока нет места в scoreboard. Максимальная длина такой очереди — 511.
Максимально возможное число одновременных клиентских коннектов — 100.
5. Структуры данных
На следующем рисунке показана временная диаграмма прохождения различных фаз клиентского запроса, при этом основная работа выполняется в ядре, в файле http_request.c.
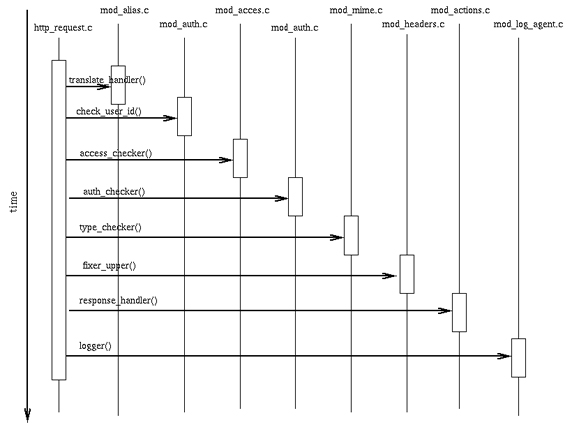
При вызове обработчика каждому модулю передается в качестве параметра одна и та же публичная структура — request_rec. При этом может происходить изменение состояния различных полей этой структуры. Responce handlers возвращают контент клиенту. Обработчик также может выполнять другой под-запрос. Структура request_rec может включать указатель на другую структуру request_rec в том случае, когда происходит редирект, а в случае под-запроса указатель может указывать на самое себя. Редирект означает вызов обработчика картинки внутри документа или вызов CGI-скрипта. При этом вызывается обработчик ap_internal_redirect, который создает новый объект request_rec. Такой объект может быть помещен в связный список request_recs.
Структура request_rec содержит в себе следующие поля:
- указатели на другие request_rec;
- указатель на пул ресурсов;
- обьекты запроса:
- информация о контенте:
- MIME headers;
- информация о запросе:
Ниже дано выборочное представление структуры request_rec с наиболее часто используемыми полями:
struct request_rec {
pool *pool;
conn_rec *connection;
server_rec *server;
/* запрос */
char *uri;
char *filename;
char *path_info;
char *args; /* QUERY_ARGS */
char *content_type;
char *content_encoding;
/* здесь представлен заголовок MIME
* также массив с переменными, передаваемый в дочерний процесс
*/
table *headers_in;
table *headers_out;
table *err_headers_out;
table *subprocess_env;
/* информация о запросе */
int header_only; /* HEAD — заголовок запроса */
char *protocol; /* Protocol */
char *method; /* GET, HEAD, POST. */
int method_number; /* M_GET, M_POST */
/* логирование */
char *the_request;
int bytes_sent;
/* флаг кеширования */
int no_cache;
/* массивы конфигурационных параметров с указателями типа void* */
void *per_dir_config;
void *request_config;
};
|
Apache использует пул ресурсов — pool — структуру данных, в которой хранится список всех выделенных ресурсов для запроса. Когда обработка запроса заканчивается, все ресурсы, затраченные на этот запрос, освобождаются. У модулей могут быть свои собственные пулы на свои нужды.
Как уже было сказано, ядро хранит таблицу конфигурационных команд. Также и каждый модуль может иметь свою собственную командную таблицу. Каждая команда представляет обьект структуры command_struct и включает:
- имя команды;
- указатель на функцию-обработчик;
- передаваемый аргумент;
- условия инициализации;
- тип и число аргументов;
- описание аргументов;
Структура scoreboard хранит список обрабатываемых запросов. Хранится статус запроса и его id. Для каждого создаваемого процесса в scoreboard добавляется запись, которая после обработки запроса удаляется. Статус процесса в этой структуре изменяется самим процессом. Статус запроса может приобретать следующие значения:
SERVER_DEAD 0
SERVER_STARTING 1 /* Server Starting up */
SERVER_READY 2 /* Waiting for connection (or accept() lock) */
SERVER_BUSY_READ 3 /* Reading a client request */
SERVER_BUSY_WRITE 4 /* Processing a client request */
SERVER_BUSY_KEEPALIVE 5 /* Waiting for more requests via keepalive */
SERVER_BUSY_LOG 6 /* Logging the request */
SERVER_BUSY_DNS 7 /* Looking up a hostname */
SERVER_GRACEFUL 8 /* server is gracefully finishing request */
SERVER_NUM_STATUS 9 /* number of status settings */
|
6. Обработчик response
Результат работы большинства обработчиков сводится к банальному изменению значения полей структуры request_rec, либо к возврату специальных кодов. Данный же обработчик отсылает реальные данные клиенту. Вначале клиенту отсылается HTTP-заголовок с помощью функции send_http_header. Если у запроса есть метка header_only, то клиенту более ничего не высылается. В противном случае, клиенту высылается само сообщение, для этого используются специальные примитивы rputc, rprintf, send_fd. Следующий код показывает обработку GET-запроса и отсылку данных клиенту:
int default_handler (request_rec *r)
{
int errstatus;
FILE *f;
if (r->method_number != M_GET) return DECLINED;
if (r->finfo.st_mode == 0) return NOT_FOUND;
if ((errstatus = set_content_length (r, r->finfo.st_size))
|| (errstatus = set_last_modified (r, r->finfo.st_mtime)))
return errstatus;
f = fopen (r->filename, "r");
if (f == NULL) {
log_reason("file permissions deny server access", r->filename, r);
return FORBIDDEN;
}
register_timeout ("send", r);
send_http_header (r);
if (!r->header_only) send_fd (f, r);
pfclose (r->pool, f);
return OK;
}
|
Эта функция может вернуть либо код ошибки, либо OK, во втором случае вызывается редирект на другой обработчик с помощью internal_redirect.
7. Пул
Основная проблема, решаемая с помощью пула — pool — это предотвращение утечек памяти.
Пул в Apache разработан таким образом, что освобождение всех ресурсов — памяти, дескрипторов и т.д. — происходит автоматически, после завершения обработки клиентского запроса. Каждому такому запросу выделяется свой собственный пул, представленный структурой pool. После обработки этот пул удаляется.
При старте Apache выделятся специальный пул — конфигурационный. При перезапуске сервера этот пул также очищается.
Память выделяется с помощью palloc, что быстрее, чем malloc. Эта функция имеет 2 аргумента — указатель на пул и количество выделяемой памяти:
int my_handler(request_rec *r)
{
struct my_structure *foo;
...
foo = (foo *)palloc (r->pool, sizeof(my_structure));
}
|
Функция pfree отсутствует, поскольку освобождение памяти идет автоматически тогда, когда освобождается пул. Есть специальные прикладные функции, выделяющие память : например, в следующем примере функция pstrcat выделяет память под 8 байтовый строковый модуль:
pstrcat (r->pool, "foo", "/", "bar", NULL);
|
Аналогично происходит открытие файлов:
FILE *f = pfopen (r->pool, r->filename, "r");
|
В отличие от работы с памятью, здесь есть соответствующая закрывающая функция pfclose.
Общим недостатком этой модели выделения памяти является вложенные пулы. Можно смоделировать такую ситуацию, при которой родительский пул освобождается раньше дочернего, при котором возможна утечка памяти для последнего. Например, можно привести в качестве примера листинг каталога сервера с большим уровнем вложенности. В этом случае для создания вложенных пулов нужно использовать make_sub_pool.
Пул также можно освободить в любой момент с помощью clear_pool или destroy_pool.
В случае подзапросов для надежного очищения памяти используется destroy_sub_request.
8. Конфигурация
Первый Apache разрабатывался с прицелом на максимальную совместимость со своим предшественником — вебсервером NCSA 1.3 — в плане чтения конфигурационных файлов. Была поставлена задача вынести максимально весь функционал из ядра в модули. Для этого в ядре была создана специальная таблица команд. Определения типа файла по суффиксу делается на основе конфигурационных директив AddType и DefaultType.
Работа с файловой системой выполняется с помощью директив Aliases и Redirect.
Работа с вложенными конфигурационными файлами выполняется на базе файлов .htaccess.
Когда сервер читает в файле директиву <Directory>, он создает структуру mime_dir_config:
typedef struct {
table *forced_types; /* AddType */
table *encoding_types; /* AddEncoding */
} mime_dir_config;
|
Команды AddType и AddEncoding обычно присутствуют в .htaccess.
Для создания такой структуры нужны 2 параметра — пул и имя каталога:
void *create_mime_dir_config (pool *p, char *dummy)
{
mime_dir_config *new =
(mime_dir_config *) palloc (p, sizeof(mime_dir_config));
new->forced_types = make_table (p, 4);
new->encoding_types = make_table (p, 4);
return new;
}
|
Если в нашем серверном каталоге, который мы только что прочитали, есть вложенный каталог, и там есть свой собственный .htaccess, нам придется объединять две структуры:
void *merge_mime_dir_configs (pool *p, void *parent_dirv, void *subdirv)
{
mime_dir_config *parent_dir = (mime_dir_config *)parent_dirv;
mime_dir_config *subdir = (mime_dir_config *)subdirv;
mime_dir_config *new =
(mime_dir_config *)palloc (p, sizeof(mime_dir_config));
new->forced_types = overlay_tables (p, subdir->forced_types,
parent_dir->forced_types);
new->encoding_types = overlay_tables (p, subdir->encoding_types,
parent_dir->encoding_types);
return new;
}
|
Архитектура первого Apache имеет свои особенности — все функции имеют префикс ap_, реализация кроссплатформенности сделана на основе отдельных модулей, модули не могут общаться друг с другом, а только с ядром, все модули можно разбить на 7 основных групп: трансляция, аутентификация, MIME, fix-ups, генераторы контента, логирование, прокси. Управление памятью реализовано на основе пулов. Система конфигурация имеет широкие возможности для предварительной настройки сервера.
Apache 1. Часть 6: Обзор API
В этом документе мы рассмотрим API первого Apache и базовые структуры.
1. Базовые концепции
Обработка запроса в Apache разбита на несколько частей:
- URL транслируется в имя файла.
- Аутентификационная проверка ID пользователя.
- Проверка авторизационного доступа (логин/пароль).
- Проверка локального доступа.
- Определяется MIME-тип запрашиваемого объекта.
- Отсылка ответа клиенту.
- Логирование.
Сначала в списке модулей ищется нужный обработчик, который потом вызывается. Обычно каждый обработчик делает одну из 3 вещей:
- В случае обработки запроса возвращает OK.
- Возвращает константу DECLINED в противном случае.
- Возвращает ошибку, при этом обработка запроса останавливается.
На отсылку ответа может накладываться множество обработчиков в зависимости от MIME-типа. Обработчик ответа может быть помечен как */*, в этом случае он может быть вызван, если не найден соответствующий MIME-тип. Обработчик представляет из себя функцию с одним аргументом — request_rec, и, как правило, возвращает целое число.
CGI модуль работает с двумя типами объектов — с CGI скриптами и с конфигурационной директивой ScriptAlias. Чтобы управлять CGI скриптами, модуль должен объявить для них обработчик. Структура модуля также включает указатели на функции, которые строят структуру на основе директивы ScriptAliases. В модуле есть код, который управляет командами ScriptAliases. В командной таблице модуля описано, где и когда вызывается внешний CGI скрипт.
Пул (Pool) представляет из себя указатель на пул ресурсов, структура cmd_parms включает информацию о конфигурационном файле. Модуль может выглядеть следующим образом:
/* декларация обработчиков */
int translate_scriptalias (request_rec *);
int type_scriptalias (request_rec *);
int cgi_handler (request_rec *);
/* таблица обработчиков для генерации ответа */
handler_rec cgi_handlers[] = {
{ "application/x-httpd-cgi", cgi_handler },
{ NULL }
};
/* процедуры для манипуляции информацией из конфигов
возвращают и передают тип void *
*/
void *make_cgi_server_config (pool *);
void *merge_cgi_server_config (pool *, void *, void *);
/* процедуры для управления команд из конфига */
extern char *script_alias(cmd_parms *, void *per_dir_config, char *fake, char *real);
command_rec cgi_cmds[] = {
{ "ScriptAlias", script_alias, NULL, RSRC_CONF, TAKE2,
"a fakename and a realname"},
{ NULL }
};
module cgi_module = {
STANDARD_MODULE_STUFF,
NULL, /* initializer */
NULL, /* dir config creator */
NULL, /* dir merger */
make_cgi_server_config, /* server config */
merge_cgi_server_config, /* merge server config */
cgi_cmds, /* command table */
cgi_handlers, /* handlers */
translate_scriptalias, /* filename translation */
NULL, /* check_user_id */
NULL, /* check auth */
NULL, /* check access */
type_scriptalias, /* type_checker */
NULL, /* fixups */
NULL, /* logger */
NULL /* header parser */
};
|
2. Структура request_rec
Аргументом обработчиков является структура request_rec. Структура описывает конкретный клиентский запрос. Как правило, один клиентский коннект генерирует один клиентский запрос. В этой структуре есть указатель на пул, который будет очищен после обработки запроса, а также информация о коннекте и о самом запросе. Структура включает набор строк, описывающих атрибуты запроса — URL, имя файла, тип контента, кодировка, таблица MIME-заголовков, которые будут посланы клиенту, переменные среды для запуска фоновых процессов. Имеются также 2 указателя на конфигурационные структуры, которые содержат информацию, полученную в результате обработки .htaccess либо директивы <Directory>. В структуре также имеется дополнительный массив данных, хранящий виртуальную конфигурационную информацию.
Декларация структуры request_rec:
struct request_rec {
pool *pool;
conn_rec *connection;
server_rec *server;
/* атрибуты запроса */
char *uri;
char *filename;
char *path_info;
char *args; /* QUERY_ARGS */
struct stat finfo; /* инициализируется ядром, st_mode устанавливается в
ноль при отсутствии файла */
char *content_type;
char *content_encoding;
/* MIME заголовки, массив переменных окружения
*
* err_headers_out сохраняются при последующих редиректах в ErrorDocument
*/
table *headers_in;
table *headers_out;
table *err_headers_out;
table *subprocess_env;
/* информация о запросе */
int header_only; /* заголовок запроса */
char *protocol; /* протокол */
char *method; /* GET, HEAD, POST, etc. */
int method_number; /* M_GET, M_POST, etc. */
/* информация для логирования */
char *the_request;
int bytes_sent;
/* клиент не просит кешировать документ */
int no_cache;
/* информация, взятая из .htaccess
*
* массив, имеющий тип void*
*/
void *per_dir_config; /* опции конфига */
void *request_config; /* информация о текущем запросе */
};
|
Как правило, структура request_rec создается и инициализируется в момент чтения запроса от клиента, но есть несколько исключений:
- Структура может быть создана, если запрос направлен на извлечение картинки или вызывается CGI скрипт. В этом случае организуется так называемый внутренний редирект.
- В случае ошибки вызывается ErrorDocument.
- Под-запросы на базе SSI.
3. Обработка запросов
Все обработчики, имеющие в качестве параметра request_rec, возвращают целочисленный результат:
- OK — успешная обработка результата;
- DECLINED — запрос отклонен;
- HTTP error.
Ошибка может вернуть, например, REDIRECT, в этом случае в headers_out должно быть указано, куда.
Как правило, работа обработчика заключается в модификации полей request_rec. Это не относится к обработчикам, которые посылают ответ клиентам. Сначала клиенту посылается HTTP заголовок, это делает ap_send_http_header. Если запрос промаркирован как header_only, то на этом отсылка заканчивается. В противном случае формируется тело ответа на основе ap_rputc и ap_rprintf.
В следующем куске кода показано, как обрабатывается GET запрос, где, в частности, показано, были ли сделаны изменения в истории запросов для данного клиента — ap_set_last_modified:
int default_handler (request_rec *r)
{
int errstatus;
FILE *f;
if (r->method_number != M_GET) return DECLINED;
if (r->finfo.st_mode == 0) return NOT_FOUND;
if ((errstatus = ap_set_content_length (r, r->finfo.st_size))
|| (errstatus = ap_set_last_modified (r, r->finfo.st_mtime)))
return errstatus;
f = fopen (r->filename, "r");
if (f == NULL) {
log_reason("file permissions deny server access", r->filename, r);
return FORBIDDEN;
}
register_timeout ("send", r);
ap_send_http_header (r);
if (!r->header_only) send_fd (f, r);
ap_pfclose (r->pool, f);
return OK;
}
|
Этот код еще не генерирует тело ответа, он посылает клиенту заголовок и возвращает код, на основе которого может быть послан ответ.
Обработчики аутентификации вызываются в случае, если соответствующая директория сконфигурирована для этого. Базовая аутентификация хранится в главном конфиге, она читается и хранится в объектах ap_auth_type, ap_auth_name, ap_requires. Естественно, во всех случаях работает базовая HTTP-аутентификация, в этом случае ap_get_basic_auth_pw инициализирует структуру connection->user, а также note_basic_auth_failure, заполняющие аутентификационный заголовок, отсылаемый клиенту.
Когда запрос проходит стадию внутреннего редиректа, встает вопрос о логировании. Редиректы добавляются в специальный связный список в рамках структуры request_rec, а сама эта структура передается в качестве аргумента обработчику, отвечающему за логирование.
4. Управление памятью
Одна из основных проблем, которая встает при разработке веб-серверов — это проблема утечки памяти, проблема с закрытием дескрипторов и т. д. Пул ресурсов разрешает эту проблему, выделяя ресурсы таким образом, что они автоматически очищаются после использования. Делается это следующим образом: выделяемая память, открываемые дескрипторы привязываются к конкретному запросу, который помещается в пул запросов.
Пул — это структура данных в обычном понимании. После обработки запроса пул очищается, и гарантированно не остается незакрытой памяти или незакрытых дескрипторов.
При перезапуске сервера управление ресурсами проходит аналогично. Для этого есть конфигурационный пул, который очищается при ре-старте. Например, функция ap_pfopen закрывает дескрипторы, которые могут быть открыты при вызове CGI скрипта.
Для выделения памяти в пул вызывается ap_palloc, которая имеет 2 аргумента: первый указывает на сам пул, второй — на размер выделяемой памяти. Для получения доступа к самому пулу нужно получить доступ к полю структуры request_rec:
int my_handler(request_rec *r)
{
struct my_structure *foo;
...
foo = (foo *)ap_palloc (r->pool, sizeof(my_structure));
}
|
Обратите внимание, что мы создали объект структуры foo и не позаботились об очистке — этого не нужно делать, это, так сказать, входит в пакет услуг — объект будет удален позже автоматически вместе с пулом данного конкретного запроса. Если вы не хотите использовать стандартный пул, вы можете организовать свой собственный так называемый sub-pool, но тогда вам самим придется заниматься его очисткой.
Есть несколько специальных функций, которые выделяют память. Функция ap_pcalloc аналогична ap_palloc, но очищает память после возвращения. ap_pstrdup выделяет память под символьную строку, возвращая указатель на нее. ap_pstrcat выделяет память для массива строк, в конце аргументов нужно поставить NULL:
ap_pstrcat (r->pool, "foo", "/", "bar", NULL);
|
Она вернет указатель на память, в которой будет суммарная строка — "foo/bar".
Есть несколько базовых пулов, указатели на которые передаются из http_main остальным функциям в качестве аргумента:
- permanent_pool — это базовый предок всех остальных пулов.
- pconf — потомок предыдущего пула, создается в момент чтения конфигурации, существует на протяжении всей жизни сервера, передается во все конфигурационные процедуры; когда инициализируется какой-то модуль, передается в функцию инициализации init().
- ptemp — временный пул, существует во время разбора конфигурационного файла.
- pchild — пул дочернего процесса или потока.
- ptrans — используется для коннектов.
- r->pool — это вложенный пул для коннект-пула, используется для подзапросов, живет столько же, сколько и данный запрос.
Наиболее часто используемый пул — r->pool. В некоторых случаях этот вариант не годится, например, потому, что время жизни connection->pool может быть дольше, чем r->pool, поскольку последний может быть вложенным, и нужно делать правильный выбор между ними.
Иногда встает дилемма выбора между r->pool и r->main->pool. При выборе второго варианта очистка пула будет выполнена после того, как ответ окончательно будет отослан клиенту и будет выполнено логирование.
Для открытия файлов используется функция ap_pfopen:
FILE *f = ap_pfopen (r->pool, r->filename, "r");
|
Есть также аналог в виде ap_popenf. В обоих случаях дескриптор закрывается при очистке пула. Есть специальные функции для закрытия файлов — ap_pfclose и ap_pclosef. Это может пригодиться в том случае, когда операционная система имеет ограничения на количество одновременно открываемых файлов.
Пул очищается с помощью clear_pool(), которая в свою очередь рекурсивно вызывает destroy_pool() для пулов-потомков. При этом важно понимать, что не происходит удаления пула, он очищается и становится доступен для повторного использования и инициализации.
Для создания вложенных пулов — sub-pools — используется функция ap_make_sub_pool, которой в качестве аргумента нужно передать родительский пул. Очищен такой пул будет во время очистки родителя.
Очистить его можно также в произвольный момент с помощью ap_clear_pool / ap_destroy_pool.
Для очистки ресурсов, выделенных на подзапрос, нужно использовать ap_destroy_sub_req. Обычно на пул подзапроса выделяется 2 килобайта, и логичнее всего такие пулы привязывать к главному запросу.
5. Конфигурация
Первый Apache с самого начала разрабатывался как совместимый со своим непосредственным предшественником — сервером NCSA 1.3. Apache аналогичным образом читает конфигурацию, также интерпретирует директивы. Другой целью было переместить весь функционал из ядра в модули. Для этого каждый модуль имеет собственную таблицу команд. Ядро должно знать порядок выполнения этих команд. Этот порядок во многом зависит от конфигурации каждой конкретной директории. В наследство от NCSA также пришла обработка файлов .htaccess. Когда URL оттранслирован в конкретный путь, сервер должен пройтись по всему этому пути иерархически, учитывая все .htaccess, которые могут попасться на каждом уровне этого пути. Прочитанная информация складывается с генеральной конфигурацией. После этого надо освободить все ресурсы, задействованные под парсинг и анализ.
В качестве примера рассмотрим код из mod_mime.c, в котором определяется тип файла по его расширению. .htaccess может включать в себя команды AddType и AddEncoding, под которые отведены две специальные таблицы:
typedef struct {
table *forced_types; /* Additional AddTyped stuff */
table *encoding_types; /* Added with AddEncoding... */
} mime_dir_config;
|
Когда сервер читает в конфигурационном файле директиву <Directory>, он находит там команду для MIME и создает структуру mime_dir_config. В модуле есть специальная функция, которая имеет два аргумента — имя директории, к которой она применяется, и пул. В модуле mod_mime с помощью ap_pallocs выделяется память и создается копия этих двух таблиц, которая потом модифицированная и возвращается:
void *create_mime_dir_config (pool *p, char *dummy)
{
mime_dir_config *new = (mime_dir_config *) ap_palloc (p,
sizeof(mime_dir_config));
new->forced_types = ap_make_table (p, 4);
new->encoding_types = ap_make_table (p, 4);
return new;
}
|
Когда сервер проходит иерархически весь путь до файла, он объединяет информацию, взятую локально в .htaccess. Следующая функция имеет три аргумента — две описанных таблицы и пул, выделенный под результат.
void *merge_mime_dir_configs (pool *p, void *parent_dirv, void *subdirv)
{
mime_dir_config *parent_dir = (mime_dir_config *)parent_dirv;
mime_dir_config *subdir = (mime_dir_config *)subdirv;
mime_dir_config *new =
(mime_dir_config *)ap_palloc (p, sizeof(mime_dir_config));
new->forced_types = ap_overlay_tables (p, subdir->forced_types,
parent_dir->forced_types);
new->encoding_types = ap_overlay_tables (p, subdir->encoding_types,
parent_dir->encoding_types);
return new;
}
|
После получения результата, ядро должно интерпретировать команды AddType и AddEncoding. Для этого ядро просматривает таблицу команд модуля, которая включает информацию о том, сколько аргументов может иметь команда, в каком формате и т. д. Обработчик AddType:
char *add_type(cmd_parms *cmd, mime_dir_config *m, char *ct, char *ext)
{
if (*ext == '.') ++ext;
ap_table_set (m->forced_types, ext, ct);
return NULL;
}
|
Обработчик имеет 4 аргумента: первые два — это результат иерархического парсинга, третий — это структура главного конфигурационного файла, четвертый — указатель на структуру cmd_parms.
Командная таблица модуля MIME может иметь следующий вид:
command_rec mime_cmds[] =
{
{ "AddType", add_type, NULL, OR_FILEINFO, TAKE2,
"a mime type followed by a file extension" },
{ "AddEncoding", add_encoding, NULL, OR_FILEINFO, TAKE2,
"an encoding (e.g., gzip), followed by a file extension" },
{ NULL }
};
|
Она включает: имя команды, функцию, которая ею управляет, указатель типа void(*), который передает cmd_parms, битовую маску, указывающую на то, где может появиться команда, флаг, указывающий на число аргументов обработчика. После этого из структуры request_rec извлекается главная конфигурация и определяется тип файла:
int find_ct(request_rec *r)
{
int i;
char *fn = ap_pstrdup (r->pool, r->filename);
mime_dir_config *conf = (mime_dir_config *)
ap_get_module_config(r->per_dir_config, &mime_module);
char *type;
if (S_ISDIR(r->finfo.st_mode)) {
r->content_type = DIR_MAGIC_TYPE;
return OK;
}
if((i=ap_rind(fn,'.')) < 0) return DECLINED;
++i;
if ((type = ap_table_get (conf->encoding_types, &fn[i])))
{
r->content_encoding = type;
/* go back to previous extension to try to use it as a type */
fn[i-1] = '\0';
if((i=ap_rind(fn,'.')) < 0) return OK;
++i;
}
if ((type = ap_table_get (conf->forced_types, &fn[i])))
{
r->content_type = type;
}
return OK;
}
|
Архитектура первого Apache построена на основе своего непосредственного предшественника — сервера NCSA. Обработка клиентского запроса проходит несколько стадий, каждую из которых, как правило, обрабатывает отдельный модуль. Базовая структура для обработки — request_rec — создается на каждый такой запрос и передается в качестве параметра обработчикам. Все такие обработчики возвращают целочисленный ответ, могут модифицировать поля этой структуры. Управление ресурсами в первом Apache построено на основе пулов, что решает все проблемы с утечкой памяти и незакрытыми дескрипторами. Пулы привязываются к базовым объектам, и время жизни пула становится равным времени жизни такого объекта.
Apache 2: Часть 7. Замечания по технике программирования
1. Coding conventions
Несколько простых правил: в строке должно быть не более 80 символов, включая пробелы. Продолжение на новой строке выравнивается с предыдущей. Перед точкой с запятой не должно быть пробелов. Аргументы функции декларируются в стиле ANSI-C.
Пробелы не ставятся перед и после скобок со списком. Аргументы разделяются запятой и одним пробелом. Отступ блока кода начинается с 4 пробелов. Фигурная скобка, открывающая блок, должна появляться в конце предыдущей линии. Например, оператор Case пишется в следующем стиле:
switch (xyz) {
case X:
/* code for X */
case Y:
/* code for Y */
case Z:
/* code for Z */
}
|
Указатель декларируется с помощью звездочки, которая присоединяется к имени переменной, а не к типу. Комментарии всегда используют /* ... */.
Область видимости переменной может быть локальной, например, в пределах одной функции или глобальной - в пределах всей программы.
Модули Apache построены на функциях, имеющих тип callback. Для того чтобы предоставить доступ к одним и тем же данным нескольким callback-функциям, используется глобальное пространство. В случае многопоточности это не проходит. Для этого в Apache есть специальный конфигурационный массив - ap_conf_vector_t. Кроме хранения конфигурационных данных, он используется для более глобальных целей.
В Apache есть несколько базовых объектов - процесс, сервер, коннект, запрос. В основном данные привязываются к этим объектам. Комбинация вектора конфигурации с пулами представляет собой фреймворк, в котором данные привязываются к соответствующему объекту. При этом убиваются два зайца:
- Конфигурационный массив предоставляет доступ к данным везде, где они востребованы.
- Пул привязан к жизненному циклу конкретного объекта, по истечении которого он очищается.
Т. е. данные могут быть ассоциированы с сервером, коннектом или запросом. Доступ к конфигурационному массиву сервера или конфигурационному массиву запроса возможен через объект сервера или запроса:
svr_cfg* my_svr_cfg =
ap_get_module_config(server->module_config, &my_module);
dir_cfg* my_dir_cfg =
ap_get_module_config(request->per_dir_config, &my_module);
|
Для инициализации переменных и их использования в рамках одного запроса, но в разных хуках, есть функции ap_set_module_config и ap_get_module_config. Инициализация:
static int my_early_hook(request_rec* r) {
req_cfg* my_req;
...
my_req = apr_palloc(r->pool, sizeof(req_cfg));
ap_set_module_config(r->request_config, &my_module, my_req);
/* инициализируем my_req */
}
|
Использование:
static int my_later_hook(request_rec* r) {
req_cfg* my_req = ap_get_module_config(r->request_config, &my_module);
/* читаем my_req */
}
|
2. Взаимодействие модулей
Модули могут взаимодействовать друг с другом различным образом. В первую очередь это делается с помощью структуры request_rec.
r->subprocess_env - это таблица типа apr_table, время ее жизни равно времени жизни запроса, и она доступна всем модулям. В ней, в частности, представлено окружение CGI. Любой модуль может прочитать из нее значения. Модули могут определить свои собственные переменные для придания прав доступа другим модулям. Модуль mod_deflate может устанавливать переменный no-gzip и force-gzip, а также nokeepalive. Благодаря этому администратор может динамически конфигурировать систему.
r->notes - таблица типа apr_table_t, имеющая время жизни, равное времени жизни запроса. Сюда модуль может сбросить сообщения, предназначенные другому модулю. Например, она может быть использована для отсылки сообщения пользователю в случае ошибки.
r->headers_in - здесь хранятся заголовки запроса, доступно всем модулям. Модули могут изменять эти заголовки, например, сюда может быть записана информация, прочитанная из куков клиента.
r->headers_out - здесь хранятся заголовки ответа клиенту. Эта информация, хранимая в формате apr_table_t, конвертируется в простой текст в фильтрах вывода.
r->err_headers_out - заголовки ответа в случае, когда вместо ответа возвращается ошибка.
3. Временные файлы
Стандартный механизм создания временного файла выглядит следующим образом:
FILE *create_tmpfile_BAD(apr_pool_t *pool)
{
FILE *ret ;
char *template = apr_pstrdup(pool, "/tmp/my-module.XXXXXX");
int fd = mkstemp(template);
if (fd == -1) {
apr_log_perror(....);
return NULL;
}
ret = fdopen(fd, "rw");
if (ret == NULL) {
apr_log_perror(....);
close(fd);
return NULL;
}
apr_pool_cleanup_register(pool, ret, (void*)fclose,
apr_pool_cleanup_null);
return ret;
}
|
Этот пример не совсем корректен по следующим причинам:
- Каталог /tmp/ корректен лишь в unix-системах.
- fdopen ссылается на POSIX.
- Тип FILE* на разных платформах ведет себя по-разному.
Вот APR-версия, гарантированно работающая на всех поддерживаемых платформах:
apr_file_t* create_tmpfile_GOOD(apr_pool_t *pool)
{
apr_file_t *ret = NULL;
const char *tempdir;
char *template;
apr_status_t rv;
rv = apr_temp_dir_get(&tempdir, pool);
if (rv != APR_SUCCESS) {
ap_log_perror(APLOG_MARK, APLOG_ERR, rv, pool, "No temp dir!");
return NULL;
}
rv = apr_filepath_merge(&template, tempdir, "my-module.XXXXXX",
APR_FILEPATH_NATIVE, pool);
if (rv != APR_SUCCESS) {
ap_log_perror(APLOG_MARK, APLOG_ERR, rv, pool,
"File path error!");
return NULL;
}
rv = apr_file_mktemp(&ret, template, 0, pool);
if (rv != APR_SUCCESS) {
ap_log_perror(APLOG_MARK, APLOG_ERR, rv, pool,
"Failed to open tempfile!");
return NULL;
}
return ret;
}
|
4. MPM
Apache поддерживает как многопроцессность, так и многопоточность. Одной из основных проблем является координация между ними. Формы взаимодействия ограничены самой платформой Apache. В первую очередь при реализации становятся актуальными два момента:
- Глобальные блокировки.
- Глобальная память.
APR содержит реализацию этих необходимых требований. В APR есть 2 типа мьютексов:
- apr_proc_mutex - мьютекс процессов.
- apr_global_mutex - глобальный мьютекс.
У глобального мьютекса более сложная инициализация. Он должен быть создан в родительском процессе в post_config фазе, причем каждый потомок должен быть приаттачен к родителю в child_init фазе:
static int my_post_config(apr_pool_t *pool, apr_pool_t *plog,
apr_pool_t *ptemp, server_rec *s)
{
/* поддерживаются несколько типов блокировок - см. apr_global_mutex.h
* APR_LOCK_DEFAULT устанавливает тип блокировки по умолчанию
*/
apr_status_t rc;
my_svr_cfg *cfg =
ap_get_module_config(s->module_config, &my_module);
rc = apr_global_mutex_create(&cfg->mutex, cfg->mutex_name,
APR_LOCK_DEFAULT, pool);
if (rc != APR_SUCCESS) {
ap_log_error(APLOG_MARK, APLOG_CRIT, rc, s,
"Parent could not create mutex %s", cfg->mutex_name);
return rc;
}
#ifdef AP_NEED_SET_MUTEX_PERMS
rc = unixd_set_global_mutex_perms(cfg->mutex);
if (rc != APR_SUCCESS) {
ap_log_error(APLOG_MARK, APLOG_CRIT, rc, cfg,
"Parent could not set permissions on global mutex:"
" check User and Group directives");
return rc;
}
#endif
apr_pool_cleanup_register(pool, cfg->mutex,
(void*)apr_global_mutex_destroy, apr_pool_cleanup_null);
return OK ;
}
static void my_child_init(apr_pool_t *pool, server_rec *s)
{
my_svr_cfg *cfg
= ap_get_module_config(s->module_config, &my_module);
apr_global_mutex_child_init(&cfg->mutex, cfg->mutex_name, pool);
}
static void my_hooks(apr_pool_t *pool)
{
ap_hook_child_init(my_child_init, NULL, NULL, APR_HOOK_MIDDLE);
ap_hook_post_config(my_post_config, NULL, NULL, APR_HOOK_MIDDLE);
ap_hook_handler(my_handler, NULL, NULL, APR_HOOK_MIDDLE);
}
|
В следующем примере будет показано создание глобального мьютекса для генератора контента my_handler. Генераторы контента в Apache являются тем местом, где более всего нужен глобальный мьютекс. Проинициализировав этот мьютекс на этапе начальной инициализации, мы затем сможем им пользоваться в любой точке:
static int my_handler(request_rec *r)
{
apr_status_t rv;
my_svr_cfg *cfg;
cfg = ap_get_module_config(r->server->module_config, &my_module);
/* захватываем мьютекс, блокируя конфигурацию модуля */
rv = apr_global_mutex_lock(cfg->mutex);
if (rv != APR_SUCCESS) {
ap_log_rerror(APLOG_MARK, APLOG_ERR, rv, r,
"my_module: failed to acquire mutex!");
return HTTP_INTERNAL_SERVER_ERROR;
}
/* регистрируя cleanup и делая блокировку, мы ничем не рискуем */
apr_pool_cleanup_register(r->pool, cfg->mutex,
(void*)apr_global_mutex_unlock,
apr_pool_cleanup_null);
/* отпускаем блокировку */
rv = apr_global_mutex_unlock(cfg->mutex);
if ( rv != APR_SUCCESS ) {
ap_log_rerror(APLOG_MARK, APLOG_ERR, rv, r,
"my_module: failed to release mutex!");
}
apr_pool_cleanup_kill(r->pool, cfg->mutex, apr_global_mutex_unlock);
return OK;
}
|
Глобальная память может быть использования для кеширования ресурса, который многократно используется. Модуль apr_shm подходит для хранения глобальных данных фиксированного размера, таких как переменные или структуры, но не указатели - для этого подходит другой модуль — apr_rmm. В следующем примере модуль mod_ldap использует комбинацию глобального кэша и динамического выделения:
apr_status_t util_ldap_cache_init(apr_pool_t *pool, util_ldap_state_t *st)
{
#if APR_HAS_SHARED_MEMORY
apr_status_t result;
apr_size_t size;
if (st->cache_file) {
/* удаляем shm сегмент с тем же именем*/
apr_shm_remove(st->cache_file, st->pool);
}
size = APR_ALIGN_DEFAULT(st->cache_bytes);
result = apr_shm_create(&st->cache_shm, size,
st->cache_file, st->pool);
if (result != APR_SUCCESS) {
return result;
}
/* Определяем размер shm сегмента */
size = apr_shm_size_get(st->cache_shm);
/* создаем rmm "handler" для получения указателя на shared memory area */
result = apr_rmm_init(&st->cache_rmm, NULL,
apr_shm_baseaddr_get(st->cache_shm), size,
st->pool);
if (result != APR_SUCCESS) {
return result;
}
#endif
/* OMITTED FOR BREVITY */
/* регистрируем cleanup для пула с вызовом apr_rmm_destroy
* и apr_shm_destroy, когда apache exits.
*/
return APR_SUCCESS;
}
|
Используя функцию apr_rmm, получаем указатель на глобальную память.
5. Secure
Каждый URL переводится на локальный путь, при этом имя файла может проходить проверку на соответствие определенным шаблонам, например [\w-_]{1-16}\.\w{3}. Подобные шаблоны могут широко варьироваться в зависимости от особенностей конкретной операционной системы. Аналогичные принципы работают тогда, когда модули Apache используют данные из заголовков клиентского запроса, из тела запроса или других источников. В случае ошибки необходимо генерировать соответствующий ErrorDocument.
На системном уровне нужно выполнять следующие требования: проверять статус всех системных вызовов и APR вызовов. В случае обнаружения ошибок останавливать обработку запроса и возвращать HTTP_INTERNAL_SERVER_ERROR. Нужно контролировать переполнение буфера. Прежде чем ваш модуль начнет писать данные в выделенный буфер, всегда проверяйте его размер.
Отказ в обслуживании - denial of service (DoS) - происходит тогда, когда сервер становится неуправляемым. Это может произойти, например, тогда, когда происходит массовая атака и сайт не в состоянии обслужить огромное число запросов, апогеем такой атаки является случай, когда атаки происходят с различных машин.
Защита от доса может быть реализована на администраторском уровне. Для этого есть ряд модулей:
- mod_evasive - ограничивает трафик по клиентскому IP.
- mod_cband - управление трафиком и числом коннектов.
- mod_load_average - отказывает в обслуживании запроса, если сервер слишком занят. В этом случае возвращается 503-я ошибка - server busy.
- mod_robots - фильтрует роботов и спам-ботов.
При написании собственного модуля хорошим тоном считаются следующие моменты:
- Используйте apr_reslist - это даст возможность администратору ограничить количество одновременных пользователей.
- Клиенту на сетевом уровне нужно выставлять таймаут.
- Если модуль поддерживает большие транзакции, например, потоковое видео, необходимо постоянно следить за освобождением памяти, используя локальные пулы.
На уровне операционной системы нужно соблюдать ряд требований. Apache не должен иметь рутовых прав, в частности, на файлы и каталоги. Выполнение CGI скриптов нужно оборачивать с помощью suexec. Должен стоять файрвол. Доступ к файловой системе должен быть описан в httpd.conf. Вызовы с префиксом apr_filepath фильтруют доступ к неавторизованным файлам и каталогам.
Одной из форм эксплойта является запись файла в каталог /tmp с последующим его выполнением. Причем это выполняется даже не на уровне сервера, а на уровне приложения (php, например). В этом случае на уровне администратора нужно выполнить следующие правила:
- На уровне прав пользователей/каталогов ограничивать пользователей Apache писать в определенные каталоги.
- Для того чтобы нельзя было запустить программу, каталог должен быть примонтирован с параметром noexec.
6. Другие языки
Модуль Apache может быть написан не только на С, но и на других языках:
- Компилируемые языки: C++ , Fortran, Modula.
- Скриптовые языки: Perl, PHP, Python, Ruby, Tcl. Наиболее полное соответствие API в этой группе языков у Perl.
Собрать и загрузить модуль можно по следующей схеме:
- Делается экспортная обвязка С-совместимого кода.
- При компиляции привязываются линки на APR.
- Линкуется как динамический объект.
- Скомпилированный модуль помещается в каталог, где находятся модули Apache.
- Загрузка прописывается в httpd.conf.
Пример компиляции:
# c++ -g -O2 -Wall -fPIC -I/usr/local/apache/include mod_foo.cpp
# c++ -shared -o mod_foo.so mod_foo.o
# cp mod_foo.so /usr/local/apache/modules/
|
Макросы, используемые в вашем модуле, должны иметь расширенную версию. Например, пусть имеется макрос:
AP_INIT_TAKE2("ValidatorDefault",
(const char*(*)())ValidatorDefault, NULL, OR_ALL,
"Default parser; default allowed parsers" )
|
Он должен быть расширен до формы:
{ "ValidatorDefault",
(const char*(*)(cmd_parms*, void*))ValidatorDefault,
__null, (1|2|4|8|16), TAKE2,
"Default parser; default allowed parsers" }
|
Сегодня мы рассмотрели несколько тем, имеющих отношение к практике безопасного программирования, такие как внутренний стиль программирования второго Apache, управление статическими и динамическими данными модулей в разрезе их жизненного цикла, основные методы общения между модулями, техника многопоточного и многопроцессного программирования, безопасность и ее поддержка на уровне администратора, работа с другими языками. Все это является подготовкой для дальнейшей практической работы по написанию собственных модулей.
Источник: Nick Kew, The Apache Modules Book.
Apache 2: Часть 8. Apache Portable Runtime (APR)
APR - это автономная библиотека, используемая ядром. Она разработана отдельно от ядра и ее назначение более широкое, чем применение только в контексте веб-сервера. В частности, на базе APR построен проект Subversion. В этом документе будет обсуждаться применение APR в модулях Apache.
Основная цель APR - создание кросс-платформенного слоя для приложений. Работа с файловой системой, сетевое программирование, управление процессами/потоками, управление памятью реализовано на низком уровне. Модули Apache используют APR и не обращаются напрямую к системным функциям, независимо от используемой платформы.
1. Обзор APR
Ядром APR являются пулы (pool), управляющие ресурсами Apache. Полный список включает более 30 модулей APR, среди которых:
apr_allocator
apr_atomic
apr_dso
apr_env
apr_errno
apr_file_info
apr_file_io
apr_fnmatch
apr_general
apr_getopt
apr_global_mutex
apr_hash
apr_inherit
apr_lib
apr_mmap
apr_network_io
apr_poll
apr_pools
apr_portable
apr_proc_mutex
apr_random
apr_ring
apr_shm
apr_signal
apr_strings
apr_support
apr_tables
apr_thread_cond
apr_thread_mutex
apr_thread_proc
apr_thread_rwlock
apr_time
apr_user
apr_version
apr_want
|
APR-UTIL - или APU - это набор утилит, включающий модули:
apr_anylock
apr_base64
apr_buckets
apr_date
apr_dbd
apr_dbm
apr_hooks
apr_ldap
apr_ldap_init
apr_ldap_option
apr_ldap_url
apr_md4
apr_md5
apr_optional
apr_optional_hooks
apr_queue
apr_reslist
apr_rmm
|
Все публичные интерфейсы имеют префикс apr_ - это внешний namespace. Внутри модуля может быть вложенный, например, для модуля apr_dbd префикс будет иметь вид apr_dbd_.
Публичные функции декларируются с помощью макроса APR_DECLARE:
APR_DECLARE(apr_status_t) apr_initialize(void);
|
Функция возвращает тип apr_status_t, например APR_SUCCESS:
apr_status_t rv;
...
rv = apr_do_something(... args ...);
if (rv != APR_SUCCESS)
{
/* log an error */
return rv;
}
|
Функции могут возвращать не только целые значения, но также строки (char* или const char*), а также void* или void.
В силу разнородности операционных систем в APR по умолчанию отключены некоторые особенности, такие, например, как многопоточность. Для их явного включения на этапе компиляции необходимо включить макрос APR_HAS_:
#if APR_HAS_THREADS
rv = apr_thread_mutex_lock(mutex);
if (rv != APR_SUCCESS) {
/* Log an error */
/* Abandon critical operation */
}
#endif
|
2. Управление ресурсами
Пул (pool) - фундаментальный блок, который является сердцевиной APR, основой для управления ресурсами. Пул может выделить память напрямую или косвенно, гарантируя ее освобождение в нужный момент. Пул может управлять не только памятью, но также файловыми дескрипторами и мьютексами. В обычной практике программирования, когда вы выделяете ресурс, вы должны позаботиться о его закрытии после того, как он будет использован, например:
char* buf = malloc(n);
... check buf is non null ...
... do something with buf ...
free(buf);
|
или
FILE* f = fopen(path, "r");
... check f is non null ...
... read from f ....
fclose(f);
|
Это простой пример. В реальной жизни сервера, когда не определен момент выделения ресурса, область видимости ресурса, его очистка - дело нетривиальное.
Модель с концепцией конструкторов/деструкторов в данной архитектуре не проходит. Приходится учитывать множество факторов: когда выделяются ресурсы, как они распределяются между объектами и т.д.
Для таких высокоуровневых языков, как lisp и java, основным механизмом управления ресурсов является т. н. garbage collector (gc). Он снимает с программиста ответственность за управление ресурсами и перекладывает ее на сам язык. У gc есть, конечно, и негативные моменты, такие как, например, невозможность управлять временем жизни выделенных объектов.
Пулы в APR реализуют альтернативную модель управления ресурсами. Помимо того, что они освобождают программиста от заботы про очистку ресурсов, они дают возможность контролировать время жизни ресурсов.
Основная парадигма звучит так: где бы вы не выделили ресурс, регистрируйте его с помощью пула. Этот пул будет сам очищать все свои ресурсы, когда истечет его собственное время жизни. Программисту остается только выбрать правильный пул.
Вместо традиционного
mytype* myvar = malloc(sizeof(mytype));
|
мы делаем
mytype* myvar = apr_palloc(pool, sizeof(mytype));
|
Причем второй вариант оказывается быстрее первого на большинстве платформ.
В качестве примера можно привести манипуляцию со строками - аналог для стандартной функции sprintf(), где даже не нужно знать размер строки:
char* result = apr_psprintf(pool, fmt, ...);
|
APR включает базовые функции для управления памятью, файлами, сокетами, мьютексами. Можно даже их не использовать, как в данном случае, нужно только зарегистрировать объект в пуле для последующей очистки:
mytype* myvar = malloc(sizeof(mytype));
apr_pool_cleanup_register(pool, myvar, free, apr_pool_cleanup_null);
|
Т. е. ресурс, выделенный стандартным образом, может быть, тем не менее, также очищен пулом, причем автоматически.
Очистка ресурса может быть явной или неявной, например, освободить какой-то ресурс прежде, чем будет обработан запрос, т. е раньше, чем это сделает соответствующий пул. Для этого есть функция - apr_pool_cleanup_kill. При ее вызове происходит раз-регистрация очистки ресурса в пуле. Рассмотрим следующий пример. Выделяем ресурсы:
my_type* my_res = my_res_alloc(args);
|
Очищаем:
apr_pool_cleanup_register(pool, my_res, my_res_free, apr_pool_cleanup_null);
rv = my_res_free(my_res);
apr_pool_cleanup_kill(pool, my_res, my_res_free);
|
Последние 3 строки можно заменить на:
apr_pool_cleanup_run(pool, my_res, my_res_free);
|
3. Пулы
Есть несколько типов пулов для разных ресурсов. Каждый такой пул привязан к определенной базовой структуре, и время жизни этой структуры есть время жизни такого пула. Основные базовые пулы:
- Пул запросов - время его жизни равно времени жизни запроса.
- Пул процессов - время его жизни равно времени жизни сервера.
- Пул коннектов.
- Конфигурационный пул.
Доступ к первым трем выполняется через request->pool, process->pool, connection->pool, к четвертому - через process->pconf. Пул процессов самый долгоживущий. Пул коннектов имеет время жизни коннекта, который в свою очередь может иметь несколько запросов. Он полезен в фильтрах, где объект запроса может быть не определен.
Все хуки имеют похожий шаблон:
int my_func(request_rec* r)
{
...
}
|
Можно использовать пул из r->pool. Это самое подходящее место для выделения ресурсов при обработке запроса. Пул процессов доступен из r->server->process->pool, он может быть использован для кеширования ресурсов, которые могут понадобиться при обработке запросов. Пул коннектов доступен через r->connection->pool.
У пулов есть свои ограничения:
- Если время жизни объекта не соответствует времени жизни стандартного объекта Apache, это требует дополнительных усилий.
- Выделение ресурсов через пул не есть thread safe. Это связано с тем, что речь идет о пулах коннектов и пулах запросов, которые обрабатываются потоками приватно.
- Пул не возвращает память операционной системе, он ее повторно использует после очистки. Поэтому, если речь идет о выделении очень больших кусков памяти, имеет смысл использовать стандартный malloc.
4. Встроенные типы данных
Обработка строк находится в apr_strings. Тут находятся простые строковые функции: сравнение, копирование, конкатенация, форматные функции типа sprintf, конвертация в другие типы данных. Управление строк привязано к пулам. Например, конкатенация произвольного числа строк:
result = apr_pstrcat(pool, str1, str2, str3, ..., NULL);
|
В модуле apr_time реализован микро-секундный таймер. Базовый тип - 64-битное целое apr_time_t.
Есть макросы совместимости:
/** @return apr_time_t as a second */
#define apr_time_sec(time) ((time) / APR_USEC_PER_SEC)
/** @return a second as an apr_time_t */
#define apr_time_from_sec(sec) ((apr_time_t)(sec) * APR_USEC_PER_SEC)
|
Имеется набор стандартных временных функций типа sleep.
В APR имеется свой собственный набор типов данных:
- apr_table - таблицы и массивы.
- apr_hash - хеш-таблицы.
- apr_queue - FIFO очереди.
- apr_ring - кольцевые структуры.
Базовый тип для массивов - apr_array_header_t, который может хранить другие объекты или указатели. Массив может расти динамически. Операции с массивом:
/* Allocate an array of type my_type */
apr_array_header_t* arr = apr_array_make(pool, sz, sizeof(my_type));
/* Allocate an uninitialized element on the array*/
my_type* newelt = apr_array_push(arr);
/* Now fill in the values of elt */
newelt->foo = abc;
newelt->bar = "foo";
/* Pop the last-in element */
my_type* oldelt = apr_array_pop(arr);
/* Iterate over all elements */
for (i = 0; i < arr->nelts; i++) {
/* A C++ reference is the clearest way to show this */
my_type& elt = arr->elts[i];
}
|
Тип apr_table_t лежит в основе таблиц: массивов для хранения пар ключ/значение. В таблицу можно добавлять элементы несколькими способами, удалять элементы (довольно медленно), искать, делать итерацию, удалять дубликаты. Таблицы нечувствительны к регистру (в отличие от APR hash table):
/* Allocate a new table */
apr_table_t* table = apr_table_make(pool, sz);
/* Set a key/value pair */
apr_table_setn(table, key, val);
/* Retrieve an entry */
val = apr_table_get(table, key);
/* Iterate over the table (see Chapter 5) */
apr_table_do(func, rec, table, NULL);
/* Clear the table */
apr_table_clear(table);
/* Merge tables */
newtable = apr_table_overlay(pool, table1, table2);
/* Prune duplicate entries */
apr_table_compress(table, flags);
|
Таблицы идеально подходят для манипуляций с такими объектами, как HTTP заголовки или переменные окружения.
Тип apr_hash_t аналогичен предыдущему, но он более низкоуровневый. У него есть два отличия:
- Ключи и значения могут быть любого типа, они чувствительны к регистру.
- Более эффективны в плане динамического роста.
Наиболее часто используемые операции для этого типа - вставка и поиск:
apr_hash_t* hash = apr_hash_make(pool);
/* key and value are pointers to arbitrary data types */
apr_hash_set(hash, key, sizeof(*key), value);
value = apr_hash_get(hash, key, sizeof(*key));
|
apr_queue_t применяется в многопоточном окружении и используется для кооперации работы нескольких тредов. Очередь может блокировать вставку/удаление элементов.
Тип APR_RING - это коллекция макросов, которая реализует циклический двойной связный список. Этот тип в частности используется в конструкции, называемой bucket brigade. bucket - это элемент кольца (корзина), brigade - само кольцо:
struct apr_bucket
{
/** Links to the rest of the brigade */
APR_RING_ENTRY(apr_bucket) link;
/** and, of course, the bucket's data fields */
};
/** список */
struct apr_bucket_brigade
{
/* Кольцо прикрепляется к пулу.
В случае, когда кольцо убивается раньше, чем это делает сам пул,
нужно будет позаботиться о специальной kill-функции
*/
apr_pool_t *p;
APR_RING_HEAD(apr_bucket_list, apr_bucket) list;
/** The freelist from which this bucket was allocated */
apr_bucket_alloc_t *bucket_alloc;
};
|
Buckets Brigades используется в Apache для управления данными, I/O, в фильтрах. Этот двойной связный список не ограничен количеством элементов. В кольце могут храниться различные типы. Имеется ряд встроенных функций:
- read - возвращает адрес и размер данных в корзине. В случае, когда для каких-то данных не хватает размера одной корзины, оставшаяся часть будет помещена во вторую корзину.
- split - разбивает данные для размещения в две корзины.
- setaside - проверка жизненности хранимых данных.
- copy - копирует корзину.
- destroy - удаляет корзину.
Каждая такая функция имеет свой враппер - apr_bucket_read(), apr_bucket_destroy(). В APR имеется ряд встроенных типов для корзин:
- file
- pipe
- socket
- heap - память
- mmap - файл
- immortal - память
- pool
- transient
- flush - метаданные
- EOS - метаданные
Для работы с файловой системой имеется набор функций:
- apr_file_io - стандартные файловые операции.
- apr_file_info.
- apr_fnmatch.
- apr_mmap.
Имеется набор функций для управления процессами и потоками:
- apr_thread_proc - создание процессов/потоков, поддержка связи parent–child.
- apr_signal - управление сигналами.
- apr_global_mutex - управление потоковыми блокировками.
- apr_proc_mutex - управление блокировками процессов.
- apr_thread_mutex / apr_thread_rwlock.
- apr_thread_cond.
5. Процессы и потоки
Для управления процессами и потоками в APR есть набор функций, которые имеют специальный префикс:
- apr_thread_proc — создание, связи parent–child, wait и т. д.
- apr_signal — базовое управление сигналами.
- apr_global_mutex — управление глобальными блокировками.
Процессы:
- apr_proc_mutex — блокировки для процессов.
- apr_shm - управление глобальными сегментами памяти.
Потоки:
- apr_thread_mutex / apr_thread_rwlock — блокировки для потоков.
- apr_thread_cond - условные переменные.
APR выполняет роль платформенно-независимого системного слоя, управляет выделенными ресурсами. Были рассмотрен стиль, пулы, управление ресурсами.
Если вы собираетесь программировать под Apache, вам, прежде всего, нужно смотреть в сторону APR.
|

 LINUX
LINUX 
 Packages
Packages
